
convert your excel file format to .csv format with using save as option
Save below content in a file with .ctl extension in the D drive under folder_name folder. Before running this .ctl make sure that table should be present in your schema with the distinct column names not like in your posted image. And the column name should be match with names of .ctl file(sc_id,
sal, etc). And the datatypes of your columns should be match with the data present in a .csv file. And also make sure that your table should be empty otherwise you should use truncate or append options in your .ctl file.
LOAD DATA
INFILE 'D:folder_namecsvfile_name.CSV'
BADFILE 'D:folder_namecsvfile_name.BAD'
DISCARDFILE 'D:folder_namecsvfile_name.log'
logfile 'D:folder_namecsvfile_name.DSC'
iNTO TABLE schema_name.table_name
FIELDS TERMINATED BY ','
TRAILING NULLCOLS
(
sc_id,
sal,
sc_cd1,
coll,
sc_cd2,
bill_mas,
sc_cd3,
wk_sal,
check_bill_month,
check_sale_wk
)
Run your .ctl file in sql plus with use of below commands
sqlldr schema_name/password@databasename control=your control file path.
If any error occurs while loading data into table those will logged into .log file. For learn more about sqlloader Refer http://docs.oracle.com/cd/B10501_01/server.920/a96652/ch05.htm
Задача. У вас есть файл Excel – и вы хотите, чтобы эти данные были помещены в таблицу. Я покажу вам, как это делается, и мы задокументируем каждый шаг с большим количеством иллюстраций.
Прочитав этот пост, вы будете готовы с уверенностью импортировать данные в существующую таблицу из Excel. Хотите создать новую таблицу из Excel? Мы тоже можем это сделать.
В нашем примере я буду использовать таблицу HR.EMPLOYEES для создания XLS-файла для нашего импорта. Мы будем использовать этот файл Excel для заполнения пустой копии таблицы EMPLOYEES в другой схеме.
Шаг 0: Пустая таблица Oracle и ваш файл Excel
У вас есть таблица Oracle и один или несколько файлов Excel.
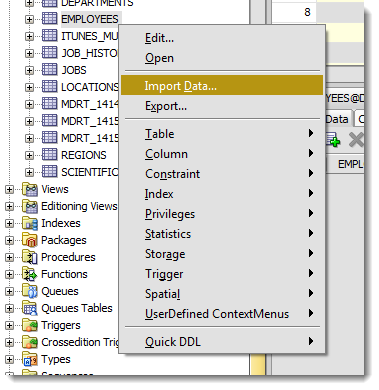
Шаг 1: Выбираем «Импорт данных» по правому щелчку мыши
Шаг 2: Выберите свой входной файл (XLSX) и проверьте данные
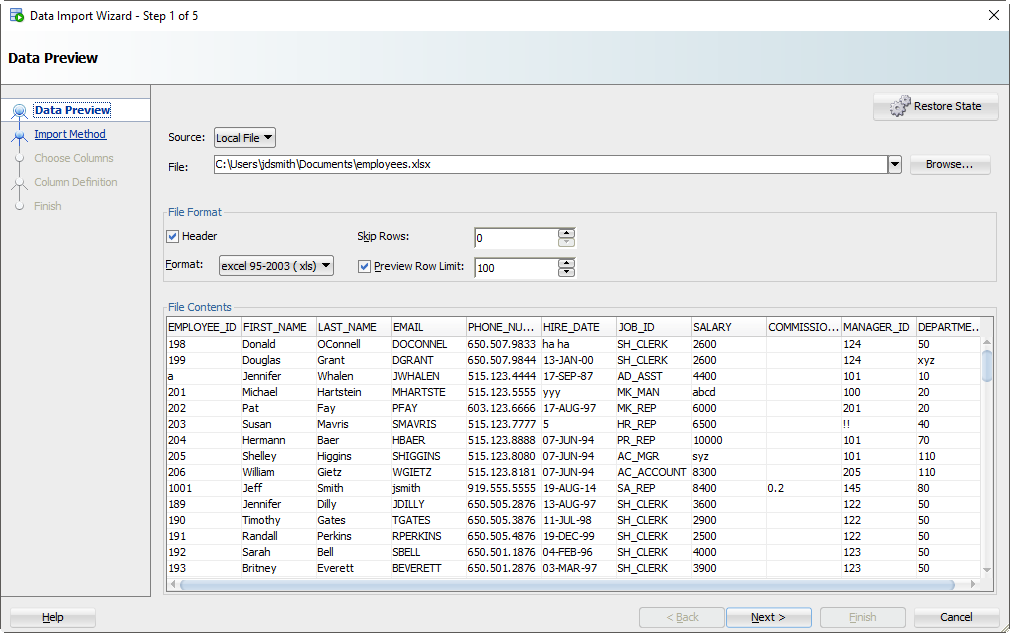
Когда вы выберете файл, мы захватим первые 100 строк для просмотра ниже. Этот «Предел строк предварительного просмотра» определяет, сколько строк вы можете использовать для проверки ИМПОРТА по мере прохождения мастера. Вы можете увеличить его, но это потребует больше ресурсов, так что не сходите с ума.
Кроме того, есть ли в вашем файле Excel заголовки столбцов? Хотим ли мы рассматривать их как строку к таблице? Скорее всего, нет. Если вы снимите флажок «Заголовок», имена столбцов станут новой строкой в вашей таблице – и, вероятно, не будут вставлены.
Иногда ваш файл Excel имеет несколько заголовков, или вам может потребоваться импортировать только определенное подмножество электронной таблицы. Используйте опцию «Пропустить строки», чтобы получить правильные данные.
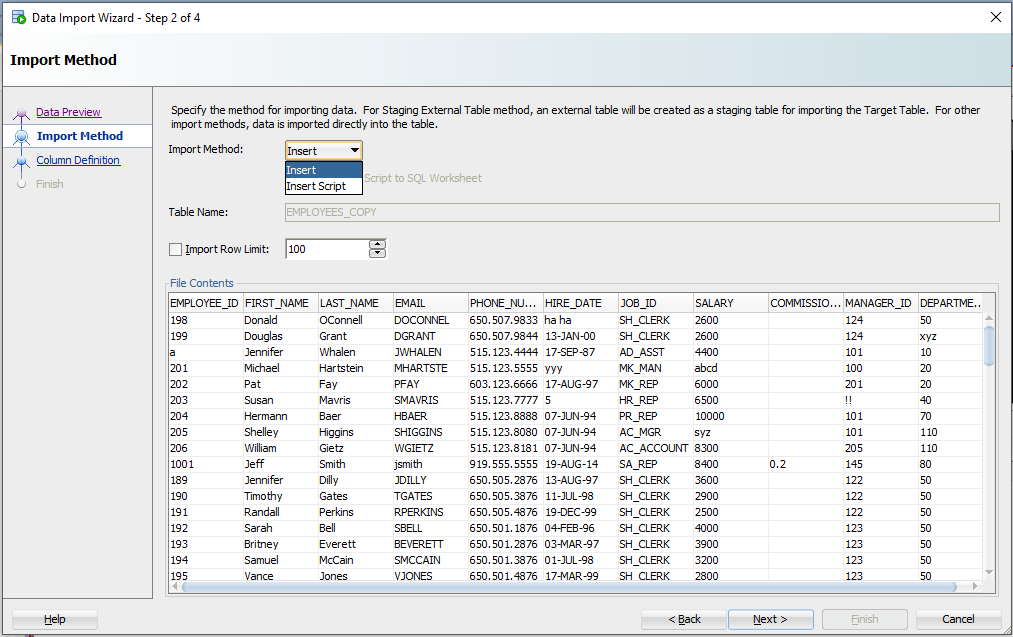
Шаг 3: Создайте сценарий или импортируйте автоматически
alt+tab туда и обратно от Excel до SQL Developer.
Для этого упражнения будет использоваться метод «Вставки» (Insert). Каждая строка, обработанная в файле Excel, приведет к выполнению инструкции INSERT в таблице, в которую мы импортируем.
Если вы выберете «Вставить скрипт», мастер завершит работу скриптом ВСТАВКИ на вашем листе SQL. Это хорошая альтернатива, если вы хотите настроить SQL, или если вам нужно отладить/посмотреть, почему метод «Insert» не работает.
Шаг 4: Выберите столбцы Excel для импорта
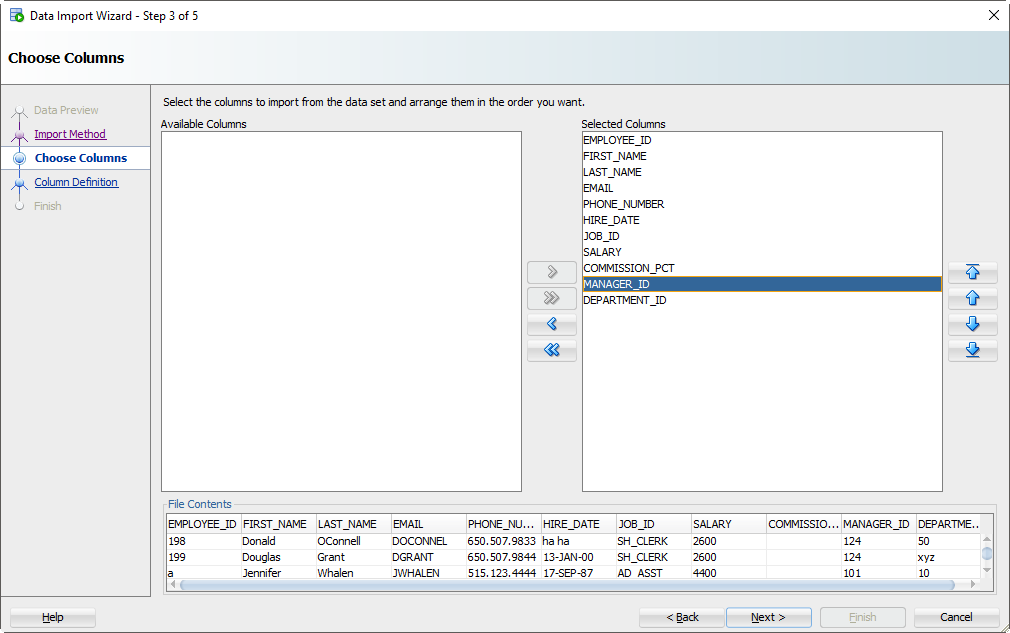
У вас может быть файл Excel со 100 столбцами, но ваша таблица имеет только 30. Здесь вы даете команду SQL Developer, какие столбцы должны использоваться для импорта. Вы также можете изменить порядок столбцов, что может сделать следующий шаг немного проще.
Шаг 5: Сопоставьте столбцы Excel со столбцами таблицы
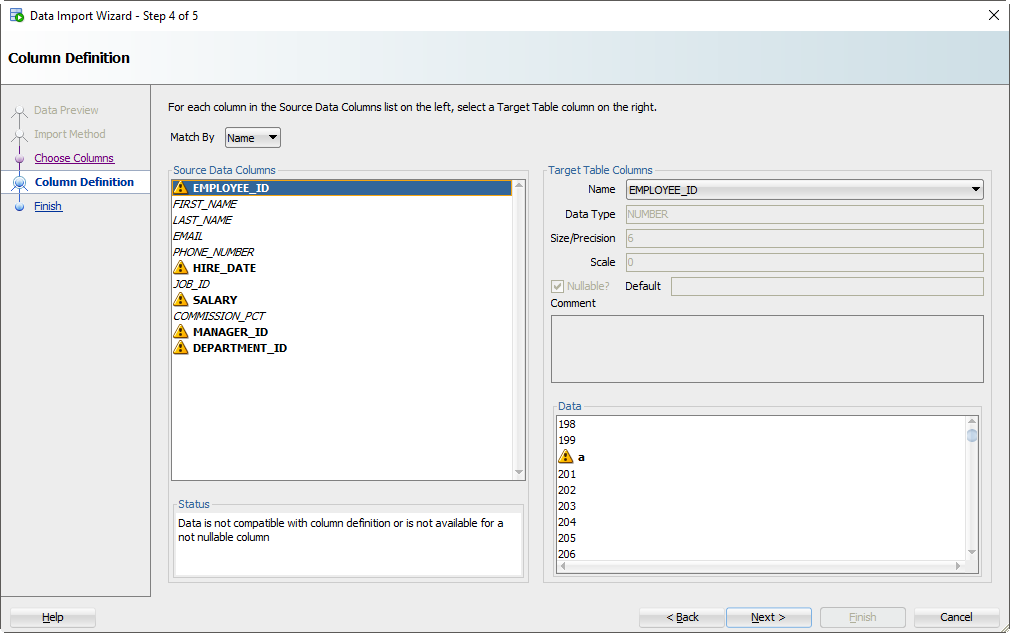
Если вы не обращаете внимания и просто позволяете Мастеру импорта делать всё по умолчанию, то сейчас самое время проснуться. Есть большая вероятность, что порядок столбцов файла Excel не будет соответствовать определению вашей таблицы. На этом шаге вы указываете SQL Developer-у, какие столбцы в электронной таблице совпадают с какими столбцами в таблице Oracle.
А помните, как мы установили это окно предварительного просмотра на 100 строк? Мы внимательно изучаем данные, ищем проблемы, пытаясь вписать их в столбец вашей таблицы. Если мы обнаружим проблему, мы пометим столбцы этими «предупреждающими» символами.
Я загрязнил свой файл Excel некоторыми намеренно ошибочными значениями, которые, как я знаю, не будут «подходить». Когда эти строки будут обнаружены в мастере, база данных их отклонит, но остальные строки будут введены.
Давайте на секунду поговорим о форматах даты и времени.
О TIMESTAMP тоже. В файле Excel у вас, вероятно, будут некоторые поля даты и времени, которые вы хотите переместить в столбцы формата DATE или TIMESTAMP. SQL Developer обрабатывает эти значения как строки – и ВАМ нужно сообщить SQL Developer формат DATE или TIMESTAMP, чтобы иметь возможность их преобразовать.
Давайте посмотрим на HIREDATE.
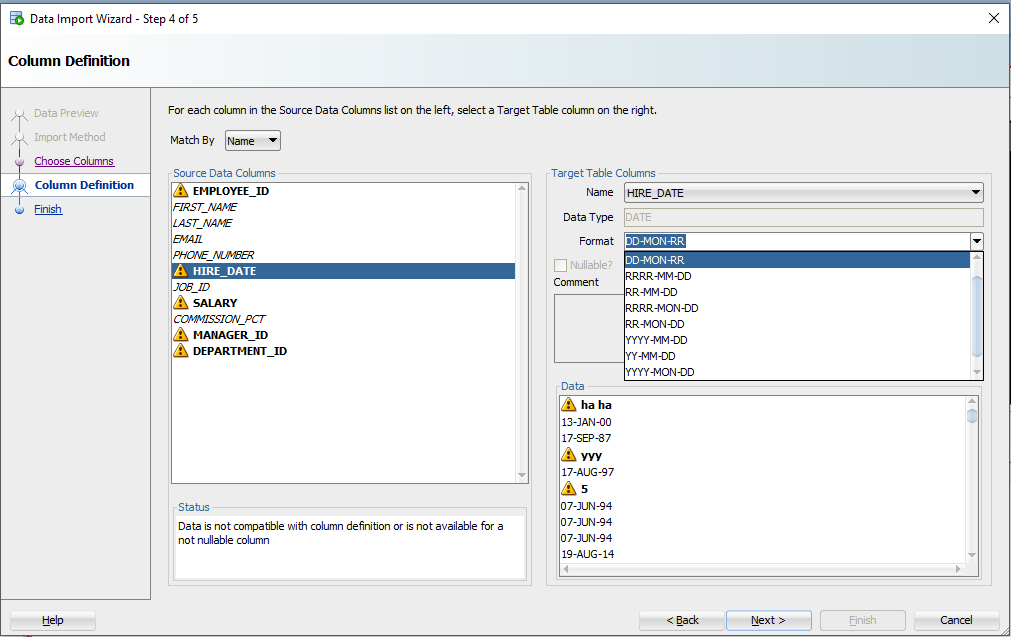
HIRE_DATE – если только вы не храните ДАТЫ в VARCHAR2, — и если вы делаете это, то делаете это НЕПРАВИЛЬНО. Всегда храните ДАТЫ в формате DATE!
Видите выпадающий селектор «Формат» (Format)? SQL Developer по умолчанию установил строку формата ДАТЫ в ‘DD-MON-RR’ – мы пытаемся угадать это на основе строк, которые мы рассматриваем в этом окне предварительного просмотра 100.
Если мы ошиблись в догадках или не смогли разобраться, вам нужно будет ввести это самостоятельно. Документы Oracle могут помочь вам определить правильную модель формата ДАТЫ. Если вы видите небольшое предупреждающее изображение рядом со значениями даты на панели данных, возможно, у вас неправильный формат.
Шаг 6: Проверьте свои настройки и ВПЕРЕД!
Нажмите на кнопку «Готово» (Finish).
Если Мастер столкнется с какими-либо проблемами при выполнении вставок, вы увидите следующее:
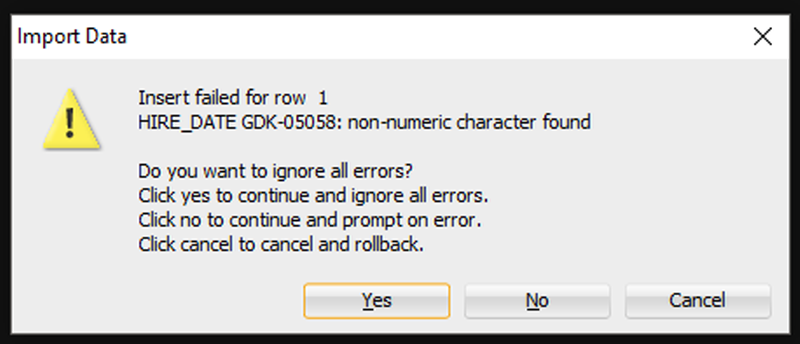
Я собираюсь сказать «Да», чтобы игнорировать все ошибки. Но если вам нужна КАЖДАЯ отдельная строка – вам нужно сказать «Отмена», чтобы начать все сначала. Затем вы можете либо исправить свои данные в файле Excel, либо внести изменения в свою таблицу, чтобы данные соответствовали/работали.
Нажав ‘Да», мы доберемся до конца нашей истории и наших данных!
Шаг 7: Посмотрите, Что сработало, а Что нет
Во-первых, есть ли плохие новости?
Если были строки, отклоненные базой данных, мы увидим их сейчас.
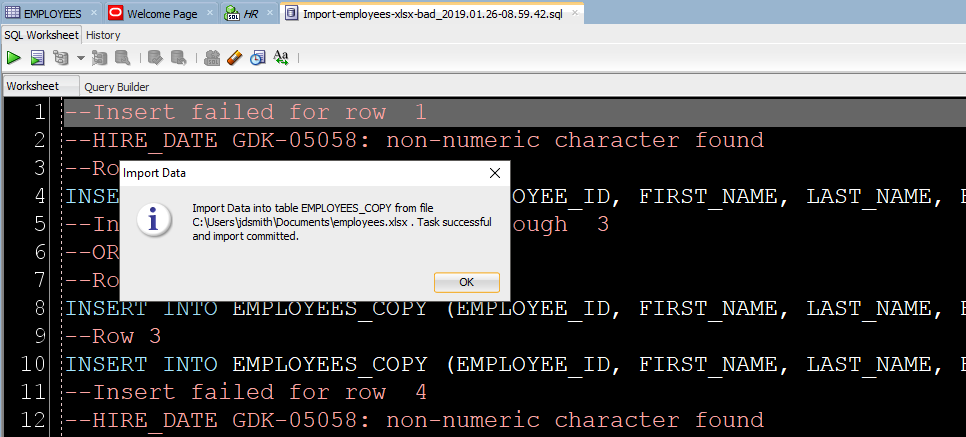
INSERT, которые мы пытались запустить, но не сработали. Вы можете изменить их вручную, чтобы исправить несколько записей. Но если у вас тысячи забракованных строк – лучше разобраться в файле (в источнике импорта).
Теперь давайте посмотрим на наши новые табличные данные!
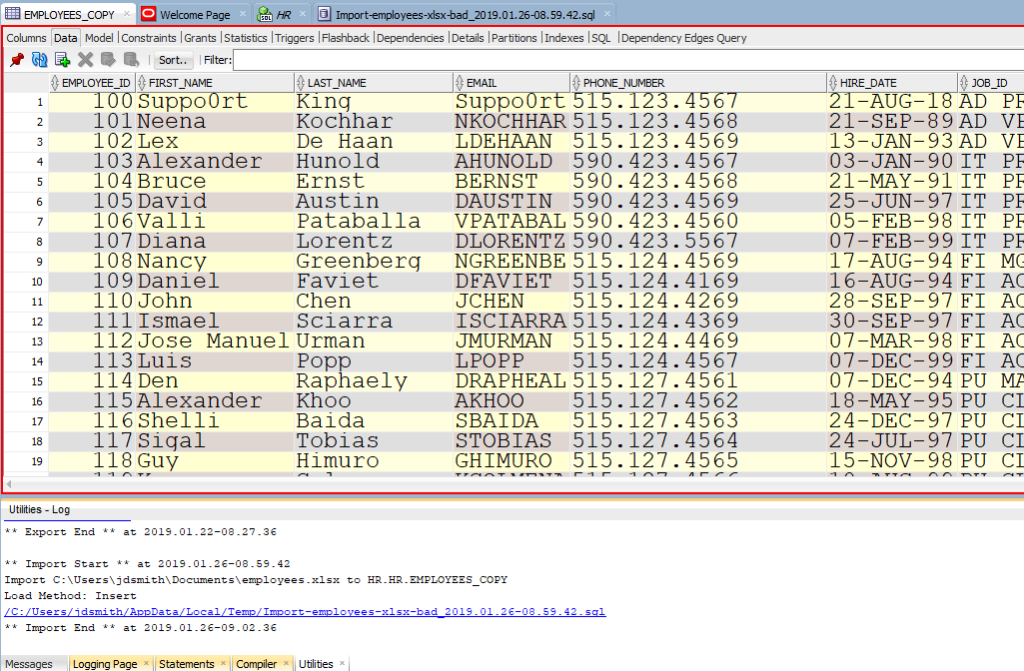
Обратите внимание на панель «Журнал» (Log). Там можно увиеть файл, с которым мы работали, и сколько времени потребовалось для загрузки данных.
Всё! Можно выдохнуть свободно. Импорт из файла Excel в таблицу базы данных Oracle завершен. В шапке статьи вы можете посмотреть видео инструкцию — копию этого мануала на английском языке.
Вас заинтересует / Intresting for you:
TL;DR – Skip to the video!
Hate GUIs, want to do this via the command-line?
THIS is your number one question – and it has been here on my blog since the day I posted it.
You have an Excel file – and you want that data put into a table. I’ll show you how, and we’ll document each step of the way with plenty of pictures.
You will be prepared to import data to an existing table from Excel with confidence after reading this post. Want to build a new table from Excel? We can do that, too.
Warning: This post has a LOT of pictures.
For our example I’ll be using the HR.EMPLOYEES table to create the XLS file for our import. We’ll use that Excel file to populate an empty copy of the EMPLOYEES table in another schema.
Step 0: The Empty Oracle Table and your Excel File
You have an Oracle table and you have one or more Excel files.

You do know how to view multiple objects at once in SQL Developer, right?
Step 1: Mouse-right click – Import Data

Step 2: Select your input (XLSX) file and verify the data
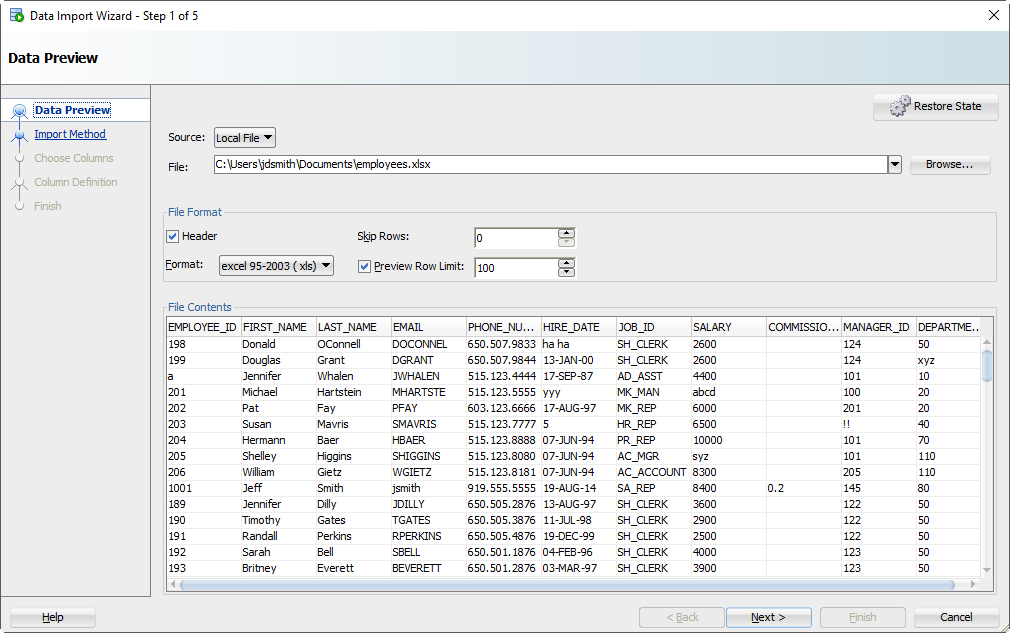
As you select the file, we’ll grab the first 100 rows for you to browse below. This ‘Preview Row Limit’ defines how many rows you can use to verify the IMPORT as we step through the wizard. You can increase it, but that will take more resources, so don’t go crazy.
Also, does your Excel file have column headers? Do we want to treat those as a row to the table? Probably not. If you uncheck the ‘Header’ flag, the column names will become a new row in your table – and probably fail to be inserted.
Sometimes your Excel file has multiple headers, or you may need to only import a certain subset of the spreadsheet. Use the ‘Skip Rows’ option to get the right data.
Step 3: Create a script or import automatically
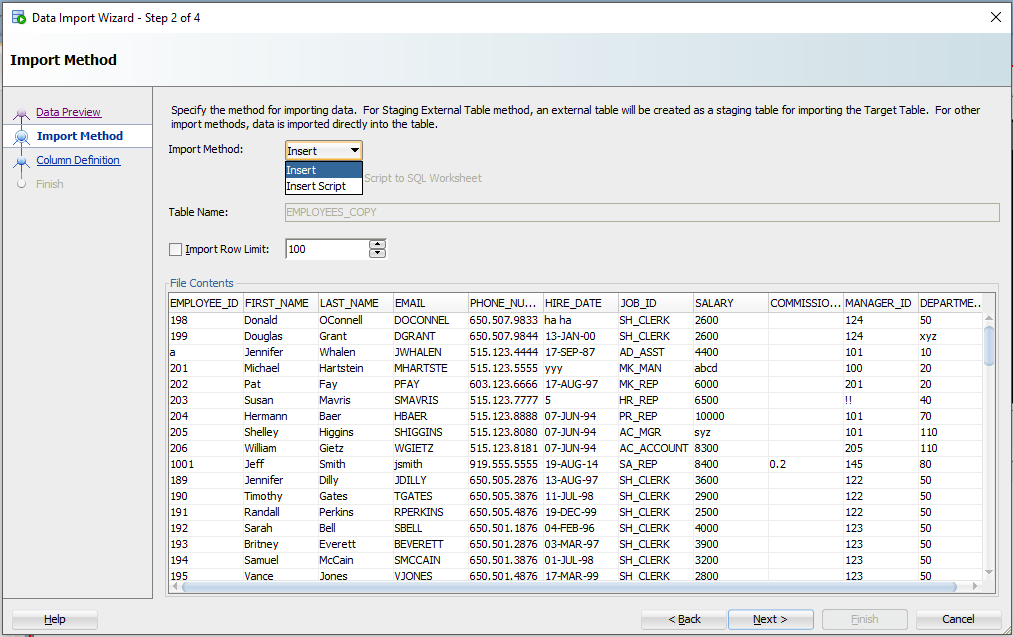
For this exercise the ‘Insert’ method will be used. Each row processed in the Excel file will result in an INSERT statement executed on the table we’re importing to.
If you choose ‘Insert Script’, the wizard will end with an INSERT Script in your SQL Worksheet. This is a nice alternative if you want to customize the SQL, or if you need to debug/see why the ‘Insert’ method isn’t working.
Working with CSV? You’ll get even more methods – great for VERY LARGE data sets.
Step 4: Select the Excel Columns to be Imported
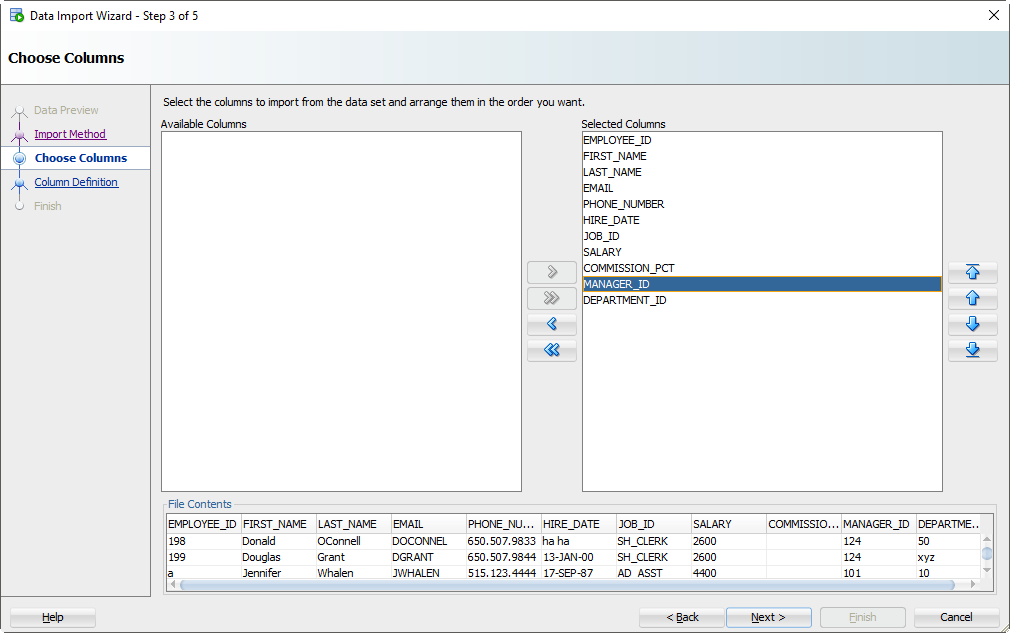
You may have an Excel file with 100 columns but your table only has 30. This is where you tell SQL Developer what columns are to be used for the import. You can also modify the column order, which may make the next step a bit easier.
Step 5: Map the Excel Columns to the Table Columns
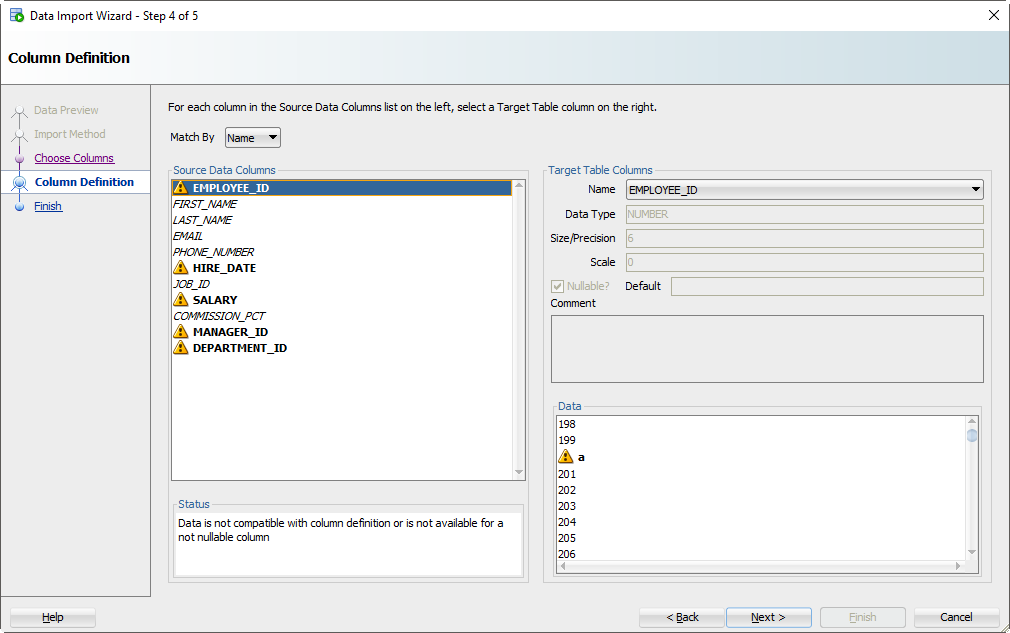
If you’re not paying attention and just letting the wizard guide you home, then now is the time to wake up. There’s a good chance the column order of the Excel file won’t match the definition of your table. This is where you will tell SQL Developer what columns in the spreadsheet match up to what columns in the Oracle table.
And remember how we set that preview window to 100 rows? We’re peaking at the data, looking for problems as we try to fit it into your table column. If we find a problem, we’ll mark the columns with those ‘warning’ symbols.
I’ve polluted my Excel file with some values that I know won’t ‘fit.’ When these rows are encountered in the wizard, they’ll be rejected by the database – but the other rows will come in.
Let’s talk about DATES for a second.
And TIMESTAMPS too. In the excel file, you’re probably going to have some date/time fields you want to move into DATE or TIMESTAMP columns. SQL Developer is treating those value as strings – and YOU need to tell SQL Developer the DATE or TIMESTAMP format to use to be able to convert them.
Let’s look at HIREDATE.
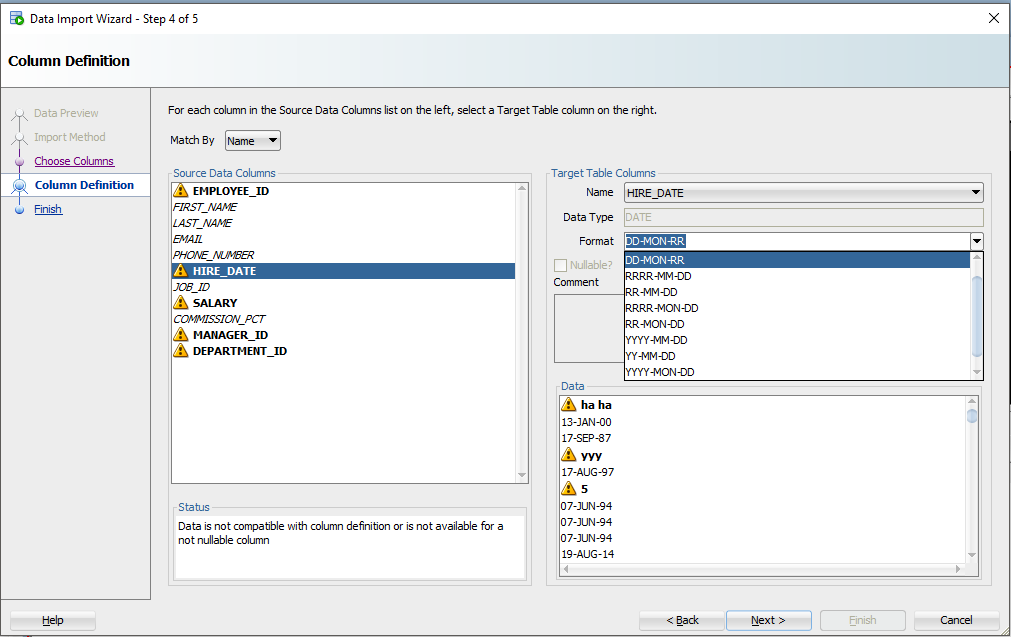
See the ‘Format’ drop down selector? SQL Developer has defaulted the DATE format string to ‘DD-MON-RR’ – we try to guess based on the rows we’re looking at in that 100 preview window.
If we have guessed wrong, or were unable to figure it out, you’ll need to input this yourself. The Oracle Docs can help you define the correct DATE Format Model. If you see the little warning graphics next to your Date values in the Data panel, you might have the wrong format.
Step 6: Verify your settings and GO!
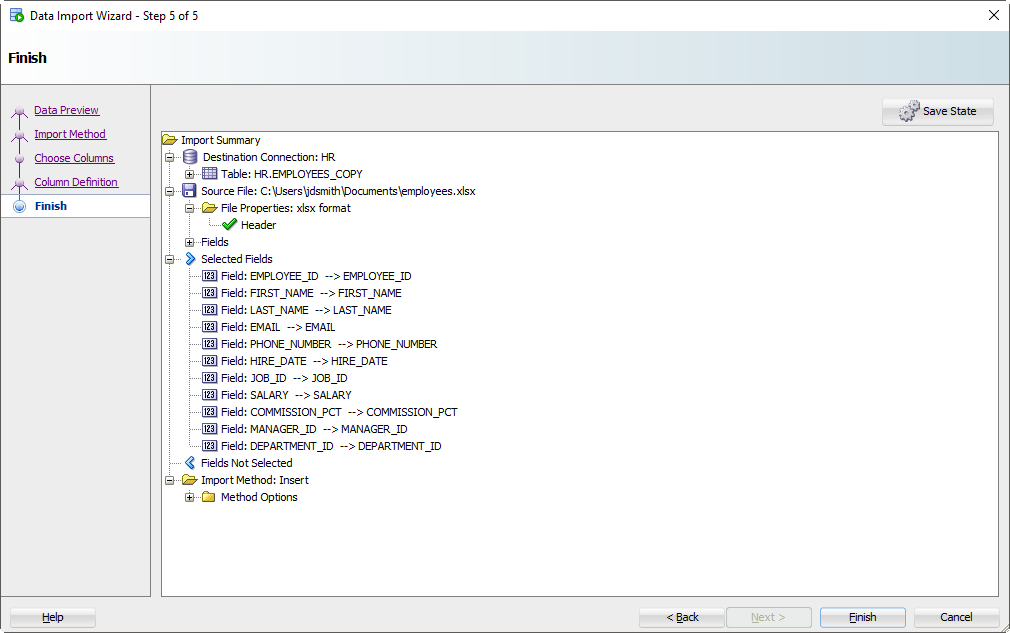
Click on the ‘Finish’ button.
If the Wizard runs into any problems doing the INSERTs, you’ll see this:
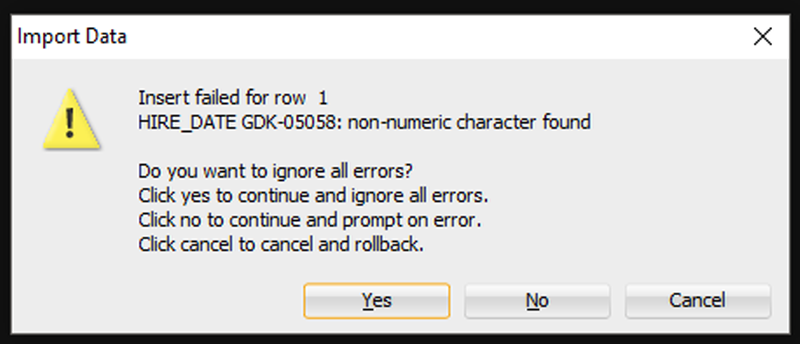
I’m going to say ‘Yes’ to ignore all the errors. But, if you need EVERY single row – you need to say ‘Cancel’ to start over. Then you can either fix your data in the Excel file, or make changes to your table so the data will fit/work.
After clicking ‘Yes’, we’ll get to the end of our story, and our data!
Step 7: See What Worked and What Didn’t
First, any bad news?
If there were rows rejected by the database, we’ll see those now.
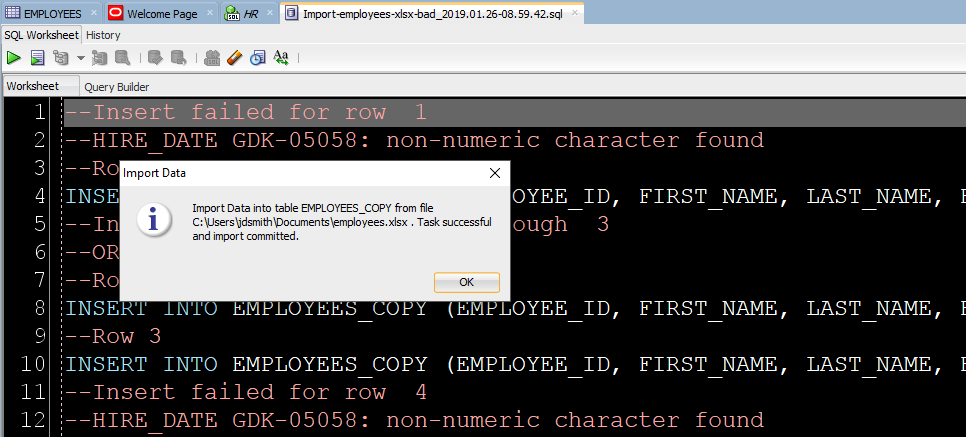
Now let’s go look at our new table data!
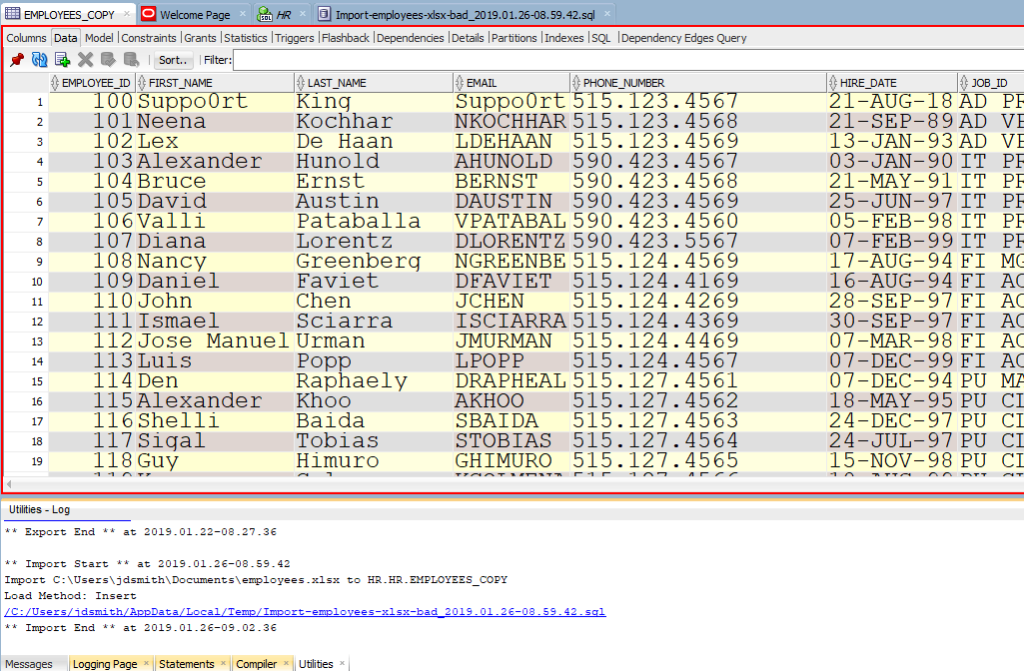
Note the ‘Log’ panel. We’ll show you the file we worked with, and how much time it took to load the data.
Just a few more pointers when it comes to Excel
- Storing data in Excel can be…dangerous
- If you have a lot of data or if this will be a repeating process, consider External Tables or SQL*Loader instead
- If you like to put data in Oracle because you understand SQL better than Excel macros, then welcome to the club 😉
- Here’s 11 more tips on Importing Excel/CSV into your database
The Movie
Are you trying to figure out how to load data from Excel into your database?
The problem: load data to Oracle
Many business analysts rely heavily upon Microsoft Excel as one of their primary sources for important business data. At some point they will need to load data into an Oracle database, and thus you will often hear them make requests such as the following:
- Copying Excel data to Oracle
- Importing Excel data to Oracle
- Loading Excel data to Oracle
- Transferring Excel data to Oracle
They key point is that regardless of how the business users ask, the request is essentially the same. Some very common ways they obtain such loading of the database data include:
Business user sending a formal data load request to their information systems people to perform and deliver the loaded Oracle table. However, this process can take time – sometimes more than the business user can wait.
Business user truly self-servicing by loading the database data themselves using a powerful tool like Quest®Toad® for Oracle, and then working with that data in Toad or some other database tool. This approach is quick and easy, plus Toad for Oracle integrates easily into the business analyst’s workflow.
In my recent blog titled “Copying database data to Microsoft Excel via Toad for Oracle” I showed how easily Toad for Oracle can export data into Excel — a favorite tool of many business analysts.
Toad for Oracle makes short work of this use case as well — how to load data from Excel into Oracle. For my example, I chose to use the Internet Movie Database (IMDB) and thus downloaded the movies title basic data. I then unzipped the file to obtain the 606 megabyte tab delimited text file named data.tsv. I then renamed that data file to movies.tsv so as not to forget what the file contains.

The solution to load data into Oracle
Many business analysts strongly favor the second choice of using Toad for Oracle to self-service and load data. In this blog I’ll review some common scenarios that facilitate easily copying Excel data to Oracle using Toad. The techniques that I’ll be showing work essentially the same in both of Toad’s primary interfaces for this task: the Schema Browser and Main-Menu—> Database —> Create —> Table. I’ll demonstrate using the Schema Browser, which is often the most common choice for this task.

Figure 1: Create a new table to load data
Now in Figure 2 below I’m inside the create table screen. First I chose to check the box for display advanced features, otherwise I would not see displayed the options which will be required. Second, I chose to open a file to read for the table’s column names. It uses the first row of data for that. Third, I chose my tab delimited text file. Finally, I pressed OK. Since my file was over 600 megabytes, it took a few seconds to process.

Figure 2: Method to populate the table columns to load data.
In Figure 3 below I now have all the columns for my table. Note that Toad has set the default datatype to VARCHAR2 for all columns. Moreover Toad also has set each column to be optional. You may need to modify these default choices as you know your data far better than Toad. Then press the OK button to create the table and load data.

Figure 3: Resulting population of table columns.
In Figure 4 below I have now created the table required to hold all the data for the IMDB movies data file. Remember, the file is over 600 megabytes in size, so the data load will likely take a few moments. But we’re more than half-way home at this point. Now I just need to import the data into my newly created table.

Figure 4: Resulting table creation.
In Figure 5 below I have now invoked Toad for Oracle’s Data Import wizard by opening the Right Hand Mouse (RHM) menu and select Import —> Data, or Main Menu —> Database—>Import—>Import Table Data. As you can now see, I am setup to initiate loading of the MOVIES table. However this is a multi-step wizard where we’ll need to specify additional information before the table can be loaded.

Figure 5: Page 1 of the data import wizard.
In Figure 6 below I am now on the second page of the data import wizard where I identify the file type and name. If you look back at Figure 2, you will see that we’ve answered two of the three key parameters. Note that we’ve yet to say that it’s a tab delimited file. Remember too that the first line in the file has the column names, so we’ll need to be able to tell Toad to skip over those.

Figure 6: Page 2 of the data import wizard.
In Figure 7 below I am now on the third page of the data import wizard where I identify the file as tab delimited text.

Figure 7: Page 3 of the data import wizard.
In Figure 8 below I am now on the fourth page of the data import wizard where I identify that Toad should start reading the table data at line 2 because the first row contains the column names. You should take your time on this page of the wizard to make sure you review the dates, times, and numbers settings based upon how your data is formatted in the text file.

Figure 8: Page 4 of the data import wizard.
In Figure 9 below I am now on the fifth page of the data import wizard where Toad has read a sample of the data rows and displays them for you to verify. Moreover, Toad displays a pop-up to see how you want to map the columns of data to the table columns. In this case it really does not matter. But had I created the columns in the table in a different order or reordered them, then the choice would have to be by matching the names.

Figure 9: Page 5 of the data import wizard.
In Figure 10 below I am now on the sixth page of the data import wizard where Toad displays the results of your selection from the prior page’s pop up where you specified the data file field to table column mapping. Again if I had reordered the columns in the table, I would have had to make changes on this page to properly align the fields to columns.

Figure 10: Page 6 of the data import wizard.
In Figure 11 below I am now on the seventh page of the data import wizard where Toad displays the field to column matching results performed upon the sample data with the column header row removed. Note that the columns displayed here are sized based upon the column name size. I’ll need to press the size cols to data button if I wish to be able to see the column values displayed in their entirety.

Figure 11: Page 7 of the data import wizard.
In Figure 12 below I am now on the eighth page of the data import wizard where Toad allows one to specify a host of parameters or options that control the actual database transaction processing. As you can see, I have said to perform batch array inserts of 500 rows, to truncate the table before loading, and to commit after every 500 rows. These choices will affect how long the actual data load takes. Remember that my data file is over 600 megabytes, so setting these parameters is critical. Now when I press the execute button, the data import process will begin.

Figure 12: Page 8 of the data import wizard.
In Figure 13 below I am now executing the data import process. The first time I ran this I got errors because the default column data types and size were VARCHAR(32) and the movies titles are much longer than that. I just chose to abort, increased the column lengths, and restarted the wizard. It then ran to completion without error. Did you note that even on my small VM running on a desktop PC that I’m getting loads of over 66,000 records per second!

Figure 13: Page 9 of the data import wizard.
Conclusion
If you are a business user who wants to copy from Excel to Oracle, use Toad. You can easily do automatic table creation and data loading as shown above. Thus you can self-service without requesting help from your information systems people. No other database tool makes copying data from Excel to Oracle quicker and easier than Toad. Plus no matter whether you’re using Toad freeware or the commercial version of Toad, the process is essentially the same.
Need help managing data? Try Toad for free!
Quest Software® is here to help you simplify complexity, reduce cost and risk, and drive performance. Maybe that’s why we’re consistently voted #1 by DBTA readers and have 95%+ customer satisfaction rate.

Toad® database management tools are cross-platform solutions from Quest® that can help new and veteran DBAs, and even “accidental” DBAs manage data in Oracle, SQL Server, DB2, SAP, MySQL, and Postgres environments.
Related Toad World posts
Blog: Copying database data to Microsoft Excel via Toad for Oracle
Useful resources
Toad for Oracle general information
Technical brief: Top Five Reasons to Choose Toad Over SQL Developer
Case study: Opening doors and creating opportunities with data insights
Have questions, comments?
Head over to the Toad for Oracle forum on Toad World®! Chat with Toad developers, and lots of experienced users.
Help your colleagues
If you think your colleagues would benefit from this blog, share it now on social media with the buttons located at the top of this blog post. Thanks!
Tags:
Toad for Oracle

Written by Bert Scalzo
Bert Scalzo is a guest-blogger for Quest and a renowned database expert, Oracle® ACE, author, database technology consultant, and formerly a member of Dell Software’s TOAD dev team. With three decades of Oracle® database experience to draw on, Bert’s webcasts garner high attendance and participation rates. His work history includes time at both Oracle Education and Oracle Consulting. Bert holds several Oracle Masters certifications and has an extensive academic background that includes a BS, MS and Ph.D. in computer science, as well as an MBA, and insurance industry designations.
Bert is a highly sought-after speaker who has presented at numerous Oracle conferences and user groups, including OOW, ODTUG, IOUG, OAUG, RMOUG and many others. Bert enjoys sharing his vast knowledge on data modeling, database benchmarking, database tuning and optimization, «star schema» data warehouses, Linux® and VMware®.
As a prolific writer, Bert has produced educational articles, papers and blogs for such well-respected publications as the Oracle Technology Network (OTN), Oracle Magazine, Oracle Informant, PC Week (eWeek), Dell Power Solutions Magazine, The LINUX Journal, LINUX.com, Oracle FAQ, Ask Toad and Toad World.
This popular author is known throughout the industry for his instructive books, which include:
• Oracle DBA Guide to Data Warehousing and Star Schemas
• TOAD Handbook (1st Edition)
• TOAD Handbook (2nd Edition)
• TOAD Pocket Reference (2nd Edition)
• Database Benchmarking: Practical Methods for Oracle & SQL Server
• Advanced Oracle Utilities: The Definitive Reference
• Oracle on VMware: Expert Tips for Database Virtualization
• Introduction to Oracle: Basic Skills for Any Oracle User
• Introduction to SQL Server: Basic Skills for Any SQL Server User
• Toad Unleashed
• Leveraging Oracle Database 12cR2 Testing Tools
• Database Benchmarking and Stress Testing
Drop Bert an email at bertscalzo2@gmail.com and he’ll write you back, and maybe send you an autographed book!
I’ve been thinking about it for quite a long time and never really had time to implement it, but it’s finally there : a pipelined table interface to read an Excel file (.xlsx) as if it were an external table.
It’s entirely implemented in PL/SQL using an object type (for the ODCI routines) and a package supporting the core functionalities.
Available for download on GitHub :
 /mbleron/ExcelTable
/mbleron/ExcelTable
Usage
ExcelTable.getRows table function :
This is the actual SQL interface, to be used in conjunction with the TABLE operator.
It returns an ANYDATASET instance whose structure is defined by the p_cols parameter.
function getRows (
p_file in blob
, p_sheet in varchar2
, p_cols in varchar2
, p_range in varchar2 default null
)
return anydataset pipelined
using ExcelTableImpl;
| Arg | Data type | Desc | Mandatory |
|---|---|---|---|
p_file |
BLOB | Input Excel file in Office Open XML format (.xlsx or .xlsm). A helper function ( ExcelTable.getFile) is available to directly reference the file from a directory. |
Yes |
p_sheet |
VARCHAR2 | Worksheet name | Yes |
p_cols |
VARCHAR2 | Column list (see specs below) | Yes |
p_range |
VARCHAR2 | Excel-like range expression that defines the table boundaries in the worksheet (see specs below) | No |
Range syntax specification
range_expr ::= ( cell_ref [ ":" cell_ref ] | col_ref ":" col_ref | row_ref ":" row_ref )
cell_ref ::= col_ref row_ref
col_ref ::= { "A".."Z" }
row_ref ::= integer
If the range is empty, the table implicitly starts at cell A1.
Otherwise, there are four ways to specify the table range :
- Range of rows :
'1:100'
In this case the range of columns implicitly starts at A. - Range of columns :
'B:E'
In this case the range of rows implicitly starts at 1. - Range of cells (top-left to bottom-right) :
'B2:F150' - Single cell anchor (top-left cell) :
'C3'
Columns syntax specification
The syntax is similar to the column list in a CREATE TABLE statement, with a couple of specifics :
column_list ::= column_expr { "," column_expr }
column_expr ::= ( identifier datatype [ "column" string_literal ] | identifier for_ordinality )
datatype ::= ( number_expr | varchar2_expr | date_expr | clob_expr )
number_expr ::= "number" [ "(" ( integer | "*" ) [ "," [ "-" ] integer ] ")" ]
varchar2_expr ::= "varchar2" "(" integer [ "char" | "byte" ] ")"
date_expr ::= "date" [ "format" string_literal ]
clob_expr ::= "clob"
for_ordinality ::= "for" "ordinality"
identifier ::= """ { char } """
string_literal ::= "'" { char } "'"
Column names must be declared using a quoted identifier.
Supported data types are :
- NUMBER – with optional precision and scale specs
- VARCHAR2 – including CHAR/BYTE semantics
Values larger than the maximum length declared are silently truncated and no error is reported. - DATE – with optional format mask
The format mask is used if the value is stored as text in the spreadsheet, otherwise the date value is assumed to be stored as date in Excel’s internal serial format. - CLOB
A special “FOR ORDINALITY” clause (like XMLTABLE or JSON_TABLE’s one) is also available to autogenerate a sequence number.
Each column definition (except for the one qualified with FOR ORDINALITY) may be complemented with an optional “COLUMN” clause to explicitly target a named column in the spreadsheet, instead of relying on the order of the declarations (relative to the range).
Positional and named column definitions cannot be mixed.
For instance :
"RN" for ordinality , "COL1" number , "COL2" varchar2(10) , "COL3" varchar2(4000) , "COL4" date format 'YYYY-MM-DD' , "COL5" number(10,2) , "COL6" varchar2(5)
"COL1" number column 'A' , "COL2" varchar2(10) column 'C' , "COL3" clob column 'D'
Examples
Using this sample file :
1- Loading all six columns, starting at cell A2, in order to skip the header :
SQL> select t.*
2 from table(
3 ExcelTable.getRows(
4 ExcelTable.getFile('TMP_DIR','ooxdata3.xlsx')
5 , 'DataSource'
6 , ' "SRNO" number
7 , "NAME" varchar2(10)
8 , "VAL" number
9 , "DT" date
10 , "SPARE1" varchar2(6)
11 , "SPARE2" varchar2(6)'
12 , 'A2'
13 )
14 ) t
15 ;
SRNO NAME VAL DT SPARE1 SPARE2
---------- ---------- ---------- ------------------- ------ ------
1 LINE-00001 66916.2986 13/10/1923 11:45:52
2 LINE-00002 96701.3427 05/09/1906 10:12:35
3 LINE-00003 68778.8698 23/01/1911 09:26:22 OK
4 LINE-00004 95110.028 03/05/1907 13:52:30 OK
5 LINE-00005 62561.5708 04/04/1927 18:10:39
6 LINE-00006 28677.1166 11/07/1923 15:10:59 OK
7 LINE-00007 16141.0202 20/11/1902 02:02:24
8 LINE-00008 80362.6256 19/09/1910 14:06:42
9 LINE-00009 10384.1973 16/07/1902 04:54:12
10 LINE-00010 5266.9097 08/08/1921 11:51:34
11 LINE-00011 12513.0679 01/07/1908 21:53:55
12 LINE-00012 66596.9707 22/03/1913 05:20:10
...
95 LINE-00095 96274.2193 08/04/1914 22:48:31
96 LINE-00096 29783.146 06/04/1915 23:49:23
97 LINE-00097 19857.7661 16/02/1909 21:21:52
98 LINE-00098 19504.3969 05/12/1917 01:56:05
99 LINE-00099 98675.8673 05/06/1906 17:41:10
100 LINE-00100 24288.2885 22/07/1920 13:25:59
100 rows selected.
2- Loading columns B and F only, from rows 2 to 10, with a generated sequence :
SQL> select t.*
2 from table(
3 ExcelTable.getRows(
4 ExcelTable.getFile('TMP_DIR','ooxdata3.xlsx')
5 , 'DataSource'
6 , q'{
7 "R_NUM" for ordinality
8 , "NAME" varchar2(10) column 'B'
9 , "SPARE2" varchar2(6) column 'F'
10 }'
11 , '2:10'
12 )
13 ) t
14 ;
R_NUM NAME SPARE2
---------- ---------- ------
1 LINE-00001
2 LINE-00002
3 LINE-00003 OK
4 LINE-00004 OK
5 LINE-00005
6 LINE-00006 OK
7 LINE-00007
8 LINE-00008
9 LINE-00009
9 rows selected.