Время на прочтение
3 мин
Количество просмотров 4.7K
Всем привет! Меня зовут Сергей Коньков — я работаю архитектором в компании CloudReports. Сегодня я расскажу, как мы создали продукт, который помогает пользователям работать с данными и в какой-то мере соединяет два мира аналитики: Excel и облачные хранилища данных.
Задача
BigQuery и другие аналитические хранилища в сочетании с современными BI инструментами перевернули работу с данными за последние годы. Возможность обрабатывать терабайты информации за секунды, интерактивные дашборды в DataStudio и PowerBI, сделали работу очень комфортной.
Однако если посмотреть глубже, можно увидеть — выиграли от этих изменений в основном профессионалы, владеющие SQL и Python и бизнес пользователи на руководящих позициях, для которых разрабатываются дашборды.
А как быть с сотнями миллионов сотрудников, для которых главным инструментом анализа был и остается Microsoft Excel? Они в каком-то смысле, остались за бортом новых изменений. Это менеджеры по продажам, владельцы малого бизнеса, руководители небольших отделов. Освоить PowerBI у них нет времени. Все что им остается это экспортировать данные из отчетов в свой любимый Excel и продолжить работу там, но это не очень удобно, занимает время и есть ограничения по объему данных.
Мы часто наблюдаем, как наши клиенты использующих Google BigQuery загружают данные в Excel с помощью различных коннекторов, натыкаясь на ограничения. И родилась идея: если Excel не теряет популярности, а данные уходят в облака, то давайте придумаем способ как помочь пользователю работать из Excel с облаком.
Вспоминаем OLAP
Да, сегодня Excel по-прежнему самый популярный инструмент для работы с информацией в мире. А Сводная таблица, это то что используют миллионы пользователей каждый день. А раньше было еще больше. Если вы работали с данными в крупной компании десять лет назад вы наверняка слышали про технологию OLAP кубов от Microsoft и других вендоров, которые создаются поверх реляционных SQL баз, и позволяют получать результаты обработки миллионов строк данных за секунды. Самым популярным способом работы с OLAP кубами была и есть сводная таблица Excel. К слову OLAP по прежнему очень распространен в корпоративном мире, это все так же часть Microsoft SQL Server, однако имеет ряд ограничений по объемам и скорости обработки и все больше уступает рынок облачным аналитическим хранилищам.
Так вот в решении этой задачи нам поможет OLAP. Как я уже писал выше в Excel есть готовый клиент для работы с OLAP, мы будем использовать его.
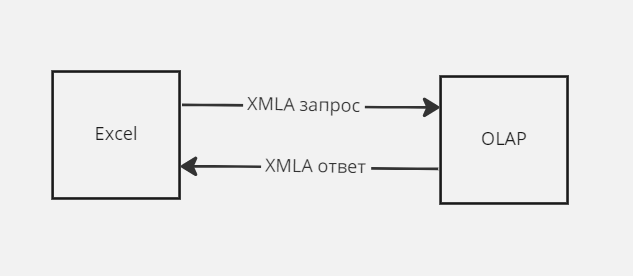
Kогда Microsoft выводил на рынок данную технологию был опубликован открытый протокол для работы с OLAP базами — XMLA (XML для аналитики). Именно этот протокол и использует Excel когда подключается к OLAP серверу. Все работает примерно так:
Решение
Идея проста — вместо OLAP сервера мы сделаем Python приложение , которое будет делать следующее:
-
принимать XMLA запросы от Excel
-
конвертировать логику XMLA запроса в SQL код
-
отправлять SQL запрос в BigQiery
-
полученный от BigQuery ответ конвертировать в XMLA и отправлять обратно в Excel
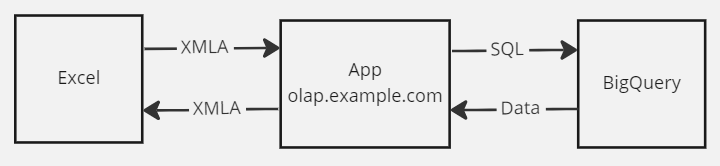
Данное приложение (App) можем опубликовать в облаке, так как Excel имеет возможность отправлять запросы XMLA запросы по протоколу HTTPS. Все будет работать примерно так:
Использование
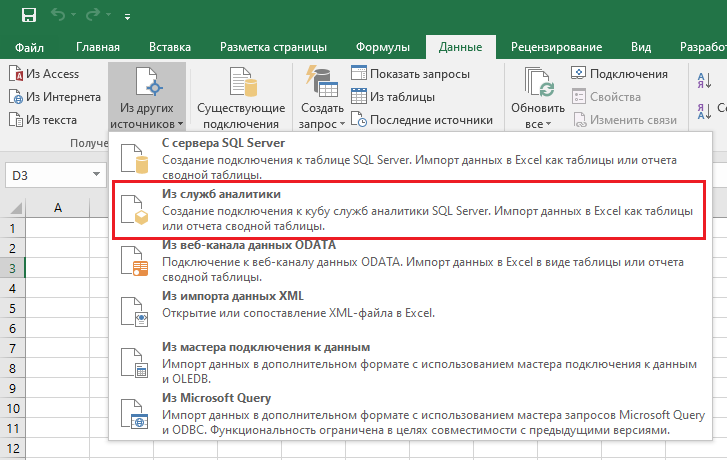
После того как мы разработали и опубликовали приложение, администратору BigQuery для начала использования достаточно просто создать таблицу и определить для соответсnвующих полей типы агрегации (сумма, минимум, максимум и т.д.). Далее пользователь в Excel используя подключение к службам аналитики (OLAP) соединяется с нашим сервисом:
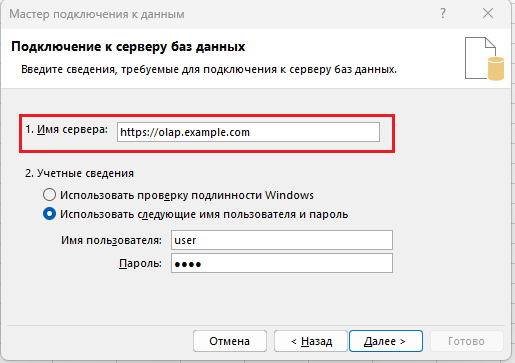
После этого мы получаем доступ к таблице BigQuery непосредственно из сводной таблицы. И можем легко «играть» с данными.
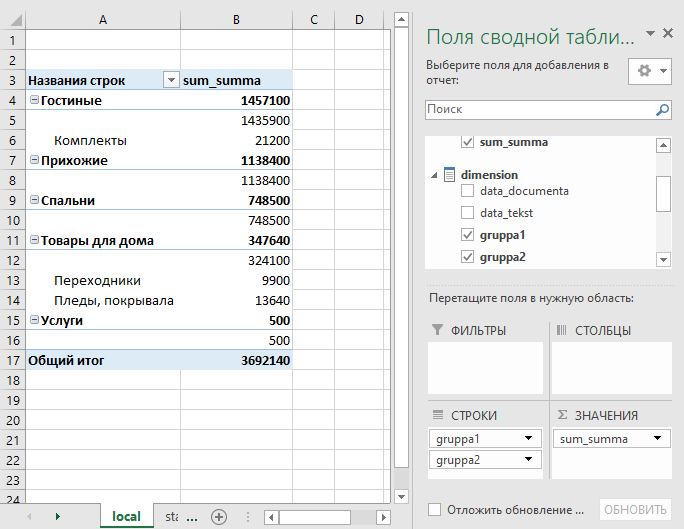
Кроме того, мы реализовали в данном сервисе слой кэширования данных для ускорения запросов и экономии затрат на BigQuery.
Что дальше
Сейчас мы активно тестируем сервис на своих клиентах и думаем над добавлением нового функционала.
Например, SQL запросы наряду с BigQuery поддерживают и другие облачные хранилища данных. Добавив один класс в наше приложение мы реализовали аналогичный механизм для ClickHouse. Скоро будет готова версия для Snowflake и Amazon Redshift.
Будем рады услышать вопросы и мнение коллег в комментариях.
Финансы в Excel
- Подробности
- Создано 24 Октябрь 2011
| Содержание |
|---|
| Использование сводных таблиц |
| Выборка уникальных значений |
| Суммирование значений |
| Двухмерный анализ |
| Многомерный анализ |
| Работа с данными |
| Обновление данных |
| Работа с результатами анализа |
| Версии интерфейса сводных таблиц |
| Внутренняя организация интерфейса сводных таблиц |
| Кэш сводной таблицы |
| Объекты VBA |
| Виды источников данных |
| Диапазоны |
| Запросы к базе данных |
| OLAP-кубы |
| PowerPivot |
Третья статья, посвященная обработке больших объемов данных с помощью Excel, описывает преимущества использования сводных таблиц. Вообще, эта статья должна была быть первой в цикле, если говорить о пользе того или иного метода работы. Действительно, интерфейс сводных таблиц специально создавался для анализа больших объемов данных, которые могут храниться не только в диапазонах электронных таблиц, но и во внешних источниках данных. Понимание принципов работы и практическое использование сводных таблиц позволяет существенно оптимизировать повседневную работу экономистов. Повышение уровня анализа данных, в свою очередь, ведет к улучшению управляемости компании и принятию верных управленческих решений менеджерами различных уровней.
Общетеоретические вопросы по работе со сводными таблицами и многомерным анализом данных описаны в другой статье на нашем сайте.
Здесь остановимся подробнее на конкретных методах обработки данных при помощи интерфейса сводных таблиц. В качестве примера используйте файл nwdata_pivot.xls.
Использование сводных таблиц
Выборка уникальных значений
Одной из самых популярных задач, решаемой при помощи сводной таблицы – это выборка уникальных значений из списка или массива данных. Использование интерфейса сводной таблицы позволяет решить эту задачу самым «элегантным» способом – без использования формул.
В примере на листе Выборка показан список стран и количество упоминаний в массиве данных.

В поле данных необходимо, чтобы стоял вид операции – «количество». Этот параметр позволяет обрабатывать в области данных сводной таблицы нечисловые поля исходных данных. Альтернативой операции подсчета количества служит стандартная функция COUNTIF. Сформировать набор уникальных значения только с помощью формул в принципе тоже возможно (см. часть 1), но это потребует очень сложных формул с вычисляемой адресацией. То есть, использование сводной таблицы в данной задаче – это самый оптимальный способ решения.
Суммирование значений
Другая популярная задача для применения интерфейса сводных таблиц – это получение итоговых значений по уникальным записям массива данных.
В примере на листе Сумма сформированы итоговые данные по заказам по каждой стране:

Вид операции «Сумма» в поле данных допускает использование только числовых полей. Прочие виды агрегации исходных данных на практике почти не используются.
Для решения задачи при помощи стандартных формул можно использовать функцию SUMIF. Очевидно, что сложность возникает не в консолидации значений, а, также как и в прошлом примере, в выборке уникального списка (в примере — названия стран).
Двухмерный анализ
Описанные ранее примеры демонстрируют анализ данных по одному критерию. Электронные таблицы позволяют наглядно представить данные в двух измерениях: по столбцам и по строкам. Сводные таблицы также имеют эти области отображения данных.
В примере на листе Таблица сформирован отчет по странам и датам, показывающий изменение показателя количества заказов во времени. Обратите внимание, что для поля типа дата применена дополнительная группировка: по месяцам и по годам.

Суммирование по нескольким критериям допустимы и через стандартные функции Excel SUMIFS, SUMPRODUCT, а также функции обработки массивов (см. часть 1). Однако, такой вариант требует предварительно известные значения параметров — ключей выборки. Кроме того, расчет при помощи формул требует значительно больше времени, что на больших объемах данных может привести к большим потерям в производительности работы.
Многомерный анализ
Кроме визуального анализа в области по строкам и столбцам, в сводных таблицах можно использовать глобальный фильтр по одному или нескольким полям исходных данных. Для этого предназначена специальная область ячеек, расположенная над сводной таблицей.
Пример на листе Фильтр демонстрирует возможность просмотра данных по компаниям одной страны с использованием области фильтра сводной таблицы:

Поле фильтра можно переместить в область строк или столбцов, что позволит просмотреть больший массив информации. Кроме описанной области фильтров, дополнительную фильтрацию данных можно осуществлять через настройку списков ключевых полей в областях строк или столбцов.
Аналогом использования фильтров сводной таблицы при помощи формул рабочего листа являются в большинстве случаев формулы обработки массивов.
Примеры на листах pivot1 и pivot2 показывают варианты отображения одной и той же информации с использованием различных настроек измерений сводной таблицы.
Работа с данными
Обновление данных
Сводная таблица может быть основана как на данных, находящихся в произвольной области ячеек, так и во внешних источниках данных. Остановимся сначала на первом варианте работы. Т.е. данные для анализа хранятся в диапазоне ячеек рабочего листа Excel.
Отчет в виде сводной таблицы может быть подготовлен как для одноразового использования, так и для постоянного применения с изменяемым набором исходных данных. Последний вариант предоставляет пользователю большие возможности по интерактивной работе: требуется настроить и отформатировать отчетную форму один раз, затем при редактировании исходных данных изменения в конечной форме будут производиться автоматически. При этом отчет не только изменяет данные, но может также добавлять и удалять строки и столбцы, что практически нереализуемо формулами рабочего листа.
Мастер построения сводной таблицы позволяет указать диапазон ячеек, используемых в качестве источника данных. Если при обновлении информации были добавлены новые строки, то они могут не попасть в источник данных сводной таблицы, и, соответственно, не будут корректно проанализированы. Эта особенность достаточно сложна для отслеживания при обработке больших объемов данных.
Изменить диапазон-источник данных для существующей сводной таблицы можно через специальный диалог Excel 2007-2010. В предыдущих версиях Excel эта интерфейсная возможность реализована в «Мастере работы со сводными таблицами», в случае, когда он запущен из активной сводной таблицы. После открытия мастера необходимо вернуться на один шаг назад:


Исправления источника данных можно также произвести программным способом. Например, через окно вычислений редактора VBA (Immediate):

