
Word: специальные символы и подстановочные знаки
В окне «Найти и заменить» Microsoft Word есть два типа подстановок — специальные символы и подстановочные знаки.
Те и другие можно вводить в строки поиска и замены, включив используя список «Special» («Специальный») в полностью открытом окне «Найти и заменить» (нажать комбинацию клавиш Ctrl+H, потом кнопку «Больше>>«).
Специальные символы — это те, которых нет на клавиатуре или которые нельзя непосредственно вписать в строки поиска/замены,
например, разрыв строки.
Если в окне поиска/замены включен чекбокс Use wildcards (Подстановочные знаки), то можно задавать достаточно сложные условия поиска и замены, потому что подстановчные знаки — это офисная реализация всё тех же регулярных выражений.

Чекбокс «Подстановочные знаки» в работе — убираем лишние пробелы в тексте
Некоторые символы и знаки можно использовать только в строке поиска, а некоторые — только в строке замены.
При этом возможность применения
части символов зависит от того, включен ли чекбокс Use wildcards (Подстановочные знаки).
Полный список подстановок в самом Word отсутствует или я его не нашёл, поэтому ниже приводится более-менее адекватный список, актуальный для всех версий Word плюс немного примеров.
1. Строка поиска
| Спец. символы | Обозначение (англ.) | Обозначение (рус.) |
| ^p | Paragraph mark (¶) | Конец абзаца (¶) |
| ^? | Any character | Любой символ |
| ^# | Any digit | Любая цифра |
| ^$ | Any letter | Любая буква |
| ^e | Endnote mark | Концевая сноска |
| ^d | Field | Поле |
| ^f | Footnote mark | Нижняя сноска |
| ^b | Section break (===End of section===) | Разрыв секции |
| ^w | Whitespace | Любое количество и комбинация обыкновенных и неразрываемых пробелов, табуляций и концов абзаца |
| Спец. символы | Обозначение (англ.) | Обозначение (рус.) |
| ^t | Tab character | Символ табуляции |
| ^a | Comment mark | Комментарий |
| ^0nnn | ANSI or ASCII characters | Любой ANSI или ASCII символ с кодом nnn |
| ^^ | Caret character | Символ ^ |
| ^g | Graphic | Графика |
| ^n | Column break (···Column Break···) | Разрыв колонки |
| ^l | Manual line break | Принудительный разрыв строки |
| ^m | Manual page break (—Page Break—) | Принудительный разрыв страницы (—Page Break—). Если опция Use wildcards включена, то ищет принудительный разрыв и страницы, и секции |
| ^+ | Em dash (—) | Длинное тире (—). Символ с кодом 0151 |
| ^= | En dash (–) | Короткое тире (–). Символ с кодом 0150 |
| ^s | Nonbreaking space (°) | Неразрывный пробел (°) |
| ^~ | Nonbreaking hypen (-) | Неразрывный дефис (-) |
| ^- | Optional hypen (¬) | Мягкий перенос (¬) |
| Подстановочные знаки | Обозначение (рус.) | Пример строки поиска | Примеры результатов поиска (в кавычках) |
| ? | Один любой символ | б?к | «бак», «бок», «бук», «б5к», «б¶к» |
| * | Любое количество любых символов | б*к | «бык», «бардак», «белый¶ полковник» |
| [] | Один из указанных символов | б[аоу]к | «бак», «бок», «бук» |
| [-] | Один символ из диапазона. Диапазон должен быть указан в порядке возрастания кодов символов. |
[а-яё] | Любая строчная русская буква |
| [А-ЯЁ] | Любая прописная русская буква | ||
| [0-9] | Любая цифра | ||
| [!] | Один любой символ, не указанный после восклицательного знака | б[!ы]к | «бак», «бок», но не «бык» |
| [!x-z] | Один любой символ, не входящий в диапазон, указанный после восклицательного знака | [!а-яё]ок | «Бок», «Док», но не «бок», «док» |
| [!0-9] | Любой символ, кроме цифр | ||
| {n} | Строго n вхождений предыдущего символа или выражения. Выражением является все то, что заключено в круглые скобки. Выражение может состоять как из конкретных символов, так и содержать спец. символы. |
10{3} | «1000», но не «100», «10000» |
| 10(20){2} | «102020», но не «1020», «10202020» | ||
| {n;} | n и более вхождений предыдущего символа или выражения | 10{3;} | «1000», «10000», «100000», но не «100» |
| {n;m} | От n до m включительно вхождений предыдущего символа или выражения | 10{3;4} | «1000», «10000», но не «100», «100000» |
| @ | Ноль или более вхождений предыдущего символа или выражения | 10@ | «10», «100», «1000», «10000» |
| < | Начало слова | <бок | «боксёр», но не «колобок» |
| > | Конец слова | бок> | «колобок», но не «боксёр» |
2. Строка замены
| Спец. символы | Обозначение (англ.) | Обозначение (рус.) |
| ^p | Paragraph mark (¶) | Разрыв абзаца (¶) |
| ^t | Tab character | Символ табуляции |
| ^0nnn | ANSI or ASCII characters | Любой ANSI или ASCII символ с кодом nnn |
| ^^ | Caret character | Символ ^ |
| ^c | Clipboard contents | Содержимое буфера обмена |
| ^& | Contents of the Find what box | Содержимое строки поиска (или то, что найдено) |
| ^n | Column break (···Column Break···) |
Разрыв колонки |
| ^l | Manual line break (¿) | Принудительный разрыв строки |
| ^m | Manual page break (—Page Break—) | Принудительный разрыв страницы |
| ^+ | Em dash (-) | Длинное тире (-). Символ с кодом 0151 |
| ^= | En dash (–) | Короткое тире (–). Символ с кодом 0150 |
| ^s | Nonbreaking space (°) | Неразрывный пробел (°) |
| ^~ | Nonbreaking hypen (-) | Неразрывный дефис (-) |
| ^- | Optional hypen (¬) | Мягкий перенос (¬) |
| Спец. символы | Обозначение (англ.) | Обозначение (рус.) |
| n | Expression n | Выражение номер n из строки поиска |
Примечание 1. В операторах {n;} и {n;m} точка с запятой означает List separator (Разделитель элементов списка) из настроек операционной системы, зависящих от локали
(например, в США — запятая, в России — точка с запятой).
Примечание 2. Для поиска в документе символов, которые в строке поиска «заняты» как специальные перед ними ставится обратный слэш ().
Например, если включена опция Use wildcards (Подстановочные знаки), для поиска восклицательного знака в строке поиска вводится !
3. Примеры для поиска
| Строка поиска | Что ищет |
| [!^0013]^0013[!^0013] | Конец абзаца в окружении двух других символов |
| ^0032{2;} | Два и более пробелов |
| [.,:;!?] | Знак препинания |
| <[0-9]@,[0-9]@> | Вещественное число, набранное через запятую |
| <[А-яЁё]@> | Русское слово (зависит от кодировки) |
4. Примеры для замены
Подстановочные знаки включены!
| Строка поиска | Строка замены | Что заменяет |
| (^0013){2;} | 1 | Удаление пустых строк (если они создавались нажатием Enter) |
| ^0032([.,:;!?]) | 1 | Удаление пробелов перед знаками препинания |
| ([0-9])^0032([0-9]) | 1^s2 | Замена пробелов между цифрами на неразрывные пробелы |
| -([0-9]) | ^01501 | Замена дефисов перед цифрами на правильный символ «минус» |
| Ивано([а-я]@>) | Петро1 | Замена Ивановых на Петровых во всех падежах сразу (конечно, фамилии должны склоняться одинаково) |
| (<[0-9]@).([0-9]@>) | 1,2 | Замена десятичных точек между цифрами на запятые |
24.09.2020, 10:16 [28988 просмотров]
Перевод строки – базовая операция, которую можно выполнить относительно текстовых данных и символов. Она встречается как в разработке, так и в операционных системах. Далее она будет рассмотрена более подробно. Также предстоит изучить формы ее представления на компьютерах и ключевые особенности.
Определение
Перевод строки – это разрыв. Так называется продолжение печати текста с новой строки (с левого края) на строчку ниже или уже на следующей странице.
String – это последовательность из нуля и более символов, которые не являются элементами новой строчки, а также терминирующего символа новой строки. Такое определение дает стандарт POSIX. На нем базируется почти все современное программное обеспечение.
Символы управления в системах
Системы, базирующиеся на ASCII или совместимом наборе символов, будут использовать или LF (перевод каретки), или CR (возврат каретки) по отдельности. Также возможно применение последовательности CR + LF.
Все текстовые редакторы отображают напечатанные данные в некоем адаптированном виде при помощи преобразований печатных элементов. Пример – перенос строки и табуляция. Соответствующие операции будут выражены в редакторе определенным образом – в виде настоящих отдельных строк или выравнивающих отступов.
Символ переноса строк обычно ставится при нажатии на клавишу Enter. Это классический вариант, но есть и другие. Многое в соответствующем вопросе зависит от того, на какой конкретно платформе будет происходить кодирование информации:
- в UNIX-системах (сюда включены также современные версии MacOS) будет использоваться всего один символ перевода строки (LF);
- в Windows задействованы для варианта – возврат каретки (CR) и перевод строки на новую (LF);
- в старых версиях MacOS, написанных до 2001 года, использовался только символ CR.
Отдельно стоит обратить внимание на Юникод. Здесь используется определенный спектр символов управления.
В Unicode
Действующий стандарты требуют, чтобы приложения, совместимые с Unicode, обязательно воспринимали как перевод строчек каждый из таких символов:
- LF – подача string;
- CR – возврат каретки;
- NEL – переход на следующую string;
- LS – разделитель строк;
- PS – разделитель абзацев.
Если используется последовательность CR + LF, она будет восприниматься системой или приложением как одно единственное действие, а не два отдельных.
Термины
Теперь можно изучить несколько понятий, которые помогут лучше освоить символы управления в ASCII:
- Перевод строчки сокращается до NEL или newline – «перевод на новую строку».
- Возврат каретки – CR. Управляющий символ, который помечается как r и имеет код 0x0D. При его выводе курсор будет перемещен к левому краю поля. Именно он будет вводится при нажатии на Enter. При записи в файл не рассматривается как отдельный компонент. Данное явление поддерживается только в Macintosh-системах.
- Подача на string или перевод. Еще один символ ASCII для управления текстовыми данными. Имеет код 0x0A, а также выражен символом n. При его использовании курсор будет перемещен на новую строку. Если речь идет о принтере, то бумага будет сдвинута вверх, а на дисплее произойдет сдвиг курсора вниз при наличии пространства. Если же места нет, текст будет прокручен вверх.
- Аппаратный (жесткий) возврат – разделитель строк, который проставляется пользователем. В машинном представлении он имеет яркую выраженность управляющими символами или тегами.
- Мягкий возврат – перед строчки, выполненный текстовым процессором в том месте, где было выбрано. Он разделяет строки в визуальном (том, который видит пользователь) представлении. В машинной интерпретации может быть никак не выражаться.
Если ввести в терминале последовательность CR + LF (код 0x0D0A), согласно семантики терминала, будет создана новая строчка.
В Word
Знак перехода на новую строчку чаще всего используется в текстовых редакторах. Пример – Word. Далее предстоит выяснить, как в том или ином случае перенести каретку на новую string в том или ином случае. В MS Word существуют несколько методов реализации соответствующей задачи.
Без создания абзаца
Иногда конец строчки не нужен – необходимо просто сделать разрыв между текстовыми данными. В этом случае можно использовать один прием MS Word. Он позволяет перейти на другую строчку, рассматривая обе strings в качестве единого целого.
Для этого потребуется выполнить следующую последовательность действий:
- Открыть документ, с которым планируется работать.
- Поставить курсор в «конец» строчки. Последний напечатанный знак в ней станет окончанием.
- Нажать сочетание Shift + Enter. Оно будет считано системой как символ переноса строки.
Теперь можно продолжить печать. Абзац окажется разорванным. Каретка будет перемещена вниз, но string будет воспринят системой как одно целое.
Для web
В случае с формированием текста для веб-страниц можно использовать другой алгоритм перехода. С его помощью переводим курсор (каретку) на новую строку для обтекания размещаемых объектов:
- В окне открытого документа необходимо поставить курсор после слова, за который требуется осуществить перенос (конец string).
- Зайти во вкладку «Макет».
- Перейти в «Параметры страницы»–«Разрывы»–«Обтекание текстом».
Остается посмотреть на получившийся результат. Никаких символов возврата каретки/перевода строки здесь не будет. Они не видны пользователю в редакторе.
В программировании
Знак символа конца строки и перехода на новую активно используется в разработке программного обеспечения. Здесь необходимо обратиться к элементам управления в ASCII.
Принцип работы приведен на Python. Здесь будет создан документ со сломанными строчками:
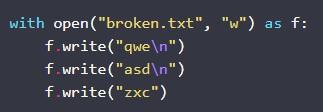
Теперь необходимо создать утилиту wc. Она будет оснащена флагом –I. Используется для подсчитывания strings в документе:
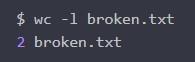
Результат покажет 2. Далее необходимо создать еще один файл с символами.
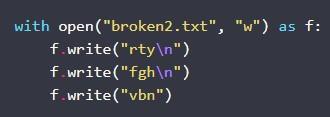
Переходя к утилите cat, потребуется «склеить» соответствующие 2 документа:
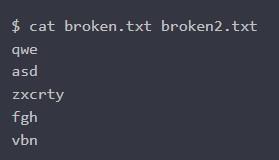
Результат будет непредсказуемым. Здесь можно увидеть полный перечень компонентов управления ASCII. А тут – сопутствующий видео-урок по изученной теме.
Чтобы лучше и быстрее вникнуть в соответствующий вопрос, рекомендуется посетить дистанционные онлайн курсы. Пример – от образовательного центра OTUS. Там быстро научат азам не только разработки приложений, но и системного администрирования. В срок до 12 месяцев получится освоить инновационные профессии с нуля. Можно выбрать одно или несколько направлений для одновременного изучения.
Хотите освоить современную IT-специальность? Огромный выбор курсов по востребованным IT-направлениям есть в Otus!
Одно из основных правил для правильного создания документов в Word – правописание. Не поймите неправильно, так как это не имеет ничего общего с грамматикой или стилем написания.
Если вы хотите, чтобы Word красиво выравнивал текст и соблюдал интервалы между абзацами, то вы должны убедиться в том, что вы не ставили лишние пробелы между словами и в ячейках, что начало абзацев расположены правильно и отступы настроены так, что документ выглядит правильно оформленным.
Было бы очень трудоемко определить определенные пространства или места в документе, где использовалось случайное двойное нажатие TAB (ТАБУЛЯЦИЯ) вместо одного, если не было бы знаков форматирования. Эти знаки являются непечатающимися символами и показывают нам места, где были использованы клавиши SPACE (ПРОБЕЛ), TAB, ENTER (ВВОД), или где находится скрытый текст.
Без них было бы практически невозможно создать документ в правильном оформлении: это займет очень много времени, чтобы исправить ошибки, которые мешают правильному выравниванию текста и объектов.
Как правило, знаки форматирования скрыты, пока вы не сделаете их видимыми нажатием ¶ на вкладке «Главная» в Word (рис. 1).

Рис. 1
Кроме того, вы можете использовать сочетания клавиш Ctrl + * или Ctrl + Shift + 8 для переключения «ПоказатьСкрыть» символов форматирования. Переключение отображения символов форматирования имеет два положения:
-
ON – включает отображение всех символов форматирования.
-
OFF – отключает отображение символов форматирования, за исключением тех, что вы решили оставить видимыми пока не измените параметры. Где же выбрать, какие символы форматирования должны остаться видимымискрытыми после нажатия на кнопку ¶?
Нажмите вкладку «Файл», а затем нажмите «Параметры» (рис. 2).

Рис .2
Нажмите «Экран» и слева, под «Всегда показывать эти знаки форматирования» выберите какие знаки форматирования вы хотите сделать видимыми всегда, даже после отключения (рис. 3).

Рис. 3
Существуют различные знаки форматирования, или иногда их называют непечатающимися символами, в Word. Рассмотрим основные из них.
Символ пробела
Точки это знаки форматирования пробелов между словами. Одно нажатие на пробел – одна точка (рис. 4).

Рис. 4
Символ абзаца
Символ (¶) представляет собой конец абзаца. После этого символа Word начинает новый абзац и перемещает курсор на новую строку (рис. 5).

Рис. 5
Знак абзаца помещается в документе при нажатии клавиши Enter на вашей клавиатуре. Текст между двумя этими символами определяется как абзац и имеет ряд свойств, которые можно регулировать независимо от остального текста (или абзацев), такие как выравнивание (по левому и правому краям, по центру и ширине), интервалы перед и после абзаца, интервалы между строками, нумерация и др.
Знак табуляции
Нажатие табуляции (TAB) отображается знаком стрелки, направленной вправо (рис. 6):

Рис. 6
Перевод строки
Знак перевода строки или  представляет собой место, где строка обрывается и текст продолжается с новой строки. Вы можете вставить перевод строки, нажав Shift+Enter.
представляет собой место, где строка обрывается и текст продолжается с новой строки. Вы можете вставить перевод строки, нажав Shift+Enter.
Функции знака перевода строки во многом схожи со знаком абзаца и имеет аналогичный эффект, за исключением, что при переводе строки не определяются новые абзацы (рис. 7).

Рис. 7
Скрытый текст
Скрытый текст представляет собой пунктирную линию под текстом, который определен как скрытый (рис. 8).

Рис. 8
Когда вы отключите знаки форматирования вышеуказанный текст будет выглядеть вот так (рис. 9):

Рис. 9
Скрытый текст не печатается. НО! Как же скрыть текст? Это очень просто 
-
Выберите текст, который вы хотите скрыть
-
Правой кнопкой на выделенном тексте и нажмите Шрифт (рис. 10)

Рис. 10
Нажмите на «Скрытый» (рис. 11)

Рис. 11
Зачем нам прятать текст? В первую очередь для настройки документа или шаблона текста, чтобы соответствовать специфическим требованиям. Вы также можете скрывать текст, если вы не хотите выводить его на печать в данный момент, но не хотите удалять.
Возвращаемся к знакам форматирования.
Якорь
Якорь представляет собой место в тексте, где некоторые объекты в документе были изменены и объект якоря оказывает влияние на поведение данного объекта в тексте. Другими словами, объект якоря, как крюк или кольцо, находится на обратной стороне картины, которые используются, чтобы повесить картину на стене.
Якорь представляет собой небольшую иконку в виде якоря корабля (рис. 12).

Рис. 12
Конец ячейки
Установлено, что в ячейках данный знак означает собой конец последнего абзаца в ячейке или в ее конце. Она отражает форматирование ячейки (рис. 13).

Рис. 13

Знаки, маленькие и важные
Уже не раз при проверках текстов ваших работ, я видела одну и ту же проблему у разных авторов: применяемые настройки выравнивания, отступов первой строки никак не отображаются на тексте, словно ничего и не было отформатировано. Разве что первая строка отступает как надо. Но остальные абзацы так и остаются на едином уровне с текстом. Зачастую это происходит, когда работу, ранее опубликованную на другом сайте, просто копируют.
Так в чем же проблема?
В том, что вместо абзаца находится разрыв строки (то, что бывает, если нажать в Ворде Shift+Enter).
Маленькая, но все-таки подлянка. То, что вам казалось началом нового абзаца было оформлено всего лишь новой строкой, продолжением того самого абзаца.
Напомню, что абзац – это отдельный объект программы MS Word. Строка же, являясь частью абзаца, не может быть, например, выровненной отдельно от других строк этого же абзаца. А так как у нас вместо абзаца выполнен разрыв строки, отступа абзаца там быть и не может.
Наш текстовый редактор похож на MS Word, он полностью поддерживает атрибуты вордовского текста, и потому все те огрехи, которые бывают при копировании текста со странички интернета всплывают в нём так же, как и в MS Word.
И потому чтобы текст на Синем сайте выглядел хорошо, поправим его, перенеся в MS Word.
Проблема с разрывами, как и другие неприятные мелочи (дефисы вместо тире, двойные отступы между абзацами, двойные пробелы между словами и т.п.) решаются буквально в считанные минуты. Если текст небольшой, можно конечно всё исправить вручную. Ну а если у вас с десяток и более страниц? Тут никакого терпения не хватит. Но не стоит отчаиваться. Умный друг Word сможет облегчить весь процесс.
Здесь я покажу, как можно исправить текст с помощью функции «найти и заменить».
Итак, у нас есть исходный текст, скопированный с сайта, где он был опубликован ранее. Зачастую он выгладит так:
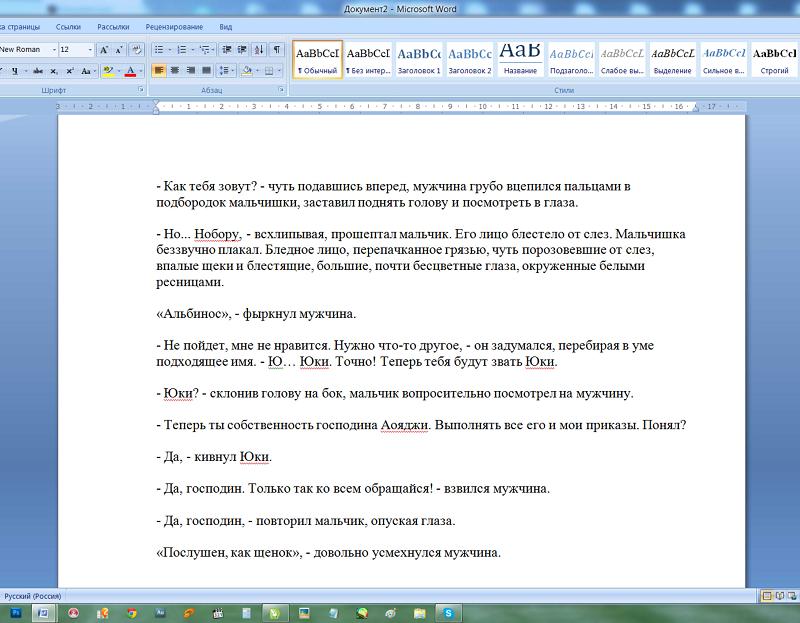
Вроде все кажется нормальным, обычный текст. Но все кардинально меняется, если применить «выравнивание по ширине». Текст разъехался по ширине окна, образовав некрасивые интервалы между словами. Вот здесь сразу же хорошо видно, где стоит разрыв строки.
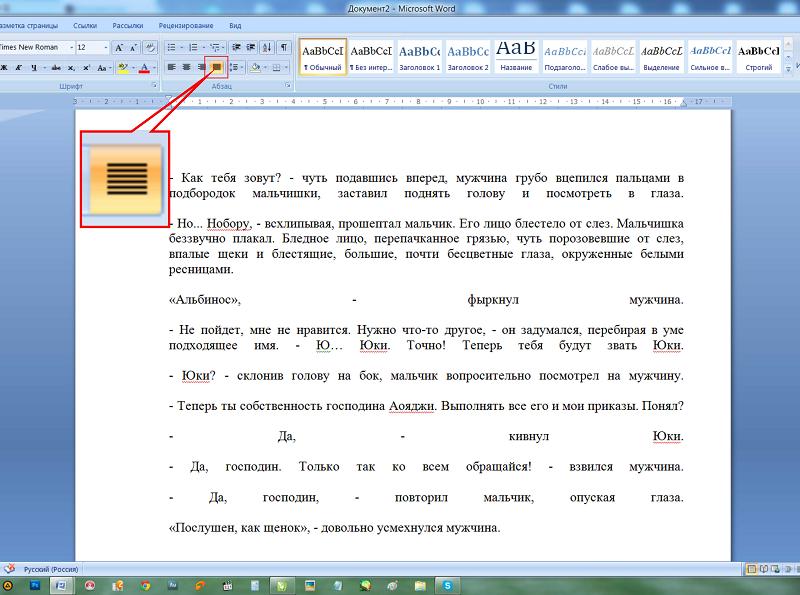
И еще более наглядно это можно увидеть, включив функцию просмотра непечатаемых знаков (отобразить все знаки).
(ИМХО. От себя порекомендую постоянно пользоваться этой кнопкой, поможет решить множество вопросов при форматировании и редактировании текстов).
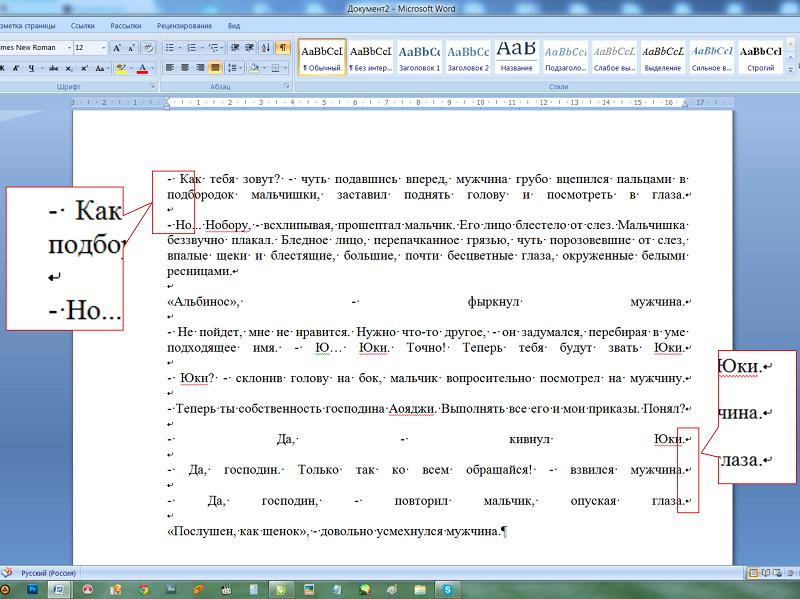
Теперь можно все наглядно увидеть. Тот самый разрыв строки выглядит, как загнутая влево стрелочка. Именно то, что вместо абзаца поставлена эта самая стрелочка и портит жизнь авторам при форматировании публикуемых работ.
Сейчас я вам покажу, как автозаменой поменять все переносы строк на абзацы по всему тексту.
Итак, наша цель – убрать знак разрыва строки, заменив его знаком абзаца. Для работы воспользуемся функцией «найти и заменить». Кнопка находится в правом нижнем углу. Либо можно вызвать окно сочетанием клавиш ctrl+h.
1. Переходим во вкладку «заменить», и, если открылось минимизированное диалоговое окно, нажимаем кнопку «больше».
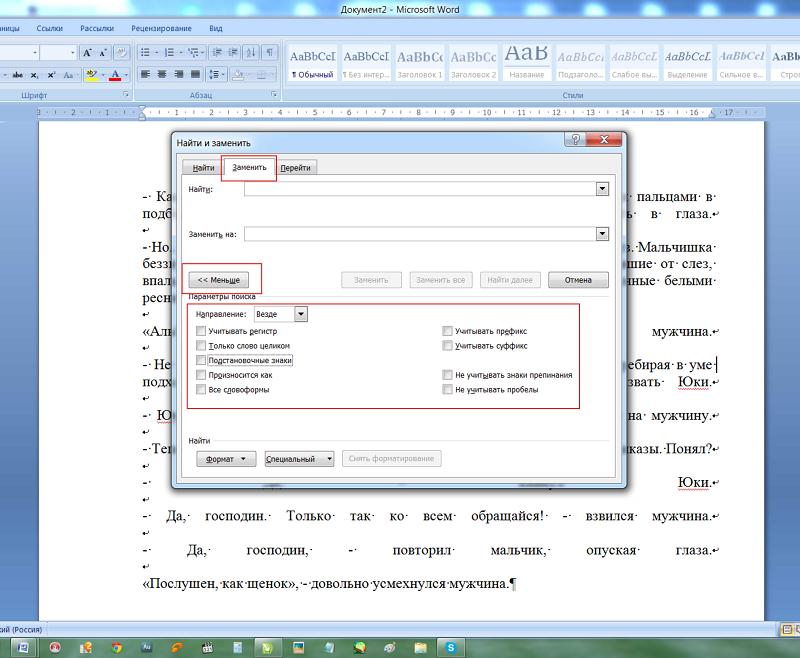
2. Убираем все флажки с параметров поиска, если они до этого стояли.
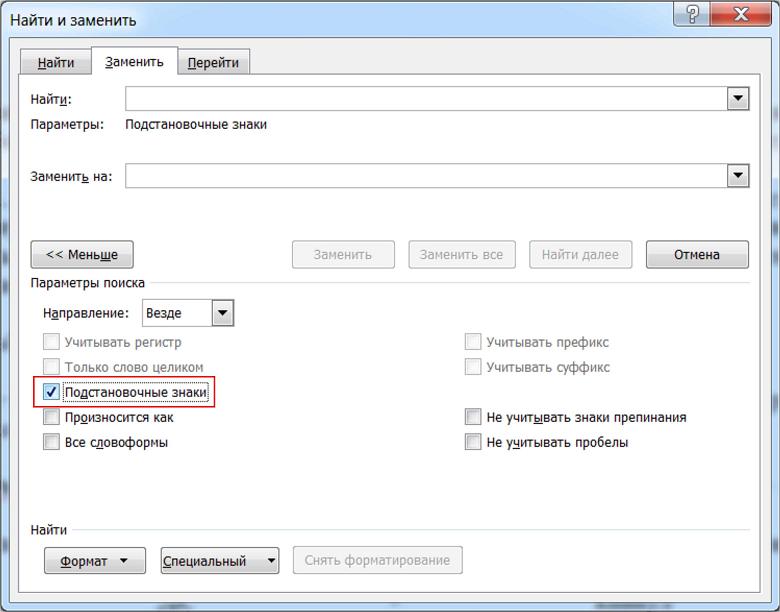
3. Ставим галочку в пункте «подстановочные знаки».
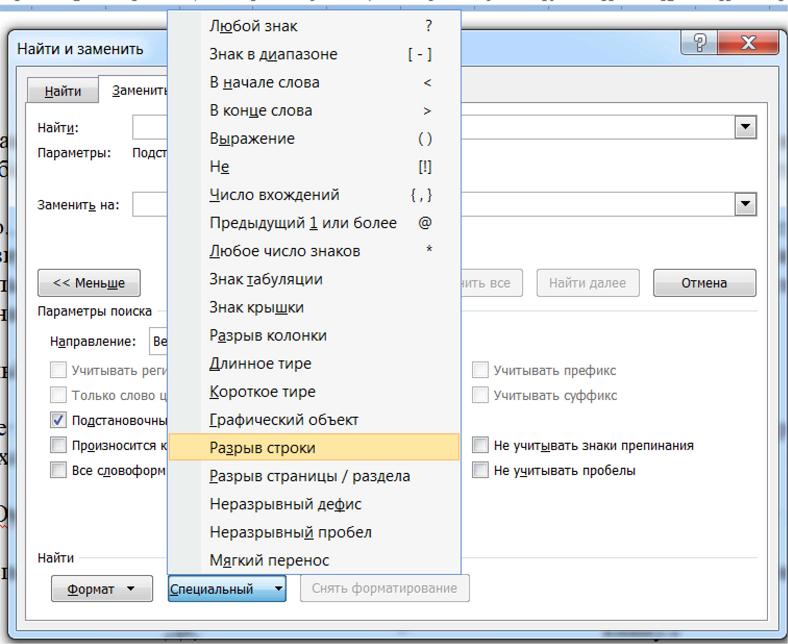
4. Ставим курсор в поле «найти», и щелкаем по кнопке «специальный». В списке выбираем «разрыв строки». В поле должен появиться значок ^|
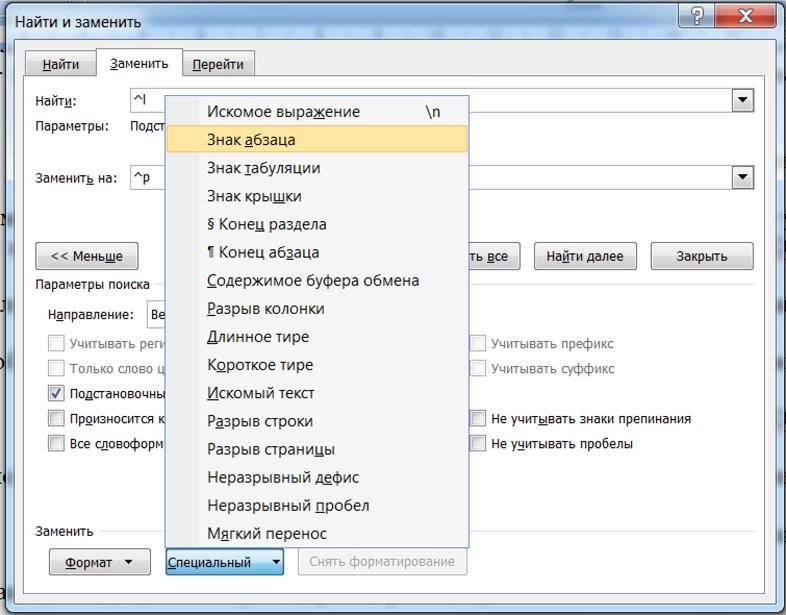
5. Щелкнув в поле «заменить на», в списке «специальный» выбираем «знак абзаца». В поле появится значок ^p.
Здесь внимательно, не спутайте с «конец абзаца» (значок ^s).
6. Теперь нажимая «заменить», можно отредактировать текст. Либо, нажав «заменить все», производим замену сразу по всему тексту.
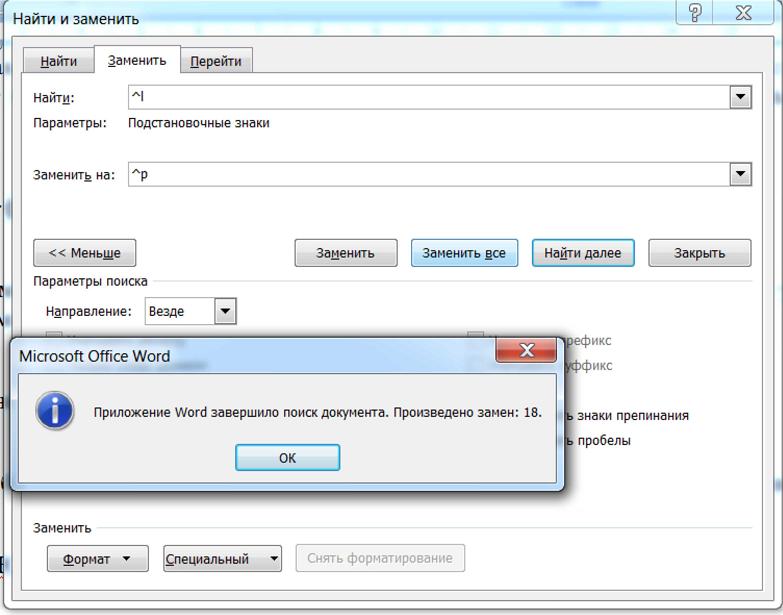
Итог. Автозамена произошла успешно. Разрывы строк во всём тексте заменены абзацами. Вот теперь можно применять и красную строку, и выравнивание по ширине, все отобразится, как должно быть.
Бывает такой вариант, когда каждая строка текста отделена разрывом строки. Нам не нужны в этих местах абзацы, но лишние разрывы портят вид. Тогда в шаге 4 вместо замены на знак абзаца ставим замену на знак пробела. Но теперь придется заменять каждый разрыв пробелом пошагово, по одному, чтобы не пропустить то место, где разрыв всё-таки нужен. В этом месте, просто не производим замену и переходим к следующей строке.
Текст красив и аккуратен… Еще не совсем! Часто встречается еще одна проблема, которую создает себе сам автор – дополнительный отступ между абзацами. Для чего он делался? Чтобы визуально разделить текст, выделить абзацы. Но, поскольку теперь есть возможность сделать отступ красной строки, такой интервал для разделения абзацев уже не нужен. Наш текст с нормальными отступами, как в Word’е получится ровным, а не рваным на куски.
Цель вторая – убрать двойной абзац.
То есть, заменить идущие подряд два символа абзаца на один.
1. Вновь вызываем диалоговое окно «Найти и заменить» (ctrl+h или кнопкой в нижнем правом углу).
2. Убираем галочку с пункта «подстановочные знаки» (обязательно, иначе замена не получится).
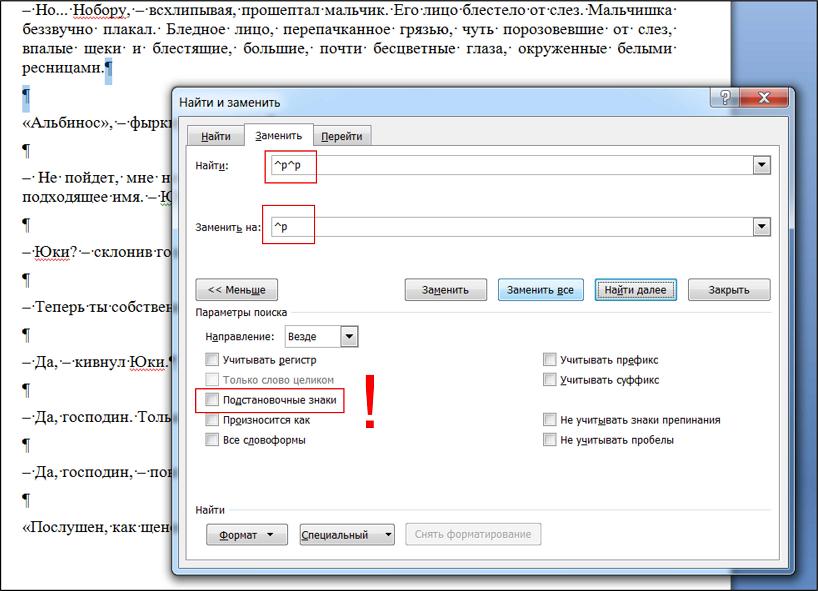
3. Скопировав значок абзаца ^p в поле «найти» два раза (получится ^p^p), оставим в поле «заменить на» его же в единственном экземпляре, и нажимаем «заменить».
И в итоге мы получим аккуратный ровный текст.
Еще одна проблема, которая портит текст работ не хуже дополнительных абзацев – это дефис, стоящий вместо тире. Этим грешат многие авторы. Автозамена, уже по умолчанию включенная в Word-е не меняет тире в начале строки (прямая речь), после запятых, точек, кавычек и т.д. Автозамена работает только для тире непосредственно между словами, и то только в том случае, когда от предыдущего текста тире отделено пробелом.
Как часто бывает, что автор набирает текст, не обращает внимания на такую мелкую деталь, как тире, ставя вместо него дефис. И в итоге вынужден потом заменять дефис на тире в диалогах по всему тексту. Вручную это опять же долго, да и всегда остается возможность недосмотреть и пропустить несколько знаков.
Но функция «найти и заменить» и здесь выручит.
Третья цель – замена дефиса на тире.
Вернее, замена дефис-пробел на тире-пробел.
Все в том же окне в поле «найти» ставим дефис, а после него пробел. Это нужно для того, чтобы не заменить на тире нужные дефисы между словами, где они употребляются без пробелов (например, «как-то», «что-либо» и т.д.). А после тире пробел имеется всегда. Если вы отделяли по тексту дефисы «вместо тире» пробелами, проблем возникнуть не должно. В противном случае, придется действовать осторожнее, и дефис в нужных местах менять на тире по одному.
Поставим курсор в поле «заменить на», щелкнем на кнопке «специальный», выбираем короткое тире (значок ^=, и тогда получим это «–» ), либо длинное тире (значок ^+, и тогда получим это «—»)
После выбранного значка тире также ставим пробел.
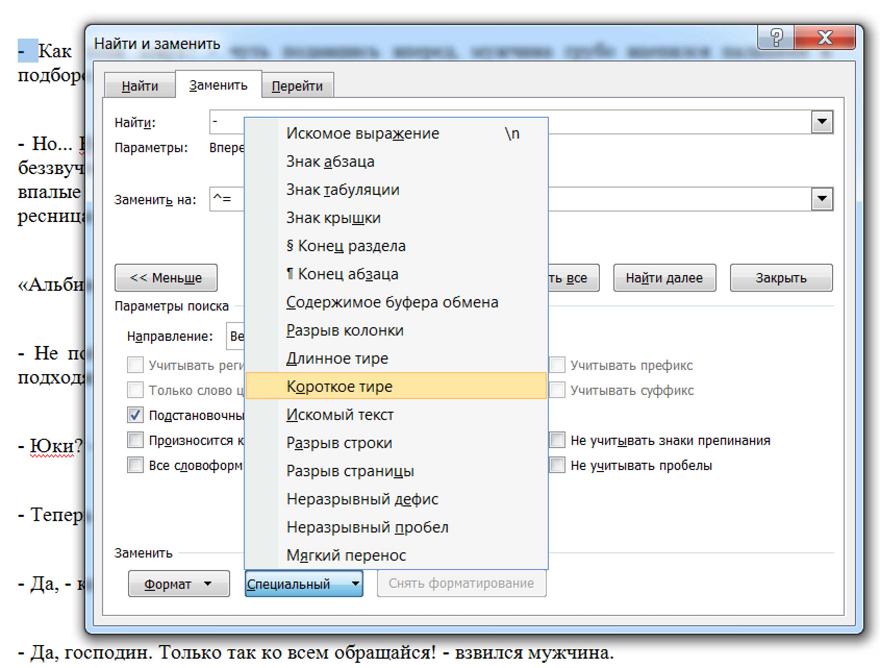
Щелкнув «заменить все», получаем результат – текст отредактирован.
Мы потратили всего несколько минут, заменив все разом, не выискивали все эти проблемы по одной во всём тексте.
Кроме описанных возможностей, можно поэкспериментировать с функцией «найти и заменить». Например, можно убирать двойные пробелы между частями предложения. Помните, Word может не только сохранять ваши работы в текстовом формате, а также существенно облегчить жизнь при редактировании и форматировании.
Автор + критик = успешное сотрудничество?!
Ваш рассказ удалён… Почему?
Когда можно обойтись без БЕТЫ?
Сам себе бета
Встречаем по одёжке
Зачем писать?
Знакомьтесь: Инквизиция Синего сайта – фантазии и реальность
О грамотности и серости
Как рождаются идеи
О комментариях и саморекламе
От сих до сих, или нужно ли знать матчасть для чтения фанфика
Почему люди не читают так, как птицы?
Что такое рецензия?
|
|||
| ac13
15.07.20 — 15:26 |
Есть вордовский шаблон с параметрами (элементами управления) WordApplication = Новый COMОбъект(«Word.Application»);
WordDocument = WordApplication.Documents.Open(ФайлВордовскогоДокумента); |
||
| RomaH
1 — 15.07.20 — 15:39 |
у символа есть код |
||
| ac13
2 — 15.07.20 — 15:47 |
(1) типа так? не помогает |
||
| sitex
3 — 15.07.20 — 15:57 |
(2) А почему 9 , а не 10 ? |
||
| vova1122
4 — 15.07.20 — 15:59 |
(2) 10 или 13 |
||
| ac13
5 — 15.07.20 — 16:02 |
МойТекст = «Иванов» + Символ(10) + «Иван» // не помогает |
||
| sitex
6 — 15.07.20 — 16:11 |
(5) Код символа «^р» = 94 |
||
| vova1122
7 — 15.07.20 — 16:12 |
а так: |
||
| sitex
8 — 15.07.20 — 16:12 |
или явно попробуй и: МойТекст = «Иванов» + Символ(94) + Символ(94) + «Иван» или просто вставь в текст сам «^р» |
||
| sitex
9 — 15.07.20 — 16:13 |
(6) А не это «^» = 94 |
||
| sitex
10 — 15.07.20 — 16:16 |
+ (8) символ(94) + символ(112) |
||
| ac13
11 — 15.07.20 — 16:16 |
(8) явно вставлять в текст тоже пробовал, просто выводит в тексте Иванов^рИван^рИванович |
||
| sitex
12 — 15.07.20 — 16:18 |
(11) версия офиса ? |
||
| ac13
13 — 15.07.20 — 16:18 |
(12) 2016 |
||
| ac13
14 — 15.07.20 — 16:22 |
нашел в тырнете Текст = «Начало текста» + символ(94) + символ(112) + » продолжение текста»; вот это надо прописывать?
Замена = ДокументWord.Content.Find; |
||
|
ac13 15 — 15.07.20 — 16:42 |
оказалось всё просто. в вордовском шаблоне в свойствах элемента управления нужно установить флажок «Разрешить возвраты каретки» |
![]()
Excel для Microsoft 365 Outlook для Microsoft 365 PowerPoint для Microsoft 365 Publisher для Microsoft 365 Excel 2021 Outlook 2021 PowerPoint 2021 Publisher 2021 Visio профессиональный 2021 Visio стандартный 2021 OneNote 2021 Excel 2019 Outlook 2019 PowerPoint 2019 Publisher 2019 Visio профессиональный 2019 Visio стандартный 2019 Excel 2016 Outlook 2016 PowerPoint 2016 OneNote 2016 Publisher 2016 Visio профессиональный 2016 Visio стандартный 2016 Excel 2013 Outlook 2013 PowerPoint 2013 OneNote 2013 Publisher 2013 Visio 2013 Excel 2010 Outlook 2010 PowerPoint 2010 OneNote 2010 Publisher 2010 Visio 2010 Visio стандартный 2010 Еще…Меньше
С помощью кодировок символов ASCII и Юникода можно хранить данные на компьютере и обмениваться ими с другими компьютерами и программами. Ниже перечислены часто используемые латинские символы ASCII и Юникода. Наборы символов Юникода, отличные от латинских, можно посмотреть в соответствующих таблицах, упорядоченных по наборам.
В этой статье
-
Вставка символа ASCII или Юникода в документ
-
Коды часто используемых символов
-
Коды часто используемых диакритических знаков
-
Коды часто используемых лигатур
-
Непечатаемые управляющие знаки ASCII
-
Дополнительные сведения
Вставка символа ASCII или Юникода в документ
Если вам нужно ввести только несколько специальных знаков или символов, можно использовать таблицу символов или сочетания клавиш. Список символов ASCII см. в следующих таблицах или статье Вставка букв национальных алфавитов с помощью сочетаний клавиш.
Примечания:
-
Многие языки содержат символы, которые не удалось уплотить в расширенный набор ACSII, содержащий 256 символов. Таким образом, существуют варианты ASCII и Юникода, которые включают региональные символы и символы. См. таблицы кодов символов Юникода по сценариям.
-
Если у вас возникают проблемы с вводом кода необходимого символа, попробуйте использовать таблицу символов.
Вставка символов ASCII
Чтобы вставить символ ASCII, нажмите и удерживайте клавишу ALT, вводя код символа. Например, чтобы вставить символ градуса (º), нажмите и удерживайте клавишу ALT, затем введите 0176 на цифровой клавиатуре.
Для ввода чисел используйте цифровую клавиатуру, а не цифры на основной клавиатуре. Если на цифровой клавиатуре необходимо ввести цифры, убедитесь, что включен индикатор NUM LOCK.
Вставка символов Юникода
Чтобы вставить символ Юникода, введите код символа, затем последовательно нажмите клавиши ALT и X. Например, чтобы вставить символ доллара ($), введите 0024 и последовательно нажмите клавиши ALT и X. Все коды символов Юникода см. в таблицах символов Юникода, упорядоченных по наборам.
Важно: Некоторые программы Microsoft Office, например PowerPoint и InfoPath, не поддерживают преобразование кодов Юникода в символы. Если вам необходимо вставить символ Юникода в одной из таких программ, используйте таблицу символов.
Примечания:
-
Если после нажатия клавиш ALT+X отображается неправильный символ Юникода, выберите правильный код, а затем снова нажмите ALT+X.
-
Кроме того, перед кодом следует ввести «U+». Например, если ввести «1U+B5» и нажать клавиши ALT+X, отобразится текст «1µ», а если ввести «1B5» и нажать клавиши ALT+X, отобразится символ «Ƶ».
Использование таблицы символов
Таблица символов — это программа, встроенная в Microsoft Windows, которая позволяет просматривать символы, доступные для выбранного шрифта.
С помощью таблицы символов можно копировать отдельные символы или группу символов в буфер обмена и вставлять их в любую программу, поддерживающую отображение этих символов. Открытие таблицы символов
-
В Windows 10 Введите слово «символ» в поле поиска на панели задач и выберите таблицу символов в результатах поиска.
-
В Windows 8 Введите слово «символ» на начальном экране и выберите таблицу символов в результатах поиска.
-
В Windows 7: Нажмите кнопку Пуск, а затем последовательно выберите команды Программы, Стандартные, Служебные и Таблица знаков.
Символы группются по шрифтам. Щелкните список шрифтов, чтобы выбрать набор символов. Чтобы выбрать символ, щелкните его, нажмите кнопку Выбрать, щелкните правой кнопкой мыши место в документе, в котором он должен быть, а затем выберите в документе кнопку Вировать.
К началу страницы
Коды часто используемых символов
Полный список символов см. в таблице символов на компьютере, таблице кодов символов ASCII или таблицах символов Юникода, упорядоченных по наборам.
|
Глиф |
Код |
Глиф |
Код |
|---|---|---|---|
|
Денежные единицы |
|||
|
£ |
ALT+0163 |
¥ |
ALT+0165 |
|
¢ |
ALT+0162 |
$ |
0024+ALT+X |
|
€ |
ALT+0128 |
¤ |
ALT+0164 |
|
Юридические символы |
|||
|
© |
ALT+0169 |
® |
ALT+0174 |
|
§ |
ALT+0167 |
™ |
ALT+0153 |
|
Математические символы |
|||
|
° |
ALT+0176 |
º |
ALT+0186 |
|
√ |
221A+ALT+X |
+ |
ALT+43 |
|
# |
ALT+35 |
µ |
ALT+0181 |
|
< |
ALT+60 |
> |
ALT+62 |
|
% |
ALT+37 |
( |
ALT+40 |
|
[ |
ALT+91 |
) |
ALT+41 |
|
] |
ALT+93 |
∆ |
2206+ALT+X |
|
Дроби |
|||
|
¼ |
ALT+0188 |
½ |
ALT+0189 |
|
¾ |
ALT+0190 |
||
|
Знаки пунктуации и диалектные символы |
|||
|
? |
ALT+63 |
¿ |
ALT+0191 |
|
! |
ALT+33 |
‼ |
203+ALT+X |
|
— |
ALT+45 |
‘ |
ALT+39 |
|
« |
ALT+34 |
, |
ALT+44 |
|
. |
ALT+46 |
| |
ALT+124 |
|
/ |
ALT+47 |
ALT+92 |
|
|
` |
ALT+96 |
^ |
ALT+94 |
|
« |
ALT+0171 |
» |
ALT+0187 |
|
« |
ALT+174 |
» |
ALT+175 |
|
~ |
ALT+126 |
& |
ALT+38 |
|
: |
ALT+58 |
{ |
ALT+123 |
|
; |
ALT+59 |
} |
ALT+125 |
|
Символы форм |
|||
|
□ |
25A1+ALT+X |
√ |
221A+ALT+X |
К началу страницы
Коды часто используемых диакритических знаков
Полный список глифов и соответствующих кодов см. в таблице символов.
|
Глиф |
Код |
Глиф |
Код |
|
|---|---|---|---|---|
|
à |
ALT+0195 |
å |
ALT+0229 |
|
|
Å |
ALT+143 |
å |
ALT+134 |
|
|
Ä |
ALT+142 |
ä |
ALT+132 |
|
|
À |
ALT+0192 |
à |
ALT+133 |
|
|
Á |
ALT+0193 |
á |
ALT+160 |
|
|
 |
ALT+0194 |
â |
ALT+131 |
|
|
Ç |
ALT+128 |
ç |
ALT+135 |
|
|
Č |
010C+ALT+X |
č |
010D+ALT+X |
|
|
É |
ALT+144 |
é |
ALT+130 |
|
|
È |
ALT+0200 |
è |
ALT+138 |
|
|
Ê |
ALT+202 |
ê |
ALT+136 |
|
|
Ë |
ALT+203 |
ë |
ALT+137 |
|
|
Ĕ |
0114+ALT+X |
ĕ |
0115+ALT+X |
|
|
Ğ |
011E+ALT+X |
ğ |
011F+ALT+X |
|
|
Ģ |
0122+ALT+X |
ģ |
0123+ALT+X |
|
|
Ï |
ALT+0207 |
ï |
ALT+139 |
|
|
Î |
ALT+0206 |
î |
ALT+140 |
|
|
Í |
ALT+0205 |
í |
ALT+161 |
|
|
Ì |
ALT+0204 |
ì |
ALT+141 |
|
|
Ñ |
ALT+165 |
ñ |
ALT+164 |
|
|
Ö |
ALT+153 |
ö |
ALT+148 |
|
|
Ô |
ALT+212 |
ô |
ALT+147 |
|
|
Ō |
014C+ALT+X |
ō |
014D+ALT+X |
|
|
Ò |
ALT+0210 |
ò |
ALT+149 |
|
|
Ó |
ALT+0211 |
ó |
ALT+162 |
|
|
Ø |
ALT+0216 |
ø |
00F8+ALT+X |
|
|
Ŝ |
015C+ALT+X |
ŝ |
015D+ALT+X |
|
|
Ş |
015E+ALT+X |
ş |
015F+ALT+X |
|
|
Ü |
ALT+154 |
ü |
ALT+129 |
|
|
Ū |
ALT+016A |
ū |
016B+ALT+X |
|
|
Û |
ALT+0219 |
û |
ALT+150 |
|
|
Ù |
ALT+0217 |
ù |
ALT+151 |
|
|
Ú |
00DA+ALT+X |
ú |
ALT+163 |
|
|
Ÿ |
0159+ALT+X |
ÿ |
ALT+152 |
К началу страницы
Коды часто используемых лигатур
Дополнительные сведения о лигатурах см. в статье Лигатура (соединение букв). Полный список лигатур и соответствующих кодов см. в таблице символов.
|
Глиф |
Код |
Глиф |
Код |
|
|---|---|---|---|---|
|
Æ |
ALT+0198 |
æ |
ALT+0230 |
|
|
ß |
ALT+0223 |
ß |
ALT+225 |
|
|
Π|
ALT+0140 |
œ |
ALT+0156 |
|
|
ʩ |
02A9+ALT+X |
|||
|
ʣ |
02A3+ALT+X |
ʥ |
02A5+ALT+X |
|
|
ʪ |
02AA+ALT+X |
ʫ |
02AB+ALT+X |
|
|
ʦ |
0246+ALT+X |
ʧ |
02A7+ALT+X |
|
|
Љ |
0409+ALT+X |
Ю |
042E+ALT+X |
|
|
Њ |
040A+ALT+X |
Ѿ |
047E+ALT+x |
|
|
Ы |
042B+ALT+X |
Ѩ |
0468+ALT+X |
|
|
Ѭ |
049C+ALT+X |
ﷲ |
FDF2+ALT+X |
К началу страницы
Непечатаемые управляющие знаки ASCII
Знаки, используемые для управления некоторыми периферийными устройствами, например принтерами, в таблице ASCII имеют номера 0–31. Например, знаку перевода страницы/новой страницы соответствует номер 12. Этот знак указывает принтеру перейти к началу следующей страницы.
Таблица непечатаемых управляющих знаков ASCII
|
Десятичное число |
Знак |
Десятичное число |
Знак |
|
|---|---|---|---|---|
|
NULL |
0 |
Освобождение канала данных |
16 |
|
|
Начало заголовка |
1 |
Первый код управления устройством |
17 |
|
|
Начало текста |
2 |
Второй код управления устройством |
18 |
|
|
Конец текста |
3 |
Третий код управления устройством |
19 |
|
|
Конец передачи |
4 |
Четвертый код управления устройством |
20 |
|
|
Запрос |
5 |
Отрицательное подтверждение |
21 |
|
|
Подтверждение |
6 |
Синхронный режим передачи |
22 |
|
|
Звуковой сигнал |
7 |
Конец блока передаваемых данных |
23 |
|
|
BACKSPACE |
8 |
Отмена |
24 |
|
|
Горизонтальная табуляция |
9 |
Конец носителя |
25 |
|
|
Перевод строки/новая строка |
10 |
Символ замены |
26 |
|
|
Вертикальная табуляция |
11 |
ESC |
27 |
|
|
Перевод страницы/новая страница |
12 |
Разделитель файлов |
28 |
|
|
Возврат каретки |
13 |
Разделитель групп |
29 |
|
|
Сдвиг без сохранения разрядов |
14 |
Разделитель записей |
30 |
|
|
Сдвиг с сохранением разрядов |
15 |
Разделитель данных |
31 |
|
|
Пробел |
32 |
DEL |
127 |
К началу страницы
Дополнительные сведения
-
Коды символов ASCII
-
Клавиатура (иврит)
-
Вставка букв национальных алфавитов с помощью сочетаний клавиш
-
Вставка флажка или другого символа
Нужна дополнительная помощь?
|
4 / 4 / 0 Регистрация: 12.07.2010 Сообщений: 160 |
|
|
1 |
|
Как заменить в ворде знак ┘08.02.2012, 12:28. Показов 51363. Ответов 3
Подскажите, пожалуйста, как можно заменить не печатающийся знак перевода строки «┘» на обычный пробел в приложении MS Office Word.
0 |

|
Programming Эксперт 94731 / 64177 / 26122 Регистрация: 12.04.2006 Сообщений: 116,782 |
08.02.2012, 12:28 |
|
3 |
|
Почетный модератор
28040 / 15771 / 981 Регистрация: 15.09.2009 Сообщений: 67,752 Записей в блоге: 78 |
|
|
08.02.2012, 12:43 |
2 |
|
включить отображение непечатаемых символов, выделить знак, скопировать,
0 |
|
440 / 33 / 4 Регистрация: 12.09.2011 Сообщений: 109 |
|
|
08.02.2012, 12:45 |
3 |
|
Решение В поле «Найти» набираете «^l» ли жмете «Специальный» —> Разрыв строки
4 |
 Сообщение было отмечено как решение
Сообщение было отмечено как решение
|
4 / 4 / 0 Регистрация: 12.07.2010 Сообщений: 160 |
|
|
08.02.2012, 13:40 [ТС] |
4 |
|
В поле «Найти» набираете «^l» ли жмете «Специальный» —> Разрыв строки Спасибо, помогло.
0 |

Разрыв строки, также известный как перенос слов, разбивает часть текста на строки, чтобы он уместился в доступную ширину страницы, окна или другой области отображения. При отображении текста перенос строки продолжается на новой строке, когда строка заполнена, так что каждая строка помещается в видимое окно, позволяя читать текст сверху вниз без какой-либо горизонтальной прокрутки. Перенос слов — это дополнительная функция большинства текстовых процессоров и веб-браузеров, позволяющая переносить строки между словами, а не внутри слов, где это возможно. Перенос слов избавляет от необходимости использовать жесткий код разделители новой строки внутри абзацев и позволяет гибко и динамически адаптировать отображение текста к дисплеям различных размеров.
Содержание
- 1 Мягкий и жесткий возврат
- 1.1 Unicode
- 2 Границы слов, расстановка переносов и жесткие пробелы
- 3 Перенос слов в тексте, содержащем китайский, японский и корейский языки
- 4 Алгоритм
- 4.1 Минимальное количество строк
- 4.2 Минимальная шероховатость
- 4.3 История
- 5 См. Также
- 6 Ссылки
- 7 Внешние ссылки
- 7.1 Алгоритм Кнута
- 7.2 Другие ссылки с переносом слов
Мягкий и жесткий возврат
Мягкий возврат или мягкий перенос — это разрыв, возникающий в результате переноса строки или переноса слов (автоматический или ручной), тогда как жесткий возврат или жесткий перенос — это преднамеренный разрыв, создающий новый абзац. При жестком возврате можно (и нужно) применять форматирование разрыва абзаца (либо отступ, либо вертикальный пробел). Мягкое обертывание позволяет автоматически регулировать длину строки с корректировкой ширины окна пользователя или настроек полей и является стандартной функцией всех современных текстовых редакторов, текстовых процессоров и почтовых клиентов. Ручные мягкие разрывы не нужны, когда перенос слов выполняется автоматически, поэтому нажатие клавиши «Enter» обычно приводит к жесткому возврату.
В качестве альтернативы, «мягкий возврат» может означать преднамеренный сохраненный разрыв строки, который не является разрывом абзаца. Например, почтовые адреса обычно печатаются в многострочном формате, но несколько строк понимаются как один абзац. Разрывы строк нужны для разделения слов адреса на строки соответствующей длины.
В современных графических текстовых процессорах Microsoft Word и OpenOffice.org ожидается, что пользователи будут вводить возврат каретки (↵ Введите ) между каждым абзацем. Параметры форматирования, такие как отступ первой строки или интервал между абзацами, вступают в силу там, где символ возврата каретки отмечает разрыв. Разрыв строки без абзаца, который является мягким возвратом, вставляется с помощью ⇧ Shift +↵ Enter или через меню и предоставляется для случаев, когда текст должен начинаться с новая строка, но никакие другие побочные эффекты начала нового абзаца не нужны.
В текстовых языках разметки мягкий возврат обычно предлагается в виде тега разметки. Например, в HTML есть тег, который имеет ту же цель, что и мягкий возврат в текстовых процессорах, описанных выше.
Unicode
Алгоритм разрыва строки Unicode определяет набор позиций, известных как возможности разрыва, которые являются подходящими местами для начала новой строки. Фактические позиции разрыва строки выбираются из числа возможных разрывов программным обеспечением более высокого уровня, которое вызывает алгоритм, а не самим алгоритмом, потому что только программное обеспечение более высокого уровня знает о ширине дисплея, на котором отображается текст, и ширине глифы, составляющие отображаемый текст.
Набор символов Unicode предоставляет символ разделителя строк, а также разделитель абзацев для представления семантики мягкого и жесткого возврата.
- 0x2028 LINE SEPARATOR
- * может использоваться для однозначного представления этой семантики
- 0x2029 PARAGRAPH SEPARATOR
- * может использоваться для однозначного представления семантики
Границы слова, расстановка переносов и пробелы
Мягкие возвраты обычно помещаются после концов полных слов или после знаков препинания, следующих за полными словами. Однако перенос слов может также происходить после дефиса внутри слова. Иногда это нежелательно и может быть заблокировано с помощью неразрывного дефиса или жесткого дефиса вместо обычного дефиса.
Слово без дефисов можно сделать переносимым, если в нем есть мягкие дефисы. Когда слово не переносится (т. Е. Не разбивается на строки), мягкий перенос не виден. Но если слово переносится по строкам, это делается по мягкому дефису, после чего оно отображается как видимый дефис в верхней строке, где слово разорвано. (В редких случаях, когда слово должно быть обернуто путем разбиения его на строки, но без дефиса, пробел нулевой ширины помещается в разрешенную точку (точки) разрыва в word.)
Иногда перенос слов между соседними словами нежелателен. В таких случаях перенос слов обычно можно заблокировать с помощью жесткого пробела или неразрывного пробела между словами вместо обычных пробелов.
Перенос слов в тексте, содержащем китайский, японский и корейский
На китайском, японском и корейском слове перенос обычно может происходить до и после любого символа Han, но некоторые символы пунктуации не могут начинать новую строку. Японский кана, буквы японского алфавита, обрабатываются так же, как и символы хань (кандзи ) по расширению, то есть слова могут быть разбиты без дефиса или других указаний. что это произошло.
Однако при определенных обстоятельствах перенос слов нежелателен. Например, перенос слов
- может быть нежелательным в личных именах, а перенос слов
- может быть нежелательным в любых составных словах (когда текст смещен слева, но только в некоторых стилях).
Большинство существующих текстовых процессоров и наборного программного обеспечения не могут справиться ни с одним из вышеуказанных сценариев.
CJK пунктуация может соответствовать или не соответствовать правилам, аналогичным вышеупомянутым особым обстоятельствам. Это до правил разрыва строки в CJK..
Однако всегда применяется особый случай правил разрыва строки в CJK: перенос строки никогда не должен происходить внутри тире и многоточия CJK. Несмотря на то, что каждый из этих знаков препинания должен быть представлен двумя символами из-за ограничения всех существующих кодировок символов , каждый из них по сути представляет собой один знак препинания шириной в два ems, а не два знака препинания шириной в одну em.
Алгоритм
Перенос слов — это проблема оптимизации. В зависимости от того, для чего нужно оптимизировать, используются разные алгоритмы.
Минимальное количество строк
Простой способ выполнить перенос слов — это использовать жадный алгоритм, который помещает в строку как можно больше слов, а затем переходит к следующую строку, чтобы сделать то же самое, пока больше не останется слов для размещения. Этот метод используется многими современными текстовыми редакторами, такими как OpenOffice.org Writer и Microsoft Word. Этот алгоритм всегда использует минимально возможное количество строк, но может привести к строкам самой разной длины. Следующий псевдокод реализует этот алгоритм:
SpaceLeft: = LineWidth для каждого слова в тексте if (Width (Word) + SpaceWidth)>SpaceLeft вставить разрыв строки перед словом в тексте SpaceLeft: = LineWidth - Width (Word) else SpaceLeft: = SpaceLeft - (Width (Word) + SpaceWidth)
Где LineWidth— ширина строки, SpaceLeft— оставшаяся ширина пространства на строке для заполнения, SpaceWidth— это ширина одного символа пробела, Text— это вводимый текст для перебора, а Word— это слово в этом тексте.
Минимальная шероховатость
Другой алгоритм, используемый в TeX, минимизирует сумму квадратов длин пробелов в конце строк для получения более эстетичного приятный результат. В следующем примере этот метод сравнивается с жадным алгоритмом, который не всегда минимизирует квадрат пространства.
Для входного текста
AAA BB CC DDDDD
с шириной строки 6 жадный алгоритм выдаст:
------ Line ширина: 6 AAA BB Оставшееся пространство: 0 CC Оставшееся пространство: 4 DDDDD Оставшееся пространство: 1
Сумма квадрата пространства, оставшегося с помощью этого метода, составляет 0 2 + 4 2 + 1 2 = 17 { displaystyle 0 ^ {2} + 4 ^ {2} + 1 ^ {2} = 17} . Однако оптимальное решение дает меньшую сумму 3 2 + 1 2 + 1 2 = 11 { displaystyle 3 ^ {2} + 1 ^ {2} + 1 ^ {2} = 11}
. Однако оптимальное решение дает меньшую сумму 3 2 + 1 2 + 1 2 = 11 { displaystyle 3 ^ {2} + 1 ^ {2} + 1 ^ {2} = 11} :
:
- ---- Ширина строки: 6 AAA Оставшееся пространство: 3 BB CC Оставшееся пространство: 1 DDDDD Оставшееся пространство: 1
Разница в том, что первая строка прерывается перед BBвместо после него, что дает лучшее правое поле и более низкую стоимость 11.
Используя алгоритм динамического программирования для выбора позиций, в которых следует разорвать линию, вместо того, чтобы жадно выбирать разрывы, решение с минимальной шероховатостью может быть найдено за время O (n 2) { displaystyle O (n ^ {2})} , где n { displaystyle n}
, где n { displaystyle n} — количество слов во входном тексте. Как правило, функция стоимости для этого метода должна быть изменена так, чтобы она не учитывала пространство, оставшееся в последней строке абзаца; эта модификация позволяет абзацу заканчиваться в середине строки без штрафных санкций. Также можно применить тот же метод динамического программирования, чтобы минимизировать более сложные функции затрат, которые объединяют другие факторы, такие как количество строк или затраты на перенос длинных слов. Более быстрые, но более сложные алгоритмы линейного времени, основанные на алгоритме SMAWK, также известны проблемой минимальной шероховатости и некоторыми другими функциями стоимости, имеющими аналогичные свойства.
— количество слов во входном тексте. Как правило, функция стоимости для этого метода должна быть изменена так, чтобы она не учитывала пространство, оставшееся в последней строке абзаца; эта модификация позволяет абзацу заканчиваться в середине строки без штрафных санкций. Также можно применить тот же метод динамического программирования, чтобы минимизировать более сложные функции затрат, которые объединяют другие факторы, такие как количество строк или затраты на перенос длинных слов. Более быстрые, но более сложные алгоритмы линейного времени, основанные на алгоритме SMAWK, также известны проблемой минимальной шероховатости и некоторыми другими функциями стоимости, имеющими аналогичные свойства.
История
В 1955 году в «блоке управления страничным принтером», разработанном Western Union, использовалась примитивная функция разрыва строки. В этой системе использовались реле, а не программируемые цифровые компьютеры, и поэтому требовался простой алгоритм, который можно было бы реализовать без буферов данных. В системе Western Union каждая строка разбивалась на первый пробел, который появлялся после 58-го символа, или на 70-м символе, если пробел не был найден.
Жадный алгоритм разбиения на строки предшествует динамическому Метод программирования, описанный Дональдом Кнутом в неопубликованной записке 1977 года, описывающей его систему набора текста TeX, и позже опубликован более подробно Knuth Plass (1981).
См. также
Ссылки
Внешние ссылки
алгоритм Кнута
- » Knuth Plass Revisited «
- « tex_wrap »:« Реализует алгоритм TeX для разбиения абзацев на строки. » Ссылка:« Разбивка абзацев на строки », DE Кнут и М.Ф. Plass, глава 3 _Digital Typography_, CSLI Lecture Notes # 78.
- Text :: Reflow — Perl-модуль для перекомпоновки текстовых файлов с использованием алгоритма разбивки на абзацы Кнута. «Алгоритм перекомпоновки пытается сохранить одинаковую длину строк, но также пытается разорвать знаки препинания и избегать разрывов внутри имени собственного или после определенных связок («a», «the» и т. д.). В результате получается файл с более «рваным» правым полем, чем создается с помощью fmt или Text :: Переносить, но его легче читать, поскольку меньше фраз разбивается на перенос строки. «
- настройка алгоритма Кнута для распознавания » мягкого переноса «.
- алгоритм разбиения Кнута. » Подробное описание модели и алгоритма можно найти в статье Дональда Кнута «Разбивая абзацы на строки», опубликованной в книге «Цифровая типография» (Стэнфорд, Калифорния: Центр изучения языка и информации, 1999 г.)), (Лекционные заметки CSLI, № 78.) »; часть Google Summer Of Code 2006
- «Устранение разрыва в алгоритмах: функциональная программа с линейным временем для форматирования абзацев», Oege de Moor, Jeremy Gibbons, 1999
Другие ссылки на перенос слов
- обратная проблема — выбор столбцов, достаточно широких, чтобы уместить (обернутый) текст (Архивная версия )
- Справочник по классу KWordWrap, используемый в графическом интерфейсе KDE
- «Элементы разбиения строк Knuth для форматирования Объекты » Саймона Пеппинга, 2006. Расширяет модель Кнута для обработки нескольких улучшений.
- « Стратегии разбиения страниц » Расширяет модель Кнута для обработки нескольких улучшений.
- « a Knuth-Plass- вроде алгоритма разбиения строк… * действительно * интересно то, чем алгоритм Adobe отличается от алгоритма Knuth-Plass. Он должен отличаться, поскольку Adobe удалось запатентовать свой алгоритм (6 510 441) ». [1]
- «Мюррей Сарджент: математика в офисе»
- «Разрыв строки» сравнивает алгоритмы различной сложности во времени.