
Содержание
- Выполнение аппроксимации
- Способ 1: линейное сглаживание
- Способ 2: экспоненциальная аппроксимация
- Способ 3: логарифмическое сглаживание
- Способ 4: полиномиальное сглаживание
- Способ 5: степенное сглаживание
- Вопросы и ответы

Среди различных методов прогнозирования нельзя не выделить аппроксимацию. С её помощью можно производить приблизительные подсчеты и вычислять планируемые показатели, путем замены исходных объектов на более простые. В Экселе тоже существует возможность использования данного метода для прогнозирования и анализа. Давайте рассмотрим, как этот метод можно применить в указанной программе встроенными инструментами.
Выполнение аппроксимации
Наименование данного метода происходит от латинского слова proxima – «ближайшая» Именно приближение путем упрощения и сглаживания известных показателей, выстраивание их в тенденцию и является его основой. Но данный метод можно использовать не только для прогнозирования, но и для исследования уже имеющихся результатов. Ведь аппроксимация является, по сути, упрощением исходных данных, а упрощенный вариант исследовать легче.
Главный инструмент, с помощью которого проводится сглаживания в Excel – это построение линии тренда. Суть состоит в том, что на основе уже имеющихся показателей достраивается график функции на будущие периоды. Основное предназначение линии тренда, как не трудно догадаться, это составление прогнозов или выявление общей тенденции.
Но она может быть построена с применением одного из пяти видов аппроксимации:
- Линейной;
- Экспоненциальной;
- Логарифмической;
- Полиномиальной;
- Степенной.
Рассмотрим каждый из вариантов более подробно в отдельности.
Урок: Как построить линию тренда в Excel
Способ 1: линейное сглаживание
Прежде всего, давайте рассмотрим самый простой вариант аппроксимации, а именно с помощью линейной функции. На нем мы остановимся подробнее всего, так как изложим общие моменты характерные и для других способов, а именно построение графика и некоторые другие нюансы, на которых при рассмотрении последующих вариантов уже останавливаться не будем.
Прежде всего, построим график, на основании которого будем проводить процедуру сглаживания. Для построения графика возьмем таблицу, в которой помесячно указана себестоимость единицы продукции, производимой предприятием, и соответствующая прибыль в данном периоде. Графическая функция, которую мы построим, будет отображать зависимость увеличения прибыли от уменьшения себестоимости продукции.
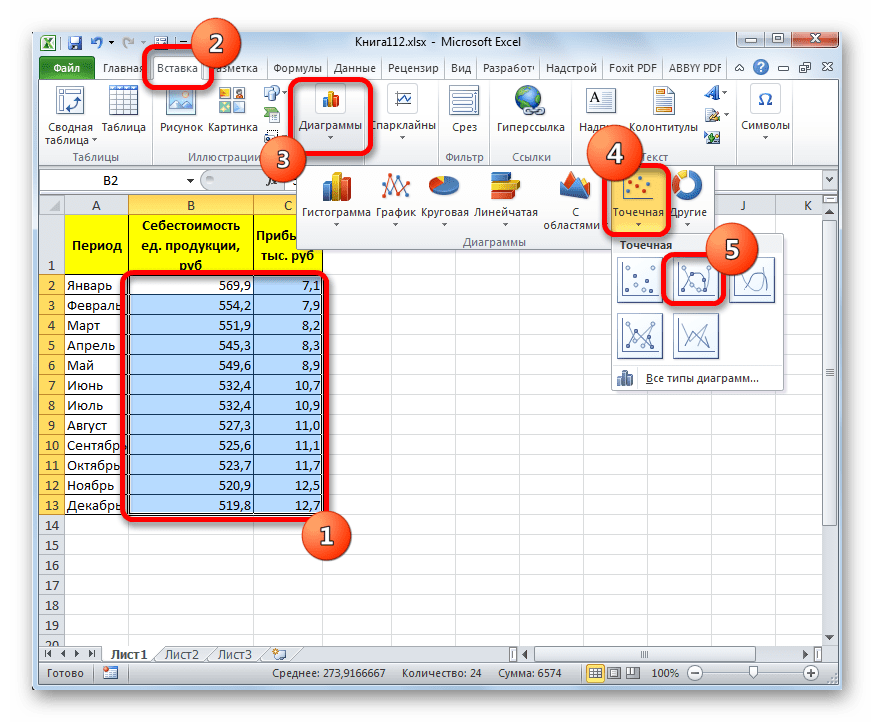
- Для построения графика, прежде всего, выделяем столбцы «Себестоимость единицы продукции» и «Прибыль». После этого перемещаемся во вкладку «Вставка». Далее на ленте в блоке инструментов «Диаграммы» щелкаем по кнопке «Точечная». В открывшемся списке выбираем наименование «Точечная с гладкими кривыми и маркерами». Именно данный вид диаграмм наиболее подходит для работы с линией тренда, а значит, и для применения метода аппроксимации в Excel.
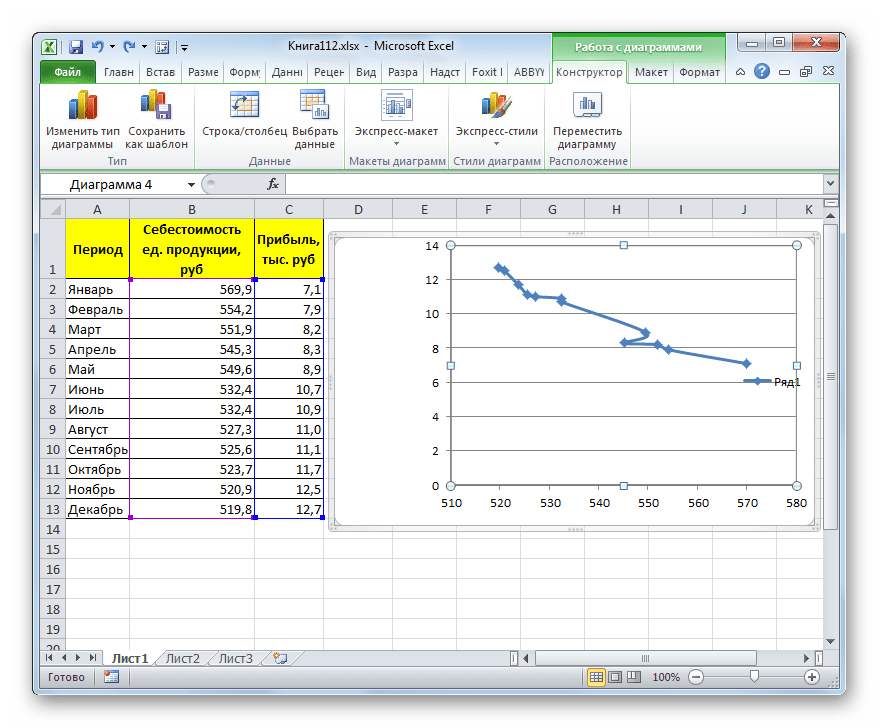
- График построен.
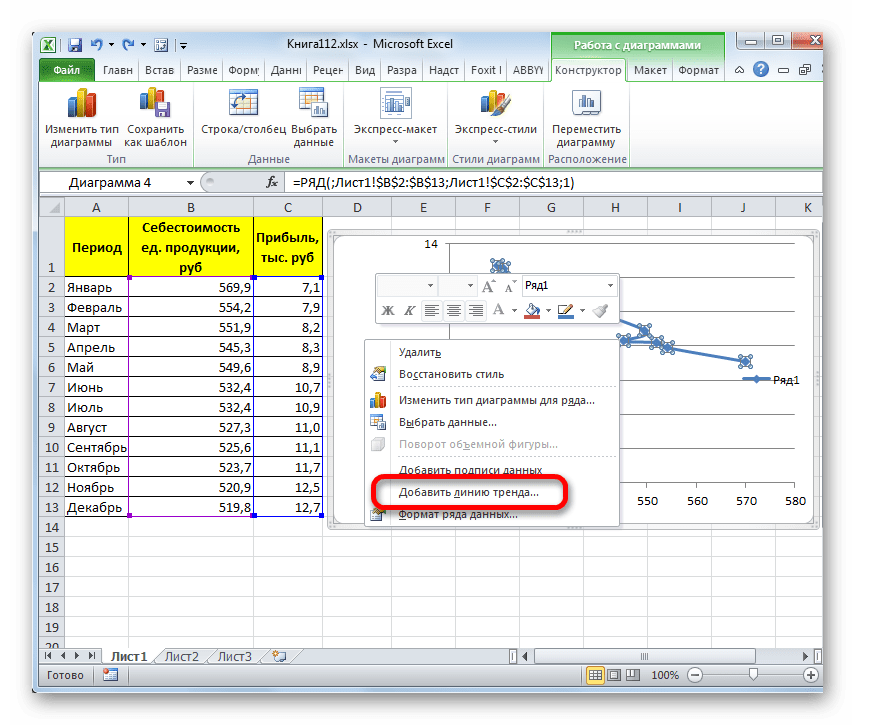
- Для добавления линии тренда выделяем его кликом правой кнопки мыши. Появляется контекстное меню. Выбираем в нем пункт «Добавить линию тренда…».

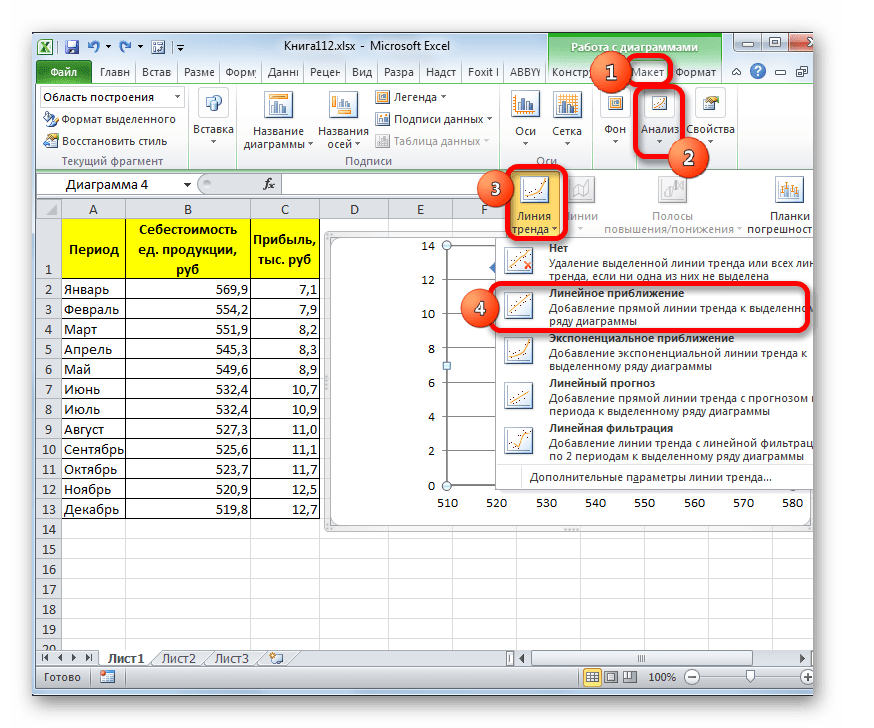
Существует ещё один вариант её добавления. В дополнительной группе вкладок на ленте «Работа с диаграммами» перемещаемся во вкладку «Макет». Далее в блоке инструментов «Анализ» щелкаем по кнопке «Линия тренда». Открывается список. Так как нам нужно применить линейную аппроксимацию, то из представленных позиций выбираем «Линейное приближение».
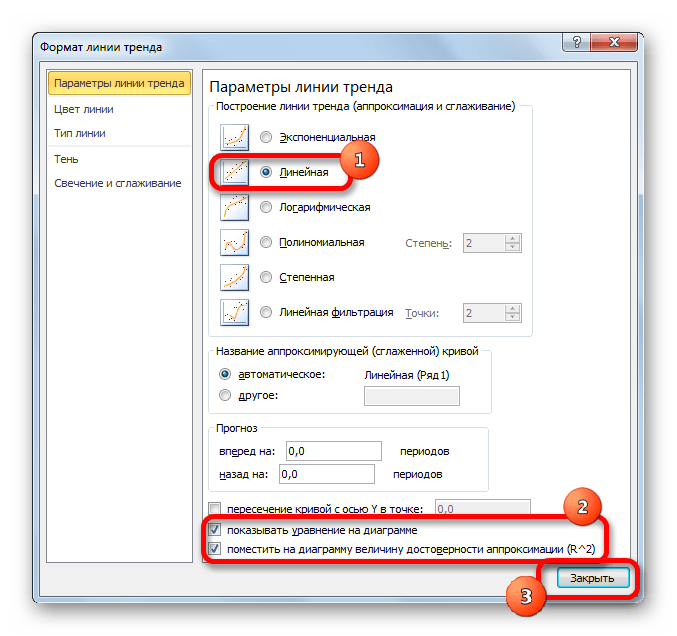
- Если же вы выбрали все-таки первый вариант действий с добавлением через контекстное меню, то откроется окно формата.
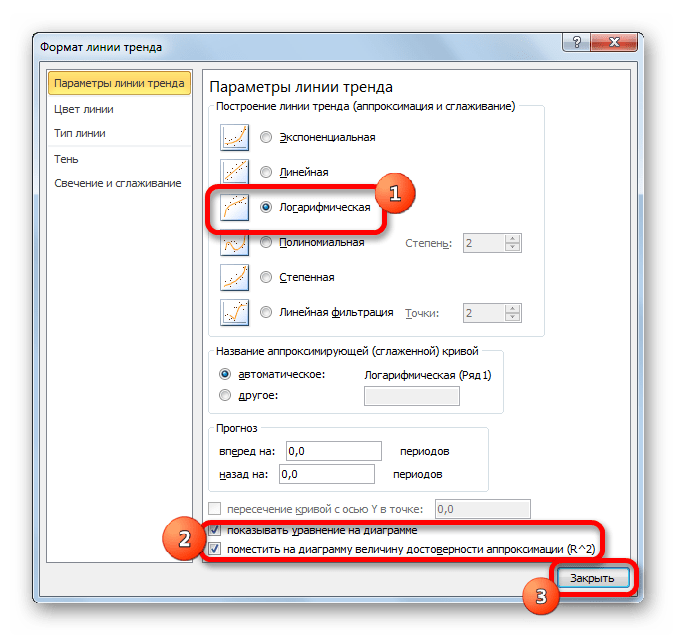
В блоке параметров «Построение линии тренда (аппроксимация и сглаживание)» устанавливаем переключатель в позицию «Линейная».
При желании можно установить галочку около позиции «Показывать уравнение на диаграмме». После этого на диаграмме будет отображаться уравнение сглаживающей функции.Также в нашем случае для сравнения различных вариантов аппроксимации важно установить галочку около пункта «Поместить на диаграмму величину достоверной аппроксимации (R^2)». Данный показатель может варьироваться от 0 до 1. Чем он выше, тем аппроксимация качественнее (достовернее). Считается, что при величине данного показателя 0,85 и выше сглаживание можно считать достоверным, а если показатель ниже, то – нет.

После того, как провели все вышеуказанные настройки. Жмем на кнопку «Закрыть», размещенную в нижней части окна.
- Как видим, на графике линия тренда построена. При линейной аппроксимации она обозначается черной прямой полосой. Указанный вид сглаживания можно применять в наиболее простых случаях, когда данные изменяются довольно быстро и зависимость значения функции от аргумента очевидна.

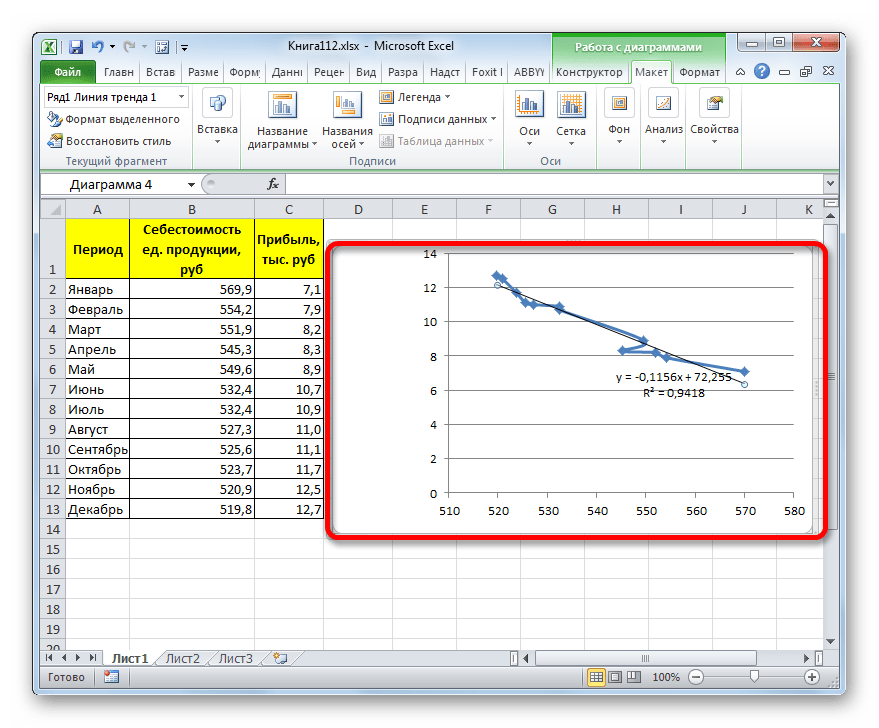
Сглаживание, которое используется в данном случае, описывается следующей формулой:
y=ax+b
В конкретно нашем случае формула принимает такой вид:
y=-0,1156x+72,255
Величина достоверности аппроксимации у нас равна 0,9418, что является довольно приемлемым итогом, характеризующим сглаживание, как достоверное.
Способ 2: экспоненциальная аппроксимация
Теперь давайте рассмотрим экспоненциальный тип аппроксимации в Эксель.
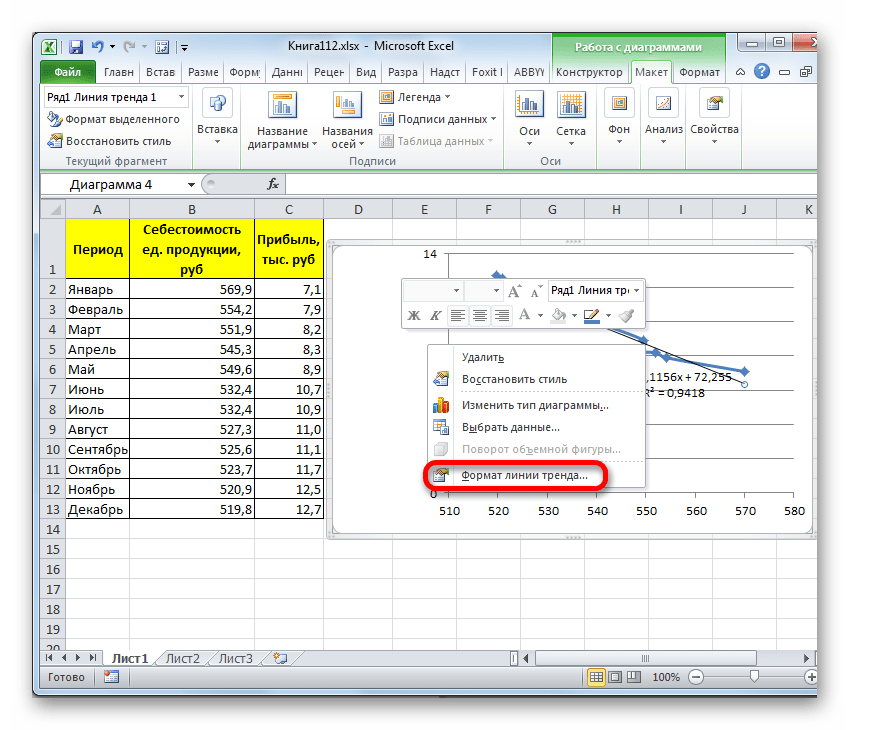
- Для того, чтобы изменить тип линии тренда, выделяем её кликом правой кнопки мыши и в раскрывшемся меню выбираем пункт «Формат линии тренда…».
- После этого запускается уже знакомое нам окно формата. В блоке выбора типа аппроксимации устанавливаем переключатель в положение «Экспоненциальная». Остальные настройки оставим такими же, как и в первом случае. Щелкаем по кнопке «Закрыть».
- После этого линия тренда будет построена на графике. Как видим, при использовании данного метода она имеет несколько изогнутую форму. При этом уровень достоверности равен 0,9592, что выше, чем при использовании линейной аппроксимации. Экспоненциальный метод лучше всего использовать в том случае, когда сначала значения быстро изменяются, а потом принимают сбалансированную форму.
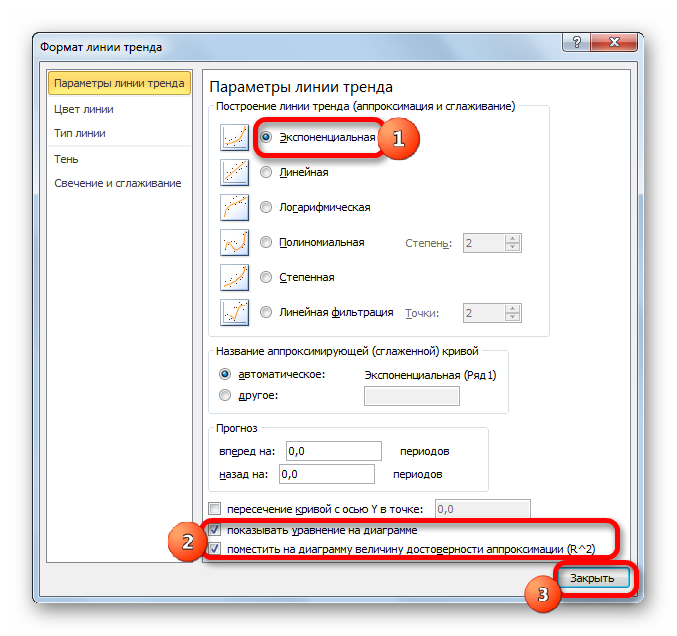
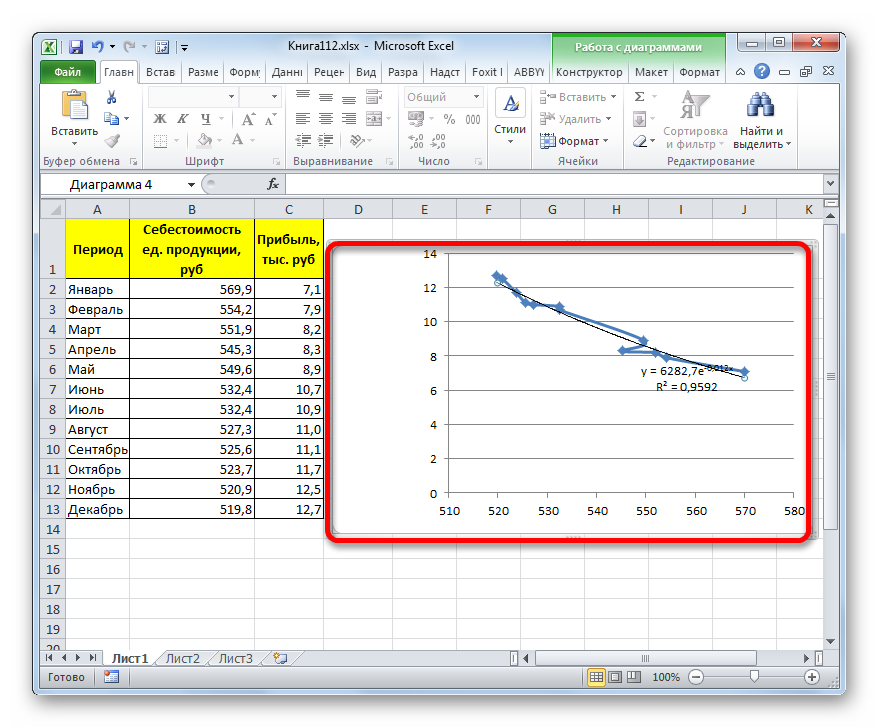
Общий вид функции сглаживания при этом такой:
y=be^x
где e – это основание натурального логарифма.
В конкретно нашем случае формула приняла следующую форму:
y=6282,7*e^(-0,012*x)
Способ 3: логарифмическое сглаживание
Теперь настала очередь рассмотреть метод логарифмической аппроксимации.
- Тем же способом, что и в предыдущий раз через контекстное меню запускаем окно формата линии тренда. Устанавливаем переключатель в позицию «Логарифмическая» и жмем на кнопку «Закрыть».
- Происходит процедура построения линии тренда с логарифмической аппроксимацией. Как и в предыдущем случае, такой вариант лучше использовать тогда, когда изначально данные быстро изменяются, а потом принимают сбалансированный вид. Как видим, уровень достоверности равен 0,946. Это выше, чем при использовании линейного метода, но ниже, чем качество линии тренда при экспоненциальном сглаживании.
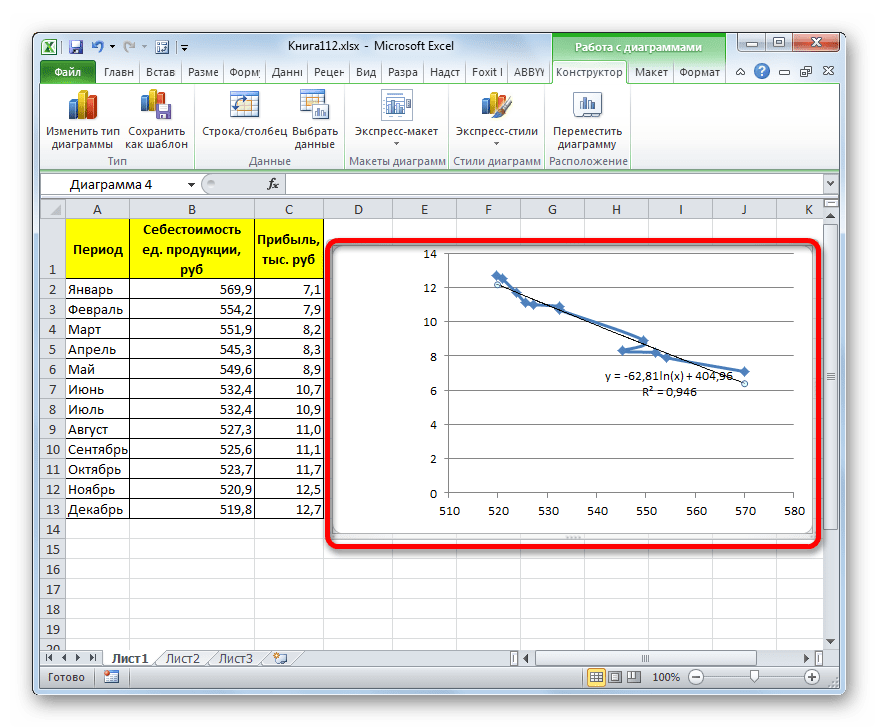
В общем виде формула сглаживания выглядит так:
y=a*ln(x)+b
где ln – это величина натурального логарифма. Отсюда и наименование метода.
В нашем случае формула принимает следующий вид:
y=-62,81ln(x)+404,96
Способ 4: полиномиальное сглаживание
Настал черед рассмотреть метод полиномиального сглаживания.
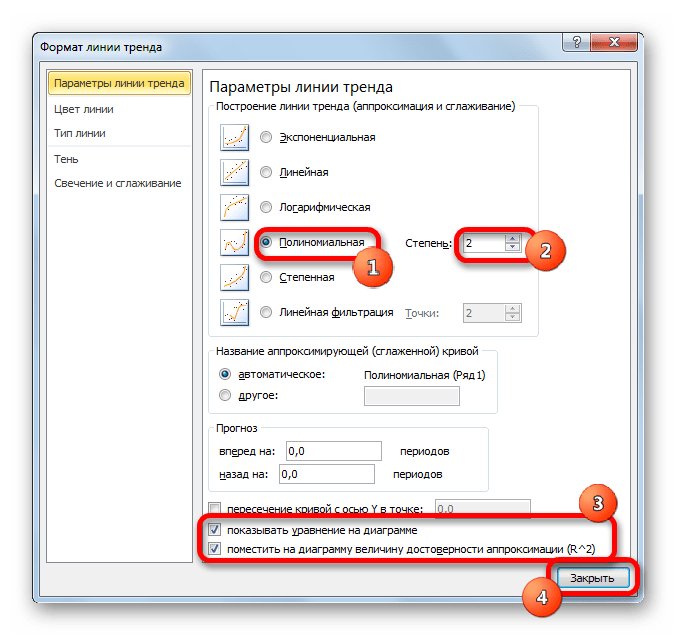
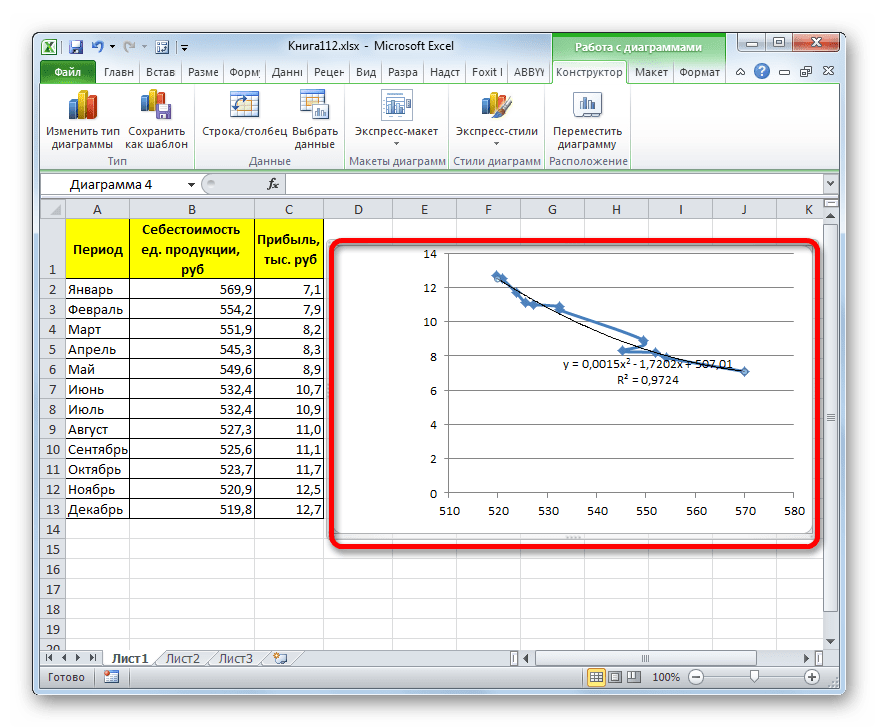
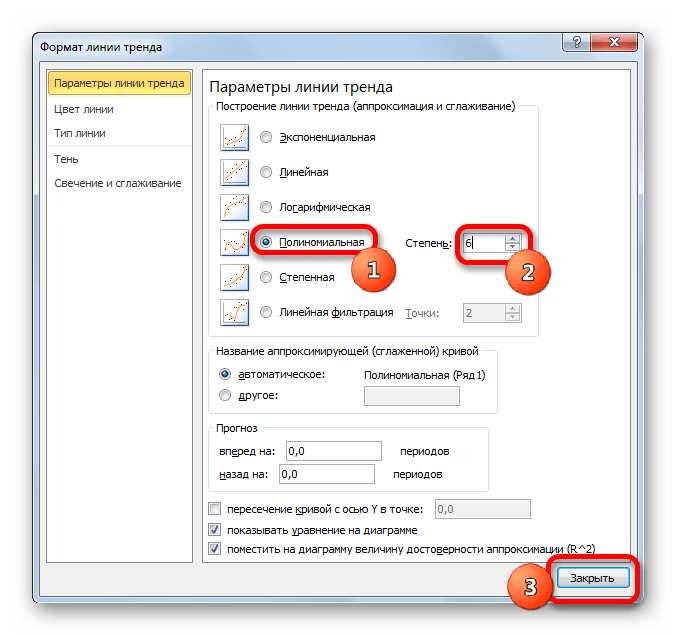
- Переходим в окно формата линии тренда, как уже делали не раз. В блоке «Построение линии тренда» устанавливаем переключатель в позицию «Полиномиальная». Справа от данного пункта расположено поле «Степень». При выборе значения «Полиномиальная» оно становится активным. Здесь можно указать любое степенное значение от 2 (установлено по умолчанию) до 6. Данный показатель определяет число максимумов и минимумов функции. При установке полинома второй степени описывается только один максимум, а при установке полинома шестой степени может быть описано до пяти максимумов. Для начала оставим настройки по умолчанию, то есть, укажем вторую степень. Остальные настройки оставляем такими же, какими мы выставляли их в предыдущих способах. Жмем на кнопку «Закрыть».
- Линия тренда с использованием данного метода построена. Как видим, она ещё более изогнута, чем при использовании экспоненциальной аппроксимации. Уровень достоверности выше, чем при любом из использованных ранее способов, и составляет 0,9724.

