
Сегодняшним постом я хочу начать серию материалов. В ней я планирую немного поговорить о том, что представляют собой файлы MS Office “изнутри”, а также об инструментах (утилитах и библиотеках) для их создания, изучения, изменения, …
 Сегодняшним постом я хочу начать еще одну серию. В ней я планирую немного поговорить о том, что представляют собой файлы MS Office “изнутри”, а также об инструментах (утилитах и библиотеках) для их создания, изучения, изменения, …
Сегодняшним постом я хочу начать еще одну серию. В ней я планирую немного поговорить о том, что представляют собой файлы MS Office “изнутри”, а также об инструментах (утилитах и библиотеках) для их создания, изучения, изменения, …
Прежде чем перейти к содержательной части некоторый предваряющий disclaimer (традиционно ![]() ):
):
● Я в основном буду касаться современных офисных форматов, тех что появились в редакции Office 2007. Их еще называют XML-based форматами, в противовес старым бинарным (и это закрепилось в расширении файлов: docx, pptx, xlsx, … – в противовес doc, ppt, xls, …), ну или просто Open XML
● Некоторая часть статей (по крайней мере в самом начале) будет основана на материалах Open XML Developer Workshop (контент и видео), который вел Doug Mahugh. Если вам не хочется ждать моих статей рекомендую обратиться к этим материалам
● Еще одним хорошим подспорьем для изучающих Open XML будет книга Воутер Ван Вугт. OpenXML. Кратко и доступно. Ранее она в электронном виде была доступна в блоге евангелиста Microsoft Владимира Габриеля, но теперь – увы. Так что, если вам интересно и не хочется тратить время на поиск, можете взять здесь.
Вроде бы все. Можно приступать.
Что такое Open Packaging Conventions?
В двух словах, это формат контейнеров, поддерживающих хранение как структурированных (XML), так и неструктурированных компонентов (картинки, видео, бинарные компоненты, …) в одном файле.
Краткая но довольно информативная статья об OPC есть на wikipedia.
Что можно сказать в общем об этом стандарте/формате? Я бы выделил такие моменты:
● Формальное описание является частью ECMA-376. Office Open XML File Formats, более конкретно – второй частью Part 2 — Open Packaging Conventions.
● Сам стандарт описывает только структуру хранения и самые общие метаданные (типа автора, даты,…) поэтому потенциально в таком контейнере можно хранить практически что угодно.
Например, вот несколько форматов, основанных на OPC от самого Microsoft:
o .docx, pptx, xlsx, .vsdx – форматы Word, Power Point, Excel и Visio
o .xps (.oxps) – формат “электронной бумаги” или формат c фиксированной разметкой, предназначенный для передачи документов без искажения форматирования (в чем-то аналог PDF).
o .vsix – формат расширений Visual Studio, начиная с версии 2010
o .cspkg – формат пакетов для Windows Azure Cloud Services
o .appx – формат пакетов приложений Windows Store (для Windows 
Что представляют собой контейнеры в OPC?
Тут нужно сделать одну существенную оговорку: сам стандарт разбивает описание контейнеров на 2 части: абстрактную модель (которая описывает из каких элементов состоят контейнеры, но ни слова не говорит о том как это должно храниться физически) и физический формат пакета, т.е. конкретную реализацию.
Т.е. в чистой теории, контейнер в OPC может храниться единый файл, а может, например, как набор отдельных ресурсов на Web-сервере. Но (!) на текущий момент определена только 1 реализация – в виде единого файла ZIP-архива.
Структура контейнеров в OPC
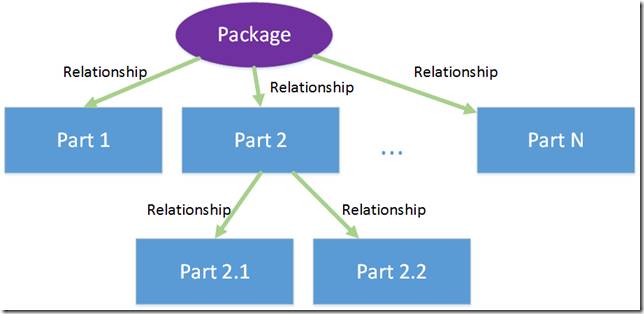
Вообще говоря, концептуальная схема пакетов в Open Packaging Conventions очень проста, она включает в себя всего два элемента:
● компоненты (parts), которые собственно и содержат хранящийся контент (любой: xml, image, video, …)
● отношения (relationships), которые определяют
o предназначение (смысл/семантику) каждой части
o отношения между частями, а также между частями и пакетом целиком
Компоненты
Как уже было сказано выше компонент в OPC это и есть основная единица хранения контента. Каждый компонент характеризуется 2-я составляющими: именем и типом содержимого.
Имя компонента состоит из набора сегментов, начинающихся с прямого слэша (“/”), вот несколько примеров:
● /hello/world/doc.xml
● /docProps/app.xml
● /image4.png
В спецификации приведены более формальные правила построения имен, из которых я укажу только основные (на мой взгляд):
● все имена должны начинаться с прямого слэша (“/”) и не должны им заканчиваться
● имя недолжно содержать пустых сегментов (т.е. /images//image1.jpg – неправильное имя)
● сегменты могут состоять из букв, цифр и знаков «!«, «$«, «&«, «‘«, «(«, «)«, «*«, «+«, «,«, «;«, «=«, «-«, «.«, «_«, «~«, «:«, «@»
● ни одно имя компонента не должно строиться как имя уже существующего компонента + новый сегмент. Т.е. если есть компонент с именем /abc/abc, то компонент с именем /abc/abc/a существовать не может, зато вполне может существовать компонент с именем /abc/abcde
● имена могут записываться Unicode-символами или использовать кодирование в виде /a/%D1%86.xml
Тип содержимого компонента задается в соответствии с RFC 2616 (раздел Media Types) т.е. в виде <type>/<subtype>:
● application/xml
● image/jpeg
● application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml
Связи
Любой компонент в пакете (а также сам пакет) может ссылаться на другие компоненты или некоторые ресурсы за пределами пакета. Для представления этих ссылок введен специальный механизм связей. По большому счету, связи позволяют решить 2 задачи:
● получить список связанных с компонентом ресурсов, без необходимости анализировать его содержимое (которое может быть очень большим, иметь разную структуру, быть зашифрованным или вообще не поддерживать хранение ссылок)
● поменять набор связей компонента, не меняя его содержимого (которое может быть, например, зашифровано или защищено цифровой подписью)
Создавая свой пакет вы, конечно же, можете не использовать связи. Вместо этого везде в коде использовать фиксированные имена компонент, а где нужны списки связанных ресурсов, ссылаться на них прямо из самих компонент. Однако, рекомендации “лучших собаководов” все же советуют использовать связи везде, где это возможно.
Информация о связях для каждого компонента (а также самого пакета), хранится в специальных компонентах связей (relationships parts) тип содержимого которых application/vnd.openxmlformats-package.relationships+xml
Имена компонентов связи строятся из имени исходных компонент, к которым:
● добавляется предпоследний сегмент с именем _rels
● дописывается “расширение” .rels
Связи самого пакета хранятся в специальном компоненте с именем /_rels/.rels
Например, если в пакете у нас есть компонент с именем /document/mainPart.xml и два связанных компонента с картинками (пусть их мена будут /images/image1.png и /images/image2.jpeg), то пакет для них будет иметь следующую структуру:
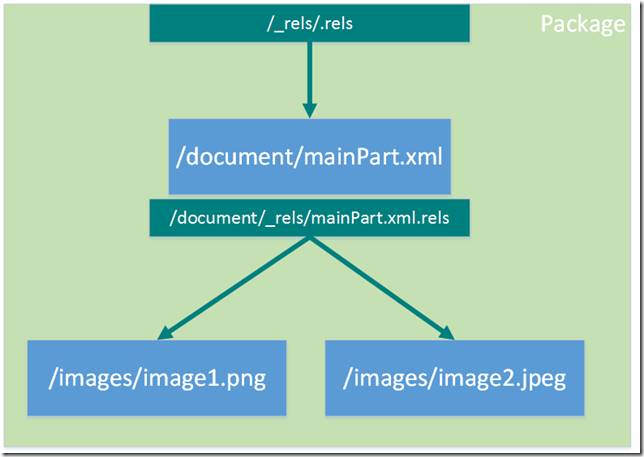
Содержимое компонента связи представляет собой XML следующего формата:
<?xml version=»1.0″ encoding=»UTF-8″ standalone=»yes»?>
<Relationships xmlns=»http://schemas.openxmlformats.org/package/2006/relationships»>
<Relationship Id=»rId1″
Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/styles»
Target=»styles.xml» />
<Relationship Id=»rId2″
Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme»
Target=»theme/theme1.xml» />
<Relationship Id=»rId3″
Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/fontTable»
Target=»fontTable.xml» />
<Relationship Id=»rId4″
Type=»http://schemas.openxmlformats.org/officeDocument/2006/relationships/image»
Target=»file:///C:UsersPublicPicturesSample%20PicturesDesert.jpg»
TargetMode=»External» />
</Relationships>
Как уже наверняка понятно из приведенного фрагмента, каждый тэг <Relationship> определяет одну связь. Его атрибуты:
|
Id |
Идентификатор связи. На него ссылаются из содержимого компонент, когда необходимо использовать конкретную связь. |
|
Type |
Тип связи. По сути дела тип указывает семантику связи. Например, две разных связи могут указывать на 2 компонента типа image/jpeg, но одно изображение будет картинкой в тексте документа, а второе – миниатюрой (thumbnail) всей страницы целиком. |
|
TargetMode |
(Необязательный) Принимает одно из возможных значений: · Internal (значение по умолчанию) – указывает, что связь ссылается на компонент пакета · External – связь указывает на ресурс за пределами пакета |
|
Target |
Адрес ресурса или компонента на который ссылается связь |
Важный момент: для обращения к компонентам и внешним ресурсам можно использовать как абсолютные адреса (для компонент это будет их полное имя), так и относительные. В последнем случае полное имя компоненты рассматривается как путь в файловой системе, каждый сегмент, кроме последнего – имя “папки”, а последний – имя “файла”. Вот несколько примеров такой адресации:
|
Имя исходного компонента |
Относительный адрес |
Результирующий адрес |
|
/mydoc/markup/page.xml |
picture.jpg |
/mydoc/markup/picture.jpg |
|
/mydoc/markup/page.xml |
images/picture.jpg |
/mydoc/markup/images/picture.jpg |
|
/mydoc/markup/page.xml |
./picture.jpg |
/mydoc/markup/picture.jpg |
|
/mydoc/markup/page.xml |
../picture.jpg |
/mydoc/picture.jpg |
|
/mydoc/markup/page.xml |
/images/picture.jpg |
/mydoc/images/picture.jpg |
|
/ |
images/picture.jpg |
/images/picture.jpg |
Вот, по большому счету и все, что касается модели пакета в OPC. Осталось сказать несколько слов о физической реализации пакетов
Пакеты на основе ZIP-архивов
Как уже было сказано выше, в спецификации OPC определена только одна реализация пакетов – на основе ZIP архивов. Она достаточно проста, поэтому я приведу её обзорно:
● все компоненты, как обычные, так и компоненты связей, хранятся в виде одного или нескольких файлов внутри архива (при этом логически они все равно адресуются как единое целое)
● для хранения типа контента каждого компонента в архиве создается специальный файл с именем [Content_Types].xml
Внутри файла [Content_Types].xml хранится XML следующего вида:
<?xml version=»1.0″ encoding=»UTF-8″ standalone=»yes»?>
<Types xmlns=»http://schemas.openxmlformats.org/package/2006/content-types»>
<Default Extension=»png» ContentType=»image/png»/>
<Default Extension=»jpeg» ContentType=»image/jpeg»/>
<Default Extension=»rels» ContentType=»application/vnd.openxmlformats-package.relationships+xml»/>
<Default Extension=»xml» ContentType=»application/xml»/>
<Override PartName=»/word/document.xml»
ContentType=»application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml»/>
<Override PartName=»/word/styles.xml»
ContentType=»application/vnd.openxmlformats-officedocument.wordprocessingml.styles+xml»/>
</Types>
Собственно, общая схема, я думаю, понятна и так: для описания типов используется два подхода:
● указание типа по расширению (тэг <Default>)
● явное указание типа для конкретного компонента (тэг <Override>)
Как заглянуть внутрь OPC-пакета?
Итак, надеюсь вас уже заинтриговало мое объяснение базовых принципов и вы уже жаждите приступить к практическому изучению (т.е. взять и разобрать по косточкам какой-нибудь офисный файл) ![]() .
.
Вот несколько способов как это можно сделать:
● Прямой (“рукопашный”) способ. Т.к. физическая реализация OPC есть ни что иное, как обычный ZIP-архив, то самый простой способ его изучить – распаковать и работать как с обычной папкой (ну или воспользоваться любимым архиватором).
o Плюс подхода – будете глубже понимать устройство.
o Минусы:
▪ Сложно отслеживать связи между компонентами (а именно они образуют структуру, а вовсе не “папки” архива)
▪ Довольно муторно редактировать, если захочется экспериментов (нужно добавлять файлы для компонентов, править файлы связей да еще и не забывать про указание типа контента, если он не стандартный)
● Open XML Package Editor Power Tool for Visual Studio 2010. Расширение для Visual Studio. Умеет открывать файлы в формате OPC, показывать и редактировать их логическую структуру (добавлять/удалять/редактировать компоненты и связи). Для редактирования содержимого компонент используется редакторы самой VS, что очень удобно для экспериментов (XML редактор в VS явно не самый плохой, особенно если в наличии есть хорошие XSD-описания).
o Минусы:
▪ Так и не нашел способа создать пакет с 0 (но это редко нужно, да и обходится созданием пакета вручную).
▪ Требует Visual Studio.
▪ Работает только в 2010 версии VS. Увы, для более новых версий студии пакет так и не обновился, хотя почти наверняка он заработает без доработок в любой последующей. А доработать установщик пакета руками не получается, т.к. это не обычный vsix ![]()
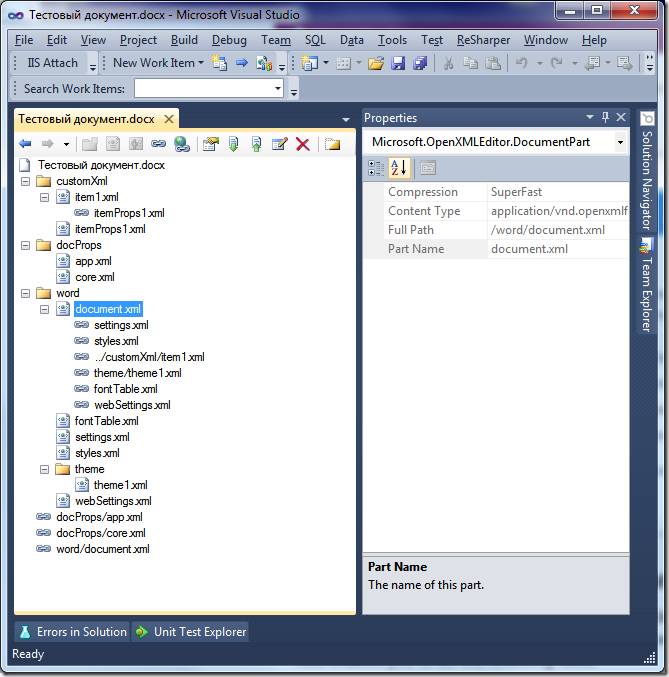
● Standalone приложение от Воутера Ван Вугта Open XML Package Explorer. По возможностям оно близко к предыдущему расширению для VS, но не требует ничего для установки, кроме .Net 3.0. У него даже есть встроенный редактор XML, правда уступающий редактору от VS. К сожалению, приложение давно не обновлялось имеет ряд неприятных ошибок… но пользоваться можно.
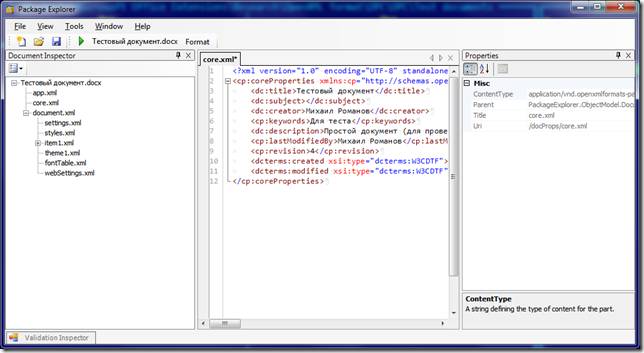
Пара слов в заключение
Как видите, стандарт OPC в своей основе довольно прост и функционален. Однако остались еще ряд нераскрытых тем. В частности мы не рассмотрели ряд возможностей, заложенных в формат OPC:
● базовые метаданные пакета (core properties)
● иконки пакета (thumbnails)
● цифровые подписи (digital signatures)
Ну и, конечно, мы еще ни слова не проговорили об API для работы с OPC пакетами.
Источник: Блог Михаила Романова.
Лекция посвящена созданию и редактированию структуры документа. Описаны структуры книжного, журнального изданий и документа в текстовом процессоре Word 2010. Показана возможность добавления титульной страницы документа. Рассмотрена процедура создания оглавления на основе стилей. Представлена возможность создания предметного указателя и использования режима просмотра документа СТРУКТУРА.
1. Уровень 2. Структура издания
Издание — документ, предназначенный для распространения содержащейся в нем информации, прошедший редакционно-издатель- скую обработку, полученный печатанием, полиграфически самостоятельно исполненный, имеющий выходные сведения.
Выходные сведения содержат фамилию автора, редактора, художника, название книги, ее тираж, объем, формат и аннотацию; способ печати; наименование предприятия, где отпечатано издание и другие данные, необходимые для информирования потребителя, библиографической обработки и статистического учета.
Структура издания — это последовательность расположения составных частей издания.
К составным частям книжного издания относятся:
1) титульный лист, который может быть одинарным и двойным. Одинарный титул имеет две страницы, первая страница содержит основные выходные сведения, позволяющие отличить издание от других, например название издания, имя автора, год издания. На обороте титульного листа размещают номер универсальной десятичной классификации (УДК) и номер библиотечно-библиографической классификации (ББК), там же находятся каталожные данные, аннотация (краткое изложение содержания и назначение издания), иногда выпу-
скные данные, знак охраны авторского права.
В многотомных, серийных, а также особо оформленных изданиях применяется двойной титульный лист, состоящий из четырех страниц. Первая страница такого титула называется авантитулом, вторая страница — контртитулом, третья страница — лицевой стороной титула, а четвертая — оборотной страницей титула.
На авантитуле располагается часть выходных сведений: название организации, от имени которой выпускается издание; данные серии,
244
в которую издание входит, если издание серийное. Если таких данных нет, то либо печатают некоторые данные (автор, заглавие, название издательства), либо печатают издательскую марку, девиз, изображение, настраивающее читателя на нужный лад, своеобразный эпиграф к серии или книге и т. п.
На контртитуле размещают:
либо общие для всего многотомного или серийного издания выходные сведения;
либо выходные сведения оригинального издания выпускаемого переводного произведения, если оно впервые публикуется в переводе;
либо только имя автора переводного произведения на языке оригинала (если перевод публикуется не впервые);
На лицевой стороне титула по ГОСТ 7.4–95 обязательны:
имена не более трех авторов моноиздания (форму и порядок устанавливают сами авторы);
заглавие;
подзаголовочные данные: тематическое подзаглавие, литературный жанр, вид издания, номер тома, имя его автора (если у томов разные авторы), заглавие тома, имя редактора (руководителя издания);
выходные данные.
На оборотную сторону титульного листа ГОСТ 7.4–95 разрешает переносить с лицевой страницы титульного листа книжных изданий:
имена более трех авторов моноиздания (перед ними в этом случае надо ставить слово Авторы:);
имя составителя (составителей);
имя ответственного (научного) редактора;
состав редколлегии;
имена художника-иллюстратора и фотографа в иллюстрированных изданиях;
имя художника-оформителя;
в серийном издании — год основания серии и имена лиц, участвовавших в создании всей серии (редактора, составителя, художника серии и членов редколлегии серии).
Вместо контртитула может находиться фронтиспис — страница
сизображением (портрет автора, специально созданная иллюстрация), образующая разворот с лицевой стороной титула.
Далее могут располагаться:
1)предисловие— сопроводительная статья, в которой поясняются, какправило, целииособенностисодержанияипостроенияпроизведения;
245
2)вступительная статья, в которой автором раскрывается тема
книги;
3)посвящение, эпиграф и т. д.
4)основной текст, который может быть поделен на любое количество частей, глав, разделов, подразделов в зависимости от содержания и объема текста. Обычно продумывается подчиненность частей текста, задается иерархическая система заголовков, часто нумерованных.
После основного текста могут присутствовать:
5)приложения — пояснения и таблицы, которые дополняют основной текст или имеют вспомогательное назначение;
6)примечания — краткие дополнения к основному тексту или пояснения небольших фрагментов, носящие справочный характер;
7)комментарии — часть издания, в котором дается толкование произведения, когда необходимо помочь читателю понять текст во всем его объеме;
перечень библиографических ссылок, выстроенный по алфа-
виту или в порядке следования ссылок;
9)перечень иллюстраций;
10)указатели — справочный материал, помогающий быстро найти нужный текст в издании. Указатели бывают предметные, термино-
логические, именные, географические, хронологические и другие с указанием страниц и с расшифровкой (не всегда). Предметные указатели используются в учебной и научной литературе. В них перечисляются термины или темы, о которых рассказывается в издании, указываются страницы, на которых они упоминаются;
11)оглавление— указательзаголовков(можетнаходитьсявначале);
12)выпускные данные — часть выходных сведений, в которой дается производственно-техническая характеристика издания, дата его прохождения в производстве, названия и адреса издательства и типографии и т. д.
Визданиях, состоящих из нескольких произведений или разделов, для украшения размещается специальный лист, отделяющий каждую часть издания. Этот лист называется шмуцтитулом. На нем размещается только заглавие произведения или заголовок части, иногда сопровождаемые изображением, эпиграфом, заголовками подчиненных подразделов, а оборот — либо оставлен чистым, либо запечатан текстом (занят начальной страницей произведения или подраздела).
Журналы и газеты часто имеют несколько отличную от книг структуру:
246
1)все титульные данные размещаются в верхней части первой
полосы;
2)оглавление в газетах встречается редко, иногда на первой странице указываются названия наиболее интересных статей. В журналах оглавление всегда присутствует. Оно может располагаться на первой или на второй странице, или через несколько страниц, что зависит от объема предшествующей рекламы;
3)аннотации к статьям размещают под заголовком с небольшой отбивкой от текста шрифтом меньшего кегля, чем основной текст;
4)выходные данные в газетах располагаются на последней полосе, в журналах обычно на обороте титульного листа.
2. Уровень 3. Структура документа Word
Цель пользователя — создать документ Word определенной структуры, определенного содержания и, соответственно, определенным образом изображаемый на экране монитора или на принтере.
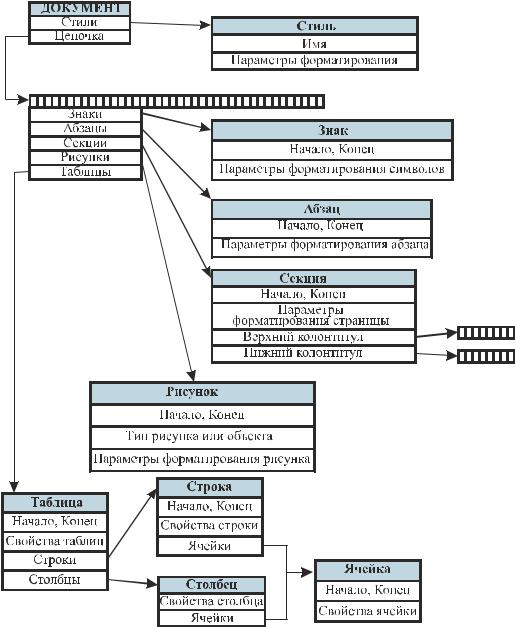
Документ Word в своей основе содержит компьютерный текст, но структура этого документа намного богаче «плоского» текста. Такой текст, следуя дословному переводу Rich Text, называют «богато оформленным». Простой плоский текст состоит из символов, текст документа Word состоит из знаков. Знак Word имеет сложную структуру. Помимо собственно символа, каждый знак содержит параметры форматирования символа, т. е. значения свойств, определяющих способ изображения. Программа Word использует специальные знаки для того, чтобы выделять в тексте различные структурные элементы: абзацы, секции, таблицы, рисунки. Причем каждый из этих элементов несет собственный набор параметров, влияющих на отображение текста. Например, параметры форматирования абзаца определяют, как Microsoft Word будет располагать слова, составляющие абзац, на строках изображения текста.
Структура документа Microsoft Word приведена на схеме рис. 14.1.
Для каждого класса задач обработки текста, стоящих перед автором, в текстовом процессоре Word используется соответствующий набор структурных элементов документа.
Структура текста небольшого документа простая: обычно заголовок и текст, разбитый на абзацы по смыслу.
Многостраничные документы имеют сложную структуру с многоуровневой иерархией. Структурные элементы такого документа называют
247
по-разному: главы, параграфы, разделы, подразделы, пункты, подпункты и т. д. Каждый структурный элемент имеет заголовок, который снабжен каким-либо текстовым обозначением или номером.
Рис. 14.1. Схема документа Word
При построении структуры документа Word использует набор встроенных стилей заголовков. При повышении или понижении уровня Word подбирает соответствующий стиль заголовка. В Word имеется специальный режим работы со структурой документа — режим СТРУКТУРА.
248
Соседние файлы в предмете Полиграфика
- #
- #
Время на прочтение
16 мин
Количество просмотров 54K
Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.
Зачем?
docx — самый популярный формат документов, поэтому задача отдавать информацию пользователю в этом формате всегда может возникнуть. Один из вариантов решения этой проблемы — использование готовой библиотеки, может не подходить по ряду причин:
- библиотеки может просто не существовать
- в проекте не нужен ещё один чёрный ящик
- ограничения библиотеки по платформам и т.п.
- проблемы с лицензированием
- скорость работы
Поэтому в этой статье будем использовать только самые базовые инструменты для работы с docx документом.
Структура docx
Для начала разоберёмся с тем, что собой представляет docx документ. docx это zip архив который физически содержит 2 типа файлов:
- xml файлы с расширениями
xmlиrels - медиа файлы (изображения и т.п.)
А логически — 3 вида элементов:
- Типы (Content Types) — список типов медиа файлов (например png) встречающихся в документе и типов частей документов (например документ, верхний колонтитул).
- Части (Parts) — отдельные части документа, для нашего документа это document.xml, сюда входят как xml документы так и медиа файлы.
- Связи (Relationships) идентифицируют части документа для ссылок (например связь между разделом документа и колонтитулом), а также тут определены внешние части (например гиперссылки).
Они подробно описаны в стандарте ECMA-376: Office Open XML File Formats, основная часть которого — PDF документ на 5000 страниц, и ещё 2000 страниц бонусного контента.
Минимальный docx
Простейший docx после распаковки выглядит следующим образом
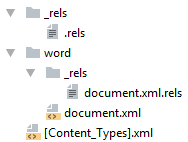
Давайте посмотрим из чего он состоит.
[Content_Types].xml
Находится в корне документа и перечисляет MIME типы содержимого документа:
<Types xmlns="http://schemas.openxmlformats.org/package/2006/content-types">
<Default Extension="rels" ContentType="application/vnd.openxmlformats-package.relationships+xml"/>
<Default Extension="xml" ContentType="application/xml"/>
<Override PartName="/word/document.xml"
ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/>
</Types>_rels/.rels
Главный список связей документа. В данном случае определена всего одна связь — сопоставление с идентификатором rId1 и файлом word/document.xml — основным телом документа.
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
<Relationship
Id="rId1"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/officeDocument"
Target="word/document.xml"/>
</Relationships>word/document.xml
Основное содержимое документа.
word/document.xml
<w:document xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships"
xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math"
xmlns:v="urn:schemas-microsoft-com:vml"
xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing"
xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing"
xmlns:w10="urn:schemas-microsoft-com:office:word"
xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"
xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml"
xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup"
xmlns:wpi="http://schemas.microsoft.com/office/word/2010/wordprocessingInk"
xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml"
xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape"
mc:Ignorable="w14 wp14">
<w:body>
<w:p w:rsidR="005F670F" w:rsidRDefault="005F79F5">
<w:r>
<w:t>Test</w:t>
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
<w:sectPr w:rsidR="005F670F">
<w:pgSz w:w="12240" w:h="15840"/>
<w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440"
w:header="720" w:footer="720" w:gutter="0"/>
<w:cols w:space="720"/>
<w:docGrid w:linePitch="360"/>
</w:sectPr>
</w:body>
</w:document>Здесь:
<w:document>— сам документ<w:body>— тело документа<w:p>— параграф<w:r>— run (фрагмент) текста<w:t>— сам текст<w:sectPr>— описание страницы
Если открыть этот документ в текстовом редакторе, то увидим документ из одного слова Test.
word/_rels/document.xml.rels
Здесь содержится список связей части word/document.xml. Название файла связей создаётся из названия части документа к которой он относится и добавления к нему расширения rels. Папка с файлом связей называется _rels и находится на том же уровне, что и часть к которой он относится. Так как связей в word/document.xml никаких нет то и в файле пусто:
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
</Relationships>Даже если связей нет, этот файл должен существовать.
docx и Microsoft Word
docx созданный с помощью Microsoft Word, да в принципе и с помощью любого другого редактора имеет несколько дополнительных файлов.
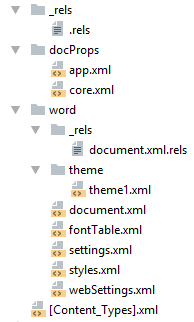
Вот что в них содержится:
docProps/core.xml— основные метаданные документа согласно Open Packaging Conventions и Dublin Core [1], [2].docProps/app.xml— общая информация о документе: количество страниц, слов, символов, название приложения в котором был создан документ и т.п.word/settings.xml— настройки относящиеся к текущему документу.word/styles.xml— стили применимые к документу. Отделяют данные от представления.word/webSettings.xml— настройки отображения HTML частей документа и настройки того, как конвертировать документ в HTML.word/fontTable.xml— список шрифтов используемых в документе.word/theme1.xml— тема (состоит из цветовой схемы, шрифтов и форматирования).
В сложных документах частей может быть гораздо больше.
Реверс-инжиниринг docx
Итак, первоначальная задача — узнать как какой-либо фрагмент документа хранится в xml, чтобы потом создавать (или парсить) подобные документы самостоятельно. Для этого нам понадобятся:
- Архиватор zip
- Библиотека для форматирования XML (Word выдаёт XML без отступов, одной строкой)
- Средство для просмотра diff между файлами, я буду использовать git и TortoiseGit
Инструменты
- Под Windows: zip, unzip, libxml2, git, TortoiseGit
- Под Linux:
apt-get install zip unzip libxml2 libxml2-utils git
Также понадобятся скрипты для автоматического (раз)архивирования и форматирования XML.
Использование под Windows:
unpack file dir— распаковывает документfileв папкуdirи форматирует xmlpack dir file— запаковывает папкуdirв документfile
Использование под Linux аналогично, только ./unpack.sh вместо unpack, а pack становится ./pack.sh.
Использование
Поиск изменений происходит следующим образом:
- Создаём пустой docx файл в редакторе.
- Распаковываем его с помощью
unpackв новую папку. - Коммитим новую папку.
- Добавляем в файл из п. 1. изучаемый элемент (гиперссылку, таблицу и т.д.).
- Распаковываем изменённый файл в уже существующую папку.
- Изучаем diff, убирая ненужные изменения (перестановки связей, порядок пространств имён и т.п.).
- Запаковываем папку и проверяем что получившийся файл открывается.
- Коммитим изменённую папку.
Пример 1. Выделение текста жирным
Посмотрим на практике, как найти тег который определяет форматирование текста жирным шрифтом.
- Создаём документ
bold.docxс обычным (не жирным) текстом Test. - Распаковываем его:
unpack bold.docx bold. - Коммитим результат.
- Выделяем текст Test жирным.
- Распаковываем
unpack bold.docx bold. - Изначально diff выглядел следующим образом:
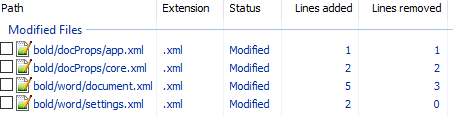
Рассмотрим его подробно:
docProps/app.xml
@@ -1,9 +1,9 @@
- <TotalTime>0</TotalTime>
+ <TotalTime>1</TotalTime>Изменение времени нам не нужно.
docProps/core.xml
@@ -4,9 +4,9 @@
- <cp:revision>1</cp:revision>
+ <cp:revision>2</cp:revision>
<dcterms:created xsi:type="dcterms:W3CDTF">2017-02-07T19:37:00Z</dcterms:created>
- <dcterms:modified xsi:type="dcterms:W3CDTF">2017-02-07T19:37:00Z</dcterms:modified>
+ <dcterms:modified xsi:type="dcterms:W3CDTF">2017-02-08T10:01:00Z</dcterms:modified>Изменение версии документа и даты модификации нас также не интересует.
word/document.xml
diff
@@ -1,24 +1,26 @@
<w:body>
- <w:p w:rsidR="0076695C" w:rsidRPr="00290C70" w:rsidRDefault="00290C70">
+ <w:p w:rsidR="0076695C" w:rsidRPr="00F752CF" w:rsidRDefault="00290C70">
<w:pPr>
<w:rPr>
+ <w:b/>
<w:lang w:val="en-US"/>
</w:rPr>
</w:pPr>
- <w:r>
+ <w:r w:rsidRPr="00F752CF">
<w:rPr>
+ <w:b/>
<w:lang w:val="en-US"/>
</w:rPr>
<w:t>Test</w:t>
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
- <w:sectPr w:rsidR="0076695C" w:rsidRPr="00290C70">
+ <w:sectPr w:rsidR="0076695C" w:rsidRPr="00F752CF">Изменения в w:rsidR не интересны — это внутренняя информация для Microsoft Word. Ключевое изменение тут
<w:rPr>
+ <w:b/>в параграфе с Test. Видимо элемент <w:b/> и делает текст жирным. Оставляем это изменение и отменяем остальные.
word/settings.xml
@@ -1,8 +1,9 @@
+ <w:proofState w:spelling="clean"/>
@@ -17,10 +18,11 @@
+ <w:rsid w:val="00F752CF"/>Также не содержит ничего относящегося к жирному тексту. Отменяем.
7 Запаковываем папку с 1м изменением (добавлением <w:b/>) и проверяем что документ открывается и показывает то, что ожидалось.
8 Коммитим изменение.
Пример 2. Нижний колонтитул
Теперь разберём пример посложнее — добавление нижнего колонтитула.
Вот первоначальный коммит. Добавляем нижний колонтитул с текстом 123 и распаковываем документ. Такой diff получается первоначально:
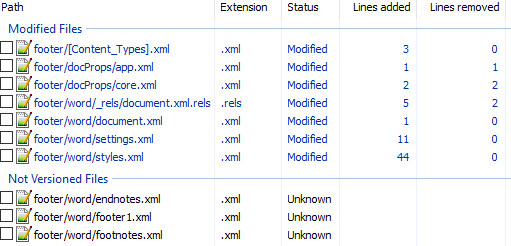
Сразу же исключаем изменения в docProps/app.xml и docProps/core.xml — там тоже самое, что и в первом примере.
[Content_Types].xml
@@ -4,10 +4,13 @@
<Default Extension="xml" ContentType="application/xml"/>
<Override PartName="/word/document.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/>
+ <Override PartName="/word/footnotes.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footnotes+xml"/>
+ <Override PartName="/word/endnotes.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.endnotes+xml"/>
+ <Override PartName="/word/footer1.xml" ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml"/>footer явно выглядит как то, что нам нужно, но что делать с footnotes и endnotes? Являются ли они обязательными при добавлении нижнего колонтитула или их создали заодно? Ответить на этот вопрос не всегда просто, вот основные пути:
- Посмотреть, связаны ли изменения друг с другом
- Экспериментировать
- Ну а если совсем не понятно что происходит:

Идём пока что дальше.
word/_rels/document.xml.rels
Изначально diff выглядит вот так:
diff
@@ -1,8 +1,11 @@
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
+ <Relationship Id="rId5" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme" Target="theme/theme1.xml"/>
<Relationship Id="rId3" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/webSettings" Target="webSettings.xml"/>
+ <Relationship Id="rId4" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/fontTable" Target="fontTable.xml"/>
<Relationship Id="rId2" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/settings" Target="settings.xml"/>
<Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/styles" Target="styles.xml"/>
- <Relationship Id="rId5" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme" Target="theme/theme1.xml"/>
- <Relationship Id="rId4" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/fontTable" Target="fontTable.xml"/>
+ <Relationship Id="rId6" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footer" Target="footer1.xml"/>
+ <Relationship Id="rId7" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/endnotes" Target="endnotes.xml"/>
+ <Relationship Id="rId8" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footnotes" Target="footnotes.xml"/>
</Relationships>Видно, что часть изменений связана с тем, что Word изменил порядок связей, уберём их:
@@ -3,6 +3,9 @@
+ <Relationship Id="rId6" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footer" Target="footer1.xml"/>
+ <Relationship Id="rId7" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/endnotes" Target="endnotes.xml"/>
+ <Relationship Id="rId8" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footnotes" Target="footnotes.xml"/>Опять появляются footer, footnotes, endnotes. Все они связаны с основным документом, перейдём к нему:
word/document.xml
@@ -15,10 +15,11 @@
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
<w:sectPr w:rsidR="0076695C" w:rsidRPr="00290C70">
+ <w:footerReference w:type="default" r:id="rId6"/>
<w:pgSz w:w="11906" w:h="16838"/>
<w:pgMar w:top="1134" w:right="850" w:bottom="1134" w:left="1701" w:header="708" w:footer="708" w:gutter="0"/>
<w:cols w:space="708"/>
<w:docGrid w:linePitch="360"/>
</w:sectPr>Редкий случай когда есть только нужные изменения. Видна явная ссылка на footer из sectPr. А так как ссылок в документе на footnotes и endnotes нет, то можно предположить что они нам не понадобятся.
word/settings.xml
diff
@@ -1,19 +1,30 @@
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<w:settings xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:w15="http://schemas.microsoft.com/office/word/2012/wordml" xmlns:sl="http://schemas.openxmlformats.org/schemaLibrary/2006/main" mc:Ignorable="w14 w15">
<w:zoom w:percent="100"/>
+ <w:proofState w:spelling="clean"/>
<w:defaultTabStop w:val="708"/>
<w:characterSpacingControl w:val="doNotCompress"/>
+ <w:footnotePr>
+ <w:footnote w:id="-1"/>
+ <w:footnote w:id="0"/>
+ </w:footnotePr>
+ <w:endnotePr>
+ <w:endnote w:id="-1"/>
+ <w:endnote w:id="0"/>
+ </w:endnotePr>
<w:compat>
<w:compatSetting w:name="compatibilityMode" w:uri="http://schemas.microsoft.com/office/word" w:val="15"/>
<w:compatSetting w:name="overrideTableStyleFontSizeAndJustification" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
<w:compatSetting w:name="enableOpenTypeFeatures" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
<w:compatSetting w:name="doNotFlipMirrorIndents" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
<w:compatSetting w:name="differentiateMultirowTableHeaders" w:uri="http://schemas.microsoft.com/office/word" w:val="1"/>
</w:compat>
<w:rsids>
<w:rsidRoot w:val="00290C70"/>
+ <w:rsid w:val="000A7B7B"/>
+ <w:rsid w:val="001B0DE6"/>А вот и появились ссылки на footnotes, endnotes добавляющие их в документ.
word/styles.xml
diff
@@ -480,6 +480,50 @@
<w:rFonts w:ascii="Times New Roman" w:hAnsi="Times New Roman"/>
<w:b/>
<w:sz w:val="28"/>
</w:rPr>
</w:style>
+ <w:style w:type="paragraph" w:styleId="a4">
+ <w:name w:val="header"/>
+ <w:basedOn w:val="a"/>
+ <w:link w:val="a5"/>
+ <w:uiPriority w:val="99"/>
+ <w:unhideWhenUsed/>
+ <w:rsid w:val="000A7B7B"/>
+ <w:pPr>
+ <w:tabs>
+ <w:tab w:val="center" w:pos="4677"/>
+ <w:tab w:val="right" w:pos="9355"/>
+ </w:tabs>
+ <w:spacing w:after="0" w:line="240" w:lineRule="auto"/>
+ </w:pPr>
+ </w:style>
+ <w:style w:type="character" w:customStyle="1" w:styleId="a5">
+ <w:name w:val="Верхний колонтитул Знак"/>
+ <w:basedOn w:val="a0"/>
+ <w:link w:val="a4"/>
+ <w:uiPriority w:val="99"/>
+ <w:rsid w:val="000A7B7B"/>
+ </w:style>
+ <w:style w:type="paragraph" w:styleId="a6">
+ <w:name w:val="footer"/>
+ <w:basedOn w:val="a"/>
+ <w:link w:val="a7"/>
+ <w:uiPriority w:val="99"/>
+ <w:unhideWhenUsed/>
+ <w:rsid w:val="000A7B7B"/>
+ <w:pPr>
+ <w:tabs>
+ <w:tab w:val="center" w:pos="4677"/>
+ <w:tab w:val="right" w:pos="9355"/>
+ </w:tabs>
+ <w:spacing w:after="0" w:line="240" w:lineRule="auto"/>
+ </w:pPr>
+ </w:style>
+ <w:style w:type="character" w:customStyle="1" w:styleId="a7">
+ <w:name w:val="Нижний колонтитул Знак"/>
+ <w:basedOn w:val="a0"/>
+ <w:link w:val="a6"/>
+ <w:uiPriority w:val="99"/>
+ <w:rsid w:val="000A7B7B"/>
+ </w:style>
</w:styles>Изменения в стилях нас интересуют только если мы ищем как поменять стиль. В данном случае это изменение можно убрать.
Посмотрим теперь собственно на сам нижний колонтитул (часть пространств имён опущена для читабельности, но в документе они должны быть):
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<w:p w:rsidR="000A7B7B" w:rsidRDefault="000A7B7B">
<w:pPr>
<w:pStyle w:val="a6"/>
</w:pPr>
<w:r>
<w:t>123</w:t>
</w:r>
</w:p>
</w:ftr>Тут виден текст 123. Единственное, что надо исправить — убрать ссылку на <w:pStyle w:val="a6"/>.
В результате анализа всех изменений делаем следующие предположения:
- footnotes и endnotes не нужны
- В
[Content_Types].xmlнадо добавить footer - В
word/_rels/document.xml.relsнадо добавить ссылку на footer - В
word/document.xmlв тег<w:sectPr>надо добавить<w:footerReference>
Уменьшаем diff до этого набора изменений:

Затем запаковываем документ и открываем его.
Если всё сделано правильно, то документ откроется и в нём будет нижний колонтитул с текстом 123. А вот и итоговый коммит.
Таким образом процесс поиска изменений сводится к поиску минимального набора изменений, достаточного для достижения заданного результата.
Практика
Найдя интересующее нас изменение, логично перейти к следующему этапу, это может быть что-либо из:
- Создания docx
- Парсинг docx
- Преобразования docx
Тут нам потребуются знания XSLT и XPath.
Давайте напишем достаточно простое преобразование — замену или добавление нижнего колонтитула в существующий документ. Писать я буду на языке Caché ObjectScript, но даже если вы его не знаете — не беда. В основном будем вызовать XSLT и архиватор. Ничего более. Итак, приступим.
Алгоритм
Алгоритм выглядит следующим образом:
- Распаковываем документ.
- Добавляем наш нижний колонтитул.
- Прописываем ссылку на него в
[Content_Types].xmlиword/_rels/document.xml.rels. - В
word/document.xmlв тег<w:sectPr>добавляем тег<w:footerReference>или заменяем в нём ссылку на наш нижний колонтитул. - Запаковываем документ.
Приступим.
Распаковка
В Caché ObjectScript есть возможность выполнять команды ОС с помощью функции $zf(-1, oscommand). Вызовем unzip для распаковки документа с помощью обёртки над $zf(-1):
/// Используя %3 (unzip) распаковать файл %1 в папку %2
Parameter UNZIP = "%3 %1 -d %2";
/// Распаковать архив source в папку targetDir
ClassMethod executeUnzip(source, targetDir) As %Status
{
set timeout = 100
set cmd = $$$FormatText(..#UNZIP, source, targetDir, ..getUnzip())
return ..execute(cmd, timeout)
}
Создаём файл нижнего колонтитула
На вход поступает текст нижнего колонтитула, запишем его в файл in.xml:
<xml>TEST</xml>В XSLT (файл — footer.xsl) будем создавать нижний колонтитул с текстом из тега xml (часть пространств имён опущена, вот полный список):
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns="http://schemas.openxmlformats.org/package/2006/relationships" version="1.0">
<xsl:output method="xml" omit-xml-declaration="no" indent="yes" standalone="yes"/>
<xsl:template match="/">
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<w:p>
<w:r>
<w:rPr>
<w:lang w:val="en-US"/>
</w:rPr>
<w:t>
<xsl:value-of select="//xml/text()"/>
</w:t>
</w:r>
</w:p>
</w:ftr>
</xsl:template>
</xsl:stylesheet>Теперь вызовем XSLT преобразователь:
do ##class(%XML.XSLT.Transformer).TransformFile("in.xml", "footer.xsl", footer0.xml") В результате получится файл нижнего колонтитула footer0.xml:
<w:ftr xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<w:p>
<w:r>
<w:rPr>
<w:lang w:val="en-US"/>
</w:rPr>
<w:t>TEST</w:t>
</w:r>
</w:p>
</w:ftr>Добавляем ссылку на колонтитул в список связей основного документа
Сссылки с идентификатором rId0 как правило не существует. Впрочем можно использовать XPath для получения идентификатора которого точно не существует.
Добавляем ссылку на footer0.xml c идентификатором rId0 в word/_rels/document.xml.rels:
XSLT
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns="http://schemas.openxmlformats.org/package/2006/relationships" version="1.0">
<xsl:output method="xml" omit-xml-declaration="yes" indent="no" />
<xsl:param name="new">
<Relationship
Id="rId0"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/footer"
Target="footer0.xml"/>
</xsl:param>
<xsl:template match="/*">
<xsl:copy>
<xsl:copy-of select="$new"/>
<xsl:copy-of select="@* | node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>Прописываем ссылки в документе
Далее надо в каждый тег <w:sectPr> добавить тег <w:footerReference> или заменить в нём ссылку на наш нижний колонтитул. Оказалось, что у каждого тега <w:sectPr> может быть 3 тега <w:footerReference> — для первой страницы, четных страниц и всего остального:
XSLT
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships"
xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"
version="1.0">
<xsl:output method="xml" omit-xml-declaration="yes" indent="yes" />
<xsl:template match="//@* | //node()">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="node()"/>
</xsl:copy>
</xsl:template>
<xsl:template match="//w:sectPr">
<xsl:element name="{name()}" namespace="{namespace-uri()}">
<xsl:copy-of select="./namespace::*"/>
<xsl:apply-templates select="@*"/>
<xsl:copy-of select="./*[local-name() != 'footerReference']"/>
<w:footerReference w:type="default" r:id="rId0"/>
<w:footerReference w:type="first" r:id="rId0"/>
<w:footerReference w:type="even" r:id="rId0"/>
</xsl:element>
</xsl:template>
</xsl:stylesheet>Добавляем колонтитул в [Content_Types].xml
Добавляем в [Content_Types].xml информацию о том, что /word/footer0.xml имеет тип application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml:
XSLT
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns="http://schemas.openxmlformats.org/package/2006/content-types" version="1.0">
<xsl:output method="xml" omit-xml-declaration="yes" indent="no" />
<xsl:param name="new">
<Override
PartName="/word/footer0.xml"
ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml"/>
</xsl:param>
<xsl:template match="/*">
<xsl:copy>
<xsl:copy-of select="@* | node()"/>
<xsl:copy-of select="$new"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>В результате
Весь код опубликован. Работает он так:
do ##class(Converter.Footer).modifyFooter("in.docx", "out.docx", "TEST")Где:
in.docx— исходный документout.docx— выходящий документTEST— текст, который добавляется в нижний колонтитул
Выводы
Используя только XSLT и ZIP можно успешно работать с документами docx, таблицами xlsx и презентациями pptx.
Открытые вопросы
- Изначально хотел использовать 7z вместо zip/unzip т… к. это одна утилита и она более распространена на Windows. Однако я столкнулся с такой проблемой, что документы запакованные 7z под Linux не открываются в Microsoft Office. Я попробовал достаточно много вариантов вызова, однако положительного результата добиться не удалось.
- Ищу XSD со схемами ECMA-376 версии 5 и комментариями. XSD версии 5 без комментариев доступен к загрузке на сайте ECMA, но без комментариев в нём сложно разобраться. XSD версии 2 с комментариями доступен к загрузке.
Ссылки
- ECMA-376
- Описание docx
- Подробная статья про docx
- Репозиторий со скриптами
- Репозиторий с преобразователем нижнего колонтитула
Written on 02 Января 2007. Posted in Visual C++
Страница 1 из 8
Хотя официально фирма Microsoft информацией по этой теме мало с кем делилась, и даже одно время пыталась препятствовать ее распространению, все же нельзя сказать, что эта информация закрыта. Ей на самом деле владеют многие. Без этой информации не существовали бы такие продукты, как антивирусы KAV и DrWEb, переводчик Stylus, пакет 1С:Предприятие и т.п. Сейчас в Интернете ее вполне достаточное количество, просто она разбросана мелкими порциями по разным малоизвестным источникам, и, что еще более неприятно, озаглавлена совсем не так, как хотелось бы нам. К сожалению, это как раз тот случай, о котором предупреждал незабвенный Козьма Прутков: на клетке слона частенько можно встретить надписи «буйвол», «мышь», «муравей», «динозавр», но только не «слон».
Цель этой статьи — попытаться собрать наиболее важные осколки информации в одно целое и указать места, где они валяются россыпью.
1. Общее описание. Терминология
| — Тот, кто хочет стать Чародеем Моря, должен знать Настоящее Имя каждой капли воды.
Урсула Ле Гуин. Волшебник Земноморья. |
Файлы документов MS WinWord с расширением .DOC представляют собой сложные объекты, организованные по правилам структурированного хранилища (structured storage). Фактически, структурированное хранилище — это отдельная файловая система от Microsoft, примерно такая же, как FAT или NTFS. Используют ее очень многие Windows-приложения разных производителей, функционирующие в рамках технологий OLE/COM/ActiveX. Вот (очень неполный!) список расширений файлов, устроенных по правилам структурированного хранилища, которые я обнаружил на своем компьютере: .DOC, .DOT, .XLS, .XLA, .WIZ, .CAG, .FLA, .PPT, .MD и пр.
Сам же дисковый файл, хранящий внутри себя структурированное хранилище, называется «файл-документ» (docfile) или «составной файл» (compound file). Первый термин применялся во времена OLE 1, второй появился в середине 90-х годов вместе с OLE 2, сейчас они обычно используются как синонимы.
В OLE существует еще понятие «составной документ» (compound document), но этот термин обозначает абстрактный подкласс хранилищ особого вида… в-общем, это уже ария несколько из другой оперы.
Внутри составной файл состоит из следующих элементов:
- «хранилища» (storages), а на самом деле это просто внутренние каталоги, описывающие состав и расположение других объектов внутри составного файла;
- «потоки» (streams), а на самом деле это своего рода файлы, массивы структурированной информации, имеющие собственное имя;
- «заблокированные данные» (lock-bytes), а на самом деле это довольно редко встречающиеся неструктурированные массивы двоичной информации, своего рода «посторонние» данные, которые разрешается иметь внутри составного файла, но которые не могут служить OLE-объектами.
Еще в литературе про OLE можно встретить термин «корневое хранилище» (root storage). Нетрудно сообразить, что он на самом деле означает всего лишь корневой каталог, т.е. главный каталог в составном файле. Фактически, так оно и есть. Но в литературе этот термин иногда используется в качестве синонима для составного файла и файл-документа, ведь они без корневого каталога не могут существовать, также как и он без них. Ну что ж, будем иметь это в виду.
Наконец, потоки (streams), на которые имеются ссылки в корневом хранилище (root storage), могут называться «наборы свойств» (property sets). На самом деле, так имеют право наименоваться не все потоки (streams), а только те из них, кто организован особым родом: имеют стандартизованный заголовок, разбиты на специфические разделы и т.п. Для нас это не слишком важно.
Разобраться в теринологических хитросплетениях мне помогла книжка:
Харрис Л. Освой самостоятельное программирование OLE за 21 день. — М.: Бином, 1995.-462 с.