
In a general case, as the title mentions, you may capture with (.*) pattern any 0 or more chars other than newline after any pattern(s) you want:
import re
p = re.compile(r'tests*:s*(.*)')
s = "test : match this."
m = p.search(s) # Run a regex search anywhere inside a string
if m: # If there is a match
print(m.group(1)) # Print Group 1 value
If you want . to match across multiple lines, compile the regex with re.DOTALL or re.S flag (or add (?s) before the pattern):
p = re.compile(r'tests*:s*(.*)', re.DOTALL)
p = re.compile(r'(?s)tests*:s*(.*)')
However, it will retrun match this.. See also a regex demo.
You can add . pattern after (.*) to make the regex engine stop before the last . on that line:
tests*:s*(.*).
Watch out for re.match() since it will only look for a match at the beginning of the string (Avinash aleady pointed that out, but it is a very important note!)
See the regex demo and a sample Python code snippet:
import re
p = re.compile(r'tests*:s*(.*).')
s = "test : match this."
m = p.search(s) # Run a regex search anywhere inside a string
if m: # If there is a match
print(m.group(1)) # Print Group 1 value
If you want to make sure test is matched as a whole word, add b before it (do not remove the r prefix from the string literal, or 'b' will match a BACKSPACE char!) — r'btests*:s*(.*).'.
Регулярные выражения (регулярные выражения) — это специальные последовательности символов, используемые для поиска или сопоставления шаблонов в строках, как объясняется в этом введении в регулярные выражения. Ранее мы показали, как использовать регулярные выражения в JavaScript и PHP. В центре внимания этой статьи — регулярные выражения Python, цель которых — помочь вам лучше понять, как работать с регулярными выражениями в Python.
Вы узнаете, как эффективно использовать функции и методы регулярных выражений Python в своих программах, поскольку мы рассмотрим нюансы, связанные с обработкой объектов регулярных выражений Python.
Содержание
- Модули регулярных выражений в Python: re и regex
- Встроенный модуль re Python
- Подборка функций
- re.search(pattern, string, flags=0) vs re.match(pattern, string, flags=0)
- re.compile (шаблон, флаги = 0)
- re.fullmatch(pattern, string, flags=0)
- re.findall(pattern, string, flags=0)
- re.sub(pattern, repl, string, count=0, flags=0)
- subn(pattern, repl, string, count=0, flags=0)
- Сопоставьте объекты и методы
- Match.group([group1, …])
- Match.groups(default=None)
- Match.start([group]) & Match.end([group])
- Pattern.search(string[, pos[, endpos]])
- re Regex Flags
- re.I (re.IGNORECASE)
- re.S (ре.DOTALL)
- re.M (re.MULTILINE)
- re.X (re.VERBOSE)
- Практические примеры регулярных выражений в Python
- Регулярное выражение проверки надежности пароля Python
- Поиск и замена Python в регулярном выражении файла
- Регулярное выражение веб-скрейпинга Python
- Заключение
Модули регулярных выражений в Python: re и regex
В Python есть два модуля — reи regex— которые облегчают работу с регулярными выражениями. Модуль reвстроен в Python, а сам regexмодуль был разработан Мэтью Барнеттом и доступен на PyPI. Модуль regexBarnett разработан с использованием встроенного reмодуля, и оба модуля имеют схожие функциональные возможности. Они различаются по реализации. Встроенный reмодуль является более популярным из двух, поэтому здесь мы будем работать с ним.
Встроенный модуль re Python
Чаще всего разработчики Python используют этот reмодуль при выполнении регулярных выражений. Общая конструкция синтаксиса регулярных выражений остается прежней (символы и символы), но модуль предоставляет некоторые функции и методы для эффективного выполнения регулярных выражений в программе Python.
Прежде чем мы сможем использовать reмодуль, мы должны импортировать его в наш файл, как и любой другой модуль или библиотеку Python:
import re
Это делает модуль доступным в текущем файле, чтобы функции и методы регулярных выражений Python были легко доступны. С помощью reмодуля мы можем создавать объекты регулярных выражений Python, манипулировать соответствующими объектами и применять флаги, где это необходимо.
Подборка функций
Модуль reимеет такие функции, как re.search(), re.match()и re.compile(), которые мы обсудим в первую очередь.
re.search(pattern, string, flags=0) vs re.match(pattern, string, flags=0)
И ищет в строке шаблон регулярного выражения Python и возвращает совпадение, если оно найдено или re.search()если объект совпадения не найден.re.match()None
Обе функции всегда возвращают первую совпадающую подстроку, найденную в заданной строке, и поддерживают значение по умолчанию 0для флага. Но пока search()функция просматривает всю строку, чтобы найти совпадение, match()ищет совпадение только в начале строки.
Просканируйте строку в поисках первого места, где шаблон регулярного выражения создает совпадение, и верните соответствующий объект совпадения. Возврат None, если ни одна позиция в строке не соответствует шаблону; обратите внимание, что это отличается от поиска совпадения нулевой длины в какой-либо точке строки.
Если ноль или более символов в начале строки соответствуют шаблону регулярного выражения, вернуть соответствующий объект соответствия. Возврат None, если строка не соответствует шаблону; обратите внимание, что это отличается от совпадения нулевой длины.
Давайте посмотрим на несколько примеров кода для дальнейшего пояснения:
search_result = [re.search](http://re.search)(r'd{2}', 'I live at 22 Garden Road, East Legon') print(search_result) print(search_result.group()) >>>> <re.Match object; span=(10, 12), match='22'> 22
match_result = re.match(r'd{2}', 'I live at 22 Garden Road, East Legon') print(match_result) print(match_result.group()) >>>> None Traceback (most recent call last): File "/home/ini/Dev./sitepoint/regex.py", line 4, in <module> print(match_result.group()) AttributeError: 'NoneType' object has no attribute 'group'
Из приведенного выше примера Noneбыло возвращено, поскольку в начале строки не было совпадения. Возникло AttributeErrorпри group()вызове метода, потому что нет объекта соответствия:
match_result = re.match(r'd{2}', "45 cars were used for the president's convoy") print(match_result) print(match_result.group()) >>>> <re.Match object; span=(0, 2), match='45'> 45
С 45, объектом соответствия в начале строки, match()метод работает просто отлично.
re.compile (шаблон, флаги = 0)
Функция compile()берет заданный шаблон регулярного выражения и компилирует его в объект регулярного выражения, используемый для поиска соответствия в строке или тексте. Он также принимает a flagв качестве необязательного второго аргумента. Этот метод полезен, потому что объект регулярного выражения можно присвоить переменной и использовать позже в нашем коде Python. Всегда не забывайте использовать необработанную строку r»…«при создании объекта регулярного выражения Python.
Вот пример того, как это работает:
regex_object = re.compile(r'b[ae]t') mo = regex_object.search('I bet, you would not let a bat be your president') print(regex_object) >>>> re.compile('b[ae]t')
re.fullmatch(pattern, string, flags=0)
Эта функция принимает два аргумента: строку, передаваемую как шаблон регулярного выражения, строку для поиска и необязательный аргумент флага. Объект соответствия возвращается, если вся строка соответствует заданному шаблону регулярного выражения. Если совпадений нет, возвращается None:
regex_object = re.compile(r'Tech is the future') mo = regex_object.fullmatch('Tech is the future, join now') print(mo) print([mo.group](http://mo.group)()) >>>> None Traceback (most recent call last): File "/home/ini/Dev./sitepoint/regex.py", line 16, in <module> print([mo.group](http://mo.group)()) AttributeError: 'NoneType' object has no attribute 'group'
Код вызывает AttributeError, потому что нет совпадения строк.
re.findall(pattern, string, flags=0)
Функция findall()возвращает список всех объектов соответствия, найденных в заданной строке. Он проходит по строке слева направо, пока не будут возвращены все совпадения. См. фрагмент кода ниже:
regex_object = re.compile(r'[A-Z]w+') mo = regex_object.findall('Pick out all the Words that Begin with a Capital letter') print(mo) >>>> ['Pick', 'Words', 'Begin', 'Capital']
В приведенном выше фрагменте кода регулярное выражение состоит из класса символов и символа слова, что гарантирует, что совпадающая подстрока начинается с заглавной буквы.
re.sub(pattern, repl, string, count=0, flags=0)
Части строки можно заменить другой подстрокой с помощью sub()функции. Он принимает как минимум три аргумента: шаблон поиска, строку замены и строку, над которой нужно работать. Исходная строка возвращается без изменений, если совпадений не найдено. Без передачи аргумента счетчика функция по умолчанию находит одно или несколько вхождений регулярного выражения и заменяет все совпадения.
Вот пример:
regex_object = re.compile(r'disagreed') mo = regex_object.sub('agreed',"The founder and the CEO disagreed on the company's new direction, the investors disagreed too.") print(mo) >>>> The founder and the CEO agreed on the company's new direction, the investors agreed too.
subn(pattern, repl, string, count=0, flags=0)
Функция subn()выполняет ту же операцию, что и sub(), но возвращает кортеж со строкой и номером произведенной замены. См. фрагмент кода ниже:
regex_object = re.compile(r'disagreed') mo = regex_object.subn('agreed',"The founder and the CEO disagreed on the company's new direction, the investors disagreed too.") print(mo) >>>> ("The founder and the CEO agreed on the company's new direction, the investors agreed too.", 2)
Сопоставьте объекты и методы
Объект соответствия возвращается, когда шаблон регулярного выражения соответствует заданной строке в методе search()или объекта регулярного выражения. match()Объекты Match имеют несколько методов, которые оказываются полезными при работе с регулярными выражениями в Python.
Match.group([group1, …])
Этот метод возвращает одну или несколько подгрупп объекта соответствия. Один аргумент вернет подгруппу сигнала; несколько аргументов вернут несколько подгрупп на основе их индексов. По умолчанию group()метод возвращает всю подстроку совпадения. Когда аргумент в group()больше или меньше, чем в подгруппах, генерируется IndexErrorисключение.
Вот пример:
regex_object = re.compile(r'(+d{3}) (d{2} d{3} d{4})') mo = regex_object.search('Pick out the country code from the phone number: +233 54 502 9074') print([mo.group](http://mo.group)(1)) >>>> +233
Аргумент, 1переданный в group(1)метод, как видно из приведенного выше примера, выбирает код страны для Ганы +233. Вызов метода без аргумента или 0в качестве аргумента возвращает все подгруппы объекта соответствия:
regex_object = re.compile(r'(+d{3}) (d{2} d{3} d{4})') mo = regex_object.search('Pick out the phone number: +233 54 502 9074') print([mo.group](http://mo.group)()) >>>> +233 54 502 9074
Match.groups(default=None)
groups()возвращает кортеж подгрупп, соответствующих заданной строке. Группы шаблонов регулярных выражений всегда заключаются в круглые скобки — ()— и эти группы возвращаются при совпадении как элементы кортежа:
regex_object = re.compile(r'(+d{3}) (d{2}) (d{3}) (d{4})') mo = regex_object.search('Pick out the phone number: +233 54 502 9074') print(mo.groups()) >>>> ('+233', '54', '502', '9074')
Match.start([group]) & Match.end([group])
Метод start()возвращает начальный индекс, а end()метод возвращает конечный индекс объекта соответствия:
regex_object = re.compile(r'sw+') mo = regex_object.search('Match any word after a space') print('Match begins at', mo.start(), 'and ends', mo.end()) print([mo.group](http://mo.group)()) >>>> Match begins at 5 and ends 9 any
В приведенном выше примере есть шаблон регулярного выражения для сопоставления любого символа слова после пробела. Найдено совпадение — ’ any’— начиная с позиции 5 и заканчивая 9.
Pattern.search(string[, pos[, endpos]])
Значение posуказывает позицию индекса, с которой должен начинаться поиск объекта совпадения. endposуказывает, где должен остановиться поиск соответствия. Значение для обоих posи endposможет быть передано в качестве аргументов в методы search()или match()после строки. Вот как это работает:
regex_object = re.compile(r'[a-z]+[0-9]') mo = regex_object.search('find the alphanumeric character python3 in the string', 20 , 30) print([mo.group](http://mo.group)()) >>>> python3
Приведенный выше код выбирает любой буквенно-цифровой символ в строке поиска.
Поиск начинается с 20-й позиции индекса строки и останавливается на 30-й.
re Regex Flags
Python позволяет использовать флаги при использовании reметодов модуля, таких как search()и match(), что дает больше контекста для регулярных выражений. Флаги — это необязательные аргументы, которые определяют, как механизм регулярных выражений Python находит объект соответствия.
re.I (re.IGNORECASE)
Этот флаг используется при выполнении совпадения без учета регистра. Механизм регулярных выражений будет игнорировать прописные или строчные буквы шаблонов регулярных выражений:
regex_object = [re.search](http://re.search)('django', 'My tech stack comprises of python, Django, MySQL, AWS, React', re.I) print(regex_object.group()) >>>> Django
re.Iгарантирует, что объект соответствия будет найден, независимо от того, в верхнем или нижнем регистре он находится.
re.S (ре.DOTALL)
Специальный ’.’символ соответствует любому символу, кроме новой строки. Введение этого флага также будет соответствовать новой строке в блоке текста или строки. См. пример ниже:
regex_object= [re.search](http://re.search)('.+', 'What is your favourite coffee flavor nI prefer the Mocha') print(regex_object.group()) >>>> What is your favourite coffee flavor
Символ ’.’находит совпадение только с начала строки и останавливается на новой строке. Введение re.DOTALLфлага будет соответствовать символу новой строки. См. пример ниже:
regex_object= [re.search](http://re.search)('.+', 'What is your favourite coffee flavor nI prefer the Mocha', re.S) print(regex_object.group()) >>>> What is your favourite coffee flavor I prefer the Mocha
re.M (re.MULTILINE)
По умолчанию ’^’специальный символ соответствует только началу строки. С введением этого флага функция ищет совпадение в начале каждой строки. Символ ’$’соответствует шаблону только в конце строки. Но re.Mфлаг гарантирует, что он также находит совпадения в конце каждой строки:
regex_object = [re.search](http://re.search)('^Jw+', 'Popular programming languages in 2022: nPython nJavaScript nJava nRust nRuby', re.M) print(regex_object.group()) >>>> JavaScript
re.X (re.VERBOSE)
Иногда шаблоны регулярных выражений Python могут быть длинными и запутанными. Флаг re.Xпомогает, когда нам нужно добавить комментарии в наш шаблон регулярного выражения. Мы можем использовать ’’’строковый формат для создания многострочного регулярного выражения с комментариями:
email_regex = [re.search](http://re.search)(r''' [a-zA-Z0-9._%+-]+ # username composed of alphanumeric characters @ # @ symbol [a-zA-Z0-9.-]+ # domain name has word characters (.[a-zA-Z]{2,4}) # dot-something ''', 'extract the email address in this string [kwekujohnson1@gmail.com](mailto:kwekujohnson1@gmail.com) and send an email', re.X) print(email_regex.group()) >>>> [kwekujohnson1@gmail.com](mailto:kwekujohnson1@gmail.com)
Практические примеры регулярных выражений в Python
Давайте теперь погрузимся в некоторые более практические примеры.
Регулярное выражение проверки надежности пароля Python
Одним из самых популярных вариантов использования регулярных выражений является проверка надежности пароля. При регистрации любой новой учетной записи существует проверка, чтобы убедиться, что мы вводим соответствующую комбинацию букв, цифр и символов для обеспечения надежного пароля.
Вот пример регулярного выражения для проверки надежности пароля:
password_regex = re.match(r""" ^(?=.*?[A-Z]) # this ensures user inputs at least one uppercase letter (?=.*?[a-z]) # this ensures user inputs at least one lowercase letter (?=.*?[0-9]) # this ensures user inputs at least one digit (?=.*?[#?!@$%^&*-]) # this ensures user inputs one special character .{8,}$ #this ensures that password is at least 8 characters long """, '@Sit3po1nt', re.X) print('Your password is' ,password_regex.group()) >>>> Your password is @Sit3po1nt
Обратите внимание на использование ’^’и ’$’, чтобы убедиться, что входная строка (пароль) соответствует регулярному выражению.
Поиск и замена Python в регулярном выражении файла
Вот наша цель для этого примера:
- Создайте файл «pangram.txt».
- Добавьте простой текст в файл,»The five boxing wizards climb quickly.»
- Напишите простое регулярное выражение Python для поиска и замены слова «взбираться» на слово «прыжок», чтобы получилась панграмма.
Вот код для этого:
#importing the regex module import re file_path="pangram.txt" text="climb" subs="jump" #defining the replace method def search_and_replace(filePath, text, subs, flags=0): with open(file_path, "r+") as file: #read the file contents file_contents = [file.read](http://file.read)() text_pattern = re.compile(re.escape(text), flags) file_contents = text_pattern.sub(subs, file_contents) [file.seek](http://file.seek)(0) file.truncate() file.write(file_contents) #calling the search_and_replace method search_and_replace(file_path, text, subs)
Регулярное выражение веб-скрейпинга Python
Иногда вам может понадобиться собрать некоторые данные в Интернете или автоматизировать простые задачи, такие как просмотр веб-страниц. Регулярные выражения очень полезны при извлечении определенных данных онлайн. Ниже приведен пример:
import urllib.request phone_number_regex = r'(d{3}) d{3}-d{4}' url = 'https://www.summet.com/dmsi/html/codesamples/addresses.html' # get response response = urllib.request.urlopen(url) # convert response to string string_object = [response.read](http://response.read)().decode("utf8") # use regex to extract phone numbers regex_object = re.compile(phone_regex) mo = regex_object.findall(string_object) # print top 5 phone numbers print(mo[: 5]) >>>> ['(257) 563-7401', '(372) 587-2335', '(786) 713-8616', '(793) 151-6230', '(492) 709-6392']
Заключение
Регулярные выражения могут варьироваться от простых до сложных. Как показывают приведенные выше примеры, они являются жизненно важной частью программирования. Чтобы лучше понять регулярное выражение в Python, хорошо бы начать со знакомства с такими вещами, как классы символов, специальные символы, якоря и конструкции группировки.
Мы можем пойти намного дальше, чтобы углубить наше понимание регулярных выражений в Python. Модуль Python reупрощает и ускоряет запуск.
Regex значительно сокращает объем кода, который нам нужно написать для таких вещей, как проверка ввода и реализация алгоритмов поиска.
Также хорошо иметь возможность отвечать на вопросы об использовании регулярных выражений, так как они часто возникают на технических собеседованиях с инженерами и разработчиками программного обеспечения.
w represents a word character, not a word in the sense you mean. That is, a single letter, from a-z and A-Z.
To match your requirement, specify ^(w+) (.*)$.
This breaks down to:
^ — The beginning of a string
( — Begin a capture group
w — Any character matching a-z or A-Z
+ — At least 1 or more of the previous type
) — End our capture group
— A space character
( — Begin our second capture group
. — Any non-newline character
* — 0 or more of the previous type
) — End the capture group
$ — End of the string
This will match, using your example sentence How to match a word followed by anything, Group 1 = How and Group 2 = to match a word followed by anything
Assuming you wanted to remove the first word, you could now use 2 in the replace field, to replace all matches with everything apart from the first word.
Or, looking at your first sentence again and you want to actually put brackets around the first word and then the rest of the sentence, replace with (1) (2) — that is, literal left parenthesis, capture group 1, literal right parenthesis, space, literal left parenthesis, capture group 2, literal right parenthesis.
Regular expression: Match everything after a particular word
Comment
0
Popularity
9/10 Helpfulness
5/10
Language
javascript
Source: stackoverflow.com
Tags: javascript
match
word

Contributed on Jun 19 2020
Xenophobic Xenomorph
0 Answers Avg Quality 2/10
Regular expression: Match everything after a particular word
Comment
-1
Popularity
9/10 Helpfulness
2/10
Language
javascript
Source: stackoverflow.com
Tags: javascript
j
Contributed on Jun 21 2020
Xenophobic Xenomorph
0 Answers Avg Quality 2/10
Regex or regular expression is a pattern-matching tool. It allows you to search text in an advanced manner.
Regex is like CTRL+F on steroids.
For example, to find out all the emails or phone numbers from text, regex can get the job done.
The downside of the regex is it takes a while to memorize all the commands. One could say it takes 20 minutes to learn, but forever to master.
In this guide, you learn the basics of regex.
We are going to use the regex online playground in regexr.com. This is a super useful platform where you can easily practice your regex skills with useful examples.
Make sure to write down each regular expression you see in this guide to truly learn what you are doing.
Regex Tutorial
To make it as beneficial as possible, this tutorial is example-heavy. This means some of the regex concepts are introduced as part of the examples. Make sure you read everything!
Anyway, let’s get started with regex.
Regex and Flags
A regular expression (or regex) starts with forward slash (/) and ends with a forward slash.
The pattern matching happens in between the forward slashes.
For instance, let’s find the word “loud” in the text document.

As you can see, this works like CTRL + F.
Next, pay attention to the letter “g” in the above regex /loud/g.
The letter “g” means that the global flag is activated. In other words, you are treating the piece of example text as one long line of text.
Most of the time you are going to use the “g” flag only.
But it is good to understand there are other flags as well.
In the regexr online editor, you can find all the possible flags in the top right corner.
Now that you understand what regex is and what is the global flag, let’s see an example.
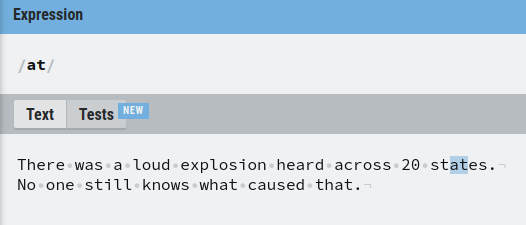
Let’s search for “at” in the piece of text:

As you can see, our regular expression found three matches of “at”.
Now, if you disable the “g” flag, it is only going to match the first occurrence of “at”.
Anyway, let’s switch the global flag back on.
So far using regex has been like using the good old CTRL+F.
However, the true power of the regular expressions shows up when we search for patterns instead of specific words.
To do this, we need to learn about the regex special characters that make pattern matching possible
Let’s start with the + charater.
The + Operator – Match One or More
Let’s search for character “s” in the example text.

This matches all “s” letters there are.
But what if you want to search for multiple “s” characters in a row?
In this case, you can use the + character after the letter “s”. This matches all the following “s” letters after the first one.

As a result, it now matches the double “s” in the text in addition to the singular “s”.
In short, the + operator matches one or more same characters in a row.
Next, let’s take a look at how optional matching works.
The ? Operator – Match Optional Characters
Optional matching is characterized by the question mark operator (?).
Optional matching means to match something that might follow.
For example, to match all letters “s” and every “s” followed by “t”, you can specify the letter “t” as an optional match using the question mark.
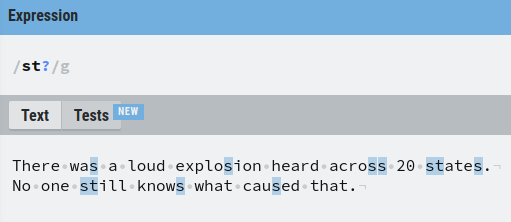
This matches:
- Each singular “s”
- Each combination of “st”.
Next up, let’s take a look at a special character that combines the + and ? characters.
The * Operator – Match Any Optional Characters
The star operator (*) means “match zero or more”.
Essentially, it is the combination of the + and the ? operators.
For example, let’s match with each letter “o” and any amount of letter “s” that follow.

This matches:
- All the singular “o” letters.
- All occurrences of “os”.
- All occurrences of “oss”.
As a matter of fact, this would match with “ossssssss” with any number of “s” letters as long as they are preceded by an “o”.
Next, let’s take a look at the wild card character.
The . Operator – Match Anything Except a New Line
In regex, the period is a special character that matches any singular character.
It acts as the wildcard.
The only character the period does not match is a line break.
For example, let’s match any character that comes before “at” in the text.

But how about matching with a dot then? The period (.) is a reserved special character, so it cannot be used.
This is where escaping is used.
The Operator – Escape a Special Character
If you are familiar with programming, you know what escaping means.
If not, escaping means to “invalidate” a reserved keyword or operator using a special character in front of its name.
As you saw in the previous example, the period character acts as a wildcard in regex. This means you cannot use it to match a dot in the text.

As you can see, /./g matches with each letter (and space) in the text, so it is not much of a help.
This is where escaping is useful.
In regex, you can escape any reserved character using a backslash ().
Anything followed by a backslash is going to be converted into a normal text character.
To match dots using regex, escape the period character with (.).

Now it matches all the dots in the text.
Let’s play with the example. To match any character that comes before a dot, add a period before the escaped period:
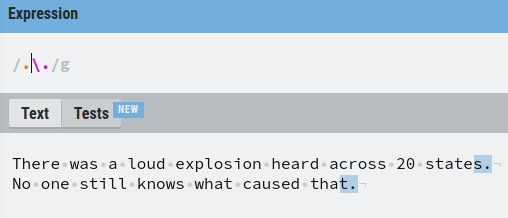
Now you understand how to match and escape characters in regex. Let’s move on to matching word characters using other special characters.
Match Different Types of Characters
You just learned how to use a backslash to escape a character.
However, the backslash has another important use case. Combining a backslash with some particular character forms an operator that can be used to match useful things.
As an example, an important special character in regex is w.
This matches all the word characters, that is, letters and digits but leaves out spaces.
For example, let’s match all the letters and digits in the text:

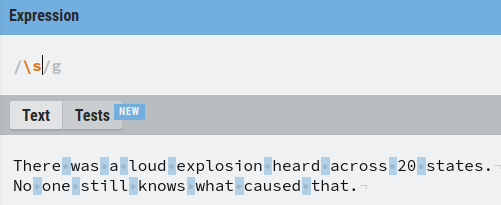
Another commonly used special operator is the space character s that matches any type of white space there is in the text.
For example, let’s match all the spaces in the text.
Of course, you can also match numeric characters only.
This happens via the d operator.
For instance, let’s match all digits in the text:

This matches with “2” and “0”.
These are the very basic special character operators there are in regex.
Next, you are going to learn how to invert these special characters.
Invert Special Characters
To invert a special character in regex, capitalize it.
- w matches any word character –> W matches with any non-word character
- s matches with any white space character –> S matches with any non-whitespace character.
- d matches with any digit –> D matches any non-digit character.
Examples:
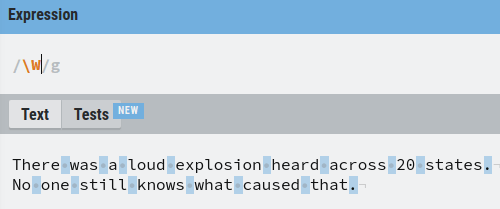


Next, let’s take a look at how to match words with a specific length.
{} – Match Specific Length
Let’s say you want to capture all the words that are longer than 2 characters long.
Now, you cannot use + or * with the w character as it does not make sense.
Instead, use the curly braces {} by specifying how many characters to match.
There are three ways to use {}:
- {n}. Match n consecutive characters.
- {n,}. Match n character or more.
- {n,m}. Match between n and m in length.
Let’s examples of each.
Example 1. Match all sets of characters that are exactly 3 in length:

Example 2. Match consecutive strings that are longer than 3 characters:

Example 3. Match any set of characters that are between 3 and 5 characters in length:

Now that you know how to deal with quantities in regex, let’s talk about grouping.
[] – Groups and Ranges
In regex, you can use character grouping. This means you match with any character in the group.
One way to group characters is by using square brackets [].
For example, let’s match with any two letters where the last letter is “s” and the first letter is either “a” or “o”.

A really handy feature of using square brackets is you can specify a range. This lets you match any letter in the specified range.
To specify a range, use the dash with the following syntax. For example, [a-z] matches any letter from a to z.
For example, let’s match with any two-letter word that ends in “s” and starts with any character from a to z.
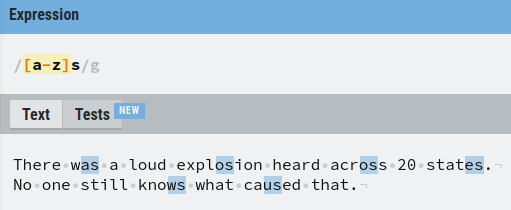
One thing you sometimes may want to do is to combine ranges.
This is also possible in regex.
For example, to find any two letters that end with “s” and start with any lowercase or uppercase letter, you can do:
/[a-zA-Z]s/g
Or if you want to match with any two letters that end with “s” and start with a number between 0 and 9, you can do:
/[0-9]s/g
Awesome.
Next, let’s take a look at another way to group characters in regex.
() Capturing Groups
In regex, capturing groups is a way to treat multiple characters as a single unit.
To create a capturing group, place the characters inside of the parenthesis.
For example, let’s match with words “The” or “the”, where the first letter is either lowercase t or uppercase T.
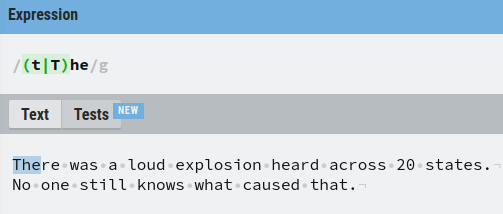
But why parenthesis? Let’s see what happens without them:
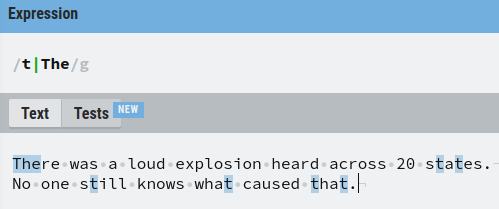
Now it matches with either any single character “t” or the word “The”.
This is the power of the capturing group. It treats the characters inside the parenthesis as a single unit.
Let’s see another example where we find any words that are 2-3 letters long and each letter in the word is either a,s,e,d.

As the last example of capturing, let’s match any words that repeat “os” two or three times in a row.

Here the “os” is not matched in the words “explosion” and “across”. This is because the “os” occurs only a single time. However, the “osososos” at the end has 3 x “os” so it gets matched.
Next up, let’s take a look at yet another special character, caret (^).
The ^ operator – Match the Beginning of a Line
The caret (^) character in regex means match with the beginning of the new line.
For example, let’s match with the letter “T” at the beginning of a text chapter.

Now, let’s see what happens when we try to match with the letter “N” at the beginning of the next line.

No matches!
But why is that? There is an “N” at the beginning of the second line.
This happens because our flag is set to “g” or “global”. We are treating the whole piece of text as a single line of text.
If you want to change this, you need to set the multiline flag in addition to the global flag.

Now the match is also made at the beginning of the second line.
However, it is easier to deal with the text as a single chunk of text, so we are going to disable the multiline flag for the rest of the guide.
Now that you know how the caret operator works in regex, let’s take a look at the next special character, the dollar sign ($).
$ End of Statement
To match the end of a statement with regex, use the dollar sign ($).
For instance, let’s match with a dot that ends the text chapter.

As you can see, this only matches the dot at the end of the second line. As mentioned before, this happens because we treat the text as a single line of text.
Awesome! Now you have learned most of the special characters you are ever going to use in regex.
Next, let’s take a look at how to really benefit from regex by learning about important concepts of lookahead and lookbehind.
Lookbehinds
In regex, a lookbehind means to match something preceded by something.
There are two types of lookbehinds:
- Positive lookbehind
- Negative lookbehind
Let’s take a look at what these do.
The (?<=) Operator – Positive Lookbehind
A positive look behind is specified by defining a group that starts with a question mark, followed by a less than sign and an equal sign, and then a set of characters.
- (?<=)
Here < means we are going to perform a look behind, and = means it is positive.
A positive lookbehind matches everything before the main expression without including it in the result.
For example, let’s match the first characters after “os” in the text.

This positive look behind does not include “os” in the matches. Instead, it checks if the matches are preceded by “os” before showing them.
This is super useful.
The (?<!) Operator – Negative Lookbehind
Another type of look behind is the negative look behind. This is basically the opposite of the positive lookbehind.
To create a negative look behind, create a group with a question mark followed by a less-than sign and an exclamation point.
- (?<!)
Here < means look behind and ! makes it negative.
As an example, let’s perform the exact same search as we did in the positive lookbehind, but let’s make it negative:

As you can see, the negative lookbehind matches everything except the first character after the word “os”. This is the exact opposite of the positive lookahead.
Now that you know what the lookbehinds do, let’s move on to very similar concepts, that is, lookaheads.
Lookaheads
In regex, a lookahead is similar to lookbehind.
A lookahead matches everything after the main expression without including it in the result.
To perform a lookahead, all you need to do is remove the less-than sign.
- (?=) is a positive lookahead.
- (?!) is a negative lookahead.
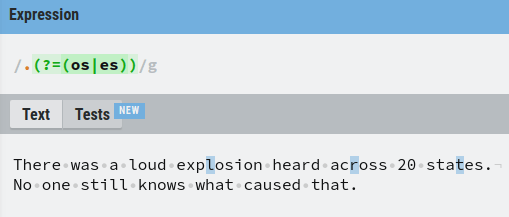
The (?=) Operator – Positive Lookahead
For example, let’s match with any singular character followed by “es” or “os”.
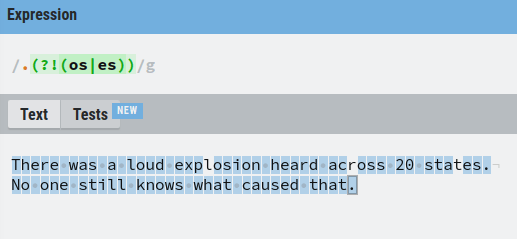
And as you guessed, a negative lookahead matches the exact opposite of what a positive lookahead does.
The (?!) Operator – Positive Lookahead
For example, let’s match everything except for the single characters that occur before “os” or “es”
Now you have all the tools to understand a slightly more advanced example using regex. Also, you are going to learn a bunch of important things at the same, so keep on reading!
Find and Replace Phone Numbers Using Regex
Let’s say we have a text document that has differently formatted phone numbers.
Our task is to find those numbers and replace them by formatting them all in the same way.

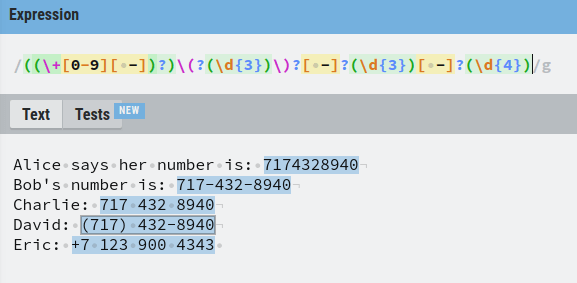
The number that belongs to Alice is simple. Just 10 digits in a row.
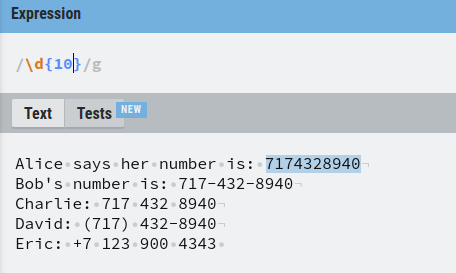
The number that belongs to Bob is a bit trickier because you need to group the regex into 5 parts:
- A group of three digits
- Dash
- A group of three digits
- Dash
- A group of four digits.
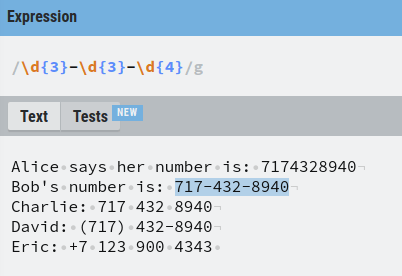
Now it matches Bob’s number.
But our goal was to match all the numbers at the same time. Now Alice’s number is no longer found.
To fix this, we need to restructure the regex again. Instead of assuming there is always a dash between the first two groups of numbers, let’s assume it is optional. As you now know, this can be done using the question mark.
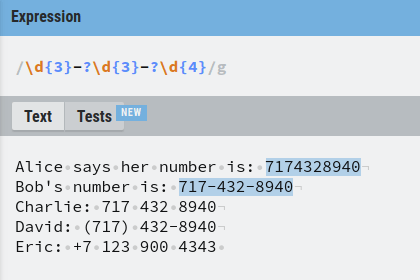
Good job.
Next up, there can also be numbers separated by space, such as Charlie’s number.
To take this into account, we must assume that the separator is either a white space or a dash. This can be done using a group with square brackets [] by placing a dash and a white space into it.
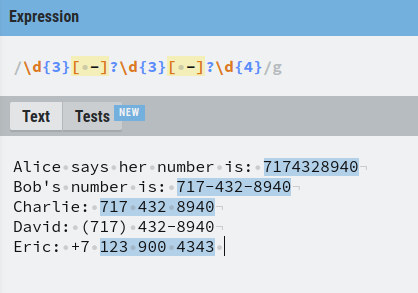
Now also Charlie’s number is matched by our regular expression.
Then there are those numbers where the first three digits are isolated by parenthesis and where the last two groups are separated by a dash.
To find these numbers, we need to add an optional parenthesis in front of the first three digits. But as you recall, parenthesis is a special character in regex, so you need to escape them using the backslash .
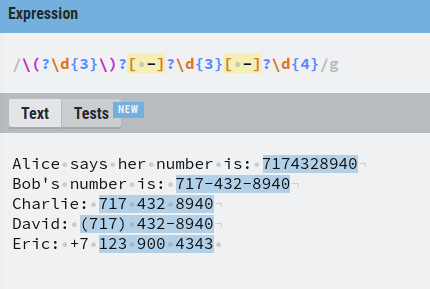
Awesome, now David’s number is also found.
Last but not least, a phone number might be formatted such that the country-specific number is in front of the number with a + sign.
To take this into account, we need to add an optional group of a + sign followed by a digit between 0-9.
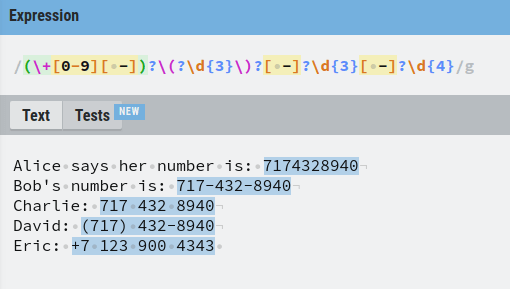
Now our regex finds every phone number there is on the list!
Next, let’s replace each number with a number such that each number is formatted in the same way.
Before we can do this, we need to capture each set of numbers by creating capturing groups for them. As you learned before, this happens by placing each set of digits into a set of parenthesis.
If you inspect the Details section of the editor, you can see that now each set of numbers in a phone number is grouped in the capture groups.
For example, let’s click the first phone number match and see the Details:
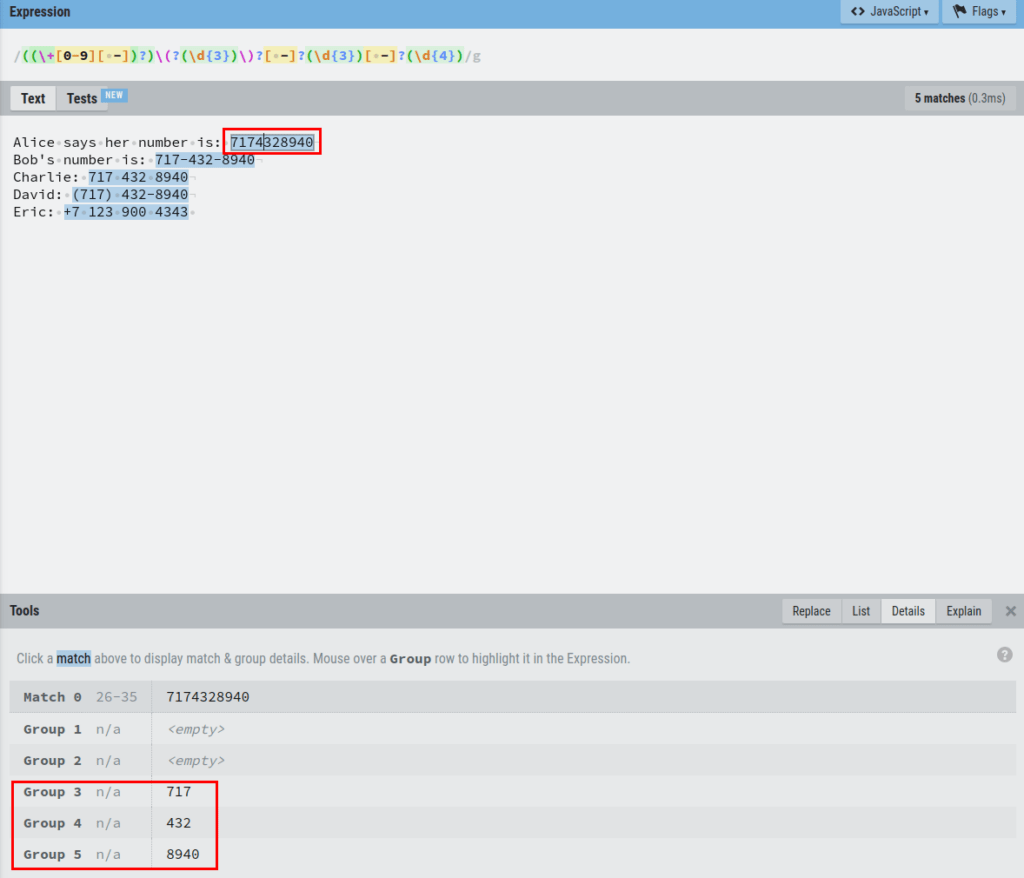
As you can see, the first phone number is grouped into three capture groups 3,4, and 5.
As another example, let’s click Eric’s number to see the details:
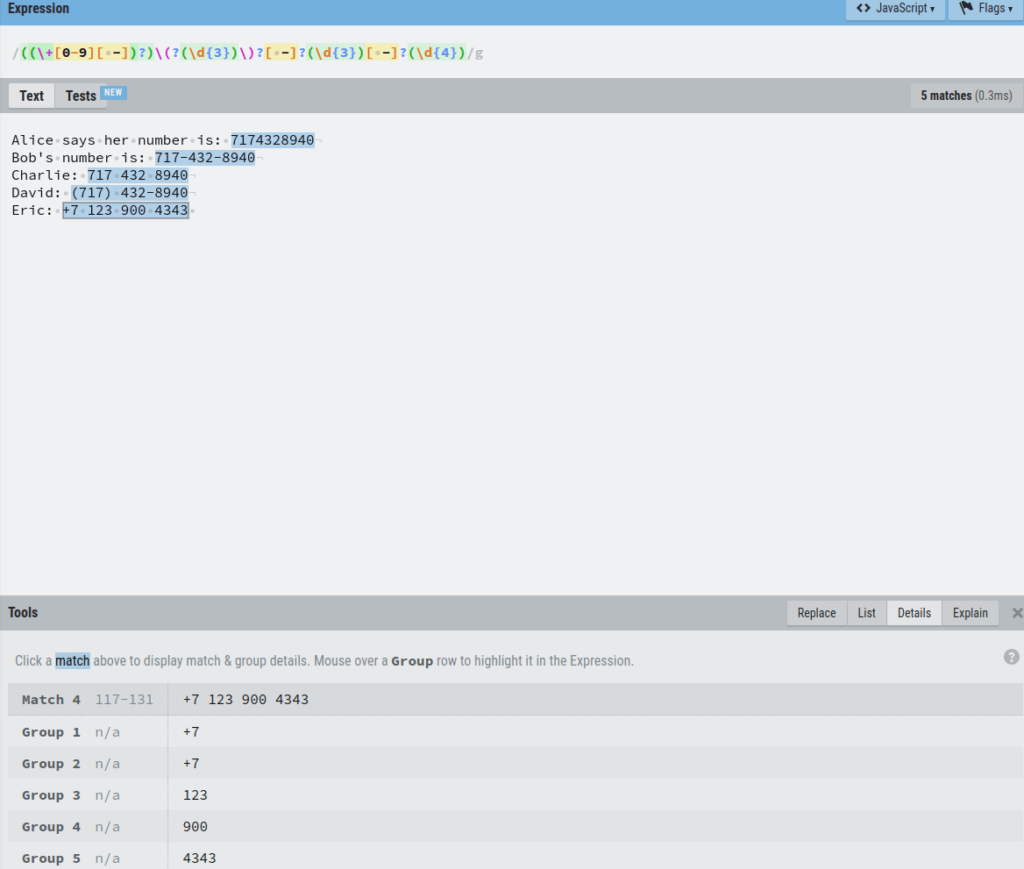
Here you can see that the number is split into groups 1, 2, 3, 4, and 5.
However, there is one problem.
The number +7 occurs twice, in group 1 and group 2.
This is not what we want.
It happens because the regex catches both the +7 with a space and without a space. Thus the 2 groups.
To get rid of this, you can specify the expression that captures the number with space as a non-capturing group.
To do this, use the ?: operator in front of the group:
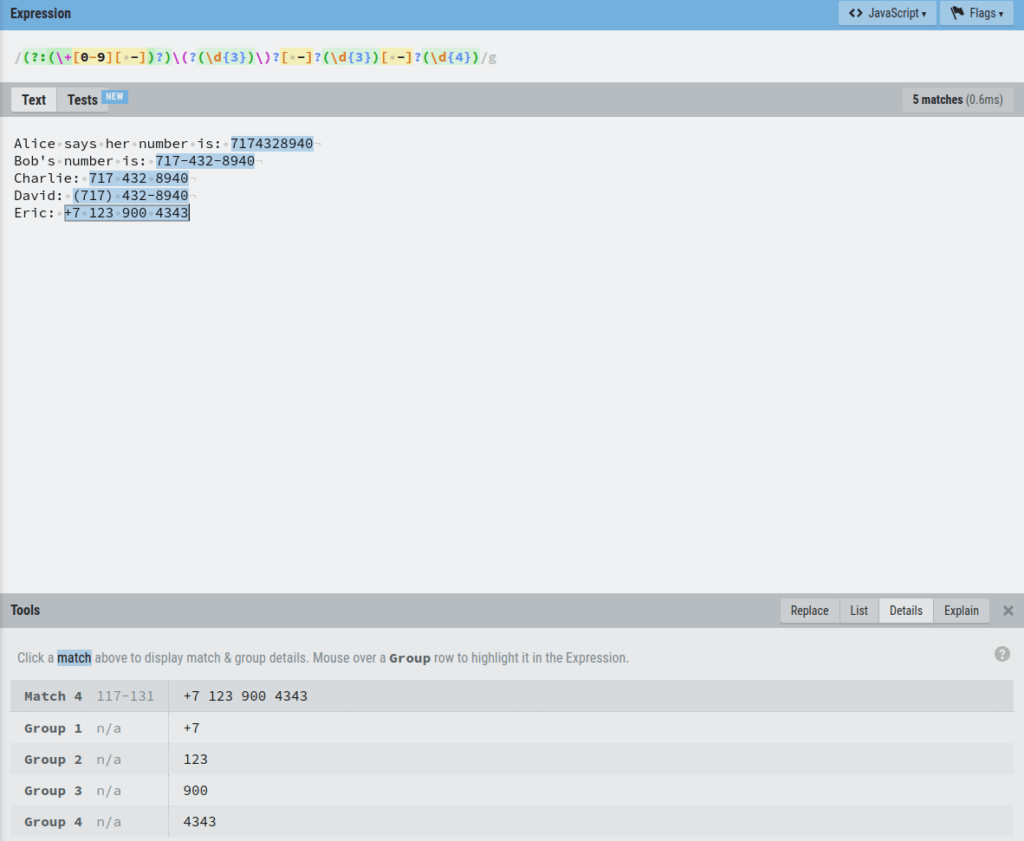
Now Eric’s number (and all the other numbers too) is nicely split into 4 groups.
Finally, we can use these four capture groups to replace the matched numbers with numbers that are formatted in the same way.
In regex, you can refer to each capture group with $n, where n is the number of the group.
To format the numbers, let’s open up the replace tab in the editor.
Let’s say we want to replace all the numbers with a number that is formatted like this:
+7 123-900-4343
And if there is no +7 in front of the number, then we leave it as:
123-900-4343
To do this, replace each phone number by referencing their capture group in the Replace section of the editor:
$1$2-$3-$4
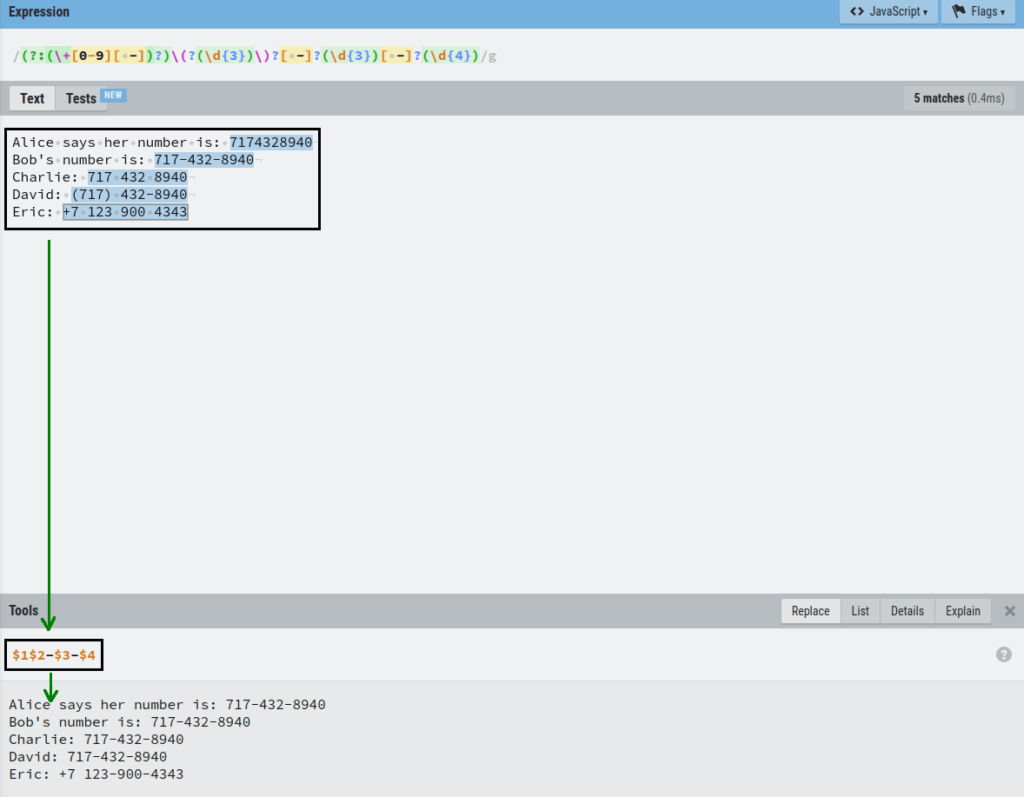
Amazing! Now all the numbers are replaced in the resulting piece of text and follow the same format.
This concludes our regex tutorial.
Conclusion
Today you learned how to use regex.
In short, regex is a commonly supported tool to match patterns in text documents.
You can use it to find and replace text that matches a specific pattern.
Most programming languages support regex. This means you can use regex in your coding projects to automate a lot of manual work when it comes to text processing.
Thanks for reading.
Happy pattern-matching!
Further Reading
How to Validate Emails with JavaScript + RegEx
About the Author

-
I’m an entrepreneur and a blogger from Finland. My goal is to make coding and tech easier for you with comprehensive guides and reviews.
Recent Posts