
Просмотров: 19
Преобразуем таблицы , полученные из 1С для анализа в Excel с помощью макросов.
Таблицы, получаемые из 1C, неудобны для анализа в Excel. На текущем уроке мы рассмотрим, как происходит создание нормальной полностью заполненной таблицы Excel для дальнейшей из выгрузки 1С за несколько минут с помощью несложных макросов на VBA.
Предлагаем для просмотра учебное видео, где наглядно показаны возможности Excel по переработке выгрузки из 1C в нормальную таблицу. Не секрет, что обычная таблица, полученная из оборотно-сальдовой ведомости по выбранному счету или общим оборотам из 1C мало подходит для анализа. Числовая информация в такой выгрузке часто дублируются. Названия напротив часто указываются только в первом случае для повторяющихся данных, много объединенных ячеек, присутствие ненужных колонок и прочее делают такие выгрузки неудобными. Данные есть, но интерпретировать их непросто.
На помощь приходит Excel и пара несложных макросов в пару строк каждый. С помощью несложных действий и макросов, которые сможет воссоздать каждый, все действия занимают не более 10-15 минут.
Перед вами два видео урока с подробным рассказом о порядке выполняемых действий и тонкостях работы. Все этапы преобразования выгрузки в Excel из 1С в удобную для анализа таблицу без повторяющихся данных и объединений ячеек показаны наглядно и с подробным объяснением каждого шага.
Вот так выглядит начальная таблица.

А вот это та же таблица, но уже подготовленная для анализа. Вся работа заняла без учета объяснений и написания макросов, которые потом можно сразу использовать для других таблиц, минут 7.

Как говорится, две большие разницы. Видео будет полезно всем, кто часто сталкивается с необходимостью делать в Excel отчет для руководства по данным из программы 1С предприятия.
А вот, собственно и само видео:
Часть первая
Часть вторая.
|
nura28  Пользователь Сообщений: 48 |
Добрый день! Есть ли возможность из 1С тянуть данные из 1С макросом иди скриптом в эксель? Как это сделать? |
|
PowerBoy Пользователь Сообщений: 141 |
В надстройке для Excel «Активные таблицы» есть возможность вытягивать данные из 1С запросами. https://vk.com/excelsql Excel + SQL = Activetables |
|
а не проще ли в самой 1с делать выгрузку в ексель, там ведь это все реализовано, просто настроить грамотно и все. |
|
|
nura28 Пользователь Сообщений: 48 |
А можно сразу четыре разных отчета из 1 С сформировывать с помощью активных таблиц? |
|
nura28 Пользователь Сообщений: 48 |
alexthegreat
, как автоматически сделать выгрузку в эксель 1С? Так можно настроить в 1С? |
|
nura28 Пользователь Сообщений: 48 |
_Igor_61
, спасибо! Но это не то! |
|
nura28 Пользователь Сообщений: 48 |
PowerBoy, а саму надстройку Активные таблицы где скачать можно? Нашла )) Изменено: nura28 — 11.04.2017 12:08:25 |
|
kru Пользователь Сообщений: 6 |
#9 21.12.2019 08:47:26
Здравствуйте. Подскажите пожалуйста, где нашли? Мне тоже пригодится. |
||
|
Макрос для выгрузки данных из другой книги |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |


Часто при формировании прайс-листов требуется выгрузить большой объём данных в текстовый файл в формате CSV (разделитель — точка с запятой, или запятая)
И далеко не всегда может помочь сохранение файла в этом формате, поскольку в выгрузку попадают лишние данные (заголовки таблиц, лишние строки и столбцы, и т.д.)
В данном случае поможет экспорт заданного диапазона ячеек в файл CSV, что проще всего сделать макросом с использованием функции Range2CSV:
Sub ЭкспортПрайсЛистаВФорматеCSV() On Error Resume Next Dim sh As Worksheet: Set sh = ActiveSheet ' обрабатывается активный лист ' диапазон ячеек с A5 до последней заполненной ячейки в столбце A ' расширенный по горизонтали на 10 столбцов (выгружаются столбцы с A по J) Dim ra As Range: Set ra = sh.Range(sh.[A5], sh.Range("A" & sh.Rows.Count).End(xlUp)).Resize(, 10) ' формируем текстовую строку, содержащую текст диапазона в формате CSV CSVtext$ = Range2CSV(ra, ";") ' можно указать другой разделитель столбцов ' создаём в папке с файлом XLS подпапку для CSV-прайсов (если такой папки ещё нет) CSVfolder$ = ThisWorkbook.Path & "CSV prices": MkDir CSVfolder$ ' формируем имя создаваемого файла CSV (c указанием текущей даты) CSVfilename$ = Format(Now, "YYYY MM DD HH-NN-SS") & ".csv" ' сохраняем текстовую CSV-строку CSVtext$ в файл с именем CSVfilename$ SaveTXTfile CSVfolder$ & CSVfilename$, CSVtext$ End Sub
Вот код самой функции Range2CSV:
Function Range2CSV(ByRef ra As Range, Optional ByVal ColumnsSeparator$ = ";", _ Optional ByVal RowsSeparator$ = vbNewLine) As String If ra.Cells.Count = 1 Then Range2CSV = ra.Value & RowsSeparator$: Exit Function If ra.Areas.Count > 1 Then Dim ar As Range For Each ar In ra.Areas Range2CSV = Range2CSV & Range2CSV(ar, ColumnsSeparator$, RowsSeparator$) Next ar Exit Function End If arr = ra.Value buffer$ = "" ' иначе конкатенация длинных текстовых строк притормаживает макрос For i = LBound(arr, 1) To UBound(arr, 1) txt = "": For j = LBound(arr, 2) To UBound(arr, 2): txt = txt & ColumnsSeparator$ & arr(i, j): Next j Range2CSV = Range2CSV & Mid(txt, Len(ColumnsSeparator$) + 1) & RowsSeparator$ ' для многократного увеличения производительности при больших диапазонах данных If Len(Range2CSV) > 50000 Then buffer$ = buffer$ & Range2CSV : Range2CSV = "" Next i Range2CSV = buffer$ & Range2CSV End Function
Улучшенная версия кода (работает заметно быстрее), и дополнительно заключает текст всех ячеек в кавычки:
Function Range2CSV(ByRef ra As Range, Optional ByVal ColumnsSeparator$ = ";", _ Optional ByVal RowsSeparator$ = vbNewLine) As String If ra.Cells.Count = 1 Then Range2CSV = ra.Value & RowsSeparator$: Exit Function If ra.Areas.Count > 1 Then Dim ar As Range For Each ar In ra.Areas Range2CSV = Range2CSV & Range2CSV(ar, ColumnsSeparator$, RowsSeparator$) Next ar Exit Function End If arr = ra.Value ' иначе конкатенация длинных текстовых строк притормаживает макрос chr34$ = Chr(34): buffer$ = "": buffer2$ = "": Const BufferLen& = 15000 For i = LBound(arr, 1) To UBound(arr, 1) txt = "": For j = LBound(arr, 2) To UBound(arr, 2) txt = txt & ColumnsSeparator$ & chr34$ & Replace(arr(i, j), chr34$, "'") & chr34$ Next j buffer$ = buffer$ & Mid(txt, Len(ColumnsSeparator$) + 1) & RowsSeparator$ ' для многократного увеличения производительности при больших диапазонах данных If Len(buffer$) > BufferLen& Then buffer2$ = buffer2$ & buffer$: buffer$ = "" If Len(buffer2$) > BufferLen& * 40 Then _ Range2CSV = Range2CSV & buffer2$: buffer2$ = "" ': DoEvents End If Next i Range2CSV = Range2CSV & buffer2$ & buffer$ End Function
Для работы макроса понадобится ещё и функция сохранения текстового файла SaveTXTfile.
Найти её можно здесь: http://excelvba.ru/code/txt
Function SaveTXTfile(ByVal filename As String, ByVal txt As String) As Boolean On Error Resume Next: Err.Clear Set fso = CreateObject("scripting.filesystemobject") Set ts = fso.CreateTextFile(filename, True) ts.Write txt: ts.Close SaveTXTfile = Err = 0 Set ts = Nothing: Set fso = Nothing End Function
Время на прочтение
9 мин
Количество просмотров 62K
Есть в IT-отрасли задачи, которые на фоне успехов в big data, machine learning, blockchain и прочих модных течений выглядят совершенно непривлекательно, но на протяжении десятков лет не перестают быть актуальными для целой армии разработчиков. Речь пойдёт о старой как мир задаче формирования и выгрузки Excel-документов, с которой сталкивался каждый, кто когда-либо писал приложения для бизнеса.
Какие возможности построения файлов Excel существуют в принципе?
- VBA-макросы. В наше время по соображениям безопасности идея использовать макросы чаще всего не подходит.
- Автоматизация Excel внешней программой через API. Требует наличия Excel на одной машине с программой, генерирующей Excel-отчёты. Во времена, когда клиенты были толстыми и писались в виде десктопных приложений Windows, такой способ годился (хотя не отличался скоростью и надёжностью), в нынешних реалиях это с трудом достижимый случай.
- Генерация XML-Excel-файла напрямую. Как известно, Excel поддерживает XML-формат сохранения документа, который потенциально можно сгенерировать/модифицировать с помощью любого средства работы с XML. Этот файл можно сохранить с расширением .xls, и хотя он, строго говоря, при этом не является xls-файлом, Excel его хорошо открывает. Такой подход довольно популярен, но к недостаткам следует отнести то, что всякое решение, основанное на прямом редактировании XML-Excel-формата, является одноразовым «хаком», лишенным общности.
- Наконец, возможна генерация Excel-файлов с использованием open source библиотек, из которых особо известна Apache POI. Разработчики Apache POI проделали титанический труд по reverse engineering бинарных форматов документов MS Office, и продолжают на протяжении многих лет поддерживать и развивать эту библиотеку. Результат этого reverse engineering-а, например, используется в Open Office для реализации сохранения документов в форматах, совместимых с MS Office.
На мой взгляд, именно последний из способов является сейчас предпочтительным для генерации MS Office-совместимых документов. С одной стороны, он не требует установки никакого проприетарного ПО на сервер, а с другой стороны, предоставляет богатый API, позволяющий использовать все функциональные возможности MS Office.
Но у прямого использования Apache POI есть и недостатки. Во-первых, это Java-библиотека, и если ваше приложение написано не на одном из JVM-языков, вы ей вряд ли сможете воспользоваться. Во-вторых, это низкоуровневая библиотека, работающая с такими понятиями, как «ячейка», «колонка», «шрифт». Поэтому «в лоб» написанная процедура генерации документа быстро превращается в обильную «лапшу» трудночитаемого кода, где отсутствует разделение на модель данных и представление, трудно вносить изменения и вообще — боль и стыд. И прекрасный повод делегировать задачу самому неопытному программисту – пусть ковыряется.
Но всё может быть совершенно иначе. Проект Xylophone под лицензией LGPL, построенный на базе Apache POI, основан на идее, которая имеет примерно 15-летнюю историю. В проектах, где я участвовал, он использовался в комбинации с самыми разными платформами и языками – а счёт разновидностей форм, сделанных с его помощью в самых разнообразных проектах, идёт, наверное, уже на тысячи. Это Java-проект, который может работать как в качестве утилиты командной строки, так и в качестве библиотеки (если у вас код на JVM-языке — вы можете подключить её как Maven-зависимость).
Xylophone реализует принцип отделения модели данных от их представления. В процедуре выгрузки необходимо сформировать данные в формате XML (не беспокоясь о ячейках, шрифтах и разделительных линиях), а Xylophone, при помощи Excel-шаблона и дескриптора, описывающего порядок обхода вашего XML-файла с данными, сформирует результат, как показано на диаграмме:

Шаблон документа (xls/xlsx template) выглядит примерно следующим образом:

Как правило, заготовку такого шаблона предоставляет сам заказчик. Вовлечённый заказчик с удовольствием принимает участие в создании шаблона: начиная с выбора нужной формы из «Консультанта» или придумывания собственной с нуля, и заканчивая размерами шрифтов и ширинами разделительных линий. Преимущество шаблона в том, что мелкие правки в него легко вносить уже тогда, когда отчёт полностью разработан.
Когда «оформительская» работа выполнена, разработчику остаётся
- Создать процедуру выгрузки необходимых данных в формате XML.
- Создать дескриптор, описывающий порядок обхода элементов XML-файла и копирования фрагментов шаблона в результирующий отчёт
- Обеспечить привязку ячеек шаблона к элементам XML-файла с помощью XPath-выражений.
С выгрузкой в XML всё более-менее понятно: достаточно выбрать адекватное XML-представление данных, необходимых для заполнения формы. Что такое дескриптор?
Если бы в форме, которую мы создаём, не было повторяющихся элементов с разным количеством (таких, как строки накладной, которых разное количество у разных накладных), то дескриптор выглядел бы следующим образом:
<element name="root">
<output range="A1:Z100"/>
</element>
Здесь root – название корневого элемента нашего XML-файла с данными, а диапазон A1:Z100 – это прямоугольный диапазон ячеек из шаблона, который будет скопирован в результат. При этом, как можно видеть из предыдущей иллюстрации, подстановочные поля, значения которых заменяются на данные из XML-файла, имеют формат ~{XPath-выражение} (тильда, фигурная скобка, XPath-выражение относительно текущего элемента XML, закрывающая фигурная скобка).
Что делать, если в отчёте нам нужны повторяющиеся элементы? Естественным образом их можно представить в виде элементов XML-файла с данными, а помочь проитерировать по ним нужным образом помогает дескриптор. Повторение элементов в отчёте может иметь как вертикальное направление (когда мы вставляем строки накладной, например), так и горизонтальное (когда мы вставляем столбцы аналитического отчёта). При этом мы можем пользоваться вложенностью элементов XML, чтобы отразить сколь угодно глубокую вложенность повторяющихся элементов отчёта, как показано на диаграмме:
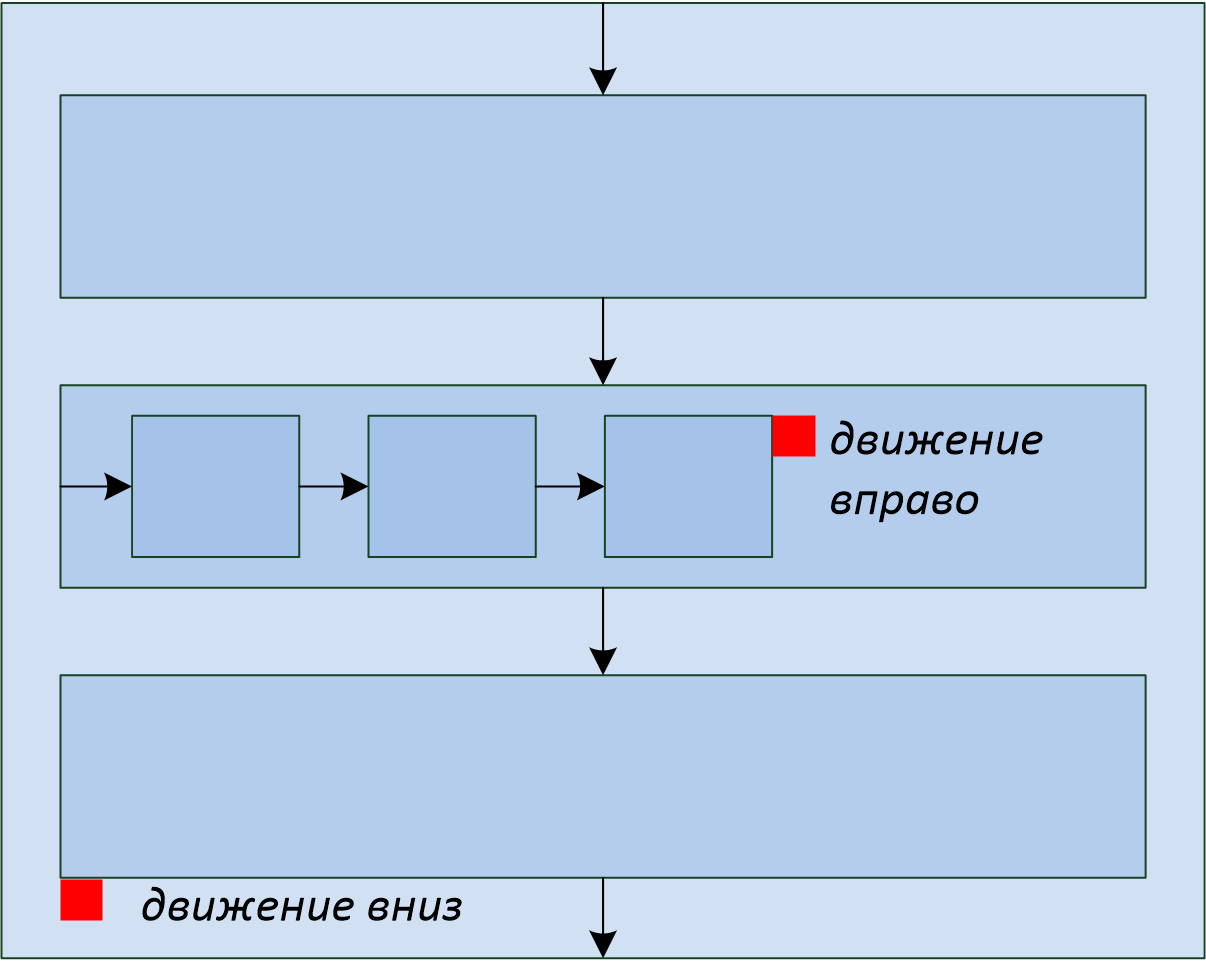
Красными квадратиками отмечены ячейки, которые будут являться левым верхним углом очередного прямоугольного фрагмента, который пристыковывает генератор отчёта.
Есть и ещё один возможный вариант повторяющихся элементов: листы в книге Excel. Возможность организовать такую итерацию тоже имеется.
Рассмотрим чуть более сложный пример. Допустим, нам надо получить сводный отчёт наподобие следующего:

Пусть диапазон лет для выгрузки выбирает пользователь, поэтому в этом отчёте динамически создаваемыми являются как строки, так и столбцы. XML-представление данных для такого отчёта может выглядеть следующим образом:
testdata.xml
<?xml version="1.0" encoding="UTF-8"?>
<report>
<column year="2016"/>
<column year="2017"/>
<column year="2018"/>
<item name="Товар 1">
<year amount="365"/>
<year amount="286"/>
<year amount="207"/>
</item>
<item name="Товар 2">
<year amount="95"/>
<year amount="606"/>
<year amount="840"/>
</item>
<item name="Товар 3">
<year amount="710"/>
<year amount="437"/>
<year amount="100"/>
</item>
<totals>
<year amount="1170"/>
<year amount="1329"/>
<year amount="1147"/>
</totals>
</report>
Мы вольны выбирать названия тэгов по своему вкусу, структура также может быть произвольной, но с оглядкой на простоту конвертации в отчёт. Например, выводимые на лист значения я обычно записываю в атрибуты, потому что это упрощает XPath-выражения (удобно, когда они имеют вид @имяатрибута).
Шаблон такого отчёта будет выглядеть так (сравните XPath-выражения с именами атрибутов соответствующих тэгов):

Теперь наступает самая интересная часть: создание дескриптора. Т. к. это практически полностью динамически собираемый отчёт, дескриптор довольно сложен, на практике (когда у нас есть только «шапка» документа, его строки и «подвал») всё обычно гораздо проще. Вот какой в данном случае необходим дескриптор:
descriptor.xml
<?xml version="1.0" encoding="UTF-8"?>
<element name="report">
<!-- Создаём лист -->
<output worksheet="Отчет" sourcesheet="Лист1"/>
<!-- И за ним слева направо заголовки столбцов -->
<iteration mode="horizontal">
<element name="(before)">
<!-- Выводим пустую ячейку в ЛВУ сводной таблицы -->
<output range="A1"/>
</element>
<element name="column">
<output range="B1"/>
</element>
</iteration>
<!-- Выводим строки: итерация с режимом вывода умолчанию, сверху вниз -->
<iteration mode="vertical">
<element name="item">
<!-- И по строке - слева направо -->
<iteration mode="horizontal">
<element name="(before)">
<!-- Заголовок строки -->
<output range="A2"/>
</element>
<!-- И за ним слева направо строку с данными -->
<element name="year">
<output range="B2"/>
</element>
</iteration>
</element>
</iteration>
<iteration>
<element name="totals">
<iteration mode="horizontal">
<element name="(before)">
<!-- Заголовок строки -->
<output range="A3"/>
</element>
<!-- И за ним слева направо строку с данными -->
<element name="year">
<output range="B3"/>
</element>
</iteration>
</element>
</iteration>
</element>
Полностью элементы дескриптора описаны в документации. Вкратце, основные элементы дескриптора означают следующее:
- element — переход в режим чтения элемента XML-файла. Может или являться корневым элементом дескриптора, или находиться внутри
iteration. С помощью атрибутаnameмогут быть заданы разнообразные фильтры для элементов, напримерname="foo"— элементы с именем тэга fooname="*"— все элементыname="tagname[@attribute='value']"— элементы с определённым именем и значением атрибутаname="(before)",name="(after)"— «виртуальные» элементы, предшествующие итерации и закрывающие итерацию.
- iteration — переход в режим итерации. Может находиться только внутри
element. Могут быть выставлены различные параметры, напримерmode="horizontal"— режим вывода по горизонтали (по умолчанию — vertical)index=0— ограничить итерацию только самым первым встреченным элементом
- output — переход в режим вывода. Основные атрибуты следующие:
sourcesheet—лист книги шаблона, с которого берётся диапазон вывода. Если не указывать, то применяется текущий (последний использованный) лист.range– диапазон шаблона, копируемый в результирующий документ, например “A1:M10”, или “5:6”, или “C:C”. (Применение диапазонов строк типа “5:6” в режиме вывода horizontal и диапазонов столбцов типа “C:C” в режиме вывода vertical приведёт к ошибке).worksheet– если определён, то в файле вывода создаётся новый лист и позиция вывода смещается в ячейку A1 этого листа. Значение этого атрибута, равное константе или XPath-выражению, подставляется в имя нового листа.
В действительности всевозможных опций в дескрипторе гораздо больше, смотрите документацию.
Ну что же, настало время скачать Xylophone и запустить формирование отчёта.
Возьмите архив с bintray или Maven Central (NB: на момент прочтения этой статьи возможно наличие более свежих версий). В папке /bin находится shell-скрипт, при запуске которого без параметров вы увидите подсказку о параметрах командной строки. Для получения результата нам надо «скормить» ксилофону все приготовленные ранее ингредиенты:
xylophone -data testdata.xml -template template.xlsx -descr descriptor.xml -out report.xlsx
Открываем файл report.xlsx и убеждаемся, что получилось именно то, что нам нужно:
Так как библиотека ru.curs:xylophone доступна на Maven Central под лицензией LGPL, её можно без проблем использовать в программах на любом JVM-языке. Пожалуй, самый компактный полностью рабочий пример получается на языке Groovy, код в комментариях не нуждается:
@Grab('ru.curs:xylophone:6.1.3')
import ru.curs.xylophone.XML2Spreadsheet
baseDir = '.'
new File(baseDir, 'testdata.xml').withInputStream {
input ->
new File(baseDir, 'report.xlsx').withOutputStream {
output ->
XML2Spreadsheet.process(input,
new File(baseDir, 'descriptor.xml'),
new File(baseDir, 'template.xlsx'),
false, output)
}
}
println 'Done.'
У класса XML2Spreadsheet есть несколько перегруженных вариантов статического метода process, но все они сводятся к передаче всё тех же «ингредиентов», необходимых для подготовки отчёта.
Важная опция, о которой я до сих пор не упомянул — это возможность выбора между DOM и SAX парсерами на этапе разбора файла с XML-данными. Как известно, DOM-парсер загружает весь файл в память целиком, строит его объектное представление и даёт возможность обходить его содержимое произвольным образом (в том числе повторно возвращаясь в один и тот же элемент). SAX-парсер никогда не помещает файл с данными целиком в память, вместо этого обрабатывает его как «поток» элементов, не давая возможности вернуться к элементу повторно.
Использование SAX-режима в Xylophone (через параметр командной строки -sax или установкой в true параметра useSax метода XML2Spreadsheet.process) бывает критически полезно в случаях, когда необходимо генерировать очень большие файлы. За счёт скорости и экономичности к ресурсам SAX-парсера скорость генерации файлов возрастает многократно. Это даётся ценой некоторых небольших ограничений на дескриптор (описано в документации), но в большинстве случаев отчёты удовлетворяют этим ограничениям, поэтому я бы рекомендовал использование SAX-режима везде, где это возможно.
Надеюсь, что способ выгрузки в Excel через Xylophone вам понравился и сэкономит много времени и нервов — как сэкономил нам.
И напоследок ещё раз ссылки:
- исходники — здесь: github.com/CourseOrchestra/xylophone
- документация — здесь: courseorchestra.github.io/xylophone
- все примеры кода из этой статьи — здесь: github.com/inponomarev/xylophone-example.