
Сегодня хотелось бы поделиться важной функцией выгрузки семантического ядра из Key Collector в excel в удобном виде.
Задействовать ее просто: зажимаем Shift и жмем на экспорт excel файла (слева в самом верху)
А на форумах советуют самостоятельно написать удобную выгрузку, хотя в функционале Кей Коллектора она уже предусмотрена.
PS: если не получается, попробуйте порыться в настройках: Настройки — Интерфейс — Экспорт: в «настройки формата XLSX» — выберите чекбокс «Создавать карту выгрузки при экспортировании нескольких групп».
Привет. В прошлый раз я начал вам показывать, как составить семантическое ядро сайта на примере интернет магазина. Сегодня продолжение, вторая часть.
Итак, в прошлый раз с помощью Базы Пастухова мы собрали все требуемые нам ключевые слова. Если же у вас нет этой самой Базы Пастухова (эту ситуацию можно понять, данный софт очень дорогой), мы парсим ключевые слова с Яндекс Вордстата. Давайте я распишу все пошагово.
- В программе Key Collector нажимаем на кнопку «Пакетный сбор из левой колонки Яндекс Вордстат» (если вы работали с Базой Пастухова, то просто загружаете в Кей Коллектор собранные «ключи»):

- В одну вкладку (группу) собираем ключевые слова из созданной нами структуры сайта. В моем случае это может быть, например, все фразы, которые содержат «коляски прогулочные».
- Также можете воспользоваться сбором поисковых подсказок, аналогично добавятся еще ключевые слова. Я вообще первые три пункта пропускаю, так как повторюсь, ключевые слова собрал уже в Базе Пастухова. А вот кнопка сбора поисковых подсказок:
- Снова раскидываем все по подгруппам, соблюдая иерархию. То есть, в моем случае получается что-то вроде этого:
- Дальше собираем частотность по требуемому региону. Собирать частотность в Key Collector можно двумя инструментами:
- Я вам настоятельно рекомендую пользоваться инструментом, которая отмечена на скриншоте выше, как цифра «2», то есть через Яндекс Директ. Вы сэкономите часы (!) своего времени. Как правильно настроить сбор частотности, изучите в официальной справке программы Key Collector.
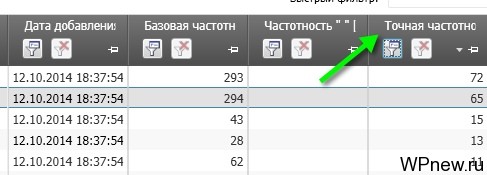
- Дальше я удаляю «запросы-пустышки». То есть я собираю точную частотность («Частотность «!» Яндекс Вордстат») и те запросы, которые меньше определенного количества, я удаляю. Если клиент требует низкочастотники или даже микроНЧ, я их, конечно оставляю. Если же вам они не нужно, то, что меньше 10-20 точной частотности, можно смело удалять. Ну, если вы сомневаетесь, какие запросы удалять, для начала просто удалите «нулевики», то есть те запросы, у которых точная частотность равна 0. А дальше будете ориентироваться уже по требуемому объему ключевых слов (точная частотность — это количество запросов данного ключевого слов в точном вхождении (с учетом падежа) за месяц):
- Не обращайте внимание на название столбцов, он у вас скорей всего называется, как «Частотность «!» Яндекс Вордстат». Любой столбец можно переименовать для удобства в настройках. Удалив «запросы-пустышки», количество ненужных ключевых фраз серьезно уменьшается.
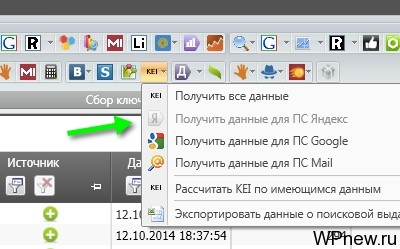
- Так как приходится ждать работу Key Collector (все зависит от размахов проекта), я стараюсь делать все, чтобы он не «простаивал» просто так без дела. Дальше я собираю данные конкурентности запросов (я ориентируюсь на Яндекс). Для этого нажимаю на кнопку «KEI» -> «Получить данные для ПС Яндекс»:
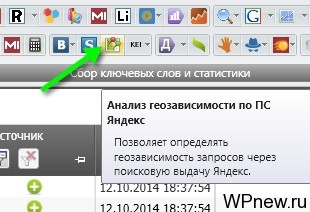
- Пока программа собирает данные, полезно бывает в некоторых случаях запустить определение геозависимости запросов. Мы прекрасно знаем, что, например, информационным сайтам очень тяжело выйти в ТОП по геозависимым запросам, они рассчитаны для коммерческих сайтов (что такое геозависимые и геонезависимые запросы?):
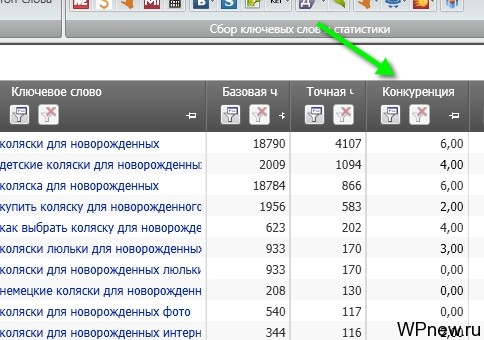
- Параллельно вы можете запустить сбор других данных для требуемого проекта. В большинство случаев для меня и клиентов достаточно знать точную частотность запроса и его конкуренцию. После того, как у меня завершится сбор данных конкуренции для Яндекса (см. пункт №8), я подсчитываю так называемые KEI:
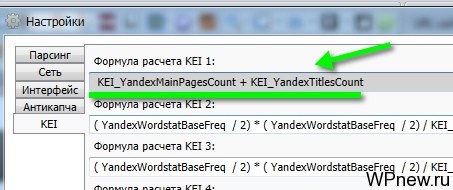
- Что такое KEI? Это некая величина, которая состоит из сложений разных величин. То есть мы сами можем задать формулу подсчета конкуренции. Я считаю конкуренцию по этой формуле: KEI_YandexMainPagesCount + KEI_YandexTitlesCount. Задается формула в настройках:
- По этой формуле наша конкуренция — это сумма количества сайтов, содержащих ключевые слова в Title главной страницы + количество сайтов, у которых в Title содержится ключевые слова на внутренних страницах. Причем анализируется только ТОП-10. То есть, например, фраза «шерстяные носки». Смотрим выдачу Яндекса (первые ТОП-10):
- Аналазируется первые 10 результатов. На скриншоте выше видно, что третий сайт не содержит в Title фразу «шерстяные носки», соответственно, он не будет считаться при подсчете KEI. То есть, допустим по данному запросу 8 сайтов содержат фразу в TItle на внутренней странице, 1 сайт в Title главной страницы, а 1 сайт вообще не содержит. Соответственно, формула посчитает 8+1=9. KEI 1, которая будет в столбце, это и будет наш показатель конкурентности, то есть максимальное значение данной цифры может быть = 10. Иногда бывает, что и все 12 показывает Key Collector, это небольшой сбой, в таких случаях вручную потом после экспорта прописываем цифру 10. То есть те запросы, которые содержат цифру 10 в столбце KEI 1 (в случае с моей формулой) получается наиболее конкурентные запросы.
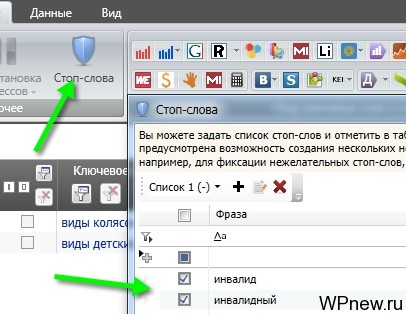
- Дальше вам нужно удалить ненужные «мусорные» ключевые слова. Например, так как я собираю семантическое ядро к детским коляскам, часто проскакивают фразы, связанные с инвалидными колясками. Поэтому, для подобных случаев используем «Стоп-слова», я просто вбил фразы «инвалид», «инвалидный» (причем не нужно «париться» со склонениями) и сразу же в таблице отмечаются те ключевые слова, которые содержат данные фразы. Потом просто нажимаем на таблицу правой кнопкой мыши и «Удалить отмеченное».
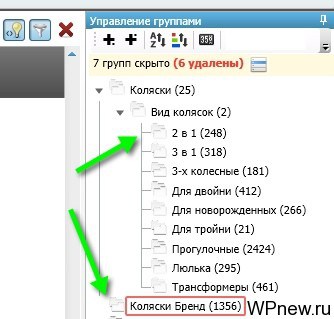
- Помимо всего это бывают такие фразы, которые содержатся в нескольких вкладках. Например: «коляска tako 2 в 1». Это ключевое слово можно отнести и к группе «2 в 1» и в тоже время в группу с брендами:
- В таких случаях нужно рассуждать логически и понять, куда лучше отнести фразу. В моем случае, человек ищет коляску именно фирмы «tako», то есть название бренда более уточняющее слово во всей фразе. Поэтому все запросы, которые содержат бренды, я осталяю только в группе «коляски бренд», а в других группах убираю. Для этого просто загрузил в «Стоп-слова» список брендов и удаляю фразы, содержие их на всех вкладках, кроме «Коляски Бренд».
- Даже после всевозможных фильтраций, не жалейте свое время, пройдитесь по спискам запросов, почистите мусор «ручками». Полностью автоматически все ненужные ключевые слова удалить просто невозможно.


И, ребята, если еще кто не в курсе: во время активной работы в Key Collector будут выскакивать капчи от поисковых систем. Я вас умоляю, не тратьте свои нервы и время, зарегистрируйтесь в сервисе Antigate, пополните счет на какие-нибудь 3$. Они вам хватят чуть ли не на полгода. И вам не придется вручную вводить капчу (это буквы и цифры с картинки). Жаль нельзя антикапчу «встроить» в браузер, было бы вообще круто. 🙂
Экспорт
Дальше экспортируем наш проект в Кей Коллекторе в обычную таблицу в Excel. Конечно, в идеале можно все ключевые слова вместить в один документ, просто по вкладкам внизу разбить на группы, категории. Но в моем случае проект относительно очень большой (интернет-магазин все-таки), у меня куча разных категорий и чтобы не запутаться клиенту, ну и будущему оптимизатору сайта (а может это буду я? 🙂 ) я разбиваю весь проект на несколько разных файлов. То есть у меня будут: коляски.xlsx, автокресла.xslx и прочее.
Перед экспортом я рекомендую немного изменить настройки Key Collector. Формат экспорта поставьте XLSX (удобнее работать в Excel), также там же внизу можете сразу отметить только те столбцы, которые вам интересны для экспорта. В моем случае это ключевое слово, его точная частотность и KEI 1, то есть конкурентность.
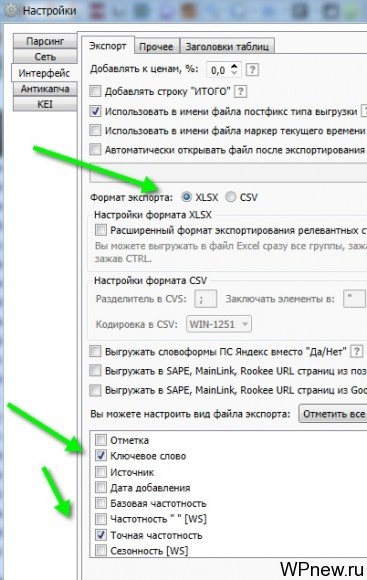
Чтобы экспортировать, просто нажмите на соответствующую кнопку. Если вам нужно выгрузить все группы сразу, то удерживайте кнопку Shift перед нажатием на кнопку экспорта:
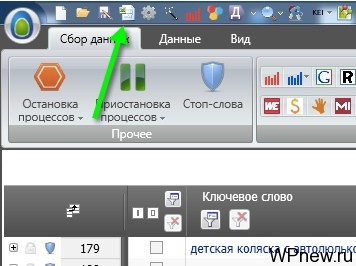
То есть получается примерно такая картина:
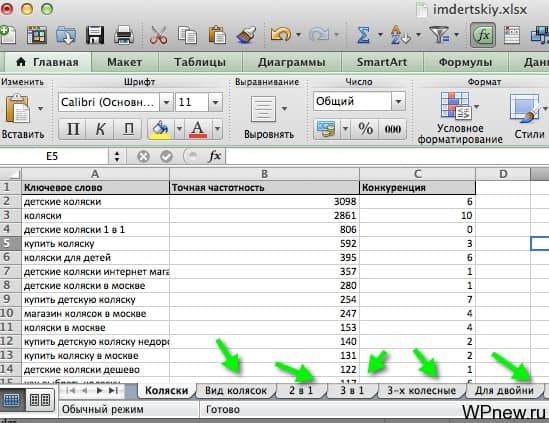
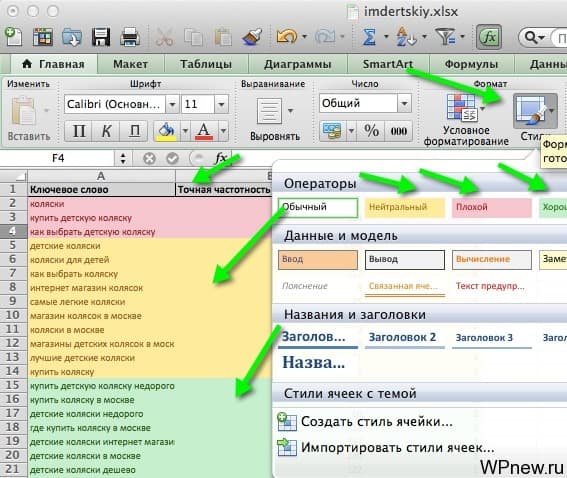
Для наибольшей наглядности можно сначала отсортировать таблицу по значению «Конкуренция» и придать соответствующие стили:
А уже потом обратно отсортировать по показателю «Точная частотность» и получится примерно такая картина:
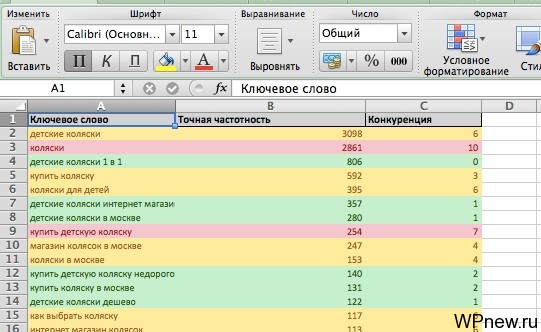
И таких куча вкладок. В сумме у меня получилась не одна тысяча запросов. Примерно такой вариант семантического ядра я отправляю клиенту.
Итог
Как видите такие программы, как Key Collector очень сильно облегчают работу, а главное дают положительный результат для будущего продвижения сайта, если же конечно пользоваться правильно. Если же проект довольно большой, как в моем случае, крайне сильно облегчает работу База Пастухова.
Если кому-то что-то не понятно, а может кто-то предпочитает в видеоформате рассказанное мною в последних уроках, не огорчайтесь. Все это более наглядно и подробно, а также много чего другого интересного вас ждет от меня уже скоро. Ждем вторую половину октября.
Теперь вы готовы пройти следующий урок: «Что делать с семантическим ядром сайта?»
Как вам урок?
Спасибо, очень приятно быть полезными!
Лучшая благодарность — это комментарий к уроку и «шеринг» в соц. сетях. Спасибо!
Помогите стать лучше, скажите что не так?
Непонятно
Урок устарел
Другое
Спасибо за помощь в развитии проекта!
Сегодня будет проведен обзор совместной работы лучшей программы для сбора семантики Key Collector и лучшей программы для кластеризации запросов Key Assort.
Заходим в программу.
1. Здесь уже собрались какие-то запросы и у нас получилось 383 фразы. Уже есть определенные данные.

Например, мы работаем с поисковой выдачей, с частотами и т.д, и нам нужно здесь распределить эти фразы по страницам. И алгоритм, который встроен в Key Collector, нас по какой-то причине не устраивает.
Мы можем уже здесь собрать данные – они нужны будут нам в Key Collector (доля главных страниц, количество вхождений в заголовки). Эти данные нужно будет еще раз собирать и в KeyAssort.
И вот чтобы не делать это дважды, мы соберем эти данные только в Key Collector. Открываем вкладку «Парсинг/Собрать данные из ПС Yandex»

Идет парсинг

Далее видим, что собрались данные по поисковой выдаче.

Что делаем дальше?
Переходим во вкладку «Файл/Экспорт/Поисковая выдача».
Выбираем Яндекс. Сниппеты не загружаем. Выбираем Экспортировать.

Выпадает вкладка, в которой нужно ввести имя файла – назовем «экспорт» (он в Excel).
Key Assort
Далее идем в KeyAssort.
-
Создаем проект (у нас он уже создан).
-
Выбираем следующее: «Файл/Импорт/С данными о поисковой выдаче».
-
В выпавшем меню о запросе безвозвратно удалить все данные нажимаем «да».
-
В появившемся окне выбираем «Выдача».
-
Появилась вкладка «Параметры импорта». Проверяем: столбец «А» — это запрос; столбец «N» — конкретные сайты.
-
Теперь выбираем в настройках тип кластеризации: «Сервис/Настройки программы/Кластеризация».

Запросы добавились. Собирать данные не нужно, они есть (в нижней строке экрана написано «Собрано данных 384 из 384»)

Здесь делаем все настройки, которые нам нужны, индивидуально.
В данном случае выбираем Силу – 4; вид кластеризации – Hard, сохраняем.
Далее в верхней панели жмем вкладку «Кластеризовать». Получаем результат.

Здесь дополнительно ничего парсить не нужно. Напомним, что эту кластеризацию нужно проверять, т.е. нужно просмотреть выборочно или все группы, корректно ли он сгруппировал.
Часто бывает так, что наша стандартная кластеризация – и тип, и сила – могут для конкретных проектов показать себя не очень хорошо. И тогда мы будем играться с силой: уменьшать, увеличивать. Допустим, получились слишком маленькие группы и слишком много несгруппированных запросов, тогда можно силу уменьшить.
Итак, все сгруппировано.
Дальше нам нужно перетащить все проекты направо. Для этого переходим в правую часть экрана, там во вкладке «Группа/Форма» вводим название – не важно, как это называется, назовем, к примеру, «категория».
Клавишей «Shift» выделяем все файлы левой части экрана и тащим направо.

Если мы не хотим никак дополнительно называть эти группы ключей, тогда назовем их как один из запросов этой группы. Если хотим, чтобы группы более осмысленно уже на этом этапе назывались, тогда здесь их просто переименовываем.
Все.
Что делаем дальше?
Экспорт. И здесь нужно экспортировать не как обычно в Excel, а экспортировать в Key Collector. Для этого в правой части экрана в верхней вкладке выбираем «Экспорт/Key Collector». Жмем, делаем файл – даем ему название в выпавшем меню.

Все, экспортировали.
Возвращаемся в Key Collector и выбираем «Файл/Импорт/Проект KeyAssort». В выпавшем меню выбираем наш файл.
В предлагаемом меню выбираем «не проверять дубли фраз» и «проверять статистику». Жмем импортировать. И он сейчас эти фразы сразу распределит по вкладкам, так же, как у нас это было в Key Assort.
Получаем категории и фразы, уже распределенные по категориям.

И дальше можно с ними работать, собирать по ним дальше данные и можно также переименовывать здесь эти группы, назвать их как-то по другому.
И если у нас получилась слишком большая группа, можно еще раз выгрузить это в Key Assort, там сгруппировать и утащить это обратно, если это вдруг для каких-то целей понадобится.
Вот такая связка. Сейчас последняя версия Key Assort и последняя версия Key Collector очень удобны для этого. И рекомендуется для этого их и использовать.
Экспорт файла Key Collector в Excel, редактирование и создание объявлений для загрузки в Директ Коммандер
Понравилось видео? Поделитесь с друзьями
<<< Предыдущий урок Следующий урок >>>
Отзыв о Наставничестве, Роман
Пошаговый тренинг по Яндекс Директ для новичков «Монстры Маркетинга Junior» (проверка домашних заданий, рекламных кампаний, доступ в закрытую мастер-группу, поддерживающие вебинары)
Пошаговый тренинг «Монстры Маркетинга 7 в 1» (более 40 видеоуроков по 2-5 часов, проверка домашних заданий, рекламных кампаний, доступ в закрытую мастер-группу, поддерживающие вебинары)
Возможно, Вам также будут интересны и другие мои обучающие материалы по Яндекс Директ:
Основы сбора ключевых слов для контекстной рекламы (3,5 часа)
Запись вебинара «19+ способов привлечения клиентов для директологов и маркетинговых агентств»
Полный каталог всех моих обучающих материалов, а также анонсы ближайших мероприятий
AdPump.ru — бесплатный сервис автоматизации создания рекламных кампаний в Яндекс Директ и Google Ads
При помощи Key Collector можно не только существенно упростить процедуру сбора семантического ядра
для рекламной кампании, но также и получить наиболее полный и качественный результат и анализ.
Стоит отметить, что данная программа работает не с готовыми базами данных и не занимается генерированием ключевых фраз, а вместо этого она позволяет собирать актуальную информацию напрямую с сервисов-источников.
Приложение позволяет получать информацию с большинства популярных русскоязычных и зарубежных источников, с помощью которых можно получить максимально полную выборку высокочастотных, среднечастотных и, конечно, низкочастотных фраз
.
С полученными результатами можно работать как, не выходя из программы, так и экспортировав их в формат Microsoft Excel или CSV.
Удобное классическое табличное представление данных с возможностью фильтрации и дополнительными всплывающими редакторами позволяет анализировать дополнительные сведения.
Key Collector активно используют не только в контекстной рекламе, но и в SEO.
Что же можно сделать с помощью Key Collector?
- 1 Парсить всевозможные ключевые фразы
для будущей рекламной кампании (из этих ключевых фраз можно сформировать семантическое ядро); - 2 Определить частотность ключевых слов, которая позволяет выявить ВЧ, СЧ и НЧ запросы для того, чтобы выяснить, что добавляем, а что удаляем;
- 3 Анализировать и выявлять запросы на геозависимость
, сезонность
; - 4 Задавать стоп-слова, например, в списке ключевых слов не нужны фразы “скачать”, “бесплатно”, то их необходимо отметить как стоп-слова и ключевые слова удалятся из таблицы.
- 5 Собирать статистику с системы Yandex.Wordstat
. - 6 Собирать статистику со счетчиков системы статистики, Yandex.Metrika
, Google.Analytics
. - 7 Собирать поисковые подсказки с шести популярных поисковых систем: Яндекс, Google, Mail, Rambler, Nigma, Yahoo, Яндекс.Директ.
- 8 Собирать похожие поисковые запросы из поисковой выдачи ПС Яндекс, Google, Mail.
- 9 Вычислять лучшую словоформу.
- 10 Собирать расширения для ключевых фраз.
- 11 Собирать статистику из сервиса Google.Adwords (бюджет, частотность и коэффициент конкуренции) и Yandex.Direct (бюджет, количество переходов, количество показов, цену клика, коэффициент эффективности CTR и данные о конкуренции — сбор информации о размещаемых объявлениях по заданным ключевым фразам).
- 12 Выгружать в формате Microsoft Excel или CSV для дальнейшей работы с фразами.
Настройка Key Collector для парсинга данных Wordstat Яндекс
Для начала необходимо скачать – купить программу на следующем сайте: https://www.key-collector.ru/ .
.
- 1 Заходим в настройки программы, но для этого необходимо кликнуть на шестеренку, расположенную в блоке основных инструментов программы, в левом верхнем углу, в соответствии с рисунком 1.
- 2 Выбираем вкладку «Парсинг», в которой будут еще несколько вкладок, из них выбираем Yandex.Direct.
- 3 Настраиваем аккаунт, для этого необходимо создать почту на Яндексе, ту которая будет предназначаться только для этой программы, чтобы вдруг не заблокировали, в соответствии с рисунком 3.
- 4 После того, как все настроено, необходимо начать новый проект, для этого необходимо нажать «Новый проект» и даем ему название, а соответствии с рисунком 4 и 5.
- 5 Указываем регион парсинга, в данном случае регион — «Екатеринбург». Для этого нужно внизу программы нажать на соответствующее поле ввода, напротив красной гистограммы и выбрать необходимый город, в соответствии с рисунком 6 и 7.
- 6 Запуск программы на парсинг данных из Яндекс Вордстата, для этого необходимо нажать в панели инструментов на значок, в виде красной гистограммы, в соответствии с рисунком 8.
- 7 В открытом окне, вводим список основных высокочастотных или среднечастотных ключевых фраз, которые были подобраны вручную для составления семантического ядра запросов и нажимаем на кнопку «Начать сбор», в соответствии с рисунком 9.
- 8 Потребуется некоторое время, пока программа закончит сбор данных.
В результате получается список из большого количества слов, в соответствии с рисунком 10. - 9 Производим чистку от нерелевантных и малоэффективных слов, которые не дадут результата для будущей рекламной кампании.
Конечно, можно заниматься ручным отсевом фраз, нажимать по каждому и отсеивать, но это займет много времени, особенно когда фраз несколько сотен тысяч. Поэтому для этого применим специальный фильтр стоп-слов, который сократит время. Необходимо нажать на иконку стоп-слова в интерфейсе программы, в соответствии с рисунком 11. - Здесь есть 2 вкладки со списком 1 и 2. В первый список задаются ненужные стоп-слова, которые никаким образом не относятся к проекту, во вторую вкладку наоборот, те слова, которые выгодны для проекта, в соответствии с рисунком 12.
- 10 Выставляем настройки, как представлено на скриншоте, подобные настройки позволяют искать совпадения во всех фразах, перебирая все слова фраз, если фраза частично совпадает со стоп-словом, такие ключевые фразы будут выделены в общей таблице, естественно, если нажать кнопку: «Отметить в таблице», в соответствии с рисунком 13. Далее нажимаем «Отметить фразы» в таблице.
- 11После того, как определены «стоп-слова», выделенные в таблице фразы можно смело удалить, выбрав вкладку «Данные» и нажав на «Удалить отмеченные фразы», в соответствии с рисунком 14.
В результате в таблице останутся те слова, которые будут значительно эффективнее для проекта. - 12 Снимаем точные частотности ключевых фраз, для того, чтобы отсеять слова-пустышки. Для этого используем статистику Яндекс.Директ, которая позволяет пакетно снимать данные, в соответствии с рисунком 15.
- 13Далее выгружаем все ключевые фразы в формат Exel для дальнейшей работы над фразами, в соответствии с рисунком 17.

Рис. 1 – Настройка программы

Рис. 2 – Настройка парсинга Yandex.Direct

Рис. 3 – Настройка аккаунта Yandex.Direct

Рис. 4 – Начало работы

Рис. 5 – Название проекта

Рис. 6 – Выбор региона

Рис. 7 – Выбор региона, например Екатеринбург

Рис. 8 – Запуск на парсинг
В открытом окне, вводим список основных высокочастотных или среднечастотных ключевых фраз, которые были подобраны вручную для составления семантического ядра запросов и нажимаем на кнопку «Начать сбор», в соответствии с рисунком 9.

Рис. 9 – Диалоговое окно для ввода ключевых фраз
Время сбора зависит от выбранного региона, а также от ключевых слов, получается, что время может занимать от нескольких минут и до нескольких часов.

Рис. 10 – Список собранных всех ключевых фраз

Рис. 11 – Иконка фильтр стоп-слова

Рис. 12 – Две вкладки списка 1 и 2 «стоп – слова»

Рис. 13 – Настройка «стоп-слова»

Рис. 14 – Удаление ненужных фраз

Рис. 15 – Сбор частоты ключевых фраз
На следующем скриншоте приведены данные, отсортированные по второй колонке «Частота «»» запросов, в соответствии с рисунком 16.
![Частота «» [YW]](https://siteactiv.ru/upload/medialibrary/152/152bfb310cdebfec102fa7950f0ba48f.png "Частота «» [YW]")
Рис. 16 – Частота «» [YW]

Рис. 17 – Экспорт ключевых фраз в формат Microsoft Excel или CSV
Сбор сезонности
Программа позволяет собирать информацию о популярности запроса за прошедший период, строить график по этим данным и высказывать предположение о сезонности заданного запроса на основании полученных данных.
Для съема информации о сезонности запроса нажмите кнопку с иконкой графика в группе кнопок «Сбор ключевых слов и статистики», в соответствии с рисунком 18.

Рис. 18 – Иконка сезонности
При съеме информации о сезонности запроса также вычисляются значения средней арифметической частотности и ее медианы. Изменить период, в течение которого рассматривается статистика для вычисления этих значений, можно в настройках сбора Yandex.Wordstat.
При необходимости можно получить статистику с группировкой по неделям, а не по месяцам. В этом случае запуск следует производить через соответствующий пункт в раскрывающемся меню кнопки сбора данных сезонности Yandex.Wordstat, в соответствии с рисунком 19.

Рис. 19 – Вид сезонности в таблице
Просмотреть расширенную информацию о сезонности можно, кликнув на ячейку, соответствующую данной фразе, в соответствии с рисунком 20.

Рис. 20 – График сезонности
При необходимости вы можете выгрузить расширенные данные о частотностях для всех фраз в файл CSV. Для этого необходимо воспользоваться соответствующей кнопкой в раскрывающемся меню кнопки запуска сбора сезонности.
Сбор статистики со счетчиков системы статистики Yandex.Metrika
Программа поддерживает сбор статистики со счетчиков системы статистики Yandex.Metrika. При помощи Key Collector можно собрать слова и трафик с указанного счетчика.
Процесс сбора статистики со счетчика Yandex.Metrika
- 1 Нажимаем кнопку с логотипом сервиса в группе кнопок «Сбор ключевых слов и статистики» и вводим данные авторизации в системе статистики, в соответствии с рисунком 21 и 22.
- 2 Выбираем периода, за который нужно получить статистику. Можно ввести период самостоятельно или воспользоваться шаблоном (квартал, год и т.д.), в соответствии с рисунком 22.
- Опция «Обновлять статистику для существующих в таблице фраз» позволяет обновлять статистику переходов для существующих ранее в таблице фраз. Например, ранее в таблице была добавлена фраза «ручка». Если опция выключена, и хоть в отчете и встретится эта фраза, но программа не запишет для нее значение переходов. Если же опция была включена, то программа обновит это значение.
- Опция «Не добавлять в таблицу новые фразы» является дополнением к предыдущей опции. Включив ее, происходит запрет программе добавлять в таблицу фразы, которых там ранее не было. Это может оказаться полезным, если необходимо просто обновить или собрать данные о переходах к ранее собранной статистике, не разбавляя список фраз в таблице новыми фразами, для которых потом может понадобиться дополнительная обработка.
- 3 Выбираем способ получения статистики: напрямую средствами API или посуточно средствами программы, в соответствии с рисунком 22.

Рис.21 – Кнопка сбора статистики со счетчика системы статистики Yandex.Metrika

Рис.22 – Ввод данных для авторизации в системе статистики Yandex.Metrika
*Для сбора статистики Yandex.Metrika необходимо авторизоваться в аккаунту, имеющего доступ к счетчикам, статистику с которых необходимо собрать. Программа поддерживает как обычный, так и пакетный сбор статистики Yandex.Metrika. При использовании обычного сбора можно либо выбрать необходимый сайт в раскрывающемся списке, либо ввести его идентификатор вручную.
- В первом случае программа просто формирует запрос к API Yandex.Metrika, передав в параметрах границы периода сбора. В ответ она получает список фраз сразу со статистикой о переходах, которую сразу можно записывать в таблицу данных. Данный режим является более быстрым, но в результате некоторые НЧ фразы могут быть не получены из-за особенностей работы самого API.
- Во втором случае программа просматривает статистику за указанный период вручную посуточно, а затем при полном завершении сбора вычисляет значения переходов. Посуточный просмотр частями иногда позволяет получить больше фраз, которые API в обычном режиме не выдает (НЧ фразы), однако это занимает существенно больше времени. Также следует учитывать, что если процесс сбора был прерван, то статистика переходов и отказов вычислена не будет. Поэтому при работе с данным режимом следует дожидаться полного завершения процесса сбора.
- Опция «Не добавлять фразу, если она уже есть на любых других вкладках» может пригодиться, если не хотим, чтоб в таблицу не поступали фразы, которые уже обработали на других вкладках.
Сбор статистики со счетчиков системы статистики Google.Analytics
Программа Key Collector поддерживает сбор статистики со счетчиков системы статистики Google.Analytics.
При помощи неё можно собрать слова, количество визитов, процентное отношение отказов и целевые страницы с указанного счетчика.
Процесс сбора статистики со счетчика Google.Analytics.
- 1 Нажимаем кнопку с логотипом сервиса в группе кнопок «Сбор ключевых слов и статистики» и после этого откроется окно сбора статистики Google Analytics, в соответствии с рисунком 23.
- Опция «Обновлять статистику для существующих в таблице фраз» позволяет обновлять статистику переходов для существующих ранее в таблице фраз.
- Опция «Не добавлять в таблицу новые фразы» является дополнением к предыдущей опции. Включив ее, можно запретить программе добавлять в таблицу фразы, которых там ранее не было. Это может оказаться полезным, если необходимо просто обновить или собрать данные о переходах к ранее собранной статистике, не разбавляя список фраз в таблице новыми фразами, для которых потом может понадобиться дополнительная обработка.
- 2 Также можно выбрать способ получения статистики: напрямую средствами API или посуточно средствами программы, в соответствии с рисунком 24.

Рис.23 — Кнопка сбора статистики со счетчика системы статистики Google.Analytics

Рис.24 — Ввод данных для авторизации в системе статистики Google.Analytics
*Для сбора статистики Google Analytics необходимо указать логин и пароль от аккаунта, имеющего доступ к счетчикам, статистику с которых будет собираться информация. При желании можно включить опцию «Сохранять данные авторизации в настройках программы».
После ввода логина и пароля нажимаем на раскрывающийся список с площадками и выбираем счетчик, статистика с которого интересует.
Затем выбираем период, за который собираем статистику.
Ввести период можно самостоятельно или же воспользоваться шаблоном (квартал, год и т.д.), в соответствии с рисунком 24.
- В первом случае программа просто формирует запрос к API Google.Analytics, передав в параметрах границы периода сбора. В ответ она получает список фраз сразу со статистикой о переходах, % отказов и целевых страницах, которую сразу можно записать в таблицу данных. Данный режим является более быстрым, но в результате некоторые НЧ фразы могут быть не получены из-за особенностей работы самого API.
- Во втором случае программа просматривает статистику за указанный период вручную посуточно, а затем при полном завершении сбора вычисляет значения переходов и % отказов. Посуточный просмотр частями иногда позволяет получить больше фраз, которые API в обычном режиме не выдает (НЧ фразы), однако это занимает существенно больше времени. Следует учитывать, что если процесс сбора был прерван, то статистика переходов и отказов вычислена не будет. Поэтому при работе с данным режимом следует дожидаться полного завершения процесса сбора.
- Опция «Не добавлять фразу, если она уже есть на любых других вкладках» может пригодиться, если необходимо, чтобы в таблицу не поступали фразы, которые уже были обработаны на других вкладках.
Поисковые подсказки
Программа поддерживает сбор поисковых подсказок с шести популярных поисковых систем: Яндекс, Google, Mail, Rambler, Nigma, Yahoo, Яндекс.Директ.
Для того чтобы собрать поисковые подсказки с интересующих поисковых систем, нажмите кнопку с иконкой трех разноцветных сот в группе кнопок «Сбор ключевых слов и статистики», в соответствии с рисунком 25.

Рис. 25 — Кнопка «поисковые подсказки»
В открывшемся окне пакетного ввода слов можно ввести вручную или загрузить из файла интересующие фразы. При этом можно выбрать, куда необходимо поместить результаты парсинга по каждой из входных фраз: на текущую вкладку или распределить по нескольким вкладкам. После этого отмечаем флажками поисковый системы, в которых следует выполнить поиск, и нажать на кнопку начала сбора информации (для того, чтобы флажок «Yandex.Direct» стал доступным, необходимо предварительно прописать один или несколько аккаунтов в «Настройках — Парсинг — Яндекс.Директ»), в соответствии с рисунком 26.

Рис.26 — Окно пакетного ввода слов для сбора поисковых подсказок
Стоит обратить внимание, что сбор подсказок с Yandex.Direct имеет очень маленький лимит количества запросов. Рекомендуется использовать сбор поисковых подсказок из Yandex.Direct только для ограниченного числа фраз при существующей необходимости.
Опция «С подбором окончаний» позволяет собирать еще больше подсказок за счет того, что программа будет подбирать окончания слов автоматически.
Перебор окончаний бесполезен, если в качестве исходных слов задаются полные слова, в соответствии с рисунком 27.

Рис.27 – Настройка «поисковых подсказок»
Стоит обратить внимание, что не надо включать опцию подбора окончаний без явной необходимости, т.к. ее использование очень сильно влияет на количество совершаемых запросов и на общее время выполнение задачи.
Похожие поисковые запросы
Key Collector поддерживает сбор похожие поисковых запросов из поисковой выдачи ПС Яндекс, Google, Mail.
Для того чтобы собрать поисковые подсказки с интересующих поисковых систем, нажмите кнопку в группе кнопок «Сбор ключевых слов и статистики», в соответствии с рисунком 28.

Рис.28 – Кнопка «Сбор ключевых слов и статистики»
В открывшемся окне пакетного ввода слов можно ввести вручную или загрузить из файла интересующие фразы. При этом можно выбрать, куда необходимо поместить результаты парсинга по каждой из входных фраз: на текущую вкладку или распределить по нескольким вкладкам. После этого необходимо отметить флажками поисковый системы, в которых следует выполнить поиск, и нажать на кнопку начала сбора информации, в соответствии с рисунком 29.

Рис.29 – Окно пакетного ввода слов
Вычисление лучшей словоформы
Для того чтобы собрать лучшие словоформы для имеющихся ключевых фраз, нажимаем на кнопку с логотипом сервиса в группе кнопок «Сбор ключевых слов и статистики» и выбираем соответствующий пункт в раскрывающемся меню кнопки, в соответствии с рисунком 30.

Рис.30 – Кнопка «Сбор ключевых слов и статистики»
Сбор расширений для ключевых фраз
Для того чтобы запустить сбор расширений (новых ключевых фраз) по имеющемуся списку фраз, нажимаем на кнопку с логотипом сервиса в группе кнопок «Сбор ключевых слов и статистики» и выбираем соответствующий пункт в раскрывающемся меню кнопки, в соответствии с рисунком 31.

Рис.31 — Кнопка «Сбор расширений ключевых фраз»
В открывшемся окне пакетного ввода слов можно ввести вручную или загрузить из файла интересующие слова. При этом предоставляется выбор, куда поместить результаты парсинга по каждой из входных фраз: на текущую вкладку или распределить по нескольким вкладкам. После нажатия кнопки запуска процесса программа приступит к сбору данных по заданным ключевым фразам, в соответствии с рисунком 32.

Рис.32 – Окно пакетного ввода слов
Если работаете с огромными проектами (десятки или сотни тысяч фраз) и собираете фразы в пакетном режиме, то может оказаться полезной опция «Не обновлять содержимое таблицы после групповых операций вставки и обновления при парсинге» в «Настройках — Интерфейс — Прочее».
Итак, в данной статье описаны возможности Key Collector для контекстной рекламы, а также рабочий способ того, как можно создать семантическое ядро (создание семантического ядра необходимо и в SEO) для рекламной кампании, используя ключевые фразы, спарсенные из Яндекс Вордстат
.
Также, мы можем определить слова – пустышки, которые будут неэффективные для РК.
Стоит выделить следующие моменты:
- 1 При создании контекстной рекламной кампании на поиск необходимо использовать запросы со средней частотностью, которые максимально точно отражают суть предложения для рекламы. А вот, при создании РК в РСЯ и КМС Google
лучше использовать общие слова, потому что чем больше будет охват аудитории в Сетях — тем лучше и эффективнее будет РК. - 2 В списке ключевых фраз стоит использовать «коммерческие» запросы, которые содержат такие слова, как «купить», «цена» и другие, потому что они смогут привести на сайт людей, которые действительно заинтересованы в покупке.
- 3 Добавляйте только те запросы, которые соответствуют предложению, иначе произойдет перерасход бюджета на нецелевые переходы.
- 4 Не используйте слова с очень низкой или нулевой частотностью (слова «пустышки»), потому что от них не будет никакой пользы.