
Рассмотренные в лабораторной работе 2 распределения вероятностей СВ
опираются на знание закона распределения СВ. Для практических задач такое
знание – редкость. Здесь закон распределения обычно неизвестен, или известен с
точностью до некоторых неизвестных параметров. В частности, невозможно
рассчитать точное значение соответствующих вероятностей, так как нельзя
определить количество общих и благоприятных исходов. Поэтому вводится статистическое
определение вероятности. По этому определению вероятность равна отношению
числа испытаний, в которых событие произошло, к общему числу произведенных
испытаний. Такая вероятность называется статистической частотой.
Связь
между эмпирической функцией распределения и функцией распределения
(теоретической функцией распределения) такая же, как связь между частотой события
и его вероятностью.
Для
построения выборочной функции распределения весь диапазон изменения случайной
величины X (выборки)
разбивают на ряд интервалов (карманов) одинаковой ширины. Число интервалов
обычно выбирают не менее 3 и не более 15. Затем определяют число значений
случайной величины X, попавших
в каждый интервал (абсолютная частота, частота интервалов).
Частота интервалов – число, показывающее сколько раз значения,
относящиеся к каждому интервалу группировки, встречаются в выборке. Поделив эти
числа на общее количество наблюдений (n), находят относительную частоту (частость) попадания
случайной величины X в заданные
интервалы.
По
найденным относительным частотам строят гистограммы выборочных функций
распределения. Гистограмма распределения частот – это графическое
представление выборки, где по оси абсцисс (ОХ) отложены величины интервалов, а
по оси ординат (ОУ) – величины частот, попадающих в данный классовый интервал.
При увеличении до бесконечности размера выборки выборочные функции
распределения превращаются в теоретические: гистограмма превращается в график
плотности распределения.
Накопленная частота интервалов – это число, полученное
последовательным суммированием частот в направлении от первого интервала к
последнему, до того интервала
включительно, для которого определяется накопленная частота.
В Excel для построения выборочных функций распределения
используются специальная функция ЧАСТОТА
и процедура Гистограмма из пакета анализа.
Функция ЧАСТОТА (массив_данных,
двоичный_массив) вычисляет частоты появления случайной величины в интервалах
значений и выводит их как массив цифр, где
•
массив_данных
— это массив или ссылка на
множество данных, для которых
вычисляются частоты;
•
двоичный_массив
— это массив интервалов, по
которым группируются значения выборки.
Процедура
Гистограмма из Пакета анализа выводит
результаты выборочного распределения в виде таблицы и графика. Параметры диалогового окна Гистограмма:
•
Входной диапазон — диапазон исследуемых данных
(выборка);
•
Интервал карманов — диапазон ячеек или набор граничных
значений, определяющих выбранные интервалы (карманы). Эти значения должны быть
введены в возрастающем порядке. Если
диапазон карманов не был введен, то набор интервалов, равномерно распределенных между минимальным и
максимальным значениями данных, будет создан
автоматически.
•
выходной диапазон предназначен для ввода ссылки на левую верхнюю ячейку выходного диапазона.
•
переключатель
Интегральный процент позволяет установить режим включения в
гистограмму графика интегральных
процентов.
•
переключатель
Вывод графика позволяет установить режим автоматического создания встроенной диаграммы на листе, содержащем
выходной диапазон.
Пример 1. Построить эмпирическое распределение веса
студентов в килограммах для следующей
выборки: 64, 57, 63, 62, 58, 61, 63, 70, 60, 61, 65, 62, 62, 40, 64, 61, 59, 59, 63, 61.
Решение
1. В ячейку А1 введите слово Наблюдения,
а в диапазон А2:А21 — значения веса
студентов (см. рис. 1).
2.
В
ячейку В1 введите названия интервалов Вес, кг. В диапазон В2:В8 введите
граничные значения интервалов (40, 45,
50, 55, 60, 65, 70).
3.
Введите
заголовки создаваемой таблицы: в ячейки С1 — Абсолютные частоты, в ячейки D1 — Относительные
частоты, в ячейки E1 — Накопленные частоты.(см. рис. 1).
4.
С
помощью функции Частота заполните столбец абсолютных частот, для этого
выделите блок ячеек С2:С8. С
панели инструментов Стандартная
вызовите Мастер функций (кнопка fx). В появившемся диалоговом окне
выберите категорию Статистические и функцию
ЧАСТОТА, после чего нажмите кнопку ОК. Указателем мыши в рабочее поле Массив_данных
введите диапазон данных наблюдений (А2:А8). В рабочее поле Двоичный_массив
мышью введите диапазон интервалов (В2:В8). Слева на клавиатуре последовательно нажмите комбинацию клавиш Ctrl+Shift+Enter. В столбце C должен появиться массив абсолютных частот (см. рис.1).
5.
В
ячейке C9 найдите общее количество
наблюдений. Активизируйте ячейку С9, на
панели инструментов Стандартная нажмите кнопку Автосумма.
Убедитесь, что диапазон суммирования указан правильно и нажмите клавишу Enter.
6.
Заполните столбец относительных частот. В ячейку введите формулу
для вычисления относительной частоты: =C2/$C$9.
Нажмите клавишу Enter. Протягиванием (за правый
нижний угол при нажатой левой кнопке мыши) скопируйте введенную формулу в диапазон и получите массив относительных частот.
7.
Заполните
столбец накопленных частот. В ячейку D2 скопируйте значение относительной
частоты из ячейки E2. В ячейку D3 введите формулу: =E2+D3. Нажмите клавишу Enter. Протягиванием (за правый нижний угол при нажатой левой кнопке мыши) скопируйте введенную формулу
в диапазон D3:D8. Получим массив накопленных
частот.

Рис. 1. Результат вычислений из
примера 1
8.
Постройте диаграмму относительных и накопленных частот. Щелчком указателя
мыши по кнопке на панели инструментов вызовите Мастер диаграмм. В появившемся диалоговом окне выберите закладку Нестандартные
и тип диаграммы График/гистограмма. После
редактирования диаграмма будет иметь такой вид, как на рис. 2.

