
JSON to excel converter

A package that converts json to CSV, excel or other table formats
- JSON to excel converter
- Sample output
- Simple json
- Nested json
- json with array property
- Installation
- Usage
- Simple usage
- Streaming usage with restarts
- Arrays
- XLSX Formatting
- Cell format
- Column widths
- Row heights
- Urls
- Custom cell rendering
- Sample output
Sample output

Simple json
[
{
"col1": "val1",
"col2": "val2"
}
]
the generated CSV/excel is:
col1 col2
==================
val1 val2
Nested json
[
{
"col1": "val1",
"col2": {
"col21": "val21",
"col22": "val22"
}
}
]
the generated CSV/excel is (in excel, col2 spans two cells horizontally):
col1 col2
col21 col22
=================================
val1 val21 val22
json with array property
[
{
"col1": "val1",
"col2": [
{
"col21": "val21"
},
{
"col21": "val22"
}
]
}
]
the generated CSV/excel is (in excel, col2 spans two cells horizontally):
col1 col2
col21 col21
=================================
val1 val21 val22
Installation
pip install json-excel-converter[extra]
where extra is:
xlsxwriterto use the xlsxwriter
Usage
Simple usage
from json_excel_converter import Converter from json_excel_converter.xlsx import Writer data = [ {'a': [1], 'b': 'hello'}, {'a': [1, 2, 3], 'b': 'world'} ] conv = Converter() conv.convert(data, Writer(file='/tmp/test.xlsx'))
Streaming usage with restarts
from json_excel_converter import Converter, LinearizationError from json_excel_converter.csv import Writer conv = Converter() writer = Writer(file='/tmp/test.csv') while True: try: data = get_streaming_data() # custom function to get iterator of data conv.convert_streaming(data, writer) break except LinearizationError: pass
Arrays
When the first row is processed, the library guesses the columns layout. In case of arrays,
a column (or more columns if the array contains json objects) is created for each
of the items in the array, as shown in the example above.
On subsequent rows the array might contain more items. The library reacts by adjusting
the number of columns in the layout and raising LinearizationError as previous rows might
be already output.
Converter.convert_streaming just raises this exception — it is the responsibility of caller
to take the right action.
Converter.convert captures this error and restarts the processing. In case of CSV
this means truncating the output file to 0 bytes and processing the data again. XLSX writer
caches all the data before writing them to excel so the restart just means discarding the cache.
If you know the size of the array in advance, you should pass it in options. Then no
processing restarts are required and LinearizationError is not raised.
from json_excel_converter import Converter, Options from json_excel_converter.xlsx import Writer data = [ {'a': [1]}, {'a': [1, 2, 3]} ] options = Options() options['a'].cardinality = 3 conv = Converter(options=options) writer = Writer(file='/tmp/test.xlsx') conv.convert(data, writer) # or conv.convert_streaming(data, writer) # no exception occurs here
XLSX Formatting
Cell format
XLSX writer enables you to format the header and data by passing an array of header_formatters or
data_formatters. Take these from json_excel_converter.xlsx.formats package or create your own.
from json_excel_converter import Converter from json_excel_converter.xlsx import Writer from json_excel_converter.xlsx.formats import LastUnderlined, Bold, Centered, Format data = [ {'a': 'Hello'}, {'a': 'World'} ] w = Writer('/tmp/test3.xlsx', header_formats=( Centered, Bold, LastUnderlined, Format({ 'font_color': 'red' })), data_formats=( Format({ 'font_color': 'green' }),) ) conv = Converter() conv.convert(data, w)
See https://xlsxwriter.readthedocs.io/format.html for details on formats in xlsxwriter
Column widths
Pass the required column widths to writer:
w = Writer('/tmp/test3.xlsx', column_widths={ 'a': 20 })
Width of nested data can be specified as well:
data = [ {'a': {'b': 1, 'c': 2}} ] w = Writer('/tmp/test3.xlsx', column_widths={ 'a.b': 20, 'a.c': 30, })

To set the default column width, pass it as DEFAULT_COLUMN_WIDTH property:
w = Writer('/tmp/test3.xlsx', column_widths={ DEFAULT_COLUMN_WIDTH: 20 })
Row heights
Row heights can be specified via the row_heights writer option:
w = Writer('/tmp/test3.xlsx', row_heights={ DEFAULT_ROW_HEIGHT: 20, # a bit taller rows 1: 40 # extra tall header })
Urls

To render url, pass a function that gets data of a row and returns url to options
data = [ {'a': 'https://google.com'}, ] options = Options() options['a'].url = lambda data: data['a'] conv = Converter(options) conv.convert(data, w)
Note: this will only be rendered in XLSX output, CSV output will silently
ignore the link.
Custom cell rendering
Override the write_cell method. The method receives cell_data
(instance of json_excel_converter.Value) and data (the original
data being written to this row). Note that this method is used both
for writing header and rows — for header the data parameter is None.
class UrlWriter(Writer): def write_cell(self, row, col, cell_data, cell_format, data): if cell_data.path == 'a' and data: self.sheet.write_url(row, col, 'https://test.org/' + data['b'], string=cell_data.value) else: super().write_cell(row, col, cell_data, cell_format, data)
Does anyone know how can I convert JSON to XLS in Python?
I know that it is possible to create xls files using the package xlwt in Python.
What if I want to convert a JSON data file to XLS file directly?
Is there a way to archive this?
![]()
Luke
1352 silver badges11 bronze badges
asked Mar 13, 2013 at 7:21
![]()
2
Using pandas (0.15.1) and openpyxl (1.8.6):
import pandas
pandas.read_json("input.json").to_excel("output.xlsx")
answered Apr 12, 2016 at 22:23
![]()
Bruno LopesBruno Lopes
2,9071 gold badge27 silver badges38 bronze badges
1
If your json file is stored in some directory then,
import pandas as pd
pd.read_json("/path/to/json/file").to_excel("output.xlsx")
If you have your json within the code then, you can simply use DataFrame
json_file = {'name':["aparna", "pankaj", "sudhir", "Geeku"],'degree': ["MBA", "BCA", "M.Tech", "MBA"],'score':[90, 40, 80, 98]}
df = pd.DataFrame(json_file).to_excel("excel.xlsx")
answered Apr 3, 2020 at 11:23
![]()
laplacelaplace
5666 silver badges15 bronze badges
1
In case someone wants to do output to Excel as a stream using Flask-REST
Pandas versions:
json_payload = request.get_json()
with NamedTemporaryFile(suffix='.xlsx') as tmp:
pandas.DataFrame(json_payload).to_excel(tmp.name)
buf = BytesIO(tmp.read())
response = app.make_response(buf.getvalue())
response.headers['content-type'] = 'application/octet-stream'
return response
and OpenPyXL version:
keys = []
wb = Workbook()
ws = wb.active
json_data = request.get_json()
with NamedTemporaryFile() as tmp:
for i in range(len(json_data)):
sub_obj = json_data[i]
if i == 0:
keys = list(sub_obj.keys())
for k in range(len(keys)):
ws.cell(row=(i + 1), column=(k + 1), value=keys[k]);
for j in range(len(keys)):
ws.cell(row=(i + 2), column=(j + 1), value=sub_obj[keys[j]]);
wb.save(tmp.name)
buf = BytesIO(tmp.read())
response = app.make_response(buf.getvalue())
response.headers['content-type'] = 'application/octet-stream'
return response
answered Jun 22, 2020 at 22:39
![]()
JackTheKnifeJackTheKnife
3,6076 gold badges54 silver badges109 bronze badges
In this Pandas tutorial, we will learn how to export JSON to Excel in Python. This guide will cover 4 simple steps to make use of Python’s json module, the Python packages requests, and Pandas.
Outline
The structure of this tutorial is as follows. In the first section, we will look at a basic example of converting JSON to an Excel file with Pandas and Python. After we have seen and briefly learned, the syntax we will continue with a section covering some examples of when this knowledge may be useful. In the third section, we will look at the prerequisites of this Python tutorial and how to install Pandas. After we are sure we have everything needed, we will go through four steps on how to save JSON to Excel in Python. Here, we will start by reading the JSON file from the hard drive and saving it as an Excel file. Furthermore, we will also look at an example when reading JSON from a URL and saving it as a .xlsx file. Finally, we will also use the Python package JSON to Excel converter.
Basic Code Example to import JSON to Excel with Python
Here is the easiest way to convert JSON data to an Excel file using Python and Pandas:
import pandas as pd
df_json = pd.read_json(‘DATAFILE.json’)
df_json.to_excel(‘DATAFILE.xlsx’)Code language: Python (python)In the code chunk above, we use the pandas library to read data from a JSON file and save it to an Excel file. Here is a step-by-step explanation of the code:
- The first line of the code imports the pandas library and gives it the name “pd”. This library provides easy-to-use data structures and data analysis tools for Python.
- The second line reads the data from the JSON file ‘DATAFILE.json’ and creates a pandas DataFrame object called ‘df_json’. A DataFrame is a two-dimensional data table, similar to a spreadsheet or SQL table.
- The third line takes the DataFrame ‘df_json’ and saves it as an Excel file named ‘DATAFILE.xlsx’ using the ‘to_excel’ method of the DataFrame.
Conversion
In this section, the problem will be briefly formulated. Now, although we can work with data using only Python and its packages, we might collaborate with people that want to work in Excel. It is, of course, true that Microsoft Excel is packed with features to keep and organize tabular data. Furthermore, getting an overview of the data in Excel might also be easier. Now, a lot of open data resources are storing data in a variety of different file formats. But sometimes, we might find out that the data is stored in the JSON format only. In some cases, we might want to obtain data from JSON and save it to Excel and send it to our collaborators. Now, in other cases, we just want to explore data ourselves, as mentioned before, using Excel.
Despite it is possible to import JSON to Excel with Microsoft Excel itself, the optimal way is to automate the conversion by importing data from JSON to Excel worksheets programmatically. Especially, if we already know Python.
Prerequisites
In this section, you will learn what you need to have installed to convert JSON data to Excel files.
Obviously, to follow this guide you will need to have Python, requests, and Pandas installed. Secondly, and not that obvious maybe, you will also need to install the package openpyxl. This package is what will be used, by Pandas, to create Excel files (e.g., .xlsx).
Now, there is one very easy way to install both Python and Pandas: installing a Python scientific distribution such as Anaconda, ActivePython, or Canopy (see here for a list of Python distributions). For example, if you install Anaconda you will get a library with useful Python packages, including Pandas.
How to Install Pandas and openpyxl
If you already have Python installed, you can use pip to install Python packages. To install Pandas and openpyxl using pip open up Windows Command Prompt or the Terminal you prefer and type the following code:
pip install pandas openpyxlCode language: Bash (bash)Sometimes, pip will warn us that there’s a newer version. If this is the case now, read the post about upgrading pip for more information.
Note that it is generally a good idea to create a virtual environment and install your new packages in this environment. Now that you have all that you need, we will continue to the next section of this tutorial. If you use a tool such as pipx you can automatically install Python packages in virtual environments. Here’s a YouTube video on how to install Pandas and Anaconda:
As a final note, before converting JSON to Excel with Python: if you need, you can use pip to install specific version of Python packages.
4 Steps to Convert JSON to Excel in Python
In this section, we will go through, step-by-step, how to import JSON data and save it as an Excel file using Python. Here’s a summary of what this chapter will cover: 1) importing pandas and json, 2) reading the JSON data from a directory, 3) converting the data to a Pandas dataframe, and 4) using Pandas to_excel method to export the data to an Excel file.
1. Importing the Pandas and json Packages
First, we start by importing Pandas and json:
import json
import pandas as pdCode language: Python (python)Now, it may be evident, but we are importing json and then Pandas to use json to read the data from the file and, after we have done this, we will use Pandas to save it as a .xlsx file.
2. Reading the JSON file
Now, we are ready to import the data from a file using the load method:
with open('./SimData/save_to_excel.json') as json_file:
data = json.load(json_file)Code language: Python (python)As you can see in the code chunk above, we are first opening a file with Python (i.e., as json_file) with the with-statement. Moreover, in the with-statement, we are using the load method. This is when we are actually reading the JSON file.
3. Creating a Pandas Dataframe
Now, before we can save the data, we have imported we need to create a dataframe:
df = pd.DataFrame(data)Code language: Python (python)In the code chunk above, we used Pandas DataFrame class to create a dataframe from the JSON data we loaded into Python in the previous section. Basically, what we do is similar to converting a Python dictionary to a Pandas dataframe. Note, adding new columns to the dataframe, before saving it, is of course also possible.
4. Saving the Imported Data as a .xlsx File
Finally, we can use the to_excel method that is available in the dataframe object:
df.to_excel('./SimData/exported_json_data.xlsx')Code language: Python (python)Now, if we want to convert JSON data to other formats such as CSV, SPSS, or STATA to name a few we can use other methods available in the dataframe object. For example, if we want to save the JSON data to a CSV file we can use the to_csv method. If you are interested in learning more about reading and writing data files with Python and Pandas check out the following blog posts:
- How to Read and Write Excel Files with Pandas
- How to Read and Write Stata (.dta) Files in R with Haven
Now, it is worth mentioning here that we actually can skip step 2 and use Pandas read_json method to import the JSON data to a dataframe. Here’s a full working example of how to save JSON data with only the Pandas package:
import pandas as pd
df = pd.read_json('./SimData/save_to_excel.json')
df.to_excel('./SimData/exported_json_data.xlsx')Code language: Python (python)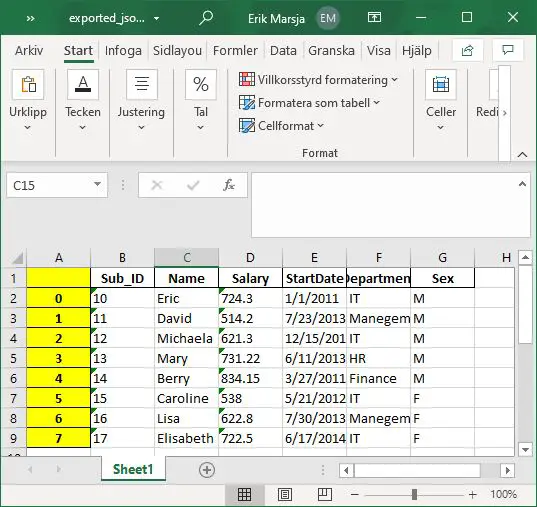
In the next section, we will look at how to read JSON data from a URL and save it as an Excel file.
JSON to Excel: Reading data from a URL
In the previous section, we learned, step-by-step, how to automatically convert JSON data to an Excel file in Python. Here, we will use the same steps, but we will read the data from a URL. First, we will look at a simple example where we can use the same code as above. However, we will change the string so that it is pointing at the URL location instead of a directory.
import pandas as pd
df = pd.read_json('http://api.open-notify.org/iss-now.json')
df.to_excel('locationOfISS.xlsx')Code language: Python (python)As you can see, we managed to read this JSON file with Python and save it as an Excel file using Pandas. In the next section, we will look at a more complex JSON file where the data is nested.
Nested JSON data to Excel
In this section, we will look at a bit more complex example. Now, sometimes the JSON data is nested, and if we use the method above, the Excel file will be messy. Luckily, we can fix this by using json_normalize from Pandas and the requests module:
import requests
from pandas.io.json import json_normalize
url = "https://think.cs.vt.edu/corgis/datasets/json/airlines/airlines.json"
resp = requests.get(url=url)
df = json_normalize(resp.json())
# Writing Excel File:
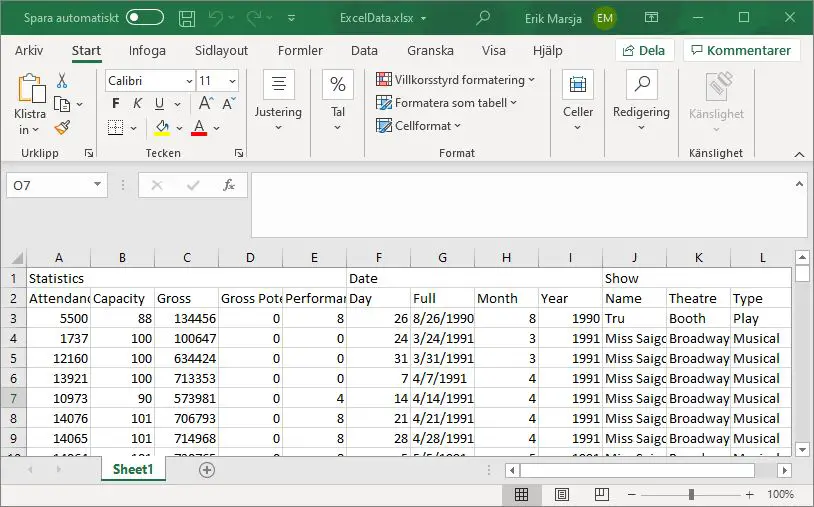
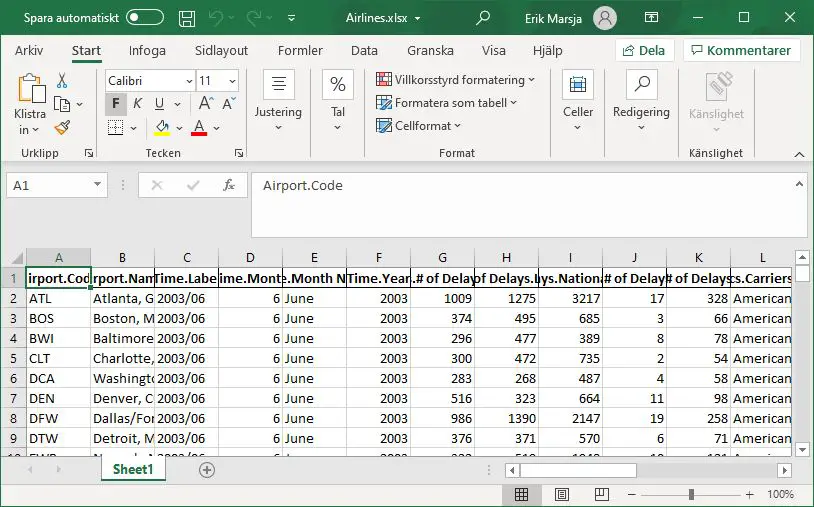
df.to_excel('Airlines.xlsx')Code language: Python (python)In the code chunk above, we first imported requests and then json_normalize. Second, we created a string with the URL to the JSON data we want to save as an Excel file. Now, the next thing we do is to use the get method, which sends a GET request to our URL. Briefly, this is pretty much reading in the webpage that we want, and we can, then, use the json method to get the json data. Finally, we used the json_normalize to create a dataframe that we saved as an Excel file. Again, saving the data we read from the JSON file is done using the to_excel method.
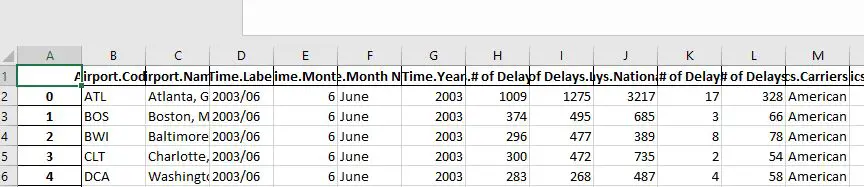
Now, as you may have noticed in the image of the output (i.e., the .xlsx files opened in Excel) we have a row that is not part of our original data. This row is the index row from the Pandas dataframe and we can, of course, get rid of this. In the next section, we will look at some of the arguments of the to_excel method. For example, if we want to get rid of the index row, we will learn how to do that. If you are interested check out the tutorial on how to read and write JSON with Python and Pandas.
Import JSON to Excel and Specifying the Sheet Name
This section will specify the sheet name using the sheet_name argument. Now, the string we input will be the name of the Worksheet in the Excel file:
df.to_excel('Airlines.xlsx', sheet_name='Session1')Code language: Python (python)In the example code above, we named the sheet ‘Session1’. However, we still can see the index column in the Excel file. In the next section, we will have a look on how to remove this index.
JSON to Excel with Pandas Removing the Index Column
To remove the index column when converting JSON to Excel using Pandas we use the index argument:
df.to_excel('Airlines.xlsx', index=False)Code language: Python (python)Now, this argument takes a bool (True/False), and the default is True. Thus, in the code example above, we set it to False, and we get this Excel file:
Of course, there are plenty of more arguments that we could use when converting JSON to Excel with Pandas. For instance, we can set the encoding of the excel file. Another thing we can do is to set the engine: openpyxl or xlsxwriter. Note, to use the to_excel method to save the JSON file to an Excel file you need to have one of them installed on your computer (see the previous section). See the documentation for more information on how to use the arguments of the to_excel method.
Other Options: the JSON to excel converter Package
Now, there are, of course, other methods and/or Python packages that we can use to convert JSON to Excel in Python. For example, we could work with the json module and choosing one of xlsxwriter or openpyxl packages. It is worth noting, however, that the resulting Python script will be a bit more complex. Furthermore, there is a Python package created just for the purpose of converting JSON to Excel: JSON to excel converter.
JSON to Excel with the JSON to Excel converter package
Here’s a how-to quickly convert JSON to a .xlsx file:
from json_excel_converter import Converter
from json_excel_converter.xlsx import Writer
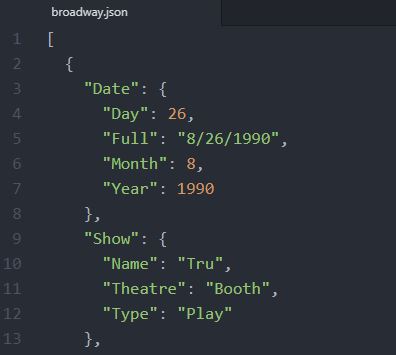
url = 'https://think.cs.vt.edu/corgis/datasets/json/broadway/broadway.json'
resp = requests.get(url=url)
conv = Converter()
conv.convert(resp.json(), Writer(file='./SimData/ExcelData.xlsx'))Code language: Python (python)This package is straightforward to use. In the example code above, we converted the airlines.json data to an Excel file. Remember, this data is nested, and one very neat thing with the JSON to Excel converter package is that it can handle this very nicely (see the image below for the resulting Excel file).
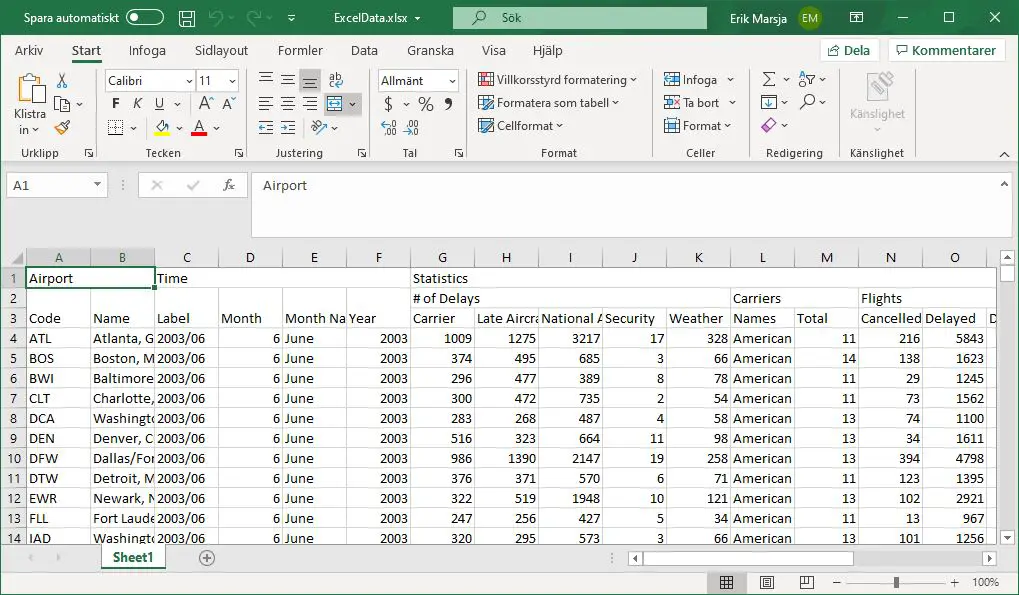
Note, however, that you need to install the xlsxwriter package to be able to use the JSON to excel converter. Both can be installed using pip: pip install json-excel-converter[xlsxwriter].
Conclusion
In this post, we have covered a lot of things related to opening JSON files and saving them as Excel files using Python. Certainly, knowing how to convert JSON data to Excel files might be useful in many situations. For instance, if we are getting the data and collaborating with someone who prefers using Excel. To summarize, in this tutorial, we have used the Python packages Pandas, json, requests, and JSON to Excel converter to read JSON files and save them as Excel files. First, we had a quick look at the syntax, then we learned four steps to convert JSON to Excel. After that, we also learned how to read the JSON data from a URL and how to work a bit with some of the arguments of the to_excel method.
Hopefully, you learned something from this Python tutorial, and if you did find it useful: please do share it on your social media accounts. Finally, if you want to learn anything, please leave a comment below, and I might put that together in a new tutorial.
A package that converts json to CSV, excel or other table formats
- JSON to excel converter
- Sample output
- Simple json
- Nested json
- json with array property
- Installation
- Usage
- Simple usage
- Streaming usage with restarts
- Arrays
- XLSX Formatting
- Cell format
- Column widths
- Row heights
- Urls
- Custom cell rendering
- Sample output
Sample output
Simple json
[ { "col1": "val1", "col2": "val2" } ]
the generated CSV/excel is:
col1 col2
==================
val1 val2
Nested json
[ { "col1": "val1", "col2": { "col21": "val21", "col22": "val22" } } ]
the generated CSV/excel is (in excel, col2 spans two cells horizontally):
col1 col2
col21 col22
=================================
val1 val21 val22
json with array property
[ { "col1": "val1", "col2": [ { "col21": "val21" }, { "col21": "val22" } ] } ]
the generated CSV/excel is (in excel, col2 spans two cells horizontally):
col1 col2
col21 col21
=================================
val1 val21 val22
Installation
pip install json-excel-converter[extra]
where extra is:
xlsxwriterto use the xlsxwriter
Usage
Simple usage
from json_excel_converter import Converter from json_excel_converter.xlsx import Writer data = [ {'a': [1], 'b': 'hello'}, {'a': [1, 2, 3], 'b': 'world'} ] conv = Converter() conv.convert(data, Writer(file='/tmp/test.xlsx'))
Streaming usage with restarts
from json_excel_converter import Converter, LinearizationError from json_excel_converter.csv import Writer conv = Converter() writer = Writer(file='/tmp/test.csv') while True: try: data = get_streaming_data() # custom function to get iterator of data conv.convert_streaming(data, writer) break except LinearizationError: pass
Arrays
When the first row is processed, the library guesses the columns layout. In case of arrays,
a column (or more columns if the array contains json objects) is created for each
of the items in the array, as shown in the example above.
On subsequent rows the array might contain more items. The library reacts by adjusting
the number of columns in the layout and raising LinearizationError as previous rows might
be already output.
Converter.convert_streaming just raises this exception — it is the responsibility of caller
to take the right action.
Converter.convert captures this error and restarts the processing. In case of CSV
this means truncating the output file to 0 bytes and processing the data again. XLSX writer
caches all the data before writing them to excel so the restart just means discarding the cache.
If you know the size of the array in advance, you should pass it in options. Then no
processing restarts are required and LinearizationError is not raised.
from json_excel_converter import Converter, Options from json_excel_converter.xlsx import Writer data = [ {'a': [1]}, {'a': [1, 2, 3]} ] options = Options() options['a'].cardinality = 3 conv = Converter(options=options) writer = Writer(file='/tmp/test.xlsx') conv.convert(data, writer) # or conv.convert_streaming(data, writer) # no exception occurs here
XLSX Formatting
Cell format
XLSX writer enables you to format the header and data by passing an array of header_formatters or
data_formatters. Take these from json_excel_converter.xlsx.formats package or create your own.
from json_excel_converter import Converter from json_excel_converter.xlsx import Writer from json_excel_converter.xlsx.formats import LastUnderlined, Bold, Centered, Format data = [ {'a': 'Hello'}, {'a': 'World'} ] w = Writer('/tmp/test3.xlsx', header_formats=( Centered, Bold, LastUnderlined, Format({ 'font_color': 'red' })), data_formats=( Format({ 'font_color': 'green' }),) ) conv = Converter() conv.convert(data, w)
See https://xlsxwriter.readthedocs.io/format.html for details on formats in xlsxwriter
Column widths
Pass the required column widths to writer:
w = Writer('/tmp/test3.xlsx', column_widths={ 'a': 20 })
Width of nested data can be specified as well:
data = [ {'a': {'b': 1, 'c': 2}} ] w = Writer('/tmp/test3.xlsx', column_widths={ 'a.b': 20, 'a.c': 30, })
To set the default column width, pass it as DEFAULT_COLUMN_WIDTH property:
w = Writer('/tmp/test3.xlsx', column_widths={ DEFAULT_COLUMN_WIDTH: 20 })
Row heights
Row heights can be specified via the row_heights writer option:
w = Writer('/tmp/test3.xlsx', row_heights={ DEFAULT_ROW_HEIGHT: 20, # a bit taller rows 1: 40 # extra tall header })
Urls
To render url, pass a function that gets data of a row and returns url to options
data = [ {'a': 'https://google.com'}, ] options = Options() options['a'].url = lambda data: data['a'] conv = Converter(options) conv.convert(data, w)
Note: this will only be rendered in XLSX output, CSV output will silently
ignore the link.
Custom cell rendering
Override the write_cell method. The method receives cell_data
(instance of json_excel_converter.Value) and data (the original
data being written to this row). Note that this method is used both
for writing header and rows — for header the data parameter is None.
class UrlWriter(Writer): def write_cell(self, row, col, cell_data, cell_format, data): if cell_data.path == 'a' and data: self.sheet.write_url(row, col, 'https://test.org/' + data['b'], string=cell_data.value) else: super().write_cell(row, col, cell_data, cell_format, data)
In this tutorial, we are going to learn how to import JSON data into an Excel spreadsheet using Python.
JSON Data Generator: https://next.json-generator.com/V1okdXgst
XlsxWriter: https://xlsxwriter.readthedocs.io/
PS: To interact with an Excel spreadsheet, I will be using win32com Python library, which is Windows only.
Buy Me a Coffee? Your support is much appreciated!
PayPal Me: https://www.paypal.me/jiejenn/5
Venmo: @Jie-Jen
Source Code:
from pprint import pprint
import os
import json
import win32com.client as win32 # pip install pywin32
"""
Step 1.1 Read the JSON file
"""
json_data = json.loads(open('data.json').read())
pprint(json_data)
"""
Step 1.2 Examing the data and flatten the records into a 2D layout
"""
rows = []
for record in json_data:
id = record['_id']
is_active = record['isActive']
email = record['email']
balance = record['balance']
first_name = record['name']['first']
last_name = record['name']['last']
tags = ','.join(record['tags'])
friends = '; '.join(['Id: {0}, name: {1}'.format(friend['id'], friend['name']) for friend in record['friends']]).strip()
rows.append([id, is_active, email, balance, first_name, last_name, tags, friends])
"""
Step 2. Inserting Records to an Excel Spreadsheet
"""
ExcelApp = win32.Dispatch('Excel.Application')
ExcelApp.Visible = True
wb = ExcelApp.Workbooks.Add()
ws = wb.Worksheets(1)
header_labels = ('id', 'is active', 'email', 'balance', 'first name', 'last name', 'tags', 'friends')
# insert header labels
for indx, val in enumerate(header_labels):
ws.Cells(1, indx + 1).Value = val
# insert Records
row_tracker = 2
column_size = len(header_labels)
for row in rows:
ws.Range(
ws.Cells(row_tracker, 1),
ws.Cells(row_tracker, column_size)
).value = row
row_tracker += 1
wb.SaveAs(os.path.join(os.getcwd(), 'Json output.xlsx'), 51)
wb.Close()
ExcelApp.Quit()
ExcelApp = None
Need: There is a JSON file, want to turn to an Excel form file
Workaround: Pandas
step:
PIP to install Pandas
At this time INFO2.json file content is:
{"time": "20210722", "name": "James", "age": "12"}
Our code is:
import pandas as pd
df = pd.read_json("info2.json")
df.to_excel("info.xlsx")
After execution, the error is as follows:
ValueError: If using all scalar values, you must pass an index

Solution:
import pandas as pd
df = pd.read_json("info2.json", typ="series")
df.to_excel("info.xlsx")
The results are as follows:

Next question, if you are multi line, what should I deal with?
Due to my handling habits:
The Info2.json format is as follows:
{"time1": "20210722", "name": "James", "age": "12"}
{"time1": "20210721", "name": "Kobe", "age": "13"}
We continue to perform the above code (regardless of the TYP = «Series») report:
ValueError: Trailing data
Solution:
import pandas as pd
df = pd.read_json("info2.json", lines=True)
df.to_excel("info.xlsx")
The results are as follows:

Perfect manual ~
oarepo / json-excel-converter
Goto Github
PK
View Code? Open in Web Editor
NEW
6.0
8.0
164 KB
A python library to convert an array or stream of JSONs into CSV or Excel. Currently beta, use at your own risk
License: MIT License
excel
csv
python
xlsxwriter
json-excel-converter’s Introduction
A package that converts json to CSV, excel or other table formats
- JSON to excel converter
- Sample output
- Simple json
- Nested json
- json with array property
- Installation
- Usage
- Simple usage
- Streaming usage with restarts
- Arrays
- XLSX Formatting
- Cell format
- Column widths
- Row heights
- Urls
- Custom cell rendering
- Sample output
Sample output

Simple json
[
{
"col1": "val1",
"col2": "val2"
}
]
the generated CSV/excel is:
col1 col2
==================
val1 val2
Nested json
[
{
"col1": "val1",
"col2": {
"col21": "val21",
"col22": "val22"
}
}
]
the generated CSV/excel is (in excel, col2 spans two cells horizontally):
col1 col2
col21 col22
=================================
val1 val21 val22
json with array property
[
{
"col1": "val1",
"col2": [
{
"col21": "val21"
},
{
"col21": "val22"
}
]
}
]
the generated CSV/excel is (in excel, col2 spans two cells horizontally):
col1 col2
col21 col21
=================================
val1 val21 val22
Installation
pip install json-excel-converter[extra]
where extra is:
xlsxwriterto use the xlsxwriter
Usage
Simple usage
from json_excel_converter import Converter from json_excel_converter.xlsx import Writer data = [ {'a': [1], 'b': 'hello'}, {'a': [1, 2, 3], 'b': 'world'} ] conv = Converter() conv.convert(data, Writer(file='/tmp/test.xlsx'))
Streaming usage with restarts
from json_excel_converter import Converter, LinearizationError from json_excel_converter.csv import Writer conv = Converter() writer = Writer(file='/tmp/test.csv') while True: try: data = get_streaming_data() # custom function to get iterator of data conv.convert_streaming(data, writer) break except LinearizationError: pass
Arrays
When the first row is processed, the library guesses the columns layout. In case of arrays,
a column (or more columns if the array contains json objects) is created for each
of the items in the array, as shown in the example above.
On subsequent rows the array might contain more items. The library reacts by adjusting
the number of columns in the layout and raising LinearizationError as previous rows might
be already output.
Converter.convert_streaming just raises this exception — it is the responsibility of caller
to take the right action.
Converter.convert captures this error and restarts the processing. In case of CSV
this means truncating the output file to 0 bytes and processing the data again. XLSX writer
caches all the data before writing them to excel so the restart just means discarding the cache.
If you know the size of the array in advance, you should pass it in options. Then no
processing restarts are required and LinearizationError is not raised.
from json_excel_converter import Converter, Options from json_excel_converter.xlsx import Writer data = [ {'a': [1]}, {'a': [1, 2, 3]} ] options = Options() options['a'].cardinality = 3 conv = Converter(options=options) writer = Writer(file='/tmp/test.xlsx') conv.convert(data, writer) # or conv.convert_streaming(data, writer) # no exception occurs here
XLSX Formatting
Cell format
XLSX writer enables you to format the header and data by passing an array of header_formatters or
data_formatters. Take these from json_excel_converter.xlsx.formats package or create your own.
from json_excel_converter import Converter from json_excel_converter.xlsx import Writer from json_excel_converter.xlsx.formats import LastUnderlined, Bold, Centered, Format data = [ {'a': 'Hello'}, {'a': 'World'} ] w = Writer('/tmp/test3.xlsx', header_formats=( Centered, Bold, LastUnderlined, Format({ 'font_color': 'red' })), data_formats=( Format({ 'font_color': 'green' }),) ) conv = Converter() conv.convert(data, w)
See https://xlsxwriter.readthedocs.io/format.html for details on formats in xlsxwriter
Column widths
Pass the required column widths to writer:
w = Writer('/tmp/test3.xlsx', column_widths={ 'a': 20 })
Width of nested data can be specified as well:
data = [ {'a': {'b': 1, 'c': 2}} ] w = Writer('/tmp/test3.xlsx', column_widths={ 'a.b': 20, 'a.c': 30, })

To set the default column width, pass it as DEFAULT_COLUMN_WIDTH property:
w = Writer('/tmp/test3.xlsx', column_widths={ DEFAULT_COLUMN_WIDTH: 20 })
Row heights
Row heights can be specified via the row_heights writer option:
w = Writer('/tmp/test3.xlsx', row_heights={ DEFAULT_ROW_HEIGHT: 20, # a bit taller rows 1: 40 # extra tall header })
Urls

To render url, pass a function that gets data of a row and returns url to options
data = [ {'a': 'https://google.com'}, ] options = Options() options['a'].url = lambda data: data['a'] conv = Converter(options) conv.convert(data, w)
Note: this will only be rendered in XLSX output, CSV output will silently
ignore the link.
Custom cell rendering
Override the write_cell method. The method receives cell_data
(instance of json_excel_converter.Value) and data (the original
data being written to this row). Note that this method is used both
for writing header and rows — for header the data parameter is None.
class UrlWriter(Writer): def write_cell(self, row, col, cell_data, cell_format, data): if cell_data.path == 'a' and data: self.sheet.write_url(row, col, 'https://test.org/' + data['b'], string=cell_data.value) else: super().write_cell(row, col, cell_data, cell_format, data)
json-excel-converter’s People
Contributors

json-excel-converter’s Issues
Implement UI for selecting columns that should be exported
Attribute Error message
Hi there, I am following a simple use scenario / test on Python3 and get this error:
Traceback (most recent call last):
File «/Users/xxx/Documents/Projects/my_tools/utilty_json/convert_json_to_excel.py», line 43, in
conv.convert(data, writer)
File «/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/json_excel_converter/converter.py», line 14, in convert
self.convert_streaming(data, writer)
File «/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/json_excel_converter/converter.py», line 24, in convert_streaming
errors = self.conv.check(d)
File «/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/json_excel_converter/linearize.py», line 192, in check
for k in value.keys():
AttributeError: ‘str’ object has no attribute ‘keys’
Any help in this would be appreciated!
Write data to an existing file, in a new sheet
Hello,
I’d like to know if it’s possible with this library to write the data to a new sheet in an existing file.
Thanks
matrix «writer» — to produce native py matrix
that would allow incorporating tool in variuos contexts — for example I have openpyxl workflow, where I’d like to use it
also could be proxy for #6
Unable to set Row Height and Column Width while creating Excel files
Hi,
Problem :
I was unable to set Row Height and Column Width while creating Excel files. It was throwing following error : Object of type TypeError is not JSON serializable
Solution :
So later i was able to resolve by changing DEFAULT_COLUMN_WIDTH and DEFAULT_ROW_HEIGHT as a string in the json-excel-converter library file.
So just want to know is it correct or do we need to make other changes ?
Stay Safe and Take Care
Thanks in advance
Integrate travis with pypi
when span > 2 ,open execl file will be error
| if cell_data.columns > 1 or cell_data.span > 1: |
when span >2 , merge_range(L197) will merge multiple times, generated execl can’t open.
this json data convert to execl will be open with a error.
[
{
«col1»: «val1»,
«col2»: [
{
«col21»: {«col31»: «val3»}
},
{
«col21»: {}
}
]
}
]
fix method:
json_excel_converter/xlsx/init.py#L179:
if cell_data.columns > 1 or cell_data.span > 1:
change to :
if (cell_data.columns > 1 or cell_data.span > 1) and cell_data.value != »:
Json Issue
Hi Team
when i use the json file below it is flat mapping everything rather than organized in different lines.
sample Json:
{«status»:»success»,»data»:[{«id»:»1″,»employee_name»:»Tiger Nixon»,»employee_salary»:»320800″,»employee_age»:»61″,»profile_image»:»»},
{«id»:»2″,»employee_name»:»Garrett Winters»,»employee_salary»:»170750″,»employee_age»:»63″,»profile_image»:»»},
{«id»:»3″,»employee_name»:»Ashton Cox»,»employee_salary»:»86000″,»employee_age»:»66″,»profile_image»:»»},
{«id»:»4″,»employee_name»:»Cedric Kelly»,»employee_salary»:»433060″,»employee_age»:»22″,»profile_image»:»»},
{«id»:»5″,»employee_name»:»Airi Satou»,»employee_salary»:»162700″,»employee_age»:»33″,»profile_image»:»»},
{«id»:»6″,»employee_name»:»Brielle Williamson»,»employee_salary»:»372000″,»employee_age»:»61″,»profile_image»:»»},
{«id»:»7″,»employee_name»:»Herrod Chandler»,»employee_salary»:»137500″,»employee_age»:»59″,»profile_image»:»»},
{«id»:»8″,»employee_name»:»Rhona Davidson»,»employee_salary»:»327900″,»employee_age»:»55″,»profile_image»:»»},
{«id»:»9″,»employee_name»:»Colleen Hurst»,»employee_salary»:»205500″,»employee_age»:»39″,»profile_image»:»»},
{«id»:»10″,»employee_name»:»Sonya Frost»,»employee_salary»:»103600″,»employee_age»:»23″,»profile_image»:»»},
{«id»:»11″,»employee_name»:»Jena Gaines»,»employee_salary»:»90560″,»employee_age»:»30″,»profile_image»:»»},
{«id»:»12″,»employee_name»:»Quinn Flynn»,»employee_salary»:»342000″,»employee_age»:»22″,»profile_image»:»»},
{«id»:»13″,»employee_name»:»Charde Marshall»,»employee_salary»:»470600″,»employee_age»:»36″,»profile_image»:»»},
{«id»:»14″,»employee_name»:»Haley Kennedy»,»employee_salary»:»313500″,»employee_age»:»43″,»profile_image»:»»},
{«id»:»15″,»employee_name»:»Tatyana Fitzpatrick»,»employee_salary»:»385750″,»employee_age»:»19″,»profile_image»:»»},
{«id»:»16″,»employee_name»:»Michael Silva»,»employee_salary»:»198500″,»employee_age»:»66″,»profile_image»:»»},
{«id»:»17″,»employee_name»:»Paul Byrd»,»employee_salary»:»725000″,»employee_age»:»64″,»profile_image»:»»},
{«id»:»18″,»employee_name»:»Gloria Little»,»employee_salary»:»237500″,»employee_age»:»59″,»profile_image»:»»},
{«id»:»19″,»employee_name»:»Bradley Greer»,»employee_salary»:»132000″,»employee_age»:»41″,»profile_image»:»»},
{«id»:»20″,»employee_name»:»Dai Rios»,»employee_salary»:»217500″,»employee_age»:»35″,»profile_image»:»»},
{«id»:»21″,»employee_name»:»Jenette Caldwell»,»employee_salary»:»345000″,»employee_age»:»30″,»profile_image»:»»},
{«id»:»22″,»employee_name»:»Yuri Berry»,»employee_salary»:»675000″,»employee_age»:»40″,»profile_image»:»»},
{«id»:»23″,»employee_name»:»Caesar Vance»,»employee_salary»:»106450″,»employee_age»:»21″,»profile_image»:»»},
{«id»:»24″,»employee_name»:»Doris Wilder»,»employee_salary»:»85600″,»employee_age»:»23″,»profile_image»:»»}]}
Thanks
Harsha
write to a pandas dataframe?
I was able to use the following line as expected.
conv = Converter()
conv.convert(res["hits"]["hits"], Writer(file="test.xlsx"))
That was nice. But I will prefer to write to a pandas dataframe. Something like this?
conv.convert(res["hits"]["hits"], Writer(df)
I can open excel file using pandas like this…
df = pd.read_excel("test.xlsx", header=list(range(9)), parse_dates=True)
But in this case, I need to find out the number of rows where the header is written. The «conv» object already knows it and can convert into multi-level column header in pandas.
MS Excel is a feature-rich tool that allows you to keep and organise tabular data. It also lets you to store data in several worksheets. Aside from data management, you may also perform sorting, graph charting, mathematical operations, and so on. JSON, on the other hand, is a popular format for storing and transmitting data in key-value pairs. In some circumstances, you may need to dynamically import data from JSON files into Excel workbooks. In line with that, this post will show you how to use Python to convert JSON data to Excel XLSX/XLS.
What do you mean by JSON Array?
JSON (JavaScript Object Notation) is a dictionary-like notation that may be utilized in Python by importing the JSON module. Every record (or row) is preserved as its own dictionary, with the column names serving as the dictionary’s Keys. To make up the whole dataset, all of these records are kept as dictionaries in a nested dictionary. It is saved together with the extension. geeksforgeeks.json
JSON format was actually based on a subset of JavaScript. It is, nevertheless, referred to as a language-independent format, and it is supported by a wide range of programming APIs. In most cases, JSON is used in Ajax Web Application Programming. Over the last few years, the popularity of JSON as an alternative to XML has gradually increased.
While many programs use JSON for data transfer, they may not keep JSON format files on their hard drive. Data is exchanged between computers that are linked via the Internet.
Example:
{
"Name":"Vikram",
"Branch":"Cse",
"year":2019,
"gpa":[
9.1,
9.5,
9.6,
9.2
]
}
Converting JSON to Excel Using Pandas in Python
Below are the methods to convert JSON file to an Excel file:
- Using Pandas Library
- Converting from JSON TO Excel without Index:
- Changing the Sheet Name
- Using JSON to Excel Converter Package
Method #1: Using Pandas Library
samplejsonfile.json:
{
"Websites":[
"SheetsTips",
"PythonPrograms",
"BtechGeeks",
"PythonArray",
"SheetsTips",
"PythonPrograms",
"BtechGeeks",
"PythonArray"
],
"Author Name":[
"Vikram",
"Ashritha",
"Manish",
"Anish",
"Pavan",
"Vishal",
"Akash",
"Ramika"
],
"Id":[
2114,
2345,
1234,
1382,
1912,
1573,
2456,
2744
],
"Gender":[
"Male",
"Female",
"Male",
"Male",
"Male",
"Male",
"Male",
"Female"
],
"State":[
"Telangana",
"Mumbai",
"Madhya Pradesh",
"Andaman and Nicobar Islands",
"Jammu and Kashmir",
"Uttar pradesh",
"Bihar",
"Andhra Pradesh"
],
"pincode":[
500014,
400001,
482001,
380001,
815353,
221712,
234113,
478583
]
}
Step#1: Importing Modules
# Import json module using the import keyword import json # Import pandas module using the import keyword import pandas as pd
Step#2: Loading the JSON File
Here we read the JSON file by specifying the location/path of the json file. Since I am using google colab here, I have uploaded a samplejsonfile.json and directly using the file name.
You can also specify the JSON file path directly, regardless of where it exists on your system.
# Open JSon file using the open() function by passing the filepath as an argument to it
with open('samplejsonfile.json') as gvn_jsonfile:
# Load/ Read the json data of the corresponding file using the load() function
# of the json module and store it in a variable
json_data = json.load(gvn_jsonfile)
Or we can also use read_json() function of the pandas module to read the JSON File. This is simple as compared to the above one. You can use either of the methods.
# Pass the json file name as an argument to the read_json() function of the
# pandas module to read the json file and store it in a variable
json_data = pd.read_json('samplejsonfile.json')
Step#3: Create a Pandas Dataframe
# Pass the above json data as an argument to the DataFrame() function of the # pandas(pd as alias name) module to create a dataframe # Store it in another variable datafrme = pd.DataFrame(json_data)
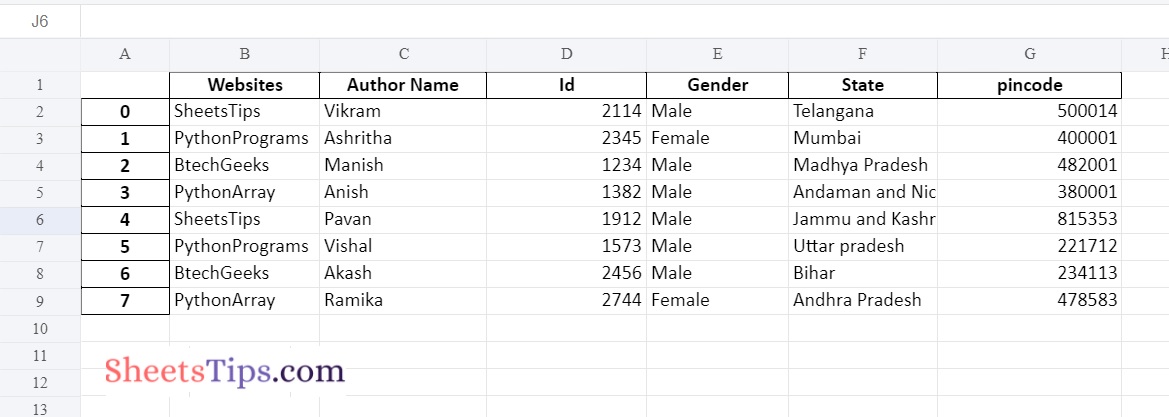
Step#4: Converting JSON Data to Excel File and Saving it
Here, we use the to_excel() method of the dataframe object to convert it into an excel file.
# Apply to_excel() function on the above dataframe to convert the given json data file
# into an excel file and save the output excel with some random name.
datafrme.to_excel('OutputExcelFile.xlsx')
Now, we can use the dataframe object’s various methods to convert JSON data to other formats such as CSV, SPSS, or STATA, to name a few. To save JSON data to a CSV file, for example, we can use the to_csv method.
Complete Code
Approach:
- Import json module using the import keyword
- Import pandas module using the import keyword
- Pass the json file name as an argument to the read_json() function of the pandas module to read the json file and store it in a variable
- Pass the above json data as an argument to the DataFrame() function of the pandas(pd as alias name) module to create a dataframe
- Store it in another variable
- Apply to_excel() function on the above dataframe to convert the given json data file
into an excel file and save the output excel with some random name. - The Exit of the Program.
Below is the implementation:
# Import json module using the import keyword
import json
# Import pandas module using the import keyword
import pandas as pd
# Pass the json file name as an argument to the read_json() function of the
# pandas module to read the json file and store it in a variable
json_data = pd.read_json('samplejsonfile.json')
# Pass the above json data as an argument to the DataFrame() function of the
# pandas(pd as alias name) module to create a dataframe
# Store it in another variable
datafrme = pd.DataFrame(json_data)
# Apply to_excel() function on the above dataframe to convert the given json data file
# into an excel file and save the output excel with some random name.
datafrme.to_excel('OutputExcelFile.xlsx')
Output:
Converting from JSON TO Excel without Index:
Approach:
- Import JSON module using the import keyword.
- Import pandas module using the import keyword.
- Pass the JSON file name as an argument to the read_json() function of the pandas module to read the JSON file and store it in a variable.
- Pass the above JSON data as an argument to the DataFrame() function of the pandas(pd as alias name) module to create a data frame.
- Store it in another variable.
- Apply to_excel() function on the above data frame to convert the given JSON data file into an excel file and save the output excel with some random name.
- Pass the index as False such that we can remove the indexes from the excel file.
- The Exit of the Program.
Below is the implementation of the above approach:
# Import json module using the import keyword
import json
# Import pandas module using the import keyword
import pandas as pd
# Pass the json file name as an argument to the read_json() function of the
# pandas module to read the json file and store it in a variable
json_data = pd.read_json('samplejsonfile.json')
# Pass the above json data as an argument to the DataFrame() function of the
# pandas(pd as alias name) module to create a dataframe
# Store it in another variable
datafrme = pd.DataFrame(json_data)
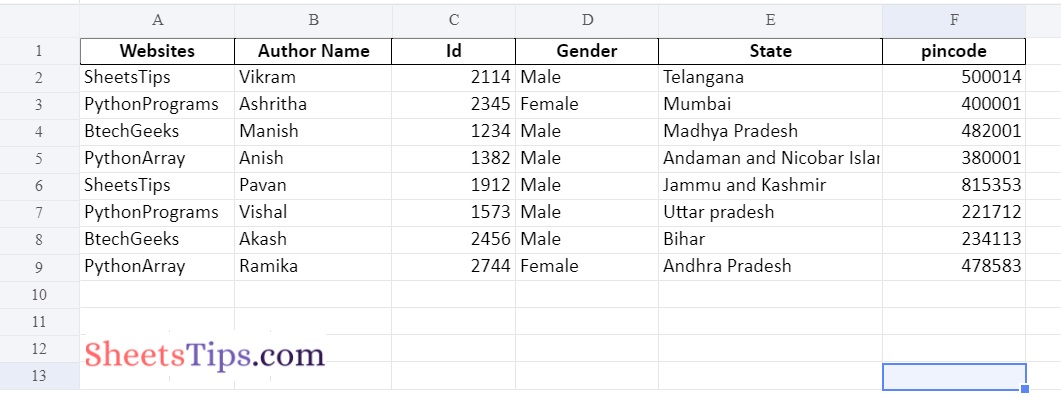
# Apply to_excel() function on the above dataframe to convert the given json data file
# into an excel file and save the output excel with some random name.
# Pass the index as False such that we can remove the indexes from the excel file
datafrme.to_excel('OutputExcelFileWithoutIndex.xlsx',index=False)
Output:
Explanation:
Here by passing index=False as an argument to the to_excel() function we can remove the indexes from the excel file while saving it
Changing the Sheet Name
We can modify the sheet name to any other name we want using the “sheet_name” argument by assigning whatever name we want to it.
The default sheet name is Sheet1, Sheet2,…..
Approach:
- Import JSON module using the import keyword
- Import pandas module using the import keyword
- Pass the JSON file name as an argument to the read_json() function of the pandas module to read the JSON file and store it in a variable.
- Pass the above JSON data as an argument to the DataFrame() function of the pandas(pd as alias name) module to create a data frame.
- Store it in another variable.
- Apply to_excel() function on the above data frame to convert the given JSON data file into an excel file and save the output excel with some random name.
- Pass the index as False such that we can remove the indexes from the excel file.
- Here by using the argument sheet_name we can give any other sheet name we want.
- The Exit of the Program.
Below is the implementation of the above approach:
# Import json module using the import keyword
import json
# Import pandas module using the import keyword
import pandas as pd
# Pass the json file name as an argument to the read_json() function of the
# pandas module to read the json file and store it in a variable
json_data = pd.read_json('samplejsonfile.json')
# Pass the above json data as an argument to the DataFrame() function of the
# pandas(pd as alias name) module to create a dataframe
# Store it in another variable
datafrme = pd.DataFrame(json_data)
# Apply to_excel() function on the above dataframe to convert the given json data file
# into an excel file and save the output excel with some random name.
# Pass the index as False such that we can remove the indexes from the excel file
# Here by using the argument sheet_name we can give any other sheet name we want.
datafrme.to_excel('OutputExcelFileWithoutIndex.xlsx',index=False, sheet_name='websitesData')
Output:
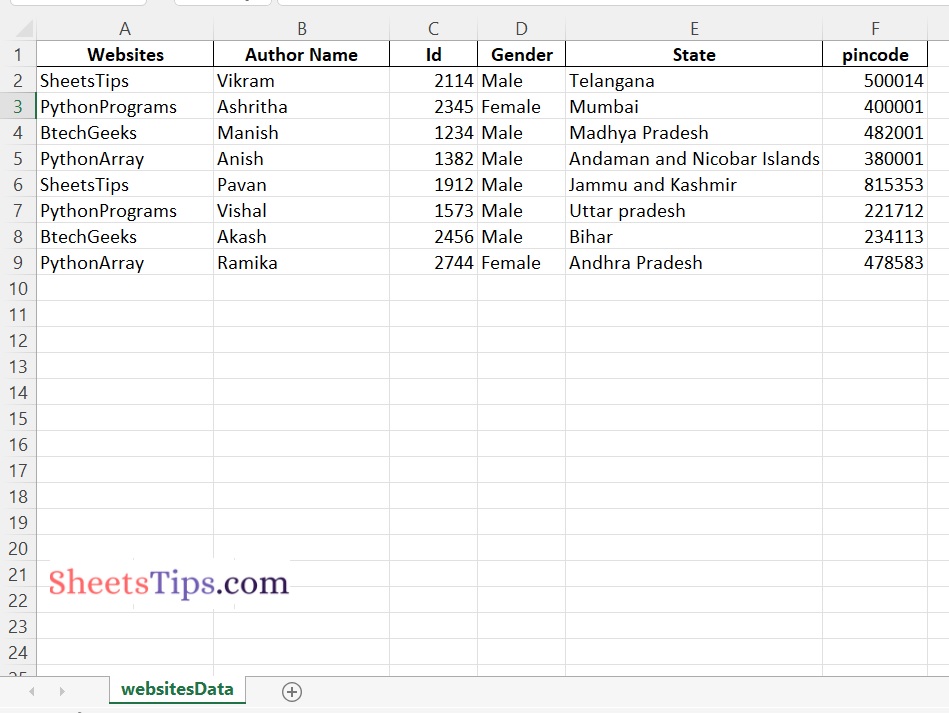
Explanation:
Here we customized the sheet name to websitesData instead of Sheet1 (which is the default one)
Method #2: Using JSON to Excel Converter Package
HTTP Requests to Get Data from the Internet:
HTTP requests are the backbone of the internet. When you navigate to a web page, your browser sends several requests to the server. The server then responds with all of the data required to generate the page, which your browser then renders so you can view it.
The general procedure is as follows: a client (such as a browser or a Python script using Requests) sends data to a URL, and the server located at that URL reads the data, decides what to do with it, and returns a response to the client. Finally, the client can select what to do with the response data.
When making an HTTP request, HTTP methods such as GET and POST define the action you’re trying to do.
The GET method is one of the most often used HTTP methods. The GET method shows that you are attempting to retrieve data from a specific resource.
A Response is a useful object for inspecting the request’s results. Make the same request again, but this time save the response value in a variable so you may examine its attributes and behaviors more closely:
response=requests.get(url)
You’ve captured the return value of get(), which is an instance of Response, and saved it in a variable called response in our example. You may now utilize a response to view a lot of information about the outcomes of your GET request.
Of course, there are alternative ways and/or Python packages that can be used to convert JSON to Excel in Python. For example, we may use the json module and one of the packages xlsxwriter or openpyxl. It should be noted, however, that the resulting Python script will be rather more sophisticated. Additionally, there is a Python package created to convert JSON to Excel.
Approach:
- Import Converter from json_excel_converter module using the import keyword.
- Import Writer from xlsx of json_excel_converter module using the import keyword.
- Give the Url of the JSON file and store it in a variable.
- Get the JSON data present from the above URL using the get() function of the requests and store it in a variable
- Call the Converter() Function and Store it in another variable.
- Convert the above JSON response to an excel file using the convert() function and write the result JSON data into some other excel file using the Writer() function.
- The Exit of the Program.
Below is the implementation:
# Import Converter from json_excel_converter module using the import keyword from json_excel_converter import Converter # Import Writer from xlsx of json_excel_converter module using the import keyword from json_excel_converter.xlsx import Writer # Give the Url of the json file and store it in a variable json_url = 'enter-url-here' # Get the json data present from the above url using the get() function of the # requets and store it in a variable json_response = requests.get(url=json_url) # Call the Converter() Function and Store it in another variable xl_converter = Converter() # Convert the above json response to excel file using the convert() function and # write the result json data into some other excel file using the Writer() function xl_converter.convert(json_response.json(), Writer(file='OutputExcelFile.xlsx'))
Sample Output:
Read Also: How to Generate Random Sentences in Python?