
Функция ФИШЕР выполняет возвращение преобразования Фишера для аргументов X. Это преобразование строит функцию, которая имеет нормальное, а не асимметричное распределение. Используется функция ФИШЕР для того чтобы проверить гипотезу с помощью коэффициента корреляции.
Описание работы функции ФИШЕР в Excel
При работе с данной функцией необходимо задать значение переменной. Сразу стоит отметить, что существуют некоторые ситуации, при которых данная функция не будет выдавать результатов. Это возможно, если переменная:
- не является числом. В такой ситуации функция ФИШЕР осуществит возвращение значения ошибки #ЗНАЧ!;
- имеет значение либо меньше -1, либо больше 1. В данном случае функция ФИШЕР возвратит значение ошибки #ЧИСЛО!.
Уравнение, которое используется для математического описания функции ФИШЕР, имеет вид:
Z’=1/2*ln(1+x)/(1-x)
Рассмотрим применение данной функции на 3-x конкретных примерах.
Оценка взаимосвязи прибыли и затрат по функции ФИШЕР
Пример 1. Используя данные об активности коммерческих организаций, требуется сделать оценку связи прибыли Y (млн руб.) и затрат X (млн руб.), используемых для разработки продукции (приведены в таблице 1).
Таблица 1 – Исходные данные:
| № | X | Y |
| 1 | 210 000 000,00 ₽ | 95 000 000,00 ₽ |
| 2 | 1 068 000 000,00 ₽ | 76 000 000,00 ₽ |
| 3 | 1 005 000 000,00 ₽ | 78 000 000,00 ₽ |
| 4 | 610 000 000,00 ₽ | 89 000 000,00 ₽ |
| 5 | 768 000 000,00 ₽ | 77 000 000,00 ₽ |
| 6 | 799 000 000,00 ₽ | 85 000 000,00 ₽ |
Схема решения таких задач выглядит следующим образом:
- Рассчитывается линейный коэффициент корреляции rxy;
- Проверяется значимость линейного коэффициента корреляции на основе t-критерия Стьюдента. При этом выдвигается и проверяется гипотеза о равенстве коэффициента корреляции нулю. При проверке этой гипотезы используется t-статистика. Если гипотеза подтверждается, t-статистика имеет распределение Стьюдента. Если расчетное значение tр > tкр, то гипотеза отвергается, что свидетельствует о значимости линейного коэффициента корреляции, а следовательно, и о статистической существенности зависимости между Х и Y;
- Определяется интервальная оценка для статистически значимого линейного коэффициента корреляции.
- Определяется интервальная оценка для линейного коэффициента корреляции на основе обратного z-преобразования Фишера;
- Рассчитывается стандартная ошибка линейного коэффициента корреляции.
Результаты решения данной задачи с применяемыми функциями в пакете Excel приведены на рисунке 1.
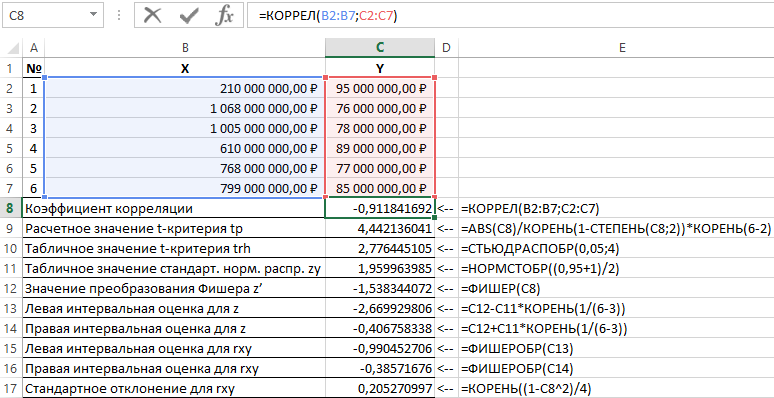
Рисунок 1 – Пример расчетов.
| № п/п | Наименование показателя | Формула расчета |
| 1 | Коэффициент корреляции | =КОРРЕЛ(B2:B7;C2:C7) |
| 2 | Расчетное значение t-критерия tp | =ABS(C8)/КОРЕНЬ(1-СТЕПЕНЬ(C8;2))*КОРЕНЬ(6-2) |
| 3 | Табличное значение t-критерия trh | =СТЬЮДРАСПОБР(0,05;4) |
| 4 | Табличное значение стандартного нормального распределения zy | =НОРМСТОБР((0,95+1)/2) |
| 5 | Значение преобразования Фишера z’ | =ФИШЕР(C8) |
| 6 | Левая интервальная оценка для z | =C12-C11*КОРЕНЬ(1/(6-3)) |
| 7 | Правая интервальная оценка для z | =C12+C11*КОРЕНЬ(1/(6-3)) |
| 8 | Левая интервальная оценка для rxy | =ФИШЕРОБР(C13) |
| 9 | Правая интервальная оценка для rxy | =ФИШЕРОБР(C14) |
| 10 | Стандартное отклонение для rxy | =КОРЕНЬ((1-C8^2)/4) |
Таким образом, с вероятностью 0,95 линейный коэффициент корреляции заключен в интервале от (–0,386) до (–0,990) со стандартной ошибкой 0,205.
Проверка статистической значимости регрессии по функции FРАСПОБР
Пример 2. Произвести проверку статистической значимости уравнения множественной регрессии с помощью F-критерия Фишера, сделать выводы.
Для проверки значимости уравнения в целом выдвинем гипотезу Н0 о статистической незначимости коэффициента детерминации и противоположную ей гипотезу Н1 о статистической значимости коэффициента детерминации:
Н0: R2 = 0;
Н1: R2 ≠ 0.
Проверим гипотезы с помощью F-критерия Фишера. Показатели приведены в таблице 2.
Таблица 2 – Исходные данные
| Показатель | SS | MS | Fрасч |
| Регрессия | 454,814 | 227,407 | 7,075 |
| Остаток | 1607,014 | 32,14 | |
| Итого | 2061,828 | — |
Для этого используем в пакете Excel функцию:
=FРАСПОБР (α;p;n-p-1)
где:
- α – вероятность, связанная с данным распределением;
- p и n – числитель и знаменатель степеней свободы, соответственно.
Зная, что α = 0,05, p = 2 и n = 53, получаем следующее значение для Fкрит (см. рисунок 2).
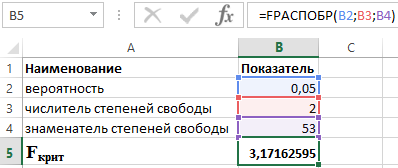
Рисунок 2 – Пример расчетов.
Таким образом можно сказать, что Fрасч > Fкрит. В итоге принимается гипотеза Н1 о статистической значимости коэффициента детерминации.
Расчет величины показателя корреляции в Excel
Пример 3. Используя данные 23 предприятий о: X — цена на товар А, тыс. руб.; Y — прибыль торгового предприятия, млн. руб, производится изучение их зависимости. Оценка регрессионной модели дала следующее: ∑(yi-yx)2 = 50000; ∑(yi-yср)2 = 130000. Какой показатель корреляции можно определить по этим данным? Рассчитайте величину показателя корреляции и, используя критерий Фишера, сделайте вывод о качестве модели регрессии.
Определим Fкрит из выражения:
Fрасч = R2/23*(1-R2)
где R – коэффициент детерминации, равный 0,67.
Таким образом, расчетное значение Fрасч = 46.
Для определения Fкрит используем распределение Фишера (см. рисунок 3).
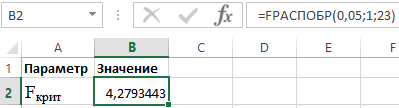
Рисунок 3 – Пример расчетов.
Скачать примеры работы функции ФИШЕР в Excel
Таким образом, полученная оценка уравнения регрессии надежна.
Содержание
- Как выполнить точный тест Фишера в Excel
- Пример: точный критерий Фишера в Excel
- FРАСПОБР для проверки значимости модели регрессии в Excel
- Функция FРАСПОБР для оценки значимости параметров модели регрессии
- Определение верхнего квартиля F-распределения Фишера в Excel
- Оценка в Excel эффективности использования технологий на производстве
- Особенности использования функции FРАСПОБР в Excel
- 4.2. Критерий Фишера
- Средство анализа «Двухвыборочный f-тест для дисперсии» надстройки «Пакет анализа» ms Excel
Как выполнить точный тест Фишера в Excel
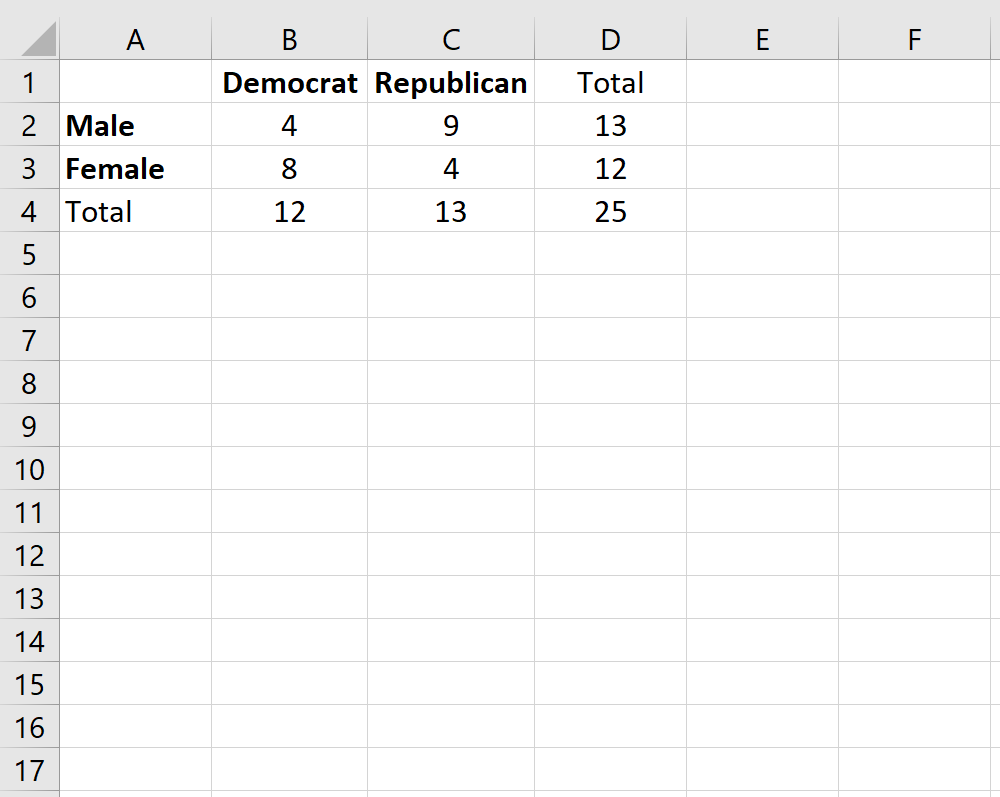
Точный критерий Фишера используется для определения того, существует ли значительная связь между двумя категориальными переменными. Обычно он используется в качестве альтернативы критерию независимости хи-квадрат, когда количество одной или нескольких ячеек в таблице 2 × 2 меньше 5.
В этом руководстве объясняется, как выполнить точный критерий Фишера в Excel.
Пример: точный критерий Фишера в Excel
Предположим, мы хотим знать, связан ли пол с предпочтениями политической партии в конкретном колледже. Чтобы изучить это, мы случайным образом опрашиваем 25 студентов в кампусе. Количество студентов, которые являются демократами или республиканцами, в зависимости от пола, показано в таблице ниже:
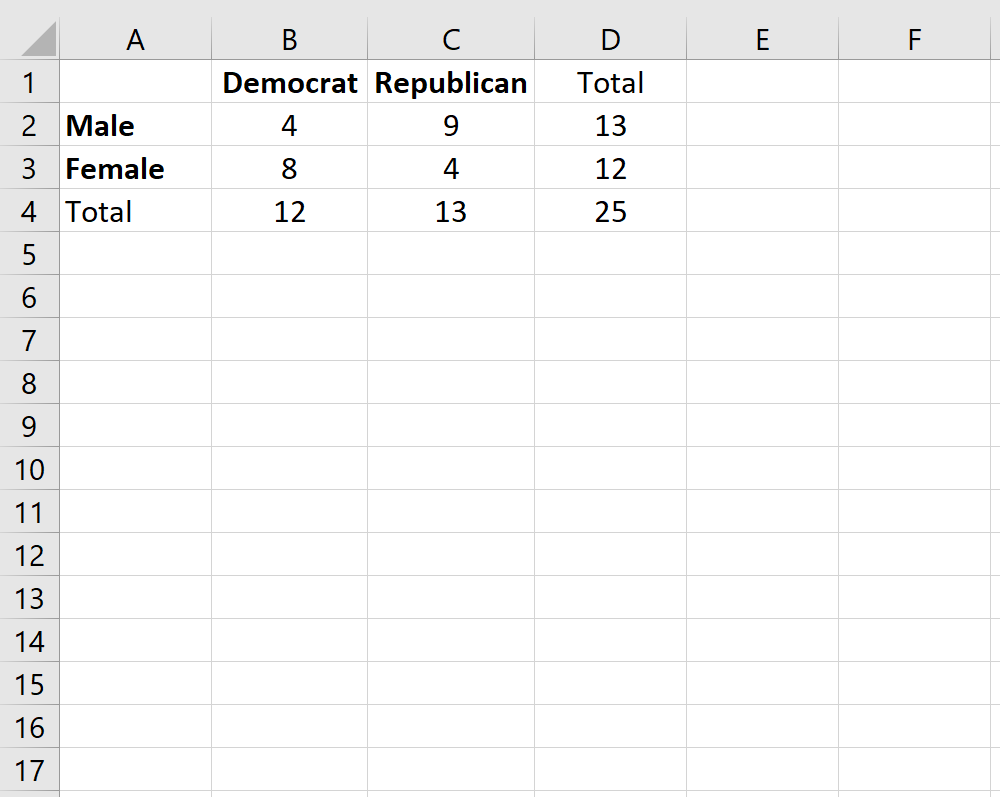
Чтобы определить, существует ли статистически значимая связь между полом и предпочтениями политической партии, мы можем выполнить точный тест Фишера.
Хотя в Excel нет встроенной функции для выполнения этого теста, мы можем использовать гипергеометрическую функцию для выполнения теста, которая использует следующий синтаксис:
=HYPGEOM.DIST(выборка_s, число_выборка, совокупность_s, число_население, кумулятивный)
- sample_s = количество «успехов» в образце
- number_sample = размер выборки
- населения_s = количество «успехов» в популяции
- number_pop = численность населения
- cumulative = если TRUE, возвращает кумулятивную функцию распределения; если FALSE, это возвращает функцию массы вероятности. Для наших целей мы всегда будем использовать TRUE.
Чтобы применить эту функцию к нашему примеру, мы выберем для использования одну из четырех ячеек в таблице 2×2. Подойдет любая ячейка, но в этом примере мы будем использовать верхнюю левую ячейку со значением «4».
Далее мы заполним следующие значения для функции:
= HYPGEOM.DIST (значение в отдельной ячейке, общее количество столбцов, общее количество строк, общий размер выборки, TRUE)
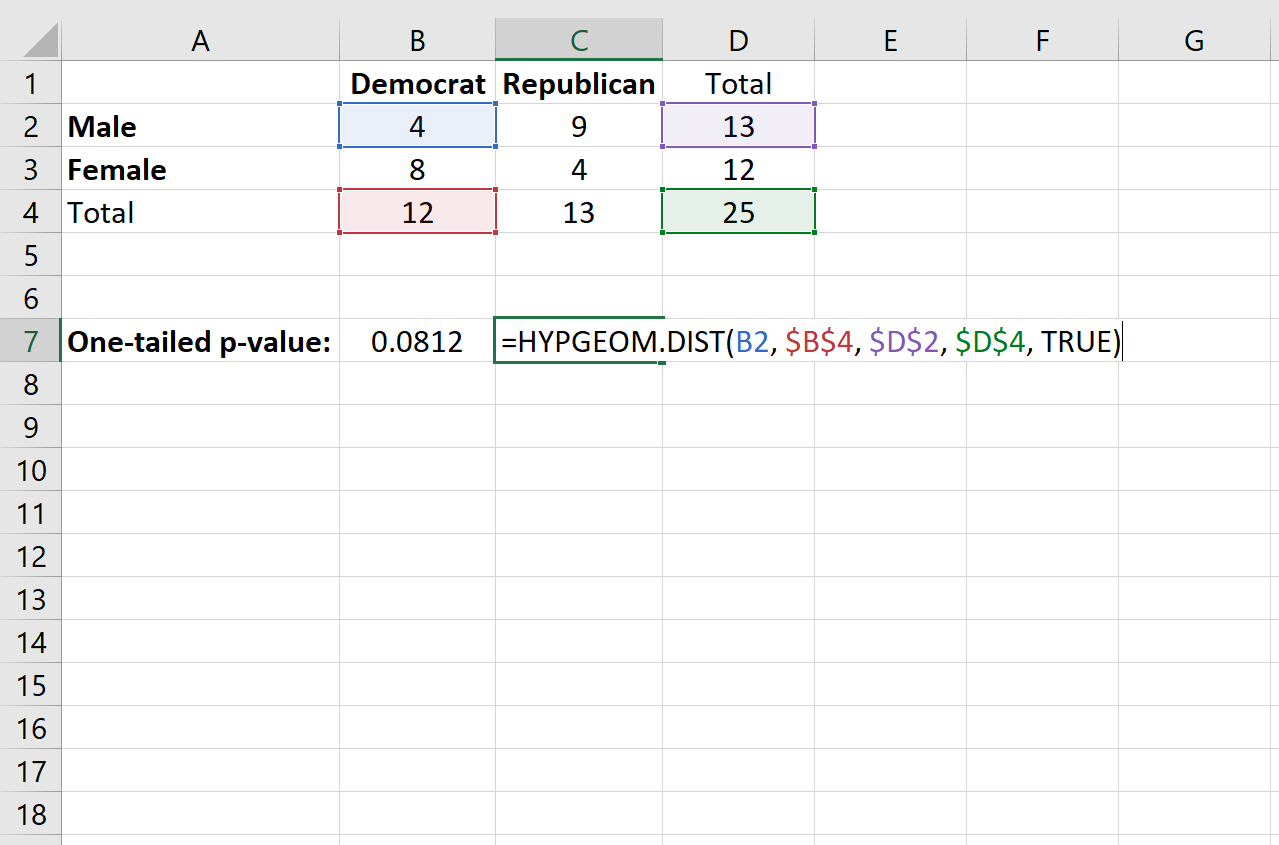
Это дает одностороннее p-значение 0,0812 .
Чтобы найти двустороннее p-значение для теста, мы сложим вместе следующие две вероятности:
- Вероятность получения x «успехов» в интересующей нас ячейке. В нашем случае это вероятность получения 4 успехов (мы уже нашли эту вероятность равной 0,0812).
- 1 — вероятность попадания (общее количество столбцов — х «успехов») в интересующую нас ячейку. В этом случае общее количество столбцов для демократа равно 12, поэтому мы найдем 1 — (вероятность 8 « успехов»)
Вот формула, которую мы будем использовать:
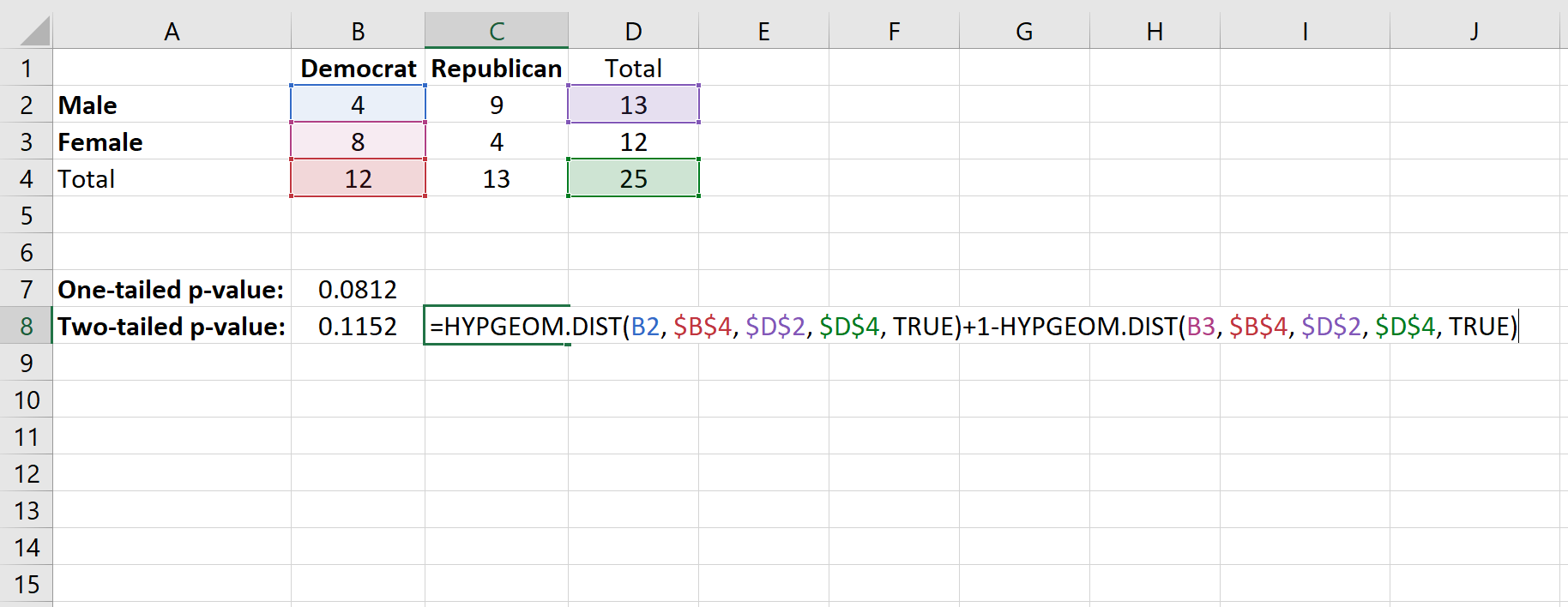
Это дает двустороннее p-значение 0,1152 .
В любом случае, проводим ли мы односторонний или двусторонний тест, p-значение не меньше 0,05, поэтому мы не можем отвергнуть нулевую гипотезу. Другими словами, у нас нет достаточных доказательств, чтобы сказать, что существует значительная связь между полом и предпочтениями политических партий.
Источник
FРАСПОБР для проверки значимости модели регрессии в Excel
Функция FПАСПОБР в Excel используется для проверки значимости модели регрессии с применением F-критерия (критерий Фишера), и возвращает числовое значение, соответствующее обратному значению для F-распределения вероятностей (верхнему квантилю). Например, если в качестве вероятности (первый аргумент функции) было введено значение уровня значимости, к примеру, 0,08, то FПАСПОБР вычислит значение случайной величины x, для которой выполняется следующее условие – P(X>x) = 0,08.
Функция FРАСПОБР для оценки значимости параметров модели регрессии
Критическое значения F может быть определено в случае, если в качестве первого аргумента рассматриваемой функции будет введено значение уровня значимости.
Для расчета F используется следующая формула:
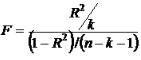
Функция оперирует двумя дополнительными критериями:
- Числитель степеней свободы: n1 = k.
- Знаменатель степеней свободы: n2 = (n – k – 1).
Через переменную k обозначают число факторов, которые были включены в исследуемую модель регрессии.
В Excel предусмотрена функция для расчета вероятности для распределения Фишера – FРАСП. Между данной и рассматриваемой функциями существует следующая взаимосвязь: =FРАСПОБР(FРАСП(x;n1;n2);n1;n2)=x.
В MS Office 2007 и более поздних версиях была введена функция F.ОБР.ПХ, которая заменила рассматриваемую функцию. FПАСПОБР была оставлена для обеспечения совместимости с документами, созданными в более старых версиях Excel.
Определение верхнего квартиля F-распределения Фишера в Excel
Пример 1. В таблице указаны вероятность, связанная с распределением Фишера, а также числитель и знаменатель степеней свободы соответственно. Определить верхний квантиль данного F-распределения.
Вид таблицы данных:
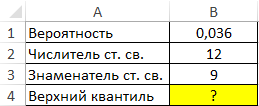
Вычислим искомое значение с помощью функции:
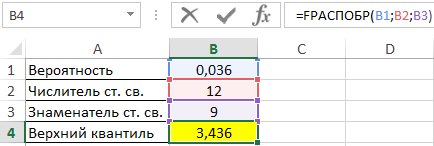
Оценка в Excel эффективности использования технологий на производстве
Пример 2. На заводе есть несколько цехов по производству одного типа продукции. Существует 3 различные технологии изготовления данной продукции. Для оценки были записаны данные о количестве часов, необходимых для производства одной партии продукции каждым цехом с использованием каждой из трех технологий. Оценить эффективность использования технологий, проанализировать полученные значения.
Вид таблицы данных:
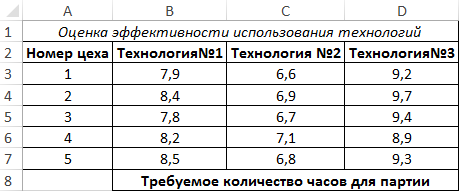
Проведем однофакторный дисперсионный анализ для данных, находящихся в диапазоне ячеек B3:D7, используя соответствующую надстройку Excel. Полученная таблица результатов:
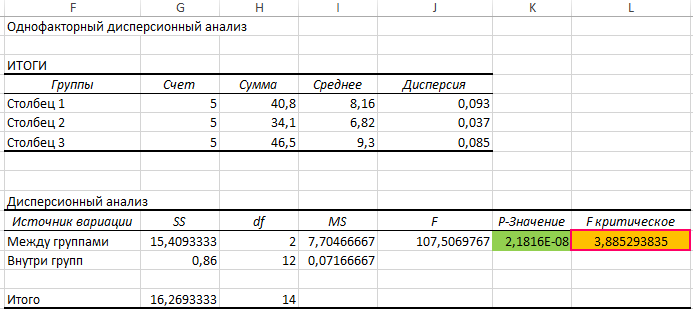
По условия поставленной задачи нас интересует выделенное значение. Поскольку оно
Здесь СЧЁТЗ(B3:D3) определяет число полей данных, а СЧЁТЗ(B3:D7) – количество исследуемых числовых значений.
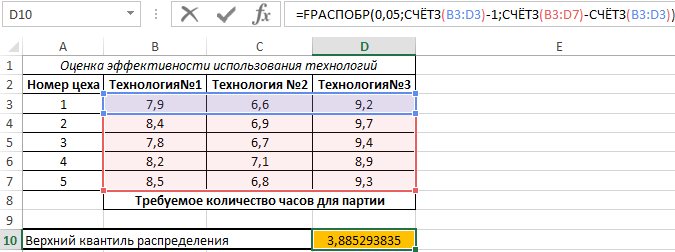
Особенности использования функции FРАСПОБР в Excel
Функция имеет следующую синтаксическую запись:
- вероятность – обязательный, принимает числовое значение, характеризующее вероятность, которая связана с распределением Фишера;
- степени_свободы1 – обязательный, принимает числовое значение, соответствующее числителю степеней свободы (равно числу факторов исследуемой регрессии);
- степени_свободы2 – обязательный, принимает числовое значение, соответствующее знаменателю степеней свободы.
- Рассматриваемая функция принимает в качестве любого из аргументов только числовые значения и данные, которые могут быть преобразованы к числам. Если любой из аргументов принимает данные недопустимого типа, будет сгенерирован код ошибки #ЗНАЧ!
- Первый аргумент должен быть задан числом из диапазона от 0 до 1. В противном случае функция FПАСПОБР вернет код ошибки #ЧИСЛО!
- Второй и третий аргумент функции должны быть заданы числами из диапазона от 1 до 10^10. При вводе значений, находящихся вне допустимого диапазона, будет сгенерирован код ошибки #ЧИСЛО!
- Рассматриваемая функция использует итеративный подход к вычислениям (последовательный подбор приближенного значения в циклах). Если спустя 100 итераций решение не было найдено, результатом выполнения функции FПАСПОБР будет код ошибки #Н/Д.
Источник
4.2. Критерий Фишера
F — критерий Фишераиспользуют для сравнения дисперсий двух генеральных совокупностей, распределенных по нормальному закону.
По независимым выборкам объема из этих совокупностей найдены выборочные дисперсии  и
и . Выдвигается гипотезаH0 — дисперсии равны, альтернативная гипотезаH1— дисперсии не равны. Вычисляется
. Выдвигается гипотезаH0 — дисперсии равны, альтернативная гипотезаH1— дисперсии не равны. Вычисляется по формуле:
по формуле:
 ,
,
где  — большая дисперсия,
— большая дисперсия, — меньшая дисперсия. По заданному уровню значимости α и числам степеней свободы
— меньшая дисперсия. По заданному уровню значимости α и числам степеней свободы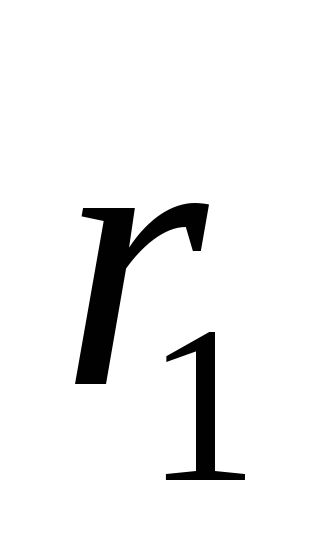 и
и (
( число степеней свободы числителя и
число степеней свободы числителя и число степеней свободы знаменателя) — определяем
число степеней свободы знаменателя) — определяем по таблицам или используя встроенные функцииMSExcel.
по таблицам или используя встроенные функцииMSExcel.
Число степеней свободы числителя определяется по формуле:
 ,
,
где n1— число вариант для большей дисперсии.
Число степеней свободы знаменателя определяется по формуле:
 ,
,
где n2 — число вариант для меньшей дисперсии.
Если  (вычисленное значение критерия
(вычисленное значение критерия  не больше критического), то принимается гипотезаH0(дисперсии равны), в противном случае (
не больше критического), то принимается гипотезаH0(дисперсии равны), в противном случае ( ) принимается гипотезаH1 (дисперсии различны).
) принимается гипотезаH1 (дисперсии различны).
При проведении тестирования двух одинаковых приборов были проведены измерения эталона. При этом первым прибором было проведено n1=11 измерений, а вторым — n2=9.
Результаты были записаны в виде отклонений от значения эталона. Требуется выяснить: одинаковой ли точностью обладают приборы.
Величина отклонений от эталонного значения для первого прибора (n1=11) внесена в столбец В,а для второго прибора (n2=9) результаты — в столбец С (рис.4.4-4.5). Средние значения отклонений одинаковы и равны нулю. Следовательно, у приборов отсутствует систематическая ошибка.
Проверка точности приборов сводится к проверке совпадения дисперсий. Если дисперсии отклонений от эталонного значения статистически равны, то приборы обладают одинаковой точностью. Выдвигается гипотеза H0 — дисперсии выборок равны, альтернативная гипотезаH1— дисперсии не равны.
В результате расчета были получены соответственно следующие значения дисперсий:  =7.35 и
=7.35 и =2.188.
=2.188.
Значение критерия 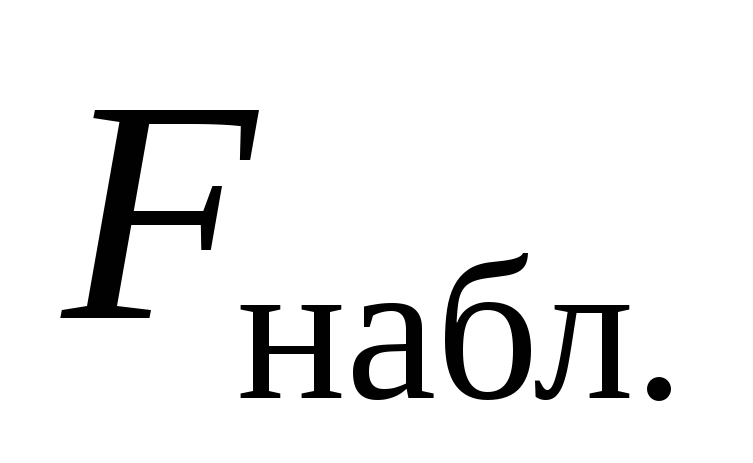 =7.35 /2.188 = 3.36.
=7.35 /2.188 = 3.36.
Для уровня значимости α =0.05; числа степеней свободы числителяr1 =11-1=10 и числа степеней свободы знаменателяr2 = 9-1= 8 находим с помощью встроенной функции FРАСПОБР().Fкрит= 3.347.
Поскольку  то гипотезаH0 отклоняется, и принимается альтернативная гипотезаH1 (дисперсии различны). Следовательно, приборы имеют различную точность.
то гипотезаH0 отклоняется, и принимается альтернативная гипотезаH1 (дисперсии различны). Следовательно, приборы имеют различную точность.
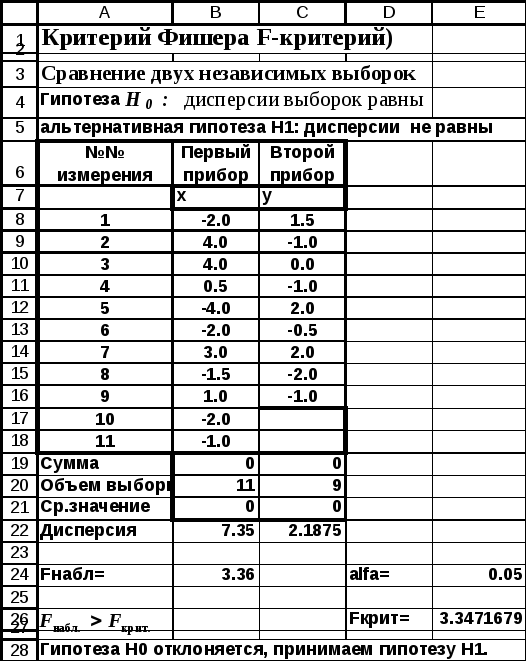
Рис. 4.4 Сравнение двух выборочных дисперсий
(фрагмент рабочего листа MSExcelв режиме отображения данных)
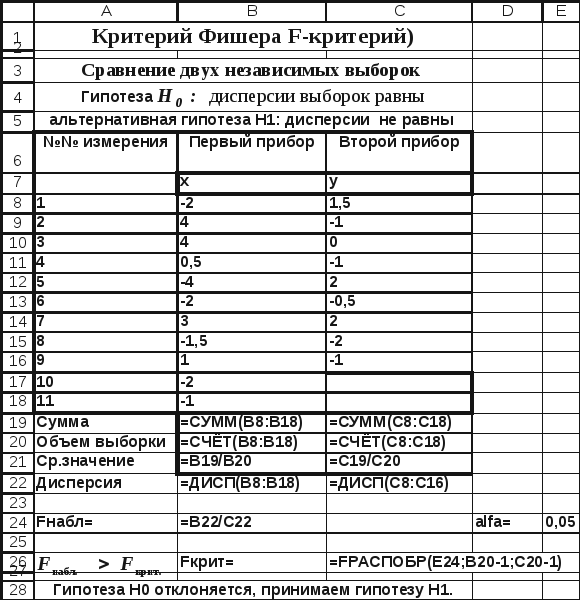
Рис. 4.5. Сравнение двух выборочных дисперсий
(фрагмент рабочего листа MSExcelв режиме отображений формул)
Средство анализа «Двухвыборочный f-тест для дисперсии» надстройки «Пакет анализа» ms Excel
Средство анализа «Двухвыборочный F-тест для дисперсии» надстройки «Пакет анализа»MSExcelслужит для проверки гипотезы о равенстве дисперсий двух выборок. Для проверки необходимо заполнить диалоговое окно, приведенное на рис.4.6, назначение всех полей ввода очевидно.

Рис. 4.6 Диалоговое окно средства анализа «Двухвыборочный F-тест для дисперсии» надстройки «Пакет анализа»MSExcel
Результаты расчета представлены на рис.4.7.
Сравните полученные результаты с результатами, полученными вручную.

Рис. 4.7 «Двухвыборочный F-тест для дисперсии»
Источник
17 авг. 2022 г.
читать 2 мин
Точный критерий Фишера используется для определения того, существует ли значительная связь между двумя категориальными переменными. Обычно он используется в качестве альтернативы критерию независимости хи-квадрат, когда количество одной или нескольких ячеек в таблице 2 × 2 меньше 5.
В этом руководстве объясняется, как выполнить точный критерий Фишера в Excel.
Пример: точный критерий Фишера в Excel
Предположим, мы хотим знать, связан ли пол с предпочтениями политической партии в конкретном колледже. Чтобы изучить это, мы случайным образом опрашиваем 25 студентов в кампусе. Количество студентов, которые являются демократами или республиканцами, в зависимости от пола, показано в таблице ниже:
Чтобы определить, существует ли статистически значимая связь между полом и предпочтениями политической партии, мы можем выполнить точный тест Фишера.
Хотя в Excel нет встроенной функции для выполнения этого теста, мы можем использовать гипергеометрическую функцию для выполнения теста, которая использует следующий синтаксис:
=HYPGEOM.DIST(выборка_s, число_выборка, совокупность_s, число_население, кумулятивный)
куда:
- sample_s = количество «успехов» в образце
- number_sample = размер выборки
- населения_s = количество «успехов» в популяции
- number_pop = численность населения
- cumulative = если TRUE, возвращает кумулятивную функцию распределения; если FALSE, это возвращает функцию массы вероятности. Для наших целей мы всегда будем использовать TRUE.
Чтобы применить эту функцию к нашему примеру, мы выберем для использования одну из четырех ячеек в таблице 2×2. Подойдет любая ячейка, но в этом примере мы будем использовать верхнюю левую ячейку со значением «4».
Далее мы заполним следующие значения для функции:
= HYPGEOM.DIST (значение в отдельной ячейке, общее количество столбцов, общее количество строк, общий размер выборки, TRUE)
Это дает одностороннее p-значение 0,0812 .
Чтобы найти двустороннее p-значение для теста, мы сложим вместе следующие две вероятности:
- Вероятность получения x «успехов» в интересующей нас ячейке. В нашем случае это вероятность получения 4 успехов (мы уже нашли эту вероятность равной 0,0812).
- 1 — вероятность попадания (общее количество столбцов — х «успехов») в интересующую нас ячейку. В этом случае общее количество столбцов для демократа равно 12, поэтому мы найдем 1 — (вероятность 8 « успехов»)
Вот формула, которую мы будем использовать:
Это дает двустороннее p-значение 0,1152 .
В любом случае, проводим ли мы односторонний или двусторонний тест, p-значение не меньше 0,05, поэтому мы не можем отвергнуть нулевую гипотезу. Другими словами, у нас нет достаточных доказательств, чтобы сказать, что существует значительная связь между полом и предпочтениями политических партий.
Дополнительные ресурсы
Как выполнить тест независимости хи-квадрат в Excel
Как выполнить критерий согласия хи-квадрат в Excel
Как рассчитать V Крамера в Excel
Министерство
образования и науки Российской Федерации
Федеральное
агентство по образованию
Саратовский
государственный технический университет
Балаковский
институт техники, технологии и управления
Методическое
указание к выполнению лабораторной
работы
по дисциплине
“Идентификация и диагностика систем
управления”
для студентов
специальности 220201
очной и заочной
форм обучения
Одобрено
редакционно-издательским
советом
Балаковского
института техники,
технологии
и управления
Балаково 2010
Цель работы:
Освоение регрессионного анализа в
пакете EXCEL.
ОСНОВНЫЕ ПОНЯТИЯ
Задачами
регрессионного анализа являются:
установление формы зависимости между
переменными, оценка функций регрессии,
оценка неизвестных значений зависимой
переменной (прогноз).
Односторонняя
зависимость случайной зависимой
переменной Y
от одной или нескольких независимых
переменных Х
называется объясняющей
регрессией.
Такая
зависимость может возникать тогда,
когда при каждом фиксированном значении
X,
соответствующее значение Y
подвержено случайному разбросу под
воздействием неконтролируемых факторов.
Такая зависимость Y(X)
называется регрессионной.
Она может
быть представлена в виде модельного
уравнения регрессии:

(1)
где
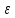
— случайная переменная характеризующая
отклонение функции регрессии.
Линейный
регрессионный анализ
— это анализ, для которого функция f(X)
линейна относительно оцениваемых
факторов. Уравнение линейной регрессии
имеет вид:

(2)
Регрессионный
анализ включает в себя две основные
компоненты:
1. оценка вектора
коэффициентов с помощью метода наименьших
квадратов:
 ;
;
2. дисперсионный
анализ.
Предпосылки
регрессионный анализ:
-
чтобы количество
экспериментальных данных было больше
либо равно 30 на один вход; -
распределение
выходной величины должно быть нормальным; -
в процессе
эксперимента дисперсия выходной
величины Y
не меняется:
 ;
; -
переменная X
изменяется с пренебрежительно малыми
ошибками, то есть является детерменированой; -
выходные переменные
Y1,
Y2,
… Yn
стохастически независимы между собой:
; -
дискретность
проведения экспериментов во времени
берется
таким образом, чтобы последовательно
взятые значения Y1,
Y2,
… Yn
были стохастически независимы, то есть
больше времени затухания автокорреляционной
функции; -
учет динамики в
регрессионном анализе производится в
виде транспортного запаздывания,
которое определяется как время нахождения
максимума взаимно корреляционной
функции X
и Y.
 ;
; ;
; берется
берется
На основании этих
предпосылок получают уравнение
регрессионной модели методом наименьших
квадратов.
Задача дисперсионного
анализа заключается в определении той
части экспериментальных данных, которая
описывается регрессионной моделью
(определяется коэффициент детерминации
R2
),
а также определение адекватности
регрессионной модели. Для этого
используется основное уравнение
дисперсионного анализа, которое имеет
вид:

(3)
где
 полная
полная
сумма квадратичных отклонений
характеризует разброс значений выходной
величины Y
вокруг его среднего значения;

— остаточная
сумма отклонений используется в качестве
критерия МНК;

сумма
обусловленная регрессией.
Коэффициент
детерминации R2
определяется
соотношением суммы обусловленной
регрессией и остаточной
суммы отклонений:

(4)
Коэффициент
детерминации изменяется от 0 до 1:

При

коэффициент детерминации

а при

коэффициент детерминации
 .
.
Чем ближе коэффициент детерминации к
1, тем точнее регрессионная модель.
При малых объемах
выборки используется коэффициент
множественной корреляции:
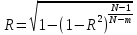
,
(5)
где N
– количество выборки; m
– количество входов.
Для оценки
адекватности регрессионной модели
используется критерий Фишера, который
определяется отношением дисперсии
обусловленной регрессией и остаточной
дисперсией:
 ,
,
(6)
Дисперсия,
обусловленная регрессией — среднее
значение квадратов отклонения
обусловленных регрессией определяется
выражением:

(7)
где fр
— число
степеней свободы суммы обусловленной
регрессией:
 ,
,
(8)
где m
– число
коэффициентов уравнения регрессии.
Остаточная дисперсия
определяется выражением:

(9)
где fост
— число
степеней свободы остаточной суммы:
 ,
,
(10)
где N
— число
экспериментов.
Для определения
адекватности регрессионной модели
сравнивают F-отношение,
рассчитанное по выражению (6), со значением
критерия Фишера выбранного из таблиц
для принятого уровня значимости

и числа степеней свободы сравниваемых
дисперсий
 и
и
 .
.

Если
 ,
,
то при соответствующем уровне значимости
регрессионная модель не адекватна.
Если
 ,
,
то при соответствующем уровне значимости
регрессионная модель адекватна.
Результаты
дисперсионного анализа сводятся в
таблицу 1.
Таблица
1.
Дисперсионный
анализ
|
SS |
f |
MS |
F |
P— |
F |
|
|
регрессия |
|
|
|
|
||
|
остатки |
|
|
|
|||
|
Итого |
|
|


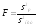





Интерпретация
результатов:
SS
— сумма квадратов; f
— число
степеней свободы; MS
— средний квадрат отклонений (дисперсия);
F—
расчетное значение отношения Фишера;
P—уровень
значимости для вычисленного значения
F;
Fкрит
— табличное значение отношения Фишера.
Если регрессионная
модель адекватна, определяют значимость
коэффициентов регрессии. Для проверки
значимости анализируется отношение
коэффициента регрессии и его
среднеквадратичного отклонения. Это
отношение является распределением
Стьюдента, то есть для определения
значимости используем t
– критерий:

(11)
где
 i,
i,
,
 —
—
значение коэффициента и его
среднеквадратичное отклонение.
Для определения
значимости коэффициента сравнивают
расчетное и табличное значение t
– критерия. Табличное значение t
– критерия определяется степенью
свободы
 и
и
значением заданной вероятности Р
: tтаб.
( ,
,
Р).
Если tрас.>tтаб.,
то коэффициент bi
является
значимым.
Доверительный
интервал определяется по формуле:
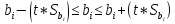
.
(12)
Если коэффициент
регрессии незначим, то соответствующий
ему входной фактор несущественно влияет
на выходную величину и его можно исключить
из регрессионной модели.
ПОРЯДОК ВЫПОЛНЕНИЯ
РАБОТЫ
-
Исходные данные
взять в таблицах(2,3) согласно варианту
(по номеру студента в журнале). -
Ввести исходные
данные в таблицу в пакете Excel. -
Подготовить два
столбца для ввода расчетных значений
Y
и остатков. -
Вызвать программу
«Регрессия»: Данные/ Анализ данных/
Регрессия. Диалоговое окно «Анализ
данных» представлено на рисунке 1.
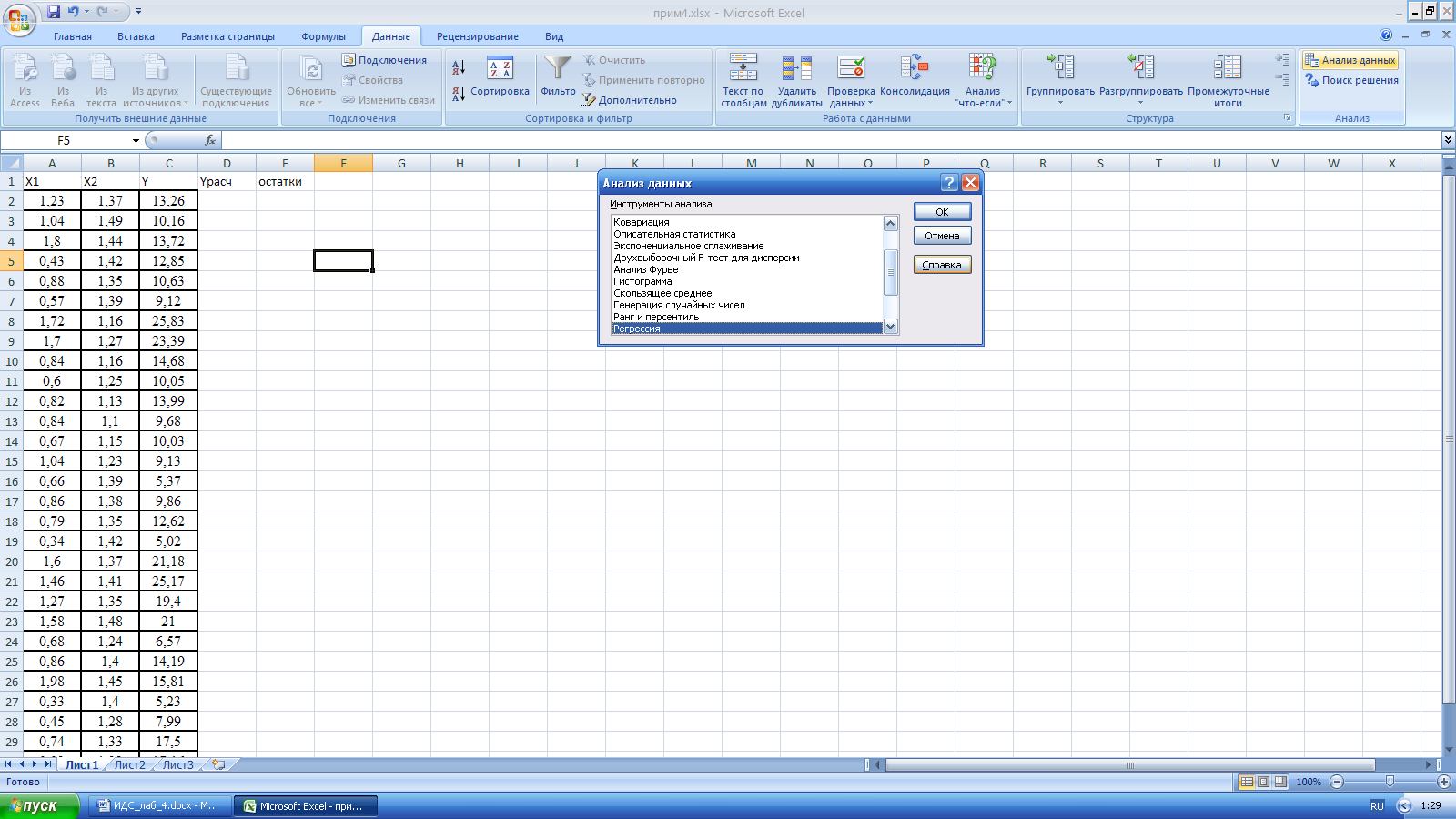
Рис. 1. Диалоговое окно «Анализ данных».
-
Ввести в диалоговое
окно «Регрессия» адреса исходных
данных:
-
входной интервал
Y,
входной интервал X
(3 столбца), -
установить уровень
надежности 95%, -
в опции «Выходной
интервал, указать левую верхнюю ячейку
места вывода данных регрессионного
анализа (первую ячейку на 2-странице
рабочего листа), -
включить опции
«Остатки» и «График остатков», -
нажать кнопку ОК
для запуска регрессионного анализа.
Диалоговое окно «Регрессия» представлено
на рисунке 2.

Рис. 2. Диалоговое окно
«Регрессия».
-
Excel выведет четыре
таблицы и два графика зависимости
остатков от переменных Х1
и Х2. -
Построить графики
для Yэксп,
Yрасч
и график ошибки прогноза (остатка). -
По полученным
графикам оценить правильность модели
по входам Х1,
Х2. -
Рассчитать
коэффициент множественной корреляции,
расчетные значения t-критериев,
доверительные интервалы коэффициентов
регрессии по выражениям (5,11,12). -
Сделать выводы
по результатам регрессионного анализа. -
Подготовить отчет
по работе.
ПРИМЕР ВЫПОЛНЕНИЯ
РАБОТЫ
Результаты
регрессионного анализа представлены
на рисунке 3.
Графики зависимости
остатков от переменных Х1
и Х2 представлены
на рисунке 4.
Графики расчетной
и экспериментальной выходной величины,
и график ошибки прогноза представлены
на рисунке 5.

Рис. 3. Пример регрессионного анализа в
пакете EXCEL


Рис.4 . Графики остатков переменных Х1,
Х2

Рис. 5. Графики Yэксп,
Yрасч и
ошибки прогноза (остатки).
По результатам
регрессионного анализа можно сказать:
-
Уравнение регрессии
полученное с помощью Excel,
имеет вид:
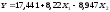
-
Коэффициент
детерминации:

Вариация результата
на 46,5% объясняется вариацией факторов.
-
Коэффициент
множественной корреляции:

-
Проверка на
адекватность модели. Анализ выполняется
при сравнении фактического и табличного
значения F-критерия
Фишера.
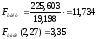
Фактическое
значение F-критерия Фишера
превышает табличное

— модель адекватна.
-
Проверка значимости
коэффициента b0.
Расчетное значение
t-критерия
для коэффициента
b0:

Табличное значение
t-критерия
tтаб.
(29, 0.975)=2.05
-
Доверительный
интервал коэффициента b0:


-
Проверка значимости
коэффициента b1.
Расчетное значение
t-критерия
для коэффициента
b1:

tрас.>tтаб.,
коэффициент b1
является значимым
-
Доверительный
интервал
коэффициента
b1:
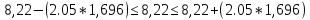

-
Проверка значимости
для коэффициентаb2.
Расчетное значение
t-критерия
для коэффициента
b2:

tрас.<tтаб.,
коэффициент b2
является не значимым, значит фактор X
2 незначительно влияет на выходную
величину Y,
и его можно исключить из уравнения
регрессии.
-
На основании
анализа значимости коэффициентов
уравнение регрессии примет вид:

Соседние файлы в папке LR-3
- #
- #
17.02.201457.34 Кб36Копия Xl0000004.xls
- #
Содержание
- Назначение и описание критерия Фишера
- Гипотезы критерия Фишера
- Графики функций
- F-распределение в MS EXCEL
- Оценка взаимосвязи прибыли и затрат по функции ФИШЕР
- Проверка статистической значимости регрессии по функции FРАСПОБР
- Таблицы по нахождению критерия Фишера и Стьюдента
- Критерии Стьюдента
- Порядок расчета критерия φ*
- Расчет в программе Excel
- Показатели качества уравнения регрессии
- Для чего используется точный критерий Фишера?
- В каких случаях можно использовать точный критерий Фишера?
- Критические точки распределения Фишера
Назначение и описание критерия Фишера
Критерий Фишера предназначен для сопоставления двух выборок по частоте встречаемости интересующего исследователя эффекта.
Критерий оценивает достоверность различий между процентными долями двух выборок, в которых зарегистрирован интересующий нас эффект.
Суть углового преобразования Фишера состоит в переводе процентных долей в величины центрального угла , который измеряется в радианах. Большей процентной доле будет соответствовать больший угол φ, а меньшей доле – меньший угол, но соотношения здесь не линейные: φ = 2*arcsin(), где P – процентная доля, выраженная в долях единицы.
При увеличении расхождения между углами φ1 и φ2 и увеличения численности выборок значение критерия возрастает. Чем больше величина φ*, тем более вероятно, что различия достоверны.
Гипотезы критерия Фишера
H0: Доля лиц, у которых проявляется исследуемый эффект, в выборке 1 не больше, чем в выборке 2.
H1: Доля лиц, у которых проявляется исследуемый эффект, в выборке 1 больше, чем в выборке 2.
Графики функций
F -распределение при небольших параметрах (
Среднее значение равно k 2 /(k 2 -2) при k 2 >2, дисперсия равна 2*k 2 2 *(k 1 +k 2 -2)/(k 1 *(k 2 -4)*(k 2 -2) 2 ) при k 2 >4.
В файле примера на листе График приведены графики плотности распределения вероятности и интегральной функции распределения .

Примечание : Для построения функции распределения и плотности вероятности можно использовать диаграмму типа График или Точечная (со сглаженными линиями и без точек). Подробнее о построении диаграмм читайте статью Основные типы диаграмм .
F-распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для F-распределения имеется специальная функция F.РАСП() , английское название – F.DIST(), которая позволяет вычислить плотность вероятности (см. формулу выше) и интегральную функцию распределения (вероятность, что случайная величина Х, имеющая F – распределение , примет значение меньше или равное х, P(X
Примечание : Плотность вероятности можно также вычислить впрямую, с помощью формул (см. файл примера ).
До MS EXCEL 2010 в EXCEL была функция FРАСП() , которая позволяет вычислить функцию распределения (точнее – правостороннюю вероятность, т.е. P(X>x)). Функция FРАСП() оставлена в MS EXCEL 2010 для совместимости. Аналогом FРАСП() является функция F.РАСП.ПХ() , появившаяся в MS EXCEL 2010.
Примеры расчетов приведены в файле примера на листе Функции .
В MS EXCEL имеется еще одна функция, использующая для расчетов F-распределение – это F.ТЕСТ(массив1;массив2) . Эта функция возвращает результат F-теста : двухстороннюю вероятность того, что разница между дисперсиями выборок “массив1” и “массив2” несущественна. Предполагается, что выборки делаются из нормального распределения.
Оценка взаимосвязи прибыли и затрат по функции ФИШЕР
Пример 1. Используя данные об активности коммерческих организаций, требуется сделать оценку связи прибыли Y (млн руб.) и затрат X (млн руб.), используемых для разработки продукции (приведены в таблице 1).
Таблица 1 – Исходные данные:
| № | X | Y |
| 1 | 210 000 000,00 ₽ | 95 000 000,00 ₽ |
| 2 | 1 068 000 000,00 ₽ | 76 000 000,00 ₽ |
| 3 | 1 005 000 000,00 ₽ | 78 000 000,00 ₽ |
| 4 | 610 000 000,00 ₽ | 89 000 000,00 ₽ |
| 5 | 768 000 000,00 ₽ | 77 000 000,00 ₽ |
| 6 | 799 000 000,00 ₽ | 85 000 000,00 ₽ |
Схема решения таких задач выглядит следующим образом:
- Рассчитывается линейный коэффициент корреляции rxy
- Проверяется значимость линейного коэффициента корреляции на основе t-критерия Стьюдента. При этом выдвигается и проверяется гипотеза о равенстве коэффициента корреляции нулю. При проверке этой гипотезы используется t-статистика. Если гипотеза подтверждается, t-статистика имеет распределение Стьюдента. Если расчетное значение tр > tкр, то гипотеза отвергается, что свидетельствует о значимости линейного коэффициента корреляции, а следовательно, и о статистической существенности зависимости между Х и Y;
- Определяется интервальная оценка для статистически значимого линейного коэффициента корреляции.
- Определяется интервальная оценка для линейного коэффициента корреляции на основе обратного z-преобразования Фишера;
- Рассчитывается стандартная ошибка линейного коэффициента корреляции.
Результаты решения данной задачи с применяемыми функциями в пакете Excel приведены на рисунке 1.

Рисунок 1 – Пример расчетов.
| № п/п | Наименование показателя | Формула расчета |
| 1 | Коэффициент корреляции | =КОРРЕЛ(B2:B7;C2:C7) |
| 2 | Расчетное значение t-критерия tp | =ABS(C8)/КОРЕНЬ(1-СТЕПЕНЬ(C8;2))*КОРЕНЬ(6-2) |
| 3 | Табличное значение t-критерия trh | =СТЬЮДРАСПОБР(0,05;4) |
| 4 | Табличное значение стандартного нормального распределения zy | =НОРМСТОБР((0,95+1)/2) |
| 5 | Значение преобразования Фишера z’ | =ФИШЕР(C8) |
| 6 | Левая интервальная оценка для z | =C12-C11*КОРЕНЬ(1/(6-3)) |
| 7 | Правая интервальная оценка для z | =C12+C11*КОРЕНЬ(1/(6-3)) |
| 8 | Левая интервальная оценка для rxy | =ФИШЕРОБР(C13) |
| 9 | Правая интервальная оценка для rxy | =ФИШЕРОБР(C14) |
| 10 | Стандартное отклонение для rxy | =КОРЕНЬ((1-C8^2)/4) |
Таким образом, с вероятностью 0,95 линейный коэффициент корреляции заключен в интервале от (–0,386) до (–0,990) со стандартной ошибкой 0,205.
Пример 2. Произвести проверку статистической значимости уравнения множественной регрессии с помощью F-критерия Фишера, сделать выводы.
Для проверки значимости уравнения в целом выдвинем гипотезу Н0 о статистической незначимости коэффициента детерминации и противоположную ей гипотезу Н1 о статистической значимости коэффициента детерминации:
Н0: R2 = 0;
Н1: R2 ≠ 0.
Проверим гипотезы с помощью F-критерия Фишера. Показатели приведены в таблице 2.
Таблица 2 – Исходные данные
| Показатель | SS | MS | Fрасч |
| Регрессия | 454,814 | 227,407 | 7,075 |
| Остаток | 1607,014 | 32,14 | |
| Итого | 2061,828 | – |
Для этого используем в пакете Excel функцию:
=FРАСПОБР (α;p;n-p-1)
где:
- α – вероятность, связанная с данным распределением;
- p и n – числитель и знаменатель степеней свободы, соответственно.
Зная, что α = 0,05, p = 2 и n = 53, получаем следующее значение для Fкрит (см. рисунок 2).

Рисунок 2 – Пример расчетов.
Таким образом можно сказать, что Fрасч > Fкрит. В итоге принимается гипотеза Н1 о статистической значимости коэффициента детерминации.
Таблицы по нахождению критерия Фишера и Стьюдента
Таблицы значений F-критерия Фишера и t-критерия Стьюдента Вы можете посмотреть здесь.
Табличное значение критерия Фишера вычисляют следующим образом:
- Определяют k1, которое равно количеству факторов (Х). Например, в однофакторной модели (модели парной регрессии) k1=1, в двухфакторной k=2.
- Определяют k2, которое определяется по формуле n — m — 1, где n — число наблюдений, m — количество факторов. Например, в однофакторной модели k2 = n — 2.
- На пересечении столбца k1 и строки k2 находят значение критерия Фишера
Для нахождения табличного значения критерия Стьюдента определяют число степеней свободы, которое определяется по формуле n — m — 1 и находят его значение при определенном уровне значимости (0,10, 0,05, 0,01).
Критерии Стьюдента
Для оценки статистической значимости модели по параметрам рассчитывают t-критерии Стьюдента.
Оценка значимости модели с помощью критерия Стьюдента проводится путем сравнения их значений с величиной случайной ошибки:

Случайные ошибки коэффициентов линейной регрессии и коэффициента корреляции определяются по формулам:

Сравнивая фактическое и табличное значения t-статистики и принимается или отвергается гипотеза о значимости модели по параметрам.
Зависимость между критерием Фишера и значением t-статистики Стьюдента определяется так

Как и в случае с оценкой значимости уравнения модели в целом, модель считается ненадежной если tтабл > tфакт
Порядок расчета критерия φ*
1. Формулируем статистические гипотезы:
Но: доля студентов, получивших оценки 4 и 5 до эксперимента такая же, как и после эксперимента;
Н1: доля студентов, получивших оценки 4 и 5 после эксперимента больше, чем до эксперимента.
2. Определяем значения углов φ1 и φ2, соответствующие долям p1 = 0,666; p2 = 0,888
φ1= 2arcsin (√p1)= 2 arcsin √0,6662 arcsin (0,816)= 2·0.954=1.908
φ2= 2arcsin (√p2)= 2 arcsin √0,888=2 arcsin (0,942)= 2·1.228=2.457
3. Вычисляем эмпирическое значение φ по формуле.
4. Сравниваем эмпирическое значение критерия с критическим (представлено в таблице 2)
Таблица 2. Критические значения критерия при различных значениях уровнях значимости α (Попов Г.И. с соавт., 2007).
| α | критические значения критерия φ* |
| 0,001 | 2,91 |
| 0,01 | 2,31 |
| 0,05 | 1,64 |
| 0,1 | 1,29 |
Расчет в программе Excel
В программу введен контрольный пример. В верхней части программы показано, как должны быть представлены исходные данные в случае связанных выборок (слева) и в случае независимых выборок (справа).
Чтобы выполнить расчет, нужно заполнить клетки, выделенные желтым цветом в нижней части таблицы. После этого будет получено эмпирическое значение критерия (фи*эмп). Затем подученное значение эмпирического значения фи нужно сравнить с критическим значением (фи* крит) на заданном уровне значимости. Эти значения приведены в табл.1. Если фи*эмп больше чем фи*крит, различия между группами статистически достоверны.
Показатели качества уравнения регрессии
| Показатель | Значение |
| Коэффициент детерминации | 0.49 |
| Средний коэффициент эластичности | 0.51 |
| Средняя ошибка аппроксимации | 10.89 |
Пример. По совокупности 25 предприятий торговли изучается зависимость между признаками: X — цена на товар А, тыс. руб.; Y — прибыль торгового предприятия, млн. руб. При оценке регрессионной модели были получены следующие промежуточные результаты: ∑(yi-yx)2 = 46000; ∑(yi-yср)2 = 138000. Какой показатель корреляции можно определить по этим данным? Рассчитайте величину этого показателя, на основе этого результата и с помощью F-критерия Фишера сделайте вывод о качестве модели регрессии.
Решение. По этим данным можно определить эмпирическое корреляционное отношение:  , где ∑(yср-yx)2 = ∑(yi-yср)2 – ∑(yi-yx)2 = 138000 – 46000 = 92 000.
, где ∑(yср-yx)2 = ∑(yi-yср)2 – ∑(yi-yx)2 = 138000 – 46000 = 92 000.
η2 = 92 000/138000 = 0.67, η = 0.816 (0.7 < η < 0.9 – связь между X и Y высокая).
F-критерий Фишера: n = 25, m = 1.
R2 = 1 – 46000/138000 = 0.67, F = 0.67/(1-0.67)x(25 – 1 – 1) = 46. FтаблПоскольку фактическое значение F > Fтабл, то найденная оценка уравнения регрессии статистически надежна.
Для чего используется точный критерий Фишера?
Точный критерий Фишера в основном применяется для сравнения малых выборок. Этому есть две весомые причины. Во-первых, вычисления критерия довольно громоздки и могут занимать много времени или требовать мощных вычислительных ресурсов. Во-вторых, критерий довольно точен (что нашло отражение даже в его названии), что позволяет его использовать в исследованиях с небольшим числом наблюдений.
Особое место отводится точному критерию Фишера в медицине. Это важный метод обработки медицинских данных, нашедший свое применение во многих научных исследованиях. Благодаря ему можно исследовать взаимосвязь определенных фактора и исхода, сравнивать частоту патологических состояний между разными группами пациентов и т.д.
В каких случаях можно использовать точный критерий Фишера?
- Сравниваемые переменные должны быть измерены в номинальной шкале и иметь только два значения, например, артериальное давление в норме или повышено, исход благоприятный или неблагоприятный, послеоперационные осложнения есть или нет.
- Критерий подходит для сравнения очень малых выборок: точный критерий Фишера может применяться для анализа четырехпольных таблиц в случае значений ожидаемого явления менее 10, что является ограничением для применения критерия хи-квадрат Пирсона.
- Точный критерий Фишера бывает односторонним и двусторонним. При одностороннем варианте точно известно, куда отклонится один из показателей. Например, во время исследования сравнивают, сколько пациентов выздоровело по сравнению с группой контроля. Предполагают, что терапия не может ухудшить состояние пациентов, а только либо вылечить, либо нет.
Двусторонний тест является предпочтительным, так как оценивает различия частот по двум направлениям. То есть оценивается верятность как большей, так и меньшей частоты явления в экспериментальной группе по сравнению с контрольной группой.
Аналогом точного критерия Фишера является Критерий хи-квадрат Пирсона, при этом точный критерий Фишера обладает более высокой мощностью, особенно при сравнении малых выборок, в связи с чем в этом случае обладает преимуществом.
Критические точки распределения Фишера
(k1— число степеней свободы большей дисперсии,
k2—число степеней свободы меньшей дисперсии)
Уровень значимости a =0.01
| k1k2 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 1 | 4052 | 4999 | 5403 | 5625 | 5764 | 5889 | 5928 | 5981 | 6022 | 6056 | 6082 | 6106 |
| 2 | 98.49 | 99.01 | 90.17 | 99.25 | 99.33 | 99.30 | 99.34 | 99.36 | 99.36 | 99.40 | 99.41 | 99.42 |
| 3 | 34.12 | 30.81 | 29.46 | 28.71 | 28.24 | 27.91 | 27.67 | 27.49 | 27.34 | 27.23 | 27.13 | 27.05 |
| 4 | 21.20 | 18.00 | 16.69 | 15.98 | 15.52 | 15.21 | 14.98 | 14.80 | 14.66 | 14.54 | 14.45 | 14.37 |
| 5 | 16.26 | 13.27 | 12.06 | 11.39 | 10.97 | 10.67 | 10.45 | 10.27 | 10.15 | 10.05 | 9.96 | 9.89 |
| 6 | 13.74 | 10.92 | 9.78 | 9.15 | 8.75 | 8.47 | 8.26 | 8.10 | 7.98 | 7.87 | 7.79 | 7.72 |
| 7 | 12.25 | 9.55 | 8.45 | 7.85 | 7.46 | 7.19 | 7.00 | 6.84 | 6.71 | 6.62 | 6.54 | 6.47 |
| 8 | 11.26 | 8.65 | 7.59 | 7.01 | 6.63 | 6.37 | 6.19 | 6.03 | 5.91 | 5.82 | 5.74 | 5.67 |
| 9 | 10.56 | 8.02 | 6.99 | 6.42 | 6.06 | 5.80 | 5.62 | 5.47 | 5.35 | 5.26 | 5.18 | 5.11 |
| 10 | 10.04 | 7.56 | 6.55 | 5.99 | 5.64 | 5.39 | 5.21 | 5.06 | 4.95 | 4.85 | 4.78 | 4.71 |
| 11 | 9.86 | 7.20 | 6.22 | 5.67 | 5.32 | 5.07 | 4.88 | 4.74 | 4.63 | 4.54 | 4.46 | 4.40 |
| 12 | 9.33 | 6.93 | 5.95 | 5.41 | 5.06 | 4.82 | 4.65 | 4.50 | 4.39 | 4.30 | 4.22 | 4.16 |
| 13 | 9.07 | 6.70 | 5.74 | 5.20 | 4.86 | 4.62 | 4.44 | 4.30 | 4.19 | 4.10 | 4.02 | 3.96 |
| 14 | 8.86 | 6.51 | 5.56 | 5.03 | 4.69 | 4.46 | 4.28 | 4.14 | 4.03 | 3.94 | 3.86 | 3.80 |
| 15 | 8.68 | 6.36 | 5.42 | 4.89 | 4.56 | 4.32 | 4.14 | 4.00 | 3.89 | 3.80 | 3.73 | 3.67 |
| 16 | 8.53 | 6.23 | 5.29 | 4.77 | 4.44 | 4.20 | 4.03 | 3.89 | 3.78 | 3.69 | 3.61 | 3.55 |
| 17 | 8.40 | 6.11 | 5.18 | 4.67 | 4.34 | 4.10 | 3.93 | 3.79 | 3.68 | 3.59 | 3.52 | 3.45 |
Уровень значимости a=0.05
| k1k2 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 1 | 161 | 200 | 216 | 225 | 230 | 234 | 237 | 239 | 241 | 242 | 243 | 244 |
| 2 | 18.5 | 19.00 | 19.16 | 19.25 | 19:30 | 19.33 | 19.36 | 19.37 | 19.38 | 19.39 | 19.40 | 19.41 |
| 3 | 10.13 | 9.55 | 9.28 | 9.12 | 9.01 | 8.94 | 8.88 | 8.84 | 8.81 | 8.78 | 8.76 | 8.74 |
| 4 | 7.71 | 6.94 | 6.59 | 6.39 | 6.26 | 6.16 | 6.09 | 6.04 | 6.00 | 5.96 | 5.93 | 5.91 |
| 5 | 6.61 | 5.79 | 5.41 | 5.19 | 5.05 | 4.95 | 4.88 | 4.82 | 4.78 | 4.74 | 4.70 | 4.68 |
| 6 | 5.99 | 5.14 | 4.76 | 4.53 | 4.39 | 4.28 | 4.21 | 4.15 | 4.10 | 4.06 | 4.03 | 4.00 |
| 7 | 5.59 | 4.74 | 4.35 | 4.12 | 3.97 | 3.87 | 3.79 | 3.73 | 3.68 | 3.63 | 3.60 | 3.57 |
| 8 | 5.32 | 4.46 | 4.07 | 3.84 | 3.69 | 3.58 | 3.50 | 3.44 | 3.39 | 3.34 | 3.31 | 3.28 |
| 9 | 5.12 | 4.26 | 3.86 | 3.63 | 3.48 | 3.37 | 3.29 | 3.23 | 3.18 | 3.13 | 3.10 | 3.07 |
| 10 | 4.96 | 4.10 | 3.71 | 3.48 | 3.33 | 3.22 | 3.14 | 3.07 | 3.02 | 2.97 | 2.94 | 2.91 |
| 11 | 4.84 | 3.98 | 3.59 | 3.36 | 3.20 | 3.09 | 3.01 | 2.95 | 2.90 | 2.86 | 2.82 | 2.79 |
| 12 | 4.75 | 3.88 | 3.49 | 3.26 | 3.11 | 3.00 | 2.92 | 2.85 | 2.80 | 2.76 | 2.72 | 2.69 |
| 13 | 4.67 | 3.80 | 3.41 | 3.18 | 3.02 | 2.92 | 2.84 | 2.77 | 2.72 | 2.67 | 2.63 | 2.60 |
| 14 | 4.60 | 3.74 | 3.34 | 3.11 | 2.96 | 2.85 | 2.77 | 2.70 | 2.65 | 2.60 | 2.56 | 2.53 |
| 15 | 4.54 | 3.68 | 3.29 | 3.06 | 2.90 | 2.79 | 2.70 | 2.64 | 2.59 | 2.55 | 2.51 | 2.48 |
| 16 | 4.49 | 3.63 | 3.24 | 3.01 | 2.85 | 2.74 | 2.66 | 2.59 | 2.54 | 2.49 | 2.45 | 2.42 |
| 17 | 4.45 | 3.59 | 3.20 | 2.96 | 2.81 | 2.70 | 2.62 | 2.55 | 2.50 | 2.45 | 2.41 | 2.38 |
Источники
- https://www.psychol-ok.ru/statistics/fisher/
- https://excel2.ru/articles/raspredelenie-fishera-f-raspredelenie-raspredeleniya-matematicheskoy-statistiki-v-ms-excel
- https://exceltable.com/funkcii-excel/primery-funkcii-fisher
- https://univer-nn.ru/ekonometrika/kriterij-fishera-i-styudenta/
- https://allasamsonova.ru/programma-rascheta-uglovogo-preobrazovanija-fishera-fi/
- https://math.semestr.ru/corel/fisher.php
- https://medstatistic.ru/methods/methods5.html
- https://math.semestr.ru/corel/table-fisher.php
По территориям региона приводятся данные за 200Х г.
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., х | Среднедневная заработная плата, руб., у |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Задание:
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнения линейной регрессии
 .
.
3. Оцените тесноту связи с помощью показателей корреляции и детерминации.
4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
5. Оцените с помощью средней ошибки аппроксимации качество уравнений.
6. Оцените с помощью F-критерия Фишера статистическую надёжность результатов регрессионного моделирования.
7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости  .
.
8. Оцените полученные результаты, выводы оформите в аналитической записке.
Решение:
Решим данную задачу с помощью Excel.
1. Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа.
Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у.
Выделите область ячеек, содержащую данные.
Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами как показано на рисунке 1.

Рисунок 1 Построение поля корреляции
Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии.
2. Для расчёта параметров уравнения линейной регрессии
воспользуемся встроенной статистической функцией ЛИНЕЙН.
Для этого:
1) Откройте существующий файл, содержащий анализируемые данные;
2) Выделите область пустых ячеек 5×2 (5 строк, 2 столбца) для вывода результатов регрессионной статистики.
3) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
4) В окне Категория выберете Статистические, в окне функция – ЛИНЕЙН. Щёлкните по кнопке ОК как показано на Рисунке 2;

Рисунок 2 Диалоговое окно «Мастер функций»
5) Заполните аргументы функции:
Известные значения у – диапазон, содержащий данные результативного признака;
Известные значения х – диапазон, содержащий данные факторного признака;
Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0;
Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения.
Щёлкните по кнопке ОК;

Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу <F2>, а затем на комбинацию клавиш <Ctrl>+<Shift>+<Enter>.
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка b | Стандартная ошибка a |
| Коэффициент детерминации R2 | Стандартная ошибка y |
| F-статистика | Число степеней свободы df |
| Регрессионная сумма квадратов
|
Остаточная сумма квадратов
|



Рисунок 4 Результат вычисления функции ЛИНЕЙН
Получили уровнение регрессии:

Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
3. Коэффициент детерминации  означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции:  .
.
Связь оценивается как тесная.
4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат.
Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле:

Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее, и то же самое произведём со значениями у.

Рисунок 5 Расчёт средних значений функции и аргумент

Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%.
С помощью инструмента анализа данных Регрессия можно получить:
— результаты регрессионной статистики,
— результаты дисперсионного анализа,
— результаты доверительных интервалов,
— остатки и графики подбора линии регрессии,
— остатки и нормальную вероятность.
Порядок действий следующий:
1) проверьте доступ к Пакету анализа. В главном меню последовательно выберите: Файл/Параметры/Надстройки.
2) В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
3) В окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
• Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
• Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия, а затем нажмите кнопку ОК.
5) Заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал Y – диапазон, содержащий данные результативного признака;
Входной интервал X – диапазон, содержащий данные факторного признака;
Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа – ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона;
6) Новый рабочий лист – можно задать произвольное имя нового листа.
Затем нажмите кнопку ОК.

Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных задачи представлены на рисунке 7.

Рисунок 7 Результат применения инструмента регрессия
5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.

Рисунок 8 Результат применения инструмента регрессия «Вывод остатка»
Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:


Рисунок 9 Расчёт средней ошибки аппроксимации
Средняя ошибка аппроксимации рассчитывается по формуле:

Качество построенной модели оценивается как хорошее, так как  не превышает 8 – 10%.
не превышает 8 – 10%.
6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера: 

Поскольку  при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателей от нуля:
 .
.
 для числа степеней свободы
для числа степеней свободы 
На рисунке 7 имеются фактические значения t-статистики:

t-критерий для коэффициента корреляции можно рассчитать двумя способами:
I способ: 
где  – случайная ошибка коэффициента корреляции.
– случайная ошибка коэффициента корреляции.
Данные для расчёта возьмём из таблицы на Рисунке 7.

II способ: 
Фактические значения t-статистики превосходят табличные значения:


Поэтому гипотеза Н0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы.
Доверительный интервал для параметра a определяется как

Для параметра a 95%-ные границы как показано на рисунке 7 составили:

Доверительный интервал для коэффициента регрессии определяется как

Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили:

Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью  параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:

Тогда прогнозное значение прожиточного минимума составит:

Ошибку прогноза рассчитаем по формуле:

где 
Дисперсию посчитаем также с помощью ППП Excel. Для этого:
1) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
2) В окне Категория выберете Статистические, в окне функция – ДИСП.Г. Щёлкните по кнопке ОК.
3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК.

Рисунок 10 Расчёт дисперсии
Получили значение дисперсии 
Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7.


Доверительные интервалы прогноза индивидуальных значений у при  с вероятностью 0,95 определяются выражением:
с вероятностью 0,95 определяются выражением:



Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным.
Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2003. – 192 с.: ил.