Данный метод наиболее успешно можно применять в том случае, если данные носят постоянно изменчивый характер. Функция, описывающая данный вид сглаживания, выглядит таким образом:
y=a1+a1*x+a2*x^2+…+an*x^nВ нашем случае формула приняла такой вид:
y=0,0015*x^2-1,7202*x+507,01 - Теперь давайте изменим степень полиномов, чтобы увидеть, будет ли отличаться результат. Возвращаемся в окно формата. Тип аппроксимации оставляем полиномиальным, но напротив него в окне степени устанавливаем максимально возможное значение – 6.
- Как видим, после этого наша линия тренда приняла форму ярко выраженной кривой, у которой число максимумов равно шести. Уровень достоверности повысился ещё больше, составив 0,9844.
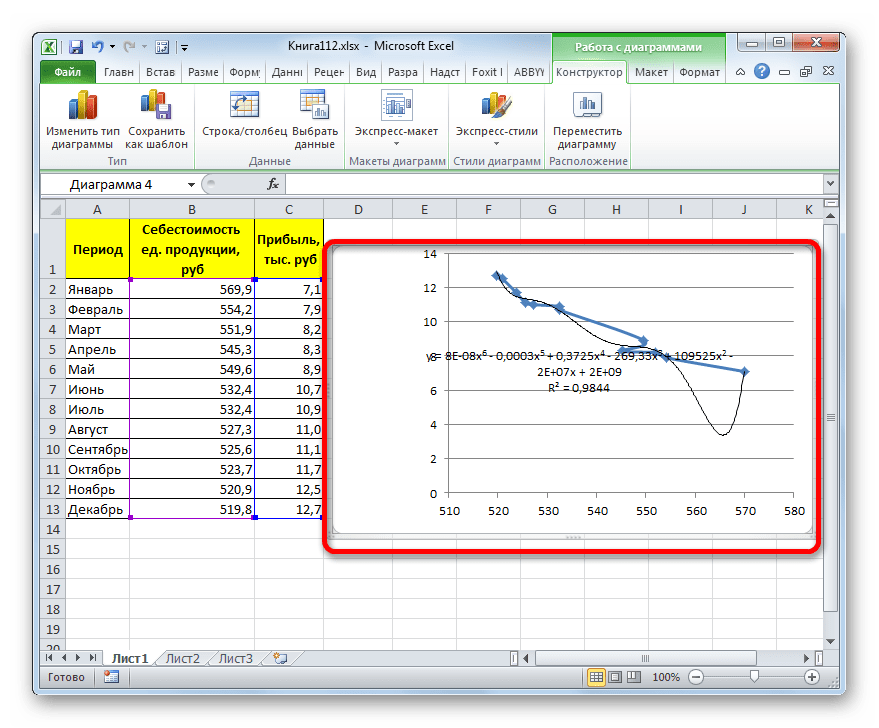
Формула, которая описывает данный тип сглаживания, приняла следующий вид:
y=8E-08x^6-0,0003x^5+0,3725x^4-269,33x^3+109525x^2-2E+07x+2E+09
Способ 5: степенное сглаживание
В завершении рассмотрим метод степенной аппроксимации в Excel.
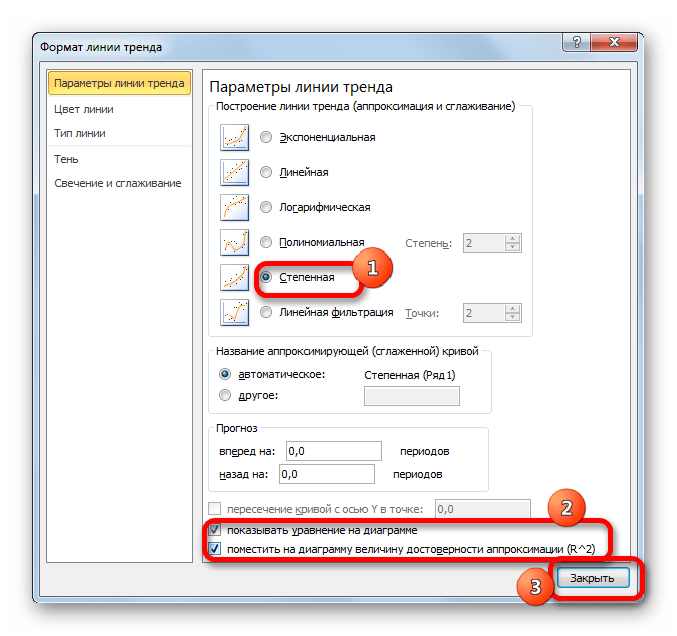
- Перемещаемся в окно «Формат линии тренда». Устанавливаем переключатель вида сглаживания в позицию «Степенная». Показ уравнения и уровня достоверности, как всегда, оставляем включенными. Жмем на кнопку «Закрыть».
- Программа формирует линию тренда. Как видим, в нашем случае она представляет собой линию с небольшим изгибом. Уровень достоверности равен 0,9618, что является довольно высоким показателем. Из всех вышеописанных способов уровень достоверности был выше только при использовании полиномиального метода.
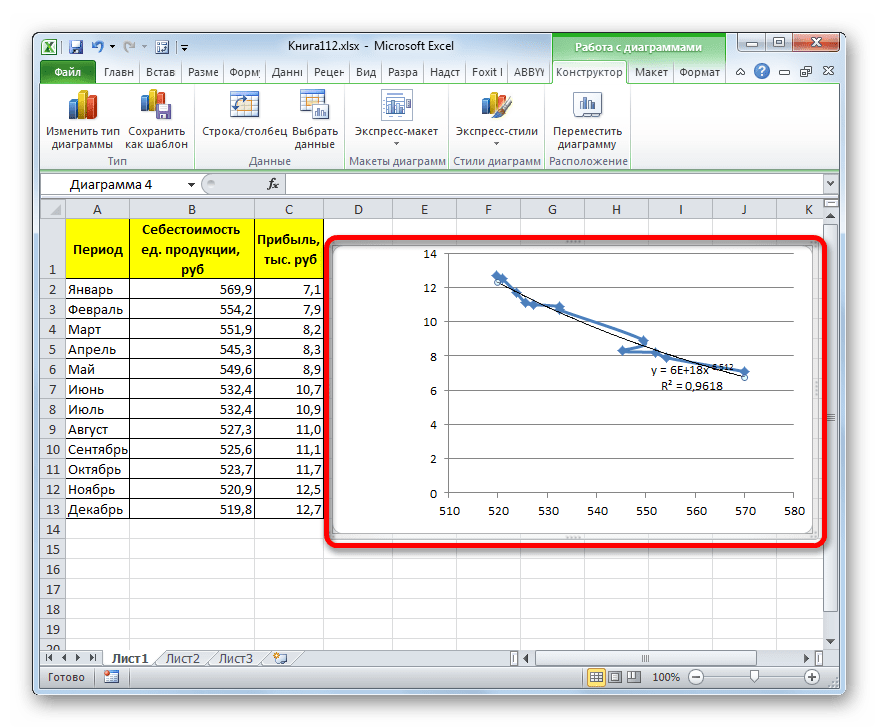
Данный способ эффективно используется в случаях интенсивного изменения данных функции. Важно учесть, что этот вариант применим только при условии, что функция и аргумент не принимают отрицательных или нулевых значений.
Общая формула, описывающая данный метод имеет такой вид:
y=bx^n
В конкретно нашем случае она выглядит так:
y = 6E+18x^(-6,512)
Как видим, при использовании конкретных данных, которые мы применяли для примера, наибольший уровень достоверности показал метод полиномиальной аппроксимации с полиномом в шестой степени (0,9844), наименьший уровень достоверности у линейного метода (0,9418). Но это совсем не значит, что такая же тенденция будет при использовании других примеров. Нет, уровень эффективности у приведенных выше методов может значительно отличаться, в зависимости от конкретного вида функции, для которой будет строиться линия тренда. Поэтому, если для этой функции выбранный метод наиболее эффективен, то это совсем не означает, что он также будет оптимальным и в другой ситуации.
Если вы пока не можете сразу определить, основываясь на вышеприведенных рекомендациях, какой вид аппроксимации подойдет конкретно в вашем случае, то есть смысл попробовать все методы. После построения линии тренда и просмотра её уровня достоверности можно будет выбрать оптимальный вариант.
В этой статье описаны синтаксис формулы и использование функции LINEST в Microsoft Excel. Ссылки на дополнительные сведения о диаграммах и выполнении регрессионного анализа можно найти в разделе См. также.
Описание
Функция ЛИНЕЙН рассчитывает статистику для ряда с применением метода наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные и затем возвращает массив, который описывает полученную прямую. Функцию ЛИНЕЙН также можно объединять с другими функциями для вычисления других видов моделей, являющихся линейными по неизвестным параметрам, включая полиномиальные, логарифмические, экспоненциальные и степенные ряды. Поскольку возвращается массив значений, функция должна задаваться в виде формулы массива. Инструкции приведены в данной статье после примеров.
Уравнение для прямой линии имеет следующий вид:
y = mx + b
или
y = m1x1 + m2x2 +… + b
если существует несколько диапазонов значений x, где зависимые значения y — функции независимых значений x. Значения m — коэффициенты, соответствующие каждому значению x, а b — постоянная. Обратите внимание, что y, x и m могут быть векторами. Функция ЛИНЕЙН возвращает массив {mn;mn-1;…;m1;b}. Функция ЛИНЕЙН может также возвращать дополнительную регрессионную статистику.
Синтаксис
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Аргументы функции ЛИНЕЙН описаны ниже.
Синтаксис
-
Известные_значения_y. Обязательный аргумент. Множество значений y, которые уже известны для соотношения y = mx + b.
-
Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
-
Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
-
-
Известные_значения_x. Необязательный аргумент. Множество значений x, которые уже известны для соотношения y = mx + b.
-
Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то массивы известные_значения_y и известные_значения_x могут иметь любую форму — при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (т. е. интервалом высотой в одну строку или шириной в один столбец).
-
Если массив известные_значения_x опущен, то предполагается, что это массив {1;2;3;…}, имеющий такой же размер, что и массив известные_значения_y.
-
-
Конст. Необязательный аргумент. Логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0.
-
Если аргумент конст имеет значение ИСТИНА или опущен, то константа b вычисляется обычным образом.
-
Если аргумент конст имеет значение ЛОЖЬ, то значение b полагается равным 0 и значения m подбираются таким образом, чтобы выполнялось соотношение y = mx.
-
-
Статистика. Необязательный аргумент. Логическое значение, которое указывает, требуется ли вернуть дополнительную регрессионную статистику.
-
Если статистика имеет true, то LINEST возвращает дополнительную регрессию; в результате возвращается массив {mn;mn-1,…,m1;b;sen,sen-1,…,se1;seb;r2;sey; F,df;ssreg,ssresid}.
-
Если аргумент статистика имеет значение ЛОЖЬ или опущен, функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b.
Дополнительная регрессионная статистика.
-
|
Величина |
Описание |
|---|---|
|
se1,se2,…,sen |
Стандартные значения ошибок для коэффициентов m1,m2,…,mn. |
|
seb |
Стандартное значение ошибки для постоянной b (seb = #Н/Д, если аргумент конст имеет значение ЛОЖЬ). |
|
r2 |
Коэффициент определения. Сравнивает предполагаемые и фактические значения y и диапазоны значений от 0 до 1. Если значение 1, то в выборке будет отличная корреляция— разница между предполагаемым значением y и фактическим значением y не существует. С другой стороны, если коэффициент определения — 0, уравнение регрессии не помогает предсказать значение y. Сведения о том, каквычисляется 2, см. в разделе «Замечания» далее в этой теме. |
|
sey |
Стандартная ошибка для оценки y. |
|
F |
F-статистика или F-наблюдаемое значение. F-статистика используется для определения того, является ли случайной наблюдаемая взаимосвязь между зависимой и независимой переменными. |
|
df |
Степени свободы. Степени свободы используются для нахождения F-критических значений в статистической таблице. Для определения уровня надежности модели необходимо сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН. Дополнительные сведения о вычислении величины df см. ниже в разделе «Замечания». Далее в примере 4 показано использование величин F и df. |
|
ssreg |
Регрессионная сумма квадратов. |
|
ssresid |
Остаточная сумма квадратов. Дополнительные сведения о расчете величин ssreg и ssresid см. в подразделе «Замечания» в конце данного раздела. |
На приведенном ниже рисунке показано, в каком порядке возвращается дополнительная регрессионная статистика.

Замечания
-
Любую прямую можно описать ее наклоном и пересечением с осью y:
Наклон (m):
Чтобы найти наклон линии, обычно записанной как m, возьмите две точки на строке (x1;y1) и (x2;y2); наклон равен (y2 — y1)/(x2 — x1).Y-перехват (b):
Y-пересечение строки, обычно записанное как b, — это значение y в точке, в которой линия пересекает ось y.Уравнение прямой имеет вид y = mx + b. Если известны значения m и b, то можно вычислить любую точку на прямой, подставляя значения y или x в уравнение. Можно также воспользоваться функцией ТЕНДЕНЦИЯ.
-
Если имеется только одна независимая переменная x, можно получить наклон и y-пересечение непосредственно, воспользовавшись следующими формулами:
Наклон:
=ИНДЕКС( LINEST(known_y,known_x’s);1)Y-перехват:
=ИНДЕКС( LINEST(known_y,known_x),2) -
Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точной является модель ЛИНЕЙН. Функция ЛИНЕЙН использует для определения наилучшей аппроксимации данных метод наименьших квадратов. Когда имеется только одна независимая переменная x, значения m и b вычисляются по следующим формулам:
где x и y — выборочные средние значения, например x = СРЗНАЧ(известные_значения_x), а y = СРЗНАЧ(известные_значения_y).
-
Функции ЛИННЕСТРОЙ и ЛОГЪЕСТ могут вычислять наилучшие прямые или экспоненциальное кривой, которые подходят для ваших данных. Однако необходимо решить, какой из двух результатов лучше всего подходит для ваших данных. Вы можетевычислить known_y(known_x) для прямой линии или РОСТ(known_y, known_x в) для экспоненциальной кривой. Эти функции без аргумента new_x возвращают массив значений y, спрогнозируемых вдоль этой линии или кривой в фактических точках данных. Затем можно сравнить спрогнозируемые значения с фактическими значениями. Для наглядного сравнения можно отобразить оба этих диаграммы.
-
Проводя регрессионный анализ, Microsoft Excel вычисляет для каждой точки квадрат разности между прогнозируемым значением y и фактическим значением y. Сумма этих квадратов разностей называется остаточной суммой квадратов (ssresid). Затем Microsoft Excel подсчитывает общую сумму квадратов (sstotal). Если конст = ИСТИНА или значение этого аргумента не указано, общая сумма квадратов будет равна сумме квадратов разностей действительных значений y и средних значений y. При конст = ЛОЖЬ общая сумма квадратов будет равна сумме квадратов действительных значений y (без вычитания среднего значения y из частного значения y). После этого регрессионную сумму квадратов можно вычислить следующим образом: ssreg = sstotal — ssresid. Чем меньше остаточная сумма квадратов по сравнению с общей суммой квадратов, тем больше значение коэффициента определения r2— индикатор того, насколько хорошо уравнение, выданное в результате регрессионного анализа, объясняет связь между переменными. Значение r2 равно ssreg/sstotal.
-
В некоторых случаях один или несколько столбцов X (предполагается, что значения Y и X — в столбцах) могут не иметь дополнительного прогнозируемого значения при наличии других столбцов X. Другими словами, удаление одного или более столбцов X может привести к одинаковой точности предсказания значений Y. В этом случае эти избыточные столбцы X следует не использовать в модели регрессии. Этот вариант называется «коллинеарность», так как любой избыточный X-столбец может быть выражен как сумма многих не избыточных X-столбцов. Функция ЛИНЕЙН проверяет коллинеарность и удаляет все избыточные X-столбцы из модели регрессии при их идентификации. Удалены столбцы X распознаются в результатах LINEST как имеющие коэффициенты 0 в дополнение к значениям 0 se. Если один или несколько столбцов будут удалены как избыточные, это влияет на df, поскольку df зависит от числа X столбцов, фактически используемых для прогнозирования. Подробные сведения о вычислении df см. в примере 4. Если значение df изменилось из-за удаления избыточных X-столбцов, это также влияет на значения Sey и F. Коллинеарность должна быть относительно редкой на практике. Однако чаще всего возникают ситуации, когда некоторые столбцы X содержат только значения 0 и 1 в качестве индикаторов того, является ли тема в эксперименте участником определенной группы или не является ее участником. Если конст = ИСТИНА или опущен, функция LYST фактически вставляет дополнительный столбец X из всех 1 значений для моделирования перехвата. Если у вас есть столбец с значением 1 для каждой темы, если мальчик, или 0, а также столбец с 1 для каждой темы, если она является женщиной, или 0, последний столбец является избыточным, так как записи в нем могут быть получены из вычитания записи в столбце «самец» из записи в дополнительном столбце всех 1 значений, добавленных функцией LINEST.
-
Вычисление значения df для случаев, когда столбцы X удаляются из модели вследствие коллинеарности происходит следующим образом: если существует k столбцов известных_значений_x и значение конст = ИСТИНА или не указано, то df = n – k – 1. Если конст = ЛОЖЬ, то df = n — k. В обоих случаях удаление столбцов X вследствие коллинеарности увеличивает значение df на 1.
-
При вводе константы массива (например, в качестве аргумента известные_значения_x) следует использовать точку с запятой для разделения значений в одной строке и двоеточие для разделения строк. Знаки-разделители могут быть другими в зависимости от региональных параметров.
-
Следует отметить, что значения y, предсказанные с помощью уравнения регрессии, возможно, не будут правильными, если они располагаются вне интервала значений y, которые использовались для определения уравнения.
-
Основной алгоритм, используемый в функции ЛИНЕЙН, отличается от основного алгоритма функций НАКЛОН и ОТРЕЗОК. Разница между алгоритмами может привести к различным результатам при неопределенных и коллинеарных данных. Например, если точки данных аргумента известные_значения_y равны 0, а точки данных аргумента известные_значения_x равны 1, то:
-
Функция ЛИНЕЙН возвращает значение, равное 0. Алгоритм функции ЛИНЕЙН используется для возвращения подходящих значений для коллинеарных данных, и в данном случае может быть найден по меньшей мере один ответ.
-
Наклон и ОТОКП возвращают #DIV/0! ошибка «#ЗНАЧ!». Алгоритм функций НАКЛОН и ОТОКП предназначен для поиска только одного ответа, и в этом случае может быть несколько ответов.
-
-
Помимо вычисления статистики для других типов регрессии с помощью функции ЛГРФПРИБЛ, для вычисления диапазонов некоторых других типов регрессий можно использовать функцию ЛИНЕЙН, вводя функции переменных x и y как ряды переменных х и у для ЛИНЕЙН. Например, следующая формула:
=ЛИНЕЙН(значения_y, значения_x^СТОЛБЕЦ($A:$C))
работает при наличии одного столбца значений Y и одного столбца значений Х для вычисления аппроксимации куба (многочлен 3-й степени) следующей формы:
y = m1*x + m2*x^2 + m3*x^3 + b
Формула может быть изменена для расчетов других типов регрессии, но в отдельных случаях требуется корректировка выходных значений и других статистических данных.
-
Значение F-теста, возвращаемое функцией ЛИНЕЙН, отличается от значения, возвращаемого функцией ФТЕСТ. Функция ЛИНЕЙН возвращает F-статистику, в то время как ФТЕСТ возвращает вероятность.
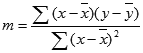
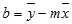
Примеры
Пример 1. Наклон и Y-пересечение
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Известные значения y |
Известные значения x |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
Результат (наклон) |
Результат (y-пересечение) |
|
2 |
1 |
|
Формула (формула массива в ячейках A7:B7) |
|
|
=ЛИНЕЙН(A2:A5;B2:B5;;ЛОЖЬ) |
Пример 2. Простая линейная регрессия
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Месяц |
Продажи |
|---|---|
|
1 |
3 100 ₽ |
|
2 |
4 500 ₽ |
|
3 |
4 400 ₽ |
|
4 |
5 400 ₽ |
|
5 |
7 500 ₽ |
|
6 |
8 100 ₽ |
|
Формула |
Результат |
|
=СУММ(ЛИНЕЙН(B1:B6; A2:A7)*{9;1}) |
11 000 ₽ |
|
Вычисляет предполагаемый объем продаж в девятом месяце на основе данных о продажах за период с первого по шестой месяцы. |
Пример 3. Множественная линейная регрессия
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Общая площадь (x1) |
Количество офисов (x2) |
Количество входов (x3) |
Время эксплуатации (x4) |
Оценочная цена (y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
142 000 ₽ |
|
2333 |
2 |
2 |
12 |
144 000 ₽ |
|
2356 |
3 |
1,5 |
33 |
151 000 ₽ |
|
2379 |
3 |
2 |
43 |
150 000 ₽ |
|
2402 |
2 |
3 |
53 |
139 000 ₽ |
|
2425 |
4 |
2 |
23 |
169 000 ₽ |
|
2448 |
2 |
1,5 |
99 |
126 000 ₽ |
|
2471 |
2 |
2 |
34 |
142 900 ₽ |
|
2494 |
3 |
3 |
23 |
163 000 ₽ |
|
2517 |
4 |
4 |
55 |
169 000 ₽ |
|
2540 |
2 |
3 |
22 |
149 000 ₽ |
|
-234,2371645 |
||||
|
13,26801148 |
||||
|
0,996747993 |
||||
|
459,7536742 |
||||
|
1732393319 |
||||
|
Формула (формула динамического массива, введенная в A19) |
||||
|
=ЛИНЕЙН(E2:E12; A2:D12; ИСТИНА; ИСТИНА) |
Пример 4. Использование статистики F и r2
В предыдущем примере коэффициент определения (r2)составляет 0,99675 (см. ячейку A17 в результатах для ЛИТН), что указывает на крепкая связь между независимыми переменными и ценой продажи. F-статистику можно использовать для определения случайности этих результатов с таким высоким значением r2.
Предположим, что на самом деле взаимосвязи между переменными не существует, просто статистический анализ вывел сильную взаимозависимость по взятой равномерной выборке 11 зданий. Величина «Альфа» используется для обозначения вероятности ошибочного вывода о существовании сильная взаимозависимости.
Значения F и df в результатах функции LINEST можно использовать для оценки вероятности возникновения более высокого F-значения. F можно сравнивать с критическими значениями в опубликованных F-таблицах или с помощью функции FРАСП в Excel для вычисления вероятности случайного возникновения большего F-значения. Соответствующее F-распределение имеет v1 и v2 степени свободы. Если n — количество точек данных и конст = ИСТИНА или опущен, то v1 = n – df – 1 и v2 = df. (Если конст = ЛОЖЬ, то v1 = n – df и v2 = df.) Функция FIST с синтаксисом FDIST(F;v1;v2) возвращает вероятность возникновения более высокого F-значения, случайного. В этом примере df = 6 (ячейка B18) и F = 459,753674 (ячейка A18).
Предположим, что альфа имеет значение 0,05, v1 = 11 – 6 – 1 = 4, а v2 = 6, критический уровень F составляет 4,53. Поскольку F = 459,753674 значительно больше 4,53, вероятность того, что F-значение этого высокой случайности превышает 4,53, крайне маловероятно. (Если значение «Альфа» = 0,05, гипотеза о том, что между known_y и known_x нет связи, отклоняется при превышении F критического уровня (4,53).) Функцию FDIST в Excel можно использовать для получения вероятности случайного возникновения F-значения. Например, FIST(459,753674, 4, 6) = 1,37E-7, очень небольшая вероятность. Можно сделать вывод о том, что формула регрессии полезна для предсказания оценочного значения офисных зданий в этой области, найдя критический уровень F в таблице или с помощью функции FDIST. Помните, что крайне важно использовать правильные значения 1 и 2, вычисленные в предыдущем абзаце.
Пример 5. Вычисление t-статистики
Другой тест позволяет определить, подходит ли каждый коэффициент наклона для оценки стоимости здания под офис в примере 3. Например, чтобы проверить, имеет ли срок эксплуатации здания статистическую значимость, разделим -234,24 (коэффициент наклона для срока эксплуатации здания) на 13,268 (оценка стандартной ошибки для коэффициента времени эксплуатации из ячейки A15). Ниже приводится наблюдаемое t-значение:
t = m4 ÷ se4 = –234,24 ÷ 13,268 = –17,7
Если абсолютное значение t достаточно велико, можно сделать вывод, что коэффициент наклона можно использовать для оценки стоимости здания под офис в примере 3. В таблице ниже приведены абсолютные значения четырех наблюдаемых t-значений.
Если обратиться к справочнику по математической статистике, то окажется, что t-критическое двустороннее с 6 степенями свободы равно 2,447 при Альфа = 0,05. Критическое значение также можно также найти с помощью функции Microsoft Excel СТЬЮДРАСПОБР. СТЬЮДРАСПОБР(0,05; 6) = 2,447. Поскольку абсолютная величина t, равная 17,7, больше, чем 2,447, срок эксплуатации — это важная переменная для оценки стоимости здания под офис. Аналогичным образом можно протестировать все другие переменные на статистическую значимость. Ниже приводятся наблюдаемые t-значения для каждой из независимых переменных.
|
Переменная |
t-наблюдаемое значение |
|---|---|
|
Общая площадь |
5,1 |
|
Количество офисов |
31,3 |
|
Количество входов |
4,8 |
|
Возраст |
17,7 |
Абсолютная величина всех этих значений больше, чем 2,447. Следовательно, все переменные, использованные в уравнении регрессии, полезны для предсказания оценочной стоимости здания под офис в данном районе.
Содержание
- 0.1 Вам понадобится
- 0.2 Инструкция
- 1 Инструкция
- 2 Инструкция
- 3 Инструкция
- 4 Инструкция
- 5 Инструкция
- 6 Инструкция
- 7 Инструкция
- 8 Инструкция
- 9 Инструкция
- 9.1 Сглаживание графика в Excel. Как быстро сделать?
- 9.2 Экспоненциальное сглаживание в Excel
- 9.3 Как найти прямую приближенных значений
Приложение Microsoft Office Excel имеет встроенные инструменты, позволяющие на основе табличных данных создавать диаграммы разных типов. График, на котором можно отобразить прямую линию, здесь тоже отнесен к диаграммам. Есть в Excel и возможность заполнить таблицу данными, вычисляемыми по заданной пользователем формуле, поэтому задачу построения прямой с использованием этой программы можно отнести к разряду не очень сложных.
Вам понадобится
- Табличный редактор Microsoft Office Excel 2007 или 2010.
Инструкция
Запустите Excel и заполните две колонки на созданном им по умолчанию листе с пустой таблицей. Первая колонка должна содержать перечень точек вдоль оси абсцисс, которые должны присутствовать на графике с прямой линией. Поместите в верхнюю ячейку (A1) этой колонки минимальное значение вдоль оси X — например, -15.Во вторую строку колонки введите знак равенства, затем кликните указателем мыши на предыдущую ячейку, введите знак плюс и наберите число, соответствующее величине приращения для каждой последующей точки по оси абсцисс. Например, чтобы между точками по оси X было расстояние в 2,5 пункта, содержимое этой ячейки (A2) должно быть таким: =A1+2,5. Чтобы закончить ввод формулы используйте клавишу Enter.Наведите указатель мыши на правый нижний угол заполненной клетки таблицы, а когда указатель трансформируется в черный плюсик, растяните ячейку вниз до последней строки колонки данных. Например, если вы хотите, чтобы прямая была построена по 15 точкам, дотащите выделение до ячейки A15.В первую строку второй колонки (B1) введите алгоритм расчета точек прямой. Скажем, если их надо вычислять по формуле y=3x-4, содержимое этой ячейки должно выглядеть так: =3*A1-4. После нажатия клавиши Enter растяните эту ячейку на всю высоту таблицы способом, который описан в предыдущем шаге.Выделите обе заполненные колонки и перейдите на вкладку «Вставка» в меню Excel. В группе команд «Диаграммы» раскройте выпадающий список «Точечная» и выберите наиболее подходящий вид графика. Сразу после этого табличный редактор рассчитает точки и поместит график в этот же лист документа.С использованием блока из трех вкладок, объединенных заголовком «Работа с диаграммами», придайте нужный вид созданному графику. Эти вкладки приложение добавляет в меню сразу после создания новой диаграммы, а позже вы можете вызвать их, выделив график щелчком мышки. Оцените статью!
Построение графиков функций в Excel
Февраль 9th, 2014
Andrey K
Построение графиков функций — одна из возможностей Excel. В этой статье мы рассмотрим процесс построение графиков некоторых математических функций: линейной, квадратичной и обратной пропорциональности.
Функция, это множество точек (x, y), удовлетворяющее выражению y=f(x). Поэтому, нам необходимо заполнить массив таких точек, а Excel построит нам на их основе график функции.
1) Рассмотрим пример построения графика линейной функции: y=5x-2
Графиком линейной функции является прямая, которую можно построить по двум точкам. Создадим табличку
В нашем случае y=5x-2. В ячейку с первым значением y введем формулу: =5*D4-2. В другую ячейку формулу можно ввести аналогично (изменив D4 на D5) или использовать маркер автозаполнения.
В итоге мы получим табличку:

Теперь можно приступать к созданию графика.
Выбираем: ВСТАВКА — > ТОЧЕЧНАЯ -> ТОЧЕЧНАЯ С ГЛАДКИМИ КРИВЫМИ И МАРКЕРАМИ (рекомендую использовать именно этот тип диаграммы)

Появиться пустая область диаграмм. Нажимаем кнопку ВЫБРАТЬ ДАННЫЕ

Выберем данные: диапазон ячеек оси абсцисс (х) и оси ординат (у). В качестве имени ряда можем ввести саму функцию в кавычках «y=5x-2» или что-то другое. Вот что получилось:

Нажимаем ОК. Перед нами график линейной функции.
2) Рассмотрим процесс построения графика квадратичной функции — параболы y=2×2-2
Параболу по двум точкам уже не построить, в отличии от прямой.
Зададим интервал на оси x, на котором будет строиться наша парабола. Выберу .
Задам шаг. Чем меньше шаг, тем точнее будет построенный график. Выберу .
Заполняю столбец со значениями х, используя маркер автозаполнения до значения х=5.

Столбец значений у рассчитывается по формуле: =2*B4^2-2. Используя маркер автозаполнения, рассчитываем значения у для остальных х.

Выбираем: ВСТАВКА — > ТОЧЕЧНАЯ -> ТОЧЕЧНАЯ С ГЛАДКИМИ КРИВЫМИ И МАРКЕРАМИ и действуем аналогично построению графика линейной функции.
Получим:

Чтобы не было точек на графике, поменяйте тип диаграммы на ТОЧЕЧНАЯ С ГЛАДКИМИ КРИВЫМИ.
Любые другие графики непрерывных функций строятся аналогично.
3) Если функция кусочная, то необходимо каждый «кусочек» графика объединить в одной области диаграмм.
Рассмотрим это на примере функции у=1/х.
Функция определена на интервалах (- беск;0) и (0; +беск)
Создадим график функции на интервалах: .
Подготовим две таблички, где х изменяется с шагом :

Находим значения функции от каждого аргумента х аналогично примерам выше.
На диаграмму вы должны добавить два ряда — для первой и второй таблички соответственно

Далее нажимаем кнопочку ДОБАВИТЬ и заполняем табличку ИЗМЕНЕНИЕ РЯДА значениями из второй таблички
 Получаем график функции y=1/x
Получаем график функции y=1/x

В дополнение привожу видео — где показан порядок действий, описанный выше.
В следующей статье расскажу как создать 3-мерные графики в Excel.
Спасибо за внимание!
Вы можете
оставить комментарий
, или
ссылку
на Ваш сайт.
Душевые термостаты, лучшие модели на
http://tools-ricambi.ru/
изготавливаются из материалов высшего качества
Приложение Microsoft Office Excel имеет встроенные инструменты, дозволяющие на основе табличных данных создавать диаграммы различных типов. График, на котором дозволено отобразить прямую линию, тут тоже отнесен к диаграммам. Есть в Excel и вероятность заполнить таблицу данными, вычисляемыми по заданной пользователем формуле, следственно задачу построения прямой с применением этой программы дозволено отнести к разряду не дюже трудных.

Вам понадобится
- Табличный редактор Microsoft Office Excel 2007 либо 2010.
Инструкция
1. Запустите Excel и заполните две колонки на сделанном им по умолчанию листе с пустой таблицей. Первая колонка должна содержать перечень точек по оси абсцисс, которые обязаны присутствовать на графике с прямой линией. Разместите в верхнюю ячейку (A1) этой колонки минимальное значение по оси X — скажем, -15.
2. Во вторую строку колонки введите знак равенства, после этого кликните указателем мыши на предыдущую ячейку, введите знак плюс и наберите число, соответствующее величине приращения для всякой дальнейшей точки по оси абсцисс. Скажем, дабы между точками по оси X было расстояние в 2,5 пункта, содержимое этой ячейки (A2) должно быть таким: =A1+2,5. Дабы завершить ввод формулы используйте клавишу Enter.
3. Наведите указатель мыши на правый нижний угол заполненной клетки таблицы, а когда указатель трансформируется в черный плюсик, растяните ячейку вниз до последней строки колонки данных. Скажем, если вы хотите, дабы прямая была построена по 15 точкам, дотащите выделение до ячейки A15.
4. В первую строку 2-й колонки (B1) введите алгорифм расчета точек прямой. Скажем, если их нужно вычислять по формуле y=3x-4, содержимое этой ячейки должно выглядеть так: =3*A1-4. Позже нажатия клавиши Enter растяните эту ячейку на всю высоту таблицы методом, тот, что описан в предыдущем шаге.
5. Выделите обе заполненные колонки и перейдите на вкладку «Вставка» в меню Excel. В группе команд «Диаграммы» раскройте выпадающий список «Точечная» и выберите особенно подходящий вид графика. Сразу позже этого табличный редактор рассчитает точки и разместит график в данный же лист документа.
6. С применением блока из 3 вкладок, объединенных заголовком «Работа с диаграммами», придайте надобный вид сделанному графику. Эти вкладки приложение добавляет в меню сразу позже создания новой диаграммы, а позднее вы можете вызвать их, выделив график щелчком мышки.
В приложении Microsoft Excel существует масса вероятностей для всесторонней обработки данных, проведения обзора и выдачи итоговых итогов в комфортном виде. Составление таблиц, диаграмм, создание функций и выдача готовых расчетов проводится дюже стремительно. Подсознательно доступный интерфейс легко понимается даже новичками-пользователями. Построение в Excel таблиц одна из самых примитивных и актуальных функций, где дозволено обширно применять все средства приложения.

Вам понадобится
- Приложение Microsoft Excel
Инструкция
1. Запустите приложение Microsoft Excel. Выделите первую строку нового листа. Увеличьте ширину строки и включите режим толстого шрифта и центрального выравнивания текста. Щелкните на первую ячейку строки. Напишите заголовок создаваемой таблицы.

2. На 2-й строке листа Excel напишите заголовки столбца. Один заголовок должен быть в одной ячейке. Раздвигайте столбцы на максимальную ширину для заполнения всей ячейки. Выделите всю строку и поставьте выравнивание во всех ее ячейках по центру.

3. Заполните все столбцы ниже наименований соответствующей информацией. Установите ячейкам формат в соответствии с внесенными в них данными. Для этого выделите мышкой группу ячеек одного формата. Щелкнув правой кнопкой мышки, откройте для выделенных ячеек контекстное меню. Выберите в нем пункт «Формат ячеек».

4. В открывшемся окне во вкладке «Число» укажите требуемое представление внесенных данных. В иных вкладках окна при желании задайте выравнивание в ячейке, цвет, шрифт и другие параметры вводимого текста.

5. При наличии в вашей таблице итоговых полей с суммирующей информацией, внесите в них формулу для подсчета данных. Для этого выделите ячейку для итоговых значений. В панели управления в поле функции поставьте знак «=». Дальше нужно указать формулу расчета. При суммировании данных из ячеек, запишите наименование ячеек в функции и поставьте знак сложения между ними. Завершив формулу, нажмите клавишу «Enter». В итоговой ячейке в таблице отобразится итог записанной формулы. Причем, итоговое значение будет механически пересчитываться при изменении значений суммируемых ячеек.
6. С поддержкой режима «Формат ячеек» установите, где это нужно, границы строк, столбцов и каждой таблицы.
7. Таблица в Excel готова, сбережете ее с поддержкой пункта меню «Файл» и дальше «Сберечь».
Прямую линию дозволено возвести по двум точкам. Координаты этих точек «спрятаны» в уравнении прямой. Уравнение расскажет о линии все секреты: как повернута, в какой стороне координатной плоскости располагается и т.д.
Инструкция
1. Почаще требуется строить прямую линию в плоскости. У всякой точки будет две координаты: х, y. Обратите внимание на уравнение прямой, оно подчиняется всеобщему виду: y=k*x ±b, где k, b — свободные числа, а y, х – те самые координаты всех точек прямой.Из уравнения всеобщего вида внятно, что для нахождения координаты y нужно знать координату х. Самое увлекательное, что значение координаты х дозволено предпочесть всякое: из каждой бесконечности вестимых чисел. Дальше подставьте х в уравнение и, решив его, обнаружьте у. Пример. Пускай дано уравнение: у=4х-3. Придумайте два всяких значения для координат 2-х точек. К примеру, х1 = 1, х2 = 5.Подставьте эти значения в уравнения для нахождения координат у. у1 = 4*1 – 3 = 1. у2 = 4*5 – 3 = 17. Получились две точки А и В, с координатами А (1; 1) и В (5; 17).
2. Следует возвести обнаруженные точки в координатной оси, объединить их и увидеть ту самую прямую, которая была описана уравнением. Для построения прямой нужно трудиться в декартовой системе координат. Начертите оси Х и У. В точке пересечения поставьте значение «нуль». Нанесите числа на оси.
3. В построенной системе подметьте две обнаруженные в 1-м шаге точки. Тезис выставления указанных точек: точка А имеет координаты х1 = 1, у1 = 1; на оси Х выберите число 1, на оси У – число 1. В этой точке и находится точка А.Точка В задана значениями х2 = 5, у2 = 17. По аналогии обнаружьте точку В на графике. Объедините А и В, дабы получилась прямая.
Видео по теме
Программа для работы с электронными таблицами Excel открывает громадные вероятности для обработки цифровой информации. Но ни одна таблица не сумеет представить процесс столь наглядно, как это сделает график функции , которой он описывается. В Excel есть и такая вероятность в пункте меню Вставка – Диаграмма (для Microsoft Office 2003).
Вам понадобится
- Программное обеспечение Microsoft Excel 2003
Инструкция
1. Откройте чистый лист книги Microsoft Excel 2003. Продумайте, с каким шагом надобно вычислять точки посторенние график а функции в таблице. Чем труднее график функции , тем меньший шаг надобно брать для больше точного построения. В первом столбце таблицы, отведенном для значений довода функции , внесите первые два наименьших значения из волнующего диапазона. Позже этого выделите их блоком при помощи «мыши».
2. Подведите курсор «мыши» к правому нижнему углу выделенного диапазона, он примет вид черного крестика. Прижмите левую кнопку и проведите вниз, остановив курсор в конце волнующего диапазона. Так получится столбец доводов функции . К примеру, если надобно получить график функции в диапазоне (-10;10) с шагом 0,5, первые два значения составят -10 и -9,5, а остановить курсор необходимо позже того, как в столбце появится число 10.
3. Для того дабы возвести столбец значений, в ячейке соседней с наименьшим значением довода установите курсор и нажмите «=». Позже этого, наберите формулу функции , взамен довода (значения «х»), непрерывно щелкая «мышью» по соседней ячейке. Позже того, как формула набрана, нажмите клавишу Enter. В ячейке появится значение функции для довода из первого столбца. Установите курсор на это значение функции . Подведя курсор «мыши» к нижнему правому углу ячейки и увидев черный крестик, протяните его до конца диапазона, прижав левую кнопку. В столбце появятся значения функции , соответствующие доводам в первом столбце.
4. Выберите в меню пункты «Вставка» – «Диаграмма». В открывшемся окне выберите «Точечная». В правой части окна выберите вид диаграммы «Точечная диаграмма со значениями, объединенными сглаживающими линиями без маркеров». Нажмите кнопку «Дальше». В открывшемся окне установите точку на пункте «Ряды в: столбцах». Щелкните по флажку, тот, что находится справа строки «Диапазон» и прижав левую кнопку «мыши» выделите каждый диапазон доводов и значений. Щелкните по вкладке того же окна «Ряд» и в строке «значения Х» «мышью» укажите диапазон доводов. Двукратно щелкните кнопу «Дальше», после этого «Готово». Полученный график будет меняться в зависимости от изменений в формуле. В иных версиях алгорифм равен и отличается только деталями.
Видео по теме
Особенно распространенная задача в геометрии – построение прямой линии. И это недаром, именно с прямой начинается построение больше трудных фигур. Координаты, которые требуются для построения, находятся в уравнении прямой.
Вам понадобится
- — карандаш либо ручка;
- — лист бумаги;
- — линейка.
Инструкция
1. Для того дабы начертить прямую , нужны две точки. Именно с них начинается построение линии. У всякой точки на плоскости есть две координаты: х и у. Они будут являться параметрами уравнения прямой: у = k*х ±b, где k и b – это свободные числа, х и у – координаты точек прямой.
2. Для того дабы обнаружить координату у, вам нужно задать некоторое значение для координаты х и подставить ее в уравнение. При этом значение координаты х может быть любым из каждой бесконечности чисел, как правильным, так и негативным. Вследствие уравнению прямой, дозволено не только возвести надобную вам прямую линию , но и узнать, под каким углом она расположена, в какой части координатной плоскости находится, является она убывающей либо вырастающей.
3. Разглядите такой пример. Пускай дано уравнение: у = 3х-2. Возьмите два всяких значения для координаты х, возможен х1 = 1, х2 = 3. Подставьте эти значения в уравнение прямой: у1 = 3*1-2 = 1, у2 = 3*3-2 = 7. В вас получатся две точки с разными координатами: А (1;1), В (3;7).
4. После этого отложите полученный точки на координатной оси, объедините их и вы увидите прямую , которую нужно было возвести по заданному уравнению. Заранее вам следует начертить в декартовой системе координат оси Х (ось абсцисс), расположенную горизонтально, и У (ось ординат), расположенную вертикально. На пересечении осей подметьте «нуль». После этого отложите числа по горизонтали и вертикали.
5. Позже этого переходите к построению. Тезис построения достаточно примитивен. Вначале подметьте первую точку А. Для этого отложите на оси Х число 1 и на оси У это же число, от того что точка А имеет координаты (1;1). Аналогичным образом постройте точку В, отложив по оси Х три единицы, а по оси У – семь. Вам останется только в поддержкой линейки объединить полученные точки и получить требуемую прямую .
Программа Microsoft Office Excel имеет уйма использований в разных областях деятельности, в том числе, такая дисциплина, как эконометрика, также задействует в работе данную программную утилиту. Фактически все действия лабораторных и фактических работы выполняются в Excel.
Инструкция
1. Для того дабы возвести регрессию , воспользуйтесь программным обеспечением Microsoft Office Excel либо его аналогами, скажем, схожей утилитой в Open Office. При этом для вычисления показателя используйте его функцию ЛИНЕЙН():(Значения_y; Значения_x; Конст; статистика).
2. Вычислите уйма точек на линии регрессии при помощи функции с наименованием «СКЛОННОСТЬ» (Значения_y; Значения_x; Новые_значения_x; Конст). Вычислите при помощи заданных чисел неведомое значение показателей m и b. Действия тут могут варьироваться в зависимости от данного вам данные задачи, следственно уточните порядок вычисления, просмотрев добавочный материал по данной теме.
3. В случае если у вас появились загвоздки с построением уравнения регрессии, используйте особую литературу по эконометрике, а также пользуйтесь дополнительны материалом тематических сайтов, скажем, лабораторные работы по данной дисциплине — Обратите внимание, что также уравнения регрессии могут быть различными, следственно обращайте внимание на дополнительную информацию в теме.
4. В случае появления у вас задач с применением программы Microsoft Office Excel скачайте особые видеоуроки по теме, которая вызывает у вас затруднения, либо запишитесь на особые обучающие курсы, которые доступны фактически для всех городов.
5. При этом удостоверитесь также, что навыки эти сгодятся вам и в будущем, от того что эконометрика нередко входит в состав программ на гуманитарных факультетах для растяжения всеобщих познаний и вряд ли сгодится в будущем, скажем, адвокатам.
Полезный совет
Постигайте вероятности Excel для вычислений.
Точка и запятая могут исполнять функции разделителя разрядов в числах, записанных в формате десятичной дроби. В большинстве англоязычных стран в качестве такого разделителя применяется точка, а в России — запятая. С этим зачастую бывает связана надобность замены точек на запятые в табличном редакторе Microsoft Office Excel.
Вам понадобится
- Табличный редактор Microsoft Office Excel.
Инструкция
1. Если в настройках вашего табличного редактора точка задана в качестве десятичного разделителя, то изменить это дозволено в одном из разделов панели установок Excel. Дабы до нее добраться, раскройте меню приложения. Это дозволено сделать, нажав клавишу Alt, а позже нее — кнопку «Ф». В меню Excel 2010 пункт «Параметры» размещен в предпоследнюю строку списка команд, а в Excel 2007 кнопка «Параметры Excel» находится в правом нижнем углу меню.
2. Выберите строку «Добавочно» в левой колонке панели настроек и в разделе «Параметры правки» обнаружьте строку «Применять системные разделители». Если в чекбоксе у этой надписи отметка стоит, то необходимое вам поле «Разграничитель целой и дробной части» редактировать немыслимо. Уберите ее, поставьте запятую в текстовое поле и нажмите кнопку OK для фиксации метаморфозы в настройках редактора.
3. Если требуется заменить точку запятой в какой-то определенной ячейке электронной таблицы, сделать это дозволено несколькими методами. Вначале выделите надобную ячейку, после этого включите режим ее редактирования — нажмите клавишу F2 либо двукратно кликните эту клетку. Переместите курсор ввода к точке и замените ее запятой. Это же дозволено сделать не в ячейке, а в строке формул — там для включения режима редактирования довольно одного щелчка.
4. Для тотального замещения запятыми всех точек во всех ячейках электронной таблицы используйте диалог поиска и замены. Для его вызова предуготовлены «жгучие клавиши» Ctrl + H и пункт «Заменить» в выпадающем списке кнопки «Обнаружить и выделить» — она размещена в группу команд «редактирование» на вкладке «Основная».
5. В поле «Обнаружить» диалога поиска и замены поставьте точку, а запятую — в поле «Заменить на». Если использования этой операции только на нынешнем листе документа будет довольно, нажмите кнопку «Заменить все» и Excel приступит к выполнению команды. Для замены на всех листах открытого документа нажмите кнопку «Параметры», установите значение «в книге» в выпадающем списке у надписи «Искать» и лишь позже этого кликните по кнопке «Заменить все».
В программе Microsoft Office Excel дозволено создавать диаграммы разных типов. Гистограмма – это диаграмма, в которой данные представлены в виде вертикальных столбиков разной высоты, значения для которых берутся из заданных ячеек.
Инструкция
1. Запустите приложение Excel и введите данные, на основании которых будет сделана столбиковая диаграмма. Выделите надобный диапазон ячеек, включая наименования строк и столбцов, которые позднее будут использованы в легенде диаграммы.
2. Перейдите на вкладку «Вставка». На стандартной панели инструментов в разделе «Диаграммы» нажмите на кнопку-миниатюру «Гистограмма». В выпадающем меню выберите из предложенных вариантов тот пример, тот, что класснее каждого подойдет для ваших целей. Гистограмма может быть конической, пирамидальной, цилиндрической либо выглядеть, как обыкновенный прямоугольный столбик.
3. Выделите сделанную гистограмму , кликнув по ней левой кнопкой мыши. Станет доступно контекстное меню «Работа с диаграммами» с тремя вкладками: «Конструктор», «Макет» и «Формат». Дабы настроить вид диаграммы по своему усмотрению – изменить тип, расположить данные в ином порядке, предпочесть подходящий жанр оформления – воспользуйтесь вкладкой «Конструктор».
4. На вкладке «Макет» отредактируйте содержимое гистограммы: присвойте наименование диаграмме и осям координат, задайте метод отображения сетки и так дальше. Часть операций дозволено исполнить в окне самой диаграммы. Кликните, к примеру, по полю «Наименование диаграммы» левой кнопкой мыши, указанная область будет выделена. Удалите имеющийся текст и введите свой личный. Дабы выйти из режима редактирования выбранного поля, кликните левой кнопкой мыши в любом месте вне границ выделения.
5. С поддержкой вкладки «Формат» настройте размеры гистограммы, подберите цвет, силуэт и результаты для фигур, применяя соответствующие разделы на панели инструментов. Часть операций с диаграммой также может быть исполнена с поддержкой мыши. Так, дабы изменить размер области гистограммы, вы можете либо воспользоваться разделом «Размер», либо подвести курсор к углу диаграммы и, удерживая нажатой левую кнопку мыши, потянуть силуэт в надобную сторону.
6. Также для настройки гистограммы дозволено воспользоваться контекстным меню, вызываемым через щелчок правой кнопкой мыши по области гистограммы. Если выделена диаграмма целиком, будут доступны всеобщие настройки. Дабы отредактировать определенную группу данных, вначале выделите ее, тогда в выпадающем меню появятся опции для выделенного фрагмента.
Программа MS Excel, даже не будучи полновесным статистическим пакетом, владеет достаточно огромным спектром вероятностей по прогнозированию событий на основе теснее имеющихся данных. Одним из особенно примитивных, на 1-й взор, методов такого предсказания является построение линии тренда.
Инструкция
1. Проще каждого возвести график функции тренда непринужденно сразу позже внесения имеющихся данных в массив. Для этого на листе с таблицей данных выделите не менее 2-х ячеек диапазона, для которого будет построен график, и сразу позже этого вставьте диаграмму. Вы можете воспользоваться такими видами диаграмм, как график, точечная, гистограмма, пузырьковая, биржевая. Остальные виды диаграмм не поддерживают функцию построения тренда.
2. В меню «Диаграмма» выберите пункт «Добавить линию тренда». В открывшемся окне на вкладке «Тип» выберите нужный тип линии тренда, что в математическом эквиваленте также обозначает и метод аппроксимации данных. При применении описываемого способа вам придется делать это «на глаз», т.к. никаких математических вычислений для построения графика вы не проводили.
3. Следственно примитивно прикиньте, какому типу функции больше каждого соответствует график имеющихся данных: линейной, логарифмической, экспоненциальной, степенной либо другой. Если же вы сомневаетесь в выборе типа аппроксимации, можете возвести несколько линий, а для большей точности прогноза на вкладке «Параметры» этого же окна подметить флажком пункт «разместить на диаграмму величину достоверности аппроксимации (R^2)».
4. Сопоставляя значения R^2 для различных линий, вы сумеете предпочесть тот тип графика, тот, что характеризует ваши данные особенно верно, а, следственно, строит особенно подлинный прогноз. Чем ближе значение R^2 к единице, тем вернее вы предпочли тип линии. Тут же, на вкладке «Параметры», вам нужно указать период, на тот, что делается прогноз.
5. Такой метод построения тренда является крайне примерным, следственно отличнее все-таки произвести правда бы самую простую статистическую обработку имеющихся данных. Это дозволит возвести прогноз больше верно.
6. Если вы полагаете, что имеющиеся данные описываются линейным уравнением, примитивно выделите их курсором и произведите автозаполнение на нужное число периодов, либо число ячеек. В данном случае нет необходимости находить значение R^2, т.к. вы предварительно подогнали прогноз к уравнению прямой.
7. Если же вы считаете, что вестимые значения переменной класснее каждого могут быть описаны с поддержкой экспоненциального уравнения, также выделите начальный диапазон и произведите автозаполнение нужного числа ячеек, удерживая правую клавишу мыши. При помощи автозаполнения вы не сумеете возвести других типов линий, помимо 2-х указанных.
8. Следственно для наибольшей точности построения прогноза вам придется воспользоваться одной из нескольких статистических функций: «ПРЕДСКАЗ», «СКЛОННОСТЬ», «РОСТ», «ЛИНЕЙН» либо «ЛГРФПРИБЛ». В этом случае вам придется высчитывать значение для всякого дальнейшего периода прогноза вручную. Если вам нужно произвести больше трудный регрессионный обзор данных, вам потребуется надстройка «Пакет обзора», которая не входит в стандартную установку MS Office.
Видео по теме
Чуть ранее мы уже писали, как красиво оформить нулевые/пустые значения на графике, чтобы диаграмма не получалась «зубчатой». Помимо этого, для лучшей визуализации информации иногда нужно сделать сглаживание графика в Excel. Как это сделать? Читайте ниже
Сразу хотел бы написать где можно почитать, как создавать графики — тут и тут. Далее разберем как сделать линию графика чуть более красивее.
Сглаживание графика в Excel. Как быстро сделать?
Часто соединения узлов графика выглядят некрасиво, если линии на графике расположены под острыми углами. Как сделать плавную линию? Правой кнопкой мыши нажимаем на сам график — выплывает окно —
Формат ряда данных (см. первую картинку) выбираем — пункт Тип линии -ставим галочку — Сглаженная линия
Теперь линия сгладилась.
Экспоненциальное сглаживание в Excel
В Excel можно подключить пакет анализа для сглаживания самих данных.
Такое сглаживание это метод применяемый для сглаживания временных рядом — статья википедии
Зайдите в меню — Параметры Excel — Надстройки — Пакет анализа (в правом окне) и в самом низу нажимайте Перейти
В открывшемся окне находим Экспоненциальное сглаживание.
Как найти прямую приближенных значений
Всегда можно построить линию приближенных значений — линию тренда — она покажет куда идет динамика графика, какое направление имеют события графика
Поделитесь нашей статьей в ваших соцсетях:
(Visited 15 074 times, 34 visits today)
Простая линейная регрессия — это метод, который мы можем использовать для понимания взаимосвязи между объясняющей переменной x и переменной отклика y.
В этом руководстве объясняется, как выполнить простую линейную регрессию в Excel.
Пример: простая линейная регрессия в Excel
Предположим, нас интересует взаимосвязь между количеством часов, которое студент тратит на подготовку к экзамену, и полученной им экзаменационной оценкой.
Чтобы исследовать эту взаимосвязь, мы можем выполнить простую линейную регрессию, используя часы обучения в качестве независимой переменной и экзаменационный балл в качестве переменной ответа.
Выполните следующие шаги в Excel, чтобы провести простую линейную регрессию.
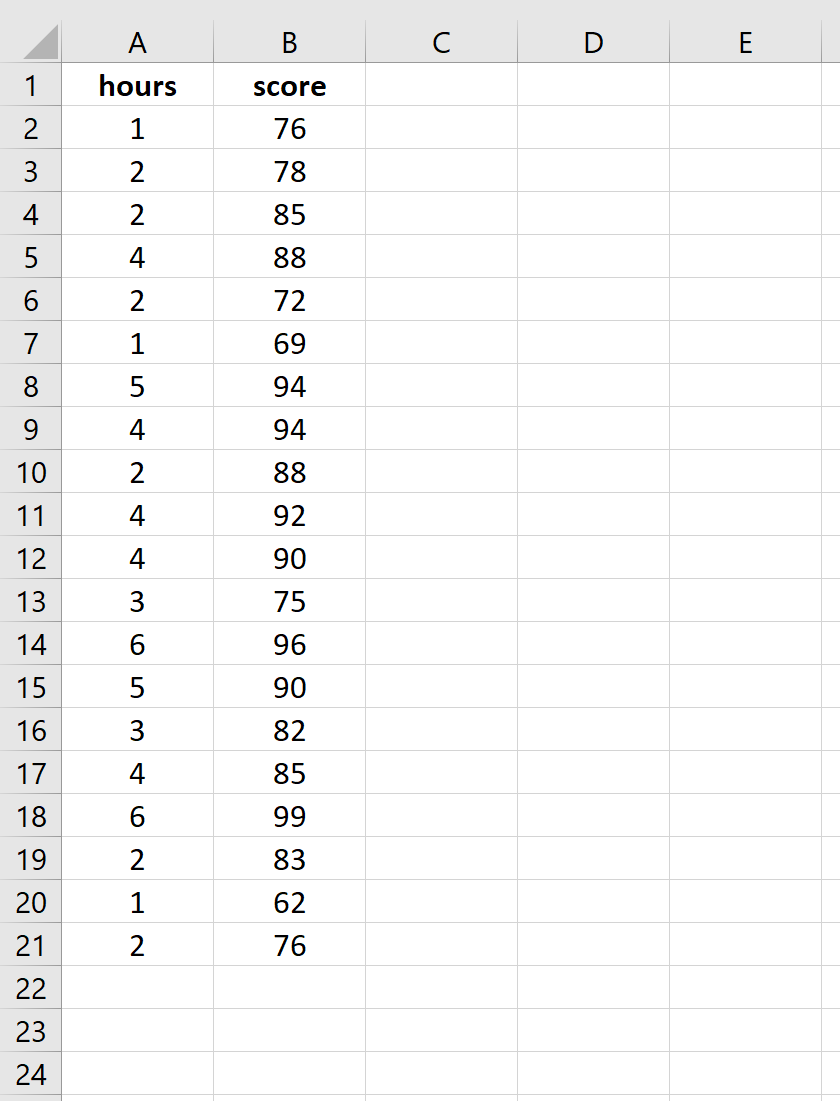
Шаг 1: Введите данные.
Введите следующие данные о количестве часов обучения и экзаменационном балле, полученном для 20 студентов:
Шаг 2: Визуализируйте данные.
Прежде чем мы выполним простую линейную регрессию, полезно создать диаграмму рассеяния данных, чтобы убедиться, что действительно существует линейная зависимость между отработанными часами и экзаменационным баллом.
Выделите данные в столбцах A и B. В верхней ленте Excel перейдите на вкладку « Вставка ». В группе « Диаграммы » нажмите « Вставить разброс» (X, Y) и выберите первый вариант под названием « Разброс ». Это автоматически создаст следующую диаграмму рассеяния:
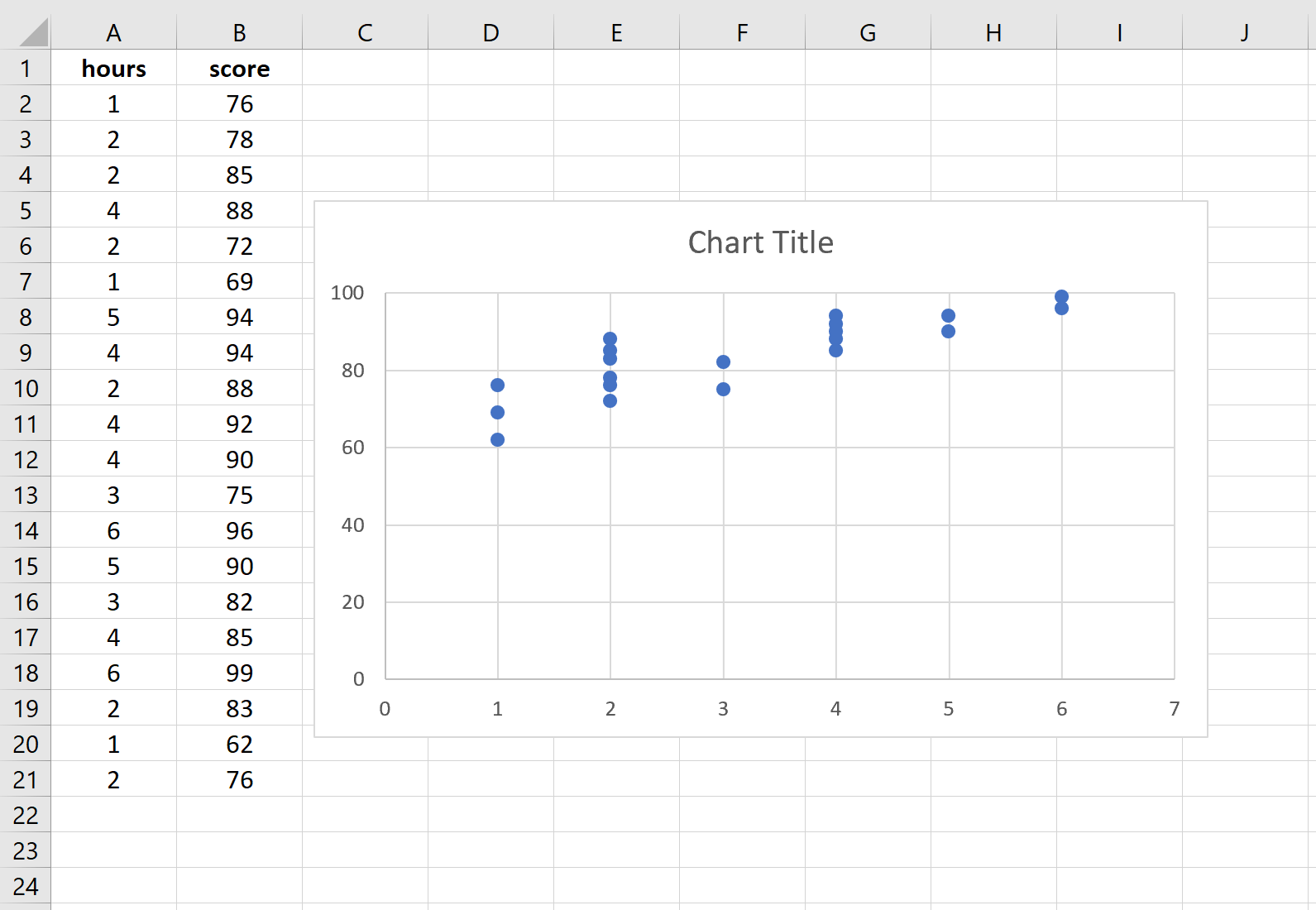
Количество часов обучения показано на оси x, а баллы за экзамены показаны на оси y. Мы видим, что между двумя переменными существует линейная зависимость: большее количество часов обучения связано с более высокими баллами на экзаменах.
Чтобы количественно оценить взаимосвязь между этими двумя переменными, мы можем выполнить простую линейную регрессию.
Шаг 3: Выполните простую линейную регрессию.
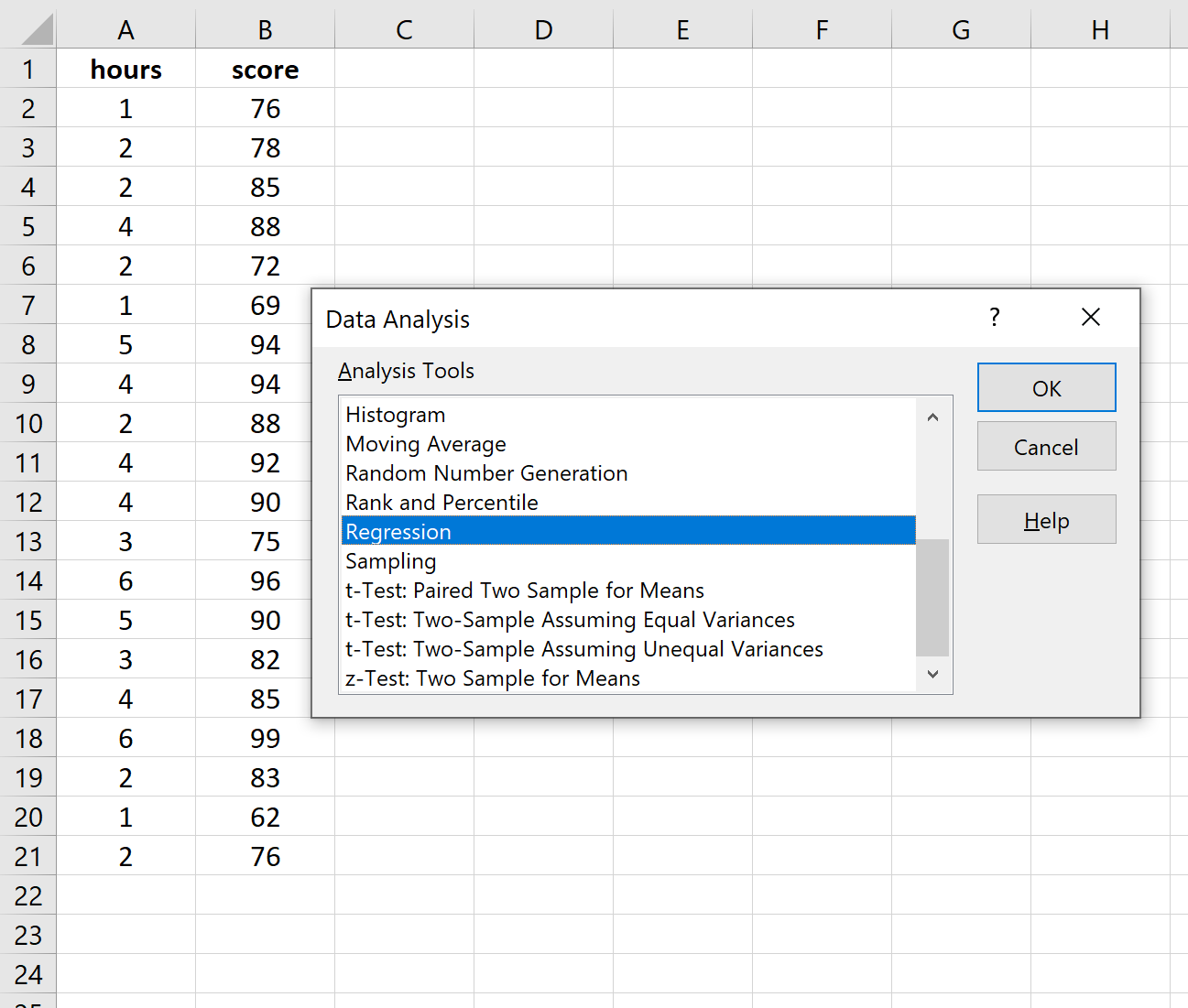
В верхней ленте Excel перейдите на вкладку « Данные » и нажмите « Анализ данных».Если вы не видите эту опцию, вам необходимо сначала установить бесплатный пакет инструментов анализа .

Как только вы нажмете « Анализ данных», появится новое окно. Выберите «Регрессия» и нажмите «ОК».
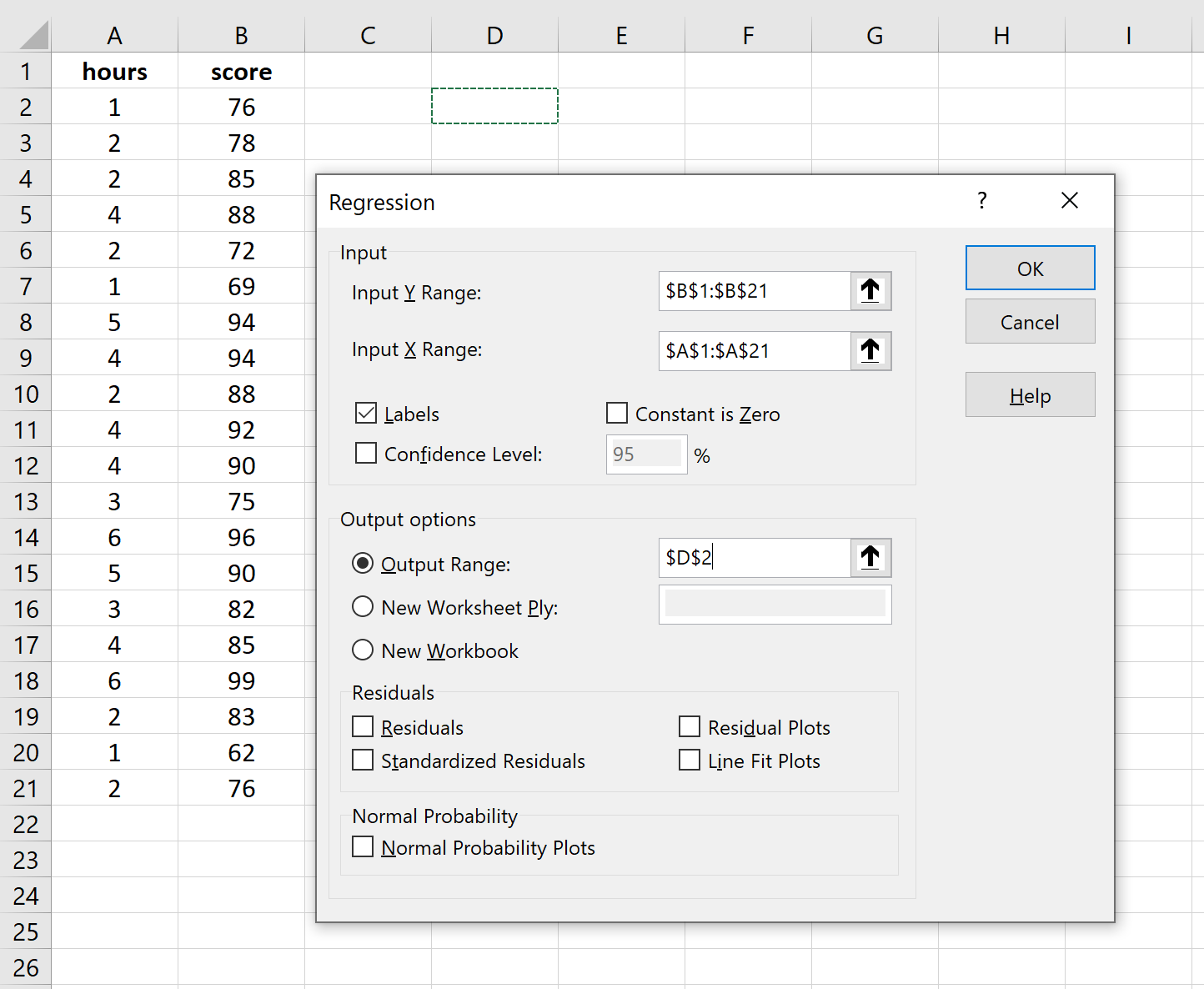
Для Input Y Range заполните массив значений для переменной ответа. Для Input X Range заполните массив значений для независимой переменной.
Установите флажок рядом с Метки , чтобы Excel знал, что мы включили имена переменных во входные диапазоны.
В поле Выходной диапазон выберите ячейку, в которой должны отображаться выходные данные регрессии.
Затем нажмите ОК .
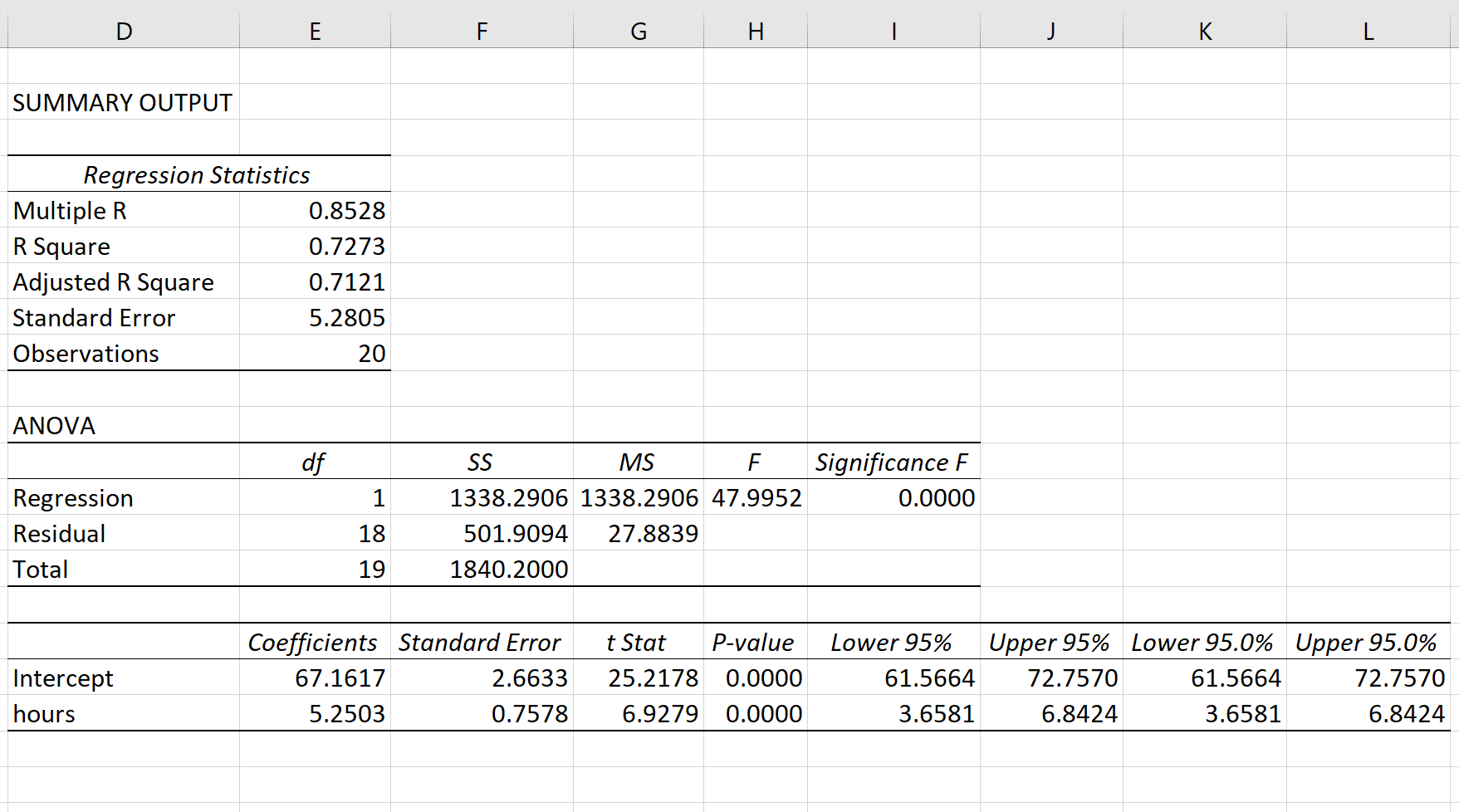
Автоматически появится следующий вывод:
Шаг 4: Интерпретируйте вывод.
Вот как интерпретировать наиболее релевантные числа в выводе:
R-квадрат: 0,7273.Это известно как коэффициент детерминации. Это доля дисперсии переменной отклика, которая может быть объяснена объясняющей переменной. В этом примере 72,73 % различий в баллах за экзамены можно объяснить количеством часов обучения.
Стандартная ошибка: 5.2805.Это среднее расстояние, на которое наблюдаемые значения отходят от линии регрессии. В этом примере наблюдаемые значения отклоняются от линии регрессии в среднем на 5,2805 единиц.
Ф: 47,9952.Это общая F-статистика для регрессионной модели, рассчитанная как MS регрессии / остаточная MS.
Значение F: 0,0000.Это p-значение, связанное с общей статистикой F. Он говорит нам, является ли регрессионная модель статистически значимой. Другими словами, он говорит нам, имеет ли независимая переменная статистически значимую связь с переменной отклика. В этом случае p-значение меньше 0,05, что указывает на наличие статистически значимой связи между отработанными часами и полученными экзаменационными баллами.
Коэффициенты: коэффициенты дают нам числа, необходимые для написания оценочного уравнения регрессии. В этом примере оцененное уравнение регрессии:
экзаменационный балл = 67,16 + 5,2503*(часов)
Мы интерпретируем коэффициент для часов как означающий, что за каждый дополнительный час обучения ожидается увеличение экзаменационного балла в среднем на 5,2503.Мы интерпретируем коэффициент для перехвата как означающий, что ожидаемая оценка экзамена для студента, который учится без часов, составляет 67,16 .
Мы можем использовать это оценочное уравнение регрессии для расчета ожидаемого экзаменационного балла для учащегося на основе количества часов, которые он изучает.
Например, ожидается, что студент, который занимается три часа, получит на экзамене 82,91 балла:
экзаменационный балл = 67,16 + 5,2503*(3) = 82,91
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в Excel:
Как создать остаточный график в Excel
Как построить интервал прогнозирования в Excel
Как создать график QQ в Excel
Для наглядной иллюстрации тенденций изменения цены применяется линия тренда. Элемент технического анализа представляет собой геометрическое изображение средних значений анализируемого показателя.
Рассмотрим, как добавить линию тренда на график в Excel.
Добавление линии тренда на график
Для примера возьмем средние цены на нефть с 2000 года из открытых источников. Данные для анализа внесем в таблицу:
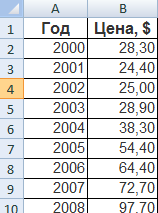
- Построим на основе таблицы график. Выделим диапазон – перейдем на вкладку «Вставка». Из предложенных типов диаграмм выберем простой график. По горизонтали – год, по вертикали – цена.
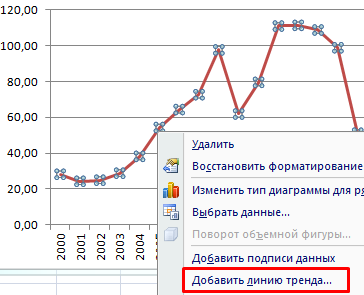
- Щелкаем правой кнопкой мыши по самому графику. Нажимаем «Добавить линию тренда».
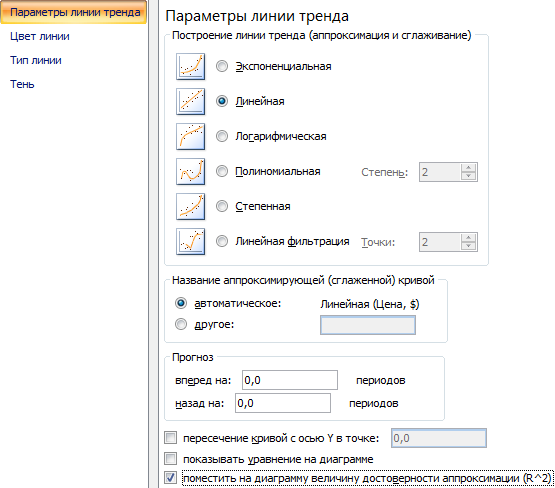
- Открывается окно для настройки параметров линии. Выберем линейный тип и поместим на график величину достоверности аппроксимации.
- На графике появляется косая линия.
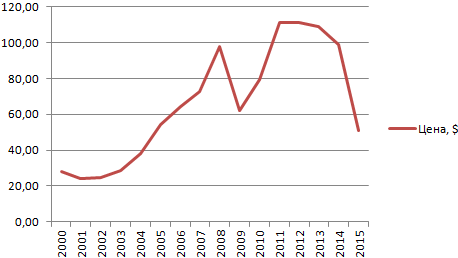
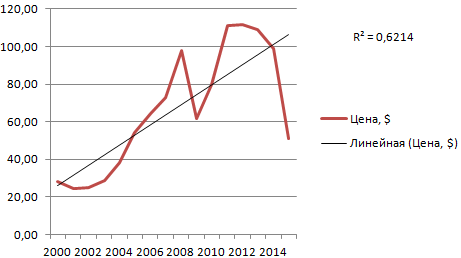
Линия тренда в Excel – это график аппроксимирующей функции. Для чего он нужен – для составления прогнозов на основе статистических данных. С этой целью необходимо продлить линию и определить ее значения.
Если R2 = 1, то ошибка аппроксимации равняется нулю. В нашем примере выбор линейной аппроксимации дал низкую достоверность и плохой результат. Прогноз будет неточным.
Внимание!!! Линию тренда нельзя добавить следующим типам графиков и диаграмм:
- лепестковый;
- круговой;
- поверхностный;
- кольцевой;
- объемный;
- с накоплением.
Уравнение линии тренда в Excel
В предложенном выше примере была выбрана линейная аппроксимация только для иллюстрации алгоритма. Как показала величина достоверности, выбор был не совсем удачным.
Следует выбирать тот тип отображения, который наиболее точно проиллюстрирует тенденцию изменений вводимых пользователем данных. Разберемся с вариантами.
Линейная аппроксимация
Ее геометрическое изображение – прямая. Следовательно, линейная аппроксимация применяется для иллюстрации показателя, который растет или уменьшается с постоянной скоростью.
Рассмотрим условное количество заключенных менеджером контрактов на протяжении 10 месяцев:
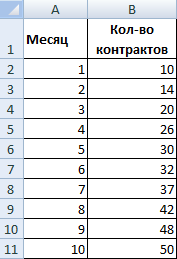
На основании данных в таблице Excel построим точечную диаграмму (она поможет проиллюстрировать линейный тип):
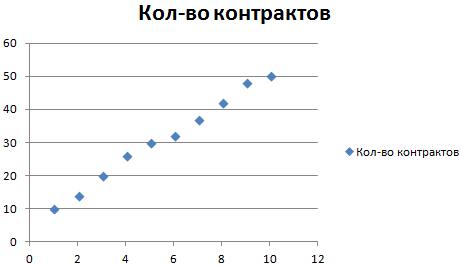
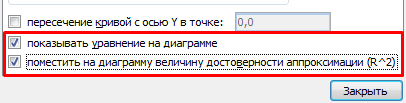
Выделяем диаграмму – «добавить линию тренда». В параметрах выбираем линейный тип. Добавляем величину достоверности аппроксимации и уравнение линии тренда в Excel (достаточно просто поставить галочки внизу окна «Параметры»).
Получаем результат:
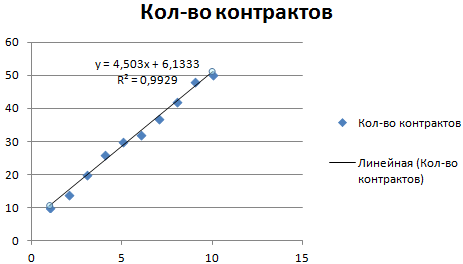
Обратите внимание! При линейном типе аппроксимации точки данных расположены максимально близко к прямой. Данный вид использует следующее уравнение:
y = 4,503x + 6,1333
- где 4,503 – показатель наклона;
- 6,1333 – смещения;
- y – последовательность значений,
- х – номер периода.
Прямая линия на графике отображает стабильный рост качества работы менеджера. Величина достоверности аппроксимации равняется 0,9929, что указывает на хорошее совпадение расчетной прямой с исходными данными. Прогнозы должны получиться точными.
Чтобы спрогнозировать количество заключенных контрактов, например, в 11 периоде, нужно подставить в уравнение число 11 вместо х. В ходе расчетов узнаем, что в 11 периоде этот менеджер заключит 55-56 контрактов.
Экспоненциальная линия тренда
Данный тип будет полезен, если вводимые значения меняются с непрерывно возрастающей скоростью. Экспоненциальная аппроксимация не применяется при наличии нулевых или отрицательных характеристик.
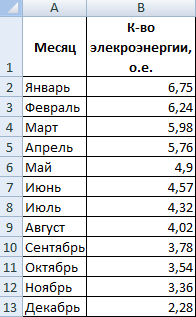
Построим экспоненциальную линию тренда в Excel. Возьмем для примера условные значения полезного отпуска электроэнергии в регионе Х:
Строим график. Добавляем экспоненциальную линию.
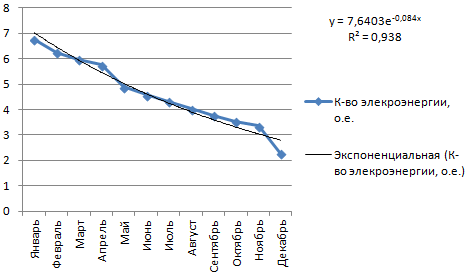
Уравнение имеет следующий вид:
y = 7,6403е^-0,084x
- где 7,6403 и -0,084 – константы;
- е – основание натурального логарифма.
Показатель величины достоверности аппроксимации составил 0,938 – кривая соответствует данным, ошибка минимальна, прогнозы будут точными.
Логарифмическая линия тренда в Excel
Используется при следующих изменениях показателя: сначала быстрый рост или убывание, потом – относительная стабильность. Оптимизированная кривая хорошо адаптируется к подобному «поведению» величины. Логарифмический тренд подходит для прогнозирования продаж нового товара, который только вводится на рынок.
На начальном этапе задача производителя – увеличение клиентской базы. Когда у товара будет свой покупатель, его нужно удержать, обслужить.
Построим график и добавим логарифмическую линию тренда для прогноза продаж условного продукта:
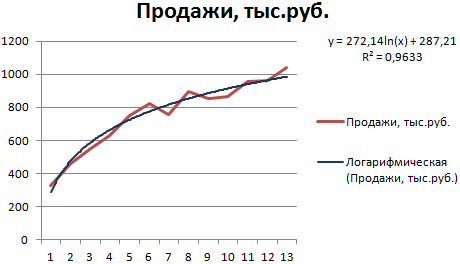
R2 близок по значению к 1 (0,9633), что указывает на минимальную ошибку аппроксимации. Спрогнозируем объемы продаж в последующие периоды. Для этого нужно в уравнение вместо х подставлять номер периода.
Например:
| Период | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| Прогноз | 1005,4 | 1024,18 | 1041,74 | 1058,24 | 1073,8 | 1088,51 | 1102,47 |
Для расчета прогнозных цифр использовалась формула вида: =272,14*LN(B18)+287,21. Где В18 – номер периода.
Полиномиальная линия тренда в Excel
Данной кривой свойственны переменные возрастание и убывание. Для полиномов (многочленов) определяется степень (по количеству максимальных и минимальных величин). К примеру, один экстремум (минимум и максимум) – это вторая степень, два экстремума – третья степень, три – четвертая.
Полиномиальный тренд в Excel применяется для анализа большого набора данных о нестабильной величине. Посмотрим на примере первого набора значений (цены на нефть).
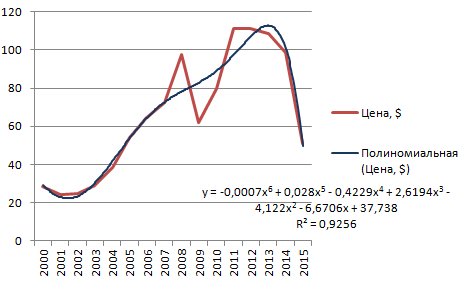
Чтобы получить такую величину достоверности аппроксимации (0,9256), пришлось поставить 6 степень.
Скачать примеры графиков с линией тренда

Зато такой тренд позволяет составлять более-менее точные прогнозы.
В Excel есть встроенные функции, которые можно использовать для отображения данных калибровки и расчета линии наилучшего соответствия. Это может быть полезно, когда вы пишете отчет о химической лаборатории или программируете поправочный коэффициент для единицы оборудования.
В этой статье мы рассмотрим, как с помощью Excel создать диаграмму, построить линейную калибровочную кривую, отобразить формулу калибровочной кривой, а затем настроить простые формулы с функциями НАКЛОН и ПЕРЕСЕЧЕНИЕ, чтобы использовать уравнение калибровки в Excel.
Чтобы выполнить калибровку, вы сравниваете показания устройства (например, температуру, отображаемую термометром) с известными значениями, называемыми стандартами (например, точки замерзания и кипения воды). Это позволяет вам создать серию пар данных, которые затем вы будете использовать для построения калибровочной кривой.
Двухточечная калибровка термометра с использованием точек замерзания и кипения воды будет иметь две пары данных: одну, когда термометр помещают в ледяную воду (32 ° F или 0 ° C), и одну в кипящую воду (212 ° F). или 100 ° C). Когда вы наносите эти две пары данных в виде точек и проводите линию между ними (калибровочная кривая), а затем, предполагая, что реакция термометра является линейной, вы можете выбрать любую точку на линии, которая соответствует значению, отображаемому термометром, и вы смог найти соответствующую «истинную» температуру.
Таким образом, линия по существу заполняет информацию между двумя известными точками для вас, чтобы вы могли быть достаточно уверены при оценке фактической температуры, когда термометр показывает 57,2 градуса, но когда вы никогда не измеряли «стандарт», который соответствует это чтение.
В Excel есть функции, которые позволяют графически отображать пары данных на диаграмме, добавлять линию тренда (калибровочную кривую) и отображать уравнение калибровочной кривой на диаграмме. Это полезно для визуального отображения, но вы также можете вычислить формулу линии, используя функции НАКЛОН и ПЕРЕСЕЧЕНИЕ Excel. Когда вы вводите эти значения в простые формулы, вы сможете автоматически рассчитать «истинное» значение на основе любого измерения.
Давайте посмотрим на пример
В этом примере мы построим калибровочную кривую из серии из десяти пар данных, каждая из которых состоит из значения X и значения Y. Значения X будут нашими «стандартами», и они могут представлять что угодно, от концентрации химического раствора, который мы измеряем с помощью научного инструмента, до входной переменной программы, которая управляет машиной для запуска мрамора.
Значения Y будут «откликами», и они будут представлять показания прибора, предоставленные при измерении каждого химического раствора, или измеренное расстояние, на котором от пусковой установки приземлился шарик с использованием каждого входного значения.
После того, как мы графически изобразим калибровочную кривую, мы будем использовать функции НАКЛОН и ПЕРЕСЕЧЕНИЕ, чтобы вычислить формулу калибровочной линии и определить концентрацию «неизвестного» химического раствора на основе показаний прибора или решить, какие входные данные мы должны дать программе, чтобы мрамор приземляется на определенном расстоянии от пусковой установки.
Шаг первый: создайте свою диаграмму
Наша простая таблица-пример состоит из двух столбцов: X-Value и Y-Value.
Начнем с выбора данных для отображения на диаграмме.
Сначала выберите ячейки столбца «X-Value».
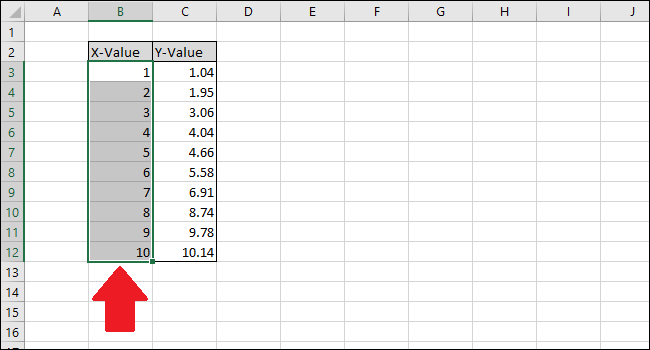
Теперь нажмите клавишу Ctrl и щелкните ячейки столбца Y-Value.
Перейдите на вкладку «Вставка».
Перейдите в меню «Графики» и выберите первую опцию в раскрывающемся списке «Точечный».
Выберите серию, щелкнув одну из синих точек. После выбора Excel обрисовывает в общих чертах точки.
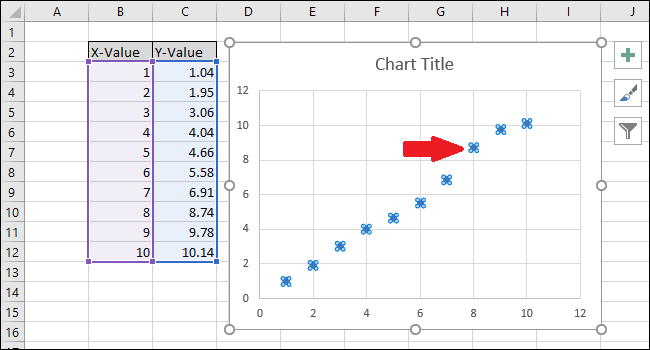
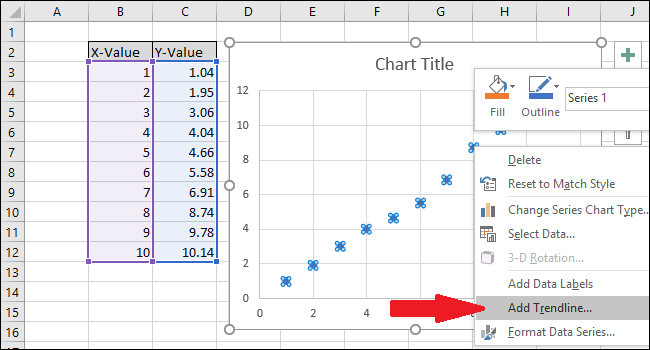
Щелкните правой кнопкой мыши одну из точек и выберите параметр «Добавить линию тренда».
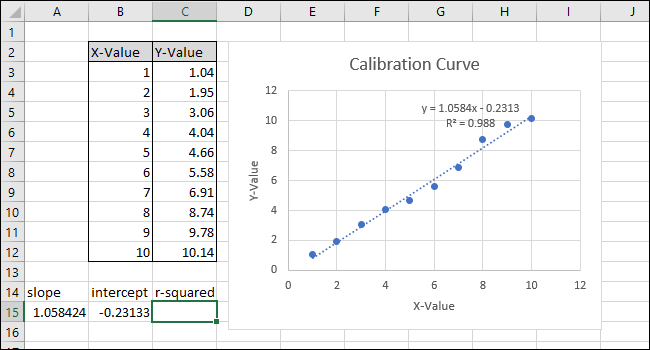
На графике появится прямая линия.
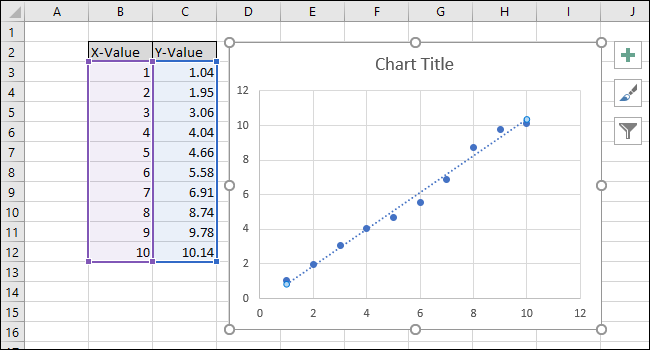
В правой части экрана появится меню «Форматировать линию тренда». Установите флажки рядом с «Отображать уравнение на диаграмме» и «Отображать значение R-квадрата на диаграмме». Значение R-квадрата — это статистика, которая показывает, насколько точно линия соответствует данным. Наилучшее значение R-квадрата составляет 1.000, что означает, что каждая точка данных касается линии. По мере того, как разница между точками данных и линией увеличивается, значение r-квадрата уменьшается, при этом 0,000 является наименьшим возможным значением.
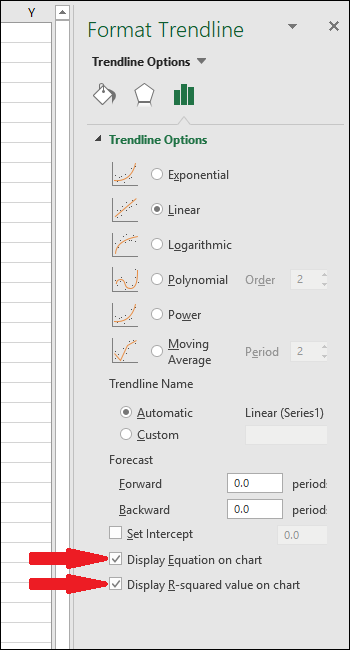
Уравнение и статистика R-квадрата линии тренда появятся на графике. Обратите внимание, что корреляция данных в нашем примере очень хорошая, со значением R-квадрат 0,988.
Уравнение имеет вид «Y = Mx + B», где M — наклон, а B — точка пересечения прямой линии с осью Y.
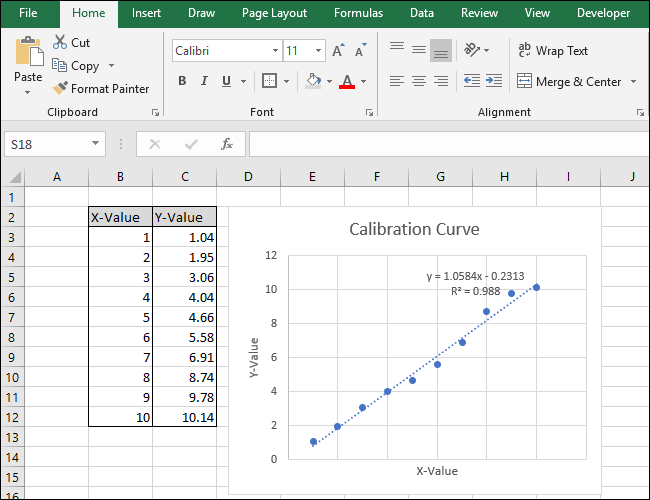
Теперь, когда калибровка завершена, давайте поработаем над настройкой диаграммы, отредактировав заголовок и добавив заголовки осей.
Чтобы изменить заголовок диаграммы, щелкните по нему, чтобы выделить текст.
Теперь введите новый заголовок, описывающий диаграмму.
Чтобы добавить заголовки к осям x и y, сначала перейдите в Инструменты диаграммы> Дизайн.
Теперь перейдите к Названиям осей> Первичный горизонтальный.
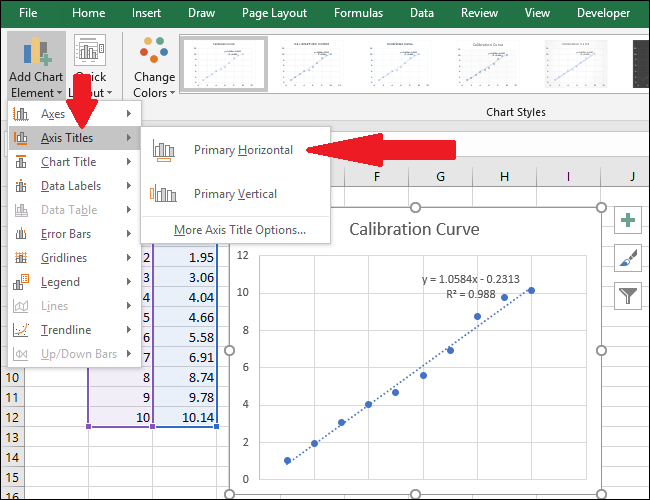 основная горизонтальная «ширина =» 650 «высота =» 500 «onload =» pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this); » onerror = ”this.onerror = null; pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);”>
основная горизонтальная «ширина =» 650 «высота =» 500 «onload =» pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this); » onerror = ”this.onerror = null; pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);”>
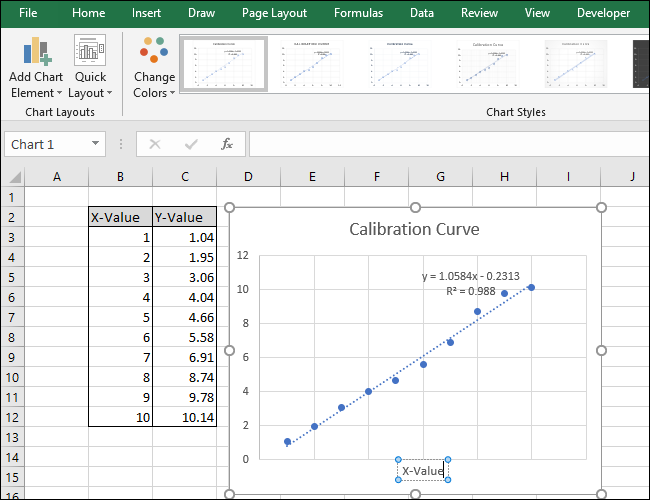
Появится заголовок оси.
Чтобы переименовать заголовок оси, сначала выберите текст, а затем введите новый заголовок.
Теперь перейдите в Названия осей> Основная вертикаль.
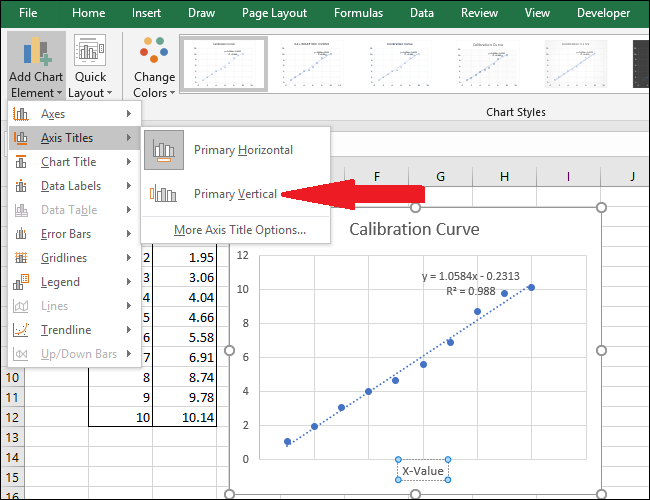
Появится название оси.
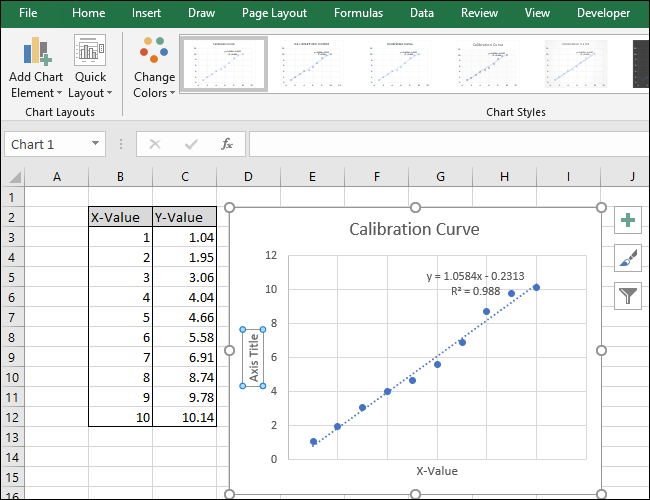
Переименуйте этот заголовок, выделив текст и введя новый заголовок.
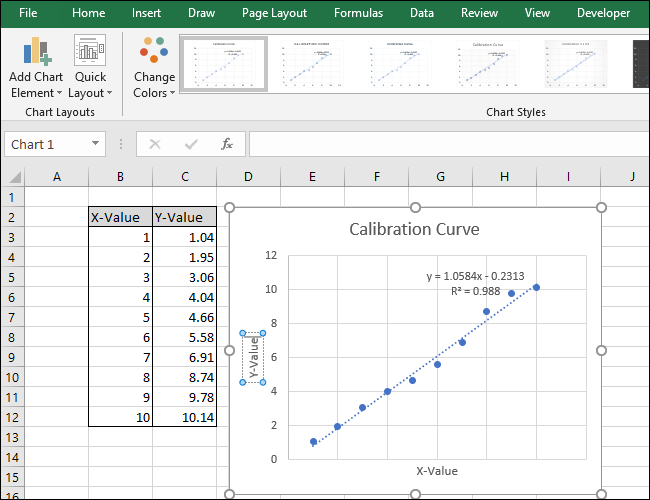
Теперь ваша диаграмма завершена.
Шаг второй: вычислить линейное уравнение и статистику R-квадрат
Теперь давайте рассчитаем линейное уравнение и статистику R-квадрата, используя встроенные в Excel функции НАКЛОН, ПЕРЕСЕЧЕНИЕ и КОРРЕЛЬ.
К нашему листу (в строке 14) мы добавили заголовки для этих трех функций. Мы выполним фактические вычисления в ячейках под этими заголовками.
Сначала мы рассчитаем НАКЛОН. Выберите ячейку A15.
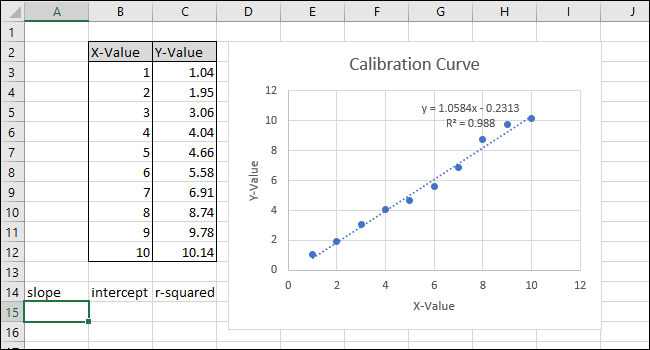
Перейдите к формулам> Дополнительные функции> Статистические данные> НАКЛОН.
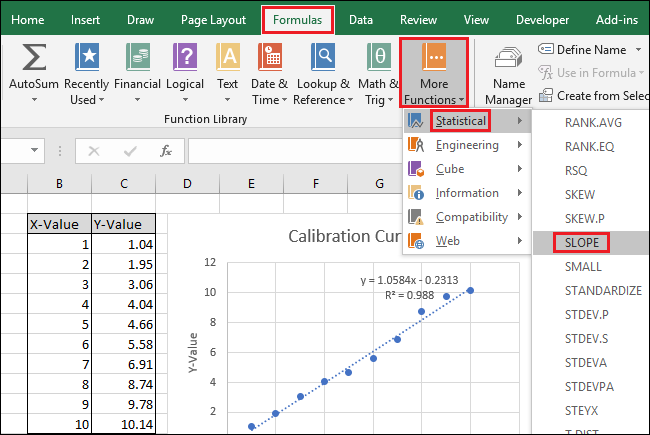
В поле «Known_xs» выберите или введите значения в ячейках столбца X-Value. Порядок полей Known_ys и Known_xs имеет значение в функции SLOPE.
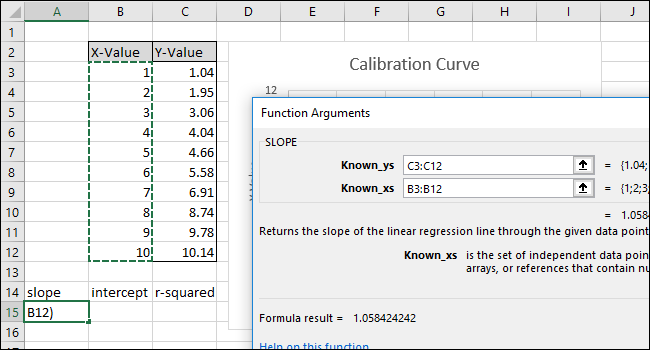
Нажмите «ОК». Окончательная формула в строке формул должна выглядеть так:
= НАКЛОН (C3: C12; B3: B12)
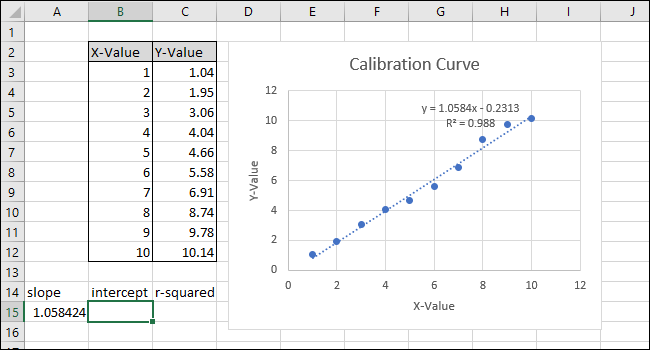
Обратите внимание, что значение, возвращаемое функцией НАКЛОН в ячейке A15, соответствует значению, отображаемому на диаграмме.
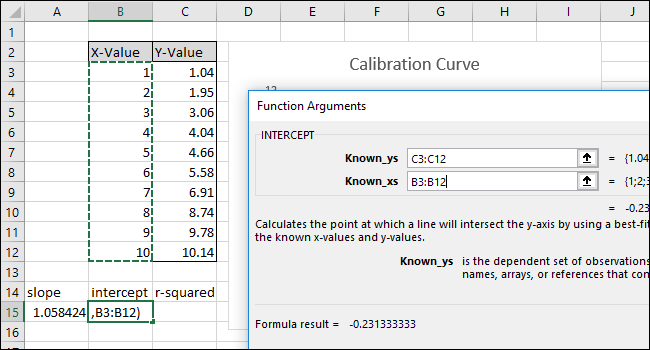
Затем выберите ячейку B15 и перейдите в раздел Формулы> Дополнительные функции> Статистические данные> ПЕРЕСЕЧЕНИЕ.
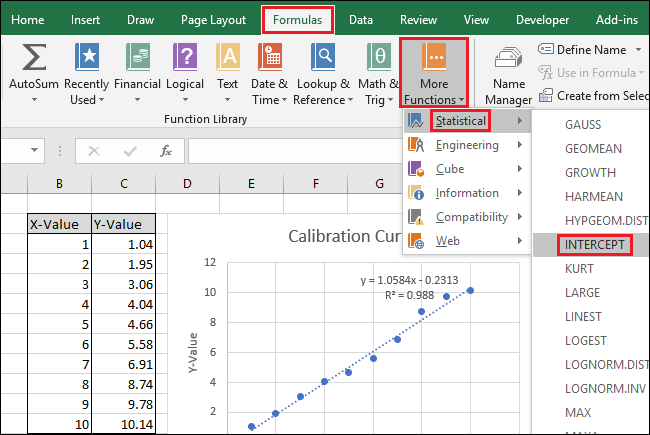
Выберите или введите ячейки столбца X-Value для поля «Known_xs». Порядок полей «Known_ys» и «Known_xs» также имеет значение в функции INTERCEPT.
Нажмите «ОК». Окончательная формула в строке формул должна выглядеть так:
= ПЕРЕСЕЧЕНИЕ (C3: C12; B3: B12)
Обратите внимание, что значение, возвращаемое функцией ПЕРЕСЕЧЕНИЕ, совпадает с точкой пересечения оси Y, отображаемой на диаграмме.
Затем выберите ячейку C15 и перейдите в раздел Формулы> Дополнительные функции> Статистические данные> CORREL.
Выберите или введите другой из двух диапазонов ячеек для поля «Массив2».
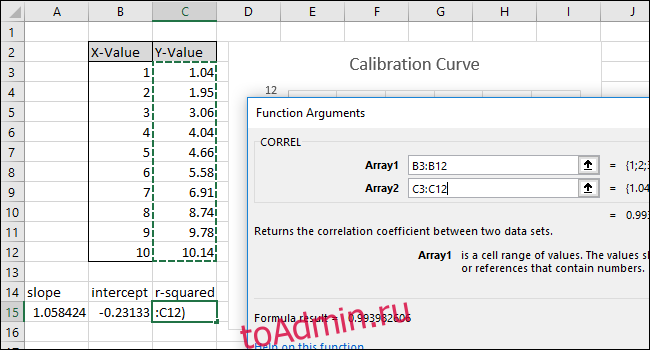
Нажмите «ОК». Формула в строке формул должна выглядеть так:
= КОРРЕЛ (B3: B12; C3: C12)
Обратите внимание, что значение, возвращаемое функцией CORREL, не соответствует значению «r-квадрат» на диаграмме. Функция КОРРЕЛ возвращает «R», поэтому мы должны возвести его в квадрат, чтобы вычислить «R-квадрат».
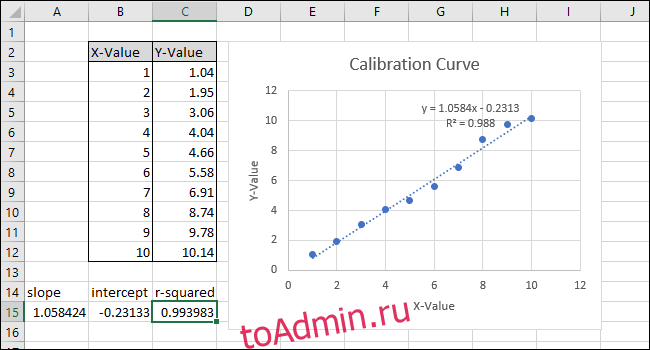
Щелкните внутри функциональной панели и добавьте «^ 2» в конец формулы, чтобы возвести в квадрат значение, возвращаемое функцией CORREL. Заполненная формула должна теперь выглядеть так:
= КОРРЕЛ (B3: B12; C3: C12) ^ 2
Нажмите Ввод.
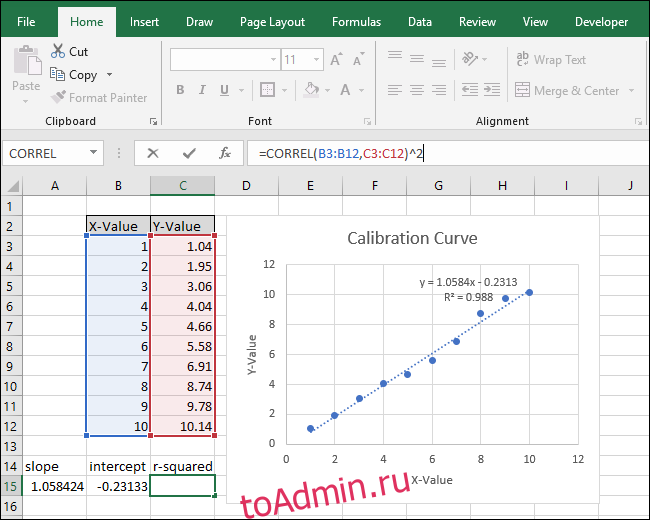
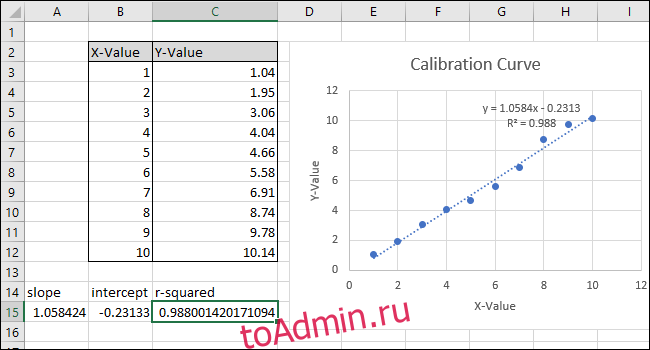
После изменения формулы значение «R-квадрат» теперь соответствует значению, отображаемому на диаграмме.
Шаг третий: настройте формулы для быстрого расчета значений
Теперь мы можем использовать эти значения в простых формулах, чтобы определить концентрацию этого «неизвестного» раствора или какие входные данные мы должны ввести в код, чтобы шарик пролетел определенное расстояние.
На этих этапах будут созданы формулы, необходимые для того, чтобы вы могли ввести значение X или Y и получить соответствующее значение на основе калибровочной кривой.
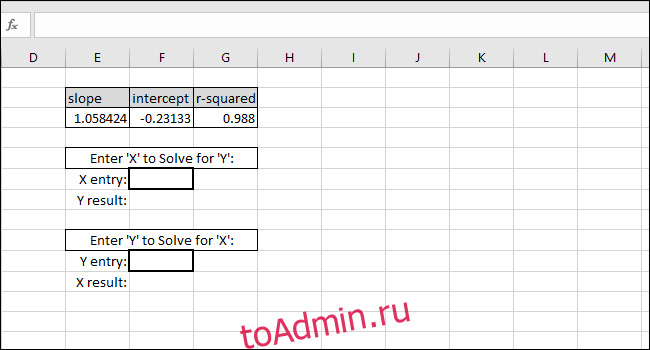
Уравнение линии наилучшего соответствия имеет форму «Значение Y = НАКЛОН * значение X + ПЕРЕСЕЧЕНИЕ», поэтому решение для «значения Y» выполняется путем умножения значения X и НАКЛОНА, а затем добавление ПЕРЕСЕЧЕНИЯ.
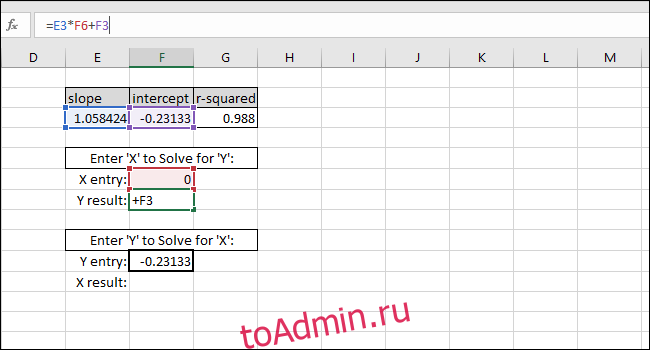
В качестве примера мы добавляем ноль в качестве значения X. Возвращаемое значение Y должно быть равно ПЕРЕСЕЧЕНИЮ линии наилучшего соответствия. Он совпадает, поэтому мы знаем, что формула работает правильно.
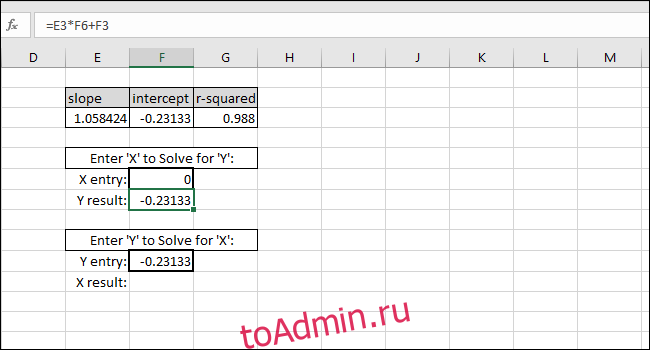
Решение для значения X на основе значения Y выполняется путем вычитания ПЕРЕСЕЧЕНИЯ из значения Y и деления результата на НАКЛОН:
X-value=(Y-value-INTERCEPT)/SLOPE
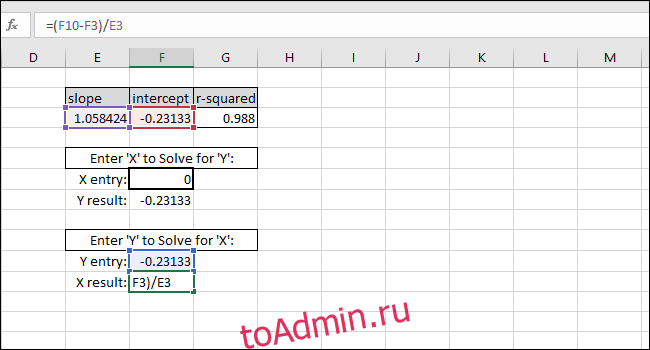
В качестве примера мы использовали ПЕРЕСЕЧЕНИЕ как Y-значение. Возвращаемое значение X должно быть равно нулю, но возвращаемое значение — 3.14934E-06. Возвращенное значение не равно нулю, потому что мы непреднамеренно усекли результат INTERCEPT при вводе значения. Однако формула работает правильно, потому что результат формулы равен 0,00000314934, что по существу равно нулю.
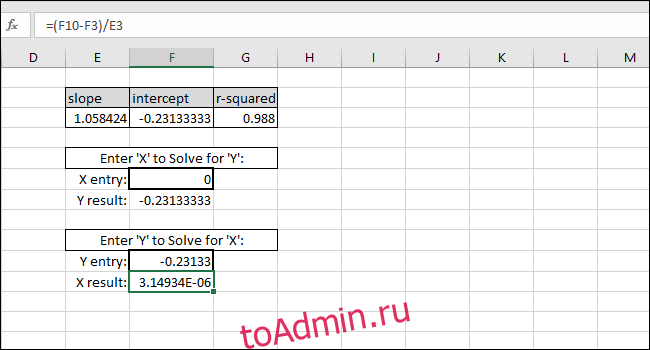
Вы можете ввести любое желаемое значение X в первую ячейку с толстой рамкой, и Excel автоматически вычислит соответствующее значение Y.
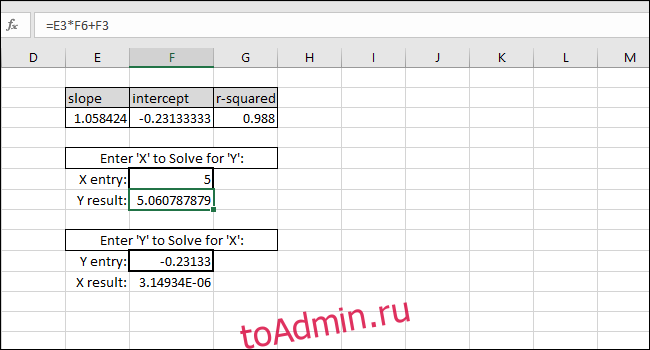
Ввод любого значения Y во вторую ячейку с толстой рамкой даст соответствующее значение X. Эта формула — то, что вы использовали бы для расчета концентрации этого раствора или того, какие входные данные необходимы для запуска шарика на определенное расстояние.
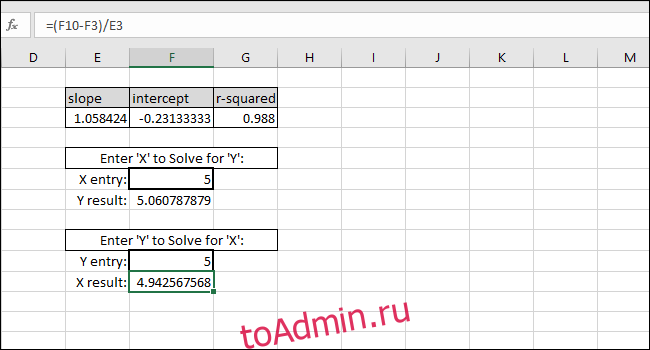
В этом случае прибор показывает «5», поэтому калибровка предполагает концентрацию 4,94, или мы хотим, чтобы шарик прошел пять единиц расстояния, поэтому калибровка предлагает ввести 4,94 в качестве входной переменной для программы, управляющей гранатометом. Мы можем быть достаточно уверены в этих результатах из-за высокого значения R-квадрата в этом примере.
Решение задач аппроксимации средствами Excel
доктор физ.– мат. наук, профессор Гавриленко В.В. ассистент Парохненко Л.М.
(Национальный транспортный университет)
Теоретическая справка. На практике при моделировании различных про-
цессов, в частности, экономических, физических, технических, социальных,
широко используются те или иные способы вычисления приближенных значе-
ний функций по известным их значениям в некоторых фиксированных точках.
Такого рода задачи приближения функций часто возникают:
∙при построении приближенных формул для вычисления значений характер-
ных величин исследуемого процесса по данным таблиц, полученным в ре-
зультате физического или вычислительного эксперимента;
∙при численном интегрировании, численном дифференцировании, числен-
ном решении дифференциальных уравнений и т.д.;
∙при необходимости вычисления значений функций в промежуточных точ-
ках рассматриваемого интервала;
∙при определении значений характерных величин процесса за пределами рас-
сматриваемого интервала, в частности, при необходимости заглянуть в
“ прошлое”), то есть при определении значений показателей процесса до на-
чала наблюдения;
∙в прогнозировании, то есть при получении предварительных оценок буду-
щих значений интересуемых показателей процесса (возможность заглянуть
в“ будущее”).
Если для моделирования некоторого процесса, заданного таблицей, по-
строить приближенно описывающую данный процесс функцию на основе ме-
тода наименьших квадратов, то она называется аппроксимирующей функцией
(регрессией), а сама задача построения аппроксимирующих функций называет-
ся задачей аппроксимации.
В данной статье рассмотрены возможности пакета Excel [1–3] при реше-
нии задач аппроксимации, а именно, приведены методы и приемы построения
(создания) регрессий для таблично заданных функций, что является основой регрессионного анализа.
ВExcel для построения регрессий имеются такие возможности, как:
1)добавление выбранных регрессий (линий тренда) в диаграмму, построенную на основе таблицы данных для исследуемой характеристики процесса (этим инструментом можно воспользоваться лишь при наличии построенной диа-
граммы);
2)использование встроенных статистических функций рабочего листа Excel,
позволяющих получать регрессии (линии тренда) на основе таблицы исход-
ных данных (использование данного инструмента предварительно не связы-
вается с наличием соответствующей диаграммы).
Добавление линий тренда в диаграмму
Для таблицы данных, описывающих некоторый процесс и представленных диаграммой, в Excel имеется эффективный инструмент регрессионного анали-
за, позволяющий:
∙ строить на основе метода наименьших квадратов и добавлять в диаграмму пять типов регрессий (линий тренда), которые с той или иной степенью точно-
сти моделируют исследуемый процесс;
∙добавлять к диаграмме уравнение построенной регрессии;
∙определять степень соответствия выбранной регрессии отображаемым на диаграмме данным.
Построенные модели процесса – линии тренда (trendlines) показывают
тенденцию изменения данных, дают возможность определять значения иссле-
дуемой характеристики в промежуточных точках, прогнозировать поведение данного процесса в будущем (задача экстраполяции), а также заглянуть в его прошлое.
На основе данных диаграммы Excel позволяет получать такие типы регрес-
сий или линий тренда, как линейный, полиномиальный, логарифмический, сте-
пенной, экспоненциальный, которые задаются уравнением y = y(x) , где x – неза-
висимая переменная, которая часто принимает значения последовательности натурального ряда чисел (1; 2; 3; …) и производит, например, отсчет времени протекания исследуемого процесса.
1. Линейная регрессия хороша при моделировании характеристик, значения которых увеличиваются или убывают с постоянной скоростью. Это наиболее простая в построении, но наименее точная модель исследуемого процесса.
Строится в соответствии с уравнением
y = m x + b ,
где m – угол наклона линейной регрессии к оси абсцисс; b – координата точки пересечения линейной регрессии с осью ординат.
2. Полиномиальная линия тренда полезна для описания характеристик,
имеющих несколько ярко выраженных экстремумов (максимумов и миниму-
мов). Выбор степени полиномиальной линии тренда (полинома) определяется количеством экстремумов исследуемой характеристики. Так, полином второй степени может хорошо описать характеристику, имеющую только один макси-
мум или минимум; полином третьей степени – не более двух экстремумов; по-
лином четвертой степени – не более трех экстремумов и т.д.
Строится в соответствии с уравнением
y = c0 + c1 x + c2 x2 + c3 x3 + c4 x4 + c5 x5 + c6 x6 ,
где коэффициенты c0 , c1, c2 ,…c6 – константы.
3. Логарифмическая линия тренда с успехом применяется при моделирова-
нии характеристик, значения которых вначале быстро растут или убывают по величине, а затем постепенно стабилизируются.
Строится в соответствии с уравнением
y = c × ln(x) + b ,
где коэффициенты b, с – константы.
4. Степенная линия тренда дает хорошие результаты, если значения иссле-
дуемой зависимости характеризуются постоянным изменением скорости роста.
Примером такой зависимости может служить график равноускоренного движе-
ния автомобиля. При наличии в данных нулевых или отрицательных значений использовать степенную линию тренда нельзя.
Строится в соответствии с уравнением
y = c × x b ,
где коэффициенты b, с – константы.
5. Экспоненциальная линия тренда следует использовать в том случае, если скорость изменения данных непрерывно возрастает. Для данных, содержащих нулевые или отрицательные значения, этот вид приближения неприменим.
Строится в соответствии с уравнением
y = c × eb×x ,
где коэффициенты b, с – константы.
При подборе линии тренда Excel автоматически рассчитывает значение величины R2, которая характеризует достоверность аппроксимации: чем ближе значение R2 к единице, тем надежнее линия тренда аппроксимирует исследуе-
мый процесс. При необходимости значение R2 всегда можно отобразить на
диаграмме.
Определяется по формуле
|
R 2 = 1 — |
Σ1 |
Σ1 = ∑(y j − Yj )2 |
S2 = ∑Yj2 — |
1 |
× (∑Yj )2 |
||||
|
S2 |
, где |
; |
. |
||||||
|
j |
j |
n j |
Для добавления линии тренда к ряду данных следует:
1. Активизировать построенную на основе ряда данных диаграмму, т.е. щелк-
нуть в пределах области диаграммы. В главном меню появится пункт Диа—
грамма.
2. После щелчка на этом пункте на экране появится меню, в котором следует выбрать команду Добавить линию тренда.
Пункты 1–2 легко реализуются также следующим приемом: направить ука-
затель мыши к графику, построенного на ряде данных, и щелкнуть правой кла-
вишей мыши, и в появившемся контекстном меню выбрать команду Добавить
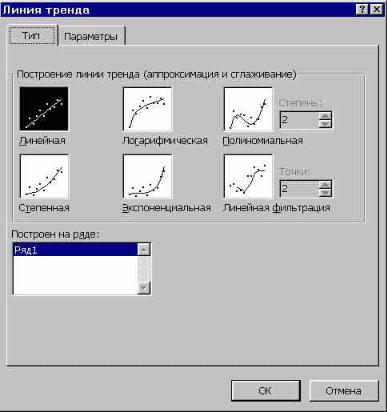
линию тренда. На экране появится диалоговое окно Линия тренда с раскры-
той вкладкой Тип (рис.1).
Рис.1. Вкладка Тип диалогового окна Формат линии тренда
3. Выбрать на вкладке Тип необходимый тип линии тренда (по умолчанию выбирается тип Линейный). Для типа Полиномиальная в поле Степень сле-
дует задать степень выбранного полинома.
4. В поле Построен на ряде перечислены все ряды данных рассматриваемой диаграммы. Для добавления линии тренда к конкретному ряду данных следует в поле Построен на ряде выбрать его имя.
5. При необходимости, перейдя на вкладку Параметры (рис.2), можно для ли-
нии тренда задать следующие параметры:
∙ Изменить название линии тренда в поле Название аппроксимирующей
(сглаженной) кривой;
∙ Задать количество периодов (вперед или назад) для прогноза в поле Про—
гноз.
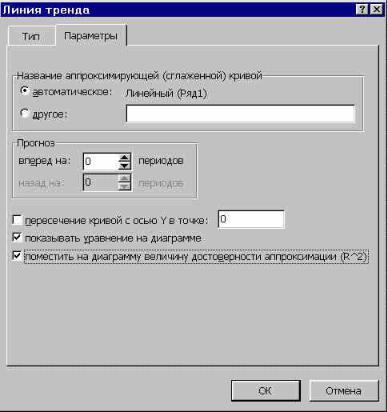
∙ Вывести в область диаграммы уравнение линии тренда, для чего следует ус-
тановить флажок для опции «показать уравнение на диаграмме».
∙ Вывести в область диаграммы значение достоверности аппроксимации R2,
для чего следует установить флажок для опции «поместить на диаграмму ве—
личину достоверности аппроксимации (R^2)».
∙ Задать точку пересечения линии тренда с осью Y, для чего следует устано-
вить флажок для опции «пересечение кривой с осью Y в точке:». 6. Нажать клавишу OK.
Рис.2. Вкладка Параметры диалогового окна Линия тренда
Для редактирования уже построенной линии тренда следует:
1. Щелкнуть левой клавишей мыши по той линии тренда, которую требуется
изменить.
2. Нажать в главном меню клавишу Формат, а появившемся контекстном ме-
ню выбрать команду Выделенная линия тренда.
Пункты 1–2 легко реализуются также следующим приемом: направить ука-
затель мыши к графику линии тренда, щелкнуть правой клавишей мыши, и в появившемся контекстном меню выбрать команду Формат линии тренда.
Еще легче реализуются пункты 1–2: двойным щелчком левой клавишей мыши по графику линии тренда.
3. На экране появится диалоговое окно Формат линии тренда (рис.3), содер-
жащее три вкладки: Вид, Тип, Параметры, причем содержимое вкладок Тип,
Параметры полностью совпадает с аналогичными вкладками диалогового ок-
на Линия тренда (рис.1–2).
4.При необходимости, перейдя на вкладку Вид (рис.3), можно для линии тренда задать тип линии, ее цвет и толщину.
5.Нажать клавишу OK.
Для удаления уже построенной линии тренда следует выбрать удаляемую линию тренда и нажать клавишу Delete.
Достоинствами этого инструмента регрессионного анализа являются:
∙ относительная легкость построения на диаграммах линии тренда без созда-
ния для нее таблицы данных;
∙достаточно широкий перечень типов предложенных линий трендов, причем в этот перечень входят наиболее часто используемые регрессии;
∙возможность прогнозирования поведения исследуемого процесса на произ-
вольное (в пределах здравого смысла) количество шагов вперед, а также назад;
∙возможность получения уравнения линии тренда в аналитическом виде;
∙возможность, при необходимости, получения оценки достоверности прове-
денной аппроксимации.
Кнедостаткам можно отнести следующие моменты:
∙построение линии тренда осуществляется лишь при наличии построенной на ряде данных диаграммы;
∙несколько загроможден процесс формирования рядов данных для исследуе-
мой характеристики на основании полученных для нее уравнений линий трен-
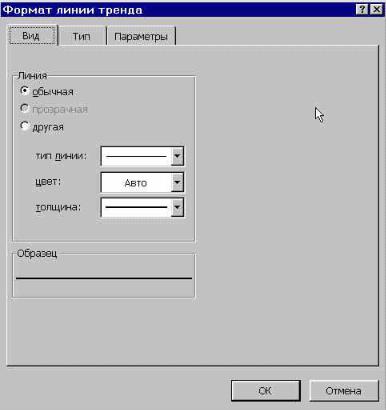
да, так как коэффициенты этих уравнений при каждом изменении значений ря-
да данных пересчитываются, но лишь в пределах области диаграммы;
∙ в отчетах сводных диаграмм при изменении представления диаграммы или связанного отчета сводной таблицы имеющиеся линии тренда не сохраняются,
то есть до проведения линий тренда или другого форматирования отчета свод-
ных диаграмм следует убедиться, что макет отчета удовлетворяет необходи-
мым требованиям.
Рис.3. Вкладка Вид диалогового окна Формат линии тренда
Линиями тренда можно дополнить ряды данных, представленные на гра-
фиках, гистограммах, плоских ненормированных диаграммах с областями, ли-
нейчатых, точечных, пузырьковых и биржевых диаграммах.
Нельзя дополнить линиями тренда ряды данных на объемных, нормиро-
ванных, лепестковых, круговых и кольцевых диаграммах. При замене типа диа-
граммы на один из вышеперечисленных, а также при изменении представления отчета сводной диаграммы или связанного отчета сводной таблицы соответст-
вующие данным линии тренда будут утеряны.
Использование встроенных функций Excel
ВExcel имеется также инструмент регрессионного анализа для построения линий тренда вне области диаграммы. Для этой цели можно использовать ряд статистических функций рабочего листа, однако все они позволяют строить лишь линейные или экспоненциальные регрессии.
ВExcel имеется несколько вариантов построения линейной регрессии (ли-
нейного тренда), в частности:
∙с помощью функции ТЕНДЕНЦИЯ;
∙с помощью функции ЛИНЕЙН;
∙с помощью функций НАКЛОН и ОТРЕЗОК.
ВExcel имеется также несколько вариантов построения экспоненциальной линии тренда, в частности:
∙с помощью функции РОСТ;
∙с помощью функции ЛГРФПРИБЛ.
Следует отметить, что приемы построения регрессий с помощью функций
ТЕНДЕНЦИЯ и РОСТ практически совпадают. То же самое можно сказать и о паре функций ЛИНЕЙН и ЛГРФПРИБЛ. Для всех этих четырех функций при создании таблицы значений используются такие возможности Excel, как формулы массивов, что несколько загромождает процесс построения регрес-
сий. Заметим также, что построение (создание) линейной регрессии, на наш взгляд, легче всего осуществить с помощью функций НАКЛОН и ОТРЕЗОК,
где первая из них определяет угловой коэффициент линейной регрессии, а вто-
рая – отрезок, отсекаемый регрессией на оси ординат.
Достоинствами данного инструмента регрессионного анализа являются:
∙ достаточно простой однотипный процесс формирования рядов данных ис-
следуемой характеристики для всех встроенных статистических функций, за-
дающих линии тренда;
∙ стандартная методика построения линий тренда на основе сформированных рядов данных;
∙ возможность прогнозирования поведения исследуемого процесса на необ-
ходимое количество шагов вперед или назад.
К недостаткам данного инструмента можно отнести то, что в Excel нет встроенных функций для создания других (кроме линейного и экспоненциаль-
ного) типов линий тренда. Это обстоятельство часто не позволяет подобрать с помощью выше перечисленных встроенных функций достаточно точную мо-
дель исследуемого процесса, а также получать близкие к реальности прогнозы.
Кроме того, при использовании функций ТЕНДЕНЦИЯ и РОСТ не известны уравнения линий тренда.
Следует отметить, что в этой статье авторы не ставили целью излагать курс регрессионного анализа с той или иной степенью полноты. Основная цель ста-
тьи – на конкретных примерах показать возможности пакета Excel при реше-
нии задач аппроксимации; продемонстрировать, каким эффективными инстру-
ментами для построения регрессий и прогнозирования обладает Excel; проил-
люстрировать, как относительно легко такие задачи могут быть решены даже пользователем, не владеющим глубокими знаниями регрессионного анализа.
Предложенная в статье методика по овладению навыков решения средства-
ми Excel такого рода задач (см. также [4 – 7], где приведены методики решения в Excel систем линейных алгебраических уравнений, нелинейных уравнений,
задач оптимизации, транспортных задач) может быть полезна и интересна пользователям. Это связано с тем, что пакет Excel установлен практически на каждом современном компьютере, в то время как такие известные специализи-
рованные математические пакеты, как Mathematica, Maple, Matlab, Mathcad,
обладающие более мощными возможностями для построения регрессий и про-
гнозирования, используются значительно меньшей пользовательской аудито-
рией.
Ниже приводятся решения конкретных задач с помощью перечисленных инструментов пакета Excel.
Задача 1. Для таблицы данных о прибыли автотранспортного предприятия за 1995–2002 г.г. необходимо выполнить следующие действия:
Содержание
- Постановка задачи на конкретном примере
- Наборы данных
- Графическая иллюстрация метода наименьших квадратов (мнк).
- Сглаживание ряда методом наименьших квадратов
- Суть метода
- Применение надстройки поиск решения
- Аппроксимация функции одной переменной методом наименьших квадратов с дополнительными условиями
- Оценка точности
- Вывод формул для нахождения коэффициентов.
- Как реализоавать метод наименьших квадратов в Excel
- Заключение
Постановка задачи на конкретном примере
Предположим, имеются два показателя X и Y. Причем Y зависит от X. Так как МНК интересует нас с точки зрения регрессионного анализа (в Excel его методы реализуются с помощью встроенных функций), то стоит сразу же перейти к рассмотрению конкретной задачи.
Итак, пусть X — торговая площадь продовольственного магазина, измеряемая в квадратных метрах, а Y — годовой товарооборот, определяемый в миллионах рублей.
Требуется сделать прогноз, какой товарооборот (Y) будет у магазина, если у него та или иная торговая площадь. Очевидно, что функция Y = f (X) возрастающая, так как гипермаркет продает больше товаров, чем ларек.
Наборы данных
Метод наименьших квадратов используется для обработки набора данных и прогнозирования будущих значений. Пусть у нас есть массивы данных X = {10, 12, 14, 16, 18, 20} и Y = {18, 22, 24, 26, 27, 28}, при этом значение Y зависит от X. Придадим этим массивам смысл. К примеру, массив X – это мощность паровой машины парохода, а Y — его ходовая скорость в узлах. Это означает, что при мощности энергетической установки в 10 тысяч лошадиных сил, пароход развивает скорость на уровне 18 морских миль в час, и так далее, так как каждое значение игрека соответствует своему иксу.
Эти данные можно представить в виде точек на декартовой плоскости, например как V1(X1, Y1), V2(X2, Y2) и так далее. Если соединить эти точки, то мы получим некую кривую, которую можем описать соответствующим уравнением y = f(x). Данное уравнение должно быть достаточно простым, но при этом максимально близко описывать полученную зависимость.
Получив кривую, мы можем продлить ее в любую сторону и узнать приблизительное значение игреков для любых иксов или наоборот. Например, аппроксимировав данные нашего примера, мы сможем узнать, какая мощность установки требуется для достижения скорости в 15 узлов. Или какую мы получим скорость, установив на борт установку мощностью в 22 тысячи лошадиных сил. Для того чтобы определить эту волшебную y = f(x), нам и необходим метод наименьших квадратов.
Графическая иллюстрация метода наименьших квадратов (мнк).
На графиках все прекрасно видно. Красная линия – это найденная прямая y = 0.165x+2.184, синяя линия – это  , розовые точки – это исходные данные.
, розовые точки – это исходные данные.

Для чего это нужно, к чему все эти аппроксимации?
Я лично использую для решения задач сглаживания данных, задач интерполяции и экстраполяции (в исходном примере могли бы попросить найти занчение наблюдаемой величины y при x=3 или при x=6 по методу МНК). Но подробнее поговорим об этом позже в другом разделе сайта.
К началу страницы
Доказательство.
Чтобы при найденных а и b функция принимала наименьшее значение, необходимо чтобы в этой точке матрица квадратичной формы дифференциала второго порядка для функции  была положительно определенной. Покажем это.
была положительно определенной. Покажем это.
Дифференциал второго порядка имеет вид:
То есть
Следовательно, матрица квадратичной формы имеет вид
причем значения элементов не зависят от а и b .
Покажем, что матрица положительно определенная. Для этого нужно, чтобы угловые миноры были положительными.
Угловой минор первого порядка  . Неравенство строгое, так как точки
. Неравенство строгое, так как точки  несовпадающие. В дальнейшем это будем подразумевать.
несовпадающие. В дальнейшем это будем подразумевать.
Угловой минор второго порядка
Докажем, что  методом математической индукции.
методом математической индукции.
-
Проверим справедливость неравенства для любого значения n, например для n=2.
Получили верное неравенство для любых несовпадающих значений
и . -
Предполагаем, что неравенство верное для n.
– верное. -
Докажем, что неравенство верное для n+1.
То есть, нужно доказать, что
исходя из предположения что – верное.Поехали.
Выражение в фигурных скобках положительно по предположению пункта 2), а остальные слагаемые положительны, так как представляют собой квадраты чисел. Этим доказательство завершено.

 и
и  .
. исходя из предположения что
исходя из предположения что 
Вывод : найденные значения а и b соответствуют наименьшему значению функции , следовательно, являются искомыми параметрами для метода наименьших квадратов.
Сглаживание ряда методом наименьших квадратов
Задание.
1. Постройте прогноз численности наличного населения города Б на 2010-2011 гг., используя методы: скользящей средней, экспоненциального сглаживания, наименьших квадратов.
2. Постройте график фактического и расчетных показателей.
3. Рассчитайте ошибки полученных прогнозов при использовании каждого метода.
4. Сравните полученные результаты, сделайте вывод.
Решение.
1. Находим параметры уравнения методом наименьших квадратов. Линейное уравнение тренда имеет вид y = bt + a
Система уравнений МНК:
a0n + a1∑t = ∑y
a0∑t + a1∑t2 = ∑y•t
| t | y | t2 | y2 | t•y |
| 1 | 58.8 | 1 | 3457.44 | 58.8 |
| 2 | 58.7 | 4 | 3445.69 | 117.4 |
| 3 | 59 | 9 | 3481 | 177 |
| 4 | 59 | 16 | 3481 | 236 |
| 5 | 58.8 | 25 | 3457.44 | 294 |
| 6 | 58.3 | 36 | 3398.89 | 349.8 |
| 7 | 57.9 | 49 | 3352.41 | 405.3 |
| 8 | 57.5 | 64 | 3306.25 | 460 |
| 9 | 56.9 | 81 | 3237.61 | 512.1 |
| 45 | 524.9 | 285 | 30617.73 | 2610.4 |
Для наших данных система уравнений имеет вид:
9a0 + 45a1 = 524.9
45a0 + 285a1 = 2610.4
Из первого уравнения выражаем а0 и подставим во второе уравнение
Получаем a0 = -0.24, a1 = 59.5
Уравнение тренда:
y = -0.24 t + 59.5
Эмпирические коэффициенты тренда a и b являются лишь оценками теоретических коэффициентов βi, а само уравнение отражает лишь общую тенденцию в поведении рассматриваемых переменных.
Коэффициент тренда b = -0.24 показывает среднее изменение результативного показателя (в единицах измерения у) с изменением периода времени t на единицу его измерения. В данном примере с увеличением t на 1 единицу, y изменится в среднем на -0.24.
Ошибка аппроксимации.
Оценим качество уравнения тренда с помощью ошибки абсолютной аппроксимации. 
Ошибка аппроксимации в пределах 5%-7% свидетельствует о хорошем подборе уравнения тренда к исходным данным.
Поскольку ошибка меньше 7%, то данное уравнение можно использовать в качестве тренда.
Однофакторный дисперсионный анализ.
Средние значения


Дисперсия

Среднеквадратическое отклонение

Коэффициент эластичности.
Коэффициент эластичности представляет собой показатель силы связи фактора t с результатом у, показывающий, на сколько процентов изменится значение у при изменении значения фактора на 1%.

Коэффициент эластичности меньше 1. Следовательно, при изменении t на 1%, Y изменится менее чем на 1%. Другими словами – влияние t на Y не существенно.
Эмпирическое корреляционное отношение.
Эмпирическое корреляционное отношение вычисляется для всех форм связи и служит для измерение тесноты зависимости. Изменяется в пределах [0;1].
где (y-yt)² = 4.4-1.08 = 3.31
В отличие от линейного коэффициента корреляции он характеризует тесноту нелинейной связи и не характеризует ее направление. Изменяется в пределах [0;1].
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 0.3 0.5 0.7 0.9 Полученная величина свидетельствует о том, что изменение временного периода t существенно влияет на y.
Коэффициент детерминации.

т.е. в 75.39% случаев влияет на изменение данных. Другими словами – точность подбора уравнения тренда – высокая.
| t | y | y(t) | (y-ycp)2 | (y-y(t))2 | (t-tp)2 | (y-y(t)) : y |
| 1 | 58.8 | 59.26 | 0.23 | 0.21 | 16 | 0.00786 |
| 2 | 58.7 | 59.03 | 0.14 | 0.11 | 9 | 0.00557 |
| 3 | 59 | 58.79 | 0.46 | 0.0431 | 4 | 0.00352 |
| 4 | 59 | 58.56 | 0.46 | 0.2 | 1 | 0.0075 |
| 5 | 58.8 | 58.32 | 0.23 | 0.23 | 0 | 0.00813 |
| 6 | 58.3 | 58.09 | 0.0004 | 0.0452 | 1 | 0.00365 |
| 7 | 57.9 | 57.85 | 0.18 | 0.0022 | 4 | 0.000825 |
| 8 | 57.5 | 57.62 | 0.68 | 0.0137 | 9 | 0.00204 |
| 9 | 56.9 | 57.38 | 2.02 | 0.23 | 16 | 0.00847 |
| 45 | 524.9 | 524.9 | 4.4 | 1.08 | 60 | 0.0476 |
Интервальный прогноз.
Определим среднеквадратическую ошибку прогнозируемого показателя.
m = 1 – количество влияющих факторов в уравнении тренда.
Uy=yn+L±K
где 
L – период упреждения; уn+L – точечный прогноз по модели на (n + L)-й момент времени; n – количество наблюдений во временном ряду; Sy – стандартная ошибка прогнозируемого показателя; Tтабл – табличное значение критерия Стьюдента для уровня значимости α и для числа степеней свободы, равного n-2.
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;α/2) = (7;0.025) = 2.365
Точечный прогноз, t = 10: y(10) = -0.24*10 + 59.5 = 57.15
57.15 – 1.08 = 56.07 ; 57.15 + 1.08 = 58.23
Интервальный прогноз:
t = 10: (56.07;58.23)
Точечный прогноз, t = 11: y(11) = -0.24*11 + 59.5 = 56.91
56.91 – 1.14 = 55.77 ; 56.91 + 1.14 = 58.05
Интервальный прогноз:
t = 11: (55.77;58.05)
2. Сглаживаем ряд методом скользящей средней. Одним из эмпирических методов является метод скользящей средней. Этот метод состоит в замене абсолютных уровней ряда динамики их средними арифметическими значениями за определенные интервалы. Выбираются эти интервалы способом скольжения: постепенно исключаются из интервала первые уровни и включаются последующие.
| t | y | ys | Формула |
| 1 | 58.8 | 58.75 | (58.8 + 58.7)/2 |
| 2 | 58.7 | 58.85 | (58.7 + 59)/2 |
| 3 | 59 | 59 | (59 + 59)/2 |
| 4 | 59 | 58.9 | (59 + 58.8)/2 |
| 5 | 58.8 | 58.55 | (58.8 + 58.3)/2 |
| 6 | 58.3 | 58.1 | (58.3 + 57.9)/2 |
| 7 | 57.9 | 57.7 | (57.9 + 57.5)/2 |
| 8 | 57.5 | 57.2 | (57.5 + 56.9)/2 |
| 9 | 56.9 | – | – |
Стандартная ошибка (погрешность) рассчитывается по формуле:
где i = (t-m-1, t)
3. Построим прогноз численности с использованием экспоненциального сглаживания. Важным методом стохастических прогнозов является метод экспоненциального сглаживания. Этот метод заключается в том, что ряд динамики сглаживается с помощью скользящей средней, в которой веса подчиняются экспоненциальному закону.
Эту среднюю называют экспоненциальной средней и обозначают St.
Она является характеристикой последних значений ряда динамики, которым присваивается наибольший вес.
Экспоненциальная средняя вычисляется по рекуррентной формуле:
St = α*Yt + (1- α)St-1
где St – значение экспоненциальной средней в момент t;
St-1 – значение экспоненциальной средней в момент (t = 1);
Что касается начального параметра S0, то в задачах его берут или равным значению первого уровня ряда у1, или равным средней арифметической нескольких первых членов ряда.
Yt – значение экспоненциального процесса в момент t;
α – вес t-ого значения ряда динамики (или параметр сглаживания).
Последовательное применение формулы дает возможность вычислить экспоненциальную среднюю через значения всех уровней данного ряда динамики.
Наиболее важной характеристикой в этой модели является α, по величине которой практически и осуществляется прогноз. Чем значение этого параметра ближе к 1, тем больше при прогнозе учитывается влияние последних уровней ряда динамики.
Если α близко к 0, то веса, по которым взвешиваются уровни ряда динамики убывают медленно, т.е. при прогнозе учитываются все прошлые уровни ряда.
В специальной литературе отмечается, что обычно на практике значение α находится в пределах от 0,1 до 0,3. Значение 0,5 почти никогда не превышается.
Экспоненциальное сглаживание применимо, прежде всего, при постоянном объеме потребления (α = 0,1 – 0,3). При более высоких значениях (0,3 – 0,5) метод подходит при изменении структуры потребления, например, с учетом сезонных колебаний.
В качестве S0 берем первое значение ряда, S0 = y1 = 58.8
| t | y | St | Формула |
| 1 | 58.8 | 58.8 | (1 – 0.1)*58.8 + 0.1*58.8 |
| 2 | 58.7 | 58.71 | (1 – 0.1)*58.7 + 0.1*58.8 |
| 3 | 59 | 58.97 | (1 – 0.1)*59 + 0.1*58.71 |
| 4 | 59 | 59 | (1 – 0.1)*59 + 0.1*58.97 |
| 5 | 58.8 | 58.82 | (1 – 0.1)*58.8 + 0.1*59 |
| 6 | 58.3 | 58.35 | (1 – 0.1)*58.3 + 0.1*58.82 |
| 7 | 57.9 | 57.95 | (1 – 0.1)*57.9 + 0.1*58.35 |
| 8 | 57.5 | 57.54 | (1 – 0.1)*57.5 + 0.1*57.95 |
| 9 | 56.9 | 56.96 | (1 – 0.1)*56.9 + 0.1*57.54 |
Прогнозирование данных с использованием экспоненциального сглаживания.
Методы прогнозирования под названием “сглаживание” учитывают эффекты выброса функции намного лучше, чем способы, использующие регрессивный анализ.
Базовое уравнение имеет следующий вид:
F(t+1) = F(t)(1 – α) + αY(t)
F(t) – это прогноз, сделанный в момент времени t; F(t+1) отражает прогноз во временной период, следующий непосредственно за моментом времени t
Стандартная ошибка (погрешность) рассчитывается по формуле:
где i = (t – 2, t)
Пример. Методом наименьших квадратов найти функции вида y=ax+b, y=ax²+bx+c, аппроксимирующие экспериментальную функцию y=f(x). В обоих случаях найти суммы квадратов невязок ∑bi². В декартовой системе координат построить экспериментальные точки и графики найденных функций y=ax+b,y=ax^2+bx+c.
Пример №5
Пример №6
Пример №3. Функция y=y(x) задана таблицей своих значений:
x: -2 -1 0 1 2
y: -0,8 -1,6 -1,3 0,4 3,2
Применяя метод наименьших квадратов, приблизить функцию многочленами 1-ой и 2-ой степеней. Для каждого приближения определить величину среднеквадратичной погрешности. Построить точечный график функции и графики многочленов.
Решение. Функция многочлена 2-ой степени имеет вид y = ax2+ bx + c.
1. Находим параметры уравнения методом наименьших квадратов. Система уравнений МНК:
a0n + a1∑x + a2∑x2= ∑y
a0∑x + a1∑x2+ a2∑x3= ∑yx
a0∑x2+ a1∑x3+ a2∑x4= ∑yx2
| x | y | x2 | y2 | x y | x3 | x4 | x2y |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| -2 | -0.8 | 4 | 0.64 | 1.6 | -8 | 16 | -3.2 |
| -1 | -1.6 | 1 | 2.56 | 1.6 | -1 | 1 | -1.6 |
| 0 | -1.3 | 0 | 1.69 | 0 | 0 | 0 | 0 |
| 1 | 0.4 | 1 | 0.16 | 0.4 | 1 | 1 | 0.4 |
| 2 | 3.2 | 4 | 10.24 | 6.4 | 8 | 16 | 12.8 |
| 0 | -0.1 | 10 | 15.29 | 10 | 0 | 34 | 8.4 |
Для наших данных система уравнений имеет вид
6a0+ 0a1+ 10a2= -0.1
0a0+ 10a1+ 0a2= 10
10a0+ 0a1+ 34a2= 8.4
Получаем a0= 0.494, a1= 1, a2= -0.84
Уравнение: y = 0.494x2+x-0.84
Суть метода
Данные таблицы можно изобразить на декартовой плоскости в виде точек M1 (x1, y1), … Mn (xn, yn). Теперь решение задачи сведется к подбору аппроксимирующей функции y = f (x), имеющей график, проходящий как можно ближе к точкам M1, M2, ..Mn.
Конечно, можно использовать многочлен высокой степени, но такой вариант не только труднореализуем, но и просто некорректен, так как не будет отражать основную тенденцию, которую и нужно обнаружить. Самым разумным решением является поиск прямой у = ax + b, которая лучше всего приближает экспериментальные данные, a точнее, коэффициентов – a и b.

