
Рассмотренные в лабораторной работе 2 распределения вероятностей СВ
опираются на знание закона распределения СВ. Для практических задач такое
знание – редкость. Здесь закон распределения обычно неизвестен, или известен с
точностью до некоторых неизвестных параметров. В частности, невозможно
рассчитать точное значение соответствующих вероятностей, так как нельзя
определить количество общих и благоприятных исходов. Поэтому вводится статистическое
определение вероятности. По этому определению вероятность равна отношению
числа испытаний, в которых событие произошло, к общему числу произведенных
испытаний. Такая вероятность называется статистической частотой.
Связь
между эмпирической функцией распределения и функцией распределения
(теоретической функцией распределения) такая же, как связь между частотой события
и его вероятностью.
Для
построения выборочной функции распределения весь диапазон изменения случайной
величины X (выборки)
разбивают на ряд интервалов (карманов) одинаковой ширины. Число интервалов
обычно выбирают не менее 3 и не более 15. Затем определяют число значений
случайной величины X, попавших
в каждый интервал (абсолютная частота, частота интервалов).
Частота интервалов – число, показывающее сколько раз значения,
относящиеся к каждому интервалу группировки, встречаются в выборке. Поделив эти
числа на общее количество наблюдений (n), находят относительную частоту (частость) попадания
случайной величины X в заданные
интервалы.
По
найденным относительным частотам строят гистограммы выборочных функций
распределения. Гистограмма распределения частот – это графическое
представление выборки, где по оси абсцисс (ОХ) отложены величины интервалов, а
по оси ординат (ОУ) – величины частот, попадающих в данный классовый интервал.
При увеличении до бесконечности размера выборки выборочные функции
распределения превращаются в теоретические: гистограмма превращается в график
плотности распределения.
Накопленная частота интервалов – это число, полученное
последовательным суммированием частот в направлении от первого интервала к
последнему, до того интервала
включительно, для которого определяется накопленная частота.
В Excel для построения выборочных функций распределения
используются специальная функция ЧАСТОТА
и процедура Гистограмма из пакета анализа.
Функция ЧАСТОТА (массив_данных,
двоичный_массив) вычисляет частоты появления случайной величины в интервалах
значений и выводит их как массив цифр, где
•
массив_данных
— это массив или ссылка на
множество данных, для которых
вычисляются частоты;
•
двоичный_массив
— это массив интервалов, по
которым группируются значения выборки.
Процедура
Гистограмма из Пакета анализа выводит
результаты выборочного распределения в виде таблицы и графика. Параметры диалогового окна Гистограмма:
•
Входной диапазон — диапазон исследуемых данных
(выборка);
•
Интервал карманов — диапазон ячеек или набор граничных
значений, определяющих выбранные интервалы (карманы). Эти значения должны быть
введены в возрастающем порядке. Если
диапазон карманов не был введен, то набор интервалов, равномерно распределенных между минимальным и
максимальным значениями данных, будет создан
автоматически.
•
выходной диапазон предназначен для ввода ссылки на левую верхнюю ячейку выходного диапазона.
•
переключатель
Интегральный процент позволяет установить режим включения в
гистограмму графика интегральных
процентов.
•
переключатель
Вывод графика позволяет установить режим автоматического создания встроенной диаграммы на листе, содержащем
выходной диапазон.
Пример 1. Построить эмпирическое распределение веса
студентов в килограммах для следующей
выборки: 64, 57, 63, 62, 58, 61, 63, 70, 60, 61, 65, 62, 62, 40, 64, 61, 59, 59, 63, 61.
Решение
1. В ячейку А1 введите слово Наблюдения,
а в диапазон А2:А21 — значения веса
студентов (см. рис. 1).
2.
В
ячейку В1 введите названия интервалов Вес, кг. В диапазон В2:В8 введите
граничные значения интервалов (40, 45,
50, 55, 60, 65, 70).
3.
Введите
заголовки создаваемой таблицы: в ячейки С1 — Абсолютные частоты, в ячейки D1 — Относительные
частоты, в ячейки E1 — Накопленные частоты.(см. рис. 1).
4.
С
помощью функции Частота заполните столбец абсолютных частот, для этого
выделите блок ячеек С2:С8. С
панели инструментов Стандартная
вызовите Мастер функций (кнопка fx). В появившемся диалоговом окне
выберите категорию Статистические и функцию
ЧАСТОТА, после чего нажмите кнопку ОК. Указателем мыши в рабочее поле Массив_данных
введите диапазон данных наблюдений (А2:А8). В рабочее поле Двоичный_массив
мышью введите диапазон интервалов (В2:В8). Слева на клавиатуре последовательно нажмите комбинацию клавиш Ctrl+Shift+Enter. В столбце C должен появиться массив абсолютных частот (см. рис.1).
5.
В
ячейке C9 найдите общее количество
наблюдений. Активизируйте ячейку С9, на
панели инструментов Стандартная нажмите кнопку Автосумма.
Убедитесь, что диапазон суммирования указан правильно и нажмите клавишу Enter.
6.
Заполните столбец относительных частот. В ячейку введите формулу
для вычисления относительной частоты: =C2/$C$9.
Нажмите клавишу Enter. Протягиванием (за правый
нижний угол при нажатой левой кнопке мыши) скопируйте введенную формулу в диапазон и получите массив относительных частот.
7.
Заполните
столбец накопленных частот. В ячейку D2 скопируйте значение относительной
частоты из ячейки E2. В ячейку D3 введите формулу: =E2+D3. Нажмите клавишу Enter. Протягиванием (за правый нижний угол при нажатой левой кнопке мыши) скопируйте введенную формулу
в диапазон D3:D8. Получим массив накопленных
частот.

Рис. 1. Результат вычислений из
примера 1
8.
Постройте диаграмму относительных и накопленных частот. Щелчком указателя
мыши по кнопке на панели инструментов вызовите Мастер диаграмм. В появившемся диалоговом окне выберите закладку Нестандартные
и тип диаграммы График/гистограмма. После
редактирования диаграмма будет иметь такой вид, как на рис. 2.

Рис. 2
Диаграмма относительных и накопленных частот из примера 1
Задания для самостоятельной работы
1. Для данных из примера 1 построить выборочные функции распределения, воспользовавшись процедурой Гистограмма из пакета Анализа.
2. Построить выборочные функции распределения
(относительные и накопленные частоты) для роста
в см. 20 студентов: 181, 169, 178, 178, 171, 179, 172, 181, 179, 168, 174, 167, 169, 171, 179, 181, 181,
183, 172, 176.
3. Найдите распределение по абсолютным частотам для
следующих результатов тестирования в
баллах: 79, 85, 78, 85, 83, 81, 95, 88, 97, 85 (используйте границы интервалов 70, 80, 90).
4. Рассмотрим любой из критериев оценки качеств педагога-профессионала,
например, «успешное решение задач обучения и воспитания». Ответ на этот вопрос
анкеты типа «да», «нет» достаточно груб. Чтобы уменьшить относительную ошибку
такого измерения, необходимо увеличить число возможных ответов на конкретный
критериальный вопрос. В табл. 1 представлены возможные варианты ответов.
Обозначим
этот параметр через х. Тогда в процессе ответа на вопрос величина х
примет дискретное значение х, принадлежащее определенному интервалу значений.
Поставим в соответствие каждому из ответов определенное числовое значение
параметра х (см. табл. 1).
Табл. 1 Критериальный вопрос: успешное решение задач обучения и воспитания
|
№ п/п |
Варианты ответов |
Х |
|
1 |
Абсолютно неуспешно |
0,1 |
|
2 |
Неуспешно |
0,2 |
|
3 |
Успешно в очень |
0,3 |
|
4 |
В определенной |
0,4 |
|
5 |
В среднем успешно, |
0,5 |
|
6 |
Успешно с |
0,6 |
|
7 |
Успешно, но |
0,7 |
|
8 |
Достаточно успешно |
0,8 |
|
9 |
Очень успешно |
0,9 |
|
10 |
Абсолютно успешно |
1 |
При проведении анкетирования в каждой отдельной
анкете параметр х принимает случайное значение, но только в пределах числового
интервала от 0,1 до 1.
Тогда в результате измерений мы получаем
неранжированный ряд случайных значений (см. табл. 2).
Таблица 2.
Результаты опроса ста учителей

