
What is this?
This is a collection of common Q&A. This is also a Community Wiki, so everyone is invited to participate in maintaining it.
Why is this?
regex is suffering from give me ze code type of questions and poor answers with no explanation. This reference is meant to provide links to quality Q&A.
What’s the scope?
This reference is meant for the following languages: php, perl, javascript, python, ruby, java, .net.
This might be too broad, but these languages share the same syntax. For specific features there’s the tag of the language behind it, example:
- What are regular expression Balancing Groups? .net
- non-word character
-
Вычислительная техника: не образующий слова символ, символ, который не является частью слова
Универсальный англо-русский словарь.
.
2011.
Смотреть что такое «non-word character» в других словарях:
-
Non-player character — A non player character (NPC), sometimes known as a non person character or non playable character, in a game is any fictional character not controlled by a player. In electronic games, this usually means a character controlled by the computer… … Wikipedia
-
Character mask — Part of a series on Marxism … Wikipedia
-
Character design of Final Fantasy — Although each installment of the Final Fantasy series is generally set in a different fictional world with separate storylines, there are some commonalities when it comes to character design. Certain design themes repeat themselves, as well as… … Wikipedia
-
Character (arts) — A character is the representation of a person in a narrative work of art (such as a novel, play, or film).[1] Derived from the ancient Greek word kharaktêr (χαρακτήρ), the earliest use in English, in this sense, dates from the Restoration,[2]… … Wikipedia
-
Word wrap — or line wrap is the feature, supported by most text editors, word processors, and web browsers, of automatically replacing some of the blank spaces between words by line breaks, such that each line fits in the viewable window, allowing text to be … Wikipedia
-
Non Sequitur (comic strip) — Non Sequitur Author(s) Wiley Miller Website http://www.gocomics.com/nonsequitur/ L … Wikipedia
-
Word salad (computer science) — Word salad is a mixture of seemingly meaningful words that together signify nothing; [Lavergne 2006:384] the phrase draws its name from the common name for a symptom of schizophrenia, Word salad. When applied to a physical theory, word salad is a … Wikipedia
-
Non-English-based programming languages — are computer programming languages that, unlike better known programming languages, do not use keywords taken from, or inspired by, the English vocabulary. Contents 1 Prevalence of English based programming languages 2 International programming… … Wikipedia
-
Non-English versions of The Simpsons — The animated TV show The Simpsons is an American English language animated sitcom which has been broadcast in the United States since 1989 on FOX. In other countries, the TV show started broadcasting later than 1989 either in its original version … Wikipedia
-
Non-breaking space — In computer based text processing and digital typesetting, a non breaking space or no break space (NBSP) is a variant of the space character that prevents an automatic line break (line wrap) at its position. In certain formats (such as HTML), it… … Wikipedia
-
Non-English usage of quotation marks — A Non English usage of quotation marks Punctuation apostrophe ( … Wikipedia
Все, что вам нужно знать о регулярных выражениях
Перевод
Ссылка на автора

Прочитав эту статью, вы получите четкое представление о том, что такое регулярные выражения, что они могут делать, а что нет.
Вы сможете судить, когда их использовать и, что более важно, когда этого не делать.
Давайте начнем с самого начала.
Что такое регулярное выражение?
На абстрактном уровне регулярное выражение, для краткости регулярное выражение, является сокращенным представлением для набора. Набор строк.
Скажем, у нас есть список всех действительных почтовых индексов. Вместо того, чтобы хранить этот длинный и громоздкий список, часто более практично иметь короткий и точный шаблон, который полностью описывает этот набор. Всякий раз, когда вы хотите проверить, является ли строка действительным почтовым индексом, вы можете сопоставить ее с шаблоном. Вы получите истинный или ложный результат, указывающий, принадлежит ли строка к набору почтовых индексов, которые представляет шаблон регулярного выражения.
Давайте расширим набор почтовых индексов. Список почтовых индексов конечен, состоит из довольно коротких строк и не особенно сложен в вычислительном отношении.
Как насчет набора строк, которые заканчиваются.csv? Может быть весьма полезным при поиске файлов данных. Этот набор бесконечен. Вы не можете составить список заранее. И единственный способ проверить членство — это перейти в конец строки и сравнить последние четыре символа. Регулярные выражения — это способ стандартизированного кодирования таких шаблонов.

Ниже приведен шаблон регулярного выражения, представляющий наш набор строк, оканчивающихся на.csv
^.*.csv$
Давайте оставим в стороне механику этого конкретного шаблона и посмотрим на практичность: механизм регулярных выражений может проверить шаблон на соответствие входной строке, чтобы увидеть, соответствует ли он. Приведенный выше шаблон соответствуетfoo.csv, но не совпадаетbar.txtилиmy_csv_file,
Прежде чем использовать регулярные выражения в своем коде, вы можете проверить их с помощью онлайн-оценщика регулярных выражений и поэкспериментировать с дружественным пользовательским интерфейсом.
мне нравиться regex101.com: вы можете выбрать изюминку движка регулярных выражений, и шаблоны хорошо разложены для вас, так что вы получите хорошее представление о том, что на самом деле делает ваш шаблон. Шаблоны регулярных выражений могут быть загадочными.
Я бы порекомендовал вам открыть regex101.com в другом окне или вкладке и поэкспериментируйте с примерами, представленными в этой статье, в интерактивном режиме. Я обещаю, вы будете гораздо лучше чувствовать паттерны регулярных выражений.

Для чего используются регулярные выражения?
Регулярные выражения полезны в любом сценарии, который выигрывает от полного или частичного сопоставления с образцом в строках. Вот некоторые распространенные случаи использования:
- проверить структуру строк
- извлекать подстроки из структурированных строк
- поиск / замена / перестановка частей строки
- разбить строку на токены
Все это регулярно появляется при выполнении работы по подготовке данных.
Строительные блоки регулярного выражения
Шаблон регулярного выражения состоит из отдельных строительных блоков. Может содержать литералы, классы персонажей, граничные сопоставители, кванторы, группы и Оператор ИЛИ,
Давайте погрузимся и посмотрим на некоторые примеры.
литералы
Основным строительным блоком в регулярном выражении является буквенный символ a.k.a. Большинство символов в шаблоне регулярных выражений не имеют специального значения, они просто соответствуют друг другу. Рассмотрим следующую схему:
I am a harmless regex pattern
Ни один из символов в этом шаблоне не имеет особого значения. Таким образом, каждый символ шаблона соответствует самому себе. Поэтому есть только одна строка, которая соответствует этому шаблону, и она идентична самой строке шаблона.

