
Содержание
- Парсер таблиц Excel
- Статья Парсим данные таблиц сайта в Excel с помощью Pandas
- Парсинг файлов Excel
- Парсер поддерживает следующие типы файлов Excel:
- Для сбора данных из файлов Excel применяется стандартный алгоритм парсера файлов, но есть и некоторые нюансы:
- Парсинг нетабличных данных с сайтов
- Проблема с нетабличными данными
- Загружаем HTML-код вместо веб-страницы
- Ищем за что зацепиться
- Фильтруем нужные данные
- Чистим мусор
- Разбираем блоки по столбцам
Парсер таблиц Excel

Обработать все файлы Excel в заданной папке, и извлечь информацию из определенных ячеек.
Искать в файлах данные не привязываясь к адресам ячеек (структура файлов немного отличается, часть данных смещена)
Этот парсер опубликован как пример использования парсера для обработки файлов, в частности, для парсинга таблиц Excel.
В качестве основы был использован парсер для перебора всех файлов в папке, но с незначительным отличием: если при парсинге файлов других типов (текстовых / Word / PDF) нам достаточно только считать данные из файла (файл временно открывается, данные считываются, и файл сразу закрывается), то при загрузке данных из файлов Excel, обрабатываемый файл должен быть открыт всё то время, пока из него считываются данные в разные столбцы.
Подробнее об этом — в инструкции по парсингу файлов Excel
Для извлечения данных с листа используется многофункциональное действие «Поиск ячеек на листе».
Оно позволяет найти на листе нужные ячейки, ориентируясь на значения соседних ячеек (например, найти на листе ячейку с заданным текстом, отступить от неё вниз/вправо/влево/вверх на заданное количество строк/столбцов, и из этой ячейки считать значение / ссылку / примечание)
Поскольку некоторые из обрабатываемых файлов могут отличаться по структуре (присутствует первый пустой столбец), необходима дополнительная коррекция файла перед обработкой (при условии, что в первом столбце меньше 5 заполненных ячеек, надо значения ячеек первого столбца перенести во второй столбец, а первый столбец листа целиком удалить). Это тоже можно сделать парсером, — в настройках этого парсера присутствует набор действий «Коррекция файла», содержащий 5 команд:
| Действие | Параметр | Значение |
|---|---|---|
| Поиск ячеек на листе | Адрес ячейки / диапазона для поиска | a1:a15 |
| Маска поиска | ?* | |
| Смещение от найденного | 0;0 | |
| Действие для целевой ячейки | GetValue | |
| Задаваемое значение | ||
| Маска найденного значения | * | |
| Заменять пустые значения на | ||
| Количество элементов массива | Сохранить результат в переменную | |
| Использовать новое значение | да | |
| Проверка на выполнение условия | Режим проверки | больше |
| Значение для сравнения | 5 | |
| Действие при выполнении условия | Новое значение, и остановить | |
| Параметр действия | Коррекция не требуется (первый столбец не пустой) | |
| Проверять другое значение | нет | |
| Другое проверяемое значение | ||
| Поиск ячеек на листе | Адрес ячейки / диапазона для поиска | a:a |
| Маска поиска | ?* | |
| Смещение от найденного | 0;1 | |
| Действие для целевой ячейки | SetValue | |
| Задаваемое значение | ||
| Маска найденного значения | * | |
| Заменять пустые значения на | ||
| Действия со столбцами | Столбцы | 1 |
| Действие для выбранных столбцов | Удалить | |
| Параметр действия |
Статья является примером использования программы «Парсер сайтов и файлов» для решения нижеописанной задачи.
Источник
Статья Парсим данные таблиц сайта в Excel с помощью Pandas
Парсинг данных. Эта штука может быть настолько увлекательной, что порой затягивает очень сильно. Ведь всегда интересно найти способ, с помощью которого можно получить те или иные данные, да еще и структурировать их в нужном виде. В статье «Простой пример работы с Excel в Python» уже был рассмотрен один из способов получить данные из таблиц и сохранить их в формате Excel на разных листах. Для этого мы искали на странице все теги, которые так или иначе входят в содержимое таблицы и вытаскивали из них данные. Но, есть способ немного проще. И, давайте, о нем поговорим.

А состоит этот способ в использовании библиотеки pandas. Конечно же, ее простой не назовешь. Это очень мощный инструмент для аналитики самых разнообразных данных. И в рассмотренном ниже случае мы лишь коснемся небольшого фрагмента из того, что вообще умеет делать эта библиотека.
Для того, чтобы написать данный скрипт нам понадобиться конечно же сам pandas. Библиотеки requests, BeautifulSoup и lxml. А также модуль для записи файлов в формате xlsx – xlsxwriter. Установить их все можно одной командой:
pip install requests bs4 lxml pandas xlsxwriter
А после установки импортировать в скрипт для дальнейшей работы с функциями, которые они предоставляют:
Так же с сайта, на котором расположены целевые таблицы нужно взять заголовки для запроса. Данные заголовки не нужны для pandas, но нужны для requests. Зачем вообще использовать в данном случае запросы? Тут все просто. Можно и не использовать вовсе. А полученные таблицы при сохранении называть какими-нибудь составными именами, вроде «Таблица 1» и так далее, но гораздо лучше и понятнее, все же собрать данные о том, как называется данная таблица в оригинале. Поэтому, с помощью запросов и библиотеки BeautifulSoup мы просто будем искать название таблицы.
Но, вернемся к заголовкам. Взял я их в инструментах разработчика на вкладке сеть у первого попавшегося запроса.
Теперь нужен список, в котором будут перечисляться года, которые представлены в виде таблиц на сайте. Эти года получаются из псевдовыпадающего списка. Я не стал использовать selenium для того, чтобы получить их со страницы. Так как обычный запрос не может забрать эти данные. Они подгружаются с помощью JS скриптов. В данном случае не так уж много данных, которые надо обработать руками. Поэтому я создал список, в которые эти данные и внес вручную:
Теперь нам нужно будет создать пустой словарь вне всяких циклов. Именно, чтобы он был глобальной переменной. Этот словарь мы и будем наполнять полученными данными, а также сохранять их него данные в таблицу Excel. Поэтому, я подумал, что проще сделать его глобальной переменной, чем тасовать из функции в функцию.
Назвал я его df, потому как все так называют. И увидев данное название в нужном контексте становиться понятно, что используется pandas. df – это сокращение от DataFrame, то есть, определенный набор данных.
Ну вот, предварительная подготовка закончена. Самое время получать данные. Давайте для начала сходим на одну страницу с таблицей и попробуем получить оттуда данные с помощью pandas.
Здесь была использована функция read_html. Pandas использует библиотеку для парсинга lxml. То есть, примерно это все работает так. Получаются данные со страницы, а затем в коде выполняется поиск с целью найти все таблицы, у которых есть тэг , а далее, внутри таблиц ищутся заголовки и данные под тэгами и , которые и возвращаются в виде списка формата DataFrame.
Давайте выполним запрос. Но вот печатать данные пока не будем. Нужно для начала понять, сколько таблиц нашлось в запросе. Так как на странице их может быть несколько. Помимо той, что на виду, в виде таблиц может быть оформлен подзаголовок или еще какая информация. Поэтому, давайте узнаем, сколько элементов списка содержится в запросе, а соответственно, столько и таблиц. Выполняем:
И видим, что найденных таблиц две. Если вывести по очереди элементы списка, то мы увидим, что нужная нам таблица, в данном случае, находиться под индексом 1. Вот ее и распечатаем для просмотра:
И вот она полученная таблица:
Как видим, в данной таблице помимо нужных нам данных, содержится так же лишний столбец, от которого желательно избавиться. Это, скажем так, можно назвать сопутствующим мусором. Поэтому, полученные данные иногда надо «причесать». Давайте вызовем метод drop и удалим ненужный нам столбец.
tables[1].drop(‘Unnamed: 0’, axis=1, inplace=True)
На то, что нужно удалить столбец указывает параметр axis, который равен 1. Если бы нужно было удалить строку, он был бы равен 0. Ну и указываем название столбца, который нужно удалить. Параметр inplace в значении True указывает на то, что удалить столбец нужно будет в исходных данных, а не возвращать нам их копию с удаленным столбцом.
А теперь нужно получить заголовок таблицы. Поэтому, делаем запрос к странице, получаем ее содержимое и отправляем для распарсивания в BeautifulSoup. После чего выполняем поиск названия и обрезаем из него все лишние данные.
Теперь, когда у нас есть таблица и ее название, отправим полученные значения в ранее созданный глобально словарь.
Вот и все. Мы получили данные по одной таблице. Но, не будем забывать, что их больше тридцати. А потому, нужен цикл, чтобы формировать ссылки из созданного ранее списка и делать запросы уже к страницам по ссылке. Давайте полностью оформим код функции. Назовем мы ее, к примеру, get_pd_table(). Ее полный код состоит из всех тех элементов кода, которые мы рассмотрели выше, плюс они запущены в цикле.
Итак, когда цикл пробежится по всем ссылкам у нас будет готовый словарь с данными турниров, которые желательно бы записать на отдельные листы. На каждом листе по таблице. Давайте сразу создадим для этого функцию pd_save().
writer = pd.ExcelWriter(‘./Турнирная таблица ПЛ РФ.xlsx’, engine=’xlsxwriter’)
Создаем объект писателя, в котором указываем имя записываемой книги, и инструмент, с помощью которого будем производить запись в параметре engine=’xlsxwriter’.
После запускаем цикл, в котором создаем объекты, то есть листы для записи из ключей списка с таблицами df, указываем, с помощью какого инструмента будет производиться запись, на какой лист. Имя листа берется из ключа словаря. А также указывается параметр index=False, чтобы не сохранялись индексы автоматически присваиваемые pandas.
df[df_name].to_excel(writer, sheet_name=df_name, index=False)
Ну и после всего сохраняем книгу:
Полный код функции сохранения значений:
Вот и все. Для того, чтобы было не скучно ждать, пока будет произведен парсинг таблиц, добавим принты с информацией о получаемой таблице в первую функцию.
print(f’Получаю данные из таблицы: ««. ‘)
И во вторую функцию, с сообщением о том, данные на какой лист записываются в данный момент.
print(f’Записываем данные в лист: ‘)
Ну, а дальше идет функция main, в которой и вызываются вышеприведенные функции. Все остальное, в виде принтов, это просто декорации, для того чтобы пользователь видел, что происходят какие-то процессы.
И ниже результат работы скрипта с уже полученными и записанными таблицами:
Как видите, использовать библиотеку pandas, по крайней мере в данном контексте, не очень сложно. Конечно же, это только самая малая часть того, что она умеет. А умеет она собирать и анализировать данные из самых разных форматов, включая такие распространенные, как: cvs, txt, HTML, XML, xlsx.
Ну и думаю, что не всегда данные будут прилетать «чистыми». Скорее всего, периодически будут попадаться мусорные столбцы или строки. Но их не особо то трудно удалить. Нужно только понимать, что и откуда.
В общем, для себя я сделал однозначный вывод – если мне понадобиться парсить табличные значения, то лучше, чем использование pandas, пожалуй и не придумаешь. Можно просто на лету формировать данные из одного формата и переводить тут же в другой без утомительного перебора. К примеру, из формата csv в json.
Спасибо за внимание. Надеюсь, что данная информация будет вам полезна
Источник
Парсинг файлов Excel
Парсер поддерживает следующие типы файлов Excel:
- .xls, .xlsx, xlsm, .xlsb и любые другие таблицы
- файлы .csv можно парсить как файлы Excel и как текстовые файлы (зависит от задачи)
Для сбора данных из файлов Excel применяется стандартный алгоритм парсера файлов, но есть и некоторые нюансы:
- Для открытия файла используется действие «Открыть файл в Excel», с параметром «Режим» равным 2 — ReadOnly (если планируется только загрузка данных из файла, без внесения изменений в обрабатываемый файл):
Действие Параметр Значение Открыть файл в Excel Путь к открываемому файлу Режим 2 — ReadOnly
ВАЖНО: Требуется принудительно закрывать обрабатываемые файлы Excel (так как файл остаётся открытым в процессе извлечения из него данных)
Поскольку в исходных данных прописана только команда открытия файла, а команду закрытия там же прописать возможности нет, — команду закрытия добавляем в спец. набор действий с названием Parser_AfterLastLevel (он срабатывает на последнем подуровне после вывода на лист):
| Действие | Параметр | Значение |
|---|---|---|
| Закрыть книгу Excel | Режим | 2 — ранее открытый парсером |
Оно позволяет искать на листе нужные ячейки, ориентируясь на значения соседних ячеек (например, найти на листе ячейку с заданным текстом, отступить от неё вниз/вправо/влево/вверх на заданное количество строк/столбцов, и из этой ячейки считать значение / ссылку / примечание)
Это же действие позволяет вносить коррективы в файл перед сбором данных (например, перенести значения из одного столбца в другой, удалить лишние столбцы, посчитать количество заполненных ячеек в диапазоне, и т.п.)
Примеры настройки парсера файлов Excel можно найти в каталоге парсеров файлов:
Источник
Парсинг нетабличных данных с сайтов
Проблема с нетабличными данными
С загрузкой в Excel табличных данных из интернета проблем нет. Надстройка Power Query в Excel легко позволяет реализовать эту задачу буквально за секунды. Достаточно выбрать на вкладке Данные команду Из интернета (Data — From internet) , вставить адрес нужной веб-страницы (например, ключевых показателей ЦБ) и нажать ОК:
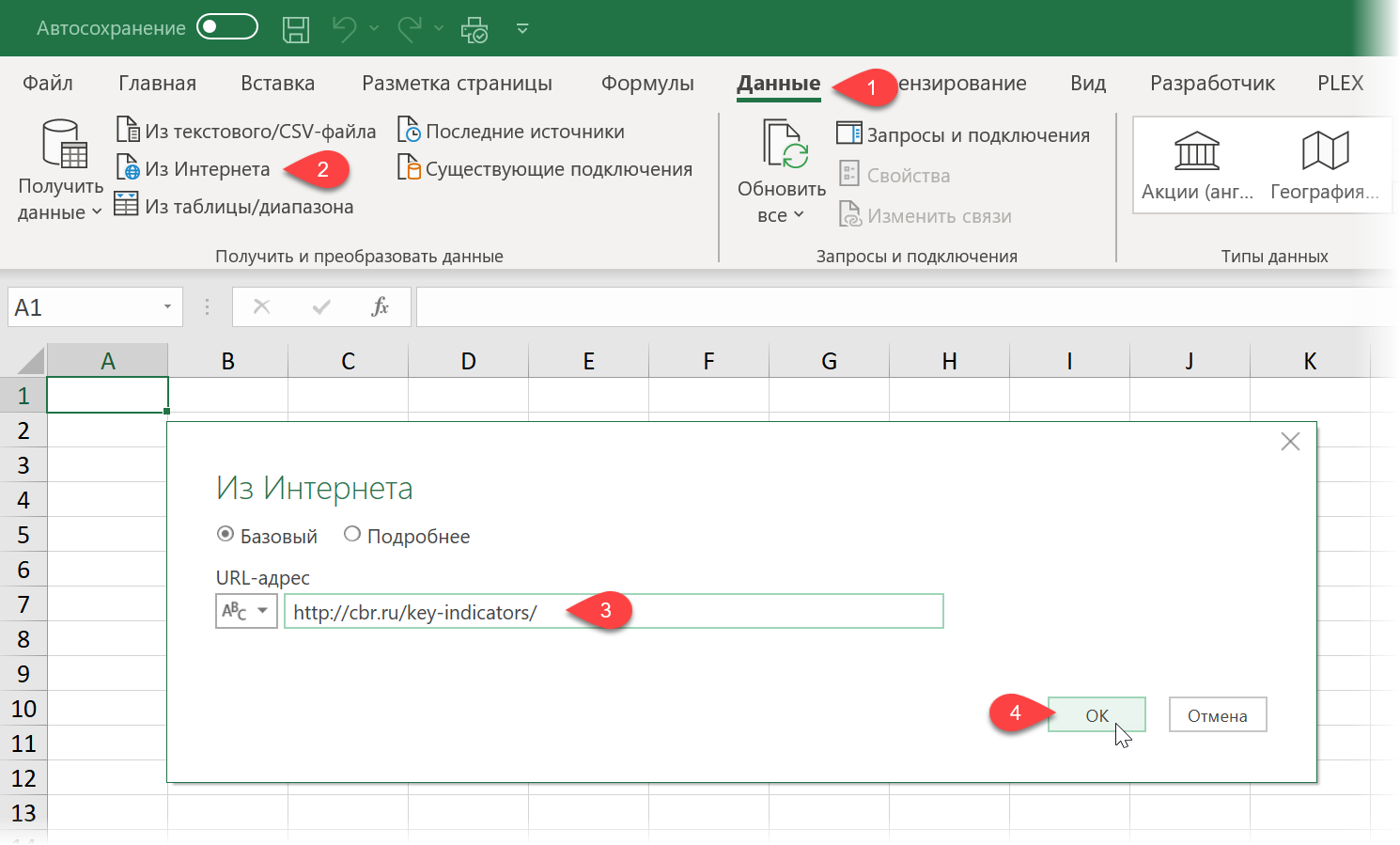
Power Query автоматически распознает все имеющиеся на веб-странице таблицы и выведет их список в окне Навигатора:
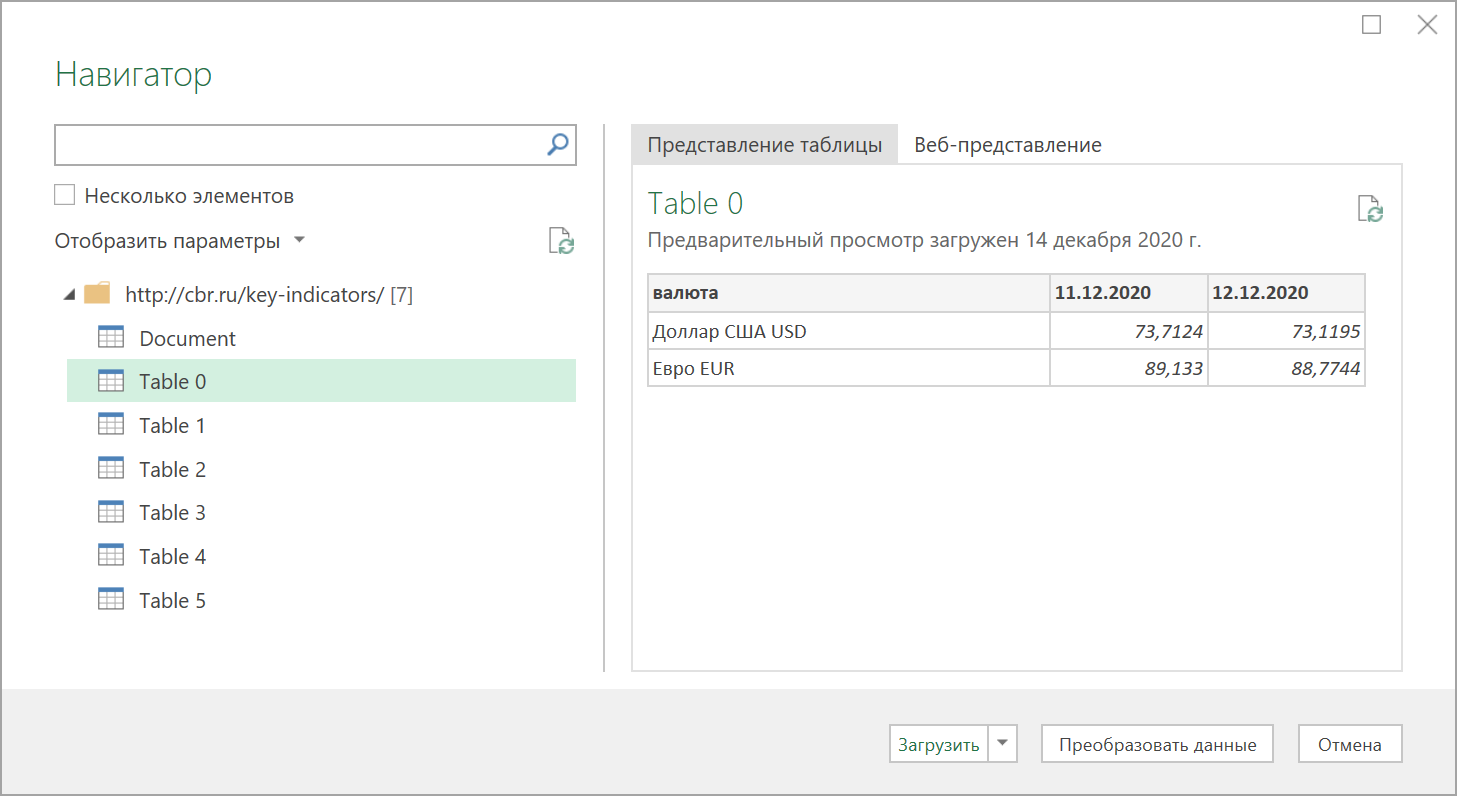
Дальше останется выбрать нужную таблицу методом тыка и загрузить её в Power Query для дальнейшей обработки (кнопка Преобразовать данные) или сразу на лист Excel (кнопка Загрузить).
Если с нужного вам сайта данные грузятся по вышеописанному сценарию — считайте, что вам повезло.
К сожалению, сплошь и рядом встречаются сайты, где при попытке такой загрузки Power Query «не видит» таблиц с нужными данными, т.е. в окне Навигатора попросту нет этих Table 0,1,2. или же среди них нет таблицы с нужной нам информацией. Причин для этого может быть несколько, но чаще всего это происходит потому, что веб-дизайнер при создании таблицы использовал в HTML-коде страницы не стандартную конструкцию с тегом , а её аналог — вложенные друг в друга теги-контейнеры
Тем не менее, есть способ обойти это ограничение 😉
В качестве тренировки, давайте попробуем загрузить цены и описания товаров с маркетплейса Wildberries — например, книг из раздела Детективы:
Загружаем HTML-код вместо веб-страницы
Сначала используем всё тот же подход — выбираем команду Из интернета на вкладке Данные (Data — From internet) и вводим адрес нужной нам страницы:
После нажатия на ОК появится окно Навигатора, где мы уже не увидим никаких полезных таблиц, кроме непонятной Document:
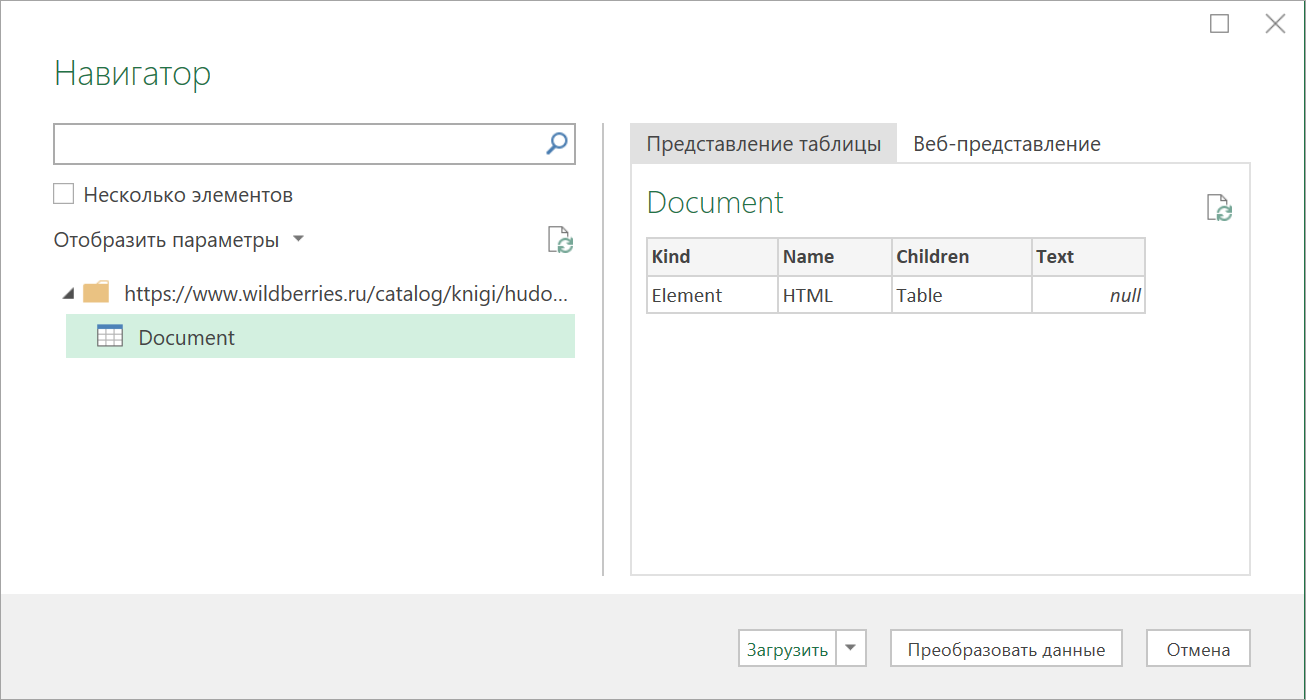
Дальше начинается самое интересное. Жмём на кнопку Преобразовать данные (Transform Data) , чтобы всё-таки загрузить содержимое таблицы Document в редактор запросов Power Query. В открывшемся окне удаляем шаг Навигация (Navigation) красным крестом:
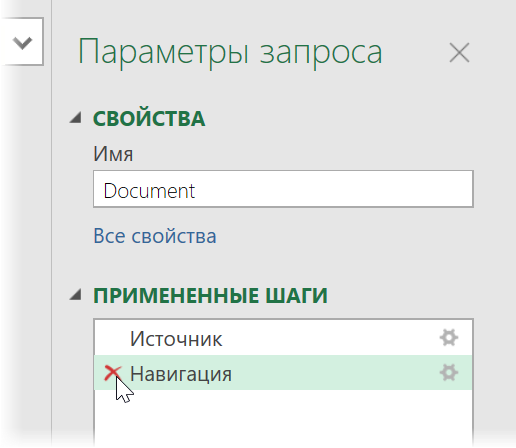
. и затем щёлкаем по значку шестерёнки справа от шага Источник (Source) , чтобы открыть его параметры:
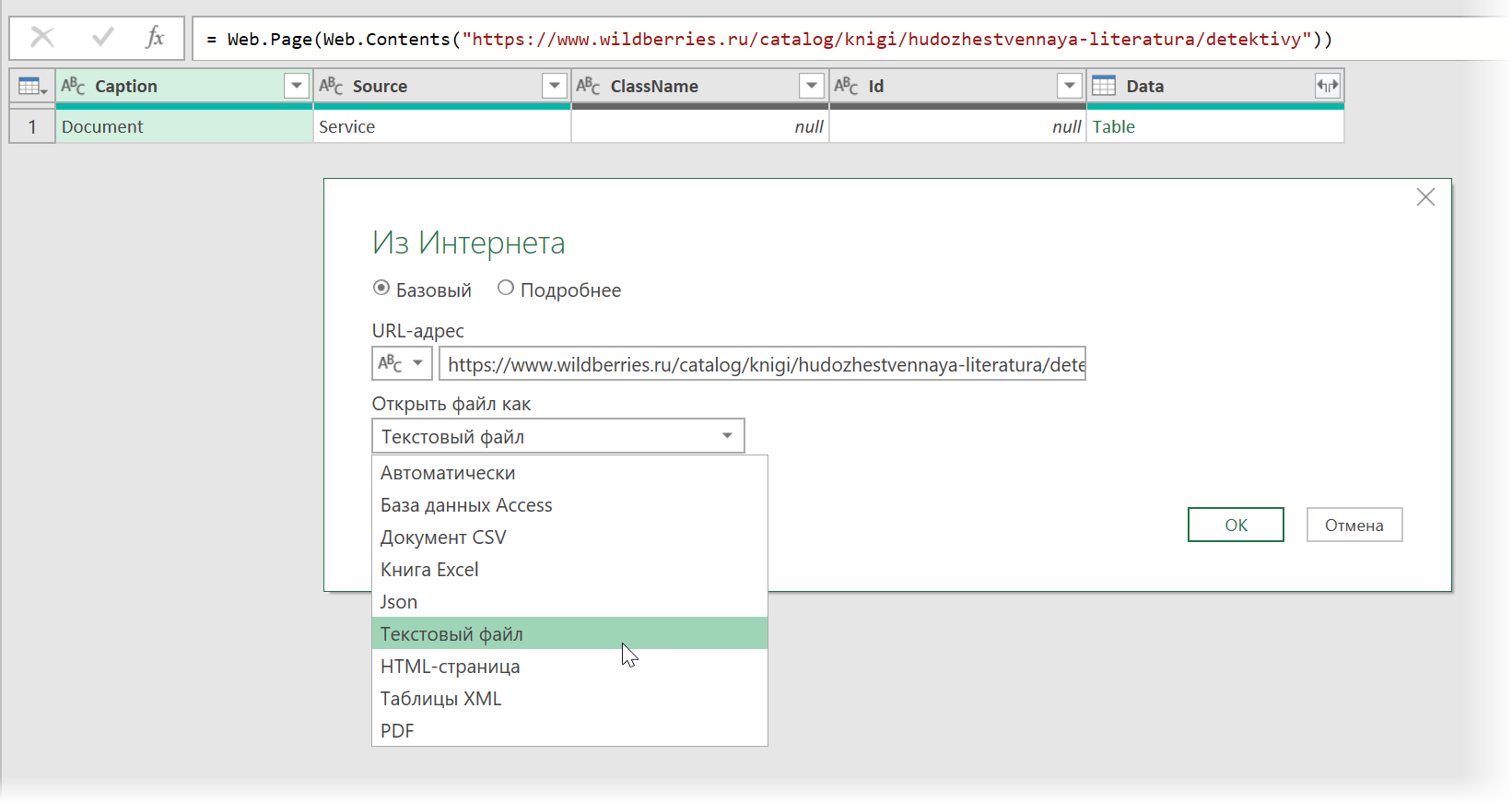
В выпадающием списке Открыть файл как (Open file as) вместо выбранной там по-умолчанию HTML-страницы выбираем Текстовый файл (Text file) . Это заставит Power Query интерпретировать загружаемые данные не как веб-страницу, а как простой текст, т.е. Power Query не будет пытаться распознавать HTML-теги и их атрибуты, ссылки, картинки, таблицы, а просто обработает исходный код страницы как текст.
После нажатия на ОК мы этот HTML-код как раз и увидим (он может быть весьма объемным — не пугайтесь):
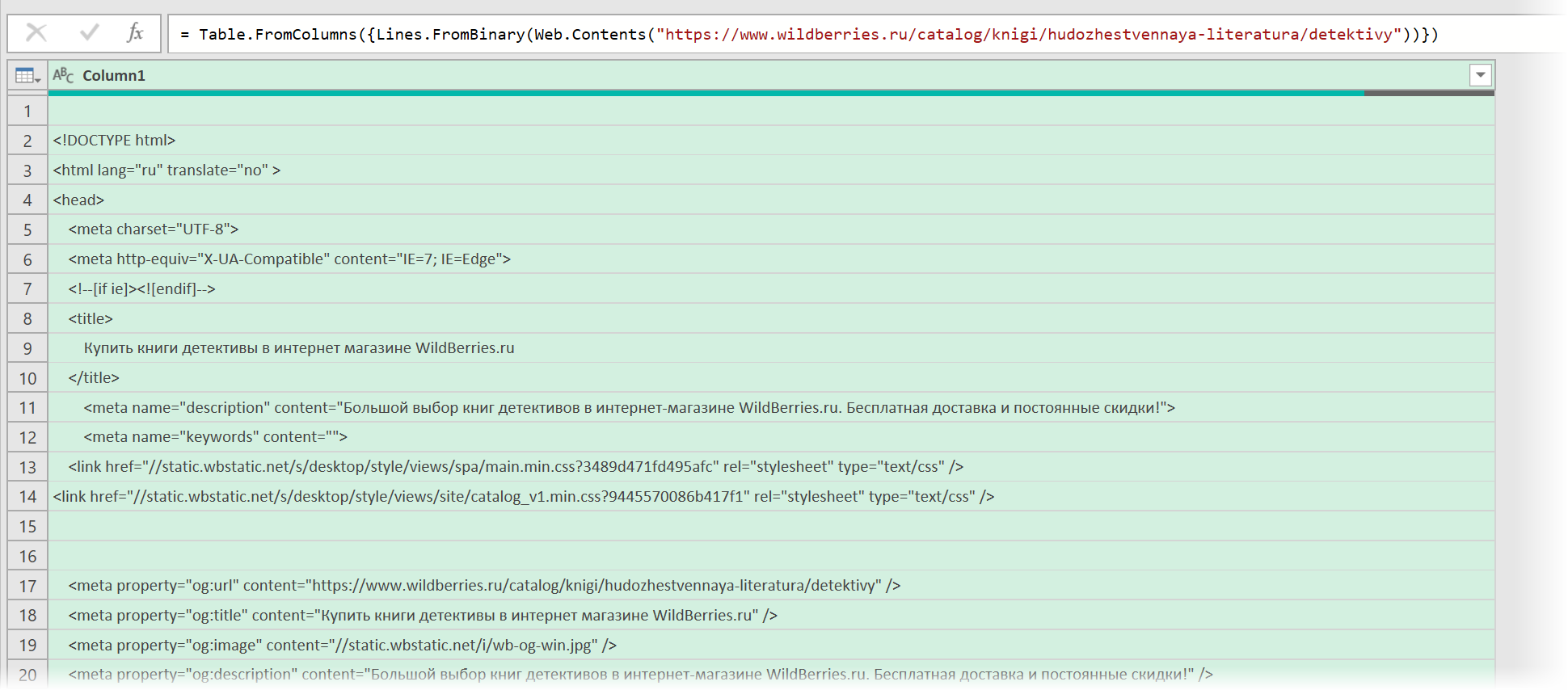
Ищем за что зацепиться
Теперь нужно понять на какие теги, атрибуты или метки в коде мы можем ориентироваться, чтобы извлечь из этой кучи текста нужные нам данные о товарах. Само-собой, тут всё зависит от конкретного сайта и веб-программиста, который его писал и вам придётся уже импровизировать.
В случае с Wildberries, промотав этот код вниз до товаров, можно легко нащупать простую логику:
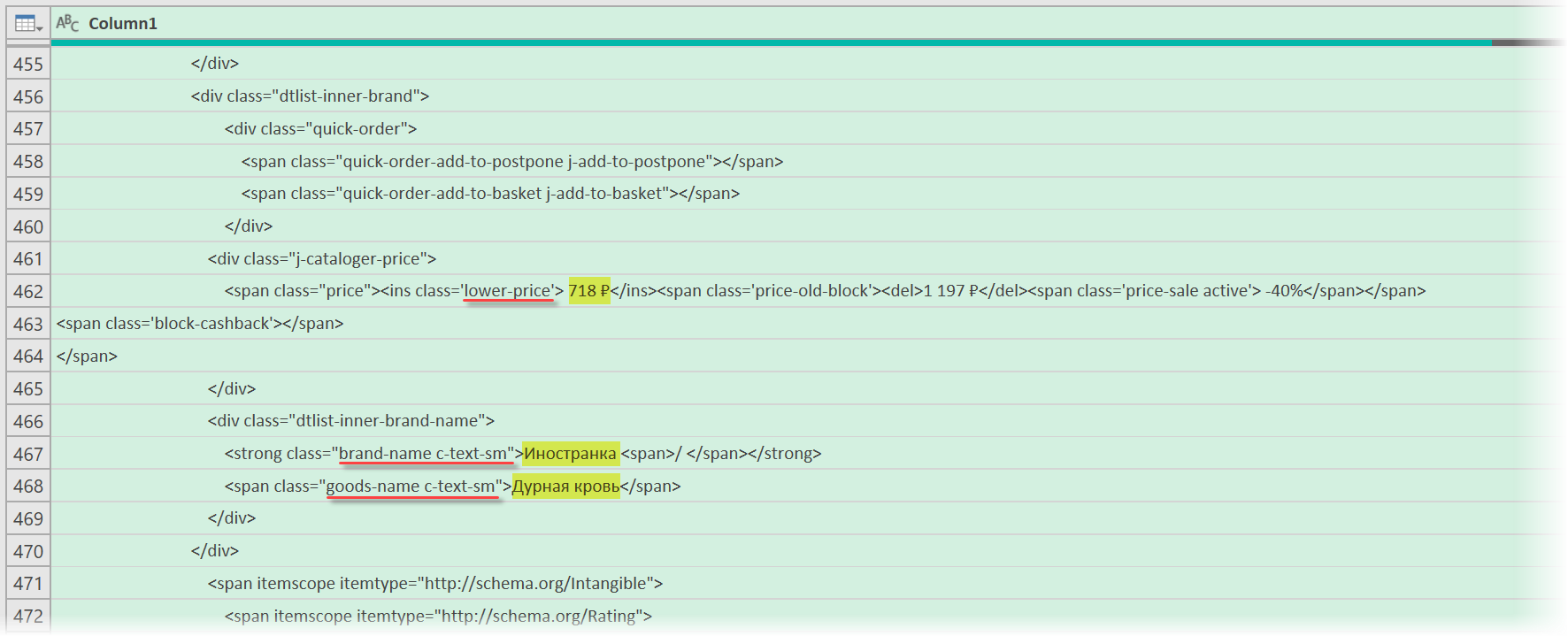
- Строчки с ценами всегда содержат метку lower-price
- Строчки с названием бренда — всегда с меткой brand-name c-text-sm
- Название товара можно найти по метке goods-name c-text-sm
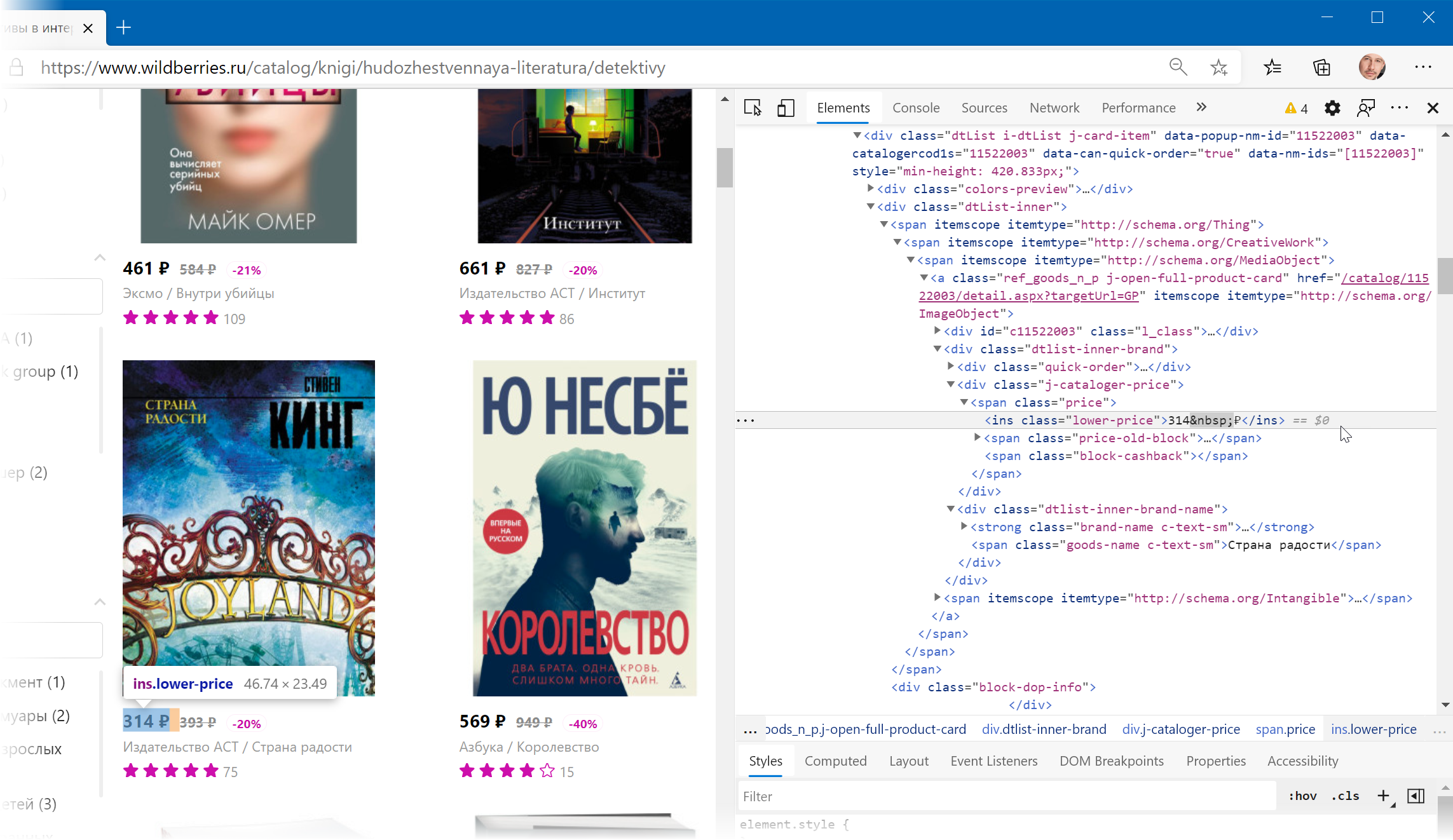
Иногда процесс поиска можно существенно упростить, если воспользоваться инструментами отладки кода, которые сейчас есть в любом современном браузере. Щёлкнув правой кнопкой мыши по любому элементу веб-страницы (например, цене или описанию товара) можно выбрать из контекстного меню команду Инспектировать (Inspect) и затем просматривать код в удобном окошке непосредственно рядом с содержимым сайта:
Фильтруем нужные данные
Теперь совершенно стандартным образом давайте отфильтруем в коде страницы нужные нам строки по обнаруженным меткам. Для этого выбираем в окне Power Query в фильтре [1] опцию Текстовые фильтры — Содержит (Text filters — Contains) , переключаемся в режим Подробнее (Advanced) [ 2] и вводим наши критерии:
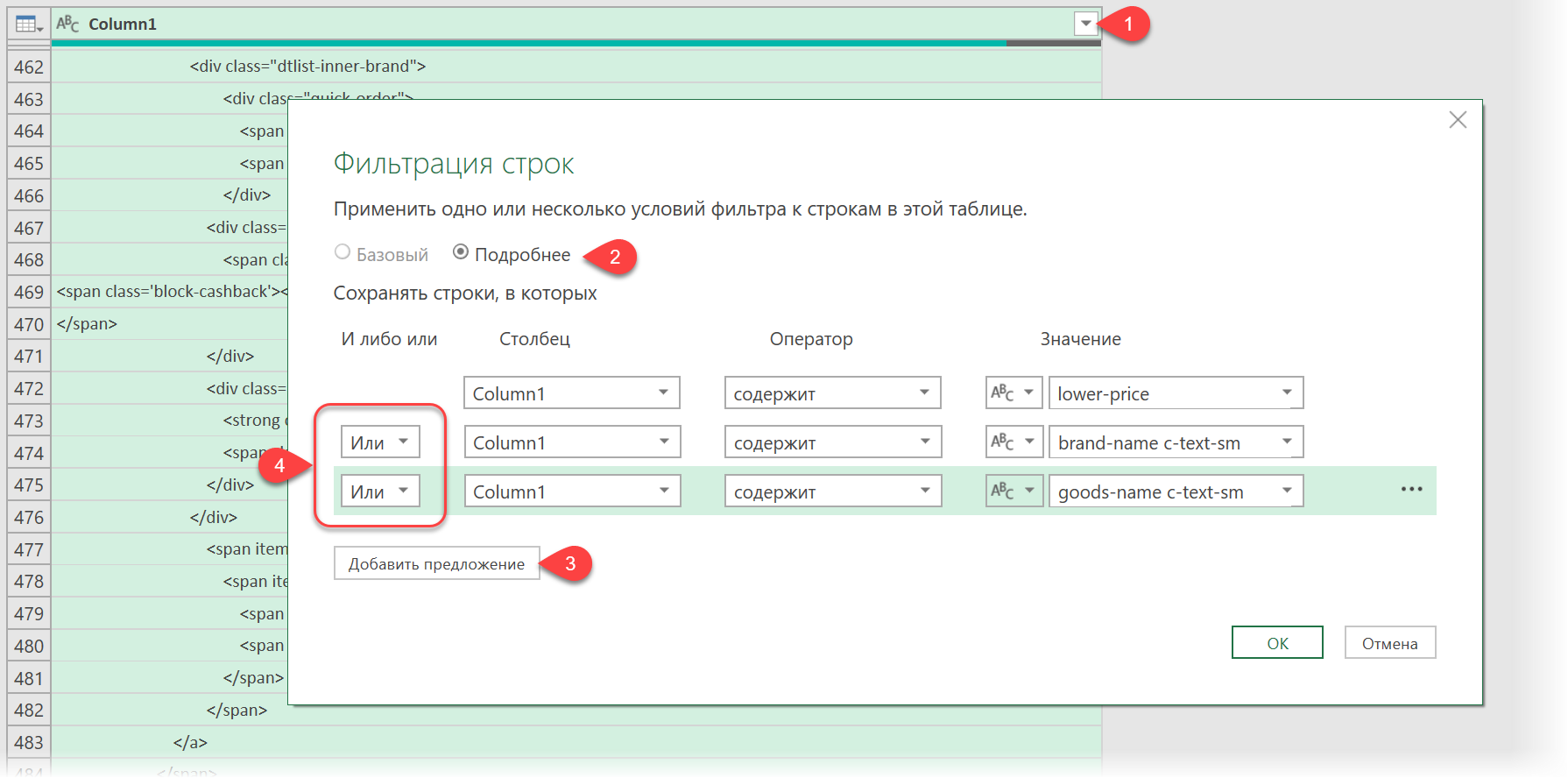
Добавление условий выполняется кнопкой со смешным названием Добавить предложение [ 3] . И не забудьте для всех условий выставить логическую связку Или (OR) вместо И (And) в выпадающих списках слева [4] — иначе фильтрация просто не сработает.
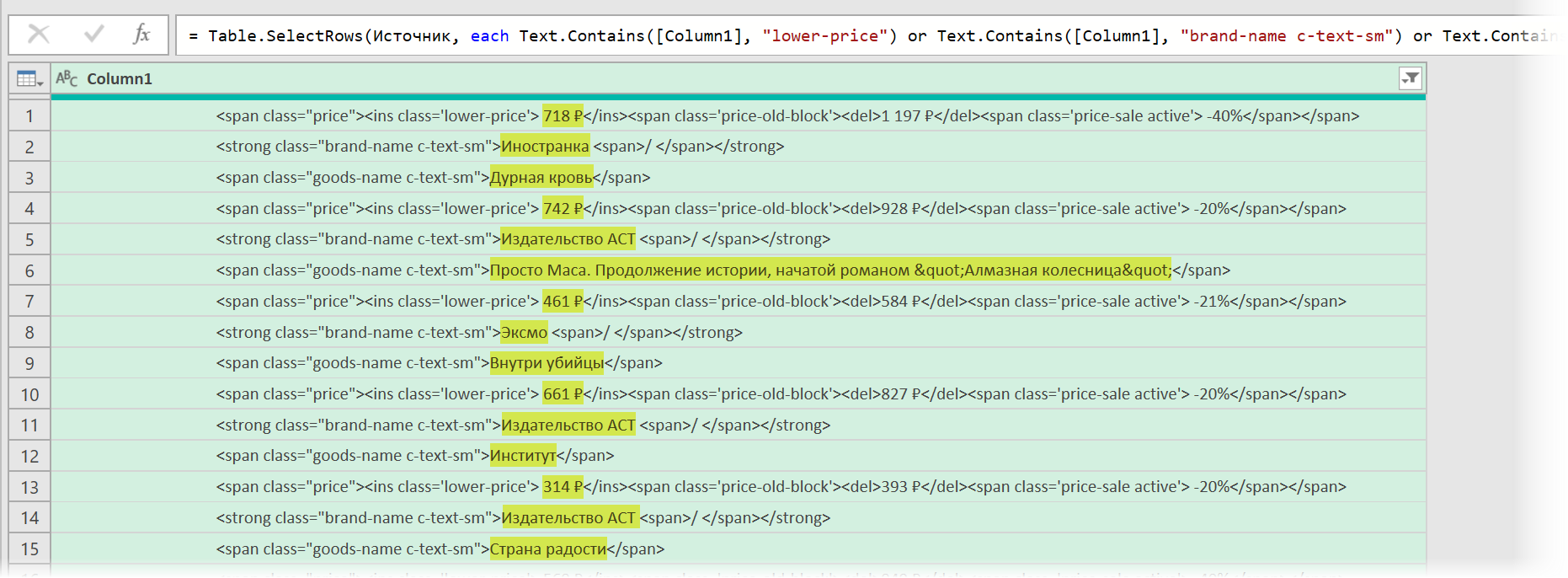
После нажатия на ОК на экране останутся только строки с нужной нам информацией:
Чистим мусор
Останется почистить всё это от мусора любым подходящим и удобным лично вам способом (их много). Например, так:
- Удалить заменой на пустоту начальный тег: через команду Главная — Замена значений (Home — Replace values) .
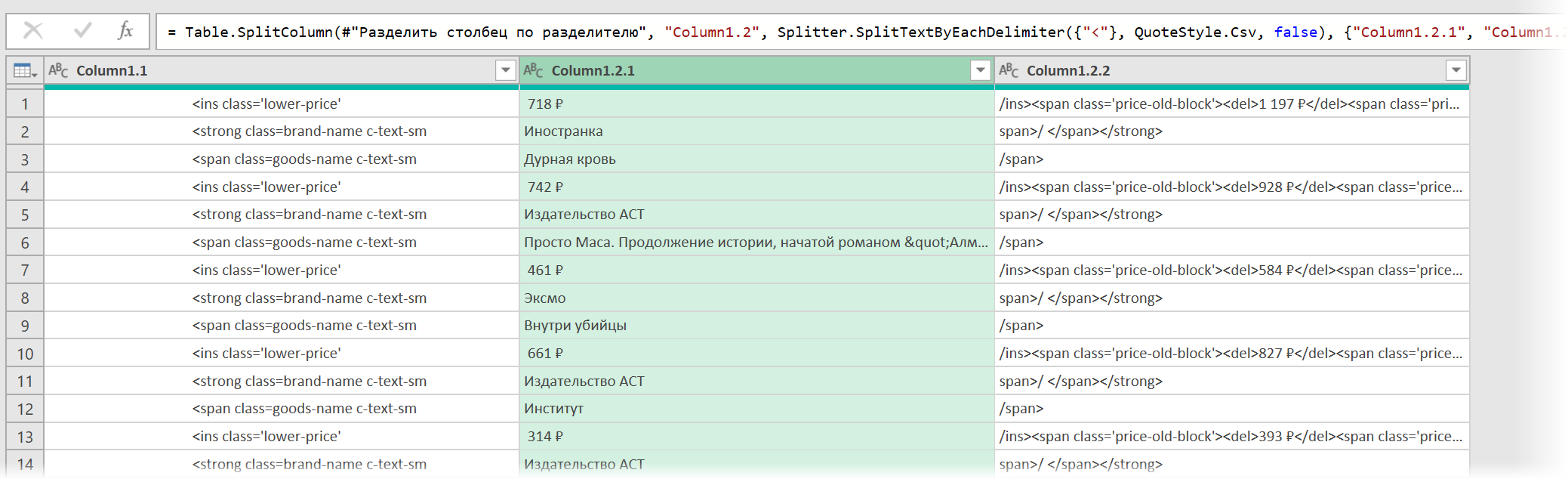
- Разделить получившийся столбец по первому разделителю » > » слева командой Главная — Разделить столбец — По разделителю (Home — Split column — By delimiter) и затем ещё раз разделить получившийся столбец по первому вхождению разделителя » » слева, чтобы отделить полезные данные от тегов:
В итоге получим наши данные в уже гораздо более презентабельном виде:
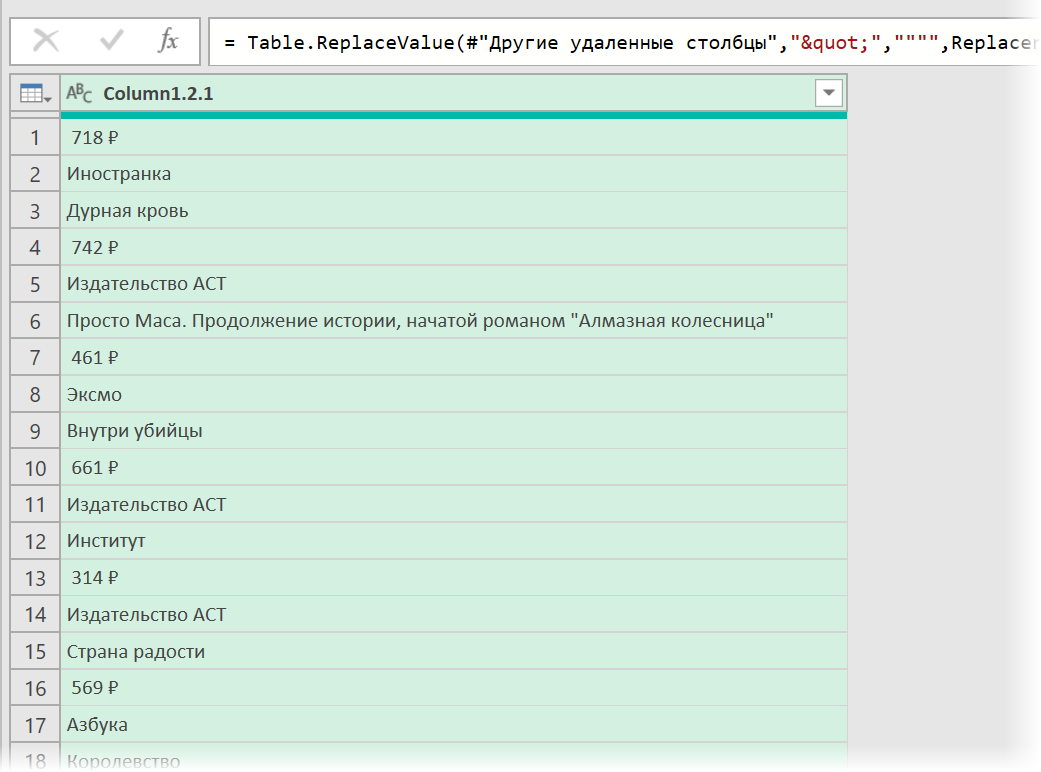
Разбираем блоки по столбцам
Если присмотреться, то информация о каждом отдельном товаре в получившемся списке сгруппирована в блоки по три ячейки. Само-собой, нам было бы гораздо удобнее работать с этой таблицей, если бы эти блоки превратились в отдельные столбцы: цена, бренд (издательство) и наименование.
Выполнить такое преобразование можно очень легко — с помощью, буквально, одной строчки кода на встроенном в Power Query языке М. Для этого щёлкаем по кнопке fx в строке формул (если у вас её не видно, то включите её на вкладке Просмотр (View) ) и вводим следующую конструкцию:
= Table.FromRows(List.Split( #»Замененное значение1″ [Column1.2.1] , 3 ))
Здесь функция List.Split разбивает столбец с именем Column1.2.1 из нашей таблицы с предыдущего шага #»Замененное значение1″ на кусочки по 3 ячейки, а потом функция Table.FromRows конвертирует получившиеся вложенные списки обратно в таблицу — уже из трёх столбцов:
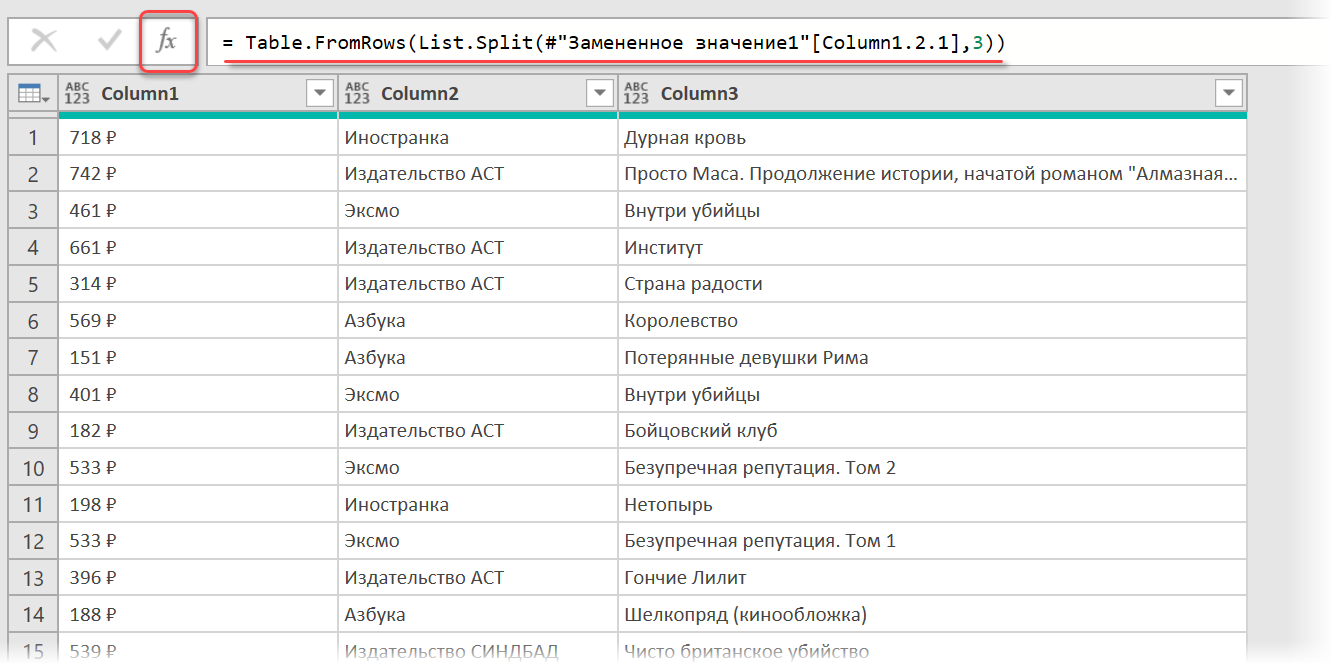
Ну, а дальше уже дело техники — настроить числовые форматы столбцов, переименовать их и разместить в нужном порядке. И выгрузить получившуюся красоту обратно на лист Excel командой Главная — Закрыть и загрузить (Home — Close & Load. )
Источник
Задача:
Обработать все файлы Excel в заданной папке, и извлечь информацию из определенных ячеек.
Искать в файлах данные не привязываясь к адресам ячеек (структура файлов немного отличается, часть данных смещена)
Описание:
Этот парсер опубликован как пример использования парсера для обработки файлов, в частности, для парсинга таблиц Excel.
В качестве основы был использован парсер для перебора всех файлов в папке, но с незначительным отличием: если при парсинге файлов других типов (текстовых / Word / PDF) нам достаточно только считать данные из файла (файл временно открывается, данные считываются, и файл сразу закрывается), то при загрузке данных из файлов Excel, обрабатываемый файл должен быть открыт всё то время, пока из него считываются данные в разные столбцы.
Подробнее об этом — в инструкции по парсингу файлов Excel
Для извлечения данных с листа используется многофункциональное действие «Поиск ячеек на листе».
Оно позволяет найти на листе нужные ячейки, ориентируясь на значения соседних ячеек (например, найти на листе ячейку с заданным текстом, отступить от неё вниз/вправо/влево/вверх на заданное количество строк/столбцов, и из этой ячейки считать значение / ссылку / примечание)
Поскольку некоторые из обрабатываемых файлов могут отличаться по структуре (присутствует первый пустой столбец), необходима дополнительная коррекция файла перед обработкой (при условии, что в первом столбце меньше 5 заполненных ячеек, надо значения ячеек первого столбца перенести во второй столбец, а первый столбец листа целиком удалить). Это тоже можно сделать парсером, — в настройках этого парсера присутствует набор действий «Коррекция файла», содержащий 5 команд:
| Действие | Параметр | Значение |
|---|---|---|
| Поиск ячеек на листе | Адрес ячейки / диапазона для поиска | a1:a15 |
| Маска поиска | ?* | |
| Смещение от найденного | 0;0 | |
| Действие для целевой ячейки | GetValue | |
| Задаваемое значение | ||
| Маска найденного значения | * | |
| Заменять пустые значения на | ||
| Количество элементов массива | Сохранить результат в переменную | |
| Использовать новое значение | да | |
| Проверка на выполнение условия | Режим проверки | больше |
| Значение для сравнения | 5 | |
| Действие при выполнении условия | Новое значение, и остановить | |
| Параметр действия | Коррекция не требуется (первый столбец не пустой) | |
| Проверять другое значение | нет | |
| Другое проверяемое значение | ||
| Поиск ячеек на листе | Адрес ячейки / диапазона для поиска | a:a |
| Маска поиска | ?* | |
| Смещение от найденного | 0;1 | |
| Действие для целевой ячейки | SetValue | |
| Задаваемое значение | {FoundCell.Text} {TargetCell.Text} | |
| Маска найденного значения | * | |
| Заменять пустые значения на | ||
| Действия со столбцами | Столбцы | 1 |
| Действие для выбранных столбцов | Удалить | |
| Параметр действия |
Есть excel-файлы, несколько сотен.
Из них нужно как-то извлечь некоторые строки, по заданному принципу (текст в них отличается).
И залить эти строки в один новый экселевский файл.
Можно сделать руками, но лень. И еще есть вариант, что данная задача будет периодически повторяться.
Подскажите, пожалуйста, какими инструментами лучше это программно сделать? Автоматически по очереди пооткрывать все файлы в директории, пропарсить, взять нужные строки, залить в новый файл.
Может, был у кого похожий опыт.
Я начал смотреть в сторону python и www.python-excel.org
Может лучше сделать это visual basic’ом? Или вообще в самом экселе есть такая возможность?
Спасибо!
P.S. Все сделал так: сперва нашел плагин для эксель, бесплатно и быстро сливающий много эксель файлов в один. Вот он.
Затем искал конкретные макросы, удаляющие строки по различным критериям, типа — пустая ячейка, текст в ячейке, цифры в ячейке.
В общем, даже не пришлось сильно разбираться с VBA, все сделал готовыми средствами.
Есть excel-файлы, несколько сотен.
Из них нужно как-то извлечь некоторые строки, по заданному принципу (текст в них отличается).
И залить эти строки в один новый экселевский файл.
Можно сделать руками, но лень. И еще есть вариант, что данная задача будет периодически повторяться.
Подскажите, пожалуйста, какими инструментами лучше это программно сделать? Автоматически по очереди пооткрывать все файлы в директории, пропарсить, взять нужные строки, залить в новый файл.
Может, был у кого похожий опыт.
Я начал смотреть в сторону python и www.python-excel.org
Может лучше сделать это visual basic’ом? Или вообще в самом экселе есть такая возможность?
Спасибо!
Парсинг сайта с помощью Excel
На первый взгляд Excel и парсинг понятия несовместимые. Как с помощью табличного редактора можно получать информацию из сети? И ведь многие недооценивают Excel, а это вполне посильная задача для него. При этом все делается стандартными методами без необходимости дополнительно что-то устанавливать/настраивать.
Разберем на конкретном примере по получению информации с сайта Минюста, а именно, нам необходим перечень действующих адвокатов Российской Федерации. Кнопки «выгрузить списочно всех адвокатов» — конечно же, нет. На официальном сайте http://lawyers.minjust.ru/ выводится по 20 адвокатов на 1 странице, всего 74 754 страниц, итого на выходе мы должны получить чуть меньше 150 тыс. адвокатов.
Для начала открываем VBA и создаем объект InternetExplorer, посредством которого будем получать данные.
Затем надо определить, как будем переходить между страницами на сайте – для этого просматриваем элемент перехода на следующую страницу. Ссылка между станицами отличается значением в конце и соответствует номеру страницы – 1.
Имея информацию о ссылке страницы — осуществляем их перебор, загружаем в InternetExplorer и забираем все данные со страницы.
В коде страницы представлена структура таблицы со всеми столбцами, которые нам необходимы: реестровый номер, ФИО адвоката, субъект РФ, номер удостоверения, текущий статус.
Для получения этой информации с помощью ключевых слов осуществляем поиск по тегам и забираем требуемые данные.
В итоге получаем список всех адвокатов в таблицу Excel для дальнейшей обработки.
Парсинг нетабличных данных с сайтов
С загрузкой в Excel табличных данных из интернета проблем нет. Надстройка Power Query в Excel легко позволяет реализовать эту задачу буквально за секунды. Достаточно выбрать на вкладке Данные команду Из интернета (Data — From internet) , вставить адрес нужной веб-страницы (например, ключевых показателей ЦБ) и нажать ОК:
Power Query автоматически распознает все имеющиеся на веб-странице таблицы и выведет их список в окне Навигатора:
Дальше останется выбрать нужную таблицу методом тыка и загрузить её в Power Query для дальнейшей обработки (кнопка Преобразовать данные) или сразу на лист Excel (кнопка Загрузить).
Если с нужного вам сайта данные грузятся по вышеописанному сценарию — считайте, что вам повезло.
К сожалению, сплошь и рядом встречаются сайты, где при попытке такой загрузки Power Query «не видит» таблиц с нужными данными, т.е. в окне Навигатора попросту нет этих Table 0,1,2. или же среди них нет таблицы с нужной нам информацией. Причин для этого может быть несколько, но чаще всего это происходит потому, что веб-дизайнер при создании таблицы использовал в HTML-коде страницы не стандартную конструкцию с тегом <TABLE>, а её аналог — вложенные друг в друга теги-контейнеры <DIV>. Это весьма распространённая техника при вёрстке веб-сайтов, но, к сожалению, Power Query пока не умеет распознавать такую разметку и загружать такие данные в Excel.
Тем не менее, есть способ обойти это ограничение 😉
В качестве тренировки, давайте попробуем загрузить цены и описания товаров с маркетплейса Wildberries — например, книг из раздела Детективы:
Загружаем HTML-код вместо веб-страницы
Сначала используем всё тот же подход — выбираем команду Из интернета на вкладке Данные (Data — From internet) и вводим адрес нужной нам страницы:
После нажатия на ОК появится окно Навигатора, где мы уже не увидим никаких полезных таблиц, кроме непонятной Document:
Дальше начинается самое интересное. Жмём на кнопку Преобразовать данные (Transform Data) , чтобы всё-таки загрузить содержимое таблицы Document в редактор запросов Power Query. В открывшемся окне удаляем шаг Навигация (Navigation) красным крестом:
. и затем щёлкаем по значку шестерёнки справа от шага Источник (Source) , чтобы открыть его параметры:
В выпадающием списке Открыть файл как (Open file as) вместо выбранной там по-умолчанию HTML-страницы выбираем Текстовый файл (Text file) . Это заставит Power Query интерпретировать загружаемые данные не как веб-страницу, а как простой текст, т.е. Power Query не будет пытаться распознавать HTML-теги и их атрибуты, ссылки, картинки, таблицы, а просто обработает исходный код страницы как текст.
После нажатия на ОК мы этот HTML-код как раз и увидим (он может быть весьма объемным — не пугайтесь):
Ищем за что зацепиться
Теперь нужно понять на какие теги, атрибуты или метки в коде мы можем ориентироваться, чтобы извлечь из этой кучи текста нужные нам данные о товарах. Само-собой, тут всё зависит от конкретного сайта и веб-программиста, который его писал и вам придётся уже импровизировать.
В случае с Wildberries, промотав этот код вниз до товаров, можно легко нащупать простую логику:
- Строчки с ценами всегда содержат метку lower-price
- Строчки с названием бренда — всегда с меткой brand-name c-text-sm
- Название товара можно найти по метке goods-name c-text-sm
Иногда процесс поиска можно существенно упростить, если воспользоваться инструментами отладки кода, которые сейчас есть в любом современном браузере. Щёлкнув правой кнопкой мыши по любому элементу веб-страницы (например, цене или описанию товара) можно выбрать из контекстного меню команду Инспектировать (Inspect) и затем просматривать код в удобном окошке непосредственно рядом с содержимым сайта:
Фильтруем нужные данные
Теперь совершенно стандартным образом давайте отфильтруем в коде страницы нужные нам строки по обнаруженным меткам. Для этого выбираем в окне Power Query в фильтре [1] опцию Текстовые фильтры — Содержит (Text filters — Contains) , переключаемся в режим Подробнее (Advanced) [ 2] и вводим наши критерии:
Добавление условий выполняется кнопкой со смешным названием Добавить предложение [ 3] . И не забудьте для всех условий выставить логическую связку Или (OR) вместо И (And) в выпадающих списках слева [4] — иначе фильтрация просто не сработает.
После нажатия на ОК на экране останутся только строки с нужной нам информацией:
Чистим мусор
Останется почистить всё это от мусора любым подходящим и удобным лично вам способом (их много). Например, так:
- Удалить заменой на пустоту начальный тег: <span > через команду Главная — Замена значений (Home — Replace values) .
- Разделить получившийся столбец по первому разделителю » > » слева командой Главная — Разделить столбец — По разделителю (Home — Split column — By delimiter) и затем ещё раз разделить получившийся столбец по первому вхождению разделителя » < » слева, чтобы отделить полезные данные от тегов:
Разбираем блоки по столбцам
Если присмотреться, то информация о каждом отдельном товаре в получившемся списке сгруппирована в блоки по три ячейки. Само-собой, нам было бы гораздо удобнее работать с этой таблицей, если бы эти блоки превратились в отдельные столбцы: цена, бренд (издательство) и наименование.
Выполнить такое преобразование можно очень легко — с помощью, буквально, одной строчки кода на встроенном в Power Query языке М. Для этого щёлкаем по кнопке fx в строке формул (если у вас её не видно, то включите её на вкладке Просмотр (View) ) и вводим следующую конструкцию:
= Table.FromRows(List.Split( #»Замененное значение1″ [Column1.2.1] , 3 ))
Здесь функция List.Split разбивает столбец с именем Column1.2.1 из нашей таблицы с предыдущего шага #»Замененное значение1″ на кусочки по 3 ячейки, а потом функция Table.FromRows конвертирует получившиеся вложенные списки обратно в таблицу — уже из трёх столбцов:
Ну, а дальше уже дело техники — настроить числовые форматы столбцов, переименовать их и разместить в нужном порядке. И выгрузить получившуюся красоту обратно на лист Excel командой Главная — Закрыть и загрузить (Home — Close & Load. )
Пример с использованием модуля Pandas:
import pandas as pd # pip install pandas
df = pd.read_excel(r'D:download1.xls', sheet_name='Лист1')
print(df)
вывод:
Артикул Наименование Тариф (прайс) на 12.06.83
0 а123 Товар А 100
1 б123 Товар Б 200
2 в123 Товар В 300
в виде обычных Vanilla Python списков или Numpy Array:
In [20]: df['Артикул'].tolist()
Out[20]: ['а123', 'б123', 'в123']
In [21]: df.values
Out[21]:
array([['а123', 'Товар А', 100],
['б123', 'Товар Б', 200],
['в123', 'Товар В', 300]], dtype=object)
In [22]: df.values.tolist()
Out[22]: [['а123', 'Товар А', 100], ['б123', 'Товар Б', 200], ['в123', 'Товар В', 300]]
In [23]: df.T.values.tolist()
Out[23]: [['а123', 'б123', 'в123'], ['Товар А', 'Товар Б', 'Товар В'], [100, 200, 300]]
PS Pandas поддерживает работу с XLSX и XLS форматами и умеет использовать следующие модули:
- xlrd, xlwt
- openpyxl
- xlsxwriter