
Рассмотрим применение в
MS
EXCEL
критерия хи-квадрат Пирсона для проверки простых гипотез.
После получения экспериментальных данных (т.е. когда имеется некая
выборка
) обычно производится выбор закона распределения, наиболее хорошо описывающего случайную величину, представленную данной
выборкой
. Проверка того, насколько хорошо экспериментальные данные описываются выбранным теоретическим законом распределения, осуществляется с использованием
критериев согласия
.
Нулевой гипотезой
, обычно выступает гипотеза о равенстве распределения случайной величины некоторому теоретическому закону.
Сначала рассмотрим применение
критерия согласия Пирсона Х
2
(хи-квадрат)
в отношении простых гипотез (параметры теоретического распределения считаются известными). Затем —
применение критерияв случае сложных гипотез
, когда задается только форма распределения, а параметры этого распределения и значение
статистики
Х
2
оцениваются/рассчитываются на основании одной и той же
выборки
.
Примечание
: Применение
критерия согласия Пирсона
Х
2
в отношении сложных гипотез см. статью
Проверка сложных гипотез критерием хи-квадрат Пирсона в MS EXCEL
.
Примечание
: В англоязычной литературе процедура применения
критерия согласия Пирсона
Х
2
имеет название
The chi-square goodness of fit test
.
Напомним процедуру проверки гипотез:
-
на основе
выборки
вычисляется значение
статистики
, которая соответствует типу проверяемой гипотезы. Например, дляпроверки гипотезы о равенстве среднего μ некоторому заданному значению μ
0
используется
t
-статистика
(еслистандартное отклонение
не известно);
-
при условии истинности
нулевой гипотезы
, распределение этой
статистики
известно и может быть использовано для вычисления вероятностей (например, для
t
-статистики
этораспределение Стьюдента
);
-
вычисленное на основе
выборки
значение
статистики
сравнивается с критическим для заданногоуровня значимости
значением (
α-квантилем
);
нулевую гипотезу
отвергают, если значение
статистики
больше критического (или если вероятность получить это значение
статистики
(p-значение
) меньше
уровня значимости
, что является эквивалентным подходом).
Проведем
проверку гипотез
для различных распределений.
Дискретный случай
Предположим, что два человека играют в кости. У каждого игрока свой набор костей. Игроки по очереди кидают сразу по 3 кубика. Каждый раунд выигрывает тот, кто выкинет за раз больше шестерок. Результаты записываются. У одного из игроков после 100 раундов возникло подозрение, что кости его соперника – несимметричные, т.к. тот часто выигрывает (часто выбрасывает шестерки). Он решил проанализировать насколько вероятно такое количество исходов противника.
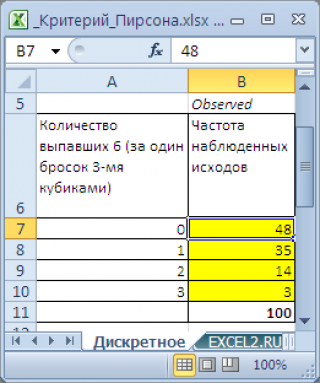
Примечание
: Т.к. кубиков 3, то за раз можно выкинуть 0; 1; 2 или 3 шестерки, т.е. случайная величина может принимать 4 значения.
Из теории вероятности нам известно, что если кубики симметричные, то вероятность выпадения шестерок подчиняется
биномиальному закону
. Поэтому, после 100 раундов частоты выпадения шестерок могут быть вычислены с помощью формулы
=БИНОМ.РАСП(A7;3;1/6;ЛОЖЬ)*100
В формуле предполагается, что в ячейке
А7
содержится соответствующее количество выпавших шестерок в одном раунде.
Примечание
: Расчеты приведены в
файле примера на листе Дискретное
.
Для сравнения
наблюденных
(Observed) и
теоретических частот
(Expected) удобно пользоваться
гистограммой
.
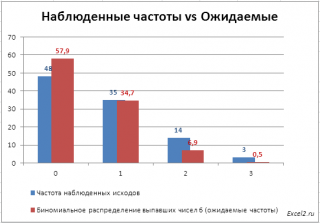
При значительном отклонении наблюденных частот от теоретического распределения,
нулевая гипотеза
о распределении случайной величины по теоретическому закону, должна быть отклонена. Т.е., если игральные кости соперника несимметричны, то наблюденные частоты будут «существенно отличаться» от
биномиального распределения
.
В нашем случае на первый взгляд частоты достаточно близки и без вычислений сложно сделать однозначный вывод. Применим
критерий согласия Пирсона Х
2
, чтобы вместо субъективного высказывания «существенно отличаться», которое можно сделать на основании сравнения
гистограмм
, использовать математически корректное утверждение.
Используем тот факт, что в силу
закона больших чисел
наблюденная частота (Observed) с ростом объема
выборки
n стремится к вероятности, соответствующей теоретическому закону (в нашем случае,
биномиальному закону
). В нашем случае объем выборки n равен 100.
Введем
тестовую
статистику
, которую обозначим Х
2
:
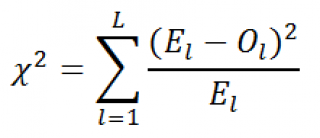
где O
l
– это наблюденная частота событий, что случайная величина приняла определенные допустимые значения, E
l
– это соответствующая теоретическая частота (Expected). L – это количество значений, которые может принимать случайная величина (в нашем случае равна 4).
Примечание
: Вышеуказанная
статистика
является частным случаем
статистики
используемой для вычисления
критерия независимости хи-квадрат
(см. статью
Критерий независимости хи-квадрат в MS EXCEL
).
Как видно из формулы, эта
статистика
является мерой близости наблюденных частот к теоретическим, т.е. с помощью нее можно оценить «расстояния» между этими частотами. Если сумма этих «расстояний» «слишком велика», то эти частоты «существенно отличаются». Понятно, что если наш кубик симметричный (т.е. применим
биномиальный закон
), то вероятность того, что сумма «расстояний» будет «слишком велика» будет малой. Чтобы вычислить эту вероятность нам необходимо знать распределение
статистики
Х
2
(
статистика
Х
2
вычислена на основе случайной
выборки
, поэтому она является случайной величиной и, следовательно, имеет свое
распределение вероятностей
).
Из многомерного аналога
интегральной теоремы Муавра-Лапласа
известно, что при n—>∞ наша случайная величина Х
2
асимптотически
распределена по закону Х
2
с L — 1 степенями свободы.
Итак, если вычисленное значение
статистики
Х
2
(сумма «расстояний» между частотами) будет больше чем некое предельное значение, то у нас будет основание отвергнуть
нулевую гипотезу
. Как и при проверке
параметрических гипотез
, предельное значение задается через
уровень значимости
. Если вероятность того, что статистика Х
2
примет значение меньше или равное вычисленному (
p
-значение
), будет меньше
уровня значимости
, то
нулевую гипотезу
можно отвергнуть.
