
For those interested in a little info about this site: it’s a side project that I developed while working on Describing Words and Related Words. Both of those projects are based around words, but have much grander goals. I had an idea for a website that simply explains the word types of the words that you search for — just like a dictionary, but focussed on the part of speech of the words. And since I already had a lot of the infrastructure in place from the other two sites, I figured it wouldn’t be too much more work to get this up and running.
The dictionary is based on the amazing Wiktionary project by wikimedia. I initially started with WordNet, but then realised that it was missing many types of words/lemma (determiners, pronouns, abbreviations, and many more). This caused me to investigate the 1913 edition of Websters Dictionary — which is now in the public domain. However, after a day’s work wrangling it into a database I realised that there were far too many errors (especially with the part-of-speech tagging) for it to be viable for Word Type.
Finally, I went back to Wiktionary — which I already knew about, but had been avoiding because it’s not properly structured for parsing. That’s when I stumbled across the UBY project — an amazing project which needs more recognition. The researchers have parsed the whole of Wiktionary and other sources, and compiled everything into a single unified resource. I simply extracted the Wiktionary entries and threw them into this interface! So it took a little more work than expected, but I’m happy I kept at it after the first couple of blunders.
Special thanks to the contributors of the open-source code that was used in this project: the UBY project (mentioned above), @mongodb and express.js.
Currently, this is based on a version of wiktionary which is a few years old. I plan to update it to a newer version soon and that update should bring in a bunch of new word senses for many words (or more accurately, lemma).
Last Update: Jan 03, 2023
This is a question our experts keep getting from time to time. Now, we have got the complete detailed explanation and answer for everyone, who is interested!
Asked by: Prof. Lorenzo Fadel PhD
Score: 4.8/5
(13 votes)
adverb. 1In a calm and steady manner. 2In a flat or horizontal way.
Is there a word levelly?
Meaning of levelly in English
in a calm way without showing any emotion: He looked levelly across at me.
What is the definition of levelly?
/ˈlev. əl.i/ in a calm way without showing any emotion: He looked levelly across at me.
What type of word is type?
Type is used as a noun to mean a member of a category. As a verb type means to write using a typewriter or keyboard. The word type has many other senses as a noun and a verb.
What type of word is studied?
As detailed above, ‘studied’ is a verb.
15 related questions found
What type of verb is to study?
[transitive, intransitive] to spend time learning about a subject by reading, going to college, etc. He sat up very late that night, studying.
What is the root word of studied?
Quick Summary. The Greek root word log means ‘word,’ and its variant suffix -logy means ‘study (of). ‘ Some common English words that use this root include biology, mythology, catalog, and prologue.
What is Type example?
The definition of a type means people, places or things that share traits which allow them to belong to the same group. An example of type is men with blond hair. noun. 20. 7.
How many classes of word are there?
There are eight types of words that are often referred to as ‘word classes’ or ‘parts of speech’ and are commonly distinguished in English: nouns, determiners, pronouns, verbs, adjectives, adverbs, prepositions, and conjunctions. However, there are some more types of words that fall outside these ‘eight types’.
What type of word is she?
In Modern English, she is a singular, feminine, third-person pronoun.
What do you understand by locale?
1 : a place or locality especially when viewed in relation to a particular event or characteristic chose a tropical island as the locale for their wedding. 2 : site, scene the locale of a story.
What is a flat or even surface?
Level, even, flat, smooth suggest a uniform surface without marked unevenness. That which is level is parallel to the horizon: a level surface; A billiard table must be level. Flat is applied to any plane surface free from marked irregularities: a flat roof.
What is anything for Lent?
/ lɛnt / PHONETIC RESPELLING. noun. (in the Christian religion) an annual season of fasting and penitence in preparation for Easter, beginning on Ash Wednesday and lasting 40 weekdays to Easter, observed by Roman Catholic, Anglican, and certain other churches.
What are the 4 levels of grammar?
There are 4 levels of grammar: (1)parts of speech, (2)sentences, (3)phrases, and (4)clauses.
What are the 4 types of grammar?
The Noam Chomsky classifies the types of grammar in four types — Type0, Type1, Type2 and Type3. It is also called Chomsky hierarchy of grammar.
What are the three main classes of words?
In this section we will discuss the major word classes of English. These are nouns, verbs, adjectives and adverbs.
What is brief example?
Brief examples are used to further illustrate a point that may not be immediately obvious to all audience members but is not so complex that is requires a more lengthy example. Extended examples are used when a presenter is discussing a more complicated topic that they think their audience may be unfamiliar with.
What is Type explain?
type. [ tīp ] n. A number of people or things having in common traits or characteristics that distinguish them as a group or class. The general character or structure held in common by a number of people or things considered as a group or class.
What is an example of time?
Time is defined as the duration in which all things happen, or a precise instant that something happens. An example of time is the Renaissance era. An example of time is breakfast at eight o’clock in the morning. An example of time is a date at noon next Saturday.
What is learning called in Latin?
doctrina noun. doctrine, instruction, science, learning, teaching. institutio noun.
What is study word origin?
Etymology is the study of the origins of words. … Another way new words come into our language is through the development of products.
WHAT DOES IT MEAN TO studied?
1 : carefully considered or prepared : thoughtful a studied response. 2 : knowledgeable, learned studied in the craft of blacksmithing. 3 : produced or marked by conscious design or premeditation : calculated studied indifference spoke with a studied accent.
What is v1 v2 v3 v4 v5 verb?
Answer: v1 is present ,v2 past ,v3 past participate ,v4 present participate, v5 simple present.
How many types of verb are there?
There are four TYPES of verbs: intransitive, transitive, linking, and passive. Intransitive and transitive verbs are in the active voice, while passive verbs are in the passive voice. Intransitive verbs are verbs that express action but that do not take an object.
Mastering a language is not an easy task, especially if you stumble upon difficult vocabulary. Take a look at how you can check the language score and figure out what the hard words are.

How to access vocabulary difficulty?
Typically, vocabulary difficulty is useful to learners as second language. And the usefulness is beyond language learning. It is very important to automatic language processing or communicative writing as well. If we know what vocabulary is easy or not, we can use those information to assess text difficulty or composing article, and assessing language level.
The problem is that there are no concrete criteria. Language itself is changing constantly.
Yesterday’s difficult vocabulary become popular today and become easy and essential vocabulary.
There are no scientific, mathematic way to measure vocabulary difficulty as well. Only useful hints are popularity in everyday usages, context within sentence, and word senses in semantics.
Twinword’s Language Score
Twinword’s approach is based on word frequency to assess vocabulary difficulty, but on top of that considered several factors like exam occurrence. We also constantly update language database reflecting Twinword Exam test taker’s vocabulary test results. To make it helpful for English language learners, 10-level difficulty system was coined.
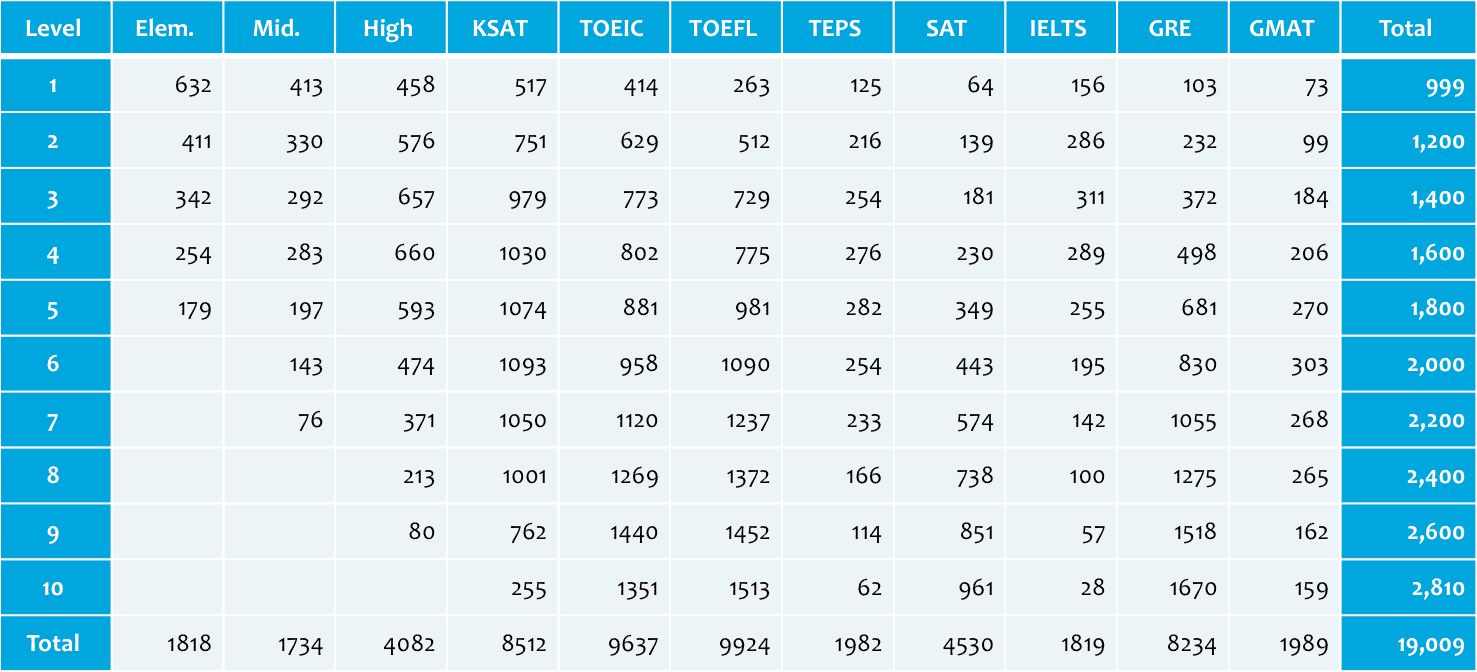
For app developers, Twinword’s language score API receive word or text and output its value(10-level difficulty) and normalized value between 0 to 1.
"ten_degree": 6,
"value": 0.18788740723541,
"version": "5.0.0",
"author": "twinword inc.",
"email": "[email protected]",
"result_code": "200",
"result_msg": "Success"
Try it yourself! Check how difficult is your writing and share how would you use language scoring API!
Also, if you want to challenge yourself and find out your understanding of complicated words, check Twinword Exam!
Language
levels.
The
grammatical
system
of
the
English
language,
like
of
other
Indo-European
languages,
is
very
complicated.
It
consists
of
smaller
subdivisions,
which
are
called
systems
too.
In
grammar
they
are
morphological
and
syntactic
ones.
In
syntax
we
discriminate
between
the
systems
of
simple
and
composite
sentences,
etc.
Prof.
V.
V.
Plotkin
suggests
the
terms
‘morosystem’
implying
the
grammatical
system
of
the
language
as
a
whole
and
‘subsystem’
and
‘microsystem’
with
reference
to
minor
system.
Thus,
the
systemic
character
of
grammar
is
beyond
doubt.
The
phonological
structure
of
language
is
also
systemic.
The
question
of
the
systemic
character
of
vocabulary
(word-stock)
remains
open.
But
of
all
lingual
aspects
grammar
is,
no
doubt,
most
systemic
since
it
is
responsible
for
the
very
organization
of
the
informative
content
of
utterance.
Language
in
general
and
grammar
in
particular
are
materialized
in
structure.
Language
structure
is
represented
by
a
level
stratification
of
its
units.
This
structure
is
of
hierarchical
character.
Graphically
the
level
stratification
of
language
can
be
depicted
by
following
table
(scheme):
Supra-proposemic
Text,
texteme,
dicteme
The
highest
communicative
unit
Promosemic
(the
level
of
major
syntax)
Proposeme
(sentence)
Communicative
unit
Phrasemic
(the
level
of
minor
syntax)
Phraseme
(word-group)
Polynominative
unit
Word
level
(lexemic)
Lexeme
(word)
Monominative
unit
Morphological
(morphemic)
Morpheme
The
smallest
meaning
full
unit
Phonological
(phonemic)
Phoneme
Distinctive
unit
Level
The
nature of the unrepresenting level
Language
unit
Units
of
language.
Units
of
language
are
divided
into
meaningless
and
meaningful.
Examples
of
the
first
kind:
phonemes,
syllable
Meaningful
are
morpheme,
word
and
others.
The
latter
are
called
– language
signs.
They
have
both
planes:
that
of
content
and
that
of
expression.
They
are
signemes.
As
to
the
way
of
expressing
lingual
units
are
divided
into
segmental
and
supra-segmental.
Segmental
units
consists
of
phonemes
and
form
phonetic
strings
of
various
status
(morphemes,
syllables).
Supra-segmental
units
do
not
exist
by
themselves,
they
are
realized
together
with
segmental
units
and
express
different
modificational
meanings
which
are
reflected
on
the
strings
of
segmental
units.
Supra-segmental
units
are
intonation
contours,
streets,
pauses
and
the
like.
Segmental
units
form
a
hierarchy
of
levels.
The
lowest
level
is
phonemic.
It
is
formed
by
phonemes,
which
are
not
language
signs,
because
they
are
purely
differential
(distinctive)
units.Units
of
all
the
higher
levels
are
meaningful.
They
are
language
signs
(signemes).
5) The Branches of linguistics
1.
General linguistic generally describes the concepts and categories of
a particular language or among all language. It also provides
analyzed theory of the language.
Descriptive
linguistic describes or gives the data to confirm or refute the
theory of particular language explained generally.
2.
Micro linguistic is narrower view. It is concerned internal view of
language itself (structure of language systems) without related to
other sciences and without related how to apply it in daily life.
Some fields of micro linguistic:
a.
Phonetics, the study of the physical properties of sounds of human
language
b.
Phonology, the study of sounds as discrete, abstract elements in the
speaker’s mind that distinguish meaning
c.
Morphology, the study of internal structures of words and how they
can be modified
d.
Syntax, the study of how words combine to form grammatical sentences
e.
Semantics, the study of the meaning of words (lexical semantics) and
fixed word combinations (phraseology), and how these combine to form
the meanings of sentences
f.
Pragmatics, the study of how utterances are used (literally,
figuratively, or otherwise) in communicative acts
g.
Discourse analysis, the analysis of language use in texts (spoken,
written, or signed)
h.
Applied linguistic is the branch of linguistic that is most concerned
with application of the concepts in everyday life, including
language-teaching.
3.
Macro linguistic is broadest view of language. It is concerned
external view of language itself with related to other sciences and
how to apply it in daily life. Some fields of micro linguistic:
a.
Stylistics, the study of linguistic factors that place a discourse in
context.
b.
Developmental linguistics, the study of the development of linguistic
ability in an individual, particularly the acquisition of language in
childhood.
c.
Historical linguistics or Diachronic linguistics, the study of
language change.
d.
Language geography, the study of the spatial patterns of languages.
e.
Evolutionary linguistics, the study of the origin and subsequent
development of language.
f.
Psycholinguistics, the study of the cognitive processes and
representations underlying language use.
g.
Sociolinguistics, the study of social patterns and norms of
linguistic variability.
h.
Clinical linguistics, the application of linguistic theory to the
area of Speech-Language Pathology.
i.
Neurolinguistics, the study of the brain networks that underlie
grammar and communication.
j.
Biolinguistics, the study of natural as well as human-taught
communication systems in animals compared to human language.
Computational
linguistics, the study of computational implementations of linguistic
structures.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
WORD STRUCTURE IN MODERN ENGLISH
I. The morphological structure of a word. Morphemes. Types of morphemes. Allomorphs.
II. Structural types of words.
III. Principles of morphemic analysis.
IV. Derivational level of analysis. Stems. Types of stems. Derivational types of words.
I. The morphological structure of a word. Morphemes. Types of Morphemes. Allomorphs.
There are two levels of approach to the study of word- structure: the level of morphemic analysis and the level of derivational or word-formation analysis.
Word is the principal and basic unit of the language system, the largest on the morphologic and the smallest on the syntactic plane of linguistic analysis.
It has been universally acknowledged that a great many words have a composite nature and are made up of morphemes, the basic units on the morphemic level, which are defined as the smallest indivisible two-facet language units.
The term morpheme is derived from Greek morphe “form ”+ -eme. The Greek suffix –eme has been adopted by linguistic to denote the smallest unit or the minimum distinctive feature.
The morpheme is the smallest meaningful unit of form. A form in these cases a recurring discrete unit of speech. Morphemes occur in speech only as constituent parts of words, not independently, although a word may consist of single morpheme. Even a cursory examination of the morphemic structure of English words reveals that they are composed of morphemes of different types: root-morphemes and affixational morphemes. Words that consist of a root and an affix are called derived words or derivatives and are produced by the process of word building known as affixation (or derivation).
The root-morpheme is the lexical nucleus of the word; it has a very general and abstract lexical meaning common to a set of semantically related words constituting one word-cluster, e.g. (to) teach, teacher, teaching. Besides the lexical meaning root-morphemes possess all other types of meaning proper to morphemes except the part-of-speech meaning which is not found in roots.
Affixational morphemes include inflectional affixes or inflections and derivational affixes. Inflections carry only grammatical meaning and are thus relevant only for the formation of word-forms. Derivational affixes are relevant for building various types of words. They are lexically always dependent on the root which they modify. They possess the same types of meaning as found in roots, but unlike root-morphemes most of them have the part-of-speech meaning which makes them structurally the important part of the word as they condition the lexico-grammatical class the word belongs to. Due to this component of their meaning the derivational affixes are classified into affixes building different parts of speech: nouns, verbs, adjectives or adverbs.
Roots and derivational affixes are generally easily distinguished and the difference between them is clearly felt as, e.g., in the words helpless, handy, blackness, Londoner, refill, etc.: the root-morphemes help-, hand-, black-, London-, fill-, are understood as the lexical centers of the words, and –less, -y, -ness, -er, re- are felt as morphemes dependent on these roots.
Distinction is also made of free and bound morphemes.
Free morphemes coincide with word-forms of independently functioning words. It is obvious that free morphemes can be found only among roots, so the morpheme boy- in the word boy is a free morpheme; in the word undesirable there is only one free morpheme desire-; the word pen-holder has two free morphemes pen- and hold-. It follows that bound morphemes are those that do not coincide with separate word- forms, consequently all derivational morphemes, such as –ness, -able, -er are bound. Root-morphemes may be both free and bound. The morphemes theor- in the words theory, theoretical, or horr- in the words horror, horrible, horrify; Angl- in Anglo-Saxon; Afr- in Afro-Asian are all bound roots as there are no identical word-forms.
It should also be noted that morphemes may have different phonemic shapes. In the word-cluster please , pleasing , pleasure , pleasant the phonemic shapes of the word stand in complementary distribution or in alternation with each other. All the representations of the given morpheme, that manifest alternation are called allomorphs/or morphemic variants/ of that morpheme.
The combining form allo- from Greek allos “other” is used in linguistic terminology to denote elements of a group whose members together consistute a structural unit of the language (allophones, allomorphs). Thus, for example, -ion/ -tion/ -sion/ -ation are the positional variants of the same suffix, they do not differ in meaning or function but show a slight difference in sound form depending on the final phoneme of the preceding stem. They are considered as variants of one and the same morpheme and called its allomorphs.
Allomorph is defined as a positional variant of a morpheme occurring in a specific environment and so characterized by complementary description.
Complementary distribution is said to take place, when two linguistic variants cannot appear in the same environment.
Different morphemes are characterized by contrastive distribution, i.e. if they occur in the same environment they signal different meanings. The suffixes –able and –ed, for instance, are different morphemes, not allomorphs, because adjectives in –able mean “ capable of beings”.
Allomorphs will also occur among prefixes. Their form then depends on the initials of the stem with which they will assimilate.
Two or more sound forms of a stem existing under conditions of complementary distribution may also be regarded as allomorphs, as, for instance, in long a: length n.
II. Structural types of words.
The morphological analysis of word- structure on the morphemic level aims at splitting the word into its constituent morphemes – the basic units at this level of analysis – and at determining their number and types. The four types (root words, derived words, compound, shortenings) represent the main structural types of Modern English words, and conversion, derivation and composition the most productive ways of word building.
According to the number of morphemes words can be classified into monomorphic and polymorphic. Monomorphic or root-words consist of only one root-morpheme, e.g. small, dog, make, give, etc. All polymorphic word fall into two subgroups: derived words and compound words – according to the number of root-morphemes they have. Derived words are composed of one root-morpheme and one or more derivational morphemes, e.g. acceptable, outdo, disagreeable, etc. Compound words are those which contain at least two root-morphemes, the number of derivational morphemes being insignificant. There can be both root- and derivational morphemes in compounds as in pen-holder, light-mindedness, or only root-morphemes as in lamp-shade, eye-ball, etc.
These structural types are not of equal importance. The clue to the correct understanding of their comparative value lies in a careful consideration of: 1)the importance of each type in the existing wordstock, and 2) their frequency value in actual speech. Frequency is by far the most important factor. According to the available word counts made in different parts of speech, we find that derived words numerically constitute the largest class of words in the existing wordstock; derived nouns comprise approximately 67% of the total number, adjectives about 86%, whereas compound nouns make about 15% and adjectives about 4%. Root words come to 18% in nouns, i.e. a trifle more than the number of compound words; adjectives root words come to approximately 12%.
But we cannot fail to perceive that root-words occupy a predominant place. In English, according to the recent frequency counts, about 60% of the total number of nouns and 62% of the total number of adjectives in current use are root-words. Of the total number of adjectives and nouns, derived words comprise about 38% and 37% respectively while compound words comprise an insignificant 2% in nouns and 0.2% in adjectives. Thus it is the root-words that constitute the foundation and the backbone of the vocabulary and that are of paramount importance in speech. It should also be mentioned that root words are characterized by a high degree of collocability and a complex variety of meanings in contrast with words of other structural types whose semantic structures are much poorer. Root- words also serve as parent forms for all types of derived and compound words.
III. Principles of morphemic analysis.
In most cases the morphemic structure of words is transparent enough and individual morphemes clearly stand out within the word. The segmentation of words is generally carried out according to the method of Immediate and Ultimate Constituents. This method is based on the binary principle, i.e. each stage of the procedure involves two components the word immediately breaks into. At each stage these two components are referred to as the Immediate Constituents. Each Immediate Constituent at the next stage of analysis is in turn broken into smaller meaningful elements. The analysis is completed when we arrive at constituents incapable of further division, i.e. morphemes. These are referred to Ultimate Constituents.
A synchronic morphological analysis is most effectively accomplished by the procedure known as the analysis into Immediate Constituents. ICs are the two meaningful parts forming a large linguistic unity.
The method is based on the fact that a word characterized by morphological divisibility is involved in certain structural correlations. To sum up: as we break the word we obtain at any level only ICs one of which is the stem of the given word. All the time the analysis is based on the patterns characteristic of the English vocabulary. As a pattern showing the interdependence of all the constituents segregated at various stages, we obtain the following formula:
un+ { [ ( gent- + -le ) + -man ] + -ly}
Breaking a word into its Immediate Constituents we observe in each cut the structural order of the constituents.
A diagram presenting the four cuts described looks as follows:
1. un- / gentlemanly
2. un- / gentleman / — ly
3. un- / gentle / — man / — ly
4. un- / gentl / — e / — man / — ly
A similar analysis on the word-formation level showing not only the morphemic constituents of the word but also the structural pattern on which it is built.
The analysis of word-structure at the morphemic level must proceed to the stage of Ultimate Constituents. For example, the noun friendliness is first segmented into the ICs: [frendlı-] recurring in the adjectives friendly-looking and friendly and [-nıs] found in a countless number of nouns, such as unhappiness, blackness, sameness, etc. the IC [-nıs] is at the same time an UC of the word, as it cannot be broken into any smaller elements possessing both sound-form and meaning. Any further division of –ness would give individual speech-sounds which denote nothing by themselves. The IC [frendlı-] is next broken into the ICs [-lı] and [frend-] which are both UCs of the word.
Morphemic analysis under the method of Ultimate Constituents may be carried out on the basis of two principles: the so-called root-principle and affix principle.
According to the affix principle the splitting of the word into its constituent morphemes is based on the identification of the affix within a set of words, e.g. the identification of the suffix –er leads to the segmentation of words singer, teacher, swimmer into the derivational morpheme – er and the roots teach- , sing-, drive-.
According to the root-principle, the segmentation of the word is based on the identification of the root-morpheme in a word-cluster, for example the identification of the root-morpheme agree- in the words agreeable, agreement, disagree.
As a rule, the application of these principles is sufficient for the morphemic segmentation of words.
However, the morphemic structure of words in a number of cases defies such analysis, as it is not always so transparent and simple as in the cases mentioned above. Sometimes not only the segmentation of words into morphemes, but the recognition of certain sound-clusters as morphemes become doubtful which naturally affects the classification of words. In words like retain, detain, contain or receive, deceive, conceive, perceive the sound-clusters [rı-], [dı-] seem to be singled quite easily, on the other hand, they undoubtedly have nothing in common with the phonetically identical prefixes re-, de- as found in words re-write, re-organize, de-organize, de-code. Moreover, neither the sound-cluster [rı-] or [dı-], nor the [-teın] or [-sı:v] possess any lexical or functional meaning of their own. Yet, these sound-clusters are felt as having a certain meaning because [rı-] distinguishes retain from detain and [-teın] distinguishes retain from receive.
It follows that all these sound-clusters have a differential and a certain distributional meaning as their order arrangement point to the affixal status of re-, de-, con-, per- and makes one understand —tain and –ceive as roots. The differential and distributional meanings seem to give sufficient ground to recognize these sound-clusters as morphemes, but as they lack lexical meaning of their own, they are set apart from all other types of morphemes and are known in linguistic literature as pseudo- morphemes. Pseudo- morphemes of the same kind are also encountered in words like rusty-fusty.
IV. Derivational level of analysis. Stems. Types of Stems. Derivational types of word.
The morphemic analysis of words only defines the constituent morphemes, determining their types and their meaning but does not reveal the hierarchy of the morphemes comprising the word. Words are no mere sum totals of morpheme, the latter reveal a definite, sometimes very complex interrelation. Morphemes are arranged according to certain rules, the arrangement differing in various types of words and particular groups within the same types. The pattern of morpheme arrangement underlies the classification of words into different types and enables one to understand how new words appear in the language. These relations within the word and the interrelations between different types and classes of words are known as derivative or word- formation relations.
The analysis of derivative relations aims at establishing a correlation between different types and the structural patterns words are built on. The basic unit at the derivational level is the stem.
The stem is defined as that part of the word which remains unchanged throughout its paradigm, thus the stem which appears in the paradigm (to) ask ( ), asks, asked, asking is ask-; thestem of the word singer ( ), singer’s, singers, singers’ is singer-. It is the stem of the word that takes the inflections which shape the word grammatically as one or another part of speech.
The structure of stems should be described in terms of IC’s analysis, which at this level aims at establishing the patterns of typical derivative relations within the stem and the derivative correlation between stems of different types.
There are three types of stems: simple, derived and compound.
Simple stems are semantically non-motivated and do not constitute a pattern on analogy with which new stems may be modeled. Simple stems are generally monomorphic and phonetically identical with the root morpheme. The derivational structure of stems does not always coincide with the result of morphemic analysis. Comparison proves that not all morphemes relevant at the morphemic level are relevant at the derivational level of analysis. It follows that bound morphemes and all types of pseudo- morphemes are irrelevant to the derivational structure of stems as they do not meet requirements of double opposition and derivative interrelations. So the stem of such words as retain, receive, horrible, pocket, motion, etc. should be regarded as simple, non- motivated stems.
Derived stems are built on stems of various structures though which they are motivated, i.e. derived stems are understood on the basis of the derivative relations between their IC’s and the correlated stems. The derived stems are mostly polymorphic in which case the segmentation results only in one IC that is itself a stem, the other IC being necessarily a derivational affix.
Derived stems are not necessarily polymorphic.
Compound stems are made up of two IC’s, both of which are themselves stems, for example match-box, driving-suit, pen-holder, etc. It is built by joining of two stems, one of which is simple, the other derived.
In more complex cases the result of the analysis at the two levels sometimes seems even to contracted one another.
The derivational types of words are classified according to the structure of their stems into simple, derived and compound words.
Derived words are those composed of one root- morpheme and one or more derivational morpheme.
Compound words contain at least two root- morphemes, the number of derivational morphemes being insignificant.
Derivational compound is a word formed by a simultaneous process of composition and derivational.
Compound words proper are formed by joining together stems of word already available in the language.
Теги:
Word structure in modern english
Реферат
Английский
Просмотров: 27606
Найти в Wikkipedia статьи с фразой: Word structure in modern english
Lecture 3. Word-building: affixation, conversion, composition, abbreviation. THE WORD-BUILDING SYSTEM OF ENGLISH 1. Word-derivation 2. Affixation 3. Conversion 4. Word-composition 5. Shortening 6. Blending 7. Acronymy 8. Sound interchange 9. Sound imitation 10. Distinctive stress 11. Back-formation Word-formation is a branch of Lexicology which studies the process of building new words, derivative structures and patterns of existing words. Two principle types of wordformation are distinguished: word-derivation and word-composition. It is evident that wordformation proper can deal only with words which can be analyzed both structurally and semantically. Simple words are closely connected with word-formation because they serve as the foundation of derived and compound words. Therefore, words like writer, displease, sugar free, etc. make the subject matter of study in word-formation, but words like to write, to please, atom, free are irrelevant to it. WORD-FORMATION WORD-DERIVATION AFFIXATION WORD-COMPOSITION CONVERSION 1. Word-derivation. Speaking about word-derivation we deal with the derivational structure of words which basic elementary units are derivational bases, derivational affixes and derivational patterns. A derivational base is the part of the word which establishes connection with the lexical unit that motivates the derivative and determines its individual lexical meaning describing the difference between words in one and the same derivative set. For example, the individual lexical meaning of the words singer, writer, teacher which denote active doers of the action is signaled by the lexical meaning of the derivational bases: sing-, write-, teach-. Structurally derivational bases fall into 3 classes: 1. Bases that coincide with morphological stems of different degrees оf complexity, i.e., with words functioning independently in modern English e.g., dutiful, day-dreamer. Bases are functionally and semantically distinct from morphological stems. Functionally the morphological stem is a part of the word which is the starting point for its forms: heart – hearts; it is the part which presents the entire grammatical paradigm. The stem remains unchanged throughout all word-forms; it keeps them together preserving the identity of the word. A derivational base is the starting point for different words (heart – heartless – hearty) and its derivational potential outlines the type and scope of existing words and new creations. Semantically the stem stands for the whole semantic structure of the word; it represents all its lexical meanings. A base represents, as a rule, only one meaning of the source word. 2. Bases that coincide with word-forms, e.g., unsmiling, unknown. The base is usually represented by verbal forms: the present and the past participles. 3. Bases that coincide with word-groups of different degrees of stability, e.g., blue-eyed, empty-handed. Bases of this class allow a rather limited range of collocability, they are most active with derivational affixes in the class of adjectives and nouns (long-fingered, blue-eyed). Derivational affixes are Immediate Constituents of derived words in all parts of speech. Affixation is generally defined as the formation of words by adding derivational affixes to different types of bases. Affixation is subdivided into suffixation and prefixation. In Modern English suffixation is mostly characteristic of nouns and adjectives coining, while prefixation is mostly typical of verb formation. A derivational pattern is a regular meaningful arrangement, a structure that imposes rigid rules on the order and the nature of the derivational base and affixes that may be brought together to make up a word. Derivational patterns are studied with the help of distributional analysis at different levels. Patterns are usually represented in a generalized way in terms of conventional symbols: small letters v, n, a, d which stand for the bases coinciding with the stems of the respective parts of speech: verbs, etc. Derivational patterns may represent derivative structure at different levels of generalization: - at the level of structural types. The patterns of this type are known as structural formulas, all words may be classified into 4 classes: suffixal derivatives (friendship) n + -sf → N, prefixal derivatives (rewrite), conversions (a cut, to parrot) v → N, compound words (musiclover). - at the level of structural patterns. Structural patterns specify the base classes and individual affixes thus indicating the lexical-grammatical and lexical classes of derivatives within certain structural classes of words. The suffixes refer derivatives to specific parts of speech and lexical subsets. V + -er = N (a semantic set of active agents, denoting both animate and inanimate objects - reader, singer); n + -er = N (agents denoting residents or occupations Londoner, gardener). We distinguish a structural semantic derivationa1 pattern. - at the level of structural-semantic patterns. Derivational patterns may specify semantic features of bases and individual meaning of affixes: N + -y = A (nominal bases denoting living beings are collocated with the suffix meaning "resemblance" - birdy, catty; but nominal bases denoting material, parts of the body attract another meaning "considerable amount" - grassy, leggy). The basic ways of forming new words in word-derivation are affixation and conversion. Affixation is the formation of a new word with the help of affixes (heartless, overdo). Conversion is the formation of a new word by bringing a stem of this word into a different paradigm (a fall from to fall). 2. Affixation Affixation is generally defined as the formation of words by adding derivational affixes to different types of bases. Affixation includes suffixation and prefixation. Distinction between suffixal and prefixal derivates is made according to the last stage of derivation, for example, from the point of view of derivational analysis the word unreasonable – un + (reason- + -able) is qualified as a prefixal derivate, while the word discouragement – (dis- + -courage) + -ment is defined as a suffixal derivative. Suffixation is the formation of words with the help of suffixes. Suffixes usually modify the lexical meaning of the base and transfer words to a different part of speech. Suffixes can be classified into different types in accordance with different principles. According to the lexico-grammatical character suffixes may be: deverbal suffixes, e.d., those added to the verbal base (agreement); denominal (endless); deadjectival (widen, brightness). According to the part of speech formed suffixes fall into several groups: noun-forming suffixes (assistance), adjective-forming suffixes (unbearable), numeral-forming suffixes (fourteen), verb-forming suffixes (facilitate), adverb-forming suffixes (quickly, likewise). Semantically suffixes may be monosemantic, e.g. the suffix –ess has only one meaning “female” – goddess, heiress; polysemantic, e.g. the suffix –hood has two meanings “condition or quality” falsehood and “collection or group” brotherhood. According to their generalizing denotational meaning suffixes may fall into several groups: the agent of the action (baker, assistant); collectivity (peasantry); appurtenance (Victorian, Chinese); diminutiveness (booklet). Prefixation is the formation of words with the help of prefixes. Two types of prefixes can be distinguished: 1) those not correlated with any independent word (un-, post-, dis-); 2) those correlated with functional words (prepositions or preposition-like adverbs: out-, up-, under-). Diachronically distinction is made between prefixes of native and foreign origin. Prefixes can be classified according to different principles. According to the lexico-grammatical character of the base prefixes are usually added to, they may be: deverbal prefixes, e.d., those added to the verbal base (overdo); denominal (unbutton); deadjectival (biannual). According to the part of speech formed prefixes fall into several groups: noun-forming prefixes (ex-husband), adjective-forming prefixes (unfair), verb-forming prefixes (dethrone), adverb-forming prefixes (uphill). Semantically prefixes may be monosemantic, e.g. the prefix –ex has only one meaning “former” – ex-boxer; polysemantic, e.g. the prefix –dis has four meanings “not” disadvantage and “removal of” to disbrunch. According to their generalizing denotational meaning prefixes may fall into several groups: negative prefixes – un, non, dis, a, in (ungrateful, nonpolitical, disloyal, amoral, incorrect); reversative prefixes - un, de, dis (untie, decentralize, disconnect); pejorative prefixes – mis, mal, pseudo (mispronounce, maltreat, pseudo-scientific); prefix of repetition (redo), locative prefixes – super, sub, inter, trans (superstructure, subway, intercontinental, transatlantic). 3. Conversion Conversion is a process which allows us to create additional lexical terms out of those that already exist, e.g., to saw, to spy, to snoop, to flirt. This process is not limited to one syllable words, e.g., to bottle, to butter, nor is the process limited to the creation of verbs from nouns, e.g., to up the prices. Converted words are extremely colloquial: "I'll microwave the chicken", "Let's flee our dog", "We will of course quiche and perrier you". Conversion came into being in the early Middle English period as a result of the leveling and further loss of endings. In Modern English conversion is a highly-productive type of word-building. Conversion is a specifically English type of word formation which is determined by its analytical character, by its scarcity of inflections and abundance of mono-and-de-syllabic words in different parts of speech. Conversion is coining new words in a different part of speech and with a different distribution but without adding any derivative elements, so that the original and the converted words are homonyms. Structural Characteristics of Conversion: Mostly monosyllabic words are converted, e.g., to horn, to box, to eye. In Modern English there is a marked tendency to convert polysyllabic words of a complex morphological structure, e.g., to e-mail, to X-ray. Most converted words are verbs which may be formed from different parts of speech from nouns, adjectives, adverbs, interjections. Nouns from verbs - a try, a go, a find, a loss From adjectives - a daily, a periodical From adverbs - up and down From conjunctions - but me no buts From interjection - to encore Semantic Associations / Relations of Conversion: The noun is the name of a tool or implement, the verb denotes an action performed by the tool, e.g., to nail, to pin, to comb, to brush, to pencil; The noun is the name of an animal, the verb denotes an action or aspect of behavior considered typical of this animal, e.g., to monkey, to rat, to dog, to fox; When the noun is the name of a part of a human body, the verb denotes an action performed by it, e.g., to hand, to nose, to eye; When the noun is the name of a profession or occupation, the verb denotes the activity typical of it, e.g., to cook, to maid, to nurse; When the noun is the name of a place, the verb will denote the process of occupying the place or by putting something into it, e.g., to room, to house, to cage; When the word is the name of a container, the verb will denote the act of putting something within the container, e.g., to can, to pocket, to bottle; When the word is the name of a meal, the verb means the process of taking it, e.g., to lunch, to supper, to dine, to wine; If an adjective is converted into a verb, the verb may have a generalized meaning "to be in a state", e.g., to yellow; When nouns are converted from verbs, they denote an act or a process, or the result, e.g., a try, a go, a find, a catch. 4. Word-composition Compound words are words consisting of at least two stems which occur in the language as free forms. Most compounds in English have the primary stress on the first syllable. For example, income tax has the primary stress on the in of income, not on the tax. Compounds have a rather simple, regular set of properties. First, they are binary in structure. They always consist of two or more constituent lexemes. A compound which has three or more constituents must have them in pairs, e.g., washingmachine manufacturer consists of washingmachine and manufacturer, while washingmachine in turn consists of washing and machine. Compound words also usually have a head constituent. By a head constituent we mean one which determines the syntactic properties of the whole lexeme, e.g., the compound lexeme longboat consists of an adjective, long and a noun, boat. The compound lexeme longboat is a noun, and it is а noun because boat is a noun, that is, boat is the head constituent of longboat. Compound words can belong to all the major syntactic categories: • Nouns: signpost, sunlight, bluebird, redwood, swearword, outhouse; • Verbs: window shop, stargaze, outlive, undertake; • Adjectives: ice-cold, hell-bent, undersized; • Prepositions: into, onto, upon. From the morphological point of view compound words are classified according to the structure of immediate constituents: • Compounds consisting of simple stems - heartache, blackbird; • Compounds where at least one of the constituents is a derived stem -chainsmoker, maid-servant, mill-owner, shop-assistant; • Compounds where one of the constituents is a clipped stem - V-day, A-bomb, Xmas, H-bag; • Compounds where one of the constituents is a compound stem - wastes paper basket, postmaster general. Compounds are the commonest among nouns and adjectives. Compound verbs are few in number, as they are mostly the result of conversion, e.g., to blackmail, to honeymoon, to nickname, to safeguard, to whitewash. The 20th century created some more converted verbs, e.g., to weekend, to streamline,, to spotlight. Such converted compounds are particularly common in colloquial speech of American English. Converted verbs can be also the result of backformation. Among the earliest coinages are to backbite, to browbeat, to illtreat, to housekeep. The 20th century gave more examples to hitch-hike, to proof-read, to mass-produce, to vacuumclean. One more structural characteristic of compound words is classification of compounds according to the type of composition. According to this principle two groups can be singled out: words which are formed by a mere juxtaposition without any connecting elements, e.g., classroom, schoolboy, heartbreak, sunshine; composition with a vowel or a consonant placed between the two stems. e.g., salesman, handicraft. Semantically compounds may be idiomatic and non-idiomatic. Compound words may be motivated morphologically and in this case they are non-idiomatic. Sunshine - the meaning here is a mere meaning of the elements of a compound word (the meaning of each component is retained). When the compound word is not motivated morphologically, it is idiomatic. In idiomatic compounds the meaning of each component is either lost or weakened. Idiomatic compounds have a transferred meaning. Chatterbox - is not a box, it is a person who talks a great deal without saying anything important; the combination is used only figuratively. The same metaphorical character is observed in the compound slowcoach - a person who acts and thinks slowly. The components of compounds may have different semantic relations. From this point of view we can roughly classify compounds into endocentric and exocentric. In endocentric compounds the semantic centre is found within the compound and the first element determines the other as in the words filmstar, bedroom, writing-table. Here the semantic centres are star, room, table. These stems serve as a generic name of the object and the determinants film, bed, writing give some specific, additional information about the objects. In exocentric compound there is no semantic centre. It is placed outside the word and can be found only in the course of lexical transformation, e.g., pickpocket - a person who picks pockets of other people, scarecrow an object made to look like a person that a farmer puts in a field to frighten birds. The Criteria of Compounds As English compounds consist of free forms, it's difficult to distinguish them from phrases, because there are no reliable criteria for that. There exist three approaches to distinguish compounds from corresponding phrases: Formal unity implies the unity of spelling solid spelling, e.g., headmaster; with a hyphen, e.g., head-master; with a break between two components, e.g., head master. Different dictionaries and different authors give different spelling variants. Phonic principal of stress Many compounds in English have only one primary stress. All compound nouns are stressed according to this pattern, e.g., ice-cream, ice cream. The rule doesn't hold with adjectives. Compound adjectives are double-stressed, e.g., easy-going, new-born, sky-blue. Stress cannot help to distinguish compounds from phrases because word stress may depend on phrasal stress or upon the syntactic function of a compound. Semantic unity Semantic unity means that a compound word expresses one separate notion and phrases express more than one notion. Notions in their turn can't be measured. That's why it is hard to say whether one or more notions are expressed. The problem of distinguishing between compound words and phrases is still open to discussion. According to the type of bases that form compounds they can be of : 1. compounds proper – they are formed by joining together bases built on the stems or on the ford-forms with or without linking element, e.g., door-step; 2. derivational compounds – by joining affixes to the bases built on the word-groups or by converting the bases built on the word-groups into the other parts of speech, e.g., longlegged → (long legs) + -ed, a turnkey → (to turn key) + conversion. More examples: do-gooder, week-ender, first-nighter, house-keeping, baby-sitting, blue-eyed blond-haired, four-storied. The suffixes refer to both of the stems combined, but not to the final stem only. Such stems as nighter, gooder, eyed do not exist. Compound Neologisms In the last two decades the role of composition in the word-building system of English has increased. In the 60th and 70th composition was not so productive as affixation. In the 80th composition exceeded affixation and comprised 29.5 % of the total number of neologisms in English vocabulary. Among compound neologisms the two-component units prevail. The main patterns of coining the two-component neologisms are Noun stem + Noun stem = Noun; Adjective stem + Noun stem = Noun. There appeared a tendency to coin compound nouns where: The first component is a proper noun, e.g., Kirlian photograph - biological field of humans. The first component is a geographical place, e.g., Afro-rock. The two components are joined with the help of the linking vowel –o- e.g., bacteriophobia, suggestopedia. The number of derivational compounds increases. The main productive suffix to coin such compound is the suffix -er - e.g., baby-boomer, all nighter. Many compound words are formed according to the pattern Participle 2 + Adv = Adjective, e.g., laid-back, spaced-out, switched-off, tapped-out. The examples of verbs formed with the help of a post-positive -in -work-in, die-in, sleep-in, write-in. Many compounds formed by the word-building pattern Verb + postpositive are numerous in colloquial speech or slang, e.g., bliss out, fall about/horse around, pig-out. ATTENTION: Apart from the principle types there are some minor types of modern wordformation, i.d., shortening, blending, acronymy, sound interchange, sound imitation, distinctive stress, back-formation, and reduplicaton. 5. Shortening Shortening is the formation of a word by cutting off a part of the word. They can be coined in two different ways. The first is to cut off the initial/ middle/ final part: Aphaeresis – initial part of the word is clipped, e.g., history-story, telephone-phone; Syncope – the middle part of the word is clipped, e.g., madam- ma 'am; specs spectacles Apocope – the final part of the word is clipped, e.g., professor-prof, editored, vampirevamp; Both initial and final, e.g., influenza-flu, detective-tec. Polysemantic words are usually clipped in one meaning only, e.g., doc and doctor have the meaning "one who practices medicine", but doctor is also "the highest degree given by a university to a scholar or scientist". Among shortenings there are homonyms, so that one and the same sound and graphical complex may represent different words, e.g., vac - vacation/vacuum, prep — preparation/preparatory school, vet — veterinary surgeon/veteran. 6. Blending Blending is a particular type of shortening which combines the features of both clipping and composition, e.g., motel (motor + hotel), brunch (breakfast + lunch), smog (smoke + fog), telethon (television + marathon), modem , (modulator + demodulator), Spanglish (Spanish + English). There are several structural types of blends: Initial part of the word + final part of the word, e.g., electrocute (electricity + execute); initial part of the word + initial part of the word, e.g., lib-lab (liberal+labour); Initial part of the word + full word, e.g., paratroops (parachute+troops); Full word + final part of the word, e.g., slimnastics (slim+gymnastics). 7. Acronymy Acronyms are words formed from the initial letters of parts of a word or phrase, commonly the names of institutions and organizations. No full stops are placed between the letters. All acronyms are divided into two groups. The first group is composed of the acronyms which are often pronounced as series of letters: EEC (European Economic Community), ID (identity or identification card), UN (United Nations), VCR (videocassette recorder), FBI (Federal Bureau of Investigation), LA (Los Angeles), TV (television), PC (personal computer), GP (General Practitioner), ТВ (tuberculosis). The second group of acronyms is composed by the words which are pronounced according to the rules of reading in English: UNESCO (United Nations Educational, Scientific, and Cultural Organization), AIDS (Acquired Immune Deficiency Syndrome), ASH (Action on Smoking and Health). Some of these pronounceable words are written without capital letters and therefore are no longer recognized as acronyms: laser (light amplification by stimulated emissions of radiation), radar (radio detection and ranging). Some abbreviations have become so common and normal as words that people do not think of them as abbreviations any longer. They are not written in capital letters, e.g., radar (radio detection and ranging), laser (light amplification by stimulated emission of radiation) yuppie, gruppie, sinbads, dinkies. Some abbreviations are only written forms but they are pronounced as full words, e.g., Mr, Mrs, Dr. Some abbreviations are from Latin. They are used as part of the language etc. - et cetera, e.g., (for example) — exampli gratia, that is - id est. Acromymy is widely used in the press, for the names of institutions, organizations, movements, countries. It is common to colloquial speech, too. Some acronyms turned into regular words, e.g., jeep -came from the expression general purpose car. There are a lot of homonyms among acronyms: MP - Member of Parliament/Military Police/Municipal Police PC - Personal Computer/Politically correct 8. Sound-interchange Sound-interchange is the formation of a new word due to an alteration in the phonemic composition of its root. Sound-interchange falls into two groups: 1) vowel-interchange, e.g., food – feed; in some cases vowel-interchange is combined with suffixation, e.g., strong – strength; 2) consonant-interchange e.g., advice – to advise. Consonant-interchange and vowel-interchange may be combined together, e.g., life – to live. This type of word-formation is greatly facilitated in Modern English by the vast number of monosyllabic words. Most words made by reduplication represent informal groups: colloquialisms and slang, hurdy-gurdy, walkie-talkie, riff-raff, chi-chi girl. In reduplication new words are coined by doubling a stem, either without any phonetic changes as in bye-bye or with a variation of the root-vowel or consonant as in ping-pong, chit-chat. 9. Sound imitation or (onomatopoeia) It is the naming of an action or a thing by more or less exact reproduction of the sound associated with it, cf.: cock-a-do-doodle-do – ку-ка-ре-ку. Semantically, according to the source sound, many onomatopoeic words fall into the following definitive groups: 1) words denoting sounds produced by human beings in the process of communication or expressing their feelings, e.g., chatter; 2) words denoting sounds produced by animals, birds, insects, e.g., moo, buzz; 3) words imitating the sounds of water, the noise of metallic things, movements, e.g., splash, whip, swing. 10. Distinctive stress Distinctive stress is the formation of a word by means of the shift of the stress in the source word, e.g., increase – increase. 11. Back-formation Backformation is coining new words by subtracting a real or supposed suffix, as a result of misinterpretation of the structure of the existing word. This type of word-formation is not highly productive in Modern English and it is built on the analogy, e.g., beggar-to beg, cobbler to cobble, blood transfusion — to blood transfuse, babysitter - to baby-sit.