
Excel — это инструмент для проведения различных видов анализа, таких как прогнозы. В данном примере рассмотрим, как использовать Excel для составления прогноза с использованием модели Хольта-Уинтерса. Готовый файл с прогнозом можно скачать в конце примера.
Как сделать модель Хольта-Винтерса для расчета прогноза в Excel
Мы будем строить нашу модель прогноза по Хольту-Винтерсу на основе статистических данных, взятых из аэропорта. Используя модель, мы попытаемся предсказать, сколько пассажиров будет обслуживаться в иностранном регулируемом воздушном сообщении в 2016-2018 годах. В нашей таблице будут столбцы, указывающие: C(Yt) — количество обслуживаемых пассажиров, D(Ft) — оценка случайных вариаций модели, E(St) — оценка тренда для модели, F(Yt*) — истекший и реальный прогнозы, G(yt-yt*);H(|yt-yt*|);I((yt-yt*)2) — расчеты, необходимые для расчета показателей MAE, MSE, RMSE, MN — альфа и бета параметры для модели.
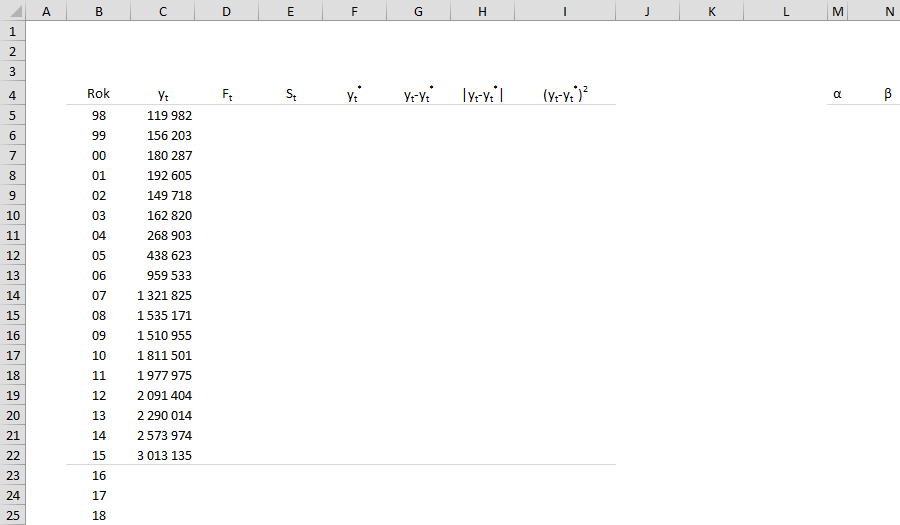
Составим прогноз с учетом всех правил модели Хольта-Винтерса используя формулы Excel и на основе полученных данных составим график для визуального анализа.
Метод прогноза по модели Хольта-Винтерса в Excel
Модель Хольта-Винтерса является одним из методов прогнозирования с использованием так называемых экспоненциальное сглаживание. Сглаживание состоит в создании взвешенного скользящего среднего, вес которого определяется по схеме — чем старше информация об изучаемом явлении, тем меньше значение для текущего прогноза. Чтобы построить модель, примите следующие предположения и формулы.
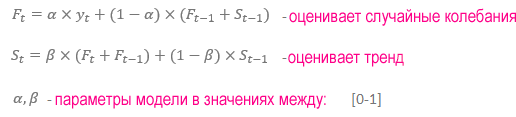
Модель рассчитывает прогнозы с истекшим сроком, то есть те, которые относятся к периоду, в котором фактическое значение уже было реализовано, и реальные прогнозы на период, который еще не произошел.

Первые значения F1 и S1 обычно:
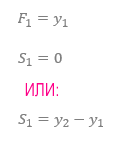
Для оценки точности прогнозов модели, так называемой фактическая ошибка просроченных прогнозов с использованием показателей:
Средняя абсолютная ошибка — сообщает нам, насколько в среднем за период прогнозирования фактические значения прогнозируемой переменной будут отклоняться относительно абсолютного значения от прогнозов.
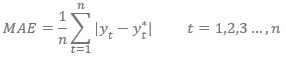
Средняя квадратическая ошибка — это средняя разница в квадрате отклонений между фактическими реализациями прогнозируемой переменной и прогноза.
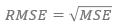
где Yt* — прогнозы истекли.
Среднеквадратичная ошибка (RMSE — Root Mean Square Error) — измеряет, насколько отклонение реализации прогнозируемой переменной от рассчитанных прогнозов.
Созданную модель можно считать хорошей, если отношение RMSE / фактического прогнозирования составляет менее 10%. Однако на практике лучшим тестом для оценки эффективности модели будет сравнение прогнозов, которые она создает, с фактическими значениями.
Формулы для модели составления прогноза Хольта-Винтерса в Excel
Теперь, согласно сделанным в начале предположениям, приведем начальные значения для параметров F1 и S1. В нашем случае это будет y1 = F1 и y2-y1 = S1. Далее мы вводим альфа и бета параметры, временно принимая их значения равными 0,4 (позже мы будем оптимизировать данные с помощью инструмента «Поиск решения» Солвера).
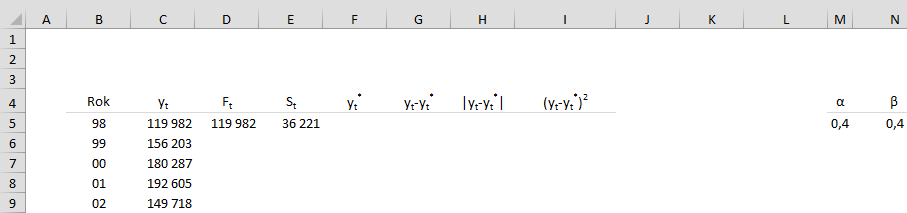
На следующем шаге мы вычисляем Ft и St одновременно в соответствии с приведенными выше формулами, перетаскивая формулы вниз.
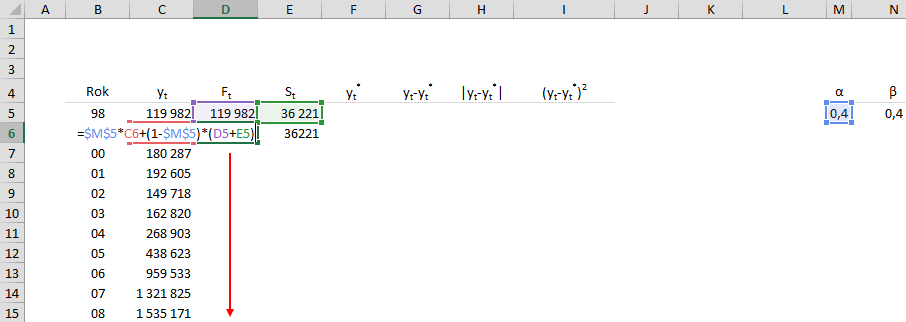
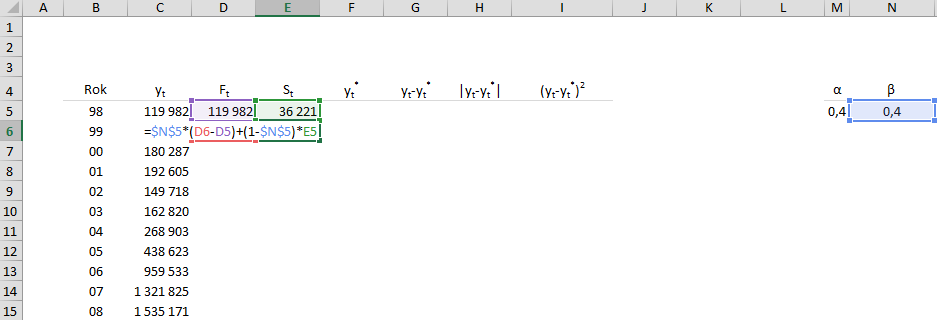
Перейдем к столбцу F, в котором с помощью формул рассчитываем, что для 1998-2015 годов прогнозы истекли, а для 2016-2018 годов — реальные прогнозы.
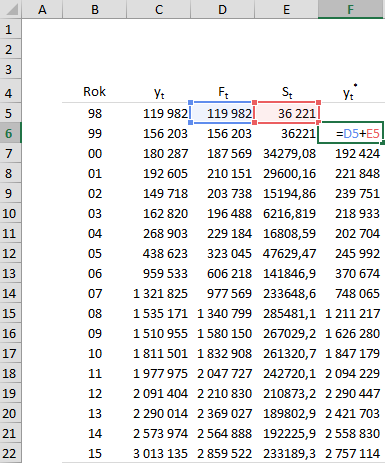
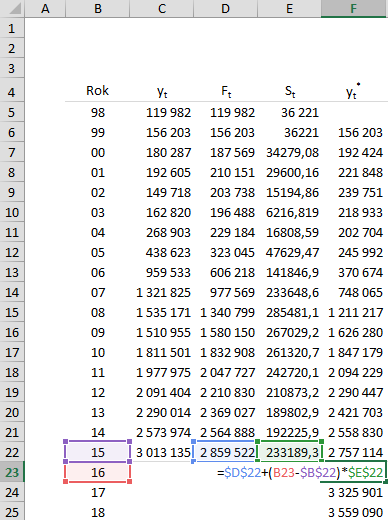
Мы заполняем столбцы GI, которые в данный момент будут использоваться для расчета фактической ошибки прогнозов с истекшим сроком (для получения абсолютного значения в столбце H мы можем использовать функцию Excel =ABS()).
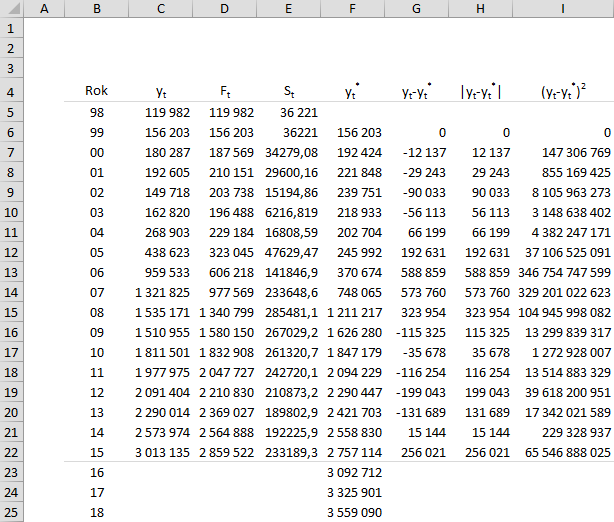
Затем, используя функцию =СРЗНАЧ() и =КОРЕНЬ(), мы вычисляем вышеуказанные индикаторы ошибок MAE, MSE и RMSE.

