
There’s multitude of ways to achieve it. Depending on the complexity of what one tries to achieve with string replacement, and depending on tools with which user is familiar, some methods may be preferred more than others.
In this answer I am using simple input.txt file, which you can use to test all examples provided here. The file contents:
roses are red , violets are blue
This is an input.txt and this doesn't rhyme
BASH
Bash isn’t really meant for text processing, but simple substitutions can be done via parameter expansion , in particular here we can use simple structure ${parameter/old_string/new_string}.
#!/bin/bash
while IFS= read -r line
do
case "$line" in
*blue*) printf "%sn" "${line/blue/azure}" ;;
*) printf "%sn" "$line" ;;
esac
done < input.txt
This small script doesn’t do in-place replacement, meaning that you would have to save new text to new file, and get rid of the old file, or mv new.txt old.txt
Side note: if you’re curious about why while IFS= read -r ; do ... done < input.txt is used, it’s basically shell’s way of reading file line by line. See this for reference.
AWK
AWK, being a text processing utility, is quite appropriate for such task. It can do simple replacements and much more advanced ones based on regular expressions. It provides two functions: sub() and gsub(). The first one only replaces only the first occurrence, while the second — replaces occurrences in whole string. For instance, if we have string one potato two potato , this would be the result:
$ echo "one potato two potato" | awk '{gsub(/potato/,"banana")}1'
one banana two banana
$ echo "one potato two potato" | awk '{sub(/potato/,"banana")}1'
one banana two potato
AWK can take an input file as argument, so doing same things with input.txt , would be easy:
awk '{sub(/blue/,"azure")}1' input.txt
Depending on the version of AWK you have, it may or may not have in-place editing, hence the usual practice is save and replace new text. For instance something like this:
awk '{sub(/blue/,"azure")}1' input.txt > temp.txt && mv temp.txt input.txt
SED
Sed is a line editor. It also uses regular expressions, but for simple substitutions it’s sufficient to do:
sed 's/blue/azure/' input.txt
What’s good about this tool is that it has in-place editing, which you can enable with -i flag.
Perl
Perl is another tool which is often used for text processing, but it’s a general purpose language, and is used in networking, system administration, desktop apps, and many other places. It borrowed a lot of concepts/features from other languages such as C,sed,awk, and others. Simple substitution can be done as so:
perl -pe 's/blue/azure/' input.txt
Like sed, perl also has the -i flag.
Python
This language is very versatile and is also used in a wide variety of applications. It has a lot of functions for working with strings, among which is replace(), so if you have variable like var="Hello World" , you could do var.replace("Hello","Good Morning")
Simple way to read file and replace string in it would be as so:
python -c "import sys;lines=sys.stdin.read();print lines.replace('blue','azure')" < input.txt
With Python, however, you also need to output to new file , which you can also do from within the script itself. For instance, here’s a simple one:
#!/usr/bin/env python
import sys
import os
import tempfile
tmp=tempfile.mkstemp()
with open(sys.argv[1]) as fd1, open(tmp[1],'w') as fd2:
for line in fd1:
line = line.replace('blue','azure')
fd2.write(line)
os.rename(tmp[1],sys.argv[1])
This script is to be called with input.txt as command-line argument. The exact command to run python script with command-line argument would be
$ ./myscript.py input.txt
or
$ python ./myscript.py input.txt
Of course, make sure that ./myscript.py is in your current working directory and for the first way, ensure it is set executable with chmod +x ./myscript.py
Python can also have regular expressions , in particular, there’s re module, which has re.sub() function, which can be used for more advanced replacements.
1. Replacing all occurrences of one string with another in all files in the current directory:
These are for cases where you know that the directory contains only regular files and that you want to process all non-hidden files. If that is not the case, use the approaches in 2.
All sed solutions in this answer assume GNU sed. If using FreeBSD or macOS, replace -i with -i ''. Also note that the use of the -i switch with any version of sed has certain filesystem security implications and is inadvisable in any script which you plan to distribute in any way.
-
Non recursive, files in this directory only:
sed -i -- 's/foo/bar/g' * perl -i -pe 's/foo/bar/g' ./*
(the perl one will fail for file names ending in | or space)).
-
Recursive, regular files (including hidden ones) in this and all subdirectories
find . -type f -exec sed -i 's/foo/bar/g' {} +If you are using zsh:
sed -i -- 's/foo/bar/g' **/*(D.)(may fail if the list is too big, see
zargsto work around).Bash can’t check directly for regular files, a loop is needed (braces avoid setting the options globally):
( shopt -s globstar dotglob; for file in **; do if [[ -f $file ]] && [[ -w $file ]]; then sed -i -- 's/foo/bar/g' "$file" fi done )The files are selected when they are actual files (-f) and they are writable (-w).
2. Replace only if the file name matches another string / has a specific extension / is of a certain type etc:
-
Non-recursive, files in this directory only:
sed -i -- 's/foo/bar/g' *baz* ## all files whose name contains baz sed -i -- 's/foo/bar/g' *.baz ## files ending in .baz -
Recursive, regular files in this and all subdirectories
find . -type f -name "*baz*" -exec sed -i 's/foo/bar/g' {} +If you are using bash (braces avoid setting the options globally):
( shopt -s globstar dotglob sed -i -- 's/foo/bar/g' **baz* sed -i -- 's/foo/bar/g' **.baz )If you are using zsh:
sed -i -- 's/foo/bar/g' **/*baz*(D.) sed -i -- 's/foo/bar/g' **/*.baz(D.)
The -- serves to tell sed that no more flags will be given in the command line. This is useful to protect against file names starting with -.
-
If a file is of a certain type, for example, executable (see
man findfor more options):find . -type f -executable -exec sed -i 's/foo/bar/g' {} +
zsh:
sed -i -- 's/foo/bar/g' **/*(D*)
3. Replace only if the string is found in a certain context
-
Replace
foowithbaronly if there is abazlater on the same line:sed -i 's/foo(.*baz)/bar1/' file
In sed, using ( ) saves whatever is in the parentheses and you can then access it with 1. There are many variations of this theme, to learn more about such regular expressions, see here.
-
Replace
foowithbaronly iffoois found on the 3d column (field) of the input file (assuming whitespace-separated fields):gawk -i inplace '{gsub(/foo/,"baz",$3); print}' file
(needs gawk 4.1.0 or newer).
-
For a different field just use
$NwhereNis the number of the field of interest. For a different field separator (:in this example) use:gawk -i inplace -F':' '{gsub(/foo/,"baz",$3);print}' file
Another solution using perl:
perl -i -ane '$F[2]=~s/foo/baz/g; $" = " "; print "@Fn"' foo
NOTE: both the awk and perl solutions will affect spacing in the file (remove the leading and trailing blanks, and convert sequences of blanks to one space character in those lines that match). For a different field, use $F[N-1] where N is the field number you want and for a different field separator use (the $"=":" sets the output field separator to :):
perl -i -F':' -ane '$F[2]=~s/foo/baz/g; $"=":";print "@F"' foo
-
Replace
foowithbaronly on the 4th line:sed -i '4s/foo/bar/g' file gawk -i inplace 'NR==4{gsub(/foo/,"baz")};1' file perl -i -pe 's/foo/bar/g if $.==4' file
4. Multiple replace operations: replace with different strings
-
You can combine
sedcommands:sed -i 's/foo/bar/g; s/baz/zab/g; s/Alice/Joan/g' file
Be aware that order matters (sed 's/foo/bar/g; s/bar/baz/g' will substitute foo with baz).
-
or Perl commands
perl -i -pe 's/foo/bar/g; s/baz/zab/g; s/Alice/Joan/g' file -
If you have a large number of patterns, it is easier to save your patterns and their replacements in a
sedscript file:#! /usr/bin/sed -f s/foo/bar/g s/baz/zab/g -
Or, if you have too many pattern pairs for the above to be feasible, you can read pattern pairs from a file (two space separated patterns, $pattern and $replacement, per line):
while read -r pattern replacement; do sed -i "s/$pattern/$replacement/" file done < patterns.txt -
That will be quite slow for long lists of patterns and large data files so you might want to read the patterns and create a
sedscript from them instead. The following assumes a <<!>space<!>> delimiter separates a list of MATCH<<!>space<!>>REPLACE pairs occurring one-per-line in the filepatterns.txt:sed 's| *([^ ]*) *([^ ]*).*|s/1/2/g|' <patterns.txt | sed -f- ./editfile >outfile
The above format is largely arbitrary and, for example, doesn’t allow for a <<!>space<!>> in either of MATCH or REPLACE. The method is very general though: basically, if you can create an output stream which looks like a sed script, then you can source that stream as a sed script by specifying sed‘s script file as -stdin.
-
You can combine and concatenate multiple scripts in similar fashion:
SOME_PIPELINE | sed -e'#some expression script' -f./script_file -f- -e'#more inline expressions' ./actual_edit_file >./outfile
A POSIX sed will concatenate all scripts into one in the order they appear on the command-line. None of these need end in a newline.
-
grepcan work the same way:sed -e'#generate a pattern list' <in | grep -f- ./grepped_file -
When working with fixed-strings as patterns, it is good practice to escape regular expression metacharacters. You can do this rather easily:
sed 's/[]$&^*./[]/\&/g s| *([^ ]*) *([^ ]*).*|s/1/2/g| ' <patterns.txt | sed -f- ./editfile >outfile
5. Multiple replace operations: replace multiple patterns with the same string
-
Replace any of
foo,barorbazwithfoobarsed -Ei 's/foo|bar|baz/foobar/g' file -
or
perl -i -pe 's/foo|bar|baz/foobar/g' file
6. Replace File paths in multiple files
Another use case of using different delimiter:
sed -i 's|path/to/foo|path/to/bar|g' *
What’s the simplest way to do a find and replace for a given input string, say abc, and replace with another string, say XYZ in file /tmp/file.txt?
I am writting an app and using IronPython to execute commands through SSH — but I don’t know Unix that well and don’t know what to look for.
I have heard that Bash, apart from being a command line interface, can be a very powerful scripting language. So, if this is true, I assume you can perform actions like these.
Can I do it with bash, and what’s the simplest (one line) script to achieve my goal?
![]()
tripleee
172k32 gold badges264 silver badges311 bronze badges
asked Feb 8, 2009 at 11:57
![]()
The easiest way is to use sed (or perl):
sed -i -e 's/abc/XYZ/g' /tmp/file.txt
Which will invoke sed to do an in-place edit due to the -i option. This can be called from bash.
If you really really want to use just bash, then the following can work:
while IFS='' read -r a; do
echo "${a//abc/XYZ}"
done < /tmp/file.txt > /tmp/file.txt.t
mv /tmp/file.txt{.t,}
This loops over each line, doing a substitution, and writing to a temporary file (don’t want to clobber the input). The move at the end just moves temporary to the original name. (For robustness and security, the temporary file name should not be static or predictable, but let’s not go there.)
For Mac users:
sed -i '' 's/abc/XYZ/g' /tmp/file.txt
(See the comment below why)
![]()
answered Feb 8, 2009 at 12:20
![]()
johnnyjohnny
12.9k2 gold badges17 silver badges8 bronze badges
9
File manipulation isn’t normally done by Bash, but by programs invoked by Bash, e.g.:
perl -pi -e 's/abc/XYZ/g' /tmp/file.txt
The -i flag tells it to do an in-place replacement.
See man perlrun for more details, including how to take a backup of the original file.
![]()
John Kugelman
345k67 gold badges523 silver badges571 bronze badges
answered Feb 8, 2009 at 12:10
![]()
AlnitakAlnitak
333k70 gold badges404 silver badges492 bronze badges
3
I was surprised when I stumbled over this…
There is a replace command which ships with the "mysql-server" package, so if you have installed it try it out:
# replace string abc to XYZ in files
replace "abc" "XYZ" -- file.txt file2.txt file3.txt
# or pipe an echo to replace
echo "abcdef" |replace "abc" "XYZ"
See man replace for more on this.
![]()
the Tin Man
158k41 gold badges213 silver badges300 bronze badges
answered Apr 9, 2013 at 15:35
![]()
rayrorayro
8036 silver badges2 bronze badges
7
This is an old post but for anyone wanting to use variables as @centurian said the single quotes mean nothing will be expanded.
A simple way to get variables in is to do string concatenation since this is done by juxtaposition in bash the following should work:
sed -i -e "s/$var1/$var2/g" /tmp/file.txt
![]()
John Kugelman
345k67 gold badges523 silver badges571 bronze badges
answered Dec 7, 2015 at 12:48
![]()
zcourtszcourts
4,7536 gold badges47 silver badges74 bronze badges
2
Bash, like other shells, is just a tool for coordinating other commands. Typically you would try to use standard UNIX commands, but you can of course use Bash to invoke anything, including your own compiled programs, other shell scripts, Python and Perl scripts etc.
In this case, there are a couple of ways to do it.
If you want to read a file, and write it to another file, doing search/replace as you go, use sed:
sed 's/abc/XYZ/g' <infile >outfile
If you want to edit the file in place (as if opening the file in an editor, editing it, then saving it) supply instructions to the line editor ‘ex’
echo "%s/abc/XYZ/g
w
q
" | ex file
Example is like vi without the fullscreen mode. You can give it the same commands you would at vi‘s : prompt.
![]()
P i
28.4k36 gold badges155 silver badges256 bronze badges
answered Feb 8, 2009 at 12:13
![]()
slimslim
39.7k12 gold badges94 silver badges126 bronze badges
4
I found this thread among others and I agree it contains the most complete answers so I’m adding mine too:
-
sedandedare so useful…by hand.
Look at this code from @Johnny:sed -i -e 's/abc/XYZ/g' /tmp/file.txt -
When my restriction is to use it in a shell script, no variable can be used inside in place of «abc» or «XYZ». The BashFAQ seems to agree with what I understand at least. So, I can’t use:
x='abc' y='XYZ' sed -i -e 's/$x/$y/g' /tmp/file.txt #or, sed -i -e "s/$x/$y/g" /tmp/file.txtbut, what can we do? As, @Johnny said use a
while read...but, unfortunately that’s not the end of the story. The following worked well with me:#edit user's virtual domain result= #if nullglob is set then, unset it temporarily is_nullglob=$( shopt -s | egrep -i '*nullglob' ) if [[ is_nullglob ]]; then shopt -u nullglob fi while IFS= read -r line; do line="${line//'<servername>'/$server}" line="${line//'<serveralias>'/$alias}" line="${line//'<user>'/$user}" line="${line//'<group>'/$group}" result="$result""$line"'n' done < $tmp echo -e $result > $tmp #if nullglob was set then, re-enable it if [[ is_nullglob ]]; then shopt -s nullglob fi #move user's virtual domain to Apache 2 domain directory ...... -
As one can see if
nullglobis set then, it behaves strangely when there is a string containing a*as in:<VirtualHost *:80> ServerName www.example.comwhich becomes
<VirtualHost ServerName www.example.comthere is no ending angle bracket and Apache2 can’t even load.
-
This kind of parsing should be slower than one-hit search and replace but, as you already saw, there are four variables for four different search patterns working out of one parse cycle.
The most suitable solution I can think of with the given assumptions of the problem.
![]()
the Tin Man
158k41 gold badges213 silver badges300 bronze badges
answered Feb 7, 2013 at 14:48
![]()
centuriancenturian
1,23013 silver badges24 bronze badges
1
You can use sed:
sed -i 's/abc/XYZ/gi' /tmp/file.txt
You can use find and sed if you don’t know your filename:
find ./ -type f -exec sed -i 's/abc/XYZ/gi' {} ;
Find and replace in all Python files:
find ./ -iname "*.py" -type f -exec sed -i 's/abc/XYZ/gi' {} ;
answered Jan 14, 2017 at 9:45
![]()
MadvinMadvin
7489 silver badges14 bronze badges
1
If the file you are working on is not so big, and temporarily storing it in a variable is no problem, then you can use Bash string substitution on the whole file at once — there’s no need to go over it line by line:
file_contents=$(</tmp/file.txt)
echo "${file_contents//abc/XYZ}" > /tmp/file.txt
The whole file contents will be treated as one long string, including linebreaks.
XYZ can be a variable eg $replacement, and one advantage of not using sed here is that you need not be concerned that the search or replace string might contain the sed pattern delimiter character (usually, but not necessarily, /). A disadvantage is not being able to use regular expressions or any of sed’s more sophisticated operations.
answered Apr 15, 2017 at 2:09
![]()
johnraffjohnraff
3172 silver badges5 bronze badges
2
You may also use the ed command to do in-file search and replace:
# delete all lines matching foobar
ed -s test.txt <<< $'g/foobar/dnw'
See more in «Editing files via scripts with ed«.
![]()
the Tin Man
158k41 gold badges213 silver badges300 bronze badges
answered Jun 14, 2009 at 16:37
1
To edit text in the file non-interactively, you need in-place text editor such as vim.
Here is simple example how to use it from the command line:
vim -esnc '%s/foo/bar/g|:wq' file.txt
This is equivalent to @slim answer of ex editor which is basically the same thing.
Here are few ex practical examples.
Replacing text foo with bar in the file:
ex -s +%s/foo/bar/ge -cwq file.txt
Removing trailing whitespaces for multiple files:
ex +'bufdo!%s/s+$//e' -cxa *.txt
Troubleshooting (when terminal is stuck):
- Add
-V1param to show verbose messages. - Force quit by:
-cwq!.
See also:
- How to edit files non-interactively (e.g. in pipeline)? at Vi SE
answered May 11, 2015 at 20:21
![]()
kenorbkenorb
152k85 gold badges671 silver badges732 bronze badges
2
Try the following shell command:
find ./ -type f -name "file*.txt" | xargs sed -i -e 's/abc/xyz/g'
![]()
kenorb
152k85 gold badges671 silver badges732 bronze badges
answered May 31, 2016 at 23:55
![]()
J AjayJ Ajay
3193 silver badges3 bronze badges
2
You can use python within the bash script too. I didn’t have much success with some of the top answers here, and found this to work without the need for loops:
#!/bin/bash
python
filetosearch = '/home/ubuntu/ip_table.txt'
texttoreplace = 'tcp443'
texttoinsert = 'udp1194'
s = open(filetosearch).read()
s = s.replace(texttoreplace, texttoinsert)
f = open(filetosearch, 'w')
f.write(s)
f.close()
quit()
answered May 3, 2016 at 18:44
![]()
Simplest way to replace multiple text in a file using sed command
Command —
sed -i ‘s#a/b/c#D/E#g;s#/x/y/z#D:/X#g;’ filename
In the above command s#a/b/c#D/E#g where I am replacing a/b/c with D/E and then after the ; we again doing the same thing
answered Jul 1, 2021 at 4:17
![]()
You can use rpl command. For example you want to change domain name in whole php project.
rpl -ivRpd -x'.php' 'old.domain.name' 'new.domain.name' ./path_to_your_project_folder/
This is not clear bash of cause, but it’s a very quick and usefull. 
answered Feb 12, 2015 at 8:34
![]()
zalexzalex
7096 silver badges14 bronze badges
For MAC users in case you don’t read the comments
As mentioned by @Austin, if you get the Invalid command code error
For the in-place replacements BSD sed requires a file extension after the -i flag to save to a backup file with given extension.
sed -i '.bak' 's/find/replace' /file.txt
You can use '' empty string if you want to skip backup.
sed -i '' 's/find/replace' /file.txt
All merit to @Austin
answered Nov 25, 2021 at 20:11
![]()
SzekelygobeSzekelygobe
2,1991 gold badge22 silver badges24 bronze badges
Open file using vim editor. In command mode
:%s/abc/xyz/g
This is the simplest
answered Dec 6, 2022 at 21:36
![]()
flash flash
8910 bronze badges
In case of doing changes in multiple files together we can do in a single line as:-
user_name='whoami'
for file in file1.txt file2.txt file3.txt; do sed -i -e 's/default_user/${user_name}/g' $file; done
Added if in case could be useful.
answered Feb 2, 2022 at 14:13
![]()
If you manage to take a deeper glimpse inside the ecosystem of the Linux operating system environment, you will discover that its built-in commands are sufficient enough to solve most of our computing problems.
One such problem is the need to find and replace text, word, or string in a file especially when you are in a server environment. A solution to this problem lets you handle nagging issues like updating the “/etc/apt/sources.list” file after a successful Linux system upgrade.
Creating the Test Text File in Linux
Create a text file with a name like “test.txt” and populate it with some text, word, or string characters. Let this file be on the same path as your terminal instance.
$ nano test.txt OR $ vi test.txt
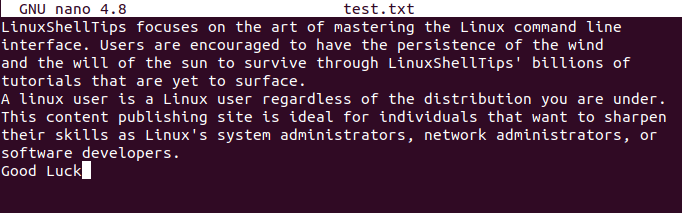
We will be using the cat command to flexible note the changes on our created test file.
$ cat test.txt
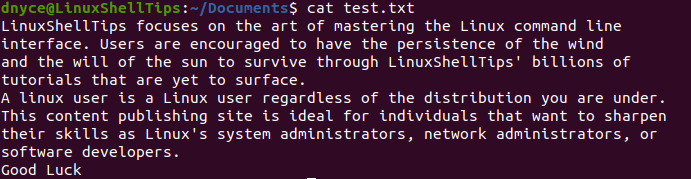
Using Sed to Find and Replace Text, Word, or String in a File
The power of this stream editor is in its easiness in accomplishing basic input streams transformation. The sed command offers a quick, easy, and timeless approach in finding and replacing targeted text, words, or string patterns in a file.
Find and Replace the First Occurrences of Text, Word, or String in File
From our created test file, we are going to update all the instances of the word “LinuxShellTips” with the alternative “this site”. The syntax of the sed command we will be using to accomplish this simple task is as follows:
$ sed -i 's/[THE_OLD_TERM]/[THE_NEW_TERM]/' [TARGETED_FILE]
With reference to the above sed command usage and syntax, we can replace our test file’s “LinuxShellTips” term with “this site” term as follows:
$ sed -i 's/LinuxShellTips/this site/' test.txt
We can now use the cat command to preview the above-proposed changes to our test file to note if any substantial edits took place.
$ cat test.txt
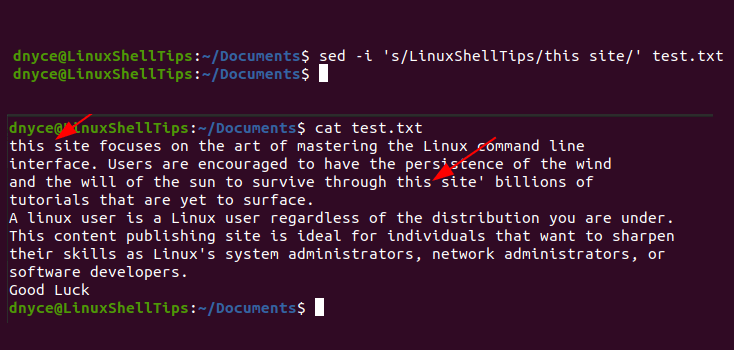
As you can see, the first two occurrences of the word “LinuxShellTips” have been replaced with the phrase “this site”.
Find and Replace All Occurrences of Text, Word, or String in File
Despite the above command having replaced all the targeted word patterns in our test file, its usage tends to be selective in most circumstances. The command works best for small files because, in big files, only the first few occurrences of a targeted word pattern might benefit from its ‘find and replace’ prowess.
To find and replace all occurrences of a word pattern in any editable file, you should adhere to the following sed command syntax.
$ sed -i 's/[THE_OLD_TERM]/[THE_NEW_TERM]/g' [TARGETED_FILE]
As you have noted, the 'g' in the above find & replace command syntax acts as a global variable so that all the global occurrences of a term in a targeted file are considered.
$ sed -i 's/this site/LinuxShellTips/g' test.txt
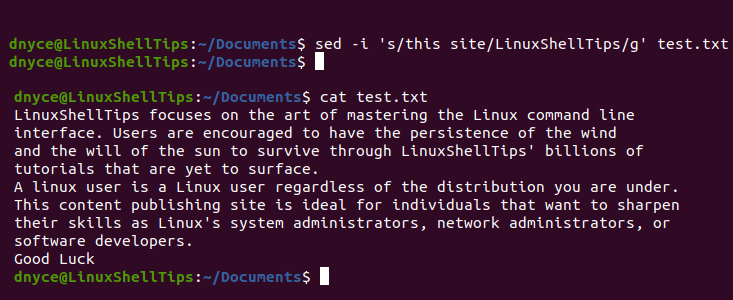
The above command finds all the global occurrences of the term “this site” and replaces it with the term “LinuxShellTips”.
Using Awk to Find and Replace Text, Word, or String in File
If you are familiar with the awk command-line utility, then you know that its powerful scripting language metrics make it a pro at text processing. Linux system administrators and professional users find this tool effective in data extraction and reporting.
The awk command syntax for a simple find-and-replace operation looks like the following snippet:
$ awk '{gsub("[THE_OLD_TERM]","[THE_NEW_TERM]"); print}' [TARGETED_FILE]
In the above syntax, awk will substitute THE_OLD_TERM from THE_NEW_TERM in the TARGETED_FILE and print the resulting file content on the system terminal.
Let us take a practical approach:
$ awk '{gsub("Linux","ubuntu"); print}' test.txt
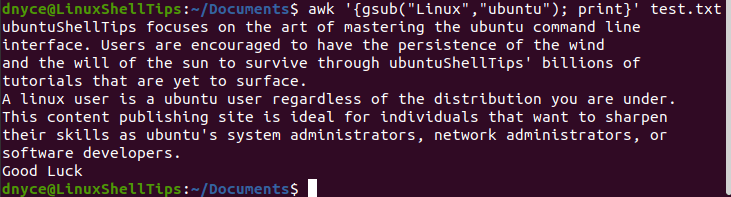
With the dynamic functionalities of both sed and awk command tools, you should now find, replace, and overwrite text, word, or string patterns in a targeted file. These tools give a system user the needed flexibility while on a command-line interface.
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
SED command in UNIX stands for stream editor and it can perform lots of functions on file like searching, find and replace, insertion or deletion. Though most common use of SED command in UNIX is for substitution or for find and replace. By using SED you can edit files even without opening them, which is much quicker way to find and replace something in file, than first opening that file in VI Editor and then changing it.
- SED is a powerful text stream editor. Can do insertion, deletion, search and replace(substitution).
- SED command in unix supports regular expression which allows it perform complex pattern matching.
Syntax:
sed OPTIONS... [SCRIPT] [INPUTFILE...]
Example:
Consider the below text file as an input.
$cat > geekfile.txt
unix is great os. unix is opensource. unix is free os. learn operating system. unix linux which one you choose. unix is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful.
Sample Commands
- Replacing or substituting string : Sed command is mostly used to replace the text in a file. The below simple sed command replaces the word “unix” with “linux” in the file.
$sed 's/unix/linux/' geekfile.txt
Output :
linux is great os. unix is opensource. unix is free os. learn operating system. linux linux which one you choose. linux is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful.
Here the “s” specifies the substitution operation. The “/” are delimiters. The “unix” is the search pattern and the “linux” is the replacement string.
By default, the sed command replaces the first occurrence of the pattern in each line and it won’t replace the second, third…occurrence in the line.
- Replacing the nth occurrence of a pattern in a line : Use the /1, /2 etc flags to replace the first, second occurrence of a pattern in a line. The below command replaces the second occurrence of the word “unix” with “linux” in a line.
$sed 's/unix/linux/2' geekfile.txt
Output:
unix is great os. linux is opensource. unix is free os. learn operating system. unix linux which one you choose. unix is easy to learn.linux is a multiuser os.Learn unix .unix is a powerful.
- Replacing all the occurrence of the pattern in a line : The substitute flag /g (global replacement) specifies the sed command to replace all the occurrences of the string in the line.
$sed 's/unix/linux/g' geekfile.txt
Output :
linux is great os. linux is opensource. linux is free os. learn operating system. linux linux which one you choose. linux is easy to learn.linux is a multiuser os.Learn linux .linux is a powerful.
- Replacing from nth occurrence to all occurrences in a line : Use the combination of /1, /2 etc and /g to replace all the patterns from the nth occurrence of a pattern in a line. The following sed command replaces the third, fourth, fifth… “unix” word with “linux” word in a line.
$sed 's/unix/linux/3g' geekfile.txt
Output:
unix is great os. unix is opensource. linux is free os. learn operating system. unix linux which one you choose. unix is easy to learn.unix is a multiuser os.Learn linux .linux is a powerful.
- Parenthesize first character of each word : This sed example prints the first character of every word in parenthesis.
$ echo "Welcome To The Geek Stuff" | sed 's/(b[A-Z])/(1)/g'
Output:
(W)elcome (T)o (T)he (G)eek (S)tuff
- Replacing string on a specific line number : You can restrict the sed command to replace the string on a specific line number. An example is
$sed '3 s/unix/linux/' geekfile.txt
Output:
unix is great os. unix is opensource. unix is free os. learn operating system. linux linux which one you choose. unix is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful.
The above sed command replaces the string only on the third line.
- Duplicating the replaced line with /p flag : The /p print flag prints the replaced line twice on the terminal. If a line does not have the search pattern and is not replaced, then the /p prints that line only once.
$sed 's/unix/linux/p' geekfile.txt
Output:
linux is great os. unix is opensource. unix is free os. linux is great os. unix is opensource. unix is free os. learn operating system. linux linux which one you choose. linux linux which one you choose. linux is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful. linux is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful.
- Printing only the replaced lines : Use the -n option along with the /p print flag to display only the replaced lines. Here the -n option suppresses the duplicate rows generated by the /p flag and prints the replaced lines only one time.
$sed -n 's/unix/linux/p' geekfile.txt
Output:
linux is great os. unix is opensource. unix is free os. linux linux which one you choose. linux is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful.
If you use -n alone without /p, then the sed does not print anything.
- Replacing string on a range of lines : You can specify a range of line numbers to the sed command for replacing a string.
$sed '1,3 s/unix/linux/' geekfile.txt
Output:
linux is great os. unix is opensource. unix is free os. learn operating system. linux linux which one you choose. unix is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful.
Here the sed command replaces the lines with range from 1 to 3. Another example is
$sed '2,$ s/unix/linux/' geekfile.txt
Output:
unix is great os. unix is opensource. unix is free os. learn operating system. linux linux which one you choose. linux is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful
Here $ indicates the last line in the file. So the sed command replaces the text from second line to last line in the file.
- Deleting lines from a particular file : SED command can also be used for deleting lines from a particular file. SED command is used for performing deletion operation without even opening the file
Examples:
1. To Delete a particular line say n in this exampleSyntax: $ sed 'nd' filename.txt Example: $ sed '5d' filename.txt
2. To Delete a last line
Syntax: $ sed '$d' filename.txt
3. To Delete line from range x to y
Syntax: $ sed 'x,yd' filename.txt Example: $ sed '3,6d' filename.txt
4. To Delete from nth to last line
Syntax: $ sed 'nth,$d' filename.txt Example: $ sed '12,$d' filename.txt
5. To Delete pattern matching line
Syntax: $ sed '/pattern/d' filename.txt Example: $ sed '/abc/d' filename.txt
SED command in Linux | Set 2
This article is contributed by Akshay Rajput and Mohak Agrawal. If you like GeeksforGeeks and would like to contribute, you can also write an article using write.geeksforgeeks.org or mail your article to review-team@geeksforgeeks.org. See your article appearing on the GeeksforGeeks main page and help other Geeks.
Please write comments if you find anything incorrect, or you want to share more information about the topic discussed above.
Like Article
Save Article