
Я когда-то уже писал подробный обзор на бесплатную надстройку Fuzzy Lookup от Microsoft, позволяющую находить соответствия двух списков при неточном совпадении данных. Недавно, с последними обновлениями Office 365, аналогичный функционал пришёл и в Power Query в Excel. До Power BI Desktop, кстати, он тоже добрался.
Давайте разберёмся, как этот инструмент работает, его плюсы, минусы и нюансы применения.
Тренироваться будем на слегка модернизированном примере из прошлой статьи про надстройку Fuzzy Lookup — двух списках, которые нужно объединить в один по совпадению адресов:

Прежде, чем начнём, обратите внимание на следующие моменты:
- Точно в этих списках совпадает только один адрес — «Пушкино, Набережная ул., д.61«. Все остальные адреса различаются с большей или меньшей степенью разброса.
- В некоторых адресах переставлены местами слова — например «Ульяновск, Лермонтова ул., д.63» и «улица Лермонтова д.63, г. Ульяновск«.
- В некоторых не хватает части данных — например, нет города в «Сиреневая ул. д.90» во второй таблице.
- Где-то город с «г.», а где-то без. С улицами — аналогично.
- Есть адреса уникальные и совершенно ни на что не похожие и ни с чем не совпадающие (Париж и Рио-де-Жанейро в конце каждого списка).
- Есть адреса с орфографическими ошибками или опечатками внутри слов (Чилябинск, Козань...)
Отдельно хочу отметить проблему с Санкт-Петербургом — этот город может быть записан кучей разных способов. Чтобы учесть этот момент при связывании нам придется заранее сделать специальную таблицу преобразований. Колонки в этой таблице должны строго называться From и To и содержать все возможные варианты наименований (столбец From) и их правильные аналоги (столбец To):

Шаг 1. Грузим исходные данные в Power Query
Сначала, само-собой, нужно загрузить все наши три исходные таблицы в Power Query. Сделать это можно несколькими способами (именованный диапазон, область печати, лист целиком), но самым удобным будет, наверное, преобразование в «умные таблицы» с помощью сочетания клавиш Ctrl+T или командой Главная — Форматировать как таблицу (Home — Format as Table).
По умолчанию, каждая умная таблица получает стандартное имя а-ля Таблица1,2… что можно, при желании изменить (но я здесь не буду).
После этого созданную «умную таблицу» можно легко залить в Power Query с помощью кнопки Из таблицы (From Table) на вкладке Данные (Data) или на вкладке Power Query (если у вас версия Excel 2010-2013 и вы установили Power Query как отдельную надстройку):

В открывшемся окне редактора запросов Power Query можно, в приципе, «допилить» наши данные при необходимости и затем сохранить полученную таблицу как подключение через Главная — Закрыть и загрузить — Закрыть и загрузить в … (Home — Close&Load — Close&Load to…):

И выбрать в следующем окне опцию Только создать подключение (Only create connection):

Всё это нужно по очереди проделать со всеми тремя таблицами, чтобы в итоге в правой панели запросов появились все три наши таблицы в режиме подключения:

Всё. Самая скучная часть — позади. Теперь переходим, непосредственно, к слиянию.
Шаг 2. Выполняем объединение
На вкладке Данные (Data) или на вкладке Power Query выбираем команду Получить данные / Создать запрос — Объединить — Объединить (Get Data / New Query — Combine queries — Merge):

Откроется окно слияния:

В этом окне нужно:
1. Выбрать в выпадающих списках Таблицы 1 и 2, которые мы хотим объединить.
2. Выделить в обеих таблицах столбцы, по которым мы связываем наши списки (колонки Адрес и Место, соответственно).
3. Чтобы увидеть потом не только совпадения, но и отличия и ясно понимать что именно мы нашли, а что нет — выбрать тип соединения Полное внешнее (Full Outer).
4. Включить (самое главное!) флажок Использовать нечеткие соответствия для слияния (Use fuzzy matching to perform the merge). Именно он заставляет Power Query искать не только точные совпадения, но и приблизительные.
Под ссылкой Параметры нечеткого соответствия (Fuzzy matching options) скрывается целый блок дополнительных настроек для нечеткого слияния:

Здесь:
- Порог подобия (Similarity Threshold) — дробный коэффициент (от 0 до 1), определяющий, насколько строгого соответствия вы требуете при сборке. При значении этого коэффициента равном единице, Power Query будет искать, фактически, только точные совпадения. При значениях близких к нулю сильно возрастает вероятность ошибки. Имеет смысл путем 2-3 попыток подобрать максимально большое значение (т.е. максимально строгий поиск), но при котором находятся все (или большинство) результатов.
- Игнорировать регистр (Ignore case) — по умолчанию Power Query учитывает регистр при поиске, т.е. различает Москва и МОСКВА, например. Включение этого флажка позволяет избавиться от регистрочувствительности при слиянии.
- Сопоставление путем объединения текстовых фрагментов (Match by combining text parts) — в переводе на человеческий язык означает, что при поиске соответствий будет производится проверка на переставление слов внутри текста (помните Ульяновск и ул.Лермонтова?)
- Если одному адресу в первой таблице соответствуте несколько похожих адресов во второй (это особенно актуально при низких значениях порога подобия), то можно ограничить количество найденных вариантов — за это отвечает параметр Максимальное число совпадений (Maximum number of matches).
- Чтобы учесть разные варианты написания Санкт-Петербурга — укажем нашу третью таблицу как Таблицу преобразования (Transformation Table).
Выполнив все настройки, нажмём на ОК и развернём в появившемся окне Power Query вторую таблицу с помощью кнопки в шапке (флажок Использовать исходное имя столбца как префикс можно снять):

В результате получим что-то похожее на:

Как видите, все адреса нашли свои аналоги, кроме уникальных Парижа и Рио-де-Жанейро, в паре с которыми появились ячейки с null, т.е. пустотой.
Шаг 3. Пишем свою М-функцию подобия
В принципе, на этом можно было бы и остановиться, но, вот, лично меня во всей этой истории смущает один момент: как определить, насколько хорошо Power Query нашёл соответствие для каждого адреса? Представьте, что вам нужно объединить подобным образом таблицы по несколько тысяч строк — вероятность ошибки при таком объеме данных уже ощутимая. Как понять, где Power Query отработал нечёткое слияние хорошо (текст совпадает почти точно), а где стоит проверить совпадение вручную и, возможно, внести правки?
Вот если бы был (помечтаем!) в наших данных столбец, где указывался бы коэффициент подобия найденных адресов, наглядно иллюстрирующий точность подбора! Как бы это упростило поиск подозрительных вариантов!
К сожалению, я не нашел в Power Query встроенных инструментов для подобного  Однако, мы можем своими силами реализовать похожую штуку, написав собственную функцию подобия двух текстовых строк на встроенном в Power Query языке М (за идею огромное спасибо и поклон в пояс Андрею VG с нашего форума).
Однако, мы можем своими силами реализовать похожую штуку, написав собственную функцию подобия двух текстовых строк на встроенном в Power Query языке М (за идею огромное спасибо и поклон в пояс Андрею VG с нашего форума).
Делаем следующее:
1. На вкладке Данные выбираем команду Получить данные / Создать запрос — Из других источников — Пустой запрос (Get Data / New Query — From other sources — Blank query).
2. В открывшемся окне редактора запросов жмем на Главной (Home) или на вкладке Просмотр (View) кнопку Расширенный редактор (Advanced Editor).
3. В появившемся окне удаляем всё, что там есть по-умолчанию и копируем-вставляем туда М-код нашей функции:
(text1 as text, text2 as text) as number =>
let
text1 = Text.Upper(text1),
text2 = Text.Upper(text2),
matching_chars = List.Count(List.Intersect({Text.ToList(text1), Text.ToList(text2)})),
average_length = (Text.Length(text1) + Text.Length(text2)) / 2,
coef = matching_chars / average_length
in
coef
Выглядеть это всё должно, в итоге, вот так:

Если интересны детали, то эта функция:
- переводит обе текстовых строки в заглавные буквы функцией Text.Upper, чтобы избежать регистрочувствительности
- разбирает исходные строки на отдельные символы функциями Text.ToList
- ищет количество совпадений символов функциями List.Intersect и List.Count и помещает его в переменную matching_chars
- вычисляет среднюю длину исходных текстовых строк с помощью функций Text.Length и помещает результат в переменную average_length
- делит число совпадений на среднюю длину, чтобы получить коэффициент подобия
Само-собой, эта логика отличается от той, что использует Power Query при поиске соответствий (а как именно это делает Power Query — знают только разработчики в Microsoft). Однако, в подавляющем большинстве реальных случаев, наша функция со своей задачей отлично справляется — проверено на опыте.
После нажатия на Готово в правой панели окна Power Query можно переименовать нашу функцию, дав ей более наглядное имя (например, КоэфПодобия вместо Запрос1).
Теперь осталось применить её к нашим данным. Выберем на вкладке Добавление столбца команду Вызвать настраиваемую функцию (Add Column — Invoke Custom Function) и введём ее аргументы в открывшемся окне:

После нажатия на ОК мы, наконец, получим желаемое — столбец, где будет виден числовой коэффициент подобия, наглядно отображающий качество подбора наших адресов:

Щёлкнув правой кнопкой мыши по заголовку получившегося столбца, можно выбрать команду Заменить ошибки (Replace Errors) и легко заменить получившиеся Error в Париже и Рио-де-Жанейро на нули. Ну, а затем отсортировать нашу таблицу по убыванию по столбцу коэффициентов и выгрузить обратно в Excel уже знакомой командой Главная — Закрыть и загрузить (Home — Close&Load):

Точные совпадения в начале списка проблем не составят, а вот строки в конце списка, возможно, потребуют вашего внимания и «доработки напильником». В любом случае, такой вариант слияния мне кажется более надежным.
P.S. А у меня в Excel такого нет!
Для всех, кто после прочтения этой статьи немедленно рванёт в свой Excel проверять наличие нечёткого поиска в Power Query, ещё разок хочу уточнить:
- У вас должен быть Office 365 по подписке, а не Office 2013, 2016, 2019 и т.д. К сожалению, политика Microsoft на данный момент такова, что только подписчики Office 365 получают все последние плюшки и нововведения типа неточного поиска, динамических массивов, новой функции ВПР (ПРОСМОТРX) и т.п.
- У вас должны быть установлены все последние обновления. Имейте ввиду, что в некоторых компаниях IT-службы намеренно тормозят и откладывают установку обновлений Office, т.к. они могут нарушать функционирование других программ (связки Excel c ERP и т.п.)
- Обновления рассылаются всем пользователям Office 365 волнами в течение нескольких недель. Неточный поиск появился у меня на одном компьютере после обновлений в конце прошлого года, а на другом — уже в начале этого. Если прямо сейчас у вас ещё нет этой функции — подождите и всё будет


Ссылки по теме
- Бесплатная надстройка Fuzzy Lookup и поиск неточный поиск текста
- Что такое Power Query, Power Pivot, Power BI и зачем они пользователю Excel
- Поиск точных совпадений с учётом регистра функцией СОВПАД
Когда вы присоединяетсяе столбцы таблицы, вам больше не требуется точное совпадение. Нечеткое соответствие позволяет сравнивать элементы в отдельных списках и присоединяться к ним, если они близко друг к другу. Вы даже можете настроить соответствие допуску или пороговое значение сходства.
Часто используется для нечеткого совпадения с текстовыми полями с полиформой, например в опросах, где вопрос о вашем любимом фрукте может иметь опечатки, сингуляры, множественное число, верхний, нижний регистр и другие варианты, которые не точно совпадают.
Нечеткое соответствие поддерживается только при операциях слияния с текстовыми столбцами. Power Query использует алгоритм сходства Jaccard для измерения сходства между парами экземпляров.
Последовательность действий
-
Чтобы открыть запрос, найдите ранее загруженную из редактора Power Query, выберем ячейку в данных и выберите запрос> Изменить. Дополнительные сведения см. в статьи Создание, изменение и загрузка запроса в Excel (Power Query).
-
Выберите Главная>
объединить >
слияние запросов. Вы также можете выбрать слияние запросов в качестве нового. Появится диалоговое окно Слияние с главной таблицей в верхней части. -
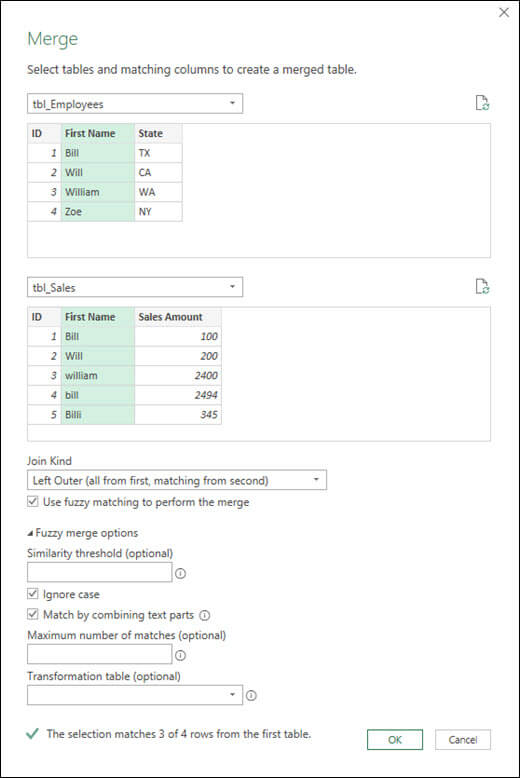
Выберите столбец, который вы хотите использовать для нечеткого совпадения. В этом примере выбрано имя.
-
В списке выберите вторичную таблицу, а затем — соответствующий столбец нечеткого совпадения. В этом примере выбрано имя.
-
Выберите тип join kind. Существует несколько способов присоединиться. По умолчанию используется левое внешнее. Дополнительные сведения о каждом типе объединения см. в этой статьи.
-
Выберите Использовать нечеткое соответствиедля выполнения слияния , выберите Нечеткие параметры, а затем выберите один из следующих вариантов:
-
Пороговое значение сходства
Указывает на необходимость совпадения двух похожих значений. Минимальное значение 0,00 вызывает соответствие всех значений друг другу. Максимальное значение 1,00 допускает только точные совпадения. Значение по умолчанию — 0,80. -
Игнорировать дело
Указывает, следует ли сравнивать текстовые значения с конфиденциальным или неохваденным образом. По умолчанию этот случай не имеет значения, поэтому он игнорируется. -
Максимальное количество совпадений
Управляет максимальным количеством совпадающих строк, которые будут возвращены для каждой входной строки. Например, если вы хотите найти только одну строку для каждой входной строки, укажите значение 1. По умолчанию возвращаются все совпадения. -
Таблица преобразования Укажите другой запрос, в который входит таблица сопоставления, чтобы некоторые значения могли быть автоматически сопоставлены в логике сопоставления. Например, при определении таблицы из двух столбцов с текстовыми столбцами «От» и «По» со значениями «Майкрософт» и «MSFT» эти значения будут считаться одинаковыми (оценка сходства — 1,00).
-
-
Power Query анализирует обе таблицы и выводит сообщение о том, сколько совпадений было сделано. В этом примере выбор соответствует 3 из 4 строк из первой таблицы. Если не использовать размытые совпадения, будут совпадать только 2 из 4 строк.
-
Если вы удовлетворены, выберите ОК. Если нет, попробуйте другие параметры нечеткого слияния, чтобы настроить свой опыт.
-
В случае удовлетворения выберите ОК.
См. также
Справка по Power Query для Excel
Слияние запросов (Power Query)
Нечеткое слияние (docs.com)
Нужна дополнительная помощь?
Tags:
Power BI, Power Query, таблица
После долгого ожидания в выпуске Power BI Desktop, выпущенном в октябре 2018 года, мы увидели наконец добавленную функцию неточного соответствия. Ура! Вы когда-нибудь хотели совместить две таблицы вместе, но не на точных совпадениях, при этом на пороге сходства? Если вы отвечаете на этот вопрос положительно, то эта функция создана для вас. Давайте подробно рассмотрим, как работает неточное соответствие в Power BI.
Включите функцию предварительного просмотра
Во время написания этого сообщения в блоге, Fuzzy matching — это функция предварительного просмотра, и вы должны включить ее в Power BI Desktop -> Files -> Options and Settings -> Options;

В окне «Options» в разделе Preview Features установите флажок “Enable fuzzy merge”,

После этого шага вам нужно будет закрыть Power BI Desktop и снова открыть его.
Пример набора данных
Для этого примера мы будем использовать образец набора данных, который содержит две очень простые таблицы ниже;
Таблица “source”, которая содержит данные сотрудников и их отделов. Обратите внимание, что поле Departmentа имеет проблемы с качеством данных. У нас есть такие значения в нем, как “Sales”и “Sale”. Или другим примером является «Managmnt» и «Management».

Как вы можете видеть, список названий отделов чист в этой таблице, и это таблица, которая должна использоваться для очистки таблицы “source”. Теперь посмотрим, как это возможно?
Fuzzy Merge
Fuzzy Merge — это способ объединения двух таблиц вместе, но не по точным критериям соответствия, а по порогу подобия. Если вы хотите узнать, что такое операция слияния и какая разница с Append, прочитайте этот пост. Если вы хотите узнать больше о том, что такое Merge, а также о разных типах объединения или слияния, прочитайте наш другой пост в блоге. Объединение или слияние — это просто объединение двух таблиц с разными структурами, но со столбцами ссылок / объединений, для доступа к столбцам из одной из таблиц в другой.
Чтобы использовать операцию слияния в «исходном» запросе, вы можете выбрать опцию «Merge Queries as New» на вкладке Home окна «Power Query Editor».

