
|
tvit  Пользователь Сообщений: 60 |
Добрый день! Подскажите, пожалуйста как оптимально по скорости/памяти решить следующую задачу: Имеются ежемесячные выгрузки из внешней системы, на которую я никак повлиять не могу. Есть справочник клиентов (текстовый файл ~4 млн.записей), в котором хранятся только ФИО + Дата рождения Мне необходимо из первого файла выбрать клиентов которые отсутствуют в справочнике и удовлетворяют определенным условиям. Таких ежемесячно бывает примерно 30-40 тыс. ФИО + ДР отобранных добавляем в справочник. Соответственно, чтобы решить данную задачу мне сейчас необходимо понять следующее: 2. Прежде чем сравнивать массивы, по-любому придется их сортировать по полю ФИО. Подскажите пожалуйста самый быстрый алгоритм, который не использует вспомогательные массивы. Не хочется делать дополнительные копии массива в памяти. |
|
А точно это должен быть Excel? Тут пора применять Access… |
|
|
JeyCi  Пользователь Сообщений: 3357 |
#3 26.08.2015 17:43:55 в любом случае, я бы посоветовала через ADO+SQL — количество строк знать не надо, обращение к txt c разделителем — как к столбцам, отбор сделать нужной SQL командой… примеры примерно такие: Точное считывание с текстового файла
— и уже в SQL-команду можно вставить нужные условия отбора WHERE, и Сортировку по нужному полю ORDER BY Использование Access для обработки больших текстовых файлов #17 Изменено: JeyCi — 26.08.2015 18:09:51 чтобы не гадать на кофейной гуще, кто вам отвечает и после этого не совершать кучу ошибок — обратитесь к собеседнику на ВЫ — ответ на ваш вопрос получите — а остальное вас не касается (п.п.п. на форумах) |
||
|
Андрей VG  Пользователь Сообщений: 11878 Excel 2016, 365 |
#4 26.08.2015 20:07:19 Доброе время суток
Такой объём явно выгружен из какой-то базы данных, что-то с трудом вериться, что кто-то в блокноте ведёт эти записи. Стоит ли тогда «огород городить» с выгрузкой и анализом через сравнение массивов, или даже, как предлагают, связывать текстовые данные в Access для построения запросов? Может сразу в этой же базе SQL-запросами получать требуемое? |
||
|
Hugo Пользователь Сообщений: 23252 |
Думаю вполне можно и кодом работу сделать — сперва читаем справочник в словарь, можно всё в массив, или построчно прочитать. |
|
tvit Пользователь Сообщений: 60 |
Спасибо всем ответившим, только я другие вопросы задавал. To HUGO: Вариант с заменой массивов словарем рабочий, вопрос только на сколько это будет медленнее по скорости чем с массивами? И еще вопрос, помню как то работал со словарем и там был глюк, который я так и не смог обойти: При проверки наличия значения в словаре оно почему-то самопроизвольно добавлялось в этот словарь, я так и не смог до конца разобраться в проблеме посему так происходит? PS На выгружаемый файл из внешней системы я никак повлиять не могу, считайте что мне его робот по почте присылает |

|
Андрей VG Пользователь Сообщений: 11878 Excel 2016, 365 |
#8 27.08.2015 08:05:07 Доброе время суток
Не совсем понимаю суть проблемы, почему нужно другому человеку отправлять исходные данные, чтобы он у себя в Excel их обрабатывал? А почему нельзя отправить уже реализованный результат? |
||||
|
ikki  Пользователь Сообщений: 9709 |
#9 27.08.2015 08:32:34
это будет быстрее. в разы, скорее — в десятки раз.
это не глюк. фрилансер Excel, VBA — контакты в профиле |
||||
|
tvit Пользователь Сообщений: 60 |
#10 27.08.2015 09:04:35
2010 |
||
|
tvit Пользователь Сообщений: 60 |
#11 27.08.2015 09:18:26 Получается если считывать в Коллекцию
Данные никто никому не отправляет, другой человек сам их выгрузит из той же внешней системы
Сейчас уже не вспомню, возможно я действительно проверял более «хитрым» способом (присваивание внутри on error) |
||||
|
Андрей VG Пользователь Сообщений: 11878 Excel 2016, 365 |
#12 27.08.2015 09:38:01
Вы правда не назвали, что это за система. Но всё равно не понимаю, если человек имеет к ней доступ, то кто мешает ему получать (в том числе и обновляемые) данные, используя SQL, в книгу Excel?
Естественно, CommandText может быть более сложным SQL запросом, чем в приведённом примере. Можно это же сделать и без программирования, задействовав MS Query. Изменено: Андрей VG — 27.08.2015 09:47:06 |
||||
|
Hugo Пользователь Сообщений: 23252 |
Я думаю что SQL будет работать намного медленнее кода на словаре и массивах. |
|
Dmitryktm  Пользователь Сообщений: 17 |
Попробуйте посмотреть в сторону надстроек Power Pivot или Power Query. Последняя надстройка (PQ) вообще творит чудеса. Может сделать всё что угодно и как угодно без макросов. Поддерживаются следующие версии Office:
|
|
Поддерживаю Dmitryktm, поэтому и был вопрос про версию. |
|
|
tvit Пользователь Сообщений: 60 |
Dmitryktm, спасибо, но это не вариант. Я не администратор своей машины, и тот человек кому я передаю программу тоже ничего не сможет установить. Сейчас пробую вариант с коллекциями. Excel занял 1.2 ГБ оперативки. пока работает, Но я на 5 млн пробовал. В след месяцах (декабре и мае) могут быть двойные зачисления, тогда не знаю что будет |
|
vikttur Пользователь Сообщений: 47199 |
Кнопка цитирования не для ответа |
|
Андрей VG Пользователь Сообщений: 11878 Excel 2016, 365 |
#18 27.08.2015 15:38:20 Игорь, зря вы так по поводу SQL. Решил, коль целый день делать нечего с имитировать (упрощённо) задачу ТС. Создал два тестовых файла.
В Users 2 000 000 записей, в UserData 15 409 218 (часть записей для 500 000 ФИО отсутствует в Users). Собственно, задача отобрать в UserData ФИО, которых нет в Users (естественно, без повторений, так как в UserData могут быть сведения об нескольких покупках одного ФИО). В коде выше добавлены процедурой AddNotIn в UserData. Попробовал сделать на словарях, вполне возможно, что допустил какую-то некорректность, код ниже, прошу дать оценку
Подождал некоторое время (минут 15) прервал. Далее, загнал в Access, проиндексировал обе таблицы по полю UserName, далее следующим кодом получил результат за 65 секунд
Ну, и тоже самое для этих же данных, помещённых в MS SQL LocalDb (естественно с индексами по UserName) — результат получен за 13 секунд
Думаю, для столь объёмных данных выводы очевидны. Не забывайте использовать в базах данных индексы и строить запросы так, чтобы эти индексы задействовались. |
||||
|
Hugo Пользователь Сообщений: 23252 |
Split(pStream.ReadAll, vbCrLf) может быть долго на большом файле, и памяти займёт много. Может лучше читать файл построчно — по времени может чуть дольше (а может и нет), но память должна экономиться. «загнал в Access, проиндексировал обе таблицы по полю UserName» — это время не учитывалось? Но вообще если SQL отработал намного быстрее — то это отлично. Вариант на словаре вроде оптимально написан, но думаю основное время теряется на чтении файлов в массив, и на этих Left$(). |
|
Андрей VG Пользователь Сообщений: 11878 Excel 2016, 365 |
#20 27.08.2015 16:39:53
Был и такой вариант — разницы особой не вижу, этот показался, что будет быстрее, по идее в Excel 2010 64bit на ПК с 8Гб памяти поместится должен.
Есть, но slit же индексирует начало массива с 0, хотя согласен For i = LBound(strOut) + 1 — правильнее.
Увы, не потянет — результат почти полмиллиона строк.
Нет, не учитывалось. Я всё пытаюсь довести мысль до tvit, что не логично выгружать данные из базы, чтобы потом кустарным способом делать тоже самое. Правда, не смотря на то, что ТС тут мимо пробегает, что не так и что не устраивает НАГЛО не сообщает. Ни тебе спасибо, ни пожалуйста.
Так она выполняется утилитой импорта, а как писал выше — это время не учитывалось.
С другой стороны SQL и базы для того разрабатывались, чтобы думать над реализаций логики получения данных в требуемом виде, а не над особенностями хранения и выбора лучшего алгоритма получения (хотя и тут присутствуют варианты и свои рекомендации для более быстрого выполнения) P. S. Прогнал ещё на SQLite — 22 секунды — хорош. Изменено: Андрей VG — 27.08.2015 17:08:44 |
||||||||||||
|
Smiley Пользователь Сообщений: 530 |
Андрей VG, добрый вечер. А можно Вас попросить любопытства ради попробовать вместо DISTINCT группировку? Будет ли быстрее? ЗЫ: а можно в Access еще проиндексировать много полей, чтобы вообще быстро было Изменено: Smiley — 27.08.2015 17:11:20 |
|
Андрей VG Пользователь Сообщений: 11878 Excel 2016, 365 |
#22 27.08.2015 18:03:35 Smiley, добрый вечер.
вышло 105 секунд. Изменено: Андрей VG — 27.08.2015 18:05:37 |
||
|
Smiley Пользователь Сообщений: 530 |
#23 27.08.2015 19:08:43
ну я поэтому и поставил смайлик Учусь программировать |
||
|
tvit Пользователь Сообщений: 60 |
#24 31.08.2015 15:00:09 Реализовал свою идею через Словари. Скорость приемлемая, за исключением последнего шага. В котором я пытаюсь сохранить Словарь в файл. На меленьких файлах скорость приемлемая, но когда размер справочника 4 млн строк, а размер занимаемой памяти Excel около 1 Гб, сохранение идет очень долго — в минуту не более 1000 строк :
|
||
|
tvit Пользователь Сообщений: 60 |
Также заметил что размер памяти при закрытии файлов и очистки вспомогательных словарей, уменьшается не сильно. Объем моего справочника 4.5 млн строк в среднем по 45 символов каждая, итого не более 200 Мб, а Эксель занимает около 1 ГБ, не пойму почему |
|
tvit Пользователь Сообщений: 60 |
Прошу прощения что сразу не отвечал на вопросы. У меня Интернет на отдельной машине. Поэтому форум нет возможности читать регулярно. |
|
Андрей VG Пользователь Сообщений: 11878 Excel 2016, 365 |
Доброе время суток P. S. А не поделитесь — сколько времени у вас уходит на поиск отсутствующих? Изменено: Андрей VG — 31.08.2015 16:36:39 |
|
tvit Пользователь Сообщений: 60 |
#28 31.08.2015 18:10:09
Завтра на работе запущу и отчитаюсь |
||
|
tvit Пользователь Сообщений: 60 |
to Андрей VG Построчное считывание файла и занесение во временный словарь: 2 476 710 за 5 минут 47 секунд Построчное считывание 2 файла: 2 025 113 за 4 мин 34 сек При попытке сохранить словарь 2.5 млн строчек в файл, комп умирает. Сохраняется не более 1000 строк в минуту, как бы это ускорить? |
|
Андрей VG Пользователь Сообщений: 11878 Excel 2016, 365 |
#30 01.09.2015 19:30:25 Доброе время суток
Хотя не понимаю, почему вы не хотите использовать Jet Access Engine? Изменено: Андрей VG — 01.09.2015 19:33:26 |
||
Как часто вы сталкиваетесь с необходимостью выгрузить в MS Excel более миллиона строк? Все фильтры на выгрузку уже были наложены ранее, но, увы, она до сих пор «не проходит по габаритам». Перед нами встает дилемма – делить, или … воспользоваться готовыми решениями для python, не изучая python!
Речь сегодня пойдет о трех библиотеках, которые позволяют писать код и при этом не писать его, а также оперировать внушительными объемами данных с минимальными знаниями английского языка или синтаксиса пресловутых «панд» (здесь и далее «панды»: pandas – open-source библиотека для python для работы с табличными данными – прим. автора). Для примера будем использовать объявления о продаже автомобилей Toyota с известного сайта.
Первая библиотека, с которой хотелось бы Вас познакомить – Bamboolib. Не секрет, что панды питаются бамбуком, и, как за всякое пропитание, за него нужно платить. Да, у Bamboolib есть платная версия, в которой реализована поддержка Apache Spark, а также есть возможность использовать свои внутренние библиотеки и нет ограничения по плагинам, в остальном же достаточно бесплатной версии.
Устанавливаем:
pip install — upgrade bamboolib — userИмпортируем:
import bamboolib as bamРаботаем:
bamПосле этого появляется графический интерфейс и возможность открыть .csv файл…

… и работать с ним через GUI, как с обычным Excel. Считанная таблица:

Обратите внимание:
- таблица имеет категориальные признаки оснащения автомобиля – «допы» вынесены в колонки, из-за чего фрейм «раздут» до 193 (!) столбцов. В обычном случае таблица не поместилась бы в стандартный вывод тетради и нам бы пришлось использовать параметр display.max_columns, чтобы посмотреть на все поля, но здесь полоса прокрутки уже есть.
- Названия столбцов содержат префикс, на скриншоте видны «o» и «I» — так нам сообщают, что типы данных в столбцах это object и int соответственно. Долгота, широта, расход топлива и объем топливного бака «f» – float. Объем бака при этом не имеет отличных от 0 значений после точки и его можно конвертировать в int просто кликнув по столбцу, выбрав из выпадающего списка целочисленный тип и нажав Execute.

Большая зеленая кнопка «Explore DataFrame» позволит нам увидеть как типы данных всех остальных столбцов, так и количество пропусков и уникальных значений, а в соседних вкладках обнаруживаются тепловая карта и матрица корреляций.

Если необходимо детально познакомиться со статистиками содержимого в столбце Seller_type, проваливаемся в него одним кликом и видим распределение, а в соседних вкладках взаимозависимости.

Слева от большой зеленой кнопки «Explore DataFrame» есть функция построения графиков. Я захотел узнать объявлений о продаже каких моделей больше всего:

Визуализация с помощью plotly и ее контекстное меню справа в углу графика позволяют работать с графиком.
Разумеется, помимо EDA и визуализации в библиотеке есть и методы для работы с датафреймом. Если Вы знакомы с «пандами», то вас встретит привычный набор методов и функций, если же нет – достаточно будет начальных знаний английского языка – все доступные операции перечислены в выпадающем списке:

Удаление, переименование, сортировка, etc. При этом интерфейс фильтрации напоминает тот самый сайт-источник. Например, мы хотим просмотреть все объявления о продаже 5-дверных полноприводных Toyota в Самаре? Пожалуйста. Отсортировать по цене? Ничего проще 🙂 Удалить столбцы? Сию минуту 🙂

Также бывает полезна группировка, это делается достаточно просто, а в дополнение мы получаем код, который библиотека написала за нас (включая импорт «панд») – его можно сохранить и использовать в том числе и без установленной bamboolib!
import pandas as pd
df = pd.read_csv(r'C:UsersolegsDesktopvato_ru.csv', sep=',', decimal='.')
df = df.loc[(df['city_name'].isin(['Самара'])) & (df['body_type'].isin(['ALLROAD_5_DOORS']))]
df = df.sort_values(by=['price'], ascending=[True])
df = df.drop(columns=['latitude', 'longitude'])
dfКак видим, «из коробки» нам предоставляется необходимый базовый набор операций с данными, включая такие вещи, как статистики и графики.
Аналогичным образом работает и библиотека Mito. Устанавливаем:
python -m pip install mitoinstaller
python -m mitoinstaller installИмпортируем:
import mitosheetРаботаем:
mitosheet.sheet()Как и у Bamboolib, у Mito есть корпоративная версия, PRO с дополнительным функционалом и бесплатная Open Source. Будем использовать последнюю, в которой помимо инструментов для исследования и трансформирования данных заявлена даже поддержка пользователей (ее не было в бесплатной версии Bamboolib).
После открытия GUI сразу же бросается в глаза различие в интерфейсе – команды выведены в «шапку», а также присутствует pivot table – сводные таблицы – и команды Undo и Redo (откатить/вернуть действие) и даже STEP HISTORY, которых не было в предыдущей библиотеке. Возможности группировки нет.

Наш датафрейм:

Полосы прокрутки на месте, в отличие от размерности. Изменить тип данных столбца (наименования которых здесь, кстати, отличаются) так же интуитивно просто – повторим те же манипуляции с фильтрацией, удалением колонок и т.д. и сравним код:
# Imported vato_ru.csv
import pandas as pd
vato_ru = pd.read_csv(r'C:UsersolegsDesktopvato_ru.csv')
# Changed trunk_volume to dtype int
vato_ru['trunk_volume'] = vato_ru['trunk_volume'].fillna(0).astype('int')
# Filtered city_name
vato_ru = vato_ru[vato_ru['city_name'] == 'Самара']
# Sorted price in ascending order
vato_ru = vato_ru.sort_values(by='price', ascending=True, na_position='first')
# Filtered body_type
vato_ru = vato_ru[vato_ru['body_type'] == 'ALLROAD_5_DOORS']
# Deleted columns latitude
vato_ru.drop(['latitude'], axis=1, inplace=True)
# Deleted columns longitude
vato_ru.drop(['longitude'], axis=1, inplace=True) С каждой манипуляцией фрейм так же перезаписывался (кроме удаления столбцов, но использован параметр inplace = True), а в случае необходимости отката нас спасает STEP HISTORY. Также среди незначительных отличий использование точного соответствия вместо .isin() при фильтрации (выпадающего списка, как в bamboolib, здесь нет) и ряд других, вдобавок каждое действие закомментировано.
Статистика менее подробная, но must have атрибуты присутствуют:

Корреляция/ковариация отсутствует. Функционал блока визуализации (также на plotly) достаточный.

К плюсам можно также отнести то, что можно подгрузить несколько датафреймов, и они будут отображаться вкладками, как листы Excel.
Третья библиотека, которая предоставляет возможность интерактивного взаимодействия с данными на языке Python без знания языка Python — D-Tale. Она бесплатная.
Устанавливаем:
pip install dtaleИмпортируем:
import dtale
import pandas as pdРаботаем:
df = pd.read_csv(‘data.csv’)
d = dtale.show(df)
d.open_browser()Да, нам действительно пришлось самим импортировать «панд», считать файл и даже вызвать пару функций из dtale, что, по сравнению с функционалом предыдущих библиотек, может показаться непростительно трудозатратным, но:

…фрейм сразу открывается в отдельном окне! Также сразу видим его размерность слева сверху и полосы прокрутки, но ни одной кнопки или тулбара. Все спрятано на кнопке в левом верхнем углу, при нажатии на которую открывается богатое меню функций – тепловая карта, корреляции, анализ пропусков, подсвечивание выбросов, графики, можно даже поставить темную тему. Сравните, как выглядят статистики (меню Describe) по столбцу «Тип продавца»:

Соседняя вкладка с распределением значений:

Функционал действительно впечатляет, из ранее упомянутых функций присутствуют не только pivot table и group by, но и transpose и resample:

Множество поддерживаемых функций влечет за собой очевидное неудобство – для простейшей конвертации типа данных столбца необходимо сначала ее найти:

…а для фильтрации знать немного синтаксиса:

Я не буду подробно демонстрировать работу всех имеющихся функций, но проведу «традиционную» манипуляцию с датафреймом и выгружу получившийся код для сравнения:
df.loc[:, 'trunk_volume'] = pd.Series(s.astype('int'), name='trunk_volume', index=df['trunk_volume'].index)
df = df[[c for c in df.columns if c not in ['latitude']]]
df = df[[c for c in df.columns if c not in ['longitude']]]
df = df.query("""(city_name == 'Самара') and (body_type == 'ALLROAD_5_DOORS')""")
df = df.sort_values(['price'], ascending=[True])Обратите внимание, что удаление столбцов происходит с использованием спискового включения, конвертация через Series, а для фильтрации используется функция .query(), что разительно отличает такой подход от ранее увиденных.
Как итог, с уверенностью можно утверждать, что на поле пользовательских интерфейсов для взаимодействия с данными есть инструменты, не требующие изучения языка программирования, но предоставляющие базовый, а иногда даже и расширенный арсенал для работы с таблицами. И арсенал этот достаточно велик для того, чтобы каждый нашел для себя библиотеку по потребностям – с user-friendly интерфейсом или упором на функциональность.
https://t.me/english_forprogrammers
источник
Просмотры: 603
Время на прочтение
11 мин
Количество просмотров 14K
Совсем недавно мне была поставлена задача, написать сервис, который будет заниматься всего лишь одной, но очень емкой задачей – собирать большой объем данных из базы, агрегировать и заполнять все это в Excel по определенному шаблону. В процессе поиска лучшего решения было опробовано несколько подходов, решены проблемы, связанные с памятью и производительностью. В этой статье я хочу поделиться с вами основными моментами и этапами реализации данной задачи.
1. Постановка задачи
В связи с тем, что мне нельзя разглашать подробности ТЗ, сущности, алгоритмы сбора данных и т. д. Пришлось придумать что-то аналогичное:
Итак представим, что у нас есть онлайн чат с высокой активностью, и заказчик хочет выгружать все сообщения, обогащенные данными о пользователе, за определенную дату в Excel. В день может копиться более 1 миллиона сообщений.
У нас есть 3 таблицы:
-
User. Хранит имя пользователя и его некий рейтинг (не важно откуда он берется и как считается)
-
Message. Хранит данные о сообщении – Имя пользователя, ДатуВремя, Текст сообщения.
-
Task. Задача на формирование отчета, которую создает заказчик. Хранит ID, Статус задачи (выполнено или нет), и два параметра: Дату сообщения начало, Дату сообщения конец.
Состав колонок будет следующим:
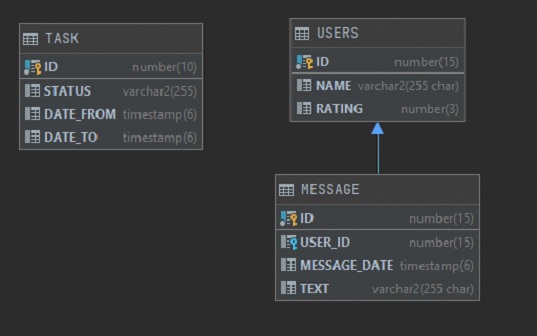
В Excel Заказчик хочет видеть 4 колонки 1) message_date. 2) name. 3) rating. 4) text. Ограничение по количеству строк 1 млн. Надо заполнить этими данными excel, а дальше заказчик уже будет работать с этими данными в екселе самостоятельно.
2. Задача понятна, начнем поиск решения
Так как в компании все стараются придерживаться единого стиля в разработке приложений, то и мне пришлось начать с самого обычного подхода, который используется во всех остальных микросервисах – это Spring + Hibernate для запуска приложения и работы с БД. В качестве БД используется Oracle, хотя использование любой другой СУБД будет плюс минус похожим.
Для старта приложения нам понадобится зависимость spring-boot-starter-data-jpa, которая объединяет в себе сразу Spring Data, Hibernate и JPA, все это нам понадобится для удобства работы с БД и нашими сущностями.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<version>2.4.5</version>
</dependency>Для тестирования добавим spring-boot-starter-test
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>И еще нам нужен сам драйвер для подключения к БД
<dependency>
<groupId>com.oracle.database.jdbc</groupId>
<artifactId>ojdbc10</artifactId>
<version>19.10.0.0</version>
</dependency>Далее нам нужно добавить некоторые настройки конфигурации. У нас будет один метод, который будет ходить в таблицу TASK, искать задачу в статусе “CREATED” и, если такая задача существует, то запускать генерацию отчета с параметрами. Предполагается, что генерация отчета может быть долгой, поэтому наш метод будет запускаться по расписанию в два потока асинхронными процессами. Так же для Spring Data укажем наш репозиторий для поиска соответствующих сущностей. Класс конфигурации будет выглядеть следующим образом:
package com.report.generator.demo.config;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.PropertySource;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.scheduling.TaskScheduler;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.concurrent.ThreadPoolTaskScheduler;
@Configuration
@EnableScheduling
@EnableAsync
@EnableJpaRepositories(basePackages = "com.report.generator.demo.repository")
@PropertySource({"classpath:application.properties"})
@ConditionalOnProperty(
value = "app.scheduling.enable", havingValue = "true", matchIfMissing = true
)
public class DemoConfig {
private static final int CORE_POOL_SIZE = 2;
@Bean(name = "taskScheduler")
public TaskScheduler getTaskScheduler() {
ThreadPoolTaskScheduler scheduler = new ThreadPoolTaskScheduler();
scheduler.setPoolSize(CORE_POOL_SIZE);
scheduler.initialize();
return scheduler;
}
}
Класс генерации отчетов содержит в себе @Scheduled метод, который раз в минуту ищет Task и, если находит, то запускает генерацию отчета с параметрами из этой таски.
@Async("taskScheduler")
@Scheduled(fixedDelay = 60000)
public void scheduledTask() {
log.info("scheduledTask is started");
Task task = getTask();
if (Objects.isNull(task)) {
log.info("task not found");
return;
}
log.info("task found");
generate(task);
}Класс стартер приложения не имеет ничего примечательного, весь код можно посмотреть на GitHub.
3. Выборка данных из БД
Т.к. в компании повсеместно используется Hibernate было решено использовать его. Добавлено entity MessageData с необходимым набором полей (id, name, rating, messageDate, test). Первой попыткой выбрать необходимые данные была попытка в лоб – выгрузить все в List<Message> с помощью простого метода:
List<Message> findAllByMessageDateBetween(Instant dateFrom, Instant dateTo);А дальше уже в цикле создавать объекты MessageData и обогащать их недостающими данными. Было очевидно, что данных подход в корне не верный и выгружать сразу миллион записей в List как минимум медленно. Но для эксперимента и замера скорости работы проверить хотелось, чтобы потом сравнить с другими вариантами. Но в результате данный набор записей выгружался около 30 минут после чего было получено OutOfMemoryError и на этом эксперимент завершился.
Даже если бы пользователь задал узкие рамки в параметрах и нам бы удалось выбрать все в один List, то дальше мы бы столкнулись со следующей проблемой – для заполнения всех необходимых колонок нужно было бы собирать id пользователей, идти снова в базу, получать их имена и рейтинги, и заполнить уже с полными данными. Сложность такого алгоритма вырастала в разы. Было понятно, что выборку надо производить по частям и переложить все возможные действия с данными на сторону бд. Чтобы не выбирать все разом и, чтобы не городить велосипедов, было решено использовать ScrollableResults. Это позволяет нам получить ссылку на курсор и итерироваться по результатам с определенным шагом. Далее пришлось переписать запрос так, чтобы он возвращал сразу все необходимые данные уже после всех джойнов, объединений, группировок и т. д.
Следующий вопрос – где хранить сам текст запроса. Это был не простая ситуация т.к. в действительности количество таблиц, которые участвовали в запросе было около десяти, количество джойнов и всяческих группировок было огромным, в результате чего текст запроса вышел на 200+ строк после ревью всевозможных коллег и утверждении самим тех лидом. Хранить такой запрос в java коде не хотелось, плюс в нем были захардкожены некоторые константы в условиях и светить ими в общем репозитории было бы неправильно. Для решения всех этих вопросов мне на помощь пришла идея использовать view. Весь текст запроса прекрасно туда вписывался, плюс на выходе мы получаем готовую сущность, с которой может работать hibernate как с обычной entity.
По началу все выглядело нормально, запрос на выборку 1 млн таких строк выполнялся за разумные 10 мин. или около того. Немного больше, чем хотелось бы, но заказчика это устраивало. Однако в процессе тестирования обнаружился серьезный минус такого подхода – когда мы выбираем 1 млн записей, запрос выполняется 10 минут, но когда мы хотим отчет по короче и указываем в параметрах границы даты поуже – у нас запрос так же выполняется 10 минут, но в результате мы можем получить хоть 1 запись, хоть миллион. Суть в том, что внутрь запроса view нельзя передавать параметры, мы можем только выполнить статический запрос и уже на результат наложить параметры. Поэтому не важно сколько будет в результате строк, в первую очередь будет выбрано все, что найдется в бд, а только потом будет применены параметры. Заказчику было все равно, его устраивало и то, что отчет с одной строкой будет формироваться практически за такое же время, что и отчет с 1 млн строк. Однако это излишне нагружало бд и было решено отказаться от этого варианта.
Оставался всего один вариант, который нам подходил – это хранимая в бд функция. В нее можно передавать параметры, она может вернуть ссылку на курсор и ее результат можно удобно маппить на нашу entity. Таким образом была описана функция, которая принимала на вход несколько параметров, и возвращала sys_refcursor, весь скрипт занял около 300 строк в реальности, а в упрощенном варианте здесь она выглядит так:
create function message_ref(
date_from timestamp,
date_to timestamp
) return sys_refcursor as
ret_cursor sys_refcursor;
begin
open ret_cursor for
select m.id,
u.name,
u.rating,
m.message_date,
m.text
from message m
left join users u on m.user_id = u.id
where m.message_date between date_from and date_to;
return ret_cursor;
end message_ref;Теперь как ее использовать? Для этого отлично подходит @NamedNativeQuery. Запрос для вызова функции выглядит следующим образом: «{ ? = call message_ref(?, ?) }», callable = true дает понять, что запрос представляет собой вызов функции, cacheMode = CacheModeType.IGNORE для указания не использовать кэш, т. к. скорость работы нам не так критична, как затрачиваемая память, ну и в конце resultClass = MessageData.class для маппинга результата на нашу entity. Класс MessageData выглядит следующим образом:
package com.report.generator.demo.repository.entity;
import lombok.Data;
import org.hibernate.annotations.CacheModeType;
import org.hibernate.annotations.NamedNativeQuery;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import java.io.Serializable;
import java.time.Instant;
import static com.report.generator.demo.repository.entity.MessageData.MESSAGE_REF_QUERY_NAME;
@Data
@Entity
@NamedNativeQuery(
name = MESSAGE_REF_QUERY_NAME,
query = "{ ? = call message_ref(?, ?) }",
callable = true,
cacheMode = CacheModeType.IGNORE,
resultClass = MessageData.class
)
public class MessageData implements Serializable {
public static final String MESSAGE_REF_QUERY_NAME = "MessageData.callMessageRef";
private static final long serialVersionUID = -6780765638993961105L;
@Id
private long id;
@Column
private String name;
@Column
private int rating;
@Column(name = "MESSAGE_DATE")
private Instant messageDate;
@Column
private String text;
}Для того чтобы не использовать кэш было решено выполнять запрос в StatelessSession. Однако есть важная особенность: если попытаться вызвать namedQuery то hibernate при попытке установить CacheMode выдаст UnsupportedOperationException. Чтобы этого избежать необходимо установить два хинта:
query.setHint(JPA_SHARED_CACHE_STORE_MODE, null);
query.setHint(JPA_SHARED_CACHE_RETRIEVE_MODE, null);В итоге наш метод генерации имеет следующий вид:
@Transactional
void generate(Task task) {
log.info("generating report is started");
try (
StatelessSession statelessSession = sessionFactory.openStatelessSession()
) {
ReportExcelStreamWriter writer = new ReportExcelStreamWriter();
Query<MessageData> query = statelessSession.createNamedQuery(MESSAGE_REF_QUERY_NAME, MessageData.class);
query.setParameter(1, task.getDateFrom());
query.setParameter(2, task.getDateTo());
query.setHint(JPA_SHARED_CACHE_STORE_MODE, null);
query.setHint(JPA_SHARED_CACHE_RETRIEVE_MODE, null);
ScrollableResults results = query.scroll(ScrollMode.FORWARD_ONLY);
int index = 0;
while (results.next()) {
index++;
writer.createRow(index, (MessageData) results.get(0));
if (index % 100000 == 0) {
log.info("progress {} rows", index);
}
}
writer.writeWorkbook();
task.setStatus(DONE.toString());
log.info("task {} complete", task);
} catch (Exception e) {
task.setStatus(FAIL.toString());
e.printStackTrace();
log.error("an error occurred with message {}. While executing the task {}", e.getMessage(), task);
} finally {
taskRepository.save(task);
}
}4. Запись данных в Excel
На данном этапе вопрос с выборкой данных из БД был решен и возник следующий вопрос – как теперь все это писать в excel так, чтобы это было быстро и не затратно по памяти. Первая попытка была самой очевидной – это использование библиотеки org.apache.poi. Тут все просто: подключаем зависимость
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>5.0.0</version>
</dependency>Создаем XSSFWorkbook далее XSSFSheet, из него уже row и так далее. Ничего примечательного, примерный код ниже:
package com.report.generator.demo.service;
import com.report.generator.demo.repository.entity.MessageData;
import org.apache.poi.xssf.usermodel.XSSFCell;
import org.apache.poi.xssf.usermodel.XSSFRow;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.FileOutputStream;
import java.io.IOException;
import java.time.Instant;
public class ReportExcelWriter {
private final XSSFWorkbook wb;
private final XSSFSheet sheet;
public ReportExcelWriter() {
this.wb = new XSSFWorkbook();
this.sheet = wb.createSheet();
createTitle();
}
public void createRow(int index, MessageData data) {
XSSFRow row = sheet.createRow(index);
setCellValue(row.createCell(0), data.getMessageDate());
setCellValue(row.createCell(1), data.getName());
setCellValue(row.createCell(2), data.getRating());
setCellValue(row.createCell(3), data.getText());
}
public void writeWorkbook() throws IOException {
FileOutputStream fileOut = new FileOutputStream(Instant.now().getEpochSecond() + ".xlsx");
wb.write(fileOut);
fileOut.close();
}
private void createTitle() {
XSSFRow rowTitle = sheet.createRow(0);
setCellValue(rowTitle.createCell(0), "Date");
setCellValue(rowTitle.createCell(1), "Name");
setCellValue(rowTitle.createCell(2), "Rating");
setCellValue(rowTitle.createCell(3), "Text");
}
private void setCellValue(XSSFCell cell, String value) {
cell.setCellValue(value);
}
private void setCellValue(XSSFCell cell, long value) {
cell.setCellValue(value);
}
private void setCellValue(XSSFCell cell, Instant value) {
cell.setCellValue(value.toString());
}
}
Но такой подход оказался не очень оптимальным. Примерно 3 минуты потребовалось на выборку 1 млн строк из бд и запись их в excel. И в итоге приводил к OutOfMemoryError. Вот пример:

А когда я выполнял его на терминалке с выделенной оперативной памятью в 2Gb, то падал он с OutOfMemoryError примерно на 30% прогресса.
Грузить весь миллион строк в память в excel было так же плохой идеей, как и выгружать весь запрос в List, очевидно, здесь надо было использовать некий stream, но хоть какой-то годный пример google тогда мне не дал. Была попытка написать свое подобие I/O Stream для работы с excel, но мысль о том, что я пишу велосипед не давала мне покоя. В результате я стал изучать библиотеку org.apache.poi пристальней и оказалось, что там уже есть пакет streaming. В этом пакете уже есть весь необходимый набор классов для работы с большим объемом данных в excel. Оставалось только заменить все ключевые классы на аналогичные из пакета streaming и все:
package com.report.generator.demo.service;
import com.report.generator.demo.repository.entity.MessageData;
import org.apache.poi.xssf.streaming.SXSSFCell;
import org.apache.poi.xssf.streaming.SXSSFRow;
import org.apache.poi.xssf.streaming.SXSSFSheet;
import org.apache.poi.xssf.streaming.SXSSFWorkbook;
import java.io.FileOutputStream;
import java.io.IOException;
import java.time.Instant;
public class ReportExcelStreamWriter {
private final SXSSFWorkbook wb;
private final SXSSFSheet sheet;
public ReportExcelStreamWriter() {
this.wb = new SXSSFWorkbook();
this.sheet = wb.createSheet();
createTitle();
}
public void createRow(int index, MessageData data) {
SXSSFRow row = sheet.createRow(index);
setCellValue(row.createCell(0), data.getMessageDate());
setCellValue(row.createCell(1), data.getName());
setCellValue(row.createCell(2), data.getRating());
setCellValue(row.createCell(3), data.getText());
}
public void writeWorkbook() throws IOException {
FileOutputStream fileOut = new FileOutputStream(Instant.now().getEpochSecond() + ".xlsx");
wb.write(fileOut);
fileOut.close();
}
private void createTitle() {
SXSSFRow rowTitle = sheet.createRow(0);
setCellValue(rowTitle.createCell(0), "Date");
setCellValue(rowTitle.createCell(1), "Name");
setCellValue(rowTitle.createCell(2), "Rating");
setCellValue(rowTitle.createCell(3), "Text");
}
private void setCellValue(SXSSFCell cell, String value) {
cell.setCellValue(value);
}
private void setCellValue(SXSSFCell cell, long value) {
cell.setCellValue(value);
}
private void setCellValue(SXSSFCell cell, Instant value) {
cell.setCellValue(value.toString());
}
}
Теперь сравним скорость обработки данных с этой библиотекой:

Вся обработка заняла пол минуты и, самое главное, никаких OutOfMemoryError.
5. Итог
В результате удалось добиться максимальной производительности за счет использования хранимой функции, StatelessSession, ScrollableResults и использования библиотеки org.apache.poi из пакета streaming. При большом желании можно улучшить производительность еще, если написать все на чистом jdbc, может быть есть еще варианты, как, что и где можно улучшить. Буду рад услышать комментарии от более опытных в этом экспертов. В данном примере не учтено ограничение на 1 млн. строк, т. к. это простая формальность и для примера не очень важна. Для наполнения БД тестовыми данными был добавлен тестовый класс DemoApplicationTests. Весь код можно посмотреть в репозитории на GitHub.
Вопрос
Мне дали CSV-файл, содержащий больше, чем MAX Excel может обработать, и мне очень нужно иметь возможность видеть все данные. Я понял и попробовал метод «разделения», но он не работает.
Немного предыстории: CSV-файл — это файл Excel CSV, и человек, который дал файл, сказал, что в нем около `2 млн. строк данных.
Когда я импортирую его в Excel, я получаю данные до строки 1,048,576, затем повторно импортирую его в новой вкладке, начиная со строки 1,048,577 в данных, но это дает мне только одну строку, а я точно знаю, что их должно быть больше (не только из-за того, что «человек» сказал, что их больше 2 миллионов, но и из-за информации в последних нескольких наборах строк).
Я подумал, что, возможно, причина этого в том, что мне предоставили CSV-файл в формате Excel CSV, и поэтому вся информация после 1,048,576 потеряна (?).
Нужно ли мне запрашивать файл в формате базы данных SQL?
42
2013-06-05T16:37:49+00:00
12
![]()
Ответ на вопрос
30-го июня 2013 в 3:23
2013-06-30T15:23:08+00:00
#19566374
Попробуйте delimit, он может быстро открыть до 2 миллиардов строк и 2 миллионов столбцов, есть бесплатная 15-дневная пробная версия. Для меня это отличная работа!
![]()
Ответ на вопрос
30-го апреля 2014 в 9:19
2014-04-30T09:19:24+00:00
#19566377
Я бы предложил загрузить файл .CSV в MS-Access.
Затем в MS-Excel вы можете создать соединение данных с этим источником (без фактической загрузки записей в рабочий лист) и создать подключенную поворотную таблицу. Вы можете иметь практически неограниченное количество строк в таблице (в зависимости от процессора и памяти: у меня сейчас 15 миллионов строк при 3 Гб памяти).
Дополнительным преимуществом является то, что теперь вы можете создавать агрегированные представления в MS-Access. Таким образом, вы можете создавать обзоры из сотен миллионов строк и затем просматривать их в MS-Excel (помните об ограничении в 2 Гб для файлов NTFS в 32-битных ОС).
![]()
Ответ на вопрос
11-го сентября 2013 в 3:39
2013-09-11T15:39:03+00:00
#19566375
Сначала нужно изменить формат файла с csv на txt. Это легко сделать, просто отредактируйте имя файла и измените csv на txt. (Windows выдаст предупреждение о возможном повреждении данных, но все в порядке, просто нажмите OK). Затем сделайте копию txt-файла, чтобы теперь у вас было два файла с 2 миллионами строк данных. Затем откройте первый txt-файл, удалите второй миллион строк и сохраните файл. Затем откройте второй файл txt, удалите первый миллион строк и сохраните файл. Теперь измените оба файла обратно в csv так же, как вы изменили их в txt.
![]()
Ответ на вопрос
5-го июня 2013 в 4:49
2013-06-05T16:49:59+00:00
#19566372
Excel 2007+ ограничен количеством строк, несколько превышающим 1 миллион (2^20, если быть точным), поэтому он никогда не загрузит ваш файл с 2 миллионами строк. Я думаю, что техника, на которую вы ссылаетесь как на разделение, является встроенной в Excel, но afaik она работает только для ширины проблем, а не для длины проблем.
Действительно самый простой способ, который я вижу сразу, это использовать какой-нибудь инструмент для разделения файлов — их там ‘куча и использовать его для загрузки полученных частичных csv файлов в несколько рабочих листов.
ps: «excel csv файлы» не существуют, есть только файлы, создаваемые Excel, которые используют один из форматов, обычно называемых csv файлами…

Simple Text Splitter download | SourceForge.net
Download Simple Text Splitter for free. A very simple text splitter that can split text based files (txt, log, srt etc.) into smaller chunks.
sourceforge.net
Microsoft Support
Microsoft support is here to help you with Microsoft products. Find how-to articles, videos, and training for Office, Windows, Surface, and more.
office.microsoft.com
![]()
Ответ на вопрос
5-го апреля 2016 в 1:15
2016-04-05T13:15:51+00:00
#19566379
Если у вас есть Matlab, вы можете открывать большие файлы CSV (или TXT) через его импорт. Инструмент предоставляет различные параметры формата импорта, включая таблицы, векторы столбцов, числовую матрицу и т. Д. Однако, поскольку Matlab является пакетом интерпретаторов, для импорта такого большого файла требуется свое время, и я смог импортировать его с более чем 2 миллионами строк примерно за 10 минут.
Инструмент доступен через вкладку «Главная» Matlab, нажав кнопку «Импорт данных». Пример изображения большой загрузки файла показан ниже:

После импорта данные отображаются в рабочей области справа, которая затем может быть дважды щелкнута в формате Excel и даже нанесена на график в разных форматах.

![]()
Ответ на вопрос
18-го мая 2018 в 8:20
2018-05-18T20:20:52+00:00
#19566382
Я смог без проблем отредактировать большой файл csv объемом 17 ГБ в Sublime Text (нумерация строк позволяет намного легче отслеживать ручное разделение), а затем свалить его в Excel на куски размером менее 1 048 576 строк. Просто и довольно быстро — менее глупо, чем исследование, установка и обучение индивидуальных решений. Быстро и грязно, но это работает.
![]()
Ответ на вопрос
22-го ноября 2016 в 6:42
2016-11-22T06:42:00+00:00
#19566380
Используйте MS Access. У меня есть файл из 2 673 404 записей. Он не откроется в блокноте ++, и Excel не загрузит более 1 048 576 записей. Он ограничен вкладкой, поскольку я экспортировал данные из базы данных mysql, и они мне нужны в формате csv. Поэтому я импортировал его в Access. Измените расширение файла на .txt, чтобы MS Access провел вас через мастер импорта.
MS Access свяжется с вашим файлом, чтобы база данных оставалась неизменной и сохраняла файл csv
![]()
Ответ на вопрос
4-го сентября 2019 в 5:55
2019-09-04T05:55:25+00:00
#19566383
Я нашел этот предмет исследования.
Существует способ скопировать все эти данные в таблицу данных Excel.
(У меня есть эта проблема раньше с файлом CSV из 50 миллионов строк)
Если есть какой-либо формат, дополнительный код может быть включен.
Попробуй это.
![]()
Ответ на вопрос
5-го мая 2015 в 3:21
2015-05-05T15:21:05+00:00
#19566378
Разделите CSV на два файла в блокноте. Это боль, но после этого вы можете просто редактировать каждый из них по отдельности в Excel.
Похожие сообщества
2


Содержание
- — Как я могу использовать в Excel более 1 миллиона строк?
- — Может ли Excel обрабатывать 4 миллиона строк?
- — Как заставить Excel обрабатывать больше данных?
- — Как открыть файл CSV с более чем 1 миллионом строк?
- — Какое максимальное количество строк в CSV-файле?
- — Есть ли ограничение на количество строк в Excel?
- — Как сохранить в Excel более 65536 строк?
- — Почему в Excel 65536 строк?
- — Что может быть мощнее Excel?
- — Как обойти ограничение на количество строк в Excel?
- — Как вы обрабатываете большие объемы данных?
Excel не может обрабатывать более 1 048 576 строк. Это максимум, который вы можете иметь на листе. @jstupl вам, конечно, потребуется использовать редактор запросов для текста.
Как загрузить большие наборы данных в модель?
- Шаг 1. Подключитесь к своим данным через Power Query. Перейдите на ленту данных и нажмите «Получить данные». …
- Шаг 2 — Загрузите данные в модель данных. В редакторе Power Query при необходимости выполните любые преобразования. …
- Шаг 3 — Проанализируйте данные с помощью сводных таблиц. Идите и вставьте сводную таблицу (Вставка> Сводная таблица)
Может ли Excel обрабатывать 4 миллиона строк?
Не многим людям нужно чтобы вывести в Excel 4 миллиона строк данных. Пункт принят. … Если вы когда-либо проверяли (нажмите End, затем клавишу со стрелкой вниз), в Excel чуть более 1 миллиона строк, но если вы начнете добавлять в эти строки одну или две формулы, вскоре у вас возникнут проблемы.
Как заставить Excel обрабатывать больше данных?
Сделать это, щелкните вкладку Power Pivot на ленте -> Управление данными -> Получить внешние данные. В списке источников данных есть много вариантов. В этом примере будут использоваться данные из другого файла Excel, поэтому выберите вариант Microsoft Excel внизу списка. Для больших объемов данных импорт займет некоторое время.
Как открыть файл CSV с более чем 1 миллионом строк?
Есть решение в Excel. Вы не можете открывать большие файлы стандартным способом, но вы может создать соединение с файлом CSV. Это работает путем загрузки данных в модель данных с сохранением ссылки на исходный файл CSV. Это позволит вам загрузить миллионы строк.
Какое максимальное количество строк в CSV-файле?
Файлы CSV не имеют ограничений на количество строк, которые вы можете добавить. им. Excel не будет содержать больше 1 миллиона строк данных, если вы импортируете файл CSV с большим количеством строк. Excel на самом деле спросит вас, хотите ли вы продолжить, если импортируете более 1 миллиона строк данных.
Есть ли ограничение на количество строк в Excel?
По данным службы поддержки Microsoft (2021 г.): максимальное количество строк в Excel составляет 1,048,576. Количество столбцов ограничено 16 384. Это относится к Excel для Microsoft 365, Excel 2019, Excel 2016, Excel 2013, Excel 2010 и Excel 2007. Еще в 2007 году немногим более миллиона строк казалось большим объемом данных.
Как сохранить в Excel более 65536 строк?
xlsx или. xlsm) имеет максимум около 1 миллиона (ровно 1048576) строк на листе. Если источник данных содержит более 65536 строк (и менее 1 миллиона строк) и вы используете ExcelWriter версии 7.0 или выше, вы можете использовать ExcelTemplate с шаблоном OOXML чтобы все данные поместились на одном листе.
Почему в Excel 65536 строк?
xls-файлы, которые вы открываете, будут ограничены этим количеством строк. Если вы указали, что хотите сохранять файлы в этом формате по умолчанию, тогда когда вы создаете новую книгу он будет ограничен 65536 строками, и [режим совместимости] появится в строке заголовка Excel.
Что может быть мощнее Excel?
Google Таблицы может быть самым популярным веб-приложением для работы с электронными таблицами, но Zoho Sheet имеет больше возможностей. И это также совершенно бесплатно. Это лучшая бесплатная альтернатива Excel, если вы ищете самое мощное решение. Как и Excel, Zoho Sheet действительно обладает множеством функций.
Как обойти ограничение на количество строк в Excel?
Предел строк в Excel
- Предел строк в Excel (содержание)
- Шаг 1. Выберите одну строку ниже, в которой вы хотите отобразить количество строк. …
- Шаг 2: Теперь удерживайте клавиши Shift и Ctrl> нажмите стрелку вниз; он перенесет вас до конца последней строки.
- Шаг 3: Щелкните правой кнопкой мыши заголовок столбца и выберите параметр скрытия.
Как вы обрабатываете большие объемы данных?
Вот 11 советов, как максимально эффективно использовать большие наборы данных.
- Берегите свои данные. «Храните необработанные данные в сыром виде: не манипулируйте ими, не имея копии», — говорит Тил. …
- Визуализируйте информацию.
- Покажите свой рабочий процесс. …
- Используйте контроль версий. …
- Запишите метаданные. …
- Автоматизируйте, автоматизируйте, автоматизируйте. …
- Считайте время вычислений. …
- Запечатлейте свое окружение.
Интересные материалы:
Как включить вспышку вне камеры с помощью выдвижной вспышки?
Как включить звук на камере?
Как включить звук срабатывания затвора камеры?
Как вручную прошить цифровую камеру?
Как вы читаете цвета на резервной камере?
Как вы держите камеру вертикально?
Как вы используете камеру на Canon 5D Mark III?
Как вы используете камеру рейнджера в юрском мире?
Как вы обслуживаете объектив камеры?
Как вы проверяете камеру?