
Word для Microsoft 365 Word 2021 Word 2019 Word 2016 Word 2013 Еще…Меньше
Если вы хотите вставить в документ Word печатный документ или рисунок, это можно сделать несколькими способами.
Примечание: Если вы ищете инструкции по подключению сканера или скопатора к Microsoft Windows, посетите веб-сайт поддержки изготовителя вашего устройства.
Сканирование изображения в Word
Для сканирования изображения в документ Word можно использовать сканер, многофункциональный принтер, копировальный аппарат с возможностью сканирования или цифровую камеру.
-
Отсканируйте изображение или сделайте его снимок с помощью цифровой камеры или смартфона.
-
Сохраните изображение в стандартном формате, таком как JPG, PNG или GIF. Поместите его в папку на своем компьютере.
-
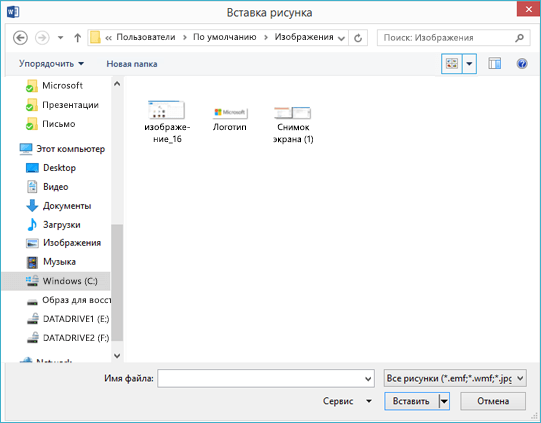
В Word, поместите курсор туда, куда вы хотите вставить отсканированное изображение, а затем на вкладке Вставка нажмите кнопку Рисунки.

-
Выберите отсканированный рисунок в диалоговом окне и нажмите кнопку Вставить.

Вставка отсканированного текста в Word
Для сканирования документа в Microsoft Word проще всего использовать наше бесплатное приложение Office Lens на смартфоне или планшете. Оно получает снимок документа с помощью камеры устройства и сохраняет его в виде редактируемого документа непосредственно в Word. Она доступна бесплатно на iPad ,iPhone, Windows Phone и Android.
Если вы не хотите использовать Office Lens, лучше всего отсканировать документ в формате PDF с помощью программного обеспечения сканера, а затем открыть его в Word.
-
В Word выберите Файл > Открыть.
-
Перейдите к папке, в которой хранится PDF-файл, и откройте его.
-
Word откроет диалоговое окно, в котором нужно подтвердить импорт текста PDF-файла. Нажмите кнопку ОК, Word импортировать текст. Word постарается сохранить форматирование текста.

Дополнительные сведения см. в статье Редактирование содержимого PDF-документа в Word.
Примечание: Точность распознавания текста зависит от качества сканирования и четкости отсканированного текста. Рукописный текст редко распознается, поэтому для лучших результатов сканируйте печатные материалы. Всегда проверяйте текст после его открытия в Word, чтобы убедиться, что он правильно распознан.
Кроме того, со сканером может поставляться приложение для распознавания текста (OCR). Обратитесь к документации своего устройства или к его производителю.
Остались вопросы о Word?
Задайте их на форуме сообщества Word Answers
Помогите нам улучшить Word
У вас есть предложения, как улучшить Word? Дайте нам знать, предоставив нам отзыв. Дополнительные сведения см. в Microsoft Office.
См. также
-
Вставка изображений в Office 2013 и Office 2016
-
Вставка подписи
-
Приложение «Сканер» для Windows: вопросы и ответы
Нужна дополнительная помощь?
Преобразование отсканированных документов и изображений в редактируемые форматы Word, Pdf, Excel и Txt (простой текст)
Доступно страниц: 10 (Вы уже использовали 0 страниц)
Если вам нужно распознать больше страниц, пожалуйста, зарегистрируйтесь
Загрузите файлы для распознавания или перетащите их на эту страницу
Поддерживаемые форматы файлов:
pdf, jpg, bmp, gif, jp2, jpeg, pbm, pcx, pgm, png, ppm, tga, tiff, wbmp
- Китайский OCR
- Немецкий OCR
- Нидерландский OCR
- Английский OCR
- Французский OCR
- Итальянский OCR
Как распознать текст с изображения?
Шаг 1
Загрузите изображения или PDF-файлы
Выберите файлы с компьютера, Google Диска, Dropbox, по ссылке или перетащив их на страницу
Шаг 2
Язык и формат
Выберите все языки, используемые в документе. Кроме того, выберите .doc или любой другой формат, который вам нужен в результате (поддерживается больше 10 текстовых форматов)
Шаг 3
Конвертируйте и скачивайте
Нажмите «Распознать», и вы можете сразу загрузить распознанный текстовый файл
![]()
Загрузить PDF
![]()
Загрузить PDF
Из этой статьи вы узнаете, как на компьютере преобразовать отсканированный документ в документ Word. Это можно сделать с помощью программы Word, если отсканированный документ сохранен в формате PDF, или с помощью бесплатного конвертера, если отсканированный документ сохранен как изображение. Если у вас есть учетная запись Microsoft и смартфон, используйте бесплатное приложение Office Lens, чтобы отсканировать документ и сохранить его в виде документа Word в облачном хранилище OneDrive.
-
1
Убедитесь, что отсканированный документ сохранен в формате PDF. Microsoft Word может преобразовать такой документ без дополнительного программного обеспечения.[1]
- Если отсканированный документ сохранен как изображение (например, в формате JPG или PNG), воспользуйтесь сервисом New OCR.
-
2
Откройте PDF-документ в Word. Этот процесс зависит от операционной системы:
- в Windows щелкните правой кнопкой мыши по PDF-файлу, выберите «Открыть с помощью», а затем в меню нажмите «Word»;
- в Mac OS X щелкните по PDF-файлу, а потом нажмите «Файл» > «Открыть с помощью» > «Word».
-
3
Нажмите OK, когда появится запрос. Word приступит к преобразованию PDF-документа в формат DOC.
- Этот процесс может занять несколько минут, если в PDF-документе большой текст или много изображений.
-
4
Активируйте редактирование файла (если потребуется). Если в верхней части окна Word отобразилась желтая полоса с предупреждением, нажмите «Включить редактирование» на желтой полосе, чтобы разблокировать документ для редактирования.
- Обычно это относится только к скачанным файлам (например, если вы скачали отсканированный документ в формате PDF из облачного хранилища).
-
5
Отредактируйте документ. Преобразованный документ не будет абсолютной копией исходного — скорее всего, вам придется добавить отсутствующие слова, удалить лишние пробелы и исправить опечатки.
-
6
Сохраните документ. Чтобы сохранить отредактированный документ в формате DOC, выполните следующие действия:
- в Windows нажмите Ctrl+S, введите имя файла, выберите папку для сохранения и нажмите «Сохранить»;
- в Mac OS X нажмите ⌘ Command+S, введите имя файла, выберите папку для сохранения (в меню «Где») и нажмите «Сохранить».
Реклама






-
1
Откройте сайт сервиса New OCR. Перейдите на страницу http://www.newocr.com/ в веб-браузере компьютера.
-
2
Нажмите Обзор. Это серая кнопка в верхней части страницы. Откроется окно Проводника (Windows) или Finder (Mac).
-
3
Выберите отсканированный файл. В окне Проводника или Finder перейдите к отсканированному документу, который сохранен как изображение, и щелкните по нему.
-
4
Нажмите Открыть. Эта кнопка находится в нижнем правом углу окна. Файл загрузится на веб-сайт.
-
5
Щелкните по Upload + OCR (Загрузить и распознать). Вы найдете эту кнопку в нижней части страницы. Текст, который есть на изображении, будет распознан и отобразится на странице.
-
6
Прокрутите вниз и нажмите Download (Скачать). Эта ссылка находится в нижней левой части страницы над полем с текстом. Раскроется меню.
-
7
Щелкните по Microsoft Word (DOC). Эта опция находится в меню «Скачать». Документ Word скачается на компьютер.
-
8
Откройте скачанный документ в программе Word. Для этого дважды щелкните по нему. Теперь изображение является документом Microsoft Word.
- Возможно, вам придется нажать «Включить редактирование» в верхней части страницы, так как по умолчанию документ может быть заблокирован для редактирования.
-
9
Отредактируйте документ. Преобразованный документ не будет абсолютной копией исходного — скорее всего, вам придется добавить отсутствующие слова, удалить лишние пробелы и исправить опечатки.
Реклама









-
1
Запустите приложение Office Lens. Нажмите на красно-белый значок с камерой и буквой «L».
- Если у вас нет этого приложения, скачайте его на Play Маркете для Android-устройства или в App Store для iPhone.
-
2
Разрешите Office Lens получить доступ к телефону. Если вы впервые запускаете Office Lens, нажмите «Разрешить» или «OK», чтобы приложение получило доступ к файлам телефона.
-
3
Коснитесь Документ. Это вкладка внизу экрана.
-
4
Направьте камеру телефона на документе. Сделайте так, чтобы весь документ, который вы хотите отсканировать, отобразился на экране.
- Убедитесь, что документ хорошо освещен, чтобы запечатлеть как можно больше деталей.
-
5
Нажмите кнопку съемки. Это красный круг в нижней части экрана. Будет сделано фото документа.
-
6
Нажмите
. Этот значок находится в правом нижнем углу экрана.
- Чтобы отсканировать больше страниц, нажмите на символ «+» в нижней части экрана.
-
7
Коснитесь Word. Вы найдете эту опцию в разделе «Сохранить» на странице «Экспортировать в».
- На Android-устройстве коснитесь квадратного значка у «Word», а затем нажмите «Сохранить» в нижней части экрана.
-
8
Войдите в свою учетную запись Microsoft. Если вы еще не авторизовались, введите адрес электронной почты и пароль. Теперь документ Word загрузится в вашу учетную запись OneDrive.
- Это должна быть учетная запись, которую вы используете для входа в Microsoft Word.
-
9
Откройте Word на компьютере. Нажмите на синий значок с белой буквой «W».
-
10
Щелкните по Открыть другие документы. Эта опция находится в левой части раздела «Последние».
- На компьютере Mac просто щелкните по значку папки у «Открыть» в левой части окна.
-
11
Нажмите Персональный OneDrive. Эта опция находится в верхней части окна. Откроется папка OneDrive.
- Если вы не видите опцию «OneDrive», нажмите «+» > «Добавить место» > «OneDrive» и войдите в свою учетную запись Microsoft.
-
12
Перейдите в папку Office Lens. Откройте папку «Документы», а затем щелкните по папке «Office Lens». Они находятся на правой панели окна.
-
13
Дважды щелкните по документу Word, который был создан с помощью приложения «Office Lens».
Реклама














Советы
- Приложение Office Lens лучше работает с текстом на бумаге, чем с текстом на экране.
Реклама
Предупреждения
- Результат распознавания текста сервисом New OCR зависит от качества текста на изображении. Чтобы получить оптимальный результат, отсканируйте документ в PDF-файл, а затем преобразуйте его с помощью программы Word (как описано в первом разделе).
Реклама
Об этой статье
Эту страницу просматривали 341 433 раза.
Была ли эта статья полезной?
![]()
Автор:
Обновлено: 19.04.2018
Представьте себе функцию, позволяющую извлечь текст из изображения и быстро вставить его в другой документ. На самом деле это возможно. Вам больше не нужно терять время, набирая все, потому что есть программы, которые используют оптическое распознавание символов (OCR) для анализа букв и слов в изображении, а затем конвертируют их в текст.
В наши дни существует так много бесплатных и эффективных опций, позволяющих извлечь текст из изображения, а не печатать его вручную. Ниже представлены самые удобные и эффективные программы и их сравнение.

Как распознать текст с картинки в Word
Содержание
- Видео — распознавание текста с картинки в WORD
- Извлечение текста с помощью OneNote
- Использование онлайн-сервисов
- Видео — Как распознавать текст с картинки, фотографии или PDF файла
- Как извлечь текст из изображений с помощью ABBY FineReader
- Онлайн версия
- Десктопная версия
- Видео — Как распознать PDF в Word
- Сравнение популярный инструментов распознавания текста
Видео — распознавание текста с картинки в WORD
Извлечение текста с помощью OneNote
OneNote OCR уже на протяжении нескольких лет остается одной из самых лучших программ для распознавания текста. Однако, распознавание это одна из тех менее известных функций, которые пользователи редко используют, но как только вы начнете ее использовать, вы будете удивлены тем, насколько быстрой и точной она может быть. Действительно, способность извлекать текст — одна из особенностей, которая делает OneNote лучше Evernote.
Это стандартная программа, скорее всего вам не придется устанавливать ее самостоятельно. Найдите ее на компьютере в папке Microsoft Office или же с помощью поиска на панели «Пуск». Запустите программу.
Инструкции по извлечению текста:
- Шаг 1. Откройте любую страницу в OneNote, желательно пустую.

Открываем любую страницу в OneNote
- Шаг 2. Перейдите в меню «Вставка»> «Изображения» и выберите файл изображения и настройте язык распознавания.

Выберите файл изображения
- Шаг 3. Щелкните правой кнопкой мыши по вставленному изображению и выберите «Копировать текст с изображения». Он сохранится в буфере обмена.



Копируем текст с изображения
Теперь вы можете вставить его куда угодно. Удалите вставленное изображение, если оно вам больше не нужно.

Вставляем текст куда угодно
На заметку! Это быстрый и удобный способ извлечения текста из картинки, но есть одно «но» — One Note работает подобным образом лишь с латиницей. Он не распознает русский текст.
Использование онлайн-сервисов
Онлайн-сервисы по распознаванию текста с изображения работают примерно по одному и тому же принципу. В примере ниже использовался Free Online OCR. На этом сайте стоит ограничение. Регистрация даст вам доступ к дополнительным функциям, недоступным для гостей: конвертировать многостраничный PDF (более 15 страниц) в текст, большие изображения и ZIP-архивы, выбирать языки распознавания, конвертировать в редактируемые форматы и многое другое. Распознать короткий тест можно и без регистрации.
- Шаг 1. Откройте сайт бесплатного OCR. Выберите изображение посредством кнопки «Select File». Это может быть и PDF файл.

Открываем сайт бесплатного OCR
- Шаг 2. Выберите язык и нажмите на кнопку «CONVERT».
Выбираем язык и нажимаем на кнопку «CONVERT»


Текст появится в поле ниже. Вы также можете скачать в формате Microsoft Word.
Этот способ имеет ряд преимуществ:
- Вам не придется скачивать и устанавливать стороннее программное обеспечение.
- Итог можно скачать в виде текстового документа.
- Это быстро.
- Более того на сайте можно распознавать текст на одном из множества предложенных языков.
Видео — Как распознавать текст с картинки, фотографии или PDF файла
Как извлечь текст из изображений с помощью ABBY FineReader
Существует две версии этой программы. Одна работает в автоматическом режиме онлайн, другая же — десктопная, ее придется скачать и установить на компьютер. Обе — платные. Однако в онлайн-версии можно бесплатно распознать текст с не более 5 страниц, а в установленной программе первое время действует пробный бесплатный период. На сегодня это один из лучших инструментов для распознавания текста с картинки.
Онлайн версия
- Шаг 1. Перейдите на сайт FineReader.

Открываем сайт FineReader
- Шаг 2. Загрузите изображение. Выберите нужный вам язык и нажмите на кнопку регистрации. Следуйте указаниям на сайте. Как только вы зарегистрируетесь, сайт перенаправит вас на другую страницу. Нажмите на кнопку «Распознать» и дождитесь окончания процесса.


Загружаем файл, выбираем язык, выбираем формат сохранения
Текст сохранится в формате docs. Скачайте его.
Десктопная версия
- Шаг 1. Запустите FreeReader и нажмите «Сканировать изображение», чтобы выбрать файл, содержащий текст. Он загрузится в программу, при необходимости их можно отредактировать, чтобы улучшить распознаваемость текста. Программа предложит вам выделить область, текст с которой нужно распознать.
- Шаг 2. Извлечение текста. Нажмите «Распознать», чтобы извлечь текст из выделения. Выбранный текст будет отображаться в текстовом окне через несколько секунд.

Извлекаем текст

Шаг 3. Проверка. В этой программе есть функция проверки. Нажав на эту кнопку, пользователь на экране будет видеть некорректно распознанные слова и фрагмент оригинала. На этом этапе можно быстро исправить практически все ошибки программы.
Шаг 4. Сохраните текст любым из предложенных способов.

Сохраняем текст
Обратите внимание:
- Во-первых, вам нужно убедиться, что исходное изображение четкое, хорошего качества.
- Во-вторых, выбор правильного механизма OCR важен, и вам нужно учитывать их сильные и слабые стороны.
- В-третьих, убедитесь, что ваши изображения масштабированы до нужного размера (не менее 300 DPI).
- Низкая контрастность приведет к плохому OCR, поэтому вам необходимо исправить это до распознавания.
- Удалите шумы и дефекты.
- Если изображение перекошено, отредактируйте его.
Видео — Как распознать PDF в Word
Сравнение популярный инструментов распознавания текста
| Название программы | OneNote | FineReader OCR Online | Free Online OCR |
|---|---|---|---|
| Условия использования | Стандартная программа, входящая в пакет Microsoft Office. Как правило, присутствует на всех компьютерах ОС Windows | Онлайн версия программы. До 5 страниц бесплатно при регистрации | Бесплатный онлайн-сервис. Не требует регистрации |
| Скорость | Мгновенное распознавание | Процесс происходит на сервере. Время ожидания не больше 5 минут | Мгновенное распознавание |
| Особенности | Это не главная функция программы, а лишь побочная. Хоть она и достаточно хороша, не ждите от нее совершенства | Сокращенная версия основной программы. В полной компьютерной версии намного больше опций, повышающих качество распознавания. Доступно распознавание теста сразу на нескольких языках, если в тексте есть вставки на другом языке. Сохраняет форматирование |
Скорость. Доступность |
| Число доступных языков | В русскоязычной версии программы доступно три языка: русский, английский, немецкий | Множество языков | Множество языков |
| Результат |  |
 |
 |
Хотя рынок заполнен программным обеспечением OCR, которое может извлекать текст из изображений, хорошая программа OCR должна делать больше, чем просто распознавание текста. Она должна поддерживать макет содержимого, текстовые шрифты и графику как в исходном документе.
Рекомендуем похожие статьи
![]()
Download Article
Convert a scan into a Word document with this easy-to-use guide
![]()
Download Article
- Opening PDF in Word
- Scanning With & Using Microsoft Lens
- Q&A
- Tips
|
|
|
Do you want to edit that PDF in Word? You can open the PDF using Word’s built-in settings or, If you have a Microsoft account and a smartphone, you can also use the free Microsoft Lens app to scan your document and save it as a Word file in your OneDrive cloud storage. This wikiHow teaches you how to convert a scanned document into an editable Word document on your Windows PC, Mac, or smartphone.
Things You Should Know
- If you have a PDF on your computer, you can open it within Word by going to «File > Open > OK.»
- Use the Microsoft Lens app from your Android, iPhone, or iPad to scan documents and open them in Word.
- If the doc you scanned is not PDF format, convert it first to be able to open it in Word.
-
1
Open Word. You can only do this in newer versions of Word (including anything newer than Word 2010). If you have Word 2010 or older, those are no longer supported versions, and importing a PDF into Word isn’t possible.
- Make sure the document you have is in PDF format.
- Opening a PDF in Word works best if the PDF is mostly text.
-
2
Click File and Open. The File tab is either at the top of your screen (Macs) or right above your document space (Windows).
- Doing this will open your file manager.
Advertisement
-
3
Double-click your PDF. Double-clicking the file once you find it will open it.
-
4
Click OK. Word will begin converting the scanned PDF into a Word document.
- This process can take several minutes if your PDF has lots of text or images.[1]
- This process can take several minutes if your PDF has lots of text or images.[1]
-
5
Clean up your document. Converting scanned files into Word documents isn’t an exact science; you may have to add missing words, remove excess spaces, and fix typos before your Word document is ready to go.
-
6
Save the document. Once you’re ready to save the converted document as its own Word file, do the following:
- Windows — Press Ctrl+S, then enter a file name, select a save location, and click Save.
- Mac — Press ⌘ Command+S, then enter a file name, select a save location from the «Where» drop-down box, and click Save.






Advertisement
-
1
Open Microsoft Lens. Tap the Microsoft Lens app icon, which resembles a red and white app with a camera iris and the letter «L» in the center of the icon.
- Microsoft Lens is a free smartphone app that allows you to take pictures of documents and turn them into PDFs. This will be super useful if you have a piece of paper that you want to edit in Word. In that case, you can take a picture of the paper, turn it into a PDF, and open it in Word.
- If you don’t have Microsoft Lens installed, you can download it from the Google Play Store for Android or from the App Store on iPhone.
-
2
Allow Microsoft Lens access to your phone. If this is your first time opening Microsoft Lens, tap Allow or OK when prompted to allow Microsoft Lens to access your phone’s files.
-
3
Tap DOCUMENT. It’s a tab at the bottom of the screen.
-
4
Point your phone’s camera at a document. Position the document that you want to scan inside the camera’s view.
- Make sure your document is well-lit and positioned on a dark background so the camera can pick up as much detail as possible.
-
5
Tap the «Capture» button. It’s a red circle at the bottom of the screen. This will take a photo of the document’s page.
- Tap Confirm if the capture is ok. Tap Retake if the document wasn’t captured correctly.
-
6
Tap Done. It’s in the bottom-right corner of the screen.
- You can scan more pages by tapping the camera with the plus icon in the bottom left corner of your screen.
-
7
Tap Word. You’ll find this option in the «SAVE TO» section.
- On Android, tap the box next to Word and then tap SAVE at the bottom of the screen[2]
.
- On Android, tap the box next to Word and then tap SAVE at the bottom of the screen[2]
-
8
Sign into your Microsoft account. If you haven’t already, enter your Microsoft account email address and password. Once signed in, your Word document will be uploaded to your OneDrive account.
- This must be the account that you use to log into Microsoft Word as well.
- You’re done using your phone.
-
9
Open Word on your computer. It’s the blue app with a white document and the letter «W» in the icon.
-
10
Click Open. It’s on the left side of the window below the «New» section.
- On Mac, simply click the folder icon that says Open on the left-hand side of the window.
-
11
Click OneDrive — Personal. It’s in the menu on the left side of the window and will prompt your OneDrive to open on the right side of the window.
- If you don’t see the OneDrive option, click + Add a Place, then click OneDrive and sign in with your Microsoft account.
-
12
Go to the Microsoft Lens folder. Click on the «Documents» folder, then click the «Microsoft/Office Lens» folder. This is on the right pane of the window.
-
13
Double-click your Word document. This opens the document you scanned using Microsoft Lens on your phone or tablet in Microsoft Word.













Advertisement
Add New Question
-
Question
Does anything here cost money? Is there any chance of getting a virus on my computer while downloading these things?

Some cost money, some don’t. The free ones run a risk of infection, but you should have an anti-virus program installed anyway.
-
Question
I followed the instructions for enabling document imaging in Word 2007, but did not find the imaging program listed under Microsoft Office Tools, then what went wrong, and how can I do it correctly?
Microsoft (for some reason) didn’t enable document imaging in Word 2007 for 64-bit computers.
-
Question
Will everything I scan become editable?
Indeed, it will. Just follow these simple steps: Go to onlineocr.net or if your file is more than 5mb, use you can use pdf2doc.com. Upload your file to these websites. When the file get uploaded, select doc or docx format and click ‘Convert’. It is a time-consuming process, especially if your file size is big. The moment it completes the conversion, click download the file. After downloading the file, go to your downloads and open the file which will automatically in MS Word. Now here you can edit your file and use it your way.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
-
Office Lens will handle physical files (e.g., paper documents) better than on-screen text.
-
If the scanned document is a JPEG or something else, convert it first.
Thanks for submitting a tip for review!
Advertisement
About This Article
Thanks to all authors for creating a page that has been read 2,552,808 times.
Is this article up to date?
Дополнительные настройки
Метод OCR
Исходный язык файла
Чтобы получить оптимальный результат, выберите все языки, которые есть в файле.
Улучшить OCR
Применить фильтр:
Конвертер DOCX
Преобразование из PDF в DOCX или из результатов сканирования в DOCX. PDF — очень удобный формат, но его сложно редактировать. Упростите извлечение цитат, редактирование текста или его повторное использование!
 Добрый день.
Добрый день.
Наверное, каждый из нас сталкивался с задачей, когда нужно перевести бумажный документ в электронный вид. Особенно это часто нужно делать тем кто учиться, работает с документацией, переводит тексты при помощи электронных словарей и т.д.
В этой статье мне хотелось бы поделиться некоторыми азами этого процесса. Вообще, сканирование и распознавание текста — довольно трудоемко, так, как большинство операций придется делать вручную. Мы попытаемся разобраться по шагам, что, как и почему.
Не все сразу понимают одну вещь. После сканирования (пригона всех листов на сканере) у вас будут картинки формата BMP, JPG, PNG, GIF (могут быть и другие форматы). Так вот с этой картинки нужно получить текст — это процедура называется распознаванием. В таком порядке и будет изложение ниже.
1. Что нужно для сканирования и распознавания?
1) Сканер
Для перевода печатных документов в текстовый вид, вам для начала нужен сканер и соответственно, «родные» программы и драйверы, которые с ним шли. При помощи них можно будет сканировать документ и сохранить его для дальнейшей обработки.
Можно воспользоваться и другими аналогами, но софт, который шел со сканером в комплекте, обычно работает быстрее и имеет больше опций.
В зависимости от того, какой у вас сканер — скорость работы может существенно различаться. Есть сканеры, которые могут получить картинку с листа за 10 сек., есть которые будут получать за 30 сек. Если сканируете книгу на 200-300 листов — думаю, не трудно подсчитать во сколько раз будет разница во времени?
2) Программа для распознавания
В нашей статье я буду показывать вам работу в одной из лучших программ для сканирования и распознавания абсолютно любых документов — ABBYY FineReader. Т.к. программа платная, то сразу дам ссылку и на другую — ее бесплатный аналог Cunei Form. Правда, я бы не стал их сравнивать, ввиду того, что FineReader выигрывает по всем параметрам, рекомендую все же попробовать именно ее.

ABBYY FineReader 11
Официальный сайт: http://www.abbyy.ru/
Одна из лучших программ в своем роде. Она предназначена для того, чтобы распознать текст на картинке. Встроено множество опций и функций. Может разобрать кучу шрифтов, поддерживает даже рукописные варианты (правда, лично не пробовал, думаю, хорошо вряд ли будет распознавать рукописный вариант, если только у вас не идеальный каллиграфический почерк). Более подробно о работе с ней будет рассказано ниже. Здесь же отметим, что в статье будет рассказано о работе в программе 11 версии.
Как правило, разные версии ABBYY FineReader не сильно отличаются друг от друга. Вы без труда сделаете то же самое и в другой. Главные отличия могут быть в удобстве, быстроте работы программы и ее возможностях. Например, более ранние версии отказываются открывать документ PDF и DJVU…
3) Документы для сканирования
Да, вот так вот, решил вынести документы отдельной графой. В большинстве случаев сканируют какие-нибудь учебники, газеты, статьи, журналы и пр. Т.е. те книги и ту литературу которая пользуется спросом. Я это к чему веду? Из личного опыта могу сказать, что многое, что вы захотите сканировать — возможно уже есть в сети! Сколько раз лично я экономил время, когда находил ту или иную книгу уже сканированную в сети. Мне оставалось только скопировать текст в документ и продолжить с ним работу.
Из этого простой совет — прежде чем что-то сканировать, проверьте, может уже кто-то отсканировал и вам не нужно терять свое время.
2. Параметры сканирования текста
Здесь я не будут рассказывать о ваших драйверах для сканера, программах, которые вместе с ним шли, ибо все модели сканеров разные, ПО тоже везде разное и угадать и тем более показать наглядно как выполнять операцию — нереально.
Но во всех сканерах есть одни и те же настройки, которые сильно могут повлиять на скорость и качество вашей работы. Вот о них таки как раз и поговорим здесь. Буду перечислять по порядку.
1) Качество сканирования — DPI
Во-первых, качество сканирования поставьте в опциях не ниже 300 DPI. Желательно даже выставить побольше, если это возможно. Чем выше показатель DPI — тем четче получиться ваша картинка, ну и тем самым, быстрее пройдет дальнейшая обработка. К тому же чем выше качество сканирования — тем меньше ошибок вам в последствии придется исправлять.
Оптимальный вариант обеспечивает, обычно, 300-400 DPI.
2) Цветность
Этот параметр очень сильно влияет на время сканирования (кстати, DPI тоже влияет, но те так сильно, и только когда пользователь ставит высокие значения).
Обычно выделяют три режима:
— черно-белый (отлично подойдет для простого текста);
— серый ( подойдет для текста с таблицами и картинками);
— цветной (для цветных журналов, книг, в общем, документов, где важна цветность).
Обычно от выбора цветности зависит время сканирования. Ведь если документ у вас большой, то даже лишние 5-10 секунд на странице в целом выльются в приличное время…
3) Фотографии
Документ вы можете получить не только сканированием, но и сфотографировав его. Как правило, в этом случае у вас будут некоторые другие проблемы: искажение картинки, смазанность. Из-за этого может потребоваться более длительная дальнейшая правка и обработка полученного текста. Лично я не рекомендую пользоваться фотоаппаратами для этого дела.
Важно отметить, что не каждый такой документ получится распознать, т.к. качество сканирования у него может быть крайне низким…
3. Распознавание текста документа
Будем считать, что заветные сканированные страницы вы получили. Чаще всего они представляют собой форматы: tif, bmb, jpg, png. В общем-то, для ABBYY FineReader — это не сильно важно…
После открытия в ABBYY FineReader картинки, программа, как правило, на автомате начинает выделять области и распознавать их. Но иногда она делает это не правильно. Для этого-то мы и рассмотрим выделение нужных областей вручную.
Важно! Не все сразу понимают, что после открытия документа в программе, слева в окне отображается исходный документ, в котором вы и выделяете различные области. После нажатия на кнопку «распознавания» программа в окне справа выведет вам готовый текст. После распознавания, кстати, целесообразно проверить текст на ошибки в том же самом FineReader.
3.1 Текст
Эта область используется для выделения текста. Картинки и таблицы нужно исключать из нее. Редкие и необычный шрифты придется вводить вручную…
Для выделения текстовой области, обратите внимание на панель в верхней части FineReader. Там есть кнопка «Т» (см. скриншот ниже, указатель мышки как раз на этой кнопке). Щелкаете по ней, затем на картинке ниже выделяете аккуратно прямоугольную область, в которой располагается текст. Кстати, в некоторых случаях нужно создавать текстовых блоков по 2-3, а иногда по 10-12 на страницу, т.к. форматирование текста может быть разным и одним прямоугольником всю область не выделить.
Важно отметить, что в текстовую область не должны попадать картинки! В дальнейшем это вам сэкономит кучу времени…
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-07-33](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-07-33.jpg)
3.2 Картинки
Используется для выделения картинок и тех областей, которые тяжело распознать из-за плохого качества, или необычности шрифта.
На скриншоте ниже указатель мышки находится на кнопке, используемой для выделения области «картинка». Кстати, в эту область можно выделить абсолютно любую часть страницы, а FineReader вставит ее потом в документ как обычную картинку. Т.е. просто «тупо» скопирует…
Обычно эту область используют для выделения плохо отсканированных таблиц, для выделения нестандартного текста и шрифта, само-собой картинок.
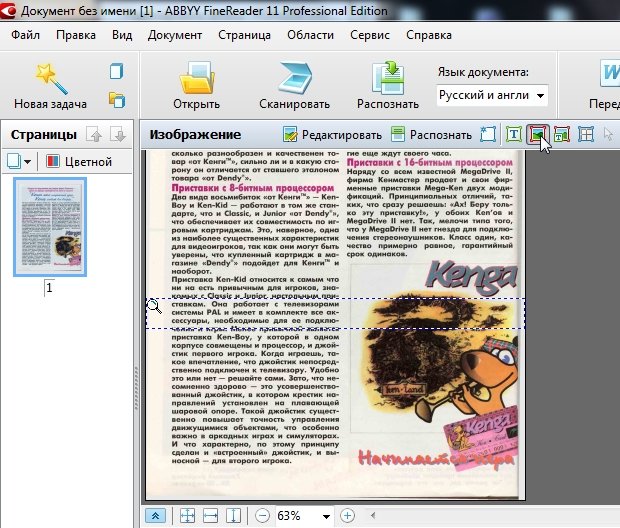
3.3 Таблицы
На скриншоте ниже показана кнопка для выделения таблиц. Вообще, лично я ее использую крайне редко. Дело в том, что вам придется довольно рутинно рисовать (фактически) каждую линию на таблице и показывать что и как программе. Если таблица небольшая и в не очень хорошем качестве, я рекомендую для этих целей использовать область «картинка». Тем самым сэкономите кучу времени, а таблицу можно потом в Word сделать быстренько на основе картинки.
![]()
3.4 Ненужные элементы
Важно отметить. Иногда на странице есть ненужные элементы, которые мешают распознать текст, или вообще не дают вам выделить нужную область. Их можно при помощи «ластика» удалить вовсе.
Для этого переходим в режим редактирования изображения.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-14-11](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-14-11.jpg)
Выбираем инструмент «ластик» и выделяем ненужную область. Она сотрется и на ее месте будет белый лист бумаги.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-14-21](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-14-21.jpg)
Кстати, рекомендую использовать вам эту опцию как можно чаще. Старайтесь все текстовые области которые вы выделили, где вам не нужен кусок текста, или присутствуют любые ненужные точки, размытости, искажения — удалять ластиком. Благодаря этому распознавание будет быстрее!
4. Распознавание файлов PDF/DJVU
Вообще, этот формат распознавания не будет отличаться ничем другим от остальных — т.е. работать с ним можно так же как с картинками. Единственное, программа не должна быть слишком старой версии, если файлы PDF/DJVU у вас не открываются — обновите версию до 11.
Небольшой совет. После открытия документа в FineReader — он автоматически начнет распознавать документ. Часто в файлах PDF/DJVU определенная область страницы не нужна во всем документе! Чтобы удалить такую область на всех страницах сделайте следующее:
1. Зайдите в раздел редактирования изображения.
2. Включите опция «обрезки».
3. Выделите область, нужную вам на всех страницах.
4. Нажмите применить ко всем страницам и обрежьте.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-19-21](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-19-21.jpg)
5. Проверка ошибок и сохранение результатов работы
Казалось бы, какие еще могут быть проблемы, когда все области были выделены, затем распознаны — бери да сохраняй… Не тут то было!
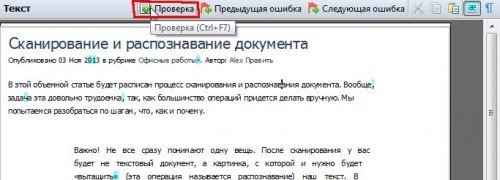
Во-первых, нужна проверка документа!
Чтобы ее включить, после распознавания, в окне справа, будет кнопка «проверка», см. скриншот ниже. После ее нажатия программа FineReader будет автоматически показывать вам те области, где у программы возникли ошибки и она не смогла достоверно определить тот или иной символ. Вам останется только выбирать, либо вы согласны с мнением программы, либо вводите свой символ.
Кстати, в половине случаев, примерно, программа будет вам предлагать готовое правильное слово — вам останется толкьо мышкой выбрать нужный вариант.
Во-вторых, после проверки вам нужно выбрать формат, в который вы сохраните результат своей работы.
Здесь FineReader дает вам развернуться на полную катушку: можно просто передать информацию в Word один в один, а можно сохранить ее в одном из десятков форматов. Но хотелось бы выделить другой важный аспект. Какой формат бы не выбрали, более важно выбрать тип копии! Рассмотрим самые интересные варианты…
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-24-08](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-24-08.jpg)
Точная копия
Все области, которые вы выделяли на странице в распознанном документе будут соответствовать точь в точь исходному документу. Очень удобный вариант, когда вам важно не потерять форматирование текста. Кстати, шрифты так же будут очень похожи на оригинал. Рекомендую при таком варианте передавать документ в Word, чтобы уже там продолжить дальнейшую работу.
Редактируемая копия
Этот вариант хорош тем, что вы получите уже форматированный вариант текста. Т.е. отступов с «километр», которые возможно были в исходном документе — вы не встретите. Полезная опция, когда вы будете значительно редактировать информацию.
Правда, не стоит выбирать, если вам важно сохранить стилистику оформления, шрифты, отступы. Иногда, если распознавание прошло не очень успешно — ваш документ может «перекосить» из-за измененного форматирования. В этом случае целесообразно выбрать точную копию.
Простой текст
Вариант для тех, кому нужен просто текст со странице без всего остального. Подойдет для документов без картинок и таблиц.
На этом статья по сканированию и распознаванию документа подошла к концу. Надеюсь, что при помощи этих простых советов вы сможете решить свои задачи…
Удачи!
- Распечатать
Оцените статью:
- 5
- 4
- 3
- 2
- 1
(12 голосов, среднее: 3.3 из 5)
Поделитесь с друзьями!
OCR РАСПОЗНАВАНИЕ ТЕКСТА ИЗ PDF И ИЗОБРАЖЕНИЙ
Выбрать языки источника
Перетащите документ в эту область
(Поддерживаемые форматы: PDF, BMP, GIF, JPG, JPEG, TIFF, PNG)
Как работает наш OCR сервис
Вы когда-нибудь хотели иметь возможность найти в печатном цифровом материале или отсканированном документе конкретный текст? Или возникла ли у вас необходимость отредактировать содержимое журнала или отсканированного PDF-документа, не перепечатывая весь документ?
Классическим решением во всех этих случаях было бы перенабрать весь контент и его отредактировать. Это все еще нормальная практика, когда дело доходит до редактирования печатных контрактов, брошюр или страниц журнала. Но мы все знаем, насколько трудоемким и беспокойным может стать это решение, если источник представляет собой обыкновенное изображение. Бесплатный OCR сервис — это то, что может решить вашу проблему, сэкономить деньги, сэкономить ваше драгоценное время и обеспечить быстрые и эффективные результаты всего за несколько шагов.
С помощью нашего сервиса вы можете преобразовать документы в формате Microsoft Word в формат PDF. Также, в любое время вы можете выполнить преобразование PDF в Word. Если необъодимо сконвертировать книгу в формате DJVU, воспользуйтесь этой ссылкой Djvu в PDF. Наш сервис также позволяет конвертировать изображения в pdf. Чтобы получить PDF из электронной книги ePub или документа Fb2, воспользуйтесь ссылкой ePub в PDF. Дополнительно разделение или объединение PDF можно выполнить на соответствующих страницах: Разделить PDF и Склеить PDF.
Что такое OCR
Оптическое распознавание символов или OCR — это технология, позволяющая преобразовывать печатные или рукописные документы в редактируемые текстовый материал. Просто отсканировав напечатанные документы с помощью программного обеспечения для распознавания текста OCR, вы можете легко конвертировать файлы в печатные копии, которые можно редактировать, копировать или распространять согласно вашим требованиям. Сканеры текста OCR очень универсальны и могут сканировать текст из изображений, печатных документов и файлов PDF. Программное обеспечение OCR можно загрузить или использовать в качестве онлайн-сервисов.
Как работает OCR
Хотя понятие «машинного распознавания текста» не ново и появилось еще в 1960-х годах, в то время компьютер мог считать единственный вариант шрифта, называемый OCR-A. С развитием технологии сканеры текста OCR стали более продвинутыми и позволили пользователям использовать эту технологию для более широкого спектра приложений. В настоящее время текстовые сканеры OCR в основном используют два различных метода для преобразования печатного текста в редактируемый.
-
Метод сопоставления матриц
Первый метод — это метод сопоставления матриц. Этот метод работает по принципу сопоставления печатного текста с базой данных шаблонов символов и шрифтов. Сканер текста OCR сканирует напечатанный текст, сравнивает его с существующей библиотекой шаблонов и, когда совпадение найдено, преобразует данные в соответствующий код ASCII. Затем вы можете манипулировать этими данными в соответствии с вашими требованиями. Этот метод быстро возвращает результаты, но из-за ограниченной базы данных символов метод сопоставления матриц имеет свои ограничения. Алгоритм завершается ошибкой, когда он пытается распознать текст, которого нет в его базе данных, и выводит неверный текст. Следовательно, пользователи должны сохранять бдительность при использовании этого метода, поскольку он может генерировать ошибки, которые необходимо будет впоследствии исправить вручную.
-
Метод извлечения особенностей
Другой метод, используемый программным обеспечением OCR, — это метод извлечения признаков текста. Этот метод основан на искусственном интеллекте, где онлайн программное обеспечение OCR предназначено для определения общих точек в форме букв, таких как искривления, наклоны и пробелы в алфавите. Сканеры текста OCR ищут эти общие точки в тексте и возвращают результаты в коде символов ASCII после того, как найден определенный процент «совпадения».
Следовательно, этот метод ищет повторяющиеся шаблоны или правила, которые представляют букву, и программное обеспечение может предсказать букву, просто просматривая общие точки, найденные в шаблоне. Метод является более гибким и может работать с большим количеством печатных или рукописных документов.Кроме того, искусственный интеллект постоянно обновляет свои знания о различных почерках и шрифтах, что делает его более универсальным в использовании и оставляет возможности дальнейших улучшений и модернизаций алгоритма.
-
OCR онлайн сервисы
Самый простой способ сконвертировать распечатанные файлы в редактируемую версию — использование онлайн-сервисов OCR, в том числе нашим сервисом. Использовать онлайн-сервисы OCR чрезвычайно просто, поскольку вам нужно только отсканировать документ, загрузить его, и файл будет преобразован в редактируемую версию. Бесплатный сервис OCR — это отличная возможность для бизнеса сэкономить своё драгоценное время и деньги.
Есть несколько преимуществ использования бесплатных услуг OCR онлайн сервисов. Эти преимущества включают в себя:
- Время, затрачиваемое на весь процесс, значительно сокращается, и большие документы можно подготовить всего за несколько минут. Редактировать контракты, страницы журналов и брошюры теперь стало очень просто.
- Упрощение процесса извлечения данных из сложных документов.
- Снижение вероятности человеческой ошибки, связанной с методом чтения и перепечатывания.
- Устранение трудозатрат в часах, необходимых для затратного процесса ввода данных.
- Сканеры текста OCR являются сложными и могут также распознавать сложные почерки, которые могут занять время, чтобы человеческий глаз мог их прочитать и обработать.
Благодаря более быстрому циклу обработки и современным сканерам распознавания текста, эта технология может сэкономить достаточно значительное количество времени и средств для пользователей, которые смогут распорядиться своим временем более эффективно.
Преимущества нашего OCR сервиса
Широкий набор исходных форматов
Отсканированные PDF документы и различные форматы изображений
Нет ограничений
Как большие многостраничные книги, так и небольшие изображения
Ресурсы клиента
Всё распознавание выполняется на наших серверах