Сгруппируйте полученную выборку, рассчитайте среднее
значение выборки, стандартное отклонение, абсолютную и относительную частоту
появления параметра, а также постройте график плотности вероятности f(x)=

где
W(x) – относительная частота наступления события;

— стандартное
отклонение;

=3,14.
Постройте график функции f(x) и сравните его с
нормальным распределением Гаусса.
Решение математических задач
средствами Excel: Практикум/ В.Я. Гельман. – СПб.: Питер, 2003 — с. 168-172
2.1.2. Эмпирическая функция распределения
Это статистический аналог функции распределения из теорвера. Данная функция определяется, как отношение:
, где – количество вариант СТРОГО МЕНЬШИХ, чем ,
при этом «икс» «пробегает» все значения от «минус» до «плюс» бесконечности.
Построим эмпирическую функцию распределения для нашей задачи. Чтобы было нагляднее, отложу варианты и их количество на числовой оси: 
На интервале – по той причине, что левее ЛЮБОЙ точки этого интервала вариант нет. Кроме того, функция равна нулю ещё и в точке . Почему? Потому, что значение определяет количество вариант (см. определение), которые СТРОГО меньше двух, а это количество равно нулю.
На промежутке – и опять обратите внимание, что значение не учитывает рабочих 3-го разряда, т.к. речь идёт о вариантах, которые СТРОГО меньше трёх (по определению).
На промежутке – и далее процесс продолжается по принципу накопления частот:
– если , то ;
– если , то ;
– и, наконец, если , то – и в самом деле, для ЛЮБОГО «икс» из интервала ВСЕ частоты расположены СТРОГО левее этого значения «икс» (см. чертёж выше).
Накопленные относительные частоты удобно заносить в отдельный столбец таблицы, при этом алгоритм вычислений очень прост: сначала сносим слева частоту (красная стрелка), и каждое следующее значение получаем как сумму предыдущего и относительной частоты из текущего левого столбца (зелёные обозначения): 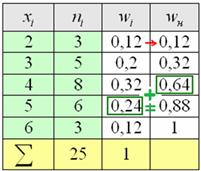
Вот ещё, кстати, один довод за вертикальную ориентацию данных – справа по надобности можно приписывать дополнительные столбцы.
Построенную функцию принято записывать в кусочном виде:
а её график представляет собой ступенчатую фигуру: 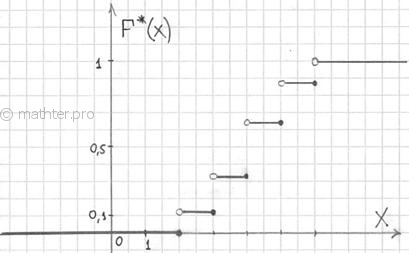
Эмпирическая функция распределения не убывает и принимает значения лишь из промежутка , и если у вас вдруг получится что-то не так, то ищите ошибку.
Теперь смотрим видео, о том, как построить эту функцию в Экселе (Ютуб).
И, конечно, вспомним основной метод математической статистики. Эмпирическая функция распределения строится по выборке и приближает теоретическую функцию распределения . Легко догадаться, что последняя появляется в результате исследования всей генеральной совокупности, но если рабочих в цехе ещё пересчитать можно, то звёзды на небе – уже вряд ли. Вот поэтому и важнА функция эмпирическая, и ещё важнее, чтобы выборка была репрезентативна, дабы приближение было хорошим.
Миниатюрное задание для закрепления материала:
Пример 5
Дано статистическое распределение совокупности: 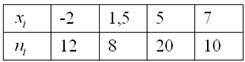
Составить эмпирическую функцию распределения, выполнить чертёж
Решаем самостоятельно – все числа уже в Экселе! Свериться с образцом можно в конце книги. По поводу красоты чертежа сильно не запаривайтесь, главное, чтобы было правильно – этого обычно достаточно для зачёта.
Из таблицы n=40, т.е.
n=4+10+6+8+7+5=40
Вычислим функцию распределения выборки 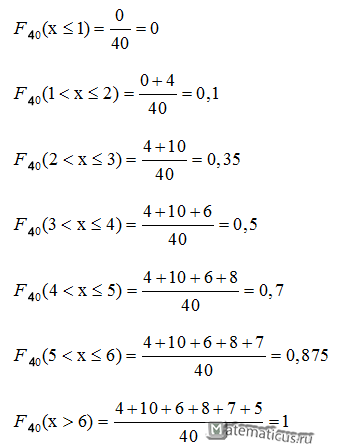
Эмпирическая функция распределения имеет вид

Построим график кусочно-постоянной эмпирической функции распределения
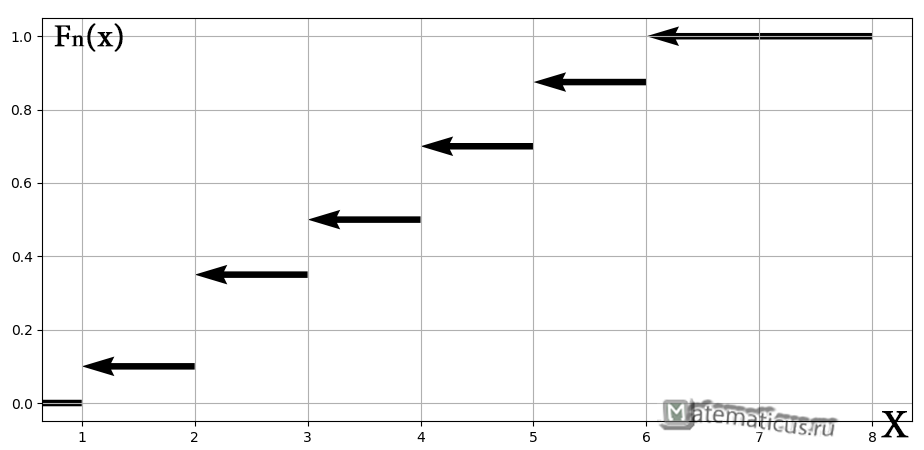
таким образом, по данным выборки можно приближенно построить функцию для неизвестной функции выборки.
2 комментария
У вас опечатка, где вы написали n=30, n=4+10+6+8+7+5=30 и F_30, так как n=40.
Построить эмпирическое распределение результатов тестирования в баллах для следующей выборки: 69, 85, 78, 85, 83, 81, 95, 88, 97, 92, 74, 83, 89, 77, 93.
В ячейку А1 введите слова Результаты, в диапазон А2:А16 – результаты тестирования.
Выберите ширину интервала 5 баллов. Тогда при крайних результатах 69 и 97 баллов, получится 7 интервалов. В ячейку С1 введите название интервалов Границы. В диапазон С2:С8 введите граничные значения интервалов: 70, 75, 80, 85, 90, 95, 100.
Введите заголовки создаваемой таблицы: в ячейку D1 – Абсолютные частоты, в ячейку Е1 – Относительные частоты, в F1 – Накопленные частоты.
Заполните столбец абсолютных частот. Для этого выделите для них блок ячеек D2:D8, вызовите Мастер функций, категория – Статистические, функция – Частота, в поле Массив данных введите диапазон данных тестирования А2:А16, в поле Массив интервалов введите диапазон интервалов С2:С8, нажмите комбинацию клавиш Ctrl+Shift+Enter. В столбце D2:D8 появится массив абсолютных частот.
В ячейке D9 найдите общее количество результатов тестирования, с помощью Автосумма.
Заполните столбец относительных частот. В ячейку Е2 введите формулу =$D2/$D$9 .
Протягиванием скопируйте полученное значение в диапазон Е3:Е8. Получим массив относительных частот.
Заполните столбец накопленных частот. В ячейку F2 скопируйте значение относительной частоты из ячейки Е2. В ячейку F3 введите формулу =F2+E3. Протягиванием скопируйте полученное значение в диапазон F4:F8. Получим массив накопленных частот.
В результате получим таблицу, представленную на рисунке 1.
Пусть Nх — число наблюдений, при которых значение признака Х меньше Х. При объеме выборки, равном П, относительная частота события Х XK.
Сама же функция F*(X) служит для оценки теоретической функции распределения F(X) генеральной совокупности.
Пример 3. Построить эмпирическую функцию по заданному распределению выборки:

