
В статистике корреляция относится к силе и направлению связи между двумя переменными. Значение коэффициента корреляции может варьироваться от -1 до 1, где -1 указывает на полную отрицательную связь, 0 указывает на отсутствие связи и 1 указывает на полную положительную связь.
Наиболее часто используемым коэффициентом корреляции является коэффициент корреляцииПирсона , который измеряет линейную связь между двумя числовыми переменными.
Одним из менее часто используемых коэффициентов корреляции является Тау Кендалла , который измеряет взаимосвязь между двумя столбцами ранжированных данных.
Формула для расчета тау Кендалла, часто обозначаемая аббревиатурой τ, выглядит следующим образом:
τ = (CD) / (C+D)
куда:
C = количество согласных пар
D = количество несогласующихся пар
В следующем примере показано, как использовать эту формулу для вычисления коэффициента ранговой корреляции Тау Кендалла для двух столбцов ранжированных данных.
Пример расчета тау Кендалла
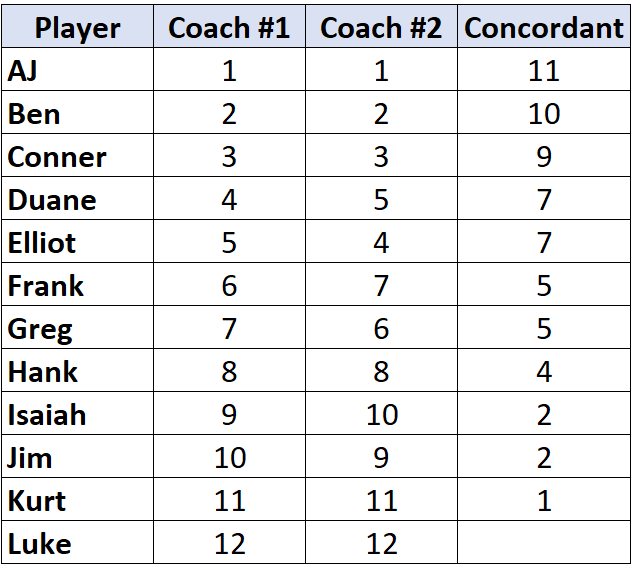
Предположим, два тренера по баскетболу ранжируют 12 своих игроков от худшего к лучшему. В следующей таблице показаны рейтинги, которые каждый тренер присвоил игрокам:
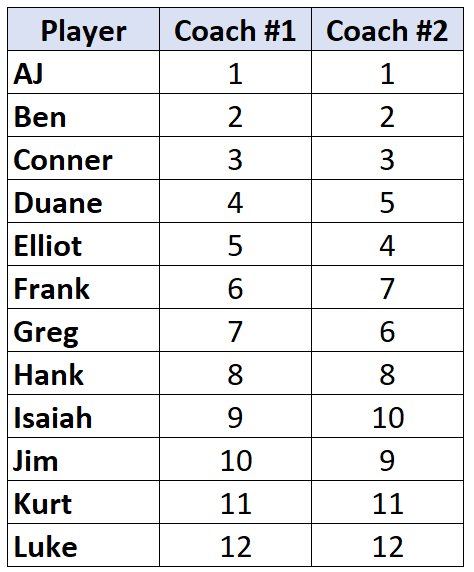
Поскольку мы работаем с двумя столбцами ранжированных данных, уместно использовать Тау Кендалла для расчета корреляции между рейтингами двух тренеров. Используйте следующие шаги для расчета Тау Кендалла:
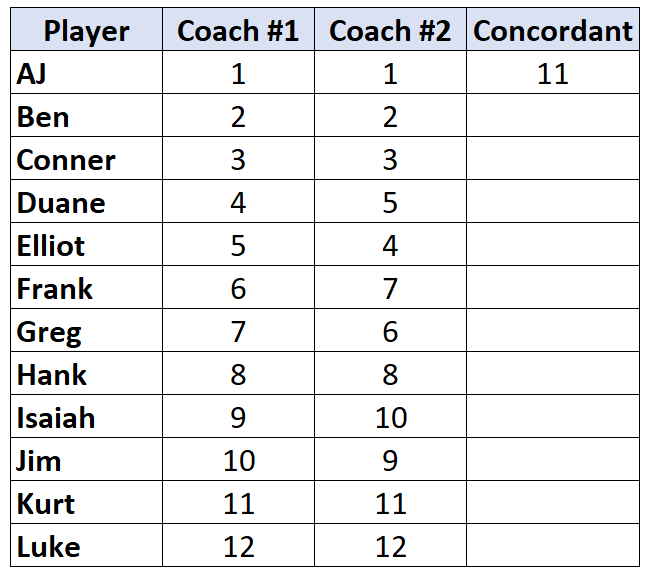
Шаг 1: Подсчитайте количество согласных пар.
Посмотрите только на ранги тренера №2. Начиная с первого игрока, посчитайте, на сколько рядов ниже него больше.Например, ниже «1» есть 11 чисел, которые больше, поэтому мы напишем 11:
Перейдите к следующему игроку и повторите процесс. Ниже «2» есть 10 чисел, которые больше, поэтому мы напишем 10:
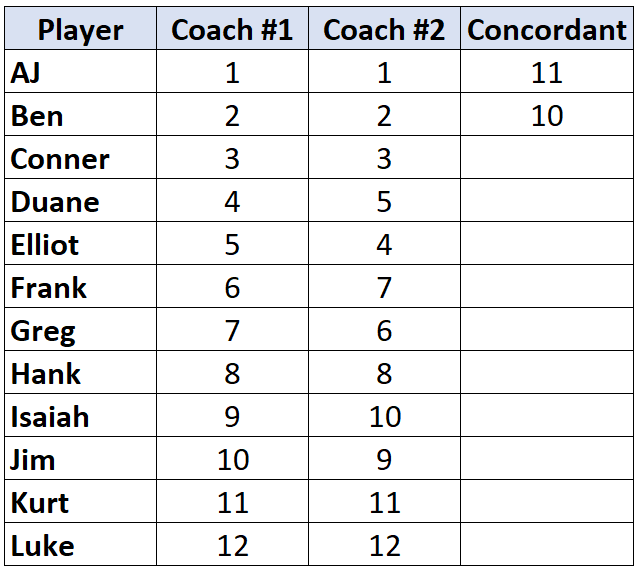
Как только мы достигаем игрока, чей ранг меньше , чем у игрока до него, мы просто присваиваем ему то же значение, что и у игрока до него. Например, у Эллиота ранг «4», что меньше ранга предыдущего игрока «5», поэтому мы просто присваиваем ему то же значение, что и игроку до него:
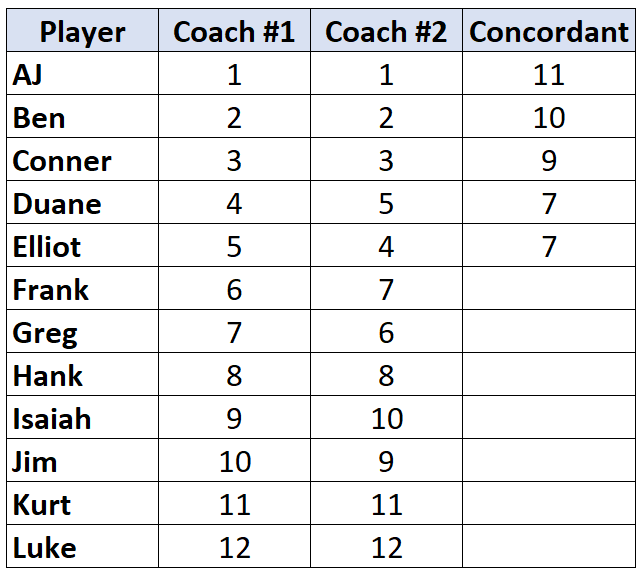
Повторите этот процесс для всех игроков:
Шаг 2: Подсчитайте количество несогласующихся пар.
Опять же, смотрите только на ранги тренера №2. Для каждого игрока посчитайте, на сколько рангов под ним меньше.Например, тренер № 2 присвоил AJ ранг «1», и ниже него нет игроков с меньшим рангом. Таким образом, мы присваиваем ему значение 0:
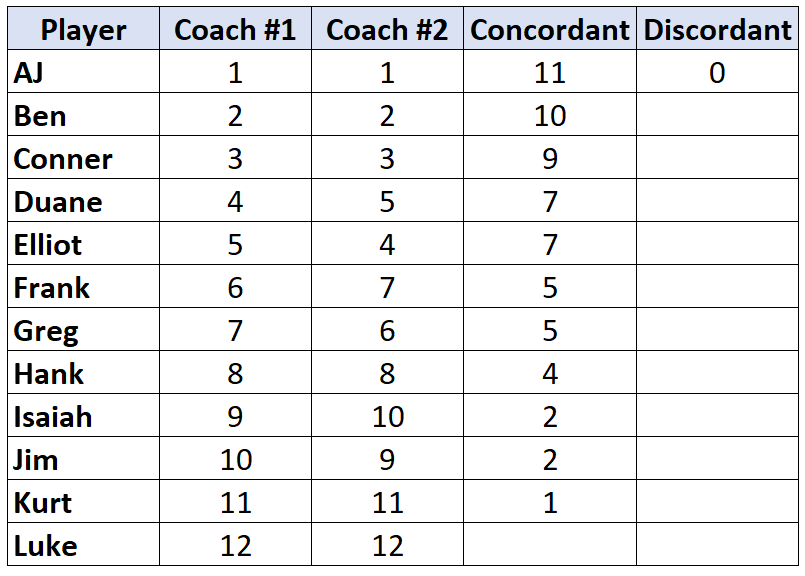
Повторите этот процесс для каждого игрока:
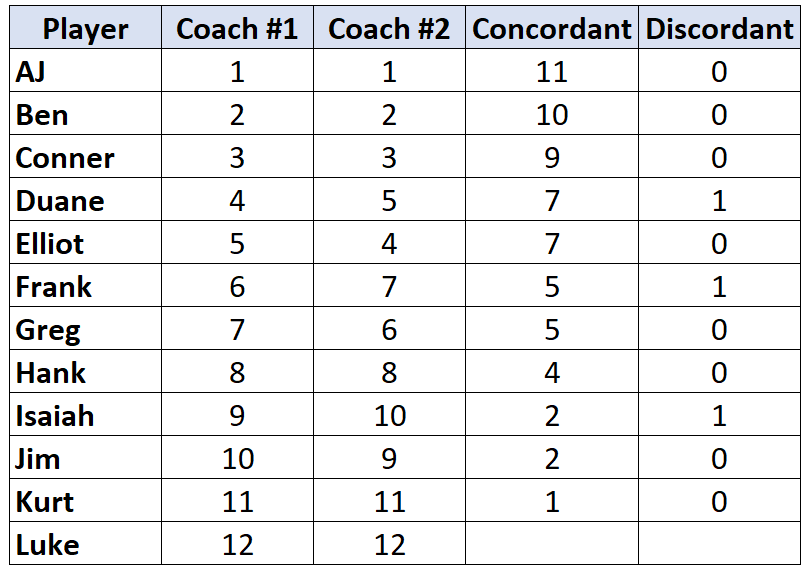
Шаг 3: Подсчитайте сумму каждого столбца и найдите Тау Кендалла.
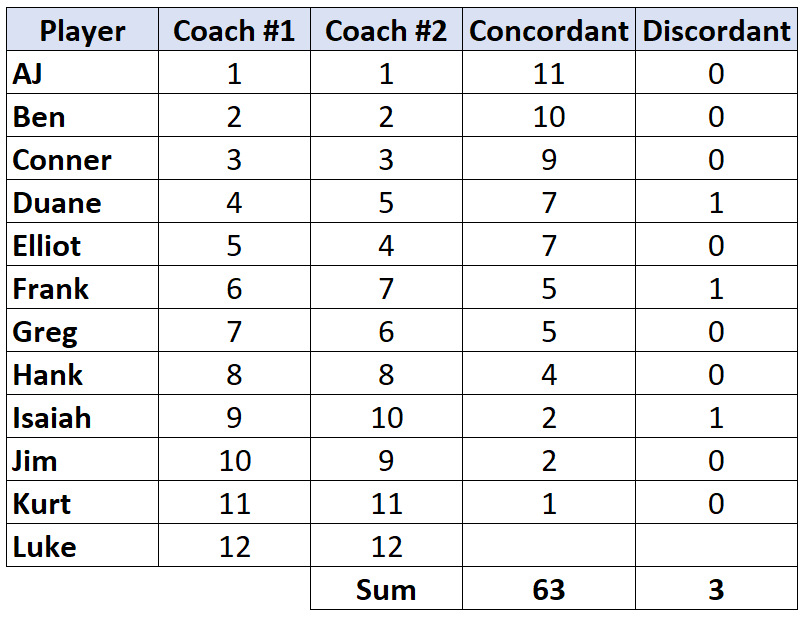
Тау Кендалла = (CD) / (C+D) = (63-3) / (63+3) = (60/66) = 0,909 .
Статистическая значимость тау Кендалла
Когда у вас более n = 10 пар, тау Кендалла обычно следует нормальному распределению. Вы можете использовать следующую формулу для расчета z-показателя тау Кендалла:
z = 3τ * √ n (n-1) / √ 2 (2n + 5)
куда:
τ = значение, которое вы рассчитали для Тау Кендалла
n = количество пар
Вот как вычислить z для предыдущего примера:
z = 3(0,909)*√12 (12-1) /√2 (2*12+5) = 4,11 .
Используя калькулятор Z-оценки для P-значения , мы видим, что p-значение для этой z-оценки составляет 0,00004 , что является статистически значимым при альфа-уровне 0,05. Таким образом, существует статистически значимая корреляция между рангами, которые два тренера присвоили игрокам.
Бонус: как рассчитать Тау Кендалла в R
В статистическом программном обеспечении R вы можете использовать функцию kendall.tau() из библиотеки VGAM для вычисления Тау Кендалла для двух векторов, которая использует следующий синтаксис:
kendall.tau(x, y)
где x и y — два числовых вектора одинаковой длины.
Следующий код иллюстрирует, как рассчитать Тау Кендалла для точных данных, которые мы использовали в предыдущем примере:
#load *VGAM*library(VGAM)
#create vector for each coach's rankings
coach_1 <- c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12)
coach_2 <- c(1, 2, 3, 5, 4, 7, 6, 8, 10, 9, 11, 12)
#calculate Kendall's Tau
kendall.tau(coach_1, coach_2)
#[1] 0.9090909
Обратите внимание, как значение Тау Кендалла совпадает со значением, рассчитанным нами вручную.
В Excel
имеется специальное средство– Мастер
диаграмм,
под руководством которого пользователь
может осуществить процесс графического
изображения статистических данных в
виде диаграмм различных типов. В Excel
предусмотрены 34 типа диаграмм: 14
стандартных и 20 нестандартных. Из них
только единственным типом диаграммы,
оси которой могут быть и линейными, и
логарифмическими, является Точечная.
В остальных типах диаграмм масштаб
оси абсцисс всегда равномерен, независимо
от «равномерности» фактических значений
аргумента функции, график которой надо
построить. То есть такие диаграммы
применимы только в тех случаях, когда
значения аргумента имеют постоянный
шаг.
Построение графика
осуществляется следующим образом:
-
Выделяется
диапазон, содержащий данные, по которым
должен быть построен график. -
Нажимается кнопка
Мастер
диаграмм,
расположенная на панели инструментов
Стандартная.
На экране появится диалоговое окно
Мастер
диаграмм (шаг 1 из 4): тип диаграммы.
В нем выбирается Тип
диаграммы. При построении диаграммы
типа Точечная
Excel
воспринимает первый ряд выделенного
диапазона исходных данных как набор
значений аргумента функций, графики
которых нужно построить (один и тот же
набор для всех функций). Следующие ряды
воспринимаются как наборы значений
самих функций (каждый ряд содержит
значения одной из функций, соответствующие
заданным значениям аргумента, находящимся
в первом ряду выделенного диапазона). -
У каждого
стандартного типа диаграммы есть
несколько видов. Их образцы представлены
в палитре Вид.
Выбрав тип диаграммы, нужно щёлкнуть
на том виде диаграммы, который лучше
всего подходит для целей исследования.
Под палитрой Вид
находится информационное окно с краткими
сведениями о выбранной диаграмме. Для
того чтобы посмотреть, как будет
выглядеть выбранная диаграмма,
построенная по данным, выделенным на
первом шаге, нажимается кнопка Просмотр
результата,
расположенная под списком типов
диаграмм. -
После выбора вида
диаграммы в левом верхнем углу палитры,
нажимается кнопка Далее,
расположенная в нижней части окна.
Открывается диалоговое окно Мастер
диаграмм (шаг 2 из 4): источник данных
диаграммы,
в верхней части которого находится
«эскиз» будущего графика.
Это диалоговое
окно имеет две вкладки: Диапазон
данных и
Ряд.
Вкладка Диапазон
данных
позволяет:
– выделить диапазон
исходных данных, по которым должна быть
построена диаграмма, если это не было
сделано до обращения к Мастеру
Диаграмм;
– исправить
неверное выделение исходных данных,
сделанное до обращения к Мастеру
Диаграмм.
На этой же вкладке
определяется ориентация рядов данных.
Делается это с помощью переключателей
Ряды в строках
и Ряды в
столбцах.
Выделение исходных
данных, по которым будет строиться
график, и исправление неверного выделения
выполняются с помощью поля ввода Диапазон
следующим образом:
–щелчком на
красно-белой кнопке минимизации,
расположенной в конце поля ввода
Диапазон,
сворачивается диалоговое окно Мастер
диаграмм (шаг 2 из 4)
в одну строку;
–с помощью мыши
выделяется нужный диапазон данных;
-щелчком на кнопке
минимизации в конце поля ввода Диапазон,
свёрнутого в строку, осуществляется
возвращение свёрнутого диалогового
окна в первоначальный вид.
Вкладка Ряд
служит для ввода названий рядов исходных
данных.
-
После проверки
правильности данных, отображённых в
окне Мастер
диаграмм (шаг 2 из 4),
нажимается кнопка Далее.
Откроется диалоговое окно Мастер
диаграмм (шаг 3 из 4: параметры диаграммы.
С помощью этого окна вводятся названия
диаграммы и осей координат, включается
или выключаются линии координатной
сетки, вводится или убирается легенда,
определяется место расположения
диаграммы и т.д. Для этого предусмотрены
вкладки Заголовки,
Оси,
Линии сетки,
Легенда.
Вводя соответствующий текст в поля
ввода и расставляя или убирая нужные
пользователю флажки в этих вкладках
формируется экспликация графика. -
Нажимается кнопка
Далее. Откроется диалоговое окно Мастер
диаграмм (шаг 4 из 4): размещение диаграммы.
В этом окне определяется вариант
размещения диаграммы в рабочей книге–
создать для неё персональный рабочий
лист или расположить на том же рабочем
листе, на котором находятся данные,
использованные для её построения.
Для перемещения
диаграммы на рабочем листе, надо щёлкнуть
в любой её точке, находящейся вне области
построения графика, и, удерживая нажатой
левую клавишу мыши, передвинуть диаграмму
в нужное место.
Для изменения
размера
диаграммы, надо «ухватиться» за один
из угловых или боковых манипуляторов
и передвинуть его в нужную сторону и на
нужное расстояние.
Для редактирования
существующей
диаграммы нужно щёлкнуть в любой её
точке. Это активизирует диаграмму и
сделает её элементы доступными для
изменения. В частности, можно более
рационально расположить заголовок
диаграммы и названия осей. Для этого
следует щёлкнуть по элементу диаграммы,
который нужно перемесить, и передвинуть
его в нужное место. Щелчком сначала
правой, а затем левой клавишей мыши по
любому элементы диаграммы можно открыть
диалоговое окно редактирования этого
элемента и внести в него нужные изменения.
При активизации
диаграммы на панели меню вместо меню
Данные
появляется
меню Диаграмма.
Используя команды этого меню, можно
более «тонко» отредактировать диаграмму.
Числовые характеристики результатов наблюдения
Следующим этапом
статистического анализа данных после
построения вариационного ряда является
характеристика отдельных свойств
распределения данных наблюдения. С этой
целью в статистике используются
специальные числовые параметры, найденные
по результатам наблюдения и отражающие
в сжатом виде основные, существенные
черты распределения данных. Эти числовые
параметры называются эмпирическими
числовыми характеристиками.
Наиболее важными числовыми характеристиками
являются характеристики положения,
вариации, асимметрии и эксцесса.
Для характеристики
положения
используются показатели
центра распределения
данных наблюдения–
средняя
арифметическая, мода и медиана.
Средняя
арифметическая для
дискретного ряда распределения
рассчитывается по формуле:
![]()
,
где
![]()
–варианты значений
признака;
–
частота повторения
данного варианта.
В интервальном
вариационном ряду
средняя арифметическая определяется
по формуле:
![]()
,
где
![]()
– середина
соответствующего интервала;
–
частота интервала.
Мода распределения–
это наиболее часто встречающееся
значение признака в совокупности. В
дискретном ряду
определение моды не требует специальных
расчётов. Мода соответствует варианту
с наибольшей частотой. В
интервальном вариационном ряду
в отличие от дискретного ряда определение
моды требует определённых расчётов на
основе специальной формулы.
Модальный интервал
(то есть содержащий моду) при интервальном
распределении с равными интервалами
определяется по наибольшей частоте, а
с неравными интервалами– по наибольшей
плотности. В первом случае мода
рассчитывается по следующей формуле:

![]()
–
нижняя граница
модального интервала;
–
величина модального
интервала;
![]()
–
частота модального
интервала;
![]()
–
частота интервала,
предшествующего модальному;
![]()
–
частота интервала,
следующего за модальным.
Во втором случае
в формуле моды вместо частот
![]()
используется
соответствующая плотность
![]()
.
Медиана
–
это значение признака, расположенное
в середине (в центре) ранжированного
ряда. Медиана делит совокупность на две
равные части– со значениями признака
меньше медианы и со значениями признака
больше медианы.
В дискретном
ряду для
вычисления медианного значения признака
сначала находят его порядковый номер:
![]()
,
где
![]()
–
число единиц
совокупности.
Полученное значение
указывает, что середина приходится на
данный номер единицы совокупности.
Необходимо определить, к какой группе
относится единица с этим порядковым
номером. Это можно сделать, рассчитав
накопленные частоты.
В интервальном
вариационном ряду
медиана определяется по формуле:
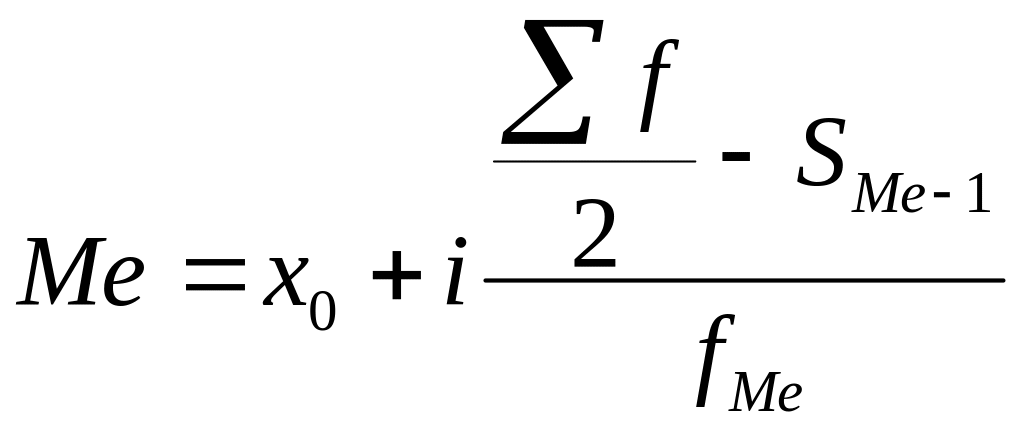
,
где
–
нижняя граница
медианного интервала;
–
величина медианного
интервала;
![]()
–
сумма всех частот
ряда;
![]()
–
накопленная частота
интервала, предшествующего медианному;
![]()
–
частота медианного
интервала.
Медианным
является интервал,
в котором сумма накопленных частот
равна или превышает полусумму частот
ряда.
Основными
характеристики вариации
признака
являются дисперсия, среднее квадратическое
(стандартное) отклонение и коэффициент
вариации. Они характеризуют степень
рассеивания данных наблюдения относительно
центра распределения.
Дисперсия
рассчитывается по формуле:
![]()
.
Среднее
квадратическое (стандартное)
отклонение
равно корню квадратному из дисперсии.
Коэффициент
вариации равен:
![]()
.
Для оценки степени
отклонения распределения исследуемой
величины от нормального распределения
используется коэффициент
асимметрии,
основанный на определении центрального
момента третьего порядка
![]()
(в
нормальном распределении его величина
равна нулю):
![]()
.
В Excel
вычисляется несмещённая состоятельная
оценка коэффициента асимметрии:
![]()
,
![]()
.
Стандартизированный
коэффициент асимметрии
![]()
имеет приближённое стандартное нормальное
распределение.
Эксцесс
представляет собой выпад вершины
эмпирического распределения вверх или
вниз от вершины кривой нормального
распределения, имеющей куполообразную
форму.
Наиболее точным
является коэффициент
эксцесса,
основанный на использовании центрального
момента четвёртого порядка:
![]()
.
Для нормального распределения
![]()
равен нулю, так как
![]()
.
В Excel
вычисляется несмещённая состоятельная
оценка коэффициента:
![]()
;
![]()
.
Стандартизированный
выборочный коэффициент эксцесса
![]()
используется при оценке степени
отклонения распределения исследуемой
случайной величины от нормального
распределения.
В Excel
числовые характеристики вычисляются
с помощью процедуры Описательная
статистика,
входящей в Пакет
анализа, и
соответствующих встроенных статистических
функций СРЗНАЧ,
МЕДИАНА, МОДА, ДИСП, ДИСПР, СТАНДОТКЛОН,
СТАНДОТКЛОНП, СРОТКЛ, КВАДРОТКЛ, СКОС
и ЭКСЦЕСС.
Для доступа к
процедуре Описательная
статистика
необходимо:
-
В меню Сервис
выделить строку Анализ
данных. -
В открывшемся
окне Анализ
данных
выделить процедуру Описательная
статистика
и щёлкнуть на кнопке ОК. На экране
появится диалоговое окно Описательная
статистика,
которое содержит следующие элементы
управления:-
поле ввода Входной
интервал.
В это поле вводится ссылка на диапазон
ячеек (входной диапазон), содержащий
статистические данные, подлежащие
обработке. Входной диапазон может быть
столбцом или группой смежных столбцов
(строкой или группой смежных строк).
Если входной диапазон представляет
собой группу столбцов (строк), то
процедура воспринимает каждый столбец
(строку) как отдельную совокупность; -
флажок Итоговая
статистика.
Если этот флажок установлен, процедура
вычисляет и помещает в таблицу
результатов решения следующие числовые
характеристики: среднюю, стандартную
ошибку средней, медиану, моду, стандартное
отклонение, дисперсию, эксцесс,
асимметрию, размах вариации, минимальное
и максимальное значение изучаемого
признака, сумму всех значений признака
и объём совокупности. Если совокупность
не имеет повторяющихся значений
признака, в строке Мода
появляется сообщение #
Н/Д!–
неопределённые данные; -
флажок Уровень
надёжности.
Флажок устанавливается в том случае,
когда необходимо вычислить доверительный
интервал для средней, соответствующий
заданной доверительной вероятности.
При этом справа от флажка открывается
поле для ввода доверительной вероятности,
выраженной в процентах. Если этот
флажок установлен, то в последней
строке таблицы результатов решения
появляется число, равное половине
длины доверительного интервала; -
флажки К-й
наименьший/К-й наибольший.
Если эти флажки установлены. то в
таблице результатов решения появляются-й
и

-й
элементы упорядоченной совокупности
(то есть единицы совокупности,
расположенные на-м
месте от её начала и от конца).
-
Назначение
переключателей Группирование
по столбцам/по строкам,
флажка Метки
в первой строке/Метки в первом столбце
и группы переключателей Выходной
интервал/Новый рабочий лист/Новая книга
рассмотрено на стр. 8-9.
Результаты решения
выводятся на экран в виде набора таблиц–
по одной таблице на каждый столбец
входного интервала (на каждую обработанную
совокупность). Каждая выходная таблица
состоит из двух столбцов. В первом
столбце указывается названия числовых
характеристик, во втором– их значения.
В заголовке указывается номер совокупности,
к которой относится данная таблица
(например, Столбец
1).
Свой наибольший
размер (18×2) таблица принимает при
установке всех четырёх флажков,
расположенных в нижней части диалогового
окна процедуры. В случае возникновения
опасности того, что таблица результатов
наложится на уже заполненные ячейки,
на экран выводится сообщение о такой
опасности. В ответ на это сообщение
пользователь должен разрешить удаление
старых данных и вывод на их место новых
(для этого надо щёлкнуть на кнопке ОК).
Формирование выборки
Метод статистического
исследования, при котором обобщающие
показатели изучаемой совокупности
устанавливаются по некоторой её части
на основе положений случайного отбора,
называется выборочным
методом.
Подлежащая изучению
по определённым признакам статистическая
совокупность, из которой производится
отбор единиц, называется генеральной.
Отобранная из генеральной совокупности
в случайном порядке некоторая часть
единиц, подвергающаяся обследованию,
называется выборочной
совокупностью
или просто выборкой.
В теории выборочного
метода разработаны и в практике
статистико-экономических исследований
применяются различные способы
формирования
выборочных совокупностей, обеспечивающие
репрезентативность. Организация
выборочного наблюдения заключается в
определении способа
и вида отбора
единиц.
Под способом
отбора
понимают порядок отбора единиц из
генеральной совокупности. Различают
два способа
отбора:
повторный и бесповторный.
При повторном
способе
каждая отобранная в случайном порядке
единица после её обследования возвращается
в генеральную совокупность и при
последующем отборе может снова попасть
в выборку. Вероятность попадания любой
единицы в выборку равна
![]()
,
и она остаётся той же самой на протяжении
всей процедуры отбора.
При бесповторном
способе
отбора попавшая в выборочную совокупность
единица после регистрации значений
наблюдаемых признаков не
возвращается в совокупность, из которой
осуществляется дальнейший отбор.
Вероятность попадания единицы в выборку
изменяется от
– для первой отбираемой единицы до
![]()
–
для последней единицы, то есть по мере
производства отбора вероятность попасть
в выборку для каждой единицы генеральной
совокупности увеличивается, тем самым
повышается репрезентативность выборки.
В зависимости
от методики формирования
выборочной совокупности различают
следующие основные
виды выборки:
-
собственно–
случайная; -
механическая;
-
типическая
(стратифицированная, расслоенная,
районированная); -
серийная (гнездовая);
-
многоступенчатая;
-
многофазная;
-
комбинированная;
-
взаимопроникающая.
В Пакете
анализа
табличного процессора Excel
имеется процедура Выборка,
реализующая повторную собственно-случайную
выборку и механическую выборку с заданным
пользователем шагом (периодом) отбора.
Формирование
выборки в Excel
осуществляется следующим образом:
-
Единицам генеральной
совокупности присваиваются порядковые
номера. Для проведения механической
выборки генеральная совокупность
должна быть каким-либо образом
упорядочена,
то есть должна быть определённая
последовательность в расположении её
единиц. Для получения результатов, не
содержащих систематическую ошибку
выборки, упорядочение необходимо
произвести по нейтральному признаку
по отношению к изучаемому. -
Порядковые номера
единиц исходной совокупности вводятся
в диапазон ячеек (входной диапазон).
Эти номера могут находиться в одном
столбце или группе смежных столбцов
одинаковой «высоты». При этом число
всех ячеек входного диапазона должно
равняться числу единиц исходной
совокупности. Если среди элементов
входного интервала имеются нечисловые
данные, то отбор не состоится, а на
экране появится сообщение «Выборка–
входной интервал содержит нечисловые
данные». -
В меню Сервис
выделяется строка Анализ
данных. -
В открывшемся
диалоговом окне Анализ
данных
выделяется процедура Выборка
и нажимается кнопка ОК. На экране
появится диалоговое окно Выборка,
которое содержит следующие элементы
управления:-
поле ввода Входной
интервал.
В это поле вводится ссылка на диапазон,
в котором хранятся номера всех единиц
генеральной совокупности, из которой
осуществляется выборка. -
Метод выборки
устанавливается с помощью переключателей
Периодический
и Случайный.
При активизации переключателя Случайный
процедура «настраивается» на выполнение
случайной выборки с повторением. Нужный
объёмвыборки вводится в поле Число
выборок.
Единицы генеральной совокупности
отбираются случайным образом. Каждая
единица исходной совокупности имеет
равную со всеми остальными единицами
возможность быть включённой в выборку.
Любая единица генеральной совокупности
может попасть в выборку более одного
раза.
-
При необходимости
реализовать механическую выборку
активизируется переключатель
Периодический.
Шаг выборки вводится в поле Период,
находящееся справа от переключателя.
В выборку войдут элементы исходной
совокупности с номерами, кратными
заданному периоду. Если входной диапазон
состоит из нескольких столбцов, то
отбираемые значения будут извлекаться
сначала из первого столбца, затем из
второго и т.д. Формирование выборки
прекращается по достижении конца
исходной совокупности.
При формировании
случайной выборки выходной интервал
представляет собой столбец с числом
ячеек, равным заданному объёму
выборки. В случае механической выборки
число ячеек выходного интервала равно
целой части результата деления объёма
исходной совокупности на шаг выборки.
Для получения
упорядоченной копии номеров единиц
совокупности, подлежащих включению в
выборку, необходимо щелчком на кнопке
Сортировка
по возрастанию,
расположенной на панели инструментов
Стандартная,
упорядочить полученный набор номеров.
Корреляционный анализ
В статистике
различают две категории зависимостей
между признаками:
1) функциональная;
2) стохастическая,
частным случаем которой является
корреляционная.
При этом признаки
для изучения взаимосвязи по их значению
делятся на два класса. Признаки,
обуславливающие изменение других,
связанных с ними признаков, называются
факторными
(х). Признаки,
изменяющиеся под действием факторных
признаков, являются результативными
(у).
Функциональной
называется связь, при которой каждому
значению факторного признака соответствует
вполне определённое значение
результативного признака. Функциональная
связь является строгой, точной, полной
зависимостью; проявляется и для каждой
единицы совокупности, и во всех случаях
наблюдения. Характерной особенностью
функциональной связи является то, что
в каждом отдельном случае известен
полный перечень факторов, влияющих на
результативный признак, а также механизм
этого влияния, выраженный определённым
уравнением.
Стохастическая
(вероятностная)
связь не проявляется в каждом отдельном
случае, а лишь в общем, среднем, при
большом числе наблюдений.
Корреляционной
называется
связь, при которой каждому значению
факторного признака может соответствовать
несколько значений результативного
признака.
Корреляционные
связи имеют ряд характеристик:
По форме
(аналитическому
выражению)
корреляционные связи между признаками
могут быть линейными (прямолинейными)
и нелинейными (криволинейными). При
линейной
форме
равномерное изменение значений одного
признака сопровождается более или менее
равномерным изменением значений другого
признака. Математически она выражается
уравнением прямой ух
= а + вх, графически — прямой линией.
При нелинейной
форме
равномерному изменению значений одного
признака соответствует неравномерное
изменение значений другого. Выражается
уравнением какой- либо кривой линии:
параболы, гиперболы, показательной,
степенной, логарифмической, логической
функции и др.
По направлению
(характеру изменения)
корреляционные связи бывают прямыми и
обратными. Прямой
(положительной)
является зависимость, при которой
направление изменения значений факторного
и результативного признаков совпадает,
то есть с увеличением факторного
признака, результативный также возрастает,
и, наоборот, при уменьшении факторного
признака результативный тоже убывает.
Обратной
(отрицательной)
называется связь, при которой изменение
значений факторного и результативного
признаков осуществляется в разных
направлениях, то есть с ростом факторного
результативный признак убывает или при
убывании факторного признака результативный
возрастает.
Степень тесноты
корреляционной связи оценивается по
специальным шкалам, например, по шкале
Чеддока.
Количественный критерий оценки тесноты
связи по шкале Чеддока
|
Величина |
Характер связи |
|
до |0,3| |
слабая |
|
|0,3|-|0,5| |
умеренная |
|
|0,5|-|0,7| |
заметная |
|
|0,7|-|0,9| |
высокая |
|
|0,9|-|1| |
весьма высокая |
|
|1| |
функциональная |
|
0 |
отсутствие связи |
Существуют и другие
менее детальные шкалы.
В статистике
различают следующие варианты зависимостей:
1) парная
корреляция
– связь между двумя признаками
(результативным и факторным);
2) частная
корреляция
– зависимость между результативным и
одним факторным признаком при
фиксированном значении других факторных
признаков;
3) множественная
корреляция
– зависимость результативного от двух
или более факторных признаков.
В практике
статистических исследований выделяют:
-
корреляционный
анализ,
который
имеет своей задачей количественное
измерение тесноты связи между признаками; -
регрессионный
анализ,
который заключается в определении
формы связи, построении одно- или
многофакторных моделей (уравнений)
регрессии; -
корреляционно-регрессионный
анализ, который
включает в себя установление аналитического
выражения (формы) и измерение степени
тесноты связи.
Следует также
различать собственно-корреляционные
(параметрические)
и непараметрические
методы
изучения взаимосвязей между признаками.
Основу применения собственно-корреляционных
методов составляют однородность и
необходимость подчинения распределения
совокупности по факторным и результативному
признаку закону нормального распределения
вероятностей. Несоблюдение этих условий
обуславливает необходимость применения
при изучении взаимосвязей непараметрических
методов.
В связи с этим
первым этапом изучения зависимостей
является установление подчинения
распределения результатов наблюдения
по изучаемым признакам закону нормального
распределения.
На соответствие
изучаемого эмпирического распределения
нормальному закону указывает близость
значений показателей центра распределения
– средней арифметической, моды и медианы.
С этой целью производится также расчёт
и оценка степени существенности
показателей асимметрии и эксцесса. В
Excel
выборочные числовые характеристики
вычисляются с помощью процедуры
Описательная
статистика,
входящей в Пакет
анализа, и
соответствующих встроенных статистических
функций (см. раздел 4).
Для проверки
гипотезы о законе распределения
изучаемого признака используются также
специальные статистические критерии.
При этом выдвигается гипотеза
![]()
о
том, что истинной функцией распределения
признака является некоторая заданная
функция
![]()
(для
нашей задачи– функция нормального
распределения). Если гипотеза
верна
(то есть, если значения признака
действительно имеют функцию распределения
),
то найденная по данным наблюдения
эмпирическая функция распределения
![]()
не
должна сильно отличаться от гипотетической
функции распределения
,
и с увеличением объёма
совокупности
различие между ними должно уменьшаться.
В связи с этим вопрос о принятии или
отклонении проверяемой гипотезы решается
в зависимости от того, насколько хорошо
согласуются эмпирическая
и гипотетическая
функции
распределения. Статистические критерии,
базирующиеся на таком подходе, называются
критериями согласия или соответствия.
В основе этих критериев лежит выбранная
статистика, которая служит мерой
расхождения между эмпирическим и
гипотетическим законами распределения
исследуемого признака.
Известны критерии К. Пирсона (хи-
квадрат), В.И. Романовского, А.Н. Колмогорова,
Б.С. Ястремского, омега-квадрат,
Крамера-Мизеса-Смирнова и др.
Excel
позволяет реализовать проверку
статистических гипотез о соответствии
эмпирических результатов наблюдения
закону нормального распределения на
основу вышеуказанных критериев согласия.
Последующий
собственно-корреляционный
анализ
статистических данных, полученных в
результате наблюдения, включает в себя:
-
построение
корреляционного поля и корреляционной
таблицы; -
вычисление
выборочных коэффициентов корреляции
и корреляционных отношений; -
проверка
статистических гипотез о значимости
корреляционной зависимости.
Корреляционное
поле и
корреляционная
таблица
служат для установления наличия и
направления зависимости между изучаемыми
признаками, дают общее представление
об этой зависимости.
В Excel
построение поля корреляции (диаграммы
рассеивания) между изучаемыми признаками
осуществляется при помощи специального
средства, служащего для графического
изображения статистических данных–
Мастера
диаграмм
(см. 19). Для построения корреляционного
поля используется тип Точечная.
На палитре Вид
выделяется диаграмма в виде изолированных
точек, находящаяся в левом верхнем углу
палитры.
Расположение точек
на графике позволяет в ряде случаев
сделать предположение о наличии,
направлении и форме взаимосвязи между
изучаемыми признаками. Так, линейное
расположение точек даёт серьёзное
основание для выбора линейной модели,
сравнительно небольшой разброс точек
относительно воображаемой кривой,
проходящей «наилучшим образом» через
эти точки, говорит о довольно сильной
зависимости между признаками, и наоборот.
Расположение точек слева на право
свидетельствует о прямой корреляции,
а справа налево– об обратной корреляции.
Для подтверждения
выводов, сделанных в результате анализа
корреляционного поля и в тех случаях,
когда корреляция между признаками имеет
явно выраженный нелинейный характер и
объём выборки велик, данные наблюдения
группируют и представляют их в виде
корреляционной таблицы, состоящей из
![]()
строк и
![]()
столбцов, где
–число
интервалов группировки по факторному
признаку и
![]()
–
число интервалов группировки по
результативному признаку. Это обусловлено
тем, что при нелинейной зависимости
вычисляются корреляционные отношения,
которые могут быть определены только
по сгруппированным данным.
Построение
корреляционной таблицы начинают с
группировки значений факторного и
результативного признаков. В Excel
для группировки данных способом равных
интервалов используются процедура
Гистограмма,
входящая в Пакет анализа (см стр.14).
Корреляционная таблица
|
Х |
Y 8640 9600 10561 11521 |
|
||||
|
|
… |
|
… |
|
||
|
|
|
… |
|
… |
|
|
|
… |
… |
… |
… |
… |
… |
… |
|
|
|
… |
|
… |
|
|
|
… |
… |
… |
… |
… |
… |
… |
|
|
|
… |
|
… |
|
|
|
|
|
… |
… |
|
–
середина
-го
интервала группировки по факторному
признаку;
–
середина
![]()
-го
интервала группировки по результативному
признаку;
–
групповая частота
«клетки», находящейся на пересечении
строки
и столбца
корреляционной таблицы;
–
групповая частота
-го
интервала группировки по факторному
признаку (число наблюдений в
-й
строке);
–групповая частота
-го
интервала группировки по результативному
признаку (число наблюдений в
-м
столбце);
–объём
изучаемой совокупности (общее число
наблюдений).
Заполнение
корреляционной таблицы даёт довольно
наглядное представление о характере
зависимости между изучаемыми признаками.
Для количественного
измерения степени тесноты связи служат
выборочные коэффициенты
корреляции
и корреляционные
отношения.
Линейный
коэффициент корреляции
рассчитывается для определения тесноты
и направления связи между двумя
корреляционными признаками в случае
наличия между ними линейной
зависимости и распределения значений
признаков близкого к нормальному.
Линейный коэффициент корреляции может
принимать значение от -1 до +1. Чем ближе
коэффициент корреляции к 1, тем сильнее
(теснее) связь между признаками. Для
определения характера связи используют
шкалу Чеддока.
В теории разработаны
и на практике применяются различные
модификации формулы расчёта данного
коэффициента:
![]()
;

;
![]()
;

;

,
где
![]()
–ковариация
факторного и результативного признаков;
![]()
,
![]()
–
среднее квадратическое (стандартное)
отклонение соответственно факторного
и результативного признака;
n
– число наблюдений.
Квадрат коэффициента
корреляции (r2)
носит название коэффициента
детерминации. Он
показывает долю вариации результативного
признака, обусловленную влиянием
вариации факторного признака.
При наличии
нелинейной
зависимости
используется более универсальный
показатель измерения тесноты связи:
корреляционное
отношение.
Различают эмпирическое и теоретическое
корреляционное отношение.
Расчет эмпирического
корреляционного отношения осуществляется
по сгруппированным данным наблюдения
и основан на использовании теоремы
(правила) сложения дисперсий:
![]()
Эмпирическое
корреляционное отношение
определяется
по формуле:
![]()
Межгрупповая
дисперсия характеризует ту часть
колеблемости результативного признака,
которая складывается под влиянием
изменения факторного признака, положенного
в основание группировки:
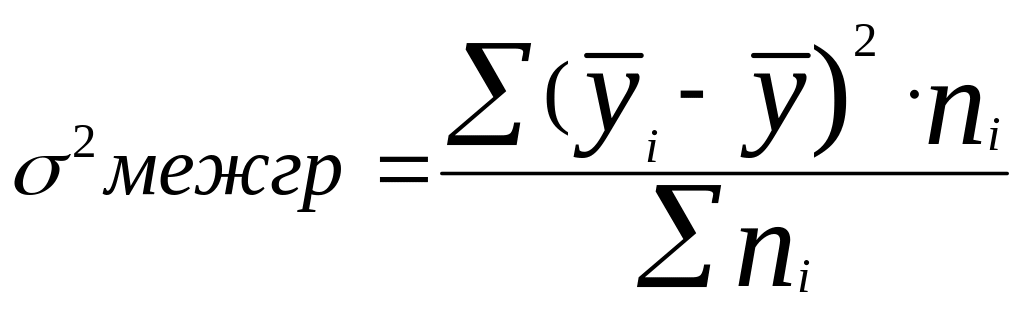
Средняя из
внутригрупповых дисперсий оценивает
ту часть вариации результативного
признака, которая обусловлена действием
других, прочих, «случайных» причин:

,
где
![]()
-дисперсия
результативного признака в соответствующей
группе.
![]()
Общая дисперсия
характеризует вариацию результативного
признака, обусловленную влиянием всех
факторов:
![]()
Расчёт теоретического
корреляционного отношения в Excel
осуществляется в рамках регрессионного
анализа, поэтому будет рассмотрен в
следующем разделе.
В Excel
вычисление выборочного коэффициента
корреляции осуществляется с помощью
процедуры Корреляция,
входящей в Пакет анализа, и встроенных
статистических функций КОРРЕЛ,
ПИРСОН
и КВПИРСОН.
При применении
процедуры Корреляция
в поле Входной
интервал
диалогового окна этой процедуры вводится
ссылка на входной диапазон (на диапазон,
содержащий данные наблюдения, подлежащие
обработке). Входной диапазон должен
содержать
![]()
смежных столбцов по
ячеек в каждом столбце или
смежных
строк по
ячеек в каждой строке.
Назначение
переключателя Группирование,
флажка Метки
и группы переключателей Выходной
интервал/Новый
рабочий лист/
Новая книга
рассмотрено в первом разделе на стр.8-9.
Статистические
функции КОРРЕЛ
и ПИРСОН
вычисляют выборочную оценку линейного
коэффициента корреляции по первой
формуле, представленной на стр. 34, и
дублируют друг друга. Синтаксис функции
КОРРЕЛ
(массив 1;
массив 2),
где массив
1– диапазон
ячеек, в который введены значения
факторного признака (например, А1:А25), а
массив 2–
диапазон ячеек, в который введены
значения результативного признака
(например, В1:В25). Статистическая функция
КВПИРСОН
вычисляет квадрат выборочного коэффициента
корреляции.
Для вычисление
эмпирического корреляционного отношения
в Excel
не предусмотрено специальных статистических
процедур и встроенных функций. Вычисление
корреляционного отношения осуществляется
по представленным выше формулам и
требует предварительного построения
корреляционной таблицы и ряда
вспомогательных расчётов.
Значимость
линейного коэффициента корреляции
проверяется на основе t
– критерия Стьюдента. При этом выдвигается
и проверяется гипотеза (![]()
)
о равенстве коэффициента корреляции в
генеральной совокупности нулю (то есть
в действительности связь между изучаемыми
признаками отсутствует, а эмпирическое
значение выборочного коэффициента
корреляции обусловлено только случайными
совпадениями
![]()
и
![]()
в
выборке).
Фактическое
значение t
— критерия рассчитывается по формуле
— для совокупностей n<50
по формуле:
![]()
;
(*)
при большом числе
наблюдений (n>100):
![]()
.
Вычисленное
значение t
– критерия сравнивается с критическим
его значением при принятом уровне
занятости α
и числе степеней свободы k
= n-2.
В социально-экономических исследованиях
уровень значимости α
обычно принимается равным 0,05.
При «ручной»
проверке гипотезы критические значения
t
находятся по таблице распределения
Стьюдента. Если расчётное значение t
– критерия больше критического, то
гипотеза о том, что линейный коэффициент
корреляции в генеральной совокупности
равен нулю и лишь в силу случайных
обстоятельств оказался равен проверяемому
значению, отклоняется, то есть коэффициент
корреляции признаётся значимым, а связь
между признаками – статистически
существенной. Если расчётное значение
t
– критерия меньше критического, то
нулевая гипотеза принимается, что
означает, что коэффициент корреляции
в генеральной совокупности в
действительности равен нулю и
соответственно эмпирический коэффициент
корреляции существенно не отличается
от нуля.
В Excel
проверка гипотезы
об отсутствии корреляции между изучаемыми
признаками осуществляется следующим
образом:
-
В ячейку (например,
В1) вводится значение выборочного
коэффициента корреляции

; -
В ячейку В2 для
определения расчётного значения t
– критерия вводится формула (*): =
В1*КОРЕНЬ (115/(1-В1^2)) (
=
117); -
В ячейку В3 для
нахождения критического значения t
– критерия Стьюдента при уровне
значимости α=
0,05 и числе степеней свободы k
=115 вводится формула: =
СТЬЮДРАСПОБР (0.05;115); -
Полученные
расчётное и критическое значения t
– критерия Стьюдента сравниваются, и
делается вывод об отклонении или
принятии нулевой гипотезы на уровне
значимости

=0,025
. Если гипотезапротиворечит реальным данным наблюдения
(отклоняется), то выборочный коэффициент
корреляции признаётся значимым и между
изучаемыми признаками существует
соответствующая по степени тесноты
корреляционная зависимость. Если
гипотеза принимается, коэффициент
корреляции признаётся незначимым.
Для оценки
значимости корреляционного отношения
![]()
используется
F
– критерий Фишера–Снедекора, вычисленный
по формуле:
![]()
,
(**)
где n
— число наблюдений; m
– число интервалов группировки или
параметров в уравнении регрессии.
При этом проверяется
гипотеза
![]()
об отсутствии корреляционной зависимости
между изучаемыми признаками. Проверяемая
гипотеза отклоняется на уровне значимости
![]()
,
если расчётное значение F
– критерия превышает его критическое
значение для принятого уровня значимости
и чисел степеней свободы k1=m-1
и k2=m-n.
В этом случае величина корреляционного
отношения признаётся значимой, а связь
между признаками существенной.
При «ручной»
проверке гипотезы используются
специальные таблицы F
– распределения. В них указывается
предельные (критические) значения F
– критерия для различных степеней
свободы k1
и k2,
которые могут быть превзойдены с
вероятностью α = 0,05.
В Excel
проверка гипотезы
об отсутствии корреляции между изучаемыми
признаками осуществляется следующим
образом:
-
В ячейку В1 вводится
объём совокупности(например, 132) в ячейку В2– число интервалов
группировки или параметров в уравнении
регрессии (например, 12); в ячейку В3–
значение выборочного корреляционного
отношения; -
В ячейку Е1 для
нахождения расчётного значения F
– критерий Фишера вводится формула
(**): =
В3^2*120/(1-В3^2)*11; -
В ячейку Е2 для
определения критического значения F
– критерий Фишера для принятого уровня
значимости=0,05
и чисел степеней свободы k1=m-1
(11) и k2=m-n
(120) вводится формула: = FРАСПОБР
(0.05;11;120). -
Полученные
расчётное и критическое значения F
– критерий Фишера сравниваются, и
делается вывод об отклонении или
принятии нулевой гипотезыи соответственно о значимости или
незначимости корреляционного отношения.
Множественный
коэффициент корреляции вычисляется
статистической процедурой Регрессия
(см. следующий раздел).
Рассмотренные
выше вычисления относятся к
собственно-корреляционным, параметрическим
методам изучения связей.
В случаях, когда
анализируется взаимосвязь между
количественными признаками, форма
распределения которых отличается от
нормальной, а также между качественными
признаками, используются так называемые
непараметрические
методы.
В основу этих методов положен принцип
нумерации значений признаков
статистического ряда.
Значения факторного
признака записываются в возрастающем
или убывающем порядке, а затем ранжируются
соответствующие им значения результативного
признака. При этом каждой единице в
упорядоченном ряду присваивается
порядковый номер, который будет её
рангом.
В случаях наличия одинаковых вариантов
каждому из них присваивается среднее
арифметическое значение их рангов.
Для определения
рангов в Excel
предусмотрены статистическая процедура
Ранг и
персентиль
и статистическая функция РАНГ.
Использование
процедуры Ранг
и персентиль
заключается в следующем:
-
В меню Сервис
выделяется строка Анализ
данных. -
В открывшемся
окне Анализ
данных
выделяется процедура Ранг
и персентиль,
нажимается кнопка ОК. На экране появляется
диалоговое окно Ранг
и персентиль. -
В поле Входной
интервал
вводится ссылка на диапазон ячеек,
содержащий данные, подлежащие
ранжированию. Входной диапазон может
быть столбцом или группой смежных
столбцов (строкой или группой смежных
строк). Если входной диапазон представляет
собой группу столбцов (строк), то
процедура воспринимает каждый столбец
(строку) как отдельную выборку. -
Устанавливается
переключатель Группирование
в нужное положение (по столбцам или
строкам). -
Флажок Метки
устанавливается, если первая строка
(столбец) входного диапазона содержит
заголовки. Если такие заголовки
отсутствуют, флажок не устанавливается. -
Щелчком на
переключателе Выходной
интервал
активизируется поле ввода, находящее
справа от этого переключателя и вводится
в него ссылка на левую верхнюю ячейку
таблицы результатов решения. В случае
необходимости результаты выводятся
на Новый
рабочий лист
или Новую
рабочую книгу.
Нажимается кнопка ОК.
Статистическая
функция РАНГ
имеет следующий синтаксис: РАНГ
(число; массив; порядок):
-
число–
номер единицы совокупности, ранг
которой надо определить. Если необходимо
осуществить ранжирование всей
совокупности сразу, то вводится диапазон
ячеек, в котором находятся данные,
подлежащие обработке; -
массив–
массив или диапазон ячеек, содержащий
единицы исследуемой совокупности
(неупорядоченные данные наблюдения); -
порядок–
величина, определяющая, как упорядочивать
(ранжировать) массив:
– если порядок
равен 0 или пропущен, массив упорядочивается
в порядке убывания;
– если порядок–
любое число, не равное нулю, то массив
упорядочивается по возрастанию.
Среди непараметрических
методов оценки тесноты связи наибольшее
значение имеют коэффициенты ранговой
корреляции Спирмена и Кендалла.
Коэффициент
корреляции рангов (Спирмена)
определяется по формуле:
r
=![]()
,
где
d
– разность между рангами соответствующих
величин двух признаков;
n
– число единиц в ряду (число пар рангов).
Коэффициент
корреляции рангов принимает любые
значения от -1 до +1. Если все ранги строго
изменяются в одном и том же порядке, то
d=0,
а r=1.
Если же ранги изменяются строго в
противоположных направлениях, то r=
-1. Значение r=0
характеризует отсутствие связи.
В Excel
вычисление коэффициента ранговой
корреляции Спирмена осуществляется
следующим образом:
1. Вводятся заголовки
исходных и расчётных данных, необходимых
для расчёта коэффициента корреляции
рангов: в ячейку А1– названия единиц
изучаемой совокупности, в ячейку В1–
название факторного признака, в ячейку
С1– названия результативного признака,
в ячейку D1–
символ
![]()
,
обозначающий ранг по факторному признаку,
в ячейку Е1– символ
![]()
,
обозначающий ранг по результативному
признаку, в ячейку– F–
символ
![]()
,
обозначающий квадрат разности между
рангами соответствующих величин двух
признаков.
2. Производится
ввод исходных данных: в диапазон ячеек
столбца А вводятся названия или номера
единиц изучаемой совокупности; в диапазон
ячеек столбца В (например, В2:В11)–
значения факторного признака, в диапазон
ячеек столбца С (С2:С11)– значения
результативного признака.
3. В диапазонах
ячеек D2:D11
и Е2:Е11 определяются соответственно
ранги по факторному и результативному
признаку с помощью описанной выше
процедуры
Ранг и персентиль
или функции РАНГ,
для чего вводятся формулы массива =
РАНГ (В2:В11; В2:В11;1)
и = РАНГ
(С2:С11; С2:С11;1).
4. В диапазоне
F2:F11
вычислить квадраты разности рангов с
помощью формулы массива: = (D2:D11-E2:E11)^2.
5. В ячейках D12,
E12
и F12
с помощью кнопки Автосуммирование
определить суммы рангов по факторному
и результативному признакам и сумму
квадрата разности рангов.
6. По формуле
рассчитывается выборочная оценка
коэффициента ранговой корреляции
Спирмена.
Значимость
коэффициента корреляции рангов для
совокупностей небольшого объёма (n£30)
проверяется по таблице предельных
значений коэффициента корреляции рангов
Спирмена при заданном уровне значимости
a
и определённом объёме совокупности.
Значимость r
может быть проверена также на основе t
– критерия Стьюдента. Расчётное значение
критерия определяется по формуле:
tрасч=
r×![]()
Значение коэффициента
корреляции считается статистически
существенным, если расчётное значение
t
– критерия Стьюдента превосходит его
критическое значение при заданном
уровне значимости a
и числе степеней свободы k=n-2.
Критическое значение t
– критерия может быть определено по
таблице распределения Стьюдента или
в Excel
по представленному выше в данном разделе
порядку.
Коэффициент
корреляции рангов Кендалла
рассчитывается
по формуле:
t=![]()
,
S=P+Q
n
– число наблюдений;
S
– сумма разностей между числом
последовательностей и числом инверсий
по результативному признаку.
Расчёт данного
коэффициента выполняется в следующей
последовательности:
-
ранги факторного
признака располагаются в порядке
возрастания; -
ранги результативного
признака располагаются в порядке,
соответствующем рангам признака х; -
для каждого ранга
результативного признака определяется
сколько чисел, находящихся справа от
него (следующих за ним) имеют величину
ранга, превышающую его величину. Суммируя
полученные таким образом числа, получаем
слагаемое P,
которое можно рассматривать как меру
соответствия последовательностей
рангов по x
и y,
и которое учитывается со знаком «+»; -
для каждого ранга
y
определяется число, следующих за ним
рангов, меньших его величины. Суммарная
величина обозначается через Q
и фиксируется со знаком «-»; -
определяется
сумма баллов S=P+Q
Коэффициент
Кендалла также изменяется в пределах
от -1 до +1. При достаточно большом числе
наблюдений между коэффициентами
корреляции рангов Спирмена и Кендалла
существует следующее соотношение: r»![]()
.
Вычисления,
связанные с коэффициентом ранговой
корреляции
![]()
,
заметно упрощаются, если результаты
ранжировки представить в виде:
![]()
,
(***)
где
![]()
–
ранг по результативному признаку той
единицы совокупности, которая по
факторному признаку имеет ранг
.
При таком
представлении ранжировки формула
коэффициента корреляции рангов Кендалла
имеет вид:
![]()
,
(****)
где
![]()
–число
единиц совокупности, для которых
![]()
и
одновременно
![]()
.
На практике
вычисляют
по формуле
![]()
,
где –![]()
–
число рангов
в ранжировке (***), для которых для которых
и
одновременно
.
В Excel
вычисление коэффициента ранговой
корреляции Кендалла осуществляется по
формуле (****) следующим образом:
1. Вводятся заголовки
исходных и расчётных данных, необходимых
для расчёта коэффициента корреляции
рангов: в ячейку А1– названия единиц
изучаемой совокупности, в ячейку В1–
название факторного признака, в ячейку
С1– названия результативного признака,
в ячейку D1–
символ
,
обозначающий ранг по факторному признаку,
в ячейку Е1– символ
,
обозначающий ранг по результативному
признаку, в ячейку– F–
символ
,
обозначающий квадрат разности между
рангами соответствующих величин двух
признаков.
2. Производится
ввод исходных данных: в диапазон ячеек
столбца А вводятся названия или номера
единиц изучаемой совокупности; в диапазон
ячеек столбца В (например, В2:В11)–
значения факторного признака, в диапазон
ячеек столбца С (С2:С11)– значения
результативного признака.
3. В диапазонах
ячеек D2:D11
и Е2:Е11 определяются соответственно
ранги по факторному и результативному
признаку с помощью описанной выше
процедуры
Ранг и персентиль
или функции РАНГ,
для чего вводятся формулы массива =
РАНГ (В2:В11; В2:В11;1)
и = РАНГ
(С2:С11; С2:С11;1).
4. Выделяется
диапазон D1:E11,
в котором находятся ранги по факторному
и результативному признакам, нажимается
кнопка Копировать
на панели инструментов Стандартная.
5. Выделяется ячейка
F1.
В меню Правка
выделяется команда Специальная
вставка.
6. В открывшемся
диалоговом окне Специальная
вставка в
группе переключателей Вставить
установливается
переключатель Значения
и нажимается
кнопка ОК. В диапазоне F2:G11
появятся «копии» рангов.
7. Выделяется
диапазон F1:G11.
В меню Данные
выделяется команда Сортировка.
8. В открывшемся
окне Сортировка
диапазона
в раскрывшемся списке Сортировать
по выбирается
поле
,
по которому надо выполнить сортировку,
и установливается переключатель по
возрастанию;
в группе переключателей Идентифицировать
поля по
установливатся
переключатель подписям
(первая строка диапазона)
и нажимается кнопка ОК.
В диапазоне F2:G11
появятся ранги по факторному и
результативному признакам, отсортированные
в порядке возрастания рангов факторного
признака.
9. В ячейку Н2
вводится формула массива =
СУММ (ЕСЛИ ($G3:$G11>G2;1;0)),
нажимаются клавиши Ctrl+Shift+
Enter
и затем эта формула копируется в ячейки
Н3:Н11. В диапазоне Н2:Н11 появятся числа
![]()
.
10. Суммируя эти
числа в ячейке Н12, находится выборочное
значение
.
11. Используя формулу
= 4* Н12/(10^2-10)-1 (машинный аналог формулы
(****)), находится выборочное значение
.
Существенность
коэффициента корреляции рангов Кендалла
проверяется
–при малом объёме
совокупности (![]()
)
с помощью таблиц точного распределения
статистики
;
– при больших n
для заданного уровня значимости a
по формуле:
t>ta×![]()
,
где
ta
– коэффициент, определяемый по таблице
нормального распределения.
Регрессионный анализ
Регрессионным
анализом называется
раздел статистики, объединяющий
практические методы исследования формы
корреляционной зависимости между
изучаемыми признаками единиц исследуемой
совокупности.
В регрессионном
анализе различают парную и множественную
регрессию. Парная
регрессия
описывает связь между двумя признаками:
факторным и результативным. Множественная
регрессия
описывает зависимость результативного
признака от нескольких факторных
признаков.
Регрессионной
моделью
системы взаимосвязанных признаков
принято считать такое уравнение
регрессии, которое включает основные
факторы, влияющие на вариацию
результативного признака, обладает
высоким (не ниже 0,5) коэффициентом
детерминации и коэффициентами регрессии,
интерпретируемыми в соответствии с
теоретическим знанием о природе связей
в изучаемой системе. Приведённое
определение включает достаточно строгие
условия: не всякое уравнение регрессии
можно считать моделью.
Регрессионный
анализ включает в себя следующие основные
этапы:
-
выбор модели
регрессии; -
оценка параметров
выбранной модели регрессии; -
проверка значимости
параметров модели регрессии и их
интерпретация; -
проверка адекватности
построенной модели регрессии.
Выбор аналитической
формы связи
осуществляется на основе:
-
логического
теоретического анализа; -
графического
изображения зависимости в виде
эмпирической линии регрессии; -
опыта предыдущих
исследований, где выбранные формы связи
давали удовлетворительные результаты; -
различных
статистико-математических критериев
адекватности конкурирующих уравнений
регрессии (остаточных дисперсий, ошибок
аппроксимации и др.).
Наиболее разработанной
в теории статистики является методология
парной регрессии. При этом для изучения
связи между изучаемыми признаками
применяются различного вида уравнения
(типы математических функций) линейной
и нелинейной зависимостей.
При анализе
линейной связи
применяется прямолинейная функция,
математическим выражением которой
является уравнение прямой линии:
yx=a+bx.
При анализе
нелинейных связей
используются следующие функции:
параболическая
yx=a+bx+cx2
гиперболическая
yx=a+![]()
показательная
yx=abx
степенная yx=axb
логарифмическая
yx=a+blgx
логистическая
yx=![]()
и др.
Решение математических
уравнений связи предполагает вычисление
по исходным данным их параметров a
и b.
Это осуществляется способом выравнивания
эмпирических (фактических) данных
методом
наименьших квадратов (МНК).
В основу этого метода положено требование
минимальности суммы разности квадрата
отклонений эмпирических значений
результативного признака от его
выровненных (теоретических) значений
yxi,
полученных по выбранному уравнению
регрессии:
![]()
.
Параметры b1,…
bn
в уравнении регрессии называют
коэффициентами
регрессии.
Если связь по направлению прямая – он
имеет положительное значение, если
обратная – отрицательное. При линейной
связи коэффициент регрессии показывает
на сколько единиц своего измерения в
среднем изменяется величина результативного
признака при изменении факторного
признака на единицу своего измерения.
В Excel
имеется две процедуры и восемь встроенных
функций для регрессионного анализа.
Они вычисляют не только выборочные
параметры регрессии, но и ещё ряд
дополнительных выборочных характеристик
исследуемой регрессионной зависимости.
К числу таких характеристик относятся:
-
общая сумма
квадратов
=

–
сумма квадратов отклонений
фактических(эмпирических) значений
результативного признака

от его среднего значения

; -
сумма квадратов,
обусловленная регрессией

=

–сумма
квадратов отклонений теоретических
(расчётных, выровненных) значений
результативного признака

от его среднего значения
;
-
сумма квадратов
остатков

=

–сумма
квадратов отклонений фактических
значений результативного признакаот его теоретических значений
;
-
числа степеней
свободы этих сумм

. -
средний квадрат
регрессии или
факторная
(систематическая) дисперсия–

–
характеризует колеблемость результативного
признака под влиянием только фактора
х, входящего в уравнение регрессии; -
средний квадрат
остатков или
остаточная
(случайная) дисперсия–

–характеризует
колеблемость результативного признака
под влиянием прочих факторов, не входящих
в уравнение регрессия.
Эти дисперсии
связаны между собой равенством, носящим
название «правило сложения дисперсий»–
![]()
;![]()
;
-
множественный
коэффициент (индекс) корреляции

;
в случае парной линейной регрессии
этот показатель совпадает с коэффициентом
корреляции,
а в случае парной нелинейной регрессии
носит название теоретического
корреляционного отношения; -
коэффициент
детерминации–

;
показывает вариацию результативного
признака, обусловленную вариацией
факторов, входящих в регрессионную
модель; -
нормированный
(скорректированный) коэффициент
детерминации
–
.
где–число
факторов, включённых в регрессионную
модель. Корректировка не производится
при условии, если

; -
стандартная
ошибка аппроксимации
(средняя
квадратическая ошибка) уравнения
регрессии:
![]()
;
где
![]()
-число
параметров в уравнении регрессии.
-
стандартное
отклонение параметров регрессии–
.
Наиболее точно эта величина может
быть определена по формуле:

,
где
![]()
–
среднее квадратическое отклонение
результативного признака (корень
квадратный из общей дисперсии);
![]()
–среднее
квадратическое отклонение
—
го факторного признака;
–величина
множественного коэффициента корреляции
по фактору
с остальными факторами.
Выборочный
коэффициент детерминации и выборочные
параметры регрессии, вычисленные по
ограниченному числу единиц изучаемой
совокупности, всегда содержат элемент
случайности, в связи, с чем возникает
необходимость проверки значимости этих
выборочных характеристик.
При проверке
значимости параметра регрессии
![]()
,
выдвигается гипотеза
![]()
о том, что фактор
не
оказывает заметного влияния на
результативный признак. Значимость
параметров
регрессии
проверяется на основе t
– критерия Стьюдента:
![]()
.
Параметр признаётся
статистически значимым, если расчётное
значение t
– критерия Стьюдента превосходит его
критическое значение, определяемое при
заданном уровне значимости α и числе
степеней свободы
![]()
.
Критическое значение t
– критерия может быть определено по
таблице распределения Стьюдента или
в Excel
по представленному в предыдущем разделе
порядку.
При проверке
значимости коэффициента детерминации
выдвигается гипотеза
![]()
о том, что коэффициент детерминации
генеральной совокупности, из которой
извлечена исследуемая выборка, равен
нулю. Эта гипотеза равносильна гипотезе
о том, что ни один из факторов, включённых
в регрессию, не оказывает существенного
влияния на результативный признак.
Поэтому проверка значимости коэффициента
детерминации является проверкой
адекватности (соответствия) выбранной
модели регрессии реальным
данным наблюдения. Значимость
коэффициента детерминации осуществляется
с помощью F-критерия.
Расчётное значение
критерия Фишера–Снедекора,
вычисляется по формуле:
![]()
,
Если
![]()
,
то гипотеза о равенстве коэффициента
детерминации нулю и несоответствии
заложенных в модели связей реально
существующим отклоняется на уровне
значимости
,
то есть коэффициент детерминации
признаётся статистически значимым, а
модель регрессии – адекватной. Величина
![]()
определяется по специальным таблицам
и зависит от заданного уровня значимости
и числа степеней свободы:
![]()
и
![]()
,
где
–
число наблюдений;
–
число факторных признаков в модели.
В качестве меры
адекватности модели регрессии
используется также процентное отношение
стандартной ошибки
![]()
к
среднему уровню результативного признака
![]()
–
относительная
ошибка аппроксимации:
![]()
, где
Если
![]()
,
то точность модели регрессии высокая,
если 10-20% – точность модели регрессии
хорошая (то есть уравнение достаточно
хорошо описывает взаимосвязь между
изучаемыми признаками), если 20-50% –
точность модели регрессии удовлетворительная.
В Excel
для проведения регрессионного анализа
существует статистическая процедура
Регрессия,
позволяющая осуществлять парную
линейную, параболическую (полиноминальную)
и множественную регрессии. Для выбора
формы связи целесообразно построить
корреляционное поле, воспользовавшись
специальным средством Мастер
диаграмм,
выбрав тип Точечная
(см. предыдущий раздел).
Парная линейная
регрессия
в Excel
осуществляется следующим образом:
-
Осуществляется
ввод исходных данных, т.е. значений
факторного и результативного признака. -
В меню Сервис
выделяется строка Анализ
Данных. -
В открывшемся
окне Анализ
данных
выделяется процедура Регрессия
и нажимается кнопка ОК. Откроется
диалоговое окно Регрессия
с пульсирующим курсором в поле ввода
Входной
интервал Y. -
С помощью мыши
выделяется диапазон ячеек, в котором
находятся эмпирические значения
результативного признака Y.
В поле ввода Входной
интервал Y
появится соответствующая ссылка. -
Нажатием клавиши
Tab
осуществляется переход в поле ввода
Входной
интервал Х.
С помощью мыши выделяется диапазон
ячеек, в котором находятся эмпирические
значения факторного признака Х. В поле
ввода Входной
интервал Х
появится соответствующая ссылка. -
Устанавливается
флажок в группе флажков Остатки.
В данную группу входят следующие
флажки:
– флажок Остатки.
При его установке на экран выводится
таблица ВЫВОД
ОСТАТКОВ, в
состав которой входит столбец Остатки;
– флажок График
остатков.
При активизации этого флажка на экран
выводятся графики зависимости остатков
от регрессионных переменных (по одному
графику на каждую переменную);
– флажок
Стандартизированные
остатки. При
установке данного флажка в таблицу
ВЫВОД ОСТАТКОВ
добавляется столбец центрированных
нормированных (стандартизированных),
которые получаются из остатков
![]()
делением их на
![]()
;
– флажок График
подбора. При
установке этого флажка на рабочий лист
выводятся
точечных графиков (по числу контролируемых
переменных). На графике, связанном с
-й
контролируемой переменной
![]()
,
=1,
2….,
,
каждому значению
![]()
этой переменной поставлены в соответствие
две точки
и
;
– флажок График
нормальной вероятности. При активизации
этого флажка на экран выводятся таблица
ВЫВОД ВЕРОЯТНОСТИ и график функции,
обратной эмпирической функции
распределения результативного признака,
выполненный на «вероятностной нормальной
бумаге».
-
Щелчком на кнопке
ОК запускается процедура Регрессия.
Помимо этого
процедура содержит также следующие
элементы управления:
-
Флажок Константа-ноль.
Устанавливается
в том случае, когда необходимо, чтобы
линия регрессии проходила через начало
координат. При этом параметрравен нулю и число параметров регрессии
равно числу факторов. -
флажок Уровень
надёжности.
Устанавливается в том случае, когда
помимо доверительных интервалов для
параметров регрессии, соответствующих
используемой по умолчанию «стандартной»
доверительной вероятности 95%, необходимо
вычислить доверительные интервалы,
доверительная вероятность которых
отличается от «стандартной».
«Нестандартная» вероятность, выраженная
в процентах, вводится в поле, расположенное
справа от рассматриваемого флажка.
Если этот флажок не установлен, то
выходной таблице параметров регрессии
будут одинаковые пары столбцов,
содержащие доверительные границы для
параметров регрессии, соответствующие
одной и той же доверительной вероятности
95% (при редактировании таблицы их можно
убрать).
Назначение флажка
Метки
и переключателей Выходной
интервал/Новый рабочий лист/ Новая книга
рассмотрено в 1 разделе.
После запуска
процедуры Регрессия
на рабочем листе появляются три таблицы
результатов этой процедуры. В первой
таблице «Регрессионная статистика»
содержатся значения множественного
коэффициента корреляции, коэффициента
детерминации, нормированного коэффициента
детерминации, стандартная ошибка
уравнения регрессии и число наблюдений.
Во второй таблице «Дисперсионный анализ»
содержатся значения сумм квадратов и
среднего квадрата регрессии, остатков
и общие., а также расчётное значение
критерия Фишера–Снедекора. В третьей
таблице в графе «Коэффициенты» по строке
«Y-
пересечение» находится значение
свободного члена уравнения регрессии
,
а по строке Х – значение параметра
![]()
.
Далее по графам расположены стандартная
ошибка, расчётное значение t
– критерия Стьюдента, доверительные
интервалы для этих параметров.
Полиноминальная
(параболическая)
регрессия
в Excel
осуществляется следующим образом:
1. В ячейки А1, В1 и
С1 вводятся метки Y,
X
и X2.
2. В диапазон А2 и
далее (например, А2: А15) вводятся значения
результативного признака, в диапазон
В2 и далее (соответственно В2:В15)– значения
факторного признака.
3.В диапазон С2 и
далее (С2: С15) вводится формула массива
= В2:В15^2
и нажимается комбинация клавиш Ctrl+Shift+
Enter.
В диапазоне
С2:С15 появится столбец квадратов значений
факторного признака.
4. В открывшемся
окне Анализ
данных
выделяется процедура Регрессия
и нажимается кнопка ОК. Откроется
диалоговое окно Регрессия
с пульсирующим курсором в поле ввода
Входной
интервал Y.
5. С помощью мыши
выделяется диапазон ячеек, в котором
находятся эмпирические значения
результативного признака Y.
В поле ввода Входной
интервал Y
появится соответствующая ссылка.
6. Осуществляется
переход в поле ввода Входной
интервал Х.
С помощью мыши выделяется диапазон
ячеек, в котором находятся эмпирические
значения факторного признака. В поле
ввода Входной
интервал Х
появится соответствующая ссылка.
7. Устанавливается
флажок в группе флажков Остатки.
8. Щелчком на кнопке
ОК запускается процедура Регрессия.
После запуска
процедуры Регрессия
на рабочем листе появляются три таблицы
результатов этой процедуры.
Множественная
линейная регрессия
в Excel
осуществляется аналогичным образом.
При этом в качестве исходных данных
вводятся значения результативного и
нескольких (![]()
)
факторных признаков.
К статистическим
функциям, предназначенным для
регрессионного анализа в Excel,
относятся ЛИНЕЙН,
НАКЛОН,
ОТРЕЗОК,
ТЕНДЕНЦИЯ,
ПРЕДСКАЗ,
СТОШYХ,
ЛГРФПРИБЛ,
РОСТ.
Из этих функций
интерес представляют функции ЛГРФПРИБЛ,
ТЕНДЕНЦИЯ
и РОСТ,
так как другие функции вычисляют
некоторые характеристики, определяемые
статистической процедурой РЕГРЕССИЯ,
а также дублируют друг друга. Эти же три
функции производят вычисления, не
предусмотренные статистической
процедурой РЕГРЕССИЯ.
Функция ЛГРФПРИБЛ
вычисляет
выборочные оценки параметров показательной
(экспоненциальной) регрессии.
Синтаксис данной
функции: ЛГРФПРИБЛ
(известные
значения у; известные значения х;, конст;
стат):
-
известные
значения у–
множество значений результативного
признака. Данный массив представляет
собой вектор-столбец размером

; -
известные
значения х–множество
значений факторных признаков.
– Если в случае
парной регрессии этот аргумент опущен,
то при вычислениях в качестве массива
известные
значения х
используется массив натуральных чисел
1,2…и
т.д. такого же размера, как и массив
известные
значения у;
– В случае
множественной регрессии, если массив
известные
значения у
представляет собой вектор-столбец, то
массив известные
значения х
должен иметь
строк и
столбцов. При этом каждый столбец этого
массива содержит
значений определённого факторного
признака;
– При вводе массива
чисел известные
значения х
с клавиатуры для разделения значений
в одной строке используют точку с
запятой, а для разделения строк–
двоеточие.
-
конст–логическая
переменная, определяющая, следует ли
включать в уравнение регрессии свободный
член.
– Если конст=1
(ИСТИНА) или опущен, то вычисляются и
коэффициенты регрессии, и свободный
член.
– Если конст=
0 (ЛОЖЬ), то предполагается, что свободный
член равен единице.
-
стат–
логическая переменная, определяющая
объём выходной информации.
– Если аргумент
стат =0
(ЛОЖЬ) или опущен, то функция выдаёт
только параметры уравнения регрессии.
При этом для вывода результатов решения
надо заранее выделить диапазон ячеек
размером
![]()
,
где
–
число факторов, включённых анализ.
– Если аргумент
стат =1
(ИСТИНА), то помимо функция выдаёт
дополнительную информацию об исследуемой
регрессионной зависимости. В этом случае
для вывода результатов решения надо
выделить диапазон ячеек размером
![]()
.
В первом столбце выделенного диапазона
находятся следующие характеристики
коэффициенты регрессии, стандартная
ошибка коэффициента регрессии, коэффициент
детерминации, расчётное значение F-
критерия Фишера, сумма квадратов,
обусловленная регрессией. Во втором
столбце находятся значения свободного
члена, его стандартная ошибка, стандартная
ошибка уравнения регрессии, число
степеней свободы, сумма квадратов
остатков.
Так как результатом
реализации функции является массив
чисел, содержащий выборочные характеристики
исследуемой регрессионной зависимости,
то функция вводится как формула массива
Ctrl+Shift+
Enter.
Например, = ЛГРФПРИБЛ
(А1:А6;В1:В6;1;1).
Функции ТЕНДЕНЦИЯ
и РОСТ
используются для вычисления расчётных
значений результативного признака,
соответствующих заданным пользователем
значениям факторных признаков, хранящимся
в массиве новые
значения х.
При этом функция ТЕНДЕНЦИЯ
вычисляет параметры линейной и других
видов регрессии, линейных относительно
входящих в них коэффициентов, таких,
например, как полиноминальная
(параболическая) регрессия
![]()
,
а функция РОСТ–
параметры экспоненциальной регрессии.
Функции вводится
как формула массива Ctrl+Shift+
Enter.
Синтаксис данных
функций идентичен: ТЕНДЕНЦИЯ
(известные значения у; известные значения
х;, новые значения х,; конст)
и РОСТ
(известные значения у; известные значения
х;, новые значения х,; конст):
-
известные
значения у–
множество значений результативного
признака. Данный массив представляет
собой вектор-столбец размером;
-
известные
значения х–множество
значений факторных признаков.
– Если в случае
парной регрессии этот аргумент опущен,
то при вычислениях в качестве массива
известные
значения х
используется массив натуральных чисел
1,2…и
т.д. такого же размера, как и массив
известные
значения у;
– В случае
множественной регрессии, если массив
известные
значения у
представляет собой вектор-столбец, то
массив известные
значения х
должен иметь
строк и
столбцов. При этом каждый столбец этого
массива содержит
значений определённого факторного
признака;
– При вводе массива
чисел известные
значения х
с клавиатуры для разделения значений
в одной строке используют точку с
запятой, а для разделения строк–
двоеточие.
-
новые значения
х– новые
значения факторных признаков, для
которых функция должна вычислить
расчётные значения результативного
признака;
– В случае
множественной регрессии, если массив
известные
значения у
представляет собой вектор-столбец, то
массив новые
значения х
должен иметь
столбцов и столько строк, сколько
расчётных значений у надо вычислить.
–Массив новые
значения х,
так же как и массив
известные значения х,
должен содержать столбец для каждого
факторного признака. Число столбцов
этих массивов должно быть одинаково.
– Если аргумент
новые значения
х опущен, то
предполагается, что он совпадает с
аргументом известные
значения х.
-
конст–логическая
переменная, определяющая, следует ли
включать в уравнение регрессии свободный
член.
– Если конст=1
(ИСТИНА) или опущен, то вычисляются и
коэффициенты регрессии, и свободный
член.
– Если конст=
0 (ЛОЖЬ), то предполагается, что свободный
член равен нулю (в случае линейной
регрессии) и единице (в случае
экспоненциальной регрессии).
Ряды динамики
Ряд
динамики–
это ряд числовых значений статистических
показателей, расположенных в хронологической
последовательности и характеризующих
изменение явления во времени.
Ряд динамики
состоит из двух
элементов:
-
уровней динамического
ряда– числовых значений статистических
показателей, характеризующих величину
изучаемого явления–
;
-
периодов (или
моментов) времени, к которым относятся
данные уровни –

.
Одной из основных
задач в процессе анализа уровней
динамического ряда является определение
основной закономерности (тенденции) их
изменений
во времени.
При этом выделяются
следующие основные
компоненты динамического ряда:
-
основная тенденция
(тренд) (Т); -
циклическая (Ц);
-
сезонная (S);
-
случайная (Е).
Первые три компоненты
формируют систематическую
составляющую
динамического ряда.
Тренд
характеризует устойчивое систематическое
изменение динамического ряда, происходящее
в течение длительного времени и
обусловленное влиянием медленно
развивающихся долговременных факторов.
Сезонная
компонента–
это колебания, периодически повторяющиеся
в некоторое определённое время каждого
года, дня месяца или часа дня.
Циклическая
(периодическая) компонента
проявляется
в том, что значение изучаемого показателя
в течение какого-то времени возрастает,
достигает определённого максимума,
затем понижается, достигает определённого
минимума, вновь возрастает до прежнего
значения и т.д.
Четвёртую компоненту
формируют случайные
колебания,
которые являются результатом действия
большого количества относительно слабых
второстепенных факторов.
Для выявления
и характеристики
основной закономерности развития
явления необходимо выявить первую
компоненту динамического ряда – тренд,
и погасить влияние других типов колебаний
на изменение уровней ряда.
С этой целью
проводят выравнивание динамических
рядов. Различают два вида выравнивания:
механическое (или сглаживание) и
аналитическое.
К приёмам
механического выравнивания
относятся:
-
усреднение левой
и правой половины ряда; -
укрупнение
периодов; -
скользящая средняя:
простая, взвешенная; -
экспоненциальное
сглаживание.
Выбор приема
выравнивания зависит от исходной
информации и задач исследования.
В среде Excel
для выравнивания динамических рядов
используются процедуры Скользящее
среднее и
Экспоненциальное
сглаживание,
входящие в Пакет анализа.
Сущность метода
скользящей средней
заключается в том, что вычисляется
средний уровень из определенного числа
первых по порядку уровней ряда, затем
– средний уровень из такого же числа
уровней, начиная со второго, затем,
начиная с третьего и т.д. Таким образом,
при расчётах среднего уровня как бы
«скользят» по ряду динамики от его
начала к концу, каждый раз отбрасывая
один уровень вначале и добавляя один
следующий. Этим объясняется название
– скользящая средняя.
![]()
;
![]()
;![]()
и т.д.
Следует
отметить, что при использовании метода
скользящей средней «теряются»
![]()
членов в начале и в конце динамического
ряда (где
–размер
интервала (окна) сглаживания). Для
восстановления «потерянных» уровней
в начале и в конце сглаженного ряда для
=3
и
=5
могут быть использованы следующие
формулы:
-
=3
(
):
![]()
;
![]()
;
-
=5(

):
![]()
;
![]()
;
![]()
;
![]()
.
Для получения
количественной модели, выражающей
основную тенденцию изменения уровней
динамического ряда во времени, используется
приём
аналитического выравнивания.
Сущность
его состоит в том, что основная тенденция
развития
![]()
рассчитывается как функция времени. В
этом случае фактические (эмпирические)
уровни заменяются теоретическими,
вычисленными по соответствующему
аналитическому уравнению.
Аналитическое
выравнивание производится в следующей
последовательности:
1)
выделяется этап развития явления и
устанавливается характер динамики на
этом этапе. Этап развития явления– это
период, в течение которого формирование
уровней динамического уровня осуществляется
под воздействием определённого набора
постоянных, периодических и разовых
факторов. Решение этой задачи осуществляется
не только с помощью статистических
методов, а в основном – на базе анализа
сущности, природы явлений и общих
законов его развития.
2)
на основе предположений о той или иной
закономерности развития выбирается
форма аналитического выражения тренда,
то есть вид аппроксимирующей математической
функции.
Основанием для
выбора уравнения тренда
могут служить:
-
качественный
анализ сущности развития данного
явления; -
результаты
предыдущих исследований в данной
области; -
графическое
изображение эмпирических или скользящих
уровней ряда динамики; -
статистико-математических
критериев адекватности.
При анализе рядов
динамики используются следующие
математические модели:
-
линейная yt
= a0
+ a1t,
где
![]()
и
![]()
–
параметры уравнения;
–
начальный уровень
тренда в момент или период, принятый за
начало отсчёта времени;
–
среднее абсолютное
изменение за единицу времени;
–
обозначение
времени.
Параметр
определяет направление развития: если
![]()
,
то уровни ряда равномерно возрастают
в среднем за единицу времени на величину
,
если
![]()
,
то происходит их равномерное снижение.
-
полиноминальная(параболическая)

,
где–степень
полинома. Наиболее применяемой в
практике статистических расчётов
является уравнение параболы
второго порядка yt
= a0
+ a1t
+ a2t2.
Значение параметров
и
идентично предыдущему уравнению.
Параметр
![]()
характеризует
изменение интенсивности развития в
единицу времени. При
![]()
происходит ускорение развития, при
![]()
–
замедление развития.
Соответственно
при параболической форме тренда возможны
следующие варианты развития:
-
если
;
–
ускорение роста; -
если
;
–
замедление роста; -
если
;
–
замедление снижения; -
если
;
–
ускорение снижения.
-
экспоненциальная

,
где
–
константа ряда,
–темп
изменения в разах. При
>1
экспоненциальный тренд выражает
тенденцию ускоренного и всё более
ускоряющегося возрастания уровней, при
<1
экспоненциальный тренд означает всё
более замедляющегося снижения уровней
динамического ряда.
-
логарифмическая

.
Логарифмическая
форма тренда применяется для отображения
тенденции замедляющегося роста уровней
при отсутствии предельно возможного
значения, например, роста спортивных
достижений, производительности агрегата,
продуктивности скота. -
гиперболическая
yt
= a0
+ a1
–
применяется для отображения тенденции
процессов, ограниченных предельным
значением уровня; -
степенная

–
применяется для отображения тенденции
явлений с разной мерой пропорциональности
изменений во времени; -
логистическая
и др.
Наиболее точным
способом выбора формы тренда является
применение
статистико-математических критериев,
в качестве которых могут выступать
остаточное среднее квадратическое
отклонение, средняя ошибка аппроксимации
(![]()
),
стандартизированная ошибка аппроксимации
(![]()
),
относительная ошибка аппроксимации
![]()
(модифицированный коэффициент вариации):
![]()
;
![]()
,
где
y
и
![]()
—
соответственно
фактические и теоретические значения
ряда динамики;
n
– число уровней
ряда;
m
– количество
параметров в уравнении тренда.
![]()
.
Предпочтение
отдаётся той функции, которая имеет
наименьшую величину критерия.
Если
![]()
,
то точность модели тренда высокая, если
=
10-20% – точность модели тренда хорошая
(то есть уравнение достаточно хорошо
описывает основную тенденцию развития
изучаемого явления), если
=20-50%
– точность модели тренда удовлетворительная.
3) Вычисляются
параметры уравнения тренда, и по ним
производится синтезирование
трендовой модели.
Расчёт параметров
уравнений тренда может быть произведён
различными способами:
-
методом средних
значений (или линейных отклонений); -
методом конечных
разностей; -
методом наименьших
квадратов.
Наиболее точным
является аналитическое выравнивание
с помощью способа
наименьших квадратов.
Суть данного способа состоит в том, что
теоретическая линия (прямая или кривая),
выравнивающая ряд, должна проходить в
максимальной близости к фактическим
уровням ряда. Математически это означает,
что сумма квадратов отклонений (разность
между фактическими и теоретическими
уровнями) должна быть минимальной:
å
(y
–
yt)2
= min.
4) На основе
синтезированной модели тренда вычисляются
теоретические уровни.
Выявление и
характеристика основной тенденции
развития дают основание для прогнозирования,
то есть для определения возможного
варианта размеров явления в будущем.
Важное значение при прогнозировании
имеют вопросы о базе и сроках
прогнозирования.
База
прогнозирования
– длина или продолжительность базисного
периода, закономерность которого будет
распространяться на будущее.
Срок
прогнозирования
(период
упреждения)
– длина будущего периода, на который
распространяется закономерность
развития явления.
Однозначного
ответа на вопрос об определении
допустимого срока прогноза нет. В
основном придерживаются следующего
правила: срок прогноза не должен превышать
третьей части длины базы прогноза.
Однако в каждом конкретном случае
необходимо учитывать особенности
изучаемого явления. При этом необходимо,
чтобы продолжительность базисного ряда
составляла определенный этап в развитии
анализируемого явления в конкретных
исторических условий.
Установление
сроков прогнозирования зависит от цели
исследования. Однако следует иметь в
виду, особенности характера изучаемого
явления. Например, ограниченные
физиологические особенности животных
(или растений), делают невозможным
увеличение продуктивности животных
(или урожайности) до бесконечности.
Кроме того, необходимо учитывать
неустойчивость экономики в условиях
переходного периода. Поэтому чем короче
сроки прогнозирования периода, тем
надежнее результат прогноза.
Разработка
прогнозного уровня динамического ряда
может осуществляться на основе
использования различных методов,
наиболее распространённым из которых
является метод экстраполяции.
Метод экстраполяции
основывается на предположении о
неизменности основных факторов,
определяющих тенденцию данного
показателя, и заключается в распространении
закономерностей развития этого
показателя, имевших место в прошлом, на
будущее.
Более точным и
распространённым методом экстраполяции
является применение
аналитического выражения тренда,
при котором в адекватную трендовую
модель подставляются значения
в будущие годы. Прогнозирование на
основе экстраполяции дает возможность
получить точечные значения прогнозируемого
уровня исследуемого показателя.
Интерполяция–
это приближённый расчёт уровней,
находящихся внутри ряда динамики, но
почему-либо неизвестных. При интерполяции
предполагается, что характер тенденции
не претерпел существенных изменений в
том промежутке времени, уровень которого
нам не известен.
Как и экстраполяция,
интерполяция может производится на
основе на
основе выравнивания динамического ряда
по какой-либо аналитической формуле.
В Excel
сглаживание динамического ряда методом
скользящей средней осуществляется
следующим образом:
1. В диапазон ячеек
вводятся уровни ряда динамики (числовые
значения изучаемого статистического
показателя).
2.В меню Сервис
выделяется
строка Анализ
данных.
3. В открывшемся
окне Анализ
данных
выделяется процедура Скользящее
среднее и
нажимается кнопка ОК. На экране появится
диалоговое окно Скользящее
среднее.
4. В поле ввода
Входной
интервал
этого окна вводится ссылка на диапазон
ячеек, содержащий уровни исследуемого
ряда динамики. Входной интервал должен
состоять из одного столбца, «высота»
которого равна числу
уровней данного ряда динамики.
5. В поле Интервал
вводится размер окна сглаживания
(по умолчанию
=3).
6. В поле Выходной
интервал
вводится ссылка на верхнюю ячейку
столбца результатов сглаживания.
Выходной интервал всегда располагается
на том же самом рабочем листе, на котором
находится входной интервал, поэтому в
диалоговом окне процедуры нет таких
позиций, как Новый
рабочий лист
и Новая
рабочая книга.
Выходной интервал состоит по крайней
мере из одного столбца, содержащего
уровни сглаженного ряда. Высота этого
столбца равна высоте входного интервала.
При установке флажка
Стандартные погрешности
в выходном интервале появляется ещё
один столбец– столбец стандартных
погрешностей. В точках, для которых
нельзя вычислить сглаженные значения
и стандартные погрешности, процедура
выводит сообщение #
Н/Д! (Нет
данных).
7. Устанавливается
флажок Вывод
графика.
Флажок Стандартные
погрешности
устанавливается при необходимости
получения стандартных погрешностей
сглаживания. Назначение флажка Метки
рассмотрено
в 1 разделе.
8. Нажимается кнопка
ОК.
Следует иметь в
виду, что процедур Скользящее
среднее
выдаёт сглаженный ряд так называемых
адаптивных скользящих средних. Этот
ряд сдвинут на
шагов вправо относительно «канонического»
ряда скользящих средних. Для сравнения
простого и адаптивного скользящих
средних в диапазоне ячеек, число которых
на
-1
меньше числа уровней исходного ряда
динамики, свободного столбца, рассчитываются
значения скользящих средних, вычисленные
по канонической формуле =
СРЗНАЧ по
диапазону из
первых уровней динамического ряда
(например, при
=3
А1:А3). Данная формула вводится в следующую
после
![]()
по
счёту ячейку столбца, предназначенного
для расчёта канонических средних
(например, при
=3–во
вторую (С2), при
=5
(С3) и т.д.). Затем данная формула копируется
в оставшийся диапазон ячеек этого
столбца. Адаптивные скользящие средние
могут быть вычислены также с помощью
статистической процедуры Добавить
линию тренда
(см. ниже).
При проведении
экспоненциального сглаживания
использование одноимённой процедуры
аналогично выше рассмотренному порядку.
Вместо поля Интервал
диалогового
окна Скользящее
среднее в
процедуре Экспоненциальное
сглаживание
заполняется поле Фактор затухания. В
это поле вводится фактор затухания
![]()
,
где
–
параметр сглаживания (вес текущего
значения при вычислении экспоненциального
среднего,
![]()
).
Параметр
характеризует
скорость реакции экспоненциального
среднего
на изменение текущего значения
динамического
ряда и одновременно определяет его
способность сглаживать случайные
колебания. Чем больше
,
тем быстрее реакция экспоненциального
среднего на изменение динамического
ряда и тем меньше его сглаживающие
возможности. В качестве приемлемого
компромисса рекомендуется брать
в пределах от 0,1 до 0,3. Следовательно,
приемлемыми значениями фактора затухания
являются значения из интервала от 0,7 до
0,9. В статистической процедуре
Экспоненциальное
сглаживание
по умолчанию
![]()
,
что противоречит рекомендациям.
При аналитическом
выравнивании в Excel
используются статистическая процедура
Регрессия
и статистические функции регрессионного
анализа ЛИНЕЙН,
ПРЕДСКАЗ,
ЛГРФПРИБЛ,
ТЕНДЕНЦИЯ и
РОСТ,
рассмотренные в предыдущем разделе. В
этом случае при использовании
статистической процедуры Регрессия
вместо значений факторного признака
вводятся натуральные числа 1,2,….
,
обозначающие порядковые номера периодов
или моментов времени. При использовании
статистических функций натуральные
числа можно не вводить, а оставить
пропущеным аргумент известные
значения х.
Тогда при вычислениях в качестве массива
известные
значения х
используется массив натуральных чисел
1,2…и
т.д. такого же размера, как и массив
известные
значения у.
Эффективным
средством аналитического выравнивания
является процедура Добавить
линию тренда,
входящая в комплекс графических средств
табличного процессора Excel.
Она вычисляет параметры выбранной
пользователем модели тренда. При
вычислениях используется МНК. Модель
тренда выбирается из набора, включающего
в себя пять наиболее распространённых
аналитических моделей: линейную,
логарифмическую, полиноминальную
(параболическую), степенную, экспоненциальную
и модель адаптивной скользящей средней
(формулы см. выше данном разделе).
Параметры аналитических моделей
вычисляются по данным наблюдения, по
которым построен график динамического
ряда. В результате реализации процедуры
в область построения графика выводятся
график функции тренда, её аналитическое
выражение и значение коэффициента
детерминации R2.
При изменении любых значений исходного
ряда динамики процедура автоматически
пересчитывает и обновляет параметры
линии тренда и её график.
Для доступа к
процедуре Добавить
линию тренда
необходимо:
1. В диапазон ячеек
определённого столбца ввести уровни
исследуемого динамического ряда.
2. С помощью Мастера
Функций построить диаграмму (график)
ряда динамики.
3. Щелчком на
диаграмме активизировать её. На панели
меню на месте пункта Данные
появится
пункт Диаграмма.
4. В пункте меню
Диаграмма
выбрать команду Добавить
линию тренда.
Откроется диалоговое окно Линия
тренда.
5. В открывшемся
окне Линия
тренда
раскрыть вкладку Тип.
6. На этой вкладке
в разделе Построение
линии тренда (аппроксимация и сглаживание)
выбрать тип (вид) функции тренда.
7. В списке Построен
на ряде
выделить ряд данных, для которых строится
линия тренда.
8. Раскрыть вкладку
Параметры
диалогового окна Линия
тренда.
Эта вкладка содержит
следующие элементы управления:
-
группу переключателей
Название аппроксимирующей (глаженной)
кривой, состоящую из двух переключателей.
При установке переключателя автоматическое
Excel
автоматически присваивает линии тренда
имя, связанное с типом этой линии и
названием данных наблюдения, по которым
строится линия тренда, например, Линейный
(Урожайность зерновых).
При установке переключателя другое
пользователь сам устанавливает имя
линии регрессии и вводит это имя в поле
Линейный
(Ряд 1),
расположенное справа от переключателя
(максимальная длина имени 256 символов); -
группу счётчиков
Прогноз,
в которую входят два счётчика: вперёд
на…единиц
и назад
на…единиц.
С помощью этих счётчиков устанавливается
срок прогноза и производится экстраполяция
и интерполяция ряда динамики. Счётчики
недоступны в режиме Скользящее
среднее; -
флажок пересечение
кривой с осью Y
в точке.
Если этот флажок не установлен, ординататочки пересечения линии тренда с осью
Y
вычисляется по данным наблюдения. Как
правило, этот флажок не устанавливается.
Используя этот флажок и расположенное
справа от него поле ввода, можно задать
нужную ординату точки пересечения (при
активном флажке и нуле в поле ввода
линия тренда пройдет через начало
координат); -
флажок показывать
уравнение на диаграмме.
При установке этого флажка в область
построения диаграммы выводится
аналитическое выражение (формула)
функции тренда; -
флажок поместить
на диаграмму величину достоверности
аппроксимации.
При установке этого флажка в область
построения диаграммы выводится значение
коэффициента детерминации R2,
который показывает, на сколько процентов
выбранная линия тренда объясняет
разброс уровней ряда. Чем больше данный
показатель, тем более точно выбрана
линия тренда. Сравнивая величину R2
по разным аналитическим моделям можно
определить аппроксимирующую функцию.
то есть наиболее точно описывающую
основную тенденцию развития изучаемого
явления.
9. Установить нужные
переключатели, счётчики и флажки.
Щёлкнуть на кнопке ОК.
Список рекомендуемой литературы
1. Вадзинский Р.
Статистические вычисления в среде
Еxcel.
–СПб.: Питер,2008.
2. Макарова Н.В.
Трофимец В.Я. Статистика в Еxcel.–
М.: Финансы и статитсика, 2006.
3. Берк К. Кэйри П.
Анализ данных с помощью MS
Еxcel.–М.:
Вильямс, 2005.
4. Васильев А.Н.
Научные вычисления в Microsoft
Excel.–М.;
Спб.; Киев: Диалектика, 2004.
5.Вуколов Э.А. Основы
статистического анализа: практикум по
статистическим методам и исследованию
операций с использованием пакетов
STATISTICA
и Еxcel.–
М.: Форум; Инфра–М, 2004.
6. Минько А.А.
Статистический анализ в среде Еxcel.–М.,
СПб., Киев: Диалектика, 2004.
7. Гайдышев И. Анализ
и обработка данных.–СПб; М.: Питер, 2001.
8.
Елисеева И.И., Юзбашев М.М. Общая теория
статистики: Учебник. М: Финансы и
статистика, 2005
9.
Ефимова М.Р., Петрова Е.В., Румянцев В.Н.
Общая теория статистики: Учебник. –
М.: ИНФРА- М, 2006.
10.
Теория статистики: Учебник / Под ред.
Р.А. Шмойловой .4-е изд., доп. и перераб. —
М.: Финансы и статистика, 2005.
11.
Теория статистики: Учебник/ Под ред.
Г.Л. Громыко.- ИНФРА- М, 2006.
75
Приведем пример расчет коэффициента ранговой корреляции  -Кендалла.
-Кендалла.
Для одного класса в 14 учащихся нам известны результаты их уровня интеллекта (IQ) и время решения серии логических заданий (X).
| № | Уровень интеллекта (IQ) | Время решения логических задач в секундах (X) |
| 1 | 100 | 154 |
| 2 | 118 | 123 |
| 3 | 112 | 120 |
| 4 | 97 | 213 |
| 5 | 99 | 200 |
| 6 | 103 | 187 |
| 7 | 102 | 155 |
| 8 | 132 | 100 |
| 9 | 122 | 114 |
| 10 | 121 | 115 |
| 11 | 115 | 107 |
| 12 | 117 | 176 |
| 13 | 109 | 143 |
| 14 | 111 | 111 |
1. Проранжируем полученные данные по столбцу IQ
| № | IQ | X |
| 4 | 1 | 14 |
| 5 | 2 | 13 |
| 1 | 3 | 9 |
| 7 | 4 | 10 |
| 6 | 5 | 12 |
| 13 | 6 | 8 |
| 14 | 7 | 3 |
| 3 | 8 | 6 |
| 11 | 9 | 2 |
| 12 | 10 | 11 |
| 2 | 11 | 7 |
| 10 | 12 | 5 |
| 9 | 13 | 4 |
| 8 | 14 | 1 |
2. Вычислим число совпадений значений P(p).
Например,
для первого испытуемого число совпадений будет равно 0, поскольку ранг второго испытуемого по столбцу X меньше, чем ранг первого испытуемого, следовательно у них нет совпадающих между собой рангов.
для третьего испытуемого число совпадений будет 1, поскольку если из ранга четвертого испытуемого по столбцу X вычесть ранг третьего испытуемого, разность будет равна 1, следовательно количество совпадающих рангов 1.
2.1. Заполняем столбец с числом совпадений для каждого испытуемого:
| № | Число совпадений P(p) |
| 4 | 0 |
| 5 | 0 |
| 1 | 1 |
| 7 | 2 |
| 6 | 0 |
| 13 | 0 |
| 14 | 3 |
| 3 | 0 |
| 11 | 9 |
| 12 | 0 |
| 2 | 0 |
| 10 | 0 |
| 9 | 0 |
| 8 | 0 |
| Сумма P(p) | 15 |
3. Подсчитываем сумму совпадающих значений P(p).
P(p) = 15
3.1. Вычислить сумму инверсий можно применив формулу:
=N*frac{(N-1)}{2} - P(p)=14*frac{13}{2} - 15=76")
4. Подставляем полученные значения в упрощенную формулу коэффициента ранговой корреляции Кендалла.
} - 1") = — 0,67
= — 0,67
5. Используя формулу вычисления эмпирического значения уровня значимости (см. пункт 4.1.):
(frac{2*14+5}{18})}}=frac{60}{18,27}=3,28")
6. По таблице «Стандартные нормальные вероятности» находим ближайшее меньшее к  , а также площадь справа под кривой распределения P
, а также площадь справа под кривой распределения P

P = 0,00007
7. Вычисляем уровень значимости по формуле: p < 2P
p < 0,00014
8. Делаем вывод:
= — 0,67, p < 0,00014
Заказ: 1000047
Выборочные коэффициенты ранговой корреляции Спирмена и Кендалла. Решение в Excel.
Описание
Три эксперта оценили инвестиционную привлекательность десяти компаний, в результате чего были получены три последовательности рангов (в первой строке приведены ранги эксперта А, во второй – ранги эксперта В, в третьей – ранги эксперта С). Определить, как согласуются оценки экспертов, используя выборочные коэффициенты ранговой корреляции Спирмена и Кендалла. Значимость коэффициентов корреляции проверить на уровне α=0,05.
Теория вероятности и математическая статистика (ТВиМС)


- Выборочные средняя, дисперсия и среднее квадратическое отклонение.
- Выборочные уравнения линейной регрессии. Решение в Excel.
- Выборочный коэффициент корреляции, вычисленный по выборке объема n=50 , равен r=0,687; γ=0,95. Найти доверительный интервал для коэффициента корреляции
- Выборочный метод статистического исследования На предприятии в порядке случайной бесповторной выборки было опрошено 100 рабочих из 1000 и получены следующие данные об их доходе за октябрь (табл. 1).Определить: 1. среднемесячный размер дохода у работников данного предприятия, гарантируя результат с вероятностью 0,997; 2. долю рабочих предприятия, имеющих месячный доход 14,0 тыс. руб. и выше, гарантируя результат с вероятностью 0,954; 3. необходимую численность выборки при определении среднего месячного дохода работников предприятия, чтобы с вероятностью 0,954 предельная ошибка выборки не превышала 0,5 тыс. руб.;
- Выборочный метод статистического исследования (расчетно-графическая работа)На предприятии в порядке случайной бесповторной выборки было опрошено 100 рабочих из 1000 и получены следующие данные об их доходе за октябрь (табл. 1).Определить: 1. среднемесячный размер дохода у работников данного предприятия, гарантируя результат с вероятностью 0,997; 2. долю рабочих предприятия, имеющих месячный доход 14,0 тыс. руб. и выше, гарантируя результат с вероятностью 0,954; 3. необходимую численность выборки при определении среднего месячного дохода работников предприятия, чтобы с вероятностью 0,954 предельная ошибка выборки не превышала 0,5 тыс. руб.;
- Выбор посадки подшипника качения на вал и в корпус
- Выбор посадок соединений. Характеристики посадок для соединений. (курсовая работа, вариант 218)
- Выборка задана интервально. Найти ее среднее значение, построить гистограмму частот.
- Выборка из большой партии электроламп содержит 20 ламп. Средняя продолжительность горения лампы из выборки оказалась равной x = 1000 ч., а среднее квадратичное отклонение продолжительности горения лампы s = 40 ч. Найти доверительные интервалы с уровнем значимости α = 0,1 и α = 0,01 для средней продолжительности горения лампы всей партии (считать, что продолжительность горения лампы Х подчиняется нормальному закону).
- Выбор метода выхода на внешний рынок (реферат)
- Выбор оборудования для системы электроснабжения предприятия (курсовой проект, Вариант 28)
- Выбор оптимального направления перевозки. (дипломная работа)
- Выборочно обследование 30 предприятий машиностроительной промышленности по валовой продукции и получены следующие данные, в млн. руб.: 18,0; 12,0; 11,9; 1,9; 5,5; 14,6; 4,8; 5,6; 4,8; 10,9; 9,7; 7,2; 12,4; 7,6; 9,7; 11,2; 4,2; 4,9; 9,6; 3,2; 8,6; 4,6; 6,7; 8,4; 6,8; 6,9; 17,9; 9,6; 14,8; 15,8. Составить интервальное распределение выборки с началом x0 = 1 и длиной частичного интервала h = 3. Построить гистограмму частот.
- Выборочно обследовано 100 заводов по величине основных производственных фондов X (млн. руб.) и объему готовой продукции Y (млн. руб.). Результаты представлены в корреляционной таблице (табл). По данным исследования требуется: 1) в прямоугольной системе координат построить эмпирические ломаные регрессии Y на X и X на Y; 2) оценить тесноту линейной корреляционной связи; 3) составить линейные уравнения регрессии Y на X и X на Y и построить их графики в одной системе координат.
Предварительный просмотр


We have noticed a general trend that with an increase in the height of a person, its weight also increases. This happens because there is a positive correlation between height and weight. As one variable increases, the other one also increases, but with this, we only get the quality measure of the data and not quantity, that by how much they are related. To solve this problem, we have a Spearman Rank Correlation coefficient whose value will tell by how two variables are related. In this article, we will learn how to calculate Spearman Rank Correlation Coefficient in excel.
What is Spearman Rank Correlation Coefficient?
Spearman rank correlation coefficient is a non-parametric measure by which we can have a numerical value of how much two variables are related. Spearman’s rank correlation coefficient works on the ranks and not the data set provided. It would be better to say that Spearman works on ordinal data.
Range of Spearman Rank Correlation Coefficient
- If the graph is monotonically increasing, then the spearman coefficient tends to 1.
- If the graph is monotonically decreasing, then the spearman coefficient tends to -1.
- If the graph is both increasing and decreasing, the spearman coefficient tends to be 0.
- A perfect 1 value signifies that data is said to have a perfect positive correlation.
- A perfect -1 value signifies that data is said to have a perfect negative correlation.
- A perfect 0 value signifies that data is said to have no relation between two variables.
Hence, the spearman coefficient value lies in the range of [-1, 1], where -1 and 1 are included.
Advantages of Spearman Rank Correlation Coefficient
As spearman works on ordinal data, so it’s a non-parametric test. The test has no relation to the actual values in the data set. This coefficient test works well with outliers. The correlation value is not distorted if there are significant outliers in the data set.
The formula for Spearman Rank Correlation Coefficient
A formula has been provided to calculate the Spearman rank coefficient. The formula is:

Where,
rs = Spearman Rank Correlation Coefficient,
di = Difference of the rank of the values in the data set,
n = Size of the data set.
Note: The Formula works only if there are no tie ranks in your data set, i.e. there should be only distinct values for each Variable.
For example:
DataSet 1: Variable1: [1, 4, 3, 5], Variable2: [3, 4, 2, 5]
DataSet 2: Variable1: [1, 2, 2, 2], Variable2: [3, 4, 2, 5]
In the above two given data sets, DataSet1 satisfies the condition, and hence the formula could be applied to find spearman coefficient, but DataSet2 do not satisfies the condition, as there are duplicate values in Variable1 of second data set, hence the formula could not be applied to find spearman coefficient.
How to Calculate Spearman Rank Correlation in Excel?
Before following the procedure to calculate the spearman coefficient, we need to understand two functions in excel, which will be helpful in calculating the coefficient.
Rank Function
=RANK.AVG(number, ref, order)
The rank specifies the rank of a given number in a dataset; one can also select the order in which rank has to appear. =RANK.AVG() takes three arguments: number, ref, and order.
Argument 1: Number is the first argument in the rank function, which specifies for which number rank has to be estimated.
Argument 2: Reference is the second argument in the rank function. One needs to provide the absolute range of the data set.
Argument 3: Order is the third argument in the rank function. The order can be either ascending(1) or descending(0).
Correl function
=CORREL(array1, array2)
Similar to the spearman rank correlation coefficient, we also have the Pearson correlation coefficient. Pearson correlation coefficient is a parametric test to calculate the correlation value of two variables. Both the test is nearly the same. Just the difference lies in that spearman works on ranks of the data, and Pearson works on the actual data. The =CORREL() function calculates the Pearson correlation coefficient. This could be very useful in finding the spearman correlation coefficient, which we will talk about in the later stage of the article. =CORREL() function takes two arguments, array1 and array2.
Argument 1: Array1 is the first argument in the correlation function. It takes the entire data set of the variable1.
Argument 2: Array2 is the second argument in the correlation function. It takes the entire data set of the variable2.
Different methods to find Spearman Coefficient in Excel
There are two different methods by which we can find the Spearman correlation rank coefficient.
Method 1: Using the Formula
Spearman rank coefficient can be found with the help of a formula, as we have mentioned in the above article, but this formula can only be used if each data set does not contain duplicate values so that the rank of each value is unique. For example, Arushi is an aspiring Chartered Accountant, daily, she used to spend her entire day either studying or playing. For 7 days, she kept track of how many hours does she study and play. On a daily basis, her study hours and playing hours vary. Arushi wants to find whether her playing hours and studying hours are positively or negatively correlated with the help of the Spearman correlation rank coefficient.
Following are the steps
Step 1: Create a new column name Study Rank. In cell D3, use the formula =RANK.AVG(B3, $B$3:$B$9, 1). This finds the rank of cell B3 for Study Hours. Press Enter.
Step 2: The number 4 appears in cell D3. This number has ranked 4 in the Study Hours data set.
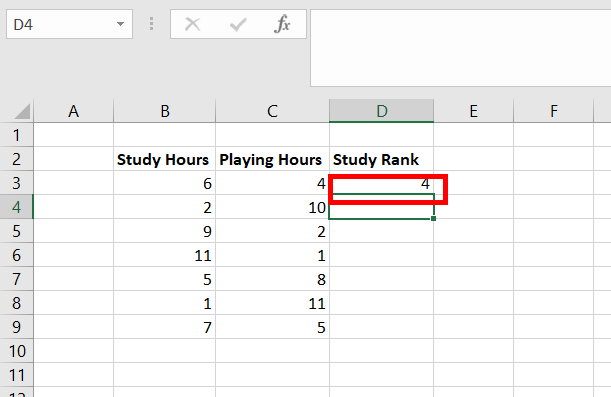
Step 3: Copy the same formula of D3 to cells D4:D9.
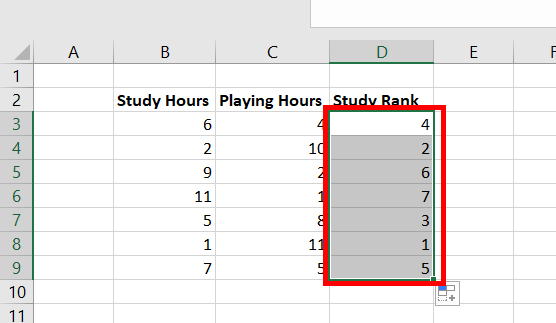
Step 4: Create a new column name Play Rank. In cell E3, use the formula =RANK.AVG(C3, $C$3:$C$9, 1). This finds the rank of cell C3 for Play Hours. Press Enter.
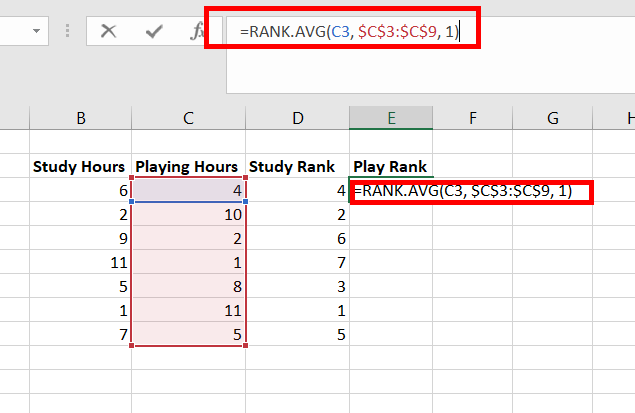
Step 5: The number 3 appears in cell E3. This number has ranked 3 in the Play Hours data set.
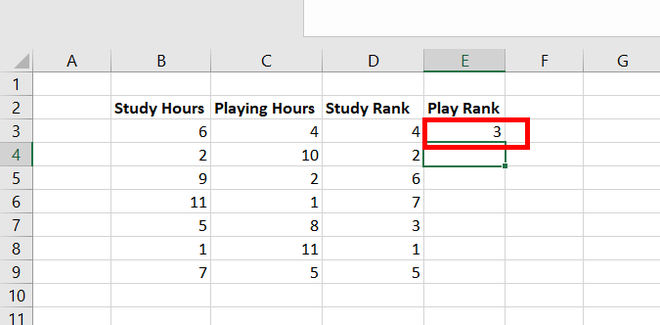
Step 6: Copy the same formula of E3 to cells E4:E9.
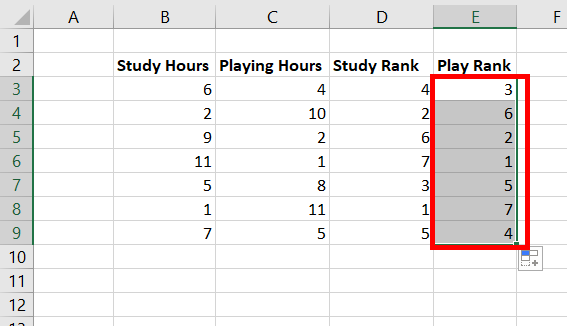
Step 7: Create a new column, name, d. In cell F3, use the formula =D3-E3. This calculates the difference in the ranks. Press Enter.
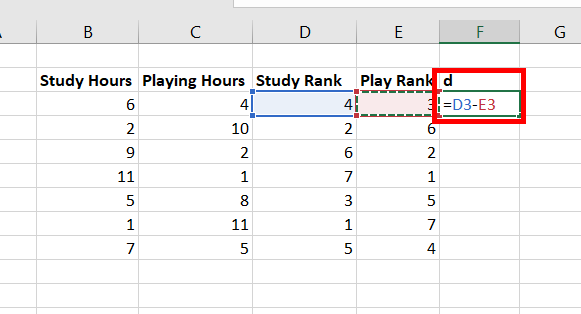
Step 8: Copy the same formula of F3 to cells F4:F9.
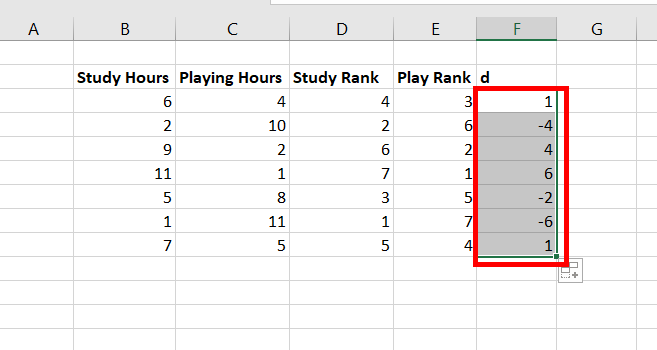
Step 9: Create a new column, name, d{square}. In cell G3, use the formula =F3^2. This calculates the square of the difference. Press Enter.
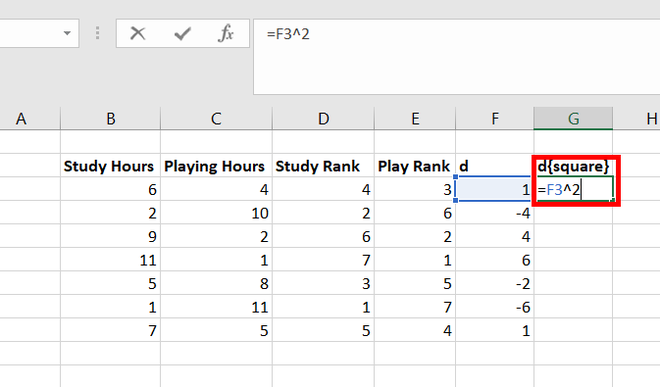
Step 10: Copy the same formula of G3 to cells G4:G9.
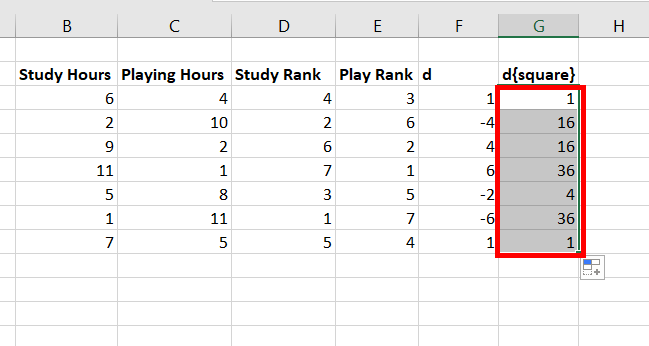
Step 11: Use =COUNT(C3:C9) function to calculate the size of the data set. Press Enter.
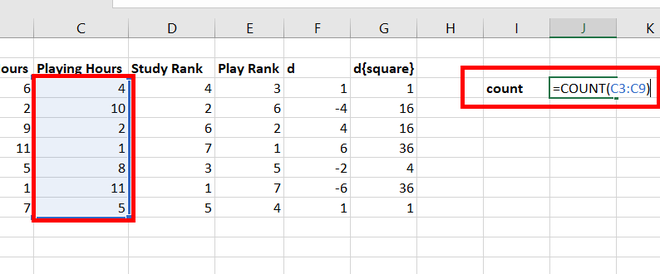
Step 12: In the cell, J3, 7 appears, which is the size of the data set.
Step 13: Use =SUM(G3:G9) function to calculate the sum of the difference between the ranks. Press Enter.
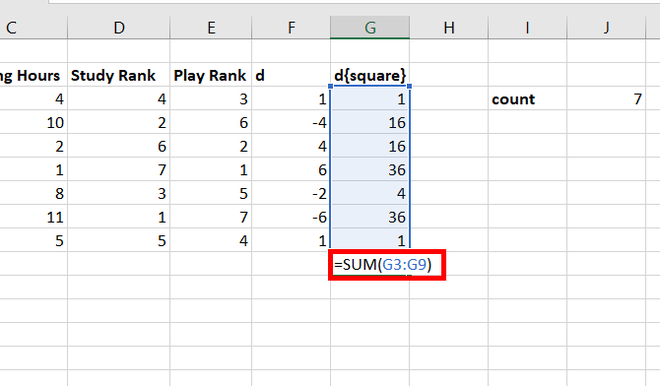
Step 14: In the cell, G10, 110 appears.
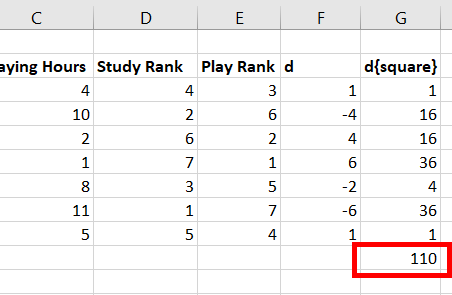
Step 15: In cell J5, apply the Spearman formula as mentioned above in the article, i.e., =1-(6*G10/(J3*(J3^2-1))). Press Enter.
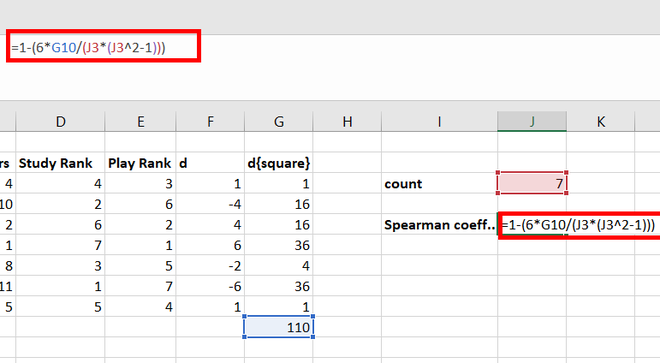
Step 16: We get the spearman correlation rank coefficient as -0.96429, which proves that studying hours and playing hours are negatively correlated.
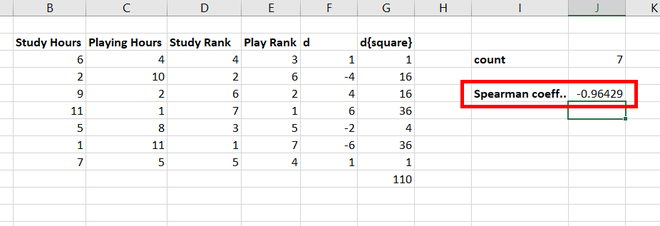
Method 2: Using =CORREL() function
We previously saw that correlated function finds the value of Pearson correlated coefficient by using arguments as data set values. We also know that the spearman coefficient works on the ranks and is a non-parametric test. The correlated function can also be used to find the spearman correlation coefficient by using arguments as data set rank values. For example, Arushi is an aspiring Chartered Accountant, daily she used to spend her entire day either studying or playing. For 7 days, she kept track of how many hours does she study and play. On a daily basis, her study hours and playing hours vary. Arushi wants to find whether her playing hours and studying hours are positively or negatively correlated with the help of the Spearman correlation rank coefficient.
Following are the steps
Step 1: Create a new column, name Study Rank. In cell D3, use the formula =RANK.AVG(B3, $B$3:$B$9, 1). This finds the rank of cell B3 for Study Hours. Press Enter.
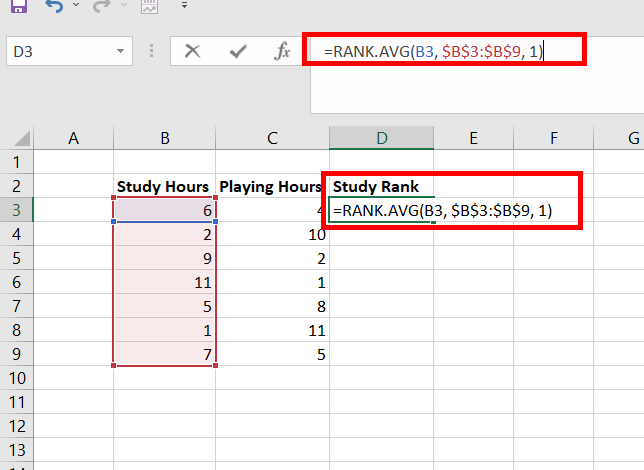
Step 2: The number 4 appears in cell D3. This number has ranked 4 in the Study Hours data set.
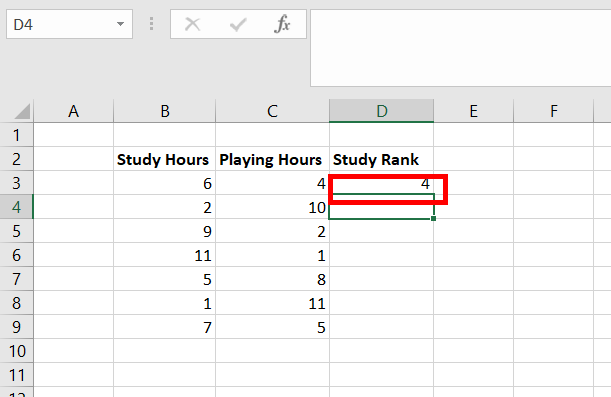
Step 3: Copy the same formula of D3 to cells D4:D9.
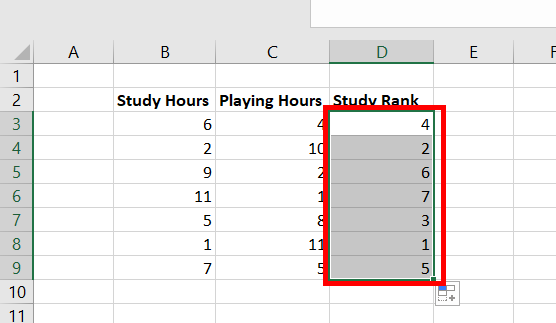
Step 4: Create a new column, name Play Rank. In cell E3, use the formula =RANK.AVG(C3, $C$3:$C$9, 1). This finds the rank of cell C3 for Play Hours. Press Enter.
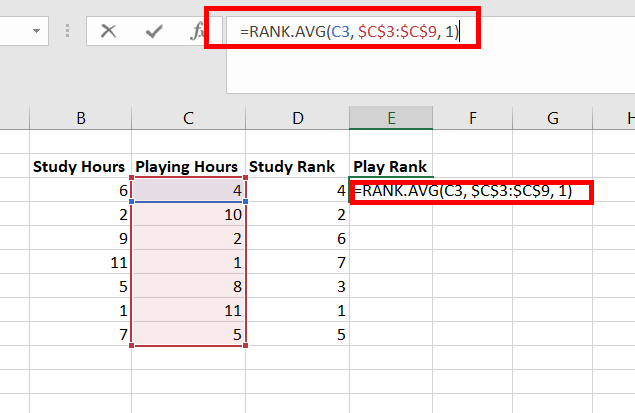
Step 5: The number 3 appears in cell E3. This number has ranked 3 in the Play Hours data set.
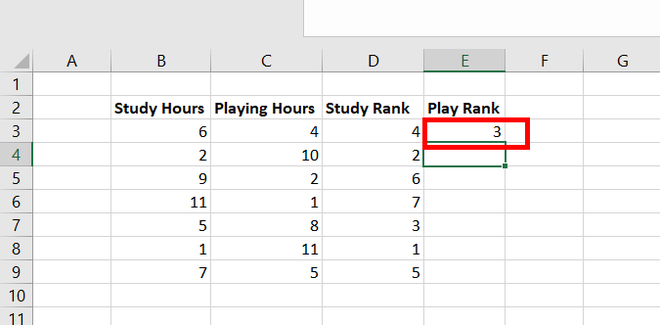
Step 6: Copy the same formula of E3 to cells E4:E9.
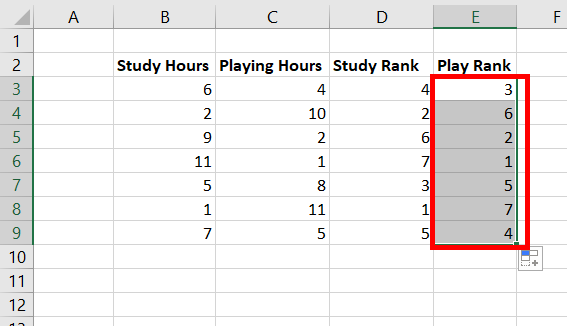
Step 7: In cell H4, use =CORREL(D3:D9, E3:E9) function to find the spearman correlation rank coefficient. Press Enter.
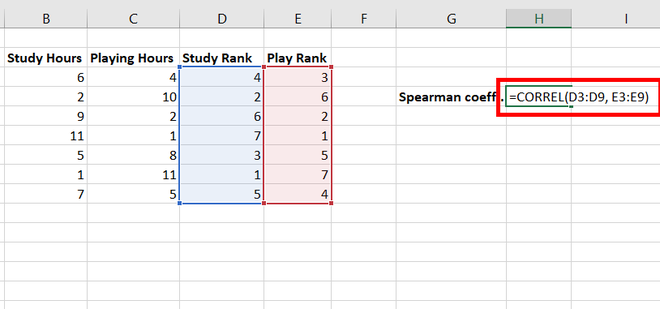
Step 8: We get the spearman correlation rank coefficient as -0.96429, which proves that studying hours and playing hours are negatively correlated.
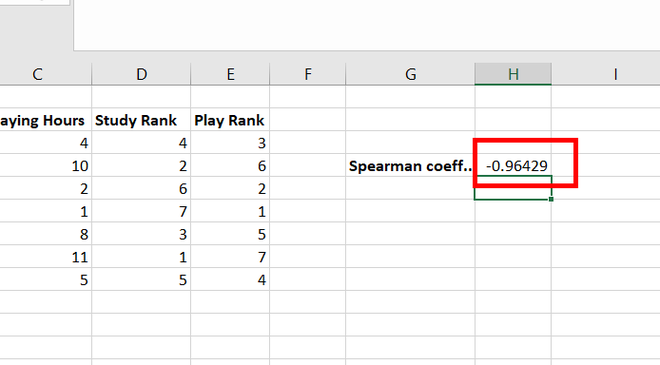
Ранговая корреляция.
Коэффициент ранговой корреляции Кендалла
Краткая теория
Коэффициент корреляции Кендалла
используется в случае, когда переменные представлены двумя порядковыми шкалами
при условии, что связанные ранги отсутствуют. Вычисление коэффициента Кендалла связано с подсчетом числа совпадений и инверсий.
Этот коэффициент изменяется в пределах
и рассчитывается по формуле:
Для расчета
все единицы ранжируются по признаку
;
по ряду другого признака
подсчитывается для каждого ранга число
последующих рангов, превышающий данный (их обозначим
через
),
и число последующих рангов ниже данного (их обозначим через
).
Можно показать, что
и коэффициент ранговой корреляции Кендалла
можно записать как
Для того, чтобы при уровне значимости
,
проверить нулевую гипотезу о равенстве нулю генерального коэффициента ранговой
корреляции
Кендалла при конкурирующей гипотезе
,
надо вычислить критическую точку:
где
– объем выборки;
– критическая точка двусторонней критической
области, которую находят
по таблице функции Лапласа
по равенству
Если
– нет
оснований отвергнуть нулевую гипотезу. Ранговая корреляционная связь между
признаками незначимая.
Если
– нулевую
гипотезу отвергают. Между признаками существует значимая ранговая
корреляционная связь.
Пример решения задачи
Задача
При
приеме на работу семи кандидатам на вакантные должности было предложено два
теста. Результаты тестирования (в баллах) приведены в таблице:
| Тест | Кандидат | ||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| 1 | 31 | 82 | 25 | 26 | 53 | 30 | 29 |
| 2 | 21 | 55 | 8 | 27 | 32 | 42 | 26 |
Вычислить
ранговый коэффициент корреляции Кендалла между
результатами тестирования по двум тестам и на уровне
оценить его значимость.
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Вычислим коэффициент
Кендалла. Ранги
факторного признака
располагаются строго в порядке возрастания и
параллельно записываются соответствующие им ранги результативного признака
. Для каждого
ранга
из числа следующих за ним рангов
подсчитывается количество больших него по величине рангов (заносится в столбец
) и число рангов,
меньших по значению (заносится в столбец
).
Искомый коэффициент корреляции Кендалла:
Вычислим
критическую точку:
-коэффициент
корреляции незначим
Вывод к задаче
Таким
образом взаимосвязь между результатами тестирования по
двум тестам является достаточно слабой.
ТРЕНИНГИ
Быстрый старт
Расширенный Excel
Мастер Формул
Прогнозирование
Визуализация
Макросы на VBA
КНИГИ
Готовые решения
Мастер Формул
Скульптор данных
ВИДЕОУРОКИ
Бизнес-анализ
Выпадающие списки
Даты и время
Диаграммы
Диапазоны
Дубликаты
Защита данных
Интернет, email
Книги, листы
Макросы
Сводные таблицы
Текст
Форматирование
Функции
Всякое
Коротко
Подробно
Версии
Вопрос-Ответ
Скачать
Купить
ПРОЕКТЫ
ОНЛАЙН-КУРСЫ
ФОРУМ
Excel
Работа
PLEX
© Николай Павлов, Planetaexcel, 2006-2022
info@planetaexcel.ru
Использование любых материалов сайта допускается строго с указанием прямой ссылки на источник, упоминанием названия сайта, имени автора и неизменности исходного текста и иллюстраций.
Техническая поддержка сайта
|
ООО «Планета Эксел» ИНН 7735603520 ОГРН 1147746834949 |
ИП Павлов Николай Владимирович ИНН 633015842586 ОГРНИП 310633031600071 |