Применение надстройки поиск решения
1. Если не включили надстройку «поиск решения», то возвращаемся к пункту Как включить надстройку «поискрешения» и включаем
2. В ячейку А1 введем значение «1». Эта единица будет первым приближением к реальному значению коэффициента (k) нашей функциональной зависимости y=kx.
3. В столбце B у нас расположились значения параметра X, в столбце C — значения параметра Y. В ячейках столбца D вводим формулу: «коэффициент k умножить на значение Х». Например, в ячейке D1 вводим «=A1*B1», в ячейке D2 вводим “=A1*B2” и т.д.

4. Мы считаем, что коэффициент к равен единице и функция f (x)=у=1*х – это первое приближение к нашему решению. Можем рассчитать сумму квадратов разностей между измеренными значениями величины Y и рассчитанными по формуле y=1*х . Можем все это сделать вручную, вбивая в формулу соответствующие ссылки на ячейки: “=(D2-C2)^2+(D3-C3)^2+(D4-C4)^2… и т.д. В конце концов ошибаемся и понимаем, что потеряли кучу времени. В Excel для расчета суммы квадратов разностей есть специальная формула, «СУММКВРАЗН», которая все за нас и сделает. Введем ее в ячейку А2 и зададим исходные данные: диапазон измеренных значений Y (столбец C) и диапазон рассчитанных значений Y (столбец D).

4. Сумму разностей квадратов рассчитали – теперь идем во вкладку «Данные» и выбираем «Поиск решения».
5. В появившемся меню в качестве изменяемой ячейки выбираем ячейку A1 (та, что с коэффициентом k).
6. В качестве целевой выбираем ячейку A2 и задаем условие «установить равной минимальному значению». Помним, что это ячейка, где у нас производится расчёт суммы квадратов разностей расчетного и измеренного значений, и сумма эта должна быть минимальной. Нажимаем «выполнить».

7. Коэффициент k подобран. Теперь можно убедиться, что рассчитанные значения теперь очень близки к измеренным.
Аппроксимация функции одной переменной методом наименьших квадратов с дополнительными условиями
Данный калькулятор использует метод наименьших квадратов (МНК) для аппроксимации функции одной переменной, аналогично калькулятору Аппроксимация функции одной переменной. Но, в отличии от указанного калькулятора, данный калькулятор поддерживает аппроксимацию функции с использованием ограничений на ее значения. То есть, можно задать условия равенства аппроксимирующей функции определенным значениям в определенных точках. Формулы аппроксимации будут выведены с учетом этих условий.
Используемый метод (метод множителей Лагранжа) накладывает ограничения на набор аппроксимирующих функций, так что этот калькулятор не поддерживает экспоненциальную аппроксимацию, аппроксимацию степенной функцией и показательную аппроксимацию. Одним словом поддерживается только линейная регрессия. Зато в него были добавлены аппроксимация полиномами 4-ой и 5-ой степени. Формулы и немного теории можно найти под калькулятором.
Если не ввести значения x, калькулятор будет считать, что значение x меняется начиная с 0 с шагом 1.
Оценка точности
При любой аппроксимации особую важность приобретает оценка ее точности. Обозначим через ei разность (отклонение) между функциональными и экспериментальными значениями для точки xi, т. е. ei = yi – f (xi).
Очевидно, что для оценки точности аппроксимации можно использовать сумму отклонений, т. е. при выборе прямой для приближенного представления зависимости X от Y нужно отдавать предпочтение той, у которой наименьшее значение суммы ei во всех рассматриваемых точках. Однако, не все так просто, так как наряду с положительными отклонениями практически будут присутствовать и отрицательные.
Решить вопрос можно, используя модули отклонений или их квадраты. Последний метод получил наиболее широкое распространение. Он используется во многих областях, включая регрессионный анализ (в Excel его реализация осуществляется с помощью двух встроенных функций), и давно доказал свою эффективность.
Вывод формул для нахождения коэффициентов.
Составляется и решается система из двух уравнений с двумя неизвестными. Находим частные производные функции по переменным а и b, приравниваем эти производные к нулю.
Решаем полученную систему уравнений любым методом (например методом подстановки или методом Крамера) и получаем формулы для нахождения коэффициентов по методу наименьших квадратов (МНК).
При данных а и b функция принимает наименьшее значение. Доказательство этого факта приведено ниже по тексту в конце страницы .
Вот и весь метод наименьших квадратов. Формула для нахождения параметра a содержит суммы  ,
,  ,
,  ,
,  и параметр n – количество экспериментальных данных. Значения этих сумм рекомендуем вычислять отдельно. Коэффициент b находится после вычисления a.
и параметр n – количество экспериментальных данных. Значения этих сумм рекомендуем вычислять отдельно. Коэффициент b находится после вычисления a.
Пришло время вспомнить про исходый пример.
Решение.
В нашем примере n=5 . Заполняем таблицу для удобства вычисления сумм, которые входят в формулы искомых коэффициентов.
Значения в четвертой строке таблицы получены умножением значений 2-ой строки на значения 3-ей строки для каждого номера i .
Значения в пятой строке таблицы получены возведением в квадрат значений 2-ой строки для каждого номера i .
Значения последнего столбца таблицы – это суммы значений по строкам.
Используем формулы метода наименьших квадратов для нахождения коэффициентов а и b. Подставляем в них соответствующие значения из последнего столбца таблицы:
Следовательно, y = 0.165x+2.184 – искомая аппроксимирующая прямая.
Осталось выяснить какая из линий y = 0.165x+2.184 или лучше аппроксимирует исходные данные, то есть произвести оценку методом наименьших квадратов.
Как реализоавать метод наименьших квадратов в Excel
В “Эксель” имеется функция для расчета значения по МНК. Она имеет следующий вид: «ТЕНДЕНЦИЯ» (известн. значения Y; известн. значения X; новые значения X; конст.). Применим формулу расчета МНК в Excel к нашей таблице.
Для этого в ячейку, в которой должен быть отображен результат расчета по методу наименьших квадратов в Excel, введем знак «=» и выберем функцию «ТЕНДЕНЦИЯ». В раскрывшемся окне заполним соответствующие поля, выделяя:
- диапазон известных значений для Y (в данном случае данные для товарооборота);
- диапазон x1, …xn, т. е. величины торговых площадей;
- и известные, и неизвестные значения x, для которого нужно выяснить размер товарооборота (информацию об их расположении на рабочем листе см. далее).
Кроме того, в формуле присутствует логическая переменная «Конст». Если ввести в соответствующее ей поле 1, то это будет означать, что следует осуществить вычисления, считая, что b = 0.
Если нужно узнать прогноз для более чем одного значения x, то после ввода формулы следует нажать не на «Ввод», а нужно набрать на клавиатуре комбинацию «Shift» + «Control»+ «Enter» («Ввод»).
Заключение
Метод наименьших квадратов — удобный метод для представления данных в виде функции. Благодаря такому представлению вы можете определить любое значение функции, оперируя небольшим набором данных или измерений.
Источники
- https://FB.ru/article/342215/metod-naimenshih-kvadratov-v-excel-regressionnyiy-analiz
- https://BBF.ru/calculators/69/
- http://www.cleverstudents.ru/articles/mnk.html
- https://math.semestr.ru/trend/least-square-method.php
- http://metallovedeniye.ru/analiz-dannyx-v-excel/metod-naimenshix-kvadratov-i-poisk-resheniya-v-excel.html
- https://planetcalc.ru/8735/?thanks=1

Михаил Витер
Эксперт по предмету «Информационные технологии»
Задать вопрос автору статьи
Определение 1
Аппроксимация табличных функций в Excel — это определение аппроксимирующей функции, которая является близкой к заданной.
Понятие аппроксимации
Среди разных методик прогнозирования следует отдельно выделить метод аппроксимации. С его помощью имеется возможность осуществления приблизительных подсчетов и вычисления планируемых показателей, за счёт подмены исходных объектов на более простые. В Excel также присутствует возможность применения этого метода с целью выполнения прогнозов и анализа.
Название этого метода произошло от латинского слова “proxima”, то есть, «ближайшая». Как раз приближение за счет упрощения и сглаживания некоторых показателей, формирование из них тенденции и считается его основой. Но эту методику можно применять не только для прогнозирования, но и для изучения уже полученных результатов. Поскольку аппроксимация выступает, по существу, как упрощение исходных данных, а упрощенную версию легче изучать.
Аппроксимация табличных функций в Excel
Основным инструментом, при помощи которого реализуется сглаживание в Excel, является формирование линии тренда. Суть заключается в том, что на базе уже существующих показателей выполняется достраивание графика функции на будущие периоды. Основным предназначением линии тренда очевидно является формирование прогнозов или определение общей тенденции.
Эта линия может быть построена с использованием одного из следующих типов аппроксимации:
линейная,
экспоненциальная,
логарифмическая,
полиномиальная,
* степенная.
Рассмотрим некоторые из этих вариантов более подробно, и начнем с линейной аппроксимации, которая фактически является линейным сглаживанием. Прежде всего, следует рассмотреть наиболее простую версию аппроксимации, то есть, при помощи линейной функции.
Замечание 1
Сначала необходимо построить график, на базе которого будет осуществляться процедура сглаживания.
«Аппроксимация табличных функций в Excel » 👇
Чтобы построить график, необходимо взять таблицу, в которой, например, помесячно указывается себестоимость единицы продукции, выпускаемой организацией, и соответствующая прибыль за данный период. Графическая функция, которую необходимо построить, будет отображать зависимость роста прибыли от уменьшения себестоимости продукции. При построении графика сначала надо выделить столбцы «Себестоимость единицы продукции» и «Прибыль». После этого следует переместиться на вкладку «Вставка». Затем на ленте в блоке инструментов «Диаграммы» выполнить щелчок указателем мыши по кнопке «Точечная». В открывшемся списке нужно выбрать наименование «Точечная с гладкими кривыми и маркерами». Как раз такой вид диаграмм больше всего подходит для работы с линией тренда, а, следовательно, и для использования метода аппроксимации в Excel.
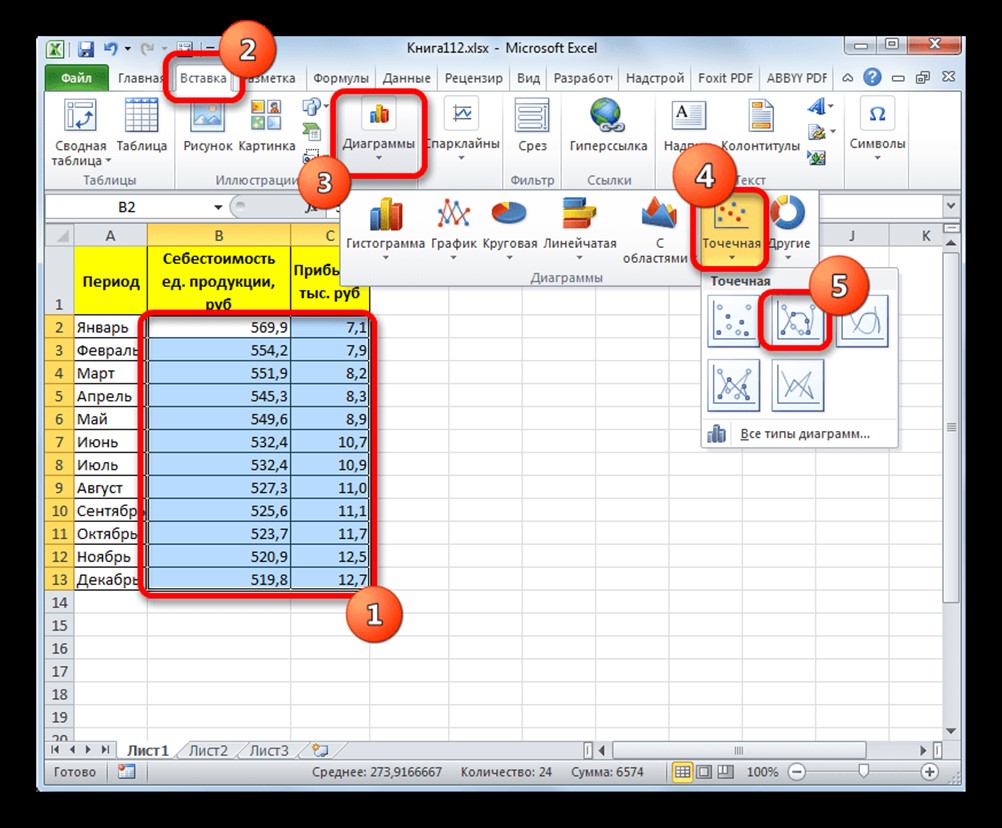
Рисунок 1. Параметры для построения графика. Автор24 — интернет-биржа студенческих работ
Затем будет построен следующий график:
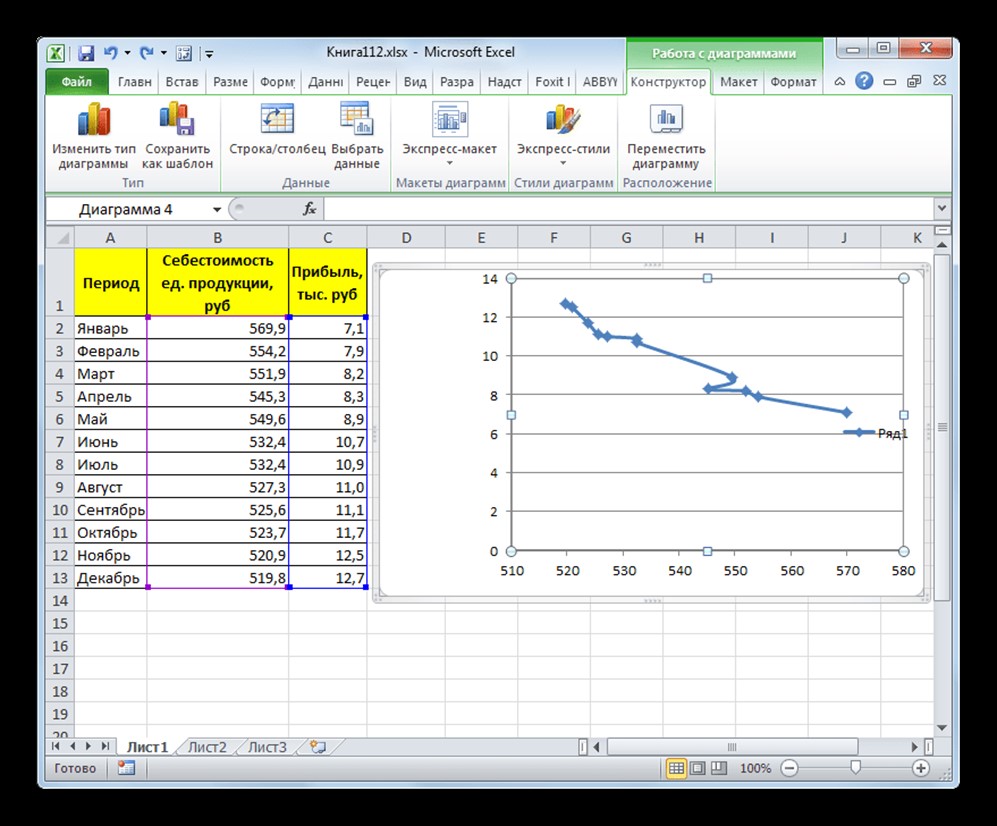
Рисунок 2. Точечная с гладкими кривыми и маркерами. Автор24 — интернет-биржа студенческих работ
Чтобы добавить линию тренда, необходимо выделить график кликом правой кнопки мыши, после чего появится контекстное меню. Следует осуществить выбор в нем пункта «Добавить линию тренда…».
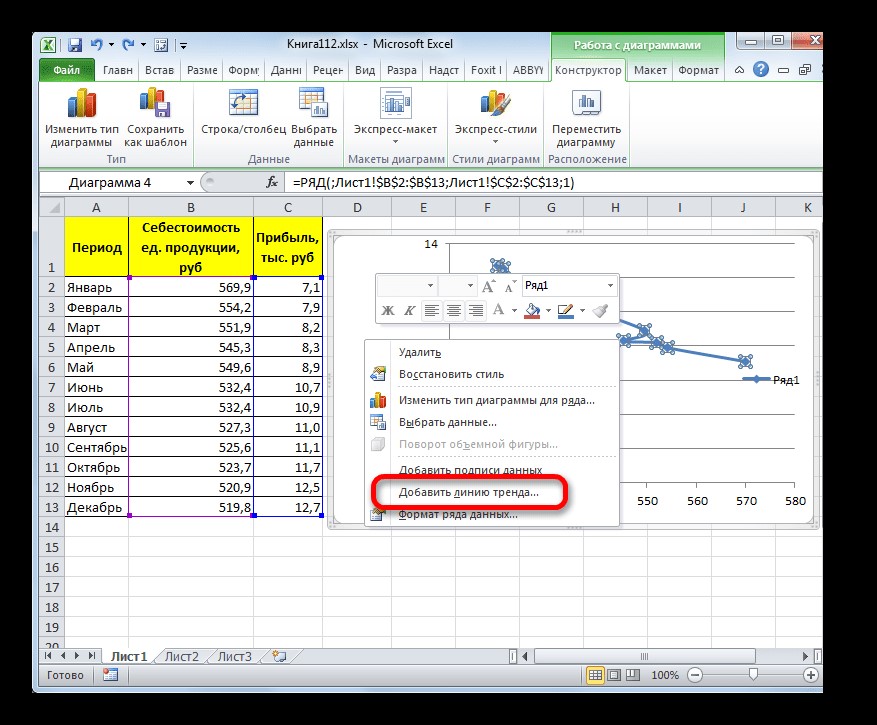
Рисунок 3. Добавить линию тренда на график. Автор24 — интернет-биржа студенческих работ
Имеется и другой вариант добавления линии тренда. В дополнительной группе вкладок на ленте «Работа с диаграммами» следует переместиться во вкладку «Макет». Затем в блоке инструментов «Анализ» необходимо сделать щелчок по кнопке «Линия тренда», после чего откроется список. Поскольку в нашем случае рассматривается применение линейной аппроксимации, то из предложенных позиций следует выбрать «Линейное приближение».
Если же был выбран первый вариант действий с добавлением через контекстное меню, то далее будет открыто окно формата. В блоке параметров «Построение линии тренда (аппроксимация и сглаживание)» необходимо установить переключатель в позицию «Линейная». Если это необходимо, то следует поставить галочку около позиции «Показывать уравнение на диаграмме». После данных действий на диаграмме будет отображено уравнение сглаживающей функции.
Кроме того, для сравнения разных вариантов аппроксимации можно установить галочку около пункта «Поместить на диаграмму величину достоверной аппроксимации (R^2)». Этот показатель варьируется в диапазоне от нуля до единицы. Чем его значение больше, тем точнее выполнена аппроксимация. Считается, что если величина данного показателя равна 0,85 и выше, то сглаживание может считаться достоверным, а если показатель ниже, то его достоверность ниже допустимой. После проведения всех вышеуказанных настроек, следует нажать на кнопку «Закрыть», размещенную в нижней части окна. Появится линия тренда.
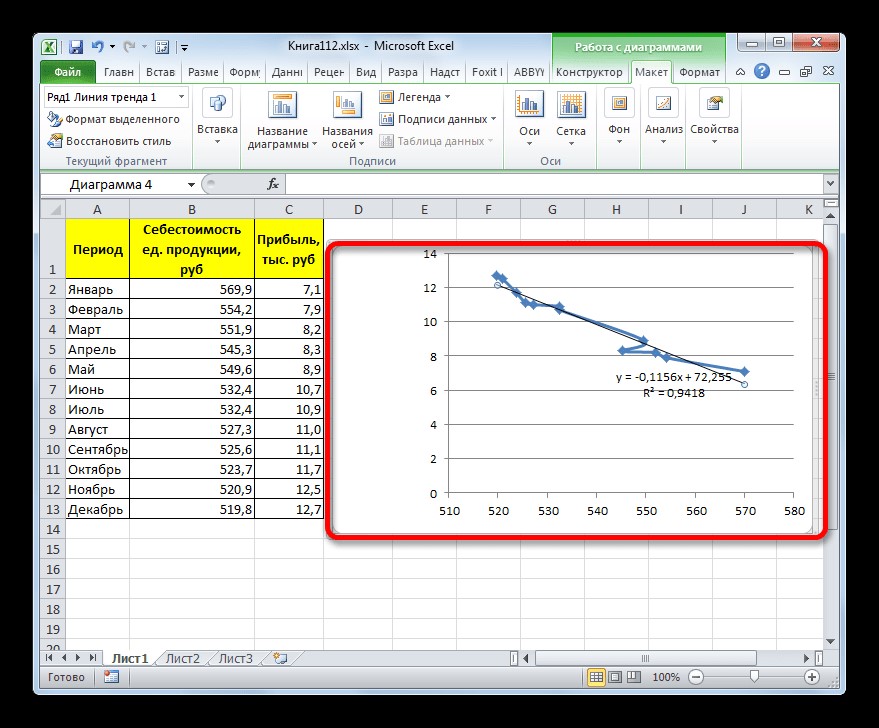
Рисунок 4. Отображение линии тренда. Автор24 — интернет-биржа студенческих работ
При выполнении линейной аппроксимации линия тренда обозначается черной прямой линией. Приведенный тип сглаживания может быть использован в самых простых случаях, когда данные меняются достаточно быстро и зависимость величины функции от аргумента является очевидной. Сглаживание, которое применяется в этом варианте, может быть описано следующей формулой:
y = ax + b.
Для конкретного варианта, приведенного выше, формула будет иметь следующий вид:
y = ‒ 0,1156x + 72,255.
Значение достоверности аппроксимации в рассмотренном случае равняется 0,9418, что считается достаточно приемлемым результатом, который характеризует сглаживание как достоверное.
Далее рассмотрим экспоненциальный тип аппроксимации в Excel. Для изменения типа линии тренда, следует выделить ее кликом правой кнопки мыши и в открывшемся меню нужно выбрать пункт «Формат линии тренда…». После этого будет запущено уже применявшееся ранее окно формата. В блоке выбора типа аппроксимации необходимо установить переключатель в положение «Экспоненциальная». Остальные настройки следует оставить такими же, как и в первом варианте, и затем выполнить щелчок по кнопке «Закрыть». После этого линия тренда будет построена на графике, как показано на рисунке ниже:
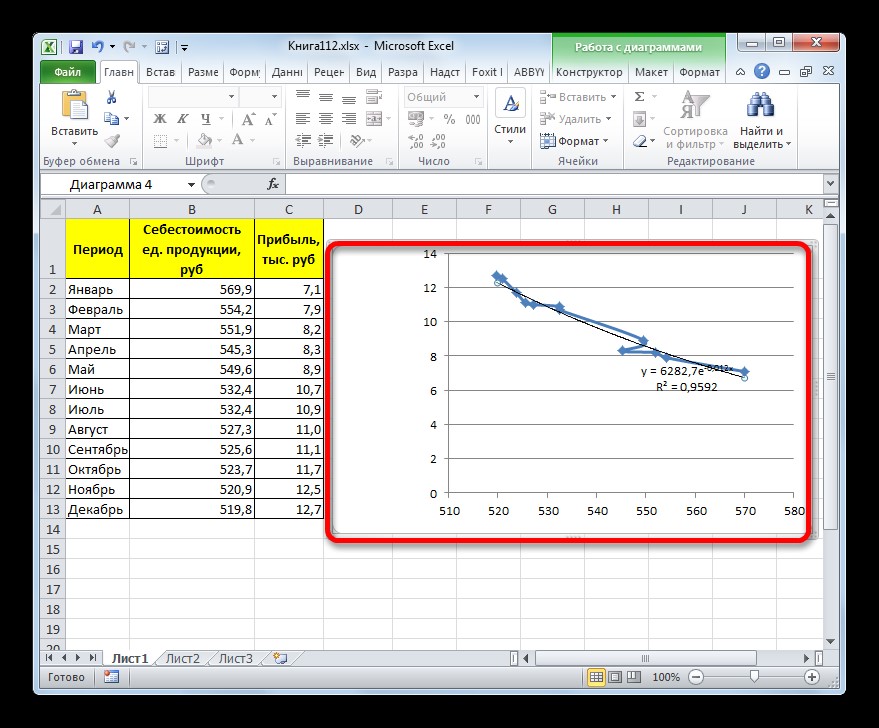
Рисунок 5. Экспоненциальный тип аппроксимации. Автор24 — интернет-биржа студенческих работ
При использовании этого метода линия тренда обладает несколько изогнутой формой. Причем уровень достоверности равняется 0,9592, что выше, чем при использовании линейной аппроксимации.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме