
From Wikipedia, the free encyclopedia
Line breaking, also known as word wrapping, is breaking a section of text into lines so that it will fit into the available width of a page, window or other display area. In text display, line wrap is continuing on a new line when a line is full, so that each line fits into the viewable window, allowing text to be read from top to bottom without any horizontal scrolling. Word wrap is the additional feature of most text editors, word processors, and web browsers, of breaking lines between words rather than within words, where possible. Word wrap makes it unnecessary to hard-code newline delimiters within paragraphs, and allows the display of text to adapt flexibly and dynamically to displays of varying sizes.
Soft and hard returns[edit]
A soft return or soft wrap is the break resulting from line wrap or word wrap (whether automatic or manual), whereas a hard return or hard wrap is an intentional break, creating a new paragraph. With a hard return, paragraph-break formatting can (and should) be applied (either indenting or vertical whitespace). Soft wrapping allows line lengths to adjust automatically with adjustments to the width of the user’s window or margin settings, and is a standard feature of all modern text editors, word processors, and email clients. Manual soft breaks are unnecessary when word wrap is done automatically, so hitting the «Enter» key usually produces a hard return.
Alternatively, «soft return» can mean an intentional, stored line break that is not a paragraph break. For example, it is common to print postal addresses in a multiple-line format, but the several lines are understood to be a single paragraph. Line breaks are needed to divide the words of the address into lines of the appropriate length.
In the contemporary graphical word processors Microsoft Word and OpenOffice.org, users are expected to type a carriage return (↵ Enter) between each paragraph. Formatting settings, such as first-line indentation or spacing between paragraphs, take effect where the carriage return marks the break. A non-paragraph line break, which is a soft return, is inserted using ⇧ Shift+↵ Enter or via the menus, and is provided for cases when the text should start on a new line but none of the other side effects of starting a new paragraph are desired.
In text-oriented markup languages, a soft return is typically offered as a markup tag. For example, in HTML there is a <br> tag that has the same purpose as the soft return in word processors described above.
Unicode[edit]
The Unicode Line Breaking Algorithm determines a set of positions, known as break opportunities, that are appropriate places in which to begin a new line. The actual line break positions are picked from among the break opportunities by the higher level software that calls the algorithm, not by the algorithm itself, because only the higher level software knows about the width of the display the text is displayed on and the width of the glyphs that make up the displayed text.[1]
The Unicode character set provides a line separator character as well as a paragraph separator to represent the semantics of the soft return and hard return.
- 0x2028 LINE SEPARATOR
- * may be used to represent this semantic unambiguously
- 0x2029 PARAGRAPH SEPARATOR
- * may be used to represent this semantic unambiguously
Word boundaries, hyphenation, and hard spaces[edit]
The soft returns are usually placed after the ends of complete words, or after the punctuation that follows complete words. However, word wrap may also occur following a hyphen inside of a word. This is sometimes not desired, and can be blocked by using a non-breaking hyphen, or hard hyphen, instead of a regular hyphen.
A word without hyphens can be made wrappable by having soft hyphens in it. When the word isn’t wrapped (i.e., isn’t broken across lines), the soft hyphen isn’t visible. But if the word is wrapped across lines, this is done at the soft hyphen, at which point it is shown as a visible hyphen on the top line where the word is broken. (In the rare case of a word that is meant to be wrappable by breaking it across lines but without making a hyphen ever appear, a zero-width space is put at the permitted breaking point(s) in the word.)
Sometimes word wrap is undesirable between adjacent words. In such cases, word wrap can usually be blocked by using a hard space or non-breaking space between the words, instead of regular spaces.
Word wrapping in text containing Chinese, Japanese, and Korean[edit]
In Chinese, Japanese, and Korean, word wrapping can usually occur before and after any Han character, but certain punctuation characters are not allowed to begin a new line.[2] Japanese kana, letters of the Japanese alphabet, are treated the same way as Han Characters (Kanji) by extension, meaning words can, and tend to be broken without any hyphen or other indication that this has happened.
Under certain circumstances, however, word wrapping is not desired. For instance,
- word wrapping might not be desired within personal names, and
- word wrapping might not be desired within any compound words (when the text is flush left but only in some styles).
Most existing word processors and typesetting software cannot handle either of the above scenarios.
CJK punctuation may or may not follow rules similar to the above-mentioned special circumstances. It is up to line breaking rules in CJK.
A special case of line breaking rules in CJK, however, always applies: line wrap must never occur inside the CJK dash and ellipsis. Even though each of these punctuation marks must be represented by two characters due to a limitation of all existing character encodings, each of these are intrinsically a single punctuation mark that is two ems wide, not two one-em-wide punctuation marks.
Algorithm[edit]
Word wrapping is an optimization problem. Depending on what needs to be optimized for, different algorithms are used.
Minimum number of lines[edit]
A simple way to do word wrapping is to use a greedy algorithm that puts as many words on a line as possible, then moving on to the next line to do the same until there are no more words left to place. This method is used by many modern word processors, such as OpenOffice.org Writer and Microsoft Word.[citation needed] This algorithm always uses the minimum possible number of lines but may lead to lines of widely varying lengths. The following pseudocode implements this algorithm:
SpaceLeft := LineWidth
for each Word in Text
if (Width(Word) + SpaceWidth) > SpaceLeft
insert line break before Word in Text
SpaceLeft := LineWidth - Width(Word)
else
SpaceLeft := SpaceLeft - (Width(Word) + SpaceWidth)
Where LineWidth is the width of a line, SpaceLeft is the remaining width of space on the line to fill, SpaceWidth is the width of a single space character, Text is the input text to iterate over and Word is a word in this text.
Minimum raggedness[edit]
A different algorithm, used in TeX, minimizes the sum of the squares of the lengths of the spaces at the end of lines to produce a more aesthetically pleasing result. The following example compares this method with the greedy algorithm, which does not always minimize squared space.
For the input text
AAA BB CC DDDDD
with line width 6, the greedy algorithm would produce:
------ Line width: 6 AAA BB Remaining space: 0 CC Remaining space: 4 DDDDD Remaining space: 1
The sum of squared space left over by this method is  . However, the optimal solution achieves the smaller sum
. However, the optimal solution achieves the smaller sum  :
:
------ Line width: 6 AAA Remaining space: 3 BB CC Remaining space: 1 DDDDD Remaining space: 1
The difference here is that the first line is broken before BB instead of after it, yielding a better right margin and a lower cost 11.
By using a dynamic programming algorithm to choose the positions at which to break the line, instead of choosing breaks greedily, the solution with minimum raggedness may be found in time  , where
, where  is the number of words in the input text. Typically, the cost function for this technique should be modified so that it does not count the space left on the final line of a paragraph; this modification allows a paragraph to end in the middle of a line without penalty. It is also possible to apply the same dynamic programming technique to minimize more complex cost functions that combine other factors such as the number of lines or costs for hyphenating long words.[3] Faster but more complicated linear time algorithms based on the SMAWK algorithm are also known for the minimum raggedness problem, and for some other cost functions that have similar properties.[4][5]
is the number of words in the input text. Typically, the cost function for this technique should be modified so that it does not count the space left on the final line of a paragraph; this modification allows a paragraph to end in the middle of a line without penalty. It is also possible to apply the same dynamic programming technique to minimize more complex cost functions that combine other factors such as the number of lines or costs for hyphenating long words.[3] Faster but more complicated linear time algorithms based on the SMAWK algorithm are also known for the minimum raggedness problem, and for some other cost functions that have similar properties.[4][5]
History[edit]
A primitive line-breaking feature was used in 1955 in a «page printer control unit» developed by Western Union. This system used relays rather than programmable digital computers, and therefore needed a simple algorithm that could be implemented without data buffers. In the Western Union system, each line was broken at the first space character to appear after the 58th character, or at the 70th character if no space character was found.[6]
The greedy algorithm for line-breaking predates the dynamic programming method outlined by Donald Knuth in an unpublished 1977 memo describing his TeX typesetting system[7] and later published in more detail by Knuth & Plass (1981).
See also[edit]
- Non-breaking space
- Typographic alignment
- Zero-width space
- Word divider
- Word joiner
References[edit]
- ^ Heninger, Andy, ed. (2013-01-25). «Unicode Line Breaking Algorithm» (PDF). Technical Reports. Annex #14 (Proposed Update Unicode Standard): 2. Retrieved 10 March 2015.
WORD JOINER should be used if the intent is to merely prevent a line break
- ^ Lunde, Ken (1999), CJKV Information Processing: Chinese, Japanese, Korean & Vietnamese Computing, O’Reilly Media, Inc., p. 352, ISBN 9781565922242.
- ^ Knuth, Donald E.; Plass, Michael F. (1981), «Breaking paragraphs into lines», Software: Practice and Experience, 11 (11): 1119–1184, doi:10.1002/spe.4380111102, S2CID 206508107.
- ^ Wilber, Robert (1988), «The concave least-weight subsequence problem revisited», Journal of Algorithms, 9 (3): 418–425, doi:10.1016/0196-6774(88)90032-6, MR 0955150.
- ^ Galil, Zvi; Park, Kunsoo (1990), «A linear-time algorithm for concave one-dimensional dynamic programming», Information Processing Letters, 33 (6): 309–311, doi:10.1016/0020-0190(90)90215-J, MR 1045521.
- ^ Harris, Robert W. (January 1956), «Keyboard standardization», Western Union Technical Review, 10 (1): 37–42.
- ^ Knuth, Donald (1977), TEXDR.AFT, retrieved 2013-04-07. Reprinted in Knuth, Donald (1999), Digital Typography, CSLI Lecture Notes, vol. 78, Stanford, California: Center for the Study of Language and Information, ISBN 1-57586-010-4.
External links[edit]
- Unicode Line Breaking Algorithm
Knuth’s algorithm[edit]
- «Knuth & Plass line-breaking Revisited»
- «tex_wrap»: «Implements TeX’s algorithm for breaking paragraphs into lines.» Reference: «Breaking Paragraphs into Lines», D.E. Knuth and M.F. Plass, chapter 3 of _Digital Typography_, CSLI Lecture Notes #78.
- Text::Reflow — Perl module for reflowing text files using Knuth’s paragraphing algorithm. «The reflow algorithm tries to keep the lines the same length but also tries to break at punctuation, and avoid breaking within a proper name or after certain connectives («a», «the», etc.). The result is a file with a more «ragged» right margin than is produced by fmt or Text::Wrap but it is easier to read since fewer phrases are broken across line breaks.»
- adjusting the Knuth algorithm to recognize the «soft hyphen».
- Knuth’s breaking algorithm. «The detailed description of the model and the algorithm can be found on the paper «Breaking Paragraphs into Lines» by Donald E. Knuth, published in the book «Digital Typography» (Stanford, California: Center for the Study of Language and Information, 1999), (CSLI Lecture Notes, no. 78.)»; part of Google Summer Of Code 2006
- «Bridging the Algorithm Gap: A Linear-time Functional Program for Paragraph Formatting» by Oege de Moor, Jeremy Gibbons, 1997
Other word-wrap links[edit]
- the reverse problem — picking columns just wide enough to fit (wrapped) text (Archived version)
- «Knuth linebreaking elements for Formatting Objects» by Simon Pepping 2006. Extends the Knuth model to handle a few enhancements.
- «a Knuth-Plass-like linebreaking algorithm … The *really* interesting thing is how Adobe’s algorithm differs from the Knuth-Plass algorithm. It must differ, since Adobe has managed to patent its algorithm (6,510,441).»[1]
- «Line breaking» compares the algorithms of various time complexities.
Разрыв строки , также известный как перенос слов , разбивает часть текста на строки таким образом, чтобы он соответствовал доступной ширине страницы, окна или другой области отображения. При отображении текста перенос строки продолжается на новую строку, когда строка заполнена, так что каждая строка помещается в видимое окно, позволяя читать текст сверху вниз без какой-либо горизонтальной прокрутки . Перенос слов — это дополнительная функция большинства текстовых редакторов , текстовых процессоров и веб-браузеров , позволяющая переносить строки между словами, а не внутри слов, где это возможно. Перенос слов избавляет от необходимости жестко запрограммировать разделители новой строки внутри абзацев и позволяет гибко и динамически адаптировать отображение текста к дисплеям различных размеров.
Мягкая и жесткая отдача
Мягкий возврат или мягкий перенос — это разрыв, возникающий в результате переноса строки или слова (автоматического или ручного), тогда как жесткий возврат или жесткий перенос — это преднамеренный разрыв, создающий новый абзац. При жестком возврате можно (и нужно) применять форматирование разрыва абзаца (либо отступ, либо вертикальный пробел). Мягкое обертывание позволяет автоматически регулировать длину строки с корректировкой ширины окна пользователя или параметров полей и является стандартной функцией всех современных текстовых редакторов, текстовых процессоров и почтовых клиентов . Ручные мягкие разрывы не нужны, когда перенос слов выполняется автоматически, поэтому нажатие клавиши «Enter» обычно приводит к жесткому возврату.
В качестве альтернативы «мягкий возврат» может означать преднамеренный сохраненный разрыв строки, который не является разрывом абзаца. Например, почтовые адреса обычно печатаются в многострочном формате, но несколько строк понимаются как один абзац. Разрывы строк нужны для разделения слов адреса на строки соответствующей длины.
В современных графических текстовых процессорах Microsoft Word и OpenOffice.org ожидается, что пользователи будут вводить символ возврата каретки ( ) между каждым абзацем. Параметры форматирования, такие как отступ первой строки или интервал между абзацами, вступают в силу там, где символ возврата каретки отмечает разрыв. Разрыв строки без абзаца, который является мягким возвратом, вставляется с помощью + или через меню и предоставляется для случаев, когда текст должен начинаться с новой строки, но никакие другие побочные эффекты начала нового абзаца нежелательны. .
↵ Enter⇧ Shift↵ Enter
В текстовых языках разметки мягкий возврат обычно предлагается в виде тега разметки. Например, в HTML есть тег <br>, который имеет ту же цель, что и мягкий возврат в текстовых процессорах, описанных выше.
Юникод
Unicode Line Ломать Алгоритм определяет набор позиций, известные как возможности разрыва , которые являются соответствующими местами , в которых , чтобы начать новую строку. Фактические позиции разрыва строки выбираются из числа возможных разрывов программным обеспечением более высокого уровня, которое вызывает алгоритм, а не самим алгоритмом, потому что только программное обеспечение более высокого уровня знает о ширине дисплея, на котором отображается текст, и ширине глифы, составляющие отображаемый текст.
Набор символов Unicode предоставляет символ разделителя строк, а также разделитель абзацев для представления семантики мягкого и жесткого возврата.
- 0x2028 СЕПАРАТОР ЛИНИИ
- * может использоваться для однозначного представления этой семантики
- 0x2029 РАЗДЕЛИТЕЛЬ ПАРАМЕТРОВ
- * может использоваться для однозначного представления этой семантики
Границы слов, расстановка переносов и пробелы
Мягкие возвраты обычно помещаются после концов полных слов или после знаков препинания, следующих за полными словами. Однако перенос слов может происходить и после дефиса внутри слова. Иногда это нежелательно и может быть заблокировано с помощью неразрывного или жесткого дефиса вместо обычного дефиса.
Слово без дефисов можно сделать переносимым, добавив в него мягкие дефисы . Когда слово не переносится (т. Е. Не разрывается на строки), мягкий перенос не виден. Но если слово переносится по строкам, это делается по мягкому дефису, после чего оно отображается как видимый дефис в верхней строке, где слово разорвано. (В редких случаях, когда слово предназначено для переноса путем разбиения его на строки, но без дефиса, пробел нулевой ширины помещается в разрешенную точку (точки) разрыва в слове.)
Иногда перенос слов между соседними словами нежелателен. В таких случаях перенос слов обычно можно заблокировать с помощью жесткого или неразрывного пробела между словами вместо обычных пробелов.
Перенос слов в тексте на китайском, японском и корейском языках
В китайском , японском и корейском языках перенос слов обычно может происходить до и после любого символа хань , но некоторые символы пунктуации не могут начинать новую строку. Японская кана , буквы японского алфавита, обрабатываются так же, как и символы хань ( кандзи ) по расширению, что означает, что слова могут быть разбиты без дефиса или других указаний на то, что это произошло.
Однако при определенных обстоятельствах перенос слов нежелателен. Например,
- перенос слов может быть нежелательным в личных именах, и
- Перенос слов может быть нежелательным в составных словах (когда текст выровнен по левому краю, но только в некоторых стилях).
Большинство существующих текстовых процессоров и программного обеспечения для набора текста не могут справиться ни с одним из вышеперечисленных сценариев.
Пунктуация CJK может соответствовать или не соответствовать правилам, аналогичным вышеупомянутым особым обстоятельствам. Это до правил разрыва строки в CJK .
Однако всегда применяется особый случай правил разрыва строки в CJK: перенос строки никогда не должен происходить внутри тире и многоточия CJK. Даже если каждый из этих знаков препинания должен быть представлен двумя символами из — за ограничения всех существующих кодировок , каждый из них по своей сути один знак препинания , который два Эмс в ширину, а не два один-эм-широкие знаки препинания.
Алгоритм
Перенос слов — это проблема оптимизации . В зависимости от того, для чего нужно оптимизировать, используются разные алгоритмы.
Минимальное количество строк
Простой способ выполнить перенос слов — использовать жадный алгоритм, который помещает как можно больше слов в строку, а затем переходит к следующей строке, чтобы сделать то же самое, пока не останется больше слов для размещения. Этот метод используется многими современными текстовыми редакторами, такими как OpenOffice.org Writer и Microsoft Word. Этот алгоритм всегда использует минимально возможное количество строк, но может привести к строкам самой разной длины. Следующий псевдокод реализует этот алгоритм:
SpaceLeft := LineWidth
for each Word in Text
if (Width(Word) + SpaceWidth) > SpaceLeft
insert line break before Word in Text
SpaceLeft := LineWidth - Width(Word)
else
SpaceLeft := SpaceLeft - (Width(Word) + SpaceWidth)
Где LineWidth— ширина строки, SpaceLeft— это оставшаяся ширина пространства в строке, которую нужно заполнить, SpaceWidth— это ширина одного символа пробела, Text— это входной текст, который нужно перебрать, и Wordэто слово в этом тексте.
Минимальная шероховатость
Другой алгоритм, используемый в TeX , минимизирует сумму квадратов длин промежутков в конце строк, чтобы получить более эстетичный результат. В следующем примере этот метод сравнивается с жадным алгоритмом, который не всегда минимизирует квадратное пространство.
Для вводимого текста
AAA BB CC DDDDD
с шириной линии 6 жадный алгоритм выдаст:
------ Line width: 6 AAA BB Remaining space: 0 CC Remaining space: 4 DDDDD Remaining space: 1
Сумма квадрата пространства, оставшегося при использовании этого метода, равна . Однако оптимальное решение дает меньшую сумму :
------ Line width: 6 AAA Remaining space: 3 BB CC Remaining space: 1 DDDDD Remaining space: 1
Разница здесь в том, что первая строка прерывается до, BBа не после нее, что дает лучшее правое поле и более низкую стоимость 11.
Используя алгоритм динамического программирования для выбора позиций, в которых следует разорвать строку, вместо того, чтобы жадно выбирать разрывы, решение с минимальной шероховатостью может быть найдено вовремя , где — количество слов во входном тексте. Как правило, функция стоимости для этого метода должна быть изменена так, чтобы она не учитывала пространство, оставшееся в последней строке абзаца; эта модификация позволяет абзацу заканчиваться в середине строки без штрафных санкций. Также можно применить тот же метод динамического программирования, чтобы минимизировать более сложные функции затрат, которые сочетают в себе другие факторы, такие как количество строк или затраты на расстановку переносов длинных слов. Более быстрые, но более сложные алгоритмы линейного времени , основанные на алгоритме SMAWK, также известны проблемой минимальной шероховатости и некоторыми другими функциями стоимости, которые имеют аналогичные свойства.
История
Примитивная функция разрыва строки была использована в 1955 году в «блоке управления страничным принтером», разработанном Western Union . В этой системе использовались реле, а не программируемые цифровые компьютеры, и поэтому требовался простой алгоритм, который можно было бы реализовать без буферов данных . В системе Western Union каждая строка была разорвана на первом пробеле, который появлялся после 58-го символа, или на 70-м символе, если пробел не был найден.
Жадный алгоритм разбиения строк появился раньше метода динамического программирования, описанного Дональдом Кнутом в неопубликованной записке 1977 года, описывающей его систему набора текста TeX и позже опубликованной более подробно Knuth & Plass (1981) .
Смотрите также
- Неразрывное пространство
- Типографское выравнивание
- Пространство нулевой ширины
- Разделитель слов
- Соединитель слов
использованная литература
внешние ссылки
- Алгоритм разрыва строки Unicode
Алгоритм Кнута
- «Новое в Knuth & Plass»
- «tex_wrap»: «Реализует алгоритм TeX для разбиения абзацев на строки.» Ссылка: «Разбивка абзацев на строки», DE Knuth и MF Plass, глава 3 _Digital Typography_, CSLI Lecture Notes # 78.
- Text :: Reflow — Perl-модуль для перекомпоновки текстовых файлов с использованием алгоритма разбиения на абзацы Кнута. «Алгоритм перекомпоновки пытается сохранить строки одинаковой длины, но также пытается разорвать знаки препинания и избежать разрывов в пределах собственного имени или после определенных связок (» a «,» the «и т. Д.). Результатом является файл с более «рваное» правое поле, чем при использовании fmt или Text :: Wrap, но его легче читать, поскольку меньше фраз разбивается на разрывы строк «.
- настройка алгоритма Кнута для распознавания «мягкого дефиса» .
- Алгоритм взлома Кнута. «Подробное описание модели и алгоритма можно найти в статье Дональда Э. Кнута« Разбивая абзацы на строки », опубликованной в книге« Цифровая типография »(Стэнфорд, Калифорния: Центр изучения языка и информации, 1999), (CSLI Lecture Notes, № 78) «; часть Google Summer Of Code 2006
- «Устранение разрыва в алгоритмах: функциональная программа с линейным временем для форматирования абзацев» , Оге де Моор, Джереми Гиббонс, 1999 г.
Другие ссылки с переносом слов
- обратная проблема — выбор столбцов, достаточно широких, чтобы уместить (обернутый) текст ( заархивированная версия )
- Описание класса KWordWrap, используемого в графическом интерфейсе KDE
- «Элементы разбиения строк Кнута для объектов форматирования» Саймона Пеппинга, 2006 г. Расширяет модель Кнута для обработки нескольких улучшений.
- «Стратегии разрыва страницы» Расширяет модель Кнута для обработки нескольких улучшений.
- «Подобный Кнута-Плассу алгоритм разбиения строк … * действительно * интересно то, чем алгоритм Adobe отличается от алгоритма Кнута-Пласса. Он должен отличаться, поскольку Adobe удалось запатентовать свой алгоритм (6 510 441)». [1]
- «Мюррей Сарджент: математика в офисе»
- «Разрыв строки» сравнивает алгоритмы различной сложности по времени.
In this article we will be looking at word-wrap and what an amazing feature it is. We will discuss word-wrap in RPG Maker and how it can be used, as well as some complications that arise because RPG Maker does not natively come with word-wrap.
What is Word Wrap?
Wikipedia has a pretty explanation on word wrap.
Word-wrap (and line-wrap) are features that determine when a line of text has reached the end of a line that they are displayed on and automatically starts a new line. The purpose of this is to avoid forcing the user to scroll horizontally to view the rest of the line (as in internet browsers), or to avoid having text cut off.
The difference between word-wrap and line-wrap is where the line break occurs. For line wrap, it will just print characters out, and once it hits the end of the line, it’ll print the next character on a new line. This may be undesirable because you might be in the middle of a word and now it doesn’t make sense. Some solutions to this include inserting a hyphen to indicate that the word continues on the next line. Sometimes it might even end up on a new page.
Word-wrap, on the other hand, will determine that it can’t print the whole word on the same line, and will start the word on the next line. This may be more desirable depending on whether you care whether words are broken apart or not.
Why It Matters
To appreciate these features, think about what happens when you don’t have them. For example, RPG Maker doesn’t have any word-wrap or line-wrap and so you end up with things like this:
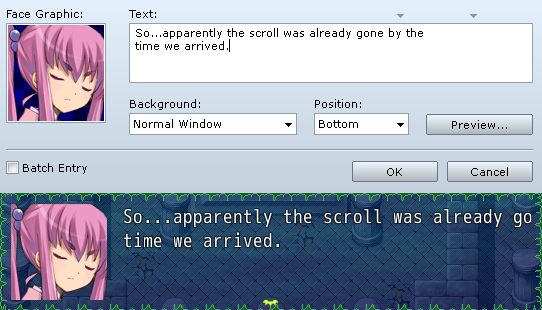
Not very pretty. Or even correct: we’re missing two-and-a-half words, because the line was too long to fit on one line.
DIY
A solution? Manually insert line breaks!
RPG Maker attempts to help you by providing some visual guidelines. You can see that there are arrows in the show text message editor that indicate when the message will likely be cut off. The first arrow is used if you are showing a face graphic, while the second arrow is used if you don’t have a face graphic.
However, these guidelines assume a few things
- You’re using the default font, and
- You’re using the default window size, and
- You’re using “plain text”
If you’re using larger or smaller fonts, those arrows aren’t very accurate (in fact it doesn’t seem very accurate for the default font either). If you want a larger or smaller window, those arrows won’t help either.
The more pressing issue is the assumption that you’re using “plain text”.
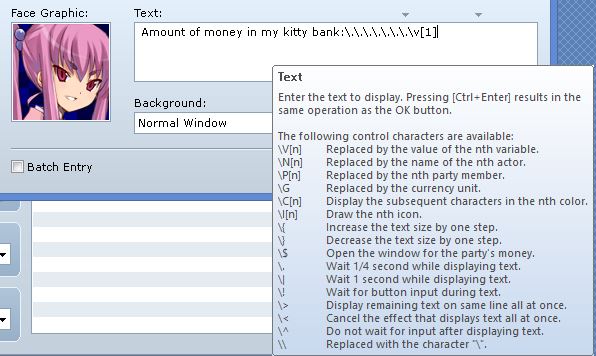
RPG Maker’s message window doesn’t just display text; it comes with a complete set of message codes that do a variety of things from controlling the speed of the text to showing the gold window to replacing certain codes with other values such as a specific actor’s name or a variable’s value. These are called message codes, and it is a very large topic so I will not be covering that in detail here.
Basically, message codes that you write in the editor are not displayed the same way in game. Codes that control the message may or may not take up any space, while codes that convert codes into other text will likely take up more space. Of course, the editor doesn’t know this. I call them “Control Codes” and “Convert Codes”based on what their function is. You can see a list of default message codes when you hover your cursor over the text window:
Here’s an example of me following the guidelines and displaying a few variables using convert codes in my message:
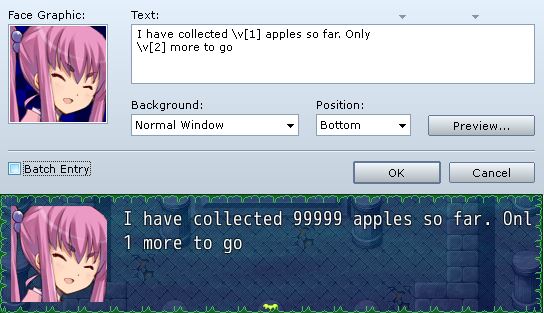
While it looks fine in the editor, I can’t say the same about the results.
Starting With Line-Wrap
If all we had to deal with was regular text, manually breaking your lines might have been a feasible solution, but in general it would be better to have automated wrapping. Because all text is displayed one character at a time, we can start off with an implementation of line-wrap to convince ourselves that it works.
We can follow a simple rule: if there’s space on the line, draw it on the same line. If there’s no more space, continue on a new line.
The default window already provides a number of methods for handling line breaks. In particular, in Window_Base there is a method called process_new_line that basically starts a new line
def process_new_line(text, pos) pos[:x] = pos[:new_x] pos[:y] += pos[:height] pos[:height] = calc_line_height(text) end
Let’s start with the “plain text” scenario. RPG Maker calls it a “normal character”:
def process_normal_character(c, pos) text_width = text_size(c).width draw_text(pos[:x], pos[:y], text_width * 2, pos[:height], c) pos[:x] += text_width end
The logic is pretty simple: draw the character, increment the x-pos by the width of the character. Rather than simply drawing text, we want to check whether the text can be drawn on the same line first.
class Window_Base
def process_normal_character(c, pos)
text_width = text_size(c).width
#---------------------------------------------
if pos[:x] + text_width >= self.contents.width
pos[:new_x] = new_line_x
process_new_line(c, pos)
end
#---------------------------------------------
draw_text(pos[:x], pos[:y], text_width * 2, pos[:height], c)
pos[:x] += text_width
end
end
Does it work?
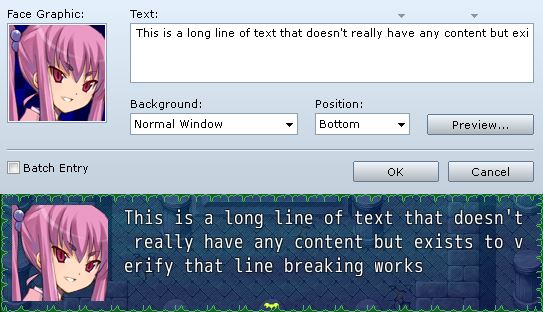
It definitely took an arbitrarily long line of text and broke it into different parts. Some things to note
- On the second line, the first character is a space. This is because the space couldn’t be drawn on the previous line.
- At the end of the second line, you can see that “verify” was broken in the middle of the word
Which is expected, since our simple logic doesn’t care what kind of character we’re looking at. You can sort of fix the second problem but printing out a hyphen before processing the line break, but that’s only if hyphens work for you.
Line-Wrap to Word-Wrap
Personally, I don’t like using hyphens to work with broken-up words. Instead, I’d prefer to just have the entire word moved onto a new line. We can’t insert our code into the same method, because that is specifically for processing an individual character, and even if we wanted to, we don’t have a reference to the text we are printing out.
We move up to the process_character method.
class Window_Base
def process_character(c, text, pos)
case c
when "n" # New line
process_new_line(text, pos)
when "f" # New page
process_new_page(text, pos)
when "e" # Control character
process_escape_character(obtain_escape_code(text), text, pos)
else # Normal character
process_normal_character(c, pos)
end
end
end
Here, we actually have a reference to the remaining text to be parsed. We can perform our word-wrap check by first grabbing all of the characters that are part of the current word and perform our checks on the spot, modifying the position as needed before we actually process the character. We’ll have to ignore word-wrap if we’re working with a message code otherwise strange things may happen (especially since we can add our own message codes).
What is a Word?
For some, this may seem to be an obvious question. However, it really isn’t. Especially if you start considering other languages. There are also cases where a word should not be broken up, for example someone’s name.
But for now let’s consider the very simple (but inaccurate) definition of a word, which is a continuous string of characters without any spaces.
class Window_Message
alias :th_message_word_wrap_process_character :process_character
def process_character(c, text, pos)
if pos[:x] + next_word_width(c, text) >= self.contents.width
pos[:new_x] = new_line_x
process_new_line(c, pos)
end
th_message_word_wrap_process_character(c, text, pos)
end
def next_word_width(c, text)
word_width = text_size(c).width
return word_width if text.empty?
return word_width + text_size(text[0, text.index(/s/)]).width
end
end
Checking the output with our new wrapping script:
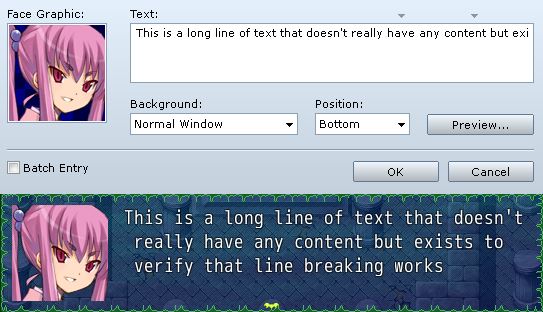
Looks better: words aren’t broken apart. Still has those leading spaces though. You probably should be checking whether you’re working with a message code or not though.
Page Breaks
A new problem appears as a result of inserting new line breaks: what happens when your line is too long and doesn’t fit in the window? Fortunately, the message window already handles this for you: during the line break processing, it also determines whether you need a new page. If you do need a new page, it will pause and wait before continuing.
class Window_Message
def process_new_line(text, pos)
@line_show_fast = false
super
if need_new_page?(text, pos)
input_pause
new_page(text, pos)
end
end
end
So this solves another problem that we would have had to deal with ourselves.
Wrapping Message Codes
You may be wondering whether our script supports message codes. Recall the two types of message codes
- Convert Codes – the engine replaces this code with the appropriate value
- Control Codes – this controls how the engine behaves when it sees a certain code
Convert codes are replaced with the appropriate value when the message is displayed, and these are always text values. This is real-time data (at the time of printing), which is an amazing feature that you simply cannot achieve in regular printed literature. Convert codes are replaced in a pre-processing step that occurs before we actually begin printing our text, so by the time word-wrapping becomes relevant, we don’t need to worry about these.
Control codes are somewhat more complicated, because they could do anything from simply altering certain behavior of the message drawer, or to draw images. You’d have to consider each one case-by-case.
Some Considerations
There are a large number of different issues that you can run into when implementing word wrapping. Here are a few.
Explicit Line Breaks
What happens to the existing line breaks in your message when you perform word-wrap. When you press enter in the text box, it automatically creates a line break and will be displayed by the window. One way to address this is to get rid of the original line breaks and let the engine figure out where they should be inserted, but this solution doesn’t work in all cases. Different word wrapping scripts provide their own implementations, such as removing all existing line breaks, but providing a custom line break character that you can use to tell the engine that you actually want a line break.
Explicit Whitespace
Sometimes you just want to put in a bunch of spaces for some reason. A decision would need to be made here on how spaces would be handled, especially when it comes to line-breaks which may result in leading whitespace.
Working with Non-Text Elements
The message window doesn’t only display text. It can display other images as well such as icons or sprites. The existing implementation of word-wrap assumed that you’re working with strictly text, which is not always true.
Because there is no standard way of drawing non-text elements, you would need to determine how the image is being drawn, and then use the image’s width in your calculations.
Performance Impact
Word-wrapping is not free. In fact, it is rather computationally expensive due to two things
- It calls Bitmap#text_size, which is slow
- It calls Bitmap#draw_text, which is slow
So if you’re trying to draw a paragraph with some 200 words, you will see a noticeable delay.
Unless you are using scripts that improve the performance of these two methods, I would suggest only using word-wrap for situations where you don’t need to draw too much text, such as the show text message events.
Word Wrap Scripts
Here are some implementations of word-wrapping for RPGMaker VXAce that provide various ways to handle all of the different issues that arise from automatic word wrapping.
- Word Wrapping Message Boxes – by KilloZapit
- ATS: Formatting – by Modern Algebra
Summary
This is a simple implementation of word wrapping for your message boxes. It only applies to the message window, and no other windows, because the message window is the only window that defines new_line_x. However, if you moved that method up into Window_Base, then you can implement word-wrapping for all windows.
Spread the Word
If you liked the post and feel that others could benefit from it, consider tweeting it or sharing it on whichever social media channels that you use. You can also follow @HimeWorks on Twitter or like my Facebook page to get the latest updates or suggest topics that you would like to read about.
This guide explains the various ways in which overflowing text can be managed in CSS.
What is overflowing text?
In CSS, if you have an unbreakable string such as a very long word, by default it will overflow any container that is too small for it in the inline direction. We can see this happening in the example below: the long word is extending past the boundary of the box it is contained in.
CSS will display overflow in this way, because doing something else could cause data loss. In CSS data loss means that some of your content vanishes. So the initial value of overflow is visible, and we can see the overflowing text. It is generally better to be able to see overflow, even if it is messy. If things were to disappear or be cropped as would happen if overflow was set to hidden you might not spot it when previewing your site. Messy overflow is at least easy to spot, and in the worst case, your visitor will be able to see and read the content even if it looks a bit strange.
In this next example, you can see what happens if overflow is set to hidden.
Finding the min-content size
To find the minimum size of the box that will contain its contents with no overflows, set the width or inline-size property of the box to min-content.
Using min-content is therefore one possibility for overflowing boxes. If it is possible to allow the box to grow to be the minimum size required for the content, but no bigger, using this keyword will give you that size.
Breaking long words
If the box needs to be a fixed size, or you are keen to ensure that long words can’t overflow, then the overflow-wrap property can help. This property will break a word once it is too long to fit on a line by itself.
Note: The overflow-wrap property acts in the same way as the non-standard property word-wrap. The word-wrap property is now treated by browsers as an alias of the standard property.
An alternative property to try is word-break. This property will break the word at the point it overflows. It will cause a break-even if placing the word onto a new line would allow it to display without breaking.
In this next example, you can compare the difference between the two properties on the same string of text.
This might be useful if you want to prevent a large gap from appearing if there is just enough space for the string. Or, where there is another element that you would not want the break to happen immediately after.
In the example below there is a checkbox and label. Let’s say, you want the label to break should it be too long for the box. However, you don’t want it to break directly after the checkbox.
Adding hyphens
To add hyphens when words are broken, use the CSS hyphens property. Using a value of auto, the browser is free to automatically break words at appropriate hyphenation points, following whatever rules it chooses. To have some control over the process, use a value of manual, then insert a hard or soft break character into the string. A hard break (‐) will always break, even if it is not necessary to do so. A soft break (­) only breaks if breaking is needed.
You can also use the hyphenate-character property to use the string of your choice instead of the hyphen character at the end of the line (before the hyphenation line break).
This property also takes the value auto, which will select the correct value to mark a mid-word line break according to the typographic conventions of the current content language.
The <wbr> element
If you know where you want a long string to break, then it is also possible to insert the HTML <wbr> element. This can be useful in cases such as displaying a long URL on a page. You can then add the property in order to break the string in sensible places that will make it easier to read.
In the below example the text breaks in the location of the <wbr>.
See also
- The HTML
<wbr>element - The CSS
word-breakproperty - The CSS
overflow-wrapproperty - The CSS
white-spaceproperty - The CSS
hyphensproperty - Overflow and Data Loss in CSS
Let’s talk about the various ways we can control how text wraps (or doesn’t wrap) on a web page. CSS gives us a lot of tools to make sure our text flows the way we want it to, but we’ll also cover some tricks using HTML and special characters.

Protecting Layout
Normally, text flows to the next line at “soft wrap opportunities”, which is a fancy name for spots you’d expect text to break naturally, like between words or after a hyphen. But sometimes you may find yourself with long spans of text that don’t have soft wrap opportunities, such as really long words or URLs. This can cause all sorts of layout issues. For example, the text may overflow its container, or it might force the container to become too wide and push things out of place.
It’s good defensive coding to anticipate issues from text not breaking. Fortunately, CSS gives us some tools for this.
Getting Overflowing Text to Wrap
Putting overflow-wrap: break-word on an element will allow text to break mid-word if needed. It’ll first try to keep a word unbroken by moving it to the next line, but will then break the word if there’s still not enough room.
See the Pen overflow-wrap: break-word by Will Boyd (@lonekorean) on CodePen.
There’s also overflow-wrap: anywhere, which breaks words in the same manner. The difference is in how it affects the min-content size calculation of the element it’s on. It’s pretty easy to see when width is set to min-content.
.top {
width: min-content;
overflow-wrap: break-word;
}.bottom {
width: min-content;
overflow-wrap: anywhere;
}
See the Pen overflow-wrap + min-content by Will Boyd (@lonekorean) on CodePen.
The top element with overflow-wrap: break-word calculates min-content as if no words are broken, so its width becomes the width of the longest word. The bottom element with overflow-wrap: anywhere calculates min-content with all the breaks it can create. Since a break can happen, well, anywhere, min-content ends up being the width of a single character.
Remember, this behavior only comes into play when min-content is involved. If we had set width to some rigid value, we’d see the same word-breaking result for both.
Breaking Words without Mercy
Another option for breaking words is word-break: break-all. This one won’t even try to keep words whole — it’ll just break them immediately. Take a look.
See the Pen word-break: break-all by Will Boyd (@lonekorean) on CodePen.
Notice how the long word isn’t moved to the next line, like it would have been when using overflow. Also notice how “words” is broken, even though it would have fit just fine on the next line.
word-break: break-all has no problem breaking words, but it’s still cautious around punctuation. For example, it’ll avoid starting a line with the period from the end of a sentence. If you want truly merciless breaking, even with punctuation, use line-break: anywhere.
See the Pen word-break: break-all vs line-break: anywhere by Will Boyd (@lonekorean) on CodePen.
See how word-break: break-all moves the “k” down to avoid starting the second line with “.”? Meanwhile, line-break: anywhere doesn’t care.
Excessive Punctuation
Let’s see how the CSS properties we’ve covered so far handle excessively long spans of punctuation.
See the Pen Excessive Punctuation by Will Boyd (@lonekorean) on CodePen.
overflow-wrap: break-word and line-break: anywhere are able to keep things contained, but then there’s word-break: break-all being weird with punctuation again — this time resulting in overflowing text.
It’s something to keep in mind. If you absolutely do not want text to overflow, be aware that word-break: break-all won’t stop runaway punctuation.
Specifying Where Words Can Break
For more control, you can manually insert word break opportunities into your text with <wbr>. You can also use a “zero-width space”, provided by the ​ HTML entity (yes, it must be capitalized just as you see it!).
Let’s see these in action by wrapping a long URL that normally wouldn’t wrap, but only between segments.
<!-- normal -->
<p>https://subdomain.somewhere.co.uk</p> <!-- <wbr> -->
<p>https://subdomain<wbr>.somewhere<wbr>.co<wbr>.uk</p>
<!-- ​ -->
<p>https://subdomain​.somewhere​.co​.uk</p>
See the Pen Manual Word Break Opportunities by Will Boyd (@lonekorean) on CodePen.
Automatic Hyphenation
You can tell the browser to break and hyphenate words where appropriate by using hyphens: auto. Hyphenation rules are determined by language, so you’ll need to tell the browser what language to use. This is done by specifying the lang attribute in HTML, possibly on the relevant element directly, or on <html>.
<p lang="en">This is just a bit of arbitrary text to show hyphenation in action.</p> p {
-webkit-hyphens: auto; /* for Safari */
hyphens: auto;
}See the Pen hyphens: auto by Will Boyd (@lonekorean) on CodePen.
Manual Hyphenation
You can also take matters into your own hands and insert a “soft hyphen” manually with the ­ HTML entity. It won’t be visible unless the browser decides to wrap there, in which case a hyphen will appear. Notice in the following demo how we’re using ­ twice, but we only see it once where the text wraps.
<p lang="en">Magic? Abraca­dabra? Abraca­dabra!</p>See the Pen Soft Hyphen by Will Boyd (@lonekorean) on CodePen.
hyphens must be set to either auto or manual for ­ to display properly. Conveniently, the default is hyphens: manual, so you should be good without any additional CSS (unless something has declared hyphens: none for some reason).
Preventing Text from Wrapping
Let’s switch things up. There may be times when you don’t want text to wrap freely, so that you have better control over how your content is presented. There are a couple of tools to help you with this.
First up is white-space: nowrap. Put it on an element to prevent its text from wrapping naturally.
See the Pen white-space: nowrap by Will Boyd (@lonekorean) on CodePen.
Preformatting Text
There’s also white-space: pre, which will wrap text just as you have it typed in your HTML. Be careful though, as it will also preserve spaces from your HTML, so be mindful of your formatting. You can also use a <pre> tag to get the same results (it has white-space: pre on it by default).
<!-- the formatting of this HTML results in extra whitespace! -->
<p>
What's worse, ignorance or apathy?
I don't know and I don't care.
</p><!-- tighter formatting that "hugs" the text -->
<p>What's worse, ignorance or apathy?
I don't know and I don't care.</p>
<!-- same as above, but using <pre> -->
<pre>What's worse, ignorance or apathy?
I don't know and I don't care.</pre>
p {
white-space: pre;
}pre {
/* <pre> sets font-family: monospace, but we can undo that */
font-family: inherit;
}
See the Pen Preformatted Text by Will Boyd (@lonekorean) on CodePen.
A Break, Where Words Can’t Break?
For line breaks, you can use <br> inside of an element with white-space: nowrap or white-space: pre just fine. The text will wrap.
But what happens if you use <wbr> in such an element? Kind of a trick question… because browsers don’t agree. Chrome/Edge will recognize the <wbr> and potentially wrap, while Firefox/Safari won’t.
When it comes to the zero-width space (​) though, browsers are consistent. None will wrap it with white-space: nowrap or white-space: pre.
<p>Darth Vader: Nooooooooooooo<br>oooo!</p><p>Darth Vader: Nooooooooooooo<wbr>oooo!</p>
<p>Darth Vader: Nooooooooooooo​oooo!</p>
See the Pen white-space: nowrap + breaking lines by Will Boyd (@lonekorean) on CodePen.
Non-Breaking Spaces
Sometimes you may want text to wrap freely, except in very specific places. Good news! There are a few specialized HTML entities that let you do exactly this.
A “non-breaking space” ( ) is often used to keep space between words, but disallow a line break between them.
<p>Something I've noticed is designers don't seem to like orphans.</p><p>Something I've noticed is designers don't seem to like orphans.</p>
See the Pen Non-Breaking Space by Will Boyd (@lonekorean) on CodePen.
Word Joiners and Non-Breaking Hyphens
It’s possible for text to naturally wrap even without spaces, such as after a hyphen. To prevent wrapping without adding a space, you can use ⁠ (case-sensitive!) to get a “word joiner”. For hyphens specifically, you can get a “non-breaking hyphen” with ‑ (it doesn’t have a nice HTML entity name).
<p>Turn right here to get on I-85.</p> <p>Turn right here to get on I-⁠85.</p>
<p>Turn right here to get on I‑85.</p>
See the Pen Word Joiners and Non-Breaking Hyphens by Will Boyd (@lonekorean) on CodePen.
CJK Text and Breaking Words
CJK (Chinese/Japanese/Korean) text behaves differently than non-CJK text in some ways. Certain CSS properties and values can be used for additional control over the wrapping of CJK text specifically.
Default browser behavior allows words to be broken in CJK text. This means that word-break: normal (the default) and word-break: break-all will give you the same results. However, you can use word-break: keep-all to prevent CJK text from wrapping within words (non-CJK text will be unaffected).
Here’s an example in Korean. Note how the word “자랑스럽게” does or doesn’t break.
See the Pen CJK Text + word-break by Will Boyd (@lonekorean) on CodePen.
Be careful though, Chinese and Japanese don’t use spaces between words like Korean does, so word-break: keep-all can easily cause long overflowing text if not otherwise handled.
CJK Text and Line Break Rules
We talked about line-break: anywhere earlier with non-CJK text and how it has no problem breaking at punctuation. The same is true with CJK text.
Here’s an example in Japanese. Note how “。” is or isn’t allowed to start a line.
See the Pen CJK Text + line-break by Will Boyd (@lonekorean) on CodePen.
There are other values for line-break that affect how CJK text wraps: loose, normal, and strict. These values instruct the browser on which rules to use when deciding where to insert line breaks. The W3C describes several rules and it’s possible for browsers to add their own rules as well.
Worth Mentioning: Element Overflow
The overflow CSS property isn’t specific to text, but is often used to ensure text doesn’t render outside of an element that has its width or height constrained.
.top {
white-space: nowrap;
overflow: auto;
}.bottom {
white-space: nowrap;
overflow: hidden;
}
See the Pen Element Overflow by Will Boyd (@lonekorean) on CodePen.
As you can see, a value of auto allows the content to be scrolled (auto only shows scrollbars when needed, scroll shows them always). A value of hidden simply cuts off the content and leaves it at that.
overflow is actually shorthand to set both overflow-x and overflow-y, for horizontal and vertical overflow respectively. Feel free to use what suits you best.
We can build upon overflow: hidden by adding text-overflow: ellipsis. Text will still be cut off, but we’ll get some nice ellipsis as an indication.
p {
white-space: nowrap;
overflow: hidden;
text-overflow: ellipsis;
}See the Pen text-overflow: ellipsis by Will Boyd (@lonekorean) on CodePen.
Bonus Trick: Pseudo-Element Line Break
You can force a line break before and/or after an inline element, while keeping it as an inline element, with a little bit of pseudo-element trickery.
First, set the content of a ::before or ::after pseudo-element to 'A', which will give you the new line character. Then set white-space: pre to ensure the new line character is respected.
<p>Things that go <span>bump</span> in the night.</p>span {
background-color: #000;
}span::before, span::after {
content: 'A';
white-space: pre;
}
See the Pen Pseudo-Element Line Breaks by Will Boyd (@lonekorean) on CodePen.
We could have just put display: block on the <span> to get the same breaks, but then it would no longer be inline. The background-color makes it easy to see that with this method, we still have an inline element.
Bonus Notes
- There’s an older CSS property named
word-wrap. It’s non-standard and browsers now treat it as an alias foroverflow-wrap. - The
white-spaceCSS property has some other values we didn’t cover:pre-wrap,pre-line, andbreak-spaces. Unlike the ones we did cover, these don’t prevent text wrapping. - The CSS Text Module Level 4 spec describes a
text-wrapCSS property that looks interesting, but at the time of writing, no browser implements it.
Time to “Wrap” Things Up
There’s so much that goes into flowing text on a web page. Most of the time you don’t really need to think about it, since browsers handle it for you. For the times when you do need more control, it’s nice to know that you have a lot of options.
Writing this was definitely a rabbit hole for me as I kept finding more and more things to talk about. I hope I’ve shown you enough to get your text to break and flow just the way you want it.
Thanks for reading!