
Содержание
- Описание статистических функций ДОВЕРИТ в Excel
- Сводка
- Дополнительные сведения
- Синтаксис
- Пример использования
- Интерпретация результатов проверки доверия
- Выводы
- Вычисление доверительного интервала в Microsoft Excel
- Процедура вычисления
- Способ 1: функция ДОВЕРИТ.НОРМ
- Способ 2: функция ДОВЕРИТ.СТЮДЕНТ
Описание статистических функций ДОВЕРИТ в Excel
Сводка
В этой статье описана функция ДОВЕРИТ в Microsoft Office Excel 2003 и Microsoft Office Excel 2007, а также сравнивает результаты функции для Excel 2003 и Excel 2007 с результатами функции ДОВЕРИТ в более ранних версиях Excel.
Значение доверительных интервалов часто неправильно интерпретировано, и мы стараемся предоставить объяснение допустимой и недопустимой выписки, которые могут быть сделаны после определения доверительного значения на основе данных.
Дополнительные сведения
Функция ДОВЕРИТ(альфа; сигма, n) возвращает значение, которое можно использовать для построения доверительный интервал для многая населения. Доверительный интервал — это диапазон значений, вы центр на основе известного значения выборки. Предполагается, что результаты наблюдений в выборке взяты из нормального распределения с известным стандартным отклонением, сигмой, а количество наблюдений в выборке — n.
Синтаксис
Параметры: альфа — вероятность и 0
Пример использования
Предположим, что оценки коэффициента аналитики следуют за обычным распределением со стандартным отклонением 15. Вы тестировали IQ-тест для 50 учащихся в вашем учебном замещаемом учебном замещаке и получили пример средней 105. Необходимо вычислить доверительный интервал в 95 % для математических вычислений. Доверительный интервал 95 % или 0,95 соответствует альфа = 1 – 0,95 = 0,05.
Чтобы проиллюстрировать функцию ДОВЕРИТ, создайте пустой Excel, скопируйте таблицу ниже и выберите ячейку A1 на Excel листе. В меню Правка выберите команду Вставить.
Примечание: В Excel 2007 нажмите кнопку Вировать в группе Буфер обмена на вкладке Главная.
Элементы в таблице ниже заполняют ячейки A1:B7 на вашем компьютере.
После вжатия этой таблицы на новый Excel нажмите кнопку Параметры вжатия и выберите пункт Найти формат назначения.
Вы можете выбрать в меню Формат пункт Столбец, а затем выбрать пункт Авто подбор по столбцу.
Примечание: В Excel 2007 г. с выбранным диапазоном ячеек нажмите кнопку Формат в группе Ячейки на вкладке Главная, а затем выберите Авто ширина столбца.
Ячейка A6 отображает значение ДОВЕРИТ. Ячейка A7 имеет то же значение, так как звонок на значение ДОВЕРИТ(альфа; сигма, n) возвращает результат вычисления:
NORMSINV(1 – alpha/2) * sigma / SQRT(n)
Непосредственно в доверии не внося изменений, но в Microsoft Excel 2002 г. была улучшена норм.В.ВОСЬМ, а затем в Excel 2002 и Excel 2007 г. были внесены дополнительные улучшения. Поэтому в этих более поздних версиях стандарта ДОВЕРИТ могут возвращаться другие (и улучшенные Excel) результаты, так как доверит их на основе нормСИНВ.
Это не означает, что в более ранних версиях Excel доверие к доверию. Неточности в нормОЛИНВ обычно связаны со значениями аргумента, близкими к 0 или очень близко к 1. На практике альфа обычно имеет 0,05, 0,01 или, возможно, 0,001. Значения альфа-значения должны быть намного меньше, чем это, например 0,0000001, прежде чем ошибки округления в НОРМСИНВ, скорее всего, будут заметили.
Примечание: В этой статье на сайте НОРМ.В.ВН можно узнать о различиях в вычислениях в нормСИНХНОВ.
Для получения дополнительных сведений щелкните номер следующей статьи, чтобы просмотреть статью в базе знаний Майкрософт:
826772 Excel статистические функции: НОРМСИНВ
Интерпретация результатов проверки доверия
Файл Excel справки для confidence был перезаписан в Excel 2003 и Excel 2007, так как все более ранние версии файла справки вводили в заблуждение при интерпретации результатов. В примере говорится: «Предположим, что в нашем примере из 50 сотрудников в пути средняя продолжительность поездки на работу составляет 30 минут со стандартным отклонением в 2,5. Мы можем быть уверены в том, что значение «0,692951» находится в интервале 30 +/- 0,692951″, где значение 0,692951 — это значение, возвращаемого значением ДОВЕРИТ(0,05, 2,5, 50).
В этом же примере в заключение говорится, что средняя продолжительность поездки на работу равна 30 ± 0,692951 минуты или от 29,3 до 30,7 минуты. Это также утверждение о том, что численность населения находится в интервале [30 –0,692951, 30 + 0,692951] с вероятностью 0,95.
Перед проведением эксперимента, который дает данные в данном примере, статистический статистик (в отличие от байеса) не может делать никаких заявлений о распределении вероятности распределения по численности населения. Вместо этого статистический статистик в классической версии имеет дело с проверкой гипотез.
Например, классическому статистику может потребоваться провести двухбоговую проверку гипотезы на основе гипотезы на основе гипотезы о нормальном распределении с известным стандартным отклонением (например, 2,5), заранее выбранным значением μ0 и предопределенным уровнем значимости (например, 0,05). Результат проверки будет основан на значении наблюдаемого значения выборки (например, 30), а гипотеза null о том, что это μ0, будет отклонена на уровне значимости 0,05, если наблюдаемое значение имеет значение слишком далеко от μ0 в любом направлении. Если гипотеза NULL отклонена, то интерпретация состоит в том, что выборка означает, что выборка означает, что гораздо больше μ0 может возникнуть менее 5 % времени при позиции, что μ0 — это истинное подмногление численности населения. После проведения этого теста статистический статистик по-прежнему не может сделать никаких заявлений о распределении вероятностей для распределения по численности населения.
С другой стороны, байесский статистический статистик начинается с предполагается распределение вероятности для распределения по численности населения (априори), собирает экспериментальные признаки так же, как и статистический статистик, и использует его для изменения его распределения вероятности для многубного распределения по численности населения и тем самым получения задняя часть распределения. Excel не предусмотрены статистические функции, которые помогли бы байесам в этом случае. Excel статистические функции классической статистики.
Доверительный интервал связан с проверкой гипотез. Учитывая экспериментальные признаки, доверительный интервал делает краткое утверждение о значениях среднего среднего гипотезы μ0, которое позволит принять нулевую гипотезу о том, что это μ0, и значения μ0, которые подавят отклонение гипотезы null о том, что это значение имеет значение μ0. Статистический статистик не может сделать ни одного заявления о вероятности того, что оно попадает в определенный интервал, так как он никогда не делает предопределенные предположения относительно этого распределения вероятности, и такие предположения потребуются, если они будут использовать экспериментальные признаки для их изменения.
Изучение связи между проверками гипотез и доверитными интервалами с помощью примера в начале этого раздела. Связь между доверим и НОРМСИНХОV, которая была заверяема в последнем разделе, имеется:
CONFIDENCE(0.05, 2.5, 50) = NORMSINV(1 – 0.05/2) * 2.5 / SQRT(50) = 0.692951
Так как выборка имеет 30-е, доверительный интервал составляет 30 +/- 0,692951.
Теперь рассмотрим двухбудную проверку гипотезы с уровнем значимости 0,05, как описано выше, в котором предполагается нормальное распределение со стандартным отклонением 2,5, выборку размером 50 и определенным гипотезой о среднего распределения ( μ0). Если это истинное решение по численности населения, то выборка будет взята из нормального распределения со стандартным отклонением μ0 и стандартным отклонением 2,5/SQRT(50). Это распределение симметрично о μ0, и вы хотите отклонить гипотезу null, если abS(выборка μ0) > некого конечного значения. Конечное значение будет таким, что если μ0 — это истинное значение по численности населения, значение выборки — μ0 больше, чем это обрезка, или значение μ0 — выборочная величина выше, чем это обрезка будет возникать с вероятностью 0,05/2. Это вырезание
NORMSINV(1 – 0.05/2) * 2.5/SQRT(50) = CONFIDENCE(0.05, 2.5, 50) = 0. 692951
Отклонить нулевую гипотезу (о численности населения = μ0), если одно из следующих заявлений истинно:
выборка «mean» — μ0 > 0. 692951
0 — пример > 0. 692951
Так как в нашем примере примере выборка » = 30″, эти две выписки становятся следующими:
30 — μ0 > 0. 692951
μ0 –30 > 0. 692951
При переописи слева отображается только μ0, что приводит к следующим утверждениям:
μ0 30 + 0. 692951
Это точно те значения μ0, которые не находятся в доверительный интервал [30 – 0,692951, 30 + 0,692951]. Поэтому доверительный интервал [30 –0,692951, 30 + 0,692951] содержит значения μ0, где null-гипотеза о том, что это μ0, не будет отклонена с учетом примеров признаков. Для значений μ0 вне этого интервала гипотеза null о том, что это μ0, будет отклонена с учетом примеров признаков.
Выводы
Неточности в более ранних версиях Excel обычно возникают при очень небольших или очень больших значениях p в нормУРОВН(p). Доверит оценивается с помощью вызовов НОРМ.СТ.ВВ(p), поэтому точность НОРМСИНВ является потенциальной проблемой для пользователей ДОВЕРИТ. Однако значения p, которые используются на практике, вряд ли являются достаточно крайними, чтобы вызывать существенные ошибки округленного округления в нормУРОВН, и производительность доверит пользователям любой версии Excel.
В большинстве статей основное внимание уделялось анализу результатов проверки доверить. Другими словами, мы спросили: «В чем смысл доверительный интервал?» Доверительный интервал часто неправильно понимается. К сожалению, Excel этой теме были Excel справки во всех версиях Excel 2003. Улучшен Excel 2003.
Источник
Вычисление доверительного интервала в Microsoft Excel

Одним из методов решения статистических задач является вычисление доверительного интервала. Он используется, как более предпочтительная альтернатива точечной оценке при небольшом объеме выборки. Нужно отметить, что сам процесс вычисления доверительного интервала довольно сложный. Но инструменты программы Эксель позволяют несколько упростить его. Давайте узнаем, как это выполняется на практике.
Процедура вычисления
Этот метод используется при интервальной оценке различных статистических величин. Главная задача данного расчета – избавится от неопределенностей точечной оценки.
В Экселе существуют два основных варианта произвести вычисления с помощью данного метода: когда дисперсия известна, и когда она неизвестна. В первом случае для вычислений применяется функция ДОВЕРИТ.НОРМ, а во втором — ДОВЕРИТ.СТЮДЕНТ.
Способ 1: функция ДОВЕРИТ.НОРМ
Оператор ДОВЕРИТ.НОРМ, относящийся к статистической группе функций, впервые появился в Excel 2010. В более ранних версиях этой программы используется его аналог ДОВЕРИТ. Задачей этого оператора является расчет доверительного интервала с нормальным распределением для средней генеральной совокупности.
Его синтаксис выглядит следующим образом:
«Альфа» — аргумент, указывающий на уровень значимости, который применяется для расчета доверительного уровня. Доверительный уровень равняется следующему выражению:
«Стандартное отклонение» — это аргумент, суть которого понятна из наименования. Это стандартное отклонение предлагаемой выборки.
«Размер» — аргумент, определяющий величину выборки.
Все аргументы данного оператора являются обязательными.
Функция ДОВЕРИТ имеет точно такие же аргументы и возможности, что и предыдущая. Её синтаксис таков:

Как видим, различия только в наименовании оператора. Указанная функция в целях совместимости оставлена в Excel 2010 и в более новых версиях в специальной категории «Совместимость». В версиях же Excel 2007 и ранее она присутствует в основной группе статистических операторов.
Граница доверительного интервала определяется при помощи формулы следующего вида:
Где X – это среднее выборочное значение, которое расположено посередине выбранного диапазона.
Теперь давайте рассмотрим, как рассчитать доверительный интервал на конкретном примере. Было проведено 12 испытаний, вследствие которых были получены различные результаты, занесенные в таблицу. Это и есть наша совокупность. Стандартное отклонение равно 8. Нам нужно рассчитать доверительный интервал при уровне доверия 97%.
- Выделяем ячейку, куда будет выводиться результат обработки данных. Щелкаем по кнопке «Вставить функцию».

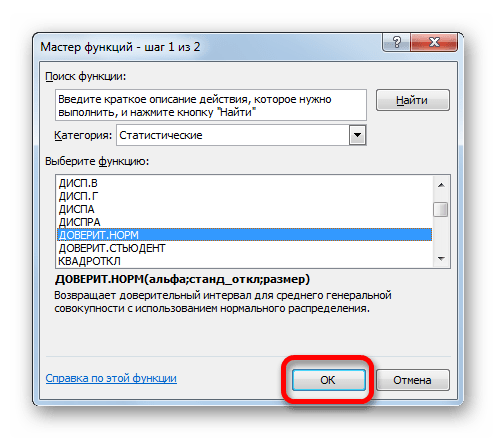
- Появляется Мастер функций. Переходим в категорию «Статистические» и выделяем наименование «ДОВЕРИТ.НОРМ». После этого клацаем по кнопке «OK».
- Открывается окошко аргументов. Его поля закономерно соответствуют наименованиям аргументов.
Устанавливаем курсор в первое поле – «Альфа». Тут нам следует указать уровень значимости. Как мы помним, уровень доверия у нас равен 97%. В то же время мы говорили, что он рассчитывается таким путем:
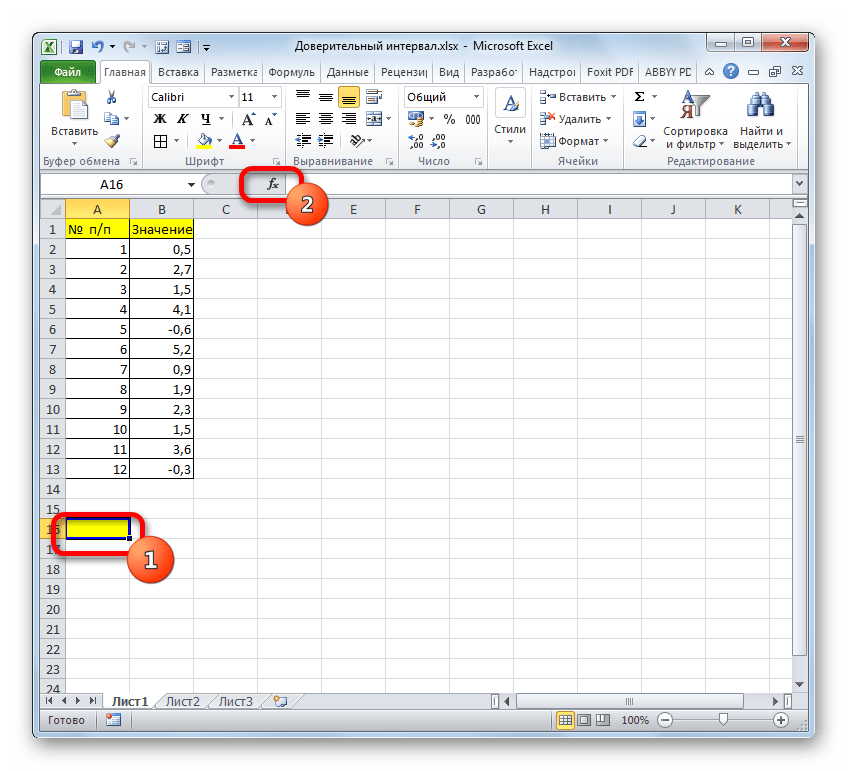
Значит, чтобы посчитать уровень значимости, то есть, определить значение «Альфа» следует применить формулу такого вида:
То есть, подставив значение, получаем:
Путем нехитрых расчетов узнаем, что аргумент «Альфа» равен 0,03. Вводим данное значение в поле.
Как известно, по условию стандартное отклонение равно 8. Поэтому в поле «Стандартное отклонение» просто записываем это число.
В поле «Размер» нужно ввести количество элементов проведенных испытаний. Как мы помним, их 12. Но чтобы автоматизировать формулу и не редактировать её каждый раз при проведении нового испытания, давайте зададим данное значение не обычным числом, а при помощи оператора СЧЁТ. Итак, устанавливаем курсор в поле «Размер», а затем кликаем по треугольнику, который размещен слева от строки формул.
Появляется список недавно применяемых функций. Если оператор СЧЁТ применялся вами недавно, то он должен быть в этом списке. В таком случае, нужно просто кликнуть по его наименованию. В обратном же случае, если вы его не обнаружите, то переходите по пункту «Другие функции…». 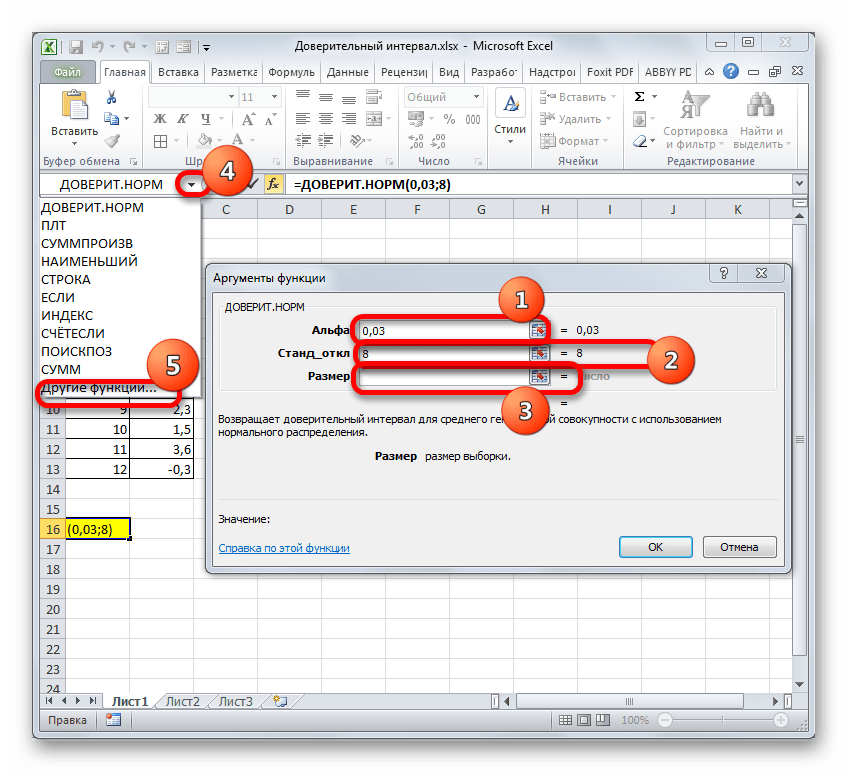
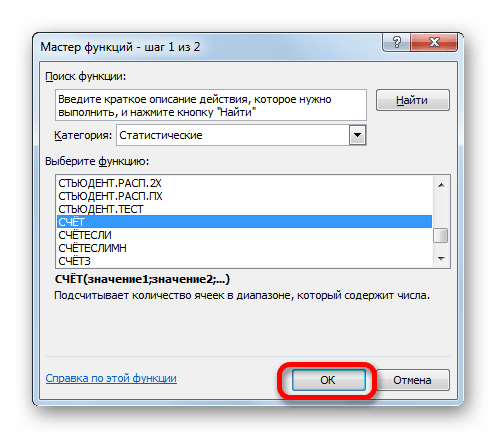
Группа аргументов «Значения» представляет собой ссылку на диапазон, в котором нужно рассчитать количество заполненных числовыми данными ячеек. Всего может насчитываться до 255 подобных аргументов, но в нашем случае понадобится лишь один.
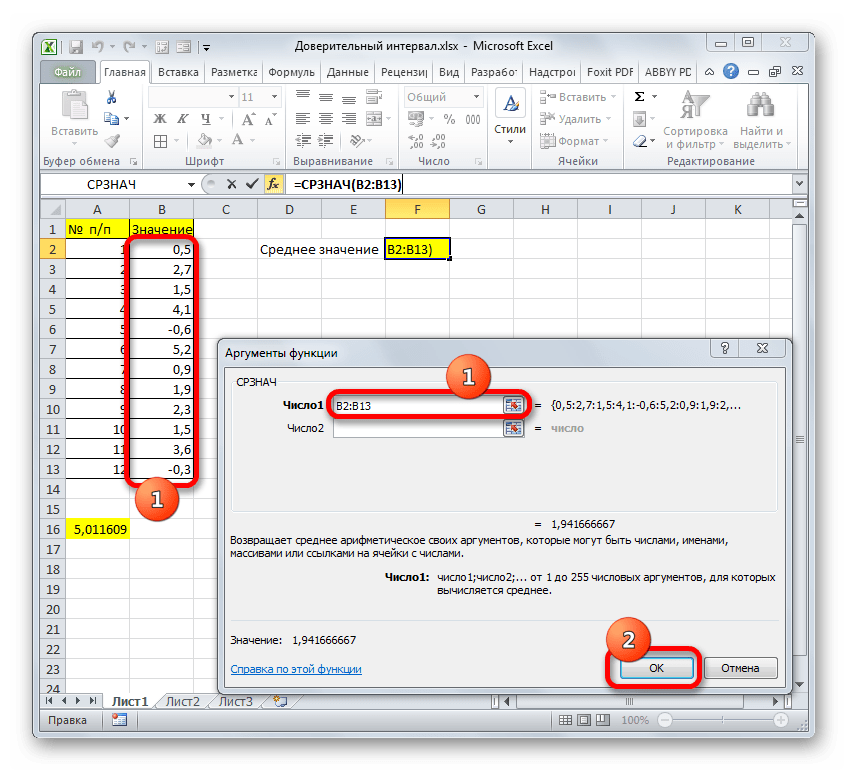
Устанавливаем курсор в поле «Значение1» и, зажав левую кнопку мыши, выделяем на листе диапазон, который содержит нашу совокупность. Затем его адрес будет отображен в поле. Клацаем по кнопке «OK». 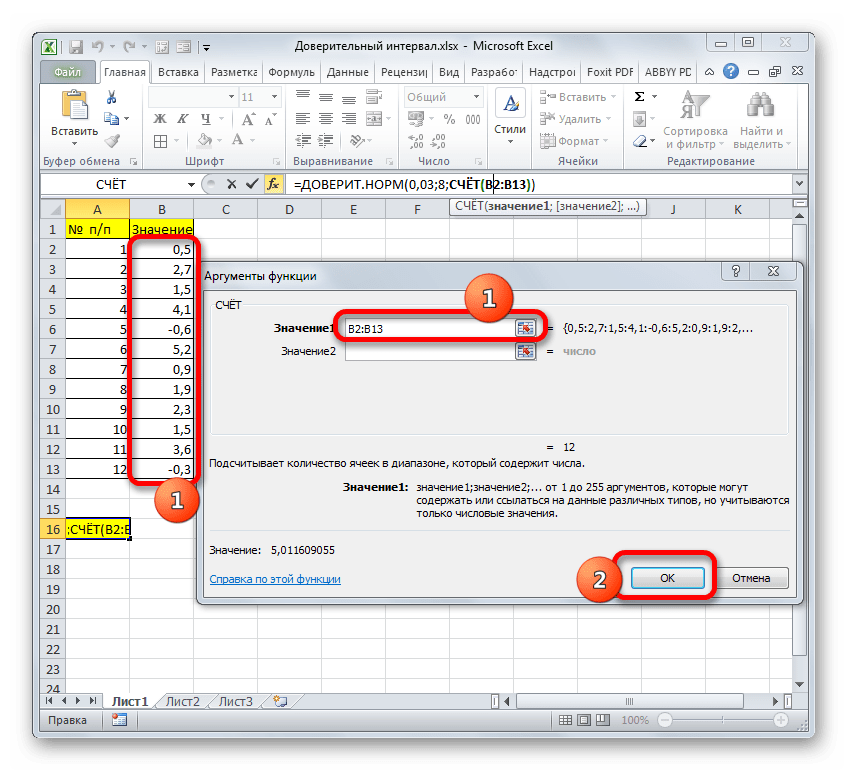
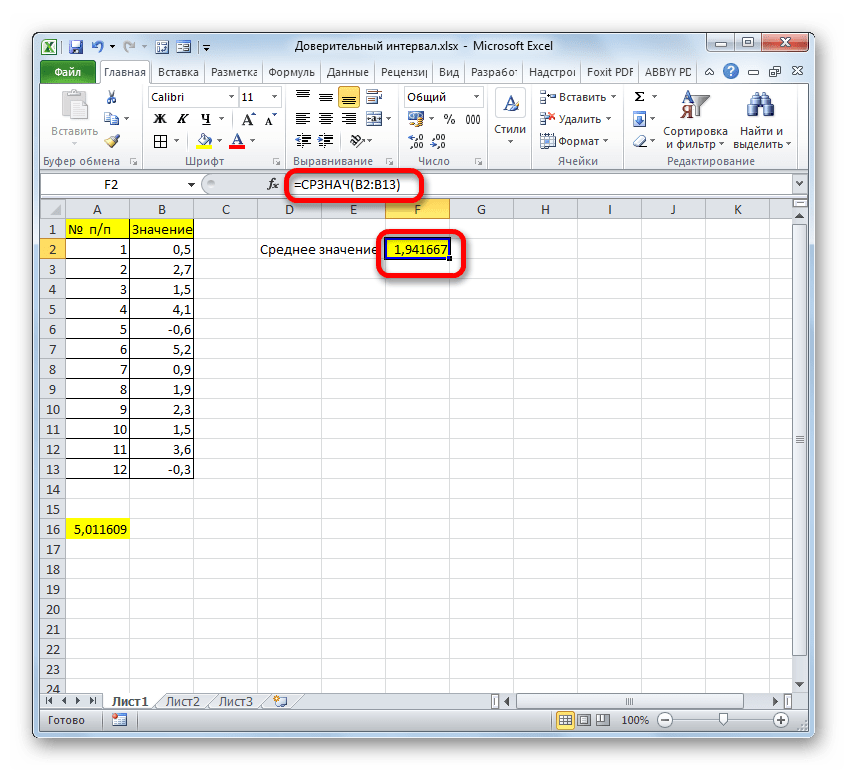
После этого приложение произведет вычисление и выведет результат в ту ячейку, где она находится сама. В нашем конкретном случае формула получилась такого вида:
Общий результат вычислений составил 5,011609. 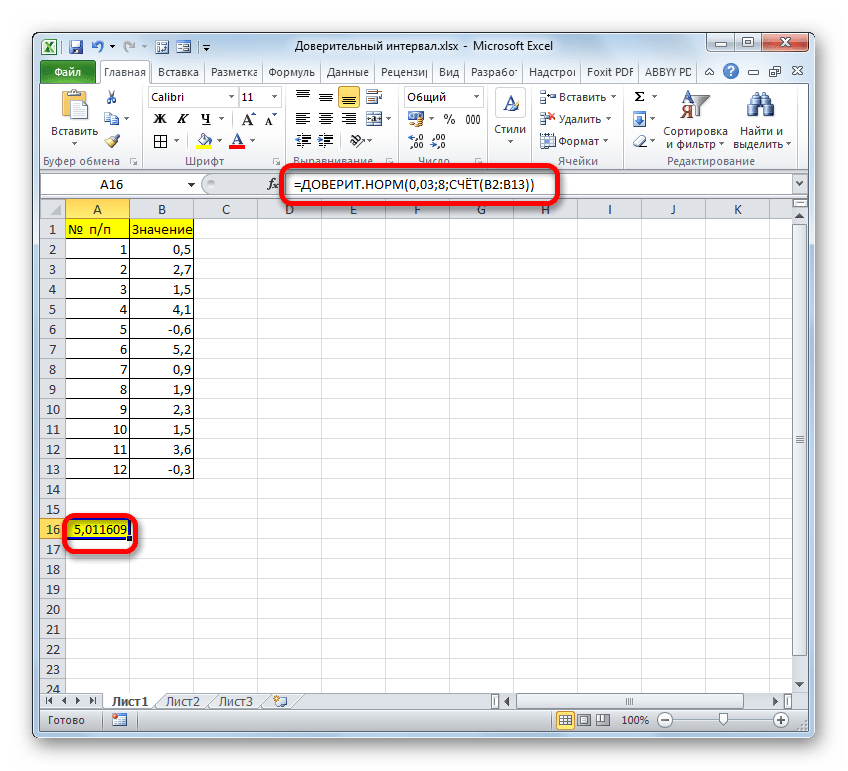
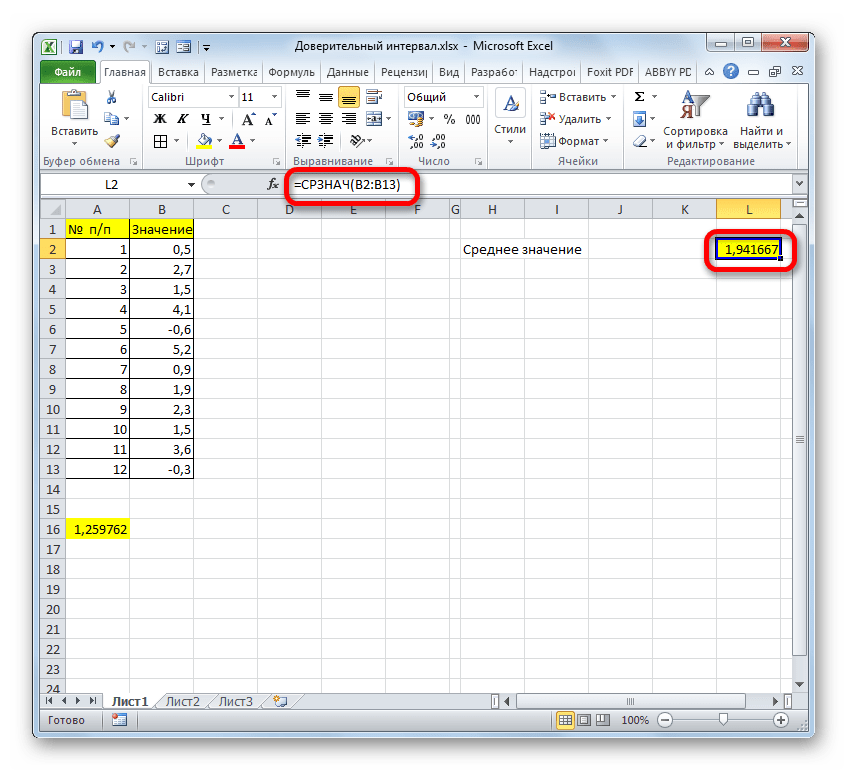
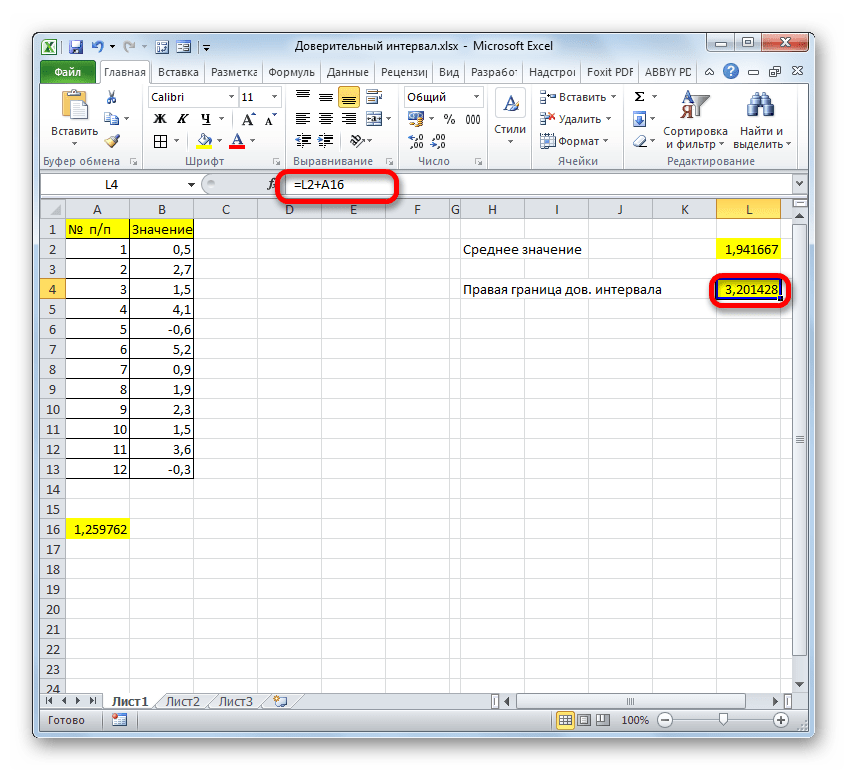
Но это ещё не все. Как мы помним, граница доверительного интервала вычисляется путем сложения и вычитания от среднего выборочного значения результата вычисления ДОВЕРИТ.НОРМ. Таким способом рассчитывается соответственно правая и левая граница доверительного интервала. Само среднее выборочное значение можно рассчитать при помощи оператора СРЗНАЧ.
Данный оператор предназначен для расчета среднего арифметического значения выбранного диапазона чисел. Он имеет следующий довольно простой синтаксис:
Аргумент «Число» может быть как отдельным числовым значением, так и ссылкой на ячейки или даже целые диапазоны, которые их содержат.
Итак, выделяем ячейку, в которую будет выводиться расчет среднего значения, и щелкаем по кнопке «Вставить функцию». 
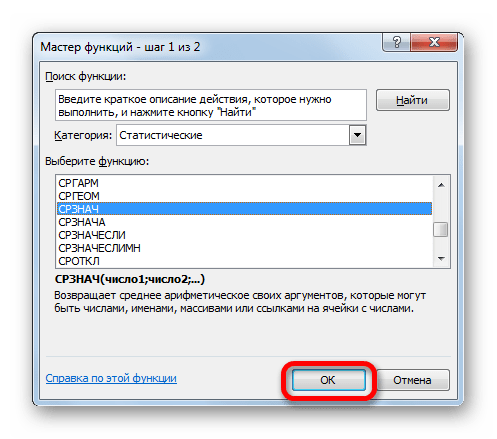
Результат вычисления: 6,953276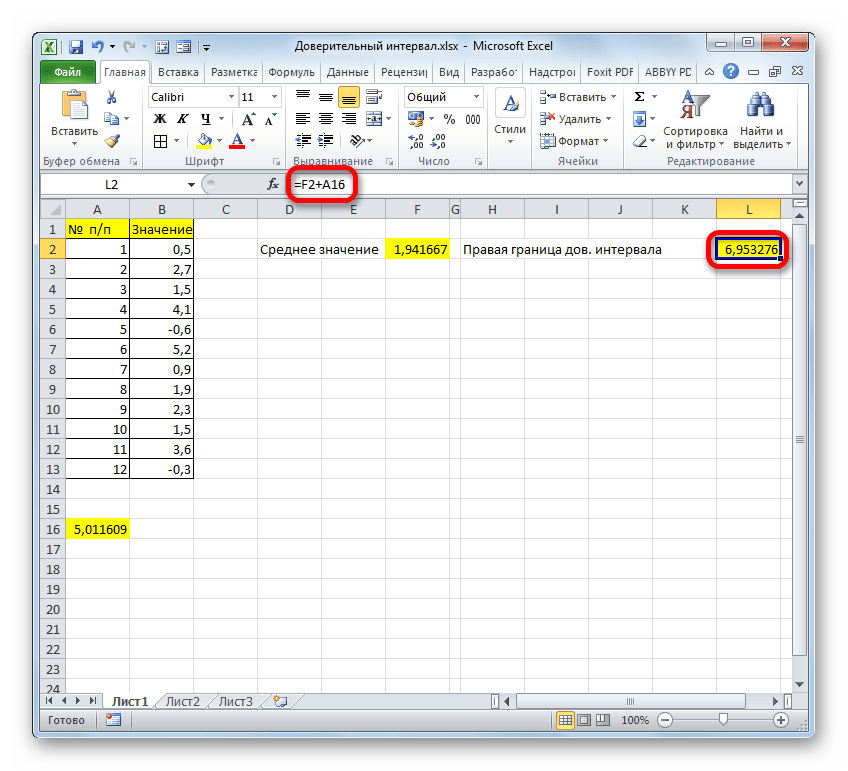
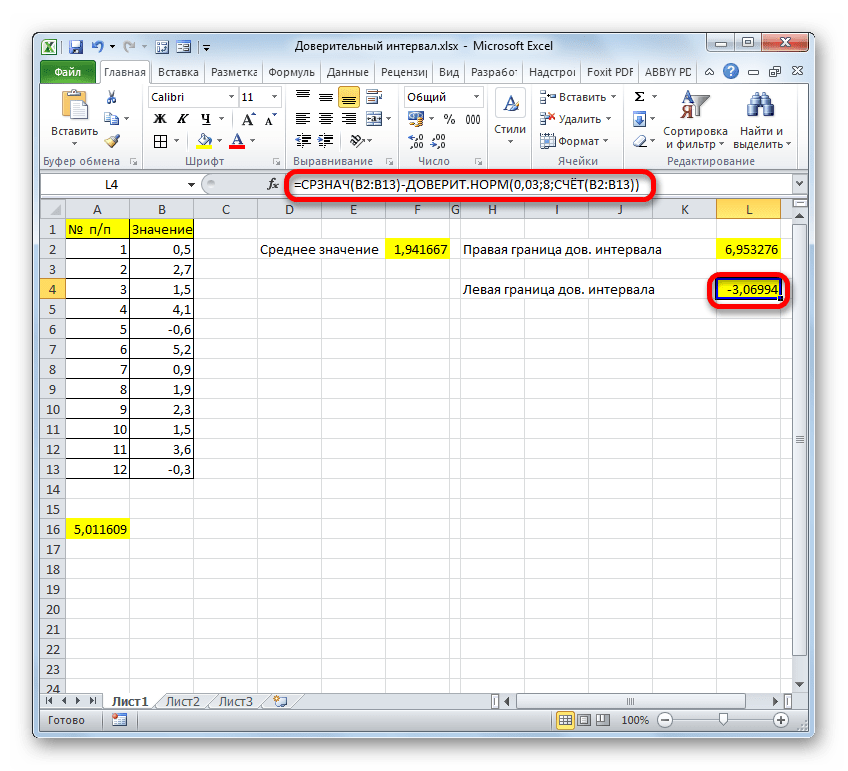
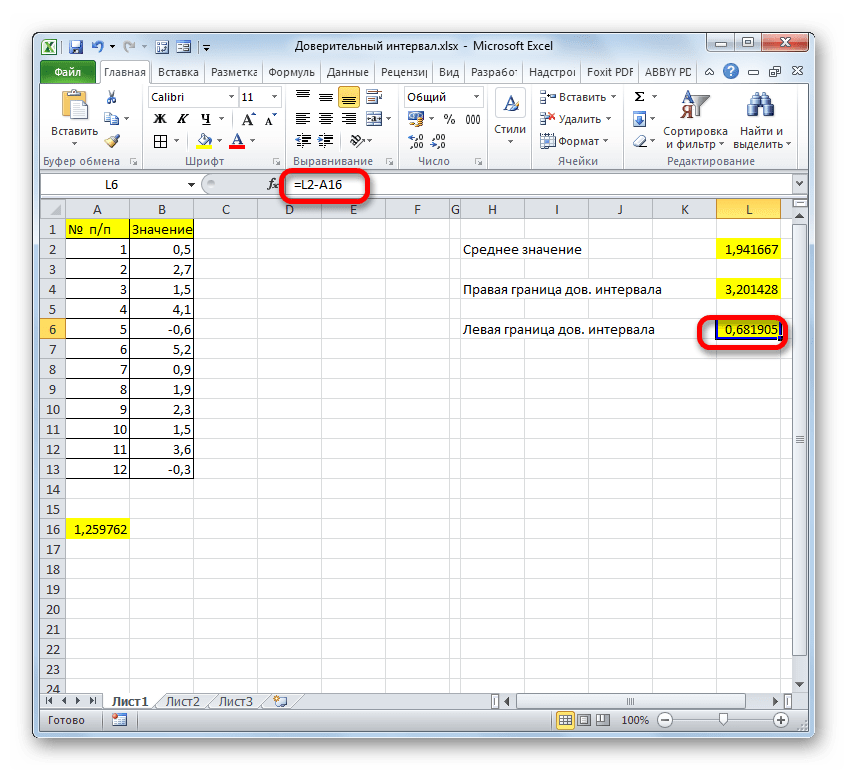
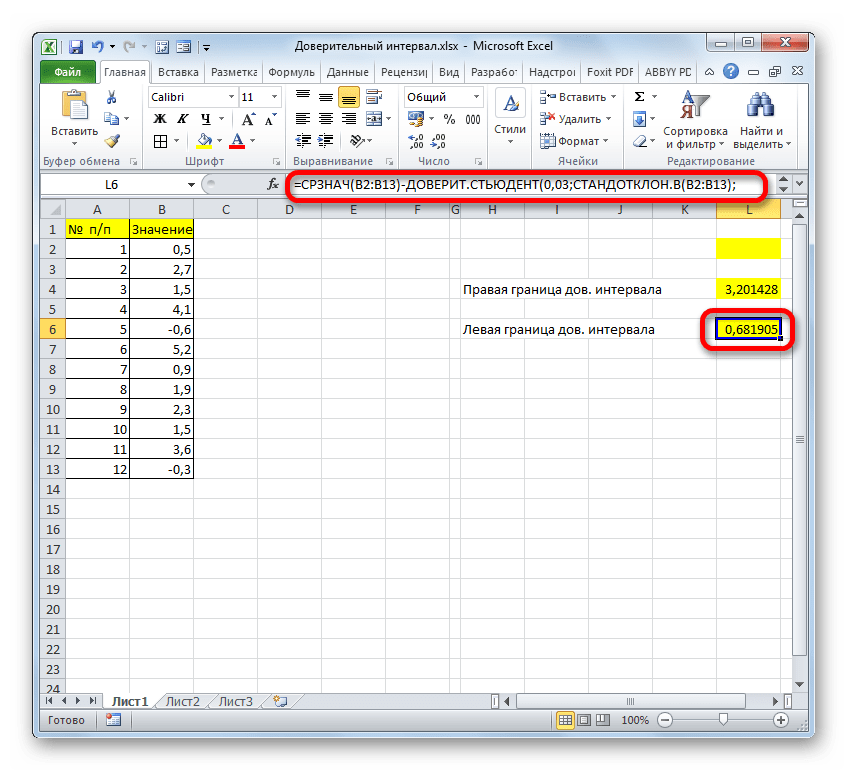
Таким же образом производим вычисление левой границы доверительного интервала, только на этот раз от результата вычисления СРЗНАЧ отнимаем результат вычисления оператора ДОВЕРИТ.НОРМ. Получается формула для нашего примера следующего типа:
Результат вычисления: -3,06994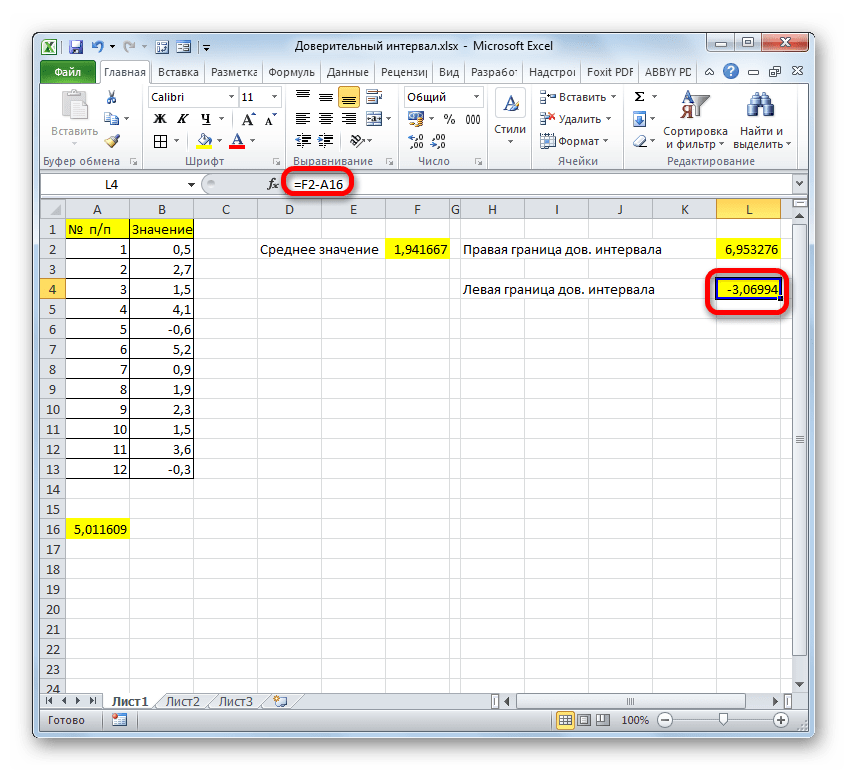
Мы попытались подробно описать все действия по вычислению доверительного интервала, поэтому детально расписали каждую формулу. Но можно все действия соединить в одной формуле. Вычисление правой границы доверительного интервала можно записать так:
=СРЗНАЧ(B2:B13)+ДОВЕРИТ.НОРМ(0,03;8;СЧЁТ(B2:B13)) 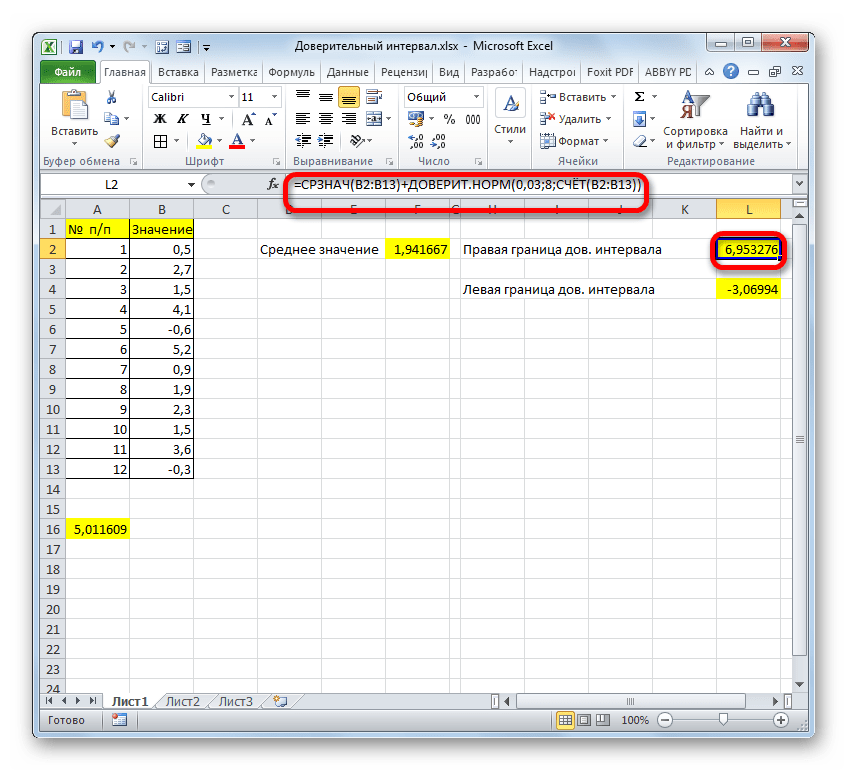
Аналогичное вычисление левой границы будет выглядеть так:
=СРЗНАЧ(B2:B13)-ДОВЕРИТ.НОРМ(0,03;8;СЧЁТ(B2:B13))
Способ 2: функция ДОВЕРИТ.СТЮДЕНТ
Кроме того, в Экселе есть ещё одна функция, которая связана с вычислением доверительного интервала – ДОВЕРИТ.СТЮДЕНТ. Она появилась, только начиная с Excel 2010. Данный оператор выполняет вычисление доверительного интервала генеральной совокупности с использованием распределения Стьюдента. Его очень удобно использовать в том случае, когда дисперсия и, соответственно, стандартное отклонение неизвестны. Синтаксис оператора такой:
Как видим, наименования операторов и в этом случае остались неизменными.
Посмотрим, как рассчитать границы доверительного интервала с неизвестным стандартным отклонением на примере всё той же совокупности, что мы рассматривали в предыдущем способе. Уровень доверия, как и в прошлый раз, возьмем 97%.
- Выделяем ячейку, в которую будет производиться расчет. Клацаем по кнопке «Вставить функцию».
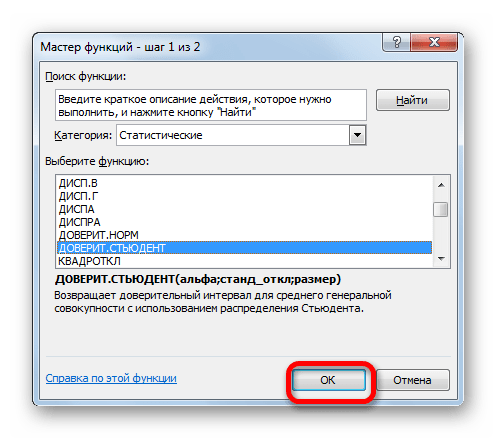
- В открывшемся Мастере функций переходим в категорию «Статистические». Выбираем наименование «ДОВЕРИТ.СТЮДЕНТ». Клацаем по кнопке «OK».
- Производится запуск окна аргументов указанного оператора.
В поле «Альфа», учитывая, что уровень доверия составляет 97%, записываем число 0,03. Второй раз на принципах расчета данного параметра останавливаться не будем.
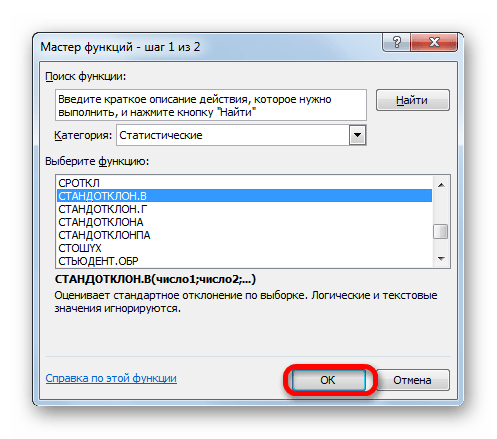
После этого устанавливаем курсор в поле «Стандартное отклонение». На этот раз данный показатель нам неизвестен и его требуется рассчитать. Делается это при помощи специальной функции – СТАНДОТКЛОН.В. Чтобы вызвать окно данного оператора, кликаем по треугольнику слева от строки формул. Если в открывшемся списке не находим нужного наименования, то переходим по пункту «Другие функции…». 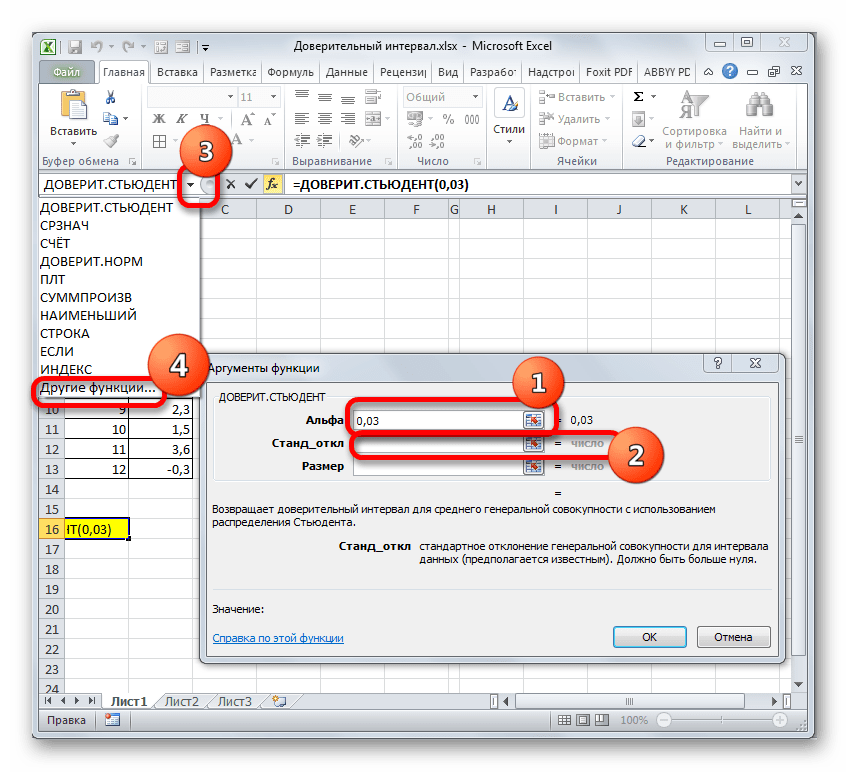
Нетрудно догадаться, что аргумент «Число» — это адрес элемента выборки. Если выборка размещена единым массивом, то можно, использовав только один аргумент, дать ссылку на данный диапазон.
Устанавливаем курсор в поле «Число1» и, как всегда, зажав левую кнопку мыши, выделяем совокупность. После того, как координаты попали в поле, не спешим жать на кнопку «OK», так как результат получится некорректным. Прежде нам нужно вернуться к окну аргументов оператора ДОВЕРИТ.СТЮДЕНТ, чтобы внести последний аргумент. Для этого кликаем по соответствующему наименованию в строке формул. 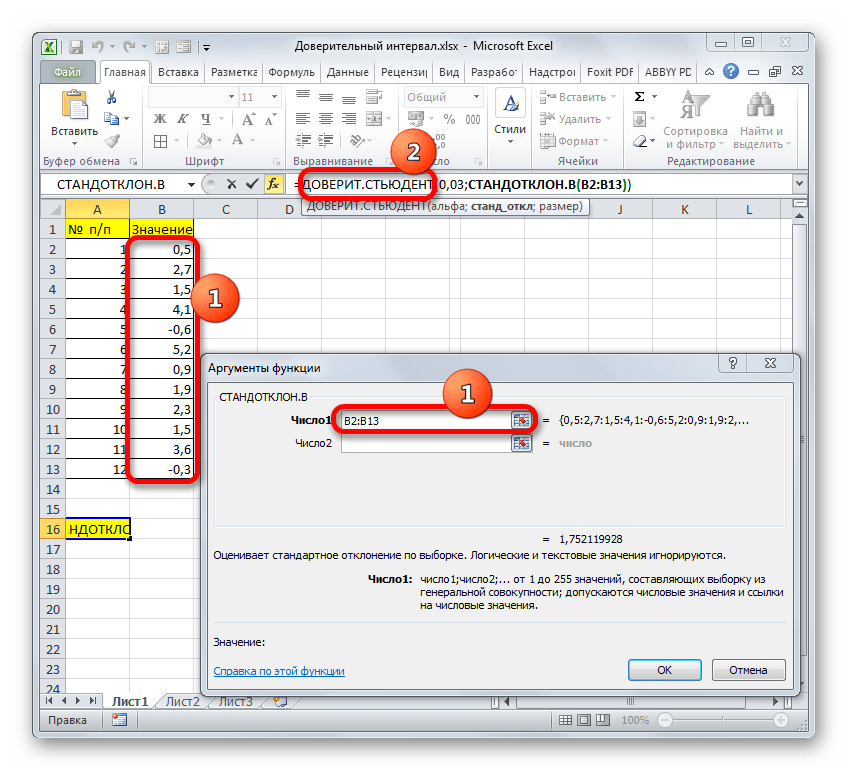
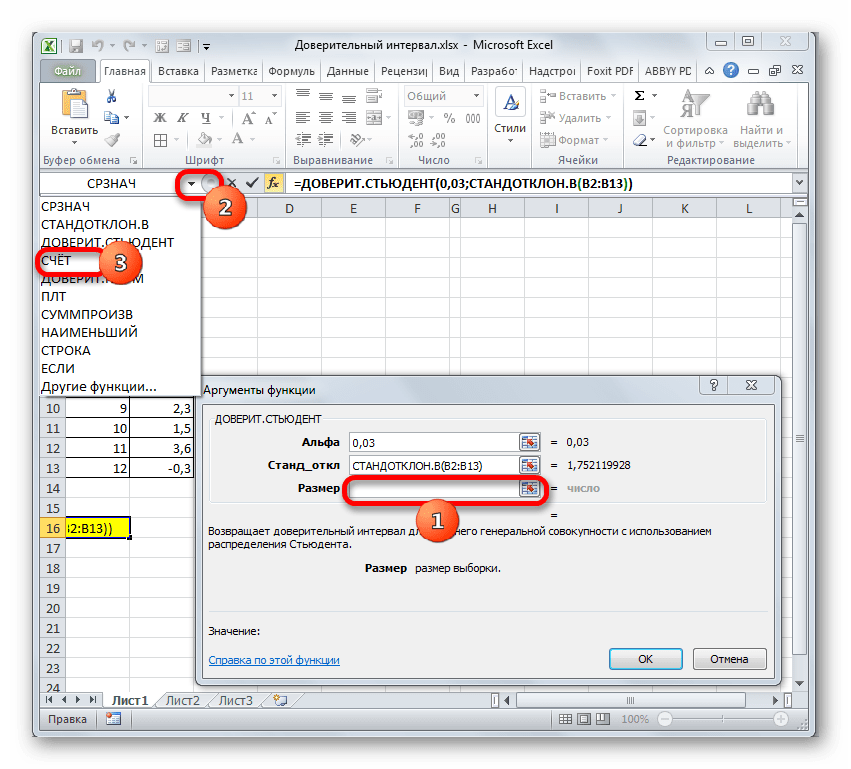
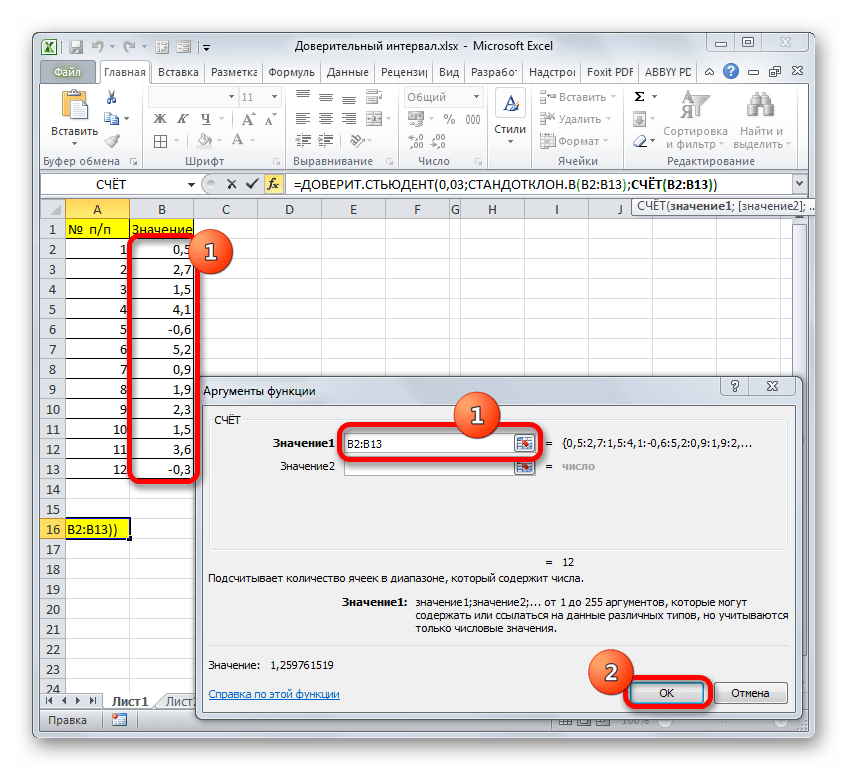
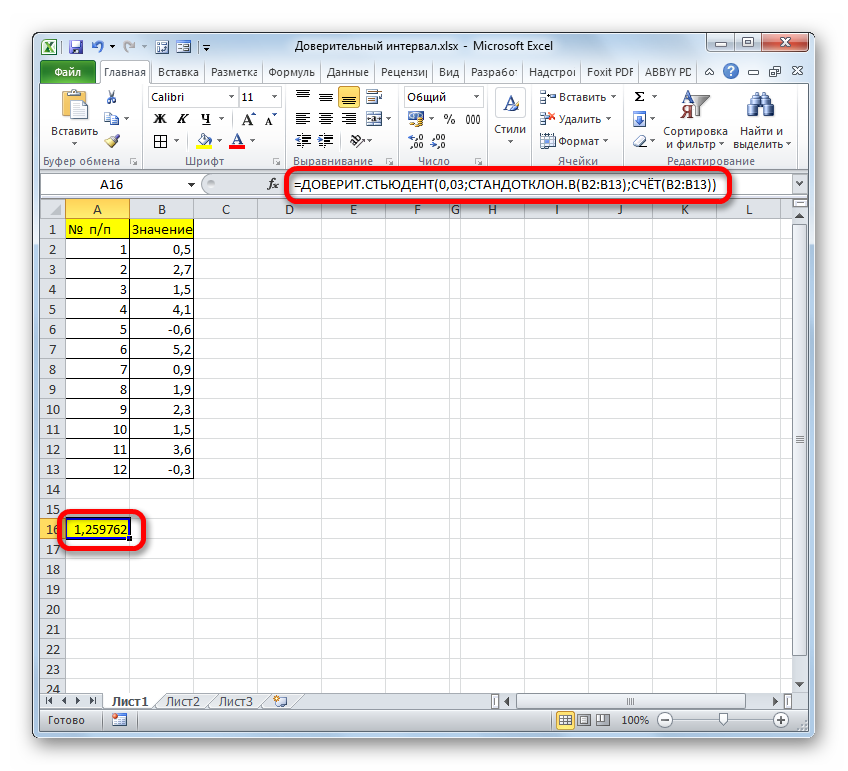
=СРЗНАЧ(B2:B13)+ДОВЕРИТ.СТЬЮДЕНТ(0,03;СТАНДОТКЛОН.В(B2:B13);СЧЁТ(B2:B13)) 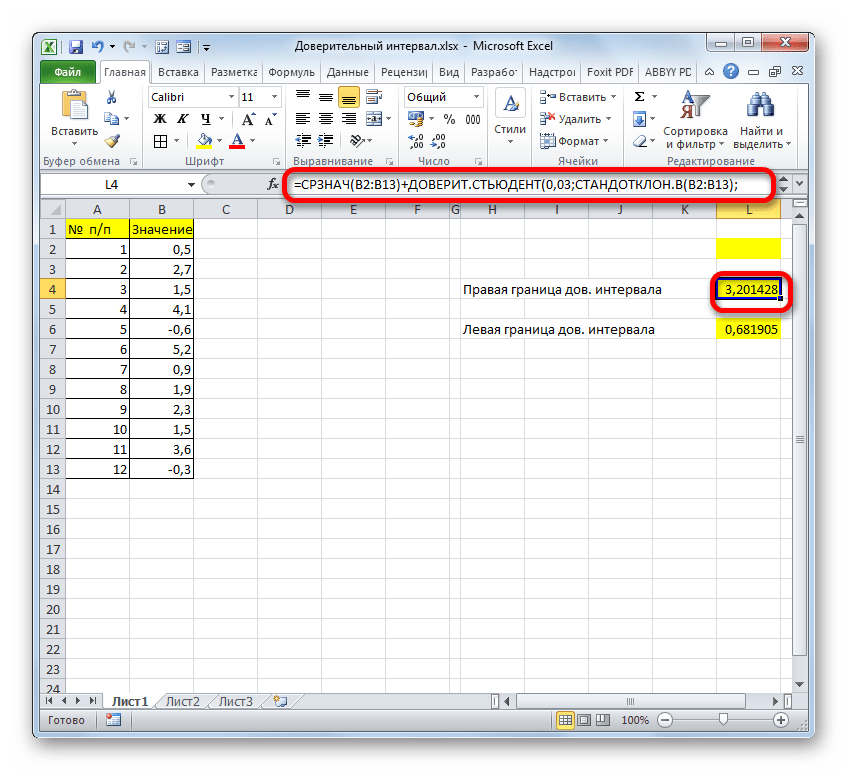
Соответственно, формула расчета левой границы будет выглядеть так:
=СРЗНАЧ(B2:B13)-ДОВЕРИТ.СТЬЮДЕНТ(0,03;СТАНДОТКЛОН.В(B2:B13);СЧЁТ(B2:B13))
Как видим, инструменты программы Excel позволяют существенно облегчить вычисление доверительного интервала и его границ. Для этих целей используются отдельные операторы для выборок, у которых дисперсия известна и неизвестна.
Источник
Содержание
- Вычисление коэффициента детерминации
- Способ 1: вычисление коэффициента детерминации при линейной функции
- Способ 2: вычисление коэффициента детерминации в нелинейных функциях
- Способ 3: коэффициент детерминации для линии тренда
- Вопросы и ответы

Одним из показателей, описывающих качество построенной модели в статистике, является коэффициент детерминации (R^2), который ещё называют величиной достоверности аппроксимации. С его помощью можно определить уровень точности прогноза. Давайте узнаем, как можно произвести расчет данного показателя с помощью различных инструментов программы Excel.
Вычисление коэффициента детерминации
В зависимости от уровня коэффициента детерминации, принято разделять модели на три группы:
- 0,8 – 1 — модель хорошего качества;
- 0,5 – 0,8 — модель приемлемого качества;
- 0 – 0,5 — модель плохого качества.
В последнем случае качество модели говорит о невозможности её использования для прогноза.
Выбор способа вычисления указанного значения в Excel зависит от того, является ли регрессия линейной или нет. В первом случае можно использовать функцию КВПИРСОН, а во втором придется воспользоваться специальным инструментом из пакета анализа.
Способ 1: вычисление коэффициента детерминации при линейной функции
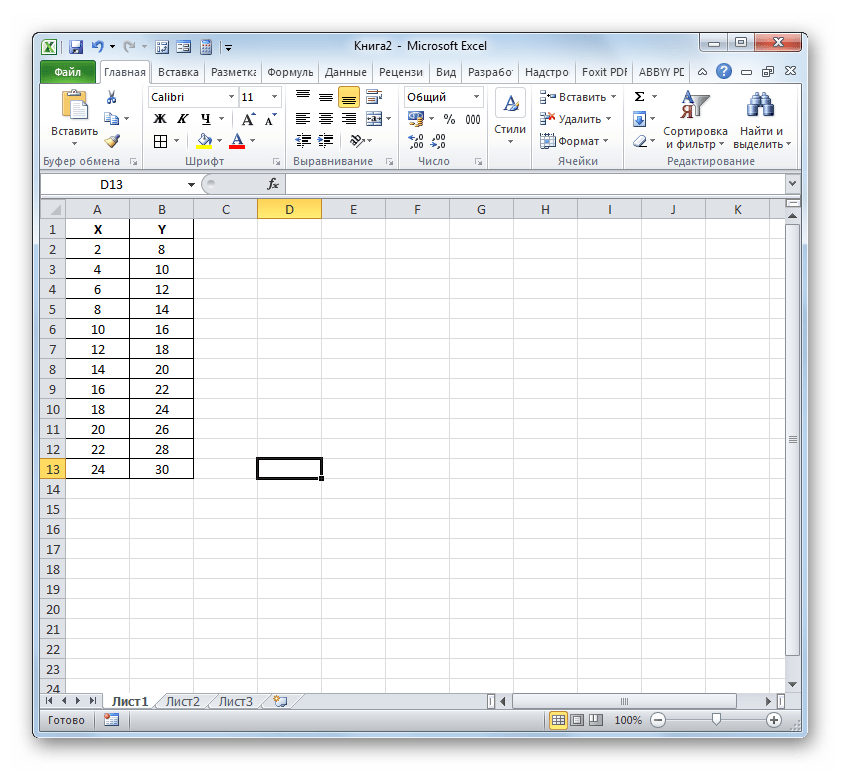
Прежде всего, выясним, как найти коэффициент детерминации при линейной функции. В этом случае данный показатель будет равняться квадрату коэффициента корреляции. Произведем его расчет с помощью встроенной функции Excel на примере конкретной таблицы, которая приведена ниже.
- Выделяем ячейку, где будет произведен вывод коэффициента детерминации после его расчета, и щелкаем по пиктограмме «Вставить функцию».
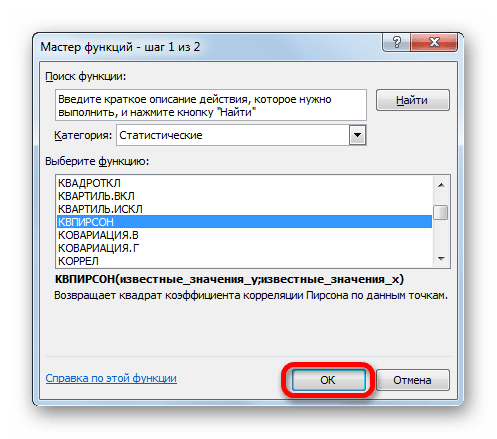
- Запускается Мастер функций. Перемещаемся в его категорию «Статистические» и отмечаем наименование «КВПИРСОН». Далее клацаем по кнопке «OK».
- Происходит запуск окна аргументов функции КВПИРСОН. Данный оператор из статистической группы предназначен для вычисления квадрата коэффициента корреляции функции Пирсона, то есть, линейной функции. А как мы помним, при линейной функции коэффициент детерминации как раз равен квадрату коэффициента корреляции.
Синтаксис этого оператора такой:
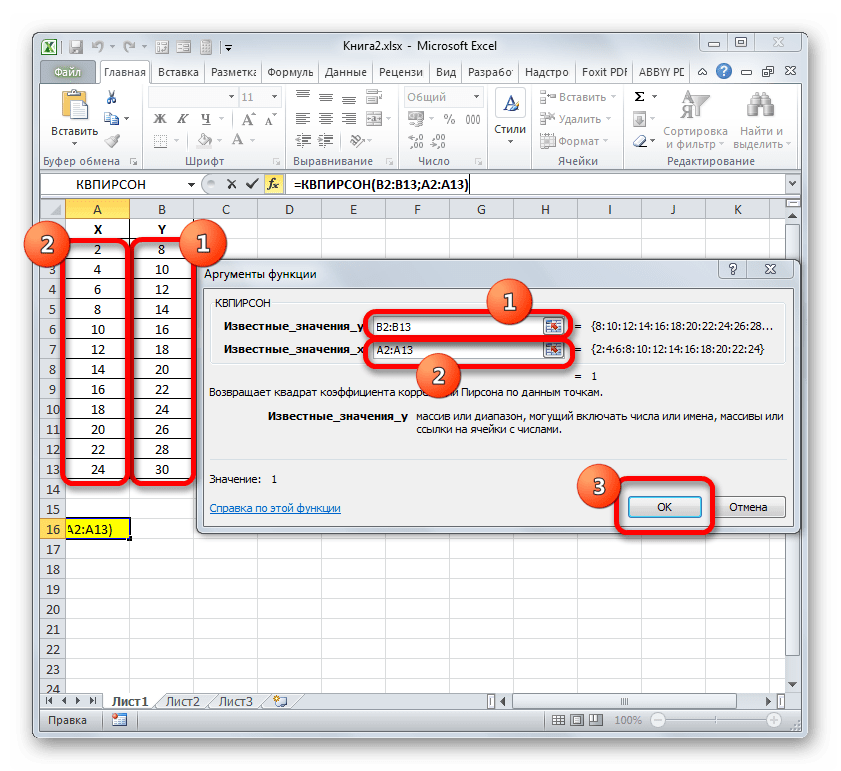
=КВПИРСОН(известные_значения_y;известные_значения_x)Таким образом, функция имеет два оператора, один из которых представляет собой перечень значений функции, а второй – аргументов. Операторы могут быть представлены, как непосредственно в виде значений, перечисленных через точку с запятой (;), так и в виде ссылок на диапазоны, где они расположены. Именно последний вариант и будет использован нами в данном примере.
Устанавливаем курсор в поле «Известные значения y». Выполняем зажим левой кнопки мышки и производим выделение содержимого столбца «Y» таблицы. Как видим, адрес указанного массива данных тут же отображается в окне.
Аналогичным образом заполняем поле «Известные значения x». Ставим курсор в данное поле, но на этот раз выделяем значения столбца «X».
После того, как все данные были отображены в окне аргументов КВПИРСОН, клацаем по кнопке «OK», расположенной в самом его низу.
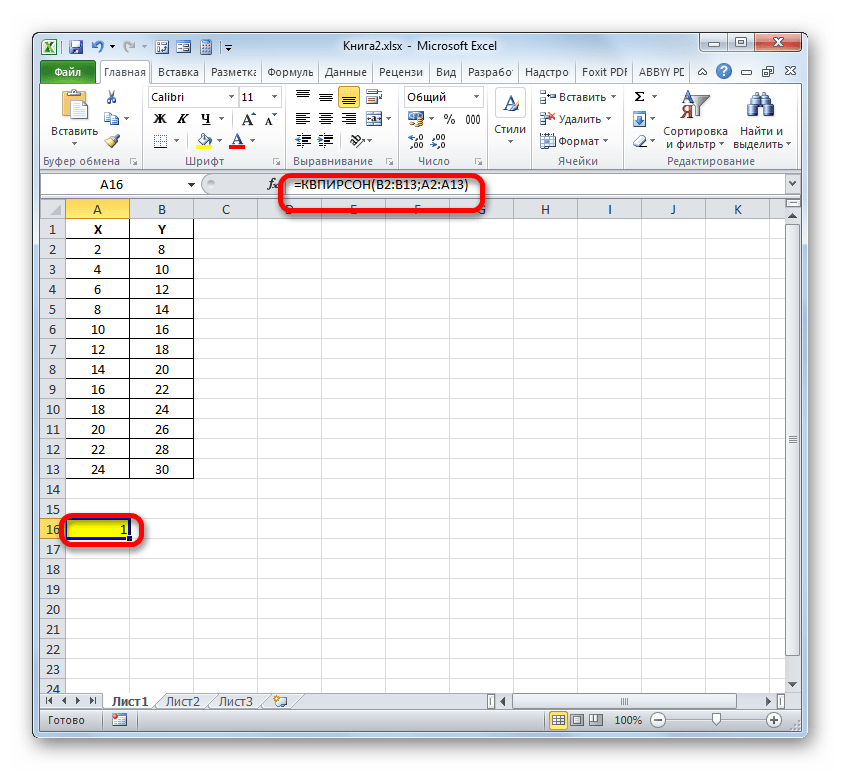
- Как видим, вслед за этим программа производит расчет коэффициента детерминации и выдает результат в ту ячейку, которая была выделена ещё перед вызовом Мастера функций. В нашем примере значение вычисляемого показателя получилось равным 1. Это значит, что представленная модель абсолютно достоверная, то есть, исключает погрешность.
Урок: Мастер функций в Microsoft Excel
Способ 2: вычисление коэффициента детерминации в нелинейных функциях
Но указанный выше вариант расчета искомого значения можно применять только к линейным функциям. Что же делать, чтобы произвести его расчет в нелинейной функции? В Экселе имеется и такая возможность. Её можно осуществить с помощью инструмента «Регрессия», который является составной частью пакета «Анализ данных».
- Но прежде, чем воспользоваться указанным инструментом, следует активировать сам «Пакет анализа», который по умолчанию в Экселе отключен. Перемещаемся во вкладку «Файл», а затем переходим по пункту «Параметры».
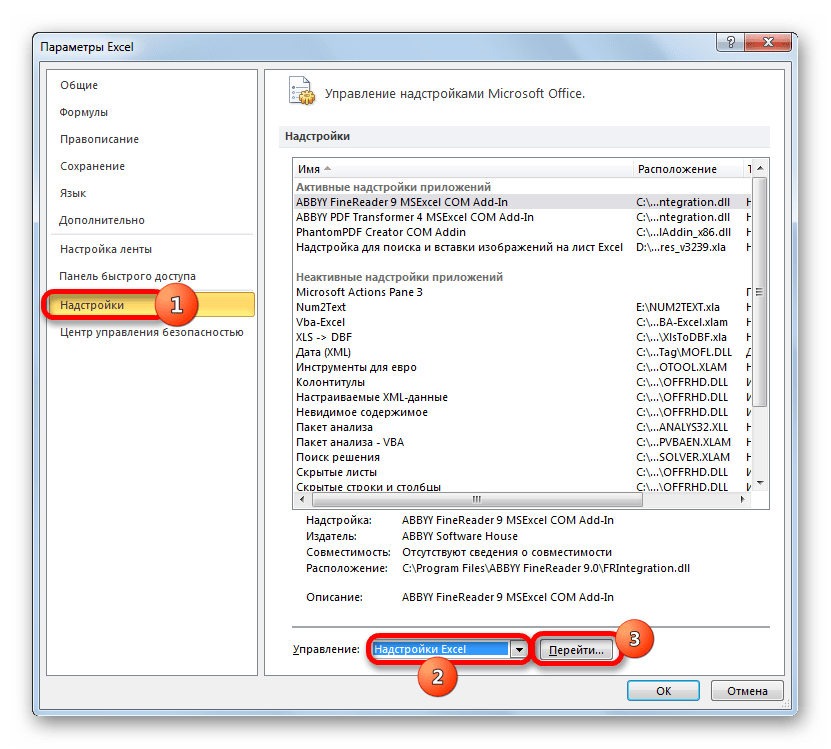
- В открывшемся окне производим перемещение в раздел «Надстройки» при помощи навигации по левому вертикальному меню. В нижней части правой области окна располагается поле «Управление». Из списка доступных там подразделов выбираем наименование «Надстройки Excel…», а затем щелкаем по кнопке «Перейти…», расположенной справа от поля.
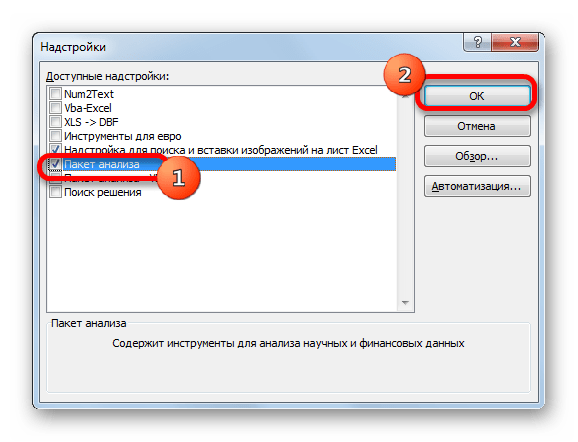
- Производится запуск окна надстроек. В центральной его части расположен список доступных надстроек. Устанавливаем флажок около позиции «Пакет анализа». Вслед за этим требуется щелкнуть по кнопке «OK» в правой части интерфейса окна.
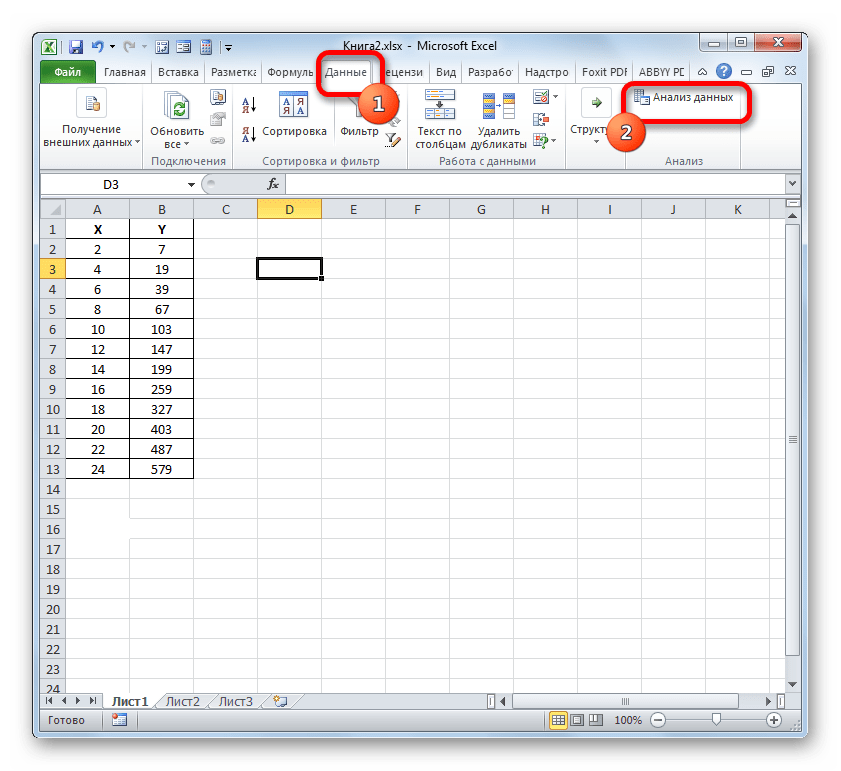
- Пакет инструментов «Анализ данных» в текущем экземпляре Excel будет активирован. Доступ к нему располагается на ленте во вкладке «Данные». Перемещаемся в указанную вкладку и клацаем по кнопке «Анализ данных» в группе настроек «Анализ».
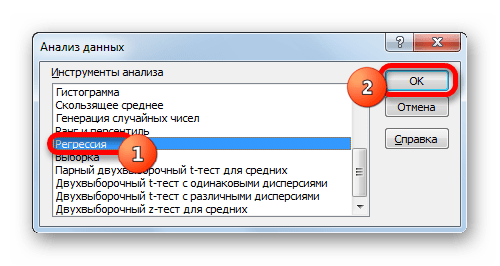
- Активируется окошко «Анализ данных» со списком профильных инструментов обработки информации. Выделяем из этого перечня пункт «Регрессия» и клацаем по кнопке «OK».
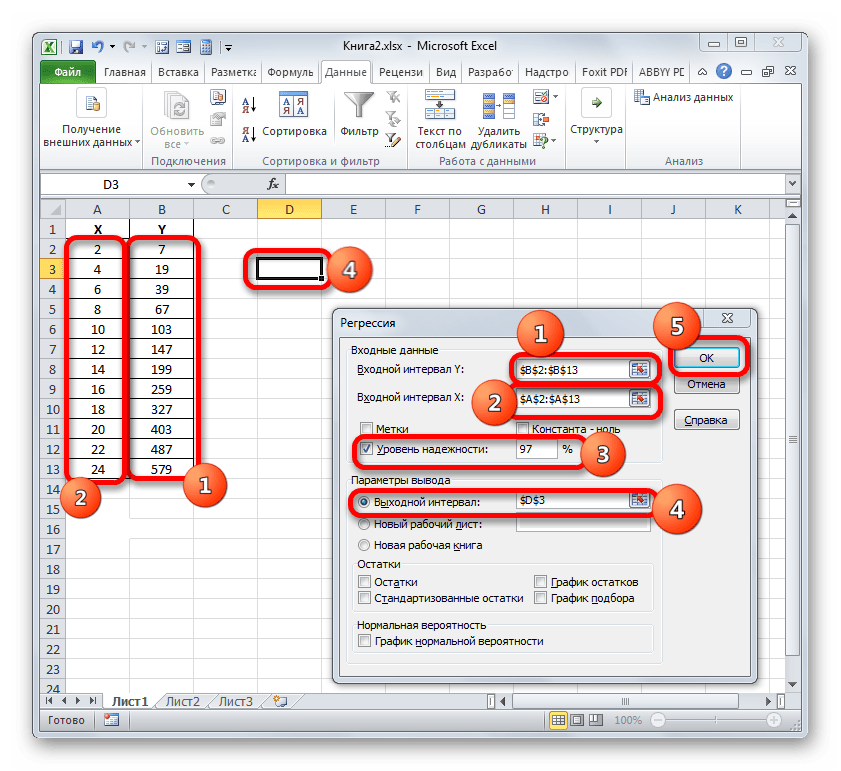
- Затем открывается окно инструмента «Регрессия». Первый блок настроек – «Входные данные». Тут в двух полях нужно указать адреса диапазонов, где находятся значения аргумента и функции. Ставим курсор в поле «Входной интервал Y» и выделяем на листе содержимое колонки «Y». После того, как адрес массива отобразился в окне «Регрессия», ставим курсор в поле «Входной интервал Y» и точно таким же образом выделяем ячейки столбца «X».
Около параметров «Метка» и «Константа-ноль» флажки не ставим. Флажок можно установить около параметра «Уровень надежности» и в поле напротив указать желаемую величину соответствующего показателя (по умолчанию 95%).
В группе «Параметры вывода» нужно указать, в какой области будет отображаться результат вычисления. Существует три варианта:
- Область на текущем листе;
- Другой лист;
- Другая книга (новый файл).
Остановим свой выбор на первом варианте, чтобы исходные данные и результат размещались на одном рабочем листе. Ставим переключатель около параметра «Выходной интервал». В поле напротив данного пункта ставим курсор. Щелкаем левой кнопкой мыши по пустому элементу на листе, который призван стать левой верхней ячейкой таблицы вывода итогов расчета. Адрес данного элемента должен высветиться в поле окна «Регрессия».
Группы параметров «Остатки» и «Нормальная вероятность» игнорируем, так как для решения поставленной задачи они не важны. После этого клацаем по кнопке «OK», которая размещена в правом верхнем углу окна «Регрессия».
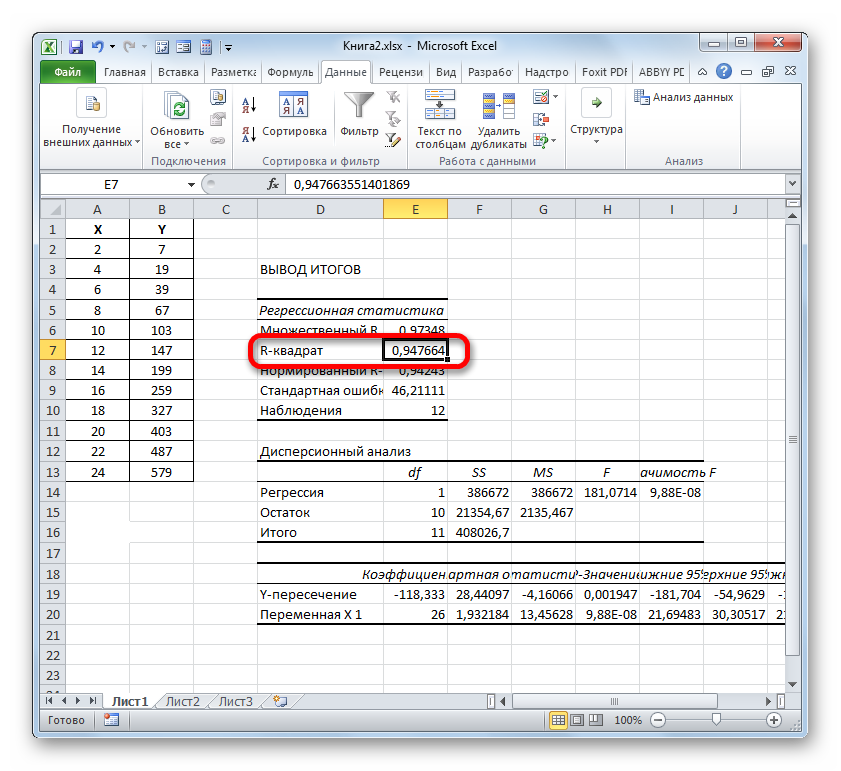
- Программа производит расчет на основе ранее введенных данных и выводит результат в указанный диапазон. Как видим, данный инструмент выводит на лист довольно большое количество результатов по различным параметрам. Но в контексте текущего урока нас интересует показатель «R-квадрат». В данном случае он равен 0,947664, что характеризует выбранную модель, как модель хорошего качества.
Способ 3: коэффициент детерминации для линии тренда
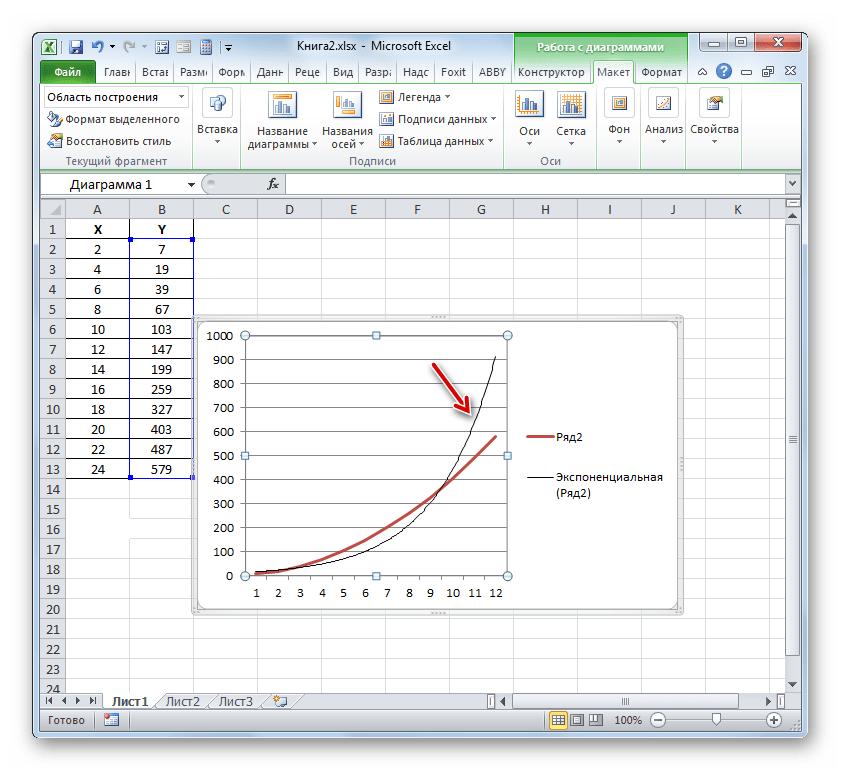
Кроме указанных выше вариантов, коэффициент детерминации можно отобразить непосредственно для линии тренда в графике, построенном на листе Excel. Выясним, как это можно сделать на конкретном примере.
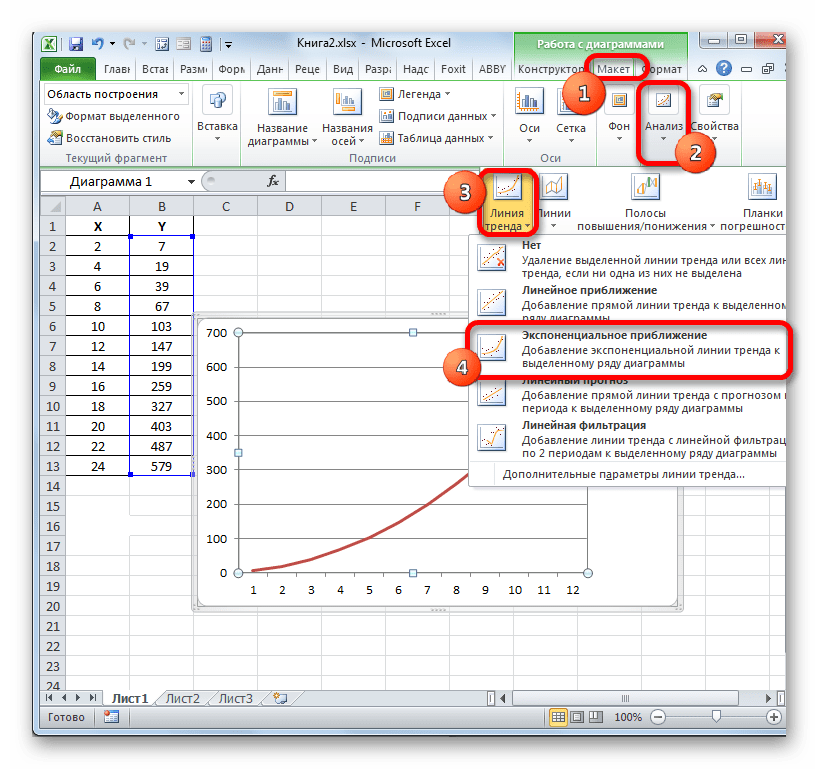
- Мы имеем график, построенный на основе таблицы аргументов и значений функции, которая была использована для предыдущего примера. Произведем построение к нему линии тренда. Кликаем по любому месту области построения, на которой размещен график, левой кнопкой мыши. При этом на ленте появляется дополнительный набор вкладок – «Работа с диаграммами». Переходим во вкладку «Макет». Клацаем по кнопке «Линия тренда», которая размещена в блоке инструментов «Анализ». Появляется меню с выбором типа линии тренда. Останавливаем выбор на том типе, который соответствует конкретной задаче. Давайте для нашего примера выберем вариант «Экспоненциальное приближение».
- Эксель строит прямо на плоскости построения графика линию тренда в виде дополнительной черной кривой.
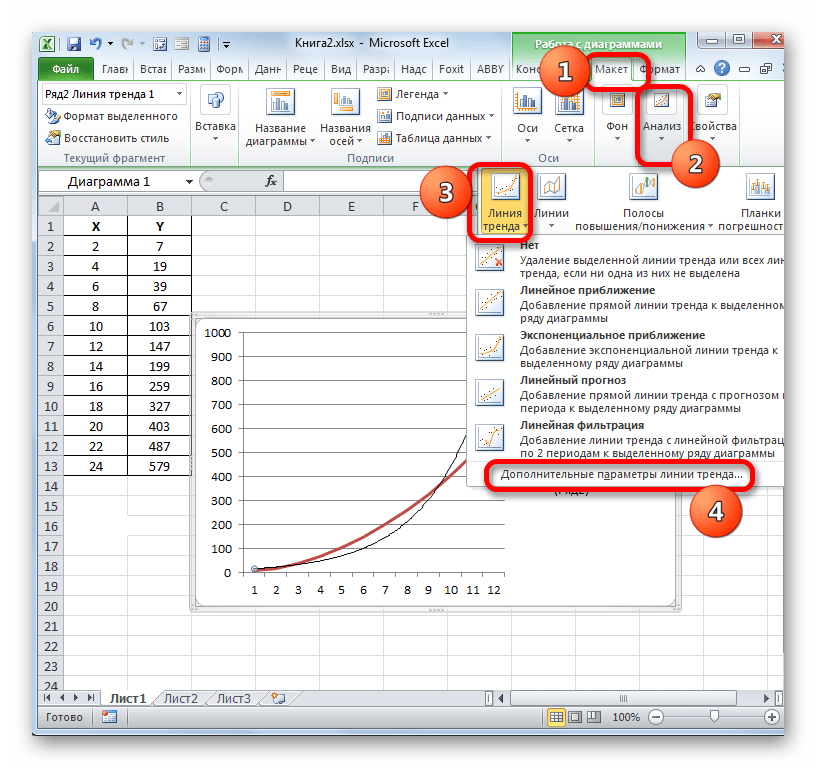
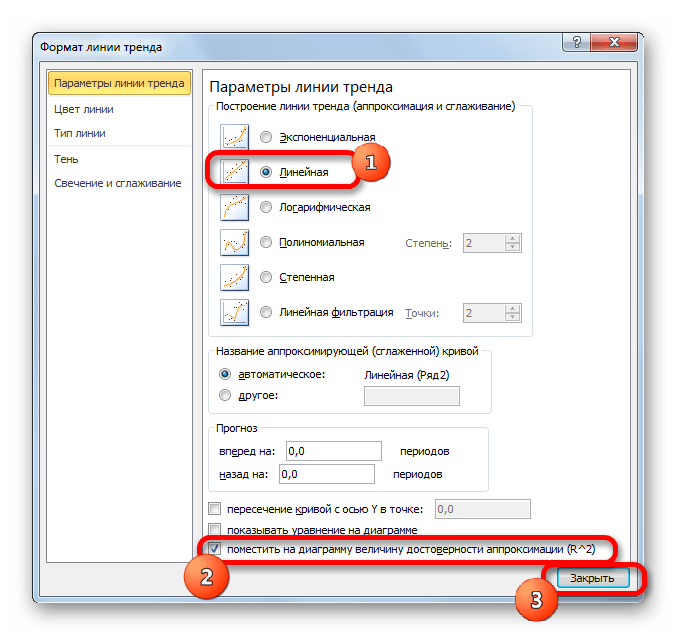
- Теперь нашей задачей является отобразить собственно коэффициент детерминации. Кликаем правой кнопкой мыши по линии тренда. Активируется контекстное меню. Останавливаем выбор в нем на пункте «Формат линии тренда…».

Для выполнения перехода в окно формата линии тренда можно выполнить альтернативное действие. Выделяем линию тренда кликом по ней левой кнопки мыши. Перемещаемся во вкладку «Макет». Клацаем по кнопке «Линия тренда» в блоке «Анализ». В открывшемся списке клацаем по самому последнему пункту перечня действий – «Дополнительные параметры линии тренда…».
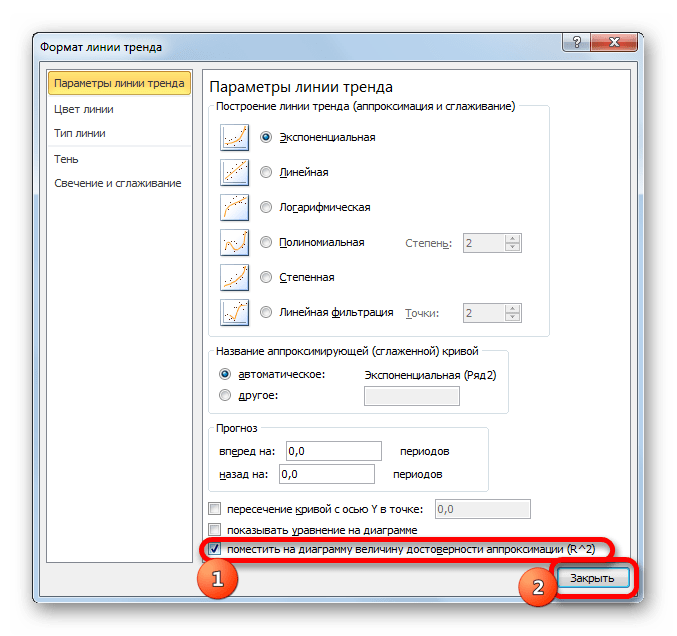
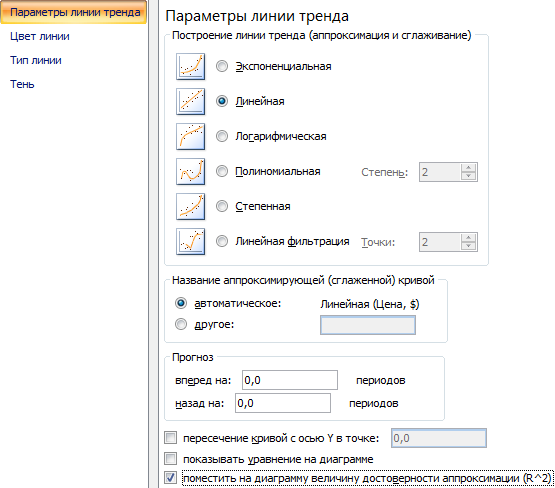
- После любого из двух вышеуказанных действий запускается окошко формата, в котором можно произвести дополнительные настройки. В частности, для выполнения нашей задачи необходимо установить флажок напротив пункта «Поместить на диаграмму величину достоверности аппроксимации (R^2)». Он размещен в самом низу окна. То есть, таким образом мы включаем отображение коэффициента детерминации на области построения. Затем не забываем нажать на кнопку «Закрыть» внизу текущего окна.
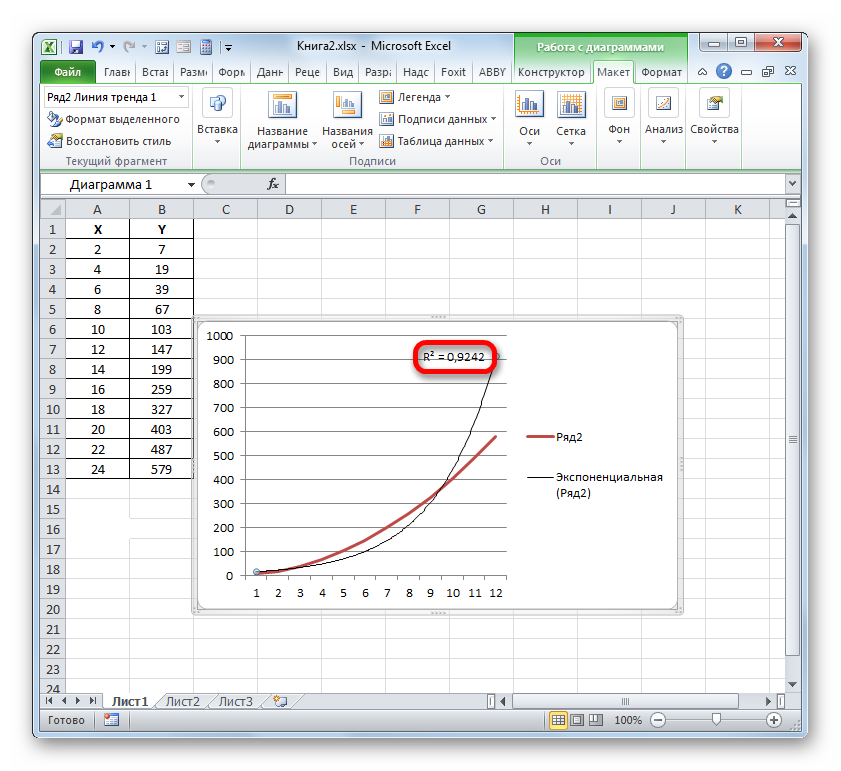
- Значение достоверности аппроксимации, то есть, величина коэффициента детерминации, будет отображено на листе в области построения. В данном случае эта величина, как видим, равна 0,9242, что характеризует аппроксимацию, как модель хорошего качества.
- Абсолютно точно таким образом можно устанавливать показ коэффициента детерминации для любого другого типа линии тренда. Можно менять тип линии тренда, произведя переход через кнопку на ленте или контекстное меню в окно её параметров, как было показано выше. Затем уже в самом окне в группе «Построение линии тренда» можно переключиться на другой тип. Не забываем при этом контролировать, чтобы около пункта «Поместить на диаграмму величину достоверности аппроксимации» был установлен флажок. Завершив вышеуказанные действия, щелкаем по кнопке «Закрыть» в нижнем правом углу окна.
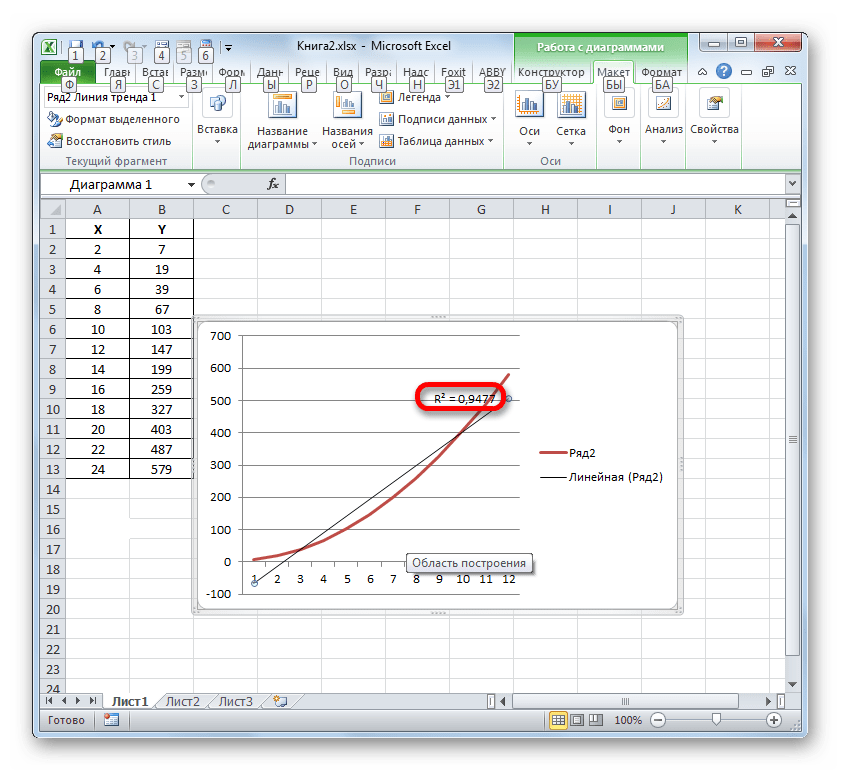
- При линейном типе линия тренда уже имеет значение достоверности аппроксимации равное 0,9477, что характеризует эту модель, как ещё более достоверную, чем рассматриваемую нами ранее линию тренда экспоненциального типа.
- Таким образом, переключаясь между разными типами линии тренда и сравнивая их значения достоверности аппроксимации (коэффициент детерминации), можно найти тот вариант, модель которого наиболее точно описывает представленный график. Вариант с самым высоким показателем коэффициента детерминации будет наиболее достоверным. На его основе можно строить самый точный прогноз.
Например, для нашего случая опытным путем удалось установить, что самый высокий уровень достоверности имеет полиномиальный тип линии тренда второй степени. Коэффициент детерминации в данном случае равен 1. Это говорит о том, что указанная модель абсолютно достоверная, что означает полное исключение погрешностей.

Но, в то же время, это совсем не значит, что для другого графика тоже наиболее достоверным окажется именно этот тип линии тренда. Оптимальный выбор типа линии тренда зависит от типа функции, на основании которой был построен график. Если пользователь не обладает достаточным объемом знаний, чтобы «на глаз» прикинуть наиболее качественный вариант, то единственным выходом определения лучшего прогноза является как раз сравнение коэффициентов детерминации, как было показано на примере выше.
Читайте также:
Построение линии тренда в Excel
Аппроксимация в Excel
В Экселе существуют два основных варианта вычисления коэффициента детерминации: использование оператора КВПИРСОН и применение инструмента «Регрессия» из пакета инструментов «Анализ данных». При этом первый из этих вариантов предназначен для использования только в процессе обработки линейной функции, а другой вариант можно использовать практически во всех ситуациях. Кроме того, существует возможность отображения коэффициента детерминации для линии трендов графиков в качестве величины достоверности аппроксимации. С помощью данного показателя имеется возможность определить тип линии тренда, который располагает самым высоким уровнем достоверности для конкретной функции.
Еще статьи по данной теме:
Помогла ли Вам статья?
Содержание
- Добавление трендовой линии на график
- Построение графика
- Создание линии
- Настройка линии
- Прогнозирование
- Базовые понятия
- Определение коэффициентов модели
- Способ расчета значений линейного тренда в Excel с помощью графика
- Способ расчета значений линейного тренда в Excel — функция ТЕНДЕНЦИЯ
- Уравнение линии тренда в Excel
- Линейная аппроксимация
- Экспоненциальная линия тренда
- Логарифмическая линия тренда в Excel
- Общая информация
- Возможности инструмента
- Разновидности
- Разбираемся с трендами в MS Excel
- Зачем нужна линия тренда
- Как построить линию тренда в MS Excel
Добавление трендовой линии на график
Данный элемент технического анализа позволяет визуально увидеть изменение цены за указанный период времени. Это может быть месяц, год или несколько лет. Информация будет отображать значение средних показателей в виде геометрических фигур. Добавить линию тренда в Excel 2010 можно с помощью встроенных стандартных инструментов.

Построение графика
 Чтобы правильно строить трендовые линии, нужно соблюдать функциональную зависимость y=f(x). Для получения корректного прогноза в столбец А вносится информация о временном периоде, а в столбец В — цена в указанный промежуток.
Чтобы правильно строить трендовые линии, нужно соблюдать функциональную зависимость y=f(x). Для получения корректного прогноза в столбец А вносится информация о временном периоде, а в столбец В — цена в указанный промежуток.
 Построение графика выполняется по следующему алгоритму:
Построение графика выполняется по следующему алгоритму:
- Первым действием нужно выделить диапазон данных, например это А1:В9, затем активировать инструмент: «Вставка»-«Диаграммы»-«Точечная»-«Точечная с гладкими кривыми и маркерами».
- После открытия графика пользователю станет доступна еще одна панель управления данными, на которой нужно выбрать следующее: «Работа с диаграммами»-«Макет»-«Линия тренда»-«Линейное приближение».
- Следующим шагом требуется выполнить двойной клик по образовавшейся линии тенденции в Excel. Когда появиться вспомогательное окно, отметить птичкой опцию «показывать уравнение на диаграмме».

Важно помнить, что если на графике имеется 2 или более линий, отображающих анализ данных, то перед выполнением 3 пункта нужно будет выбрать одну из них и включить в тенденцию. Эта короткая инструкция поможет начинающим специалистам разобраться, как строится линия тренда в Экселе.
Создание линии
Дальнейшая работа будет происходить непосредственно с трендовой линией.
Добавление тренда на диаграмму происходит следующим образом:

- Перейти во вкладку «Работа с диаграммами», затем выбрать раздел «Макет»-«Анализ» и после подпункт «Линия тенденции». Появится выпадающий список, в котором необходимо активировать строку «Линейное приближение».
- Если все выполнено правильно, в области построения диаграмм появится кривая линия черного цвета. По желанию цветовую гамму можно будет изменить на любую другую.
Этот способ поможет создать и построить тренд в Excel 2016 или более ранних версиях.
 Однако важно помнить, что вставить линию нельзя для диаграмм и графиков следующего типа:
Однако важно помнить, что вставить линию нельзя для диаграмм и графиков следующего типа:
- лепесткового;
- кругового;
- поверхностного;
- кольцевого;
- объемного;
- с накоплением.
Настройка линии
Построение линий тренда имеет ряд вспомогательных настроек, которые помогут придать графику законченный и презентабельный вид.
Необходимо запомнить следующее:
- Чтобы добавить название диаграмме, нужно дважды кликнуть по ней и в появившемся окне ввести заголовок. Для выбора расположения имени графика необходимо перейти во вкладку «Работа с диаграммами», затем выбрать «Макет» и «Название диаграммы». После этого появится список с возможным расположением заглавия.
- Дополнительно в этом же разделе можно найти пункт, отвечающий за названия осей и их расположение относительно графика. Интересно, что для вертикальной оси разработчики программы продумали возможность повернутого расположения наименования, чтобы диаграмма читалась удобно и выглядела гармонично.
 Чтобы внести изменения непосредственно в построение линий, нужно в разделе «Макет» найти «Анализ», затем «Прямая тренда» и в самом низу списка нажать «Дополнительные параметры…». Здесь можно изменить цвет и формат линии, выбрать один из параметров сглаживания и аппроксимации (степенный, полиноминальный, логарифмический и т.д.).
Чтобы внести изменения непосредственно в построение линий, нужно в разделе «Макет» найти «Анализ», затем «Прямая тренда» и в самом низу списка нажать «Дополнительные параметры…». Здесь можно изменить цвет и формат линии, выбрать один из параметров сглаживания и аппроксимации (степенный, полиноминальный, логарифмический и т.д.).- Еще есть функция определения достоверности построенной модели. Для этого в дополнительных настройках требуется активировать пункт «Разместить на график величину достоверности аппроксимации» и после этого закрыть окно. Наилучшим значением является 1. Чем сильнее полученный показатель отличается от нее, тем ниже достоверность модели.

Прогнозирование
Для получения наиболее точного прогноза необходимо сменить построенный график на гистограмму. Это поможет сравнить уравнения.
 Для этого выполняем последовательность действий:
Для этого выполняем последовательность действий:
- Вызвать для графика контекстное меню и выбрать «Изменить тип диаграммы».
- Появится новое окно с настройками, в котором требуется найти опцию «Гистограмма» и после выбрать подвид с группировкой.
Теперь пользователю должны быть видны оба графика. Они визуализируют одни и те же данные, но имеют разные уравнения для образования тенденции.
Общая тенденция движения параметра сохраняется на обеих диаграммах, что говорит об аппроксимации (приближении) трендовой прямой.
Следующим шагом необходимо сравнить уравнения точки пересечения с осями на разных диаграммах.
Для визуального отображения нужно сделать следующее:

- Перевести гистограмму в простой точечный график с гладкими кривыми и маркерами. Процесс выполняется через пункт контекстного меню «Изменить тип диаграммы…».
- Выполнить двойной клик по прямой образовавшейся тенденции, задать ей параметр прогноза назад на 12,0 и сохранить изменения.
Такая настройка поможет увидеть, что угол наклона тенденции меняется в зависимости от вида графика, но общее направление движения остается неизменным. Это свидетельствует о том, что построить линию тренда в Эксель можно лишь в качестве дополнительного инструмента анализа и брать его в расчет следует только как приближающий параметр. Строить аналитические прогнозы, основываясь лишь на этой прямой, не рекомендуется.
Базовые понятия
Думаю, еще со школы все знакомы с линейной функцией, она как раз и лежит в основе тренда:
Y(t) = a0 + a1*t + E
Y — это объем продаж, та переменная, которую мы будем объяснять временем и от которого она зависит, то есть Y(t);
t — номер периода (порядковый номер месяца), который объясняет план продаж Y;
a0 — это нулевой коэффициент регрессии, который показывает значение Y(t), при отсутствии влияния объясняющего фактора (t=0);
a1 — коэффициент регрессии, который показывает, на сколько исследуемый показатель продаж Y зависит от влияющего фактора t;
E — случайные возмущения, которые отражают влияния других неучтенных в модели факторов, кроме времени t.
Определение коэффициентов модели
Строим график. По горизонтали видим отложенные месяцы, по вертикали объем продаж:

В Google Sheets выбираем Редактор диаграмм -> Дополнительные и ставим галочку возле Линии тренда. В настройках выбираем Ярлык — Уравнение и Показать R^2.
Если вы делаете все в MS Excel, то правой кнопкой мыши кликаем на график и в выпадающем меню выбираем «Добавить линию тренда».
По умолчанию строится линейная функция. Справа выбираем «Показывать уравнение на диаграмме» и «Величину достоверности аппроксимации R^2».
Вот, что получилось:

На графике мы видим уравнение функции:
y = 4856*x + 105104
Она описывает объем продаж в зависимости от номера месяца, на который мы хотим эти продажи спрогнозировать. Рядом видим коэффициент детерминации R^2, который говорит о качестве модели и на сколько хорошо она описывает наши продажи (Y). Чем ближе к 1, тем лучше.
У меня R^2 = 0,75. Это средний показатель, он говорит о том, что в модели не учтены какие-то другие значимые факторы помимо времени t, например, это может быть сезонность.
Способ расчета значений линейного тренда в Excel с помощью графика
 Выделяем анализируемый объём продаж и строим график, где по оси Х — наш временной ряд (1, 2, 3… — январь, февраль, март …), по оси У – объёмы продаж. Добавляем линию тренда и уравнение тренда на график. Получаем уравнение тренда y=135134x+4594044
Выделяем анализируемый объём продаж и строим график, где по оси Х — наш временной ряд (1, 2, 3… — январь, февраль, март …), по оси У – объёмы продаж. Добавляем линию тренда и уравнение тренда на график. Получаем уравнение тренда y=135134x+4594044
Для прогнозирования нам необходимо рассчитать значения линейного тренда, как для анализируемых значений, так и для будущих периодов.
При расчете значений линейного тренде нам будут известны:
- Время – значение по оси Х;
- Значение “a” и “b” уравнения линейного тренда y(x)=a+bx;
Рассчитываем значения тренда для каждого периода времени от 1 до 25, а также для будущих периодов с 26 месяца до 36.
Например, для 26 месяца значение тренда рассчитывается по следующей схеме: в уравнение подставляем x=26 и получаем y=135134*26+4594044=8107551
27-го y=135134*27+4594044=8242686
Способ расчета значений линейного тренда в Excel — функция ТЕНДЕНЦИЯ
Рассчитаем значения линейного тренда с помощью стандартной функции Excel:
=ТЕНДЕНЦИЯ(известные значения y; известные значения x; новые значения x; конста)
Подставляем в формулу
- известные значения y – это объёмы продаж за анализируемый период (фиксируем диапазон в формуле, выделяем ссылку и нажимаем F4);
- известные значения x – это номера периодов x для известных значений объёмов продаж y;
- новые значения x – это номера периодов, для которых мы хотим рассчитать значения линейного тренда;
- константа – ставим 1, необходимо для того, чтобы значения тренда рассчитывались с учетом коэффицента (a) для линейного тренда y=a+bx;
Для того чтобы рассчитать значения тренда для всего временного диапазона, в “новые значения x” вводим диапазон значений X, выделяем диапазон ячеек равный диапазону со значениями X с формулой в первой ячейке и нажимаем клавишу F2, а затем — клавиши CTRL + SHIFT + ВВОД.
В предложенном выше примере была выбрана линейная аппроксимация только для иллюстрации алгоритма. Как показала величина достоверности, выбор был не совсем удачным.
Следует выбирать тот тип отображения, который наиболее точно проиллюстрирует тенденцию изменений вводимых пользователем данных. Разберемся с вариантами.
Линейная аппроксимация
Ее геометрическое изображение – прямая. Следовательно, линейная аппроксимация применяется для иллюстрации показателя, который растет или уменьшается с постоянной скоростью.
Рассмотрим условное количество заключенных менеджером контрактов на протяжении 10 месяцев:

На основании данных в таблице Excel построим точечную диаграмму (она поможет проиллюстрировать линейный тип):

Выделяем диаграмму – «добавить линию тренда». В параметрах выбираем линейный тип. Добавляем величину достоверности аппроксимации и уравнение линии тренда в Excel (достаточно просто поставить галочки внизу окна «Параметры»).

Получаем результат:

Обратите внимание! При линейном типе аппроксимации точки данных расположены максимально близко к прямой. Данный вид использует следующее уравнение:
y = 4,503x + 6,1333
- где 4,503 – показатель наклона;
- 6,1333 – смещения;
- y – последовательность значений,
- х – номер периода.
Прямая линия на графике отображает стабильный рост качества работы менеджера. Величина достоверности аппроксимации равняется 0,9929, что указывает на хорошее совпадение расчетной прямой с исходными данными. Прогнозы должны получиться точными.
Чтобы спрогнозировать количество заключенных контрактов, например, в 11 периоде, нужно подставить в уравнение число 11 вместо х. В ходе расчетов узнаем, что в 11 периоде этот менеджер заключит 55-56 контрактов.
Экспоненциальная линия тренда
Данный тип будет полезен, если вводимые значения меняются с непрерывно возрастающей скоростью. Экспоненциальная аппроксимация не применяется при наличии нулевых или отрицательных характеристик.
Построим экспоненциальную линию тренда в Excel. Возьмем для примера условные значения полезного отпуска электроэнергии в регионе Х:

Строим график. Добавляем экспоненциальную линию.

Уравнение имеет следующий вид:
y = 7,6403е^-0,084x
- где 7,6403 и -0,084 – константы;
- е – основание натурального логарифма.
Показатель величины достоверности аппроксимации составил 0,938 – кривая соответствует данным, ошибка минимальна, прогнозы будут точными.
Логарифмическая линия тренда в Excel
Используется при следующих изменениях показателя: сначала быстрый рост или убывание, потом – относительная стабильность. Оптимизированная кривая хорошо адаптируется к подобному «поведению» величины. Логарифмический тренд подходит для прогнозирования продаж нового товара, который только вводится на рынок.
На начальном этапе задача производителя – увеличение клиентской базы. Когда у товара будет свой покупатель, его нужно удержать, обслужить.
Построим график и добавим логарифмическую линию тренда для прогноза продаж условного продукта:

R2 близок по значению к 1 (0,9633), что указывает на минимальную ошибку аппроксимации. Спрогнозируем объемы продаж в последующие периоды. Для этого нужно в уравнение вместо х подставлять номер периода.
Например:
| Период | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| Прогноз | 1005,4 | 1024,18 | 1041,74 | 1058,24 | 1073,8 | 1088,51 | 1102,47 |
Для расчета прогнозных цифр использовалась формула вида: =272,14*LN(B18)+287,21. Где В18 – номер периода.
Общая информация
Линия тренда – это инструмент статистического анализа, который позволяет спрогнозировать дальнейшее развитие событий. Чтобы построить кривую, необходимо иметь массив данных, который отображает изменение величины во времени. На основании этой информации строится график, а затем применятся специализированная функция. Рассмотрим изменение цены золота за грамм в долларах с 2015 по 2019 год.
- Составляете небольшую таблицу.

- На основании этих данных строите линейный график. Для этого переходите во вкладку Вставка на Панели инструментов и выбираете нужный тип диаграммы.

- Получается некоторая кривая.

- Необходимо отредактировать график при помощи стандартных инструментов, которые находятся во вкладках Конструктор, Макет и Формат. Переименовываете диаграмму, выставляете пределы по вертикальной оси, чтобы изменения величины были более явными, подписываете оси, добавляете контрольные точки, а также подпись данных. После этого проводите окончательное форматирование.

- Чтобы добавить линию тренда, необходимо во вкладке Макет нажать одноименную кнопку и выбрать нужный тип приближения.

На заметку! Если линия тренда не активна, то используется не тот тип диаграммы. Данная функция работает только с диаграммами типа гистограмма, график, линейчатая и точечная.
6. Так выглядит линия тренда на графике.

На заметку! Построение линии приближения идентично для редакторов 2007, 2010 и 2016 годов выпуска.
Возможности инструмента
Рассмотрим подробнее настройки функции. Для перехода в окно параметров из выпадающего списка нужно выбрать последнюю строчку.

Окно содержит четыре настройки, в которые входят цвет, объем и тип линии, а также параметры самого инструмента.

Параметры линии тренда можно условно поделить на четыре блока:
- Тип приближения.
- Название полученной кривой, которое формируется автоматически или может быть задано пользователем.
- Блок прогнозирования, который позволяет продлить линию тренда на заданное количество периодов вперед или назад, на основании имеющихся данных. Что позволяет оценить дальнейшее изменение исследуемой величины.
- Дополнительные опции, которые отражают математическую составляющую кривой. Самой интересной и полезной строчкой здесь является величина достоверности. Если значение коэффициента близко к единице, то ошибка минимальна и дальнейший прогноз будет достаточно точным.

Выведем на исходный график уравнение линии и коэффициент достоверности.

Как видите, значение близко к 0,5, это говорит о низкой достоверности полученной линии тренда, и дальнейший прогноз будет ошибочным.
Разновидности
1 Линейная аппроксимация отлично подойдет для исследования величины, которая стабильно растет или убывает. Тогда кривая будет иметь вид прямой. Формула будет содержать одну переменную. Коэффициент достоверности близок к единице, что говорит о высокой точности совпадения прямой и массива данных. На основании такой линии тренда прогноз будет достаточно точным.

2. Экспоненциальная кривая используется только для массивов с положительными значениями, которые изменяются непрерывно.

3. Логарифмическую линию тренда целесообразнее использовать, если на первоначальном этапе наблюдается резкое увеличение или снижение показателя, а потом наступает период стабильности. Здесь формула содержит логарифм натуральный.

4. Полиномиальная аппроксимация применяется при большом количестве неоднородных данных. В основе лежит степенное уравнение, при этом количество степеней зависит от числа максимумов. Применим этот тип для первоначального примера с золотом.

Уравнение показывает переменные до третьей степени, поскольку график имеет два пика. Также видим, что коэффициент достоверности близок к единице (вместо 0,5 при линейной аппроксимации), значит линия тренда выбрана правильно и дальнейший прогноз будет точным.
Как видите, для статистического анализа данных необходимо правильно выбрать тип математического уравнения, которое максимально точно будет соответствовать характеру изменения величины. На основании полученных кривых можно осуществлять прогноз, подставляя в уравнение необходимое число.
Разбираемся с трендами в MS Excel
Большой ошибкой со стороны владельца сайта будет воспринимать диаграмму как есть. Да, невооруженным взглядом видно, что синий и оранжевый столбики «осени» выросли по сравнению с «весной» и тем более «летом». Однако важны не только цифры и величина столбиков, но и зависимость между ними. То есть в идеале, при общем росте, «оранжевые» столбики просмотров должны расти намного сильнее «синих», что означало бы то, что сайт не только привлекает больше читателей, но и становится больше и интереснее.
Что же мы видим на графике? Оранжевые столбики «осени» как минимум ни чем не больше «весенних», а то и меньше. Это свидетельствует не об успехе, а скорее наоборот — посетители прибывают, но читают в среднем меньше и на сайте не задерживаются!
Самое время бить тревогу и… знакомится с такой штукой как линия тренда .
Зачем нужна линия тренда
Линия тренда «по-простому», это непрерывная линия составленная на основе усредненных на основе специальных алгоритмов значений из которых строится наша диаграмма. Иными словами, если наши данные «прыгают» за три отчетных точки с «-5» на «0», а следом на «+5», в итоге мы получим почти ровную линию: «плюсы» ситуации очевидно уравновешивают «минусы».
Исходя из направления линии тренда гораздо проще увидеть реальное положение дел и видеть те самые тенденции, а следовательно — строить прогнозы на будущее. Ну а теперь, за дело!
Как построить линию тренда в MS Excel

Щелкните правой кнопкой мыши по одному из «синих» столбцов, и в контекстном меню выберите пункт «Добавить линию тренда» .
На листе диаграммы теперь отображается пунктирная линия тренда. Как видите, она не совпадает на 100% со значениями диаграммы — построенная по средневзвешенным значениям, она лишь в общих чертах повторяет её направление. Однако это не мешает нам видеть устойчивый рост числа посещений сайта — на общем результате не сказывается даже «летняя» просадка.

Линия тренда для столбца «Посетители»
Теперь повторим тот же фокус с «оранжевыми» столбцами и построим вторую линию тренда. Как я и говорил раньше: здесь ситуация не так хороша. Тренд явно показывает, что за расчетный период число просмотров не только не увеличилось, но даже начало падать — медленно, но неуклонно.

Ещё одна линия тренда позволяет прояснить ситуацию
Мысленно продолжив линию тренда на будущие месяцы, мы придем к неутешительному выводу — число заинтересованных посетителей продолжит снижаться. Так как пользователи здесь не задерживаются, падение интереса сайта в ближайшем будущем неизбежно вызовет и падение посещаемости.
Следовательно, владельцу проекта нужно срочно вспоминать чего он такого натворил летом («весной» все было вполне нормально, судя по графику), и срочно принимать меры по исправлению ситуации.
Источники
- https://strategy4you.ru/graficheskij-analiz/liniya-trenda-v-excel.html
- https://thisisdata.ru/blog/postroyeniye-funktsiy-trenda-v-excel/
- https://4analytics.ru/trendi/5-sposobov-rascheta-znacheniie-lineienogo-trenda-v-ms-excel.html
- https://exceltable.com/grafiki/liniya-trenda-v-excel
- https://mirtortov.ru/lineinyi-trend-v-eksel-liniya-trenda-v-excel-na-raznyh-grafikah.html
- https://mir-tehnologiy.ru/liniya-trenda-v-excel/
Аппроксимация в Excel
 (Обратите внимание на дополнительный раздел от 04.06.2017 в конце статьи.)
(Обратите внимание на дополнительный раздел от 04.06.2017 в конце статьи.)
Учет и контроль! Те, кому за 40 должны хорошо помнить этот лозунг из эпохи построения социализма и коммунизма в нашей стране.
Но без хорошо налаженного учета невозможно эффективное функционирование ни страны, ни области, ни предприятия, ни домашнего хозяйства при любой общественно-экономической формации общества! Для составления прогнозов и планов деятельности и развития необходимы исходные данные. Где их брать? Только один достоверный источник – это ваши статистические учетные данные предыдущих периодов времени.
Учитывать результаты своей деятельности, собирать и записывать информацию, обрабатывать и анализировать данные, применять результаты анализа для принятия правильных решений в будущем должен, в моем понимании, каждый здравомыслящий человек. Это есть ничто иное, как накопление и рациональное использование своего жизненного опыта. Если не вести учет важных данных, то вы через определенный период времени их забудете и, начав заниматься этими вопросами вновь, вы опять наделаете те же ошибки, что делали, когда впервые этим занимались.
«Мы, помню, 5 лет назад изготавливали до 1000 штук таких изделий в месяц, а сейчас и 700 еле-еле собираем!». Открываем статистику и видим, что 5 лет назад и 500 штук не изготавливали…
«Во сколько обходится километр пробега твоего автомобиля с учетом всех затрат?» Открываем статистику – 6 руб./км. Поездка на работу – 107 рублей. Дешевле, чем на такси (180 рублей) более чем в полтора раза. А бывали времена, когда на такси было дешевле…
«Сколько времени требуется для изготовления металлоконструкций уголковой башни связи высотой 50 м?» Открываем статистику – и через 5 минут готов ответ…
«Сколько будет стоить ремонт комнаты в квартире?» Поднимаем старые записи, делаем поправку на инфляцию за прошедшие годы, учитываем, что в прошлый раз купили материалы на 10% дешевле рыночной цены и – ориентировочную стоимость мы уже знаем…
Ведя учет своей профессиональной деятельности, вы всегда будете готовы ответить на вопрос начальника: «Когда. ». Ведя учет домашнего хозяйства, легче спланировать расходы на крупные покупки, отдых и прочие расходы в будущем, приняв соответствующие меры по дополнительному заработку или по сокращению необязательных расходов сегодня.
В этой статье я на простом примере покажу, как можно обрабатывать собранные статистические данные в Excel для возможности дальнейшего использования при прогнозировании будущих периодов.
Аппроксимация в Excel статистических данных аналитической функцией.
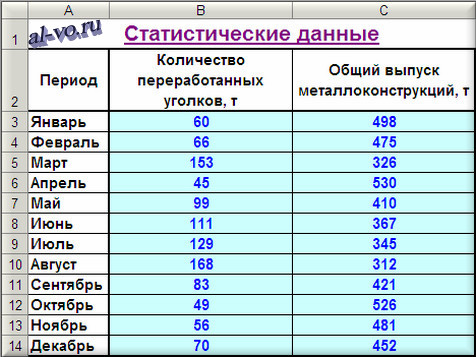
Производственный участок изготавливает строительные металлоконструкции из листового и профильного металлопроката. Участок работает стабильно, заказы однотипные, численность рабочих колеблется незначительно. Есть данные о выпуске продукции за предыдущие 12 месяцев и о количестве переработанного в эти периоды времени металлопроката по группам: листы, двутавры, швеллеры, уголки, трубы круглые, профили прямоугольного сечения, круглый прокат. После предварительного анализа исходных данных возникло предположение, что суммарный месячный выпуск металлоконструкций существенно зависит от количества уголков в заказах. Проверим это предположение.
Прежде всего, несколько слов об аппроксимации. Мы будем искать закон – аналитическую функцию, то есть функцию, заданную уравнением, которое лучше других описывает зависимость общего выпуска металлоконструкций от количества уголкового проката в выполненных заказах. Это и есть аппроксимация, а найденное уравнение называется аппроксимирующей функцией для исходной функции, заданной в виде таблицы.
1. Включаем Excel и помещаем на лист таблицу с данными статистики.
2. Далее строим и форматируем точечную диаграмму, в которой по оси X задаем значения аргумента – количество переработанных уголков в тоннах. По оси Y откладываем значения исходной функции – общий выпуск металлоконструкций в месяц, заданные таблицей.
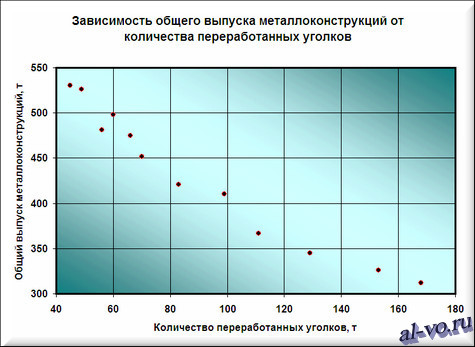
О том, как построить подобную диаграмму, подробно рассказано в статье «Как строить графики в Excel?».
3. «Наводим» мышь на любую из точек на графике и щелчком правой кнопки вызываем контекстное меню (как говорит один мой хороший товарищ — работая в незнакомой программе, когда не знаешь, что делать, чаще щелкай правой кнопкой мыши…). В выпавшем меню выбираем «Добавить линию тренда…».
4. В появившемся окне «Линия тренда» на вкладке «Тип» выбираем «Линейная».
5. Далее на вкладке «Параметры» ставим 2 галочки и нажимаем «ОК».
6. На графике появилась прямая линия, аппроксимирующая нашу табличную зависимость.
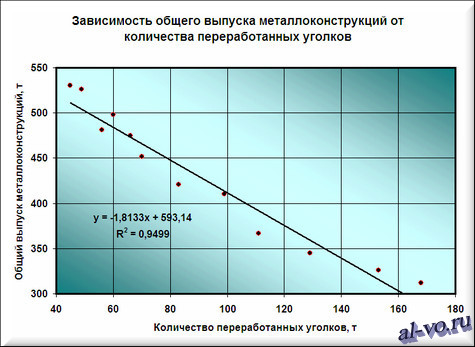
Мы видим кроме самой линии уравнение этой линии и, главное, мы видим значение параметра R 2 – величины достоверности аппроксимации! Чем ближе его значение к 1, тем наиболее точно выбранная функция аппроксимирует табличные данные!
7. Строим линии тренда, используя степенную, логарифмическую, экспоненциальную и полиномиальную аппроксимации по аналогии с тем, как мы строили линейную линию тренда.
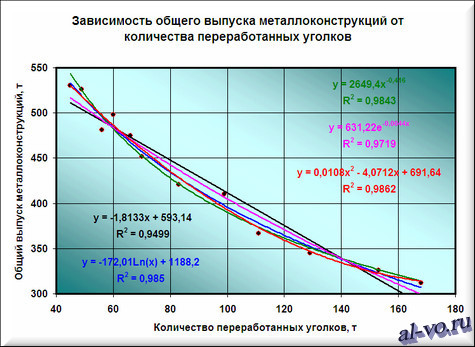
Лучше всех из выбранных функций аппроксимирует наши данные полином второй степени, у него максимальный коэффициент достоверности R 2 .
Однако хочу вас предостеречь! Если вы возьмете полиномы более высоких степеней, то, возможно, получите еще лучшие результаты, но кривые будут иметь замысловатый вид…. Здесь важно понимать, что мы ищем функцию, которая имеет физический смысл. Что это означает? Это означает, что нам нужна аппроксимирующая функция, которая будет выдавать адекватные результаты не только внутри рассматриваемого диапазона значений X, но и за его пределами, то есть ответит на вопрос: «Какой будет выпуск металлоконструкций при количестве переработанных за месяц уголков меньше 45 и больше 168 тонн!» Поэтому я не рекомендую увлекаться полиномами высоких степеней, да и параболу (полином второй степени) выбирать осторожно!
Итак, нам необходимо выбрать функцию, которая не только хорошо интерполирует табличные данные в пределах диапазона значений X=45…168, но и допускает адекватную экстраполяцию за пределами этого диапазона. Я выбираю в данном случае логарифмическую функцию, хотя можно выбрать и линейную, как наиболее простую. В рассматриваемом примере при выборе линейной аппроксимации в excel ошибки будут больше, чем при выборе логарифмической, но не на много.
8. Удаляем все линии тренда с поля диаграммы, кроме логарифмической функции. Для этого щелкаем правой кнопкой мыши по ненужным линиям и в выпавшем контекстном меню выбираем «Очистить».
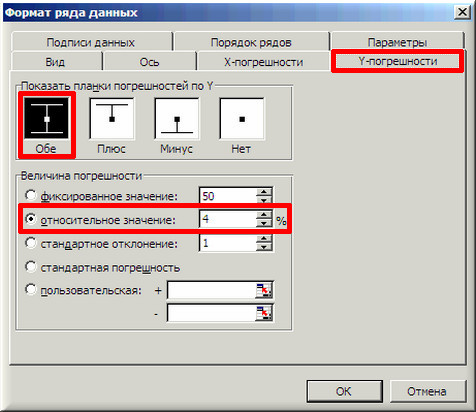
9. В завершении добавим к точкам табличных данных планки погрешностей. Для этого правой кнопкой мыши щелкаем на любой из точек на графике и в контекстном меню выбираем «Формат рядов данных…» и настраиваем данные на вкладке «Y-погрешности» так, как на рисунке ниже.
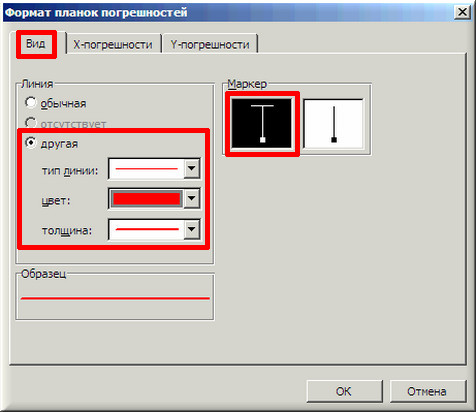
10. Затем щелкаем по любой из линий диапазонов погрешностей правой кнопкой мыши, выбираем в контекстном меню «Формат полос погрешностей…» и в окне «Формат планок погрешностей» на вкладке «Вид» настраиваем цвет и толщину линий.
Аналогичным образом форматируются любые другие объекты диаграммы в Excel!
Окончательный результат диаграммы представлен на следующем снимке экрана.
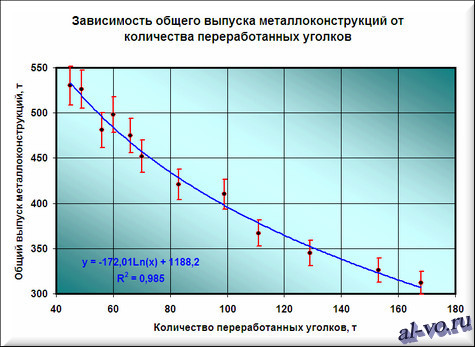
Итоги.
Результатом всех предыдущих действий стала полученная формула аппроксимирующей функции y=-172,01*ln (x)+1188,2. Зная ее, и количество уголков в месячном наборе работ, можно с высокой степенью вероятности (±4% — смотри планки погрешностей) спрогнозировать общий выпуск металлоконструкций за месяц! Например, если в плане на месяц 140 тонн уголков, то общий выпуск, скорее всего, при прочих равных составит 338±14 тонн.
Для повышения достоверности аппроксимации статистических данных должно быть много. Двенадцать пар значений – это маловато.
Из практики скажу, что хорошим результатом следует считать нахождение аппроксимирующей функции с коэффициентом достоверности R 2 >0,87. Отличный результат – при R 2 >0,94.
На практике бывает трудно выделить один самый главный определяющий фактор (в нашем примере – масса переработанных за месяц уголков), но если постараться, то в каждой конкретной задаче его всегда можно найти! Конечно, общий выпуск продукции за месяц реально зависит от сотни факторов, для учета которых необходимы существенные трудозатраты нормировщиков и других специалистов. Только результат все равно будет приблизительным! Так стоит ли нести затраты, если есть гораздо более дешевое математическое моделирование!
В этой статье я лишь прикоснулся к верхушке айсберга под названием сбор, обработка и практическое использование статистических данных. О том удалось, или нет, мне расшевелить ваш интерес к этой теме, надеюсь узнать из комментариев и рейтинга статьи в поисковиках.
Затронутый вопрос аппроксимации функции одной переменной имеет широкое практическое применение в разных сферах жизни. Но гораздо большее применение имеет решение задачи аппроксимации функции нескольких независимых переменных…. Об этом и не только читайте в следующих статьях на блоге.
Подписывайтесь на анонсы статей в окне, расположенном в конце каждой статьи или в окне вверху страницы.
Не забывайте подтверждать подписку кликом по ссылке в письме, которое придет к вам на указанную почту (может прийти в папку «Спам»).
С интересом прочту Ваши комментарии, уважаемые читатели! Пишите!
P.S. (04.06.2017)
Высокоточная красивая замена табличных данных простым уравнением.
Вас не устраивают полученные точность аппроксимации (R 2 2 =0,9963.
Что такое R² в Excel, и зачем нужен тренд на графике?
Когда научный руководитель сказал мне о необходимости указать на графике R² (р квадрат), я растерялся. В тот момент я не знал о трендах в диаграммах и графиках Excel. Этот материал поможет сориентироваться начинающим.
Что такое R² в Экселе
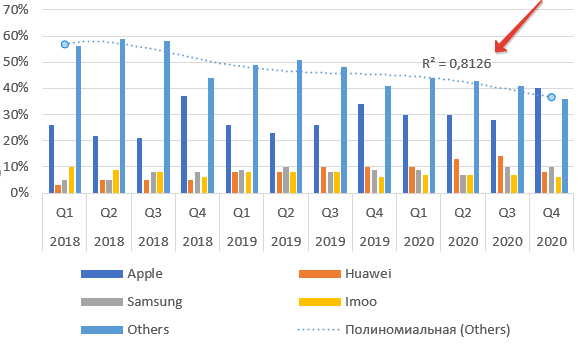
Для примера возьмем данные о продажах умных часов по брендам. Саму таблицу и график можно найти по этой ссылке на сайте CounterPointResearch. Там много подобной информации.
Выделяем диапазон данных и добавляем диаграмму. Теперь наводим мышь на столбцы бренда Others — «остальные», нажимаем правую клавишу мыши. Выбираем пункт Добавить линию тренда.
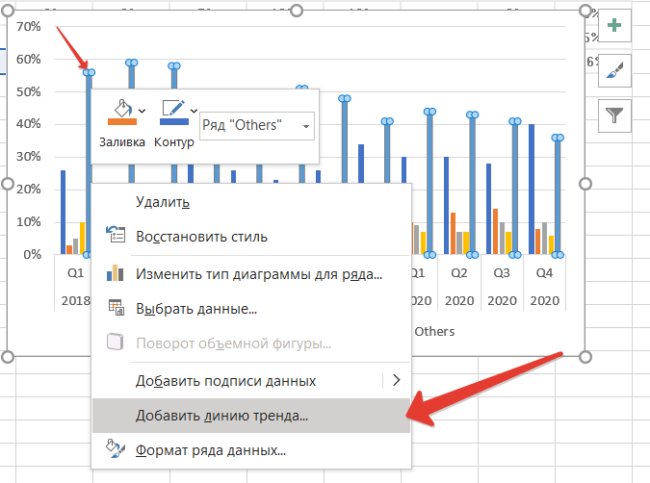
По умолчанию тренд линейный. Чуть позднее расскажу, как выбрать иную функцию, и стоит ли это делать. Теперь подводим курсор мыши к тренду и снова нажимаем правую кнопку.
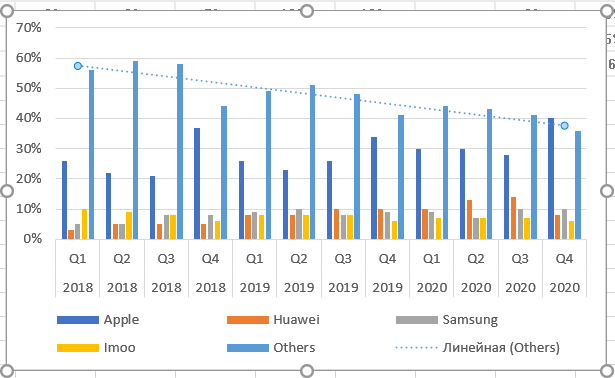
Добавляем на график R².
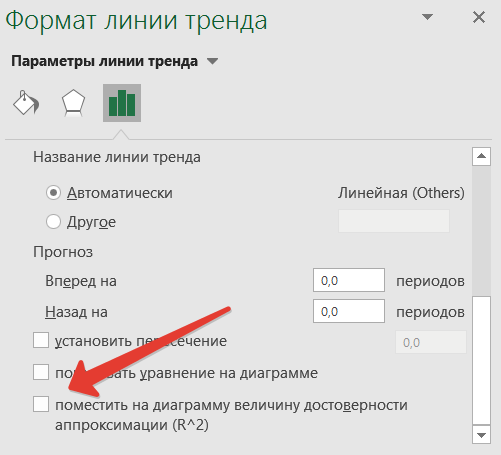
Как видим из названия пункта, это величина достоверности апроксимации. Максимальное значение параметра Р-квадрат единица. Но получить ее можно только на специально подогнанных данных в реальной жизни приемлемое значение 0,8-0,9. В нашем случае — 0,78, что неплохо.
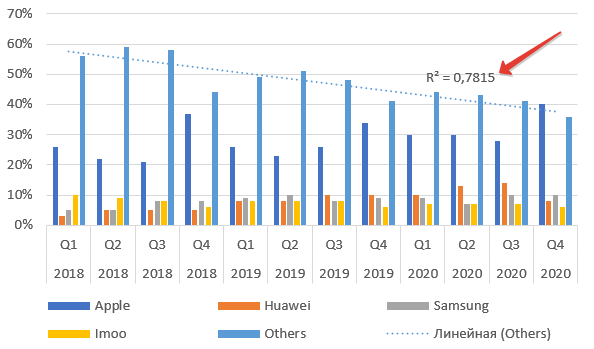
Стоит ли добиваться максимального значения R²
Улучшить достоверность апроксимации можно меняя вид кривой. Это можно сделать в открывающемся справа окошке Формат линии тренда.
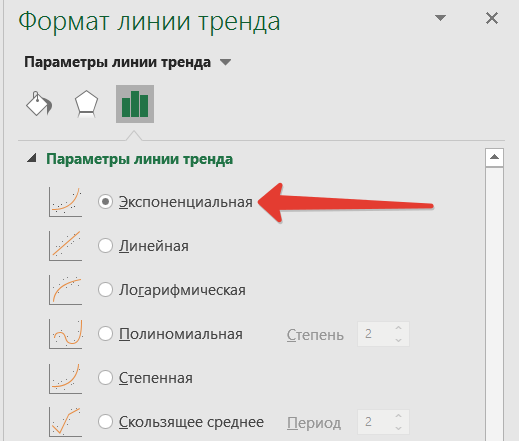
Если использовать полиноминальную функцию, то апроксимацию можно улучшить значительно. Но вот смысла это не имеет. Экономические показатели обычно укладываются в линейный (рост/падение) или экспоненциальный тренд. Экспоненциально, например, растет число клиентов быстрорастущей фирмы.
Выбор полиноминальной функции может и улучшит показатель достоверности, а вот прогноз сделает менее точным.
Как использовать тренд для прогноза
Кроме определения общего положения дел (рост/снижение), тренд может предсказать значения показателей в будущем. Это делается в окошке Формата линии тренда.

Попробуем предсказать продажи умных часов в первом квартале 2021 году и сравним их с фактом. Добавим два линейных тренда для Apple и Остальных.
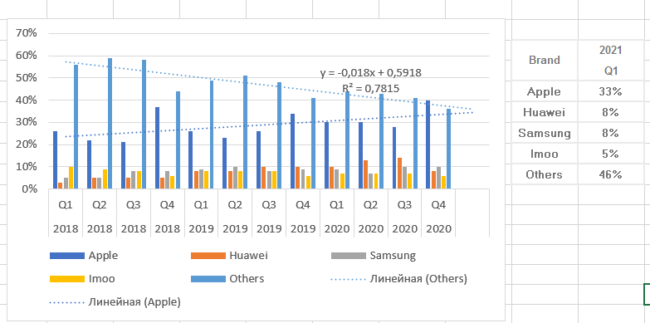
Как видим, по яблочным часа прогноз построен верно, по остальным функция прогнозирует значение около 35%, а в реальности 46%. Возможно, это связано с выходом новых игроков на рынок или снижением доли Huawei. Мы имеем дело с относительными показателями (доля), а не с натуральными. Кстати, полиноминальный прогноз для категории Остальные дал бы еще менее точный прогноз, хотя R² и выше, что подтверждает необходимость осторожно выбирать функцию.
Почитайте и другие статьи про работу с таблицами Excel на нашем сайте. Например, у нас есть полезный материал об условном оформлении ячеек в таблице.
Расчет коэффициента детерминации в Microsoft Excel
Одним из показателей, описывающих качество построенной модели в статистике, является коэффициент детерминации (R^2), который ещё называют величиной достоверности аппроксимации. С его помощью можно определить уровень точности прогноза. Давайте узнаем, как можно произвести расчет данного показателя с помощью различных инструментов программы Excel.
Вычисление коэффициента детерминации
В зависимости от уровня коэффициента детерминации, принято разделять модели на три группы:
- 0,8 – 1 — модель хорошего качества;
- 0,5 – 0,8 — модель приемлемого качества;
- 0 – 0,5 — модель плохого качества.
В последнем случае качество модели говорит о невозможности её использования для прогноза.
Выбор способа вычисления указанного значения в Excel зависит от того, является ли регрессия линейной или нет. В первом случае можно использовать функцию КВПИРСОН, а во втором придется воспользоваться специальным инструментом из пакета анализа.
Способ 1: вычисление коэффициента детерминации при линейной функции
Прежде всего, выясним, как найти коэффициент детерминации при линейной функции. В этом случае данный показатель будет равняться квадрату коэффициента корреляции. Произведем его расчет с помощью встроенной функции Excel на примере конкретной таблицы, которая приведена ниже.
-
Выделяем ячейку, где будет произведен вывод коэффициента детерминации после его расчета, и щелкаем по пиктограмме «Вставить функцию».
Происходит запуск окна аргументов функции КВПИРСОН. Данный оператор из статистической группы предназначен для вычисления квадрата коэффициента корреляции функции Пирсона, то есть, линейной функции. А как мы помним, при линейной функции коэффициент детерминации как раз равен квадрату коэффициента корреляции.
Синтаксис этого оператора такой:
Таким образом, функция имеет два оператора, один из которых представляет собой перечень значений функции, а второй – аргументов. Операторы могут быть представлены, как непосредственно в виде значений, перечисленных через точку с запятой (;), так и в виде ссылок на диапазоны, где они расположены. Именно последний вариант и будет использован нами в данном примере.
Устанавливаем курсор в поле «Известные значения y». Выполняем зажим левой кнопки мышки и производим выделение содержимого столбца «Y» таблицы. Как видим, адрес указанного массива данных тут же отображается в окне.
Аналогичным образом заполняем поле «Известные значения x». Ставим курсор в данное поле, но на этот раз выделяем значения столбца «X».
После того, как все данные были отображены в окне аргументов КВПИРСОН, клацаем по кнопке «OK», расположенной в самом его низу.
Способ 2: вычисление коэффициента детерминации в нелинейных функциях
Но указанный выше вариант расчета искомого значения можно применять только к линейным функциям. Что же делать, чтобы произвести его расчет в нелинейной функции? В Экселе имеется и такая возможность. Её можно осуществить с помощью инструмента «Регрессия», который является составной частью пакета «Анализ данных».
-
Но прежде, чем воспользоваться указанным инструментом, следует активировать сам «Пакет анализа», который по умолчанию в Экселе отключен. Перемещаемся во вкладку «Файл», а затем переходим по пункту «Параметры».
В открывшемся окне производим перемещение в раздел «Надстройки» при помощи навигации по левому вертикальному меню. В нижней части правой области окна располагается поле «Управление». Из списка доступных там подразделов выбираем наименование «Надстройки Excel…», а затем щелкаем по кнопке «Перейти…», расположенной справа от поля.
Производится запуск окна надстроек. В центральной его части расположен список доступных надстроек. Устанавливаем флажок около позиции «Пакет анализа». Вслед за этим требуется щелкнуть по кнопке «OK» в правой части интерфейса окна.
Пакет инструментов «Анализ данных» в текущем экземпляре Excel будет активирован. Доступ к нему располагается на ленте во вкладке «Данные». Перемещаемся в указанную вкладку и клацаем по кнопке «Анализ данных» в группе настроек «Анализ».
Активируется окошко «Анализ данных» со списком профильных инструментов обработки информации. Выделяем из этого перечня пункт «Регрессия» и клацаем по кнопке «OK».
Затем открывается окно инструмента «Регрессия». Первый блок настроек – «Входные данные». Тут в двух полях нужно указать адреса диапазонов, где находятся значения аргумента и функции. Ставим курсор в поле «Входной интервал Y» и выделяем на листе содержимое колонки «Y». После того, как адрес массива отобразился в окне «Регрессия», ставим курсор в поле «Входной интервал Y» и точно таким же образом выделяем ячейки столбца «X».
Около параметров «Метка» и «Константа-ноль» флажки не ставим. Флажок можно установить около параметра «Уровень надежности» и в поле напротив указать желаемую величину соответствующего показателя (по умолчанию 95%).
В группе «Параметры вывода» нужно указать, в какой области будет отображаться результат вычисления. Существует три варианта:
- Область на текущем листе;
- Другой лист;
- Другая книга (новый файл).
Остановим свой выбор на первом варианте, чтобы исходные данные и результат размещались на одном рабочем листе. Ставим переключатель около параметра «Выходной интервал». В поле напротив данного пункта ставим курсор. Щелкаем левой кнопкой мыши по пустому элементу на листе, который призван стать левой верхней ячейкой таблицы вывода итогов расчета. Адрес данного элемента должен высветиться в поле окна «Регрессия».
Группы параметров «Остатки» и «Нормальная вероятность» игнорируем, так как для решения поставленной задачи они не важны. После этого клацаем по кнопке «OK», которая размещена в правом верхнем углу окна «Регрессия».
Способ 3: коэффициент детерминации для линии тренда
Кроме указанных выше вариантов, коэффициент детерминации можно отобразить непосредственно для линии тренда в графике, построенном на листе Excel. Выясним, как это можно сделать на конкретном примере.
-
Мы имеем график, построенный на основе таблицы аргументов и значений функции, которая была использована для предыдущего примера. Произведем построение к нему линии тренда. Кликаем по любому месту области построения, на которой размещен график, левой кнопкой мыши. При этом на ленте появляется дополнительный набор вкладок – «Работа с диаграммами». Переходим во вкладку «Макет». Клацаем по кнопке «Линия тренда», которая размещена в блоке инструментов «Анализ». Появляется меню с выбором типа линии тренда. Останавливаем выбор на том типе, который соответствует конкретной задаче. Давайте для нашего примера выберем вариант «Экспоненциальное приближение».
Эксель строит прямо на плоскости построения графика линию тренда в виде дополнительной черной кривой.
Теперь нашей задачей является отобразить собственно коэффициент детерминации. Кликаем правой кнопкой мыши по линии тренда. Активируется контекстное меню. Останавливаем выбор в нем на пункте «Формат линии тренда…».
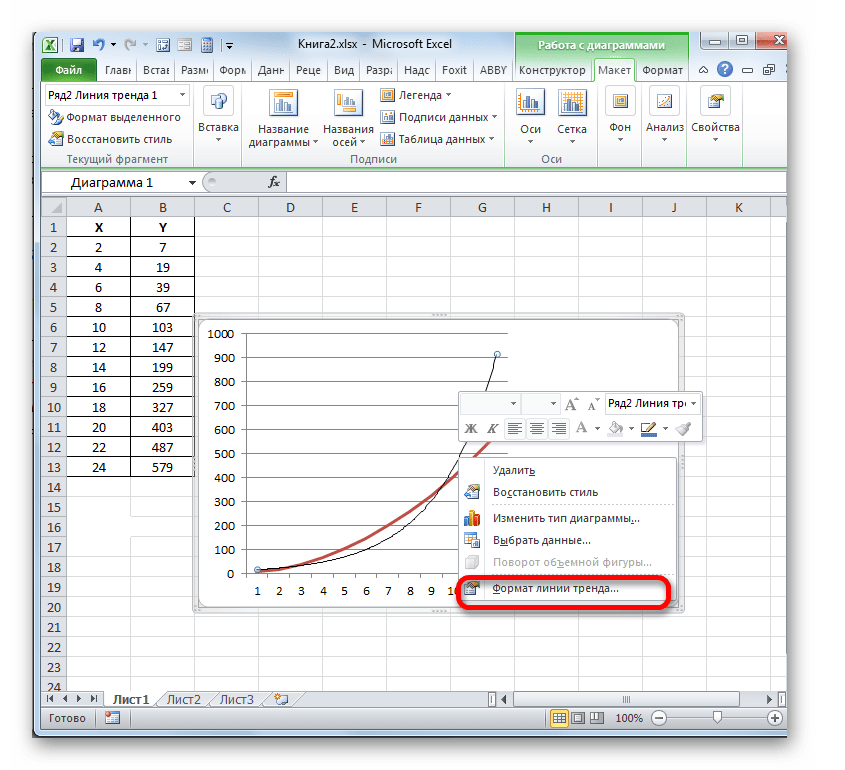
Для выполнения перехода в окно формата линии тренда можно выполнить альтернативное действие. Выделяем линию тренда кликом по ней левой кнопки мыши. Перемещаемся во вкладку «Макет». Клацаем по кнопке «Линия тренда» в блоке «Анализ». В открывшемся списке клацаем по самому последнему пункту перечня действий – «Дополнительные параметры линии тренда…».
После любого из двух вышеуказанных действий запускается окошко формата, в котором можно произвести дополнительные настройки. В частности, для выполнения нашей задачи необходимо установить флажок напротив пункта «Поместить на диаграмму величину достоверности аппроксимации (R^2)». Он размещен в самом низу окна. То есть, таким образом мы включаем отображение коэффициента детерминации на области построения. Затем не забываем нажать на кнопку «Закрыть» внизу текущего окна.
Значение достоверности аппроксимации, то есть, величина коэффициента детерминации, будет отображено на листе в области построения. В данном случае эта величина, как видим, равна 0,9242, что характеризует аппроксимацию, как модель хорошего качества.
Абсолютно точно таким образом можно устанавливать показ коэффициента детерминации для любого другого типа линии тренда. Можно менять тип линии тренда, произведя переход через кнопку на ленте или контекстное меню в окно её параметров, как было показано выше. Затем уже в самом окне в группе «Построение линии тренда» можно переключиться на другой тип. Не забываем при этом контролировать, чтобы около пункта «Поместить на диаграмму величину достоверности аппроксимации» был установлен флажок. Завершив вышеуказанные действия, щелкаем по кнопке «Закрыть» в нижнем правом углу окна.
При линейном типе линия тренда уже имеет значение достоверности аппроксимации равное 0,9477, что характеризует эту модель, как ещё более достоверную, чем рассматриваемую нами ранее линию тренда экспоненциального типа.
Таким образом, переключаясь между разными типами линии тренда и сравнивая их значения достоверности аппроксимации (коэффициент детерминации), можно найти тот вариант, модель которого наиболее точно описывает представленный график. Вариант с самым высоким показателем коэффициента детерминации будет наиболее достоверным. На его основе можно строить самый точный прогноз.
Например, для нашего случая опытным путем удалось установить, что самый высокий уровень достоверности имеет полиномиальный тип линии тренда второй степени. Коэффициент детерминации в данном случае равен 1. Это говорит о том, что указанная модель абсолютно достоверная, что означает полное исключение погрешностей.
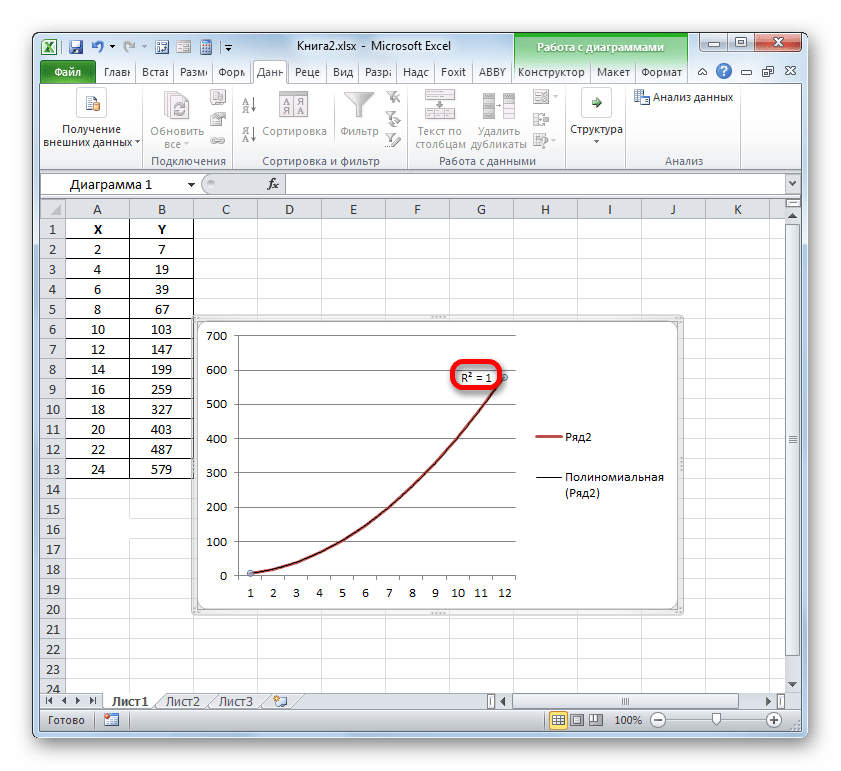
Но, в то же время, это совсем не значит, что для другого графика тоже наиболее достоверным окажется именно этот тип линии тренда. Оптимальный выбор типа линии тренда зависит от типа функции, на основании которой был построен график. Если пользователь не обладает достаточным объемом знаний, чтобы «на глаз» прикинуть наиболее качественный вариант, то единственным выходом определения лучшего прогноза является как раз сравнение коэффициентов детерминации, как было показано на примере выше.
В Экселе существуют два основных варианта вычисления коэффициента детерминации: использование оператора КВПИРСОН и применение инструмента «Регрессия» из пакета инструментов «Анализ данных». При этом первый из этих вариантов предназначен для использования только в процессе обработки линейной функции, а другой вариант можно использовать практически во всех ситуациях. Кроме того, существует возможность отображения коэффициента детерминации для линии трендов графиков в качестве величины достоверности аппроксимации. С помощью данного показателя имеется возможность определить тип линии тренда, который располагает самым высоким уровнем достоверности для конкретной функции.
Помимо этой статьи, на сайте еще 12779 полезных инструкций.
Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.
источники:
http://myfreesoft.ru/chto-takoe-r2-v-excel-i-zachem-nuzhen-trend-na-grafike.html
http://lumpics.ru/coefficient-of-determination-in-excel/
Для наглядной иллюстрации тенденций изменения цены применяется линия тренда. Элемент технического анализа представляет собой геометрическое изображение средних значений анализируемого показателя.
Рассмотрим, как добавить линию тренда на график в Excel.
Добавление линии тренда на график
Для примера возьмем средние цены на нефть с 2000 года из открытых источников. Данные для анализа внесем в таблицу:
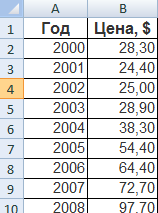
- Построим на основе таблицы график. Выделим диапазон – перейдем на вкладку «Вставка». Из предложенных типов диаграмм выберем простой график. По горизонтали – год, по вертикали – цена.
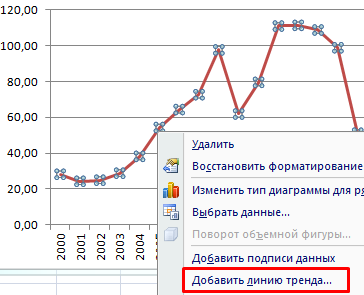
- Щелкаем правой кнопкой мыши по самому графику. Нажимаем «Добавить линию тренда».
- Открывается окно для настройки параметров линии. Выберем линейный тип и поместим на график величину достоверности аппроксимации.
- На графике появляется косая линия.
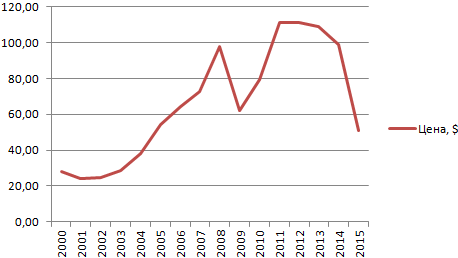
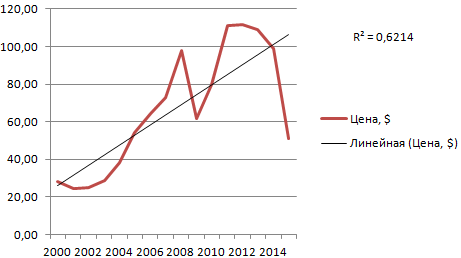
Линия тренда в Excel – это график аппроксимирующей функции. Для чего он нужен – для составления прогнозов на основе статистических данных. С этой целью необходимо продлить линию и определить ее значения.
Если R2 = 1, то ошибка аппроксимации равняется нулю. В нашем примере выбор линейной аппроксимации дал низкую достоверность и плохой результат. Прогноз будет неточным.
Внимание!!! Линию тренда нельзя добавить следующим типам графиков и диаграмм:
- лепестковый;
- круговой;
- поверхностный;
- кольцевой;
- объемный;
- с накоплением.
Уравнение линии тренда в Excel
В предложенном выше примере была выбрана линейная аппроксимация только для иллюстрации алгоритма. Как показала величина достоверности, выбор был не совсем удачным.
Следует выбирать тот тип отображения, который наиболее точно проиллюстрирует тенденцию изменений вводимых пользователем данных. Разберемся с вариантами.
Линейная аппроксимация
Ее геометрическое изображение – прямая. Следовательно, линейная аппроксимация применяется для иллюстрации показателя, который растет или уменьшается с постоянной скоростью.
Рассмотрим условное количество заключенных менеджером контрактов на протяжении 10 месяцев:
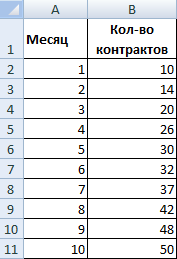
На основании данных в таблице Excel построим точечную диаграмму (она поможет проиллюстрировать линейный тип):
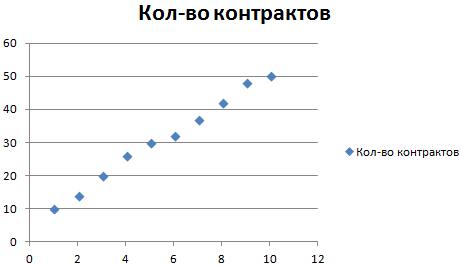
Выделяем диаграмму – «добавить линию тренда». В параметрах выбираем линейный тип. Добавляем величину достоверности аппроксимации и уравнение линии тренда в Excel (достаточно просто поставить галочки внизу окна «Параметры»).
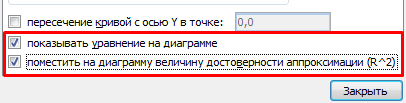
Получаем результат:
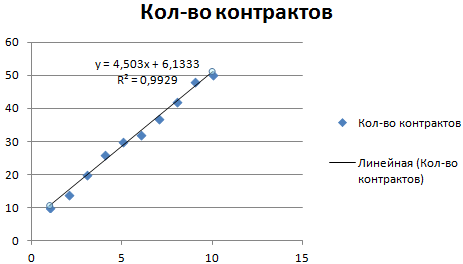
Обратите внимание! При линейном типе аппроксимации точки данных расположены максимально близко к прямой. Данный вид использует следующее уравнение:
y = 4,503x + 6,1333
- где 4,503 – показатель наклона;
- 6,1333 – смещения;
- y – последовательность значений,
- х – номер периода.
Прямая линия на графике отображает стабильный рост качества работы менеджера. Величина достоверности аппроксимации равняется 0,9929, что указывает на хорошее совпадение расчетной прямой с исходными данными. Прогнозы должны получиться точными.
Чтобы спрогнозировать количество заключенных контрактов, например, в 11 периоде, нужно подставить в уравнение число 11 вместо х. В ходе расчетов узнаем, что в 11 периоде этот менеджер заключит 55-56 контрактов.
Экспоненциальная линия тренда
Данный тип будет полезен, если вводимые значения меняются с непрерывно возрастающей скоростью. Экспоненциальная аппроксимация не применяется при наличии нулевых или отрицательных характеристик.
Построим экспоненциальную линию тренда в Excel. Возьмем для примера условные значения полезного отпуска электроэнергии в регионе Х:
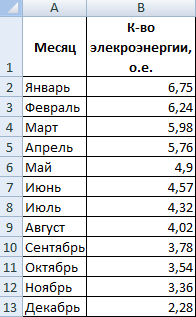
Строим график. Добавляем экспоненциальную линию.
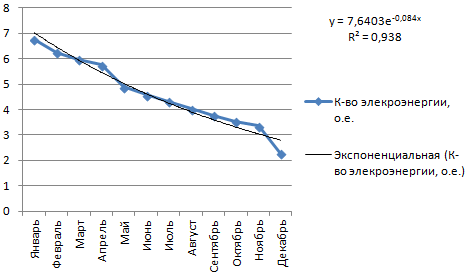
Уравнение имеет следующий вид:
y = 7,6403е^-0,084x
- где 7,6403 и -0,084 – константы;
- е – основание натурального логарифма.
Показатель величины достоверности аппроксимации составил 0,938 – кривая соответствует данным, ошибка минимальна, прогнозы будут точными.
Логарифмическая линия тренда в Excel
Используется при следующих изменениях показателя: сначала быстрый рост или убывание, потом – относительная стабильность. Оптимизированная кривая хорошо адаптируется к подобному «поведению» величины. Логарифмический тренд подходит для прогнозирования продаж нового товара, который только вводится на рынок.
На начальном этапе задача производителя – увеличение клиентской базы. Когда у товара будет свой покупатель, его нужно удержать, обслужить.
Построим график и добавим логарифмическую линию тренда для прогноза продаж условного продукта:
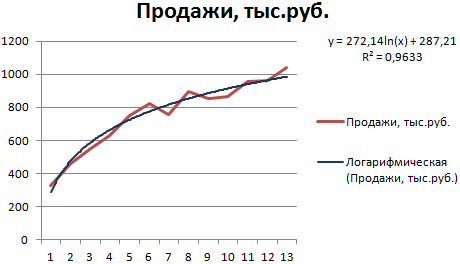
R2 близок по значению к 1 (0,9633), что указывает на минимальную ошибку аппроксимации. Спрогнозируем объемы продаж в последующие периоды. Для этого нужно в уравнение вместо х подставлять номер периода.
Например:
| Период | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| Прогноз | 1005,4 | 1024,18 | 1041,74 | 1058,24 | 1073,8 | 1088,51 | 1102,47 |
Для расчета прогнозных цифр использовалась формула вида: =272,14*LN(B18)+287,21. Где В18 – номер периода.
Полиномиальная линия тренда в Excel
Данной кривой свойственны переменные возрастание и убывание. Для полиномов (многочленов) определяется степень (по количеству максимальных и минимальных величин). К примеру, один экстремум (минимум и максимум) – это вторая степень, два экстремума – третья степень, три – четвертая.
Полиномиальный тренд в Excel применяется для анализа большого набора данных о нестабильной величине. Посмотрим на примере первого набора значений (цены на нефть).
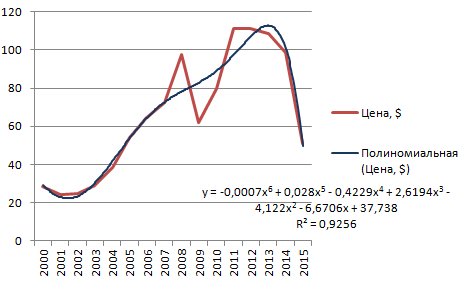
Чтобы получить такую величину достоверности аппроксимации (0,9256), пришлось поставить 6 степень.
Скачать примеры графиков с линией тренда

Зато такой тренд позволяет составлять более-менее точные прогнозы.