Чтобы не задумываться над корректностью размеров диапазона-источника данных сводной таблицы, можно изначально при построении задать диапазон строк с большим запасом. Например, зная, что предполагаемый объем строк не превышает 10000, можно сразу задать это значение в виде размера диапазона. Такая избыточность на практике не приведет к видимым замедлениям в работе интерфейса сводной таблицы. Пустые значения в измерениях отчета можно скрыть. Недостаток этого метода проявляется, в первую очередь, при работе с полями типа «дата». Стандартный интерфейс сводной таблицы позволяет реализовать различные группировки при работе с типом «дата» (по месяцам, по кварталам), но при наличии пустых значений эти возможности становятся недоступными, так как Excel определяет такой столбец как текстовый..
В дополнение к рассмотренным методам управления источником данных, предлагаем настраивать диапазон строк сводной таблицы активного рабочего листа программными методами. Если источник данных занимает рабочую область листа целиком, то можно использовать такую команду:
ActiveSheet.PivotTables(1).SourceData = _
Left(ActiveSheet.PivotTables(1).SourceData, _
InStr(ActiveSheet.PivotTables(1).SourceData, "!")) & _
Range(Application.ConvertFormula( _
ActiveSheet.PivotTables(1).SourceData, xlR1C1, xlA1) _
).Worksheet.UsedRange.Address(ReferenceStyle:=xlR1C1)
Самым надежным, но медленным способом, является последовательная проверка строк листа-источника с последующим заполнением свойства SourceData активной сводной таблицы. Обратите внимание, что это свойство хранится только в R1C1-адресации.
Макрос можно вызывать по событию Worksheet_Activate, либо настроить «горячую» клавишу.
Работа с результатами анализа
Сводная таблица располагается в диапазоне ячеек рабочего листа Excel. Написание формул рабочего листа в границах сводной таблицы не допускается как при вводе вручную, так и программными методами. Теоретически допустима работа с ячейками, располагающимися в пределах границ сводной таблицы, при помощи ссылок для внешних формул. Часто на практике используется также функция VLOOKUP для поиска по столбцу сводной таблицы. Этот способ необходимо использовать с большой осторожностью — интерфейс сводного отчета предполагает изменение положения отображаемых данных относительно прямоугольных координат рабочего листа без какого-либо влияния на источник этих данных. То есть, нет никакой гарантии, что указанная в формуле ссылка внутрь сводной таблицы будет отображать правильное значение при дальнейшей работе с файлом. При этом источник данных может не меняться.
Имеются альтернативные способы обработки результатов сводной таблицы:
- Копирование и вставка значений сводной таблицы на другой лист (с использованием функции «Специальная вставка») с дальнейшим поиском дынных уже по этому сформированному диапазону ячеек. Нарушить целостность данных в пределах простой таблицы гораздо сложнее, чем в сводной. Очевидно, что главным недостатком этого способа работы, является использование ручных операций после каждого обновления источника данных.
- Использовать возможности функции GETPIVOTDATA (Excel 2002 и более поздние версии). Данная функция предполагает доступ к данным не по координатам рабочего листа, а по измерениям сводной таблицы. Для источников данных типа OLAP-куб предусмотрены специальные функции доступа к данным и измерениям: CUBEVALUE, CUBEMEMBER и другие (Excel 2007-2010). Данный способ работы неудобен, а также существенно замедляет работу, если требуется получить много различных значений сводной таблицы.
- Отказаться от сводной таблицы для получения результатов. Вместо этого использовать формулы рабочего листа (см. Часть 1). Этот способ, несмотря на сложность реализации, может оказаться самым удобным в том случае, если на результатах основываются другие вычисления, а источник данных часто обновляется.
Версии интерфейса сводных таблиц
В новом формате файла xlsx (Excel 2007-2010) существенно изменены возможности интерфейса сводных таблиц. В предыдущие версии интерфейса (97-2003) вносились только «косметические» изменения:
- Excel 2000 (9.0) – базовая версия интерфейса сводных таблиц.
- Excel XP (10.0) – новая функция GETPIVOTDATE
- Excel 2003 (11.0) – похоже, что вообще никаких изменений не вносилось
- Excel 2007 (12.0) – новая версия интерфейса сводных таблиц с поддержкой расширенных диапазонов. Улучшена производительность, изменен внешний вид интерфейса. Сохранена совместимость со старым форматом.
- Excel 2010 (14.0) – поддержка надстройки PowerPivot. Работа с обновляемыми OLAP-кубами.
Основные изменения в новом формате файла (2007-2010):
- В одном столбце могут располагаться несколько полей сводной таблицы, выделенных отступами (сжатая форма).
- Срезы сводной таблицы позволяют визуально отображать текущий фильтрующий набор значений.
- Измерения в области фильтра поддерживают множественный выбор.
- Элементы измерения могут быть скрыты/отображены через кнопки, расположенные в той же ячейке, что и сам заголовок.
- Появилось несколько новых параметров в свойствах поля и таблицы.
- Доступны стили сводных таблиц, позволяющие изменить внешний вид отчетов в любой момент времени.
Для лучшего понимания отличий скачайте и откройте файлы-примеров nwdata_pivot1.xlsx и nwdata_pivot2.xlsx (в арихиве nwdata_pivot.zip). В первом файле представлен отчет в старом формате, во втором – в новом, исходные данные одинаковые.


Внутренняя организация интерфейса сводных таблиц
Для лучшего понимания принципов работы сводной таблицы рассмотрим внутреннюю организацию интерфейса.
Кэш сводной таблицы
При создании или обновлении сводной таблицы, независимо от выбранного типа источника, Excel переносит данные в промежуточное хранилище, так называемый, кэш сводной таблицы. Структура организации данных в кэше позволяет существенно оптимизировать агрегацию данных и вычисления в сводной таблице. Хранение данных в собственном кэше позволяет использовать различные источники данных с сохранением схожей функциональности.
Данные в кэше обновляются при нажатии кнопки «Обновить» интерфейса сводной таблицы (кнопка на ленте или в контекстном меню), либо по заданному интервалу времени, если такая установка задана в параметрах. Режим вычислений Excel (автоматический или ручной) при этом никак не влияет на сводную таблицу.
Несколько сводных таблиц (или диаграмм) могут отображать данные одного и того же кэша. Этот вариант работы используется для отображения нескольких отчетных форм одних и тех же данных без использования интерфейса настройки измерений. В этом случае при обновлении одной из таблиц автоматически перестраивается и та, что основана на том же кэше.
Объекты VBA
Доступ к данным программными методами возможен на уровне объектов сводной таблицы — объект PivotTable. Другие объекты сводной таблицы отвечают за расположение и визуальное отображение элементов и данных. К ним относятся коллекции полей: PivotFields, ColumnFields, RowFields, PageFields, DataFields. Варианты значений полей доступны через коллекции объектов PivotItems.
Универсальная возможность обращения к данным непосредственно в кэш (объект PivotCache) почему-то не предусмотрена разработчиками Excel. Логика при этом не совсем понятна. Как уже отмечалось, данные кэша хранятся отдельно и их даже можно увидеть в файле формата xlsx, если открыть этот файл как zip-архив. В зависимости от типа источника данных можно попытаться использовать свойство SourceData (для сводных таблиц на основе диапазона) или Recordset (для источников типа «запрос к базе данных»).
Вычисляемые поля и объекты сводной таблицы (CalculatedFields, CalculatedItems) имеют собственный механизм расчетов и дерево зависимостей формул, не относящееся к формулам рабочего листа Excel. На практике мы рекомендуем по возможности избегать большого количества вычисляемых полей в сводных таблицах, так как это приводит к существенному замедлению расчетов. Для источников данных в виде диапазонов ячеек часто можно просто добавить столбец с обычной формулой в исходные данные, а для запросов к базам данных — добавить вычисления непосредственно в текст SQL-запроса.
Виды источников данных
Глобально можно разделить источники данных на 3 типа:
- Диапазоны ячеек
- Запросы к базе данных
- OLAP-кубы и PowerPivot2010 как один из вариантов реализации OLAP-механизма.
Диапазоны
Первый вариант работы – самый распространенный на практике; предыдущие описания примеров относятся как раз к данным, хранящимся в диапазоне ячеек.
Стандартный интерфейс Excel не позволяет строить сводный отчет на основе нескольких диапазонов ячеек. Причина такого ограничения не очень понятна. Есть подозрение, что разработчики просто не могут предложить интуитивно-понятный интерфейс пользователя для решения данной задачи. Техническая реализация задачи не выглядит слишком сложной – требуется просто заполнить кэш данных. В разделе Надстройки нашего сайта представлено наше собственное решение для построения сложных сводных отчетов.
Запросы к базе данных
Запросы к базе данных могут быть реализованы с использованием различных технических механизмов: Microsoft Query, ADO, ODBC. Независимо от интерфейса доступа к данным объединяющим фактором этого варианта работы является заполнение кэша сводной таблицы непосредственно из внешнего источника. При дальнейшей работе со сводной таблицей запрос может быть выполнен повторно, после чего данные будут заново перенесены в кэш. Этот метод позволяет анализировать данные из внешних источников (учетных систем) в реальном времени. При разрыве связи с источником данных, анализ может производиться на последних данных, попавших в кэш.
OLAP-кубы
OLAP-куб предоставляет промежуточный уровень подготовки информации для многомерного анализа в сводных таблицах. Куб хранит информацию о доступных типах полей (измерение или данные), иерархические зависимости полей, агрегированные значения (промежуточные итоги) и другие вычисляемые элементы. Главным преимуществом использования кубов перед прямыми запросами в базу данных является высокая производительность, так как данные перемещаются и агрегируются в промежуточном хранилище. Очевиден и недостаток данного метода – данные OLAP-куба могут содержать неактуальную информацию, что зависит от настроек хранилища.
До версии Office 2007 простой OLAP-куб можно было подготовить при помощи Microsoft Query, но в последних версиях эту возможность по непонятным причинам отключили. Разработчики настоятельно рекомендуют использовать SQL Server Analysis Service для создания и настройки OLAP-кубов. Рекомендация полезная, но, во-первых, этот сервис входит в состав только платных версий SQL Server, а, во-вторых, требует серьезного изучения, как интерфейса, так и языка обработки MDX-запросов.
http://ru.wikipedia.org/wiki/MDX
В примере к статье представлен архив nwdata_cube.zip с двумя файлами nwdata_cube.cub, nwdata_cube.xls. Обратите внимание на изменения в интерфейсе сводной таблицы при использовании OLAP-куба в качестве источника данных:
- Наличие иерархических измерений, нет возможности поменять родительский и дочерний элемент местами.
- Недопустимо перемещение измерений в область данных и наоборот.
- Промежуточные итоги отображаются для всех элементов, а не по текущему фильтру группы.
PowerPivot
Для Excel 2010 доступна специальная надстройка PowerPivot, которая является, по большому счету, альтернативным механизмом реализации OLAP-кубов. При помощи PowerPivot можно обрабатывать миллионы записей различных информационных файлов и баз данных с огромной производительностью. При этом интерфейс пользователя для конечного анализа данных реализован в Excel 2010.
С высокой вероятностью эта надстройка войдет в состав следующей версии Excel в качестве базовой функциональности. Мы очень надеемся посвятить описанию работы PowerPivot отдельную статью или даже цикл статей. На сегодняшний день PowerPivot + Excel являются, пожалуй, самым мощным инструментом для анализа больших объемов данных.

Официальный сайт PowerPivot:
http://www.powerpivot.com/
Смотри также
» Динамический источник данных сводной таблицы
При работе со сводными таблицами несколько раз сталкивался с проблемой, когда новые данные не попадали в отчет. Сводная таблица была…
» Сводная таблица Excelfin.ru
Надстройка предназначена для создания сводных таблиц на основе нескольких диапазонов данных файла Excel. Пользовательский интерфейс в…
» Обработка больших объемов данных. Часть 2. Интерфейс
В статье систематизируются простые приемы обработки больших объемов данных при помощи стандартных методов интерфейса Excel. Информация…
» Обработка больших объемов данных. Часть 1. Формулы
Одним из самых популярных методов использования электронных таблиц является обработка данных, полученных из учетных систем….
» Сводные таблицы
Первый интерфейс сводных таблиц, называемых также сводными отчеты, был включен в состав Excel еще в 1993м году (версии Excel 5.0). Несмотря на…
Excel открывает большие возможности в обработке массива цифр и строк. Сегодня мы разберем, как в excel обработать большой объем данных. В этой части мы не будем разбирать макросы. Цель этой статьи — научиться работать с самыми доступными и простыми формулами excel, которые помогут выполнить нашу работу в большинстве случаев.
Статья будет разделена на 2 части. Содержание первой части, представлена ниже. Начнем без теории. Вряд ли она вам интересна.
Содержание:
- Как в excel найти повторяющееся значение
- Как в excel быстро удалить дублирующиеся строки
- Работа со сводной таблицей в excel
- Как в excel «подтянуть» данные из другого листа или файла
- Что такое функции правсимв и левсимв и как их применять
Как в excel найти повторяющееся значение
В своде данных мы можем столкнуться с проблемой, когда нам нужно из большого количества строк быстро найти повторяющиеся строки. Ведь в одной строке может быть одно значение, а во второй, по такому же наименованию товара, дубль или другое значение.
Возьмем таблицу. В столбец Е ставим равно и затем, в поиске «Другие функции» ищем нужную нам формулу (см. рис 1)
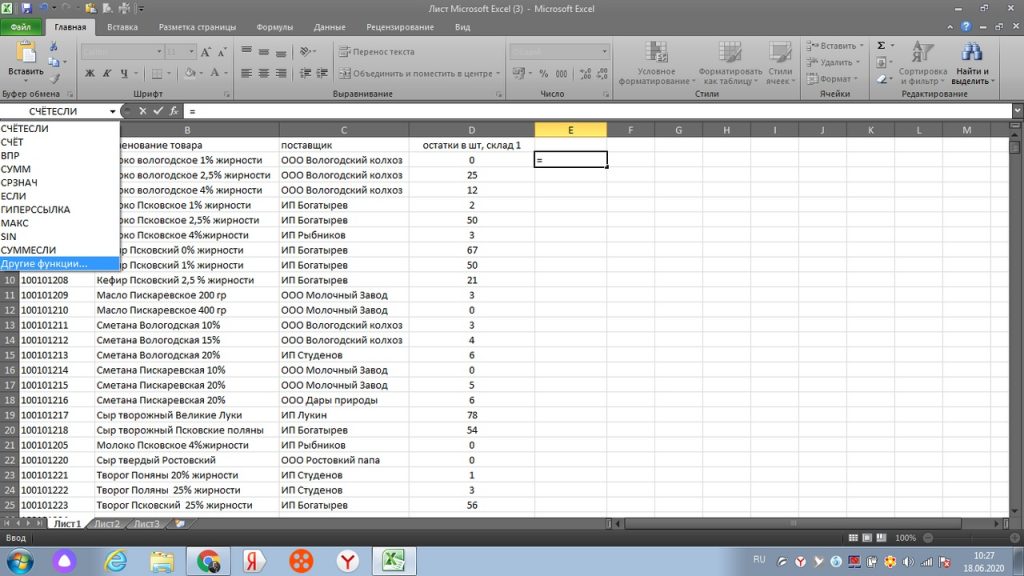
Для поиска повторяющегося значения, в данном случае, в коде товара по столбцу А, мы будем пользоваться простой формулой = СЧЕТЕСЛИ
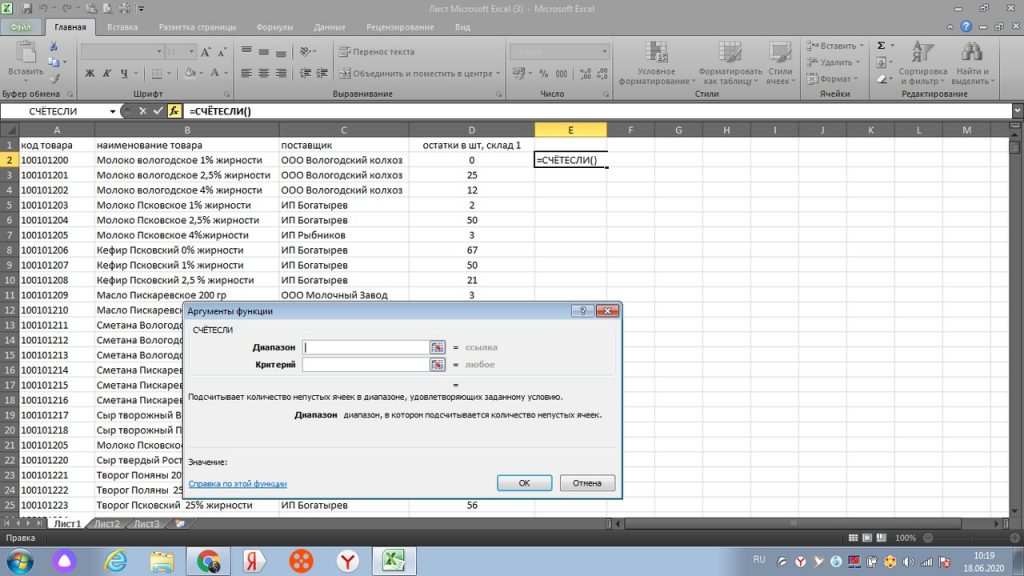
Выделяем весь столбец «А», и в диапазоне аргументов функций ( маленькое голубое окошко посреди экрана), у нас появляется А:А, то есть весь выделенный диапазон по этому столбцу. см. рис 3.
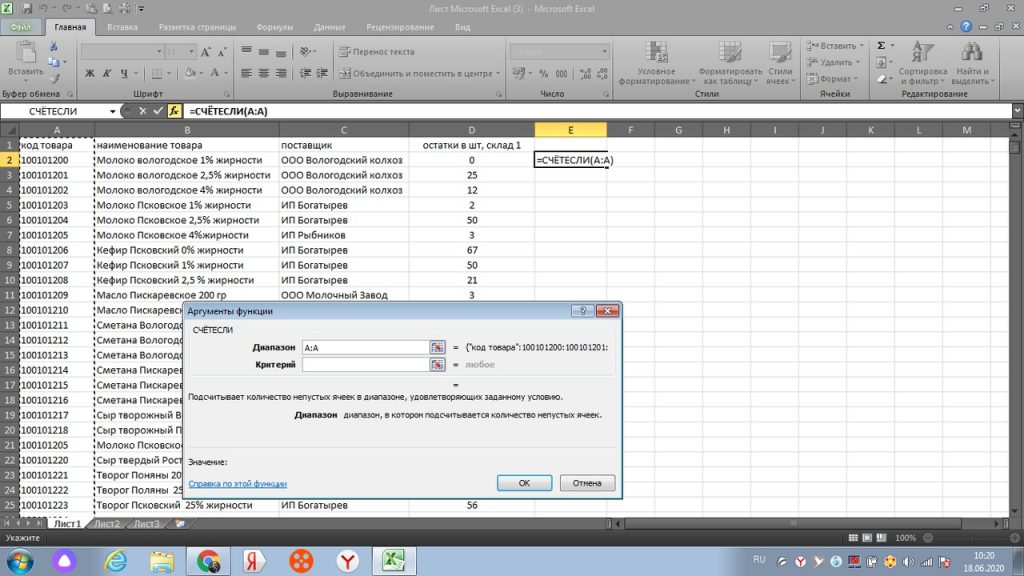
Переходим в окно «критерий», и выделяем только первую строку по коду товара. У нас она отразится, как А2. см. рис. 3.
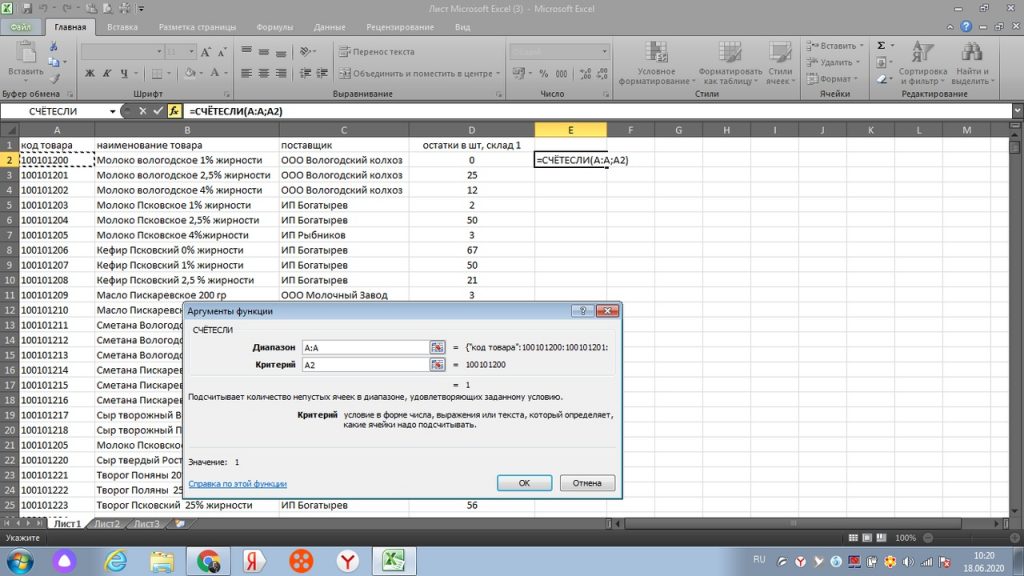
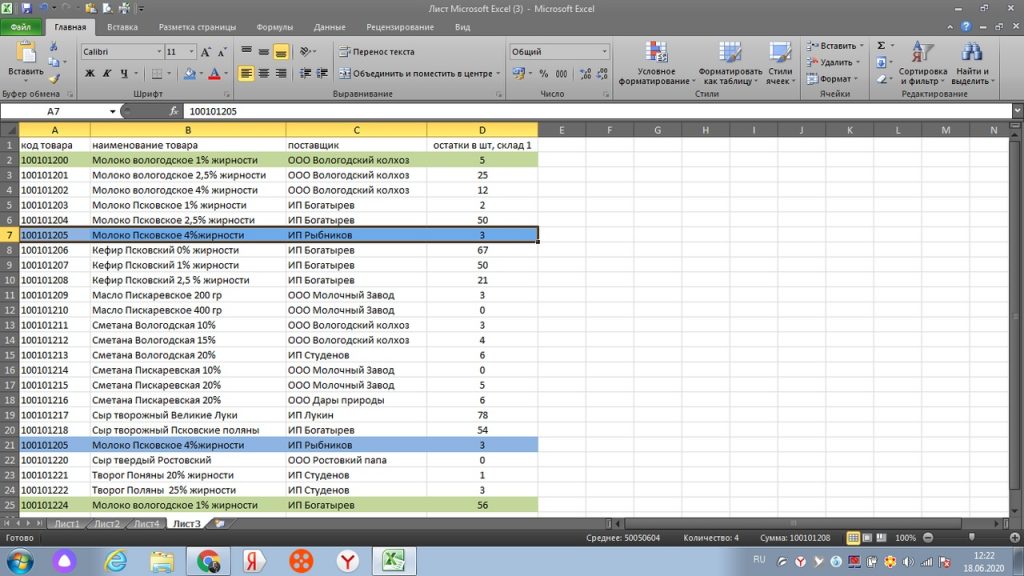
Далее, нажимаем «ок», и в столбце «Е» появляется цифра 1. Это значит, что по товару 100101200 Молоко Вологодское 1% жирности, только один такой товар, нет дублей. См. рис 5.
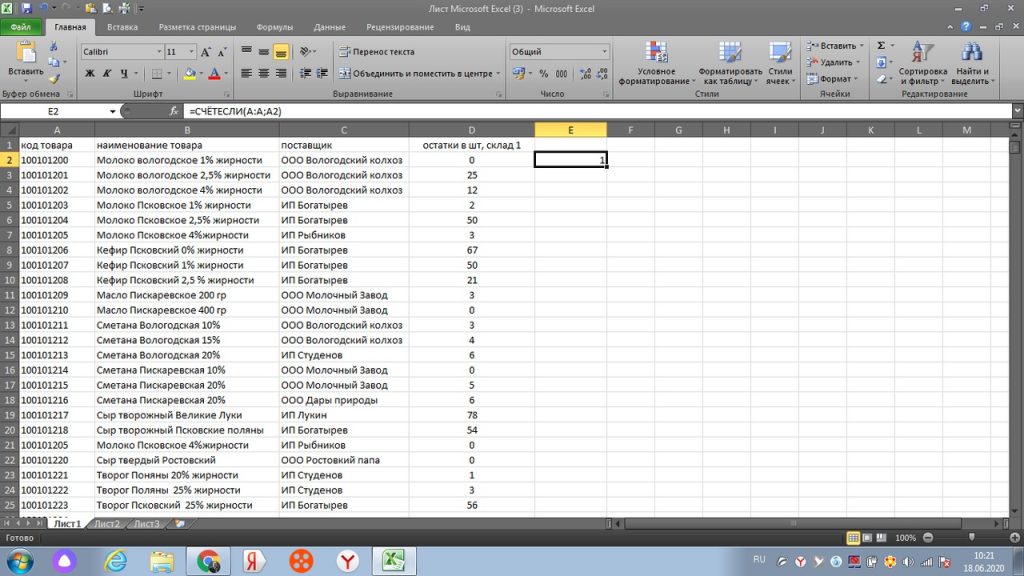
«Протягиваем» значения по столбцу «Е» вниз, и мы получаем результат, а именно, какие товары у нас имеют дубль в нашем списке, см рис 6. У нас проявилось 2 одинаковых товара, (их excel обозначил цифрой 2), которые, для наглядности вручную выделил желтым.
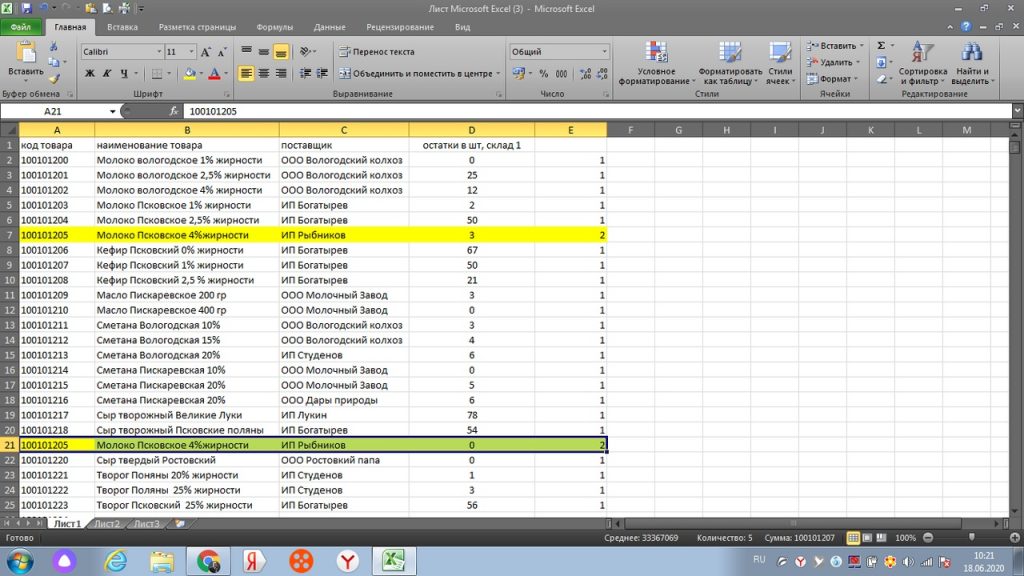
Если бы у нас было три одинаковых товара в списке, то excel, соответственно, проставил цифру 3. И так далее. Уже через простой фильтр, можно выделить, все, что больше 1 и увидеть полную картину.
Как в excel удалить дублирующиеся строки
По сути, метод, указанный выше, уже выполняет наш запрос. Однако, если Вам не нужны данные с повторяющихся строк, а требуется просто их удалить, тогда есть наиболее простой способ быстрого удаления дублей.
Мы воспользуемся функцией, которая уже встроена в панель excel. См. на панели закладку » ДАННЫЕ». Наша функция так и называется «Удалить дубликаты».
Мы выделяем область поиска, у нас это вновь столбец А. См рис 7.
(В более поздней версии excel, можно все находить через поисковое окно.)
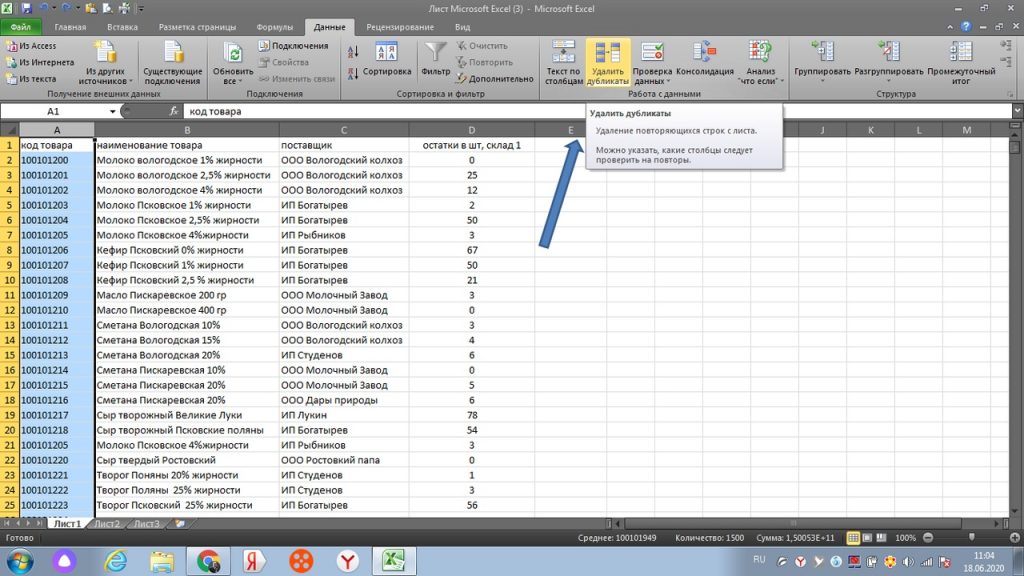
Далее нам просто нужно подтвердить удаление. Однако, для наглядности, выделил зеленым те задвоенные строки, которые у нас есть. Это строка 7 и 21. См рис 8.
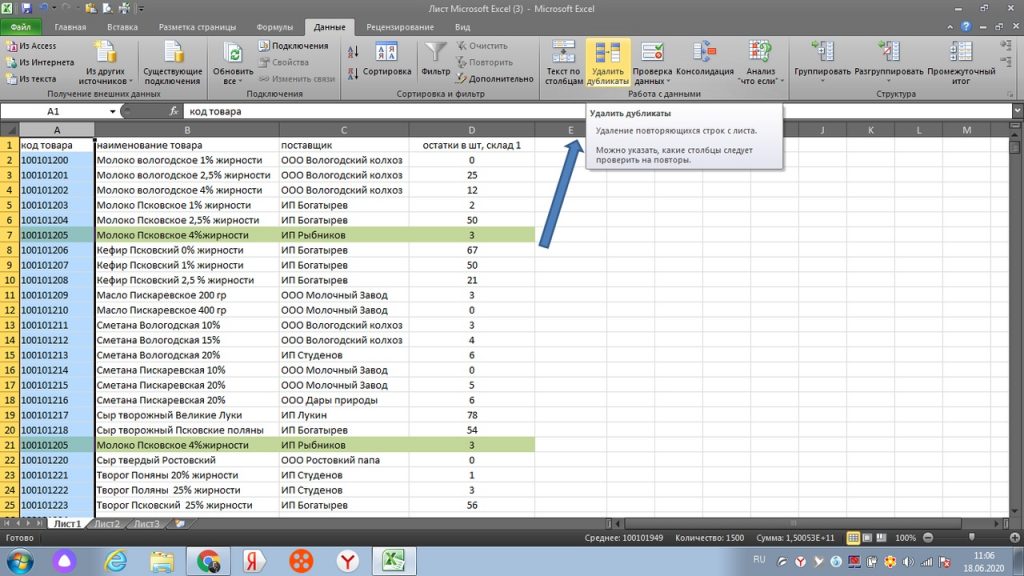
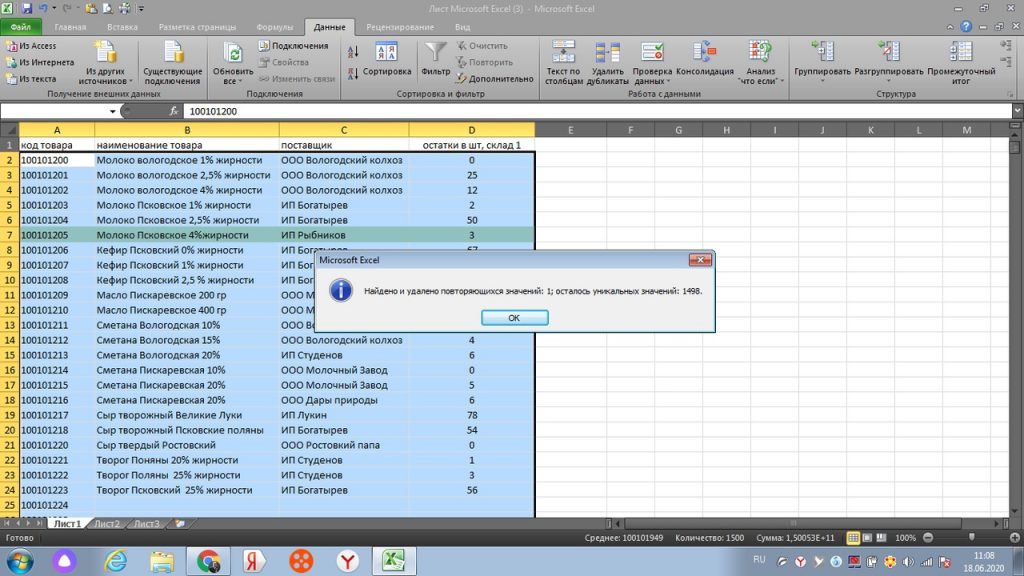
Теперь на панели жмем кнопку «удалить дубликаты». У нас появляется окошко. Здесь нам автоматически предлагает удалить всю горизонтальную строку, то есть «автоматически расширить выделенный диапазон». Жмем на кнопку «удалить дубликаты». См рис 9
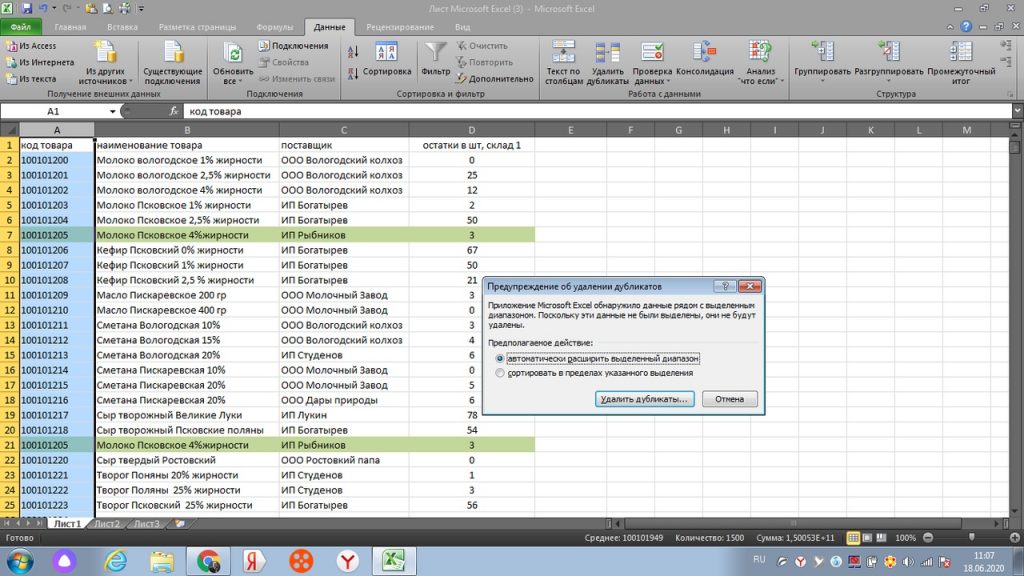
После этого мы видим, что указаны столбцы отмеченные галочками, которые будут удалены по дублирующейся горизонтальной строке. См. рис 10. Мы жмем «ок».
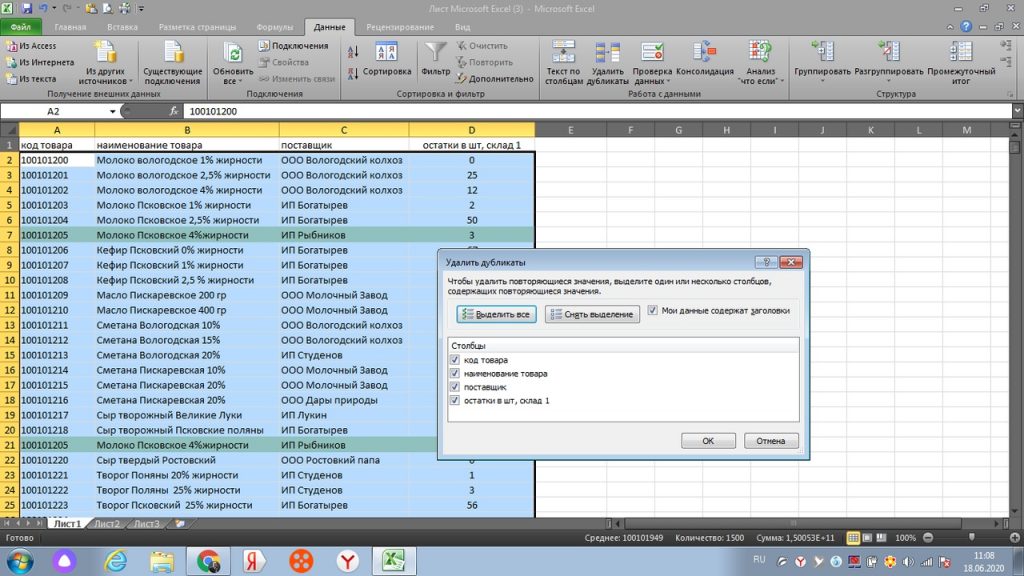
Все. Теперь мы видим окно с оповещением, что дубль в количестве 1 строки был удален. Теперь, на месте 21-ой строки по товару-дублю, появился следующий товар из нижнего списка. См. рис 11.
Исходя из описания, может показаться, что по времени занимает не меньше, чем в первом варианте, но на самом деле это не так. Я просто эту функцию расписал очень подробно.
Как в excel обработать большой объем данных, сводная таблица
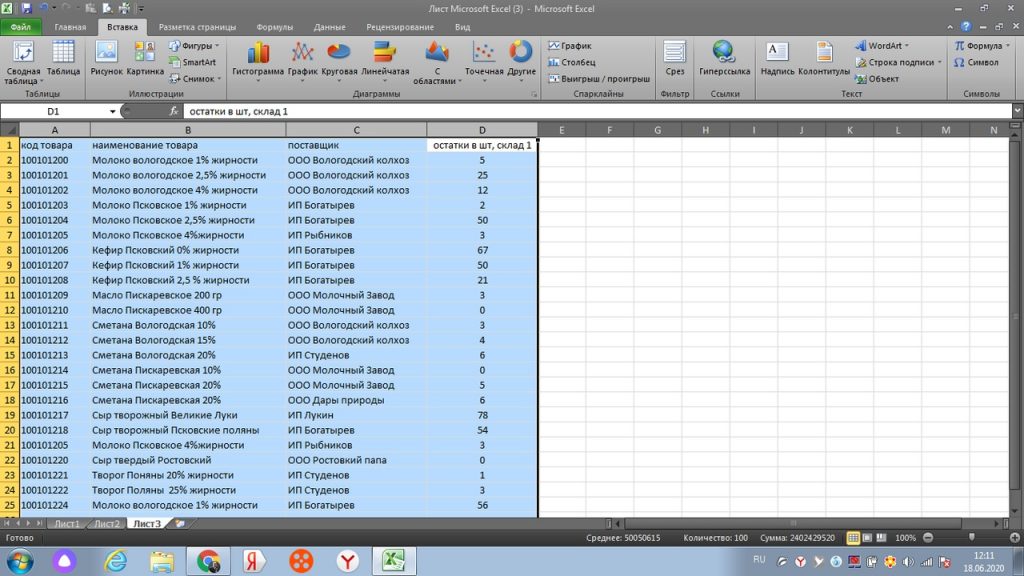
Сводная таблица служит для объединения разрозненной информации воедино. Сегодня мы также научимся это делать. Здесь нет ничего сложного. К примеру нам требуется, сколько же у нас есть одного и того же товара, не по брендам, а по виду товара.
Смотрим нашу таблицу. В панели инструментов ищем закладку «ВСТАВКА». Под панелью инструментов, в верхнем левом углу, появляется иконка, которая так и называется «Сводная таблица». см. рис 12. (Или ищем ее в поиске новой версии excel)
Мы выделяем все столбцы или столбцы интересующих нас значений.
Затем нажимаем на иконку «сводная таблица». У нас выходит окошко, в котором выделен диапазон столбцов. По умолчанию, excel предлагает сводную таблицу вынести на новый лист. см. рис 13. Мы так и делаем.
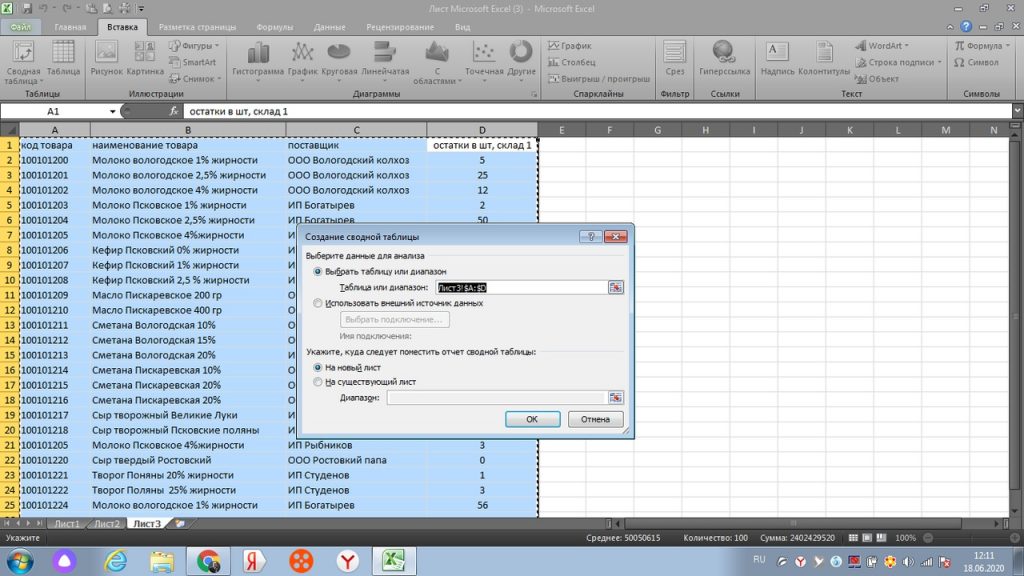
Подтверждаем команду нажав кнопку «ок». Получаем на новом листе нашей страницы excel возможность построения сводной таблицы, см рис 14.
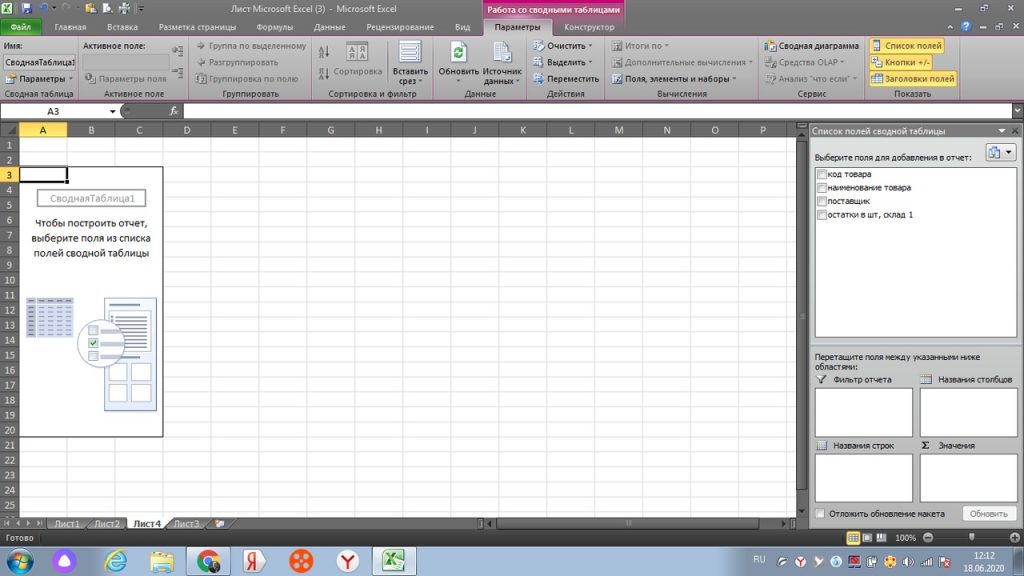
Теперь мы выбираем нужные нам значения из правого верхнего участка. Раз мы договорились, что нам нужно знать сколько у нас товара по одному наименованию, то выбираем галкой наименование товара. См. рис 15.
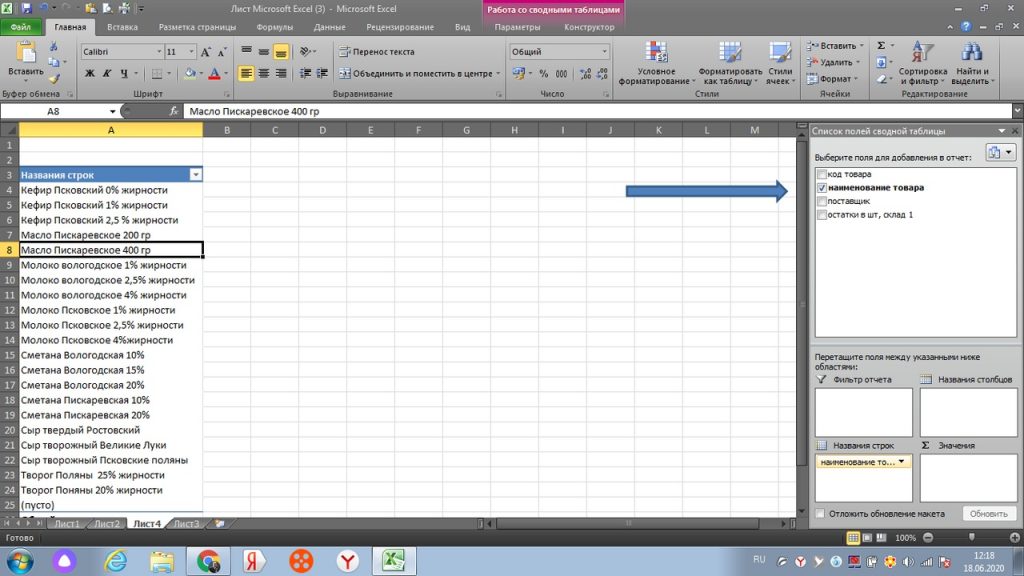
По аналогии, мы ставим галку напротив количества (остатки в шт, склад 1).
При этом, перемещаем данные с количеством не в окно «название строк», а в окно «Значения». см. рис 16
Здесь мы видим, что у нас появился дополнительный столбец, но пока не по количеству штук каждого товара, а по количеству строк. Далее мы делаем следующую операцию.
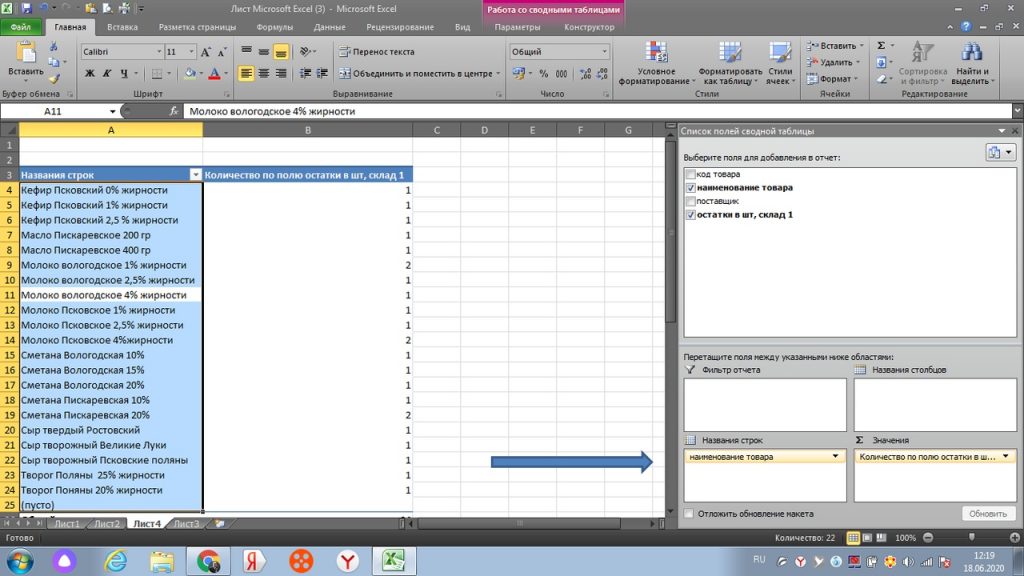
Правой клавишей мыши нажимаем на столбец с количеством. См. рис 17. У нас открывается окно, где в строке ИТОГИ ПО, мы ставим галку не по количеству (строк), как на картинке, а по сумме.
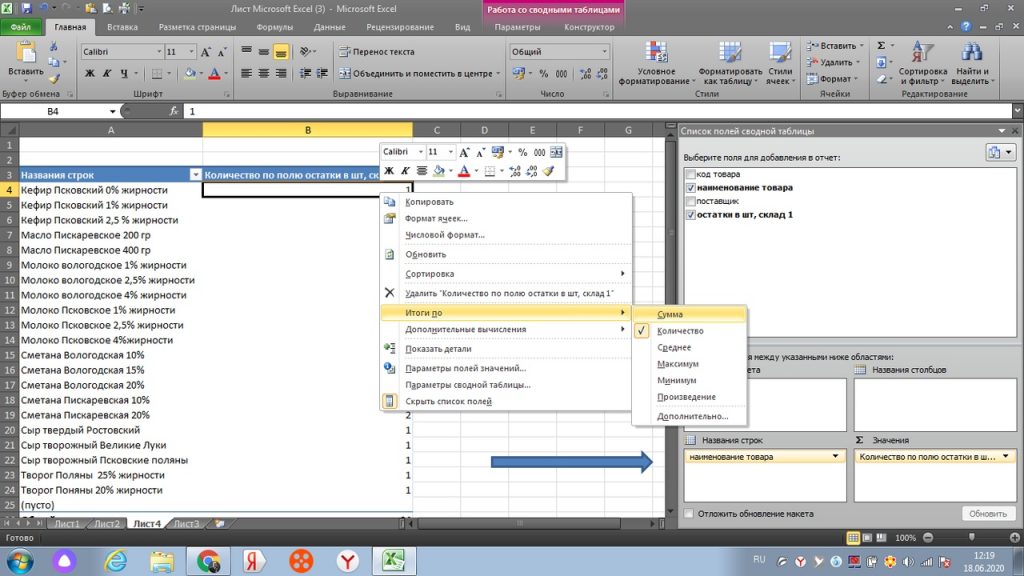
Теперь мы получаем именно сведенное количество по каждому товару. См рис 18.
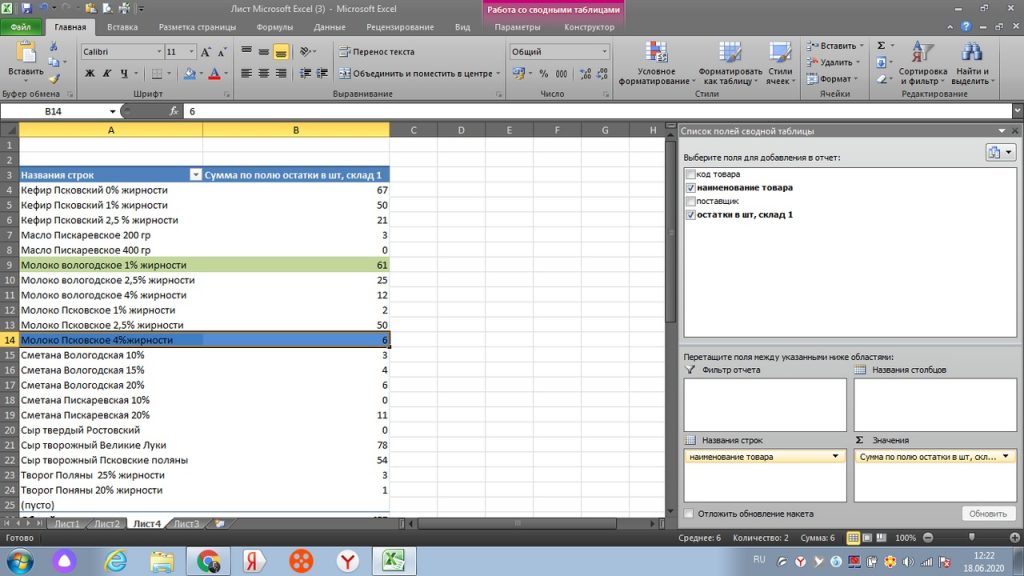
Для сравнения и наглядности, возвращаемся в исходный лист, (см. рис 19) и мы видим:
одинаковые товары по наименованию, помеченные синим цветом 3+3 = 6 штук.
одинаковые товары, помеченные зеленым 5+56 = 61 штука.
Тоже самое у нас в сводной таблице ( рис 18), 6 и 61 штука.
В сводную таблицу можно добавить поставщика и так далее. Можно ее сделать более сложной в плане количества учитываемый столбцов. Это уже дело необходимости и практики. Один-два раза сделаете, поймете суть. Потом, навык, как в excel обработать большой объем данных на уровне сводной таблицы, уже никогда не забудете.
Как в excel подтянуть данные из одного диапазона в другой, с помощью функции ВПР
Будет логичным, если сразу же покажу, как в excel «подтянуть» данные из другого листа или файла, в другой. Для этого есть замечательная функция ВПР. Мы разберем, как пользоваться этим на уже знакомых нам данных.
К примеру, Вам нужно свести цифры воедино с другого магазина, склада заявки на один лист Excel. Это делается по ключевому значению, которое должно быть во всех источниках данных. Это может быть уникальный код товара или его наименование.
Сразу оговорюсь по наименованию или текстовому значению, функция ВПР бескомпромиссна.
Если в наименовании товара есть пробел или точка, (любое отклонение) то для нее это будет уже другое значение.
Также необходимо, что бы все источники были в одном формате. Если мы говорим о числах, то в числовом формате.
Итак, у нас есть исходный файл, на листе 1, (см. рис 20)
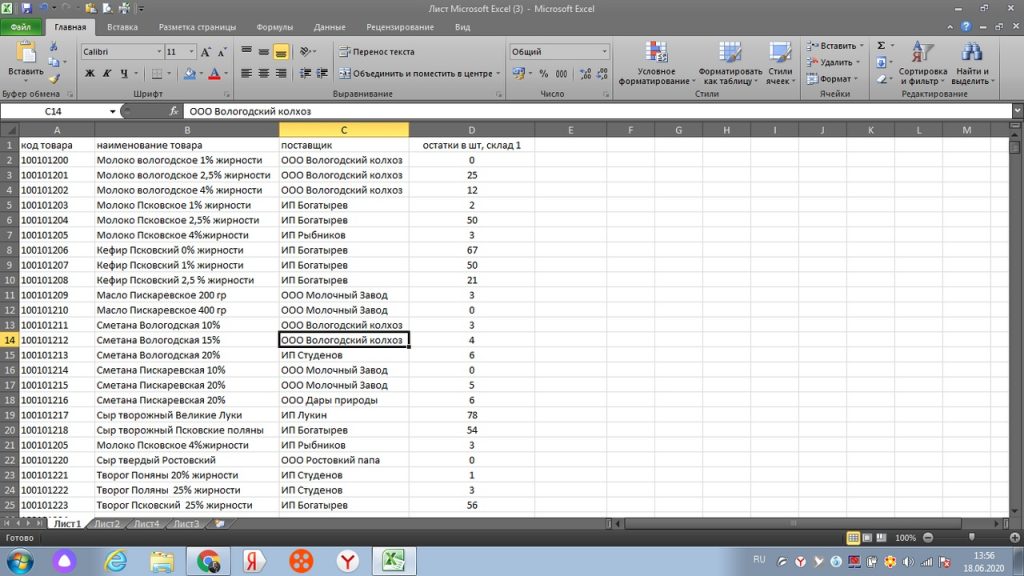
Из листа 2, (рис 21) мы будем подтягивать цифры в лист 1. Обратите внимание, что количества на листах разное. Строки также могут быть смещены в списке или перемешаны, поэтому, простым сложением одной цифры с другой нам не обойтись.
Для нас данные на листе 1 те, к которым нужно подтянуть другие значения. Также действуем через знак равно «=». В левом верхнем углу, через поиск других функций, находим ВПР, см рис 22.
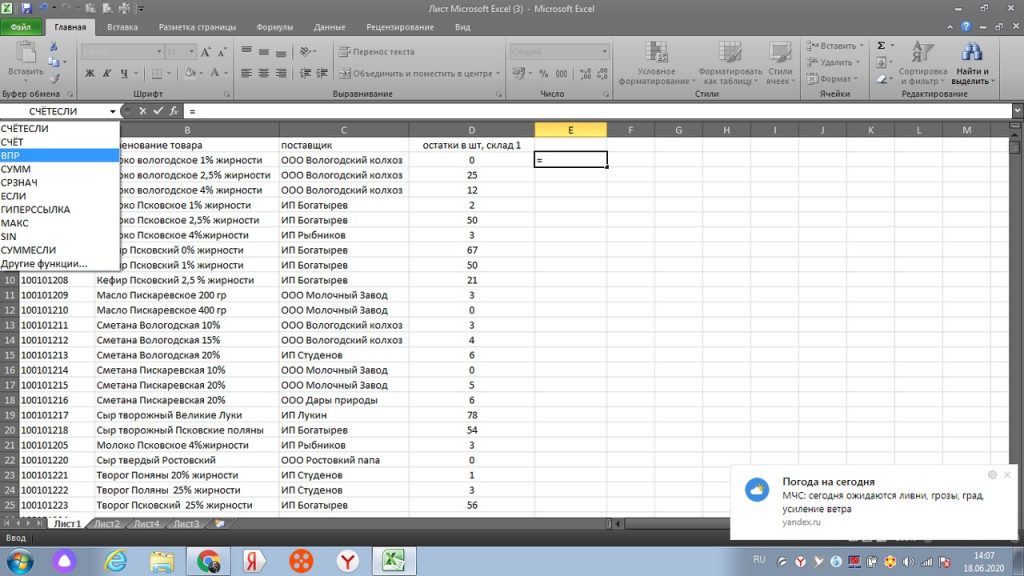
Затем, у нас открывается окно и мы выделяем весь столбец А, то есть искомое значение. Оно в новом окне выделяется, как А:А, см рис 23.
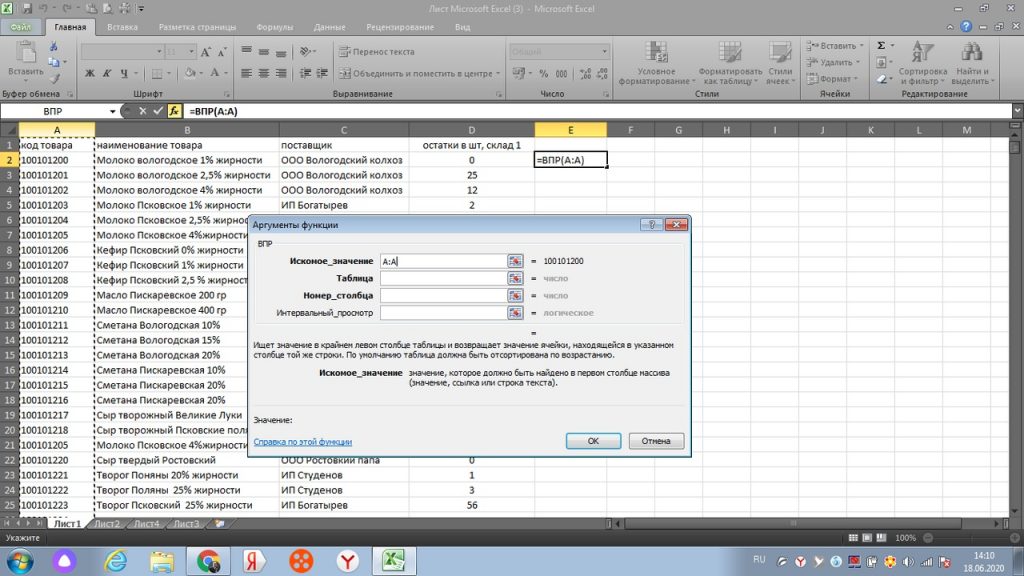
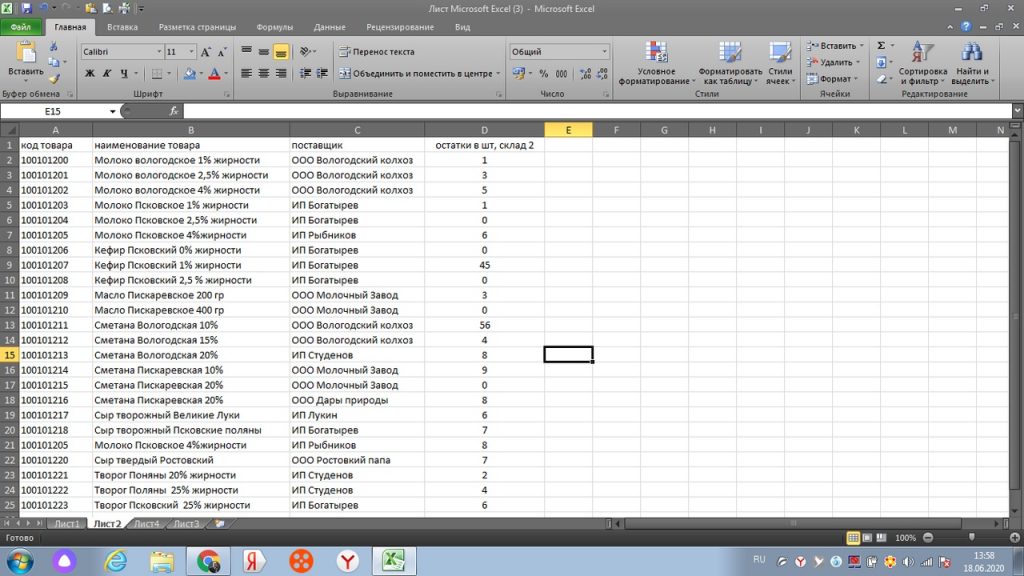
Далее, мышкой переходим в самом окошке на вторую строку «таблица», только после этого переходим на лист 2 нашего файла.
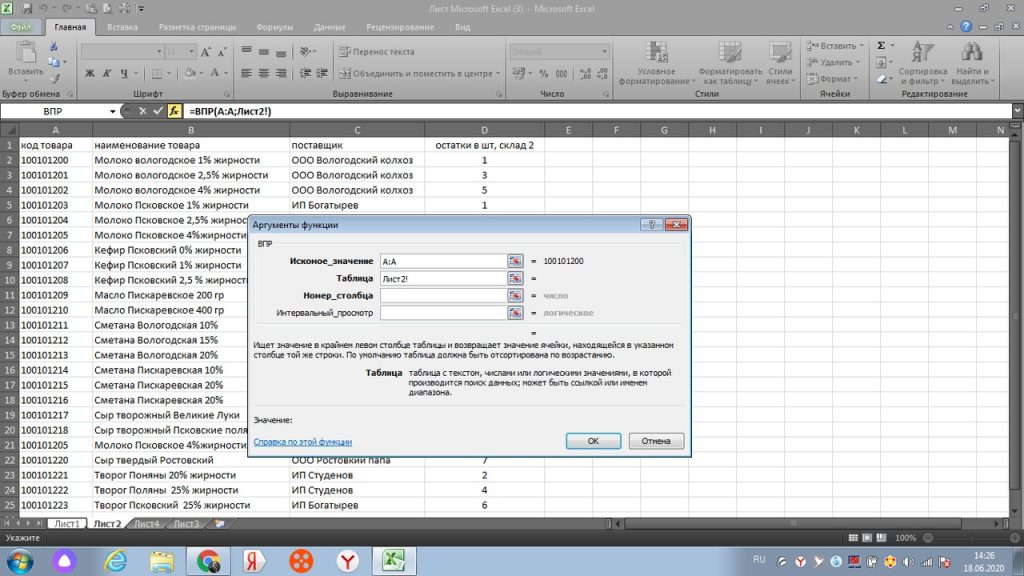
И от столбца «А» выделяем и протягиваем к столбцу с количеством. В данном случае, к столбцу «D», см рис 25.
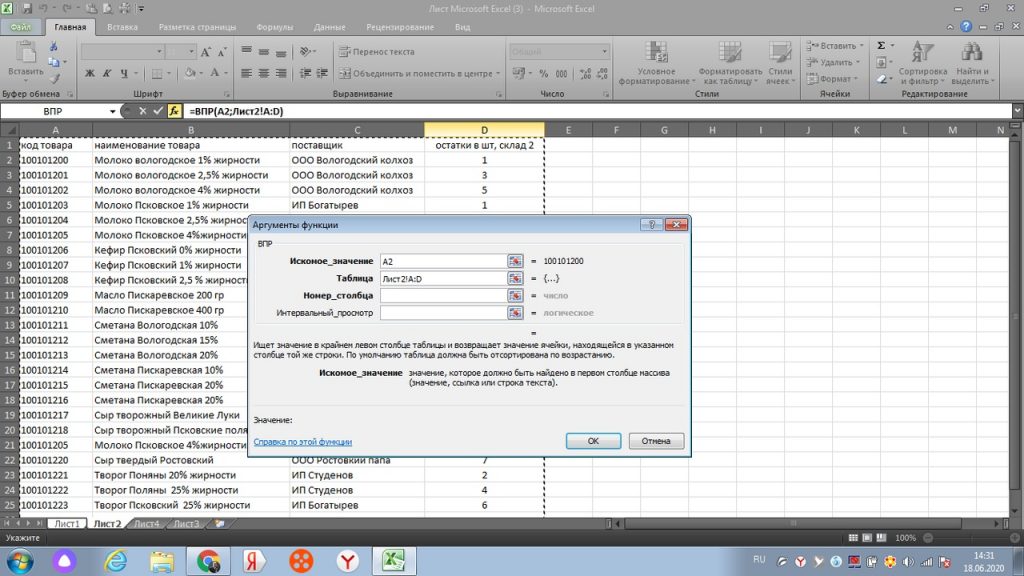
Столбец D, это четвертый столбец начиная с искомого значения, то есть с кода товара в столбце А.
Поэтому, мы ставим в третьем поле окошка «номер столбца» цифру 4. и в поле «интервальный просмотр» всего ноль. В итоге у нас получается заполненное окошко, см рис 26.
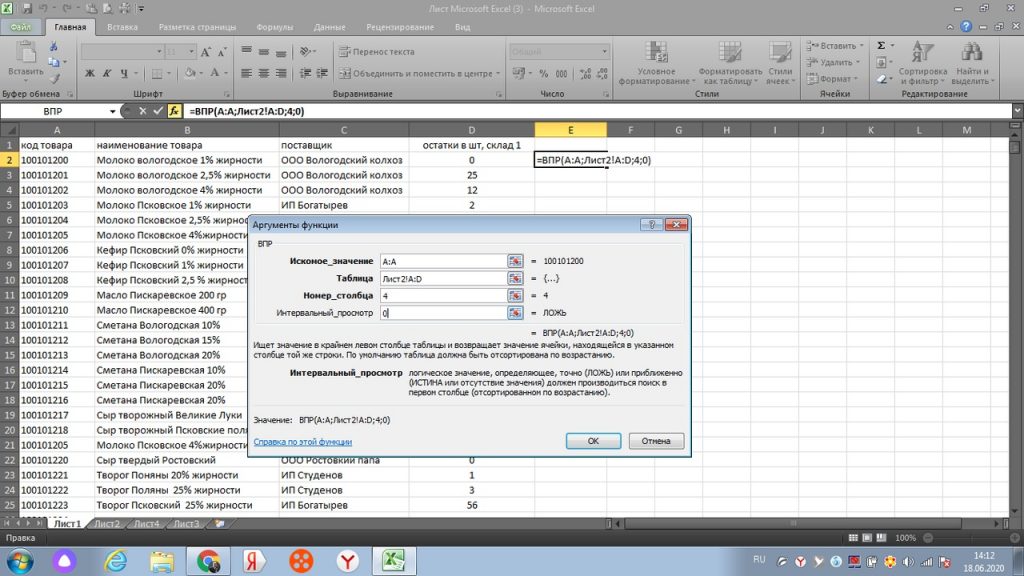
Нажимаем «ок», и получаем подтянутую цифру со второго листа, по коду товара 100101200. см. рис 27.
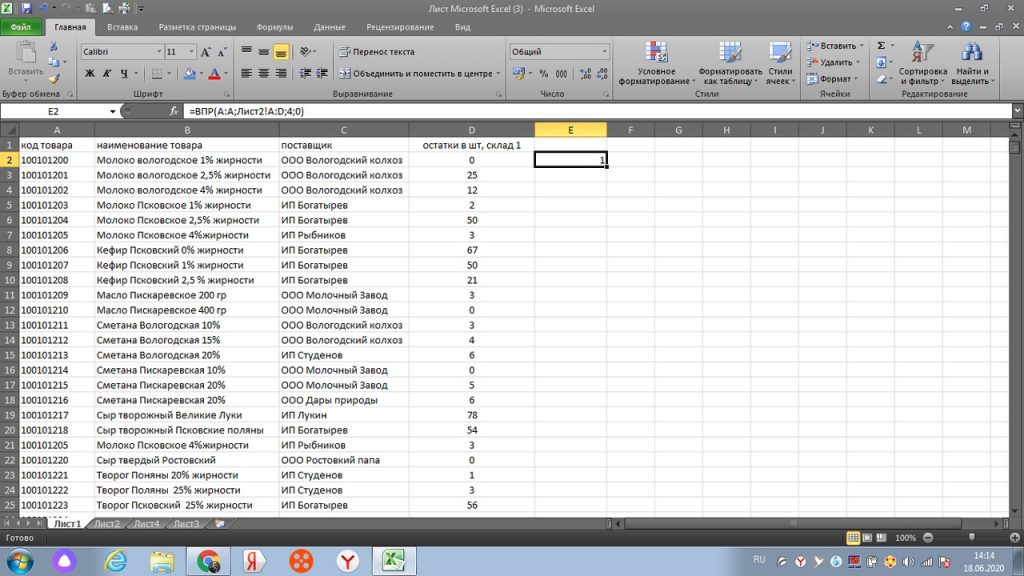
Протягиваем значение вниз, столбец D заполняется цифрами с листа 2. см. рис 28. Здесь нам остается просто сложить одни цифры с другими простой формулой сложения и протянуть вниз.
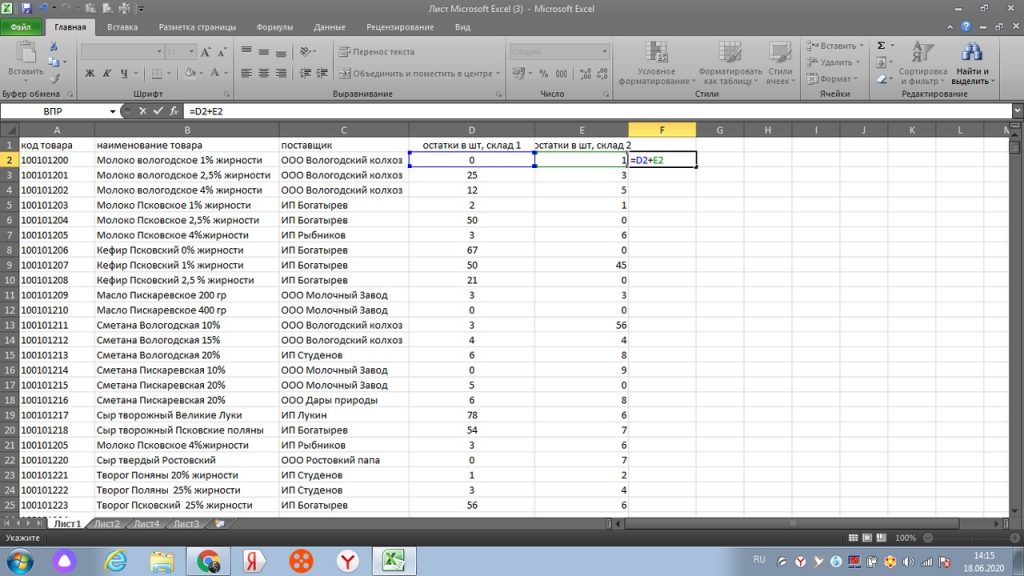
Таким образом, мы можем подтянуть значение из большого массива данных, которое вручную искать долго и не целесообразно, если есть функция ВПР.
Важный момент. Если Вы подтягиваете из другого файла, то файлы должны быть сохранены. И еще. Формулы подтянутых значений остаются. Вам нужна цифры привести в значения или не удалять и не менять значения, которые Вы подтягивали.
Как в excel обработать большой объем данных, функция правсимв и левсимв
Бывает, что необходимо для работы с функцией ВПР, привести искомые значения, и значение которые мы подтягиваем в единую форму. Как мы говорили выше, для ВПР любое отклонение, даже пробел, это уже другое значение.
Для этого, нам в помощь функция excel: правсимв и левсимв. То есть с помощью этой функции можно слева или справа нашего значения, например наименования товара, убрать лишние знаки.
Итак,, нам нужно взять только часть от полного наименования. Смотрим наш рис 29, к примеру, нам нужно только слово «молоко». Мы также в окне поиска формул ищем = левсимв.
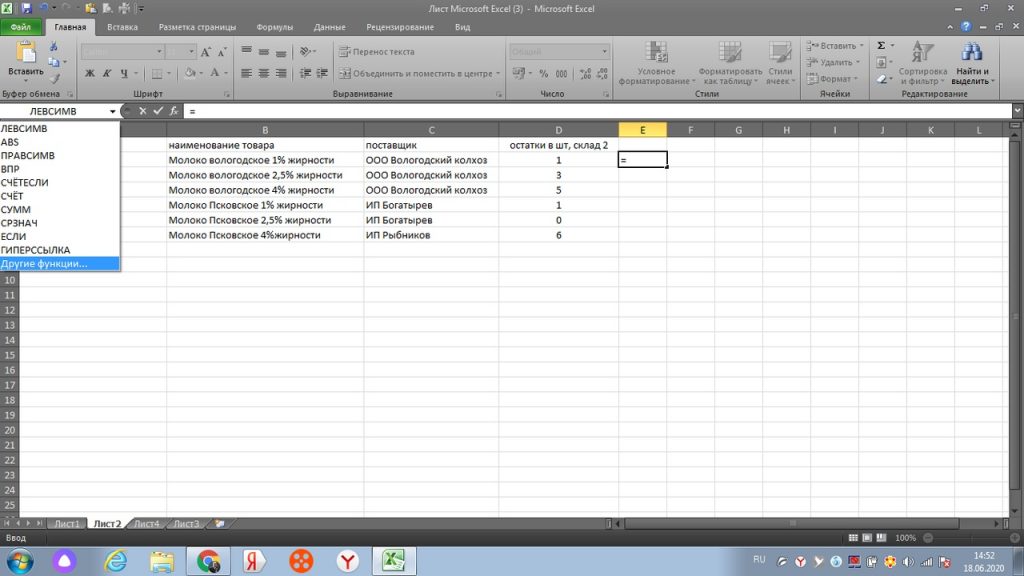
У нас появляется окошко, см рис 30.
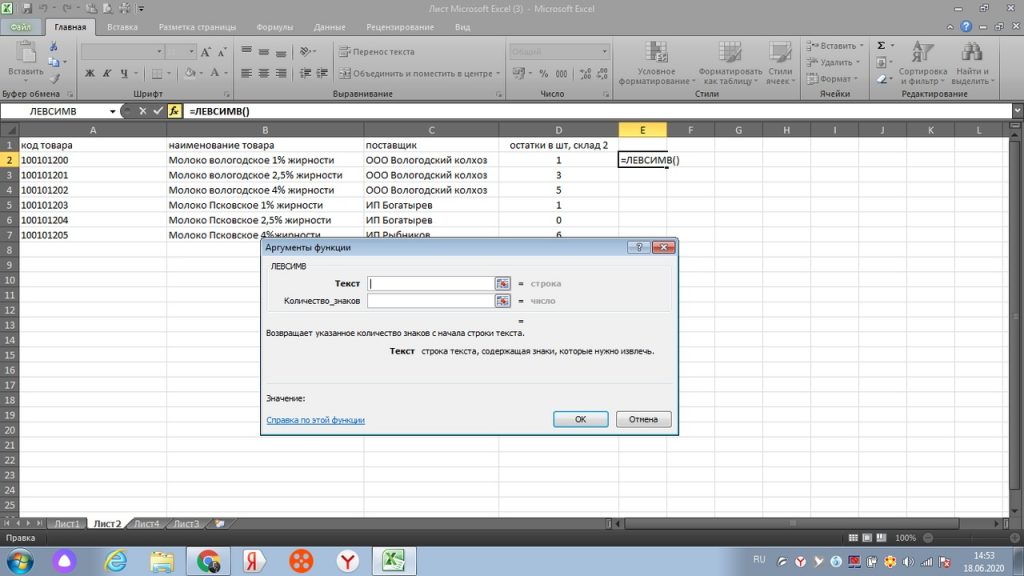
Мы выделяем интересующий нас столбец «В», в строке «текст» он появляется как В:В, см рис 31.
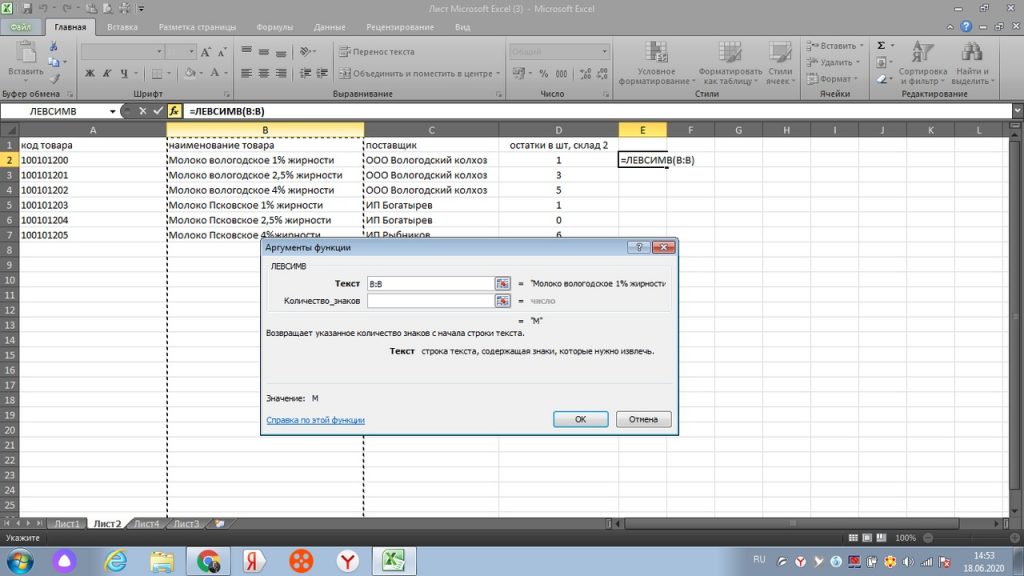
Далее, в строку «количество знаков» мы ставим ту цифру, сколько букв или символов содержит слово или слова с пробелом начиная с левой стороны. Если нам нужно только слово «молоко», то в нем, с учетом пробела 7 букв, поэтому, ставим цифру 7. См. рис 32.
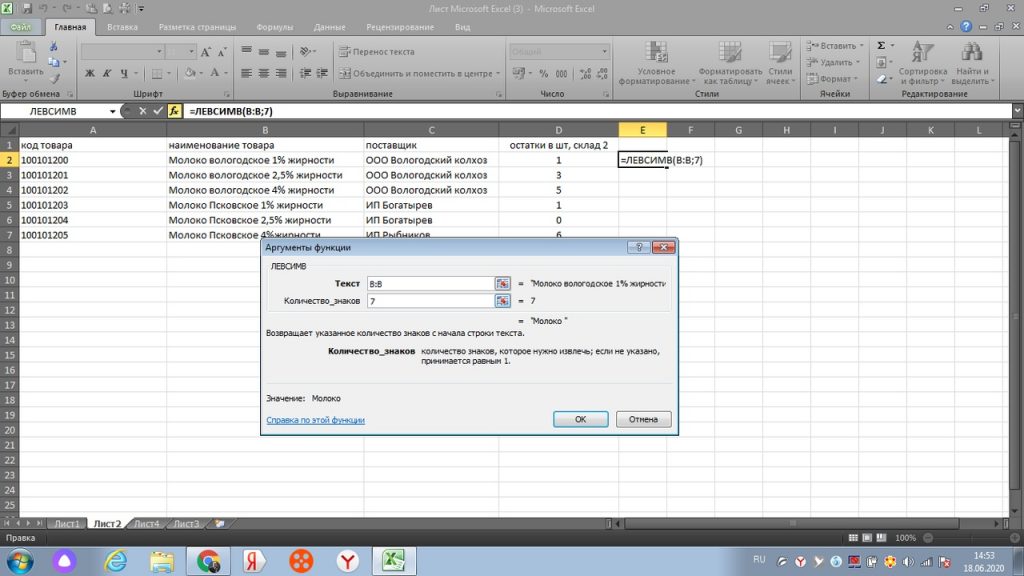
Вот и обрезалось наше наименование только в нужное нам слово, см. рис 33.
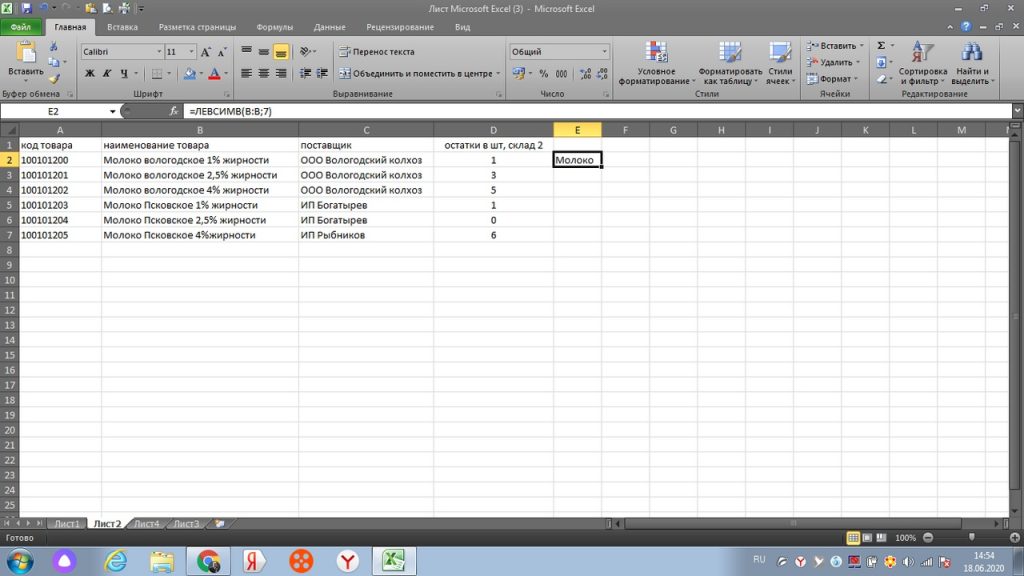
Теперь остается только «протянуть» вниз, и все значения с первыми 7-ю символами с левой стороны, будут в нашей таблице., см рис 34.
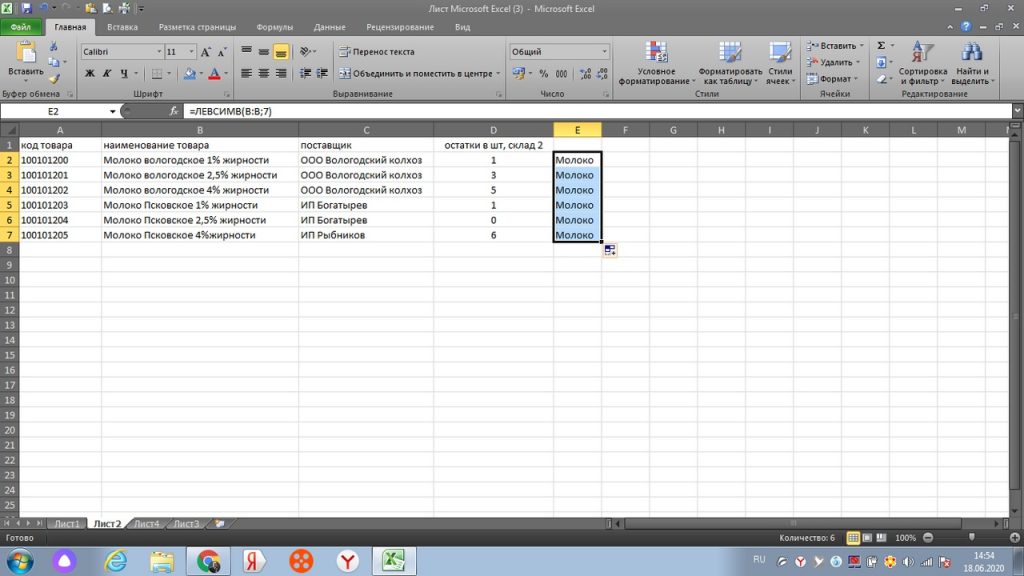
По аналогии, можно пользоваться функцией ПРАВСИМВ. Здесь все тоже самое, только символы оставляет с правой стороны. Эту функцию часто применяют на числовых значениях, когда код имеет дополнительные обозначения или отделяется, например точкой.
Заключение
Я отдельно сделал статью, как в excel вести учет и планирование товарных запасов. Ели интересно, статью можно почитать здесь.
Чтобы не утяжелять прочтение, разделю материал на две части. В следующей части пойдет речь о том, как в excel обработать большой объем данных с помощью функции СЦЕПИТЬ, построения графиков и диаграмм. Как автоматически подсветить значения верхнего или нижнего порога, и как седлать пароль на страницу или всю книгу в excel, и так далее.
Надеюсь материал был полезным, всего Вам хорошего. Успехов!
Содержание
MS Excel
27 сентября, 2017
Евгений Довженко о том, как можно эффективно работать даже с огромными массивами данных.

Любой сотрудник компании, работающий в отделе продаж, финансов, маркетинга, логистики, сталкивается с необходимостью работать с данными, анализировать их.

Excel — незаменимый помощник для достижения этих целей. Мы импортируем информацию, «подтягиваем» ее, систематизируем. На ее основе строим диаграммы, сводные таблицы, планируем, прогнозируем.
Однако в Excel до недавнего времени было 2 важных ограничения:

Мы не могли разместить на рабочем листе Excel более миллиона строк (а наши данные о продажах за 2 года занимают, например, 10 млн строк).

Мы знали, как создать и настроить интерактивные и обновляемые отчеты, но это отнимало много времени.
Единственный инструмент в Excel — сводные таблицы — позволял быстро обрабатывать наши данные.
С другой стороны, есть категория пользователей, которые работают со сложными BI-системами. Это системы бизнес-аналитики (business intelligence), которые дают возможность быстро визуализировать, «крутить» данные и извлекать из них ценную информацию (data mining). Однако внедрение и поддержка таких систем требует значительного участия IT-специалистов и больших финансовых вложений.
До Excel 2010 было четкое разделение на анализ малого и большого объема данных: Excel с одной стороны и сложные BI-системы — с другой.
Начиная с версии 2010, в Excel добавили инструменты, в названиях которых присутствует слово power: Power Query, Power Pivot и Power View. Они позволили сгладить грань между пользователями Excel и комплексных BI-систем.
Power Query
Чтобы работать с данными, к ним нужно подключиться, отобрать, преобразовать или, другими словами, привести их к нужному виду.
Для этого и необходим Power Query. До версии Excel 2013 включительно этот инструмент был в виде надстройки, которую можно было установить бесплатно с сайта Microsoft.
В версии 2016 это уже встроенный в программу инструментарий, находящийся на вкладке «Данные» (Data) в разделе «Скачать и преобразовать» (Get and Transform).
Перечень источников информации, к которым можно подключаться — огромный: от баз данных (их в последней версии 10) до Facebook и Google таблиц (рис. 1).
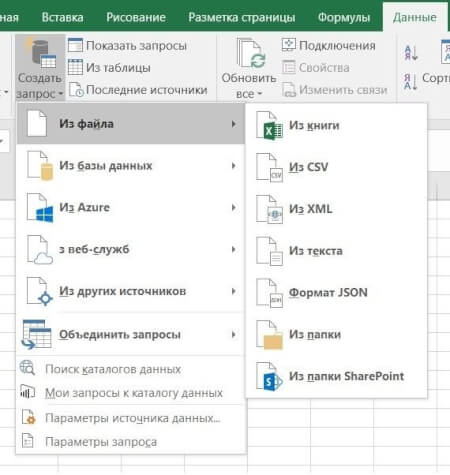
Рис 1. Выбор источника данных в Power Query
Вот некоторые возможности Power Query по подготовке и преобразованию данных:

отбор строк и столбцов, создание пользовательских (вычисляемых) столбцов

преобразование данных с помощью числовых, текстовых функций, функций даты и времени

транспонирование таблицы, разворачивание по столбцам (Pivot) и наоборот — сворачивание данных, организованных по столбцам, в построчный вид (Unpivot)

объединение нескольких таблиц: как вниз — одну под другую, так и связывание по общей колонке (единому ключу)
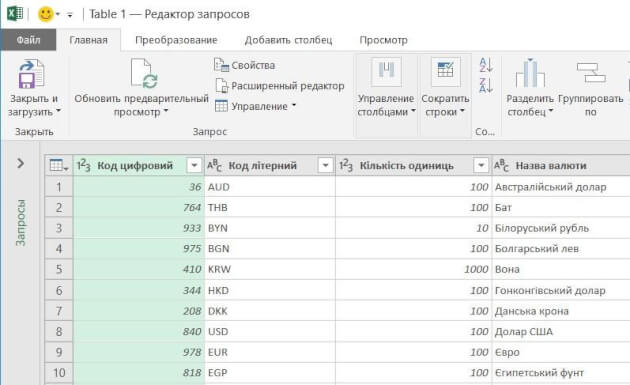
Рис 2. Окно редактора Power Query
Ну и конечно, после выгрузки подготовленных данных в Excel они будут автоматически обновляться, если в источнике данных появятся новые строки.
Пример
Компания в своей аналитике использует текущие курсы трех валют, которые ежедневно обновляются на сайте Национального банка.
Таблица на сайте непригодна для прямого использования (рисунок 2-1):

все валюты не нужны

в колонке «Курс» в качестве разделителя целой и дробной частей используется точка (в наших региональных настройках — запятая)

в колонке «Курс» отображается показатель за разное количество единиц валюты: за 100, за 1000 и т. д. (указано в отдельной колонке «Количество единиц»)
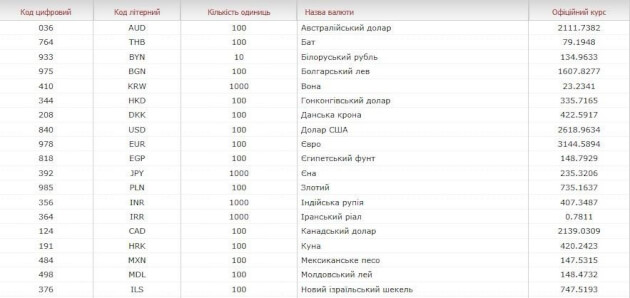
Рис. 2-1. Так выглядит таблица с курсами валют на сайте Нацбанка.
С помощью Power Query мы подключаемся к таблице текущих курсов валют на сайте НБУ и в этом редакторе готовим запрос на извлечение данных:

В колонке «Курс» меняем точку на запятую (инструмент «Замена значений»).

Создаем вычисляемый столбец, в котором курсы валют в колонке «Курс» делятся на количество единиц валюты из колонки «Количество единиц».

Удаляем лишние столбцы и оставляем только строки валют, с которыми работаем.

Выгружаем полученную таблицу на рабочий лист Excel.
Результат показан на рисунке 2-2.
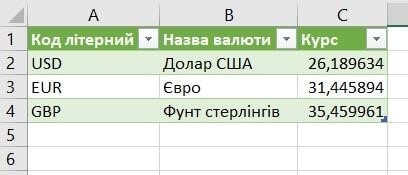
Рис. 2-2. Так выглядит результирующая таблица в нашем Excel файле.
Курсы валют на сайте Нацбанка меняются каждый день. Но при обновлении данных в документе Excel наш, один раз подготовленный, запрос пройдет через все шаги, и результирующая таблица всегда будет в нужном виде, но уже с актуальными курсами.
Power Pivot
У вас данные находятся в разрозненных источниках? Некоторые таблицы содержат больше 1 млн строк? Вам нужно все это объединить в одну модель данных и анализировать с помощью, например, сводной таблицы Excel? Здесь понадобится Power Pivot — надстройка Excel, которая по умолчанию включена в версии Pro Plus и выше (начиная с версии 2010).
В Power Pivot вы можете добавлять данные из разных источников, связывать таблицы между собой (рисунок 3). Таблицы при этом не обязательно должны находиться на рабочих листах Excel. Вместо этого они по-прежнему будут храниться в файле Excel, но просматривать их можно в окне Power Pivot (рис. 4). Поэтому нет ограничения на количество строк — в вашем файле Excel могут находиться таблицы и в сотни миллионов строк.
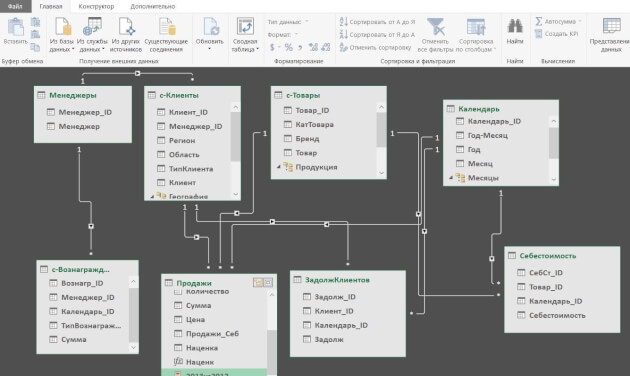
Рис. 3. Окно Power Pivot в представлении диаграммы
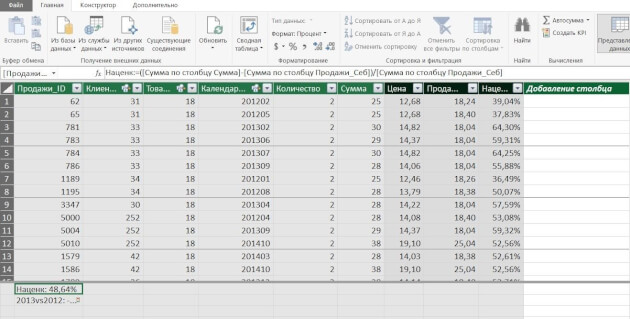
Рис. 4. Окно Power Pivot в представлении данных
Вот некоторые возможности Power Pivot, помимо описанных выше:

добавлять вычисляемые столбцы и поля (меры), в том числе основанные на расчетах из нескольких таблиц

создавать и мониторить в сводной таблице ключевые показатели эффективности (KPI)

создавать иерархические структуры (например, по географическому признаку — регион, область, город, район)
И обрабатывать все это с помощью сводной таблицы Excel, построенной на модели данных.
Пример. У предприятия в базе данных (или отдельных файлах Excel) в 5 таблицах хранится информация о продажах, клиентах, товаре и его классификации, менеджерах по продажам и закупочных ценах продукции. Необходимо провести анализ по объемам продаж и маржинальности по менеджерам.
С помощью Power Pivot:
добавляем все 5 таблиц в модель данных

связываем таблицы по общим ключам (столбцам)

в таблице «Продажи» создаем вычисляемый столбец «Продажи в закупочных ценах», умножив количество штук из таблицы «Продажи» на закупочную цену из таблицы «Цена закупки»

создаем вычисляемое поле (меру) «Маржа»

с помощью инструмента «Ключевые показатели эффективности» устанавливаем цель по маржинальности и настраиваем визуализацию — как выполнение цели будет визуализироваться в сводной таблице
Теперь можно «крутить» эти данные в сводной таблице или в отчете Power View (следующий инструмент) и анализировать маржинальность по товарам, менеджерам, регионам, клиентам.
Power View
Иногда сводная таблица — не лучший вариант визуализации данных. В таком случае можно создавать отчеты Power View. Как и Power Pivot, Power View — это надстройка Excel, которая по умолчанию включена в версии Pro Plus и выше (начиная с версии 2010).
В отличие от сводной таблицы, в отчет Power View можно добавлять диаграммы и другие визуальные объекты. Здесь нет такого количества настроек, как в диаграммах Excel. Но в том то и сила инструмента — мы не тратим время на настройку, а быстро создаем отчет, визуализирующий данные в определенном разрезе.
Вот некоторые возможности Power View:

— быстро добавлять в отчет таблицы, диаграммы (без необходимости настройки)

организовывать срезы и фильтры

уходить на разные уровни детализации данных

добавлять карты и располагать на них данные

создавать анимированные диаграммы
Пример отчета Power View — на рисунке 5.
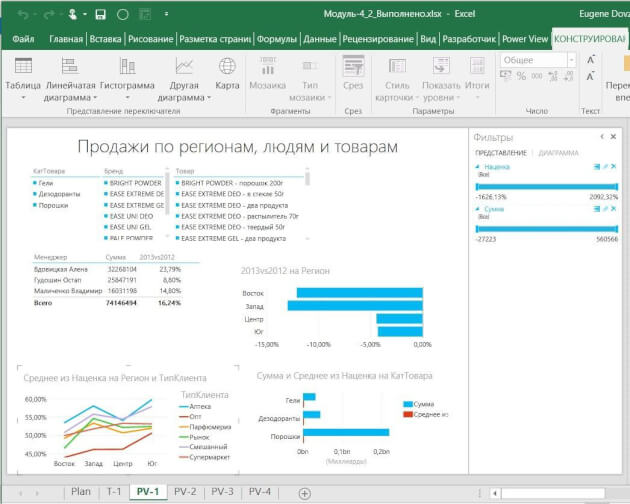
Рис. 5. Пример отчета Power View
Даже самые внушительные массивы данных можно систематизировать и визуализировать — главное не ограничиваться поверхностными возможностями Excel, а брать из его функций все возможное.


Хотите получать дайджест статей?
Одно письмо с лучшими материалами за неделю. Подписывайтесь, чтобы ничего не упустить.
Спасибо за подписку!
Курс по теме:
«Advanced Excel»
Программы
Ведет
Никита
Свидло
![]()
16 мая
13 июня

How’s your experience in working on a large Excel file in Windows 10, like ~10MB? In fact, accountants for example, are producing Excel files with much bigger size than 10MB. Some people noticed that large files are likely to cause a crash in Excel. Is the file size responsible for the crash?
As a matter of fact, big file size is not the real culprit for the Excel crashing issue. It’s said that unstable, crashing, or freezing workbooks only tend to happen when your spreadsheets have grown to at least 20MB in size, given how much processing power modern computers have. Hence, you should consider other factors that crash Excel when the file you’re working on is far less than 20MB in size.
Why Large Excel Files Crash
Except for the fact that the excel file is really large over 20MB, chances are that there are other factors that make your Excel unsteady to use. The factors are basically as follows:
- Formatting, styles, and shapes in a worksheet
- Calculations and formulas in a worksheet
- Computer’s RAM issue
How to Make Large Excel Files Work Faster Without Crash
- Important
- A large excel file usually contains hundreds of rows of critical data with many styles and formulas in it, so you must take good care of the workbook by making a real-time backup, in case one day unexpected data loss happens due to the Excel crash, not responding or stop working suddenly before you can click Save. We suggest everyone turn on auto save in Excel, to save the workbook every 1~5 minutes.
Next, we’re going to troubleshoot a slow workbook upon opening or editing in Excel around the discussed three factors. No matter it’s a small or big Excel file since it causes a crashing issue in Excel, the given solutions in each section should help.
Step 1. Remove Excessive Formatting
Formatting cells on your worksheet can make the right information easy to see at a glance, but formatting cells that aren’t being used (especially entire rows and columns) can cause your workbook’s file size to grow quickly. Microsoft has its own add-on called Clean Excess Cell Formatting, which is available on Excel’s Inquire tab in Microsoft Office 365 and Office Professional Plus 2013. If you don’t see the Inquire tab in Excel, do the following to enable the Inquire add-in:
- Click File > Options > Add-Ins.
- Make sure COM Add-ins is selected in the Manage box, and click Go.
![]()
- In the COM Add-Ins box, check Inquire, and then click OK. The Inquire tab should now be visible in the ribbon.
To remove the excess formatting in the current worksheet, do the following:
- On the Inquire tab, click Clean Excess Cell Formatting.
- Choose whether to clean only the active worksheet or all worksheets. After excess formatting has been cleared, click Yes to save changes to the sheets or No to cancel.
Step 2. Remove Unused Styles
Too many different styles on an Excel workbook are likely to cause a specific error of «Too many different cell formats», and the alongside symptom is a constant crash in Excel. Hence, you should avoid using multiple styles on one worksheet. To clean up workbooks that already contain several styles, you can use one of the following third-party tools suggested by Microsoft.
- Excel formats (xlsx, xlsm) — XLStyles Tool.
- Binary Excel formats (xls, xlsb), workbooks protected by a password, and encrypted workbooks — Remove Styles Add-in.
Step 3. Remove Conditional Formatting
- Under Home, click Conditional Formatting.
- Choose Clear Rules.
- Select Clear Rules from Entire Sheet
- If multiple sheets adopt the rule, repeat the steps to clear them all
Step 4. Remove Calculations and Formulas
If you’ve gone through the above three-step check and removable unnecessary cell formatting, styles, and conditional formatting, but still work clumsily on a large Excel workbook, you may need to look at the formulas and calculations in your worksheet. You don’t have to check every calculation and fomula you’ve applied in the file, but those primary ones tend to eat a lot of your computer’s resources.
- Formulas that reference entire rows or columns
- SUMIF, COUNTIF, and SUMPRODUCT
- Large number of formulas
- Volatile functions
- Array formulas
Step 5. Examine the Computer RAM Issue
Last but not the least, if none of the four-step efforts speed up the performance in working on a large Excel file in Windows 10, it may be an issue with your computer’s memory. Follow the 10 tips on how to solve high RAM memory usage issue in Windows 10.
How to Repair Corrupted Large Excel Files Efficiently
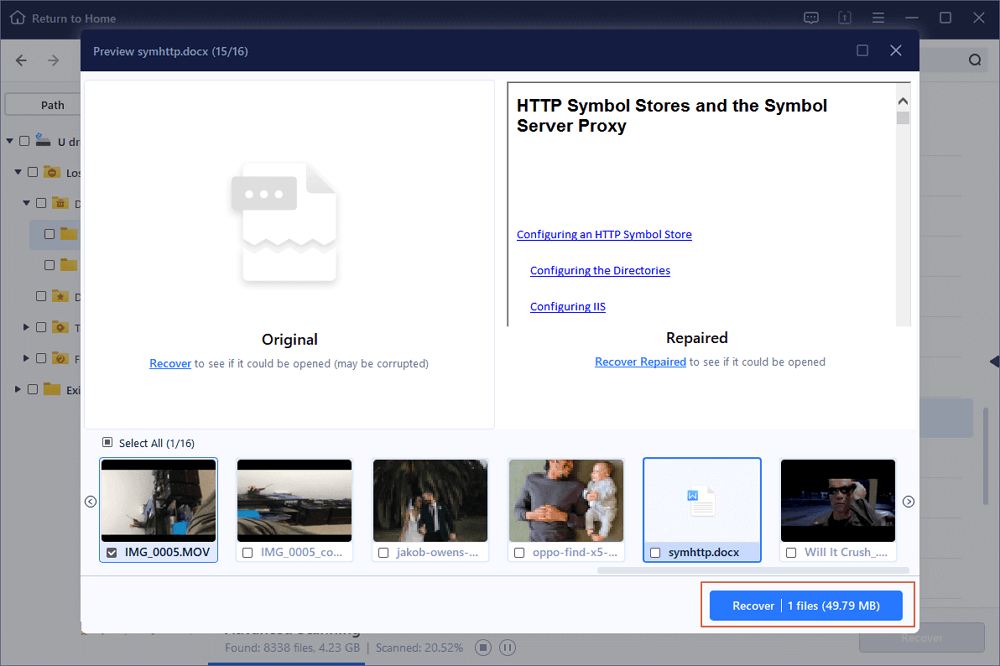
What if Excel has crashed and corrupted the files? How can you fix damaged Excel in time? Try EaseUS Data Recovery Wizard. This advanced file repair tool resolves Excel file corruption and restores the .XLS/.XLSX file data. It fixes all types of Excel corruption errors, such as unrecognizable format, unreadable content, Excel runtime error, etc.
With this file repair tool, you can:
- Repair corrupted Excel with tables, images, charts, formulas, etc.
- Repair multiple .XLS and .XLSX at one time
- Fix damaged Excel files in 2019, 2016, 2013, 2010, 2007, 2003, and 2000
To repair a large Excel file that is inaccessible, follow the below guides. EaseUS file repair software also helps you repair corrupted Word, PowerPoint, and PDF documents.
Step 1. Launch EaseUS Data Recovery Wizard, and then scan disk with corrupted documents. This software enables you to fix damaged Word, Excel, PPT, and PDF files in same steps.
Step 2. EaseUS data recovery and repair tool will scan for all lost and corrupted files. You can find the target files by file type or type the file name in the search box.
Step 3. EaseUS Data Recovery Wizard can repair your damaged documents automatically. After file preview, you can click «Recover» to save the repaired Word, Excel, and PDF document files to a safe location.