
Слияние двух списков без дубликатов
Классическая ситуация: у вас есть два списка, которые надо слить в один. Причем в исходных списках могут быть как уникальные элементы, так и совпадающие (и между списками и внутри), но на выходе нужно получить список без дубликатов (повторений):

Давайте традиционно рассмотрим несколько способов решения такой распространенной задачи — от примитивных «в лоб» до более сложных, но изящных.
Способ 1. Удаление дубликатов
Можно решить задачу самым простым путем — руками скопировать элементы обоих списков в один и применить потом к полученному набору инструмент Удалить дубликаты с вкладки Данные (Data — Remove Duplicates):

Само-собой, такой способ не подойдет, если данные в исходных списках часто меняются — придется повторять всю процедуру после каждого изменения заново.
Способ 1а. Сводная таблица
Этот способ является, по сути, логическим продолжением предыдущего. Если списки не очень большого размера и заранее известно предельное количество элементов в них (например, не больше 10), то можно объединить две таблицы в одну прямыми ссылками, добавить справа столбец с единичками и построить по получившейся таблице сводную:

Как известно, сводная таблица игнорирует повторы, поэтому на выходе мы получим объединенный список без дубликатов. Вспомогательный столбец с 1 нужен только потому, что Excel умеет строить сводные по таблицам, содержащим, по крайней мере, два столбца.
При изменении исходных списков новые данные по прямым ссылкам попадут в объединенную таблицу, но сводную придется обновить уже вручную (правой кнопкой мыши — Обновить). Если не нужен пересчет «на лету», то лучше воспользоваться другими вариантами.
Способ 2. Формула массива
Можно решить проблему формулами. В этом случае пересчет и обновление результатов будет происходить автоматически и мгновенно, сразу после изменений в исходных списках. Для удобства и краткости давайте дадим нашим спискам имена Список1 и Список2, используя Диспетчер имен на вкладке Формулы (Formulas — Name Manager — Create):

После именования, нужная нам формула будет выглядеть следующим образом:

На первый взгляд выглядит жутковато, но, на самом деле, все не так страшно. Давайте я разложу эту формулу на несколько строк, используя сочетание клавиш Alt+Enter и отступы пробелами, как мы делали, например тут:

Логика тут следующая:
- Формула ИНДЕКС(Список1;ПОИСКПОЗ(0;СЧЁТЕСЛИ($E$1:E1;Список1); 0) выбирает все уникальные элементы из первого списка. Как только они заканчиваются — начинает выдавать ошибку #Н/Д:

- Формула ИНДЕКС(Список2;ПОИСКПОЗ(0;СЧЁТЕСЛИ($E$1:E1;Список2); 0)) аналогичным образом извлекает уникальные элементы из второго списка.
- Вложенные друг в друга две функции ЕСЛИОШИБКА реализуют вывод сначала уникальных из списка-1, а потом из списка-2 друг за другом.

Обратите внимание, что это формула массива, т.е. после набора ее нужно ввести в ячейку не обычным Enter, а сочетанием клавиш Ctrl+Shift+Enter и затем скопировать (протянуть) вниз на нижестоящие ячейки с запасом.
В английской версии Excel эта формула выглядит как:
=IFERROR(IFERROR(INDEX(Список1, MATCH(0, COUNTIF($E$1:E1, Список1), 0)), INDEX(Список2, MATCH(0, COUNTIF($E$1:E1, Список2), 0))), «»)
Минус у такого подхода в том, что формулы массива ощутимо замедляют работу с файлом, если в исходных таблицах большое (несколько сотен и более) количество элементов.
Способ 3. Power Query
Если в ваших исходных списках большое количество элементов, например, по несколько сотен или тысяч, то вместо медленной формулы массива лучше использовать принципиально другой подход, а именно — инструменты надстройки Power Query. Эта надстройка по умолчанию встроена в Excel 2016. Если у вас Excel 2010 или 2013, то ее можно отдельно скачать и установить (бесплатно).
Алгоритм действий следующий:
- Открываем отдельную вкладку установленной надстройки Power Query (если у вас Excel 2010-2013) или просто идем на вкладку Данные (если у вас Excel 2016).
- Выделяем первый список и жмем кнопку Из таблицы/диапазона (From Range/Table). На вопрос про создание из нашего списка «умной таблицы» — соглашаемся:

- Открывается окно редактора запросов, где будет видно загруженные данные и имя запроса Таблица1 (можно поменять на свое, если хотите).
- Делаем двойной щелчок в заголовок таблицы (слово Список1) и переименовываем на любой другой (например Люди). Каки именно назвать — не важно, но придуманное название нужно запомнить, т.к. его придется использовать потом еще раз при импорте второй таблицы. Объединить две таблицы в дальнейшем получится только если заголовки их столбцов совпадают.
- Разворачиваем выпадающий список в левом верхнем углу Закрыть и загрузить и выбираем Закрыть и загрузить в… (Close&Load to…):

- В следующем диалоговом окне (оно может выглядеть немного по-другому — не пугайтесь) выбираем Только создать подключение (Only create connection):

- Повторяем всю процедуру (пункты 2-6) для второго списка. При переименовании заголовка столбца важно использовать то же имя (Люди), что и в предыдущем запросе.
- В окне Excel на вкладке Данные (Data) или на вкладке Power Query выбираем Получить данные — Объединить запросы — Добавить (Get Data — Merge Queries — Append):

- В появившемся диалоговом окне выбираем наши запросы из выпадающих списков:

- В итоге получим новый запрос, где два списка будут соединены друг под другом. Осталось удалить дубликаты кнопкой Удалить строки — Удалить дубликаты (Delete Rows — Delete Duplicates):

- Готовый запрос можно переименовать справа на панели параметров, дав ему вменяемое имя (это будет имя таблицы-результата по факту) и все и можно все выгружать на лист командой Закрыть и загрузить (Close&Load):








В будущем, при любых изменениях или дополнениях в исходных списках, достаточно будет лишь правой кнопкой мыши обновить таблицу результатов.
Ссылки по теме
- Как собрать несколько таблиц из разных файлов с помощью Power Query
- Извлечение уникальных элементов из списка
- Как сравнить два списка между собой на совпадения и отличия
Это глава из книги: Майкл Гирвин. Ctrl+Shift+Enter. Освоение формул массива в Excel.
Предыдущая глава Оглавление Следующая глава
Оператор конкатенации – амперсанд & – позволяет объединить два элемента так, чтобы они стали единым целым. Вы можете соединять числа, текст (в кавычках), результаты формулы и др. Вы увидите, как использовать амперсанд, чтобы создать оператор массива, содержащий поиск по двум критериям.
На рис. 5.1 показаны исходные данные в диапазоне A2:C16 и отчет, который вы хотите создать в диапазоне E2:G10. Кросс-табличный отчет должен показывать объем продаж для каждого кода товара и соответствующего типа: левостороннего (L) и правостороннего (R). Для расчетов вы хотите создать формулу в ячейке F4, а затем скопировать ее в диапазон F4:G10. Проблема в том, что для каждой ячейки в диапазоне F4:G10, у вас есть два критерия поиска. Например, в ячейке F4, объем 30 взят на основе значения кода товара в ячейке E4 и значения L в ячейке F3. Стандартные функции поиска Excel запрограммированы так, чтобы искать только одно значение в одном столбце. Один из способов решения задачи – объединить два критерия поиска в один внутри формулы. (Предполагается, что таблица А2:С16 содержит по одной комбинации кода и типа товара, например, 2А35-2А36 типа L представлен в таблице одной строкой.)

Рис. 5.1. Цель – создать перекрестную таблицу, основанную на двух критериях поиска
Скачать заметку в формате Word или pdf, примеры в формате Excel2013
Вы можете использовать функцию поиска ИНДЕКС. В качестве аргумента массив выберите диапазон значений, которые вы хотите извлечь; в нашем случае – это С3:С16 (рис. 5.2). Поскольку мы будем протягивать нашу формулу, мы подготовимся заранее и введем диапазон $C$3:$C$16 в абсолютных ссылках, чтобы он не исказился при протягивании формулы.

Рис. 5.2. Начните ввод формулы на основе функции ИНДЕКС
Введите разделитель – точку с запятой, и переходите к набору аргумента номер_строки. Поскольку ваш массив одномерный (содержит по одному элементу в каждой строке), второй аргумент функции ИНДЕКС фактически соответствует номеру элемента в массиве. Вы должны выбрать объем продаж, одновременно отвечающий коду товара 2А35-2А36 и типу L. Функция ПОИСКПОЗ подходит для определения относительного положения элемента в списке. Вы можете поместить ПОИСКПОЗ в аргумент номер_строки функции ИНДЕКС (рис. 5.3). В аргументе искомое_значение функции ПОИСКПОЗ вы сначала введете ссылку на ячейку с кодом товара, затем символ соединения – амперсанд &, и, наконец ссылку на ячейку типа товара (лево-/правосторонний). Обратите внимание на тип ссылок – они смешанные. Это опять же требуется для того, чтобы формула не «съехала» при протаскивании. [1]

Рис. 5.3. Создайте критерий поиска состоящий из двух элементов
Чтобы убедиться, что $E4&F$3 – одно значение, выделите этот элемент в формуле, и нажмите F9 (рис. 5.4). Используйте сочетание клавиш Ctrl+Z, чтобы отменить этот расчет и вернуться к набору формулы.

Рис. 5.4. Используя F9, вы можете увидеть, что операция объединения создала единый аргумент искомое_значение
Введите точку с запятой и перейдите к вводу массива, в котором вы и будет искать относительную позицию элемента $E4&F$3. Поскольку у вас есть две колонки, вы также объедините их (рис. 5.5). В процессе соединения двух колонок вы собственно и выполнили операцию конкатенации массивов.

Рис. 5.5. Аргумент просматриваемый_массив функции ПОИСПОЗ содержит оператор конкатенации массивов
Мы можете увидеть, что соединили две колонки и создали один массив, если выделите аргумент просматриваемый_массив и нажмете F9 (рис. 5.6). Неправда ли, это удивительно! Прямо в формуле, вы объединили два столбца в один. Не забудьте отменить расчет, нажав Ctrl+Z.

Рис. 5.6. Если вычислить аргумент просматриваемый_массив, вы увидите единый массив
Чтобы закончить ввод формулы ПОИСКПОЗ задайте аргумент тип_соответствия равным нулю (рис. 5.7); это укажет Excel искать точное совпадение. Введите две закрывающие скобки (напоминаю, что выбранный вами массив С3:С16 содержит один столбец, так что аргумент номер_столбца функции ИНДЕКС можно опустить).

Рис. 5.7. Задайте тип_соответствия равным 0
Поскольку функция ПОИСКПОЗ изначально не запрограммирована на обработку операторов массива, нажмите Ctrl+Shift+Enter и скопируйте формулу на диапазон F4:G10 (рис. 5.8).

Рис. 5.8. Введите формул в ячейку F4 нажав Ctrl+Shift+Enter и скопируйте формулу по диапазону
Вы можете усовершенствовать вашу формулу конкатенации массивов. Представьте, например, вы соединили значения 30 и 20 и получили 3020. А если такое значение есть в одном из столбцов!? Чтобы застраховаться от подобных казусов введите какой-нибудь дополнительный редко встречающийся символ в качестве разделителя двух массивов (рис. 5.9).

Рис. 5.9. Дополнительный символ обезопасит формулу
А что, если у вас 3 критерия? Четыре? Вы можете соединить их все в формуле массива. Однако, операция конкатенации может потребоваться много времени для расчета формулы. Рассмотрите в качестве альтернативы функцию для работы с базой данных БИЗВЛЕЧЬ. БИЗВЛЕЧЬ является одной из самых привлекательных функций Excel. Если ваш набор данных содержит заголовки столбцов, БИЗВЛЕЧЬ можете сделать выборку на основе нескольких критериев. БД-функции могут работать как с И, так и с ИЛИ критериями. И критерии должны находиться в одной строке (рис. 5.10), ИЛИ критерии должны быть в разных строках (см. главу 11).
Как упоминалось ранее в этой книге, недостатком БД-функций являются проблемы с их копированием вдоль столбца, так как каждый раз нужно формировать область критериев отбора. Если вам не нужно копировать формулу в другие ячейки, функция БИЗВЛЕЧЬ – лучший выбор, так как ее проще написать и скорость ее работы выше. Если вам необходимо скопировать формулу в другие ячейки, вы можете использовать БИЗВЛЕЧЬ совместно с инструментом Таблица данных (см. описание к рис. 4.16 в главе 4).

Рис. 5.10. Функция БИЗВЛЕЧЬ легче в создании и быстрее в работе, чем формула массива; однако, ее нельзя «протащить» по столбцу
Еще одной альтернативой функции массива является вспомогательный столбец, в котором будут соединены критерии (так называемый объединенный ключ). Когда такой столбец создан, стандартная функция ВПР легко справится с извлечением нужных данных (рис. 5.11). Обратите внимание, вам достаточно вставить пустой столбец А и в ячейке А3 ввести формулу =B3&"|"&C3, которая легко копируется вниз по столбцу. Далее в аргументе искомое_значение функции ВПР создайте конкатенацию двух критериев $F4&"|"&G$3. Если вы можете позволить себе создание дополнительной колонки, решение с помощью ВПР – лучший выбор по сравнению с формулой массива. ВПР проще и работает быстрее.

Рис. 5.11. Если есть возможность, используйте вспомогательный столбец и функцию ВПР
Наконец, если вам не требуется немедленного обновления результатов, для создания перекрестного отчета вы можете использовать сводную таблицу (рис. 5.12). Обычно сводные таблицы используются для агрегирования данных, но они также могут использоваться и для особого их представления (упорядочения).

Рис. 5.12. Если вы не нуждаетесь в немедленном обновлении результатов, возможно лучшее решение – сводная таблица
Рассмотрим еще один прием, позволяющий решить задачу выборки по двум критериям. Примените поиск на основании так называемого приблизительного совпадения; в этом случае значение аргумента тип_сопоставления функции ПОИСКПОЗ равен 1 или опущен (рис. 5.13).

Рис. 5.13. Аргумент тип_сопоставления функции ПОИСКПОЗ
Выборка на основании приблизительного совпадение работает гораздо быстрее, чем на основании точного соответствия. В первом случае Excel выполняет бинарный поиск, последовательно разбивая таблицу на половинки. Во втором случае Excel ищет, просматривая весь столбец сверху вниз. Отсортируйте по возрастанию сначала столбец L/R?, а затем столбец Код товара; таким образом, массив внутри формулы будет отсортирован по возрастанию. Далее, обратите внимание, что аргумент тип_сопоставления функции ПОИСКПОЗ опущен; по умолчанию поиск выполняется на основе приблизительного совпадения.

Рис. 5.14. Если вы хотите ускорить работу формулы, отсортируйте два столбца и используйте поиск на основании приблизительного совпадения
Если у вас есть возможность отсортировать два столбца, вы можете упростить вашу формулу массива, использовав вместо конструкции ИНДЕКС(ПОИСКПОЗ(…)) функцию ПРОСМОТР. Функция ПРОСМОТР может обрабатывать массив без нажатия Ctrl+Shift+Enter. Функция ПРОСМОТР ищет только приблизительное совпадение (поэтому-то исходные данные и должны быть отсортированы). Кроме того, эта функция имеет отдельные аргументы для столбца в котором вы ищите совпадения, названном просматриваемый_вектор, и для столбца, который содержит значения, которые вы хотите получить – вектор_результатов (рис. 5.15).

Рис. 5.15. Функция ПРОСМОТР ищет приблизительное совпадение и может обрабатывать массив без Ctrl+Shift+Enter
Предварительная сортировка ускорит и работу функции ВПР, описанной на рис. 5.11. Если вы отсортируете по вспомогательному столбцу, вы можете использовать приблизительное совпадение, опустив четвертый аргумент функции ВПР: =ВПР($F4&"|"&G$3;$A$3:$D$16;4) (рис. 5.16). Для больших наборов данных, переход от поиска точного соответствия к приблизительному может значительно сократить время расчета формулы.

Рис. 5.16. Ускоряем функцию ВПР; отличие от рис. 5.11 в том, что диапазон А3:D16 отсортирован по столбцу А, а в функции ВПР опущен четвертый аргумент
Ранее в этой книге, вы познакомились с тремя функциями, которые могут обрабатывать массивы без Ctrl+Shift+Enter: СУММПРОИЗВ, АГРЕГАТ и ПРОСМОТР. Четвертой такой функцией является ИНДЕКС.
Следующий пример выглядит немного искусственно, но он показывает, как оператор массива, помещенный в аргумент функции ИНДЕКС может обрабатываться без Ctrl+Shift+Enter. Вернитесь к рис. 5.7, где приведена формула массива для поиска по двум критериям. Поскольку операция с массивами была расположена в аргументе просматриваемый_массив функции ПОИСКПОЗ, вам пришлось использовать Ctrl+Shift+Enter (функция ПОИСКПОЗ не была изначально запрограммирована для операций с массивами). Повторное использование функции ИНДЕКС позволяет вам изменить формулу, которая теперь не потребует нажатия Ctrl+Shift+Enter.
Обычно функция ИНДЕКС ищет один элемент в двумерном (строку и столбец) или одномерном массиве (только строку или только столбец). Но ИНДЕКС может также искать целиком строку или столбец. В этом случае, функция вернет массив элементов. Синтаксис функции
ИНДЕКС(массив;номер_строки;[номер_столбца])
Для поиска всего столбца разместите в аргументе номер_строки ноль или оставьте его пустым. Это укажет функции ИНДЕКС получить весь столбец, т.е. все строки. Это означает, что вы можете разместить оператор конкатенации массивов в аргументе массив функции ИНДЕКС и оставить аргумент номер_строки пустым (рис. 5.17). Функция ИНДЕКС вернет массив, состоящий из всех объединенных элементов и предоставит этот массив в распоряжение функции ПОИСКПОЗ. Но… теперь ввод формулы не потребует нажатия Ctrl+Shift+Enter.

Рис. 5.17. Разместите оператор конкатенации массивов в аргументе массив функции ИНДЕКС и оставить аргумент номер_строки пустым
Следующие пять аргументов четырех функций могут обрабатывать массивы без Ctrl+Shift+Enter:
- Массив1, массив2 и др. аргументы функции СУММПРОИЗВ
- Просматриваемый_вектор функции ПРОСМОТР
- Вектор_результатов функции ПРОСМОТР
- Массив функции ИНДЕКС
- Массив функции АГРЕГАТ для функций от 14 до 19
[1] Подробнее см., например, Относительные, абсолютные и смешанные ссылки на ячейки в Excel
TLDR and self guided — Here’s the example workbook.
Yes, there is a way to join arrays in pre-office 2016. I know this has been answered by ImaginaryHuman above, but I have another way, it returns an array, and it’s a little easier to read (IMHO). I’m going to break out evolutions of the formula so that you can find one that fits your use case. I’ve highlighted the use cases in bold so you can find yours quickly. I know this is rather verbose, but I am the kind of person who likes to know how a solution works, so I’m going to try to give you the same courtesy.
The formula relies on nested IF statements and INDEX/CHOOSE structures. It works with ranges, named ranges, and even table columns. All of my examples show four ranges, hence three IF statements, but this can be strung up to (I think) 64 ranges if you care for that many nested IF statements.
For these examples, the data ranges are A3:B6, A9:B11, A14:B19, and A22:B32. The resulting array formula is put in the range E3:E26 and finished with a Ctrl+Shift+Enter to make it an array formula. Your data can go wherever you like — you are not tied to these ranges — just substitute your ranges appropriately.
If your data is in contiguous ranges:
=IF(ROW()-ROW(E3)<ROWS(A3:A6),INDEX(A3:B6,ROW()-ROW(E3)+1,COLUMN()-COLUMN(E3)+1),
IF(ROW()-ROW(E3)<ROWS(A3:A6)+ROWS(A9:A11),INDEX(A9:B11,ROW()-ROW(E3)-ROWS(A9:A11),COLUMN()-COLUMN(E3)+1),
IF(ROW()-ROW(E3)<ROWS(A3:A6)+ROWS(A9:A11)+ROWS(A14:A19),INDEX(A14:B19,ROW()-ROW(E3)-ROWS(A3:A6)-ROWS(A9:A11)+1,COLUMN()-COLUMN(E3)+1),
INDEX(A22:B32,ROW()-ROW(E3)-ROWS(A3:A6)-ROWS(A9:A11)-ROWS(A14:A19)+1,COLUMN()-COLUMN(E3)+1))))
How it works:
- The
IFstatement makes sure that we are in the first range by subtracting the current row from the top of the output range in cellE3and comparing it to the number of cells in the first input range ofA3:B6. - The INDEX statement chooses an item from the first input range of
A3:B6, given a row and column offset calculated from cellE3. - If the row is not in the first range it moves on to the next
IFstatement, which repeats the process but compares the current row of the array to the length of the first two ranges. The process repeats for any further nestedIFstatements.
If your data is not in contiguous ranges, you need a column showing what range the data originally came from, or both:
=IF(ROW()-ROW(E3)<ROWS(A3:A6),INDEX(CHOOSE({1,2,3},{1},A3:A6,B3:B6),ROW()-ROW(E3)+1,COLUMN()-COLUMN(E3)+1),
IF(ROW()-ROW(E3)<ROWS(A3:A6)+ROWS(A9:A11),INDEX(CHOOSE({1,2,3},{2},A9:A11,B9:B11),ROW()-ROW(E3)-ROWS(A3:A6)+1,COLUMN()-COLUMN(E3)+1),
IF(ROW()-ROW(E3)<ROWS(A3:A6)+ROWS(A9:A11)+ROWS(A14:A19),INDEX(CHOOSE({1,2,3},{3},A14:A19,B14:B19),ROW()-ROW(E3)-ROWS(A3:A6)-ROWS(A9:A11)+1,COLUMN()-COLUMN(E3)+1),
INDEX(CHOOSE({1,2,3},{4},A22:A32,B22:B32),ROW()-ROW(E3)-ROWS(A3:A6)-ROWS(A9:A11)-ROWS(A14:A19)+1,COLUMN()-COLUMN(E3)+1))))
How it works:
- All the principles for the
IFandINDEXstatements remain the same as above. - A
CHOOSEstatement is added which allows you to select non-contiguous columns of data or a static array with whatever identifier you want for each range. In this case, I went with numbers (1,2,3,4). - The
CHOOSEstatement can have as many columns as you like — just change the first argument to{1,2,3,4}for four columns and add your fourth column as the last argument. Do the same for any subsequent columns (i.e.{1,2,3,4,5}and add your fifth column as the last argument.
If you have horizontal data instead of vertical data, you can use TRANSPOSE to make the previous example work. Just nest the TRANSPOSE function inside the CHOOSE function like this:
CHOOSE({1,2,3},{1},TRANSPOSE(A3:C3),TRANSPOSE(A4:C4)
You can clean up the formula significantly with named ranges or tables. This example builds on the previous one allowing data not in contiguous ranges and provides an identifier column showing where the data came from:
=IF(ROW()-ROW(E3)<ROWS(Table1),INDEX(CHOOSE({1,2,3},{1},Table1[Column1],Table1[Column2]),ROW()-ROW(E3)+1,COLUMN()-COLUMN(E3)+1),
IF(ROW()-ROW(E3)<ROWS(Table1)+ROWS(Table2),INDEX(CHOOSE({1,2,3},{2},Table2[Column1],Table2[Column2]),ROW()-ROW(E3)-ROWS(Table1)+1,COLUMN()-COLUMN(E3)+1),
IF(ROW()-ROW(E3)<ROWS(Table1)+ROWS(Table2)+ROWS(Table3),INDEX(CHOOSE({1,2,3},{3},Table3[Column1],Table3[Column2]),ROW()-ROW(E3)-ROWS(Table1)-ROWS(Table2)+1,COLUMN()-COLUMN(E3)+1),
INDEX(CHOOSE({1,2,3},{4},Table4[Column1],Table4[Column2]),ROW()-ROW(E3)-ROWS(Table1)-ROWS(Table2)-ROWS(Table3)+1,COLUMN()-COLUMN(E3)+1))))
If that isn’t enough, you can do more housekeeping for readability by creating some named values. The first thing that can be done is to define at what row we start getting data from each table. For this example, I have named these Table2_UL, Table3_UL, and Table4_UL. Their code formula in the name manager looks like this:
Table2_UL:=ROWS(Table1)Table3_UL:=Table2_UL+ROWS(Table2)Table4_UL:=Table3_UL+ROWS(Table3)
As you can see, each one builds upon the last so its output is dynamic. We now have a much more readable formula:
=IF(ROW()-ROW(E3)<Table2_UL,INDEX(CHOOSE({1,2,3},{1},Table1[Column1],Table1[Column2]),ROW()-ROW(E3)+1,COLUMN()-COLUMN(E3)+1),
IF(ROW()-ROW(E3)<Table3_UL,INDEX(CHOOSE({1,2,3},{2},Table2[Column1],Table2[Column2]),ROW()-ROW(E3)-Table2_UL+1,COLUMN()-COLUMN(E3)+1),
IF(ROW()-ROW(E3)<Table4_UL,INDEX(CHOOSE({1,2,3},{3},Table3[Column1],Table3[Column2]),ROW()-ROW(E3)-Table3_UL+1,COLUMN()-COLUMN(E3)+1),
INDEX(CHOOSE({1,2,3},{4},Table4[Column1],Table4[Column2]),ROW()-ROW(E3)-Table4_UL+1,COLUMN()-COLUMN(E3)+1))))
But that’s not enough for me. I want to get rid of all those nasty references to ROW() and COLUMN(). We can do that by defining two more values in the name manager that keep track of our current row and column for us:
Output_CC:=COLUMN()-COLUMN(Sheet1!E3)+1Output_CR:=ROW()-ROW(Sheet1!E3)+1
Finally, we have something that is near human readable:
=IF(Output_CR-1<Table2_UL,INDEX(CHOOSE({1,2,3},{1},Table1[Column1],Table1[Column2]),Output_CR,Output_CC),
IF(Output_CR-1<Table3_UL,INDEX(CHOOSE({1,2,3},{2},Table2[Column1],Table2[Column2]),Output_CR-Table2_UL,Output_CC),
IF(Output_CR-1<Table4_UL,INDEX(CHOOSE({1,2,3},{3},Table3[Column1],Table3[Column2]),Output_CR-Table3_UL,Output_CC),
INDEX(CHOOSE({1,2,3},{4},Table4[Column1],Table4[Column2]),Output_CR-Table4_UL,Output_CC))))
If we really want to take it all the way, we can turn our CHOOSE statements into named values as well. Just do the following for each of your input tables in the Name Manager, making sure to give each a unique name:
Table1_IN: =CHOOSE({1,2,3},{1},Table1[Column1],Table1[Column2])
Now we can read the formula really easy:
=IF(Output_CR-1<Table2_UL,INDEX(Table1_IN,Output_CR,Output_CC),
IF(Output_CR-1<Table3_UL,INDEX(Table2_IN,Output_CR-Table2_UL,Output_CC),
IF(Output_CR-1<Table4_UL,INDEX(Table3_IN,Output_CR-Table3_UL,Output_CC),
INDEX(Table4_IN,Output_CR-Table4_UL,Output_CC))))
Again, though, that is not enough because you cannot turn on the filter and sort arrays A-Z. You get the error «You can’t change part of an array.» There is a workaround, though! It requires a helper column and duplicating your output. It can be duplicated to a plain old range or into a table. To allow you to both sort and filter your data, create a helper column to the left of the array output, in this case, starting in D3. If your data does not need to be ranked (like all text columns), create static numbering (1, 2, 3, 4, etc). In this example, column G contains a number to be ranked. If it does need to be ranked enter the following formula in D3 and drag it down:
=RANK.EQ(G3,G$3:G$26,0)+COUNTIF(G$3:G3,G3)-1
Change the final argument to 1 if you need an ascending ranking instead. You now have an out of order ranking if your data was ranked or an unsortable array with a static number next to it if not. Now we duplicate the data into a range or table. In column I, starting at I3, create static numbering as long as the dataset (ie 1, 2, 3, 4). Now to the right in cell J3 enter a VLOOKUP that refers to the data in the source array:
=VLOOKUP($I3,$D$3:$G$26,COLUMNS($I$3:J3),FALSE)
Drag the formula down and then drag it right. You can now sort and filter your data just as if it was a normal range.
Иногда для удобства требуется объединить три и более списка значений в один.
Пусть дано 5 списков и все они разной длины (см. Файл примера ).
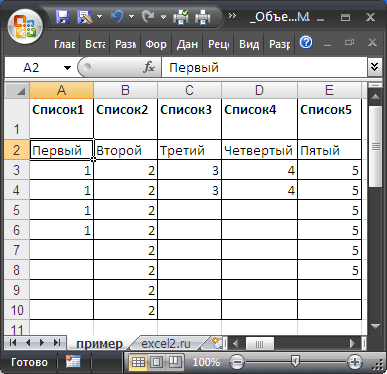
Задача
Объединим все значения из 5 списков в один. Задача объединения 2-х списков решена в одноименной
статье
.
Решение1 (Простое)
Объединенный спискок будем строить на основе функции СМЕЩ()
=СМЕЩ(заголовок первого списка;Номер элемента в списке;Номер списка-1)
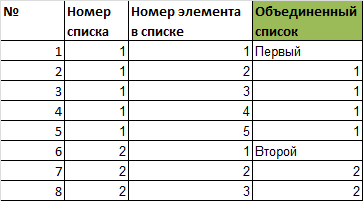
Создадим небольшую служебную таблицу для подсчета количества значений в каждом списке и определения позиции первого элемента каждого списка в объединенном списке.
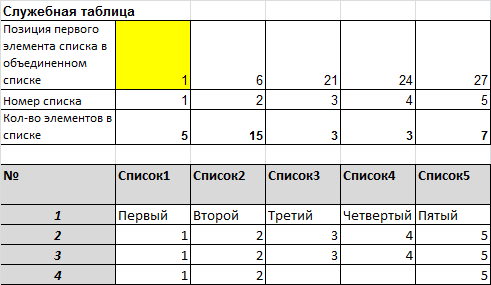
Эта таблица позволит нам сопоставить каждой позиции объединенного списка Номер исходного списка:
=ГПР(СТРОКА()-СТРОКА($H$11);$B$7:$F$8;2;ИСТИНА)
- выражение СТРОКА()-СТРОКА($H$11) генерирует последовательность 1; 2; 3; 4…
- функция ГПР() — горизонтальный аналог ВПР() выбирает по позиции первого элемента каждого списка в объединенном списке номер исходного списка.
Номер списка является смещением по столбцам в формуле на основе СМЕЩ()
Подробности можно посмотреть в файле примера на листе Пример2.
Решение2 (сложное, с формулами массива и именованными формулами)
Сначала создадим
именованный диапазон
, содержащий значения из всех списков. Для этого:
-
выделите, диапазон
A
2:
E
10
; -
на вкладке
Формулы
в группе
Определенные имена
выберите команду
Присвоить имя
; -
в поле
Имя
введите:
Диапазон_Списков
; -
убедитесь, что в поле
Диапазон
введена формула =пример!$A$2:$E$10 - нажмите ОК.
Для вывода всех значений из 5 списков в один столбец будем использовать функцию ИНДЕКС() . Эта функция будет последовательно выводить значения из всех ячеек диапазона
Диапазон_Списков
на основании их номера столбца и номера строки. Осталось только определить адреса не пустых ячеек.
Создадим массив пар (номер столбца; номер строки) для всех ячеек диапазона. Для этого применим трюк: значения пары будем хранить в виде обычного числа, но формировать его будем по определенному правилу: правая часть числа будет содержать номер строки (для этого выделяется два разряда, т.е. максимальная длина списка может быть 99), а левая часть числа будет содержать номер столбца. Например, число 512 будет означать: 5-й столбец, 12-ая строка. Естественно, при необходимости можно увеличить разрядность для хранения номеров строк (формула из файла примера позволяет столбцам иметь до 9999 строк).
Технически осуществим это так. Сначала определим номер столбца и строки левого верхнего угла нашего
Диапазона_Списков
. Для этого создайте две
именованные формулы
=МИН(СТОЛБЕЦ(Диапазон_Списков)) и =МИН(СТРОКА(Диапазон_Списков))
Создайте еще одну
именованную формулу
Адреса:
=ЕСЛИ(ЕПУСТО(Диапазон_Списков);»»; —((СТОЛБЕЦ(Диапазон_Списков)-Мин_Столбец+1)&ВЫБОР(ДЛСТР(СТРОКА(Диапазон_Списков)-Мин_Строка+1);»0″;»»)&СТРОКА(Диапазон_Списков)-Мин_Строка+1))
Эта формула вернет массив адресов из нашего диапазона {101;201;301;401;501: 102;202;302;»»;502: 103;203;303;»»;503: 10…}. Вместо адресов пустых ячеек в массиве содержатся значения
Пустой текст
(«»). Номера столбцов и строк отсчитываются от левой верхней ячейки
Диапазона_список
.
Заключительный этап. Формируем объединенный список. Запишем в ячейке следующую формулу: =ЕСЛИОШИБКА(ИНДЕКС(Диапазон_Списков; —ПРАВСИМВ(НАИМЕНЬШИЙ(Адреса;СТРОКА(Z1));2);—ЛЕВСИМВ(НАИМЕНЬШИЙ(Адреса;СТРОКА(Z1)); ДЛСТР(НАИМЕНЬШИЙ(Адреса;СТРОКА(Z1)))-2));»»)
Функция НАИМЕНЬШИЙ() будет последовательно извлекать все числа, содержащие адреса ячеек. Функция ПРАВСИМВ() будет извлекать из этих чисел номер строки, а функция ЛЕВСИМВ() – номер столбца. Эти две функции возвращают текстовые значения, поэтому применим двойное отрицание (—), чтобы преобразовать текст в число (см. статью
Преобразование чисел из текстового формата в числовой (часть 1)
).
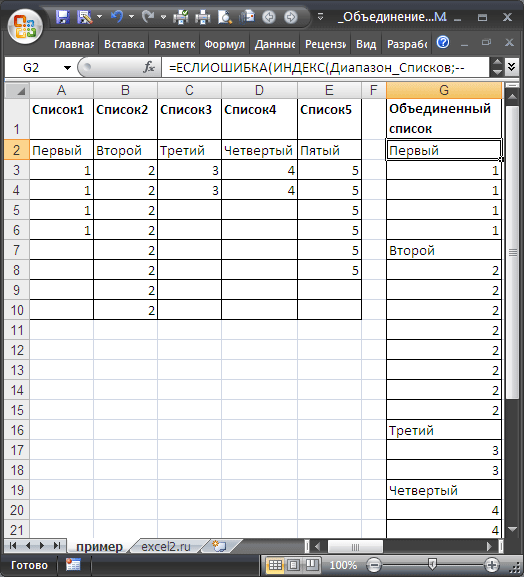
Таким образом можно объединить нужное количество столбцов, каждый из которых длиной не более 99 строк.
Для объединения столбцов, каждый из которых длиной не более 9999 строк нужно использовать формулу
=ЕСЛИОШИБКА(ИНДЕКС(Диапазон_Списков;—ПРАВСИМВ(НАИМЕНЬШИЙ(Адреса;СТРОКА(Z1));4);—ЛЕВСИМВ(НАИМЕНЬШИЙ(Адреса;СТРОКА(Z1));ДЛСТР(НАИМЕНЬШИЙ(Адреса;СТРОКА(Z1)))-4));»»)
Именованную формулу
Адреса
также придется подкорректировать:
=ЕСЛИ(ЕПУСТО(Диапазон_Списков);»»;—((СТОЛБЕЦ(Диапазон_Списков)-Мин_Столбец+1)&ВЫБОР(ДЛСТР(СТРОКА(Диапазон_Списков)-Мин_Строка+1);»000″;»00″;»0″;»»)&СТРОКА(Диапазон_Списков)-Мин_Строка+1))
Примечание
: при объединении большого количества столбцов с количеством строк >100, расчет формулы может притормаживать.
Здравствуйте!
Диапазоны разной длины A1:A3 и B1:B2 в памяти представлены массивами {3:2:1} и {4:5}. Как формулой объединить массивы в один, т.е. получить {3:2:1:4:5} без использования вспомогательных ячеек?
Заранее спасибо за ответ!
Спасибо за ответ.
Наксолько я понял, Ваш вопрос — об объединении массивов в одну строку, тогда как необходимо получить _массив_.
Цитата: Alexxey от 10.11.2011, 21:16
Ваш вопрос — об объединении массивов в одну строку, тогда как необходимо получить _массив_.
А Ваш? Вы просили
Цитироватьформулой объединить массивы в один, т.е. получить
одномерный (в одну строку, точнее в один столбец) массив.
По ссылке я именно об этом и спрашивал.
Вы видите какую-то разницу или я что-то недопонял?
Ваш вопрос я понял так:
Из _одного_ массива значений {«любое значение1″;»любое значение2″;»любое значение3»}
получить одно значение «любое значение1любое значение2любое значение3».
Тогда как мне нужно из _нескольких_ массивов получить один массив.
Эксель изощрён, но не злонамерен.
Буду благодарен помощи в освоении VBA.
Не работает UDF
Public Function MyUnion(Array1, Array2) As Double()
Rem получить объединенный массив
Dim N As Integer
Dim Arr, ArrItem As Double
Dim UnionArr() As Double
For Each Arr In Array1
ReDim Preserve UnionArr(0 To N)
UnionArr(N) = Arr
N = N + 1
Next
For Each Arr In Array2
ReDim Preserve UnionArr(0 To N)
UnionArr(N) = Arr
N = N + 1
Next
MyUnion = UnionArr
End Function
В чем проблема?
Alexxey, у меня Ваша функция работает.
(на всякий случай добавил немного извращённый  вариант):
вариант):
Эксель изощрён, но не злонамерен.
Ну и формульный вариант (тоже извращенный)
Спасибо за помощь! Понять бы еще и формульный вариант… Буду изучать
Здравствуйте!
Как использовать рассматриваемые функции соединения используя ссылки на исходные объединяемые массивы?
Заранее благодарен за ответ!
Цитата: Alexxey от 01.12.2011, 23:44
Как использовать рассматриваемые функции соединения используя ссылки на исходные объединяемые массивы?
Alexxey, в прикреплённом два макроса.
Первый — выделяет диапазон, соответствующий размеру возвращаемому функцией массиву (или (почти) любой формулы, возвращающей массив) и затем его вставляет.
Второй — удаляет формулы из ячеек диапазона-массива, кроме первой ячейки.
Эксель изощрён, но не злонамерен.
Спасибо Вам за помощь!
К сожалению, мой вопрос, вероятно, не достаточно четко сформулирован,
и поэтому Ваш ответ не совсем решил мой вопрос. Могли бы Вы загрузить мой модифицированный вопрос, я постарался его расписать более понятно.
Alexxey, сорь, я невнимательно прочитал то что Вы хотите.
Так ? :
Эксель изощрён, но не злонамерен.
Так точно! Спасибо! Не догадался, что ИНДЕКС может возвращать массивы.
ну и мой вариант формулами
Спасибо за формульный вариант- не могу понять, за счет чего в нем осуществляется склейка 2-х массивов.