
Все курсы > Программирование на Питоне > Занятие 4
Для построения модели нам нужны данные. И очень часто эти данные содержатся во внешних файлах. Мы уже столкнулись с этим, когда работали с рекомендательными системами и временными рядами. Предлагаю сегодня рассмотреть этот вопрос более детально.
Общее описание процесса

В целом работа с файлами в Google Colab состоит из следующих этапов.
- Этап 1. Подгрузка файлов с локального компьютера на сервер Google
- Этап 2. Чтение файла
- Этап 3. Построение модели и прогноз
- Этап 4. Сохранение результата в новом файле на сервере Google
- Этап 5. Скачивание обратно на жесткий диск
Пройдемся по каждому из них. Но прежде поговорим про данные.
Датасет «Титаник»
На этом занятии предлагаю взять датасет о пассажирах корабля «Титаник», который, как известно, затонул в 1912 году при столкновении с айсбергом. Часть пассажиров выжила, но многие, к сожалению, погибли. В предложенном датасете собрана информация о самих пассажирах (признаки), а также о том, выжили они или нет (целевая переменная).

Данные уже разделены на обучающую и тестовую выборки. Скачаем их.
Также откроем ноутбук к этому занятию⧉
Если внешние файлы хранятся на локальном компьютере, то нам нужно подгрузить их в так называемое «Сессионное хранилище» (session storage, по сути, сервер Google).
Слово «сессионное» указывает на то, что данные, как я уже говорил, хранятся временно и после завершения очередной сессии стираются.
Подгрузить данные с локального компьютера можно двумя способами.
Способ 1. Вручную через вкладку «Файлы»
Этот способ мы использовали до сих пор. В качестве напоминания приведу скриншоты подгрузки файла train.csv.


Способ 2. Через объект files библиотеки google.colab
К объекту files мы применяем метод .upload(), который передает нам словарь. Ключами этого словаря будут названия файлов, а значениями — сами подгруженные данные. Приведем пример с файлом test.csv.
|
# из библиотеки google.colab импортируем класс files from google.colab import files # создаем объект этого класса, применяем метод .upload() uploaded = files.upload() |
Нам будет предложено выбрать файл на жестком диске.


|
# посмотрим на содержимое переменной uploaded uploaded |
|
{‘test.csv’: b’PassengerId,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarkedrn892,3,»Kelly, Mr. James»,male,34.5,0,0,330911,7.8292,,Qrn893,3,»Wilkes, Mrs. James (Ellen Needs)»,female,47,1,0,363272,7,,Srn894,2,… } |
Все что идет после двоеточия (
:) и есть наш файл. Он содержится в формате bytes, о чем свидетельствует буква b перед строкой файла (подробнее об этом ниже).
Этап 2. Чтение файлов
После загрузки оба файла (train.csv и test.csv) оказываются в сессионном хранилище в папке под названием /content/.

Просмотр содержимого в папке /content/
Модуль os и метод .walk()
Для того чтобы просмотреть ее содержимое внутри ноутбука, мы можем воспользоваться модулем os (отвечает за взаимодействие Питона с операционной системой) и, в частности, методом .walk() (позволяет «пройтись» по содержимому конкретной папки).
|
# импортируем модуль os import os # выводим пути к папкам (dirpath) и наименования файлов (filenames) и после этого for dirpath, _, filenames in os.walk(‘/content/’): # во вложенном цикле проходимся по названиям файлов for filename in filenames: # и соединяем путь до папок и входящие в эти папки файлы # с помощью метода path.join() print(os.path.join(dirpath, filename)) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
/content/test.csv /content/train.csv /content/.config/gce /content/.config/.last_update_check.json /content/.config/config_sentinel /content/.config/.last_opt_in_prompt.yaml /content/.config/active_config /content/.config/.last_survey_prompt.yaml /content/.config/logs/2021.11.01/13.34.55.836922.log /content/.config/logs/2021.11.01/13.34.28.082269.log /content/.config/logs/2021.11.01/13.34.08.637862.log /content/.config/logs/2021.11.01/13.34.55.017895.log /content/.config/logs/2021.11.01/13.33.47.856572.log /content/.config/logs/2021.11.01/13.34.35.080342.log /content/.config/configurations/config_default /content/sample_data/anscombe.json /content/sample_data/README.md /content/sample_data/california_housing_test.csv /content/sample_data/mnist_train_small.csv /content/sample_data/california_housing_train.csv /content/sample_data/mnist_test.csv |
Первые два файла и есть наши данные. В скрытой подпапке /.config/ содержатся служебные файлы, а в подпапке /sample_data/ — примеры датасетов, хранящиеся в Google Colab по умолчанию.
Команда !ls
Кроме того, если нас интересуют только видимые файлы и папки, мы можем воспользоваться командой !ls (ls означает to list, т.е. «перечислить»).
|
sample_data test.csv train.csv |
Подобным образом мы можем заглянуть внутрь папки sample_data.
|
!ls /content/sample_data/ |
|
anscombe.json mnist_test.csv california_housing_test.csv mnist_train_small.csv california_housing_train.csv README.md |
Теперь прочитаем файл сначала из переменной uploaded, а затем напрямую из папки /content/.
Чтение из переменной uploaded
Как мы уже сказали выше, в словаре uploaded файл содержится в формате bytes.
|
# посмотрим на тип значений словаря uploaded type(uploaded[‘test.csv’]) |
Основная особенность: информация в объекте bytes представляет собой последовательность байтов (byte string), в то время как обычная строка — это последовательность символов (character string). Компьютер понимает первый тип, мы (люди) — второй.
Для того чтобы прочитать информацию из объекта bytes, ее нужно декодировать (decode). Если мы захотим вернуть ее обратно в объект bytes, соответственно, закодировать (encode).

Таким образом, чтобы прочитать данные напрямую из словаря uploaded, вначале нам нужно преобразовать эти данные в обычную строку.
|
# обратимся к ключу словаря uploaded и применим метод .decode() uploaded_str = uploaded[‘test.csv’].decode() # на выходе получаем обычную строку print(type(uploaded_str)) |
Выведем первые 35 значений.
|
PassengerId,Pclass,Name,Sex,Age,Sib |
Если разбить строку методом .split() по символам r (возврат к началу строки) и n (новая строка), то на выходе мы получим список.
|
uploaded_list = uploaded_str.split(‘rn’) type(uploaded_list) |
Пройдемся по этому списку и выведем первые четыре значения.
|
# не забудем создать индекс с помощью функции enumerate() for i, line in enumerate(uploaded_list): # начнем выводить записи print(line) # когда дойдем до четвертой строки if i == 3: # прервемся break |
|
PassengerId,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked 892,3,»Kelly, Mr. James»,male,34.5,0,0,330911,7.8292,,Q 893,3,»Wilkes, Mrs. James (Ellen Needs)»,female,47,1,0,363272,7,,S 894,2,»Myles, Mr. Thomas Francis»,male,62,0,0,240276,9.6875,,Q |
Вот нам и пригодился оператор break. Как мы видим, первая строка — это заголовок (header), остальные — информация по каждому из пассажиров.
Использование функции open() и конструкции with open()
Такого же результата можно добиться с помощью базовой функции open().
Обратите внимание, здесь мы читаем файл непосредственно из папки /content/. Декодировать файл уже не нужно.
Функция open() возвращает объект, который используется для чтения и изменения файла. Откроем файл train.csv.
|
# передадим функции open() адрес файла # параметр ‘r’ означает, что мы хотим прочитать (read) файл f1 = open(‘/content/train.csv’, ‘r’) |
Вначале попробуем применить метод .read().
|
# метод .read() помещает весь файл в одну строку # выведем первые 142 символа (если параметр не указывать, выведется все содержимое) print(f1.read(142)) # в конце файл необходимо закрыть f1.close() |
|
PassengerId,Survived,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked 1,0,3,»Braund, Mr. Owen Harris»,male,22,1,0,A/5 21171,7.25,,S |
Для наших целей метод .read() не очень удобен. Будет лучше пройтись по файлу в цикле for.
|
# снова откроем файл f2 = open(‘/content/train.csv’, ‘r’) # пройдемся по нашему объекту в цикле for и параллельно создадим индекс for i, line in enumerate(f2): # выведем строки без служебных символов по краям print(line.strip()) # дойдя до четвертой строки, прервемся if i == 3: break # не забудем закрыть файл f2.close() |
|
PassengerId,Survived,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked 1,0,3,»Braund, Mr. Owen Harris»,male,22,1,0,A/5 21171,7.25,,S 2,1,1,»Cumings, Mrs. John Bradley (Florence Briggs Thayer)»,female,38,1,0,PC 17599,71.2833,C85,C 3,1,3,»Heikkinen, Miss. Laina»,female,26,0,0,STON/O2. 3101282,7.925,,S |
Еще один способ — использовать конструкцию with open(). В этом случае специально закрывать файл не нужно.
|
# скажем Питону: «открой файл и назови его f3» with open(‘/content/test.csv’, ‘r’) as f3: # «пройдись по строкам без служебных символов» for i, line in enumerate(f3): print(line.strip()) # и «прервись на четвертой строке» if i == 3: break |
|
PassengerId,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked 892,3,»Kelly, Mr. James»,male,34.5,0,0,330911,7.8292,,Q 893,3,»Wilkes, Mrs. James (Ellen Needs)»,female,47,1,0,363272,7,,S 894,2,»Myles, Mr. Thomas Francis»,male,62,0,0,240276,9.6875,,Q |
Чтение через библиотеку Pandas
Вероятно наиболее удобный и подходящий для наших целей способ чтения файлов — это преобразование напрямую в датафрейм библиотеки Pandas. С этим методом в целом мы уже знакомы.
|
# импортируем библиотеку import pandas as pd # применим функцию read_csv() и посмотрим на первые три записи файла train.csv train = pd.read_csv(‘/content/train.csv’) train.head(3) |

|
# сделаем то же самое с файлом test.csv test = pd.read_csv(‘/content/test.csv’) test.head(3) |

Примечание. На скриншотах приведена лишь часть датафреймов, полностью их можно посмотреть в ноутбуке⧉.
Этап 3. Построение модели и прогноз
Давайте ненедолго отвлечемся от работы с файлами и построим несложную модель, которая предскажет погиб пассажир (обозначим этот факт через 0) или выжил (1). Прежде всего, концептуально обсудим, что нам нужно сделать.
Для понимания дальнейшей работы очень советую пройти или повторить первые три раздела вводного курса. На этом занятии я предполагаю, что вы с ними уже знакомы.
- Шаг 1. Обработать и проанализировать данные
- Шаг 2. Разделить обучающую выборку (train) на признаки (X_train) и целевую переменную (y_train)
- Шаг 3. Обучить модель логистической регрессии
- Шаг 4. Подготовить тестовые данные (X_test) и построить прогноз
А теперь обо всем по порядку.
Шаг 1. Обработка и анализ данных
Исследовательский анализ данных (EDA)
Напомню, что основная задача EDA — выявить взаимосвязь между признаками и целевой переменной. Воспользуемся методом .info(), чтобы обобщенно посмотреть на наши данные.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
<class ‘pandas.core.frame.DataFrame’> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): # Column Non-Null Count Dtype — —— ————— —— 0 PassengerId 891 non-null int64 1 Survived 891 non-null int64 2 Pclass 891 non-null int64 3 Name 891 non-null object 4 Sex 891 non-null object 5 Age 714 non-null float64 6 SibSp 891 non-null int64 7 Parch 891 non-null int64 8 Ticket 891 non-null object 9 Fare 891 non-null float64 10 Cabin 204 non-null object 11 Embarked 889 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.7+ KB |
Как мы видим, у нас 12 переменных. Одна из них (Survived) — зависимая (целевая), остальные — независимые (признаки). Всего в датасете 891 запись, при этом в нескольких переменных есть пропуски.
Ниже приведено короткое описание каждой из переменных:
- PassengerId — id пассажира
- Survived — погиб (0) или выжил (1)
- Pclass — класс билета (первый (1), второй (2) или третий (3))
- Name — имя пассажира
- Sex — пол
- Age — возраст
- SibSp — количество братьев и сестер или супругов на борту
- Parch — количество родителей и детей на борту
- Ticket — номер билета
- Fare — стоимость билета
- Cabin — номер каюты
- Embarked — порт посадки (C — Шербур; Q — Квинстаун; S — Саутгемптон)
Проведем несложный визуальный анализ данных.
|
# для построения графиков воспользуемся новой для нас библиотекой seaborn import seaborn as sns |
У нас есть несколько потенциально значимых категориальных переменных, целевая переменная — тоже категориальная. В этом случае удобно использовать столбчатую диаграмму (bar chart), где каждый столбец также разбит на категории. В библиотеке seaborn такую диаграмму можно построить с помощью функции countplot().
|
# посмотрим насколько значим класс билета для выживания пассажира # с помощью x и hue мы можем уместить две категориальные переменные на одном графике sns.countplot(x = ‘Pclass’, hue = ‘Survived’, data = train) |

Мы видим, что погибших пассажиров в третьем классе гораздо больше, чем выживших. При этом в первом классе больше выживших, чем погибших. Очевидно класс билета имеет значение.
|
# кто выживал чаще, мужчины или женщины? sns.countplot(x = ‘Sex’, hue = ‘Survived’, data = train) |

Большинство мужчик погибло. Большая часть женщин выжила. Пол также значим для построения прогноза.
Пропущенные значения
Посмотрим, что можно сделать с пропущенными значениями (missing values).
|
# выявим пропущенные значения с помощью .isnull() и посчитаем их количество sum() train.isnull().sum() |
|
PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 177 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 2 dtype: int64 |
Больше всего пропущенных значений в переменной Cabin. Они также есть в переменных Age и Embarked.
|
# переменная Cabin (номер каюты), скорее всего, не является самой важной # избавимся от нее с помощью метода .drop() # (параметр axis отвечает за столбцы, inplace = True сохраняет изменения) train.drop(columns = ‘Cabin’, axis = 1, inplace = True) |
|
# а вот Age (возраст) точно важен, заменим пустые значения средним арифметическим train[‘Age’].fillna(train[‘Age’].mean(), inplace = True) |
В данном случае мы применили метод .fillna(), то есть «заполнить пропуски», к столбцу Age (через
train[‘Age’]) и заполнили пропуски средним значением этого же столбца через
train[‘Age’].mean().
Более подробно с преобразованием датафреймов мы познакомимся на курсе анализа и обработки данных. На данном этапе важно просто понимать логику нашей работы.
|
# у нас остаются две пустые строки в Embarked, удалим их train.dropna(inplace = True) |
Посмотрим на результат.
|
PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 0 SibSp 0 Parch 0 Ticket 0 Fare 0 Embarked 0 dtype: int64 |
Категориальные переменные
Теперь нужно поработать с категориальными переменными (categorical variable). Как мы помним, модель не сможет подобрать веса, если значения выражены словами (например, male и female в переменной Sex или C, Q, S в переменной Embarked).
Кроме того, когда категория выражена не 0 и 1, мы все равно не можем оставить ее без изменения. Например, если не трогать переменную Pclass, то модель воспримет классы 1, 2 и 3 как количественную переменную (проще говоря, число), а не как категорию.
И в первом, и во втором случае к переменным нужно применить one-hot encoding. Мы уже познакомились с этим методом, когда разбирали нейронные сети. В библиотеке Pandas есть метод .get_dummies(), который как раз и выполнит необходимые преобразования.
В статистике, dummy variable или вспомогательная переменная — это переменная, которая принимает значения 0 или 1 в зависимости от наличия определенного признака.
Применим этот метод на практике.
|
# применим one-hot encoding к переменной Sex (пол) с помощью метода .get_dummies() pd.get_dummies(train[‘Sex’]).head(3) |

Первый пассажир — мужчина (в колонке male стоит 1), второй и третий — женщина. Помимо этого, если присмотреться, то станет очевидно, что мы можем обойтись только одним столбцом. В частности, в столбце male уже содержится достаточно информации о поле (если 1 — мужчина, если 0 — женщина). Это значит, что первый столбец можно удалить.
|
# удалим первый столбец, он избыточен sex = pd.get_dummies(train[‘Sex’], drop_first = True) sex.head(3) |

Сделаем то же самое для переменных Pclass и Embarked.
|
embarked = pd.get_dummies(train[‘Embarked’], drop_first = True) pclass = pd.get_dummies(train[‘Pclass’], drop_first = True) |
Еще раз замечу, что переменную Survived трогать не надо. Она уже выражена через 0 и 1.
Присоединим новые (закодированные) переменные к исходному датафрейму train. Для этого используем функцию .concat().
|
train = pd.concat([train, pclass, sex, embarked], axis = 1) |
Отбор признаков
Теперь давайте отберем те переменные (feature selection), которые мы будем использовать в модели.
- В первую очередь, удалим исходные (до применения one-hot encoding) переменные Sex, Pclass и Embarked
- Кроме того, переменные PassengerId, Name и Ticket вряд ли скажут что-то определенное о шансах на выживание пассажира, удалим и их
|
# применим функцию drop() к соответствующим столбцам train.drop([‘PassengerId’, ‘Pclass’, ‘Name’, ‘Sex’, ‘Ticket’, ‘Embarked’], axis = 1, inplace = True) train.head(3) |

Как вы видите, теперь все переменные либо количественные (Age, SibSp, Parch, Fare), либо категориальные и выражены через 0 и 1.
Нормализация данных
На занятиях по классификации и кластеризации мы уже говорили о важности приведения количественных переменных к одному масштабу. В противном случае модель может неоправданно придать большее значение признаку с большим масштабом.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# импортируем класс StandardScaler from sklearn.preprocessing import StandardScaler # создадим объект этого класса scaler = StandardScaler() # выберем те столбцы, которые мы хотим масштабировать cols_to_scale = [‘Age’, ‘Fare’] # рассчитаем среднее арифметическое и СКО для масштабирования данных scaler.fit(train[cols_to_scale]) # применим их train[cols_to_scale] = scaler.transform(train[cols_to_scale]) # посмотрим на результат train.head(3) |

Остается небольшой технический момент. Переменные 2 и 3 (второй и третий класс) выражены числами, а не строками (их выдает отсутствие кавычек в коде ниже). Так быть не должно.
|
Index([‘Survived’, ‘Age’, ‘SibSp’, ‘Parch’, ‘Fare’, 2, 3, ‘male’, ‘Q’, ‘S’], dtype=’object’) |
Преобразуем эти переменные в тип str через функцию map().
|
train.columns = train.columns.map(str) |
Шаг 2. Разделение обучающей выборки на признаки и целевую переменную
|
# поместим в X_train все кроме столбца Survived X_train = train.drop(‘Survived’, axis = 1) # столбец ‘Survived’ станет нашей целевой переменной (y_train) y_train = train[‘Survived’] |

Шаг 3. Обучение модели логистической регрессии
Воспользуемся моделью логистической регрессии из библиотеки sklearn и передадим ей обучающую выборку.
|
# импортируем логистическую регрессию из модуля linear_model библиотеки sklearn from sklearn.linear_model import LogisticRegression # создадим объект этого класса и запишем его в переменную model model = LogisticRegression() # обучим нашу модель model.fit(X_train, y_train) |
Остается сделать прогноз и оценить качество модели. При этом обратите внимание, что в тестовых данных отсутствует целевая переменная (почему это так, расскажу ниже), поэтому чтобы иметь хоть какое-то представление о качестве модели, нам необходимо вначале использовать обучающую выборку для построения прогноза.
|
# сделаем предсказание класса на обучающей выборке y_pred_train = model.predict(X_train) |
Теперь мы можем сравнить прогнозные значения с фактическими. Построим матрицу ошибок (confusion matrix).
|
# построим матрицу ошибок from sklearn.metrics import confusion_matrix # передадим ей фактические и прогнозные значения conf_matrix = confusion_matrix(y_train, y_pred_train) # преобразуем в датафрейм conf_matrix_df = pd.DataFrame(conf_matrix) conf_matrix_df |

Для удобства интерпретации добавим подписи.
|
conf_matrix_labels = pd.DataFrame(conf_matrix, columns = [‘Прогноз погиб’, ‘Прогноз выжил’], index = [‘Факт погиб’, ‘Факт выжил’]) conf_matrix_labels |

Также давайте посмотрим на метрику accuracy. Она показывает долю правильно предсказанных значений. То есть мы берем тех, кого верно предсказали как погибших (true negative, TN, таких было 478), и тех, кого верно предсказали как выживших (true positive, TP, 237), и делим на общее число прогнозов.
|
# рассчитаем метрику accuracy вручную round((478 + 237)/(478 + 237 + 71 + 103), 3) |
|
# импортируем метрику accuracy из sklearn from sklearn.metrics import accuracy_score # так же передадим ей фактические и прогнозные значения model_accuracy = accuracy_score(y_train, y_pred_train) # округлим до трех знаков после запятой round(model_accuracy, 3) |
На обучающей выборке наша модель показала результат в 80,4%. При этом только на тестовой выборке мы можем объективно оценить качество нашего алгоритма.
Шаг 4. Построение прогноза на тестовых данных
Посмотрим на тестовые данные.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
<class ‘pandas.core.frame.DataFrame’> RangeIndex: 418 entries, 0 to 417 Data columns (total 11 columns): # Column Non-Null Count Dtype — —— ————— —— 0 PassengerId 418 non-null int64 1 Pclass 418 non-null int64 2 Name 418 non-null object 3 Sex 418 non-null object 4 Age 332 non-null float64 5 SibSp 418 non-null int64 6 Parch 418 non-null int64 7 Ticket 418 non-null object 8 Fare 417 non-null float64 9 Cabin 91 non-null object 10 Embarked 418 non-null object dtypes: float64(2), int64(4), object(5) memory usage: 36.0+ KB |
Взглянув на сводку по тестовым данным, становится заметна одна сложность. Мы обучили модель на обработанных данных. В частности, мы заполнили пропуски, закодировали категориальные переменные и убрали лишние признаки. Кроме того, мы масштабировали количественные переменные и превратили названия столбцов в строки.
Для того чтобы наша модель смогла работать с тестовой выборкой нам нужно таким же образом обработать и эти данные.
При этом обратите внимание, мы не нарушаем принципа разделения данных, поскольку меняем тестовую выборку так же, как мы меняли обучающую.
|
# для начала дадим датасету привычное название X_test X_test = test |
|
# заполним пропуски в переменных Age и Fare средним арифметическим X_test[‘Age’].fillna(test[‘Age’].mean(), inplace = True) X_test[‘Fare’].fillna(test[‘Fare’].mean(), inplace = True) |
|
# выполним one-hot encoding категориальных переменных sex = pd.get_dummies(X_test[‘Sex’], drop_first = True) embarked = pd.get_dummies(X_test[‘Embarked’], drop_first = True) pclass = pd.get_dummies(X_test[‘Pclass’], drop_first = True) |
|
# присоединим новые столбцы к исходному датафрейму X_test = pd.concat([test, pclass, sex, embarked], axis = 1) # и удалим данные, которые теперь не нужны X_test.drop([‘PassengerId’, ‘Pclass’, ‘Name’, ‘Sex’, ‘Cabin’, ‘Ticket’, ‘Embarked’], axis = 1, inplace = True) # посмотрим на результат X_test.head(3) |

Теперь нужно масштабировать количественные переменные. Для этого мы будем использовать те параметры (среднее арифметическое и СКО), которые мы получили при обработке обучающей выборки. Так мы сохраним единообразие изменений и избежим утечки данных (data leakage).
|
# применим среднее арифметическое и СКО обучающей выборки для масштабирования тестовых данных X_test[cols_to_scale] = scaler.transform(X_test[cols_to_scale]) X_test.head(3) |

Остается превратить название столбцов в строки.
|
X_test.columns = X_test.columns.map(str) |
И сделать прогноз на тестовой выборке.
|
y_pred_test = model.predict(X_test) |
На выходе мы получаем массив с прогнозами.
|
# посмотрим на первые 10 прогнозных значений y_pred_test[:10] |
|
array([0, 0, 0, 0, 1, 0, 1, 0, 1, 0]) |
Этап 4. Сохранение результата в новом файле на сервере
Теперь, когда прогноз готов, мы можем сформировать новый файл, назовем его result.csv, в котором будет содержаться id пассажира и результат, погиб или нет. Приведу пример того, что мы хотим получить.
|
# файл с примером можно загрузить не с локального компьютера, а из Интернета url = ‘https://www.dmitrymakarov.ru/wp-content/uploads/2021/11/titanic_example.csv’ # просто поместим его url в функцию read_csv() example = pd.read_csv(url) example.head(3) |

Перед созданием нужного нам файла (1) соберем данные в новый датафрейм.
|
# возьмем индекс пассажиров из столбца PassengerId тестовой выборки ids = test[‘PassengerId’] # создадим датафрейм из словаря, в котором # первая пара ключа и значения — это id пассажира, вторая — прогноз «на тесте» result = pd.DataFrame({‘PassengerId’: ids, ‘Survived’: y_pred_test}) # посмотрим, что получилось result.head() |

И (2) создадим новый файл.
|
# создадим новый файл result.csv с помощью функции to_csv(), удалив при этом индекс result.to_csv(‘result.csv’, index = False) # файл будет сохранен в ‘Сессионном хранилище’ и, если все пройдет успешно, выведем следующий текст: print(‘Файл успешно сохранился в сессионное хранилище!’) |
|
Файл успешно сохранился в сессионное хранилище! |
Новый файл появится в «Сессионном хранилище».

Этап 5. Скачивание обратно на жесткий диск
После этого мы можем скачать файл на жесткий диск.
|
# применим метод .download() объекта files files.download(‘/content/result.csv’) |
Вот что у нас получилось.

Про соревнования на Kaggle
Вы вероятно заметили, что мы так и не узнали насколько хорош наш алгоритм на тестовой выборке. У нас просто нет тестовой целевой переменной (y_test).
Дело в том, что эти данные взяты с платформы, которая называется Kaggle⧉.

На этой платформе проводятся соревнования по машинному обучению. Участники получают данные, строят модели и затем подгружают свой результат. Kaggle его оценивает и тот или те, чья модель наиболее точна — выигрывают.
Соревнование «Титаник»
«Титаник» — одно из стартовых соревнований Kaggle для новичков. Предлагаю прямо сейчас в нем поучавствовать. На странице соревнования⧉, после того как вы зарегистрировались на сайте и присоединились к самому соревнованию, у вас появится возможность подгрузить файл с результатом.
Для этого зайдите на вкладку Submit Predictions⧉, (1) подгрузите файл result.csv с локального компьютера и (2) нажмите кнопку Make Submission.
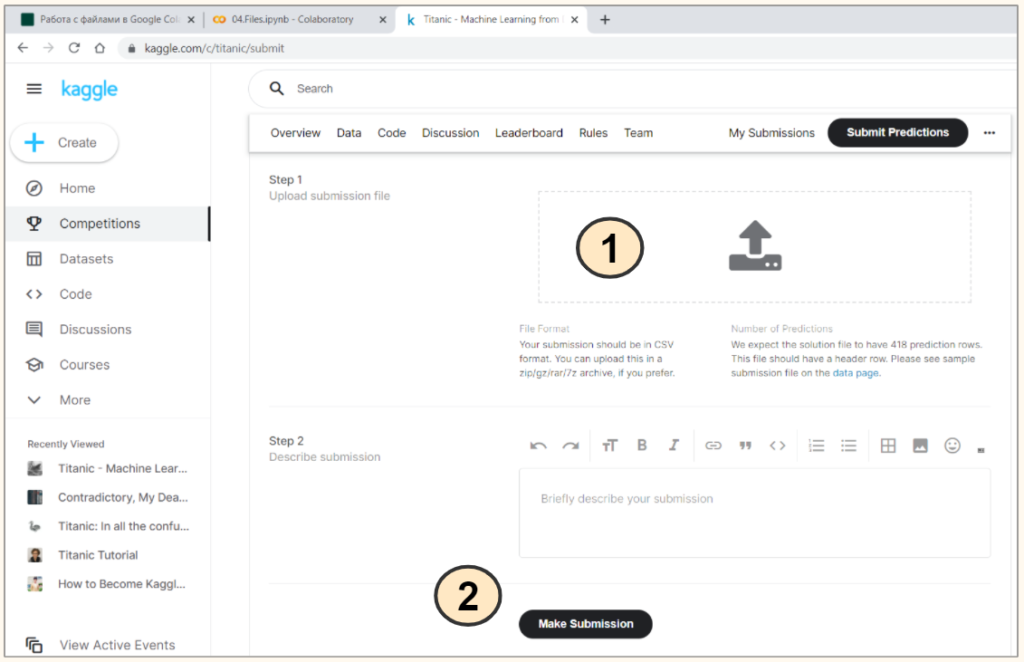
Платформа сама рассчитает accuracy вашего прогноза «на тесте» (Score). В нашем случае accuracy составляет 0,77033 или 77,03%. Чуть хуже, чем показатель «на трейне» (напомню, там было 80,4%).

Нажав на Jump to your position on the leaderboard, система сообщит вам ваше место в рейтинге участников (лидерборде).

Мы с вами оказались на 9512 месте из примерно 14500 участников. Для первого раза это хороший результат.
Подведем итог
Первая часть занятия была посвящена работе с внешними файлами. Мы научились:
- Подгружать внешний файл в сессионное хранилище
- Читать этот файл внутри ноутбука
- Обучать модель «на трейне» и делать прогноз на тестовых данных
- Подгружать прогноз в сессионное хранилище
- Скачивать его на жесткий диск
Во второй части мы приняли участие в соревновании «Титаник» на платформе Kaggle. Подгрузив прогноз, платформа сообщила нам accuracy нашей модели «на тесте» и наше место в лидерборде.
Вопросы для закрепления
Как вы считаете, что предпочтительнее использовать, функцию open() или конструкцию with open()?
Посмотреть правильный ответ
Ответ: конструкция with open() является более предпочтительной, в частности, потому что после отработки блока with Питон сам закрывает файл.
Какие данные мы подгрузили на платформу Kaggle?
Посмотреть правильный ответ
Ответ: мы подгрузили прогноз на тестовой выборке (y_pred_test). Платформа сравнила прогноз с фактическими данными y_test (то есть целевой переменной), которых у нас изначально не было, и рассчитала accuracy. На основе этой метрики нам было присвоено место в рейтинге участников.
В следующий раз мы подробнее изучим возможности Питона по работе с датой и временем.
First, I import io, pandas and files from google.colab
import io
import pandas as pd
from google.colab import files
Then I upload the file using an upload widget
uploaded = files.upload()
You will something similar to this (click on Choose Files and upload the xlsx file):

Let’s suppose that the name of the files is my_spreadsheet.xlsx, so you need to use it in the following line:
df = pd.read_excel(io.BytesIO(uploaded.get('my_spreadsheet.xlsx')))
And that’s all, now you have the first sheet in the df dataframe. However, if you have multiple sheets you can change the code into this:
First, move the io call to another variable
xlsx_file = io.BytesIO(uploaded.get('my_spreadsheet.xlsx'))
And then, use the new variable to specify the sheet name, like this:
df_first_sheet = pd.read_excel(xlsx_file, 'My First Sheet')
df_second_sheet = pd.read_excel(xlsx_file, 'My Second Sheet')
I just wondering that is it possible to load local data files(like .xlsx or .csv files that on my google drive) into Colaboratory?
asked Nov 16, 2017 at 1:25
![]()
1
I was a bit confused by the example for loading local files on first glance as there was no place to specify a file path. All you need to do is copy and paste the recipe to figure this out, but to be clear:
from google.colab import files
uploaded = files.upload()
will open an upload dialogue window where you can browse and select your local files for upload.
Then
for fn in uploaded.keys():
print('User uploaded file "{name}" with length {length} bytes'.format(
name=fn, length=len(uploaded[fn])))
will show you the keys to access what you just uploaded.
Edit for additional clarification: The dictionary uploaded will have keys of the selected filenames — so if for example you select a file my_test.txt, then you would access that file using uploaded['my_test.txt'].
answered Nov 16, 2017 at 16:50
![]()
elzelz
5,2383 gold badges28 silver badges30 bronze badges
5
First, executing this cell should create an inline «Choose Files» button
from google.colab import files
uploaded = files.upload()
After selecting your file(s), uploaded will be a dictionary of keys (the file names) and values (the encoded file objects). To decode the files for a library such as Pandas, try
import pandas as pd
import io
df = pd.read_csv(io.StringIO(uploaded['filename.csv'].decode('utf-8')))
After this your dataframe df should be ready to go
answered Mar 12, 2018 at 1:05
![]()
Zachary NaglerZachary Nagler
7211 gold badge6 silver badges16 bronze badges
4
Yes, all of these scenarios are supported.
For recipes to access local and Drive files, check out the I/O example notebook.
For access to xls files, you’ll want to upload the file to Google Sheets. Then, you can use the gspread recipes in the same I/O example notebook.
A recently added way to upload local files is to use the ‘Files’ tab in the right hand side drawer.

From there, you can upload a local file using the ‘upload’ button.

(You can also download files by right clicking on them in the file tree.)
answered Nov 16, 2017 at 1:51
![]()
Bob SmithBob Smith
34.9k11 gold badges96 silver badges90 bronze badges
2
To load local data files to Colab:
Method 1: Google Drive Method
- Upload data file from system memory to Google drive.
-
Mount Google drive in Colab
from google.colab import drive
drive.mount('/content/gdrive') -
Then->
path = "/gdrive/My Drive/filename"
You can now access google drive files in Google Colab.
Method 2: Direct Load
from google.colab import files
def getLocalFiles():
_files = files.upload()
if len(_files) >0:
for k,v in _files.items():
open(k,'wb').write(v)
getLocalFiles()
Method 3: Using import files
from google.colab import files
uploaded = files.upload()
answered Jan 6, 2019 at 7:09
![]()
2
It’s a 2 step process.
Step 1 : First invoke a file selector with in your colab notebook with the following code
from google.colab import files
uploaded = files.upload()
this will take you to a file browser window
step 2 : To load the content of the file into Pandas dataframe, use the following code
import pandas as pd
import io
df = pd.read_csv(io.StringIO(uploaded['iris.csv'].decode('utf-8')))
print(df)
![]()
Mr. T
11.8k10 gold badges30 silver badges53 bronze badges
answered Jun 23, 2018 at 8:57
![]()
Sri ramSri ram
712 silver badges4 bronze badges
1
Putting this out there as an alternative for people who prefer another way to upload more files — this basically allows you to upload your files through Google Drive.
Run the below code (found this somewhere previously but I can’t find the source again — credits to whoever wrote it!):
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools
!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null
!apt-get update -qq 2>&1 > /dev/null
!apt-get -y install -qq google-drive-ocamlfuse fuse
from google.colab import auth
auth.authenticate_user()
from oauth2client.client import GoogleCredentials
creds = GoogleCredentials.get_application_default()
import getpass
!google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret} < /dev/null 2>&1 | grep URL
vcode = getpass.getpass()
!echo {vcode} | google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret}
Click on the first link that comes up which will prompt you to sign in to Google; after that another will appear which will ask for permission to access to your Google Drive.
Then, run this which creates a directory named ‘drive’, and links your Google Drive to it:
!mkdir -p drive
!google-drive-ocamlfuse drive
If you do a !ls now, there will be a directory drive, and if you do a !ls drive you can see all the contents of your Google Drive.
So for example, if I save my file called abc.txt in a folder called ColabNotebooks in my Google Drive, I can now access it via a path drive/ColabNotebooks/abc.txt
answered Mar 17, 2018 at 2:23
![]()
yl_lowyl_low
1,1292 gold badges17 silver badges26 bronze badges
1
To get data from your system to colab try this:
from google.colab import files
uploaded = files.upload()
Choose the file you want to upload and hit enter and its done.
For example, I have uploaded an image and displayed it using the code below:
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('image.jpg')
img_cvt = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img_cvt)
plt.show()
![]()
BcK
2,5181 gold badge13 silver badges27 bronze badges
answered Jul 6, 2018 at 8:02
![]()
Say, You have a folder on your Google drive named Colab and a csv is file located there.
To load this file
import pandas as pd
titanic = pd.read_csv(“drive/Colab/Titanic.csv”)
titanic.head(5)
Before that, you may need to run these command:
Run these codes first in order to install the necessary libraries and perform authorization.
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools
!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null
!apt-get update -qq 2>&1 > /dev/null
!apt-get -y install -qq google-drive-ocamlfuse fuse
from google.colab import auth
auth.authenticate_user()
from oauth2client.client import GoogleCredentials
creds = GoogleCredentials.get_application_default()
import getpass
!google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret} < /dev/null 2>&1 | grep URL
vcode = getpass.getpass()
!echo {vcode} | google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret}
When you run the code above, you should see a result like this:

Click the link, copy verification code and paste it to text box.
After completion of the authorization process,
mount your Google Drive:
!mkdir -p drive
!google-drive-ocamlfuse drive
answered Mar 23, 2018 at 3:50
![]()
SudarshanSudarshan
89014 silver badges27 bronze badges
You can use this URL for uploading your files in Google Colab:
https://colab.research.google.com/notebooks/io.ipynb#scrollTo=vz-jH8T_Uk2c
go to Local file system>Downloading files to your local file system
Then run the code. After that, browser button will be appeared for you to uploading your files from your PC.
answered Jan 23, 2019 at 8:21
![]()
Hamed BaziyadHamed Baziyad
1,9145 gold badges27 silver badges40 bronze badges
Skip to content
This pandemic has taken a lot from me. Please help.
Donate..!
or
Buy me a coffee please..!
First connect your google drive
from google.colab import drive
drive.mount('/content/gdrive')
Once you execute the above you will be asked authorization code for gdrive. This can be obtained using the link provided when you execute the above code.
Now import the openpyxl module and create a workbook as,
from openpyxl import Workbook wb = Workbook() test_filename = 'test_workbook.xlsx'
You can save the above workbook in your google drive directly by using the following code
wb.save('/content/gdrive/My Drive/'+test_filename)
Let’s again load the same file with following code,
from openpyxl import load_workbook
wb = load_workbook('/content/gdrive/My Drive/'+test_filename)
So this how you can create, load and edit a excel file stored in gdrive from google colab environment.
I hope this is helpful.
I am honored to have you on this page.
Thanks.
4 Secret Steps to make Money from Home as a Freelancer
![]()
Перевод
Ссылка на автора
Наука о данных — ничто без данных. Да, это очевидно. Что не так очевидно, так это последовательность шагов, связанных с получением данных в формате, который позволяет исследовать данные. Возможно, у вас есть набор данных в формате CSV (сокращение отзначения через запятую) но понятия не имею, что делать дальше. Этот пост поможет вам начать изучать данные, загрузив файл CSV в Colab.
Colab(сокращение от Colab Laboratory) — это бесплатная платформа от Google, которая позволяет пользователям кодировать на Python. Colab — это, по сути, версия Google Suite для ноутбука Jupyter. Некоторые из преимуществ Colab перед Jupyter включают более простую установку пакетов и совместное использование документов. Тем не менее, при загрузке файлов, таких как файлы CSV, требуется дополнительное кодирование. Я покажу вам три способа загрузки CSV-файла в Colab и вставки его в фрейм данных Pandas.
(Примечание: есть пакеты Python, которые содержат общие наборы данных. Я не буду обсуждать загрузку этих наборов данных в этой статье.)
Для начала войдите в свою учетную запись Google и перейдите на Google Drive. Нажать нановыйКнопка слева и выберитеColaboratoryесли он установлен (если не нажмите наПодключите больше приложений, найдите Колабораторию и установите ее). Оттуда импортируйте Pandas, как показано ниже (у Colab она уже установлена).
import pandas as pd
1) Из Github (файлы <25 МБ)
Самый простой способ загрузить файл CSV — из вашего репозитория GitHub. Нажмите на набор данных в вашем хранилище, затем нажмите наПросмотр Raw, Скопируйте ссылку на набор необработанных данных и сохраните ее как строковую переменную с именем url в Colab, как показано ниже (более чистый метод, но в этом нет необходимости). Последний шаг — загрузить url в Pandas read_csv, чтобы получить фрейм данных.
url = 'copied_raw_GH_link'df1 = pd.read_csv(url)# Dataset is now stored in a Pandas Dataframe
2) с локального диска
Для загрузки с локального диска начните со следующего кода:
from google.colab import files
uploaded = files.upload()
Он предложит вам выбрать файл. Нажмите на «Выберите файлыЗатем выберите и загрузите файл. Подождите, пока файл будет загружен на 100%. Вы должны увидеть имя файла, как только Colab загрузил его.
Наконец, введите следующий код, чтобы импортировать его в фрейм данных (убедитесь, что имя файла совпадает с именем загруженного файла).
import iodf2 = pd.read_csv(io.BytesIO(uploaded['Filename.csv']))# Dataset is now stored in a Pandas Dataframe
3) С Google Диска через PyDrive
Это самый сложный из трех методов. Я покажу его тем, кто загрузил файлы CSV на свой диск Google для контроля рабочего процесса. Сначала введите следующий код:
# Code to read csv file into Colaboratory:!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials# Authenticate and create the PyDrive client.
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
При появлении запроса нажмите на ссылку, чтобы получить аутентификацию, чтобы Google мог получить доступ к вашему диску. Вы должны увидеть экран с «Google Cloud SDK хочет получить доступ к вашей учетной записи Google» на вершине. Получив разрешение, скопируйте указанный код подтверждения и вставьте его в поле в Colab.
После завершения проверки перейдите к CSV-файлу на Google Диске, щелкните его правой кнопкой мыши и выберите «Получите доступную ссылку». Ссылка будет скопирована в ваш буфер обмена. Вставьте эту ссылку в строковую переменную в Colab.
link = 'https://drive.google.com/open?id=1DPZZQ43w8brRhbEMolgLqOWKbZbE-IQu' # The shareable link
То, что вы хотите, это часть идентификаторапосле знака равенства, Чтобы получить эту часть, введите следующий код:
fluff, id = link.split('=')print (id) # Verify that you have everything after '='
Наконец, введите следующий код, чтобы получить этот файл в кадре данных
downloaded = drive.CreateFile({'id':id})
downloaded.GetContentFile('Filename.csv')
df3 = pd.read_csv('Filename.csv')# Dataset is now stored in a Pandas Dataframe
Последние мысли
Это три подхода к загрузке файлов CSV в Colab. Каждый из них имеет свои преимущества в зависимости от размера файла и от того, как вы хотите организовать рабочий процесс. Как только данные будут представлены в более хорошем формате, таком как Pandas Dataframe, вы готовы приступить к работе.
Бонусный метод — Мой драйв

Большое спасибо за вашу поддержку. В честь этой статьи, достигшей 50 тыс. Просмотров и 25 тыс. Чтений, я предлагаю бонусный метод для загрузки CSV-файлов в Colab. Этот довольно простой и чистый. В вашем Google Диске («Мой Драйв»), Создайте папку с именемданныев месте по вашему выбору. Здесь вы будете загружать свои данные.
В блокноте Colab введите следующее:
from google.colab import drive
drive.mount('/content/drive')
Как и в случае с третьим методом, команды приведут вас к шагу аутентификации Google. Вы должны увидеть экран сGoogle Drive File Stream хочет получить доступ к вашей учетной записи Google.Получив разрешение, скопируйте указанный код подтверждения и вставьте его в поле в Colab.
В записной книжке нажмите на уголь>в левом верхнем углу ноутбука и нажмите нафайлы, Найдитеданныепапку, которую вы создали ранее и найти ваши данные. Щелкните правой кнопкой мыши на ваших данных и выберитеКопировать путь, Сохраните этот скопированный путь в переменную, и вы готовы к работе.
path = "copied path"
df_bonus = pd.read_csv(path)# Dataset is now stored in a Pandas Dataframe
Что хорошо в этом методе, так это то, что вы можете получить доступ к набору данных из отдельной папки набора данных, созданной на вашем собственном Google Диске, без дополнительных действий, связанных с третьим методом.