
The
definition of the word meaning
presents no less difficulty than the definition of the word itself.
The word meaning
renders the emotion or the concept in the mind of the speaker which
he wants to convey to the listener in the process of
communication. By
concept we understand any discrete unit of human cognition. The
word being a unit of language enters a number of combinations with
other units stands in functional relations to other linguistic signs.
Thus the meaning of the word not only fixes concepts by way of
generalizing and reflecting reality, but it is realized on contexts
and combinations. The meaning of the word is not homogeneous. It is
closely connected with the object it names and the concept it fixes.
It is also connected with the sound form besides it is realized in
different relations with other concepts. There are two main
approaches to word meaning: 1. relative approach, according to which
each linguistic sign (word) gets its meaning only in some semantic
field or paradigmatic relations. 2. the referential or denotational
approach, according to which the meaning of the word is autonomous,
it’s an integral part of the word, though is realized in contexts
and this approach is shown as a triangle (symbol – the word,
concept – thought; referent – object, denoted by the word).
28 Word meaning and motivation.
The
relationship between morphemic structure and meaning is termed
morphological motivation. The main criteria in morphological
motivation is the relationship between morphemes. All one-morpheme
words (look, eat) are non-motivated. Such words as writer, worker are
described as motivated. Phonetic motivation is represented by such
words as swish, boom, splash. Beside grammatical and lexical meanings
some linguists also distinguish the co-called structural meaning,
i.e. words in a sentence are joined together according to some
specific rules (a diggled-boggle, a boggled diggle). Motivation is
the relationship existing between the morpheme or phonemic
composition and the structural pattern of the word, on the one hand,
and its meaning on the other. The words are motivated: 1.
Structurally (a shoe-maker), but sometimes due to the character of
the lexical meaning of a morphological motivation becomes rather
relevant or weak (flower-girl); 2. Phonetically (swish, boom); 3.
Semantically (the dawn of life). Sometimes motivation of the words
may be lost: a) one of the elements of compound words dropped out of
usage (mermaid – русалка,
mere – море);
b) the loss of the primary meaning of the word (spoon – щепка).
34
Homonyms.
Definition, formal classification. Homonyms
are words
which are identical in sound and spelling, or, at least, in one of
these aspects, but different in their meaning.E. g. bank, n. —a
shore,bank, n. —an
institution for receiving, lending, exchanging, and safeguarding
money. ball, n. —a
sphere; any spherical body,ball, n. —a
large dancing party. Homonyms which are the same in sound and
spelling are traditionally termed homonyms
proper. Bean, n.
and been, Past
Part, of to
be are
homophone- they
are the same in sound but different in spelling. Homographs- words
which are the same in spelling but different in sound(lead v – show
smb the way, lead n – a heavy, rather soft metal). When analysing
different cases of homonymy we find that some words are homonymous in
all their forms, i.e. we observe full h. of the paradigms of two or
more different words, e.g., in seal1 —‘a
sea animal’ and seal2 —‘a
design printed on paper by means of a stamp’. When only some of the
word-forms(seal, seals, etc.) are homonymous, whereas others(sealed,
sealing) are not, we can speak of partial
h. — find,
found, found, and found, founded, founded.
.lexico-grammatical
classification of homonyms. Homonyms
may be also classified by the type of meaning into lexical,
lexico-grammatical and grammatical homonyms.
In seal1 n and seal2 n, e.g.,
the part-of-speech meaning of the word and the grammatical meanings
of all its forms are identical (seal [si:l] Common Case Singular,
seal’s [si:lz] Possessive Case Singular for both seal1 and
seal2). The
difference is confined to the lexical meaning only: seal1 denotes
‘a sea animal’,‘the fur of this animal’,etc., seal2—‘a
design printed on paper,the stamp by which the design is made’etc.
So we can say that seal2 and
seal1 are
lexical homonyms because they differ in lexical
meaning.If
we compare seal1—‘a
sea animal’, and (to) seal3—‘to
close tightly, we shall observe not only a difference in the lexical
meaning of their homonymous word-forms but a difference in their
grammatical meanings as well. Identical sound-forms, i.e.
seals[si:lz] (Common Case Plural of the noun) and (he) seals[si:lz]
(third person Singular of the verb) possess each of them different
grammatical meanings. As both grammatical and lexical meanings differ
we describe these homonymous word-forms as lexico-grammatical. Modern
English abounds in homonymic word-forms differing in grammatical
meaning only. e.g. brother’s —brothers —the
Possessive Case Singular and the Common Case Plural. It
may be easily observed
that grammatical
homonymy is
the homonymy of different
word-forms of one and the same word.
Sources
of homonyms. The
two main sources of h. are:1.diverging
meaning development
of a polysemantic word. This process can be observed when different
meanings of the same word move so far away from each other that they
come to be regarded as two separate units.
Ex.: flower and flour originally
were one wordmeaning ‘the flower’ and ‘the finest part of
wheat’.2.convergent
sound development of
two or more different words. Ex, OE. ic
and OE. еаzе have
become identical in pronunciation(ME. I
and eye). A number of lexico-grammatical homonyms appeared as a
result of convergent sound development of the verb and the noun
(MnE.love — (to)
love and OE. lufu
— lufian). Words
borrowed from other languages may through phonetic convergence become
homonymous. ONorse. ras
and Fr. race
are homonymous in Modern English (race1 [reis]
— ‘running’ and race2 [reis] —
‘a distinct
ethnical stock’).
35
Types of
Synonyms. The role of synonyms it the development of the
vocabulary.The
only existing classification system for synonyms was established by
Academician Vinogradov, the famous Russian scholar. In his
classification system there are three types of
synonyms: ideographic (which
he defined as words conveying the same concept but differing in
shades of meaning), stylistic (differing
in stylistic characteristics) and absolute (coinciding
in all their shades of meaning and in all their stylistic
characteristics) A more modern and a more effective approach to the
classification of synonyms may be based on the definition describing
synonyms as words differing in connotations.
36
The themantic
groups and semantic fields. Classification
of vocabulary items into thematic
groups is
based on the co-occurrence of words in certain repeatedly used
contexts. In linguistic contexts co-occurrence maу be
observed on different levels. On the level of word-groups the
word question, for
instance, is often found in collocation with the verbs raise,
put forward, discuss, etc.,
with the adjectives urgent,
vital, disputable and
so on. The verb
accept occurs
in numerous contexts together with the nouns proposal,
invitation, plan and
others.As a rule, thematic groups deal with contexts on the level of
the sentence. Words in thematic groups are joined together by common
contextual associations within the framework of the sentence and
reflect the interlinking of things or events. Common contextual
association of the words,
e.g. tree—grow—green;journey—train—taxi—bags—ticket
or sunshine—brightly—blue—sky, is
due to the regular co-occurrence of these words in a number of
sentences. Words making up a thematic group belong to different parts
of speech and do not possess any common denominator of meaning.
Contextual associations formed by the speaker of a language are
usually conditioned by the context of situation which necessitates
the use of certain words. When watching a play, for example, we
naturally speak of the actors who act the
main parts, of
good (or bad)
staging of
the play, of the wonderful scenery and
so on. When we go shopping it
is usual to speak of the prices, of the
goods we buy, of the
shops. Words
may be classified according to the concepts underlying their meaning.
This classification is closely connected with the theory of
conceptual or semantic
fields.
By the term “semantic fields” we understand closely knit sectors
of vocabulary each characterised by a common concept. For example,
the words blue,
red, yellow, black, etc.
may be described as making up the semantic field of colours, thewords
mother, father, brother, cousin, etc.
— as members of the semantic field.In
practical lang. learning thematic groups are often listed under
various headings, e. g. “At the Theatre”, “At School”,
“Shopping”, and are often found in textbooks and courses of
conversational English.The members of the semantic fields are not
synonyms but all of them are joined together by some common semantic
component — the
concept of colours or the concept of kinship, etc. It is argued that
we cannot possibly know the exact meaning of the word if we do not
know the structure of the SF to which the word belongs, the number of
the members and the concepts covered by them.It should also be
pointed out that different meanings of polysemantic words make it
possible to refer the same word to different lexico-semantic groups.
Thus, e.g. make in
the meaning of ‘construct’ is naturally a member of the same
lexico-semantic group as the verbs produce,
manufacture, etc , whereas
in the meaning of compel it
is regarded as a member of a different lexico-semantic group made up
by the verbs force,
induce.
37
Semantic
contrasts and antonymy. General problems(contrast, contradiction)The
term antonyms indicate words of the same category of parts of speech
which have contrasting meanings. And nearly identical in distribution
associated and used together so that their implication aspects render
contrary or contradictory notion:love-hate, early-late. The
opposition here is obvious, each component means the opposite of the
other. Almost every word can have synonyms comparatativly, few have
antonyms. Antonyms apposition is characterized of a)qualitative
adj-s:new-old, big-little. b)word derived from word qualitative
adj-s:gladly-sadly, sadness-gladness. c)words concern with feeling or
state and their derivatives:triumph-disaster, hope-dispair. d)words
denoting directions and position in space: up-down, far-near.
Polysemantic words may have antonyms in some of their meanings and
none in the others. E.g.a shot/long story, a short/tall man. Not so
many years ago antonymy was not universally accepted as a linguistic
problem, and the opposition within antonymic pairs was regarded as
purely logical and finding no reflection in the semantic structures
of these words. The contrast between heat and cold or big and small,
said most scholars, is the contrast of things opposed by their very
nature. Nowadays most scholars agree that in the semantic structures
of all words, which regularly occur in antonymic pairs, a special
antonymic connotation can be singled out. We are so used to coming
across hot and cold together, in the same contexts, that even when we
find hot alone, we cannot help subconsciously registering it as not
cold, that is, contrast it to its missing antonym. Contradictions
represent the type of semnantic relantions that exist between pairs
like dead and alive) single and married.
Classification
of antonyms. Depending
on the type of polarity ant-s are usually classified into absolute
and derivational. Absolute ant-s are words regularly contrasted as
homogeneous members connected by copulative, disjunctive and
adversative conjunctions or parallel constructions: good or bad,
right or wrong. Derivational a. are formed with the help of affixes
dis, un, less, ful:selfish-unselfish, useless-useful. The
contradiction is expressed morphologically and symantically too.
Absolute ant-s can be arranged into a series according to increasing
difference in one of the qualities:young-middle aged-old;
love-resentment-hate. A-s mostly form pairs not groups.
38
Connotations
of synonyms.I.The
connotation of degree
or intensity can
be traced in such groups of synonyms as to surprise — to astonish —
to amaze — to astound; to shout — to yell — to bellow — to roar.
IIconnotation of duration:
to stare — to glare — to gaze — to glance — to peep — to peer. all
the synonyms except to glance denote a lasting act of looking at smb
or smth, whereas to glance describes a brief, passing look. IIIThe
synonyms to stare — to glare — to gaze are differentiated from the
other words of the group by emotive connotations,
and from each other by the nature of the emotion they
imply. In the group alone — single — lonely — solitary, the adjective
lonely also has an emotive connotation. IV.
The evaluative connotation
conveys the speaker’s attitude towards the referent, labelling it as
good or bad. So in the group well-known — famous — notorious —
celebrated, the adjective notorious bears a negative evaluative
connotation and celebrated a positive one. V.The causativeconnotation
can be illustrated by the examples to sparkle and to glitter given
above: one’s eyes sparkle with positive emotions and glitter with
negative emotions. VI.The connotation of manner can
be singled out in some groups of verbal synonyms. The verbs to stroll
— to stride — to trot — to pace — to swagger — to stagger — to
stumble all denote different ways and types of walking,. VII.The
verbs to peep and to peer is the connotation of attendant
circumstances.
VIII.The synonyms pretty, handsome, beautiful have been mentioned as
the ones which are more or less interchangeable. Yet, each of them
describes a special type of human beauty: beautiful is mostly
associated with classical features and a perfect figure, handsome
with a tall stature, a certain robustness and fine pro portions,
pretty with small delicate features and a fresh complexion. This
connotation may be defined as the connotation of attendant
features.
IX.Stylistic connotations.
Examples :Meal. Snack, bite (coll.), snap (dial.), repast,
refreshment, feast (formal).
39
Sources
of synonyms. Euphemisms. 1)borrowings:
to ask(eng)-to question(fr)-interrogate(lat); to
gather(eng)-assemble(fr)-collect(lat) 2)dialects or
variations(amer)radio-(british)wireless; (irish)lass-(eng)girl; 3)new
formations with a post positive: to postphone-to put off, to
return-to come back, to betray-to give a way; 4)word-building by
means of :a)synonymas, affixes:changeable-changefull; b) composition
and affixation:trader-tradesman; c)affixation and
conversion:saying-say; 5) by means of shortening:microfone-mike,
doctor-doc; 6) a special groups of synonymas is comprised by the
Euphemisms. There are words in every language which people
instinctively avoid because they are considered indecent, indelicate,
rude, too direct or impolite. As the «offensive» referents,
for which these words stand, must still be alluded to, they are often
described in a round-about way, by using substitutes called
euphemisms. The
word lavatory has
produced many euphemisms:powder
room,washroom,restroom,retiring room,(public) comfort station,
ladies’ (room),gentlemen’s (room),water-closet,w.c., public
conveniences and
even Windsor. Pregnancy: in
an interesting condition,in a delicate condition,in the family
way,with a baby coming,(big) with child,expecting. Drunk:
intoxicated (form.),under the influence (form.),tipsy,mellow, fresh,
high, merry, flustered, overcome, full (coll.), drunk as a lord
(coll.), drunk as an owl (coll.), boiled (sl.), fried (sl.), tanked
(sl.), tight (sl.), stiff (sl.), pickled (sl.), soaked (sl.), three
sheets to the wind (sl.), high as a kite (sl.), half-seas-over (sl.),
etc. All the euphemisms that have been described so far are used to
avoid the so-called social taboos. Their use is inspired by social
convention. Euphemisms
may be:a) based on some social or ethical standard of behavior not to
hurt other people’s feelinfs: poor-underprivilaged
disaipled-invalid; 2) the requinment of style:to die-to join the
majority, to pass away, to go west; 3)religious taboo:the name of
God-good heavens.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Chapter 8 how words develop new meanings
It has been mentioned that the systems of meanings of polysemantic words evolve gradually. The older a word is, the better developed is its semantic structure. The normal pattern of a word’s semantic development is from monosemy to a simple semantic structure encompassing only two or three meanings, with a further movement to an increasingly more complex semantic structure.
In this chapter we shall have a closer look at the complicated processes by which words acquire new meanings.
There are two aspects to this problem, which can be generally described in the following way: a) Why should new meanings appear at all? What circumstances cause and stimulate their development? b) How does it happen? What is the nature of the very process of development of new meanings?
Let us deal with each of these questions in turn.
Causes of Development of New Meanings
The first group of causes is traditionally termed historical or extra-linguistic.
Different kinds of changes in a nation’s social life, in its culture, knowledge, technology, arts lead to gaps appearing in the vocabulary which beg to be filled. Newly created objects, new concepts and phenomena must be named. We already know of two ways for providing new names for newly created concepts:
making new words (word-building) and borrowing foreign ones. One more way of filling such vocabulary gaps is by applying some old word to a new object or notion.
When the first textile factories appeared in England, the old word mill was applied to these early industrial enterprises. In this way, mill (a Latin borrowing of the first century В. С.) added a new meaning to its former meaning «a building in which corn is ground into flour». The new meaning was «textile factory».
A similar case is the word carriage which had (and still has) the meaning «a vehicle drawn by horses», but, with the first appearance of railways in England, it received a new meaning, that of «a railway car».
The history of English nouns describing different parts of a theatre may also serve as a good illustration of how well-established words can be used to denote newly-created objects and phenomena. The words stalls, box, pit, circle had existed for a long time before the first theatres appeared in England. With their appearance, the gaps in the vocabulary were easily filled by these widely used words which, as a result, developed new meanings.1
New meanings can also be developed due to linguistic factors (the second group of causes).
Linguistically speaking, the development of new meanings, and also a complete change of meaning, may be caused through the influence of other words, mostly of synonyms.1
Let us consider the following examples.
The Old English verb steorfan meant «to perish». When the verb to die was borrowed from the Scandinavian, these two synonyms, which were very close in their meaning, collided, and, as a result, to starve gradually changed into its present meaning: «to die (or suffer) from hunger».
The history of the noun deer is essentially the same. In Old English (O. E. deor) it had a general meaning denoting any beast. In that meaning it collided with the borrowed word animal and changed its meaning to the modern one («a certain kind of beast», R. олень).
The noun knave (O. E. knafa) suffered an even more striking change of meaning as a result of collision with its synonym boy. Now it has a pronounced negative evaluative connotation and means «swindler, scoundrel».
The Process of Development and Change of Meaning
The second question we must answer in this chapter is how new meanings develop. To find the answer to this question we must investigate the inner mechanism of this process, or at least its essential features. Let us examine the examples given above from a new angle, from within, so to speak.
Why was it that the word mill — and not some other word — was selected to denote the first textile factories? There must have been some connection between the former sense of mill and the new phenomenon to which it was applied. And there was apparently such a connection. Mills which produced flour, were mainly driven by water. The textile factories also firstly used water power. So, in general terms, the meanings of mill, both the old and the new one, could be defined as «an establishment using water power to produce certain goods». Thus, the first textile factories were easily associated with mills producing flour, and the new meaning of mill appeared due to this association. In actual fact, all cases of development or change of meaning are based on some association. In the history of the word carriage, the new travelling conveyance was also naturally associated in people’s minds with the old one: horse-drawn vehicle > part of a railway train. Both these objects were related to the idea of travelling. The job of both, the horse-drawn carriage and the railway carriage, is the same: to carry passengers on a journey. So the association was logically well-founded.
Stalls and box formed their meanings in which they denoted parts of the theatre on the basis of a different type of association. The meaning of the word box «a small separate enclosure forming a part of the theatre» developed on the basis of its former meaning «a rectangular container used for packing or storing things». The two objects became associated in the speakers’ minds because boxes in the earliest English theatres really resembled packing cases. They were enclosed on all sides and heavily curtained even on the side facing the audience so as to conceal the privileged spectators occupying them from curious or insolent stares.
The association on which the theatrical meaning of stalls was based is even more curious. The original meaning was «compartments in stables or sheds for the accommodation of animals (e. g. cows, horses, etc.)», There does not seem to be much in common between the privileged and expensive part of a theatre and stables intended for cows and horses, unless we take into consideration the fact that theatres in olden times greatly differed from what they are now. What is now known as the stalls was, at that time, standing space divided by barriers into sections so as to prevent the enthusiastic crowd from knocking one other down and hurting themselves. So, there must have been a certain outward resemblance between theatre stalls and cattle stalls. It is also possible that the word was first used humorously or satirically in this new sense.
The process of development of a new meaning (or a change of meaning) is traditionally termed transference.
Some scholars mistakenly use the term «transference of meaning» which is a serious mistake. It is very important to note that in any case of semantic change it is not the meaning but the word that is being transferred from one referent onto another (e. g. from a horse-drawn vehicle onto a railway car). The result of such a transference is the appearance of a new meaning.
Two types of transference are distinguishable depending on the two types of logical associations underlying the semantic process.
Transference Based on Resemblance (Similarity)
This type of transference is also referred to as linguistic metaphor. A new meaning appears as a result of associating two objects (phenomena, qualities, etc.) due to their outward similarity. Box and stall, as should be clear from the explanations above, are examples of this type of transference.
Other examples can be given in which transference is also based on the association of two physical objects. The noun eye, for instance, has for one of its meanings «hole in the end of a needle» (cf. with the R. ушко иголки), which also developed through transference based on resemblance. A similar case is represented by the neck of a bottle.
The noun drop (mostly in the plural form) has, in addition to its main meaning «a small particle of water or other liquid», the meanings: «ear-rings shaped as drops of water» (e. g. diamond drops) and «candy of the same shape» (e. g. mint drops). It is quite obvious that both these meanings are also based on resemblance. In the compound word snowdrop the meaning of the second constituent underwent the same shift of meaning (also, in bluebell). In general, metaphorical change of meaning is often observed in idiomatic compounds.
The main meaning of the noun branch is «limb or subdivision of a tree or bush». On the basis of this meaning it developed several more. One of them is «a special field of science or art» (as in a branch of linguistics). This meaning brings us into the sphere of the abstract, and shows that in transference based on resemblance an association may be built not only between two physical objects, but also between a concrete object and an abstract concept.
The noun bar from the original meaning barrier developed a figurative meaning realized in such contexts as social bars, colour bar, racial bar. Here, again, as in the abstract meaning of branch, a concrete object is associated with an abstract concept.
The noun star on the basis of the meaning «heavenly body» developed the meaning «famous actor or actress». Nowadays the meaning has considerably widened its range, and the word is applied not only to screen idols (as it was at first), but, also, to popular sportsmen (e. g. football stars), pop-singers, etc. Of course, the first use of the word star to denote a popular actor must have been humorous or ironical: the mental picture created by the use of the word in this new meaning was a kind of semi-god surrounded by the bright rays of his glory. Yet, very soon the ironical colouring was lost, and, furthermore the association with the original meaning considerably weakened and is gradually erased.
The meanings formed through this type of transference are frequently found in the informal strata of the vocabulary, especially in slang (see Ch. 1). A red-headed boy is almost certain to be nicknamed carrot or ginger by his schoolmates, and the one who is given to spying and sneaking gets the derogatory nickname of rat. Both these meanings are metaphorical, though, of course, the children using them are quite unconscious of this fact.
The slang meanings of words such as nut, onion (= head), saucers (= eyes), hoofs (= feet) and very many others were all formed by transference based on resemblance.
Transference Based on Contiguity
Another term for this type of transference is linguistic metonymy. The association is based upon subtle psychological links between different objects and phenomena, sometimes traced and identified with much difficulty. The two objects may be associated together because they often appear in common situations, and so the image of one is easily accompanied by the image of the other; or they may be associated on the principle of cause and effect, of common function, of some material and an object which is made of it, etc.
Let us consider some cases of transference based on contiguity. You will notice that they are of different kinds.
The Old English adjective glad meant «bright, shining» (it was applied to the sun, to gold and precious stones, to shining armour, etc.). The later (and more modern) meaning «joyful» developed on the basis of the usual association (which is reflected in most languages) of light with joy (cf. with the R. светлое настроение; светло на душе).
The meaning of the adjective sad in Old English was «satisfied with food» (cf. with the R. сыт(ый) which is a word of the same Indo-European root). Later this meaning developed a connotation of a greater intensity of quality and came to mean «oversatisfied with food; having eaten too much». Thus, the meaning of the adjective sad developed a negative evaluative connotation and now described not a happy state of satisfaction but, on the contrary, the physical unease and discomfort of a person who has had too much to eat. The next shift of meaning was to transform the description of physical discomfort into one of spiritual discontent because these two states often go together. It was from this prosaic source that the modern meaning of sad «melancholy», «sorrowful» developed, and the adjective describes now a purely emotional state. The two previous meanings («satisfied with food» and «having eaten too much») were ousted from the semantic structure of the word long ago.
The foot of a bed is the place where the feet rest when one lies in the bed, but the foot of a mountain got its name by another association: the foot of a mountain is its lowest part, so that the association here is founded on common position.
By the arms of an arm-chair we mean the place where the arms lie when one is sitting in the chair, so that the type of association here is the same as in the foot of a bed. The leg of a bed (table, chair, etc.), though, is the part which serves as a support, the original meaning being «the leg of a man or animal». The association that lies behind this development of meaning is the common function: a piece of furniture is supported by its legs just as living beings are supported by theirs.
The meaning of the noun hand realized in the context hand of a clock (watch) originates from the main meaning of this noun «part of human body». It also developed due to the association of the common function:
the hand of a clock points to the figures on the face of the clock, and one of the functions of human hand is also that of pointing to things.
Another meaning of hand realized in such contexts as factory hands, farm hands is based on another kind of association: strong, skilful hands are the most important feature that is required of a person engaged in physical labour (cf. with the R. рабочие руки).
The adjective dull (see the scheme of its semantic structure in Ch. 7) developed its meaning «not clear or bright» (as in a dull green colour; dull light; dull shapes) on the basis of the former meaning «deficient in eyesight», and its meaning «not loud or distinct» (as in dull sounds) on the basis of the older meaning «deficient in hearing». The association here was obviously that of cause and effect: to a person with weak eyesight all colours appear pale, and all shapes blurred; to a person with deficient hearing all sounds are indistinct.
The main (and oldest registered) meaning of the noun board was «a flat and thin piece of wood; a wooden plank». On the basis of this meaning developed the meaning «table» which is now archaic. The association which underlay this semantic shift was that of the material and the object made from it: a wooden plank (or several planks) is an essential part of any table. This type of association is often found with nouns denoting clothes: e. g. a taffeta («dress made of taffeta»); a mink («mink coat»), a jersy («knitted shirt or sweater»).
Meanings produced through transference based on contiguity sometimes originate from geographical or proper names. China in the sense of «dishes made of porcelain» originated from the name of the country which was believed to be the birthplace of porcelain.
Tweed («a coarse wool cloth») got its name from the river Tweed and cheviot (another kind of wool cloth) from the Cheviot hills in England.
The name of a painter is frequently transferred onto one of his pictures: a Matisse = a painting by Matisse.1
Broadening (or Generalization) of Meaning.
Narrowing (or Specialization) of Meaning
Sometimes, the process of transference may result in a considerable change in range of meaning. For instance, the verb to arrive (French borrowing) began its life in English in the narrow meaning «to come to shore, to land». In Modern English it has greatly widened its combinability and developed the general meaning «to come» (e. g. to arrive in a village, town, city, country, at a hotel, hostel, college, theatre, place, etc.). The meaning developed through transference based on contiguity (the concept of coming somewhere is the same for both meanings), but the range of the second meaning is much broader.
Another example of the broadening of meaning is pipe. Its earliest recorded meaning was «a musical wind instrument». Nowadays it can denote any hollow oblong cylindrical body (e. g. water pipes). This meaning developed through transference based on the similarity of shape (pipe as a musical instrument is also a hollow oblong cylindrical object) which finally led to a considerable broadening of the range of meaning.
The word bird changed its meaning from «the young of a bird» to its modern meaning through transference based on contiguity (the association is obvious). The second meaning is broader and more general.
It is interesting to trace the history of the word girl as an example of the changes in the range of meaning in the course of the semantic development of a word.
In Middle English it had the meaning of «a small child of either sex». Then the word underwent the process of transference based on contiguity and developed the meaning of «a small child of the female sex», so that the range of meaning was somewhat narrowed. In its further semantic development the word gradually broadened its range of meaning. At first it came to denote not only a female child but, also, a young unmarried woman, later, any young woman, and in modern colloquial English it is practically synonymous to the noun woman (e. g. The old girl must be at least seventy), so that its range of meaning is quite broad.
The history of the noun lady somewhat resembles that of girl. In Old English the word (hlxfdiZq)denoted the mistress of the house, i. e. any married woman. Later, a new meaning developed which was much narrower in range: «the wife or daughter of a baronet» (aristocratic title). In Modern English the word lady can be applied to any woman, so that its range of meaning is even broader than that of the O. E. hlxfdiZq. In Modern English the difference between girl and lady in the meaning of woman is that the first is used in colloquial style and sounds familiar whereas the second is more formal and polite. Here are some more examples of narrowing of meaning:
Deer: | any beast | > | a certain kind of beast |
Meat: | any food | > | a certain food product) |
Boy: | any young person of the male sex | > | servant of the male sex |
It should be pointed out once more that in all these words the second meaning developed through transference based on contiguity, and that when we speak of them as examples of narrowing of meaning we simply imply that the range of the second meaning is more narrow than that of the original meaning.
The So-called «Degeneration» («Degradation») and «Elevation» of Meaning
These terms are open to question because they seem to imply that meanings can become «better» or «worse» which is neither logical nor plausible. But, as a matter-of-fact, scholars using these terms do not actually mean the degeneration or elevation of meaning itself, but of the referent onto which a word is transferred, so that the term is inaccurate.
But let us try and see what really stands behind the examples of change of meaning which are traditionally given to illustrate degeneration and elevation of meaning.
I. «Degeneration» of meaning.
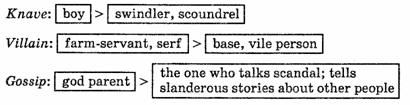
These examples show that the second meaning, in contrast with the one from which it developed, denotes a person of bad repute or character. Semantically speaking, the second meaning developed a negative evaluative connotation which was absent in the first meaning.
Such a readjustment in the connotative structure accompanying the process of transference can be sometimes observed in other parts of speech, and not only in nouns.
E. g. Silly: | happy | > | foolish |
II. «Elevation» of meaning.
Fond: | foolish] > | loving, affectionate |
Nice: | foolish] > | fine, good |
In these two cases the situation is reversed: the first meaning has a negative evaluative connotation, and the second meaning has not. It is difficult to see what is actually «elevated» here. Certainly, not the meaning of the word. Here are two more examples.
Tory: | brigand, highwayman | > | member of the Tories |
Knight: | manservant | > |»noble, courageous man]
In the case of Tory, the first meaning has a pronounced negative connotation which is absent in the second meaning. But why call it «elevation»? Semantically speaking, the first meaning is just as good as the second, and the difference lies only in the connotative structure.
The case of knight, if treated linguistically, is quite opposite to that of Tory: the second meaning acquired a positive evaluative connotation that was absent in the first meaning. So, here, once more, we are faced with a mere readjustment of the connotative components of the word.
There are also some traditional examples of «elevation» in which even this readjustment cannot be traced.
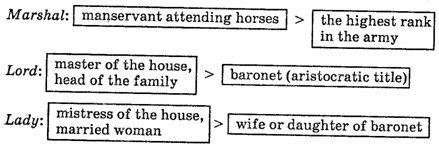
In these three words the second meaning developed due to the process of transference based on contiguity. Lord and lady are also examples of narrowing of meaning if we compare the range of the original and of the resultant meanings. No connotations of evaluation can be observed in either of the meanings. The fact that in all these three cases the original meaning denoted a humble ordinary person and the second denotes a person of high rank is absolutely extralinguistic.
All that has been said and the examples that have been given show that the terms «degradation» and «elevation» of meaning are imprecise and do not seem to be an objective reflection of the semantic phenomena they describe.
It would be more credible to state that some cases of transference based on contiguity may result in development or loss of evaluative connotations.
Exercises
I. Consider your answers to the following.
1. What causes the development of new meanings? Give examples.
2. What is the basis of development or change of meaning? Explain what we mean by the term transference.
3. What types of transference can you name?
4. What is meant by the widening and the narrowing of meaning?
5. Give examples of the so-called «degradation» and «elevation» of meaning. Why are these terms imprecise?
II. Read the following extracts and explain the semantic processes by which the italicized words acquired their meanings
1. ‘Bureau’, a desk, was borrowed from French in the 17thc. In Modern French (and English) it means not only the desk but also the office itself and the authority exercised by the office. Hence the familiar bureaucracy is likely to become increasingly familiar. The desk was called so because covered with bureau, a thick coarse cloth of a brown russet.
(From The Romance of Words by E. Weekley)
2. An Earl of Spencer made a short overcoat fashionable for some time. An Earl of Sandwich invented a form of light refreshment which enabled him to take a meal without leaving the card-table. Hence we have such words as spencer and sandwich in English.
(From The Romance of Words by E. Weekley)
3. A common name for overalls or trousers is jeans. In the singular jean is also a term for a durable twilled cotton and is short for the phrase jean fustian which first appeared in texts from the sixteenth century. Fustian (a Latin borrowing) is a cotton or cotton and linen fabric, and jean is the modern spelling of Middle English Jene or Gene, from Genes, the Middle French j name of the Italian city Genoa, where it was made and shipped abroad.
(From The Merriam-Webster Book of Word Histories)
4. Formally barn meant «a storehouse for barley»; today it has widened to mean «any kind of storehouse» for animals or equipment as well as any kind of grain. | The word picture used to refer only to a representation ;:: made with paint; today it can be a photograph or a representation made with charcoal, pencil or any other ; means. A pen used to mean «feather» but now has become generalized to include several kinds of writing implements — fountain, ballpoint, etc. The meaning of sail as limited to moving on water in a ship with sails has now generalized to mean «moving on water in any ship».
(From Teaching English Linguistically by J. Malmstrom, J. Lee)
III. Read the following extract and criticize the author’s treatment of the examples. Provide your own explanations.
Words degenerate in meaning also. In the past villain meant «farm labourer»; counterfeiter meant «imitator» without criminal connotations, and sly meant «skilful». A knave meant a «boy» and immoral meant «not customary», and hussy was a «housewife».
Other words improve in meanings. Governor meant «pilot» and constable meant «stable attendant». Other elevations are enthusiasm which formally meant «fanaticism», knight which used to mean «youth», angel which simply meant «messenger» and pretty which meant «sly». No one can predict the direction of change of meaning, but changes occur constantly.
(From Teaching English Linguistically by J. Malmstrom, J. Lee)
IV. Explain the logical associations in the following groups of meaning for the same words. Define the type of transference which has taken place.
1. The wing of a bird — the wing of a building; the eye of a man — the eye of a needle; the hand of a child — the hand of a clock; the heart of a man — the heart of the matter; the bridge across-the-river — the bridge of the nose; the tongue of a person — the tongue of a bell; the tooth of a boy — the tooth of a comb; the coat of a girl — the coat of a dog.
2. Green grass — green years; black shoes — black despair; nickel (metal) — a nickel (coin); glass — a glass; copper (metal) — a copper (coin); Ford (proper name) — a Ford (car); Damascus (town in Syria) — damask; Kashmir (town in North India) — cashmere.
V. Analyse the process of development of new meanings in the italicized words in the examples given below.
1.I put the letter well into the mouth of the box and let it go and it fell turning over and over like an autumn leaf. 2. Those v/ho had been the head of the line paused momentarily on entry and looked around curiously. 3. A cheerful-looking girl in blue jeans came up to the stairs whistling. 4. Seated behind a desk, he wore a light patterned suit, switch from his usual tweeds. 5. Oh, Steven, I read a Dickens the other day. It was awfully funny. 6. They sat on the rug before the fireplace, savouring its warmth, watching the rising tongues of flame. 7. He inspired universal confidence and had an iron nerve. 8. A very small boy in a green jersey with light red hair cut square across his forehead was peering at Steven between the electric fire and the side of the fireplace. 9. While the others were settling down, Lucy saw Pearson take another bite from his sandwich. 10. As I walked nonchalantly past Hugo’s house on the other side they were already carrying out the Renoirs.
VI. Explain the basis for the following jokes. Trace the logical associations between the different meanings of the same word.
1. Father was explaining to his little son the fundamentals of astronomy.
«That’s a comet.»
«A what?»
«A comet. You know what a comet is?» «No.»
«Don’t you know what they call a star with a tail?»
«Sure — Mickey Mouse.»
2. «Pa, what branches did you take when you went to school?»
«I never went to high school, son, but when I attended the little log school-house they used mostly hickory and beech and willow.»
3. What has eyes yet never sees? (Potato)
4. H e (in telephone booth)’. I want a box for two.
Voice (at the other end): Sorry, but we don’t have boxes for two.
He: But aren’t you the box office of the theatre? Voice: No, we are the undertakers.
VII. In the examples given below identify the eases of widening and narrowing of meaning.
1. While the others waited the elderly executive filled his pipe and lit it. 2. Finn was watching the birds. 3. The two girls took hold of one another, one acting gentleman, the other lady; three or four more pairs of girls immediately joined them and began a waltz. 4. He was informed that the president had not arrived at the bank, but was on his way. 5. Smokey had followed a dictum all his life: If you want a woman to stick beside you, pick an ugly one. Ugly ones stay to slice the meat and stir the gravy.
VIII. Have the italicized words evaluative connotations in their meanings? Motivate your answer and comment on the history of the words.
1. The directors now assembling were admirals and field marshals of commerce. 2. For a businessman to be invited to serve on a top-flight bank board is roughly equivalent to being knighted by the British Queen. 3.1 had a nice newsy gossip with Mrs. Needham before you turned up last night. 4. The little half-starved guy looked more a victim than a. villain. 5. Meanwhile I nodded my head vigorously and directed a happy smile in the direction of the two ladies. 6.1 shook hands with Tom; it seemed silly not to, for I felt suddenly as though I were talking to a child.
IX. Read the following. Find examples of «degeneration» and «elevation» of meaning. Comment on the history of the words.
1. King Arthur invented Conferences because he was secretly a Weak King and liked to know what his memorable thousand and one knights wanted to do next. As they were all jealous knights he had to have the memorable Round Table made to have the Conferences at, so that it was impossible to say which was top knight.
(From 1066 and All That by C. W. Sellar, R. J. Yeatman)
2. Alf: Where are you going, Ted?
Ted: Fishing at the old mill.
Alf: But what about school?
Ted: Don’t be silly. There aren’t any fish there!
X. Try your hand at the following scientific research. Write a short essay on the development of the meanings of three of the following words. Try to explain each shift of meaning. Use «The Shorter Oxford Dictionary» or «The Merriam-Webster Book of Word Histories».
Fee, cattle, school, pupil, nice, pen, gossip, coquette, biscuit, apron, merry, silly, doom, duke, pretty, yankee.
Introduction
Recent research emphasises the importance of good vocabulary knowledge: individuals with better vocabulary perform better on reading comprehension tests, and have better educational outcomes (Armstrong et al., 2017; Cain & Oakhill, 2014). Despite widespread acceptance that incidental learning from natural linguistic environments (e.g., conversations, books, TV) is the main source of vocabulary learning (Batterink & Neville, 2011; Nagy, Herman & Anderson, 1985; Nagy, Anderson & Herman, 1987), most studies of vocabulary learning in adults use highly artificial stimuli, tasks, and learning conditions. The current experiments focus on learning from naturalistic fiction stories that are read by participants in their native language without any explicit instructions to learn the new vocabulary that the stories contain. We investigate the extent to which people’s ability to retain newly-learned word meanings over time is improved by requiring them to retrieve these word meanings during the intervening period between encoding and a later test. The presence of such a beneficial “testing effect” has been well established through studies of explicit, intentional learning (for reviews, see Roediger & Butler, 2011; Rowland, 2014), but it is unclear whether retrieval would similarly enhance memory for vocabulary learned under more naturalistic, incidental learning conditions. The finding that vocabulary learning from naturalistic materials could be significantly boosted by a brief episode of testing could provide a simple approach to boosting vocabulary gains in real-world settings.
Incidental vocabulary learning is defined as learning words and their meanings whilst engaged in another activity such as listening or reading for comprehension (Hulstijn, 2003). A real-life context in which adults often learn new words and their meanings is when reading fiction, due to the rich and varied situations that are often depicted (Nation, 2017). Studies of word learning from stories by adult native-language (L1) readers have adopted highly naturalistic methods by using either authentic texts (Godfroid et al., 2017; Saragi, Nation & Meister, 1978) or texts modified or written specifically for the purposes of the studies (Batterink & Neville, 2011; Henderson et al., 2015; Pellicer-Sánchez, 2016). In these studies participants read works of fiction with the primary focus being on comprehension, with vocabulary learning as a by-product. To discourage intentional learning strategies, readers are not given any instruction to learn new vocabulary encountered in a text and are not informed that their memory will later be tested.
The current study uses a paradigm developed by Hulme, Barsky & Rodd (2019) in which participants encounter artificial new meanings for familiar English words in the context of custom-written short stories (e.g., learning that a foam is a type of safe concealed within a piece of furniture). This ability to learn new word meanings is a key aspect of vocabulary development: around 80% of common English words have more than one definition (Rodd, 2018; Rodd, Gaskell & Marslen-Wilson, 2002). Adults often learn additional word senses/meanings, and continue to update their knowledge of these words throughout their adult lives (Betts et al., 2018; Gaskell, Cairney & Rodd, 2019; Gilbert et al., 2018, 2021; Rodd et al., 2013). Examples of reasons why adults learn new meanings for familiar words include language evolution (e.g., the internet-related meaning of “troll”), or learning a new subject or activity (e.g., the sailing term “boom”; Eligio & Kaschak, 2021; Rodd et al., 2012, 2016). New meanings are often learned when reading stories, especially of the science fiction or fantasy genres (e.g., a “galleon” is a coin of the wizarding currency in the Harry Potter series of novels by J. K. Rowling). Recently, Fang, Perfetti & Stafura (2016) proposed that learning new meanings for familiar words is a dual-phase process whereby familiarity with the word form may facilitate learning with the initial encounters, but inhibition due to meaning competition begins to take effect after subsequent exposures to the newly ambiguous word (Maciejewski et al., 2020; Maciejewski & Klepousniotou, 2020; see Rodd, 2020 for review).
Hulme, Barsky & Rodd (2019) found that participants were able to recall the new meanings for the known words reasonably well (38.5% correct) after only two exposures in a story context, with a linear increase in meaning recall with additional exposures (63.5% correct after eight exposures). Interestingly, Hulme, Barsky & Rodd (2019)’s participants showed no significant forgetting of the new meanings they had learned at a surprise test one week later across all of the exposure conditions. The current study further examines this incidental form of word learning by (i) comparing performance to a more explicit learning condition and (ii) investigating the potential boost to performance from an immediate test of knowledge after training. Understanding how these two factors impact on long-term retention of vocabulary will provide a critical foundation for subsequent development of interventions to boost vocabulary acquisition.
The conditions of initial vocabulary acquisition (incidental or intentional) prompt different types of information processing, which may affect retention of word meanings in different ways. Vocabulary learned under intentional conditions may be retained better over time because more attention is directly focussed on encoding the word meanings, and the meaning is made more explicit. This more strategic processing might be particularly important for facilitating access to prior knowledge in the case of learning new ambiguous words where the learner may benefit from more explicitly noticing the mismatch between the familiar word meaning and the new meaning. In contrast, incidental vocabulary learning from story reading may benefit from the rich and informative story contexts (Webb, 2008), and it has been suggested that the increased mental effort required to encode new word meanings inferred from context may be beneficial for retention (Hulstijn, 1992). However, it is also important to consider that while incidental vocabulary learning is usually contextualised (with words embedded in informative contexts from which meaning is inferred), intentional vocabulary learning may also involve context, or it can be decontextualised.
The consensus from the literature on adult second language (L2) learning (e.g., Hulstijn, 1992; Lehmann, 2007; Peters et al., 2009), and research with teenagers learning L1 vocabulary (Konopak et al., 1987) is that intentional learning offers greater vocabulary gains and is more efficient than incidental learning. However, some other studies have found little difference (Lehmann, 2007), or even an efficiency advantage in terms of words learned per min for incidental learning (Mason & Krashen, 2004). Several recent studies with adult L1 readers have also found good levels of native language vocabulary acquisition from reading alone (Batterink & Neville, 2011; Godfroid et al., 2017; Pellicer-Sánchez, 2016). A further key factor that could differ between vocabulary acquisition under incidental and intentional learning conditions is the impact of testing on subsequent retention.
The “testing effect” refers to the finding that testing memory following training can enhance long-term retention, as the additional retrieval practice at test affords an opportunity for further learning (for reviews, see Roediger & Butler, 2011; Rowland, 2014). The effect has been demonstrated as robust in various experiments using explicit, intentional learning conditions. However, it is unclear whether the testing effect would provide a similar benefit for vocabulary learned under incidental learning conditions. Given that the vast majority of native language words and their meanings are learned incidentally (Batterink & Neville, 2011), it is important to examine the impact of the testing effect under such learning conditions. If the presence of a quick, immediate vocabulary test can indeed enhance learning/retention for incidentally learned vocabulary this could potentially provide a simple method for boosting vocabulary gains from story reading, especially within educational settings.
In vocabulary learning research, retrieval practice has been shown to lead to better retention of new words over time with adults learning second language (L2) vocabulary under intentional conditions (e.g., Fritz et al., 2007; Karpicke & Roediger, 2008; Van den Broek et al., 2013, 2018), and similarly with children learning novel L1 words (Goossens et al., 2014a, 2014b; Toppino & Cohen, 2009). The testing effect further enhances retention when feedback is provided on performance on the immediate test (e.g., Pashler et al., 2005), but retrieval practice is often beneficial even in the absence of any feedback (Roediger & Butler, 2011). The precise neurocognitive mechanism underlying the testing effect is currently unclear, but it has recently been suggested that retrieval practice may provide a fast track to consolidation of new information through the online reactivation of related knowledge (Antony et al., 2017; see the General Discussion for further discussion).
It is possible that different learning conditions preceding retrieval practice could moderate the testing effect for various reasons. For example, it is thought that semantic elaboration may be key to the neurocognitive mechanism underlying the testing effect (Carpenter, 2009). If this is the case, then the richer story contexts during encoding in the incidental condition could provide more fertile material for semantic elaboration, thus enhancing the testing effect. On the other hand, research has suggested that the benefits of retrieval practice are greater when retrieval success during practice is high (Rowland, 2014). Therefore, if intentional learning is more effective than incidental learning then this could lead to a stronger testing effect following encoding under intentional learning conditions.
Retrieval practice has been shown to benefit long-term retention of information learned under a variety of conditions (e.g., Butler, 2010; Karpicke & Roediger, 2008; Roediger & Karpicke, 2006a; Van den Broek et al., 2013), although little research has compared across different learning conditions. One study (Goossens et al., 2014a) directly compared the impact of testing on children’s learning of novel L1 vocabulary from a story context to learning new words in isolation. Results showed that children correctly recalled more word meanings that had been tested, and children in the word list condition remembered the word meanings better overall than those in the story condition. The testing effect was also slightly stronger for the word list condition. However, learning was not incidental in either condition in this study, and children who heard the story also had the meanings of the words explained to them. Furthermore, the participants in this study were children (aged 8–11), and results may differ for adults whose advanced language skills and vocabulary knowledge make them better equipped to learn more successfully from the richer contexts that stories provide. It therefore remains to be seen whether the benefit of retrieval practice would differ for the learning of new word meanings acquired solely under incidental conditions in a story context, as compared with learning under intentional conditions.
Experiment 1: incidental versus intentional learning
Experiment 1 compared the story-reading method designed by Hulme, Barsky & Rodd (2019) for studying incidental learning of new meanings for familiar words with a more conventional, intentional training procedure. This provided a baseline assessment of how well adults are able to learn new word meanings from a naturalistic incidental learning paradigm as compared to a more conventional explicit approach to vocabulary learning, and provided a foundation for the subsequent preregistered experiments to investigate learning performance in more detail. Specifically, Experiments 2 and 3 follow up on Experiment 1 to examine whether the inclusion of an immediate test of new vocabulary knowledge aids learning and improves memory of new word meanings 24 h later. This may be especially pertinent for vocabulary acquired through incidental learning conditions as it may prompt participants to adopt different information processing strategies after initial acquisition.
In Experiment 1 participants learned novel meanings for existing unambiguous words through both incidental story-reading (as in the study by Hulme, Barsky & Rodd, 2019) and a newly developed intentional task-based learning procedure, with the same number of exposures to items. The two learning conditions were implemented based on typical paradigms for these two types of learning. However, it is important to note that there are multiple differences in the learning experience, for example only the incidental learning paradigm required participants to infer meaning from context. While it is more common for incidental learning to be contextualised in this way, some intentional learning paradigms also involve contextualised learning (see for example: Van den Broek et al., 2018). The stories used in the incidental learning condition combined naturalistic elements of authentic texts (Godfroid et al., 2017; Saragi, Nation & Meister, 1978) with precise experimental control over the exposure to items within the text (Batterink & Neville, 2011; Pellicer-Sánchez, 2016). Items were encountered incidentally within the stories that participants read for comprehension and were central to the narrative.
Participants’ knowledge of the new meanings for all items was assessed first through cued recall, and second through a multiple-choice meaning-to-word matching test. The recall measure is a harder test with fewer cues to help retrieve memories of the new word meanings, while the multiple-choice test is a recognition measure with more cues and is therefore the easier of the two tests. Using two tests of learning with different difficulty levels allowed us to reduce the possibility of floor/ceiling effects. The tests were administered both immediately after learning, and again 24 h later to assess longer-term retention. Based on the previous research, we predicted that learning of new word meanings would be better for the intentional learning condition, although we expected reasonably good vocabulary learning for the incidental learning condition in line with the findings of Hulme, Barsky & Rodd (2019). We also predicted there would be little forgetting after 24 h, although we had no specific predictions as to whether this would differ for new word meanings acquired through incidental or intentional learning conditions. Our predictions were the same for the cued recall test the and multiple-choice meaning-to-word matching test.
The materials, data, and analysis scripts for Experiment 1 can be found on the Open Science Framework (OSF; https://osf.io/k32tw). For all experiments we report all measures, conditions, data exclusions, and how we established the sample size.
Method
Participants
We aimed to recruit 40 participants for Experiment 1. The study by Hulme, Barsky & Rodd (2019) included 64 participants who were trained on four items (one per exposure condition) in one of 16 experiment versions (four participants per version). In this study participants were trained on eight items (four items per learning condition) in one of eight experiment versions (five participants per version), we therefore expected power to be comparable to that of Hulme, Barsky & Rodd (2019). Forty participants were included in the experiment (age: M = 30.1 years, SD = 7.1; 23 female). Participants were recruited through the Prolific recruitment website (Damer & Bradley, 2014) using pre-screening criteria. They gave their informed consent before taking part (by means of ticking boxes in the online consent form). The UCL Experimental Psychology Ethics Committee granted ethical approval for the research (Ref: EP/2017/009). Participants were invited to take part if they were a current UK resident, a monolingual native speaker of British English, and had no diagnosis of reading or language impairments. They were paid for their participation in the first session of the experiment (£5) and additionally upon completion of the second session 24 h later (£1). Of the 40 participants who completed the first session, 31 also completed the 24-h follow-up session on time (77.5%). One additional participant was excluded from the second session due to completing it after the deadline (within 6 h of receiving the invitation for the follow-up session).
Five additional participants were excluded from the study—two were not monolingual native British English speakers, and three got more than one of the multiple-choice comprehension questions wrong when reading the stories (see Procedure). Excluded participants were replaced during recruitment.
Materials
Novel word meanings
The stimuli were 16 real English nouns that were given artificial new meanings, taken from the study by Hulme, Barsky & Rodd (2019) (see Table S1 for the stimuli: https://osf.io/m4wxa). The new meanings were unrelated to the existing meanings of the words, and described hypothetical innovations, discoveries, and inventions. There was one definition sentence for each of the stimulus words that described its new meaning, for example: “A foam is a safe that is incorporated into a piece of furniture with a wooden panel concealing the key lock, and each is individually handcrafted so that no intruders are able to recognize the chief use of the furniture.” The sentences were matched for length (M = 32.9 words, SD = 3.7). Each new meaning had three distinguishing semantic features to maintain a similar level of complexity for each new concept, for example, for foam: “a safe inside a piece of furniture,” “has a hidden key lock,” and “individually handcrafted to fool intruders.” The words and their meanings were incorporated into story narratives for the incidental learning condition, and the definition sentences were presented to participants in the definition reading phase of the intentional learning condition.
Three shorter paraphrased excerpts of the definition sentences were created for use in the two-alternative multiple-choice training task (length: M = 11.29 words; SD = 2.13), with each sentence describing a semantic feature of that item (e.g., for “foam”: “A secure place to store valuables within an item of furniture.”; “A safe with a wooden panel disguising the key lock.”; and “A bespoke handcrafted piece of furniture containing a safe hidden from intruders.”). Paraphrased versions were used to encourage participants to read the whole sentence each time, rather than relying on recognition of the first words (see Table S2 for the short sentences: https://osf.io/m4wxa).
An additional longer paraphrased version of each of the definition sentences (which were used in the test of cued recall of word forms in Hulme, Barsky & Rodd (2019)’s study) were used in the multiple-choice test at the end of this experiment (see Table S3 for the sentences used for the multiple-choice test: https://osf.io/m4wxa).
Short stories
The four short stories from Hulme, Barsky & Rodd (2019)’s study were used to present stimuli to participants in the incidental learning condition in this experiment (see the Supplementary Materials for the stories: https://osf.io/m4wxa). These stories (ranging 2307-2446 words in length) were written by a professional children’s author (Story 1: Pink Candy Dream), and an unpublished author (Story 2: Prisons, Story 3: Reflections upon a Tribe, and Story 4: The Island and Elsewhere), and were designed to be interesting for an adult audience. Each story incorporated four of the items in the context of their new meanings, with each item appearing a total of eight times at naturally distributed positions within a story. No item appeared in more than four consecutive sentences, and all items occurred on at least two different pages of the story. On the first presentation of a stimulus word, sufficient information was given to allow the reader to derive the new meaning from the context from the first exposure, for example, “‘Yes,’ I murmured, breathing again. ‘I knew it! It’s a foam.’ The ornate chaise longue was no ordinary piece of furniture but concealed a built-in safe with an intricate key-operated locking system.” The amount of information about each new meaning in subsequent exposures varied naturally with the story narratives. A degree of inference was required to extract the meaning from the context to reflect natural word learning from reading where explicit definitions are rarely given.
Design
The experiment employed a within-participants and within-items design: participants were trained on four items through the incidental learning condition and four items through the intentional learning condition. Each participant was trained on only half the total number of stimuli as this was deemed to be a feasible number of new meanings to learn in a single session. To ensure each new word meaning was seen an even number of times in each condition, and that the order of learning conditions was counterbalanced across participants (to minimise any order effects), we created eight versions of the experiment. Participants were pseudorandomly assigned to one of the eight versions of the experiment. Time of test (immediate vs. 24 h later) was also within-participants (based on the 31 participants who completed both sessions). The dependent measures were accuracy in cued recall of the new word meanings, and accuracy in the multiple-choice test.
Procedure
The experiment was run online using Qualtrics (Qualtrics, 2015), and participants were instructed to complete each session in one sitting without breaks. Participants were asked to read the stories and definitions carefully, and were not told that their memory for the new word meanings would be tested. Participants were told that the aim of the experiment was to investigate subjective reading style and comprehension. After completing the first session, participants were also not informed that they would be contacted at the same time the following day to invite them to complete the second session to discourage the use of deliberate memorisation strategies.
Participants read one of the short stories in the incidental learning condition. Each story was divided into five pages of roughly even length and displayed on-screen one page at a time. After each page, a multiple-choice comprehension question appeared on a separate screen asking about details of the story’s plot from the preceding page (without probing details of the novel word meanings). Participants were instructed to read the story closely, and to answer a multiple-choice comprehension question after each page. Participants were able to re-read sentences on the current page, although no instructions were given to participants on this; they were not able to go back to reread previous pages. For the comprehension questions participants had to select the correct answer from four options that appeared in a randomised order; they were designed to be very easy for any participant who had attentively read the text. Participants were excluded if they got more than one of the comprehension questions wrong.
The intentional learning condition consisted of two phases which both repeated once: definition sentence reading, followed by two-alternative multiple-choice meaning-to-word matching. In the definition reading phase, participants were presented with sentences that described the key semantic features of each of the novel word meanings, stating the word to which it referred. These four definition sentences were presented one at a time on separate pages, and the order of presentation was randomised for each participant. Participants were instructed to read each definition carefully to make sure they understood it before proceeding to the next one.
Once participants had read all of the definition sentences once, they moved immediately on to the two-alternative multiple-choice meaning-to-word matching task. Participants were presented one at a time with three shortened, paraphrased versions of the definitions of each of the novel meanings. For each item participants were instructed to choose the correct word for the new meaning from two options: the correct word and one foil word. After selecting one of the options, participants were provided with feedback, which either said “Correct answer!” or “Incorrect.”. The short sentences were presented in a pseudorandomised order, ensuring that the sentences referring to each item were roughly evenly spaced, and none referring to the same item occurred one after another. The foil word for each trial was one of the other words from the intentional training condition. Each foil word was paired an even number of times with each correct word, and the order that the correct word and foil appeared in was randomised for each trial. The two phases of the intentional training were then repeated in the same order. This gave a total of two exposures to the novel word meanings from the definition sentence reading phase and six exposures to the new meanings from the multiple-choice task, totalling eight exposures—equal to the number of exposures in the incidental learning condition. Participants spent more time reading the story (including comprehension questions; M = 12 mins 30 s, SD = 4 mins 34 s) than they spent on the intentional training task (M = 5 mins 28 s, SD = 2 mins 55 s), t(39) = 11.43, p < .001.
After they had completed training through both the incidental and intentional learning conditions, participants completed a brief filler task. This was the 34-item version of the Mill Hill vocabulary test (Mill Hill Vocabulary Test, Set A: Multiple Choice: Raven, Raven & Court, 1998). For each item, participants were required to select one word from a list of six options that most closely matched the meaning of the presented word. None of the stimulus items appeared in the filler task. The purpose of this task was to counteract any recency effects of memory for stimulus items encountered toward the end of training; responses were not analysed.
Participants were next given a cued recall test of all eight of the new meanings they had encountered in the experiment. Participants saw each of the eight words they had been trained on and were asked to recall the appropriate new meaning and type it into a text box. They were encouraged to provide as much detail as possible and to try to answer in full sentences even if they were unsure of their answer. If they could not remember anything about the new meaning for the word, they were instructed to type “don’t know.” The order of presentation of the words was randomised for each participant, with the four words from each training method randomly intermixed within the test; this was also the case for the subsequent test.
The second test was an eight-alternative multiple-choice meaning-to-word matching test. Participants were presented one at a time with paraphrased definitions of the novel word meanings they had been trained on. The sentences omitted the words to which they were referring, and for each novel meaning participants were asked to select the word that they thought matched the definition from a list of all eight of the stimulus words they had encountered throughout the experiment. The order of the eight words to choose from was randomised for each test item, and the order of presentation of the new meanings was randomised for each participant.
Finally, participants provided their demographics details and answered some questions about their reading habits. These questions were used to maintain the impression that the experiment was investigating general reading and comprehension and the responses were not analysed.
Exactly 24 h after the first session, participants were invited to take part in a short 24-h follow-up to the experiment. Thirty-one participants completed the follow-up tests, which they did an average of 24 h and 1 min (SD = 54 mins, range = 22 h 26 mins–28 h 2 mins) after the first session. The follow-up tests consisted of a repeat of the two tests from the first session of the experiment in the same order.
Results
Analysis procedure
Responses from the multiple-choice test were either coded as “1” for correct or “0” for incorrect with regards to which word had been selected to match with the meaning. Responses for the cued recall test were independently coded for accuracy by the experimenter and a research assistant, blind to condition, as either “1” for correctly recalled meanings or “0” for incorrect1
. Responses were leniently coded as correct if at least one correct semantic feature was recalled. Any ambiguous or partially correct responses were resolved on a case-by-case basis through discussion. One item (“bruise”) was excluded from the analyses for the cued recall measure, as the percentage of participants who gave a correct response for that item in one of the two learning conditions (incidental, 20.0%) was more than two standard deviations below the grand mean for all items across both learning conditions (M = 72.3%; SD = 23.5).
Data were analysed with logistic mixed effects models using the lme4 package (version 1.1–7; Bates et al., 2015) and R statistical software (version 3.0.2; R Core Team, 2017). Four separate models were created: one for each test measure comparing the accuracy between day one and day two (including only the participants who completed both test sessions, N = 31), and for each measure for all participants tested on day one only (N = 40). These latter analyses aimed to verify that the data from this larger set of participants did not differ from the subset who chose to complete both sessions.
Due to a potential effect of counterbalancing order, in that participants who completed the intentional condition first may suspect that they would be tested on the words in the stories, we included a factor for the order of the learning conditions in our models. The contrasts for the fixed effects were defined using deviation coding for learning condition (incidental: −0.5, intentional: 0.5), and the order of the learning conditions (first: −0.5, second: 0.5), with the interaction coded by multiplying the contrasts for these two factors. The two models comparing performance between day one and day two contained additional fixed effects for time (day one: −0.5, day two: 0.5), and the interactions between time and learning condition, time and learning order, and the three-way interaction. Random effects structures were determined by identifying the maximal model (Barr et al., 2013). This included by-participant and by-item random intercepts, and by-participant and by-item random slopes for learning condition2
. The models comparing performance between day 1 and day 2 also included by-participant and by-item random slopes for time and the interaction between time and learning condition. Where the maximal model failed to converge, we simplified the models by removing the correlations between the by-participant and by-item random slopes and random intercepts without removing any of the random slopes, as recommended by Barr et al. (2013). Significance of the fixed effects and interactions was assessed using likelihood ratio tests comparing the full model to models with each fixed factor/interaction of interest removed in turn (but leaving in any interaction involving a factor of interest that has been removed). Follow-up analyses were carried out in the case of any significant interaction using the same method. The p-values for the simple effects analyses were compared against a Bonferroni-corrected α of .025. All data and analysis scripts for this experiment are available via the Open Science Framework (OSF; https://osf.io/k32tw).
Cued recall of meanings
The accuracy data for cued recall of the new meanings comparing performance between day one and day two (N = 31; see Fig. 1) showed a reasonably high level of accuracy for items learned through both learning conditions. But accuracy was significantly higher overall for items learned through the intentional learning condition (day one: 85.2%; day two: 84.9%) than those learned under incidental conditions (day one: 62.1%; day two: 70.1%) (χ2(1) = 14.32, p < .001). There was no significant main effect of time of test (χ2(1) = 1.23, p = .268), nor of learning order (χ2(1) = 0.83, p = .362). While accuracy improved slightly between day one and day two for items learned through the stories and remained at a similar level for items learned through the intentional condition, the interaction between learning condition and time was non-significant (χ2(1) = 1.57, p = .210). The interactions between learning condition and learning order (χ2(1) = 2.16, p = .141), learning order and time of test (χ2(1) = 1.79, p = .181), and the three-way interaction (χ2(1) = 0.83, p = .361) were also non-significant.
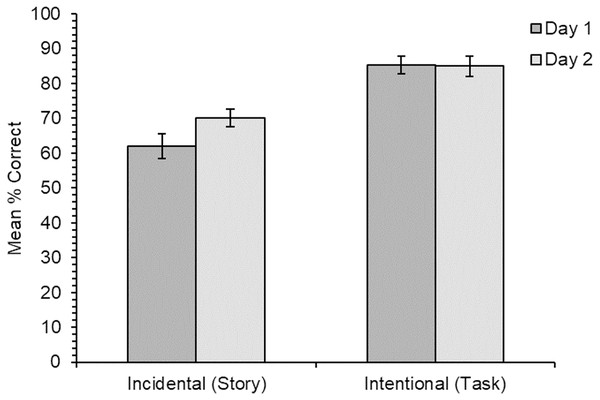
Figure 1: Experiment 1. Mean percentage of correct responses on the cued recall test for each learning condition, when tested on day one (immediately after learning) and 24 h later (N = 31).
The LME analyses were carried out on the raw binary accuracy data, however mean percentage accuracy data are displayed in the graphs. Error bars show standard errors for the means, adjusted for the within-participants design (Cousineau, 2005).
The accuracy data for all participants on day one only (N = 40) showed a similar pattern: significantly higher accuracy for items learned through the intentional training condition than the incidental condition (χ2(1) = 21.35, p < .001), and no significant main effect of learning order (χ2(1) = 0.0007, p = .979). However, there was a significant interaction between learning condition and learning order (χ2(1) = 4.68, p = .030): accuracy was higher for items learned through the stories when this had been the first condition in the experiment (70.0%) than when this had been the second condition (47.5%), whilst the opposite was the case for items learned through the intentional condition (first: 82.1%; second: 95.0%). This unexpected result could have been driven by participants becoming somewhat fatigued by the second task and this fatigue effect having greater impact on the story reading task, which took longer. However, this does not perhaps explain why participants’ performance in the intentional condition was slightly higher when it was the second condition in the experiment rather than the first condition.
Multiple-choice meaning-to-word matching
The results for accuracy on the multiple-choice meaning-to-word matching test comparing results between day one and day two (N = 31) are shown in Fig. 2. Accuracy was high in both learning conditions, but was slightly higher for the intentional learning condition (day one: 96.0%; day two: 87.9%) than for the incidental learning condition (day one: 83.9%; day two: 83.1%), although this difference was non-significant (χ2(1) = 3.66, p = .056). The main effect of time was also non-significant (χ2(1) = 3.81, p = .051), as was the main effect of learning order (χ2(1) = 0.002, p = .966). Interestingly, the interaction between learning condition and time was significant (χ2(1) = 3.85, p = .05). The interaction between learning condition and learning order was non-significant (χ2(1) = 2.24, p = .135), as was the interaction between time and learning order (χ2(1) = 0.01, p = .929), and the three-way interaction (χ2(1) = 0.48, p = .488).
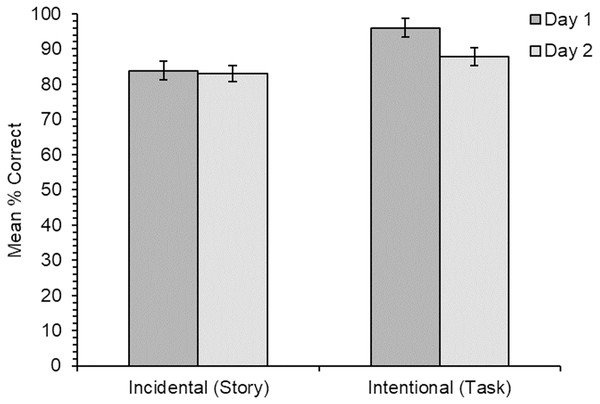
Figure 2: Experiment 1. Mean percentage of correct responses on the multiple-choice test for each learning condition, when tested on day one (immediately after learning) and day two (24 h later; N = 31).
Error bars show standard errors for the means, adjusted for the within-participants factor of learning condition (Cousineau, 2005).
To follow up on the significant interaction between learning condition and time, two simple effects analyses were carried out to determine the significance of time within each of the two learning conditions separately. For the incidental learning condition there was no significant effect of time (χ2(1) = 0.10, p = .750), indicating no forgetting between day one and day two. However, there was a significant effect of time for the intentional learning condition (χ2(1) = 6.07, p = .014), which was slightly lower on day two than day one. (The p-values for these simple effects analyses were compared against a Bonferroni-corrected α of .025).
In the accuracy data for the multiple-choice test for all participants on day one only (N = 40), accuracy was again high overall for both conditions. Accuracy appeared slightly higher for items learned through the intentional condition (95.7%) than for items learned through the incidental condition (81.9%), but there was no significant main effect of learning condition (χ2(1) = 1.18, p = .277). There was also no significant main effect of learning order (χ2(1) = 0.004, p = .950), and no significant interaction (χ2(1) = 2.52, p = .113).
Discussion
Experiment 1 aimed to determine how easily novel meanings for familiar words can be acquired incidentally through story reading, as compared with a more intentional learning procedure. The results showed that accuracy in cued recall of new word meanings was significantly higher in the intentional learning condition than the incidental learning condition: 85.2% compared with 62.1% when measured immediately after training. The accuracy data for the multiple-choice meaning-to-word matching test showed a similar pattern (96.0% for the intentional condition and 83.9% for the incidental condition at the immediate test), although for this measure the main effect of learning condition was non-significant. Furthermore, reading the story took participants a significantly longer amount of time, so more was learned in a shorter amount of time through the intentional training task.
These findings are broadly consistent with those of L2 vocabulary learning studies that have found intentional learning to be more efficient than incidental learning of vocabulary (Hulstijn, 1992; Peters et al., 2009). Although recall accuracy was higher for the intentional learning condition, there was also a reasonably high level of acquisition of new meanings for familiar words through the incidental learning condition. This is very similar to the results of the study by Hulme, Barsky & Rodd (2019), where accuracy in recalling new meanings for familiar words was 63.5% after eight exposures in an incidental learning context (accuracy in cued recall of word forms was 69.2%). These results therefore support the findings of recent studies showing good acquisition of L1 vocabulary from reading (Batterink & Neville, 2011; Godfroid et al., 2017; Pellicer-Sánchez, 2016). An additional consideration is that we included multiple-choice comprehension questions between pages of the stories in our incidental learning condition. While these did not probe details of the new word meanings, it is possible that they could have improved comprehension by increasing metacognitive awareness of the comprehension process, similar to a “guided learning” scenario (Blything, Hardie & Cain, 2020).
Interestingly, the multiple-choice test showed a significant interaction between learning condition and time of test, although there was no such significant interaction in the recall measure. Following up on the significant interaction in the multiple-choice measure, simple effects analyses showed that there was significant forgetting after 24 h of items learned in the intentional condition (8% reduction in accuracy between the immediate test and delayed test), but there was no forgetting of items learned incidentally through story reading. This absence of significant forgetting after a 24-h delay replicates the finding from Hulme, Barsky & Rodd (2019) who reported no significant forgetting on this paradigm after a seven-day delay. A possible explanation for this lack of forgetting is that new word meanings learned in a more semantically rich context, such as from stories, may be retained better. New word meanings encountered in stories contain additional contextual information relating to the narrative (e.g., characters’ thoughts and feelings), providing additional cues for participants to rely on for later retrieval. The stories are also more interesting and engaging so may be more memorable for participants in general. However, another possibility is that this difference is a function of initial learning level, as initial performance was very high in the intentional condition and so had further to fall. A further alternative explanation for this finding is that the lack of forgetting of items learned incidentally through story reading could be due to memory reactivations during sleep. Memory consolidation during sleep has been shown to be preferential towards initially weaker memory traces and less supportive to memories that have already established robust representations (Drosopoulos et al., 2007). Since recall and recognition accuracy was lower for items acquired through incidental learning conditions, this is a compelling alternative explanation for why there was less forgetting of items learned through story reading.
In addition, the additional retrieval practice for the test immediately after training may have aided learning in the incidental, story reading condition. Further supporting this possibility, items learned through the incidental condition showed a slight improvement (8% increase) in cued recall accuracy between the test on day one and the test on day two. The second test task in the immediate test session (multiple-choice meaning-to-word matching) may therefore have boosted learning, manifesting as improved cued recall at the delayed test. The potential involvement of a testing effect (Roediger & Karpicke, 2006a) in long-term retention of new meanings for familiar words is examined in detail in Experiments 2 and 3.
Experiment 2: the testing effect in incidental and intentional learning
The aim of Experiment 2 was to investigate whether 24-h retention of novel word meanings that were learned through story reading can be boosted by introducing a test of participants’ knowledge immediately after training. As with Experiment 1, performance was compared to a more conventional explicit learning baseline (the same intentional training procedure as in Experiment 1). Participants were tested immediately after training on half of the items they saw in each learning condition, and then given a surprise test 24 h later in which they were tested on the other half of the items for the first time, as well as being retested on items that had been tested the previous day. As for Experiment 1, both test sessions consisted of cued recall of the new meanings, followed by a multiple-choice meaning-to-word matching test.
We predicted that there would be better long-term retention for items that were tested immediately after training, compared with those that were not tested, for both the incidental and intentional conditions. There was no specific prediction as to whether the magnitude of the testing effect would differ for the different learning conditions. Additionally, we expected to replicate the findings from Experiment 1 that retention would be better overall for novel meanings learned through intentional conditions, but that there would be less forgetting under incidental conditions.
Experiment 2 was preregistered through the Open Science Framework; the preregistration can be retrieved from https://osf.io/e5zmk (Hulme & Rodd, 2016, November 4). Any deviations from the preregistration are noted in the Method and Results sections for this experiment. The materials, data, and analysis scripts for Experiment 2 can be found on the Open Science Framework (OSF; https://osf.io/upmnr).
Method
Participants
We aimed to recruit 96 participants for Experiment 2 in which participants were trained on eight items (two items per cell: four per learning condition, and four per test type) in one of 16 experiment versions (six participants per version). The sample size was established in consideration of the study by Hulme, Barsky & Rodd (2019) and Experiment 1. As this experiment has the additional independent variable of test type, a larger sample size was used in Experiment 2 than Experiment 1 to achieve comparable power with a smaller number of items per cell.
Ninety-nine participants were included in the experiment (age: M = 32.31 years, SD = 8.14; 56 female); we accidentally over-recruited by three participants when pseudorandomly assigning participants to the experiment versions and kept these participants. Participants were recruited in the same way as for Experiment 1. They gave their informed consent before taking part (by means of ticking boxes in the online consent form) and were paid for their participation at the end of each session (£6 for session one and £2 for session two). The UCL Experimental Psychology Ethics Committee granted ethical approval for the research (Ref: EP/2017/009).
An additional 36 participants took part in the first session but did not complete session two by the deadline (within 6 h of receiving the invitation for the delayed test) and were excluded. (This additional data exclusion was used for Experiments 2 and 3 to ensure sufficient power to examine the testing effect within-participants, for which a complete set of immediate and delayed test data was critical.) A further twenty-one participants were excluded due to getting more than one of the multiple-choice comprehension questions wrong when reading the stories (see Experiment 1 Procedure), and two further participants were excluded for attempting the experiment more than once. Finally, five participants were excluded for being outliers in their mean reading speed (faster than 543.4 words per min, 2 SD above the mean). Excluded participants were replaced during recruitment.
Materials
The stimuli for the present experiment were identical to those used in Experiment 1.
Design
The experiment used a within-participants and within-items design, with two independent variables: learning condition (two levels: incidental and intentional) and test type (three levels: immediate test (tested in the first session), delayed test (tested for the first time in the second session), and delayed retest (tested for the second time in the second session)). The dependent variables were accuracy in cued recall of meanings and multiple-choice meaning-to-word matching.
There were sixteen versions of the experiment to ensure the items were seen an even number of times in each condition, with the order of the learning conditions counterbalanced across participants. Participants were pseudorandomly assigned to one of the sixteen versions of the experiment. As in Experiment 1, each participant was trained on half the total number of stimuli (eight items; four in each learning condition), with the items in each condition and the order of the learning conditions counterbalanced across participants. Further counterbalancing accounted for which stimulus items were or were not tested immediately following training across participants.
Procedure
The procedure for the incidental and intentional learning conditions was identical to that of Experiment 1, and immediately following training participants completed the same Mill Hill vocabulary test (Mill Hill Vocabulary Test, Set A: Multiple Choice: Raven, Raven & Court, 1998) as a filler task. Participants were then immediately tested on half of the items that they had been trained on through the incidental and intentional learning conditions (four items, two trained through each training method). The tests were the same as for Experiment 1: cued recall of meanings followed by multiple-choice meaning-to-word matching. The items were tested in a random order in each of the two tests, with no feedback given to participants. In the multiple-choice test only the four words that a participant was being immediately tested on appeared as the four alternative responses to choose from for each test item; the order of these was also randomised for each test item.
Exactly 24 h after the first session of the experiment had been made available, participants were asked to take part in the second session: the delayed test. Participants were not aware beforehand that they would be asked to complete this test to discourage them from rehearsing and intentionally retaining information about the novel word meanings. As such, unfortunately 36 participants did not return to complete session two; 99 participants were therefore included in the analysis. Participants began the delayed test an average of 24 h and 25 mins (SD = 57 mins, range = 22 h 45 mins–27 h 21 mins) after the training session. The tests were the same as those that had been used for the immediate test in the same order. This time participants were tested on all of the stimuli that they had been trained on (eight items). The order of presentation of the items in each of the two tests was again randomised for each participant, and for the multiple-choice test the order of the eight stimulus words to choose from was again randomised for each test item.
Results
Analysis procedure
Responses for the cued recall test and multiple-choice test were coded for accuracy (“1” for correct and “0” for incorrect) in the same way as for Experiment 1.
Upon completion of the experiment, we realised that test type was confounded with differing test difficulty between the immediate test and the two delayed test types for the multiple-choice meaning-to-word matching measure. This was because in the immediate test participants could choose from four alternative words to pair with the appropriate meaning on each trial (as they were only tested on half the total items they were trained on: four items, two trained through each training condition). In contrast, in the delayed test participants had to choose from eight alternatives (as they were tested on all eight of the items they had been trained on). The results from the immediate multiple-choice test are therefore not comparable to the results from the two delayed test types, so the analysis for this measure was only carried out on the subset of results for the two delayed test types. This is a deviation from the analysis plan outlined in the preregistration of this experiment. The analysis of the cued recall measure was carried out according to the preregistration.
The data were analysed, as in the previous experiment, using logistic mixed effects models with the lme4 package (version 1.1–12; Bates et al., 2015) and R statistical software (version 3.3.2, R Core Team, 2017), with two separate models for the analysis of data from the two measures. The model used to analyse the cued recall data contained three factors: test type (three levels: immediate, delayed first test, delayed second test), learning condition (two levels: incidental, intentional), and order of the learning conditions in the experiment (two levels: first, second). The contrasts for the fixed effect of test type were defined using Helmert coding, with one contrast comparing the immediate test to the two delayed tests combined (immediate: 0.67, delayed first test: –0.33, delayed second test: –0.33), and a second comparing the two delayed test types to each other (immediate: 0, delayed first test: –0.5, delayed second test: 0.5). Deviation coding was used to specify the contrasts for the fixed effects of learning condition (incidental: –0.5, intentional: 0.5) and learning order (first: –0.5, second: 0.5).
The model used to analyse the multiple-choice data also had three factors: test type (2 levels: delayed first test, delayed second test), learning condition (2 levels: incidental, intentional), and learning order (2 levels: first, second). The contrasts were specified using deviation coding for the fixed effects of test type (delayed first test: −0.5, delayed second test: 0.5), learning condition (incidental: −0.5, intentional: 0.5), and learning order (first: −0.5, second: 0.5). The procedure for determining the appropriate random effects structure and significance of the fixed effects/interactions was the same as described for Experiment 1. The model used to analyse the multiple-choice data used the maximal random effects structure; the one for the cued recall measure was simplified by removing the correlations between the by-participant and by-item random slopes and random intercepts (as recommended by Barr et al., 2013).
Following on from the main analysis for the cued recall measure, firstly three pairwise comparisons (with Bonferroni adjustment for multiple comparisons, α = .017) were carried out to compare the different levels of test type to each other. This was done by taking a subset of the data for each pair of levels of test type and creating a model for each containing the same fixed and random effects as the model used for the main analysis, although the contrast for test type was coded using deviation coding (immediate: 0.5, delayed first test: −0.5; immediate: 0.5, delayed second test: −0.5; delayed first test: −0.5, delayed second test: 0.5). Secondly, further follow-up pairwise comparisons (with Bonferroni correction for multiple comparisons, α = .017) were made for the three 2 × 2 interactions between the pairs of test types and the two learning conditions to determine whether the difference between any two test types differed between the two learning conditions. Finally, six simple effects pairwise comparisons (with Bonferroni adjustment for multiple comparisons, α = .008) were run to test for any significant differences between the different test types within the two learning conditions. This was done by taking further subsets of the data for the pairs of levels of test type separately for the incidental and intentional learning conditions and creating models with only fixed effects for test type, learning order, and the interaction (with random effects for test type for participants and items).
The only follow-up analyses carried out for the multiple-choice test were two simple effects pairwise comparisons (with Bonferroni correction for multiple comparisons, α = .025). This was done in the same way as the simple effects analyses for the cued recall measure. All data and analysis scripts for this experiment are available via the Open Science Framework (OSF; https://osf.io/upmnr).
Cued recall of meanings
Data for the cued recall test (Fig. 3) showed that accuracy was significantly higher for items trained through the intentional than the incidental learning condition (χ2(1) = 34.83, p < .001). There was also a significant main effect of test type (χ2(2) = 25.78, p < .001); the main effect of learning order was non-significant (χ2(1) = 2.50, p = .114). There was a significant interaction between learning condition and test type (χ2(2) = 13.86, p < .001), but the interaction between learning condition and learning order was not significant (χ2(1) = 0.09, p = .760). There was an unexpected significant interaction between test type and learning order (χ2(2) = 9.24, p = .010); the three-way interaction was not significant (χ2(2) = 3.23, p = .199) (Results for all the analyses for the cued recall test are also presented in Table 1 for clarity of the different levels of follow-up analysis for this measure).
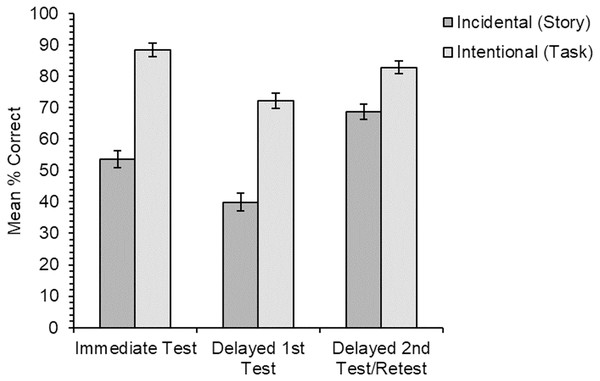
Figure 3: Experiment 2. Mean percentage of correct responses in the cued recall test for each learning condition and for the three different test types in the experiment.
Error bars show standard error of the means adjusted for the within-participants design (Cousineau, 2005).
Table 1:
Results for the linear mixed effects model analyses for the cued recall test in Experiment 2 showing the main analyses and the different levels of follow-up analyses.
| Fixed effect or interaction | χ2 | df | p |
|---|---|---|---|
| 1. Main analysis (α = .05) | |||
| Learning condition (Incidental vs. Intentional) | 34.83 | 1 | <.001 |
| Test type (Immediate vs. Delayed 1st vs. Delayed 2nd) | 25.78 | 2 | <.001 |
| Learning order (First task vs. Second task) | 2.50 | 1 | .114 |
| Learning condition × Test type | 13.86 | 2 | <.001 |
| Learning condition × Learning order | 0.09 | 1 | .760 |
| Test type × Learning order | 9.24 | 2 | .010 |
| Learning condition × Test type × Learning order | 3.23 | 2 | .199 |
| 2. Follow-up pairwise comparisons of the different levels of Test type (α = .017) | |||
| Immediate vs. Delayed 1st tests | 19.99 | 1 | <.001 |
| Delayed 1st vs. Delayed 2nd tests | 18.83 | 1 | <.001 |
| Immediate vs. Delayed 2nd tests | 0.89 | 1 | .345 |
| 3. Follow-up pairwise comparisons of 2 × 2 interactions between pairs of levels of Test type and the two Learning conditions (α = .017) | |||
| Learning condition × Immediate vs. Delayed 2nd tests | 16.24 | 1 | <.001 |
| Learning condition × Immediate vs. Delayed 1st tests | 2.29 | 1 | .130 |
| Learning condition × Delayed 1st vs. Delayed 2nd tests | 2.97 | 1 | .085 |
| 4. Simple effects analyses of differences between levels of Test type within the two Learning conditions (α = .008) | |||
| Immediate vs. Delayed 1st tests for Incidental learning | 5.88 | 1 | .015 |
| Delayed 1st vs. Delayed 2nd tests for Incidental learning | 15.27 | 1 | <.001 |
| Immediate vs. Delayed 2nd tests for Incidental learning | 14.59 | 1 | <.001 |
| Immediate vs. Delayed 1st tests for Intentional learning | 18.27 | 1 | <.001 |
| Delayed 1st vs. Delayed 2nd tests for Intentional learning | 8.39 | 1 | .004 |
| Immediate vs. Delayed 2nd tests for Intentional learning | 4.25 | 1 | .039 |
| Exploratory analyses: Pairwise comparisons of 2 × 2 interactions between pairs of levels of Test type and the two Learning orders (α = .017) | |||
| Learning order × Delayed 1st vs. Delayed 2nd tests | 7.12 | 1 | .008 |
| Learning order × Immediate vs. Delayed 2nd tests | 0.12 | 1 | .729 |
| Learning order × Immediate vs. Delayed 1st tests | 5.15 | 1 | .023 |
| Exploratory analyses: Simple effects analyses of differences between levels of Test type within the two Learning orders (α = .025) | |||
| First task vs. Second task for Immediate test | 2.25 | 1 | .134 |
| First task vs. Second task for Delayed 1st test | 2.04 | 1 | .154 |
| First task vs. Second task for Delayed 2nd test | 4.91 | 1 | .027 |
To further investigate the significant main effect of test type, three pairwise comparisons between the different levels of test type were carried out. The results revealed that there was a significant effect of overnight forgetting (difference between the delayed 1st and immediate tests) (χ2(1) = 19.99, p < .001), with better recall of new meanings when tested immediately than when tested for the first time after a delay. There was also a significant testing effect (difference between the delayed 2nd and delayed 1st tests) (χ2(1) = 18.83, p < .001), with higher recall accuracy for items that were being tested for the second time than for those being tested for the first time after the delay. However, there was no significant difference in cued recall accuracy between the immediate and delayed 2nd tests (χ2(1) = 0.89, p = .345; α = .017), suggesting these items were protected against forgetting.
To further investigate the significant interaction between learning condition and test type, the second set of follow-up analyses were pairwise comparisons for the three 2 × 2 interactions between the pairs of test types and the two learning conditions. Results showed that there was a significant interaction between learning condition and the difference between the immediate and delayed 2nd tests (χ2(1) = 16.24, p < .001). Items learned incidentally from stories showed some improvement between the immediate test and the retest on day two, while items learned through the intentional learning condition showed a small amount of forgetting. There was no significant interaction between learning condition and the difference between either the immediate and delayed 1st tests (χ2(1) = 2.29, p = .130) or between the delayed 1st and delayed 2nd tests (χ2(1) = 2.97, p = .085; α = .017).
In the final set of follow-up analyses, six simple effects pairwise comparisons were run to test for any significant differences between the different test types within the two learning conditions. The results revealed that for the incidental learning condition there was no significant difference in recall accuracy for items tested for the first time after the delay than for items tested immediately after training at the corrected level (χ2(1) = 5.88, p = .015), that is no significant forgetting. There was significantly better cued recall accuracy for items tested for the second time after the delay than those tested for the first time (χ2(1) = 15.27, p < 0.001): a significant testing effect. There was also significantly better recall of new meanings tested for the second time after the delay than the immediate test (χ2(1) = 14.59, p < 0.001). For the intentional learning condition, there was significantly lower recall accuracy for items tested for the first time after the delay than those tested immediately (χ2(1) = 18.27, p < .001), showing significant forgetting. There was better recall accuracy for items tested for the second time after the delay than those tested for the first time (χ2(1) = 8.39, p = .004): a significant testing effect. There was no significant difference (at the corrected level) between items tested for the second time following the delay and when tested immediately after training (χ2(1) = 4.25, p = .039; α = .008).
Additionally, although not specified in the preregistration, exploratory follow-up analyses were carried out to examine the nature of the unexpected interaction between test type and learning order. These were three pairwise comparisons of the 2 × 2 interactions between the pairs of test types and the two learning orders (first or second position in the experiment). Results revealed a significant interaction between position and the difference between the delayed 1st and delayed 2nd tests (χ2(1) = 7.12, p = .008). Items appeared to be recalled better at the delayed 1st test when they had been presented in the first condition in the training session, whereas items were recalled better at the delayed 2nd test when they had been trained in the second condition. There was no significant interaction between the immediate and delayed 2nd tests (χ2(1) = 0.12, p = .729), nor between the immediate and delayed 1st tests (χ2(1) = 5.15, p = .023) at the Bonferroni-corrected level (α = .017). However, further follow-up analyses of the simple effects pairwise comparisons of learning order within the delayed 1st and delayed 2nd test types were both non-significant at the Bonferroni-corrected level (both p > .025).
Multiple-choice meaning-to-word matching
The analysis of the data for the multiple-choice meaning-to-word matching test (Fig. 4) was only carried out on the subset of results for the two delayed test types. Overall accuracy was very high, and it was significantly higher for items trained through the intentional condition than the incidental condition across all test types (χ2(1) = 8.44, p = .004). The main effect of test type was also significant (χ2(1) = 6.71, p = .010), with slightly greater accuracy for items that had been tested previously than for those that had not been; there was no significant main effect of learning order (χ2(1) = 0.32, p = .569). The interaction between learning condition and test type was not significant (χ2(1) = 0.61, p = .435), nor was the interaction between learning condition and learning order (χ2(1) = 1.23, p = .268), nor the interaction between test type and learning order (χ2(1) = 1.32, p = .251). The three-way interaction was also not significant (χ2(1) = 0.06, p = .810).
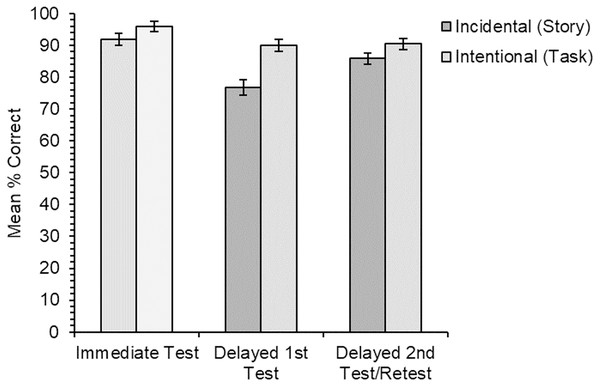
Figure 4: Experiment 2. Mean percentage of correct responses in the multiple-choice test for each learning condition and for the three different test types in the experiment.
Note that the results from the immediate test (with lighter shading) are not comparable to those from the two delayed test types due to an underlying difference in test difficulty. Error bars show standard error of the means adjusted for the within-participants design (Cousineau, 2005).
Following on from the main analysis, two simple effects pairwise comparisons tested for any significant differences between the different test types within the two learning conditions. In the incidental learning condition, the difference between items tested for the second time following the delay and those tested for the first time was non-significant at the corrected level (χ2(1) = 4.62, p = .032). For the intentional learning condition, there was also no significant difference in accuracy between items tested for the first or second time after the delay (χ2(1) = 3.53, p = .060; α = .025).
Discussion
The aim of Experiment 2 was to examine whether testing memory immediately after training enhances long-term retention of new word meanings acquired through incidental and intentional learning conditions, and to see whether any testing effect differs depending on the learning conditions. As in Experiment 1, new word meanings were learned better overall through intentional learning conditions than through incidental learning conditions. Accuracy in both the cued recall and multiple-choice tests was significantly higher for items trained through the intentional learning condition.
Cued recall accuracy was also higher overall immediately after training than when items were tested for the first time after 24 h. This demonstrates some overnight forgetting of the new meanings for the words in the absence of an intervening test. Furthermore, there was numerically but not significantly (at the corrected level) more forgetting of items trained through the intentional learning condition than those learned through a story, both with and without prior retrieval practice. This is in line with the findings of Experiment 1, where accuracy on the multiple-choice test was lower after 24 h for items learned through the intentional condition, but not for items learned through the stories.
Critically, both the cued recall and multiple-choice tests revealed an overall testing effect: new word meanings were recalled and recognised significantly better after 24 h when they had been tested immediately after training than when they were being tested for the first time. As predicted, in the cued recall measure this main effect of testing was also significant in the simple effects analyses that looked at incidental and intentional learning separately. This is in line with studies that have found a benefit of prior retrieval on learning information from different contexts, such as list of foreign language vocabulary words and their translations (Van den Broek et al., 2013) and information from prose passages (Roediger & Karpicke, 2006b).
The lack of difference in cued recall accuracy between performance on the immediate test and the delayed test for items being tested for the second time suggests that the retrieval practice protected these items against forgetting. The testing effect seen in the present study therefore at least partly explains why participants in Experiment 1 and those in the study by Hulme, Barsky & Rodd (2019) showed such good retention after one day and one week respectively. In the present experiment both the cued recall and multiple-choice tests were administered to all participants at both time points. It is therefore unclear whether either of these tests on its own would produce a similar testing effect, or if the combination of the two was important for boosting long-term retention. It also remains to be seen whether one of these test types is better than the other for enhancing retention of new word meanings learned incidentally through reading.
In sum, Experiment 2 demonstrated that testing memory of new meanings for familiar words benefits their future retention. This was the case for recalling word meanings learned either incidentally through story reading or through an intentional learning condition. As in Experiment 1, participants learned vocabulary more efficiently through the intentional learning condition, but performance for both learning conditions was good. There was a trend in the data towards less forgetting of items trained incidentally through the stories, and a trend suggesting a larger testing effect for incidentally-trained items. However, these interactions were non-significant; further research is warranted to investigate whether incidentally-trained items in particular could benefit from the additional learning opportunity afforded by the immediate test. Either the immediate cued recall or multiple-choice test, or indeed a combination of the two, may have produced the observed testing effect; Experiment 3 investigates which of these test methods could be more beneficial for retention. The results of this experiment will guide future development of real-world intervention studies aimed to boost vocabulary learning from story reading.
Experiment 3: immediate test method
The testing effect has been observed in studies using various methods of immediate test, most usually with cued recall (e.g., Karpicke & Smith, 2012), but also with other methods such as multiple-choice (e.g., Roediger & Marsh, 2005). There are several possibilities as to why certain methods of immediate testing may be more beneficial for future retention. The retrieval effort hypothesis states that testing is more helpful for long-term retention when it is more effortful (Pyc & Rawson, 2009). For example, in a study in which young adults learned the meanings of novel L1 vocabulary words, Karpicke & Roediger (2007) showed that increasing retrieval difficulty by increasing the delay between initial study and initial testing led to better long-term retention than when initial retrieval effort was lower. Tests of productive vocabulary knowledge, such as cued recall of word meanings, are more difficult than recognition tests in which word meanings are supplied (Pellicer-Sánchez, 2016); therefore an immediate cued recall test may be more advantageous for future retention than a multiple-choice test. Indeed, findings from many studies (for a review see Rowland, 2014) suggest effortful processing to be an important attribute of the testing effect.
Conversely, immediate testing may be particularly beneficial when it assists with restructuring learned information into a format that is more helpful for long-term retention. Multiple-choice recognition tests may aid retention due to response choices cueing the retrieval of marginal knowledge that may otherwise not be easily accessible (Marsh et al., 2007). They may also provide an opportunity for additional learning of some items through the process of elimination of foils (Marsh et al., 2007) even in the absence of feedback on response choice. However, foil answers in multiple-choice tests may also lead to learning of incorrect information (Butler et al., 2006; Marsh et al., 2007; Roediger & Marsh, 2005).
Some studies have directly compared the effects of immediate cued recall and multiple-choice tests on long-term retention. Duchastel (1981) investigated secondary school students’ retention of a prose passage following immediate testing with either a short-answer test (akin to cued recall), a multiple-choice test, or a free recall test. Long-term retention (measured by a delayed cued recall test) was better for those who had the immediate short-answer test, but no testing effect was observed for the other two groups. However, Duchastel (1981) found no testing effect for any group on the delayed free recall test, and the delayed cued recall measure was very similar to the immediate test for the short-answer test group. More recently, Nakata (2016) compared retrieval methods including cued recall and multiple-choice recognition in a study of paired-associate learning of novel L2 words. Recall was found to be most beneficial for acquiring novel words’ orthography (spelling), whereas recognition was more beneficial otherwise (Nakata, 2016).
One concern is that information learned with the help of retrieval practice could be relatively inflexible and constrained, and may therefore not transfer to different delayed tests. Tran, Rohrer & Pashler, 2014 and others have found that retrieval practice may not benefit later tests that require making deductive inferences about the learned information. Furthermore, Hogan & Kintsch (1971) found that immediate test methods that provide further exposure (i.e., recognition tests) were more beneficial than free recall for recognition two days later, whereas both free recall and recognition boosted performance on delayed free recall.
However, the degree to which different methods of immediate test aid future retention can also differ depending on factors such as the provision of feedback. Kang et al. (2007) found that participants who had an immediate multiple-choice test performed better on delayed multiple-choice and short-answer tests than participants who had an immediate short-answer test (Experiment 1; Kang et al., 2007). However, in a second experiment where feedback was provided on initial test performance (Experiment 2; Kang et al., 2007), the group with the immediate short-answer test performed better on the delayed tests than those whose immediate test had been multiple-choice, supporting the retrieval effort hypothesis (Pyc & Rawson, 2009). Other studies have also found that the testing effect can transfer across different test methods (Butler, 2010; McDaniel et al., 2007; Rohrer, Taylor & Sholar, 2010), with cued recall usually found to be more beneficial for long-term retention than recognition tests.
The aim of Experiment 3 was to investigate the impact of immediate test method (cued recall vs. multiple-choice meaning-to-word matching) on retention of new word meanings learned through stories. A secondary aim was to rule out the possibility that the testing effect in Experiment 2 was simply a practice effect due to having previously completed the same test, and that retrieval practice can generalise to a different delayed test. We predicted that the results would replicate the key finding from Experiment 2 of better long-term retention for items tested immediately after training (regardless of testing method) than items not tested previously. Additionally, we predicted that cued recall would be more beneficial for long-term retention of new word meanings than multiple-choice meaning-to-word matching as, according to the retrieval effort hypothesis (Pyc & Rawson, 2009), production tests that require more effortful retrieval than recognition tests (Roediger & Butler, 2011; Rowland, 2014) are more helpful for retention. However, it was also possible that the multiple-choice meaning-to-word matching test could result in better subsequent retention as this test provides participants with additional cues that provide an additional learning opportunity (Marsh et al., 2007). Finally, it was possible that the testing effect would not transfer across test tasks (Hogan & Kintsch, 1971; Tran, Rohrer & Pashler, 2014), and so the benefit of each method of immediate test would only be seen for the delayed test of the same type, in which case it could be characterised as more of a practice effect.
Experiment 3 was preregistered through the Open Science Framework; the preregistration is available at https://osf.io/c59tz (Hulme & Rodd, 2017, June 23). Any deviations from the preregistration are noted in the Method and Results sections for this experiment. The materials, data, and analysis scripts for Experiment 3 can be found on the Open Science Framework (OSF; https://osf.io/eh2c6).
Method
Participants
We aimed to recruit 96 participants for Experiment 3 in which participants were trained on eight items (four per testing condition) in one of two groups (who had different immediate tests), with eight experiment versions (12 participants per version). The sample size was established in consideration of the previous experiments. While there were more items per cell per participant in Experiment 3 than Experiment 2, the additional between-participants factor of test method meant that a similarly large sample was required to achieve comparable power in this experiment.
Ninety-eight participants were included in the experiment (age: M = 33.7 years, SD = 8.0; 64 female); we over-recruited by two participants when pseudorandomly assigning participants to the experiment versions and kept these participants. Participants were recruited in the same way as for Experiments 1 and 2. They gave their informed consent before taking part (by means of ticking boxes in the online consent form) and were paid for their participation at the end of each session (£4 for session one and £2 for session two). The UCL Experimental Psychology Ethics Committee granted ethical approval for the research (Ref: EP/2017/009).
An additional 18 participants took part in the first session but did not complete session two by the deadline (within 6 h of receiving the invitation for the delayed test) and were excluded. A further thirty-five participants were excluded due to getting more than one of the multiple-choice comprehension questions wrong in either of the stories they read (see Experiment 1 Procedure). Seven further participants were excluded due to a technical issue during data collection, and two participants were excluded for being outliers in their mean reading speed (faster than 806.2 words per min, 2 SD above the mean). Excluded participants were replaced during recruitment.
Materials
The stimuli for Experiment 3 were identical to those used in the previous experiments. One additional different paraphrased version of each of the definition sentences was created so that a differently worded definition would be presented in the immediate and delayed multiple-choice meaning-to-word matching tests to counteract any direct practice effects (see Table S3 for the additional paraphrased definitions: https://osf.io/tnb94).
Design
The experiment used a mixed design with two independent variables: immediate test method (two levels: cued recall and meaning-to-word matching) was manipulated between participants, and whether items were or were not previously tested (two levels: not previously tested vs. previously tested) was manipulated within subjects. The dependent variables were accuracy in cued recall of the new meanings and multiple-choice meaning-to-word matching, measured at the delayed test time point.
There were eight versions of the experiment to ensure the stimuli were seen an even number of times in each condition across participants. Participants were pseudorandomly assigned to one of the eight versions of the experiment. As in Experiments 1 and 2, each participant was trained on half the total number of stimuli (eight items per participant; two separate stories). For the key factor of immediate test method, half of the participants (N = 49) were given a cued recall test of half of their items (four items) immediately after training, and the other half of the participants (N = 48) were given a multiple-choice meaning-to-word matching test of half of their items immediately after training. The items that were or were not tested immediately following training were also counterbalanced across participants.
Procedure
The first session of the experiment began with the incidental training procedure. Participants first read one of the short stories; the procedure for this was identical to that of the previous experiments. They were then asked to rate how enjoyable and clear they found the story, and answer some questions about their subjective reading style, which took around 2 mins—this served as a brief interval between the two stories. Participants then read a second story. Immediately following training participants completed the same Mill Hill vocabulary test as used in the previous experiments (Mill Hill Vocabulary Test, Set A: Multiple Choice: Raven, Raven & Court, 1998) as a filler task. Participants were then given an immediate test of half the items they had been trained on (four items, two from each story), which was either a cued recall test or a multiple-choice meaning-to-word matching test. The items were tested in a randomised order in both of the test tasks, with no feedback given to participants. In the multiple-choice meaning-to-word matching test, only the four words that a participant was being immediately tested on appeared as the four alternative responses to choose from for each test item; the order of hese was also randomised for each test item.
Exactly 24 h after the first session of the experiment had been made available, the participants were asked to take part in the second session of the experiment: the surprise delayed test. Again participants were not aware of this delayed test beforehand; unfortunately 18 participants did not return to complete session two and were replaced during data collection. Participants completed the delayed test an average of 24 h and 31 mins (SD = 57 mins; range = 22 h 40 mins–27 h 25 mins) after the training session. The tests used for the delayed test session were the same as for the immediate test, but this time participants completed both tests: cued recall of meanings followed by multiple-choice meaning-to-word matching. At the delayed test participants were tested on all of the stimuli that they had been trained on (eight items). The order of presentation of the items in each of the two tests was again randomised for each participant. For the multiple-choice test, different paraphrased versions of the definition sentences were used to those that had appeared in the immediate test, and the order of the eight words to choose from was randomised for each test item.
Results
Analysis procedure
Responses on the cued recall and multiple-choice tests were coded for accuracy in the same way as for the previous experiments. The data were again analysed using logistic mixed effects models with the lme4 package (version 1.1–13; Bates et al., 2015) and R statistical software (version 3.3.3; R Core Team, 2017). Two models were created to analyse the results of the two delayed tests of cued recall and multiple-choice meaning-to-word matching separately. Contrasts for the fixed effects were defined using deviation coding for whether items were or were not immediately tested (not previously tested: –0.5, previously tested: 0.5), and the immediate test method (cued recall: –0.5, multiple-choice: 0.5), with the interaction coded by multiplying the contracts for these two factors. The model for the cued recall data used the maximal random effects structure, with by-participant and by-item random intercepts, a by-participants random slope for whether items were or were not previously tested, and by-items random slopes for whether items were or were not previously tested, method of immediate test, and the interaction. The model for the multiple-choice measure was simplified by removing the correlations between the random slopes and random intercepts (as recommended by Barr et al., 2013).
Following on from the main analysis, simple effects analyses were carried out to determine significance of whether items had or had not been immediately tested within each of the two immediate test methods separately. All data and analysis scripts for this experiment are available via the Open Science Framework (https://osf.io/eh2c6).
Cued recall of meanings
The accuracy data for cued recall (measured in the delayed test session) are shown in Fig. 5. Cued recall performance was low overall when items had not been tested immediately after training and was similar for the immediate cued recall group (26.5%) and immediate multiple-choice meaning-to-word matching group (25.5%): there was no significant main effect of immediate test method (χ2(1) = 0.47, p = .491). This is reassuring as it shows that the two groups of participants (who had different immediate test methods) performed similarly overall. There was a significant main effect of whether items were or were not immediately tested (χ2(1) = 23.73, p < .001): performance was much higher when items had been tested immediately after training. Although accuracy appeared higher for the immediate multiple-choice group (58.3%) than for the immediate cued recall group (49.5%) when items had been previously tested, the interaction was non-significant (χ2(1) = 3.18, p = .074). The planned simple effects follow-up analysis showed that there was a significant effect of whether items were or were not immediately tested within the immediate cued recall group (χ2(1) = 8.25, p = .004), and also within the multiple-choice meaning-to-word matching group (χ2(1) = 25.10, p < .001; α = .025).

Figure 5: Experiment 3. Mean percentage of correct responses in the cued recall test measured at the delayed test for participants whose immediate test was cued recall, and for those whose immediate test was multiple-choice when items were or were not previously tested.
Error bars show standard error of the means adjusted for the within-participants factor of whether items were or were not previously tested (Cousineau, 2005).
Multiple-choice meaning-to-word matching
The accuracy data for the multiple-choice meaning-to-word matching test (measured in the delayed test session) are shown in Fig. 6. Performance on this test was much higher overall than on the cued recall test. Accuracy was significantly lower when items had not been tested immediately after training (χ2(1) = 14.54, p < .001), and there was no significant main effect of immediate test method (χ2(1) = 2.38, p = .123). Concerning a possible interaction between whether items were or were not immediately tested and the immediate test method, the simple means for accuracy were similar for the immediate cued recall group (60.5%) and the immediate multiple-choice meaning-to-word matching group (63.5%) when there was no previous test. This is again reassuring as it shows that the two groups of participants (who had different immediate test methods) performed similarly overall. Although the simple means for accuracy on items that had been tested previously appeared to be higher for the immediate multiple-choice group (78.6%) than for the immediate cued recall group (67.5%), the interaction was non-significant (χ2(1) = 2.48, p = .116). The planned simple effects follow-up analysis showed that the effect of whether items were or were not immediately tested was non-significant within the immediate cued recall group (χ2(1) = 3.31, p = .069). The effect was, however, significant within the multiple-choice meaning-to-word matching group (χ2(1) = 10.76, p = .001; α = .025).
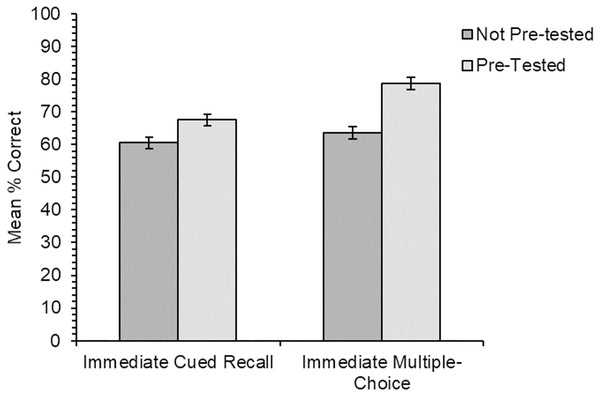
Figure 6: Experiment 3. Mean percentage of correct responses in the multiple-choice test measured at the delayed test for participants whose immediate test was cued recall, and for those whose immediate test was multiple-choice, when items were or were not previously tested.
Error bars show standard error of the means adjusted for the within-participants factor of whether items were or were not previously tested (Cousineau, 2005).
Discussion
Experiment 3 replicated the key finding from Experiment 2: testing memory immediately after training significantly boosted retention of new word meanings learned incidentally through story reading as measured at the delayed tests 24 h later. Importantly, Experiment 3 showed that testing memory immediately after training using either cued recall or multiple-choice alone was sufficient to result in a significant testing effect. This is consistent with studies that have found a testing effect arising from an immediate cued recall test (Karpicke & Smith, 2012) or an immediate test using multiple-choice questions (Roediger & Marsh, 2005).
The results provide no strong evidence for a particular benefit for either of these two testing methods: the retention benefits following the immediate multiple-choice test were non-significantly larger than the immediate cued recall test. The simple effects showed that the immediate multiple-choice test significantly boosted performance on both of the delayed tests, while the immediate cued recall test only significantly enhanced performance on the delayed cued recall test but not on the delayed multiple-choice test (the effect was marginally significant at the uncorrected level).
Finally, the immediate multiple-choice test enhanced delayed cued recall of the new word meanings. This cross-task transfer effect suggests that the observed benefit is not simply due to practising the same test previously. This demonstrates that knowledge retained from prior testing can be flexibly applied to new contexts of retrieval, in line with the findings of Rohrer, Taylor & Sholar (2010) and others.
General discussion
The present experiments investigated participants’ ability to learn new word meanings from naturalistic story contexts. Specifically we (i) compared performance in this relatively incidental learning condition to a more conventional explicit learning paradigm and (ii) examined the role of testing memory after training in enhancing future retention of new word meanings.
Incidental versus intentional learning
In Experiments 1 and 2 participants learned new meanings for familiar words better under intentional learning conditions than incidentally through reading stories. These findings are in line with those of studies that have compared incidental and intentional learning in studies of L2 vocabulary learning (Hulstijn, 1992; Peters et al., 2009) and L1 vocabulary learning with adolescents (Konopak et al., 1987).
The intentional and incidental learning paradigms differed in several important ways, making it difficult to draw firm conclusions for the specific underlying cause of this difference. It may be driven by additional attentional focus on word meanings in the intentional learning condition, while in the incidental learning condition participants’ attention was directed towards other aspects of the rich narrative context of the stories. The two learning paradigms also differed in the spacing of the words, which were systematically spaced throughout the intentional learning task. In the stories, on the other hand, the new word meanings appeared at naturally-occurring intervals such that some exposures occurred relatively close together. Spacing stimuli apart has been widely shown to aid learning (for review see: Dempster, 1996).
Additionally, there is the possibility of an internal testing effect within the intentional learning task. The multiple-choice meaning-to-word matching portion of the intentional learning task was similar to the multiple-choice meaning-to-word matching task used in the testing phase, which produced a testing effect on its own in Experiment 3. The multiple-choice training task also included simple feedback on performance (“correct” or “incorrect”), and feedback can enhance the benefit of tests for future retention. The trend in the data of Experiment 2 towards a larger testing effect for the incidental learning condition could possibly be because the intentional learning condition already involved a limited testing effect.
As well as the overall differences in performance between learning conditions immediately after training, there were also differences in longer-term retention. After 24 h, participants in Experiment 1 (and non-significantly in Experiment 2) had forgotten some of the new word meanings learned under intentional conditions, but there was very little forgetting of items learned incidentally across both experiments. In Experiment 2 the trend for reduced forgetting of items learned under incidental conditions was present regardless of an immediate test. The significant interaction between day and learning condition in Experiment 1 provides evidence for a difference in the amount of forgetting: word meanings learned incidentally, although harder to learn initially, may be forgotten less quickly than those learned under intentional conditions. This is possibly due to the more semantically rich context of the stories providing participants with additional and more varied cues, which are advantageous for later retrieval of the new word meanings, or due to higher engagement as the stories are more enjoyable. An alternative possibility is that this difference is a function of the initial learning level as performance in the intentional learning condition was higher and so had further to fall. Another possibility is that memory consolidation during sleep may have played a role in preferentially strengthening the weaker memory traces of items acquired through incidental conditions (Drosopoulos et al., 2007). Nevertheless, while intentional learning conditions were better for more efficient acquisition, incidental learning may lead to less forgetting of word meanings over time. However, replication of the latter finding is warranted in future research in a design that matches on initial performance level between the different learning conditions. This may also help to determine whether the observed changes in performance over time reflect real differences in forgetting or differences in the two conditions in terms of different sensitivity to recall thresholds following the immediate test (see Kornell, Bjork & Garcia, 2011 for a discussion). Future replication of this finding is also important given the non-significant interaction between learning condition and immediate versus delayed first test in Experiment 2.
The testing effect
A large overall testing effect was found in both Experiments 2 and 3: retrieval practice following initial exposure boosted retention of new meanings for familiar words. Cued recall of the new word meanings was boosted by 28.8% for the incidental learning condition and 10.6% for the intentional learning condition in Experiment 2. This effect therefore likely explains the high levels of cued recall and multiple-choice accuracy in Experiment 1 after one day, and in Hulme, Barsky & Rodd (2019)’s study after seven days. This finding adds to the growing literature highlighting the role of testing in aiding vocabulary learning. A possible alternative explanation for this finding is that testing may bias participants towards selectively remembering tested items, so the effect may be driven by the cost to the untested items. Relatedly, research has shown that the retention of selected memories can be modulated after learning by giving simple verbal instructions on their future importance (Van Dongen et al., 2012). However, several studies in the literature using a between-subjects design (e.g., Experiment 2 of Roediger & Karpicke, 2006a) have demonstrated that the practice of testing enhances learning, rather than just biasing which items are remembered.
The testing effect in Experiment 2 was elicited with both a cued recall and multiple-choice test immediately after training. However, the findings of Experiment 3 illustrated that either a cued recall test or a multiple-choice test alone was sufficient to produce a significant testing effect following incidental learning through story reading. There was no clear evidence that either of the two testing methods was superior to the other for enhancing memory retention, although the retention benefits for the immediate multiple-choice test were non-significantly larger than for the cued recall test. Previous research has shown cued recall (short answer questions) to be more helpful for memory retention in some contexts (Duchastel, 1981; McDaniel et al., 2007; McDaniel, Roediger & McDermott, 2007). However, recent research has suggested that the relative benefit of the testing method may depend on the type of information being learned. Nakata (2016) found that recall was most helpful for acquiring novel words’ orthography (spelling), whereas recognition was more beneficial otherwise.
Despite the growing body of research on the benefits of retrieval practice for retention, the neurocognitive mechanisms underlying the testing effect remain somewhat unclear (Antony et al., 2017). Influential models of word learning have not yet provided an account of the testing effect. The Complementary Learning Systems (CLS) model of word learning, for example, describes how word forms are initially encoded into episodic memory in the hippocampus, and are integrated into semantic memory in the neocortex following a period of offline consolidation, such as during sleep (Davis & Gaskell, 2009). However, this model does not account for the effect of conscious retrieval on memory for new words and their meanings. Antony et al. (2017) recently suggested that a similar mechanism may underlie both offline consolidation and the testing effect, which may provide a fast track to consolidation. They argue that retrieval practice brings about the formation of flexible hippocampal-neocortical representations through the online reactivation of related knowledge (Antony et al., 2017). The testing effect is therefore important to consider in conjunction with offline consolidation processes to garner a full picture of how novel word meanings are remembered. Future research should explore whether the testing effect involves a similar mechanism as unconscious offline learning processes, thus providing a fast track to consolidation.
The findings of the present experiments have important methodological implications for studies of word learning. The enhancing effects of retrieval practice on memory are clearly shown here, and in other previous research. Studies considering the impact of factors such as the role of sleep for consolidation should (and do) consider this important aspect. For example, Henderson et al. (2015) compared adults’ and children’s explicit memory of new words using cued recall and recognition tests administered both immediately and 24 h later. They note that for both adults and children “explicit phonological memory was enhanced after off-line consolidation” p.413 (Henderson et al., 2015). However, this finding could also, at least in part, be attributable to a testing effect, as the 24-h tests repeated the 0-h tests that participants completed immediately after training. Nevertheless, other studies in this field have isolated effects of sleep from effects of testing using alternative designs, including train twice, test once (e.g., Weighall et al., 2017), and AM-PM designs to compare 12-h periods associated with wake and sleep (e.g., Henderson et al., 2012; James, Gaskell & Henderson, 2020). The testing effect is therefore an important consideration for studies of the cognitive mechanisms underlying vocabulary learning and retention that include repeated testing of trained words. Studies of sleep and vocabulary learning would benefit from using designs that avoid having multiple test sessions. For example, training different items at different times and testing all items in one final session (e.g., Experiment 1 of Tamminen & Gaskell, 2013), or using a between-groups design to compare between two different times of test (e.g., Experiment 1 of Tamminen, Davis & Rastle, 2015) avoids contaminating results of potential consolidation with those of a testing effect.
The testing effect has previously been shown to generalise to educational settings. For example, Roediger et al. (2011) found that repeated testing of real course content with multiple-choice (and some short-answer tests) successfully boosted middle school students’ grades on their social studies course. A similar study with a middle school science class (McDaniel et al., 2011) found that multiple-choice tests gave large gains (13–25%) in learning and retention, assessed by end-of-unit exams, especially when tests were taken closer to exam time. Similar benefits of retrieval practice have been seen for college students (McDaniel et al., 2007; McDaniel, Roediger & McDermott, 2007), and Larsen, Butler & Roediger, 2008 have advocated the use of test-enhanced learning in medical education. Our findings in Experiments 2 and 3 have important practical implications for vocabulary learning. Students learning vocabulary incidentally from reading storybooks or textbooks can benefit from being tested following initial encounters with new word meanings. Testing appears to be effective using either cued recall or multiple-choice methods, so incorporating it as part of a strategy for efficient vocabulary learning could be easy to implement. Tests are often considered solely as tools to assess learning, however they also provide an important opportunity for additional learning and reinforcement of knowledge.
Conclusions
The first two experiments confirmed that new word meanings are learned more efficiently under intentional learning conditions than incidentally through story reading. However, there was also some evidence of less forgetting of items learned through stories, suggesting that word meanings learned in a more semantically rich context could be retained better. The second two experiments showed that testing memory aids retention of new word meanings acquired under either incidental or intentional learning conditions. Both cued recall and recognition (multiple-choice) tests enhanced retention, but multiple-choice tests gave non-significantly better performance, even with no feedback. Furthermore the testing effect transferred across test tasks: immediate multiple-choice meaning-to-word matching improved accuracy on the delayed cued recall test, so the effect is not restricted to benefitting the same test.
The present study has demonstrated that testing memory following initial exposure is a powerful way to improve learning and long-term retention of vocabulary knowledge. Importantly, we found that retrieval practice benefitted vocabulary retention from different learning conditions and using different methods of immediate test. The vast majority of new vocabulary is learned through reading from mid-childhood onwards. Test-enhanced learning could therefore be particularly useful if implemented during vocabulary development to boost children’s vocabulary gains from story reading.
Contents lists available at ScienceDirect
English for Specific Purposes
journal homepage: http://ees.elsevier.com/esp/default.asp
Learning technical words through L1 and L2: Completeness and accuracy of word meanings
Dana Gablasova*
Department of Linguistics and English Language, County South, Lancaster University, Lancaster LA1 4YL, United Kingdom
ARTICLE INFO
ABSTRACT
Article history: Available online xxx
Keywords:
Technical vocabulary Vocabulary acquisition Reading to learn Bilingual education L1 vs. L2 vocabulary learning
This paper investigates the quality of knowledge of technical words that high-school students learned from subject reading. In particular, it focuses on similarities and differences between students who learned new words through their L1 and their L2. In the study, 72 students were divided into two groups and asked to read and listen to two expository texts. One group received the texts in their L1 (Slovak) and the other group in their L2 (English). Afterwards the participants were tested on their knowledge of twelve technical words that appeared in the texts. The responses were examined in terms of the completeness of word meaning and the presence of errors. The results showed that compared to the L1-instructed students, the L2-instructed participants provided word meanings that were less complete and less precise. Word meanings from both groups contained errors involving omission of correct meaning components and inclusion of incorrect meaning components. L2-instructed participants made more errors of both kinds. The differences between the two groups are discussed with respect to vocabulary acquisition and subject learning.
© 2015 The Author. Published by Elsevier Ltd. This is an open access article under the CC BY
license (http://creativecommons.org/licenses/by/4.0/).
1. Introduction
Mastering technical vocabulary is an integral part of subject learning (Bravo & Cervetti, 2009; Woodward-Kron, 2008). As students learn about new concepts, they also acquire new words for communicating and demonstrating this knowledge (Mohan & van Naerssen, 1997). However, for many students, especially those accessing their education through a non-native language, disciplinary vocabulary also remains one of the most challenging areas. Growing research evidence shows that L2-medium educated students struggle with comprehending, learning and using subject-specific terms in the course of their studies (Evans & Green, 2007; Evans & Morrison, 2011; Mezek, 2013; Lessard-Clouston, 2006; Ryan, 2012). This study aims to improve our understanding of the demands that learning disciplinary, technical words places on non-native speakers of the instructional language. In particular, this study focuses on learning of the meanings of new technical words that appear in a written context with explicit clues.
It is becoming increasingly more common for students to study content through a non-native language, whether in bilingual programmes in their home country or as international students abroad. In these educational contexts, teaching is as a rule delivered by subject (not language) specialists who follow the methodology typical of mainstream classes. However, it remains unclear whether these methods are also suitable for L2-medium students as little is known about the difference between learning of specialised vocabulary through L1 and L2.
* Tel.: +44 (0) 1524 593 045. E-mail address: d.gablasova@lancaster.ac.uk.
http://dx.doi.org/10.1016/j.esp.2015.04.002
0889-4906/© 2015 The Author. Published by Elsevier Ltd. This is an open access article under the CC BY license (http://creativecommons.org/licenses/by/ 4.0/).
To date, most evidence regarding L2 vocabulary acquisition has come from studies that did not use an L1 baseline. This is due to practical difficulties of directly comparing vocabulary acquisition through L1 and L2 (Gablasova, 2014) mainly caused by two factors: First, most words learned by L2 users are already known to L1 speakers of the same age, making it difficult to compare acquisition of the same set of words. Second, learning through L2 usually involves the mapping of a new L2 word form onto an already existing L1 concept or word (Jiang, 2000) rather than acquiring both a new concept and a new form simultaneously, as is common in L1 learning. However, this is not the case with the acquisition of low frequency, subject-specific vocabulary (e.g. coniferous or gnosticism). These words are typically acquired in the study of academic subjects and involve learning of a new word meaning along with a new form. This is true equally of the students learning the subjects through their first as well as their second language, enabling researchers to study L2 vocabulary learning in direct contrast to L1 learning.
Since technical words combine language and subject knowledge (Bravo & Cervetti, 2009), findings from this study will be of interest not only to vocabulary researchers, but also to subject specialists involved in teaching content through students’ second language. By exploring differences or similarities found between native and non-native speakers of the language of instruction this investigation will contribute to more targeted pedagogical approaches to the teaching of subject terminology than has been possible so far.
1.1. Learning specialised vocabulary in academic contexts
Technical words are a special group of vocabulary characterised by several features: they are low frequency words restricted to a particular domain in which they appear with a fairly high frequency (Nation, 2001; Nation & Hwang, 1995; Chung & Nation, 2004; Pearson, 1998) ; they are part of the taxonomy of knowledge in a particular subject area (Chung & Nation, 2004) with a clear relationship to other terms in that area (Pearson, 1998). Nevertheless, despite a general agreement on these criteria, the distinction between technical and non-technical uses of words is not always clear-cut (e.g. Chung & Nation, 2003; Chung & Nation, 2004; Ryan, 2012; Pearson, 1998). As Chung and Nation (2004) point out, this distinction is often context-sensitive because «technicalness is a functional aspect of a word» (p. 251).
Vocabulary development can be studied with a focus on different dimensions of word knowledge (Nation, 2001), but in the case of technical words it is the semantic dimension that is arguably of particular importance as these words serve to denote concepts with accuracy and precision (Pearson, 1998). So far, several studies have focused on vocabulary learning in the course of academic study (e.g. Haynes & Baker, 1993; Mezek, 2013; Lessard-Clouston, 2006; Parry, 1991,1993; Vidal, 2003; 2011; Ryan, 2012). Some of these studies (Haynes & Baker, 1993; Lessard-Clouston, 2006; Parry, 1991,1993; Ryan, 2012) also addressed the quality of word meanings acquired by students in greater detail. For instance, in a longitudinal case study of lexical acquisition by an anthropology student, Parry (1993) found that the student was partly successful at inferring new word meanings from disciplinary texts, but her guesses contained semantic errors: her definitions of the new words were often either too broad or too narrow, and added components to or subtracted components from the original meaning. However, as this study merely described the knowledge gained through the medium of L2, it remains unclear whether these cases of semantic imprecision are typical of L2 learning of subject-specific words or whether they are common to all students learning a subject-matter, regardless of the language of instruction (L1 or L2).
Evidence of the challenges faced specifically by L2 students has come from contrastive studies that compared the gains in specialised vocabulary by L1 and L2 users (Haynes & Baker, 1993; Lessard-Clouston, 2006; Ryan, 2012). These studies report that compared to L1 users, the word meanings acquired and retained by L2 users were of lower quality in terms of the depth of knowledge, and the L2 speakers were able to provide fewer details about the meaning of the technical words. The problems experienced by L2-medium students in these studies were mainly attributed to a lower mastery of the L2, in particular to a limited number of links in the mental lexicon (Lessard-Clouston, 2006) and a smaller vocabulary size (Haynes & Baker, 1993). However, two of these studies (Lessard-Clouston, 2006; Ryan, 2012) were based on a rather small number of L2 speakers (fewer than ten) and, thus, the data allowed for mostly qualitative analysis. Also, the comparison of native and non-native speakers in these studies is not straightforward because the L1 speakers had a relatively large amount of prior knowledge of most of the target words. Indeed, as Haynes and Baker (1993) report, in a special case when both the concept and the form of a target word were equally new to L1 and L2 speakers, both groups of students had a similar difficulty acquiring this word and tended to «focus on one dimension of meaning to the exclusion of others» (p.148), a strategy that appears to be comparable to that observed by Parry (1993). Therefore, to evaluate the effect of the language of acquisition on lexical gains we need to study a greater number of cases where technical words are acquired in parallel through L1 and L2.
1.2. Factors affecting vocabulary learning from reading
Research on vocabulary acquisition from reading has identified several factors that affect the ability to pick up words from context (Huckin & Coady, 1999; Paribakht & Wesche, 1999). Among the most important factors are the degree and type of contextual support (Hulstijn, Hollander, & Greidanus, 1996; Hulstijn, 2003; Swanborn & de Glopper, 1999; Webb, 2008). More specifically, words that appear with explicit and rich clues have a better chance of being learned. This relationship is also reflected in the practice of textbook writers, who are aware of the importance of the context for learning new words. In textbooks, new technical words, therefore, often appear with a pedagogical context, i.e. with a definition or explanation of the word (Haynes & Baker, 1993). This so-called lexical familiarisation is intentionally placed in the text to help the reader with
understanding and acquiring word meanings (Bramki & Williams, 1984). As a result of this ‘strong’ context, when word meanings are inferred, the process is not dependent on random or insufficient textual clues that could lead to incorrect guessing (Frantzen, 2003). Overt clues to word meanings are especially important as the acquisition of specialised vocabulary often involves the most difficult type of lexical learning, i.e. the learning of both a new concept and a label for that concept (Jenkins & Dixon, 1983).
Another group of factors affecting vocabulary learning is related to individual characteristics of readers. Here, overall vocabulary size is crucial as it determines how much information from the context the reader is able to process and use in constructing the meaning of unknown words (Nagy, Anderson, & Herman, 1987; Paribakht & Wesche, 1999; Vidal, 2003; Wesche & Paribakht, 2010). According to the research on the effect of glosses on students’ lexical gains, the ability to understand the glosses proved to be an essential pre-requisite of learning previously unknown words (for an overview of this research see Schmitt, 2008). Admittedly, it is L2 users who may be affected most by their limited proficiency and vocabulary size, but when reading subject-specific texts containing lower-frequency vocabulary, native speakers may also encounter unfamiliar words (Nelson-Herber, 1986) and face challenges learning technical vocabulary.
1.3. Research questions
Words are acquired gradually, in a process in which the knowledge of the word and its use is both expanded and refined (Jiang, 2000; Nation, 2001; Sonaiya, 1991). This study examines students’ initial understanding of new word meanings after encountering technical words in a natural context (an expository text from a textbook). The aim is to establish to what extent the acquisition of technical terms in L2 is similar to or different from that in L1. This study provides a description of the word meanings derived from expository texts by L2 users and compares this to a baseline of L1 users who derived the same words from L1 texts. The acquired word meanings are analysed with respect to their completeness and correctness of information. Two specific questions are addressed:
Research question 1: What is the difference in the completeness of technical word meanings acquired through L1 and L2?
Research question 2: Is there a difference in the nature of errors in the technical word meanings acquired through L1 and L2?
2. Method
2.1. Participants
Participants in this study were 72 students recruited from two high schools in Slovakia with a Slovak-English CLIL (Content and Language Integrated Learning) bilingual programme. The participants (17-20 years old) were drawn from among students in the last two years of study and were proficient users of English, having spent a minimum of 3.5 years in a bilingual programme. At the end of their high-school study these students are expected to reach B2/C1 level of English as established by the Common European Framework of Reference for Languages (CEFR). Three tests were used to measure participants’ L2 language proficiency in terms of vocabulary size (X_Lex and Y_Lex) (Meara, 2005) and productive language skills (C-test) (for a more detailed description of the tests and the rationale for using them see Gablasova, 2012). Based on their scores, participants were divided into two groups balanced for L2 proficiency. As can be seen from Table 1, an independent-samples t-test showed no statistically significant difference between the two groups in terms of proficiency.
The first group of participants (referred to as the control group or the L1-instructed participants) received all materials in their L1 and the second group (the L2-instructed participants) received the materials in their L2.
2.2. Materials
The materials in the study were two expository texts approximately 800 words long and audio recordings of those texts. The texts described two topics new to the participating students: the History and the Geography of New Zealand. The first text described the arrival of the Maori to New Zealand and the development of the Maori lifestyle thereafter; the second text described the region of the High Country of the South Island in New Zealand. The reading materials were based on two
Table 1
L2 proficiency tests by group.
Test L1-instructed (N = 35) L2-instructed (N = 37)a t df Sig.
Mean SD Mean SD
X_Lex 4077.1 566.8 4075.7 541.7 .011 70 .991
Y_Lex 2101.4 714.3 2105.6 628.1 -.026 69 .979
C-test 70.80 9.31 68.90 11.76 .751 69 .455
a Number of participants taking the C-test and Y_Lex was 36.
textbook texts: A Concise New Zealand History (Wikibooks, 2007) and Year 12 Geography Study Guide: NCEA Level 2 (Billing et al., 2008) (see Gablasova, 2012 for more details on the development of the reading materials). A lexical analysis based on the frequency lists from the British National Corpus processed by the RANGE programme (Heatley, Nation, & Coxhead, 2002) showed that about ninety percent of the words in the texts were from the five thousand most frequent words in English (History text: 89.08% of tokens; Geography text: 86.57% of tokens). The texts were first developed in English and translated into Slovak by the researcher and checked by two native speakers of Slovak. Participants in the study both read the texts and listened to them (for the rationale see Section 2.3). The English and Slovak recordings of the texts were made by a female native speaker of English and a female native speaker of Slovak. The full texts can be seen in Gablasova (2012, 2014).
2.2.1. Target words
Twelve target words were placed in the texts along with a form of lexical familiarisation (a definition). Where possible, the definitions of the target words were adapted from high-school textbooks in order to ensure they were appropriate for the given age group. The target words in this study can be defined as Steps 3 and 4 of Chung and Nation’s (2004) scale. Following the definition in the scale, these words are closely related either to the domain of history and culture of New Zealand or to the field of geography and do not appear frequently in other domains.
The twelve target words (TWs) were selected according to the following criteria: a) they were all nouns (six abstract and six concrete), b) they were not known to participants either in their L1 or L2 (see Section 2.3.1) and c) they had a similar form and pronunciation in English and in Slovak (e.g. ampelography and ampelografia). Using the same TWs in L1 and L2 allowed us to study the acquisition of the same set of technical words through the two languages in a parallel manner. Each of the two texts contained six target words. The following twelve TWs were used (the number in the brackets signals the number of occurrences of each word in the text): ampelography (2), diastrophism (1), ecocentrism (2), kumara (1), moa (3), moko (3), pa (2), perendale (1), rcd (2), terroir (3), transhumance (1) and whanau (3). The TWs selected were largely words of Latin or Greek origin and thus cognate in the two languages, or loanwords from Maori borrowed both to English and Slovak. Table 2 shows an example of lexical familiarisation which the target words appeared with in the texts (all lexical familiarisations used with the TWs discussed in this article can be seen in the Supplementary data). As shown in the example, all occurrences of the TWs were restricted to the lexical familiarisation of the word.
Although word and textual characteristics (such as frequency of occurrence or length of words) play an important role in the learning of words (Cervetti, Hiebert, Pearson, & McClung, in press), it was not possible to control these features due to the above criteria. However, as the participants in both groups were tested on the same set of words, the differences in their learning gains can with a high degree of likelihood be attributed to the language of learning rather than to individual properties of the words or the contexts in which they were embedded. Moreover, no statistically significant correlations were found between the semantic quality of the acquired words and the number of TW occurrences in the text, their length (measured in number of letters and syllables both in Slovak and in English), or the number of words in the lexical familiarisation of the TWs.
2.3. Procedure
The study consisted of a pre-test, a reading session and a post-test. The participants were tested individually. At the beginning, the participants were told that the study focused on content learning by bilinguals and that they would be asked about the content of two texts.
The participants first completed a pre-test assessing their knowledge of the TWs. In the session that followed, the participants were first given 10 min to read the first text after which they listened to it while being able to follow it. The same procedure was repeated with the second text. One group of participants read the texts and listened to them in English (their L2), the other group in Slovak (their L1). Overall, the participants spent about 30 min with the texts. The listening-while-reading modality was employed in addition to reading in order to ensure that the participants paid attention to the whole of the text (cf. Horst, Cobb, & Meara, 1998) as well as to familiarise them with the pronunciation of the TWs. The reading session was followed by a two-minute non-verbal distractor task (a puzzle). After that, the participants completed a post-test in which they were asked to orally answer questions about the texts, including the questions about the target words.
2.3.1. Instruments
2.3.1.1. Pre-test. As the purpose of the study was to measure the acquisition of new word meanings, it was important to establish that the participants had no previous knowledge of the TWs either in their L1 or L2. Prior knowledge of the TWs was
Table 2
An example of lexical familiarisation used in the texts.
Target word Lexical familiarisation
Ampelography The quality of the wine production and vine disease prevention is now much improved with advances in ampelography
(the science which specialises in identification and classification of vines by comparing the shape and colour of the vine
leaves and grape berries).
pre-tested using a vocabulary list asking the participants to indicate their knowledge of the words by ticking one of the options on the following scale (adapted from Paribakht and Wesche (1997)): 1) I have never seen/heard the word, 2) I have seen/heard the word before but don’t know what it means, 3) I know what the word means. Altogether, the list contained 68 words which appeared in the two texts. In order to test the general knowledge of the topics of the two texts, the participants were asked eight open questions each related to a main idea in the texts (cf. Zaki & Ellis, 1999). The pre-test showed that the participants did not have any prior knowledge of the TWs and were not familiar with the selected topics. Both instruments are available in the Supplementary data.
2.3.1.2. Post-test. The post-test was computer-administered. The questions appeared on the computer screen and participants gave the answers orally. The post-test consisted of 36 questions that covered information in the two texts. Twelve of these questions asked about the meaning of the target words (e.g. What is ampelography?), and the remaining 24 questions asked about other information from the texts. The 36 questions were divided into two blocks with half of the questions being asked in English and the other half in Slovak (the presentation of the blocks was counterbalanced). Each block contained questions about six TWs: thus, participants answered questions about six TWs in their L1 and six questions in their L2. Participants received the same questions, regardless of whether they read the texts in Slovak or in English.
Participants were tested in both of their languages to counterbalance the influence of having to transfer the knowledge from their instructional into their non-instructional language. As they were proficient speakers of L2, this did not result in problems with communication. The data from both parts of the test are therefore presented together.
2.4. Analysis and coding
Previous studies that examined the quality of expressible word knowledge focused on the completeness and restric-tiveness of word meanings (e.g. Johnson & Anglin, 1995) as well as correctness of the semantic information (e.g. Fukkink, Blok, & De Glopper, 2001; Parry, 1993). In order to capture the different degrees of semantic knowledge, the coding framework in this study combines the two dimensions. Earlier research also stressed the importance of employing measures sensitive enough to capture the more fine-grained differences between the different degrees of lexical knowledge (Swanborn & de Glopper, 1999).
Participants’ responses were first divided into a) those that showed some evidence of TW learning (altogether 642 definitions) and b) those that did not (i.e. the participant could not recall any information about the TW or gave an incorrect answer) (altogether 222 definitions). Only those answers that showed some evidence of lexical learning were examined further (for the discussion of the number of form-meaning connections formed by each group, see Gablasova, 2012,2014). The quality of the word meanings provided by the participants was determined with respect to the inclusion of correct and incorrect core and minor meaning components. A list of correct meaning components was made on the basis of the information provided about each TW in the texts. These were divided into core (major) and minor meaning components after consulting a dictionary and also following an analysis of students’ answers. Based on this, a four-point scale (presented in Table 3) was developed and used for scoring participants’ answers. Examples of each scoring category can be seen in Table 4.
All examples in Table 4 are taken from the elicited definitions of transhumance with the exception of 1b which is taken from the definition of ecocentrism. The definition of ecocentrism in the text was as follows: «Ecocentrism is a nature-centred worldview based on the belief that all living organisms are equally important.» Transhumance was defined in the following way: «Transhumance — the seasonal movement (before winter) of stock from exposed, high mountain slopes to the more sheltered foothills and river flats. This avoids large stock-losses due to the bitter cold of winter.» All answers in the table were elicited in English. 3a shows an example in which the component ‘stock’ was replaced by ‘sheep’, thereby somewhat limiting the meaning of the word (as ‘sheep’ are a subset of ‘livestock’). 3b shows an example in which ‘moving’ was substituted by ‘driving out’. As the meaning of the latter expression could be paraphrased as ‘to force to go away’ it adds to the original meaning a component which was not implied in the text. Example 2a demonstrates a response in which a core meaning component (here ‘livestock’) was left out altogether. 2b is an example of a response in which a core component (‘livestock’) was replaced by another component (‘crops’). 1a shows a response in which only a short phrase (‘before winter’) overlapped with the original meaning, the rest being inaccurate. 1b is an example of a vague definition, which did not restrict the meaning of the word sufficiently.
Table 3
Coding scale for the semantic quality of the definitions.
Score Category Description of the category
4 points Adequate definition All core meaning components of the word meaning included
3 points Near-adequate definition a. Omission of a minor meaning component
b. Inclusion of a minor incorrect information (e.g. one incorrect meaning component)
2 points Partially adequate definition a. Omission of a core meaning component
b. Inclusion of a major incorrect information (e.g. an incorrect superordinate)
1 point Insufficiently adequate definition a. Includes a correct keyword/phrase from the original definition, but otherwise incorrect
b. Vague
Table 4
Examples of the coding framework categories.
4 Transhumance it is when people move their cattle the sheep from the harsh mountain sides down into deep valleys when where
where they are protected from the weather and bad conditions in winter. 3a it’s moving sheeps before winter from cold hills to some to more flat country because of cold winters
3b the livestock is driven out of high parts of country to low parts because of cold winters
2a it’s moving [livestock] from mountainous areas to more to the places where the rivers are especially before winter
2b transhumance is the movement of the crops from the high areas from the highlands before the winter because the winter and the cold
can can destroy them so they are moving them to lowlands 1a it’s the change in weather before winter
1b ecocentrism is about nature
In order to compare the quality of participants’ definitions, the author first coded all of the data in the post-test. A second coder, a proficient speaker of both Slovak and English, then coded 25 percent of the student responses. Inter-rater reliability was measured by Spearman’s rho. The correlation between the two raters was .83, p < .001, which was deemed sufficient for the rating of semantic quality.
Participants’ answers with scores 1, 2 and 3 were further analysed to determine what type of error contributed to the less-than-full score. As follows from the coding scheme in Table 3, two types of errors were identified and coded: a) a missing meaning component (i.e. a component which should have been included but was left out) and b) inclusion of an incorrect component. To establish the reliability of the error rating, a second coder coded 25 percent of all cases that received scores 1 to 3. Cronbach’s alpha was used to calculate the inter-rater reliability. The analysis yielded an alpha of .898, indicating a high level of reliability.
3. Results
3.1. RQ1: completeness of word meanings
The first research question addressed the quality of the newly learned word meanings. The completeness of the definitions produced by the two groups of participants was compared using a chi-square test. The descriptive statistics are reported in Table 5. The chi-square analysis found a statistically significant difference between the performance of the L1- and L2-instructed groups (c2 = 14.498, df = 3, p < .01). Figure 1 shows the quality of TWs’ definitions according to the four-point scale presented in Table 3.
As can be seen from Figure 1, there were both similarities and differences between the two groups of participants. Nearly 70 percent of the definitions from the L1-instructed participants were of high quality (scores 3 and 4). In fact, almost 30 percent of the word meanings were given the highest score and could be considered complete (i.e. the participants formed a good representation of the concept). In comparison, the L2-instructed participants were less likely to reach the highest score: only about one fifth of their word meanings could be considered complete. However, 40 percent of their definitions were judged as nearly complete, the same number as achieved by L1-instructed participants. Over 40 percent of the definitions of the L2-instructed participants contained considerable semantic problems (scores 1 or 2), with omissions of correct components or inclusions of incorrect components resulting in changes to the meanings of the TWs. While fewer definitions from L1 group received a score of 2, the number of word meanings judged as insufficient was very similar to the L2-instructed group.
These findings are in line with the outcomes of previous studies which reported that students learning through their L1 outperformed their peers who learned disciplinary terms through their second language (Haynes & Baker, 1993; Lessard-Clouston, 2006). Building on this earlier research, the four-point scale used in this study allowed us to estimate more precisely the extent and nature of the difference between the knowledge gains of native and non-native speakers.
3.2. RQ2: errors identified in the definitions of the target words
The second research question focused on the nature of errors that appeared in learners’ definitions of the new words. Table 6 reports the distribution of two types of errors: a) errors due to missing components and b) errors due to the inclusion of
Table 5
Between-group comparison of the quality of definitions.
Group Responses
Score Total
4 3 2 1
L1-instructed (N = 35) 95 130 82 33 340
27.9% 38.2% 24.1% 9.7%
L2-instructed (N = 37) 54 116 106 26 302
17.9% 38.4% 35.1% 8.6%
10% 0%
Score 4 Score 3 Score 2 Scorel
Figure 1. The quality of word meanings.
false components. The percentages in the table show the proportion of each type of error out of all answers scored 1 to 4. The chi-square test showed a statistically significant difference between the L1- and L2-instructed groups (c2 = 24.07, df = 2, p < .01).
As can be seen from the table, an omission of a meaning component was the most common error in participants’ answers regardless of the language of learning (L1 or L2) and accounted for more than a half of the incomplete answers in both groups. With respect to incorrect components that added elements to the correct meaning of the TWs, these account for one fifth of the answers from the L1-instructed group and for more than one quarter of answers of the L2-instructed group. Whereas the majority of the answers from both groups of participants contained errors, the definitions of the L2-instructed participants contained a higher proportion of errors of both kinds. Word learning can hardly be complete after one exposure only (Nation, 2001), despite support from informative context (Webb, 2008), a fact illustrated by the performance of the L1 baseline. Nevertheless, the L2-instructed students acquired word meanings to a lesser extent than the L1 control group and the possible reasons for this difference are discussed below.
3.2.1. Omission of correct meaning components
An omission of meaning components was responsible for the majority of errors in both groups of participants. While most missing components appeared to be distributed randomly across all definitions in both groups, some systematic omissions were observed in the answers of the L2-instructed students and could account for the higher number of missing components in the answers from this group. These omissions appear to result from specific lexical gaps in the vocabulary of these students, which is especially likely as these meaning components were expressed by words of low frequency in the original English text.
This observation can be illustrated by the examples of transhumance and moa. In the text, moa was defined as a ‘flightless’ extinct bird. Out of 27 acceptable definitions provided by the L1-instructed participants, 16 contained the ‘flightless’ component. On the other hand, it was included only in 7 out of 29 definitions given by the L2-instructed participants. The difference was statistically significant (c2 = 7.13, df = 1, p < .01). In the case of transhumance (a seasonal movement of farm animals), ‘stock’, a word from the definition in the text, appeared to be problematic for the L2-instructed participants. Whereas most of the L1-instructed participants included the concept of ‘animals’ in their answers (28 out of 29), this was true only for two thirds (14 out of 20) of the L2-instructed participants. This difference was statistically significant (Log Likelihood = 4.76, p < .05. Log Likelihood rather than chi-square was used here as more than twenty percent of cells had frequency lower than five which can affect the reliability of the chi-square product).
Table 6
Between-group comparison of two types of errors.
Group Errors Error-free definitions Total
Missing component Incorrect component
N % N % N %
L1-instructed L2-instructed 175 51.5 169 56.0 70 20.6 79 26.2 95 27.9 54 17.9 340 302
■ Ll-instructecf
■ L2-lnstructed
The lack of familiarity with words surrounding the target word has been identified as a cause of incorrect or imprecise guessing before (Parry, 1991; Haynes & Baker, 1993; Wesche & Paribakht, 2010). As the above examples show, even relatively proficient students struggled with some specific low-frequency words (e.g. ‘flightless’ and ‘stock’). However, these particular gaps did not result in incorrect guessing; rather the students were able to construct an incomplete, but correct interpretation of the word. The gaps in the vocabulary knowledge of the L2-instructed participants prevented them from acquiring a more complete lexical and conceptual knowledge of the subject-matter than expected on the basis of the performance of their L1-instructed peers. It seems that at higher levels of L2 proficiency, lexical knowledge of learners is very heterogeneous, depending on individual learning trajectories (Henriksen, Albrechtsen, & Haastrup, 2004) (e.g. while the participants struggled with ‘stock’ and ‘flightless’ they had no problems with other less frequent words such as ‘fortified’, ‘vineyard’ or ‘skeleton’ which appeared in the definitions of some of the other TWs). As a result, the relationship between vocabulary size and the lexical gains may be less predictable for L2- than for L1-instructed students.
3.2.2. Inclusion of incorrect meaning components
Whereas omitting a meaning component is something that cannot be avoided if participants have not understood a particular word in the TW’s lexical familiarisation, the reasons for adding incorrect, additional information to the original word meaning are more complex. In this part, therefore, close attention will be paid to the sources of false attributes and the possible reasons for their inclusion in students’ answers.
This type of error was found in the answers of the participants from both groups. As this study investigated students’ lexical gains in terms of expressible word knowledge, a certain portion of minor incorrect components could be attributed to the transfer of information from one language to another as well as to the semantic changes (e.g. extension or narrowing) that can result from paraphrasing and use of one’s own words. While there was no systematic distribution of incorrect components in the definitions of the L1-instructed participants, an interesting pattern of incorrect additions was identified in the answers of the L2-instructed participants. In these cases, false meaning components resulted in major modifications to the meaning of the TWs and could thus not be explained merely by an imprecise word choice. Several examples of such inclusion by the L2-instructed participants are discussed below.
In the first set of examples, taken from the definitions of transhumance, the incorrect component in the answers of the L2-instructed participants appeared in the place of a correct (but missing) meaning component. While in the definitions of moa discussed earlier the component ‘flightless’ was left out altogether, in the case of transhumance the missing component (‘farm animals’) was in several cases replaced by another component, i.e. ‘people’. Example 1 shows a definition which omitted the component, while Examples 2 and 3 show answers with an incorrect component.
(1) It’s moving from mountainous areas to more to the places where the rivers are especially before winter.
(2) It is a seasonal movement of the people from High Country.
(3) It is a movement of people living in highlands because of bad conditions, it’s seasonal.
It seems that in the search for the missing component, the L2-instructed participants used (in this case, misleading) morphological information and analysed the word as consisting of the following two components:
■ trans — something to do with movement or change, and
■ humance — something to do with human beings
Transhumance thus appears to be an example of what Laufer (1989) described as a deceptively transparent word and students’ errors could be attributed to their over-reliance on morphological clues. A similar type of error was also found in the definitions of other words. However, in these cases, rather than being misled by textual clues, participants appeared to be shifting their definitions to a concept they were already familiar with. For example, whanau (an extended family that makes decisions together) was defined as a ‘leader of a family’ by three L2-instructed students (Examples 4-6, translated from Slovak). The examples show that the students opted for a more common concept of a leader of an organisation rather than the less common notion of a shared leadership.
(4) Whanau is a family member who decides about the future of the members of other members of the family
(5) Whanau is actually something like a tribal elder who decided about everything and he also gave a permission or he decided about who will marry who [… ]
(6) Whanau is a chief of individual tribes who actually is in charge of everything [… ]
Another example of a similar error can be seen in the case of rcd (a virus used to reduce the rabbit population in New Zealand). As shown in Examples 7 and 8 (translated from Slovak), three L2-instructed participants shifted the meaning from ‘a virus’ (a rather uncommon way of dealing with pests) to ‘a poison’ or ‘a chemical’. This modification is even more remarkable as the English and Slovak words for ‘virus’ are very similar (Slovak: virus, [vi:jus]). It is thus highly unlikely that the change could occur due to a lack of familiarity with this particular word.
(7) Rcd is a poison for rabbits (two participants gave this answer)
(8) Rcd is a chemical or some method used to eliminate pests that is rabbits
In the examples above, the L2-participants produced several correct meaning components as well as one or more incorrect components in their answers. As a result, the inclusion of an incorrect component modified the meaning of the word which then denoted a related, but different concept. In some definitions students even included additional components to the word meanings, strengthening the shift to a different concept. This could be observed in the definitions of ampelography, a botanical science concerned with vines (the definition of ampelography as it appeared in the text is shown in Table 2). The definitions of several L2-instructed participants modified (shifted) the meaning of the word to include the notion of wine tasting or wine-drinking. This shift was in several cases signalled by an explicit inclusion of new meaning components, such as ‘taste’ as shown in Examples 9 and 10 (the answers were translated from students’ L1).
(9) It is a science which is concerned with wine, its taste and growing.
(10) It’s a science which is concerned with examining wine, its shape, its colour, its taste in other words it assesses the quality of wine basically dividing it into some categories.
Six L2-instructed participants included ‘taste’ or ‘tasting’ in their answers in the post-test (out of 24 definitions). By contrast, no reference to wine-tasting or wine-drinking was found in the answers of the L1-instructed participants. In some cases the participants themselves acknowledged that the additional meaning components were not consistent with the rest of the interpretation, as shown by a comment made by a participant when discussing the meaning of ampelography (the use of italics in the English translation of students’ answers signals that the word was produced originally in English, although the rest of the answer was given in Slovak).
(11) I think that there was shape that some kind of shape I didn’t get it the shape of wine?
Although it is possible that unfamiliarity with a particular lexical item (e.g. mistaking ‘wine’ for ‘vine’) could contribute to the modified word meanings, examples from across different TWs suggest that this is likely to be only a partial explanation.
4. Discussion
4.1. Vocabulary learning
With respect to vocabulary acquisition from a supportive reading context, the results showed that providing explicit clues can result in relatively high lexical gains both for L1 and (proficient) L2 speakers. This is in line with research that found that a rich context supports acquisition of word meanings (Webb, 2008). On the other hand, the findings also confirm that even explicit contextualised clues and the full mastery of the language of input (in the case of the L1-instructed participants) do not necessarily result in a complete knowledge of the new words. Thus, repeated exposures (e.g. Rott, 1999; Webb, 2007) or deeper involvement (e.g. Laufer & Girsai, 2008) with learning may be needed.
The results also showed that lexical development is not always linear in the sense that with every new exposure the knowledge of the word becomes progressively more complete and precise. This was especially the case with the students who learned TWs through their L2. As can be seen from the data, the empty ‘slots’ (missing components) in the word meanings can become replaced by information from other sources and result in a (sometimes) coherent albeit incorrect concept. This evidence supports the dynamic view of lexical acquisition «which consists of both learning and unlearning, i.e. adding other semantic attributes that are not yet included, but also unlearning false attributes that are incorrectly included in the hypothesized word definition» (Fukkink et al., 2001, p. 490). It is important to acknowledge this dimension of developing word knowledge (i.e. the inclusion of erroneous information) in pedagogical practice as incorrect inferences might be retained in the long-term (Parry, 1991), especially if learners are not aware that their knowledge is only partially correct (Laufer & Yano, 2001).
The study showed that contrastive studies of L1 and L2 vocabulary can be valuable for our understanding of the processes involved in vocabulary development, as the L1-instructed students provided an important benchmark for interpreting the performance of the L2-instructed students. Above all, the results from the L1-instructed students showed that not all word meaning errors should be attributed to processing in L2, but may be typical of vocabulary learning in general.
4.2. Reasons for including incorrect components in students’ answers
Previous research showed that in some cases L2 speakers tend to draw on morphological or contextual knowledge rather than on direct textual clues when constructing the meaning of a text (e.g. Grabe, 2009; Koda, 2004). However, this strategy of dealing with a deficiency in one language area by exploiting knowledge in another area can easily result in incorrect or imprecise text comprehension. The reasons for L2 users’ reliance on these sources have often been attributed to insufficient
mastery of the language which prevented these speakers from using the textual clues present in the text. For example, as Koda (2004, p. 59) observed,
[w]hen much of the text is unfamiliar, readers are likely to either give up or draw on their background knowledge -activated through a small collection of familiar words — in making sense of the text, rather than constructing its meaning from the information presented.
However, although this may be a very common as well as a very likely reason for L2 users’ mistakes, it does not seem to fully explain the performance of participants in this study. While some of the erroneous or incomplete answers can most likely be attributed to specific lexical gaps (e.g. insufficient familiarity with words such as ‘flightless’ or ‘vine’), the L2-instructed participants in this research were reasonably proficient users of the second language and their answers showed understanding of most of the words in the text. In some cases they were even aware of the inconsistencies between their interpretation and the textual clues (as shown in Example 11). Despite this, they still modified their interpretation to fit a concept they were already familiar with. If L2 proficiency alone cannot account for the incorrect meaning components, what are other possible explanations?
First of all, in their attempts to construct the word meanings from perhaps not a fully comprehended input, some of the L1-and L2-instructed participants simply omitted the problematic components, while others (mainly the L2-instructed participants) replaced these components with incorrect ones. The latter practice could be motivated by an effort to create a coherent concept since, as pointed out by Anderson and Nagy (1991, p. 705), «[p]eople strive for coherence; they fill slots with the information given when possible, by inference when necessary». Thus, when a reader fails to construct a model of the meaning of a text, different sources of knowledge interact to «impose a certain degree of coherence on an interpretation that [the reader] may be required to provide» (Grabe, 2009, p. 49). Participants’ ‘strive for coherence’ was perhaps even reinforced by the need to produce the meaning of the word ‘on record’ and the reluctance to produce something vague or lacking in coherence (Roebuck, 1998). However, if this alone were the case, a similar tendency should have also been observed in the answers of the L1-instructed students.
It is possible that the tendency of the L2-instructed students to use information that did not appear in the texts to create a coherent concept is also related to the depth of knowledge activation. We can assume that the superior language mastery of the L1 readers served both to activate the relevant word/concept associations as well as to suppress the less strongly related ones. By contrast, the gaps in the vocabulary of the L2 readers (e.g. ‘stock’) might have resulted in the competing information not being deactivated with sufficient strength. As this study shows, it is equally important that the students learn both what the word meaning includes as well as what it does not (i.e. where the boundaries of words are (Sonaiya, 1991)).
The fact that the L2 users were affected by their prior knowledge in the lexical learning (as indicated by Examples 4-6 and 7-8) could also be the result of resorting to a familiar strategy in L2 vocabulary learning, namely that of mapping the new L2 meaning onto an existing L1 concept or parts thereof (Jiang, 2000; Takac, 2008). A similar approach to inferring the meanings of words with a familiar form, but a new meaning sense was reported by Haynes and Baker (1993), who observed that the participants preferred to select from among the senses they already knew rather than to create a new entry in their mental lexicon.
The results from this study are not surprising in terms of the sources of the L2-instructed participants’ errors. Rather, it is interesting how strong the competing sources of information can be for L2 users. Even when aware of inconsistencies, the L2-instructed participants did not refine or change the interpretation which they incorrectly based on their prior knowledge or morphological clues.
4.3. Implications for learning of disciplinary words
The findings of this study have some important implications for students and teachers in bilingual programmes such as CLIL (Content and Language Integrated Learning). The technical word knowledge of the L2-instructed participants was less precise and less elaborate than that of the L1-learning group due to the former having a higher number of missing components and a greater tendency to include incorrect components. The purpose of studying an academic subject is to gain new or deeper understanding (e.g. to learn about new concepts or to refine existing concepts). Yet, the L2-instructed students showed a tendency to rely on the strategy of resorting to their existing knowledge and known concepts which can negatively affect their learning progress. Pedagogical attention should therefore be focused in particular on the completeness and accuracy of technical word meaning. Several specific pedagogical implications related to these two areas can be suggested.
One of the problems with the quality of word meanings acquired by the L2-instructed participants in this study stemmed from difficulties with the language used to define the terms. To increase effectiveness of learning technical terms, the understanding of this ‘pre-requisite vocabulary’ should be assured (Armbruster, 1992; Schmitt, 2008), whether as part of a class activity or in an individual vocabulary-learning task. For example, Mezek (2013) found evidence that when students engage more actively with the words in the definitions of the disciplinary terms (e.g. by rephrasing) their learning of the words improves.
In line with the previous research (Nation, 2001), this study also showed that exposure to TWs limited to one learning occasion even when the TWs are embedded in informative context is in most cases not sufficient for complete acquisition of the word meaning. Similar to the finding reported by Haynes and Baker (1993), students in this study often stressed one aspect of the word’s meaning and ignored or understated other meaning components. Multiple exposures to the target items
would give students an opportunity to attend to several aspects of the meaning of complex words and would allow them to notice potential inconsistencies in their understanding of the words. Content classes, with their focus on a particular subject, provide an excellent opportunity for repeated engagement of students with key subject terms (Nation & Webb, 2011; Bravo & Cervetti, 2009). Apart from providing opportunities for students to encounter the subject words in subject-related discussion and activities, Flannigan and Greenwood (2007) also encourage subject teachers to introduce direct vocabulary-oriented activities targeting the completeness of students’ understanding of technical words such as semantic feature analysis.
Finally, the awareness of the problem areas in learning subject-specific words should be reflected not only in teaching, but also in assessing knowledge of technical words. Traditional assessment procedures used in L2-medium classes that, for example, elicit only the general class word (What is ampelography? — A science.) or ask the students for a translation into L1 (cf. Dalton-Puffer, 2007) are often not sensitive enough to detect problems with completeness and accuracy of acquired technical vocabulary. If students have a partially correct understanding of the concepts, as was often the case in this study, the problems may remain largely unidentified. A word definition task such as the one used in this study could therefore be used as one of the means of a more thorough assessment of students’ knowledge of technical words.
4.4. Limitations and further research
It should be noted that this study focused only on the lexical knowledge that students were able to verbalise and it is possible that testing receptive knowledge would reveal larger gains in students’ lexical development. However, it should be stressed that subject teachers often rely on (oral) defining for probing into the depth and accuracy of students’ conceptual and linguistic knowledge which makes this method a suitable tool for research with practical educational implications.
Another limitation is that this research focused on establishing the differences between two groups of learners with respect to the language through which they learned the disciplinary words. Having focused on the group performance, the complex interplay of individual characteristics of learners (e.g. working memory) with textual and word characteristics could not be explored in greater depth. There is ample evidence from prior research that some words are harder to learn than others (e.g. Laufer, 1989) and this is true of disciplinary vocabulary as well (e.g. Cervetti et al., in press; Gablasova, 2014; Vidal, 2003). Future research should therefore address these variables in order to provide a detailed model of the acquisition of technical words from informative context by advanced L2 speakers.
5. Conclusion
The paper contributes to deepening our understanding of the vocabulary needs of students who are considered proficient enough to undertake study of academic subjects through their L2, yet who may face additional cognitive demands as a result of working in a non-native language. The study described in detail several aspects of developing word knowledge, characterised by missing or erroneous information, pointing towards the gap between the L1 and L2-medium students. Given the number of students studying through the medium of their L2, special attention needs to be devoted to developing pedagogical techniques that can help these students as well as their teachers to apply suitable strategies for enhancing this important dimension of subject knowledge.
Acknowledgement
I would like to thank Vaclav Brezina, Christine Feak and two anonymous reviewers for their valuable comments on different drafts of the article. The research presented in this article was supported by Education New Zealand and the ESRC Centre for Corpus Approaches to Social Science, ESRC grant reference ES/K002155/1.
Appendix A. Supplementary data
Supplementary data related to this article can be found at http://dx.doi.org/10.1016/j.esp.2015.04.002
References
Anderson, R. C., &Nagy, W. E. (1991). Word meanings. In M. L. Barr, M. L. Kamil, P. Mosenthal, &P. D. Pearson (Eds.), Handbook of reading research (Vol. II, pp.
690-724)White Plains: Longman. Armbruster, B. (1992). Vocabulary in content area lessons. The Reading Teacher, 45(7), 550-551.
Billing, A., Broad, T., Carter, K., Coombe, P., Maguire, G., Skinner, B., & Stirling, S. (2008). Year 12 geography study guide: NCEA level 2. Auckland: ESA Publications.
Bramki, D., & Williams, R. (1984). Lexical familiarization in economics text books. Reading in a Foreign Language, 2(1), 169-181. http://www.nflrc.hawaii.edu/ rfl/PastIssues/rfl21bramki.pdf
Bravo, M. A., & Cervetti, A. (2009). Teaching vocabulary through text and experience in content areas. In M. F. Graves (Ed.), Essential readings on vocabulary
instructions (pp. 141-152). Newark: International Reading Association. Cervetti, G., Hiebert, E., Pearson, D., & McClung, N. Factors that influence the difficulty of science words. Journal of Literacy Research (in press). Chung, T. M., & Nation, P. (2003). Technical vocabulary in specialised texts. Reading in a foreign language, 15(2), 103-116. Chung, T. M., & Nation, P. (2004). Identifying technical vocabulary. System, 32(2), 251-263. http://dx.doi.org/10.1016Zj.system.2003.11.008. Dalton-Puffer, C. (2007). Discourse in content and language integrated learning (CLIL) classrooms. Amsterdam: John Benjamins.
Evans, S., & Green, C. (2007). Why EAP is necessary: A survey of Hong Kong tertiary students. Journal of English for Academic Purposes, 6(1), 3-17. http://dx. doi.org/10.1016/j.jeap.2006.11.005.
Evans, S., & Morrison, B. (2011). Meeting the challenges of English-medium higher education: The first year experience in Hong Kong. English for Specific Purposes, 30(3), 198-208. http://dx.doi.org/10.1016Zj.esp.2011.01.001.
Flannigan, K., & Greenwood, S. C. (2007). Effective content vocabulary instruction in the middle: Matching students, purposes, words and strategies. Journal of Adolescent & Adult Literacy, 51, 226-238. http://dx.doi.org/10.1598/JAAL.51.3.3.
Frantzen, D. (2003). Factors affecting how second language Spanish students derive meaning from context. The Modern Language Journal, 87(2), 168-199. http://dx.doi.org/10.1111/1540-4781.00185.
Fukkink, R. G., Blok, H., &De Glopper, K. (2001). Deriving word meaning from written context: A multicomponential skill. Language Learning, 51(3), 477-496. http://dx.doi.org/10.1111/0023-8333.00162.
Gablasova, D. (2012). Learning and expressing technical vocabulary through the medium ofL1 and L2 by Slovak-English bilingual high-school students. PhD thesis. The University of Auckland. Available from: https://researchspace.auckland.ac.nz/handle/2292/19419
Gablasova, D. (2014). Learning and retaining specialized vocabulary from textbook reading: Comparison of learning outcomes through L1 and L2. The Modern Language Journal, 98(4), 976-991. http://dx.doi.org/10.1111/modl.12150.
Grabe, W. (2009). Reading in a second language: Moving from theory to practice. New York: Cambridge University Press.
Haynes, M., & Baker, I. (1993). American and Chinese readers learning from lexical familiarization in English texts. In T. Huckin, M. Haynes, & J. Coady (Eds.), Second language reading and vocabulary learning (pp. 130-152). Norwood, NJ: Ablex.
Heatley, A., Nation, I. S. P., & Coxhead, A. (2002). RANGE and FREQUENCY programs. Retrieved from http://www.vuw.ac.nz/lals/publications/software.aspx
Henriksen, B., Albrechtsen, D., & Haastrup, K. (2004). The relationship between vocabulary size and reading comprehension in the L2. Angles on the English-Speaking World, 4,129-140.
Horst, M., Cobb, T., & Meara, P. (1998). Beyond a clockwork orange: Acquiring second language vocabulary through reading. Reading in a Foreign Language, 11 (2), 207-223.
Huckin, T., & Coady, J. (1999). Incidental vocabulary acquisition in a second language. Studies in Second Language Acquisition, 21(02), 181-193.
Hulstijn, J. H. (2003). Incidental and intentional learning. In C. J. Doughty, & M. H. Long (Eds.), The handbook of second language acquisition (pp. 349-381). Oxford: Blackwell.
Hulstijn, J. H., Hollander, M., & Greidanus, T. (1996). Incidental vocabulary learning by advanced foreign language students: The influence of marginal glosses, dictionary use and reoccurrence of unknown words. The Modern Language Journal, 80(3), 327-339. http://dx.doi.org/10.1111/j.1540-4781.1996. tb01614.x.
Jenkins, J. R., & Dixon, R. (1983). Vocabulary learning. Contemporary Educational Psychology, 8(3), 237-260.
Jiang, N. (2000). Lexical representation and development in a second language. Applied Linguistics, 21(1), 47-77. http://dx.doi.org/10.1093/applin/21.1.47.
Johnson, C. J., & Anglin, J. M. (1995). Qualitative developments in the content and form of children’s definitions. Journal of Speech and Hearing Research, 38(3), 612-629. http://dx.doi.org/10.1044/jshr.3803.612.
Koda, K. (2004). Insight into second language reading: A cross-linguistic approach. New York: Cambridge University Press.
Laufer, B. (1989). A factor of difficulty in vocabulary learning: Deceptive transparency. AILA Review, 6(1), 10-20.
Laufer, B., & Girsai, N. (2008). Vocabulary learning: A case for contrastive analysis and translation. Applied Linguistics, 29(4), 694-716. http://dx.doi.org/10. 1093/applin/amn018.
Laufer, B., & Yano, Y. (2001). Understanding unfamiliar words in a text: Do L2 learners understand how much they don’t understand? Reading in a Foreign Language, 13(2), 549-566. http://nflrc.hawaii.edu/rfl/Pastlssues/rfl132laufer.pdf
Lessard-Clouston, M. (2006). Breadth and depth specialized vocabulary learning in theology among native and non-native English speakers. Canadian Modern Language Review/La Revue canadienne des langues vivantes, 63(2), 175-198. http://dx.doi.org/10.3138/cmlr.63.2.175.
Meara, P. (2005). Designing vocabulary tests for English, Spanish and other languages. In C. S. Butler, M. de los Ángeles Gómez-Gonzáles, & S. Doval-Suárez (Eds.), The dynamics of language use: Functional and contrastive perspectives (pp. 271-285). Amsterdam: John Benjamins.
Mezek, S. (2013). Learning terminology from reading texts in English: The effects of note-taking strategies. Nordic Journal of English Studies, 13(1), 133-161. http://ub016045.ub.gu.se/ojs/index.php/njes/article/view/1800/1574
Mohan, B., & van Naerssen, M. (1997). Understanding cause-effect: Learning through language. Forum, 35(4), 22-29.
Nagy, W. E., Anderson, R. C., & Herman, P. A. (1987). Learning word meanings from context during normal reading. American Educational Research Journal, 24(2), 237-270. http://dx.doi.org/10.3102/00028312024002237.
Nation, l. S. P. (2001). Learning vocabulary in another language. New York: Cambridge University Press.
Nation, P., & Hwang, K. (1995). Where would general service vocabulary stop and special purpose vocabulary begin? System, 23, 35-41. http://dx.doi.org/10. 1016/0346-251X(94)00050-G.
Nation, I. S. P., & Webb, S. (2011). Content-based instruction and vocabulary learning. In E. Hinkel (Ed.), Vol 2. Handbook of research in second language teaching and learning (pp. 631-644)New York: Routledge.
Nelson-Herber, J. (1986). Expanding and refining vocabulary in content areas. Journal ofReading, 29(7), 626-633. http://www.jstor.org/stable/40029690
Paribakht, T. S., & Wesche, M. (1997). Vocabulary enhancement activities and reading for meaning in second language vocabulary acquisition. In J. Coady, & T. Huckin (Eds.), Second language vocabulary acquisition (pp. 174-200). Cambridge: Cambridge University Press.
Paribakht, T. S., & Wesche, M. (1999). Reading and «incidental» L2 vocabulary acquisition. Studies in Second Language Acquisition, 21(02), 195-224.
Parry, K. (1991). Building a vocabulary through academic reading. TESOL Quarterly, 25(4), 629-653. http://dx.doi.org/10.2307/3587080.
Parry, K. (1993). Too many words: Learning the vocabulary of an academic subject. In T. Huckin, M. Haynes, & J. Coady (Eds.), Second language reading and vocabulary learning (pp. 109-129). Norwood, NJ: Ablex.
Pearson, J. (1998). Terms in context. Amsterdam: John Benjamins.
Roebuck, R. (1998). Reading and recall in L1 and L2: A sociocultural approach. Stanford: Ablex.
Rott, S. (1999). The effect of exposure frequency on intermediate language learners’ incidental vocabulary acquisition and retention through reading. Studies in Second Language Acquisition, 21 (4), 589-619.
Ryan, G. (2012). Technical vocabulary acquisition through texts. A corpus and a case study in theology classroom. Saarbrücken: Lambert Academic Publishing.
Schmitt, N. (2008). Review article: Instructed second language vocabulary learning. Language Teaching Research, 12(3), 329-363. http://dx.doi.org/10.1177/ 1362168808089921.
Sonaiya, R. (1991). Vocabulary acquisition asa process of continuous lexical disambiguation. IRAL, 29(4), 273-284. http://dx.doi.org/10.1515/iral.1991.29.4.273.
Swanborn, M. S. L., & de Glopper, K. (1999). Incidental word learning while reading: A meta-analysis. Review of Educational Research, 69(3), 261-285. http:// dx.doi.org/10.3102/00346543069003261.
TakaSc, V. P. (2008). Vocabulary learning strategies and foreign language acquisition. Clevedon, UK: Multilingual Matters.
Vidal, K. (2003). Academic listening: A source of vocabulary acquisition? Applied Linguistics, 24(1), 56-89. http://dx.doi.org/10.1093/applin/24.156.
Vidal, K. (2011). A comparison of the effects of reading and listening on incidental vocabulary acquisition. Language Learning, 61(1), 219-258. http://dx.doi. org/10.1111/j.1467-9922.2010.00593.x.
Webb, S. (2007). The effects of repetition on vocabulary knowledge. Applied Linguistics, 28(1), 46-65. http://dx.doi.org/10.1093/applin/aml048.
Webb, S. (2008). The effects of context on incidental vocabulary learning. Reading in a Foreign Language, 20(2), 232-245. http://nflrc.hawaii.edu/rfl/ October2008/webb/webb.pdf
Wesche, M., & Paribakht, T. S. (2010). Lexical inferencing in first and second language: Cross-linguistic dimensions. Bristol: Multilingual Matters.
Wikibooks. (2007). A concise New Zealand history. Available online from: http://en.wikibooks.org/wiki/New_Zealand_History
Woodward-Kron, R. (2008). More than just jargon — The nature and role of specialist language in learning disciplinary knowledge. Journal of English for
Academic Purposes, 7(4), 234-249. http://dx.doi.org/10.1016/jjeap.2008.10.004. Zaki, H., & Ellis, R. (1999). Learning vocabulary through interacting with a written text. In R. Ellis (Ed.), Learning a second language through intraction (pp. 151169). Amsterdam: John Benjamins.
Dana Gablasova is a Senior Research Associate at Lancaster University. She is the co-author of the New General Service List which appeared in Applied Linguistics. Her research interests include the learning and use of disciplinary language by L1 and L2 speakers, advanced spoken production and vocabulary acquisition.