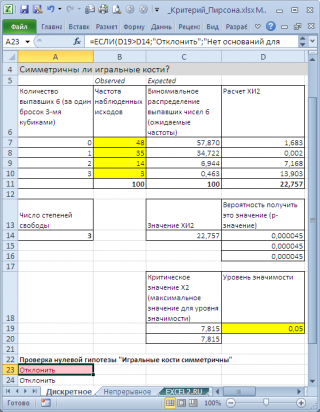
В нашем случае, значение статистики равно 22,757. Вероятность, что статистика Х
2
примет значение больше или равное 22,757 очень мала (0,000045) и может быть вычислена по формулам
=ХИ2.РАСП.ПХ(22,757;4-1)
или
=ХИ2.ТЕСТ(Observed; Expected)
Примечание
: Функция
ХИ2.ТЕСТ()
специально создана для проверки связи между двумя категориальными переменными (см.
статью про критерий независимости
).
Вероятность 0,000045 существенно меньше обычного
уровня значимости
0,05. Так что, у игрока есть все основания подозревать своего противника в нечестности (
нулевая гипотеза
о его честности отвергается).
При применении
критерия Х
2
необходимо следить за тем, чтобы объем
выборки
n был достаточно большой, иначе будет неправомочна аппроксимация
Х
2
-распределением
распределения
статистики Х
2
. Обычно считается, что для этого достаточно, чтобы наблюденные частоты (Observed) были больше 5. Если это не так, то малые частоты объединяются в одно или присоединяются к другим частотам, причем объединенному значению приписывается суммарная вероятность и, соответственно, уменьшается число степеней свободы
Х
2
-распределения
.
Для того чтобы улучшить качество применения
критерия Х
2
(
увеличить его мощность
), необходимо уменьшать интервалы разбиения (увеличивать L и, соответственно, увеличивать количество
степеней свободы
), однако этому препятствует ограничение на количество попавших в каждый интервал наблюдений (д.б.>5).
Примечание
: Рассмотренный выше пример является частным случаем применения
критерия независимости хи-квадрат
(chi-square test), который позволяет определить есть ли связь между двумя категориальными переменными (см. статью
Критерий независимости хи-квадрат в MS EXCEL
).
СОВЕТ
: О проверке других видов гипотез см. статью
Проверка статистических гипотез в MS EXCEL
.
Непрерывный случай
Критерий согласия Пирсона
Х
2
можно применить так же в случае
непрерывного распределения
.
Рассмотрим некую
выборку
, состоящую из 200 значений.
Нулевая гипотеза
утверждает, что
выборка
сделана из
стандартного нормального распределения
.
Примечание
: Cлучайные величины в
файле примера на листе Непрерывное
сгенерированы с помощью формулы
=НОРМ.СТ.ОБР(СЛЧИС())
. Поэтому, новые значения
выборки
генерируются при каждом пересчете листа.
Соответствует ли имеющийся набор данных
нормальному распределению
можно визуально оценить
с помощью графика проверки на нормальность (normal probability plot)
.
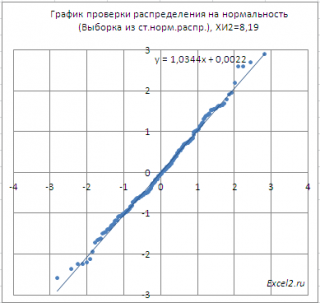
Как видно из диаграммы, значения выборки довольно хорошо укладываются вдоль прямой. Однако, как и в
дискретном случае
для
проверки гипотезы
применим
Критерий согласия Пирсона Х
2
.
Для этого разобьем диапазон изменения случайной величины на интервалы с шагом 0,5
стандартных отклонений
. Вычислим наблюденные и теоретические частоты. Наблюденные частоты вычислим с помощью функции
ЧАСТОТА()
, а теоретические – с помощью функции
НОРМ.СТ.РАСП()
.
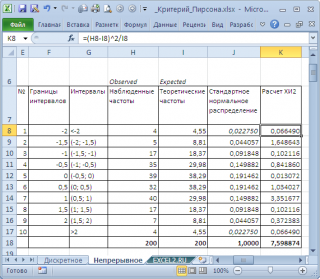
Примечание
: Как и для
дискретного случая
, необходимо следить, чтобы
выборка
была достаточно большая, а в интервал попадало >5 значений.
Вычислим статистику Х
2
и сравним ее с критическим значением для заданного
уровня значимости
(0,05). Т.к. мы разбили диапазон изменения случайной величины на 10 интервалов, то число степеней свободы равно 9. Критическое значение можно вычислить по формуле
=ХИ2.ОБР.ПХ(0,05;9)
или
=ХИ2.ОБР(1-0,05;9)
На диаграмме выше видно, что значение статистики равно 8,19, что существенно выше
критического значения
–
нулевая гипотеза
не отвергается.
Ниже приведена
диаграмма
, на которой
выборка
приняла маловероятное значение и на основании
критерия
согласия Пирсона Х
2
нулевая гипотеза была отклонена (не смотря на то, что случайные значения были сгенерированы с помощью формулы
=НОРМ.СТ.ОБР(СЛЧИС())
, обеспечивающей
выборку
из
стандартного нормального распределения
).
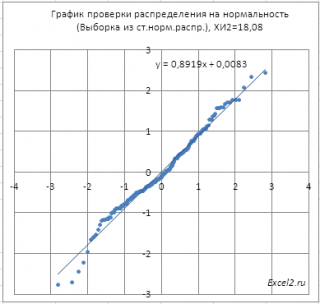
Нулевая гипотеза
отклонена, хотя визуально данные располагаются довольно близко к прямой линии.
В качестве примера также возьмем
выборку
из
непрерывного равномерного распределения
U(-3; 3). В этом случае, даже из графика очевидно, что
нулевая гипотеза
должна быть отклонена.
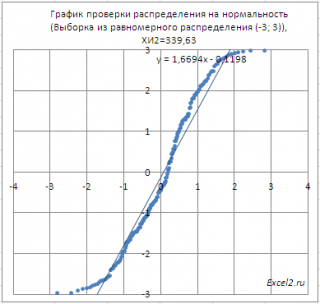
Критерий
согласия Пирсона Х
2
также подтверждает, что
нулевая гипотеза
должна быть отклонена.
В статье рассматривается процедура создания шаблона Excel и опыт его применения для автоматического построения гистограмм и кривых Гаусса по результатам данных экспериментальных наблюдений с одновременной оценкой согласия по критерию Пирсона в учебном процессе. Показываются преимущества данного метода перед ручным счетом по проверке рассмотренного критерия.
Ключевые слова: шаблон Excel, гистограмма, кривая распределения, критерий согласия Пирсона
В современном мире к статистике проявляется большой интерес, поскольку это отличный инструмент для анализа и принятия решений, а также это отличное средство для поиска причин нарушений процесса и их устранения. Статистический анализ применим во многих сферах, где существуют большие массивы данных: металлургии, а также в экономике, биологии, политике, социологии и т. д. Рассмотрим использование некоторых средств статистического анализа, а именно — гистограмм для обработки больших массивов данных.
Целью первичной обработки экспериментальных наблюдений обычно является выбор закона распределения, наиболее хорошо описывающего случайную величину, выборку которой мы наблюдали. Проверка того, насколько хорошо наблюдаемая выборка описывается теоретическим законом, осуществляется с использованием различных критериев согласия. Целью проверки гипотезы о согласии опытного распределения с теоретическим является стремление удостовериться в том, что данная модель теоретического закона не противоречит наблюдаемым данным, и использование ее не приведет к существенным ошибкам при вероятностных расчетах. Некорректное использование критериев согласия может приводить к необоснованному принятию или необоснованному отклонению проверяемой гипотезы [1].
Сходимость результатов наблюдений можно оценить наиболее полно, если их распределение является нормальным. Поэтому исключительно важную роль при обработке результатов наблюдений играет проверка нормальности распределения.
Эта задача представляет собой частный случай более общей проблемы, заключающейся в подборе теоретической функции распределения, в некотором смысле наилучшим образом согласующейся с опытными данными. Сама процедура проверки нормальности распределения относится к распространенной стандартной и довольно тривиальной задаче обработки данных и достаточно подробно и широко описана в различной литературе по метрологии и статистической обработке данных измерений [2- 4].
Данные, получаемые в результате измерений при контроле технологических процессов, оценке характеристик различных объектов и др. для дальнейшей обработки желательно представлять в виде теоретического распределения, максимально соответствующего экспериментальному распределению. Проверку гипотезы о виде функции распределения в настоящее время проводят по различным критериям согласия — Пирсона, Колмогорова, Смирнова и другим в соответствии с новыми разработанными нормативными документами — рекомендациями по стандартизации [5, 6].
Наиболее часто используется критерий Пирсона 2. Однако применение критериев согласия требует обычно довольно значительного объёма данных. Так, критерий Пирсона обычно рекомендуется использовать при объёме выборки не менее 50…100. Поэтому при небольшом объёме выборки проверку гипотезы о виде функции распределения проводят приближёнными методами — графическим методом или по асимметрии и эксцессу. Применение критерия Пирсона для ручной обработки данных очень подробно было изложено в известной работе [2]. Как свидетельствует опыт проверок согласия экспериментальных данных с теоретическими по различным критериям, эта процедура является очень трудоемкой, требует некоторой усидчивости и особого внимания при обработке от исследователя, как правило, не исключает ошибок в работе и не вызывает особого энтузиазма у выполняющего эту работу.
Решение задач статистического анализа связано со значительными объемами вычислений. Проведение реальных многовариантных статистических расчетов в ручном режиме является очень громоздкой и трудоемкой задачей и без использования компьютера в настоящее время практически невозможно. В настоящее время разработано достаточное количество универсальных и специализированных программных средств для статистического анализа и обработки экспериментальных данных. Автор предлагает к рассмотрению достаточно простой и эффективный шаблон для быстрого построения гистограммы и кривой нормального распределения.
По виду гистограммы можно предположить (принять гипотезу) о том, что выборка случайных чисел подчиняется нормальному закону распределения. Далее, для того чтобы убедиться в правильности выбранной гипотезы надо, первое — построить график гипотетического нормального закона распределения, выбрав в качестве параметров (математического ожидания и среднего квадратического отклонения) их оценки (среднее и стандартное отклонение), и совместить график гипотетического распределения с графиком гистограммы. И, второе — используя в данном случае, как пример, критерий согласия Пирсона, установить справедливость выбранной гипотезы.
Рассмотрим порядок действий при работе с критерием Пирсона в среде Excel.
1. Полученные в результате измерений значения 100 случайных результатов измерений внести в ячейки A1:A100 шаблона Excel и приступить к построению гистограммы на основе данных, назначая длину интервала (карман) и выбирая необходимое число интервалов.
2. Затем на этом же листе создается таблица, в которую посредством формул Excel вносятся основные расчетные величины, используемые для построения гистограммы и кривой Гаусса: среднее арифметическое, стандартное отклонение, минимальное и максимальное значения выборки, размах, величина кармана (рис. 1).
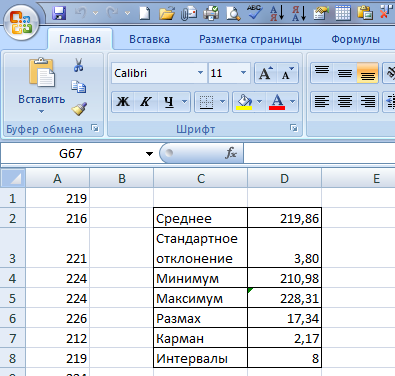
Рис. 1. Фрагмент таблицы с исходными данными
В ячейку D2 вносится формула =СРЗНАЧ(A1:A100), D3: =СТАНДОТКЛОН(A1:A100), D4: =МИН(A1:A100), D5: =МАКС(A1:A100), D6: =D5-D4, D7: =D6/D8. В ячейку D8 вводится число интервалов, которое для числа измерений, равным 100, может быть принято от 7 до 12.
Для оценки оптимального для нашего массива данных количества интервалов можно воспользоваться формулой Стерджесса: k~1+3,322lgN, где N— количество всех значений величины. Например, для N = 100, n = 7,6, которое должно быль округлено до целого числа, округляем до n = 8.
3. Интервал карманов вычисляют так: разность максимального и минимального значений массива, деленная на количество интервалов: ![]() .
.
4. Теперь в каждой ячейке шаг за шагом прибавляем полученное значение ширины кармана: сначала к минимальному значению нашего массива (ячейка D4), затем в следующей ячейке ниже — к полученной сумме и т. д. Так постепенно доходим до максимального значения. Таким образом, мы и построили интервалы карманов в виде столбца значений.
Интервалом считается следующий диапазон: (i-1; i] или i<значения<=i (нестрогая верхняя граница интервала — это значение в ячейке, нижняя строгая граница — значение в предыдущей ячейке).
5. Выделяем столбец рядом с нашими карманами, нажимаем «F2» и вводим функцию: =ЧАСТОТА (массив данных; диапазон карманов) и нажимаем Ctr+Shift+Enter.
6. В выделенном нами столбце напротив границ интервалов (а мы знаем, что это нестрогие верхние границы) появилось количество значений исходного массива, которые попадают в интервал (рис. 2).
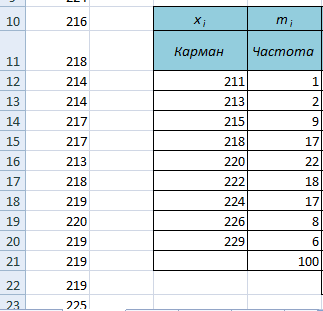
Рис. 2. Количество значений исходного массива, попавших в интервалы (частоты)
Построение теоретического закона распределения
Для построения теоретического закона распределения совместно с гистограммой и проверкой согласия по критерию хи-квадрат Пирсона автоматически заполняется таблица 1 после ввода экспериментальных данных в ячейки A1:A100.
Таблица 1
|
xi |
mi |
n∙pi |
|
|
карманы |
частота |
теоретическая частота |
статистика U |
Для построения этой таблицы надо воспользоваться таблицей карман — частота процедуры Гистограмма. В этой таблице обозначены:
xi — границы интервалов группировки (карманы — получены как результат выполнения процедуры Гистограмма);
mi — количество элементов выборки, попавших в i–ый интервал (частота — получена в результате процедуры Гистограмма).
Для построения этой таблицы в Excel к столбцам карман — частота процедуры Гистограмма надо добавить столбцы n∙pi (теоретическая частота) и ![]() (статистика U).
(статистика U).
Проверка согласия эмпирического и теоретического законов распределения по критерию хи-квадрат Пирсона.
В ячейку столбца, помеченного именем U, вводим формулу,
![]() , (1)
, (1)
Критическое значение статистики U, которая имеет распределение![]() с r степенями свободы (число степеней свободы определяется как число частичных интервалов минус 1), определяется при помощи функции ХИ2ОБР.
с r степенями свободы (число степеней свободы определяется как число частичных интервалов минус 1), определяется при помощи функции ХИ2ОБР.
Функция ХИ2ОБР вызывается следующим образом. В главном меню Excel выбирается закладка Формулы → Вставить функцию →в диалоговом окне Мастер функций— шаг 1 из 2 вкатегории Статистические →ХИ2ОБР (рис. 3).
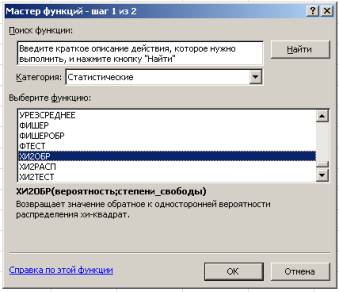
Рис. 3. Диалоговое окно выбора функции ХИ2ОБР
В диалоговом окне Аргументы функции ХИ2ОБР заполняются поля как показано на рис. 4, задаваясь уровнем значимости ![]() (например, 0,05, что соответствует доверительной вероятности Р = 0,95) и предварительно выбрав ячейку для результата вычисления функции.
(например, 0,05, что соответствует доверительной вероятности Р = 0,95) и предварительно выбрав ячейку для результата вычисления функции.
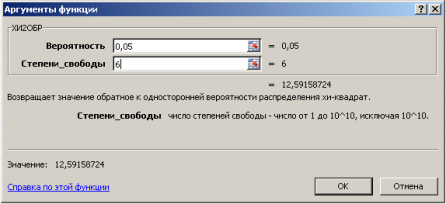
Рис. 4. Диалоговое окно функции ХИ2ОБР с заполненными полями ввода
Размножим формулу (1) в диапазонах ячеек [F12; F20] и [F51; F61]. В ячейке F21 получим сумму содержимого ячеек F12; F20 (рис. 5). В ячейке F62 получим сумму содержимого ячеек F51; F61 (рис. 6).
В ячейке F21 получено значение статистики: U = 2,09, а в ячейке F62 — U = 3,43 при доверительной вероятности Р = 0,95.
Теперь с помощью стандартного инструмента для построения гистограмм («вставка/гистограмма» и т. д.) на этом же листе Excel можно построить гистограммы распределения с кривой Гаусса для разных чисел интервалов (в данном случае n = 8 и n = 10) (рис. 5 и 6).
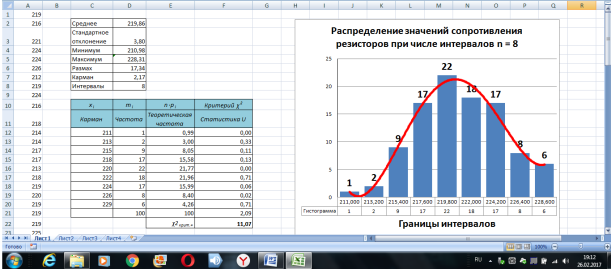
Рис. 5. Вид гистограммы и кривой распределения при числе интервалов n = 8 (пример)
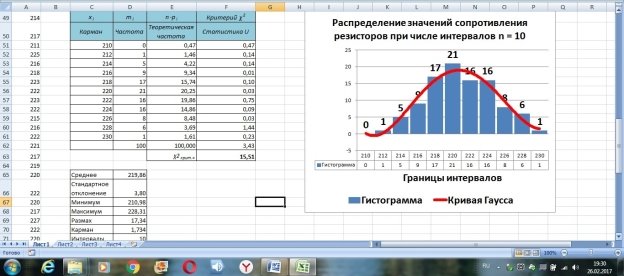
Рис. 6. Вид гистограммы и кривой распределения при числе интервалов n = 10 (пример)
Шаблон позволяет варьировать числом интервалов и величиной кармана, при этом автоматически изменяется внешний вид гистограммы и кривой нормального распределения. Исследователь может подобрать наиболее «красивый» вид гистограммы и аппроксимирующей кривой Гаусса, одновременно изменив значение доверительной вероятности и числа степеней свободы и добившись при этом выполнения критерия ![]() Пирсона.
Пирсона.
Если значение статистики U оказалось меньше критического значения ![]() при заданной доверительной вероятности, то гипотеза, состоящая в том, что исследуемая выборка подчиняется нормальному закону распределения, принимается. Вданном примере значение обеих статистик U оказалось меньше критического значения
при заданной доверительной вероятности, то гипотеза, состоящая в том, что исследуемая выборка подчиняется нормальному закону распределения, принимается. Вданном примере значение обеих статистик U оказалось меньше критического значения ![]() и
и![]() Следовательно, мы можем распространить данный закон распределения на всю генеральную совокупность исследуемых объектов (партию изделий, сменную выработку, месячный план и т. д.).
Следовательно, мы можем распространить данный закон распределения на всю генеральную совокупность исследуемых объектов (партию изделий, сменную выработку, месячный план и т. д.).
Более подробно указанная тема была рассмотрена в статье автора в сборнике «Законодательная и прикладная метрология» [7].
Выводы
- Существовавшая ранее традиционная «ручная» обработка данных при проверке нормального (и других) законов распределения и построении гистограмм являлась достаточно трудоемкой задачей, не исключавшей появление ошибок, обнаружение которых зачастую требовало значительных затрат времени и моральных сил исследователя.
- Появление пакетов офисных программ, в частности Excel 2010 и ее последующих версий, позволяет значительно сократить трудоемкость обработки данных и практически исключает появление ошибок в расчетах.
Литература:
1. Лемешко Б. Ю., Постовалов С. Н. О правилах проверки согласия опытного распределения с теоретическим. — Методы менеджмента качества. Надежность и контроль качества. — 1999, № 11. — С. 34–43.
2. Бурдун Г. Д., Марков Б. Н. Основы метрологии. Учебное пособие для вузов. — М.: Изд. стандартов, 1975. — 336 с.
3. Сулицкий В. Н. Методы статистического анализа в управлении: Учеб. пособие. — М.: Дело, 2002. — 520 с.
4. Иванов О. В. Статистика / Учебный курс для социологов и менеджеров. Часть 2. Доверительные интервалы. Проверка гипотез. Методы и их применение. — М.: Изд. МГУ им. М. В. Ломоносова, 2005. — 220 с.
5. Рекомендации по стандартизации Р 50.1.033–2001. Прикладная статистика. Правила проверки согласия опытного распределения с теоретическим. Часть 1. Критерии типа хи-квадрат. — М.: ФГУП «Стандартинформ», 2006. — 87 с.
6. Рекомендации по стандартизации Р 50.1.037–2002. Прикладная статистика. Правила проверки согласия опытного распределения с теоретическим. Часть II. Непараметрические критерии. — М.: ИПК Изд. стандартов, 2002. — 62 с.
7. Фаюстов А. А. Проверка гипотезы о нормальном распределении выборки по критерию согласия Пирсона средствами приложения Excel. — Законодательная и прикладная метрология, 2016, № 6. — С. 3–9.
Основные термины (генерируются автоматически): статистический анализ, критерий согласия, массив данных, вид функции распределения, интервал карманов, максимальное значение, минимальное значение, построение гистограммы, различный критерий согласия, стандартное отклонение.
Вместо заполнения большого количества
таблиц можно воспользоваться
статистическими функциями.
Проверку гипотезы о
законе нормального распределения
выполним на примере интервального
вариационного ряда, построенного в
пункте 2.2, и статистических характеристик
ряда из пункта 3.4.
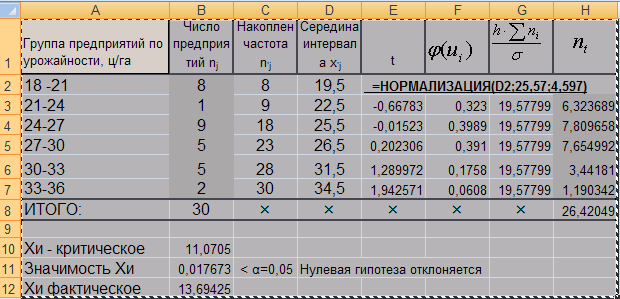
Рис. 3. Хи тест
-
Находим
нормализованные значения признака
(рис 1.). Вызываем список функций, выбираем
функцию «НОРМАЛИЗАЦИЯ» (STANDATRDIZE).
В поле «Х»
вводим название ячейки первого интервала,
во втором поле среднее значение по
выборке, в третьем поле стандартное
отклонение выборки. Копируем данную
формулу для остальных строк. -
По
таблице плотности распределения φ(u)
находим
вероятность распределения этих значений
и заполняем следующий столбец. -
Следующий
столбец заполняем рассчитанным
выражением.
-
Находим
теоретические частоты по формуле (2) и
заполняем последний 8 столбец. -
Далее,
для вычисления критерия Пирсона,
воспользуемся функцией «ХИ2ТЕСТ». В
поле «Фактический интервал» выделяем
массив фактических частот, в поле
«Ожидаемый интервал» вводим массив
теоретических частот. В результате
получаем значимость фактического
критерия Пирсона. Чтобы получить
фактическое значение критерия Пирсона,
воспользуемся функцией «ХИ2ОБР». В поле
«вероятность» вводим полученную
значимость критерия (ячейка B11),
а в поле «степени_свободы» соответствующее
число степеней свободы для данной
группировки. В данном случае n-1=5
(n – число
групп).
Полученную в пункте
5 фактическую значимость критерия
Пирсона «p»
сравниваем с установленным уровнем
значимости «α». Если αфакт<α=0,05,
то утверждаем, что эмпирическое
распределение сходно с теоретическим
и нулевая гипотеза отвергается. Далее,
если нужно, мы находим фактическое
значение критерия по значимости «α»
и числа степеней
свободы.
4.Корреляционно-регрессионный анализ
4.1.Определение параметров уравнения регрессии и показателей тесноты корреляционной связи
Социально-экономические
явления находятся между собой в сложной
взаимосвязи, зависимости. По характеру
зависимости статистика различает два
вида связей:
1)функциональную;
2)корреляционную.
Корреляционная связь характеризуется
тем, что между изменением независимой
переменной (факторного признака) и
зависимой переменной нет полного
соответствия: каждому значению факторного
признака может соответствовать
распределение значений результативного.
Корреляционная связь проявляется лишь
в массе случаев – в совокупности
достаточно большого объема. При этом
изменение независимой величины ведет
к изменению среднего значения зависимой
переменной.
По направлению различают прямые и
обратные связи. При прямой связи с
увеличением факторного признака
увеличивается результативный. При
обратной связи с ростом факторного
признака значения результативного
уменьшаются.
По аналитическому выражению связи
делятся на прямолинейные (линейные) и
криволинейные (нелинейные). Линейная
связь выражается линейной функцией
(уравнением прямой), нелинейная –
криволинейной в виде параболы, гиперболы,
показательной кривой и т.д.
Функция, отображающая корреляционную
связь между признаками, называется
уравнением регрессии. Уравнение регрессии
выражается функцией у = f(х1,х2,…,
хn).
Уравнения регрессии
могут иметь следующую форму.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Функция ПИРСОН (вводить следует PEARSON на английском) предназначена для вычисления коэффициента корреляции Пирсона r. Данную функцию используют в работе в том случае, когда необходимо отразить степень линейной зависимости между двумя массивами данных. В Excel имеется несколько функций с помощью которых можно получить такой же результат, однако универсальность и простота функции Пирсон делают выбор в ее пользу.
Как работает функция ПИРСОН в Excel?
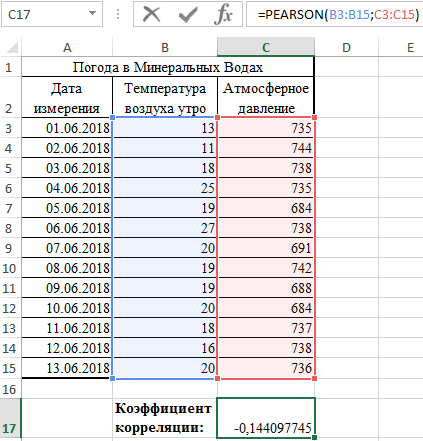
Рассмотрим пример расчета корреляции Пирсона между двумя массивами данных при помощи функции PEARSON в MS EXCEL. Первый массив представляет собой значения температур, второй давление в определенный летний период. Пример заполненной таблицы изображен на рисунке:
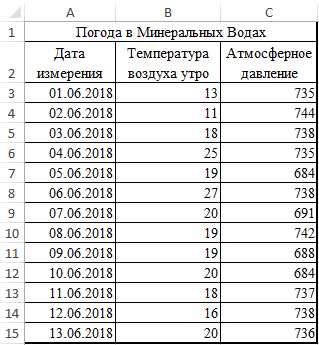
Задача следующая: необходимо определить взаимосвязь между температурой и давлением за июнь месяц.
Пример решения с функцией ПИРСОН при анализе в Excel
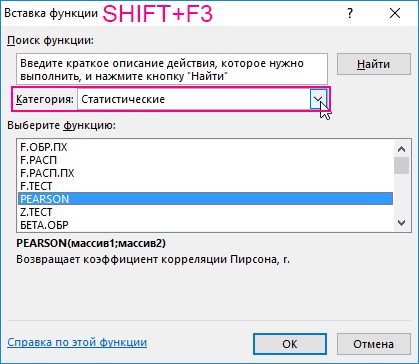
- Выберем ячейку С17 в которой должен будет посчитаться критерий Пирсона как результат и нажмем кнопку мастер функций «fx» или комбинацию горячих клавиш (SHIFT+F3). Откроется мастер функций, в поле Категория необходимо выбрать «Статистические». В списке статистических функций выбрать PEARSON и нажать Ok:
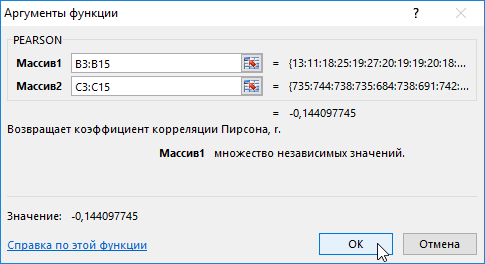
- В меню аргументов выбрать Массив 1, в примере это утренняя температура воздуха, а затем массив 2 – атмосферное давление.
- В результате в ячейке С17 получим коэффициент корреляции Пирсона. В нашем случае он отрицательный и приблизительно равен -0,14.
Данный показатель -0,14 по Пирсону, который вернула функция, говорит об неблагоприятной зависимости температуры и давления в раннее время суток.
Функция ПИРСОН пошаговая инструкция
Коэффициент корреляции является самым удобным показателем сопряженности количественных признаков.
Задача: Определить линейный коэффициент корреляции Пирсона.
Пример решения:
- В таблице приведены данные для группы курящих людей. Первый массив х — представляет собой возраст курящего, второй массив y представляет собой количество сигарет, выкуренных в день.
- Выберем ячейку В4 в которой должен будет посчитаться результат и нажмем кнопку мастер функций fx (SHIFT+F3).
- В группе Статистические выберем функцию PEARSON.
- Выделим Массив 1 – возраст курящего, затем Массив 2 – число сигарет, выкуренных в день.
- Нажмем кнопку ОК и увидим критерий нормального распределения Пирсона в ячейке В4.

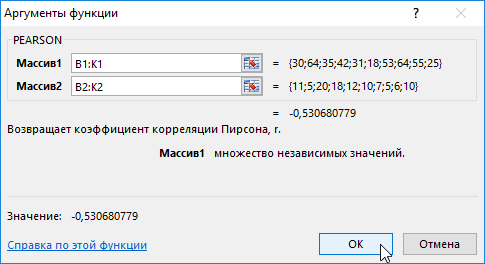

Таким образом, по результату вычисления статистическим выводом эксперимента выявлена отрицательная зависимость между возрастом и количеством выкуренных сигарет в день.
Корреляционный анализ по Пирсону в Excel
Задача: школьникам были даны тесты на наглядное и вербальное мышление. Измерялось среднее время решения заданий теста в секундах. Психолога интересует вопрос: существует ли взаимосвязь между временем решения этих задач?
Пример решения: представим исходные данные в виде таблицы:
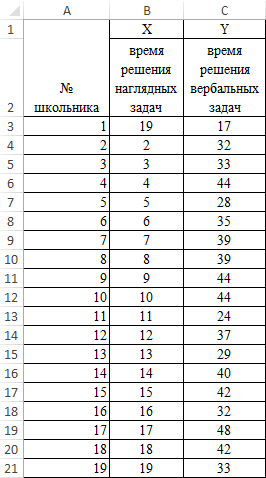
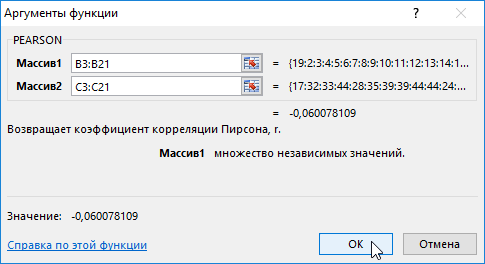
- Переходим курсором в ячейку F2. Откроем мастер функций fx (SHIFT+F3) или вводим вручную.
- Выберем функцию PEARSON.
- Выделим мышкой Массив1, затем Массив 2.
- Нажмем ОК и в ячейке F2 получим критерий согласия Пирсона.
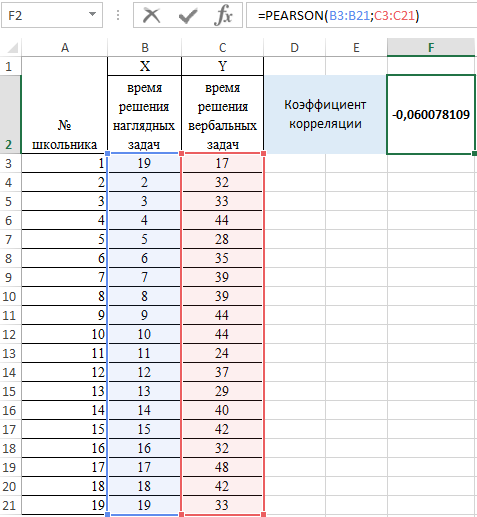
Интерпретация результата вычисления по Пирсону
Величина коэффициента линейной корреляции Пирсона не может превышать +1 и быть меньше чем -1. Эти два числа +1 и -1 – являются границами для коэффициента корреляции. Когда при расчете получается величина большая +1 или меньшая -1 – следовательно, произошла ошибка в вычислениях.
Если коэффициент корреляции по модулю оказывается близким к 1, то это соответствует высокому уровню связи между переменными.
Скачать примеры функции ПИРСОН для корреляции в Excel
Если же получен знак минус, то большей величине одного признака соответствует меньшая величина другого. Иначе говоря, при наличии знака минус, увеличению одной переменной (признака, значения) соответствует уменьшение другой переменной. Такая зависимость носит название обратно пропорциональной зависимости. Эти положения очень важно четко усвоить для правильной интерпретации полученной корреляционной зависимости.
До конца XIX века нормальное распределение считалась всеобщим законом вариации данных. Однако К. Пирсон заметил, что эмпирические частоты могут сильно отличаться от нормального распределения. Встал вопрос, как это доказать. Требовалось не только графическое сопоставление, которое имеет субъективный характер, но и строгое количественное обоснование.
Так был изобретен критерий χ2 (хи квадрат), который проверяет значимость расхождения эмпирических (наблюдаемых) и теоретических (ожидаемых) частот. Это произошло в далеком 1900 году, однако критерий и сегодня на ходу. Более того, его приспособили для решения широкого круга задач. Прежде всего, это анализ категориальных данных, т.е. таких, которые выражаются не количеством, а принадлежностью к какой-то категории. Например, класс автомобиля, пол участника эксперимента, вид растения и т.д. К таким данным нельзя применять математические операции вроде сложения и умножения, для них можно только подсчитать частоты.
Наблюдаемые частоты обозначим О (Observed), ожидаемые – E (Expected). В качестве примера возьмем результат 60-кратного бросания игральной кости. Если она симметрична и однородна, вероятность выпадения любой стороны равна 1/6 и, следовательно, ожидаемое количество выпадения каждой из сторон равна 10 (1/6∙60). Наблюдаемые и ожидаемые частоты запишем в таблицу и нарисуем гистограмму.

Нулевая гипотеза заключается в том, что частоты согласованы, то есть фактические данные не противоречат ожидаемым. Альтернативная гипотеза – отклонения в частотах выходят за рамки случайных колебаний, расхождения статистически значимы. Чтобы сделать строгий вывод, нам потребуется.
- Обобщающая мера расхождения между наблюдаемыми и ожидаемыми частотами.
- Распределение этой меры при справедливости гипотезы о том, что различий нет.
Начнем с расстояния между частотами. Если взять просто разницу О — E, то такая мера будет зависеть от масштаба данных (частот). Например, 20 — 5 =15 и 1020 – 1005 = 15. В обоих случаях разница составляет 15. Но в первом случае ожидаемые частоты в 3 раза меньше наблюдаемых, а во втором случае – лишь на 1,5%. Нужна относительная мера, не зависящая от масштаба.
Обратим внимание на следующие факты. В общем случае количество категорий, по которым измеряются частоты, может быть гораздо больше, поэтому вероятность того, что отдельно взятое наблюдение попадет в ту или иную категорию, довольно мала. Раз так, то, распределение такой случайной величины будет подчинятся закону редких событий, известному под названием закон Пуассона. В законе Пуассона, как известно, значение математического ожидания и дисперсии совпадают (параметр λ). Значит, ожидаемая частота для некоторой категории номинальной переменной Ei будет являться одновременное и ее дисперсией. Далее, закон Пуассона при большом количестве наблюдений стремится к нормальному. Соединяя эти два факта, получаем, что, если гипотеза о согласии наблюдаемых и ожидаемых частот верна, то, при большом количестве наблюдений, выражение
![]()
имеет стандартное нормальное распределение.
Важно помнить, что нормальность будет проявляться только при достаточно больших частотах. В статистике принято считать, что общее количество наблюдений (сумма частот) должна быть не менее 50 и ожидаемая частота в каждой группе должна быть не менее 5. Только в этом случае величина, показанная выше, имеет стандартное нормальное распределение. Предположим, что это условие выполнено.
У стандартного нормального распределения почти все значение находятся в пределах ±3 (правило трех сигм). Таким образом, мы получили относительную разность в частотах для одной группы. Нам нужна обобщающая мера. Просто сложить все отклонения нельзя – получим 0 (догадайтесь почему). Пирсон предложил сложить квадраты этих отклонений.
![]()
Это и есть статистика для критерия Хи-квадрат Пирсона. Если частоты действительно соответствуют ожидаемым, то значение статистики Хи-квадрат будет относительно не большим (отклонения находятся близко к нулю). Большое значение статистики свидетельствует в пользу существенных различий между частотами.
«Большой» статистика Хи-квадрат становится тогда, когда появление наблюдаемого или еще большего значения становится маловероятным. И чтобы рассчитать такую вероятность, необходимо знать распределение статистики Хи-квадрат при многократном повторении эксперимента, когда гипотеза о согласии частот верна.
Как нетрудно заметить, величина хи-квадрат также зависит от количества слагаемых. Чем больше слагаемых, тем больше ожидается значение статистики, ведь каждое слагаемое вносит свой вклад в общую сумму. Следовательно, для каждого количества независимых слагаемых, будет собственное распределение. Получается, что χ2 – это целое семейство распределений.
И здесь мы подошли к одному щекотливому моменту. Что такое число независимых слагаемых? Вроде как любое слагаемое (т.е. отклонение) независимо. К. Пирсон тоже так думал, но оказался неправ. На самом деле число независимых слагаемых будет на один меньше, чем количество групп номинальной переменной n. Почему? Потому что, если мы имеем выборку, по которой уже посчитана сумма частот, то одну из частот всегда можно определить, как разность общего количества и суммой всех остальных. Отсюда и вариация будет несколько меньше. Данный факт Рональд Фишер заметил лет через 20 после разработки Пирсоном своего критерия. Даже таблицы пришлось переделывать.
По этому поводу Фишер ввел в статистику новое понятие – степень свободы (degrees of freedom), которое и представляет собой количество независимых слагаемых в сумме. Понятие степеней свободы имеет математическое объяснение и проявляется только в распределениях, связанных с нормальным (Стьюдента, Фишера-Снедекора и сам Хи-квадрат).
Чтобы лучше уловить смысл степеней свободы, обратимся к физическому аналогу. Представим точку, свободно движущуюся в пространстве. Она имеет 3 степени свободы, т.к. может перемещаться в любом направлении трехмерного пространства. Если точка движется по какой-либо поверхности, то у нее уже две степени свободы (вперед-назад, вправо-влево), хотя и продолжает находиться в трехмерном пространстве. Точка, перемещающаяся по пружине, снова находится в трехмерном пространстве, но имеет лишь одну степень свободы, т.к. может двигаться либо вперед, либо назад. Как видно, пространство, где находится объект, не всегда соответствует реальной свободе перемещения.
Примерно также распределение статистики может зависеть от меньшего количества элементов, чем нужно слагаемых для его расчета. В общем случае количество степеней свободы меньше наблюдений на число имеющихся зависимостей.
Таким образом, распределение хи квадрат (χ2) – это семейство распределений, каждое из которых зависит от параметра степеней свободы. Формальное определение следующее. Распределение χ2 (хи-квадрат) с k степенями свободы — это распределение суммы квадратов k независимых стандартных нормальных случайных величин.
Далее можно было бы перейти к самой формуле, по которой вычисляется функция распределения хи-квадрат, но, к счастью, все давно подсчитано за нас. Чтобы получить интересующую вероятность, можно воспользоваться либо соответствующей статистической таблицей, либо готовой функцией в Excel.
Интересно посмотреть, как меняется форма распределения хи-квадрат в зависимости от количества степеней свободы.

С увеличением степеней свободы распределение хи-квадрат стремится к нормальному. Это объясняется действием центральной предельной теоремы, согласно которой сумма большого количества независимых случайных величин имеет нормальное распределение. Про квадраты там ничего не сказано )).
Проверка гипотезы по критерию Хи квадрат Пирсона
Вот мы и подошли к проверке гипотез по методу хи-квадрат. В целом техника остается прежней. Выдвигается нулевая гипотеза о том, что наблюдаемые частоты соответствуют ожидаемым (т.е. между ними нет разницы, т.к. они взяты из той же генеральной совокупности). Если этот так, то разброс будет относительно небольшим, в пределах случайных колебаний. Меру разброса определяют по статистике Хи-квадрат. Далее либо полученную статистику сравнивают с критическим значением (для соответствующего уровня значимости и степеней свободы), либо, что более правильно, рассчитывают наблюдаемый p-value, т.е. вероятность получить такое или еще больше значение статистики при справедливости нулевой гипотезы.
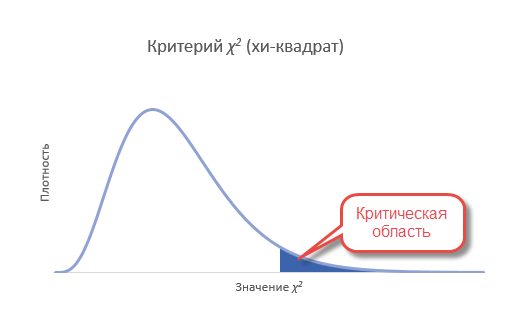
Т.к. нас интересует согласие частот, то отклонение гипотезы произойдет, когда статистика окажется больше критического уровня. Т.е. критерий является односторонним. Однако иногда (иногда) требуется проверить левостороннюю гипотезу. Например, когда эмпирические данные уж оооочень сильно похожи на теоретические. Тогда критерий может попасть в маловероятную область, но уже слева. Дело в том, что в естественных условиях, маловероятно получить частоты, практически совпадающие с теоретическими. Всегда есть некоторая случайность, которая дает погрешность. А вот если такой погрешности нет, то, возможно, данные были сфальсифицированы. Но все же обычно проверяют правостороннюю гипотезу.
Вернемся к задаче с игральной костью. Рассчитаем по имеющимся данным значение статистики критерия хи-квадрат.
![]()
Теперь найдем критическое значение при 5-ти степенях свободы (k) и уровне значимости 0,05 (α) по таблице критических значений распределения хи квадрат.

То есть квантиль 0,05 хи квадрат распределения (правый хвост) с 5-ю степенями свободы χ20,05; 5 = 11,1.
Сравним фактическое и табличное значение. 3,4 (χ2) < 11,1 (χ20,05; 5). Расчетный значение оказалось меньшим, значит гипотеза о равенстве (согласии) частот не отклоняется. На рисунке ситуация выглядит вот так.

Если бы расчетное значение попало в критическую область, то нулевая гипотеза была бы отклонена.
Более правильным будет рассчитать еще и p-value. Для этого нужно в таблице найти ближайшее значение для заданного количества степеней свободы и посмотреть соответствующий ему уровень значимости. Но это прошлый век. Воспользуемся ЭВМ, в частности MS Excel. В эксель есть несколько функций, связанных с хи-квадрат.

Ниже их краткое описание.
ХИ2.ОБР – критическое значение Хи-квадрат при заданной вероятности слева (как в статистических таблицах)
ХИ2.ОБР.ПХ – критическое значение при заданной вероятности справа. Функция по сути дублирует предыдущую. Но здесь можно сразу указывать уровень α, а не вычитать его из 1. Это более удобно, т.к. в большинстве случаев нужен именно правый хвост распределения.
ХИ2.РАСП – p-value слева (можно рассчитать плотность).
ХИ2.РАСП.ПХ – p-value справа.
ХИ2.ТЕСТ – по двум диапазонам частот сразу проводит тест хи-квадрат. Количество степеней свободы берется на одну меньше, чем количество частот в столбце (так и должно быть), возвращая значение p-value.
Давайте пока рассчитаем для нашего эксперимента критическое (табличное) значение для 5-ти степеней свободы и альфа 0,05. Формула Excel будет выглядеть так:
=ХИ2.ОБР(0,95;5)
Или так
=ХИ2.ОБР.ПХ(0,05;5)
Результат будет одинаковым – 11,0705. Именно это значение мы видим в таблице (округленное до 1 знака после запятой).
Рассчитаем, наконец, p-value для 5-ти степеней свободы критерия χ2 = 3,4. Нужна вероятность справа, поэтому берем функцию с добавкой ПХ (правый хвост)
=ХИ2.РАСП.ПХ(3,4;5) = 0,63857
Значит, при 5-ти степенях свободы вероятность получить значение критерия χ2 = 3,4 и больше равна почти 64%. Естественно, гипотеза не отклоняется (p-value больше 5%), частоты очень хорошо согласуются.
А теперь проверим гипотезу о согласии частот с помощью теста хи квадрат и функции Excel ХИ2.ТЕСТ.

Никаких таблиц, никаких громоздких расчетов. Указав в качестве аргументов функции столбцы с наблюдаемыми и ожидаемыми частотами, сразу получаем p-value. Красота.
Представим теперь, что вы играете в кости с подозрительным типом. Распределение очков от 1 до 5 остается прежним, но он выкидывает 26 шестерок (количество всех бросков становится 78).

p-value в этом случае оказывается 0,003, что гораздо меньше чем, 0,05. Есть серьезные основания сомневаться в правильности игральной кости. Вот, как выглядит эта вероятность на диаграмме распределения хи-квадрат.

Статистика критерия хи-квадрат здесь получается 17,8, что, естественно, больше табличного (11,1).
Надеюсь, мне удалось объяснить, что такое критерий согласия χ2 (хи-квадрат) Пирсона и как с его помощью проверяются статистические гипотезы.
Напоследок еще раз о важном условии! Критерий хи-квадрат исправно работает только в случае, когда количество всех частот превышает 50, а минимальное ожидаемое значение для каждой группы не меньше 5. Если в какой-либо категории ожидаемая частота менее 5, но при этом сумма всех частот превышает 50, то такую категорию объединяют с ближайшей, чтобы их общая частота превысила 5. Если это сделать невозможно, или сумма частот меньше 50, то следует использовать более точные методы проверки гипотез. О них поговорим в другой раз.
Ниже находится видео ролик о том, как в Excel проверить гипотезу с помощью критерия хи-квадрат.
Скачать файл с примером.
Поделиться в социальных сетях: