
Neural Excel — это аналитическая надстройка для Microsoft Excel, позволяющая работать с нейронными сетями. Простая в использовании надстройка позволяет быстро сконфигурировать и обучить нейронную сеть прямо в среде Microsoft Excel. Инструмент ориентирован на людей, которые хотят быстро получить отдачу от использования нейронных сетей и при этом не сильно углубляться в теорию. Надстройка позволяет использовать обученные сети как непосредственно в Microsoft Excel, так и интегрировать их в свои собственные приложения. Простота использования и минимум настроек делают это приложение отличным выбором для студентов и начинающих специалистов в области нейронных сетей.
Области применения
Финансовые операции:
-
Прогнозирование поведения клиента
-
Прогнозирование и оценка риска предстоящей сделки
-
Прогнозирование возможных мошеннических действий
-
Прогнозирование остатков средств на корреспондентских счетах банка
-
Прогнозирование движения наличности, объемов оборотных средств
-
Прогнозирование экономических параметров и фондовых индексов
Бизнес-аналитика и поддержка принятия решений:
-
Выявление тенденций, корреляций, типовых образцов и исключений в больших объемах данных
-
Анализ работы филиалов компании
-
Сравнительный анализ конкурирующих фирм
Планирование работы предприятия:
-
Прогнозирование объемов продаж
-
Прогнозирование загрузки производственных мощностей
-
Прогнозирование спроса на новую продукцию
Другие приложения:
-
Оценка стоимости недвижимости
-
Контроль качества выпускаемой продукции
-
Системы слежения за состоянием оборудования
-
Проектирование и оптимизация сетей связи, сетей электроснабжения
-
Прогнозирование потребления энергии
Функциональные возможности программы
Neural Excel выполнена в виде надстройки Microsoft Excel, что дает возможность очень простой установки. Программа позволяет конфигурировать и обучать многослойные нейронные сети непосредственно в Microsoft Excel, начиная с 2007 версии.
Конфигурация сети может быть задана как пользователем, так и получена автоматически в процессе обучения.
Обученные нейронные сети могут быть сохранены непосредственно в книге Microsoft Excel в виде формул (функция поддерживается на версиях Microsoft Excel, начиная с 2010). Кроме того, использование сетей в виде формул позволяет автоматически пересчитывать выходные данные при изменении входных параметров.
Обученные нейронные сети могут быть также сохранены в файл, а учитывая, что в комплекте с программой поставляются компоненты Delphi (а в ближайшее время будут добавлены и компоненты для Visual Studio) с исходными кодами, то пользователь имеет возможность интегрировать сети в свои собственные приложения буквально несколькими строчками кода.
Опционально можно задавать генерацию листов с итоговой статистикой, копией обучающего множества и листа с шаблоном тестового множества.
Условия использования
Neural Excel является бесплатной программой для использования как в учебных, так и в коммерческих целях. По возможности, просим указывать в своих работах, что использовалось приложение Neural Excel, и давать ссылку на наш сайт.
Презентация программы…
Поддержка проекта
Программа является полностью бесплатной, но Вы можете поддержать авторов, предложив новые идеи по совершенствованию функционала или описав найденную ошибку.
При описании ошибки обязательно укажите версию и разрядность офиса, текст ошибки (а лучше приложите скриншот окна) и последовательность Ваших действий, после которых возникла ошибка.
В современном мире трудно найти человека, который бы не слышал про нейронные сети. Кажется, их применяют всюду: оживление фотографий, DeepFake, маски для фото в соцсетях и прочее. Но для большинства людей они являются чем-то абстрактным и непонятным.
Однако создать свою нейросеть можно даже не имея знаний о языках программирования, и используя простейший инструмент, знакомый любому офисному сотруднику – MS Excel.
Схематично моя будущая нейросеть выглядит так:
Это упрощенная схема перцептрона. Перцептрон – простейший вид нейронных сетей, в основе которых лежит математическая модель восприятия информации мозгом, состоящая из сенсоров, ассоциативных и реагирующих элементов. На вход подаются значения признаков, которые могут быть равны 0 или 1. Строгая бинарность обусловлена тем, что признаки – это, своего рода, сенсоры, и они могут находиться либо в состоянии покоя (равны 0), либо в состоянии возбуждения (равны 1). Затем эти признаки умножатся на вес и суммируются. После при помощи функции активации (сигмоиды) получаю значения на выходе от 0 до 1. Таким образом, главной задачей является нахождение весов, обеспечивающих наиболее точное прогнозирование.
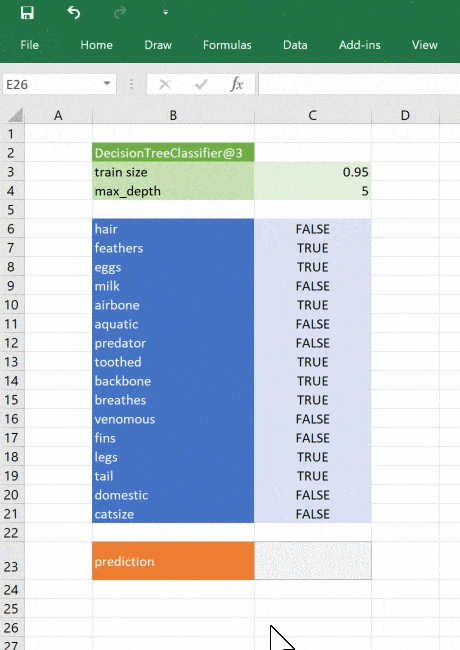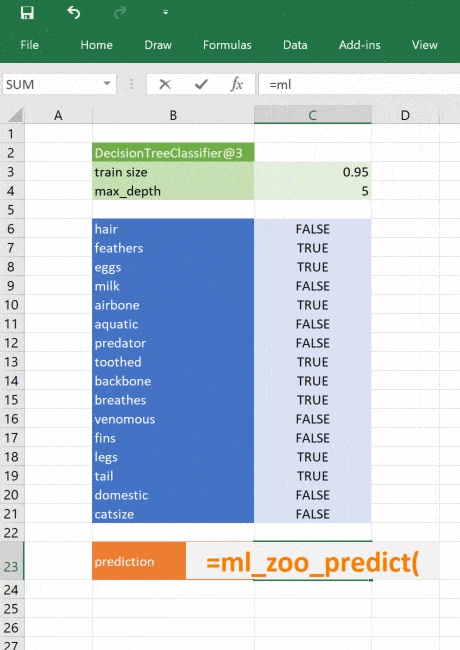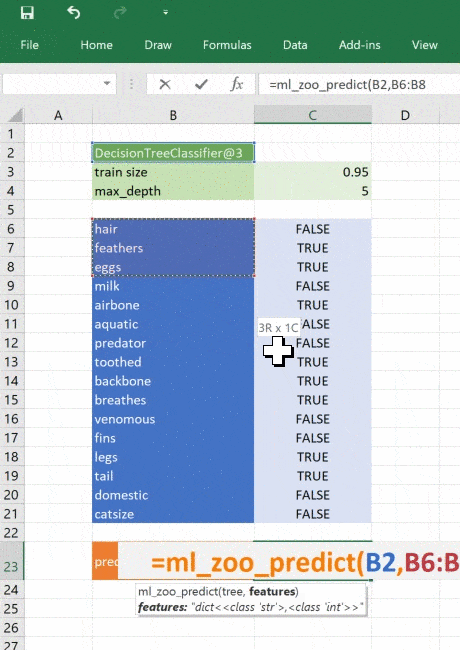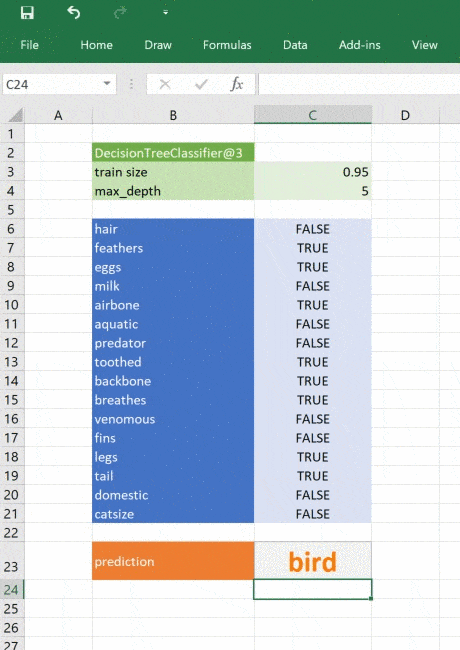
Представлю, что требуется по определенному набору признаков научить нейросеть определять является ли животное домашней кошкой или нет.
В датасете имеется 9 признаков, если экземпляр им обладает, то ставится 1, если нет, то 0. Целевой столбец назван «Выход»: 1 – значит экземпляр кошка, 0 – не кошка. В идеале нейросеть должна предсказать 1 для всех кошек и 0 для всех не кошек.
Первый шаг – создание таблицы поиска весов для каждого признака:
В диапазоне M3:U2 генерирую случайные величины весов при помощи формулы СЛЧИС().
Далее создаю столбцы для Bias (смещение) и Output (предсказание модели):
Формула в ячейке W3:
=B3*M3+C3*N3+D3*O3+E3*P3+F3*Q3+G3*R3+H3*S3+I3*T3+J3*U3
Протягиваю формулу до ячейки W14.
Bias – нейрон смещения. Простыми словами, это дополнительная информация о природе данных для модели, способ показать модели, «в какую сторону думать».
Формула в ячейке output – функция сигмоиды:
=ЕСЛИ(Bias=0;0;1/(1+(EXP(-Bias))))
Данная функция необходима для интерпретации значения bias. Мне нужно получить значения от 0 до 1. Output – предсказание модели. Если значение меньше 0.5, то экземпляр не является кошкой, если больше, то является.
Создаю таблицу для корректировки весов:
В ячейке Z3 следующая формула:
=($K3-$X3)*B3*$X3*(1-$X3)
Протягиваю её на весь диапазон Z1:AH14
Возвращаюсь в блок с весами: в ячейку М4 прописываю формулу: =M3+Z3
Протягиваю её на диапазон M4:U14:
В диапазоне AJ3:AJ14 пишу формулу: =ЕСЛИ(X3<0,5;0;1) – если значение в столбце Output больше, либо равно 0.5, то модель предполагает, что в строке домашняя кошка.
В диапазоне AK3:AK14 пишу формулу: =ЕСЛИ(K3=1;ЕСЛИ(AJ3=K3;1;0);»») – проверяю правильно ли модель предсказала домашнюю кошку.
В диапазоне AL3:AL14 пишу формулу: =ЕСЛИ(K3=0;ЕСЛИ(AJ3=K3;1;0);»»)– проверяю правильно ли модель предсказала не домашнюю кошку.
В ячейках AK15 и AL15 формулы СРЗНАЧ() для отображения доли правильных ответов.
На рисунке видно, что на данный момент модель считает все записи домашними кошками (цифра 1 в столбце «Предсказание»).
Копирую диапазон M14:U14 и вставляю значения в диапазон M3:U3:
Смотрю результат:
Теперь модель не все записи считает домашними кошками, но результат пока ещё не лучший.
Совершаю ещё несколько итераций. Копирую диапазон M14:U14 и вставляю значения в диапазон M3:U3. В таблице ниже видно, как менялись предсказания после каждого цикла:
В итоге, моя нейросеть после восьми итераций верно предсказала значения для всех строк.
Используя полученные веса из диапазона M14:U14, можно проверять другие комбинации признаков, и модель будет предсказывать является ли представленная строка домашней кошкой или нет.
Видно, что модель неидеальна, так как неверно предсказала рысь. Зато манула она определила верно, несмотря на то, что он больше походит на домашнюю кошку, чем рысь. На самом деле 100%-я точность для нейросетей невозможна, поэтому полученный результат можно считать неплохим. На практике использование MS Excel для задач машинного обучения — не очень хорошая идея, так как он не может работать с большим объемом данных, да и создан совершенно для другого. Однако, используя методы, представленные в посте, можно самостоятельно «поиграть» с данными, что поможет понять базовые принципы работы нейросетей.
Время на прочтение
9 мин
Количество просмотров 12K

К старту курса о машинном и глубоком обучении делимся переводом статьи, автор которой показывает на практике, как модель машинного обучения может использоваться через Excel. Зачем это нужно? Компании больше и больше вкладывают в исследования и разработку моделей прогнозов; по мнению автора оригинала статьи, разработчика и основателя компании PyXLL доступ к ML-моделям через Excel открывает новые горизонты. Вы сможете показать модель пользователям Excel, у которых нет опыта программирования или широких знаний в области статистики. При желании можно создавать инструменты разработки и тренировки моделей полностью в Excel, например строить графы в TensorFlow. Весь исходный код из статьи доступен на GitHub.
Надстройка Excel PyXLL встраивает Python в Excel и позволяет расширять возможности Excel через Python. С помощью этой надстройки мы можем добавлять новые функции, макросы, меню и в целом перенести преимущества экосистемы Python и машинное обучение прямо в Excel. К концу статьи мы построим модель классификации животных.
Python для Machine Learning
Python хорошо подходит для машинного обучения, у него большой массив поддерживаемых пакетов, упрощающих программирование и сокращающих время разработки. ML и DL очень хорошо поддерживаются несколькими пакетами, поэтому Python — идеальный выбор. Посмотрим на распространённые пакеты для ML на Python.
Scikit-Learn
Пакет scikit-learn — это лаконичный и последовательный интерфейс к общим алгоритмам ML, упрощая введение ML в производственные системы. Библиотека сочетает высокую производительность, де-факто она отраслевой стандарт машинного обучения на Python. В статье мы будем работать именно с ней.
TensorFlow
TensorFlow от Google. Эта библиотека с открытым исходным кодом для расчёта графов потоков данных оптимизирована для целей ML. Она была разработана, чтобы удовлетворять высоким требованиям обучения нейронных сетей в среде Google и является преемницей DistBelief — основанной на нейронных сетях системы глубокого обучения, применяется в пограничных областях исследований Google.
Впрочем, TensorFlow не строго научна и достаточно обобщена, чтобы применяться в различных прикладных задачах. Ключевая особенность TensorFlow — многослойная система узлов, которая быстро тренирует сети искусственного интеллекта на больших наборах данных. В Google это даёт возможность распознавать голос и находить объекты на изображениях.
Keras
Keras — написанная на Python Open Source библиотека для нейронных сетей. Она способна работать поверх TensorFlow, Microsoft Cognitive Toolkit или Theano и имеет архитектуру, которая позволяет быстро проводить эксперименты с глубоким обучением и сосредоточена на модульности, расширяемости и удобстве пользователя. Из документации следует, что работать с Keras можно, когда вам нужна библиотека глубокого обучения, которая:
-
Обладая перечисленными выше преимуществами, позволяет просто и быстро прототипировать решения.
-
Поддерживает свёрточные и рекуррентные нейронные сети, а также их комбинирование.
-
Без проблем работает на CPU и GPU.
PyTorch
PyTorch — это научный вычислительный пакет на Python, он работает в двух направлениях:
-
Как замена NumPy с возможностью задействовать графические процессоры.
-
Как платформа исследования Deep Learning с максимумом гибкости и скорости.
Деревья решений
Деревья решений — техника машинного обучения для решения задач регрессии и классификации. Дерево делит набор данных на множество наборов по признакам так, что одно дерево владеет одним подмножеством данных. Конечные узлы дерева — листья — содержат прогнозы и используются в новых запросах к натренированной модели. Пример ниже поможет понять, как это работает. Предположим, мы имеем набор данных со множеством признаков животных: млекопитающих, птиц, рептилий, насекомых, моллюсков и амфибий. Интуитивно разделить этот набор можно так:
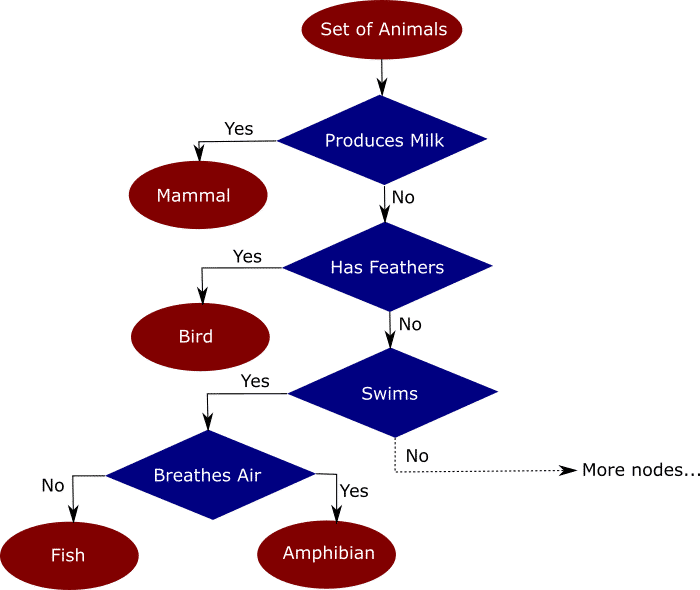
Распределение данных по деревьям на основе признака упрощает классификацию новых данных, точность которой зависит от того, насколько точно деревья отражают действительность. В незаконченное дерево на рисунке выше я заложил мои знания и интуитивные представления о животных. Модель выясняет, как распределить признаки по новым данным — это и называется машинным обучением.
Алгоритм быстро анализирует большой объём данных, чего вручную сделать невозможно. В работе деревьев решений множество аспектов, от математики до логики их построения. Мы не будем касаться этих деталей, но построим модель и я покажу, как работать с ней в Excel.
Тренировка модели
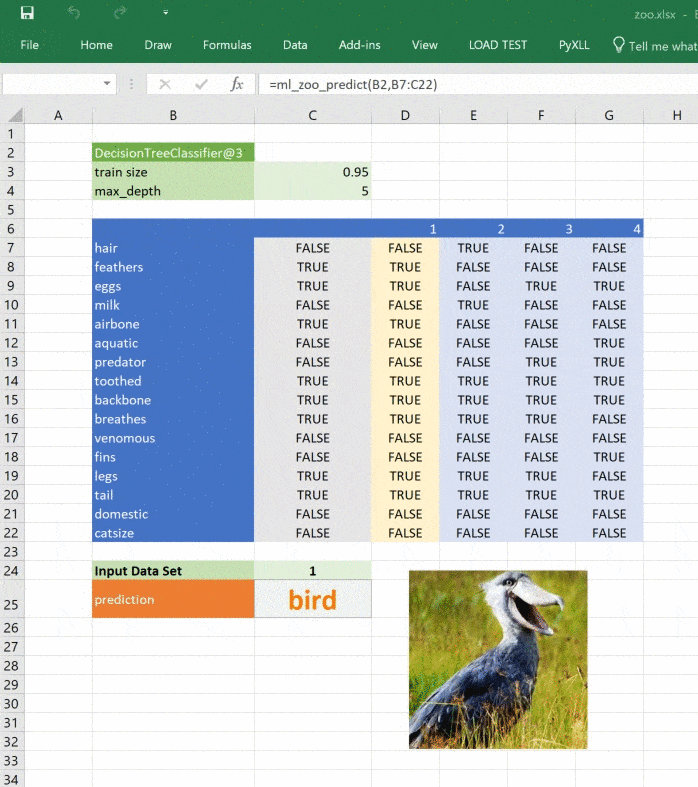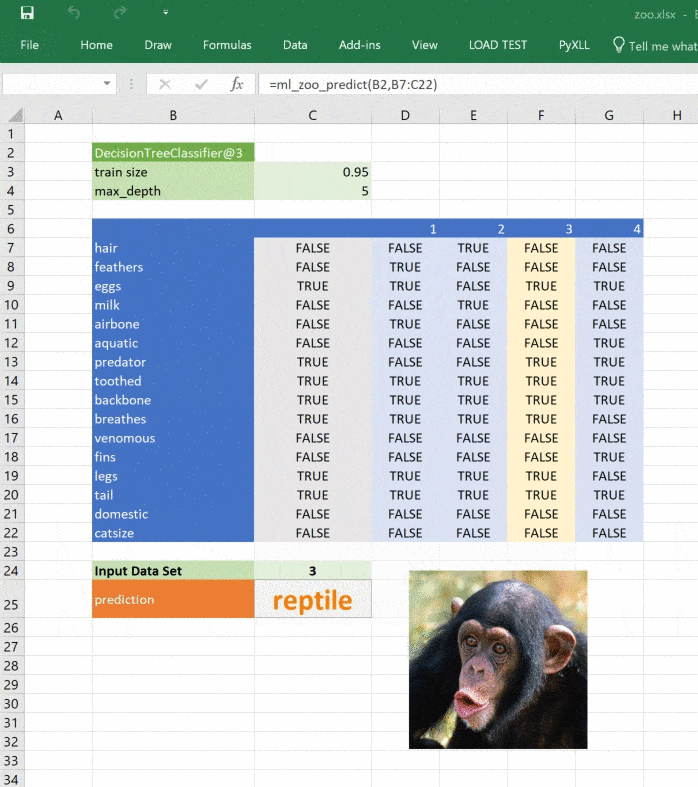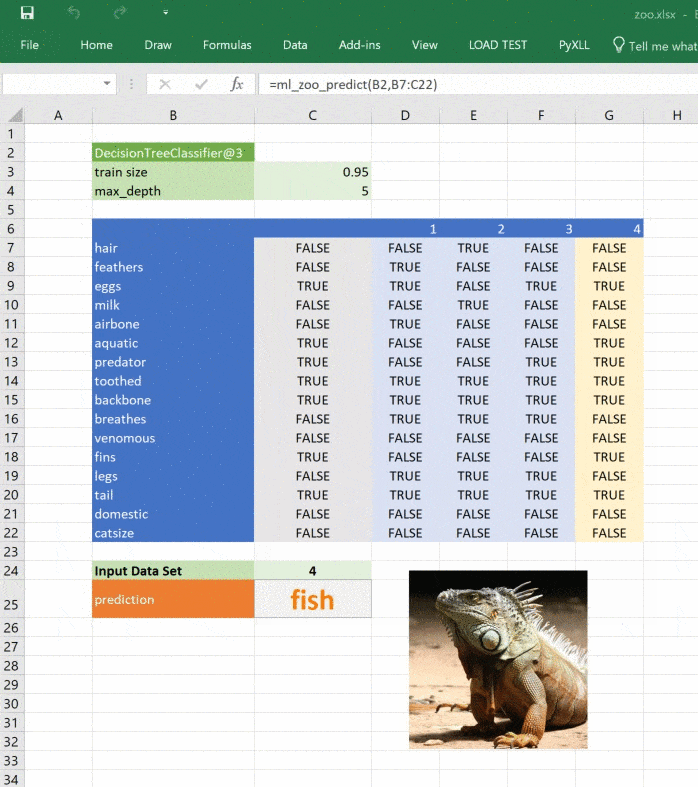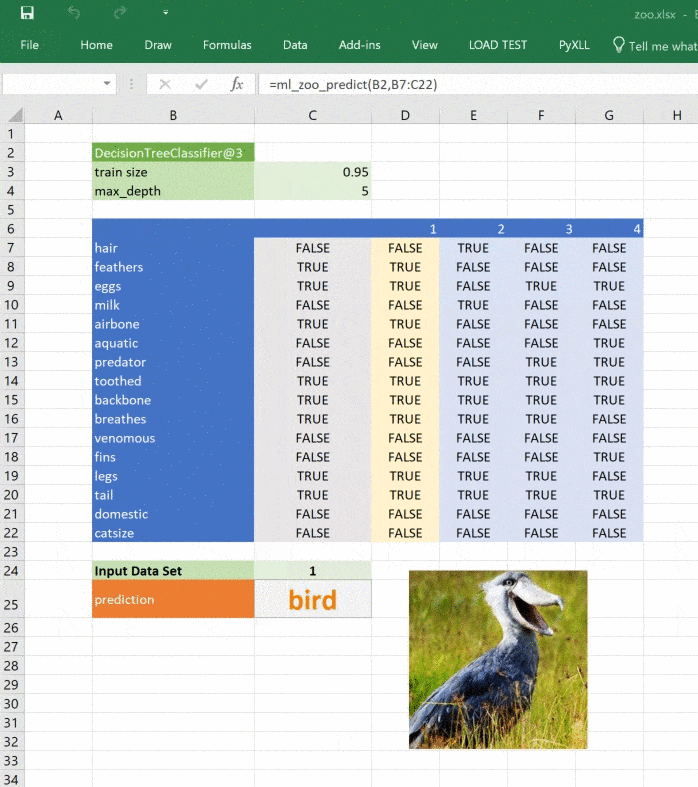
Натренируем модель классифицировать животных при помощи деревьев решений. Воспользуемся для этого набором данных UCI Zoo Data Set из 101 животного, в наборе 17 логических признаков и один признак, который мы будем прогнозировать.
Для загрузки данных воспользуемся pandas, а для построения дерева — scikit-learn. Загрузим данные во фрейм Pandas, разделим на признаки и целевой класс, то есть класс животного. Затем разделим данные на тренировочный и тестовый наборы. Scikit-Learn использует тренировочный набор для обучения деревьев, а тестовый резервируется для проверки точности модели.
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
import pandas as pd
# Read the input csv file
dataset = pd.read_csv("zoo.csv")
# Drop the animal names since this is not a good feature to split the data on
dataset = dataset.drop("animal_name", axis=1)
# Split the data into features and target
features = dataset.drop("class", axis=1)
targets = dataset["class"]
# Split the data into a training and a testing set
train_features, test_features, train_targets, test_targets =
train_test_split(features, targets, train_size=0.75)Начинается самое интересное: при помощи классификатора дерева решений в scikit-learn обучим модель на тренировочных данных. Чтобы модель не переобучилась и могла работать, настроим несколько параметров. Максимальная глубина дерева будет равна 5. Поэкспериментируйте со значениями, чтобы увидеть влияние глубины на результаты.
# Train the model
tree = DecisionTreeClassifier(criterion="entropy", max_depth=5)
tree = tree.fit(train_features, train_targets)Эти две строки строят и обучают модель. Чтобы проверить её точность, подадим на вход данные, которых она не видела.
# Predict the classes of new, unseen data
prediction = tree.predict(test_features)
# Check the accuracy
score = tree.score(test_features, test_targets)
print("The prediction accuracy is: {:0.2f}%".format(score * 100))Воспользуемся моделью и выполним прогноз на новых данных:
# Try predicting based on some features
features = {
"hair": 0,
"feathers": 1,
"eggs": 1,
"milk": 0,
"airbone": 1,
"aquatic": 0,
"predator": 0,
"toothed": 1,
"backbone": 1,
"breathes": 1,
"venomous": 0,
"fins": 0,
"legs": 1,
"tail": 1,
"domestic": 0,
"catsize": 0
}
features = pd.DataFrame([features], columns=train_features.columns)
prediction = tree.predict(features)[0]
print("Best guess is {}".format(prediction])Вызовем модель из Excel
Теперь загрузим модель в Excel, который хорошо подходит для интерактивных данных. Он работает почти везде, вы сможете показать модель незнакомым с разработкой людям, это даёт массу преимуществ в бизнесе, особенно когда модель применяется как часть пакетной системы или системы реального времени. Возможность вызывать модель интерактивно может оказаться по-настоящему полезной, когда нужно понять поведение системы.
К счастью, наша модель написана на Python и перенести её в Excel просто. В PyXLL есть всё необходимое, чтобы писать на Python в Excel. Нужно только добавить несколько декораторов @xl_func из модуля pyxll и настроить надстройку PyXLL для загрузки модуля с моделью. Если вы не знакомы с PyXLL, посмотрите введение в PyXLL в руководстве пользователя.
Построим дерево решений
Начнём с функции. Пользователь вызовет её, чтобы получить объект дерева, а затем этот объект для прогнозирования пройдёт через последовательность функций. Снова построим дерево, но пример будет сложнее: сохраним натренированную при помощи pickle и затем вместо того, чтобы каждый раз её создавать, загрузим её в Excel и настроим параметры, это будет интересно!
from pyxll import xl_func
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
import pandas as pd
import os
@xl_func("float, int, int: object")
def ml_get_zoo_tree(train_size=0.75, max_depth=5, random_state=245245):
# Load the zoo data
dataset = pd.read_csv(os.path.join(os.path.dirname(__file__), "zoo.csv"))
# Drop the animal names since this is not a good feature to split the data on
dataset = dataset.drop("animal_name", axis=1)
# Split the data into a training and a testing set
features = dataset.drop("class", axis=1)
targets = dataset["class"]
train_features, test_features, train_targets, test_targets =
train_test_split(features, targets, train_size=train_size, random_state=random_state)
# Train the model
tree = DecisionTreeClassifier(criterion="entropy", max_depth=max_depth)
tree = tree.fit(train_features, train_targets)
# Add the feature names to the tree for use in predict function
tree._feature_names = features.columns
return treeКод выше совпадает с кодом, который мы видели ранее, за исключением декоратора @xl_func, который сообщает дополнению PyXLL о том, какая функция Python должна стать пользовательской функцией Excel.
Строка float, int, int: object — это сигнатура функции. Она необязательна, но без этой сигнатуры пользователь сможет передавать в функцию свои типы, например, строки и это может привести к сбою. Возвращаемый тип object означает, что классификатор идёт через Excel как объект Python, функция возвращает дескриптор, который возможно передать другим функциям Python.
Код нужно добавить в список модулей конфигурационного файла pyxll.cfg, также необходима надстройка PyXLL, если вы не установили её.
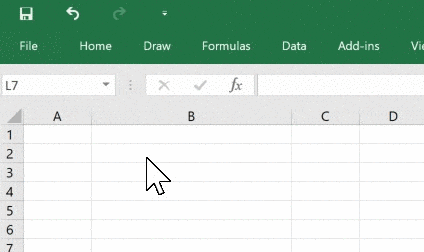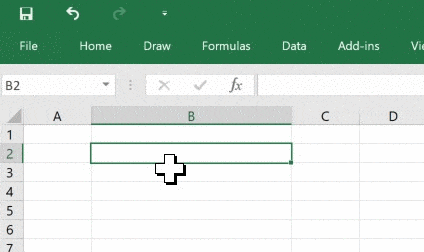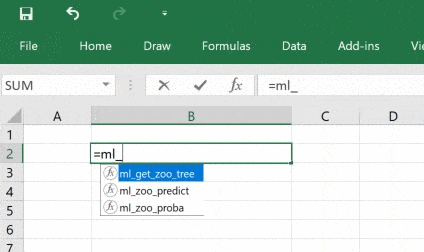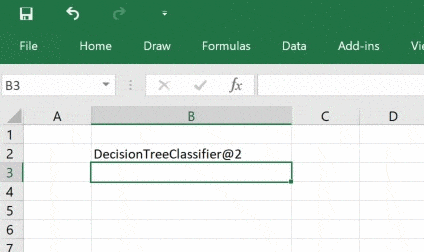
Все аргументы функции имеют значение по умолчанию, поэтому необязательны, но при желании со входными данными можно экспериментировать.
Прогнозируем класс животного
Теперь всё, что нужно для работы с моделью — ещё одна функция для передачи входных данных и получения прогноза. Используем тот же код, что и раньше, но обернём его декоратором @xl_func.
_zoo_classifications = {
1: "mammal",
2: "bird",
3: "reptile",
4: "fish",
5: "amphibian",
6: "insect",
7: "mollusc"
}
@xl_func("object tree, dict features: var")
def ml_zoo_predict(tree, features):
# Convert the features dictionary into a DataFrame with a single row
features = pd.DataFrame([features], columns=tree._feature_names)
# Get the prediction from the model
prediction = tree.predict(features)[0]
return _zoo_classifications[prediction]Модель возвращает целое число — спрогнозированный класс. Словарь _zoo_classifications содержит эти числа и понятные человеку названия классов.
Эта функция берёт объект дерева из ml_get_zoo_tree и список пар ключ-значение, переданных в неё как словарь. В словаре сопоставлены имена признаков, с которыми мы работали при конструировании дерева, и входные признаки. Их сопоставление таково, что при вызове tree.predict признаки упорядочены правильно.
Это простой пример, натренированный на минимуме данных, но принцип применим к любой сложной модели. При помощи Python вы можете исследовать, разрабатывать и строить модель, чтобы получить ценные инсайты и быстрые прогнозы на реальных данных.
Небольшое дополнение
Чёрно-белые листы с цифрами нравятся всем, но иногда мне нравится добавлять небольшие детали ради привлекательности таблицы. PyXLL позволяет получить доступ к объектной модели Excel с помощью функции xl_app. Объектная модель Excel точно совпадает с той, что применяется в VBA. Функция ниже создаёт на листе объект изображения и загружает его.
from pyxll import xl_app
def show_image_in_excel(classification, figname="prediction_image"):
"""Plot a figure in Excel"""
# Show the figure in Excel as a Picture object on the same sheet
# the function is being called from.
xl = xl_app()
sheet = xl.ActiveSheet
# if a picture with the same figname already exists then get the position
# and size from the old picture and delete it.
for old_picture in sheet.Pictures():
if old_picture.Name == figname:
height = old_picture.Height
width = old_picture.Width
top = old_picture.Top
left = old_picture.Left
old_picture.Delete()
break
else:
# otherwise create a new image
top_left = sheet.Cells(1, 1)
top = top_left.Top
left = top_left.Left
width, height = 100, 100
# insert the picture
filename = os.path.join(os.path.dirname(__file__), "images", _zoo_classifications[classification] + ".jpg")
picture = sheet.Shapes.AddPicture(Filename=filename,
LinkToFile=0, # msoFalse
SaveWithDocument=-1, # msoTrue
Left=left,
Top=top,
Width=width,
Height=height)
# set the name of the new picture so we can find it next time
picture.Name = fignameВызов ml_zoo_predict обновляет изображение в Excel при каждом изменении прогноза. Функция обновляет Excel, поэтому вызывать её нужно после вычислений, именно этим занимается async_call из pyxll, а ниже вы видите новую версию ml_zoo_predict:
from pyxll import xl_func, async_call
@xl_func("object tree, dict features: var")
def ml_zoo_predict(tree, features):
# Convert the features dictionary into a DataFrame with a single row
features = pd.DataFrame([features], columns=tree._feature_names)
# Get the prediction from the model
prediction = tree.predict(features)[0]
# Update the image in Excel
async_call(show_image_in_excel, prediction)
return _zoo_classifications[prediction]Изображение обновляется при изменении прогноза:
Этот материал — яркое напоминание о том, что Excel может справляться с задачами машинного обучения, а область ML сложна, но её сложность преодолима и если вы хотите изменить карьеру или вывести ваши навыки на новый уровень, то можете обратить внимание на наши курсы по Machine Learning, аналитике данных или присмотреться к флагманскому курсу Data Science. Также вы можете узнать, как начать или продолжить развитие в других направлениях:

Data Science и Machine Learning
-
Профессия Data Scientist
-
Профессия Data Analyst
-
Курс «Математика для Data Science»
-
Курс «Математика и Machine Learning для Data Science»
-
Курс по Data Engineering
-
Курс «Machine Learning и Deep Learning»
-
Курс по Machine Learning
Python, веб-разработка
-
Профессия Fullstack-разработчик на Python
-
Курс «Python для веб-разработки»
-
Профессия Frontend-разработчик
-
Профессия Веб-разработчик
Мобильная разработка
-
Профессия iOS-разработчик
-
Профессия Android-разработчик
Java и C#
-
Профессия Java-разработчик
-
Профессия QA-инженер на JAVA
-
Профессия C#-разработчик
-
Профессия Разработчик игр на Unity
От основ — в глубину
-
Курс «Алгоритмы и структуры данных»
-
Профессия C++ разработчик
-
Профессия Этичный хакер
А также:
-
Курс по DevOps
Содержание
- 1 2.1 Искусственный нейрон
- 2 2.2 Узлы
- 3 2.3 Смещение
- 4 2.4 Составленная структура
- 5 2.5 Обозначение
- 6 3.1 Пример прямого распространения
- 7 3.2 Первая попытка реализовать процесс прямого распространения
- 8 3.3 Более эффективная реализация
- 9 3.4 Векторизация в нейронных сетях
- 10 3.5 Умножение матриц
- 11 4.1 Простой пример на коде
- 12 4.2 Функция оценки
- 13 4.3 Градиентный спуск в нейронных сетях
- 14 4.4 Пример двумерного градиентного спуска
- 15 4.5 Углубляемся в обратное распространение
- 16 4.6 Распространение в скрытых слоях
- 17 4.7 Векторизация обратного распространения
- 18 4.8 Реализация этапа градиентного спуска
- 19 4.9 Конечный алгоритм градиентного спуска
- 20 5.1 Масштабирование данных
- 21 5.2 Создание тестов и учебных наборов данных
- 22 5.3 Настройка выходного слоя
- 23 5.4 Создаем нейросеть
Приходилось ли вам строить прогнозы будущего на основе большого объема данных или классифицировать неизвестное? Требовалось ли вам принимать решения исходя из новых неполных данных?
Несомненно, вы сталкивались с подобными ситуациями. При принятии решений полной информации не бывает никогда. Однако если у вас имеются исторические данные, NeuralTools может вам помочь! NeuralTools — это приложение, осуществляющее интеллектуальный анализ данных с помощью нейронных сетей в среде Microsoft Excel. NeuralTools позволяет строить точные прогнозы на основе закономерностей, обнаруженных в имеющихся данных. NeuralTools изучает структуру данных, как это бы сделал человеческий мозг. Достигнув понимания ваших данных, NeuralTools сможет анализировать новые вводы и создавать интеллектуальные прогнозы. Ваша табличная модель будет «думать» за вас лучше, чем это когда–либо было возможно!
NeuralTools помогает принимать решений при выдаче кредитов, прогнозируя вероятность возврата денег новым заемщиком. Программа используется для снижения транзакционного риска путем идентификации транзакций по банковским и кредитным картам, которые, скорее всего, являются мошенническими. В операторских центрах с помощью NeuralTools прогнозируют объемы звонков для формирования стратегий кадрового обеспечения. Медицинские специалисты используют NeuralTools для диагностики неизвестных опухолей и других болезней. И этот список далеко не исчерпывающий!
Подробнее о том, как быстро научиться работать в NeuralTools
Посмотрите видео по функциям NeuralTools (на английском языке)
NeuralTools также доступен на английском, испанском, немецком, французском, португальском, японском и китайском языках.
» Обновить
Новое средство просмотра данных NeuralTools позволяет вам просматривать любые наборы данных Excel с помощью того же ядра построения диаграмм, которое используется для построения графиков и таблиц @RISK. Средство просмотра данных может запрашивать данные из любого источника; для его работы не требуется выполнять моделирование.
Благодаря простому в использовании интуитивному интерфейсу пользователь может просто выбрать любую переменную, чтобы моментально создать графики с помощью мощного ядра построения графиков Palisade. Созданные графики можно обрабатывать, настраивать и использовать для создания отчетов и демонстраций. Вы можете создавать гистограммы, кумулятивные диаграммы, графы тенденций, ящичковые диаграммы и многое другое.
» Подробнее о новых функциях NeuralTools 7
Анализ на основе нейронных сетей включает три базовых шага: обучение сети на имеющихся данных, тестирование точности сети и создание прогнозов по новым данным. Только NeuralTools может выполнить эту процедуру автоматически в рамках одной простой операции!
NeuralTools может автоматически обновлять прогнозы при изменении входных данных, поэтому вам не придется вручную повторно запускать прогнозирование при получении новых данных. При использовании NeuralTools вместе с программой Evolver от Palisade или функцией поиска решения Excel вы сможете оптимизировать сложные решения и достичь поставленных целей. Такие возможности не предоставляет никакой другой пакет на базе нейронных сетей!
NeuralTools работает в той же среде, что и вы — в Excel. NeuralTools использует интерфейс Excel, поэтому научиться работать с программой будет очень легко. Neural Tools позволит вам в простой среде Excel создавать надежные и точные прогнозы.
ФУНКЦИИ
Функция динамического прогнозирования обеспечивает автоматическое обновление прогнозов при изменении входных данных (только Промышленная версия)
Автоматическое обучение, тестирование и прогнозирование за одну простую операцию
Ускоренное формирование более качественных прогнозов
Полноценная надстройка с функциями в стиле Excel, интерфейсом панели инструментов, меню и командами Excel.
Анализ воздействия переменных ранжирует влияние входных переменных на прогнозы
Анализ чувствительности тестирования
Возможность обучения и анализа данных, распределенных по нескольким листам
Случаи в наборе данных можно автоматически или вручную помечать тегами как данные обучения, тестирования и прогнозирования
Сопоставление переменных: переменные в разных наборах данных (обучение, тестирование и прогнозирование) не должны быть представлены в одинаковом порядке и иметь одинаковые имена
Менеджер нейронных сетей позволяет легко управлять обученными нейронными сетями
Возможность сохранения нейронных сетей в книгах Excel и в файлах формата NeuralTools
Возможность использования как для категорийных, так и для числовых данных
Отсутствие потребности в создании фиктивных переменных для категорийных данных: NeuralTools интерпретирует категорийные данные напрямую
Настройка графиков и отчетов с использованием стандартных функций Excel
Программа предназначена для совместного использования с StatTools, @RISK, Evolver и другими продуктами Palisade
ПРЕИМУЩЕСТВА
Повторный пересчет прогнозов при изменении условий не требуется; программа поддерживает оптимизацию входных переменных в режиме реального времени.
Быстрая и простая настройка анализов
Программа экономит время и помогает принимать лучшие решения
Понятный интерфейс и быстрое обучение
Возможность выбора и выделения новых входных переменных для получения более точных прогнозов
Оценка надежности результатов тестирования на основе размера набора данных тестирования
Практически неограниченные аналитические возможности
Быстрая и простая настройка анализа с возможностью задания индивидуальных параметров
Удобное управление наборами данных
Организованное хранение нейронных сетей для быстрого извлечения
Возможность использования обученных нейронных сетей на нескольких листах
Возможность анализа широкого спектра проблем
Экономия времени и улучшенная наглядность
Большое разнообразие вариантов отчетов для использования в презентациях
Объединение анализа с другими методиками
Доступны две версии NeuralTools: Профессиональная и Промышленная. Профессиональная версия позволяет создавать наборы данных, содержащие не более 1000 случаев, тогда как в Промышленной версии количество случаев не ограничено. Промышленная версия также включает функцию динамического прогнозирования, которая обеспечивает автоматическое обновление результатов при изменении входных данных
NeuralTools поставляется отдельно или в составе DecisionTools Suite — комплексного пакета для анализа рисков и принятия решений от компании Palisade. DecisionTools Suite включает программу @RISK которая позволяет осуществлять моделирование по методу Монте-Карло, BigPicture построения диаграмм связей и исследoвaниe дaнных, PrecisonTree для анализа на основе дерева решений, TopRank для анализа типа «что если», NeuralTools и StatTools для анализа данных и многое другое. Программа NeuralTools полностью совместима со всеми программами DecisionTools и может комбинироваться с ними для повышения точности интерпретации и анализа. Например:
NeuralTools и Evolver
Сочетание NeuralTools с Evolver позволяет оптимизировать решение сложных задач. Настройте инструмент Evolver для создания последовательности прогнозов NeuralTools и используйте соответствующие ячейки Evolver в качестве входных данных для Neural tools. Затем наблюдайте за совместной работой Evolver и NeuralTools, чтобы получить прогноз оптимального решения.
Посмотрите, как работают вместе NeuralTools и Evolver (на английском языке)
NeuralTools и RISKOptimizer
Вы можете использовать NeuralTools вместе с RISKOptimizer, выполняя моделирование по методу Монте-Карло по каждому из экспериментальных решений и составляя прогнозы результатов в режиме реального времени.
» Более подробно о DecisionTools Suite
Цена комплекта DecisionTools Suite ниже, чем стоимость двух отдельных продуктов. Вы экономите более 50% при покупке комплекта вместо приобретения всех компонентов по отдельности. Лучший анализ по отличной цене — с DecisionTools Suite.
» Таблица сравнения цен
Пакет NeuralTools доступен в разных лицензионных вариантах, включая корпоративную, сетевую и учебную лицензии. Помимо программного обеспечения вы можете заказать книги, а также учебно-консультационные услуги — это обеспечит максимальную отдачу от инвестиций.
NeuralTools прогнозы рассчитываются 100% в течение Excel, поддерживаются палисад выборки и статистика доказала в более чем двадцати лет использования. Палисад не попытка переписать Excel во внешнем recalculator набирать скорость.Пересчет из одной или имеет несовместимый плохо воспроизводимые макрос или функция может кардинально изменить результаты. Где она будет происходить, и когда? Получить точные результаты, используя NeuralTools!
Совместимость: @RISK и программное обеспечение DecisionTools Suite совместимы со всеми 32-разрядными и 64-разрядными версиями Microsoft Office 2007 и новее, работающими в Microsoft Windows Vista и новее.
64–разрядная технология позволяет Excel и программному обеспечению DecisionTools получить доступ к большему объему памяти компьютера, чем когда-либо. Это обеспечивает большую вычислительную мощность и позволяет создавать большие модели.
Отличный гайд про нейросеть от теории к практике. Вы узнаете из каких элементов состоит ИНС, как она работает и как ее создать самому.
Если вы в поисках пособия по искусственным нейронным сетям (ИНС), то, возможно, у вас уже имеются некоторые предположения относительно того, что это такое. Но знали ли вы, что нейронные сети — основа новой и интересной области глубинного обучения? Глубинное обучение — область машинного обучения, в наше время помогло сделать большой прорыв во многих областях, начиная с игры в Го и Покер с живыми игроками, и заканчивая беспилотными автомобилями. Но, прежде всего, глубинное обучение требует знаний о работе нейронных сетей.

В этой статье будут представлены некоторые понятия, а также немного кода и математики, с помощью которых вы сможете построить и понять простые нейронные сети. Для ознакомления с материалом нужно иметь базовые знания о матрицах и дифференциалах. Код будет написан на языке программирования Python с использованием библиотеки numpy. Вы построите ИНС, используя Python, которая с высокой точностью классифицировать числа на картинках.
Искусственные нейросеть (ИНС) — это программная реализация нейронных структур нашего мозга. Мы не будем обсуждать сложную биологию нашей головы, достаточно знать, что мозг содержит нейроны, которые являются своего рода органическими переключателями. Они могут изменять тип передаваемых сигналов в зависимости от электрических или химических сигналов, которые в них передаются. Нейросеть в человеческом мозге — огромная взаимосвязанная система нейронов, где сигнал, передаваемый одним нейроном, может передаваться в тысячи других нейронов. Обучение происходит через повторную активацию некоторых нейронных соединений. Из-за этого увеличивается вероятность вывода нужного результата при соответствующей входной информации (сигналах). Такой вид обучения использует обратную связь — при правильном результате нейронные связи, которые выводят его, становятся более плотными.
Искусственные нейронные сети имитируют поведение мозга в простом виде. Они могут быть обучены контролируемым и неконтролируемым путями. В контролируемой ИНС, сеть обучается путем передачи соответствующей входной информации и примеров исходной информации. Например, спам-фильтр в электронном почтовом ящике: входной информацией может быть список слов, которые обычно содержатся в спам-сообщениях, а исходной информацией — классификация для уведомления (спам, не спам). Такой вид обучения добавляет веса связям ИНС, но это будет рассмотрено позже.
Неконтролируемое обучение в ИНС пытается «заставить» ИНС «понять» структуру передаваемой входной информации «самостоятельно». Мы не будем рассматривать это в данном посте.
2.1 Искусственный нейрон
Биологический нейрон имитируется в ИНС через активационную функцию. В задачах классификации (например определение спам-сообщений) активационная функция должна иметь характеристику «включателя». Иными словами, если вход больше, чем некоторое значение, то выход должен изменять состояние, например с 0 на 1 или -1 на 1 Это имитирует «включение» биологического нейрона. В качестве активационной функции обычно используют сигмоидальную функцию:

Которая выглядит следующим образом:
|
import matplotlib.pylab as plt import numpy as np x = np.arange(-8, 8, 0.1) f = 1 / (1 + np.exp(-x)) plt.plot(x, f) plt.xlabel(‘x’) plt.ylabel(‘f(x)’) plt.show() |

Из графика можно увидеть, что функция «активационная» — она растет с 0 до 1 с каждым увеличением значения х. Сигмоидальная функция является гладкой и непрерывной. Это означает, что функция имеет производную, что в свою очередь является очень важным фактором для обучения алгоритма.
2.2 Узлы
Как было упомянуто ранее, биологические нейроны иерархически соединены в сети, где выход одних нейронов является входом для других нейронов. Мы можем представить такие сети в виде соединенных слоев с узлами. Каждый узел принимает взвешенный вход, активирует активационную функцию для суммы входов и генерирует выход.

Круг на картинке изображает узел. Узел является «местоположением» активационной функции, он принимает взвешенные входы, складывает их, а затем вводит их в активационную функцию. Вывод активационной функции представлен через h. Примечание: в некоторых источниках узел также называют перцептроном.
Что такое «вес»? По весу берутся числа (не бинарные), которые затем умножаются на входе и суммируются в узле. Иными словами, взвешенный вход в узел имеет вид:
где wi— числовые значения веса ( b мы будем обсудим позже). Весы нам нужны, они являются значениями, которые будут меняться в течение процесса обучения. b является весом элемента смещения на 1, включение веса b делает узел гибким. Проще это понять на примере.
2.3 Смещение
Рассмотрим простой узел, в котором есть по одному входу и выходу:
Ввод для активационной функции в этом узле просто x1w1. На что влияет изменение в w1 в этой простой сети?
|
w1 = 0.5 w2 = 1.0 w3 = 2.0 l1 = ‘w = 0.5’ l2 = ‘w = 1.0’ l3 = ‘w = 2.0’ for w, l in : f = 1 / (1 + np.exp(-x * w)) plt.plot(x, f, label = l) plt.xlabel(‘x’) plt.ylabel(‘h_w(x)’) plt.legend(loc = 2) plt.show() |
Здесь мы можем видеть, что при изменении веса изменяется также уровень наклона графика активационной функции. Это полезно, если мы моделируем различные плотности взаимосвязей между входами и выходами. Но что делать, если мы хотим, чтобы выход изменялся только при х более 1? Для этого нам нужно смещение. Рассмотрим такую сеть со смещением на входе:
|
w = 5.0 b1 = -8.0 b2 = 0.0 b3 = 8.0 l1 = ‘b = -8.0’ l2 = ‘b = 0.0’ l3 = ‘b = 8.0’ for b, l in : f = 1 / (1 + np.exp(-(x * w + b))) plt.plot(x, f, label = l) plt.xlabel(‘x’) plt.ylabel(‘h_wb(x)’) plt.legend(loc = 2) plt.show() |
Из графика можно увидеть, что меняя «вес» смещения b, мы можем изменять время запуска узла. Смещение очень важно в случаях, когда нужно имитировать условные отношения.
2.4 Составленная структура
Выше было объяснено, как работает соответствующий узел / нейрон / перцептрон. Но, как вы знаете, в полной нейронной сети находится много таких взаимосвязанных между собой узлов. Структуры таких сетей могут принимать мириады различных форм, но самая распространенная состоит из входного слоя, скрытого слоя и выходного слоя. Пример такой структуры приведены ниже:
Ну рисунке выше можно увидеть три слоя сети — Слой 1 является входным слоем, где сеть принимает внешние входные данные. Слой 2 называют скрытым слоем, этот слой не является частью ни входа, ни выхода. Примечание: нейронные сети могут иметь несколько скрытых слоев, в данном примере для примера был показан лишь один. И наконец, Слой 3 является исходным слоем. Вы можете заметить, что между Шаром 1 (Ш1) и Шаром 2 (Ш2) существует много связей. Каждый узел в Ш1 имеет связь со всеми узлами в Ш2, при этом от каждого узла в Ш2 идет по одной связи к единому выходному узлу в Ш3. Каждая из этих связей должна иметь соответствующий вес.
2.5 Обозначение
Вся математика, приведенная выше, требует очень точной нотации. Нотация, которая используется здесь, используется и в руководстве по глубинному обучению от Стэнфордского Университета. В следующих уравнениях вес соответствующего связи будет обозначаться как w ij(l), где i — номер узла в слое l+1, а j- номер узла в слое l. Например, вес связи между узлом 1 в слое 1 и узлом 2 в слое 2 будет обозначаться как w 21(l). Непонятно, почему индексы 2-1 означают связь 1-2? Такая нотация более понятна, если добавить смещения.
Из графика выше видно, что смещение 1 связано со всеми узлами в соседнем слое. Смещение в Ш1 имеет связь со всеми узлами в Ш2. Так как смещение не является настоящим узлом с активационной функцией, оно не имеет и входов (его входное значение всегда равно константе). Вес связи между смещением и узлом будем обозначать через bi(l), где i- номер узла в слое l+1, так же, как в w ij(l). К примеру с w 21(l) вес между смещением в Ш1 и вторым узлом в Ш2 будет иметь обозначение b2(1).
Помните, что эти значения -w ij(l)и bi(l) — будут меняться в течение процесса обучения ИНС.
Обозначение связи с исходным узлом будет выглядеть следующим образом: hjl, где j- номер узла в слое l. Тогда в предыдущем примере, связью с исходным узлом является h1(2).
Теперь давайте рассмотрим, как рассчитывать выход сети, когда нам известны вес и вход. Процесс нахождения выхода в нейронной сети называется процессом прямого распространения.
Чтобы продемонстрировать, как находить выход, имея уже известный вход, в нейронных сетях, начнем с предыдущего примера с тремя слоями. Ниже такая система представлена в виде системы уравнений:
, где f(∙) — активационная функция узла, в нашем случае сигмоидальная функция. В первой строке h1(2)— выход первого узла во втором слое, его входами соответственно являются w11(1)x1(1), w12(1)x2(1),w13(1)x3(1) и b1(1). Эти входы было сложены, а затем переданы в активационную функцию для расчета выхода первого узла. С двумя следующими узлами аналогично.
Последняя строка рассчитывает выход единого узла в последнем третьем слое, он является конечной исходной точкой в нейронной сети. В нем вместо взвешенных входных переменных (x1,x2,x3)берутся взвешенные выходы узлов с другой слоя (h1(2),h2(2),h3(2))и смещения. Такая система уравнений также хорошо показывает иерархическую структуру нейронной сети.
3.1 Пример прямого распространения
Приведем простой пример первого вывода нейронной сети языке Python . Обратите внимание, веса w11(1),w12(1),… между Ш1 и Ш2 идеально могут быть представлены в матрице:
Представим эту матрицу через массивы библиотеки numpy.
|
import numpy as np w1 = np.array(, ]) |
Мы просто присвоили некоторые рандомные числовые значения весу каждой связи с Ш1. Аналогично можно сделать и с Ш2:
|
w2 = np.zeros((1, 3)) w2 = np.array() |
Мы можем присвоить некоторые значения весу смещения в Ш1 и Ш2:
|
b1 = np.array() b2 = np.array() |
Наконец, перед написанием основной программы для расчета выхода нейронной сети, напишем отдельную функцию для активационной функции:
|
def f(x): return 1 / (1 + np.exp(-x)) |
3.2 Первая попытка реализовать процесс прямого распространения
Приведем простой способ расчета выхода нейронной сети, используя вложенные циклы в Python. Позже мы быстро рассмотрим более эффективные способы.
|
def simple_looped_nn_calc(n_layers, x, w, b): for l in range(n_layers — 1): #Формируется входной массив — перемножения весов в каждом слое# Если первый слой, то входной массив равен вектору х# Если слой не первый, вход для текущего слоя равен# выходу предыдущего if l == 0: node_in = x else : node_in = h #формирует выходной массив для узлов в слое l + 1 h = np.zeros((w.shape, ))#проходит по строкам массива весов for i in range(w.shape): #считает сумму внутри активационной функции f_sum = 0 #проходит по столбцам массива весов for j in range(w.shape): f_sum += w * node_in #добавляет смещение f_sum += b #использует активационную функцию для расчета #i — того выхода, в данном случае h1, h2, h3 h = f(f_sum) return h |
Данная функция принимает в качестве входа номер слоя в нейронной сети, х — входной массив / вектор:
|
w = b = #Рандомный входной вектор x x = |
Функция сначала проверяет, чем является входной массив для соответствующего слоя с узлами / весами. Если рассматривается первый слой, то входом для второго слоя является входной массив xx, Умноженный на соответствующие веса. Если слой не первый, то входом для последующего будет выход предыдущего.
Вызов функции:
|
simple_looped_nn_calc(3, x, w, b) |
возвращает результат 0.8354. Можно проверить правильность, вставив те же значения в систему уравнений:
3.3 Более эффективная реализация
Использование циклов — не самый эффективный способ расчета прямого распространения на языке Python , потому что циклы в этом языке программирования работают довольно медленно. Мы кратко рассмотрим лучшие решения. Также можно будет сравнить работу алгоритмов, используя функцию в IPython:
|
%timeit simple_looped_nn_calc(3, x, w, b) |
В данном случае процесс прямого распространения с циклами занимает около 40 микросекунд. Это довольно быстро, но не для больших нейронных сетей с > 100 узлами на каждом слое, особенно при их обучении. Если мы запустим этот алгоритм на нейронной сети с четырьмя слоями, то получим результат 70 микросекунд. Эта разница является достаточно значительной.
3.4 Векторизация в нейронных сетях
Можно более компактно написать предыдущие уравнения, тем самым найти результат эффективнее. Сначала добавим еще одну переменную zi(l), которая является суммой входа в узел i слоя l, Включая смещение. Тогда для первого узла в Ш2, z будет равна:
, где n- количество узлов в Ш1. Используя это обозначение, систему уравнений можно сократить:
Обратите внимание на W, что означает матричную форму представления весов. Помните, что теперь все элементы в уравнении сверху являются матрицами / векторами. Но на этом упрощение не заканчивается. Данные уравнения можно свести к еще более краткому виду:
Так выглядит общая форма процесса прямого распространения, выход слоя l становится входом в слой l+1. Мы знаем, что h(1) является входным слоем x, а h(nl)(где nl- номер слоя в сети) является исходным слоем. Мы также не стали использовать индексы i и j-за того, что можно просто перемножить матрицы — это даст нам тот же результат. Поэтому данный процесс и называется «векторизацией». Этот метод имеет ряд плюсов. Во-первых, код его реализации выглядит менее запутанным. Во-вторых, используются свойства по линейной алгебре вместо циклов, что делает работу программы быстрее. С numpy можно легко сделать такие подсчеты. В следующей части быстро повторим операции над матрицами, для тех, кто их немного подзабыл.
3.5 Умножение матриц
Распишем z(l+1)=W(l)h(l)+b(l) на выражение из матрицы и векторов входного слоя ( h(l)=x):
Для тех, кто не знает или забыл, как перемножаются матрицы. Когда матрица весов умножается на вектор, каждый элемент в строке матрицы весов умножается на каждый элемент в столбце вектора, после этого все произведения суммируются и создается новый вектор (3х1). После перемножения матрицы на вектор, добавляются элементы из вектора смещения и получается конечный результат.
Каждая строка полученного вектора соответствует аргументу активационной функции в оригинальной НЕ матричной системе уравнений выше. Это означает, что в Python мы можем реализовать все, не используя медленные циклы. К счастью, библиотека numpy дает возможность сделать это достаточно быстро, благодаря функциям-операторам над матрицами. Рассмотрим код простой и быстрой версии функции simple_looped_nn_calc:
|
def matrix_feed_forward_calc(n_layers, x, w, b): for l in range(n_layers — 1): if l == 0: node_in = x else : node_in = h z = w.dot(node_in) + b h = f(z) return h |
Обратите внимание на строку 7, в которой происходит перемножение матрицы и вектора. Если вместо функции умножения a.dot (b) вы используете символ *, то получится нечто похожее на поэлементное умножение вместо настоящего произведения матриц.
Если сравнить время работы этой функции с предыдущей на простой сети с четырьмя слоями, то мы получим результат лишь на 24 микросекунды меньше. Но если увеличить количество узлов в каждом слое до 100-100-50-10, то мы получим гораздо большую разницу. Функция с циклами в этом случае дает результат 41 миллисекунду, когда у функции с векторизацией это занимает лишь 84 микросекунды. Также существуют еще более эффективные реализации операций над матрицами, которые используют пакеты глубинного обучения, такие как TensorFlow и Theano.
На этом все о процессе прямого распространения в нейронных сетях. В следующих разделах мы поговорим о способах обучения нейронных сетей, используя градиентный спуск и обратное распространение.
Расчеты значений весов, которые соединяют слои в сети, это как раз то, что мы называем обучением системы. В контролируемом обучении идея заключается в том, чтобы уменьшить погрешность между входом и нужным выходом. Если у нас есть нейросеть с одним выходным слоем и некоторой вход xx и мы хотим, чтобы на выходе было число 2, но сеть выдает 5, то нахождение погрешности выглядит как abs(2-5)=3. Говоря языком математики, мы нашли норму ошибки L1(Это будет рассмотрено позже).
Смысл контролируемого обучения в том, что предоставляется много пар вход-выход уже известных данных и нужно менять значения весов, основываясь на этих примерах, чтобы значение ошибки стало минимальным. Эти пары входа-выхода обозначаются как (x(1),y(1)),…,(x(m),y(m)), где m является количеством экземпляров для обучения. Каждое значение входа или выхода может представлять собой вектор значений, например x(1) не обязательно только одно значение, оно может содержать N-размерный набор значений. Предположим, что мы обучаем нейронную сеть выявлению спам-сообщений — в таком случае x(1) может представлять собой количество соответствующих слов, которые встречаются в сообщении:
y(1) в этом случае может представлять собой единое скалярное значение, например, 1 или 0, обозначающий, было сообщение спамом или нет. В других приложениях это также может быть вектор с K измерениями. Например, мы имеем вход xx, Который является вектором черно-белых пикселей, считанных с фотографии. При этом y может быть вектором с 26 элементами со значениями 1 или 0, обозначающие, какая буква была изображена на фото, например (1,0,…,0)для буквы а, (0,1,…,0) для буквы б и т.д.
В обучении сети, используя (x,y), целью является улучшение нахождения правильного y при известном x. Это делается через изменение значений весов, чтобы минимизировать погрешность. Как тогда менять их значение? Для этого нам и понадобится градиентный спуск. Рассмотрим следующий график:
На этом графике изображено погрешность, зависящую от скалярного значения веса, w. Минимально возможная погрешность обозначена черным крестиком, но мы не знаем какое именно значение w дает нам это минимальное значение. Подсчет начинается с рандомного значения переменной w, которая дает погрешность, обозначенную красной точкой под номером «1» на кривой. Нам нужно изменить w таким образом, чтобы достичь минимальной погрешности, черного крестика. Одним из самых распространенных способов является градиентный спуск.
Сначала находится градиент погрешности на «1» по отношению к w. Градиент является уровнем наклона кривой в соответствующей точке. Он изображен на графике в виде черных стрелок. Градиент также дает некоторую информацию о направлении — если он положителен при увеличении w, то в этом направлении погрешность будет увеличиваться, если отрицательный — уменьшаться (см. График). Как вы уже поняли, мы пытаемся сделать, чтобы погрешность с каждым шагом уменьшалась. Величина градиента показывает, как быстро кривая погрешности или функция меняется в соответствующей точке. Чем больше значение, тем быстрее меняется погрешность в соответствующей точке в зависимости от w.
Метод градиентного спуска использует градиент, чтобы принимать решение о следующей смены в w для того, чтобы достичь минимального значения кривой. Он итеративным методом, каждый раз обновляет значение w через:
, где wн означает новое значение w, wст— текущее или «старое» значение w, ∇error является градиентом погрешности на wст и α является шагом. Шаг α также будет означать, как быстро ответ приближается к минимальной погрешности. При каждой итерации в таком алгоритме градиент должен уменьшаться. Из графика выше можно заметить, что с каждым шагом градиент «стихает». Как только ответ достигнет минимального значения, мы уходим из итеративного процесса. Выход можно реализовать способом условия «если погрешность меньше некоторого числа». Это число называют точностью.
4.1 Простой пример на коде
Рассмотрим пример простой имплементации градиентного спуска для нахождения минимума функции f(x)=x4-3×3+2 на языке Python . Градиент этой функции можно найти аналитически через производную f»(x)=4×3-9×2. Это означает, что для любого xx мы можем найти градиент по этой простой формуле. Мы можем найти минимум через производную — x=2.25.
|
x_old = 0 # Нет разницы, какое значение, главное abs(x_new — x_old) > точность x_new = 6 # Алгоритм начинается с x = 6 gamma = 0.01 # Размер шага precision = 0.00001 # Точность def df(x): y = 4 * x * * 3 — 9 * x * * 2 return y while abs(x_new — x_old) > precision: x_old = x_new x_new += -gamma * df(x_old) print(«Локальный минимум находится на %f» % x_new) |
Вывод этой функции: «Локальный минимум находится на 2.249965», что удовлетворяет правильному ответу с некоторой точностью. Этот код реализует алгоритм изменения веса, о котором рассказывалось выше, и может находить минимум функции с соответствующей точностью. Это был очень простой пример градиентного спуска, нахождение градиента при обучении нейронной сети выглядит несколько иначе, хотя и главная идея остается той же — мы находим градиент нейронной сети и меняем веса на каждом шагу, чтобы приблизиться к минимальной погрешности, которую мы пытаемся найти. Но в случае ИНС нам нужно будет реализовать градиентный спуск с многомерным вектором весов.
Мы будем находить градиент нейронной сети, используя достаточно популярный метод обратного распространения ошибки, о котором будет написано позже. Но сначала нам нужно рассмотреть функцию погрешности более детально.
4.2 Функция оценки
Существует более общий способ изобразить выражения, которые дают нам возможность уменьшить погрешность. Такое общее представление называется функция оценки. Например, функция оценки для пары вход-выход (xz, yz) в нейронной сети будет выглядеть следующим образом:
Выражение является функцией оценки учебного экземпляра zth, где h(nl)является выходом последнего слоя, то есть выход нейронной сети. h(nl) можно представить как yпyп, Что означает полученный результат, когда нам известен вход xz. Две вертикальные линии означают норму L2 погрешности или сумму квадратов ошибок. Сумма квадратов погрешностей является довольно распространенным способом представления погрешностей в системе машинного обучения. Вместо того, чтобы брать абсолютную погрешность abs(ypred(xz)-yz), мы берем квадрат погрешности. Мы не будем обсуждать причину этого в данной статье. 1/2 в начале просто константой, которая нормализует ответ после того, как мы продифференцируем функцию оценки во время обратного распространения.
Обратите внимание, что приведенная ранее функция оценки работает только с одной парой (x,y). Мы хотим минимизировать функцию оценки со всеми mm парами вход-выход:
Тогда как же мы будем использовать функцию J для обучения наших сетей? Конечно, используя градиентный спуск и обратное распространение ошибок. Сначала рассмотрим градиентный спуск в нейронных сетях более детально.
4.3 Градиентный спуск в нейронных сетях
Градиентный спуск для каждого веса w(ij)(l) и смещение bi(l) в нейронной сети выглядит следующим образом:
Выражение выше фактически аналогично представлению градиентного спуска:
wnew=wold-α*∇error. Нет лишь некоторых обозначений, но достаточно понимать, что слева расположены новые значения, а справа — старые. Опять же задействован итерационный метод для расчета весов на каждой итерации, но на этот раз основываясь на функции оценки J(w,b).
Значения ∂/∂wij(l)и ∂/∂bi(l) являются частными производными функции оценки, основываясь на значениях веса. Что это значит? Вспомните простой пример градиентного спуска ранее, каждый шаг зависит от наклона погрешности / оценки по отношению к весу. Производная также имеет значение наклона / градиента. Конечно, производная обозначается как d/dx. x в нашем случае является вектором, а это значит, что наша производная тоже будет вектором, который является градиент каждого измерения x.
4.4 Пример двумерного градиентного спуска
Рассмотрим пример стандартного двумерного градиентного спуска. Ниже представлены диаграмму работы двух итеративных двумерных градиентных спусков:
Синим обозначены контуры функции оценки, они обозначают области, в которых значение погрешности примерно одинаковы. Каждый шаг (p1→p2→p3) В градиентном спуске используют градиент или производную, которые обозначаются стрелкой / вектором. Этот вектор проходит через два пространства и показывает направление, в котором находится минимум. Например, производная, исчисленная в p1 может быть d/dx=, Где производная является вектором с двумя значениями. Частичная производная ∂/∂x1 в этом случае равна скаляру →- иными словами, это значение градиента только в одном измерении поискового пространства (x1).
В нейронных сетях не существует простой полной функции оценки, с которой можно легко посчитать градиент, похожей на функцию, которую мы ранее рассматривали f(x)=x4-3×3+2). Мы можем сравнить выход нейронной сети с нашим ожидаемым значением y(z), После чего функция оценки будет меняться из-за изменения в значениях веса, но как мы это сделаем со всеми скрытыми слоями в сети?
Поэтому нам нужен метод обратного распространения. Этот метод дает нам возможность «делить» функцию оценки или ошибку со всеми весами в сети. Другими словами, мы можем выяснить, как каждый вес влияет на погрешность.
4.5 Углубляемся в обратное распространение
Если математика вам не очень хорошо дается, то вы можете пропустить этот раздел. В следующем разделе вы узнаете, как реализовать обратное распространение языке программирования. Но если вы не против немного больше поговорить о математике, то продолжайте читать, вы получите более глубокие знания по обучению нейронных сетей.
Сначала, давайте вспомним базовые уравнения для нейронной сети с тремя слоями из предыдущих разделов:
Выход этой нейронной сети находится по формуле:
Мы можем упростить это уравнение к h1(3)=f(z1(2)), добавив новое значение z1(2), которое означает:
Предположим, что мы хотим узнать, как влияет изменение в весе w12(2) на функцию оценки. Это означает, что нам нужно вычислить ∂J/∂w12(2). Чтобы сделать это, нужно использовать правило дифференцирования сложной функции:
Если присмотреться, то правая часть полностью сокращается (по принципу 2552=22=1). ∂J∂w12(2) были разбиты на три множителя, два из которых можно прекрасно заменить. Начнем с ∂z1(2)/∂w12(2):
Частичная производная z1(2) по w12(2) зависит только от одного произведения в скобках, w12(1)h2(2), Так как все элементы в скобках, кроме w12(2), не изменяются. Производная от константы всегда равна 1, а ∂/∂w12(2))сокращается до просто h2(2), Что является обычным выходом второго узла из слоя 2.
Следующая частичная производная сложной функции ∂h1(3)/∂z1(2) является частичной производной активационной функции выходного узла h1(3). Так что нам нужно брать производные активационной функции, следует условие ее включения в нейронные сети — функция должна быть дифференцированной. Для сигмоидальной активационной функции производная будет выглядеть так:
, где f(z)является самой активационной функцией. Теперь нам нужно разобраться, что делать с ∂J∂h1(3). Вспомните, что J(w,b,x,y) есть функция квадрата погрешности, выглядит так:
здесь y1 является ожидаемым выходом для выходного узла. Опять используем правило дифференцирования сложной функции:
Мы выяснили, как находить ∂J/∂w12(2)по крайней мере для весов связей с исходным слоем. Перед тем, как перейти к одному из скрытых слоев, введем некоторые новые значения δ, чтобы немного сократить наши выражения:
, где i является номером узла в выходном слое. В нашем примере есть только один узел, поэтому i=1. Напишем полный вид производной функции оценки:
, где выходной слой, в нашем случае, l=2, а i соответствует номеру узла.
4.6 Распространение в скрытых слоях
Что делать с весами в скрытых слоях (в нашем случае в слое 2)? Для весов, которые соединены с выходным слоем, производная ∂J/∂h=-(yi-hi(nl))имела смысл, т.к. функция оценки может быть сразу найдена через сравнение выходного слоя с существующими данными. Но выходы скрытых узлов не имеют подобных уже существующих данных для проверки, они связаны с функцией оценки только через другие слои узлов. Как мы можем найти изменения в функции оценки из-за изменений весов, которые находятся глубоко в нейронной сети? Как уже было сказано, мы используем метод обратного распространения.
Мы уже сделали тяжелую работу по правилу дифференцирования сложных функций, теперь рассмотрим все более графически. Значение, которое будет обратно распространяться, — δi(nl), т.к. оно в ближайшей связи с функцией оценки. А что с узлом j во втором слое (скрытом слое)? Как он влияет на δi(nl) в нашей сети? Он меняет другие значения из-за веса wij(2)(см. диаграмму ниже, где j=1 i=1).
Как можно понять из рисунка, выходной слой соединяется со скрытым узлом из-за веса. В случае, когда в исходном слое есть только один узел, общее выражение скрытого слоя будет выглядеть так:
, где j номер узла в слое l. Но что будет, если в исходном слое находится много выходных узлов? В этом случае δj(l) находится по взвешенной сумме всех связанных между собой погрешностей, как показано на диаграмме ниже:
На рисунке показано, что каждое значение δ из исходного слоя суммируется для нахождения δ1(2), Но каждый выход δ должен быть взвешенным соответствующими значению wi1(2). Другими словами, узел 1 в слое 2 способствует изменениям погрешностей в трех выходных узлах, при этом полученная погрешность (или значение функции оценки) в каждом из этих узлов должна быть «передана назад» значению δ этого узла. Сформируем общее выражение значение δ для узлов в скрытом слое:
, где j является номером узла в слое l, i- номер узла в слое l+1(что аналогично обозначениям, которое мы использовали ранее). s(l+1)— это количество узлов в слое l+1.
Теперь мы знаем, как находить:
Но что делать с весами смещения? Принцип работы с ними аналогичный обычным весам, используя правила дифференцирования сложных функций:
Отлично, теперь мы знаем, как реализовать градиентный спуск в нейронных сетях:
Однако, для такой реализации, нам нужно будет снова применить циклы. Как мы уже знаем из предыдущих разделов, циклы в языке программирования Python работают довольно медленно. Нам нужно будет понять, как можно векторизовать такие подсчеты.
4.7 Векторизация обратного распространения
Для того, чтобы понять, как векторизовать процесс градиентного спуска в нейронных сетях, рассмотрим сначала упрощенную векторизованную версию градиента функции оценки (внимание: это пока неправильная версия!):
Что представляет собой h(l)? Все просто, вектор (sl×1), где sl является количеством узлов в слое l. Как тогда выглядит произведение h(l)δ(l+1)? Мы знаем, что α×∂J/∂W(l) должно быть того же размера, что и матрица весов W(l), Мы также знаем, что результат h(l)δ(l+1) должен быть того же размера, что и матрица весов для слоя l. Иными словами, произведение должно быть размера (sl + 1× sl).
Мы знаем, что δ(l+1) имеет размер (sl+1×1), а h (l)— размер (sl×1). По правилу умножения матриц, если матрицу (n×m)умножить на матрицу (o×p), То мы получим матрицу размера (n×p). Если мы просто перемножим h(l) на δ(l+1), то количество столбцов в первом векторе (один столбец) не будет равно количеству строк во втором векторе (3 строки). Поэтому, для того, чтобы можно было умножить эти матрицы и получить результат размера (sl+1× sl), Нужно сделать трансформирование. Оно меняет в матрице столбцы на строки и наоборот (например матрицу вида (sl×1)на (1×sl)). Трансформирование обозначается как буква T над матрицей. Мы можем сделать следующее:
Используя операцию трансформирования, мы можем достичь результата, который нам нужен.
Еще одно трансформирование нужно сделать с суммой погрешностей в обратном распространении:
символ (∙) в предыдущем выражении означает поэлементное умножение (произведение Адамара), не является умножением матриц. Обратите внимание, что произведение матриц (((W(l))Tδ(l+1))требует еще одного сложения весов и значений δ.
4.8 Реализация этапа градиентного спуска
Как тогда интегрировать векторизацию в этапы градиентного спуска нашего алгоритма? Во-первых, вспомним полный вид нашей функции оценки, который нам нужно сократить:
Из формулы видно, что полная функция оценки состоит из суммы поэтапных расчетов функции оценки. Также следует вспомнить, как находится градиентный спуск (поэлементная и векторизованная версии):
Это означает, что по прохождению через экземпляры обучения нам нужно иметь отдельную переменную, которая равна сумме частных производных функции оценки каждого экземпляра. Такая переменная соберет в себе все значения для «глобального» подсчета. Назовем такую «суммированную» переменную ΔW(l). Соответствующая переменная для смещения будет обозначаться как Δb(l). Следовательно, при каждой итерации в процессе обучения сети нам нужно будет сделать следующие шаги:
Выполняя эти операции на каждой итерации, мы подсчитываем упомянутую ранее сумму Σmz= 1∂/∂W(l)J( w , b , x(z), y(z))(и аналогичная формула для b). После того, как будут проитерированы все экземпляры и получены все значения δ, мы обновляем значения параметров веса:
4.9 Конечный алгоритм градиентного спуска
И, наконец, мы пришли к определению метода обратного распространения через градиентный спуск для обучения наших нейронных сетей. Финальный алгоритм обратного распространения выглядит следующим образом:
Рандомная инициализация веса для каждого слоя W(l). Когда итерация < границы итерации:
01. Зададим ΔW и Δb начальное значение ноль
02. Для экземпляров от 1 до m: а. Запустите процесс прямого распространения через все nl слоев. Храните вывод активационной функции в h(l)б. Найдите значение δ( nl) выходного слоя. Обновите ΔW(l)и Δb( l ) для каждого слоя
03. Запустите процесс градиентного спуска, используя:
Из этого алгоритма следует, что мы будем повторять градиентный спуск, пока функция оценки не достигнет минимума. На этом этапе нейросеть считается обученной и готовой к использованию.
Далее мы попробуем реализовать этот алгоритм на языке программирования для обучения нейронной сети распознаванию чисел, написанных от руки.
В предыдущем разделе мы рассмотрели теорию по обучению нейронной сети через градиентный спуск и метод обратного распространения. В этом разделе мы используем полученные знания на практике — напишем код, который прогнозирует, основываясь на данных MNIST. База данных MNIST — это набор примеров в нейронных сетях и глубинном обучении. Она включает в себя изображения цифр, написанных от руки, с соответствующими ярлыками, которые объясняют, что это за число. Каждое изображение размером 8х8 пикселей. В этом примере мы используем сети данных MNIST для библиотеки машинного обучения scikit learn в языке программирования Python . Пример такого изображения можно увидеть под кодом:
|
from sklearn.datasets import load_digits digits = load_digits() print(digits.data.shape) import matplotlib.pyplot as plt plt.gray() plt.matshow(digits.images) plt.show() |
Код, который мы собираемся написать в нашей нейронной сети, будет анализировать цифры, которые изображают пиксели на изображении. Для начала, нам нужно отсортировать входные данные. Для этого мы сделаем две следующие вещи:
01. Масштабировать данные
02. Разделить данные на тесты и учебные тесты
5.1 Масштабирование данных
Почему нам нужно масштабировать данные? Во-первых, рассмотрим представление пикселей одного из сетов данных:
Заметили ли вы, что входные данные меняются в интервале от 0 до 15? Достаточно распространенной практикой является масштабирование входных данных так, чтобы они были только в интервале от , или . Это делается для более легкого сравнения различных типов данных в нейронной сети. Масштабирование данных можно легко сделать через библиотеку машинного обучения scikit learn:
|
from sklearn.preprocessing import StandardScaler X_scale = StandardScaler() X = X_scale.fit_transform(digits.data) X Out: array() |
Стандартный инструмент масштабирования в scikit learn нормализует данные через вычитание и деление. Вы можете видеть, что теперь все данные находятся в интервале от -2 до 2. По же на счет выходных данных yy, то обычно нет необходимости их масштабировать.
5.2 Создание тестов и учебных наборов данных
В машинном обучении появляется такой феномен, который называется «переобучением». Это происходит, когда модели, во время учебы, становятся слишком запутанными — они достаточно хорошо обучены, но когда им передаются новые данные, которые они никогда на «видели», то результат, который они выдают, становится плохим. Иными словами, модели генерируются не очень хорошо. Чтобы убедиться, что мы не создаем слишком сложные модели, обычно набор данных разбивают на учебные наборы и тестовые наборы. Учебный набором данных, на которых модель будет учиться, а тестовый набор — это данные, на которых модель будет тестироваться после завершения обучения. Количество учебных данных должно быть всегда больше тестовых данных. Обычно они занимают 60-80% от набора данных.
Опять же, scikit learn легко разбивает данные на учебные и тестовые наборы:
|
from sklearn.model_selection import train_test_split y = digits.target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4) |
В этом случае мы выделили 40% данных на тестовые наборы и 60% соответственно на обучение. Функция train_test_split в scikit learn добавляет данные рандомно в различные базы данных — то есть, функция не берет первые 60% строк для учебного набора, а то, что осталось, использует как тестовый.
5.3 Настройка выходного слоя
Для того, чтобы получать результат — числа от 0 до 9, нам нужен выходной слой. Более-менее точная нейросеть, как правило, имеет выходной слой с 10 узлами, каждый из которых выдает число от 0 до 9. Мы хотим научить сеть так, чтобы, например, при цифре 5 на изображении, узел с цифрой 5 в исходном слое имел наибольшее значение. В идеале, мы бы хотели иметь следующий вывод: . Но на самом деле мы можем получить что-то похожее на это: . В таком случае мы можем взять крупнейших индекс в исходном массиве и считать это нашим полученным числом.
В данных MNIST нужны результаты от изображений записаны как отдельное число. Нам нужно конвертировать это единственное число в вектор, чтобы его можно было сравнивать с исходным слоем с 10 узлами. Иными словами, если результат в MNIST обозначается как «1», то нам нужно его конвертировать в вектор: . Такую конвертацию осуществляет следующий код:
|
import numpy as np def convert_y_to_vect(y): y_vect = np.zeros((len(y), 10)) for i in range(len(y)): y_vect] = 1 return y_vect |
|
y_v_train = convert_y_to_vect(y_train) y_v_test = convert_y_to_vect(y_test) y_train, y_v_train Out: (1, array()) |
Этот код конвертирует «1» в вектор .
5.4 Создаем нейросеть
Следующим шагом является создание структуры нейронной сети. Для входного слоя, мы знаем, что нам нужно 64 узла, чтобы покрыть 64 пикселей изображения. Как было сказано ранее, нам нужен выходной слой с 10 узлами. Нам также потребуется скрытый слой в нашей сети. Обычно, количество узлов в скрытых слоях не менее и не больше количества узлов во входном и выходном слоях. Объявим простой список на языке Python , который определяет структуру нашей сети:
Мы снова используем сигмоидальную активационную функцию, так что сначала нужно объявить эту функцию и ее производную:
|
def f(x): return 1 / (1 + np.exp(-x)) |
|
def f_deriv(x): return f(x) * (1 — f(x)) |
Сейчас мы не имеем никакого представления, как выглядит наша нейросеть. Как мы будем ее учить? Вспомним наш алгоритм из предыдущих разделов:
Рандомно инициализируем веса для каждого слоя W(l) Когда итерация
Introduction
This article is written for you who is curious of the mathematics behind neural networks, NN. It might also be useful if you are trying to develop your own NN. It is a cell by cell walk through of a three layer NN with two neurons in each layer. Excel is used for the implementation.
- Download neuralnetwork Sigmoid — 1.2
- Download neuralnetwork Leaky ReLu — 1.2
Background
If you are still reading this, we probably have at least one thing in common. We are both curious about Machine Learning and Neural Networks. There are several frameworks and free api:s in this area and it might be smarter to use them than inventing something that is already there. But on the other hand, it does not hurt to know how machine learning works in depth. And it is also a lot more fun to explore things in depth.
My journey into machine learning has perhaps just started. And I started by Googling, reading a lot of great stuff on the internet. I also saw a few good YouTube videos. But I it was hard to gain enough knowledge to start coding my own AI.
Finally, I found this blog post: A Step by Step Backpropagation Example by Matt Mazur. It suited me, and the rest of this text is based on it.
Construction
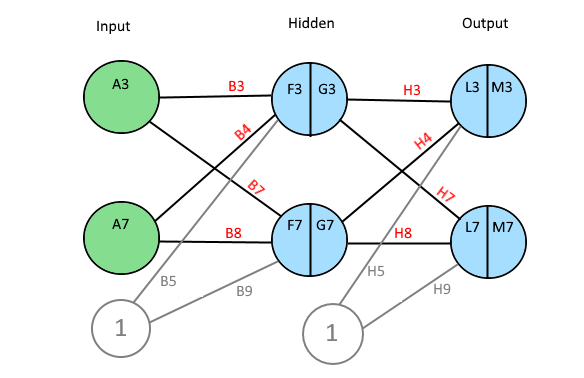
A Neural Network, NN, consists of many layers of neurons. A Neuron has a value and connections with weights to all other neurons in the next layer.
The first layer is the input layer and the last layer is the output layer. Between input and output, there might be one or many hidden layers. The number of neurons in a layer is variable.
If a NN is used to, for example, classify images, the number of neurons in the input layer is of course equal to the number of pixels in the image. Then in the output, each neuron represents a classification of the image. (E.g., a type of animal, a flower or a digit.)
Calculations
Before the calculations, all the weights in the NN have to be initialized with random numbers.
The image below is a print screen of the spread sheet that I refer to in the rest of this article. It might be a good idea to keep an open window of that sheet. That should make it easier to follow along.
A tip: Row 2 is the order of calculations.

Step 1 — 3. Forward Pass
The value of one neuron is calculated by taking the sum of every previous neuron multiplied by its weight.
An extra bias weight which has no neuron is also added:
F3 = A3 * B3 + A7 * B4 + B5
The value is normalized through a activation function. There are several different activation functions used in neural networks.
I have used the logistic function: 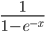
G3 = 1 / (1 + EXP(-F3))
Step 4 — 5. Forward Pass
The neurons of the output layer is calculated the same way as hidden layer.
L3 = G3 * H3 + G7 * H4 + H5 and M3 = 1 / (1 + EXP(-L3))
Step 6 — 7. The Error
The error of each output neuron is calculated using an expected or a target value. When classifying images, it is common to set one neuron close to 1 and the rest of the neurons close to zero.
For the errors in column Q:
Q3 = (M3 — O3)²
and:
Q7 = (M7 — O7)²
The total Error R5 is the average of all errors and should get closer and closer to zero as the network is trained.
R5 = (Q3 + Q7) / 2
Backward Propagation
A Neural Network is trained by passing it lots of train data repeatedly.
Then, for every iteration, errors and deltas are calculated. This is used to make small adjustments to all the weights in such a way that the network becomes better and better.
This is called backpropagation.
Since the total error can be expressed as a mathematical functions of each weight, one can derive those functions to obtain the slopes of the function curves in one point. The slopes indicate the direction towards a minimum for the total error and proportionally how much each weight should be adjusted in order for the total error to approach zero.
A delta value is calculated below for each weight. The deltas are stored in column I and D, for output and hidden layer respectively.
Chain Rule — Friend of Backpropagation
In practice, we want to derive the total error R5 with respect to H3 so we first to express R5 as a function of H3 using substitutions.
Since
R5 = (Q3 + Q7) / 2 R5 = (M3 - O3)² / 2 + (M7 - O7)² / 2
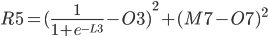
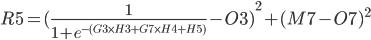
The above function does not look very easy to derive. Is it even possible?
We will instead use the chain rule2.
It states that if we have a composition of two or more functions f(g(x)) and let F(x) = f(g(x)), we can derive like this:
F’(x) = f’(g(x)) * g’(x) or in another notation:
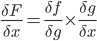
In our case, we have the following dependency:
R5(M3(L3(H3))) and we can write:
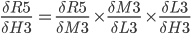
Step 9. Output layer Deltas
The function for the total error R5 is derived with respect to the first weight H3 of the output layer.
In the above formula, the chain rule is used to make it simpler to derive.
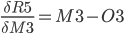
Since:
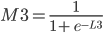
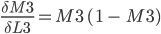
Proof of derivation of Logistic function found in this article3.
Since 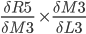 will be used later in the backpropagation, it is stored in the cell
will be used later in the backpropagation, it is stored in the cell P3.
P3 = (M3-O3) * M3 * (1 - M3)
The last derivative of the chain of derivatives above is simpler.
Since L3 = G3 * H3 + G7 * H4 + H5
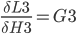
We can now put everything together and store 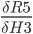 into cell I3.
into cell I3.
I3 = P3 * G3
The rest of the weights in output layer is calculated the same way and we get:
P7 = (M7-O7) * M7 * (1 - M7) I4 = G7 * P3 I5 = 1 * P3 (bias neuron) I7 = G3 * P7 I8 = G7 * P7 I9 = 1 * P7 (bias neuron)
Step 10. Backpropagation in Hidden Layer
In this step, we calculate:
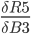
The chain rule from previous steps helps to transform it to something we can use:
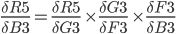
First term also must be split up on both errors Q3 and Q7 so:
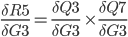
First look at this:
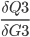
It can be further split up like this:
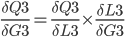
First 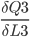 is already stored in
is already stored in P3 = (M3-O3) * M3* (1 - M3)
Since L3 = G3 * H3 + G7 * H4 + H5

When we put the above together, we get:
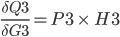
And in the same way as above:

First problem is solved.
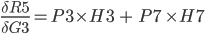
Time for 
We know that:
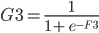
And we have previously learned to derive the logistic function.
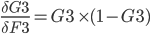
And now:
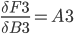
Because:
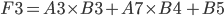
We now put the above together to get one expression for the derivative of the total error with respect to first weight of the hidden layer.
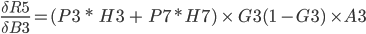
This is stored in cell C3.
The calculations for the above is repeated for all hidden layer weights:
C3 = (P3 * H3 + P7 *H7) * (G3 *(1 - G3)) * A3 C4 = (P3 * H3 + P7 *H7) * (G3 *(1 - G3)) * A7 C5 = (P3 * H3 + P7 *H7) * (G3 *(1 - G3)) * 1 C7 = (P3 * H4 + P7 *H8) * (G7 *(1 - G7)) * A3 C8 = (P3 * H4 + P7 *H8) * (G7 *(1 - G7)) * A7 C9 = (P3 * H4 + P7 *H8) * (G7 *(1 - G7)) * 1
Now it is easy to calculate new weights using a selected learning rate from cell A13.
For example: (new B3)
D3 = B3 - C3 * A13
There is a macro connected to the train button in the Excel document. The macro iterates many times and we can see how the output neurons in column M gets closer and closer to their target values and that the total Error in R5 gets closer and closer to zero.

Update in version 1.1:
I discovered that it is possible to improve learning rate and accuracy by using the activation function Leaky Relu4:
f(x) = x if x > 0 otherwise f(x) = x/20
It may be a good exercise to replace the Logistic Function with Leaky Relu.
Hints:
G3 = IFS(F3 > 0; F3; F3 <= 0; F3/20) and P3= (M3-O3) * IFS(M3 > 0;1;M3<=0;1/20)
(Also attaching new version of the xls file, just in case…)
Final Words
I realize this article might take some time to digest. I tried to explain it as I understood it. Please comment below if you find any errors.
After I sorted out how NNs work in Excel, I wrote a C# program that can interpret hand written digits. It has a Windows Forms user interface which works well. It seems to recognize almost any digit I draw, even ugly once. That was a proof to me that my understanding of Artificial Neural Networks is correct so far.
That article can be found here:
Handwritten digits reader UI5
Links
- A Step by Step Backpropagation Example — Matt Mazur.
- Chain rule — Wikipedia
- Logistic function — Wikipedia
- Rectifier (neural networks) — Wikipedia
- Handwritten digits reader UI — Kristian Ekman
History
- 1st January, 2019 — Version 1.0
- 8th January, 2019 — Version 1.1
- Replaced Logistic activation function with LeakyReLu
- 11th January, 2019 — Version 1.2
- Update of names of biases in diagrams
- 23th Januray, 2019 — Version 1.3
- Changed du calculation to the total error to the average av errors
This member has not yet provided a Biography. Assume it’s interesting and varied, and probably something to do with programming.