
Нелинейная регрессия в Excel
Добрый день, уважаемые читатели блога! Сегодня мы поговорим о нелинейных регрессиях. Решение линейных регрессий можно посмотреть по ССЫЛКЕ.
Данный способ применяется, в основном, в экономическом моделировании и прогнозировании. Его цель – пронаблюдать и выявить зависимости между двумя показателями.
Основными типами нелинейных регрессий являются:
- полиномиальные (квадратичная, кубическая);
- гиперболическая;
- степенная;
- показательная;
- логарифмическая.
Также могут применяться различные комбинации. Например, для аналитики временных рядов в банковской сфере, страховании, демографических исследованиях используют кривую Гомпцера, которая является разновидностью логарифмической регрессии.
В прогнозировании с помощью нелинейных регрессий главное выяснить коэффициент корреляции, который покажет нам есть ли тесная взаимосвязь меду двумя параметрами или нет. Как правило, если коэффициент корреляции близок к 1, значит связь есть, и прогноз будет довольно точен. Ещё одним важным элементом нелинейных регрессий является средняя относительная ошибка (А), если она находится в промежутке <8…10%, значит модель достаточно точна.
На этом, пожалуй, теоретический блок мы закончим и перейдём к практическим вычислениям.
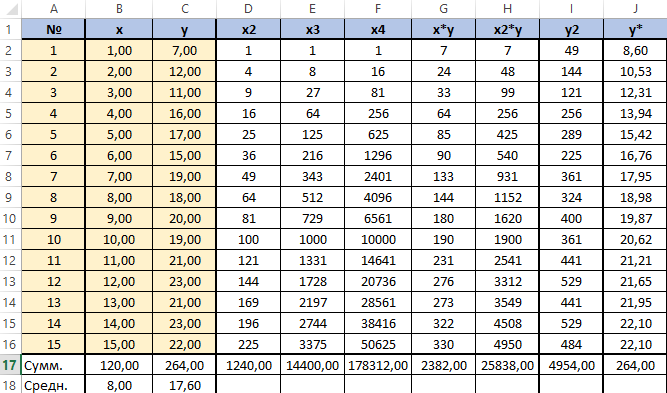
У нас имеется таблица продаж автомобилей за промежуток 15 лет (обозначим его X), количество шагов измерений будет аргумент n, также имеется выручка за эти периоды (обозначим её Y), нам нужно спрогнозировать какова будет выручка в дальнейшем. Построим следующую таблицу:

Для исследования нам потребуется решить уравнение (зависимости Y от X): y=ax2+bx+c+e. Это парная квадратичная регрессия. Применим в этом случае метод наименьших квадратов, для выяснения неизвестных аргументов — a, b, c. Он приведёт к системе алгебраических уравнений вида:

Для решения этой системы воспользуемся, к примеру, методом Крамера. Видим, что входящие в систему суммы являются коэффициентами при неизвестных. Для их вычисления добавим в таблицу несколько столбцов (D,E,F,G,H) и подпишем соответственно смыслу вычислений — в столбце D возведём x в квадрат, в E в куб, в F в 4 степень, в G перемножим показатели x и y, в H возведём x в квадрат и перемножим с y.
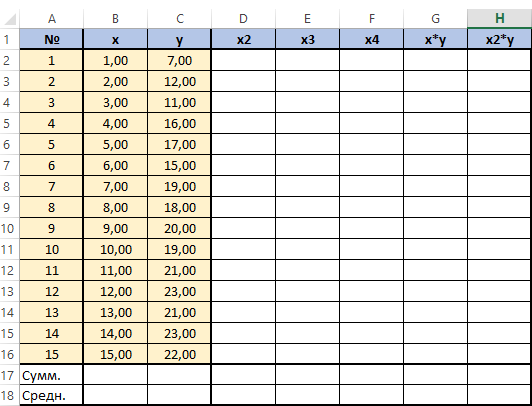
Получится заполненная нужными для решения уравнения таблица вида.
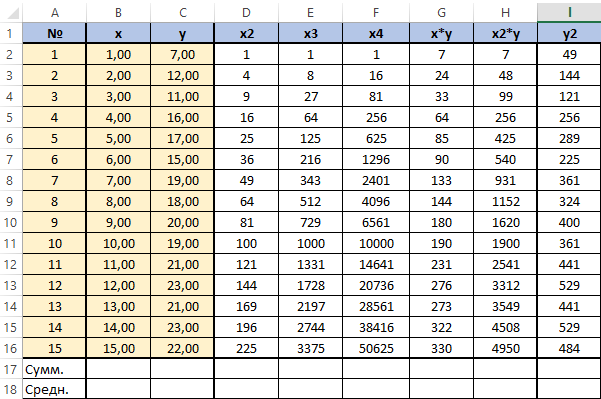
Далее посчитаем суммы по каждому столбцу — воспользуемся ∑ в программе Excel.
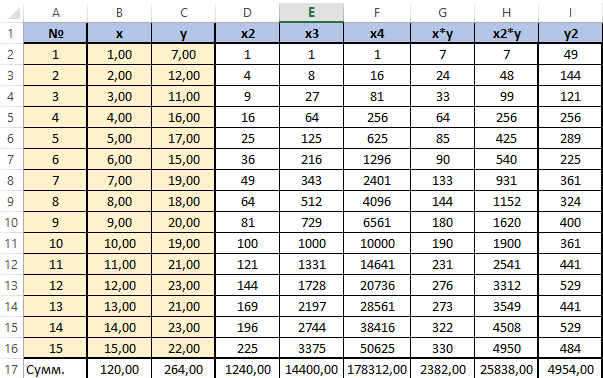
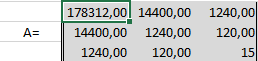
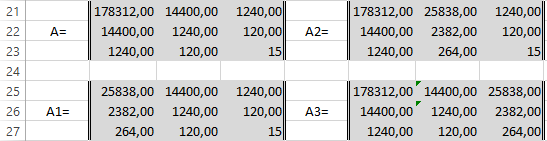
Сформируем матрицу A системы, состоящую из коэффициентов при неизвестных в левых частях уравнений. Поместим её в ячейку А22 и назовём «А=«. Следуем той системе уравнений, которую мы избрали для решения регрессии.
То есть, в ячейку B21 мы должны поместить сумму столбца, где возводили показатель X в четвёртую степень — F17. Просто сошлёмся на ячейку — «=F17». Далее нам необходима сумма столбца где возводили X в куб — E17, далее идём строго по системе. Таким образом, нам необходимо будет заполнить всю матрицу.
В соответствии с алгоритмом Крамера наберём матрицу А1, подобную А, в которой вместо элементов первого столбца должны размещаться элементы правых частей уравнений системы. То есть сумма столбца X в квадрате умноженная на Y, сумма столбца XY и сумма столбца Y.

Также нам понадобятся ещё две матрицы — назовём их А2 и А3 в которых второй и третий столбцы будут состоять из коэффициентов правых частей уравнений. Картина будет такова.
Следуя избранному алгоритму, нам нужно будет вычислить значения определителей (детерминантов, D) полученных матриц. Воспользуемся формулой МОПРЕД. Результаты разместим в ячейках J21:K24.

Расчёт коэффициентов уравнения по Крамеру будем производить в ячейках напротив соответствующих детерминантов по формуле: a (в ячейке M22) — «=K22/K21»; b (в ячейке M23) — «=K23/K21»; с (в ячейке M24) — «=K24/K21».

Получим наше искомое уравнение парной квадратичной регрессии:
y=-0,074x2+2,151x+6,523
Оценим тесноту линейной связи индексом корреляции.
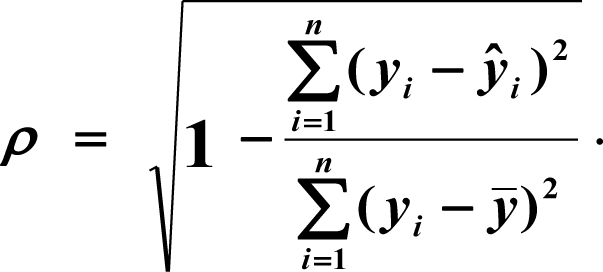
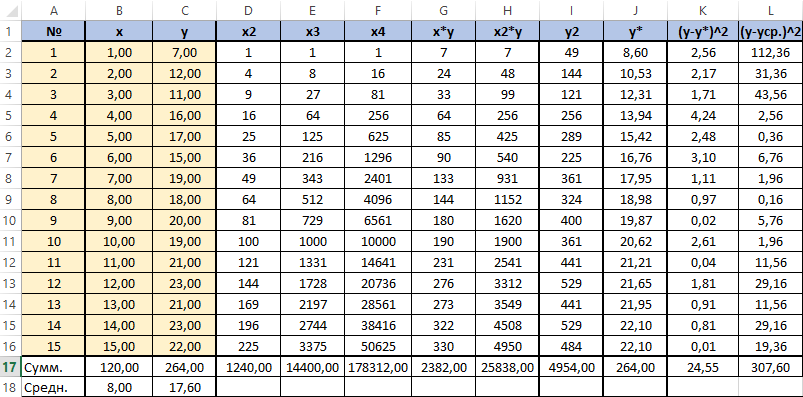
Для вычисления добавим в таблицу дополнительный столбец J (назовём его y*). Расчёта будет следующей (согласно полученному нами уравнению регрессии) — «=$m$22*B2*B2+$M$23*B2+$M$24». Поместим её в ячейку J2. Останется протянуть вниз маркер автозаполнения до ячейки J16.
Для вычисления сумм (Y-Y усредненное)2 добавим в таблицу столбцы K и L с соответствующими формулами. Среднее по столбцу Y посчитаем с помощью функции СРЗНАЧ.
В ячейке K25 разместим формулу подсчёта индекса корреляции — «=КОРЕНЬ(1-(K17/L17))».
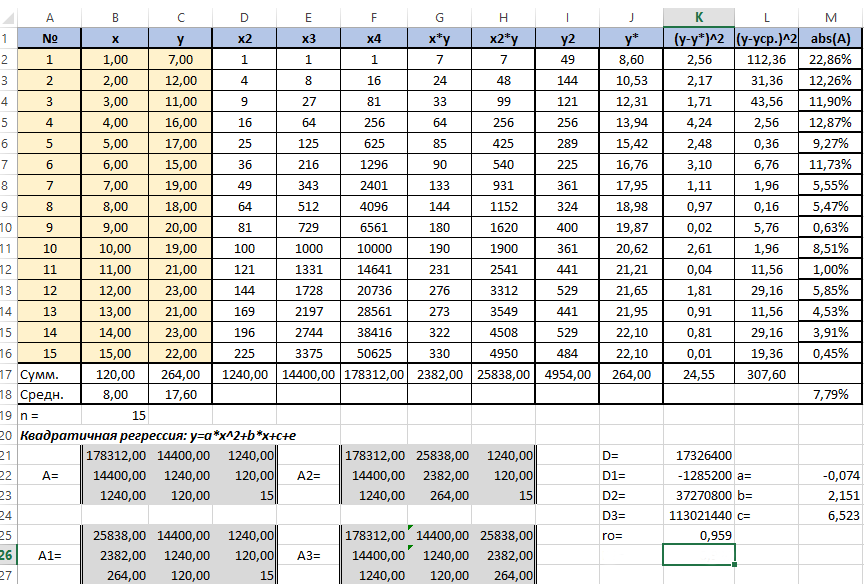
Видим, что значение 0,959 очень близко к 1, значит между продажами и годами есть тесная нелинейная связь.
Осталось оценить качество подгонки полученного квадратичного уравнения регрессии (индекс детерминации). Он рассчитывается по формуле квадрата индекса корреляции. То есть формула в ячейке K26 будет очень проста — «=K25*K25».
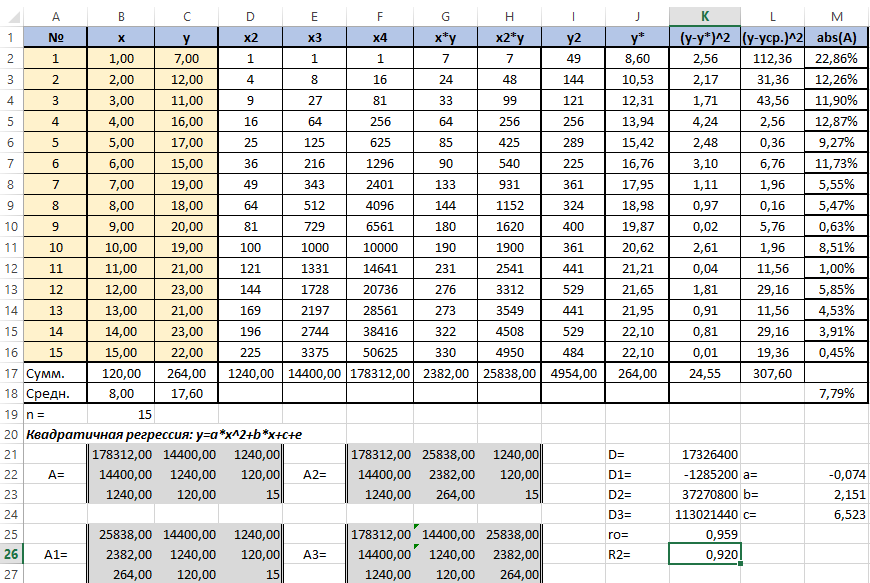
Коэффициент 0,920 близок к 1, что свидетельствует о высоком качестве подгонки.
Последним действием будет вычисление относительной ошибки. Добавим столбец и внесём туда формулу: «=ABS((C2-J2)/C2), ABS — модуль, абсолютное значение. Протянем маркером вниз и в ячейке M18 выведем среднее значение (СРЗНАЧ), назначим ячейкам процентный формат. Полученный результат — 7,79% находится в пределах допустимых значений ошибки <8…10%. Значит вычисления достаточно точны.
Если возникнет необходимость, по полученным значениям мы можем построить график.
Файл с примером прилагается — ССЫЛКА!
Нелинейная регрессия в Excel
Нелинейная регрессия в Excel
Добрый день, уважаемые читатели блога! Сегодня мы поговорим о нелинейных регрессиях. Решение линейных регрессий можно посмотреть по ССЫЛКЕ.
Данный способ применяется, в основном, в экономическом моделировании и прогнозировании. Его цель – пронаблюдать и выявить зависимости между двумя показателями.
Основными типами нелинейных регрессий являются:
- полиномиальные (квадратичная, кубическая);
- гиперболическая;
- степенная;
- показательная;
- логарифмическая.
Также могут применяться различные комбинации. Например, для аналитики временных рядов в банковской сфере, страховании, демографических исследованиях используют кривую Гомпцера, которая является разновидностью логарифмической регрессии.
В прогнозировании с помощью нелинейных регрессий главное выяснить коэффициент корреляции, который покажет нам есть ли тесная взаимосвязь меду двумя параметрами или нет. Как правило, если коэффициент корреляции близок к 1, значит связь есть, и прогноз будет довольно точен. Ещё одним важным элементом нелинейных регрессий является средняя относительная ошибка (А), если она находится в промежутке
На этом, пожалуй, теоретический блок мы закончим и перейдём к практическим вычислениям.
У нас имеется таблица продаж автомобилей за промежуток 15 лет (обозначим его X), количество шагов измерений будет аргумент n, также имеется выручка за эти периоды (обозначим её Y), нам нужно спрогнозировать какова будет выручка в дальнейшем. Построим следующую таблицу:
Для исследования нам потребуется решить уравнение (зависимости Y от X): y=ax 2 +bx+c+e. Это парная квадратичная регрессия. Применим в этом случае метод наименьших квадратов, для выяснения неизвестных аргументов — a, b, c. Он приведёт к системе алгебраических уравнений вида:
Для решения этой системы воспользуемся, к примеру, методом Крамера. Видим, что входящие в систему суммы являются коэффициентами при неизвестных. Для их вычисления добавим в таблицу несколько столбцов (D,E,F,G,H) и подпишем соответственно смыслу вычислений — в столбце D возведём x в квадрат, в E в куб, в F в 4 степень, в G перемножим показатели x и y, в H возведём x в квадрат и перемножим с y.
Получится заполненная нужными для решения уравнения таблица вида.
Далее посчитаем суммы по каждому столбцу — воспользуемся ∑ в программе Excel.
Сформируем матрицу A системы, состоящую из коэффициентов при неизвестных в левых частях уравнений. Поместим её в ячейку А22 и назовём «А=«. Следуем той системе уравнений, которую мы избрали для решения регрессии.
То есть, в ячейку B21 мы должны поместить сумму столбца, где возводили показатель X в четвёртую степень — F17. Просто сошлёмся на ячейку — «=F17». Далее нам необходима сумма столбца где возводили X в куб — E17, далее идём строго по системе. Таким образом, нам необходимо будет заполнить всю матрицу.
В соответствии с алгоритмом Крамера наберём матрицу А1, подобную А, в которой вместо элементов первого столбца должны размещаться элементы правых частей уравнений системы. То есть сумма столбца X в квадрате умноженная на Y, сумма столбца XY и сумма столбца Y.
Также нам понадобятся ещё две матрицы — назовём их А2 и А3 в которых второй и третий столбцы будут состоять из коэффициентов правых частей уравнений. Картина будет такова.
Следуя избранному алгоритму, нам нужно будет вычислить значения определителей (детерминантов, D) полученных матриц. Воспользуемся формулой МОПРЕД. Результаты разместим в ячейках J21:K24.
Расчёт коэффициентов уравнения по Крамеру будем производить в ячейках напротив соответствующих детерминантов по формуле: a (в ячейке M22) — «=K22/K21»; b (в ячейке M23) — «=K23/K21»; с (в ячейке M24) — «=K24/K21».
Получим наше искомое уравнение парной квадратичной регрессии:
y=-0,074x 2 +2,151x+6,523
Оценим тесноту линейной связи индексом корреляции.
Для вычисления добавим в таблицу дополнительный столбец J (назовём его y*). Расчёта будет следующей (согласно полученному нами уравнению регрессии) — «=$m$22*B2*B2+$M$23*B2+$M$24». Поместим её в ячейку J2. Останется протянуть вниз маркер автозаполнения до ячейки J16.
Для вычисления сумм (Y-Y усредненное) 2 добавим в таблицу столбцы K и L с соответствующими формулами. Среднее по столбцу Y посчитаем с помощью функции СРЗНАЧ.
В ячейке K25 разместим формулу подсчёта индекса корреляции — «=КОРЕНЬ(1-(K17/L17))».
Видим, что значение 0,959 очень близко к 1, значит между продажами и годами есть тесная нелинейная связь.
Осталось оценить качество подгонки полученного квадратичного уравнения регрессии (индекс детерминации). Он рассчитывается по формуле квадрата индекса корреляции. То есть формула в ячейке K26 будет очень проста — «=K25*K25».
Коэффициент 0,920 близок к 1, что свидетельствует о высоком качестве подгонки.
Последним действием будет вычисление относительной ошибки. Добавим столбец и внесём туда формулу: «=ABS((C2-J2)/C2), ABS — модуль, абсолютное значение. Протянем маркером вниз и в ячейке M18 выведем среднее значение (СРЗНАЧ), назначим ячейкам процентный формат. Полученный результат — 7,79% находится в пределах допустимых значений ошибки
Если возникнет необходимость, по полученным значениям мы можем построить график.
Регрессионный анализ в Microsoft Excel

Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Подключение пакета анализа
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
-
Перемещаемся во вкладку «Файл».


Открывается окно параметров Excel. Переходим в подраздел «Надстройки».

В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».


Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».

Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Линейная регрессия в программе Excel
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк . В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.
- Кликаем по кнопке «Анализ данных». Она размещена во вкладке «Главная» в блоке инструментов «Анализ».

Открывается небольшое окошко. В нём выбираем пункт «Регрессия». Жмем на кнопку «OK».

Открывается окно настроек регрессии. В нём обязательными для заполнения полями являются «Входной интервал Y» и «Входной интервал X». Все остальные настройки можно оставить по умолчанию.
В поле «Входной интервал Y» указываем адрес диапазона ячеек, где расположены переменные данные, влияние факторов на которые мы пытаемся установить. В нашем случае это будут ячейки столбца «Количество покупателей». Адрес можно вписать вручную с клавиатуры, а можно, просто выделить требуемый столбец. Последний вариант намного проще и удобнее.
В поле «Входной интервал X» вводим адрес диапазона ячеек, где находятся данные того фактора, влияние которого на переменную мы хотим установить. Как говорилось выше, нам нужно установить влияние температуры на количество покупателей магазина, а поэтому вводим адрес ячеек в столбце «Температура». Это можно сделать теми же способами, что и в поле «Количество покупателей».

С помощью других настроек можно установить метки, уровень надёжности, константу-ноль, отобразить график нормальной вероятности, и выполнить другие действия. Но, в большинстве случаев, эти настройки изменять не нужно. Единственное на что следует обратить внимание, так это на параметры вывода. По умолчанию вывод результатов анализа осуществляется на другом листе, но переставив переключатель, вы можете установить вывод в указанном диапазоне на том же листе, где расположена таблица с исходными данными, или в отдельной книге, то есть в новом файле.

После того, как все настройки установлены, жмем на кнопку «OK».

Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Помимо этой статьи, на сайте еще 12683 инструкций.
Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Регрессионный анализ данных в Excel
Регрессионный анализ – это набор статистических методов, позволяющих изучить влияние одной или нескольких независимых переменных на зависимую. Давайте разберемся, каким образом можно выполнить данный анализ в программе Excel.
Включение функции анализа в программе
Для начала нужно активировать функцию программы, с помощью которой мы будем проводить анализ. Для этого делаем следующее:
- Открываем меню “Файл”.

