
Лабораторная работа
Статистические функции Excel
Цель работы: Освоение приемов работы с функциями массивов (табличными функциями). Изучение элементарных статистических функций Excel
- Формулы массивов (табличные формулы)
Массивом называют блок ячеек электронной таблицы, который используется для создания формул, возвращающих некоторое множество результатов или оперирующих множеством значений, а не отдельными значениями.
Формулы массивов (иногда их называют табличными формулами), используют несколько множеств значений (массивов аргументов), и возвращают одно или несколько значений. Такие формулы позволяют обращаться с блоками, как с обычной ячейкой.
Рассмотрим работу с использованием массивов на следующем примере. Требуется определить прибыль для каждого года деятельности отеля, представленного в таблице 1.
Таблица 1.
Пример использования функций массива
|
A |
B |
C |
D |
|
|
1 |
Год |
Приход |
Расход |
Прибыль |
|
2 |
2005 |
200 |
150 |
{B2:B5-C2:C5} |
|
3 |
2006 |
360 |
230 |
{B2:B5-C2:C5} |
|
4 |
2007 |
410 |
250 |
{B2:B5-C2:C5} |
|
5 |
2008 |
200 |
180 |
{B2:B5-C2:C5} |
Выделим блок D2:D5. Начнем ввод формулы – наберем знак =. Выделим блок B2:B5, наберем знак минус -, выделим блок С2:С5. Ввод формул массива заканчивается комбинацией клавиш Ctrl+Shift+Enter. После нажатия такой комбинации во всех ячейках блока D2:D5 появится формула {B2:B5-C2:C5}.
- Основные правила работы с формулами массива:
- перед вводом формулы нужно выделить ячейку или диапазон для результатов, если формула возвращает несколько значений, то диапазон результатов должен быть того же размера, что и диапазон исходных данных;
- фигурные скобки, отмечающие формулу массива, вводятся при завершении ввода формулы клавишами Ctrl+Shift+Enter, если фигурные скобки ввести вручную, такой ввод будет воспринят Excel как текст.
- для редактирования формулы массива необходимо выделить блок, активировать строку формул, внести изменения и завершить редактированием клавишами Ctrl+Shift+Enter;
- блок ячеек может указываться присвоенным ему именем (клавиша F3 и выбор имени в диалоге «Вставка имени»;
- массив исходных данных и массив результатов могут быть многомерными, т.е. включать несколько строк и столбцов.
- Функции Excel, используемые для статистического анализа
Статистический анализ данных необходим для оценки деятельности фирмы и прогноза ее работы на какой-то срок. Такой анализ основывается на сборе информации, определении по представленным массивам данных оценок, статистических показателей и тенденций развития фирмы.
В категорию статистических функций Excel входит около 80 функций, кроме того, значительное число функций статистического анализа входят в надстройку «Пакет анализа».
Для выполнения задания потребуются статистические функции, полное описание которых приведено ниже.
- МАКС(число1;число2; …) — возвращает наибольшее значение из набора значений.
- Число1, число2,…— от 1 до 30 чисел, среди которых требуется найти наибольшее.
- Можно задавать аргументы, которые являются числами, пустыми ячейками, логическими значениями или текстовыми представлениями чисел. Аргументы, которые являются значениями ошибки или текстами, не преобразуемыми в числа, вызывают значения ошибок.
- Если аргумент является массивом или ссылкой, то в нем учитываются только числа. Пустые ячейки, логические значения или текст в массиве или ссылке игнорируются. Если логические значения или текст не должны игнорироваться, следует использовать функцию МАКСА. Если аргументы не содержат чисел, то функция МАКС возвращает 0 (ноль);
- МИН(число1;число2; …) — возвращает наименьшее значение из набора значений, в остальном полностью аналогична функции ^ МАКС;
- СРЗНАЧ(число1; число2; …) — возвращает среднее (арифметическое) своих аргументов.
- Число1, число2, … — это от 1 до 30 аргументов, для которых вычисляется среднее.
- Аргументы должны быть либо числами, либо именами, массивами или ссылками, содержащими числа.
- Если аргумент, который является массивом или ссылкой, содержит тексты, логические значения или пустые ячейки, то такие значения игнорируются; однако ячейки, которые содержат нулевые значения, учитываются;
ТЕНДЕНЦИЯ (известные_значения_y; известные_значения_x; новые значения_x; конст) — возвращает значения в соответствии с линейным трендом, т.е. аппроксимирует прямой линией (по методу наименьших квадратов) массивы ”известные_значения_y” и “известные_значения_x”. Возвращает значения y, в соответствии с этой прямой для заданного массива новые_значения_x.
- Известные_значения_y — множество значений y, которые уже известны для соотношения y = mx + b.
- Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная. - Известные_значения_x — необязательное множество значений x, которые уже известны для соотношения y = mx + b.
- Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то известные_значения_y и известные_значения_x могут иметь любую форму, при условии, что они имеют одинаковую размерность.
- Если используется более одной переменной, то известные_значения_y должны быть вектором (то есть интервалом высотой в одну строку или шириной в один столбец).
Если известные_значения_x опущены, то предполагается, что это массив {1;2;3;…} такого же размера, как и известные_значения_y. - Новые_значения_x — новые значения x, для которых ТЕНДЕНЦИЯ возвращает соответствующие значения y. Новые_значения_x должны содержать столбец (или строку) для каждой независимой переменной, как иизвестные_значения_x. Таким образом, если известные_значения_y — это один столбец, то известные_значения_x и новые_значения_x должны иметь такое же количество столбцов. Если известные_значения_y — это одна строка, то известные_значения_x и новые_значения_x должны иметь такое же количество строк.
- Если новые_значения_x опущены, то предполагается, что они совпадают с известные_значения_x.
- Если опущены оба массива известные_значения_x и новые_значения_x, то предполагается, что это массив {1;2;3;…} такого же размера, что и известные_значения_y.
- Конст — логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0.
- Если конст имеет значение ИСТИНА или опущено, то b вычисляется обычным образом.
- Если конст имеет значение ЛОЖЬ, то b полагается равным 0, и значения m подбираются таким образом, чтобы выполнялось соотношение y = mx.
РОСТ(известные_значения_y;известные_значения_x;новые_значения_x; конст) — возвращает значения y для последовательности новых значений x, задаваемых с помощью существующих x- и y-значений, т.е. функция рассчитывает прогнозируемый экспоненциальный рост на основании имеющихся данных.
- Известные_значения_y — это множество значений y, которые уже известны в соотношении y = b*mx. Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная. Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
- Известные_значения_x — это необязательное множество значений x, которые уже известны для соотношения y=b*mx. Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_xинтерпретируется как отдельная переменная. Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то известные_значения_y иизвестные_значения_x могут иметь любую форму, при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (то есть интервалом высотой в одну строку или шириной в один столбец). Если известные_значения_x опущены, то предполагается, что это массив {1;2;3;…} такого же размера, как и известные_значения_y.
- Новые_значения_x — это новые значения x, для которых РОСТ возвращает соответствующие значения y. Новые_значения_x должны содержать столбец (или строку) для каждой независимой переменной, как иизвестные_значения_x. Таким образом, если известные_значения_y — это один столбец, то известные_значения_x и новые_значения_x должны иметь такое же количество столбцов. Если известные_значения_y — это одна строка, то известные_значения_x и новые_значения_x должны иметь такое же количество строк. Если аргумент новые_значения_x опущен, то предполагается, что он совпадает с аргументом известные_значения_x. Если оба аргумента известные_значения_x и новые_значения_x опущены, то предполагается, что это массив {1;2;3;…} такого же размера, как и известные_значения_y.
- Конст — это логическое значение, которое указывает, требуется ли, чтобы константа b была равна 1. Если конст имеет значение ИСТИНА или опущено, то b вычисляется обычным образом. Если конст имеет значение ЛОЖЬ, то b полагается равным 1, а значения m подбираются так, чтобы y = mx.
ПРЕДСКАЗ(x, известные_значения_y, известные_значения_x) – вычисляет или предсказывает будущее значение по существующим значениям. Предсказываемое значение — это значение y, соответствующее заданному значению x. Значения x и y известны; новое значение предсказывается с использованием линейной регрессии. Эту функцию можно использовать для прогнозирования будущих продаж, потребностей в оборудовании или тенденций потребления.
- Функция ПРЕДСКАЗ имеет аргументы, указанные ниже.
- x — обязательный аргумент. Точка данных, для которой предсказывается значение.
- Известные_значения_y — обязательный аргумент. Зависимый массив или интервал данных.
- Известные_значения_x — обязательный аргумент. Независимый массив или интервал данных.
- Если x не является числом, функция ПРЕДСКАЗ возвращает значение ошибки #ЗНАЧ!.
- Если аргументы «известные_значения_y» и «известные_значения_x» пусты или количество точек данных в этих аргументах не совпадает, функция ПРЕДСКАЗ возвращает значение ошибки #Н/Д.
- Если дисперсия аргумента «известные_значения_x» равна 0, функция ПРЕДСКАЗ возвращает значение ошибки #ДЕЛ/0!.
- Замечания
- 1) Формулы, которые возвращают массивы, должны быть введены как формулы массива.
2) При вводе константы массива для аргумента, такого как известные_значения_x, следует использовать точку с запятой для разделения значений в одной строке и двоеточие для разделения строк.
- Задание
Для приведенных в таблице 2 данных о реализации гостиничных услуг сетью отелей «Европа» вычислить:
- минимальные, максимальные и среднее показатели по каждому кварталу;
- средние показатели по каждому отелю;
- вычислить средний доход по всей сети отелей за отчетный период;
- дать оценку работы каждого отеля: «хорошо», если доход отеля превышает средний по сети, и «плохо», если доход меньше среднего по сети;
- построить линейную и экспоненциальную модель деятельности сети отелей и дать прогноз для двух следующих кварталов;
- оценить относительные отклонения для среднего значения и «Тенденции», для среднего значения и «Роста».
^ Таблица 2.
Исходные данные
|
A |
B |
C |
D |
E |
F |
G |
|
|
1 |
Отель |
1 кв. |
2 кв. |
3 кв. |
4 кв. |
Среднее по |
Оценка |
|
отелю |
|||||||
|
2 |
Швеция |
1500 |
2000 |
6000 |
8000 |
||
|
3 |
Дания |
1400 |
5000 |
4100 |
5000 |
||
|
4 |
Норвегия |
3600 |
3600 |
3000 |
4500 |
||
|
5 |
Финляндия |
1100 |
1045 |
9100 |
7800 |
||
|
6 |
Германия |
3850 |
3650 |
7800 |
11000 |
||
|
7 |
Польша |
6800 |
7250 |
8122 |
9450 |
||
|
8 |
Чехия |
6590 |
7050 |
6400 |
6440 |
||
|
9 |
Словакия |
930 |
3970 |
4512 |
4600 |
||
|
10 |
Венгрия |
8912 |
7490 |
3570 |
8000 |
||
|
11 |
Болгария |
3590 |
3800 |
5464 |
5954 |
||
|
12 |
Мин |
||||||
|
13 |
Мах |
||||||
|
14 |
Среднее |
||||||
|
15 |
1 |
2 |
3 |
4 |
|||
|
16 |
Тенденция по среднему |
||||||
|
17 |
Рост по среднему |
||||||
|
18 |
Погрешность |
||||||
|
тенденции |
|||||||
|
19 |
Погрешность |
||||||
|
роста |
|||||||
|
20 |
Лучший отель по сети |
||||||
|
Доход |
- Технология выполнения
- Минимальные, максимальные и средние значения по кварталам и средние значения по турам подсчитываются с помощью Мастера функций.
- Для оценки работы отеля используется среднее значение дохода по сети и функция ЕСЛИ().
- Функция Тенденция показывает динамику изменения данных и позволяет получить прогноз на будущее. При этом изменение данных описывается линейным уравнением. Для определения Тенденции:
- Выделить новый диапазон ячеек для размещения результатов (B16:E16);
- В строке формул вставить функцию Тенденция и в Мастере функций в поле аргумента известные_значения_y указать диапазон средних по кварталу значений.
- Известные_значения_x можно не устанавливать, т.к. это 1, 2, 3, 4 кварталы.
- Выйти из Мастера функций – Ok.
- Установить курсор в строке формул, нажать комбинацию клавиш Ctrl+Shift+Enter, в выделенном новом массиве появятся результаты.
- Функция Тенденция показывает линейную модель изменения показателей, экспоненциальная модель строится функцией Рост.
- Самостоятельно вычислите функцию Рост для средних по кварталам, подобно тому, как вычислялась функция Тенденция.
- Вычислить прогноз развития событий на ближайшие два квартала, используя функцию Тенденция:
- Справа от ячейки со значением Тенденция для 4-го квартала выделить две свободные ячейки.
- Вставить функцию Тенденция и в Мастере функций указать:
- в поле известные_значения_y вычисленные ранее значения Тенденция за четыре квартала (диапазон B16:E16);
- в поле новые_значения_x – диапазон F15:G15 – кварталы 5 и 6, для которых выполняется прогноз.
- Завершить работу Мастера – Ok, завершить ввод функции массива Ctrl+Shift+Enter, в выделенных ячейках появятся предсказанные по линейной модели значения для 5 и 6 кварталов.
- Таким же образом рассчитать прогноз по экспоненциальной модели с помощью функции Рост.
- Оценить относительные отклонения в процентах для среднего значения и Тенденции, для среднего значения и Роста (для каждого из четырех кварталов) по формуле:
Относительное отклонение=(yфакт — yмодели)/yмодели,
где yфакт — среднее значение;
yмодели – значение, определенное с помощью Тенденции или Роста.
Пример расчета показателей работы отелей по первому кварталу приведен в таблице 3.
Таблица 3.
Пример расчета показателей работы отелей по первому кварталу
|
A |
B |
|
|
13 |
Мин |
=МИН(В3:В12) |
|
14 |
Мах |
=МАКС(В3:В12) |
|
15 |
Среднее |
=СРЗНАЧ(В3:В12) |
|
17 |
Тенденция по среднему |
=ТЕНДЕНЦИЯ(В15:Е15) |
|
18 |
Рост по среднему |
=РОСТ(В15:Е15) |
|
19 |
Погрешность |
=(В15-В17)/В17 |
|
тенденции |
||
|
20 |
Погрешность |
=(В15-В18)/В18 |
|
роста |
||
|
21 |
Лучший отель по сети |
=ИНДЕКС($А$3:В12;ПОИСКПОЗ(МАКС(В3:В12);В3:В12;0);1) |
|
22 |
Доход |
=ИНДЕКС($А$3:В12;ПОИСКПОЗ(МАКС(В3:В12);В3:В12;0);2) |
Результаты расчетов приведены в таблице 4.
Таблица 4.
Результаты расчетов
|
A |
B |
C |
D |
E |
F |
G |
|
|
1 |
Отель |
1 кв. |
2 кв. |
3 кв. |
4 кв. |
Среднее по |
Оценка |
|
отелю |
|||||||
|
2 |
Швеция |
1500 |
2000 |
6000 |
8000 |
4375 |
Плохо |
|
3 |
Дания |
1400 |
5000 |
4100 |
5000 |
3875 |
Плохо |
|
4 |
Норвегия |
3600 |
3600 |
3000 |
4500 |
3675 |
Плохо |
|
5 |
Финляндия |
1100 |
1045 |
9100 |
7800 |
4761,25 |
Плохо |
|
6 |
Германия |
3850 |
3650 |
7800 |
11000 |
6575 |
Хорошо |
|
7 |
Польша |
6800 |
7250 |
8122 |
9450 |
7905,5 |
Хорошо |
|
8 |
Чехия |
6590 |
7050 |
6400 |
6440 |
6620 |
Хорошо |
|
9 |
Словакия |
930 |
3970 |
4512 |
4600 |
3503 |
Плохо |
|
10 |
Венгрия |
8912 |
7490 |
3570 |
8000 |
6993 |
Хорошо |
|
11 |
Болгария |
3590 |
3800 |
5464 |
5954 |
4702 |
Плохо |
|
12 |
Мин |
930 |
1045 |
3000 |
4500 |
||
|
13 |
Мах |
8912 |
7490 |
9100 |
11000 |
||
|
14 |
Среднее |
3827 |
4486 |
5807 |
7074 |
5298 |
|
|
15 |
1 |
2 |
3 |
4 |
5 |
6 |
|
|
16 |
Тенденция по среднему |
3639 |
4745 |
5852 |
6958 |
8064 |
9170 |
|
17 |
Рост по среднему |
3760 |
4639 |
5724 |
7063 |
8714 |
10752 |
|
18 |
Погрешность |
5,17% |
-5,48% |
-0,77% |
1,67% |
||
|
тенденции |
|||||||
|
19 |
Погрешность |
1,79% |
-3,32% |
1,44% |
0,17% |
||
|
роста |
|||||||
|
20 |
Лучший отель по сети |
Венгрия |
Венгрия |
Финляндия |
Германия |
||
|
21 |
Доход |
8912 |
7490 |
9100 |
11000 |
Дополнительные задания
- Выполнить условное форматирование Столбца Оценка – выделить красным цветом отели, доход которых меньше среднего.
- Определить лучший отель по сети за квартал и его доход.
- Дополнить таблицу строкой Предсказание для 5 и 6 кварталов.
- Построить диаграмму – график изменения доходов по кварталам и тенденцию изменения доходов по кварталам, включая прогноз на два следующие квартала, а также рост изменения доходов по кварталам.
Пример для отеля «Венгрия» представлен на диаграмме 1.

