
Regex or regular expression is a pattern-matching tool. It allows you to search text in an advanced manner.
Regex is like CTRL+F on steroids.
For example, to find out all the emails or phone numbers from text, regex can get the job done.
The downside of the regex is it takes a while to memorize all the commands. One could say it takes 20 minutes to learn, but forever to master.
In this guide, you learn the basics of regex.
We are going to use the regex online playground in regexr.com. This is a super useful platform where you can easily practice your regex skills with useful examples.
Make sure to write down each regular expression you see in this guide to truly learn what you are doing.
Regex Tutorial
To make it as beneficial as possible, this tutorial is example-heavy. This means some of the regex concepts are introduced as part of the examples. Make sure you read everything!
Anyway, let’s get started with regex.
Regex and Flags
A regular expression (or regex) starts with forward slash (/) and ends with a forward slash.
The pattern matching happens in between the forward slashes.
For instance, let’s find the word “loud” in the text document.

As you can see, this works like CTRL + F.
Next, pay attention to the letter “g” in the above regex /loud/g.
The letter “g” means that the global flag is activated. In other words, you are treating the piece of example text as one long line of text.
Most of the time you are going to use the “g” flag only.
But it is good to understand there are other flags as well.
In the regexr online editor, you can find all the possible flags in the top right corner.
Now that you understand what regex is and what is the global flag, let’s see an example.
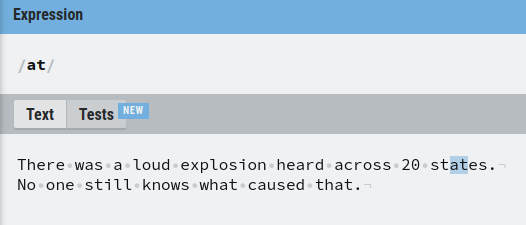
Let’s search for “at” in the piece of text:

As you can see, our regular expression found three matches of “at”.
Now, if you disable the “g” flag, it is only going to match the first occurrence of “at”.
Anyway, let’s switch the global flag back on.
So far using regex has been like using the good old CTRL+F.
However, the true power of the regular expressions shows up when we search for patterns instead of specific words.
To do this, we need to learn about the regex special characters that make pattern matching possible
Let’s start with the + charater.
The + Operator – Match One or More
Let’s search for character “s” in the example text.

This matches all “s” letters there are.
But what if you want to search for multiple “s” characters in a row?
In this case, you can use the + character after the letter “s”. This matches all the following “s” letters after the first one.

As a result, it now matches the double “s” in the text in addition to the singular “s”.
In short, the + operator matches one or more same characters in a row.
Next, let’s take a look at how optional matching works.
The ? Operator – Match Optional Characters
Optional matching is characterized by the question mark operator (?).
Optional matching means to match something that might follow.
For example, to match all letters “s” and every “s” followed by “t”, you can specify the letter “t” as an optional match using the question mark.
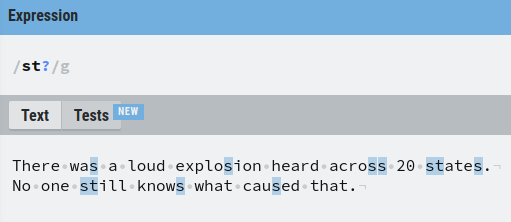
This matches:
- Each singular “s”
- Each combination of “st”.
Next up, let’s take a look at a special character that combines the + and ? characters.
The * Operator – Match Any Optional Characters
The star operator (*) means “match zero or more”.
Essentially, it is the combination of the + and the ? operators.
For example, let’s match with each letter “o” and any amount of letter “s” that follow.

This matches:
- All the singular “o” letters.
- All occurrences of “os”.
- All occurrences of “oss”.
As a matter of fact, this would match with “ossssssss” with any number of “s” letters as long as they are preceded by an “o”.
Next, let’s take a look at the wild card character.
The . Operator – Match Anything Except a New Line
In regex, the period is a special character that matches any singular character.
It acts as the wildcard.
The only character the period does not match is a line break.
For example, let’s match any character that comes before “at” in the text.

But how about matching with a dot then? The period (.) is a reserved special character, so it cannot be used.
This is where escaping is used.
The Operator – Escape a Special Character
If you are familiar with programming, you know what escaping means.
If not, escaping means to “invalidate” a reserved keyword or operator using a special character in front of its name.
As you saw in the previous example, the period character acts as a wildcard in regex. This means you cannot use it to match a dot in the text.

As you can see, /./g matches with each letter (and space) in the text, so it is not much of a help.
This is where escaping is useful.
In regex, you can escape any reserved character using a backslash ().
Anything followed by a backslash is going to be converted into a normal text character.
To match dots using regex, escape the period character with (.).

Now it matches all the dots in the text.
Let’s play with the example. To match any character that comes before a dot, add a period before the escaped period:
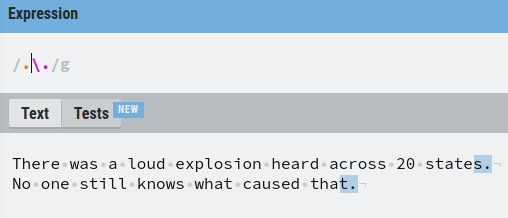
Now you understand how to match and escape characters in regex. Let’s move on to matching word characters using other special characters.
Match Different Types of Characters
You just learned how to use a backslash to escape a character.
However, the backslash has another important use case. Combining a backslash with some particular character forms an operator that can be used to match useful things.
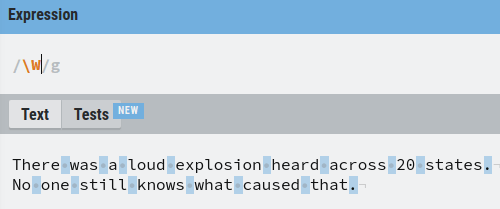
As an example, an important special character in regex is w.
This matches all the word characters, that is, letters and digits but leaves out spaces.
For example, let’s match all the letters and digits in the text:

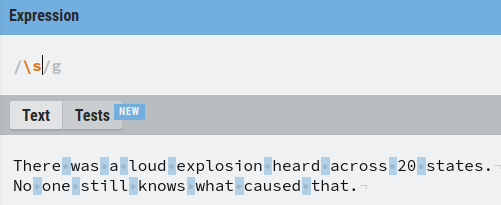
Another commonly used special operator is the space character s that matches any type of white space there is in the text.
For example, let’s match all the spaces in the text.
Of course, you can also match numeric characters only.
This happens via the d operator.
For instance, let’s match all digits in the text:

This matches with “2” and “0”.
These are the very basic special character operators there are in regex.
Next, you are going to learn how to invert these special characters.
Invert Special Characters
To invert a special character in regex, capitalize it.
- w matches any word character –> W matches with any non-word character
- s matches with any white space character –> S matches with any non-whitespace character.
- d matches with any digit –> D matches any non-digit character.
Examples:


Next, let’s take a look at how to match words with a specific length.
{} – Match Specific Length
Let’s say you want to capture all the words that are longer than 2 characters long.
Now, you cannot use + or * with the w character as it does not make sense.
Instead, use the curly braces {} by specifying how many characters to match.
There are three ways to use {}:
- {n}. Match n consecutive characters.
- {n,}. Match n character or more.
- {n,m}. Match between n and m in length.
Let’s examples of each.
Example 1. Match all sets of characters that are exactly 3 in length:

Example 2. Match consecutive strings that are longer than 3 characters:

Example 3. Match any set of characters that are between 3 and 5 characters in length:

Now that you know how to deal with quantities in regex, let’s talk about grouping.
[] – Groups and Ranges
In regex, you can use character grouping. This means you match with any character in the group.
One way to group characters is by using square brackets [].
For example, let’s match with any two letters where the last letter is “s” and the first letter is either “a” or “o”.

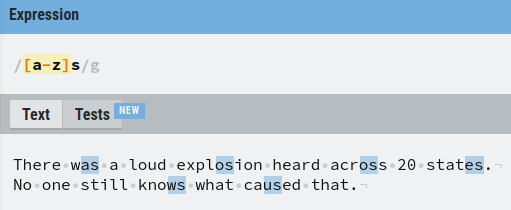
A really handy feature of using square brackets is you can specify a range. This lets you match any letter in the specified range.
To specify a range, use the dash with the following syntax. For example, [a-z] matches any letter from a to z.
For example, let’s match with any two-letter word that ends in “s” and starts with any character from a to z.
One thing you sometimes may want to do is to combine ranges.
This is also possible in regex.
For example, to find any two letters that end with “s” and start with any lowercase or uppercase letter, you can do:
/[a-zA-Z]s/g
Or if you want to match with any two letters that end with “s” and start with a number between 0 and 9, you can do:
/[0-9]s/g
Awesome.
Next, let’s take a look at another way to group characters in regex.
() Capturing Groups
In regex, capturing groups is a way to treat multiple characters as a single unit.
To create a capturing group, place the characters inside of the parenthesis.
For example, let’s match with words “The” or “the”, where the first letter is either lowercase t or uppercase T.
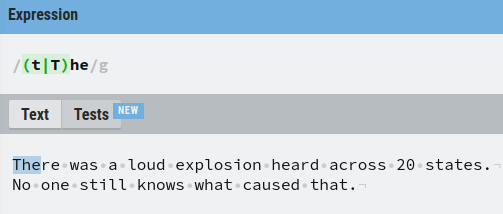
But why parenthesis? Let’s see what happens without them:
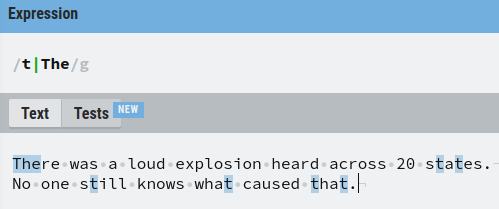
Now it matches with either any single character “t” or the word “The”.
This is the power of the capturing group. It treats the characters inside the parenthesis as a single unit.
Let’s see another example where we find any words that are 2-3 letters long and each letter in the word is either a,s,e,d.

As the last example of capturing, let’s match any words that repeat “os” two or three times in a row.

Here the “os” is not matched in the words “explosion” and “across”. This is because the “os” occurs only a single time. However, the “osososos” at the end has 3 x “os” so it gets matched.
Next up, let’s take a look at yet another special character, caret (^).
The ^ operator – Match the Beginning of a Line
The caret (^) character in regex means match with the beginning of the new line.
For example, let’s match with the letter “T” at the beginning of a text chapter.

Now, let’s see what happens when we try to match with the letter “N” at the beginning of the next line.

No matches!
But why is that? There is an “N” at the beginning of the second line.
This happens because our flag is set to “g” or “global”. We are treating the whole piece of text as a single line of text.
If you want to change this, you need to set the multiline flag in addition to the global flag.

Now the match is also made at the beginning of the second line.
However, it is easier to deal with the text as a single chunk of text, so we are going to disable the multiline flag for the rest of the guide.
Now that you know how the caret operator works in regex, let’s take a look at the next special character, the dollar sign ($).
$ End of Statement
To match the end of a statement with regex, use the dollar sign ($).
For instance, let’s match with a dot that ends the text chapter.

As you can see, this only matches the dot at the end of the second line. As mentioned before, this happens because we treat the text as a single line of text.
Awesome! Now you have learned most of the special characters you are ever going to use in regex.
Next, let’s take a look at how to really benefit from regex by learning about important concepts of lookahead and lookbehind.
Lookbehinds
In regex, a lookbehind means to match something preceded by something.
There are two types of lookbehinds:
- Positive lookbehind
- Negative lookbehind
Let’s take a look at what these do.
The (?<=) Operator – Positive Lookbehind
A positive look behind is specified by defining a group that starts with a question mark, followed by a less than sign and an equal sign, and then a set of characters.
- (?<=)
Here < means we are going to perform a look behind, and = means it is positive.
A positive lookbehind matches everything before the main expression without including it in the result.
For example, let’s match the first characters after “os” in the text.

This positive look behind does not include “os” in the matches. Instead, it checks if the matches are preceded by “os” before showing them.
This is super useful.
The (?<!) Operator – Negative Lookbehind
Another type of look behind is the negative look behind. This is basically the opposite of the positive lookbehind.
To create a negative look behind, create a group with a question mark followed by a less-than sign and an exclamation point.
- (?<!)
Here < means look behind and ! makes it negative.
As an example, let’s perform the exact same search as we did in the positive lookbehind, but let’s make it negative:

As you can see, the negative lookbehind matches everything except the first character after the word “os”. This is the exact opposite of the positive lookahead.
Now that you know what the lookbehinds do, let’s move on to very similar concepts, that is, lookaheads.
Lookaheads
In regex, a lookahead is similar to lookbehind.
A lookahead matches everything after the main expression without including it in the result.
To perform a lookahead, all you need to do is remove the less-than sign.
- (?=) is a positive lookahead.
- (?!) is a negative lookahead.
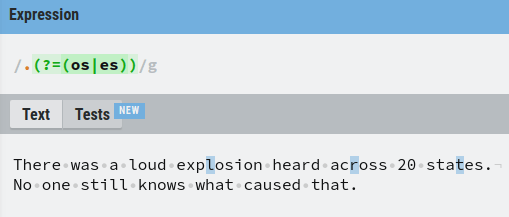
The (?=) Operator – Positive Lookahead
For example, let’s match with any singular character followed by “es” or “os”.
And as you guessed, a negative lookahead matches the exact opposite of what a positive lookahead does.
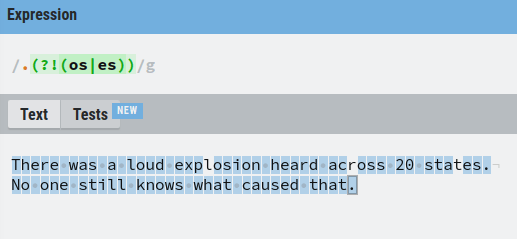
The (?!) Operator – Positive Lookahead
For example, let’s match everything except for the single characters that occur before “os” or “es”
Now you have all the tools to understand a slightly more advanced example using regex. Also, you are going to learn a bunch of important things at the same, so keep on reading!
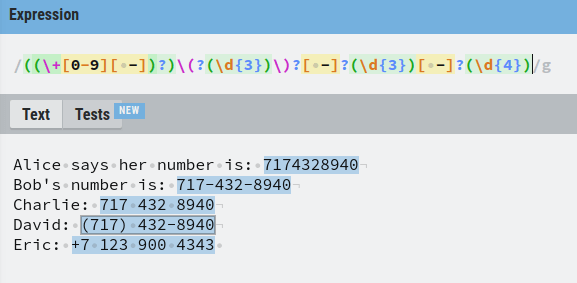
Find and Replace Phone Numbers Using Regex
Let’s say we have a text document that has differently formatted phone numbers.
Our task is to find those numbers and replace them by formatting them all in the same way.

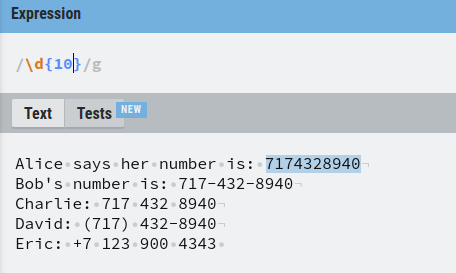
The number that belongs to Alice is simple. Just 10 digits in a row.
The number that belongs to Bob is a bit trickier because you need to group the regex into 5 parts:
- A group of three digits
- Dash
- A group of three digits
- Dash
- A group of four digits.
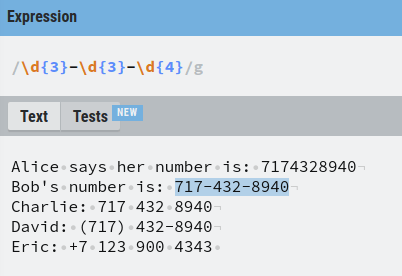
Now it matches Bob’s number.
But our goal was to match all the numbers at the same time. Now Alice’s number is no longer found.
To fix this, we need to restructure the regex again. Instead of assuming there is always a dash between the first two groups of numbers, let’s assume it is optional. As you now know, this can be done using the question mark.
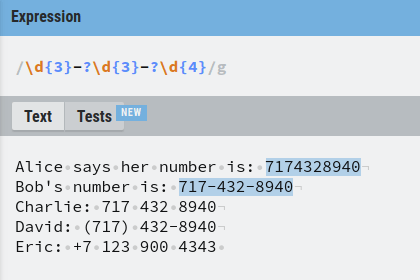
Good job.
Next up, there can also be numbers separated by space, such as Charlie’s number.
To take this into account, we must assume that the separator is either a white space or a dash. This can be done using a group with square brackets [] by placing a dash and a white space into it.
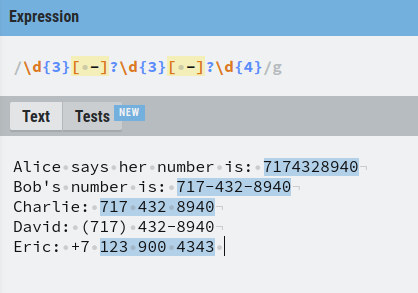
Now also Charlie’s number is matched by our regular expression.
Then there are those numbers where the first three digits are isolated by parenthesis and where the last two groups are separated by a dash.
To find these numbers, we need to add an optional parenthesis in front of the first three digits. But as you recall, parenthesis is a special character in regex, so you need to escape them using the backslash .
Awesome, now David’s number is also found.
Last but not least, a phone number might be formatted such that the country-specific number is in front of the number with a + sign.
To take this into account, we need to add an optional group of a + sign followed by a digit between 0-9.
Now our regex finds every phone number there is on the list!
Next, let’s replace each number with a number such that each number is formatted in the same way.
Before we can do this, we need to capture each set of numbers by creating capturing groups for them. As you learned before, this happens by placing each set of digits into a set of parenthesis.
If you inspect the Details section of the editor, you can see that now each set of numbers in a phone number is grouped in the capture groups.
For example, let’s click the first phone number match and see the Details:
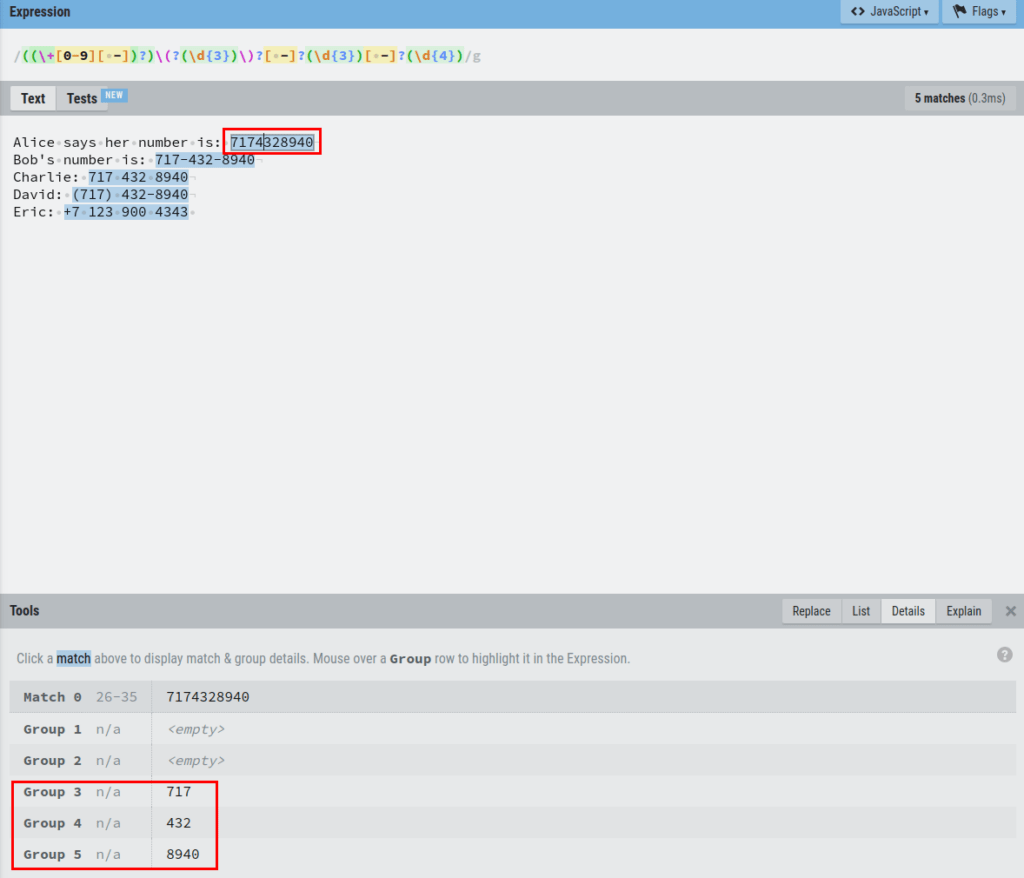
As you can see, the first phone number is grouped into three capture groups 3,4, and 5.
As another example, let’s click Eric’s number to see the details:
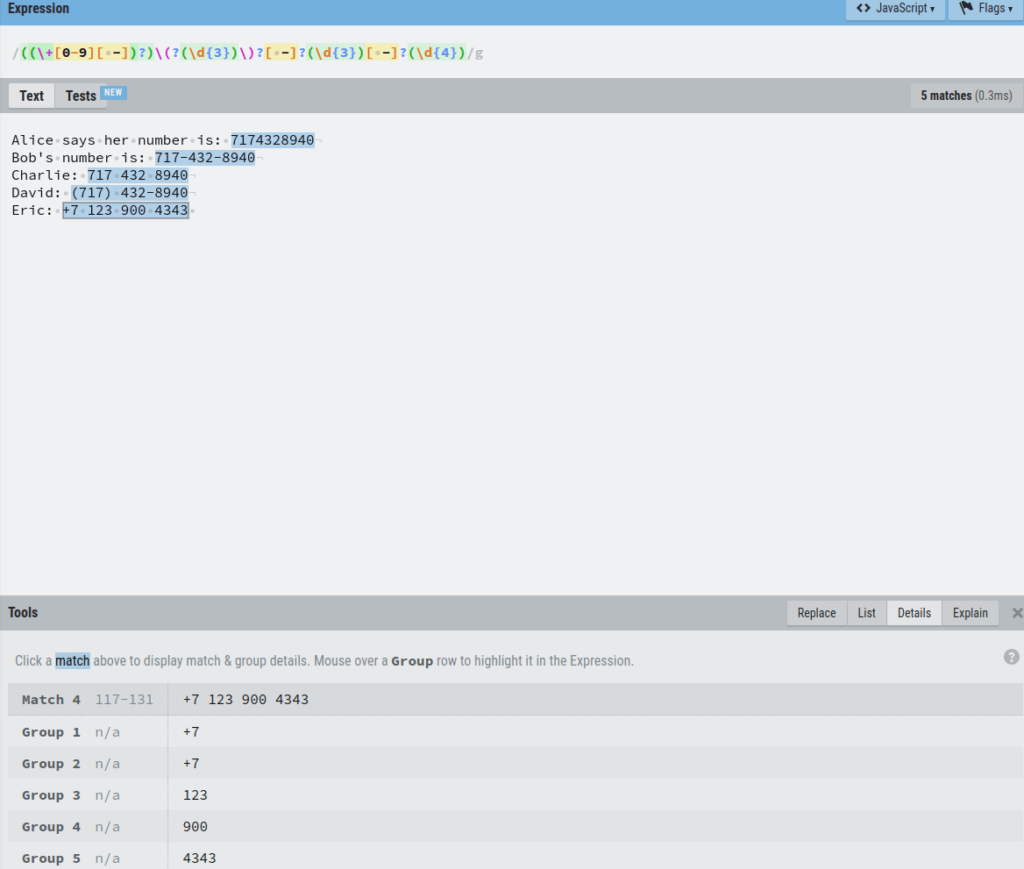
Here you can see that the number is split into groups 1, 2, 3, 4, and 5.
However, there is one problem.
The number +7 occurs twice, in group 1 and group 2.
This is not what we want.
It happens because the regex catches both the +7 with a space and without a space. Thus the 2 groups.
To get rid of this, you can specify the expression that captures the number with space as a non-capturing group.
To do this, use the ?: operator in front of the group:
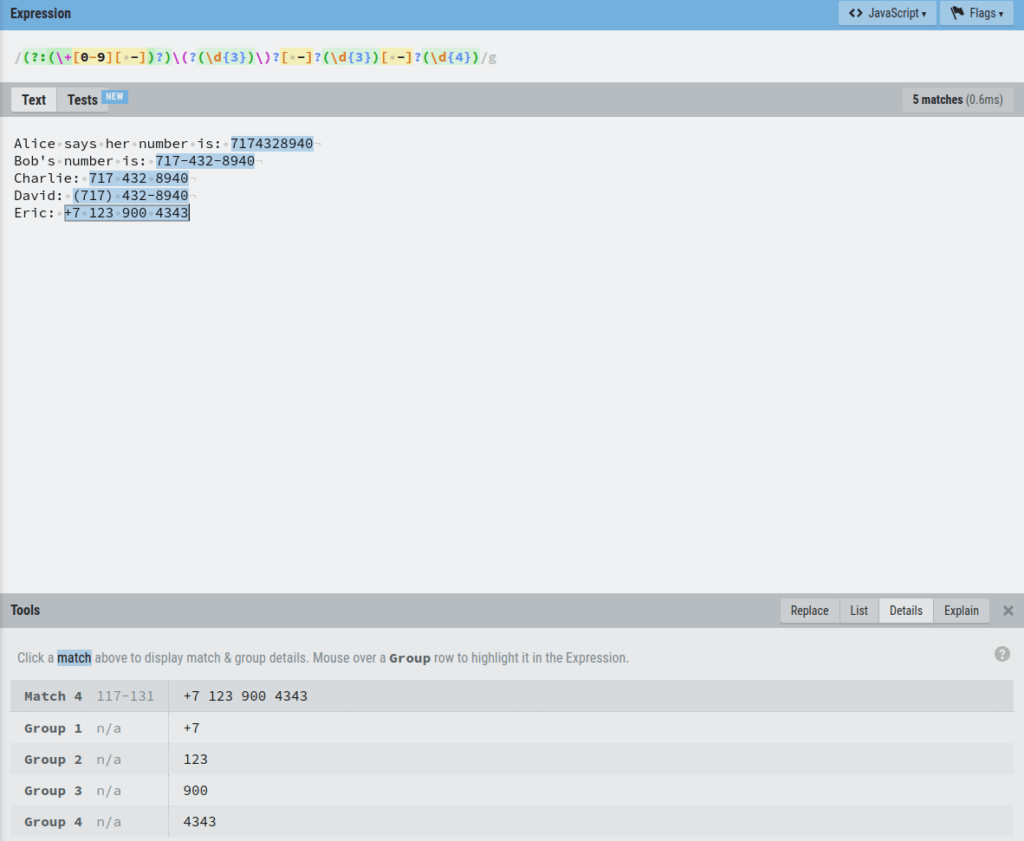
Now Eric’s number (and all the other numbers too) is nicely split into 4 groups.
Finally, we can use these four capture groups to replace the matched numbers with numbers that are formatted in the same way.
In regex, you can refer to each capture group with $n, where n is the number of the group.
To format the numbers, let’s open up the replace tab in the editor.
Let’s say we want to replace all the numbers with a number that is formatted like this:
+7 123-900-4343
And if there is no +7 in front of the number, then we leave it as:
123-900-4343
To do this, replace each phone number by referencing their capture group in the Replace section of the editor:
$1$2-$3-$4
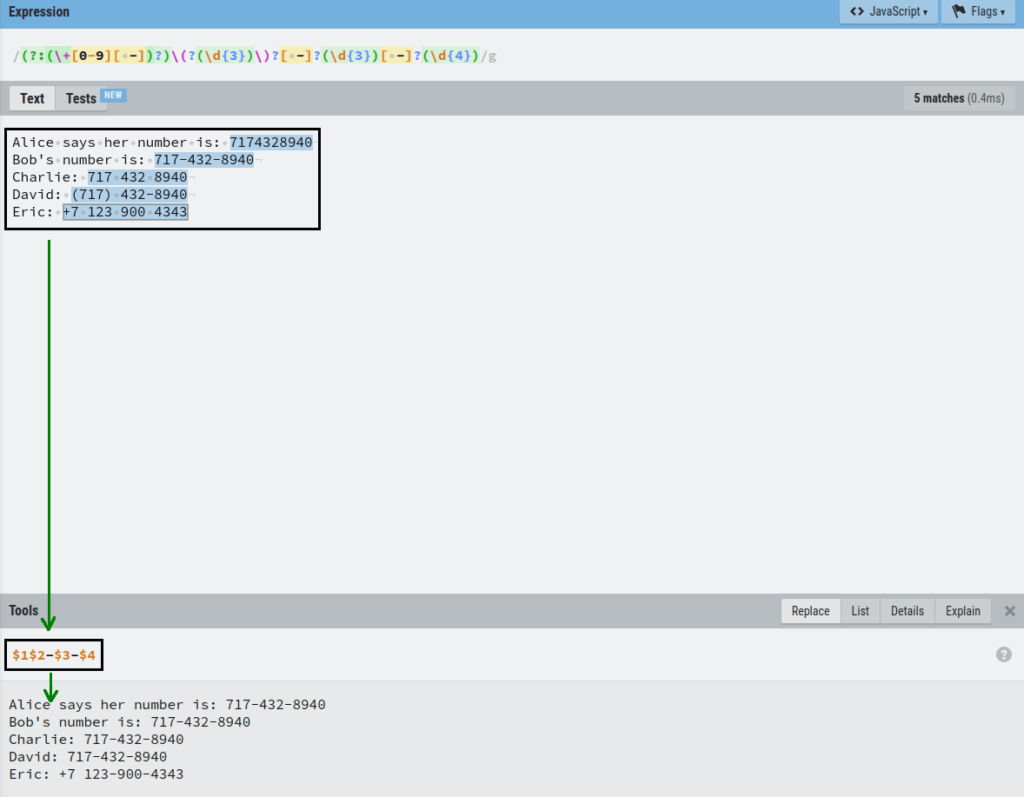
Amazing! Now all the numbers are replaced in the resulting piece of text and follow the same format.
This concludes our regex tutorial.
Conclusion
Today you learned how to use regex.
In short, regex is a commonly supported tool to match patterns in text documents.
You can use it to find and replace text that matches a specific pattern.
Most programming languages support regex. This means you can use regex in your coding projects to automate a lot of manual work when it comes to text processing.
Thanks for reading.
Happy pattern-matching!
Further Reading
How to Validate Emails with JavaScript + RegEx
About the Author

-
I’m an entrepreneur and a blogger from Finland. My goal is to make coding and tech easier for you with comprehensive guides and reviews.
Recent Posts
This section is a brief summary of regexp syntax that can be used for creating search and replace as well as issue navigation patterns.

RegEx syntax reference
|
Character |
Description |
|---|---|
|
|
Marks the next character as either a special character or a literal. For example:
|
|
|
Matches the beginning of input. |
|
|
Matches the end of input. |
|
|
Matches the preceding character zero or more times. For example, «zo*» matches either z or zoo. |
|
|
Matches the preceding character one or more times. For example, «zo+» matches zoo but not z. |
|
|
Matches the preceding character zero or one time. For example, |
|
|
Matches any single character except a newline character. |
|
|
Matches subexpression and remembers the match. If a part of a regular expression is enclosed in parentheses, that part of the regular expression is grouped together. Thus a regex operator can be applied to the entire group.
|
|
x |
Matches either x or y. For example, |
|
{ |
n is a non negative integer. Matches exactly n times. For example, |
|
{ |
n is a non negative integer. Matches at least n times. For example,
|
|
|
m and n are nonnegative integers. Matches at least n and at most m times. For example, |
|
|
A character set. Matches any one of the enclosed characters. For example, |
|
|
A negative character set. Matches any character not enclosed. For example, |
|
|
A range of characters. Matches any character in the specified range. For example, «[a-z]» matches any lowercase alphabetic character in the range a through z. |
|
|
A negative range characters. Matches any character not in the specified range. For example, |
|
|
Matches a word boundary, that is, the position between a word and a space. For example, |
|
|
Matches a non-word boundary. |
|
|
Matches a digit character. Equivalent to |
|
|
Matches a non-digit character. Equivalent to |
|
|
Matches a form-feed character. |
|
|
Matches a newline character. |
|
|
Matches a carriage return character. |
|
|
Matches any white space including space, tab, form-feed, and so on. Equivalent to |
|
|
Matches any nonwhite space character. Equivalent to |
|
|
Matches a tab character. |
|
|
Matches a vertical tab character. |
|
|
Matches any word character including underscore. Equivalent to |
|
|
Matches any non-word character. Equivalent to |
|
|
Matches num, where num is a positive integer, denoting a reference back to remembered matches. For example, |
|
|
Matches n, where n is an octal escape value. Octal escape values should be 1, 2, or 3 digits long. For example,
Octal escape values should not exceed 256. If they do, only the first two digits comprise the expression. Allows ASCII codes to be used in regular expressions. |
|
|
Matches n, where n is a hexadecimal escape value. Hexadecimal escape values must be exactly two digits long. For example, Allows ASCII codes to be used in regular expressions. |
|
|
Finds a |
|
|
This regex entered in the search field, means that you are trying to find a |
|
|
Changes the case of the next character to the lower case. Use this type of regex in the replace field. |
|
|
Changes the case of the next character to the upper case. Use this type of regex in the replace field. |
|
|
Changes the case of all the subsequent characters up to |
|
|
Changes the case of all the subsequent characters up to |
|
|
This is a pattern for «negative lookahead». For example, |
|
|
This is a pattern for «positive lookahead». For example, |
|
|
This is a pattern for «positive lookbehind». For example, |
|
|
This is a pattern for «negative lookbehind». For example, |
Since IntelliJ IDEA supports all the standard regular expressions syntax, you can check https://www.regular-expressions.info for more information about the syntax.
Tips and Tricks
IntelliJ IDEA provides intention actions to check validity of the regular expressions, and edit regular expressions in a scratchpad. Place the caret at a regular expression, and press Alt+Enter. The suggestion list of intention actions, available in this context, appears:

-
Choose , and press Enter. The dialog that pops up, shows the current regular expression in the upper pane. In the lower pane, type the string to which this expression should match. If the regular expression matches the entered string, IntelliJ IDEA displays a green check mark against the regex. If the regular expression doesn’t match, then
 is displayed.
is displayed.
-
Choose , and press Enter. The regular expression opens for editing in a separate tab in the editor. Note that this is only a scratchpad and no file is physically created:

As you type in the scratchpad, all changes are synchronized with the original regular expression. To close the scratchpad, press Ctrl+F4.
 is displayed.
is displayed.

Last modified: 26 January 2023
Hey all i have found the following code that finds a word within the page:
JSFiddle & Original Page
function searchAndHighlight(searchTerm, selector) {
if(searchTerm) {
//var wholeWordOnly = new RegExp("\g"+searchTerm+"\g","ig"); //matches whole word only
//var anyCharacter = new RegExp("\g["+searchTerm+"]\g","ig"); //matches any word with any of search chars characters
var selector = selector || "body"; //use body as selector if none provided
var searchTermRegEx = new RegExp(searchTerm,"ig");
var matches = $(selector).text().match(searchTermRegEx);
if(matches) {
$('.highlighted').removeClass('highlighted'); //Remove old search highlights
$(selector).html($(selector).html()
.replace(searchTermRegEx, "<span class='highlighted'>"+searchTerm+"</span>"));
if($('.highlighted:first').length) { //if match found, scroll to where the first one appears
$(window).scrollTop($('.highlighted:first').position().top);
}
return true;
}
}
return false;
}
$(document).ready(function() {
$('#search-button').on("click",function() {
if(!searchAndHighlight($('#search-term').val())) {
alert("No results found");
}
});
});
Within the code you can see it has var anyCharacter = new RegExp(«g[«+searchTerm+»]g»,»ig»); //matches any word with any of search chars characters.
However, when i try using that RegExp like so:
var searchTermRegEx = new RegExp("\g["+searchTerm+"]\g","ig");
it doesnt seem to return any results then even if i type in an exact name.
Any help would be great!
There are three separate approaches to pattern matching provided by PostgreSQL: the traditional SQL LIKE operator, the more recent SIMILAR TO operator (added in SQL:1999), and POSIX-style regular expressions. Aside from the basic “does this string match this pattern?” operators, functions are available to extract or replace matching substrings and to split a string at matching locations.
The pattern matching operators of all three kinds do not support nondeterministic collations. If required, apply a different collation to the expression to work around this limitation.
9.7.1. LIKE
stringLIKEpattern[ESCAPEescape-character]stringNOT LIKEpattern[ESCAPEescape-character]
The LIKE expression returns true if the string matches the supplied pattern. (As expected, the NOT LIKE expression returns false if LIKE returns true, and vice versa. An equivalent expression is NOT (.)string LIKE pattern)
If pattern does not contain percent signs or underscores, then the pattern only represents the string itself; in that case LIKE acts like the equals operator. An underscore (_) in pattern stands for (matches) any single character; a percent sign (%) matches any sequence of zero or more characters.
Some examples:
'abc' LIKE 'abc' true 'abc' LIKE 'a%' true 'abc' LIKE '_b_' true 'abc' LIKE 'c' false
LIKE pattern matching always covers the entire string. Therefore, if it’s desired to match a sequence anywhere within a string, the pattern must start and end with a percent sign.
To match a literal underscore or percent sign without matching other characters, the respective character in pattern must be preceded by the escape character. The default escape character is the backslash but a different one can be selected by using the ESCAPE clause. To match the escape character itself, write two escape characters.
It’s also possible to select no escape character by writing ESCAPE ''. This effectively disables the escape mechanism, which makes it impossible to turn off the special meaning of underscore and percent signs in the pattern.
According to the SQL standard, omitting ESCAPE means there is no escape character (rather than defaulting to a backslash), and a zero-length ESCAPE value is disallowed. PostgreSQL‘s behavior in this regard is therefore slightly nonstandard.
The key word ILIKE can be used instead of LIKE to make the match case-insensitive according to the active locale. This is not in the SQL standard but is a PostgreSQL extension.
The operator ~~ is equivalent to LIKE, and ~~* corresponds to ILIKE. There are also !~~ and !~~* operators that represent NOT LIKE and NOT ILIKE, respectively. All of these operators are PostgreSQL-specific. You may see these operator names in EXPLAIN output and similar places, since the parser actually translates LIKE et al. to these operators.
The phrases LIKE, ILIKE, NOT LIKE, and NOT ILIKE are generally treated as operators in PostgreSQL syntax; for example they can be used in expression operator ANY (subquery) constructs, although an ESCAPE clause cannot be included there. In some obscure cases it may be necessary to use the underlying operator names instead.
Also see the starts-with operator ^@ and the corresponding starts_with() function, which are useful in cases where simply matching the beginning of a string is needed.
9.7.2. SIMILAR TO Regular Expressions
stringSIMILAR TOpattern[ESCAPEescape-character]stringNOT SIMILAR TOpattern[ESCAPEescape-character]
The SIMILAR TO operator returns true or false depending on whether its pattern matches the given string. It is similar to LIKE, except that it interprets the pattern using the SQL standard’s definition of a regular expression. SQL regular expressions are a curious cross between LIKE notation and common (POSIX) regular expression notation.
Like LIKE, the SIMILAR TO operator succeeds only if its pattern matches the entire string; this is unlike common regular expression behavior where the pattern can match any part of the string. Also like LIKE, SIMILAR TO uses _ and % as wildcard characters denoting any single character and any string, respectively (these are comparable to . and .* in POSIX regular expressions).
In addition to these facilities borrowed from LIKE, SIMILAR TO supports these pattern-matching metacharacters borrowed from POSIX regular expressions:
-
|denotes alternation (either of two alternatives). -
*denotes repetition of the previous item zero or more times. -
+denotes repetition of the previous item one or more times. -
?denotes repetition of the previous item zero or one time. -
{m}denotes repetition of the previous item exactlymtimes. -
{m,}denotes repetition of the previous itemmor more times. -
{m,n}denotes repetition of the previous item at leastmand not more thanntimes. -
Parentheses
()can be used to group items into a single logical item. -
A bracket expression
[...]specifies a character class, just as in POSIX regular expressions.
Notice that the period (.) is not a metacharacter for SIMILAR TO.
As with LIKE, a backslash disables the special meaning of any of these metacharacters. A different escape character can be specified with ESCAPE, or the escape capability can be disabled by writing ESCAPE ''.
According to the SQL standard, omitting ESCAPE means there is no escape character (rather than defaulting to a backslash), and a zero-length ESCAPE value is disallowed. PostgreSQL‘s behavior in this regard is therefore slightly nonstandard.
Another nonstandard extension is that following the escape character with a letter or digit provides access to the escape sequences defined for POSIX regular expressions; see Table 9.20, Table 9.21, and Table 9.22 below.
Some examples:
'abc' SIMILAR TO 'abc' true 'abc' SIMILAR TO 'a' false 'abc' SIMILAR TO '%(b|d)%' true 'abc' SIMILAR TO '(b|c)%' false '-abc-' SIMILAR TO '%mabcM%' true 'xabcy' SIMILAR TO '%mabcM%' false
The substring function with three parameters provides extraction of a substring that matches an SQL regular expression pattern. The function can be written according to standard SQL syntax:
substring(stringsimilarpatternescapeescape-character)
or using the now obsolete SQL:1999 syntax:
substring(stringfrompatternforescape-character)
or as a plain three-argument function:
substring(string,pattern,escape-character)
As with SIMILAR TO, the specified pattern must match the entire data string, or else the function fails and returns null. To indicate the part of the pattern for which the matching data sub-string is of interest, the pattern should contain two occurrences of the escape character followed by a double quote ("). The text matching the portion of the pattern between these separators is returned when the match is successful.
The escape-double-quote separators actually divide substring‘s pattern into three independent regular expressions; for example, a vertical bar (|) in any of the three sections affects only that section. Also, the first and third of these regular expressions are defined to match the smallest possible amount of text, not the largest, when there is any ambiguity about how much of the data string matches which pattern. (In POSIX parlance, the first and third regular expressions are forced to be non-greedy.)
As an extension to the SQL standard, PostgreSQL allows there to be just one escape-double-quote separator, in which case the third regular expression is taken as empty; or no separators, in which case the first and third regular expressions are taken as empty.
Some examples, with #" delimiting the return string:
substring('foobar' similar '%#"o_b#"%' escape '#') oob
substring('foobar' similar '#"o_b#"%' escape '#') NULL
9.7.3. POSIX Regular Expressions
Table 9.16 lists the available operators for pattern matching using POSIX regular expressions.
Table 9.16. Regular Expression Match Operators
|
Operator Description Example(s) |
|---|
|
String matches regular expression, case sensitively
|
|
String matches regular expression, case insensitively
|
|
String does not match regular expression, case sensitively
|
|
String does not match regular expression, case insensitively
|
POSIX regular expressions provide a more powerful means for pattern matching than the LIKE and SIMILAR TO operators. Many Unix tools such as egrep, sed, or awk use a pattern matching language that is similar to the one described here.
A regular expression is a character sequence that is an abbreviated definition of a set of strings (a regular set). A string is said to match a regular expression if it is a member of the regular set described by the regular expression. As with LIKE, pattern characters match string characters exactly unless they are special characters in the regular expression language — but regular expressions use different special characters than LIKE does. Unlike LIKE patterns, a regular expression is allowed to match anywhere within a string, unless the regular expression is explicitly anchored to the beginning or end of the string.
Some examples:
'abcd' ~ 'bc' true 'abcd' ~ 'a.c' true — dot matches any character 'abcd' ~ 'a.*d' true —*repeats the preceding pattern item 'abcd' ~ '(b|x)' true —|means OR, parentheses group 'abcd' ~ '^a' true —^anchors to start of string 'abcd' ~ '^(b|c)' false — would match except for anchoring
The POSIX pattern language is described in much greater detail below.
The substring function with two parameters, substring(, provides extraction of a substring that matches a POSIX regular expression pattern. It returns null if there is no match, otherwise the first portion of the text that matched the pattern. But if the pattern contains any parentheses, the portion of the text that matched the first parenthesized subexpression (the one whose left parenthesis comes first) is returned. You can put parentheses around the whole expression if you want to use parentheses within it without triggering this exception. If you need parentheses in the pattern before the subexpression you want to extract, see the non-capturing parentheses described below.string from pattern)
Some examples:
substring('foobar' from 'o.b') oob
substring('foobar' from 'o(.)b') o
The regexp_count function counts the number of places where a POSIX regular expression pattern matches a string. It has the syntax regexp_count(string, pattern [, start [, flags ]]). pattern is searched for in string, normally from the beginning of the string, but if the start parameter is provided then beginning from that character index. The flags parameter is an optional text string containing zero or more single-letter flags that change the function’s behavior. For example, including i in flags specifies case-insensitive matching. Supported flags are described in Table 9.24.
Some examples:
regexp_count('ABCABCAXYaxy', 'A.') 3
regexp_count('ABCABCAXYaxy', 'A.', 1, 'i') 4
The regexp_instr function returns the starting or ending position of the N‘th match of a POSIX regular expression pattern to a string, or zero if there is no such match. It has the syntax regexp_instr(string, pattern [, start [, N [, endoption [, flags [, subexpr ]]]]]). pattern is searched for in string, normally from the beginning of the string, but if the start parameter is provided then beginning from that character index. If N is specified then the N‘th match of the pattern is located, otherwise the first match is located. If the endoption parameter is omitted or specified as zero, the function returns the position of the first character of the match. Otherwise, endoption must be one, and the function returns the position of the character following the match. The flags parameter is an optional text string containing zero or more single-letter flags that change the function’s behavior. Supported flags are described in Table 9.24. For a pattern containing parenthesized subexpressions, subexpr is an integer indicating which subexpression is of interest: the result identifies the position of the substring matching that subexpression. Subexpressions are numbered in the order of their leading parentheses. When subexpr is omitted or zero, the result identifies the position of the whole match regardless of parenthesized subexpressions.
Some examples:
regexp_instr('number of your street, town zip, FR', '[^,]+', 1, 2)
23
regexp_instr('ABCDEFGHI', '(c..)(...)', 1, 1, 0, 'i', 2)
6
The regexp_like function checks whether a match of a POSIX regular expression pattern occurs within a string, returning boolean true or false. It has the syntax regexp_like(string, pattern [, flags ]). The flags parameter is an optional text string containing zero or more single-letter flags that change the function’s behavior. Supported flags are described in Table 9.24. This function has the same results as the ~ operator if no flags are specified. If only the i flag is specified, it has the same results as the ~* operator.
Some examples:
regexp_like('Hello World', 'world') false
regexp_like('Hello World', 'world', 'i') true
The regexp_match function returns a text array of matching substring(s) within the first match of a POSIX regular expression pattern to a string. It has the syntax regexp_match(string, pattern [, flags ]). If there is no match, the result is NULL. If a match is found, and the pattern contains no parenthesized subexpressions, then the result is a single-element text array containing the substring matching the whole pattern. If a match is found, and the pattern contains parenthesized subexpressions, then the result is a text array whose n‘th element is the substring matching the n‘th parenthesized subexpression of the pattern (not counting “non-capturing” parentheses; see below for details). The flags parameter is an optional text string containing zero or more single-letter flags that change the function’s behavior. Supported flags are described in Table 9.24.
Some examples:
SELECT regexp_match('foobarbequebaz', 'bar.*que');
regexp_match
--------------
{barbeque}
(1 row)
SELECT regexp_match('foobarbequebaz', '(bar)(beque)');
regexp_match
--------------
{bar,beque}
(1 row)
Tip
In the common case where you just want the whole matching substring or NULL for no match, the best solution is to use regexp_substr(). However, regexp_substr() only exists in PostgreSQL version 15 and up. When working in older versions, you can extract the first element of regexp_match()‘s result, for example:
SELECT (regexp_match('foobarbequebaz', 'bar.*que'))[1];
regexp_match
--------------
barbeque
(1 row)
The regexp_matches function returns a set of text arrays of matching substring(s) within matches of a POSIX regular expression pattern to a string. It has the same syntax as regexp_match. This function returns no rows if there is no match, one row if there is a match and the g flag is not given, or N rows if there are N matches and the g flag is given. Each returned row is a text array containing the whole matched substring or the substrings matching parenthesized subexpressions of the pattern, just as described above for regexp_match. regexp_matches accepts all the flags shown in Table 9.24, plus the g flag which commands it to return all matches, not just the first one.
Some examples:
SELECT regexp_matches('foo', 'not there');
regexp_matches
----------------
(0 rows)
SELECT regexp_matches('foobarbequebazilbarfbonk', '(b[^b]+)(b[^b]+)', 'g');
regexp_matches
----------------
{bar,beque}
{bazil,barf}
(2 rows)
Tip
In most cases regexp_matches() should be used with the g flag, since if you only want the first match, it’s easier and more efficient to use regexp_match(). However, regexp_match() only exists in PostgreSQL version 10 and up. When working in older versions, a common trick is to place a regexp_matches() call in a sub-select, for example:
SELECT col1, (SELECT regexp_matches(col2, '(bar)(beque)')) FROM tab;
This produces a text array if there’s a match, or NULL if not, the same as regexp_match() would do. Without the sub-select, this query would produce no output at all for table rows without a match, which is typically not the desired behavior.
The regexp_replace function provides substitution of new text for substrings that match POSIX regular expression patterns. It has the syntax regexp_replace(source, pattern, replacement [, start [, N ]] [, flags ]). (Notice that N cannot be specified unless start is, but flags can be given in any case.) The source string is returned unchanged if there is no match to the pattern. If there is a match, the source string is returned with the replacement string substituted for the matching substring. The replacement string can contain n, where n is 1 through 9, to indicate that the source substring matching the n‘th parenthesized subexpression of the pattern should be inserted, and it can contain & to indicate that the substring matching the entire pattern should be inserted. Write \ if you need to put a literal backslash in the replacement text. pattern is searched for in string, normally from the beginning of the string, but if the start parameter is provided then beginning from that character index. By default, only the first match of the pattern is replaced. If N is specified and is greater than zero, then the N‘th match of the pattern is replaced. If the g flag is given, or if N is specified and is zero, then all matches at or after the start position are replaced. (The g flag is ignored when N is specified.) The flags parameter is an optional text string containing zero or more single-letter flags that change the function’s behavior. Supported flags (though not g) are described in Table 9.24.
Some examples:
regexp_replace('foobarbaz', 'b..', 'X')
fooXbaz
regexp_replace('foobarbaz', 'b..', 'X', 'g')
fooXX
regexp_replace('foobarbaz', 'b(..)', 'X1Y', 'g')
fooXarYXazY
regexp_replace('A PostgreSQL function', 'a|e|i|o|u', 'X', 1, 0, 'i')
X PXstgrXSQL fXnctXXn
regexp_replace('A PostgreSQL function', 'a|e|i|o|u', 'X', 1, 3, 'i')
A PostgrXSQL function
The regexp_split_to_table function splits a string using a POSIX regular expression pattern as a delimiter. It has the syntax regexp_split_to_table(string, pattern [, flags ]). If there is no match to the pattern, the function returns the string. If there is at least one match, for each match it returns the text from the end of the last match (or the beginning of the string) to the beginning of the match. When there are no more matches, it returns the text from the end of the last match to the end of the string. The flags parameter is an optional text string containing zero or more single-letter flags that change the function’s behavior. regexp_split_to_table supports the flags described in Table 9.24.
The regexp_split_to_array function behaves the same as regexp_split_to_table, except that regexp_split_to_array returns its result as an array of text. It has the syntax regexp_split_to_array(string, pattern [, flags ]). The parameters are the same as for regexp_split_to_table.
Some examples:
SELECT foo FROM regexp_split_to_table('the quick brown fox jumps over the lazy dog', 's+') AS foo;
foo
-------
the
quick
brown
fox
jumps
over
the
lazy
dog
(9 rows)
SELECT regexp_split_to_array('the quick brown fox jumps over the lazy dog', 's+');
regexp_split_to_array
-----------------------------------------------
{the,quick,brown,fox,jumps,over,the,lazy,dog}
(1 row)
SELECT foo FROM regexp_split_to_table('the quick brown fox', 's*') AS foo;
foo
-----
t
h
e
q
u
i
c
k
b
r
o
w
n
f
o
x
(16 rows)
As the last example demonstrates, the regexp split functions ignore zero-length matches that occur at the start or end of the string or immediately after a previous match. This is contrary to the strict definition of regexp matching that is implemented by the other regexp functions, but is usually the most convenient behavior in practice. Other software systems such as Perl use similar definitions.
The regexp_substr function returns the substring that matches a POSIX regular expression pattern, or NULL if there is no match. It has the syntax regexp_substr(string, pattern [, start [, N [, flags [, subexpr ]]]]). pattern is searched for in string, normally from the beginning of the string, but if the start parameter is provided then beginning from that character index. If N is specified then the N‘th match of the pattern is returned, otherwise the first match is returned. The flags parameter is an optional text string containing zero or more single-letter flags that change the function’s behavior. Supported flags are described in Table 9.24. For a pattern containing parenthesized subexpressions, subexpr is an integer indicating which subexpression is of interest: the result is the substring matching that subexpression. Subexpressions are numbered in the order of their leading parentheses. When subexpr is omitted or zero, the result is the whole match regardless of parenthesized subexpressions.
Some examples:
regexp_substr('number of your street, town zip, FR', '[^,]+', 1, 2)
town zip
regexp_substr('ABCDEFGHI', '(c..)(...)', 1, 1, 'i', 2)
FGH
9.7.3.1. Regular Expression Details
PostgreSQL‘s regular expressions are implemented using a software package written by Henry Spencer. Much of the description of regular expressions below is copied verbatim from his manual.
Regular expressions (REs), as defined in POSIX 1003.2, come in two forms: extended REs or EREs (roughly those of egrep), and basic REs or BREs (roughly those of ed). PostgreSQL supports both forms, and also implements some extensions that are not in the POSIX standard, but have become widely used due to their availability in programming languages such as Perl and Tcl. REs using these non-POSIX extensions are called advanced REs or AREs in this documentation. AREs are almost an exact superset of EREs, but BREs have several notational incompatibilities (as well as being much more limited). We first describe the ARE and ERE forms, noting features that apply only to AREs, and then describe how BREs differ.
Note
PostgreSQL always initially presumes that a regular expression follows the ARE rules. However, the more limited ERE or BRE rules can be chosen by prepending an embedded option to the RE pattern, as described in Section 9.7.3.4. This can be useful for compatibility with applications that expect exactly the POSIX 1003.2 rules.
A regular expression is defined as one or more branches, separated by |. It matches anything that matches one of the branches.
A branch is zero or more quantified atoms or constraints, concatenated. It matches a match for the first, followed by a match for the second, etc.; an empty branch matches the empty string.
A quantified atom is an atom possibly followed by a single quantifier. Without a quantifier, it matches a match for the atom. With a quantifier, it can match some number of matches of the atom. An atom can be any of the possibilities shown in Table 9.17. The possible quantifiers and their meanings are shown in Table 9.18.
A constraint matches an empty string, but matches only when specific conditions are met. A constraint can be used where an atom could be used, except it cannot be followed by a quantifier. The simple constraints are shown in Table 9.19; some more constraints are described later.
Table 9.17. Regular Expression Atoms
| Atom | Description |
|---|---|
(re) |
(where re is any regular expression) matches a match for re, with the match noted for possible reporting |
(?:re) |
as above, but the match is not noted for reporting (a “non-capturing” set of parentheses) (AREs only) |
. |
matches any single character |
[chars] |
a bracket expression, matching any one of the chars (see Section 9.7.3.2 for more detail) |
k |
(where k is a non-alphanumeric character) matches that character taken as an ordinary character, e.g., \ matches a backslash character |
c |
where c is alphanumeric (possibly followed by other characters) is an escape, see Section 9.7.3.3 (AREs only; in EREs and BREs, this matches c) |
{ |
when followed by a character other than a digit, matches the left-brace character {; when followed by a digit, it is the beginning of a bound (see below) |
x |
where x is a single character with no other significance, matches that character |
An RE cannot end with a backslash ().
Table 9.18. Regular Expression Quantifiers
| Quantifier | Matches |
|---|---|
* |
a sequence of 0 or more matches of the atom |
+ |
a sequence of 1 or more matches of the atom |
? |
a sequence of 0 or 1 matches of the atom |
{m} |
a sequence of exactly m matches of the atom |
{m,} |
a sequence of m or more matches of the atom |
{m,n} |
a sequence of m through n (inclusive) matches of the atom; m cannot exceed n |
*? |
non-greedy version of * |
+? |
non-greedy version of + |
?? |
non-greedy version of ? |
{m}? |
non-greedy version of {m} |
{m,}? |
non-greedy version of {m,} |
{m,n}? |
non-greedy version of {m,n} |
The forms using {...} are known as bounds. The numbers m and n within a bound are unsigned decimal integers with permissible values from 0 to 255 inclusive.
Non-greedy quantifiers (available in AREs only) match the same possibilities as their corresponding normal (greedy) counterparts, but prefer the smallest number rather than the largest number of matches. See Section 9.7.3.5 for more detail.
Note
A quantifier cannot immediately follow another quantifier, e.g., ** is invalid. A quantifier cannot begin an expression or subexpression or follow ^ or |.
Table 9.19. Regular Expression Constraints
| Constraint | Description |
|---|---|
^ |
matches at the beginning of the string |
$ |
matches at the end of the string |
(?=re) |
positive lookahead matches at any point where a substring matching re begins (AREs only) |
(?!re) |
negative lookahead matches at any point where no substring matching re begins (AREs only) |
(?<=re) |
positive lookbehind matches at any point where a substring matching re ends (AREs only) |
(?<!re) |
negative lookbehind matches at any point where no substring matching re ends (AREs only) |
Lookahead and lookbehind constraints cannot contain back references (see Section 9.7.3.3), and all parentheses within them are considered non-capturing.
9.7.3.2. Bracket Expressions
A bracket expression is a list of characters enclosed in []. It normally matches any single character from the list (but see below). If the list begins with ^, it matches any single character not from the rest of the list. If two characters in the list are separated by -, this is shorthand for the full range of characters between those two (inclusive) in the collating sequence, e.g., [0-9] in ASCII matches any decimal digit. It is illegal for two ranges to share an endpoint, e.g., a-c-e. Ranges are very collating-sequence-dependent, so portable programs should avoid relying on them.
To include a literal ] in the list, make it the first character (after ^, if that is used). To include a literal -, make it the first or last character, or the second endpoint of a range. To use a literal - as the first endpoint of a range, enclose it in [. and .] to make it a collating element (see below). With the exception of these characters, some combinations using [ (see next paragraphs), and escapes (AREs only), all other special characters lose their special significance within a bracket expression. In particular, is not special when following ERE or BRE rules, though it is special (as introducing an escape) in AREs.
Within a bracket expression, a collating element (a character, a multiple-character sequence that collates as if it were a single character, or a collating-sequence name for either) enclosed in [. and .] stands for the sequence of characters of that collating element. The sequence is treated as a single element of the bracket expression’s list. This allows a bracket expression containing a multiple-character collating element to match more than one character, e.g., if the collating sequence includes a ch collating element, then the RE [[.ch.]]*c matches the first five characters of chchcc.
Note
PostgreSQL currently does not support multi-character collating elements. This information describes possible future behavior.
Within a bracket expression, a collating element enclosed in [= and =] is an equivalence class, standing for the sequences of characters of all collating elements equivalent to that one, including itself. (If there are no other equivalent collating elements, the treatment is as if the enclosing delimiters were [. and .].) For example, if o and ^ are the members of an equivalence class, then [[=o=]], [[=^=]], and [o^] are all synonymous. An equivalence class cannot be an endpoint of a range.
Within a bracket expression, the name of a character class enclosed in [: and :] stands for the list of all characters belonging to that class. A character class cannot be used as an endpoint of a range. The POSIX standard defines these character class names: alnum (letters and numeric digits), alpha (letters), blank (space and tab), cntrl (control characters), digit (numeric digits), graph (printable characters except space), lower (lower-case letters), print (printable characters including space), punct (punctuation), space (any white space), upper (upper-case letters), and xdigit (hexadecimal digits). The behavior of these standard character classes is generally consistent across platforms for characters in the 7-bit ASCII set. Whether a given non-ASCII character is considered to belong to one of these classes depends on the collation that is used for the regular-expression function or operator (see Section 24.2), or by default on the database’s LC_CTYPE locale setting (see Section 24.1). The classification of non-ASCII characters can vary across platforms even in similarly-named locales. (But the C locale never considers any non-ASCII characters to belong to any of these classes.) In addition to these standard character classes, PostgreSQL defines the word character class, which is the same as alnum plus the underscore (_) character, and the ascii character class, which contains exactly the 7-bit ASCII set.
There are two special cases of bracket expressions: the bracket expressions [[:<:]] and [[:>:]] are constraints, matching empty strings at the beginning and end of a word respectively. A word is defined as a sequence of word characters that is neither preceded nor followed by word characters. A word character is any character belonging to the word character class, that is, any letter, digit, or underscore. This is an extension, compatible with but not specified by POSIX 1003.2, and should be used with caution in software intended to be portable to other systems. The constraint escapes described below are usually preferable; they are no more standard, but are easier to type.
9.7.3.3. Regular Expression Escapes
Escapes are special sequences beginning with followed by an alphanumeric character. Escapes come in several varieties: character entry, class shorthands, constraint escapes, and back references. A followed by an alphanumeric character but not constituting a valid escape is illegal in AREs. In EREs, there are no escapes: outside a bracket expression, a followed by an alphanumeric character merely stands for that character as an ordinary character, and inside a bracket expression, is an ordinary character. (The latter is the one actual incompatibility between EREs and AREs.)
Character-entry escapes exist to make it easier to specify non-printing and other inconvenient characters in REs. They are shown in Table 9.20.
Class-shorthand escapes provide shorthands for certain commonly-used character classes. They are shown in Table 9.21.
A constraint escape is a constraint, matching the empty string if specific conditions are met, written as an escape. They are shown in Table 9.22.
A back reference (n) matches the same string matched by the previous parenthesized subexpression specified by the number n (see Table 9.23). For example, ([bc])1 matches bb or cc but not bc or cb. The subexpression must entirely precede the back reference in the RE. Subexpressions are numbered in the order of their leading parentheses. Non-capturing parentheses do not define subexpressions. The back reference considers only the string characters matched by the referenced subexpression, not any constraints contained in it. For example, (^d)1 will match 22.
Table 9.20. Regular Expression Character-Entry Escapes
| Escape | Description |
|---|---|
a |
alert (bell) character, as in C |
b |
backspace, as in C |
B |
synonym for backslash ( |
cX |
(where X is any character) the character whose low-order 5 bits are the same as those of X, and whose other bits are all zero |
e |
the character whose collating-sequence name is ESC, or failing that, the character with octal value 033 |
f |
form feed, as in C |
n |
newline, as in C |
r |
carriage return, as in C |
t |
horizontal tab, as in C |
uwxyz |
(where wxyz is exactly four hexadecimal digits) the character whose hexadecimal value is 0xwxyz |
Ustuvwxyz |
(where stuvwxyz is exactly eight hexadecimal digits) the character whose hexadecimal value is 0xstuvwxyz |
v |
vertical tab, as in C |
xhhh |
(where hhh is any sequence of hexadecimal digits) the character whose hexadecimal value is 0xhhh (a single character no matter how many hexadecimal digits are used) |
|
the character whose value is 0 (the null byte) |
xy |
(where xy is exactly two octal digits, and is not a back reference) the character whose octal value is 0xy |
xyz |
(where xyz is exactly three octal digits, and is not a back reference) the character whose octal value is 0xyz |
Hexadecimal digits are 0—9, a—f, and A—F. Octal digits are 0—7.
Numeric character-entry escapes specifying values outside the ASCII range (0–127) have meanings dependent on the database encoding. When the encoding is UTF-8, escape values are equivalent to Unicode code points, for example u1234 means the character U+1234. For other multibyte encodings, character-entry escapes usually just specify the concatenation of the byte values for the character. If the escape value does not correspond to any legal character in the database encoding, no error will be raised, but it will never match any data.
The character-entry escapes are always taken as ordinary characters. For example, 135 is ] in ASCII, but 135 does not terminate a bracket expression.
Table 9.21. Regular Expression Class-Shorthand Escapes
| Escape | Description |
|---|---|
d |
matches any digit, like [[:digit:]] |
s |
matches any whitespace character, like [[:space:]] |
w |
matches any word character, like [[:word:]] |
D |
matches any non-digit, like [^[:digit:]] |
S |
matches any non-whitespace character, like [^[:space:]] |
W |
matches any non-word character, like [^[:word:]] |
The class-shorthand escapes also work within bracket expressions, although the definitions shown above are not quite syntactically valid in that context. For example, [a-cd] is equivalent to [a-c[:digit:]].
Table 9.22. Regular Expression Constraint Escapes
| Escape | Description |
|---|---|
A |
matches only at the beginning of the string (see Section 9.7.3.5 for how this differs from ^) |
m |
matches only at the beginning of a word |
M |
matches only at the end of a word |
y |
matches only at the beginning or end of a word |
Y |
matches only at a point that is not the beginning or end of a word |
Z |
matches only at the end of the string (see Section 9.7.3.5 for how this differs from $) |
A word is defined as in the specification of [[:<:]] and [[:>:]] above. Constraint escapes are illegal within bracket expressions.
Table 9.23. Regular Expression Back References
| Escape | Description |
|---|---|
m |
(where m is a nonzero digit) a back reference to the m‘th subexpression |
mnn |
(where m is a nonzero digit, and nn is some more digits, and the decimal value mnn is not greater than the number of closing capturing parentheses seen so far) a back reference to the mnn‘th subexpression |
Note
There is an inherent ambiguity between octal character-entry escapes and back references, which is resolved by the following heuristics, as hinted at above. A leading zero always indicates an octal escape. A single non-zero digit, not followed by another digit, is always taken as a back reference. A multi-digit sequence not starting with a zero is taken as a back reference if it comes after a suitable subexpression (i.e., the number is in the legal range for a back reference), and otherwise is taken as octal.
9.7.3.5. Regular Expression Matching Rules
In the event that an RE could match more than one substring of a given string, the RE matches the one starting earliest in the string. If the RE could match more than one substring starting at that point, either the longest possible match or the shortest possible match will be taken, depending on whether the RE is greedy or non-greedy.
Whether an RE is greedy or not is determined by the following rules:
-
Most atoms, and all constraints, have no greediness attribute (because they cannot match variable amounts of text anyway).
-
Adding parentheses around an RE does not change its greediness.
-
A quantified atom with a fixed-repetition quantifier (
{m}or{m}?) has the same greediness (possibly none) as the atom itself. -
A quantified atom with other normal quantifiers (including
{m,n}withmequal ton) is greedy (prefers longest match). -
A quantified atom with a non-greedy quantifier (including
{m,n}?withmequal ton) is non-greedy (prefers shortest match). -
A branch — that is, an RE that has no top-level
|operator — has the same greediness as the first quantified atom in it that has a greediness attribute. -
An RE consisting of two or more branches connected by the
|operator is always greedy.
The above rules associate greediness attributes not only with individual quantified atoms, but with branches and entire REs that contain quantified atoms. What that means is that the matching is done in such a way that the branch, or whole RE, matches the longest or shortest possible substring as a whole. Once the length of the entire match is determined, the part of it that matches any particular subexpression is determined on the basis of the greediness attribute of that subexpression, with subexpressions starting earlier in the RE taking priority over ones starting later.
An example of what this means:
SELECT SUBSTRING('XY1234Z', 'Y*([0-9]{1,3})');
Result: 123
SELECT SUBSTRING('XY1234Z', 'Y*?([0-9]{1,3})');
Result: 1
In the first case, the RE as a whole is greedy because Y* is greedy. It can match beginning at the Y, and it matches the longest possible string starting there, i.e., Y123. The output is the parenthesized part of that, or 123. In the second case, the RE as a whole is non-greedy because Y*? is non-greedy. It can match beginning at the Y, and it matches the shortest possible string starting there, i.e., Y1. The subexpression [0-9]{1,3} is greedy but it cannot change the decision as to the overall match length; so it is forced to match just 1.
In short, when an RE contains both greedy and non-greedy subexpressions, the total match length is either as long as possible or as short as possible, according to the attribute assigned to the whole RE. The attributes assigned to the subexpressions only affect how much of that match they are allowed to “eat” relative to each other.
The quantifiers {1,1} and {1,1}? can be used to force greediness or non-greediness, respectively, on a subexpression or a whole RE. This is useful when you need the whole RE to have a greediness attribute different from what’s deduced from its elements. As an example, suppose that we are trying to separate a string containing some digits into the digits and the parts before and after them. We might try to do that like this:
SELECT regexp_match('abc01234xyz', '(.*)(d+)(.*)');
Result: {abc0123,4,xyz}
That didn’t work: the first .* is greedy so it “eats” as much as it can, leaving the d+ to match at the last possible place, the last digit. We might try to fix that by making it non-greedy:
SELECT regexp_match('abc01234xyz', '(.*?)(d+)(.*)');
Result: {abc,0,""}
That didn’t work either, because now the RE as a whole is non-greedy and so it ends the overall match as soon as possible. We can get what we want by forcing the RE as a whole to be greedy:
SELECT regexp_match('abc01234xyz', '(?:(.*?)(d+)(.*)){1,1}');
Result: {abc,01234,xyz}
Controlling the RE’s overall greediness separately from its components’ greediness allows great flexibility in handling variable-length patterns.
When deciding what is a longer or shorter match, match lengths are measured in characters, not collating elements. An empty string is considered longer than no match at all. For example: bb* matches the three middle characters of abbbc; (week|wee)(night|knights) matches all ten characters of weeknights; when (.*).* is matched against abc the parenthesized subexpression matches all three characters; and when (a*)* is matched against bc both the whole RE and the parenthesized subexpression match an empty string.
If case-independent matching is specified, the effect is much as if all case distinctions had vanished from the alphabet. When an alphabetic that exists in multiple cases appears as an ordinary character outside a bracket expression, it is effectively transformed into a bracket expression containing both cases, e.g., x becomes [xX]. When it appears inside a bracket expression, all case counterparts of it are added to the bracket expression, e.g., [x] becomes [xX] and [^x] becomes [^xX].
If newline-sensitive matching is specified, . and bracket expressions using ^ will never match the newline character (so that matches will not cross lines unless the RE explicitly includes a newline) and ^ and $ will match the empty string after and before a newline respectively, in addition to matching at beginning and end of string respectively. But the ARE escapes A and Z continue to match beginning or end of string only. Also, the character class shorthands D and W will match a newline regardless of this mode. (Before PostgreSQL 14, they did not match newlines when in newline-sensitive mode. Write [^[:digit:]] or [^[:word:]] to get the old behavior.)
If partial newline-sensitive matching is specified, this affects . and bracket expressions as with newline-sensitive matching, but not ^ and $.
If inverse partial newline-sensitive matching is specified, this affects ^ and $ as with newline-sensitive matching, but not . and bracket expressions. This isn’t very useful but is provided for symmetry.
9.7.3.6. Limits and Compatibility
No particular limit is imposed on the length of REs in this implementation. However, programs intended to be highly portable should not employ REs longer than 256 bytes, as a POSIX-compliant implementation can refuse to accept such REs.
The only feature of AREs that is actually incompatible with POSIX EREs is that does not lose its special significance inside bracket expressions. All other ARE features use syntax which is illegal or has undefined or unspecified effects in POSIX EREs; the *** syntax of directors likewise is outside the POSIX syntax for both BREs and EREs.
Many of the ARE extensions are borrowed from Perl, but some have been changed to clean them up, and a few Perl extensions are not present. Incompatibilities of note include b, B, the lack of special treatment for a trailing newline, the addition of complemented bracket expressions to the things affected by newline-sensitive matching, the restrictions on parentheses and back references in lookahead/lookbehind constraints, and the longest/shortest-match (rather than first-match) matching semantics.
9.7.3.7. Basic Regular Expressions
BREs differ from EREs in several respects. In BREs, |, +, and ? are ordinary characters and there is no equivalent for their functionality. The delimiters for bounds are { and }, with { and } by themselves ordinary characters. The parentheses for nested subexpressions are ( and ), with ( and ) by themselves ordinary characters. ^ is an ordinary character except at the beginning of the RE or the beginning of a parenthesized subexpression, $ is an ordinary character except at the end of the RE or the end of a parenthesized subexpression, and * is an ordinary character if it appears at the beginning of the RE or the beginning of a parenthesized subexpression (after a possible leading ^). Finally, single-digit back references are available, and < and > are synonyms for [[:<:]] and [[:>:]] respectively; no other escapes are available in BREs.
9.7.3.8. Differences from SQL Standard and XQuery
Since SQL:2008, the SQL standard includes regular expression operators and functions that performs pattern matching according to the XQuery regular expression standard:
-
LIKE_REGEX -
OCCURRENCES_REGEX -
POSITION_REGEX -
SUBSTRING_REGEX -
TRANSLATE_REGEX
PostgreSQL does not currently implement these operators and functions. You can get approximately equivalent functionality in each case as shown in Table 9.25. (Various optional clauses on both sides have been omitted in this table.)
Table 9.25. Regular Expression Functions Equivalencies
| SQL standard | PostgreSQL |
|---|---|
|
regexp_like( or |
OCCURRENCES_REGEX( |
regexp_count( |
POSITION_REGEX( |
regexp_instr( |
SUBSTRING_REGEX( |
regexp_substr( |
TRANSLATE_REGEX( |
regexp_replace( |
Regular expression functions similar to those provided by PostgreSQL are also available in a number of other SQL implementations, whereas the SQL-standard functions are not as widely implemented. Some of the details of the regular expression syntax will likely differ in each implementation.
The SQL-standard operators and functions use XQuery regular expressions, which are quite close to the ARE syntax described above. Notable differences between the existing POSIX-based regular-expression feature and XQuery regular expressions include:
-
XQuery character class subtraction is not supported. An example of this feature is using the following to match only English consonants:
[a-z-[aeiou]]. -
XQuery character class shorthands
c,C,i, andIare not supported. -
XQuery character class elements using
p{UnicodeProperty}or the inverseP{UnicodeProperty}are not supported. -
POSIX interprets character classes such as
w(see Table 9.21) according to the prevailing locale (which you can control by attaching aCOLLATEclause to the operator or function). XQuery specifies these classes by reference to Unicode character properties, so equivalent behavior is obtained only with a locale that follows the Unicode rules. -
The SQL standard (not XQuery itself) attempts to cater for more variants of “newline” than POSIX does. The newline-sensitive matching options described above consider only ASCII NL (
n) to be a newline, but SQL would have us treat CR (r), CRLF (rn) (a Windows-style newline), and some Unicode-only characters like LINE SEPARATOR (U+2028) as newlines as well. Notably,.andsshould countrnas one character not two according to SQL. -
Of the character-entry escapes described in Table 9.20, XQuery supports only
n,r, andt. -
XQuery does not support the
[:syntax for character classes within bracket expressions.name:] -
XQuery does not have lookahead or lookbehind constraints, nor any of the constraint escapes described in Table 9.22.
-
The metasyntax forms described in Section 9.7.3.4 do not exist in XQuery.
-
The regular expression flag letters defined by XQuery are related to but not the same as the option letters for POSIX (Table 9.24). While the
iandqoptions behave the same, others do not:-
XQuery’s
s(allow dot to match newline) andm(allow^and$to match at newlines) flags provide access to the same behaviors as POSIX’sn,pandwflags, but they do not match the behavior of POSIX’ssandmflags. Note in particular that dot-matches-newline is the default behavior in POSIX but not XQuery. -
XQuery’s
x(ignore whitespace in pattern) flag is noticeably different from POSIX’s expanded-mode flag. POSIX’sxflag also allows#to begin a comment in the pattern, and POSIX will not ignore a whitespace character after a backslash.
-