Решение. Находим объем выборки: П = 10 + 15 + 25 = 50. Наименьшая варианта равна 2, поэтому F*(X) = 0 при Х ≤ 2. Значение Х 6. Напишем формулу искомой эмпирической функции:
4. Рассмотрим любой из критериев оценки качеств педагога-профессионала, например, «успешное решение задач обучения и воспитания». Ответ на этот вопрос анкеты типа «да», «нет» достаточно груб. Чтобы уменьшить относительную ошибку такого измерения, необходимо увеличить число возможных ответов на конкретный критериальный вопрос. В табл. 1 представлены возможные варианты ответов.
Обозначим этот параметр через х. Тогда в процессе ответа на вопрос величина х примет дискретное значение х, принадлежащее определенному интервалу значений. Поставим в соответствие каждому из ответов определенное числовое значение параметра х (см. табл. 1).
Интервальный вариационный ряд и его характеристики
Интервальный вариационный ряд – это ряд распределения, в котором однородные группы составлены по признаку, меняющемуся непрерывно или принимающему слишком много значений.
Здесь k — число интервалов, на которые разбивается ряд.
Размах вариации – это длина интервала, в пределах которой изменяется исследуемый признак: $ F=x_-x_ $
Правило Стерджеса
Эмпирическое правило определения оптимального количества интервалов k, на которые следует разбить ряд из N чисел: $ k=1+lfloorlog_2 Nrfloor $ или, через десятичный логарифм: $ k=1+lfloor 3,322cdotlg Nrfloor $
Скобка (lfloor rfloor) означает целую часть (округление вниз до целого числа).
Скобка (lceil rceil) означает округление вверх, в данном случае не обязательно до целого числа.
Заметим, что поскольку шаг h находится с округлением вверх, последний узел (a_kgeq x_).
Интервальный вариационный ряд и его характеристики: построение, гистограмма, выборочная дисперсия и СКО
Небольшое значение стандартного отклонения выражается в более «тощей и высокой кривой, плотно прижимающейся к среднему значению. Чем больше стандартное, тем «толще», ниже и растянутее получается кривая.

Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Получили следующий набор данных 18,38,28,29,26,38,34,22,28,30,22,23,35,33,27,24,30,32,28,25,29,26,31,24,29,27,32,24,29,29 Постройте интервальный ряд и исследуйте его. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Частота интервалов – число, показывающее сколько раз значения, относящиеся к каждому интервалу группировки, встречаются в выборке. Поделив эти числа на общее количество наблюдений (n), находят относительную частоту (частость) попадания случайной величины X в заданные интервалы.
Эмпирические распределения — Мегаобучалка
Существует также теоретическая функция распределения (функция распределения генеральной совокупности). Ее отличие от выборочной функции распределения состоит в определении объективной возможности или вероятности события X
Создание массива с нормальным распределением
Итак, чтобы сгенерировать массив данных с нормальным распределением, нам понадобится функция НОРМ.ОБР() – это обратная функция от НОРМ.РАСП(), которая возвращает нормально распределенную переменную для заданной вероятности для определенного среднего значения и стандартного отклонения. Синтаксис формулы выглядит следующим образом:
=НОРМ.ОБР(вероятность; среднее_значение; стандартное_отклонение)
Другими словами, я прошу Excel посчитать, какая переменная будет находится в вероятностном промежутке от 0 до 1. И так как вероятность возникновения продукта с весом в 100 грамм максимальная и будет уменьшаться по мере отдаления от этого значения, то формула будет выдавать значения близких к 100 чаще, чем остальных.
Давайте попробуем разобрать на примере. Выстроим график распределения вероятностей от 0 до 1 с шагом 0,01 для среднего значения равным 100 и стандартным отклонением 1,5.

Как видим из графика точки максимально сконцентрированы у переменной 100 и вероятности 0,5.
Этот фокус мы используем для генерирования случайного массива данных с нормальным распределением. Формула будет выглядеть следующим образом:
=НОРМ.ОБР(СЛЧИС(); среднее_значение; стандартное_отклонение)
Создадим массив данных для нашего примера со средним значением 100 грамм и стандартным отклонением 1,5 грамма и протянем нашу формулу вниз.

Теперь, когда массив данных готов, мы можем выстроить график с нормальным распределением.
Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Все несколько проще Данные- Анализ данных- Генерация случайных чисел Распределение Нормальное Данные- Анализ данных- Гистограмма- Галка на вывод графика Карманы можно даже не задавать. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
После того, как вы создали гистограмму, вам может потребоваться внести корректировки в то, как выглядит ваш график. Для изменения дизайна и стиля используйте вкладку “Конструктор”. Эта вкладка отображается на Панели инструментов, когда вы выделяете левой клавишей мыши гистограмму. С помощью дополнительных настроек в разделе “Конструктор” вы сможете:
8. Постройте диаграмму относительных и накопленных частот. Щелчком указателя мыши по кнопке Анализ данных вкладки Данные вызовите Пакет анализа, выберите в нем опцию Гистограмма и постройте график абсолютных и накопленных частот. После редактирования диаграмма будет иметь такой вид, как на рис. 2.
Как сменить строки и столбцы в гистограмме
Для того чтобы сменить порядок строк и столбцов в гистограмме проделайте следующие шаги:


Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Построить эмпирическое распределение веса студентов в килограммах для следующей выборки 64, 57, 63, 62, 58, 61, 63, 70, 60, 61, 65, 62, 62, 40, 64, 61, 59, 59, 63, 61. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
8. Постройте диаграмму относительных и накопленных частот. Щелчком указателя мыши по кнопке Анализ данных вкладки Данные вызовите Пакет анализа, выберите в нем опцию Гистограмма и постройте график абсолютных и накопленных частот. После редактирования диаграмма будет иметь такой вид, как на рис. 2.

Эмпирическая функция распределения
- автоматически рассчитаны интервалы значений (карманы);
- подсчитано количество значений из указанного массива данных, попадающих в каждый интервал (построена таблица частот);
- если поставлена галочка напротив пункта Вывод графика , то вместе с таблицей частот будет выведена гистограмма.
Размеры карманов одинаковы и равны 103,428571428571. Это значение можно получить так: =(МАКС( Исходные_данные )-МИН( Исходные_данные ))/7 где Исходные_данные – именованный диапазон , содержащий наши данные.
Как построить график
Построение графика эмпирической функции распределения возможно после вычисления ее значений на всей числовой оси. Для рассмотренного примера схематическое изображение будет выглядеть так:

Эмпирическая функция распределения
Гистограмма распределения – это инструмент, позволяющий визуально оценить величину и характер разброса данных. Создадим гистограмму для непрерывной случайной величины с помощью встроенных средств MS EXCEL из надстройки Пакет анализа и в ручную с помощью функции ЧАСТОТА() и диаграммы.
Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
И так как вероятность возникновения продукта с весом в 100 грамм максимальная и будет уменьшаться по мере отдаления от этого значения, то формула будет выдавать значения близких к 100 чаще, чем остальных. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Другими словами, я прошу Excel посчитать, какая переменная будет находится в вероятностном промежутке от 0 до 1. И так как вероятность возникновения продукта с весом в 100 грамм максимальная и будет уменьшаться по мере отдаления от этого значения, то формула будет выдавать значения близких к 100 чаще, чем остальных.
Характеристики нормального распределения
- Значения рассматриваемой функции F * (x) располагаются на отрезке [0; 1].
- Функция имеет неубывающий характер.
- При минимальной варианте x1 верно равенство F * (x)=0 при условии, что х1. При максимальной варианте хkверно равенство F * (x)=1 при условии х>xk.
Если выбор количества интервалов или их диапазонов не устраивает, то можно в диалоговом окне указать нужный массив интервалов (если интервал карманов включает текстовый заголовок, то нужно установить галочку напротив поля Метка ).
17 авг. 2022 г.
читать 3 мин
Выборочное распределение — это вероятностное распределение определенной статистики , основанное на множестве случайных выборок из одной совокупности .
В этом руководстве объясняется, как выполнить следующие действия с выборочными распределениями в Excel:
- Сгенерируйте выборочное распределение.
- Визуализируйте распределение выборки.
- Рассчитайте среднее значение и стандартное отклонение выборочного распределения.
- Рассчитайте вероятности относительно выборочного распределения.
Создание выборочного распределения в Excel
Предположим, мы хотим сгенерировать выборочное распределение, состоящее из 1000 выборок, в каждой из которых размер выборки равен 20 и происходит от нормального распределения со средним значением 5,3 и стандартным отклонением 9 .
Мы можем легко сделать это, введя следующую формулу в ячейку A2 нашего рабочего листа:
= NORM.INV ( RAND (), 5.3, 9)
Затем мы можем навести указатель мыши на правый нижний угол ячейки, пока не появится крошечный + , и перетащить формулу на 20 ячеек вправо и на 1000 ячеек вниз:
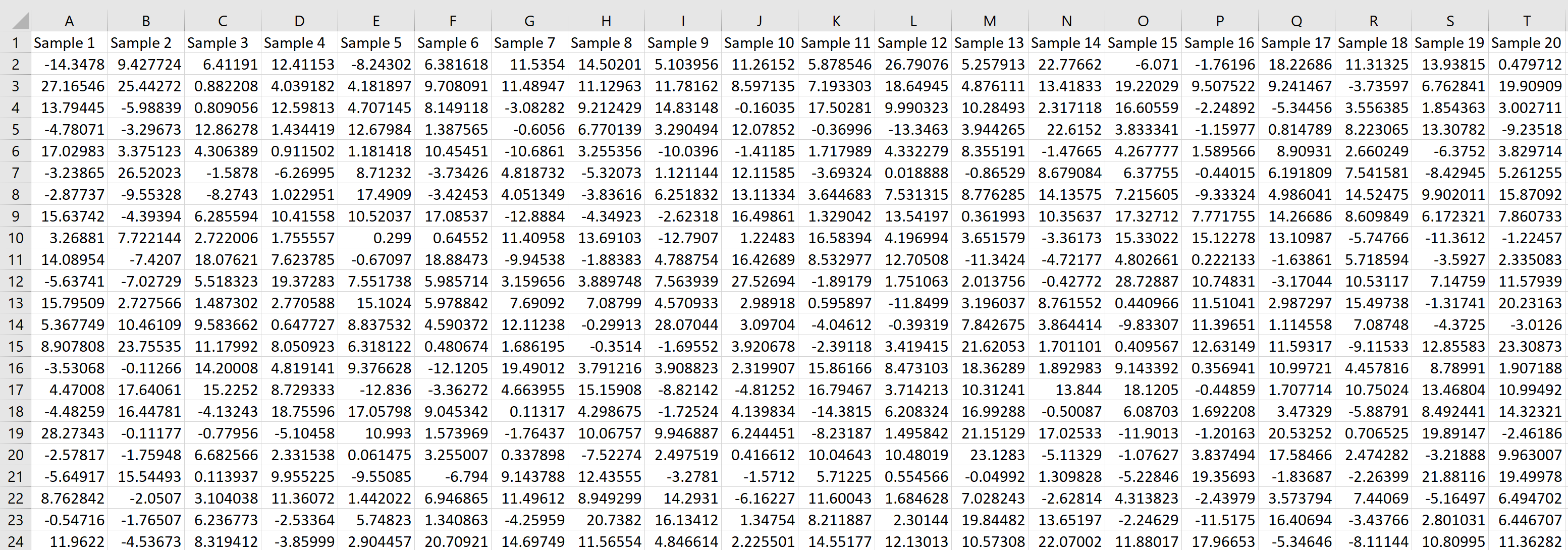
Каждая строка представляет выборку размера 20, в которой каждое значение получено из нормального распределения со средним значением 5,3 и стандартным отклонением 9.
Найдите среднее значение и стандартное отклонение
Чтобы найти среднее значение и стандартное отклонение этого выборочного распределения средних значений выборки, мы можем сначала найти среднее значение каждой выборки, введя следующую формулу в ячейку U2 нашего рабочего листа:
= AVERAGE (A2:T2)
Затем мы можем навести указатель мыши на правый нижний угол ячейки, пока не появится крошечный + , и дважды щелкнуть, чтобы скопировать эту формулу в каждую другую ячейку в столбце U:

Мы видим, что первая выборка имела среднее значение 7,563684, вторая выборка имела среднее значение 10,97299 и так далее.
Затем мы можем использовать следующие формулы для расчета среднего значения и стандартного отклонения среднего значения выборки:

Теоретически среднее значение выборочного распределения должно быть 5,3. Мы видим, что фактическое среднее значение выборки в этом примере равно 5,367869 , что близко к 5,3.
И теоретически стандартное отклонение выборочного распределения должно быть равно s/√n, что будет равно 9/√20 = 2,012. Мы видим, что фактическое стандартное отклонение выборочного распределения составляет 2,075396 , что близко к 2,012.
Визуализируйте распределение выборки
Мы также можем создать простую гистограмму для визуализации выборочного распределения выборочных средних.
Для этого просто выделите все средние значения выборки в столбце U, щелкните вкладку « Вставка », затем выберите параметр « Гистограмма » в разделе « Диаграммы ».
В результате получается следующая гистограмма:
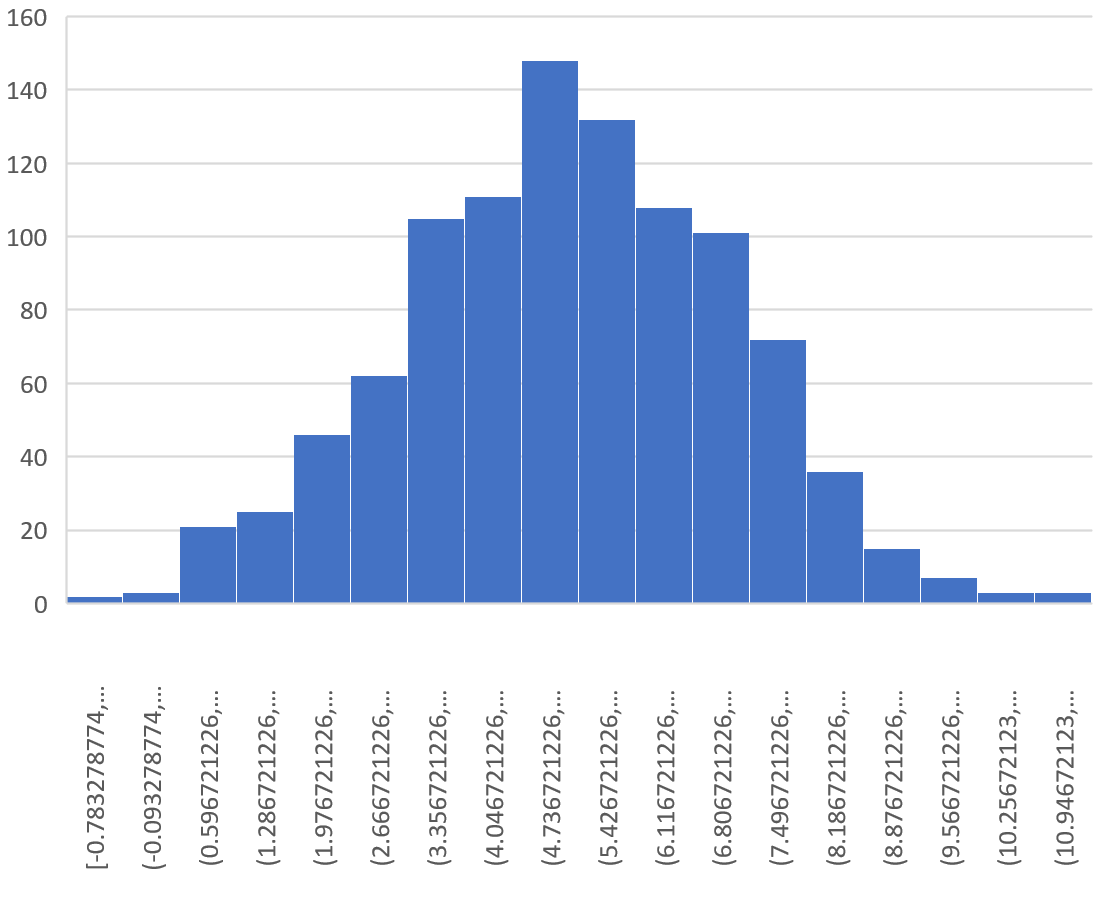
Мы видим, что распределение выборки имеет форму колокола с пиком около значения 5.
Однако из хвостов распределения мы можем видеть, что некоторые выборки имели средние значения больше 10, а некоторые — меньше 0.
Рассчитать вероятности
Мы также можем рассчитать вероятность получения определенного значения среднего значения выборки на основе среднего значения совокупности, стандартного отклонения совокупности и размера выборки.
Например, мы можем использовать следующую формулу, чтобы найти вероятность того, что среднее значение выборки меньше или равно 6, учитывая, что среднее значение генеральной совокупности равно 5,3, стандартное отклонение генеральной совокупности равно 9 и размер выборки равен:
= COUNTIF (U2:U1001, " <=6 ")/ COUNT (U2:U1001)
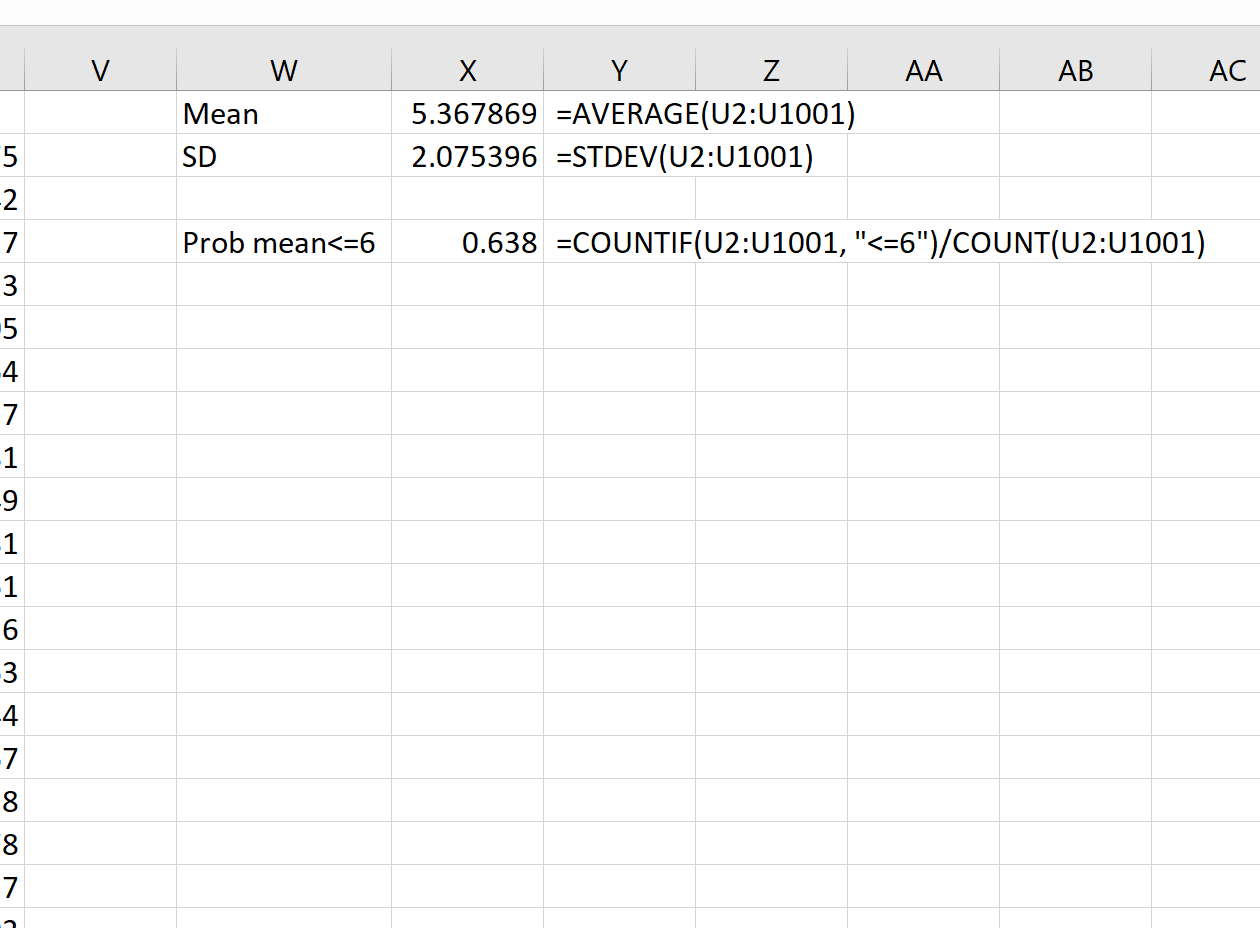
Мы видим, что вероятность того, что среднее значение выборки меньше или равно 6, составляет 0,638.
Это очень близко к вероятности, рассчитанной Калькулятором распределения выборки :

Дополнительные ресурсы
Введение в выборочные распределения
Калькулятор распределения выборки
Введение в центральную предельную теорему
ВАРИАЦИОННЫЕ РЯДЫ.
ВЫБОРОЧНАЯ ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ
- Авторы
- Файлы работы
- Сертификаты
Растеряев Н.В. 1, Елисеев С.А. 1
1Филиал Федерального государственного автономного образовательного учреждения высшего образования «Южный федеральный университет» в г. Новошахтинске Ростовской области (филиал ЮФУ в г. Новошахтинске)
Комментарии
Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке «Файлы работы» в формате PDF
овладеть навыками составления дискретных и интервальных вариационных рядов выборки, построения выборочной (эмпирической) функции распределения в среде ЭТ MS.
Краткая теория
Для решения задач, связанных с анализом данных при наличии случайных непредсказуемых воздействий, разработан математический аппарат ‒ математическая статистика, что позволяет выявлять закономерности на основе случайностей, делать на их основе обоснованные выводы и прогнозы.
Важнейшими понятиями математической статистики являются понятия генеральной совокупности и выборки.
Генеральной совокупностью наблюдаемого признака (случайной величины) Х называют множество всевозможных значений, принимаемых наблюдаемым признаком Х.
Часть отобранных объектов из генеральной совокупности называется выборочной совокупностью, или выборкой. Результаты измерений изучаемого признака nобъектов выборочной совокупности порождают nзначений х1, х2, … , хn случайной величины X . Число nназывается объемом выборки.
Выборку можно рассматривать двояко:
а) как случайный вектор длины n, каждая компонента которого имеет такое же распределение, как и наблюдаемый признак;
б) как на результаты измерений, т.е. набор n чисел.
Случайная величина Х называется дискретной случайной величиной, если она принимает свое значение из некоторого конечного фиксированного набора, например, случайная величина Х ‒ число появления шестерки при двух бросках игрального кубика
Х: 0,1,2 .
Случайная величина Х называется непрерывной случайной величиной, если она принимает любое значение из некоторого интервала (в том числе ‒ ∞ и +∞), например, рост человека.
После получения выборки имеем данные, которые представляют собой множество чисел, расположенных в беспорядке. Анализ таких данных весьма затруднителен, и для изучения скрытых закономерностей их подвергают определенной обработке.
Простейшая операция – ранжирование опытных данных, результатом которого являются значения, расположенные в порядке неубывания. Если среди элементов встречаются одинаковые, то они объединяются в одну группу. Значение случайной величины, соответствующее отдельной группе сгруппированного ряда наблюдаемых данных, называется вариантом, а изменение этого значения – варьированием. Варианты будем обозначать строчными буквами с соответствующими порядковому номеру группы индексами x(1) , x(2) , …, x(N) , где N – число групп. При этом x(1)< x(2)< … < x(N).
Численность отдельной группы сгруппированного ряда данных называется частотой ni , где i – индекс варианта, а отношение частоты данного варианта к общей сумме частот называется частностью (или относительной частотой) и обозначается ωi , i = 1, …,N , т.е.
ωi=nij=1Nnj ,
при этом j=1Nnj=n ‒ объему выборки.
Дискретным вариационным рядомназывается ранжированная совокупность вариантов x(i) с соответствующими им частотами niили частностями ωi .
Если число возможных значений дискретной случайной величины достаточно велико или наблюдаемая случайная величина является непрерывной, то строят интервальный вариационный ряд, под которым понимают упорядоченную совокупность интервалов варьирования значений случайной величины с соответствующими частотами или частностями попаданий в каждый из них значений случайной величины.
Как правило, частичные интервалы, на которые разбивается весь интервал варьирования, имеют одинаковую длину Δ, которая может быть вычислена по следующей формуле
∆=RN=xmax-xminN .
где R – размах варьирования (изменения) случайной величины;
xmax , xmin – наибольшее и наименьшее значения исследуемой случайной величины;
N – число частичных интервалов группировки.
Некоторые авторы рекомендуют пользоваться следующими эмпирическими формулами для определения числа интервалов:
, N = 5.lg(n) ,
N = 1 + 3,322.lg(n) ‒ формула Стерджеса.
В рекомендациях по стандартизации Р 50.1.033-2001 «Прикладная статистика. Правила проверки согласия опытного распределения с теоретическим. Часть I. Критерии типа хи-квадрат» рекомендует следующие значения N в зависимости от объема выборки n:
|
Объем выборки n |
Число интервалов группировки N |
|
40 ‒ 100 |
7 ‒ 9 |
|
100 ‒ 500 |
8 ‒ 12 |
|
500 ‒ 1000 |
10 ‒ 16 |
|
1000 ‒ 10000 |
12 ‒ 22 |
В теории вероятностей для характеристики распределения случайной величины служит функция распределения
,
определяющую для каждого значения х вероятность того, что случайная величина Х примет значение, меньшее х, т.е. равная вероятности события , где – любое действительное число.
Одной из основных характеристик выборки является выборочная (эмпирическая) функция распределения
,
где – количество элементов выборки, меньших чем . Другими словами, есть относительная частота появления события в n независимых испытаниях. Главное различие между и состоит в том, что определяет вероятность события A, а выборочная функция распределения – относительную частоту этого события.
Свойства функции :
1. .
2. – неубывающая функция.
3.
Функция является «ступенчатой», имеются разрывы в точках, которым соответствуют наблюдаемые значения вариантов. Величина скачка равна относительной частоте варианта.
Аналитически задается следующим соотношением:
Fn*x= 0 при x≤x1 ;j=1i-1ωj при x(i-1)x(N) ,
где – соответствующие относительные частоты;
– элементы вариационного ряда (варианты).
Замечание. В случае интервального вариационного ряда под понимается середина i-го частичного интервала. Эмпирическую функцию распределения непрерывной случайной величины так же называют «накопленная частота».
Перед вычислением полезно построить дискретный или интервальный вариационный ряд.
Пример выполнения
Постановка задачи 1. На телефонной станции проводились наблюдения над числом неправильных соединений в минуту. Наблюдения в течение 30 минут дали следующие результаты (табл. 1).
Таблица 1.
|
3 |
0 |
1 |
5 |
1 |
2 |
4 |
5 |
3 |
4 |
|
2 |
4 |
2 |
0 |
2 |
3 |
1 |
3 |
2 |
1 |
|
4 |
3 |
0 |
2 |
1 |
0 |
4 |
2 |
3 |
2 |
Требуется найти дискретный вариационный ряд, выборочную (эмпирическую) функцию распределения данной выборки и построить ее график в среде ЭТ MS Excel.
Решение.
Очевидно, что число X является дискретной случайной величиной, а полученные данные есть значения этой случайной величины.
В результате выполнения операций ранжирования и группировки были получены шесть значений случайной величины (варианты): 0; 1; 2; 3; 4; 5. При этом значение 0 в этой группе встречается 4 раза, значение 1 – 5 раз, значение 2 – 8 раз, значение 3 – 6 раз, значение 4 – 5 раз, значение 5 – 2 раза. Вычисленные значения частот и частностей приведены в табл. 2.
Таблица 2.
|
Индекс |
1, 2, 3, 4, 5, 6 |
|
|
Вариант |
0, 1, 2, 3, 4, 5 |
|
|
Частота |
4, 5, 8, 6, 5, 2 |
|
|
Частность |
Используя данный дискретный вариационный ряд (см. табл. 2), вычислим значения по формуле, приведенной выше, и занесем их в табл. 3.
Таблица 3.
|
x |
|
|
x 0 |
0 |
|
0 < x 1 |
|
|
1 < x 2 |
|
|
2 < x 3 |
|
|
3 < x 4 |
|
|
4 < x 5 |
|
|
x > 5 |
По данным таблицы 3 построим график эмпирической функции распределения.
Решение задачи в среде ЭТ MSExcel. Для решения задачи в среде ЭТ MS Excel необходимо выполнить следующие действия:
1. Идентифицируйте свою работу, переименовав Лист1 в Титульный лист и записав номер лабораторной работы, ее название, кто выполнил и проверил.
2. Переименуйте Лист 2 в Дискретный. Наберите массив 30 значений исходных данных выборки.
3. Найдите величины хmax, хmin, n, используя встроенные функции Excel МАКС, МИН и СЧЕТ.
4. Сформируйте столбец вариант x(i)от 0 до 5 и с помощью функции ЧАСТОТА найдите частоту появления значений случайной величины Х в данном интервале.
Синтаксис функции:
ЧАСТОТА(массив данных;массив интервалов).
Массив данных ‒ массив или ссылка на множество данных, для которых вычисляются частоты. В нашем случае это диапазон B2:K2. Если массив данных не содержит значений, то функция ЧАСТОТА возвращает массив нулей.
Массив интервалов ‒ массив или ссылка на множество интервалов, в которые группируются значения аргумента массив данных. В нашем случае это диапазон F7:F12. Если массив интервалов не содержит значений, то функция ЧАСТОТА возвращает количество элементов в аргументе Массив данных.
Функция ЧАСТОТА вводится как формула массива после выделения интервала смежных ячеек, в которые нужно вернуть полученный массив частот.
Количество элементов в возвращаемом массиве на единицу больше числа элементов в массиве интервалов. Дополнительный элемент в возвращаемом массиве содержит количество значений, больших, чем максимальное значение в интервалах, т.е. больше 5 в нашем случае.
Поскольку данная функция возвращает массив, она должна задаваться в качестве формулы массива и работа с ней завершается трехклавишной комбинацией CTRL+SHIFT+ENTER.
Функция ЧАСТОТА игнорирует пустые ячейки и тексты.
5. Сформируйте столбец частностей, вычислив значения ωi , i = 1, …,6 по формуле
ωi=nin .
6. Сформируйте столбец значений выборочной функции распределения . При этом первое значение в ячейке I7 просто копируется из ячейки Н7.
Следующее значение вычисляется как накопленная сумма предыдущего значения ω1 из ячейки I7 и текущего значения ω2 из ячейки Н8:
=I7+H8 .
Затем данная формула копируется автозаполнением в остальные ячейки диапазона, с выходом на значение, равное 1.
7. Построим график эмпирической функции распределения. С использованием штатных средств Мастера диаграмм ЭТ MS Excel построить ступенчатый график функции распределения дискретной случайной величины нельзя.
Покажем, как в MS Excel все-таки можно построить такой график.
7.1. Расположим данные полученного дискретного вариационного ряда так, как показано на рисунке ниже.
При этом данные копируются из предыдущей таблицы. Используют контекстное меню команды Вставка: Параметры вставки → Значения
7.2. В разреженную таким образом таблицу введем ряд дополнений. В ячейку К7 введем значение -2, а в ячейку К20 значение 7, это границы интервала [-2 ;7] на котором будет построен наш график. В оставшиеся пустые ячейки введем значения, чуть меньшие значений полученных вариант (см. случай а) ниже).
Два первых значения функции F(x) в ячейках L7 и L8 примем равным нулю, т.к. при x ≤ x(1) . В оставшиеся пустые ячейки скопируем значения функции, расположенные выше (см. случай б) выше).
7.3. По данным, находящимся в диапазоне ячеек K7:L20, с помощью Мастера диаграмм, построим диаграмму типа Точечная без маркеров. Отформатируем диаграмму, убрав маркеры и задав линию, соединяющую табличные значения.
Т.к. функция ‒ непрерывна слева в любой точке x, т. е. , то устраним неоднозначность в точках разрыва, “вырезав” соответствующие значения. Для этого построим точечный график по данным первого и последнего столбца полученного дискретного вариационного ряда.
8. Постройте пунктирные линии в вырезанных точках графика. Для этого выделим точки графика и на вкладке Макет в группе Анализ нажмём кнопку Планки погрешностей, а затем выберем строку Дополнительные параметры планок погрешностей … .
В диалоговом окне Формат планок погрешностей выполните установки, представленные ниже. Установите радиокнопку – пользовательская и в появившемся окне, в поле ввода Отрицательное значение ошибки введите значения столбца F(x).
Получили график функции распределения с пунктирными линиями.
9. Сделайте выводы и сохраните работу в вашем каталоге.
Постановка задачи 2. Исследуется рост учащихся (в сантиметрах) в студенческой группе из 25 человек. Получена выборка (см. табл. 4) из следующих 25 значений.
Таблица 4.
|
184 |
182 |
182 |
180 |
177 |
|
179 |
173 |
179 |
192 |
173 |
|
190 |
163 |
177 |
186 |
170 |
|
178 |
185 |
173 |
179 |
165 |
|
179 |
173 |
179 |
166 |
170 |
Требуется: найти интервальныйвариационный ряд, выборочную (эмпирическую) функцию распределения данной выборки и построить ее график в среде ЭТ MS Excel.
Решение.
Найдем максимальное и минимальное значения в исследуемой выборке
xmax=192 , xmin=163 см.
Вычислим размах варьирования R исследуемого признака по формуле
R=xmax-xmin=29.
Для нахождения числа интервалов группировки N воспользуемся формулой
N≈n=25=5.
Далее следует группировка выборки. При этом интервал варьирования признака [xmin, xmax] разбивается на N интервалов группировки одинаковой длины ∆, а затем подсчитывается число попаданий признака в j-й интервал группировки – ni,i=.
∆=RN=xmax-xminN =5,8≈6.
