
Приветствую посетителей блога statanaliz.info. В данной статье рассмотрим, что такое «выборочная несмещенная дисперсия».
Тема не нова, так как с таким показателями как размах значений, среднее линейное отклонение, дисперсия, среднеквадратичное (стандартное) отклонение, коэффициент вариации мы уже знакомы.
Понятие о сплошном и выборочном наблюдении
С точки зрения охвата объекта исследования, статистический анализ можно разделить на два вида: сплошной и выборочный. Сплошной статанализ предполагает изучение генеральной совокупности данных, то есть всего явления во всем его многообразии без распространения выводов на другие элементы, не входящие в анализируемую совокупность. Из названия данного типа явствует, что наблюдению подвергаются тотально все элементы. Результат анализа распространяется на всю генеральную совокупность без каких-либо допущений и поправок на ошибку. Данный тип статистического исследования является наиболее полным и точным, так как дополнительные знания почерпнуть уже неоткуда – информация собрана со всех элементов объекта исследования. Это бесспорный плюс.
Отличным примером сплошного наблюдения является перепись населения. «Всесоюзная перепись населения» — красиво звучало! Кстати, советская статистика, как и наука в целом, была одной из самых лучших в мире. Денег на проведение сплошных обследований не жалели, так как при СССР статистика выполняла свою прямую функцию – исследовала реальность, без чего невозможно было строить «светлое будущее». При этом советские ученые-статистики справедливо критиковали буржуазную статистику за то, что те скрывают от народа реальное положение дел и используют статистику для промывки мозгов. Об этом, кстати, писали и сами буржуи. Более практичный пример сплошного наблюдения – опрос жителей многоэтажного дома на предмет заваривания мусоропровода. Опрашиваются все, результат дает вполне однозначный ответ об отношении жителей к мусоропроводу. Ошибки в выводах маловероятны.
Как бы там ни было, у сплошного наблюдения есть отрицательное качество: на организацию и проведение исследования могут потребоваться значительные ресурсы. Одно дело взять пробу из партии товаров, другое – проверять всю партию. Одно дело опросить тысячу прохожих на улице, совсем другое – организовать перепись населения.
В противовес сплошному придумали выборочное наблюдение. Название метода точно отражает его суть: из генеральной совокупности отбирается и анализируется только часть данных, а выводы распространяют на всю генеральную совокупность. Отбор данных происходит таким образом, чтобы выборка была репрезентативной, то есть, сохранила внутреннюю структуру и закономерности генеральной совокупности. Если это условие не соблюдено, то дальнейший анализ во многом теряет смысл.
Сам анализ выборочных данных происходит так же, как и при сплошном наблюдении (рассчитываются различные показатели, делаются прогнозы и т.д.), только с поправкой на ошибку. Это значит, что рассчитывая тот или иной показатель, мы понимаем, что при повторной выборке его значение будет другим. К примеру, провели опрос общественного мнения. Опрос показал, что за кандидата N желают проголосовать 60% опрошенных. Если провести еще один такой же опрос, даже в том же месте, то результат будет отличаться. То есть, взяв первое значение 60%, следует понимать, что с той или иной вероятностью оно могло быть, скажем, и 58%, и 62%. Точность и разброс выборочных показателей зависят от характера данных и их количества.
У выборочного наблюдения есть один существенный плюс и один минус, однако по сравнению со сплошным наблюдением крайности меняются местами. Плюс заключается в том, что для проведения выборочного обследования требуется гораздо меньше ресурсов. Минус – в том, что выборочное наблюдение всегда ошибочно. Поэтому основная задача проведения выборочного наблюдения – добиться максимальной точности при приемлемых затратах на его проведение.
Выборочная несмещенная дисперсия
И вот, стало быть, дисперсия. Дисперсия, как и доля или средняя арифметическая, также меняет свое значение от выборки к выборке, но здесь есть интересная особенность. Дисперсия ведь рассчитывается от средней величины, а она в свою очередь, тоже рассчитывается по выборке, то есть является ошибочной. Как же это обстоятельство влияет на саму дисперсию?
Если бы мы знали истинную среднюю величину (по генеральной совокупности), то ошибка дисперсии была бы связана только с нерепрезентативностью, то есть с тем, что данные в выборке оказались бы ближе или дальше от средней, чем в целом по генеральной совокупности. При этом при многократном повторении данные стремились бы к своему реальному расположению относительно средней.
Выборочный показатель, который при многократном повторении выборки стремится к своему теоретическому значению, называется несмещенной оценкой. Почему оценкой? Потому что мы не знаем реальное значение показателя (по генеральной совокупности), и с помощью выборочного наблюдения пытаемся его оценить. Оценка показателя – это есть его характеристика, рассчитанная по выборке.
Теперь смотрим внимательно на выборочную среднюю. Выборочная средняя – это несмещенная оценка математического ожидания, так как средняя из выборочных средних стремится к своему теоретическому значению по генеральной совокупности. Где она расположена? Правильно, в центре выборки! Средняя всегда находится в центре значений, по которым рассчитана – на то она и средняя. А раз выборочная средняя находится в центре выборки, то из этого следует, что сумма квадратов расстояний от каждого значения выборки до выборочной средней всегда меньше, чем до любой другой точки, в том числе и до генеральной средней. Это ключевой момент. А раз так, то дисперсия в каждой выборке будет занижена. Средняя из заниженных дисперсий также даст заниженное значение. То есть при многократном повторении эксперимента выборочная дисперсия не будет стремиться к своему истинному значению (как выборочная средняя), а будет смещена относительно истинного значения по генеральной совокупности.
Отклонение выборочной средней от генеральной показано на рисунке.

Несмещенность оценки – одна из важных характеристик статистического показателя. Смещенная оценка показателя заранее говорит о тенденции к ошибке. Поэтому показатели стараются оценивать таким образом, чтобы их оценки были несмещенными (как у средней арифметической). Чтобы решить проблему смещенности выборочной дисперсии, в ее расчет вносят корректировку – умножают на n/(n-1), либо сразу при расчете в знаменатель ставят не n, а n-1. Получается так.
Выборочная смещенная дисперсия:
![]()
Выборочная несмещенная дисперсия:
![]()
Под выборочной дисперсией понимают, как правило, именно несмещенный вариант.
Теперь посмотрим на практическую сторону отличия смещенной и несмещенной дисперсии. Соотношение между выборочной и генеральной дисперсией составляет n/n-1. Несложно догадаться, что с ростом n (объема выборки) данное выражение стремится к 1, то есть разница между значениями выборочной и генеральной дисперсиями уменьшается.
Так, в выборке из 11 наблюдений относительная разница составляет 11/10 = 10%. При 21 наблюдениях, отличие сокращается до 5%, при 31 наблюдении – до 3,3%, при 51 – до 2%, при 101 – до 1%. Короче, при достаточно большой выборке данных (50 и выше наблюдений) относительная разница между смещенной и несмещенной дисперсией практически исчезает. Оценка параметра, когда с ростом выборки его отклонение от теоретического значения уменьшается, называется асимптотически несмещенной оценкой.
При переходе к среднеквадратичном отклонению по выборке (корень из выборочной дисперсии) разница становится еще меньше.
Таким образом, эффект смещенной дисперсии проявляется в небольших выборках. В больших выборках можно использовать генеральную дисперсию, что как бы не усложняет и не упрощает жизнь. Вручную сейчас никто не считает. Все легко посчитать в Excel. Но понимать различие в терминологии и в сути показателей все же следует.
Из данной статьи неплохо бы усвоить следующее.
1. Формула генеральной дисперсии в выборке дает смещенную оценку.
2. В знаменателе несмещенной оценки n-1 вместо n.
3. При большом объеме выборки (от 100 наблюдений) разница между смещенной и несмещенной дисперсиями практически исчезает.
4. Стандартное отклонение по выборке – это корень из выборочной дисперсии.
До новых встреч на блоге statanaliz.info.
Поделиться в социальных сетях:

1 .
.
Выборочная оценка математического
ожидания – выборочное среднее![]()
в Excel
вычисляется с помощью
функция СРЗНАЧ,
при этом
реализуется формула
 .
.
2 .
.
Оценка дисперсии – несмещенная
(исправленная) выборочная дисперсия![]() может быть получена с помощью функцииДИСП.
может быть получена с помощью функцииДИСП.
В Excel
реализована формула
 .
.
3.
Несмещенное выборочное средние
квадратические отклонения (стандартное
отклонение)
![]() вычисляется
вычисляется
с помощью функции
СТАНДОТКЛОН.
Вычисления
в Excel
выполнены по формуле
 .
.
4 .
.
Выборочная (смещенная) оценка дисперсии

вычисляется с помощью
функция ДИСПР.
Результат
вычисления выборочных оценок
![]() ,
,
![]() ,
,
![]() и
и![]()
показан на рис.1.

… … … …
… … …

Рис.
1. Фрагмент листа Excel
с исходными данными и выборочными
оценками параметров.
2. Описательная статистика.
Выполните
процедуру Описательная
статистика.
В
главном меню Excel
выбрать: Данные
→ Анализ данных → Описательная статистика
→ ОК.
В
появившемся окне Описательная
статистика
ввести:
Входной
интервал –
100 случайных чисел в ячейках $A$3:
$A$102;
Группирование
— по столбцам;
Выходной
интервал –
адрес ячейки, с которой начинается
таблица Описательная
статистика – например,
$D$8;
Итоговая
статистика
– поставить галочку. ОК.
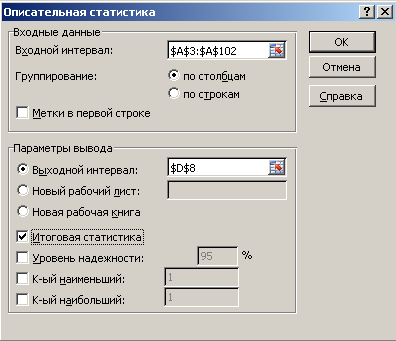
Рис.
2. Диалоговое окно Описательная
статистика
с заполненными полями ввода.
На
листе Excel
появится таблица – Столбец
1. В
таблице даются все необходимые параметры,
кроме моды Mo(X).

Рис.
3. Таблица Описательная
статистика
Таблица содержит
описательные статистики, в частности:
Среднее
– оценка математического ожидания
![]() ;
;
Стандартное
отклонение
– оценка среднего квадратического
отклонения![]() ;
;
Дисперсия
– выборочная исправленная дисперсия
![]() ;
;
Эксцесс
и Асимметричность
– оценки эксцесса и асимметрии;
Медиана
– оценка
медианы;
Мода
– оценка
моды, #Н/Д – нет данных (наиболее часто
встречающееся значение случайной
величины в выборке).
Приблизительное
равенство нулю оценок эксцесса и
асимметрии, и приблизительное равенство
оценки среднего оценке медианы дает
предварительное основание выбрать в
качестве основной гипотезы H0
распределения элементов генеральной
совокупности — нормальный закон.
Интервал
– размах выборки;
Минимум
– минимальное значение случайной
величины в выборке ![]() ;
;
Максимум
– максимальное значение случайной
величины в выборке ![]() .
.
Результаты
процедуры Описательная
статистика
потребуются в дальнейшем при построении
теоретического закона распределения.
3. Построение гистограммы
В
главном меню Excel
выбрать Данные
→ Анализ данных → Гистограмма → ОК.
Далее
необходимо заполнить поля ввода в
диалоговом окне Гистограмма.
Входной
интервал:
100 случайных чисел в ячейках $A$3:
$A$102;
Интервал
карманов:
не
заполнять;
Выходной
интервал:
адрес ячейки, с которой начинается вывод
результатов процедуры Гистограмма;
Вывод
графика –
поставьте галочку.
Если
поле ввода Интервал
карманов не
заполняется, то процедура вычисляет
число интервалов группировки k
и границы интервалов автоматически по
формуле.
![]() ,
,
где,
скобки
![]() означают – округление до целой части
означают – округление до целой части
числа в меньшую сторону.
В
рассматриваемом варианте n
= 100,
следовательно, k
= 11.
Действительно:

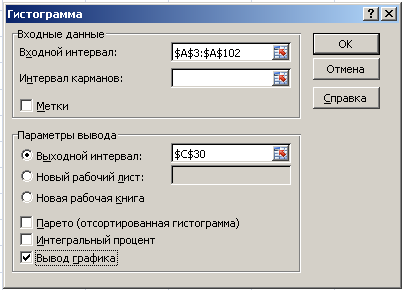
Рис.
4. Диалоговое окно Гистограмма.
В
результате выполнения процедуры
Гистограмма
появляется таблица, содержащая границы
xi
интервалов
группировки (столбец – Карман)
и частоту попадания случайных величин
выборки mi
в i–ый
интервал (столбец
–
Частота).
Справа от таблицы
– график гистограммы.
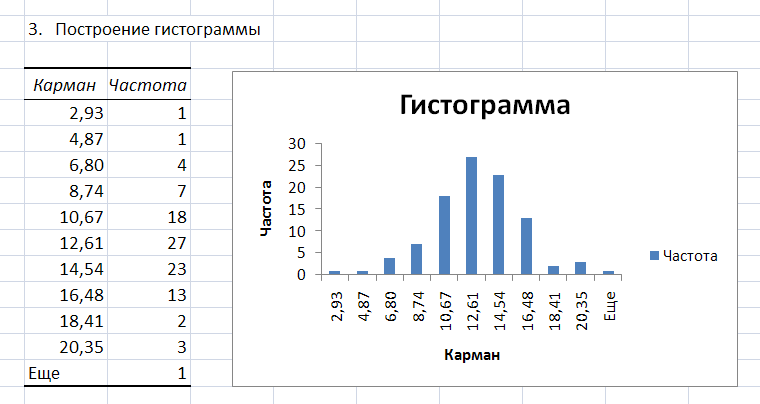
Рис.
5. Фрагмент листа Excel
с результатами процедуры Гистограмма.
По
виду гистограммы можно предположить
(принять гипотезу) о том, что выборка
случайных чисел подчиняется нормальному
закону распределения.
Далее,
для того чтобы убедиться в правильности
выбранной гипотезы (по крайней мере
визуально) надо, первое – построить
график гипотетического нормального
закона распределения, выбрав в качестве
параметров (математического ожидания
и среднего квадратического отклонении)
их оценки (среднее и стандартное
отклонение), и совместить график
гипотетического распределения с графиком
гистограммы.
И,
второе – используя критерий согласия
Пирсона установить справедливость
выбранной гипотезы.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Содержание
- Вычисление дисперсии
- Способ 1: расчет по генеральной совокупности
- Способ 2: расчет по выборке
- Вопросы и ответы

Среди множества показателей, которые применяются в статистике, нужно выделить расчет дисперсии. Следует отметить, что выполнение вручную данного вычисления – довольно утомительное занятие. К счастью, в приложении Excel имеются функции, позволяющие автоматизировать процедуру расчета. Выясним алгоритм работы с этими инструментами.
Вычисление дисперсии
Дисперсия – это показатель вариации, который представляет собой средний квадрат отклонений от математического ожидания. Таким образом, он выражает разброс чисел относительно среднего значения. Вычисление дисперсии может проводиться как по генеральной совокупности, так и по выборочной.
Способ 1: расчет по генеральной совокупности
Для расчета данного показателя в Excel по генеральной совокупности применяется функция ДИСП.Г. Синтаксис этого выражения имеет следующий вид:
=ДИСП.Г(Число1;Число2;…)
Всего может быть применено от 1 до 255 аргументов. В качестве аргументов могут выступать, как числовые значения, так и ссылки на ячейки, в которых они содержатся.
Посмотрим, как вычислить это значение для диапазона с числовыми данными.
- Производим выделение ячейки на листе, в которую будут выводиться итоги вычисления дисперсии. Щелкаем по кнопке «Вставить функцию», размещенную слева от строки формул.
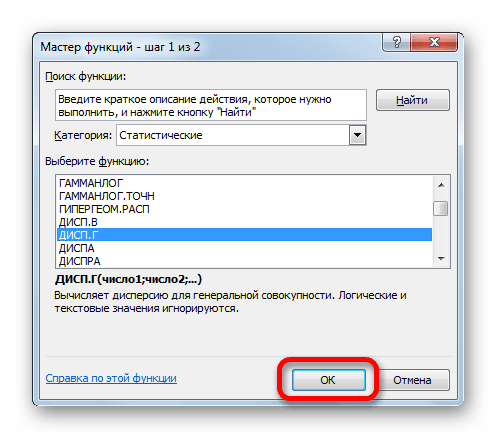
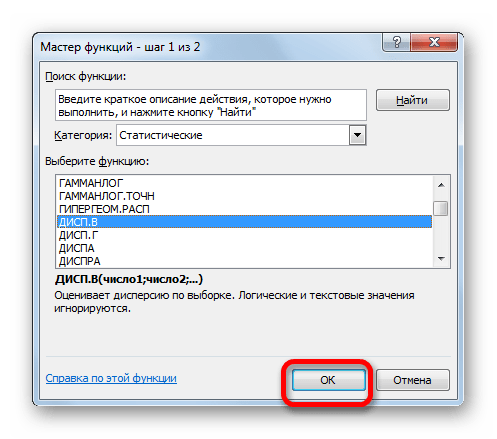
- Запускается Мастер функций. В категории «Статистические» или «Полный алфавитный перечень» выполняем поиск аргумента с наименованием «ДИСП.Г». После того, как нашли, выделяем его и щелкаем по кнопке «OK».
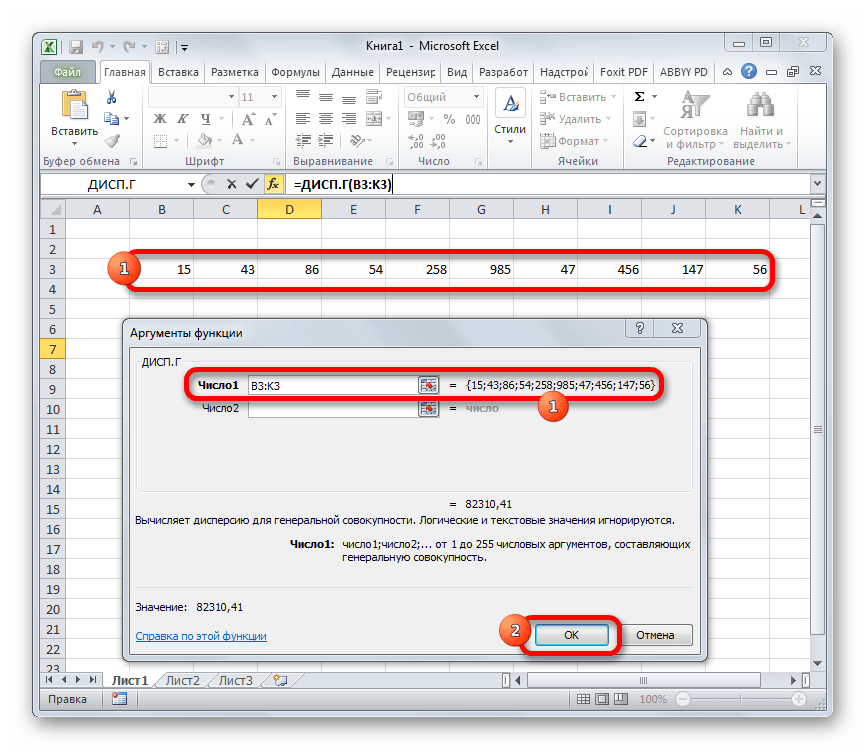
- Выполняется запуск окна аргументов функции ДИСП.Г. Устанавливаем курсор в поле «Число1». Выделяем на листе диапазон ячеек, в котором содержится числовой ряд. Если таких диапазонов несколько, то можно также использовать для занесения их координат в окно аргументов поля «Число2», «Число3» и т.д. После того, как все данные внесены, жмем на кнопку «OK».
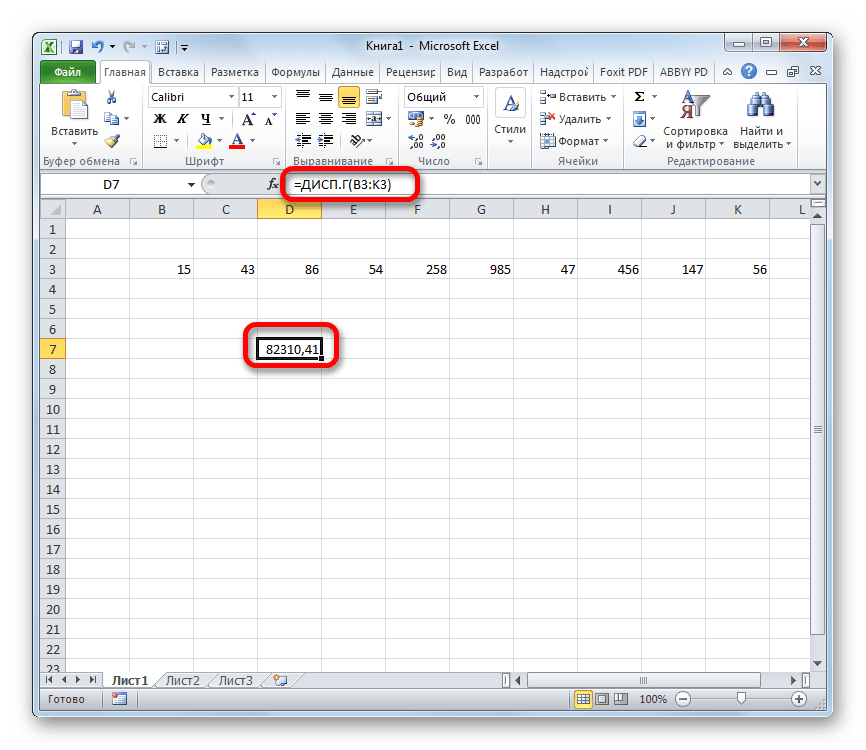
- Как видим, после этих действий производится расчет. Итог вычисления величины дисперсии по генеральной совокупности выводится в предварительно указанную ячейку. Это именно та ячейка, в которой непосредственно находится формула ДИСП.Г.
Урок: Мастер функций в Эксель
Способ 2: расчет по выборке
В отличие от вычисления значения по генеральной совокупности, в расчете по выборке в знаменателе указывается не общее количество чисел, а на одно меньше. Это делается в целях коррекции погрешности. Эксель учитывает данный нюанс в специальной функции, которая предназначена для данного вида вычисления – ДИСП.В. Её синтаксис представлен следующей формулой:
=ДИСП.В(Число1;Число2;…)
Количество аргументов, как и в предыдущей функции, тоже может колебаться от 1 до 255.

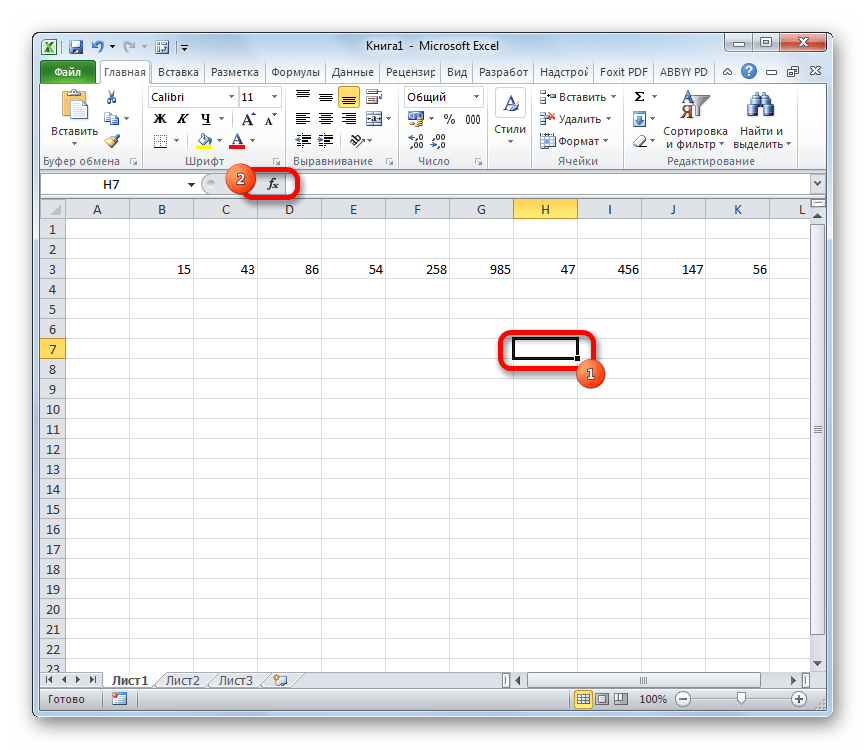
- Выделяем ячейку и таким же способом, как и в предыдущий раз, запускаем Мастер функций.
- В категории «Полный алфавитный перечень» или «Статистические» ищем наименование «ДИСП.В». После того, как формула найдена, выделяем её и делаем клик по кнопке «OK».
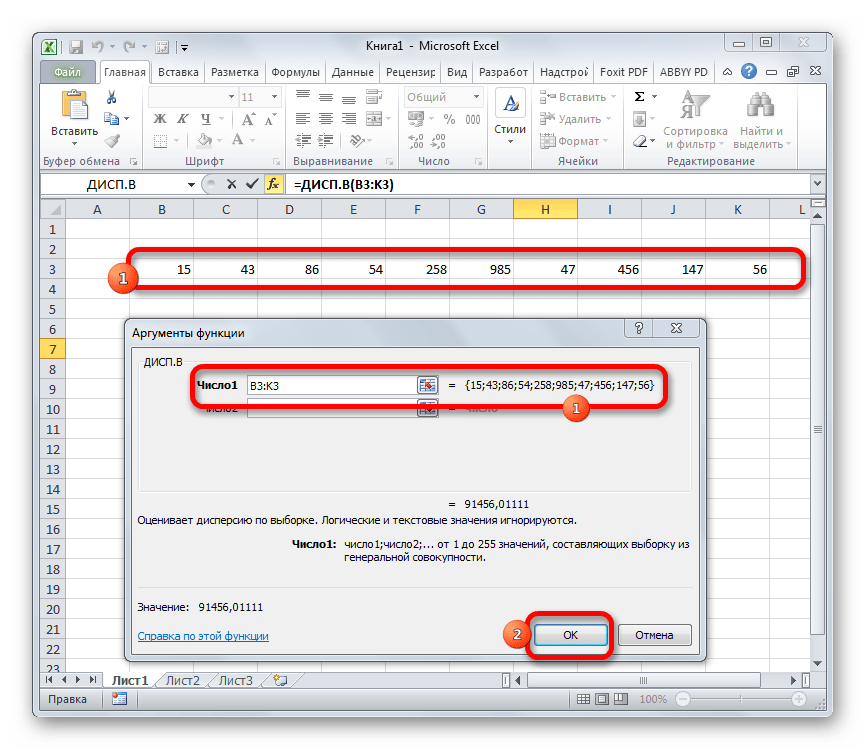
- Производится запуск окна аргументов функции. Далее поступаем полностью аналогичным образом, как и при использовании предыдущего оператора: устанавливаем курсор в поле аргумента «Число1» и выделяем область, содержащую числовой ряд, на листе. Затем щелкаем по кнопке «OK».
- Результат вычисления будет выведен в отдельную ячейку.
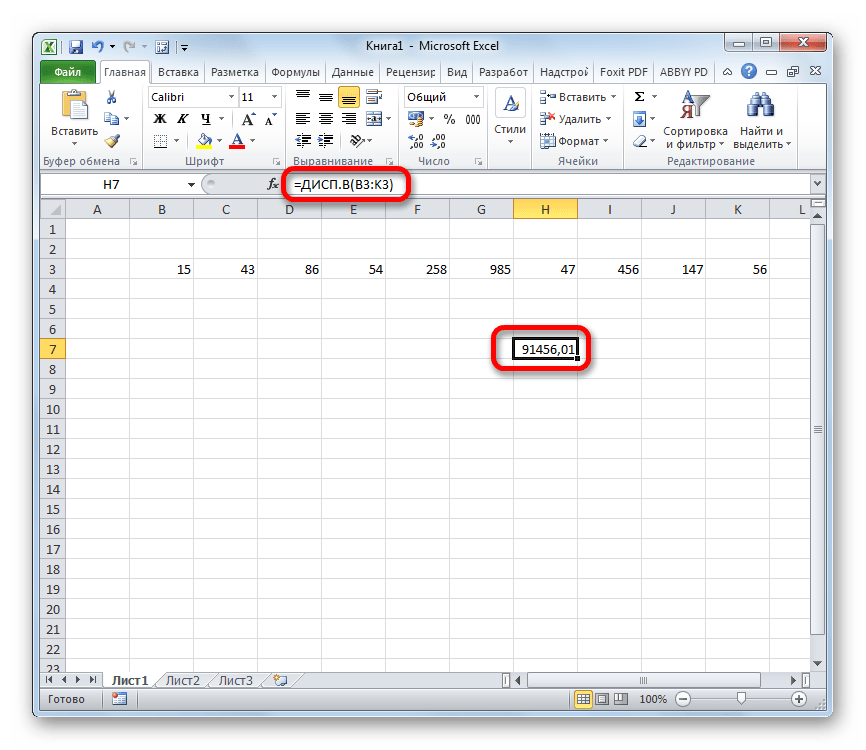
Урок: Другие статистические функции в Эксель
Как видим, программа Эксель способна в значительной мере облегчить расчет дисперсии. Эта статистическая величина может быть рассчитана приложением, как по генеральной совокупности, так и по выборке. При этом все действия пользователя фактически сводятся только к указанию диапазона обрабатываемых чисел, а основную работу Excel делает сам. Безусловно, это сэкономит значительное количество времени пользователей.
Еще статьи по данной теме:
Помогла ли Вам статья?
Программа Excel предлагает пользователям 6 итоговых функций, отображаемых в списке Итоги по, и 5 дополнительных итоговых функций, доступ к которым открывается после выбора параметра Дополнительно (More Options) в списке Итоги по. Эти функции описаны в следующем списке.
- Сумма (Sum). Суммирует все числовые данные.
- Количество (Count). Подсчитывает количество всех ячеек, включая ячейки с числами, текстом и ошибками. Операция эквивалентна функции Excel СЧЁТЗ ().
- Среднее (Average). Вычисляет среднее значение.
- Максимум (Мах). Выводит максимальное значение.
- Минимум (Min). Выводит минимальное значение.
- Произведение (Product). Перемножает все ячейки. Например, если ваш набор данных содержал ячейки с числами 3, 4 и 5, то в результате будет выведено значение 60.
- Количество чисел (Count Nums). Подсчитывает только числовые ячейки. Операция эквивалентна функции Excel СЧЁТ ().
- Смещенное, несмещенное отклонение (StdDev, StdDevP). Подсчитывает стандартное отклонение. Используйте операцию Несмещенное отклонение, если набор данных содержит генеральную совокупность. Если набор данных содержит выборку из генеральной совокупности, используйте операцию Смещенное отклонение.
- Смещенная, несмещенная дисперсия (Var, VarP). Подсчитывает статистическую дисперсию. Если ваши данные содержат только выборку из генеральной совокупности, используйте операцию Смешенная дисперсия для поиска расхождений в данных.
Стандартное отклонение позволяет выяснить, насколько тесно группируются результаты вокруг среднего значения.
Содержание
- 1 Вычисление дисперсии
- 1.1 Способ 1: расчет по генеральной совокупности
- 1.2 Способ 2: расчет по выборке
- 1.3 Помогла ли вам эта статья?
- 2 Использование метода «сырого счета» (пример с готовкой)
- 3 Расчет дисперсии в Excel
- 4 Вычисляем дисперсию
- 4.1 Рассчитываем по генеральной совокупности
- 4.2 Производим расчет по выборке
- 4.3 Видео: Расчет дисперсии в Excel
- 5 Заключение
- 5.1 Это может быть интересно:
- 6 Как рассчитать дисперсию в Excel?
- 6.1 Присоединяйтесь к нам!
- 7 Расчет стандартного отклонения
- 8 Расчет среднего арифметического
- 9 Расчет коэффициента вариации
- 10 Среднеквадратическое отклонение
- 11 Коэффициент осциляции
- 12 Дисперсия
- 13 Максимум и минимум

Среди множества показателей, которые применяются в статистике, нужно выделить расчет дисперсии. Следует отметить, что выполнение вручную данного вычисления – довольно утомительное занятие. К счастью, в приложении Excel имеются функции, позволяющие автоматизировать процедуру расчета. Выясним алгоритм работы с этими инструментами.
Вычисление дисперсии
Дисперсия – это показатель вариации, который представляет собой средний квадрат отклонений от математического ожидания. Таким образом, он выражает разброс чисел относительно среднего значения. Вычисление дисперсии может проводиться как по генеральной совокупности, так и по выборочной.
Способ 1: расчет по генеральной совокупности
Для расчета данного показателя в Excel по генеральной совокупности применяется функция ДИСП.Г. Синтаксис этого выражения имеет следующий вид:
=ДИСП.Г(Число1;Число2;…)
Всего может быть применено от 1 до 255 аргументов. В качестве аргументов могут выступать, как числовые значения, так и ссылки на ячейки, в которых они содержатся.
Посмотрим, как вычислить это значение для диапазона с числовыми данными.
- Производим выделение ячейки на листе, в которую будут выводиться итоги вычисления дисперсии. Щелкаем по кнопке «Вставить функцию», размещенную слева от строки формул.
- Запускается Мастер функций. В категории «Статистические» или «Полный алфавитный перечень» выполняем поиск аргумента с наименованием «ДИСП.Г». После того, как нашли, выделяем его и щелкаем по кнопке «OK».
- Выполняется запуск окна аргументов функции ДИСП.Г. Устанавливаем курсор в поле «Число1». Выделяем на листе диапазон ячеек, в котором содержится числовой ряд. Если таких диапазонов несколько, то можно также использовать для занесения их координат в окно аргументов поля «Число2», «Число3» и т.д. После того, как все данные внесены, жмем на кнопку «OK».
- Как видим, после этих действий производится расчет. Итог вычисления величины дисперсии по генеральной совокупности выводится в предварительно указанную ячейку. Это именно та ячейка, в которой непосредственно находится формула ДИСП.Г.

Урок: Мастер функций в Эксель
Способ 2: расчет по выборке
В отличие от вычисления значения по генеральной совокупности, в расчете по выборке в знаменателе указывается не общее количество чисел, а на одно меньше. Это делается в целях коррекции погрешности. Эксель учитывает данный нюанс в специальной функции, которая предназначена для данного вида вычисления – ДИСП.В. Её синтаксис представлен следующей формулой:
=ДИСП.В(Число1;Число2;…)
Количество аргументов, как и в предыдущей функции, тоже может колебаться от 1 до 255.
- Выделяем ячейку и таким же способом, как и в предыдущий раз, запускаем Мастер функций.
- В категории «Полный алфавитный перечень» или «Статистические» ищем наименование «ДИСП.В». После того, как формула найдена, выделяем её и делаем клик по кнопке «OK».
- Производится запуск окна аргументов функции. Далее поступаем полностью аналогичным образом, как и при использовании предыдущего оператора: устанавливаем курсор в поле аргумента «Число1» и выделяем область, содержащую числовой ряд, на листе. Затем щелкаем по кнопке «OK».
- Результат вычисления будет выведен в отдельную ячейку.

Урок: Другие статистические функции в Эксель
Как видим, программа Эксель способна в значительной мере облегчить расчет дисперсии. Эта статистическая величина может быть рассчитана приложением, как по генеральной совокупности, так и по выборке. При этом все действия пользователя фактически сводятся только к указанию диапазона обрабатываемых чисел, а основную работу Excel делает сам. Безусловно, это сэкономит значительное количество времени пользователей.
Мы рады, что смогли помочь Вам в решении проблемы.
Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
Да Нет
Дисперсия — это мера рассеяния, описывающая сравнительное отклонение между значениями данных и средней величиной. Является наиболее используемой мерой рассеяния в статистике, вычисляемая путем суммирования, возведенного в квадрат, отклонения каждого значения данных от средней величины. Формула для вычисления дисперсии представлена ниже:
где:
s2 – дисперсия выборки;
xср — среднее значение выборки;
n — размер выборки (количество значений данных),
(xi – xср) — отклонение от средней величины для каждого значения набора данных.
Для лучшего понимания формулы, разберем пример. Я не очень люблю готовку, поэтому занятием этим занимаюсь крайне редко. Тем не менее, чтобы не умереть с голоду, время от времени мне приходится подходить к плите для реализации замысла по насыщению моего организма белками, жирами и углеводами. Набор данных, редставленный ниже, показывает, сколько раз Ренат готовит пищу каждый месяц:
Первым шагом при вычислении дисперсии является определение среднего значения выборки, которое в нашем примере равняется 7,8 раза в месяц. Остальные вычисления можно облегчить с помощью следующей таблицы.
Финальная фаза вычисления дисперсии выглядит так:
Для тех, кто любит производить все вычисления за один раз, уравнение будет выглядеть следующим образом:
Использование метода «сырого счета» (пример с готовкой)
Существует более эффективный способ вычисления дисперсии, известный как метод «сырого счета». Хотя с первого взгляда уравнение может показаться весьма громоздким, на самом деле оно не такое уж страшное. Можете в этом удостовериться, а потом и решите, какой метод вам больше нравится.
где:
— сумма каждого значения данных после возведения в квадрат,
— квадрат суммы всех значений данных.
Не теряйте рассудок прямо сейчас. Позвольте представить все это в виде таблицы, и тогда вы увидите, что вычислений здесь меньше, чем в предыдущем примере.
Как видите, результат получился тот же, что и при использовании предыдущего метода. Достоинства данного метода становятся очевидными по мере роста размера выборки (n).
Как вы уже, наверное, догадались, в Excel присутствует формула, позволяющая рассчитать дисперсию. Причем, начиная с Excel 2010 можно найти 4 разновидности формулы дисперсии:
1) ДИСП.В – Возвращает дисперсию по выборке. Логические значения и текст игнорируются.
2) ДИСП.Г — Возвращает дисперсию по генеральной совокупности. Логические значения и текст игнорируются.
3) ДИСПА — Возвращает дисперсию по выборке с учетом логических и текстовых значений.
4) ДИСПРА — Возвращает дисперсию по генеральной совокупности с учетом логических и текстовых значений.
Для начала разберемся в разнице между выборкой и генеральной совокупностью. Назначение описательной статистики состоит в том, чтобы суммировать или отображать данные так, чтобы оперативно получать общую картину, так сказать, обзор. Статистический вывод позволяет делать умозаключения о какой-либо совокупности на основе выборки данных из этой совокупности. Совокупность представляет собой все возможные исходы или измерения, представляющие для нас интерес. Выборка — это подмножество совокупности.
Например, нас интересует совокупность группы студентов одного из Российских ВУЗов и нам необходимо определить средний бал группы. Мы можем посчитать среднюю успеваемость студентов, и тогда полученная цифра будет параметром, поскольку в наших расчетах будет задействована целая совокупность. Однако, если мы хотим рассчитать средний бал всех студентов нашей страны, тогда эта группа будет нашей выборкой.
Разница в формуле расчета дисперсии между выборкой и совокупностью заключается в знаменателе. Где для выборки он будет равняться (n-1), а для генеральной совокупности только n.
Теперь разберемся с функциями расчета дисперсии с окончаниями А, в описании которых сказано, что при расчете учитываются текстовые и логические значения. В данном случае при расчете дисперсии определенного массива данных, где встречаются не числовые значения, Excel будет интерпретировать текстовые и ложные логические значения как равными 0, а истинные логические значения как равными 1.
Итак, если у вас есть массив данных, рассчитать его дисперсию ни составит никакого труда, воспользовавшись одной из перечисленных выше функций Excel.
В статистике используется огромное количество показателей, и один из них — расчет дисперсии в Excel. Если это делать самому вручную, уйдет очень много времени, можно допустить уйму ошибок. Сегодня мы рассмотрим, как разложить математические формулы на простые функции. Давайте разберем несколько самых простых, быстрых и удобных способов расчёта, которые позволят все сделать в считанные минуты.
Вычисляем дисперсию
Дисперсией случайной величины называется математическое ожидание квадрата отклонения случайной величины от ее математического ожидания.
Рассчитываем по генеральной совокупности
Чтобы вычислить мат. ожидание в программе будет применяться функция ДИСП.Г, а ее синтаксис выглядит следующим образом «=ДИСП.Г(Число1;Число2;…)».
Возможно применить максимум 255 аргументов, не более. Аргументами могут быть простые числа или ссылки на ячейки, в которых они указаны. Давайте рассмотрим, как посчитать дисперсию в Microsoft Excel:
1. Первым делом следует выделить ячейку, где будет отображаться итог вычислений, а далее кликнуть по кнопке «Вставить функцию».
2. Откроется оболочка управления функциями. Там нужно искать функцию «ДИСП.Г», которая может быть в категории «Статистические» или «Полный алфавитный перечень». Когда она будет найдена, следует выделить ее и кликнуть «ОК».
3. Запустится окно с аргументами функции. В нем нужно выделить строку «Число 1» и на листе выделить диапазон ячеек с числовым рядом.
4. После этого в ячейке, куда была введена функция будут выведены результаты расчетов.
Вот так несложно можно найти дисперсию в Excel.
Производим расчет по выборке
В данном случае выборочная дисперсия в Excel высчитывается с указанием в знаменателе не общего количества чисел, а на одно меньше. Это делается для более меньшей погрешности при помощи специальной функции ДИСП.В, синтаксис которой =ДИСП.В(Число1;Число2;…). Алгоритм действий:
- Как и в предыдущем методе нужно выделить ячейку для результата.
- В мастере функции следует найти «ДИСП.В» в категории «Полный алфавитный перечень» или «Статистические».
- Далее появится окно, и действовать следует также, как и в предыдущем методе.
Видео: Расчет дисперсии в Excel
Заключение
Дисперсия в Excel вычисляется очень просто, намного быстрее и удобнее, чем делать это вручную, ведь функция математическое ожидание довольно сложная и на ее вычисление может уйти много времени и сил.
Это может быть интересно:
Цель данной статьи показать, как математические формулы, с которыми вы можете столкнуться в книгах и статьях, разложить на элементарные функции в Excel.
В данной статье мы разберем формулы среднеквадратического отклонения и дисперсии и рассчитаем их в Excel.
Перед тем как переходить к расчету среднеквадратического отклонения и разбирать формулу, желательно разобраться в элементарных статистических показателях и обозначениях.
Рассматривая формулы моделей прогнозирования, мы встретимся со следующими показателями:
Например, у нас есть временной ряд — продажи по неделям в шт.
|
Неделя |
||||||||||
|
Отгрузка, шт |
Сморите пример расчета здесь: среднеквадратическое отклонние и дисперсия
Для этого временного ряда i=1, n=10, ,
Рассмотрим формулу среднего значения:
|
Неделя |
||||||||||
|
Отгрузка, шт |
Для нашего временного ряда определим среднее значение
Также для выявления тенденций помимо среднего значения представляет интерес и то, насколько наблюдения разбросаны относительно среднего. Среднеквадратическое отклонение показывает меру отклонения наблюдений относительно среднего.
Формула расчета среднеквадратического отклонение для выборки следующая:
Разложим формулу на составные части и рассчитаем среднеквадратическое отклонение в Excel на примере нашего временного ряда.
1. Рассчитаем среднее значение для этого воспользуемся формулой Excel =СРЗНАЧ(B11:K11)
=СРЗНАЧ(ссылка на диапазон) = 100/10=10
2. Определим отклонение каждого значения ряда относительно среднего
для первой недели = 6-10=-4
для второй недели = 10-10=0
для третей = 7-1=-3 и т.д.
3. Для каждого значения ряда определим квадрат разницы отклонения значений ряда относительно среднего
для первой недели = (-4)^2=16
для второй недели = 0^2=0
для третей = (-3)^2=9 и т.д.
4. Рассчитаем сумму квадратов отклонений значений относительно среднего с помощью формулы =СУММ(ссылка на диапазон (ссылка на диапазон с )
=16+0+9+4+16+16+4+9+0+16=90
5. , для этого сумму квадратов отклонений значений относительно среднего разделим на количество значений минус единица (Сумма((Xi-Xср)^2))/(n-1)
=90/(10-1)=10
6. Среднеквадратическое отклонение равно = корень(10)=3,2
Итак, в 6 шагов мы разложили сложную математическую формулу, надеюсь вам удалось разобраться со всеми частями формулы и вы сможете самостоятельно разобраться в других формулах.
Скачать файл с примером
Рассмотрим еще один показатель, который в будущем нам понадобятся — дисперсия.
Как рассчитать дисперсию в Excel?
Дисперсия — квадрат среднеквадратического отклонения и отражает разброс данных относительно среднего.
Рассчитаем дисперсию:
Скачать файл с примером
Итак, теперь мы умеем рассчитывать среднеквадратическое отклонение и дисперсию в Excel. Надеемся, полученные знания пригодятся вам в работе.
Точных вам прогнозов!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:
- Novo Forecast Lite — автоматический расчет прогноза в Excel.
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Зарегистрируйтесь и скачайте решения Статья полезная? Поделитесь с друзьями
Коэффициент вариации – это сравнение рассеивания двух случайно взятых величин. Величины имеют единицы измерения, что приводит к получению сопоставимого результата. Этот коэффициент нужен для подготовки статистического анализа.
С помощью него инвесторы могут рассчитать показатели риска перед тем, как сделать вклады в выбранные активы. Он полезен, когда у выбранных активов различная доходность и степень риска. К примеру, у одного актива может быть высокий доход и степень риска тоже высокая, а у другого, наоборот, малый доход и степень риска соответственно меньшая.
Расчет стандартного отклонения
Стандартное отклонение является статистической величиной. С помощью расчета этой величины пользователь получит информацию о том, насколько отклоняются данные в ту или иную сторону относительно среднего значения. Стандартное отклонение в Excel рассчитывается в несколько шагов.
Подготавливаете данные: открываете страницу, где будут происходить расчеты. В нашем случае это картинка, но может быть любой другой файл. Главное собрать ту информацию, которую будете использовать в таблице для рассчета.
Вводите данные в любой табличный редактор (в нашем случае Excel), заполняя ячейки слева направо. Начинать следует с колонки «А». Заголовки вводите в строке сверху, а названия в тех же столбцах, которые относятся к заголовкам, только ниже. Затем дату и данные, которые подлежат расчету, справа от даты.
Этот документ сохраняете.
Теперь переходим к самому вычислению. Выделяете курсором ячейку после последнего введенного значения снизу.
Вписываете знак «=» и прописываете далее формулу. Знак равенства обязателен. Иначе программа не посчитает предложенные данные. Формула вводится без пробелов.
Утилита выдаст названия нескольких формул. Выбираете «СТАНДОТКЛОН». Это формула вычисления стандартного отклонения. Существует два вида расчета:
- с вычислением по выборке;
- с вычислением по генеральной совокупности.
Выбрав одну из них, указываете диапазон данных. Вся введенная формула будет выглядеть так: «=СТАНДОТКЛОН (В2: В5)».
Затем кликаете по кнопке «Enter». Полученные данные появятся в отмеченном пункте.
Расчет среднего арифметического
Вычисляется, когда пользователю необходимо создать отчет, например, по заработной плате в его компании. Делается это следующим образом:
- открываете утилиту. В верхней строке набираете ряд нужных цифр;
- под первой цифрой ставите курсор. В верхней строке программы выбираете вкладку «Редактирование», затем кнопку «Сумма». В выпавшем окне выбираете значение «Среднее»;
- после того, как кликните в том пункте на котором стоит курсор, появится формула;
- останется только выделить диапазон и кликнуть по кнопке «Ввод». А в ячейке теперь отобразится результат из взятых данных выше.
Расчет коэффициента вариации
Формула расчета коэффициента вариации:
V= S/X, где S – это стандартное отклонение, а X – среднее значение.
Для того, чтобы посчитать коэффициент вариации в Excel, необходимо найти стандартное отклонение и среднее арифметическое. То есть проделав первые два расчета, которые были показаны выше, можно перейти к работе над коэффициентом вариации.
Для этого открываете Excel, заполняем два поля, куда следует вписать полученные числа стандартного отклонения и среднего значения.
Теперь выделяете ячейку, которую отвели под число для вычисления вариации. Открываете вкладку «Главная», если она не открыта. Кликаете по инструменту «Число». Выбираете процентный формат.
Переходите к отмеченной ячейке и кликаете по ней дважды. Затем вводите знак равенства и выделяете пункт, куда вписан итог стандартного отклонения. Затем кликаете на клавиатуре по кнопке «слэш» или «разделить» (выглядит так: «/»). Выделяете пункт, куда вписано среднее арифметическое, и кликаете по кнопке «Enter». Должно получиться так:
А вот и результат после нажатия «Enter»:
Также для расчета коэффициента вариации можно использовать онлайн калькуляторы, например planetcalc.ru и allcalc.ru. Достаточно внести необходимые цифры и запустить расчет, после чего получить необходимые сведения.
Среднеквадратическое отклонение
Среднеквадратичное отклонение в Excel решается с помощью двух формул:
Простыми словами, извлекается корень из дисперсии. Как вычислить дисперсию рассмотрено ниже.
Среднее квадратичное отклонение является синонимом стандартного и вычисляется точное также. Выделяется ячейка для результата под числами, которые нужно рассчитать. Вставляется одна из функций, указанных на рисунке выше. Кликается кнопка «Enter». Результат получен.
Коэффициент осциляции
Соотношением размаха вариации к среднему – называется коэффициентом осциляции. Готовых формул в Экселе нет, поэтому нужно компоновать несколько функций в одну.
Функциями, которые необходимо скомпоновать, являются формулы среднего значения, максимума и минимума. Этот коэффициент используют для сравнения набора данных.
Дисперсия
Дисперсия – это функция, с помощью которой характеризуют разброс данных вокруг математического ожидания. Вычисляется по следующему уравнению:
Переменные принимают такие значения:
В Excel есть две функции, которые определяют дисперсию:
- Дисп.Г – используется относительно небольших выборок.
- Дисп.В – вычисление несмещенной дисперсии.
Чтобы произвести расчет, под числами, которые необходимо посчитать, выделяется ячейка. Заходите во вкладку вставки функции. Выбираете категорию «Статистические». В выпавшем списке выбираете одну из функций и кликаете по кнопке «Enter».
Максимум и минимум
Максимум и минимум нужны для того, чтобы не искать вручную среди большого количества чисел минимальное или максимальное число.
Чтобы вычислить максимум, выделяете весь диапазон необходимых чисел в таблице и отдельную ячейку, затем кликаете по значку «Σ» или «Автосумма». В выпавшем окне выбираете «Максимум» и, нажав кнопку «Enter» получаете нужное значение.
Тоже самое делаете, чтобы получить минимум. Только выбираете функцию «Минимум».