
Электронные таблицы как средство разработки бизнес-приложений
Время на прочтение
8 мин
Количество просмотров 9.9K
Excel часто используется как универсальное средство для разработки бизнес-приложений. В этой статье я хочу сравнить, существующие без особых изменений уже более 30 лет, электронные таблицы с современной классической императивной парадигмой программирования глазами архитектора ПО. Затем я хочу рассказать о своей работе над новым табличным процессором, который исправляет многие недостатки, выявленные при сравнении, тем самым позволяя создавать более надежные, масштабируемые и легкие для поддержки и дальнейшего развития, бизнес-приложения.
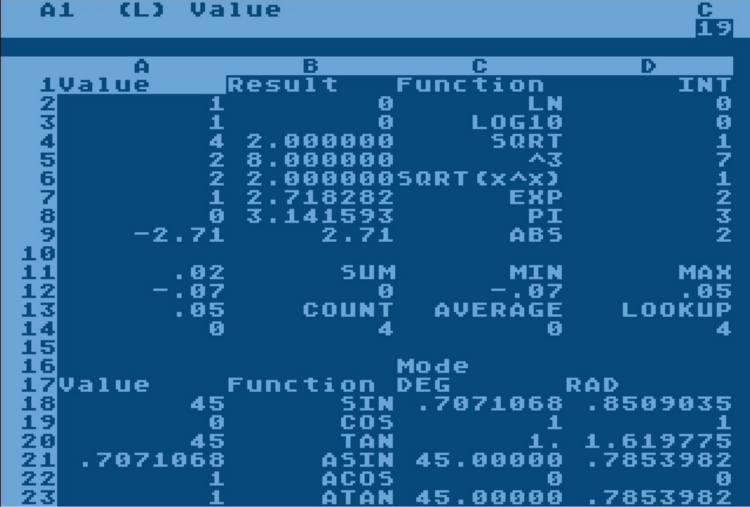
Электронные таблицы и их возможности
Принцип, по которому работают современные электронные таблицы (Microsoft Excel, LibreOffice Calc или Google Sheets) появился в конце 70-х – середине 80-х годов. Двухмерный массив ячеек, как модель данных, и возможность автоматических вычислений с помощью формул появились в VisiCalc в 1979 году. Трехмерный массив ячеек (возможность пользоваться несколькими листами) впервые появился в 1985 в Boeing Calc.
В теории, электронные таблицы ничем не уступают любому языку программирования. Существует машина Тьюринга на формулах Excel (линк), а это значит, что любой алгоритм, который можно реализовать с помощью компьютера, можно реализовать в Excel. Вопрос только в удобстве и эффективности такой реализации.
На практике я встречал очень сложные системы, реализованные в Excel. Например, финансовая модель развития международного аэропорта с возможностью вносить множество разных типов объектов (парковки, склады, полосы, …) и пересчетом квадратных метров и парковочных мест в cash flow (расходы за годы строительства vs прибыль за годы эксплуатации) с учетом разных моделей инфляции. На то чтобы «переписать» такой «эксельчик» на Java с использованием реляционной базы данных может уйти от нескольких человеко-месяцев до нескольких человеко-лет. В этом конкретном случае реляционная модель в базе данных насчитывала более 50 таблиц. Самое интересное, что такого «переписывания» можно было бы избежать, если бы электронные таблицы позволяли не только создавать программное обеспечение, но и делали бы возможным его сопровождение и масштабирование. Для конечного пользователя (экономиста) система на Java это шаг назад, потому что он больше не видит промежуточные результаты и не может сам изменить или дополнить модель.
Выходит, что одну и ту же задачу можно решить, как электронной таблицей, так и универсальным языком программирования. Значит, мы можем сравнить сильные и слабые стороны этих двух инструментов, как средств создания бизнес-приложений. Здесь мы попробуем взглянуть на Excel глазами программиста-архитектора и применим правила архитектуры ПО, которые уже устоялись в классической разработке софта.
Достоинства электронных таблиц
- Интуитивно понятный концепт: каждый из нас в школе видел и заполнял таблички на листочках в клеточку и играл в морской бой. Большинство людей, которые работают с Экселем, никогда не проходили никакого специального обучения (в лучшем случае коллега за полчаса показал на какие кнопки нажимать). Это большое преимущество перед языками программирования, где «C++ за 21 день» звучит даже слишком оптимистично.
- Открытое и статичное состояние облегчает отладку: сложность поиска ошибки в программе чаще всего заключается в том, чтобы поймать тот момент времени, когда что-то пошло не так. Приходиться использовать breakpoints и прокручивать программу по шагам. В электронной таблице состояние статично. Поиск ошибки сводится к тому, чтобы найти первую ячейку с неправильным результатом.
- Реактивность: мы просто задаем формулу, а система сама знает в каком порядке и когда пересчитывать ячейки. Этот концепт, который относительно недавно стал популярным в разработке UI, был основой электронных таблиц с самого начала.
Недостатки электронных таблиц
- Слабо структурированная модель данных: электронные таблицы используют трехмерный массив ячеек как модель данных. Это лучше чем неструктурированный текст в Notepad, но значительно хуже строгой типизации Java или нормализованной реляционной структуры базы данных. В любую ячейку можно записать любой тип данных. Заголовки или значения не различаются. Сказать заранее, что будет в момент исполнения по ссылке E5 невозможно. Зависимости между таблицами неявно хранятся в параметрах функции VLOOKUP и ломаются при неосторожном добавлении колонки. По-моему, это и является одной из основных причин ошибок.
- Высокая избыточность: у программистов хорошо себя зарекомендовал так называемый принцип DRY (Don’t repeat yourself — не повторяйся). Чаще всего мы стараемся писать логику один раз, давать ей название (например, в виде имени функции/метода) и потом ссылаться на нее когда это необходимо. В табличных процессорах мы копируем формулы. Сначала это конечно удобно, но в итоге, понять, где применяется та или другая формула очень сложно. Любое изменение объема данных ведет к необходимости копировать формулы. Это очень сильно затрудняет поддержку и дальнейшее развитие моделей в табличных процессорах.
- Отсутствие интерактивности интерфейса: электронные таблицы не позволяют динамически изменять способ отображения данных. Также отсутствует возможность создавать запрограммированные операции выполняемые, например, по нажатию кнопки.
Как сделать электронные таблицы лучше?
Меня зовут Вадим. Я CTO в CubeWeaver и уже довольно давно занимаюсь разработкой нового табличного процессора. Несколько лет назад я уже писал (линк) про раннюю версию системы, но с тех пор многое изменилось и в этом году проект дошел до коммерческой стадии.
Вот список новшеств моего проекта, которые позволяют устранить перечисленные выше недостатки, стараясь при этом сохранить преимущества электронных таблиц:
Многомерная модель данных
Многомерная модель данных широко используется в Business Intelligence и OLAP системах, предназначенных для анализа данных. Суть модели заключается в том, чтобы хранить данные в ячейках многомерного куба, грани которого подписаны заголовками бизнес-объектов:
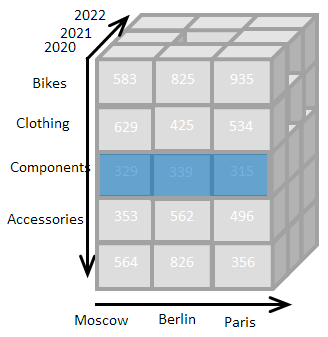
В интерфейсе программы отображается не весь многомерный куб, а его двумерный срез, соответствующий выбранной нами комбинации фильтров:
При реализации такой модели в реляционной BI системе, часто используют схему снежинки (snowflake schema). Кубы реализуются таблицами фактов (fact table), а заголовки на гранях хранятся в таблицах измерений (dimension table).
В моей системе кубы называются рабочими листами (worksheets), а заголовки на гранях куба называются элементами списков (list items).
Каждая ячейка такого многомерного рабочего листа имеет уникальный адрес, состоящий из надписей на гранях. Например, значение 935 на изображении имеет адрес: Bikes, 2020, Paris.
Каждый элемент списка имеет название и идентификатор. В ссылках на ячейки используются идентификаторы, и вышеуказанный адрес в формуле мог бы выглядеть так (ссылки заключаются в квадратные скобки):
[PROD:23, YEAR:2020, CITY:24], где PROD это идентификатор списка «продукт», а 23 идентификатор элемента «Bikes».
Применение многомерной модели позволяет значительно улучшить ситуацию с недостатком номер 1. Во-первых, заголовки теперь хранятся отдельно от численных данных. Во-вторых, введение дополнительного измерения «метрика» (или «позиция отчета») позволяет адресовать ячейки не по порядковому номеру, а по семантическому смыслу, исключая ошибки из-за добавления или удаления столбцов или строк.
Конечно, нужно сказать, что такой подход слегка портит ситуацию с преимуществом номер 1. В морской бой играли все, а в четырехмерные шахматы только некоторые студенты-математики. Но опыт показывает, что благодаря двумерному представлению куба, большинство пользователей довольно быстро привыкают к новой модели данных.
Функция JOIN и метаданные
Многомерная модель позволяет использовать метаданные для описания ячеек. Метод адресации описанный выше означает, что каждая ячейка рабочего листа соответствует определенному набору элементов списка (например, году, продукту и точке продажи). Списки в свою очередь могут иметь атрибуты (колонки), что делает их похожими на обычные реляционные таблицы. Например, можно добавить колонку «валюта» к списку «точка продажи», связывая таким образом списки «точка продажи» и «валюта» в реляцию с кардинальностью many-to-one.
Функция JOIN дает возможность динамически ссылаться на ячейки, используя такую связь. Эта функция заменяет VLOOKUP, устраняя при этом необходимость работать с индексами.
Пример: для того чтобы посчитать сумму продаж по миру, нужно сначала сконвертировать сумму продаж по каждой стране в единую валюту (умножить позицию «продажи» на курс обмена). В Excel мы бы хранили 2 таблицы: список стран с валютой для каждой страны и список валют с курсом обмена. Для того чтобы найти правильный курс мы бы использовали функцию VLOOKUP два раза: найти код валюты по названию страны и найти курс обмена по коду валюты.
Ссылка на ячейку с курсом обмена, могла бы выглядеть так:
EX_RATES.[COUNTRY.join(CURRENCY)], где
EX_RATES — название рабочего листа с курсами обмена валют
COUNTRY — измерение со странами
CURRENCY — измерение с валютами
Цепочки связей могут быть любой длины, например: STORE.join(COUNTRY).join(CURRENCY)
Фактически, строя модель, мы создаем схему снежинки. Функция JOIN позволяет формулам динамически ссылаться на ячейки рабочих листов, используя связи между таблицами (списками) этой схемы. При этом зависимости между ячейками явно указаны в аргументах функции JOIN.
Зона действия формул
Возможность указать зону действия формулы (area of effect) позволяет избавиться от необходимости копировать формулы.
По каждому измерению куба мы задаем набор элементов, на которые действует формула, как например: все года, продукты типа «велосипед», позиция отчета «выручка». На практике это выглядит вот так (Синим цветом отмечена цель формулы, красным и оранжевым её аргументы. Список выбранных элементов по каждому измерению находиться внизу экрана):
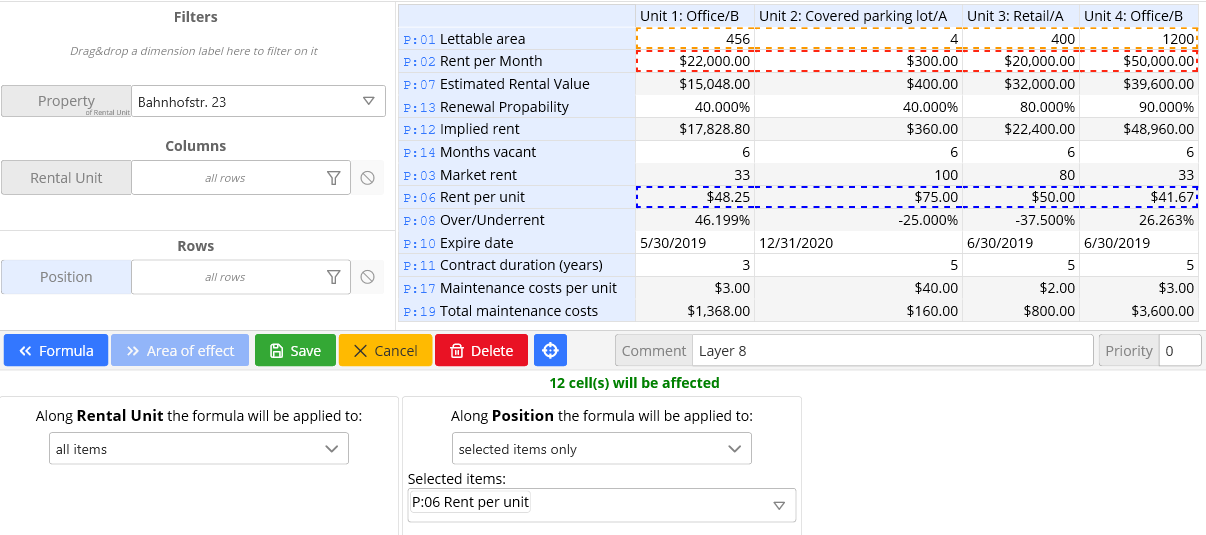
Этот подход устраняет недостаток номер 2 и позволяет добавлять и удалять элементы или даже измерения, не изменяя формулу. Также отпадает необходимость искать все ячейки, в которые формула была скопирована, каждый раз, когда мы хотим ее изменить.
Интерактивность ячеек
Это нововведение позволяет создавать интерактивные интерфейсы, используя формулы. Формулы можно использовать не только для того чтобы вычислить значение ячейки, но и для форматирования ячеек (cell formatting), изменения цвета ячеек (cell color) и для того чтобы спрятать или показать группу ячеек или целые колонки или строки (cell visibility). Ячейки можно форматировать не только как числа, даты и текст, но и как кнопки, флажки (checkbox) и списки выбора (dropdown).
Таким образом, например, цвет ячеек может меняться в зависимости от значения ячейки. Флажок или список выбора в одном листе может отображать, прятать или блокировать на запись ячейки в другом листе.
Кнопки в ячейках позволяют создавать довольно сложные операции со значениями ячеек. Создавая кнопку, мы задаем цель операции (cell range) и формулу, которая выполняется один раз для каждой из целевых ячеек. На одной кнопке может быть несколько операций. Так, нажатие на кнопку может, например, скопировать данные из предыдущего года в следующий или распределить содержимое ячейки по нескольким другим ячейкам, пропорционально какой-то величине (splashing).
Кнопки в сочетании с ограничениями доступа пользователя позволяют создавать необратимую функциональность. Так, например пользователь получивший доступ к кнопке, но не получивший доступ к целевой ячейке, сможет записать в ячейку только то, что позволит ему формула в кнопке.
Заключение
Новый табличный процессор позволяет создавать значительно более сложные модели, чем это возможно в других системах. При этом модели остаются понятными и простыми в сопровождении. Также значительно уменьшается вероятность ошибок в формулах.
Платой за эти преимущества является повышенная сложность системы. Прежде чем начать работать, пользователь должен создать модель данных в виде списков и кубов.
В целом система рассчитана на технически более грамотного пользователя, чем Excel (например, экономисты с базовыми знаниями программирования или программисты, работающие над экономическими моделями).
С удовольствием отвечу на ваши вопросы в комментариях или личных сообщениях. Также, в интернете можно найти документация к системе и несколько обучающих видео.
Сводные таблицы
- Подробности
- Создано 27 Апрель 2011
| Содержание |
|---|
| Термины многомерного анализа данных |
| Многомерные данные, измерения |
| OLAP |
| Виртуальный куб данных |
| Сводная таблица |
| Редактирование сводных таблиц |
| Подготовка многомерных данных |
| От автофильтра к сводному отчету |
| Свойства и форматирование |
| Сводная диаграмма |
| Доступ к внешним данным |
Первый интерфейс сводных таблиц, называемых также сводными отчеты, был включен в состав Excel еще в 1993м году (версии Excel 5.0). Несмотря на множество полезных функциональных возможностей, он практически не применяется в работе большинством пользователей Excel. Даже опытные пользователи зачастую подразумевают под термином «сводный отчет» нечто построенное с помощью сложных формул. Попробуем популяризировать использование сводных таблиц в повседневной работе экономистов. В статье обсуждаются теоретические основы создания сводных отчетов, даются практические рекомендации по их использованию, а также приводится пример доступа к данным на основе нескольких таблиц.
Термины многомерного анализа данных
Большинство экономистов слышали термины «многомерные данные», «виртуальный куб», «OLAP-технологии» и т.п. Но при детальном разговоре обычно выясняется, что почти все не очень представляют, о чем идет речь. То есть люди подразумевают нечто сложное и обычно не имеющее отношение к их повседневной деятельности. На самом деле это не так.
Многомерные данные, измерения
Можно с уверенностью утверждать, что экономисты практически постоянно сталкиваются с многомерными данными, но пытаются представить их в предопределенном виде с помощью электронных таблиц. Под многомерностью здесь подразумевается возможность ввода, просмотра или анализа одной и той же информации с изменением внешнего вида, применением различных группировок и сортировок данных. Например, план продаж можно проанализировать по следующим критериям:
- виды или группы товаров;
- бренды или категории товаров;
- периоды (месяц, квартал, год);
- покупатели или группы покупателей;
- регионы продаж
- и т.п.
Каждый из приведенных критериев в терминах многомерного анализа данных называется «измерением». Можно сказать, что измерение характеризует информацию по определенному набору значений. Специальным типом измерения многомерной информации являются «данные». В нашем примере данными плана продаж могут являться:
- объем продаж;
- цена продажи;
- индивидуальная скидка
- и т.п.
Теоретически данные могут также являться стандартным измерением многомерной информации (например, можно сгруппировать данные по цене продажи), но обычно все-таки данные являются специальным типом значений.
Таким образом, можно сказать, что в практической работе экономисты используются два типа информации: многомерные данные (фактические и плановые числа, имеющие множество признаков) и справочники (характеристики или измерения данных).
OLAP
Аббревиатура OLAP (online analytical processing) в дословном переводе звучит как «аналитическая обработка в реальном времени». Определение не очень конкретное, под него можно подвести практически любой отчет любого программного продукта. По смыслу OLAP подразумевает технологию работы со специальными отчетами, включая программное обеспечение, для получения и анализа как раз многомерных структурированных данных. Одним из популярных программных продуктов, реализующих OLAP-технологии, является SQL Server Analysis Server. Некоторые даже ошибочно считают его единственным представителем программной реализации данной концепции.
Виртуальный куб данных
«Виртуальный куб» (многомерный куб, OLAP-куб) — это специальный термин, предложенный некоторыми поставщиками специализированного программного обеспечения. OLAP-системы обычно готовят и хранят данные в собственных структурах, а специальные интерфейсы анализа (например, сводные отчеты Excel) обращаются к данным этих виртуальных кубов. При этом использование подобного выделенного хранилища совсем не обязательно для обработки многомерной информации. В общем случае, виртуальный куб – это и есть массив специально оптимизированных многомерных данных, который используется для создания сводных отчетов. Он может быть получен как через специализированные программные средства, так и через простой доступ к таблицам базы данных или любой другой источник, например к таблице Excel.
Сводная таблица
«Сводный отчет» (сводная таблица, Pivot Table) — это пользовательский интерфейс для отображения многомерных данных. С помощью данного интерфейса можно группировать, сортировать, фильтровать и менять расположение данных с целью получения различных аналитических выборок. Обновление отчета производится простыми средствами пользовательского интерфейса, данные автоматически агрегируются по заданным правилам, при этом не требуется дополнительный или повторный ввод какой-либо информации. Интерфейс сводных таблиц Excel является, пожалуй, самым популярным программным продуктом для работы с многомерными данными. Он поддерживает в качестве источника данных как внешние источники данных (OLAP-кубам и реляционным базам данных), так и внутренние диапазоны электронных таблиц. Начиная с версии 2000 (9.0), Excel поддерживает также графическую форму отображения многомерных данных – сводная диаграмма (Pivot Chart).
Реализованный в Excel интерфейс сводных таблиц позволяет расположить измерения многомерных данных в области рабочего листа. Для простоты можно представлять себе сводную таблицу, как отчет, лежащий сверху диапазона ячеек (на самом деле есть определенная привязка форматов ячеек к полям сводной таблицы). Сводная таблица Excel имеет четыре области отображения информации: фильтр, столбцы, строки и данные. Измерения данных именуются полями сводной таблицы. Эти поля имеют собственные свойства и формат отображения.
Еще раз хочется обратить внимание, что сводная таблица Excel предназначена исключительно для анализа данных без возможности редактирования информации. Ближе по смыслу было бы повсеместное употребление термина «сводный отчет» (Pivot Report), и именно так этот интерфейс и назывался до 2000го года. Но почему-то в последующих версиях разработчики от него отказались.
Редактирование сводных таблиц
По своему определению OLAP-технология, в принципе, не подразумевает возможность изменения исходных данных при работе с отчетами. Тем не менее, на рынке сформировался целый класс программных систем, реализующих возможности как анализа, так и непосредственного редактирования данных в многомерных таблицах. В основном такие системы ориентированы на решение задач бюджетирования.
Используя встроенные средства автоматизации Excel, можно решить множество нестандартных задач. Пример реализации редактирования для сводных таблиц Excel на основе данных рабочего листа можно найти на нашем сайте.
Подготовка многомерных данных
Подойдем к практическому применению сводных таблиц. Попробуем проанализировать данные о продажах в различных направлениях. Файл pivottableexample.xls состоит из нескольких листов. Лист Пример содержит основную информацию о продажах за определенный период. Для простоты примера будем анализировать единственный числовой показатель – объем продажи в кг. Имеются следующие ключевые измерения данных: продукция, покупатель и перевозчик (транспортная компания). Кроме того, имеются несколько дополнительных измерений данных, являющихся признаками продукта: тип, бренд, категория, поставщик, а также покупателя: тип. Эти данные собраны на листе Справочники. На практике подобных измерений может быть гораздо больше.
Лист Пример содержит стандартное средство анализа данных – автофильтр. Глядя на пример заполнения таблицы, очевидно, что нормальному анализу поддаются данные о продажах по датам (они расположены по столбцам). Кроме того, используя автофильтр можно попробовать просуммировать данные по сочетаниям одного или нескольких ключевых критериев. Совершенно отсутствует информация о брендах, категориях и типах. Нет возможности сгруппировать данные с автоматическим суммированием по определенному ключу (например, по покупателям). Кроме того, набор дат зафиксирован, и просмотреть итоговую информацию за определенный период, например, 3 дня, автоматическими средствами не удастся.
Вообще, наличие предопределенного расположения даты в данном примере – главный недостаток таблицы. Расположив даты по столбцам, мы как бы предопределили измерение этой таблицы, таким образом, лишив себя возможности использовать анализ с помощью сводных таблиц.
Во-первых, надо избавиться от этого недостатка – т.е. убрать предопределенное расположение одного из измерений исходных данных. Пример корректной таблицы – лист Продажи.
Таблица имеет форму журнала ввода информации. Здесь дата является равноправным измерением данных. Также следует заметить, что для последующего анализа в сводных таблицах совершенно безразлично относительное положение строк друг относительно друга (иначе говоря, сортировка). Этими свойствами обладают записи в реляционных базах данных. Именно на анализ больших объемов баз данных ориентирован в первую очередь интерфейс сводных таблиц. Поэтому необходимо придерживаться этих правил и при работе с источником данных в виде диапазонов ячеек. При этом никто не запрещает использовать в работе интерфейсные средства Excel – сводные таблицы анализируют только данные, а форматирование, фильтры, группировки и сортировки исходных ячеек могут быть произвольными.
От автофильтра к сводному отчету
Теоретически на данных листа Продажи уже можно проводить анализ в трех измерениях: товары, покупатели и перевозчики. Данные о свойствах продукции и покупателей на данном листе отсутствуют, что, соответственно, не позволит показать их и в сводной таблице. В нормальном режиме создания сводной таблицы для исходных данных Excel не позволяет связывать данные нескольких таблиц по определенным полям. Обойти это ограничение можно программными средствами – см. пример-дополнение к данной статье на нашем сайте. Чтобы не прибегать к программным методам обработки информации (тем более, что они и не универсальны), следует добавить дополнительные характеристики непосредственно в форму ввода журнала – см. лист ПродажиАнализ.
 |
Применение функций VLOOKUP позволяет легко дополнить исходные данные недостающими характеристиками. Теперь, применяя автофильтр, можно анализировать данные в различных измерениях. Но остается нерешенной проблема группировок. Например, отследить сумму только по брендам на определенные даты достаточно проблематично. Если ограничиваться формулами Excel, то нужно строить дополнительные выборки, используя функцию SUMIF.
Теперь посмотрим какие возможности дает интерфейс сводных таблиц. На листе СводАнализ построено несколько отчетов на основе диапазона ячеек с данными листа ПродажиАнализ.
Первая таблица анализа построена через интерфейс Excel 2007 Лента Вставка Сводная таблица (в Excel 2000-2003 меню Данные Сводная таблица).
Вторая и третья таблицы созданы через копирование и последующую настройку. Источник данных для всех таблиц один и тот же. Можете это проверить, изменив исходные данные, затем надо обновить данные сводных отчетов.
С нашей точки зрения, преимущества в наглядности информации очевидны. Вы можете менять местами фильтры, столбцы и строки и, скрывать определенные группы значений любых измерений, применять ручное перетаскивание и автоматическую сортировку.
Свойства и форматирование
Кроме непосредственного отображения данных, имеется большой набор возможностей по отображению внешнего вида сводных таблиц. Лишние данные можно скрывать, используя фильтры. Для единичного элемента или поля проще пользоваться пунктом контекстного меню Удалить (в версии 2000-2003 Скрыть).
 |
Для полей данных таблицы можно задать единый формат отображения. Это делается не через формат ячейки, а через специальный диалог настройки формата поля.
 |
Задавать отображение других элементов сводной таблицы также желательно не через форматирование ячейки, а через настройку поля или элемента сводной таблицы. Для этого необходимо подвести указатель мыши к нужному элементу, дождаться появления специальной формы курсора (в виде стрелки), затем через одинарный клик выделить выбранный элемент. После выделения можно изменять вид через ленту, контекстное меню или вызывать стандартный диалог формата ячейки:
 |
Кроме формата отображения в ячейках, сводная таблица включает несколько специальных свойств, управляющих внешним видом и расположением элементов. Диалоги настройки проще всего вызываются через контекстное меню: Параметры сводной таблицы или Параметры поля сводной таблицы.
Кроме того, в Excel 2007 появилось множество предопределенных стилей отображения сводной таблицы:
 |
Сводная диаграмма
Нажав кнопку на ленте «Сводная диаграмма», можно сформировать специальный тип диаграммы, отображающей данные сводной таблицы:
 |
Обратите внимание, что в диаграмме активны управляющие фильтры и области перетаскивания.
Доступ к внешним данным
Как уже отмечалось, пожалуй, наибольший эффект от применения сводных таблиц можно получить при доступе к данным внешних источников – OLAP-кубам и запросам к базам данных. Такие источники обычно хранят большие объемы информации, а также имеют предопределенную реляционную структуру, что позволяет легко определить измерения многомерных данных (поля сводной таблицы).
Excel поддерживает множество типов источников внешних данных:
 |
Наибольшего эффекта от использования внешних источников информации можно добиться, применяя средства автоматизации (программы VBA) как для получения данных, так и для их предварительной обработки в сводных таблицах.
Смотри также
» Динамический источник данных сводной таблицы
При работе со сводными таблицами несколько раз сталкивался с проблемой, когда новые данные не попадали в отчет. Сводная таблица была…
» Обработка больших объемов данных. Часть 3. Сводные таблицы
Третья статья, посвященная обработке больших объемов данных с помощью Excel, описывает преимущества использования сводных таблиц….
» Сводная таблица Excelfin.ru
Надстройка предназначена для создания сводных таблиц на основе нескольких диапазонов данных файла Excel. Пользовательский интерфейс в…
» Сводный отчет на основе нескольких таблиц Excel
В стандартном режиме Excel позволяет строить сводные отчеты на основе диапазона ячеек, расположенного на одном рабочем листе. Собрать…
» Обновление списков сводной таблицы
При работе со сводными таблицами, сохраненными в качестве отчетов и использующих обновляемые исходные данные, выпадающие списки полей…
Project Gubin/Vlasov Visiology© 2022
ШАГ 2
Источники и модель данных
ЗАГРУЗКА ДАННЫХ
Платформа VISIOLOGY поддерживает работу одновременно с несколькими источниками данных, подключая которые, можно создавать сложные схемы данных.
В этом шаге мы рассмотрим интерфейс базы данных ViQube и основные принципы работы с ним, а также — разберемся с понятием OLAP и настройкой многомерного представления
ОСНОВНЫЕ ИСТОЧНИКИ ДАННЫХ ДЛЯ VIQUBE:
Также альтернативными источниками данных может служить компонент SmartForms и API БД ViQube. О них я расскажу в других уроках.
СОЗДАНИЕ ЗАГРУЗЧИКА
После того, как Вы определились с источниками данных, необходимо создать и настроить Загрузчики, для этого:
Откройте настройки интерфейса БД ViQube
Раскройте настройки «Базы данных»
Выберите элемент «Загрузчики»
Нажмите кнопку «Добавить загрузчик»
Введите имя для загрузчика





Далее приступаем к настройке источника данных:
Выберите тип загрузчика
Укажите корректные настройки для загрузчика
Нажмите кнопку «Сохранить настройки»
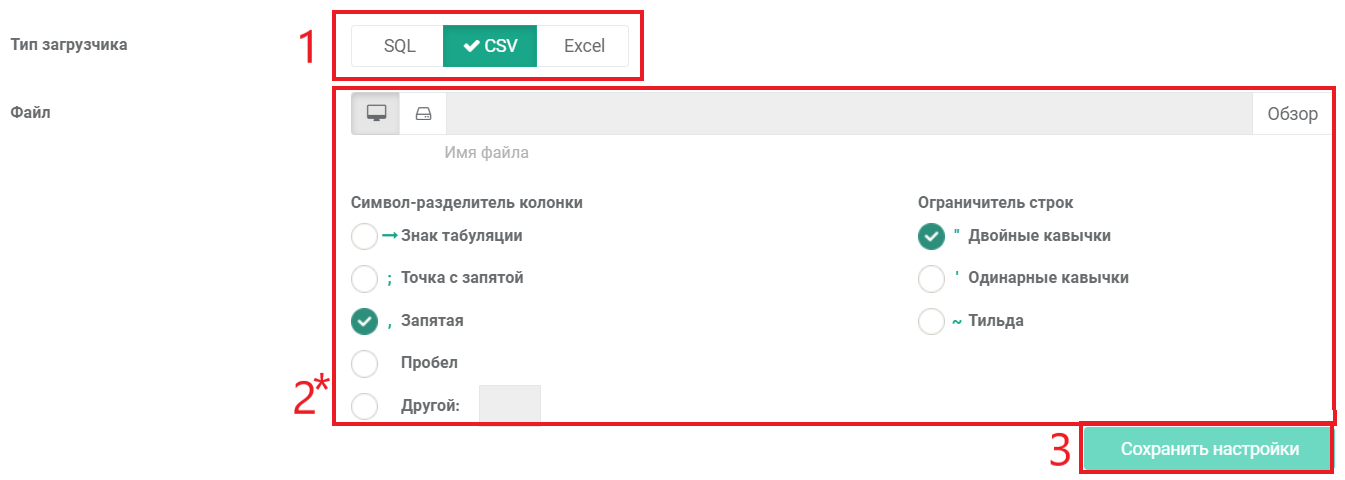



* Для каждого из типов загрузчиков есть свой набор настроек.
НАСТРОЙКИ ТИПА ЗАГРУЗЧИКОВ
Каждый из загрузчиков содержит в настройках свои уникальные параметры. Рассмотрим каждый из них:
-
Для работы с загрузчиком типа SQL вам необходимо будет предварительно создать «SQL- подключение» к внешней базе, затем выбрать его в списке подключений. Далее напишите SQL-запрос, результат выполнения которого будет таблица, которая загрузится в БД ViQube
-
Источником данных для такого загрузчика будет текстовый файл формата CSV. Для корректной загрузки таких файлов важно знать логическую структуру исходного файла, чтобы верно указать символы-ограничители колонок и строк.
-
Если источником данных является Excel таблица, то для корректной загрузки информация должна храниться на первом листе загружаемого файла.
Важно точно определить, что будет источником для загрузки данных.
Выбор SQL загрузчика данных
Загрузка данных из CSV файла
Загрузка данных из Excel файла
МНОГОМЕРНАЯ МОДЕЛЬ ДАННЫХ
Следующим этапом является создание многомерной модели данных для упорядочения данных в БД, а также хорошей компоновки и связи в многомерной структуре.
Перед тем как приступить к настройке — немного теории.
OLAP (online analytical processing) — это оперативный анализ данных. Давайте попробуем определить это понятие на человеческом языке.
OLAP база данных опирается на многомерную модель данных, то есть такая база позволяет анализировать множество разных параметров с разных сторон. Также она обрабатывает многомерные массивы данных, то есть такие, в которых каждый элемент массива связан с другими элементами.
Поэтому OLAP позволяет строить гипотезы, выявлять причинно-следственные связи между разными параметрами, моделировать поведение системы при изменениях.
Данные при этом организованы в виде многомерных кубов — осями будут отслеживаемые параметры, на их пересечении находятся данные. Пользователи могут выбирать нужные параметры и получать информацию по разным измерениям.

Структура OLAP-куба
Многомерная модель данных, это альтернатива обычной табличной или «реляционной» модели.
Сводные таблицы («pivot tables») Excel построены именно на многомерной логике. Идея модели заключается в разделении данных на показатели (или «меры») и измерения (аналог справочников). По показателям мы агрегируем (например, считаем сумму или среднее), а по измерениям группируем или фильтруем.
Важным этапом будет то, какой вид имеют загружаемые таблицы. Таблицы для создания многомерного представления бывают двух типов:
-
Таблица, содержащая в себе количественные и качественные данные о событии факта, которым в свою очередь является строка в виде записи в таблице. Проще говоря, это таблица, которая содержит столбцы, данные которых мы можем посчитать/агрегировать.
-
Таблица, содержащая качественную информацию, на которую могут ссылаться значения из столбцов в таблице фактов.
Многомерная модель данных в платформе содержит следующие элементы:
-
Элемент, логически объединяющий показатели и измерения в единую структуру.
-
Элемент, отвечающий за количественные данные факта, которые возможно сагрегировать по выбранной функции агрегации.
-
Элемент, отвечающий за качественную характеристику, совершенную над фактом.
Важно помнить, что платформа VISIOLOGY поддерживает объединение многомерной модели данных по типу «Звезда».

ViTalk
Виртуальный ассистент
Настройка элементов многомерной модели
НАСТРОЙКА МНОГОМЕРНОЙ МОДЕЛИ
Последний этап в данном шаге — это настройка многомерной модели в БД ViQube.
Ранее мы говорили о создании «Загрузчиков» и понятии OLAP. Теперь же нам предстоит объединить эти знания.
Вернёмся в интерфейс загрузчика и выберем кнопку «Настроить структуру».
Перед вами откроется интерфейс настроек многомерной структуры (модели данных).

Прежде чем приступить к мэппингу, проверьте корректность настроек. Чек-лист с настройками я покажу ниже.

ViTalk
Виртуальный ассистент
ЧЕК-ЛИСТ ПРОВЕРКИ НАСТРОЕК
✔ Проверить типы данных;
✔ Проверить маску даты для колонки с датой;
✔ Определить тип таблицы (фактов/справочник).
После проверки настроек по данному чек-листу можем продолжить.
Если таблица является «Таблицей фактов», то для нее необходимо создать группу показателей, для этого:
Нажмите кнопку «Добавить».
В выпадающем меню выберите
пункт «Группа показателей».
Введите название для группы
показателей.



Теперь можно приступить к настройке столбцов.
Рекомендуем начинать со столбцов, которые можно определить как показатели, далее — разметить столбцы, содержащие дату, и в самом конце — определять столбцы как атрибуты измерения.
Чтобы было проще запомнить, я пользуюсь алгоритмом «цифры — дата — текст».

ViTalk
Виртуальный ассистент
Чтобы определить столбец как показатель, необходимо:
Нажмите на перечеркнутый круг в заголовке столбца
В выпадающем меню выберите пункт «Показатели»
Выберите функцию агрегации



В данном случае необходимо выбрать функцию агрегации по умолчанию. В дальнейшей работе её без труда можно будет изменить.
ViTalk
Виртуальный ассистент
Для определения столбца «Дата» к системному календарному измерению выполните следующие пункты:
Нажмите на перечеркнутый круг в заголовке столбца
В выпадающем меню выберите пункт «Дата»
Выберите подходящую детализацию данных



Помните, что календарное измерение является системным, платформа сама создаст нужную иерархию 

ViTalk
Виртуальный ассистент
Для определения столбца как атрибут измерения выполните следующие пункты:
Нажмите на перечеркнутый круг в заголовке столбца.



Выберите «Создать новое» для случая, если такого измерения в системе нет, либо «Выбрать существующие», если хотите привязать данные к существующему измерению.
В выпадающем меню выберите пункт «Измерение»
При помощи «Общего измерения» вы можете объединять различные источники данных, что потом поможет вам совмещать эти источники на одной визуализации.

ViTalk
Виртуальный ассистент
Мы также записали на тему этого урока видео, посмотреть его можно на нашем официальном Youtube-канале.
Мы также записали на тему этого урока видео, посмотреть его можно на нашем официальном Youtube-канале.
Таким образом, когда у нас появилось понимание, каким образом должна выглядеть многомерная структура, приступим к выполнению первого практического задания.
Если у Вас появились вопросы — напишите нам.
Электронные таблицы как средство разработки бизнес-приложений +14
Программирование, SQL, Ненормальное программирование, ERP-системы, Разработка для Office 365
Рекомендация: подборка платных и бесплатных курсов таргетированной рекламе — https://katalog-kursov.ru/
Excel часто используется как универсальное средство для разработки бизнес-приложений. В этой статье я хочу сравнить, существующие без особых изменений уже более 30 лет, электронные таблицы с современной классической императивной парадигмой программирования глазами архитектора ПО. Затем я хочу рассказать о своей работе над новым табличным процессором, который исправляет многие недостатки, выявленные при сравнении, тем самым позволяя создавать более надежные, масштабируемые и легкие для поддержки и дальнейшего развития, бизнес-приложения.
Электронные таблицы и их возможности
Принцип, по которому работают современные электронные таблицы (Microsoft Excel, LibreOffice Calc или Google Sheets) появился в конце 70-х – середине 80-х годов. Двухмерный массив ячеек, как модель данных, и возможность автоматических вычислений с помощью формул появились в VisiCalc в 1979 году. Трехмерный массив ячеек (возможность пользоваться несколькими листами) впервые появился в 1985 в Boeing Calc.
В теории, электронные таблицы ничем не уступают любому языку программирования. Существует машина Тьюринга на формулах Excel (линк), а это значит, что любой алгоритм, который можно реализовать с помощью компьютера, можно реализовать в Excel. Вопрос только в удобстве и эффективности такой реализации.
На практике я встречал очень сложные системы, реализованные в Excel. Например, финансовая модель развития международного аэропорта с возможностью вносить множество разных типов объектов (парковки, склады, полосы, …) и пересчетом квадратных метров и парковочных мест в cash flow (расходы за годы строительства vs прибыль за годы эксплуатации) с учетом разных моделей инфляции. На то чтобы «переписать» такой «эксельчик» на Java с использованием реляционной базы данных может уйти от нескольких человеко-месяцев до нескольких человеко-лет. В этом конкретном случае реляционная модель в базе данных насчитывала более 50 таблиц. Самое интересное, что такого «переписывания» можно было бы избежать, если бы электронные таблицы позволяли не только создавать программное обеспечение, но и делали бы возможным его сопровождение и масштабирование. Для конечного пользователя (экономиста) система на Java это шаг назад, потому что он больше не видит промежуточные результаты и не может сам изменить или дополнить модель.
Выходит, что одну и ту же задачу можно решить, как электронной таблицей, так и универсальным языком программирования. Значит, мы можем сравнить сильные и слабые стороны этих двух инструментов, как средств создания бизнес-приложений. Здесь мы попробуем взглянуть на Excel глазами программиста-архитектора и применим правила архитектуры ПО, которые уже устоялись в классической разработке софта.
Достоинства электронных таблиц
- Интуитивно понятный концепт: каждый из нас в школе видел и заполнял таблички на листочках в клеточку и играл в морской бой. Большинство людей, которые работают с Экселем, никогда не проходили никакого специального обучения (в лучшем случае коллега за полчаса показал на какие кнопки нажимать). Это большое преимущество перед языками программирования, где «C++ за 21 день» звучит даже слишком оптимистично.
- Открытое и статичное состояние облегчает отладку: сложность поиска ошибки в программе чаще всего заключается в том, чтобы поймать тот момент времени, когда что-то пошло не так. Приходиться использовать breakpoints и прокручивать программу по шагам. В электронной таблице состояние статично. Поиск ошибки сводится к тому, чтобы найти первую ячейку с неправильным результатом.
- Реактивность: мы просто задаем формулу, а система сама знает в каком порядке и когда пересчитывать ячейки. Этот концепт, который относительно недавно стал популярным в разработке UI, был основой электронных таблиц с самого начала.
Недостатки электронных таблиц
- Слабо структурированная модель данных: электронные таблицы используют трехмерный массив ячеек как модель данных. Это лучше чем неструктурированный текст в Notepad, но значительно хуже строгой типизации Java или нормализованной реляционной структуры базы данных. В любую ячейку можно записать любой тип данных. Заголовки или значения не различаются. Сказать заранее, что будет в момент исполнения по ссылке E5 невозможно. Зависимости между таблицами неявно хранятся в параметрах функции VLOOKUP и ломаются при неосторожном добавлении колонки. По-моему, это и является одной из основных причин ошибок.
- Высокая избыточность: у программистов хорошо себя зарекомендовал так называемый принцип DRY (Don’t repeat yourself — не повторяйся). Чаще всего мы стараемся писать логику один раз, давать ей название (например, в виде имени функции/метода) и потом ссылаться на нее когда это необходимо. В табличных процессорах мы копируем формулы. Сначала это конечно удобно, но в итоге, понять, где применяется та или другая формула очень сложно. Любое изменение объема данных ведет к необходимости копировать формулы. Это очень сильно затрудняет поддержку и дальнейшее развитие моделей в табличных процессорах.
- Отсутствие интерактивности интерфейса: электронные таблицы не позволяют динамически изменять способ отображения данных. Также отсутствует возможность создавать запрограммированные операции выполняемые, например, по нажатию кнопки.
Как сделать электронные таблицы лучше?
Меня зовут Вадим. Я CTO в CubeWeaver и уже довольно давно занимаюсь разработкой нового табличного процессора. Несколько лет назад я уже писал (линк) про раннюю версию системы, но с тех пор многое изменилось и в этом году проект дошел до коммерческой стадии.
Вот список новшеств моего проекта, которые позволяют устранить перечисленные выше недостатки, стараясь при этом сохранить преимущества электронных таблиц:
Многомерная модель данных
Многомерная модель данных широко используется в Business Intelligence и OLAP системах, предназначенных для анализа данных. Суть модели заключается в том, чтобы хранить данные в ячейках многомерного куба, грани которого подписаны заголовками бизнес-объектов:
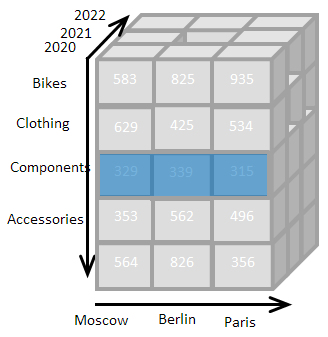
В интерфейсе программы отображается не весь многомерный куб, а его двумерный срез, соответствующий выбранной нами комбинации фильтров:

При реализации такой модели в реляционной BI системе, часто используют схему снежинки (snowflake schema). Кубы реализуются таблицами фактов (fact table), а заголовки на гранях хранятся в таблицах измерений (dimension table).
В моей системе кубы называются рабочими листами (worksheets), а заголовки на гранях куба называются элементами списков (list items).
Каждая ячейка такого многомерного рабочего листа имеет уникальный адрес, состоящий из надписей на гранях. Например, значение 935 на изображении имеет адрес: Bikes, 2020, Paris.
Каждый элемент списка имеет название и идентификатор. В ссылках на ячейки используются идентификаторы, и вышеуказанный адрес в формуле мог бы выглядеть так (ссылки заключаются в квадратные скобки):
[PROD:23, YEAR:2020, CITY:24], где PROD это идентификатор списка «продукт», а 23 идентификатор элемента «Bikes».
Применение многомерной модели позволяет значительно улучшить ситуацию с недостатком номер 1. Во-первых, заголовки теперь хранятся отдельно от численных данных. Во-вторых, введение дополнительного измерения «метрика» (или «позиция отчета») позволяет адресовать ячейки не по порядковому номеру, а по семантическому смыслу, исключая ошибки из-за добавления или удаления столбцов или строк.
Конечно, нужно сказать, что такой подход слегка портит ситуацию с преимуществом номер 1. В морской бой играли все, а в четырехмерные шахматы только некоторые студенты-математики. Но опыт показывает, что благодаря двумерному представлению куба, большинство пользователей довольно быстро привыкают к новой модели данных.
Функция JOIN и метаданные
Многомерная модель позволяет использовать метаданные для описания ячеек. Метод адресации описанный выше означает, что каждая ячейка рабочего листа соответствует определенному набору элементов списка (например, году, продукту и точке продажи). Списки в свою очередь могут иметь атрибуты (колонки), что делает их похожими на обычные реляционные таблицы. Например, можно добавить колонку «валюта» к списку «точка продажи», связывая таким образом списки «точка продажи» и «валюта» в реляцию с кардинальностью many-to-one.
Функция JOIN дает возможность динамически ссылаться на ячейки, используя такую связь. Эта функция заменяет VLOOKUP, устраняя при этом необходимость работать с индексами.
Пример: для того чтобы посчитать сумму продаж по миру, нужно сначала сконвертировать сумму продаж по каждой стране в единую валюту (умножить позицию «продажи» на курс обмена). В Excel мы бы хранили 2 таблицы: список стран с валютой для каждой страны и список валют с курсом обмена. Для того чтобы найти правильный курс мы бы использовали функцию VLOOKUP два раза: найти код валюты по названию страны и найти курс обмена по коду валюты.
Ссылка на ячейку с курсом обмена, могла бы выглядеть так:
EX_RATES.[COUNTRY.join(CURRENCY)], где
EX_RATES — название рабочего листа с курсами обмена валют
COUNTRY — измерение со странами
CURRENCY — измерение с валютами
Цепочки связей могут быть любой длины, например: STORE.join(COUNTRY).join(CURRENCY)
Фактически, строя модель, мы создаем схему снежинки. Функция JOIN позволяет формулам динамически ссылаться на ячейки рабочих листов, используя связи между таблицами (списками) этой схемы. При этом зависимости между ячейками явно указаны в аргументах функции JOIN.
Зона действия формул
Возможность указать зону действия формулы (area of effect) позволяет избавиться от необходимости копировать формулы.
По каждому измерению куба мы задаем набор элементов, на которые действует формула, как например: все года, продукты типа «велосипед», позиция отчета «выручка». На практике это выглядит вот так (Синим цветом отмечена цель формулы, красным и оранжевым её аргументы. Список выбранных элементов по каждому измерению находиться внизу экрана):
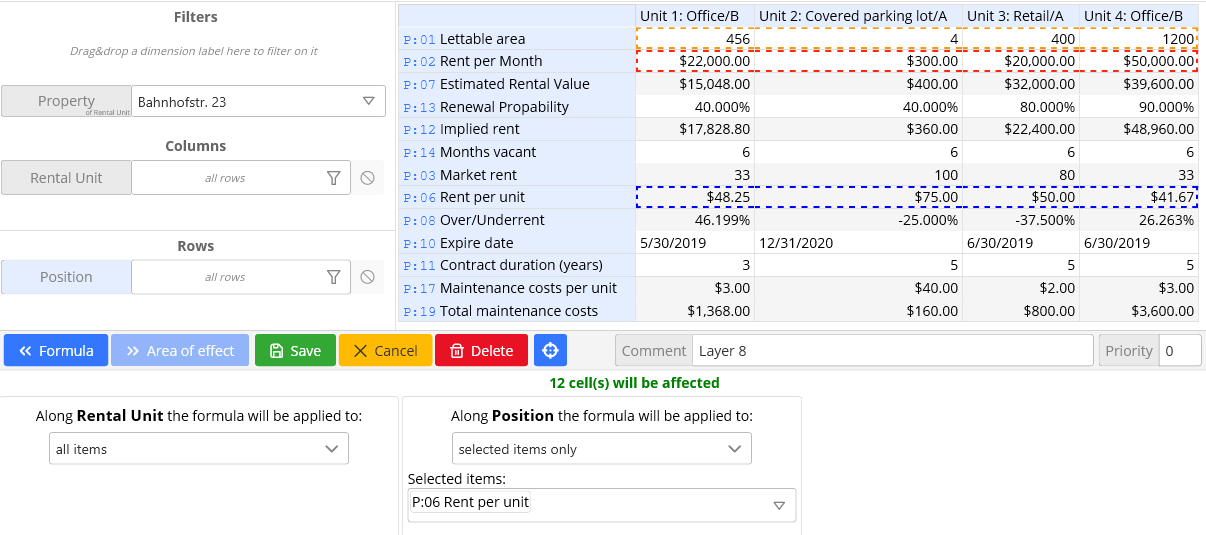
Этот подход устраняет недостаток номер 2 и позволяет добавлять и удалять элементы или даже измерения, не изменяя формулу. Также отпадает необходимость искать все ячейки, в которые формула была скопирована, каждый раз, когда мы хотим ее изменить.
Интерактивность ячеек
Это нововведение позволяет создавать интерактивные интерфейсы, используя формулы. Формулы можно использовать не только для того чтобы вычислить значение ячейки, но и для форматирования ячеек (cell formatting), изменения цвета ячеек (cell color) и для того чтобы спрятать или показать группу ячеек или целые колонки или строки (cell visibility). Ячейки можно форматировать не только как числа, даты и текст, но и как кнопки, флажки (checkbox) и списки выбора (dropdown).
Таким образом, например, цвет ячеек может меняться в зависимости от значения ячейки. Флажок или список выбора в одном листе может отображать, прятать или блокировать на запись ячейки в другом листе.
Кнопки в ячейках позволяют создавать довольно сложные операции со значениями ячеек. Создавая кнопку, мы задаем цель операции (cell range) и формулу, которая выполняется один раз для каждой из целевых ячеек. На одной кнопке может быть несколько операций. Так, нажатие на кнопку может, например, скопировать данные из предыдущего года в следующий или распределить содержимое ячейки по нескольким другим ячейкам, пропорционально какой-то величине (splashing).
Кнопки в сочетании с ограничениями доступа пользователя позволяют создавать необратимую функциональность. Так, например пользователь получивший доступ к кнопке, но не получивший доступ к целевой ячейке, сможет записать в ячейку только то, что позволит ему формула в кнопке.
Заключение
Новый табличный процессор позволяет создавать значительно более сложные модели, чем это возможно в других системах. При этом модели остаются понятными и простыми в сопровождении. Также значительно уменьшается вероятность ошибок в формулах.
Платой за эти преимущества является повышенная сложность системы. Прежде чем начать работать, пользователь должен создать модель данных в виде списков и кубов.
В целом система рассчитана на технически более грамотного пользователя, чем Excel (например, экономисты с базовыми знаниями программирования или программисты, работающие над экономическими моделями).
С удовольствием отвечу на ваши вопросы в комментариях или личных сообщениях. Также, в интернете можно найти документация к системе и несколько обучающих видео.
Модель данных позволяет интегрировать данные из нескольких таблиц, эффективно создавая реляционный источник данных в книге Excel. В Excel модели данных используются прозрачно, предоставляя табличные данные, используемые в сводных таблицах и сводных диаграммах. Модель данных визуализируются как коллекция таблиц в списке полей, и в большинстве раз вы даже не узнаете, что она существует.
Прежде чем приступить к работе с моделью данных, необходимо получить некоторые данные. Для этого мы будем использовать интерфейс Get & Transform (Power Query), поэтому вам может потребоваться выполнить шаг назад и посмотреть видео, или следуйте нашему руководству по обучению по get & Transform и Power Pivot.
Где есть Power Pivot?
-
Excel 2016 & Excel для Microsoft 365 — Power Pivot включен в ленту.
-
Excel 2013 — Power Pivot входит в Office профессиональный плюс Excel 2013, но не включен по умолчанию. Дополнительные сведения о запуске надстройки Power Pivot для Excel 2013.
-
Excel 2010 — скачайте надстройку Power Pivot, а затем установите надстройку Power Pivot.
Где находится get & Transform (Power Query)?
-
Excel 2016 & Excel для Microsoft 365 . Get & Transform (Power Query) интегрировано с Excel на вкладке «Данные«.
-
Excel 2013 — Power Query — это надстройка, которая входит в Excel, но ее необходимо активировать. Перейдите к разделу «Параметры >» > надстроек, а затем в раскрывающемся списке «Управление» в нижней части панели выберите com-надстройки > Go. Проверьте microsoft Power Query Excel, а затем ОК, чтобы активировать его. На Power Query будет добавлена вкладка Power Query.
-
Excel 2010 — скачивание и установка Power Query надстройки.. После активации на ленту Power Query вкладки.
Начало работы
Сначала необходимо получить некоторые данные.
-
В Excel 2016 и Excel для Microsoft 365 используйте data >Get & Transform Data > Get Data > Get Data to import data from any number of external data sources, such as a text file, Excel workbook, website, Microsoft Access, SQL Server, or another relational database that contains multiple related tables.
В Excel 2013 и 2010 перейдите к Power Query >получения внешних данных и выберите источник данных.
-
Excel предложит выбрать таблицу. Если вы хотите получить несколько таблиц из одного источника данных, установите флажок «Включить выбор нескольких таблиц «. При выборе нескольких таблиц Excel автоматически создает модель данных.
Примечание: В этих примерах мы используем книгу Excel с вымышленными сведениями о классах и оценках учащихся. Вы можете скачать пример книги модели данных учащихся и следовать инструкциям. Вы также можете скачать версию с готовой моделью данных..

-
Выберите одну или несколько таблиц и нажмите кнопку «Загрузить «.
Если необходимо изменить исходные данные, можно выбрать параметр «Изменить «. Дополнительные сведения см. в статье «Общие сведения Редактор запросов (Power Query)».
Теперь у вас есть модель данных, которая содержит все импортированные таблицы, и они будут отображаться в списке полей сводной таблицы.
Примечания:
-
Модели создаются неявно, когда вы импортируете в Excel несколько таблиц одновременно.
-
Модели создаются явно, если вы импортируете данные с помощью надстройки Power Pivot. В надстройке модель представлена в макете с вкладками, аналогичном Excel, где каждая вкладка содержит табличные данные. Дополнительные сведения об импорте данных с помощью надстройки Power Pivotсм. в статье «Получение данных с помощью SQL Server данных».
-
Модель может содержать одну таблицу. Чтобы создать модель на основе только одной таблицы, выберите таблицу и нажмите кнопку Добавить в модель данных в Power Pivot. Это может понадобиться в том случае, если вы хотите использовать функции Power Pivot, например отфильтрованные наборы данных, вычисляемые столбцы, вычисляемые поля, ключевые показатели эффективности и иерархии.
-
Связи между таблицами могут создаваться автоматически при импорте связанных таблиц, у которых есть связи по первичному и внешнему ключу. Excel обычно может использовать импортированные данные о связях в качестве основы для связей между таблицами в модели данных.
-
Советы по сокращению размера модели данных см. в статье «Создание модели данных, оптимизированной для памяти, с помощью Excel и Power Pivot».
-
Дополнительные сведения см. в руководстве по импорту данных в Excel и созданию модели данных.
Создание связей между таблицами
Следующим шагом является создание связей между таблицами, чтобы вы могли извлекать данные из любой из них. Каждая таблица должна иметь первичный ключ или уникальный идентификатор поля, например идентификатор учащегося или номер класса. Самый простой способ — перетащить эти поля, чтобы подключить их в представлении схемы Power Pivot.
-
Перейдите в power Pivot > Manage.
-
На вкладке « Главная» выберите » Представление схемы».
-
Будут отображены все импортированные таблицы, и может потребоваться некоторое время, чтобы изменить их размер в зависимости от количества полей в каждой из них.
-
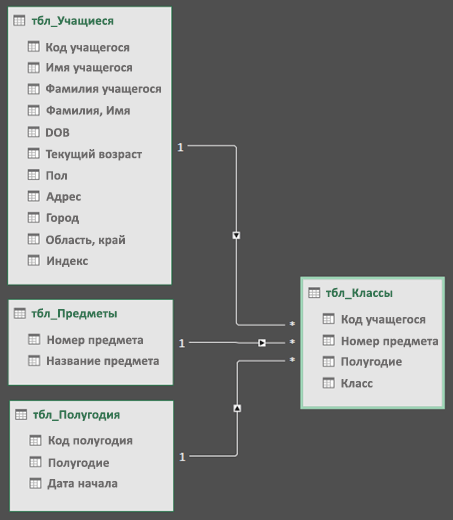
Затем перетащите поле первичного ключа из одной таблицы в следующую. В следующем примере показано представление схемы таблиц учащихся.
Мы создали следующие ссылки:
-
tbl_Students | Идентификатор учащегося > tbl_Grades | Идентификатор учащегося
Другими словами, перетащите поле «Идентификатор учащегося» из таблицы «Учащиеся» в поле «Идентификатор учащегося» в таблице «Оценки».
-
tbl_Semesters | Идентификаторы > tbl_Grades | Семестр
-
tbl_Classes | Номер класса > tbl_Grades | Номер класса
Примечания:
-
Имена полей не обязательно должны совпадать для создания связи, но они должны быть одинаковыми типами данных.
-
Соединители в представлении схемы имеют «1» с одной стороны, а «*» — с другой. Это означает, что между таблицами существует связь «один ко многим», которая определяет, как данные используются в сводных таблицах. См. дополнительные сведения о связях между таблицами в модели данных.
-
Соединители указывают только на наличие связи между таблицами. На самом деле они не показывают, какие поля связаны друг с другом. Чтобы просмотреть ссылки, перейдите в раздел Power Pivot > Manage > Design > Relationships > Управление связями. В Excel можно перейти к разделу «>данных».
-
Создание сводной таблицы или сводной диаграммы с помощью модели данных
Книга Excel может содержать только одну модель данных, но эта модель может содержать несколько таблиц, которые можно многократно использовать в книге. Вы можете добавить дополнительные таблицы в существующую модель данных в любое время.
-
В Power Pivotперейдите к разделу » Управление».
-
На вкладке « Главная» выберите сводную таблицу.
-
Выберите место размещения сводной таблицы: новый лист или текущее расположение.
-
Нажмите кнопку «ОК», и Excel добавит пустую сводную таблицу с областью списка полей справа.
Затем создайте сводную таблицу или сводную диаграмму. Если вы уже создали связи между таблицами, можно использовать любое из их полей в сводной таблице. Мы уже создали связи в образце книги модели данных учащихся.
Добавление имеющихся несвязанных данных в модель данных
Предположим, вы импортировали или скопировали много данных, которые вы хотите использовать в модели, но не добавили их в модель данных. Принудительно отправить новые данные в модель очень просто.
-
Начните с выбора любой ячейки в данных, которые необходимо добавить в модель. Это может быть любой диапазон данных, но лучше всего использовать данные, отформатированные в виде таблицы Excel .
-
Добавьте данные одним из следующих способов.
-
Щелкните Power Pivot > Добавить в модель данных.
-
Выберите Вставка > Сводная таблица и установите флажок Добавить эти данные в модель данных в диалоговом окне «Создание сводной таблицы».
Диапазон или таблица будут добавлены в модель как связанная таблица. Дополнительные сведения о работе со связанными таблицами в модели см. в статье Добавление данных с помощью связанных таблиц Excel в Power Pivot.
Добавление данных в таблицу Power Pivot данных
В Power Pivot невозможно добавить строку в таблицу, введя текст непосредственно в новой строке, как это можно сделать на листе Excel. Но можно добавить строки , скопируйте и вставьте или обновите исходные данные и обновите модель Power Pivot.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
См. также
Ознакомьтесь & по преобразованию и обучению Power Pivot
Общие сведения о редакторе запросов (Power Query)
Создание модели данных, оптимизированной для памяти, с помощью Excel и Power Pivot
Руководство. Импорт данных в Excel и создание модели данных
Определение источников данных, используемых в модели данных книги
Связи между таблицами в модели данных