
I’m trying to convert a string to a list of words using python. I want to take something like the following:
string = 'This is a string, with words!'
Then convert to something like this :
list = ['This', 'is', 'a', 'string', 'with', 'words']
Notice the omission of punctuation and spaces. What would be the fastest way of going about this?
![]()
pigrammer
2,3201 gold badge9 silver badges24 bronze badges
asked May 31, 2011 at 0:09
![]()
rectangletanglerectangletangle
49.7k93 gold badges203 silver badges275 bronze badges
I think this is the simplest way for anyone else stumbling on this post given the late response:
>>> string = 'This is a string, with words!'
>>> string.split()
['This', 'is', 'a', 'string,', 'with', 'words!']
answered Dec 6, 2012 at 0:22
![]()
1
Try this:
import re
mystr = 'This is a string, with words!'
wordList = re.sub("[^w]", " ", mystr).split()
How it works:
From the docs :
re.sub(pattern, repl, string, count=0, flags=0)
Return the string obtained by replacing the leftmost non-overlapping occurrences of pattern in string by the replacement repl. If the pattern isn’t found, string is returned unchanged. repl can be a string or a function.
so in our case :
pattern is any non-alphanumeric character.
[w] means any alphanumeric character and is equal to the character set
[a-zA-Z0-9_]
a to z, A to Z , 0 to 9 and underscore.
so we match any non-alphanumeric character and replace it with a space .
and then we split() it which splits string by space and converts it to a list
so ‘hello-world’
becomes ‘hello world’
with re.sub
and then [‘hello’ , ‘world’]
after split()
let me know if any doubts come up.
![]()
answered May 31, 2011 at 0:13
![]()
BryanBryan
6,4992 gold badges28 silver badges16 bronze badges
3
To do this properly is quite complex. For your research, it is known as word tokenization. You should look at NLTK if you want to see what others have done, rather than starting from scratch:
>>> import nltk
>>> paragraph = u"Hi, this is my first sentence. And this is my second."
>>> sentences = nltk.sent_tokenize(paragraph)
>>> for sentence in sentences:
... nltk.word_tokenize(sentence)
[u'Hi', u',', u'this', u'is', u'my', u'first', u'sentence', u'.']
[u'And', u'this', u'is', u'my', u'second', u'.']
answered May 31, 2011 at 0:15
![]()
Tim McNamaraTim McNamara
17.8k4 gold badges52 silver badges82 bronze badges
The most simple way:
>>> import re
>>> string = 'This is a string, with words!'
>>> re.findall(r'w+', string)
['This', 'is', 'a', 'string', 'with', 'words']
answered May 31, 2011 at 2:19
![]()
JBernardoJBernardo
31.9k10 gold badges90 silver badges115 bronze badges
Using string.punctuation for completeness:
import re
import string
x = re.sub('['+string.punctuation+']', '', s).split()
This handles newlines as well.
answered May 31, 2011 at 0:24
![]()
mtrwmtrw
33.8k7 gold badges61 silver badges71 bronze badges
0
Well, you could use
import re
list = re.sub(r'[.!,;?]', ' ', string).split()
Note that both string and list are names of builtin types, so you probably don’t want to use those as your variable names.
![]()
martineau
118k25 gold badges164 silver badges293 bronze badges
answered May 31, 2011 at 0:10
![]()
CameronCameron
95.1k24 gold badges196 silver badges221 bronze badges
Inspired by @mtrw’s answer, but improved to strip out punctuation at word boundaries only:
import re
import string
def extract_words(s):
return [re.sub('^[{0}]+|[{0}]+$'.format(string.punctuation), '', w) for w in s.split()]
>>> str = 'This is a string, with words!'
>>> extract_words(str)
['This', 'is', 'a', 'string', 'with', 'words']
>>> str = '''I'm a custom-built sentence with "tricky" words like https://stackoverflow.com/.'''
>>> extract_words(str)
["I'm", 'a', 'custom-built', 'sentence', 'with', 'tricky', 'words', 'like', 'https://stackoverflow.com']
answered Jun 8, 2017 at 9:55
![]()
Paulo FreitasPaulo Freitas
13k13 gold badges73 silver badges96 bronze badges
Personally, I think this is slightly cleaner than the answers provided
def split_to_words(sentence):
return list(filter(lambda w: len(w) > 0, re.split('W+', sentence))) #Use sentence.lower(), if needed
answered May 18, 2018 at 5:47
![]()
A regular expression for words would give you the most control. You would want to carefully consider how to deal with words with dashes or apostrophes, like «I’m».
answered May 31, 2011 at 0:14
![]()
tofutimtofutim
22.3k20 gold badges85 silver badges146 bronze badges
list=mystr.split(" ",mystr.count(" "))
![]()
josliber♦
43.7k12 gold badges100 silver badges133 bronze badges
answered Aug 11, 2015 at 15:14
![]()
This way you eliminate every special char outside of the alphabet:
def wordsToList(strn):
L = strn.split()
cleanL = []
abc = 'abcdefghijklmnopqrstuvwxyz'
ABC = abc.upper()
letters = abc + ABC
for e in L:
word = ''
for c in e:
if c in letters:
word += c
if word != '':
cleanL.append(word)
return cleanL
s = 'She loves you, yea yea yea! '
L = wordsToList(s)
print(L) # ['She', 'loves', 'you', 'yea', 'yea', 'yea']
I’m not sure if this is fast or optimal or even the right way to program.
answered Jul 30, 2017 at 15:22
![]()
def split_string(string):
return string.split()
This function will return the list of words of a given string.
In this case, if we call the function as follows,
string = 'This is a string, with words!'
split_string(string)
The return output of the function would be
['This', 'is', 'a', 'string,', 'with', 'words!']
answered Feb 4, 2022 at 12:43
![]()
This is from my attempt on a coding challenge that can’t use regex,
outputList = "".join((c if c.isalnum() or c=="'" else ' ') for c in inputStr ).split(' ')
The role of apostrophe seems interesting.
answered May 28, 2015 at 6:30
![]()
Probably not very elegant, but at least you know what’s going on.
my_str = "Simple sample, test! is, olny".lower()
my_lst =[]
temp=""
len_my_str = len(my_str)
number_letter_in_data=0
list_words_number=0
for number_letter_in_data in range(0, len_my_str, 1):
if my_str[number_letter_in_data] in [',', '.', '!', '(', ')', ':', ';', '-']:
pass
else:
if my_str[number_letter_in_data] in [' ']:
#if you want longer than 3 char words
if len(temp)>3:
list_words_number +=1
my_lst.append(temp)
temp=""
else:
pass
else:
temp = temp+my_str[number_letter_in_data]
my_lst.append(temp)
print(my_lst)
answered Mar 15, 2021 at 20:03
![]()
1
You can try and do this:
tryTrans = string.maketrans(",!", " ")
str = "This is a string, with words!"
str = str.translate(tryTrans)
listOfWords = str.split()
![]()
answered Aug 12, 2013 at 13:49
![]()
Tools
Tools.FromDev

This is a free online tool to extract unique words from any plain text. The tool also shows the number of unique words extracted. You can just copy/paste the new line separated words from the result text box.
Word lists are useful way to memorize certain words. This tool makes it easy to find unique
words from any text and create a list. This word list finder is used by many people to create their ad campaigns based on selected words.
In plain text, many words are repeated. This tool can help you identify all the words that
are present.
Unique words can be used to identify many things. e.g. Many SEO experts may use it for
keyword densityand other analysis purposes.
Unique words are handy to create word clouds too. Just throw these words into a word cloud
maker and it will do the magic.
Yes, this tool can easily be used for any text and can help you identify all unique words.
Give it a try.
This tool uses browser memory to process the text. It can support a very large text depending
on your browser.
On a Macbook Pro it can easily identify several thousand words
How to use VocabGrabber:
- Copy text from any document
- Paste the copied text into the box
- Grab your vocabulary words!
See it in action!
Try VocabGrabber with one of our samples:
Nouns:
Adjectives:
Verbs:
Adverbs:
- How does Vocabgrabber work?

- VocabGrabber analyzes any text you’re interested in, generating lists of the most useful vocabulary words and showing you how those words are used in context. Just copy text from a document and paste it into the box, and then click on the «Grab Vocabulary!» button. VocabGrabber will automatically create a list of vocabulary from your text, which you can then sort, filter, and save.
- Select any word on the list and you’ll see a snapshot of the Visual Thesaurus map and definitions for that word, along with examples of the word in your text. Click on the word map or the highlighted word in the example to see the Visual Thesaurus in action.
- Want to try it out? Click on one of our sample texts to fill the box and start grabbing!

- How can I view my vocabulary list?
- After you grab the vocabulary from a text, you will see a list of words and phrases in «tag cloud» view. In the default view, words in the vocab list are arranged by relevance (more on that below!). In the tag cloud, words that appear most frequently in the text are displayed in a larger font size. The color of the words is based on whether they match one of our seven subject areas (Arts & Literature, Geography, Math, People, Science, Social Studies, Vocabulary).
- You can also choose «list» view, which will give you the vocab list in a table, with columns displaying each word’s subject areas, relevance score, and number of occurrences in the text. Or you can select «gallery» view, displaying a thumbnail image of each word’s map in the Visual Thesaurus.

- How can I sort my vocabulary list?
- Above the word list you’ll see four different sorting options: Relevance, A-Z, Occurrences, and Familiarity. By default the words are arranged from most relevant to least relevant. The other options allow you to sort your list alphabetically, by number of occurrences in the text, or by how familiar the words are in written English overall. To reverse any of these orderings, just click on the name of the option again to toggle the list order.

- How can I filter my list by subject?
- Your list will initially have the «Show All Words» box checked. But if you want to focus on vocabulary in one or more particular subjects, just click the appropriate box or boxes. The number in parentheses next to the subject name indicates how many words in the text match the subject.
- Subjects include academic areas of interest (Arts & Literature, Science, and Social Studies), names of historical figures and places (People and Geography), and words that are of particular importance for language learners at all levels (Vocabulary).
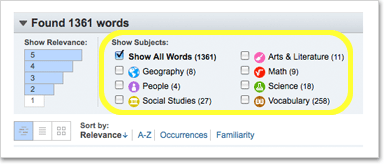
- How can I filter my list by relevance? (And what is relevance, anyway?)
- All the words in your vocab list are ranked with a relevance score of 1 to 5, with 5 being the most relevant to the text. We calculate relevance by comparing how frequently words are used in the text versus how they are used in written English overall. That allows us to zero in on which words are most significant for the average reader.
- By default, the vocab list displays words with relevance 2 through 5, leaving off the words that score only 1 and are therefore least significant. But you can choose any combination of scores by clicking on the bars under «Show Relevance.»

- How can I add VocabGrabber to my browser toolbar?
- In the top right-hand corner, click on the button next to «Add VocabGrabber to your Toolbar.» Then follow the directions for your browser to install the VocabGrabber directly on your toolbar. Once installed, you’ll be able to use the VocabGrabber on any online text without having to copy and paste. Just click on the VocabGrabber «bookmarklet» and the VocabGrabber will immediately start grabbing the vocabulary from whatever page you’re reading in your browser.

- How can I create a Visual Thesaurus word list from my vocabulary?
- Individual subscribers to the Visual Thesaurus can generate word lists from VocabGrabber results. Subscribers can click a button that says «Create Word List,» which automatically selects whichever vocabulary words you have displayed based on your sorting and filtering options. You can then add a title to your word list and choose to include an example sentence of each word drawn from the text you’re analyzing. (If the word appears more than once in the text, you can pick which example sentence you want to use.) You can also customize the list by deselecting any words that you don’t want to appear. Then just click on «Save Word List» to add it to your collection of Visual Thesaurus word lists.
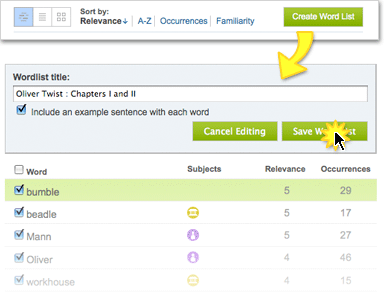
Let’s create a new list!
Whatever you’re learning (or teaching), Vocabulary.com can help.
Sort: Relevance
Sort: Hardest First
Sort: Easiest First
Sort: List/Text Order
Sort: A-Z
Sort: Most Occurrences
Select First 10
Select First 25
Select First 50
Deselect All Words
Select the definitions you would like to focus on:
Select a featured example sentence:
Include Example Sentences
Your list is ready for learning.
Continue by creating a free basic account.
Working on it…
We’re creating your list right now.
Use R to scrape and mine text from the web to create personalised discipline specific vocabulary lists!
I love playing with R and I have recently learnt how to scrape and text mine websites. I am going to provide a short tutorial on how to do this using an example I hope you find useful.
Learning the jargon of a new topic that you’re interested in can significantly increase your comprehension of the subject matter, so it can be important to spend some time getting to know the lingo. But how can you work out the most important words in the area. You could find lists of key words but these may only identify words that people within the field think you need to learn. Another way is to created a vocabulary list by identifying the most common words across several texts on the topic. This is what we will be doing.
First of all you will need a topic. I will be using the topics of nutrigenomics because Jess (my wife) has recently become interested in learning about the interaction between nutrition and the genome. Now that we have a topic we will follow the following process to created our vocabulary list:
- Find the documents that you will use to build your vocabulary list.
- Scrape the text from the website.
- Clean up the text to get rid of useless information.
- Identify the most common words across the texts.
Finding the Documents
I am going to use PLOS ONE to find papers on nutrigenomics because it is open access and I will be able to retrieve the information I want. I start by searching PLOS ONE for the nutrigenomics, which finds 192 matches as of the 22/08/2015. Each match is listed by the paper name which contains a hyperlink to the URL for the full paper with the text we are interested in. In R we will use URL’s to find the website we are interested in and scrape it’s text. In order to scrape the text from every paper we will need to retrieve the corresponding URL’s for each paper. To do this we will use the magic of package rvest which allows you to specify specific elements of a website to scrape, in this case we will be scraping the URL links associated with the heading of each paper returned in our PLOS ONE search. So lets get started!

First take note of the URL from your PLOS ONE search. In my case it is: http://journals.plos.org/plosone/search?q=nutrigenomics&filterJournals=PLoSONE. As I mentioned earlier there are 192 results associated with this search but they don’t all show up on the same page. However, if I go to the bottom of the page at select to see 30 results per page the URL changes to specify the number of results per page. We can use this to our advantage and change the number from 30 to 192, which then gets the whole list of papers on one page and more importantly all their associated URL’s on one page, e.g. http://journals.plos.org/plosone/search?q=nutrigenomics&sortOrder=RELEVANCE&filterJournals=PLoSONE&resultsPerPage=192. We are going to use this URL to find all of the URL’s to our papers.
First we will open R and load the package that we require to get our vocabulary list. I like to use rvest.
install.packages("rvest")
install.packages("tm")
install.packages("SnowballC")
install.packages("stringr")
install.packages("wordcloud")
library(stringr)
library(tm)
library(SnowballC)
library(rvest)
Now we can create a vector which contains the html for for the PLOS ONE nutrigenics search, with all returned papers on the same page. This literally pulls down the html code from the web address that you parse to the html() function.
paperList <- html("http://journals.plos.org/plosone/search?q=nutrigenomics&sortOrder=RELEVANCE&filterJournals=PLoSONE&resultsPerPage=192")
Using this HTML code, we can now locate the URL’s associated with each paper title with the special rvest function html_nodes(). This function uses css or xpath syntax to identify specific locations within the structure of a HTML document. So to pull out the URL’s we are after we will need to determine the path to them. This can be easily done on a Google chrome web browser using the inspect element functionality (I am not sure whether other web browser have a similar function but I am sure they do).
In Google chrome go to the list of papers in the PLOS ONE search page, right click on one of the paper titles and select ‘inspect element’. This will split your window in half and show you the HTML for the webpage. In the HTML viewer the code for the specific element that you clicked on will be highlighted, this is what you want. You can right click this highlighted section and select ‘copy css path’ or ‘copy xpath’ and you will get the specific location for that node to use in html_nodes(). However, we want to specify every URL associated with a paper title in the document so we will need to use a path the contains common elements for every location we are interested in. Luckily ‘css path’ and ‘xpath’ syntax can specific multiple locations if they contain the same identifying elements. By looking at the HTML with Google chromes inspect element we can see that the URL’s we are interested in are identified by class="search-results-title" and contained within a href="URL" tag. These two elements are common for each of our papers but will not include href= for links elsewhere on the page.

The code to retrieve the URL’s occurs in three parts; first we parse our HTML file, then we specify the locations we are interested in with html_nodes(), and finally we indicate what we want to retrieve. In this case we will be retreiving a HTML attribute using the function html_attr()
paperURLs <- paperList %>%
html_nodes(xpath="//*[@class='search-results-title']/a") %>%
html_attr("href")
This returns a list of 192 URL’s that specify the location of the papers we are interested in.
head(paperURLs)
## [1] "/plosone/article?id=10.1371/journal.pone.0001681"
## [2] "/plosone/article?id=10.1371/journal.pone.0082825"
## [3] "/plosone/article?id=10.1371/journal.pone.0060881"
## [4] "/plosone/article?id=10.1371/journal.pone.0026669"
## [5] "/plosone/article?id=10.1371/journal.pone.0110614"
## [6] "/plosone/article?id=10.1371/journal.pone.0112665"
If you look closely you will notice that the URL’s are missing the beginning of a proper web address. Using these URLs will result in a retrieval error. To fix this we will add the start to the URL’s with paste(). Here we are simply saying paste the string http://journals.plos.org to the beginning of each of out paperURLs and separate these two strings by no space.
paperURLs <- paste("http://journals.plos.org", paperURLs, sep = "")
# Check it out
head(paperURLs)
## [1] "http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0001681"
## [2] "http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0082825"
## [3] "http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0060881"
## [4] "http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0026669"
## [5] "http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0110614"
## [6] "http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0112665"
As you can see we now have a complete URL. Try copy/pasting one into your browser to make sure it is working.
Scraping the Text
We can scrape the text from these papers, using the URLs we have just extracted. We will do this by pulling down each paper in its HTML format.
Using the URL’s we have extracted from the previous step we will pull down the HTML file for each of the 192 papers. We will use sapply() to do this, which is a looping function that allows us to run html() on every item whithin a list. This step is pulling a large amount of information from the web so it might take a few minutes to run.
paper_html <- sapply(1:length(paperURLs),
function(x) html(paperURLs[x]))
Now we can extract the text from all of these HTML files. Using the inspect element functionality of Google chrome we have determined that the content of the articles is found within class="article-content". We are using html_text() to extract only text from the html documents and trim off any white space with stringr function str_trim(). Because we have a list of 192 HTML documents we will iterate over each document using the awesome sapply() function. Where 1:length(paper_html) simply says iterate the following function where x equals 1 until 192.
paperText <- sapply(1:length(paper_html), function(x) paper_html[[1]] %>%
html_nodes(xpath="//*[@class='article-content']") %>%
html_text() %>%
str_trim(.))
This results in a very large vector containing the text for each of the 192 papers we are interested in.
Cleaning the Text
Now that we have all of the text that we are interested in we can transform it into a format used for text mining and start to clean it up clean it up.
First we need to load the tm and SnowballC packages.tm is used for text mining and SnowballC has some useful functions that will be explained later.
Now we will transform it into a document corpus using the tm function Corpus() and specifying that the text is of a VectorSource().
paperCorp <- Corpus(VectorSource(paperText))
Now we will remove any text elements that are not useful to us. This includes punctuation, common words such as ‘a’, ‘is’, ‘the’, and remove numbers.
First we will remove any special characters that we might find in the document. To determine what these will be take some time to look at one of the paperText elements.
# Check it out by running the following code.
paperText[[1]]
Now that we have identified the special?characters that we want to get rid of we can?remove them using the following function.
for(j in seq(paperCorp))
{
paperCorp[[j]] <- gsub(":", " ", paperCorp[[j]])
paperCorp[[j]] <- gsub("n", " ", paperCorp[[j]])
paperCorp[[j]] <- gsub("-", " ", paperCorp[[j]])
}
The tm package has several built in functions to remove common elements from text, which are rather self explanatory given their names.
paperCorp <- tm_map(paperCorp, removePunctuation)
paperCorp <- tm_map(paperCorp, removeNumbers)
It is really important to run the tolower argument in tm_map(), which changes all characters “to lower” characters. (NOTE: I didn’t do this in the beginning and it caused me trouble when I tried to remove specific words in later steps. Thanks to phiver on stackoverflow for helping fix this problem for me!). We will also remove commonly used words in the english language, using the removeWords stopwords() arguments.
paperCorp <- tm_map(paperCorp, tolower)
paperCorp <- tm_map(paperCorp, removeWords, stopwords("english"))
We also want to remove all the common endings to english words, such as ‘ing’, ‘es, and ‘s’. This is referred to as ‘stemming’ and is done with a function in the SnowballC package.
paperCorp <- tm_map(paperCorp, stemDocument)
To make sure none of our filtering has left any annoying white space we will make sure to remove it.
paperCorp <- tm_map(paperCorp, stripWhitespace)
If you have a look at this document you can see that it is very different from when you started.
paperCorp[[1]]
Now we tell R to treat the processed documents as text documents.
paperCorpPTD <- tm_map(paperCorp, PlainTextDocument)
Finally we use this plain text document to create a document term matrix. This is a large matrix that contains statistics about each of the words that are contained within the document. We use the document term matrix that we use to look at the details of our documents.
dtm <- DocumentTermMatrix(paperCorpPTD)
dtm
## <<DocumentTermMatrix (documents: 192, terms: 1684)>>
## Non-/sparse entries: 323328/0
## Sparsity : 0%
## Maximal term length: 27
## Weighting : term frequency (tf)
We are close but there’s still one cleaning step that we need to do. There will be words that occur commonly in our document that we aren’t interested. We will want to remove these words but first we need to identify what they are. To do this we will find the frequent terms in the document term matrix. We can calculate the frequency of each of our terms and then creat a data.frame where they are order from most frequent to least frequent. We can look through the most common terms in the dataframe and remove those that we aren’t interested in. First we will calculate the frequency of each term.
termFreq <- colSums(as.matrix(dtm))
# Have a look at it.
head(termFreq)
## able abolished absence absorption abstract acad
## 192 192 192 1344 192 960
Now we will create a dataframe and order it by term frequency.
tf <- data.frame(term = names(termFreq), freq = termFreq)
tf <- tf[order(-tf[,2]),]
# Have a look at it.
head(tf)
## term freq
## fatty fatty 29568
## pparα pparα 23232
## acids acids 22848
## gene gene 15360
## dietary dietary 12864
## article article 12288
As we can see there are a number of terms that are simply a product of the text being scraped from a website, e.g. ‘google’, ‘article’, etc. Now go through the list and make not of all of the terms that aren’t important to you. Once you have a list remove the words from the paperCorp document.
paperCorp <- tm_map(paperCorp, removeWords, c("also", "article", "analysis",
"download", "google", "figure",
"fig", "groups", "however",
"high", "human", "levels",
"larger", "may", "number",
"shown", "study", "studies", "this",
"using", "two", "the", "scholar",
"pubmedncbi", "view", "the", "biol",
"via", "image", "doi", "one"
))
There will also be particular terms that should occur together but which end up being split up in the text matrix. We will replace these terms so they occure together.
for (j in seq(paperCorp))
{
paperCorp[[j]] <- gsub("fatty acid", "fatty_acid", paperCorp[[j]])
}
Now we have to recreate our document term matrix.
paperCorp <- tm_map(paperCorp, stripWhitespace)
paperCorpPTD <- tm_map(paperCorp, PlainTextDocument)
dtm <- DocumentTermMatrix(paperCorpPTD)
termFreq <- colSums(as.matrix(dtm))
tf <- data.frame(term = names(termFreq), freq = termFreq)
tf <- tf[order(-tf[,2]),]
head(tf)
## term freq
## pparα pparα 23232
## fatty_acids fatty_acids 22272
## gene gene 15360
## dietary dietary 12864
## expression expression 10752
## genes genes 9408
From this dataset we will create a word cloud of the most frequent terms. The number of words being displayed is determined by ‘max.words’. We will do this using the wordcloud package.
require(wordcloud)
wordcloud(tf$term, tf$freq, max.words = 100, rot.per = 0.2, colors = brewer.pal(5, "Dark2"))

You can use the tm dataframe to find common terms that occur in your field and build a vocabulary list.
By changing your search term in PLoS ONE you can create a vocabulary list for any scientific field you like.
That’s it, have fun!!
If anyone has suggested changes to the code, qeustions or comments, please leave a reply below.