Когда мы уже рассчитали показатели, мы можем приступить к оптимизации альфа- и бета-параметров, чтобы индекс MAE был как можно меньше. Для этого мы будем использовать аналитический инструмент в Excel «Поиск решения», доступный на вкладке «ДАННЫЕ» в группе «Анализ». Параметры поиска решения устанавливаются так, чтобы минимизировать индекс MAE, изменяя ячейки, помеченные как альфа и бета, закрытые в интервале [0-1].
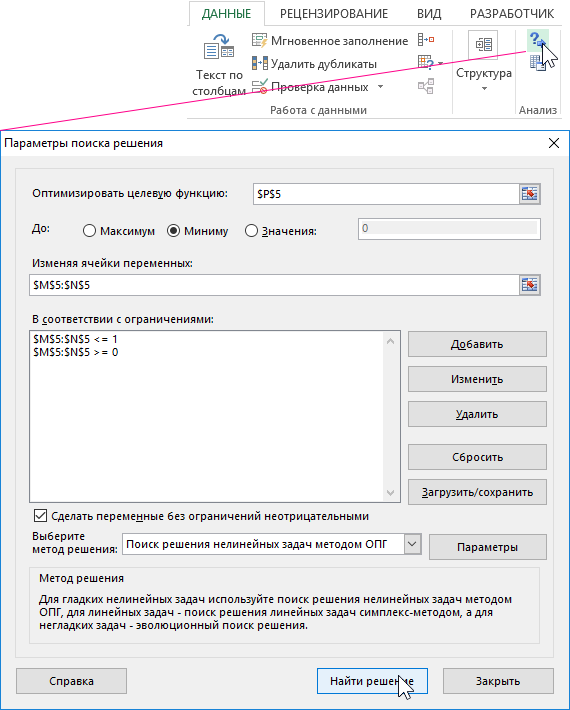
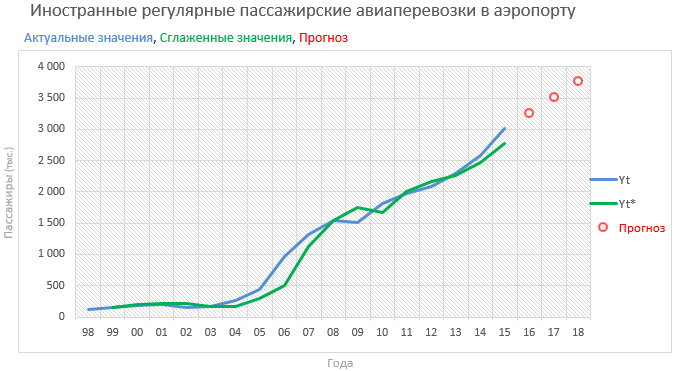
После нажатия кнопки «Найти решение» и сохранения полученных результатов параметры альфа- и бета-сглаживания должны быть a = 1 и b = 0.228657122399511. На этом этапе мы можем предварительно проверить, может ли наша модель использоваться в качестве эффективного инструмента прогнозирования. Для этой цели мы рассчитываем коэффициент приемлемости прогноза, определенный формулой RMSE / фактическим прогнозом для последующих периодов T16-T18. В нашем случае на 2016 год это 5%, поэтому прогноз можно считать достоверным. Наконец, стоит визуализировать весь анализ на графике, принимая реальные значения и прогнозы в виде серии данных.
Скачать пример прогноза по модели Хольта-Винтерса в Excel
Когда у нас есть прогноз, ничего не остается делать, кроме как следить за новыми данными, чтобы проверить, имеет ли смысл использовать модель. Из того, что можно найти на одном из информационных порталов о авиаперелетах данной компании, общее количество ее обслуженных пассажиров в 2017 году составило более 4,6 млн. человек. Поэтому высокая вероятность, что прогнозируемые нами значения работают на практике.
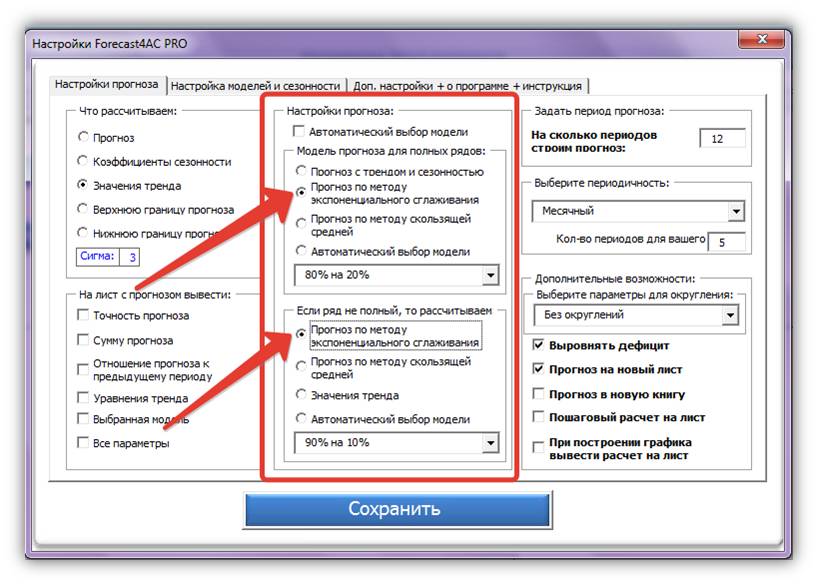
1. В настройках прогноза в разделе «Настройки прогноза» выбираем «Прогноз по методу экспоненциального сглаживания»:
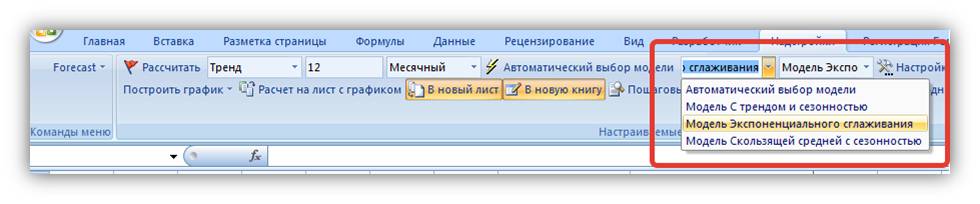
или на панели Excel «Модель Экспоненциального сглаживания» (можно выбрать если не нажата кнопка «Автоматический выбор модели»):
2. Выбираем, какой у нас временной ряд (дневной, месячный, квартальный или введите количество периодов в цикле):

3. Задаем, на сколько периодов рассчитываем прогноз:

4. Для автоматического подбора модели и коэффициентов сглаживания ставим галочки «Автоматический выбор модели». Аналогично с коэффициентами сглаживания.
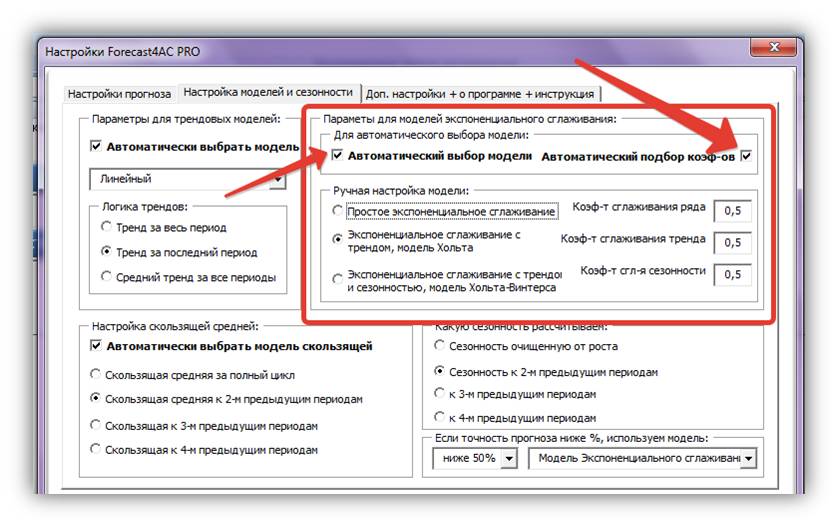
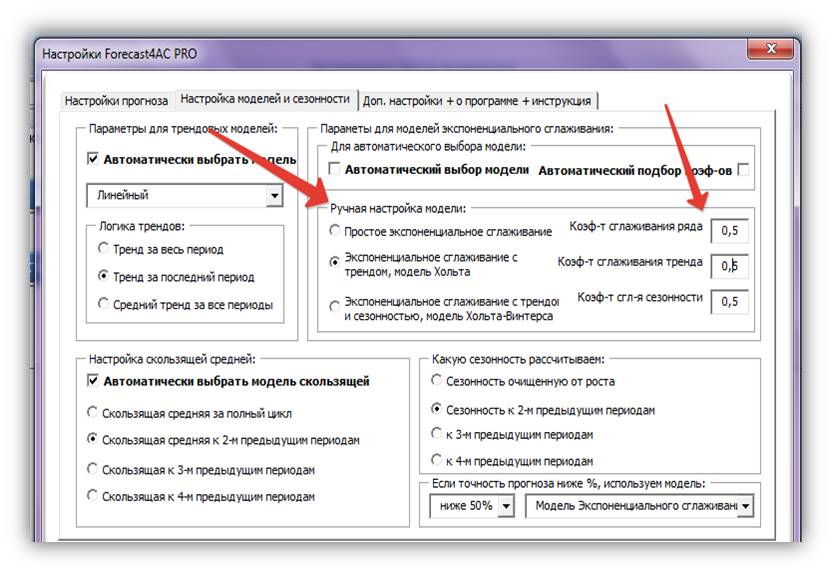
5. Для ручной настройки параметров модели экспоненциального сглаживания снимаем галочки «Автоматический выбор модели» и»Автоматический подбор коэффициентов».
Настраиваем параметры модели в области настроек «Параметры для модели экспоненциального сглаживания»:
Выбираем одну из трех моделей экспоненциального сглаживания (простое, Хольта или Хольта-Винтерса);
Вводим коэффициенты сглаживания:
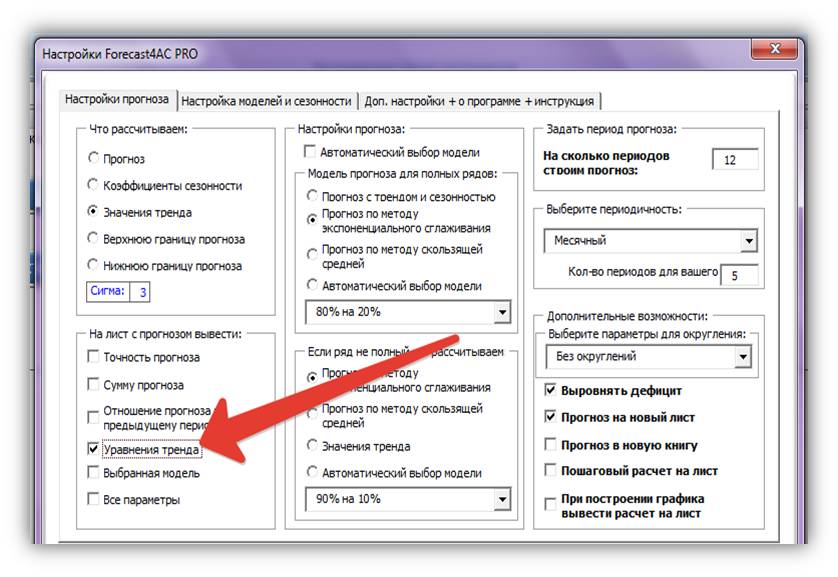
6. Для того, чтобы вывести коэффициенты сглаживания для каждого временного ряда, вы можете поставить галочку «уравнение тренда» в области «На лист с прогнозом».
7. Сохраняем настройки, открываем любой файл Excel с данными, на основании которых хотим сделать прогноз, например, как этот файл продажи по месяцам.
Важно, чтобы данные не содержали промежуточных итогов по столбцам, иначе они попадут в расчет прогноза.
8. Устанавливаем курсор мыши в ячейку, с которой хотите, чтобы программа рассчитала прогноз (ячейку выделил жёлтым цветом).
9. Нажимаем кнопку с «Рассчитать».
Готово! Прогноз по методу экспоненциального сглаживания рассчитан.
Важно! Программа начнет расчет прогноза с той ячейки с данными, в которую вы установите курсор. Например, если вы установите курсор не в январь, который выделен желтым во вложенном файле, а установите на март, то программа сделает расчет начиная с марта.
.
Составляющие временного ряда
При анализе временного ряда выделяют три составляющие: тренд, сезонность и шум. Тренд — это общая тенденция, сезонность,
как следует из названия — влияния периодичности (день недели, время года и т.д.) и, наконец, шум — это случайные факторы.
Что бы понять отличие этих трёх величин, смоделируем функцию расстояния от земли до луны. Известно, что в среднем луна
каждый год отдаляется на 4 см — это тренд, в течение дня луна совершает оборот вокруг земли и расстояние колеблется
от ~362600 км до ~405400 км — это сезонность. Шум — это «случайные» факторы, например, влияние других планет.
Если мы изобразим сумму этих трёх графиков, то мы получим временной ряд — функцию, показывающую изменение расстояния от земли
до луны во времени.
Тренд. Методы сглаживания
Методы сглаживания необходимы для удаления шума из временного ряда. Существуют различные способы сглаживания, основные — это
метод скользящей средней и метод экспоненциального сглаживания.
Метод скользящей средней
Идея метода скользящего среднего заключается в смещении точки графика на среднее значение некоторого интервала.
В качестве интервала берут нечётное количество участков, например, три — предыдущий, текущий и следующий периоды,
находится среднее и принимается в качестве сглаженного значения:
Si = Σkj=-k(xi+j)/(2k+1)
У данного метода есть проблема: случайное высокое или низкое значение сильно влияют на скользящую линию. В качестве
решения были введены веса. Для распределение веса используют оконные функции, основные оконные функции — это окно Дирихле
(прямоугольная функция), В-сплайны, полиномы, синусоидальные и косинусоидальные:
График 4. Окно Ганна для n=5 (косинусоидальное окно)
График 5. Синусоидальное окно для n=5
Минусы использования скользящей средней — это сложность вычислений и некорректные данные на концах графика.
| Исходные данные | Скользящая средняя | Взвешенная скользящая средняя (синусоидальное окно, n=5) | Взвешенная скользящая средняя (окно Ганна, n=5) |
| 800 | 831 | 283 | 0 |
| 861 | 917 | 470 | 400 |
| 1090 | 1018 | 549 | 431 |
| 1322 | 1063 | 658 | 545 |
| 980 | 1179 | 696 | 661 |
| 1325 | 1299 | 713 | 490 |
| 1568 | 1191 | 782 | 663 |
| 891 | 1314 | 784 | 784 |
| 1472 | 1401 | 760 | 446 |
| 1673 | 1372 | 821 | 736 |
| 1450 | 1349 | 935 | 837 |
| 800 | 1673 | 800 | 725 |
| 2768 | 1815 | 946 | 400 |
| 2243 | 1891 | 1230 | 1384 |
| 1752 | 2157 | 1360 | 1122 |
| 1865 | 2105 | 1164 | 876 |
| 2560 | 2348 | 1229 | 933 |
| 3214 | 2582 | 1538 | 1280 |
| 2690 | 3043 | 1732 | 1607 |
| 3707 | 3204 | 2528 | 1345 |
| Таблица 1. Сглаживание методом скользящей средней |
График 6. Сглаживание скользящей средней. Красный — исходные данные, персиковый — скользящая средняя,
жёлтая и охра — скользящая средняя, взвешенная синусоидальным окном с n=7 и n=3 соответственно
Как видно из графика, увеличение n выдаёт более плавную функцию, таким образом нивелируя более мелкие колебания во временном ряду.
Обратите внимание, что при сглаживании не имеет значения, совпадает график среднего с графиком данных или нет,
целью является построение правильной формы.
Метод экспоненциального сглаживания
Метод экспоненциального сглаживания получил своё название потому, что в сглаженной функции экспоненциально убывает влияние предыдущего периода
с неким коэффициентом чувствительности α. Сглаженное значение находится как разница между предыдущим действительным значением и
рассчитанным значением:
D’t = α·Dt-1 + (1-α)·D’t-1
Коэффициент чувствительности, α, выбирается между 0 и 1, в качестве базиса используют значение 0,3. Если есть достаточная выборка,
то коэффициент подбирается путём оптимизации.
| Исходные данные | Экспоненциальное сглаживание, α=0,1 | Экспоненциальное сглаживание, α=0,6 |
| 800 | 800 | 800 |
| 861 | -640 | 160 |
| 1090 | 662 | 453 |
| 1322 | -487 | 473 |
| 980 | 571 | 604 |
| 1325 | -416 | 346 |
| 1568 | 507 | 657 |
| 891 | -300 | 678 |
| 1472 | 359 | 263 |
| 1673 | -176 | 778 |
| 1450 | 326 | 693 |
| 800 | -148 | 593 |
| 2768 | 213 | 243 |
| 2243 | 85 | 1564 |
| 1752 | 148 | 720 |
| 1865 | 42 | 763 |
| 2560 | 149 | 814 |
| 3214 | 122 | 1210 |
| 2690 | 212 | 1444 |
| 3707 | 78 | 1036 |
| Таблица 2. Экспоненциальное сглаживание |
График 7. Экспоненциальное сглаживание с α=0,1 (персиковая линия) и α=0,6 (жёлтая линия)
Методы прогнозирования
Методы прогнозирования основываются на выявлении тенденции во временном ряду и последующем использовании найденного значения
для предсказания будущих значений. В методах прогнозирования выделяют тренд и сезонность, в общем случае, все типы сезонности могут
быть найдены последовательными итерациями. Например, при анализе данных за год, можно выделить сезонность времени года, а в оставшемся
тренде найти сезонность по дням недели и так далее.
Двойное экспоненциальное сглаживание
Двойное экспоненциальное сглаживание выдаёт сглаженное значение уровня и тенденции.
Внимание! Может возникнуть путаница, метод Хольт-Винтерса отличается терминами: тренд, сезонность и шум
соответственно называются уровень, тренд и сезонность.
Smooth — сглаживание, сглаженный уровень на период τ, sτ, зависит от значения уровня на текущий период (Dτ),
тренда за предыдущий период (tτ-1) и рассчитанного сглаженного значения на предыдущий период (sτ-1):
sτ = αDτ + (1 — α)(sτ-1 + tτ-1)
Trend — тенденция, тренд на период τ, tτ, зависит от рассчитанного сглаженного значения за предыдущий и текущий периоды
(sτ и sτ-1) и от предыдущей тенденции:
tτ = β(sτ-sτ-1) + (1-β)tτ-1
Рассчитанные по данным формулам уровень и тренд могут быть использованы в прогнозировании:
D’τ+h = sτ + h·tτ
При расчёте, значения s и t для первого периода назначают s1 = D1 и t=0
График 8. Данные (персиковая линия), экспоненциальное сглаживание — уровень (жёлтая линия), тренд
(линия цвета охры) и прогноз (чёрная линия) методом экспоненциального сглаживания
Метод Хольт-Винтерса
Метод Хольт-Винтерса включает в себя сезонную составляющую, т.е. периодичность. Существуют две разновидности метода —
мультипликативный и аддитивный. В отличие от двойного экспоненциального сглаживания, метод Хольт-Винтерса изучает также
влияние периодичности.
Общая идея нахождения значений сглаженного уровня, тренда и периодичности заключается в следующем: сглаженный уровень (s — smooth, иногда используют l — level)
— это базовый уровень значений, тренд (t — trend) — это показатель скорости роста, разница между сглаженными значениями текущего и предыдущего периода.
Для изучения периодичности (p — period), мы разбиваем данные на периоды размером k и выделяем влияние каждого элемента (1,2,…,k) периода на
сглаженный уровень.
Для более точных расчётов вводится показатель обратной связи.
В общем понимании, обратная связь — это влияние предыдущих значений
на новые: например, когда Вы начинаете говорить, Вы регулируете громкость своего голоса в зависимости от того, что слышат Ваши уши —
это и есть обратная связь.
Для начала расчётов, значения s, t и k, в самом простом виде, могут быть выбраны как sτ = Dτ, t = 0, p = 0.
k — длина выбранного периода:
sτ = α(Dτ — pτ-k) + (1 — α)(sτ-1 + tτ-1)
С поправкой на предыдущие значения tτ-k (обратная связь)
tτ = β(sτ-sτ-1) + (1-β)tτ-1
С поправкой на предыдущие значения pτ-k (обратная связь)
pτ = γ(Dτ — sτ) + (1-γ)pτ-k
Для прогнозирования используется следующая формула:
xτ+h = Dτ + htτ + pτ-k+h
Мультипликативный метод Хольт-Винтерса
Мультипликативный метод отличается от аддитивного тем, что параметры, влияющие на периодичность и сглаженный уровень
рассчитываются отношением:
pτ = γ(Dτ/sτ) + (1-γ)pτ-k
sτ = α(Dτ/pτ-k) + (1 — α)(sτ-1 + tτ-1)
tτ = β(sτ-sτ-1) + (1-β)tτ-1
Для прогнозирования используется следующая формула:
xτ+h = (Dτ + htτ)pτ-k+h
Метод Хольт-Винтерса в excel
Таблица для скачивания в форматах ods и
xls.
Качество прогнозирования
Проверка качества прогнозирования возможна в случае наличия достаточной выборки и является важной проверкой на достоверность
прогноза, для проверки и оптимизации значений α, β и γ необходимо построить прогноз на существующие данные,
например, если у нас в наличии данные за пять лет и мы хотим предсказать следующий год, то необходимо построить модель на первых
четырёх годах, проверить и оптимизировать коэффициенты для минимизации ошибки между прогнозом и данными на 5й год. После оптимизации
модель может быть перестроена с учётом последнего периода для повышения точности, далее следует построение прогноза.
Методы оптимизации будут описаны в отдельной статье, ниже представлен пример прогнозирования методом Хольт Винтерса.
График 9. Данные о посещаемости сайта за четыре недели
| # | Данные | s | t | p | s | t | p |
|---|---|---|---|---|---|---|---|
| 1 | 93 | 93 | 0 | 0 | 93 | 0 | 0 |
| 2 | 91 | 92 | -0.1 | -0.5 | 92 | -0.1 | 0.99 |
| 3 | 72 | 84 | -0.89 | -6 | 84 | -0.89 | 0.93 |
| 4 | 75 | 80 | -1.2 | -2.5 | 80 | -1.2 | 0.97 |
| 5 | 75 | 77 | -1.38 | -1 | 77 | -1.38 | 0.99 |
| 6 | 57 | 68 | -2.14 | -5.5 | 68 | -2.14 | 0.92 |
| 7 | 66 | 66 | -2.13 | 0 | 66 | -2.13 | 1 |
| 8 | 123 | 88 | 0.28 | 17.5 | 38 | -4.72 | 1.62 |
| 9 | 85 | 87 | 0.15 | -1.25 | 54 | -2.65 | 1.28 |
| 10 | 85 | 89 | 0.34 | -5 | 67 | -1.09 | 1.1 |
| 11 | 91 | 91 | 0.51 | -1.25 | 77 | 0.02 | 1.08 |
| 12 | 102 | 96 | 0.96 | 2.5 | 87 | 1.02 | 1.08 |
| 13 | 73 | 90 | 0.26 | -11.25 | 85 | 0.72 | 0.89 |
| 14 | 60 | 78 | -0.97 | -9 | 75 | -0.35 | 0.9 |
| 15 | 99 | 79 | -0.77 | 18.75 | 69 | -0.92 | 1.53 |
| 16 | 108 | 91 | 0.51 | 7.88 | 75 | -0.23 | 1.36 |
| 17 | 98 | 96 | 0.96 | -1.5 | 80 | 0.29 | 1.16 |
| 18 | 104 | 100 | 1.26 | 1.38 | 87 | 0.96 | 1.14 |
| 19 | 83 | 93 | 0.43 | -3.75 | 84 | 0.56 | 1.03 |
| 20 | 68 | 88 | -0.11 | -15.63 | 81 | 0.2 | 0.86 |
| 21 | 62 | 81 | -0.8 | -14 | 76 | -0.32 | 0.86 |
| 22 | 59 | 64 | -2.42 | 6.88 | 61 | -1.79 | 1.25 |
| 23 | 80 | 66 | -1.98 | 10.94 | 59 | -1.81 | 1.36 |
| 24 | 121 | 87 | 0.32 | 16.25 | 76 | 0.07 | 1.38 |
| 25 | 112 | 97 | 1.29 | 8.19 | 85 | 0.96 | 1.23 |
| 26 | 85 | 94 | 0.86 | -6.38 | 85 | 0.86 | 1.02 |
| 27 | 106 | 106 | 1.97 | -7.82 | 101 | 2.37 | 0.95 |
| 28 | 82 | 103 | 1.47 | -17.5 | 100 | 2.03 | 0.84 |
График 9. Пример предсказания посещаемости сайта на основе данных за четыре недели. Жёлтая линия — исходные данные, красная — прогноз на пятую
неделю на основе первых четырёх. Закрашена линия сглаженного уровня при α=0.4, β=0.1, γ=0.5
Пункт шестой — «Построение прогноза продаж: основные методы прогнозирования»
Наконец-то мы подобрались к самому основному шагу нашей карты данных — «Построение прогноза продаж». Здесь я вкратце расскажу, какие методы прогнозирования наиболее распространены и популярны и приведу формулы их использования. А в следующей части данной статьи, я расскажу об обработке получившегося прогноза: наложении сезонности, округлении, учете промо и так далее.
Напомню, что до этого мы проделали довольно большой путь: подготовили корректную историю продаж, очищенную от нестабильных показателей, рассчитали коэффициенты сезонности и промо-объемы будущих периодов и определились с элементами графического интерфейса (GUI) нашего будущего инструмента прогнозирования. А теперь, мы будем рассматривать методы прогнозирования и строить сам прогноз.
Классификация методов прогнозирования.
Методы прогнозирования делятся на две группы или класса: интуитивные (субъективные или качественные) и формализованные (объективные или количественные). Интуитивные методы прогнозирования — это такие методы, основой которых НЕ являются сухие расчеты, математика и статистика. Они, в первую очередь, основаны на оценках группы экспертов и предназначены для прогнозирования объемов новой позиции, у которой нет истории продаж. Либо для прогнозирования объемов позиции, история продаж которой настолько нестабильна, что невозможно подобрать под нее адекватную математическую модель. В пример можно привести такие методы, как «Метод Дельфи», «Мозговой штурм», «Опрос/анкетирование» и так далее, но в данной статье данные методы прогнозирования рассмотрены не будут.
Здесь будут рассмотрены следующие формализованные методы прогнозирования:
- Линейная регрессия
- Полиномиальный прогноз
- Экспоненциальное сглаживание
- Модель Хольта
- Модель Хольта-Винтерса
- Модель Тейла-Вейджа
Немного расскажу про каждый из них, а также затрону метод «прогнозирования по свойствам». А в конце статьи, помимо готового примера в Excel с формулами расчета, добавлю ссылки на некоторые источники информации о методах прогнозирования, может кому-то будет полезно.
Методы прогнозирования: метод линейной регрессии.
Построение прогноза с помощью метода линейной регрессии — один из наиболее простых, часто-встречающихся и распространенных (если рассматривать Excel) методов прогнозирования. Часто встречается он как раз из-за того, что в Excel его очень легко применить — достаточно воспользоваться функцией ЛИНЕЙН, ПРЕДСКАЗ или ТЕНДЕНЦИЯ, где исходными данными будут являться номера периодов и соответствующие им объемы продаж.
Для нахождения прогноза на период x, мы воспользуемся уравнением y=k*x+b, где k — угловой коэффициент, который находится с помощью метода наименьших квадратов (на основании предыдущих периодов x и соответствующих значений y), а b — это точка, в которой наш график пересекается с осью y. Данное уравнение описывает линию, которая называется линия тренда, которая показывает динамику продаж и прогнозы на последующие периоды.
На гистограмме ниже изображены столбцы с объемами продаж для соответствующего периода (номера недель по оси X), пунктирная линия, которая как раз является линией тренда и столбец c предсказанным значением (соответствует «продолжению» линии тренда):

Данный метод один из самых простейших, и чаще всего используется для прогнозирования более-менее стабильных и регулярных продаж, однако при максимально аккуратном «сглаживании» промо-объемов, он подойдет и для нестабильных рядов. Важно отметить, что если история продаж у нас не очень большая (менее 4-5 периодов), данный метод прогнозирования не рекомендуется к использованию.
Также важно, что если мы хотим добавить к прогнозному значению коэффициент сезонности, то для начала, перед расчетом прогнозного значения, историю продаж необходимо «выровнять», то есть очистить от сезонных колебаний. А уже потом считать прогноз и накладывать сезонность.
Хочу отметить, что в моем опыте работы данный метод прогнозирования в совокупности с корректным сглаживанием числового ряда, а также с корректными значениями планируемых промо-объемов, которые мне предоставлял отдел трейд-маркетинга, достигал достаточно высокой точности прогнозирования (выше 80%).
Методы прогнозирования: полиномиальный прогноз.
Построение прогноза с помощью полинома немного похоже на построение прогноза с помощью предыдущего метода. Здесь, для нахождения прогноза на последующие периоды вместо линейного уравнение, мы используем полином третьей степени вида y = a*x³+b*x²+c*x+d или полином второй степени вида y = a*x²+b*x+c, где коэффициенты a,b,c,d постоянны и находятся с помощью различных методов решения систем линейных уравнений, на основании предыдущих периодов x и соответствующим им объемов продаж y.
Если степень полинома будет выше третьей — линия, которой описывается наш числовой ряд будет максимально приближена к реальным значениям, но при этом будет не очень пригодна для построения прогноза (особенно, если строите прогноз сразу на несколько периодов). Как раз на примере ниже это очень заметно:

Полином пятой степени дает неудовлетворительные результаты в прогнозе.
Здесь используется полином пятой степени. Да, линия почти совпадает с фактическим значениям, но при этом даже невооруженным глазом видно, что прогноз на 31 и 32-ую неделю крайне неадекватный. Поэтому использовать полиномы выше третьей степени не рекомендуется.
Методы прогнозирования: модель на основе экспоненциального сглаживания.
Первоначально, модель экспоненциального сглаживания использовалась для сглаживания числового ряда. Однако, спустя какое-то время, данную модель немного видоизменили и приспособили для краткосрочного прогнозирования. Модель приемлема для нахождения прогноза только на 1 период вперед.
Для нахождения прогноза Y̅ на период t+1, используется следующая формула:

где yt — значение факта на период t, Y̅t — сглаженное значение на период t, а α — коэффициент или параметр сглаживания, который принимает значение 0<α<1.
При применении данной модели все сводится к выбору оптимального значения α. Следует отметить, что чем меньше значение α, тем больше модель учитывает фактические показатели почти всех прошедших периодов. Если же значение близится к единице, то на модель будет оказывать наибольшее влияние только несколько последних периодов, а сам числовой ряд будет наименее сглажен.
Единого метода определения α не существует, но для его нахождения можно выбрать следующие варианты:
- В некоторых источниках рекомендуют использовать значение 0,2<α<0,3, поэтому просто предлагается оставить параметр сглаживания примерно в этих рамках.
- Использовать формулу α = 2/(n-1), где n — количество периодов для экспоненциального сглаживания. Например, грубо говоря, если n=8, то модель будет учитывать значения последних восьми периодов в числовом ряду, и α будет равен 0,25.
Также, возникает проблема нахождения Y̅1: для его расчета необходимо предыдущее значение факта y на период t = 0, а у нас такого, естественно, нет. Поэтому, за Y̅1 можно принять значение y1.
Гистограмма с линией экспоненциального сглаживания по которой строится прогноз выглядит так (α=0,4):

Данный метод неплохой, но он не учитывает тренд продукции и сезонные колебания (поэтому первоначально числовой ряд нужно очистить от сезонности, как и в линейной регрессии), то есть лучше всего подходит для стабильных числовых рядов. Плюс ко всему, как я уже говорил, подходит для построения прогноза только на 1 период вперед. Для числового ряда с учетом тренда можно использовать улучшенную модель экспоненциального сглаживания (метод Хольта), а если еще необходимо учесть сезонность, то можно использовать Метод Хольта-Винтерса или Метод Тейла-Вейджа, о которых я напишу далее.
Методы прогнозирования: модель на основе экспоненциального сглаживания с учетом тренда (Метод Хольта).
Данная модель — усовершенствованная версия модели экспоненциального сглаживания с учетом тренда продаж.
Формула нахождения прогноза Y̅ на период t+d следующая:

где d — порядковый номер периода, на который мы делаем прогноз (то есть если числовой ряд состоит из 10 периодов, а прогноз мы делаем на 11, то d =1), а At и Bt — адаптивные переменные: A — экспоненциально-сглаженное фактическое значение , а B — значение тренда. Находятся данные переменные по следующим формулам:

И как в случае с обычным экспоненциальным сглаживанием, здесь тоже есть параметры, но их уже два: α1 и α2. И оба они принимают значения ∈(0,1). Подбирать эти параметры нужно так, чтобы прогнозы, построенные на уже имеющиеся периоды с фактическими значениями, с помощью полученной модели, давали наименьшую ошибку прогноза (во многих источниках рекомендуют использовать RMSE или MAPE). Напомню, для нахождения RMSE используется следующая формула:
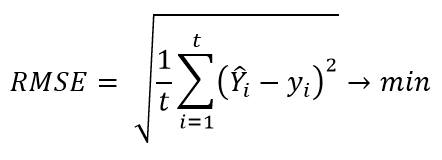
Для нахождения A1 должно использоваться A0, но так как его не существует, мы, опять же, как и в случае с обычным экспоненциальным сглаживанием, вместо него используем фактическое значение y1, а вместо B1 используем 0.
Методы прогнозирования: модель на основе экспоненциального сглаживания с учетом тренда и мультипликативной сезонности (Метод Хольта-Винтерса).
Данная модель — тоже усовершенствованная версия модели экспоненциального сглаживания, только здесь помимо тренда, добавлена еще и мультипликативная сезонность. Подходит модель для работы с числовыми рядами, в которых присутствует ярко-выраженная сезонность или цикличность.
Формула расчета прогноза Y̅ на период t+d следующая:

где d — порядковый номер прогнозируемого периода (как и в предыдущем примере), L — это количество периодов в одном цикле (для месячного прогнозирования — 12, для квартального — 4, для ежедневного — 7). At и Bt — адаптивные переменные: A — экспоненциально-сглаженное фактическое значение, а B — значение тренда. А C с большим индексом «t+(d mod L) — L» — значение сезонности в процентах. Индекс переменной C может немного смутить, но на самом деле все проще, чем кажется: просто используем C из прошлого цикла соответствующего периода (для прогноза на март используем коэффициент сезонности марта прошлого цикла).
Сами переменные A,B и C рассчитываются по следующим формулам:

При использовании Метода Хольта-Винтерса рассчитывать коэффициенты сезонности перед построением не нужно, их расчет включен в формулу. Однако очищать числовой ряд от неадекватных значений все так же необходимо. Также, стоит отметить, что для корректной «работы» данной модели, история продаж должна содержать как минимум несколько циклов для корректного расчета сезонности (для месячного прогнозирования, необходима история продаж как минимум за 2-3 последних года).
Особенности расчета начальных переменных:
- Для A1 можно использовать y1
- Для B1 можно использовать 0
- В первом цикле при расчете A мы должны ссылаться на C прошлых циклов, но так как их нет, вместо C можно использовать 1 (то есть, пренебречь сезонностью)
- А для расчета сезонностей самого первого цикла(!) для каждого периода можно использовать формулу Ct=yt/At
Параметры α1,α2,α3 ∈(0,1), как и в предыдущей модели, подбираются путем минимизации ошибки прогноза (RMSE или MAPE).
Методы прогнозирования: модель на основе экспоненциального сглаживания с учетом тренда и аддитивной сезонности (Метод Тейла-Вейджа).
Данная модель также разработана на основе экспоненциального сглаживания, в которую добавлен тренд и сезонность, но теперь не мультипликативная, а аддитивная. Особенности здесь такие же, как и в методе Хольта-Винтерса. Основное отличие в том, что здесь сезонность является не коэффициентом, на который мы умножаем полученный прогноз, а целым числом, которое мы прибавляем или вычитаем из прогноза.
Формула расчета прогноза Y̅ на период t+d следующая:

где d — порядковый номер прогнозируемого периода (как и в предыдущем примере), L — это количество периодов в одном цикле (для месячного прогнозирования — 12, для квартального — 4, для ежедневного — 7). At и Bt — адаптивные переменные: A — сглаженное фактическое значение (с помощью экспоненты), а B — значение тренда. А C с большим индексом «t+(d mod L) — L» — значение сезонности в процентах.
Сами переменные A,B и C рассчитываются по следующим формулам:

Особенности расчета начальных переменных:
- Для A1 можно использовать y1
- Для B1 можно использовать 0
- В первом цикле при расчете A мы должны ссылаться на C прошлых циклов, но так как их нет, вместо C можно использовать 0 (то есть пренебречь сезонностью)
- А для расчета сезонностей самого первого цикла(!) для каждого периода можно использовать формулу Ct=yt-At
Параметры α1,α2,α3 ∈(0,1), как и в предыдущей модели, подбираются путем минимизации ошибки прогноза (RMSE или MAPE).
Методы прогнозирования: построение прогноза основанное на свойствах.
Данный способ довольно интересный, чаще всего используется для определения спроса какого-либо нового продукта. Его нельзя полноценно отнести к формализованному методу, но и интуитивным назвать его тоже нельзя.
Рассмотрим его суть на примере телевизора. Предположим, что этот телевизор — новинка на рынке и необходимо рассчитать его прогноз продаж. Для начала, мы рассматриваем свойства данного телевизора (его функции и характеристики), например такие:
- Диагональ экрана
- Фирма-изготовитель
- Разрешение экрана
- Наличие Smart-TV
- Возможность подключения USB
- Частота экрана
- Габариты
- Возможность крепления на стену
- Цвет
- Частота обновления экрана
- И так далее..
Далее, мы просматриваем статистику продаж других телевизоров и смотрим, как часто покупался какой-либо другой телевизор с тем или иным перечисленным свойством. И на основе всех этих данных, составляем некое уравнение, которое учтет частоту приобретения телевизора с каждым свойством по отдельности. И с помощью полученного уравнения рассчитаем примерный прогноз продаж нашей новинки.
Метод довольно грубый и не очень точный, однако при прогнозировании новинки с большим перечнем свойств, может очень сильно помочь. И да, телевизор — не совсем удачный продукт, так как он не является регулярным или с ярко-выраженной сезонностью, да и к тому же можно их всегда закупить побольше, так как у них нет таких сроков годности, как у пищевой продукции. Однако, именно как пример — он очень подходит, потому что максимально легок для восприятия.
Методы прогнозирования: итоги и полезные ссылки.
Здесь были рассмотрены самые распространенные и наиболее простые способы/методы прогнозирования. Помимо них существует еще и другие, в том числе и более сложные, например:
- Модели на основе авторегрессии и среднего скользящего (ARIMA или модель Бокса-Дженкинса, ARIMAX и SARIMA)
- Модели на основе нейронных сетей (построение прогноза с помощью искусственного интеллекта)
- Прогнозирование с помощью «бутстреппинга»
- И другие модели/способы/методы прогнозирования
Возможно, спустя какое-то время, по некоторым из них будут написаны отдельные статьи (либо будет расширена текущая).
Файл с примерами расчетов в Excel, можно скачать нажав на кнопку ниже:
Методы прогнозирования: скачать пример
Так как статья про методы прогнозирования получилась довольно большой, информация про «Обработку прогноза» вынесена в отдельную статью: «Прогнозирование, шаг 6.2: обработка прогноза».
Если вы хотите больше узнать больше информации по прогнозированию, изучить более сложные модели и методы прогнозирования, то вам могут пригодиться следующие ссылки:
- Диссертация кандидата технических наук Чучуевой И.А. — «Модель прогнозирования временных рядов по выборке максимального подобия»
- Блог Чучуевой Ирины на Хабре — mbureau
- Учебное пособие Тихонова Э.Е. — «Методы прогнозирования в условиях рынка» (хочу отметить, что Чучуева Ирина в своем блоге как раз опровергает некоторые суждения Тихонова, именно поэтому данное пособие, как и диссертация Ирины вызывают еще больший интерес)
- Учебник Лукашина Ю. П. «Адаптивные методы краткосрочного прогнозирования временных рядов» — можно найти в свободном доступе в интернете
- Ресурс, посвященный анализу данных и прогнозированию — MachineLearning.ru
- Статья «Прогнозирование временных рядов с помощью модели экспоненциального сглаживания Хольта-Винтерса»
- Учебное пособие Снитюка В.Е. «Прогнозирование. Модели. Методы. Алгоритмы»
- Статья Юрова В.М. «Моделирование нестационарных временных рядов с выраженными колебаниями с использованием инструментов Excel»
- Учебное пособие Арженовского С.В. «Статистические методы прогнозирования»
- Учебное пособие Сухарева М.Г. «Методы прогнозирования»
Анализ временных рядов
Составляющие временного ряда
При анализе временного ряда выделяют три составляющие: тренд, сезонность и шум. Тренд — это общая тенденция, сезонность, как следует из названия — влияния периодичности (день недели, время года и т.д.) и, наконец, шум — это случайные факторы.
Что бы понять отличие этих трёх величин, смоделируем функцию расстояния от земли до луны. Известно, что в среднем луна каждый год отдаляется на 4 см — это тренд, в течение дня луна совершает оборот вокруг земли и расстояние колеблется от
405400 км — это сезонность. Шум — это «случайные» факторы, например, влияние других планет. Если мы изобразим сумму этих трёх графиков, то мы получим временной ряд — функцию, показывающую изменение расстояния от земли до луны во времени.
Тренд. Методы сглаживания
Методы сглаживания необходимы для удаления шума из временного ряда. Существуют различные способы сглаживания, основные — это метод скользящей средней и метод экспоненциального сглаживания.
Метод скользящей средней
Идея метода скользящего среднего заключается в смещении точки графика на среднее значение некоторого интервала. В качестве интервала берут нечётное количество участков, например, три — предыдущий, текущий и следующий периоды, находится среднее и принимается в качестве сглаженного значения:
У данного метода есть проблема: случайное высокое или низкое значение сильно влияют на скользящую линию. В качестве решения были введены веса. Для распределение веса используют оконные функции, основные оконные функции — это окно Дирихле (прямоугольная функция), В-сплайны, полиномы, синусоидальные и косинусоидальные:
Минусы использования скользящей средней — это сложность вычислений и некорректные данные на концах графика.
| Исходные данные | Скользящая средняя | Взвешенная скользящая средняя (синусоидальное окно, n=5) | Взвешенная скользящая средняя (окно Ганна, n=5) |
| 800 | 858 | 283 | 0 |
| 915 | 869 | 482 | 400 |
| 892 | 985 | 528 | 458 |
| 1334 | 1069 | 621 | 446 |
| 1136 | 1067 | 692 | 667 |
| 905 | 1171 | 680 | 568 |
| 1310 | 1111 | 659 | 453 |
| 1094 | 1159 | 681 | 655 |
| 1328 | 1221 | 740 | 547 |
| 1151 | 1236 | 729 | 664 |
| 1370 | 1462 | 765 | 576 |
| 1999 | 1495 | 899 | 685 |
| 1460 | 1950 | 1000 | 1000 |
| 2971 | 1878 | 1244 | 730 |
| 1080 | 2260 | 1192 | 1486 |
| 3530 | 2495 | 1419 | 540 |
| 2400 | 2148 | 1498 | 1765 |
| 1582 | 2857 | 1504 | 1200 |
| 3914 | 2602 | 1512 | 791 |
| 2510 | 2669 | 2269 | 1957 |
| Таблица 1. Сглаживание методом скользящей средней |
Как видно из графика, увеличение n выдаёт более плавную функцию, таким образом нивелируя более мелкие колебания во временном ряду. Обратите внимание, что при сглаживании не имеет значения, совпадает график среднего с графиком данных или нет, целью является построение правильной формы.
Метод экспоненциального сглаживания
Метод экспоненциального сглаживания получил своё название потому, что в сглаженной функции экспоненциально убывает влияние предыдущего периода с неким коэффициентом чувствительности α. Сглаженное значение находится как разница между предыдущим действительным значением и рассчитанным значением:
Коэффициент чувствительности, α, выбирается между 0 и 1, в качестве базиса используют значение 0,3. Если есть достаточная выборка, то коэффициент подбирается путём оптимизации.
| Исходные данные | Экспоненциальное сглаживание, α=0,1 | Экспоненциальное сглаживание, α=0,6 |
| 800 | 800 | 800 |
| 915 | -640 | 160 |
| 892 | 668 | 485 |
| 1334 | -512 | 341 |
| 1136 | 594 | 664 |
| 905 | -421 | 416 |
| 1310 | 469 | 377 |
| 1094 | -291 | 635 |
| 1328 | 371 | 402 |
| 1151 | -201 | 636 |
| 1370 | 296 | 436 |
| 1999 | -129 | 648 |
| 1460 | 316 | 940 |
| 2971 | -138 | 500 |
| 1080 | 421 | 1583 |
| 3530 | -271 | 15 |
| 2400 | 597 | 2112 |
| 1582 | -297 | 595 |
| 3914 | 426 | 711 |
| 2510 | 8 | 2064 |
| Таблица 2. Экспоненциальное сглаживание |
Методы прогнозирования
Методы прогнозирования основываются на выявлении тенденции во временном ряду и последующем использовании найденного значения для предсказания будущих значений. В методах прогнозирования выделяют тренд и сезонность, в общем случае, все типы сезонности могут быть найдены последовательными итерациями. Например, при анализе данных за год, можно выделить сезонность времени года, а в оставшемся тренде найти сезонность по дням недели и так далее.
Двойное экспоненциальное сглаживание
Двойное экспоненциальное сглаживание выдаёт сглаженное значение уровня и тенденции.
Внимание! Может возникнуть путаница, метод Хольт-Винтерса отличается терминами: тренд, сезонность и шум соответственно называются уровень, тренд и сезонность.
Smooth — сглаживание, сглаженный уровень на период τ, sτ, зависит от значения уровня на текущий период (Dτ), тренда за предыдущий период (tτ-1) и рассчитанного сглаженного значения на предыдущий период (sτ-1):
sτ = αDτ + (1 — α)(sτ-1 + tτ-1)
Trend — тенденция, тренд на период τ, tτ, зависит от рассчитанного сглаженного значения за предыдущий и текущий периоды (sτ и sτ-1) и от предыдущей тенденции:
tτ = β(sτ-sτ-1) + (1-β)tτ-1
Рассчитанные по данным формулам уровень и тренд могут быть использованы в прогнозировании:
D’τ+h = sτ + h·tτ
При расчёте, значения s и t для первого периода назначают s1 = D1 и t=0
Метод Хольт-Винтерса
Метод Хольт-Винтерса включает в себя сезонную составляющую, т.е. периодичность. Существуют две разновидности метода — мультипликативный и аддитивный. В отличие от двойного экспоненциального сглаживания, метод Хольт-Винтерса изучает также влияние периодичности.
Общая идея нахождения значений сглаженного уровня, тренда и периодичности заключается в следующем: сглаженный уровень (s — smooth, иногда используют l — level) — это базовый уровень значений, тренд (t — trend) — это показатель скорости роста, разница между сглаженными значениями текущего и предыдущего периода. Для изучения периодичности (p — period), мы разбиваем данные на периоды размером k и выделяем влияние каждого элемента (1,2. k) периода на сглаженный уровень.
Для более точных расчётов вводится показатель обратной связи.
В общем понимании, обратная связь — это влияние предыдущих значений на новые: например, когда Вы начинаете говорить, Вы регулируете громкость своего голоса в зависимости от того, что слышат Ваши уши — это и есть обратная связь.
Для начала расчётов, значения s, t и k, в самом простом виде, могут быть выбраны как sτ = Dτ, t = 0, p = 0.
Для прогнозирования используется следующая формула:
Мультипликативный метод Хольт-Винтерса
Мультипликативный метод отличается от аддитивного тем, что параметры, влияющие на периодичность и сглаженный уровень рассчитываются отношением:
Для прогнозирования используется следующая формула:
Метод Хольт-Винтерса в excel
Таблица для скачивания в форматах ods и xls.
Качество прогнозирования
Проверка качества прогнозирования возможна в случае наличия достаточной выборки и является важной проверкой на достоверность прогноза, для проверки и оптимизации значений α, β и γ необходимо построить прогноз на существующие данные, например, если у нас в наличии данные за пять лет и мы хотим предсказать следующий год, то необходимо построить модель на первых четырёх годах, проверить и оптимизировать коэффициенты для минимизации ошибки между прогнозом и данными на 5й год. После оптимизации модель может быть перестроена с учётом последнего периода для повышения точности, далее следует построение прогноза.
Методы оптимизации будут описаны в отдельной статье, ниже представлен пример прогнозирования методом Хольт Винтерса.
Анализ временных рядов, тренд ряда динамики, точечная оценка прогноза
МЕТОДИЧЕСКИЕ РЕКОМЕНДАЦИИ
Анализ временных рядов
Временной ряд (или ряд динамики) – это упорядоченная по времени последовательность значений некоторой произвольной переменной величины. Тем самым, временной ряд существенным образом отличается от простой выборки данных. Каждое отдельное значение данной переменной называется отсчётом (уровнем элементов) временного ряда.
Временные ряды состоят из двух элементов:
- периода времени, за который или по состоянию на который приводятся числовые значения;
- числовых значений того или иного показателя, называемых уровнями ряда.
Временные ряды классифицируются по следующим признакам:
- по форме представления уровней: ряды абсолютных показателей, относительных показателей, средних величин;
- по количеству показателей, когда определяются уровни в каждый момент времени: одномерные и многомерные временные ряды;
- по характеру временного параметра: моментные и интервальные временные ряды. В моментных временных рядах уровни характеризуют значения показателя по состоянию на определенные моменты времени. В интервальных рядах уровни характеризуют значение показателя за определенные периоды времени. Важная особенность интервальных временных рядов абсолютных величин заключается в возможности суммирования их уровней. Отдельные же уровни моментного ряда абсолютных величин содержат элементы повторного счета. Это делает бессмысленным суммирование уровней моментных рядов;
- по расстоянию между датами и интервалами времени выделяют равноотстоящие – когда даты регистрации или окончания периодов следуют друг за другом с равными интервалами и неполные (неравноотстоящие) – когда принцип равных интервалов не соблюдается;
- по наличию пропущенных значений: полные и неполные временные ряды. Временные ряды бывают детерминированными и случайными: первые получают на основе значений некоторой неслучайной функции (ряд последовательных данных о количестве дней в месяцах); вторые есть результат реализации некоторой случайной величины;
- в зависимости от наличия основной тенденции выделяют стационарные ряды – в которых среднее значение и дисперсия постоянны и нестационарные – содержащие основную тенденцию развития.
Временные ряды, как правило, возникают в результате измерения некоторого показателя. Это могут быть как показатели (характеристики) технических систем, так и показатели природных, социальных, экономических и других систем (например, погодные данные). Типичным примером временного ряда можно назвать биржевой курс, при анализе которого пытаются определить основное направление развития (тенденцию или тренда).
Анализ временных рядов – совокупность математико-статистических методов анализа, предназначенных для выявления структуры временных рядов и для их прогнозирования. Сюда относятся, в частности, методы регрессионного анализа. Выявление структуры временного ряда необходимо для того, чтобы построить математическую модель того явления, которое является источником анализируемого временного ряда. Прогноз будущих значений временного ряда используется для эффективного принятия решений.
Прогноз, характеристики и параметры прогнозирования
Прогноз (от греч. 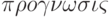 – предвидение, предсказание) – предсказание будущего с помощью научных методов, а также сам результат предсказания. Прогноз – это научная модель будущего события, явлений и т.п.
– предвидение, предсказание) – предсказание будущего с помощью научных методов, а также сам результат предсказания. Прогноз – это научная модель будущего события, явлений и т.п.
Прогнозирование, разработка прогноза; в узком значении – специальное научное исследование конкретных перспектив развития какого-либо процесса.
- по срокам: краткосрочные, среднесрочные, долгосрочные;
- по масштабу: личные, на уровне предприятия (организации), местные, региональные, отраслевые, мировые (глобальные).
К основным методам прогнозирования относятся:
- статистические методы;
- экспертные оценки (метод Дельфи);
- моделирование.
Прогноз – обоснованное суждение о возможном состоянии объекта в будущем или альтернативных путях и сроках достижения этих состояний. Прогнозирование – процесс разработки прогноза. Этап прогнозирования – часть процесса разработки прогнозов, характеризующаяся своими задачами, методами и результатами. Деление на этапы связано со спецификой построения систематизированного описания объекта прогнозирования, сбора данных, с построением модели, верификацией прогноза.
Прием прогнозирования – одна или несколько математических или логических операций, направленных на получение конкретного результата в процессе разработки прогноза. В качестве приема могут выступать сглаживание динамического ряда, определение компетентности эксперта, вычисление средневзвешенного значения оценок экспертов и т. д.
Модель прогнозирования – модель объекта прогнозирования, исследование которой позволяет получить информацию о возможных состояниях объекта прогнозирования в будущем и (или) путях и сроках их осуществления.
Метод прогнозирования – способ исследования объекта прогнозирования, направленный на разработку прогноза. Методы прогнозирования являются основанием для методик прогнозирования.
Методика прогнозирования – совокупность специальных правил и приемов (одного или нескольких методов) разработки прогнозов.
Прогнозирующая система – система методов и средств их реализации, функционирующая в соответствии с основными принципами прогнозирования. Средствами реализации являются экспертная группа, совокупность программ и т. д. Прогнозирующие системы могут быть автоматизированными и неавтоматизированными.
Прогнозный вариант – один из прогнозов, составляющих группу возможных прогнозов.
Объект прогнозирования – процесс, система, или явление, о состоянии которого даётся прогноз.
Характеристика объекта прогнозирования – качественное или количественное отражение какого-либо свойства объекта прогнозирования.
Переменная объекта прогнозирования – количественная характеристика объекта прогнозирования, которая является или принимается за изменяемую в течение периода основания и (или) периода упреждения прогноза.
Период основания прогноза – промежуток времени, за который используют информацию для разработки прогноза. Этот промежуток времени называют также периодом предыстории.
Период упреждения прогноза – промежуток времени, на который разрабатывается прогноз.
Прогнозный горизонт – максимально возможный период упреждения прогноза заданной точности.
Точность прогноза – оценка доверительного интервала прогноза для заданной вероятности его осуществления.
Достоверность прогноза – оценка вероятности осуществления прогноза для заданного доверительного интервала.
Ошибка прогноза – апостериорная величина отклонения прогноза от действительного состояния объекта.
Источник ошибки прогноза – фактор, способный привести к появлению ошибки прогноза. Различают источники регулярных и нерегулярных ошибок.
Верификация прогноза – оценка достоверности и точности или обоснованности прогноза.
Статистические методы прогнозирования – научная и учебная дисциплина, к основным задачам которой относятся разработка, изучение и применение современных математико-статистических методов прогнозирования на основе объективных данных; развитие теории и практики вероятностно-статистического моделирования экспертных методов прогнозирования; методов прогнозирования в условиях риска и комбинированных методов прогнозирования с использованием совместно экономико-математических и эконометрических (как математико-статистических, так и экспертных) моделей. Научной базой статистических методов прогнозирования является прикладная статистика и теория принятия решений.
Простейшие методы восстановления используемых для прогнозирования зависимостей исходят из заданного временного ряда, т. е. функции, определённой в конечном числе точек на оси времени. Временной ряд при этом часто рассматривается в рамках той или иной вероятностной модели, вводятся другие факторы (независимые переменные), помимо времени, например, объем денежной массы. Временной ряд может быть многомерным. Основные решаемые задачи – интерполяция и экстраполяция. Метод наименьших квадратов в простейшем случае (линейная функция от одного фактора) был разработан К. Гауссом в 1794–1795 гг. Могут оказаться полезными предварительные преобразования переменных, например, логарифмирование. Наиболее часто используется метод наименьших квадратов при нескольких факторах.
Оценивание точности прогноза (в частности, с помощью доверительных интервалов) – необходимая часть процедуры прогнозирования. Обычно используют вероятностно-статистические модели восстановления зависимости, например, строят наилучший прогноз по методу максимального правдоподобия. Разработаны параметрические (обычно на основе модели нормальных ошибок) и непараметрические оценки точности прогноза и доверительные границы для него (на основе Центральной Предельной Теоремы теории вероятностей). Применяются также эвристические приемы, не основанные на вероятностно-статистической теории: метод скользящих средних, метод экспоненциального сглаживания.
Многомерная регрессия, в том числе с использованием непараметрических оценок плотности распределения – основной на настоящий момент статистический аппарат прогнозирования. Нереалистическое предположение о нормальности погрешностей измерений и отклонений от линии (поверхности) регрессии использовать не обязательно; однако для отказа от предположения нормальности необходимо опереться на иной математический аппарат, основанный на многомерной Центральной Предельной Теореме теории вероятностей, технологии линеаризации и наследования сходимости. Он позволяет проводить точечное и интервальное оценивание параметров, проверять значимость их отличия от 0 в непараметрической постановке, строить доверительные границы для прогноза.
Уравнение тренда временного ряда
Рассматривая временной ряд как множество результатов наблюдений изучаемого процесса, проводимых последовательно во времени, в качестве основных целей исследования временных рядов можно выделить: выявление и анализ характерного изменения параметра у, оценка возможного изменения параметра в будущем (прогноз).
Значения временного ряда можно представить в виде: 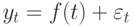 , где f (t) – неслучайная функция, описывающая связь оценки математического ожидания со временем,
, где f (t) – неслучайная функция, описывающая связь оценки математического ожидания со временем, 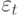 – случайная величина, характеризующая отклонение уровня от f(t ).
– случайная величина, характеризующая отклонение уровня от f(t ).
Неслучайная функция f (t) называется трендом. Тренд отражает характерное изменение (тенденцию) yt за некоторый промежуток времени. На практике в качестве тренда выбирают несколько возможных теоретических или эмпирических моделей. Могут быть выбраны, например, линейная, параболическая, логарифмическая, показательная функции. Для выявления типа модели на координатную плоскость наносят точки с координатами ( t, yt ) и по характеру расположения точек делают вывод о виде уравнения тренда. Для получения уравнения тренда применяют различные методы: сглаживание с помощью скользящей средней, метод наименьших квадратов и другие.
Уравнение тренда линейного вида будем искать в виде yt=f(t ), где f (t) = a0+a1(t ).
Пример 1. Имеется временной ряд:
| ti | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| xti | 2 | 1 | 4 | 4 | 6 | 8 | 7 | 9 | 12 | 11 |
Построим график xti во времени. Добавим на графике линию тренда исходных значений ряда. При этом, щелкнув правой кнопкой мыши по линии тренда, можно вызвать контекстное меню «Формат линии тренда», а в нем поставить флажок «показывать уравнение на диаграмме», тогда на диаграмме высветится уравнение линии тренда, вычисленное встроенными возможностями Excel .

Чтобы определить уравнение тренда, необходимо найти значения коэффициентов а0 и а1. Эти коэффициенты следует определять, исходя из условия минимального отклонения значений функции f (t) в точках ti от значений исходного временного ряда в тех же точках ti . Это условие можно записать в виде (на основе метода наименьших квадратов):
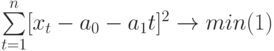
где n – количество значений временного ряда.
Для того, чтобы найти значения а0 и а1, необходимо иметь систему из двух уравнений. Эти уравнения можно получить, используя условие равенства нулю производной функции в точках её экстремума. В нашем случае эта функция имеет вид 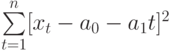 . Обозначим её через Q . Найдем производные функции Q(а0, а1) по переменным а0 и а1. Получим систему уравнений:
. Обозначим её через Q . Найдем производные функции Q(а0, а1) по переменным а0 и а1. Получим систему уравнений:
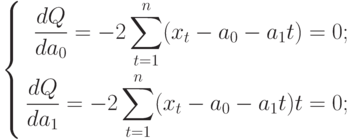
Полученная система может быть преобразована (математически) в систему так называемых нормальных уравнений. При этом уравнения примут вид:
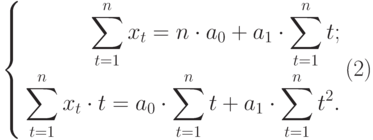
Теперь необходимо решить преобразованную систему уравнений относительно а0 и а1. Однако предварительно следует составить и заполнить вспомогательную таблицу:
| t | t 2 | хt | хtt |
|---|---|---|---|
| 1 | 1 | 2 | 2 |
| 2 | 4 | 1 | 2 |
| 3 | 9 | 4 | 12 |
| 4 | 16 | 4 | 16 |
| 5 | 25 | 6 | 30 |
| 6 | 36 | 8 | 48 |
| 7 | 49 | 7 | 49 |
| 8 | 64 | 9 | 72 |
| 9 | 81 | 12 | 108 |
| 10 | 100 | 11 | 110 |
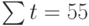 |
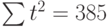 |
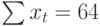 |
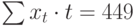 |
Подставив значения n = 10 в систему уравнений (2), получим
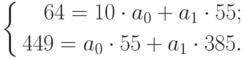
Решив систему уравнений относительно а0 и а1, получим а0 = -0,035, а1 = 1,17. Тогда функция тренда заданного временного ряда f (t) имеет вид:
f (t) = -0,035 + 1,17t.
Изобразим полученную функцию на графике.

Временной ряд приведен в таблице. Используя средства MS Excel :
- построить график временного ряда;
- добавить линию тренда и ее уравнение;
- найти уравнение тренда методом наименьших квадратов, сравнить уравнения (выше на графике и полученное);
- построить график временного ряда и полученной функции тренда в одной системе координат.
1. Реализация аспирина по аптеке (у.е.) за последние 7 недель приведена в таблице:
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| хti | 3,2 | 3,3 | 2,9 | 2,2 | 1,6 | 1,5 | 1,2 |
2. Динамика потребления молочных продуктов (у.е.) по району за последние 7 месяцев:
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| хti | 30 | 29 | 27 | 24 | 25 | 24 | 23 |
3. Динамика числа работников, занятых в одной из торговых сетей города за последние 8 лет приведена в таблице:
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 280 | 361 | 384 | 452 | 433 | 401 | 512 | 497 |
4. Динамика потребления сульфаниламидных препаратов в клинике по годам (тыс. упаковок):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 14 | 21 | 29 | 33 | 38 | 44 | 46 | 50 |
5. Динамика продаж однокомнатных квартир в городе за последние 8 лет (тыс. ед.):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| уt | 39 | 40 | 36 | 34 | 36 | 37 | 33 | 35 |
6. Динамика потребления антибиотиков в клинике (тыс. упаковок):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 10 | 17 | 18 | 13 | 17 | 21 | 25 | 29 |
7. Динамика производства хлебобулочных изделий на хлебозаводе (тонн):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 510 | 502 | 564 | 680 | 523 | 642 | 728 | 665 |
8. Динамика потребления противовирусных препаратов по аптечной сети в начале эпидемии гриппа (тыс. единиц):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 36 | 42 | 34 | 38 | 12 | 32 | 26 | 20 |
9. Динамика потребления противовирусных препаратов по аптечной сети в конце эпидемии гриппа (тыс. единиц):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 46 | 52 | 44 | 48 | 32 | 42 | 36 | 30 |
10. Динамика потребления витаминов по аптечной сети в весенний период (с марта по апрель) в разные годы (у.е.):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 0,9 | 1,7 | 1,5 | 1,7 | 1,5 | 2,1 | 2,5 | 3,6 |
Пример 2. Используя данные примера 1, приведенного выше, вычислить точечный прогноз исходного временного ряда на 5 шагов вперед.
Исходя из условия задачи, необходимо определить точечную оценку прогноза для t = 11, 12, 13, 14, 15, где t в данном случае – шаг упреждения.
Рассмотрим решение этой задачи средствами Microsoft Excel . При решении данной задачи следует так же, как и в примере 1, ввести исходные данные. Выделив данные, построить точечный график, щелкнув правой кнопкой мыши по ряду данных, вызвать контекстное меню и выбрать «Добавить линию тренда».
Щелкнув правой кнопкой мыши по линии тренда, вызвать контекстное меню, выбрать «Формат линии тренда», в окне Параметры линии тренда указать прогноз на 5 периодов и поставить флажок в окошке «Показывать уравнение на диаграмме (рис. 14.3 рис. 14.3.). В версии Excel ранее 2007 окно диалога представлено на рисунке 14.4 рис. 14.4.


Итоговый график представлен на рисунке 14.5 рис. 14.5.

Значения прогноза для 11, 12, 13, 14 и 15 уровней получим, используя функцию ПРЕДСКАЗ( ). Данная функция позволяет получить значения прогноза линейного тренда. Вычисленные значения: 12,87, 14,04, 15,22, 16,39, 17,57.
Значения точечного прогноза для исходного временного ряда на 5 шагов вперед можно вычислить и с помощью уравнения функции тренда f(t ), найденного по методу наименьших квадратов. Для этого в полученное для f (t) выражение необходимо подставить значения t = 11, 12, 13, 14, 15. В результате получим (эти значения следует рассчитать, сформировав формулу в табличном процессоре MS Excel ):
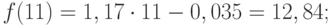
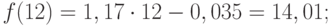
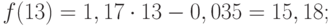
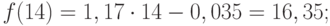
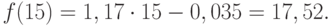
Сравнивая результаты точечных прогнозных оценок, полученных разными способами, выявляем, что данные отличаются незначительно, таким образом, в любом из способов расчета присутствует определенная погрешность (ошибка) прогноза ().
Используя значения временного ряда Задания 1 согласно вашего варианта, вычислить точечный прогноз на 4 шага вперед. Продлить линию тренда на 4 прогнозных значения, вывести уравнение тренда, определить эти значения с помощью функции ПРЕДСКАЗ() или ТЕНДЕНЦИЯ(), а также по выражению функции тренда f(t ), полученному по методу наименьших квадратов в Задании 1. Сравнить полученные результаты.
Компоненты временного ряда
ТЕМА 5. МЕТОДЫ АНАЛИЗА ВРЕМЕННЫХ РЯДОВ
Лекция 9. Компоненты временного ряда. Модели тренда. Индексы сезонности.
Основная цель анализа временных рядов – прогнозирование будущего состояния объекта (процесса), получение базовой информации для принятия управленческих решений. Для реализации прогноза необходима модель, адекватно описывающая поведение ряда. Выбор конкретной модели определяется характером изменения уровней ряда, присутствием тех или иных компонент.
Компоненты временного ряда
Уровни рядов динамики формируются под влиянием множества факторов. Одни из них действуют стабильно на протяжении длительного периода времени и формируют основную тенденцию временного ряда, которая называется трендом.
Ряд факторов влияют на уровни ряда с определенной периодичностью, циклически (экономические циклы, циклы солнечной активности и т.п.). Для обнаружения и анализа влияния циклических факторов необходимы достаточно длинные временные ряды.
Повторяющиеся колебания уровней внутри года – результат влияния сезонных факторов.
Влияние случайных факторов на уровни ряда происходит без какой-либо периодичности, и, следовательно, не поддается измерению.
Исходя из вышесказанного, уровень временного ряда может быть представлен как функция четырех компонент:
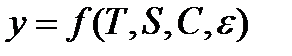 ,(9.1)
,(9.1)
где T – трендовая компонента; S – сезонная компонента; C – циклическая компонента; 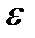 – случайная компонента.
– случайная компонента.
Чем сильнее влияние не трендовых компонент, тем сложнее выявить и описать основную тенденцию ряда, а именно это является центральной задачей при построении моделей временных рядов.
Сгладить влияние на уровни ряда не трендовых компонент позволяет процедура выравнивания временных рядов. Суть этой процедурысостоит в замене фактических уровней изучаемого ряда теоретическими. Теоретические уровни –это уровни, в той или иной мере очищенные от влиянияне трендовых компонент и полученные врезультате определенных расчетов, преобразований исходного ряда.
В арсенале статистикидва приема выравнивания временных рядов: механическое выравнивание и аналитическое.
Механическое выравнивание может быть осуществлено:
« Методом укрупнения интервалов. Данный метод предполагает объединение временных периодов и расчет по ним либо суммарных значений показателей, либо средних величин. Например, если ряд был представлен данными по месяцам, то выравнивание будет заключаться в объединении уровней и представлении ряда данными по кварталам. Укрупнение временных интервалов приведет к снижению степени колеблемости уровней и к более отчетливому проявлению тенденции.
« Метод скользящей средней.Данный метод предполагает расчет среднего уровня за определенный временной интервал (например, 3-5 лет), и дальнейшее скольжение интервала по временному ряду (напомним, что в средних величинах происходит взаимопогашение влияния случайных факторов). Полученные средние (выровненные) значения уровней относятся к середине интервала, по которому рассчитываются средние. Так, если период скольжения три года, первая средняя величина будет рассчитана:
 , а полученное среднее значение будет отнесено ко второму периоду. Далее рассчитывается средняя величина следующих 3-х уровней:
, а полученное среднее значение будет отнесено ко второму периоду. Далее рассчитывается средняя величина следующих 3-х уровней:
 , полученное значение будет отнесено к третьему периоду ряда и т.д.
, полученное значение будет отнесено к третьему периоду ряда и т.д.
Если период скольжения – четная величина, то применяют метод центрирования. Этот прием выражается в подсчете средней арифметической величины из значений, полученных по двум шагам скольжения.
Увеличение периода скольжения позволяет более отчетливо проявиться основной тенденции, однако результатом является существенно укороченный временной ряд, что неблагоприятно может сказаться на качестве трендовой модели.
Аналитическое выравнивание позволяет не только выявить основную тенденцию ряда, но и получить аналитическую форму тренда в виде уравнения.
Уравнение (модель) тренда – это парное уравнение регрессии, в качестве фактора в котором выступает время (t).Переменная «t» задается простой последовательностью чисел от 1 до n. В общем виде уравнение может быть записано:
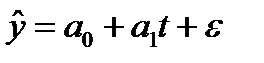 , (9.2)
, (9.2)
где 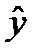 – зависимая переменная, условное среднее значение уровней временного ряда;
– зависимая переменная, условное среднее значение уровней временного ряда;  и
и 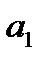 – параметры уравнения тренда; t– независимая переменная, фактор-время;
– параметры уравнения тренда; t– независимая переменная, фактор-время; 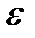 — случайная составляющая.
— случайная составляющая.
Расчет параметров трендовой модели осуществляется с использованием метода наименьших квадратов (о котором говорилось в теме регрессионного анализа).
Центральной проблемой построения трендовой модели является выбор типа уравнения тренда, наилучшим образом описывающего основную тенденцию изучаемого ряда. Для решения этой задачи могут быть использованы:
· графическое представление временного ряда;
· метод конечных разностей;
· формализованный подход, т.е. метод критериев.
При графическом представлении временных рядов по оси абсцисс откладываются периоды или моменты времени, по оси ординат – значения уровней ряда. Расположение эмпирической линии тренда на графике позволяет выдвинуть гипотезу о типе уравнения тренда.
Метод конечных разностей основан на свойствах математических функций и анализе показателей изменения уровней временных рядов. Так, если примерно постоянными являются первые разности (абсолютные приросты), для описания тренда можно воспользоваться полиномом первой степени (линейной функцией). Если примерно постоянны вторые разности (показатели ускорения), то следует использовать полином второй степени и т.д.
В настоящее время выбор функции, для описания тренда, как правило, формализован, т.е. осуществляется с использованием статистических критериев на базе пакетов прикладных программ. Аналитик одновременно строит несколько уравнений тренда, а затем, исходя из значений определенных критериев, выбирает одно, дающее лучшую аппроксимацию.
В качестве критериев выбора модели тренда могут быть использованы следующие характеристики:
1. Минимальная сумма квадратов отклонений теоретических значений уровней ряда (полученных на основе уравнения тренда) от фактических:
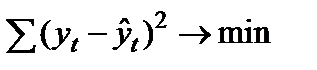 , (9.3)
, (9.3)
где yt– фактическое значение уровня ряда периода t; 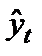 — теоретическое значение уровень ряда периода t.
— теоретическое значение уровень ряда периода t.
2. Минимальная величина остаточной дисперсии ( 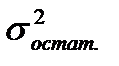 )
)  или минимальное значение среднеквадратической ошибки уравнения тренда
или минимальное значение среднеквадратической ошибки уравнения тренда 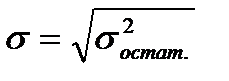 .
.
3. Минимальное значение средней ошибки аппроксимации:
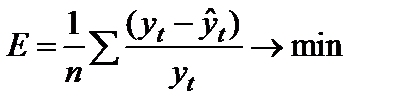 . (9.4)
. (9.4)
4. Максимальное значение F-критерия Фишера, оценивающего значимость уравнения в целом (см. тему регрессионного анализа): 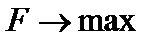 .
.
5. Максимальное значение коэффициента детерминации, характеризующего долю объясненной дисперсии в общей дисперсии результативного признака: 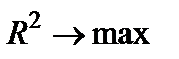 .
.
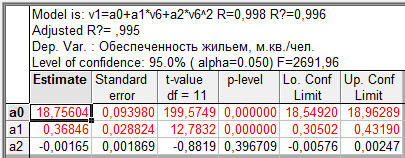
Продолжая анализировать динамику показателя обеспеченности жильем, построим три уравнения тренда, используя линейную функцию, параболу второго порядка и экспоненту. Результаты расчетов, выполненных в пакете STATISTICA, представлены в таблицах 9.1, 9.2, 9.3 (структура и анализ таблиц трендовых моделей аналогичны таблицам парных уравнений регрессии.См. соответствующую лекцию.).
Таблица 9.1 — Линейный тренд временного ряда показателей общей площади жилых помещений, приходящейся в среднем на одного жителя, м.кв./чел.
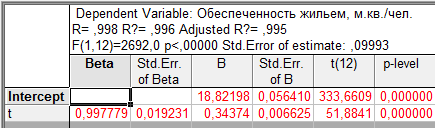
Графа «В» таблицы содержит значения параметров уравнения, t- статистика позволяет оценить статистическую значимость параметров модели. В верхней части таблицы приведены значения коэффициента корреляции (R), коэффициента детерминации (R?= 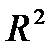 ), скорректированного коэффициента детерминации (AdjustedR?) и F — критерия Фишера (F).
), скорректированного коэффициента детерминации (AdjustedR?) и F — критерия Фишера (F).
Уравнение может быть записано: y = 18,82 + 0,34 t.
Таблица 9.2 — Параболический тренд временного ряда показателей общей жилой площади, приходящейся в среднем на одного жителя, м.кв./чел.
Расчет характеристик, содержащихся в таблицах 9.2 и 9.3, выполнен в процедуре нелинейного оценивания программыSTATISTICA, в этих таблицах значения параметров уравнения находятся в графе Estimate, в двух последних графах дополнительно приводятся значения границ доверительных интервалов для генеральных параметров.
Таблица 9.3 — Экспоненциальный тренд временного ряда показателей общей жилой площади, приходящейся в среднем на одного жителя, м.кв./чел.
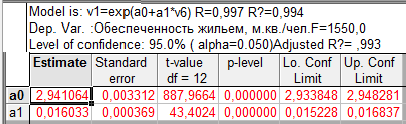
Для анализа результатов расчетов и выбора модели тренда построим сводную таблицу 9.4.
Таблица 9.4 — Оценка статистической значимости параметров и уравнений тренда
| Уравнение тренда | 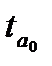 |
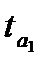 |
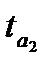 |
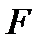 |
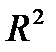 |
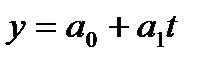 |
333,66 | 51,88 | — | 2692,0 | 0,995 |
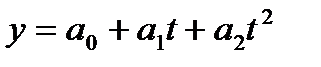 |
199,58 | 12,78 | 0,88 | 2691,96 | 0,995 |
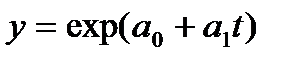 |
887,97 | 43,40 | — | 1550,0 | 0,994 |
Параметры линейной и экспоненциальной моделей статистически значимы, поскольку расчетное значение t — статистики для каждого параметра больше табличного значения t — статистики с учетом принятого уровня значимости и соответствующего числа степеней свободы (  (0,05; 12)=2,179). Расчетные значения F — критерия, также превышающие табличное значение (
(0,05; 12)=2,179). Расчетные значения F — критерия, также превышающие табличное значение (  (1,12)=4,75), следовательно, уравнения в целом и значения коэффициента детерминации статистически значимы, т.е. данные модели позволяют объяснить существенную часть вариации зависимой переменной — показателя обеспеченности жильем населения России.
(1,12)=4,75), следовательно, уравнения в целом и значения коэффициента детерминации статистически значимы, т.е. данные модели позволяют объяснить существенную часть вариации зависимой переменной — показателя обеспеченности жильем населения России.
В уравнении полинома второго порядка параметр 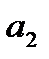 статистически не значим, поскольку
статистически не значим, поскольку  (0,88) (2,11)=3,98), оно не может быть использовано для прогнозирования значений зависимой переменной.
(0,88) (2,11)=3,98), оно не может быть использовано для прогнозирования значений зависимой переменной.
Выбор между двумя статистически значимыми уравнениями осуществляется на основе значений коэффициентов детерминации, характеризующих долю объясненной дисперсии в общей дисперсии зависимой переменной. Предпочтение следует отдать линейной модели, которой соответствует большее значение коэффициента детерминации ( =0,995).
Уравнение тренда может бытьпризнано моделью, пригодной для прогнозирования, если оно отвечает следующим требованиям:
· уравнение в целом статистически значимо (оценка по F-критерию);
· все параметры уравнения статистически значимы (оценка по t-статистике);
· в остатках уравнения отсутствует автокорреляция.
Процедуры оценки статистической значимости уравнения в целом и его параметров подробно рассмотрены в разделе КРА. Остановимся на оценке автокорреляции в остатках модели.
Остатки– это разность между фактическими значениями уровней временного ряда и выровненными (теоретическими) значениями, полученными по уравнению тренда.
Фактические уровни: Теоретические
(выровненные) уровни: Остатки:
y1 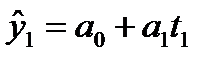
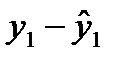
y2 

y3 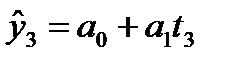

…… ………………………. ……………..
yt 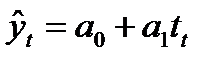

Рисунок 9.1 — Определение величины остатков модели временного ряда
Автокорреляция остатков – это зависимость остатков периода t от остатков предшествующих периодов (t-i). Если построенное уравнение обеспечивает удовлетворительную аппроксимацию, то отклонения от тренда (остатки) должны носить случайный характер и в их последовательности не должно быть корреляции.
Исследование автокорреляции остатков трендовой модели имеет особое значение, если ставится задача прогнозирования поведения временного ряда. Дело в том, что наличие автокорреляции свидетельствует о наличии тенденции в остатках, т.е. о сохранении в них части полезной информации. Поскольку основная задача построения трендовой модели – как можно более полно описать основную тенденцию изучаемого ряда – сохранение тенденции в остатках, говорит о том, что модель не может быть признана пригодной для получения прогнозаудовлетворительногокачества.
Оценка автокорреляции в остатках может быть проведена на основе коэффициентов автокорреляции, либо с использованием специального критерия — критерияДарбина-Уотсона.
Если остатки периода t обозначить  , а остатки предшествующего периода
, а остатки предшествующего периода 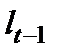 , то коэффициент автокорреляции, предложенный М. Езекиэлом и К. Фоксом, будет рассчитываться:
, то коэффициент автокорреляции, предложенный М. Езекиэлом и К. Фоксом, будет рассчитываться:
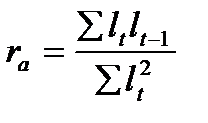 . (9.5)
. (9.5)
Коэффициент автокорреляции изменяется в пределах:  , как и обычный парный коэффициент корреляции. Близость значения коэффициента к нулю означает отсутствие автокорреляции, к единице – наличие автокорреляции в остатках.
, как и обычный парный коэффициент корреляции. Близость значения коэффициента к нулю означает отсутствие автокорреляции, к единице – наличие автокорреляции в остатках.
По достаточно большим временным рядам могут быть рассчитаны коэффициенты автокорреляции разных порядков, т.е. коэффициенты, оценивающие зависимость не только между остатками соседних периодов, но между остатками, разделенными двумя, тремя и большим числом временных интервалов. Интервал, разделяющий зависимые остатки, называют лагом. Величина лага определяет порядок коэффициента автокорреляции. Последовательность коэффициентов автокорреляции разного порядка называется автокорреляционной функцией, которая характеризует зависимость величины коэффициентов автокорреляции от величины лага.
В таблице 9.5 приведены фактические (ObservedValue), теоретические (PredictedValue), т.е. рассчитанные по линейной модели, значения показателя обеспеченности жильем и величины остатков (Residual), равные разности значений двух первых столбцов.
Таблица 9.5 — Фактические, теоретические уровни и остатки линейного тренда временного ряда показателей общей жилой площади, приходящейся в среднем на одного жителя, м.кв./чел.
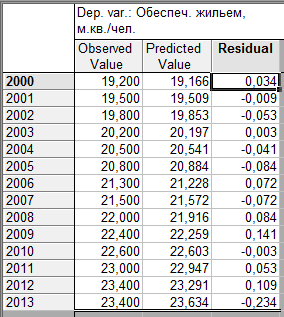
Для оценки автокорреляции остатков рассчитаем коэффициенты автокорреляции. Поскольку анализируемый временной ряд содержит всего 14 уровней, то рассчитаем коэффициенты лишь трех порядков: первого, который покажет степень корреляционной зависимости между смежными значениями остатков; второго, т.е. будет дана оценка зависимости между остатками, разделенными двумя годами; третьего порядка — оценка корреляционной связи между остатками с интервалом в три года.
Автокорреляционная функция остатков линейной модели и ее графическое отображение представлены на рисунке 9.2.
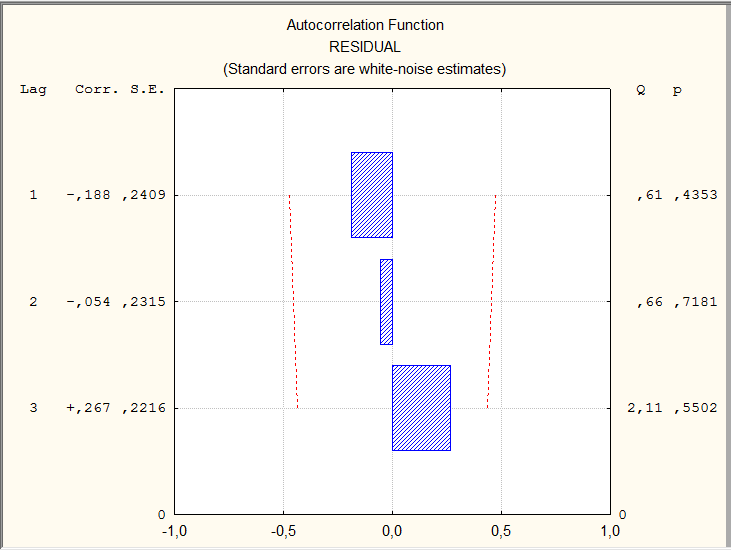
Рисунок 9.2 — Автокорреляционная функция остатков линейной модели временного ряда показателей общей жилой площади, приходящейся в среднем на одного жителя, м.кв./чел.
Графическое отображение коэффициентов автокорреляции (прямоугольники) сопровождается числовыми значениями этих характеристик (графа Corr.): коэффициент автокорреляции первого порядка 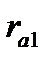 = — 0,188, второго
= — 0,188, второго 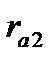 = -0,054, третьего
= -0,054, третьего 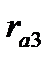 =0,267. На порядок коэффициентов автокорреляции указывает величина лага (Lag). Статистическую значимость коэффициентов можно оценить, рассчитав t — статистику:
=0,267. На порядок коэффициентов автокорреляции указывает величина лага (Lag). Статистическую значимость коэффициентов можно оценить, рассчитав t — статистику:
 (9.6)
(9.6)
где: 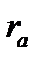 – коэффициент автокорреляции,
– коэффициент автокорреляции, 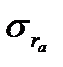 — стандартная ошибка коэффициента автокорреляции (графаS.E.).
— стандартная ошибка коэффициента автокорреляции (графаS.E.).
В результате расчетов получены следующие величины t — статистики:  =0,78,
=0,78,  =0,23 и
=0,23 и 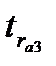 =1,2. Все значения t — статистики не превышают табличного значения ( (0,05)=2,179), которое находится по таблице распределения Стьюдента, поскольку объем данных менее 30. Таким образом, полученные значения коэффициентов автокорреляции статистически не значимы. Проведенная оценкаговорит об отсутствии автокорреляции в остатках линейной модели тренда. Этот вывод подтверждается и графическим представлением автокорреляционной функции: величины коэффициентов, представленные прямоугольниками, не выходят за пределы доверительных интервалов, обозначенных пунктирными линиями.
=1,2. Все значения t — статистики не превышают табличного значения ( (0,05)=2,179), которое находится по таблице распределения Стьюдента, поскольку объем данных менее 30. Таким образом, полученные значения коэффициентов автокорреляции статистически не значимы. Проведенная оценкаговорит об отсутствии автокорреляции в остатках линейной модели тренда. Этот вывод подтверждается и графическим представлением автокорреляционной функции: величины коэффициентов, представленные прямоугольниками, не выходят за пределы доверительных интервалов, обозначенных пунктирными линиями.
Рассмотрим еще один метод оценки автокорреляции в остатках — критерий Дарбина-Уотсона (D-W). Используя введенные ранее обозначения (см. 9.5), критерий может быть рассчитан следующим образом:
 . (9.10)
. (9.10)
Между критерием Дарбина-Уотсона и коэффициентом автокорреляции существует следующее соотношение: 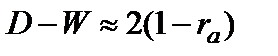 .
.
Исходя из этого соотношения, очевидно, что если:
Таким образом, значение критерия может изменяться в пределах:
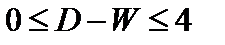 . (9.11)
. (9.11)
Близость D-W к 0 и к 4 означает присутствие автокорреляции в остатках, к 2 – ее отсутствие.
КритерийДарбина-Уотсона табулирован. По таблицам, исходя из числа уровней динамического ряда и числа факторов в уравнении тренда, находят границы значения критерия:  ,
, 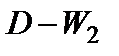 — нижняя и верхняя границы критерия.
— нижняя и верхняя границы критерия.
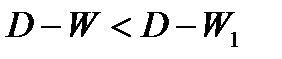 — автокорреляция в остатках присутствует;
— автокорреляция в остатках присутствует;
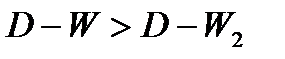 — автокорреляция в остатках отсутствует;
— автокорреляция в остатках отсутствует;
Если 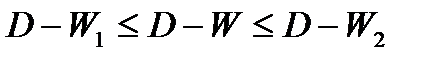 — возникает ситуация неопределенности, которая требует дальнейшего исследования ряда в условиях увеличения объема данных, или использования иного типа модели.
— возникает ситуация неопределенности, которая требует дальнейшего исследования ряда в условиях увеличения объема данных, или использования иного типа модели.
Оценивая остатки линейной модели рассматриваемого примера, в программе STATISTICA было получено значение критерия Дарбина-Уотсона=1,91. Табличные значения верхней и нижней границ критерия (см. приложение . )следующие: = 1,05, =1,35. Поскольку расчетное значение критерия (1,91) превышает верхнюю границу табличного значения (1,35), подтверждается вывод об отсутствии автокорреляции в остатках модели тренда временного ряда показателей общей жилой площади, приходящейся в среднем на одного жителя, м.кв./чел.
Таким образом, весь комплекс требований, необходимых для признания модели тренда пригодной для прогнозирования, выполнен: уравнение тренда статистически значимо, параметры статистически значимы, в остатках модели отсутствует автокорреляция.
Регрессионную модель тренда, отвечающую всем формальным требованиям, можно использовать для оценки величины переменной y в последующие периоды времени t. Чтобы получить, так называемый, точечный прогноз при заданном значении t, вычисляется значение построенной функции регрессии в точке t.
В рассматриваемом примере исходный временной ряд включал 14 уровней (данные с 2000 по 2013 годы), следовательно, точечный прогноз может быть выполнен на 15-й период(на 2014 год) и дальнейшие периоды. Подставляя в уравнение значение t=15 (y=18,82 + 0,34*15), получаем, что прогнозируемое среднее значение показателя обеспеченности жильем в России в 2014 году составит 23,92 м.кв./чел.
Однако следует помнить, что уравнение тренда описывает лишь общую тенденцию изменения показателя. Фактическая реализация событий отличается от прогнозируемой. Совпадение фактических и прогнозных значений маловероятно. Уравнение тренда всегда содержит ошибку, которую принято оценивать среднеквадратической (стандартной) ошибкой тренда:
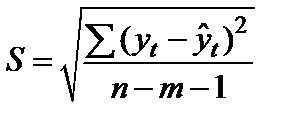
где  — фактическое значение уровня ряда периода t;
— фактическое значение уровня ряда периода t;  — значение уровня ряда периода t, рассчитанное по уравнению тренда; n – число уровней ряда; m – число факторов, включенных в уравнение;n-m-1 –число степеней свободы остаточной дисперсии.
— значение уровня ряда периода t, рассчитанное по уравнению тренда; n – число уровней ряда; m – число факторов, включенных в уравнение;n-m-1 –число степеней свободы остаточной дисперсии.
Как видим, средняя ошибка тренда – это корень квадратный из остаточной дисперсии, которая оценивает степень колеблемости уровней временного ряда ( ) относительно тренда ( ). Среднеквадратическая ошибка тренда, таким образом, характеризует: насколько в среднем отличаются значения уровней ряда, рассчитанные на основе уравнения, от их фактических значений.
С учетом ошибки тренда может быть рассчитан доверительный интервал прогноза:
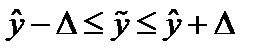 (9.13)
(9.13)
где 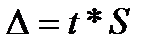 —предельная ошибка;t – коэффициент доверия, величина которого находится по таблице Стьюдента, исходя из принятого исследователем уровня значимости и соответствующего числа степеней свободы (n-m-1).
—предельная ошибка;t – коэффициент доверия, величина которого находится по таблице Стьюдента, исходя из принятого исследователем уровня значимости и соответствующего числа степеней свободы (n-m-1).
При выполнении расчетов с использованием специализированных компьютерных программ, величина ошибки определяется в одной процедуре с расчетом значений параметров уравнения. В таблице 9.1 представлено значение стандартной ошибка линейного тренда (St.Errorofesimate): S=0,0999. Величина коэффициента доверия, исходя из уровня значимости 0,05 и числа степеней свободы 12 (14-1-1), равна 2,179 (см. прил. Табл. Стьюд.), тогда
 2,179 * 0,0999 = 0,218. Доверительный интервал будет рассчитан:
2,179 * 0,0999 = 0,218. Доверительный интервал будет рассчитан:  и окончательно —
и окончательно — 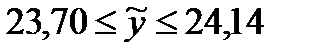 . Таким образом, с вероятностью 0,95 можно утверждать, что в среднем показатель обеспеченности жильем в регионах России в 2014 году будет не ниже 23,7 и не выше 24,14 квадратных метров на человека (заметим, что фактическое значение показателя в 2014 году по данным Росстата составило 23,7 квадратных метра на человека).
. Таким образом, с вероятностью 0,95 можно утверждать, что в среднем показатель обеспеченности жильем в регионах России в 2014 году будет не ниже 23,7 и не выше 24,14 квадратных метров на человека (заметим, что фактическое значение показателя в 2014 году по данным Росстата составило 23,7 квадратных метра на человека).
Прогнозирование на основе временных рядов называют экстраполяцией — продлением в будущее тенденции, сложившейся в прошлом. Следовательно, доверять результатам прогнозирования можно при условии, что факторы, повлиявшие на формирование тенденции в прошлом, неизменно будут действовать и в будущем. Еще один практический совет, выработанный статистикой: период упреждения, т.е. период на который делается прогноз, не должен превышать 1/3 длины ряда, на основе которого построена модель.
источники:
http://intuit.ru/studies/courses/3659/901/lecture/32720
http://poisk-ru.ru/s43356t9.html