
Microsoft Power Map для Excel — это инструмент для трехмерной визуализации данных, который позволяет взглянуть на информацию по-новому. Вы можете получить результаты, которые недоступны при использовании традиционных двухмерных таблиц и диаграмм.
В Power Map можно отображать географические и временные данные на глобусе или пользовательской карте, показывать их изменение со временем, создавать наглядные туры и делиться ими с другими людьми. С помощью Power Map можно:
-
Карта данных Отобразить на картах Bing более миллиона строк данных в объемном формате из таблицы или модели данных Excel.
-
Обнаружение информации Повысьте понимание, просматривая данные в географическом пространстве и просматривая изменение данных с отметками времени с течением времени.
-
Делитесь историями Сделайте снимки экрана и создайте кинематографические управляемые видеотуры, которые можно сделать более интересными для широкой аудитории, как никогда раньше. Или экспортировать туры в видео и поделиться ими таким же образом.
Кнопка Карта находится в группе Туры на вкладке Вставка ленты Excel, как показано на этом рисунке.

Примечания:
-
Если вы не нашли эту кнопку в своей версии Excel, см. раздел Я не вижу кнопку Power Map в Excel.
-
Если у вас есть подписка Приложения Microsoft 365 для предприятий, вы можете использовать Power Map Excel в составе средств самостоятельной бизнес-аналитики. При добавлении новых возможностей и внесении усовершенствований в Power Map вы получите их в рамках своего плана подписки.
Чтобы узнать о планах Microsoft 365 подписки, ознакомьтесь с Microsoft 365 профессиональныйplus и сравните все планы Microsoft 365 для бизнеса.
-
Если вы раньше устанавливали предварительную версию Power Map, у вас будет временно две кнопки Карта на вкладке Вставка: одна в группе Туры и одна в группе Power Map. При нажатии кнопки Карта в группе Туры включается текущая версия Power Map и удаляются все предварительные версии.
Создание первой карты Power Map
Если у вас есть данные Excel с географическими свойствами в табличном формате или в модели данных (такие как строки и столбцы, содержащие названия городов, областей, краев, стран или регионов, почтовые индексы либо значения долготы и широты), вы готовы приступить к работе. Вот как это сделать:
-
В Excel откройте книгу, которая содержит таблицу или данные модели, которые вы хотите изучить в Power Map.
Сведения о подготовке данных см. в подготовьте данные для Power Map.
Чтобы просмотреть примеры наборов данных, прокрутите страницу вниз до следующего раздела этой статьи.
-
Щелкните любую ячейку в таблице.
-
Щелкните Вставить > Карта. При первом нажатии кнопки Карта автоматически включается Power Map.
Power Map Bing используется для геокодирования данных на основе их географических свойств. Через несколько секунд появится глобус рядом с первым экраном области слоев.
-
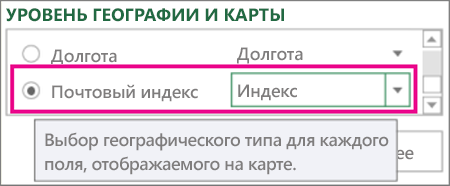
В области слоев проверьте, правильно ли сопоставлены поля, и щелкните стрелку раскрывающегося списка для неправильных полей, чтобы сопоставить их с нужными географическими свойствами.
Например, убедитесь, что почтовый индекс распознается в поле «Индекс».

-
Когда Power Map отображает данные, на глобусе появляются точки.
-
Нажмите кнопку Далее для статистической обработки и дальнейшей визуализации данных на карте.
Изучение примеров наборов данных в Power Map
С помощью примеров наборов данных можно ознакомиться с Power Map. Просто скачайте одну из следующих книг, в которые уже есть геопро пространственные записи, необходимые для начала работы. Как в приложениях Dallas Utilities, так и в службе food Inspections в Сиэтле есть данные с отметкой времени, которые позволяют просматривать данные с течением времени.
-
Данные о преступлениях
-
Моделирование сезонного
-
Продуктовые проверки в Сиэтле
-
Power Stations
Дальнейшие действия по работе с данными в Power Map
-
Работа с данными с помощью тура Power Map
-
Геокодирование данных Power Map
-
Визуализация данных в Power Map
-
Создание пользовательской карты в Power Map
Нужна дополнительная помощь?
Не импортировать
Данные столбца не будут импортированы.
WBS
При выборе опции WBS строки со значениями (не пустые) будут идентифицированы как уровни WBS, данные будут импортированы в текущий/новый проект в поле Название WBS.
Если значения столбца не являются уникальными, то плагин присвоит ячейке с дублем статус «Преобразовано», а повторяющемуся названию при импорте добавит суффикс “-ТВ” и порядковый номер, при многократном повторении.
Структуру и иерархию плагин определяет в соответствии с пробелами/отступами в ячейках исходного файла excel.
Для задания отступов в Excel используйте горячие клавиши: ctrl+alt+tab и ctrl+alt+shift+tab
Строки, относящиеся к уровням WBS, окрашиваются разными цветами по уровням.
Для отключения уровня wbs используйте левый системный столбец таблицы в процессемаппинга.
wbs /название работы
При выборе опции wbs/название данные из ячеек столбца будут внесены в текущий/новый проект в поле название WBS и работы соответственно.
Имя wbs в одном уровне иерархии должно быть уникально, если в одном уровне будут присутствовать одинаковые имена, то плагин прибавит к имени цифру.
Структуру и иерархию плагин определяет в соответствии с пробелами/отступами в ячейках исходного файла excel.
Плагин определяет уровни WBS по следующей информации в строках:
- Кол-во пустых ячеек в строке больше 50%;
- В строке нет ячеек с выбранными полями плановых/фактических дат.
Если плагин определил неверно уровни WBS, попробуйте указать столбец с датой старта работы, нажав на название столбца, и после этого снова выберите столбец WBS/название работы, чтобы плагин пересчитал уровни wbs:

Название работы
При выборе опции Название работы данные из ячеек столбца будут внесены в текущий/новый проект в поле Название работы.
Сущ. WBS code
При создании новых работ или WBS в существующем проекте, верхний уровень по умолчанию создается в корне проекта. Для создания новой WBS или работы в существующей иерархии необходимо в столбце Excel указать путь WBS, в которой будут созданы новые элементы.
Путь WBS — это серия WBS id записанная через разделитель.
Более подробная информация по импорту в существующую структуру: release-note-20
id сущ. Работы
При импорте данных в существующий проект опция id сущ. Работы идентифицирует существующее работы в графике по полю Идентификатор работы.
Если данные неоднозначно определяются или не могут быть идентифицированы, плагин отобразит статусы в ячейках.
id новой работы
При выборе опции id новой работы данные столбца будут внесены в поле Идентификатор работы.
Идентификаторы работ должны быть уникальными, в случае обнаружение дубликатов, плагин преобразует данные ячеек, добавив суффикс “-ТВ” и порядковый номер, если присутствует многократное дублирование.
старт
При выборе опции Старт данные столбца будут внесены в поле Планируемое начало работы.
финиш
При выборе опции Финиш данные столбца будут внесены в поле Планируемое окончание работы.
Для импорта плановой даты финиша работы выберите тип длительности работы — Фиксированная длительность и кол-во.
фактический старт
При выборе опции фактический старт данные столбца будут внесены в поле Факт. Начало работы..
фактический финиш
При выборе опции фактический финиш данные столбца будут внесены в поле Факт. окончание работы.
Используйте формат ячеек «Дата» в исходном файле при импорте календарных данных работ графика, или при использовании текстового формата придерживайтесь следующего оформления данных: 'DD.MM.YYYY','DD.MM.YY','DD/MM/YY','DD-MM-YY'
Длительность
При выборе опции Длительность данные столбца будут внесены в поле работы Исходная (план) длительность.
Нажмите на опцию, в открывшемся меню, выберите единицу измерения длительности ( дни или часы).
При импорте исходной длительности работы выберите тип длительности работы — Фиксированная длительность и кол-во.
польз. поле работы
При выборе опции польз. поле работы появится меню с перечнем доступных пользовательских полей работ.
Выберите нужное пользовательское поле работы, в которое будут внесены значения столбца.
Формат импортируемых значений польз полей должен соответствовать формату пользовательского поля из БД (текстовый, числовой или дата), иначе плагин выдаст в соответствующих ячейках статусы с сообщением о преобразовании исходного формата ячеек или недопустимого формата, который не может быть импортирован/преобразован.
Для типа данных индикатор значением могут служить следующие данные:
- ‘red’,’красный’,’udf_g1′,’1′
- ‘yellow’ ‘желтый’ ‘udf_g2’ ‘2’
- ‘green’ ‘зеленый’ ‘udf_g3’ ‘3’
- ‘blue’ ‘синий’ ‘udf_g4’ ‘4’
код работы
При выборе опции код работы появится меню с перечнем наименований кодов работ из БД. Необходимо выбрать код работы. Плагин идентифицирует данные столбца соответственно значениям и описаниям выбранного кода. При наличии возможных вариантов будет выбран первый в списке, пользователю будет предложено изменить выбор из оставшихся вариантов.
ресурс по id
При выборе опции ресурс по id плагин выполняет поиск соответствия импортируемых данных идентификаторам ресурсов в БД.
ресурс по ед. изм.
При выборе опции ресурс по ед. изм. плагин выполняет поиск соответствия импортируемых данных единицам измерения ресурсов в БД.
Для ограничения области поиска ресурса: в появившемся меню с перечнем ресурсов, выберите ресурсы по ед. измерения.
Для выбора целой ветки ресурсов кликните дважды левой кнопкой мыши по названию ветки, для отмены выбора кликните повторно.
ресурс по названию
При выборе опции ресурс по названию плагин выполняет поиск соответствия импортируемых данных и названий ресурсов в БД.
Для ограничения области поиска ресурса в появившемся меню с перечнем ресурсов выберите ресурсы с соответствующими названиями.
Для выбора целой ветки ресурсов кликните дважды левой кнопкой мыши по названию ветки, для отмены выбора кликните повторно.
плановое кол-во ресурса
При выборе опции плановое кол-во ресурса данные столбца будут импортированы в поле плановое количество назначения ресурса. Ресурс необходимо выбрать из дополнительного выпадающего списка. В качестве ресурса может выступать другое поле, оно отображается вверху списка номером столбца и названием поля:
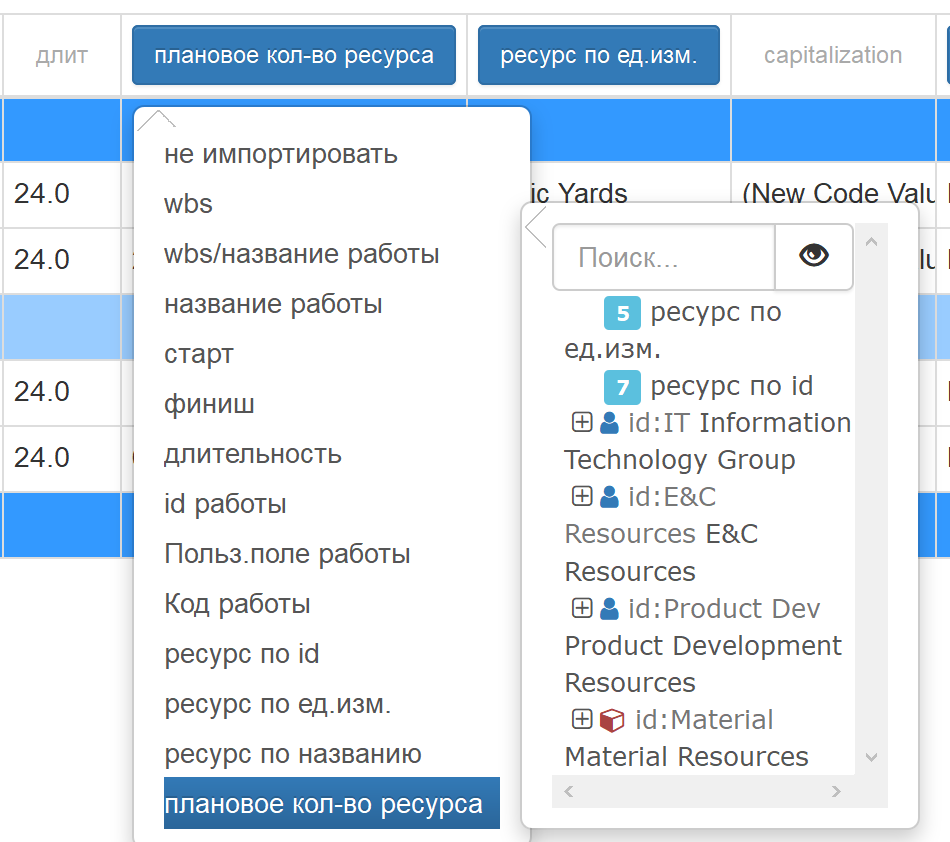
При выборе подобного ресурса в название поля добавляется номер столбца, в котором создается этот ресурс:
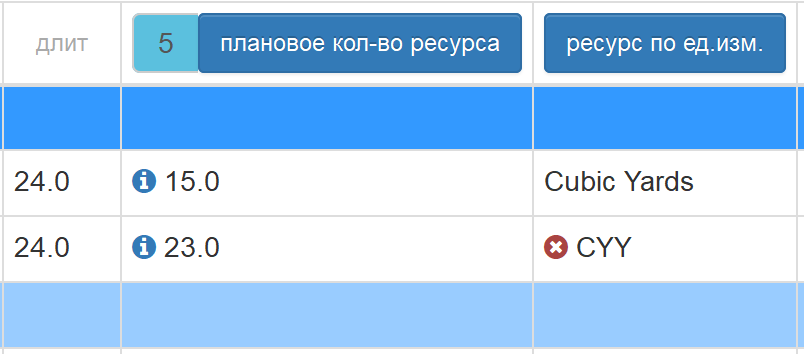
фактическое кол-во ресурса
При выборе опции фактическое кол-во ресурса данные столбца будут импортированы в поле фактическое количество назначения ресурса.
Выбор ресурса аналогично плановому кол-ву ресурса
фактическое кол-во за период ресурса
При выборе опции фактическое кол-во за период ресурса данные столбца будут импортированы в поле факт. количество за период.
Выбор ресурса аналогично плановому кол-ву ресурса
расценка ресурса
Опция расценка ресурса импортирует данные столбца в поле назначения ресурса Расценка. Тип расценки изменятся на пользовательский.
Выбор ресурса аналогично плановому кол-ву ресурса
стоимость ресурса
Опция стоимость ресурса изменит тип расценки назначения на пользовательский и импортирует в поле Расценка значение, рассчитанное по формуле: Стоимость / План. Кол-во (не равное 0).
Выбор ресурса аналогично плановому кол-ву ресурса
Фин. Период
Опция фин. период импортирует данные столбца в поле значение по финансовому периоду.
При выборе опции появится меню с перечнем дат начала финансовых периодов, выберите период в который будут внесены значения.
После выбора даты фин. периода из списка выберите назначение ресурса.
При импорте серии значений финансовых периодов выберите дату начала и назначение ресурса, затем в последнем столбце серии значении выберите поле Фин. Период и нажмите кнопку Конец фин.периодов. Промежуточные даты периодов и целевой ресурс заполнятся автоматически.
Связи работы
Данное поле позволяет импортировать зависимости работ для новых элементов и для существующих работ в БД, в том числе из других проектов.
Форматы записи:
<Номер строки последователя/предшественника><Тип связи(опционально)><Задержка в часах(опционально)>
Например:
- 45SS-5 — будет создана связь SS с задержкой -5 часов с работой из строки номер 45
- 34 — будет создана связь FS (по умолчанию) с работой из строки 34
<Id работы><:><Тип связи(опционально)><Задержка в часах(опционально)><:><Id проекта>
ОБРАТИТЕ ВНИМАНИЕ НА РАЗДЕЛИТЕЛЬ :
Например:
- A1010:FF-5:TB222 — будет создана связь FF с задержкой -5 часов с работой A1010 из проекта TB222
- A1010 — будет создана связь FS (по умолчанию) c работой A1010 из выбранного для импорта проекта. Если id работы задан цифрами и может совпадать с номером строки — испльзуйте разделитель и укажите тип связи: A1010:FS
- A1010:SS — будет создана связь SS с работой A1010 из выбранного для импорта проекта
- A1010:TB2020 — будет создана связь FS (по умолчанию) с работой A1010 из проекта TB2020
При указание только номера строки — будет создана связь FS ( финиш старт).
Более подробная информация по созданию зависимостей: release-note-20
Обновление назначенных ресурсов
Опции ресурс по ID/ ед. изм./названию, а также все опции с количественными параметрами ресурса,включая Фин.Период, можно использовать для назначения новых ресурсов на работы или для обновления назначений ресурсов при импорте данных в существующий проект.
Для обновления ресурса выполните следующий порядок действий:
- Активируйте знак обновления напротив необходимого поля мэппинга.
- Выберите поле для мэппинга напротив знака обновления.
- При необходимости выберите параметры в появившемся меню.
Для назначения новых ресурсов на работу выполните все пункты выше описанных действий кроме 1.
При обновлении ресурсов в выпадающем меню выбора ресурсов можно идентифицировать ресурс по типу (напр.: Материальный)
Если назначения ресурсов на работы уже идентифицированы в одном из столбцов, то плагин автоматически будет ссылаться на него, в выпадающем меню номер идентифицирующего столбца и название выделятся синим цветом.
Содержание
- Исходные данные
- Что такое сводная таблица?
- Как создать сводную таблицу.
- Организуйте свои исходные данные
- Создаем и размещаем макет
- Как добавить поле
- Откуда данные и что надо на выходе?
- Выделите исходные данные, если нужно
- Куда поместить сводную таблицу?
- Работа с макетом
- Список полей сводной диаграммы
- Фильтры в сводной диаграмме
- Power Query
- Power Pivot
Исходные данные
Сейчас на простом примере мы научимся создавать сводные таблицы и познакомимся с некоторыми их возможностями.
Для примера в качестве исходных данных возьмем ведомость основных средств компании и определим стоимость позиций по каждому филиалу с помощью сводной таблицы.

Перед созданием сводной таблицы убедитесь, что в исходной таблице отсутствуют пустые заголовки. Это требуется потому что каждый столбец таблицы становиться полем сводной таблицы, по которому можно собрать данные.
Советую также преобразовывать исходный диапазон данных в таблицу (Главная – Форматировать как таблицу). Тогда при добавлении или удалении строк и столбцов не придется менять ссылку на этот диапазон в сводном отчете.
Что такое сводная таблица?
Это инструмент для изучения и обобщения больших объемов данных, анализа связанных итогов и представления отчетов. Они помогут вам:
- представить большие объемы данных в удобной для пользователя форме.
- группировать информацию по категориям и подкатегориям.
- фильтровать, сортировать и условно форматировать различные сведения, чтобы вы могли сосредоточиться на самом актуальном.
- поменять строки и столбцы местами.
- рассчитать различные виды итогов.
- разворачивать и сворачивать уровни данных, чтобы узнать подробности.
- представить в Интернете сжатые и привлекательные таблицы или печатные отчеты.
Например, у вас множество записей в электронной таблице с цифрами продаж шоколада:

И каждый день сюда добавляются все новые сведения. Одним из возможных способов суммирования этого длинного списка чисел по одному или нескольким условиям является использование формул, как было продемонстрировано в руководствах по функциям СУММЕСЛИ и СУММЕСЛИМН.
Однако, когда вы хотите сравнить несколько показателей по каждому продавцу либо по отдельным товарам, использование сводных таблиц является гораздо более эффективным способом. Ведь при использовании функций вам придется писать много формул с достаточно сложными условиями. А здесь всего за несколько щелчков мыши вы можете получить гибкую и легко настраиваемую форму, которая суммирует ваши цифры как вам необходимо.
Вот посмотрите сами.
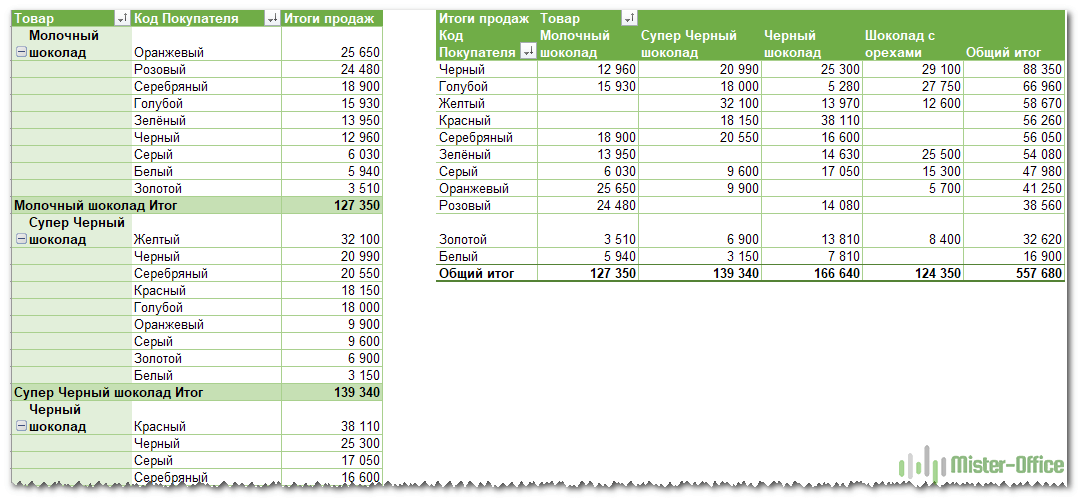
Этот скриншот демонстрирует лишь несколько из множества возможных вариантов анализа продаж.
Как создать сводную таблицу.
Многие думают, что создание отчетов при помощи сводных таблиц для «чайников» является сложным и трудоемким процессом. Но это не так! Microsoft много лет совершенствовала эту технологию, и в современных версиях Эксель они очень удобны и невероятно быстры.
Фактически, вы можете сделать это всего за пару минут. Для вас – небольшой самоучитель в виде пошаговой инструкции:
Организуйте свои исходные данные
Перед созданием сводного отчета организуйте свои данные в строки и столбцы, а затем преобразуйте диапазон данных в таблицу. Для этого выделите все используемые ячейки, перейдите на вкладку меню «Главная» и нажмите «Форматировать как таблицу».
Использование «умной» таблицы в качестве исходных данных дает вам очень хорошее преимущество – ваш диапазон данных становится «динамическим». Это означает, что он будет автоматически расширяться или уменьшаться при добавлении или удалении записей. Поэтому вам не придется беспокоиться о том, что в свод не попала самая свежая информация.
Полезные советы:
- Добавьте уникальные, значимые заголовки в столбцы, они позже превратятся в имена полей.
- Убедитесь, что исходная таблица не содержит пустых строк или столбцов и промежуточных итогов.
- Чтобы упростить работу, вы можете присвоить исходной таблице уникальное имя, введя его в поле «Имя» в верхнем правом углу.
Создаем и размещаем макет
Выберите любую ячейку в исходных данных, а затем перейдите на вкладку Вставка > Сводная таблица .

Откроется окно «Создание ….. ». Убедитесь, что в поле Диапазон указан правильный источник данных. Затем выберите местоположение для свода:
- Выбор нового рабочего листа поместит его на новый лист, начиная с ячейки A1.
- Выбор существующего листа разместит в указанном вами месте на существующем листе. В поле «Диапазон» выберите первую ячейку (то есть, верхнюю левую), в которую вы хотите поместить свою таблицу.
Нажатие ОК создает пустой макет без цифр в целевом местоположении, который будет выглядеть примерно так:

Полезные советы:
- В большинстве случаев имеет смысл размещать на отдельном рабочем листе. Это особенно рекомендуется для начинающих.
- Ежели вы берете информацию из другой таблицы или рабочей книги, включите их имена, используя следующий синтаксис: [workbook_name]sheet_name!Range. Например, [Книга1.xlsx] Лист1!$A$1:$E$50. Конечно, вы можете не писать это все руками, а просто выбрать диапазон ячеек в другой книге с помощью мыши.
- Возможно, было бы полезно построить таблицу и диаграмму одновременно. Для этого в Excel 2016 и 2013 перейдите на вкладку «Вставка», щелкните стрелку под кнопкой «Сводная диаграмма», а затем нажмите «Диаграмма и таблица». В версиях 2010 и 2007 щелкните стрелку под сводной таблицей, а затем — Сводная диаграмма.
- Организация макета.
Область, в которой вы работаете с полями макета, называется списком полей. Он расположен в правой части рабочего листа и разделен на заголовок и основной раздел:
- Раздел «Поле» содержит названия показателей, которые вы можете добавить. Они соответствуют именам столбцов исходных данных.
- Раздел «Макет» содержит область «Фильтры», «Столбцы», «Строки» и «Значения». Здесь вы можете расположить в нужном порядке поля.
Изменения, которые вы вносите в этих разделах, немедленно применяются в вашей таблице.
Как добавить поле
Чтобы иметь возможность добавить поле в нужную область, установите флажок рядом с его именем.
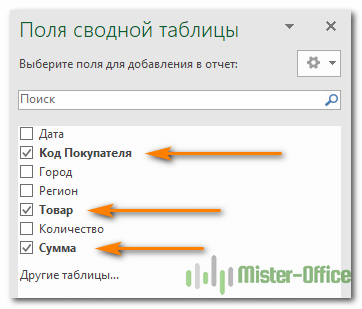
По умолчанию Microsoft Excel добавляет поля в раздел «Макет» следующим образом:
- Нечисловые добавляются в область Строки
- Числовые добавляются в область значений
- Дата и время добавляются в область Столбцы.
Откуда данные и что надо на выходе?

На этом шаге необходимо выбрать откуда будут взяты данные для сводной таблицы. В нашем с Вами случае думать нечего – “в списке или базе данных Microsoft Excel”. Но. В принципе, данные можно загружать из внешнего источника (например, корпоративной базы данных на SQL или Oracle). Причем Excel “понимает” практически все существующие типы баз данных, поэтому с совместимостью больших проблем скорее всего не будет. Вариант В нескольких диапазонах консолидации (Multiple consolidation ranges) применяется, когда список, по которому строится сводная таблица, разбит на несколько подтаблиц, и их надо сначала объединить (консолидировать) в одно целое. Четвертый вариант “в другой сводной таблице…” нужен только для того, чтобы строить несколько различных отчетов по одному списку и не загружать при этом список в оперативную память каждый раз.
Вид отчета – на Ваш вкус – только таблица или таблица сразу с диаграммой.
Выделите исходные данные, если нужно

На втором шаге необходимо выделить диапазон с данными, но, скорее всего, даже этой простой операции делать не придется – как правило Excel делает это сам.
Куда поместить сводную таблицу?

На третьем последнем шаге нужно только выбрать местоположение для будущей сводной таблицы. Лучше для этого выбирать отдельный лист – тогда нет риска что сводная таблица “перехлестнется” с исходным списком и мы получим кучу циклических ссылок. Жмем кнопку Готово (Finish) и переходим к самому интересному – этапу конструирования нашего отчета.
Работа с макетом
То, что Вы увидите далее, называется макетом (layout)сводной таблицы. Работать с ним несложно – надо перетаскивать мышью названия столбцов (полей) из окна Списка полей сводной таблицы (Pivot Table Field List) в области строк (Rows), столбцов (Columns), страниц (Pages) и данных (Data Items) макета. Единственный нюанс – делайте это поточнее, не промахнитесь! В процессе перетаскивания сводная таблица у Вас на глазах начнет менять вид, отображая те данные, которые Вам необходимы. Перебросив все пять нужных нам полей из списка, Вы должны получить практически готовый отчет.

Останется его только достойно отформатировать:

Список полей сводной диаграммы
Как и в случае Power PivotTable, список полей Power PivotChart также содержит две вкладки – ACTIVE и ALL. На вкладке ВСЕ отображаются все таблицы данных в модели данных Power Pivot. На вкладке ACTIVE отображаются таблицы, из которых поля добавляются в сводную диаграмму.

Аналогично, области такие же, как и в случае с сводной диаграммой Excel. Там четыре области –
-
ОСЬ (Категории)
-
ЛЕГЕНДА (серия)
-
∑ ЦЕННОСТИ
-
ФИЛЬТРЫ
ОСЬ (Категории)
ЛЕГЕНДА (серия)
∑ ЦЕННОСТИ
ФИЛЬТРЫ
Как вы видели в предыдущем разделе, легенда заполняется значениями ∑. Кроме того, кнопки полей добавляются в сводную диаграмму для упрощения фильтрации отображаемых данных.
Фильтры в сводной диаграмме
Вы можете использовать полевые кнопки Оси на графике для фильтрации отображаемых данных. Нажмите на стрелку на кнопке поля Ось – Регион.

Раскрывающийся список выглядит следующим образом:

Вы можете выбрать значения, которые вы хотите отобразить. Кроме того, вы можете поместить поле в область ФИЛЬТРЫ для фильтрации значений.
Перетащите поле Регион в область ФИЛЬТРЫ. Кнопка «Фильтр отчетов» – область отображается на сводной диаграмме.

Нажмите на стрелку на кнопке «Фильтр отчетов» – «Регион». Раскрывающийся список выглядит следующим образом:

Вы можете выбрать значения, которые вы хотите отобразить.
Еще в 2013 году специально созданная группа разработчиков внутри Microsoft выпустила для Excel бесплатную надстройку Power Query (другие названия – Data Explorer, Get&Transform), которая умеет массу полезных для повседневной работы вещей:
- Загружать данные в Excel из почти 40 различных источников, среди которых базы данных (SQL, Oracle, Access, Teradata…), корпоративные ERP-системы (SAP, Microsoft Dynamics, 1C…), интернет-сервисы (Facebook, Google Analytics, почти любые сайты).
- Собирать данные из файлов всех основных типов данных (XLSX, TXT, CSV, JSON, HTML, XML…), как поодиночке, так и сразу оптом – из всех файлов указанной папки. Из книг Excel можно автоматически загружать данные сразу со всех листов.
- Зачищать полученные данные от “мусора”: лишних столбцов или строк, повторов, служебной информации в “шапке”, лишних пробелов или непечатаемых символов и т.п.
- Приводить данные в порядок: исправлять регистр, числа-как-текст, заполнять пробелы, добавлять правильную “шапку” таблицы, разбирать “слипшийся” текст на столбцы и склеивать обратно, делить дату на составляющие и т.д.
- Всячески трансформировать таблицы, приводя их в желаемый вид (фильтровать, сортировать, менять порядок столбцов, транспонировать, добавлять итоги, разворачивать кросс-таблицы в плоские и сворачивать обратно).
- Подставлять данные из одной таблицы в другую по совпадению одного или нескольких параметров, т.е. прекрасно заменяет функцию ВПР (VLOOKUP) и ее аналоги.
Power Query встречается в двух вариантах: как отдельная надстройка для Excel 2010-2013, которую можно скачать с официального сайта Microsoft и как часть Excel 2016. В первом случае после установки в Excel появляется отдельная вкладка:

В Excel 2016 весь функционал Power Query уже встроен по умолчанию и находится на вкладке Данные (Data) в виде группы Получить и преобразовать (Get & Transform):

Возможности этих вариантов совершенно идентичны.
Принципиальной особоенностью Power Query является то, что все действия по импорту и трансформации данных запоминаются в виде запроса – последовательности шагов на внутреннем языке программирования Power Query, который лаконично называется “М”. Шаги можно всегда отредактировать и воспроизвести повторно любое количество раз (обновить запрос).
Основное окно Power Query обычно выглядит примерно так:

По моему мнению, это самая полезная для широкого круга пользователей надстройка из всех перечисленных в этой статье. Очень много задач, для которых раньше приходилось либо жутко извращаться с формулами, либо писать макросы – теперь легко и красиво делаются в Power Query. Да еще и с последующим автоматическим обновлением результатов. А учитывая бесплатность, по соотношению “цена-качество” Power Query просто вне конкуренции и абсолютный must have для любого средне-продвинутого пользователя Excel в наши дни.
Power Pivot
Power Pivot – это тоже надстройка для Microsoft Excel, но предназначенная немного для других задач. Если Power Query сосредоточена на импорте и обработке, то Power Pivot нужен, в основном, для сложного анализа больших объемов данных. В первом приближении, можно думать о Power Pivot как о прокачанных сводных таблицах.

Общие принципы работы в Power Pivot следующие:
- Сначала мы загружаем данные в Power Pivot – поддерживается 15 различных источников: распространенные БД (SQL, Oracle, Access…), файлы Excel, текстовые файлы, веб-каналы данных. Кроме того, можно использовать Power Query как источник данных, что делает анализ почти всеядным.
- Затем между загруженными таблицами настраиваются связи или, как еще говорят, создается Модель Данных. Это позволит в будущем строить отчеты по любым полям из имеющихся таблиц так, будто это одна таблица. И никаких ВПР опять же.
- При необходимости, в Модель Данных добавляют дополнительные вычисления с помощью вычисляемых столбцов (аналог столбца с формулами в “умной таблице”) и мер (аналог вычисляемого поля в сводной). Всё это пишется на специальном внутреннем языке Power Pivot, который называется DAX (Data Analysis eXpressions).
- На листе Excel по Модели Данных строятся интересующие нас отчеты в виде сводных таблиц и диаграмм.
Главное окно Power Pivot выглядит примерно так:

А так выглядит Модель Данных, т.е. все загруженные таблицы с созданными связями:

У Power Pivot есть ряд особенностей, делающих её уникальным инструментом для некоторых задач:
- В Power Pivot нет предела по количеству строк (как в Excel). Можно грузить таблицы любого размера и спокойно работать с ними.
- Power Pivot очень хорошо умеет сжимать данные при загрузке их в Модель. 50 Мб исходный текстовый файл может легко превратиться в 3-5 Мб после загрузки.
- Поскольку “под капотом” у Power Pivot, по сути, полноценный движок базы данных, то с большими объемами информации он справляется очень быстро. Нужно проанализировать 10-15 млн. записей и построить сводную? И все это на стареньком ноутбуке? Без проблем!
К сожалению, пока что Power Pivot входит не во все версии Excel. Если у вас Excel 2010, то скачать её можно бесплатно с сайта Microsoft. А вот если у вас Excel 2013-2016, то всё зависит от вашей лицензии, т.к. в некоторых вариантах она включена (Office Pro Plus, например), а в некоторых нет (Office 365 Home, Office 365 Personal и т.д.)
Источники
- https://micro-solution.ru/excel/pivot-tables/first-pivot-table
- https://mister-office.ru/excel/excel-pivot-table.html
- https://www.planetaexcel.ru/techniques/8/130/
- https://coderlessons.com/tutorials/bolshie-dannye-i-analitika/izuchite-excel-power-pivot/excel-power-pivot-charts-sozdanie
- https://www.planetaexcel.ru/techniques/24/5854/
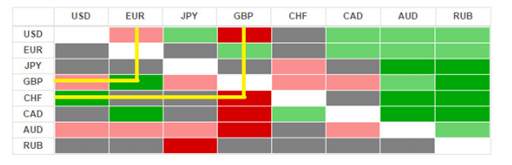
Визуализация геоданных на карте
Если ваша компания имеет филиалы по стране или продает не только в пределах МКАД, то рано или поздно вы столкнетесь с задачей наглядно отобразить числовые данные из Microsoft Excel (продажи, заявки, объемы, клиентов) на географической карте с привязкой к конкретным городам и регионам. Давайте вкратце пробежимся по основным способам визуализации геоданных, которые существуют в Excel.
Способ 1. Быстро и бесплатно — компонент Bing Maps
Начиная с 2013 версии в Excel встроен магазин приложений, т.е. появилась возможность докупать, скачивать и устанавливать дополнительные модули и надстройки с недостающими функциями. Один из таких компонентов как раз и позволяет наглядно отображать числовые данные на карте — он называется Bing Maps и, что особенно приятно, абсолютно бесплатен. Для его установки откройте вкладку Вставка — Магазин (Insert — Office Apps):

После вставки компонента на листе должен появится динамический контейнер с картой. Для визуализации на карте вашей информации нужно выделить диапазон с геоданными и нажать кнопку Показать местоположения (Show Locations):

При необходимости в настройках (иконка с шестеренкой в правом верхнем углу компонента) можно поменять цвета и тип отображаемых диаграмм:

Также возможно быстро отфильтровать города, отобразив только нужные (значок воронки в правом верхнем углу компонента).
Спокойно можно привязываться не только к городам, но и к другим объектам: областям (например, Тульская область), автономным округам (например, Ямало-Ненецкий АО) и республикам (Татарстан) — тогда кругляш диаграммы будет отображен в центре области. Главное, чтобы название в таблице совпадали с подписями на карте.
Итого в плюсах этого способа: легкая бесплатная реализация, автоматическая привязка к карте, два типа диаграмм, удобная фильтрация.
В минусах: нужен Excel 2013 с доступом в интернет, нельзя выделять области и районы.
Способ 2. Гибко и красиво — режим карты в отчетах Power View
Некоторые версии Microsoft Excel 2013 идут в комплекте с мощной надстройкой визуализации отчетов, которая называется Power View и позволяет (помимо всего прочего, а умеет она много!) наглядно отображать данные на карте. Для активации надстройки откройте вкладку Разработчик (Developer) и щелкните по кнопке Надстройки COM (COM Add-ins). В открывшемся окне поставьте галочку напротив Power View и нажмите ОК. После всех этих манипуляций на вкладке Вставка (Insert) у вас должна появиться кнопка Power View.
Теперь можно выделить диапазон с исходными данными нажать на эту кнопку — в вашей книге будет создан новый лист (больше похожий на слайд из Power Point), где отобразятся выделенные данные в виде таблицы:

Превратить таблицу в географическую карту можно легко с помощью кнопки Карта (Map) на вкладке Конструктор (Design):

Обратите особое внимание на правую панель Поля Power View — на ней, в отличие от примитивных Bing Maps, перетаскивая мышью названия столбцов (полей) из исходной таблицы и бросая их в разные области, можно очень гибко настраивать получившееся геопредставление:
- В область Местоположения (Locations) нужно закинуть столбец из исходной таблицы содержащий географические названия.
- Если у вас нет столбца с названием, но есть колонки с координатами, то их нужно поместить в области Долгота (Longitude) и Широта (Latitude), соответственно.
- Если в область Цвет (Color) закинуть товар, то каждый пузырек будет кроме размера (отображающего общую прибыль по городу) детализирован на дольки по товарам.
- Добавление поля в области Вертикальных или Горизонтальных множителей (Dividers) разделит одно карту на несколько по этому полю (в нашем примере — по кварталам).
Также на появившейся сверху контекстной вкладке Макет (Layout) можно настроить фон карты (цветная, ч/б, контурная, вид со спутника), подписи, заголовки, легенду и т.д.

Если данных очень много, то на вкладке Power View можно включить специальную Область фильтров (Filters), где с помощью привычных галочек можно выбрать какие именно города или товары нужно показать на карте:

Итого в плюсах: легкость использования и гибкость настройки, возможность дробить одну карту на несколько по категориям.
В минусах: Power View есть не во всех комплектациях Excel 2013, нет других типов диаграмм кроме пузырьковых и круговых.
Способ 3. Дорого и профессионально — надстройка Power Map
Это отдельная COM-надстройка для максимально тяжелых случаев, когда нужна сложная, профессионально выглядящая, анимированная визуализация большого количества данных на любой (даже пользовательской карте), причем с видео динамики процесса во времени. На этапе разработки она имела рабочее название GeoFlow, а позже была переименована в Power Map. К сожалению, в полноценном варианте эта надстройка доступна только покупателям либо полной версии Microsoft Office 2013 Pro, либо подписчикам корпоративных версий Office 365 с тарифным планом Business Intelligence (BI). Однако превьюшку этой надстройки товарищи из Microsoft дают скачать «на поиграться» совершенно бесплатно, за что им спасибо.
Ссылка на скачивание Power Map Preview с Microsoft Download Center (12 Мб)
После скачивания и установки надстройку нужно подключить на вкладке Разработчик — Надстройки COM (Developer — COM Add-ins) аналогично Power View из предыдущего пункта. После этого на вкладке Вставка должна появиться кнопка Карта (Map). Если теперь выделить таблицу с исходными данными:

… и нажать кнопку Карта, то мы попадем в отдельное окно надстройки Microsoft Power Map:

Если не вдаваться в детали (которых тут хватит на отдельный тренинг на полдня), то общие принципы работы с картой тут те же, что и в Power View, описанной выше:
«Вау-моментом» надстройки Power Map можно, пожалуй, назвать предельную легкость создания анимированных видеообзоров на основе сделанных карт. Достаточно сделать несколько копий текущей сцены с разных углов просмотра и разным масштабом — и надстройка автоматически создаст 3D-анимацию облета вашей карты с акцентированием внимания на выбранных местах. Полученное видео потом легко сохраняется в mp4-формате в виде отдельного файла для вставки, например, на слайд Power Point.
Способ 4. Пузырьковая диаграмма с «доработкой напильником»
Самый «колхозный» способ из всех перечисленных, но зато работающий во всех версиях Excel. Построить пузырьковую диаграмму (Bubble Chart), отключить у нее оси, сетку, легенду… т.е. все, кроме пузырей. Затем вручную подогнать положение пузырей, подложив под диаграмму скачанное заранее изображение нужной карты:

Минусы этого способа очевидны: долго, муторно, много ручной работы. Да еще и вывод подписей к пузырям представляет собой отдельную проблему, когда их много.
Плюсы в том, что этот вариант будет работать в любой версии Excel, в отличие от следующих способов, где обязательно требуется Excel 2013. Да и подключение к интернету не требуется.
Способ 5. Сторонние приложения и надстройки
Раньше существовало несколько надстроек и плагинов для Excel, позволяющих с той или иной степенью удобства и красоты реализовать отображение данных на карте. Сейчас подавляющее большинство из них либо заброшены разработчиками, либо в стадии тихого отмирания — с Power Map конкурировать тяжело 
Из оставшихся в живых достойны упоминания:
- MapCite — пожалуй, самая мощная из всех. Умеет привязываться к карте по названиям населенных пунктов, областей, округов и координатам. Выводит данные в виде точек или тепловой карты. Использует карты Bing в виде основы. Автоматом умеет кидать созданную карту в презентации Power Point. Для скачивания доступна бесплатная trial-версия, полная версия стоит 99$/год.
- Esri Maps — надстройка от компании Esri также позволяющая подгружать и анализировать геоданные из Excel на карты. Много настроек, различные типы диаграмм, поддерживает русский язык. Есть бесплатная демо-версия. Полная версия требует подписки на картографический сервис ArcGis.
- MapLand— одна из первых надстроек на эту тему, созданных еще для Excel 97-2003. Идет с набором карт в виде графических примитивов, к которым и привязываются данные с листа. Дополнительные карты надо докупать. Для скачивания доступна демка под разные версии Excel, Pro версия стоит 299$.
- Overview
- Repeat Address Mapping
- Working with Zip files
- Cleaning Address Strings
- Making a Repeat Address Table
- Using 3d Maps to make a point map
- Choropleth Mapping
- Merging in Data from a Pivot Table
- Creating Custom Region Choropleth Map
- Homework
- Extra – Creating an Animated Hot Spot Map
Overview
This week I will illustrate three different types of mapping techniques you can do in Excel: repeat address, choropleth, and kernel density hot spot maps. Excel has only very basic mapping capabilities, and most crime analysts will use a full fledged Geographic Information System (GIS) to do more sophisticated data manipulation. (Check out my graduate level GIS course for example.)
But Excel has recently made some mapping capabilities available, so I will show how to do some simple mapping techniques. Either download the data from ELearning, or download it from here.
Repeat Address Mapping
Working with Zip files
For those not familiar with zip files, I often use them to send larger files as one (nicer for emailing or opening up a set of files). It compresses the data, and makes it one file, so easier to share. So here is what that zip file looks like on my machine in the Windows folder view.
But to work with them you need to unzip them. Right click on the zipped folder and select Extract All.

Then it brings up a dialogue for the location of where to save the files. By default it saves it in the same folder that the zip file is located in. If you are working in the lab, you might want to change it to where you store all of your files for class. Then hit Extract to de-compress the files.

You can see I have a new folder named Lab04_Mapping.

To do the reverse, what is typical is to place all of the files in a single folder. Then you can right click on the folder, and then select Send To -> Compressed (zipped) folder

And that will subsequently create a zip file in the same folder (if you still have Lab04_Mapping.zip in the same folder, it will make a new one named Lab04_Mapping (2).zip).
That is the zip file service that comes for free with Windows. Another popular compression tool is 7-zip. That tool can do either traditiona zip compression, or even better compression .7z. (But note not everyone will have access to 7z, to some users may not be able to use it.)
Cleaning Address Strings
In this section, I will illustrate some simple text manipulation you can do in Excel. This is common to clean addresses, in many systems you will have extra text in the address column that prevents proper geocoding.
Go ahead and open up the DallasIncidents.csv file in Excel, and turn the data into a table. It is pretty big (just short of 100,000 total incidents), so takes a minute.

Select column G (City), and right click Insert.

This will create a new blank column in-between IncidentAddress and City. Name that column CleanedAddress. Then select the IncidentAddress column (F), double click the right edge of the F column at the top to expand it, and hit Ctrl+F to bring up the Find & Replace dialogue.

Type in APT in the Find What box, and then hit the Find Next button, this should take you to row 5,740, and show that an address with Harry Hines Blvd accidently has an apartment number included.

Having extra text like that will often make the geocoding engine fail. This dataset is pretty clean already (DPD must use some type of data validation already when inputting addresses), but it has a few of these APT notes misplaced in the main address field. To fix this what we are going to do is to search for the text APT, and then only return the text string. This will require nesting several functions together:
- The
LEFTfunction to return the string - The
FINDfunction to search the address string for if it containsAPT - and the
IFERRORfunction, to just return the original string if it does not contain any extra APT notes.
So first, in our new (and so far empty) column and row 5740, type in the formula =LEFT([@IncidentAddress],10). You can see in the update this just grabs the first 10 characters in the string.

To strip out the APT text, and keep the address stuff we want, we need to replace the hard coded 10 with where the APT string starts. The function FIND lets us do that, so lets replace our formula now with =LEFT([@IncidentAddress],FIND(" APT",[@IncidentAddress])). I include the space before APT to prevent catching street names that might include APT within them, e.g. something like RAPTOR ST would not be captured.

We can see now that this works for the Harry Hines address, but gives us errors for the others that do not have APT contained in them. This is because if » APT» is not contained in the original IncidentAddress string, the FIND function will return an error. So to fix this we will use the IFERROR function. Now update the formula to read =LEFT([@IncidentAddress],IFERROR(FIND(" APT",[@IncidentAddress]),100)). In long form to make the nesting easier to read, here is how the formula goes:
=LEFT([@IncidentAddress],
IFERROR(
FIND(" APT",[@IncidentAddress]),
100
)
)Here we use 100 as just a long number that will contain the full address for any cells that do not contain » APT“. Another option sticking just to the data would be to replace 100 with LEN([@IncidentAddress]). And now we can see that our new address field works out just dandy.

Now right click on column K (ApartmentNumber) and Insert a new column. To use the Excel geocoder, we need to submit one string with the full address (include City, State, and Zipcode). Name the column FullAddress, and then type in the formula =CONCATENATE([@CleanedAddress],[@City])

Whoops, we can see that there is no space in-between our address field, and the city name Dallas. Now redo the formula, inserting ", " inbetween the two columns, =CONCATENATE([@CleanedAddress],", ",[@City])

That looks better now. Go ahead and add in the State and Zipcode, incorporating extra spaces and comma’s in where appropriate. So in the end mine looks like =CONCATENATE([@CleanedAddress],", ",[@City],", ",[@State]," ",[@ZipCode]).

Next up, doing repeat address mapping.
Making a Repeat Address Table
Go ahead and make a pivot table of the incidents, using FullAddress for rows, and ucr_redString for the columns, and Count of ucr_redString for the values.

Select the dropdown arrow in the Rowlabels area, and navigate to Value Filters -> Greater Than:

Then input 30 as the selection criteria and hit OK. This will limit the table to places with a total of 30 or more incidents (across all crime types).

Now right click on the header row of the pivot table, and select Pivot Table Options.

With the Layout and Format tab selected, in the empty cells option type 0. Then hit OK.

You will see the table now has 0’s instead of blanks for empty crime counts.

Using 3d Maps to make a point map
Before we move onto making a map (which is only available in newer versions of Excel, not sure if they are available for Mac editions), we need to save our worksheet as an xlsx file. So go to File -> Save As, navigate to where you want to save the file, and in the dropdown select Excel Workbook.

Also maps does not work with PivotTable (only regular tables). So we need to transfer our Pivot Table data into a new location. So, make a new worksheet, and label it RepeatAddress. Then from the Pivot Table copy-paste cells A4:K222. Then turn that data into a Table. I renamed A1 then to say address.
With that data, now in the top toolbar go to Insert, and then select the 3D Map option.

This should bring up a map! And Excel automatically figures out to geocode the locations. You can zoom into the locations around Dallas to check it out. I also click the Map Labels option (brings up street names), and the Flat Map option here.

Now we will style our map, showing addresses with more crimes as larger circles. (We will check the geocoding in a bit.) In the right hand side, click the bubble looking icon just below the Data layer, and then select the Add Field option below Size, and select Grand Total as the field.

This will make the bubbles too big, so expand the Layer Options (below Size), and set the Size to 20%, Thickness to 0, and Opacity to 80%. Here I also change the color to a more pink/salmon. Now you can see variation in crime areas a bit better.

You can zoom into the map and select the circles, which brings up a tool tip. Here I zoom into the largest bubble. Uh-oh, it is 1400 S Lamar St. This is just DPD headquarters! I don’t want to map that.

So navigate back to the RepeatAddress worksheet. Then sort the data by descending values on the Grand Total Column. Then select the Lamar St row, and right click and select Delete.

Now if we go back to our Map, the bubble is still there. But lets hit the Refresh Data button, and then see the map update with no more bubble on S Lamar St.

Now we are going to check our geocoding results. In the Layer table of contents on the right, above the Location box there is a little % button. Here it says 0%, and click that:

You can see a bunch of warning yellow triangles, but it just happens to be because of the proper case versus all uppercase addresses. So even though it says 0% mapped with confidence, it doesn’t appear to be that bad.

Click the Result column header twice, and this will sort the 3 cases that were not matched at all to the top of the table. (If you only click once, it will sort them to the bottom, all the way on page 5.)

We now need to change the data so it will map. I typically use a mix of googling (Fun Way appears to be a small road around Fair Park). And it happens that LBJ in the Excel (Bing) maps is listed under its full name, Lyndon B Johnson. Lets navigate back to the RepeatAddress sheet, and edit these few locations.
To make it easier I selected out just those three addresses in the Address column. Select the dropdown arrow on the Address column, the select the Text Filters -> Custom Filter option.

Then in the options to the right, make sure the contains option is selected, and in the two rows type FUN WAY and L B J (for the latter make sure there are spaces). Then click OK.

You should now see our three bad addresses selected.

For LBJ, we just need to edit the address to be Lyndon B Johnson and will it subsequently geocode. For Fun Way it is alittle more difficult, as that address is not in Bing maps at all. So edit LBJ to say Lyndon B Johnson instead (keeping the same address). But for the 1600 FUN WAY I am going to just use Cotton Bowl Circle (as it is pretty close). Leave the 1550 Fun Way as is.

Now go back to the map page, click the Refresh Data button, and then scroll the map to Fair Park. You should now see our big bubble that (that used to be 1600 Fun Way).

If you go back to the Mapping Confidence dialogue and sort again by Results, you should now only see the 1550 Fun Way address.

I am not going to worry about fixing this last address for now. One way would be back in the original data, whenever you encounter FUN WAY, change that address to simply Cotton Bowl Circle. That would collapse the two FUN WAY addresses together in the final map.
Choropleth Mapping
Next up, we are going to create a choropleth map of crime densities per DPD reporting areas. Small geographic areas made up by DPD to patrolling essentially.
First we are going to add in a file of all of the reporting areas. Navigate back to the main Excel document, and create a new worksheet and title it, ReportingAreas. Then select cell A1, and in the top toolbar go to the Data tab, and select From Text.

Then in the dialogue, navigate to the RA_Data.csv file location, and select that file. and click Import.

In Step 1 of 3 in Text Import Wizard, make sure Delimited is checked, as well as My Data has headers. Then click Next.

Then in the next step, make sure Comma is selected. It will then make the fields have lines inbetween them (whereas if you leave it as Tab it will just import all of the data as one big string in one column).

Then in the step 3 of the Wizard you can keep the defaults for how it treats columns, and then just click Finish.

Then finally you get alittle Import Data dialogue that asks where you want to import the data. Make sure =$A$1 is chosen, and then click OK.

You may be asking what is the benefit of doing it this way, as opposed to opening up the CSV file and just dragging the sheet into the current workbook. The answer is when you do it this way, the data is linked in the workbook. If you edit the CSV file, your values in the Excel workbook will change.
Here it does not make much of a difference, later in the semester though I will show how when linking to an Access database this will be really helpful behavior.
Merging in Data from a Pivot Table
Go to the original DallasIncidents_2017 sheet, and select the Design tab in the top toolbar. Then rename the table to Incident_Data.

Then navigate back to the ReportingAreas sheet and select cell R1. Then insert a Pivot Table – fill out the Select a table option to be Incident_Data, and the location to be R1 in the reporting areas worksheet. Then click OK.

In the Pivot Table, place ReportingArea for the rows, and count of ReportingArea for the Values.

This looks like it lines right up with our other data we imported, but if you scroll down further you can see it does not line up directly forever. In cell K2, type an equal sign, and then select cell S2. You will see a formula pop up that looks like =GETPIVOTDATA("ReportingArea",$R$1,"ReportingArea",1001)

Change the 1001 in the end to be B2. Then hit enter, and double click the formula to extend down the entire dataset. Here I also named the column CountCrimes. If you scroll down to row 44, you will see an error.

To fix this, we are going to nest our function within an IFERROR function. So change the function reference to =IFERROR(GETPIVOTDATA("ReportingArea",$R$1,"ReportingArea",B44),0). Then make sure to update that function both above and below in the column. (Note, the mapping functions in Excel will not work if you have errors in the data files.)

Now to end we are going to make a field that is the density of crimes per square mile. In K1, write CrimeDens, and in K2, the formula is just K2/J2.

For reference, if you are not working with Pivot Tables, another function to that of GETPIVOTDATA that can accomplish a similar task is called VLOOKUP. But here the Pivot Table specific function is a better choice.
Creating Custom Region Choropleth Map
Select cells A1:K1157, and then in the 3D map option select Add Selected Data to 3d Maps.

The map should now be the focus, and you should have a Layer 2 option in the right table of contents, but is empty (if not click the Add Layer button). Turn the point map off (by clicking the Eyeball in Layer 1). And then in the Location field in the dropdown select RA.

Then in the dropdown for the RA select Custom Region (.kml, .shp).

You then get a pop-up to import custom regions, Go ahead and click Yes, and then navigate to the DPD_ReportingAreas.kml file. (This is a type of geographic file, specifically one associated with Google Earth.)

In the Regions selection, change the default Name to RA. Then click Import.

You should see them populate as a bunch of points in the map. In the table of contents on the right, change the Viz. type to region. Then in the value section change it to CountCrimes.

Then in the layer options I changed a few options to get alittle more difference across the areas.
![]()
Note to create an image of the map, you can click on the Capture-Screen button on the top left, and then paste the resulting image into whatever document you are using.
This ends up not showing much variation and looks washed out. One way to make more variation in the map is to bin the data (such as via quantiles). (ToDo for another time!)
Homework
For your homework, create a table of the top 10 repeat addresses for Robberies in Dallas. Then for the mapping portion, create a Choropleth map of the robbery rates per population for reporting areas (see the POP2010 field). Insert both of the those into a powerpoint presentation, then save as a PDF, and turn the PDF in.
See below for an additional extra credit opportunity via making a kernel density map.
On my personal website I have created an example of creating an animated hot spot map over time. Check out the video for illustration.
For 5 points extra credit, create an animated hot spot map for one particular crime type in Dallas and turn it in.
Время на прочтение
10 мин
Количество просмотров 10K
Считается, что Data Mining — это магическое снадобье из SQL, Python, Power BI и других волшебных компонент. Мало кто знает, что при правильном подходе с Data Mining может совладать офисный планктон с помощью одного лишь Excel.
Если вы абсолютно далеки от Data Mining, но хотите причаститься его таинств, это руководство в картинках по шагам сделано для вас. Особенно полезно тем, кто никогда бы даже не подумал сделать подобное самостоятельно.
Если вы владеете специальными инструментами для работы с данными, то будет интересно узнать ваше мнение о решениях без «рокет сайнс» (как о явлении в целом, так и о данном кейсе).

В качестве практического вопроса будем рассматривать визуализацию данных из объявлений на популярных сайтах продажи квартир. Визуальный анализ — основа основ Data Mining, а при отсутствии специальных знаний — и вовсе единственный способ для понимания смысла, содержащегося в большом количестве данных. Это настолько фундаментальный навык, что ему посвящена целая народная мудрость:
Лучше один раз увидеть, чем сто раз услышать*
*Это все, что нужно знать о достоинствах визуального анализа.
Термины
Тепловая карта (heat map) – обозначение какого-либо показателя цветом:
Как правило, более высокие значения обозначаются красными оттенками, более низкие – синими. Обычная цветовая шкала выглядит так:
![]()
Географическая тепловая карта – обозначение показателя цветом на географической карте. Более высокие значения температуры показаны более красными оттенками в привязке к географическим точкам:
Географическая тепловая карта цен – обозначение цветом цен в разных географических местах.
В нашем случае это будут цены на квартиры.
Данные
Цены на квартиры будем брать с общеизвестных досок объявлений А и Ц. Для сбора объявлений без программирования нужно воспользоваться готовым парсером. В данном случае выберем наиболее доступный по причине его бесплатности и наиболее удобный из-за простоты установки в три клика в Excel.
Парсеру надо дать понять какие объявления нужно скачивать. Для этого используется ссылка на доску объявлений.
Для подготовки ссылки для скачивания объявлений с доски объявления А открываем браузер, в браузере открываем сайт доски объявлений, выбираем регион (для примера → Брянск) и раздел → квартиры. В адресном поле браузера получаем ссылку: https://www.avito.ru/bryanskaya_oblast/kvartiry. В последней части ссылки видим раздел → kvartiry, перед ней расположен регион → bryanskaya_oblast. Вместо Брянска можно указать свой регион, а вместо раздела квартир можно указать дома-дачи-коттеджи или земельные-участки. Также можно использовать фильтры (например новостройки или вторичка, количество комнат) и они отобразятся в составе ссылки. Скажем спасибо доске объявлений А за такой понятный порядок формирования ссылок.
Для подготовки ссылки с доски объявлений Ц придется сделать дополнительный шаг: после выбора региона, раздела, фильтров и нажатия кнопки «Найти» нужная ссылка еще не будет готова. Для завершения подготовки ссылки нужно перейти на вторую страницу списка объявлений. После этого ссылка в адресной строке браузера примет вид https:// cian.ru/cat.php?deal_type=sale&engine_version=2&offer_type=flat&p=2®ion=4562&room1=1&room2=1. Раздел квартир здесь будет в offer_type=flat, а регион – в region=4562. Скажем «фу» доске объявлений Ц за не самый удобный порядок формирования ссылок.
Готовые ссылки как есть копируем из адресной строки браузера (нажатием кнопок Ctrl+A и Ctrl+C) и вставляем в парсере нажатием кнопки Добавить ссылку. Для обеих ссылок можно указать один и тот же новый файл Excel, в который будут сохраняться объявления.
Чтобы код для парсинга доски объявлений А загрузился в Excel → в настройках парсера (расположены в Excel на вкладке Надстройки) ставим галочку у парсера доски объявлений А и выключаем галочки у сохранения фотографий из объявлений, у сохранения копии объявлений, у открывания номера телефона и у других ненужных опций. То же самое повторяем с настройками парсера доски объявлений Ц.
Теперь ссылки полностью готовы для загрузки объявлений. Нажимаем в меню парсера кнопку Старт и ждем около 20 секунд до загрузки первого объявления. Да, процесс совсем не быстрый и займет время. Можно уменьшить интервал запросов в настройках парсера до 10 или 5 секунд и иногда это даже прокатывает. Но обычно доски объявлений очень не любят ботов и сразу закрывают доступ к данным (бан). Конечно, эти ограничения можно обойти и загружать данные в 100 раз быстрее, но это дороже.
Загружаемые объявления выглядят примерно так:

Таких строк может быть несколько тысяч. В нашем примере это около 5000 объявлений для Брянской области в октябре 2021.
Из множества данных нам понадобятся только широта, долгота, цена, общая площадь и офер:
|
Широта |
Долгота |
Цена |
Общая |
Офер |
|
53,2656 |
34,35292 |
5030000 |
64,2 |
Продам |
|
53,20856 |
34,46647 |
2443000 |
51 |
Продам |
|
53,26398 |
34,33171 |
10000 |
40 |
Сдам |
|
53,54983 |
33,76486 |
750000 |
35 |
Продам |
|
… |
Это сырые данные, которые требуют подготовки.
Подготовка
Отделим аренду от продажи. Для этого добавим фильтр по полю «офер» и выделим только предложения продажи. Можно и наоборот – оставить только предложения аренды и работать дальше с ними.

Выделим отфильтрованные данные, Ctrl+G → только видимые:

Копируем их Ctrl+C и вставим на новый лист Ctrl+V:
|
Широта |
Долгота |
Цена |
Общая |
|
53,2656 |
34,35292 |
5030000 |
64,2 |
|
53,20856 |
34,46647 |
2443000 |
51 |
|
53,54983 |
33,76486 |
750000 |
35 |
|
53,31711 |
34,30244 |
1450000 |
62 |
|
53,26612 |
34,33491 |
2950000 |
36 |
|
… |
Если показывать цены на многокомнатные квартиры одним цветом и цены однушек другим цветом, в результате получим карту размещения жилья по числу комнат. Для анализа цен этот показатель слишком сырой. Вместо него используем среднюю цену за квадратный метр.
При делении цены квартиры на общую площадь получим цену одного квадратного метра. Этот показатель лучше отражает ценность жилья с учетом всех ценообразующих факторов: расположения, состояния, отделки и окружения. Поэтому добавим колонку с ценой одного квадратного метра и уберем колонки с ценой и общей площадью:
|
Широта |
Долгота |
За 1 кв.м. |
|
53,2656 |
34,35292 |
78348,91 |
|
53,20856 |
34,46647 |
47901,96 |
|
53,54983 |
33,76486 |
21428,57 |
|
53,31711 |
34,30244 |
23387,1 |
|
53,26612 |
34,33491 |
81944,44 |
|
… |
Теперь проведем стандартные процедуры проверки заведомо ошибочных данных.
У нас есть две группы данных: географическое положение и цена. Для проверки обеих групп используем визуальный контроль.
Поместим имеющиеся географические точки на обычную диаграмму Excel:

Посмотрим координаты крайних точек Брянской области. Широта должна быть от 51,5039 до 54,021, долгота от 31,1432 до 35,1917. Некоторые наши точки выходят за эти пределы. Опустим здесь рассмотрение причин появления испорченных данных и возможных путей их восстановления, т.к. это не относится прямо к цели визуализации данных и противоречит принятому ограничению квалификации пользователя. По этой же причине используем грубый, но простой способ избавления от испорченных данных.
Заменим нулями строки, где долгота и широта выходят за границы региона → с помощью простой формулы:

Затем добавим фильтр и уберем отображение строк с нолями:

Выделим все строки отфильтрованных колонок данных, затем Сtrl+G → только видимые:

Копируем их Ctrl+C и вставим в новое место (рядом) Ctrl+V.
Очищенные таким образом долготы и широты точек отправляем на новую диаграмму Excel и видим результат очистки:

Теперь также с помощью визуального анализа очистим данные о ценах.
Для этого построим гистограмму, чтобы посмотреть сколько каких значений цены в нашей выборке.
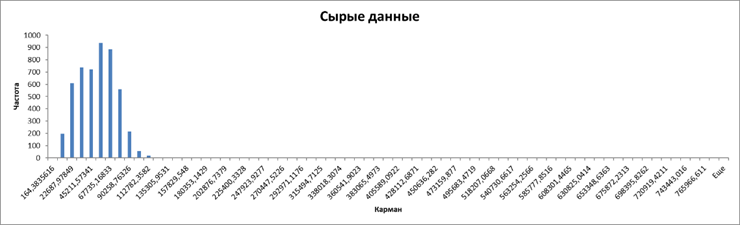
Город рос в естественных условиях (построен не одномоментно по единому плану), имеет развитое сельское хозяйство и небольшие промышленные предприятия (не лакшери центр). Теория говорит, что при таких обстоятельствах цены на финансовые активы (жилье – один из базовых финансовых активов) должны быть распределены логнормально.
Присутствие на гистограмме длиннющего тощего хвоста и асимметрия основной части распределения являются характерными признаками логнормального распределения. То есть в данном случае практика соответствует теории.
Практический смысл этой гистограммы: если данные из правой части отметить на карте одним цветом, из средней — вторым и из левой — третьим, то вся карта будет залита одним цветом. Потому что в средней и в правой частях точек почти нет. Аналитического смысла у такой карты не будет.
Чтобы избавиться от упомянутого эффекта нужно отбросить хвост распределения, а заодно и данные из первого левого кармана. В результате получим такую гистограмму:

Теперь количество данных в разных частях более-менее сопоставимо. Количество карманов здесь посчитано Excel автоматически и оно явно избыточно для того, чтобы каждый уровень цены обозначать своим цветом. Поэтому в дальнейшем перестроим гистограмму по количеству карманов в соответствии с количеством цветов, которые будут использованы на карте. В нашем случае будем использовать 7 цветов.
Перед разбивкой данных по карманам рассмотрим еще одно обстоятельство, которое стоит учесть на этапе подготовки данных. Дело в том, что точки на карте могут располагаться слишком тесно. Например, здесь шесть объявлений расположены в одном доме и перекрывают друг друга даже на самом крупном масштабе:
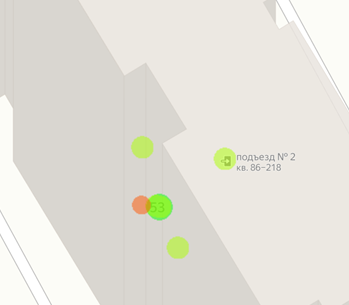
На более мелких масштабах эти метки полностью сольются и станут неразличимы.
Чтобы избавиться от излишней в данном случае детализации данных проведем их усреднение. Для усреднения данных воспользуемся следующим приемом.
Обычная точность указания координат использует 6 знаков после запятой. Например, широта 52,549374 и долгота 31,897056. Четвертый знак после запятой соответствует масштабу придомовой территории. В нашем примере в диапазон долготы от 31,8965 до 31,8974 попадают все объявления, относящиеся к одному строению. Используем это обстоятельство для группировки данных в процессе усреднения.
Добавляем к имеющимся данным столбцы с округленными до 3 знака широтой и долготой. Еще одним столбцом добавляем символьную сумму этих двух последних столбцов:

Что в результате дает:

После чего сортируем все столбцы по колонке с текстом и применяем Промежуточный итог:

В результате данные разбиваются на группы близколежащих точек, для которых вычисляются средние цены и координаты:

Для замены групп на точки со средними значениями → сворачиваем все группы, выделяем колонки координат и цены:

Затем выделяем только видимые ячейки Ctrl+G → только видимые, копируем Ctrl+C:

После чего вставляем скопированное на новый лист. Теперь на каждом здании будет не больше одной точки с данными, которая соответствует среднему значению всех относящихся к зданию объявлений:

С помощью такого приема можно провести усреднение цен на уровне группы зданий или по кварталу.
После такого прореживания осталось меньше половины точек. Благодаря этому карта цен будет значительно меньше перегружена данными в самых насыщенных местах.
Получившийся набор данных предстоит разложить по карманам в зависимости от величины цены. Для 7 цветов = 7 карманов гистограмма выглядит так:

Данные из первого левого столбца гистограммы будут синего цвета, из последнего правого — красными, а из расположенных между ними — оттенками зеленого:

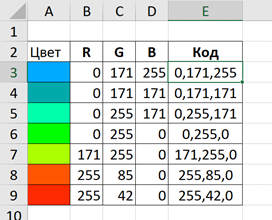
Цвет получается смешиванием красного (R), зеленого (G) и синего (B). Интенсивность каждого цвета находится в диапазоне от 0 до 255. Смешивание для получения показанных цветов приведено в следующей таблице.
|
Цвет |
R |
G |
B |
Код |
|
Синий |
0 |
171 |
255 |
0,171,255 |
|
0 |
171 |
171 |
0,171,171 |
|
|
0 |
255 |
171 |
0,255,171 |
|
|
Зеленый |
0 |
255 |
0 |
0,255,0 |
|
171 |
255 |
0 |
171,255,0 |
|
|
255 |
85 |
0 |
255,85,0 |
|
|
Красный |
255 |
42 |
0 |
255,42,0 |
Обозначения из столбца Код будут использованы для окрашивания данных на карте.
Полученный результат можно считать подготовленными данными для отображения их на карте.
Обработка
Имеющиеся цены разделим на 7 равных интервалов. (В этой области знаний интервалы синонимы диапазонов, и еще их называют карманами.)
Для определения ширины интервала разницу максимальной и минимальной цен нужно разделить на количество карманов. В нашем случае данные такие:
|
Минимум |
4000 |
|
Максимум |
109253,1 |
|
Кол-во карманов |
7 |
|
Ширина кармана |
15036 |
И карманы:
|
1 |
3999 |
— |
19035 |
|
2 |
19035 |
— |
34071 |
|
3 |
34071 |
— |
49107 |
|
4 |
49107 |
— |
64144 |
|
5 |
64144 |
— |
79180 |
|
6 |
79180 |
— |
94216 |
|
7 |
94216 |
— |
109253 |
Для получения данных первого кармана нужно скопировать данные широты и долготы для цен от 3999 до 19035 и вставить в новое место. Цены копировать не нужно, они использовались только для разбивки данных по карманам и больше не пригодятся. Аналогично для второго кармана копируем широты и долготы для цен от 19035 до 34071 и вставляем их рядом с данными из первого кармана. Повторив семь раз получим в результате:

В каждом кармане две колонки: левая — широта и правая — долгота. Количество строк в каждом кармане разное, как было показано на последней гистограмме.
Теперь данные полностью готовы для их помещения на карту.
Карта
Для построения карты нужно сделать три шага:
Добавить шаблон карты → Заполнить шаблон данными → Показать результат
Шаблон карты добавляется кнопкой Добавить в меню парсера. Если в меню парсера нет кнопок для работы с картой, то в настройках парсера нужно включить опцию Excel → График на карте.

В первой строке шаблона указаны значения по умолчанию, которые можно изменять. В левой таблице вставляются подготовленные данные о ценах. Правая таблица служит для вывода на карте подписей к конкретным точкам.
Для вставки в шаблон данных о ценах из первого кармана нужно в ячейку A3 вставить ссылку на диапазон данных о широте и долготе, которые указаны в двух колонках первого кармана, вот эти:

Для примера это диапазон Q4:R582 на листе По карманам в файле Брянск 10(октябрь)-21.xlsx.
Вставить ссылку на этот диапазон можно с помощью функции Ссылка(диапазон).
В ячейке А3 шаблона пишем название функции:
")
В качестве единственного аргумента функции Ссылка указываем диапазон Q4:R582 на листе По карманам:

В результате получаем:

Точки данных первого кармана ранее условились обозначать синим цветом с кодом 0,171,255. Для примера формулы ниже: таблица с кодами цветов находится на листе Палитра. Код синего цвета находится в ячейке Е3:
Для вставки ссылки на ячейку в Excel не требуется использовать специальную функцию, поэтому в ячейке шаблона В3 вставляем ссылку на ячейку кода синего цвета обычным способом:

В результате:

Размер точек определяется из субъективных соображений. Для примера примем размер 10:

На этом шаблон карты полностью готов для отображения данных из первого кармана.
Посмотрим что получилось. Для этого нажимаем кнопку Отобразить в меню парсера, после чего открывается новое окно:

Метки на карте отсутствуют из-за масштаба. Зумим колесом мышки и получаем:

Закрываем окно с картой, добавляем данные из второго кармана:

Данные из второго кармана отображаются поверх данных первого кармана:

После добавления всех оставшихся карманов:

На карте:
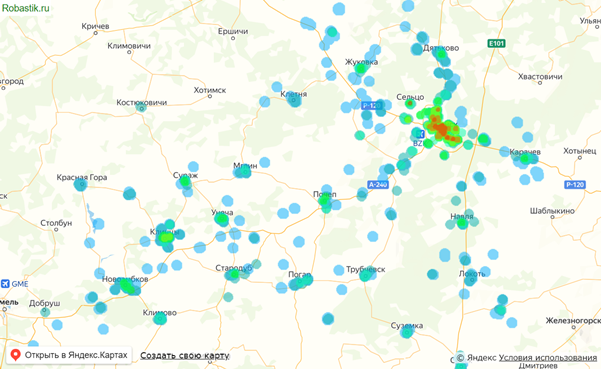
Это и есть визуализация цен на географической карте, сделанная в Excel без программирования. Ее можно зумить и двигать как обычную карту в браузере. Для копирования карты в буфер в парсере есть специальная кнопка Копировать.
В завершение отметим на карте какое-нибудь место, например Аграрный университет. Координаты широты и долготы БГАУ возьмем по указанной ссылке и вставим в ячейки J3 и К3. Ссылку на ячейки с координатами вставим в ячейку шаблона Н3:

Увидим БГАУ на карте и оценим его влияние на цену недвижимости:

Файл Excel с примером можно скачать здесь.
Many financial systems do a fine job of generating standard reports,
but accountants often need more. In those cases, accountants can
create custom solutions in Excel, but that approach has drawbacks. For
instance, a typical process may involve exporting some type of data,
perhaps a trial balance, and then opening it in Excel. Once the data
is in Excel, the person preparing the report may need to manually
reformat the data, aggregate some numbers, and/or change some report
labels or headers. It’s a process that can be time-consuming and prone
to error, especially when it has to be repeated regularly, such as
with the preparation of financial statements from a trial balance.
The good news is that Excel provides the tools necessary to automate
much of the process. This article explores features, functions, and
techniques that allow for the creation of recurring reports in Excel.
STRATEGY
This article focuses on building a balance sheet from a trial balance
exported from an accounting system such as QuickBooks, but the
underlying strategy can be implemented in a number of situations.
The overriding concept is that data is exported in an
Excel-compatible format so that it can be opened in Excel and saved in
a worksheet within an Excel workbook. These values need to find their
way into the recurring report, in this case the balance sheet, in an
automated way. Two typical problems encountered when trying to get the
trial balance data to flow into the balance sheet are that the
category labels are different and that multiple accounts may need to
be aggregated to flow to a single report line.
What does it mean that the labels are different? Consider, as an
example, the item labeled “checking” in the trial balance. The value
of “checking” is reflected in the balance sheet being produced but
under the label “Cash and Cash Equivalents.” The difference in labels
prevents the use of clever lookup formulas such as VLOOKUP. Instead, a
typical approach would be to use a direct cell reference, such as =A1,
to retrieve the value. The problem with direct cell references is that
there is no guarantee that account values will reside in the same cell
each period. For example, “Checking” might be in cell A1 one month,
but in cell A2 the next. Such changes generate errors and inefficiencies.
Further complicating the report generation is that multiple accounts
often need to be summed up to compute a balance sheet line item. For
example, the three accounts “Checking,” “Savings,” and “Certificates
of Deposit” need to be aggregated in the balance sheet item “Cash and
Cash Equivalents.” Again, direct cell references, such as =A1+A3+A5,
can be used, but the possibility looms that when the updated trial
balance arrives, the accounts will be in different cells, resulting in
errors and inefficiencies.
Both issues can be addressed with a mapping table, or map for short.
With a map, the data doesn’t flow directly from the trial balance to
the balance sheet report. Instead, the data flows from the trial
balance into the map and then from the map into the balance sheet.
The map contains the information Excel needs to fully automate the
data flow, including translating the labels and aggregating account
values. Building the map is fairly easy. Indeed, all that is needed is
a single Excel feature, Tables, and a single Excel function, SUMIFS.
Both were introduced with Excel 2007 for Windows and are unavailable
in earlier versions.
TABLE INTRODUCTION
While the map and trial balance data could be stored in ordinary
ranges, it is better to store them in a table. To use the Tables
feature, enter the initial data into ordinary cells, then convert the
data range into a table by selecting any cell within the range and
clicking on Table on the Insert tab.
The conversion of an ordinary range into a table applies several
special properties, two of which are auto-expansion and structured
table references. With auto-expansion, the table automatically expands
to include new data typed or pasted immediately under the table. Any
formulas that reference the table will automatically include the new
data. A structured table reference is a naming system that allows
references to the table and selected areas within the table¬¬, for
example, a specific column.
Excel names tables using a simple naming convention: Table1, Table2,
Table3, and so on. You can always rename a table by using the
TableTools > Design > Table Name setting. Structured
table references begin with the table name, followed by the desired
table area within square brackets. For example, the reference for a
column named Account in a table named
TrialBalance would be
TrialBalance[Account]. Excel automatically enters the
correct reference when you select the desired area with your mouse.
The next requirement in this automation process is an efficient and
reliable way to pull values from the data source into the map and then
from the map into the report. That tool is the SUMIFS function.
SUMIFS INTRODUCTION
The SUMIFS function is officially known as a conditional summing
function. In practice, it adds only those rows that meet a condition
or conditions.
Here is one way to think about it: Add up this column of
numbers, but include only those rows where this column is
equal to this value. For example, add up the amount column
but include only those rows where the account is equal to cash. The
function arguments use similar logic. First is the column of numbers
to add. Then the remaining arguments come in pairs: first the criteria
range and then the criteria value.
The syntax for the SUMIFS function follows:
=SUMIFS(sum_range, criteria_range1, criteria1, …)
Where:
- sum_range is the range of numbers to add;
- criteria_range1 is the first criteria range;
- criteria1 is the first criteria value; and
- … up to 127 criteria range/value pairs are supported.
The SUMIFS function in this example is used to pull the values
from the data table into the map and then from the map into the
report.
WALK-THROUGH
This walk-through goes through the process of using the Tables and
SUMIFS tools to produce an automated recurring report. To follow the
walk-through, download the free Excel file at excel-university.com/map.
START HERE
The first worksheet is the Start Here sheet, which
stores the year-end date and then computes the current-year and
prior-year values based on the date entered, as shown below.

For convenience, this worksheet was prepared with a few Excel
features, described below, none of which is strictly necessary, just
personal preference. First, the key cells are named. The year-end date
input cell is named date_ye, the current-year cell is
named date_cy, and the prior-year cell is named
date_py. They were named by selecting each cell and
typing the desired name into the name box, just to the left of the
formula bar. The current-year cell was computed with the YEAR
function, which returns the year of the date. The input cell was
shaded with the input cell style (Home > Cell Styles >
Input) and the calculated cells with the calculation style
(Home > Cell Styles > Calculation), just to
make them pretty and easy to identify.
TRIAL BALANCE
The next worksheet contains the trial balance, which was exported
from our accounting system. To take advantage of the special
properties of tables, convert this ordinary range to a table by
selecting a data cell and then clicking the Insert >
Tables command icon. Doing so helps ensure that in the next
period, when an updated trial balance is flowed, any additional rows
will automatically be included because the tables auto-expand.
The trial balance table is shown below.

Note that the table has Account,
Period, and Amount columns. Because
comparative reports are being prepared, the Period
column ensures that the formulas pull the correct values.
Another option is to change the default table name,
Table1, to a more meaningful name, such as
tbl_tb, by updating the Table Tools > Design >
Table Name field.
MAP
The next worksheet is the map, which translates the account names to
the report labels, identifies groups, and retrieves the values from
the trial balance.
Type in the account names and report labels, and then use the SUMIFS
function to retrieve the values from the trial balance, as shown below.

The PerTB column represents the account names per
the trial balance, the PerBSheet column represents
the report labels on the balance sheet, and the PerPL
column represents the report labels per the income statement. Setting
up multiple report label columns makes it possible to send the same
amount values into multiple reports, even if the labels are different
on each report. The CurrentYear column represents the
current-year amounts, and the PriorYear column
represents the prior-year amounts, based on the current- and
prior-year cell values on the Start Here sheet. If an
updated trial balance includes a new account, you will need to
manually add a row to the map to provide Excel with the proper report labels.
The formula used to populate the CurrentYear column,
which retrieves the values from the trial balance table for all rows
in the defined current year, is:
=SUMIFS(tbl_tb[Amount],tbl_tb[Period],date_cy,tbl_tb[Account],[@PerTB])
Where:
- tbl_tb[Amount] is the column of numbers to add;
- tbl_tb[Period] is the first criteria range, the trial balance
period column; - date_cy is the first criteria value, the current year per the
Start Here sheet; - tbl_tb[Account] is the second criteria range, the trial balance
account column; and - [@PerTB] is the second criteria value, the map’s account name.
A similar formula populates the PriorYear
column. (Please note that the SUMIF function can’t be used
here because it has only one criteria range.)
Now that the map is built and properly retrieving values from the
trial balance, all that remains is the report.
REPORT
The SUMIFS function pulls the values from the map into the balance
sheet, as shown below.

The formula in cell D15, which computes the current-period amount for
cash, is:
=SUMIFS(tbl_map[CurrentYear],tbl_map[PerBSheet],B15)
Where:
- tbl_map[CurrentYear] is the current-year column in the map table;
- tbl_map[PerBSheet] is the balance sheet label column in the map
table; and - B15 is the report label on the balance sheet.
This formula can be filled down throughout the report.
Note that the report headers are dynamic, and they retrieve the
values from the Start Here sheet.
UPDATING
In the next period, simply paste in an updated trial balance, and the
values flow into the map and into the report automatically thanks to
the SUMIFS formulas. In the next year, change the year-end date on the
Start Here sheet, and the correct values will be
pulled into the report. If any new accounts are added, take a moment
and add them to the map so that the workbook knows which report line
the new account belongs to. Similarly, if an account name changes,
update it in the map.
ADDITIONAL RESOURCES
Download the Excel sample file at excel-university.com/map.
Jeff Lenning (jeff@clickconsulting.com)
is the founder and president of Click Consulting Inc. in Irvine, Calif.
To comment on this article or to suggest an idea for another
article, contact Jeff Drew, senior editor, at
jdrew@aicpa.org
or 919-402-4056.
AICPA RESOURCES
JofA articles
- “Microsoft
Office 2013,” April 2013, page 32 - “Pivotal
Advance Boosts Excel’s Power,” Sept. 2011, page 40
CPE self-study
Advanced Excel: Practical Applications for the Accounting
Professional (#745754)
Conference
Practitioners Symposium and Tech+ Conference, June 9–11, Las Vegas
For more information or to make a purchase or register, go to cpa2biz.com or call the Institute at 888-777-7077.
Information Management and Technology Assurance (IMTA) Section
and CITP credential
The Information Management and Technology Assurance (IMTA) division
serves members of the IMTA Membership Section, CPAs who hold the
Certified Information Technology Professional (CITP) credential, other
AICPA members, and accounting professionals who want to maximize
information technology to provide information management and/or
technology assurance services to meet their clients’ or organization’s
operational, compliance, and assurance needs. To learn about the IMTA
division, visit aicpa.org/IMTA.
Information about the CITP credential is available at aicpa.org/CITP.