При этом каждый интервал группировки Δi= (ai;bi) характеризуется своим правым и левым концом, числом ni – попаданием признака в этот интервал. Иногда интервал характеризуют не границами, а его средним значением.
Дальнейшие вычисления удобно представить в табл. 5.
Таблица 5.
|
i |
Интервал группировки Δi |
Кол-во попаданий в интервал |
Частоты ni |
Относительные частоты ωi=nin |
Накопленные частоты |
|
1 |
162,5-168,5 |
│││ |
3 |
3/25 |
3/25 |
|
2 |
168,5-174,5 |
│││││ │ |
6 |
6/25 |
9/25 |
|
3 |
174,5-180,5 |
│││││ ││││ |
9 |
9/25 |
18/25 |
|
4 |
180,5-186,5 |
│││││ |
5 |
5/25 |
23/25 |
|
5 |
186,5-192,5 |
││ |
2 |
2/25 |
252/25 = 1 |
|
∑ |
25 |
1 |
Чтобы значение исследуемого признака не попадало на границы интервала группировки, примем минимальное значение признака не 163, а 162,5 и от этого значения начнем строить интервалы длиной Δ = 6 (см. второй столбец табл. 5).
Откладывая по оси абсцисс средние значения интервалов группировки, а по оси ординат – значения накопленных частот, строим график эмпирической функции растределения.
Решение задачи в среде ЭТ MSExcel. Для решения задачи в среде ЭТ MS Excel необходимо выполнить следующие действия:
1. Переименуйте Лист 3 в Непрерывный. Наберите массив 25 значений исходных данных выборки.
2. Найдите величины хmax, хmin, n, N, Δокругл используя встроенные функции Excel МАКС, МИН, СЧЕТ, КОРЕНЬ и ОКРУГЛ.
3. Сформируйте столбец интервалов варьирования от значения 162,5 с шагом Δ = 6. Первое значение набираем с клавиатуры, а второе вычисляем с помощью формулы
=E9+$C$13 .
Остальные значения получим копированием с помощью Автозаполнения.
4. Сформируйте столбец Частота и с помощью функции ЧАСТОТА найдите частоту появления значений исследуемой случайной величины Х в каждом из интервалов.
5. Заполните столбец относительных частот, рассчитав значение в ячейке G9 по формуле
=F9/$C$10 .
Остальные значения получим копированием формулы с помощью Автозаполнения.
6. Вычислите середины интервалов группировки, рассчитав значение в ячейке Н9 по формуле
=(E9+E10)/2 .
Остальные значения в диапазоне Н10:Н13 получим копированием формулы с помощью Автозаполнения.
7. Заполните столбец накопленных частот. При этом, значение в ячейке I9 получим, копируя значение ячейки G10 по формуле
=G10 .
Значение в ячейке I10 получим по формуле
=I9+G11 .
Остальные значения в диапазоне I11:I13 получим, копируя формулу с помощью Автозаполнения.
8. По данным двух последних столбцов построим график эмпирической функции распределения.
9. Сделайте выводы и сохраните работу в вашем каталоге.
Лист Excel лабораторной работы имеет вид, представленный на рисунке.
Исходные данные для самостоятельного решения
Задание 1. Имеется выборка непрерывной случайной величины объема n = 26 (табл. 6).
Задание 2. Имеется выборка дискретной случайной величины объема n = 30 (табл. 7).
Требуется: найти дискретный и интервальныйвариационные ряды, выборочную (эмпирическую) функцию распределения данных выборок и построить их графики в среде ЭТ MS Excel.
Таблица 6.
|
№ варианта |
Выборка |
||||||||||||
|
1 |
11,7 |
9,83 |
5,49 |
7,43 |
9,92 |
3,41 |
6,83 |
8,22 |
8,30 |
8,14 |
9,29 |
9,27 |
7,43 |
|
7,41 |
3,56 |
7,72 |
12,1 |
6,06 |
10,6 |
6,76 |
8,21 |
9,86 |
8,13 |
9,04 |
4,75 |
9,33 |
|
|
2 |
4,49 |
9,25 |
7,94 |
9,10 |
6,27 |
6,77 |
3,47 |
8,84 |
6,48 |
4,92 |
6,98 |
10,1 |
6,32 |
|
6,36 |
5,16 |
7,92 |
12,0 |
7,46 |
7,01 |
13,0 |
7,34 |
6,71 |
5,48 |
9,95 |
11,9 |
8,89 |
|
|
3 |
6,13 |
8,56 |
9,77 |
9,17 |
8,89 |
6,19 |
7,70 |
6,96 |
6,72 |
6,08 |
4,41 |
5,52 |
9,59 |
|
9,02 |
6,22 |
4,86 |
6,33 |
6,28 |
8,60 |
7,38 |
7,84 |
7,24 |
6,85 |
6,50 |
8,28 |
4,98 |
|
|
4 |
6,52 |
9,27 |
7,91 |
5,77 |
8,02 |
3,07 |
2,22 |
5,76 |
11,6 |
6,62 |
7,07 |
12,5 |
1,65 |
|
10,5 |
3,67 |
7,62 |
4,94 |
5,39 |
3,64 |
4,62 |
8,88 |
6,75 |
5,77 |
6,38 |
10,3 |
5,74 |
|
|
5 |
8,18 |
9,56 |
6,06 |
5,85 |
6,78 |
5,60 |
10,8 |
7,70 |
6,44 |
8,64 |
6,95 |
5,66 |
4,84 |
|
4,96 |
4,62 |
5,57 |
6,47 |
5,97 |
8,02 |
3,66 |
9,24 |
4,13 |
6,58 |
7,51 |
5,67 |
7,89 |
|
|
6 |
10,2 |
9,23 |
8,77 |
10,4 |
9,44 |
9,09 |
6,30 |
9,42 |
6,12 |
9,69 |
8,59 |
8,68 |
7,97 |
|
8,64 |
6,45 |
5,29 |
5,00 |
8,42 |
8,84 |
8,26 |
6,66 |
6,96 |
6,51 |
6,72 |
6,00 |
5,36 |
|
|
7 |
7,13 |
9,12 |
9,77 |
9,17 |
8,89 |
6,19 |
7,71 |
6,96 |
6,72 |
6,08 |
4,41 |
5,52 |
9,59 |
|
8,06 |
6,26 |
4,86 |
6,33 |
6,28 |
8,60 |
7,38 |
7,84 |
7,24 |
6,85 |
6,50 |
8,28 |
4,98 |
|
|
8 |
3,53 |
9,56 |
7,03 |
9,18 |
7,45 |
5,59 |
6,85 |
11,3 |
7,90 |
6,00 |
6,68 |
5,66 |
8,64 |
|
8,87 |
4,58 |
11,3 |
5,02 |
4,33 |
9,31 |
10,3 |
5,99 |
6,98 |
5,23 |
8,75 |
7,73 |
9,16 |
|
|
9 |
3,38 |
7,87 |
4,04 |
8,21 |
4,08 |
3,46 |
4,37 |
6,66 |
1,46 |
5,59 |
3,78 |
8,73 |
5,57 |
|
8,22 |
3,25 |
3,38 |
4,20 |
2,49 |
6,11 |
4,54 |
6,53 |
5,20 |
3,84 |
5,35 |
9,72 |
4,63 |
|
|
10 |
4,21 |
5,68 |
3,45 |
6,79 |
3,39 |
2,99 |
3,88 |
3,77 |
1,43 |
5,96 |
4,94 |
6,55 |
5,92 |
|
4,20 |
4,25 |
5,64 |
5,58 |
5,87 |
5,05 |
3,55 |
7,95 |
4,45 |
5,85 |
6,68 |
1,24 |
7,09 |
Таблица 7.
|
№ варианта |
Выборка |
||||||||||||||
|
1 |
4 |
0 |
2 |
5 |
1 |
2 |
4 |
5 |
3 |
4 |
4 |
0 |
1 |
5 |
1 |
|
2 |
3 |
2 |
0 |
2 |
3 |
1 |
3 |
2 |
1 |
2 |
4 |
2 |
0 |
2 |
|
|
2 |
2 |
0 |
3 |
5 |
1 |
2 |
4 |
5 |
3 |
4 |
4 |
0 |
1 |
5 |
1 |
|
1 |
3 |
4 |
0 |
2 |
3 |
1 |
3 |
2 |
1 |
2 |
4 |
2 |
0 |
2 |
|
|
3 |
2 |
3 |
2 |
0 |
2 |
3 |
1 |
1 |
2 |
3 |
2 |
4 |
2 |
0 |
2 |
|
2 |
0 |
3 |
5 |
1 |
2 |
4 |
5 |
3 |
4 |
4 |
0 |
1 |
5 |
1 |
|
|
4 |
4 |
2 |
1 |
5 |
1 |
2 |
4 |
5 |
3 |
4 |
4 |
0 |
1 |
5 |
1 |
|
3 |
3 |
4 |
0 |
2 |
3 |
1 |
3 |
2 |
1 |
2 |
4 |
2 |
0 |
2 |
|
|
5 |
2 |
3 |
4 |
0 |
2 |
1 |
2 |
3 |
2 |
1 |
2 |
2 |
4 |
0 |
2 |
|
4 |
3 |
2 |
2 |
1 |
3 |
1 |
3 |
2 |
2 |
1 |
4 |
2 |
2 |
0 |
|
|
6 |
2 |
3 |
2 |
1 |
2 |
2 |
4 |
0 |
2 |
4 |
4 |
0 |
1 |
5 |
1 |
|
1 |
3 |
2 |
2 |
1 |
4 |
2 |
2 |
0 |
1 |
2 |
4 |
2 |
0 |
2 |
|
|
7 |
4 |
3 |
2 |
2 |
5 |
3 |
1 |
3 |
2 |
2 |
1 |
4 |
2 |
2 |
0 |
|
2 |
3 |
2 |
1 |
2 |
2 |
4 |
0 |
2 |
4 |
4 |
0 |
1 |
5 |
1 |
|
|
8 |
5 |
3 |
4 |
4 |
0 |
1 |
5 |
1 |
2 |
2 |
1 |
4 |
2 |
2 |
0 |
|
3 |
2 |
1 |
2 |
4 |
2 |
0 |
2 |
2 |
0 |
4 |
0 |
1 |
5 |
1 |
|
|
9 |
2 |
3 |
2 |
1 |
2 |
2 |
4 |
0 |
2 |
4 |
4 |
0 |
1 |
5 |
1 |
|
5 |
3 |
4 |
4 |
0 |
1 |
5 |
1 |
2 |
2 |
1 |
4 |
2 |
2 |
0 |
|
|
10 |
0 |
2 |
3 |
5 |
1 |
2 |
4 |
5 |
3 |
4 |
4 |
0 |
1 |
5 |
1 |
|
4 |
2 |
1 |
5 |
1 |
2 |
4 |
5 |
3 |
4 |
4 |
0 |
1 |
5 |
1 |
Просмотров работы: 10656
Код для цитирования: