
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel Web App Excel 2010 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
Возвращает вертикальный массив из наиболее часто встречающихся (повторяющихся) значений в массиве или диапазоне данных. Для получения горизонтального массива используйте функцию ТРАНСП(МОДА.НСК(число1;число2…)).
При наличии нескольких мод будет возвращено несколько значений. Поскольку данная функция возвращает массив значений, она должна вводиться как формула массива.
Синтаксис
МОДА.НСК((число1;[число2];…)
Аргументы функции МОДА.НСК описаны ниже.
-
Число1 Обязательный. Первый числовой аргумент, для которого требуется вычислить моду.
-
Число2… Необязательный. От 1 до 254 числовых аргументов, для которых требуется вычислить моду. Вместо аргументов, разделенных точкой с запятой, можно использовать массив или ссылку на массив.
Замечания
-
Аргументы могут быть либо числами, либо содержащими числа именами, массивами или ссылками.
-
Если аргумент, который является массивом или ссылкой, содержит текст, логические значения или пустые ячейки, эти значения игнорируются; ячейки, содержащие нулевые значения, учитываются.
-
Аргументы, которые представляют собой значения ошибок или текст, не преобразуемый в числа, вызывают ошибку.
-
Если набор данных не содержит повторяющихся точек данных, функция МОДА.НСК возвращает значение ошибки #Н/Д.
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
||
|
1 |
||
|
2 |
||
|
3 |
||
|
4 |
||
|
3 |
||
|
2 |
||
|
1 |
||
|
2 |
||
|
3 |
||
|
5 |
||
|
6 |
||
|
1 |
||
|
Формула |
Описание |
Результат |
|
=МОДА.НСК(A2:A13) |
Формула =РЕЖИМ. Формула МУМСК(A2:A13)должна быть введена как формула массива. Если в качестве формулы массива ввели формулу, то режим. MULT возвращает 1, 2 и 3 в качестве режимов, поскольку они отображаются 3 раза. Если формула не введена как формула массива, единственным результатом будет 1. Это будет такой же результат, как при использовании режима. Функция SNGL. Когда я создал формулу массива, мы добавили несколько дополнительных ячеек, чтобы убедиться, что возвращаются все режимы. Я создал формулу массива в диапазоне C15:C22. Если режимы добавления не существуют, #N/A. |
1 |
|
2 |
||
|
3 |
||
|
#Н/Д |
||
|
#Н/Д |
||
|
#Н/Д |
||
|
#Н/Д |
||
|
#Н/Д |
Нужна дополнительная помощь?
Функция МОДА в Excel выполняет поиск повторяющихся либо наиболее часто встречающихся элементов в массиве или значений в диапазоне данных и возвращает эти значения.
Функция МОДА.НСК выполняет поиск наиболее встречающихся значений среди диапазона данных или элементов массива и возвращает вертикальный массив этих значений.
Функция МОДА.ОДН находит наиболее встречающееся значение в массиве или диапазоне данных и возвращает данное значение.
Примеры использования функций МОДА в Excel
Пример 1. В ходе лабораторной работы эмпирическим путем были получены несколько значений одной и той же физической величины. Для расчета ее приближенного значения было решено определить моду из диапазона полученных значений. Ниже рассмотрим, как найти моду в Excel.
Таблица данных:
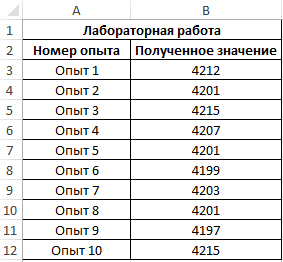
Для определения наиболее часто встречаемого значения используем формулу:
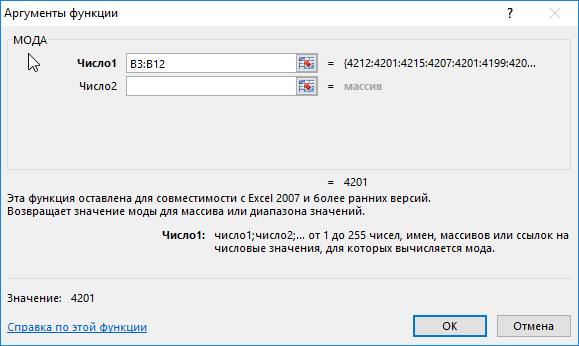
Описание аргументов:
B3:B12 – массив значений, в котором необходимо определить наиболее повторяющееся значение.
Результат вычислений:
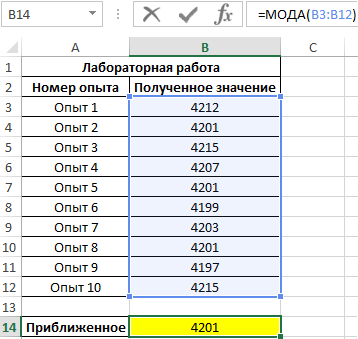
Пример использования функции МОДА.НСК в Excel
Пример 2. В ряде числовых значений, полученном в результате работы генератора случайных чисел, необходимо определить повторяющиеся числа. Теперь смотрим как посчитать моду в Excel.
Заполним столбец «Случайные числа» с использованием функции СЛУЧМЕЖДУ(1;100), то есть случайными числами из диапазона от 1 до 100:
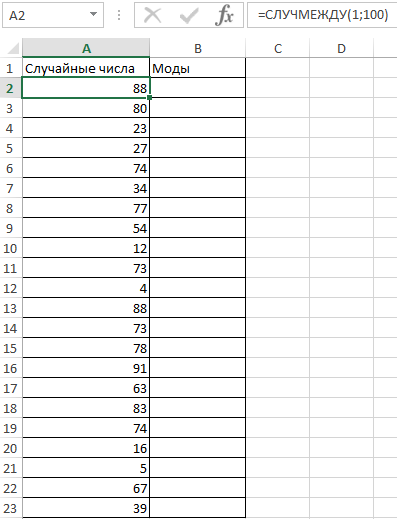
Примечание: функция СЛУЧМЕЖДУ выполняет пересчет полученных случайных значений при каждом вводе нового значения в любую ячейку, поэтому значения в столбце A2 на разных изображениях могут отличаться.
Выделим диапазон ячеек B2:B23 и введем формулу:
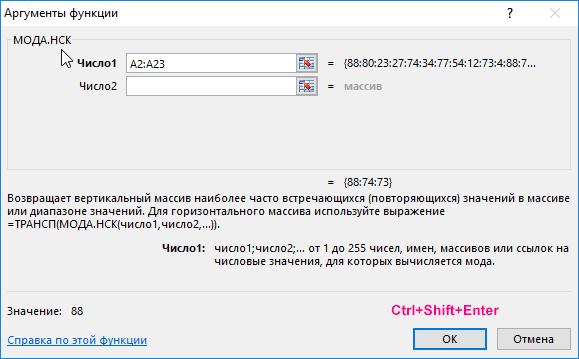
Для ввода формулы используем комбинацию клавиш Ctrl+Shift+Enter, чтобы функция была выполнена в массиве. В результате получим:
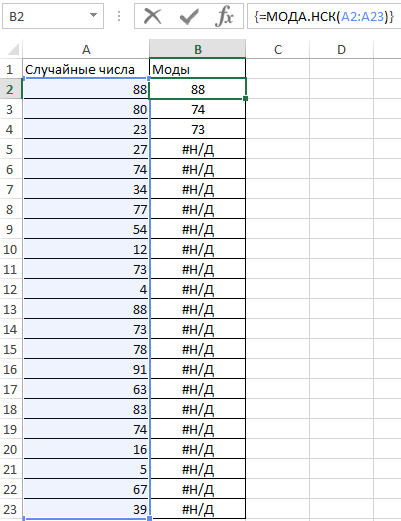
В указанном диапазоне случайных чисел повторяются значения 48, 47 и 53. Поскольку остальные числа являются уникальными, для ячеек B5:B23 сгенерирован код ошибки #Н/Д (то есть, формула не нашла запрашиваемое значение).
Пример работы с функцией МОДА.ОДН в Excel
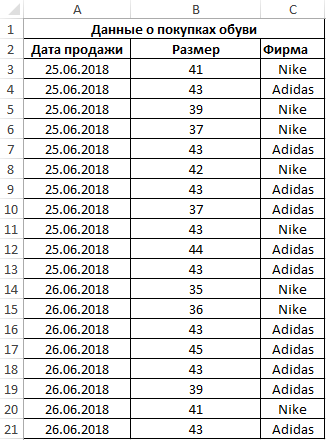
Пример 3. Поставщик обувного магазина поинтересовался у владельца, какой размер обуви пользуется наибольшим спросом. Экономист просмотрел данные из таблицы покупок и практически сразу дал ответ. Как ему это удалось?
Таблица данных о покупках:
Как вычислить моду в Excel? Для определения размера, который пользуется наибольшим спросом, использована формула моды:
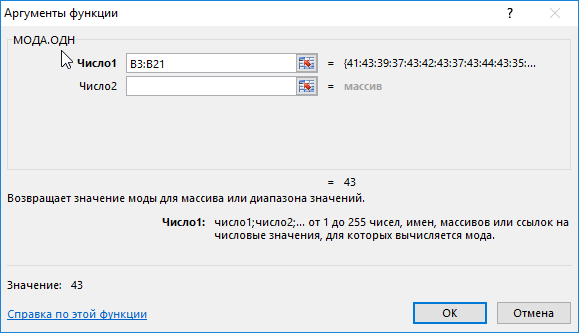
Полученный результат:
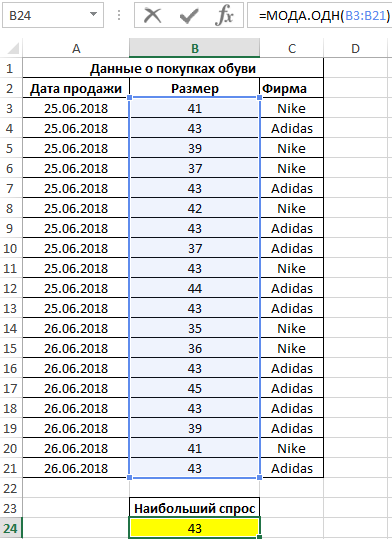
Примечание: в отличие от среднего арифметического значения (для данного примера – примерно 41), мода определяет наиболее часто встречаемое событие в диапазоне событий. Ее рационально использовать для решения статистических задач, связанных с анализом нормально распределенных данных.
Функции МОДА, МОДА.НСК и МОДА.ОДН в Excel и особенности их использования
Функция МОДА имеет следующие аргументы:
- число 1 – обязательный для заполнения аргумент, характеризующий первое числовое значение, для которого необходимо определить моду.
- [число 2] и последующие аргументы являются необязательными для заполнения и характеризуют последующие числовые значения, для которых требуется найти значение моды.
Аргументы модификации функции имеют одинаковый смысл.
Примечания 1:
- Максимальное количество аргументов в рассматриваемых функциях – не более 255.
- Вместо аргументов типа число 1; число 2;…;число n можно указывать массив значений или ссылку на диапазон ячеек.
- В качестве аргументов принимаются объекты данных следующих типов: имена, которые содержат числа, массивы числовых значений и ссылки.
- Все рассматриваемые функции для определения моды игнорируют пустые, логические значения и текстовые строки, содержащиеся в диапазоне значений, переданном в качестве аргумента.
- Если все элементы массива или диапазона чисел, переданных в качестве аргументов для всех трех функций являются уникальными (повторяющиеся значения отсутствуют), результатом работы данных функций будет являться код ошибки #Н/Д.
- Если функция МОДА.НСК была использована в качестве обычной функции, будет возвращено единственное значение моды. Для отображения нескольких мод необходимо выделить диапазон ячеек, ввести формулу и ее аргументы, использовать сочетание клавиш Ctrl+Shift+Enter для вывода массива вычисленных результатов.
Примечание 2: функция МОДА была разработана для ранних версий Excel и пока поддерживается новыми версиями программы, однако в последующих версиях поддержка данной функции может быть отменена. Вместо данной функции предлагается использование двух ее аналогов, которые будут рассмотрены ниже.
Примечания 3:
- Для возврата горизонтального массива наиболее встречающихся значений следует использовать запись вида ТРАНСП(МОДА.НСК(число 1; число 2;…;число n).
- МОДА.НСК принадлежит к классу формул массива и может возвращать как одну, так и несколько мод. Для записи в качестве формулы массива необходимо использовать сочетание клавиш Ctrl+Shift+Enter.
Примечание 4: функции МОДА и МОДА.ОДН определяют центральную тенденцию множества чисел в статическом распределении способом определения моды (существуют еще два распространенных способа: поиск среднего значения и медианы), то есть путем поиска элемента, значение которого наиболее часто встречается в определенном наборе чисел.
В этом учебном материале вы узнаете, как использовать Excel функцию МОДА.НСК с синтаксисом и примерами.
Описание
Microsoft Excel функция МОДА.НСК возвращает вертикальный массив наиболее часто встречающихся чисел в диапазоне чисел. Эта функция полезна, если чаще всего встречается более одного числа.
СОВЕТ: Если эту формулу ввести как формулу массива, она вернет несколько режимов. Если эта формула не введена как формула массива, она вернет только один режим и будет вести себя так же, как функции МОДА и МОДА.ОДН.
Функция МОДА.НСК — это встроенная в Excel функция, которая относится к категории статистических функций.
Её можно использовать как функцию рабочего листа (WS) в Excel.
В качестве функции рабочего листа функцию МОДА.НСК можно ввести как часть формулы в ячейку рабочего листа.
Синтаксис
Синтаксис функции МОДА.НСК в Microsoft Excel:
МОДА.НСК(число1;[число2];…)
Аргументы или параметры
- число1;[число2];…
- Каждое число может быть диапазоном, ячейкой или числовым значением. Может быть до 255 чисел.
Возвращаемое значение
Функция МОДА.НСК возвращает вертикальный массив числовых значений, если он введен как формула массива.
Он возвращает только одно числовое значение, если не введено как обычная формула.
Если все числовые значения в наборе уникальны, функция МОДА.НСК возвращает ошибку #Н/Д.
Если текстовое значение, такое как «Б», введено в качестве параметра, функция МОДА.НСК вернет #ЗНАЧ!
Если ссылка на диапазон или ячейку содержит нечисловые значения, такие как текстовые значения, логические значения или пустые ячейки, эти значения будут проигнорированы.
Примечание
- См. также функции МОДА.ОДН и МОДА.
Применение
- Excel для Office 365, Excel 2019, Excel 2016, Excel 2013, Excel 2011 для Mac, Excel 2010
Тип функции
- Функция рабочего листа (WS)
Пример (как функция рабочего листа)
Давайте рассмотрим несколько примеров функции Excel МОДА.НСК, чтобы понять, как использовать Excel функцию МОДА.НСК в качестве функции рабочего листа в Microsoft Excel:

На основе электронной таблицы Excel выше, следующее примеры МОДА.НСК вернут:
|
{=МОДА.НСК(A2:A10)} Результат: 100 ‘Первый режим в вертикальном массиве (результат в ячейке C2) {=МОДА.НСК(A2:A10)} Результат: 700 ‘Второй режим в вертикальном массиве (результат в ячейке C3) |
Как ввести формулу массива
Функция МОДА.НСК будет возвращать несколько режимов, если введена как формула массива, но как вы вводите формулу массива? Давайте покажем вам, как! Сначала выделите ячейки в которых, вы хотел бы отобразить результаты функции МОДА.НСК. В этом примере мы выделили ячейки C2:C3.

Затем введите формулу МОДА.НСК в строке формул (но не нажимайте клавишу ENTER). В этом примере мы ввели формулу:
Теперь нажмите Ctrl+Shift+Enter, чтобы создать формулу в виде формулы массива. При этом формула будет заключена в квадратные скобки:
Теперь в ячейках C2 и C3 будут отображаться результаты функции МОДА.НСК в виде вертикального массива с первым режимом в ячейке C2 и вторым режимом в ячейке C3. Поскольку формула массива привязана к обеим ячейкам C2 и C3, вы должны выделить весь диапазон C2:C3 для редактирования или очистки формулы массива.
Содержание
- Как найти среднее значение, медиану и моду в Excel (с примерами)
- Пример: нахождение среднего значения в Excel
- Пример: поиск медианы в Excel
- Пример: поиск режима в Excel
- МОДА.ОДН (функция МОДА.ОДН)
- Синтаксис
- Замечания
- Пример
- Функция МОДА
- Синтаксис
- Замечания
- Пример
- Функция МОДА ее модификации МОДА.НСК и МОДА.ОДН в Excel
- Примеры использования функций МОДА в Excel
- Пример использования функции МОДА.НСК в Excel
- Пример работы с функцией МОДА.ОДН в Excel
- Функции МОДА, МОДА.НСК и МОДА.ОДН в Excel и особенности их использования
- Медиана, среднее арифметическое и мода – как посчитать в Excel
- Среднее арифметическое
- Медиана – чем отличается от среднего значения
- Что лучше – медиана или среднее значение
- Что такое мода
- Средневзвешенное значение
Вы можете использовать следующие формулы, чтобы найти среднее значение, медиану и моду набора данных в Excel:
Стоит отметить, что каждая из этих формул просто игнорирует нечисловые или пустые значения при расчете этих показателей для диапазона ячеек в Excel.
В следующих примерах показано, как использовать эти формулы на практике со следующим набором данных:
Пример: нахождение среднего значения в Excel
Среднее значение представляет собой среднее значение в наборе данных.
На следующем снимке экрана показано, как рассчитать среднее значение набора данных в Excel:
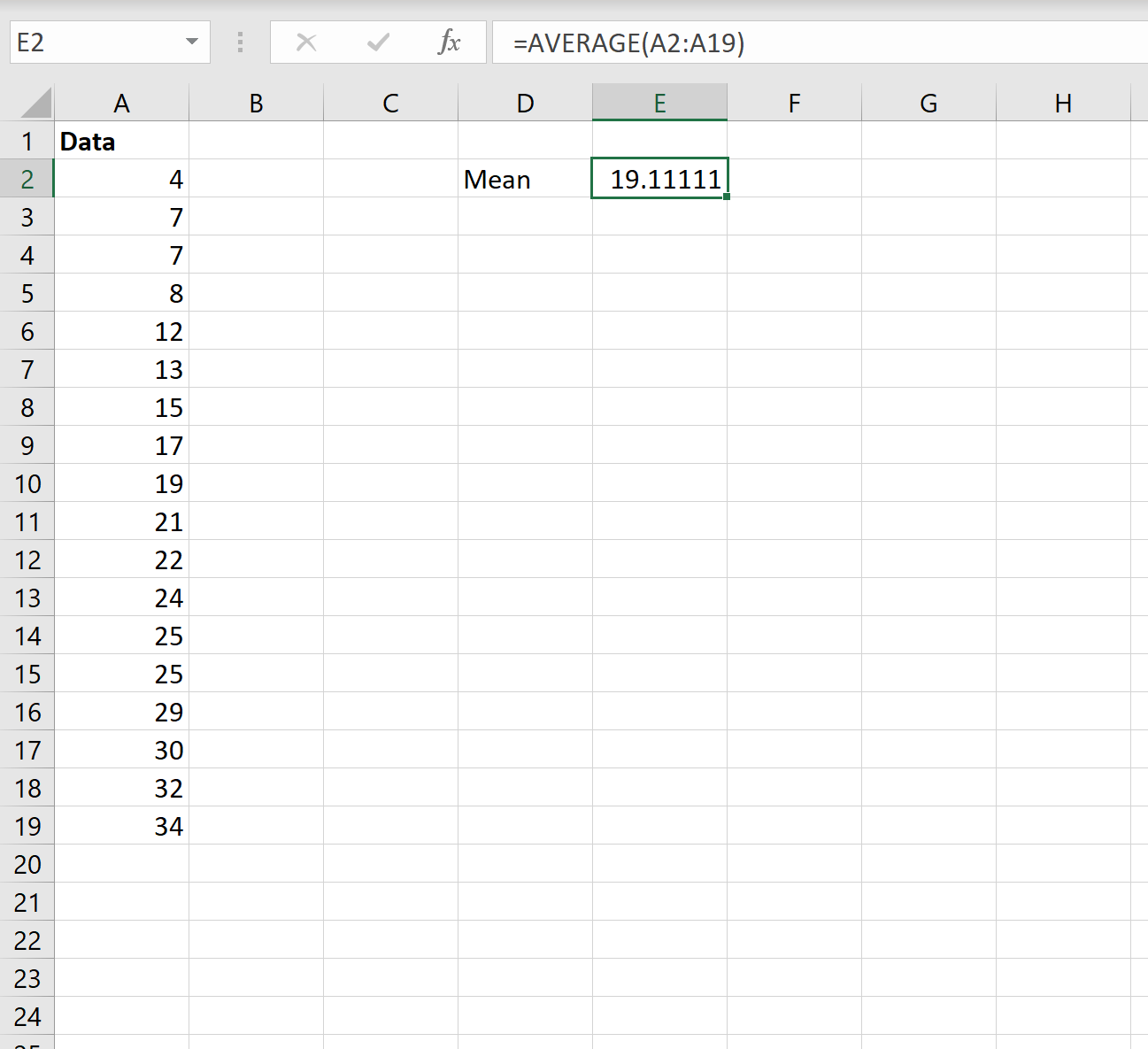
Среднее значение получается 19,11 .
Пример: поиск медианы в Excel
Медиана представляет собой среднее значение в наборе данных, когда все значения расположены от наименьшего к наибольшему.
На следующем снимке экрана показано, как рассчитать медиану набора данных в Excel:
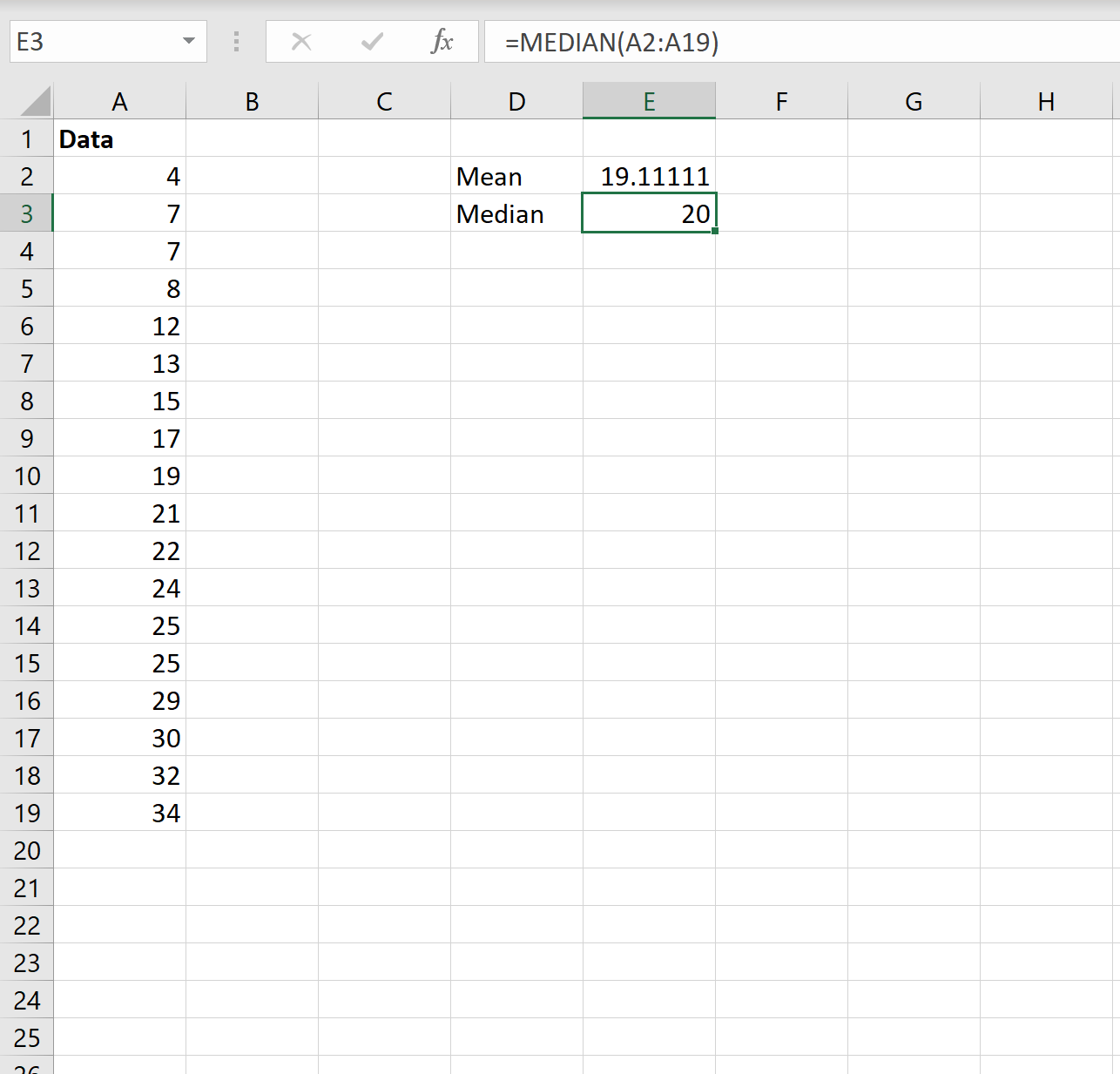
Медиана получается 20 .
Пример: поиск режима в Excel
Мода представляет значение, которое чаще всего встречается в наборе данных. Обратите внимание, что набор данных может не иметь режима, иметь один режим или несколько режимов.
На следующем снимке экрана показано, как рассчитать режим(ы) набора данных в Excel:
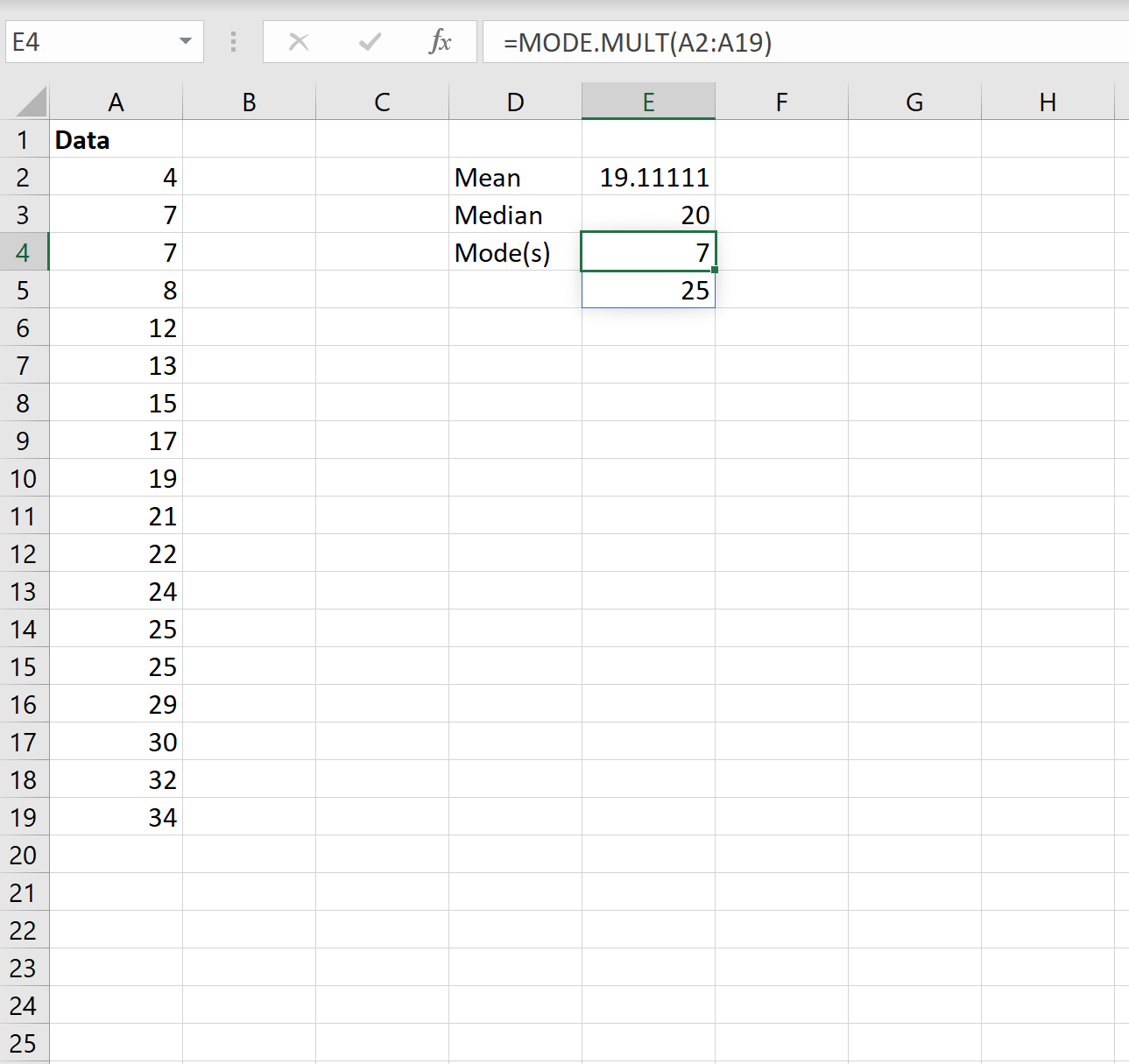
Моды оказываются 7 и 25.Каждое из этих значений встречается в наборе данных дважды, что встречается чаще, чем любое другое значение.
Источник
МОДА.ОДН (функция МОДА.ОДН)
Возвращает наиболее часто встречающееся или повторяющееся значение в массиве или интервале данных.
Синтаксис
Аргументы функции МОДА.ОДН описаны ниже.
Число1 Обязательный. Первый аргумент, для которого требуется вычислить моду.
Число2. Необязательный. Аргументы 2—254, для которых требуется вычислить моду. Вместо аргументов, разделенных точкой с запятой, можно использовать массив или ссылку на массив.
Замечания
Аргументы могут быть либо числами, либо содержащими числа именами, массивами или ссылками.
Если аргумент, который является массивом или ссылкой, содержит текст, логические значения или пустые ячейки, эти значения игнорируются; ячейки, содержащие нулевые значения, учитываются.
Аргументы, которые являются значениями ошибки или текстами, не преобразуемыми в числа, приводят к возникновению ошибок.
Если набор данных не содержит повторяющихся точек данных, функция МОДА.ОДН возвращает значение ошибки #Н/Д.
Примечание: Функция МОДА.ОДН измеряет центральную тенденцию, которая является центром группы чисел в статистическом распределении. Существует три наиболее распространенных способа определения центральной тенденции.
Среднее значение — это среднее арифметическое, которое вычисляется путем сложения набора чисел с последующим делением полученной суммы на их количество. Например, средним значением для чисел 2, 3, 3, 5, 7 и 10 будет 5, которое является результатом деления их суммы, равной 30, на их количество, равное 6.
Медиана — это число, которое является серединой множества чисел, то есть половина чисел имеют значения большие, чем медиана, а половина чисел имеют значения меньшие, чем медиана. Например, медианой для чисел 2, 3, 3, 5, 7 и 10 будет 4.
Мода — это число, наиболее часто встречающееся в данном наборе чисел. Например, модой для чисел 2, 3, 3, 5, 7 и 10 будет 3.
При симметричном распределении множества чисел все три значения центральной тенденции будут совпадать. При смещенном распределении множества чисел значения могут быть разными.
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Источник
Функция МОДА
Предположим, что вы хотите узнать наиболее распространенное количество видов птицы в образце видов птицы на критической заболоченой за 30-летней период времени или узнать наиболее часто посещаемые телефонные вызовы в центре поддержки по телефону в некритовые часы. Для вычисления режима группы чисел используйте функцию РЕЖИМ.
Режим возвращает наиболее часто повторяющийся (повторяющийся) значение в массиве или диапазоне данных.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новых функциях см. в разделах Функция МОДА.НСК и Функция МОДА.ОДН.
Синтаксис
Аргументы функции МОДА описаны ниже.
Число1 Обязательный. Первый числовой аргумент, для которого требуется вычислить моду.
Число2. Необязательный. От 1 до 255 числовых аргументов, для которых вычисляется мода. Вместо аргументов, разделенных точкой с запятой, можно воспользоваться массивом или ссылкой на массив.
Замечания
Аргументы могут быть либо числами, либо содержащими числа именами, массивами или ссылками.
Если аргумент, который является массивом или ссылкой, содержит текст, логические значения или пустые ячейки, эти значения игнорируются; ячейки, содержащие нулевые значения, учитываются.
Аргументы, которые являются значениями ошибки или текстами, не преобразуемыми в числа, приводят к возникновению ошибок.
Если множество данных не содержит одинаковых данных, функция МОДА возвращает значение ошибки #Н/Д.
Функция МОДА измеряет центральную тенденцию, которая является центром множества чисел в статистическом распределении. Существует три наиболее распространенных способа определения центральной тенденции:
Среднее значение — это среднее арифметическое, которое вычисляется путем сложения набора чисел с последующим делением полученной суммы на их количество. Например, средним значением для чисел 2, 3, 3, 5, 7 и 10 будет 5, которое является результатом деления их суммы, равной 30, на их количество, равное 6.
Медиана — это число, которое является серединой множества чисел, то есть половина чисел имеют значения большие, чем медиана, а половина чисел имеют значения меньшие, чем медиана. Например, медианой для чисел 2, 3, 3, 5, 7 и 10 будет 4.
Мода — это число, наиболее часто встречающееся в данном наборе чисел. Например, модой для чисел 2, 3, 3, 5, 7 и 10 будет 3.
При симметричном распределении множества чисел все три значения центральной тенденции будут совпадать. При смещенном распределении множества чисел значения могут быть разными.
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Источник
Функция МОДА ее модификации МОДА.НСК и МОДА.ОДН в Excel
Функция МОДА в Excel выполняет поиск повторяющихся либо наиболее часто встречающихся элементов в массиве или значений в диапазоне данных и возвращает эти значения.
Функция МОДА.НСК выполняет поиск наиболее встречающихся значений среди диапазона данных или элементов массива и возвращает вертикальный массив этих значений.
Функция МОДА.ОДН находит наиболее встречающееся значение в массиве или диапазоне данных и возвращает данное значение.
Примеры использования функций МОДА в Excel
Пример 1. В ходе лабораторной работы эмпирическим путем были получены несколько значений одной и той же физической величины. Для расчета ее приближенного значения было решено определить моду из диапазона полученных значений. Ниже рассмотрим, как найти моду в Excel.
Для определения наиболее часто встречаемого значения используем формулу:
B3:B12 – массив значений, в котором необходимо определить наиболее повторяющееся значение.
Пример использования функции МОДА.НСК в Excel
Пример 2. В ряде числовых значений, полученном в результате работы генератора случайных чисел, необходимо определить повторяющиеся числа. Теперь смотрим как посчитать моду в Excel.
Заполним столбец «Случайные числа» с использованием функции СЛУЧМЕЖДУ(1;100), то есть случайными числами из диапазона от 1 до 100:
Примечание: функция СЛУЧМЕЖДУ выполняет пересчет полученных случайных значений при каждом вводе нового значения в любую ячейку, поэтому значения в столбце A2 на разных изображениях могут отличаться.
Выделим диапазон ячеек B2:B23 и введем формулу:
Для ввода формулы используем комбинацию клавиш Ctrl+Shift+Enter, чтобы функция была выполнена в массиве. В результате получим:
В указанном диапазоне случайных чисел повторяются значения 48, 47 и 53. Поскольку остальные числа являются уникальными, для ячеек B5:B23 сгенерирован код ошибки #Н/Д (то есть, формула не нашла запрашиваемое значение).
Пример работы с функцией МОДА.ОДН в Excel
Пример 3. Поставщик обувного магазина поинтересовался у владельца, какой размер обуви пользуется наибольшим спросом. Экономист просмотрел данные из таблицы покупок и практически сразу дал ответ. Как ему это удалось?
Таблица данных о покупках:
Как вычислить моду в Excel? Для определения размера, который пользуется наибольшим спросом, использована формула моды:
Примечание: в отличие от среднего арифметического значения (для данного примера – примерно 41), мода определяет наиболее часто встречаемое событие в диапазоне событий. Ее рационально использовать для решения статистических задач, связанных с анализом нормально распределенных данных.
Функции МОДА, МОДА.НСК и МОДА.ОДН в Excel и особенности их использования
Функция МОДА имеет следующие аргументы:
- число 1 – обязательный для заполнения аргумент, характеризующий первое числовое значение, для которого необходимо определить моду.
- [число 2] и последующие аргументы являются необязательными для заполнения и характеризуют последующие числовые значения, для которых требуется найти значение моды.
Аргументы модификации функции имеют одинаковый смысл.
- Максимальное количество аргументов в рассматриваемых функциях – не более 255.
- Вместо аргументов типа число 1; число 2;…;число n можно указывать массив значений или ссылку на диапазон ячеек.
- В качестве аргументов принимаются объекты данных следующих типов: имена, которые содержат числа, массивы числовых значений и ссылки.
- Все рассматриваемые функции для определения моды игнорируют пустые, логические значения и текстовые строки, содержащиеся в диапазоне значений, переданном в качестве аргумента.
- Если все элементы массива или диапазона чисел, переданных в качестве аргументов для всех трех функций являются уникальными (повторяющиеся значения отсутствуют), результатом работы данных функций будет являться код ошибки #Н/Д.
- Если функция МОДА.НСК была использована в качестве обычной функции, будет возвращено единственное значение моды. Для отображения нескольких мод необходимо выделить диапазон ячеек, ввести формулу и ее аргументы, использовать сочетание клавиш Ctrl+Shift+Enter для вывода массива вычисленных результатов.
Примечание 2: функция МОДА была разработана для ранних версий Excel и пока поддерживается новыми версиями программы, однако в последующих версиях поддержка данной функции может быть отменена. Вместо данной функции предлагается использование двух ее аналогов, которые будут рассмотрены ниже.
- Для возврата горизонтального массива наиболее встречающихся значений следует использовать запись вида ТРАНСП(МОДА.НСК(число 1; число 2;…;число n).
- МОДА.НСК принадлежит к классу формул массива и может возвращать как одну, так и несколько мод. Для записи в качестве формулы массива необходимо использовать сочетание клавиш Ctrl+Shift+Enter.
Примечание 4: функции МОДА и МОДА.ОДН определяют центральную тенденцию множества чисел в статическом распределении способом определения моды (существуют еще два распространенных способа: поиск среднего значения и медианы), то есть путем поиска элемента, значение которого наиболее часто встречается в определенном наборе чисел.
Источник
Для различных аналитических целей часто требуется получить средний уровень различных показателей: средний возраст, средняя зарплата и т.д. Первое, что приходит на ум – это найти простое среднее арифметическое. Но всегда ли это правильно? В этой статье разберемся, что такое медиана, среднее арифметическое и мода. А также научимся считать их в Excel.
Среднее арифметическое
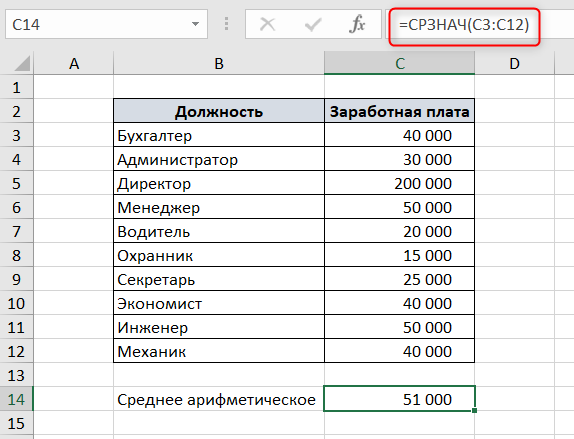
Среднее арифметическое значение – это сумма всех элементов выборки, поделенная на количество этих элементов.
Например, есть список должностей и заработных плат. Чтобы посчитать среднюю заработную плату в Excel, воспользуемся функцией СРЗНАЧ.
Медиана – это середина набора чисел, отсортированного по возрастанию.
Другими словами, 50% наблюдений ниже медианы и 50% наблюдений выше медианы. Медиана всегда равно удалена от начала и от конца набора чисел.
Если набор чисел состоит из нечетного количества элементов, то медианой будет число, которое находится в середине.

Если набор чисел состоит из четного числа элементов, то медиана будет равна среднему арифметическому между двумя центральными элементами списка.
Чтобы наглядно увидеть, чем отличается медиана от среднеарифметического значения на нашем первом примере с зарплатой, отсортируем список по возрастанию.
Поскольку в списке 10 элементов – четное количество – то медианой будет среднее арифметическое 5 и 6 элементов.

Чтобы посчитать медиану в Excel, воспользуемся функцией МЕДИАНА. В качестве аргументов функция принимает числовые значения ряда данных.
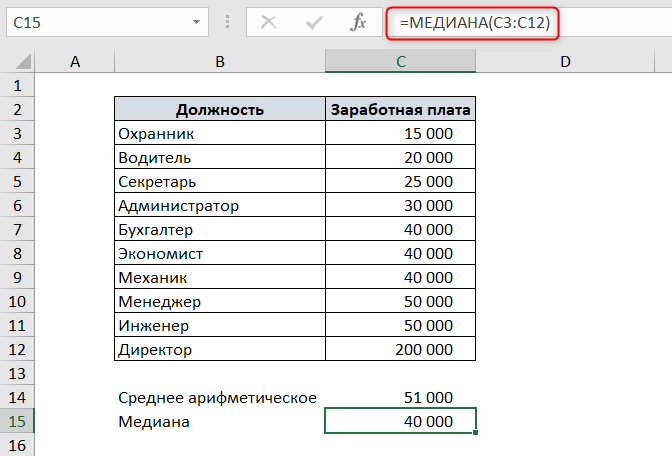
Как видите, медиана не равна среднему значению.
На этот вопрос однозначного ответа нет, все зависит от целей вашего анализа.
Основные отличия медианы от среднего арифметического:
- Медиана в отличие от среднего арифметического игнорирует выбросы данных (выбросы – это значения, которые значительно отличаются от основного массива выборки).
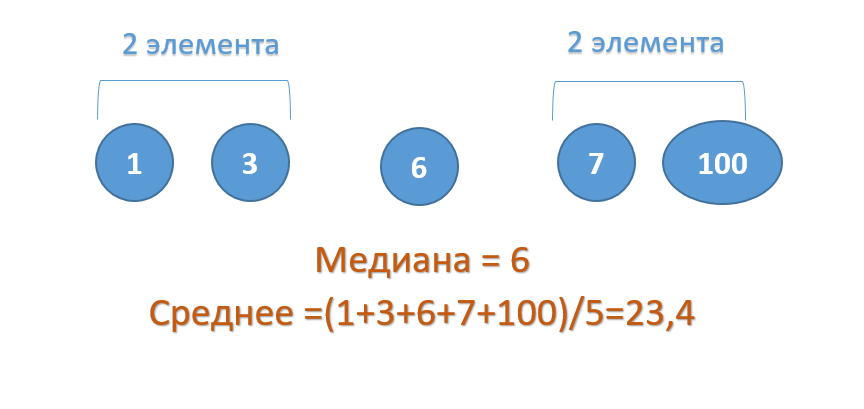
В данном примере число 100 – это выброс, т.к. оно значительно отличается от основной других чисел в ряду. И при расчете среднего арифметического это число 100 исказило среднее – оно стало значительно больше остальных чисел.
Медиана же останется неизменной, даже если вместо 100 мы укажем 1000, т.к. середина ряда все равно будет число 6.
Это свойство медианы – игнорировать выбросы – особенно полезно, когда нужно посчитать среднюю зарплату или средний возраст. В целом, медиана более точно определяет середину выборки, чем среднее арифметическое, поскольку устойчива к искажениям.
- Свойство медианы игнорировать выбросы, на самом деле, не всегда полезно. Оно может скрыть из виду важные моменты, тогда как среднее арифметическое, завысив или занизив среднее, поможет обратить на них внимание.
В нашем примере с заработной платой среднее арифметическое заработных плат выше, чем медиана. Это может обратить внимание на то, что одна из заработных плат (в данном случае – директора) сильно отличается от заработных плат других сотрудников.
- Если ряд данных имеет нормальное или близкое к нормальному распределение, то медиана или среднее значение будут равны или близки друг к другу.
- Если среднее значение больше медианы, то распределение положительно искажено (т.е. имеет выбросы в сторону больших значений). И наоборот, если среднее значение меньше медианы, то выборка отрицательно искажена (преобладают меньшие значения).
Что такое мода
Мода – это наиболее часто встречающееся значение выборки.
В нашем примере мода – это заработная плата 40000, т.к. это значение встречается 3 раза, в то время, как остальные значения – один или два раза.
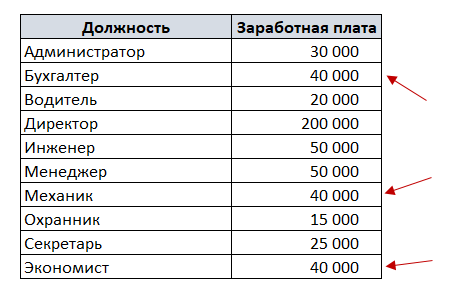
Чтобы посчитать моду в Excel, используем функцию МОДА.
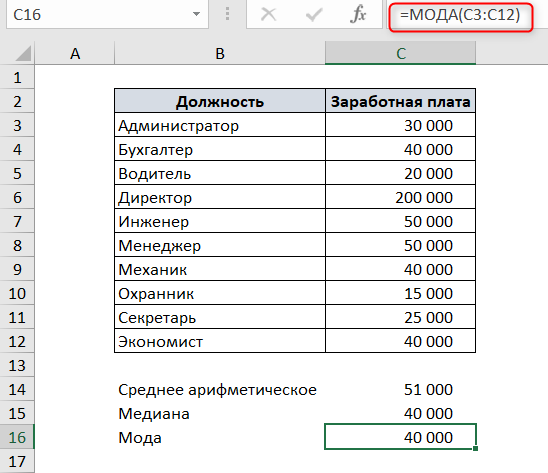
Для чего считать моду? Пример использования моды на коммерческом предприятии: для планирования производства обуви необходимо определить размер, который наиболее часто приобретают покупатели.
Средневзвешенное значение
Средневзвешенное значение отличается от среднего арифметического тем, что каждому элементу ряда присваивается «вес» — или как бы «значимость» его в ряду.
Для того, что определить средневзвешенное, сумма элементов ряда, умноженная на их «вес», делится на количество элементов.
Рассмотрим на том же примере с зарплатой. Добавим к таблице два столбца: количество сотрудников и ФОТ (в этом столбце умножим заработную плату одного сотрудника на количество сотрудников).

Чтобы посчитать средневзвешенную заработную плату, разделим сумму всех зарплат сотрудников на сумму количества сотрудников.
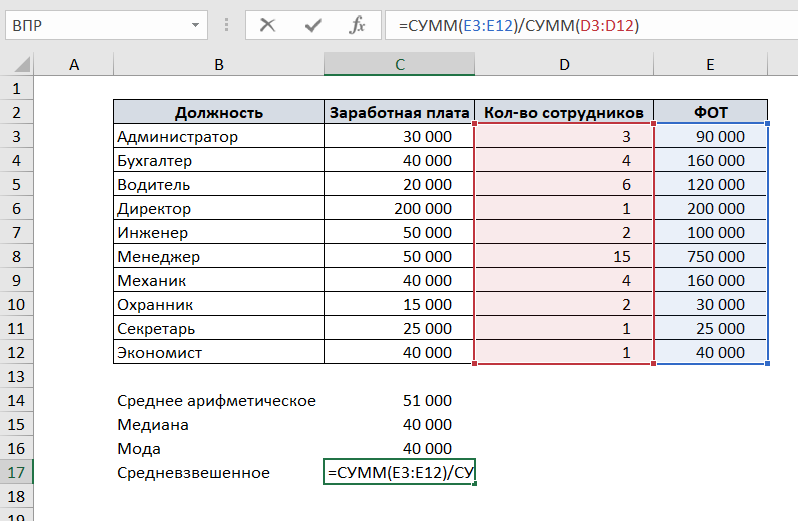
Таким образом, зарплату каждого сотрудника мы «взвесили» на количество сотрудников каждой должности.
Если разложить формулу средневзвешенного подобно, то получается:
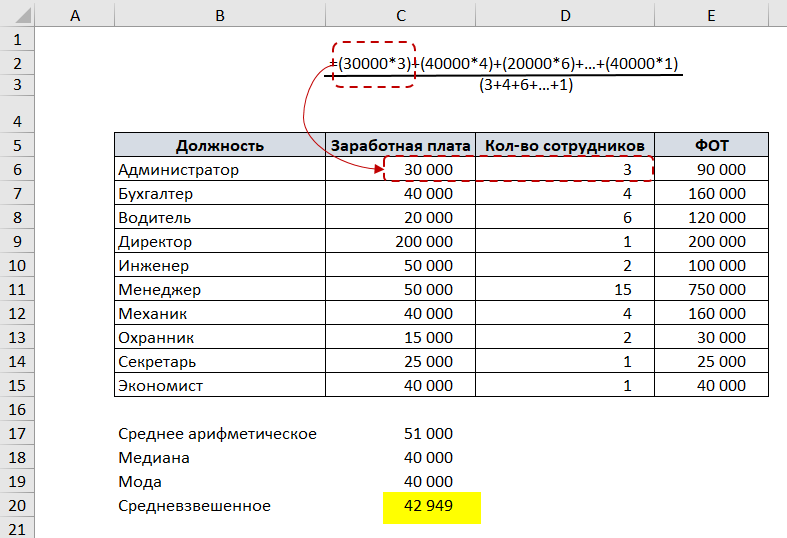
Для данного примера медиана, среднее арифметическое, средневзвешенное и мода отличаются.
Таким образом, в этом статье мы разобрались, что такое медиана, среднее арифметическое и мода и узнали, при помощи каких функций их можно посчитать в Excel.
 Сообщество Excel Analytics | обучение Excel
Сообщество Excel Analytics | обучение Excel
 Канал на Яндекс.Дзен
Канал на Яндекс.Дзен
Источник
Рассмотрим инструмент Описательная статистика, входящий в надстройку Пакет Анализа. Рассчитаем показатели выборки: среднее, медиана, мода, дисперсия, стандартное отклонение и др.
Задача
описательной статистики
(descriptive statistics) заключается в том, чтобы с использованием математических инструментов свести сотни значений
выборки
к нескольким итоговым показателям, которые дают представление о
выборке
.В качестве таких статистических показателей используются:
среднее
,
медиана
,
мода
,
дисперсия, стандартное отклонение
и др.
Опишем набор числовых данных с помощью определенных показателей. Для чего нужны эти показатели? Эти показатели позволят сделать определенные
статистические выводы о распределении
, из которого была взята
выборка
. Например, если у нас есть
выборка
значений толщины трубы, которая изготавливается на определенном оборудовании, то на основании анализа этой
выборки
мы сможем сделать, с некой определенной вероятностью, заключение о состоянии процесса изготовления.
Содержание статьи:
- Надстройка Пакет анализа;
-
Среднее выборки
;
-
Медиана выборки
;
-
Мода выборки
;
-
Мода и среднее значение
;
-
Дисперсия выборки
;
-
Стандартное отклонение выборки
;
-
Стандартная ошибка
;
-
Ассиметричность
;
-
Эксцесс выборки
;
-
Уровень надежности
.
Надстройка Пакет анализа
Для вычисления статистических показателей одномерных
выборок
, используем
надстройку Пакет анализа
. Затем, все показатели рассчитанные надстройкой, вычислим с помощью встроенных функций MS EXCEL.
СОВЕТ
: Подробнее о других инструментах надстройки
Пакет анализа
и ее подключении – читайте в статье
Надстройка Пакет анализа MS EXCEL
.
Выборку
разместим на
листе
Пример
в файле примера
в диапазоне
А6:А55
(50 значений).
Примечание
: Для удобства написания формул для диапазона
А6:А55
создан
Именованный диапазон
Выборка.
В диалоговом окне
Анализ данных
выберите инструмент
Описательная статистика
.

После нажатия кнопки
ОК
будет выведено другое диалоговое окно,
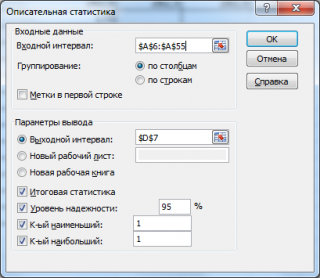
в котором нужно указать:
входной интервал
(Input Range) – это диапазон ячеек, в котором содержится массив данных. Если в указанный диапазон входит текстовый заголовок набора данных, то нужно поставить галочку в поле
Метки в первой строке (
Labels
in
first
row
).
В этом случае заголовок будет выведен в
Выходном интервале.
Пустые ячейки будут проигнорированы, поэтому нулевые значения необходимо обязательно указывать в ячейках, а не оставлять их пустыми;
выходной интервал
(Output Range). Здесь укажите адрес верхней левой ячейки диапазона, в который будут выведены статистические показатели;
Итоговая статистика (
Summary
Statistics
)
. Поставьте галочку напротив этого поля – будут выведены основные показатели выборки:
среднее, медиана, мода, стандартное отклонение
и др.;-
Также можно поставить галочки напротив полей
Уровень надежности (
Confidence
Level
for
Mean
)
,
К-й наименьший
(Kth Largest) и
К-й наибольший
(Kth Smallest).
В результате будут выведены следующие статистические показатели:
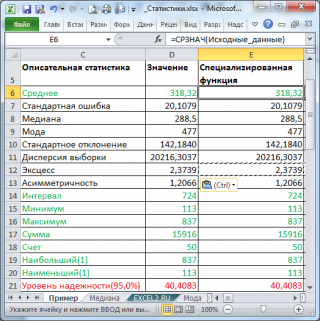
Все показатели выведены в виде значений, а не формул. Если массив данных изменился, то необходимо перезапустить расчет.
Если во
входном интервале
указать ссылку на несколько столбцов данных, то будет рассчитано соответствующее количество наборов показателей. Такой подход позволяет сравнить несколько наборов данных. При сравнении нескольких наборов данных используйте заголовки (включите их во
Входной интервал
и установите галочку в поле
Метки в первой строке
). Если наборы данных разной длины, то это не проблема — пустые ячейки будут проигнорированы.
Зеленым цветом на картинке выше и в
файле примера
выделены показатели, которые не требуют особого пояснения. Для большинства из них имеется специализированная функция:
Интервал
(Range) — разница между максимальным и минимальным значениями;
Минимум
(Minimum) – минимальное значение в диапазоне ячеек, указанном во
Входном интервале
(см.статью про функцию
МИН()
);
Максимум
(Maximum)– максимальное значение (см.статью про функцию
МАКС()
);
Сумма
(Sum) – сумма всех значений (см.статью про функцию
СУММ()
);
Счет
(Count) – количество значений во
Входном интервале
(пустые ячейки игнорируются, см.статью про функцию
СЧЁТ()
);
Наибольший
(Kth Largest) – выводится К-й наибольший. Например, 1-й наибольший – это максимальное значение (см.статью про функцию
НАИБОЛЬШИЙ()
);
Наименьший
(Kth Smallest) – выводится К-й наименьший. Например, 1-й наименьший – это минимальное значение (см.статью про функцию
НАИМЕНЬШИЙ()
).
Ниже даны подробные описания остальных показателей.
Среднее выборки
Среднее
(mean, average) или
выборочное среднее
или
среднее выборки
(sample average) представляет собой
арифметическое среднее
всех значений массива. В MS EXCEL для вычисления среднего выборки используется функция
СРЗНАЧ()
.
Выборочное среднее
является «хорошей» (несмещенной и эффективной) оценкой
математического ожидания
случайной величины (подробнее см. статью
Среднее и Математическое ожидание в MS EXCEL
).
Медиана выборки
Медиана
(Median) – это число, которое является серединой множества чисел (в данном случае выборки): половина чисел множества больше, чем
медиана
, а половина чисел меньше, чем
медиана
. Для определения
медианы
необходимо сначала
отсортировать множество чисел
. Например,
медианой
для чисел 2, 3, 3,
4
, 5, 7, 10 будет 4.
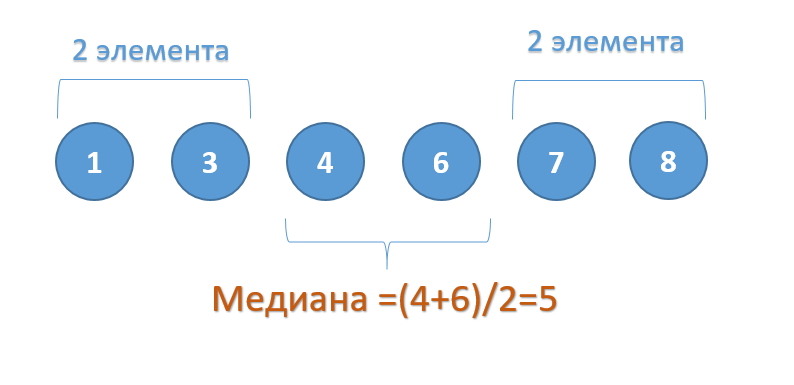
Если множество содержит четное количество чисел, то вычисляется
среднее
для двух чисел, находящихся в середине множества. Например,
медианой
для чисел 2, 3,
3
,
5
, 7, 10 будет 4, т.к. (3+5)/2.
Если имеется длинный хвост распределения, то
Медиана
лучше, чем
среднее значение
, отражает «типичное» или «центральное» значение. Например, рассмотрим несправедливое распределение зарплат в компании, в которой руководство получает существенно больше, чем основная масса сотрудников.
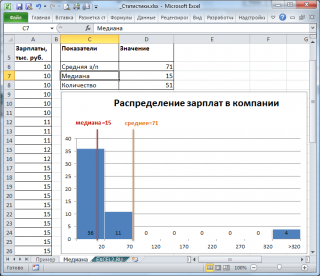
Очевидно, что средняя зарплата (71 тыс. руб.) не отражает тот факт, что 86% сотрудников получает не более 30 тыс. руб. (т.е. 86% сотрудников получает зарплату в более, чем в 2 раза меньше средней!). В то же время медиана (15 тыс. руб.) показывает, что
как минимум
у 50% сотрудников зарплата меньше или равна 15 тыс. руб.
Для определения
медианы
в MS EXCEL существует одноименная функция
МЕДИАНА()
, английский вариант — MEDIAN().
Медиану
также можно вычислить с помощью формул
=КВАРТИЛЬ.ВКЛ(Выборка;2) =ПРОЦЕНТИЛЬ.ВКЛ(Выборка;0,5).
Подробнее о
медиане
см. специальную статью
Медиана в MS EXCEL
.
СОВЕТ
: Подробнее про
квартили
см. статью, про
перцентили (процентили)
см. статью.
Мода выборки
Мода
(Mode) – это наиболее часто встречающееся (повторяющееся) значение в
выборке
. Например, в массиве (1; 1;
2
;
2
;
2
; 3; 4; 5) число 2 встречается чаще всего – 3 раза. Значит, число 2 – это
мода
. Для вычисления
моды
используется функция
МОДА()
, английский вариант MODE().
Примечание
: Если в массиве нет повторяющихся значений, то функция вернет значение ошибки #Н/Д. Это свойство использовано в статье
Есть ли повторы в списке?
Начиная с
MS EXCEL 2010
вместо функции
МОДА()
рекомендуется использовать функцию
МОДА.ОДН()
, которая является ее полным аналогом. Кроме того, в MS EXCEL 2010 появилась новая функция
МОДА.НСК()
, которая возвращает несколько наиболее часто повторяющихся значений (если количество их повторов совпадает). НСК – это сокращение от слова НеСКолько.
Например, в массиве (1; 1;
2
;
2
;
2
; 3;
4
;
4
;
4
; 5) числа 2 и 4 встречаются наиболее часто – по 3 раза. Значит, оба числа являются
модами
. Функции
МОДА.ОДН()
и
МОДА()
вернут значение 2, т.к. 2 встречается первым, среди наиболее повторяющихся значений (см.
файл примера
, лист
Мода
).
Чтобы исправить эту несправедливость и была введена функция
МОДА.НСК()
, которая выводит все
моды
. Для этого ее нужно ввести как
формулу массива
.
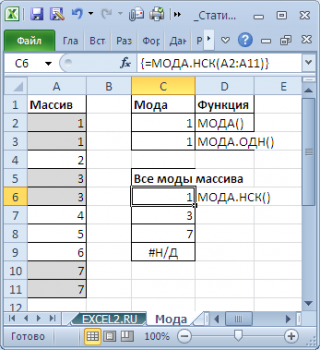
Как видно из картинки выше, функция
МОДА.НСК()
вернула все три
моды
из массива чисел в диапазоне
A2:A11
: 1; 3 и 7. Для этого, выделите диапазон
C6:C9
, в
Строку формул
введите формулу
=МОДА.НСК(A2:A11)
и нажмите
CTRL+SHIFT+ENTER
. Диапазон
C
6:
C
9
охватывает 4 ячейки, т.е. количество выделяемых ячеек должно быть больше или равно количеству
мод
. Если ячеек больше чем м
о
д, то избыточные ячейки будут заполнены значениями ошибки #Н/Д. Если
мода
только одна, то все выделенные ячейки будут заполнены значением этой
моды
.
Теперь вспомним, что мы определили
моду
для выборки, т.е. для конечного множества значений, взятых из
генеральной совокупности
. Для
непрерывных случайных величин
вполне может оказаться, что выборка состоит из массива на подобие этого (0,935; 1,211; 2,430; 3,668; 3,874; …), в котором может не оказаться повторов и функция
МОДА()
вернет ошибку.
Даже в нашем массиве с
модой
, которая была определена с помощью
надстройки Пакет анализа
, творится, что-то не то. Действительно,
модой
нашего массива значений является число 477, т.к. оно встречается 2 раза, остальные значения не повторяются. Но, если мы посмотрим на
гистограмму распределения
, построенную для нашего массива, то увидим, что 477 не принадлежит интервалу наиболее часто встречающихся значений (от 150 до 250).
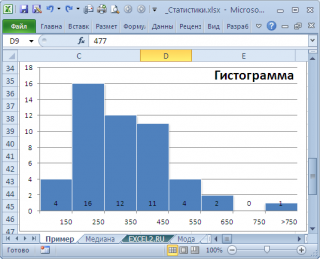
Проблема в том, что мы определили
моду
как наиболее часто встречающееся значение, а не как наиболее вероятное. Поэтому,
моду
в учебниках статистики часто определяют не для выборки (массива), а для функции распределения. Например, для
логнормального распределения
мода
(наиболее вероятное значение непрерывной случайной величины х), вычисляется как
exp
(
m
—
s
2
)
, где m и s параметры этого распределения.
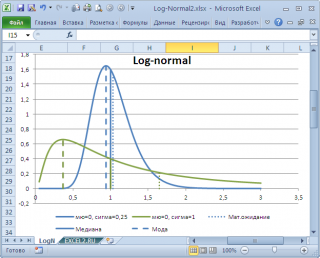
Понятно, что для нашего массива число 477, хотя и является наиболее часто повторяющимся значением, но все же является плохой оценкой для
моды
распределения, из которого взята
выборка
(наиболее вероятного значения или для которого плотность вероятности распределения максимальна).
Для того, чтобы получить оценку
моды
распределения, из
генеральной совокупности
которого взята
выборка
, можно, например, построить
гистограмму
. Оценкой для
моды
может служить интервал наиболее часто встречающихся значений (самого высокого столбца). Как было сказано выше, в нашем случае это интервал от 150 до 250.
Вывод
: Значение
моды
для
выборки
, рассчитанное с помощью функции
МОДА()
, может ввести в заблуждение, особенно для небольших выборок. Эта функция эффективна, когда случайная величина может принимать лишь несколько дискретных значений, а размер
выборки
существенно превышает количество этих значений.
Например, в рассмотренном примере о распределении заработных плат (см. раздел статьи выше, о Медиане),
модой
является число 15 (17 значений из 51, т.е. 33%). В этом случае функция
МОДА()
дает хорошую оценку «наиболее вероятного» значения зарплаты.
Примечание
: Строго говоря, в примере с зарплатой мы имеем дело скорее с
генеральной совокупностью
, чем с
выборкой
. Т.к. других зарплат в компании просто нет.
О вычислении
моды
для распределения
непрерывной случайной величины
читайте статью
Мода в MS EXCEL
.
Мода и среднее значение
Не смотря на то, что
мода
– это наиболее вероятное значение случайной величины (вероятность выбрать это значение из
Генеральной совокупности
максимальна), не следует ожидать, что
среднее значение
обязательно будет близко к
моде
.
Примечание
:
Мода
и
среднее
симметричных распределений совпадает (имеется ввиду симметричность
плотности распределения
).
Представим, что мы бросаем некий «неправильный» кубик, у которого на гранях имеются значения (1; 2; 3; 4; 6; 6), т.е. значения 5 нет, а есть вторая 6.
Модой
является 6, а среднее значение – 3,6666.
Другой пример. Для
Логнормального распределения
LnN(0;1)
мода
равна =EXP(m-s2)= EXP(0-1*1)=0,368, а
среднее значение
1,649.
Дисперсия выборки
Дисперсия выборки
или
выборочная дисперсия (
sample
variance
) характеризует разброс значений в массиве, отклонение от
среднего
.
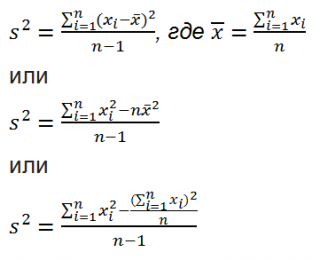
Из формулы №1 видно, что
дисперсия выборки
это сумма квадратов отклонений каждого значения в массиве
от среднего
, деленная на размер выборки минус 1.
В MS EXCEL 2007 и более ранних версиях для вычисления
дисперсии выборки
используется функция
ДИСП()
. С версии MS EXCEL 2010 рекомендуется использовать ее аналог — функцию
ДИСП.В()
.
Дисперсию
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
):
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1) =(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1)
–
формула массива
Дисперсия выборки
равна 0, только в том случае, если все значения равны между собой и, соответственно, равны
среднему значению
.
Чем больше величина
дисперсии
, тем больше разброс значений в массиве относительно
среднего
.
Размерность
дисперсии
соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность
дисперсии
будет кг
2
. Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из
дисперсии – стандартное отклонение
.
Подробнее о
дисперсии
см. статью
Дисперсия и стандартное отклонение в MS EXCEL
.
Стандартное отклонение выборки
Стандартное отклонение выборки
(Standard Deviation), как и
дисперсия
, — это мера того, насколько широко разбросаны значения в выборке
относительно их среднего
.
По определению,
стандартное отклонение
равно квадратному корню из
дисперсии
:
![]()
Стандартное отклонение
не учитывает величину значений в
выборке
, а только степень рассеивания значений вокруг их
среднего
. Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х
выборок
: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у
выборок
существенно отличается.
В MS EXCEL 2007 и более ранних версиях для вычисления
Стандартного отклонения выборки
используется функция
СТАНДОТКЛОН()
. С версии MS EXCEL 2010 рекомендуется использовать ее аналог
СТАНДОТКЛОН.В()
.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
):
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)) =КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Подробнее о
стандартном отклонении
см. статью
Дисперсия и стандартное отклонение в MS EXCEL
.
Стандартная ошибка
В
Пакете анализа
под термином
стандартная ошибка
имеется ввиду
Стандартная ошибка среднего
(Standard Error of the Mean, SEM).
Стандартная ошибка среднего
— это оценка
стандартного отклонения
распределения
выборочного среднего
.
Примечание
: Чтобы разобраться с понятием
Стандартная ошибка среднего
необходимо прочитать о
выборочном распределении
(см. статью
Статистики, их выборочные распределения и точечные оценки параметров распределений в MS EXCEL
) и статью про
Центральную предельную теорему
.
Стандартное отклонение распределения выборочного среднего
вычисляется по формуле σ/√n, где n — объём
выборки, σ — стандартное отклонение исходного
распределения, из которого взята
выборка
. Т.к. обычно
стандартное отклонение
исходного распределения неизвестно, то в расчетах вместо
σ
используют ее оценку
s
—
стандартное отклонение выборки
. А соответствующая величина s/√n имеет специальное название —
Стандартная ошибка среднего.
Именно эта величина вычисляется в
Пакете анализа.
В MS EXCEL
стандартную ошибку среднего
можно также вычислить по формуле
=СТАНДОТКЛОН.В(Выборка)/ КОРЕНЬ(СЧЁТ(Выборка))
Асимметричность
Асимметричность
или
коэффициент асимметрии
(skewness) характеризует степень несимметричности распределения (
плотности распределения
) относительно его
среднего
.
Положительное значение
коэффициента асимметрии
указывает, что размер правого «хвоста» распределения больше, чем левого (относительно среднего). Отрицательная асимметрия, наоборот, указывает на то, что левый хвост распределения больше правого.
Коэффициент асимметрии
идеально симметричного распределения или выборки равно 0.

Примечание
:
Асимметрия выборки
может отличаться расчетного значения асимметрии теоретического распределения. Например,
Нормальное распределение
является симметричным распределением (
плотность его распределения
симметрична относительно
среднего
) и, поэтому имеет асимметрию равную 0. Понятно, что при этом значения в
выборке
из соответствующей
генеральной совокупности
не обязательно должны располагаться совершенно симметрично относительно
среднего
. Поэтому,
асимметрия выборки
, являющейся оценкой
асимметрии распределения
, может отличаться от 0.
Функция
СКОС()
, английский вариант SKEW(), возвращает коэффициент
асимметрии выборки
, являющейся оценкой
асимметрии
соответствующего распределения, и определяется следующим образом:
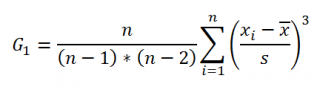
где n – размер
выборки
, s –
стандартное отклонение выборки
.
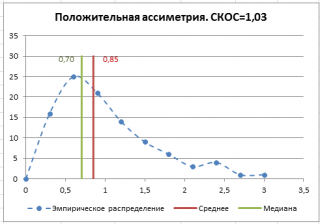
В
файле примера на листе СКОС
приведен расчет коэффициента
асимметрии
на примере случайной выборки из
распределения Вейбулла
, которое имеет значительную положительную
асимметрию
при параметрах распределения W(1,5; 1).
Эксцесс выборки
Эксцесс
показывает относительный вес «хвостов» распределения относительно его центральной части.
Для того чтобы определить, что относится к хвостам распределения, а что к его центральной части, можно использовать границы μ +/-
σ
.
Примечание
: Не смотря на старания профессиональных статистиков, в литературе еще попадается определение
Эксцесса
как меры «остроконечности» (peakedness) или сглаженности распределения. Но, на самом деле, значение
Эксцесса
ничего не говорит о форме пика распределения.
Согласно определения,
Эксцесс
равен четвертому
стандартизированному моменту:
![]()
Для
нормального распределения
четвертый момент равен 3*σ
4
, следовательно,
Эксцесс
равен 3. Многие компьютерные программы используют для расчетов не сам
Эксцесс
, а так называемый Kurtosis excess, который меньше на 3. Т.е. для
нормального распределения
Kurtosis excess равен 0. Необходимо быть внимательным, т.к. часто не очевидно, какая формула лежит в основе расчетов.
Примечание
: Еще большую путаницу вносит перевод этих терминов на русский язык. Термин Kurtosis происходит от греческого слова «изогнутый», «имеющий арку». Так сложилось, что на русский язык оба термина Kurtosis и Kurtosis excess переводятся как
Эксцесс
(от англ. excess — «излишек»). Например, функция MS EXCEL
ЭКСЦЕСС()
на самом деле вычисляет Kurtosis excess.
Функция
ЭКСЦЕСС()
, английский вариант KURT(), вычисляет на основе значений выборки несмещенную оценку
эксцесса распределения
случайной величины и определяется следующим образом:
![]()
Как видно из формулы MS EXCEL использует именно Kurtosis excess, т.е. для выборки из
нормального распределения
формула вернет близкое к 0 значение.
Если задано менее четырех точек данных, то функция
ЭКСЦЕСС()
возвращает значение ошибки #ДЕЛ/0!
Вернемся к
распределениям случайной величины
.
Эксцесс
(Kurtosis excess) для
нормального распределения
всегда равен 0, т.е. не зависит от параметров распределения μ и σ. Для большинства других распределений
Эксцесс
зависит от параметров распределения: см., например,
распределение Вейбулла
или
распределение Пуассона
, для котрого
Эксцесс
= 1/λ.
Уровень надежности
Уровень
надежности
— означает вероятность того, что
доверительный интервал
содержит истинное значение оцениваемого параметра распределения.
Вместо термина
Уровень
надежности
часто используется термин
Уровень доверия
. Про
Уровень надежности
(Confidence Level for Mean) читайте статью
Уровень значимости и уровень надежности в MS EXCEL
.
Задав значение
Уровня
надежности
в окне
надстройки Пакет анализа
, MS EXCEL вычислит половину ширины
доверительного интервала для оценки среднего (дисперсия неизвестна)
.
Тот же результат можно получить по формуле (см.
файл примера
):
=ДОВЕРИТ.СТЬЮДЕНТ(1-0,95;s;n)
s —
стандартное отклонение выборки
, n – объем
выборки
.
Подробнее см. статью про
построение доверительного интервала для оценки среднего (дисперсия неизвестна)
.
Excel функция МОДА (MODE)
Microsoft Excel функция МОДА возвращает наиболее часто встречающееся число из набора чисел.
Эта функция была заменена функциями МОДА.ОДН и МОДА.НСК, начиная с Excel 2010.
Функция МОДА — это встроенная в Excel функция, которая относится к категории статистических функций.
Её можно использовать как функцию рабочего листа (WS) в Excel.
Как функцию рабочего листа, функцию МОДА можно ввести как часть формулы в ячейке рабочего листа.
Синтаксис
Синтаксис функции МОДА в Microsoft Excel:
Аргументы или параметры
Возвращаемое значение
Функция МОДА возвращает числовое значение.
Если все числовые значения в диапазоне уникальны, функция МОДА возвращает ошибку #Н/Д.
Если текстовое значение, такое как «A», вводится в качестве параметра, функция МОДА вернет #ЗНАЧ!
Если ссылка на диапазон или ячейку содержит нечисловые значения, такие как текстовые значения, логические значения или пустые ячейки, эти значения будут проигнорированы.
Примечание
- См. также функции МОДА.ОДН и МОДА.НСК.
Применение
- Excel для Office 365, Excel 2019, Excel 2016, Excel 2013, Excel 2011 для Mac, Excel 2010, Excel 2007, Excel 2003
Тип функции
- Функция рабочего листа (WS)
Пример (как функция рабочего листа)
Рассмотрим несколько примеров функции МОДА, чтобы понять, как использовать Excel функцию МОДА как функцию рабочего листа в Microsoft Excel: 
На основании, приведенной выше электронной таблицы Excel могут быть возвращены следующие примеры МОДА:
Размахом ряда чисел называется разность между наибольшим и наименьшим из этих чисел. Модой ряда чисел называется число, которое встречается в данном ряду чаще других. Ряд чисел может иметь более одной моды, а может не иметь моды совсем. Модой ряда 32, 26, 18, 26, 15, 21, 26 является число 26, встречается 3 раза.
Как найти моду в ряду распределения?
Для интервального ряда мода определяется по формуле: Mo=XMo+hMo⋅fMo−fMo−1(fMo−fMo−1)+(fMo−fMo+1), XMo — левая граница модального интервала, hMo — длина модального интервала, fMo−1 — частота премодального интервала, fMo — частота модального интервала, fMo+1 — частота послемодального интервала.
Как рассчитать медиану в Excel?
Для определения медианы в MS EXCEL существует одноименная функция МЕДИАНА() , английский вариант MEDIAN(). Медиана не обязательно совпадает со средним значением (mean, average) в выборке . Совпадение имеет место только в том случае, если значения в выборке распределены симметрично относительно среднего .
Как определить моду в статистике пример?
Мода – это то значение в анализируемой совокупности данных, которое встречается чаще других, поэтому нужно посмотреть на частоты значений и отыскать максимальное из них. Например, в наборе данных 3, 4, 6, 7, 3, 5, 3, 4 модой будет значение 3 – повторяется чаще остальных. Это в дискретном ряду, и здесь все просто.
Как найти моду графически?
Моду и медиану в интервальном ряду можно определить графически. Мода определяется по гистограмме распределения. Для этого выбирается самый высокий прямоугольник, который является в данном случае модальным. Затем правую вершину модального прямоугольника соединяем с правым верхним углом предыдущего прямоугольника.
Как рассчитывается медиана?
Медианой ряда чисел (медианой числового ряда) называется число, стоящее посередине упорядоченного по возрастанию ряда чисел — в случае, если количество чисел нечётное. Если же количество чисел в ряду чётно, то медианой ряда является полусумма двух стоящих посередине чисел упорядоченного по возрастанию ряда.
Как найти медиану в ряду распределения?
(Если отсортированный ряд содержит нечетное число признаков, то номер медианы вычисляют по формуле: Ме = (n(число признаков в совокупности) + 1)/2, в случае четного числа признаков медиана будет равна средней из двух признаков находящихся в середине ряда).
Чем является медиана в ряду распределения?
Медиана — это такое значение признака, которое разделяет ранжированный ряд распределения на две равные части — со значениями признака меньше медианы и со значениями признака больше медианы. Для нахождения медианы, нужно отыскать значение признака, которое находится на середине упорядоченного ряда.
Что такое медиана в ряду чисел?
Медиа́на (от лат. mediāna «середина») набора чисел — число, которое находится в середине этого набора, если его упорядочить по возрастанию, то есть такое число, что половина из элементов набора не меньше него, а другая половина не больше.
Что такое медиана в Excel?
Медиана — это число, которое является серединой множества чисел, то есть половина чисел имеют значения большие, чем медиана, а половина чисел имеют значения меньшие, чем медиана. Например, медианой для чисел 2, 3, 3, 5, 7 и 10 будет 4. Мода — это число, наиболее часто встречающееся в данном наборе чисел.
Как рассчитать дисперсию в Excel?
Для распределений, представленных в MS EXCEL , дисперсию можно вычислить аналитически, как функцию от параметров распределения. Например, для Биномиального распределения дисперсия равна произведению его параметров: n*p*q. Примечание : Дисперсия, является вторым центральным моментом , обозначается D[X], VAR(х), V(x).
Как найти медиану по выборке?
Для удобства нахождения медианы сначала нужно отсортировать выборку в возрастающем или убывающем порядке . Тогда элемент, стоящий ровно посередине, будет медианой.
Что такое мода и медиана в статистике?
В статистике модой называется величина признака (варианта), которая чаще всего встречается в данной совокупности. Медианой в статистике называется варианта, которая находится в середине вариационного ряда. Медиана делит ряд пополам. Обозначают медиану символом.
Как определить медианное значение?
Медиану рассчитывают по определенному правилу. Для начала (после ранжирования данных) находят медианный интервал. Это такой интервал, через который проходит искомое медианное значение. Определяется с помощью накопленной доли ранжированных интервалов.
Что такое мода в математике?
Мода — значение во множестве наблюдений, которое встречается наиболее часто. Иногда в совокупности встречается более чем одна мода (например: 2, 6, 6, 6, 8, 9, 9, 9, 10; мода = 6 и 9). Из структурных средних величин только мода обладает таким уникальным свойством. .
Как найти моду в excel
Здравствуйте, друзья. В этой статье расскажу, как в Эксель получить наиболее часто использующееся число в массиве. Для этого применяем формулу МОДА:

В примере выше есть ведомость оценок для учеников 1-3 классов. С помощью функции МОДА мы узнали, что наибольшее количество участников получили в этом списке четвёрку.
МОДА принимает в качестве аргумента:
- Ссылку на диапазон
- Массив значений
- Именованный диапазон
- Перечень чисел, массивов, диапазонов через точку с запятой
Функция игнорирует ячейки с текстом, логическими значениями, пустые. Если она не может определить наиболее часто встречающееся значение – выводит ошибку #Н/Д. Чтобы ее перехватить, можете использовать функцию-обработчик.
В последних версиях Excel, разработчики пометили функцию МОДа, как устаревшую. Вместо нее предлагают использовать:
- МОДА.ОДН( массив ) – оптимизированный аналог МОДЫ
- МОДА.НСК( массив ) – выводит список из наиболее частотных цифр, содержащихся в массиве
Используются эти функции так же само, однако более оптимальны с точки зрения внутреннего кода.
Как найти моду в экселе?
Мода это цифра (число) чаще всего повторяющаяся в наборе цифр (чисел) в экселе (если имеется ввиду продукт microsoft excel) существует такая функция. В нужной Вам ячейке неубходимо указать «=МОДА(:)» а вместо знака ** выделить диапазон чисел из которых вы ищете.
Пример: =МОДА(А1:А101). На указанной Вами ячейке программа найдёт моду числ в ячейках от a1 до a101.
Желаю удачи в познании экселя!
Актуальный вопрос на самом деле. Итак, чтобы нам это сделать необходимо : ввести функцию «MODE» в ячейку, в которой мы хотим увидеть итоговый результат. Формат функции следующий: «=MODE(Cx:Dy)», где C и D являются — столбца первой и последней ячейки набора чисел,а вот х и y – это номер первой и последней строки набора чисел.Это, как правило, можно и посчитать в автоматическом режиме , написав просто » мода» в русскоязычном экселе ( пишите мода и выделяете тот столбец, то есть признак, который вы и хотите посчитать).
Содержание
- Статистические функции
- МАКС
- МИН
- СРЗНАЧ
- СРЗНАЧЕСЛИ
- МОДА.ОДН
- МЕДИАНА
- СТАНДОТКЛОН
- НАИБОЛЬШИЙ
- НАИМЕНЬШИЙ
- РАНГ.СР
- Вопросы и ответы

Статистическая обработка данных – это сбор, упорядочивание, обобщение и анализ информации с возможностью определения тенденции и прогноза по изучаемому явлению. В Excel есть огромное количество инструментов, которые помогают проводить исследования в данной области. Последние версии этой программы в плане возможностей практически ничем не уступают специализированным приложениям в области статистики. Главными инструментами для выполнения расчетов и анализа являются функции. Давайте изучим общие особенности работы с ними, а также подробнее остановимся на отдельных наиболее полезных инструментах.
Статистические функции
Как и любые другие функции в Экселе, статистические функции оперируют аргументами, которые могут иметь вид постоянных чисел, ссылок на ячейки или массивы.
Выражения можно вводить вручную в определенную ячейку или в строку формул, если хорошо знать синтаксис конкретного из них. Но намного удобнее воспользоваться специальным окном аргументов, которое содержит подсказки и уже готовые поля для ввода данных. Перейти в окно аргумента статистических выражений можно через «Мастер функций» или с помощью кнопок «Библиотеки функций» на ленте.
Запустить Мастер функций можно тремя способами:
- Кликнуть по пиктограмме «Вставить функцию» слева от строки формул.
- Находясь во вкладке «Формулы», кликнуть на ленте по кнопке «Вставить функцию» в блоке инструментов «Библиотека функций».
- Набрать на клавиатуре сочетание клавиш Shift+F3.

При выполнении любого из вышеперечисленных вариантов откроется окно «Мастера функций».
Затем нужно кликнуть по полю «Категория» и выбрать значение «Статистические».

После этого откроется список статистических выражений. Всего их насчитывается более сотни. Чтобы перейти в окно аргументов любого из них, нужно просто выделить его и нажать на кнопку «OK».

Для того, чтобы перейти к нужным нам элементам через ленту, перемещаемся во вкладку «Формулы». В группе инструментов на ленте «Библиотека функций» кликаем по кнопке «Другие функции». В открывшемся списке выбираем категорию «Статистические». Откроется перечень доступных элементов нужной нам направленности. Для перехода в окно аргументов достаточно кликнуть по одному из них.


Урок: Мастер функций в Excel
МАКС
Оператор МАКС предназначен для определения максимального числа из выборки. Он имеет следующий синтаксис:
=МАКС(число1;число2;…)

В поля аргументов нужно ввести диапазоны ячеек, в которых находится числовой ряд. Наибольшее число из него эта формула выводит в ту ячейку, в которой находится сама.
МИН
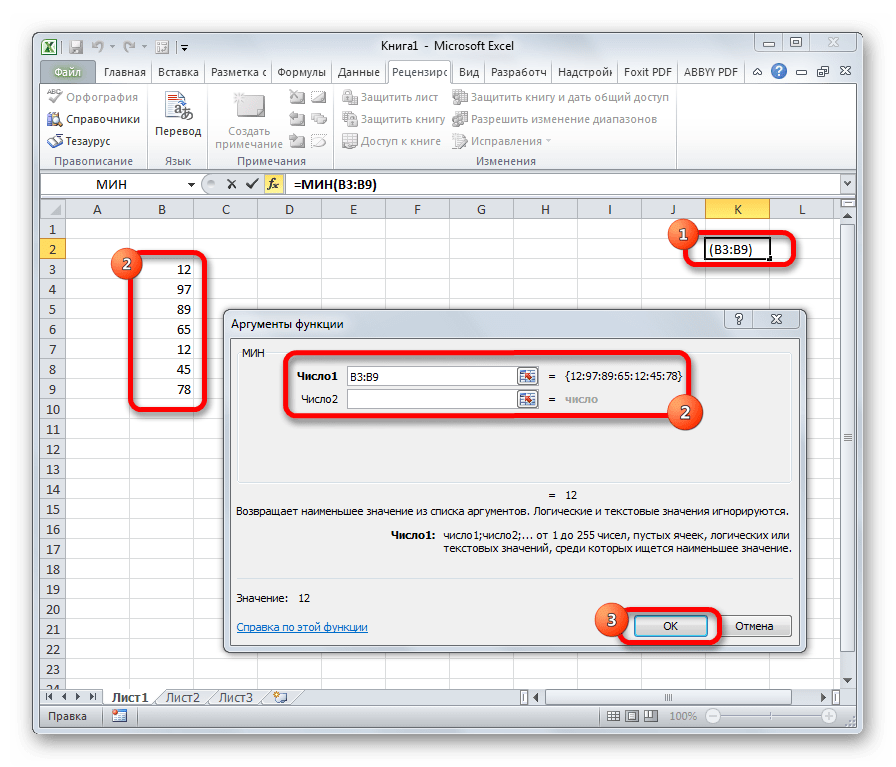
По названию функции МИН понятно, что её задачи прямо противоположны предыдущей формуле – она ищет из множества чисел наименьшее и выводит его в заданную ячейку. Имеет такой синтаксис:
=МИН(число1;число2;…)
СРЗНАЧ
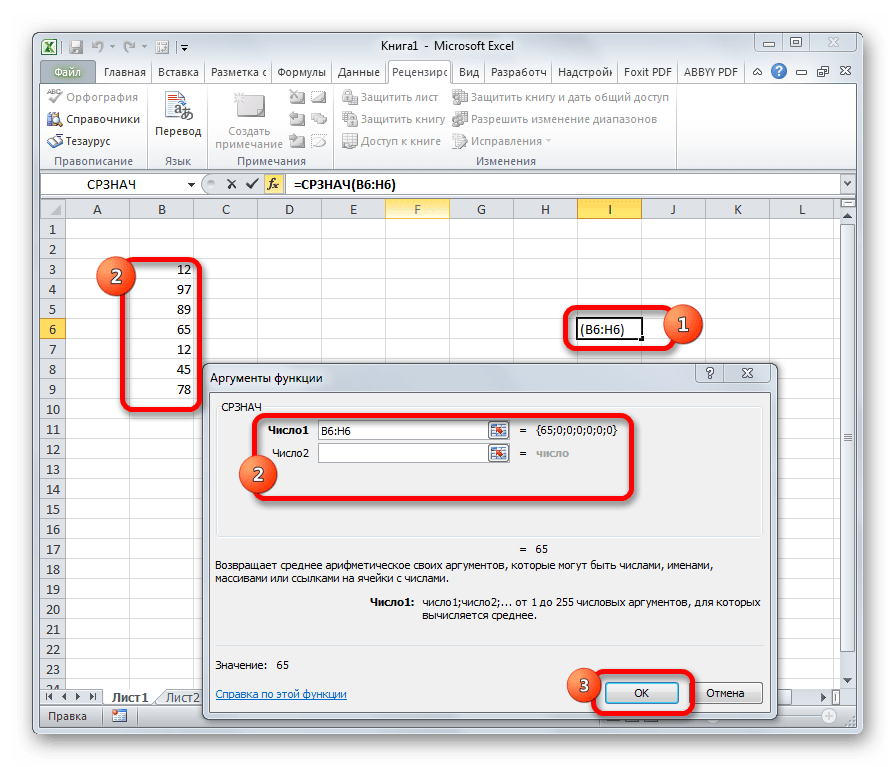
Функция СРЗНАЧ ищет число в указанном диапазоне, которое ближе всего находится к среднему арифметическому значению. Результат этого расчета выводится в отдельную ячейку, в которой и содержится формула. Шаблон у неё следующий:
=СРЗНАЧ(число1;число2;…)
СРЗНАЧЕСЛИ
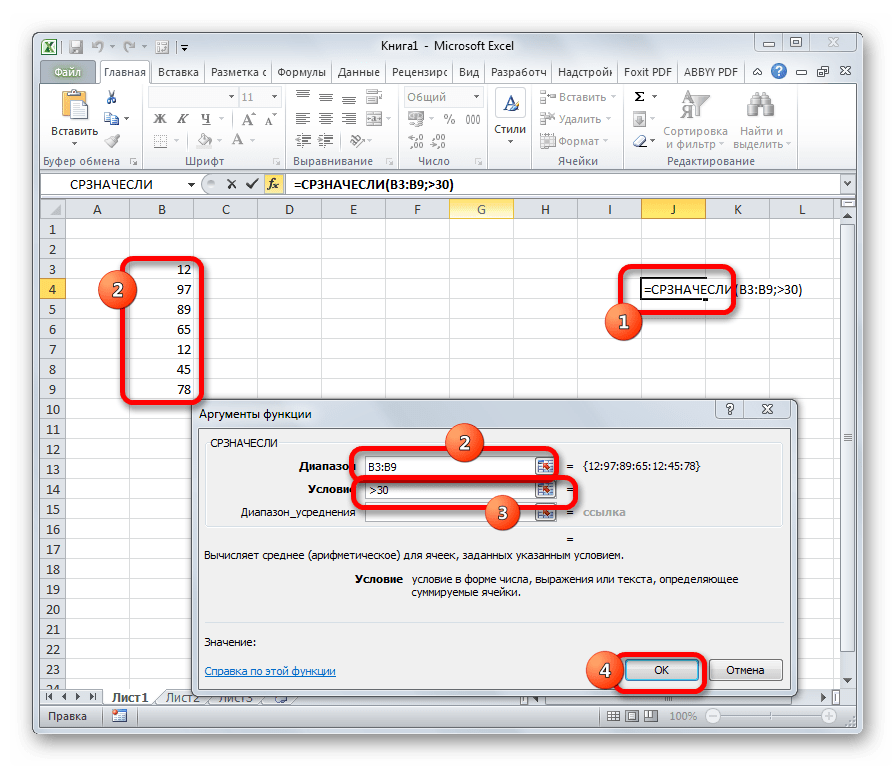
Функция СРЗНАЧЕСЛИ имеет те же задачи, что и предыдущая, но в ней существует возможность задать дополнительное условие. Например, больше, меньше, не равно определенному числу. Оно задается в отдельном поле для аргумента. Кроме того, в качестве необязательного аргумента может быть добавлен диапазон усреднения. Синтаксис следующий:
=СРЗНАЧЕСЛИ(число1;число2;…;условие;[диапазон_усреднения])
МОДА.ОДН
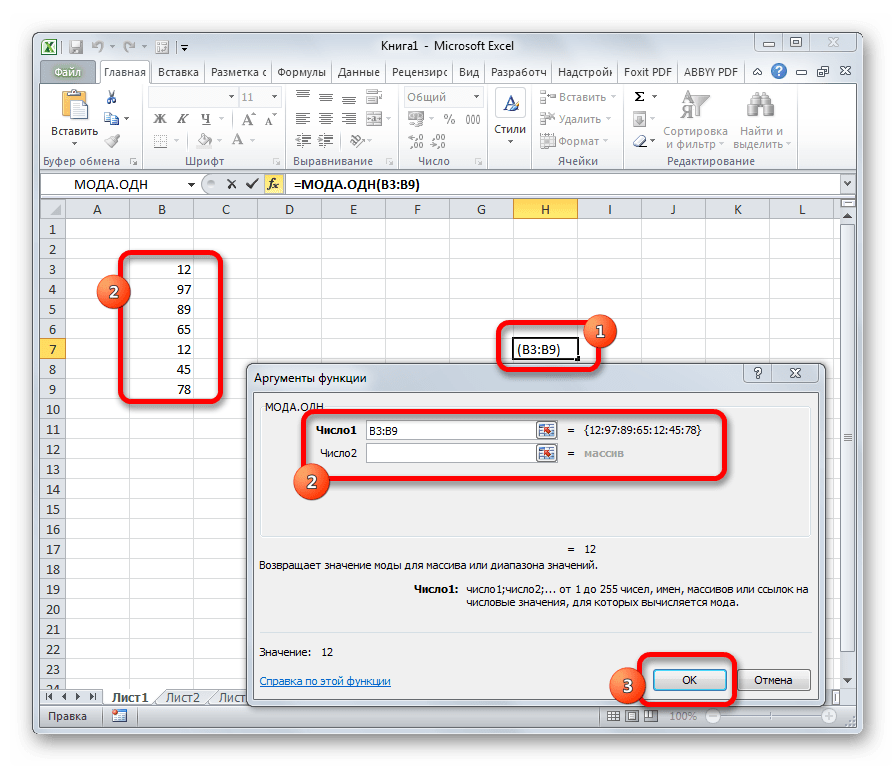
Формула МОДА.ОДН выводит в ячейку то число из набора, которое встречается чаще всего. В старых версиях Эксель существовала функция МОДА, но в более поздних она была разбита на две: МОДА.ОДН (для отдельных чисел) и МОДА.НСК(для массивов). Впрочем, старый вариант тоже остался в отдельной группе, в которой собраны элементы из прошлых версий программы для обеспечения совместимости документов.
=МОДА.ОДН(число1;число2;…)
=МОДА.НСК(число1;число2;…)
МЕДИАНА
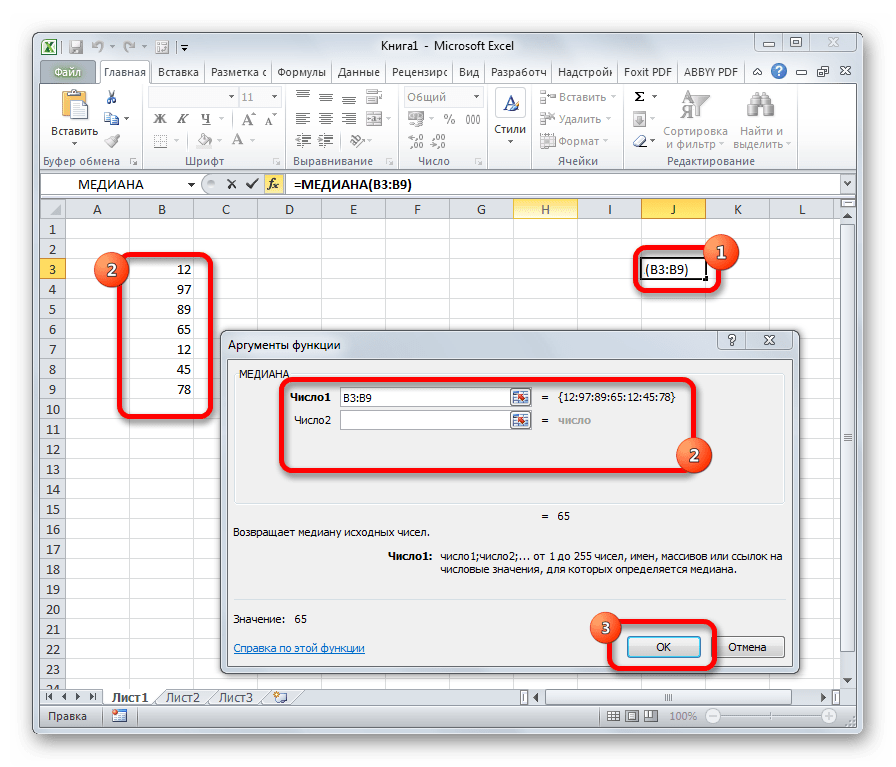
Оператор МЕДИАНА определяет среднее значение в диапазоне чисел. То есть, устанавливает не среднее арифметическое, а просто среднюю величину между наибольшим и наименьшим числом области значений. Синтаксис выглядит так:
=МЕДИАНА(число1;число2;…)
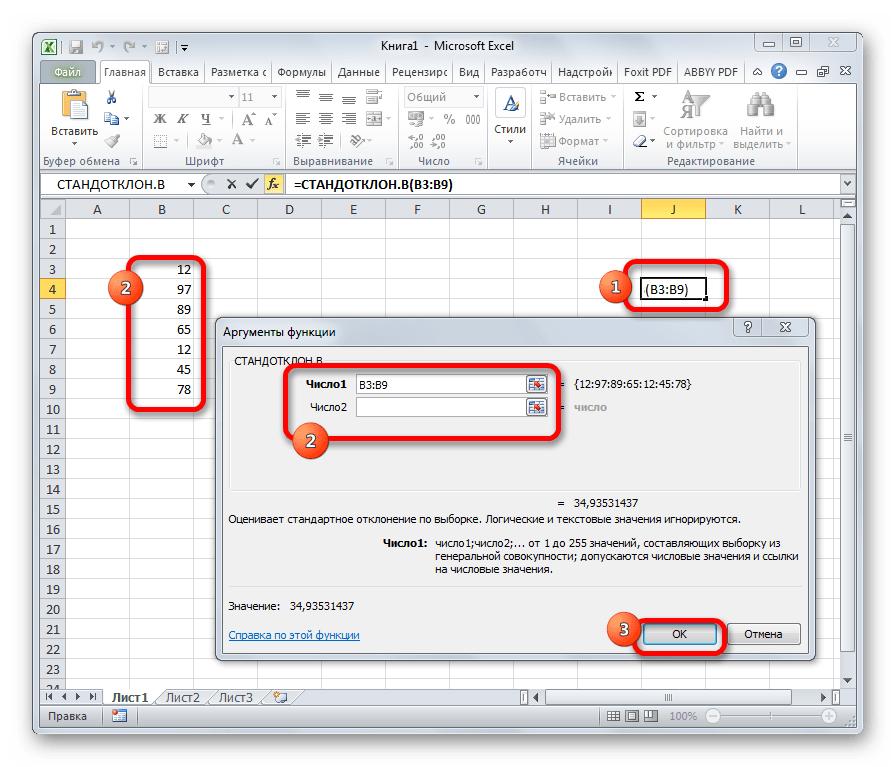
СТАНДОТКЛОН
Формула СТАНДОТКЛОН так же, как и МОДА является пережитком старых версий программы. Сейчас используются современные её подвиды – СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г. Первая из них предназначена для вычисления стандартного отклонения выборки, а вторая – генеральной совокупности. Данные функции используются также для расчета среднего квадратичного отклонения. Синтаксис их следующий:
=СТАНДОТКЛОН.В(число1;число2;…)
=СТАНДОТКЛОН.Г(число1;число2;…)
Урок: Формула среднего квадратичного отклонения в Excel
НАИБОЛЬШИЙ
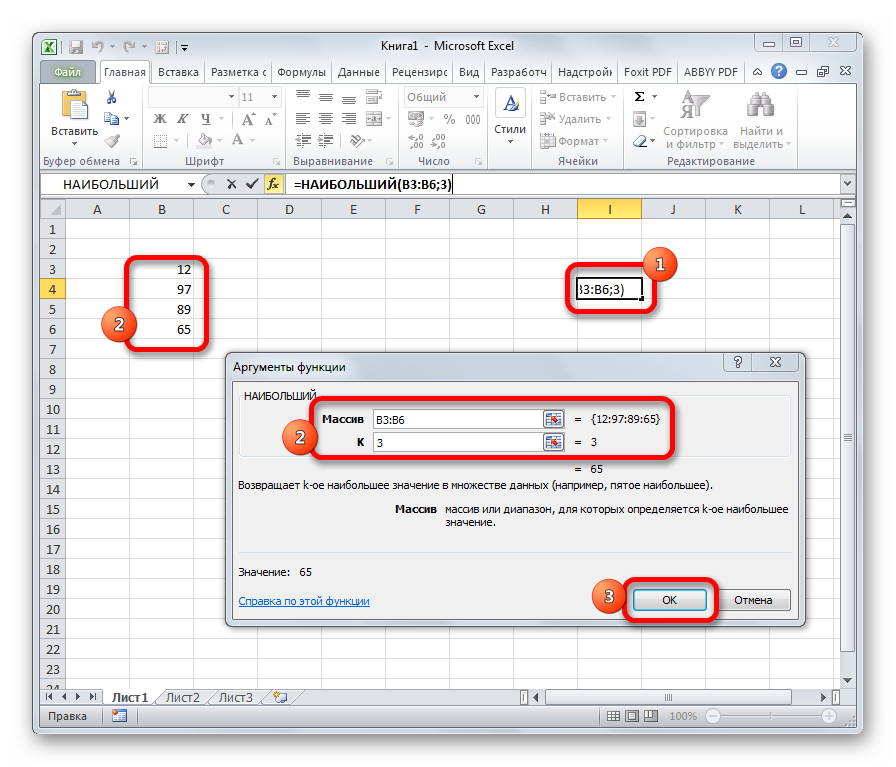
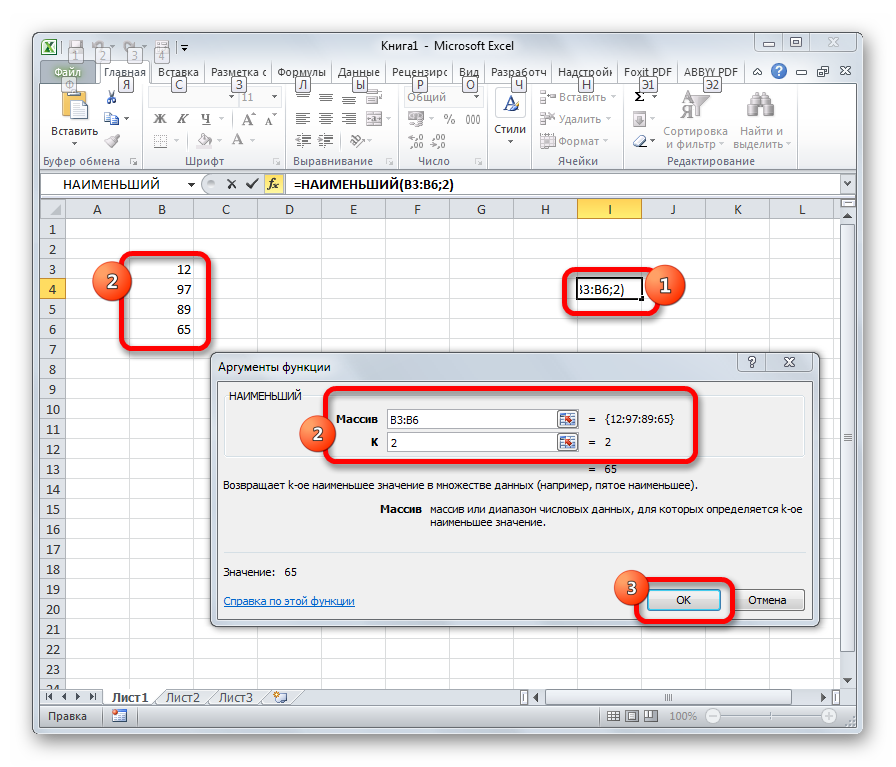
Данный оператор показывает в выбранной ячейке указанное в порядке убывания число из совокупности. То есть, если мы имеем совокупность 12,97,89,65, а аргументом позиции укажем 3, то функция в ячейку вернет третье по величине число. В данном случае, это 65. Синтаксис оператора такой:
=НАИБОЛЬШИЙ(массив;k)
В данном случае, k — это порядковый номер величины.
НАИМЕНЬШИЙ
Данная функция является зеркальным отражением предыдущего оператора. В ней также вторым аргументом является порядковый номер числа. Вот только в данном случае порядок считается от меньшего. Синтаксис такой:
=НАИМЕНЬШИЙ(массив;k)
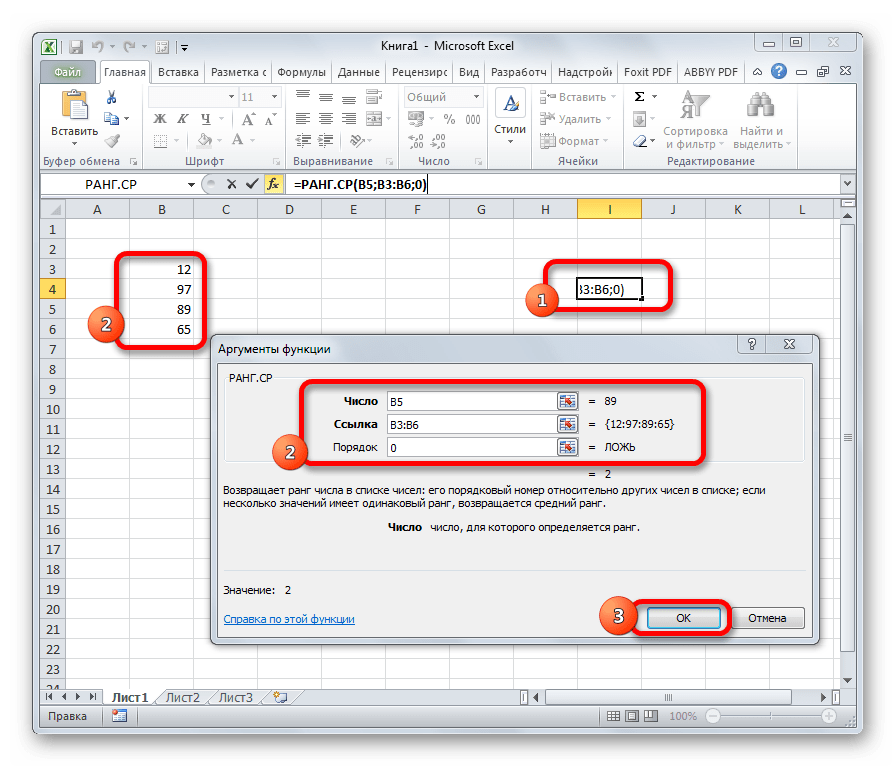
РАНГ.СР
Эта функция имеет действие, обратное предыдущим. В указанную ячейку она выдает порядковый номер конкретного числа в выборке по условию, которое указано в отдельном аргументе. Это может быть порядок по возрастанию или по убыванию. Последний установлен по умолчанию, если поле «Порядок» оставить пустым или поставить туда цифру 0. Синтаксис этого выражения выглядит следующим образом:
=РАНГ.СР(число;массив;порядок)
Выше были описаны только самые популярные и востребованные статистические функции в Экселе. На самом деле их в разы больше. Тем не менее, основной принцип действий у них похожий: обработка массива данных и возврат в указанную ячейку результата вычислительных действий.
Поиск и подсчет самых частых значений
Необходимость поиска наибольших и наименьших значений в любом бизнесе очевидна: самые прибыльные товары или ценные клиенты, самые крупные поставки или партии и т.д.
Но наравне с этим, иногда приходится искать в данных не топовые, а самые часто встречающиеся значения, что хоть и звучит похоже, но, по факту, совсем не то же самое. Применительно к магазину, например, это может быть поиск не самых прибыльных, а самых часто покупаемых товаров или самое часто встречающееся количество позиций в заказе, минут в разговоре и т.п.
В такой ситуации задачу придется решать немного по-разному, в зависимости от того, с чем мы имеем дело — с числами или с текстом.
Поиск самых часто встречающихся чисел
Предположим, перед нами стоит задача проанализировать имеющиеся данные по продажам в магазине, с целью определить наиболее часто встречающееся количество купленных товаров. Для определения самого часто встречающегося числа в диапазоне можно использовать функцию МОДА (MODE):

Т.е., согласно нашей статистике, чаще всего покупатели приобретают 3 шт. товара.
Если существует не одно, а сразу несколько значений, встречающихся одинаково максимальное количество раз (несколько мод), то для их выявления можно использовать функцию МОДА.НСК (MODE.MULT). Ее нужно вводить как формулу массива, т.е. выделить сразу несколько пустых ячеек, чтобы хватило на все моды с запасом и ввести в строку формул =МОДА.НСК(B2:B16) и нажать сочетание клавиш Ctrl+Shift+Enter.
На выходе мы получим список всех мод из наших данных:

Т.е., судя по нашим данным, часто берут не только по 3, но и по 16 шт. товаров. Обратите внимание, что в наших данных только две моды (3 и 16), поэтому остальные ячейки, выделенные «про запас», будут с ошибкой #Н/Д.
Частотный анализ по диапазонам функцией ЧАСТОТА
Если же нужно проанализировать не целые, а дробные числа, то правильнее будет оценивать не количество одинаковых значений, а попадание их в заданные диапазоны. Например, нам необходимо понять какой вес чаще всего бывает у покупаемых товаров, чтобы правильно выбрать для магазина тележки и упаковочные пакеты подходящего размера. Другими словами, нам нужно определить сколько чисел попадает в интервал 1..5 кг, сколько в интервал 5..10 кг и т.д.
Для решения подобной задачи можно воспользоваться функцией ЧАСТОТА (FREQUENCY). Для нее нужно заранее подготовить ячейки с интересующими нас интервалами (карманами) и затем выделить пустой диапазон ячеек (G2:G5) по размеру на одну ячейку больший, чем диапазон карманов (F2:F4) и ввести ее как формулу массива, нажав в конце сочетание Ctrl+Shift+Enter:

Частотный анализ сводной таблицей с группировкой
Альтернативный вариант решения задачи: создать сводную таблицу, где поместить вес покупок в область строк, а количество покупателей в область значений, а потом применить группировку — щелкнуть правой кнопкой мыши по значениям весов и выбрать команду Группировать (Group). В появившемся окне можно задать пределы и шаг группировки:

… и после нажатия на кнопку ОК получить таблицу с подсчетом количества попаданий покупателей в каждый диапазон группировки:

Минусы такого способа:
- шаг группировки может быть только постоянным, в отличие от функции ЧАСТОТА, где карманы можно задать абсолютно любые
- сводную таблицу нужно обновлять при изменении исходных данных (щелчком правой кнопки мыши — Обновить), а функция пересчитывается автоматически «на лету»
Поиск самого часто встречающегося текста
Если мы имеем дело не с числами, а с текстом, то подход к решению будет принципиально другой. Предположим, что у нас есть таблица из 100 строк с данными о проданных в магазине товарах, и нам нужно определить, какие товары покупались наиболее часто?
Самым простым и очевидным решением будет добавить рядом столбец с функцией СЧЁТЕСЛИ (COUNTIF), чтобы подсчитать количество вхождений каждого товара в столбце А:

Затем, само-собой, отсортировать получившийся столбец по убыванию и посмотреть на первые строчки.
Или же добавить к исходному списку столбец с единичками и построить по получившейся таблице сводную, подсчитав суммарное количество единичек для каждого товара:

Если исходных данных не очень много и принципиально не хочется пользоваться сводными таблицами, то можно использовать формулу массива:

Давайте разберем ее по кусочкам:
- СЧЁТЕСЛИ(A2:A20;A2:A20) – формула массива, которая ищет по очереди количество вхождений каждого товара в диапазоне A2:A100 и выдаст на выходе массив с количеством повторений, т.е., фактически, заменяет собой дополнительный столбец
- МАКС – находит в массиве вхождений самое большое число, т.е. товар, который покупали чаще всего
- ПОИСКПОЗ – вычисляет порядковый номер строки в таблице, где МАКС нашла самое большое число
- ИНДЕКС – выдает из таблицы содержимое ячейки с номером, который нашла ПОИСКПОЗ
Ссылки по теме
- Подсчет количества уникальных значений в списке
- Извлечение уникальных элементов из списка с повторами
- Группировка в сводных таблицах