
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
При регрессиальном анализе функция LOGEST вычисляет экспоненциальное значение, которое подгощает данные, и возвращает массив значений, описыващих эту кривую. Поскольку данная функция возвращает массив значений, она должна вводиться как формула массива.
Примечание: Если у вас установлена текущая версия Microsoft 365, можно просто ввести формулу в верхней левой ячейке диапазона вывода и нажать клавишу ВВОД, чтобы подтвердить использование формулы динамического массива. Иначе формулу необходимо вводить с использованием прежней версии массива, выбрав диапазон вывода, введя формулу в левой верхней ячейке диапазона и нажав клавиши CTRL+SHIFT+ВВОД для подтверждения. Excel автоматически вставляет фигурные скобки в начале и конце формулы. Дополнительные сведения о формулах массива см. в статье Использование формул массива: рекомендации и примеры.
Описание
Уравнение кривой имеет следующий вид:
y = b*m^x
или
y = (b*(m1^x1)*(m2^x2)*_)
если существует несколько значений x, где зависимые значения y являются функцией независимых значений x. Значения m являются основанием, возводимым в степень x, а значения b постоянны. Обратите внимание на то, что y, x и m могут быть векторами. Функция ЛГРФПРИБЛ возвращает массив {mn;mn-1;…;m1;b}.
ЛГРФПРИБЛ(известные_значения_y;[известные_значения_x];[конст];[статистика])
Аргументы функции ЛГРФПРИБЛ описаны ниже.
-
known_y — обязательный аргумент. Множество значений y в уравнении y = b*m^x, которые уже известны.
-
Если массив «известные_значения_y» содержит один столбец, каждый столбец массива «известные_значения_x» интерпретируется как отдельная переменная.
-
Если массив «известные_значения_y» содержит одну строку, каждая строка массива «известные_значения_x» интерпретируется как отдельная переменная.
-
-
Known_x Необязательный. Множество значений x, которые могут быть уже известны для соотношения y = b*m^x.
-
Массив известные_значения_x может включать одно или более множеств переменных. Если используется только одна переменная, то известные_значения_y и известные_значения_x могут быть диапазонами любой формы, если только они имеют одинаковые размерности. Если используется более одной переменной, то аргумент известные_значения_y должен быть диапазоном ячеек высотой в одну строку или шириной в один столбец (так называемым вектором).
-
Если аргумент известные_значения_x опущен, то предполагается, что это массив {1;2;3;…} такого же размера, как и известные_значения_y.
-
-
Const — необязательный аргумент. Логическое значение, которое указывает, должна ли константа b равняться 1.
-
Если аргумент «конст» имеет значение ИСТИНА или опущен, то b вычисляется обычным образом.
-
Если аргумент «конст» имеет значение ЛОЖЬ, то b полагается равным 1 и значения m подбираются так, чтобы удовлетворить соотношению y = m^x.
-
-
Статистика Необязательный аргумент. Логическое значение, которое указывает, требуется ли вернуть дополнительную регрессионную статистику.
-
Если аргумент «статистика» имеет значение ИСТИНА, функция ЛГРФПРИБЛ возвращает дополнительную статистику по регрессии, т. е. возвращает массив {mn;mn-1;…;m1;b:sen;sen-1;…;se1;seb:r 2;sey;F;df:ssreg;ssresid}.
-
Если аргумент «статистика» имеет значение ЛОЖЬ или опущен, функция ЛГРФПРИБЛ возвращает только коэффициенты m и константу b.
-
Сведения о дополнительной статистике по регрессии см. в разделе Функция ЛИНЕЙН.
-
Чем больше график ваших данных напоминает экспоненциальную кривую, тем лучше вычисленная кривая будет аппроксимировать данные. Подобно функции ЛИНЕЙН, функция ЛГРФПРИБЛ возвращает массив, который описывает зависимость между значениями, но ЛИНЕЙН подгоняет прямую линию к имеющимся данным, а ЛГРФПРИБЛ подгоняет экспоненциальную кривую. Дополнительные сведения см. в разделе, посвященном функции ЛИНЕЙН.
-
Если имеется только одна независимая переменная x, то значения пересечения с осью y (b) можно получить непосредственно, используя следующую формулу:
Y-перехват (b):
ИНДЕКС(LOGEST(known_y,known_x),2)Для предсказания будущих значений y можно использовать уравнение y = b*m^x, но в приложении Microsoft Excel для этой цели предусмотрена функция РОСТ. Дополнительные сведения см. в разделе Функция РОСТ.
-
При вводе константы массива (например, в качестве аргумента известные_значения_x) следует использовать точку с запятой для разделения значений в одной строке и двоеточие для разделения строк. Знаки-разделители могут быть другими в зависимости от региональных параметров.
-
Следует помнить, что значения y, предсказанные с помощью уравнения регрессии, могут быть недостоверными, если они находятся вне диапазона значений y, которые использовались для определения коэффициентов уравнения.
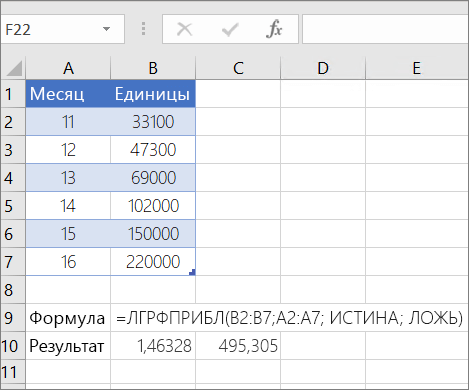
Чтобы она правильно работала, необходимо ввести в Excel формулу массива выше. После ввода формулы нажмите ввод, если у вас есть текущая Microsoft 365 подписка. в противном случае нажмите CTRL+SHIFT+ВВОД. Если формула не введена как формула массива, единственным результатом будет 1,4633.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
Нужна дополнительная помощь?
Функция ЛГРФПРИБЛ в Excel предназначена для определения значений, на основе которых может быть построена экспоненциальная кривая, аппроксимирующая имеющиеся числовые данные, и возвращает массив значений. Для корректной работы рассматриваемой функции ее следует вводить как формулу массива.
Методы аппроксимации табличных данных в Excel
Функция ЛГРФПРИБЛ возвращает данные, необходимые для построения кривой, описываемой следующим уравнением:
F(x) = b*СТЕПЕНЬ(m;x)
Если имеется две и более переменных, это уравнение переписывается следующим образом:
F(x1,x2,…xn)=b*СТЕПЕНЬ(m1;x1)*СТЕПЕНЬ(m2;x2)*…*СТЕПЕНЬ(mn;xn)
Возвращаемые рассматриваемой функцией данные представляют собой следующий массив:
{mn;mn-1;…;m1;b}
То есть, имеем массив оснований, возводимых в степени (известные значения переменных x), и коэффициент b.
Пример 1. В таблице приведены данные, характеризующие динамику курса доллара на протяжении 10 лет (с 2006 по 2016 год). Необходимо спрогнозировать курс доллара на 2019 год на основании имеющихся данных.
Вид таблицы данных:
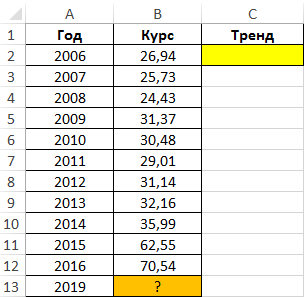
Для расчета тренда (коэффициент, используемый для предсказания последующих значений курса) используем функцию:
=ЛГРФПРИБЛ(B2:B12;A2:A12)
Описание аргументов:
- B2:B12 – известные данные зависимой переменной (значения курса);
- A2:A12 – известные данные независимой переменной (года).
Результат расчетов:
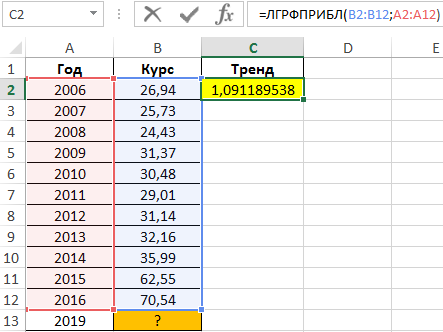
Для предсказания курса на 2019 год используем формулу:
Результат вычислений:
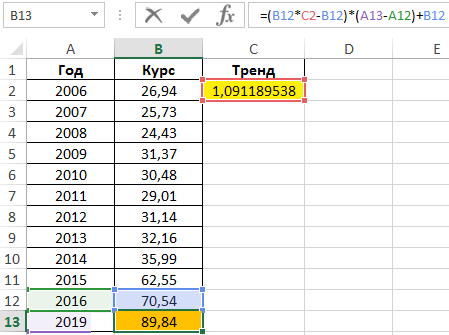
Как видно, полученное значение имеет небольшую степень достоверности. Использование данного типа аппроксимации для предсказания курса валют нерационально.
Прогнозирование финансовых результатов методом аппроксимации в Excel
Пример 2. В таблице имеются данные о зарплатах за прошедший год (помесячно). Определить оптимальный способ предсказания размеров зарплат для последующих периодов.
Вид таблицы данных:
Определим коэффициенты достоверности аппроксимации для линейной и экспоненциальной функций с помощью следующих функций (вводить как формулы массива CTRL+SHIFT+Enter):
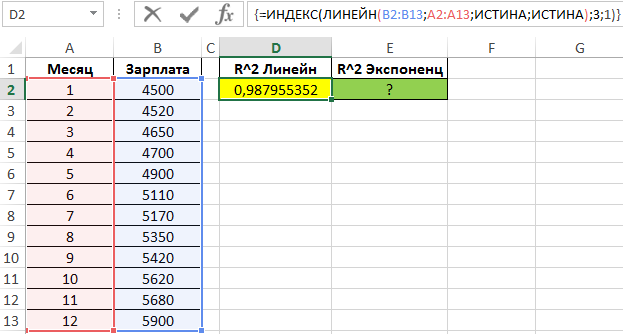
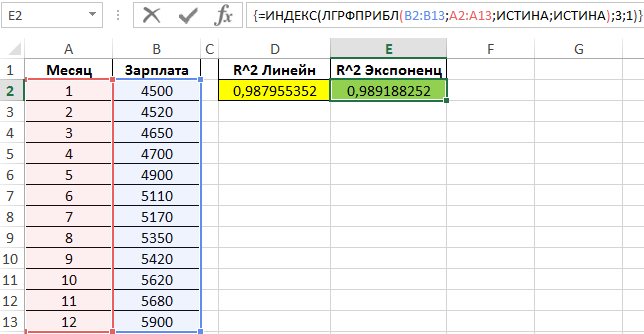
Поскольку обе функции возвращают результат в виде массива данных, в котором в третьей строке первого столбца содержится искомое значение R^2, используем функцию ИНДЕКС для возврата желаемого результата.
Чем ближе значение R^2 к 1, тем выше точность аппроксимации. Как видно, наибольшую точность обеспечивает экспоненциальная функция. Однако разница не является существенной, поэтому использование функции ЛИНЕЙН является допустимым в данном случае.
Правила метода аппроксимации по функции ЛГРФПРИБЛ в Excel
Функция имеет следующую синтаксическую запись:
=ЛГРФПРИБЛ(известные_значения_y;[известные_значения_x];[конст];[статистика])
Описание аргументов:
- известные_значения_y – обязательный, принимает ссылку на диапазон ячеек или массив данных — числовые значения, которые характеризуют состояние зависимой переменной y из указанного выше уравнения;
- [известные_значения_x] – необязательный, принимает ссылку на диапазон ячеек или массив чисел, которые являются уже известными значениями независимой переменной x. Если явно не указан, по умолчанию принимается массив значений {1;2;…N}, где N – количество элементов в массиве, характеризующем известные_значения_y;
- [конст] – необязательный, принимает данные логического типа, интерпретируемые следующим образом: ИСТИНА или явно не указан – функция вычисляет значение коэффициента b из приведенного выше уравнения, ЛОЖЬ – значение данного коэффициента принимается равным 1;
- [статистика] – необязательный, принимает логические значения ИСТИНА (функция возвращает дополнительные данные на основе проведенного регрессионного анализа) или ЛОЖЬ (значение по умолчанию) – функция возвращает только значения коэффициентов m и b.
Примечания:
- Точность вычислений рассматриваемой функцией зависит от степени близости графика, построенного на основе имеющихся значений, к экспоненциальной кривой.
- В качестве первого или второго аргументов могут быть введены константы массивов, при этом необходимо соблюдать требования к размерностям.
- Если аргумент известные_значения_y указан в виде ссылки на диапазон ячеек, формирующих строку или столбец, каждая строка или столбец соответственно будут интерпретированы как отдельная переменная.
- Если данная функция используется для расчетов с указанием только одной переменной x, первый и второй аргументы могут быть указаны в виде ссылок на диапазоны любой формы. Если по условию имеются две и более переменных x, первый и второй аргументы должны быть указаны в виде векторов данных. Размеры массивов должны совпадать в любом случае.
- Если требуется определить будущие значения переменных (предсказать), можно использовать функцию РОСТ.
Функция ЛГРФПРИБЛ в регрессионном анализе вычисляется экспоненциальная кривая, аппроксимирующая данные, и возвращается массив значений, описывающий эту кривую.
Описание функции
В регрессионном анализе вычисляется экспоненциальная кривая, аппроксимирующая данные, и возвращается массив значений, описывающий эту кривую. Поскольку данная функция возвращает массив значений, она должна вводиться как формула массива. Уравнение кривой имеет следующий вид:
y = b*m^xили
y = (b*(m1^x1)*(m2^x2)*_)если существует несколько значений x, где зависимые значения y являются функцией независимых значений x. Значения m являются основанием, возводимым в степень x, а значения b постоянны. Обратите внимание на то, что y, x и m могут быть векторами. Функция ЛГРФПРИБЛ возвращает массив {mn;mn-1;…;m1;b}.
Синтаксис
=ЛГРФПРИБЛ(известные_значения_y; [известные_значения_x]; [конст]; [статистика])Аргументы
известные_значения_yизвестные_значения_xконстстатистика
Обязательный. Множество значений y, которые уже известны для соотношения y = b*m^x.
- Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
- Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
Необязательный. Множество значений x, которые могут быть уже известны для соотношения y = b*m^x.
- Массив известные_значения_x может включать одно или более множеств переменных. Если используется только одна переменная, то известные_значения_y и известные_значения_x могут быть диапазонами любой формы, если только они имеют одинаковые размерности. Если используется более одной переменной, то аргумент известные_значения_y должен быть диапазоном ячеек высотой в одну строку или шириной в один столбец (так называемым вектором).
- Если аргумент известные_значения_x опущен, то предполагается, что это массив {1;2;3;…} такого же размера, как и известные_значения_y.
Необязательный. Логическое значение, которое указывает, требуется ли, чтобы константа b была равна 1.
- Если аргумент «конст» имеет значение ИСТИНА или опущен, то b вычисляется обычным образом.
- Если аргумент «конст» имеет значение ЛОЖЬ, то b полагается равным 1 и значения m подбираются так, чтобы удовлетворить соотношению y = m^x.
Необязательный. Логическое значение, которое указывает, требуется ли вернуть дополнительную регрессионную статистику.
- Если аргумент «статистика» имеет значение ИСТИНА, функция ЛГРФПРИБЛ возвращает дополнительную статистику по регрессии, т. е. возвращает массив {mn;mn-1;…;m1;b:sen;sen-1;…;se1;seb:r 2;sey;F;df:ssreg;ssresid}.
- Если аргумент «статистика» имеет значение ЛОЖЬ или опущен, функция ЛГРФПРИБЛ возвращает только коэффициенты m и константу b.
Замечания
- Чем больше график ваших данных напоминает экспоненциальную кривую, тем лучше вычисленная кривая будет аппроксимировать данные. Подобно функции ЛИНЕЙН, функция ЛГРФПРИБЛ возвращает массив, который описывает зависимость между значениями, но ЛИНЕЙН подгоняет прямую линию к имеющимся данным, а ЛГРФПРИБЛ подгоняет экспоненциальную кривую.
- Если имеется только одна независимая переменная x, то значения пересечения с осью y (b) можно получить непосредственно, используя следующую формулу:
=ИНДЕКС(ЛГРФПРИБЛ(известные_значения_y;известные_значения_x);2) - Для предсказания будущих значений y можно использовать уравнение
y = b*m^xно в приложении Microsoft Excel для этой цели предусмотрена функция РОСТ.
- Формулы, которые возвращают массивы, должны быть введены как формулы массива.
- При вводе константы массива (например, в качестве аргумента известные_значения_x) следует использовать точку с запятой для разделения значений в одной строке и двоеточие для разделения строк. Знаки-разделители могут быть другими в зависимости от региональных параметров.
- Следует помнить, что значения y, предсказанные с помощью уравнения регрессии, могут быть недостоверными, если они находятся вне диапазона значений y, которые использовались для определения коэффициентов уравнения.
Пример
Метод наименьших квадратов (МНК) основан на минимизации суммы квадратов отклонений выбранной функции от исследуемых данных. В этой статье аппроксимируем имеющиеся данные с помощью экспоненциальной
функции.
Метод наименьших квадратов
(англ.
Ordinary
Least
Squares
,
OLS
) является одним из базовых методов регрессионного анализа в части оценки неизвестных параметров
регрессионных моделей
по выборочным данным. Основная статья про МНК —
МНК: Метод Наименьших Квадратов в MS EXCEL
.
В этой статье рассмотрена только экспоненциальная зависимость, но ее выводы можно применить и к показательной зависимости, т.к. любую показательную функцию можно свести к экспоненциальной:
y=a*m
x
=a*(e
ln(m)
)
x
= a*e
x*ln(m)
=a*e
bx
, где b= ln(m))
В свою очередь экспоненциальную зависимость y=a*EXP(b*x) при a>0 можно свести к случаю
линейной зависимости
с помощью замены переменных (см.
файл примера
).
После замены переменных Y=ln(y) и A=ln(a) вычисления полностью аналогичны линейному случаю Y=b*x+A. Для нахождения коэффициента
a
необходимо выполнить обратное преобразование a=
EXP(A)
.
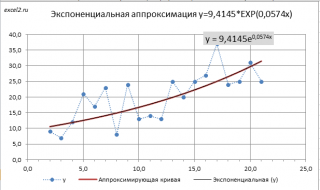
Примечание
: Построить линию тренда по методу наименьших квадратов можно также с помощью инструмента диаграммы
Линия тренда
(
Экспоненциальная линия тренда
). Поставив в диалоговом окне галочку в поле «показывать уравнение на диаграмме» можно убедиться, что найденные выше параметры совпадают со значениями на диаграмме. Подробнее о диаграммах см. статью
Основы построения диаграмм в MS EXCEL
.
Следствием замены Y=ln(y) и A=ln(a) являются дополнительные ограничения: a>0 и y>0. При уменьшении х (в сторону больш
и
х по модулю отрицательных чисел) соответствующее значение
y
асимптотически стремится к 0. Именно такую линию тренда и строит инструмент диаграммы
Линия тренда.
Если среди значений
y
есть отрицательные, то с помощью инструмента
Линия тренда
экспоненциальную линию тренда построить не удастся.
Чтобы обойти это ограничение используем другое уравнение экспоненциальной зависимости y=a*EXP(b*x)+с, где по прежнему a>0, т.е. при росте
х
значения
y
также будут увеличиваться. В качестве
с
можно взять некую заранее известную нижнюю границу для
y
, ниже которой
у
не может опускаться, т.е. у>с. Далее заменой переменных Y=ln(y-c) и A=ln(a) опять сведем задачу к линейному случаю (см.
файл примера лист Экспонента2
).
Если при росте
х
значения
y
уменьшаются по экспоненциальной кривой, т.е. a<0 (существует некая верхняя граница
с
для
у
), то к линейному случаю Y=b*x+A свести задачу позволит замена переменных Y=ln(c-y) и A=ln(-a) (см.
файл примера лист Экспонента3
).
Функция РОСТ()
Еще одним способом построить линию экспоненциального тренда является использование функции
РОСТ()
, английское название GROWTH.
Синтаксис функции следующий:
РОСТ(
известные_значения_y; [известные_значения_x]; [новые_значения_x]; [конст]
)
Для работы функции нужно просто ввести ссылки на массив значений переменной Y (аргумент
известные_значения_y
) и на массив значений переменной Х (аргумент
известные_значения_x
). Функция рассчитает прогнозные значения Y для Х, указанных в
аргументе новые_значения_x
. Если требуется, чтобы экспоненциальная кривая y=a*EXP(b*x) имела a=1, т.е. проходила бы через точку (0;1), то необязательный аргумент
конст
должен быть установлен равным ЛОЖЬ (или 0).
Если среди значений
y
есть отрицательные, то с помощью функции
РОСТ()
аппроксимирующую кривую построить не удастся.
Безусловно, использование функции
РОСТ()
часто удобно, т.к. не требуется делать замену переменных и сводить задачу к линейному случаю.
Наконец, покажем как с помощью функции
РОСТ()
вычислить коэффициенты уравнения y=
a
*EXP(
b
*x).
Примечание
: В MS EXCEL имеется специальная функция
ЛГРФПРИБЛ()
, которая позволяет вычислить коэффициенты уравнения y=a*EXP(b*x). Об этой функции см. ниже.
Чтобы вычислить коэффициент
a
(значение Y в точке Х=0) используйте формулу
=РОСТ(C26:C45;B26:B45;0)
. В диапазонах
C26:C45
и
B26:B45
должны находиться массивы значений переменной Y и X соответственно.
Чтобы вычислить коэффициент
b
используйте формулу:
=
LN(РОСТ(C26:C45;B26:B45;МИН(B26:B45))/
РОСТ(C26:C45;B26:B45;МАКС(B26:B45)))/
(МИН(B26:B45)-МАКС(B26:B45))
Функция ЛГРФПРИБЛ()
Функция
ЛГРФПРИБЛ()
на основе имеющихся значений переменных Х и Y подбирает методом наименьших квадратов коэффициенты
а
и
m
уравнения y=
a
*
m
^x.
Используя свойство степеней a
mn
=(a
m
)
n
приведем уравнение экспоненциального тренда y=
a
*EXP(
b
*x)=
a
*e
b
*x
=
a
*(e
b
)
x
к виду y=
a
*
m
^x, сделав замену переменной m= e
b
=EXP(
b
).
Чтобы вычислить коэффициенты уравнения y=
a
*EXP(
b
*x) используйте следующие формулы:
=
LN(ЛГРФПРИБЛ(C26:C45;B26:B45))
— коэффициент
b
=
ИНДЕКС(ЛГРФПРИБЛ(C26:C45;B26:B45);;2)
— коэффициент
a
Примечание
: Функция
ЛГРФПРИБЛ()
, английское название LOGEST, является
формулой массива, возвращающей несколько значений
. Поэтому, например, для вывода коэффициентов уравнения необходимо выделить 2 ячейки в одной строке, в
Строке формул
ввести =
ЛГРФПРИБЛ(C26:C45;B26:B45)
, затем для ввода формулы вместо обычного
ENTER
нажать
CTRL
+
SHIFT
+
ENTER
.
Функция
ЛГРФПРИБЛ()
имеет линейный аналог – функцию
ЛИНЕЙН()
, которая рассмотрена в статье про простую линейную регрессию. Если 4-й аргумент этой функции (
статистика
) установлен ИСТИНА, то
ЛГРФПРИБЛ()
возвращает регрессионную статистику:
стандартные ошибки для оценок коэффициентов регрессии, коэффициент детерминации, суммы квадратов:
SSR
,
SSE
и др.
Примечание
: Особой нужды в функции
ЛГРФПРИБЛ()
нет, т.к. с помощью логарифмирования и замены переменной показательную функцию y=
a
*
m
^x можно свести к линейной ln(y)=ln(a)+x*ln(m)=> Y=A+bx. То же справедливо и для экспоненциальной функции y=
a
*EXP(
b
*x).
Содержание
- Процедура прогнозирования
- Способ 1: линия тренда
- Способ 2: оператор ПРЕДСКАЗ
- Способ 3: оператор ТЕНДЕНЦИЯ
- Способ 4: оператор РОСТ
- Способ 5: оператор ЛИНЕЙН
- Способ 6: оператор ЛГРФПРИБЛ
- Вопросы и ответы

Прогнозирование – это очень важный элемент практически любой сферы деятельности, начиная от экономики и заканчивая инженерией. Существует большое количество программного обеспечения, специализирующегося именно на этом направлении. К сожалению, далеко не все пользователи знают, что обычный табличный процессор Excel имеет в своем арсенале инструменты для выполнения прогнозирования, которые по своей эффективности мало чем уступают профессиональным программам. Давайте выясним, что это за инструменты, и как сделать прогноз на практике.
Процедура прогнозирования
Целью любого прогнозирования является выявление текущей тенденции, и определение предполагаемого результата в отношении изучаемого объекта на определенный момент времени в будущем.
Способ 1: линия тренда
Одним из самых популярных видов графического прогнозирования в Экселе является экстраполяция выполненная построением линии тренда.
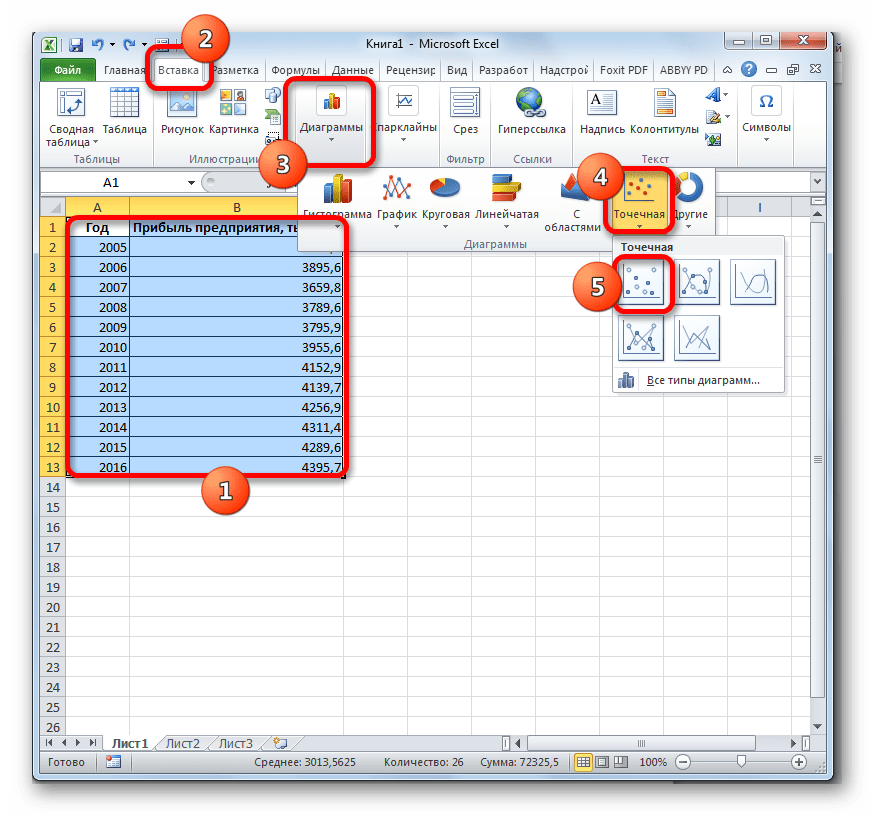
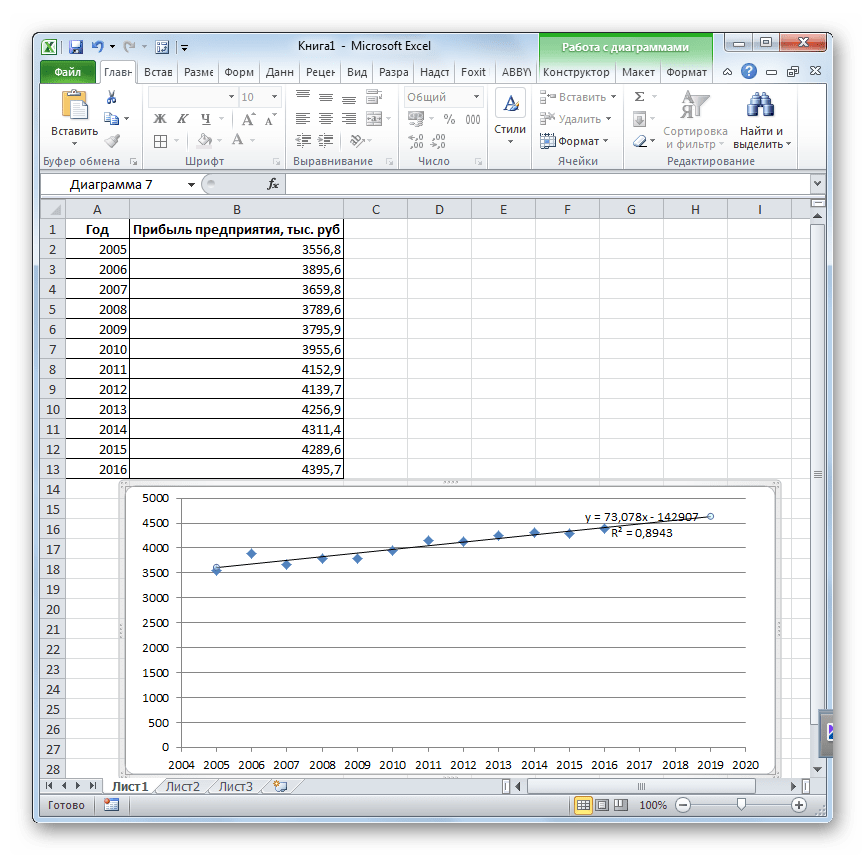
Попробуем предсказать сумму прибыли предприятия через 3 года на основе данных по этому показателю за предыдущие 12 лет.
- Строим график зависимости на основе табличных данных, состоящих из аргументов и значений функции. Для этого выделяем табличную область, а затем, находясь во вкладке «Вставка», кликаем по значку нужного вида диаграммы, который находится в блоке «Диаграммы». Затем выбираем подходящий для конкретной ситуации тип. Лучше всего выбрать точечную диаграмму. Можно выбрать и другой вид, но тогда, чтобы данные отображались корректно, придется выполнить редактирование, в частности убрать линию аргумента и выбрать другую шкалу горизонтальной оси.
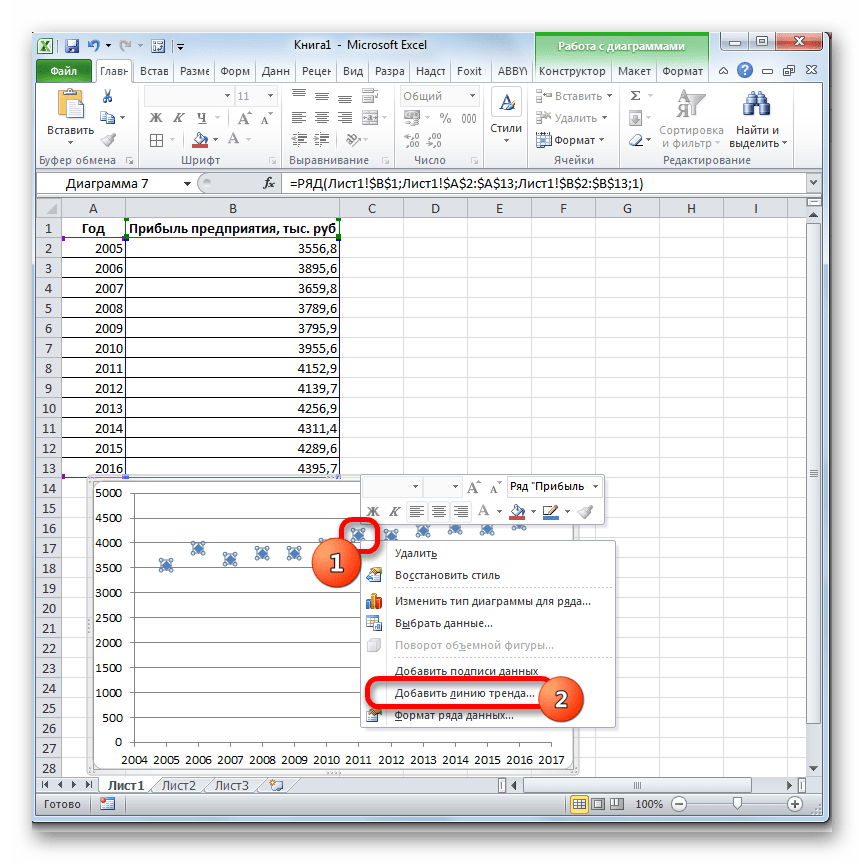
- Теперь нам нужно построить линию тренда. Делаем щелчок правой кнопкой мыши по любой из точек диаграммы. В активировавшемся контекстном меню останавливаем выбор на пункте «Добавить линию тренда».
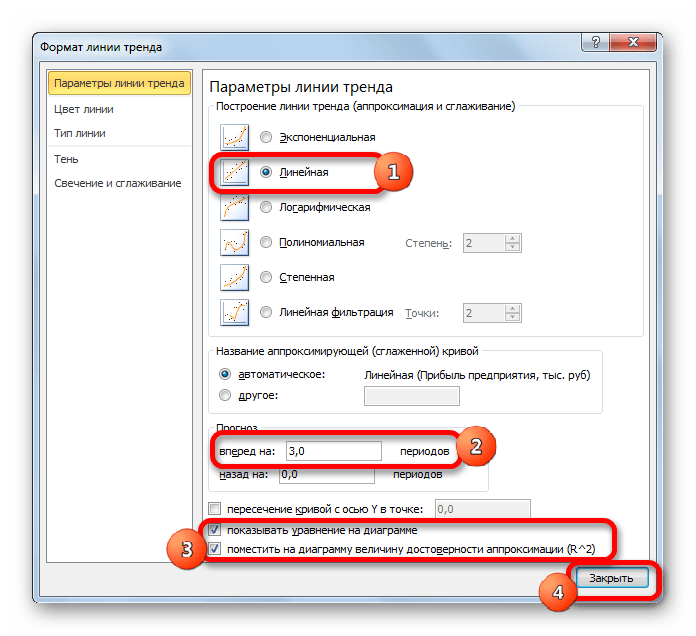
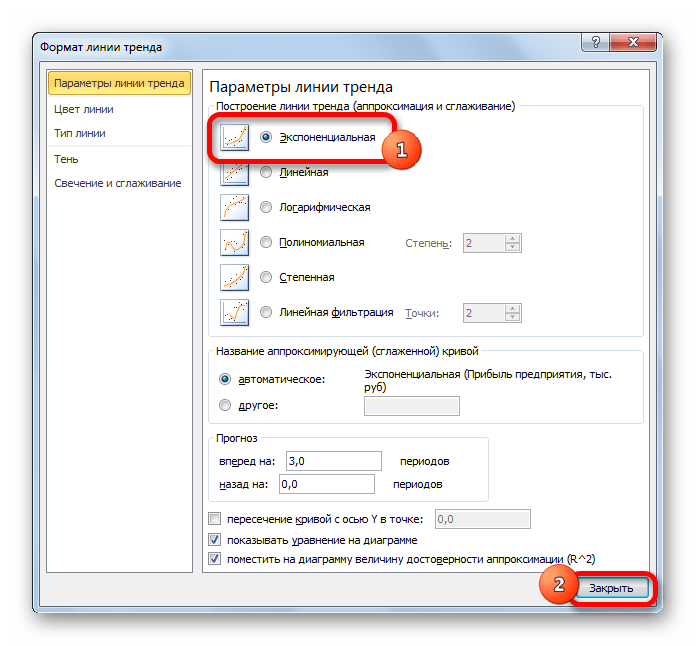
- Открывается окно форматирования линии тренда. В нем можно выбрать один из шести видов аппроксимации:
- Линейная;
- Логарифмическая;
- Экспоненциальная;
- Степенная;
- Полиномиальная;
- Линейная фильтрация.
Давайте для начала выберем линейную аппроксимацию.
В блоке настроек «Прогноз» в поле «Вперед на» устанавливаем число «3,0», так как нам нужно составить прогноз на три года вперед. Кроме того, можно установить галочки около настроек «Показывать уравнение на диаграмме» и «Поместить на диаграмме величину достоверности аппроксимации (R^2)». Последний показатель отображает качество линии тренда. После того, как настройки произведены, жмем на кнопку «Закрыть».
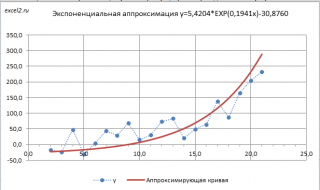
- Линия тренда построена и по ней мы можем определить примерную величину прибыли через три года. Как видим, к тому времени она должна перевалить за 4500 тыс. рублей. Коэффициент R2, как уже было сказано выше, отображает качество линии тренда. В нашем случае величина R2 составляет 0,89. Чем выше коэффициент, тем выше достоверность линии. Максимальная величина его может быть равной 1. Принято считать, что при коэффициенте свыше 0,85 линия тренда является достоверной.
- Если же вас не устраивает уровень достоверности, то можно вернуться в окно формата линии тренда и выбрать любой другой тип аппроксимации. Можно перепробовать все доступные варианты, чтобы найти наиболее точный.

Нужно заметить, что эффективным прогноз с помощью экстраполяции через линию тренда может быть, если период прогнозирования не превышает 30% от анализируемой базы периодов. То есть, при анализе периода в 12 лет мы не можем составить эффективный прогноз более чем на 3-4 года. Но даже в этом случае он будет относительно достоверным, если за это время не будет никаких форс-мажоров или наоборот чрезвычайно благоприятных обстоятельств, которых не было в предыдущих периодах.
Урок: Как построить линию тренда в Excel
Способ 2: оператор ПРЕДСКАЗ
Экстраполяцию для табличных данных можно произвести через стандартную функцию Эксель ПРЕДСКАЗ. Этот аргумент относится к категории статистических инструментов и имеет следующий синтаксис:
=ПРЕДСКАЗ(X;известные_значения_y;известные значения_x)
«X» – это аргумент, значение функции для которого нужно определить. В нашем случае в качестве аргумента будет выступать год, на который следует произвести прогнозирование.

«Известные значения y» — база известных значений функции. В нашем случае в её роли выступает величина прибыли за предыдущие периоды.
«Известные значения x» — это аргументы, которым соответствуют известные значения функции. В их роли у нас выступает нумерация годов, за которые была собрана информация о прибыли предыдущих лет.
Естественно, что в качестве аргумента не обязательно должен выступать временной отрезок. Например, им может являться температура, а значением функции может выступать уровень расширения воды при нагревании.
При вычислении данным способом используется метод линейной регрессии.
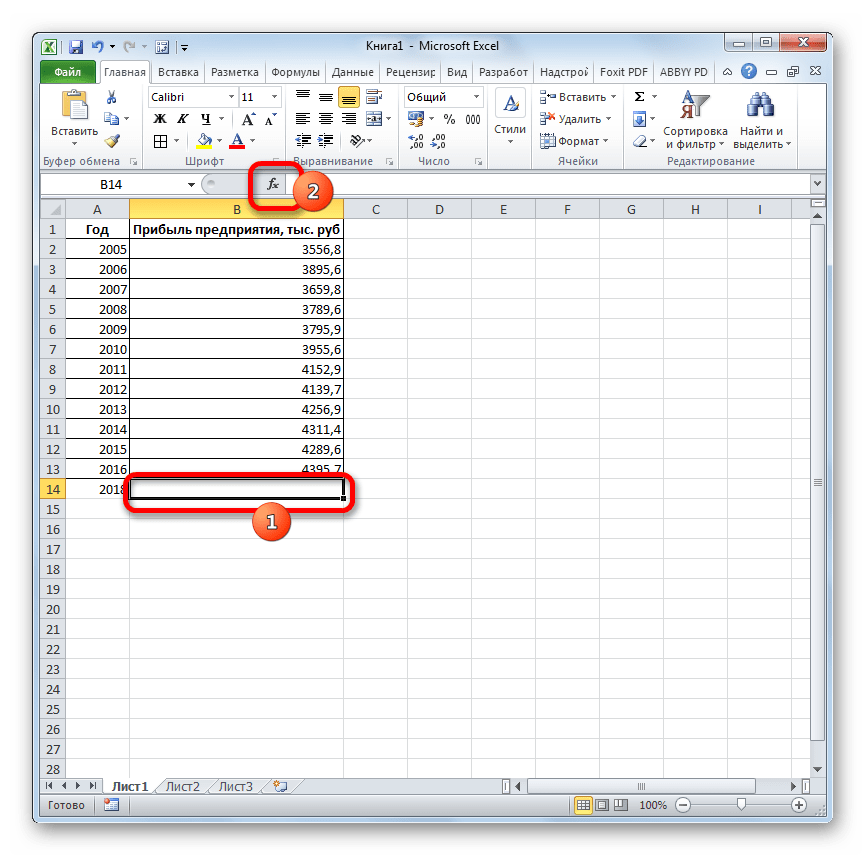
Давайте разберем нюансы применения оператора ПРЕДСКАЗ на конкретном примере. Возьмем всю ту же таблицу. Нам нужно будет узнать прогноз прибыли на 2018 год.
- Выделяем незаполненную ячейку на листе, куда планируется выводить результат обработки. Жмем на кнопку «Вставить функцию».
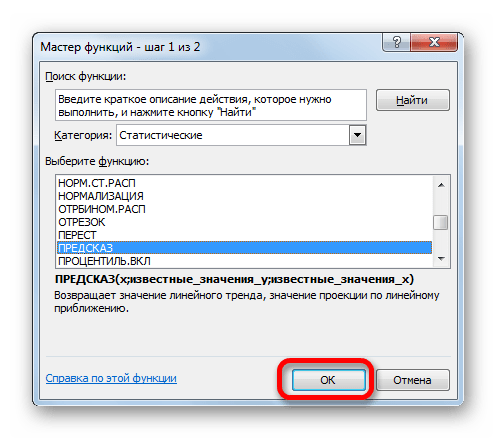
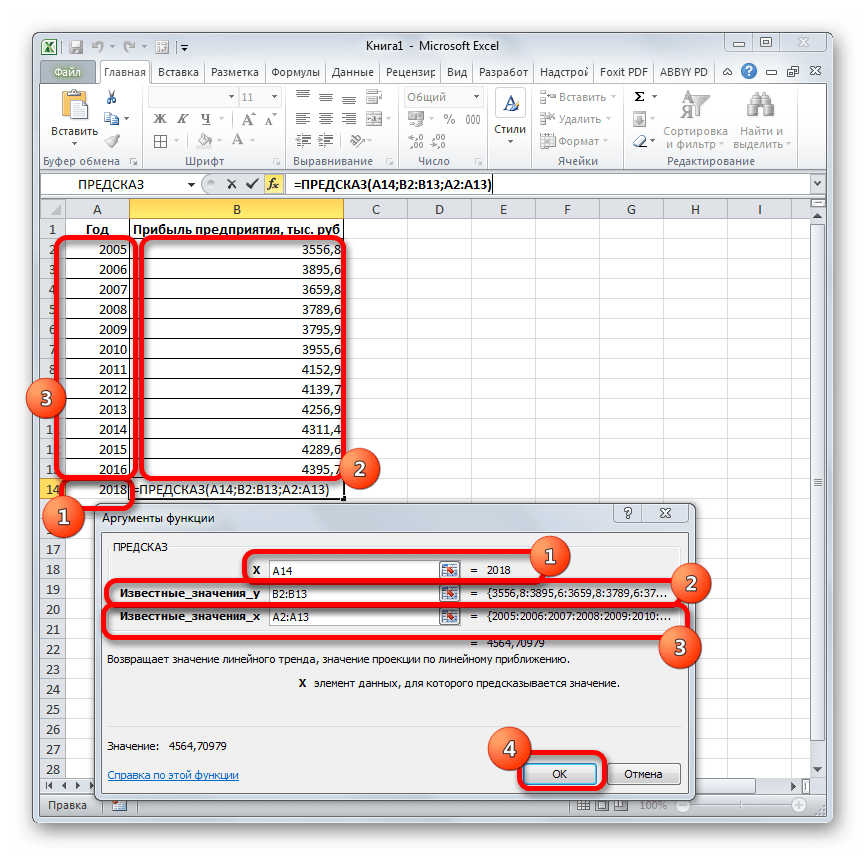
- Открывается Мастер функций. В категории «Статистические» выделяем наименование «ПРЕДСКАЗ», а затем щелкаем по кнопке «OK».
- Запускается окно аргументов. В поле «X» указываем величину аргумента, к которому нужно отыскать значение функции. В нашем случаем это 2018 год. Поэтому вносим запись «2018». Но лучше указать этот показатель в ячейке на листе, а в поле «X» просто дать ссылку на него. Это позволит в будущем автоматизировать вычисления и при надобности легко изменять год.
В поле «Известные значения y» указываем координаты столбца «Прибыль предприятия». Это можно сделать, установив курсор в поле, а затем, зажав левую кнопку мыши и выделив соответствующий столбец на листе.
Аналогичным образом в поле «Известные значения x» вносим адрес столбца «Год» с данными за прошедший период.
После того, как вся информация внесена, жмем на кнопку «OK».
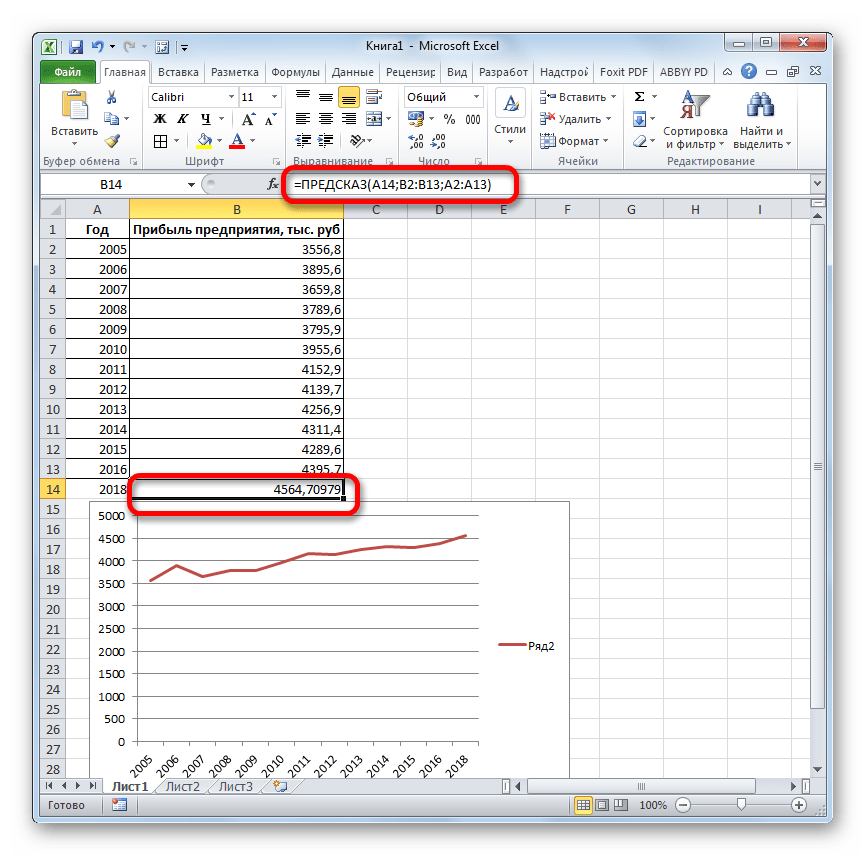
- Оператор производит расчет на основании введенных данных и выводит результат на экран. На 2018 год планируется прибыль в районе 4564,7 тыс. рублей. На основе полученной таблицы мы можем построить график при помощи инструментов создания диаграммы, о которых шла речь выше.
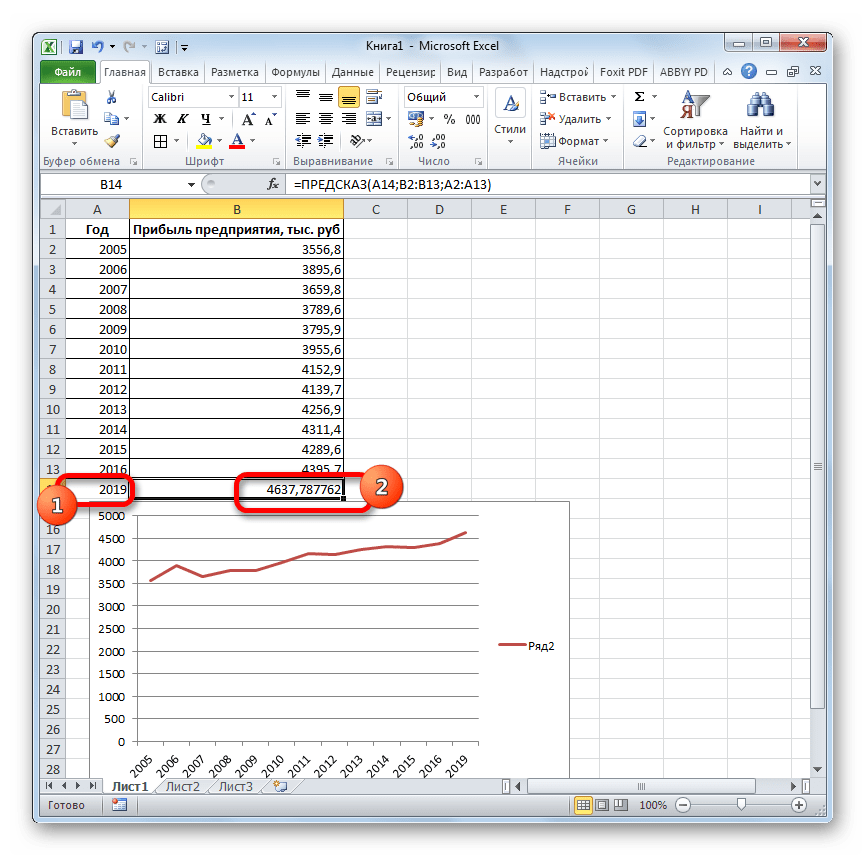
- Если поменять год в ячейке, которая использовалась для ввода аргумента, то соответственно изменится результат, а также автоматически обновится график. Например, по прогнозам в 2019 году сумма прибыли составит 4637,8 тыс. рублей.
Но не стоит забывать, что, как и при построении линии тренда, отрезок времени до прогнозируемого периода не должен превышать 30% от всего срока, за который накапливалась база данных.
Урок: Экстраполяция в Excel
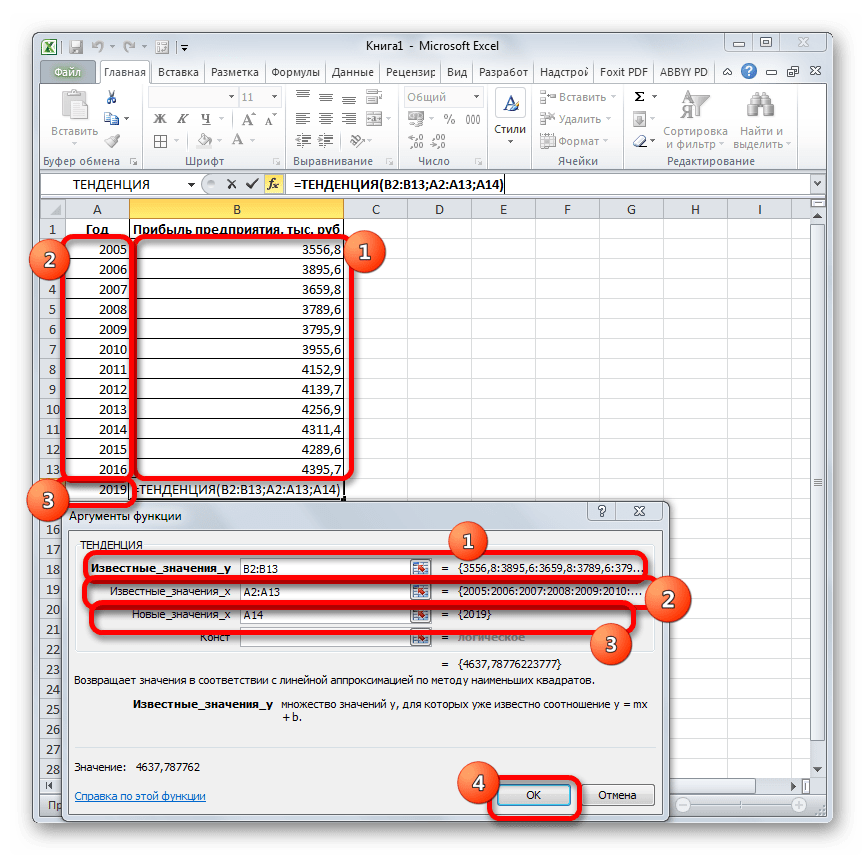
Способ 3: оператор ТЕНДЕНЦИЯ
Для прогнозирования можно использовать ещё одну функцию – ТЕНДЕНЦИЯ. Она также относится к категории статистических операторов. Её синтаксис во многом напоминает синтаксис инструмента ПРЕДСКАЗ и выглядит следующим образом:
=ТЕНДЕНЦИЯ(Известные значения_y;известные значения_x; новые_значения_x;[конст])
Как видим, аргументы «Известные значения y» и «Известные значения x» полностью соответствуют аналогичным элементам оператора ПРЕДСКАЗ, а аргумент «Новые значения x» соответствует аргументу «X» предыдущего инструмента. Кроме того, у ТЕНДЕНЦИЯ имеется дополнительный аргумент «Константа», но он не является обязательным и используется только при наличии постоянных факторов.
Данный оператор наиболее эффективно используется при наличии линейной зависимости функции.
Посмотрим, как этот инструмент будет работать все с тем же массивом данных. Чтобы сравнить полученные результаты, точкой прогнозирования определим 2019 год.
- Производим обозначение ячейки для вывода результата и запускаем Мастер функций обычным способом. В категории «Статистические» находим и выделяем наименование «ТЕНДЕНЦИЯ». Жмем на кнопку «OK».
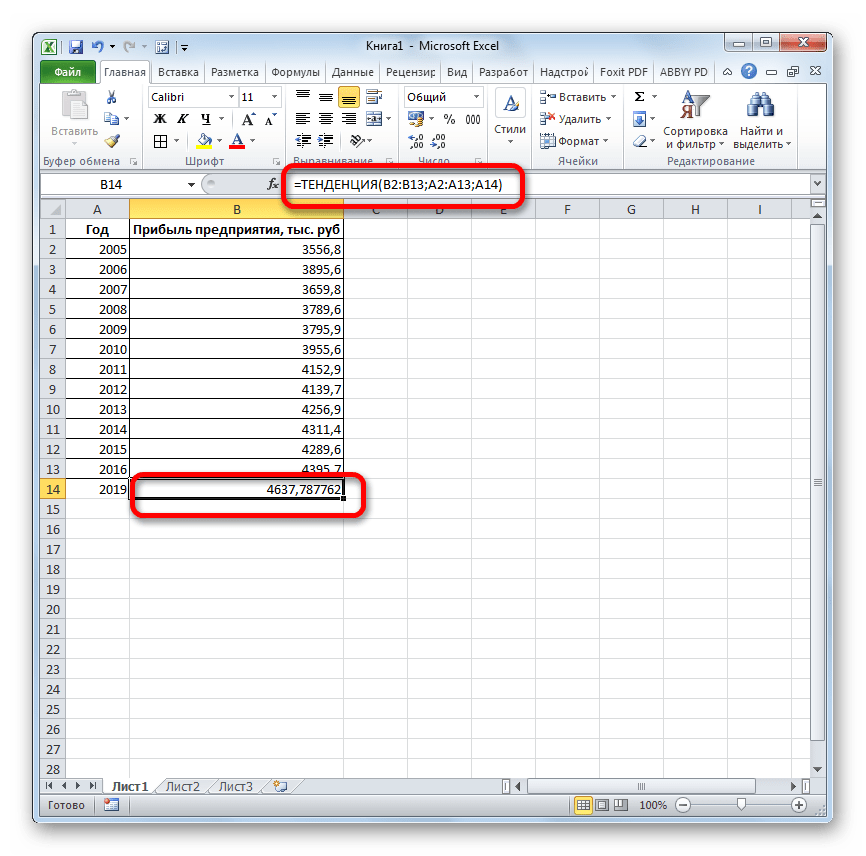
- Открывается окно аргументов оператора ТЕНДЕНЦИЯ. В поле «Известные значения y» уже описанным выше способом заносим координаты колонки «Прибыль предприятия». В поле «Известные значения x» вводим адрес столбца «Год». В поле «Новые значения x» заносим ссылку на ячейку, где находится номер года, на который нужно указать прогноз. В нашем случае это 2019 год. Поле «Константа» оставляем пустым. Щелкаем по кнопке «OK».
- Оператор обрабатывает данные и выводит результат на экран. Как видим, сумма прогнозируемой прибыли на 2019 год, рассчитанная методом линейной зависимости, составит, как и при предыдущем методе расчета, 4637,8 тыс. рублей.
Способ 4: оператор РОСТ
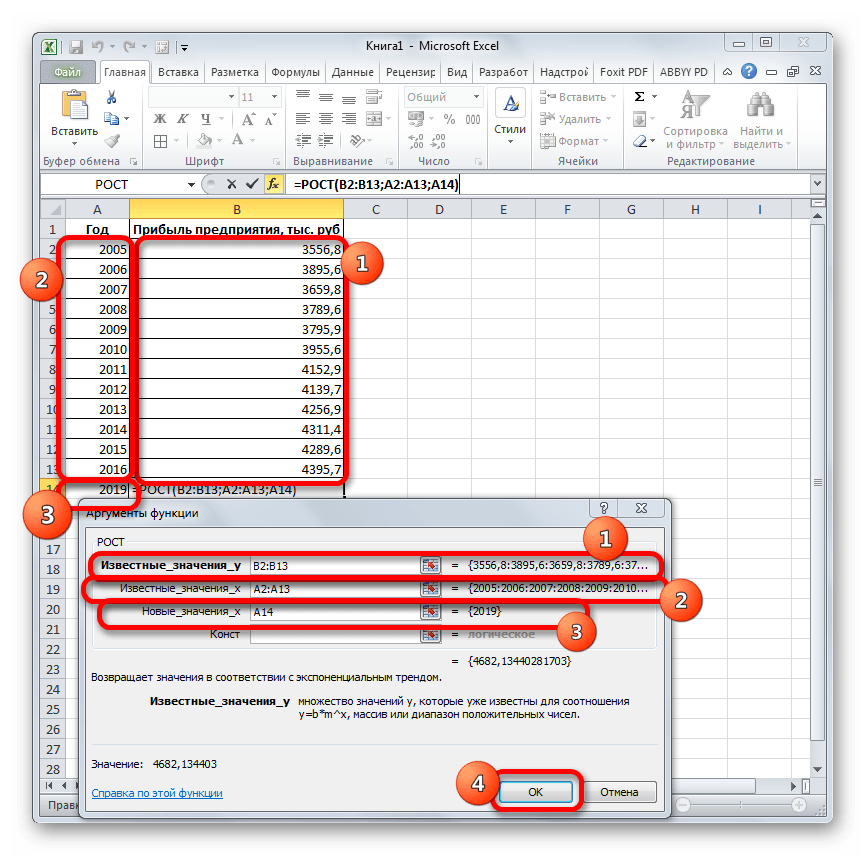
Ещё одной функцией, с помощью которой можно производить прогнозирование в Экселе, является оператор РОСТ. Он тоже относится к статистической группе инструментов, но, в отличие от предыдущих, при расчете применяет не метод линейной зависимости, а экспоненциальной. Синтаксис этого инструмента выглядит таким образом:
=РОСТ(Известные значения_y;известные значения_x; новые_значения_x;[конст])
Как видим, аргументы у данной функции в точности повторяют аргументы оператора ТЕНДЕНЦИЯ, так что второй раз на их описании останавливаться не будем, а сразу перейдем к применению этого инструмента на практике.
- Выделяем ячейку вывода результата и уже привычным путем вызываем Мастер функций. В списке статистических операторов ищем пункт «РОСТ», выделяем его и щелкаем по кнопке «OK».
- Происходит активация окна аргументов указанной выше функции. Вводим в поля этого окна данные полностью аналогично тому, как мы их вводили в окне аргументов оператора ТЕНДЕНЦИЯ. После того, как информация внесена, жмем на кнопку «OK».
- Результат обработки данных выводится на монитор в указанной ранее ячейке. Как видим, на этот раз результат составляет 4682,1 тыс. рублей. Отличия от результатов обработки данных оператором ТЕНДЕНЦИЯ незначительны, но они имеются. Это связано с тем, что данные инструменты применяют разные методы расчета: метод линейной зависимости и метод экспоненциальной зависимости.
Способ 5: оператор ЛИНЕЙН
Оператор ЛИНЕЙН при вычислении использует метод линейного приближения. Его не стоит путать с методом линейной зависимости, используемым инструментом ТЕНДЕНЦИЯ. Его синтаксис имеет такой вид:
=ЛИНЕЙН(Известные значения_y;известные значения_x; новые_значения_x;[конст];[статистика])
Последние два аргумента являются необязательными. С первыми же двумя мы знакомы по предыдущим способам. Но вы, наверное, заметили, что в этой функции отсутствует аргумент, указывающий на новые значения. Дело в том, что данный инструмент определяет только изменение величины выручки за единицу периода, который в нашем случае равен одному году, а вот общий итог нам предстоит подсчитать отдельно, прибавив к последнему фактическому значению прибыли результат вычисления оператора ЛИНЕЙН, умноженный на количество лет.
- Производим выделение ячейки, в которой будет производиться вычисление и запускаем Мастер функций. Выделяем наименование «ЛИНЕЙН» в категории «Статистические» и жмем на кнопку «OK».
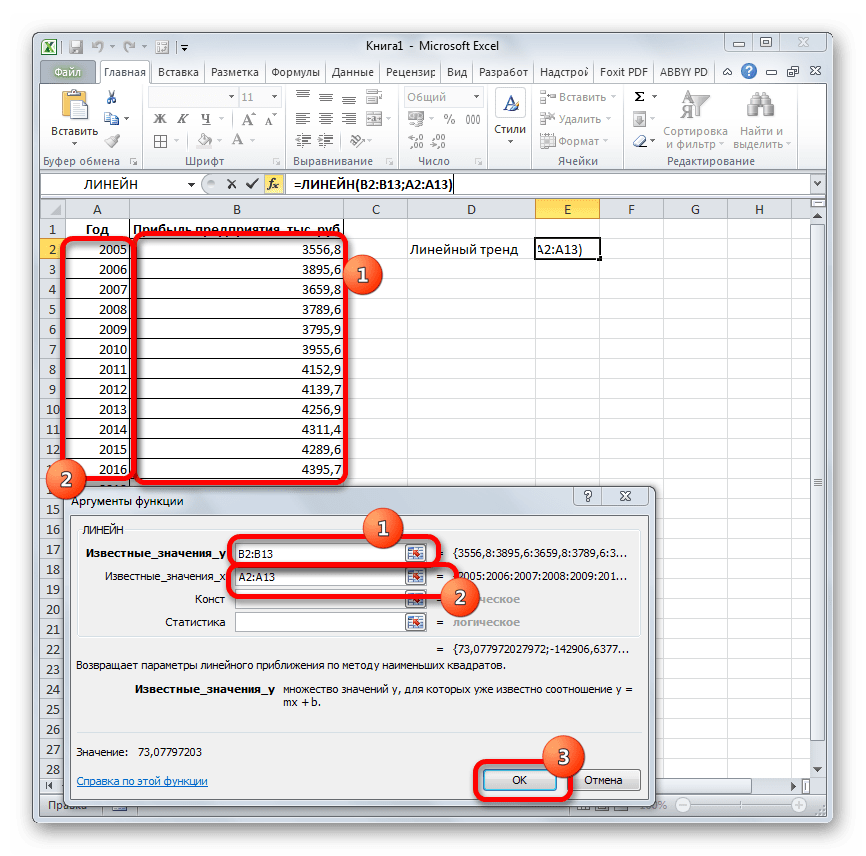
- В поле «Известные значения y», открывшегося окна аргументов, вводим координаты столбца «Прибыль предприятия». В поле «Известные значения x» вносим адрес колонки «Год». Остальные поля оставляем пустыми. Затем жмем на кнопку «OK».
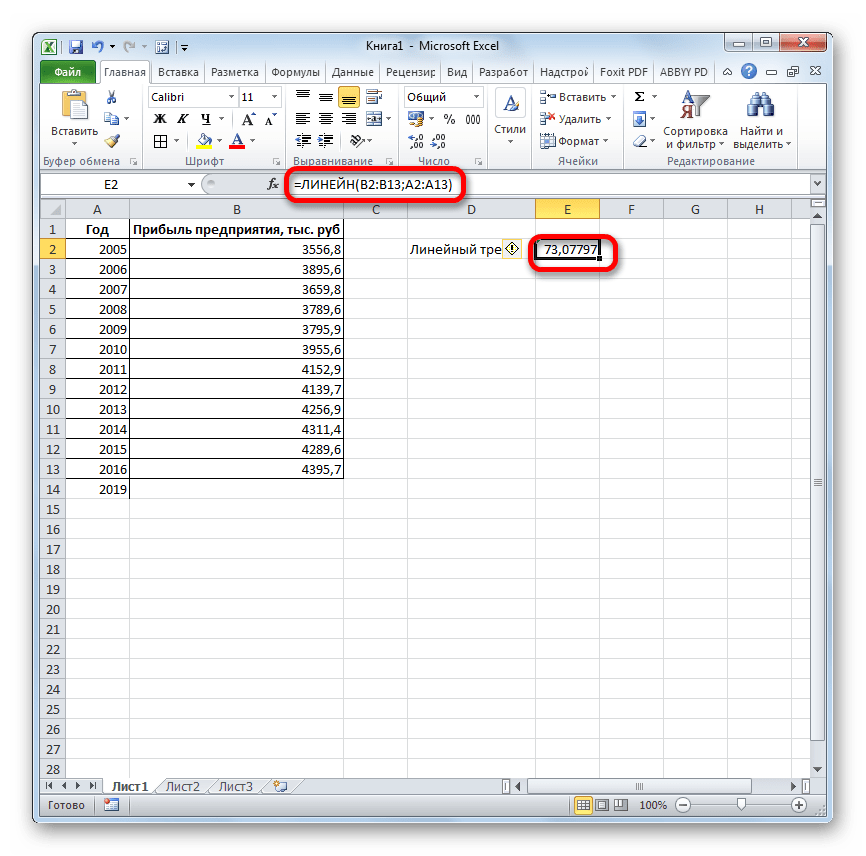
- Программа рассчитывает и выводит в выбранную ячейку значение линейного тренда.
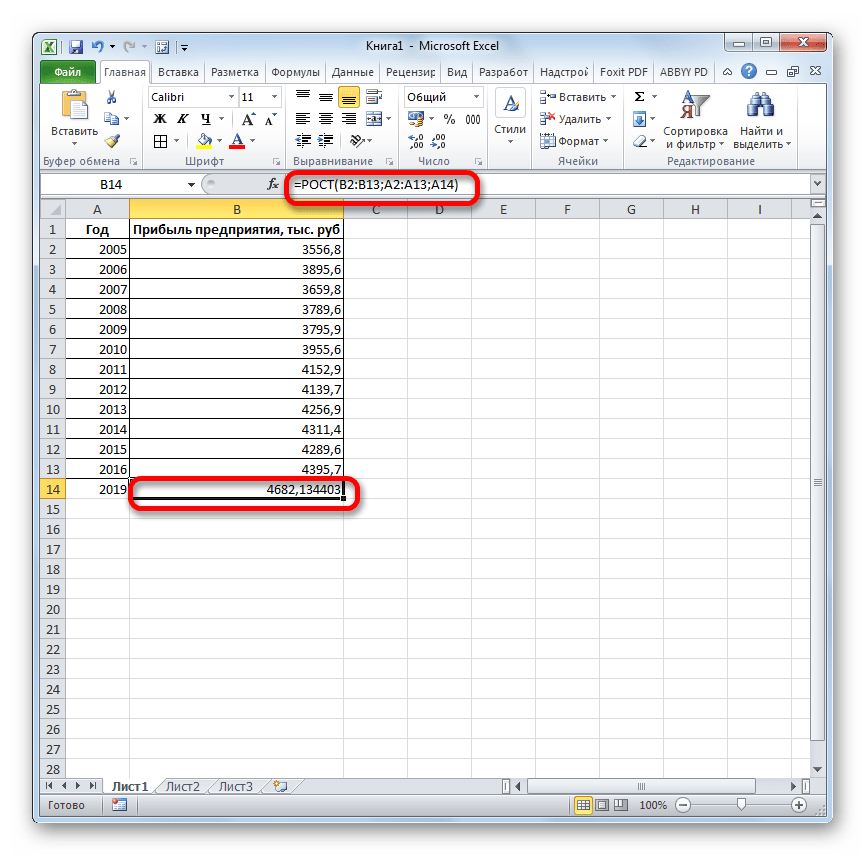
- Теперь нам предстоит выяснить величину прогнозируемой прибыли на 2019 год. Устанавливаем знак «=» в любую пустую ячейку на листе. Кликаем по ячейке, в которой содержится фактическая величина прибыли за последний изучаемый год (2016 г.). Ставим знак «+». Далее кликаем по ячейке, в которой содержится рассчитанный ранее линейный тренд. Ставим знак «*». Так как между последним годом изучаемого периода (2016 г.) и годом на который нужно сделать прогноз (2019 г.) лежит срок в три года, то устанавливаем в ячейке число «3». Чтобы произвести расчет кликаем по кнопке Enter.
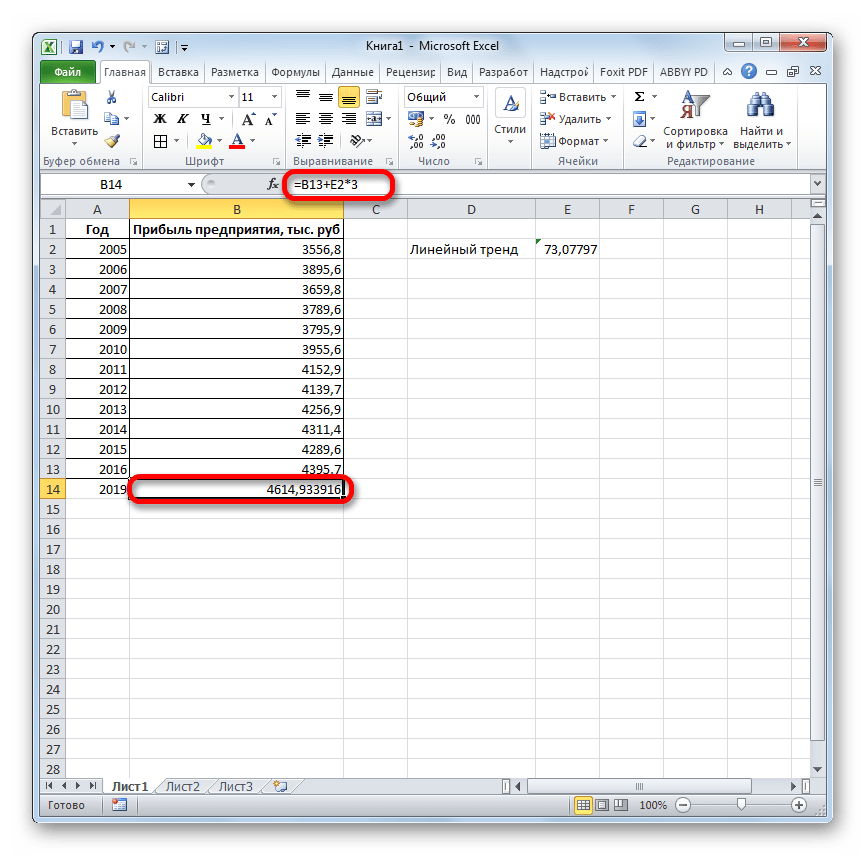
Как видим, прогнозируемая величина прибыли, рассчитанная методом линейного приближения, в 2019 году составит 4614,9 тыс. рублей.
Способ 6: оператор ЛГРФПРИБЛ
Последний инструмент, который мы рассмотрим, будет ЛГРФПРИБЛ. Этот оператор производит расчеты на основе метода экспоненциального приближения. Его синтаксис имеет следующую структуру:
= ЛГРФПРИБЛ (Известные значения_y;известные значения_x; новые_значения_x;[конст];[статистика])
Как видим, все аргументы полностью повторяют соответствующие элементы предыдущей функции. Алгоритм расчета прогноза немного изменится. Функция рассчитает экспоненциальный тренд, который покажет, во сколько раз поменяется сумма выручки за один период, то есть, за год. Нам нужно будет найти разницу в прибыли между последним фактическим периодом и первым плановым, умножить её на число плановых периодов (3) и прибавить к результату сумму последнего фактического периода.
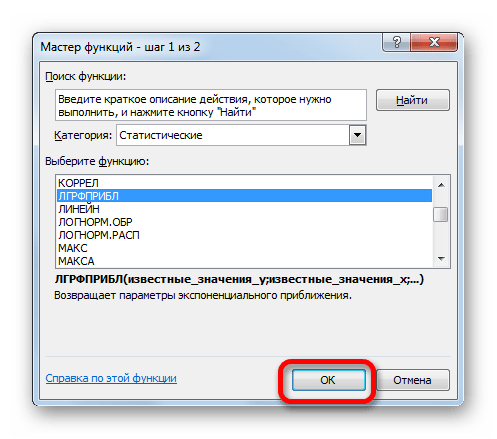
- В списке операторов Мастера функций выделяем наименование «ЛГРФПРИБЛ». Делаем щелчок по кнопке «OK».
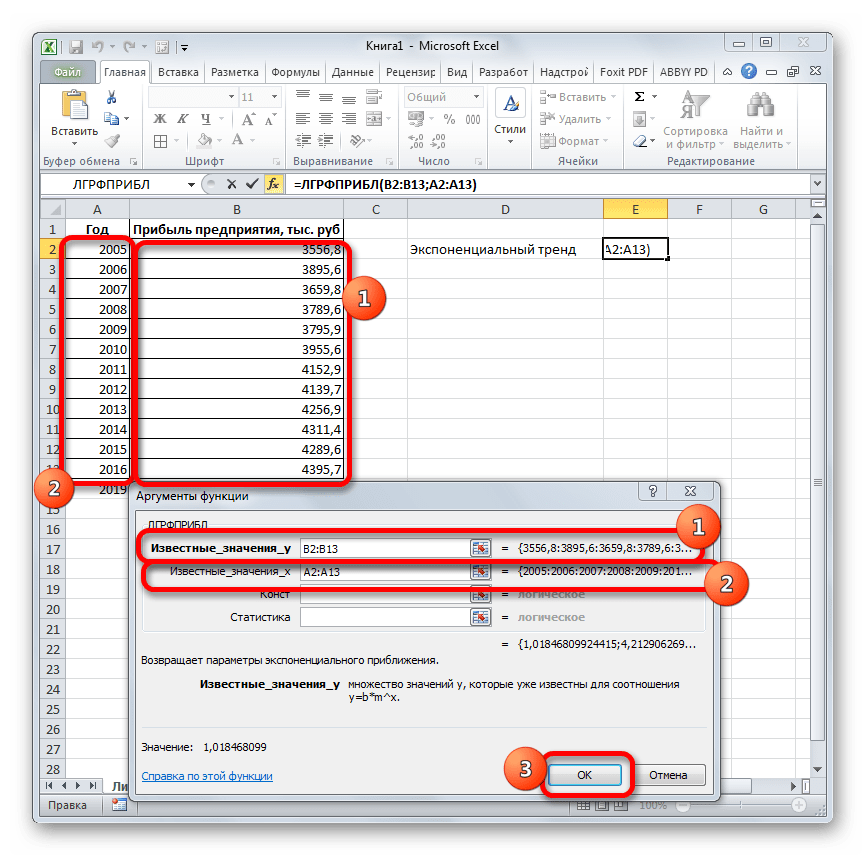
- Запускается окно аргументов. В нем вносим данные точно так, как это делали, применяя функцию ЛИНЕЙН. Щелкаем по кнопке «OK».
- Результат экспоненциального тренда подсчитан и выведен в обозначенную ячейку.
- Ставим знак «=» в пустую ячейку. Открываем скобки и выделяем ячейку, которая содержит значение выручки за последний фактический период. Ставим знак «*» и выделяем ячейку, содержащую экспоненциальный тренд. Ставим знак минус и снова кликаем по элементу, в котором находится величина выручки за последний период. Закрываем скобку и вбиваем символы «*3+» без кавычек. Снова кликаем по той же ячейке, которую выделяли в последний раз. Для проведения расчета жмем на кнопку Enter.
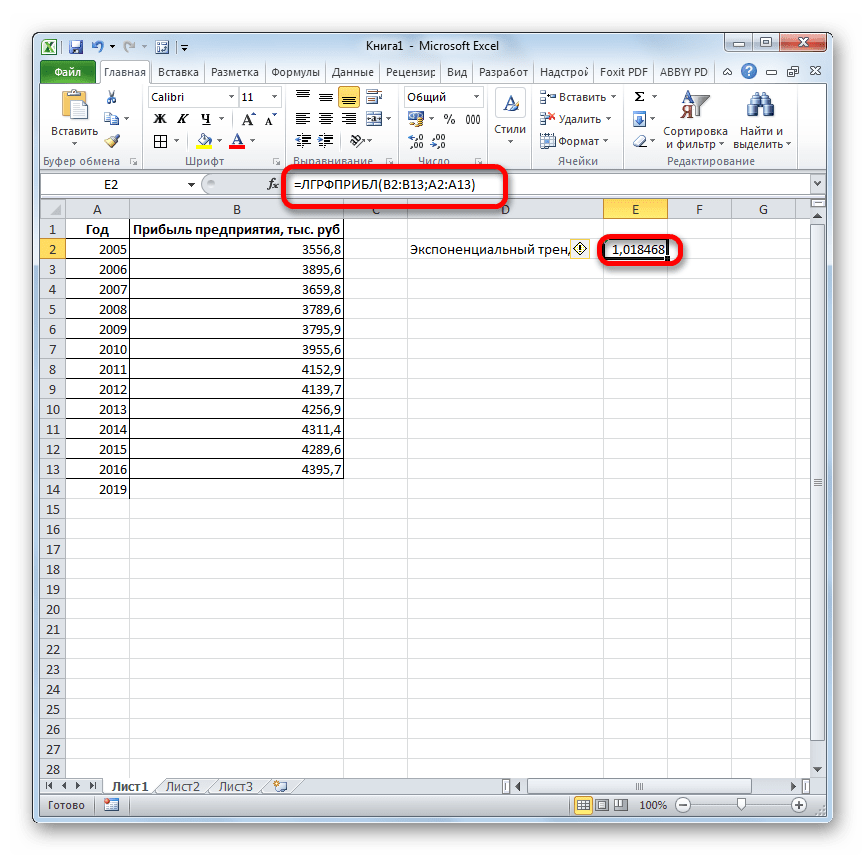
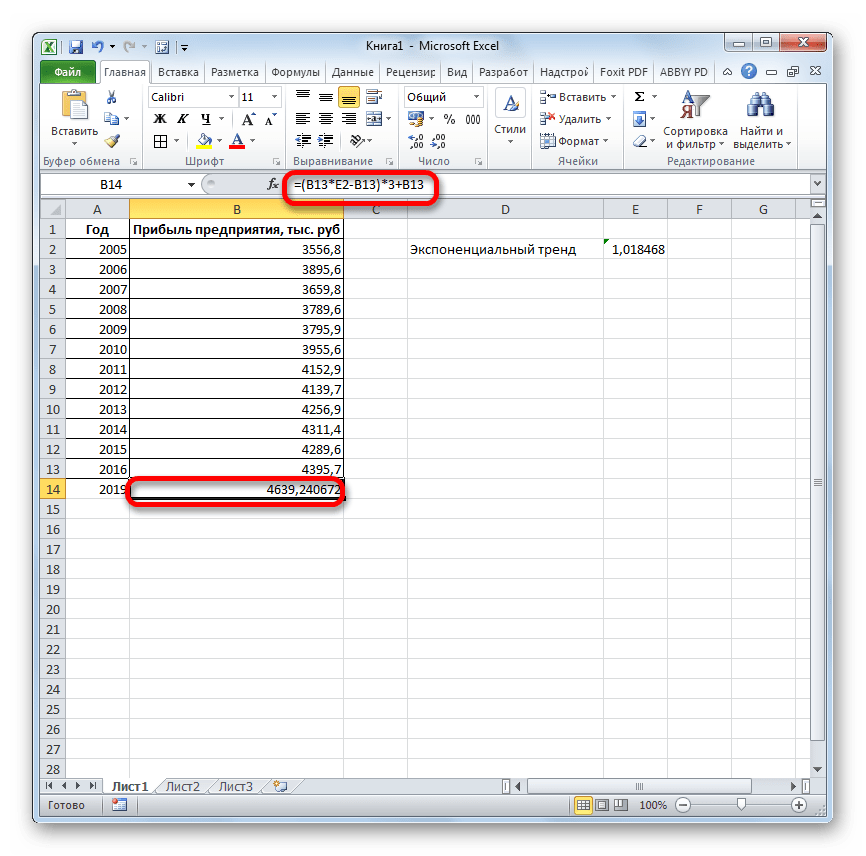
Прогнозируемая сумма прибыли в 2019 году, которая была рассчитана методом экспоненциального приближения, составит 4639,2 тыс. рублей, что опять не сильно отличается от результатов, полученных при вычислении предыдущими способами.
Урок: Другие статистические функции в Excel
Мы выяснили, какими способами можно произвести прогнозирование в программе Эксель. Графическим путем это можно сделать через применение линии тренда, а аналитическим – используя целый ряд встроенных статистических функций. В результате обработки идентичных данных этими операторами может получиться разный итог. Но это не удивительно, так как все они используют разные методы расчета. Если колебание небольшое, то все эти варианты, применимые к конкретному случаю, можно считать относительно достоверными.