
![]()
Автор:
Обновлено: 19.04.2018
Представьте себе функцию, позволяющую извлечь текст из изображения и быстро вставить его в другой документ. На самом деле это возможно. Вам больше не нужно терять время, набирая все, потому что есть программы, которые используют оптическое распознавание символов (OCR) для анализа букв и слов в изображении, а затем конвертируют их в текст.
В наши дни существует так много бесплатных и эффективных опций, позволяющих извлечь текст из изображения, а не печатать его вручную. Ниже представлены самые удобные и эффективные программы и их сравнение.

Как распознать текст с картинки в Word
Содержание
- Видео — распознавание текста с картинки в WORD
- Извлечение текста с помощью OneNote
- Использование онлайн-сервисов
- Видео — Как распознавать текст с картинки, фотографии или PDF файла
- Как извлечь текст из изображений с помощью ABBY FineReader
- Онлайн версия
- Десктопная версия
- Видео — Как распознать PDF в Word
- Сравнение популярный инструментов распознавания текста
Видео — распознавание текста с картинки в WORD
Извлечение текста с помощью OneNote
OneNote OCR уже на протяжении нескольких лет остается одной из самых лучших программ для распознавания текста. Однако, распознавание это одна из тех менее известных функций, которые пользователи редко используют, но как только вы начнете ее использовать, вы будете удивлены тем, насколько быстрой и точной она может быть. Действительно, способность извлекать текст — одна из особенностей, которая делает OneNote лучше Evernote.
Это стандартная программа, скорее всего вам не придется устанавливать ее самостоятельно. Найдите ее на компьютере в папке Microsoft Office или же с помощью поиска на панели «Пуск». Запустите программу.
Инструкции по извлечению текста:
- Шаг 1. Откройте любую страницу в OneNote, желательно пустую.

Открываем любую страницу в OneNote
- Шаг 2. Перейдите в меню «Вставка»> «Изображения» и выберите файл изображения и настройте язык распознавания.

Выберите файл изображения
- Шаг 3. Щелкните правой кнопкой мыши по вставленному изображению и выберите «Копировать текст с изображения». Он сохранится в буфере обмена.



Копируем текст с изображения
Теперь вы можете вставить его куда угодно. Удалите вставленное изображение, если оно вам больше не нужно.

Вставляем текст куда угодно
На заметку! Это быстрый и удобный способ извлечения текста из картинки, но есть одно «но» — One Note работает подобным образом лишь с латиницей. Он не распознает русский текст.
Использование онлайн-сервисов
Онлайн-сервисы по распознаванию текста с изображения работают примерно по одному и тому же принципу. В примере ниже использовался Free Online OCR. На этом сайте стоит ограничение. Регистрация даст вам доступ к дополнительным функциям, недоступным для гостей: конвертировать многостраничный PDF (более 15 страниц) в текст, большие изображения и ZIP-архивы, выбирать языки распознавания, конвертировать в редактируемые форматы и многое другое. Распознать короткий тест можно и без регистрации.
- Шаг 1. Откройте сайт бесплатного OCR. Выберите изображение посредством кнопки «Select File». Это может быть и PDF файл.

Открываем сайт бесплатного OCR
- Шаг 2. Выберите язык и нажмите на кнопку «CONVERT».
Выбираем язык и нажимаем на кнопку «CONVERT»


Текст появится в поле ниже. Вы также можете скачать в формате Microsoft Word.
Этот способ имеет ряд преимуществ:
- Вам не придется скачивать и устанавливать стороннее программное обеспечение.
- Итог можно скачать в виде текстового документа.
- Это быстро.
- Более того на сайте можно распознавать текст на одном из множества предложенных языков.
Видео — Как распознавать текст с картинки, фотографии или PDF файла
Как извлечь текст из изображений с помощью ABBY FineReader
Существует две версии этой программы. Одна работает в автоматическом режиме онлайн, другая же — десктопная, ее придется скачать и установить на компьютер. Обе — платные. Однако в онлайн-версии можно бесплатно распознать текст с не более 5 страниц, а в установленной программе первое время действует пробный бесплатный период. На сегодня это один из лучших инструментов для распознавания текста с картинки.
Онлайн версия
- Шаг 1. Перейдите на сайт FineReader.

Открываем сайт FineReader
- Шаг 2. Загрузите изображение. Выберите нужный вам язык и нажмите на кнопку регистрации. Следуйте указаниям на сайте. Как только вы зарегистрируетесь, сайт перенаправит вас на другую страницу. Нажмите на кнопку «Распознать» и дождитесь окончания процесса.


Загружаем файл, выбираем язык, выбираем формат сохранения
Текст сохранится в формате docs. Скачайте его.
Десктопная версия
- Шаг 1. Запустите FreeReader и нажмите «Сканировать изображение», чтобы выбрать файл, содержащий текст. Он загрузится в программу, при необходимости их можно отредактировать, чтобы улучшить распознаваемость текста. Программа предложит вам выделить область, текст с которой нужно распознать.
- Шаг 2. Извлечение текста. Нажмите «Распознать», чтобы извлечь текст из выделения. Выбранный текст будет отображаться в текстовом окне через несколько секунд.

Извлекаем текст

Шаг 3. Проверка. В этой программе есть функция проверки. Нажав на эту кнопку, пользователь на экране будет видеть некорректно распознанные слова и фрагмент оригинала. На этом этапе можно быстро исправить практически все ошибки программы.
Шаг 4. Сохраните текст любым из предложенных способов.

Сохраняем текст
Обратите внимание:
- Во-первых, вам нужно убедиться, что исходное изображение четкое, хорошего качества.
- Во-вторых, выбор правильного механизма OCR важен, и вам нужно учитывать их сильные и слабые стороны.
- В-третьих, убедитесь, что ваши изображения масштабированы до нужного размера (не менее 300 DPI).
- Низкая контрастность приведет к плохому OCR, поэтому вам необходимо исправить это до распознавания.
- Удалите шумы и дефекты.
- Если изображение перекошено, отредактируйте его.
Видео — Как распознать PDF в Word
Сравнение популярный инструментов распознавания текста
| Название программы | OneNote | FineReader OCR Online | Free Online OCR |
|---|---|---|---|
| Условия использования | Стандартная программа, входящая в пакет Microsoft Office. Как правило, присутствует на всех компьютерах ОС Windows | Онлайн версия программы. До 5 страниц бесплатно при регистрации | Бесплатный онлайн-сервис. Не требует регистрации |
| Скорость | Мгновенное распознавание | Процесс происходит на сервере. Время ожидания не больше 5 минут | Мгновенное распознавание |
| Особенности | Это не главная функция программы, а лишь побочная. Хоть она и достаточно хороша, не ждите от нее совершенства | Сокращенная версия основной программы. В полной компьютерной версии намного больше опций, повышающих качество распознавания. Доступно распознавание теста сразу на нескольких языках, если в тексте есть вставки на другом языке. Сохраняет форматирование |
Скорость. Доступность |
| Число доступных языков | В русскоязычной версии программы доступно три языка: русский, английский, немецкий | Множество языков | Множество языков |
| Результат |  |
 |
 |
Хотя рынок заполнен программным обеспечением OCR, которое может извлекать текст из изображений, хорошая программа OCR должна делать больше, чем просто распознавание текста. Она должна поддерживать макет содержимого, текстовые шрифты и графику как в исходном документе.
Рекомендуем похожие статьи
Бывало ли у вас такое, что, например, партнеры по бизнесу прислали какую-то документацию или проект договора о сотрудничестве в виде файла графического формата (обычной картинки или документа PDF)? По всей видимости, с этим сталкивались, если не все, то очень многие. А ведь документ вам бывает нужно срочно изменить, а чаще всего это касается редактирования текстовой части, которая может содержаться в исходном файле. Как распознать текст с картинки, чтобы затратить на это минимум времени и избежать возможного появления всевозможных ошибок и опечаток? Об этом и многом другом далее и пойдет речь. Способов «вытаскивания» текста из файлов графических типов или универсального формата PDF на сегодняшний день существует много, однако при рассмотрении некоторых из них будем отталкиваться от наиболее интересных, простых и понятных любому пользователю методов.
Как распознать текст с картинки в Word?
Начать стоит с одного из самых простых методов, который подойдет всем без исключения пользователям. Если речь идет о том, чтобы «вытащить» текст из PDF-документа, а затем отредактировать его и сохранить в «родном» формате текстового редактора Word, далеко ходить не нужно, поскольку все последние версии этого приложения, начиная с «Офиса» 2010 года выпуска, поддерживают работу с файлами PDF и позволяют их редактировать точно так же просто, как если бы это был самый обычный документ Word.
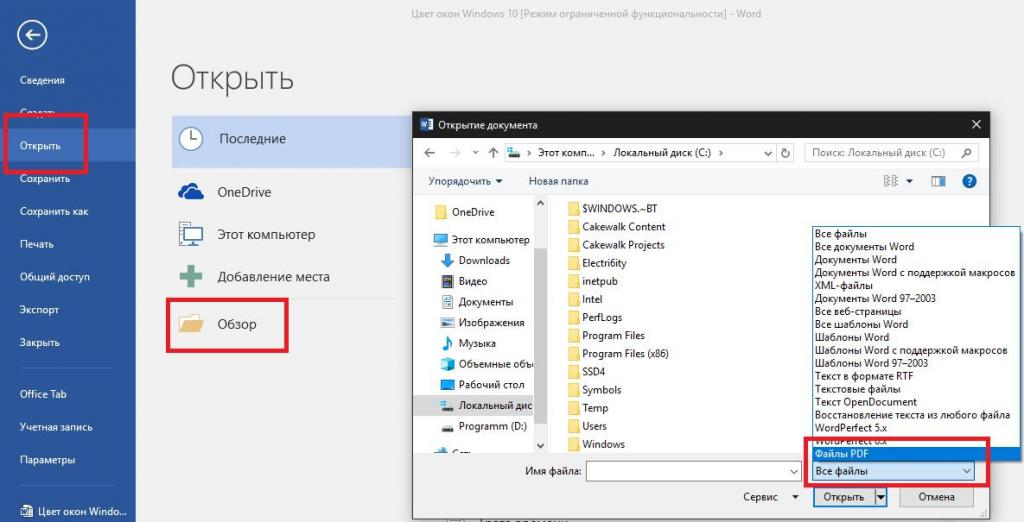
Чтобы в «Ворде» распознать текст с картинки формата PDF, который, если кто не знает, относится именно к графическим типам файлов, достаточно задать открытие документа, а в типе файла выбрать именно формат PDF. После этого текст можно будет и отредактировать, и сохранить повторно в виде «родного» формата редактора, выбрав в том же поле нужный тип (например, DOC или DOCX).
Дополнительные инструменты для Office 2003
Если же проблема состоит в том, как распознать текст с картинки в редакторе, входящем в состав офисного пакета, скажем, 2003 года, в котором формат PDF не поддерживается, то и в этом случае ничего сложного нет.
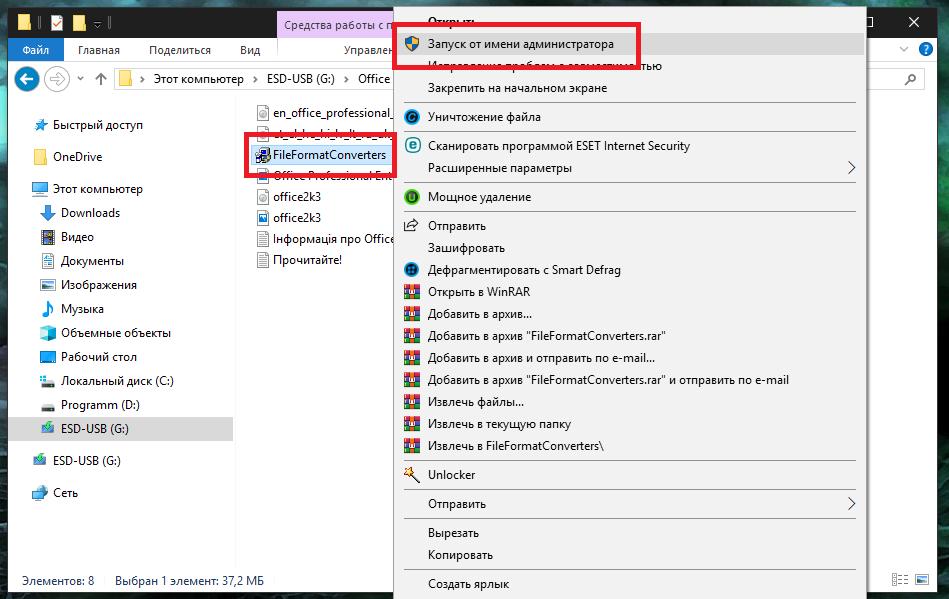
В довесок к самому текстовому редактору дополнительно можно установить инструмент в виде интегрируемого в Word расширения под названием File Format Converters, который добавит возможностей редактору в том плане, что он сможет работать и с файлами PDF, и с документами обновленных форматов вроде DOCX.
Как распознать текст с картинки в PDF?
Еще один способ извлечения текста непосредственно из графического объекта в PDF-формате состоит в том, чтобы воспользоваться любым из известных редакторов, рассчитанных на работу с такими документами. Одним из наиболее универсальных и практичных приложений можно назвать небезызвестную программу Reader от Adobe. Обратите внимание, что в данном случае речь идет именно о приложении «Ридер», а не об аналогичном просмотрщике «Акробат», который поддерживает только чтение документов (просмотр без возможности редактирования).
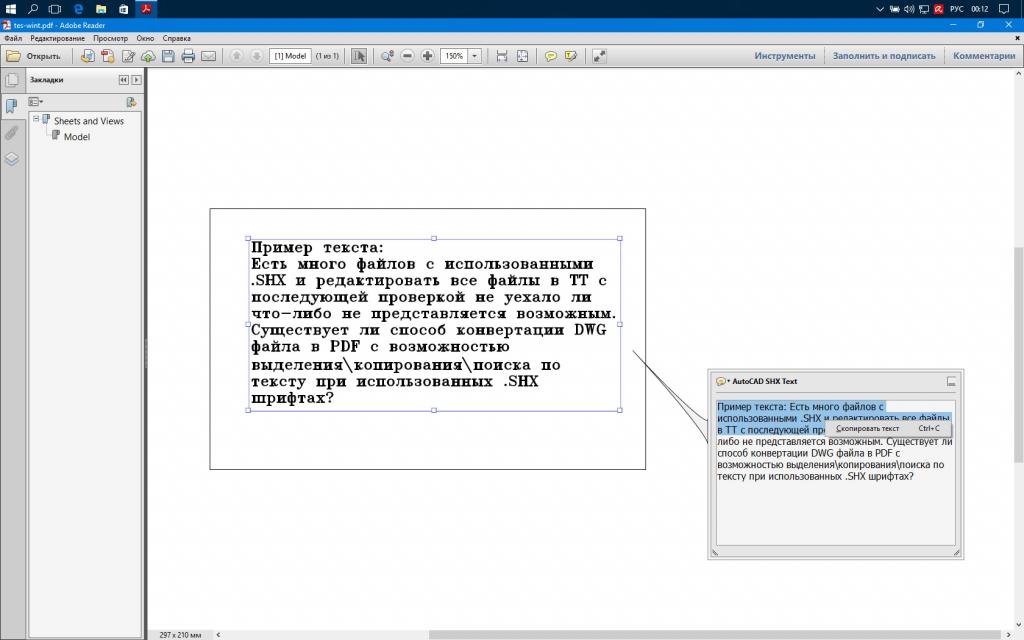
В самой программе вам нужно будет просто выделить нужный фрагмент текста, скопировать его в буфер обмена, а затем вставить в документ Word и сохранить в нужном конечном формате.
Использование приложения OneNote
Если разбираться в тонкостях того, как распознать текст с картинки без использования вышеописанных приложений, можно посоветовать воспользоваться еще одним уникальным апплетом, входящим в состав последних модификаций и сборок самих офисных пакетов, под названием OneNote, о возможностях которого многие пользователи в большинстве своем или забывают, или не знают вовсе. В программе потребуется для удобства работы всего лишь создать пустой документ, используя меню вставки поместить в него изображение с текстом из графического файла (любого формата), а затем настроить язык распознавания.
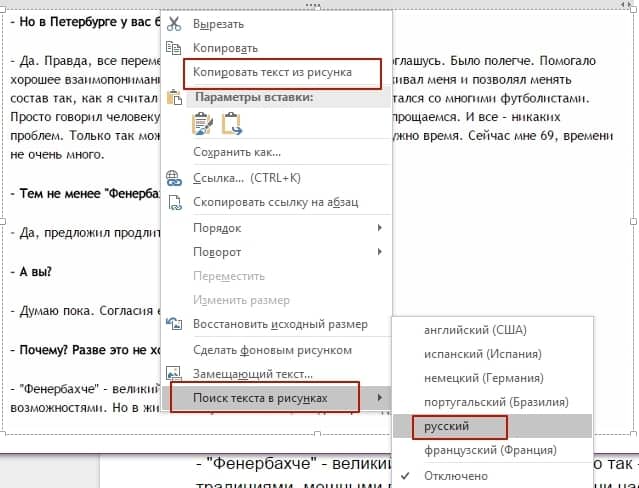
После этого останется только скопировать текст в буфер обмена, для чего используется специальный пункт «Копировать текст с картинки», после чего его можно будет вставить из буфера в любую другую программу.
Примечание: если вопросы касаются того, как с картинки распознать китайский текст или содержимое, представленное на любом другом неподдерживаемом для отображения языке, вам потребуется установить дополнительный языковой пакет, загрузив его, например, из официального источника Microsoft и интернете.
Система распознавания ABBYY Finereader
Естественно, если речь идет исключительно о том, как распознать текст с картинки в графических форматах, лучше всего применять для этого специализированные OCR-системы. Одной из самых мощных и популярных является программа ABBYY Finereader, а также ее онлайн-аналог в виде официального интернет-портала.
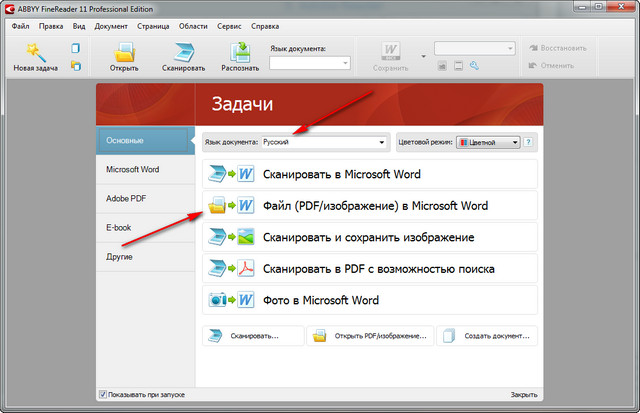
Это приложение работает по типу виртуального сканера, в котором нужно всего лишь задать направление распознавания, а иногда может потребоваться указать язык исходного документа (это относится к устаревшим версиям пакета). Когда сканирование текста на том же печатном листе или в графическом файле будет закончено, он будет автоматически перенаправлен, например, в Word или в любой другой офисный редактор.
Конвертеры форматов
Пока это были самые простые приложения, позволяющие распознать текст с картинки. Программы для выполнения таких действий включают в себя и еще одну категорию ПО, называемого конвертерами. Они интересны тем, что выполнять именно распознавание текстового содержимого графического файла в них не нужно. Суть состоит в том, чтобы переконвертировать исходный графический формат в выбранный текстовый, после чего преобразованный файл и можно будет открыть в нужном редакторе. Кроме того, очень часто именно такие приложения оказываются максимально эффективными, когда вам требуется обработать несколько десятков однотипных документов. Это называется пакетным режимом. Что же до самих программ, их в том же интернете можно найти огромное количество.
Среди наиболее востребованных приложений можно отметить утилиты для преобразования PDF-файлов в любые другие форматы, конвертеры PDF или JPG в Word, универсальные преобразователи любого типа графики в текстовые файлы и т. д.
Онлайн-сервисы: нюансы использования и возможные ограничения
Наконец, если ни одно из предложенных решений вам не подходит, заниматься преобразованиями вручную просто лень или нет времени, пожалуйста, в интернете представлено огромное количество ресурсов, на которых все эти операции будут выполнены без вашего прямого участия. От вас потребуется только загрузить исходный графический файл, дождаться окончания извлечения текста и скачать готовый текстовый файл на собственный компьютер (или даже просто скопировать текст из окна с результатом). Правда, неудобство некоторых таких сервисов состоит только в том, что зачастую могут устанавливаться ограничения по количеству одновременно загружаемых для обработки файлов и лимиты, касающиеся их размера, не говоря уже и о том, что некоторые сервисы являются отнюдь не бесплатными. Зато многие из таких ресурсов определяют используемый в тексте язык автоматически, что избавляет вас от дополнительных ненужных действий по переводу.


Все мы уже привыкли фотографировать расписание, документы, страницы книг и многое другое, но по ряду причин «извлечь» текст со снимка или картинки, сделав его пригодным для редактирования, все же требуется.
Особенно часто с необходимостью преобразовать фото в текст сталкиваются школьники и студенты. Это естественно, ведь никто не будет переписывать или набирать текст, зная, что есть более простые методы. Было бы прям идеально, если бы преобразовать картинку в текст можно было в Microsoft Word, вот только данная программа не умеет ни распознавать текст, ни конвертировать графические файлы в текстовые документы.
Единственная возможность «поместить» текст с JPEG-файла (джипег) в Ворд — это распознать его в сторонней программе, а затем уже оттуда скопировать его и вставить или же просто экспортировать в текстовый документ.
Содержание
Содержание
- 1
Распознавание текста - 2
Вставка текста в документ и экспорт - 3
Видео-урок по переводу текста с фотографии в Word файл - 4
Преобразование текста на фото в документ Ворд онлайн
Распознавание текста
ABBYY FineReader по праву является самой популярной программой для распознавания текста. Именно главную функцию этого продукта мы и будем использовать для наших целей — преобразования фото в текст. Из статьи на нашем сайте вы можете более подробно узнать о возможностях Эбби Файн Ридер, а также о том, где скачать эту программу, если она еще не установлена на у вас на ПК.

Распознавание текста с помощью ABBYY FineReader
Скачав программу, установите ее на компьютер и запустите. Добавьте в окно изображение, текст на котором необходимо распознать. Сделать это можно простым перетаскиванием, а можно нажать кнопку «Открыть», расположенную на панели инструментов, а затем выбрать необходимый графический файл.
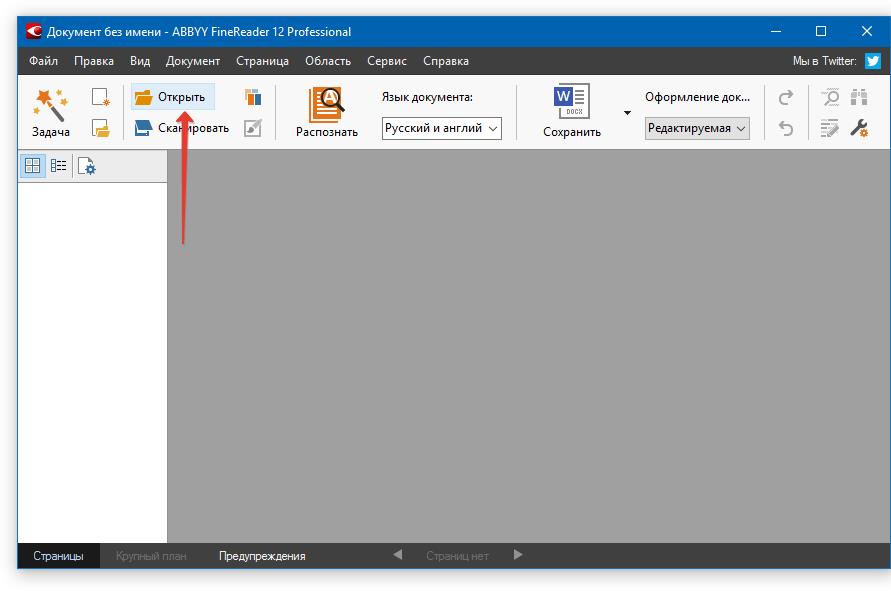
Теперь нажмите на кнопку «Распознать» и дождитесь, пока Эбби Файн Ридер просканирует изображение и извлечет из него весь текст.
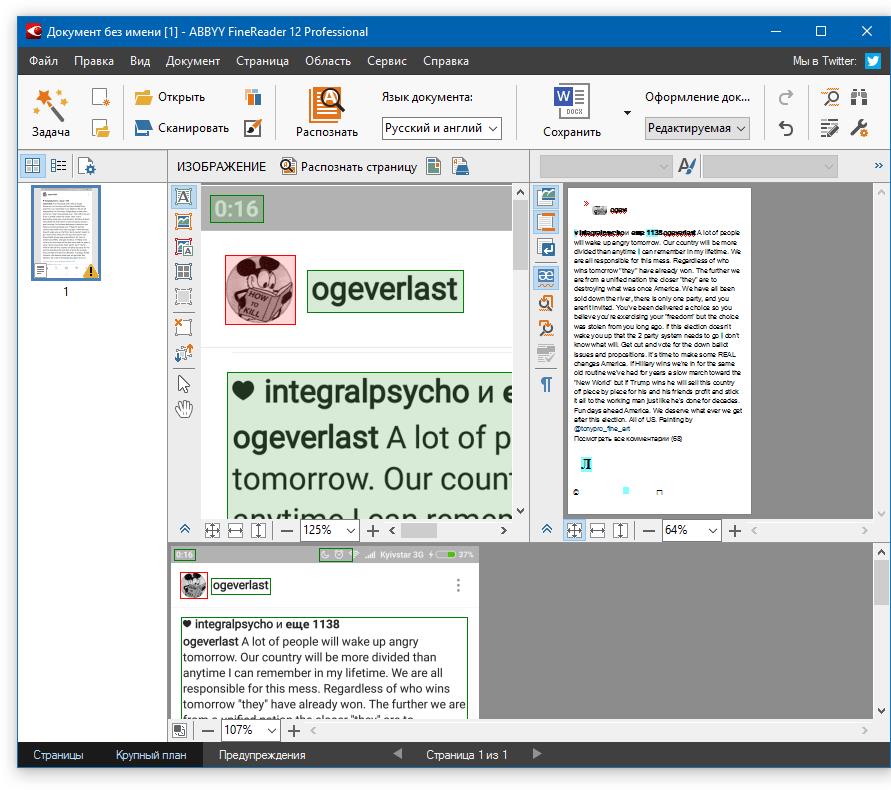
Вставка текста в документ и экспорт
Когда FineReader распознает текст, его можно будет выделить и скопировать. Для выделения текста используйте мышку, для его копирования нажмите «CTRL+С».
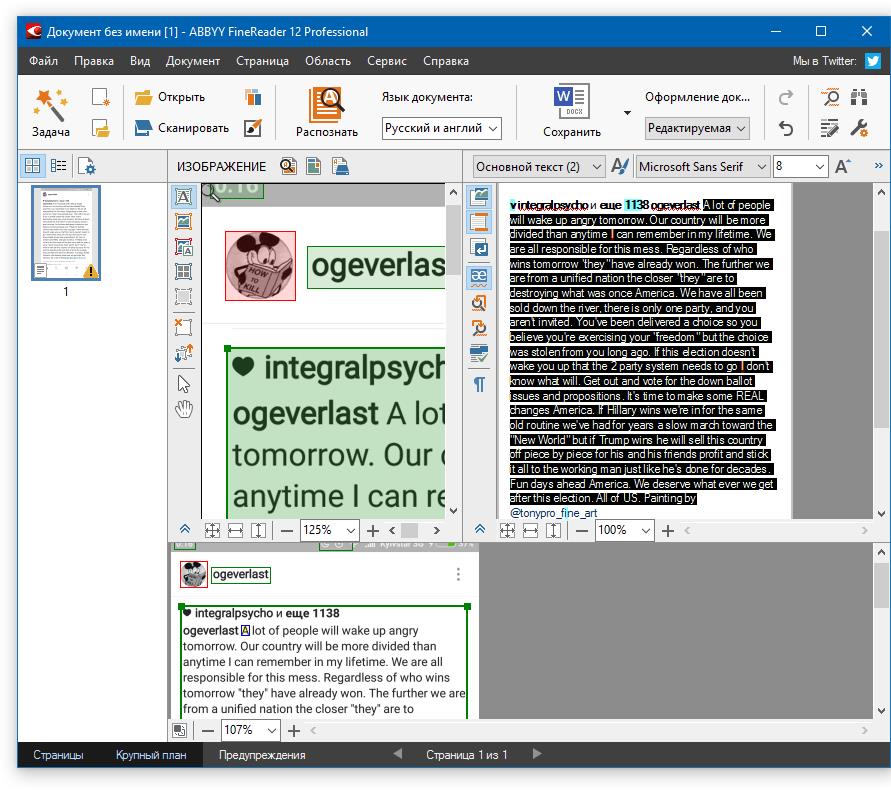
Теперь откройте документ Microsoft Word и вставьте в него текст, который сейчас содержится в буфере обмена. Для этого нажмите клавиши «CTRL+V» на клавиатуре.
Урок: Использование горячих клавиш в Ворде
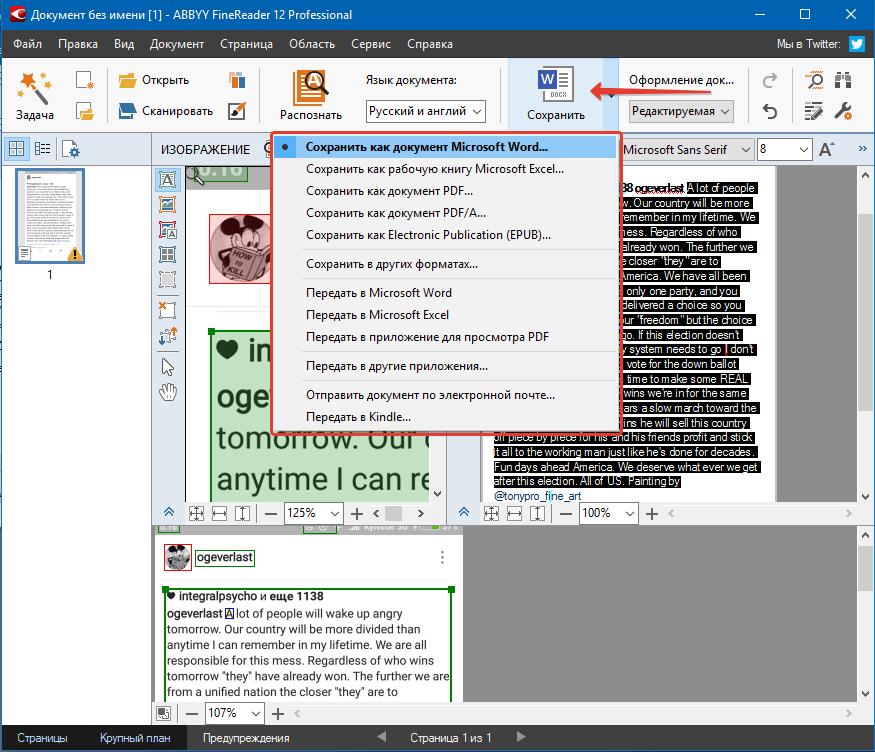
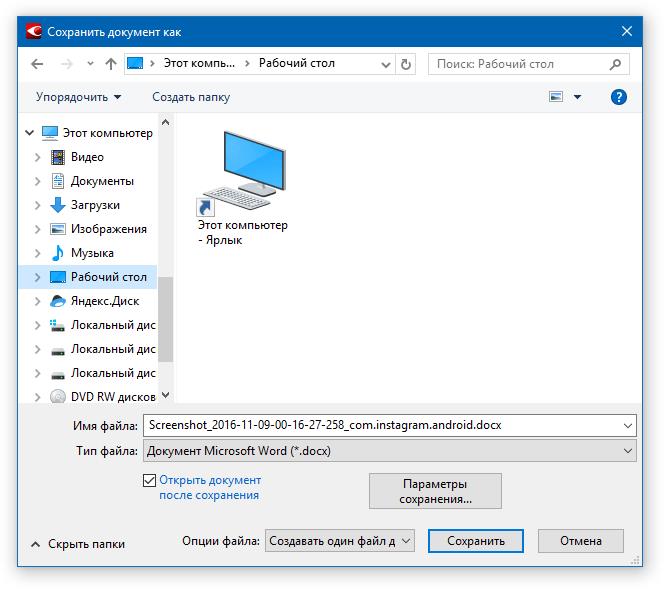
Помимо просто копирования/вставки текста из одной программы в другую, Эбби Файн Ридер позволяет экспортировать распознанный им текст в файл формата DOCX, который для MS Word является основным. Что для этого требуется сделать? Все предельно просто:
- выберите необходимый формат (программу) в меню кнопки «Сохранить», расположенной на панели быстрого доступа;
-

- кликните по этому пункту и укажите место для сохранения;
-
- задайте имя для экспортируемого документа.
После того, как текст будет вставлен или экспортирован в Ворд, вы сможете его отредактировать, изменить стиль, шрифт и форматирование. Наш материал на данную тему вам в этом поможет.
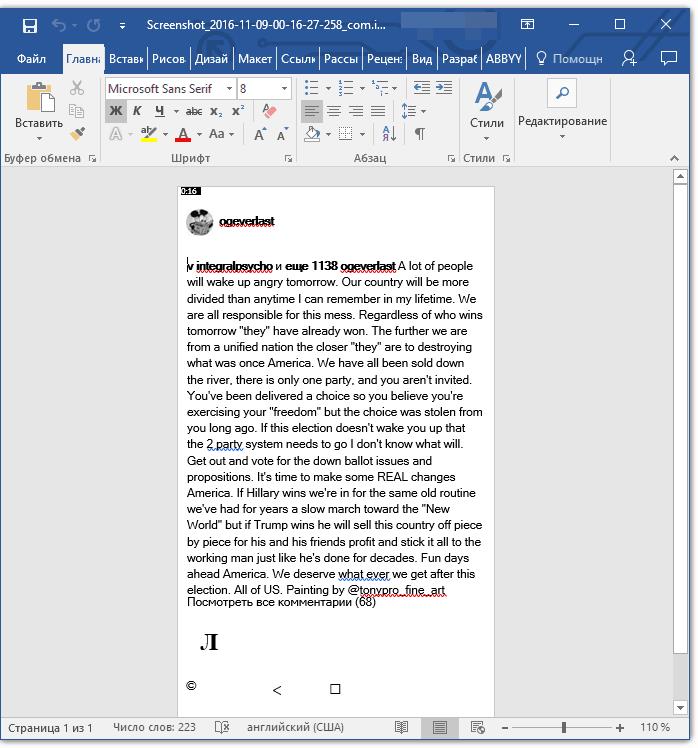
Примечание: В экспортированном документе будет содержаться весь распознанный программой текст, даже тот, который вам, возможно, и не нужен, или тот, который распознан не совсем корректно.
Урок: Форматирование текста в MS Word
Видео-урок по переводу текста с фотографии в Word файл
Преобразование текста на фото в документ Ворд онлайн
Если вы не хотите скачивать и устанавливать на свой компьютер какие-либо сторонние программы, преобразовать изображение с текстом в текстовый документ можно онлайн. Для этого существует множество веб-сервисов, но лучший из них, как нам кажется, это FineReader Online, который использует в своей работе возможности того же программного сканера ABBY.
ABBY FineReader Online
Перейдите по вышеуказанной ссылке и выполните следующие действия:
1. Авторизуйтесь на сайте, используя профиль Facebook, Google или Microsoft и подтвердите свои данные.
Примечание: Если ни один из вариантов вас не устраивает, придется пройти полную процедуру регистрации. В любом случае, сделать это не сложнее, чем на любом другом сайте.
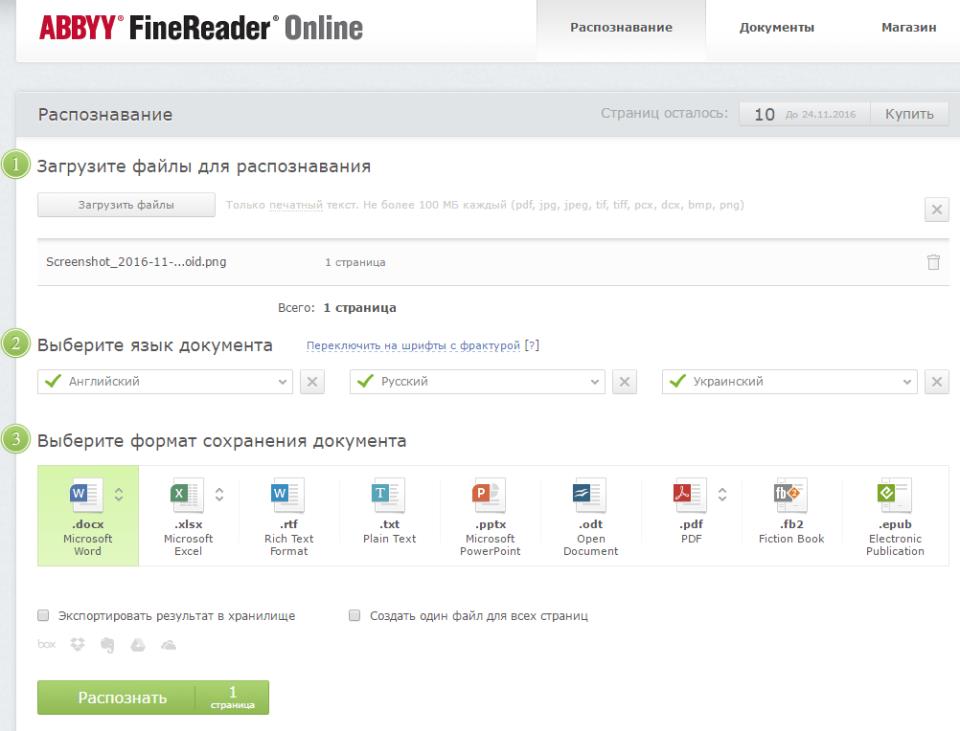
2. Выберите пункт «Распознать» на главной странице и загрузите на сайт изображение с текстом, который нужно извлечь.
3. Выберите язык документа.
4. Выберите формат, в котором требуется сохранить распознанный текст. В нашем случае это DOCX, программы Microsoft Word.
5. Нажмите кнопку «Распознать» и дождитесь, пока сервис просканирует файл и преобразует его в текстовый документ.
6. Сохраните, точнее, скачайте файл с текстом на компьютер.

Примечание: Онлайн-сервис ABBY FineReader позволяет не только сохранить текстовый документ на компьютер, но и экспортировать его в облачные хранилища и другие сервисы. В числе таковые BOX, Dropbox, Microsoft OneDrive, Google Drive и Evernote.
После того, как файл будет сохранен на компьютер, вы сможете его открыть и изменить, отредактировать.
На этом все, из данной статьи вы узнали, как перевести текст в Ворд. Несмотря на то, что данная программа не способна самостоятельно справиться с такой, казалось бы, простой задачей, сделать это можно с помощью стороннего софта — программы Эбби Файн Ридер, или же специализированных онлайн-сервисов.
Обновлено: 13.04.2023
Мы разобрались с принципами работы систем оптического распознавания символов. Кратко ознакомились с историей развития технологий OCR. В публикации рассмотрим, зачем нужны программы для распознавания текста, назовём наиболее распространённые из них. Какие приложения для работы со сканами знаете вы? А кроме FineReader?
Цель применения приложений
При помощи сканера, камеры смартфона или фотоаппарата создаются цифровые копии бумажных документов. Воспринимать их содержимое на дисплее компьютера и ноутбука комфортно. На портативных устройствах просматривать страницу, содержимое которой не помещается на экран, неудобно. Придётся постоянно перетаскивать изображение по дисплею, масштабировать его.
Использовать скан книги, выдержки из периодического издания в качестве цитаты или исходника для работы (реферата, доклада, курсовой работы) можно после превращения картинки в текст. Для этого следует осуществить распознавание документа. Помогут в этом системы оптического распознавания информации – приложения, которые извлекают из графических файлов текстовую информацию, передают её в текстовый редактор или документ. Вследствие появляется возможность её редактирования, обработки.

Часто поверх изображения накладывается текстовый слой, как на картинке выше. Так сохраняется внешний вид страниц книги и появляется возможность копирования, редактирования её содержимого.
Сканеры с программным обеспечением для распознавания символов широко применяются в библиотеках, архивных фондах для оцифровки бумажных книг, журналов, газет, брошюр, писем, прочих рукописей и бумажных документов с возможностью их дальнейшего редактирования или извлечения текстовой информации. Корпорация Google около 20 лет занимается оцифровкой архивов и книг, исторических источников.
Сколько времени займёт набор на клавиатуре пары цитат длиной в несколько абзацев? Считанные минуты. Если для выполнения курсовой или дипломной работы нужно набрать с десяток страниц, уйдут часы. Программы распознавания текста (OCR) решат проблему за десятки секунд, причём они справляются с сохранением структуры документа. Приложения определяют наличие таблиц, картинок, диаграмм, списков, справляются с текстом на нескольких языках, формулами. Они сохраняют тип и размер шрифта, способны очищать исходное изображение от дефектов: потёртости, желтизна бумаги, огрехи печати, перегибы страниц и прочее.
Примеры
- CuneiForm;
- SimpleOCR;
- MyScript Stylus;
- Office Lens;
- Readiris 17;
- Readiris Pro;
- Freemore OCR;
- Scanitto Pro.
Самой известной программой оптического распознавания текстов является FineReader от компании ABBYY. Из инструмента для оцифровки файлов она превратилась в мощный инструмент для работы с цифровыми документами. Также разработаны десятки веб-сервисов для решения поставленной задачи.

Чтобы перевести изображение со сканера или любого другого цифрового носителя в текст, который возможно отредактировать в редакторе, на компьютер должна быть установлена программа распознавания текста.
Для чего нужна программа распознавания текста?
К примеру, перед Вами стоит задание написать реферат или доклад. Поиск материала в интернете ни к чему не привел, и Вы обратились за помощью к книгам. Однако текста в книгах много и времени на его перепечатку может занять у Вас все свободное время. Именно в таких ситуациях необходима программа распознавания текста. Вам потребуется лишь сканировать необходимый для распознавания текст, а затем программа распознавания текста из картинок извлечь текст. Данный процесс происходит достаточно быстро.
Виды программ распознания текста
– OCR CUNEIFORM. Это бесплатна программа российского разработчика Cognitive Technologies. Данная программа распознавания текста обеспечивает удобное, качественное и быстрое распознавание текста и сохраняет исходный вид документа. Также OCR CuneiForm поддерживает распознавание текста более чем с 20 языков.
– ABBYY Finereader. Существует три пакета этой программы. Они отличаются своими возможностями, ценой, пользовательским интерфейсом и типом лицензии. Данная программа распознавания текста обеспечивает распознавание более чем со 180 языков.
– OmniPage. Эта программа распознавания текста отличается точностью и высокой скоростью распознавания. Обеспечивает распознание более 120 языков. Также данная программа распознавания текста может поддерживать параллельную работу с несколькими документами. Вы можете корректировать, сохранять и открывать несколько документов одновременно.
– Readiris. Программа распознавания текста Readiris превосходно распознает документы, которые содержат сложную верстку, иллюстрации и таблицы. Также данная программа распознавания текста отличается улучшенной работой с PDF форматами, распознаванием 1 пакета в несколько файлов, поддержкой сжатия выходных файлов и др. Также эта программа хорошо распознает PDF и DjVu файлы.
– Microsoft Office Document Imaging. Данная программа распознавания текста от компании Microsoft может работать только с 2 языками: языком локализации MS Office и английским. Чтобы программа поддерживала другие языки, необходимо установить пакет MUI.
Установка программы распознавания текста
Если Вы не хотите сами заниматься решением этой проблемы, то наши специалисты помогут Вам! Качественная компьютерная помощь в Москве по доступной цене. Список услуг указан на странице Цены. На все работы даётся гарантия, а самое главное их выполняют профессионалы.




Пожалуй, каждый пользователь ПК хотя бы раз сталкивался с необходимостью оцифровать текст, напечатанный на обычном листе бумаги. Конечно же, эту операцию можно выполнить и вручную, но что делать, если документ состоит из десятков или даже сотен страниц? К счастью, существуют специальные программы для распознавания текста, которые помогут вам значительно ускорить процесс оцифровки документов и сделают его более комфортным. О них и пойдет речь далее.
Зачем нужны эти программы?
Итак, программы для распознавания текста (Optical Character Recognition) предназначены для конвертирования машинописного или печатного текста в цифровые данные. Кроме того, эти же утилиты могут преобразовывать скриншоты, фотографии и PDF-файлы в обычные документы Microsoft Word.
После того как текст будет оцифрован, вы сможете работать с ним точно так же, как если бы вы напечатали его вручную. К примеру, вы можете отсканировать или сфотографировать газетную статью, прогнать ее через программу для распознавания текстов, а затем редактировать по своему усмотрению.
FineReader

Приложение умеет работать почти со всеми форматами изображений и цифровых документов, а также оснащено встроенным редактором и сервисом для проверки орфографии. Кроме того, интерфейс программы достаточно понятный, так что вам не придется тратить много времени на его освоение.
Главным недостатком приложения является то, что оно платное. Впрочем, вы можете попробовать воспользоваться взломанной версией.
CuneiForm
В отличие от FineReader, CuneiForm является бесплатной программой для распознавания текста. Она поддерживает более 20 языков, отлично работает со всеми популярными графическими форматами, а также легко переносит из исходного файла таблицы и графики. Помимо этого, у приложения имеется собственная база словарей, которую к тому же можно расширять.

Стоит сказать, что CuneiForm распознает текст не так точно, как тот же Fine Reader. Тем не менее для большинства обычных пользователей возможностей программы будет вполне достаточно. Более того, разработчики постоянно совершенствуют свое детище. Уже сейчас приложение может составить конкуренцию своим платным аналогам, а в будущем не исключено, что и переплюнет их.
OmniPage
Еще одна платная программа для сканирования и распознавания текстов. OmniPage легко справляется с документами в формате PDF, а также прочими файлами изображений. Утилита поддерживает больше сотни языков, имеет встроенные словари медицинских, юридических и технических терминов, а также отличается высокой скоростью работы.

К особенностям OmniPage можно отнести возможность создавать из текста аудиофайлы. При этом вы сможете одним кликом конвертировать изображение в звук, что значительно сэкономит ваше время.
FineReader Online
А это уже не программа для распознавания текстов, а полноценный онлайн-сервис, который не требует установки на компьютер. Версия Online имеет несколько ограниченный набор функций, по сравнению с десктопным FineReader, но все же со своими базовыми задачами она справляется на отлично. Распознав текст, вы сможете либо скачать его на компьютер, либо сразу же загрузить в облачное хранилище.
К сожалению, как и ее старший собрат, FineReader Online – это платная программа. Деньги взимаются за каждую распознанную страницу, но в месяц каждому пользователю выдается несколько бесплатных попыток.
New OCR
New ORC – это еще один удобный онлайн-сервис, который к тому же совершенно бесплатный. Помимо распознавания текстов, в нем вы сможете откорректировать яркость и контрастность исходного изображения, повернуть его при необходимости, а также выбирать формат конечного документа.
Приложения для смартфонов
Для распознавания текста можно использовать инструмент, который практически всегда под рукой у каждого человека. Речь идет о смартфоне или планшете. Так, установив соответствующее приложение, вы сможете сфотографировать текст, а затем сразу же конвертировать его в цифровой формат.

Самыми популярными мобильными программами для распознавания текста считаются TextGrabber + Translator (здесь есть еще и функция переводчика), CamScanner и Mobile Document Scanner. Каждая из них лучше подходит для тех или иных устройств, так что вам придется поэкспериментировать.
Для создания электронных библиотек и архивов путем перевода книг и документов в цифровой вариант и при необходимости редактирования полученного по факсу документа используются специальные системы распознавания символов (Optical Character Recognition, OCR).
С помощью сканера можно получить изображение страницы с текстом в графическом формате.
Но работать с этим текстом невозможно, потому что любое сканирование – это всего лишь изображение
Текст можно будет читать, распечатывать, но только не редактировать.
Для перевода графического документа в текстовый файл необходимо провести распознавание текста.
Программное обеспечение для распознавания текста
Преобразование графического изображения в текст занимаются программы, используюшие принцип оптического распознавания.
Современные программы с OCR умеют:
- распознавать тексты, набранные не только разными шрифтами, но и самыми экзотическими, в том числе и рукописных
- корректно работать с текстами, содержащими слова на нескольких языках
- распознавать таблицы
- распознавать нечетко набранные или написанные тексты
Видео YouTube
Само собой, распознать текст — это еще полдела. После этого нужно обеспечить сохранение результата в файле текстового формата, например Microsoft Word.
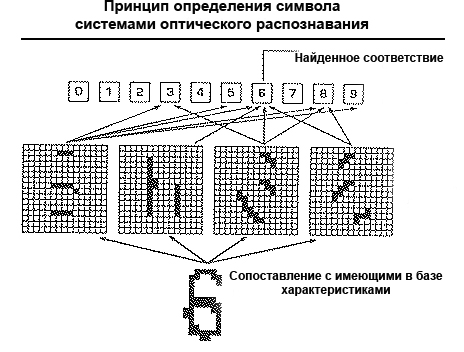
В процессе распознавания документов в плохом качестве (машинописный текст, факс) используется метод распознавания символов по наличию определенных структурных элементов — отрезков, колец, дуг.
Самые распространенные системы оптического распознавания текста — ABBYY FineReader и CuneiForm.

ABBYY Finereader является омнифонтовой системой распознавания текстов. Это значит, что она позволяет распознавать тексты, набранные практически любыми шрифтами.
Одним из козырей FineReader является поддержка огромного (для таких программ) количества языков распознавания — более 176 (экзотические, древние языки, популярные языки программирования)
Для запуска процесса распознавания достаточно положить лист бумаги в сканер и нажать кнопку Scan & Read на панели инструментов. Все остальные операции (сканирование, разбивка изображения на части, распознавание текста) выполнятся автоматически.
Параметры сканирования
Качество распознавания зависит от качества сканированного изображения.
Его можно регулировать установками параметров сканирования (тип изображения, разрешения, яркости, и т. д.).
Самым практичным разрешением для сканирования текстов — 300 dpi, для текстов, набранных мелкимшрифтом — 400-600 dpi.

Рис. Окно программы Cuneiform
Завершение распознавания
Распознав страницы, FineReader предложит сканировать и распознавать дальше (если сканируется книга)или сохранить текст в форматы — от документов Microsoft Office до HTML и PDF.
При распознавании FineReader сохраняет все параметры форматирования документа с его графическим оформлением.
Читайте также:
- Система наук об управлении кратко
- Проблема языка в современном искусстве кратко
- Плакат правила поведения при пожаре в школе
- Частные школы зеленоград рейтинг
- Мотивационная сфера в юношеском возрасте кратко
Как вытащить текст Word из картинки
Перед каждым пользователем ПК хоть раз возникала необходимость получения текстовой информации из картинок. Работая в программах для набора, иногда приходится перепечатывать текст, находящийся в растровом или векторном изображении. Этот долгий процесс можно сократить, если знать, как из картинки вытащить текст в Word.

Для преобразования текста на картинке в документ Ворд — следуйте инструкциям ниже
Выход из ситуации
Обычно процесс распознавания с изображения достаточно трудоёмкий. В нём основную работу придётся делать вручную, но конечный результат сэкономит общее затраченное время. Это бывает необходимо, когда в распоряжении присутствует только электронное изображение документа или страницы книги, с которой нужно вытащить текст.
Вместо собственноручного перепечатывания информации, можно воспользоваться специализированными программами и сервисами, которые автоматизируют эту работу. Они позволяют распознать текст, используя картинки большинства популярных форматов, среди которых jpg, gif и png.
Порядок работ
Если данные находятся на печатном документе, с него придётся предварительно сделать изображение. Для этого потребуется сканер. Также это бывает необходимо, если текст на картинке имеет плохое разрешение или он размытый. К сканеру должны прилагаться «родные» драйвера и программы, которые позволят перевести всё в высоком качестве. На результат влияет не только чёткость букв, но и их «ровное» положение, а также отсутствие помех.

Если вам необходимо получить текст с бумажного носителя — потребуется сканер
При неимении сканера можно обойтись фотоаппаратом. В этом случае потребуется правильно выставить свет. На следующем этапе требуется использование специальных программ, которые позволят непосредственно распознать текст с jpg. Среди таких программ особое место занимает ABBYY FineReader, которая считается лидером на рынке. Она платная, но её качество соответствует стоимости.
Особенности процесса
В функционале программного обеспечения присутствует много функций, позволяющих работать с большинством шрифтов. Среди передовых возможностей присутствует способность распознать рукописный текст Word из jpg. Она имеет много преимуществ:
- выбор качества. Пользователь может сам остановить предпочтительное качество для сканирования. Лучше выбирать не ниже 300 DPI, чтобы программа затрагивала для обработки даже мелкие детали, и смогла работать с мелкими шрифтами.
- цветность. Необходимо, когда на изображении присутствуют таблицы или другая символика. В других же вариантах предпочтительно выбирать чёрно-белый режим, который уберёт смещения цветового диапазона с букв, сделав их чище. Цветной режим подойдёт для ярких картинок, где важно передать цвет текста.
- фотография. Если картинка выполнена снимком, программа повысит приоритет сканирования. Также можно непосредственно с ABBYY FineReader сфотографировать текст, чтобы распознать его в jpg. Правда, это сильно ухудшит качество, отчего финальный результат будет иметь много ошибок.
Среди аналогичных программ присутствуют также бесплатные сервисы. Среди них выделяется также Google Drive, которая доступная непосредственно в браузере. Работа с OCR Convert имеет среднее качество, поэтому подходит для тех, у кого изображение имеет высокое расширение и чёткие шрифты. Сервис i2OCR предлагает аналогичные услуги, только картинки можно ещё загрузить с URL-ссылки. Они имеют больше любительский формат, поэтому не рассматриваются для профессионального использования.

Открыв картинку через Google Документы, вы получите документ с уже распознанным текстом
Получить результат
После начала сканирования обычно проходит пару минут, чтобы получить результат. Этот показатель зависит от сложности и количества располагаемого текста. После старта работы, программы в автоматическом режиме будут выделять участки для проверки, и преобразовать их. После окончания процесса, можно повторно распознать jpg данные, или сосредоточиться на определённых участках документа.
Готовый результат экспортируется в файл Word. Полученный текст можно редактировать при наблюдении ошибок, или продолжить с ним дальнейшую работу. Распознать текст с jpg картинок не представляет труда, если правильно подготовить изображение. Этот процесс может существенно сэкономить время, в отличие от ручного перепечатывания информации.
Поскольку работа с распознаванием текста с картинки требует качественного исходника, нужно изначально найти изображение с высоким разрешением. Это ускорит сам процесс обработки данных, а также уменьшит общий объем ошибок.
Преобразование изображения JPEG в текст в MS Word

Все мы уже привыкли фотографировать расписание, документы, страницы книг и многое другое, но по ряду причин «извлечь» текст со снимка или картинки, сделав его пригодным для редактирования, все же требуется.
Особенно часто с необходимостью преобразовать фото в текст сталкиваются школьники и студенты. Это естественно, ведь никто не будет переписывать или набирать текст, зная, что есть более простые методы. Было бы прям идеально, если бы преобразовать картинку в текст можно было в Microsoft Word, вот только данная программа не умеет ни распознавать текст, ни конвертировать графические файлы в текстовые документы.
Единственная возможность «поместить» текст с JPEG-файла (джипег) в Ворд — это распознать его в сторонней программе, а затем уже оттуда скопировать его и вставить или же просто экспортировать в текстовый документ.
Распознавание текста
ABBYY FineReader по праву является самой популярной программой для распознавания текста. Именно главную функцию этого продукта мы и будем использовать для наших целей — преобразования фото в текст. Из статьи на нашем сайте вы можете более подробно узнать о возможностях Эбби Файн Ридер, а также о том, где скачать эту программу, если она еще не установлена на у вас на ПК.

Скачав программу, установите ее на компьютер и запустите. Добавьте в окно изображение, текст на котором необходимо распознать. Сделать это можно простым перетаскиванием, а можно нажать кнопку «Открыть», расположенную на панели инструментов, а затем выбрать необходимый графический файл.

Теперь нажмите на кнопку «Распознать» и дождитесь, пока Эбби Файн Ридер просканирует изображение и извлечет из него весь текст.

Вставка текста в документ и экспорт
Когда FineReader распознает текст, его можно будет выделить и скопировать. Для выделения текста используйте мышку, для его копирования нажмите «CTRL+С».

Теперь откройте документ Microsoft Word и вставьте в него текст, который сейчас содержится в буфере обмена. Для этого нажмите клавиши «CTRL+V» на клавиатуре.

Помимо просто копирования/вставки текста из одной программы в другую, Эбби Файн Ридер позволяет экспортировать распознанный им текст в файл формата DOCX, который для MS Word является основным. Что для этого требуется сделать? Все предельно просто:
- выберите необходимый формат (программу) в меню кнопки «Сохранить», расположенной на панели быстрого доступа;

кликните по этому пункту и укажите место для сохранения;

После того, как текст будет вставлен или экспортирован в Ворд, вы сможете его отредактировать, изменить стиль, шрифт и форматирование. Наш материал на данную тему вам в этом поможет.

Примечание: В экспортированном документе будет содержаться весь распознанный программой текст, даже тот, который вам, возможно, и не нужен, или тот, который распознан не совсем корректно.

Видео-урок по переводу текста с фотографии в Word файл
Преобразование текста на фото в документ Ворд онлайн
Если вы не хотите скачивать и устанавливать на свой компьютер какие-либо сторонние программы, преобразовать изображение с текстом в текстовый документ можно онлайн. Для этого существует множество веб-сервисов, но лучший из них, как нам кажется, это FineReader Online, который использует в своей работе возможности того же программного сканера ABBY.

Перейдите по вышеуказанной ссылке и выполните следующие действия:
1. Авторизуйтесь на сайте, используя профиль Facebook, Google или Microsoft и подтвердите свои данные.
Примечание: Если ни один из вариантов вас не устраивает, придется пройти полную процедуру регистрации. В любом случае, сделать это не сложнее, чем на любом другом сайте.

2. Выберите пункт «Распознать» на главной странице и загрузите на сайт изображение с текстом, который нужно извлечь.

3. Выберите язык документа.
4. Выберите формат, в котором требуется сохранить распознанный текст. В нашем случае это DOCX, программы Microsoft Word.

5. Нажмите кнопку «Распознать» и дождитесь, пока сервис просканирует файл и преобразует его в текстовый документ.
6. Сохраните, точнее, скачайте файл с текстом на компьютер.
Примечание: Онлайн-сервис ABBY FineReader позволяет не только сохранить текстовый документ на компьютер, но и экспортировать его в облачные хранилища и другие сервисы. В числе таковые BOX, Dropbox, Microsoft OneDrive, Google Drive и Evernote.

После того, как файл будет сохранен на компьютер, вы сможете его открыть и изменить, отредактировать.
На этом все, из данной статьи вы узнали, как перевести текст в Ворд. Несмотря на то, что данная программа не способна самостоятельно справиться с такой, казалось бы, простой задачей, сделать это можно с помощью стороннего софта — программы Эбби Файн Ридер, или же специализированных онлайн-сервисов.
Мы рады, что смогли помочь Вам в решении проблемы.
Помимо этой статьи, на сайте еще 11905 инструкций.
Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Бесплатный сервис по распознаванию
текста из изображений
который поможет получить напечатанный текст из PDF документов и фотографий
- Загрузка файла
- По ссылке
Принцип работы ресурса
Отсканируйте или сфотографируйте текст для распознавания
Загрузите файл
Выберите язык содержимого текста в файле
После обработки файла, получите результат * длительность обработки файла может составлять до 60 секунд
- Форматы файлов
- Изображения: jpg, jpeg, png
- Мульти-страничные документы: pdf
- Сохранение результатов
- Чистый текст (txt)
- Adobe Acrobat (pdf)
- Microsoft Word (docx)
- OpenOffice (odf)
Наши преимущества
- Легкий и удобный интерфейс
- Мультиязычность
Сайт переведен на 9 языков - Быстрое распознавание текста
- Неограниченное количество запросов
- Отсутствие регистрации
- Защита данных. Данные между серверами передаются по SSL + автоматически будут удалены
- Поддержка 35+ языков распознавания текста
- Использование движка Tesseract OCR
- Распознавание области изображения (в разработке)
- Обработано более чем 19.6M+ запросов
Основные возможности
Распознавание отсканированных файлов и фотографий, которые содержат текст
Форматирование бумажных и PDF-документов в редактируемые форматы
Приветствуем студентов, офисных работников или большой библиотеки!
У Вас есть учебник или любой журнал, текст из которого необходимо получить, но нет времени чтобы напечатать текст?
Наш сервис поможет сделать перевод текста с фото. После получения результата, Вы сможете загрузить текст для перевода в Google Translate, конвертировать в PDF-файл или сохранить его в Word формате.
OCR или Оптическое Распознавание Текста никогда еще не было таким простым. Все, что Вам необходимо, это отсканировать или сфотографировать текст, далее выбрать файл и загрузить его на наш сервис по распознаванию текста. Если изображение с текстом было достаточно точным, то Вы получите распознанный и читабельный текст.
Сервис не поддерживает тексты написаны от руки.
Поддерживаемые языки:
Русский, Українська, English, Arabic, Azerbaijani, Azerbaijani — Cyrillic, Belarusian, Bengali, Tibetan, Bosnian, Bulgarian, Catalan; Valencian, Cebuano, Czech, Chinese — Simplified, Chinese — Traditional, Cherokee, Welsh, Danish, Deutsch, Greek, Esperanto, Estonian, Basque, Persian, Finnish, French, German Fraktur, Irish, Gujarati, Haitian; Haitian Creole, Hebrew, Croatian, Hungarian, Indonesian, Icelandic, Italiano, Javanese, Japanese, Georgian, Georgian — Old, Kazakh, Kirghiz; Kyrgyz, Korean, Latin, Latvian, Lithuanian, Dutch; Flemish, Norwegian, Polish Język polski, Portuguese, Romanian; Moldavian, Slovakian, Slovenian, Spanish; Castilian, Spanish; Castilian — Old, Serbian, Swedish, Syriac, Tajik, Thai, Turkish, Uzbek, Uzbek — Cyrillic, Vietnamese
© 2014-2021 img2txt Сервис распознавания изображений / v.0.6.6.0