Рис. 2
Диаграмма относительных и накопленных частот из примера 1
Задания для самостоятельной работы
1. Для данных из примера 1 построить выборочные функции распределения, воспользовавшись процедурой Гистограмма из пакета Анализа.
2. Построить выборочные функции распределения
(относительные и накопленные частоты) для роста
в см. 20 студентов: 181, 169, 178, 178, 171, 179, 172, 181, 179, 168, 174, 167, 169, 171, 179, 181, 181,
183, 172, 176.
3. Найдите распределение по абсолютным частотам для
следующих результатов тестирования в
баллах: 79, 85, 78, 85, 83, 81, 95, 88, 97, 85 (используйте границы интервалов 70, 80, 90).
4. Рассмотрим любой из критериев оценки качеств педагога-профессионала,
например, «успешное решение задач обучения и воспитания». Ответ на этот вопрос
анкеты типа «да», «нет» достаточно груб. Чтобы уменьшить относительную ошибку
такого измерения, необходимо увеличить число возможных ответов на конкретный
критериальный вопрос. В табл. 1 представлены возможные варианты ответов.
Обозначим
этот параметр через х. Тогда в процессе ответа на вопрос величина х
примет дискретное значение х, принадлежащее определенному интервалу значений.
Поставим в соответствие каждому из ответов определенное числовое значение
параметра х (см. табл. 1).
Табл. 1 Критериальный вопрос: успешное решение задач обучения и воспитания
|
№ п/п |
Варианты ответов |
Х |
|
1 |
Абсолютно неуспешно |
0,1 |
|
2 |
Неуспешно |
0,2 |
|
3 |
Успешно в очень |
0,3 |
|
4 |
В определенной |
0,4 |
|
5 |
В среднем успешно, |
0,5 |
|
6 |
Успешно с |
0,6 |
|
7 |
Успешно, но |
0,7 |
|
8 |
Достаточно успешно |
0,8 |
|
9 |
Очень успешно |
0,9 |
|
10 |
Абсолютно успешно |
1 |
При проведении анкетирования в каждой отдельной
анкете параметр х принимает случайное значение, но только в пределах числового
интервала от 0,1 до 1.
Тогда в результате измерений мы получаем
неранжированный ряд случайных значений (см. табл. 2).
Таблица 2.
Результаты опроса ста учителей

Сгруппируйте полученную выборку, рассчитайте среднее
значение выборки, стандартное отклонение, абсолютную и относительную частоту
появления параметра, а также постройте график плотности вероятности f(x)=

где
W(x) – относительная частота наступления события;

— стандартное
отклонение;

=3,14.
Постройте график функции f(x) и сравните его с
нормальным распределением Гаусса.
Решение математических задач
средствами Excel: Практикум/ В.Я. Гельман. – СПб.: Питер, 2003 — с. 168-172
history 9 апреля 2013 г.
- Группы статей
- Формулы массива
- Подсчет Чисел
Функция ЧАСТОТА( ) , английская версия FREQUENCY() , вычисляет частоту попадания значений в заданные пользователем интервалы и возвращает соответствующий массив чисел.
Функцией ЧАСТОТА() можно воспользоваться, например, для подсчета количества результатов тестирования, попадающих в определенные интервалы (См. Файл примера )
Синтаксис функции
ЧАСТОТА ( массив_данных ; массив_интервалов )
Массив_данных — массив или ссылка на множество ЧИСЛОвых данных, для которых вычисляются частоты.
Массив_интервалов — массив или ссылка на множество интервалов, в которые группируются значения аргумента «массив_данных».
Функция ЧАСТОТА() вводится как формула массива после выделения диапазона смежных ячеек, в которые требуется вернуть полученный массив распределения (частот). Т.е. после ввода формулы необходимо вместо нажатия клавиши ENTER нажать сочетание клавиш CTRL+SHIFT+ENTER .
Количество элементов в возвращаемом массиве на единицу больше числа элементов в массиве « массив_интервалов ». Дополнительный элемент в возвращаемом массиве содержит количество значений, превышающих верхнюю границу интервала, содержащего наибольшие значения (см. пример ниже).
Пример
Пусть в диапазоне А2:А101 имеется исходный массив чисел от 1 до 100.

Подсчитаем количество чисел, попадающих в интервалы 1-10; 11-20; . 91-100.
Сформируем столбце С массив верхних границ диапазонов (интервалов). Для наглядности в столбце D сформируем текстовые значения соответствующие границам интервалов (1-10; 11-20; . 91-100).
Для ввода формулы выделим диапазон Е2:Е12 , состоящий из 11 ячеек (на 1 больше, чем число верхних границ интервалов). В Строке формул введем =ЧАСТОТА($A$2:$A$101;$C$2:$C$11) . После ввода формулы необходимо нажать сочетание клавиш CTRL+SHIFT+ENTER . Диапазон Е2:Е12 заполнится значениями:
- в Е2 — будет содержаться количество значений из А2:А101 , которые меньше или равны 10;
- в Е3 — количество значений из А2:А101 , которые меньше или равны 20, но больше 10;
- в Е11 — количество значений из А2:А101 , которые меньше или равны 100, но больше 90;
- в Е12 — количество значений из А2:А101 , которые больше 100 (таких нет, т.к. исходный массив содержит числа от 1 до 100).
Примечание . Функцию ЧАСТОТА() можно заменить формулой = СУММПРОИЗВ(($A$5:$A$104>C5)*($A$5:$A$104 (См. Файл примера )
Частотный анализ по интервалам функцией ЧАСТОТА (FREQUENCY)
При анализе данных периодически возникает задача подсчитать количество значений, попадающих в заданные интервалы «от и до» (в статистике их называют «карманы»). Например, подсчитать количество звонков определенной длительности при разборе статистики по мобильной связи, чтобы понимать какой тариф для нас выгоднее:

Для решения подобной задачи можно воспользоваться функцией ЧАСТОТА (FREQUENCY) . Ее синтаксис прост:
=ЧАСТОТА( Данные ; Карманы )
- Карманы — диапазон с границами интервалов, попадание в которые нас интересует
- Данные — диапазон с исходными числовыми значениями, которые мы анализируем
Обратите внимание, что эта функция игнорирует пустые ячейки и ячейки с текстом, т.е. работает только с числами.
Для использования функции ЧАСТОТА нужно:
- заранее подготовить ячейки с интересующими нас интервалами-карманами (желтые F2:F5 в нашем примере)
- выделить пустой диапазон ячеек (G2:G6) по размеру на одну ячейку больший, чем диапазон карманов (F2:F5)
- ввести функцию ЧАСТОТА и нажать в конце сочетание Ctrl+Shift+Enter, т.е. ввести ее как формулу массива
Во всех предварительно выделенных ячейках посчитается количество попаданий в заданные интервалы. Само-собой, для реализации подобной задачи можно использовать и другие способы (функцию СЧЁТЕСЛИ, сводные таблицы и т.д.), но этот вариант весьма хорош.
Кроме того, с помощью функции ЧАСТОТА можно легко подсчитывать количество уникальных чисел в наборе с помощью простой формулы массива:
![]()
Загрузить PDF
![]()
Загрузить PDF
В статистике абсолютная частота показывает, какое количество раз конкретное значение появляется в наборе данных. В отличие от нее, накопительная частота показывает сумму (или нарастающий итог) всех частот вплоть до текущей точки в наборе данных. Не беспокойтесь, если поначалу это кажется не совсем понятным: возьмите ручку и лист бумаги, и вы быстро во всем разберетесь!
-

1
Отсортируйте набор данных. «Набор данных» — это просто изучаемый вами список числовых значений. Отсортируйте его так, чтобы числа располагались по возрастанию.[1]
- Пример: предположим, список чисел представляет собой количество книг, которые каждый студент прочитал за последний месяц. После сортировки у вас получился следующий набор чисел: 3, 3, 5, 6, 6, 6, 8.
-
2
Посчитайте абсолютную частоту каждой величины. Частота значения показывает, сколько раз данное значение появляется в наборе данных. Это число можно называть абсолютной частотой, чтобы не путать его с накопительной частотой. Наиболее простой способ заключается в том, чтобы составить таблицу. Вверху левой колонки напишите «Значение» (или укажите, что измеряется данными числами). Вверху второй колонки напишите «Частота». Заполните таблицу для всех значений из списка.[2]
- Пример: вверху левой колонки напишите «Количество книг», а вверху правой колонки — «Частота».
- Во второй строке напишите первое количество прочитанных книг, то есть число 3.
- Посчитайте, сколько раз число 3 встречается в списке данных. В списке есть два числа 3, поэтому во второй строке колонки «Частота» запишите цифру 2.
- Повторите данную процедуру для всех значений списка, пока не заполните таблицу:
- 3 | Ч = 2
- 5 | Ч = 1
- 6 | Ч = 3
- 8 | Ч = 1
-
3
Найдите накопительную частоту для первого значения. Накопительная частота отвечает на вопрос «сколько раз встречается в списке данное значение или меньшая величина?». Всегда начинайте с наименьшего значения в наборе данных. Поскольку в нашем примере нет меньших значений, для данной величины накопительная частота равна абсолютной.[3]
-
Пример: наименьшее значение равно 3. Количество прочитавших 3 книги студентов составляет 2. Никто из студентов не прочитал меньшее число книг, поэтому накопительная частота равна 3. Впишите это значение в третью колонку таблицы:
- 3 | F = 2 | НЧ=2
-
Пример: наименьшее значение равно 3. Количество прочитавших 3 книги студентов составляет 2. Никто из студентов не прочитал меньшее число книг, поэтому накопительная частота равна 3. Впишите это значение в третью колонку таблицы:
-
4
Найдите накопительную частоту для следующей величины. Перейдите к следующему значению списка. Выше мы определили, сколько раз встречается в списке наименьшая величина. Чтобы определить накопительную частоту для второго значения списка, необходимо прибавить его абсолютную частоту к накопительной частоте предыдущего значения. Иными словами, следует взять последнюю накопительную частоту и прибавить к ней абсолютную частоту данной величины.[4]
-
Пример:
- 3 | Ч = 2 | НЧ = 2
- 5 | Ч = 1 | НЧ = 2+1 = 3
-
Пример:
-
5
Повторите процедуру для остальных значений. Постепенно продвигайтесь к более высоким числам. При этом каждый раз прибавляйте текущую абсолютную частоту к последней накопительной частоте.
-
Пример:
- 3 | Ч = 2 | НЧ = 2
- 5 | Ч = 1 | НЧ = 2 + 1 = 3
- 6 | Ч = 3 | НЧ = 3 + 3 = 6
- 8 | Ч = 1 | НЧ = 6 + 1 = 7
-
Пример:
-
6
Проверьте полученные результаты. В итоге вы сложите абсолютные частоты всех значений списка. Конечная накопительная частота должна соответствовать числу значений в списке. Есть два способа проверить, так ли это:
- Сложите абсолютные частоты всех значений: 2 + 1 + 3 + 1 = 7, в результате у вас получится накопительная частота.
- Посчитайте число значений в наборе данных. В нашем примере список имел следующий вид: 3, 3, 5, 6, 6, 6, 8. В этом списке семь величин, и итоговая накопительная частота также равна 7.
Реклама






-
1
Поймите разницу между дискретными и непрерывными данными. Дискретные данные можно посчитать, они не дробятся на более мелкие составляющие. Непрерывные данные часто не поддаются конечному счету, между двумя произвольными величинами обязательно найдутся другие возможные значения. Ниже приведена пара примеров:[5]
- Количество собак является дискретным множеством. Нет такого понятия, как половина собаки.
- Глубина снега представляет собой непрерывное множество. Она возрастает постепенно и непрерывно, а не на дискретные величины. Если вы измерите глубину снега в сантиметрах, то точное значение может оказаться, например, 20,6 сантиметра.
-
2
Разбейте непрерывные данные на интервалы. Наборы непрерывных данных часто имеют большое количество значений. Если попробовать представить такой набор описанным выше методом, таблица получится слишком длинной и малопонятной. В этом случае удобно разбить данные на отдельные интервалы. Эти интервалы должны быть одинаковой длины (например, 0—10, 11–20, 21–30 и так далее) независимо от того, сколько значений попадает в каждый интервал. Ниже приведена возможная таблица для непрерывного набора данных:[6]
- Набор данных: 233, 259, 277, 278, 289, 301, 303
- Таблица (в первой колонке интервал значений, во второй частота, в третьей накопительная частота):
- 200–250 | 1 | 1
- 251–300 | 4 | 1 + 4 = 5
- 301–350 | 2 | 5 + 2 = 7
-
3
Постройте линейный график. После того как вы рассчитаете накопительную частоту, возьмите лист миллиметровой бумаги. Отложите по горизонтальной оси (ось x) значения из набора данных, а по вертикальной (ось y) — накопительную частоту, и постройте график. Это значительно облегчит последующие вычисления.[7]
- Например, если набор данных включает числа от 1 до 8, отложите по горизонтальной оси 8 делений. Над каждым делением отметьте точкой соответствующее ему значение накопительной частоты. Соедините получившиеся точки линией.
- Если какое-либо значение не встречается, его абсолютная частота составляет 0. В этом случае прибавьте 0 к последней величине накопительной частоты и поставьте точку на том же уровне, что и в предыдущий раз.
- Поскольку накопительная частота всегда растет с продвижением к большим значениям, с перемещением вправо линия будет оставаться на той же самой высоте или подниматься. Если в какой-то точке линия опустилась вниз, значит, вы допустили ошибку (например, вместо накопительной частоты взяли абсолютную).
-
4
Найдите по графику медиану. Медиана — это значение, расположенное точно посередине набора данных. Половина значений находится выше медианы, а вторая половина расположена ниже нее. Медиану можно найти по графику следующим образом:
- Посмотрите на последнее значение в самом правом конце графика. Для него величина y соответствует суммарной накопительной частоте, которая равна общему числу точек в наборе данных. Предположим, эта величина равна 16.
- Умножьте эту величину на ½ и найдите соответствующее значение на оси y. В нашем примере получится 8. Найдите число 8 на оси y.
- Найдите точку на линии графика, значение y которой соответствует найденной величине. Проведите от цифры 8 на оси y горизонтальную прямую и определите точку ее пересечения с линией графика. Именно эта точка делит набор данных точно пополам.
- Найдите значение x в данной точке. Проведите из точки вертикальную прямую до пересечения с осью x. Точка пересечения определит медиану для изучаемого набора данных. Например, если получилось 65, значит половина данных расположена ниже 65, а вторая половина лежит выше этого значения.
-
5
Найдите по графику квартили. Квартили делят набор данных на четыре части. Эта процедура очень похожа на определение медианы. Единственное различие заключается в нахождении значений y:
- Чтобы определить величину y для нижнего квартиля, умножьте максимальное значение накопительной частоты на ¼. В результате вы получите значение x, ниже которого будет лежать ровно ¼ всех данных.
- Чтобы найти величину y для верхнего квартиля, умножьте максимальное значение накопительной частоты на ¾. В результате вы получите значение x, ниже которого будет лежать ¾, а выше — ¼ всех данных.
Реклама





Советы
- С помощью интервалов можно представлять любые большие, в том числе и дискретные наборы данных.
Реклама
Об этой статье
Эту страницу просматривали 72 083 раза.
Была ли эта статья полезной?
Функция ЧАСТОТА() — Подсчет ЧИСЛОвых значений в MS EXCEL
Функция ЧАСТОТА( ) , английская версия FREQUENCY(), вычисляет частоту попадания значений в заданные пользователем интервалы и возвращает соответствующий массив чисел.
Функцией ЧАСТОТА() можно воспользоваться, например, для подсчета количества результатов тестирования, попадающих в определенные интервалы (См. Файл примера )
Синтаксис функции
ЧАСТОТА(массив_данных;массив_интервалов)
Массив_данных — массив или ссылка на множество ЧИСЛОвых данных, для которых вычисляются частоты.
Массив_интервалов — массив или ссылка на множество интервалов, в которые группируются значения аргумента «массив_данных».
Функция ЧАСТОТА() вводится как формула массива после выделения диапазона смежных ячеек, в которые требуется вернуть полученный массив распределения (частот). Т.е. после ввода формулы необходимо вместо нажатия клавиши ENTER нажать сочетание клавиш CTRL+SHIFT+ENTER.
Количество элементов в возвращаемом массиве на единицу больше числа элементов в массиве «массив_интервалов». Дополнительный элемент в возвращаемом массиве содержит количество значений, превышающих верхнюю границу интервала, содержащего наибольшие значения (см. пример ниже).
Пусть в диапазоне А2:А101 имеется исходный массив чисел от 1 до 100.
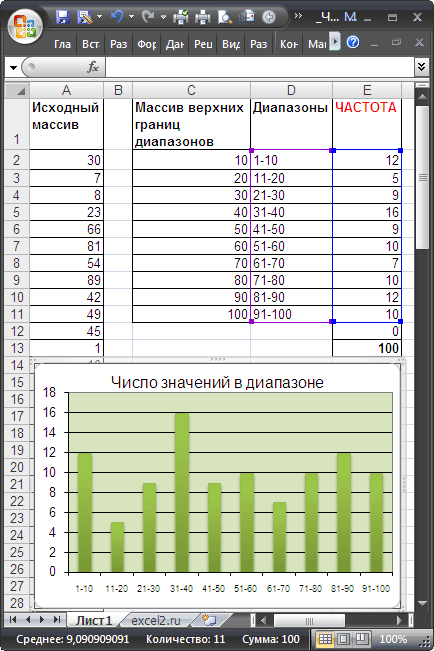
Подсчитаем количество чисел, попадающих в интервалы 1-10; 11-20; . 91-100.
Сформируем столбце С массив верхних границ диапазонов (интервалов). Для наглядности в столбце D сформируем текстовые значения соответствующие границам интервалов (1-10; 11-20; . 91-100).
Для ввода формулы выделим диапазон Е2:Е12, состоящий из 11 ячеек (на 1 больше, чем число верхних границ интервалов). В Строке формул введем =ЧАСТОТА($A$2:$A$101;$C$2:$C$11) . После ввода формулы необходимо нажать сочетание клавиш CTRL+SHIFT+ENTER. Диапазон Е2:Е12 заполнится значениями:
- в Е2 — будет содержаться количество значений из А2:А101, которые меньше или равны 10;
- в Е3 — количество значений из А2:А101, которые меньше или равны 20, но больше 10;
- в Е11 — количество значений из А2:А101, которые меньше или равны 100, но больше 90;
- в Е12 — количество значений из А2:А101, которые больше 100 (таких нет, т.к. исходный массив содержит числа от 1 до 100).
Примечание. Функцию ЧАСТОТА() можно заменить формулой = СУММПРОИЗВ(($A$5:$A$104>C5)*($A$5:$A$104 Похожие задачи
Глава 16. Функция массива ЧАСТОТА
Это глава из книги: Майкл Гирвин. Ctrl+Shift+Enter. Освоение формул массива в Excel.
Знакомство с функциями массива началось в главе 9. Мы узнали о функциях: ТРАНСП, МОДА.НСК и ТЕНДЕНЦИЯ. Настоящая заметка знакомит с четвертой функцией массива – ЧАСТОТА. Эта функция очень простая, но весьма мощная и универсальная. Она находит массу применений. Основная задача функции ЧАСТОТА – подсчитать, сколько чисел попадают в диапазон (рис. 16.1).

Рис. 16.1. Функция ЧАСТОТА подсчитывает, сколько результатов попали в тот или иной диапазон; диапазоны в D5:D10 не являются частью формулы; они показаны для иллюстрации
Скачать заметку в формате Word или pdf, примеры в формате Excel
Функция ЧАСТОТА в диапазоне Е5:Е10 введена с помощью Ctrl+Shift+Enter. Функция возвращает вертикальный массив, показывающий число вхождений результатов гонки в каждую категорию (диапазон). Например, в диапазон от 45 до 50 с попало 5 результатов. Функция содержит два аргумента: массив_данных и массив_интервалов (массив_карманов). Обратите внимание, что функция возвращает значений на одно больше чем массив_интервалов. Экстра-значение нужно на случай, если вы не предоставите «правильное» максимальное значение в массиве интервалов, и найдутся значения, выходящие за верхнюю границу максимального диапазона. Обратите внимание:
- Первый диапазон включает все значения, которые меньше или равны первой границе.
- Далее диапазоны формируются так, что нижняя граница не входит в диапазон, а верхняя – входит.
- Последний диапазон включает все значения, которые больше, чем последняя граница.
- Функция возвращает вертикальный массив. Если вам нужен горизонтальный массив, используйте функцию ТРАНСП (рис. 16.2).
- Если аргумент массив_карманов содержит N значений, диапазон введения функции ЧАСТОТА должен содержать N+1 ячеек.
- Функция ЧАСТОТА игнорирует пустые ячейки и текст.
- Если массив_интервалов содержит дубли, во все диапазоны-дубли, кроме первого, функция вернет 0.
- После того, как функция введена с помощью Ctrl+Shift+Enter, результирующий массив становится единым блоком и отдельные ячейки нельзя ни удалить, ни отредактировать. Но вы можете удалить все значения.
- Функция ЧАСТОТА может использоваться внутри больших формул массивов, возвращая вертикальный массив.

Рис. 16.2. Используйте функцию массива ТРАНСП, если нужно получить горизонтальный массив
Сравнение функций СЧЁТЕСЛИ, СЧЁТЕСЛИМН и ЧАСТОТА
Когда ваша цель – подсчет числа вхождений между нижней и верхней границами, вы должны рассмотреть, будут ли значения границ входить в диапазоны. Если у вас есть категории, подобные показанным на рис. 16.3, использовать функцию ЧАСТОТА гораздо проще, чем функции СЧЁТЕСЛИ или СЧЁТЕСЛИМН. Вы видите, что вам придется создать три разные формулы, если вы все же решите использовать СЧЁТЕСЛИ или СЧЁТЕСЛИМН вместо функции ЧАСТОТА. В данном примере ваш выбор однозначен – функция ЧАСТОТА.

Рис. 16.3. Функции СЧЁТЕСЛИ и СЧЁТЕСЛИМН сложнее, чем ЧАСТОТА; Чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Однако, если диапазоны включает нижнюю границу, но не верхнюю (рис. 16.4) функция ЧАСТОТА не подойдет. Кроме того, вы можете предусмотреть введение нижней и верхней границ для всех диапазонов, так что формулы примут одинаковый вид. В этом примере, вы отметаете функцию ЧАСТОТА, и скорее всего, предпочтете СЧЁТЕСЛИМН.

Рис. 16.4. СЧЁТЕСЛИ и СЧЁТЕСЛИМН более гибки по сравнению с функцией ЧАСТОТА при задании различных условий по вхождению границ в диапазоны
В следующей главе вы используете полученные знания о функции ЧАСТОТА для построения формул подсчета уникальных элементов в списке.
Частотный анализ по интервалам функцией ЧАСТОТА (FREQUENCY)
При анализе данных периодически возникает задача подсчитать количество значений, попадающих в заданные интервалы «от и до» (в статистике их называют «карманы»). Например, подсчитать количество звонков определенной длительности при разборе статистики по мобильной связи, чтобы понимать какой тариф для нас выгоднее:
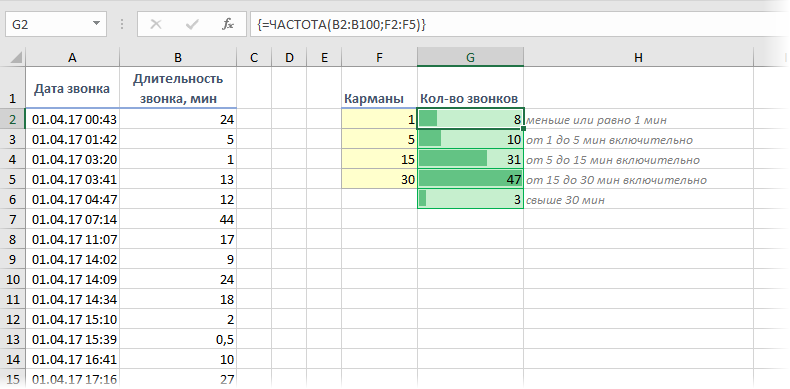
Для решения подобной задачи можно воспользоваться функцией ЧАСТОТА (FREQUENCY) . Ее синтаксис прост:
=ЧАСТОТА( Данные ; Карманы )
- Карманы — диапазон с границами интервалов, попадание в которые нас интересует
- Данные — диапазон с исходными числовыми значениями, которые мы анализируем
Обратите внимание, что эта функция игнорирует пустые ячейки и ячейки с текстом, т.е. работает только с числами.
Для использования функции ЧАСТОТА нужно:
- заранее подготовить ячейки с интересующими нас интервалами-карманами (желтые F2:F5 в нашем примере)
- выделить пустой диапазон ячеек (G2:G6) по размеру на одну ячейку больший, чем диапазон карманов (F2:F5)
- ввести функцию ЧАСТОТА и нажать в конце сочетание Ctrl+Shift+Enter, т.е. ввести ее как формулу массива
Во всех предварительно выделенных ячейках посчитается количество попаданий в заданные интервалы. Само-собой, для реализации подобной задачи можно использовать и другие способы (функцию СЧЁТЕСЛИ, сводные таблицы и т.д.), но этот вариант весьма хорош.
Кроме того, с помощью функции ЧАСТОТА можно легко подсчитывать количество уникальных чисел в наборе с помощью простой формулы массива:
Функция ЧАСТОТА
Функция частота Вычисляет частоту возникновения значений в диапазоне значений и возвращает вертикальный массив чисел. Функцией ЧАСТОТА можно воспользоваться, например, для подсчета количества результатов тестирования, попадающих в интервалы результатов. Поскольку данная функция возвращает массив, ее необходимо вводить как формулу массива.
Аргументы функции ЧАСТОТА описаны ниже.
дата_аррай Обязательный. Массив или ссылка на множество значений, для которых вычисляются частоты. Если аргумент «массив_данных» не содержит значений, функция ЧАСТОТА возвращает массив нулей.
бинс_аррай — обязательный аргумент. Массив или ссылка на множество интервалов, в которые группируются значения аргумента «массив_данных». Если аргумент «массив_интервалов» не содержит значений, функция ЧАСТОТА возвращает количество элементов в аргументе «массив_данных».
Примечание: Если у вас установлена текущая версия Office 365, можно просто ввести формулу в верхней левой ячейке диапазона вывода и нажать клавишу ВВОД, чтобы подтвердить использование формулы динамического массива. Иначе формулу необходимо вводить с использованием прежней версии массива, выбрав диапазон вывода, введя формулу в левой верхней ячейке диапазона и нажав клавиши CTRL+SHIFT+ВВОД для подтверждения. Excel автоматически вставляет фигурные скобки в начале и конце формулы. Дополнительные сведения о формулах массива см. в статье Использование формул массива: рекомендации и примеры.
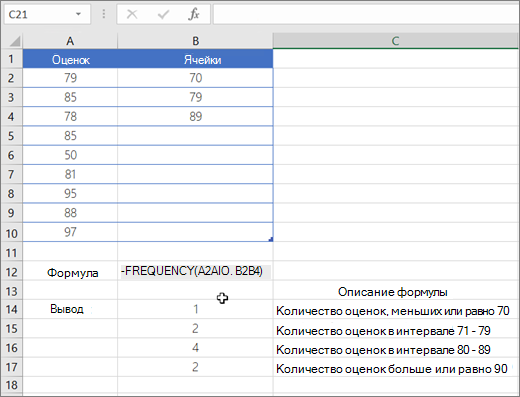
Количество элементов в возвращаемом массиве на единицу больше числа элементов в массиве «массив_интервалов». Дополнительный элемент в возвращаемом массиве содержит количество значений, превышающих верхнюю границу интервала, содержащего наибольшие значения. Например, при подсчете трех диапазонов значений (интервалов), введенных в три ячейки, убедитесь в том, что функция ЧАСТОТА возвращает значения в четырех ячейках. Дополнительная ячейка возвращает число значений в аргументе «массив_данных», превышающих значение верхней границы третьего интервала.
Функция ЧАСТОТА пропускает пустые ячейки и текст.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community, попросить помощи в сообществе Answers community, а также предложить новую функцию или улучшение на веб-сайте Excel User Voice.
Примечание: Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Была ли информация полезной? Для удобства также приводим ссылку на оригинал (на английском языке).
KT Богомолов / МУ / ЗАДАНИЕ_1_СТАТИСТИКА / Дополнительные материалы / Построение гистограмм в Excel_2014
![]()
Построение гистограмм в Microsoft Excel
Перед построением гистограммы выполняется группировка данных по близким признакам. При группировании по количественному признаку все множество значений признака делится на
Для определения оптимального количества интервалов может быть использована формула Стерджесса:
n = 1 + (3,322 × lgN )
где N — количество наблюдений. В этом случае величина интервала:
h = ( V max — V min )/ n
Поскольку количество групп не может быть дробным числом, то полученную по этой формуле величину округляют до целого большего числа.
Нижнюю границу первого интервала принимают равной минимальному значению x min . Верхняя граница первого интервала соответствует значению ( x min + h ). Для последующих групп
границы определяются аналогично, то есть последовательно прибавляется величина интервала h .
В Excel для построения гистограмм используются статистическая функция ЧАСТОТА в сочетании с мастером построения обычных диаграмм и процедура Гистограмма из пакета анализа .
Функция ЧАСТОТА (массив_данных, двоичный_массив) вычисляет частоты появления случайной величины в интервалах значений и выводит их как массив цифр, где
• Массив_данных — массив исходных данных, для которых вычисляются частоты;
• Массив_интервалов — это массив интервалов, по которым группируются значения выборки .
Перед вызовом функции ЧАСТОТА необходимо выделить столбец c числом ячеек, равным числу интервалов n , в который будут выведены результаты выполнения функции.
Вызвать Мастер функций (кнопка f x ):
и функцию ЧАСТОТА .

В поле Массив_данных ввести диапазон данных наблюдений А3:А102 (с листа ‘Расчетные данные’) . В поле Массив_интервалов ввести диапазон интервалов с того же листа ([‘Расчетные данные’!F16:F23] – в данном примере).
При завершении ввода данных нажать комбинацию клавиш Ctrl+Shift+Enter.
В предварительно выделенном столбце (C5:C12 – в данном примере) должен появиться массив
Столбец Накопленные частоты получается последовательным суммированием относительных частот (в процентном формате) в направлении от первого интервала к последнему.
В завершении с помощью Мастера диаграмм строится диаграмма абсолютных и накопленных частот с выбором типа диаграммы соотвественно гистограмма и график.
Для автоматизированного построения гистограммы средствами Excel необходимо обратиться к меню « Сервис Анализ данных» . (Excel 2003) или на вкладке Данные выбрать Анализ данных
(Excel 2007. 2010):
В появившемся списке выбрать инструмент Гистограмма и щелкнуть на кнопке ОК. Появится окно гистограммы, где задаются следующие параметры:

Входной интервал :– адреса ячеек, содержащие выборочные данные.
Интервал карманов : (необязательный параметр) – адреса ячеек, содержащие границы интервалов. Это поле предлагается оставить пустым, предоставив Excel самому вычислить границы интервалов (карманов – в терминах Excel).
Метки – флажок, включаемый, если первая строка во входных данных содержит заголовки. Если заголовки отсутствуют, то флажок следует выключить.
Выходной интервал: / Новый рабочий лист: / Новая рабочая книга.
Включенный переключатель Выходной интервал требует ввода адреса верхней ячейки, начиная с которой будут размещаться вычисленные относительные частоты j .
В положении переключателя Новый рабочий лист: открывается новый лист, в котором начиная с ячейки А1 размещаются частности j .
В положении переключателя Новая рабочая книга открывается новая книга, на первом листе которой начиная с ячейки А1 размещаются частности j .
Парето ( отсортированная гистограмма ) – устанавливается, чтобы представить j в порядке их убывания. Если параметр выключен, то j приводятся в порядке следования интервалов.
Интегральный процент – устанавливается в активное состояние для расчета выраженных в процентах накопленных относительных частот (аналог значений столбца Накопленные частоты ).
Вывод графика – устанавливается в активное состояние для автоматического создания встроенной диаграммы на листе, содержащем частоты.
Как правило, гистограммы изображаются в виде смежных прямоугольных областей. Поэтому столбики гистограммы следует расширить до соприкосновения друг с другом. Для этого необходимо щелкнуть мышью на диаграмме, далее на панель инструментов Диаграмма , раскрыть список инструментов и выбрать элемент Ряд ‘Частота’ , после чего щелкнуть на кнопке Формат ряда . В появившемся одноименном диалоговом окне необходимо активизировать закладку Параметры и в поле Ширина зазора установить значение 0 ((Excel 2003):

В Excel 2007. 2010 встать на любой столбик гистограммы и правой кнопкой мыши выбрать
Формат ряда данных:
Для построения теоретической кривой нормального распределения по эмпирическим данным необходимо найти теоретические частоты.
В Excel для вычисления значений нормального распределения используются функция НОРМРАСП, которая вычисляет значения вероятности нормальной функции распределения для указанного среднего и стандартного отклонения.
Функция имеет параметры:
НОРМРАСП (х; среднее; стандартное_откл; интегральная) , где:
х — значения выборки, для которых строится распределение; среднее — среднее арифметическое выборки; стандартное_откл — стандартное отклонение распределения;
интегральный — логическое значение, определяющее форму функции. Если интегральная имеет значение ИСТИНА(1), то функция НОРМРАСП возвращает интегральную функцию распределения; если это аргумент имеет значение ЛОЖЬ (0), то вычисляет значение функция плотности распределения.
Для получения абсолютных значений плотностей распределения (теоретических частот) достаточно найденные значения вероятности умножить на величину интервала h и количество наблюдений N = 100 по каждой строке.
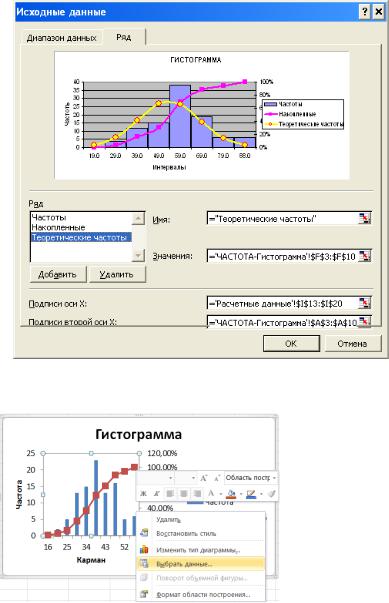
Для завершения выполнения задания необходимо внести полученные значения теоретических частот на рисунок с гистограммой, добавив ряд в закладке Исходные данные и выбрав тип диаграммы
– график ((Excel 2003):
В Excel 2007. 2010 находясь в обласи гистограммы по правой кнопке мыши выбрать Выбрать данные (или по одноименной кнопке на вкладке Конструктор ):
и в появившемся окне провести манипуляции с вводом нового ряда «Теоретические частоты»:
2.1.2. Эмпирическая функция распределения
Это статистический аналог функции распределения из теорвера. Данная функция определяется, как отношение:
, где – количество вариант СТРОГО МЕНЬШИХ, чем ,
при этом «икс» «пробегает» все значения от «минус» до «плюс» бесконечности.
Построим эмпирическую функцию распределения для нашей задачи. Чтобы было нагляднее, отложу варианты и их количество на числовой оси: 
На интервале – по той причине, что левее ЛЮБОЙ точки этого интервала вариант нет. Кроме того, функция равна нулю ещё и в точке . Почему? Потому, что значение определяет количество вариант (см. определение), которые СТРОГО меньше двух, а это количество равно нулю.
На промежутке – и опять обратите внимание, что значение не учитывает рабочих 3-го разряда, т.к. речь идёт о вариантах, которые СТРОГО меньше трёх (по определению).
На промежутке – и далее процесс продолжается по принципу накопления частот:
– если , то ;
– если , то ;
– и, наконец, если , то – и в самом деле, для ЛЮБОГО «икс» из интервала ВСЕ частоты расположены СТРОГО левее этого значения «икс» (см. чертёж выше).
Накопленные относительные частоты удобно заносить в отдельный столбец таблицы, при этом алгоритм вычислений очень прост: сначала сносим слева частоту (красная стрелка), и каждое следующее значение получаем как сумму предыдущего и относительной частоты из текущего левого столбца (зелёные обозначения): 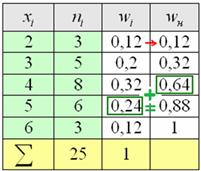
Вот ещё, кстати, один довод за вертикальную ориентацию данных – справа по надобности можно приписывать дополнительные столбцы.
Построенную функцию принято записывать в кусочном виде:
а её график представляет собой ступенчатую фигуру: 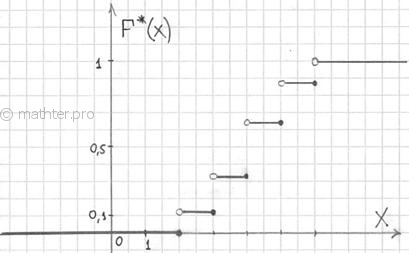
Эмпирическая функция распределения не убывает и принимает значения лишь из промежутка , и если у вас вдруг получится что-то не так, то ищите ошибку.
Теперь смотрим видео, о том, как построить эту функцию в Экселе (Ютуб).
И, конечно, вспомним основной метод математической статистики. Эмпирическая функция распределения строится по выборке и приближает теоретическую функцию распределения . Легко догадаться, что последняя появляется в результате исследования всей генеральной совокупности, но если рабочих в цехе ещё пересчитать можно, то звёзды на небе – уже вряд ли. Вот поэтому и важнА функция эмпирическая, и ещё важнее, чтобы выборка была репрезентативна, дабы приближение было хорошим.
Миниатюрное задание для закрепления материала:
Пример 5
Дано статистическое распределение совокупности: 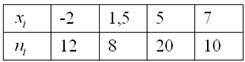
Составить эмпирическую функцию распределения, выполнить чертёж
Решаем самостоятельно – все числа уже в Экселе! Свериться с образцом можно в конце книги. По поводу красоты чертежа сильно не запаривайтесь, главное, чтобы было правильно – этого обычно достаточно для зачёта.
Из таблицы n=40, т.е.
n=4+10+6+8+7+5=40
Вычислим функцию распределения выборки 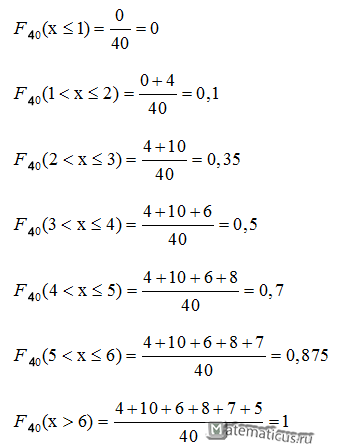
Эмпирическая функция распределения имеет вид

Построим график кусочно-постоянной эмпирической функции распределения
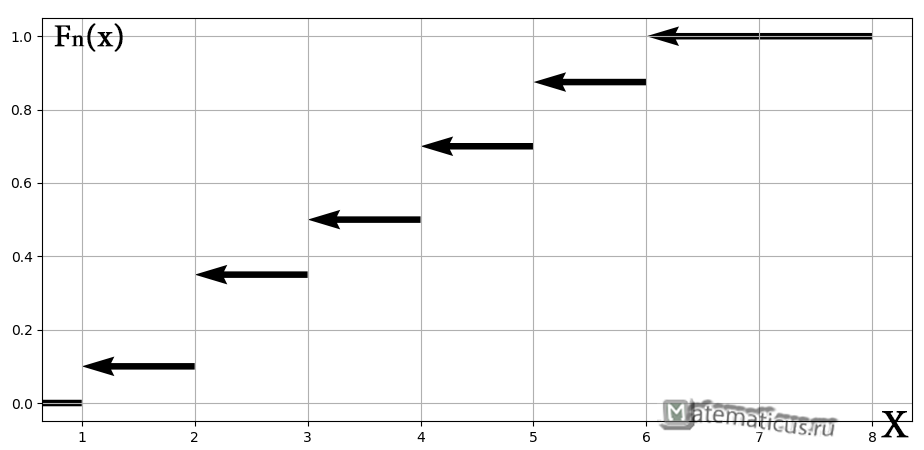
таким образом, по данным выборки можно приближенно построить функцию для неизвестной функции выборки.
2 комментария
У вас опечатка, где вы написали n=30, n=4+10+6+8+7+5=30 и F_30, так как n=40.
Построить эмпирическое распределение результатов тестирования в баллах для следующей выборки: 69, 85, 78, 85, 83, 81, 95, 88, 97, 92, 74, 83, 89, 77, 93.
В ячейку А1 введите слова Результаты, в диапазон А2:А16 – результаты тестирования.
Выберите ширину интервала 5 баллов. Тогда при крайних результатах 69 и 97 баллов, получится 7 интервалов. В ячейку С1 введите название интервалов Границы. В диапазон С2:С8 введите граничные значения интервалов: 70, 75, 80, 85, 90, 95, 100.
Введите заголовки создаваемой таблицы: в ячейку D1 – Абсолютные частоты, в ячейку Е1 – Относительные частоты, в F1 – Накопленные частоты.
Заполните столбец абсолютных частот. Для этого выделите для них блок ячеек D2:D8, вызовите Мастер функций, категория – Статистические, функция – Частота, в поле Массив данных введите диапазон данных тестирования А2:А16, в поле Массив интервалов введите диапазон интервалов С2:С8, нажмите комбинацию клавиш Ctrl+Shift+Enter. В столбце D2:D8 появится массив абсолютных частот.
В ячейке D9 найдите общее количество результатов тестирования, с помощью Автосумма.
Заполните столбец относительных частот. В ячейку Е2 введите формулу =$D2/$D$9 .
Протягиванием скопируйте полученное значение в диапазон Е3:Е8. Получим массив относительных частот.
Заполните столбец накопленных частот. В ячейку F2 скопируйте значение относительной частоты из ячейки Е2. В ячейку F3 введите формулу =F2+E3. Протягиванием скопируйте полученное значение в диапазон F4:F8. Получим массив накопленных частот.
В результате получим таблицу, представленную на рисунке 1.
Пусть Nх — число наблюдений, при которых значение признака Х меньше Х. При объеме выборки, равном П, относительная частота события Х XK.
Сама же функция F*(X) служит для оценки теоретической функции распределения F(X) генеральной совокупности.
Пример 3. Построить эмпирическую функцию по заданному распределению выборки:

Решение. Находим объем выборки: П = 10 + 15 + 25 = 50. Наименьшая варианта равна 2, поэтому F*(X) = 0 при Х ≤ 2. Значение Х 6. Напишем формулу искомой эмпирической функции:
4. Рассмотрим любой из критериев оценки качеств педагога-профессионала, например, «успешное решение задач обучения и воспитания». Ответ на этот вопрос анкеты типа «да», «нет» достаточно груб. Чтобы уменьшить относительную ошибку такого измерения, необходимо увеличить число возможных ответов на конкретный критериальный вопрос. В табл. 1 представлены возможные варианты ответов.
Обозначим этот параметр через х. Тогда в процессе ответа на вопрос величина х примет дискретное значение х, принадлежащее определенному интервалу значений. Поставим в соответствие каждому из ответов определенное числовое значение параметра х (см. табл. 1).