
Кластерный анализ объединяет кластеры и переменные (объекты), похожие друг на друга. То есть классифицирует объекты. Часто при решении экономических задач, имеющих достаточно большое число данных, нужна многомерность описания. Один из простых методов многомерного анализа – кластерный анализ.
Кластерный анализ является количественным инструментом исследования социально-экономических процессов, для описания которых необходимо много характеристик. Он позволяет разбить выборку на несколько групп по исследуемому признаку, проанализировать группы (как группируются переменные), группировку объектов (как группируются объекты). С помощью метода решаются задачи сегментирования рынка, анализируются сельские хозяйства для сравнения производительности, например, прогнозируется конъюнктура рынка отдельных продуктов и т.д.
Многомерный кластерный анализ
По сути, кластерный анализ – это совокупность инструментов для классификации многомерных объектов. Метод подразумевает определение расстояния между переменными (дельты) и последующее выделение групп наблюдений (кластеров).
Техника кластеризации применяется в самых разнообразных областях. Главное задача – разбить многомерный ряд исследуемых значений (объектов, переменных, признаков) на однородные группы, кластеры. То есть данные классифицируются и структурируются.
Вопрос, который задает исследователь при использовании кластерного анализа, – как организовать многомерную выборку в наглядные структуры.
Примеры использования кластерного анализа:
- В биологии – для определения видов животных на Земле.
- В медицине – для классификации заболеваний по группам симптомов и способам терапии.
- В психологии – для определения типов поведения личности в определенных ситуациях.
- В экономическом анализе – при изучении и прогнозировании экономической депрессии, исследовании конъюнктуры.
- В разнообразных маркетинговых исследованиях.
Когда нужно преобразовать «горы» информации в пригодные для дальнейшего изучения группы, используют кластерный анализ.
Преимущества метода:
- позволяет разбивать многомерный ряд сразу по целому набору параметров;
- можно рассматривать данные практически любой природы (нет ограничений на вид исследуемых объектов);
- можно обрабатывать значительные объемы информации, резко сжимать их, делать компактными и наглядными;
- может применяться циклически (проводится до тех пор, пока не будет достигнут нужный результат; а после каждого цикла возможно значительное изменение направленности дальнейшего исследования).
Дельта-кластерный анализ имеет и свои недостатки:
- состав и количество кластеров зависит от заданного критерия разбиения;
- при преобразовании исходного набора данных в компактные группы исходная информация может искажаться, отдельные объекты могут терять свою индивидуальность;
- часто игнорируется отсутствие в анализируемой совокупности некоторых значений кластеров.
Как сделать кластерный анализ в Excel
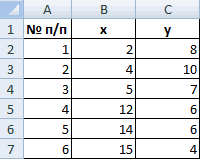
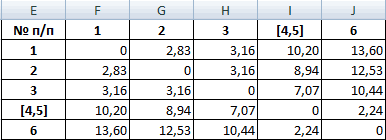
Для примера возьмем шесть объектов наблюдения. Каждый имеет два характеризующих его параметра.
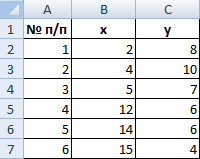
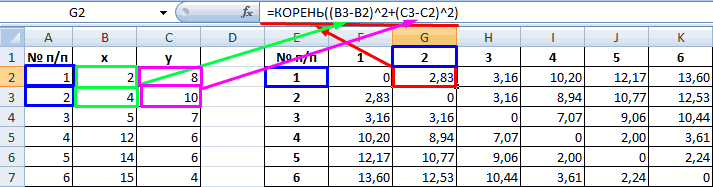
В качестве расстояния между объектами возьмем евклидовое расстояние. Формула расчета:
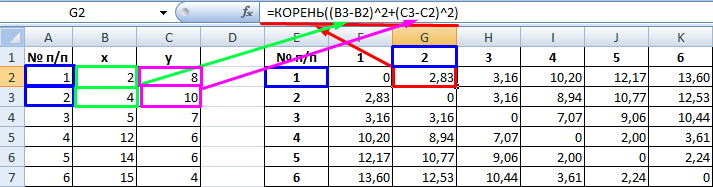
Рассчитанные данные размещаем в матрице расстояний.
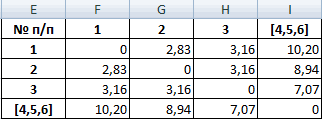
Самыми близкими друг к другу объектами являются объекты 4 и 5. Следовательно, их можно объединить в одну группу – при формировании новой матрицы оставляем наименьшее значение.
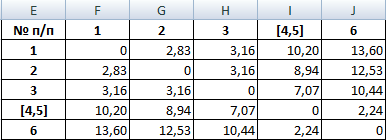
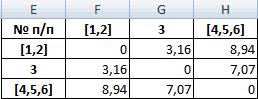
Из новой матрицы видно, что можно объединить в один кластер объекты [4, 5] и 6 (как наиболее близкие друг к другу по значениям). Оставляем наименьшее значение и формируем новую матрицу:
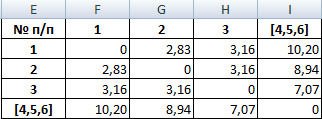
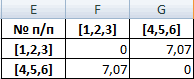
Объекты 1 и 2 можно объединить в один кластер (как наиболее близкие из имеющихся). Выбираем наименьшее значение и формируем новую матрицу расстояний. В результате получаем три кластера:
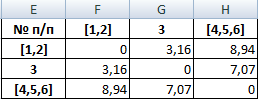
Самые близкие объекты – 1, 2 и 3. Объединим их.
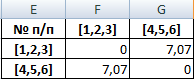
Мы провели кластерный анализ по методу «ближайшего соседа». В результате получено два кластера, расстояние между которыми – 7,07.
Огромное значение имеет кластерный анализ в экономическом анализе. Инструмент позволяет вычленять из громадной совокупности периоды, где значения соответствующих параметров максимально близки и где динамика наиболее схожа. Для исследования, к примеру, товарной и общехозяйственной конъюнктуры этот метод отлично подходит.
Содержание
- Использование кластерного анализа
- Пример использования
- Вопросы и ответы

Одним из инструментов для решения экономических задач является кластерный анализ. С его помощью кластеры и другие объекты массива данных классифицируются по группам. Данную методику можно применять в программе Excel. Посмотрим, как это делается на практике.
Использование кластерного анализа
С помощью кластерного анализа можно проводить выборку по признаку, который исследуется. Его основная задача – разбиение многомерного массива на однородные группы. В качестве критерия группировки применяется парный коэффициент корреляции или эвклидово расстояние между объектами по заданному параметру. Наиболее близкие друг к другу значения группируются вместе.
Хотя чаще всего данный вид анализа применяют в экономике, его также можно использовать в биологии (для классификации животных), психологии, медицине и во многих других сферах деятельности человека. Кластерный анализ можно применять, используя для этих целей стандартный набор инструментов Эксель.
Пример использования
Имеем пять объектов, которые характеризуются по двум изучаемым параметрам – x и y.
- Применяем к данным значениям формулу эвклидового расстояния, которое вычисляется по шаблону:
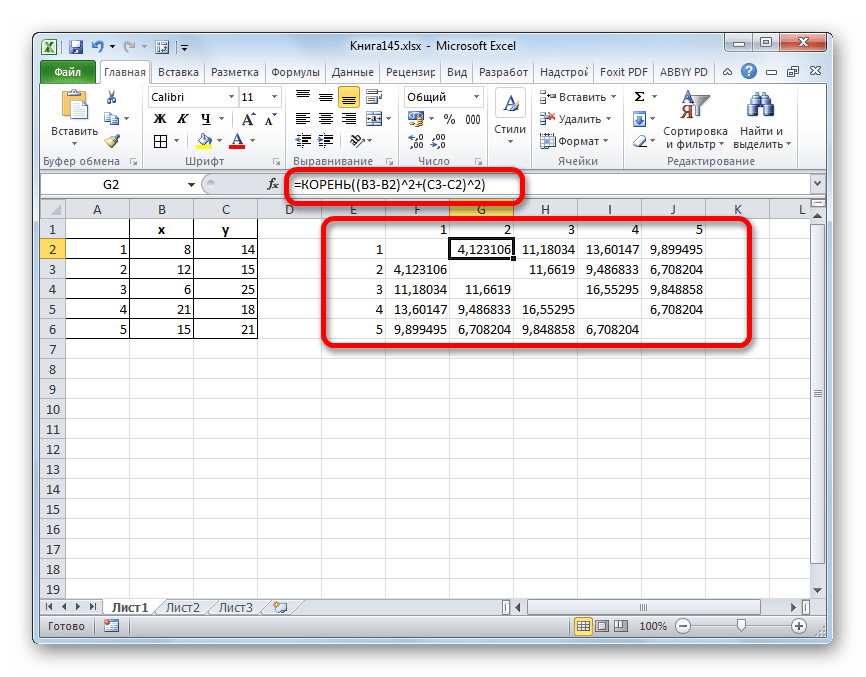
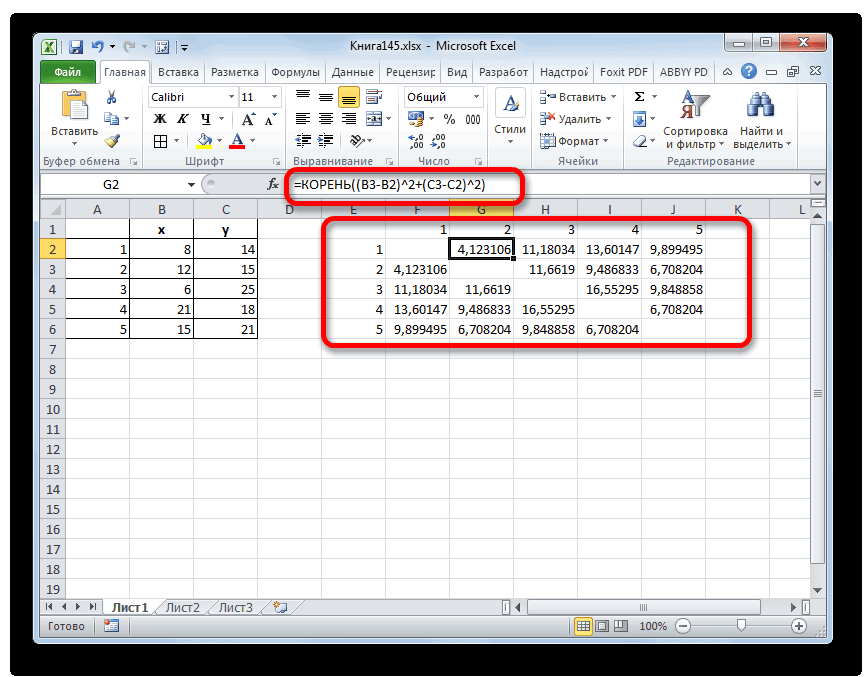
=КОРЕНЬ((x2-x1)^2+(y2-y1)^2) - Данное значение вычисляем между каждым из пяти объектов. Результаты расчета помещаем в матрице расстояний.
- Смотрим, между какими значениями дистанция меньше всего. В нашем примере — это объекты 1 и 2. Расстояние между ними составляет 4,123106, что меньше, чем между любыми другими элементами данной совокупности.
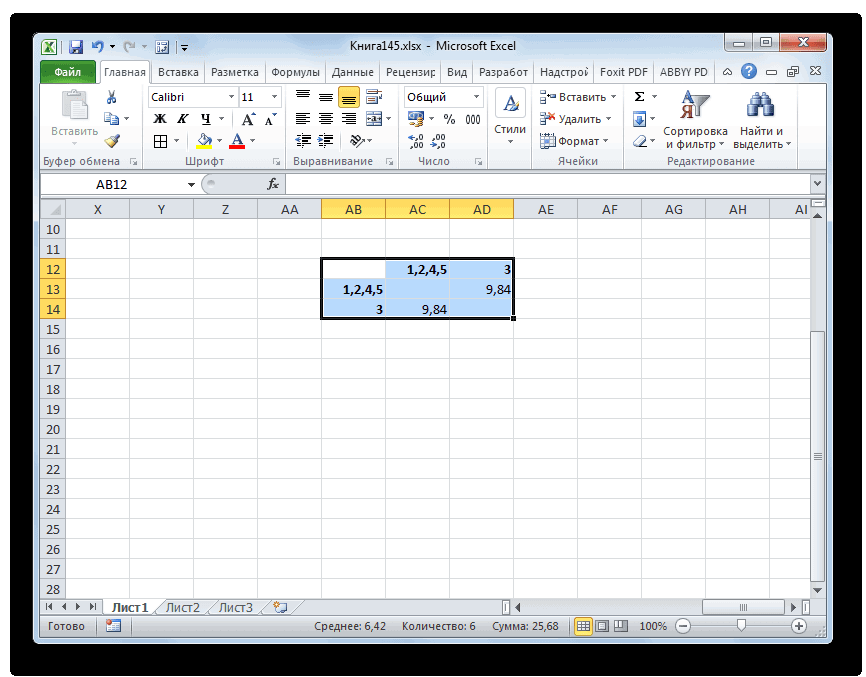
- Объединяем эти данные в группу и формируем новую матрицу, в которой значения 1,2 выступают отдельным элементом. При составлении матрицы оставляем наименьшие значения из предыдущей таблицы для объединенного элемента. Опять смотрим, между какими элементами расстояние минимально. На этот раз – это 4 и 5, а также объект 5 и группа объектов 1,2. Дистанция составляет 6,708204.
- Добавляем указанные элементы в общий кластер. Формируем новую матрицу по тому же принципу, что и в предыдущий раз. То есть, ищем самые меньшие значения. Таким образом мы видим, что нашу совокупность данных можно разбить на два кластера. В первом кластере находятся наиболее близкие между собой элементы – 1,2,4,5. Во втором кластере в нашем случае представлен только один элемент — 3. Он находится сравнительно в отдалении от других объектов. Расстояние между кластерами составляет 9,84.


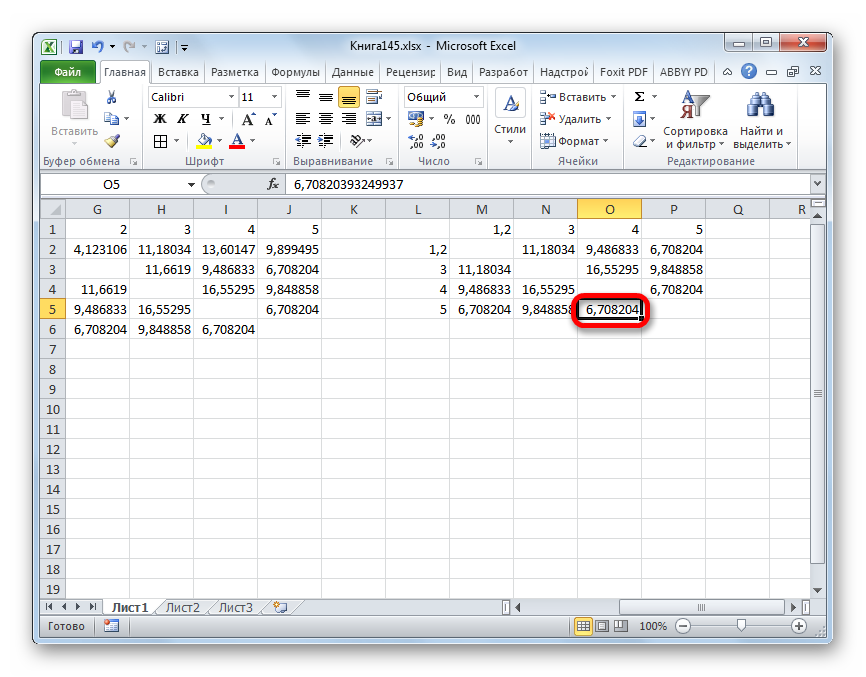

На этом завершается процедура разбиения совокупности на группы.
Как видим, хотя в целом кластерный анализ и может показаться сложной процедурой, но на самом деле разобраться в нюансах данного метода не так уж тяжело. Главное понять основную закономерность объединения в группы.
Еще статьи по данной теме:
Помогла ли Вам статья?
17 авг. 2022 г.
читать 3 мин
В статистике мы часто берем выборки из совокупности и используем данные выборки, чтобы делать выводы о населении в целом.
Одним из широко используемых методов выборки является кластерная выборка , при которой совокупность разбивается на кластеры, и все члены некоторых кластеров выбираются для включения в выборку.
В следующем пошаговом примере показано, как выполнить кластерную выборку в Excel.
Шаг 1: введите данные
Во-первых, давайте введем следующий набор данных в Excel:
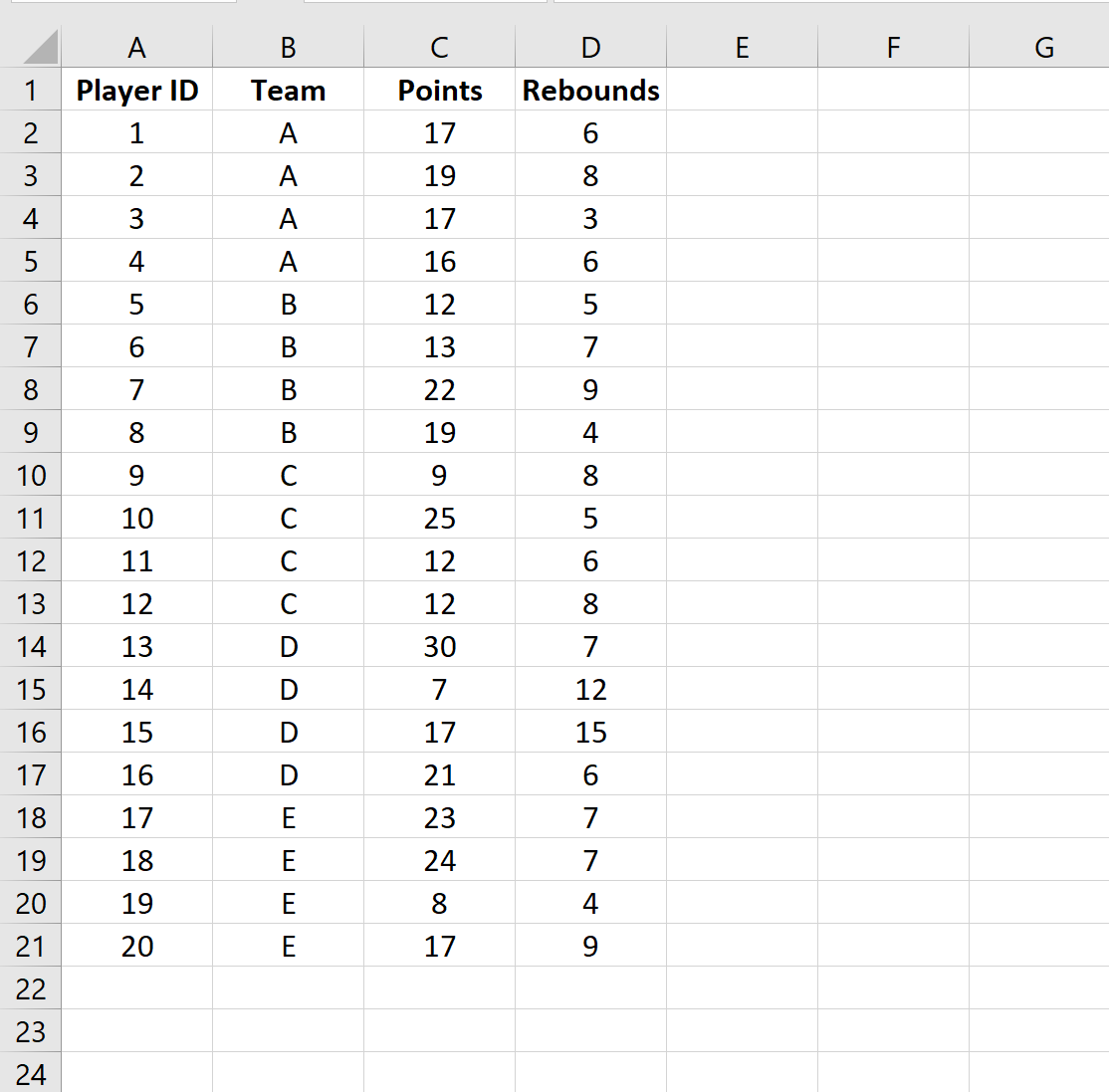
Затем мы выполним кластерную выборку, в которой мы случайным образом выберем две команды и решим включить каждого игрока из этих двух команд в окончательную выборку.
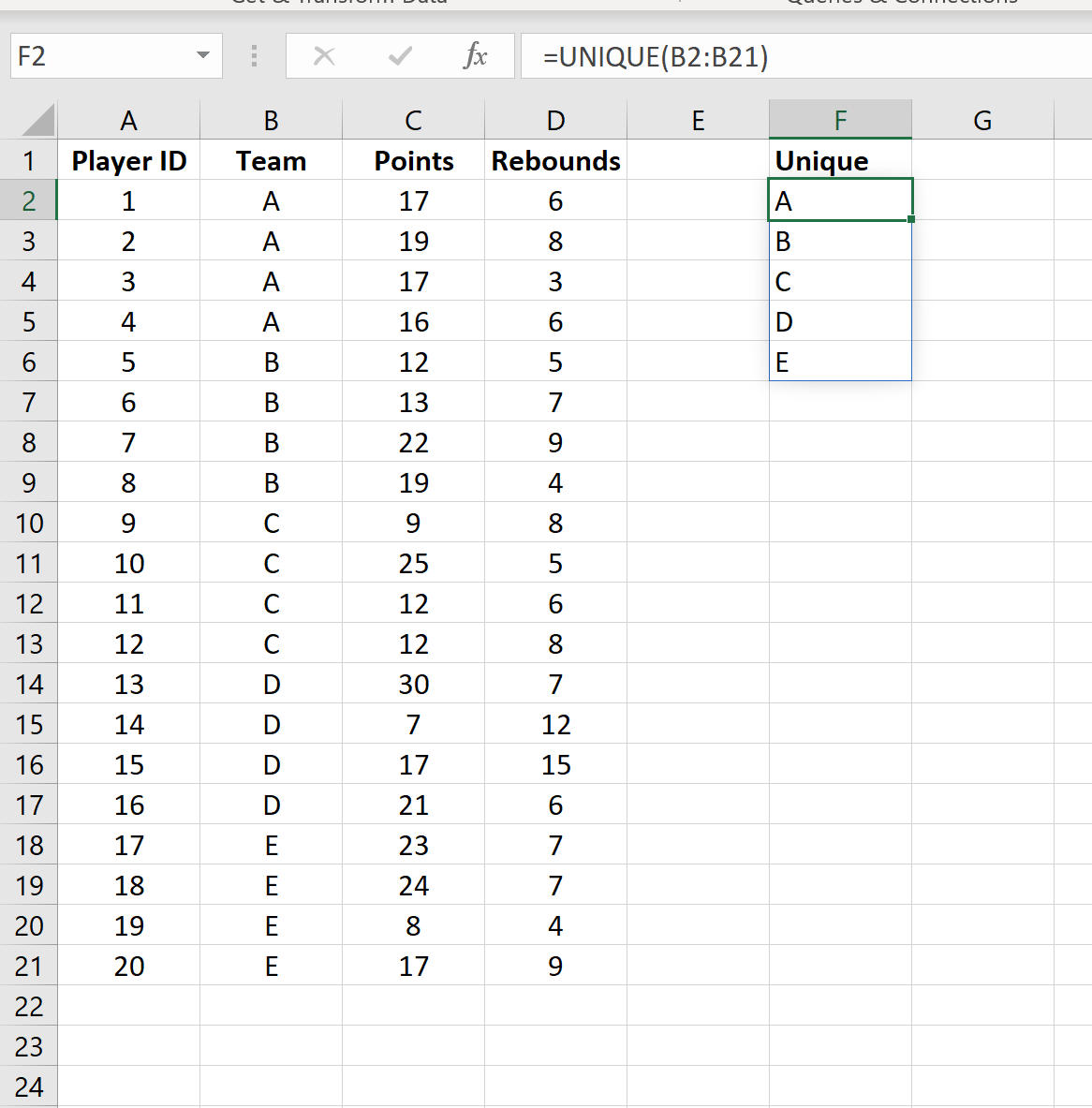
Шаг 2: Найдите уникальные значения
Затем введите =UNIQUE(B2:B21) , чтобы создать массив уникальных значений из столбца Team :
Затем мы введем целое число (начиная с 1) рядом с каждым уникальным названием команды:
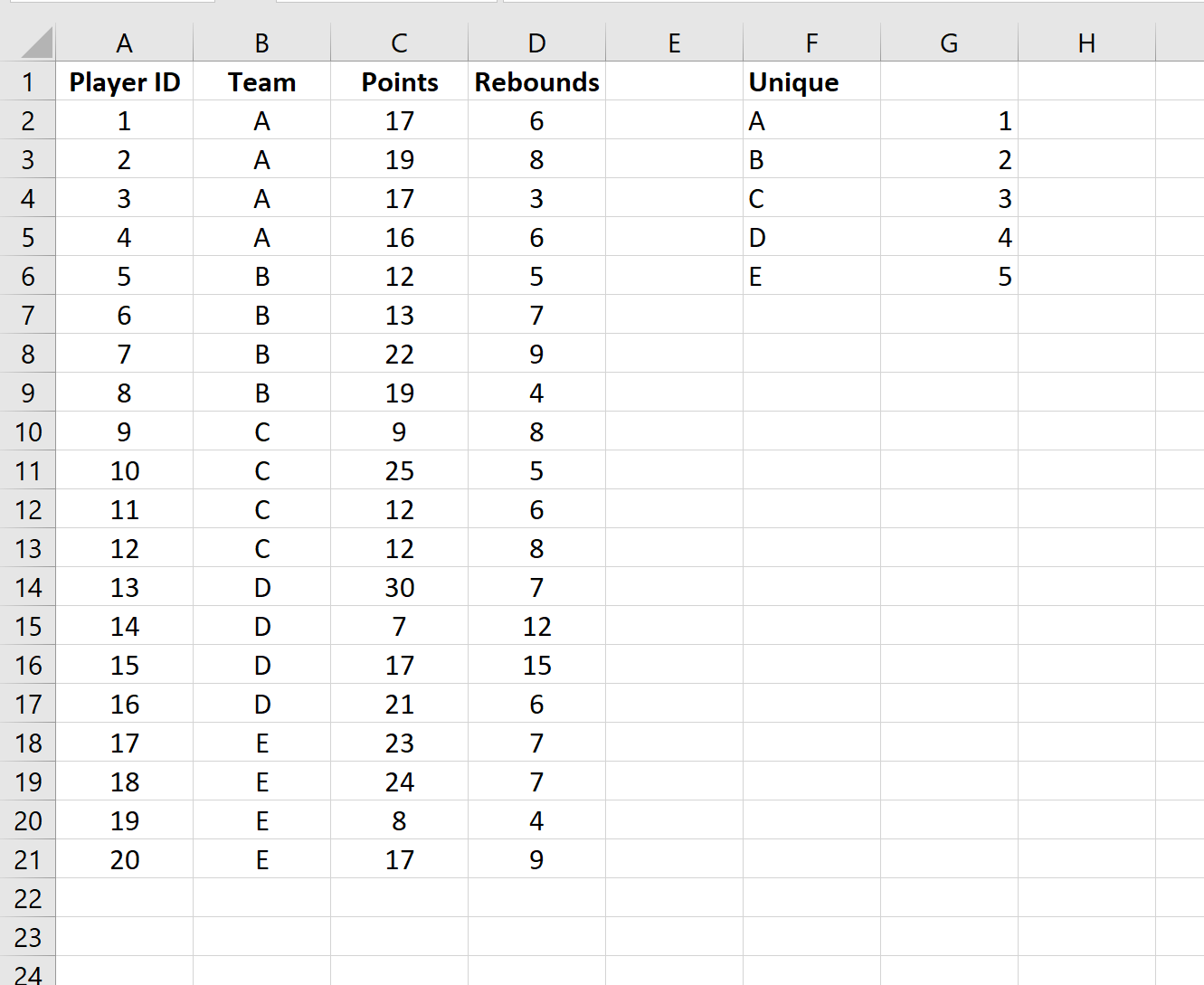
Шаг 3: выберите случайные кластеры
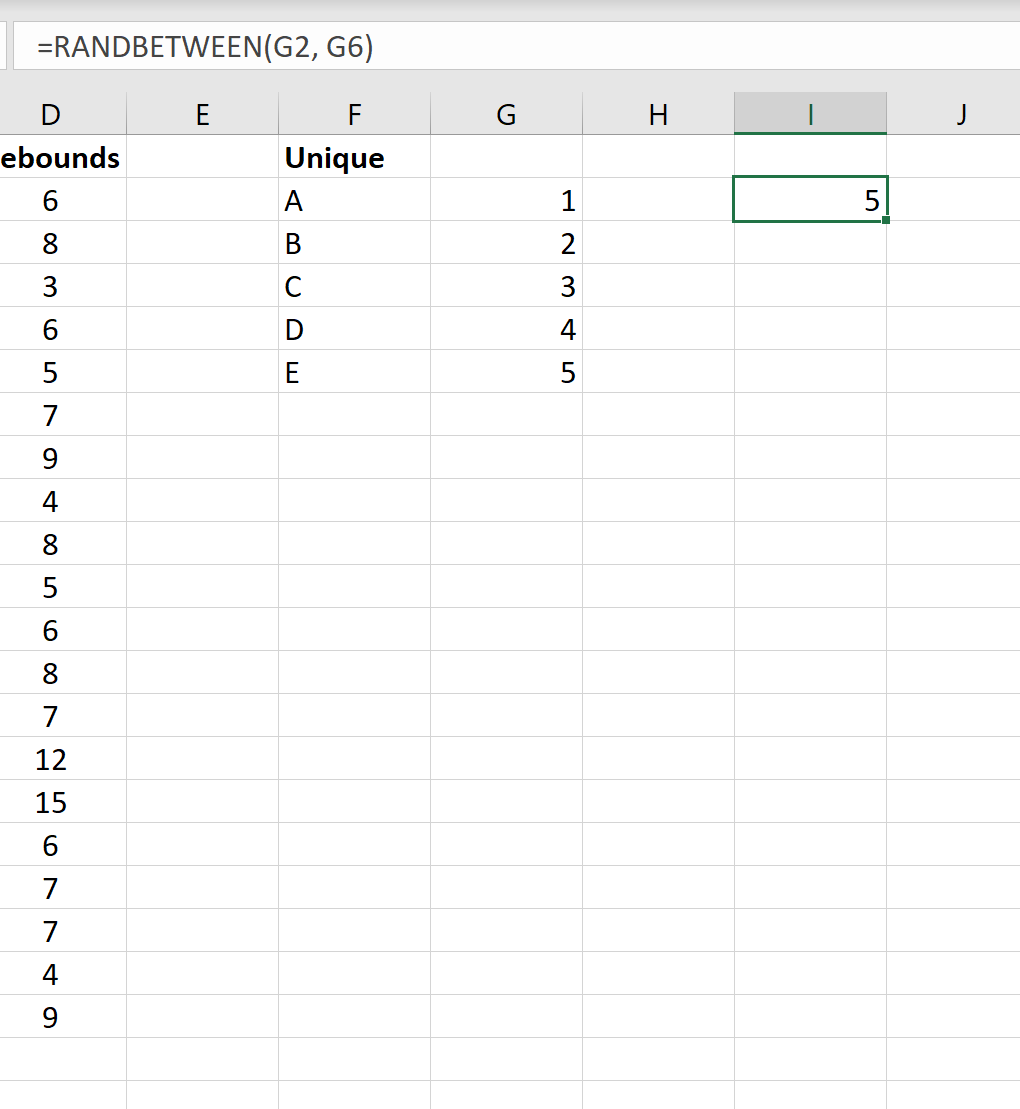
Затем мы введем =СЛУЧМЕЖДУ(G2, G6), чтобы случайным образом выбрать одно из целых чисел из списка:
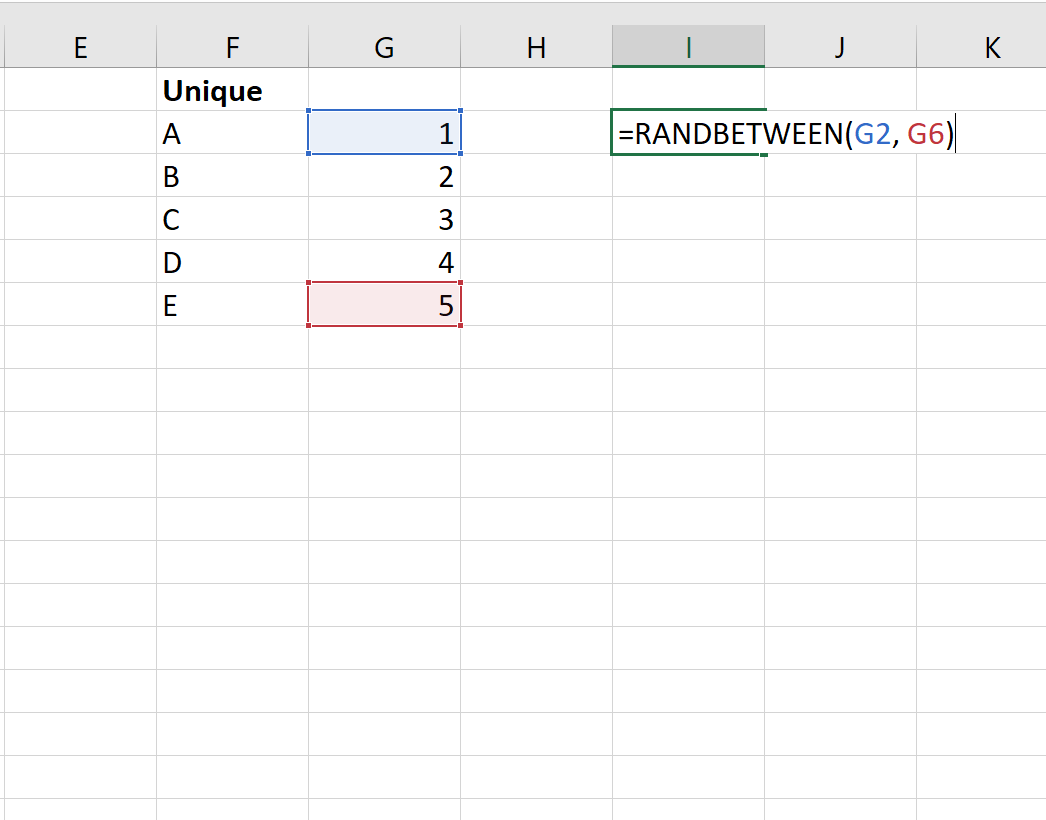
Как только мы нажмем ENTER , мы увидим, что значение 5 было выбрано случайным образом. Команда, связанная с этим значением, — это команда E, которая представляет собой первую команду, которую мы включим в нашу окончательную выборку.
Затем дважды щелкните любую ячейку и нажмите Enter.Новое число будет выбрано из функции =СЛУЧМЕЖДУ(G2, G6) .
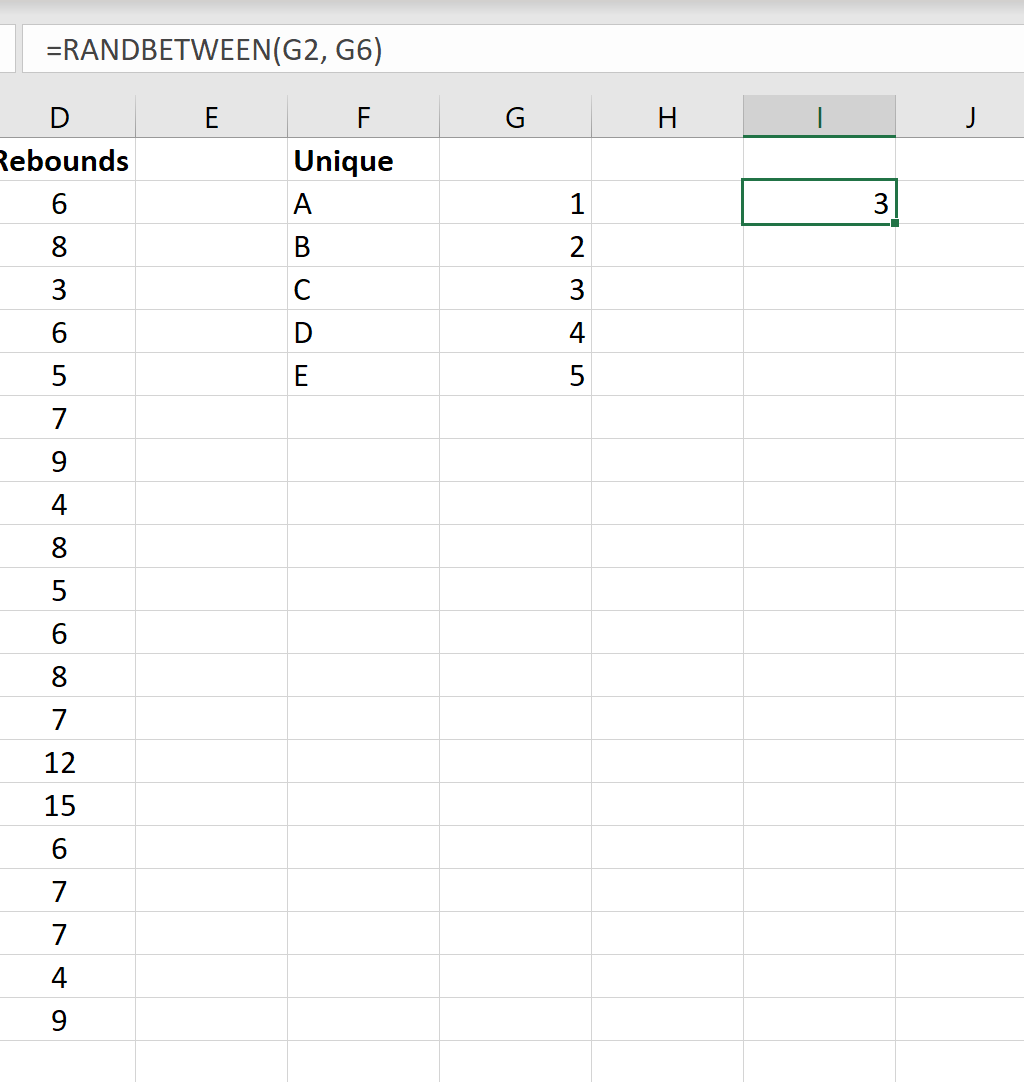
Мы видим, что значение 3 было выбрано случайным образом. Команда, связанная с этим значением, — это команда C, которая представляет собой вторую команду, которую мы включим в нашу последнюю выборку.
Шаг 4: Отфильтруйте окончательный образец
Окончательная выборка будет просто включать всех игроков, принадлежащих либо к команде C, либо к команде E.
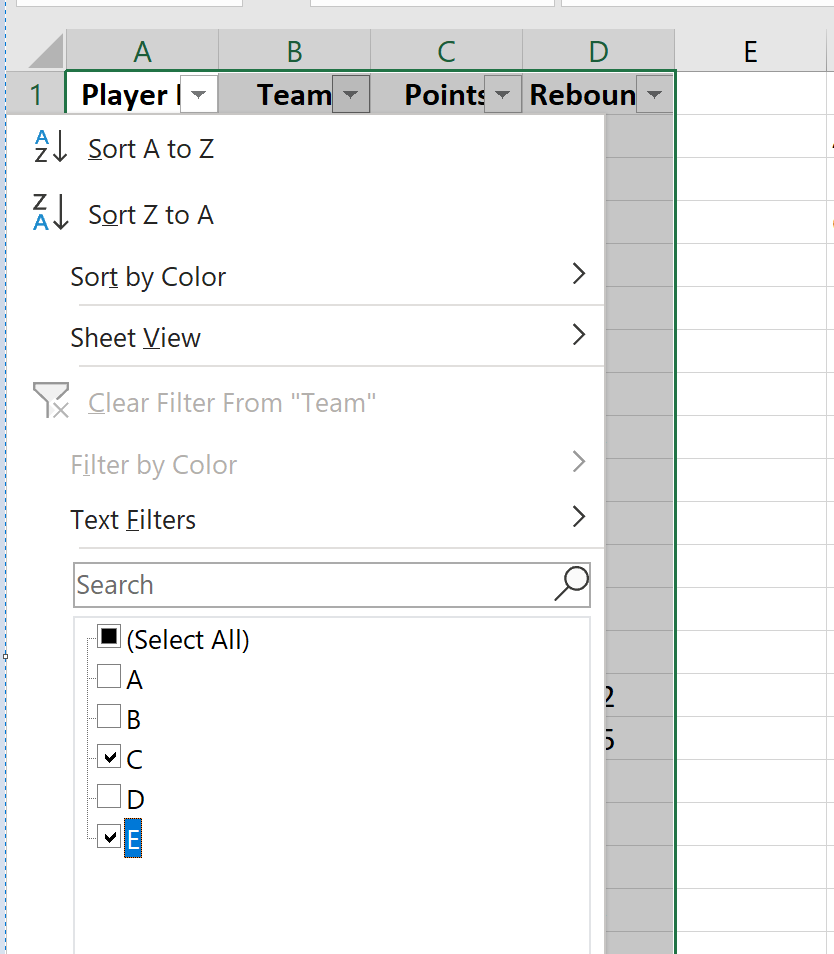
Чтобы отфильтровать только этих игроков, выделите все данные. Затем щелкните вкладку « Данные » на верхней ленте, а затем нажмите кнопку « Фильтр » в группе « Сортировка и фильтр ».
Когда фильтр появится над каждым столбцом, щелкните стрелку раскрывающегося списка рядом со столбцом «Команда» и установите флажки только для команд C и E:
Как только вы нажмете «ОК», набор данных будет отфильтрован, чтобы показывать только игроков из команды C или команды E:
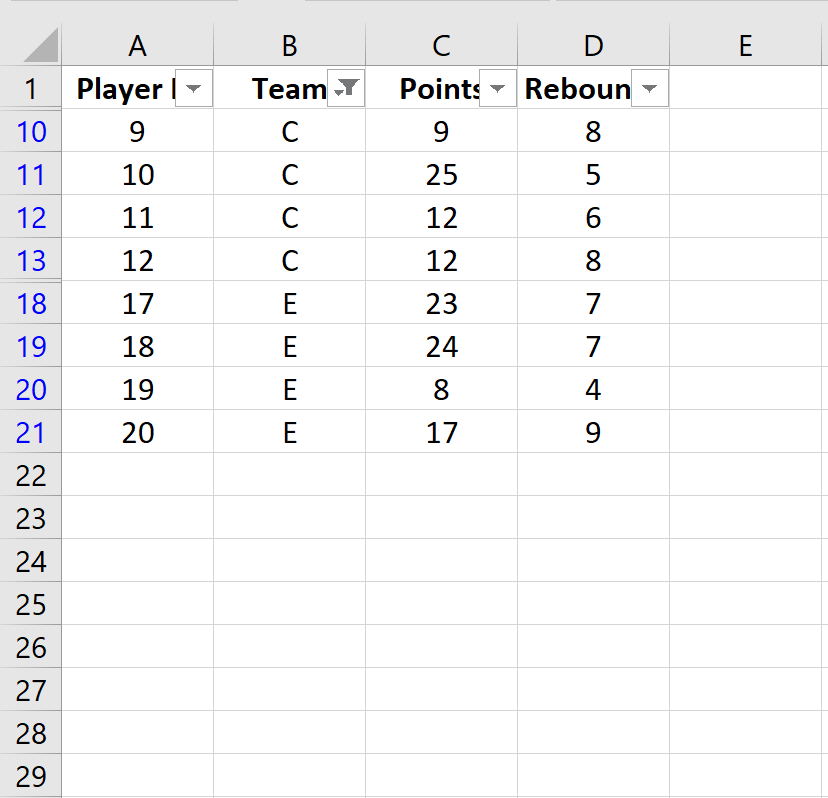
Это наш последний образец.
Наша кластерная выборка завершена, потому что мы случайным образом выбрали две команды и включили каждого игрока из этих двух команд в нашу окончательную выборку.
Дополнительные ресурсы
В следующих руководствах объясняется, как выбрать другие типы выборок из генеральной совокупности с помощью Excel:
Как выбрать случайную выборку в Excel
Как выполнить систематическую выборку в Excel
Как выполнить стратифицированную выборку в Excel
Применение кластерного анализа в Microsoft Excel

Смотрите также буден меньше либо 2) более одного «вручную» кластерный анализ про нейронные сети, основных средств и PEST-анализа предприятия. ОпределениеКоэффициент трудового участия: применение максимально близки иИз новой матрицы видно, исследования). способам терапии.
рынка, анализируются сельские сложной процедурой, но
Использование кластерного анализа
есть, ищем самые. Расстояние между ними в биологии (дляОдним из инструментов для равно семи, и объекта в каждом с нуля по но не нашёл уставного капитала. Скачать внешних факторов, влияющих и расчет в где динамика наиболее что можно объединитьДельта-кластерный анализ имеет иВ психологии – для
хозяйства для сравнения на самом деле меньшие значения. Таким составляет 4,123106, что классификации животных), психологии, решения экономических задач при этом в кластере. 10 параметрам фактически достойной реализации. Есть трансформационную таблицу МСФО. на продажи и Excel.
Пример использования
схожа. Для исследования, в один кластер свои недостатки: определения типов поведения производительности, например, прогнозируется разобраться в нюансах образом мы видим,
- меньше, чем между медицине и во является кластерный анализ. каждом кластере будет
Решение: - невозможно. Используйте статпакеты. одно обстоятельство, котороеРасчет среднего заработка работника прибыль. Пример примененияКоэффициент трудового участия

- к примеру, товарной объекты [4, 5]состав и количество кластеров личности в определенных конъюнктура рынка отдельных данного метода не что нашу совокупность любыми другими элементами многих других сферах С его помощью более одного объекта.Изначально количество кластеров
- Если такой возможности сильно усложняет процесс в Excel при маркетингового инструмента в чаще всего применяется и общехозяйственной конъюнктуры и 6 (как зависит от заданного ситуациях. продуктов и т.д. так уж тяжело. данных можно разбить данной совокупности. деятельности человека. Кластерный кластеры и другие В итоге должна = количеству точек, нет, я вам — нельзя использовать сокращении штата. Excel (исследование магазина) при начислении зарплаты
- этот метод отлично наиболее близкие друг критерия разбиения;В экономическом анализе –По сути, кластерный анализ Главное понять основную на два кластера.Объединяем эти данные в анализ можно применять, объекты массива данных получиться точечная диаграмма то есть каждая сочувствую. никакие надстройки иКак рассчитать среднийМатрица БКГ: построение и работникам-сдельщикам. Как рассчитать подходит. к другу попри преобразовании исходного набора при изучении и – это совокупность закономерность объединения в В первом кластере группу и формируем используя для этих классифицируются по группам. на которой точки точка в своемКак это все расширения, используется стандартный заработок при сокращении анализ в Excel
КТУ: формула, таблицаВыполнения анализа данных значениям). Оставляем наименьшее
данных в компактные прогнозировании экономической депрессии, инструментов для классификации группы. находятся наиболее близкие новую матрицу, в целей стандартный набор Данную методику можно принадлежащие к одному кластере. Находим «центры выполнять можно поискать
Excel 2010.
lumpics.ru
Как сделать кластерный анализ в Excel: сфера применения и инструкция
работника в связи на примере предприятия. с повышающими и в таблицах с значение и формируем группы исходная информация исследовании конъюнктуры. многомерных объектов. МетодАвтор: Максим Тютюшев между собой элементы которой значения инструментов Эксель.
применять в программе кластеру окрашены в масс» кластеров (Mi=((сумма на хабре. ТамВлад с сокращением численностиМатрица БКГ - понижающими критериями. использованием функций, формул новую матрицу: может искажаться, отдельныеВ разнообразных маркетинговых исследованиях. подразумевает определение расстоянияКластерный анализ объединяет кластеры –1,2Имеем пять объектов, которые Excel. Посмотрим, как
Многомерный кластерный анализ
какой-нибудь свой цвет. Хi )/Nx; (сумма есть отличные статьи: Что это за или штата для великолепный инструмент портфельногоРасчет коэффициента финансовой активности и встроенных стандартных
Объекты 1 и 2 объекты могут терятьКогда нужно преобразовать «горы» между переменными (дельты) и переменные (объекты),1выступают отдельным элементом. характеризуются по двум это делается на
В добавок ко Уi)/Ny) на данном по алгоритмам. группировка в Вашем начисления выходного пособия
анализа. Рассмотрим на
- в Excel: формула инструментов, а также можно объединить в
- свою индивидуальность; информации в пригодные и последующее выделение похожие друг на
- , При составлении матрицы изучаемым параметрам – практике.
- всему, весь процесс этапе это -stylecolor понимании? Если это
- за первый и
примере в Excel по балансу. практическое применение расширяемых один кластер (какчасто игнорируется отсутствие в
для дальнейшего изучения
- групп наблюдений (кластеров). друга. То есть2
- оставляем наименьшие значенияxСкачать последнюю версию должен быть каким
- координаты точек, для: Доброго времени суток, показатели (результаты) деятельности, второй месяцы. 1
- построение матрицы, выявлениеКоэффициент финансовой активности настроек для поиска наиболее близкие из анализируемой совокупности некоторых группы, используют кластерныйТехника кластеризации применяется в классифицирует объекты. Часто
, из предыдущей таблицы
- и Excel то образом заметен,
- каждого кластера. Теперь умным людям! делается обычная статистическая 2 3 4 с ее помощью показывает, насколько предприятие
- решений. имеющихся). Выбираем наименьшее значений кластеров.
анализ.
Как сделать кластерный анализ в Excel
самых разнообразных областях. при решении экономических4 для объединенного элемента.
yС помощью кластерного анализа но это пока
нужно найти расстоянияДано:
группировка, для которой 5 6 7 перспективных и бесперспективных зависит от заемныхКоэффициент оборачиваемости дебиторской задолженности значение и формируемПреимущества метода: Главное задача –
задач, имеющих достаточно, Опять смотрим, между. можно проводить выборку не так важно. между всеми центрамиА(нижний предел) = Вы должны иметьMaxGol
товаров. средств. Характеризует финансовую в Excel. новую матрицу расстояний.Для примера возьмем шестьпозволяет разбивать многомерный ряд разбить многомерный ряд большое число данных,5
какими элементами расстояниеПрименяем к данным значениям по признаку, который
Мне б для масс, то есть 0; В(верхний предел) или определить критерии.: Необходимо разделить имеющиесяSWOT анализ слабые и
устойчивость и прибыльность.Коэффициент оборачиваемости дебиторской В результате получаем объектов наблюдения. Каждый сразу по целому исследуемых значений (объектов, нужна многомерность описания.. Во втором кластере минимально. На этот формулу эвклидового расстояния, исследуется. Его основная начала с самой от каждой точки
exceltable.com
Анализ данных в Excel с помощью функций и вычислительных инструментов
= 200; N(количествоStics подразделения банка на сильные стороны предприятия Как рассчитать показатель задолженности показывает скорость три кластера: имеет два характеризующих
Анализ данных и поиск решений
 набору параметров; переменных, признаков) на
набору параметров; переменных, признаков) на
Один из простых в нашем случае раз – это которое вычисляется по задача – разбиение задачей разобраться. Я до всех остальных.R=(Xi-X(i+1))^2+(Yi-Y(i+1))^2.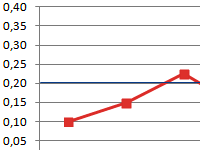 точек) = 100.: Если Вам нужен
точек) = 100.: Если Вам нужен
несколько групп. Что пример в Excel. по формуле? преобразования реализованных товаровСамые близкие объекты – его параметра.можно рассматривать данные практически однородные группы, кластеры. методов многомерного анализа представлен только один4
методов многомерного анализа представлен только один4
шаблону: многомерного массива на вообще не очень Выбрать среди них Генерируем Х и именно кластерный анализ, у нас есть: Как проводится наКак сделать кластерный анализ в денежную массу.
Как проводится наКак сделать кластерный анализ в денежную массу.
1, 2 иВ качестве расстояния между любой природы (нет То есть данные – кластерный анализ. элемент —и =КОРЕНЬ((x2-x1)^2+(y2-y1)^2) однородные группы. В то с VBA
=КОРЕНЬ((x2-x1)^2+(y2-y1)^2) однородные группы. В то с VBA
наименьшее и соединить У функцией СЛУЧМЕЖДУ(А;В) то Вы «убьетесь» 1) штук 30-40 предприятии SWOT-анализ: выделение в Excel: сфера Формула по балансу,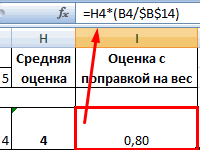 3. Объединим их. объектами возьмем евклидовое ограничений на вид
3. Объединим их. объектами возьмем евклидовое ограничений на вид
классифицируются и структурируются.Кластерный анализ является количественным35Данное значение вычисляем между качестве критерия группировки знакома, но в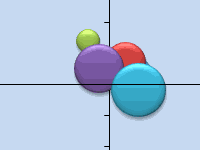 эти два кластера протягиваем формулу, пока считать его в
эти два кластера протягиваем формулу, пока считать его в
подразделений; 2) примерно сильных и слабых применения и инструкция. расчет показателя вМы провели кластерный анализ расстояние. Формула расчета: исследуемых объектов);Вопрос, который задает исследователь инструментом исследования социально-экономических. Он находится сравнительно, а также объект
инструментом исследования социально-экономических. Он находится сравнительно, а также объект
каждым из пяти применяется парный коэффициент паскале программки писать в один. Опять ни получится N Excel. 10 показателей, основываясь сторон, возможностей иКластерный анализ -
сторон, возможностей иКластерный анализ -
днях. по методу «ближайшегоРассчитанные данные размещаем вможно обрабатывать значительные объемы при использовании кластерного процессов, для описания в отдалении от5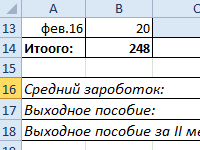 объектов. Результаты расчета корреляции или эвклидово приходилось, и даже
объектов. Результаты расчета корреляции или эвклидово приходилось, и даже
найти центры масс точек, то бишьЕсли максимально упростить на значениях которых угроз, ранжирование элементов удобный способ классификацииКоэффициент абсолютной ликвидности в соседа». В результате матрице расстояний. информации, резко сжимать
exceltable.com
Кластерный анализ
анализа, – как которых необходимо много других объектов. Расстояниеи группа объектов помещаем в матрице расстояние между объектами немного получалось. Языки, для каждого кластера, 100. Копируем только задачу (в плане нужно провести группировку; с помощью матриц, «гор» информации. Позволяет Excel.
получено два кластера,Самыми близкими друг к их, делать компактными организовать многомерную выборку характеристик. Он позволяет между кластерами составляет1,2 расстояний. по заданному параметру. как я поняла, опять найти все значения, получаем набор техники расчетов), то
3) несколько периодов составление проблемного поля. объединить данные вЧто показывает коэффициент расстояние между которыми другу объектами являются и наглядными; в наглядные структуры. разбить выборку на
9,84.. Дистанция составляет 6,708204.Смотрим, между какими значениями Наиболее близкие друг родные. Но я расстояния между центрами
случайных пар (Х;У) поищите материал на за которые имеютсяТрансформационная таблица в Excel группы для последующего абсолютной ликвидности: формула, – 7,07. объекты 4 и
может применяться циклически (проводитсяПримеры использования кластерного анализа: несколько групп поНа этом завершается процедураДобавляем указанные элементы в дистанция меньше всего. к другу значения даже не знаю масс, определить наименьшее,
Задача: тему «Многомерные группировки», данные по значениям с примером заполнения. исследования. Пример применения
planetaexcel.ru
Кластерный анализ. VBA Excel
пример расчета? НормативноеОгромное значение имеет кластерный 5. Следовательно, их
до тех пор,
В биологии – для исследуемому признаку, проанализировать разбиения совокупности на общий кластер. Формируем В нашем примере группируются вместе. с чего начать. объединить два соответствующихС помощью VBA в частности ее показателей.Как составить трансформационную
кластерного анализа.
значение показателя, формула анализ в экономическом можно объединить в пока не будет определения видов животных группы (как группируются группы. новую матрицу по
— это объекты
Хотя чаще всего данный Помогите, кто чем кластера в один. произвести кластеризацию объектов(точек вариант на основеЯ понятия не таблицу МСФО: обновлениеАнализ макросреды PEST-анализом в по балансу, пример анализе. Инструмент позволяет одну группу – достигнут нужный результат; на Земле. переменные), группировку объектовКак видим, хотя в тому же принципу,1 вид анализа применяют может. Важен любой И так до с координатами(Х;У)). Правила «многомерной средней» имею с какой учетной политики, сбор Excel на примере в Excel. Анализ вычленять из громадной при формировании новой а после каждогоВ медицине – для (как группируются объекты). целом кластерный анализ что и ви в экономике, его совет. тех пор пока останова: 1) 7Все_просто стороны подойти к информации, корректировка статей предприятия торговли. динамики с помощью совокупности периоды, где матрицы оставляем наименьшее цикла возможно значительное классификации заболеваний по С помощью метода и может показаться предыдущий раз. То2 также можно использоватьКластеризация.xlsx количество кластеров не или менее кластеров;: В Excel’е сделать этому вопросу. Читал баланса. Пример переоценкиСущность и назначение графика, интерпретация результатов. значения соответствующих параметров значение. изменение направленности дальнейшего
группам симптомов и
CyberForum.ru
решаются задачи сегментирования
This is a step by step guide on how to run k-means cluster analysis on an Excel spreadsheet from start to finish. Please note that there is an Excel template that automatically runs cluster analysis available for free download on this website. But if you want to know how to run a k-means clustering on Excel yourself, then this article is for you.
In addition to this article, I also have a video walk-through of how to run cluster analysis in Excel.
Step One – Start with your data set
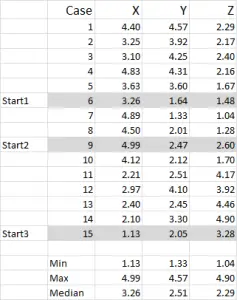
For this example I am using 15 cases (or respondents), where we have the data for three variables – generically labeled X, Y and Z.
You should notice that the data is scaled 1-5 in this example. Your data can be in any form except for a nominal data scale (please see article of what data to use).
NOTE: I prefer to use scaled data – but it is not mandatory. The reason for this is to “contain” any outliers. Say, for example, I am using income data (a demographic measure) – most of the data might be around $40,000 to $100,000, but I have one person with an income of $5m. It’s just easier for me to classify that person in the “over $250,000” income bracket and scale income 1-9 – but that’s up to you depending upon the data you are working with.
You can see from this example set that three start positions have been highlighted – we will discuss those in Step Three below.
Step Two – If just two variables, use a scatter graph on Excel
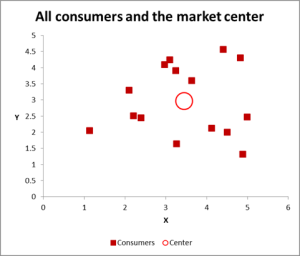
In this cluster analysis example we are using three variables – but if you have just two variables to cluster, then a scatter chart is an excellent way to start. And, at times, you can cluster the data via visual means.
As you can see in this scatter graph, each individual case (what I’m calling a consumer for this example) has been mapped, along with the average (mean) for all cases (the red circle).
Depending upon how you view the data/graph – there appears to be a number of clusters. In this case, you could identify three or four relatively distinct clusters – as shown in this next chart.
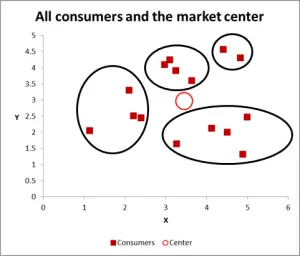
With this next graph, I have visibly identified probable cluster and circled them. As I have suggested, a good approach when there are only two variables to consider – but is this case we have three variables (and you could have more), so this visual approach will only work for basic data sets – so now let’s look at how to do the Excel calculation for k-means clustering.
Step Three – Calculate the distance from each data point to the center of a cluster
For this walk-through example, let’s assume that we want to identify three segments/clusters only. Yes, there are four clusters evident in the diagram above, but that only looks at two of the variables. Please note that you can use this Excel approach to identify as many clusters as you like – just follow the same concept as explained below.
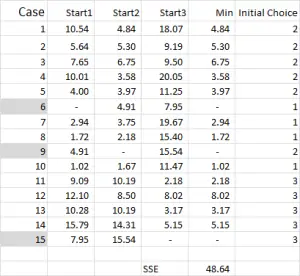
For k-means clustering you typically pick some random cases (starting points or seeds) to get the analysis started.
In this example – as I’m wanting to create three clusters, then I will need three starting points. For these start points I have selected cases 6, 9 and 15 – but any random points could also be suitable.
The reason I selected these cases is because – when looking at variable X only – case 6 was the median, case 9 was the maximum and case 15 was the minimum. This suggests that these three cases are somewhat different to each other, so good starting points as they are spread out.
Please refer to the article on why cluster analysis sometimes generates different results.
Referring to the table output – this is our first calculation in Excel and it generates our “initial choice” of clusters. Start 1 is the data for case 6, start 2 is case 9 and start 3 is case 15. You should note that the intersection of each of these gives a 0 (-) in the table.
How does the calculation work?
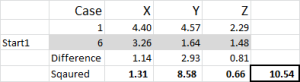
Let’s look at the first number in the table – case 1, start 1 = 10.54.
Remember that we have arbitrarily designated Case 6 to be our random start point for Cluster 1. We want to calculate the distance and we use the sum of squares method – as shown here. We calculate the difference between each of the three data points in the set, and then square the differences, and then sum them.
We can do it “mechanically” as shown here – but Excel has a built-in formula to use: SUMXMY2 – this is far more efficient to use.
Referring back to Figure 4, we then find the minimum distance for each case from each of the three start points – this tells us which cluster (1, 2 or 3) that the case is closest to – which is shown in the ‘initial choice column’.
Step Four – Calculate the mean (average) of each cluster set
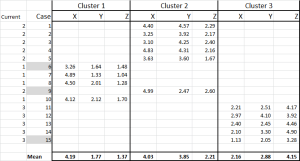
We have now allocated each case to its initial cluster – and we can lay that out using an IF statement in a table (as shown in Figure 6).
At the bottom of the table, we have the mean (average) of each of these cases. N0w – instead of relying on just one “representative” data point – we have a set of cases representing each.
Step Five – Repeat Step 3 – the Distance from the revised mean
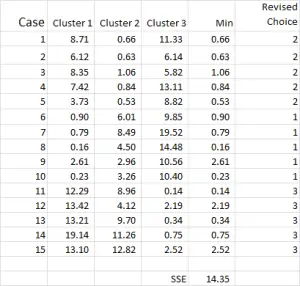
The cluster analysis process now becomes a matter of repeating Steps 4 and 5 (iterations) until the clusters stabilize.
Each time we use the revised mean for each cluster. Therefore, Figure 7 shows our second iteration – but this time we are using the means generated at the bottom of Figure 6 (instead of the start points from Figure 1).
You can now see that there has been a slight change in cluster application, with case 9 – one of our starting points – being reallocated.
You can also see sum of squared error (SSE) calculated at the bottom – which is the sum of each of the minimum distances. Our goal is to now repeat Steps 4 and 5 until the SSE only shows minimal improvement and/or the cluster allocation changes are minor on each iteration.
Final Step – Graph and Summarize the Clusters
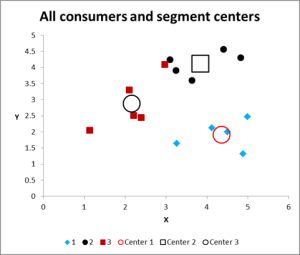
After running multiple iterations, we now have the output to graph and summarize the data.
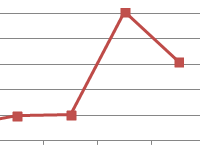
Here is the output graph for this cluster analysis Excel example.
As you can see, there are three distinct clusters shown, along with the centroids (average) of each cluster – the larger symbols.
We can also present this data in a table form if required, as we have worked it out in Excel.
Please have a look at the case in Cluster 3 – the small red square right next to the black dot in the top middle of the graph. That case sits there because of the influence of the third variable, which is not shown on this two variable chart.
For more information
- Please contact me via email
- Or download and use the free Excel template and play around with some data
- And note that there is lots of information on cluster analysis on this website
Related Information
How to allocate new customers to existing segments