
This tutorial will help you set up and interpret a Principal Component Analysis (PCA) in Excel using the XLSTAT software.
Dataset for running a principal component analysis in Excel
The data are from the US Census Bureau and describe the changes in the population of 51 states between 2000 and 2001. The initial dataset has been transformed to rates per 1000 inhabitants, with the data for 2001 serving as the focus for the analysis. This dataset is also used in our tutorial.
Goal of this tutorial
Our goal with this PCA example is to analyze the correlations between the variables and to find out if the changes in population in some states are very different from the ones in other states.
What is Principal Component Analysis?
Principal Component Analysis is a very useful method to analyze numerical data structured in a M observations / N variables table. It allows to:
-
Quickly visualize and analyze correlations between the N variables,
-
Visualize and analyze the M observations (initially described by the N variables) on a low dimensional map, the optimal view for a variability criterion,
-
Build a set of P uncorrelated factors
The limits of Principal Component Analysis stem from the fact that it is a projection method, and sometimes the visualization can lead to false interpretations. There are however some tricks to avoid these pitfalls.
It is also important to note that PCA is an exploratory statistical tool and does not generally allow to test hypotheses. The advantage of this aspect is that PCA’s may be run several times with observations or variables being removed or added at every run, as long as those manipulations are justified in the interpretations.
How to set up a Principal Component Analysis in Excel using XLSTAT?
-
Open XLSTAT
-
Select the XLSTAT / Analyzing data / Principal components analysis command. The Principal Component Analysis dialog box will appear.
-
Select the data on the Excel sheet. In this example, the data start from the first row, so it is quicker and easier to use columns selection. This explains why the letters corresponding to the columns are displayed in the selection boxes.
-
Select Observations/variables in the Data format field because of the format of the input data.
-
Select Correlation in the PCA type field. The PCA type that will be used during the computations is the Correlation matrix, which corresponds to the Pearson correlation coefficient. Covariance matrices allocate more weight to variables with higher variances. Spearman’s correlations may be more appropriate when running the PCA on variables with different distributions.

-
In the Outputs tab, activate the option to display significant correlations in bold characters (Test significancy).
-
In the Charts tab, in order to display the labels on all charts, and to display all the observations (observations charts and biplots), uncheck the filtering option. If there is a lot of data, displaying the labels might slow down the global display of the results. Displaying all the observations might make the results unreadable. In these cases, filtering the observations to display is recommended.
-
Click OK to launch the computations.
-
Confirm the axes for which you want to display plots. In this example, the percentage of variability represented by the first two factors is not very high (67.72%); to avoid a misinterpretation of the results, we have decided to complement the results with a second chart on axes 1 and 3.


How to interpret the results of a Principal Component Analysis in Excel using XLSTAT?
How to interpret a PCA correlation matrix?
The first result to look at is the correlation matrix. We can see right away that the rates of people below and above 65 are negatively correlated (r = -1). Either of the two variables could have been removed without effect on the quality of the results. We can also see that the Net Domestic Migration has low correlation with the other variables, including the Net International migration. This means that U.S. nationals and non-nationals may be moving to a state for different sets of reasons.

How to interpret Eigenvalues in Principal Component Analysis?
The next table and the corresponding chart are related to a mathematical object, the eigenvalues, which reflect the quality of the projection from the N-dimensional initial table (N=7 in this example) to a lower number of dimensions. In this example, we can see that the first eigenvalue equals 3.567 and represents 51% of the total variability. This means that if we represent the data on only one axis, we will still be able to see % of the total variability of the data.
Each eigenvalue corresponds to a factor, and each factor to a one dimension. A factor is a linear combination of the initial variables, and all the factors are un-correlated (r=0). The eigenvalues and the corresponding factors are sorted by descending order of how much of the initial variability they represent (converted to %).
Broadly speaking, factor = PCA dimension = PCA axis


Ideally, the first two or three eigenvalues will correspond to a high % of the variance, ensuring us that the maps based on the first two or three factors are a good quality projection of the initial multi-dimensional table. In this example, the first two factors allow us to represent 67.72% of the initial variability of the data. This is a good result, but we’ll have to be careful when we interpret the maps as some information might be hidden in the next factors. We can see here that although we initially had 7 variables, the number of factors is 6. This is due to the two age variables, which are negatively correlated (-1). The number of «useful» dimensions has been automatically detected.
How to interpret results related to variables in PCA?
The first map is called the correlation circle (below on axes F1 and F2). It shows a projection of the initial variables in the factors space. When two variables are far from the center, then, if they are: Close to each other, they are significantly positively correlated (r close to 1); If they are orthogonal, they are not correlated (r close to 0); If they are on the opposite side of the center, then they are significantly negatively correlated (r close to -1).
When the variables are close to the center, some information is carried on other axes, and that any interpretation might be hazardous. For example, we might be tempted to interpret a correlation between the variables Net Domestic migration and Net International Migration although, in fact, there is none. This can be confirmed either by looking at the correlation matrix or by looking at the correlation circle on axes F1 and F3.

The correlation circle is useful in interpreting the meaning of the axes. In this example, the horizontal axis is linked with age and population renewal, and the vertical axis with domestic migration. These trends will be helpful in interpreting the next map. To confirm that a variable is well linked with an axis, take a look at the squared cosines table: the greater the squared cosine, the greater the link with the corresponding axis. The closer the squared cosine of a given variable is to zero, the more careful you have to be when interpreting the results in terms of trends on the corresponding axis. Looking at this table we can see that the trends for international migration would be best viewed on a F2/F3 map.

How to interpret results related to observations in PCA?
The next chart can be the ultimate goal of the Principal Component Analysis (PCA). It enables you to look at the observations on a two- dimensional map, and to identify trends. We can see that the demographics of Nevada and Florida are unique, as are the demographics of Utah and Alaska, two states that share common characteristics. Going back to the table, we can confirm that Utah and Alaska have a low population rate of people over age 65. Utah has the highest birth rate in the U.S., and Alaska ranks high as well.
 It is also possible to display biplots, which are simultaneous representations of variables and observations in the PCA space.
It is also possible to display biplots, which are simultaneous representations of variables and observations in the PCA space.
Click to view a 3D visualization on the first three axes generated by XLSTAT-3DPlot.
Note on the usage of Principal Component Analysis
Principal component analysis is often performed before a regression, to avoid using correlated variables, or before clustering the data, to have a better overview of the variables. The number of clusters might sometimes be a simple guess based on the maps. The above demographic data have also been used in the tutorial on hierarchical clustering. The «>65 pop» variable has been removed as its inclusion would double the weight of the age variables in the analysis.
Going further
Adding supplementary variables to the PCA
It is possible to add supplementary variables to the PCA after it has been computed. This may help increasing interpretation quality. In XLSTAT, those variables can be selected under the Suppl. Data tab of the PCA dialog box. Supplementary variables can be divided into two types:
-
Qualitative supplementary variables: they allow to color observations on the map according to the category they belong to. In this tutorial’s example, we could have added a column defining if a state is mostly republican or mostly democrat.
-
Quantitative supplementary variables: these variables can be added to see how they correlate with the group of variables that have been used to build the PCA. In the case where PCA is performed before a regression, the explanatory variables can be used to construct the PCA while the dependent variable can be added as a supplementary variable. This may help to roughly detect which explanatory variables could have the strongest effects on the dependent variable.
Running an Agglomerative Hierarchical Clustering (AHC) after a PCA
You can also launch an AHC by clicking on the button below the table of factor scores. An orange arrow allows you to go directly to the end of the table if it contains many variables.
 By clicking on this button, the AHC dialog box is then automatically configured and you just have to click on the OK button to launch the analysis.
By clicking on this button, the AHC dialog box is then automatically configured and you just have to click on the OK button to launch the analysis.
 Click here to see how to interpret the results of the AHC analysis.
Click here to see how to interpret the results of the AHC analysis.
Watch our video on PCA analysis
The following video will help you better understand PCA and its implementation in XLSTAT.

Was this article useful?
- Yes
- No
Метод главных компонент: определение, применение, пример расчета

Метод главных компонентов (английский — principal component analysis, PCA) упрощает сложность высокоразмерных данных, сохраняя тенденции и шаблоны. Он делает это, преобразуя данные в меньшие размеры, которые действуют, как резюме функций. Такие данные очень распространены в разных отраслях науки и техники, и возникают, когда для каждого образца измеряются несколько признаков, например, таких как экспрессия многих видов. Подобный тип данных представляет проблемы, вызванные повышенной частотой ошибок из-за множественной коррекции данных.
Метод похож на кластеризацию — находит шаблоны без ссылок и анализирует их, проверяя, взяты ли образцы из разных групп исследования, и имеют ли они существенные различия. Как и во всех статистических методах, его можно применить неправильно. Масштабирование переменных может привести к разным результатам анализа, и очень важно, чтобы оно не корректировалось, на предмет соответствия предыдущему значению данных.
Цели анализа компонентов
Основная цель метода — обнаружить и уменьшить размерность набора данных, определить новые значимые базовые переменные. Для этого предлагается использовать специальные инструменты, например, собрать многомерные данные в матрице данных TableOfReal, в которой строки связаны со случаями и столбцами переменных. Поэтому TableOfReal интерпретируется как векторы данных numberOfRows, каждый вектор которых имеет число элементов Columns.
Традиционно метод главных компонентов выполняется по ковариационной матрице или по корреляционной матрице, которые можно вычислить из матрицы данных. Ковариационная матрица содержит масштабированные суммы квадратов и кросс-произведений. Корреляционная матрица подобна ковариационной матрице, но в ней сначала переменные, то есть столбцы, были стандартизованы. Вначале придется стандартизировать данные, если дисперсии или единицы измерения переменных сильно отличаются. Чтобы выполнить анализ, выбирают матрицу данных TabelOfReal в списке объектов и даже нажимают перейти.
Это приведет к появлению нового объекта в списке объектов по методу главных компонент. Теперь можно составить график кривых собственных значений, чтобы получить представление о важности каждого. И также программа может предложить действие: получить долю дисперсии или проверить равенство числа собственных значений и получить их равенство. Поскольку компоненты получены путем решения конкретной задачи оптимизации, у них есть некоторые «встроенные» свойства, например, максимальная изменчивость. Кроме того, существует ряд других их свойств, которые могут обеспечить факторный анализ:
- дисперсию каждого, при этом доля полной дисперсии исходных переменных задается собственными значениями;
- вычисления оценки, которые иллюстрируют значение каждого компонента при наблюдении;
- получение нагрузок, которые описывают корреляцию между каждым компонентом и каждой переменной;
- корреляцию между исходными переменными, воспроизведенными с помощью р–компонента;
- воспроизведения исходных данных могут быть воспроизведены с р–компонентов;
- «поворот» компонентов, чтобы повысить их интерпретируемость.
Выбор количества точек хранения
Существует два способа выбрать необходимое количество компонентов для хранения. Оба метода основаны на отношениях между собственными значениями. Для этого рекомендуется построить график значений. Если точки на графике имеют тенденцию выравниваться и достаточно близки к нулю, то их можно игнорировать. Ограничивают количество компонентов до числа, на которое приходится определенная доля общей дисперсии. Например, если пользователя удовлетворяет 95% от общей дисперсии — получают количество компонентов (VAF) 0.95.
Основные компоненты получают проектированием многомерного статистического анализа метода главных компонентов datavectors на пространстве собственных векторов. Это можно сделать двумя способами — непосредственно из TableOfReal без предварительного формирования PCA объекта и затем можно отобразить конфигурацию или ее номера. Выбрать объект и TableOfReal вместе и «Конфигурация», таким образом, выполняется анализ в собственном окружении компонентов.
Если стартовая точка оказывается симметричной матрицей, например, ковариационной, сначала выполняют сокращение до формы, а затем алгоритм QL с неявными сдвигами. Если же наоборот и отправная точка является матрица данных, то нельзя формировать матрицу с суммами квадратов. Вместо этого, переходят от численно более стабильного способа, и образуют разложения по сингулярным значениям. Тогда матрица будет содержать собственные векторы, а квадратные диагональные элементы — собственные значения.
Виды линейных комбинаций
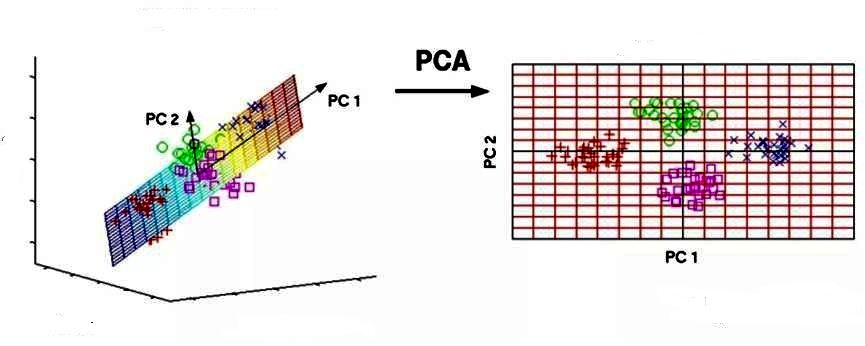
Основным компонентом является нормализованная линейная комбинация исходных предикторов в наборе данных по методу главных компонент для чайников. На изображении выше PC1 и PC2 являются основными компонентами. Допустим, есть ряд предикторов, как X1, X2. Xp.
Основной компонент можно записать в виде: Z1 = 11X1 + 21X2 + 31X3 + . + p1Xp
- Z1 — является первым главным компонентом;
- p1 — является вектором нагрузки, состоящим из нагрузок (1, 2.) первого основного компонента.
Нагрузки ограничены суммой квадрата равного 1. Это связано с тем, что большая величина нагрузок может привести к большой дисперсии. Он также определяет направление основной компоненты (Z1), по которой данные больше всего различаются. Это приводит к тому, что линия в пространстве р-мер, ближе всего к n-наблюдениям.
Близость измеряется с использованием среднеквадратичного евклидова расстояния. X1..Xp являются нормированными предикторами. Нормализованные предикторы имеют среднее значение, равное нулю, а стандартное отклонение равно единице. Следовательно, первый главный компонент — это линейная комбинация исходных предикторных переменных, которая фиксирует максимальную дисперсию в наборе данных. Он определяет направление наибольшей изменчивости в данных. Чем больше изменчивость, зафиксированная в первом компоненте, тем больше информация, полученная им. Ни один другой не может иметь изменчивость выше первого основного.
Первый основной компонент приводит к строке, которая ближе всего к данным и сводит к минимуму сумму квадрата расстояния между точкой данных и линией. Второй главный компонент (Z2) также представляет собой линейную комбинацию исходных предикторов, которая фиксирует оставшуюся дисперсию в наборе данных и некоррелирована Z1. Другими словами, корреляция между первым и вторым компонентами должна равняться нулю. Он может быть представлен как: Z2 = 12X1 + 22X2 + 32X3 + . + p2Xp.
Если они некоррелированы, их направления должны быть ортогональными.
Процесс прогнозирования тестовых данных
После того как вычислены главные компоненты начинают процесс прогнозирования тестовых данных с их использованием. Процесс метода главных компонент для чайников прост.

Например, необходимо сделать преобразование в тестовый набор, включая функцию центра и масштабирования в языке R (вер.3.4.2) и его библиотеке rvest. R — свободный язык программирования для статистических вычислений и графики. Он был реконструирован в 1992 году для решения статистических задач пользователями. Это полный процесс моделирования после извлечения PCA.
Набор данных Python:

Для реализации PCA в python импортируют данные из библиотеки sklearn. Интерпретация остается такой же, как и пользователей R. Только набор данных, используемый для Python, представляет собой очищенную версию, в которой отсутствуют вмененные недостающие значения, а категориальные переменные преобразуются в числовые. Процесс моделирования остается таким же, как описано выше для пользователей R. Метод главных компонент, пример расчета:

Спектральное разложение
Идея метода основного компонента заключается в приближении этого выражения для выполнения факторного анализа. Вместо суммирования от 1 до p теперь суммируются от 1 до m, игнорируя последние p-m членов в сумме и получая третье выражение. Можно переписать это, как показано в выражении, которое используется для определения матрицы факторных нагрузок L, что дает окончательное выражение в матричной нотации. Если используются стандартизованные измерения, заменяют S на матрицу корреляционной выборки R.

Это формирует матрицу L фактор-нагрузки в факторном анализе и сопровождается транспонированной L. Для оценки конкретных дисперсий фактор-модель для матрицы дисперсии-ковариации.
Теперь будет равна матрице дисперсии-ковариации минус LL ‘ .
Основные компоненты определяются по формуле
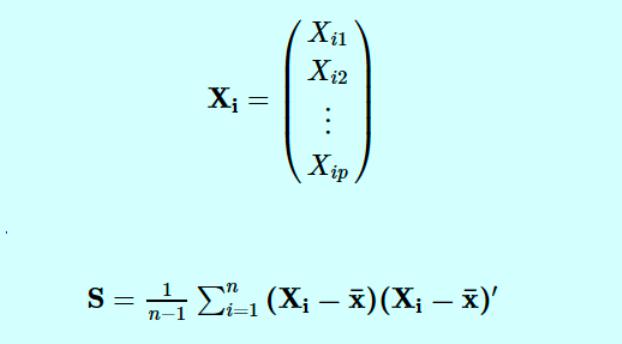
- Xi — вектор наблюдений для i-го субъекта.
- S обозначает нашу выборочную дисперсионно-ковариационную матрицу.
Тогда p собственные значения для этой матрицы ковариации дисперсии, а также соответствующих собственных векторов для этой матрицы.
Собственные значения S:λ^1, λ^2, . , λ^п.
Собственные векторы S:е^1, e^2, . , e^п.
Анализ Excel в биоинформатике
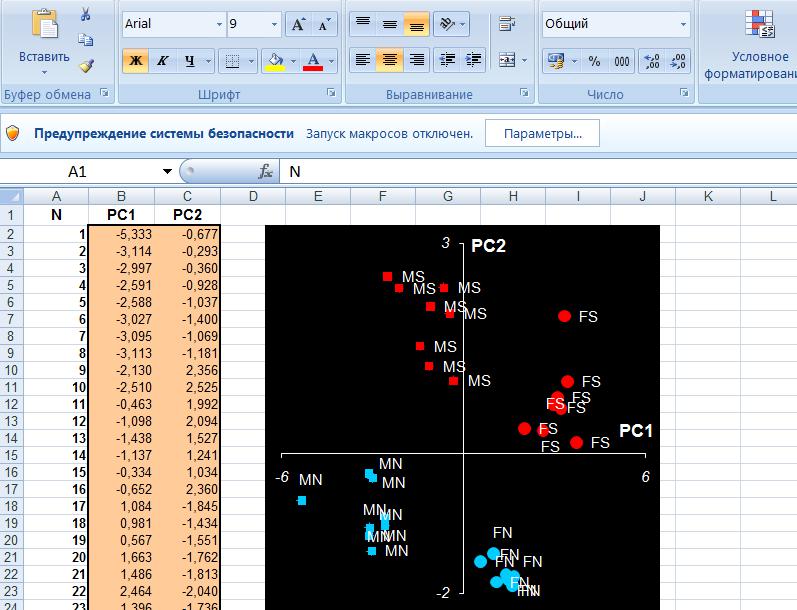
Анализ PCA — это мощный и популярный метод многомерного анализа, который позволяет исследовать многомерные наборы данных с количественными переменными. По этой методике широко используется метод главных компонент в биоинформатике, маркетинге, социологии и многих других областях. XLSTAT предоставляет полную и гибкую функцию для изучения данных непосредственно в Excel и предлагает несколько стандартных и расширенных опций, которые позволят получить глубокое представление о пользовательских данных.
Можно запустить программу на необработанных данных или на матрицах различий, добавить дополнительные переменные или наблюдения, отфильтровать переменные в соответствии с различными критериями для оптимизации чтения карт. Кроме того, можно выполнять повороты. Легко настраивать корреляционный круг, график наблюдений в качестве стандартных диаграмм Excel. Достаточно перенести данные из отчета о результатах, чтобы использовать их в анализе.
XLSTAT предлагает несколько методов обработки данных, которые будут использоваться на входных данных до вычислений основного компонента:
- Pearson, классический PCA, который автоматически стандартизирует данные для вычислений, чтобы избежать раздутого влияния переменных с большими отклонениями от результата.
- Ковариация, которая работает с нестандартными отклонениями.
- Полихорические, для порядковых данных.
Примеры анализа данных размерностей
Можно рассмотреть метод главных компонентов на примере выполнения симметричной корреляционной или ковариационной матрицы. Это означает, что матрица должна быть числовой и иметь стандартизованные данные. Допустим, есть набор данных размерностью 300 (n) × 50 (p). Где n — представляет количество наблюдений, а p — число предикторов.
Поскольку имеется большой p = 50, может быть p(p-1)/2 диаграмма рассеяния. В этом случае было бы хорошим подходом выбрать подмножество предиктора p (p 21 сентября, 2018
Содержание
В этом пособии рассказывается о методе главных компонент (Principal Component Analysis, PCA) – базовом подходе, применяемом в хемометрике для решения разнообразных задач. Текст ориентирован, прежде всего, на специалистов в области анализа экспериментальных данных: химиков, физиков, биологов, и т.д. Он может служить пособием для исследователей, начинающих изучение этого вопроса. Продолжить изучение вопроса можно с помощью указанной Литературы
В пособии интенсивно используются понятия и методы матричной алгебры – вектор, матрица, и т.п. Читателям, которые плохо знакомы с этим аппаратом, рекомендуется изучить, или, хотя бы просмотреть, пособие «Матрицы и векторы».
Изложение иллюстрируется примерами, выполненными в рабочей книге Excel «People.xls» которая сопровождает этот документ . Эта книга может работать без использования Chemometrics Add-In.
Ссылки на примеры помещены в текст как объекты Excel. По форме, эти примеры имеют абстрактный, модельный характер, однако, по сути, они тесно связаны с задачами, встречающимися на практике. Предполагается, что читатель имеет базовые навыки работы в среде Excel, умеет проводить простейшие матричные вычисления с использованием функций листа, таких как MMULT , TREND . Освежить эти знания можно с помощью пособия Матричные операции в Excel.
1. Базовые сведения
1.1. Данные
Метод главных компонент применяется к данным, записанным в виде матрицы X – прямоугольной таблицы чисел размерностью I строк и J столбцов.

Рис. 1 Матрица данных
Традиционно строки этой матрицы называются образцами. Они нумеруются индексом i, меняющимся от 1 до I. Столбцы называются переменными, и они нумеруются индексом j= 1, …, J.
Цель PCA – извлечение из этих данных нужной информации. Что является информацией, зависит от сути решаемой задачи. Данные могут содержать нужную нам информацию, они даже могут быть избыточными. Однако, в некоторых случаях, информации в данных может не быть совсем.
Размерность данных – число образцов и переменных – имеет большое значение для успешной добычи информации. Лишних данных не бывает – лучше, когда их много, чем мало. На практике это означает, что если получен спектр какого–то образца, то не нужно выбрасывать все точки, кроме нескольких характерных длин волн, а использовать их все, или, по крайней мере, значительный кусок.
Данные всегда (или почти всегда) содержат в себе нежелательную составляющую, называемую шумом. Природа этого шума может быть различной, но, во многих случаях, шум – это та часть данных, которая не содержит искомой информации. Что считать шумом, а что – информацией, всегда решается с учетом поставленных целей и методов, используемых для ее достижения.
Шум и избыточность в данных обязательно проявляют себя через корреляционные связи между переменными. Погрешности в данных могут привести к появлению не систематических, а случайных связей между переменными. Понятие эффективного (химического) ранга и скрытых, латентных переменных, число которых равно этому рангу, является важнейшим понятием в PCA
1.2. Интуитивный подход
Постараемся передать суть метода главных компонент, используя интуитивно–понятную геометрическую интерпретацию. Начнем с простейшего случая, когда имеются только две переменные x1 и x2. Такие данные легко изобразить на плоскости (Рис. 2).

Рис. 2 Графическое представление двумерных данных
Каждой строке исходной таблицы (т.е. образцу) соответствует точка на плоскости с соответствующими координатами. Они обозначены пустыми кружками на Рис. 2. Проведем через них прямую, так, чтобы вдоль нее происходило максимальное изменение данных. На рисунке эта прямая выделена синим цветом; она называется первой главной компонентой – PC1. Затем спроецируем все исходные точки на эту ось. Получившиеся точки закрашены красным цветом. Теперь мы можем предположить, что на самом деле все наши экспериментальные точки и должны были лежать на этой новой оси. Просто какие–то неведомые силы отклонили их от правильного, идеального положения, а мы вернули их на место. Тогда все отклонения от новой оси можно считать шумом, т.е. ненужной нам информацией. Правда, мы должны быть в этом уверены. Проверить шум ли это, или все еще важная часть данных, можно поступив с этими остатками так же, как мы поступили с исходными данными – найти в них ось максимальных изменений. Она называется второй главной компонентой (PC2). И так надо действовать, до тех пор, пока шум уже не станет действительно шумом, т.е. случайным хаотическим набором величин.
В общем, многомерном случае, процесс выделения главных компонент происходит так:
- Ищется центр облака данных, и туда переносится новое начало координат – это нулевая главная компонента (PC0)
- Выбирается направление максимального изменения данных – это первая главная компонента (PC1)
- Если данные описаны не полностью (шум велик), то выбирается еще одно направление (PC2) – перпендикулярное к первому, так чтобы описать оставшееся изменение в данных и т.д.


Рис. 3 Графическое представление метода главных компонент
В результате, мы переходим от большого количества переменных к новому представлению, размерность которого значительно меньше. Часто удается упростить данные на порядки: от 1000 переменных перейти всего к двум. При этом ничего не выбрасывается – все переменные учитываются. В то же время несущественная для сути дела часть данных отделяется, превращается в шум. Найденные главные компоненты и дают нам искомые скрытые переменные, управляющие устройством данных.
1.3. Понижение размерности
Суть метода главных компонент – это существенное понижение размерности данных. Исходная матрица X заменяется двумя новыми матрицами T и P, размерность которых, A, меньше, чем число переменных (столбцов) J у исходной матрицы X

Рис. 4 Декомпозиция матрицы X
Вторая размерность – число образцов (строк) I сохраняется. Если декомпозиция выполнена правильно – размерность A выбрана верно, то матрица T несет в себе столько же информации, сколько ее было в начале, в матрице X. При этом матрица T меньше, и, стало быть, проще, чем X.
2. Метод главных компонент
2.1. Формальное описание
Пусть имеется матрица переменных X размерностью (I × J), где I – число образцов (строк), а J – это число независимых переменных (столбцов), которых, как правило, много (J>>1). В методе главных компонент используются новые, формальные переменные ta (a=1,…A), являющиеся линейной комбинацией исходных переменных xj (j=1,…J)
ta=pa1x1+… + paJxJ
С помощью этих новых переменных матрица X разлагается в произведение двух матриц T и P –

Матрица T называется матрицей счетов (scores). Ее размерность (I × A).
Матрица P называется матрицей нагрузок (loadings). Ее размерность (J × A ).
E – это матрица остатков, размерностью (I × J).

Рис. 5 Разложение по главным компонентам
Новые переменные ta называются главными компонентами (Principal Components), поэтому и сам метод называется методом главных компонент (PCA). Число столбцов – ta в матрице T, и pa в матрице P, равно A, которое называется числом главных компонент (PC). Эта величина заведомо меньше числа переменных J и числа образцов I.
Важным свойством PCA является ортогональность (независимость) главных компонент. Поэтому матрица счетов T не перестраивается при увеличении числа компонент, а к ней просто прибавляется еще один столбец – соответствующий новому направлению. Тоже происходит и с матрицей нагрузок P.
2.2. Алгоритм
Чаще всего для построения PCA счетов и нагрузок, используется рекуррентный алгоритм NIPALS, который на каждом шагу вычисляет одну компоненту. Сначала исходная матрица X преобразуется (как минимум – центрируется; см. раздел 2.12) и превращается в матрицу E0, a=0. Далее применяют следующий алгоритм.
После вычисления очередной (a-ой) компоненты, полагаем ta=t и pa=p. Для получения следующей компоненты надо вычислить остатки Ea+1 = Ea – t p t и применить к ним тот же алгоритм, заменив индекс a на a+1. Программа для реализации PCA в среде MatLab приведена в пособии MatLab. Руководство для начинающих .
В этом пособии для построения PCA используется специальная надстройка для программы Excel (Add–In) Chemometrics.xla. Она дополняет список стандартных функций Excel и позволяет проводить PCA разложение на листах рабочей книги. Подробности об этой программе можно прочитать в пособии Проекционные методы в системе Excel.
После того, как построено пространство из главных компонент, новые образцы Xnew могут быть на него спроецированы, иными словами – определены матрицы их счетов Tnew. В методе PCA это делается очень просто
Tnew.=. Xnew P
2.3. PCA и SVD
Метод главных компонент тесно связан с другим разложением – по сингулярным значениям, SVD. В последнем случае исходная матрица X разлагается в произведение трех матриц
Здесь U – матрица, образованная ортонормированными собственными векторами ur матрицы XX t , соответствующим значениям λr;
V– матрица, образованная ортонормированными собственными векторами vr матрицы X t X;
S – положительно определенная диагональная матрица, элементами которой являются сингулярные значения σ 1 ≥. ≥σ R ≥0 равные квадратным корням из собственных значений λr

Связь между PCA и SVD определяется следующими простыми соотношениями
2.4. Счета
Матрица счетов T дает нам проекции исходных образцов (J –мерных векторов x1,…,xI) на подпространство главных компонент (A-мерное). Строки t1,…,tI матрицы T – это координаты образцов в новой системе координат. Столбцы t1,…,tA матрицы T – ортогональны и представляют проекции всех образцов на одну новую координатную ось.
При исследовании данных методом PCA, особое внимание уделяется графикам счетов. Они несут в себе информацию, полезную для понимания того, как устроены данные. На графике счетов каждый образец изображается в координатах (ti, tj), чаще всего – (t1, t2), обозначаемых PC1 и PC2. Близость двух точек означает их схожесть, т.е. положительную корреляцию. Точки, расположенные под прямым углом, являются некоррелироваными, а расположенные диаметрально противоположно – имеют отрицательную корреляцию.


Рис.6 График счетов
Подробнее о том, как из графиков счетов извлекается полезная информация, будет рассказано в примере.
Для матрицы счетов имеют место следующие соотношения –
где величины λ 1 ≥. ≥λ A ≥0 – это собственные значения. Они характеризуют важность каждой компоненты

Нулевое собственное значение λ0 определяется как сумма всех собственных значений, т.е.

Для вычисления PCA- счетов в надстройке Chemometrics Add-In используется функция ScoresPCA .
2.5. Нагрузки
Матрица нагрузок P – это матрица перехода из исходного пространства переменных x1, …xJ (J-мерного) в пространство главных компонент (A-мерное). Каждая строка матрицы P состоит из коэффициентов, связывающих переменные t и x (1). Например, a-я строка – это проекция всех переменных x1, …xJ на a-ю ось главных компонент. Каждый столбец P – это проекция соответствующей переменной xj на новую систему координат.


Рис.7 График нагрузок
График нагрузок применяется для исследования роли переменных. На этом графике каждая переменная xj отображается точкой в координатах (pi, pj), например (p1, p2). Анализируя его аналогично графику счетов, можно понять, какие переменные связаны, а какие независимы. Совместное исследование парных графиков счетов и нагрузок, также может дать много полезной информации о данных.
В методе главных компонент нагрузки – это ортогональные нормированные вектора, т.е.
Для вычисления PCA- нагрузок в надстройке Chemometrics Add-In используется функция Loadings PCA .
2.6. Данные специального вида
Результат моделирования методом главных компонент не зависит от порядка, в котором следуют образцы и/или переменные. Иными словами строки и столбцы в исходной матрице X можно переставить, но ничего принципиально не изменится. Однако, в некоторых случаях, сохранять и отслеживать этот порядок очень полезно – это позволяет лучше понять устройство моделируемых данных.

Рис. 8 Данные ВЭЖХ–ДДМ
Рассмотрим простой пример – моделирование данных, полученных методом высокоэффективной жидкостной хроматографией с детектированием на диодной матрице (ВЭЖХ–ДДМ). Данные представляются матрицей, размерностью 30 образцов (I) на 28 переменных (J). Образцы соответствуют временам удерживания от 0 до 30 с, а переменные – длинам волн от 220 до 350 нм, на которых происходит детектирование. Данные ВЭЖХ–ДДМ представлены на Рис 8.
Эти данные хорошо моделируются методом PCA с двумя главными компонентами. Ясно, что в этом примере нам важен порядок, в котором идут образцы и переменные – он задается естественным ходом времени и спектральным диапазоном. Полученные счета и нагрузки полезно изобразить на графиках в зависимости от соответствующего параметра – счета от времени, а нагрузки от длины волны. (см. Рис 9)


Рис. 9 Графики счетов и нагрузок для данных ВЭЖХ–ДДМ
Подробнее этот пример разобран в пособии Разрешение многомерных кривых .
2.7. Погрешности
PCA декомпозиция матрицы X является последовательным, итеративным процессом, который можно оборвать на любом шаге a=A. Получившаяся матрица

вообще говоря, отличается от матрицы X. Разница между ними

называется матрицей остатков.
Рассмотрим геометрическую интерпретацию остатков. Каждый исходный образец xi (строка в матрице X) можно представить как вектор в J– мерном пространстве с координатами


Рис. 10 Геометрия PCA
PCA проецирует его в вектор, лежащий в пространстве главных компонент, ti=(ti1, ti2, …tiA) размерностью A. В исходном пространстве этот же вектор ti имеет координаты

Разница между исходным вектором и его проекцией является вектором остатков

Он образует i–ю строку в матрице остатков E.

Рис.11 Вычисление остатков
Исследуя остатки можно понять, как устроены данные и хорошо ли они описываются PCA моделью.
Для вычисления PCA- остатков можно использовать приемы, описанные в пособии Расширение возможностей Chemometrics Add-In.

определяет квадрат отклонения исходного вектора xi от его проекции на пространство PC. Чем оно меньше, тем лучше приближается i–ый образец.
Эта же величина, деленная на число переменных

Среднее (для всех образцов) расстояние v0 вычисляется как

Оценка общая (для всех образцов) дисперсии вычисляется так –

2.8. Проверка
В случае, когда PCA модель предназначена для предсказания или для классификации, а не для простого исследования данных, такая модель нуждается в подтверждении (валидации). При проверке методом тест–валидации исходный массив данных состоит из двух независимо полученных наборов, каждый из которых является достаточно представительным. Первый набор, называемый обучающим, используется для моделирования. Второй набор, называемый проверочным, служит только для проверки модели. Построенная модель применяется к данным из проверочного набора, и полученные результаты сравниваются с проверочными значениями. Таким образом принимается решение о правильности, точности моделирования.

Рис.12 Обучающий и проверочный наборы
В некоторых случаях объем данных слишком мал для такой проверки. Тогда применяют другой метод – перекрестной проверки (кросс–валидация), о котором можно прочитать здесь.
Используется также проверка методом коррекции размахом, суть которой предлагается изучить самостоятельно.
2.9. «Качество» декомпозиции
Результатом PCA моделирования являются величины  – оценки, найденные по модели, построенной на обучающем наборе Xc. Результатом проверки служат величины
– оценки, найденные по модели, построенной на обучающем наборе Xc. Результатом проверки служат величины  – оценки проверочных значений Xt, вычисленные по той же модели, но как новые образцы (3). Отклонение оценки от проверочного значения вычисляют как матрицу остатков: в обучении
– оценки проверочных значений Xt, вычисленные по той же модели, но как новые образцы (3). Отклонение оценки от проверочного значения вычисляют как матрицу остатков: в обучении
 ,
,
 .
.
Следующие величины характеризуют «качество» моделирования в среднем.
Полная дисперсия остатков в обучении (TRVC) и в проверке (TRVP) –


Полная дисперсия выражается в тех же единицах (точнее их квадратах), что и исходные величины X.
Объясненная дисперсия остатков в обучении (ERVC) и в проверке (ERVP)


Объясненная дисперсия – это относительная величина. При ее вычислении используется естественная нормировка – сумма квадратов всех исходных величин xij. Обычно она выражается в процентах или в долях единицы. Во всех этих формулах величины eij – это элементы матриц Ec или Et. Для характеристик, наименование которых оканчивается на C (например, TRVC), используется матрица Ec (обучение), а для тех, которые оканчиваются на P (например, TRVP), берется матрица Et (проверка).
2.10. Выбор числа главных компонент
Как уже отмечалось выше, метод главных компонент – это итерационная процедура, в которой новые компоненты добавляются последовательно, одна за другой. Важно знать, когда остановить этот процесс, т.е. как определить правильное число главных компонент, A. Если это число слишком мало, то описание данных будет не полным. С другой стороны, избыточное число главных компонент приводит к переоценке, т.е. к ситуации, когда моделируется шум, а не содержательная информация.
Для выбора значения числа главных компонент обычно используется график, на котором объясненная дисперсия (ERV) изображается в зависимости от числа PC. Пример такого графика приведен на Рис. 13.

Рис. 13 Выбор числа PC
Из этого графика видно, что правильное число PC – это 3 или 4. Три компоненты объясняют 95%, а четыре 98% исходной вариации. Окончательное решение о величине A можно принять только после содержательного анализа данных.
Другим полезным инструментом является график, на котором изображаются собственные значения (4) в зависимости от числа PC. Пример показан на Рис.14.

Рис. 14 График собственных значений
Из этого рисунка опять видно, что для a=3 происходит резкое изменение формы графика – излом. Поэтому верное число PC – это три или четыре.
2.11. Неединственность PCA
Разложение по методу главных компонент

не является единственным. Вместо матриц T и P можно использовать другие матрицы  и
и  , которые дадут аналогичную декомпозицию
, которые дадут аналогичную декомпозицию

с той же матрицей ошибок E. Простейший пример – это одновременное изменение знаков у соответствующих компонент векторов ta и pa, при котором произведение

остается неизменным. Алгоритм NIPALS дает именно такой результат – с точностью до знака, поэтому его реализация в разных программах может приводить к расхождениям в направлениях главных компонент.
Более сложный случай – это одновременное вращение матриц T и P. Пусть R – это ортогональная матрица вращения размерностью A × A , т.е такая матрица, что R t =R –1 . Тогда

Заметим, что новые матрицы счетов и нагрузок сохраняют все свойства старых,
 .
.
Это свойство PCA называется вращательной неопределенностью. Оно интенсивно используется при решении задач разделения кривых, в частности методом прокрустова вращения. Если отказаться от условий ортогональности главных компонент, то декомпозиция матрицы станет еще более общей. Пусть теперь R – это произвольная невырожденная матрица размерностью A × A . Тогда

Эти матрицы счетов и нагрузок уже не удовлетворяют условию ортогональности и нормирования. Зато они могут состоять только из неотрицательных элементов, а также подчиняться другим требованиям, накладываемым при решении задач разделения сигналов.
2.12. Подготовка данных
Во многих случаях, перед применением PCA, исходные данные нужно предварительно подготовить: отцентрировать и/или отнормировать. Эти преобразования проводятся по столбцам – переменным.
Центрирование – это вычитание из каждого столбца xj среднего (по столбцу) значения
 .
.
Центрирование необходимо потому, что оригинальная PCA модель (2) не содержит свободного члена.
Второе простейшее преобразование данных – это нормирование. Это преобразование выравнивает вклад разных переменных в PCA модель. При этом преобразовании каждый столбец xj делится на свое стандартное отклонение.

Комбинация центрирования и нормирования по столбцам называется автошкалированием.

Любое преобразование данных – центрирование, нормирование, и т.п. – всегда делается сначала на обучающем наборе. По этому набору вычисляются значения mj и sj, которые затем применяются и к обучающему, и к проверочному набору.
В надстройке Chemometrics Add In подготовка данных проводится автоматически. Если подготовку нужно провести вручную, то для нее можно использовать стандартные функции листа или специальную пользовательскую функцию.
В задачах, где структура исходных данных X априори предполагает однородность и гомоскедастичность, подготовка данных не только не нужна, но и вредна. Именно такой случай представляют ВЭЖХ–ДДМ данные, рассмотренные в пособии Разрешение многомерных кривых.
2.1 3 . Размах и отклонение
При заданном числе главных компонент A, величина

называется размахом (leverage). Эта величина равна квадрату расстояния Махаланобиса от центра модели до i–го образца в пространстве счетов, поэтому размах характеризует как далеко находится каждый образец в гиперплоскости главных компонент.
Для размаха имеет место соотношение

которое выполняется тождественно – по построению PCA.
Другой важной характеристикой PCA модели является отклонение v i , которое вычисляется как сумма квадратов остатков (6) – квадрат эвклидова расстояния от плоскости главных компонент до объекта i.
Две эти величины: hi и vi определяют положение объекта (образца) относительно имеющейся PCA модели. Слишком большие значения размаха и/или отклонения свидетельствуют об особенности такого объекта, который может быть экстремальным или выпадающим образцом.
Анализ величин hi и vi составляет основу SIMCA – метода классификации с обучением.
3. Люди и страны
3.1. Пример
Метод главных компонент иллюстрируется примером, помещенным в файл People.xls.
Этот файл включает в себя следующие листы:
Layout: схемы, объясняющая имена массивов, используемых в примере
Data: данные, используемые в примере.
MVA: PCA декомпозиция, выполненная с помощью надстройки Chemometrics.xla
PCA: копия всех результатов PCA не привязанная к надстройке Chemometrics.xla
Scores1–2: анализ младших счетов PC1–PC2
Scores3–4: анализ старших счетов PC3–PC4
3.2. Данные
Анализ базируется на данных европейского демографического исследования, опубликованных в книге К. Эсбенсена.
По причинам дидактического характера используется лишь небольшой набор из 32 человек, из которых 16 представляют Северную Европу (Скандинавия) и столько же – Южную (Средиземноморье). Для баланса выбрано одинаковое количество мужчин и женщин – по 16 человек. Люди характеризуются двенадцатью переменными, перечисленными в Табл. 1.
Табл. 1 Переменные, использованные в демографическом анализе
| Height | Рост: в сантиметрах |
| Weight | Вес: в килограммах |
| Hair | Волосы: короткие: –1, или длинные: +1 |
| Shoes | Обувь: размер по европейскому стандарту |
| Age | Возраст: в годах |
| Income | Доход: в тысячах евро в год |
| Beer | Пиво: потребление в литрах в год |
| Wine | Вино: потребление в литрах в год |
| Sex | Пол: мужской: –1, или женский: +1 |
| Strength | Сила: индекс, основанный на проверке физических способностей |
| Region | Регион: север : –1, или юг: +1 |
| IQ | Коэффициент интеллекта, измеряемый по стандартному тесту |
Заметим, что такие переменные, как Sex, Hair и Region имеют дискретный характер с двумя возможными значениями: –1 или +1, тогда как остальные девять переменных могут принимать непрерывные числовые значения.

Рис. 15 Исходные данные в примере People
3.3. Исследование данных
Прежде всего, любопытно посмотреть на графиках, как связаны между собой все эти переменные. Зависит ли рост (Height ) от веса (Weight)? Отличаются ли женщины от мужчин в потреблении вина (Wine)? Связан ли доход (Income) с возрастом (Age)? Зависит ли вес (Weight) от потребления пива (Beer)?




Рис. 16 Связи между переменными в примере People.
Женщины (F) обозначены кружками ● и ● , а мужчины (M) – квадратами ■ и ■ .
Север (N) представлен голубым ■ , а юг (S) – красным цветом ● .
Некоторые из этих зависимостей показаны на Рис.16. Для наглядности на всех графиках использованы одни и те же обозначения: женщины (F) показаны кружками, мужчины (M) – квадратами, север (N) представлен голубым, а юг (S) – красным цветом.
Связь между весом (Weight) и ростом (Height) показана на Рис.16a. Очевидна, прямая (положительная) пропорциональность. Учитывая маркировку точек, можно заметить также, что мужчины (M) в большинстве своем тяжелее и выше женщин (F).
На Рис. 16b показана другая пара переменных: вес (Weight) и пиво (Beer). Здесь, помимо очевидных фактов, что большие люди пьют больше, а женщины – меньше, чем мужчины, можно заметить еще две отдельные группы – южан и северян. Первые пьют меньше пива при том же весе.
Эти же группы заметны и на Рис.16c, где показана зависимость между потреблением вина (Wine) и пива (Beer). Из него видно, что связь между этими переменными отрицательна – чем больше потребляется пива, тем меньше вина. На юге пьют больше вина, а на севере – пива. Интересно, что в обеих группах женщины располагаются слева, но не ниже по отношению к мужчинам. Это означает, что, потребляя меньше пива, прекрасный пол не уступает в вине.
Последний график на Рис. 16d показывает, как связаны возраст (Age) и доход (Income). Легко видеть, что даже в этом сравнительно небольшом наборе данных есть переменные, как с положительной, так и с отрицательной корреляцией.
Можно ли построить графики для всех пар переменных выборки? Вряд ли. Проблема состоит в том, что для 12 переменных существует 12(12–1)/2=66 таких комбинаций.
3.4. Подготовка данных
Перед тем, как подвергнуть данные анализу методом главных компонент, их надо подготовить. Простой статистический расчет показывает, что они нуждаются в автошкалировании (См. Рис. 17)

Рис. 17 Средние значения и СКО для переменных в примере People.
Средние значения по многим переменным отличаются от нуля. Кроме того, среднеквадратичные отклонения сильно разнятся. После автошкалирования среднее значение всех переменных становится равно нулю, а отклонение – единица.

Рис. 18 Автошкалированные данные в примере People.
В принципе, данные можно было бы не преобразовывать явно, на листе, а оставить как есть. Ведь стандартные хемометрические процедуры, собранные в программе Chemometrics могут центрировать и шкалировать данные при выполнении вычислений. Однако матрица автошкалированных данных понадобится нам при вычислении остатков в разделе 3.8 .
3.5. Вычисление счетов и нагрузок
Для построения PCA декомпозиции можно воспользоваться стандартными функциями ScoresPCA и LoadingsPCA, имеющимися в надстройке Chemometrics. Мы вычислим все 12 возможных главных компонент. В качестве первого аргумента используется исходный, не преобразованный массив данных, поэтому последний аргумент в обеих функциях равен 3 – автошкалирование.

Рис. 19 Вычисление матрицы счетов

Рис. 20 Вычисление матрицы нагрузок
В этом пособии все PCA вычисления проводятся в книге People.xls на листе MVA. Для удобства читателя эти же результаты продублированы на листе PCA как числа, без ссылки на надстройку Chemometrics.xla. Остальные листы рабочей книги связаны не с данными на листе MVA, с данными на листе PCA. Поэтому файл People.xls можно использовать даже тогда, когда надстройка Chemometrics.xla не установлена на компьютере.
3.6. Графики счетов
Посмотрим на графики счетов, которые показывают, как расположены образцы в проекционном пространстве.
На графике младших счетов PC1–PC2 (Рис. 21) мы видим четыре отдельные группы, разложенные по четырем квадрантам: слева – женщины (F), справа – мужчины (M), сверху – юг (S), а снизу – север (N). Из этого сразу становится ясен смысл первых двух направлений PC1 и PC2. Первая компонента разделяет людей по полу, а вторая – по месту жительства. Именно эти факторы наиболее сильно влияют на разброс свойств.

Рис. 21 График счетов (PC1 – PC2) с обозначениями, использованными ранее на Рис 16
Продолжим изучение, построив график старших счетов PC3– PC4 (Рис. 22 ).

Рис. 22 График счетов (PC3 – PC4) с новыми обозначениями:
размер и цвет символов отражает доход – чем больше и светлее, тем он больше. Числа представляют возраст
Здесь уже не видно таких отчетливых групп. Тем не менее, внимательно исследовав этот график совместно с таблицей исходных данных, можно, после некоторых усилий, сделать вывод о том, что PC3 отделяет старых/богатых людей от молодых/бедных. Чтобы сделать это более очевидным, мы изменили обозначения. Теперь каждый человек показан кружком, цвет и размер которого меняется в зависимости от дохода – чем больше и светлее, тем больше доход. Рядом показан возраст каждого объекта. Как видно, возраст и доход уменьшается слева направо, т.е. вдоль PC3. А вот смысл PC4 нам по–прежнему не ясен.
3.7. Графики нагрузок
Чтобы разобраться с этим, построим соответствующие графики нагрузок. Они подскажут нам, какие переменные и как связаны между собой, что влияет на что.
Из графика младших компонент мы сразу видим, что переменные рост (Height), вес (Weight), сила (Strength) и обувь (Shoes) образуют компактную группу в правой части графика. Они практически сливаются, что означает их тесную положительную корреляцию. Переменные волосы (Hair) и пол (Sex) находятся в другой группе, лежащей по диагонали от первой группы. Это свидетельствует о высокой отрицательной корреляции между переменными из этих групп, например, силой (Strength) и полом (Sex). Наибольшие нагрузки на вторую компоненту имеют переменные вино (Wine) и регион (Region), также тесно связанные друг с другом. Переменная доход (Income) лежит на первом графике напротив переменной регион (Region), что отражает дифференциацию состоятельности: Север–Юг. Можно заметить также и антитезу переменных пиво (Beer) –регион/вино(Region/Wine).


Рис. 23 Графики нагрузок: PC1 – PC2 и PC3 – PC4
Из второго графика мы видим большие нагрузки переменных возраст (Age) и доход (Income) на ось PC3, что соответствует графику счетов на Рис. 21. Рассмотрим, переменные пиво (Beer) и IQ. Первая из них имеет большие нагрузки как на PC1, так и на PC2, фактически формируя диагональ взаимоотношений между объектами на графике счетов. Переменная IQ не обнаруживает связи с другими переменным, так как ее значения близки к нулю для нагрузок первых трех PC, и проявляет она себя только в четвертой компоненте. Мы видим, что значения IQ не зависят от места жительства, физиологических характеристик и пристрастий к напиткам.
Впервые PCA был применен еще в начале 20–го века в психологических исследованиях, когда верили, что такие показатели, как IQ или криминальное поведение можно объяснить с помощью индивидуальных физиологических и социальных характеристик. Если сравнить результаты PCA с графиками, построенными нами ранее для пар переменных, видно, что PCA сразу дает всеобъемлющее представление о структуре данных, которое можно «охватить одним взглядом» (точнее, с помощью четырех графиков). Поэтому, одна из наиболее сильных сторон PCA в исследовании структур данных – это переход от большого числа не связанных между собой графиков пар переменных к очень небольшому числу графиков счетов и нагрузок.
3.8. Исследование остатков
Сколько главных компонент нужно использовать в этом примере? Для ответа на вопрос нужно исследовать, как изменяется качество описания при увеличении числа PC. Заметим, что в этом примере мы не будем проводить проверку – в этом нет необходимости, т.к. PCA модель нужна только для исследования данных. Она не будет использоваться далее для прогнозирования, классификации, и т.п.

Рис. 24 Графики собственных значений
На Рис.24 показано, как, в зависимости от числа PC, меняются собственные значения λ . Видно, что около PC=5 происходит изменение в их поведении. Для расчета показателей TRV и ERV можно получить матрицу остатков E для каждого числа главных компонент A и вычислить требуемые показатели. Пример такого расчета для значения A=4 приведен на листе Residuals.

Рис. 25 Анализ остатков
Однако те же характеристики можно получить и проще, если воспользоваться соотношениями

Эти величины представлены на Рис. 26

Рис. 26 Графики полной (TRV) и объясненной (ERV) дисперсии остатков
Из этих зависимостей видно, что для описания данных достаточно четырех PC – они моделируют 94% данных, или, иными словами, шум, оставшийся после проекции на четырехмерное пространство PC1–PC4, оставляет всего 6% от исходных данных.
Заключение
Рассмотренный пример позволил взглянуть лишь на малую часть возможностей, предоставляемых PCA–моделированием. Мы рассмотрели задачу исследования данных, которая не предполагает дальнейшего использования построенной модели для предсказания или классификации.
Метод PCA дает основу разнообразным методам, применяемым в хемометрике. В задачах классификации – это метод SIMCA, в задачах калибровки – это метод PCR, в задачах разделения кривых – это EFA, WFA и т.д.
Как работает метод главных компонент (PCA) на простом примере

В этой статье я бы хотел рассказать о том, как именно работает метод анализа главных компонент (PCA – principal component analysis) с точки зрения интуиции, стоящей за ее математическим аппаратом. Максимально просто, но подробно.
Математика вообще очень красивая и изящная наука, но порой ее красота скрывается за кучей слоев абстракции. Показать эту красоту лучше всего на простых примерах, которые, так сказать, можно покрутить, поиграть и пощупать, потому что в конце концов все оказывается гораздо проще, чем кажется на первый взгляд – самое главное понять и представить.
В анализе данных, как и в любом другом анализе, порой бывает нелишним создать упрощенную модель, максимально точно описывающую реальное положение дел. Часто бывает так, что признаки довольно сильно зависят друг от друга и их одновременное наличие избыточно.
К примеру, расход топлива у нас меряется в литрах на 100 км, а в США в милях на галлон. На первый взгляд, величины разные, но на самом деле они строго зависят друг от друга. В миле 1600м, а в галлоне 3.8л. Один признак строго зависит от другого, зная один, знаем и другой.
Но гораздо чаще бывает так, что признаки зависят друг от друга не так строго и (что важно!) не так явно. Объем двигателя в целом положительно влияет на разгон до 100 км/ч, но это верно не всегда. А еще может оказаться, что с учетом не видимых на первый взгляд факторов (типа улучшения качества топлива, использования более легких материалов и прочих современных достижений), год автомобиля не сильно, но тоже влияет на его разгон.
Зная зависимости и их силу, мы можем выразить несколько признаков через один, слить воедино, так сказать, и работать уже с более простой моделью. Конечно, избежать потерь информации, скорее всего не удастся, но минимизировать ее нам поможет как раз метод PCA.
Выражаясь более строго, данный метод аппроксимирует n-размерное облако наблюдений до эллипсоида (тоже n-мерного), полуоси которого и будут являться будущими главными компонентами. И при проекции на такие оси (снижении размерности) сохраняется наибольшее количество информации.
Шаг 1. Подготовка данных
Здесь для простоты примера я не буду брать реальные обучающие датасеты на десятки признаков и сотни наблюдений, а сделаю свой, максимально простой игрушечный пример. 2 признака и 10 наблюдений будет вполне достаточно для описания того, что, а главное – зачем, происходит в недрах алгоритма.

В данной выборке у нас имеются два признака, сильно коррелирующие друг с другом. С помощью алгоритма PCA мы сможем легко найти признак-комбинацию и, ценой части информации, выразить оба этих признака одним новым. Итак, давайте разбираться!
Для начала немного статистики. Вспомним, что для описания случайной величины используются моменты. Нужные нам – мат. ожидание и дисперсия. Можно сказать, что мат. ожидание – это «центр тяжести» величины, а дисперсия – это ее «размеры». Грубо говоря, мат. ожидание задает положение случайной величины, а дисперсия – ее размер (точнее, разброс).
Сам процесс проецирования на вектор никак не влияет на значения средних, так как для минимизации потерь информации наш вектор должен проходить через центр нашей выборки. Поэтому нет ничего страшного, если мы отцентрируем нашу выборку – линейно сдвинем ее так, чтобы средние значения признаков были равны 0. Это очень сильно упростит наши дальнейшие вычисления (хотя, стоит отметить, что можно обойтись и без центрирования).
Оператор, обратный сдвигу будет равен вектору изначальных средних значений – он понадобится для восстановления выборки в исходной размерности.
Дисперсия же сильно зависит от порядков значений случайной величины, т.е. чувствительна к масштабированию. Поэтому если единицы измерения признаков сильно различаются своими порядками, крайне рекомендуется стандартизировать их. В нашем случае значения не сильно разнятся в порядках, так что для простоты примера мы не будем выполнять эту операцию.
Шаг 2. Ковариационная матрица
В случае с многомерной случайной величиной (случайным вектором) положение центра все так же будет являться мат. ожиданиями ее проекций на оси. А вот для описания ее формы уже недостаточно толькое ее дисперсий по осям. Посмотрите на эти графики, у всех трех случайных величин одинаковые мат.ожидания и дисперсии, а их проекции на оси в целом окажутся одинаковы!

Для описания формы случайного вектора необходима ковариационная матрица.
Это матрица, у которой (i,j)-элемент является корреляцией признаков (Xi, Xj). Вспомним формулу ковариации:
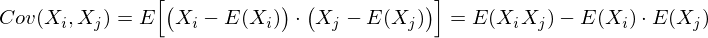
В нашем случае она упрощается, так как
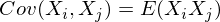
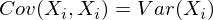
и это справедливо для любых случайных величин.
Таким образом, в нашей матрице по диагонали будут дисперсии признаков (т.к. i = j), а в остальных ячейках – ковариации соответствующих пар признаков. А в силу симметричности ковариации матрица тоже будет симметрична.
Замечание: Ковариационная матрица является обобщением дисперсии на случай многомерных случайных величин – она так же описывает форму (разброс) случайной величины, как и дисперсия.
И действительно, дисперсия одномерной случайной величины – это ковариационная матрица размера 1×1, в которой ее единственный член задан формулой Cov(X,X) = Var(X).
Итак, сформируем ковариационную матрицу Σ для нашей выборки. Для этого посчитаем дисперсии Xi и Xj, а также их ковариацию. Можно воспользоваться вышенаписанной формулой, но раз уж мы вооружились Python’ом, то грех не воспользоваться функцией numpy.cov(X). Она принимает на вход список всех признаков случайной величины и возвращает ее ковариационную матрицу и где X – n-мерный случайный вектор (n-количество строк). Функция отлично подходит и для расчета несмещенной дисперсии, и для ковариации двух величин, и для составления ковариационной матрицы.
(Напомню, что в Python матрица представляется массивом-столбцом массивов-строк.)
Шаг 3. Собственные вектора и значения (айгенпары)
О’кей, мы получили матрицу, описывающую форму нашей случайной величины, из которой мы можем получить ее размеры по x и y (т.е. X1 и X2), а также примерную форму на плоскости. Теперь надо найти такой вектор (в нашем случае только один), при котором максимизировался бы размер (дисперсия) проекции нашей выборки на него.
Замечание: Обобщение дисперсии на высшие размерности — ковариационная матрица, и эти два понятия эквивалентны. При проекции на вектор максимизируется дисперсия проекции, при проекции на пространства больших порядков – вся ее ковариационная матрица.
Итак, возьмем единичный вектор на который будем проецировать наш случайный вектор X. Тогда проекция на него будет равна v T X. Дисперсия проекции на вектор будет соответственно равна Var(v T X). В общем виде в векторной форме (для центрированных величин) дисперсия выражается так:
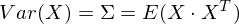
Соответственно, дисперсия проекции:

Легко заметить, что дисперсия максимизируется при максимальном значении v T Σv. Здесь нам поможет отношение Рэлея. Не вдаваясь слишком глубоко в математику, просто скажу, что у отношения Рэлея есть специальный случай для ковариационных матриц:


Последняя формула должна быть знакома по теме разложения матрицы на собственные вектора и значения. x является собственным вектором, а λ – собственным значением. Количество собственных векторов и значений равны размеру матрицы (и значения могут повторяться).
Кстати, в английском языке собственные значения и векторы именуются eigenvalues и eigenvectors соответственно.
Мне кажется, это звучит намного более красиво (и кратко), чем наши термины.
Таким образом, направление максимальной дисперсии у проекции всегда совпадает с айгенвектором, имеющим максимальное собственное значение, равное величине этой дисперсии.
И это справедливо также для проекций на большее количество измерений – дисперсия (ковариационная матрица) проекции на m-мерное пространство будет максимальна в направлении m айгенвекторов, имеющих максимальные собственные значения.
Размерность нашей выборки равна двум и количество айгенвекторов у нее, соответственно, 2. Найдем их.
В библиотеке numpy реализована функция numpy.linalg.eig(X), где X – квадратная матрица. Она возвращает 2 массива – массив айгензначений и массив айгенвекторов (векторы-столбцы). И векторы нормированы — их длина равна 1. Как раз то, что надо. Эти 2 вектора задают новый базис для выборки, такой что его оси совпадают с полуосями аппроксимирующего эллипса нашей выборки.
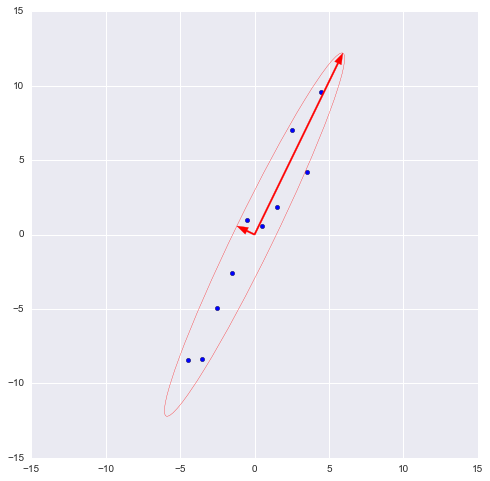
На этом графике мы апроксимировали нашу выборку эллипсом с радиусами в 2 сигмы (т.е. он должен содержать в себе 95% всех наблюдений – что в принципе мы здесь и наблюдаем). Я инвертировал больший вектор (функция eig(X) направляла его в обратную сторону) – нам важно направление, а не ориентация вектора.
Шаг 4. Снижение размерности (проекция)
Наибольший вектор имеет направление, схожее с линией регрессии и, спроецировав на него нашу выборку, мы потеряем информацию, сравнимую с суммой остаточных членов регрессии (только расстояние теперь евклидово, а не дельта по Y). В нашем случае зависимость между признаками очень сильная, так что потеря информации будет минимальна. «Цена» проекции — дисперсия по меньшему айгенвектору — как видно из предыдущего графика, очень невелика.
Замечание: диагональные элементы ковариационной матрицы показывают дисперсии по изначальному базису, а ее собственные значения – по новому (по главным компонентам).
Часто требуется оценить объем потерянной (и сохраненной) информации. Удобнее всего представить в процентах. Мы берем дисперсии по каждой из осей и делим на общую сумму дисперсий по осям (т.е. сумму всех собственных чисел ковариационной матрицы).
Таким образом, наш больший вектор описывает 45.994 / 46.431 * 100% = 99.06%, а меньший, соответственно, примерно 0.94%. Отбросив меньший вектор и спроецировав данные на больший, мы потеряем меньше 1% информации! Отличный результат!
Замечание: На практике, в большинстве случаев, если суммарная потеря информации составляет не более 10-20%, то можно спокойно снижать размерность.
Для проведения проекции, как уже упоминалось ранее на шаге 3, надо провести операцию v T X (вектор должен быть длины 1). Или, если у нас не один вектор, а гиперплоскость, то вместо вектора v T берем матрицу базисных векторов V T . Полученный вектор (или матрица) будет являться массивом проекций наших наблюдений.
dot(X,Y) — почленное произведение (так мы перемножаем векторы и матрицы в Python)
Нетрудно заметить, что значения проекций соответствуют картине на предыдущем графике.
Шаг 5. Восстановление данных
С проекцией удобно работать, строить на ее основе гипотезы и разрабатывать модели. Но не всегда полученные главные компоненты будут иметь явный, понятный постороннему человеку, смысл. Иногда полезно раскодировать, к примеру, обнаруженные выбросы, чтобы посмотреть, что за наблюдения за ними стоят.
Это очень просто. У нас есть вся необходимая информация, а именно координаты базисных векторов в исходном базисе (векторы, на которые мы проецировали) и вектор средних (для отмены центровки). Возьмем, к примеру, наибольшее значение: 10.596… и раскодируем его. Для этого умножим его справа на транспонированный вектор и прибавим вектор средних, или в общем виде для всей выборки: X T v T +m
Разница небольшая, но она есть. Ведь потерянная информация не восстанавливается. Тем не менее, если простота важнее точности, восстановленное значение отлично аппроксимирует исходное.
Вместо заключения – проверка алгоритма
Итак, мы разобрали алгоритм, показали как он работает на игрушечном примере, теперь осталось только сравнить его с PCA, реализованным в sklearn – ведь пользоваться будем именно им.
Параметр n_components указывает на количество измерений, на которые будет производиться проекция, то есть до скольки измерений мы хотим снизить наш датасет. Другими словами – это n айгенвекторов с самыми большими собственными числами. Проверим результат снижения размерности:
Мы возвращали результат как матрицу вектор-столбцов наблюдений (это более канонический вид с точки зрения линейной алгебры), PCA в sklearn же возвращает вертикальный массив.
В принципе, это не критично, просто стоит отметить, что в линейной алгебре канонично записывать матрицы через вектор-столбцы, а в анализе данных (и прочих связанных с БД областях) наблюдения (транзакции, записи) обычно записываются строками.
Проверим и прочие параметры модели – функция имеет ряд атрибутов, позволяющих получить доступ к промежуточным переменным:
— Вектор средних: mean_
— Вектор(матрица) проекции: components_
— Дисперсии осей проекции (выборочная): explained_variance_
— Доля информации (доля от общей дисперсии): explained_variance_ratio_
Замечание: explained_variance_ показывает выборочную дисперсию, тогда как функция cov() для построения ковариационной матрицы рассчитывает несмещенные дисперсии!
Сравним полученные нами значения со значениями библиотечной функции.
Единственное различие – в дисперсиях, но как уже упоминалось, мы использовали функцию cov(), которая использует несмещенную дисперсию, тогда как атрибут explained_variance_ возвращает выборочную. Они отличаются только тем, что первая для получения мат.ожидания делит на (n-1), а вторая – на n. Легко проверить, что 45.99 ∙ (10 — 1) / 10 = 41.39.
Все остальные значения совпадают, что означает, что наши алгоритмы эквивалентны. И напоследок замечу, что атрибуты библиотечного алгоритма имеют меньшую точность, поскольку он наверняка оптимизирован под быстродействие, либо просто для удобства округляет значения (либо у меня какие-то глюки).

Замечание: библиотечный метод автоматически проецирует на оси, максимизирующие дисперсию. Это не всегда рационально. К примеру, на данном рисунке неаккуратное снижение размерности приведет к тому, что классификация станет невозможна. Тем не менее, проекция на меньший вектор успешно снизит размерность и сохранит классификатор.
Итак, мы рассмотрели принципы работы алгоритма PCA и его реализации в sklearn. Я надеюсь, эта статья была достаточно понятна тем, кто только начинает знакомство с анализом данных, а также хоть немного информативна для тех, кто хорошо знает данный алгоритм. Интуитивное представление крайне полезно для понимания того, как работает метод, а понимание очень важно для правильной настройки выбранной модели. Спасибо за внимание!
источники:
http://www.chemometrics.ru/old/Tutorials/pca.htm
http://habr.com/ru/post/304214/
Время на прочтение
10 мин
Количество просмотров 221K
В этой статье я бы хотел рассказать о том, как именно работает метод анализа главных компонент (PCA – principal component analysis) с точки зрения интуиции, стоящей за ее математическим аппаратом. Максимально просто, но подробно.
Математика вообще очень красивая и изящная наука, но порой ее красота скрывается за кучей слоев абстракции. Показать эту красоту лучше всего на простых примерах, которые, так сказать, можно покрутить, поиграть и пощупать, потому что в конце концов все оказывается гораздо проще, чем кажется на первый взгляд – самое главное понять и представить.
В анализе данных, как и в любом другом анализе, порой бывает нелишним создать упрощенную модель, максимально точно описывающую реальное положение дел. Часто бывает так, что признаки довольно сильно зависят друг от друга и их одновременное наличие избыточно.
К примеру, расход топлива у нас меряется в литрах на 100 км, а в США в милях на галлон. На первый взгляд, величины разные, но на самом деле они строго зависят друг от друга. В миле 1600м, а в галлоне 3.8л. Один признак строго зависит от другого, зная один, знаем и другой.
Но гораздо чаще бывает так, что признаки зависят друг от друга не так строго и (что важно!) не так явно. Объем двигателя в целом положительно влияет на разгон до 100 км/ч, но это верно не всегда. А еще может оказаться, что с учетом не видимых на первый взгляд факторов (типа улучшения качества топлива, использования более легких материалов и прочих современных достижений), год автомобиля не сильно, но тоже влияет на его разгон.
Зная зависимости и их силу, мы можем выразить несколько признаков через один, слить воедино, так сказать, и работать уже с более простой моделью. Конечно, избежать потерь информации, скорее всего не удастся, но минимизировать ее нам поможет как раз метод PCA.
Выражаясь более строго, данный метод аппроксимирует n-размерное облако наблюдений до эллипсоида (тоже n-мерного), полуоси которого и будут являться будущими главными компонентами. И при проекции на такие оси (снижении размерности) сохраняется наибольшее количество информации.
Шаг 1. Подготовка данных
Здесь для простоты примера я не буду брать реальные обучающие датасеты на десятки признаков и сотни наблюдений, а сделаю свой, максимально простой игрушечный пример. 2 признака и 10 наблюдений будет вполне достаточно для описания того, что, а главное – зачем, происходит в недрах алгоритма.
Сгенерируем выборку:
x = np.arange(1,11)
y = 2 * x + np.random.randn(10)*2
X = np.vstack((x,y))
print X
OUT:
[[ 1. 2. 3. 4. 5.
6. 7. 8. 9. 10. ]
[ 2.73446908 4.35122722 7.21132988 11.24872601 9.58103444
12.09865079 13.78706794 13.85301221 15.29003911 18.0998018 ]]
В данной выборке у нас имеются два признака, сильно коррелирующие друг с другом. С помощью алгоритма PCA мы сможем легко найти признак-комбинацию и, ценой части информации, выразить оба этих признака одним новым. Итак, давайте разбираться!
Для начала немного статистики. Вспомним, что для описания случайной величины используются моменты. Нужные нам – мат. ожидание и дисперсия. Можно сказать, что мат. ожидание – это «центр тяжести» величины, а дисперсия – это ее «размеры». Грубо говоря, мат. ожидание задает положение случайной величины, а дисперсия – ее размер (точнее, разброс).
Сам процесс проецирования на вектор никак не влияет на значения средних, так как для минимизации потерь информации наш вектор должен проходить через центр нашей выборки. Поэтому нет ничего страшного, если мы отцентрируем нашу выборку – линейно сдвинем ее так, чтобы средние значения признаков были равны 0. Это очень сильно упростит наши дальнейшие вычисления (хотя, стоит отметить, что можно обойтись и без центрирования).
Оператор, обратный сдвигу будет равен вектору изначальных средних значений – он понадобится для восстановления выборки в исходной размерности.
Xcentered = (X[0] - x.mean(), X[1] - y.mean())
m = (x.mean(), y.mean())
print Xcentered
print "Mean vector: ", m
OUT:
(array([-4.5, -3.5, -2.5, -1.5, -0.5, 0.5, 1.5, 2.5, 3.5, 4.5]),
array([-8.44644233, -8.32845585, -4.93314426, -2.56723136, 1.01013247,
0.58413394, 1.86599939, 7.00558491, 4.21440647, 9.59501658]))
Mean vector: (5.5, 10.314393916)
Дисперсия же сильно зависит от порядков значений случайной величины, т.е. чувствительна к масштабированию. Поэтому если единицы измерения признаков сильно различаются своими порядками, крайне рекомендуется стандартизировать их. В нашем случае значения не сильно разнятся в порядках, так что для простоты примера мы не будем выполнять эту операцию.
Шаг 2. Ковариационная матрица
В случае с многомерной случайной величиной (случайным вектором) положение центра все так же будет являться мат. ожиданиями ее проекций на оси. А вот для описания ее формы уже недостаточно толькое ее дисперсий по осям. Посмотрите на эти графики, у всех трех случайных величин одинаковые мат.ожидания и дисперсии, а их проекции на оси в целом окажутся одинаковы!
Для описания формы случайного вектора необходима ковариационная матрица.
Это матрица, у которой (i,j)-элемент является корреляцией признаков (Xi, Xj). Вспомним формулу ковариации:
В нашем случае она упрощается, так как
E(Xi) = E(Xj) = 0:
Заметим, что когда Xi = Xj:
и это справедливо для любых случайных величин.
Таким образом, в нашей матрице по диагонали будут дисперсии признаков (т.к. i = j), а в остальных ячейках – ковариации соответствующих пар признаков. А в силу симметричности ковариации матрица тоже будет симметрична.
Замечание: Ковариационная матрица является обобщением дисперсии на случай многомерных случайных величин – она так же описывает форму (разброс) случайной величины, как и дисперсия.
И действительно, дисперсия одномерной случайной величины – это ковариационная матрица размера 1×1, в которой ее единственный член задан формулой Cov(X,X) = Var(X).
Итак, сформируем ковариационную матрицу Σ для нашей выборки. Для этого посчитаем дисперсии Xi и Xj, а также их ковариацию. Можно воспользоваться вышенаписанной формулой, но раз уж мы вооружились Python’ом, то грех не воспользоваться функцией numpy.cov(X). Она принимает на вход список всех признаков случайной величины и возвращает ее ковариационную матрицу и где X – n-мерный случайный вектор (n-количество строк). Функция отлично подходит и для расчета несмещенной дисперсии, и для ковариации двух величин, и для составления ковариационной матрицы.
(Напомню, что в Python матрица представляется массивом-столбцом массивов-строк.)
covmat = np.cov(Xcentered)
print covmat, "n"
print "Variance of X: ", np.cov(Xcentered)[0,0]
print "Variance of Y: ", np.cov(Xcentered)[1,1]
print "Covariance X and Y: ", np.cov(Xcentered)[0,1]
OUT:
[[ 9.16666667 17.93002811]
[ 17.93002811 37.26438587]]
Variance of X: 9.16666666667
Variance of Y: 37.2643858743
Covariance X and Y: 17.9300281124
Шаг 3. Собственные вектора и значения (айгенпары)
О’кей, мы получили матрицу, описывающую форму нашей случайной величины, из которой мы можем получить ее размеры по x и y (т.е. X1 и X2), а также примерную форму на плоскости. Теперь надо найти такой вектор (в нашем случае только один), при котором максимизировался бы размер (дисперсия) проекции нашей выборки на него.
Замечание: Обобщение дисперсии на высшие размерности — ковариационная матрица, и эти два понятия эквивалентны. При проекции на вектор максимизируется дисперсия проекции, при проекции на пространства больших порядков – вся ее ковариационная матрица.
Итак, возьмем единичный вектор на который будем проецировать наш случайный вектор X. Тогда проекция на него будет равна vTX. Дисперсия проекции на вектор будет соответственно равна Var(vTX). В общем виде в векторной форме (для центрированных величин) дисперсия выражается так:
Соответственно, дисперсия проекции:
Легко заметить, что дисперсия максимизируется при максимальном значении vT Σv. Здесь нам поможет отношение Рэлея. Не вдаваясь слишком глубоко в математику, просто скажу, что у отношения Рэлея есть специальный случай для ковариационных матриц:
и
Последняя формула должна быть знакома по теме разложения матрицы на собственные вектора и значения. x является собственным вектором, а λ – собственным значением. Количество собственных векторов и значений равны размеру матрицы (и значения могут повторяться).
Кстати, в английском языке собственные значения и векторы именуются eigenvalues и eigenvectors соответственно.
Мне кажется, это звучит намного более красиво (и кратко), чем наши термины.
Таким образом, направление максимальной дисперсии у проекции всегда совпадает с айгенвектором, имеющим максимальное собственное значение, равное величине этой дисперсии.
И это справедливо также для проекций на большее количество измерений – дисперсия (ковариационная матрица) проекции на m-мерное пространство будет максимальна в направлении m айгенвекторов, имеющих максимальные собственные значения.
Размерность нашей выборки равна двум и количество айгенвекторов у нее, соответственно, 2. Найдем их.
В библиотеке numpy реализована функция numpy.linalg.eig(X), где X – квадратная матрица. Она возвращает 2 массива – массив айгензначений и массив айгенвекторов (векторы-столбцы). И векторы нормированы — их длина равна 1. Как раз то, что надо. Эти 2 вектора задают новый базис для выборки, такой что его оси совпадают с полуосями аппроксимирующего эллипса нашей выборки.
На этом графике мы апроксимировали нашу выборку эллипсом с радиусами в 2 сигмы (т.е. он должен содержать в себе 95% всех наблюдений – что в принципе мы здесь и наблюдаем). Я инвертировал больший вектор (функция eig(X) направляла его в обратную сторону) – нам важно направление, а не ориентация вектора.
Шаг 4. Снижение размерности (проекция)
Наибольший вектор имеет направление, схожее с линией регрессии и, спроецировав на него нашу выборку, мы потеряем информацию, сравнимую с суммой остаточных членов регрессии (только расстояние теперь евклидово, а не дельта по Y). В нашем случае зависимость между признаками очень сильная, так что потеря информации будет минимальна. «Цена» проекции — дисперсия по меньшему айгенвектору — как видно из предыдущего графика, очень невелика.
Замечание: диагональные элементы ковариационной матрицы показывают дисперсии по изначальному базису, а ее собственные значения – по новому (по главным компонентам).
Часто требуется оценить объем потерянной (и сохраненной) информации. Удобнее всего представить в процентах. Мы берем дисперсии по каждой из осей и делим на общую сумму дисперсий по осям (т.е. сумму всех собственных чисел ковариационной матрицы).
Таким образом, наш больший вектор описывает 45.994 / 46.431 * 100% = 99.06%, а меньший, соответственно, примерно 0.94%. Отбросив меньший вектор и спроецировав данные на больший, мы потеряем меньше 1% информации! Отличный результат!
Замечание: На практике, в большинстве случаев, если суммарная потеря информации составляет не более 10-20%, то можно спокойно снижать размерность.
Для проведения проекции, как уже упоминалось ранее на шаге 3, надо провести операцию vTX (вектор должен быть длины 1). Или, если у нас не один вектор, а гиперплоскость, то вместо вектора vT берем матрицу базисных векторов VT. Полученный вектор (или матрица) будет являться массивом проекций наших наблюдений.
_, vecs = np.linalg.eig(covmat)
v = -vecs[:,1])
Xnew = dot(v,Xcentered)
print Xnew
OUT:
[ -9.56404107 -9.02021624 -5.52974822 -2.96481262 0.68933859
0.74406645 2.33433492 7.39307974 5.3212742 10.59672425]
dot(X,Y) — почленное произведение (так мы перемножаем векторы и матрицы в Python)
Нетрудно заметить, что значения проекций соответствуют картине на предыдущем графике.
Шаг 5. Восстановление данных
С проекцией удобно работать, строить на ее основе гипотезы и разрабатывать модели. Но не всегда полученные главные компоненты будут иметь явный, понятный постороннему человеку, смысл. Иногда полезно раскодировать, к примеру, обнаруженные выбросы, чтобы посмотреть, что за наблюдения за ними стоят.
Это очень просто. У нас есть вся необходимая информация, а именно координаты базисных векторов в исходном базисе (векторы, на которые мы проецировали) и вектор средних (для отмены центровки). Возьмем, к примеру, наибольшее значение: 10.596… и раскодируем его. Для этого умножим его справа на транспонированный вектор и прибавим вектор средних, или в общем виде для всей выборки: XTvT+m
n = 9 #номер элемента случайной величины
Xrestored = dot(Xnew[n],v) + m
print 'Restored: ', Xrestored
print 'Original: ', X[:,n]
OUT:
Restored: [ 10.13864361 19.84190935]
Original: [ 10. 19.9094105]
Разница небольшая, но она есть. Ведь потерянная информация не восстанавливается. Тем не менее, если простота важнее точности, восстановленное значение отлично аппроксимирует исходное.
Вместо заключения – проверка алгоритма
Итак, мы разобрали алгоритм, показали как он работает на игрушечном примере, теперь осталось только сравнить его с PCA, реализованным в sklearn – ведь пользоваться будем именно им.
from sklearn.decomposition import PCA
pca = PCA(n_components = 1)
XPCAreduced = pca.fit_transform(transpose(X))
Параметр n_components указывает на количество измерений, на которые будет производиться проекция, то есть до скольки измерений мы хотим снизить наш датасет. Другими словами – это n айгенвекторов с самыми большими собственными числами. Проверим результат снижения размерности:
print 'Our reduced X: n', Xnew
print 'Sklearn reduced X: n', XPCAreduced
OUT:
Our reduced X:
[ -9.56404106 -9.02021625 -5.52974822 -2.96481262 0.68933859
0.74406645 2.33433492 7.39307974 5.3212742 10.59672425]
Sklearn reduced X:
[[ -9.56404106]
[ -9.02021625]
[ -5.52974822]
[ -2.96481262]
[ 0.68933859]
[ 0.74406645]
[ 2.33433492]
[ 7.39307974]
[ 5.3212742 ]
[ 10.59672425]]
Мы возвращали результат как матрицу вектор-столбцов наблюдений (это более канонический вид с точки зрения линейной алгебры), PCA в sklearn же возвращает вертикальный массив.
В принципе, это не критично, просто стоит отметить, что в линейной алгебре канонично записывать матрицы через вектор-столбцы, а в анализе данных (и прочих связанных с БД областях) наблюдения (транзакции, записи) обычно записываются строками.
Проверим и прочие параметры модели – функция имеет ряд атрибутов, позволяющих получить доступ к промежуточным переменным:
— Вектор средних: mean_
— Вектор(матрица) проекции: components_
— Дисперсии осей проекции (выборочная): explained_variance_
— Доля информации (доля от общей дисперсии): explained_variance_ratio_
Замечание: explained_variance_ показывает выборочную дисперсию, тогда как функция cov() для построения ковариационной матрицы рассчитывает несмещенные дисперсии!
Сравним полученные нами значения со значениями библиотечной функции.
print 'Mean vector: ', pca.mean_, m
print 'Projection: ', pca.components_, v
print 'Explained variance ratio: ', pca.explained_variance_ratio_, l[1]/sum(l)
OUT:
Mean vector: [ 5.5 10.31439392] (5.5, 10.314393916)
Projection: [[ 0.43774316 0.89910006]] (0.43774316434772387, 0.89910006232167594)
Explained variance: [ 41.39455058] 45.9939450918
Explained variance ratio: [ 0.99058588] 0.990585881238
Единственное различие – в дисперсиях, но как уже упоминалось, мы использовали функцию cov(), которая использует несмещенную дисперсию, тогда как атрибут explained_variance_ возвращает выборочную. Они отличаются только тем, что первая для получения мат.ожидания делит на (n-1), а вторая – на n. Легко проверить, что 45.99 ∙ (10 — 1) / 10 = 41.39.
Все остальные значения совпадают, что означает, что наши алгоритмы эквивалентны. И напоследок замечу, что атрибуты библиотечного алгоритма имеют меньшую точность, поскольку он наверняка оптимизирован под быстродействие, либо просто для удобства округляет значения (либо у меня какие-то глюки).
Замечание: библиотечный метод автоматически проецирует на оси, максимизирующие дисперсию. Это не всегда рационально. К примеру, на данном рисунке неаккуратное снижение размерности приведет к тому, что классификация станет невозможна. Тем не менее, проекция на меньший вектор успешно снизит размерность и сохранит классификатор.
Итак, мы рассмотрели принципы работы алгоритма PCA и его реализации в sklearn. Я надеюсь, эта статья была достаточно понятна тем, кто только начинает знакомство с анализом данных, а также хоть немного информативна для тех, кто хорошо знает данный алгоритм. Интуитивное представление крайне полезно для понимания того, как работает метод, а понимание очень важно для правильной настройки выбранной модели. Спасибо за внимание!
P.S.: Просьба не ругать автора за возможные неточности. Автор сам в процессе знакомства с дата-анализом и хочет помочь таким же как он в процессе освоения этой удивительной области знаний! Но конструктивная критика и разнообразный опыт всячески приветствуются!
Анализ данных и их оптимизация в Excel
С помощью средств анализа «что если» в Microsoft Excel можно экспериментировать с различными наборами значений в одной или нескольких формулах для изучения всех возможных результатов.
Формулы и функции в Excel автоматически пересчитывают результат при изменении содержимого ячеек, на которые имеются ссылки в данной формуле или функции. Другими словами, можно отвечать на вопросы типа «что-если». Например, при анализе финансовой функции ПЛТ ответить на вопрос, что будет, если первый взнос при получении ипотечной ссуды будет составлять не 20% от цены, а 15%.
Итак, проиллюстрируем проведение анализа данных «что-если» на примере работы функции ПЛТ, которая вычисляет величину выплаты по ссуде на основе постоянных выплат и постоянной процентной ставки.
Пс — приведенная к текущему моменту стоимость или общая сумма, которая на текущий момент равноценна ряду будущих платежей, называемая также основной суммой.
Бс — значение будущей стоимости, т. е. желаемого остатка средств после последней выплаты. Если этот аргумент опущен, предполагается, что он равен 0 (например, значение «бс» для займа равно 0).
Тип — число 0 (ноль) или 1, обозначающее, когда должна производиться выплата.
Рассмотрим пример использования функции ПЛТ в Exceel.
Итак, требуется определить ежемесячные выплаты по займу в 20 000 руб., взятому на 16 месяцев под 11% годовых.
Для решения задачи выделяем ячейку на рабочем листе Excel (в нашел случаи ячейка А1) и в строку формул вводим следующее выражение: =ПЛТ(11%/12; 16; 20000) (Рис.1.1)

Нажав на клавишу Enter , мы получаем величину ежемесячных выплат по ссуде, которая составит -1350 руб. Рис.1.2

При ином значении банковской учетной ставки, следует сделать исправления в ранее введенной функции в Excel.

Рис. 1.3 — Пример расчета Excel, в котором исходные данные в отдельные ячейки
При изменении любых значений на рис.3 результаты расчета автоматически обновляются в разделе Результат расчета.
Вывод: Рассмотренный выше примеры показывают, что размещение исходных данных в отдельные ячейки упрощает анализ зависимости выходного результата от изменения исходных данных с использованием анализа данных «Что если» в Exceel.
Анализ данных и их оптимизация в Excel
В ячейке G3 этой таблицы определена точно такая же формула, как и в ячейке D7. Первый столбец таблицы подстановки заполнен значениями аргумента функции ПЛТ, в зависимости от которого требуется проанализировать поведение финансовой функции (в нашем случае от 11 до 15%).

Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
С помощью этого инструмента определяется значение в одной ячейке исходных данных, которое требуется для получения требуемого значения в ячейке результата. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Для примера выше мы хотим получит выручку, которую принес нам Петров в городе Москва. Формула имеет вид СУММЕСЛИМН(C2:C13;A2:A13;E2;B2:B13;F2), где C2:C13 — диапазон со значениями выручки, которые необходимо просуммировать; А2:А13 — диапазон с фамилиями, которые мы будем проверять; Е2 — ссылка на конкретную фамилию; B2:B13 — ссылка на диапазон с городами; F2 — ссылка на конкретный город.

10 наиболее полезных функций при анализе данных в Excel — ExcelGuide: Про Excel и не только
- Выполнить команду меню Сервис > Поиск решения, чтобы вызвать диалоговое окно Поиск решения (рис. 4.2)
- Установить курсор в поле Установить целевую ячейку диалогового окна и щелкнуть мышкой на целевой ячейке Е7 (рис. 4.2).
- Установить курсор в поле Изменяя ячейки диалогового окна и выделить диапазон изменяемых ячеек С3:С6.
- Установить курсор в поле Ограничения и щелкнуть на кнопке Добавить . В появившееся диалоговое окно, показанное на рис. 4.3, вводить поочередно все ограничения (рис. 4.4).
- Щелкнуть на кнопке Выполнить диалогового окна Поиск решения.
Метод главных компонент считается статистическим методом. Однако есть другой подход, приводящий к методу главных компонент, но не являющийся статистическим. Этот подход связан с получением наилучшей проекции точек наблюдения в пространстве меньшей размерности. Для решения подобной задачи необходимо знать матрицу вторых моментов.
ГПР
Функция ГПР выполняет туже задачу, что и ВПР, только она просматривает первую строку в поиске искомого значения и для получения результата сдвигается на указанное количество строк вниз.

— Таблица- диапазон данных на листе, где в первой строке мы ищем искомое значение и сдвигаемся на необходимое количество строк.
— Интервальный просмотр — ставьте всегда 0, тогда Эксель будет искать точное совпадение, что нам и нужно в большинстве случаев.
Если вы хотите более подробно изучить, как пользоваться функцией ГПР — прочитайте статью на нашем сайте «Функция ГПР в Excel».
Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
В функции СЦЕПИТЬ A2; ;B2 , первый параметр А2 — ссылка на ячейку с фамилией; второй параметр — пробел, что бы итоговый текст смотрелся нормально; третий параметр В2 — ссылка на ячейку с именем. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
— Интервальный просмотр — Может принимать параметр 0 или ЛОЖЬ, что обозначает что совпадение между искомым значением и значением в первом столбце таблицы должен быть точным; либо 1 или ИСТИНА, соответственно совпадение должно быть неточным. Настоятельно рекомендую использовать только параметр ЛОЖЬ, иначе можно получать непредсказуемые результаты.
Сингулярное разложение тензоров и тензорный метод главных компонент [ ]
Множество решений λj находят решением характеристического уравнения | R — λI| = 0. Х арактеристики вариации λj — показатели оценок дисперси й каждой главной компоненты. Суммарное значение Σλj равно сумме оценок дисперсий элементарных признаков x j. При условии стандартизации исходных данных, эта сумма равна числу элементарных признаков k.
Анализ главных компонент – это метод понижения размерности Датасета (Dataset), который преобразует больший набор переменных в меньший с минимальными потерями информативности.
Уменьшение количества переменных в наборе данных происходит в ущерб точности, но хитрость здесь заключается в том, чтобы потерять немного в точности, но обрести простоту. Поскольку меньшие наборы данных легче исследовать и визуализировать, анализ данных становится намного проще и быстрее для Алгоритмов (Algorithm) Машинного обучения (ML).
Идея PCA проста: уменьшить количество переменных в наборе данных, сохранив при этом как можно больше информации.
Шаг первый. Стандартизация
Мы осуществляем Стандартизацию (Standartization) исходных переменных, чтобы каждая из них вносила равный вклад в анализ. Почему так важно выполнить стандартизацию до PCA? Метод очень чувствителен к Дисперсиям (Variance) исходных Признаков (Feature). Если есть больши́е различия между диапазонами исходных переменных, те переменные с бо́льшими диапазонами будут преобладать над остальными (например, переменная, которая находится в диапазоне от 0 до 100, будет преобладать над переменной, которая находится в диапазоне от 0 до 1), что приведет к необъективным результатам. Преобразование данных в сопоставимые масштабы может предотвратить эту ситуацию.
Математически это можно сделать путем вычитания Среднего значения (Mean) из каждого значения и деления полученной разности на Стандартное отклонение (Standard Deviation). После стандартизации все переменные будут преобразованы в исходные значения.
Шаг второй. Матрица ковариации
Цель этого шага – понять, как переменные отличаются от среднего по отношению друг к другу, или, другими словами, увидеть, есть ли между ними какая-либо связь. Порой переменные сильно коррелированы и содержат избыточную информацию, и чтобы идентифицировать эти взаимосвязи, мы вычисляем Ковариационную матрицу (Covariance Matrix).
Ковариационная матрица представляет собой симметричную матрицу размера p × p (где p – количество измерений), где в качестве ячеек пребывают коэффициенты ковариации, связанные со всеми возможными парами исходных переменных. Например, для трехмерного набора данных с 3 переменными x, y и z ковариационная матрица представляет собой следующее:

Поскольку ковариация переменной с самой собой – это ее дисперсия, на главной диагонали (от верхней левой ячейки к нижней правой), у нас фактически есть дисперсии каждой исходной переменной. А поскольку ковариация коммутативна (в ячейке XY значение равно YX), элементы матрицы симметричны относительно главной диагонали.
Что коэффициенты ковариации говорят нам о корреляциях между переменными? На самом деле, имеет значение знак ковариации. Если коэффициент – это:
- положительное число, то две переменные прямо пропорциональны, то есть второй увеличивается или уменьшается вместе с первым.
- отрицательное число, то переменные обратно пропорциональны, то есть второй увеличивается, когда первый уменьшается, и наоборот.
Теперь, когда мы знаем, что ковариационная матрица – это не более чем таблица, которая отображает корреляции между всеми возможными парами переменных, давайте перейдем к следующему шагу.
Шаг третий. Вычисление собственных векторов
Собственные векторы (Eigenvector) и Собственные значения (Eigenvalues) – это понятия из области Линейной алгебры (Linear Algebra), которые нам нужно экстраполировать из ковариационной матрицы, чтобы определить так называемые главные компоненты данных. Давайте сначала поймем, что мы подразумеваем под этим термином.
Главная компонента – это новая переменная, смесь исходных. Эти комбинации выполняются таким образом, что новые переменные (то есть главные компоненты) не коррелированы, и большая часть информации в исходных переменных помещается в первых компонентах. Итак, идея состоит в том, что 10-мерный датасет дает нам 10 главных компонент, но PCA пытается поместить максимум возможной информации в первый, затем максимум оставшейся информации во второй и так далее, пока не появится что-то вроде того, что показано на графике ниже:

Такая организация информации в главных компонентах позволит нам уменьшить размерность без потери большого количества информации за счет отбрасывания компонент с низкой информативностью.
Здесь важно понимать, что главные компоненты менее интерпретируемы и не имеют никакого реального значения, поскольку они построены как линейные комбинации исходных переменных.
С геометрической точки зрения, главные компоненты представляют собой Векторы (Vector) данных, которые объясняют максимальное количество отклонений. Главные компоненты – новые оси, которые обеспечивают лучший угол для оценки данных, чтобы различия между наблюдениями были лучше видны.
Поскольку существует столько главных компонент, сколько переменных в наборе, главные компоненты строятся таким образом, что первый из них учитывает наибольшую возможную дисперсию в наборе данных. Например, предположим, что диаграмма рассеяния нашего набора данных выглядит так:

Можем ли мы проецировать первый главный компонент? Да, это линия, которая соответствует фиолетовым отметкам, потому что она проходит через начало координат, и проекции точек на компонент наиболее короткие. Говоря математически, это линия, которая максимизирует дисперсию (среднее квадратов расстояний от проецируемых красных точек до начала координат).
Второй главный компонент рассчитывается таким же образом, при условии, что он не коррелирован (т.е. перпендикулярен) первому главному компоненту и учитывает следующую по величине дисперсию. Это продолжается до тех пор, пока не будет вычислено p главных компонент, равное исходному количеству переменных.
Теперь, когда мы поняли, что подразумевается под главными компонентами, давайте вернемся к собственным векторам и собственным значениям. Прежде всего, нам нужно знать, что они всегда «ходят парами», то есть каждый собственный вектор имеет собственное значение. И их количество равно количеству измерений данных. Например, для 3-мерного набора данных есть 3 переменных, следовательно, есть 3 собственных вектора с 3 соответствующими собственными значениями.
За всей магией, описанной выше, стоят собственные векторы и собственные значения, потому что собственные векторы матрицы ковариации на самом деле являются направлениями осей, где наблюдается наибольшая дисперсия (большая часть информации) и которые мы называем главными компонентами. А собственные значения – это просто коэффициенты, прикрепленные к собственным векторам, которые дают величину дисперсии, переносимую в каждом основном компоненте.
Ранжируя собственные векторы в порядке от наибольшего к наименьшему, мы получаем главные компоненты в порядке значимости.
Шаг четвертый. Вектор признака
Как мы видели на предыдущем шаге, вычисляя собственные векторы и упорядочивая их по собственным значениям в в порядке убывания, мы можем ранжировать основные компоненты в порядке значимости. На этом этапе мы выбираем, оставить ли все эти компоненты или отбросить те, которые имеют меньшее значение, и сформировать с оставшимися матрицу векторов, которую мы называем Вектором признака (Feature Vector).
Итак, вектор признаков – это просто матрица, в столбцах которой есть собственные векторы компонент, которые мы решили оставить. Это первый шаг к уменьшению размерности, потому что, если мы решим оставить только p собственных векторов (компонент) из n, окончательный набор данных будет иметь только p измерений.
Шаг 5. Трансформирование данных по осям главных компонент
На предыдущих шагах, помимо стандартизации, мы не вносили никаких изменений в данные, а просто выбирали основные компоненты и формировали вектор признаков, но исходной набор данных всегда остается.
На этом последнем этапе цель состоит в переориентации данных с исходных осей на оси, представленные главными компонентами (отсюда и название «Анализ главных компонент»). Это можно сделать, перемножив транспонированный исходный набор данных на транспонированный вектор признаков.
PCA и Scikit-learn
PCA можно реализовать с помощью SkLearn. Для начала импортируем необходимые библиотеки:
import numpy as np
import pandas as pd
import sklearn
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScalerМы будем использовать датасет банка, автоматизирующего выдачу кредитных продуктов своим клиентам:
df = pd.read_csv('https://www.dropbox.com/s/9t04t1haanbdvvt/bank-data-for-pca.csv?dl=1')
dfСоздадим список признаков, подлежащих уменьшению. Это макроэкономические показатели с невысоким уровнем важности, которые почти не попали в список выше. Выберем сокращаемые и Целевую переменные (Target Variable):
X = df[['Возраст', 'Длительность', 'Кампания', 'День недели', 'Предыдущий контакт', 'Индекс потребительских цен', 'Европейская межбанковская ставка', 'Количество сотрудников в компании']]
y = df.iloc[:, -1]Выберем cамые важные признаки с помощью функции SelectKBest, которая использует критерий Хи-квадрат (Chi Square):
bestfeatures = SelectKBest(score_func = chi2, k = 'all')
fit = bestfeatures.fit(X, y)Создадим объект dfscores, куда отправим, соответственно, очки важности всех признаков датасета:
dfscores = pd.DataFrame(fit.scores_)
dfcolumns = pd.DataFrame(X.columns)Создадим для коэффициентов отдельный объект, соединив названия столбцов и очки, и отобразим пять признаков, набравших наибольшее количество очков:
featureScores = pd.concat([dfcolumns, dfscores], axis = 1)
featureScores.columns = ['Specs', 'Score']
print(featureScores.nlargest(5, 'Score'))Неожиданно, но самыми важными признаками оказались количество сотрудников в компании и порядковый номер рекламной кампании, в которой участвует клиент:
Specs Score
1 Длительность 1.760568e+06
7 Количество сотрудников в компании 5.251380e+03
6 Европейская межбанковская ставка 3.239336e+03
4 Предыдущий контакт 3.089714e+03
2 Кампания 5.419261e+02Создадим список признаков, подлежащих понижению. Это макроэкономические показатели с невысоким уровнем важности, которые почти не попали в список выше:
features = ['Колебание уровня безработицы', 'Индекс потребительских цен', 'Индекс потребительской уверенности', 'Европейская межбанковская ставка']
x = df.loc[:, features].valuesВыполним стандартизацию объекта X. StandardScaler() на месте заменяет данные на их стандартизированную версию, и мы получаем признаки, где все значения как бы центрированы относительно нуля. Такое преобразование необходимо, чтобы правильно объединить признаки между собой.
x = StandardScaler().fit_transform(x)
pd.DataFrame(data = x, columns = features).head()Результат выглядит следующим образом:

Мы хотим получить один главный компонент. Передадим функции обучающие данные:
pca = PCA(n_components = 1)
principalComponents = pca.fit_transform(x)
principalDf = pd.DataFrame(data = principalComponents, columns = ['principal component 1'])
principalDf.head()Мы получили вот такой главный компонент:

Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Автор оригинальной статьи: Zakaria Jaadi
Фото: @codyrs