
A Monte Carlo simulation can be developed using Microsoft Excel and a game of dice. A Monte Carlo simulation is a method for modeling probabilities by using random numbers to approximate and simulate possible outcomes. Today, it is widely used as an analysis tool. It plays a key part in various fields such as finance, physics, chemistry, and economics.
Key Takeaways
- The Monte Carlo method seeks to improve the analysis of data using random data sets and probability calculations.
- A Monte Carlo simulation can be developed using Microsoft Excel and a game of dice.
- A data table can be used to generate the results—a total of5,000 results are needed to prepare the Monte Carlo simulation.
Monte Carlo Simulation
The Monte Carlo method was invented by John von Neumann and Stanislaw Ulam in the 1940s and seeks to solve complex problems using random and probabilistic methods. The term Monte Carlo refers the administrative area of Monaco popularly known as a place where European elites gamble.
The Monte Carlo simulation method computes the probabilities for integrals and solves partial differential equations, thereby introducing a statistical approach to risk in a probabilistic decision. Although many advanced statistical tools exist to create Monte Carlo simulations, it is easier to simulate the normal law and the uniform law using Microsoft Excel and bypass the mathematical underpinnings.
When to Use the Monte Carlo Simulation
We use the Monte Carlo method when a problem is too complex and difficult to do by direct calculation. Using the simulation can help provide solutions for situations that prove uncertain. A large number of iterations allows a simulation of the normal distribution. It can also be used to understand how risk works, and to comprehend the uncertainty in forecasting models.
As noted above, the simulation is often used in many different disciplines including finance, science, engineering, and supply chain management—especially in cases where there are far too many random variables in play. For example, analysts may use Monte Carlo simulations in order to evaluate derivatives including options or to determine risks including the likelihood that a company may default on its debts.
Game of Dice
For the Monte Carlo simulation, we isolate a number of key variables that control and describe the outcome of the experiment, then assign a probability distribution after a large number of random samples is performed. In order to demonstrate, let’s take a game of dice as a model. Here’s how the dice game rolls:
• The player throws three dice that have six sides three times.
• If the total of the three throws is seven or 11, the player wins.
• If the total of the three throws is: three, four, five, 16, 17, or 18, the player loses.
• If the total is any other outcome, the player plays again and re-rolls the dice.
• When the player throws the dice again, the game continues in the same way, except that the player wins when the total is equal to the sum determined in the first round.
It is also recommended to use a data table to generate the results. Moreover, 5,000 results are needed to prepare the Monte Carlo simulation.
To prepare the Monte Carlo simulation, you need 5,000 results.
Step 1: Dice Rolling Events
First, we develop a range of data with the results of each of the three dice for 50 rolls. To do this, it is proposed to use the «RANDBETWEEN(1,6)» function. Thus, each time we click F9, we generate a new set of roll results. The «Outcome» cell is the sum total of the results from the three rolls.
Step 2: Range of Outcomes
Then, we need to develop a range of data to identify the possible outcomes for the first round and subsequent rounds. There is a three-column data range. In the first column, we have the numbers one to 18. These figures represent the possible outcomes following rolling the dice three times: The maximum being 3 x 6 = 18. You will note that for cells one and two, the findings are N/A since it is impossible to get a one or a two using three dice. The minimum is three.
In the second column, the possible conclusions after the first round are included. As stated in the initial statement, either the player wins (Win) or loses (Lose), or they replay (Re-roll), depending on the result (the total of three dice rolls).
In the third column, the possible conclusions to subsequent rounds are registered. We can achieve these results using the «IF» function. This ensures that if the result obtained is equivalent to the result obtained in the first round, we win, otherwise we follow the initial rules of the original play to determine whether we re-roll the dice.
Step 3: Conclusions
In this step, we identify the outcome of the 50 dice rolls. The first conclusion can be obtained with an index function. This function searches the possible results of the first round, the conclusion corresponding to the result obtained. For example, when we roll a six, we play again.
One can get the findings of other dice rolls, using an «OR» function and an index function nested in an «IF» function. This function tells Excel, «If the previous result is Win or Lose,» stop rolling the dice because once we have won or lost we are done. Otherwise, we go to the column of the following possible conclusions and we identify the conclusion of the result.
Step 4: Number of Dice Rolls
Now, we determine the number of dice rolls required before losing or winning. To do this, we can use a «COUNTIF» function, which requires Excel to count the results of «Re-roll» and add the number one to it. It adds one because we have one extra round, and we get a final result (win or lose).
Step 5: Simulation
We develop a range to track the results of different simulations. To do this, we will create three columns. In the first column, one of the figures included is 5,000. In the second column, we will look for the result after 50 dice rolls. In the third column, the title of the column, we will look for the number of dice rolls before obtaining the final status (win or lose).
Then, we will create a sensitivity analysis table by using the feature data or Table Data table (this sensitivity will be inserted in the second table and third columns). In this sensitivity analysis, the numbers of events of one to 5,000 must be inserted into cell A1 of the file. In fact, one could choose any empty cell. The idea is simply to force a recalculation each time and thus get new dice rolls (results of new simulations) without damaging the formulas in place.
Step 6: Probability
We can finally calculate the probabilities of winning and losing. We do this using the «COUNTIF» function. The formula counts the number of «win» and «lose» then divides by the total number of events, 5,000, to obtain the respective proportion of one and the other. We finally see that the probability of getting a Win outcome is 73.2% and getting a Lose outcome is therefore 26.8%.
Существует
несколько видов формул прямоугольников:
-
«Формула левых прямоугольников.
В общем виде формула левых прямоугольниковна отрезке[x0;xn]выглядит следующим образом(21):
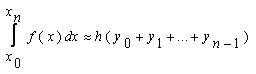
В данной формуле x0=a,
xn=b, так как любой интеграл
в общем виде выглядит: (см. формулу18).
h можно вычислить по формуле 19.
y0, y1,…, yn-1— это значения соответствующей функции
f(x) в точкахx0, x1,…,
xn-1(xi=xi-1+h).
-
Формула правых прямоугольников.
В общем виде формула правых прямоугольниковна отрезке[x0;xn]выглядит следующим образом(22):
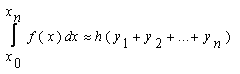
В данной формуле x0=a, xn=b(см. формулу для левых прямоугольников).
h можно вычислить по той же формуле, что
и в формуле для левых прямоугольников.
y1, y2,…, yn— это значения соответствующей функции
f(x) в точкахx1, x2,…,
xn(xi=xi-1+h).
-
Формула средних прямоугольников.
В общем виде формула средних
прямоугольниковна отрезке[x0;xn]выглядит следующим образом(23):
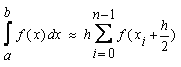
Где
xi=xi-1+h.
В данной формуле, как и в предыдущих,
требуется h умножать сумму значений
функции f(x), но уже не просто подставляя
соответствующие значения x0,x1,…,xn-1в функцию f(x), а прибавляя к каждому из
этих значенийh/2(x0+h/2, x1+h/2,…,
xn-1+h/2), а затем только подставляя
их в заданную функцию.
h можно вычислить по той же формуле, что
и в формуле для левых прямоугольников.»
[6]
На практике
данные способы реализуются следующим
образом:
|
a) |
|
|
по |
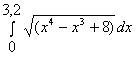
-
Mathcad;
-
Excel.
|
b) |
|
|
по |
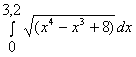
-
Mathcad;
-
Excel.
|
c) |
|
|
по |
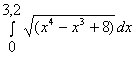
Для того, чтобы вычислить интеграл по
формуле средних прямоугольников в
Excel, необходимо выполнить следующие
действия:
-
Продолжить работу в том же документе,
что и при вычислении интеграла по
формулам левых и правых прямоугольников. -
В ячейку E6 ввести текст xi+h/2, а в F6 —
f(xi+h/2). -
Ввести в ячейку E7 формулу =B7+$B$4/2,
скопировать эту формулу методом
протягивания в диапазон ячеек E8:E16 -
Ввести в ячейку F7 формулу =КОРЕНЬ(E7^4-E7^3+8),
скопировать эту формулу методом
протягивания в диапазон ячеек F8:F16 -
Ввести в ячейку F18 формулу =СУММ(F7:F16).
-
Ввести в ячейку F19 формулу =B4*F18.
-
Ввести в ячейку F20 текст средних.
В итоге получаем следующее:
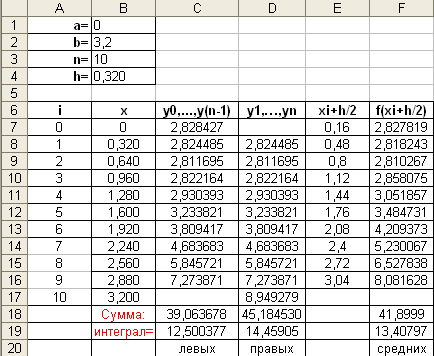
Ответ: значение заданного интеграла
равно 13,40797.
Исходя из полученных результатов,
можно сделать вывод, что формула средних
прямоугольников является наиболее
точной, чем формулы правых и левых
прямоугольников.
1. Метод Монте-Карло
«Основная
идея метода Монте-Карло заключается в
многократном повторении случайных
испытаний. Характерной особенностью
метода Монте-Карло является использование
случайных чисел (числовых значений
некоторой случайной величины). Такие
числа можно получать с помощью датчиков
случайных чисел. Например, в языке
программирования Turbo Pascal имеется
стандартная функция random
, значениями которой являются случайные
чис¬ла, равномерно распределенные на
отрезке [0;
1].
Сказанное означает, что если разбить
указанный отрезок на некоторое число
равных интервалов и вычислить значение
функции random большое число раз, то в
каждый интервал попадет приблизительно
одинаковое количество случайных чисел.
В языке программирования basin подобным
датчиком является функция rnd. В табличном
процессоре MS Excel функция СЛЧИС
возвращает равномерно распределенное
случайное число большее или равное 0 и
меньшее 1 (изменяется при пересчете)»
[7].
|
Рассмотрим |
|
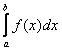
Для
того чтобы его вычислить, необходимо
воспользоваться формулой ():
![]()
,
где (i=1, 2, …, n) – случайные числа, лежащие
в интервале [a;b].
Для
получения таких чисел на основе
последовательности случайных чисел xi
, равномерно распределенных в интервале
[0;1], достаточно выполнить преобразование
xi=a+(b-a)xi.
На практике
данный способ реализуется следующим
образом:
|
Вычислить |
|
по |
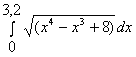
Для того, чтобы вычислить интеграл
методом Монте-Карло в Excel, необходимо
выполнить следующие действия:
-
В ячейку B1 ввести текст n=.
-
В ячейку B2 ввести текст a=.
-
В ячейку B3 ввести текст b=.
В ячейку C1 ввести число 10.
-
В ячейку C2 ввести число 0.
-
В ячейку C3 ввести число 3,2.
-
В ячейку A5 ввести I, в В5 – xi, в C5 – f(xi).
-
Ячейки A6:A15 заполнить числами 1,2,3, …,10
– так как n=10. -
Ввести в ячейку B6 формулу =СЛЧИС()*3,2
(происходит генерация чисел в диапазоне
от 0 до 3,2), скопировать эту формулу
методом протягивания в диапазон ячеек
В7:В15. -
Ввести в ячейку C6 формулу =КОРЕНЬ(B6^4-B6^3+8),
скопировать эту формулу методом
протягивания в диапазон ячеек C7:C15. -
Ввести в ячейку B16 текст «сумма», в B17 –
«(b-a)/n», в B18 – «I=». -
Вести в ячейку C16 формулу =СУММ(C6:C15).
-
Вести в ячейку C17 формулу =(C3-C2)/C1.
-
Вести в ячейку C18 формулу =C16*C17.
В итоге получаем:
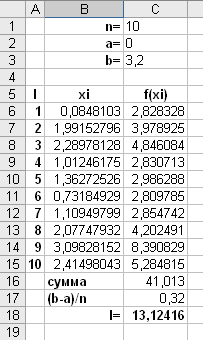
Ответ: значение заданного интеграла
равно 13,12416.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
17.02.2016593.41 Кб40чм.doc
- #
- #
- #
- #
- #
Помогаю со студенческими работами здесь
Вычисление интеграла методом Монте-Карло
Задания под буквой б
Вычисление интеграла методом Монте-Карло
Здравствуйте!
Задача такая: пользователь в текстовом файле задает координаты точек (любое…
Вычисление интеграла методом Монте-Карло
Здравствуйте. Необходима программа, вычисляющая интеграл методом Монте-Карло для функции…
Вычисление интеграла методом Монте-Карло
5.5. Вычисление интеграла методом Монте–Карло.
Вычислить значения функции в заданных точках…
Вычисление интеграла методом Монте-Карло
Нужно вычислить интеграл, как показано на первой картинке внизу темы. На второй картинке сам…
Поиск интеграла методом Монте-Карло
Добрый день. Неполучается написать код для метода монте-карло для поиска интеграла.
Помогите…
Искать еще темы с ответами
Или воспользуйтесь поиском по форуму:
Содержание
- 1 Оценка риска инвестиционного проекта
- 2 Заключение
- 3 Моделирование Монте-Карло
- 4 Игра в кости
- 5 Шаг 1: События прокатки в кости
- 6 Шаг 2: Диапазон результатов
- 7 Шаг 3: Выводы
- 8 Шаг 4: Количество рулонов кости
- 9 Шаг 5: Моделирование
- 10 Шаг 6: Вероятность
| Срок выполнения | от 1 дня |
| Цена | от 100 руб./задача |
| Предоплата | 50 % |
| Кто будет выполнять? | преподаватель или аспирант |
ЗАКАЗАТЬ РЕШЕНИЕ ЗАДАЧ МЕТОДОМ МОНТЕ-КАРЛО
Один из самых прикладных методов статистической оценки риска. К нему нужно отнестись с большим участием. В данной статье будет рассмотрен пример имитационного моделирования с использованием данного подхода.
Метод Монте-Карло получил своё название за то, что предназначен осуществить оценку предельно случайных событий. А что, как ни казино, которых в Монте-Карло много, связано со случайностью больше всего?
В процессе работы нам понадобится «генератор случайных чисел» из MS Excel и функция «Описательная статистика».
Оценка риска инвестиционного проекта
Есть следующие условия задачи:

Таким образом, нам нужно оценить три периода – за три года. Запишем все исходные данные в таблицу. Значения, полученные в ячейках D5-X5, имеют формулу для вычисления или есть в условиях задачи. Вы, как экономист, с формулами должны быть знакомы. Обратите внимание на заголовок, выделенный красным цветом на рисунке ниже – «Имитационная модель NCF1». Это говорит о том, что мы имитируем первый год, а всего их будет три на разных листах в MS Excel. На новый лист переключиться внизу окна программы.

Теперь в MS Excel переключаемся на «Данные» и выбираем пункт «Анализ данных».

В появившемся окне выбираем «Генерация случайных чисел». Выполняем генерацию с параметрами, продемонстрированными на картинке ниже, для пункта «Кол-во пользователей».

Параметры будут отталкиваться от среднего значения 250, оно есть в ожидаемых значениях в нашей таблице. Нужно выполнить 1000 генераций. Если вы знакомы со статистикой, то понимаете, что большее количество испытаний даёт более точную оценку. Используя метод Монте-Карло, можно имитировать и 10 000 значений для большей точности.
После мы имитируем все стохастические, то есть, меняющиеся значения по аналогии, как показано выше. Копируем формулы переменных или констант из ячеек D7-X7 под «Результаты имитации» с учетом имитированных значений. Получаем следующий результат.

Как видим, платежи по налогам за имущество, например, являются постоянным значением на весь год, поэтому это значение везде одинаковое, а другие меняются, потому что рассчитываются по формулам, и в эти формулы входят меняющиеся значение, имитированные нами. Не забывайте, что значений в каждом столбце должно быть по тысяче.
Теперь делаем то же самое, но для имитационной модели NCF2.

Это второй год работы проекта. Как видим, под «СКО» процентные соотношения увеличились. Об этом говорится в условии задачи, что налоги и зарплата должны расти каждый год.
Повторяем это действие в третий раз, увеличивая налоги и зарплаты, как говорит условие.
Наибольшую важность в оценке инвестиционного проекта имеет параметр NCF – чистый денежный поток. Копируем все значения NCF на четвертый лист с каждой из трёх предыдущих страниц.

Формула для расчета NPV есть вверху картинки. Используем её. Теперь точно так же заходим в «Данные», жмём на «Анализ данных» и выбираем там «Описательная статистика». Вот, что в появившемся окне вам нужно указать.

Во входном интервале выбирается 1000 полученных значений NPV. Выходной интервал можете выбрать произвольно. На выходе у вас будет таблица со статистическими данными.

Вы, как экономист, должны понимать, о чем говорит каждое значение, если нет, то нужно прочитать отдельную статью или главу учебника. Наша статья о том, метод Монте-Карло применяется с использованием функций MS Excel.
Заключение
Генерация случайных чисел – наше всё. Именно в оценке того, к чему может привести случайность, заключается статистический метод Монте-Карло. Это работает не только в экономике, но и везде, где есть случайность. Можете посмотреть, как это делается, применительно к зоологии в видео ниже.
31.01.2014 Григорий Цапко Бизнес-планирование, Калькуляторы, шаблоны, форматы, Малый бизнес
Предлагаю вашему вниманию шаблон для анализа инвестиционного проекта методом Монте-Карло.
Предлагаемый шаблон на основе анализа инвестиционного проекта служит иллюстрацией реализации метода моделирования получившим название «Монте-Карло». Название метода говорит само за себя: в основе моделирования будущих событий лежит использование большого количества случайных величин.
Подобный метод моделирования событий приемлем в тех случаях, когда существует неопределенность относительно значений тех или иных величин.
Считается, что данный метод был использован в работах над атомной бомбой, когда пытались рассчитать количество обогащённого урана необходимое для производства заряда. Слишком маленькое количество могло не дать развиться цепной реакции, а слишком большое было чревато дополнительными месяцами работы над получением необходимого количества урана.
Итак, мы имеем инвестиционный проект, который будет реализован в течение, предположим, 5 лет.
Нам точно не известна цена за которую мы будем реализовывать нашу продукцию, неизвестно точное количество продукции и неизвестно точное значение переменных затрат на ее производство. Это будут случайные величины.
Однако экспертным путем мы определили некий диапазон, в котором будут лежать эти значения.
Например, цена будет не ниже 30 руб. и не выше 40 руб., количество не меньше 150 и не больше 300 единиц, переменные затраты в диапазоне 15 до 20 руб. Цифры могут быть совершенно различными. Важно то, что мы имеем представление о диапазоне их вероятных значений.
Именно значения в этих диапазонах мы и будем моделировать для оценки общей привлекательности проекта.
Для генерации случайных величин мы будем использовать функцию СЛУЧМЕЖДУ, с указанием в качестве аргументов нижней и верхней границы диапазона.
Полученные величины будут использоваться для расчета денежных потоков и чистой приведенной стоимости проекта (NPV).
Генерируется достаточно большое количество вариантов (опытов) и все они обрабатываются методами статистического анализа. В нашем шаблоне мы используем 5 000 опытов, но их может быть и 1 000 000, правда кардинально на результаты это не повлияет.
Это основная философия данного метода. Далее лишь техника реализации.
На листе «Имитация» указываем диапазоны изменения величин, указываем постоянные параметры проекта, а также формируем таблицу в 5 000 строк.
В каждой строке у нас есть случайное значение объема производства, переменных затрат и цены реализации. Также по каждой строке на основе этих данных рассчитываются такие показатели как выручка, прибыль (за минусом постоянных расходов и налога), денежный поток и чистая приведенная стоимость проекта за 5 лет с учетом заданной ставки дисконтирования.
Далее переходим к анализу полученных результатов.
На листе «Результаты анализа» выводим значение минимума, максимума, среднего значения, стандартного отклонения и коэффициента вариации интересующих нас показателей.
По большому счету, нас интересует показатель NPV.
Для него мы рассчитываем также количество случаев, когда NPV0 для всей совокупности в 5000 опытов.
Вместе с сумой убытков и суммой доходов, эти значения могут дать представление о мере рискованности проекта и масштабе возможных потерь.
Далее, используя стандартное распределение оцениваем вероятность получения того или иного значения NPV. Например, безубыточный проект имеет NPV > 0.
Установив в качестве значения Х (это наше NPV) ноль, мы получим вероятность получения убытка в 3%.
Для определения вероятности используем функцию НОРМ.СТ.РАСП, имеющую следующий синтаксис:
=НОРМ.СТ.РАСП(z,интегральная)
Z Обязательный. Значение, для которого строится распределение.
Интегральная Обязательный. Логическое значение, определяющее форму функции. Если аргумент «интегральная» имеет значение ИСТИНА, функция НОРМ.СТ.РАСП возвращает интегральную функцию распределения; если этот аргумент имеет значение ЛОЖЬ, возвращается весовая функция распределения.
Для определения значения Z используем функцию НОРМАЛИЗАЦИЯ, имеющую следующий синтаксис:
=НОРМАЛИЗАЦИЯ(x, среднее, стандартное_откл)
x Обязательный. Нормализуемое значение. В нашем случае это NPV.
Среднее Обязательный. Среднее арифметическое распределения.
Стандартное_откл Обязательный. Стандартное отклонение распределения.
Среднее значение и стандартное отклонение для NPV мы рассчитали в таблице «Результаты анализа».
Мы разработаем симуляцию Монте-Карло с использованием Microsoft Excel и игра в кости. Моделирование Монте-Карло — математический численный метод, который использует случайные ничьи для выполнения вычислений и сложных проблем. Сегодня он широко используется и играет ключевую роль в различных областях, таких как финансы, физика, химия, экономика и многие другие.
Моделирование Монте-Карло
Метод Монте-Карло был изобретен Николаем Метрополисом в 1947 году и направлен на решение сложных проблем с использованием случайных и вероятностных методов. Термин «Монте-Карло» происходит от административного района Монако, широко известного как место, где европейские элиты играют в азартные игры. Мы используем метод Монте-Карло, когда проблема слишком сложна и сложна при непосредственном вычислении. Большое количество итераций позволяет моделировать нормальное распределение.
Метод моделирования методом Монте-Карло вычисляет вероятности для интегралов и решает уравнения в частных производных, тем самым вводя статистический подход к риску в вероятностном решении. Несмотря на то, что существует множество современных статистических инструментов для создания симуляций Монте-Карло, проще моделировать нормальный закон и единообразный закон с использованием Microsoft Excel и обходить математические основы.
Для моделирования Монте-Карло мы выделяем ряд ключевых переменных, которые контролируют и описывают результат эксперимента и назначают распределение вероятности после выполнения большого количества случайных выборок. Давайте возьмем игру в кости как модель.
Игра в кости
Вот как игра в кости играется:
• Игрок бросает три кости, которые имеют 6 сторон 3 раза.
• Если общее количество 3 бросков составляет 7 или 11, игрок выигрывает.
• Если общее количество 3 бросков: 3, 4, 5, 16, 17 или 18, проигрыватель проигрывает.
• Если общий результат — любой другой результат, игрок снова играет и повторно свертывает штамп.
• Когда игрок снова бросает кубик, игра продолжается таким же образом, за исключением того, что игрок выигрывает, когда сумма равна сумме, определенной в первом раунде.
Рекомендуется также использовать таблицу данных для генерации результатов. Более того, для подготовки моделирования методом Монте-Карло требуется 5 000 результатов.
Шаг 1: События прокатки в кости
Сначала мы разрабатываем ряд данных с результатами каждого из 3 кубиков для 50 рулонов. Для этого предлагается использовать функцию «RANDBETWEEN (1. 6)». Таким образом, каждый раз, когда мы нажимаем F9, мы генерируем новый набор результатов каротажа. Ячейка «Результат» — это сумма итогов трех рулонов.

.
Шаг 2: Диапазон результатов
Затем нам нужно разработать ряд данных для определения возможных результатов для первого раунда и последующих раундов. Ниже приведен диапазон данных с тремя столбцами.В первом столбце у нас есть числа от 1 до 18. Эти цифры представляют собой возможные результаты после того, как катятся кости 3 раза: максимум составляет 3 * 6 = 18. Вы заметите, что для ячеек 1 и 2 результаты N / A, так как невозможно получить 1 или 2, используя 3 кости. Минимальное значение равно 3.
Во втором столбце включены возможные выводы после первого раунда. Как указано в первоначальном заявлении, либо игрок выигрывает (выигрывает), либо проигрывает (проигрывает), либо повторяет его (Re-roll), в зависимости от результата (всего 3 кубика).
В третьей колонке регистрируются возможные выводы для последующих раундов. Мы можем достичь этих результатов, используя функцию «If. «Это гарантирует, что если полученный результат будет эквивалентен результату, полученному в первом раунде, мы выиграем, иначе мы будем следовать первоначальным правилам первоначальной игры, чтобы определить, будем ли мы повторно бросать кости.

.
Шаг 3: Выводы
На этом этапе мы определяем результат 50 кубиков. Первый вывод можно получить с помощью индексной функции. Эта функция выполняет поиск возможных результатов первого раунда, вывод, соответствующий полученному результату. Например, при получении 6, как это имеет место на рисунке ниже, мы снова играем.
Можно получить результаты других рулонов кости, используя функцию «Or» и функцию индекса, вложенную в функцию «If». Эта функция сообщает Excel: «Если предыдущий результат -« Выиграть или проиграть », перестаньте бросать кости, потому что как только мы выиграли или проиграли, мы закончили. В противном случае мы переходим к столбцу следующих возможных выводов, и мы определяем вывод результата.

…
Шаг 4: Количество рулонов кости
Теперь мы определяем количество бросков кубиков, необходимых до проигрыша или выигрыша. Для этого мы можем использовать функцию «Countif», которая требует, чтобы Excel подсчитывал результаты «Re-Roll» и добавлял номер 1 к ней. Он добавляет один, потому что у нас есть один дополнительный раунд, и мы получаем окончательный результат (выигрываем или проигрываем).

.
Шаг 5: Моделирование
Мы разрабатываем диапазон для отслеживания результатов различных симуляций. Для этого мы создадим три столбца. В первом столбце одна из приведенных цифр — 5 000. Во второй колонке мы будем искать результат после 50 кубиков. В третьем столбце, в заголовке столбца, мы будем искать количество бросков кубиков, прежде чем получить окончательный статус (выиграть или проиграть).
Затем мы создадим таблицу анализа чувствительности с использованием данных характеристик или таблицы данных таблицы (эта чувствительность будет вставлена во вторую таблицу и в третьи столбцы). В этом анализе чувствительности номера событий 1 — 5, 000 должны быть вставлены в ячейку A1 файла. Фактически, можно было выбрать любую пустую ячейку. Идея состоит в том, чтобы просто произвести перерасчет каждый раз и таким образом получить новые броски кубиков (результаты новых симуляций), не повредив формулы на месте.
Шаг 6: Вероятность
Мы можем, наконец, вычислить вероятности выигрыша и проигрыша. Мы делаем это с помощью функции «Countif».Формула подсчитывает количество «выигрышей» и «проиграет», а затем делит на общее количество событий, 5, 000, чтобы получить соответствующую долю одного и другого. Наконец, мы видим, что вероятность получить выигрыш составляет 73. 2%, а результат Lose — 26,8%.

Не так давно я прочитал замечательную книгу Дугласа Хаббарда Как измерить всё, что угодно. Оценка стоимости нематериального в бизнесе. В кратком конспекте книги я обещал, что одному из разделов – Оценка риска: введение в моделирование методом Монте-Карло – я посвящу отдельную заметку. Да всё как-то не складывалось. И вот недавно я стал более внимательно изучать методы управления валютными рисками. В материалах, посвященных этой тематике, часто упоминается моделирование методом Монте-Карло. Так что обещанный материал перед вами.
* * *
Приведу простой пример моделирования методом Монте-Карло для тех, кто никогда не работал с ним ранее, но имеет определенное представление об использовании электронных таблиц Excel.
Предположим, что вы хотите арендовать новый станок. Стоимость годовой аренды станка 400 000 дол., и договор нужно подписать на несколько лет. Поэтому, даже не достигнув точки безубыточности, вы всё равно не сможете сразу вернуть станок. Вы собираетесь подписать договор, думая, что современное оборудование позволит сэкономить на трудозатратах и стоимости сырья и материалов, а также считаете, что материально-техническое обслуживание нового станка обойдется дешевле.
Скачать заметку в формате Word, примеры в формате Excel
Ваши калиброванные специалисты по оценке дали следующие интервалы значений ожидаемой экономии и годового объема производства:
| экономия на материально-техническом обслуживании (maintenance savings, MS) | от 10 до 20 дол. на единицу продукции |
| экономия на трудозатратах (labour savings, LS) | от «–2» до 8 дол. на единицу продукции |
| экономия на сырье и материалах (raw materials savings, RMS) | от 3 до 9 дол. на единицу продукции |
| объем производства (production level, PL) | от 15 000 до 35 000 единиц продукции в год |
| стоимость годовой аренды (точка безубыточности — breakeven) | 400 000 дол. |
Годовая экономия составит: (MS + LS + RMS) х PL
Конечно, этот пример слишком прост, чтобы быть реалистичным. Объем производства каждый год меняется, какие-то затраты снизятся, когда рабочие окончательно освоят новый станок, и т.д. Но мы в этом примере намеренно пожертвовали реализмом ради простоты.
Если мы возьмем медиану (среднее) каждого из интервалов значений, то получим годовую экономию: (15 + 3 + 6) х 25 000 = 600 000 (дол.)
Похоже, что мы не только добились безубыточности, но и получили кое-какую прибыль, но не забывайте – существуют неопределенности. Как же оценить рискованность этих инвестиций? Давайте, прежде всего, определим, что такое риск в данном контексте. Чтобы получить риск, мы должны наметить будущие результаты с присущими им неопределенностями, причем какие-то из них – с вероятностью понести ущерб, поддающийся количественному определению. Один из способов взглянуть на риск – представить вероятность того, что мы не добьемся безубыточности, то есть что наша экономия окажется меньше годовой стоимости аренды станка. Чем больше нам не хватит на покрытие расходов на аренду, тем больше мы потеряем. Сумма 600 000 дол. – это медиана интервала. Как определить реальный интервал значений и рассчитать по нему вероятность того, что мы не достигнем точки безубыточности?
Поскольку точные данные отсутствуют, нельзя выполнить простые расчеты для ответа на вопрос, сможем ли мы добиться требуемой экономии. Есть методы, позволяющие при определенных условиях найти интервал значений результирующего параметра по диапазонам значений исходных данных, но для большинства проблем из реальной жизни такие условия, как правило, не существуют. Как только мы начинаем суммировать и умножать разные типы распределений, задача обычно превращается в то, что математики называют неразрешимой или не имеющей решения обычными математическими методами проблемой. Поэтому взамен мы пользуемся методом прямого подбора возможных вариантов, ставшим возможным благодаря появлению компьютеров. Из имеющихся интервалов мы выбираем наугад множество (тысячи) точных значений исходных параметров и рассчитываем множество точных значений искомого показателя.
Моделирование методом Монте-Карло – превосходный способ решения подобных проблем. Мы должны лишь случайным образом выбрать в указанных интервалах значения, подставить их в формулу для расчета годовой экономии и рассчитать итог. Одни результаты превысят рассчитанную нами медиану 600 000 дол., а другие окажутся ниже. Некоторые будут даже ниже требуемых для безубыточности 400 000 дол.
Вы легко сможете осуществить моделирование методом Монте-Карло на персональном компьютере с помощью программы Excel, но для этого понадобится чуть больше информации, чем 90%-ный доверительный интервал. Необходимо знать форму кривой распределения. Для разных величин больше подходят кривые одной формы, чем другой. В случае 90%-ного доверительного интервала обычно используется кривая нормального (гауссова) распределения. Это хорошо знакомая всем колоколообразная кривая, на которой большинство возможных значений результатов группируются в центральной части графика и лишь немногие, менее вероятные, распределяются, сходя на нет к его краям (рис. 1).
Вот как выглядит нормальное распределение:
Рис.1. Нормальное распределение. По оси абсцисс число сигм.
Особенности:
- значения, располагающиеся в центральной части графика, более вероятны, чем значения по его краям;
- распределение симметрично; медиана находится точно посредине между верхней и нижней границами 90%-ного доверительного интервала (CI);
- «хвосты» графика бесконечны; значения за пределами 90%-ного доверительного интервала маловероятны, но все же возможны.
Для построения нормального распределения в Excel можно воспользоваться функцией =НОРМРАСП(Х; Среднее; Стандартное_откл; Интегральная), где
Х – значение, для которого строится нормальное распределение;
Среднее – среднее арифметическое распределения; в нашем случае = 0;
Стандартное_откл – стандартное отклонение распределения; в нашем случае = 1;
Интегральная – логическое значение, определяющее форму функции; если аргумент «интегральная» имеет значение ИСТИНА, функция НОРМРАСП возвращает интегральную функцию распределения; если этот аргумент имеет значение ЛОЖЬ, возвращается функция плотности распределения; в нашем случае = ЛОЖЬ.
Говоря о нормальном распределении, необходимо упомянуть о таком связанном с ним понятии, как стандартное отклонение. Очевидно, не все обладают интуитивным пониманием, что это такое, но поскольку стандартное отклонение можно заменить числом, рассчитанным по 90%-ному доверительному интервалу (смысл которого интуитивно понимают многие), я не буду здесь подробно на нем останавливаться. Рисунок 1 показывает, что в одном 90%-ном доверительном интервале насчитывается 3,29 стандартного отклонения, поэтому нам просто нужно будет сделать преобразование.
В нашем случае следует создать в электронной таблице генератор случайных чисел для каждого интервала значений. Начнем, например, с MS – экономии на материально-техническом обслуживании. Воспользуемся формулой Excel: =НОРМОБР(вероятность;среднее;стандартное_откл), где
Вероятность – вероятность, соответствующая нормальному распределению;
Среднее – среднее арифметическое распределения;
Стандартное_откл – стандартное отклонение распределения.
В нашем случае:
Среднее (медиана) = (Верхняя граница 90%-ного CI + Нижняя граница 90%-ного СI)/2;
Стандартное отклонение = (Верхняя граница 90%-ного CI – Нижняя граница 90%-ного СI)/3,29.
Для параметра MS формула имеет вид: =НОРМОБР(СЛЧИС();15;(20-10)/3,29), где
СЛЧИС – функция, генерирующая случайные числа в диапазоне от 0 до 1;
15 – среднее арифметическое диапазона MS;
(20-10)/3,29 = 3,04 – стандартное отклонение; напомню, что смысл стандартного отклонения в следующем: в интервал 3,29*Стандарт_откл, расположенный симметрично относительного среднего, попадает 90% всех значений случайной величины (в нашем случае MS)
Распределение величины экономии на материально-техническом обслуживании для 100 случайных нормально распределенных значений:
Рис. 2. Вероятность распределения MS по диапазонам значений; о том, как построить такое распределение с помощью сводной таблицы см. Вычисления в сводной таблице (в области значений) в Excel 2013
Поскольку мы использовали «лишь» 100 случайных значений, распределение получилось не таким уж и симметричным. Тем не менее, около 90% значений попали в диапазон экономии на MS от 10 до 20 долл. (если быть точным, то 91%).
Построим таблицу на основе доверительных интервалов параметров MS, LS, RMS и PL (рис. 3). Два последних столбца показывают результаты расчетов на основе данных других столбцов. В столбце «Общая экономия» показана годовая экономия, рассчитанная для каждой строки. Например, в случае реализации сценария 1 общая экономия составит (14,3 + 5,8 + 4,3) х 23 471 = 570 834 долл. Столбец «Достигается ли безубыточность?» вам на самом деле не нужен. Я включил его просто для информативности. Создадим в Excel 10 000 строк-сценариев.
Рис. 3. Расчет сценариев методом Монте-Карло в Excel
Чтобы оценить полученные результаты, можно использовать, например, сводную таблицу, которая позволяет подсчитать число сценариев в каждом 100-тысячном диапазоне. Затем вы строите график, отображающий результаты расчета (рис. 4). Этот график показывает, какая доля из 10 000 сценариев будут иметь годовую экономию в том или ином интервале значений. Например, около 3% сценариев дадут годовую экономию более 1М дол.
Рис. 4. Распределение общей экономии по диапазонам значений. По оси абсцисс отложены 100-тысячные диапазоны размера экономии, а по оси ординат доля сценариев, приходящихся на указанный диапазон
Из всех полученных значений годовой экономии примерно 15% будут меньше 400К дол. Это означает, что вероятность ущерба составляет 15%. Данное число и представляет содержательную оценку риска. Но риск не всегда сводится к возможности отрицательной доходности инвестиций. Оценивая размеры вещи, мы определяем ее высоту, массу, обхват и т.д. Точно так же существуют и несколько полезных показателей риска. Дальнейший анализ показывает: есть 4%-ная вероятность того, что завод вместо экономии будет терять ежегодно по 100К дол. Однако полное отсутствие доходов практически исключено. Вот что подразумевается под анализом риска – мы должны уметь рассчитывать вероятности ущерба разного масштаба. Если вы действительно измеряете риск, то должны делать именно это.
В некоторых ситуациях можно пойти более коротким путем. Если все распределения значений, с которыми мы работаем, будут нормальными и нам надо просто сложить интервалы этих значений (например, интервалы затрат и выгод) или вычесть их друг из друга, то можно обойтись и без моделирования методом Монте-Карло. Когда необходимо суммировать три вида экономии из нашего примера, следует провести простой расчет. Чтобы получить искомый интервал, используйте шесть шагов, перечисленных ниже:
1) вычтите среднее значение каждого интервала значений из его верхней границы; для экономии на материально-техническом обслуживании 20 – 15 = 5 (дол.), для экономии на трудозатратах – 5 дол. и для экономии на сырье и материалах – 3 дол.;
2) возведите в квадрат результаты первого шага 52 = 25 (дол.) и т.д.;
3) суммируйте результаты второго шага 25 + 25 + 9 = 59 (дол.);
4) извлеките квадратный корень из полученной суммы: получится 7,7 дол.;
5) сложите все средние значения: 15 + 3 + 6 = 24 (дол.);
6) прибавьте к сумме средних значений результат шага 4 и получите верхнюю границу диапазона: 24 + 7,7 = 31,7 дол.; вычтите из суммы средних значений результат шага 4 и получите нижнюю границу диапазона 24 – 7,7 = 16,3 дол.
Таким образом, 90%-ный доверительный интервал для суммы трех 90%-ных доверительных интервалов по каждому виду экономии составляет 16,3–31,7 дол.
Мы использовали следующее свойство: размах суммарного интервала равен квадратному корню из суммы квадратов размахов отдельных интервалов .
Иногда нечто похожее делают, суммируя все «оптимистические» значения верхней границы и «пессимистические» значения нижней границы интервала. В данном случае мы получили бы на основе наших трех 90%-ных доверительных интервалов суммарный интервал 11–37 дол. Этот интервал несколько шире, чем 16,3–31,7 дол. Когда такие расчеты выполняются при обосновании проекта с десятками переменных, расширение интервала становится чрезмерным, чтобы его игнорировать. Брать самые «оптимистические» значения для верхней границы и «пессимистические» для нижней – все равно что думать: бросив несколько игральных костей, мы во всех случаях получим только «1» или только «6». На самом же деле выпадет некое сочетание низких и высоких значений. Чрезмерное расширение интервала – распространенная ошибка, которая, несомненно, часто приводит к принятию необоснованных решений. В то же время описанный мной простой метод прекрасно работает, когда у нас есть несколько 90%-ных доверительных интервалов, которые необходимо суммировать.
Однако наша цель не только суммировать интервалы, но и умножить их на объем производства, значения которого также даны в виде диапазона. Простой метод суммирования годится только для вычитания или сложения интервалов значений.
Моделирование методом Монте-Карло требуется и тогда, когда не все распределения являются нормальными. Хотя другие типы распределений не входят в предмет данной книги, упомянем о двух из них — равномерном и бинарном (рис. 5, 6).
Рис. 5. Равномерное распределение (не идеальное, а построенное с помощью функции СЛЧИС в Excel)
Особенности:
- вероятность всех значений одинакова;
- распределение симметрично, без перекосов; медиана находится точно посредине между верхней и нижней границами интервала;
- значения за пределами интервала невозможны.
Для построения данного распределения в Excel была использована формула: СЛЧИС()*(UB – LB) + LB, где UB – верхняя граница; LB – нижняя граница; с последующим разбиением всех значений на диапазоны с помощью сводной таблицы.
Рис. 6. Бинарное распределение (распределение Бернулли)
Особенности:
- возможны только два значения;
- существует единственная вероятность одного значения (в данном случае 60%); вероятность другого значения равна единице минус вероятность первого значения
Для построения случайного распределения данного вида в Excel использовалась функция: =ЕСЛИ(СЛЧИС()
Мы разработаем симуляцию Монте-Карло с использованием Microsoft Excel и игра в кости. Моделирование Монте-Карло — математический численный метод, который использует случайные ничьи для выполнения вычислений и сложных проблем. Сегодня он широко используется и играет ключевую роль в различных областях, таких как финансы, физика, химия, экономика и многие другие.
Моделирование Монте-Карло
Метод Монте-Карло был изобретен Николаем Метрополисом в 1947 году и направлен на решение сложных проблем с использованием случайных и вероятностных методов. Термин «Монте-Карло» происходит от административного района Монако, широко известного как место, где европейские элиты играют в азартные игры. Мы используем метод Монте-Карло, когда проблема слишком сложна и сложна при непосредственном вычислении. Большое количество итераций позволяет моделировать нормальное распределение.
Метод моделирования методом Монте-Карло вычисляет вероятности для интегралов и решает уравнения в частных производных, тем самым вводя статистический подход к риску в вероятностном решении. Несмотря на то, что существует множество современных статистических инструментов для создания симуляций Монте-Карло, проще моделировать нормальный закон и единообразный закон с использованием Microsoft Excel и обходить математические основы.
Для моделирования Монте-Карло мы выделяем ряд ключевых переменных, которые контролируют и описывают результат эксперимента и назначают распределение вероятности после выполнения большого количества случайных выборок. Давайте возьмем игру в кости как модель.
Игра в кости
Вот как игра в кости играется:
• Игрок бросает три кости, которые имеют 6 сторон 3 раза.
• Если общее количество 3 бросков составляет 7 или 11, игрок выигрывает.
• Если общее количество 3 бросков: 3, 4, 5, 16, 17 или 18, проигрыватель проигрывает.
• Если общий результат — любой другой результат, игрок снова играет и повторно свертывает штамп.
• Когда игрок снова бросает кубик, игра продолжается таким же образом, за исключением того, что игрок выигрывает, когда сумма равна сумме, определенной в первом раунде.
Рекомендуется также использовать таблицу данных для генерации результатов. Более того, для подготовки моделирования методом Монте-Карло требуется 5 000 результатов.
Шаг 1: События прокатки в кости
Сначала мы разрабатываем ряд данных с результатами каждого из 3 кубиков для 50 рулонов. Для этого предлагается использовать функцию «RANDBETWEEN (1. 6)». Таким образом, каждый раз, когда мы нажимаем F9, мы генерируем новый набор результатов каротажа. Ячейка «Результат» — это сумма итогов трех рулонов.

Шаг 2: Диапазон результатов
Затем нам нужно разработать ряд данных для определения возможных результатов для первого раунда и последующих раундов. Ниже приведен диапазон данных с тремя столбцами.В первом столбце у нас есть числа от 1 до 18. Эти цифры представляют собой возможные результаты после того, как катятся кости 3 раза: максимум составляет 3 * 6 = 18. Вы заметите, что для ячеек 1 и 2 результаты N / A, так как невозможно получить 1 или 2, используя 3 кости. Минимальное значение равно 3.
Во втором столбце включены возможные выводы после первого раунда. Как указано в первоначальном заявлении, либо игрок выигрывает (выигрывает), либо проигрывает (проигрывает), либо повторяет его (Re-roll), в зависимости от результата (всего 3 кубика).

В третьей колонке регистрируются возможные выводы для последующих раундов. Мы можем достичь этих результатов, используя функцию «If. «Это гарантирует, что если полученный результат будет эквивалентен результату, полученному в первом раунде, мы выиграем, иначе мы будем следовать первоначальным правилам первоначальной игры, чтобы определить, будем ли мы повторно бросать кости.

Шаг 3: Выводы
На этом этапе мы определяем результат 50 кубиков. Первый вывод можно получить с помощью индексной функции. Эта функция выполняет поиск возможных результатов первого раунда, вывод, соответствующий полученному результату. Например, при получении 6, как это имеет место на рисунке ниже, мы снова играем.

Можно получить результаты других рулонов кости, используя функцию «Or» и функцию индекса, вложенную в функцию «If». Эта функция сообщает Excel: «Если предыдущий результат -« Выиграть или проиграть », перестаньте бросать кости, потому что как только мы выиграли или проиграли, мы закончили. В противном случае мы переходим к столбцу следующих возможных выводов, и мы определяем вывод результата.

…
Шаг 4: Количество рулонов кости
Теперь мы определяем количество бросков кубиков, необходимых до проигрыша или выигрыша. Для этого мы можем использовать функцию «Countif», которая требует, чтобы Excel подсчитывал результаты «Re-Roll» и добавлял номер 1 к ней. Он добавляет один, потому что у нас есть один дополнительный раунд, и мы получаем окончательный результат (выигрываем или проигрываем).

Шаг 5: Моделирование
Мы разрабатываем диапазон для отслеживания результатов различных симуляций. Для этого мы создадим три столбца. В первом столбце одна из приведенных цифр — 5 000. Во второй колонке мы будем искать результат после 50 кубиков. В третьем столбце, в заголовке столбца, мы будем искать количество бросков кубиков, прежде чем получить окончательный статус (выиграть или проиграть).

Затем мы создадим таблицу анализа чувствительности с использованием данных характеристик или таблицы данных таблицы (эта чувствительность будет вставлена во вторую таблицу и в третьи столбцы). В этом анализе чувствительности номера событий 1 — 5, 000 должны быть вставлены в ячейку A1 файла. Фактически, можно было выбрать любую пустую ячейку. Идея состоит в том, чтобы просто произвести перерасчет каждый раз и таким образом получить новые броски кубиков (результаты новых симуляций), не повредив формулы на месте.
Шаг 6: Вероятность
Мы можем, наконец, вычислить вероятности выигрыша и проигрыша. Мы делаем это с помощью функции «Countif».Формула подсчитывает количество «выигрышей» и «проиграет», а затем делит на общее количество событий, 5, 000, чтобы получить соответствующую долю одного и другого. Наконец, мы видим, что вероятность получить выигрыш составляет 73. 2%, а результат Lose — 26,8%.