Диаграмма 1.
- Добавить на график линию тренда.
- Проще всего построить график функции тренда непосредственно сразу после внесения имеющихся данных в массив. Для этого на листе с таблицей данных выделите не менее двух ячеек диапазона, для которого будет построен график, и сразу после этого вставьте диаграмму. Вы можете воспользоваться такими видами диаграмм, как график, точечная, гистограмма, пузырьковая, биржевая. Остальные виды диаграмм не поддерживают функцию построения тренда.
- В меню «Диаграмма» выберите пункт «Добавить линию тренда». В открывшемся окне на вкладке «Тип» выберите необходимый тип линии тренда, что в математическом эквиваленте также означает и способ аппроксимации данных. При использовании описываемого метода вам придется делать это «на глаз», т.к. никаких математических вычислений для построения графика вы не проводили.
- Поэтому просто прикиньте, какому типу функции более всего соответствует график имеющихся данных: линейной, логарифмической, экспоненциальной, степенной или иной. Если же вы сомневаетесь в выборе типа аппроксимации, можете построить несколько линий, а для большей точности прогноза на вкладке «Параметры» этого же окна отметить флажком пункт «поместить на диаграмму величину достоверности аппроксимации (R^2)».
- Сравнивая значения R^2 для разных линий, вы сможете выбрать тот тип графика, который характеризует ваши данные наиболее точно, а, следовательно, строит наиболее достоверный прогноз. Чем ближе значение R^2 к единице, тем точнее вы выбрали тип линии. Здесь же, на вкладке «Параметры», вам необходимо указать период, на который делается прогноз.
- Такой способ построения тренда является весьма приблизительным, поэтому лучше все-таки произвести хотя бы самую примитивную статистическую обработку имеющихся данных. Это позволит построить прогноз более точно.
- Если вы предполагаете, что имеющиеся данные описываются линейным уравнением, просто выделите их курсором и произведите автозаполнение на необходимое число периодов, или количество ячеек. В данном случае нет необходимости находить значение R^2, т.к. вы заранее подогнали прогноз к уравнению прямой.
- Если же вы считаете, что известные значения переменной лучше всего могут быть описаны с помощью экспоненциального уравнения, также выделите исходный диапазон и произведите автозаполнение необходимого количества ячеек, удерживая правую клавишу мыши. При помощи автозаполнения вы не сможете построить других типов линий, кроме двух указанных.
Рабочее окно для построения линии тренда представлено на рисунке 1.

Рисунок 1.
ЛАБОРАТОРНАЯ РАБОТА
«Статистические функции MS Excel 2013. Построение рядов данных»
Цели работы:
-
научиться применять статистические функции для обработки данных; закрепить навыки форматирования таблицы;
-
воспитывать в себе аккуратность и внимательность при выполнении работ с электронными таблицами;
-
развивать логическое мышление, необходимое для работы с большими массивами информации
Задание:
-
изучите п.1 «Учебный материал»;
-
выполните задания, приведенные в п.2;
-
ответьте на контрольные вопросы (п.3).
-
Учебный материал
-
-
Функции категории Статистические
-
Статистические функции позволяют выполнять статистический анализ диапазонов данных: нахождение минимального и максимального значения среди исходных чисел, выполнение элементарного подсчёта числовых значений, подсчёт числовых значений в соответствии с определённым условием и т.д. Статистические функции входят в категорию Статистические Мастера функций (рис.1).

Рис.1. Окно Мастера функций с выбранное категорией функций Статистические
Рассмотрим ряд статистических функций, встречающихся в простейших вычислениях.
-
Нахождение минимального значения (среди числовых значений) в списке аргументов с помощью функции МИН. Формат записи функции:
МИН (число1; число2;…)
Количество допустимых аргументов, среди которых находится минимальное значение, равно 255.
Пример. Найти наименьшее значение цены на книгу «Гарри Поттер и дары смерти» среди магазинов города. Пусть в ячейках B3:B7 внесены значения цены (рис.2). Установите курсор в ячейку В9, вызовите Мастер функций и из категории Статистические выберите функцию МИН. Укажите исходные значения и нажмите OK.
-
Нахождение максимального значения (среди числовых значений) в списке аргументов с помощью функции МАКС. Формат записи функции:
МАКС (число1; число2;…)
Количество допустимых аргументов, среди которых находится максимальное значение, равно 255.
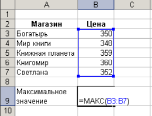
Пример. Найти максимальное значение цены на книгу «Гарри Поттер и дары смерти» среди магазинов города. Пусть в ячейках B3:B7 внесены значения цены (рис.3). Установите курсор в ячейку В9, вызовите Мастер функций и из категории Статистические выберите функцию МАКС. Укажите исходные значения и нажмите OK.
Рис. 2. Нахождение минимального значения среди аргументов
Рис. 3. Нахождение максимального значения среди аргументов
-
Нахождение среднего арифметического значения с помощью функции СРЗНАЧ. Формат записи функции:
СРЗНАЧ(число1; число2;…)
Количество допустимых аргументов, среди которых находится среднее значение, равно 255.
Пример. Найти среднее значение цены на книгу «Гарри Поттер и дары смерти» в магазинах города. Пусть в ячейках B3:B7 внесены значения цены (рис. 4). Установите курсор в ячейку В9, вызовите Мастер функций и из категории Статистические выберите функцию СРЗНАЧ. Укажите исходные данные и нажмите OK.

Рис. 4. Нахождение среднего значения среди аргументов
-
Подсчет количества значений в списке аргументов осуществляется с помощью функции СЧЕТ. Формат записи функции:
СЧЕТ(число1; число2;…)
Количество допустимых аргументов, среди которых находится среднее значение, равно 255.
Пример. Найти количество студентов, получающих стипендию. Пусть в ячейках B3:B7 внесены сведения о стипендии студентов группы (рис.5). Установите курсор в ячейку В9, вызовите Мастер функций и из категории Статистические выберите функцию СЧЕТ. Укажите исходные данные и нажмите OK. В ячейке В9 будет найдено искомое значение.

Рис. 5. Нахождение количества числовых значений среди аргументов
-
Нахождение количества значений, удовлетворяющих заданному условию, выполняется с помощью функции СЧЕТЕСЛИ. Формат записи функции:
СЧЕТЕСЛИ(диапазон; критерий),
где диапазон – диапазон, в котором подсчитывается количество непустых ячеек;
критерий – проверяемое условие в заданном интервале (в форме числа, выражения, текста).
Примеры записи функции:
-
=СЧЕТЕСЛИ(А1:А9; 85) – подсчитывает, сколько раз число 85 встречается в интервале А1:А9;
-
=СЧЕТЕСЛИ(А1:А9; “>85”) – подсчитывает, сколько раз в интервале А1:А9 встречаются числа, большие 85;
-
=СЧЕТЕСЛИ(А1:А9; “высший”) – подсчитывает, сколько раз в интервале А1:А9 встречается слово «высший»;
-
=СЧЕТЕСЛИ(А1:А9; “в*”) – подсчитывает, сколько раз в интервале А1:А9 встречаются слова, начинающиеся на букву «в».
Обратите внимание на то, что если в качестве критерия указываются не числовые значения, а текст или символы, то они заключаются в кавычки.
-
Определение ранга (номера позиции) числа в списке других чисел (т.е. порядкового номера относительно других чисел списка) выполняется с помощью функции РАНГ. РВ. Формат записи функции:
РАНГ.РВ(число; ссылка; порядок),
где число – число, для которого определяется ранг (порядковый номер);
ссылка – массив или ссылка на список чисел, с которым сравнивается число;
порядок – число (0 либо отличное от 0), определяющее способ ранжирования (в порядке убывания или возрастания).
Пример. Используем функцию РАНГ.РВ, которая присвоит номер места каждой марке автомобиля в зависимости от определенного параметра. Пусть в ячейки В3:В8 занесены значения расхода топлива на 100 км пробега (рис.6). Наилучшим будем считать автомобиль, имеющий минимальный расход. В ячейку С3 занесем формулу
=РАНГ.РВ(B3;$B$3:$B$8;1)
и скопируем ее в оставшиеся ячейки С4:С8. Аргументы в этой формуле означают следующее: В3 – адрес ячейки, которой присваиваем в ячейке С3 номер искомого места; $B$3:$B$8 – блок ячеек, в который занесены все известные значения расхода топлива и среди которых мы выясняем ранг. Здесь используем абсолютную адресацию ($) для того, чтобы при копировании формулы из ячейки С3 адрес участвующих в вычислении ячеек В3:В8 не изменялся. Последний аргумент функции 1 указывает на то, что сравнение результатов происходит в порядке возрастания, т.е. наилучшим результатом считаем наименьший. Если поставим 0, то лучшим результатом будет наибольший, как, например, в случае с объемом двигателя (рис.7).
Рис. 22. Нахождение ранга числа в порядке возрастания значений
Рис.7. Нахождение ранга числа в порядке убывания значений
-
-
Построение рядов данных
-
Для ввода в смежные ячейки повторяющейся с определенной закономерностью информации (текст, даты, числа), т.е. построения рядов данных, существует несколько способов.
-
Использование маркера заполнения и перетаскивания ячеек.
Пусть необходимо построить ряд чисел от 1 до 5,5 с шагом 0,5, т.е. получить арифметическую прогрессию. Для этого:
-
в окне открытого листа введите данные в первую ячейку диапазона (рис.8);
-
наведите курсор мыши на правый нижний угол ячейки (там располагается маркер заполнения) и, когда курсор станет тонким черным крестом, при нажатой левой кнопке мыши протащите маркер заполнения вниз по столбцу;
-
в конце нужного диапазона отпустите левую кнопку мыши. Оцените результат.
В данном случае в новые ячейки заносятся соответствующие значения, а также форматы исходной ячейки.



Рис.8. Использование маркера заполнения для получения арифметической прогрессии
Если после ввода первых двух значений потянуть за маркер заполнения при нажатой клавише <Ctrl>, то будет реализован принцип автозаполнения, а не получение арифметической прогрессии, и во всех ячейках получится чередование чисел 1 и 1,5 (рис.9).


Рис.9. Использование маркера заполнения для автозаполнения ячеек
-
Использование команды Прогрессия.
-
Занесите в ячейку А1 число 1;
-
выберите команду Прогрессия…, находящуюся в группе Редактирование вкладки Главная (рис.10), которая позволяет заполнить ряд соответствующим образом;

Рис.10. Команда Прогрессия для заполнения рядов данных
-
в появившемся диалоговом окне установите параметры, как показано на рис.11.

Рис.11. Диалоговое окно для построения рядов данных
-
нажмите ОК. Оцените результат.
3) Использование формул.
-
Занесите в ячейку А1 число 1;
-
по условию задачи, каждое следующее число отличается от предыдущего на 0,5, поэтому для построения ряда чисел воспользуемся формулой: =А1+0,5, которую внесем в ячейку А2 и с помощью маркера скопируем по столбцу вниз (рис.12).

Рис.12. Построение ряда чисел с использованием формулы
4) Использование параметров автозаполнения.
-
Введите данные в первую ячейку диапазона;
-
наведите курсор мыши на правый нижний угол ячейки и, когда курсор станет тонким черным крестом, при нажатой правой кнопке мыши протащите маркер заполнения, верх или вниз по столбцу либо вправо или влево по строке;
-
в конце нужного диапазона отпустите правую кнопку мыши;
-
в контекстном меню выберите соответствующий пункт:
-
«Копировать ячейки» – будут копироваться и значения, и форматы исходной ячейки;
-
«Заполнить только форматы» – будет копироваться только формат исходной ячейки;
-
«Заполнить только значения» – будет копироваться только значение исходной ячейки.
-
Задание к лабораторной работе
Для выполнения лабораторной работы введите исходные данные в соответствии с выданным номером задания. Отформатируйте таблицу по приведенным ниже параметрам.
-
-
Заголовок таблицы Применение статистических функций сделайте жирным шрифтом, размер шрифта – 12 пт. Для центрирования заголовка таблицы необходимо выделить ячейки A1:G2 и нажать на кнопку Объединить и поместить в центре
 , расположенную в группе Выравнивание вкладки Главная. Затем, не убирая курсора с объединенных ячеек, в контекстном меню выберите команду Формат ячеек и в открывшемся диалоговом окне выберите: вкладка Выравнивание→область Выравнивание→по горизонтали – по центру; по вертикали — по центру;
, расположенную в группе Выравнивание вкладки Главная. Затем, не убирая курсора с объединенных ячеек, в контекстном меню выберите команду Формат ячеек и в открывшемся диалоговом окне выберите: вкладка Выравнивание→область Выравнивание→по горизонтали – по центру; по вертикали — по центру; -
Заголовки столбцов таблицы (№ п/п; ФИО студента; Рост (см); Вес (кг)… и т.д. в зависимости от варианта задания) – по центру, полужирным шрифтом, размер шрифта – 10 пт). Возможность отображать текст внутри ячейки таблицы в несколько строк добивается следующим образом:
-
-
-
выделить ячейки A3:G3, формат которых требуется изменить;
-
в контекстном меню выберите команду Формат ячеек и в открывшемся диалоговом окне выберите: вкладка Выравнивание→область Выравнивание→по горизонтали – по центру; по вертикали — по центру;
-
в области Отображение установить флажок переносить по словам.
-
-
-
Ячейки А4:А13 заполните значениями от 1 до 10 одним из способов, описанных в п.1.2 «Построение рядов данных».
-
К тексту ячеек B15:B22 примените начертание курсив и сделайте перенос по словам.
-
Выделите ячейки A1:G13 таблицы. С помощью кнопки Границы→Все границы
 группы Шрифт измените границы таблицы.
группы Шрифт измените границы таблицы. -
Символ, соответствующий степени 2 числа, можно вставить с помощью команды Символ группы Символы вкладки Вставка. Другой способ указания символа степени: написать степень числа, выделить его, нажать кнопку группы Шрифт и в появившемся диалоговом окне во вкладке Шрифт в области Видоизменение установить флажок надстрочный.
-
Задание 1
Задание. Для данной группы студентов определить (искомые значения разместить в соответствующих выделенных ячейках, как показано на рис.13. На вашем рабочем листе цвет ячеек изменять не обязательно):
-
минимальное значение роста, веса и бега на 100 м;
-
максимальное значение роста, веса и бега на 100 м;
-
среднее значение роста, веса и бега на 100 м;
-
количество студентов, имеющих рост < 180 см;
-
количество студентов, имеющих рост > 185 см;
-
количество студентов, имеющих вес < 80 кг;
-
количество студентов, имеющих вес > 85 кг;
-
количество студентов, участвовавших в соревновании;
-
ранг студентов (порядковый номер относительно друг друга) в беге на 100 м.

Рис.13. Исходные данные для выполнения лабораторной работы
Задание 2
Задание. Для данной группы продуктов определить (искомые значения разместить в соответствующих выделенных ячейках, как показано на рис.14. На вашем рабочем листе цвет ячеек изменять не обязательно):
-
минимальное значение цен в магазинах;
-
максимальное значение цен в магазинах;
-
среднее значение цен в магазинах;
-
количество продуктов, название которых начинается на букву «м»;
-
количество продуктов, название которых начинается на букву «к»;
-
количество продуктов дороже 25 руб.;
-
количество продуктов дешевле 25 руб.;
-
количество продуктов, ассортимент которых обновлялся;
-
ранг продуктов магазина «Рублик» (порядковый номер относительно стоимости друг друга).

Рис.14. Исходные данные для выполнения лабораторной работы
Задание 3
Задание. Для данной группы услуг определить (искомые значения разместить в соответствующих выделенных ячейках, как показано на рис.15. На вашем рабочем листе цвет ячеек изменять не обязательно):
-
минимальное значение цен в парикмахерских;
-
максимальное значение цен в парикмахерских;
-
среднее значение цен на услуги парикмахерских;
-
количество услуг со стоимостью < 200 руб.;
-
количество услуг со стоимостью ≥200 руб.;
-
среднее значение стоимости стрижек в парикмахерской «Люкс»;
-
средняя стоимость других услуг (отличных от стрижек) парикмахерской «Люкс»;
-
количество скидок;
-
ранг стоимости услуг парикмахерской «Аванта» (порядковый номер стоимости относительно друг друга).

Рис.15. Исходные данные для выполнения лабораторной работы
Задание 4
Задание. Для данной группы услуг определить (искомые значения разместить в соответствующих выделенных ячейках, как показано на рис.16. На вашем рабочем листе цвет ячеек изменять не обязательно):
-
минимальное значение цен на услуги компаний сотовой связи;
-
максимальное значение цен на услуги компаний сотовой связи;
-
среднее значение цен на услуги компаний сотовой связи;
-
количество услуг со стоимостью < 2 руб.;
-
количество услуг со стоимостью ≥2 руб.;
-
среднее значение стоимости звонков оператора «МТС»;
-
средняя стоимость других услуг (отличных от звонков) оператора «МТС»;
-
количество скидок именинникам;
-
ранг стоимости услуг оператора «МТС» (порядковый номер стоимости относительно друг друга).

Рис.16. Исходные данные для выполнения лабораторной работы
Задание 5
Задание. Для данной группы услуг определить (искомые значения разместить в соответствующих выделенных ячейках, как показано на рис.17. На вашем рабочем листе цвет ячеек изменять не обязательно):
-
минимальное значение населения, площади территории страны, количества городов-миллионеров;
-
максимальное значение населения, площади территории страны, количества городов-миллионеров;
-
среднее значение населения, площади территории страны, количества городов-миллионеров;
-
количество стран с населением < 100 млн. чел.;
-
количество стран с населением ≥ 100 млн. чел.;
-
количество стран площадью территории >5 млн. км2;
-
количество стран площадью территории <1 млн. км2;
-
количество стран, берега которых омываются океанами;
-
ранг стран по площади территории (порядковый номер страны относительно значений площадей).

Рис.17. Исходные данные для выполнения лабораторной работы
Задание 6
Задание. Для данной группы услуг определить (искомые значения разместить в соответствующих выделенных ячейках, как показано на рис.18. На вашем рабочем листе цвет ячеек изменять не обязательно):
-
минимальное значение населения, площади территории страны, количества городов-миллионеров;
-
максимальное значение населения, площади территории страны, количества городов-миллионеров;
-
среднее значение населения, площади территории страны, количества городов-миллионеров;
-
количество стран с населением < 100 млн. чел.;
-
количество стран с населением ≥ 100 млн. чел.;
-
количество стран площадью территории >10 млн. км2;
-
количество стран площадью территории <1 млн. км2;
-
количество стран с океанами;
-
ранг стран по населению (порядковый номер страны относительно значений количества человек).

Рис.18. Исходные данные для выполнения лабораторной работы
Задание 7
Задание. Для данной группы услуг определить (искомые значения разместить в соответствующих выделенных ячейках, как показано на рис.19. На вашем рабочем листе цвет ячеек изменять не обязательно):
-
минимальное значение длины реки, площади бассейна реки и количества крупных городов, где эти реки протекают;
-
максимальное значение длины реки, площади бассейна реки и количества крупных городов;
-
среднее значение длины рек, площади бассейна и количества крупных городов;
-
количество рек длиной < 5000 км;
-
количество рек длиной ≥ 5000 км;
-
количество рек с площадью бассейна >1000 тыс. км²;
-
количество рек с площадью бассейна ≤ 1000 тыс. км²;
-
количество стран с указанными реками;
-
ранг рек по длине (порядковый номер реки относительно значений длины).

Рис.19. Исходные данные для выполнения лабораторной работы
-
Контрольные вопросы
-
Назовите известные вам функции из категорий Статистические и их аргументы.
-
Сколько аргументов могут иметь функции МИН и МАКС?
-
Каковы отличия функций СЧЕТ и СЧЕТЕСЛИ. Назовите аргументы этих функций.
-
С какой целью в функции РАНГ.РВ используется абсолютная адресация ячеек?
-
Самостоятельно выясните назначение и работу функций НАИМЕНЬШИЙ, НАИБОЛЬШИЙ, ТЕНДЕНЦИЯ категории Статистические, используя справку по каждой из них. Приведите примеры.
Цели работы:
-
научиться применять
статистические функции для обработки
данных; -
закрепить навыки
форматирования таблицы.
Задание:
-
изучите п.1 «Учебный
материал»; -
выполните задания,
приведенные в п.2; -
ответьте на
контрольные вопросы (п.3).
-
Учебный материал
-
Функции категории Статистические
Статистические
функции позволяют выполнять статистический
анализ диапазонов данных: нахождение
минимального и максимального значения
среди исходных чисел, выполнение
элементарного подсчёта числовых
значений, подсчёт числовых значений в
соответствии с определённым условием
и т.д. Статистические функции входят в
категорию Статистические
Мастера функций (рис.17).

Рис.17. Окно Мастера функций с выбранное
категорией функций Статистические
Рассмотрим ряд
статистических функций, встречающихся
в простейших вычислениях.
-
Нахождение
минимального значения
(среди числовых значений) в списке
аргументов с помощью функции МИН.
Формат записи функции:
Мин (число1; число2;…)
Количество
допустимых аргументов, среди которых
находится минимальное значение, равно
255.
Пример.
Найти наименьшее значение цены на книгу
«Гарри Поттер и дары смерти» среди
магазинов города. Пусть в ячейках B3:B7
внесены значения цены (рис.18). Установите
курсор в ячейку В9, вызовите Мастер
функций и из категории Статистические
выберите функцию МИН. Укажите исходные
значения и нажмите OK.
-
Нахождение
максимального значения
(среди числовых значений) в списке
аргументов с помощью функции МАКС.
Формат записи функции:
Макс (число1; число2;…)
Количество
допустимых аргументов, среди которых
находится максимальное значение, равно
255.
Пример.
Найти максимальное значение цены на
книгу «Гарри Поттер и дары смерти» среди
магазинов города. Пусть в ячейках B3:B7
внесены значения цены (рис.19). Установите
курсор в ячейку В9, вызовите Мастер
функций и
из категории Статистические
выберите функцию МАКС. Укажите исходные
значения и нажмите OK.
|
Рис. 18. Нахождение |
Рис. 19. Нахождение |

-
Нахождение
среднего арифметического значения
с помощью функции СРЗНАЧ.
Формат записи функции:
Срзнач(число1; число2;…)
Количество
допустимых аргументов, среди которых
находится среднее значение, равно 255.
Пример.
Найти среднее значение цены на книгу
«Гарри Поттер и дары смерти» в магазинах
города. Пусть в ячейках B3:B7
внесены значения цены (рис. 20). Установите
курсор в ячейку В9, вызовите Мастер
функций и из категории Статистические
выберите функцию СРЗНАЧ.
Укажите исходные данные и нажмите OK.

Рис. 20. Нахождение среднего значения
среди аргументов
-
Подсчет количества
значений в списке аргументов осуществляется
с помощью функции СЧЕТ.
Формат записи функции:
Счет(число1; число2;…)
Количество
допустимых аргументов, среди которых
находится среднее значение, равно 255.
Пример. Найти
количество студентов, получающих
стипендию. Пусть в ячейках B3:B7
внесены сведения о стипендии студентов
группы (рис.21). Установите курсор в ячейку
В9, вызовите Мастер функций и из категории
Статистические выберите функцию СЧЕТ.
Укажите исходные данные и нажмите OK.
В ячейке В9 будет найдено искомое
значение.
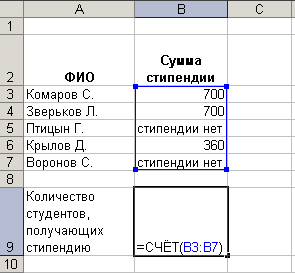
Рис. 21. Нахождение количества числовых
значений среди аргументов
-
Нахождение
количества значений, удовлетворяющих
заданному условию,
выполняется с помощью функции СЧЕТЕСЛИ.
Формат записи функции:
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
|
Единственный в мире Музей Смайликов |
|

 Скачать 103.42 Kb.
Скачать 103.42 Kb.
Подборка по базе: Статистика. Практическая работа №1 Стариков.docx, Практическая работа «Целостный педагогический процесс_ единство , контрольная работа тоэ.docx, Деньги и их роль в экономике. Индивидуальная работа. Епифанова Е, Практическая работа №1.docx, Практическая работа #1 УП.pdf.pdf, 11.02.2022 контрольная работа.docx, Курсовая работа — Особенности рекламных акций и кампаний на прим, Практическая работа № 1.docx, Вредова К. Курсовая работа 1118СОЭ11.docx
Лабораторная работа 1
Тема 2.3. Статистические функции MS Excel
Задание
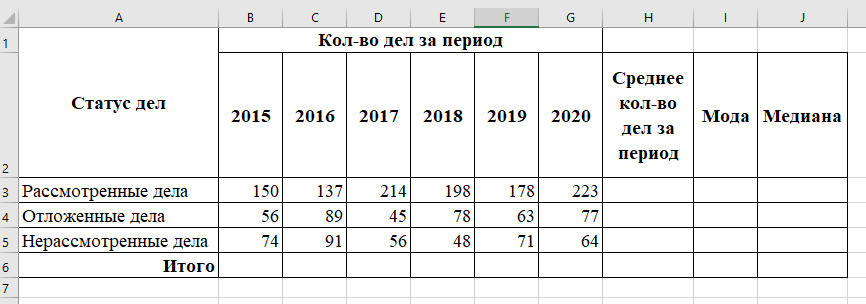
1. Создадим электронную таблицу на Листе 1 по образцу.
2. Определим по приведенным данным следующие значения:
- общее количество дел за каждый год данного периода;
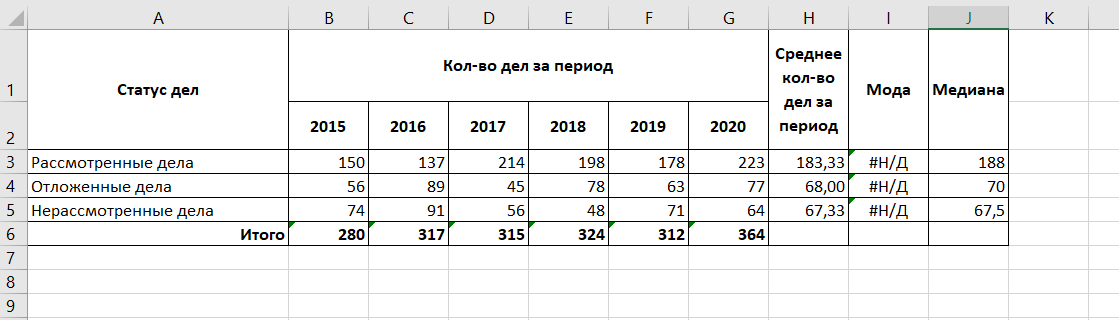
В6=СУММ(B3:B5), автоматически продлим формулу вправо
- среднее количество дел за период для каждого статуса дел;
Н3=СРЗНАЧ(B3:G3), автоматически продлим формулу вниз
- значения моды и медианы для каждого статуса дел за указанный период.
I3=МОДА.ОДН(B3:G3)
J3=МЕДИАНА(B3:G3)
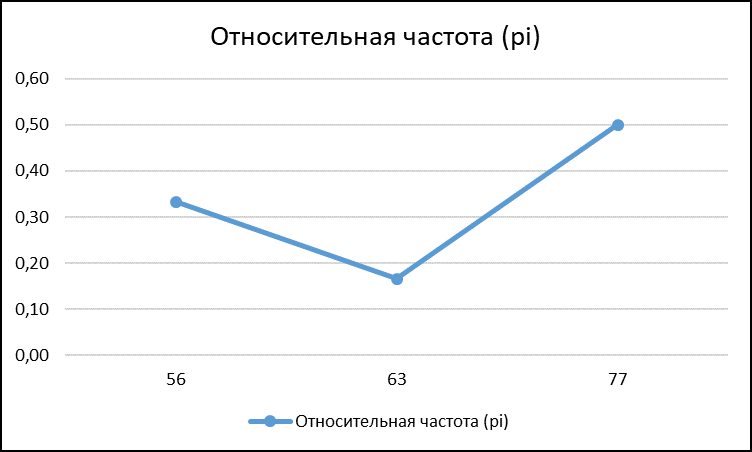
3. На Листе 2 построим полигон частот для дел со статусом «Отложенные дела».
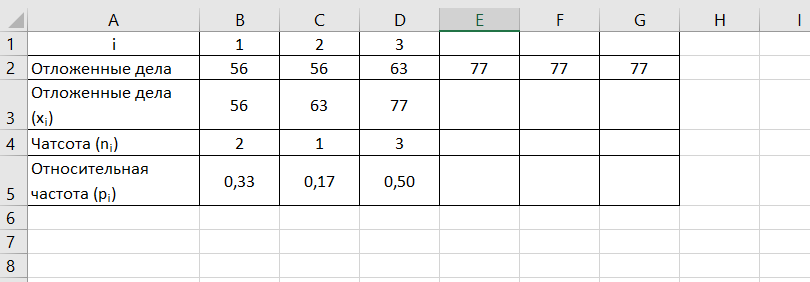
Исходные данные:
| Отложенные дела | 56 | 77 | 56 | 77 | 63 | 77 |
После группировки данные будут представлены в виде статистического ряда.
Оформим таблицу на Листе 2 по образцу.
- Определим частоту ni, относительную частоту pi.
В4=ТРАНСП(ЧАСТОТА($B$2:$G$2;$B$3:$D$3))
В5=B4/СУММ($B$4:$D$4)
- Построим полигон относительных частот pi(xi).
- Авторы
- Файлы работы
- Сертификаты
Коваль О.В. 1, Аверьянова С.Ю. 1
1Филиал Южного федерального университета в г.Новошахтинске Ростовской области
Комментарии
Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке «Файлы работы» в формате PDF
овладеть навыками расчета числовых характеристик выборки с помощью Надстройки Пакет Анализа ЭТ MS Excel.
Краткая теория
В ЭТ MS Excel имеется набор мощных инструментов для работы с выборками и углубленного статистического анализа данных, называемый Пакет анализа, который может быть использован для решения задач статистической обработки выборочных данных.
Надстройка Пакет анализа вызывается командой главного меню Данные → Анализ данных. В появившемся окне Анализ данных выбираем пункт Описательная статистика.
Далее откроется окно Описательная статистика, в котором необходимо сделать нужные установки.
Входной диапазон. Ссылка на диапазон, содержащий анализируемые данные. Ссылка должна состоять не менее чем из двух смежных диапазонов данных, данные в которых расположены по строкам или столбцам.
Группирование. Установите переключатель в положение «По столбцам» или «По строкам» в зависимости от расположения данных во входном диапазоне.
Метки в первой строке/Метки в первом столбце. Если первая строка исходного диапазона содержит названия столбцов, установите переключатель в положение Метки в первой строке. Если названия строк находятся в первом столбце входного диапазона, установите переключатель в положение Метки в первом столбце. Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически.
Уровень надежности. Установите флажок, если в выходную таблицу необходимо вывести границу доверительного интервала для среднего. В поле введите требуемое значение в процентах. Например, значение 95% вычисляет уровень надежности среднего с уровнем значимости 0,05.
К-ый наибольший. Установите флажок, если в выходную таблицу необходимо включить строку для k-го наибольшего значения для каждого диапазона данных. В соответствующем окне введите число k. Если k равно 1, эта строка будет содержать максимальное значение выборки.
К-ый наименьший. Установите флажок, если в выходную таблицу необходимо включить строку для k-го наименьшего значения для каждого диапазона данных. В соответствующем окне введите число k. Если k равно 1, эта строка будет содержать минимальное значение выборки.
Выходной диапазон. Введите ссылку на левую верхнюю ячейку выходного диапазона. Этот инструмент анализа выводит два столбца сведений для каждого набора данных. Левый столбец содержит метки статистических данных; правый столбец содержит статистические данные. Состоящий их двух столбцов диапазон статистических данных будет выведен для каждого столбца или для каждой строки входного диапазона в зависимости от положения переключателя Группирование.
Если хотим вывести результаты расчета на новый лист, то установите переключатель, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. Если в этом есть необходимость, введите имя нового листа в поле, расположенном напротив соответствующего положения переключателя.
Если хотим вывести результаты расчета в новой книге, то установите переключатель, чтобы открыть новую книгу и вставить результаты анализа в ячейку A1 на первом листе в этой книге.
Итоговая статистика. Установите флажок, если в выходном диапазоне необходимо получить по одному полю для каждого из следующих видов статистических данных, представленных в таблице 2.
Таблица 2.
|
Значение |
Примечания |
|
Среднее |
Выборочное среднее х=1n∙i=1nxi. Функция СРЗНАЧ. |
|
Стандартная ошибка |
Оценка среднеквадратичного отклонения выборочного среднего. Вычисляется по формуле 1n∙(n-1)∙i=1n(xi-x)2 |
|
Медиана |
Число, которое является серединой множества чисел, то есть половина чисел имеют значения большие, чем медиана, а половина чисел имеют значения меньшие, чем медиана. Функция МЕДИАНА. |
|
Мода |
Наиболее часто встречающееся значение в выборке. Если нет одинаковых значений, то возвращается значение ошибки #Н/Д. Функция МОДА.ОДН. |
|
Стандартное отклонение |
Оценка среднеквадратичного отклонения генеральной совокупности S=1n-1∙i=1n(xi-x)2. Функция СТАНДОТКЛОН.В. |
|
Дисперсия выборки |
Оценка дисперсии генеральной совокупности . Функция ДИСП.В. |
|
Эксцесс |
Выборочный эксцесс. Функция ЭКСЦЕСС. |
|
Асимметрич-ность |
Коэффициент асимметрии. Функция СКОС. |
|
Интервал |
Размах варьирования R = xmax ‒ xmin . |
|
Минимум |
Минимальное значение в выборке. Функция МИН. |
|
Максимум |
Максимальное значение в выборке. Функция МАКС. |
|
Сумма |
Сумма всех значений в выборке. Функция СУММ. |
|
Счет |
Объем выборки. Функция СЧЕТ. |
|
Наибольший |
k-тое наибольшее значение выборки. Если k=1, то выводится максимальное значение. Функция НАИБОЛЬШИЙ. |
|
Наименьший |
k-тое наименьшее значение выборки. Если k=1, то выводится минимальное значение. Функция НАИМЕНЬШИЙ |
|
Уровень надежности |
Параметр показывает возможность отклонения среднего по выборке, от среднего для генеральной совокупности, при заданном уровне надежности. |
Замечание. Следует обратить внимание на то, что расчет параметров в режиме Описательная статистика имеет ряд важных особенностей:
1. В качестве значений параметров: Стандартное отклонение, Дисперсия выборки, Эксцесс, Асимметричность – Excel генерирует оценки соответствующих параметров для генеральной совокупности, а не для выборки.
2. Для применения Описательной статистики предварительное ранжирование исходных данных не требуется: при вычислении показателей ранжирование выполняется автоматически.
3. Появление в ячейке Мода индикатора ошибки #Н/Д указывает на то, что в анализируемых данных нет одинаковых значений признака. В этом случае в качестве моды Мо выбирается то значение признака, которое соответствует максимальной ординате теоретической кривой распределения.
4. Индикатор ошибки #ДЕЛ/0! В ячейке Эксцесс и/или Асимметричность означает, что в результативной таблице стандартное отклонение является нулевым или же заданный входной диапазон данных содержит менее четырех элементов данных
5. Стандартная ошибка ‒ это разность между ожидаемыми и наблюдаемыми значениями исследуемого признака.
Стандартная ошибка или ошибка среднегонаходится из выражения
m=Sn .
Стандартная ошибка – это параметр, характеризующий степень возможного отклонения среднего значения, полученного на исследуемой ограниченной выборке, от истинного среднего значения, полученного на всей совокупности элементов. С помощью стандартной ошибки задается так называемый доверительный интервал. 95%-ый доверительный интервал, равный х ± 2т , обозначает диапазон, в который с вероятностью р = 0,95 (при достаточно большом числе наблюдений п>30) попадает среднее значение генеральной совокупности.
Пример выполнения
Постановка задачи. Приведены объемы дневной выручки (в тыс. руб.) 24 продавцов колбасных изделий, работающих в разных районах города (см. табл.1).
Таблица 1.
|
20,2 |
19,3 |
19,9 |
23,1 |
18,8 |
17,4 |
|
19,9 |
18,3 |
16,4 |
17,3 |
18,3 |
15,8 |
|
20,5 |
20,6 |
19,4 |
18,7 |
16,3 |
18,4 |
|
21,6 |
21,2 |
19,3 |
19,1 |
19,3 |
18,8 |
Требуется: выполнить описательную статистику выборки с помощью Надстройки Пакет Анализа ЭТ MS Excel.
Решение задачи в среде ЭТ MSExcel. Для решения задачи в среде ЭТ MS Excel необходимо выполнить следующие действия:
1. Идентифицируйте свою работу, переименовав Лист1 в Титульный лист и записав номер лабораторной работы, ее название, кто выполнил и проверил.
2. Переименуйте Лист 2 в Исходные данные и наберите столбец исходных данных.
3. Вычислите величины хmax, хmin, R, n, N, Nокругл., Δ и Δокругл. , используя встроенные функции Excel МАКС, МИН, СЧЕТ, КОРЕНЬ и ОКРУГЛ.
4. Сформируйте столбец интервалов группировки. Наберите команду Данные → Анализ данных → Гистограмма и в появившемся диалоговом окне выполните нужные установки. Отформатируйте полученную таблицу и построенную гистограмму выборки.
5. Наберите команду Данные → Анализ данных → Описательная статистика и в появившемся диалоговом окне выполните нужные установки.
6. Щелчок по кнопке «ОК» приводит к появлению результирующей таблицы статистических характеристик выборки.
7. Повторно вычислим найденные характеристики с помощью встроенных функций MS Excel или формул. Сравним полученные результаты.
8. Сделайте выводы и сохраните работу в вашем каталоге.
Исходные данные для самостоятельного решения
Задание. Имеется выборка объема n = 27 (табл. 2).
Требуется: выполнить описательную статистику выборки с помощью Надстройки Пакет Анализа ЭТ MS Excel.
Таблица 2.
|
№ варианта |
Выборка |
||||||||
|
1 |
22,5 |
20,2 |
19,3 |
19,9 |
23,1 |
18,8 |
17,4 |
21,6 |
19,1 |
|
21,6 |
19,9 |
18,3 |
16,4 |
17,3 |
18,3 |
15,8 |
21,2 |
19,3 |
|
|
17,8 |
20,5 |
20,6 |
19,4 |
18,7 |
16,3 |
18,4 |
19,3 |
18,8 |
|
|
2 |
18,8 |
20,2 |
19,3 |
19,9 |
23,2 |
22,5 |
17,4 |
21,8 |
19,2 |
|
19,4 |
18,7 |
16,3 |
18,4 |
19,3 |
18,8 |
19,4 |
18,7 |
16,3 |
|
|
20,5 |
20,6 |
19,4 |
18,7 |
16,3 |
18,4 |
19,3 |
18,8 |
17,8 |
|
|
2 |
20,2 |
19,3 |
19,9 |
23,1 |
18,8 |
17,4 |
21,6 |
19,1 |
22,4 |
|
18,7 |
20,2 |
19,3 |
19,9 |
23,2 |
22,5 |
17,4 |
21,8 |
19,2 |
|
|
18,1 |
19,8 |
18,2 |
16,4 |
17,2 |
21,8 |
15,8 |
21,2 |
19,2 |
|
|
3 |
19,4 |
18,7 |
16,3 |
18,4 |
19,3 |
18,8 |
19,4 |
18,7 |
16,3 |
|
18,5 |
20,6 |
19,4 |
20,7 |
16,3 |
18,4 |
19,3 |
18,8 |
17,8 |
|
|
20,1 |
19,3 |
19,9 |
23,1 |
18,8 |
17,4 |
21,6 |
19,1 |
22,4 |
|
|
4 |
19,7 |
20,2 |
19,3 |
18,9 |
23,2 |
22,5 |
17,4 |
21,8 |
19,2 |
|
18,3 |
19,8 |
18,2 |
16,4 |
17,2 |
21,8 |
15,8 |
21,2 |
19,2 |
|
|
19,7 |
18,7 |
16,3 |
18,4 |
19,3 |
18,8 |
19,4 |
18,7 |
16,3 |
|
|
5 |
19,4 |
20,7 |
16,3 |
18,4 |
19,3 |
18,8 |
17,8 |
18,7 |
20,2 |
|
19,9 |
23,1 |
18,8 |
17,4 |
21,6 |
19,1 |
22,4 |
18,1 |
19,8 |
|
|
19,3 |
18,9 |
23,2 |
22,5 |
17,4 |
21,8 |
19,2 |
19,4 |
18,7 |
|
|
6 |
18,7 |
16,3 |
18,4 |
19,3 |
18,8 |
19,4 |
18,7 |
18,5 |
20,6 |
|
20,6 |
19,4 |
20,7 |
16,3 |
18,4 |
19,3 |
18,8 |
18,4 |
19,3 |
|
|
19,3 |
19,9 |
23,1 |
18,8 |
17,4 |
21,6 |
19,1 |
18,4 |
19,3 |
|
|
7 |
16,3 |
18,4 |
19,3 |
18,8 |
19,4 |
18,7 |
18,5 |
20,6 |
18,7 |
|
19,4 |
20,7 |
16,3 |
18,4 |
19,3 |
18,8 |
18,4 |
19,3 |
20,6 |
|
|
19,9 |
23,1 |
18,8 |
17,4 |
21,6 |
19,1 |
18,4 |
19,3 |
19,3 |
|
|
8 |
19,3 |
19,9 |
23,1 |
18,8 |
17,4 |
21,6 |
19,1 |
22,5 |
20,2 |
|
18,3 |
16,4 |
17,3 |
18,3 |
15,8 |
21,2 |
19,3 |
21,6 |
19,9 |
|
|
20,6 |
19,4 |
18,7 |
16,3 |
18,4 |
19,3 |
18,8 |
17,8 |
20,5 |
|
|
9 |
19,4 |
20,7 |
16,3 |
18,4 |
19,3 |
18,8 |
17,8 |
18,7 |
20,2 |
|
19,9 |
23,1 |
18,8 |
17,4 |
21,6 |
19,1 |
22,4 |
18,1 |
19,8 |
|
|
19,3 |
18,9 |
23,2 |
22,5 |
17,4 |
21,8 |
19,2 |
19,4 |
18,7 |
|
|
10 |
18,7 |
16,3 |
18,4 |
19,3 |
18,8 |
19,4 |
18,7 |
18,5 |
20,6 |
|
20,6 |
19,4 |
20,7 |
16,3 |
18,4 |
19,3 |
18,8 |
18,4 |
19,3 |
|
|
16,4 |
20,4 |
20,8 |
19,4 |
18,7 |
17,8 |
18,4 |
19,4 |
18,8 |
Просмотров работы: 4378
Код для цитирования: