
По территориям региона приводятся данные за 200Х г.
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., х | Среднедневная заработная плата, руб., у |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Задание:
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнения линейной регрессии
 .
.
3. Оцените тесноту связи с помощью показателей корреляции и детерминации.
4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
5. Оцените с помощью средней ошибки аппроксимации качество уравнений.
6. Оцените с помощью F-критерия Фишера статистическую надёжность результатов регрессионного моделирования.
7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости  .
.
8. Оцените полученные результаты, выводы оформите в аналитической записке.
Решение:
Решим данную задачу с помощью Excel.
1. Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа.
Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у.
Выделите область ячеек, содержащую данные.
Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами как показано на рисунке 1.

Рисунок 1 Построение поля корреляции
Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии.
2. Для расчёта параметров уравнения линейной регрессии
воспользуемся встроенной статистической функцией ЛИНЕЙН.
Для этого:
1) Откройте существующий файл, содержащий анализируемые данные;
2) Выделите область пустых ячеек 5×2 (5 строк, 2 столбца) для вывода результатов регрессионной статистики.
3) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
4) В окне Категория выберете Статистические, в окне функция – ЛИНЕЙН. Щёлкните по кнопке ОК как показано на Рисунке 2;

Рисунок 2 Диалоговое окно «Мастер функций»
5) Заполните аргументы функции:
Известные значения у – диапазон, содержащий данные результативного признака;
Известные значения х – диапазон, содержащий данные факторного признака;
Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0;
Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения.
Щёлкните по кнопке ОК;

Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу <F2>, а затем на комбинацию клавиш <Ctrl>+<Shift>+<Enter>.
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка b | Стандартная ошибка a |
| Коэффициент детерминации R2 | Стандартная ошибка y |
| F-статистика | Число степеней свободы df |
| Регрессионная сумма квадратов
|
Остаточная сумма квадратов
|



Рисунок 4 Результат вычисления функции ЛИНЕЙН
Получили уровнение регрессии:

Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
3. Коэффициент детерминации  означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции:  .
.
Связь оценивается как тесная.
4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат.
Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле:

Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее, и то же самое произведём со значениями у.

Рисунок 5 Расчёт средних значений функции и аргумент

Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%.
С помощью инструмента анализа данных Регрессия можно получить:
— результаты регрессионной статистики,
— результаты дисперсионного анализа,
— результаты доверительных интервалов,
— остатки и графики подбора линии регрессии,
— остатки и нормальную вероятность.
Порядок действий следующий:
1) проверьте доступ к Пакету анализа. В главном меню последовательно выберите: Файл/Параметры/Надстройки.
2) В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
3) В окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
• Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
• Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия, а затем нажмите кнопку ОК.
5) Заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал Y – диапазон, содержащий данные результативного признака;
Входной интервал X – диапазон, содержащий данные факторного признака;
Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа – ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона;
6) Новый рабочий лист – можно задать произвольное имя нового листа.
Затем нажмите кнопку ОК.

Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных задачи представлены на рисунке 7.

Рисунок 7 Результат применения инструмента регрессия
5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.

Рисунок 8 Результат применения инструмента регрессия «Вывод остатка»
Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:


Рисунок 9 Расчёт средней ошибки аппроксимации
Средняя ошибка аппроксимации рассчитывается по формуле:

Качество построенной модели оценивается как хорошее, так как  не превышает 8 – 10%.
не превышает 8 – 10%.
6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера: 

Поскольку  при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателей от нуля:
 .
.
 для числа степеней свободы
для числа степеней свободы 
На рисунке 7 имеются фактические значения t-статистики:

t-критерий для коэффициента корреляции можно рассчитать двумя способами:
I способ: 
где  – случайная ошибка коэффициента корреляции.
– случайная ошибка коэффициента корреляции.
Данные для расчёта возьмём из таблицы на Рисунке 7.

II способ: 
Фактические значения t-статистики превосходят табличные значения:


Поэтому гипотеза Н0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы.
Доверительный интервал для параметра a определяется как

Для параметра a 95%-ные границы как показано на рисунке 7 составили:

Доверительный интервал для коэффициента регрессии определяется как

Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили:

Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью  параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:

Тогда прогнозное значение прожиточного минимума составит:

Ошибку прогноза рассчитаем по формуле:

где 
Дисперсию посчитаем также с помощью ППП Excel. Для этого:
1) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
2) В окне Категория выберете Статистические, в окне функция – ДИСП.Г. Щёлкните по кнопке ОК.
3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК.

Рисунок 10 Расчёт дисперсии
Получили значение дисперсии 
Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7.


Доверительные интервалы прогноза индивидуальных значений у при  с вероятностью 0,95 определяются выражением:
с вероятностью 0,95 определяются выражением:



Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным.
Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2003. – 192 с.: ил.
Спрос и предложение – главные компоненты рынка, взаимосвязанные и взаимодействующие друг с другом. Эти категории помогают понять механизм формирования рыночной цены и потребления товаров, выстроить модель поведения покупателя и продавца.
Отслеживать спрос и предложение своего товара предприятие может средствами Microsoft Excel.
Как построить график спроса и предложения в Excel
Спрос – это желание обладать товаром или услугой, подкрепленное возможностью. То есть «хочу и могу». Не просто потребность, а платежеспособность в отношении определенного продукта в существующих рыночных условиях.
Величина спроса – число товаров и услуг, которое человек готов купить в данный момент, в данном месте, за данную цену.
На величину объема сбыта влияют прямо и косвенно множество факторов:
- активность рекламной кампании;
- мода;
- вкус покупателя, ожидания;
- размер дохода потребителя;
- полезность товара;
- доступность;
- стоимость схожих категорий товаров и т.д.
Зависимость между величиной спроса и факторами – это функция спроса. В экономической практике принято рассматривать функцию спроса от цены. В данном случае все определяющие величину спроса факторы считаются неизменными.
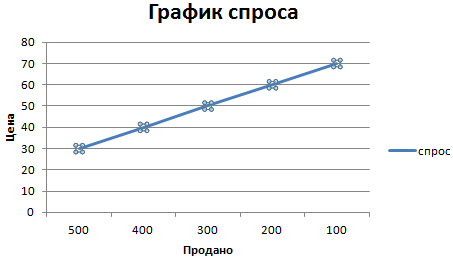
Графическая иллюстрация функции спроса от цены – кривая спроса. Основное свойство данного экономического параметра: уменьшение цены ведет к возрастанию сбыта продукта. И, напротив, высокая стоимость продукта ограничивает спрос на него.
Обратная зависимость имеет фундаментальный характер. Потому ее считают законом спроса. Изобразим его наглядно с помощью графика.
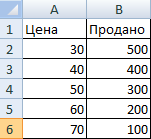
- Внесем данные по ценам на товар и по количеству проданных единиц в шкалу спроса:
- Переходим на вкладку «Вставка», инструмент «Диаграммы» — выбираем тип графика.
- Для настройки делаем график активным, чтобы появилось дополнительная группа закладок под названием «Работа с диаграмами». Выбераем закладку «Конструктор», а в ней инструмент «Выбрать данные».
- В окне «Выбор источника данных» из левой колонки «Элементы легенды (ряды)» удаляем данные «Продано».
- В этом же окне в правой колонке «Подписи горизонтальной оси (категории)» жмем «Изменить».
- Выделяем диапазон ячеек B2:B6 чтобы автоматически заполнить параметрами поле в появившимся окне «Подписи оси».
Обратите внимание! Количество продукции – ось абсцисс (горизонтальная). Цена – ось ординат (вертикальная).
Полноценный анализ ситуации на рынке невозможен без рассмотрения предложения. Это совокупность продуктов и услуг, которые присутствуют на рынке и предлагаются продавцом покупателю за определенную цену.
У данной экономической категории есть величина (число товаров и услуг, предлагаемых в конкретный временной промежуток, в конкретном месте, по определенной цене).
Цена предложения – прогнозируемый показатель. Это минимальная сумма, за которую продавец согласен предложить потребителю свой товар.
Объем предложения зависит, соответственно, от цены. Только в данном случае наблюдается обратная зависимость (ср.: объем): чем ниже цена, тем меньше предлагаемой продукции. Продавец лучше придержит часть товара на складе, чем отдаст за бесценок. Хотя на объем предложения влияет не только стоимость.
Функция предложения от цены показывает зависимость величины предложения от его денежной оценки.
Добавим в демонстрационную табличку еще один столбец. Условно назовем его «Предложено»:
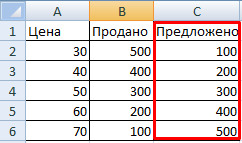
Теперь отобразим на графике сразу 2 показателя: «Спрос» и «Предложение». В одной области. Для этой цели подойдет точечная диаграмма.
Выделяем таблицу с исходными данными и выберем инструмент: «Вставка»-«Точечная»-«Точечная с гладкими кривыми и маркерами».
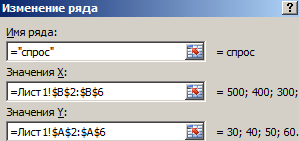
Снова выбираем «Конструктор»-«Выбрать данные» и задаем параметры в окне «Изменение ряда» для графиков:
спрос:
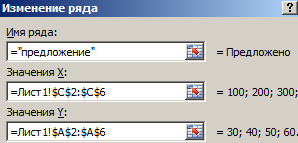
 предложение:
предложение:
Следим, чтобы горизонталь показывала количество, а вертикаль – цену. Получаем результат:
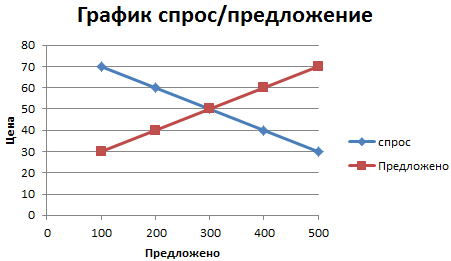
Интерпретируем. Пересечение графиков иллюстрирует становление равновесной цены (50 рублей) и равновесного количества продаж (300 единиц). Область выше равновесной цены – избыток продукции. Производитель вынужден постепенно уменьшать стоимость. Область ниже равновесной цены – дефицит. Цены будут повышаться.
Как найти эластичность спроса в Excel
Эластичность спроса – это степень чувствительности показателя к изменению факторов. Данный критерий расчетный, представлен в виде коэффициентов.
Прямая эластичность по привлекательной цене для потребителя определяется как процентное изменение объема к процентному изменению цены. Измерим коэффициент методом центральной точки (чаще всего используемым).
Для примера возьмем следующие данные:
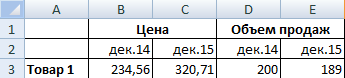
Введем формулу коэффициента эластичности спроса по цене: =((E3-D3)/(E3+D3))/((C3-B3)/(C3+B3)).
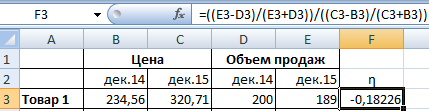
Знак «минус» указывает на отрицательный наклон кривой спроса. Коэффициент эластичности характеризует относительное изменение объема продаж при бесконечно малом изменении стоимости. Так как показатель меньше 0, то график сдвинется влево. Экономический смысл: повышение цены в текущий момент времени повлечет уменьшение будущей стоимости.
Как найти эластичность предложения в Excel
Эластичность предложения – это расчетный показатель чувствительности объема к изменению рыночной цены.
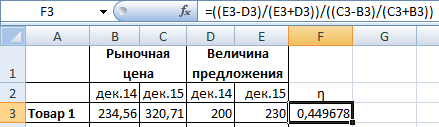
При расчете коэффициента используется та же формула: изменение объема предложения / изменение стоимости.
Скачать график спроса и предложения в Excel
Анализ результата. Относительно неэластичное предложение. Предлагаемый объем продукции остается неизменным для перепродажи по любой стоимости.
По десяти кредитным учреждениям получены данные, характеризующие зависимость объема прибыли (Y, млн.руб.) от величины доходов по кредитам (X1, млн.руб.), доходов по депозитам (X2, млн.руб.) и размера внутрибанковских расходов (X3, млн.руб.).
1. Осуществить выбор факторных признаков для построения многофакторной регрессионной модели.
2. Рассчитать параметры регрессионной модели. Оценить ее качество.
3. Для характеристики модели определить:
4. средние коэффициенты эластичности;
7. Оценить с помощью t-критерия Стьюдента статистическую значимость коэффициентов уравнения множественной регрессии.
8. Построить регрессионную модель со статистически значимыми факторами. Оценить ее качество.
9. Определить точечный и интервальный прогноз результативного показателя.
I. Выбор факторных признаков для построения модели осуществляется с помощью матрицы коэффициентов парной корреляции. Для её построения необходимо:
выбрать Сервис->Анализ данных->Корреляция
заполнить необходимые поля диалогового меню (рисунок 1)

Рис.1. Ввод параметров инструмента «Корреляция»
Результаты представлены на рисунке 2.

Рис.2. Таблица коэффициентов парных корреляций
Для выявления явления мультиколлинеарности необходимо проанализировать коэффициенты парной корреляции между факторными признаками. Если имеют место коэффициенты, значение которых по модулю больше 0,8, то, следовательно, мультиколлинеарность присутствует, и это явление необходимо устранять. Если же значения коэффициентов парной корреляции между факторными признаками, взятые по модулю, меньше величины 0,8, то явление мультиколлинеарности отсутствует, и, следовательно, все факторные признаки можно включать в модель множественной регрессии.
Так как  , т.е. между факторными признаками X1 и X3 существует явление мультиколлинеарности, то для построения модели выбираем тот факторный признак, который оказывает большее влияние на результативный признак (фактор, для которого коэффициент парной корреляции с результативным признаком, взятый по модулю, является большим).
, т.е. между факторными признаками X1 и X3 существует явление мультиколлинеарности, то для построения модели выбираем тот факторный признак, который оказывает большее влияние на результативный признак (фактор, для которого коэффициент парной корреляции с результативным признаком, взятый по модулю, является большим).

Следовательно, фактор X3 оказывает большее влияние на результативный признак (Y) и этот фактор рекомендуется в модели оставить. Фактор X1 оказывает меньшее влияние на результативный признак (Y) и этот фактор рекомендуется из модели исключить.
Таким образом, для построения модели множественной регрессии выбираются два факторных признака — Х2 (величина доходов по депозитам) и Х3 (величина внутрибанковских расходов).
II. Расчет параметров регрессионной модели можно осуществить с помощью инструмента анализа данных Регрессия, отличие заключается в том, что в качестве диапазона значений фактора X необходимо указать диапазон значений факторов X2 и X3 (рисунок 3).

Рис.3. Ввод параметров регрессии
Результаты построение множественной регрессии представлены на рисунке 4.

Рис.4. Вывод итогов регрессии
На основании полученных данных можно записать уравнение множественной регрессии
Y=-16,2872 + 0,197247*X2 + 0,592429*X3
Оценим качество построенной модели множественной регрессии по следующим направлениям:
Коэффициент детерминации  = 0.794176 достаточно близок к 1, следовательно, качество модели можно признать высоким.
= 0.794176 достаточно близок к 1, следовательно, качество модели можно признать высоким.
Критерий Фишера F = 13,50486 > Fтабл = 4,74 , следовательно, уравнение регрессии признается статистически значимым и может быть использовано для анализа и прогнозирования экономических процессов.
Для вычисления Fтабл необходимо определить:
— степень свободы числителя m=2 (число факторных признаков);
— степень свободы знаменателя n-m-1=10-2-1=7;
— уровень значимости  =0,05.
=0,05.
III. Оценим качество построенной модели множественной регрессии с помощью коэффициентов эластичности, b — и D — коэффициентов.
Коэффициент эластичности определяется:
 , (1)
, (1)
где  — среднее значение соответствующего факторного признака,
— среднее значение соответствующего факторного признака,
 — среднее значение результативного признака.
— среднее значение результативного признака.
bi – коэффициенты регрессии соответствующих факторных признаков.
ß-коэффициент определяется по следующей формуле:
 , (2)
, (2)
где  — среднеквадратическое отклонение (СКО) соответствующего факторного признака (рассчитывается как корень квадратный из дисперсии признака),
— среднеквадратическое отклонение (СКО) соответствующего факторного признака (рассчитывается как корень квадратный из дисперсии признака),
 — СКО результативного признака.
— СКО результативного признака.
∆-коэффициент определяется по следующей формуле:
 , (3)
, (3)
где  — коэффициент парной корреляции результативного и соответствующего факторного признаков,
— коэффициент парной корреляции результативного и соответствующего факторного признаков,
 — коэффициент детерминации.
— коэффициент детерминации.
На рисунке 5 представлены формулы расчетов описанных выше коэффициентов

Рис.5. Формулы расчетов коэффициентов
Результаты вычислений представлены в таблице 2.
Результаты расчета бета-, дельта- и коэффициентов эластичности
| Y | X2 | X3 | |
| Ср.знач | 47,8 | 59,4 | 88,4 |
| Эласт. | 0,245 | 0,881 | |
| Дисп | 134,6 | 67,6 | 247,8 |
| СКО | 11,60 | 8,221 | 15,74 |
| bi | 0,197 | 0,592 | |
 |
0,139 | 0,803 | |
 |
0,599 | 0,883 | |
 |
0,105 | 0,894 |
Частный коэффициент эластичности показывает, на сколько процентов изменится среднее значение результативного признака, если среднее значение конкретного факторного признака изменится на 1 %, т.е., при увеличении на 1% величины доходов по депозитным операциям (Х2) прибыль банка увеличится на 0,245 % (Э2 = 0,245), при увеличении на 1% размера внутрибанковских расходов (X3) объём прибыли увеличится на 0,88% (Э3 =0,881).
β-коэффициент показывает, на какую величину изменится СКО результативного признака, если СКО конкретного факторного признака изменится на 1 единицу, т.е. при увеличении на 1 единицу СКО доходов по депозитам (X2), СКО объёма прибыли увеличится на 0,14 (  =0,139774); при увеличении на 1 единицу СКО внутрибанковских расходов СКО прибыли организации увеличится на 0,804 единицы (
=0,139774); при увеличении на 1 единицу СКО внутрибанковских расходов СКО прибыли организации увеличится на 0,804 единицы (  = 0,803801 ).
= 0,803801 ).
∆-коэффициент показывает удельный вес влияния конкретного факторного признака в совместном влиянии всех факторных признаков на результативный показатель, т.е. удельный вес влияния внутрибанковских расходов (X3) на объём прибыли (результативный признак) составляет 89,4% (∆3 = 0,8944), а удельное влияние доходов по депозитам (Х2) на прибыль составляет 10,5 % ( ∆2 = 0,1055).
IV. Для оценки статистической значимости факторных признаков модели множественной регрессии используется t-критерий Стьюдента.
С помощью функции СТЬЮДРАСПОБР(0,05;7) определим табличное значение t табл = 2,364624.
Сравним расчетные значения t-статистики, взятые по модулю, с табличным значением этого критерия (расчетные значения берутся из столбца t-статистика таблицы 3 регрессионного анализа).
Результаты регрессионного анализа
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | Нижние 95,0% | Верхние 95,0% | |
| Y-пересечение | -16,2872 | 14,93 | -1,0904 | 0,311 | -51,60 | 19,03 | -51,60 | 19,03 |
| X2 | 0,197 | 0,295 | 0,66857 | 0,525 | -0,500 | 0,894 | -0,500 | 0,894 |
| X3 | 0,592 | 0,154 | 3,84478 | 0,006 | 0,228 | 0,956 | 0,228 | 0,956 |
t х2 = 0,668573 tтаб=2,364624, следовательно, фактор Х3 признается статистически значимым и информативным. Такой фактор рекомендуется в модели регрессии оставить.
Построим регрессионную модель со статистически значимыми факторами. Для конкретного примера статистически значимым фактором является только фактор Х3 (величина внутрибанковских расходов). Подробное построение регрессионных моделей рассмотрено ранее. Осуществим следующие установки в окне Регрессия (рисунок 6).

Рис.6. Диалоговое окно Регрессия
Получим следующие результаты (рисунок 7)
| ВЫВОД ИТОГОВ | ||||||||
| Регрессионная статистика | ||||||||
| Множественный R | 0,88376 | |||||||
| R-квадрат | 0,78103 | |||||||
| Нормированный R-квадрат | 0,75366 | |||||||
| Стандартная ошибка | 5,75868 | |||||||
| Наблюдения | ||||||||
| Дисперсионный анализ | ||||||||
| df | SS | MS | F | Знач. F | ||||
| Регрессия | 946,300 | 946,300 | 28,53 | 0,000693 | ||||
| Остаток | 265,299 | 33,1624 | ||||||
| Итого | 1211,6 | |||||||
| Коэфф. | Стандар ошибка | t-статист. | P-Знач. | Нижние 95% | Верхние 95% | Нижние 95,0% | Верхние 95,0% | |
| Y-пересечение | -9,78049 | 10,93189 | -0,894 | 0,397 | -34,9895 | 15,42 | -34,9895 | 15,4285 |
| X3 | 0,65136 | 0,12193 | 5,34184 | 0,000693 | 0,370178 | 0,9325 | 0,370178 | 0,932548 |
Рис.7. Вывод итогов регрессии
Запишем уравнение зависимости прибыли организации от величины внутрибанковских расходов (Х3):
Y = 0,651363*Х3 – 9,78049
Качество этой модели может быть оценено по коэффициенту детерминации =0,781, следовательно, размер прибыли кредитных организаций на 78,1 % зависит от величины внутрибанковских расходов.
При сравнении качества регрессии y = f (X3) с качеством регрессии
y = f (X2, X3) , имеющей =0,794, можно утверждать, что улучшение качества модели не произошло.
Значение F-критерия Фишера составляет 28,53 > Fтабл (1,8)=5,32 , следовательно, построенное уравнение регрессии признается статистически значимым и может быть использовано для анализа и прогнозирования процессов.
Построение точечного прогноза прибыли кредитного учреждения (результативного показателя) может быть осуществлено по уравнению множественной регрессии, построенной в пункте 4 задачи, или по уравнению регрессии, содержащего только статистически значимые факторы (пункт 5 задачи).
Воспользуемся уравнением множественной регрессии, так как качество этой модели признано лучшим:
Для построения точечного прогноза результативного признака необходимо рассчитать точечные прогнозы факторных признаков (величины доходов организации по депозитам и величины внутрибанковских расходов). Для этого построим графики X2(t), X3(t) и тренд по каждому из факторов (рисунок 8, 9).

Рис. 8. Выбор типа диаграммы

Рис.9. Выбор источника данных
На полученной диаграмме необходимо добавить линию тренда:
Диаграмма->Добавить линию тренда.
В настройках тренда в закладке Параметры указать (рисунок 10):

 Прогноз вперед на 1 единицу
Прогноз вперед на 1 единицу
Показать уравнение на диаграмме
Поместить на диаграмму величину достоверности аппроксимации.

Рис.10. Параметры линии тренда
Результат построения представлен на рисунке 11.

Рис.11. Построение прогноза величины доходов по депозитам (X2)
В полученное уравнение тренда
Х2 = 1,8061*х + 49,467 ,
в котором в качестве факторного признака выступает «время», необходимо подставить следующий момент времени. Так как временной ряд факторного признака Х2 представлен 10 наблюдениями, то следующий момент времени будет представлен числом 11.
X2Прогн.=1,8061*11+49,467 = 69,3341 (млн.руб.)
Осуществляя аналогичные установки для фактора Х3, построим прогноз по величине внутрибанковских расходов (рисунок 12) .

Рис.12. Построение прогноза величины внутрибанковских расходов (X3)
Определим прогнозное значение внутрибанковских расходов из построенного уравнения тренда:
X3Прогн.=4,9455 *11+61,2=115,6005 (млн.руб.)
Рассчитанные значения прогнозов по факторам Х2 и Х3 подставим в уравнение множественной регрессии:
Y=0,197247*X2 + 0,592429*X3 — 16,2872
YПрогн. = 0,197247*X2 Прогн. + 0,592429*X3 прогн. — 16,2872
Определим интервальный прогноз результирующего показателя, для этого рассчитаем ширину доверительного интервала по формуле:
 (4)
(4)
где  = 5,968678 (стандартная ошибка из таблицы регрессионной статистики, рисунок 17),
= 5,968678 (стандартная ошибка из таблицы регрессионной статистики, рисунок 17),
Y Прогн. – рассчитанное выше значение точечного прогноза результативного признака,
Кр= tтаб= 2,364624 табличный коэффициент Стьюдента, можно определить с помощью функции СТЬЮДРАСПОБР(0,05;7)
 — среднее значение результативного признака (прибыли кредитной организации).
— среднее значение результативного признака (прибыли кредитной организации).
Подставляя эти значения в выше записанную формулу, получим:
U(k)= 5,968678*2,364624*√(1+0,1+326,6634/1211,6)= 16,51731
Таким образом, прогнозное значение прибыли кредитных организаций
Yпрогн= 65,873832 , будет находиться между верхней границей, равной
65,873832 + 16,51731 = 82,39113827 (млн.руб.)
и нижней границей, равной
65,873832 – 16,51731= 49,3565254 (млн.руб.)
Вывод: Прогнозное значение прибыли исследуемых кредитных организаций, рассчитанное по уравнению множественной регрессии, будет находиться в интервале от 49,36 мл.руб. до 82,39 млн.руб.
Данное уравнение регрессии признано статистически значимым по критерию Фишера и обладает достаточно высоким качеством, следовательно, результаты расчетов можно признать надежными и достоверными.
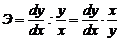
где dy/dx=y’ — производная функции.
Эластичность функции показывает приближенно, на сколько процентов изменяется функция y=f(x) при изменении независимой переменной x на 1%.
Различают обобщающие (средние) и точечные коэффициенты эластичности.
Обобщающий коэффициент эластичности рассчитывается для среднего значения 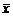 :
: 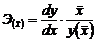 и показывает, на сколько процентов изменится у относительно своего среднего уровня при росте х на 1 % относительно своего среднего уровня.
и показывает, на сколько процентов изменится у относительно своего среднего уровня при росте х на 1 % относительно своего среднего уровня.
Точечный коэффициент эластичности рассчитывается для конкретного значения х = х: 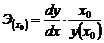 и показывает, на сколько процентов изменится у относительно уровня у(х) при увеличении х на 1% от уровня х.
и показывает, на сколько процентов изменится у относительно уровня у(х) при увеличении х на 1% от уровня х.
В зависимости от вида зависимости между х и у формулы расчета коэффициентов эластичности будут меняться. Основные формулы приведены в таблице.
| Вид функции y = f(x) | Точечный коэффициент эластичности | Средний коэффициент эластичности |
| Линейная y = b + b1x |  |
|
| Парабола y= a + bx + cx 2 | |
|
| Равносторонняя гипербола y = a + b/x | |
|
| Степенная y=ax b | Э(x) = b | Э(x) = b |
| Показательная y=ab x | Э(x)=x ln(b) | |
Только для степенных функций y=a·x b коэффициент эластичности представляет собой постоянную независящую от х величину (равную в данном случае параметру b ). Именно поэтому степенные функции широко используются в эконометрических исследованиях. Параметр b в таких функциях имеет четкую экономическую интерпретацию – он показывает процентное изменение результата при увеличении фактора на 1% . Так, если зависимость спроса у от цен p характеризуется уравнением вида: y=200p -1,5 , то, следовательно, с увеличением цен на 1% спрос снижается в среднем на 1,5% .
Несмотря на широкое использование в эконометрике коэффициентов эластичности, возможны случаи, когда их расчет экономического смысла не имеет. Это происходит тогда, когда для рассматриваемых признаков бессмысленно определение изменения значений в процентах. Например, бессмысленно определять, на сколько процентов изменится заработная плата с ростом возраста рабочего на 1% . В такой ситуации степенная функция, даже если она оказывается наилучшей по формальным соображениям (исходя из наибольшего значения R 2 ), не может быть экономически интерпретирована.
Расчет коэффициента эластичности для линейной функции производят через калькулятор Линейная парная регрессия (см. для нелинейной функции).
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2 );
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.

Модель линейной регрессии имеет следующий вид:
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».

- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.



После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).



В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.

- Строим корреляционное поле: «Вставка» — «Диаграмма» — «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».




Теперь стали видны и данные регрессионного анализа.

- Формула эластичности цены
Формула эластичности цены (Содержание)
- Формула эластичности цены
- Примеры формулы эластичности цены (с шаблоном Excel)
- Калькулятор формулы эластичности цены
Формула эластичности цены
Ценовая эластичность спроса может рассматриваться как отражение покупателя или поведения потребителя из-за изменения цены, с другой стороны, ценовая эластичность предложения будет измерять поведение производителя. Обе метрики вливаются в другие. Каждый из них важен при анализе экономики рынка, но, в конце концов, именно ценовая эластичность спроса будет учитываться большинством компаний или компаний при разработке стратегии продаж.
Итак, для расчета эластичности спроса по цене можно использовать следующую формулу.
Price Elasticity of Demand = % Change in the Quantity Demanded (ΔQ) / % Change in the Price (ΔP)
Price Elasticity of Supply = % Change in the Quantity Supplied (ΔQ) / % Change in the Price (ΔP)
Примеры формулы эластичности цены (с шаблоном Excel)
Давайте рассмотрим пример, чтобы лучше понять формулу расчета эластичности цены.
Вы можете скачать этот шаблон Excel по формуле эластичности цены здесь — Шаблон Excel по формуле эластичности цены
Формула эластичности цены — пример № 1
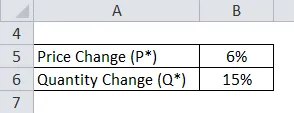
Давайте рассмотрим простой пример, чтобы понять то же самое. Предположим, что цена на апельсины упадет на 6%, скажем, с 3, 49 долл. США за бушель до 3, 29 долл. США за бушель. В ответ на это покупатели продуктов увеличат свои покупки апельсинов на 15%. Какова его ценовая эластичность?
Решение:
Ценовая эластичность спроса на апельсины рассчитывается по приведенной ниже формуле
Эластичность спроса по цене =% изменения требуемого количества (ΔQ) /% изменения цены (ΔP)
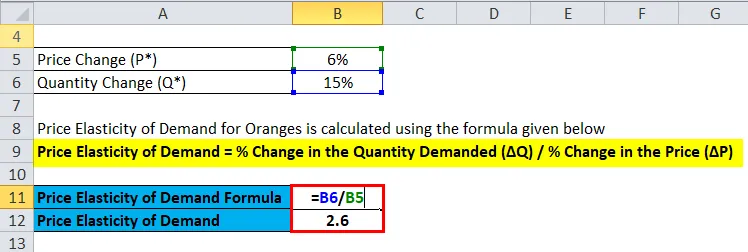
- Эластичность спроса по цене = 15% / 6%
- Эластичность спроса по цене = 2, 6
и, следовательно, эластичность будет в 2, 6 раза, что должно указывать на то, что апельсины достаточно эластичны в отношении их спроса.
Формула эластичности цены — пример № 2
Uber — это одна из онлайн-платформ или приложений для бронирования поездок по выбору потребителя, и он может ездить куда угодно из своего первоначального места в городе. У Uber есть концепция спроса и цены, которая, где его цена постоянно меняется, зависит от спроса. В частности, он имеет одну спорную функцию ценового скачка, которая будет использовать большие объемы данных о спросе (т. Е. Гонщиках) и предложении (т. Е. Водителях) и регулировать цены в режиме реального времени и для поддержания равновесия между каждым и ежеминутно. Он также имеет концепцию повышения цен, что в конечном итоге приведет к снижению спроса.
Согласно имеющимся данным, при переходе от нулевого скачка к скачку 1, 2х можно было бы заметить точно точное падение спроса примерно на 27%. Итак, какова ценовая эластичность цены Uber всплеска?

Решение:
Как можно видеть, при резком росте спроса наблюдается резкое снижение спроса. Рассчитаем его ценовую эластичность:
Ценовая эластичность спроса рассчитывается по приведенной ниже формуле
Эластичность спроса по цене =% изменения требуемого количества (ΔQ) /% изменения цены (ΔP)
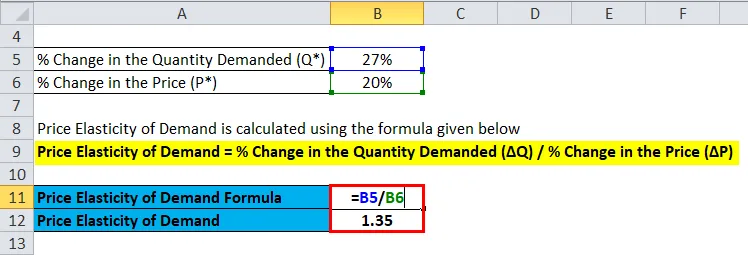
Эластичность спроса по цене = 27% / 20%
Эластичность спроса по цене = 1, 35
Следовательно, из приведенного выше рисунка можно сделать вывод, что потребители Uber относительно эластичны по цене.
Формула эластичности цены — пример № 3
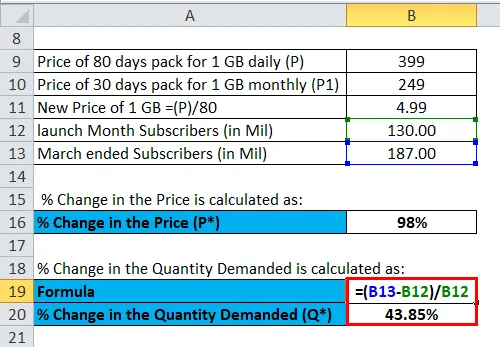
Возьмем другой пример индустрии мобильной связи в Индии, скажем, JIO, которая запустила свою сеть с очень дешевыми скоростями передачи данных, где она предложила план 399, где потребители будут получать 1 ГБ данных ежедневно в течение 80 дней, а также бесплатные звонки и роуминг, тогда как рынок предлагал 1 ГБ данных по цене 249 за 1 ГБ, которая длилась всего месяц. Reliance Jio запустил свои мобильные услуги в коммерческую эксплуатацию в начале 5 сентября 2016 года, и за 1 год своей деятельности поставщик услуг превысил 130 миллионов, а в конце марта 2018 года Jio (RIL) сообщила, что абонентская база составляет 187 миллионов, что означает Компания или фирма добавили около 9 миллионов пользователей в апреле, мае и июне.
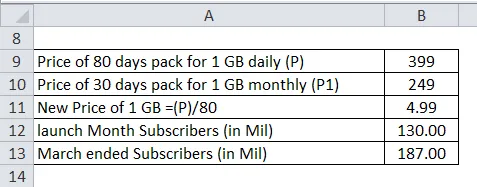
Решение:
% Изменения цены (ΔP) рассчитывается как:
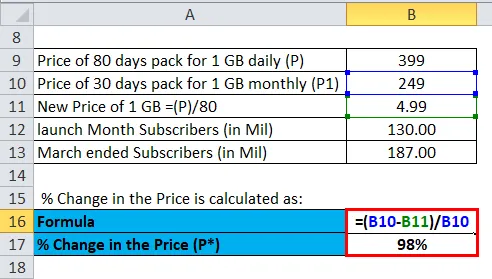
% Изменения требуемого количества (ΔQ) рассчитывается как:
Ценовая эластичность спроса рассчитывается по приведенной ниже формуле
Эластичность спроса по цене =% изменения требуемого количества (ΔQ) /% изменения цены (ΔP)
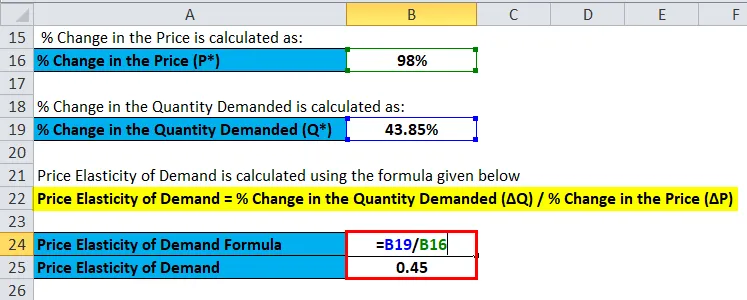
Эластичность спроса по цене = 43, 85% / 98%
Эластичность спроса по цене = 0, 45
Пояснение формулы эластичности цены
Закон спроса гласит, что по мере увеличения цены товара или товара спрос на этот товар или товар со временем будет уменьшаться при всех равных условиях. Следовательно, когда цена товара или товара уменьшается, спрос на этот товар или товар также увеличивается. Следовательно, закон спроса определяет обратную зависимость между количественными факторами продукта и ценой, что и пытается выразить эластичность формулы. Первая часть приносит изменение количества, а вторая — изменение цены.
Закон снабжения, с другой стороны, гласит, что увеличение цены продукта приведет к увеличению поставляемого количества, причем все факторы будут постоянными. То есть поставляемое количество будет двигаться в том же направлении, что и цена. Производственные подразделения или компания будут вкладывать больше средств в производство и будут поставлять больше продуктов для продажи по повышенной цене, поскольку это приведет к увеличению продукта. Следовательно, закон предложения будет определять прямую связь между количеством и ценой. Это была вторая формула, которая пытается сказать, что изменения в количестве обусловлены изменениями в цене.
Актуальность и использование формулы эластичности цены
Продукт или товар будут считаться высокоэластичными, если его оценка выше 1, а это означает, что на изменение спроса в значительной степени влияет спрос.
Оценка от 0 до 1 может считаться неэластичной, поскольку изменение или изменение цены лишь незначительно влияет на спрос на продукт. Продукт или товар с эластичностью 0 будут считаться совершенно неэластичными, так как изменение цены не повлияет на спрос. Многие предметы первой необходимости или предметы домашнего обихода обладают эластичностью спроса по очень низкой цене, поскольку люди нуждаются в них независимо от цены. Например, Бензин. Предметы роскоши, такие как авиабилеты, телевизоры с большим экраном, как правило, будут иметь более высокую эластичность по цене, поскольку они не являются необходимыми в повседневной жизни.
Калькулятор формулы эластичности цены
Вы можете использовать следующий калькулятор эластичности цены.
| % Изменения требуемого количества | |
| % Изменение цены | |
| Ценовая эластичность спроса | |
| Эластичность спроса по цене = |
|
Рекомендуемые статьи
Это руководство по формуле эластичности цены. Здесь мы обсудим, как рассчитать эластичность цены вместе с практическими примерами. Мы также предоставляем Калькулятор эластичности цены с загружаемым шаблоном Excel. Вы также можете посмотреть следующие статьи, чтобы узнать больше —
- Формула нормы прибыли
- Формула для соотношения кислотных испытаний
- Примеры формулы цены наценки
- Стоимость проданной формулы товара
- Формула эластичности | Пример с шаблоном Excel
Ниже приведены условия задач, и текстовый отчет о решении. Закачка полного решения(документы doc и xlsx в архиве zip) начнется автоматически через 10 секунд.
Задача 1. По данным приведенным в таблице 1 провести регрессионный анализ, используя следующие зависимости: линейную, квадратическую, гиперболическую, показательную, степенную, логарифмическую. Выбрать лучшую модель.
Таблица 1 – Исходные данные
|
№ п/п |
X |
Y |
|
1 |
1 |
12 |
|
2 |
2 |
18 |
|
3 |
3 |
15 |
|
4 |
4 |
25 |
|
5 |
5 |
26 |
|
6 |
6 |
34 |
|
7 |
7 |
37 |
|
8 |
8 |
47 |
Решение.
Для решения поставленной задачи и упрощения расчетов воспользуемся средствами табличного процессора MS Excel.
Первым этапом будет ввод исходных данных и построение линейной модели регрессии.
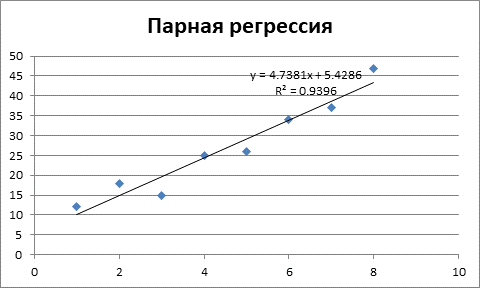
Рисунок 1 – Получение параметров линейной модели регрессии.
Таким образом, получили следующее линейное уравнение регрессии:
![]()
На рисунке 1 показано значение коэффициента детерминации R2 = 0,94. То есть 94% значений переменной Y объясняется значениями переменной X. Таким образом, можно говорить о высоком качестве уравнения регрессии.
Следующим этапом будет построение квадратического уравнения регрессии.
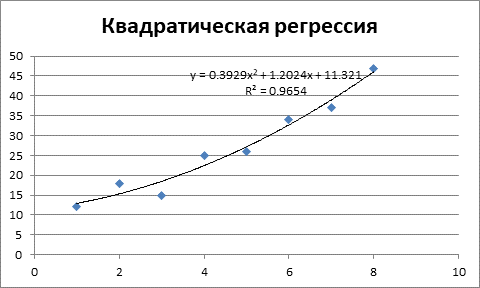
Рисунок 2 – Квадратическое уравнение регрессии и коэффициент детерминации.
Как видим из рисунка 2, коэффициент детерминации составляет R2 = 0,9654, то есть качество уравнения несколько выше линейного уравнения.
Следующим этапом будет получение показательного уравнения регрессии.
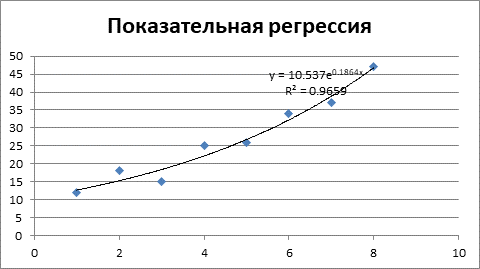
Рисунок 3 – Показательная регрессия и коэффициент детерминации.
Уравнение показательной регрессии объясняет 94,06% значений зависимой переменной Y от факторной переменной X.
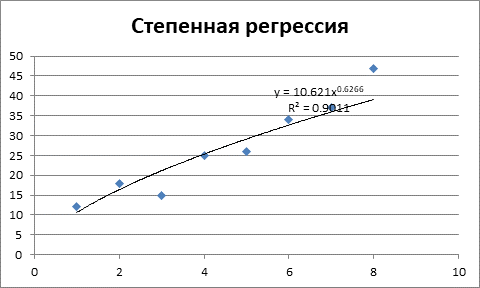
Рисунок 4 – Степенная регрессия и коэффициент детерминации.
Согласно рис. 4 полученное уравнение регрессии объясняет 87,7% значений зависимой переменной Y. Данное уравнение достаточно хуже по качеству, чем предыдущие.
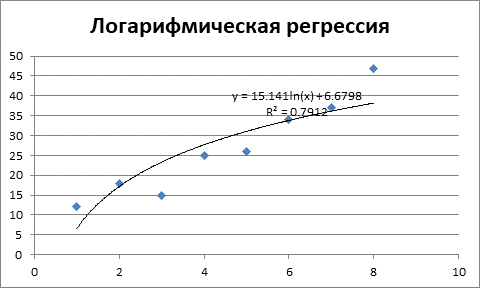
Рисунок 5 – Логарифмическая регрессия и коэффициент детерминации
Коэффициент детерминации логарифмического уравнения регрессии говорит о достаточно хорошем качестве уравнения регрессии, однако оно уступает по качеству предыдущим уравнениям.
В заключении строим график гиперболической регрессии.
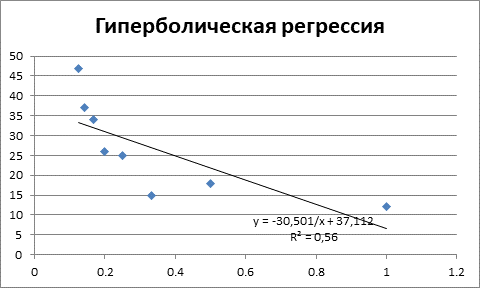
Рисунок 6 – Гиперболическая регрессия и коэффициент детерминации
Как видим данное уравнение регрессии является наихудшим по качеству, поскольку объясняет только 56% значений зависимой переменной Y.
Наилучшим по качеству уравнением регрессии в данной задаче является уравнение квадратической регрессии. Данное уравнение объясняет 96,54% значений зависимой переменной Y.
Задача 2. По данным приведенным в таблице 2 требуется:
1. Построить линейное уравнение регрессии Y по X.
2. Рассчитать линейный коэффициент корреляции, коэффициент детерминации и среднюю ошибку аппроксимации.
3. Рассчитать коэффициент эластичности.
Таблица 2 – Исходные данные
|
№ п / п |
X |
Y |
|
1 |
10 |
33 |
|
2 |
9 |
40 |
|
3 |
9 |
20 |
|
4 |
7 |
34 |
|
5 |
9 |
35 |
|
6 |
12 |
44 |
|
7 |
10 |
37 |
|
8 |
6 |
30 |
Решение.
Для решения поставленной задачи воспользуемся средствами табличного процессора MS Excel.
Для этого создаем новый лист и вводим исходные данные
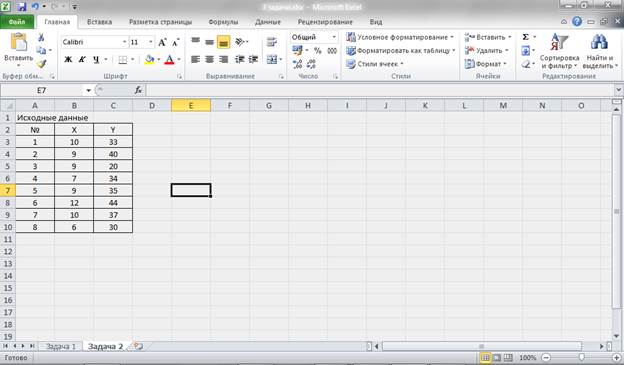
Рисунок 7 – Исходные данные.
Уравнение парной регрессии имеет вид:
![]()
— x, y – факторная и зависимые переменные;
— a, b – коэффициенты уравнения.
Коэффициенты уравнения парной линейной регрессии будем искать с помощью метода наименьших квадратов и табличного процессора MS Excel. Согласно МНК коэффициенты уравнения находятся по следующим формулам:
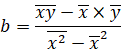
![]()
Составим дополнительную таблицу и произведем промежуточные расчеты в табличном процессоре:
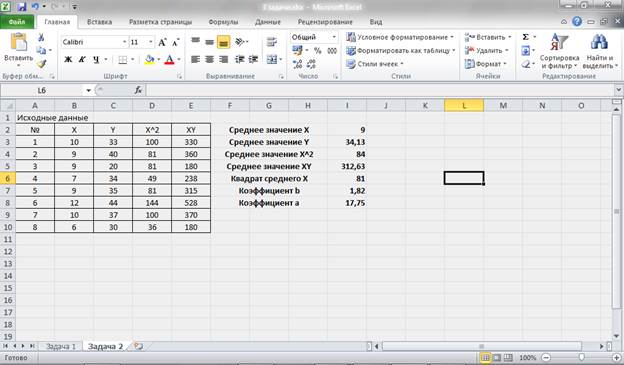
Рисунок 8 – Промежуточные расчеты и расчет коэффициентов уравнения.
В результате мы получили уравнение парной линейной регрессии:
![]()
Коэффициент корреляции, как правило используется для оценки направления и тесноты связи между зависимой и факторной переменными. Однако уже сейчас мы можем предположить направление связи между X и Y по знаку в уравнении регрессии.
Поскольку в уравнении стоит знак «+», то можно предположить наличие прямой связи между X и Y, т.е. значения Y напрямую зависят от значений X.
С помощью средств табличного процессора оценим тесноту этой связи:
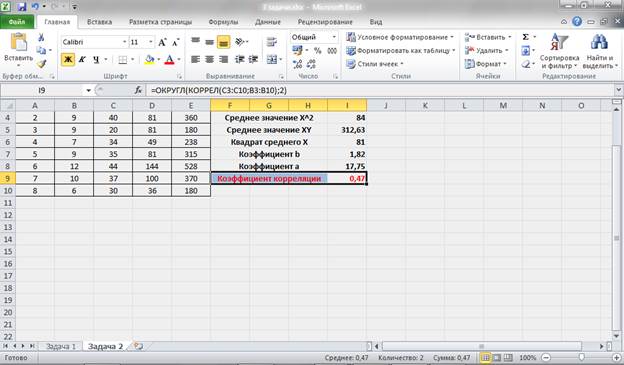
Рисунок 9 – Оценка тесноты связи с помощью коэффициента корреляции.
Коэффициент корреляции ryx = 0,47. Отсюда можно сделать вывод, что между переменными X и Y существует умеренная связь. Положительное значение коэффициента корреляции подтверждает наше предположение о направлении связи – Y зависит от X.
Между коэффициентом корреляции и коэффициентом детерминации существует взаимосвязь:
![]()
Отсюда получаем значение коэффициента детерминации: R2 = 0,22. То есть уравнение регрессии объясняет 22% значений зависимой переменной. Можно говорить о невысоком качестве уравнения регрессии.
Для подтверждения наших выводов о качестве уравнения рассчитаем показатель средней ошибки аппроксимации:
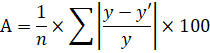
Проведем дополнительные расчеты:
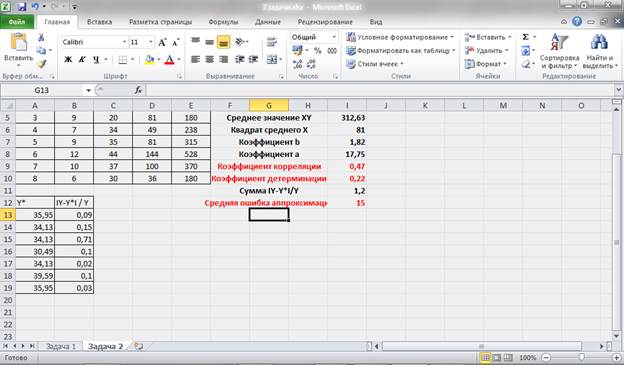
Рисунок 10 – Промежуточные расчеты и расчет средней ошибки аппроксимации.
Получаем, что средняя ошибка аппроксимации не попадает в предел до 5 – 8% (А = 15%), что подтверждает наш вывод о невысоком качестве уравнения регрессии.
Коэффициент эластичности определим по следующей формуле:
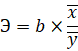
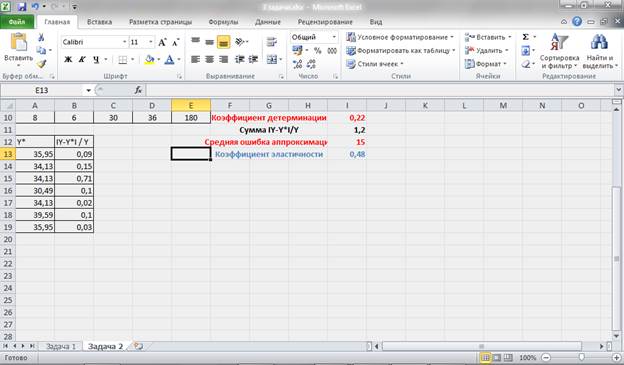
Рисунок 11 – Расчет коэффициента эластичности.
Таким образом, при изменении значения Х на 1% значение Y изменится на 0,48%.
Задача 3. По данным приведенным в таблице 3 требуется:
1. Построить линейную модель множественной регрессии.
2. Записать стандартизированное уравнение множественной регрессии.
3. Рассчитать коэффициенты парной, частной и множественной корреляции. Проанализировать их.
Таблица 3 – Исходные данные
|
№ п / п |
Х1 |
X2 |
Y |
|
1 |
12 |
12 |
133 |
|
2 |
8 |
22 |
135 |
|
3 |
8 |
15 |
120 |
|
4 |
7 |
19 |
125 |
|
5 |
9 |
17 |
130 |
|
6 |
10 |
11 |
144 |
|
7 |
7 |
10 |
137 |
|
8 |
9 |
28 |
121 |
Решение.
Для решения поставленной задачи используем возможности и средства табличного процессора MS Excel. Вводим исходные данные.
Для построения модели множественной регрессии проведем дополнительные расчеты:
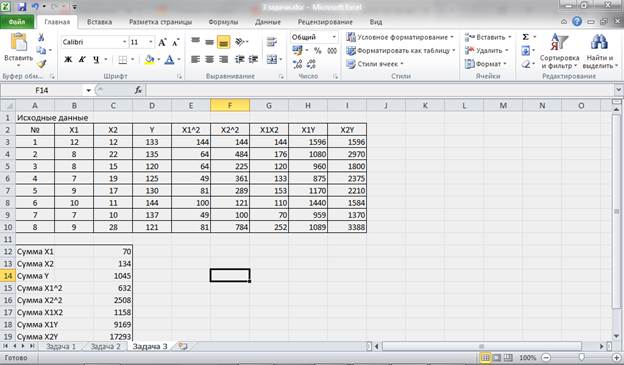
Рисунок 12 – Промежуточные расчеты.
Параметры уравнения множественной регрессии для двухфакторной модели можно определить из системы уравнений:
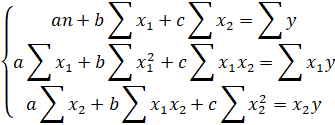
Запишем действующую систему уравнений:
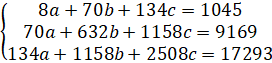
Данную систему можно решить методом Крамера при условии, что матрица, составленная из коэффициентов при неизвестных, не являтся вырожденной, т.е. Δ ≠ 0.
Для упрощения вычислений рассчитываем определитель матрицы, составленной из коэффициентов при неизвестных:
Δ = 39 424
Поскольку исходная матрица не является вырожденной система уравнений имеет решение.
Δ1 = 5 399 564
Δ2 = 28 780
Δ3 = -29 948
Отсюда находим коэффициенты при неизвестных в уравнении регрессии:
— a = 136,96
— b = 0,73
— c = -0,76.
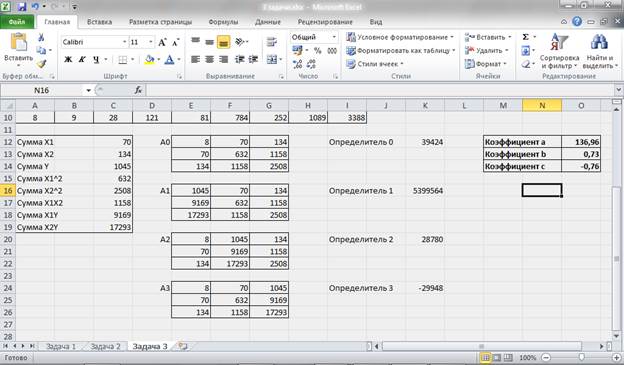
Рисунок 13 – Расчет параметров уравнения множественной регрессии.
Таким образом, мы получаем следующее уравнение множественной регрессии:
![]()
Для построения уравнения множественной регрессии в стандартизированной форме проведем расчет стандартных ошибок и коэффициентов стандартизированного уравнения:
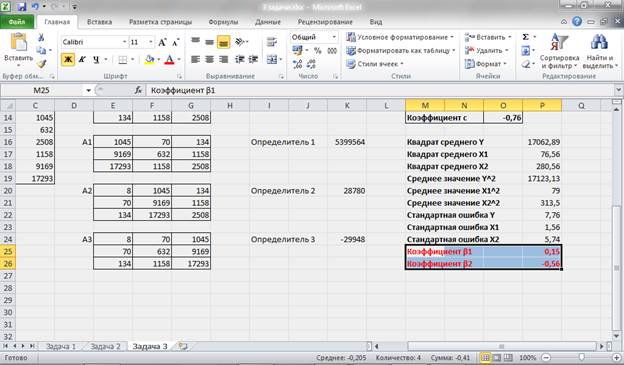
Рисунок 14 – Расчет коэффициентов стандартизированного уравнения.
Таким образом, стандартизированное уравнение множественной регрессии примет вид: ty = 0,15tx1 – 0,56tx2
Для расчета парной, частной и множественной корреляции воспользуемся таким инструментом табличного процессора, как пакет анализа, для построения корреляционной матрицы:
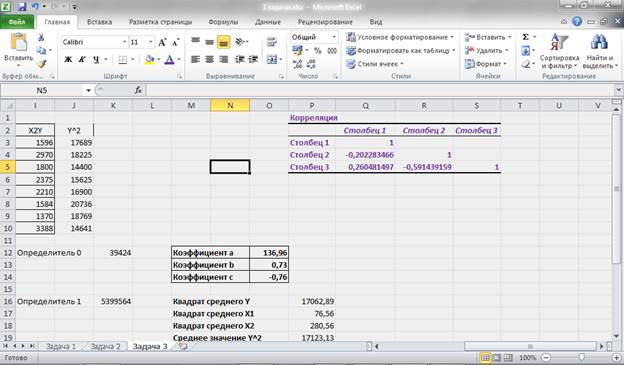
Рисунок 15 – Расчет корреляционной матрицы.
Как видим из рис. 15. Наибольшая связь обратного направления присутствует между переменными Y и X2, т.е. по сути Х2 зависит от значений Y. Прямая же связь между Y и X1 хоть и присутствует, но она достаточно слабая.
Также присутствует слабая обратная связь между переменными X1 и X2.
Список литературы
Список литературы
1. Айвазян С.А., Мхитарян В.С. Прикладная статистика и основы эконометрики. Учебник для вузов. – М.ЮНИТИ, 1998. – с. 621 – 632; 751 – 766.
2. Бородич С.А. Эконометрика: Учебное пособие. – Мн.: Новое знание, 2001. – с. 98 – 115; 121 – 147; 200 – 222
3. Доугерти К. Введение в эконометрику: Пер. с англ. – М.: ИНФРА-М, 1999. – XIV, с. 53 – 111
4. Кремер Н.Ш., Путко Б.А. Эконометрика: Учебник для вузов / Под ред. Проф. Н.Ш. Кремера. – М.: ЮНИТИ-ДАНА, 2002. – с. 50 – 80
5. Кулинич Е.И. Эконометрия. – М.: Финансы и статистика, 2001. с. 43 – 83
6. Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. Начальный курс. Учебное пособие. 2-е изд. – М.: Дело, 1998. – с. 17 – 42
7. Практикум по эконометрике: Учебное пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2002. – с. 5 – 48