Избегание буквальных персонажей
Какие символы имеют особое значение? В следующем списке показаны символы, которые имеют особое значение в регулярном выражении. Они должны избежать обратной косой черты, если они должны представлять себя.
Рассмотрим следующую схему:
+21.5
Шаблон состоит только из литералов —+имеет особое значение и был экранирован, так что.— и, следовательно, шаблон соответствует только одной строке:+21.5

Соответствующие непечатные символы
Иногда необходимо сослаться на какой-нибудь непечатаемый символ, такой как символ табуляции ⇥ или символ новой строки ↩
Лучше всего использовать правильные escape-последовательности для них:
Если вам нужно сопоставить разрыв строки, они обычно бывают одного из двух вариантов:
nчасто упоминается как новая строка в стиле Unixrnчасто упоминается как перевод строки в стиле Windows
Чтобы поймать обе возможности, вы можете сопоставитьr?nчто означает: необязательноrс последующимn

Соответствие любому символу Юникода
Иногда вам нужно сопоставить символы, которые лучше всего выражены с использованием их индекса Unicode Иногда символ просто не может быть напечатан — как контрольные символы, такие как ASCIINUL,ESC,VTи т.п.
Иногда ваш язык программирования просто не поддерживает помещение определенных символов в шаблоны. Персонажи вне BMP, такие как 𝄞 или смайлики часто не поддерживаются дословно.
Во многих движках регулярных выражений — таких как Java, JavaScript, Python и Ruby — вы можете использоватьuHexIndexэкранировать синтаксис для соответствия любому символу по индексу Unicode. Скажем, мы хотим сопоставить символ для натуральных чисел: ℕ — U + 2115
Шаблон для соответствия этому персонажу:u2115

Другие механизмы часто предоставляют эквивалентный escape-синтаксис. В Go вы бы использовалиx{2115}соответствовать ℕ
Поддержка Unicode и escape-синтаксис варьируется в зависимости от движка. Если вы планируете сопоставлять технические символы, музыкальные символы или смайлики — особенно за пределами BMP — проверьте документацию движка regex, который вы используете, чтобы быть уверенным в адекватной поддержке для вашего варианта использования.
Экранирование частей шаблона
Иногда шаблон требует, чтобы последовательные символы экранировались как литералы. Скажем, он должен соответствовать следующей строке:+???+
Шаблон будет выглядеть так:
+???+
Необходимость избегать каждого символа как буквального затрудняет чтение и понимание.
В зависимости от вашего движка регулярных выражений, может быть способ начать и завершить буквальный раздел в вашем шаблоне. Проверьте свои документы. В Java и Perl последовательности символов, которые должны интерпретироваться буквально, могут быть заключены вQа такжеE, Следующая схема эквивалентна приведенной выше:
Q+???+E
Экранирование частей шаблона также может быть полезно, если он составлен из частей, некоторые из которых должны интерпретироваться буквально, как предоставляемые пользователем поисковые слова.
Если ваш движок регулярных выражений не имеет этой функции, экосистема часто предоставляет функцию для экранирования всех символов со специальным значением из строки шаблона, таких как lodash escapeRegExp,
Оператор ИЛИ
Символ трубы|является оператором выбора. Это соответствует альтернативам. Предположим, что шаблон должен соответствовать строкам1а также2
Следующая схема делает свое дело:
1|2
Шаблоны слева и справа от оператора являются допустимыми альтернативами.

Следующий шаблон соответствуетWilliam Turnerа такжеBill Turner
William Turner|Bill Turner
Вторая часть альтернатив последовательноTurner, Было бы удобно поставить альтернативыWilliamа такжеBillи упомянутьTurnerтолько один раз. Следующий шаблон делает это:
(William|Bill) Turner
Это выглядит более читабельным. Он также вводит новую концепцию: группы.
группы
Вы можете группировать подшаблоны в разделы, заключенные в круглые скобки. Они группируют содержащиеся выражения в единый блок. Группировка частей шаблона имеет несколько применений:
- Упростите запись регулярных выражений, сделав намерение более понятным
- подать заявление кванторы к подвыражениям
- извлечь подстроки, соответствующие группе
- заменить подстроки, соответствующие группе
Давайте посмотрим на регулярное выражение с группой:(William|Bill) Turner
Группы иногда называют «группами захвата», потому что в случае совпадения совпадающая подстрока каждой группы захватывается и доступна для извлечения.

То, как захваченные группы становятся доступными, зависит от используемого вами API. В JavaScript звонят"my string".match(/pattern/)возвращает массив совпадений, Первый элемент — это полная совпавшая строка, а последующие элементы — это подстроки, соответствующие группам шаблонов в порядке появления в шаблоне.
Пример: шахматная запись
Рассмотрим строку, идентифицирующую шахматная доска поле. Поля на шахматной доске могут быть идентифицированы как A1-A8 для первого столбца, B1-B8 для второго столбца и так далее до H1-H8 для последнего столбца. Предположим, что строка, содержащая это обозначение, должна быть проверена, а компоненты (буква и цифра) извлечены с использованием групп захвата. Следующее регулярное выражение сделает это.
(A|B|C|D|E|F|G|H)(1|2|3|4|5|6|7|8)
Хотя приведенное выше регулярное выражение допустимо и выполняет свою работу, оно несколько неуклюже. Это работает так же хорошо, и это немного более кратко:
([A-H])([1-8])

Это выглядит более лаконично. Но он вводит новую концепцию: классы персонажей.
Классы персонажей
Классы символов используются для определения набора разрешенных символов. Набор разрешенных символов заключен в квадратные скобки, и каждый допустимый символ указан в списке. Класс персонажа[abcdef]эквивалентно(a|b|c|d|e|f), Поскольку класс содержит альтернативы, он соответствует ровно одному символу.
Шаблон[ab][cd]соответствует ровно 4 струнамac,ad,bc, а такжеbd, Оно делаетнесовпадениеab, первый символ совпадает, но второй символ должен быть либоcилиd,
Предположим, что шаблон должен соответствовать двухзначному коду. Шаблон, соответствующий этому, может выглядеть так:
[0123456789][0123456789]
Этот шаблон соответствует всем 100 двузначным строкам в диапазоне от00в99,
Изменяется
Часто бывает утомительно и подвержено ошибкам перечислять все возможные символы в классе символов Последовательные символы могут быть включены в класс символов как диапазоны, используя оператор тире:[0-9][0-9]

Символы упорядочены по числовому индексу — в 2019 году это почти всегда Индекс Юникод, Если вы работаете с числами, латинскими символами и пунктуацией, вместо этого вы можете взглянуть на гораздо меньший исторический набор Unicode: ASCII,
Цифры от нуля до девяти кодируются последовательно через кодовые точки:U+0030для0кодировать точкуU+0039для9Итак, набор символов[0–9]допустимый диапазон
Строчные и заглавные буквы латинского алфавита также кодируются последовательно, поэтому часто встречаются и классы символов для буквенных символов. Следующий набор символов соответствует любому строчному латинскому символу:
[a-z]
Вы можете определить несколько диапазонов в пределах одного класса символов. Следующий класс символов соответствует всем латинским символам в нижнем и верхнем регистре:
[A-Za-z]
Может сложиться впечатление, что вышеприведенный шаблон может быть сокращен до:
[A-z]
Это допустимый класс символов, но он соответствует не только A-Z и a-z, но и всем символам, определенным между Z и a, таким как[,, а также^,

Если вы рвете волосы, проклиная глупость людей, которые определили ASCII и вводите этот ошеломляющий разрыв, немного задержите лошадей. ASCII был определен в то время, когда вычислительные мощности были гораздо более ценными, чем сегодня.
смотреть на
A hex: 0x41 bin: 0100 0001а такжеa hex: 0x61 bin: 0110 0001Как конвертировать прописные и строчные буквы? Вы переворачиваетеодиннемного. Это верно для всего алфавита. ASCII оптимизирован для упрощения преобразования регистра. Люди, определяющие ASCII, были очень вдумчивыми. Некоторые желательные качества должны были быть принесены в жертву для других. Пожалуйста.
Вы можете спросить, как поставить-персонаж в класс персонажа. В конце концов, он используется для определения диапазонов. Большинство двигателей интерпретируют-символ буквально, если помещен как первый или последний символ в классе:[-+0–9]или[+0–9-], Некоторые двигатели требуют экранирования с обратной косой чертой:[-+0–9]
Отрицания
Иногда полезно определить класс символов, который соответствует большинству символов, за исключением нескольких определенных исключений. Если определение класса символов начинается с^набор перечисленных символов инвертируется. Например, следующий класс допускает любой символ, если он не является ни цифрой, ни подчеркиванием.
[^0-9_]

Обратите внимание, что^символ интерпретируется как литерал, если это не первый символ класса, как в[f^o]и что это граничный сопоставитель если используется вне классов персонажей.
Предопределенные классы символов
Некоторые классы символов используются так часто, что для них определены сокращенные обозначения. Рассмотрим класс персонажа[0–9], Он соответствует любому символу цифры и используется так часто, что для него есть мнемоническая запись:d,
В следующем списке показаны классы символов с наиболее распространенными сокращенными обозначениями, которые могут поддерживаться любым используемым вами механизмом регулярных выражений.
Большинство движков поставляются с исчерпывающим списком предопределенных классов символов, соответствующих определенным блокам или категориям стандарта Unicode, пунктуации, конкретных алфавитов и т. Д. Эти дополнительные классы символов часто специфичны для используемого движка и не очень переносимы.
Класс персонажей Dot
Наиболее распространенным классом предопределенных символов является точка, и она сама по себе заслуживает небольшого раздела. Соответствует любому символу, кроме символов конца строки, таких какrа такжеn,
Следующий шаблон соответствует любой трехсимвольной строке, заканчивающейся строчными буквами x:
..x

На практике точка часто используется для создания в шаблоне разделов «все может пойти сюда». Часто сочетается с квантор а также.*используется для соответствия разделам «что-нибудь» или «все равно».

Обратите внимание, что.персонаж теряет свое особое значение при использовании внутри класса персонажа. Класс персонажа[.,]просто соответствует двум символам: точка и запятая.
В зависимости от используемого вами механизма регулярных выражений вы можете установитьdotAll флаг выполнения в таком случае.будет соответствовать всему, включая терминаторы строки.
Граничные совпадения
Сопоставители границ — также известные как «якоря» — не соответствуют символу как таковому, они соответствуют границе. Они соответствуют позициям между персонажами, если хотите. Наиболее распространенные якоря^а также$, Они соответствуют началу и концу строки соответственно. В следующей таблице приведены наиболее часто поддерживаемые анкеры.
Привязка к началу и окончанию
Рассмотрим операцию поиска цифр в многострочном тексте. Шаблон[0–9]находит каждую цифру в тексте, независимо от того, где она находится Шаблон^[0–9]находит каждую цифру, которая является первым символом в строке.

Та же идея относится к окончанию строки$,

Aа такжеZилиzякоря полезны для сопоставления многострочных строк. Они привязывают начало и конец всего ввода. Верхний регистрZВариант допускает конечные переводы строк и совпадения непосредственно перед этим, эффективно отбрасывая любой завершающий перевод строки в совпадении.
Якоря A и Z поддерживаются большинством распространенных движков регулярных выражений, за исключением заметного JavaScript.
Предположим, необходимо проверить, является ли текст двухстрочной записью, указывающей шахматную позицию. Вот как выглядит строка ввода:
Column: F
Row: 7
Следующий шаблон соответствует приведенной выше структуре:
AColumn: [A-H]r?nRow: [1-8]Z

Совпадения всего слова
bЯкорь соответствует краю любой буквенно-цифровой последовательности. Это полезно, если вы хотите выполнить поиск по «всему слову». Следующий шаблон ищет отдельный верхний регистрI,
bIb

Шаблон не соответствует первой буквеIllinoisпотому что нет границы слова справа. Следующая буква — это буква слова, определяемая классом символовwкак[a-zA-Z0–9_]— а не буква, не состоящая из слов, которая будет представлять собой границу.
Давайте заменимIllinoisсI!linois, Восклицательный знак не является символом слова и, таким образом, представляет собой границу.

Разные Якоря
Несколько эзотерическая граница без словBэто отрицаниеb, Это соответствует любой позиции, которая не соответствуетb, Это соответствует каждой позиции между персонажамивпробелы и буквенно-цифровые последовательности.
Некоторые движки регулярных выражений поддерживаютGграничный сопоставитель. Это полезно при использовании регулярных выражений программно, и шаблон применяется к строке повторно, пытаясь найти шаблон для всех совпадений. в петле, Он привязывается к позиции последнего найденного матча.
Кванторы
Любой литерал или группа символов соответствует вхождению ровно одного символа. Шаблон[0–9][0–9]соответствует ровно двум цифрам. Квантификаторы помогают указать ожидаемое количество совпадений шаблона. Они записываются с помощью фигурных скобок. Следующее эквивалентно[0–9][0–9]
[0-9]{2}
Основные обозначения могут быть расширены для обеспечения верхних и нижних границ. Скажем, необходимо совпадать от двух до шести цифр. Точное число варьируется, но оно должно быть от двух до шести. Следующая запись делает это:
[0-9]{2,6}

Верхняя граница является необязательной, если она опущена, допустимо любое количество вхождений, равное или превышающее нижнюю границу. Следующий пример соответствует двум или более последовательным цифрам.
[0-9]{2,}
Есть несколько предопределенных сокращений для распространенных квантификаторов, которые очень часто используются на практике.
? квантор
?квантификатор эквивалентен{0, 1}, что означает: необязательное единственное вхождение. Предыдущий шаблон может не совпадать или совпадать один раз.
Давайте найдем целые числа, необязательно с префиксом плюс или минус:[-+]?d{1,}

+ Квантификатор
+квантификатор эквивалентен{1,}, что означает: хотя бы одно вхождение.
Мы можем изменить наш шаблон сопоставления целых чисел сверху, чтобы сделать его более понятным, заменив{1,}с+и мы получаем:[-+]?d+

* Квантор
*квантификатор эквивалентен{0,}, что означает: ноль или более вхождений. Вы увидите это очень часто в сочетании с точкой как.*, что означает: любому персонажу все равно, как часто.
Давайте сопоставим список целых чисел через запятую. Пробелы между записями не допускаются, и должно присутствовать хотя бы одно целое число:d+(,d+)*
Мы сопоставляем целое число, за которым следует любое количество групп, содержащих запятую, за которой следует целое число.

Жадный по умолчанию
Предположим, что требуется соответствие доменной части по URL-адресу http в группе захвата. Следующая идея кажется хорошей идеей: сопоставьте протокол, затем захватите домен, а затем необязательный путь. Идея примерно переводит на это:
http://(.*)/?
Если вы используете движок, который использует
/regex/нотации, как JavaScript, вы должны избежать прямой косой черты:http://(.*)/?.*
Он соответствует протоколу, захватывает то, что следует за протоколом как домен, и допускает дополнительную косую черту и некоторый произвольный текст после этого, который будет путь к ресурсу.

Как ни странно, группа получает следующие входные строки:
Результаты несколько удивительны, так как шаблон был разработан для захвата только доменной части, но, похоже, он захватывает все до конца URL.
Это происходит потому, что каждый квантификатор, встречающийся в шаблоне, пытается сопоставить как можно большую часть строки Кванторы называютсяжадныйИменно по этой причине.
Давайте проверим соответствие поведения:http://(.*)/?.*
Жадный*в группе захвата находится первый встреченный квантификатор..Класс символов, к которому он применяется, соответствует любому символу, поэтому квантификатор простирается до конца строки. Таким образом, группа захвата захватывает все. Но подождите, вы говорите, есть/?.*часть в конце. Ну, да, и это соответствует тому, что осталось от строки — ничего, a.k.a пустая строка — отлично. Косая черта является необязательной, за ней следует ноль или более символов. Пустая строка подходит. Весь шаблон соответствует просто отлично.
Альтернативы жадному соответствию
Жадность по умолчанию, но не единственная разновидность квантификаторов. Каждый квантификатор имеетнеохотныйверсия, которая соответствуетнаименеевозможное количество символов. Жадные версии квантификаторов преобразуются в неохотные версии путем добавления?им.
В следующей таблице приведены обозначения для всех квантификаторов.
Quanfier{n}эквивалентен как в жадных, так и неохотных версиях. Для остальных количество совпавших символов может отличаться. Давайте еще раз рассмотрим приведенный выше пример и изменим группу захвата так, чтобы она соответствовала как можно меньшему количеству в надежде на правильное получение доменного имени.
http://(.*?)/?.*

Используя этот шаблон, ничто — точнее пустая строка — не захватывается группой. Почему это? Группа захвата теперь захватывает как можно меньше: ничего.(.*?)ничего не захватывает,/?ничего не соответствует, и.*соответствует всему, что осталось от строки. Итак, еще раз, этот шаблон не работает, как предполагалось.
Пока что группа захвата совпадает слишком мало или слишком много. Давайте вернемся к жадному квантификатору, но запретим символ косой черты в имени домена, а также потребуем, чтобы имя домена было длиной не менее одного символа.
http://([^/]+)/?.*
Этот шаблон жадно захватывает один или несколько символов, не являющихся косыми чертами, после протокола в качестве домена, и, в конце концов, если возникает какая-либо дополнительная косая черта, за ним может следовать любое количество символов в пути.

Производительность квантификатора
Жадные и неохотные квантификаторы подразумевают некоторые накладные расходы времени выполнения. Если присутствует только несколько таких квантификаторов, проблем нет. Но если каждая вложенная группа с множественными значениями определяется количественно как жадная или неохотная, определение самого длинного или самого короткого из возможных совпадений является нетривиальной операцией, которая подразумевает бегание вперед-назад по входной строке, регулируя длину каждого совпадения квантификатора, чтобы определить, совпадает ли выражение в целом ,
Патологические случаи катастрофический откат может произойти. Если проблема связана с производительностью или злонамеренным вводом данных, лучше предпочесть неохотные квантификаторы, а также взглянуть на третий вид квантификаторов: собственнические квантификаторы.
Притяжательные квантификаторы: никогда не сдаваться
Притяжательные квантификаторы, если они поддерживаются вашим движком, во многом похожи на жадные квантификаторы, с той разницей, что они не поддерживают возврат. Они пытаются сопоставить максимально возможное количество символов, и, как только они это делают, они никогда не выдают совпадающих символов, чтобы соответствовать возможным совпадениям для любых других частей шаблона.
Они отмечены добавлением+на базу жадный квантификатор.
Они представляют собой быстродействующую версию «жадных» квантификаторов, что делает их хорошим выбором для чувствительных к производительности операций.
Давайте посмотрим на них в движке PHP. Во-первых, давайте посмотрим на простые жадные совпадения. Давайте сопоставим несколько цифр, а затем девять:([0–9]+)9
Сопоставляется с входной строкой:123456789жадный квантификатор сначала будет соответствовать всему вводу, а затем вернет9Таким образом, остальная часть шаблона имеет шанс совпадения.

Теперь, когда мы заменим жадный на собственнический квантификатор, он будет соответствовать всему вводу, а затем откажется вернуть9чтобы избежать возврата, и это приведет к тому, что весь шаблон не будет совпадать вообще.

Когда бы вы хотели собственнического поведения? Когда вы знаете, что вы всегда хотите самый длинный мыслимый матч.
Допустим, вы хотите извлечь часть имени файла из путей файловой системы. Давайте предположим/в качестве разделителя пути. Тогда то, что мы фактически хотим, это последний бит строки после последнего появления/,
Притяжательный шаблон хорошо работает здесь, потому что мы всегда хотим использовать все имена папок перед записью имени файла. Нет необходимости в части имен папок, потребляющих шаблоны, когда-либо возвращать символы. Соответствующий шаблон может выглядеть так:
/?(?:[^/]+/)++(.*)
Примечание: использование PHP
/regex/обозначения здесь, так что косые черты экранированы.
Мы хотим разрешить абсолютные пути, поэтому мы позволяем вводу начинаться с дополнительной косой черты. Затем мы собственноручно используем имена папок, состоящие из серии символов без косой черты, за которыми следует косая черта Я использовал группа без захвата для этого — так это обозначено как(?:pattern)вместо просто(pattern), Все, что осталось после последней косой черты, — это то, что мы собираем в группу для извлечения.

Группы без захвата
Группы без захвата соответствуют точно так же, как нормальные группы. Тем не менее, они не делают свой соответствующий контент доступным. Если нет необходимости захватывать контент, его можно использовать для повышения производительности сопоставления. Номера для записи записываются как:(?:pattern)
Предположим, мы хотим убедиться, что шестнадцатеричная строка действительна. Он должен состоять из четного числа шестнадцатеричных цифр каждая между0–9илиa-f, Следующее выражение выполняет работу с использованием группы:
([0-9a-f][0-9a-f])+
Поскольку цель группы в шаблоне состоит в том, чтобы убедиться, что цифры идут парами, а фактически сопоставленные цифры не имеют никакого значения, группу также можно заменить более быстродействующей группой без захвата:
(?:[0-9a-f][0-9a-f])+

Атомные группы
Существует также быстродействующая версия группы без захвата, которая не поддерживает возврат. Это называется «независимой не захватывающей группой» или «атомной группой».
Написано как(?>pattern)
Элементарная группа — это группа без захвата, которую можно использовать для оптимизации сопоставления с шаблоном по скорости. Обычно это поддерживается механизмами регулярных выражений, которые также поддерживают собственнические квантификаторы.
Его поведение также похоже на притяжательные квантификаторы: как только атомная группа сопоставила часть строки, это первое совпадение является постоянным. Группа никогда не будет пытаться повторно сопоставить другим способом, чтобы приспособить другие части схемы.
a(?>bc|b)cМатчиabccно это не соответствуетabc,
Первый успешный матч атомной группыbcи так и останется. Нормальная группа будет повторно соответствовать во время возврата, чтобы приспособитьcв конце шаблона для успешного матча. Но первый матч атомной группы является постоянным, он не изменится.
Это полезно, если вы хотите соответствовать как можно быстрее, и не хотите, чтобы какой-либо возврат был в любом случае.
Скажем, мы сопоставляем часть имени файла пути. Мы можем сопоставить атомарную группу любых символов, за которыми следует косая черта. Затем запишите остальное:
(?>.*/)(.*)
Примечание: использование PHP
/regex/обозначения здесь, так что косые черты экранированы.

Обычная группа также справилась бы с этой задачей, но исключение возможности возврата назад улучшает производительность. Если вы сопоставите миллионы входных данных с нетривиальными шаблонами регулярных выражений, вы заметите разницу.
Это также повышает устойчивость к злонамеренному вводу данных, предназначенному для DoS-атаки на службу, инициируя катастрофический откат сценарии.
Вернуться Отзывы
Иногда полезно сослаться на что-то, что ранее совпадало в строке. Предположим, что строковое значение допустимо, только если оно начинается и заканчивается одной и той же буквой. Слова «альфа», «радар», «удар», «уровень» и «звезды» являются примерами. Можно захватить часть строки в группе и обратиться к этой группе позже в шаблоне шаблона: обратная ссылка.
Обратные ссылки в шаблоне регулярных выражений записываются с использованиемnсинтаксис, гдеnэто номер группы захвата. Нумерация слева направо, начиная с 1. Если группы являются вложенными, они нумеруются в том порядке, в котором встречаются их открывающие скобки. Группа 0 всегда означает все выражение.
Следующий шаблон сопоставляет входные данные, которые имеют как минимум 3 символа и начинаются и заканчиваются одной и той же буквой:
([a-zA-Z]).+1
На словах: строчная или заглавная буква — эта буква записывается в группу, за которой следует любая непустая строка, за которой следует буква, которую мы записали в начале матча.

Давайте немного расширимся. Входная строка сопоставляется, если она содержит буквенно-цифровую последовательность — думаю: слово — более одного раза. Границы слов используются для обеспечения соответствия целых слов.
b(w+)b.*b1b

Поиск и замена обратных ссылок
Регулярные выражения полезны в операциях поиска и замены. Типичный вариант использования — найти подстроку, которая соответствует шаблону, и заменить ее чем-то другим. Большинство API, использующих регулярные выражения, позволяют ссылаться на группы захвата из шаблона поиска в строке замены.
Эти обратные ссылки позволяют эффективно переставлять части входной строки.
Рассмотрим следующий сценарий: входная строка содержит префикс символа A-Z, за которым следует дополнительный пробел, за которым следует 3–6-значное число. Строки какA321,B86562,F 8753, а такжеL 287,
Задача состоит в том, чтобы преобразовать его в другую строку, состоящую из числа, за которым следует тире, за которым следует префикс символа.
Input Output
A321 321-A
B86562 86562-B
F 8753 8753-F
L 287 287-L
Первым шагом для преобразования одной строки в другую является захват каждой части строки в группе захвата. Шаблон поиска выглядит так:
([A-Z])s?([0-9]{3,6})
Он захватывает префикс в группу, учитывает необязательный пробел, а затем записывает цифры во вторую группу Обратные ссылки в замещающей строке записываются с помощью$nсинтаксис, гдеnэто номер группы захвата. Строка замены для этой операции должна сначала ссылаться на группу, содержащую цифры, затем на литеральную черту, а затем на первую группу, содержащую префикс букв. Это дает следующую строку замены:
$2-$1
таким образомA321совпадает с шаблоном поиска, ставяAв$1а также312в$2, Строка замены организована так, чтобы дать желаемый результат: сначала идет число, затем тире, затем префикс буквы.

Обратите внимание, что, так как$символ имеет особое значение в строке замены, он должен быть экранирован как$$если он должен быть вставлен как символ.
Этот вид поиска и замены с поддержкой регулярных выражений часто предлагается текстовыми редакторами. Предположим, у вас есть список путей в вашем редакторе, и задача под рукой состоит в том, чтобы префикс имени файла каждого файла подчеркиванием. Тропинка/foo/bar/file.txtдолжен стать/foo/bar/_file.txt
Со всем, что мы узнали, мы можем сделать это так:

Смотри, но не трогай: смотри вперед и смотри сзади
Иногда полезно утверждать, что строка имеет определенную структуру, но не соответствует ей. Чем это полезно?
Давайте напишем шаблон, который соответствует всем словам, за которыми следует слово, начинающееся сa
Давай попробуемb(w+)s+aон привязывается к границе слова и сопоставляет символы слова, пока не увидит пробел, за которым следует символ a.

В приведенном выше примере мы сопоставляемlove,swat,fly, а такжеto, но не в состоянии захватитьanдоant, Это потому чтоaначалоanбыл потреблен как часть матчаto, Мы отсканировали этоaи словоanне имеет шансов на совпадение.
Было бы замечательно, если бы был способ утверждать свойства первого символа следующего слова, фактически не потребляя его.
Конструкции, утверждающие существование, но не потребляющие входные данные, называются «lookahead» и «lookbehind».
Смотреть вперед
Lookaheads используются, чтобы утверждать, что образец соответствует впереди. Они написаны как(?=pattern)
Давайте использовать его, чтобы исправить наш шаблон:
b(w+)(?=s+a)
Мы поместили пространство и начальныйaследующего слова в поле зрения, поэтому при сканировании строки на совпадения они проверяются, но не расходуются.

Негативный прогноз утверждает, что его модель не совпадает впереди. Это обозначается как(?!pattern)
Давайте найдем все слова, за которыми не следует слово, начинающееся сa,
b(w+)b(?!s+a)
Мы сопоставляем целые слова, за которыми не следует пробел иa,

Смотреть за
Взгляд сзади служит для той же цели, что и взгляд, но он применяется слева от текущей позиции, а не справа. Многие движки регулярных выражений ограничивают тип шаблона, который вы можете использовать в ретроспективе, потому что применение шаблона в обратном направлении — это то, для чего они не оптимизированы. Проверьте свои документы!
Взгляд сзади написан как(?<=pattern)
Он утверждает существование чего-либо до текущей позиции. Давайте найдем все слова, которые идут после слова, оканчивающегося наrилиt,
(?<=[rt]s)(w+)
Мы утверждаем, что естьrилиtсопровождаемый пробелом, тогда мы фиксируем последовательность символов слова, которая следует.

Есть также негативный взгляд на то, что слева не существует шаблона. Написано как(?<!pattern)
Давайте перевернем найденные слова: мы хотим сопоставить все слова, которые идут после слов, не заканчивающихся наrилиt,
(?<![rt]s)b(w+)
Мы сопоставляем все словаb(w+)и предваряя(?<![rt]s)мы гарантируем, что перед любыми словами, которым мы сопоставляем, не предшествует слово, заканчивающееся наrилиt,

Сплит модели
Если вы работаете с API, который позволяет разбивать строку по шаблону, часто полезно помнить о взглядах и взглядах назад.
Разделение регулярных выражений обычно использует шаблон в качестве разделителя и удаляет разделитель из частей. Помещение разделителей в заголовок или в задний план делает его подходящим, не удаляя части, которые просто просматривались.
Предположим, у вас есть строка, разделенная:, в котором некоторые части являются метками, состоящими из буквенных символов, а некоторые являются метками времени в форматеHH:mm,
Давайте посмотрим на входную строкуtime_a:9:23:time_b:10:11
Если мы просто разделимся на:мы получаем части: [time_a, 9, 32, time_b, 10, 11]

Допустим, мы хотим улучшить путем разделения, только если:имеет письмо с обеих сторон. Разделитель сейчас[a-z]:|:[a-z]

Мы получаем части: [time_, 9:32, ime_, 10:11]Мы потеряли соседние символы, так как они были частью разделителя
Если мы уточним разделитель, чтобы использовать соседние символы для просмотра вперед и назад, их существование будет проверено, но они не будут совпадать как часть разделителя:(?<[a-z]):|:(?=[a-z])

Наконец мы получаем части, которые мы хотим:[time_a, 9:32, time_b, 10:11]
Модификаторы Regex
Большинство механизмов регулярных выражений позволяют устанавливать флаги или модификаторы для настройки аспектов процесса сопоставления с образцом. Обязательно ознакомьтесь с тем, как ваш двигатель выбирает такие модификаторы.
Они часто делают разницу между непрактично сложным паттерном и тривиальным.
Можно ожидать, что вы найдете модификаторы чувствительности (без учета регистра), параметры привязки, режим полного совпадения и внутреннего сопоставления, а также режим dotAll, который позволяет.класс символов соответствует всему, включая терминаторы строки.
JavaScript, питон, Джава, Рубин, .СЕТЬ
Давайте посмотрим на JavaScript, например. Если вам нужен режим без учета регистра и только первое найденное совпадение, вы можете использоватьiмодификатор, и не забудьте опуститьgмодификатор.

Ограничения регулярных выражений
Дойдя до конца этой статьи, вы можете почувствовать, что все возможные проблемы с разбором строк могут быть решены, как только вы получите регулярные выражения под вашим поясом.
Ну нет.
Эта статья представляет регулярные выражения в качестве сокращенной записи для наборов строк. Если у вас есть точное регулярное выражение для почтовых индексов, у вас есть сокращенная запись для набора всех строк, представляющих действительные почтовые индексы. Вы можете легко проверить входную строку, чтобы проверить, является ли она элементом этого набора. Однако есть проблема.
Есть много значимых наборов строк, для которых нет регулярных выражений!
Например, набор допустимых программ на JavaScript не имеет регулярных выражений. Никогда не будет шаблона регулярного выражения, который может проверить, является ли источник JavaScript синтаксически правильным.
В основном это связано с неспособностью регулярных выражений иметь дело с вложенными структурами произвольной глубины. Регулярные выражения по своей природе нерекурсивны. XML и JSON являются вложенными структурами, как и исходный код многих языков программирования. Другой пример — палиндромы — слова, которые читаются одинаково вперед и назад, какгоночный автомобиль —очень простая форма вложенной структуры. Каждый персонаж открывает или закрывает уровень вложенности.

Вы можете создавать шаблоны, которые будут соответствовать вложенным структурам до определенной глубины, но вы не можете написать шаблон, который соответствует вложенности произвольной глубины.
Вложенные структуры часто оказываются не регулярный, Если вы интересуетесь теорией вычислений и классификацией языков, то есть наборов строк, загляните в Хомская иерархия, Формальные грамматики а также Формальные Языки,
Знайте, когда достичь другого Молота
Позвольте мне закончить словами предостережения. Я иногда вижу попытки использовать регулярные выражения не только для лексического анализа — идентификации и извлечения токенов из строки — но также и для семантического анализа, пытающегося также интерпретировать и проверить значение каждого токена.
Хотя лексический анализ является вполне допустимым вариантом использования регулярных выражений, попытка семантической проверки чаще всего приводит к созданию другая проблема,
Множественное число «regex» означает «сожалеет»
Позвольте мне проиллюстрировать это на примере.
Предположим, что строка должна быть адресом IPv4 в десятичной записи с точками, разделяющими числа. Регулярное выражение должно проверять, что входная строка действительно является адресом IPv4. Первая попытка может выглядеть примерно так:
([0-9]{1,3}).([0-9]{1,3}).([0-9]{1,3}).([0-9]{1,3})
Он соответствует четырем группам от одной до трех цифр, разделенных точкой. Некоторые читатели могут почувствовать, что эта модель не работает. Это соответствует111.222.333.444например, который не является действительным IP-адресом.
Если вы сейчас чувствуете необходимость изменить шаблон, чтобы он проверял для каждой группы цифр, что закодированное число должно быть от 0 до 255 — с возможными ведущими нулями — тогда вы на пути к созданию второй проблемы и сожалеете.
Попытка сделать это ведет от лексического анализа — определения четырех групп цифр — к семантическому анализу, проверяющему, что группы цифр переводятся в допустимые числа.
Это дает значительно более сложное регулярное выражение, примеры которого можно найти Вот, Я бы порекомендовал решить такую проблему, захватив каждую группу цифр с помощью шаблона регулярных выражений, затем преобразовав захваченные элементы в целые числа и проверив их диапазон в отдельном логическом шаге.

При работе с регулярными выражениями компромисс между сложностью, ремонтопригодностью, производительностью и правильностью всегда должен быть осознанным решением. В конце концов, шаблон регулярного выражения настолько же «только для записи», насколько может получить вычислительный синтаксис. Трудно правильно читать шаблоны регулярных выражений, не говоря уже об их отладке и расширении.
Мой совет — использовать их как мощный инструмент для обработки строк, но не переоценивать их возможности и способность людей справляться с ними.
Если есть сомнения, подумайте о том, чтобы достать еще один молоток в коробке
In this tutorial, we learn how to find non-word characters in a string using JavaScript Regular Expression. Actually, word characters include A-Z, a-z, 0-9 and _. Coming to the non-word characters except word characters like !, @, #, $, %, ^, &, *, (, ), {, } etc. Non-word characters, we denote as W. We all know about RegExp (Regular Expression) in JavaScript. RegExp is an object that specifies the pattern used to do a search and replace operations on a string or for input validation. RegExp was introduced in ES1 and it is fully supported by all browsers.
ASCII code for non-word characters are
! — 33, @ — 64, #- 35, $ — 36, % — 37, ^ — 94, & — 38, * — 42, + — 43, — — 45, ( — 40, ) — 41.
Now, we will check how to find non-word characters using RegExp.
Syntax
Syntax for non-word or W character is
new RegExp("W") or simply /W/
/W/, is introduced in ES1. It is fully supported by all browsers. Like, Chrome, IE, Safari, Opera, FireFox and Edge.
RegExp has modifiers like g, i, m. «g» for performing global matches, «i» for performing case-insensitive matching and «m» for performing multiline matching.
The syntax for W with a modifier like,
new RegExp("W", "g") or simply /W/g
Steps to find non-word character in a string
STEP 1 — Declare and define a string with some non-word characters.
STEP 2 — Define regular expression pattern.
STEP 3 — Find the non-word characters by matching the string with the regex pattern.
STEP 4 — Display the result.
Example
In the below example, we use RegExp and the match() method to find non-word in a string.
<!DOCTYPE html>
<html>
<body>
<h1>Finding non-word character</h1>
<p>Non-word characters :
<p id="result"></p>
</p>
<script>
let text = "_HiWelcome@2022%!$%&*@!{[()]}";
let pattern = /W/g;
let result = text.match(pattern);
document.getElementById("result").innerHTML = result;
</script>
</body>
</html>
Example
Here, If non-word characters exist in the given text, match() method will return an array of existing non-word characters. If not, it will return as null. Let’s see another example.
<!DOCTYPE html>
<html>
<body>
<h1>Finding non-word character</h1>
<p id="result"></p>
<script>
let text = "_HiWelcome2022";
let pattern = /W/g;
let result = text.match(pattern);
if(result == null){
document.getElementById("result").innerHTML = "Sorry, No non-word present in the text";
}else{
document.getElementById("result").innerHTML = "Non-word character(s):" +result;
}
</script>
</body>
</html>
Here, there are no non-word characters present in the text. The match() method returned as null. So, if the statement is executed. If text has non-word characters as shown in the first example, then match() method will return an array of existing nonword characters. So, the else statement will execute.
Example
Now, we will check how to replace word character(s) in a given text. Let’s see an example
<!DOCTYPE html>
<html>
<body>
<h1>Replace non-word character(s)</h1>
<p>After replacing non-word character(s) :
<p id="result"></p>
</p>
<script>
let text = "_HiWelcome@2022%!$%&*@!{[()]}";
let pattern = /W/g;
let result = text.split(pattern).join(" ");
document.getElementById("result").innerHTML = result;
</script>
</body>
</html>
Example
We will also check another way to replace non-word character(s). Let’s see an example
<!DOCTYPE html>
<html>
<body>
<h1>Replace non-word character(s)</h1>
<p>After replacing non-word character(s) :
<p id="result"></p>
</p>
<script>
let text = "_HiWelcome@2022%!$%&*@!{[()]}";
let pattern = /W/g;
let result = text.replace(pattern , " ");
document.getElementById("result").innerHTML = result;
</script>
</body>
</html>
As we discussed, g for global matches. Instead of stopping with the first occurrence, it will look for all the occurrences.
I Hope, this tutorial will help you to know how to find non-word characters using RegExp in JavaScript.
This section provides an overview of regular expression characters and recommend practices.
Match Characters
| Notation | Characters Matched | Example |
|---|---|---|
| d | Any digit from 0 to 9 | ddd matches 101 but not 10a |
| D | Any character that is not a numeric digit (0 to 9) | DDD matches abc but not 101 |
| w | Any word character, for example, a-z, A-z, 0-9, and the underscore character _ (also matches Unicode-based word characters from non-latin alphabets and scripts) | www matches abc but not &@# |
| W | Any non-word character | WWW matches $#! but not abc |
| s | Matches any whitespace character | sss matches (three spaces) but not abc |
| S | Matches any non-whitespace character | SSS matches a1_ but not (three spaces) |
| . | Matches any character | . matches any character except line breaks |
| [ ] | Any character between the square bracket | [abc] matches a or b or c but not other characters |
| [^ ] | Matches any character except the characters appearing after the ^ and before the ] | [^abc] matched def but not abc |
Repetition Characters
| Notation | Characters Matched | Example |
|---|---|---|
|
{n} |
Matches n of the previous item | w{4} matches AAAA but not A |
|
{n, } |
Matches n or more of the previous item | w{4, } matches AAAAA but not A |
| {n,m} |
Matches at least n and at most m of the previous item. If n is 0 that makes the character optional ({,9}) |
A{2,3} matches AA and AAA but not A or AAAA |
| ? | Matches the previous item 0 or 1 times | A? matches A or nothing but not AA |
| + | Matches the previous item 1 or more times | A+ matches A, AA, AAA but not nothing |
| * | Matches the previous item 0 or more times | A* matches nothing, A or any number of A characters |
Position Characters
| Notation | Description |
|---|---|
| ^ | The following pattern must be at the start of the string, or for a multi-line string, at the beginning of a line. For multi-line text (string containing a carriage return), the multi-line flag option needs to be set. |
| $ | The preceding pattern must be at the end of the string, or for a multi-line string, at the end of a line. |
| A | The preceding pattern must be at the start of the string; the multi-line flag is ignored. |
| Z | The preceding pattern must be at the end of the string; the multi-line pattern is ignored. |
| b | Matches a word boundary, essentially the point between a word character (a-z, A-Z, 0-9, _) and a non-word character (the start of a word). |
| B | Matches a position that is not a word boundary (not the start of a word) |
Grouping
| Notation | Characters Matched | Example |
|---|---|---|
| ()? | Matches the pattern inside the brackets 0 or 1 times | (Error)? matches Error or nothing |
| ()+ | Matches the pattern inside the brackets 1 or more times | (w+s)+ matches AA AA |
| ()* | Matches the pattern inside the brackets 0 or more times | (w+s)* matches nothing or AA AA |
The Non-Greedy Qualifier (?)
The non-greedy qualifier is a question mark (?) following a repetition character (*+?). The non-greedy qualifier is used to tell the regex engine that it should stop matching the current match as soon as the next match criterion is met. The non-greedy qualifier is used in combination with a repetition qualifier in order to create a non-greedy match. The non-greedy qualifier improves performance when you want to match any text value up to a specific text value where the specific text value can be uniquely specified within the regex.
For example, suppose your regex needs to match the following log:
02/28/2007 16:55:22 MsgID=1590 : Failed authentication for user john.doe user account locked out
If you use the following regex, incorrect values will be parsed for the login field due to the fact that user occurs twice in the log message. Using this regex will cause “account” to be parsed into the login field.
MsgID=1590.*user (?<login>w+.?w*)
This is because “.*” will match everything to the end of the log message. When the regex engine reaches the end of the log message it will begin looking backwards in the log message for the next match. As soon as it finds the last occurrence of “user” it will match for that portion of the log message. Since the specified regex for “login” will match account, it will use that match and continue.
To make the regex take the first occurrence of the next match you use the non-greedy qualifier. The following regex will parse the correct value into the login field because it will stop the previous match (.*) as soon as “user” is encountered.
MsgID=1590.*?user (?<login>w+.?w*)
Reserved Characters
The regex engine used by LogRhythm has 12 reserved characters that have special meaning. If any of these characters need to be used as a literal character they will need to be escaped using the backslash () character, otherwise known as the escape character. The reserved characters are:
- The opening square bracket [
- The opening round bracket (
- The closing round bracket )
- The backslash
- The caret ^
- The dollar sign $
- The period .
- The vertical bar or pipe symbol |
- The question mark ?
- The asterisk or Kleene star *
- The plus sign +
- The opening curly bracket {
- The closing curly bracket }
The following regex, which is meant to match any IPv4 address (a.b.c.d), is a simple example of how to escape reserved characters:
d+.d+.d+.d+
As you can see each of the periods of the IP address are escaped meaning the regex engine will look for the actual period (.) character in the string instead of looking for any character. Without the escape slash, the period refers to any character, which would radically change the meaning of the expression.
Other Special Characters
| Special Character | Description |
|---|---|
| n | Matches newline |
| r | Matches carriage return |
| t | Matches tab |
| nnn |
Matches ASCII character specified by octal number nnn For example, |
| xnn |
Matches ASCII character specified by hexadecimal number nn For example, |
| unnn | Matches the Unicode character specified by the four hexadecimal digits replaced by nnn |
| cD |
Matches a control character For example, |
Regex Recommended Practices
The following are some recommended practices for regex development. All regex examples use the following log.
02/28/2007 16:55:22 MsgID=1590 : Failed authentication for user “any.user” user account locked out
| Name | Recommended Pattern | Description |
|---|---|---|
| Negative Character Class | “[^”]*” for double quote delimiters, ,[^,]*, for comma delimiters, or |[^|]*| for pipe delimiters. Can be used for any type of predictable delimiter. |
Use negative character classes in log messages with clear delimiters, such as quotation marks, commas, or pipes. This will match any character that is not the delimiter. This can greatly improve parsing performance vs a more generic match, such as .*?. Example: MsgID=1589.*?users”(?<account>[^”]*)” |
| Non-greedy Match | .*? |
If you need to match any characters until a specific set of characters appears, use this pattern. Example: MsgID=1590.*?users”(?<account>[^”]*)” |
| Overloading Map Tags | (?<[map tag]>[regex]) |
Map tags should almost always be overloaded. The default regex for map tags is .* which will match everything to the end of the log. Example: MsgID=1590.*?users”(?<account>[^”]*)”s(?<tag1>.*?)$ |
| Preceding and trailing values | Not applicable |
Always match as much constant text as possible. The more information the regex has to evaluate, the faster it will be at identifying non-matching logs. For any parsed field, it is best to search for a constant value before and after the value being parsed. Example: MsgID=1590.*?users”(?<account>[^”]*)”s(?<tag1>.*?)$ |
| Look Aheads |
(?=[regex])[regex] (?![regex])[regex] |
Positive and negative look ahead allows for an initial check in the regex to see if a case is satisfied in the log messages. These are useful for finding a value later in a log to reduce extraneous processing for non-matching logs. Do not use for values that appear very early in a log message, such as just past a Syslog header. Look ahead is more costly than regular expressions if the match is always found early. Example: (?=.*?match contains this phrase)s<sip>s |
| Multiline character match pattern | [rn] | Using a character class containing both r (return) and n (newline) allows for either multiline character to appear as well as both in either order. Some log messages vary in the order of these new lines and others only contain a newline. |
| Narrow Character Classes | [a-z0-9_]+ | The shorthand character class w matches Latin alphabet characters, Hindu-Arabic numerals (0-9), underscores as well other scripts supported in Unicode. Narrowing the match to only the relevant character set will yield better performance. |
Author(s): Hrishikesh Patel
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Regular Expression (RegEx) in Python: The Basics
Master the fundamentals of RegEx in Python

Consider you have a lot of text data, and you want to extract meaningful information. For example, you might want to extract hashtags, @mentions, URLs, etc. from any tweets. What’s the best way to do it? You got it right — it is to use a regular expression or regex. The regex is a sequence of characters that form a pattern that matches the text. We can define a pattern for hashtags, and it can be used to match any hashtags in the given tweets.
Though regex implementation is mostly similar across different programming languages, there can be minor differences. In this story, you’ll learn to use regex in Python. This story covers the basics of regex. I’ll write another story for advanced regex.
RegEx in Python
Python has a dedicated package called ‘re’ for working with regex. Click here to read its documentation. It has different functions such as .search(), .split(), .findall(), .sub(), etc. I will show the usage of the findall() function to find all desired information from the text using the regex pattern.

You may wonder what the small character “r” means before the regex pattern and how we can generate different patterns. Let’s dive into that!
Raw string in Python
Before delving deep into the regex, it is crucial to understand what raw string is. Python has special characters such as newline character (n), tab space(t), etc. in strings. What if we need n to be a part of the string instead of being treated specially? In this case, we should use raw strings. The following example illustrates the difference between normal and raw strings. Using raw strings for regex patterns is recommended to avoid the Python interpreter treating the strings unexpectedly.

Summary of typical regex metacharacters
Metacharacters are characters with special meaning in the regex pattern. For example, metacharacter d represents a digit from 0 to 9. The following table summarizes basic metacharacters used in regex.

1. Literal match
In the absence of metacharacters, you can get an exact match.

2. Match a digit using d
d represents any digit from 0 to 9.

3. Match a non-digit using D
D matches any single non-digit character.

4. Match a word character using w
w matches any single word character. It can include anything from A to Z, a to z, numbers 0 to 9, and an underscore(_).

5. Match a non-word character using W
Non-word characters include anything except the word characters mentioned above.

6. Match whitespace with s
s allows to match single whitespace character.

7. Match a non-whitespace with S
S can be used to match single non-whitespace character.

Quantifiers in regex
Let’s first extract a phone number from the text.

Since d matches a single digit, we must write it ten times to extract a
ten-digit number. But wait — it doesn’t look pretty. Here’s the solution — use quantifiers for characters in the pattern.
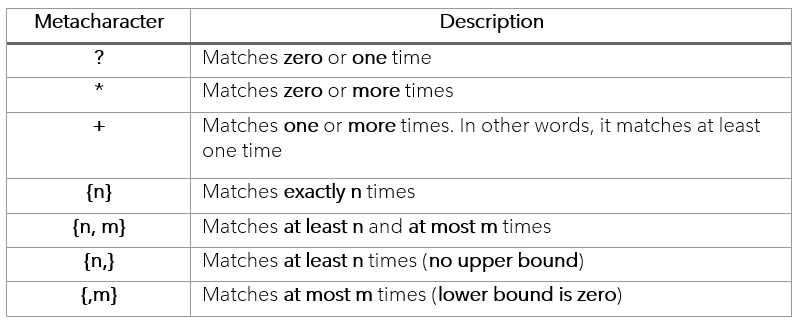
1. Match one or more times using +
The + matches one or more occurrences of its preceding character. So d+ means match one or more occurrences of a digit.

Similarly, you can match zero or more occurrences of its preceding character using *. So w* means to match zero or more occurrences of a word character.
2. Match exactly n occurrences using {n}
The {n} matches exactly n occurrences of its preceding character in the pattern. So

Other variations:
- {n,m} — Matches its preceding character at least n and at most m times e.g., d{2, 4} will match a digit at least two times and at most 4 times.
- {n,} — Matches its preceding character at least n times and there is no upper limit e.g., w{4,} will match a word character at least four times with no upper limit.
- {,m} — Matches its preceding character from zero to m times e.g., D{,4} will match any non-digit character at most four times, while it can be zero time as well.
3. Match zero or one-time using?
The ? matches its preceding character zero or one time. For example, cats? will match cat as well as cats.

Note — All these quantifiers are applied to their preceding characters, not the entire word e.g., in mango+ pattern, the + only applies to the last character o, not the word mango.
But what if you want to match the special characters like ,*, +,? etc. Since these are special characters, you cannot directly match them as shown below:

The solution is to use the escape character before the special character to be matched e.g., use + in the regex to match + . Similarly, you can use \ in the pattern to match in the text.

Thanks for reading this far. I now have a bonus for you.
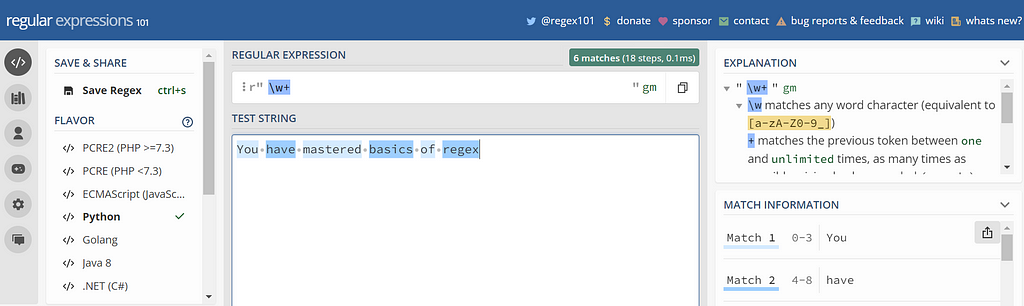
Bonus
There is a really cool website https://regex101.com/, where you can test your regex pattern. It also supports different programming languages. Go check out the page and have some fun with regex.
Thanks for reading my first ever story on medium. I will appreciate your feedback, and please feel free to post your questions in the comments. Follow me on Medium if you’d like more stories like this.
![]()
Regular Expression (RegEx) in Python : The Basics was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI