
ordered_list = [ "Mon","Tue","Wed","Thu","Fri","Sat","Sun"]
wb = Workbook('dem.xlsx')
ws = wb.add_worksheet("New Sheet")
first_row=0
for header in ordered_list:
col=ordered_list.index(header)
ws.write(first_row,col,header)
col=1
for j in po:
row=ordered_list.index(j[0])
ws.write(col,row,j[1])
col+=1
wb.close()
I have list po = [(‘Mon’, 6421), (‘Tue’, 6412), (‘Wed’, 12416), (‘Thu’, 23483), (‘Fri’, 8978), (‘Sat’, 7657), (‘Sun’, 6555)]. I have to print this list in Excel Sheet like
mon 6421
Tue 6412
wed 12416
'''
'''
Sun 6555
But I am getting like this. Can anyone help me to solve this.
Mon Tue Wed Thu Fri Sat Sun
6421
6412
12416
23483
8978
7657
6555
17 авг. 2022 г.
читать 2 мин
Часто вас может заинтересовать экспорт фрейма данных pandas в Excel. К счастью, это легко сделать с помощью функции pandas to_excel() .
Чтобы использовать эту функцию, вам нужно сначала установить openpyxl , чтобы вы могли записывать файлы в Excel:
pip install openpyxl
В этом руководстве будет объяснено несколько примеров использования этой функции со следующим фреймом данных:
import pandas as pd
#create DataFrame
df = pd.DataFrame({'points': [25, 12, 15, 14, 19],
'assists': [5, 7, 7, 9, 12],
'rebounds': [11, 8, 10, 6, 6]})
#view DataFrame
df
points assists rebounds
0 25 5 11
1 12 7 8
2 15 7 10
3 14 9 6
4 19 12 6
Пример 1: базовый экспорт
В следующем коде показано, как экспортировать DataFrame по определенному пути к файлу и сохранить его как mydata.xlsx :
df.to_excel (r'C:UsersZachDesktopmydata.xlsx')
Вот как выглядит фактический файл Excel:
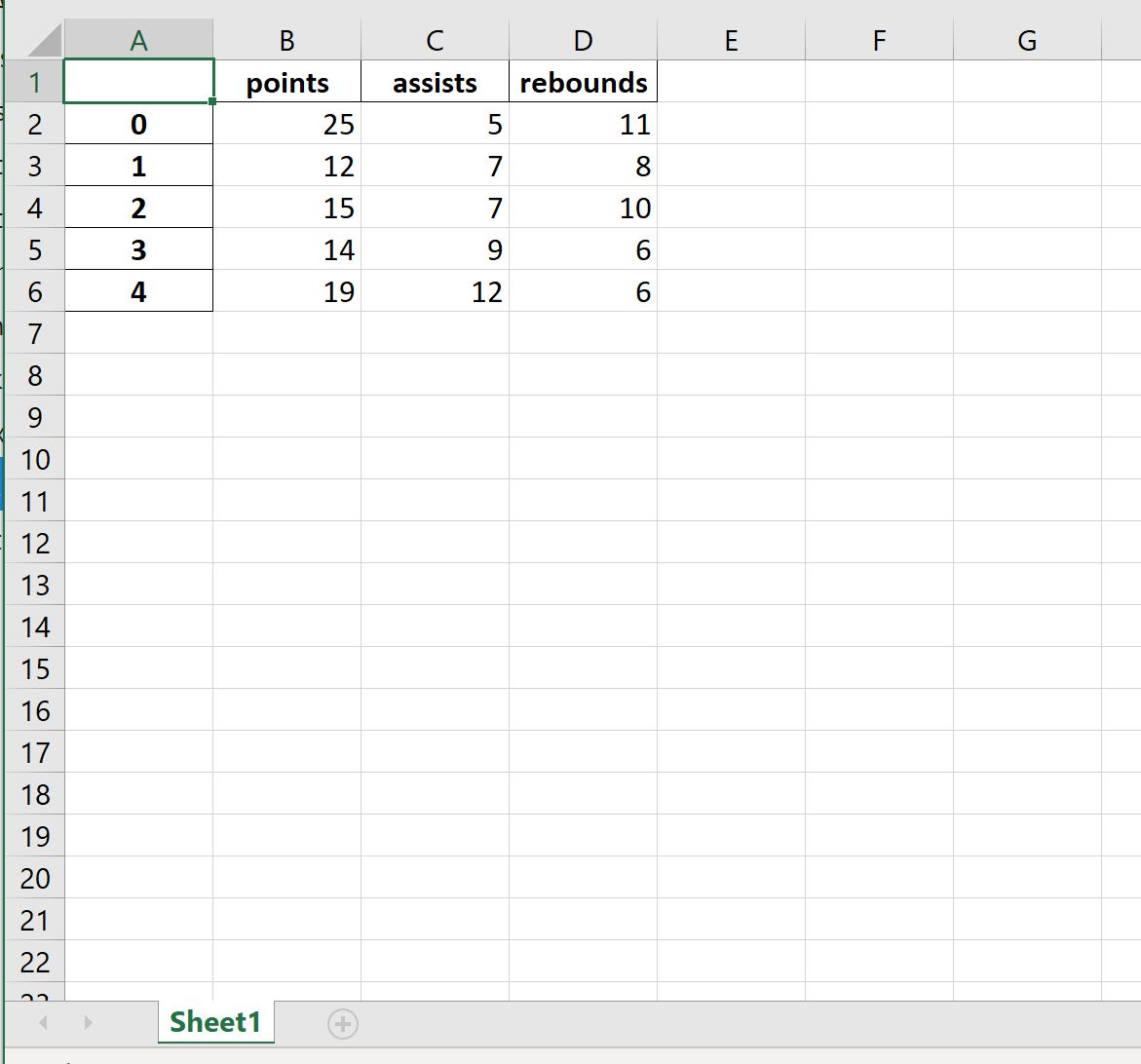
Пример 2: Экспорт без индекса
В следующем коде показано, как экспортировать DataFrame в определенный путь к файлу и удалить столбец индекса:
df.to_excel (r'C:UsersZachDesktopmydata.xlsx', index= False )
Вот как выглядит фактический файл Excel:
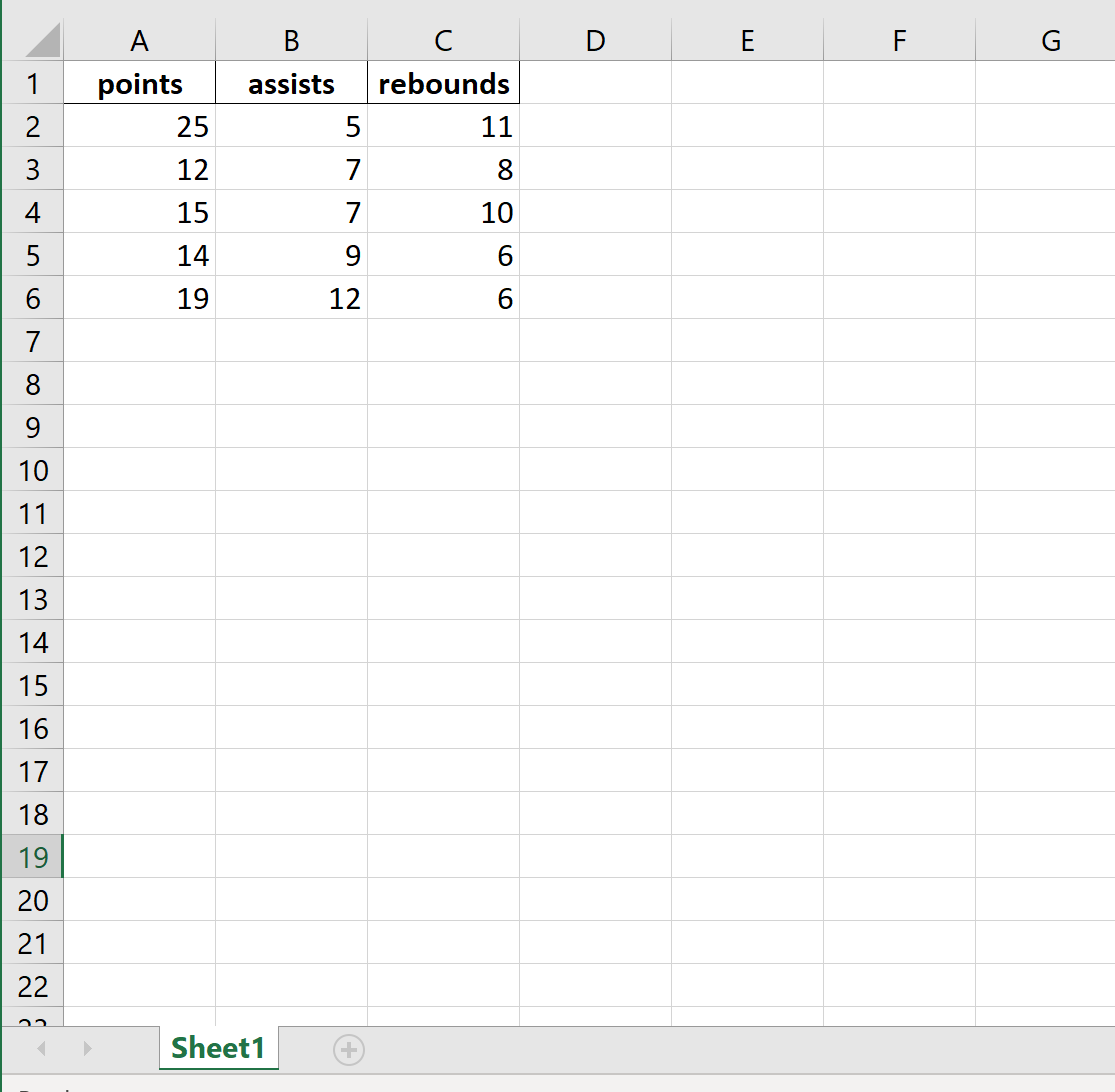
Пример 3: Экспорт без индекса и заголовка
В следующем коде показано, как экспортировать DataFrame в определенный путь к файлу и удалить столбец индекса и строку заголовка:
df.to_excel (r'C:UsersZachDesktopmydata.xlsx', index= False, header= False )
Вот как выглядит фактический файл Excel:
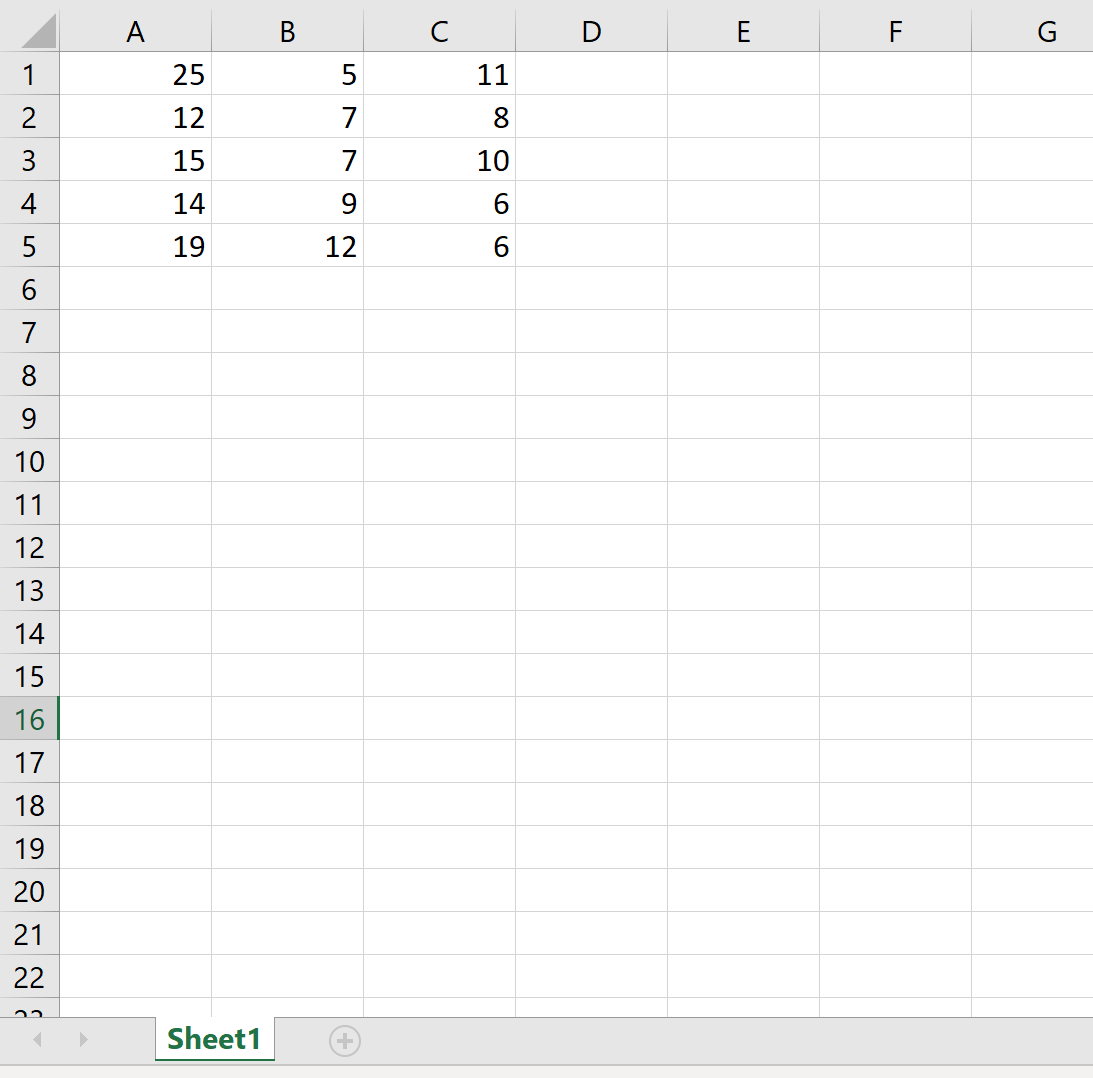
Пример 4: Экспорт и имя листа
В следующем коде показано, как экспортировать DataFrame в определенный путь к файлу и назвать рабочий лист Excel:
df.to_excel (r'C:UsersZachDesktopmydata.xlsx', sheet_name='this_data')
Вот как выглядит фактический файл Excel:
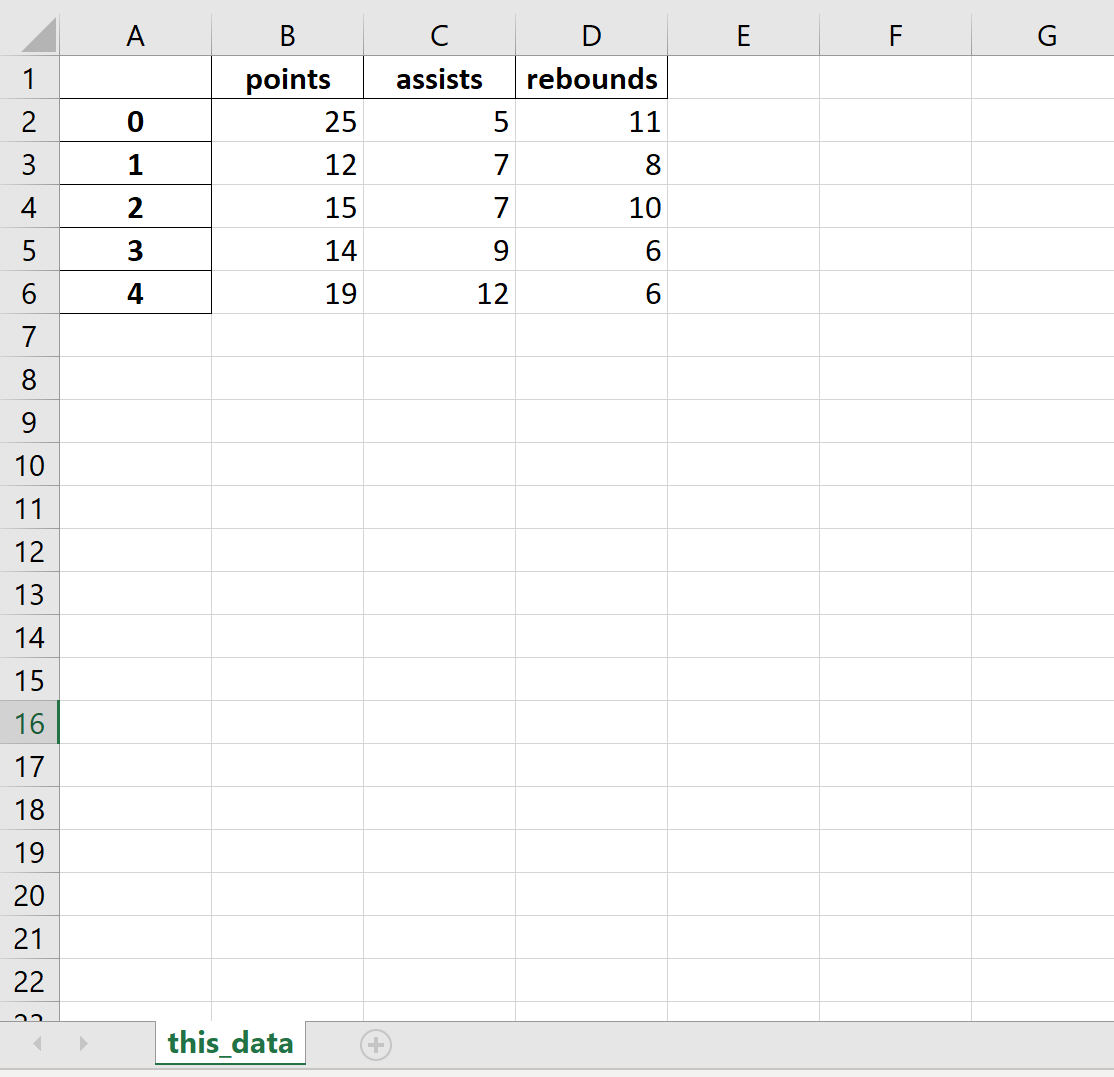
Полную документацию по функции to_excel() можно найти здесь .
We will save data from Pandas DataFrame to Excel file.
import pandas as pd
my_dict={
'NAME':['Ravi','Raju','Alex'],
'ID':[1,2,3],'MATH':[30,40,50],
'ENGLISH':[20,30,40]
}
df = pd.DataFrame(data=my_dict)
df.to_excel('D:my_file.xlsx')-
to_excel() : DataFrame to excel file
By default we will have index as left most column. We can remove index by using option index=False
df.to_excel('D:my_file.xlsx',index=False)Storing Path
We can keep in D drive ( root )
df.to_excel('D:my_file.xlsx')Inside data directory
df.to_excel('D:datamy_file.xlsx')Storing different worksheets
Excel has worksheets to store data in different sheets.
When we create a new excel file the data stored in Sheet1. We can create different Sheets and store data in different worksheets.
By using sheet_name we can store in worksheet with specific name sheet_name=’my_Sheet_1′
df.to_excel('D:my_file.xlsx',index=False,sheet_name='my_Sheet_1')This will store our data in my_sheet_1 worksheet of file name my_file.xlsx at root of D drive.
multiple worksheets
We will use one object of ExcelWriter to create multiple worksheets in a excel file.
import pandas as pd
my_dict={
'NAME':['Ravi','Raju','Alex'],
'ID':[1,2,3],'MATH':[30,40,50],
'ENGLISH':[20,30,40]
}
df = pd.DataFrame(data=my_dict)
df2 = df.copy() # copy of df
with pd.ExcelWriter('D:my_file.xlsx') as my_excel_obj: #Object created
df.to_excel(my_excel_obj,sheet_name='my_Sheet_1')
df2.to_excel(my_excel_obj,sheet_name='my_Sheet_2')Above code will create excel file with two worksheets. Here the new file name is my_file.xlsx with two worksheets.
Appending worksheets
We will add two more worksheets to the existing files by opening the file in append mode.
Note that we are using the same my_file.xlsx file created in above code.
We will be using mode=’a’ and engine=’openpyxl’ while creating the ExcelWriter object.
import pandas as pd
my_dict={
'NAME':['Ravi','Raju','Alex'],
'ID':[1,2,3],'MATH':[30,40,50],
'ENGLISH':[20,30,40]
}
df = pd.DataFrame(data=my_dict)
df2 = df.copy() # copy of df
with pd.ExcelWriter('D:my_file.xlsx',mode='a',engine='openpyxl') as my_excel_obj:
df.to_excel(my_excel_obj,sheet_name='my_Sheet_3')
df2.to_excel(my_excel_obj,sheet_name='my_Sheet_4')This code will add two more worksheets my_Sheet_3 and my_Sheet_4 to existing workbook my_file.xlsx .
While executing the above code, you may get error saying Append mode is not supported with xlsxwriter. To solve this issue use engine=’openpyxl’ while creating the ExcelWriter object.
Data from MySQL table
We can read data from MySQL table and then store them in excel file.
import mysql.connector
import pandas as pd
my_connect = mysql.connector.connect(
host="localhost",
user="userid",
passwd="password",
database="my_tutorial"
)
####### end of connection ####
sql="SELECT * FROM student "
df = pd.read_sql(sql,my_connect )
df.to_excel('D:my_file.xlsx')In above code we have first connected to MySQL database and then collected the records of student table by using read_sql() to a DataFrame. Finally we saved them in an excel file using to_excel().
Using SQLAlchemy MySQL connection
Read more on MySQL with SQLAlchemy connection. Below code will create student.xlsx file in the same directory, you can add path ( as above ) if you want the file to be created at different location.
import pandas as pd
from sqlalchemy import create_engine
my_conn = create_engine("mysql+mysqldb://userid:pw@localhost/my_db")
sql="SELECT * FROM student "
df = pd.read_sql(sql,my_conn)
df.to_excel('D:\my_data\student.xlsx') # Add the pathWe can collect data of different classes from our student table and store them in one excel file by keeping in different worksheets. So all students of class Four will be in one worksheet named as Four and similarly another worksheet for class Three students. You can extend this to other classes also.
import pandas as pd
from sqlalchemy import create_engine
my_conn = create_engine("mysql+mysqldb://userid:pw@localhost/my_db")
sql="SELECT * FROM student WHERE class='Three'"
sql2="SELECT * FROM student WHERE class='Four'"
df=pd.read_sql(sql,my_conn) # class Three students
df2=pd.read_sql(sql2,my_conn) # class Four students
with pd.ExcelWriter('D:\my_data\student.xlsx',engine='openpyxl') as my_obj:
df.to_excel(my_obj,sheet_name='Three')
df2.to_excel(my_obj,sheet_name='Four')More about xlsxwriter
Separator sep
By default sep=»,» , This is one char length strig used to spearate data in a row.
df.to_excel('D:my_file.xlsx',sep='#',index=False)na_rep Blank data
How to handle if data is blank, we can use na_rep=’*’
df.to_excel('D:my_file.xlsx',na_rep='*')Storing part of the data
We can filter the DataFrame and then save the rows in xlsx file. For this we will use our test.csv file as we have more rows.
Now let us store only two columns, class and name
import pandas as pd
df=pd.read_csv('test.csv')
df=df.loc[:,['class','name']]
df = pd.DataFrame(data=df)
df.to_excel('my_file.xlsx',index=False)We can use various other filters to manage the data and store in CSV file. You can rad more on filters sections.
Data input and output from Pandas DataFrame
Pandas
read_csv
to_csv
read_excel
to_string()