Затем вы можете выбрать вторую таблицу и выбрать « Department» в качестве поля объединения

Этот процесс даст вам следующий результат (после расширения вывода столбца слияния);

Вы можете видеть, что операция Merge только находит сценарии EXACT Matching. Раздел «Sale» не соответствует таблице Department , потому что в конце отсутствует «S» в соответствии с «Sales».
Теперь давайте посмотрим, как работает Fuzzy. Чтобы использовать Fuzzy Merge, просто установите флажок в диалоговом окне Merge tables;

Когда вы включаете неточное соответствие, вы можете настроить его в «fuzzy merge operations». Вы можете оставить все опциональным или установить значения. Давайте сначала посмотрим на образец вывода этой операции, а затем посмотрим, каковы параметры. Это пример вывода Fuzzy Merge:

Вы можете видеть три выделенные записи, которые не были распознаны как точное совпадение в нормальной операции слияния, не соответствуют результатам неточного слияния. Fuzzy merge проверяет сходство между полями объединения, и если их сходство больше, чем пороговая конфигурация, оно передает его как успешное совпадение. Вы можете видеть, что «Managmnt» может соответствовать «Management» с этой пороговой конфигурацией, но «Mangmt» не показывает, что порог сходства выше, чем ставка сходства этих двух текстовых значений друг с другом.
Вы можете играть с опциями Fuzzy Merge и получать разные результаты. Вот объяснение этих вариантов:
|
Опция |
Допустимое значение |
Описание |
|
Threshold |
значение между 0.00 и 1.00 |
Если сходство между двумя текстовыми значениями превышает пороговое значение, это будет считаться успешным действием. Значение 1.00 означает точное совпадение. |
|
Ignore Case |
true/false |
Если вы хотите, чтобы алгоритм сходства работал независимо от букв верхнего или нижнего регистра, выберите этот параметр. |
|
Ignore Space |
true/false |
Если вы хотите, чтобы алгоритм сходства работал независимо от количества пробелов в тексте, выберите эту опцию. |
|
Maximum Number of Matches |
Положительное число от 0 до 2147483647 |
Количество строк, которые могут быть сопоставлены с одним значением. |
|
Transformation Table |
table |
Это похоже на таблицу сопоставлений, давайте проверим ее немного позже. Это дает вам возможность использовать собственную таблицу сопоставления. В этой таблице должно быть не менее двух столбцов «To» и «From». |
Функции Power Query
В дополнение к опции, добавленной в графическом интерфейсе Power Query, у нас также есть две функции Power Query, которые выполняют Fuzzy Merge, это:
Table.FuzzyJoin
Table.FuzzyNestedJoin
Обе эти функции имеют одинаковые конфигурации неточности, их единственное различие состоит в том, что один из них дает вам расширенный вывод (FuzzyJoin), другой дает тот же результат, что и тот, который вы видите в графическом интерфейсе с выводом столбца таблицы после слияния (FuzzyNestedJoin). Если вы используете эти две функции непосредственно в сценарии M, у вас будет еще несколько параметров для настройки, которые предназначены для параллелизма и настроек культуры.
Это параметры двух вышеперечисленных функций;

Таблица преобразования
Иногда в операции слияния вам нужна таблица соответствия. Эта таблица называется здесь как Transformation Table. Ниже приведен пример таблицы соответствия:

Обратите внимание, что эта таблица должна содержать по крайней мере два столбца “To”, и “From”. И не забывайте, что Power Query чувствителен к регистру!
Теперь вы можете выбрать эту таблицу в своей операции Merge в конфигурации Fuzzy, как показано ниже;

Этот процесс похож на объединение таблицы “source”, которая является первой таблицей в нашем Merge, с таблицей “Department”, основанной на столбце “Department”, а затем “Department Name” , а затем слияние с таблицей “mapping”, основанной на столбце “To” и “Department Name”. На выводе появится столбец “To” таблицы соответствия. Вот пример вывода:

Резюме
Соответствие, основанное на пороге сходства, или нечеткое соответствие — это фантастическая функция, добавленная в Power Query и Power BI, однако она по-прежнему является функцией предварительного просмотра, и у нее может возникнуть еще одна конфигурация.
@SalaLoocki Hi there,
I have the same problem, I discovered that I can amend the regular matching formula with the fuzzing formula.
You first matching the 2 tables and then add the word «Fuzzy» here (Formula Bar):
= Table.FuzzyNestedJoin(#»Changed Type», {«Last Name»}, Table4, {«Last Name»}, «Table4», JoinKind.LeftOuter)

I hope this helped you
|
нечеткий поиск power query |
||||||||
Ответить |
||||||||
Ответить |
