
|
Comoc  Пользователь Сообщений: 3 |
Здравствуйте. Подскажите можно ли так построить график в Excel так что бы координата х выглядела как на рисунке. В приложенном excel есть таблица и график на нем нужно получить такую же ось х. Буду очень благодарен за помощь. Прикрепленные файлы
|
|
vikttur Пользователь Сообщений: 47199 |
Клетчатка — это что-то с биологии |
|
Comoc Пользователь Сообщений: 3 |
|
|
Chonard Пользователь Сообщений: 132 |
Пока вы меняете название темы, параллельно попробуйте выделить ряд данных (значение по осиу), потом Вставка-График. Посторится диаграмма по категориям. Идете в Конструктор-Выбрать Данные- Там меняете подписи по горизонтальной оси на нужные вам *(нужно выделитьзначения по оси х — в верхней строчке вашей таблицы) и будет так, как вы хотите. Прикрепленные файлы
|
|
Comoc Пользователь Сообщений: 3 |
Спасибо, большое разобрался. Изменено: Comoc — 27.10.2016 17:17:49 |
|
С.М.  Пользователь Сообщений: 936 |
#6 27.10.2016 23:41:02
Прикрепленные файлы
Изменено: С.М. — 29.10.2016 04:05:15 |
|
17 авг. 2022 г.
читать 2 мин
Вероятность описывает вероятность того, что некоторое событие произойдет.
Мы можем рассчитать вероятности в Excel, используя функцию PROB , которая использует следующий синтаксис:
ПРОБ(x_диапазон, вероятностный_диапазон, нижний_предел, [верхний_предел])
куда:
- x_range: диапазон числовых значений x.
- prob_range: диапазон вероятностей, связанных с каждым значением x.
- нижний_предел: нижний предел значения, для которого вы хотите получить вероятность.
- upper_limit: Верхний предел значения, для которого вы хотите получить вероятность. По желанию.
В этом руководстве представлено несколько примеров использования этой функции на практике.
Пример 1: Вероятность игры в кости
На следующем изображении показана вероятность выпадения кубика с определенным значением при данном броске:

Поскольку кости с одинаковой вероятностью выпадут на каждом значении, вероятность одинакова для каждого значения.
На следующем рисунке показано, как найти вероятность того, что кубик выпадет на число от 3 до 6:

Вероятность оказывается равной 0,5 .
Обратите внимание, что аргумент верхнего предела является необязательным. Таким образом, мы могли бы использовать следующий синтаксис, чтобы найти вероятность того, что кости приземлятся только на 4:
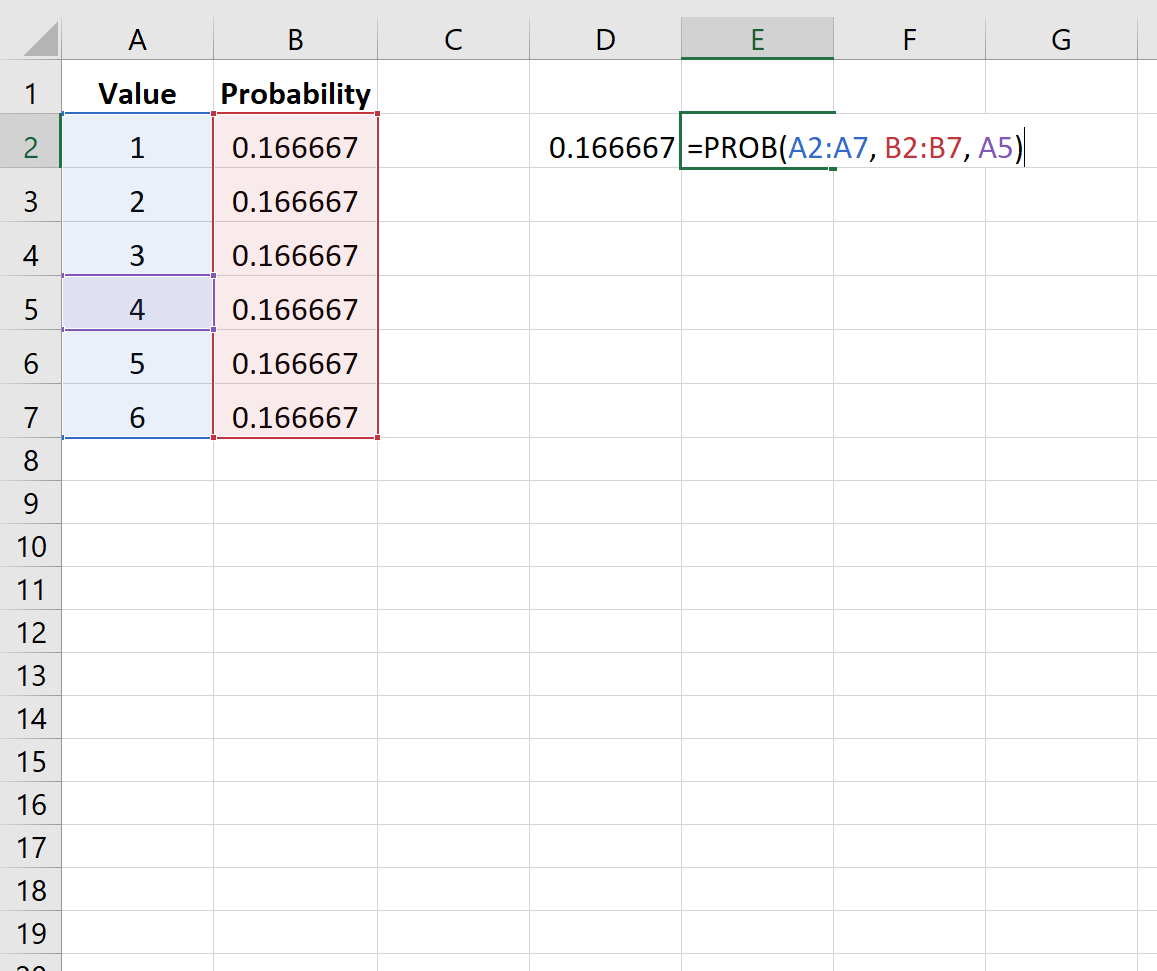
Вероятность оказывается равной 0,166667 .
Пример 2: Вероятность продаж
На следующем изображении показана вероятность того, что компания продаст определенное количество товаров в предстоящем квартале:

На следующем рисунке показано, как найти вероятность того, что компания совершит 3 или 4 продажи:
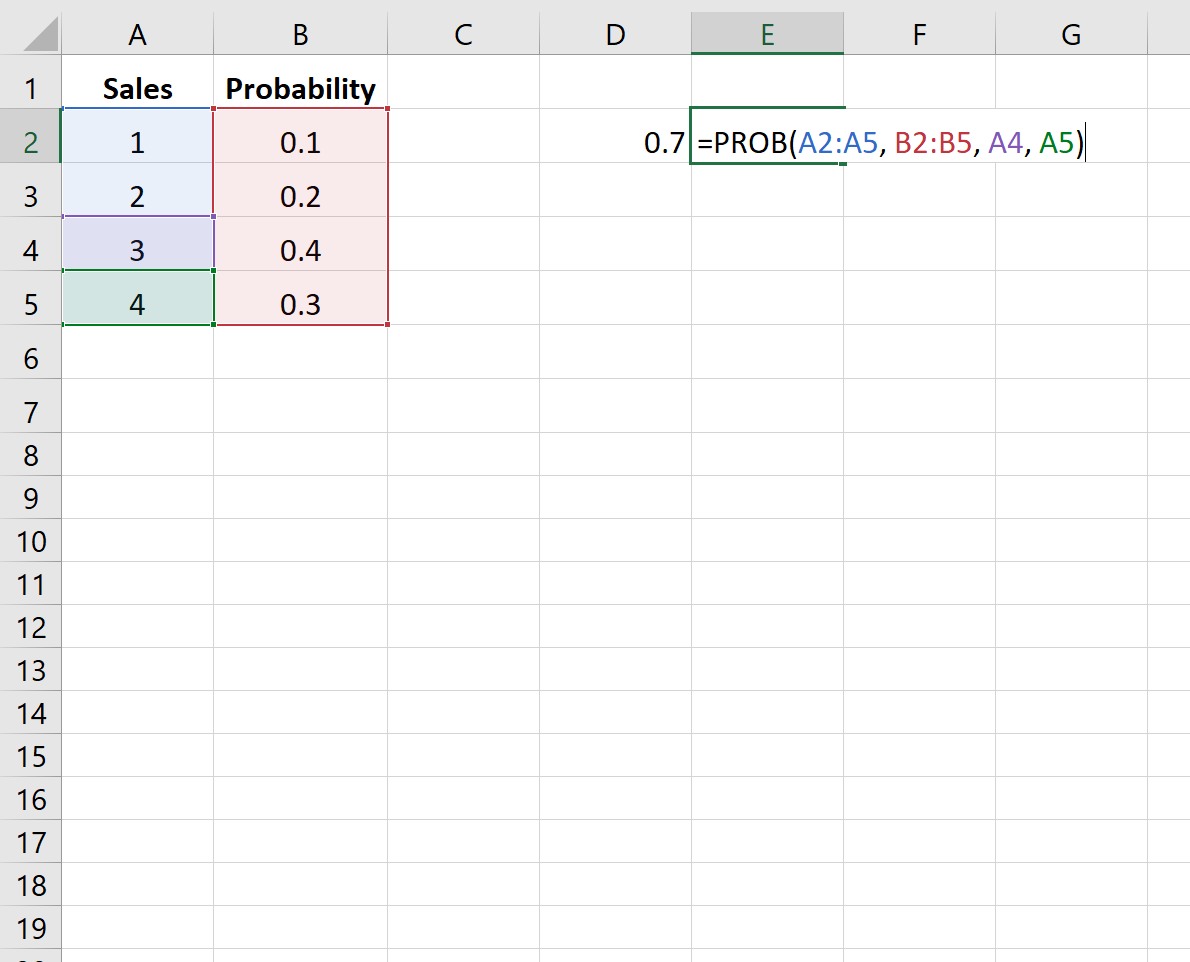
Вероятность оказывается равной 0,7 .
Дополнительные ресурсы
Как рассчитать относительную частоту в Excel
Как рассчитать кумулятивную частоту в Excel
Как создать частотное распределение в Excel
Написано
![]()
Замечательно! Вы успешно подписались.
Добро пожаловать обратно! Вы успешно вошли
Вы успешно подписались на кодкамп.
Срок действия вашей ссылки истек.
Ура! Проверьте свою электронную почту на наличие волшебной ссылки для входа.
Успех! Ваша платежная информация обновлена.
Ваша платежная информация не была обновлена.
Очень часто при работе в Excel необходимо использовать вычисления вероятности появления некоторого события. Для этого используется статистическая функция ВЕРОЯТНОСТЬ.
Примеры использования функции вероятность для расчетов в Excel
Стоит отметить, что используются часто в Excel и другие статистические функции, к примеру:
- ДИСП;
- ГИПЕРГЕОМ.РАСП;
- СРЗНАЧ и другие.
Функция выполняет вычисление вероятности того, что значения с интервала находятся в заданных пределах. В случае, если верхний предел не будет задан, то будет возвращена вероятность того, что значения аргумента x_интервал будет равно значению аргумента под названием нижний_предел.
Вычисление процента вероятности события в Excel
Пример 1. Дана таблица диапазона числовых значений, а также вероятностей, которые им соответствуют:
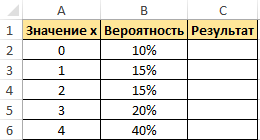
Необходимо при использовании данной статистической функции вычислить вероятность события, что значение с указанного интервала входит в интервал [1;4].
Для этого введем функцию со следующими аргументами:
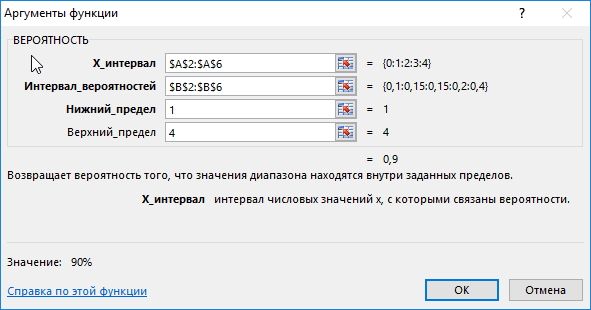
тут:
- х_интервал – это начальные данные (0, …, 4);
- интервал вероятностей является множеством вероятностей для начальных данных (0,15; 0,1; 0,15; 0,2; 0,4);
- нижний предел равен значению 1;
- верхний предел равен 4.
В результате выполненных вычислений получим:
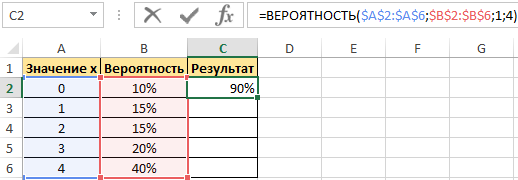
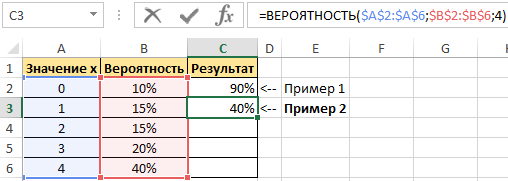
Пример 2. В условии предыдущего примера нужно вычислить вероятность события «значение х равно 4».
Введем в ячейку С3 введем функцию с такими аргументами:
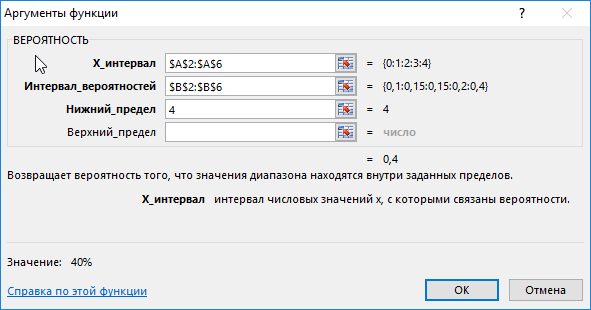
тут:
- х_интервал – начальные параметры (0, …, 4);
- интервал вероятностей – совокупность вероятностей для параметров (0,1; 0,15; 0,2; 0,15; 0,4);
- нижний предел – 4;
В данном примере верхний предел не указан, поскольку необходимо конкретное значение вероятности, а именно для значения 4.
Получим:
Функция ВЕРОЯТНОСТЬ при нескольких условиях интервалов
Пример 3. В условии примера 1 нужно вычислить вероятность того, что значения интервала [0; 4] будут находится находятся внутри интервалов [0;1] и [3;4].
Введем формулу:
Описание формул аналогичные предыдущим примерам.
В результате выполненных вычислений получим:

Скачать примеры функции ВЕРОЯТНОСТЬ в Excel
Таким образом составив формулу можно с помощью данной функции вычислить процент вероятности при нескольких условиях.
Примечание. 1 – биномиальная кривая; 2 –
трехпараметрическая кривая.
По полученным значениям К
и р строят аналитическую кривую обеспеченности на полулогарифмической
сетке, называемой клетчаткой вероятности (см. рис. 6). Данные для построения
горизонтальной шкалы клетчатки вероятностей приведены в табл. 3 приложения. В
ней буквой х обозначены расстояния от середины шкалы,
соответствующей значению р=50%, до требуемой абсциссы. А вертикальная
шкала клетчатки – равномерная.
4. Аппроксимация эмпирической
кривой трехпараметрической зависимостью (кривая С.М. Крицкого – М.Ф. Менкеля).Из табл. 2 приложения выписывают в табл. 11 величины Кр,
соответствующие условию (10), вычисленному значению Сv и выбранным значениям вероятности
превышения р. Далее рассчитывают значения расходов, например, для р=1%
Qр=2,5 ∙ 3,505 = 8,76 м3/с.
На следующем этапе строят аналитическую кривую обеспеченности.
Анализ графиков
показывает, что аналитические кривые практически совпадают в области малых
значений ВП. В области больших значений ВП кривая трехпараметрического
распределения проходит ближе к эмпирической кривой.
ЛАБОРАТОРНАЯ
РАБОТА 4
ОПРЕДЕЛЕНИЕ
ХАРАКТЕРИСТИК ТВЕРДОГО СТОКА РЕКИ
Вводные понятия
Речными наносами называются продукты
разрушения земной коры в виде сыпучих материалов, перемещаемых потоком воды в
речном русле. Расход и сток наносов обычно устанавливается одновременно с
определением расхода и стока воды в реке.
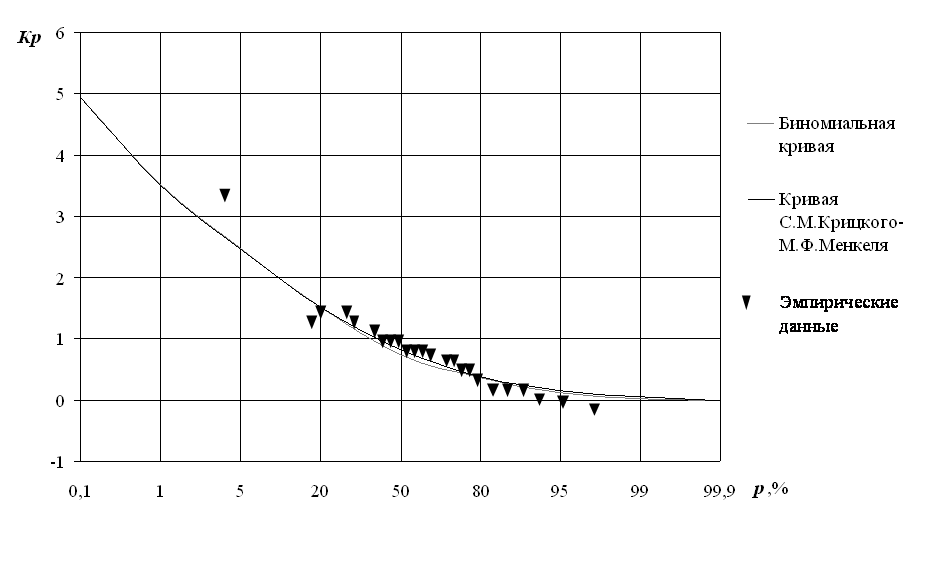
Рис. 6. Кривые обеспеченности максимальных расходов воды
В зависимости от
характера передвижения наносы подразделяются на взвешенные и донные. Взвешенные наносы мелких фракций
подхватываются восходящими струями речного потока и движутся с массой воды.
Донные наносы перемещаются под действием пульсации придонных струй или
находятся в состоянии покоя. Если скорость течения воды увеличивается, донные наносы переходят во
взвешенное состояние и наоборот – при уменьшении скорости часть наиболее
крупных взвешенных наносов начинает перемещаться по дну. Количество взвешенных
наносов, содержащихся в воде, характеризуется мутностью р, г/м3.
Порядок выполнения работы
1. Сбор данных. Для
определения характеристик твердого стока реки из таблицы «Взвешенные наносы»
гидрологического ежегодника выписывают среднемесячные значения мутности для
всех месяцев года и помещают в табл. 12. В нее же из таблицы «Ежедневные
расходы воды» гидрологического ежегодника записывают значения среднемесячных
расходов воды.
Таблица 12
Взвешенные
наносы
|
Месяц |
Мутность р, |
Расход воды Qp, м3/с |
Массовый наносов Qн.мас, кг/с |
Объемныйрасход наносов Qн.об, м3/с |
Объем наносов Vн, м3 |
Накоплен-ная сумма объемов ∑Vн, м3 |
|
I |
0 |
0,99 |
0 |
0 |
0 |
0 |
|
II |
0 |
0,59 |
0 |
0 |
0 |
0 |
|
III |
0 |
0,44 |
0 |
0 |
0 |
0 |
|
IV |
20 |
3,36 |
67,2 |
0,061 |
158,1 |
158,1 |
|
V |
80 |
17,4 |
1392 |
1,265 |
3388,2 |
3546,3 |
|
VI |
27 |
10,6 |
286 |
0,26 |
673,9 |
4220,2 |
|
VII |
21 |
12,3 |
258 |
0,234 |
626,7 |
4846,9 |
|
VIII |
28 |
22,7 |
635,6 |
0,578 |
1547,6 |
6394,5 |
|
IX |
10 |
11,8 |
118 |
0,107 |
277,3 |
6671,8 |
|
X |
7,3 |
6,15 |
45 |
0,041 |
109,8 |
6781,6 |
|
XI |
5,7 |
3,82 |
21,8 |
0,02 |
51,8 |
6840,6 |
|
XII |
0 |
0,87 |
0 |
0 |
0 |
6840,6 |
Введение
Программа ComposeFreq является составной частью комплекса HydroStatCalc, но может вызываться и применяться независимо. В том случае, когда она вызывается из головного блока HydroStatCalc опцией «Составная кривая», ей передаются данные выбранного ряда. Для независимого применения ComposeFreq необходима подготовка специальных файлов данных. Требования к содержанию и формату таких файлов изложены в разделе 1.2.
Программа предназначена для решения задач, связанных с построением кривых обеспеченностей и расчетом обеспеченных значений гидрологических характеристик в случае существенной генетической неоднородности данных выборки. В качестве примера можно рассматривать ряды максимальных расходов дождевых паводков рек Дальнего Востока. В этом районе максимумы паводков в подавляющем большинстве случаев формируются муссонными дождями. Из общего ряда резко выделяются паводки тайфунного происхождения. Более тривиальным примером может служить ряд максимальных годовых расходов, включающий как максимальные расходы весеннего половодья, так и дождевых паводков.
Эмпирические распределения генетически неоднородных выборок обычно неодномодальны, зачастую содержат несколько значений, резко отличающихся от остальных членов ряда, и не могут быть удовлетворительно аппроксимированы теоретическими распределениями, применяемыми в гидрологии. На практике это приводит к большим неопределенностям и ошибкам в оценках значений гидрологических характеристик редкой повторяемости.
Решение изложенной задачи, реализованное в предлагаемой программе, предполагает возможность разделения общего ряда ежегодных значений изучаемой характеристики на два или несколько генетически однородных подмножества. Технически программа допускает выделение до шести таких подмножеств, однако реально их допустимое число ограничено общей продолжительностью ряда. Число данных в каждом из подмножеств должно быть достаточно для расчета параметров кривой Пирсона III типа или Крицкого-Менкеля. Программа организует последовательное выполнение расчетов с построением кривых обеспеченностей для всех выделенных подмножеств и, на заключительном этапе, построение составной кривой на основе методики, разработанной А. В. Рождественским и изложенной в [6]. Деление ряда на подмножества производится по признакам их генетической однородности и не может быть автоматизировано. Для выполнения расчетов пользователь должен обозначить принадлежность каждого из значений ряда к тому или иному подмножеству. Выделение генетически однородных подмножеств является задачей, требующей основательного профессионального подхода и зачастую не может быть решена без привлечения дополнительной информации. Именно поэтому предусмотрена возможность независимого применения программы с обращением к предварительно подготовленным файлам данных с внесенными обозначениями подмножеств. В терминологии интерфейса программы генетически однородные подмножества называются «категориями» данных. Это название подмножеств и будет нами использоваться в последующем изложении.
При вызове программы возникает окно с тестом, содержащим предупреждение, что программа служит единственно для решения изложенной специальной задачи, а ее применение требует предварительной проработки вопроса о физической неоднородности исследуемого ряда и принадлежности каждого из его значений к той или иной категории.
На данном этапе разработки программы остается не решенной задача для случая, когда подмножество значений того или иного типа не достаточно для вычисления трех параметров распределения: среднего, Cv и Cs. Вместе с тем нередки случаи, когда ряд включает всего 1 — 2 или 3 значения, резко неоднородных, по отношению к остальной части ряда. Решение такой задачи остается предметом для последующих работ.
Текст разделов 2.2 и 2.3 данного описания программы проиллюстрирован на примере расчета составной кривой обеспеченностей модуля годового стока для изученного бассейна р. Большой Узень – г. Новоузенск. Этот яркий пример физической неоднородности ряда многолетних данных использован в [5,6] при изложении принципиальных основ методики выполняемых расчетов. Поставляемый пользователям пакет программы ComposeFreq содержит файл записи данных этого ряда, при вызове которого пользователь может самостоятельно повторить приведенный в описании расчет.
Многолетний ряд данных разделен в этом примере на 3 подмножества с существенными генетическими отличиями в процессе формирования годового стока, сопряженными с изменениями действующей площади водосбора.
Частным случаем задачи являются ситуации, когда некоторая часть ряда представлена нулевыми значениями рассматриваемой характеристики. Подобные ситуации встречаются при анализе рядов характеристик минимального стока (в случае пересыхающих водотоков), рядов характеристик дождевых паводков, зимних оттепелей, а в районах крайнего юга страны и в рядах характеристик весеннего половодья.
2.1 Особенности выполнение расчетов для рядов, содержащих восстановленные данные
При построениях кривых обеспеченностей гидрологических характеристик, физическая однородность которых не вызывает существенных сомнений, широко применяется продление рядов по данным бассейнов-аналогов. В программном комплексе HydroStatCalc заложена возможность продления расчетных рядов тремя способами:
- применением аппарата множественной корреляции с автоматическим подбором наилучших сочетаний аналогов;
- по связи с данными аналога, указанного пользователем, с визуальным контролем графика применяемой связи;
- методом восстановления данных коротких рядов (не более 6 значений).
Запись продленных рядов осуществляется программами в отдельный файл, аналогичный по своей структуре исходному файлу наблюденных данных.
В ComposeFreq программе сохранена техническая возможность действий с продленными рядами гидрологических характеристик при сохранении обозначений восстановленных членов ряда. Однако этим не устраняются возникающие принципиальные затруднения.
Эмпирические связи гидрологических характеристик изученных бассейнов, относящихся к разным типам гидрометеорологического процесса, принципиально не остаются едиными. Аналогично тому, как каждому типу процесса свойственна своя эмпирическая кривая распределения, также и данные каждой категории образуют связи не совпадающие, в общем случае, между собой. При использовании единой статистической связи типовые различия данных полностью игнорируются.
Для преодоления этого затруднения можно рекомендовать следующую последовательность действий:
- на основе имеющейся исходной записи многолетних данных расчетного ряда и рядов аналогов создать файлы аналогичной структуры, содержащие данные каждой конкретной категории (относящиеся к одному типу процесса);
- выполнить расчеты по восстановлению данных и из полученного продленного ряда удалить все значения за годы, когда тип процесса не соответствовал исследуемому;
- произвести совмещение полученных рядов в единый ряд с обозначением категории данных для каждого его значения.
Разумеется, практическая реализация всей этой процедуры требует большого внимания и весьма трудоемка. На данном этапе ее автоматизация остается задачей последующих программных разработок.
Изложенный алгоритм действий может быть применен при условии, если смена типов определяющего гидрометеорологического процесса в многолетних рядах данных синхронна для множества бассейнов изучаемой территории. В противном случае принципиальные трудности использования восстановления данных и их использования в расчетах обеспеченных значений характеристики при ее физической неоднородности становятся практически непреодолимыми. Во всяком случае, в настоящее время не усматривается даже принципиального подхода к решению этой задачи. В таких случаях следует ограничиваться использованием в расчетах рядов наблюденных значений.
- Подготовка и ввод исходных данных
Программа ComposeFreq может быть вызвана из HydroStatCalc после выделения любой колонки данных считанного файла. В этом случае выделенный ряд данных передается программе автоматически. При этом, необходимо прежде всего указать сколько категорий разнотипных данных содержит введенный ряд. Пока число категорий не названо, все остальные действия пользователю не доступны. Технически это значение не может быть более 6. Однако при назначении числа категорий следует исходить из условия, что число значений в каждом выделенном подмножестве данных должно быть достаточно для вычислений среднего, Cv и Cs. Минимальное допустимое число значений в подмножестве принимается равным 7.
Введенный ряд данных отображается в таблице, содержащей три колонки. В первой из них отображается год наблюдений, во второй – сами значения характеристики, третья предназначена для ввода числовых обозначений (1-6) категорий данных и при вызове программы из HydroStatCalc остается не заполненной.
Далее следует обозначить числовым кодом категорию каждого из значений ряда. Ввод числовых кодов производится с помощью окна редактора с раскрывающимся списком их возможных значений. Это окно появляется на панели сразу за указанием общего числа категорий. Значение кода, введенное из этого окна, передается выделенной строке таблицы и отображается в ее третьем столбце. Запись кодов может производиться как последовательно в хронологическом порядке, так и в произвольном порядке для любой выделенной строки таблицы. Выделение строки, на которую указывает курсор, производится щелчком левой кнопки мыши. Таким же образом ранее введенные коды могут быть изменены (рисунок 2.1).
При частой смене типов процесса введение кодов в хронологическом порядке трудоемко. Ускорения процесса можно добиться, имея в виду, что при нажатии на клавишу Enter клавиатуры компьютера выделенной строке передается текущее значение кода, установленное в окне редактора.
Переход к выполнению расчетов осуществляется с помощью клавиши «Готово». Эта клавиша остается недоступной до тех пор, пока остается неопределенным категория хотя бы одного значения таблицы.
Рис. 2.1. Панель управления подготовительными операциями по применению программы с таблицей введенных данных и инструментами управления.
Как уже указывалось, деление общего ряда данных на категории по типу гидрометеорологического процесса требует предварительного анализа, зачастую с привлечением дополнительной информации. Выполнять такую проработку уже при обращении к программе бывает затруднительно. Если расчеты составной кривой обеспеченностей нужно выполнить для небольшого числа бассейнов, удобнее произвести подготовку специальных файлов предварительно с помощью Excel.
Для этого нужно в новую таблицу Excel скопировать из базовой записи данных HydroStatCalc колонку, содержащую годы наблюдений и колонку данных одного расчетного бассейна вместе с числовым кодом поста. В третьей колонке следует проставить числовые коды категорий данных от 1 до общего числа таких категорий. Первая строка создаваемой таблицы должна повторять первую строку базовой записи данных. Две первые колонки второй ее строки содержат слово «Годы» и код поста. В третьей колонке второй строки целесообразно записать название поста.
После заполнения таблицы ее следует записать как текстовой файл с разделителем – знаком табуляции под новым неповторяющимся именем с расширением «txt». Созданный файл поместить в директорию «Данные». Поставляемый комплект программы содержит файл Б.Узень~prlng.txt с записью ряда значений модуля годового стока для поста р. Большой Узень – г. Новоузенск, который служит и примером подготовки данных для данной программы.
При наличии специального файла данных программу ComposeFreq следует вызвать как самостоятельную. В этом случае будет дано оповещение, что программе не передан ряд данных и открыта возможность обращения к чтению подготовленного файла. Окно выбора файла для чтения открывается клавишей «Читать из файла» в нижней части панели управления.
В результате чтения заранее подготовленного специального файла данных оказываются заполненными все три колонки таблицы. До нажатия клавиши «Готово» сохраняется возможность изменения кода категории в любой выделенной строке таблицы.
В процессе выполнения действий по делению общего ряда данных на подмножества разных категорий или корректировке предварительно выполненного деления известную помощь может оказать просмотр хронологического графика многолетних колебаний изучаемой характеристики и кривой обеспеченностей, построенной по данным всего ряда. Построение таких графиков производится обращением к соответствующим заданиям главного меню программы «Хронология» и «Обеспеченности». При активизации любой точки этих графиков программа сообщает, к какой из категорий отнесено соответствующее значение ряда (рисунки 2.2 и 2.3). После обращения к клавише «Готово» доступ к этим заданиям меню прекращается.

Рис. 2.2 Хронологический график многолетних колебаний в ряду исследуемой гидрологической характеристики.
У любой активизированной точки графика возникает надпись с указанием, к какой категории данных отнесено соответствующее значение ряда.

Рис. 2.3. Кривая обеспеченностей, построенная по данным всего ряда исследуемой гидрологической характеристики.
У любой активизированной точки графика возникает надпись с указанием, года и категории данных, к которой отнесено соответствующее значение ряда.
- Расчет составной кривой обеспеченностей
Переход к выполнению расчетов происходит с нажатием клавиши «Готово». Процесс расчетов включает последовательное построение кривых обеспеченностей для каждого из выделенных подмножеств данных определенной категории. Категория данных, обрабатываемых на каждом этапе расчетов, обозначается надписью красного цвета над правым верхнем углом графика.
В данной программе полностью сохранена методика статистических расчетов, реализованная во FreqShrt2008 комплекса HydroStatCalc. Почти без изменений сохранено и оформление средств управления действиями программы по выбору типа теоретической кривой и подбору ее параметров. Организация интерфейса управления этими действиями, подробно изложенная в описании HydroStatCalc, здесь не рассматривается. Главное отличие заключается в том, что в ComposeFreq не предусмотрена возможность сохранения нескольких вариантов подбора теоретической кривой с последующим выбором из них расчетного варианта. Кроме того, в данной программе исключена возможность применения интерполяции эмпирической кривой обеспеченностей ломаной линией. Построение частных кривых обеспеченностей для трех выделенных подмножеств ряда максимальных расходов дождевых паводков по данным поста р. Полометь – д. Дворец представлено на рисунках 2.4, 2.5 и 2.6.
Рис. 2.4. Построение кривой обеспеченностей максимальных расходов для подмножества данных категории 1 (паводки на спаде половодья). Активизирована панель выбора типа теоретического распределения.

Рис. 2.5. Построение кривой обеспеченностей максимальных расходов для подмножества данных категории 2 (летние паводки, вызванные фронтальными ливнями). 2 – кривая Крицкого-Менкеля при назначении параметров Cv и Cs методом наибольшего правдоподобия; 3 – кривая Пирсона III типа при автоматическом подборе значения Cs.
Рис. 2.6. Построение кривой обеспеченностей максимальных расходов для подмножества данных категории 3 (максимумы длительных летне-осенних дождевых периодов).
2 – кривая Пирсона III типа при использовании эмпирических значений параметров Cv и Cs с поправками; 3 – та же кривая при автоматическом подборе значения Cs.
Также как в программе FreqShrt2008 при нажатии на клавишу «Стат. Параметры» график кривой обеспеченностей перестраивается в уменьшенном виде, справа от него возникает панель для вывода расчетных статистических характеристик, а ниже таблица расчетных квантилей (но без строки стандартных ошибок их расчета).
В этом состоянии окна программы при обращении к клавише «Записать» производится запись статистических характеристик обрабатываемого подмножества данных одной категории в текстовом файле «Статистики. txt» директории «Протоколы». При этом в четвертом поле строки вместо периода наблюдений записывается числовой код категории данных. После выполнения расчетов для первой из выделенных категорий этой записи предшествует строка, содержащая характеристики всего ряда в обычной для HydroStatCalc форме. Кроме того, в файл «Варианты подбора. txt» производится запись расчетных квантилей распределения, установленного для подмножества данных этой категории. Числовой код категории данных помещается в третьем поле строки этого файла вместо условного обозначения гидрологической характеристики.
При нажатии на клавишу «Записать» автоматически происходит переход к расчетам кривой обеспеченности для подмножества данных следующей категории. Если же все выделенные категории данных ряда исчерпаны, выполняется результирующий расчет и построение составной кривой обеспеченностей. Для сохранения окончательных результатов расчета в этом случае также необходимо нажать на клавишу «Записать» (рисунок 2.7).
Рис. 2.7. Отображение результатов построения составной кривой обеспеченностей
в состоянии окна программы, создаваемого клавишей «Стат. Параметры».
Запись окончательных результатов расчета составной кривой производится в файл «Результаты. txt» в объеме и последовательности, аналогичных записи, выполняемой программой FreqShrt2008, но без оценок стандартной ошибки расчета квантилей распределения. В поле строки, отведенном для обозначения типа примененной теоретической кривой, проставляется «Составная».
2.4 Выполнение расчетов с применением сведений об исторических экстремумах
В ComposeFreq, также как и в HydroStatCalc реализована возможность учета литературных, архивных, археологических и иных данных об исторических экстремумах исследуемой гидрологической характеристики. Принципиальные положения методики использования этой информации не имеют отличий от изложенного в описании комплекса HydroStatCalc. Здесь также различаются два случая:
— исторический экстремум характеристики наблюдался за границами периода наблюдений гидрологического поста;
— наблюденному экстремальному значению характеристики может быть поставлена в соответствие обеспеченность, не соответствующая продолжительности периода наблюдений поста.
Однако имеются и существенные различия. При расчете составной кривой обеспеченностей необходимо знать к какой категории данных относится информация об исторических экстремумах. По этой причине сведения об исторических экстремумах введенные и записанные ранее с помощью HydroStatCalc не могут быть использованы для решения данной задачи. Их просто следует принять во внимание. Во многих случаях отнесение исторических экстремумов к определенной категории данных не вызывает затруднений. Так, сведения об историческом непревзойденном максимуме дождевого паводка на реках Дальнего Востока без сомнений будут отнесены к подмножеству данных о тайфунных паводках. В других случаях категориальная индентификация исторических данных потребует более распространенной информации: сведений о том, в какой период года наблюдалось явление, какими последствиями оно сопровождалось и т. п.
По названным причинам программа ComposeFreq не предполагает, что запись сведений об исторических экстремумах выполнена заранее. Опция основного меню, вызывающая панель для ввода этой информации, не доступна пока производятся действия со всем рядом данных. Возможность обращения к этой опции открывается только при обработке данных по конкретным выделенным подмножествам данных. Для каждого из выделенных подмножеств могут быть приняты сведения об исторических экстремумах за два года, как включенных в общий период наблюдений, так и за его пределами.
3 Программа восстановления данных по коротким рядам (менее 6 лет)