
Содержание
- Подключение пакета анализа
- Виды регрессионного анализа
- Линейная регрессия в программе Excel
- Разбор результатов анализа
- Вопросы и ответы

Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Подключение пакета анализа
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
- Перемещаемся во вкладку «Файл».
- Переходим в раздел «Параметры».
- Открывается окно параметров Excel. Переходим в подраздел «Надстройки».
- В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».
- Открывается окно доступных надстроек Эксель. Ставим галочку около пункта «Пакет анализа». Жмем на кнопку «OK».





Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».

Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк. В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.
- Кликаем по кнопке «Анализ данных». Она размещена во вкладке «Главная» в блоке инструментов «Анализ».
- Открывается небольшое окошко. В нём выбираем пункт «Регрессия». Жмем на кнопку «OK».
- Открывается окно настроек регрессии. В нём обязательными для заполнения полями являются «Входной интервал Y» и «Входной интервал X». Все остальные настройки можно оставить по умолчанию.
В поле «Входной интервал Y» указываем адрес диапазона ячеек, где расположены переменные данные, влияние факторов на которые мы пытаемся установить. В нашем случае это будут ячейки столбца «Количество покупателей». Адрес можно вписать вручную с клавиатуры, а можно, просто выделить требуемый столбец. Последний вариант намного проще и удобнее.
В поле «Входной интервал X» вводим адрес диапазона ячеек, где находятся данные того фактора, влияние которого на переменную мы хотим установить. Как говорилось выше, нам нужно установить влияние температуры на количество покупателей магазина, а поэтому вводим адрес ячеек в столбце «Температура». Это можно сделать теми же способами, что и в поле «Количество покупателей».

С помощью других настроек можно установить метки, уровень надёжности, константу-ноль, отобразить график нормальной вероятности, и выполнить другие действия. Но, в большинстве случаев, эти настройки изменять не нужно. Единственное на что следует обратить внимание, так это на параметры вывода. По умолчанию вывод результатов анализа осуществляется на другом листе, но переставив переключатель, вы можете установить вывод в указанном диапазоне на том же листе, где расположена таблица с исходными данными, или в отдельной книге, то есть в новом файле.
После того, как все настройки установлены, жмем на кнопку «OK».






Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
history 26 января 2019 г.
- Группы статей
- Статистический анализ
Проведем множественный регрессионный анализ с помощью надстройки
MS
EXCEL
Пакет анализа
.
Эффективно использовать
надстройку Пакет анализа
могут только пользователи знакомые с теорией
множественного регрессионного анализа
.
В данной статье решены следующие задачи:
-
Показано как в MS EXCEL выполнить
регрессионный анализ
с помощью
надстройки Пакет анализа
(инструмент Регрессия), т.е. как вызвать надстройку и правильно заполнить входные данные; - Даны пояснения по разделам отчета, формированного надстройкой;
-
Даны комментарии обо всех показателях, рассчитанных надстройкой, и приведены ссылки на соответствующие разделы статей, посвященные
простой линейной регрессии
.
В
надстройке Пакет анализа
для построения
линейной
регрессионной
модели
(как
простой
, так и
множественной
)
имеется специальный инструмент
Регрессия
.
После выбора этого инструмента откроется окно, в котором требуется заполнить следующие поля (см.
файл примера лист Надстройка
):
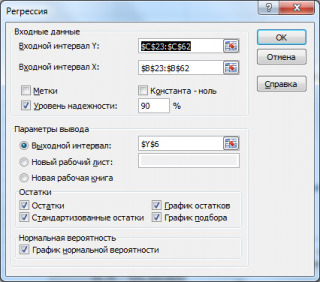
Входной интервал
Y
: ссылка на массив значений переменной Y. Ссылку можно указать с заголовком. В этом случае, при выводе результатов надстройка использует Ваш заголовок (для этого в окне требуется установить галочку
Метки
);
Входной интервал Х
: ссылка на значения переменных Х (нужно указать все столбцы со значениями Х). Ссылку рекомендуется делать на диапазон с заголовками (в окне не забудьте установить галочку
Метки
);
Константа-ноль
: если галочка установлена, то надстройка подбирает плоскость регрессии с
b
0
=0;
Уровень надежности
: Это значение используется для построениядоверительных интервалов для наклона и сдвига
.
