
 Здравствуйте.
Здравствуйте.
В офисной работе иногда нужно написать какой-нибудь текст таким же шрифтом, который был использован в документе. Хорошо, если он есть в электронном варианте, а если только в бумажном? Вот иногда и приходится определять шрифт по скану (картинке).
Впрочем, причины узнать шрифт могут быть и другие: вы увидели красивую надпись и хотите создать что-то подобное; вам нужно исправить (подправить) какую-то подпись под картинкой (так, чтобы она не выделялась среди другого текста) и т.д.
В общем, как бы там ни было, в этой статье предложу несколько вариантов как это можно сделать. Сразу отмечу, что если на изображении запечатлен какой-то уникальный шрифт (который нигде ранее не использовался, т.е. дизайнер его создал самостоятельно) — то найти его не удастся (хотя, скорее всего, вы сможете подобрать что-то похожее).
Ладно, ближе к теме…
📌 Дополнение!
Если у вас есть только картинка на бумаге (распечатанный документ), то для начала работы вам необходимо перевести ее в электронную версию (отсканировать). Сделать сейчас это можно с помощью обычного смартфона на Андроид.

*
Распознавание шрифта на картинке
📌 Вариант 1: с помощью ABBY Fine Reader
Если кто-то не слышал о такой программе как ABBY Fine Reader — то кратко скажу, что она предназначена для распознавания текста с картинок, PDF-файлов, сканов и пр. (т.е. на входе — у вас обычный графический файл; на выходе — программа выдает вам текст, который можно перенести в Word).
*
👉 FineReader и его аналоги (всё самое нужное): https://ocomp.info/raspoznat-tekst.html
👉 Официальный сайт ABBY Fine Reader — https://pdf.abbyy.com/
*
Так вот, Fine Reader по умолчанию при распознавании текста не меняет шрифт! То есть, при процессе распознавании шрифт текста будет выбран тот, который запечатлен у вас на графическом файле (фото, картинке и пр.).
*
Покажу на примере, как это работает…
1) Установку и запуск программы я опускаю (они стандартны и никаких сложностей возникнуть не должно).
Далее нужно нажать по меню «Файл/Открыть PDF или изображение» и указать картинку/фото, на котором находится нужный текст…
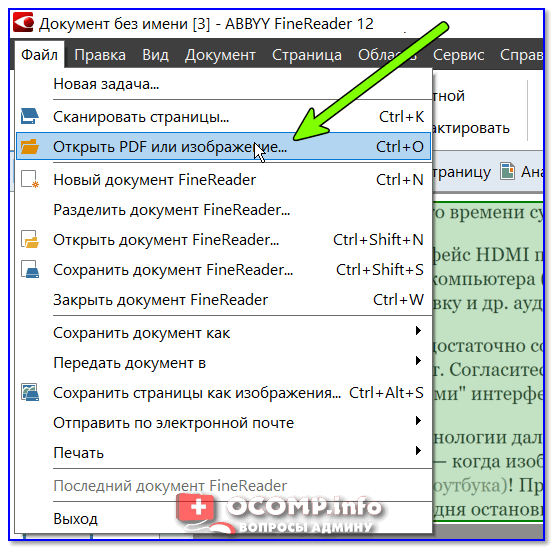
Открыть PDF или изображение
2) Распознавание картинки по умолчанию происходит автоматически (примечание: слева отображается исходная картинка — справа результаты распознавания).
В общем, когда программа закончит свою работу — останется только кликнуть в нужный участок полученного текста, и вы увидите его шрифт. В качестве примера ниже я загрузил скриншот странички своего сайта, Fine Reader выдал шрифт Georgia (правильно!).
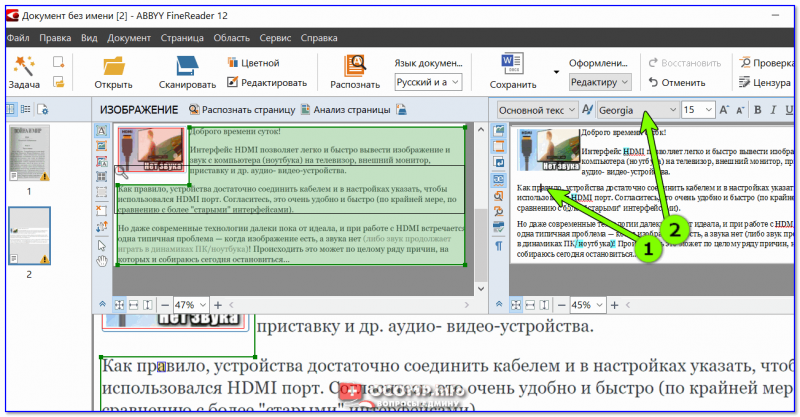
Шрифт Georgia (Скриншот ABBY FineReader)
Проверить это достаточно просто — перейти в браузер, открыть любую страничку сайта ocomp.info и посмотреть исходный код документа (на скрине ниже показано, как это выглядит в Chrome). 👇
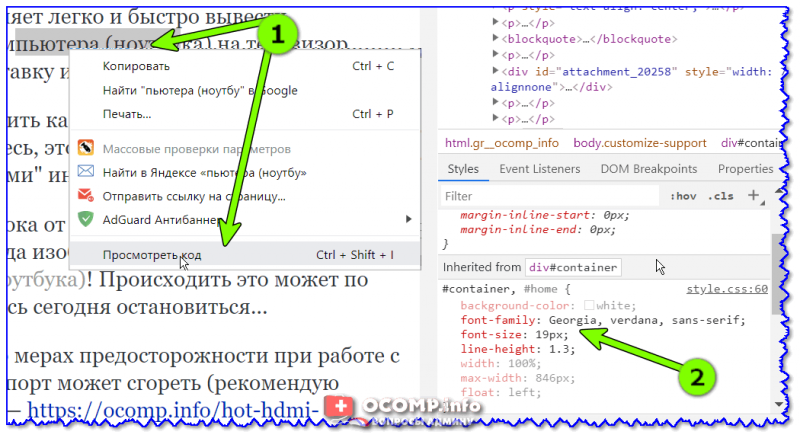
Проверка, что Georgia
В качестве еще одного примера взял фото разворота книги «Война и Мир». Используемый шрифт — Times New Roman.
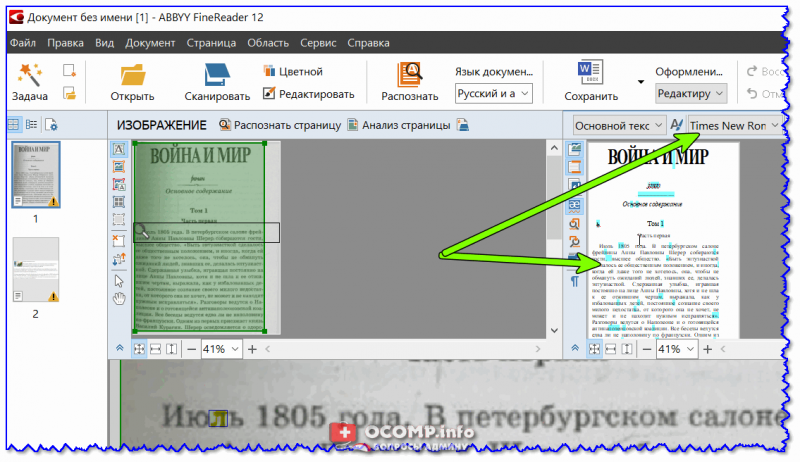
Times New Roman — скриншот из ABBY FineReader
Удобно?
Вполне! Я думаю, что этот способ — один из наиболее эффективных (особенно, если речь касается русскоязычного текста).
Примечание: если на распознаваемом фото/картинке будет использоваться редкий шрифт (которого нет в вашей системе) — FineReader подберет автоматически наиболее похожий из тех, что есть.
*
📌 Вариант 2: с помощью онлайн сервисов
Онлайн-сервисы удобны прежде всего тем, что вы сразу же можете приступить к работе (ничего не устанавливая и не настраивая). С другой стороны, их функциональность и эффективность — достаточно низкая (по крайней мере, для работы с ними нужно иметь куда качественнее изображение, чем для того же Fine Reader).
Впрочем, есть и преимущество: они могут определить шрифт даже в том случае, если у вас его нет на ПК.
Ниже привожу несколько ссылок:
- https://www.fontspring.com/matcherator (сервис для авто-распознавания шрифта. Обычно всегда рекомендует платные версии шрифтов, в то время как они почти не отличаются от обычных…);
- https://www.myfonts.com/WhatTheFont (аналогичный сервис);
- https://www.whatfontis.com/ (аналог предыдущих, правда работает через раз, но все-таки…);
- https://www.xfont.ru/russian (богатая коллекция русских шрифтов);
- https://fontstorage.com/ru/ (И еще одна… Здесь собрано более 1000 разнообразных шрифтов! 😉).
*
Работа с вышеприведенными сервисами строится либо в ручном варианте (когда вы сами подбираете шрифт, сравнивая его с оригиналом), либо в авто-варианте (когда сервис по схожести подберет вам коллекцию шрифтов).
Рассмотрю работу в одном из сервисов — myfonts.com (он первый в моем мини- списке). После перехода на сайт — вам нужно загрузить изображение и выбрать область текста на нем (см. шаг 1 и 2 на скриншоте ниже). 👇
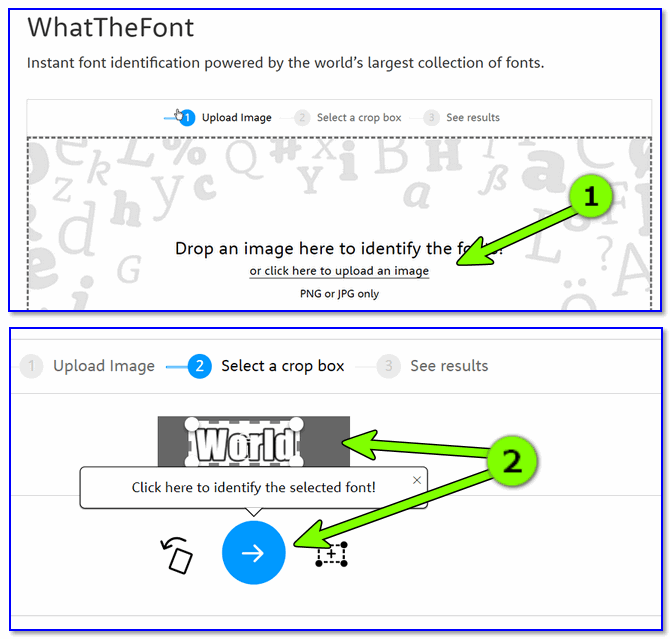
Загрузка картинки и выбор текстовой области
Далее перед вами появится список шрифтов: из него можете выбрать тот, который наиболее похож на ваш (обычно, первый в списке тот, что нужен).
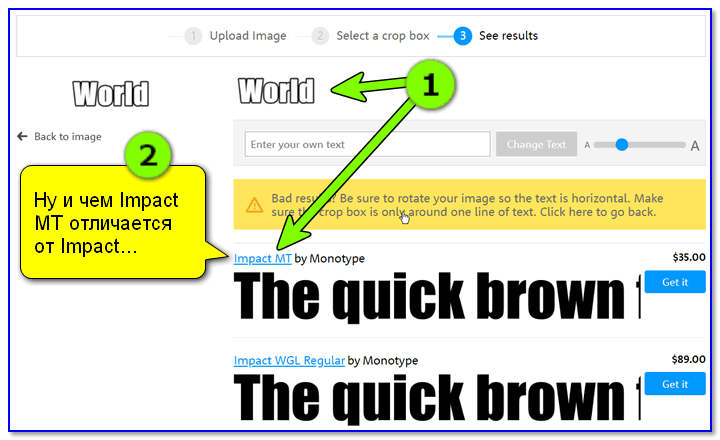
Ну и чем Impact MT отличается от Impact… (результаты работы)
Отмечу, что англоязычные сервисы не очень хорошо работают с русским текстом (часто вместо конкретного шрифта подбираются какие-то 📌крякозабры).
Примечание: также обратите внимание, что платные шрифты (которые вам будут предлагать купить на различных сервисах) часто почти не отличаются от бесплатных, тех, что уже установлены в вашей системе.
*
На этом пока всё. Иные варианты — приветствуются!
Удачи!
✌
Первая публикация: 28.05.2019
Корректировка: 2.04.2022


Полезный софт:
-

- Видео-Монтаж

Отличное ПО для создания своих первых видеороликов (все действия идут по шагам!).
Видео сделает даже новичок!
-
- Ускоритель компьютера

Программа для очистки Windows от «мусора» (удаляет временные файлы, ускоряет систему, оптимизирует реестр).
В процессе работы с текстовым процессором Word у пользователей иногда возникает необходимость обработать не только набранный ими (или другими людьми) текст, но и редактировать отсканированные фрагменты. Например, чтобы не перепечатывать вручную какой-либо текст, письмо или что-нибудь другое, сканированное и полученное в таком виде. Раньше, пока не были в ходу системы распознавания, так называемые OCR, как раз и приходилось заниматься такой нудной работой. Сегодня же можно просто использовать не только многочисленные сторонние программы, но и встроенные средства Windows и, в частности, Microsoft Office. Это даже удобнее, ведь не нужно держать под рукой установленный софт, быть привязанным к одному компьютеру и т. п. А в современном мире это достаточно много значит.

Итак, есть отсканированный текст и задача вставить его в собственный документ так, чтобы после этот фрагмент можно было править. Есть два пути; рассмотрим оба.
Первый путь
Он заключается в том, чтобы использовать встроенные средства Microsoft Word. Дело в том, что если вставить сканированный фрагмент без дополнительных действий, то он будет просто картинкой. Основной текст его будет обтекать, и редактировать вы сможете разве что размер и прозрачность. Это особенно досадно, когда нужно переделать всего-то пару строчек. Но если вставить этот отсканированный фрагмент как объект Microsoft Image Viewer в Word, то он вставится как обычный, доступный для редактирования текст. Для этого нужно проследить, чтобы файл был с расширением .tiff, а если нет, то воспользоваться Paint, открыв его и перезаписав в нужном формате. После этого в дело вступает специальный компонент платформы Microsoft Office, о котором мы упоминали чуть выше. Именно его вам следует открыть в главном меню. Если его нет, то придётся покопаться в панели управления.


Найдите в ней пункт «Установка и удаление программ», найдите в открывшемся списке Office и перейдите к выбору компонентов. Среди них вы как раз и найдёте Image Viewer, необходимый нам для выполнения задачи. После установки он появится в главном меню.

Так вот, после его открытия, drag’n’drop’ом или через меню окна, откройте в этой программе сканированный файл. Нужно будет подождать пару минут, так как на экране появится прогресс-бар, отображающий ход распознавания. По завершении процесса, собственно, откроется окно с распознанным текстом. Его вы можете скопировать в Word для дальнейшего редактирования. Конечно, вы должны учитывать, что распознавание текста, искажённого сканированием, может пройти не идеально, так что стоит провести так называемую «вычитку», то есть отредактировать его, исправляя неправильно распознанные символы. Гораздо хуже дело обстоит с рукописным текстом, вероятность, что его удастся отредактировать, сильно коррелирует с цветом бумаги и чернил, качеством сканирования и, конечно, разборчивостью почерка. Но такая работа достаточно редко проводится с рукописным текстом, обычно всё же речь идёт о напечатанном.

Второй путь
В общем говоря, второй способ состоит в том же самом, что и первый, с той только разницей, что для включения режима распознавания текста и его редактирования используется сначала сторонний софт, а потом уже Word. Потребуется установленная программа. Возможно, она даже будет работать лучше, чем решение от Microsoft, так как подобные программы разрабатываются и проектируются специально для этой задачи. Авторы обещают практически 100% точность в работе с печатным текстом и чуть более скромные цифры, когда речь заходит о рукописном. Но чтобы отделить маркетинговые уловки от истинного положения вещей, придётся ступить на стезю эмпирической проверки.

Программа ABBYY FineReader
На практике оказывается, что разрыв не столь велик. Да, кому-то может показаться удобным, что не нужно включать режим редактирования текста через связку Microsoft Image Viewer — Microsoft Word, но ведь для этого придётся использовать другую связку программ, а точность распознавания символов будет для печатных документов и так стабильно высокой. Поэтому причины платить больше за одну из этих программ, когда есть решение, встроенное в пакет Office — весьма туманны. Другое дело, если вы имеете дело с частными случаями. Например, у вас есть много отсканированных в плохом качестве документов, которые нужно оцифровать и подготовить для режима редактирования. Тогда узкоспециализированный софт, настроенный под работу с шумом и искажениями в таких изображениях, разумеется, будет предсказуемо лучше. Он точнее обработает лист с символами, корректнее распознает их и передаст в Word для дальнейшей работы. Но таких случаев не так уж много и, как правило, рядовой пользователь с ними не сталкивается. Поэтому для типовых задач этот путь уже практически не используется.

Программа Скан Корректор А4
Особенности корректировки текстовых документов
Однако под редактированием может подразумеваться не только исключительно правка отсканированных документов, но и вообще любая корректура. Начнём с самого простого — удаления символов. Для этого предусмотрены клавиши Backspace и Delete. Первый вариант удаляет символ, стоящий слева от курсора мыши. Второй, соответственно, тот, что находится правее курсора.
Также нам может понадобиться отделить друг от друга отдельные абзацы для повышения общей читабельности. Используем для этой цели клавишу ввода Enter. Если мы хотим выполнить обратную процедуру, то занимаем место в самом начале второго абзаца. Нажатие кнопки Delete пододвинет второй абзац вплотную к предыдущему.
Ещё возникает потребность работать сразу с целым текстовым фрагментом. Например, нам нужно перенести кусок текста в другую часть документа. Для этого мы выделяем его левой кнопкой мышки. После этого делаем один щелчок правой её кнопкой. Из выпавшего перечня действий выбираем «копировать» или «вырезать». Переходим на то место, куда нужно перенести фрагмент. Клик правой кнопкой мыши — выбираем команду «вставить». Теперь текст переместится на новое место.

Во время набора текста обязательно случаются ошибки, а порой, сразу целая серия. В этой ситуации очень удобно отменить свои действия, чтобы не удалять вручную каждый неверный символ. Этот момент можно значительно упростить, если знать, как действовать. На главной панели вверху нужно найти стрелочку, показывающую обратное направление. Она может выглядеть по-разному в различных версиях Word. Или же воспользоваться горячей комбинацией клавиш «Ctrl+Z». Происходит отмена последнего набранного символа.
Может возникнуть потребность вставки в имеющийся текст специальных символов. Для этого в редакторе от Майкрософт предусмотрена «Вставка», а в ней ищем вкладку «Символы». Осталось лишь выбрать тот символ, который необходимо вставить, и он будет применён ко всему документу. Ещё один случай — заменить конкретное слово другим по всему тексту. Вручную делать это много раз очень долго, однако разработчики Word позаботились и упростили эту задачу. Сначала выбираем комбинацию Ctrl+H. После этого всплывает окошко, в котором нам предлагается выбрать то слово, что подлежит замене. В соседнем окошке указываем новое слово и нажимаем «применить».

Опция исправления ошибок позволит отредактировать не только орфографические ошибки, но и синтаксис. Редактор и сам подчеркнёт неправильную орфографию при помощи красной волнистой линии, а грамматические ошибки выделяются зелёной линией. Это существенно облегчает задачу пользователю, которому следует перейти в раздел с названием Рецензирование. После этого переходим во вкладку «Правописание». Редактор сам будет предлагать заменить неправильные слова или те, которых нет в предусмотренном словаре, на правильные.

При редактировании у пользователя появляется широкий выбор изменения шрифтов, которые находятся во вкладке с соответствующим названием. Их создано десятки видов, а некоторые даже в старинных стилях, наподобие готического, однако наиболее популярным является Times New Roman. Для работы выбирают различный размер шрифта, но более востребованными являются №№12 и 14. А готовый шрифт можно сделать жирным, отметить подчеркиванием, сделать курсивом.
Многим, кто работает с большими объёмами текстов по учёбе и работе, приходится делать нумерацию страниц в пределах одного документа. Для того чтобы пронумеровать их, перейдём во вкладку «Вставка», где предусмотрено немало интересных инструментов. Выберем «номер страницы», а затем место, куда будет проставлена нумерация на каждой из страниц документа. В большинстве случаев это бывает внизу посередине. Это основные функции, о которых следует знать начинающему редактору при работе с Word любой версии.

Послесловие
Пакет Office представляет собой широкий набор инструментов для решения самых разнообразных задач. У каждой из входящих в него программ есть своя функциональность, и они дополняют друг друга при выполнении офисных работ. В частности, для редактирования отсканированных документов в Word потребуется программа распознавания, и в пакете она представлена. Такая структура «всё-в-одном» весьма удобна, так как не приходится думать, где найти и как установить сторонний софт, не нужно разбираться с особенностями его интерфейса: есть решения, выполненные в едином стиле. Поэтому Office был и остаётся стандартом де-факто для офисной работы.
Что же касается возможности вставить изображение напрямую в Word и редактировать его прямо оттуда, то пока что такой режим не поддерживается. Однако учитывая тенденции на объединение программ внутри пакета и уход в онлайн (мы имеем в виду Office365), стоит этого вскоре ожидать. Сейчас же нужно будет установить требуемый компонент (если он ещё не был установлен) и работать именно так.
Если в распознанном тексте некорректно отображается шрифт или на месте некоторых букв стоят
значки «?» или «□»
Если в окне Текст вместо некоторых букв стоят значки «?» или «□»,
проверьте используемые шрифты: они должны содержать все символы языка документа.
 Подробнее см. «Шрифты, необходимые для корректного
Подробнее см. «Шрифты, необходимые для корректного
отображения символов поддерживаемых языков в редакторе ABBYY FineReader».
Вы можете изменить шрифт в уже распознанном документе не запуская процесс распознавания еще раз.
Как изменить шрифт, если у вас небольшой документ:
- Выделите абзац, в котором некорректно отображается шрифт.
- В его контекстном меню выберите пункт
Свойства. - На панели Свойства текста в списке шрифтов выберите шрифт.
Выделенный абзац будет отображаться указанным шрифтом.
Как изменить шрифт в большом
документе, форматирование текста в котором
определено стилями:
- В меню
Сервис выберите пункт
Редактор стилей…. - В открывшемся диалоге Редактор стилей
выберите стиль и измените шрифт. - Нажмите кнопку
ОК.
Свойства стиля будут изменены. Весь текст, форматирование которого
определено данным стилем, будет отображаться указанным шрифтом.
Внимание!
В документе ABBYY FineReader, распознанном или отредактированном на другом
компьютере, может некорректно отображаться распознанный текст. Убедитесь,
что на вашем компьютере установлены шрифты, которые используются в этом
документе.
Не копируется текст из PDF: причины, способы изменения формата и советы специалистов
Бывало у вас такое, что вам необходимо текст, присутствующий в каком-то PDF-документе, вставить в другую программу для редактирования, но в файле PDF текст не копируется? Как бы посоветовали поступить в такой ситуации? Далеко не многие пользователи догадываются о том, что можно воспользоваться не одним, а несколькими простыми способами, позволяющими «разрулить» ситуацию. Но для начала давайте остановимся на некоторых стандартных случаях и их причинах, а затем попробуем найти наиболее подходящее решение для каждого из них. Сразу стоит отметить, что изменять оригинальный формат документа не всегда целесообразно.
Почему текст из PDF не копируется?
 You will be interested: How dangerous is the new coronavirus?
You will be interested: How dangerous is the new coronavirus?
Итак, первой и основной причиной невозможности копирования содержимого документов PDF большинство специалистов считает установку всевозможных запретов на подобные действия в самих файлах.
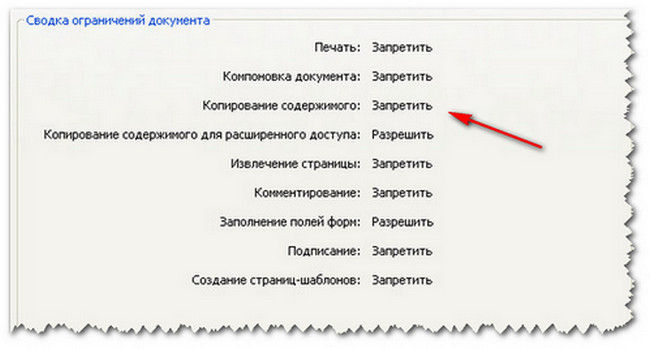
Это могут быть и пароли на открытие, и запреты на копирование, и даже защита документа при попытке вывода содержимого на печать. Еще одна не менее распространенная ситуация, связанная с тем, что текст из PDF не копируется, может быть связана с повреждением самого файла или нарушением его оригинальной структуры. Реже можно встретить и случаи, когда пользователь использует для извлечения текстового содержимого из PDF-документа не совсем подходящее приложение. Так, например, очень многие эксперты сходятся во мнении, что у Adobe Reader возможностей в сравнении с Acrobat гораздо больше. Поэтому, если текст из PDF не копируется в «Акробате», первым делом попробуйте выполнить аналогичную операцию в «Ридере». Вполне возможно, это даст желаемый результат. Но в большинстве случаев это, увы, не помогает, поскольку содержимое попросту защищено от копирования, а пароль скрыт глубоко внутри самого файла. Как обойти такие ограничения рассмотрим чуть позже, а пока остановимся еще на одной ситуации, которая тоже многих пользователей ставит в тупик.
Почему текст из PDF копируется иероглифами?
Теперь предположим, что защита от копирования в оригинальном документе не установлена и все вроде бы нормально. Но почему-то при переносе содержимого в другой редактор текст из PDF копируется иероглифами. Связано это только с тем, что оригинал имеет отличную от стандартной кодировку. Чаще всего специалисты в такой ситуации предлагают самый простой выход, при котором даже изменять начальный формат документа не потребуется. Исходя из того, что текст из PDF копируется с неправильной кодировкой, ее нужно сменить.
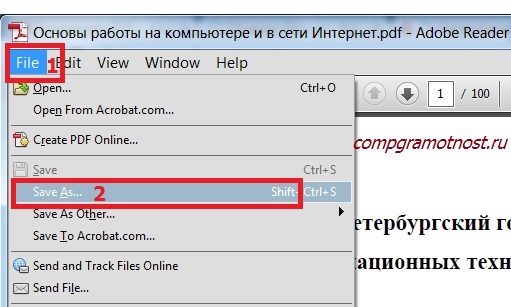
Для этого проще всего воспользоваться файловым меню любого редактора PDF, выбрать пункт «Сохранить как. » (Save As…), а затем в окне сохранения нажать кнопку параметров (Settings) и выбрать другую кодировку. Обычно достаточно поменять оригинальный стандарт на UTF-8. При повторном открытии документа текст можно будет скопировать и вставить в любой другой текстовый редактор в неизменном виде. Также перекодировать файл можно на каком-нибудь интернет-ресурсе вроде Decoder.
Как обойти запрет копирования в самом файле?
Теперь давайте посмотрим, что можно сделать для обхода всевозможных запретов и блокировок.
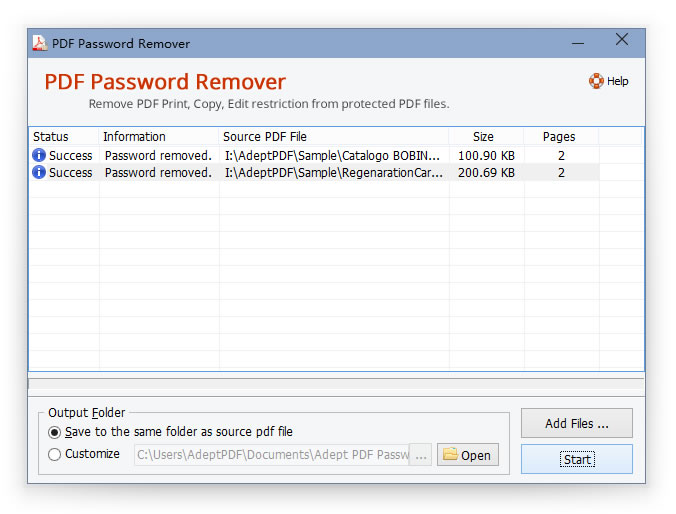
Если текст из PDF не копируется ни под каким предлогом, можете воспользоваться пиратским методом, выполнив снятие ограничений или удаление установленных паролей в программе PDF Password Remover. Если это результата не даст, можете зайти на какой-нибудь специализированный сайт вроде PDFPirate или FreeMyPDF и попытаться снять защиту там. Однако каждый должен понимать, что в случае с некоторыми официальными документами такая методика является противозаконной.
Открытие файла PDF в Word
Еще одна простая методика, рекомендуемая для устранения множества проблем с оригинальными PDF-документами, которые необходимо отредактировать, состоит в том, чтобы не копировать исходное содержимое в «просмотрщике» или редакторе PDF, а открыть файл непосредственно в той программе, с использованием которой предполагается производить редактирование.
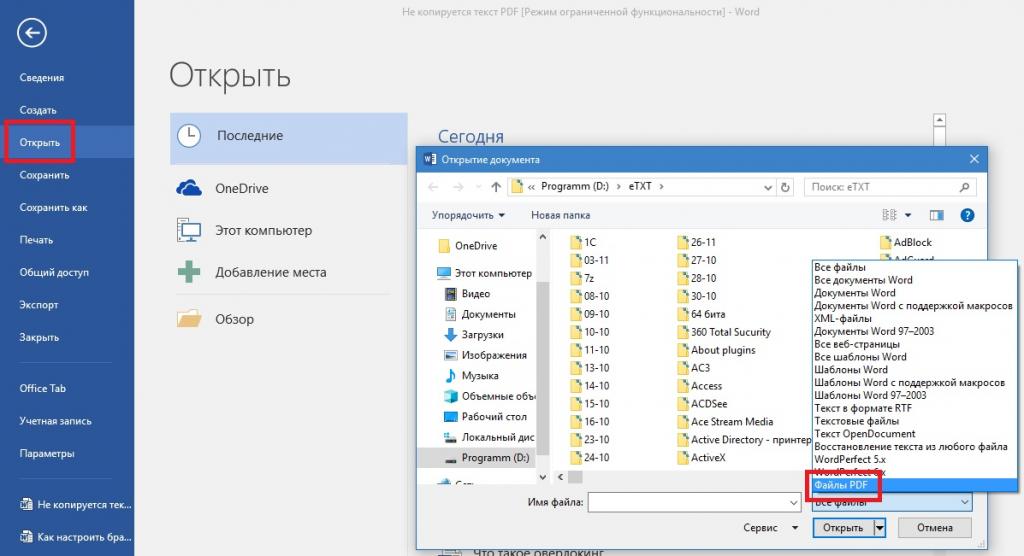
В случае с текстовыми документами, проще всего воспользоваться универсальным «Вордом» и открыть искомый документ в этом приложении, выбрав соответствующий тип файла. Если документ откроется без проблем, его можно будет и отредактировать, и сохранить в нужном формате.
Как преобразовать текст PDF в Word?
Но давайте предположим, что исходный документ в текстовых редакторах не открывается (мало ли что может быть) и в «родных» редакторах текст из PDF не копируется.
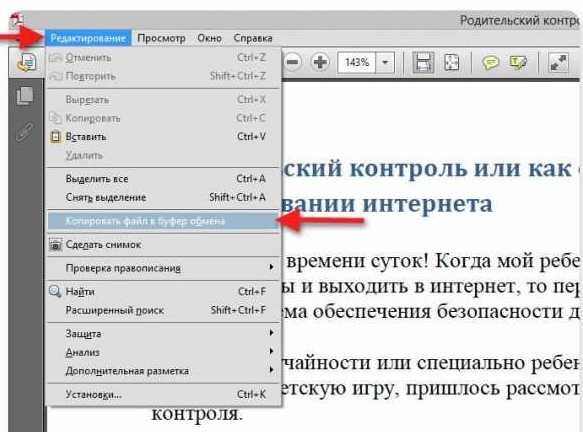
В этом случае для преобразования файла именно в документ Word попробуйте в PDF-редакторе выбрать не копирование текста, а копирование файла в буфер обмена целиком, после чего вставьте содержимое в Word. Способ, конечно, далеко не самый удобный, поскольку вставка будет иметь графический формат, и отредактировать материал будет невозможно.
В этой ситуации оптимальным решением станет смена формата оригинального документа на любой другой. В интернете сейчас выложено достаточно много программ-конвертеров, например, PDF to Word Converter и др. В выбранном приложении обычно достаточно просто указать начальный файл и конечный формат после преобразования. При помощи таких апплетов, кстати, можно преобразовать PDF не только в Word. Существуют и программы для конвертирования в Excel.
Проблемы с самим текстом в PDF-документах
Иногда бывает и так, что в оригинальном файле текстовое содержимое могло быть изначально создано путем сканирования какого-то печатного документа. Совершенно очевидно, что при таком подходе текст был сохранен именно в графическом формате. При этом и на него могли быть установлены запреты на копирование или печать. Как поступить в такой ситуации?
Использование системы оптического распознавания
В этом случае на помощь приходят системы оптического распознавания OCR. Практически все эксперты сходятся во мнении, что оптимальным вариантом станет выбор пакета ABBY Finereader. Конечно, программа не бесплатная, но на просторах «Рунета» можно найти уже активированные (взломанные) версии или модификации с ключом активации.
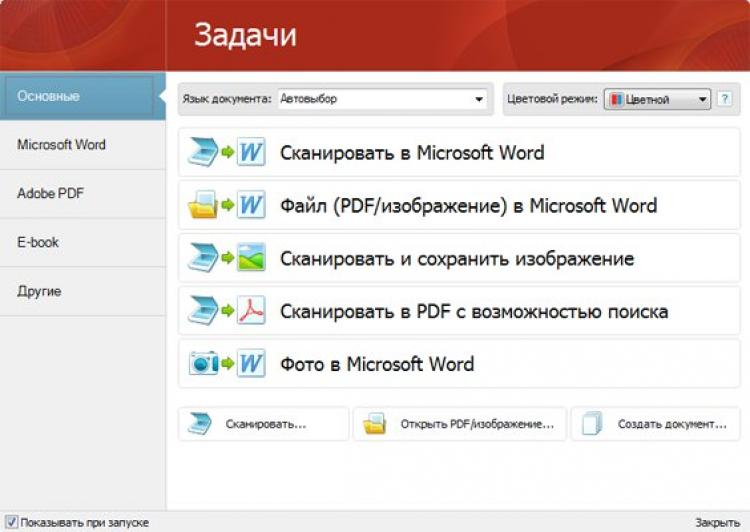
В самом приложении в стартовом окне выбрать преобразование файла PDF/изображения в документ Word. Система самостоятельно распознает текст с картинки и отправит его в Word, после чего можно будет выполнить редактирование и сохранить новый документ.
Конвертирование в другие форматы
Наконец, если стоит задача преобразовать текст в другие нестандартные форматы, обычно для этих целей рекомендуется применять все те же конвертеры, выбирая либо узконаправленные программы (например, PDF to JPEG для конвертирования в графические файлы), либо универсальные приложения, поддерживающие не один, а несколько форматов, среди которых будет тот, что нужен. Иногда можно использовать и онлайн-сервисы, но это неудобно по соображениям больших временных затрат и ограничений по размеру добавляемых файлов (или их количеству).
Заключение
Подводя итоги, можно выделить несколько основных моментов. Во-первых, изменять исходный формат не всегда нужно, поскольку выполнить копирование можно либо в более продвинутом редакторе, как в случае с «Акробатом» и «Ридером», либо открыть файл непосредственно в той программе для работы с текстовым содержимым, в которую нужно вставить исходный материал, как в случае с Word. Во-вторых, для сброса паролей и запретов лучше всего применять специальные приложения (пусть даже это и выглядит незаконно). В-третьих, большинство конвертеров в процессе преобразования форматов запреты, как правило, игнорируют, так что и их использование выглядит весьма перспективным. В-четвертых, не стоит сбрасывать со счетов и системы распознавания текста, которые иногда выглядят даже лучше, чем все предыдущее. В-пятых, существует мнение, что иногда преобразование можно выполнить при помощи виртуальных принтеров, но такой вариант годится только для тех случаев, когда исходный текстовый фрагмент нужно преобразовать в графику.
При конвертации pdf в word иероглифы. Что делать, если вместо текста иероглифы (в Word, браузере или текстовом документе). Копируем текст из PDF файла в Word с помощью онлайн конвертеров
Вопрос пользователя
Здравствуйте.
Подскажите пожалуйста, почему у меня некоторые странички в браузере отображают вместо текста иероглифы, квадратики и не пойми что (ничего нельзя прочесть). Раньше такого не было.
Заранее спасибо.
Доброго времени суток!
Действительно, иногда при открытии какой-нибудь интернет-странички вместо текста показываются различные «крякозабры» (как я их называю), и прочитать это нереально.
Происходит это из-за того, что текст на страничке написан в одной кодировке (более подробно об этом можете узнать из ), а браузер пытается его открыть в другой. Из-за такого рассогласования, вместо текста — непонятный набор символов.
Попробуем исправить это.
Исправляем иероглифы на текст
Вообще, раньше Internet Explorer часто выдавал подобные крякозабры, современные же браузеры (Chrome, Яндекс-браузер, Opera, Firefox) — довольно неплохо определяет кодировку, и ошибаются очень редко. Скажу даже больше, в некоторых версиях браузера уже убрали выбор кодировки, и для «ручной» настройки этого параметра нужно скачивать дополнения, или лезть в дебри настроек за 10-ток галочек.
И так, предположим браузер неправильно определили кодировку и вы увидели следующее (как на скрине ниже).
Чаще всего путаница бывает между кодировками UTF (Юникод) и Windows-1251 (большинство русскоязычных сайтов выполнены в этих кодировках).
- нажать левый ALT — чтобы сверху показалось меню. Нажать меню «Вид»;
- выбрать пункт «Кодировка текста» , далее выбрать Юникод . Вуаля — иероглифы на странички сразу же стали обычным текстом (скрин ниже)!
Еще один совет : если в браузере не можете найти, как сменить кодировку (а дать инструкцию для каждого браузера — вообще нереально!), я рекомендую попробовать открыть страничку в другом браузере. Очень часто другая программа открывает страницу так, как нужно.
Текстовые документы
Очень много вопросов по крякозабрам задаются при открытии каких-нибудь текстовых документов. Особенно старых, например при чтении Readme в какой-нибудь программе прошлого века (например, к играм).
Разумеется, что многие современные блокноты просто не могут прочитать DOS»овскую кодировку, которая использовалась ранее. Чтобы решить сию проблему, рекомендую использовать редактор Bread 3.
Bred 3
Простой и удобный текстовый блокнот. Незаменимая вещь, когда нужно работать со старыми текстовыми файлами. Bred 3 за один клик мышкой позволяет менять кодировку и делать не читаемый текст читаемым! Поддерживает кроме текстовых файлов довольно большое разнообразие документов. В общем, рекомендую!
Попробуйте открыть в Bred 3 свой текстовый документ (с которым наблюдаются проблемы). Пример показан у меня на скрине ниже.
Для работы с текстовыми файлами различных кодировок так же подойдет еще один блокнот — Notepad++. Вообще, конечно, он больше подходит для программирования, т.к. поддерживает различные подсветки, для более удобного чтения кода.
Пример смены кодировки показан ниже: чтобы прочитать текст, достаточно в примере ниже, достаточно было сменить кодировку ANSI на UTF-8.
WORD»овские документы
Очень часто проблема с крякозабрами в Word связана с тем, что путают два формата Doc и Docx . Дело в том, что с 2007 Word (если не ошибаюсь) появился формат Docx (позволяет более сильнее сжимать документ, чем Doc, да и надежнее защищает его).
Так вот, если у вас старый Word, который не поддерживает этот формат — то вы, при открытии документа в Docx, увидите иероглифы и ничего более.
Решения есть 2:
- скачать на сайте Microsoft спец. дополнение, которое позволяет открывать в старом Word новые документы. Только из личного опыта могу сказать, что открываются далеко не все документы, к тому же сильно страдает разметка документа (что в некоторых случаях очень критично);
- использовать аналоги Word (правда, тоже разметка в документе будет страдать);
- обновить Word до современной версии.
Так же при открытии любого документа в Word (в кодировке которого он «сомневается»), он на выбор предлагает вам самостоятельно указать оную. Пример показан на рисунке ниже, попробуйте выбрать:
- Widows (по умолчанию);
- MS DOS;
- Другая.
Окна в различных приложениях Windows
Бывает такое, что какое-нибудь окно или меню в программе показывается с иероглифами (разумеется, прочитать что-то или разобрать — нереально).
- Руссификатор. Довольно часто официальной поддержки русского языка в программе нет, но многие умельца делают руссификаторы. Скорее всего, на вашей системе — данный руссификатор работать отказался. Поэтому, совет простой: попробовать поставить другой;
- Переключение языка. Многие программы можно использовать и без русского, переключив в настройках язык на английский. Ну в самом деле: зачем вам в какой-то утилите, вместо кнопки «Start» перевод «начать»?
- Если у вас раньше текст отображался нормально, а щас нет — попробуйте восстановить Windows, если, конечно, у вас есть точки восстановления (подробно об этом здесь — );
- Проверить настройки языков и региональных стандартов в Windows, часто причина кроется именно в них.
Языки и региональные стандарты в Windows
Чтобы открыть меню настроек:
- нажмите Win+R ;
- введите intl.cpl , нажмите Enter.
intl.cpl — язык и регион. стандарты
Проверьте чтобы во вкладке «Форматы» стояло «Русский (Россия) // Использовать язык интерфейса Windows (рекомендуется)» (пример на скрине ниже).
Во вкладке местоположение поставьте расположение Россия.
И во вкладке дополнительно установите язык системы на «Русский (Россия)». После этого сохраните настройки и перезагрузите ПК. Затем вновь проверьте, нормально ли отображается интерфейс нужной программы.
И напоследок, наверное, для многих это очевидно, и все же некоторые открывают определенные файлы в программах, которые не предназначены для этого: к примеру в обычном блокноте пытаются прочитать файл DOCX или PDF. Естественно, в этом случае вы вместо текста будут наблюдать за крякозабрами, используйте те программы, которые предназначены для данного типа файла (WORD 2007+ и Adobe Reader для примера выше).
На сим всё, удачи!
Наверное, каждый пользователь ПК сталкивался с подобной проблемой: открываешь интернет-страничку или документ Microsoft Word — а вместо текста видишь иероглифы (различные «крякозабры», незнакомые буквы, цифры и т.д. (как на картинке слева…)).
Хорошо, если вам этот документ (с иероглифами) не особо важен, а если нужно обязательно его прочитать?! Довольно часто подобные вопросы и просьбы помочь с открытием подобных текстов задают и мне. В этой небольшой статье я хочу рассмотреть самые популярные причины появления иероглифов (разумеется, и устранить их).
Иероглифы в текстовых файлах (.txt)
Самая популярная проблема. Дело в том, что текстовый файл (обычно в формате txt, но так же ими являются форматы: php, css, info и т.д.) может быть сохранен в различных кодировках .
Кодировка — это набор символов, необходимый для того, чтобы полностью обеспечить написание текста на определенном алфавите (в том числе цифры и специальные знаки). Более подробно об этом здесь: https://ru.wikipedia.org/wiki/Набор_символов
Чаще всего происходит одна вещь: документ открывается просто не в той кодировке из-за чего происходит путаница, и вместо кода одних символов, будут вызваны другие. На экране появляются различные непонятные символы (см. рис. 1)…
Рис. 1. Блокнот — проблема с кодировкой
Как с этим бороться?
На мой взгляд лучший вариант — это установить продвинутый блокнот, например Notepad++ или Bred 3. Рассмотрим более подробно каждую из них.
Один из лучших блокнотов как для начинающих пользователей, так и для профессионалов. Плюсы: бесплатная программа, поддерживает русский язык, работает очень быстро, подсветка кода, открытие всех распространенных форматов файлов, огромное количество опций позволяют подстроить ее под себя.
В плане кодировок здесь вообще полный порядок: есть отдельный раздел «Кодировки» (см. рис. 2). Просто попробуйте сменить ANSI на UTF-8 (например).
После смены кодировки мой текстовый документ стал нормальным и читаемым — иероглифы пропали (см. рис. 3)!
Рис. 3. Текст стал читаемый… Notepad++
Еще одна замечательная программа, призванная полностью заменить стандартный блокнот в Windows. Она так же «легко» работает со множеством кодировок, легко их меняет, поддерживает огромное число форматов файлов, поддерживает новые ОС Windows (8, 10).
Кстати, Bred 3 очень помогает при работе со «старыми» файлами, сохраненных в MS DOS форматах. Когда другие программы показывают только иероглифы — Bred 3 легко их открывает и позволяет спокойно работать с ними (см. рис. 4).
Если вместо текста иероглифы в Microsoft Word
Самое первое, на что нужно обратить внимание — это на формат файла. Дело в том, что начиная с Word 2007 появился новый формат — «docx » (раньше был просто «doc «). Обычно, в «старом» Word нельзя открыть новые форматы файлов, но случается иногда так, что эти «новые» файлы открываются в старой программе.
Просто откройте свойства файла, а затем посмотрите вкладку «Подробно » (как на рис. 5). Так вы узнаете формат файла (на рис. 5 — формат файла «txt»).
Если формат файла docx — а у вас старый Word (ниже 2007 версии) — то просто обновите Word до 2007 или выше (2010, 2013, 2016).
Далее при открытии файла обратите внимание (по умолчанию данная опция всегда включена, если у вас, конечно, не «не пойми какая сборка») — Word вас переспросит: в какой кодировке открыть файл (это сообщение появляется при любом «намеке» на проблемы при открытии файла, см. рис. 5).
Рис. 6. Word — преобразование файла
Чаще всего Word определяет сам автоматически нужную кодировку, но не всегда текст получается читаемым. Вам нужно установить ползунок на нужную кодировку, когда текст станет читаемым. Иногда, приходится буквально угадывать, в как был сохранен файл, чтобы его прочитать.
Рис. 8. браузер определил неверно кодировку
Чтобы исправить отображение сайта: измените кодировку. Делается это в настройках браузера:
- Google chrome: параметры (значок в правом верхнем углу)/дополнительные параметры/кодировка/Windows-1251 (или UTF-8);
- Firefox: левая кнопка ALT (если у вас выключена верхняя панелька), затем вид/кодировка страницы/выбрать нужную (чаще всего Windows-1251 или UTF-8) ;
- Opera: Opera (красный значок в верхнем левом углу)/страница/кодировка/выбрать нужное.
Таким образом в этой статье были разобраны самые частые случаи появления иероглифов, связанных с неправильно определенной кодировкой. При помощи выше приведенных способов — можно решить все основные проблемы с неверной кодировкой.
Буду благодарен за дополнения по теме. Good Luck
Вопрос от пользователя
Добрый день.
Подскажите пожалуйста. У меня есть один файл формата PDF, и мне нужно его отредактировать (поменять часть текста, поставить заголовки и выделения). Думаю, что лучше всего такую операцию провести в WORD.
Как конвертировать этот файл в формат DOCX (с которым работает WORD)? Пробовала несколько сервисов, но некоторые выдают ошибку, другие — переносят текст, но теряют картинки. Можно ли сделать лучше?
Марина Иванова (Нижний Новгород)
Да, в офисной работе время от времени приходится сталкиваться с такой задачей. В некоторых случаях, она решается довольно легко, в других — всё очень непросто ☺.
Дело в том, что PDF файлы могут быть разными:
- в форме картинок : когда каждая страничка представляет из себя фото/картинку, т.е. текста там нет в принципе. Самый сложный вариант для работы, т.к. перевести это все в текст — это все равно что работать со сканированным листом (у кого есть сканер — тот поймет ☺). В этом случае целесообразно пользоваться спец. программами;
- в форме текста : в файле есть текст, который сжат в формат PDF и защищен (не защищен) от редактирования (с этим типом, как правило, работать легче). В этом случае сгодятся и онлайн-сервисы, и программы.
В статье рассмотрю несколько способов преобразования PDF в WORD. Думаю, что из них каждый для себя сможет найти самый подходящий, и выполнит сию задачу ☺.
Программами
Microsoft Word
В новых версиях Word (по крайней мере в 2016) есть специальный инструмент по преобразованию PDF файлов. Причем, от вас ничего ненужно — достаточно открыть какую-нибудь «пдф-ку» и согласиться на преобразование. Через пару минут — получите результат.
И, кстати, данная функция в Word работает весьма неплохо (причем, с любыми типами PDF файлов). Именно поэтому, рекомендую попробовать сей способ в первую очередь.
Как пользоваться : сначала откройте Word, затем нажмите «файл/открыть» и выберите нужный вам файл.
На вопрос о преобразование — просто согласитесь. Через некоторое время увидите свой файл в форме текста.

Плюсы : быстро; не нужно никаких телодвижений от пользователя; приемлемый результат.
Минусы : программа платная; часть форматирования документа может потеряться; далеко не все картинки будут перенесены; на процесс преобразования никак нельзя повлиять — всё идет в авто-режиме.
Примечание!
Вместо Word и Excel можно использовать другие бесплатные аналоги с похожим функционалом. О них я рассказывал в этой статье:
ABBY Fine Reader
Ограничения в пробной версии : 100 страниц для распознавания; софт работает в течении 30 дней после установки.
А вот эта программа одна из самых универсальных — ей можно «скормить» любой файл PDF, картинку, фото, скан. Работает она по следующему принципу: выделяются блоки текста, картинок, таблиц (есть авто-режим, а есть ручной), а затем распознает с этих блоков текст. На выходе вы получаете обычный документ Word.
Кстати, последние версии программы отличаются направленностью на начинающего пользователя — пользоваться программой очень просто. В первом приветственном окне выберите «Изображение или PDF-файл в Microsoft Word» (см. скрин ниже).

Fine Reader — популярные задачи, вынесенные в стартовое окно приветствия
Далее программа автоматически разобьет ваш документ по страничкам, и на каждой страничке сама выделит все блоки и распознает их. Вам останется подправить ошибки и сохранить документ в формат DOCX (кстати, Fine Reader может сохранить и в другие форматы: HTML, TXT, DOC, и пр.).

Fine Reader — распознавание текста и картинок в PDF файле
Плюсы : можно перевести любую картинку или PDF файл в текстовый формат; лучшие алгоритмы распознавания; есть опции для проверки распознанного текста; можно работать даже с самыми безнадежными файлами, от которых отказались все остальные сервисы и программы.
Минусы : программа платная; нужно вручную указывать блоки на каждой из страничек.
Readiris Pro
Ограничение пробной версии : 10 дней использования или обработка 100 страниц.
Эта программа некоторый конкурент Fine Reader. Она поможет сканировать документ с принтера (даже если у вас нет драйверов на него!), а потом распознать информацию со скана и сохранить ее в Word (в этой статье нас интересует вторая часть, а именно распознавание ☺).
Кстати, благодаря очень тесной интеграции с Word — программа способна распознать математические формулы, различные не стандартные символы, иероглифы и т.д.

Плюсы : распознавание разных языков (английский, русский и пр.); множество форматов для сохранения; неплохие алгоритмы; системные требования ниже, чем у других программ аналогов.
Минусы : платная; встречаются ошибки и необходима ручная обработка.
Free PDF to Word Converter
Сайт разработчика: http://www.free-pdf-to-word-converter.com/

Очень простая программа для быстрой конвертации файлов PDF в DOC. Программа полностью бесплатна, и при преобразовании — старается сохранить полностью исходное форматирование (чего многим аналогам так не хватает).
Несмотря на то, что в программе нет русского, разобраться со всем достаточно просто: в первом окне указываете PDF файлы (Select File — т.е. выбрать файлы); во втором — формат для сохранения (например, DOC); в третьем — папку, куда будут сохранены преобразованные документы (по умолчанию, используется «Мои документы»).
В общем-то, в целом хороший и удобный инструмент для преобразования относительно несложных файлов.
Онлайн-сервисами
Small PDF

Smallpdf.com — бесплатное решение всех PDF проблем
Отличный и бесплатный сервис для преобразования и работы с PDF файлами. Здесь есть все, что может пригодиться: сжатие, конвертирование между JPG, Word, PPT, объединение PDF, поворачивание, редактирование и пр.!
Преимущества:
- качественное и быстрое преобразование, редактирование;
- простой и удобный интерфейс: разберется даже совсем начинающий пользователь;
- доступно на всех платформах: Windows, Android, Linux и пр.;
- работа с сервисом бесплатна.
- не работает с некоторыми типами файлов PDF (там, где нужно проводить распознавание картинок).
Конвертер PDF
Стоимость: около 9$ в месяц

Этот сервис позволяет бесплатно обрабатывать только две странички (за остальное придется доплатить). Зато сервис позволяет конвертировать PDF файл в самые различные форматы: Word, Excel, Power Point, в картинки и т.д. Также у него используются отличные от аналогов алгоритмы (позволяют получить качество обработки файла на порядок выше, чем у аналогов). Собственно, благодаря этой функциональности и алгоритмам, я и добавил его в обзор.
Кстати, по первым двум страничкам сможете сделать вывод, стоит ли покупать подписку на сервис (стоимость около 9$ за месяц работы).
ZamZar

Многофункциональный онлайн-конвертер, работает с кучей форматов: MP4, MP3, PDF, DOC, MKV, WAV и многие другие. Несмотря на то, что сервис выглядит несколько странным, пользоваться им достаточно просто: т.к. все действия выполняются пошагово (см. на скрин выше: Шаг 1, 2, 3, 4 (Step 1, 2, 3, 4)).
- Step 1 (ШАГ 1) — выбор файла.
- Step 2 (ШАГ 2) — в какой формат конвертировать.
- Step 3 (ШАГ 3) — необходимо указать свою почту (кстати, возможно вам будет статья о том, ).
- Step 4 (ШАГ 4) — кнопка для запуска конвертирования.
Особенности:
- куча форматов для конверта из одного в другой (в том числе PDF);
- возможность пакетной обработки;
- очень быстрый алгоритм;
- сервис бесплатный;
- есть ограничение на размер файла — не более 50 МБ;
- результат конверта приходит на почту.
Convertio

Мощный и бесплатный сервис по онлайн-работе с различными форматами. Что касается PDF — то сервис может конвертировать их в DOC формат (кстати, сервис работает даже со сложными «пдф-ками», с которыми остальные не смогли справиться), сжимать, объединять и пр.
Ограничений на размер файлов и их структуру — не выявлено. Для добавления файла необязательно даже иметь его на диске — достаточно указать URL адрес, а с сервиса уже скачать готовый документ в формате DOC. Очень удобно, рекомендую!
iLOVEPDF

Похожий на предыдущий сайт: также есть весь функционал для работы с PDF — сжатие, объединение, разбивка, конвертация (в различные форматы). Позволяет быстро преобразовать различные небольшие PDF файлы.
Из минусов : сервис не может обработать файлы, которые состоят из картинок (т.е. «пдф-ки» где нет текста, здесь вы с них ничего не вытащите — сервис вернет вам ошибку, что текста в файле нет).
PDF.io

Весьма интересный и многофункциональный онлайн-сервис. Позволяет конвертировать PDF в: Excel, Word, JPG, HTML, PNG (и те же самые операции в обратном направлении). Кроме этого, на этом сервисе можно сжимать файлы подобного типа, объединять и разделять страницы. В общем-то, удобный помощник в офисной работе ☺.
Из минусов : сервис справляется не с всеми типами файлов (в частности, про некоторые пишет, что в них нет текста).
Дополнения приветствуются.
Довольно часто используется для публикации разного рода электронных документов. В PDF публикуются научные работы, рефераты, книги, журналы и многое другие.
Сталкиваясь с документом в PDF формате, пользователи часто не знают, как скопировать текст в Ворд. Если у вас также возникла подобная проблема, то наша статья должна вам помочь. Здесь вы узнаете 4 способа, как скопировать текст из PDF в Ворд.
Самый простой способ скопировать текст из PDF в Ворд это обычное копирование, которым вы пользуетесь постоянно. Откройте ваш PDF файл в любой программе для просмотра PDF файлов (например, можно использовать Adobe Reader), выделите нужную часть текста, кликните по ней правой кнопкой мышки и выберите пункт «Копировать».
Также вы можете скопировать текст с помощью комбинации клавиш CTRL-C. После копирования текст можно вставить в Ворд или любой другой текстовый редактор.
К сожалению, данный способ копирования текста далеко не всегда подходит. от копирования, тогда вам не удастся выполнить копирование текста. Также в PDF документе могут быть таблицы или картинки, которые нельзя просто так скопировать. Если вы столкнулись с подобной проблемой, то следующие способы копирования текста из ПДФ должны вам помочь.
Копируем текст из PDF файла в Word с помощью ABBYY FineReader
ABBYY FineReader это программа для распознавания текста. Обычно данную программу используют для распознавания текста на отсканированных изображениях. Но, с помощью ABBYY FineReader можно распознавать и PDF файлы. Для этого откройте ABBYY FineReader, нажмите на кнопку «Открыть» и выберите нужный вам PDF файл.

После того как программа закончит распознавание текста нажмите на кнопку «Передать в Word».

После этого перед вами должен открыться документ Ворд с текстом из вашего PDF файла.
Копируем текст из PDF файла в Word c помощью конвертера
Если у вас нет возможности воспользоваться программой ABBYY FineReader, то можно прибегнуть к программам-конвертерам. Такие программы позволят конвертировать PDF документ в Word файл. Например, можно использовать бесплатную программу .
Для того чтобы сконвертировать PDF документ в Word файл с помощью UniPDF вам нужно просто открыть программу, добавить в нее нужный PDF файл, выбрать конвертацию в Word и нажать на кнопку «Convert».

Копируем текст из PDF файла в Word с помощью онлайн конвертеров
Также существуют онлайн конвертеры, которые позволяют сконвертировать PDF файл в Word файл. Обычно такие онлайн конвертеры работают хуже, чем специализированные программы, но они позволят скопировать текст из PDF в Ворд без установки дополнительного софта. Поэтому их также нужно упомянуть.
Использовать такие конвертеры довольно просто. Все что вам нужно сделать, это загрузить файл и нажать на кнопку «Конвертировать». А после завершения конвертации нужно будет скачать файл обратно.
При печати pdf файла на принтере печатаются иероглифы или как говорили мои бухгалтера на старой работе «Виталий подойди у нас при печати pdf абракадабра распечатывается «. Сегодня на работе возникла такая же фигня и т.к. я стараюсь в своем блоге описывать по максимуму решения таких проблем и решил выложить инструкцию по исправлению иероглифов в pdf файлах. Так вот эту проблему можно решить тремя способами(может есть и еще но я опишу те какие знаю ).

1 Способ
Это самый надежный и проверенный временем способ!!
- Открыть редактор реестра (Пуск -> Выполнить -> regedit.exe)
- Перейти в
HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindows NTCurrentVersionFontSubstitutes - Удалить параметры: «Courier,0»=»Courier New,204″
«Arial,0»=»Arial,204″ - Перезагрузить ПК
PS перезагрузить комп нужно обязательно.
2 Способ
Самый долгий наверное из всех трех способ, это скачать русифицированную версию самого adobe reader:
- Скачать последнюю версию adobe reader с официального сайта http://get.adobe.com/ru/reader/
- После этого открываем фаил и радуемся жизни
2 Способ
Так вот первый способ самый быстрый но и самый не качественный в плане разрешения распечатывающегося документа:
- При печати документа зайдите в дополнительно и выберите печать как изображения (File — print -advanced — галочка print as image)
4 Способ
Этот способ самый действенный и кардинальный т.к. решение данного косяка будет осуществлен на уровне реестра windows:
PDF Квадраты и символы при копировании
Как-то раз мне на стол принесли PDF-файл с просьбой скопировать содержимое текста, мол сами не могут т.к. при копировании текст превращается в квадраты, крякозяблы и странные символы. «Кодировка, защита или недостающие шрифты», подумал я, это ж легко. Однако пережимы pdf, снятие защиты через онлайн сервисы и прочие простые решения не помогли. При копировании со всех созданных вариантов данного pdf имеем такую картину:
p, blockquote 1,0,1,0,0 —>
Поиски решения
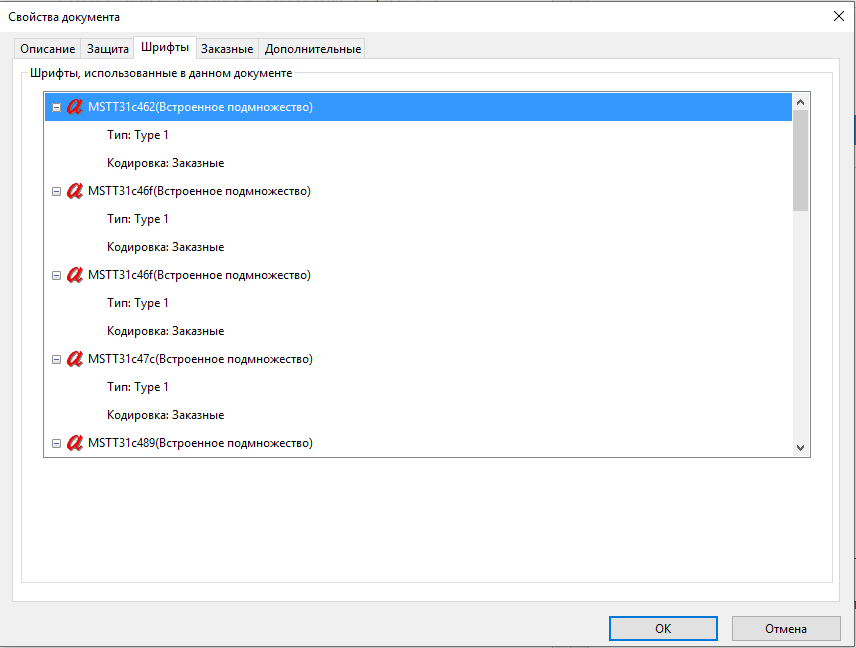
Открываем PDF в программе Acrobat reader, скачать его можно по ссылке идем в редактирование — защита — параметры защиты. Самой защиты на моем PDF не оказалось, однако на вкладке Шрифты указаны отсутствующие у меня на компе шрифты с заказной кодировкой. Скорее всего дело в этом, можно погуглив найти и установить недостающий шрифт, однако в моем случае такое решение не прокатит. Шрифт MSTT31c, кодировка — заказная.
p, blockquote 2,0,0,0,0 —>
Быстрое решение
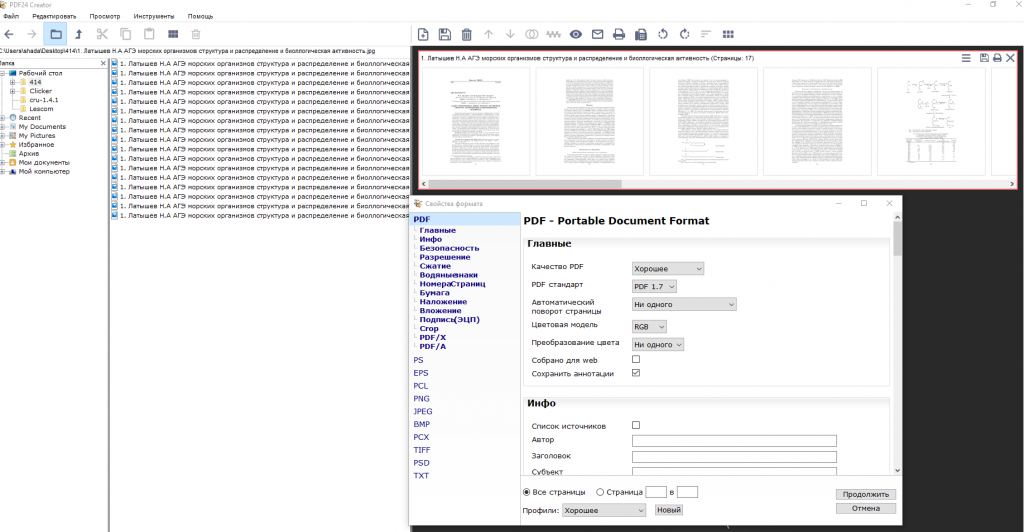
Дабы особо не ломать голову, выбираем самое простое решение. Мы попросту разобьем данный PDF на JPEG файлы и заново пересоберем, используя Pdf 24 Creator или его аналоги. (см. Конвертация PDF в JPEG и обратно).
p, blockquote 3,1,0,0,0 —>
Открываем программу — тыкаем Pdf конструктор, ищем наш файл и перетаскиваем в правую часть окна и тыкаем сохранить. В появившемся окне жмем «Настраиваемый» и выбираем Jpeg. DPI оставляйте как есть и жмите продолжить. Вам предложат путь куда вы сохраните весь ваш файл в виде изображений.
Не закрывая программу идем в папку куда сохранили изображения и перетаскиваем их на правую часть. Сохраняем как PDF, получаем слепленный из изображений файл, с которого пока что нельзя копировать ничего. Осталось чуть-чуть.
p, blockquote 5,0,0,0,0 —>
Снова открываем программу, на этот раз жмем Recognize text, выбираем язык документа, желаемое качество, жмем Add files и выбираем созданный на прошлом шаге файл. И всё, жмем Start, по завершению из нашего PDF можно с легкостью копировать текст. Надеюсь помог =)
Работа по распознаванию изображений состоит из следующих этапов:
- Получить отсканированные изображения (сканы).
- Открыть их в OCR-программе (FineReader).
- Сделать разметку страниц на блоки. То есть, разбить страницу на области, в каждой из которых будет находиться или текст, или рисунки, или таблицы, или другое однородное содержимое.
- Собственно распознавание.
- Вычитка распознанного, сверка полученного текста и исходных сканов.
- Сохранение полученных результатов в одном из документальных форматов (DOC, RTF, PDF, HTML и т. д.).
При распознавании текстов возможны два варианта: или вы сканируете материал сами, или работаете с уже отсканированным текстом.
В первом случае этапы «Получить изображения» и «Открыть изображения» объединяются в одно — FineReader полученные сканы сразу же открывает в своем пакете. Во втором случае этап «Получить изображения» уже пройден, надо только открыть их в программе.
Рассмотрим оба варианта по очереди.
Отсканировать текст в FineReader
Сканирование запускается через «Файл → Сканировать страницы» или кнопкой меню «Сканировать», или Ctrl-K.
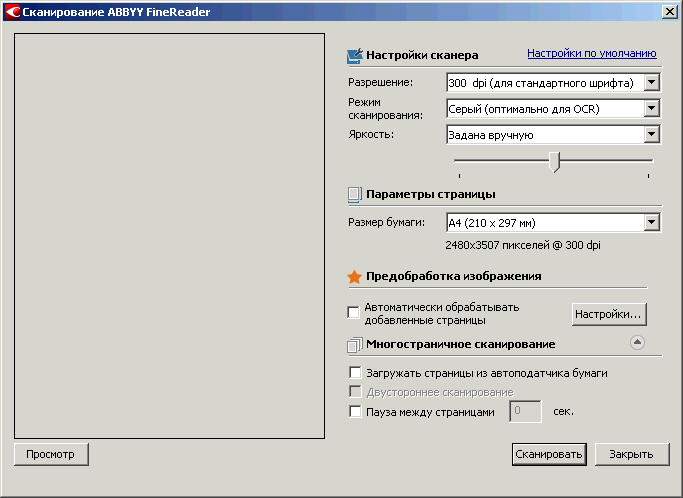
Рис. 1 Интерфейс сканирования
Однако, прежде чем начинать сканировать, неплохо бы разобраться, как получить сканы, наиболее оптимальные для распознавания. А для этого понять, чем «хороший» (с точки зрения FineReader) скан отличается от «не очень хорошего».
Для качественного распознавания программе требуется три вещи. Во-первых, возможность надежно отличить текст и иллюстрации от фона страницы. Во-вторых, чтобы буквы, цифры и прочее содержимое были четкими и разборчивыми, чтобы не возникало ситуаций «здесь и человеческий глаз не всегда поймет, что именно напечатано». В-третьих, строки текста на скане должны идти так же ровно, как они напечатаны на странице книги, без перекосов и искажений. Есть еще и другие требования к качественному скану, но эти можно считать ключевыми.
1. Для надежного различения «здесь текст, а здесь фон страницы» требуется, чтобы переход между тем и другим был резким, не размытым. Вот образцы страниц с плохой и с хорошей четкостью. Во первом случае, естественно, будет распознаваться хуже, с большим количеством ошибок.

Рис. 2. Размытые границы литер

Рис. 3. Четкие границы литер
Обычная причина размытых границ «текст-фон» — сканирование с нарушенной фокусировкой, то, что обычно называют «не в фокусе». Поэтому перед началом работы желательно проверить ваш сканер на этот момент.
Другая причина, которая может помешать различению текста и фона — слишком «плотный» фон страницы. В норме он должен быть или чисто белым, или белым с небольшой примесью какого-нибудь цвета. Если сканируются книги старых изданий, где бумага часто бывает пожелтевшей, то фон тоже может быть желтоватый (но умеренно).
Если же фон выглядит заметно перетемненным, то такие страницы опять же будут распознаваться хуже.
То, какой вид будет у фона, зависит от выставленной яркости сканирования. Ее можно регулировать через движок «Яркость». Для начала имеет смысл поставить 50%, проверить, что при этом будет, при необходимости поправить.
2. Разборчивость литер текста в основном зависит от яркости и от разрешения сканирования.
Если яркость слишком велика, линии букв будут будут рваными, они станут как бы рассыпаться на отдельные кусочки. Если яркость мала, то детали букв начинают сливаться между собой, возникают бесформенные пятна. И то, и другое для программ распознавания не очень-то съедобная «пища».
Яркость здесь настраивается так же, как и в предыдущем случае — ставим для начала в интерфейсе сканирования 50%, а дальше по ситуации.
Рис. 4. Страница со слишком большой яркостью

Рис. 5. Страница со слишком маленькой яркостью (перетемненный фон страницы)

Рис. 6. А вот эта же страница, но в нормальном виде
Разрешение сканирования определяет сколько пикселей в скане будет приходиться на каждую букву. Если этих пикселей достаточно для отрисовки контура буквы, то проблем при распознавании не будет. Если же недостаточно, то буквы могут стать плохо различимыми даже для человеческого глаза, не говоря уже о программах распознавания.

Рис. 7. Здесь отсканировано на 100 точек
Рисунки 7-9 также можно считать примерами несколько перетемненного фона.

Рис. 8. То же самое, но на 200 точек

Рис. 9. То же самое, но на 400 точек
При выборе разрешения обычно руководствуются следующими правилами:
- 300 точек выбирается для книг массовых изданий (страницы заполненные текстом обычного размера, почти без рисунков);
- 400 точек выбирается для книг и журналов с заметным объемом текста небольшими кеглями (примечания, подписи под рисунками, таблицы, врезки мелким текстом);
- 600 точек выбирается для книг, напечатанных совсем мелкими кеглями (многие справочники и энциклопедии, книги-миниатюры). Или же с мелкодеталированными рисунками, например, гравюрами. Сюда же надо отнести многие книги издания 1990-х годов — тогда издатели экономили на бумаге и часто печатали совсем крохотульными буквами.
Интерфейс сканирования в FineReader позволяет выбирать только 300 точек или 600 (строка «Разрешение»). Поэтому если у вас много материала, который желательно делать на 400 точек, то лучше сканировать не из-под FineReader, а из программы, идущей вместе со сканером.
Или же в настройках FineReader переключиться с собственного интерфейса программы на TWAIN-интерфейс вашего сканера («Сервис → Настройки → закладка «Сканировать/Открыть» → щелкнуть внизу по «Использовать интерфейс сканера»). Тогда вы сможете сканировать из FineReader, но работать будете в интерфейсе сканера (обычно там больший объем настроек и функций).
3. Ровные, аккуратно выглядящие строчки текста в основном обеспечиваются предобработкой изображения («пред-» в данном случае означает «выполняемое после сканирования, но перед распознаванием»). После правильно сделанной предобработки содержимое страниц будет распознаваться с более высоким качеством.
FineReader для этого имеет достаточно богатый набор функций, который можно увидеть в настройках программы, на закладке «Сканировать/Открыть». Также это окошко можно вызвать через кнопку «Настройки» в окошке интерфейса сканирования.
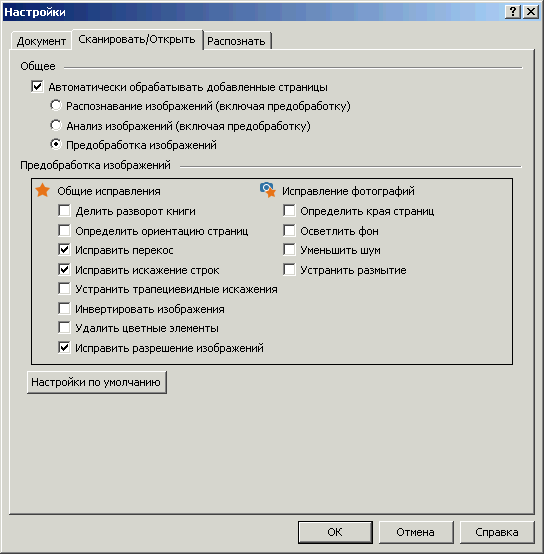
Рис. 10. Настройки предобработки
«Делить разворот книги» надо выбирать, когда книга сканировалась не постранично, а разворотами. Тогда для распознавания они будут нарезаны постранично.
«Определять ориентацию страниц» используется в том случае, если книга сканировалась повернутой набок. Тогда она будет развернута в свое нормальное положение. Но если в книге есть страницы, которые напечатаны повернутыми на 90 градусов относительно основной массы, то галочку здесь лучше снять. Иначе при выводе распознанного в PDF вы можете получить часть страниц в «книжной» ориентации, а часть — в «альбомной». Повернуть нужные страницы в этом случае лучше вручную, во встроенном редакторе изображений
«Исправить перекосы» устраняет перекосы страниц. Настройка однозначно необходимая, но надо иметь в виду, что PDF «Текст под изображением страницы», полученный из таких сканов, будет иметь не совсем аккуратный вид — сероватые клинья по краям страницы (там где делался поворот).
«Исправить искажения строк» выравнивает изгибы строк, которые при сканировании часто образуются около переплета (их еще называют «усы»).

Рис. 11. Пример страницы с изгибами строк
«Устранить трапециевидные искажения» исправляет деформации страниц, появляющиеся если книга не очень плотно прижата к стеклу сканера.
«Инвертировать изображения» необходима, если в сканируемом материале много текста «светлые буквы на темном фоне» и вы хотите преобразовать их в обычное «темные буквы на светлом фоне».
«Удалить цветные элементы» полезно, если на странице вида «черные буквы на белом фоне» надо убрать разные ненужности, вроде пометок ручкой на полях, подписей и печатей (офисная документация), а то и просто пятен. Но если на этой же странице есть какие-то сделанные в цвете «нужности» — графики, диаграммы или фотографии, то галочку ставить нельзя. Иначе будут удалены и они.
«Исправить разрешение изображений» — пункт, требующий более развернутого пояснения, чем предыдущие. Дело в том, что процесс распознавания в FineReader очень чувствителен к тому, какое разрешение выставлено в свойствах данного изображения. От этого существенно зависит то, насколько точно будут определены кегли букв текста, межбуквенные и межстрочные расстояния и прочее подобное. Поэтому галочка здесь необходима. Кроме того, не стоит удивляться, если по ходу распознавания вы будете постоянно получать сообщения FineReader «на странице такой-то неправильно выставлено разрешение и хорошо бы его исправить».
Кроме настроек предобработки на закладке «Сканировать/Открыть» есть блок настроек «Общее». Здесь задается набор основных действий, которые будут выполнены над открываемыми страницами. Варианты таких действий могут быть следующие:
- просто открыть отсканированные изображения, ничего с ними при этом не делая. Для этого надо снять галочку «Автоматически обрабатывать добавленные страницы».
Подобное имеет смысл только в том случае, если у вас сканы настолько высокого качества, что их уже ничем особенно не улучшишь. Можно сразу отправлять на распознавание. Бывает конечно и такое, но гораздо реже, чем хотелось бы :-), поэтому галочку лучше оставить. - открыть изображения, выполнить предобработку, но до вашей команды пока больше ничего не делать. Для этого надо выбрать пункт «Предобработка изображений».
Так обычно делают если надо не запускать сразу распознавание, а сначала посмотреть, что получилось в результате предобработки, насколько она хорошо отработала по данному набору изображений. - открыть изображения, выполнить предобработку, выполнить разметку на блоки, распознавание пока не запускать. Для этого надо выбрать пункт «Анализ изображений (включая предобработку)».
Наиболее часто выбираемый вариант. Сканы у вас вполне приличного качества, то, что с ними сделает предобработка вы хорошо представляете, проверять после нее нет необходимости. Значит соединяем в одно три описанных выше этапа работы с изображениями и начинаем смотреть насколько хорошо сделана разметка. - все этапы распознавания проходят автоматически, без какого-либо промежуточного контроля. Вы сразу получаете готовый результат и начинаете его вычитывать. Для этого надо выбрать пункт «Распознавание изображений (включая предобработку)». Так имеет смысл делать только если у вас сканы хорошего качества и с очень простым внешним видом — например сплошной текст на одном языке и ничего более. Во всех остальных случаях лучше выбирать вариант 2 или 3. Особенно если у вас страницы со сложным форматированием, таблицами, диаграммами, рисунками и т. д.

Рис. 12. Пример страницы со сложной версткой

Рис. 13. Пример страницы со сложной версткой
Открыть изображения в FineReader
Это второй вариант работы с изображениями: не сканировать их самому, а получить в уже готовом виде и открыть в FineReader. Делается через кнопку «Открыть» в меню основного окна или через «Файл → Открыть PDF или изображение», или через Ctrl-O.
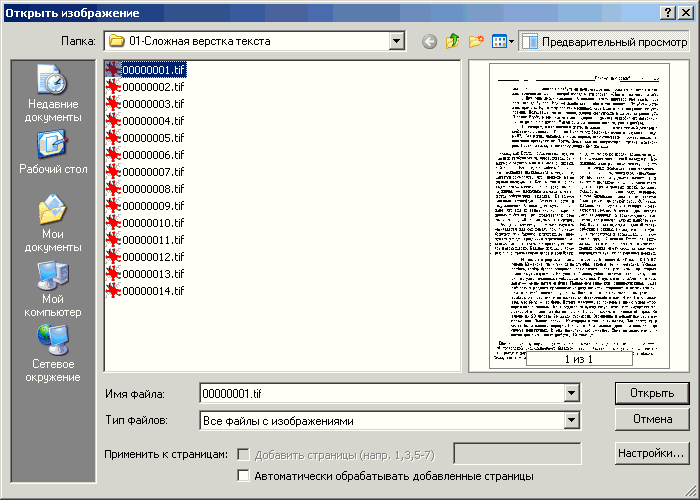
Рис. 14. Окно «Открыть изображение»
В открывшемся окошке Проводника выбираете изображения, задаёте необходимые настройки (кнопка «Настройки») и нажимаете «Открыть». Настройки здесь используются те же самые, что описаны для сканирования, работать с ними надо так же.
Когда страницы открыты в FineReader, то пакет по умолчанию создается безымянным («Документ без имени») и хранится в TMP-папке, только в пределах текущего сеанса работы. Чтобы случайно не потерять результаты работы, рекомендуется сразу же после создания сохранить пакет под каким-нибудь постоянным именем («Файл → Сохранить документ FineReader»).
Разметка страниц на блоки
После того, как вы открыли сканы, надо выполнить разметку страниц на блоки. Это делается через «Документ → Анализ документа» или через Ctrl-Shift-E.
Основных рабочих целей у разметки две.
Во-первых, отделить то, что на странице есть текст, от того, что текстом не является. «Текстом» в данном случае считается все, что FineReader в состоянии распознать. «Не-текстом» соответственно считается все, что он распознать не в состоянии. В основном это иллюстративная часть страницы — рисунки, чертежи, графики, диаграммы и прочее подобное. Формулы, рукописные записи и ноты с этой точки зрения тоже считаются не-текстом — распознавать их FineReader пока не умеет. А значит при разметке их надо пометить, как «картинка».
Во-вторых, еще надо то, что есть текст, разметить по категориям — просто текст, таблицы, примечания (сноски), колонтитулы, оглавления и тому подобное. Чтобы потом, когда вы будете читать распознанное в текстовом редакторе, все эти элементы выглядели бы именно так, как вы и привыкли (были бы отформатированы соответствующим образом).
Размеченная страница может иметь примерно следующий вид:

Рис. 15. Окно «Изображение» с размеченной страницей
Теперь надо просмотреть разметку, сделанную программой на каждой из страниц и при необходимости поправить ее.
Погрешности разметки обычно бывают следующих видов.
1. Какая-то часть содержимого страницы (текст, рисунок и т. д.) выделена правильно в смысле границ области, но ей присвоено не то содержимое. Например, фрагмент текста размечен, как рисунок или наоборот.
В этом случае надо щелкнуть мышью по такой области, открыть контекстное меню, выбрать в нем «Изменить тип области», в открывшейся подменюшке выбрать требуемый тип («Текст», «Таблица», «Картинка», «Фоновая картинка», «Штрих-код»).

Рис. 16. Контекстное меню «Изменить тип области»
Быстро посмотреть где какая область можно по цвету рамок. «Текст» выделяется рамками темно-зеленого цвета, «Таблица» — синего, «Картинка» — светло-красного, «Фоновая картинка» — темно-красного, «Штрих-код» — светло-зеленого.
2. В смысле содержимого область выделена правильно, но в смысле размеров (границ) выделено не все, что в данном случае требовалось. Или же наоборот — попал кусок от соседней области с другим содержимым.

Рис. 17. Страница с некорректно сделанной разметкой
К верхней области «картинка» прихвачены окружающие ее подписи (должны быть размечены, как «текст»).
В нижнюю область «картинка» при разметке не попала часть изображения.
Чтобы это поправить, надо сначала щелкнуть в окошке «Изображение» по кнопке «Стрелка».
![]()
А затем щелкать по каждой неправильно размеченной области и перемещать ее границы. Примерно таким же образом, как обычно перемещают границы окошек открытых программ.
3. Какая-то часть содержимого страницы разметкой вообще пропущена, не попала ни в одну из созданных областей.
Рис. 18. Из разметки выпала формула (не попала ни в один из блоков)
Здесь надо будет создать на странице новую область (выделить пропущенную часть страницы рамкой), а затем присвоить созданной области нужный тип.
Для этого надо сначала щелкнуть в окошке «Изображение» по значку «Выделить зону распознавания»
![]()
После этого обвести нужный участок рамкой (как обычно в графическом редакторе выделяют часть рисунка) и наконец задать тип области. Последняя операция уже описана в пункте 1.
Если текстовая часть страницы вам нужна просто, как сплошной текст (что чаще всего и бывает), то этого вполне достаточно. Если же вы хотите, чтобы в Word различные элементы оформления распознанных страниц (примечания, колонтитулы) выглядели бы именно, как примечания и колонтитулы, то надо проверить и этот момент.
Регулируется он через контекстное меню. Щелкаете по нужной области «Текст» на проверяемой странице, в контекстном меню выбираете пункт «Назначение текста», внутри его подменюшки смотрите против какого пункта стоит галочка (обычно это «Автоопределение»). Если стоит не там, где надо, переключаетесь на нужный элемент.

Рис. 19. Контекстное меню «Назначение текста»
Распознавание
После того, как исправлены ошибки в разметке, можно запускать распознавание. Это делается через «Документ → Распознать документ» или через Ctrl-Shift-R. Перед этим не забудьте выставить язык распознавания и задать необходимые настройки.
Язык выставляется через окошко «Язык документа» в панели кнопок основного окна программы.
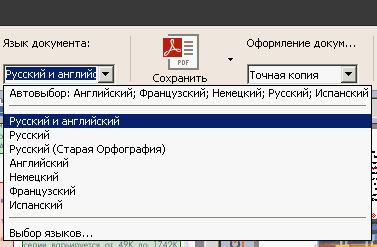
Рис. 20. Выбор языка через основное меню
Или в настройках («Сервис → Настройки → закладка «Документ»).
Рис. 21. Выбор языка через настройки FineReader
Если в открывшемся списке нет нужного вам языка, то нажмите «Выбор языков» в нижней части списка и в открывшемся окошке поставьте галочку против необходимого вам языка (набора языков). После этого он будет добавлен в список.
В настройках распознавания («Сервис → Настройки → закладка «Распознать») режим распознавания лучше оставить в умолчательном значении («Тщательное распознавание»). «Быстрое распознавание» имеет смысл ставить только если у вас что-то несложное по виду и с очень хорошим качеством сканирования. Например, отсканированная в черно-белом распечатка текстового документа без иллюстраций.
Рис. 22. Настройки, закладка «Распознать»
Из остальных настроек основное значение имеет группа «Определение структурных элементов». Здесь перечислены детали оформления страниц: сноски (примечания), колонтитулы, списки, оглавления. Когда против элемента поставлена галочка, он будет распознан и сохранен в DOC/RTF/DOCX не просто как часть текста на странице, а именно, как сноска, колонтитул, список или оглавление.
Только не забудьте при этом важный момент. Если вам приходится распознавать области с подобным содержимым, то одной галочки в настройках закладки «Распознать» может оказаться мало. Кроме этого еще требуется на этапе разметки правильно пометить эти области маркером «Назначение текста» из контекстного меню.
Вычитка
Вычитку распознанного текста в FineReader можно делать двумя способами. Или с помощью функции «Проверка», или обычным образом, просматривая страницы во встроенном редакторе FineReader. Через окно «Крупный план» сверяем со сканом, где есть ошибки — исправляем.
Функция «Проверка» запускается кнопкой в правом верхнем углу меню или через Ctrl-F7. Ее работа построена на том, что во время распознавания FineReader помечает символы и слова, которые были распознаны с недостаточно высоким уровнем достоверности. То есть, у программы по их поводу есть некоторое сомнение «может это действительно тот символ, который вам предъявлен, но может быть и что-то другое». Во время проверки такие сомнительные места по очереди показываются пользователю, чтобы он при необходимости их поправил.
Окно проверки устроено достаточно просто. В верхней его части показывается фрагмент страницы, в котором находится проверяемый символ. В нижней части выводится строка распознанного текста с этим символом, а также расположены несколько кнопок для несложного редактирования.
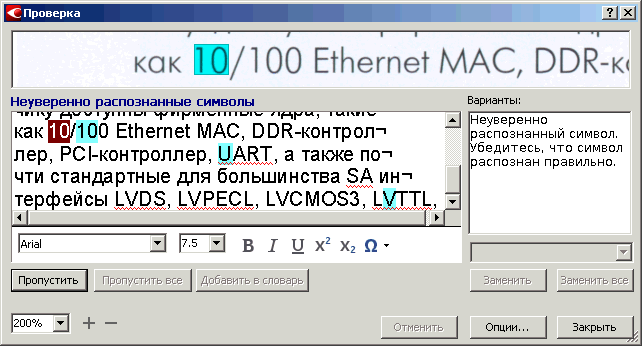
Рис. 23. Окно «Проверка»
Если все порядке, символ определен правильно, то нажимаем на «Пропустить». Если он определен неверно, то вводим правильное значение или с помощью клавиатуры, или если на клавиатуре такого нет, то с помощью кнопки «Вставить символ» (греческая буква «омега»). После чего нажимаем на «Подтвердить».
Аналогичным образом действуем если символ распознан верно, а вот его форматирование — неверно. Например в тексте книги в каком-то месте идет курсив, а распознался он, как обычный шрифт. Для переформатирования используем кнопки в нижней части окна.
Но возможности окна проверки все-таки достаточно ограничены. И по тому, какого размера кусочек страницы может быть показан в верхней части окна, и по возможностям редактирования, которые здесь имеются. Поэтому все перемещения по тексту, от одной точки проверки до другой, отслеживаются еще и в окнах «Текст» и «Крупный план». Все время, пока идет работа, курсоры в «Тексте» и «Крупном плане» перемещаются синхронно их положению в «Проверке».
Если в проверяемом фрагменте страницы (в его скане) вдруг потребовалось увидеть больше, чем несколько слов, показанных в «Проверке», то можно это сделать в «Крупном плане». Если для правки текущей ошибки требуются возможности редактора из «Текста», то можно на время переключиться в него (просто щелкнув по его окошку), сделать необходимую работу и вернуться обратно в «Проверку» (щелкнув по ее окошку). После возвращения в «Проверку», там будут отображены все изменения, которые вы сделали в «Тексте».

Рис. 24. Пример работы в одновременно открытых окнах «Проверка», «Текст» и «Крупный план»
Если вам окошко «Проверка» с его ограниченными возможностями не очень-то удобно (привыкли работать со всеми удобствами текстовых редакторов и привычки менять не собираетесь), то можно с самого начала делать эту работу в окне «Текст».
Места, требующие проверки, там отображаются в полном объеме — это символы и слова, выделенные светло-голубым. Возможность перемещаться от ошибки к ошибке, не просматривая всю страницу целиком, тоже имеется — кнопки «Следующая ошибка» и «Предыдущая ошибка» на панели кнопок с левой стороны окна.
Теоретически, по замыслу создателей FineReader, окна «Проверка» должно быть вполне достаточно для полноценной вычитки распознанного текста. Все сомнительные места отмечены, движемся вдоль них, правим ошибки, на выходе получаем полностью вычищенный текст.
Но, как это часто бывает, теория здесь расходится с повседневной практикой работы. В распознанных текстах систематически встречаются ошибочные места, которые, как ошибки, не помечены. То есть FineReader распознает какой-то символ/слово неверно, но при этом с полной уверенностью, что распознал правильно.
Поэтому для полноценной вычитки одного только окна «Проверка» обычно бывает недостаточно — в особенности если в тексте много научных или технических терминов, профессионального жаргона и тому подобной «несловарности». Надо еще пройтись по распознанному вручную — внимательно просмотреть его в окне «Текст» и проверить все мало-мальски сомнительные места.
Вычитка текста в окне «Текст» мало чем отличается от обычной корректорской работы. Настраиваете окна «Текст» и «Крупный план» так, чтобы они занимали большую часть рабочего окна программы, переходите к очередной проверяемой странице, просматриваете ее текст. Если обнаруживаете сомнительное или явно ошибочное место, то щелкаете по нему — при этом курсор в «Крупном плане» устанавливается точно в том же самом месте оригинала (скана). Сравниваете оригинал и распознанное, при необходимости правите, двигаетесь дальше.
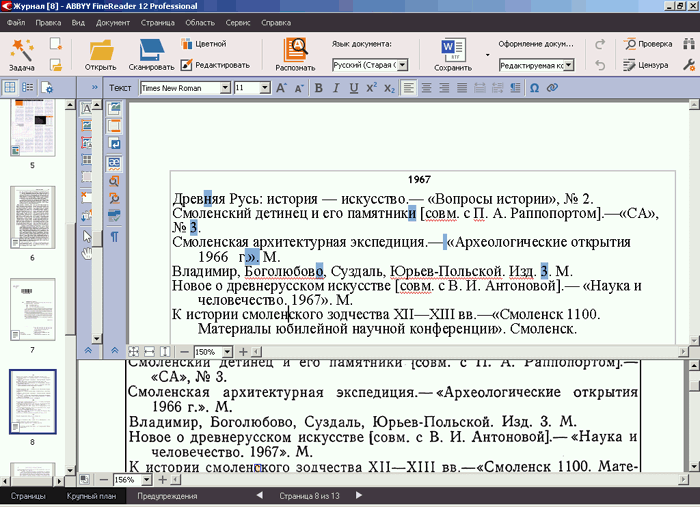
Рис. 25. Вычитка с помощью окон «Текст» и «Крупный план»
Функциональность редактора окна «Текст» ничем особо не отличается от функциональности любого текстового редактора средней степени сложности. Вид у кнопок в меню достаточно типовой, каких-либо проблем при работе с ними возникать не должно. Если надо поправить какой-то символ, который на клавиатуре отсутствует, то, как и в окошке «Проверка», надо нажать на кнопку с греческой «омегой» и в открывшейся таблице выбрать необходимое.
Сохранение результатов
Когда отсканированный материал распознан и вычитан, его надо сохранить в одном из документальных форматов — DOC, DOCX, RTF, PDF, HTML и т. д. Это делается через «Файл → Сохранить документ как → выбрать нужный формат» или через кнопку «Сохранить» в основном меню FineReader.
В открывшемся окошке Проводника выбираете формат, через кнопку «Настройки» задаете параметры сохранения, нажимаете «ОК». Если хотите сразу же посмотреть нет ли заметных ошибок во внешнем виде сохраненного текста, то кроме этого поставьте галочку в «Открыть документ после сохранения». Тогда он сразу же будет открыт в редакторе (браузере, программе просмотра).
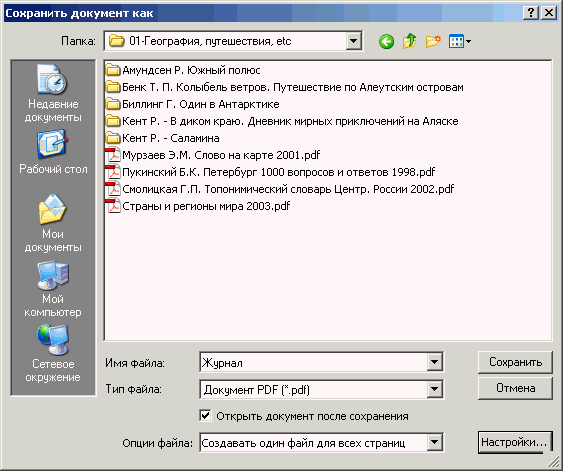
Рис. 26. Окно сохранения распознанного текста
Обычная практика распознавания — на вход поступает отсканированный текст книги или журнала, на выходе все его страницы сохраняются в файл с названием этой книги. Именно такая настройка «Создавать один файл для всех страниц» стоит по умолчанию в строке «Опции файла». Если же у вас распознается не какой-то цельный текст, а просто россыпь страниц (например офисная документация), то здесь надо будет выставить «Сохранять отдельный файл для каждой страницы».
Настройки сохранения в форматах DOC, DOCX, RTF
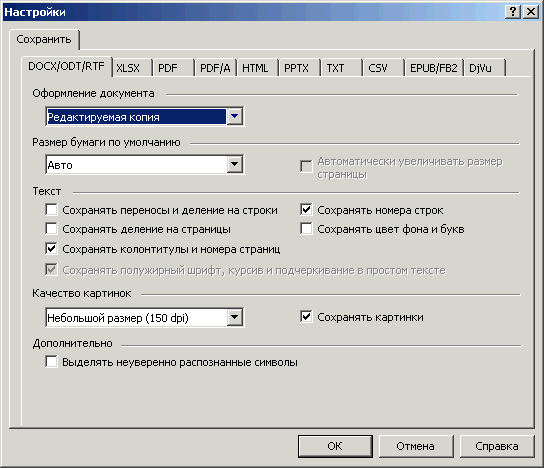
Рис. 27. Настройки сохранения в DOC/DOCX/RTF
Ключевое и основное, что здесь надо выбрать — это с какой степенью точности в сохраняемом документе будет отображен внешний вид оригинала (один из режимов сохранения в окошке «Оформление документа»). Все остальные настройки — не более, чем уточнение и деталировка этого пункта.
Вариантов выбора здесь четыре: «Точная копия», «Редактируемая копия», «Форматированный текст» и «Простой текст».
1. «Точная копия».
По замыслу разработчиков здесь должно было быть практически зеркальное подобие распознаваемой страницы. Именно потому так и названо. С точным воспроизведением шрифтов, размеров букв (кеглей), расстояний между буквами в словах, расстояний между словами, строками и абзацами и других деталей верстки. Идея, в общем-то, неплохая, но возможности реализовать ее в задуманном объеме у FineReader обычно не хватает.
Шрифты и их начертание (Normal, Italic, Bold) часто воспроизводятся по принципу «как выйдет, так и получится». Могут быть переданы точно. Может случиться так, что шрифт, использованный на распознаваемой странице, будет замещен другим шрифтом (сходным по виду, но другим). Может случиться так, что начертание Normal будет распознано как Bold или же наоборот. И так далее, и тому подобное.
С воспроизведение кеглей, расстояний и прочего форматирования ситуация не намного лучше — более или менее точно воспроизвести внешний вид (верстку) распознаваемой страницы обычно удается лишь в случаях чего-нибудь не очень сложного.
В результате получается не очень понятно что — Word-документ, который можно только читать (ну и копировать оттуда текст). Редактировать его за пределами «пару букв убрать, пару букв вставить» малореально. А редактировать таки требуется — он ведь дальше пойдет в какую-то работу, а значит надо будет переделывать форматирование под потребности будущего использования.
С одной стороны весь текст здесь раскидан по многочисленным фреймам, что изрядно осложняет работу с ним. С другой стороны во время распознавания программа генерирует кучу Word’овских стилей — все форматирование в тексте делается исключительно через стили. Вполне обычно, когда на текст книги среднего размера (300-400 страниц) генерируется несколько сотен различных стилей. Что еще больше усложняет редактирование.
Резюме — выбирать этот режим сохранения особого смысла не имеет, работать с сохраненным текстом здесь достаточно неудобно.
Если же вам требуется полное воспроизведение внешнего вида оригинала, то это и проще, и практичнее сделать в виде PDF «Текст под изображением страницы» или же PDF «Только текст и картинки» (об этих способах вывода немного ниже).
2. «Редактируемая копия».
По смыслу это облегченная версия «Точной копии». Внешний вид оригинала воспроизводится не с такой степенью дотошности, как в предыдущем случае, фреймов с текстом заметно поменьше (хотя периодически попадаются). Однако, хоть этот вариант и называется «редактируемым», работать с ним тоже, не сказать чтобы удобно.
Если Word-документ нужен, как есть, только для просмотреть его его содержимое и скопировать нужный фрагмент текста, то вполне можно использовать и этот вариант. Если же требуется много переделывать, переформатировывать и так далее, то лучше выбирать что-то другое.
Причина та же самая — слишком много возни по преобразованию текста из того вида, который выдаст «Редактируемая копия», в тот вид, который может потребоваться вам. Все еще осталось какое-то количество текста во фреймах, в форматировании все еще сохраняется тенденция точно воспроизводить внешний вид (верстку) оригинала. Да и привычка генерировать кучу стилей никуда не делась.
Резюме — работать с текстом здесь не так хлопотно, как в «Точной копии», но по прежнему оставляет желать лучшего.
3. «Форматированный текст».
Степень соответствия оригиналу здесь сведена к минимуму — воспроизведение шрифтов и кеглей, примерного расположения материала на страницах оригинала, общего вида текста и таблиц.
Работать с этим вариантом заметно проще, чем с предыдущими, однако все еще затруднительно из-за большого количества стилей. Впрочем это достаточно просто лечится — можно быстро пройтись по тексту и наложить на него ваш собственный комплект стилей.
4. «Простой текст».
Хотя он называется «Простой текст», но здесь можно сохранять как сам текст, так и текст с картинками. Форматирование в этом варианте сведено к минимуму — обычные Word’овские абзацы от одного края страницы до другого, плюс воткнутые между ними картинки. Привычная по предыдущим вариантам куча стилей тоже не генерируется.
Но при желании даже здесь можно оставить исходную разбивку на строки и на страницы. Плюс сохранять начертания шрифта — обычный, курсив, полужирный.
Обычно для сохранения выбирается или «Форматированный текст», или «Простой текст» — в зависимости от того, что вы собираетесь делать дальше и как использовать распознанное.
Теперь об остальных настройках этого окна.
- «Размер бумаги по умолчанию».
Здесь задается Word’овская настройка «Параметры страницы → Размер бумаги», то есть на бумаге какого формата вы будете делать распечатку. Обычно выставляется А4. Но надо иметь в виду, что в режимах «Точная копия» и «Редактируемая копия» один к одному сохраняется не только содержимое распознанной страницы, но и ее исходный размер. В результате если поставить здесь формат бумаги, больший, чем размер страницы, то при печати вокруг текста будут пустые поля. Если же поставить меньший формат, то часть материала страницы может быть потеряна (окажется за границами листа бумаги). - «Сохранять переносы и деление на строки».
Если галочка поставлена, то будет сохранена та разбивка на строки, которая имеется в оригинале. Переносы строк в этом случае делаются мягкими. Если галочки не ставить, то текст пойдет обычными Word-овскими абзацами, со строками от одного края страницы до другого. - «Сохранять деление на страницы».
Если галочка поставлена, то будет сохранена та разбивка на страницы, которая имеется в оригинале. Если галочки не ставить, то текст на страницы будет разбивать сам Word. - «Сохранять колонтитулы и номера страниц».
Если галочка поставлена, то текст, размеченный и распознанный, как колонтитулы и номера страниц, будет сохранен и размещен в соответствующих Word-овских полях. Если галочку не ставить, то эта часть текста вообще не выводится. - «Сохранять номера строк».
Если галочка поставлена, то в списках с пронумерованными строками будет сохранена нумерация этих строк. - «Сохранять цвет фона и букв».
Если галочка поставлена, то текст, напечатанный в цвете (или на цветном фоне), будет выведен, как в оригинале. Если галочки не ставить, то весь текст будет выводиться обычным образом — черным на белом фоне (или на белым на черном фоне). - «Сохранять полужирный шрифт, курсив и подчеркивание в простом тексте».
Вывод в «Простой текст» можно делать по принципу «все одним и тем же начертанием, Normal», а можно с сохранением начертания, которое было в оригинале. Здесь как раз этот момент и регулируется. - «Выделять неуверенно распознанные символы».
Эту галочку надо ставить если вы предпочитаете вычитывать распознанный текст не в FineReader, а в каком-нибудь текстовом редакторе. Тогда все пометки символов и слов, которые у вас были в окне «Текст», будут воспроизведены в сохраненном документе. - «Сохранять картинки».
Определяется будут ли кроме текста сохраняться еще и изображения. - «Качество картинок».
Здесь определяется степень сжатия изображений из оригинала. Оно может регулироваться по трем направлениям — через различные алгоритмы сжатия, через разрешение сохраняемого изображения и через глубину цвета в нем. Подробности можно посмотреть, если в строке «Качество картинок» выбрать вариант «Пользовательское». Наиболее практично пользоваться именно им, а не пресетами «Небольшой размер (150 dpi)» и «Высокое качество (разрешение исходного изображения)».
Рис. 28. Окно настройки качества изображения
Поскольку при уменьшении исходного разрешения и последующем сжатии возможны плохо предсказуемые искажения, то галочку «Уменьшать исходное разрешение изображения» лучше убрать.
Глубину цвета ставите по ситуации. Если изображения нужны, как есть, то выбираете «Не менять цветность изображения». Если достаточно просто общего вида, точное воспроизведение цветов не обязательно, то выбираете «Конвертировать цветные изображения в серые». Преобразование цветных и серых изображений в черно-белые лучше не выбирать, потому что бинаризация может давать много искажений (причем плохо предсказуемых). Пункт «Автоматически» тоже лучше не выбирать — не очень понятно какая логика работы там заложена и что вы при этом будете получать на выходе.
Движок «Качество» (цифры в нем) можно считать аналогом настройки «Quality» в JPEG-сжатии и регулировать здесь по опыту работы с JPEG-изображениями.
Настройки сохранения в форматах PDF и PDF/A

Рис. 29. Настройки сохранения в PDF
Режимов сохранения здесь тоже четыре: «Только текст и картинки», «Текст поверх изображения страницы», «Текст под изображением страницы», «Только изображение».
- «Только текст и картинки».
Здесь вы фактически получите PDF-вариант того, что выдается в «Точной копии» — распознанный текст и иллюстрации из окна «Текст» в виде, максимально приближенном к оригиналу. Качество воспроизведения оригинала здесь выше, чем в DOC/DOCX/RTF, поскольку PDF-формат имеет для этого заметно больше возможностей. - «Текст поверх изображения страницы».
Это PDF, состоящий из двух слоев — исходное изображение (нижний слой), на которое наложен распознанный текст (верхний слой). Такой вариант достаточно удобен, если PDF потом будет редактироваться - «Текст под изображением страницы».
Это PDF составленный из тех же двух слоев — исходное изображение и распознанный текст. Только они идут в обратном порядке — изображение верхним слоем, текст нижним (невидимым) слоем. Такой способ вывода еще называется «PDF с текстовой подложкой» и используется, когда надо получить с одной стороны точную копию внешнего вида оригинала, а с другой стороны возможность копировать текст этого оригинала. - «Только изображение».
Это PDF, собранный из исходных изображений. Кроме самих изображений там больше ничего нет.
Теперь об остальных настройках этого окошка.
1. «Размер бумаги по умолчанию».
В PDF-выводе смысл этой настройки такой же, как и в предыдущем случае — формат листа, на котором будет печататься страница.
В предыдущем случае говорилось о правиле «если страница меньше, чем заданный формат, то вокруг текста будут пустые поля, если больше — часть текста будет обрезана». В PDF оно соблюдается еще более жестко, поскольку здесь исходная страница в любом варианте воспроизводится один к одному. Поэтому наиболее разумно ставить здесь «Использовать размер оригинала».
2. «Сохранять цвет фона и букв».
3. «Сохранять колонтитулы».
Смысл этих двух настроек такой же, как и в предыдущем случае.
4. «Создать оглавление».
Если в настройках распознавания была поставлена галочка «Определение структурных элементов → Оглавление», то распознанное таким образом оглавление книги может быть использовано для автоматического создания оглавления в PDF-файле.
5. «Разрешить теги PDF».
В PDF теги — это функциональный аналог Word-вских стилей, способ структурной разметки содержимого PDF-файла. С их помощью сохраняется информация о разбивке текста на главы, о заголовках, оглавлении, иллюстрациях, таблицах, примечаниях, гиперссылках, математических формулах и прочем подобном.
Если вам надо будет часто копировать из PDF куски текста, то галочку здесь стоит поставить. Тогда скопированный текст будет гораздо больше соответствовать тому, как он выглядит на странице PDF.
Также теги полезны если PDF приходится просматривать на экранах различных размеров — от десктопов до смартфонов. В таких случаях PDF-читалкам приходится переформатировывать содержимое страниц под текущий размер экрана и с теговой разметкой это проходит значительно более аккуратно, без заметных искажений первоначального вида.
6. «Использовать смешанное растровое содержимое (MRC)».
MRC (Mixed Raster Content) — это название технологии сжатия, способной давать заметно большие кратности сжатия, чем известные всем JPEG и JPEG 2000. Многие знакомы с ней по формату DjVu — он построен именно на базе MRC. Выбор «надо ставить галочку или нет» здесь неоднозначный и определяется исходя из вашего расклада дел.
Основной плюс — размер получаемого PDF. Может быть в несколько раз меньше PDF, полученного с теми же настройками сжатия, но без MRC.
Какие могут быть минусы:
— MRC-сжатие так устроено, что при работе всегда дает плохо предсказуемое количество искажений. По причине того, что искажения здесь только частью зависят от настроек сжатия, а в изрядной мере от содержимого страницы. Текст, рисунки, графики, фотографии — при MRC-сжатии все они ведут себя заметно по разному и дают разное количество искажений.
— заметно большая ресурсоемкость при сжатии и просмотре таких PDF. Даже на сегодняшних компьютерах MRC-PDF может открываться и пролистываться не привычно-плавно, а скачками, когда очередная страница выводится на экран не вся сразу, а по частям.
7. «Сохранять картинки».
8. «Качество изображения».
Смысл этих настроек такой же, как и в предыдущем случае — надо или не надо при создании PDF сохранять изображения и с каким уровнем сжатия их сохранять. Рекомендации тоже аналогичные — убрать галочку из «Уменьшить исходное разрешение», цветность лучше не менять, движок «Качество» выставлять по аналогии со сжатием в JPEG 2000.
9. «Шрифты».
Если поставить «Использовать шрифты Windows», то для распознавания и последующего вывода будет использоваться тот набор шрифтов, который установлен у вас на компьютере. Если поставить «Использовать предопределенные шрифты», то только тот комплект шрифтов, который устанавливается при инсталляции FineReader.
Предпочтительнее выставлять первый вариант, поскольку при этом будет использоваться гораздо большее разнообразие шрифтов и программе будет легче подбирать соответствие шрифтам распознаваемых книг.
10. «Встраивать шрифты».
Если вам требуется, чтобы при просмотре PDF-файла на другом компьютере он был виден именно так, как вы его получили (именно в этих шрифтах), то надо поставить здесь галочку.
11. «Параметры защиты PDF».
Здесь можно выставить парольную защиту на просмотр PDF, печать, копирование из него текста и рисунков, редактирование.
Если у вас возникнут вопросы по работе FineReader, на которые вы не нашли ответа в тексте статьи, то их можно задать на форуме разработчиков программы.