- Щелкаем по пункту “Параметры”.
- В нижней части содержимого подраздела “Надстройки” выбираем значение “Надстройки Excel” для параметра “Управление”, после чего кликаем “Перейти”.



Линейный регрессионный анализ
Выделяют несколько разновидностей регрессий: линейная, гиперболическая, множественная, логарифмически линейная, нелинейная, обратная, парная.
В рамках данной статьи мы рассмотрим линейную регрессию. В общем виде ее функция выглядит так:
В данном уравнении:
- Y – переменная, влияние на которую нужно найти;
- X – факторы, влияющие на переменную;
- A – коэффициенты регрессии, определяющие значимости факторов;
- N – общее количество факторов.
Чтобы было понятнее, давайте разберем конкретный практический пример. Допустим, у нас есть таблица, в которой представлена информация по среднесуточной температуре и количеству осадков с разбивкой по месяцам.

Наша задача – выяснить, как температура влияет на осадки. Приступи к ее выполнению.
- Щелкаем по кнопке “Анализ данных”.
- В открывшемся окошке отмечаем пункт “Регрессия”, после чего щелкаем OK.
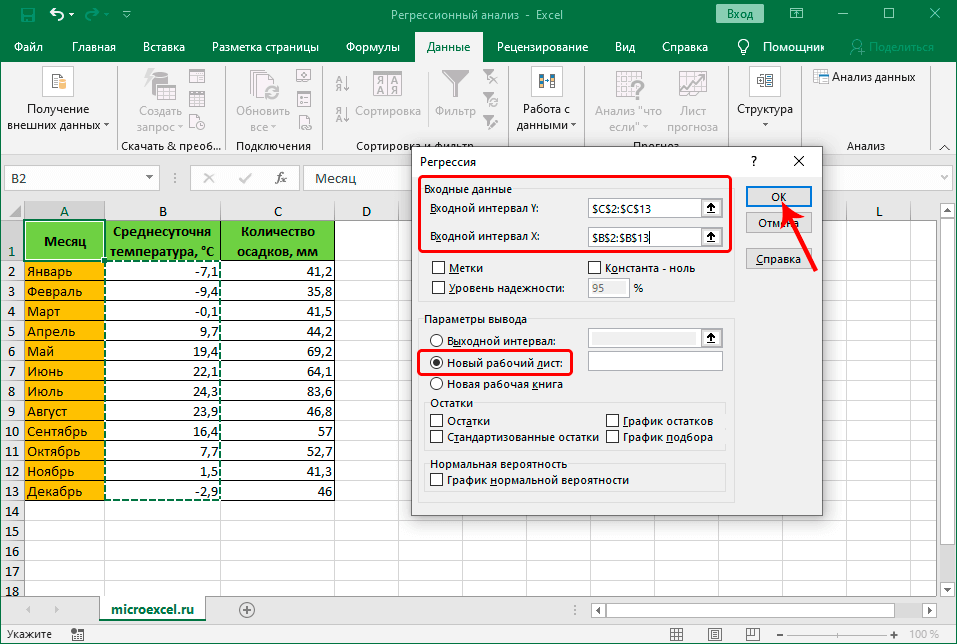
- Перед нами появится окно, в котором нужно настроить параметры регрессии:
- в поле “Входной интервал_Y” пишем координаты диапазона ячеек, в которых находятся переменные, влияние на которые нам нужно выяснить. У нас это столбец “Количество осадков, мм”. Координаты диапазона можно указать как вручную, используя клавиши на клавиатуре, так и выделив его в самой таблице с помощью зажатой левой кнопки мыши.
- в поле “Входной интервал_X” указываем координаты диапазона ячеек с данными, влияние которых нам нужно найти. В нашем случае – это столбец “Среднесуточная температура”.
- Остальные параметры не являются обязательными и, чаще всего, остаются незаполненными. У нас есть возможность установить метки, значения уровня надежности в процентах, константу-ноль, график нормальной вероятности и т.д. Пожалуй, самым важным здесь является способ вывода результатов анализа. Доступны следующие варианты: на новом листе (по умолчанию), в новой книге или в указанном диапазоне на этом же листе. Мы оставим все как есть и жмем кнопку OK.

Анализ полученных результатов
После корректного заполнения всех параметров и нажатия кнопки OK отобразятся результаты анализа (в зависимости от выбранного способа). В нашем случае – на отдельном листе.

Ключевым показателем здесь является R-квадрат (коэффициент детерминации), значение которого характеризует качество модели. Приемлемым считается значение не менее 0,5 (или 50%).
Также следует обратить внимание на ячейку, расположенную на пересечении строки “Y-пересечение” и столбца “Коэффициенты”. Здесь показывается, каким будет значение Y (количество осадков), если все остальные факторы будут равны нулю.
Ячейка на пересечении строки “Переменная X 1” и столбца “Коэффициенты” содержит значение, характеризующее степень зависимости Y от X. Коэф. 0,89 в нашем случае говорит о достаточно сильной связи между переменными.
Заключение
Регрессионный анализ – сложная и трудоемкая задача, которая требует определенных математических и статистических знаний. Но с помощью стандартных инструментов Эксель ее выполнение можно значительно облегчить.
источники:
http://lumpics.ru/regression-analysis-in-excel/
http://microexcel.ru/regressionnyj-analiz/
Вычислим коэффициент корреляции и ковариацию для разных типов взаимосвязей случайных величин.
Коэффициент корреляции
(
критерий корреляции
Пирсона, англ. Pearson Product Moment correlation coefficient)
определяет степень
линейной
взаимосвязи между случайными величинами.
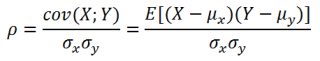
где Е[…] – оператор
математического ожидания
, μ и σ –
среднее
случайной величины и ее
стандартное отклонение
.
Как следует из определения, для вычисления
коэффициента корреляции
требуется знать распределение случайных величин Х и Y. Если распределения неизвестны, то для оценки
коэффициента корреляции
используется
выборочный коэффициент корреляции
r
(
еще он обозначается как
R
xy
или
r
xy
)
:
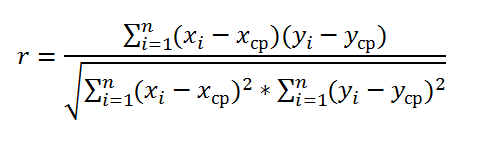
Как видно из формулы для расчета
корреляции
, знаменатель (произведение стандартных отклонений с точностью до безразмерного множителя) просто нормирует числитель таким образом, что
корреляция
оказывается безразмерным числом от -1 до 1.
Корреляция
и
ковариация
предоставляют одну и туже информацию, но
корреляцией
удобнее пользоваться, т.к. она является безразмерной величиной.
Рассчитать
коэффициент корреляции
и
ковариацию выборки
в MS EXCEL не представляет труда, так как для этого имеются специальные функции
КОРРЕЛ()
и
КОВАР()
. Гораздо сложнее разобраться, как интерпретировать полученные значения, большая часть статьи посвящена именно этому.
Теоретическое отступление
Напомним, что
корреляционной связью
называют статистическую связь, состоящую в том, что различным значениям одной переменной соответствуют различные
средние
значения другой (с изменением значения Х
среднее значение
Y изменяется закономерным образом). Предполагается, что
обе
переменные Х и Y являются
случайными
величинами и имеют некий случайный разброс относительно их
среднего значения
.
Примечание
. Если случайную природу имеет только одна переменная, например, Y, а значения другой являются детерминированными (задаваемыми исследователем), то можно говорить только о регрессии.
Таким образом, например, при исследовании зависимости среднегодовой температуры нельзя говорить о
корреляции
температуры и года наблюдения и, соответственно, применять показатели
корреляции
с соответствующей их интерпретацией.
Корреляционная связь
между переменными может возникнуть несколькими путями:
-
Наличие причинной зависимости между переменными. Например, количество инвестиций в научные исследования (переменная Х) и количество полученных патентов (Y). Первая переменная выступает как
независимая переменная (фактор)
, вторая —
зависимая переменная (результат)
. Необходимо помнить, что зависимость величин обуславливает наличие корреляционной связи между ними, но не наоборот. - Наличие сопряженности (общей причины). Например, с ростом организации растет фонд оплаты труда (ФОТ) и затраты на аренду помещений. Очевидно, что неправильно предполагать, что аренда помещений зависит от ФОТ. Обе этих переменных во многих случаях линейно зависят от количества персонала.
- Взаимовлияние переменных (при изменении одной, вторая переменная изменяется, и наоборот). При таком подходе допустимы две постановки задачи; любая переменная может выступать как в роли независимой переменной и в роли зависимой.
Таким образом,
показатель корреляции
показывает, насколько сильна
линейная взаимосвязь
между двумя факторами (если она есть), а регрессия позволяет прогнозировать один фактор на основе другого.
Корреляция
, как и любой другой статистический показатель, при правильном применении может быть полезной, но она также имеет и ограничения по использованию. Если
диаграмма рассеяния
показывает четко выраженную линейную зависимость или полное отсутствие взаимосвязи, то
корреляция
замечательно это отразит. Но, если данные показывают нелинейную взаимосвязь (например, квадратичную), наличие отдельных групп значений или выбросов, то вычисленное значение
коэффициента корреляции
может ввести в заблуждение (см.
файл примера
).
Корреляция
близкая к 1 или -1 (т.е. близкая по модулю к 1) показывает сильную линейную взаимосвязь переменных, значение близкое к 0 показывает отсутствие взаимосвязи. Положительная
корреляция
означает, что с ростом одного показателя другой в среднем увеличивается, а при отрицательной – уменьшается.
Для вычисления коэффициента корреляции требуется, чтобы сопоставляемые переменные удовлетворяли следующим условиям:
- количество переменных должно быть равно двум;
-
переменные должны быть количественными (например, частота, вес, цена). Вычисленное среднее значение этих переменных имеет понятный смысл: средняя цена или средний вес пациента. В отличие от количественных, качественные (номинальные) переменные принимают значения лишь из конечного набора категорий (например, пол или группа крови). Этим значениям условно сопоставлены числовые значения (например, женский пол – 1, а мужской – 2). Понятно, что в этом случае вычисление
среднего значения
, которое требуется для нахождения
корреляции
, некорректно, а значит некорректно и вычисление самой
корреляции
; -
переменные должны быть случайными величинами и иметь
нормальное распределение
.
Двумерные данные могут иметь различную структуру. Для работы с некоторыми из них требуются определенные подходы:
-
Для данных с нелинейной связью
корреляцию
нужно использовать с осторожностью. Для некоторых задач бывает полезно преобразовать одну или обе переменных так, чтобы получить линейную взаимосвязь (для этого требуется сделать предположение о виде нелинейной связи, чтобы предложить нужный тип преобразования). -
С помощью
диаграммы рассеяния
