Анализ данных в Excel предполагает сама конструкция табличного процессора. Очень многие средства программы подходят для реализации этой задачи.
Excel позиционирует себя как лучший универсальный программный продукт в мире по обработке аналитической информации. От маленького предприятия до крупных корпораций, руководители тратят значительную часть своего рабочего времени для анализа жизнедеятельности их бизнеса. Рассмотрим основные аналитические инструменты в Excel и примеры применения их в практике.
Инструменты анализа Excel
Одним из самых привлекательных анализов данных является «Что-если». Он находится: «Данные»-«Работа с данными»-«Что-если».
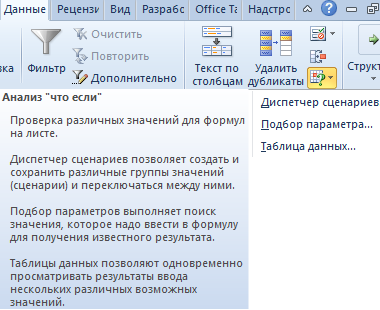
Средства анализа «Что-если»:
- «Подбор параметра». Применяется, когда пользователю известен результат формулы, но неизвестны входные данные для этого результата.
- «Таблица данных». Используется в ситуациях, когда нужно показать в виде таблицы влияние переменных значений на формулы.
- «Диспетчер сценариев». Применяется для формирования, изменения и сохранения разных наборов входных данных и итогов вычислений по группе формул.
- «Поиск решения». Это надстройка программы Excel. Помогает найти наилучшее решение определенной задачи.
Практический пример использования «Что-если» для поиска оптимальных скидок по таблице данных.
Другие инструменты для анализа данных:
Анализировать данные в Excel можно с помощью встроенных функций (математических, финансовых, логических, статистических и т.д.).
Сводные таблицы в анализе данных
Чтобы упростить просмотр, обработку и обобщение данных, в Excel применяются сводные таблицы.
Программа будет воспринимать введенную/вводимую информацию как таблицу, а не простой набор данных, если списки со значениями отформатировать соответствующим образом:
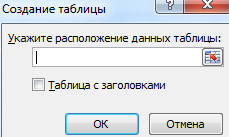
- Перейти на вкладку «Вставка» и щелкнуть по кнопке «Таблица».
- Откроется диалоговое окно «Создание таблицы».
- Указать диапазон данных (если они уже внесены) или предполагаемый диапазон (в какие ячейки будет помещена таблица). Установить флажок напротив «Таблица с заголовками». Нажать Enter.
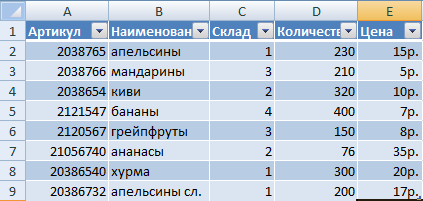
К указанному диапазону применится заданный по умолчанию стиль форматирования. Станет активным инструмент «Работа с таблицами» (вкладка «Конструктор»).
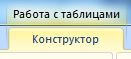
Составить отчет можно с помощью «Сводной таблицы».
- Активизируем любую из ячеек диапазона данных. Щелкаем кнопку «Сводная таблица» («Вставка» — «Таблицы» — «Сводная таблица»).
- В диалоговом окне прописываем диапазон и место, куда поместить сводный отчет (новый лист).
- Открывается «Мастер сводных таблиц». Левая часть листа – изображение отчета, правая часть – инструменты создания сводного отчета.
- Выбираем необходимые поля из списка. Определяемся со значениями для названий строк и столбцов. В левой части листа будет «строиться» отчет.
Создание сводной таблицы – это уже способ анализа данных. Более того, пользователь выбирает нужную ему в конкретный момент информацию для отображения. Он может в дальнейшем применять другие инструменты.
Анализ «Что-если» в Excel: «Таблица данных»
Мощное средство анализа данных. Рассмотрим организацию информации с помощью инструмента «Что-если» — «Таблица данных».
Важные условия:
- данные должны находиться в одном столбце или одной строке;
- формула ссылается на одну входную ячейку.
Процедура создания «Таблицы данных»:
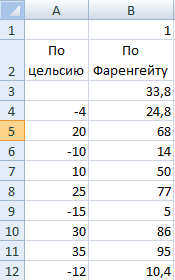
- Заносим входные значения в столбец, а формулу – в соседний столбец на одну строку выше.
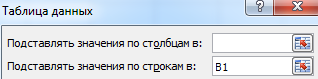
- Выделяем диапазон значений, включающий столбец с входными данными и формулой. Переходим на вкладку «Данные». Открываем инструмент «Что-если». Щелкаем кнопку «Таблица данных».
- В открывшемся диалоговом окне есть два поля. Так как мы создаем таблицу с одним входом, то вводим адрес только в поле «Подставлять значения по строкам в». Если входные значения располагаются в строках (а не в столбцах), то адрес будем вписывать в поле «Подставлять значения по столбцам в» и нажимаем ОК.
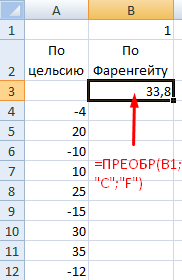
Анализ предприятия в Excel: примеры
Для анализа деятельности предприятия берутся данные из бухгалтерского баланса, отчета о прибылях и убытках. Каждый пользователь создает свою форму, в которой отражаются особенности фирмы, важная для принятия решений информация.
- скачать систему анализа предприятий;
- скачать аналитическую таблицу финансов;
- таблица рентабельности бизнеса;
- отчет по движению денежных средств;
- пример балльного метода в финансово-экономической аналитике.
Для примера предлагаем скачать финансовый анализ предприятий в таблицах и графиках составленные профессиональными специалистами в области финансово-экономической аналитике. Здесь используются формы бухгалтерской отчетности, формулы и таблицы для расчета и анализа платежеспособности, финансового состояния, рентабельности, деловой активности и т.д.
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Еще…Меньше
Если вам нужно разработать сложный статистический или инженерный анализ, вы можете сэкономить время и этапы с помощью этого средства. Вы предоставляете данные и параметры для каждого анализа, а средство использует соответствующие статистические или инженерные функции для вычисления и отображения результатов в выходной таблице. Некоторые средства создают диаграммы в дополнение к выходным таблицам.
Функции анализа данных можно применять только на одном листе. Если анализ данных проводится в группе, состоящей из нескольких листов, то результаты будут выведены на первом листе, на остальных листах будут выведены пустые диапазоны, содержащие только форматы. Чтобы провести анализ данных на всех листах, повторите процедуру для каждого листа в отдельности.
Ниже описаны инструменты, включенные в пакет анализа. Для доступа к ним нажмите кнопкуАнализ данных в группе Анализ на вкладке Данные. Если команда Анализ данных недоступна, необходимо загрузить надстройку «Пакет анализа».
-
Откройте вкладку Файл, нажмите кнопку Параметры и выберите категорию Надстройки.
-
В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
Если вы используете Excel для Mac, в строке меню откройте вкладку Средства и в раскрывающемся списке выберите пункт Надстройки для Excel.
-
В диалоговом окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
-
Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
-
Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
-
Примечание: Чтобы включить Visual Basic для приложений (VBA) для надстройки «Надстройка анализа», вы можете загрузить надстройку VBA так же, как и надстройку «Надстройка анализа». В поле Доступные надстройки выберите «Надстройка анализа — VBA».
Существует несколько видов дисперсионного анализа. Нужный вариант выбирается с учетом числа факторов и имеющихся выборок из генеральной совокупности.
Однофакторный дисперсионный анализ
Этот инструмент выполняет простой анализ дисперсии данных для двух или более выборок. Анализ дает проверку гипотезы о том, что каждая выборка взята из одного и того же распределения вероятности на основе альтернативной гипотезы о том, что для всех выборок распределение вероятности не одно и то же. Если есть только два примера, можно использовать функцию T.ТЕСТ. В более чем двух примерах нет удобного обобщения T.ВМЕСТОэтого можно использовать модель Anova для одного фактора.
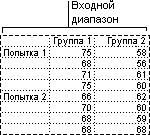
Двухфакторный дисперсионный анализ с повторениями
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам. Например, в эксперименте по измерению высоты растений последние обрабатывали удобрениями от различных изготовителей (например, A, B, C) и содержали при различной температуре (например, низкой и высокой). Таким образом, для каждой из 6 возможных пар условий {удобрение, температура}, имеется одинаковый набор наблюдений за ростом растений. С помощью этого дисперсионного анализа можно проверить следующие гипотезы:
-
Извлечены ли данные о росте растений для различных марок удобрений из одной генеральной совокупности. Температура в этом анализе не учитывается.
-
Извлечены ли данные о росте растений для различных уровней температуры из одной генеральной совокупности. Марка удобрения в этом анализе не учитывается.
Извлечены ли шесть выборок, представляющих все пары значений {удобрение, температура}, используемые для оценки влияния различных марок удобрений (для первого пункта в списке) и уровней температуры (для второго пункта в списке), из одной генеральной совокупности. Альтернативная гипотеза предполагает, что влияние конкретных пар {удобрение, температура} превышает влияние отдельно удобрения и отдельно температуры.
Двухфакторный дисперсионный анализ без повторений
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам, как в случае двухфакторного дисперсионного анализа с повторениями. Однако в таком анализе предполагается, что для каждой пары параметров есть только одно измерение (например, для каждой пары параметров {удобрение, температура} из предыдущего примера).
Функции CORREL и PEARSON вычисляют коэффициент корреляции между двумя переменными измерения, если для каждой переменной наблюдаемы измерения по каждому из N-объектов. (Любые отсутствующие наблюдения по любой теме вызывают игнорирование в анализе.) Средство анализа корреляции особенно удобно использовать, если для каждого субъекта N имеется более двух переменных измерения. Она содержит выходную таблицу — матрицу корреляции, которая показывает значение CORREL (или PEARSON),примененного к каждой из возможных пар переменных измерения.
Коэффициент корреляции, как и ковариана, — это мера степени, в которой две единицы измерения «различаются». В отличие от ковариации коэффициент корреляции масштабирован таким образом, что его значение не зависит от единиц измерения, выраженных в двух переменных измерения. (Например, если двумя переменными измерения являются вес и высота, то значение коэффициента корреляции не изменяется, если вес преобразуется из фунта в фунты.) Значение любого коэффициента корреляции должно быть включительно от -1 до +1 включительно.
Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, т. е. большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция).
Средства корреляции и коварианс могут использоваться в одном и том же параметре, если у вас есть N различных переменных измерения, наблюдаемые для набора людей. Каждый из инструментов корреляции и ковариции дает выходную таблицу — матрицу, которая показывает коэффициент корреляции или коварианс между каждой парой переменных измерения соответственно. Разница заключается в том, что коэффициенты корреляции масштабироваться в зависимости от -1 и +1 включительно. Соответствующие ковариансы не масштабироваться. Коэффициент корреляции и коварианс — это показатели степени, в которой две переменные «различаются».
Инструмент Ковариана вычисляет значение функции КОВАРИАНА. P для каждой пары переменных измерения. (Прямое использование КОВАРИАНА. P вместо ковариана является разумной альтернативой, если есть только две переменные измерения, то есть N=2.) Запись в диагонали выходной таблицы средства Коварица в строке i, столбце i — коварианс i-й переменной измерения. Это только дисперсия по численности населения для этой переменной, вычисляемая функцией ДИСПЕРС.P.
Ковариационный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть большие значения из одного набора данных связаны с большими значениями другого набора (положительная ковариация) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная ковариация), или данные двух диапазонов никак не связаны (ковариация близка к нулю).
Инструмент анализа «Описательная статистика» применяется для создания одномерного статистического отчета, содержащего информацию о центральной тенденции и изменчивости входных данных.
Инструмент анализа «Экспоненциальное сглаживание» применяется для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. При анализе используется константа сглаживания a, величина которой определяет степень влияния на прогнозы погрешностей в предыдущем прогнозе.
Примечание: Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к большим промежуткам между предсказанными значениями.
Двухвыборочный F-тест применяется для сравнения дисперсий двух генеральных совокупностей.
Например, можно использовать F-тест по выборкам результатов заплыва для каждой из двух команд. Это средство предоставляет результаты сравнения нулевой гипотезы о том, что эти две выборки взяты из распределения с равными дисперсиями, с гипотезой, предполагающей, что дисперсии различны в базовом распределении.
С помощью этого инструмента вычисляется значение f F-статистики (или F-коэффициент). Значение f, близкое к 1, показывает, что дисперсии генеральной совокупности равны. В таблице результатов, если f < 1, «P(F <= f) одностороннее» дает возможность наблюдения значения F-статистики меньшего f при равных дисперсиях генеральной совокупности и F критическом одностороннем выдает критическое значение меньше 1 для выбранного уровня значимости «Альфа». Если f > 1, «P(F <= f) одностороннее» дает возможность наблюдения значения F-статистики большего f при равных дисперсиях генеральной совокупности и F критическом одностороннем дает критическое значение больше 1 для «Альфа».
Инструмент «Анализ Фурье» применяется для решения задач в линейных системах и анализа периодических данных на основе метода быстрого преобразования Фурье (БПФ). Этот инструмент поддерживает также обратные преобразования, при этом инвертирование преобразованных данных возвращает исходные данные.

Инструмент «Гистограмма» применяется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений. При этом рассчитываются числа попаданий для заданного диапазона ячеек.
Например, можно получить распределение успеваемости по шкале оценок в группе из 20 студентов. Таблица гистограммы состоит из границ шкалы оценок и групп студентов, уровень успеваемости которых находится между самой нижней границей и текущей границей. Наиболее часто встречающийся уровень является модой диапазона данных.
Совет: В Excel 2016 теперь можно создавать гистограммы и диаграммы Парето.
Инструмент анализа «Скользящее среднее» применяется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Скользящее среднее, в отличие от простого среднего для всей выборки, содержит сведения о тенденциях изменения данных. Этот метод может использоваться для прогноза сбыта, запасов и других тенденций. Расчет прогнозируемых значений выполняется по следующей формуле:
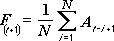
где
-
N — число предшествующих периодов, входящих в скользящее среднее;
-
A
j — фактическое значение в момент времени j; -
F
j — прогнозируемое значение в момент времени j.
Инструмент «Генерация случайных чисел» применяется для заполнения диапазона случайными числами, извлеченными из одного или нескольких распределений. С помощью этой процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей. Например, можно использовать нормальное распределение для моделирования совокупности данных по росту людей или использовать распределение Бернулли для двух вероятных исходов, чтобы описать совокупность результатов бросания монеты.
Средство анализа Ранг и процентиль создает таблицу, которая содержит порядковую и процентную ранг каждого значения в наборе данных. Можно проанализировать относительное положение значений в наборе данных. В этом средстве используются функции РАНГ. EQ и PERCENTRANK. INC. Если вы хотите учитывать связанные значения, используйте РАНГ. Функция EQ, которая обрабатывает связанные значения как имеющие одинаковый ранг или использует РАНГ.Функция AVG, которая возвращает средний ранг связанных значений.
Инструмент анализа «Регрессия» применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
В средстве регрессии используется функция LINEST.
Инструмент анализа «Выборка» создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки или построения диаграммы, можно использовать представительную выборку. Кроме того, если предполагается периодичность входных данных, то можно создать выборку, содержащую значения только из отдельной части цикла. Например, если входной диапазон содержит данные для квартальных продаж, создание выборки с периодом 4 разместит в выходном диапазоне значения продаж из одного и того же квартала.
Двухвыборочный t-тест проверяет равенство средних значений генеральной совокупности по каждой выборке. Три вида этого теста допускают следующие условия: равные дисперсии генерального распределения, дисперсии генеральной совокупности не равны, а также представление двух выборок до и после наблюдения по одному и тому же субъекту.
Для всех трех средств, перечисленных ниже, значение t вычисляется и отображается как «t-статистика» в выводимой таблице. В зависимости от данных это значение t может быть отрицательным или неотрицательным. Если предположить, что средние генеральной совокупности равны, при t < 0 «P(T <= t) одностороннее» дает вероятность того, что наблюдаемое значение t-статистики будет более отрицательным, чем t. При t >=0 «P(T <= t) одностороннее» делает возможным наблюдение значения t-статистики, которое будет более положительным, чем t. «t критическое одностороннее» дает пороговое значение, так что вероятность наблюдения значения t-статистики большего или равного «t критическое одностороннее» равно «Альфа».
«P(T <= t) двустороннее» дает вероятность наблюдения значения t-статистики, по абсолютному значению большего, чем t. «P критическое двустороннее» выдает пороговое значение, так что значение вероятности наблюдения значения t- статистики, по абсолютному значению большего, чем «P критическое двустороннее», равно «Альфа».
Парный двухвыборочный t-тест для средних
Парный тест используется, когда имеется естественная парность наблюдений в выборках, например, когда генеральная совокупность тестируется дважды — до и после эксперимента. Этот инструмент анализа применяется для проверки гипотезы о различии средних для двух выборок данных. В нем не предполагается равенство дисперсий генеральных совокупностей, из которых выбраны данные.
Примечание: Одним из результатов теста является совокупная дисперсия (совокупная мера распределения данных вокруг среднего значения), вычисляемая по следующей формуле:
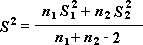
Двухвыборочный t-тест с одинаковыми дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных поступили из распределения с одинаковыми дисперсиями. Его называют гомике t-тестом. Этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения.
Двухвыборочный t-тест с различными дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных были полученными из распределения с неравными дисперсиями. Его называют гетероскестическими t-тестами. Как и в предыдущем примере с равными дисперсиями, этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения. Этот тест можно использовать, если в двух примерах есть отдельные объекты. Используйте тест Парный, описанный в примере, если существует один набор тем и две выборки представляют измерения по каждой теме до и после обработки.
Для определения тестовой величины t используется следующая формула.
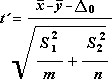
Следующая формула используется для вычисления степеней свободы (df). Так как результат вычисления обычно не является integer, значение df округлится до ближайшего другого, чтобы получить критическое значение из таблицы t. Функция Excel T .Test использует вычисляемую величину df без округлений, так как можно вычислить значение для T.ТЕСТ с неинтегрированной df. Из-за этих разных подходов к определению степеней свободы результаты T.Тест и этот t-тест будут отличаться в случае неравных дисперсий.
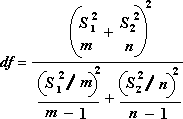
Z-тест. Средство анализа «Две выборки для середины» выполняет два примера z-теста для средств со известными дисперсиями. Этот инструмент используется для проверки гипотезы NULL о том, что между двумя значениями численности населения нет различий между односторонними или двухбокльными альтернативными гипотезами. Если дисперсии не известны, функция Z .Вместо этого следует использовать тест.
При использовании этого инструмента следует внимательно просматривать результат. «P(Z <= z) одностороннее» на самом деле есть P(Z >= ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. «P(Z <= z) двустороннее» на самом деле есть P(Z >= ABS(z) или Z <= -ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. Двусторонний результат является односторонним результатом, умноженным на 2. Инструмент «z-тест» можно также применять для гипотезы об определенном ненулевом значении разницы между двумя средними генеральных совокупностей. Например, этот тест можно использовать для определения разницы выступлений на соревнованиях двух автомобилей разных марок.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
См. также
Создание гистограммы в Excel 2016
Создание диаграммы Парето в Excel 2016
Загрузка средства анализа в Excel
Инженерные функции (справка)
Общие сведения о формулах в Excel
Рекомендации, позволяющие избежать появления неработающих формул
Поиск ошибок в формулах
Сочетания клавиш и горячие клавиши в Excel
Функции Excel (по алфавиту)
Функции Excel (по категориям)
Нужна дополнительная помощь?
Без чего нельзя обойтись в датасайенс-проекте? Конечно, без данных!
Именно об этом пойдет речь в сегодняшней статье. Мы поделимся с вами 15 датасетами, которые можно использовать для анализа данных и их визуализации, классификации текстов/изображений, создания системы рекомендаций и многого другого.
Анализ данных
Работать с наборами данных, перечисленными в этом разделе, можно с помощью Pandas и Numpy.
Exam Scores
Набор данных Exam Scores содержит оценки учащихся по различным предметам (математике, чтению, письму), а также другие данные о них, такие как пол, этническая принадлежность и тип ланча. Вы можете провести анализ и получить средний балл по конкретному полу, узнать, сдал/не сдал ученик экзамен и многое другое.
PartImageNet
На основе ImageNet собрали новый датасет, в котором разметили отдельно части разных объектов: лапы/хвост/тело/голову животных, кузов/колеса автомобиля и т.п. В датасете 24k изображений из 158 классов орининального ImageNet’а
Pokemon Dataset
В Pokemon Dataset содержатся статистические данные по 721 покемону. Там указаны их тип, HP, атака, особая атака, особая защита и скорость. Вы можете поиграть с этими данными и провести поиск, чтобы, например, найти покемона с самыми высокими показателями атаки и защиты.
Если вы новичок в Pandas, настоятельно рекомендуем изучить основы работы с этим набором данных, просмотрев этот туториал.
Netflix movies and TV shows
В базе данных Netflix movies and TV shows собраны все фильмы и сериалы, доступные на Netflix на середину 2021 года. Здесь можно найти такие данные, как название, режиссер, рейтинг, год выпуска и продолжительность. Имеются недостающие данные, а некоторые столбцы нуждаются в очистке перед работой с ними в проекте.
Визуализация данных
Следующие датасеты пригодятся для создания визуализаций. В этих целях применяются matplotlib, seaborn и даже pandas.
FIFA 22 player dataset
Набор данных FIFA 22 player dataset содержит данные о футболистах из видеоигры FIFA, такие как дата рождения футболиста, его рост, вес и общий рейтинг. Самое интересное, что на сайте есть данные игроков не только за 2022 год, но и с 2016 по 2022 год, так что вы можете увидеть эволюцию рейтинга каждого игрока с помощью линейных графиков и других средств визуализации.
Population dataset
Population dataset содержит данные о численности населения за каждые 5 лет с 1955 по 2020 год для большинства стран мира. В наборе данных есть 3 столбца: страна, год и численность населения. Данные пригодны для создания простых визуализаций, таких как круговые или столбчатые диаграммы, боксплоты и гистограммы.
The Simpsons и Avatar The Last Airbender
Почему бы немного не развлечься и не научиться создавать визуализации? На Kaggle есть бесплатные наборы данных таких телешоу, как The Simpsons и Avatar The Last Airbender. Там вы найдете все серии и сценарии и сможете создать визуализации, чтобы показать, у кого больше всего реплик, кто с кем говорит, а также составить облако слов и провести анализ настроений.
Автоматизация
Вместо того чтобы повторять такие задачи, как создание отчетов в Excel, можно автоматизировать их с помощью Python.
Supermarket sales
Большинству из нас хоть раз в жизни приходилось создавать отчет в Excel с использованием набора данных о продажах. Почему бы не автоматизировать этот процесс? Датасет Supermarket sales содержит данные о продажах супермаркета за 3 месяца. Вы можете использовать эти данные для создания сводной таблицы и гистограммы в Excel, используя Python.
Регрессионный анализ
Boston House Prices
Это популярный набор данных для составления линейной регрессии. В датасете содержится информация о домах Бостона — уровень преступности на душу населения по городу, среднее количество комнат в жилище, ставка налога на недвижимость в расчете на $10 000 и многое другое.
Скачать этот набор данных можно с помощью библиотеки sklearn:
from sklearn.datasets import load_boston
boston_dataset = load_boston()Классификация текста
Если вы занимаетесь NLP (обработкой естественного языка), вам пригодятся эти наборы данных. Для работы с ними необходимо использовать такие библиотеки, как sklearn, NLTK, gensim, spaCy и т. д.
IMDB Dataset
IMDB Dataset содержит 50 тысяч отзывов о фильмах с определенным отношением (положительным/отрицательным). Эти данные отлично подходят для построения модели, которая классифицирует текст как положительный или отрицательный, т. е. проводит бинарную классификацию текста.
60k Stack Overflow Questions
Этот набор данных содержит 60 тысяч вопросов на Stack Overflow с 2016 по 2020 год. Есть 3 типа вопросов: HQ (высококачественные сообщения без единой правки), LQ_EDIT (низкокачественные сообщения с отрицательной оценкой и несколькими правками сообщества) и LQ_CLOSE (низкокачественные сообщения, которые были закрыты сообществом без единой правки).
Вы можете использовать этот датасет при прогнозировании тегов для вопроса. Это более сложная задача, чем в предыдущем проекте, поскольку может быть не только 2, но и больше вариантов для тегов. В этом случае необходимо использовать многозначную классификацию.
Классификация изображений
В отличие от других наборов данных, перечисленных в статье, следующие датасеты содержат в основном изображения, которые можно использовать для построения модели классификации. Для этого необходимо использовать Tensor Flow, Open CV и т. д.
Rock Paper Scissors
Если вам нравится игра “камень-ножницы-бумага”, вы не заскучаете с этим набором данных. Rock Paper Scissors содержит 2892 изображения рук в позиции “камень/ножницы/бумага”. Он обычно используется для классификации изображений, но ему можно найти и другие применения.
Face Mask Detection
Этот набор данных состоит из 1376 изображений. На 690 изображениях люди носят маску, а на 686 картинках маски нет.
Вы можете использовать этот датасет для построения модели, которая определяет, носит ли человек маску на лице. В конце работы над проектом наденьте маску и с помощью камеры компьютера самостоятельно протестируйте эту модель.
Система рекомендаций
Вы когда-нибудь задумывались над тем, каким образом такие компании, как Netflix и YouTube, рекомендуют пользователям фильмы и видео? Вы можете использовать приведенный ниже набор данных для создания собственной системы рекомендаций и понять, как она работает.
MovieLens
Эта база данных содержит 20 миллионов оценок и 465 000 случаев использования тегов, примененных 138 000 пользователями к 27 000 фильмов. Идеально подходит для тех, кто хочет создать свою систему рекомендаций фильмов с нуля.
https://t.me/ai_machinelearning_big_data
Просмотры: 1 911
Если вам по работе или учёбе приходится погружаться в океан цифр и искать в них подтверждение своих гипотез, вам определённо пригодятся эти техники работы в Microsoft Excel. Как их применять — показываем с помощью гифок.

Юлия Перминова
Тренер Учебного центра Softline с 2008 года.
1. Сводные таблицы
Базовый инструмент для работы с огромным количеством неструктурированных данных, из которых можно быстро сделать выводы и не возиться с фильтрацией и сортировкой вручную. Сводные таблицы можно создать с помощью нескольких действий и быстро настроить в зависимости от того, как именно вы хотите отобразить результаты.
Полезное дополнение. Вы также можете создавать сводные диаграммы на основе сводных таблиц, которые будут автоматически обновляться при их изменении. Это полезно, если вам, например, нужно регулярно создавать отчёты по одним и тем же параметрам.
Как работать
Исходные данные могут быть любыми: данные по продажам, отгрузкам, доставкам и так далее.
- Откройте файл с таблицей, данные которой надо проанализировать.
- Выделите диапазон данных для анализа.
- Перейдите на вкладку «Вставка» → «Таблица» → «Сводная таблица» (для macOS на вкладке «Данные» в группе «Анализ»).
- Должно появиться диалоговое окно «Создание сводной таблицы».
- Настройте отображение данных, которые есть у вас в таблице.
Перед нами таблица с неструктурированными данными. Мы можем их систематизировать и настроить отображение тех данных, которые есть у нас в таблице. «Сумму заказов» отправляем в «Значения», а «Продавцов», «Дату продажи» — в «Строки». По данным разных продавцов за разные годы тут же посчитались суммы. При необходимости можно развернуть каждый год, квартал или месяц — получим более детальную информацию за конкретный период.
Набор опций будет зависеть от количества столбцов. Например, у нас пять столбцов. Их нужно просто правильно расположить и выбрать, что мы хотим показать. Скажем, сумму.
Можно её детализировать, например, по странам. Переносим «Страны».
Можно посмотреть результаты по продавцам. Меняем «Страну» на «Продавцов». По продавцам результаты будут такие.
2. 3D-карты
Этот способ визуализации данных с географической привязкой позволяет анализировать данные, находить закономерности, имеющие региональное происхождение.
Полезное дополнение. Координаты нигде прописывать не нужно — достаточно лишь корректно указать географическое название в таблице.
Как работать
- Откройте файл с таблицей, данные которой нужно визуализировать. Например, с информацией по разным городам и странам.
- Подготовьте данные для отображения на карте: «Главная» → «Форматировать как таблицу».
- Выделите диапазон данных для анализа.
- На вкладке «Вставка» есть кнопка 3D-карта.
Точки на карте — это наши города. Но просто города нам не очень интересны — интересно увидеть информацию, привязанную к этим городам. Например, суммы, которые можно отобразить через высоту столбика. При наведении курсора на столбик показывается сумма.
Также достаточно информативной является круговая диаграмма по годам. Размер круга задаётся суммой.
3. Лист прогнозов
Зачастую в бизнес-процессах наблюдаются сезонные закономерности, которые необходимо учитывать при планировании. Лист прогноза — наиболее точный инструмент для прогнозирования в Excel, чем все функции, которые были до этого и есть сейчас. Его можно использовать для планирования деятельности коммерческих, финансовых, маркетинговых и других служб.
Полезное дополнение. Для расчёта прогноза потребуются данные за более ранние периоды. Точность прогнозирования зависит от количества данных по периодам — лучше не меньше, чем за год. Вам требуются одинаковые интервалы между точками данных (например, месяц или равное количество дней).
Как работать
- Откройте таблицу с данными за период и соответствующими ему показателями, например, от года.
- Выделите два ряда данных.
- На вкладке «Данные» в группе нажмите кнопку «Лист прогноза».
- В окне «Создание листа прогноза» выберите график или гистограмму для визуального представления прогноза.
- Выберите дату окончания прогноза.
В примере ниже у нас есть данные за 2011, 2012 и 2013 годы. Важно указывать не числа, а именно временные периоды (то есть не 5 марта 2013 года, а март 2013-го).
Для прогноза на 2014 год вам потребуются два ряда данных: даты и соответствующие им значения показателей. Выделяем оба ряда данных.
На вкладке «Данные» в группе «Прогноз» нажимаем на «Лист прогноза». В появившемся окне «Создание листа прогноза» выбираем формат представления прогноза — график или гистограмму. В поле «Завершение прогноза» выбираем дату окончания, а затем нажимаем кнопку «Создать». Оранжевая линия — это и есть прогноз.
4. Быстрый анализ
Эта функциональность, пожалуй, первый шаг к тому, что можно назвать бизнес-анализом. Приятно, что эта функциональность реализована наиболее дружественным по отношению к пользователю способом: желаемый результат достигается буквально в несколько кликов. Ничего не нужно считать, не надо записывать никаких формул. Достаточно выделить нужный диапазон и выбрать, какой результат вы хотите получить.
Полезное дополнение. Мгновенно можно создавать различные типы диаграмм или спарклайны (микрографики прямо в ячейке).
Как работать
- Откройте таблицу с данными для анализа.
- Выделите нужный для анализа диапазон.
- При выделении диапазона внизу всегда появляется кнопка «Быстрый анализ». Она сразу предлагает совершить с данными несколько возможных действий. Например, найти итоги. Мы можем узнать суммы, они проставляются внизу.
В быстром анализе также есть несколько вариантов форматирования. Посмотреть, какие значения больше, а какие меньше, можно в самих ячейках гистограммы.
Также можно проставить в ячейках разноцветные значки: зелёные — наибольшие значения, красные — наименьшие.
Надеемся, что эти приёмы помогут ускорить работу с анализом данных в Microsoft Excel и быстрее покорить вершины этого сложного, но такого полезного с точки зрения работы с цифрами приложения.
Читайте также:
- 10 быстрых трюков с Excel →
- 20 секретов Excel, которые помогут упростить работу →
- 10 шаблонов Excel, которые будут полезны в повседневной жизни →
With a Data Table in Excel, you can easily vary one or two inputs and perform What-if analysis. A Data Table is a range of cells in which you can change values in some of the cells and come up with different answers to a problem.
There are two types of Data Tables −
- One-variable Data Tables
- Two-variable Data Tables
If you have more than two variables in your analysis problem, you need to use Scenario Manager Tool of Excel. For details, refer to the chapter – What-If Analysis with Scenario Manager in this tutorial.
One-variable Data Tables
A one-variable Data Table can be used if you want to see how different values of one variable in one or more formulas will change the results of those formulas. In other words, with a one-variable Data Table, you can determine how changing one input changes any number of outputs. You will understand this with the help of an example.
Example
There is a loan of 5,000,000 for a tenure of 30 years. You want to know the monthly payments (EMI) for varied interest rates. You also might be interested in knowing the amount of interest and Principal that is paid in the second year.
Analysis with One-variable Data Table
Analysis with one-variable Data Table needs to be done in three steps −
Step 1 − Set the required background.
Step 2 − Create the Data Table.
Step 3 − Perform the Analysis.
Let us understand these steps in detail −
Step 1: Set the required background
-
Assume that the interest rate is 12%.
-
List all the required values.
-
Name the cells containing the values, so that the formulas will have names instead of cell references.
-
Set the calculations for EMI, Cumulative Interest and Cumulative Principal with the Excel functions – PMT, CUMIPMT and CUMPRINC respectively.
Your worksheet should look as follows −
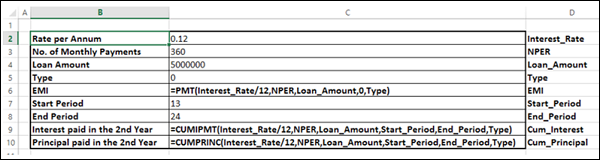
You can see that the cells in column C are named as given in the corresponding cells in column D.
Step 2: Create the Data Table
-
Type the list of values i.e. interest rates that you want to substitute in the input cell down the column E as follows −
-
Type the first function (PMT) in the cell one row above and one cell to the right of the column of values. Type the other functions (CUMIPMT and CUMPRINC) in the cells to the right of the first function.
Now, the two rows above the Interest Rate values look as follows −
As you observe, there is an empty row above the Interest Rate values. This row is for the formulas that you want to use.

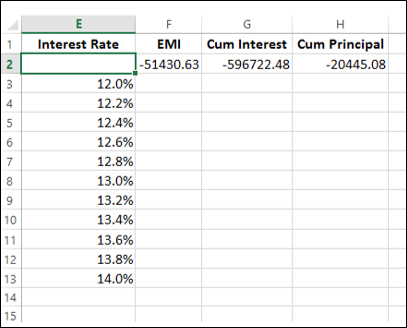
The Data Table looks as given below −
Step 3: Do the analysis with the What-If Analysis Data Table Tool
-
Select the range of cells that contains the formulas and values that you want to substitute, i.e. select the range – E2:H13.
-
Click the DATA tab on the Ribbon.
-
Click What-if Analysis in the Data Tools group.
-
Select Data Table in the dropdown list.
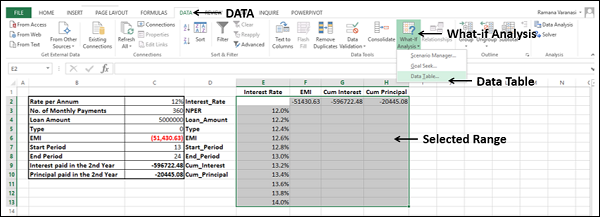
Data Table dialog box appears.
- Click the icon in the Column input cell box.
- Click the cell Interest_Rate, which is C2.
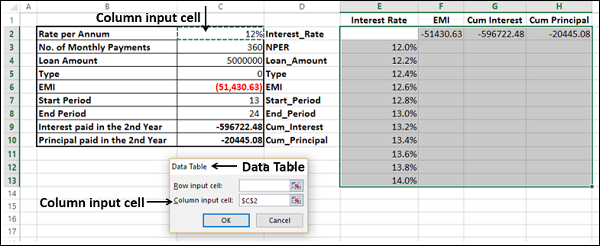
You can see that the Column input cell is taken as $C$2. Click OK.
The Data Table is filled with the calculated results for each of the input values as shown below −
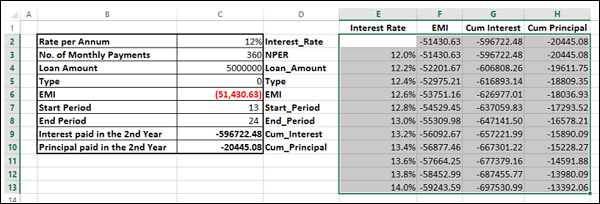
If you can pay an EMI of 54,000, you can observe that the interest rate of 12.6% is suitable for you.
Two-variable Data Tables
A two-variable Data Table can be used if you want to see how different values of two variables in a formula will change the results of that formula. In other words, with a twovariable Data Table, you can determine how changing two inputs changes a single output. You will understand this with the help of an example.
Example
There is a loan of 50,000,000. You want to know how different combinations of interest rates and loan tenures will affect the monthly payment (EMI).
Analysis with Two-variable Data Table
Analysis with two-variable Data Table needs to be done in three steps −
Step 1 − Set the required background.
Step 2 − Create the Data Table.
Step 3 − Perform the Analysis.
Step 1: Set the required background
-
Assume that the interest rate is 12%.
-
List all the required values.
-
Name the cells containing the values, so that the formula will have names instead of cell references.
-
Set the calculation for EMI with the Excel function – PMT.
Your worksheet should look as follows −

You can see that the cells in the column C are named as given in the corresponding cells in the column D.
Step 2: Create the Data Table
-
Type =EMI in cell F2.
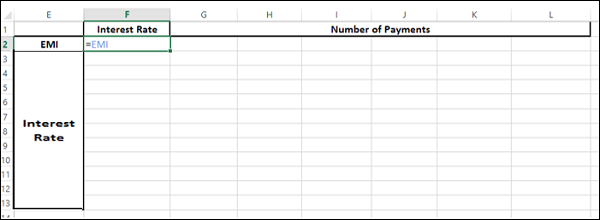
-
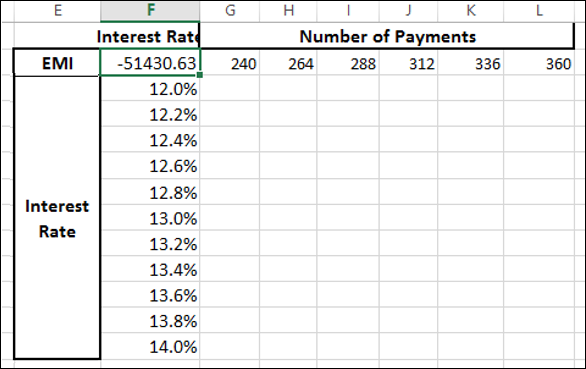
Type the first list of input values, i.e. interest rates down the column F, starting with the cell below the formula, i.e. F3.
-
Type the second list of input values, i.e. number of payments across row 2, starting with the cell to the right of the formula, i.e. G2.
The Data Table looks as follows −
Do the analysis with the What-If Analysis Tool Data Table
-
Select the range of cells that contains the formula and the two sets of values that you want to substitute, i.e. select the range – F2:L13.
-
Click the DATA tab on the Ribbon.
-
Click What-if Analysis in the Data Tools group.
-
Select Data Table from the dropdown list.
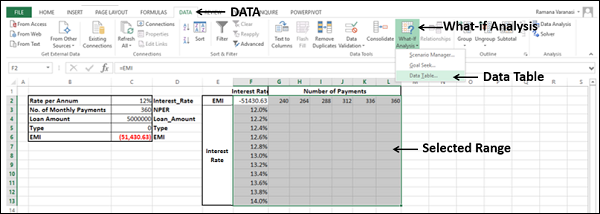
Data Table dialog box appears.
- Click the icon in the Row input cell box.
- Click the cell NPER, which is C3.
- Again, click the icon in the Row input cell box.
- Next, click the icon in the Column input cell box.
- Click the cell Interest_Rate, which is C2.
- Again, click the icon in the Column input cell box.
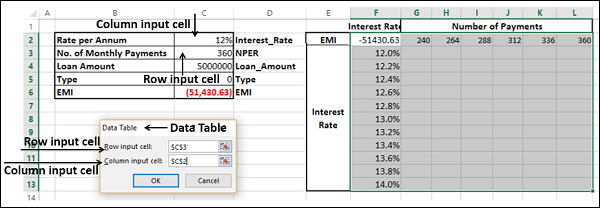
You will see that the Row input cell is taken as $C$3 and the Column input cell is taken as $C$2. Click OK.
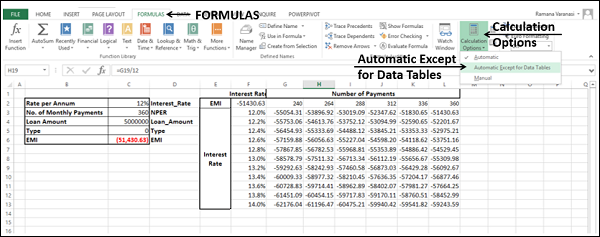
The Data Table gets filled with the calculated results for each combination of the two input values −
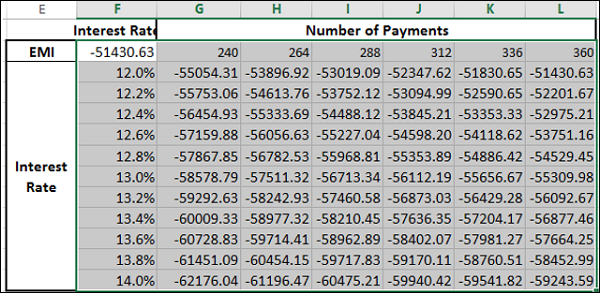
If you can pay an EMI of 54,000, the interest rate of 12.2% and 288 EMIs are suitable for you. This means the tenure of the loan would be 24 years.
Data Table Calculations
Data Tables are recalculated each time the worksheet containing them is recalculated, even if they have not changed. To speed up the calculations in a worksheet that contains a Data Table, you need to change the calculation options to Automatically Recalculate the worksheet but not the Data Tables, as given in the next section.
Speeding up the Calculations in a Worksheet
You can speed up the calculations in a worksheet containing Data Tables in two ways −
- From Excel Options.
- From the Ribbon.
From Excel Options
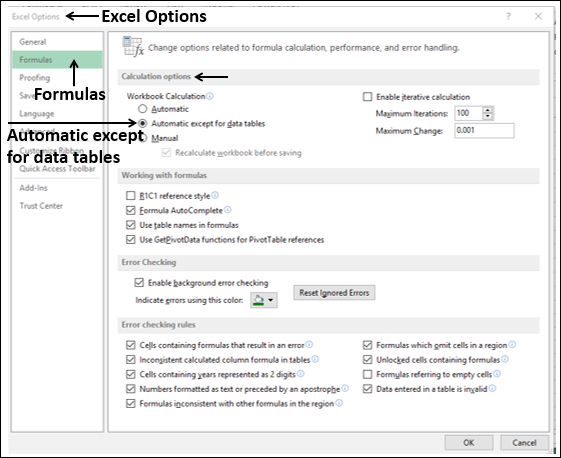
- Click the FILE tab on the Ribbon.
- Select Options from the list in the left pane.
Excel Options dialog box appears.
-
From the left pane, select Formulas.
-
Select the option Automatic except for data tables under Workbook Calculation in the Calculation options section. Click OK.
From the Ribbon
-
Click the FORMULAS tab on the Ribbon.
-
Click the Calculation Options in the Calculations group.
-
Select Automatic Except for Data Tables in the dropdown list.