Уровень надежности
= 1-
альфа
. Если галочка не установлена или установлена, но
уровень значимости
= 95%, то надстройка все равно рассчитывает границы доверительных интервалов, причем дублирует их. Если галочка установлена, а
уровень надежности
отличен от 95%, то рассчитываются 2
доверительных интервала
: один для 95%, другой для введенного значения. Для демонстрации вышесказанного введем 90%;
Выходной интервал:
диапазон ячеек, куда будут помещены результаты вычислений. Достаточно указать левую верхнюю ячейку этого диапазона;
Остатки
: будут вычислены
остатки модели
, т.е. разница между наблюденными и предсказанными значениями Yi для всех наблюдений n;
Стандартизированные остатки
: Вышеуказанные значения остатков будут поделены на значение ихстандартного отклонения
;
График остатков
: Для каждой переменной X
j
будет построенаточечная диаграмма
: значения остатков и соответствующее значение Х
ji
(при прогнозировании на основании значений 2-х переменных Х будет построено 2 диаграммы (j=1 и 2));
График подбора:
Для каждой переменной X
j
будут построеныточечные диаграммы с двумя рядами данных
: точки данных (X
ji
;Y
i
) и (X
ji
;Y
iпредсказанное
);-
График нормальной вероятности: Будет построена точечная диаграмма с названием График
нормального распределения
. По сути — это график значений переменной Y,
отсортированных по возрастанию
.
В результате вычислений будет заполнен указанный
Выходной интервал.
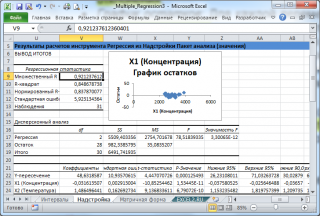
Тот же результат можно получить с помощью формул (см.
файл примера лист Надстройка
, столбцы I:T).
Результаты вычислений, выполненных надстройкой, полностью совпадают с вычислениями сделанными нами в статье про
множественную линейную регрессию
с помощью функций
ЛИНЕЙН()
,
ТЕНДЕНЦИЯ()
и др. Использование альтернативных формул помогает разобраться с алгоритмом расчета показателей регрессии.
Отчет, сформированный надстройкой, состоит из следующих разделов:
Раздел «Регрессионная статистика»:
Множественный R.
В случае множественной линейной регрессии — это квадратный корень изкоэффициента детерминации
R
2
R-квадрат
. В случае множественной линейной регрессии – это
коэффициент детерминации
R
2
Нормированный R-квадрат
. Подробнее см.здесь
(англ. термин Adjusted R-squared)
Стандартная ошибка
. Подробнее см.здесь
;
Наблюдения
. Количество значений Y.
Раздел «Дисперсионный анализ»:
См. раздел
Проверка гипотез в статье о множественной регрессии
.
df
– степени свободы (Degrees of Freedom).
SS
– сумма квадратов (Sum of Squares)
MS
– SS/df (MSR и MSE)
F
– значение статистики F
0
(MSR/MSE)
Значимость
F
– p-значение, функция
F.РАСП.ПХ()
Другие результаты:
Коэффициенты
: оценка параметров модели
b
j
. См. разделОценка неизвестных параметров
.
Стандартная ошибка
:Стандартные ошибки вышеуказанных статистик
t-статистика
: значение тестовой статистики t
0
, которая имеетраспределение Стьюдента
. Используется для проверки значимости индивидуальных коэффициентов. t
0
– отношение оценки коэффициента регрессии и егостандартного отклонения
(модуль этого значения). Если это значение меньше критического значения
=СТЬЮДЕНТ.ОБР.2Х(0,05;DF)
, то коэффициент не значимый.
P-Значение
: Используется для проверки значимости индивидуальных коэффициентов. Если вероятность
t-статистики
меньше
уровня значимости
(обычно 0,05), то коэффициент не значимый-
Нижние 95% и Верхние 95%: границы
доверительных интервалов для оценок неизвестных параметров модели
с уровнем значимости =1-95%=5%=0,05.
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Еще…Меньше
Если вам нужно разработать сложный статистический или инженерный анализ, вы можете сэкономить время и этапы с помощью этого средства. Вы предоставляете данные и параметры для каждого анализа, а средство использует соответствующие статистические или инженерные функции для вычисления и отображения результатов в выходной таблице. Некоторые средства создают диаграммы в дополнение к выходным таблицам.
Функции анализа данных можно применять только на одном листе. Если анализ данных проводится в группе, состоящей из нескольких листов, то результаты будут выведены на первом листе, на остальных листах будут выведены пустые диапазоны, содержащие только форматы. Чтобы провести анализ данных на всех листах, повторите процедуру для каждого листа в отдельности.