у некоторых данных можно наблюдать неравную вариацию (разброс). Проблема неодинаковой вариации состоит в том, что места с высокой вариацией не только предоставляют наименее точную информацию, но и оказывают наибольшее влияние при расчете статистических показателей. Эту проблему также часто решают с помощью преобразования данных, например, с помощью логарифмирования. - У некоторых данных можно наблюдать разделение на группы (clustering), что может свидетельствовать о необходимости разделения совокупности на части.
- Выброс (резко отклоняющееся значение) может исказить вычисленное значение коэффициента корреляции. Выброс может быть причиной случайности, ошибки при сборе данных или могут действительно отражать некую особенность взаимосвязи. Так как выброс сильно отклоняется от среднего значения, то он вносит большой вклад при расчете показателя. Часто расчет статистических показателей производят с и без учета выбросов.
Использование MS EXCEL для расчета корреляции
В качестве примера возьмем 2 переменные
Х
и
Y
и, соответственно,
выборку
состоящую из нескольких пар значений (Х
i
; Y
i
). Для наглядности построим
диаграмму рассеяния
.
Примечание
: Подробнее о построении диаграмм см. статью
Основы построения диаграмм
. В
файле примера
для построения
диаграммы рассеяния
использована
диаграмма График
, т.к. мы здесь отступили от требования случайности переменной Х (это упрощает генерацию различных типов взаимосвязей: построение трендов и заданный разброс). В случае реальных данных необходимо использовать диаграмму типа Точечная (см. ниже).
Расчеты
корреляции
проведем для различных случаев взаимосвязи между переменными:
линейной, квадратичной
и при
отсутствии связи
.
Примечание
: В
файле примера
можно задать параметры линейного тренда (наклон, пересечение с осью Y) и степень разброса относительно этой линии тренда. Также можно настроить параметры квадратичной зависимости.
В
файле примера
для построения
диаграммы рассеяния
в случае отсутствия зависимости переменных использована диаграмма типа Точечная. В этом случае точки на диаграмме располагаются в виде облака.
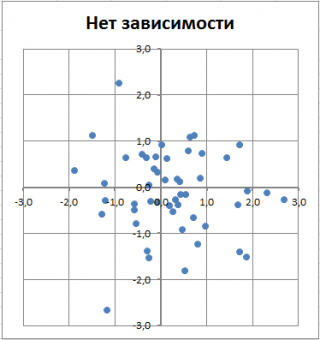
Примечание
: Обратите внимание, что изменяя масштаб диаграммы по вертикальной или горизонтальной оси, облаку точек можно придать вид вертикальной или горизонтальной линии. Понятно, что при этом переменные останутся независимыми.
Как было сказано выше, для расчета
коэффициента корреляции
в MS EXCEL существует функций
КОРРЕЛ()
. Также можно воспользоваться аналогичной функцией
PEARSON()
, которая возвращает тот же результат.
Для того, чтобы удостовериться, что вычисления
корреляции
производятся функцией
КОРРЕЛ()
по вышеуказанным формулам, в
файле примера
приведено вычисление
корреляции
с помощью более подробных формул:
=
КОВАРИАЦИЯ.Г(B28:B88;D28:D88)/СТАНДОТКЛОН.Г(B28:B88)/СТАНДОТКЛОН.Г(D28:D88)
=
КОВАРИАЦИЯ.В(B28:B88;D28:D88)/СТАНДОТКЛОН.В(B28:B88)/СТАНДОТКЛОН.В(D28:D88)
Примечание
: Квадрат
коэффициента корреляции
r равен
коэффициенту детерминации
R2, который вычисляется при построении линии регрессии с помощью функции
КВПИРСОН()
. Значение R2 также можно вывести на
диаграмме рассеяния
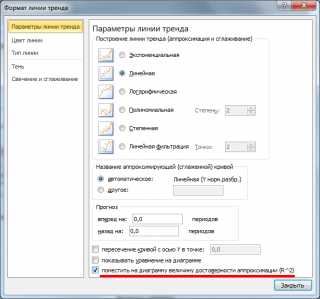
, построив линейный тренд с помощью стандартного функционала MS EXCEL (выделите диаграмму, выберите вкладку
Макет
, затем в группе
Анализ
нажмите кнопку
Линия тренда
и выберите
Линейное приближение
). Подробнее о построении линии тренда см., например, в
статье о методе наименьших квадратов
.
Использование MS EXCEL для расчета ковариации
Ковариация
близка по смыслу с
дисперсией
(также является мерой разброса) с тем отличием, что она определена для 2-х переменных, а
дисперсия
— для одной. Поэтому, cov(x;x)=VAR(x).
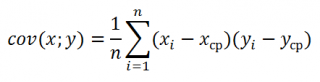
Для вычисления ковариации в MS EXCEL (начиная с версии 2010 года) используются функции
КОВАРИАЦИЯ.Г()
и
КОВАРИАЦИЯ.В()
. В первом случае формула для вычисления аналогична вышеуказанной (окончание
.Г
обозначает
Генеральная совокупность
), во втором – вместо множителя 1/n используется 1/(n-1), т.е. окончание
.В
обозначает
Выборка
.
Примечание
: Функция
КОВАР()
, которая присутствует в MS EXCEL более ранних версий, аналогична функции
КОВАРИАЦИЯ.Г()
.
Примечание
: Функции
КОРРЕЛ()
и
КОВАР()
в английской версии представлены как CORREL и COVAR. Функции
КОВАРИАЦИЯ.Г()
и
КОВАРИАЦИЯ.В()
как COVARIANCE.P и COVARIANCE.S.
Дополнительные формулы для расчета
ковариации
:
=
СУММПРОИЗВ(B28:B88-СРЗНАЧ(B28:B88);(D28:D88-СРЗНАЧ(D28:D88)))/СЧЁТ(D28:D88)
=
СУММПРОИЗВ(B28:B88-СРЗНАЧ(B28:B88);(D28:D88))/СЧЁТ(D28:D88)
=
СУММПРОИЗВ(B28:B88;D28:D88)/СЧЁТ(D28:D88)-СРЗНАЧ(B28:B88)*СРЗНАЧ(D28:D88)
Эти формулы используют свойство
ковариации
:
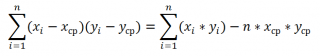
Если переменные
x
и
y
независимые, то их ковариация равна 0. Если переменные не являются независимыми, то дисперсия их суммы равна:
VAR(x+y)= VAR(x)+ VAR(y)+2COV(x;y)
А
дисперсия
их разности равна
VAR(x-y)= VAR(x)+ VAR(y)-2COV(x;y)
Оценка статистической значимости коэффициента корреляции
При проверке значимости
коэффициента корреляции
нулевая гипотеза состоит в том, что
коэффициент корреляции
равен нулю, альтернативная — не равен нулю (про
проверку гипотез
см. статью
Проверка гипотез
).
Для того чтобы проверить гипотезу, мы должны знать распределение случайной величины, т.е.
коэффициента корреляции
r. Обычно, проверку гипотезы осуществляют не для r, а для случайной величины t
r
:
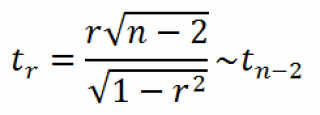
которая имеет
распределение Стьюдента
с n-2 степенями свободы.
Если вычисленное значение случайной величины |t
r
| больше, чем критическое значение t
α,n-2
(α- заданный
уровень значимости
), то нулевую гипотезу отклоняют (взаимосвязь величин является статистически значимой).
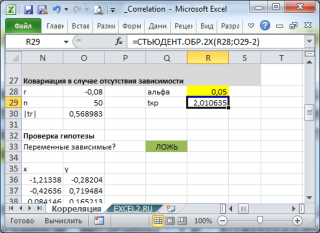
Надстройка Пакет анализа
В
надстройке Пакет анализа
для вычисления ковариации и корреляции
имеются одноименные инструменты
анализа
.
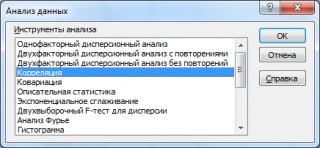
После вызова инструмента появляется диалоговое окно, которое содержит следующие поля:
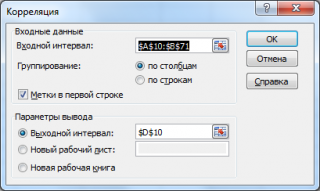
Входной интервал
: нужно ввести ссылку на диапазон с исходными данными для 2-х переменных
Группирование
: как правило, исходные данные вводятся в 2 столбца
Метки в первой строке
: если установлена галочка, то
Входной интервал
должен содержать заголовки столбцов. Рекомендуется устанавливать галочку, чтобы результат работы Надстройки содержал информативные столбцы
Выходной интервал
: диапазон ячеек, куда будут помещены результаты вычислений. Достаточно указать левую верхнюю ячейку этого диапазона.
Надстройка возвращает вычисленные значения корреляции и ковариации (для ковариации также вычисляются дисперсии обоих случайных величин).

Nonlinear regression is a regression technique that is used when the relationship between a predictor variable and a response variable does not follow a linear pattern.
The following step-by-step example shows how to perform nonlinear regression in Excel.
Step 1: Create the Data
First, let’s create a dataset to work with:

Step 2: Create a Scatterplot
Next, let’s create a scatterplot to visualize the data.
First, highlight the cells in the range A1:B21. Next, click the Insert tab along the top ribbon, and then click the first plot option under Scatter:

The following scatterplot will appear:

Step 3: Add a Trendline
Next, click anywhere on the scatterplot. Then click the + sign in the top right corner. In the dropdown menu, click the arrow next to Trendline and then click More Options:

In the window that appears to the right, click the button next to Polynomial. Then check the boxes next to Display Equation on chart and Display R-squared value on chart.

This produces the following curve on the scatterplot:

Note that you may need to experiment with the value for the Order of the polynomial until you find the curve that best fits the data.
Step 4: Write the Regression Equation
From the plot we can see that the equation of the regression line is as follows:
y = -0.0048x4 + 0.2259x3 – 3.2132x2 + 15.613x – 6.2654
The R-squared tells us the percentage of the variation in the response variable that can be explained by the predictor variables.
The R-squared for this particular curve is 0.9651. This means that 96.51% of the variation in the response variable can be explained by the predictor variables in the model.
Additional Resources
How to Perform Simple Linear Regression in Excel
How to Perform Multiple Linear Regression in Excel
How to Perform Logarithmic Regression in Excel
How to Perform Exponential Regression in Excel
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.

Модель линейной регрессии имеет следующий вид:
У = а0 + а1х1 +…+акхк.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.



После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).



В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
Пример:

- Строим корреляционное поле: «Вставка» — «Диаграмма» — «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».




Теперь стали видны и данные регрессионного анализа.