
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
В этой статье описаны синтаксис формулы и использование RSQ
в Microsoft Excel.
Описание
Возвращает квадрат коэффициента корреляции Пирсона для точек данных в аргументах «известные_значения_y» и «известные_значения_x». Дополнительные сведения см. в статье Функция PEARSON. Значение квадрата R показывает, насколько дисперсии y связана с дисперсией x.
Синтаксис
КВПИРСОН(известные_значения_y;звестные_значения_x)
Аргументы функции КВПИРСОН описаны ниже.
-
Известные_значения_y Обязательный. Массив или диапазон точек данных.
-
Известные_значения_x Обязательный. Массив или диапазон точек данных.
Замечания
-
Аргументы могут быть либо числами, либо содержащими числа именами, массивами или ссылками.
-
Учитываются логические значения и текстовые представления чисел, которые непосредственно введены в список аргументов.
-
Если аргумент, который является массивом или ссылкой, содержит текст, логические значения или пустые ячейки, то такие значения пропускаются; однако ячейки, которые содержат нулевые значения, учитываются.
-
Аргументы, которые представляют собой значения ошибок или текст, не преобразуемый в числа, приводят к возникновению ошибки.
-
Если аргументы известные_значения_y и известные_значения_x пусты или указанное в них количество число точек данных не совпадает, функция КВПИРСОН возвращает значение ошибки #Н/Д.
-
Если known_y и known_x содержат только 1 точку данных, RSQ возвращает #DIV/0! значение ошибки #ЗНАЧ!.
-
Коэффициент корреляции Пирсона (r) вычисляется с помощью следующего уравнения:

где x и y — выборочные средние значения СРЗНАЧ(массив1) и СРЗНАЧ(массив2).
Функция КВПИРСОН возвращает значение r2, являющееся квадратом коэффициента корреляции.
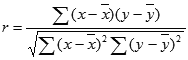
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
||
|
Известные значения y |
Известные значения x |
|
|
2 |
6 |
|
|
3 |
5 |
|
|
9 |
11 |
|
|
1 |
7 |
|
|
8 |
5 |
|
|
7 |
4 |
|
|
5 |
4 |
|
|
Формула |
Описание |
Результат |
|
=КВПИРСОН(A3:A9; B3:B9) |
Квадрат значения корреляции Пирсона между точками данных в диапазоне A3:A9 и B3:B9. |
0,05795 |
Нужна дополнительная помощь?
Функция КВПИРСОН возвращает квадрат коэффициента корреляции Пирсона для точек данных.
Описание функции КВПИРСОН
Возвращает квадрат коэффициента корреляции Пирсона для точек данных в аргументах «известные_значения_y» и «известные_значения_x». Дополнительные сведения см. в разделе Функция PEARSON. Значение квадрата R можно интерпретировать как отношение дисперсии для y к дисперсии для x.
Синтаксис
=КВПИРСОН(известные_значения_y;известные_значения_x)Аргументы
искомое_значениеискомое_значение
Обязательный. Массив или диапазон точек данных.
Обязательный. Массив или диапазон точек данных.
Замечания
- Аргументы должны быть либо числами, либо содержащими числа именами, массивами или ссылками.
- Учитываются логические значения и текстовые представления чисел, которые введены непосредственно в список аргументов.
- Если аргумент, который является массивом или ссылкой, содержит текст, логические значения или пустые ячейки, эти значения игнорируются; ячейки, содержащие нулевые значения, учитываются.
- Аргументы, которые представляют собой значения ошибок или текст, не преобразуемый в числа, приводят к возникновению ошибки.
- Если аргументы известные_значения_y и известные_значения_x пусты или указанное в них количество число точек данных не совпадает, функция КВПИРСОН возвращает значение ошибки #Н/Д.
- Если аргументы известные_значения_y и известные_значения_x содержат только одну точку данных, функция КВПИРСОН возвращает значение ошибки #ДЕЛ/0!.
- Коэффициент корреляции Пирсона (r) вычисляется с помощью следующего уравнения:

где: $$overline{x}, overline{y}$$ — выборочные средние значения СРЗНАЧ(массив1) и СРЗНАЧ(массив2).

Функция КВПИРСОН возвращает значение r2, являющееся квадратом коэффициента корреляции.
Пример
Содержание
- Вычисление коэффициента детерминации
- Способ 1: вычисление коэффициента детерминации при линейной функции
- Способ 2: вычисление коэффициента детерминации в нелинейных функциях
- Способ 3: коэффициент детерминации для линии тренда
- Вопросы и ответы

Одним из показателей, описывающих качество построенной модели в статистике, является коэффициент детерминации (R^2), который ещё называют величиной достоверности аппроксимации. С его помощью можно определить уровень точности прогноза. Давайте узнаем, как можно произвести расчет данного показателя с помощью различных инструментов программы Excel.
Вычисление коэффициента детерминации
В зависимости от уровня коэффициента детерминации, принято разделять модели на три группы:
- 0,8 – 1 — модель хорошего качества;
- 0,5 – 0,8 — модель приемлемого качества;
- 0 – 0,5 — модель плохого качества.
В последнем случае качество модели говорит о невозможности её использования для прогноза.
Выбор способа вычисления указанного значения в Excel зависит от того, является ли регрессия линейной или нет. В первом случае можно использовать функцию КВПИРСОН, а во втором придется воспользоваться специальным инструментом из пакета анализа.
Способ 1: вычисление коэффициента детерминации при линейной функции
Прежде всего, выясним, как найти коэффициент детерминации при линейной функции. В этом случае данный показатель будет равняться квадрату коэффициента корреляции. Произведем его расчет с помощью встроенной функции Excel на примере конкретной таблицы, которая приведена ниже.
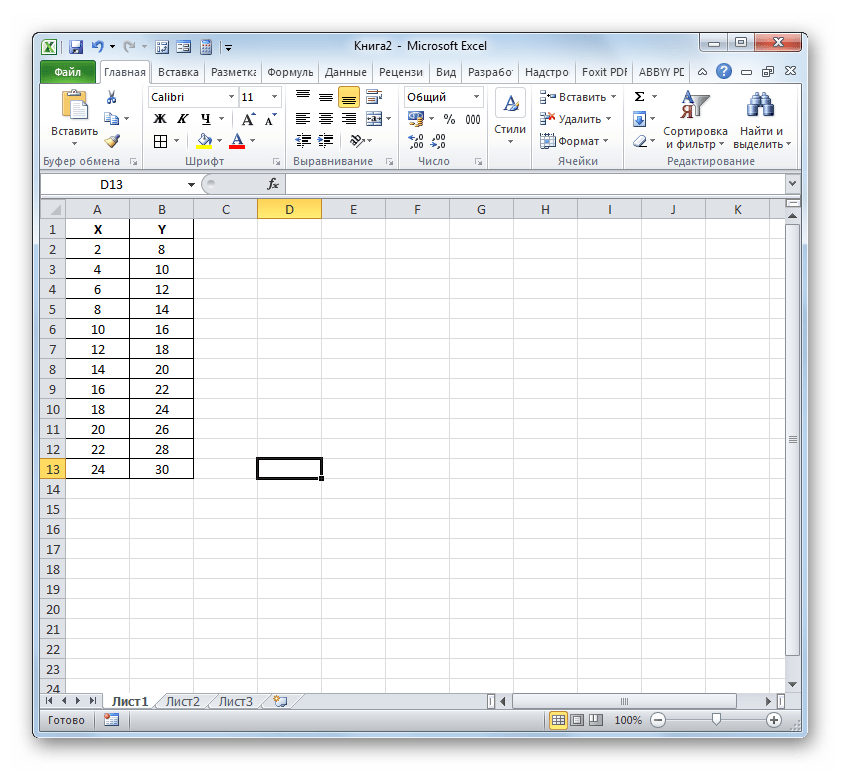
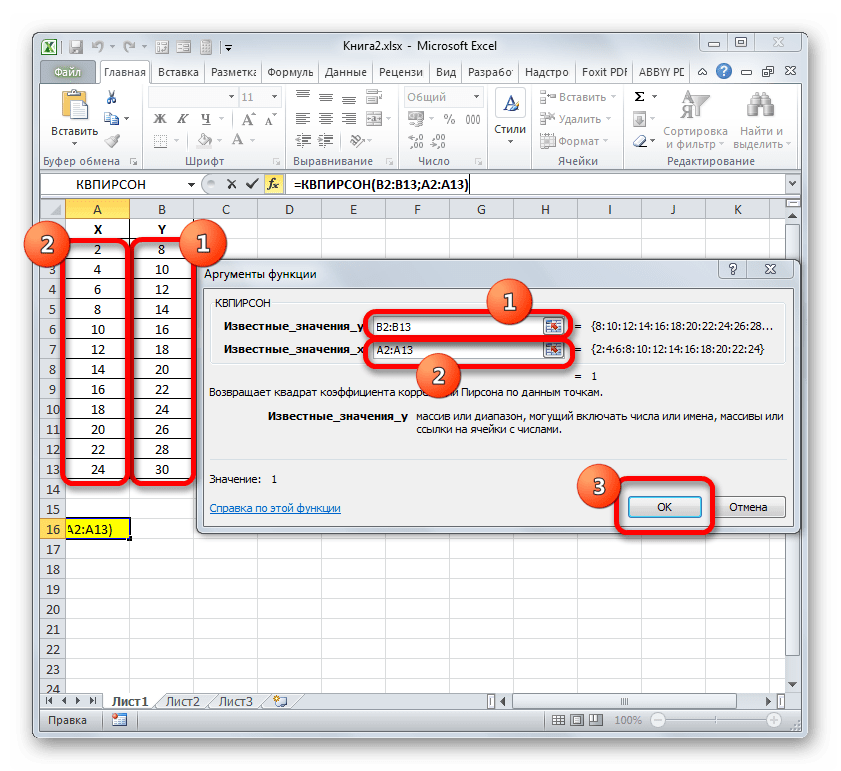
- Выделяем ячейку, где будет произведен вывод коэффициента детерминации после его расчета, и щелкаем по пиктограмме «Вставить функцию».
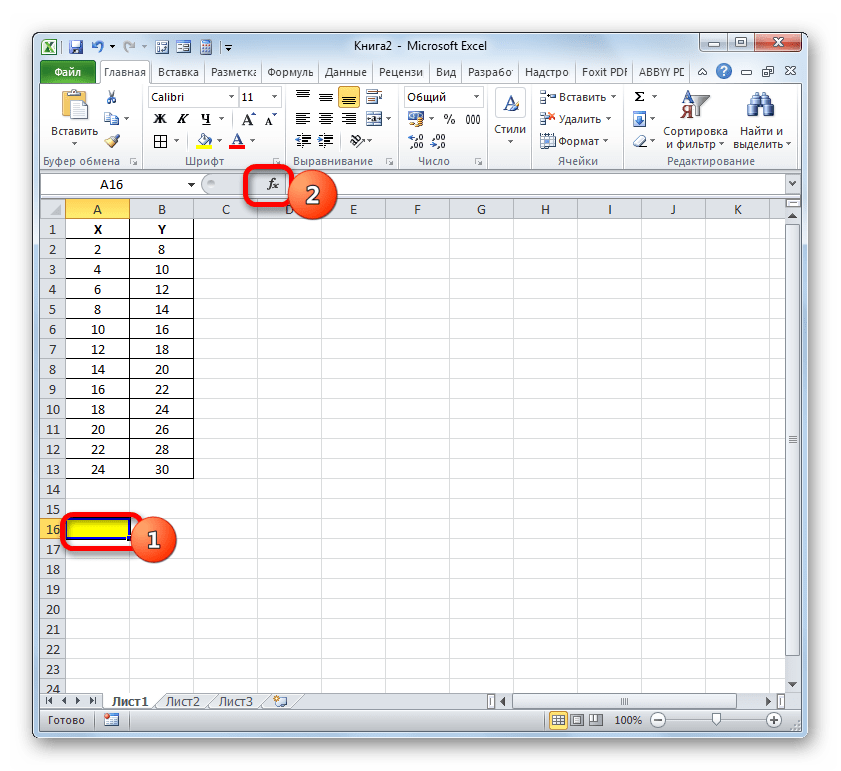
- Запускается Мастер функций. Перемещаемся в его категорию «Статистические» и отмечаем наименование «КВПИРСОН». Далее клацаем по кнопке «OK».
- Происходит запуск окна аргументов функции КВПИРСОН. Данный оператор из статистической группы предназначен для вычисления квадрата коэффициента корреляции функции Пирсона, то есть, линейной функции. А как мы помним, при линейной функции коэффициент детерминации как раз равен квадрату коэффициента корреляции.
Синтаксис этого оператора такой:
=КВПИРСОН(известные_значения_y;известные_значения_x)Таким образом, функция имеет два оператора, один из которых представляет собой перечень значений функции, а второй – аргументов. Операторы могут быть представлены, как непосредственно в виде значений, перечисленных через точку с запятой (;), так и в виде ссылок на диапазоны, где они расположены. Именно последний вариант и будет использован нами в данном примере.
Устанавливаем курсор в поле «Известные значения y». Выполняем зажим левой кнопки мышки и производим выделение содержимого столбца «Y» таблицы. Как видим, адрес указанного массива данных тут же отображается в окне.
Аналогичным образом заполняем поле «Известные значения x». Ставим курсор в данное поле, но на этот раз выделяем значения столбца «X».
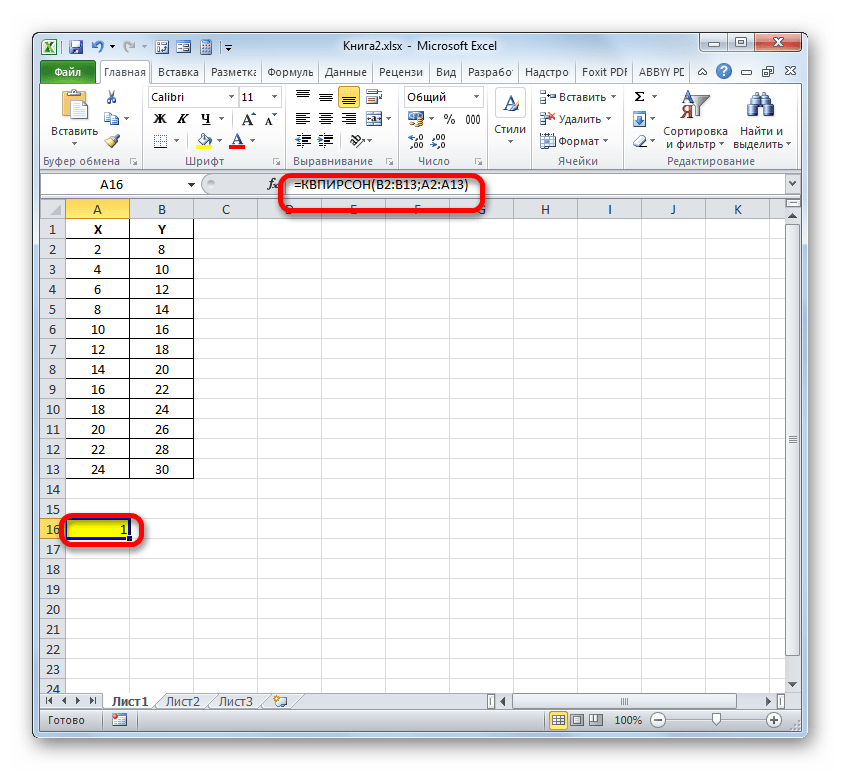
После того, как все данные были отображены в окне аргументов КВПИРСОН, клацаем по кнопке «OK», расположенной в самом его низу.
- Как видим, вслед за этим программа производит расчет коэффициента детерминации и выдает результат в ту ячейку, которая была выделена ещё перед вызовом Мастера функций. В нашем примере значение вычисляемого показателя получилось равным 1. Это значит, что представленная модель абсолютно достоверная, то есть, исключает погрешность.

Урок: Мастер функций в Microsoft Excel
Способ 2: вычисление коэффициента детерминации в нелинейных функциях
Но указанный выше вариант расчета искомого значения можно применять только к линейным функциям. Что же делать, чтобы произвести его расчет в нелинейной функции? В Экселе имеется и такая возможность. Её можно осуществить с помощью инструмента «Регрессия», который является составной частью пакета «Анализ данных».
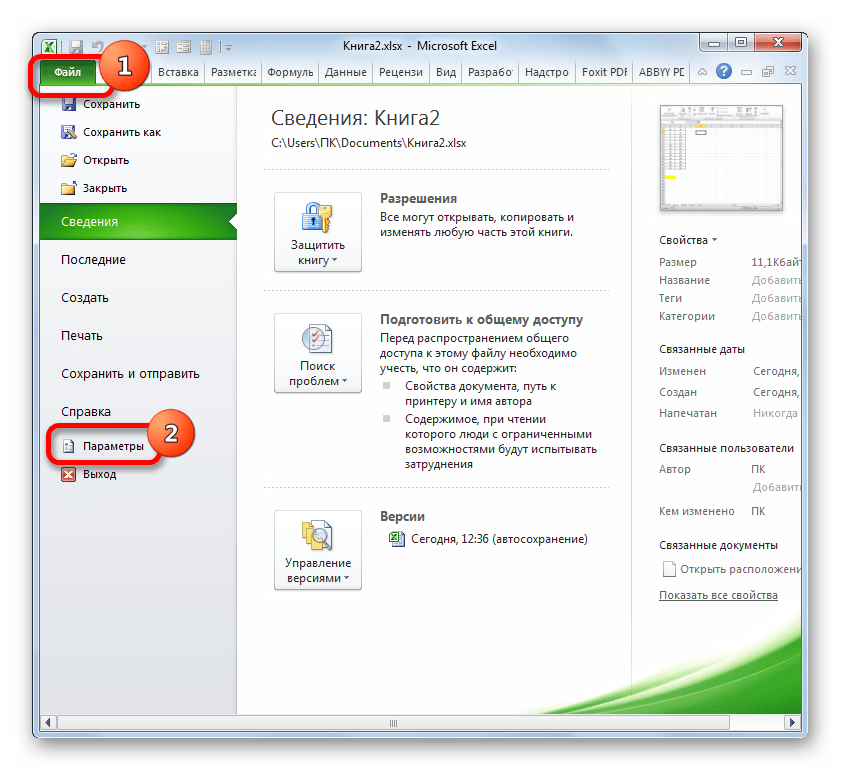
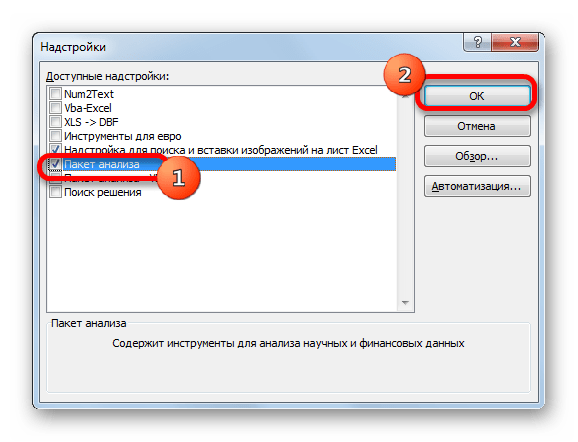
- Но прежде, чем воспользоваться указанным инструментом, следует активировать сам «Пакет анализа», который по умолчанию в Экселе отключен. Перемещаемся во вкладку «Файл», а затем переходим по пункту «Параметры».
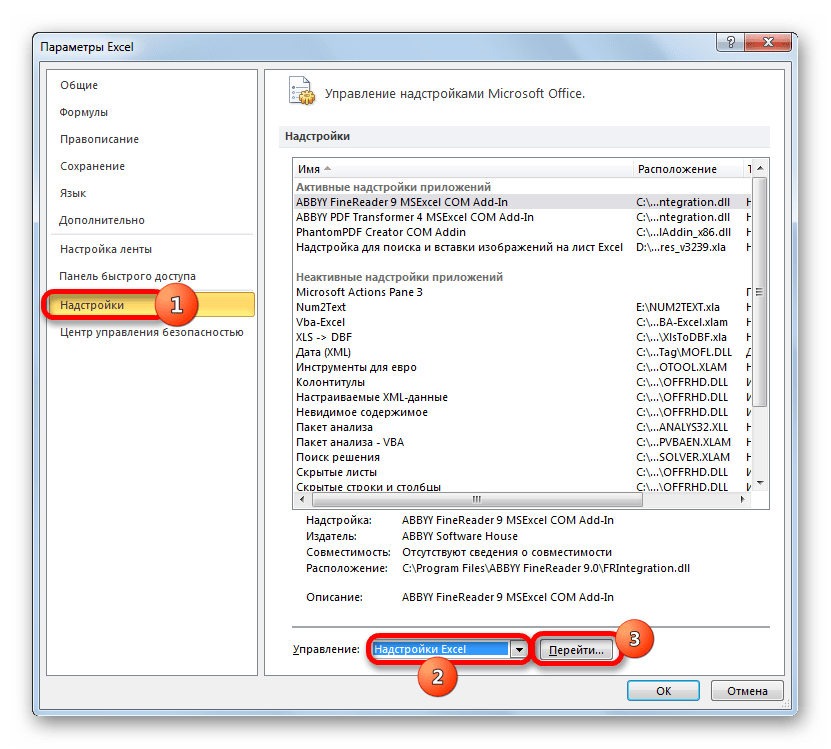
- В открывшемся окне производим перемещение в раздел «Надстройки» при помощи навигации по левому вертикальному меню. В нижней части правой области окна располагается поле «Управление». Из списка доступных там подразделов выбираем наименование «Надстройки Excel…», а затем щелкаем по кнопке «Перейти…», расположенной справа от поля.
- Производится запуск окна надстроек. В центральной его части расположен список доступных надстроек. Устанавливаем флажок около позиции «Пакет анализа». Вслед за этим требуется щелкнуть по кнопке «OK» в правой части интерфейса окна.
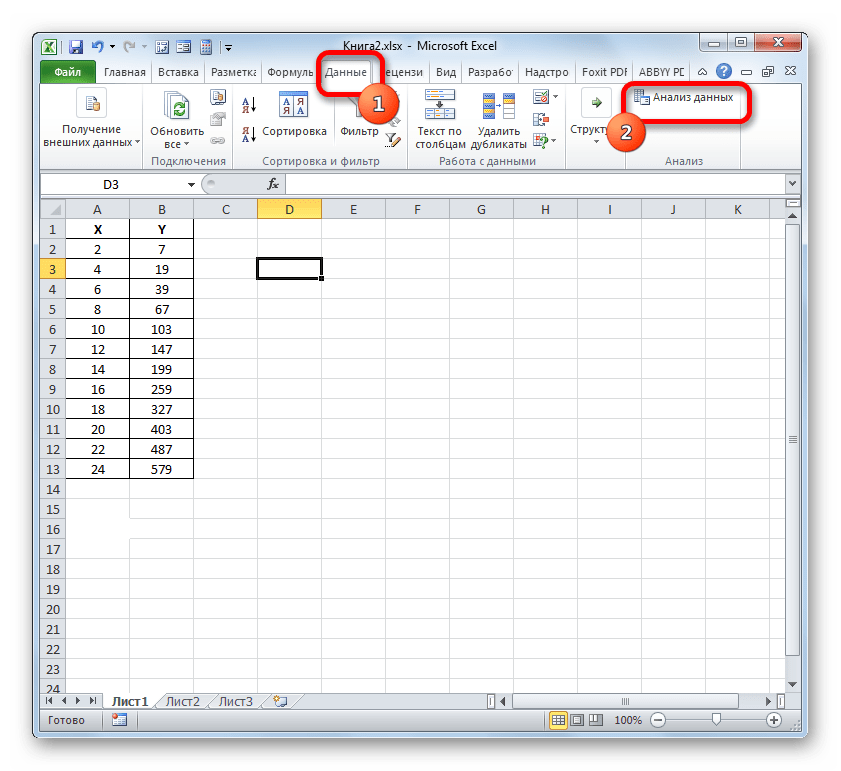
- Пакет инструментов «Анализ данных» в текущем экземпляре Excel будет активирован. Доступ к нему располагается на ленте во вкладке «Данные». Перемещаемся в указанную вкладку и клацаем по кнопке «Анализ данных» в группе настроек «Анализ».
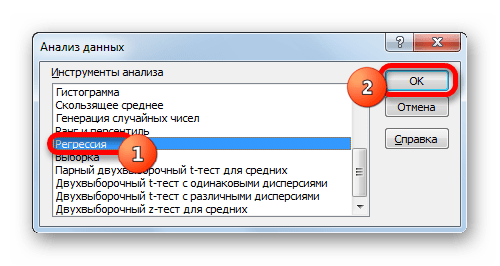
- Активируется окошко «Анализ данных» со списком профильных инструментов обработки информации. Выделяем из этого перечня пункт «Регрессия» и клацаем по кнопке «OK».
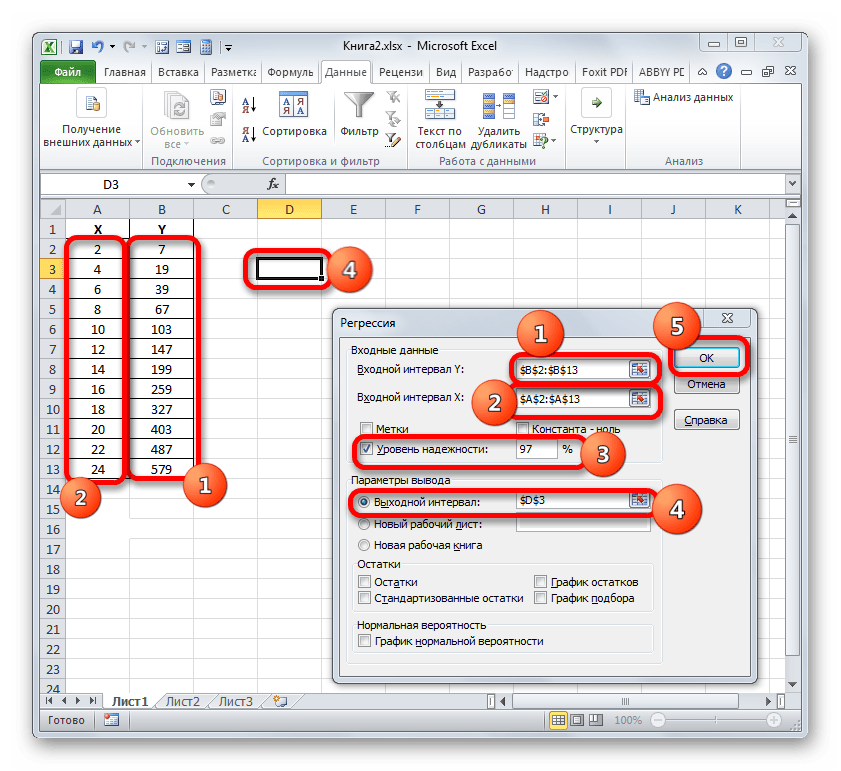
- Затем открывается окно инструмента «Регрессия». Первый блок настроек – «Входные данные». Тут в двух полях нужно указать адреса диапазонов, где находятся значения аргумента и функции. Ставим курсор в поле «Входной интервал Y» и выделяем на листе содержимое колонки «Y». После того, как адрес массива отобразился в окне «Регрессия», ставим курсор в поле «Входной интервал Y» и точно таким же образом выделяем ячейки столбца «X».
Около параметров «Метка» и «Константа-ноль» флажки не ставим. Флажок можно установить около параметра «Уровень надежности» и в поле напротив указать желаемую величину соответствующего показателя (по умолчанию 95%).
В группе «Параметры вывода» нужно указать, в какой области будет отображаться результат вычисления. Существует три варианта:
- Область на текущем листе;
- Другой лист;
- Другая книга (новый файл).
Остановим свой выбор на первом варианте, чтобы исходные данные и результат размещались на одном рабочем листе. Ставим переключатель около параметра «Выходной интервал». В поле напротив данного пункта ставим курсор. Щелкаем левой кнопкой мыши по пустому элементу на листе, который призван стать левой верхней ячейкой таблицы вывода итогов расчета. Адрес данного элемента должен высветиться в поле окна «Регрессия».
Группы параметров «Остатки» и «Нормальная вероятность» игнорируем, так как для решения поставленной задачи они не важны. После этого клацаем по кнопке «OK», которая размещена в правом верхнем углу окна «Регрессия».
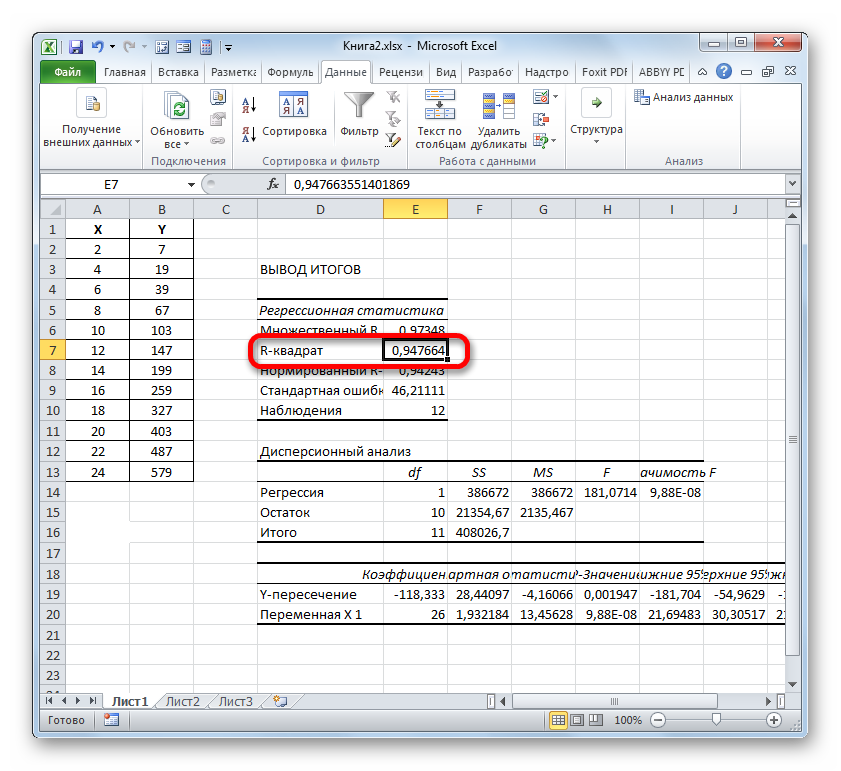
- Программа производит расчет на основе ранее введенных данных и выводит результат в указанный диапазон. Как видим, данный инструмент выводит на лист довольно большое количество результатов по различным параметрам. Но в контексте текущего урока нас интересует показатель «R-квадрат». В данном случае он равен 0,947664, что характеризует выбранную модель, как модель хорошего качества.
Способ 3: коэффициент детерминации для линии тренда
Кроме указанных выше вариантов, коэффициент детерминации можно отобразить непосредственно для линии тренда в графике, построенном на листе Excel. Выясним, как это можно сделать на конкретном примере.
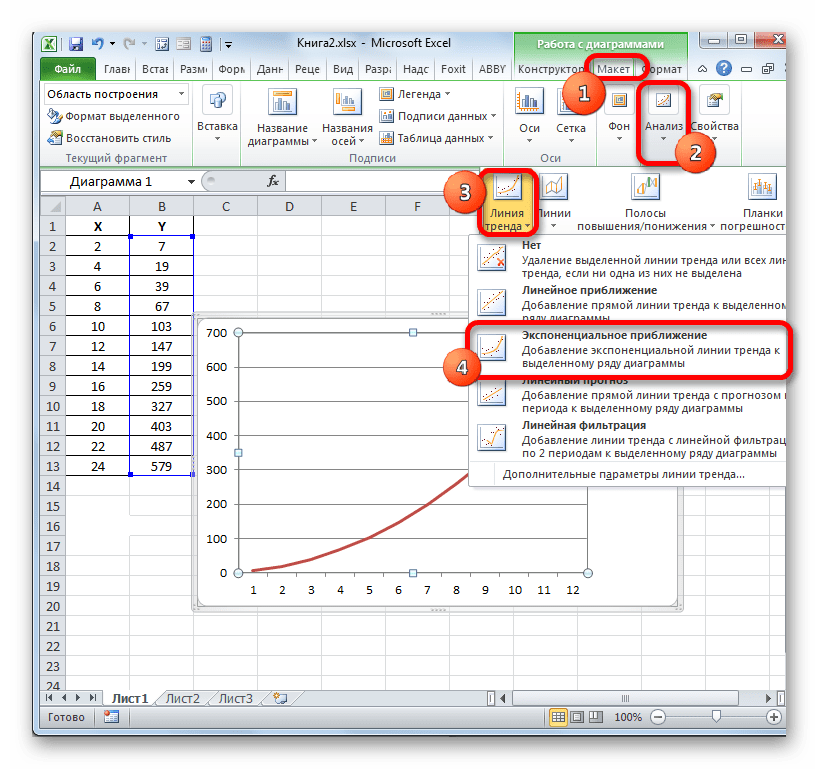
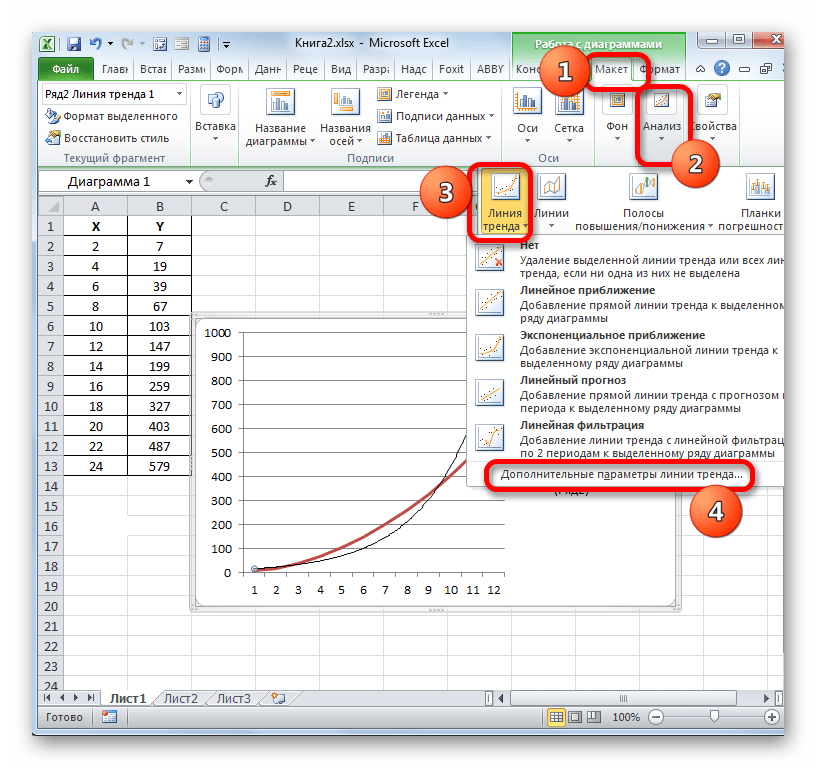
- Мы имеем график, построенный на основе таблицы аргументов и значений функции, которая была использована для предыдущего примера. Произведем построение к нему линии тренда. Кликаем по любому месту области построения, на которой размещен график, левой кнопкой мыши. При этом на ленте появляется дополнительный набор вкладок – «Работа с диаграммами». Переходим во вкладку «Макет». Клацаем по кнопке «Линия тренда», которая размещена в блоке инструментов «Анализ». Появляется меню с выбором типа линии тренда. Останавливаем выбор на том типе, который соответствует конкретной задаче. Давайте для нашего примера выберем вариант «Экспоненциальное приближение».
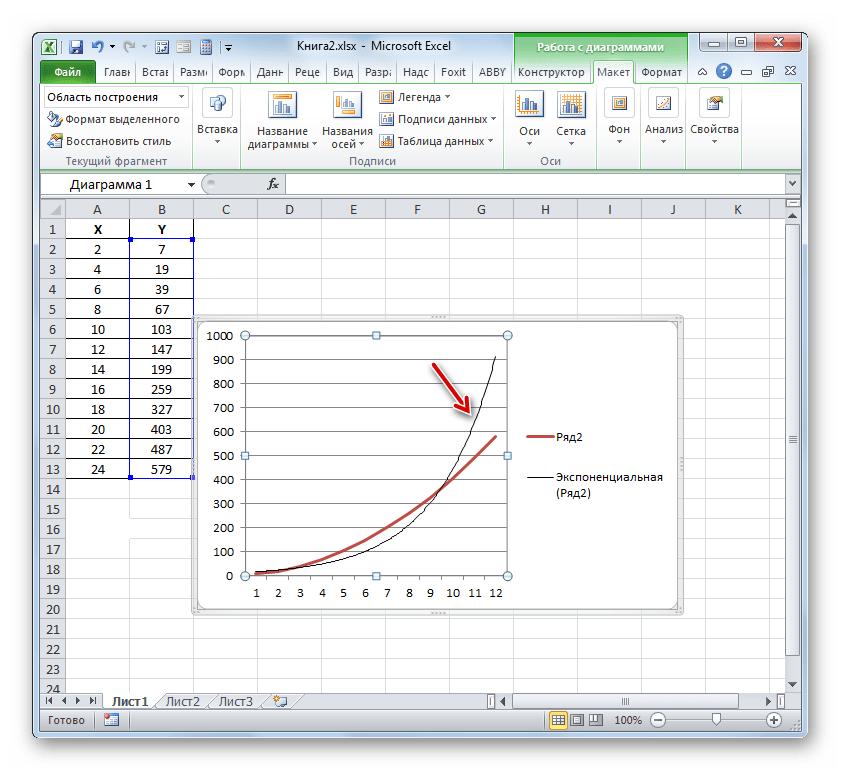
- Эксель строит прямо на плоскости построения графика линию тренда в виде дополнительной черной кривой.
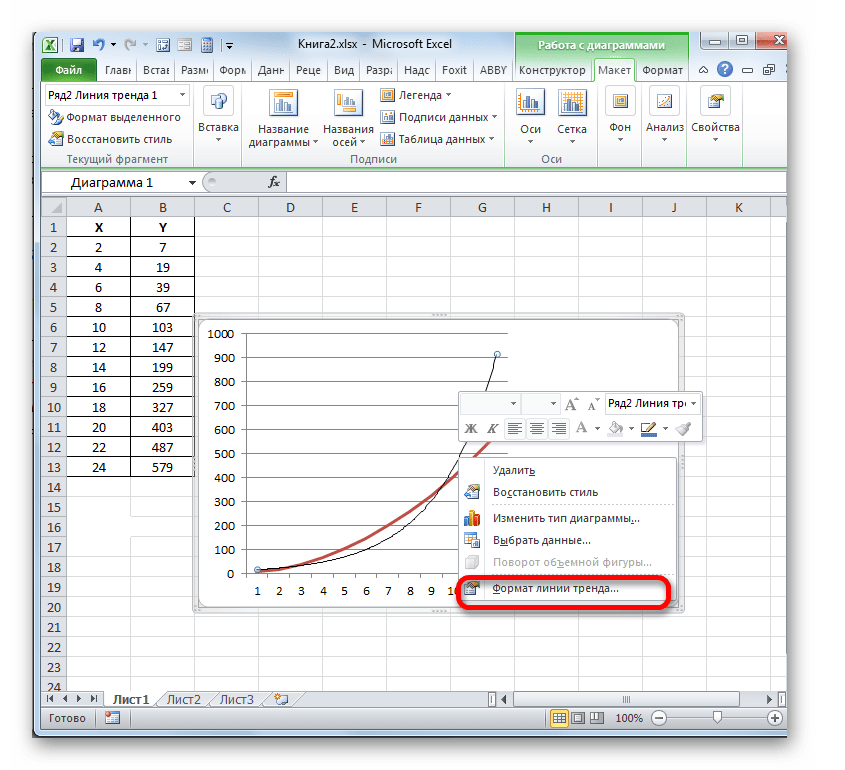
- Теперь нашей задачей является отобразить собственно коэффициент детерминации. Кликаем правой кнопкой мыши по линии тренда. Активируется контекстное меню. Останавливаем выбор в нем на пункте «Формат линии тренда…».

Для выполнения перехода в окно формата линии тренда можно выполнить альтернативное действие. Выделяем линию тренда кликом по ней левой кнопки мыши. Перемещаемся во вкладку «Макет». Клацаем по кнопке «Линия тренда» в блоке «Анализ». В открывшемся списке клацаем по самому последнему пункту перечня действий – «Дополнительные параметры линии тренда…».
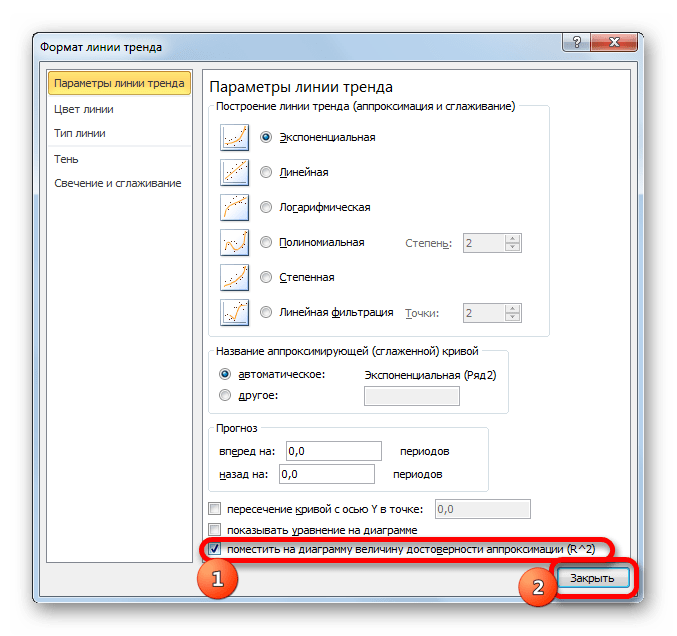
- После любого из двух вышеуказанных действий запускается окошко формата, в котором можно произвести дополнительные настройки. В частности, для выполнения нашей задачи необходимо установить флажок напротив пункта «Поместить на диаграмму величину достоверности аппроксимации (R^2)». Он размещен в самом низу окна. То есть, таким образом мы включаем отображение коэффициента детерминации на области построения. Затем не забываем нажать на кнопку «Закрыть» внизу текущего окна.
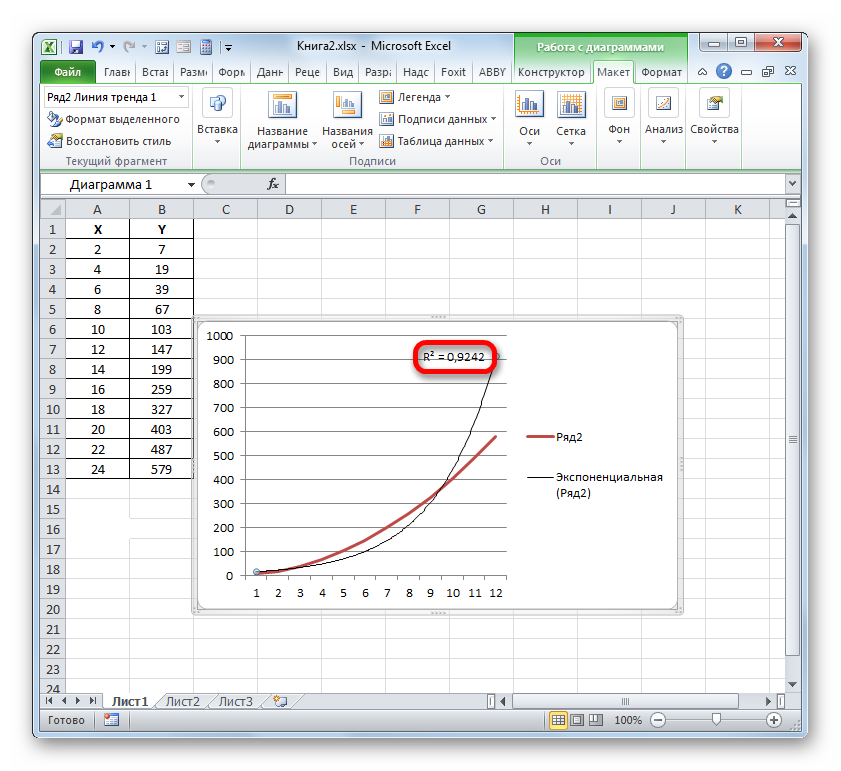
- Значение достоверности аппроксимации, то есть, величина коэффициента детерминации, будет отображено на листе в области построения. В данном случае эта величина, как видим, равна 0,9242, что характеризует аппроксимацию, как модель хорошего качества.
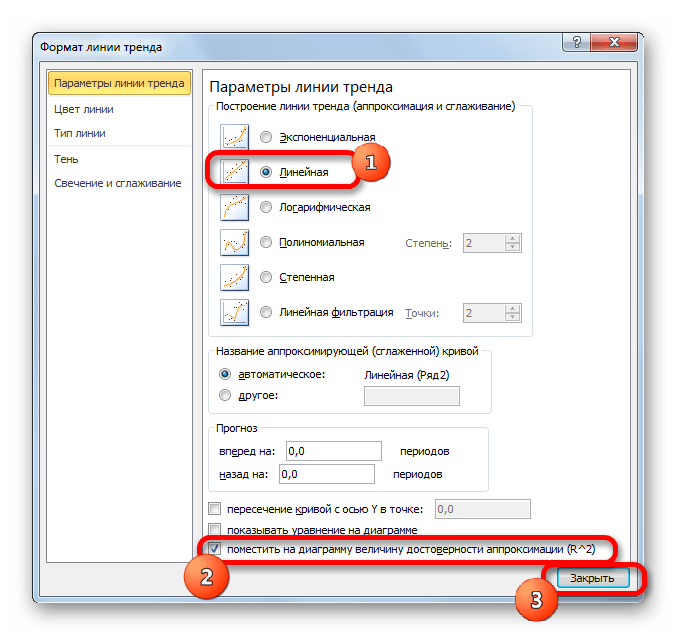
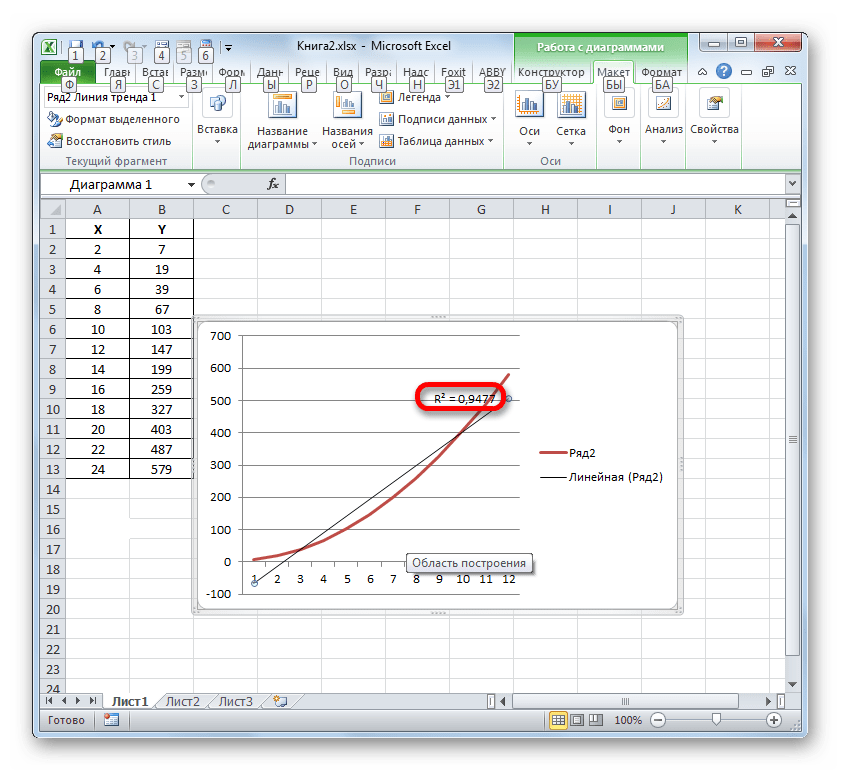
- Абсолютно точно таким образом можно устанавливать показ коэффициента детерминации для любого другого типа линии тренда. Можно менять тип линии тренда, произведя переход через кнопку на ленте или контекстное меню в окно её параметров, как было показано выше. Затем уже в самом окне в группе «Построение линии тренда» можно переключиться на другой тип. Не забываем при этом контролировать, чтобы около пункта «Поместить на диаграмму величину достоверности аппроксимации» был установлен флажок. Завершив вышеуказанные действия, щелкаем по кнопке «Закрыть» в нижнем правом углу окна.
- При линейном типе линия тренда уже имеет значение достоверности аппроксимации равное 0,9477, что характеризует эту модель, как ещё более достоверную, чем рассматриваемую нами ранее линию тренда экспоненциального типа.
- Таким образом, переключаясь между разными типами линии тренда и сравнивая их значения достоверности аппроксимации (коэффициент детерминации), можно найти тот вариант, модель которого наиболее точно описывает представленный график. Вариант с самым высоким показателем коэффициента детерминации будет наиболее достоверным. На его основе можно строить самый точный прогноз.
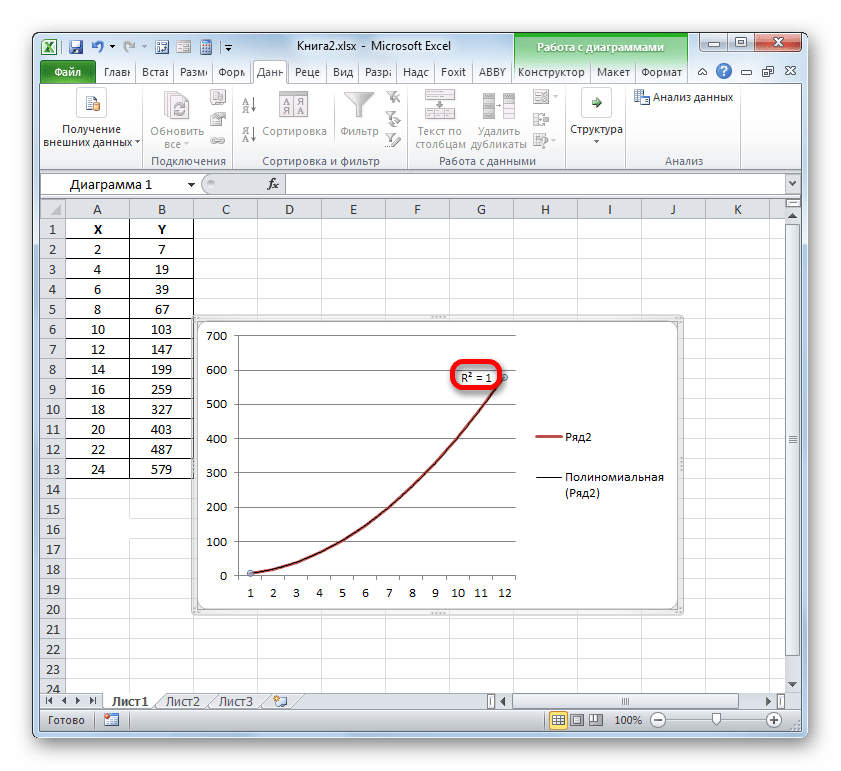
Например, для нашего случая опытным путем удалось установить, что самый высокий уровень достоверности имеет полиномиальный тип линии тренда второй степени. Коэффициент детерминации в данном случае равен 1. Это говорит о том, что указанная модель абсолютно достоверная, что означает полное исключение погрешностей.

Но, в то же время, это совсем не значит, что для другого графика тоже наиболее достоверным окажется именно этот тип линии тренда. Оптимальный выбор типа линии тренда зависит от типа функции, на основании которой был построен график. Если пользователь не обладает достаточным объемом знаний, чтобы «на глаз» прикинуть наиболее качественный вариант, то единственным выходом определения лучшего прогноза является как раз сравнение коэффициентов детерминации, как было показано на примере выше.
Читайте также:
Построение линии тренда в Excel
Аппроксимация в Excel
В Экселе существуют два основных варианта вычисления коэффициента детерминации: использование оператора КВПИРСОН и применение инструмента «Регрессия» из пакета инструментов «Анализ данных». При этом первый из этих вариантов предназначен для использования только в процессе обработки линейной функции, а другой вариант можно использовать практически во всех ситуациях. Кроме того, существует возможность отображения коэффициента детерминации для линии трендов графиков в качестве величины достоверности аппроксимации. С помощью данного показателя имеется возможность определить тип линии тренда, который располагает самым высоким уровнем достоверности для конкретной функции.
Еще статьи по данной теме:
Помогла ли Вам статья?
Описание:Возвращает квадрат коэффициента
корреляции Пирсона для точек данных в
аргументах известные_значения_y и
известные_значения_x. Дополнительные
сведения см. в описании функции ПИРСОН.
Значение r-квадрат можно интерпретировать
как отношение дисперсии для y к дисперсии
для x.
Синтаксис:
КВПИРСОН(известные_значения_y;известные_значения_x)
Известные_значения_y— массив или интервал точек данных.
Известные_значения_x— массив или интервал точек данных.
Замечания:
—
Аргументы должны быть либо числами,
либо содержащими числа именами, массивами
или ссылками.
—
Учитываются логические значения и
текстовые представления чисел, которые
введены непосредственно в список
аргументов.
—
Если аргумент, который является массивом
или ссылкой, содержит текст, логические
значения или пустые ячейки, эти значения
игнорируются; ячейки, содержащие нулевые
значения, учитываются.
—
Аргументы, которые представляют собой
значения ошибок или текст, не преобразуемый
в числа, приводят к возникновению ошибки.
—
Если аргументы известные_значения_y и
известные_значения_x пусты или указанное
в них количество число точек данных не
совпадает, функция КВПИРСОН возвращает
значение ошибки #Н/Д.
—
Если аргументы известные_значения_y и
известные_значения_x содержат только
одну точку данных, функция КВПИРСОН
возвращает значение ошибки #ДЕЛ/0!.
—
Коэффициент корреляции Пирсона (r)
вычисляется с помощью следующего
уравнения:

где
x и y — выборочные средние значения
СРЗНАЧ(массив1) и СРЗНАЧ(массив2).
Функция
КВПИРСОН возвращает значение r2,
являющееся квадратом коэффициента
корреляции.
64. Функция скос
Описание:Возвращает асимметрию распределения.
Асимметрия характеризует степень
несимметричности распределения
относительно его среднего. Положительная
асимметрия указывает на отклонение
распределения в сторону положительных
значений. Отрицательная асимметрия
указывает на отклонение распределения
в сторону отрицательных значений.
Синтаксис:
СКОС(число1;число2;
…)
Число1,
число2, …— от 1 до 255
аргументов, для которых вычисляется
асимметрия. Вместо аргументов, разделяемых
точкой с запятой, можно использовать
один массив или одну ссылку на массив.
Замечания:
—
Аргументы должны быть либо числами,
либо содержащими числа именами, массивами
или ссылками.
—
Учитываются логические значения и
текстовые представления чисел, которые
введены непосредственно в список
аргументов.
—
Если аргумент, который является массивом
или ссылкой, содержит текст, логические
значения или пустые ячейки, эти значения
игнорируются; ячейки, содержащие нулевые
значения, учитываются.
—
Аргументы, которые представляют собой
значения ошибок или текст, не преобразуемый
в числа, приводят к возникновению ошибки.
—
Если имеется менее трех точек данных
или стандартное отклонение равно нулю,
функция СКОС возвращает значение ошибки
#ДЕЛ/0!.
—
Уравнение для асимметрии имеет следующий
вид:
![]()
65. Функция наклон
Описание:Возвращает наклон линии линейной
регрессии для точек данных в аргументах
известные_значения_y и известные_значения_x.
Наклон определяется как частное от
деления расстояния по вертикали на
расстояние по горизонтали между двумя
любыми точками прямой; иными словами,
наклон — это скорость изменения значений
вдоль прямой.
Синтаксис:
НАКЛОН(известные_значения_y;известные_значения_x)
Известные_значения_y— массив или интервал ячеек, содержащих
числовые зависимые точки данных.
Известные_значения_x— множество независимых точек данных.
Замечания:
—
Аргументы должны быть либо числами,
либо содержащими числа именами, массивами
или ссылками.
—
Если аргумент, который является массивом
или ссылкой, содержит текст, логические
значения или пустые ячейки, эти значения
игнорируются; ячейки, содержащие нулевые
значения, учитываются.
—
Если аргументы известные_значения_y и
известные_значения_x пусты или количество
содержащихся в них точек не совпадает,
функция НАКЛОН возвращает значение
ошибки #Н/Д.
—
Уравнение наклона линии регрессии имеет
следующий вид:

где
x и y — выборочные средние значения
СРЗНАЧ(массив1) и СРЗНАЧ(массив2).
—
Основной алгоритм, используемый в
функциях НАКЛОН и ОТРЕЗОК, отличается
от основного алгоритма функции ЛИНЕЙН.
Разница между алгоритмами может привести
к различным результатам при неопределенных
и коллинеарных данных. Например, если
точки данных аргумента известные_значения_y
равны 0, а точки данных аргумента
известные_значения_x равны 1, то справедливо
указанное ниже.
—
Функции НАКЛОН и ОТРЕЗОК возвращают
значение ошибки #ДЕЛ/0!. Алгоритм функций
НАКЛОН и ОТРЕЗОК используется для поиска
только одного ответа, а в данном случае
их может быть несколько;
—
Функция ЛИНЕЙН возвращает значение,
равное 0. Алгоритм функции ЛИНЕЙН
используется для возвращения подходящих
значений для коллинеарных данных, и в
данном случае может быть найден хотя
бы один ответ.
Соседние файлы в папке лаб.раб_1
- #
- #
- #
- #
![]()
0
1 ответ:
![]()
0
0
Функция КВПИРСОН в Microsoft Excel это статистическая функция отвечающая за вычисления квадратного значения коэффициента корреляции Пирсона, для заданных двух точек икс и игрек. Пользуется двумя обязательным аргументами, значение точек икс и значение точек игрек.
Читайте также
![]()
ACOSH(число) — Возвращает гиперболический арккосинус числа. В качестве аргумента выступает число с плавающей точкой (как двойной, так и одинарной точности), также в качестве аргумента может приниматься целое число. Число должно быть равно или больше единицы.
![]()
Функция SINH в Microsoft Excel относится к функциям математики и тригонометрии, она вычисляет гиперболический синус заданного угла, используя для этого один аргумент ( который является обязательным) — любое вещественное число.
![]()
PHONETIC это функция Microsoft Excel, которая относится к подразделу текстовых функций. Эта функция извлекает фонетические знаки, которые называются фуригана, из выбранного текста или выбранной текстовой строки.
![]()
Функция БЗРАСПИС в Microsoft Excel относится к финансовым функциям, и она вычисляет сколько составит заданная сумма, когда она изменится за счет сложных процентных ставок. В основном используется для определения будущей суммы инвестиции с изменением процентных ставок.
![]()
Функция TAN в Excel
выполняет возвращение тангенса числа/заданного угла.
Применяется функция TAN в формуле для вычисления тангенса заданного угла.
Подробнее о том, как действует применение формулы с использованием функции TAN Вы найдете здесь.
