
На чтение 7 мин. Просмотров 30k.
Содержание
- Получить первое не пустое значение в списке
- Получить первое текстовое значение в списке
- Получить первое текстовое значение с ГПР
- Получить позицию последнего совпадения
- Получить последнее совпадение содержимого ячейки
- Получить n-е совпадение
- Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
- Получить n-ое совпадение с ВПР
- Если ячейка содержит одну из многих вещей
- Поиск первой ошибки
- Поиск следующего наибольшего значения
- Несколько совпадений в списке, разделенных запятой
- Частичное совпадение чисел с шаблоном
- Частичное совпадение с ВПР
- Положение первого частичного совпадения
Получить первое не пустое значение в списке
{ = ИНДЕКС( диапазон ; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( диапазон ); 0 )) }

Если вам нужно получить первое не пустое значение (текст или число) в диапазоне в одной колонке вы можете использовать формулу массива на основе функций ИНДЕКС, ПОИСКПОЗ и ЕПУСТО.
В данном примере мы используем эту формулу:
{ = ИНДЕКС( B3: B11; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( B3: B11 ); 0 )) }
Таким образом, суть проблемы заключается в следующем: мы хотим получить первую не пустую ячейку, но для этого нет конкретной формулы в Excel. Мы могли бы использовать ВПР с шаблоном *, но это будет работать только для текста, а не для чисел.
Таким образом, нам нужно строить функциональные возможности для нужных нам формул. Способ сделать это состоит в использовании функции массива, которая «тестирует» ячейки и возвращает массив истина/ложь значения, которые мы можем сопрягать с ПОИСКПОЗ.
Работая изнутри, ЕПУСТО оценивает ячейки в диапазоне В3: В11 и возвращает результат и массив, который выглядит следующим образом:
{ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА}
Каждая ЛОЖЬ представляет собой ячейку в диапазоне, который не является пустой.
Далее, ПОИСКПОЗ ищет ЛОЖЬ внутри массива и возвращает позицию первого наденного совпадения, в этом случае 2. На данный момент, формула в примере теперь выглядит следующим образом:
{ = ИНДЕКС( B3: B11; 2; 0 )) }
И, наконец, функция ИНДЕКС выводит значение в положении 2 в массиве, в этом случае число 10.
Получить первое текстовое значение в списке
= ВПР ( «*»; диапазон; 1; ЛОЖЬ)
Если вам нужно получить первое текстовое значение в списке (диапазон один столбец), вы можете использовать функцию ВПР, чтобы установить точное соответствие, с шаблонным символом для поиска.

В данном примере формула в D7 является:
= ВПР ( «*» ; B5: B11 ; 1 ; ЛОЖЬ)
Групповой символ звездочка (*) соответствует любому текстовому значению.
Получить первое текстовое значение с ГПР
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)

Для поиска и получения первого текстового значения во всем диапазоне столбцов, вы можете использовать функцию ГПР с групповым символом. В примере формула в F5 является:
= ГПР ( «*»; С5: Е5; 1; 0 )
Значение поиска является «*», групповым символом, который соответствует одному или более текстовому значению.
Получить позицию последнего совпадения
{ = МАКС( ЕСЛИ ( Величины = знач ; СТРОКА(величина) — СТРОКА(ИНДЕКС( Величины; 1 ; 1 )) + 1 )) }
Для того, чтобы получить позицию последнего совпадения (т.е. последнего вхождения) от значения поиска, вы можете использовать формулу, основанную на ЕСЛИ, СТРОКА, ИНДЕКС, ПОИСКПОЗ и MAКС функций.

В примере формула в G6:
=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
Суть этой формулы состоит в том, что мы строим список номеров строк для данного диапазона, соответствующие по значению, а затем используем функцию MAКС, чтобы получить наибольшее количество строк, что соответствует последнему значению соответствия.
Получить последнее совпадение содержимого ячейки
= ПРОСМОТР( 2 ; 1 / ПОИСК ( вещи ; А1 ); вещи )
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть последнее совпадение, найденное в списке, вы можете использовать формулу, основанную на ПРОСМОТР и ПОИСК функций. В случае нескольких найденных совпадений, формула вернет последнее совпадение из списка «вещей».

В примере формула в С5:
=ПРОСМОТР(2;1/ПОИСК($E$4:$E$7;B4);$E$4:$E$7)
Получить n-е совпадение
= НАИМЕНЬШИЙ( ЕСЛИ( логический тест; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); n )
Для того, чтобы получить позицию n-го совпадения (например, второе значение соответствия заданному, третье значение соответствия и т.д.), вы можете использовать формулу, основанную на функции НАИМЕНЬШИЙ.
= НАИМЕНЬШИЙ( ЕСЛИ( список = E5 ; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); F5 )
Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
{ = ИНДЕКС( массив; НАИМЕНЬШИЙ( ЕСЛИ( величины = знач ; СТРОКА ( величины ) — СТРОКА ( ИНДЕКС( величины; 1 ; 1 )) + 1 ); n-й )) }

Чтобы получить n-ое совпадение, используя ИНДЕКС и ПОИСКПОЗ, вы можете использовать формулу массива с функциями ЕСЛИ и НАИМЕНЬШИЙ, чтобы выяснить номер строки совпадения.
Получить n-ое совпадение с ВПР
= ВПР( id_формулы; стол; 4; 0 )
Чтобы получить n-ое совпадение с ВПР, вам необходимо добавить вспомогательный столбец в таблицу , которая строит уникальный идентификатор , который включает счетчик.

Эта формула зависит от вспомогательного столбца, который добавляется в качестве первого столбца таблицы исходных данных. Вспомогательный столбец содержит формулу, которая строит уникальное значение взгляда вверх от существующего идентификатора и счетчика. Счетчик подсчитывает сколько раз уникальный идентификатор появился в таблице данных.
В примере, формула ячейки J6 вспомогательного столбца выглядит следующим образом:
=ВПР(J3&»-«&I6;B4:G11;4;0)
Если ячейка содержит одну из многих вещей
{ = ИНДЕКС( результаты ;ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК( вещи ; A1 )); 0 )) }
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть пользовательский результат для первого найденного совпадения, вы можете использовать формулу ИНДЕКС/ПОИСКПОЗ, основанную на функции поиска.
{ = ИНДЕКС( результаты ; ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК ( вещи ; B5 )); 0 )) }
Эта формула использует два названных диапазона: E5: E8 называется «вещи» и F5: F8 называется «Результаты». Убедитесь, что вы используете диапазоны имен с одинаковыми именами (на основе ваших данных). Если вы не хотите использовать именованные диапазоны, используйте абсолютные ссылки вместо этого.
Поиск первой ошибки
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА(диап ); 0 ) }
Если вам нужно найти первую ошибку в диапазоне ячеек, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ЕОШИБКА функциях.

В приведенном примере формула:
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА( B4: B11 ); 0 ) }
Работая изнутри, функция ЕОШИБКА возвращает значение ИСТИНА, если значение является признанной ошибкой, и ЛОЖЬ, если нет.
Когда дается диапазон ячеек (массив ячеек) функция ЕОШИБКА будет возвращать массив истина/ложь значений. В примере, это результирующий массив выглядит следующим образом:
{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ}
Обратите внимание, что 6-е значение (что соответствует 6-й ячейке в диапазоне) истинно, так как ячейка В9 содержит #Н/A.
Поиск следующего наибольшего значения
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )

Для того, чтобы найти «следующее наибольшее» значение в справочной таблице, можно использовать формулу, основанную на ИНДЕКС и ПОИСКПОЗ. В примере формула в F6 является:
=ИНДЕКС(C5:C9;ПОИСКПОЗ(F4;B5:B9)+1)
Несколько совпадений в списке, разделенных запятой
{ = ОБЪЕДИНИТЬ ( «;» ; ИСТИНА ; ЕСЛИ( диапазон1 = E5 ; диапазон2 ; «» )) }
Для поиска и извлечения нескольких совпадений, разделенных запятыми (в одной ячейке), вы можете использовать функцию ЕСЛИ с функцией ОБЪЕДИНИТЬ.
{ = ОБЪЕДИНИТЬ( «;» ; ИСТИНА ; ЕСЛИ( группа = E5 ; имя ; «» )) }
Эта формула использует «имя» — именованный диапазон (B5: B11) и «группа» — (C5: C11).
Частичное совпадение чисел с шаблоном
{ = ПОИСКПОЗ( «*» & номер & «*» ; ТЕКСТ( диапазон ; «0» ); 0 ) }
Для того, чтобы выполнить частичное совпадение (подстроки) против чисел, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ТЕКСТ.

Excel поддерживает символы подстановки «*» и «?». Тем не менее, если вы используете специальные символы с номером, вы будете преобразовывать числовое значение в текстовое значение. Другими словами, «*» & 99 & «*» = «* 99 *» (текстовая строка).
Если попытаться найти текстовое значение в диапазоне чисел, совпадение завершится неудачно.
Решение
Одно из решений заключается в преобразовании чисел в диапазоне поиска для текстовых значений, а затем сделать нормальный поиск с ПОИСКПОЗ, ВПР и т.д.
Другой вариант
Другой способ, чтобы преобразовать числа в текст, чтобы сцепить пустую строку. Эта формула работает так же, как выше формуле:
= ПОИСКПОЗ ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
Частичное совпадение с ВПР
Если вы хотите получить информацию из таблицы на основе частичного совпадения, вы можете сделать это с помощью ВПР в режиме точного соответствия, и групповые символы.

В примере формула ВПР выглядит следующим образом:
=ВПР($H$2&»*»;$B$3:$E$12;2;0)
В этой формуле, значение представляет собой именованный диапазон, который относится к Н2, а также данные , представляет собой именованный диапазон , который относится к B3: E102. Без названных диапазонов, формула может быть записана следующим образом:
Положение первого частичного совпадения
= ПОИСКПОЗ ( «* текст *» ; диапазон; 0 )
Для того, чтобы получить позицию первого частичного совпадения (то есть ячейку, которая содержит текст, который вы ищете), вы можете использовать функцию ПОИСКПОЗ со специальными символами.

В примере формула в Е7:
=ПОИСКПОЗ(«*»&E6&»*»;B5:B10;0)
Функция ПОИСКПОЗ возвращает позицию или «индекс» в первом совпадении на основании значения поиска в диапазоне.
ПОИСКПОЗ поддерживает подстановочное согласование со звездочкой «*» (один или несколько символов) или знаком вопроса «?» (один символ), но только тогда, когда третий аргумент, тип_сопоставления, установлен в ЛОЖЬ или ноль.
Поиск значений в списке данных
Excel для Microsoft 365 Excel для Интернета Excel 2021 Excel 2019 Excel 2016 Excel 2013 Excel 2010 Excel 2007 Еще…Меньше
Предположим, что вы хотите найти расширение телефона сотрудника, используя его номер эмблемы или правильную ставку комиссионных за объем продаж. Вы можете искать данные для быстрого и эффективного поиска определенных данных в списке, а также для автоматической проверки правильности данных. После поиска данных можно выполнить вычисления или отобразить результаты с возвращаемой величиной. Существует несколько способов поиска значений в списке данных и отображения результатов.
Что необходимо сделать
-
Точное совпадение значений по вертикали в списке
-
Подыыывка значений по вертикали в списке с помощью приблизительного совпадения
-
Подстановка значений по вертикали в списке неизвестного размера с использованием точного совпадения
-
Точное совпадение значений по горизонтали в списке
-
Подыыывка значений по горизонтали в списке с использованием приблизительного совпадения
-
Создание формулы подступа с помощью мастера подметок (только в Excel 2007)
Точное совпадение значений по вертикали в списке
Для этого можно использовать функцию ВLOOKUP или сочетание функций ИНДЕКС и НАЙТИПОЗ.
Примеры ВРОТ

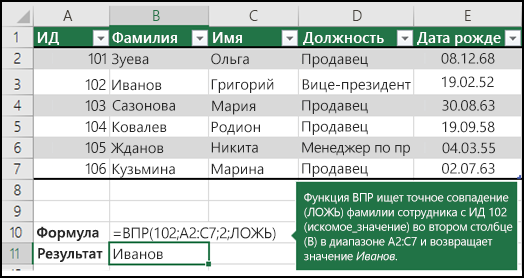
Дополнительные сведения см. в этой информации.
Примеры индексов и совпадений
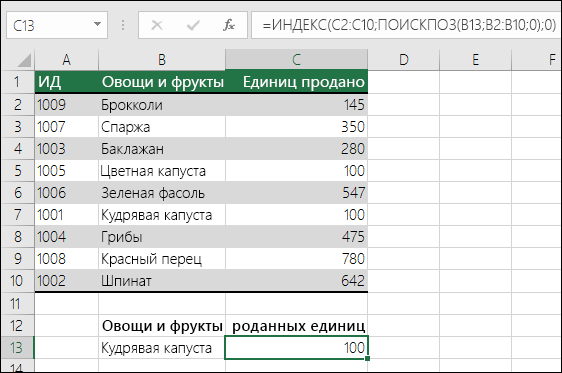
Что означает:
=ИНДЕКС(нужно вернуть значение из C2:C10, которое будет соответствовать ПОИСКПОЗ(первое значение «Капуста» в массиве B2:B10))
Формула ищет в C2:C10 первое значение, соответствующее значению «Ольга» (в B7), и возвращает значение в C7(100),которое является первым значением, которое соответствует значению «Ольга».
Дополнительные сведения см. в функциях ИНДЕКС иФУНКЦИЯ MATCH.
К началу страницы
Подыыывка значений по вертикали в списке с помощью приблизительного совпадения
Для этого используйте функцию ВЛВП.
Важно: Убедитесь, что значения в первой строке отсортировали в порядке возрастания.
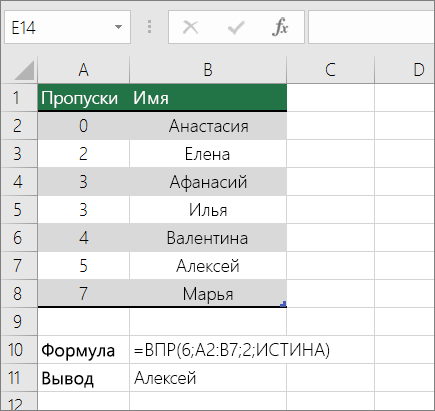
В примере выше ВРОТ ищет имя учащегося, у которого 6 просмотров в диапазоне A2:B7. В таблице нет записи для 6 просмотров, поэтому ВРОТ ищет следующее самое высокое совпадение меньше 6 и находит значение 5, связанное с именем Виктор,и таким образом возвращает Его.
Дополнительные сведения см. в этой информации.
К началу страницы
Подстановка значений по вертикали в списке неизвестного размера с использованием точного совпадения
Для этого используйте функции СМЕЩЕНИЕ и НАЙТИВМЕСЯК.
Примечание: Используйте этот подход, если данные в диапазоне внешних данных обновляются каждый день. Вы знаете, что цена находится в столбце B, но вы не знаете, сколько строк данных возвращает сервер, а первый столбец не отсортировали по алфавиту.
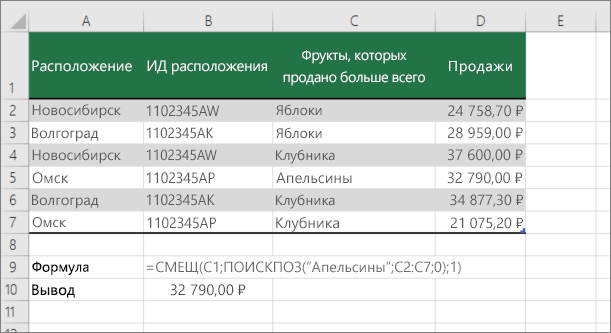
C1 — это левые верхние ячейки диапазона (также называемые начальной).
MATCH(«Оранжевая»;C2:C7;0) ищет «Оранжевые» в диапазоне C2:C7. В диапазон не следует включать запускаемую ячейку.
1 — количество столбцов справа от начальной ячейки, из которых должно быть возвращено значение. В нашем примере возвращается значение из столбца D, Sales.
К началу страницы
Точное совпадение значений по горизонтали в списке
Для этого используйте функцию ГГПУ. См. пример ниже.
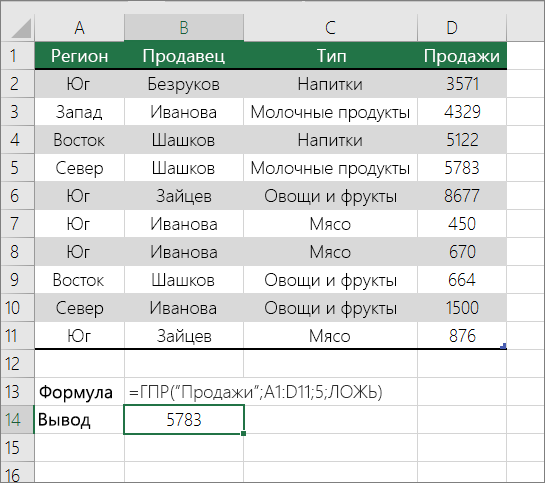
Г ПРОСМОТР ищет столбец «Продажи» и возвращает значение из строки 5 в указанном диапазоне.
Дополнительные сведения см. в сведениях о функции Г ПРОСМОТР.
К началу страницы
Подыыывка значений по горизонтали в списке с использованием приблизительного совпадения
Для этого используйте функцию ГГПУ.
Важно: Убедитесь, что значения в первой строке отсортировали в порядке возрастания.
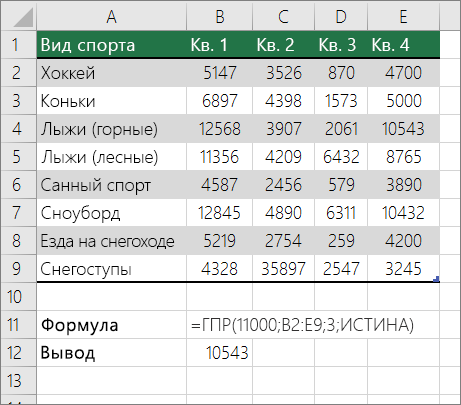
В примере выше ГЛЕБ ищет значение 11000 в строке 3 указанного диапазона. Она не находит 11000, поэтому ищет следующее наибольшее значение меньше 1100 и возвращает значение 10543.
Дополнительные сведения см. в сведениях о функции Г ПРОСМОТР.
К началу страницы
Создание формулы подступа с помощью мастера подметок (толькоExcel 2007 )
Примечание: В Excel 2010 больше не будет надстройки #x0. Эта функция была заменена мастером функций и доступными функциями подменю и справки (справка).
В Excel 2007 создается формула подытов на основе данных на основе данных на основе строк и столбцов. Если вы знаете значение в одном столбце и наоборот, мастер под поисков помогает находить другие значения в строке. В формулах, которые он создает, используются индекс и MATCH.
-
Щелкните ячейку в диапазоне.
-
На вкладке Формулы в группе Решения нажмите кнопку Под поиск.
-
Если команда Подытов недоступна, вам необходимо загрузить мастер под надстройка подытогов.
Загрузка надстройки «Мастер подстройок»
-
Нажмите кнопку Microsoft Office
 , выберите Параметры Excel и щелкните категорию Надстройки.
, выберите Параметры Excel и щелкните категорию Надстройки. -
В поле Управление выберите элемент Надстройки Excel и нажмите кнопку Перейти.
-
В диалоговом окне Доступные надстройки щелкните рядом с полем Мастер подстрок инажмите кнопку ОК.
-
Следуйте инструкциям мастера.
 , выберите Параметры Excel и щелкните категорию Надстройки.
, выберите Параметры Excel и щелкните категорию Надстройки.К началу страницы
Нужна дополнительная помощь?
Ссылка на это место страницы:
#title
- Получить первое не пустое значение в списке
- Получить первое текстовое значение в списке
- Получить первое текстовое значение с ГПР
- Получить позицию последнего совпадения
- Получить последнее совпадение содержимого ячейки
- Получить n-е совпадение
- Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
- Получить n-ое совпадение с ВПР
- Если ячейка содержит одну из многих вещей
- Поиск первой ошибки
- Поиск следующего наибольшего значения
- Несколько совпадений в списке, разделенных запятой
- Частичное совпадение чисел с шаблоном
- Частичное совпадение с ВПР
- Положение первого частичного совпадения
- Скачать файл
Ссылка на это место страницы:
#punk01
{ = ИНДЕКС( диапазон ; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( диапазон ); 0 )) }
{ = INDEX( диапазон ; MATCH( FALSE; ISBLANK ( диапазон ); 0 )) }

Если вам нужно получить первое не пустое значение (текст или число) в диапазоне в одной колонке вы можете использовать формулу массива на основе функций ИНДЕКС, ПОИСКПОЗ и ЕПУСТО.
В данном примере мы используем эту формулу:
{ = ИНДЕКС( B3: B11; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( B3: B11 ); 0 )) }
{ = INDEX( B3:B11; MATCH( FALSE; ISBLANK ( B3:B11 ); 0 )) }
Таким образом, суть проблемы заключается в следующем: мы хотим получить первую не пустую ячейку, но для этого нет конкретной формулы в Excel. Мы могли бы использовать ВПР с шаблоном *, но это будет работать только для текста, а не для чисел.
Таким образом, нам нужно строить функциональные возможности для нужных нам формул. Способ сделать это состоит в использовании функции массива, которая «тестирует» ячейки и возвращает массив истина/ложь значения, которые мы можем сопрягать с ПОИСКПОЗ.
Работая изнутри, ЕПУСТО оценивает ячейки в диапазоне В3: В11 и возвращает результат и массив, который выглядит следующим образом:
{ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА}
Каждая ЛОЖЬ представляет собой ячейку в диапазоне, который не является пустой.
Далее, ПОИСКПОЗ ищет ЛОЖЬ внутри массива и возвращает позицию первого наденного совпадения, в этом случае 2. На данный момент, формула в примере теперь выглядит следующим образом:
{ = ИНДЕКС( B3: B11; 2; 0 )) }
{ = INDEX( B3:B11; 2; 0 )) }
И, наконец, функция ИНДЕКС выводит значение в положении 2 в массиве, в этом случае число 10.
Ссылка на это место страницы:
#punk02
= ВПР ( «*»; диапазон; 1; ЛОЖЬ)
= VLOOKUP ( «*»; диапазон; 1; FALSE)
Если вам нужно получить первое текстовое значение в списке (диапазон один столбец), вы можете использовать функцию ВПР, чтобы установить точное соответствие, с шаблонным символом для поиска.

В данном примере формула в D7 является:
= ВПР ( «*» ; B5: B11 ; 1 ; ЛОЖЬ)
= VLOOKUP ( «*» ; B5:B11 ; 1 ; FALSE)
Групповой символ звездочка (*) соответствует любому текстовому значению.
Ссылка на это место страницы:
#punk03
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( «*»; диапазон; 1; FALSE)

Для поиска и получения первого текстового значения во всем диапазоне столбцов, вы можете использовать функцию ГПР с групповым символом. В примере формула в F5 является:
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( «*»; диапазон; 1; FALSE)
Значение поиска является «*», групповым символом, который соответствует одному или более текстовому значению.
Ссылка на это место страницы:
#punk04
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( «*»; диапазон; 1; FALSE)
Для того, чтобы получить позицию последнего совпадения (т.е. последнего вхождения) от значения поиска, вы можете использовать формулу, основанную на ЕСЛИ, СТРОКА, ИНДЕКС, ПОИСКПОЗ и MAКС функций.

=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
=MAX(IF(B4:B11=G5;ROW(B4:B11)-ROW(INDEX(B4:B11;1;1))+1))
Суть этой формулы состоит в том, что мы строим список номеров строк для данного диапазона, соответствующие по значению, а затем используем функцию MAКС, чтобы получить наибольшее количество строк, что соответствует последнему значению соответствия.
Ссылка на это место страницы:
#punk05
=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
=MAX(IF(B4:B11=G5;ROW(B4:B11)-ROW(INDEX(B4:B11;1;1))+1))
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть последнее совпадение, найденное в списке, вы можете использовать формулу, основанную на ПРОСМОТР и ПОИСК функций. В случае нескольких найденных совпадений, формула вернет последнее совпадение из списка «вещей».

=ПРОСМОТР(2;1/ПОИСК($E$4:$E$7;B4);$E$4:$E$7)
=LOOKUP(2;1/SEARCH($E$4:$E$7;B4);$E$4:$E$7)
Ссылка на это место страницы:
#punk06
= НАИМЕНЬШИЙ( ЕСЛИ( логический тест; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); n )
= SMALL( IF( логический тест; СТРОКА( список ) — MIN( ROW( список )) + 1 ); n )
Для того, чтобы получить позицию n-го совпадения (например, второе значение соответствия заданному, третье значение соответствия и т.д.), вы можете использовать формулу, основанную на функции НАИМЕНЬШИЙ.
= НАИМЕНЬШИЙ( ЕСЛИ( список = E5 ; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); F5 )
= SMALL( IF( список = E5 ; ROW( список ) — MIN( ROW( список )) + 1 ); F5 )
Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Ссылка на это место страницы:
#punk07
{ = ИНДЕКС( массив; НАИМЕНЬШИЙ( ЕСЛИ( величины = знач ; СТРОКА ( величины ) — СТРОКА ( ИНДЕКС( величины; 1 ; 1 )) + 1 ); n-й )) }
{ = INDEX( массив; SMALL( IF( величины = знач ; ROW ( величины ) — ROW ( INDEX( величины; 1 ; 1 )) + 1 ); n-й )) }

Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Ссылка на это место страницы:
#punk08
= ВПР( id_формулы; стол; 4; 0 )
= VLOOKUP( id_формулы; стол; 4; 0 )
Чтобы получить n-ое совпадение с ВПР, вам необходимо добавить вспомогательный столбец в таблицу , которая строит уникальный идентификатор , который включает счетчик.

Эта формула зависит от вспомогательного столбца, который добавляется в качестве первого столбца таблицы исходных данных.
Вспомогательный столбец содержит формулу, которая строит уникальное значение взгляда вверх от существующего идентификатора и счетчика. Счетчик подсчитывает сколько раз уникальный идентификатор появился в таблице данных.
В примере, формула ячейки J6 вспомогательного столбца выглядит следующим образом:
=ВПР(J3&»-«&I6;B4:G11;4;0)
=VLOOKUP(J3&»-«&I6;B4:G11;4;0)
Ссылка на это место страницы:
#punk09
{ = ИНДЕКС( результаты ;ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК( вещи ; A1 )); 0 )) }
{ = INDEX( результаты ;MATCH( TRUE ; ISNUMBER( SEARCH( вещи ; A1 )); 0 )) }
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть пользовательский результат для первого найденного совпадения, вы можете использовать формулу ИНДЕКС/ПОИСКПОЗ, основанную на функции поиска.
{ = ИНДЕКС( результаты ; ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК ( вещи ; B5 )); 0 )) }
= INDEX( результаты ; MATCH( TRUE ; ISNUMBER( SEARCH ( вещи ; B5 )); 0 ))
Эта формула использует два названных диапазона: E5: E8 называется «вещи» и F5: F8 называется «Результаты». Убедитесь, что вы используете диапазоны имен с одинаковыми именами (на основе ваших данных). Если вы не хотите использовать именованные диапазоны, используйте абсолютные ссылки вместо этого.
Ссылка на это место страницы:
#punk10
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА(диап ); 0 ) }
{ = MATCH( TRUE ; ISERROR(диап ); 0 ) }
Если вам нужно найти первую ошибку в диапазоне ячеек, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ЕОШИБКА функциях.

В приведенном примере формула:
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА( B4: B11 ); 0 ) }
{ = MATCH( TRUE ; ISERROR( B4:B11 ); 0 ) }
Работая изнутри, функция ЕОШИБКА возвращает значение ИСТИНА, если значение является признанной ошибкой, и ЛОЖЬ, если нет.
Когда дается диапазон ячеек (массив ячеек) функция ЕОШИБКА будет возвращать массив истина/ложь значений. В примере, это результирующий массив выглядит следующим образом:
{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ}
Обратите внимание, что 6-е значение (что соответствует 6-й ячейке в диапазоне) истинно, так как ячейка В9 содержит #Н/A.
Ссылка на это место страницы:
#punk11
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )
=INDEX ( данные; MATCH( поиск ; значения ) + 1 )

Для того, чтобы найти «следующее наибольшее» значение в справочной таблице, можно использовать формулу, основанную на ИНДЕКС и ПОИСКПОЗ. В примере формула в F6 является:
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )
=INDEX ( данные; MATCH( поиск ; значения ) + 1 )
Ссылка на это место страницы:
#punk12
{ = ОБЪЕДИНИТЬ ( «;» ; ИСТИНА ; ЕСЛИ( диапазон1 = E5 ; диапазон2 ; «» )) }
{ = ОБЪЕДИНИТЬ ( «;» ; TRUE ; IF( диапазон1 = E5 ; диапазон2 ; «» )) }
Для поиска и извлечения нескольких совпадений, разделенных запятыми (в одной ячейке), вы можете использовать функцию ЕСЛИ с функцией ОБЪЕДИНИТЬ.
{ = ОБЪЕДИНИТЬ( «;» ; ИСТИНА ; ЕСЛИ( группа = E5 ; имя ; «» )) }
Эта формула использует «имя» — именованный диапазон (B5: B11) и «группа» — (C5: C11).
Ссылка на это место страницы:
#punk13
{ = ПОИСКПОЗ( «*» & номер & «*» ; ТЕКСТ( диапазон ; «0» ); 0 ) }
{ = MATCH( «*» & номер & «*» ; TEXT( диапазон ; «0» ); 0 ) }
Для того, чтобы выполнить частичное совпадение (подстроки) против чисел, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ТЕКСТ.

Excel поддерживает символы подстановки «*» и «?». Тем не менее, если вы используете специальные символы с номером, вы будете преобразовывать числовое значение в текстовое значение. Другими словами, «*» & 99 & «*» = «* 99 *» (текстовая строка).
Если попытаться найти текстовое значение в диапазоне чисел, совпадение завершится неудачно.
Одно из решений заключается в преобразовании чисел в диапазоне поиска для текстовых значений, а затем сделать нормальный поиск с ПОИСКПОЗ, ВПР и т.д.
Другой способ, чтобы преобразовать числа в текст, чтобы сцепить пустую строку. Эта формула работает так же, как выше формуле:
= ПОИСКПОЗ ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
= MATCH ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
Ссылка на это место страницы:
#punk14
Если вы хотите получить информацию из таблицы на основе частичного совпадения, вы можете сделать это с помощью ВПР в режиме точного соответствия, и групповые символы.

В примере формула ВПР выглядит следующим образом:
=ВПР($H$2&»*»;$B$3:$E$12;2;0)
=VLOOKUP($H$2&»*»;$B$3:$E$12;2;0)
В этой формуле, значение представляет собой именованный диапазон, который относится к Н2, а также данные , представляет собой именованный диапазон , который относится к B3: E102. Без названных диапазонов, формула может быть записана следующим образом:
Ссылка на это место страницы:
#punk15
= ПОИСКПОЗ ( «* текст *» ; диапазон; 0 )
= MATCH ( «* текст *» ; диапазон; 0 )
Для того, чтобы получить позицию первого частичного совпадения (то есть ячейку, которая содержит текст, который вы ищете), вы можете использовать функцию ПОИСКПОЗ со специальными символами.

=ПОИСКПОЗ(«*»&E6&»*»;B5:B10;0)
=MATCH(«*»&E6&»*»;B5:B10;0)
Функция ПОИСКПОЗ возвращает позицию или «индекс» в первом совпадении на основании значения поиска в диапазоне.
ПОИСКПОЗ поддерживает подстановочное согласование со звездочкой «*» (один или несколько символов) или знаком вопроса «?» (один символ), но только тогда, когда третий аргумент, тип_сопоставления, установлен в ЛОЖЬ или ноль.
Ссылка на это место страницы:
#punk16
Файлы статей доступны только зарегистрированным пользователям.
1. Введите свою почту
2. Нажмите Зарегистрироваться
3. Обновите страницу
Вместо этого блока появится ссылка для скачивания материалов.

Привет! Меня зовут Дмитрий. С 2014 года Microsoft Cretified Trainer. Вместе с командой управляем этим сайтом. Наша цель — помочь вам эффективнее работать в Excel.
Изучайте наши статьи с примерами формул, сводных таблиц, условного форматирования, диаграмм и макросов. Записывайтесь на наши курсы или заказывайте обучение в корпоративном формате.

Подписывайтесь на нас в соц.сетях:
Получить первое числовое значение в столбце или строке
Чтобы получить первое числовое значение из диапазона из одного столбца или одной строки, вы можете использовать формулу, основанную на ИНДЕКС, МАТЧ и ISNUMBER функций.

Как получить первое числовое значение в списке?
Чтобы получить первое числовое значение в списке как показано выше, комбинация функций ИНДЕКС, ПОИСКПОЗ и ЕЧИСЛО поможет вам в этом: функция ЕЧИСЛО проверяет каждое значение в списке, являются ли они числами или нет. Затем функция ПОИСКПОЗ выполняет точное совпадение, чтобы определить положение первого числового значения. Затем INDEX получит значение в этой позиции.
Общий синтаксис
=INDEX(range,MATCH(TRUE,ISNUMBER(range),0))
√ Примечание. Это формула массива, требующая ввода с помощью Ctrl + Shift + Enter.
- ассортимент: Диапазон из одного столбца или одной строки, из которого нужно вернуть первое числовое значение.
Чтобы получить первое числовое значение в списке, скопируйте или введите формулу ниже в ячейку E4 и нажмите Ctrl + Shift + Enter чтобы получить результат:
= ИНДЕКС (B4: B15, ПОИСКПОЗ (ИСТИНА; ЕДИНИЦА (B4: B15), 0))

Пояснение формулы
=INDEX(B4:B15,MATCH(TRUE,ISNUMBER(B4:B15),0))
- ЕЧИСЛО (B4: B15): Функция ЕЧИСЛО оценивает каждое значение в диапазоне B4: B15. Он вернет ИСТИНА, если значение является числом, иначе ЛОЖЬ. Итак, он сгенерирует такой массив: {ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА}.
- МАТЧ (ИСТИНА;ЕЧИСЛО (B4: B15), 0) = МАТЧ (ИСТИНА;{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА}, 0): Наблюдения и советы этой статьи мы подготовили на основании опыта команды match_type 0 заставляет функцию ПОИСКПОЗ возвращать позицию первого ИСТИНА значение в массиве. Итак, функция вернет 4.
- ПОКАЗАТЕЛЬ(B4: B15,МАТЧ (ИСТИНА;ЕЧИСЛО (B4: B15), 0)) = ПОКАЗАТЕЛЬ(B4: B15,4): Затем функция ИНДЕКС возвращает 4ое значение диапазона B4: B15, Которая является 99.
Связанные функции
Функция ИНДЕКС в Excel
Функция ИНДЕКС Excel возвращает отображаемое значение на основе заданной позиции из диапазона или массива.
Функция ПОИСКПОЗ в Excel
Функция ПОИСКПОЗ в Excel ищет определенное значение в диапазоне ячеек и возвращает относительное положение значения.
Связанные формулы
Получить n-е совпадение с помощью INDEX
Чтобы найти n-е совпадение значения из диапазона и получить соответствующие данные, вы можете использовать формулу, основанную на функциях ИНДЕКС, СТРОКА, НАИМЕНЬШИЙ и ЕСЛИ.
Лучшие инструменты для работы в офисе
Kutools for Excel — Помогает вам выделиться из толпы
Хотите быстро и качественно выполнять свою повседневную работу? Kutools for Excel предлагает 300 мощных расширенных функций (объединение книг, суммирование по цвету, разделение содержимого ячеек, преобразование даты и т. д.) и экономит для вас 80 % времени.
- Разработан для 1500 рабочих сценариев, помогает решить 80% проблем с Excel.
- Уменьшите количество нажатий на клавиатуру и мышь каждый день, избавьтесь от усталости глаз и рук.
- Станьте экспертом по Excel за 3 минуты. Больше не нужно запоминать какие-либо болезненные формулы и коды VBA.
- 30-дневная неограниченная бесплатная пробная версия. 60-дневная гарантия возврата денег. Бесплатное обновление и поддержка 2 года.
")
Вкладка Office — включение чтения и редактирования с вкладками в Microsoft Office (включая Excel)
- Одна секунда для переключения между десятками открытых документов!
- Уменьшите количество щелчков мышью на сотни каждый день, попрощайтесь с рукой мыши.
- Повышает вашу продуктивность на 50% при просмотре и редактировании нескольких документов.
- Добавляет эффективные вкладки в Office (включая Excel), точно так же, как Chrome, Firefox и новый Internet Explorer.
")
Комментарии (0)
Оценок пока нет. Оцените первым!
- Первые N символов – формула в Excel
- Разбить столбец по количеству символов
- Извлечь первые символы автозаполнением
- Извлечь первые символы с помощью регулярных выражений
- Оставить первые / последние N символов в строке в 1 клик
Простейшая задача – взять и отделить от ячейки первый символ, скопировав его в соседний столбец. Или выбрать и оставить в ней первые 2, 3, 4… N символов.
Например, в строках переменной длины первые 6 символов – определенный цифровой код, который нужно скопировать в отдельный столбец.
Или задача является частью другой, где нужно сделать первую букву ячейки заглавной, а для этого, ее нужно вытащить из ячейки.
Рассмотрим все известные решения, снабдив их примерами. Итак, поехали.
Вытащить первый символ или N символов ячейки формулой проще простого. И есть даже 2 функции Excel, которые в этом помогут:
- ЛЕВСИМВ;
- ПСТР.
А так будут выглядеть формулы, извлекающие первые N символов из ячейки A1. Подставьте свое число вместо N, чтобы формулы работали:
Заметное отличие первой функции от второй — в отсутствии параметра, отвечающего за позицию, с которой начинается извлечение. Поэтому, если вычислить позицию первого вхождения определенного символа в ячейке, с помощью этой функции можно извлечь его, даже если он не является первым символом строки.
Например:
- извлечь текст после цифр
- извлечь первые N цифр
- сделать первую букву ячейки заглавной
Разбить столбец по количеству символов
Можно получить первые N символов столбца, разбив его по количеству символов. Первые N останутся, а остальные будут перенесены в соседний справа. Можно разбить и на несколько — Excel не ставит ограничений на количество столбцов.
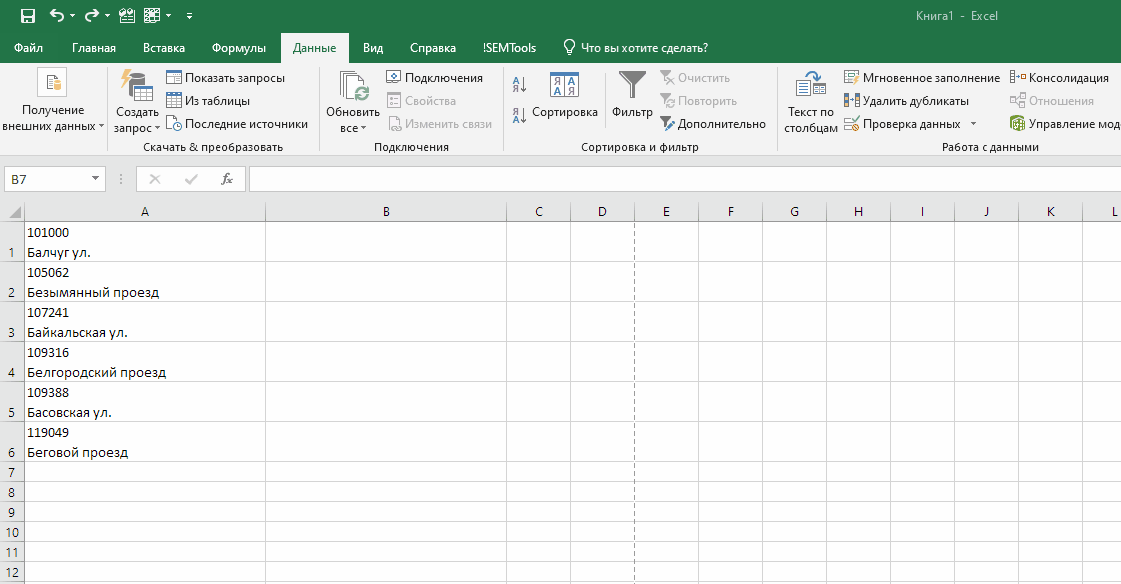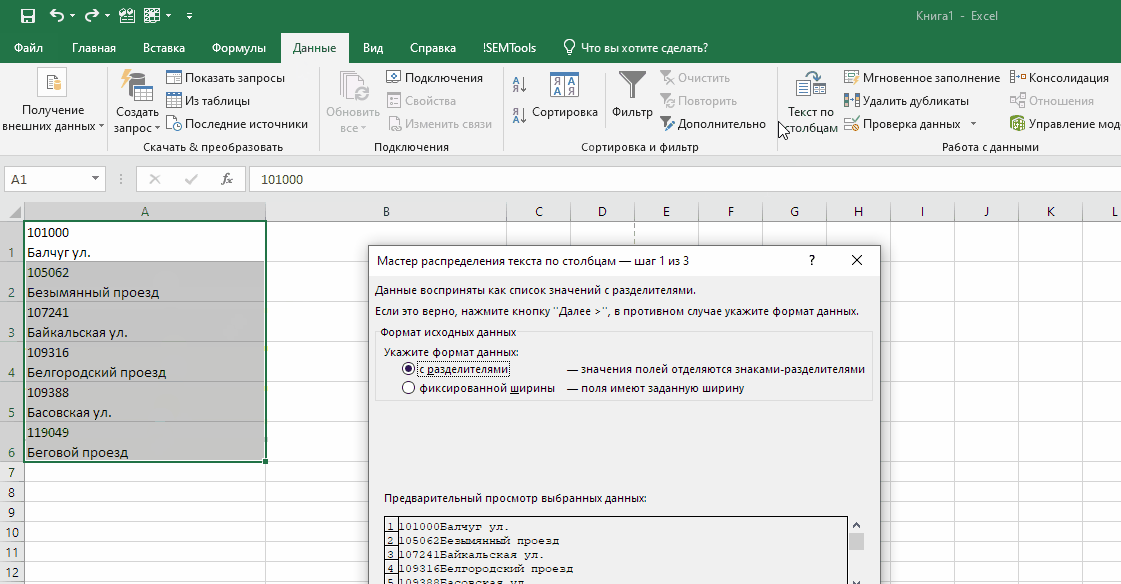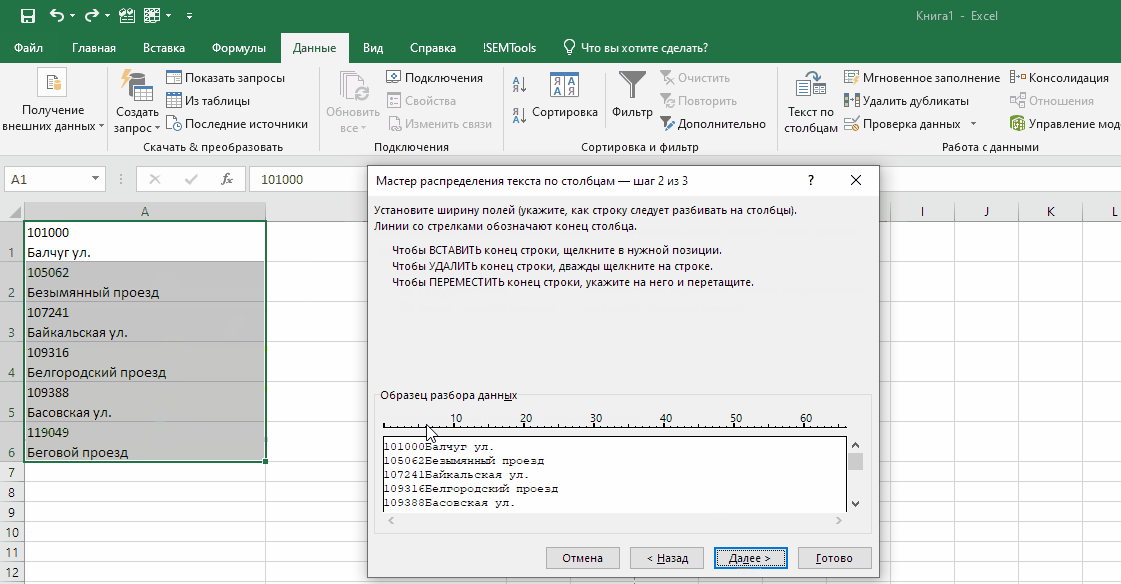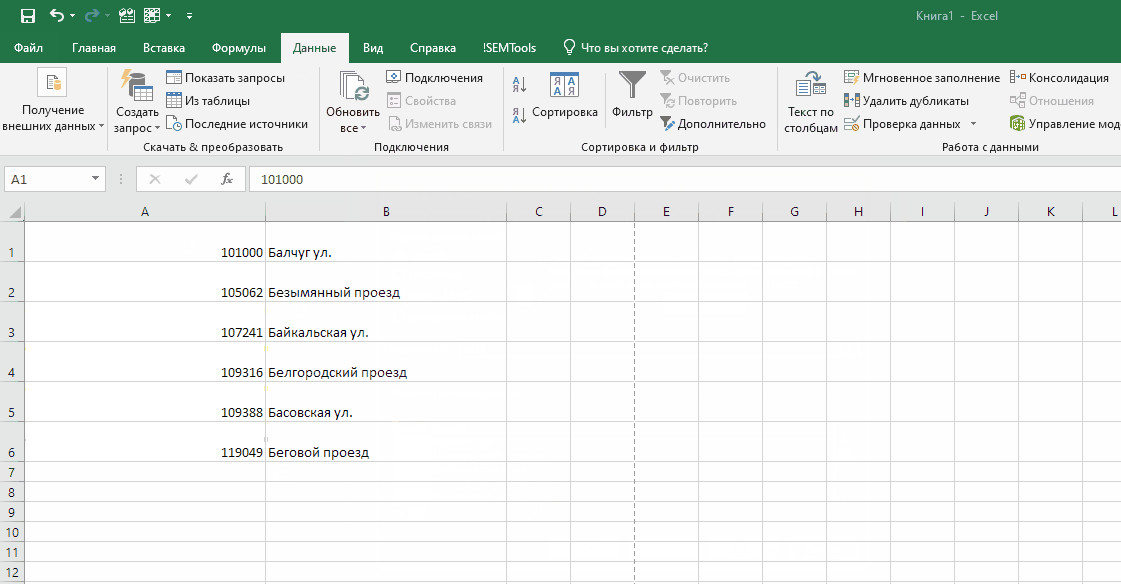
В отличие от формул, у процедур есть свои отличия, которые можно трактовать как плюсы и минусы в зависимости от ситуации. В данном случае отличие от формул в следующих моментах:
- разбивка по столбцам не сохраняет исходный столбец
- это единоразовая процедура, в отличие от формул, которые пересчитываются при обновлении данных
- удобный момент — одна процедура создает сразу несколько столбцов
- направление разбивки — только вправо
- если справа есть данные, они могут быть перезаписаны, если не отменить операцию и не создать пустой столбец/столбцы.
Извлечь первые символы автозаполнением
Автозаполнение – замечательная процедура в Excel. Алгоритм действий прост.
- Заполняем пару ячеек соседнего столбца вручную;
- Уже при вводе третьей может быть предложено автозаполнение;
- Если согласны – жмём клавишу Ввод (Enter).
Однако с этой процедурой нужно быть осторожным. Алгоритм, который используется при автозаполнении, не показывается, поэтому результат может не соответствовать ожиданиям. Обычно алгоритм можно «доучить», чтобы он понял, что от него хотят.

Извлечь первые символы с помощью регулярных выражений
Чтобы выбрать из строки символы по регулярным выражениям, в Google Spreadsheets доступна функция REGEXEXTRACT. Там она существует уже очень давно.
А вот Microsoft не столь серьезно озадачились вопросом – официально регулярные выражения в Excel существуют только как подключаемый модуль VBA. Поэтому доступны очень узкому кругу посвященных специалистов с навыками программирования на нем.
Чтобы сделать их необычайно гибкий синтаксис доступным обычным пользователям, я включил их поддержку в формулы и процедуры своей надстройки !SEMTools.
Подробно тут – регулярные выражения в Excel и примеры регулярных выражений. А ниже на картинке – примеры формул, которые позволят извлечь первые N символов, в том числе букв или цифр по отдельности, из любой ячейки.

Функции доступны абсолютно бесплатно и работают при подключенной надстройке !SEMTools для Excel даже в стартовой версии.
Оставить первые / последние N символов в строке в 1 клик
Ну и напоследок – на панели !SEMTools доступны процедуры, позволяющие максимально легко и быстро выбрать первые или последние символы из ячеек.
Можно выделять одну ячейку, несколько, целый столбец или даже несколько несвязанных диапазонов – процедура обработает все выделенные данные. При желании можно вернуться назад на 1 шаг.
Если активна опция «Выводить результат справа», исходные данные не меняются, а извлеченные символы выводятся в соседний столбец/столбцы.
Смотрите демонстрацию ниже:

Процедуры доступны в полной версии надстройки, но попробовать можно и бесплатно.
Жмите кнопку ниже, чтобы скачать и подключить надстройку к вашему Excel! Процедура займет всего пару минут.
Если вы оказались на этой странице, то наверняка сталкиваетесь с другими похожими задачами.
Сотни инструментов надстройки для Excel !SEMTools помогут решить эти задачи буквально в один клик!