Ниже описаны инструменты, включенные в пакет анализа. Для доступа к ним нажмите кнопкуАнализ данных в группе Анализ на вкладке Данные. Если команда Анализ данных недоступна, необходимо загрузить надстройку «Пакет анализа».
-
Откройте вкладку Файл, нажмите кнопку Параметры и выберите категорию Надстройки.
-
В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
Если вы используете Excel для Mac, в строке меню откройте вкладку Средства и в раскрывающемся списке выберите пункт Надстройки для Excel.
-
В диалоговом окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
-
Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
-
Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
-
Примечание: Чтобы включить Visual Basic для приложений (VBA) для надстройки «Надстройка анализа», вы можете загрузить надстройку VBA так же, как и надстройку «Надстройка анализа». В поле Доступные надстройки выберите «Надстройка анализа — VBA».
Существует несколько видов дисперсионного анализа. Нужный вариант выбирается с учетом числа факторов и имеющихся выборок из генеральной совокупности.
Однофакторный дисперсионный анализ
Этот инструмент выполняет простой анализ дисперсии данных для двух или более выборок. Анализ дает проверку гипотезы о том, что каждая выборка взята из одного и того же распределения вероятности на основе альтернативной гипотезы о том, что для всех выборок распределение вероятности не одно и то же. Если есть только два примера, можно использовать функцию T.ТЕСТ. В более чем двух примерах нет удобного обобщения T.ВМЕСТОэтого можно использовать модель Anova для одного фактора.
Двухфакторный дисперсионный анализ с повторениями
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам. Например, в эксперименте по измерению высоты растений последние обрабатывали удобрениями от различных изготовителей (например, A, B, C) и содержали при различной температуре (например, низкой и высокой). Таким образом, для каждой из 6 возможных пар условий {удобрение, температура}, имеется одинаковый набор наблюдений за ростом растений. С помощью этого дисперсионного анализа можно проверить следующие гипотезы:
-
Извлечены ли данные о росте растений для различных марок удобрений из одной генеральной совокупности. Температура в этом анализе не учитывается.
-
Извлечены ли данные о росте растений для различных уровней температуры из одной генеральной совокупности. Марка удобрения в этом анализе не учитывается.
Извлечены ли шесть выборок, представляющих все пары значений {удобрение, температура}, используемые для оценки влияния различных марок удобрений (для первого пункта в списке) и уровней температуры (для второго пункта в списке), из одной генеральной совокупности. Альтернативная гипотеза предполагает, что влияние конкретных пар {удобрение, температура} превышает влияние отдельно удобрения и отдельно температуры.
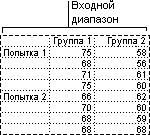
Двухфакторный дисперсионный анализ без повторений
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам, как в случае двухфакторного дисперсионного анализа с повторениями. Однако в таком анализе предполагается, что для каждой пары параметров есть только одно измерение (например, для каждой пары параметров {удобрение, температура} из предыдущего примера).
Функции CORREL и PEARSON вычисляют коэффициент корреляции между двумя переменными измерения, если для каждой переменной наблюдаемы измерения по каждому из N-объектов. (Любые отсутствующие наблюдения по любой теме вызывают игнорирование в анализе.) Средство анализа корреляции особенно удобно использовать, если для каждого субъекта N имеется более двух переменных измерения. Она содержит выходную таблицу — матрицу корреляции, которая показывает значение CORREL (или PEARSON),примененного к каждой из возможных пар переменных измерения.
Коэффициент корреляции, как и ковариана, — это мера степени, в которой две единицы измерения «различаются». В отличие от ковариации коэффициент корреляции масштабирован таким образом, что его значение не зависит от единиц измерения, выраженных в двух переменных измерения. (Например, если двумя переменными измерения являются вес и высота, то значение коэффициента корреляции не изменяется, если вес преобразуется из фунта в фунты.) Значение любого коэффициента корреляции должно быть включительно от -1 до +1 включительно.
Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, т. е. большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция).
Средства корреляции и коварианс могут использоваться в одном и том же параметре, если у вас есть N различных переменных измерения, наблюдаемые для набора людей. Каждый из инструментов корреляции и ковариции дает выходную таблицу — матрицу, которая показывает коэффициент корреляции или коварианс между каждой парой переменных измерения соответственно. Разница заключается в том, что коэффициенты корреляции масштабироваться в зависимости от -1 и +1 включительно. Соответствующие ковариансы не масштабироваться. Коэффициент корреляции и коварианс — это показатели степени, в которой две переменные «различаются».
Инструмент Ковариана вычисляет значение функции КОВАРИАНА. P для каждой пары переменных измерения. (Прямое использование КОВАРИАНА. P вместо ковариана является разумной альтернативой, если есть только две переменные измерения, то есть N=2.) Запись в диагонали выходной таблицы средства Коварица в строке i, столбце i — коварианс i-й переменной измерения. Это только дисперсия по численности населения для этой переменной, вычисляемая функцией ДИСПЕРС.P.
Ковариационный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть большие значения из одного набора данных связаны с большими значениями другого набора (положительная ковариация) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная ковариация), или данные двух диапазонов никак не связаны (ковариация близка к нулю).
Инструмент анализа «Описательная статистика» применяется для создания одномерного статистического отчета, содержащего информацию о центральной тенденции и изменчивости входных данных.
Инструмент анализа «Экспоненциальное сглаживание» применяется для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. При анализе используется константа сглаживания a, величина которой определяет степень влияния на прогнозы погрешностей в предыдущем прогнозе.
Примечание: Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к большим промежуткам между предсказанными значениями.
Двухвыборочный F-тест применяется для сравнения дисперсий двух генеральных совокупностей.
Например, можно использовать F-тест по выборкам результатов заплыва для каждой из двух команд. Это средство предоставляет результаты сравнения нулевой гипотезы о том, что эти две выборки взяты из распределения с равными дисперсиями, с гипотезой, предполагающей, что дисперсии различны в базовом распределении.
С помощью этого инструмента вычисляется значение f F-статистики (или F-коэффициент). Значение f, близкое к 1, показывает, что дисперсии генеральной совокупности равны. В таблице результатов, если f < 1, «P(F <= f) одностороннее» дает возможность наблюдения значения F-статистики меньшего f при равных дисперсиях генеральной совокупности и F критическом одностороннем выдает критическое значение меньше 1 для выбранного уровня значимости «Альфа». Если f > 1, «P(F <= f) одностороннее» дает возможность наблюдения значения F-статистики большего f при равных дисперсиях генеральной совокупности и F критическом одностороннем дает критическое значение больше 1 для «Альфа».
Инструмент «Анализ Фурье» применяется для решения задач в линейных системах и анализа периодических данных на основе метода быстрого преобразования Фурье (БПФ). Этот инструмент поддерживает также обратные преобразования, при этом инвертирование преобразованных данных возвращает исходные данные.

Инструмент «Гистограмма» применяется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений. При этом рассчитываются числа попаданий для заданного диапазона ячеек.
Например, можно получить распределение успеваемости по шкале оценок в группе из 20 студентов. Таблица гистограммы состоит из границ шкалы оценок и групп студентов, уровень успеваемости которых находится между самой нижней границей и текущей границей. Наиболее часто встречающийся уровень является модой диапазона данных.
Совет: В Excel 2016 теперь можно создавать гистограммы и диаграммы Парето.
Инструмент анализа «Скользящее среднее» применяется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Скользящее среднее, в отличие от простого среднего для всей выборки, содержит сведения о тенденциях изменения данных. Этот метод может использоваться для прогноза сбыта, запасов и других тенденций. Расчет прогнозируемых значений выполняется по следующей формуле:
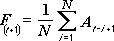
где
-
N — число предшествующих периодов, входящих в скользящее среднее;
-
A
j — фактическое значение в момент времени j; -
F
j — прогнозируемое значение в момент времени j.
Инструмент «Генерация случайных чисел» применяется для заполнения диапазона случайными числами, извлеченными из одного или нескольких распределений. С помощью этой процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей. Например, можно использовать нормальное распределение для моделирования совокупности данных по росту людей или использовать распределение Бернулли для двух вероятных исходов, чтобы описать совокупность результатов бросания монеты.
Средство анализа Ранг и процентиль создает таблицу, которая содержит порядковую и процентную ранг каждого значения в наборе данных. Можно проанализировать относительное положение значений в наборе данных. В этом средстве используются функции РАНГ. EQ и PERCENTRANK. INC. Если вы хотите учитывать связанные значения, используйте РАНГ. Функция EQ, которая обрабатывает связанные значения как имеющие одинаковый ранг или использует РАНГ.Функция AVG, которая возвращает средний ранг связанных значений.
Инструмент анализа «Регрессия» применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
В средстве регрессии используется функция LINEST.
Инструмент анализа «Выборка» создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки или построения диаграммы, можно использовать представительную выборку. Кроме того, если предполагается периодичность входных данных, то можно создать выборку, содержащую значения только из отдельной части цикла. Например, если входной диапазон содержит данные для квартальных продаж, создание выборки с периодом 4 разместит в выходном диапазоне значения продаж из одного и того же квартала.
Двухвыборочный t-тест проверяет равенство средних значений генеральной совокупности по каждой выборке. Три вида этого теста допускают следующие условия: равные дисперсии генерального распределения, дисперсии генеральной совокупности не равны, а также представление двух выборок до и после наблюдения по одному и тому же субъекту.
Для всех трех средств, перечисленных ниже, значение t вычисляется и отображается как «t-статистика» в выводимой таблице. В зависимости от данных это значение t может быть отрицательным или неотрицательным. Если предположить, что средние генеральной совокупности равны, при t < 0 «P(T <= t) одностороннее» дает вероятность того, что наблюдаемое значение t-статистики будет более отрицательным, чем t. При t >=0 «P(T <= t) одностороннее» делает возможным наблюдение значения t-статистики, которое будет более положительным, чем t. «t критическое одностороннее» дает пороговое значение, так что вероятность наблюдения значения t-статистики большего или равного «t критическое одностороннее» равно «Альфа».
«P(T <= t) двустороннее» дает вероятность наблюдения значения t-статистики, по абсолютному значению большего, чем t. «P критическое двустороннее» выдает пороговое значение, так что значение вероятности наблюдения значения t- статистики, по абсолютному значению большего, чем «P критическое двустороннее», равно «Альфа».
Парный двухвыборочный t-тест для средних
Парный тест используется, когда имеется естественная парность наблюдений в выборках, например, когда генеральная совокупность тестируется дважды — до и после эксперимента. Этот инструмент анализа применяется для проверки гипотезы о различии средних для двух выборок данных. В нем не предполагается равенство дисперсий генеральных совокупностей, из которых выбраны данные.
Примечание: Одним из результатов теста является совокупная дисперсия (совокупная мера распределения данных вокруг среднего значения), вычисляемая по следующей формуле:
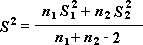
Двухвыборочный t-тест с одинаковыми дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных поступили из распределения с одинаковыми дисперсиями. Его называют гомике t-тестом. Этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения.
Двухвыборочный t-тест с различными дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных были полученными из распределения с неравными дисперсиями. Его называют гетероскестическими t-тестами. Как и в предыдущем примере с равными дисперсиями, этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения. Этот тест можно использовать, если в двух примерах есть отдельные объекты. Используйте тест Парный, описанный в примере, если существует один набор тем и две выборки представляют измерения по каждой теме до и после обработки.
Для определения тестовой величины t используется следующая формула.
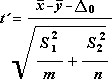
Следующая формула используется для вычисления степеней свободы (df). Так как результат вычисления обычно не является integer, значение df округлится до ближайшего другого, чтобы получить критическое значение из таблицы t. Функция Excel T .Test использует вычисляемую величину df без округлений, так как можно вычислить значение для T.ТЕСТ с неинтегрированной df. Из-за этих разных подходов к определению степеней свободы результаты T.Тест и этот t-тест будут отличаться в случае неравных дисперсий.
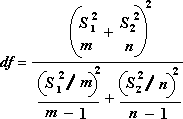
Z-тест. Средство анализа «Две выборки для середины» выполняет два примера z-теста для средств со известными дисперсиями. Этот инструмент используется для проверки гипотезы NULL о том, что между двумя значениями численности населения нет различий между односторонними или двухбокльными альтернативными гипотезами. Если дисперсии не известны, функция Z .Вместо этого следует использовать тест.
При использовании этого инструмента следует внимательно просматривать результат. «P(Z <= z) одностороннее» на самом деле есть P(Z >= ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. «P(Z <= z) двустороннее» на самом деле есть P(Z >= ABS(z) или Z <= -ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. Двусторонний результат является односторонним результатом, умноженным на 2. Инструмент «z-тест» можно также применять для гипотезы об определенном ненулевом значении разницы между двумя средними генеральных совокупностей. Например, этот тест можно использовать для определения разницы выступлений на соревнованиях двух автомобилей разных марок.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
См. также
Создание гистограммы в Excel 2016
Создание диаграммы Парето в Excel 2016
Загрузка средства анализа в Excel
Инженерные функции (справка)
Общие сведения о формулах в Excel
Рекомендации, позволяющие избежать появления неработающих формул
Поиск ошибок в формулах
Сочетания клавиш и горячие клавиши в Excel
Функции Excel (по алфавиту)
Функции Excel (по категориям)
Нужна дополнительная помощь?
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.

Модель линейной регрессии имеет следующий вид:
У = а0 + а1х1 +…+акхк.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.



После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).



В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
Пример:

- Строим корреляционное поле: «Вставка» — «Диаграмма» — «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».




Теперь стали видны и данные регрессионного анализа.
Вот руководство по выполнению регрессионного анализа на ПК с Windows 11/10. Регрессионный анализ — это статистический метод, используемый для оценки набора данных. Он используется для определения отношения между набором из двух или более переменных в наборе данных. Это в основном позволяет вам анализировать важные и неважные факторы из набора данных, а затем принимать соответствующее решение. Теперь, если вы хотите выполнить регрессионный анализ без ручных вычислений, этот пост вам поможет.
В этой статье мы обсудим различные способы проведения регрессионного анализа на ПК с Windows 11/10. Вам не нужно ничего делать вручную. Просто импортируйте свой набор данных, выберите входные переменные и визуализируйте результаты. Используя упомянутые методы, вы можете выполнять линейный, нелинейный, множественный и другие регрессионные анализы. Давайте теперь подробно рассмотрим методы!
Как вы выполняете регрессионный анализ?
Регрессионный анализ можно выполнить с помощью Excel в Windows 11/10. Вы также можете использовать стороннее бесплатное программное обеспечение, которое позволяет рассчитывать регрессионный анализ. Кроме того, вы даже можете выполнять регрессионный анализ онлайн с помощью специального бесплатного веб-сайта. Мы подробно обсудили все эти методы ниже. Итак, давайте оформим заказ!
Как выполнить регрессионный анализ в Excel?
Вы можете легко выполнить регрессионный анализ в Excel и других выпусках, включив надстройку. Это дополнение называется Data Analysis ToolPak, которое предустановлено в Microsoft Excel. Просто выполните простые шаги, чтобы включить эту надстройку в Excel, и тогда вы сможете выполнить несколько анализов данных. Мы обсудили пошаговую процедуру проведения регрессионного анализа в Microsoft Excel. Вы можете проверить это ниже.
Связанное чтение: Что такое Data Analytics и для чего он используется?
Вот методы, которые вы можете использовать для выполнения регрессионного анализа ваших наборов данных в Windows 11/10:
- Выполните регрессионный анализ в Microsoft Excel.
- Используйте бесплатное ПО JASP или Statcato для выполнения регрессионного анализа.
- Выполняйте регрессионный анализ онлайн с помощью бесплатного веб-сервиса.
Обсудим подробно вышеперечисленные методы!
1]Выполните регрессионный анализ в Microsoft Excel
Вы можете выполнить регрессионный анализ с помощью приложения Microsoft Excel. Специальная надстройка Data Analysis ToolPak в Excel позволяет выполнять регрессионный анализ и некоторый другой анализ данных. Вам придется вручную включить эту надстройку, чтобы использовать ее функции. Давайте посмотрим на процедуру использования надстройки пакета Excel Data Analysis ToolPak для регрессионного анализа.
Как выполнить регрессионный анализ в Microsoft Excel:
Вот основные шаги для проведения регрессионного анализа в Microsoft Excel:
- Запустите приложение Microsoft Excel.
- Перейдите на вкладку Файл> Параметры> Надстройки.
- Щелкните по кнопке Go.
- Включите надстройку Data Analysis ToolPak и вернитесь на главный экран Excel.
- Импортируйте свои наборы данных и выберите входные данные с зависимыми и независимыми переменными.
- Перейдите на вкладку «Данные».
- Нажмите кнопку анализа данных.
- Выберите «Регрессия» и нажмите кнопку «ОК».
- Введите входной диапазон X и Y и другие параметры вывода.
- Нажмите кнопку ОК, чтобы просмотреть результаты регрессионного анализа.
Давайте теперь подробно обсудим вышеупомянутые шаги.
Сначала запустите приложение Microsoft Excel, а затем включите надстройку Data Analysis ToolPak. Для этого нажмите «Файл»> «Параметры» и перейдите на вкладку «Надстройки». Здесь нажмите кнопку «Перейти» рядом с опцией «Управление надстройками Excel». Затем установите флажок надстройки Data Analysis ToolPak и нажмите кнопку OK, чтобы включить ее.
Теперь импортируйте свои наборы данных из Excel или любого другого поддерживаемого файла, или вы можете создать новый набор данных. Выберите поля входных данных, для которых вы хотите выполнить регрессионный анализ.
Затем перейдите на вкладку «Данные» и нажмите кнопку «Анализ данных».
После этого выберите параметр «Регрессия» из доступных инструментов анализа данных и нажмите кнопку «ОК».
Затем вам нужно ввести входной диапазон X (независимая переменная) и Y (зависимая переменная), для которого вы хотите провести регрессионный анализ. Кроме того, вы также можете выбрать параметры остатков, такие как стандартизованные остатки, графики аппроксимации линий, графики остатков и т. Д. Также, некоторые другие параметры, такие как нормальная вероятность, уровень достоверности, метка и т. Д.
Настройте все вышеперечисленные параметры и нажмите кнопку ОК, чтобы визуализировать результаты.
Он показывает статистику регрессии, включая коэффициент, стандартную ошибку, t Stat, значение P, значимость F, множественные R, стандартную ошибку, наблюдения, степени свободы, сумму квадратов, средние квадраты, значение F и многое другое.
Вы можете сохранить результаты на том же листе Excel или распечатать результаты.
Точно так же вы также можете выполнять анализ, включая тесты ANOVA, ковариацию, описательную статистику, экспоненциальное сглаживание, анализ Фурье, гистограмму, скользящее среднее, выборку, t-тест и т. Д.
2]Используйте бесплатное ПО JASP для выполнения регрессионного анализа
Вы можете использовать стороннее бесплатное ПО для выполнения регрессионного анализа набора данных. Есть несколько бесплатных программ, позволяющих анализировать данные. Здесь мы собираемся использовать бесплатное программное обеспечение под названием JASP и Statcato. Используя эти два бесплатных программного обеспечения, вы можете выполнять регрессионный анализ и многие другие анализы данных:
- JASP
- Statcato
1]JASP
JASP — это специальная бесплатная программа для статистического анализа для Windows 11/10. Используя его, вы можете выполнять регрессионный анализ, описательные тесты, T-тесты, ANOVA, частотные тесты, анализ главных компонентов, исследовательский факторный анализ, мета-анализ, сводная статистика, SEM, визуальное моделирование, а также подтверждающий факторный анализ. Он предлагает специальную регрессию, в которой вы можете выполнять линейный, корреляционный и логистический регрессионный анализ. Давайте узнаем, как это сделать.
Вот основные шаги для проведения регрессионного анализа в JASP:
- Скачайте и установите JASP.
- Запустите программу.
- Импортируйте свой набор данных.
- Перейдите на вкладку «Регрессия».
- Выберите классический или байесовский тип регрессии.
- Выберите зависимые и независимые переменные и настройте другие параметры.
- Просматривайте и экспортируйте результаты.
Давайте теперь подробнее рассмотрим вышеупомянутые шаги!
Во-первых, вам необходимо загрузить и установить на свой компьютер бесплатное ПО JASP. А затем запустите основной графический интерфейс этого программного обеспечения.
Теперь перейдите в меню с тремя полосами и нажмите на Открытым возможность импорта наборов данных из локально сохраненных файлов Excel, CSV, TSV, ODS, TXT и т. д. Вы также можете импортировать свои входные данные из своей учетной записи OSF (Open Science Framework). Кроме того, он поставляется с несколькими образцами наборов данных, которые вы можете использовать в своем исследовании и анализе.
Затем перейдите на вкладку «Регрессия» и выберите тип регрессионного анализа, который вы хотите выполнить, например логистический, линейный или корреляционный.
После этого выберите зависимые и независимые переменные, а затем настройте несколько других параметров, таких как метод, вес WLS, модель, спецификация метода или критерии и многое другое. Вы также можете выбрать значения, которые вы хотите вычислить в регрессионном анализе, такие как остатки, изменение квадрата R, матрица ковариации, диагностика коллинеарности, частичные и частичные корреляции, соответствие модели и многое другое. Кроме того, вы можете построить различные графики с вычисленной статистикой регрессионного анализа, включая зависимые остатки в / с, ковариаты для остатков в / с, гистограмму остатков в / с и некоторые другие графики.
По мере настройки всех описанных выше параметров в правой части отображается регрессионный анализ. Вы можете экспортировать результаты регрессионного анализа в документ HTML или PDF.
Это одно из лучших бесплатных программ для выполнения регрессионного анализа и многого другого. Вы можете скачать это удобное бесплатное ПО с сайта jasp-stats.org.
2]Statcato
Еще одна бесплатная программа, которую вы можете попробовать выполнить регрессионный анализ, — это Statcato. Это бесплатное программное обеспечение с открытым исходным кодом для выполнения статистического анализа. Он позволяет выполнять регрессионный анализ, а также несколько других типов анализа данных. Некоторые из методов анализа данных, представленных в нем, включают тесты гипотез, дисперсионный анализ, описательную статистику, тесты нормальности, размер выборки, непараметрические тесты и многое другое.
Он позволяет выполнять линейную регрессию, множественную регрессию, матрицу корреляции, нелинейную регрессию и т. Д. Давайте посмотрим, как использовать это программное обеспечение.
Вот основные шаги для выполнения регрессионного анализа в Statcato:
- Загрузите это программное обеспечение.
- Запустите файл Jar.
- Импортируйте или создайте входной набор данных.
- Зайдите в меню статистики.
- Нажмите на опцию Корреляция и регрессия.
- Выберите желаемый тип регрессии.
- Выберите зависимые и независимые переменные.
- Просмотр и сохранение регрессионного анализа.
Давайте теперь подробно обсудим вышеупомянутые шаги!
Во-первых, вам необходимо загрузить это бесплатное программное обеспечение с сайта statcato.org. Затем разархивируйте загруженную zip-папку и запустите исполняемый файл Jar. Для использования этого приложения в вашей системе должна быть установлена Java.
Теперь откройте файл, содержащий входной набор данных, или вы также можете создать новый набор данных в его интерфейсе, похожем на электронную таблицу.
Затем перейдите в меню «Статистика» и нажмите «Корреляция и регрессия», а затем выберите тип регрессионного анализа, который вы хотите выполнить.
После этого выберите независимую и зависимую переменную, для которой вы хотите провести регрессионный анализ, и настройте другие параметры. Затем нажмите кнопку ОК.
Он отобразит результаты регрессионного анализа в специальном окне.
Регрессионный анализ в основном включает статистические данные, такие как уравнение регрессии, объясненная вариация, необъяснимая вариация, коэффициент детерминации, стандартная ошибка оценки, статистика теста, p-значение и многое другое.
Вы можете скопировать результаты или сделать распечатку.
Это еще одно хорошее программное обеспечение для статистического анализа, которое позволяет вычислять различную статистику, выполнять анализ данных и строить различные виды графиков.
Читать: x
3]Выполните регрессионный анализ онлайн с помощью бесплатного веб-сервиса.
Вы также можете выполнить регрессионный анализ онлайн, используя специальный бесплатный веб-сервис. Здесь мы собираемся использовать этот веб-сервис под названием socscistatistics.com. Он позволяет выполнять линейный и множественный регрессионный анализ в режиме онлайн. Кроме того, на этом веб-сайте вы также можете найти другие статистические инструменты, такие как тесты ANOVA, калькулятор хи-квадрат, калькулятор проверки знаков, калькулятор стандартных ошибок, T-тесты и многое другое.
Как выполнить регрессионный анализ онлайн:
Вот основные шаги для выполнения регрессионного анализа онлайн с помощью socscistatistics.com:
- Откройте веб-браузер.
- Перейдите на сайт socscistatistics.com.
- Перейдите на страницу калькулятора регрессии.
- Введите значения для зависимых и независимых переменных.
- Нажмите на опцию Рассчитать уравнение регрессии.
Во-первых, запустите веб-браузер и откройте socscistatistics.com. Теперь вам нужно перейти к Калькулятор множественной регрессии или Калькулятор линейной регрессии страницу, какой бы метод регрессионного анализа вы ни выбрали.
Затем введите соответствующие входные значения в столбцы X (независимый) и Y (зависимый). Вы также можете ввести оценочные значения.
После этого нажмите на опцию Рассчитать уравнение регрессии.
Затем в том же окне отобразятся результаты регрессионного анализа.
Результаты регрессионного анализа включают график, уравнение регрессии, сумму квадратов, сумму произведений, средние значения и многое другое.
Вот и все! Надеюсь, это руководство поможет вам найти подходящий метод для выполнения регрессионного анализа ваших наборов данных в Windows 11/10.
Теперь прочтите:
.