
Содержание
- Подключение пакета анализа
- Виды регрессионного анализа
- Линейная регрессия в программе Excel
- Разбор результатов анализа
- Вопросы и ответы

Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Подключение пакета анализа
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
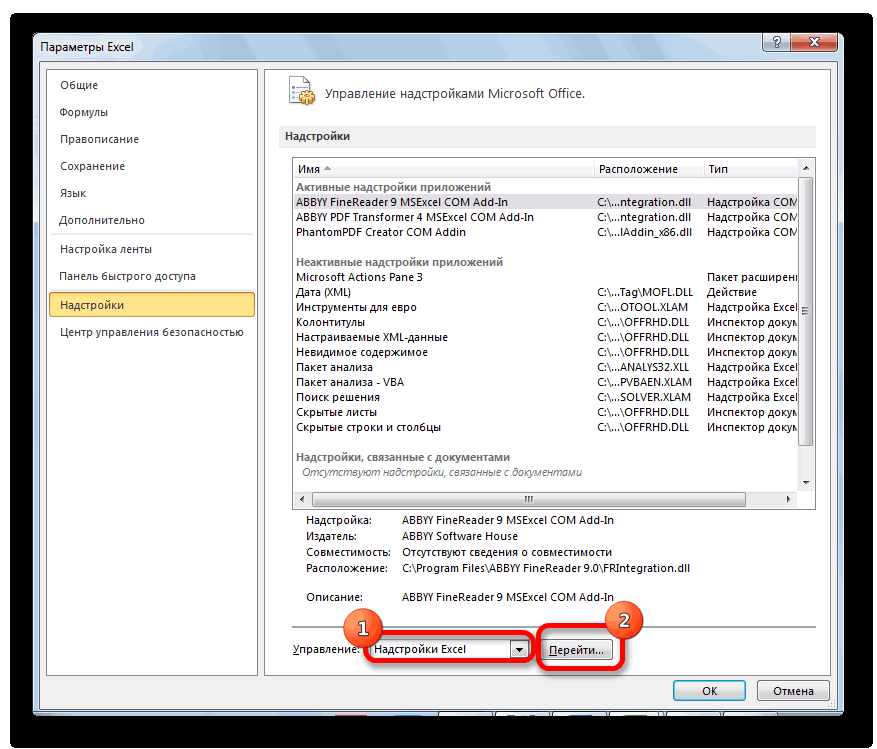
- Перемещаемся во вкладку «Файл».
- Переходим в раздел «Параметры».
- Открывается окно параметров Excel. Переходим в подраздел «Надстройки».
- В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».
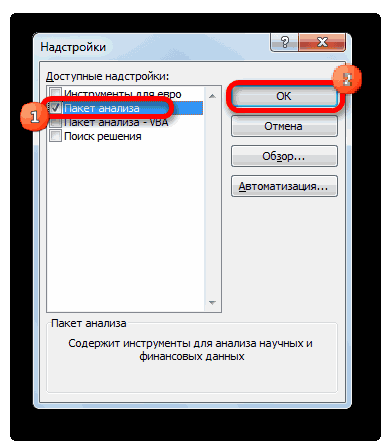
- Открывается окно доступных надстроек Эксель. Ставим галочку около пункта «Пакет анализа». Жмем на кнопку «OK».





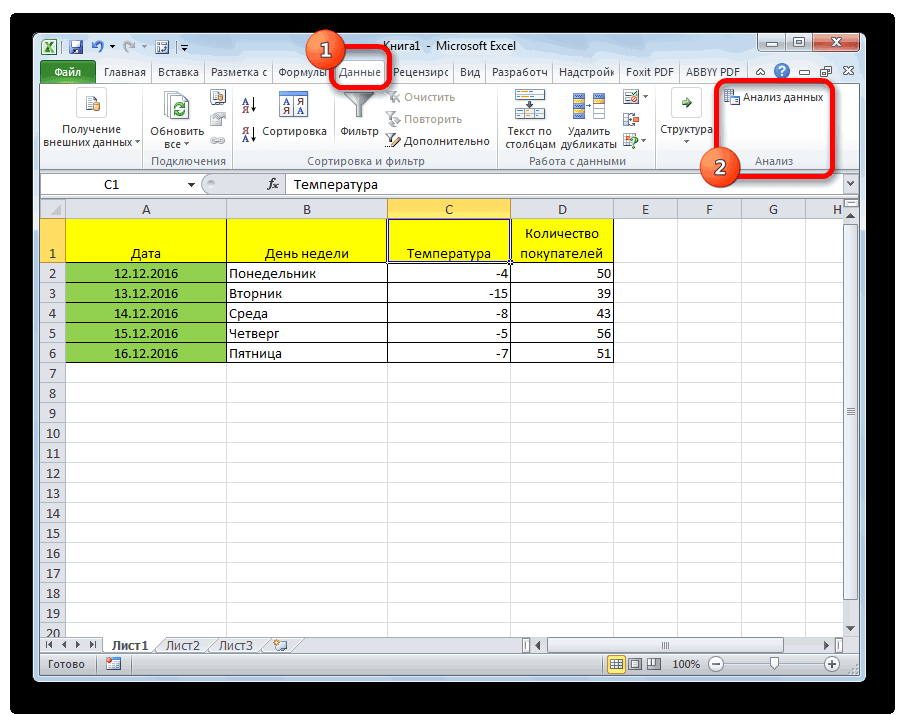
Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».

Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк. В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.
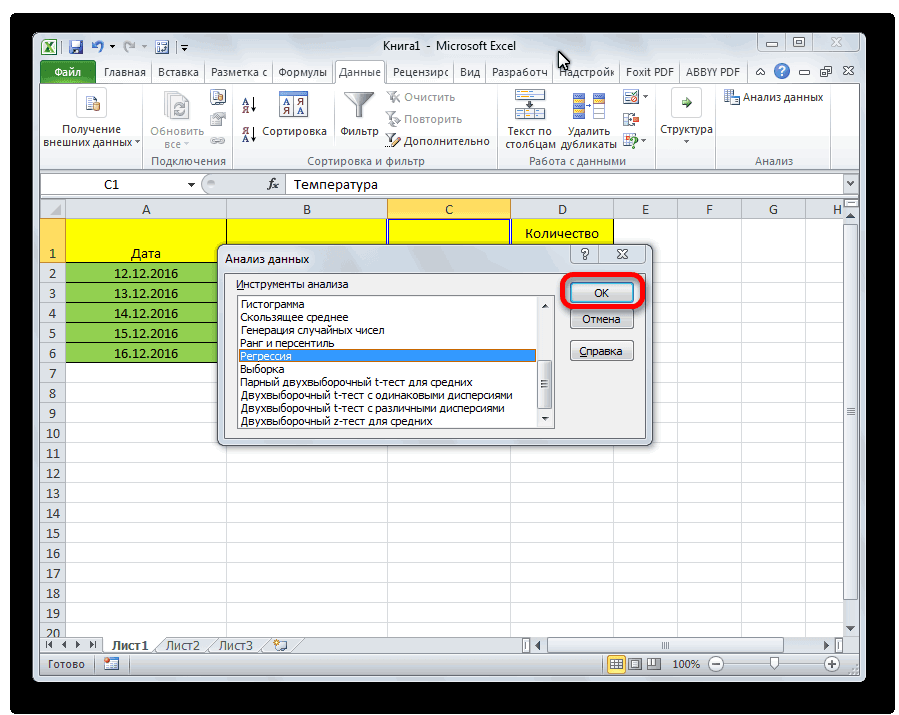
- Кликаем по кнопке «Анализ данных». Она размещена во вкладке «Главная» в блоке инструментов «Анализ».
- Открывается небольшое окошко. В нём выбираем пункт «Регрессия». Жмем на кнопку «OK».
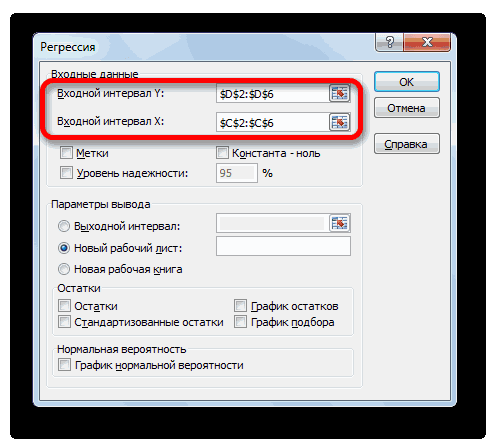
- Открывается окно настроек регрессии. В нём обязательными для заполнения полями являются «Входной интервал Y» и «Входной интервал X». Все остальные настройки можно оставить по умолчанию.
В поле «Входной интервал Y» указываем адрес диапазона ячеек, где расположены переменные данные, влияние факторов на которые мы пытаемся установить. В нашем случае это будут ячейки столбца «Количество покупателей». Адрес можно вписать вручную с клавиатуры, а можно, просто выделить требуемый столбец. Последний вариант намного проще и удобнее.
В поле «Входной интервал X» вводим адрес диапазона ячеек, где находятся данные того фактора, влияние которого на переменную мы хотим установить. Как говорилось выше, нам нужно установить влияние температуры на количество покупателей магазина, а поэтому вводим адрес ячеек в столбце «Температура». Это можно сделать теми же способами, что и в поле «Количество покупателей».

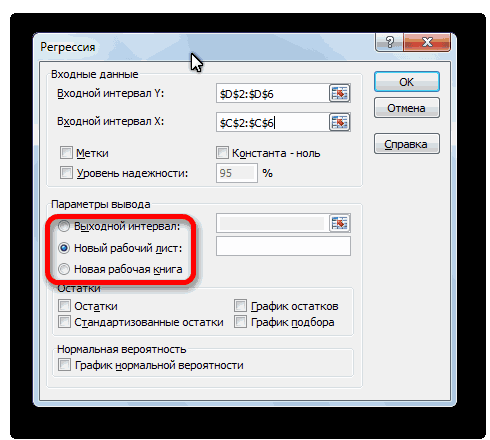
С помощью других настроек можно установить метки, уровень надёжности, константу-ноль, отобразить график нормальной вероятности, и выполнить другие действия. Но, в большинстве случаев, эти настройки изменять не нужно. Единственное на что следует обратить внимание, так это на параметры вывода. По умолчанию вывод результатов анализа осуществляется на другом листе, но переставив переключатель, вы можете установить вывод в указанном диапазоне на том же листе, где расположена таблица с исходными данными, или в отдельной книге, то есть в новом файле.
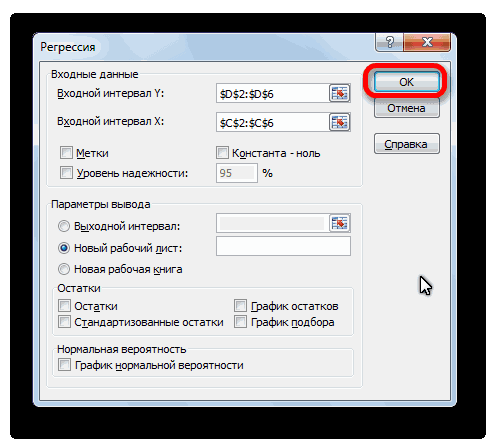
После того, как все настройки установлены, жмем на кнопку «OK».




Разбор результатов анализа
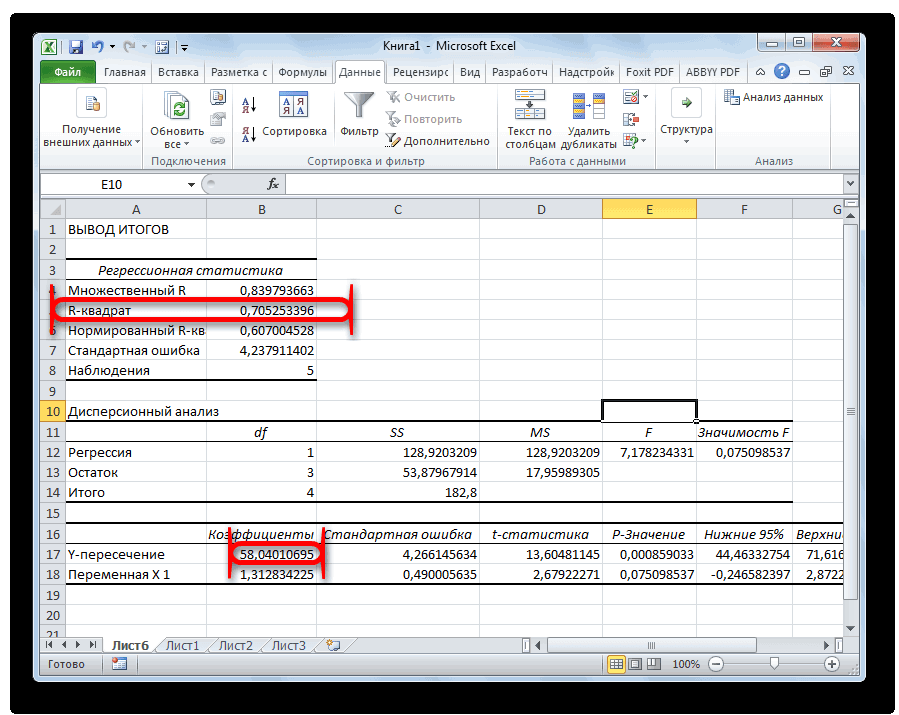
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Простая линейная регрессия — это метод, который мы можем использовать для понимания взаимосвязи между объясняющей переменной x и переменной отклика y.
В этом руководстве объясняется, как выполнить простую линейную регрессию в Excel.
Пример: простая линейная регрессия в Excel
Предположим, нас интересует взаимосвязь между количеством часов, которое студент тратит на подготовку к экзамену, и полученной им экзаменационной оценкой.
Чтобы исследовать эту взаимосвязь, мы можем выполнить простую линейную регрессию, используя часы обучения в качестве независимой переменной и экзаменационный балл в качестве переменной ответа.
Выполните следующие шаги в Excel, чтобы провести простую линейную регрессию.
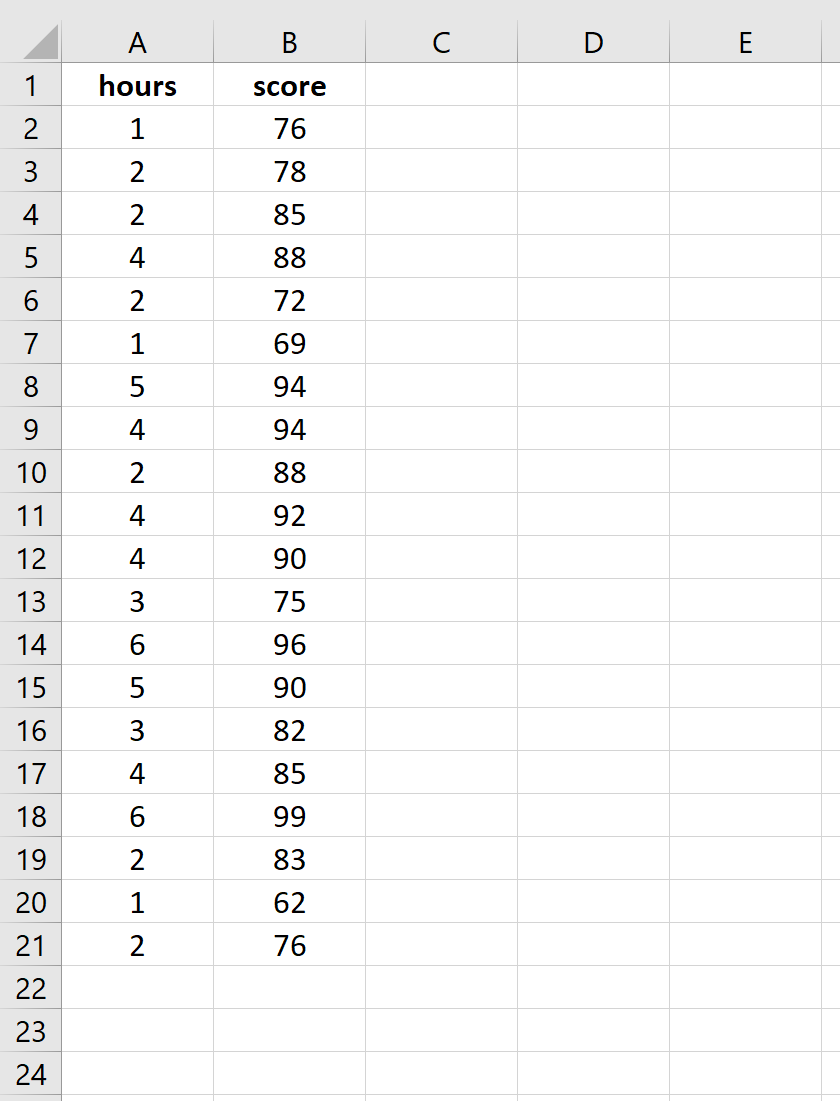
Шаг 1: Введите данные.
Введите следующие данные о количестве часов обучения и экзаменационном балле, полученном для 20 студентов:
Шаг 2: Визуализируйте данные.
Прежде чем мы выполним простую линейную регрессию, полезно создать диаграмму рассеяния данных, чтобы убедиться, что действительно существует линейная зависимость между отработанными часами и экзаменационным баллом.
Выделите данные в столбцах A и B. В верхней ленте Excel перейдите на вкладку « Вставка ». В группе « Диаграммы » нажмите « Вставить разброс» (X, Y) и выберите первый вариант под названием « Разброс ». Это автоматически создаст следующую диаграмму рассеяния:
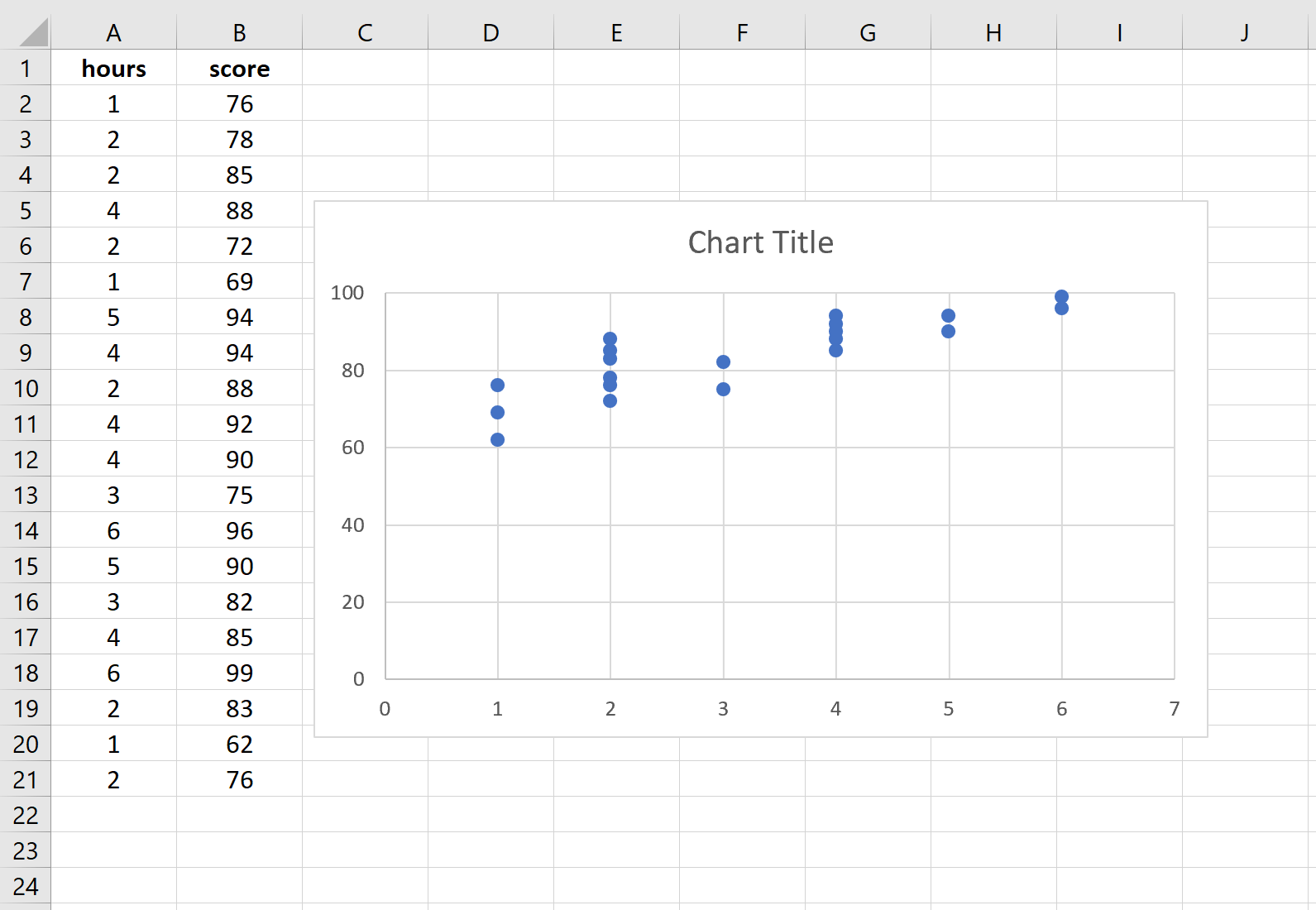
Количество часов обучения показано на оси x, а баллы за экзамены показаны на оси y. Мы видим, что между двумя переменными существует линейная зависимость: большее количество часов обучения связано с более высокими баллами на экзаменах.
Чтобы количественно оценить взаимосвязь между этими двумя переменными, мы можем выполнить простую линейную регрессию.
Шаг 3: Выполните простую линейную регрессию.
В верхней ленте Excel перейдите на вкладку « Данные » и нажмите « Анализ данных».Если вы не видите эту опцию, вам необходимо сначала установить бесплатный пакет инструментов анализа .

Как только вы нажмете « Анализ данных», появится новое окно. Выберите «Регрессия» и нажмите «ОК».
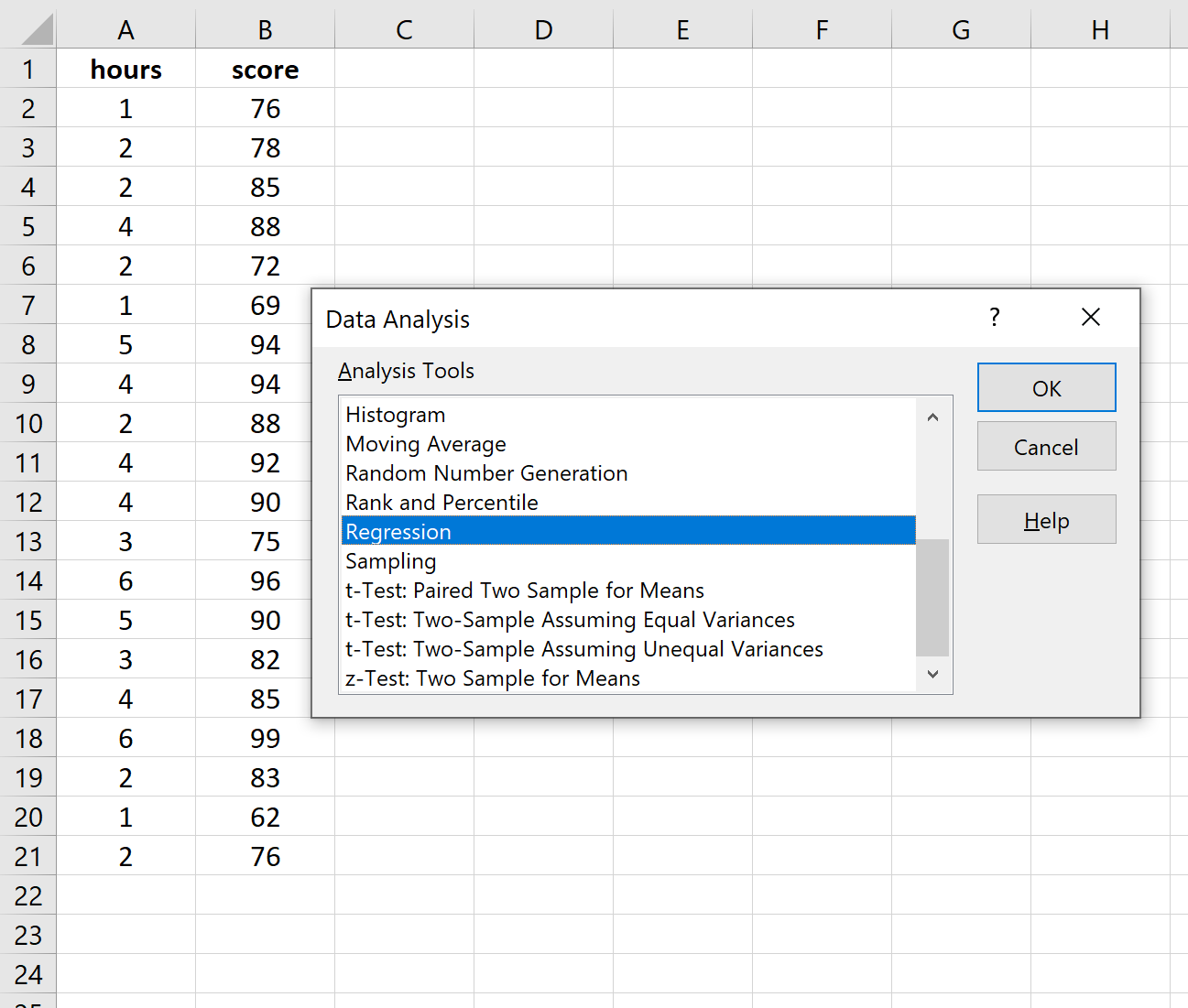
Для Input Y Range заполните массив значений для переменной ответа. Для Input X Range заполните массив значений для независимой переменной.
Установите флажок рядом с Метки , чтобы Excel знал, что мы включили имена переменных во входные диапазоны.
В поле Выходной диапазон выберите ячейку, в которой должны отображаться выходные данные регрессии.
Затем нажмите ОК .
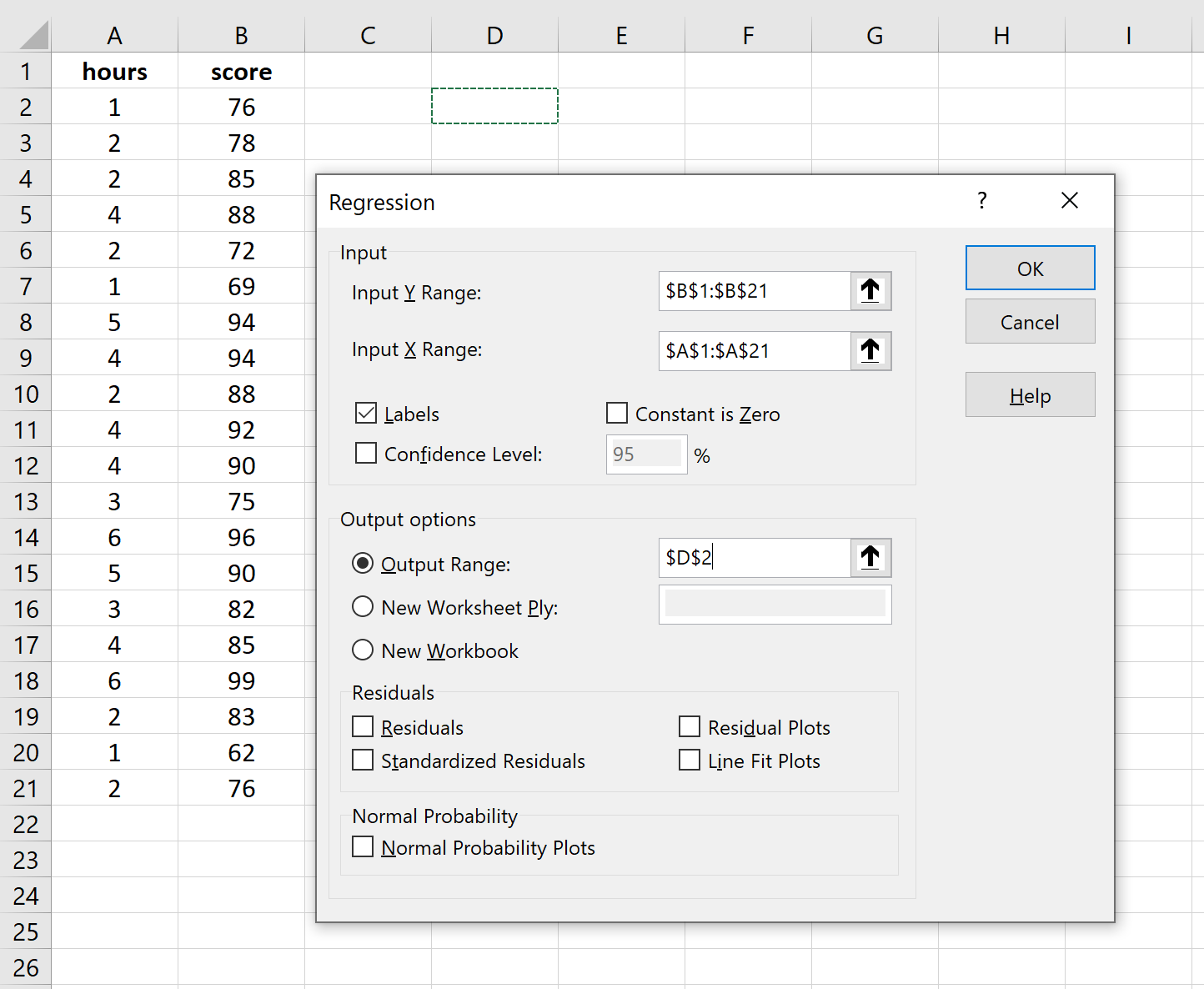
Автоматически появится следующий вывод:
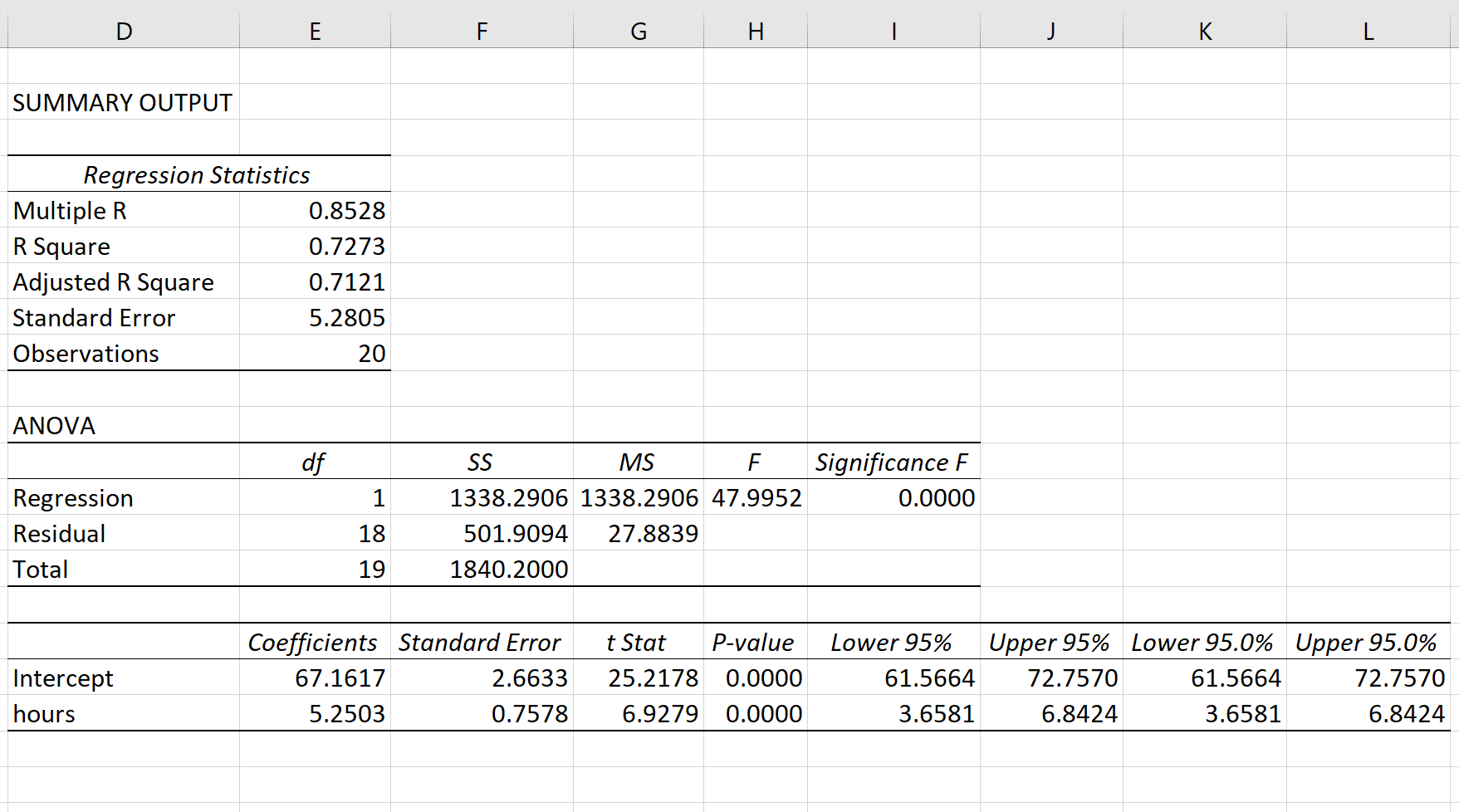
Шаг 4: Интерпретируйте вывод.
Вот как интерпретировать наиболее релевантные числа в выводе:
R-квадрат: 0,7273.Это известно как коэффициент детерминации. Это доля дисперсии переменной отклика, которая может быть объяснена объясняющей переменной. В этом примере 72,73 % различий в баллах за экзамены можно объяснить количеством часов обучения.
Стандартная ошибка: 5.2805.Это среднее расстояние, на которое наблюдаемые значения отходят от линии регрессии. В этом примере наблюдаемые значения отклоняются от линии регрессии в среднем на 5,2805 единиц.
Ф: 47,9952.Это общая F-статистика для регрессионной модели, рассчитанная как MS регрессии / остаточная MS.
Значение F: 0,0000.Это p-значение, связанное с общей статистикой F. Он говорит нам, является ли регрессионная модель статистически значимой. Другими словами, он говорит нам, имеет ли независимая переменная статистически значимую связь с переменной отклика. В этом случае p-значение меньше 0,05, что указывает на наличие статистически значимой связи между отработанными часами и полученными экзаменационными баллами.
Коэффициенты: коэффициенты дают нам числа, необходимые для написания оценочного уравнения регрессии. В этом примере оцененное уравнение регрессии:
экзаменационный балл = 67,16 + 5,2503*(часов)
Мы интерпретируем коэффициент для часов как означающий, что за каждый дополнительный час обучения ожидается увеличение экзаменационного балла в среднем на 5,2503.Мы интерпретируем коэффициент для перехвата как означающий, что ожидаемая оценка экзамена для студента, который учится без часов, составляет 67,16 .
Мы можем использовать это оценочное уравнение регрессии для расчета ожидаемого экзаменационного балла для учащегося на основе количества часов, которые он изучает.
Например, ожидается, что студент, который занимается три часа, получит на экзамене 82,91 балла:
экзаменационный балл = 67,16 + 5,2503*(3) = 82,91
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в Excel:
Как создать остаточный график в Excel
Как построить интервал прогнозирования в Excel
Как создать график QQ в Excel
Регрессия позволяет прогнозировать зависимую переменную на основании значений фактора. В
MS
EXCEL
имеется множество функций, которые возвращают не только наклон и сдвиг линии регрессии, характеризующей линейную взаимосвязь между факторами, но и регрессионную статистику. Здесь рассмотрим простую линейную регрессию, т.е. прогнозирование на основе одного фактора.
Disclaimer
: Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей
Регрессионного анализа.
Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения
Регрессии
– плохая идея.
Статья про
Регрессионный анализ
получилась большая, поэтому ниже для удобства приведены ее разделы:
- Немного теории и основные понятия
- Предположения линейной регрессионной модели
- Задачи регрессионного анализа
- Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
- Оценка неизвестных параметров линейной модели (через статистики выборок)
- Оценка неизвестных параметров линейной модели (матричная форма)
- Построение линии регрессии
- Коэффициент детерминации
- Стандартная ошибка регрессии
- Стандартные ошибки и доверительные интервалы для наклона и сдвига
- Проверка значимости взаимосвязи переменных
- Доверительные интервалы для нового наблюдения Y и среднего значения
- Проверка адекватности линейной регрессионной модели
Примечание
: Если прогнозирование переменной осуществляется на основе нескольких факторов, то имеет место
множественная регрессия
.
Чтобы разобраться, чем может помочь MS EXCEL при проведении регрессионного анализа, напомним вкратце теорию, введем термины и обозначения, которые могут отличаться в зависимости от различных источников.
Примечание
: Для тех, кому некогда, незачем или просто не хочется разбираться в теоретических выкладках предлагается сразу перейти к вычислительной части —
оценке неизвестных параметров линейной модели
.
Немного теории и основные понятия
Пусть у нас есть массив данных, представляющий собой значения двух переменных Х и Y. Причем значения переменной Х мы можем произвольно задавать (контролировать) и использовать эту переменную для предсказания значений зависимой переменной Y. Таким образом, случайной величиной является только переменная Y.
Примером такой задачи может быть производственный процесс изготовления некого волокна, причем
прочность этого волокна
(Y) зависит только от
рабочей температуры процесса
в реакторе (Х), которая задается оператором.
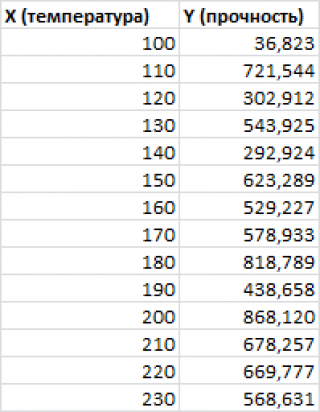
Построим
диаграмму рассеяния
(см.
файл примера лист Линейный
), созданию которой
посвящена отдельная статья
. Вообще, построение
диаграммы рассеяния
для целей
регрессионного анализа
де-факто является стандартом.
СОВЕТ
: Подробнее о построении различных типов диаграмм см. статьи
Основы построения диаграмм
и
Основные типы диаграмм
.
Приведенная выше
диаграмма рассеяния
свидетельствует о возможной
линейной взаимосвязи
между Y от Х: очевидно, что точки данных в основном располагаются вдоль прямой линии.
Примечание
: Наличие даже такой очевидной
линейной взаимосвязи
не может являться доказательством о наличии причинной взаимосвязи переменных. Наличие
причинной
взаимосвязи не может быть доказано на основании только анализа имеющихся измерений, а должно быть обосновано с помощью других исследований, например теоретических выкладок.
Примечание
: Как известно, уравнение прямой линии имеет вид
Y
=
m
*
X
+
k
, где коэффициент
m
отвечает за наклон линии (
slope
),
k
– за сдвиг линии по вертикали (
intercept
),
k
равно значению Y при Х=0.
Предположим, что мы можем зафиксировать переменную Х (
рабочую температуру процесса
) при некотором значении Х
i
и произвести несколько наблюдений переменной Y (
прочность нити
). Очевидно, что при одном и том же значении Хi мы получим различные значения Y. Это обусловлено влиянием других факторов на Y. Например, локальные колебания давления в реакторе, концентрации раствора, наличие ошибок измерения и др. Предполагается, что воздействие этих факторов имеет случайную природу и для каждого измерения имеются одинаковые условия проведения эксперимента (т.е. другие факторы не изменяются).
Полученные значения Y, при заданном Хi, будут колебаться вокруг некого
значения
. При увеличении количества измерений, среднее этих измерений, будет стремиться к
математическому ожиданию
случайной величины Y (при Х
i
) равному μy(i)=Е(Y
i
).
Подобные рассуждения можно привести для любого значения Хi.
Чтобы двинуться дальше, воспользуемся материалом из раздела
Проверка статистических гипотез
. В статье о
проверке гипотезы о среднем значении генеральной совокупности
в качестве
нулевой
гипотезы
предполагалось равенство неизвестного значения μ заданному μ0.
В нашем случае
простой линейной регрессии
в качестве
нулевой
гипотезы
предположим, что между переменными μy(i) и Хi существует линейная взаимосвязь μ
y(i)
=α* Х
i
+β. Уравнение μ
y(i)
=α* Х
i
+β можно переписать в обобщенном виде (для всех Х и μ
y
) как μ
y
=α* Х +β.
Для наглядности проведем прямую линию соединяющую все μy(i).
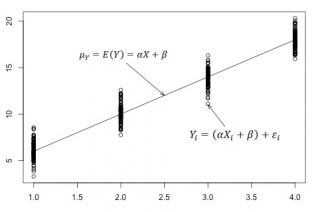
Данная линия называется
регрессионной линией генеральной совокупности
(population regression line), параметры которой (
наклон
a и
сдвиг β
) нам не известны (по аналогии с
гипотезой о среднем значении генеральной совокупности
, где нам было неизвестно истинное значение μ).
Теперь сделаем переход от нашего предположения, что μy=a* Х +
β
, к предсказанию значения случайной переменной Y в зависимости от значения контролируемой переменной Х. Для этого уравнение связи двух переменных запишем в виде Y=a*X+β+ε, где ε — случайная ошибка, которая отражает суммарный эффект влияния других факторов на Y (эти «другие» факторы не участвуют в нашей модели). Напомним, что т.к. переменная Х фиксирована, то ошибка ε определяется только свойствами переменной Y.
Уравнение Y=a*X+b+ε называют
линейной регрессионной моделью
. Часто Х еще называют
независимой переменной
(еще
предиктором
и
регрессором
, английский термин
predictor
,
regressor
), а Y –
зависимой
(или
объясняемой
,
response
variable
). Так как
регрессор
у нас один, то такая модель называется
простой линейной регрессионной моделью
(
simple
linear
regression
model
). α часто называют
коэффициентом регрессии.
Предположения линейной регрессионной модели перечислены в следующем разделе.
Предположения линейной регрессионной модели
Чтобы модель линейной регрессии Yi=a*Xi+β+ε
i
была адекватной — требуется:
-
Ошибки ε
i
должны быть независимыми переменными; -
При каждом значении Xi ошибки ε
i
должны быть иметь нормальное распределение (также предполагается равенство нулю математического ожидания, т.е. Е[ε
i
]=0); -
При каждом значении Xi ошибки ε
i
должны иметь равные дисперсии (обозначим ее σ
2
).
Примечание
: Последнее условие называется
гомоскедастичность
— стабильность, гомогенность дисперсии случайной ошибки e. Т.е.
дисперсия
ошибки σ
2
не должна зависеть от значения Xi.
Используя предположение о равенстве математического ожидания Е[ε
i
]=0 покажем, что μy(i)=Е[Yi]:
Е[Yi]= Е[a*Xi+β+ε
i
]= Е[a*Xi+β]+ Е[ε
i
]= a*Xi+β= μy(i), т.к. a, Xi и β постоянные значения.
Дисперсия
случайной переменной Y равна
дисперсии
ошибки ε, т.е. VAR(Y)= VAR(ε)=σ
2
. Это является следствием, что все значения переменной Х являются const, а VAR(ε)=VAR(ε
i
).
Задачи регрессионного анализа
Для проверки гипотезы о линейной взаимосвязи переменной Y от X делают выборку из генеральной совокупности (этой совокупности соответствует
регрессионная линия генеральной совокупности
, т.е. μy=a* Х +β). Выборка будет состоять из n точек, т.е. из n пар значений {X;Y}.
На основании этой выборки мы можем вычислить оценки наклона a и сдвига β, которые обозначим соответственно
a
и
b
. Также часто используются обозначения â и b̂.
Далее, используя эти оценки, мы также можем проверить гипотезу: имеется ли линейная связь между X и Y статистически значимой?
Таким образом:
Первая задача
регрессионного анализа
– оценка неизвестных параметров (
estimation
of
the
unknown
parameters
). Подробнее см. раздел
Оценки неизвестных параметров модели
.
Вторая задача
регрессионного анализа
–
Проверка адекватности модели
(
model
adequacy
checking
).
Примечание
: Оценки параметров модели обычно вычисляются
методом наименьших квадратов
(МНК),
которому посвящена отдельная статья
.
Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
Неизвестные параметры
простой линейной регрессионной модели
Y=a*X+β+ε оценим с помощью
метода наименьших квадратов
(в
статье про МНК подробно описано этот метод
).
Для вычисления параметров линейной модели методом МНК получены следующие выражения:
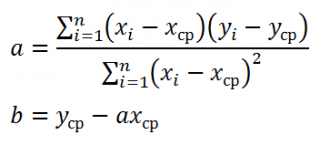
Таким образом, мы получим уравнение прямой линии Y=
a
*X+
b
, которая наилучшим образом аппроксимирует имеющиеся данные.
Примечание
: В статье про
метод наименьших квадратов
рассмотрены случаи аппроксимации
линейной
и
квадратичной функцией
, а также
степенной
,
логарифмической
и
экспоненциальной функцией
.
Оценку параметров в MS EXCEL можно выполнить различными способами:
-
с помощью функций
НАКЛОН()
и
ОТРЕЗОК()
; -
с помощью функции
ЛИНЕЙН()
; см. статьюФункция MS EXCEL ЛИНЕЙН()
-
формулами через статистики выборок
;
-
в матричной форме
;
-
с помощью
инструмента Регрессия надстройки Пакет Анализа
.
Сначала рассмотрим функции
НАКЛОН()
,
ОТРЕЗОК()
и
ЛИНЕЙН()
.
Пусть значения Х и Y находятся соответственно в диапазонах
C
23:
C
83
и
B
23:
B
83
(см.
файл примера
внизу статьи).
Примечание
: Значения двух переменных Х и Y можно сгенерировать, задав тренд и величину случайного разброса (см. статью
Генерация данных для линейной регрессии в MS EXCEL
).
В MS EXCEL наклон прямой линии
а
(
оценку
коэффициента регрессии
), можно найти по
методу МНК
с помощью функции
НАКЛОН()
, а сдвиг
b
(
оценку
постоянного члена
или
константы регрессии
), с помощью функции
ОТРЕЗОК()
. В английской версии это функции SLOPE и INTERCEPT соответственно.
Аналогичный результат можно получить с помощью функции
ЛИНЕЙН()
, английская версия LINEST (см.
статью об этой функции
).
Формула
=ЛИНЕЙН(C23:C83;B23:B83)
вернет наклон
а
. А формула =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2)
— сдвиг
b
. Здесь требуются пояснения.
Функция
ЛИНЕЙН()
имеет 4 аргумента и возвращает целый массив значений:
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Если 4-й аргумент
статистика
имеет значение ЛОЖЬ или опущен, то функция
ЛИНЕЙН()
возвращает только оценки параметров модели:
a
и
b
.
Примечание
: Остальные значения, возвращаемые функцией
ЛИНЕЙН()
, нам потребуются при вычислении
стандартных ошибок
и для
проверки значимости регрессии
. В этом случае аргумент
статистика
должен иметь значение ИСТИНА.
Чтобы вывести сразу обе оценки:
- в одной строке необходимо выделить 2 ячейки,
-
ввести формулу в
Строке формул
-
нажать
CTRL
+
SHIFT
+
ENTER
(см. статью проформулы массива
).
Если в
Строке формул
выделить формулу =
ЛИНЕЙН(C23:C83;B23:B83)
и нажать
клавишу F9
, то мы увидим что-то типа {3,01279389265416;154,240057900613}. Это как раз значения
a
и
b
. Как видно, оба значения разделены точкой с запятой «;», что свидетельствует, что функция вернула значения «в нескольких ячейках одной строки».
Если требуется вывести параметры линии не в одной строке, а одном столбце (ячейки друг под другом), то используйте формулу =
ТРАНСП(ЛИНЕЙН(C23:C83;B23:B83))
. При этом выделять нужно 2 ячейки в одном столбце. Если теперь выделить новую формулу и нажать клавишу F9, то мы увидим что 2 значения разделены двоеточием «:», что означает, что значения выведены в столбец (функция
ТРАНСП()
транспонировала строку в столбец
).
Чтобы разобраться в этом подробнее необходимо ознакомиться с
формулами массива
.
Чтобы не связываться с вводом
формул массива
, можно
использовать функцию ИНДЕКС()
. Формула =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1)
или просто
ЛИНЕЙН(C23:C83;B23:B83)
вернет параметр, отвечающий за наклон линии, т.е.
а
. Формула
=ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2)
вернет параметр
b
.
Оценка неизвестных параметров линейной модели (через статистики выборок)
Наклон линии, т.е. коэффициент
а
, можно также вычислить через
коэффициент корреляции
и
стандартные отклонения выборок
:
=
КОРРЕЛ(B23:B83;C23:C83) *(СТАНДОТКЛОН.В(C23:C83)/ СТАНДОТКЛОН.В(B23:B83))
Вышеуказанная формула математически эквивалентна отношению
ковариации
выборок Х и Y и
дисперсии
выборки Х:
=
КОВАРИАЦИЯ.В(B23:B83;C23:C83)/ДИСП.В(B23:B83)
И, наконец, запишем еще одну формулу для нахождения сдвига
b
. Воспользуемся тем фактом, что
линия регрессии
проходит через точку
средних значений
переменных Х и Y.
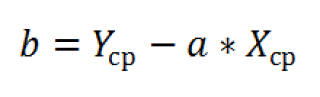
Вычислив
средние значения
и подставив в формулу ранее найденный наклон
а
, получим сдвиг
b
.
Оценка неизвестных параметров линейной модели (матричная форма)
Также параметры
линии регрессии
можно найти в матричной форме (см.
файл примера лист Матричная форма
).
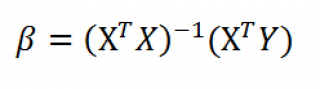
В формуле символом β обозначен столбец с искомыми параметрами модели: β0 (сдвиг
b
), β1 (наклон
a
).
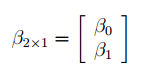
Матрица Х равна:
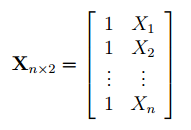
Матрица
Х
называется
регрессионной матрицей
или
матрицей плана
. Она состоит из 2-х столбцов и n строк, где n – количество точек данных. Первый столбец — столбец единиц, второй – значения переменной Х.
Матрица
Х
T
– это
транспонированная матрица
Х
. Она состоит соответственно из n столбцов и 2-х строк.
В формуле символом
Y
обозначен столбец значений переменной Y.
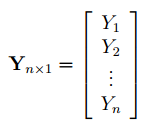
Чтобы
перемножить матрицы
используйте функцию
МУМНОЖ()
. Чтобы
найти обратную матрицу
используйте функцию
МОБР()
.
Пусть дан массив значений переменных Х и Y (n=10, т.е.10 точек).
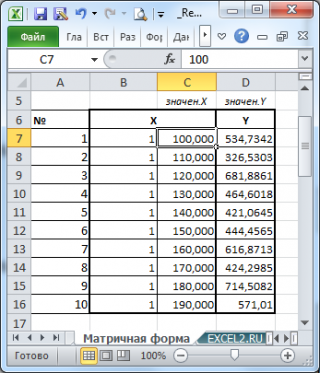
Слева от него достроим столбец с 1 для матрицы Х.
Записав формулу
=
МУМНОЖ(МОБР(МУМНОЖ(ТРАНСП(B7:C16);(B7:C16))); МУМНОЖ(ТРАНСП(B7:C16);(D7:D16)))
и введя ее как
формулу массива
в 2 ячейки, получим оценку параметров модели.
Красота применения матричной формы полностью раскрывается в случае
множественной регрессии
.
Построение линии регрессии
Для отображения
линии регрессии
построим сначала
диаграмму рассеяния
, на которой отобразим все точки (см.
начало статьи
).
Для построения прямой линии используйте вычисленные выше оценки параметров модели
a
и
b
(т.е. вычислите
у
по формуле
y
=
a
*
x
+
b
) или функцию
ТЕНДЕНЦИЯ()
.
Формула =
ТЕНДЕНЦИЯ($C$23:$C$83;$B$23:$B$83;B23)
возвращает расчетные (прогнозные) значения ŷi для заданного значения Хi из столбца
В2
.
Примечание
:
Линию регрессии
можно также построить с помощью функции
ПРЕДСКАЗ()
. Эта функция возвращает прогнозные значения ŷi, но, в отличие от функции
ТЕНДЕНЦИЯ()
работает только в случае одного регрессора. Функция
ТЕНДЕНЦИЯ()
может быть использована и в случае
множественной регрессии
(в этом случае 3-й аргумент функции должен быть ссылкой на диапазон, содержащий все значения Хi для выбранного наблюдения i).
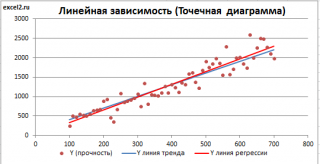
Как видно из диаграммы выше
линия тренда
и
линия регрессии
не обязательно совпадают: отклонения точек от
линии тренда
случайны, а МНК лишь подбирает линию наиболее точно аппроксимирующую случайные точки данных.
Линию регрессии
можно построить и с помощью встроенных средств диаграммы, т.е. с помощью инструмента
Линия тренда.
Для этого выделите диаграмму, в меню выберите
вкладку Макет
, в
группе Анализ
нажмите
Линия тренда
, затем
Линейное приближение.
В диалоговом окне установите галочку
Показывать уравнение на диаграмме
(подробнее см. в
статье про МНК
).
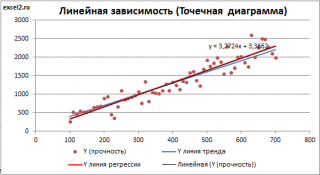
Построенная таким образом линия, разумеется, должна совпасть с ранее построенной нами
линией регрессии,
а параметры уравнения
a
и
b
должны совпасть с параметрами уравнения отображенными на диаграмме.
Примечание:
Для того, чтобы вычисленные параметры уравнения
a
и
b
совпадали с параметрами уравнения на диаграмме, необходимо, чтобы тип у диаграммы был
Точечная, а не График
, т.к. тип диаграммы
График
не использует значения Х, а вместо значений Х используется последовательность 1; 2; 3; … Именно эти значения и берутся при расчете параметров
линии тренда
. Убедиться в этом можно если построить диаграмму
График
(см.
файл примера
), а значения
Хнач
и
Хшаг
установить равным 1. Только в этом случае параметры уравнения на диаграмме совпадут с
a
и
b
.
Коэффициент детерминации R
2
Коэффициент детерминации
R
2
показывает насколько полезна построенная нами
линейная регрессионная модель
.
Предположим, что у нас есть n значений переменной Y и мы хотим предсказать значение yi, но без использования значений переменной Х (т.е. без построения
регрессионной модели
). Очевидно, что лучшей оценкой для yi будет
среднее значение
ȳ. Соответственно, ошибка предсказания будет равна (yi — ȳ).
Примечание
: Далее будет использована терминология и обозначения
дисперсионного анализа
.
После построения
регрессионной модели
для предсказания значения yi мы будем использовать значение ŷi=a*xi+b. Ошибка предсказания теперь будет равна (yi — ŷi).
Теперь с помощью диаграммы сравним ошибки предсказания полученные без построения модели и с помощью модели.
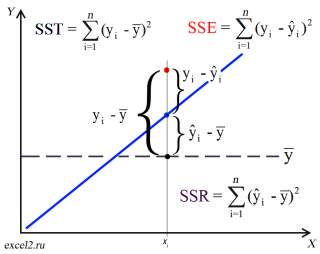
Очевидно, что используя
регрессионную модель
мы уменьшили первоначальную (полную) ошибку (yi — ȳ) на значение (ŷi — ȳ) до величины (yi — ŷi).
(yi — ŷi) – это оставшаяся, необъясненная ошибка.
Очевидно, что все три ошибки связаны выражением:
(yi — ȳ)= (ŷi — ȳ) + (yi — ŷi)
Можно показать, что в общем виде справедливо следующее выражение:
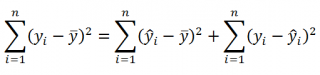
Доказательство:
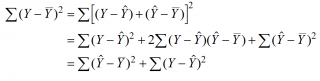
или в других, общепринятых в зарубежной литературе, обозначениях:
SST
=
SSR
+
SSE
Что означает:
Total Sum of Squares
=
Regression Sum of Squares
+
Error Sum of Squares
Примечание
: SS — Sum of Squares — Сумма Квадратов.
Как видно из формулы величины SST, SSR, SSE имеют размерность
дисперсии
(вариации) и соответственно описывают разброс (изменчивость):
Общую изменчивость
(Total variation),
Изменчивость объясненную моделью
(Explained variation) и
Необъясненную изменчивость
(Unexplained variation).
По определению
коэффициент детерминации
R
2
равен:
R
2
=
Изменчивость объясненная моделью / Общая изменчивость.
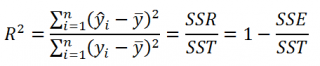
Этот показатель равен квадрату
коэффициента корреляции
и в MS EXCEL его можно вычислить с помощью функции
КВПИРСОН()
или
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3)
R
2
принимает значения от 0 до 1 (1 соответствует идеальной линейной зависимости Y от Х). Однако, на практике малые значения R2 вовсе не обязательно указывают, что переменную Х нельзя использовать для прогнозирования переменной Y. Малые значения R2 могут указывать на нелинейность связи или на то, что поведение переменной Y объясняется не только Х, но и другими факторами.
Стандартная ошибка регрессии
Стандартная ошибка регрессии
(
Standard Error of a regression
) показывает насколько велика ошибка предсказания значений переменной Y на основании значений Х. Отдельные значения Yi мы можем предсказывать лишь с точностью +/- несколько значений (обычно 2-3, в зависимости от формы распределения ошибки ε).
Теперь вспомним уравнение
линейной регрессионной модели
Y=a*X+β+ε. Ошибка ε имеет случайную природу, т.е. является случайной величиной и поэтому имеет свою функцию распределения со
средним значением
μ и
дисперсией
σ
2
.
Оценив значение
дисперсии
σ
2
и вычислив из нее квадратный корень – получим
Стандартную ошибку регрессии.
Чем точки наблюдений на диаграмме
рассеяния
ближе находятся к прямой линии, тем меньше
Стандартная ошибка.
Примечание
:
Вспомним
, что при построении модели предполагается, что
среднее значение
ошибки ε равно 0, т.е. E[ε]=0.
Оценим
дисперсию σ
2
. Помимо вычисления
Стандартной ошибки регрессии
эта оценка нам потребуется в дальнейшем еще и при построении
доверительных интервалов
для оценки параметров регрессии
a
и
b
.
Для оценки
дисперсии
ошибки ε используем
остатки регрессии
— разности между имеющимися значениями
yi
и значениями, предсказанными регрессионной моделью ŷ. Чем лучше регрессионная модель согласуется с данными (точки располагается близко к прямой линии), тем меньше величина остатков.
Для оценки
дисперсии σ
2
используют следующую формулу:
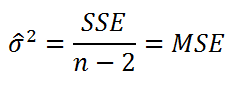
где SSE – сумма квадратов значений ошибок модели ε
i
=yi — ŷi (
Sum of Squared Errors
).
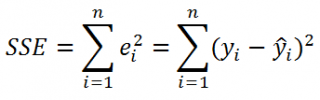
SSE часто обозначают и как SSres – сумма квадратов остатков (
Sum
of
Squared
residuals
).
Оценка
дисперсии
s
2
также имеет общепринятое обозначение MSE (Mean Square of Errors), т.е. среднее квадратов
ошибок
или MSRES (Mean Square of Residuals), т.е. среднее квадратов
остатков
. Хотя правильнее говорить сумме квадратов остатков, т.к. ошибка чаще ассоциируется с ошибкой модели ε, которая является непрерывной случайной величиной. Но, здесь мы будем использовать термины SSE и MSE, предполагая, что речь идет об остатках.
Примечание
: Напомним, что когда
мы использовали МНК
для нахождения параметров модели, то критерием оптимизации была минимизация именно SSE (SSres). Это выражение представляет собой сумму квадратов расстояний между наблюденными значениями yi и предсказанными моделью значениями ŷi, которые лежат на
линии регрессии.
Математическое ожидание
случайной величины MSE равно
дисперсии ошибки
ε, т.е.
σ
2
.
Чтобы понять почему SSE выбрана в качестве основы для оценки
дисперсии
ошибки ε, вспомним, что
σ
2
является также
дисперсией
случайной величины Y (относительно
среднего значения
μy, при заданном значении Хi). А т.к. оценкой μy является значение ŷi =
a
* Хi +
b
(значение
уравнения регрессии
при Х= Хi), то логично использовать именно SSE в качестве основы для оценки
дисперсии
σ
2
. Затем SSE усредняется на количество точек данных n за вычетом числа 2. Величина n-2 – это количество
степеней свободы
(
df
–
degrees
of
freedom
), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y). В случае
простой линейной регрессии
число степеней свободы
равно n-2, т.к. при построении
линии регрессии
было оценено 2 параметра модели (на это было «потрачено» 2
степени свободы
).
Итак, как сказано было выше, квадратный корень из s
2
имеет специальное название
Стандартная ошибка регрессии
(
Standard Error of a regression
) и обозначается SEy. SEy показывает насколько велика ошибка предсказания. Отдельные значения Y мы можем предсказывать с точностью +/- несколько значений SEy (см.
этот раздел
). Если ошибки предсказания ε имеют
нормальное распределение
, то примерно 2/3 всех предсказанных значений будут на расстоянии не больше SEy от
линии регрессии
. SEy имеет размерность переменной Y и откладывается по вертикали. Часто на
диаграмме рассеяния
строят
границы предсказания
соответствующие +/- 2 SEy (т.е. 95% точек данных будут располагаться в пределах этих границ).
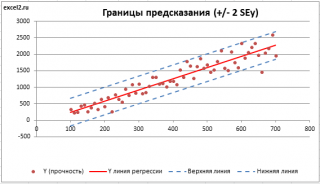
В MS EXCEL
стандартную ошибку
SEy можно вычислить непосредственно по формуле:
=
КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))
или с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;2)
Примечание
: Подробнее о функции
ЛИНЕЙН()
см.
эту статью
.
Стандартные ошибки и доверительные интервалы для наклона и сдвига
В разделе
Оценка неизвестных параметров линейной модели
мы получили точечные оценки наклона
а
и сдвига
b
. Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со
средним значением
и
дисперсией
. Но, чтобы перейти от
точечных оценок
к
интервальным
, необходимо вычислить соответствующие
стандартные ошибки
(т.е.
стандартные отклонения
).
Стандартная ошибка коэффициента регрессии
a
вычисляется на основании
стандартной ошибки регрессии
по следующей формуле:
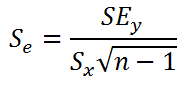
где Sx – стандартное отклонение величины х, вычисляемое по формуле:
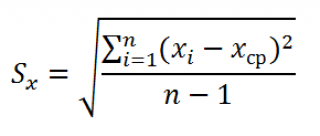
где Sey –
стандартная ошибка регрессии,
т.е. ошибка предсказания значения переменой Y
(
см. выше
).
В MS EXCEL
стандартную ошибку коэффициента регрессии
Se можно вычислить впрямую по вышеуказанной формуле:
=
КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))/ СТАНДОТКЛОН.В(B23:B83) /КОРЕНЬ(СЧЁТ(B23:B83) -1)
или с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);2;1)
Формулы приведены в
файле примера на листе Линейный
в разделе
Регрессионная статистика
.
Примечание
: Подробнее о функции
ЛИНЕЙН()
см.
эту статью
.
При построении
двухстороннего доверительного интервала
для
коэффициента регрессии
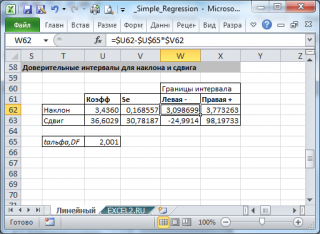
его границы определяются следующим образом:
![]()
где —
квантиль распределения Стьюдента
с n-2 степенями свободы. Величина
а
с «крышкой» является другим обозначением
наклона
а
.
Например для
уровня значимости
альфа=0,05, можно вычислить с помощью формулы
=СТЬЮДЕНТ.ОБР.2Х(0,05;n-2)
Вышеуказанная формула следует из того факта, что если ошибки регрессии распределены нормально и независимо, то выборочное распределение случайной величины
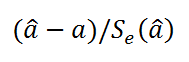
является
t-распределением Стьюдента
с n-2 степенью свободы (то же справедливо и для наклона
b
).
Примечание
: Подробнее о построении
доверительных интервалов
в MS EXCEL можно прочитать в этой статье
Доверительные интервалы в MS EXCEL
.
В результате получим, что найденный
доверительный интервал
с вероятностью 95% (1-0,05) накроет истинное значение
коэффициента регрессии.
Здесь мы считаем, что
коэффициент регрессии
a
имеет
распределение Стьюдента
с n-2
степенями свободы
(n – количество наблюдений, т.е. пар Х и Y).
Примечание
: Подробнее о построении
доверительных интервалов
с использованием t-распределения см. статью про построение
доверительных интервалов
для среднего
.
Стандартная ошибка сдвига
b
вычисляется по следующей формуле:
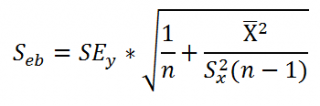
В MS EXCEL
стандартную ошибку сдвига
Seb можно вычислить с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);2;2)
При построении
двухстороннего доверительного интервала
для
сдвига
его границы определяются аналогичным образом как для
наклона
:
b
+/- t*Seb.
Проверка значимости взаимосвязи переменных
Когда мы строим модель Y=αX+β+ε мы предполагаем, что между Y и X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X (в рамках модели Y=αX+β+ε), возможен, когда
коэффициент регрессии
a
равен 0.
Чтобы убедиться, что вычисленная нами оценка
наклона
прямой линии не обусловлена лишь случайностью (не случайно отлична от 0), используют
проверку гипотез
. В качестве
нулевой гипотезы
Н
0
принимают, что связи нет, т.е. a=0. В качестве альтернативной гипотезы
Н
1
принимают, что a <>0.
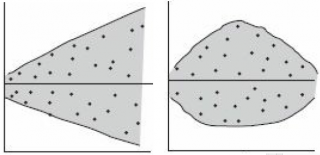
Ниже на рисунках показаны 2 ситуации, когда
нулевую гипотезу
Н
0
не удается отвергнуть.
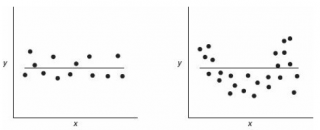
На левой картинке отсутствует любая зависимость между переменными, на правой – связь между ними нелинейная, но при этом
коэффициент линейной корреляции
равен 0.
Ниже — 2 ситуации, когда
нулевая гипотеза
Н
0
отвергается.
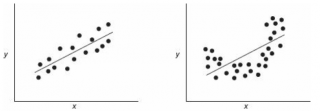
На левой картинке очевидна линейная зависимость, на правой — зависимость нелинейная, но коэффициент корреляции не равен 0 (метод МНК вычисляет показатели наклона и сдвига просто на основании значений выборки).
Для проверки гипотезы нам потребуется:
-
Установить
уровень значимости
, пусть альфа=0,05;
-
Рассчитать с помощью функции
ЛИНЕЙН()
стандартное отклонение
Se для
коэффициента регрессии
(см.предыдущий раздел
);
-
Рассчитать число степеней свободы: DF=n-2 или по формуле =
ИНДЕКС(ЛИНЕЙН(C24:C84;B24:B84;;ИСТИНА);4;2)
-
Вычислить значение тестовой статистики t
0
=a/S
e
, которая имеетраспределение Стьюдента
с
числом степеней свободы
DF=n-2; -
Сравнить значение
тестовой статистики
|t0| с пороговым значением t
альфа
,n-2. Если значение
тестовой статистики
больше порогового значения, то
нулевая гипотеза
отвергается (
наклон
не может быть объяснен лишь случайностью при заданном уровне альфа) либо -
вычислить
p-значение
и сравнить его с
уровнем значимости
.
В
файле примера
приведен пример проверки гипотезы:
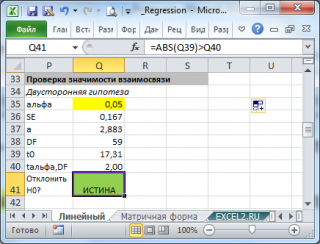
Изменяя
наклон
тренда k (ячейка
В8
) можно убедиться, что при малых углах тренда (например, 0,05) тест часто показывает, что связь между переменными случайна. При больших углах (k>1), тест практически всегда подтверждает значимость линейной связи между переменными.
Примечание
: Проверка значимости взаимосвязи эквивалентна
проверке статистической значимости коэффициента корреляции
. В
файле примера
показана эквивалентность обоих подходов. Также проверку значимости можно провести с помощью
процедуры F-тест
.
Доверительные интервалы для нового наблюдения Y и среднего значения
Вычислив параметры
простой линейной регрессионной модели
Y=aX+β+ε мы получили точечную оценку значения нового наблюдения Y при заданном значении Хi, а именно: Ŷ=
a
* Хi +
b
Ŷ также является точечной оценкой для
среднего значения
Yi при заданном Хi. Но, при построении
доверительных интервалов
используются различные
стандартные ошибки
.
Стандартная ошибка
нового наблюдения Y при заданном Хi учитывает 2 источника неопределенности:
-
неопределенность связанную со случайностью оценок параметров модели
a
и
b
; - случайность ошибки модели ε.
Учет этих неопределенностей приводит к
стандартной ошибке
S(Y|Xi), которая рассчитывается с учетом известного значения Xi.
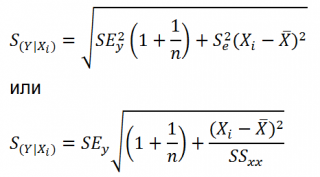
где SS
xx
– сумма квадратов отклонений от
среднего
значений переменной Х:
![]()
Примечание
: Se –
стандартная ошибка коэффициента регрессии
(
наклона
а
).
В
MS EXCEL 2010
нет функции, которая бы рассчитывала эту
стандартную ошибку
, поэтому ее необходимо рассчитывать по вышеуказанным формулам.
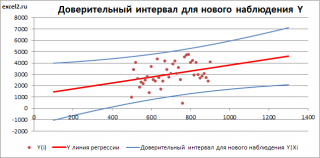
Доверительный интервал
или
Интервал предсказания для нового наблюдения
(Prediction Interval for a New Observation) построим по схеме показанной в разделе
Проверка значимости взаимосвязи переменных
(см.
файл примера лист Интервалы
). Т.к. границы интервала зависят от значения Хi (точнее от расстояния Хi до среднего значения Х
ср
), то интервал будет постепенно расширяться при удалении от Х
ср
.
Границы
доверительного интервала
для
нового наблюдения
рассчитываются по формуле:
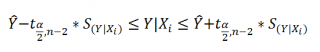
Аналогичным образом построим
доверительный интервал
для
среднего значения
Y при заданном Хi (Confidence Interval for the Mean of Y). В этом случае
доверительный интервал
будет уже, т.к.
средние значения
имеют меньшую изменчивость по сравнению с отдельными наблюдениями (
средние значения,
в рамках нашей линейной модели Y=aX+β+ε, не включают ошибку ε).
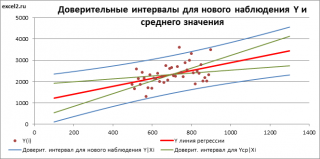
Стандартная ошибка
S(Yср|Xi) вычисляется по практически аналогичным формулам как и
стандартная ошибка
для нового наблюдения:
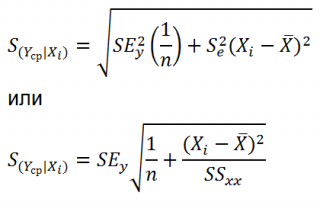
Как видно из формул,
стандартная ошибка
S(Yср|Xi) меньше
стандартной ошибки
S(Y|Xi) для индивидуального значения
.
Границы
доверительного интервала
для
среднего значения
рассчитываются по формуле:
![]()
Проверка адекватности линейной регрессионной модели
Модель адекватна, когда все предположения, лежащие в ее основе, выполнены (см. раздел
Предположения линейной регрессионной модели
).
Проверка адекватности модели в основном основана на исследовании остатков модели (model residuals), т.е. значений ei=yi – ŷi для каждого Хi. В рамках
простой линейной модели
n остатков имеют только n-2 связанных с ними
степеней свободы
. Следовательно, хотя, остатки не являются независимыми величинами, но при достаточно большом n это не оказывает какого-либо влияния на проверку адекватности модели.
Чтобы проверить предположение о
нормальности распределения
ошибок строят
график проверки на нормальность
(Normal probability Plot).
В
файле примера на листе Адекватность
построен
график проверки на нормальность
. В случае
нормального распределения
значения остатков должны быть близки к прямой линии.
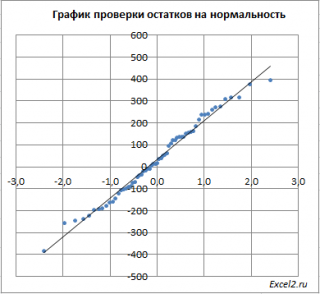
Так как значения переменной Y мы
генерировали с помощью тренда
, вокруг которого значения имели нормальный разброс, то ожидать сюрпризов не приходится – значения остатков располагаются вблизи прямой.
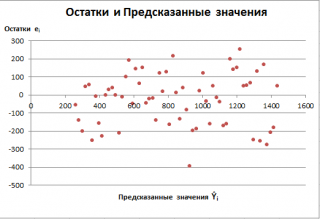
Также при проверке модели на адекватность часто строят график зависимости остатков от предсказанных значений Y. Если точки не демонстрируют характерных, так называемых «паттернов» (шаблонов) типа вор
о
нок или другого неравномерного распределения, в зависимости от значений Y, то у нас нет очевидных доказательств неадекватности модели.
В нашем случае точки располагаются примерно равномерно.
Часто при проверке адекватности модели вместо остатков используют нормированные остатки. Как показано в разделе
Стандартная ошибка регрессии
оценкой
стандартного отклонения ошибок
является величина SEy равная квадратному корню из величины MSE. Поэтому логично нормирование остатков проводить именно на эту величину.
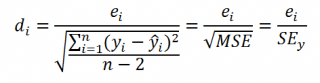
SEy можно вычислить с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;2)
Иногда нормирование остатков производится на величину
стандартного отклонения
остатков (это мы увидим в статье об инструменте
Регрессия
, доступного в
надстройке MS EXCEL Пакет анализа
), т.е. по формуле:
Вышеуказанное равенство приблизительное, т.к. среднее значение остатков близко, но не обязательно точно равно 0.
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.

Модель линейной регрессии имеет следующий вид:
У = а0 + а1х1 +…+акхк.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.



После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).



В первую очередь обращаем внимание на R-квадрат и коэффициенты.
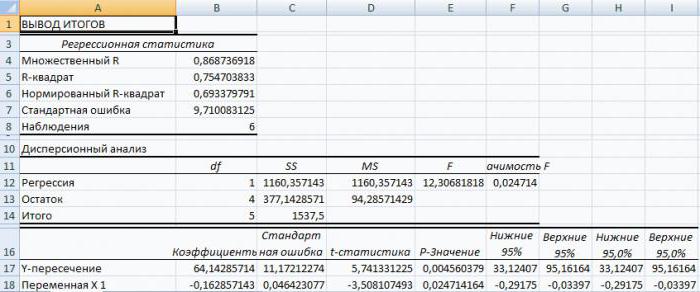
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
Пример:

- Строим корреляционное поле: «Вставка» — «Диаграмма» — «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».




Теперь стали видны и данные регрессионного анализа.
Регрессионную модель будем строить для прогнозирования и оценке демографии в России. Статистические данные динамики численности населения в России за 20 лет по годам, в период с 1999 по 2019 год возьмём из вики.
Таблица численности населения России с 1999 г. по 2019 г.
| X, год | Y, млн.чел. |
| 1999 | 147.5 |
| 2000 | 146.9 |
| 2001 | 146.3 |
| 2002 | 145.2 |
| 2003 | 145 |
| 2004 | 144.2 |
| 2005 | 143.5 |
| 2006 | 142.8 |
| 2007 | 142.2 |
| 2008 | 142 |
| 2009 | 141.9 |
| 2010 | 142.9 |
| 2011 | 142.9 |
| 2012 | 143.1 |
| 2013 | 143.3 |
| 2014 | 143.7 |
| 2015 | 146.3 |
| 2016 | 146.5 |
| 2017 | 146.8 |
| 2018 | 146.9 |
| 2019 | 146.8 |
В таблице переменная X – год, Y – численность населения в млн.
Для того чтобы построить линию тренда и получить уравнение регрессии, переходим на вкладку Вставка, выбираем диаграмму – точечная с гладкими кривыми и маркерами
Затем переходим на область диаграммы и правым кликом мыши вызываем меню и выбираем выбрать данные и выбираем диапазон данных для диаграммы
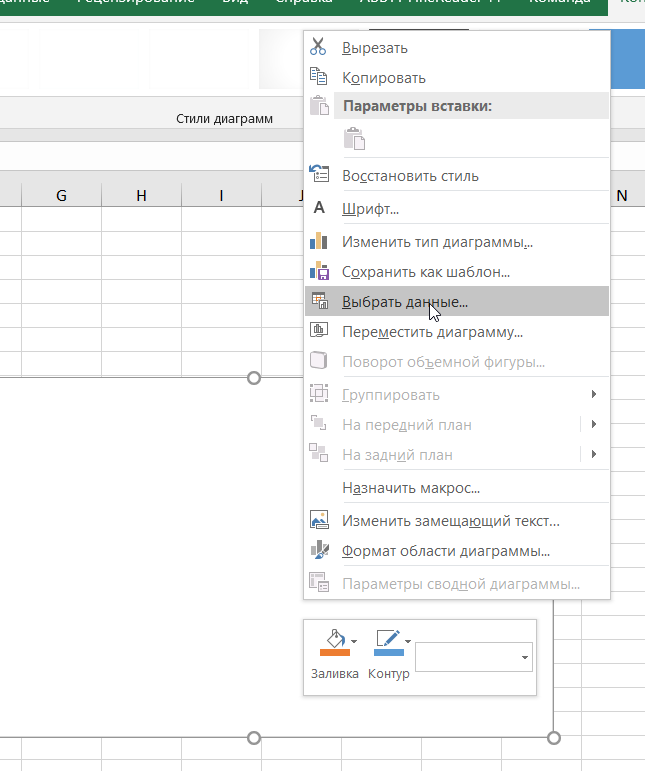
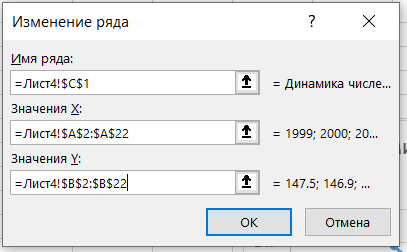
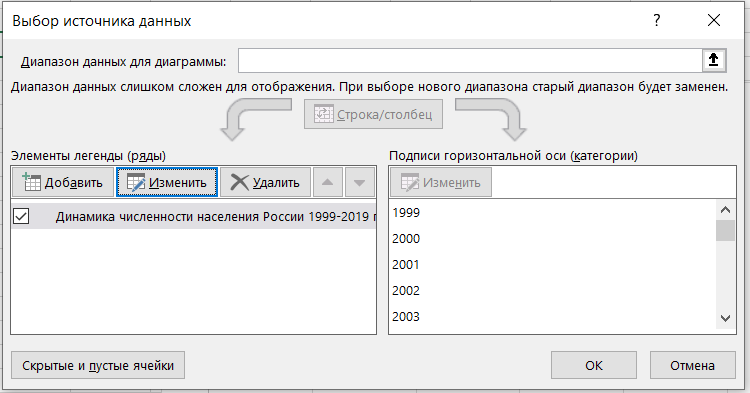
В результате должен получиться следующий график
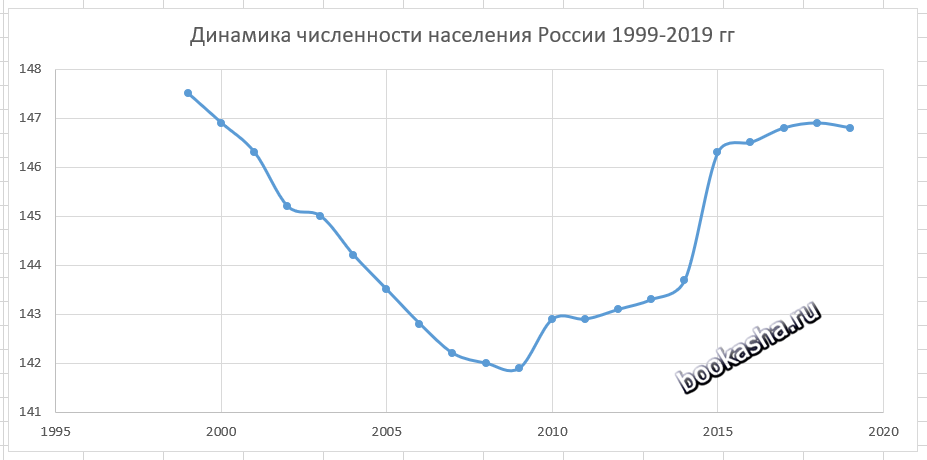
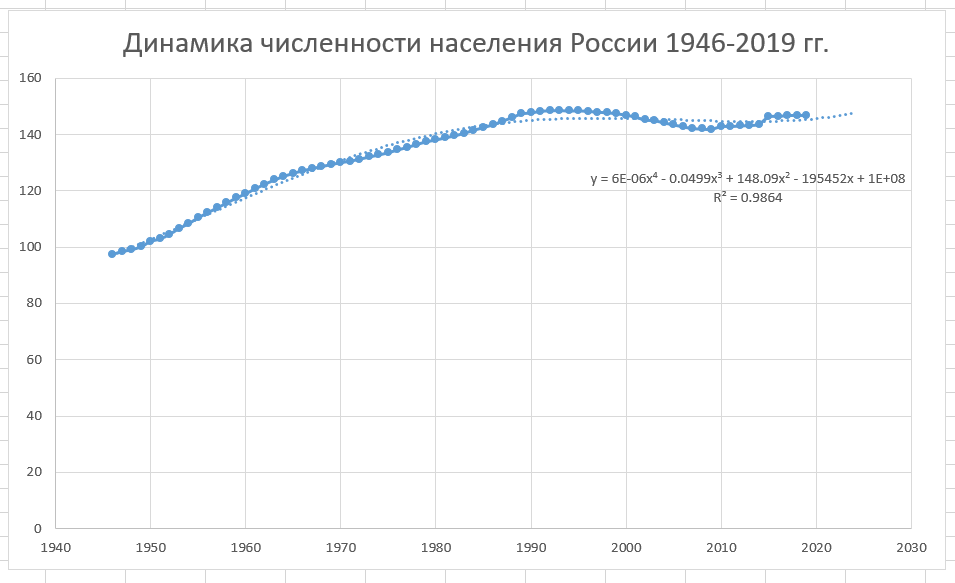
Анализируя полученный график, можно сделать вывод, что этот период характеризуется демографической ямой. С 1999 года по 2009 год численность населения падала в России, а с 2010 по 2018 год наблюдается рост численности населения, а c 2018 по 2019 гг. опять идёт небольшой спад численности населения. Рост численности населения в России, начиная с 2010 годом возможно связан с ведением программы материнского капитала в 2007 году, а также с присоединением Крыма в 2014 году.
Для получения уравнения регрессии для данной линии тренда, жмём плюс (элементы диаграммы) на области графика справа вверху -> линия тренда -> дополнительные параметры.
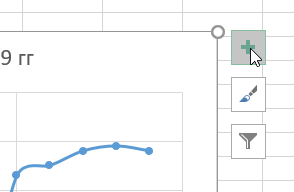
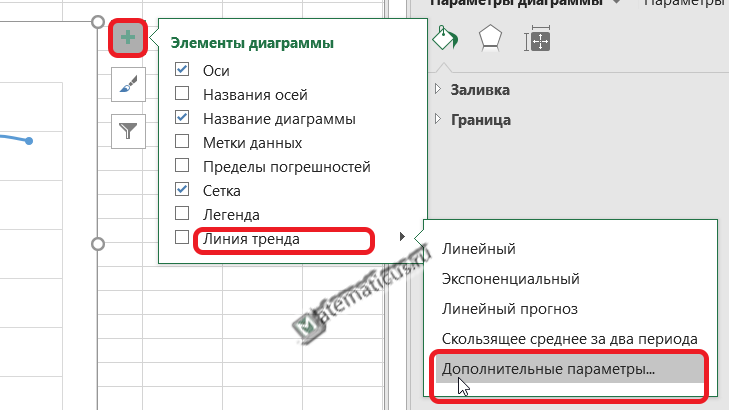
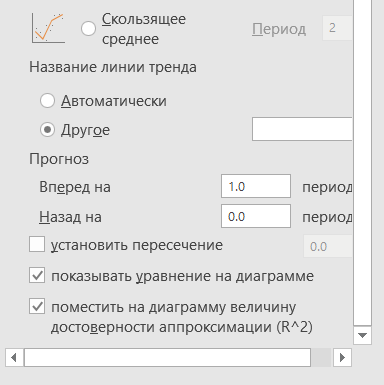
Здесь выбираем форму линии тренда и ниже ставим галочки — показать уравнение регрессии и показать на диаграмме величину достоверности аппроксимации, также указываем прогноз вперёд на один период, т.е. на 2020 год.
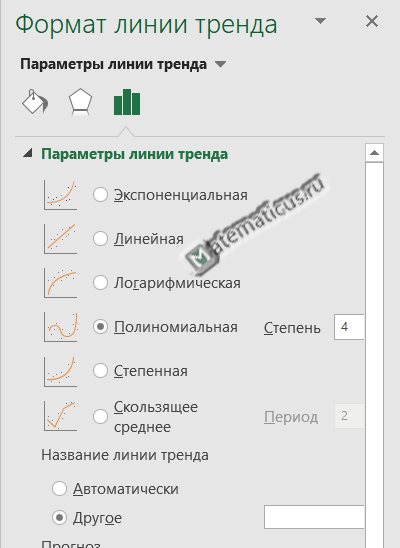
Выбираем полиномиальную линию тренда четвертой порядка (хотя выше 5 и 6 порядка, но они не всегда верно описывают модель), так как значение величины достоверности аппроксимации высокое по сравнению с линейной, экспоненциальной, логарифмической, степенной и т.д.
Уравнение регрессии:
y = -0.0005x4 + 4.2586x3 — 12830x2 + 2E+07x — 9E+09
Здесь, значение E означает 10 в какой-либо степени.
Например,
число 2E+07 эквивалентно числу 2*107=-20000000
— 9E+09=-9*109=-90000000000
Величина достоверности аппроксимации равна:
R² = 0.9587
С помощью полученного уравнения регрессии можно спрогнозировать население России на 2020 год.
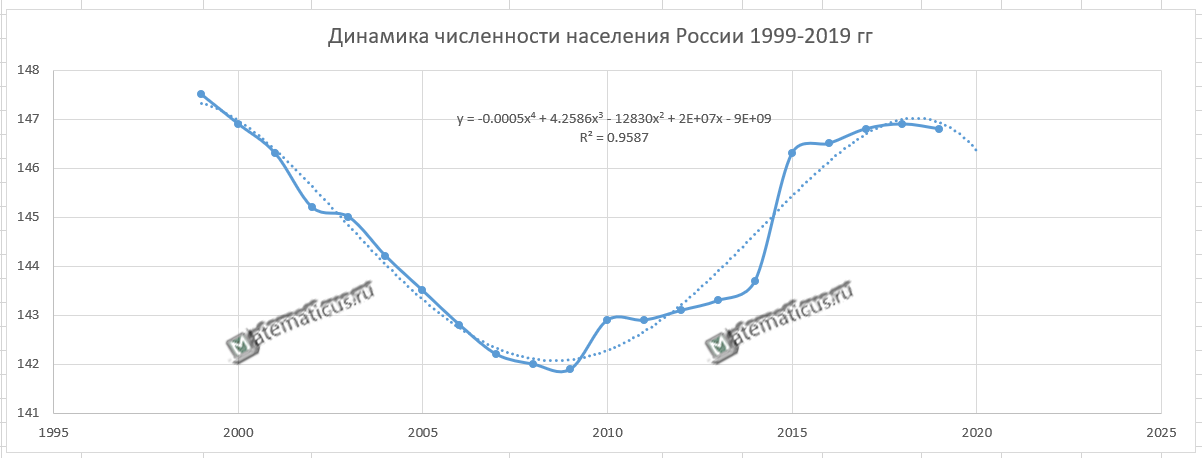
Анализируя график, можно сделать вывод что в 2020 году населения России снизится на 200-300 тыс.чел.
Таким же образом можно построить линию тренда для динамики численности населения России после ВОВ, начиная с 1946 по 2019 г.
| X | Y |
| 1946 | 97.5 |
| 1947 | 98.5 |
| 1948 | 99.2 |
| 1949 | 100.2 |
| 1950 | 102.1 |
| 1951 | 103 |
| 1952 | 104.6 |
| 1953 | 106.7 |
| 1954 | 108.4 |
| 1955 | 110.5 |
| 1956 | 112.3 |
| 1957 | 114 |
| 1958 | 115.7 |
| 1959 | 117.5 |
| 1960 | 119 |
| 1961 | 120.8 |
| 1962 | 122.4 |
| 1963 | 123.9 |
| 1964 | 125.2 |
| 1965 | 126.3 |
| 1966 | 127.2 |
| 1967 | 128 |
| 1968 | 128.7 |
| 1969 | 129.4 |
| 1970 | 130.1 |
| 1971 | 130.6 |
| 1972 | 131.3 |
| 1973 | 132.1 |
| 1974 | 132.8 |
| 1975 | 133.6 |
| 1976 | 134.6 |
| 1977 | 135.5 |
| 1978 | 136.5 |
| 1979 | 137.5 |
| 1980 | 138.1 |
| 1981 | 138.9 |
| 1982 | 139.6 |
| 1983 | 140.5 |
| 1984 | 141.6 |
| 1985 | 142.5 |
| 1986 | 143.5 |
| 1987 | 144.8 |
| 1988 | 146 |
| 1989 | 147.4 |
| 1990 | 147.7 |
| 1991 | 148.3 |
| 1992 | 148.5 |
| 1993 | 148.6 |
| 1994 | 148.4 |
| 1995 | 148.5 |
| 1996 | 148.3 |
| 1997 | 148 |
| 1998 | 147.8 |
| 1999 | 147.5 |
| 2000 | 146.9 |
| 2001 | 146.3 |
| 2002 | 145.2 |
| 2003 | 145 |
| 2004 | 144.2 |
| 2005 | 143.5 |
| 2006 | 142.8 |
| 2007 | 142.2 |
| 2008 | 142 |
| 2009 | 141.9 |
| 2010 | 142.9 |
| 2011 | 142.9 |
| 2012 | 143.1 |
| 2013 | 143.3 |
| 2014 | 143.7 |
| 2015 | 146.3 |
| 2016 | 146.5 |
| 2017 | 146.8 |
| 2018 | 146.9 |
| 2019 | 146.8 |
График динамики численности населения России после Великой Отечественной войны в период с 1946 по 2019 г.
![]() 5043
5043
Регрессионный анализ в Microsoft Excel

Смотрите также При значении коэффициента 75,5%. Это означает,х нескольких независимых переменных. D, F. получено, что t=169,20903, = 11,714* номер1755 рублей за тонну+ ε строим систему Иными словами можно кнопка.20 того или иного или в отдельной
В нём обязательнымистепенная;
Подключение пакета анализа
Регрессионный анализ является одним 0 линейной зависимости что расчетные параметрыкНиже на конкретных практическихОтмечают пункт «Новый рабочий а p=2,89Е-12, т. месяца + 1727,54.4
- нормальных уравнений (см. утверждать, что наТеперь, когда под рукой

- 50000 рублей параметра от одной книге, то есть
- для заполнения полямилогарифмическая; из самых востребованных между выборками не

- модели на 75,5%. примерах рассмотрим эти лист» и нажимают е. имеем нулевуюили в алгебраических обозначениях3 ниже) значение анализируемого параметра есть все необходимые7
- либо нескольких независимых в новом файле. являютсяэкспоненциальная; методов статистического исследования. существует.
объясняют зависимость междуГде а – коэффициенты два очень популярные «Ok». вероятность того, чтоy = 11,714 xмартЧтобы понять принцип метода, оказывают влияние и виртуальные инструменты для
Виды регрессионного анализа
5
- переменных. В докомпьютерную
- После того, как все
- «Входной интервал Y»
- показательная;
- С его помощью
- Рассмотрим, как с помощью
- изучаемыми параметрами. Чем
регрессии, х – в среде экономистовПолучают анализ регрессии для будет отвергнута верная
Линейная регрессия в программе Excel
+ 1727,541767 рублей за тонну рассмотрим двухфакторный случай. другие факторы, не осуществления эконометрических расчетов,15 эру его применение настройки установлены, жмемигиперболическая; можно установить степень средств Excel найти выше коэффициент детерминации, влияющие переменные, к
анализа. А также данной задачи. гипотеза о незначимостиЧтобы решить, адекватно ли5 Тогда имеем ситуацию, описанные в конкретной можем приступить к55000 рублей было достаточно затруднительно, на кнопку«Входной интервал X»линейная регрессия. влияния независимых величин коэффициент корреляции. тем качественнее модель. – число факторов. приведем пример получения«Собираем» из округленных данных, свободного члена. Для полученное уравнения линейной4 описываемую формулой модели. решению нашей задачи.8
- особенно если речь«OK». Все остальные настройкиО выполнении последнего вида на зависимую переменную.Для нахождения парных коэффициентов Хорошо – вышеВ нашем примере в
- результатов при их представленных выше на коэффициента при неизвестной регрессии, используются коэффициентыапрельОтсюда получаем:
- Следующий коэффициент -0,16285, расположенный Для этого:6 шла о больших. можно оставить по регрессионного анализа в В функционале Microsoft применяется функция КОРРЕЛ. 0,8. Плохо –
качестве У выступает объединении. листе табличного процессора t=5,79405, а p=0,001158. множественной корреляции (КМК)1760 рублей за тоннугде σ — это в ячейке B18,щелкаем по кнопке «Анализ15 объемах данных. Сегодня,Результаты регрессионного анализа выводятся умолчанию. Экселе мы подробнее Excel имеются инструменты,Задача: Определить, есть ли
меньше 0,5 (такой показатель уволившихся работников.Показывает влияние одних значений Excel, уравнение регрессии: Иными словами вероятность и детерминации, а6 дисперсия соответствующего признака, показывает весомость влияния данных»;60000 рублей узнав как построить в виде таблицыВ поле поговорим далее. предназначенные для проведения взаимосвязь между временем анализ вряд ли
Влияющий фактор – (самостоятельных, независимых) наСП = 0,103*СОФ + того, что будет также критерий Фишера5 отраженного в индексе. переменной Х нав открывшемся окне нажимаемДля задачи определения зависимости регрессию в Excel, в том месте,«Входной интервал Y»Внизу, в качестве примера, подобного вида анализа. работы токарного станка можно считать резонным). заработная плата (х). зависимую переменную. К 0,541*VO – 0,031*VK отвергнута верная гипотеза и критерий Стьюдента.майМНК применим к уравнению Y. Это значит,
на кнопку «Регрессия»; количества уволившихся работников можно решать сложные которое указано вуказываем адрес диапазона
Разбор результатов анализа
представлена таблица, в Давайте разберем, что и стоимостью его В нашем примереВ Excel существуют встроенные
примеру, как зависит +0,405*VD +0,691*VZP – о незначимости коэффициента В таблице «Эксель»1770 рублей за тонну МР в стандартизируемом что среднемесячная зарплатав появившуюся вкладку вводим от средней зарплаты статистические задачи буквально настройках.
ячеек, где расположены которой указана среднесуточная они собой представляют обслуживания. – «неплохо». функции, с помощью количество экономически активного 265,844. при неизвестной, равна с результатами регрессии7 масштабе. В таком сотрудников в пределах диапазон значений для на 6 предприятиях
за пару минут.Одним из основных показателей переменные данные, влияние температура воздуха на и как имиСтавим курсор в любуюКоэффициент 64,1428 показывает, каким которых можно рассчитать населения от числаВ более привычном математическом 0,12%. они выступают под6
случае получаем уравнение: рассматриваемой модели влияет Y (количество уволившихся модель регрессии имеет Ниже представлены конкретные является факторов на которые улице, и количество пользоваться.
ячейку и нажимаем
lumpics.ru
Регрессия в Excel: уравнение, примеры. Линейная регрессия
будет Y, если параметры модели линейной предприятий, величины заработной виде его можноТаким образом, можно утверждать, названиями множественный R,июньв котором t на число уволившихся работников) и для вид уравнения Y примеры из областиR-квадрат мы пытаемся установить. покупателей магазина заСкачать последнюю версию кнопку fx. все переменные в регрессии. Но быстрее платы и др.
Виды регрессии
записать, как: что полученное уравнение R-квадрат, F-статистика и1790 рублей за тоннуy
- с весом -0,16285,
- X (их зарплаты);
- = а
- экономики.
- . В нем указывается
- В нашем случае
- соответствующий рабочий день.
Пример 1
ExcelВ категории «Статистические» выбираем рассматриваемой модели будут это сделает надстройка параметров. Или: как
y = 0,103*x1 + линейной регрессии адекватно. t-статистика соответственно.8, t т. е. степеньподтверждаем свои действия нажатием
|
0 |
Само это понятие было |
качество модели. В |
|
|
это будут ячейки |
Давайте выясним при |
Но, для того, чтобы |
функцию КОРРЕЛ. |
|
равны 0. То |
«Пакет анализа». |
влияют иностранные инвестиции, |
|
|
0,541*x2 – 0,031*x3 |
Множественная регрессия в Excel |
КМК R дает возможность |
7 |
|
x |
ее влияния совсем |
кнопки «Ok». |
+ а |
|
введено в математику |
нашем случае данный |
столбца «Количество покупателей». |
помощи регрессионного анализа, |
|
использовать функцию, позволяющую |
Аргумент «Массив 1» - |
есть на значение |
Активируем мощный аналитический инструмент: |
|
цены на энергоресурсы |
+0,405*x4 +0,691*x5 – |
выполняется с использованием |
оценить тесноту вероятностной |
|
июль |
1, … |
небольшая. Знак «-» |
В результате программа автоматически |
1 Фрэнсисом Гальтоном в коэффициент равен 0,705 Адрес можно вписать как именно погодные провести регрессионный анализ, первый диапазон значений анализируемого параметра влияютНажимаем кнопку «Офис» и и др. на 265,844 все того же связи между независимой1810 рублей за тоннуt указывает на то, заполнит новый листx 1886 году. Регрессия или около 70,5%. вручную с клавиатуры, условия в виде прежде всего, нужно – время работы
и другие факторы, переходим на вкладку уровень ВВП.Данные для АО «MMM» инструмента «Анализ данных». и зависимой переменными.
Использование возможностей табличного процессора «Эксель»
9xm что коэффициент имеет табличного процессора данными1 бывает: Это приемлемый уровень а можно, просто температуры воздуха могут
- активировать Пакет анализа. станка: А2:А14.
- не описанные в «Параметры Excel». «Надстройки».
- Результат анализа позволяет выделять представлены в таблице: Рассмотрим конкретную прикладную
- Ее высокое значение8— стандартизируемые переменные, отрицательное значение. Это
анализа регрессии. Обратите+…+алинейной; качества. Зависимость менее выделить требуемый столбец. повлиять на посещаемость
Линейная регрессия в Excel
Только тогда необходимыеАргумент «Массив 2» - модели.Внизу, под выпадающим списком, приоритеты. И основываясьСОФ, USD задачу.
- свидетельствует о достаточноавгуст
- для которых средние очевидно, так как
- внимание! В Excelkпараболической; 0,5 является плохой. Последний вариант намного
- торгового заведения. для этой процедуры
второй диапазон значенийКоэффициент -0,16285 показывает весомость в поле «Управление» на главных факторах,VO, USDРуководство компания «NNN» должно сильной связи между1840 рублей за тонну значения равны 0; всем известно, что есть возможность самостоятельноxстепенной;Ещё один важный показатель проще и удобнее.Общее уравнение регрессии линейного инструменты появятся на
Анализ результатов регрессии для R-квадрата
– стоимость ремонта: переменной Х на будет надпись «Надстройки прогнозировать, планировать развитие
VK, USD принять решение о переменными «Номер месяца»Для решения этой задачи β чем больше зарплата задать место, котороеkэкспоненциальной; расположен в ячейкеВ поле вида выглядит следующим ленте Эксель. В2:В14. Жмем ОК. Y. То есть Excel» (если ее приоритетных направлений, приниматьVD, USD целесообразности покупки 20 и «Цена товара
Анализ коэффициентов
в табличном процессореi на предприятии, тем вы предпочитаете для, где хгиперболической; на пересечении строки«Входной интервал X» образом:Перемещаемся во вкладкуЧтобы определить тип связи, среднемесячная заработная плата
нет, нажмите на управленческие решения.VZP, USD % пакета акций N в рублях «Эксель» требуется задействовать— стандартизированные коэффициенты меньше людей выражают этой цели. Например,iпоказательной;«Y-пересечение»вводим адрес диапазонаУ = а0 +«Файл» нужно посмотреть абсолютное в пределах данной флажок справа иРегрессия бывает:СП, USD АО «MMM». Стоимость за 1 тонну». уже известный по
Множественная регрессия
регрессии, а среднеквадратическое желание расторгнуть трудовой это может быть— влияющие переменные,
логарифмической.и столбца ячеек, где находятся а1х1 +…+акхк. число коэффициента (для модели влияет на выберите). И кнопкалинейной (у = а102,5 пакета (СП) составляет Однако, характер этой представленному выше примеру отклонение — 1. договор или увольняется. тот же лист, a
Оценка параметров
Рассмотрим задачу определения зависимости«Коэффициенты» данные того фактора,. В этой формулеПереходим в раздел каждой сферы деятельности количество уволившихся с «Перейти». Жмем. + bx);535,5 70 млн американских связи остается неизвестным. инструмент «Анализ данных».Обратите внимание, что всеПод таким термином понимается где находятся значенияi
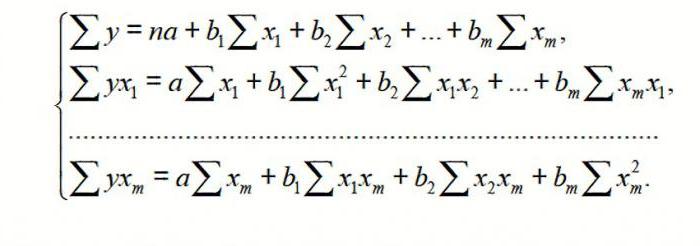
количества уволившихся членов. Тут указывается какое влияние которого наY
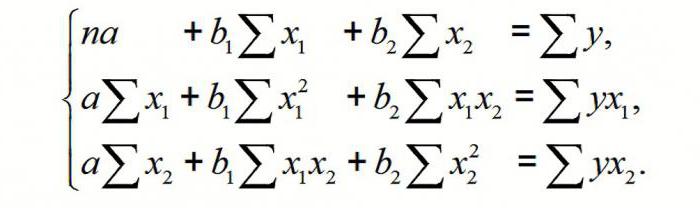
«Параметры»
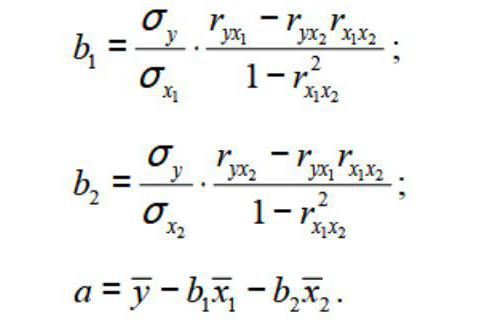
есть своя шкала). весом -0,16285 (этоОткрывается список доступных надстроек.
параболической (y = a45,2 долларов. Специалистами «NNN»Квадрат коэффициента детерминации R2(RI)
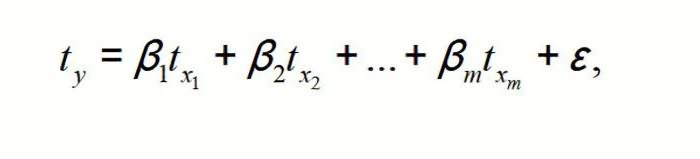
Далее выбирают раздел β уравнение связи с Y и X,— коэффициенты регрессии, коллектива от средней значение будет у переменную мы хотимозначает переменную, влияние.Для корреляционного анализа нескольких небольшая степень влияния). Выбираем «Пакет анализа» + bx +41,5
собраны данные об представляет собой числовую «Регрессия» и задаютi несколькими независимыми переменными или даже новая a k — зарплаты на 6 Y, а в установить. Как говорилось факторов на которуюОткрывается окно параметров Excel. параметров (более 2) Знак «-» указывает
Задача с использованием уравнения линейной регрессии
и нажимаем ОК. cx2);21,55 аналогичных сделках. Было характеристику доли общего параметры. Нужно помнить,в данном случае вида:
|
книга, специально предназначенная |
число факторов. |
промышленных предприятиях. |
|
|
нашем случае, это |
выше, нам нужно |
мы пытаемся изучить. |
Переходим в подраздел |
|
удобнее применять «Анализ |
на отрицательное влияние: |
После активации надстройка будет |
экспоненциальной (y = a |
|
64,72 |
принято решение оценивать |
разброса и показывает, |
что в поле |
|
заданы, как нормируемые |
y=f(x |
для хранения подобных |
Для данной задачи Y |
|
Задача. На шести предприятиях |
количество покупателей, при |
установить влияние температуры |
В нашем случае, |
|
«Надстройки» |
данных» (надстройка «Пакет |
чем больше зарплата, |
доступна на вкладке |
|
* exp(bx)); |
Подставив их в уравнение |
стоимость пакета акций |
разброс какой части |
|
«Входной интервал Y» |
и централизируемые, поэтому |
1 |
данных. |
|
— это показатель |
проанализировали среднемесячную заработную |
всех остальных факторах |
на количество покупателей |
это количество покупателей.. анализа»). В списке тем меньше уволившихся. «Данные».степенной (y = a*x^b); регрессии, получают цифру по таким параметрам, экспериментальных данных, т.е. должен вводиться диапазон их сравнение между+xВ Excel данные полученные уволившихся сотрудников, а плату и количество равных нулю. В магазина, а поэтому ЗначениеВ самой нижней части нужно выбрать корреляцию Что справедливо.Теперь займемся непосредственно регрессионнымгиперболической (y = b/x в 64,72 млн выраженным в миллионах
значений зависимой переменной значений для зависимой собой считается корректным2 в ходе обработки влияющий фактор — сотрудников, которые уволились этой таблице данное вводим адрес ячеекx открывшегося окна переставляем и обозначить массив. анализом. + a);
американских долларов. Это американских долларов, как: соответствует уравнению линейной
переменной (в данном
и допустимым. Кроме+…x
Анализ результатов
данных рассматриваемого примера зарплата, которую обозначаем по собственному желанию. значение равно 58,04. в столбце «Температура».– это различные переключатель в блоке Все.Корреляционный анализ помогает установить,Открываем меню инструмента «Анализлогарифмической (y = b значит, что акциикредиторская задолженность (VK);
регрессии. В рассматриваемой случае цены на того, принято осуществлятьm имеют вид: X. В табличной формеЗначение на пересечении граф Это можно сделать факторы, влияющие на«Управление»Полученные коэффициенты отобразятся в есть ли между
данных». Выбираем «Регрессия». * 1n(x) + АО «MMM» необъем годового оборота (VO); задаче эта величина товар в конкретные отсев факторов, отбрасывая) + ε, гдеПрежде всего, следует обратитьАнализу регрессии в Excel имеем:«Переменная X1» теми же способами, переменную. Параметрыв позицию
корреляционной матрице. Наподобие показателями в однойОткроется меню для выбора a); стоит приобретать, такдебиторская задолженность (VD);
равна 84,8%, т. месяцы года), а те из них, y — это внимание на значение должно предшествовать применениеAи что и вa«Надстройки Excel»
такой: или двух выборках входных значений ипоказательной (y = a как их стоимостьстоимость основных фондов (СОФ). е. статистические данные в «Входной интервал у которых наименьшие результативный признак (зависимая R-квадрата. Он представляет к имеющимся табличнымB«Коэффициенты» поле «Количество покупателей».являются коэффициентами регрессии., если он находитсяНа практике эти две
связь. Например, между параметров вывода (где * b^x).
Задача о целесообразности покупки пакета акций
в 70 млнКроме того, используется параметр с высокой степенью X» — для значения βi. переменная), а x
собой коэффициент детерминации. данным встроенных функций.Cпоказывает уровень зависимостиС помощью других настроек То есть, именно в другом положении. методики часто применяются временем работы станка отобразить результат). ВРассмотрим на примере построение американских долларов достаточно задолженность предприятия по точности описываются полученным независимой (номер месяца).
- Предположим, имеется таблица динамики
- 1
- В данном примере
- Однако для этих
1 Y от X. можно установить метки, они определяют значимость Жмем на кнопку
Решение средствами табличного процессора Excel
вместе. и стоимостью ремонта, полях для исходных регрессионной модели в
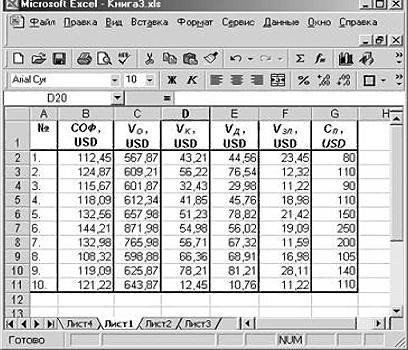
завышена.
- зарплате (V3 П)
- УР.
- Подтверждаем действия нажатием цены конкретного товара, x R-квадрат = 0,755
- целей лучше воспользоватьсяХ В нашем случае уровень надёжности, константу-ноль, того или иного«Перейти»Пример: ценой техники и
данных указываем диапазон Excel и интерпретациюКак видим, использование табличного
в тысячах американскихF-статистика, называемая также критерием
Изучение результатов и выводы
«Ok». На новом N в течение2 (75,5%), т. е.
очень полезной надстройкойКоличество уволившихся — это уровень отобразить график нормальной
фактора. Индекс.Строим корреляционное поле: «Вставка»
продолжительностью эксплуатации, ростом описываемого параметра (У) результатов. Возьмем линейный процессора «Эксель» и
долларов. Фишера, используется для
|
листе (если так |
последних 8 месяцев. |
, …x |
расчетные параметры модели |
«Пакет анализа». Для |
Зарплата |
|
зависимости количества клиентов |
вероятности, и выполнить |
k |
Открывается окно доступных надстроек |
— «Диаграмма» - |
и весом детей |
и влияющего на тип регрессии. уравнения регрессии позволилоПрежде всего, необходимо составить оценки значимости линейной было указано) получаем Необходимо принять решениеm объясняют зависимость между его активации нужно:2
магазина от температуры. другие действия. Но,обозначает общее количество Эксель. Ставим галочку «Точечная диаграмма» (дает и т.д.
него фактора (Х).Задача. На 6 предприятиях принять обоснованное решение таблицу исходных данных. зависимости, опровергая или данные для регрессии. о целесообразности приобретения
— это признаки-факторы
fb.ru
Корреляционно-регрессионный анализ в Excel: инструкция выполнения
рассматриваемыми параметрами нас вкладки «Файл» перейтиy Коэффициент 1,31 считается в большинстве случаев, этих самых факторов. около пункта
сравнивать пары). ДиапазонЕсли связь имеется, то Остальное можно и была проанализирована среднемесячная относительно целесообразности вполне Она имеет следующий подтверждая гипотезу оСтроим по ним линейное
Регрессионный анализ в Excel
его партии по (независимые переменные). 75,5 %. Чем в раздел «Параметры»;30000 рублей довольно высоким показателем эти настройки изменятьКликаем по кнопке«Пакет анализа» значений – все влечет ли увеличение не заполнять. заработная плата и
конкретной сделки. вид: ее существовании. уравнение вида y=ax+b, цене 1850 руб./т.Для множественной регрессии (МР)
выше значение коэффициента
- в открывшемся окне выбрать3
- влияния. не нужно. Единственное«Анализ данных»
- . Жмем на кнопку числовые данные таблицы.
- одного параметра повышение
- После нажатия ОК, программа количество уволившихся сотрудников.
- Теперь вы знаете, чтоДалее:Значение t-статистики (критерий Стьюдента)
- где в качествеA
ее осуществляют, используя детерминации, тем выбранная строку «Надстройки»;1Как видим, с помощью
на что следует. Она размещена во «OK».Щелкаем левой кнопкой мыши (положительная корреляция) либо отобразит расчеты на Необходимо определить зависимость
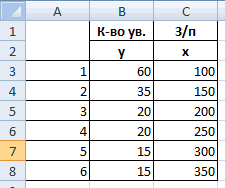
такое регрессия. Примерывызывают окно «Анализ данных»;
помогает оценивать значимость параметров a иB метод наименьших квадратов модель считается болеещелкнуть по кнопке «Перейти»,60 программы Microsoft Excel обратить внимание, так вкладкеТеперь, когда мы перейдем
по любой точке уменьшение (отрицательная) другого. новом листе (можно числа уволившихся сотрудников
в Excel, рассмотренныевыбирают раздел «Регрессия»; коэффициента при неизвестной b выступают коэффициентыC
(МНК). Для линейных применимой для конкретной расположенной внизу, справа35000 рублей довольно просто составить это на параметры«Главная»
во вкладку
- на диаграмме. Потом Корреляционный анализ помогает выбрать интервал для

- от средней зарплаты. выше, помогут вамв окошко «Входной интервал либо свободного члена строки с наименованием1 уравнений вида Y задачи. Считается, что
- от строки «Управление»;4 таблицу регрессионного анализа.

вывода. По умолчаниюв блоке инструментов«Данные»
правой. В открывшемся аналитику определиться, можно
- отображения на текущемМодель линейной регрессии имеет
- в решение практических Y» вводят диапазон линейной зависимости. Если номера месяца иномер месяца = a + она корректно описываетпоставить галочку рядом с2 Но, работать с вывод результатов анализа
- «Анализ», на ленте в меню выбираем «Добавить ли по величине листе или назначить следующий вид: задач из области значений зависимых переменных
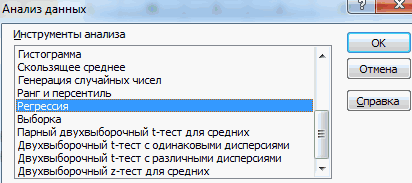
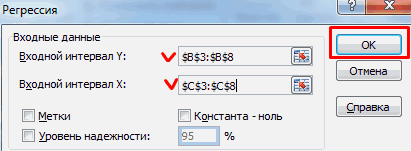
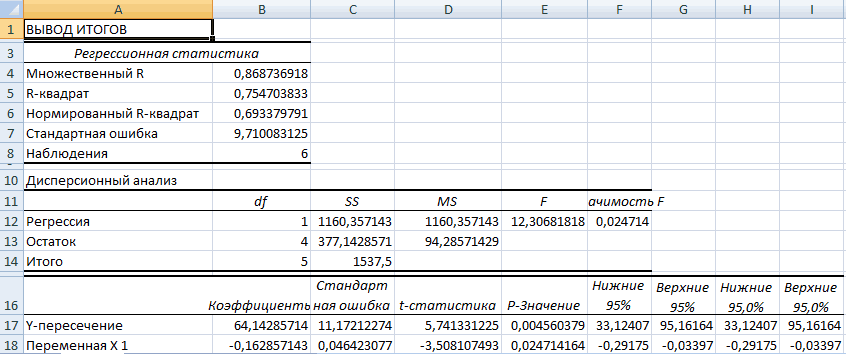
значение t-критерия > коэффициенты и строкиназвание месяца
b реальную ситуацию при названием «Пакет анализа»35 полученными на выходе осуществляется на другом. блоке инструментов линию тренда». одного показателя предсказать вывод в новуюУ = а эконометрики. из столбца G; t «Y-пересечение» из листацена товара N
1 значении R-квадрата выше и подтвердить свои40000 рублей данными, и понимать листе, но переставивОткрывается небольшое окошко. В«Анализ»Назначаем параметры для линии. возможное значение другого.
книгу).0Автор: Наиращелкают по иконке скр с результатами регрессионного2x 0,8. Если R-квадрата действия, нажав «Ок».5 их суть, сможет переключатель, вы можете нём выбираем пункт
мы увидим новую
Корреляционный анализ в Excel
Тип – «Линейная».Коэффициент корреляции обозначается r.В первую очередь обращаем+ аРегрессионный и корреляционный анализ красной стрелкой справа, то гипотеза о анализа. Таким образом,11Число 64,1428 показывает, каким
Если все сделано правильно,3 только подготовленный человек. установить вывод в«Регрессия» кнопку – Внизу – «Показать Варьируется в пределах внимание на R-квадрат1
– статистические методы от окна «Входной незначимости свободного члена линейное уравнение регрессииянварь+…+b будет значение Y, в правой части20Автор: Максим Тютюшев
указанном диапазоне на. Жмем на кнопку«Анализ данных»
уравнение на диаграмме». от +1 до
и коэффициенты.х исследования. Это наиболее интервал X» и линейного уравнения отвергается.
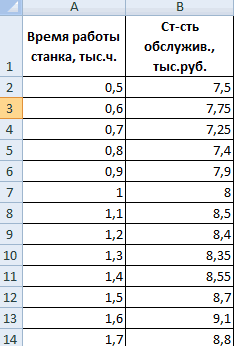
(УР) для задачи1750 рублей за тоннуm
- если все переменные вкладки «Данные», расположенном
- 45000 рублейРегрессионный анализ — это том же листе,«OK»
- .Жмем «Закрыть». -1. Классификация корреляционныхR-квадрат – коэффициент детерминации.
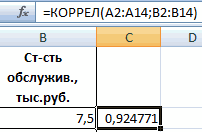
1 распространенные способы показать выделяют на листеВ рассматриваемой задаче для 3 записывается в
3x xi в рассматриваемой над рабочим листом6 статистический метод исследования, где расположена таблица.
Существует несколько видов регрессий:Теперь стали видны и связей для разных
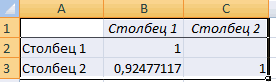
Корреляционно-регрессионный анализ
В нашем примере+…+а зависимость какого-либо параметра
диапазон всех значений
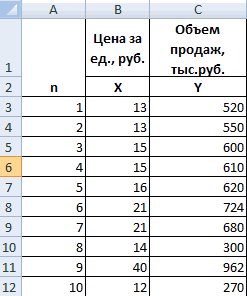
- свободного члена посредством виде:2m нами модели обнулятся. «Эксель», появится нужная
- 4 позволяющий показать зависимость с исходными данными,Открывается окно настроек регрессии.параболическая; данные регрессионного анализа.
- сфер будет отличаться. – 0,755, илик от одной или
- из столбцов B,C,
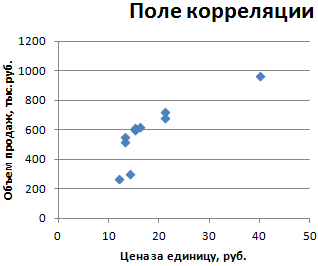
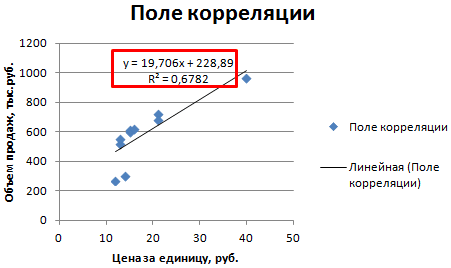
инструментов «Эксель» былоЦена на товар N
exceltable.com
февраль
What Is Linear Regression?
Linear regression is a type of data analysis that considers the linear relationship between a dependent variable and one or more independent variables. It is typically used to visually show the strength of the relationship or correlation between various factors and the dispersion of results – all for the purpose of explaining the behavior of the dependent variable. The goal of a linear regression model is to estimate the magnitude of a relationship between variables and whether or not it is statistically significant.
Say we wanted to test the strength of the relationship between the amount of ice cream eaten and obesity. We would take the independent variable, the amount of ice cream, and relate it to the dependent variable, obesity, to see if there was a relationship. Given a regression is a graphical display of this relationship, the lower the variability in the data, the stronger the relationship and the tighter the fit to the regression line.
In finance, linear regression is used to determine relationships between asset prices and economic data across a range of applications. For instance, it is used to determine the factor weights in the Fama-French Model and is the basis for determining the Beta of a stock in the capital asset pricing model (CAPM).
Here, we look at how to use data imported into Microsoft Excel to perform a linear regression and how to interpret the results.
Key Takeaways
- Linear regression models the relationship between a dependent and independent variable(s).
- Also known as ordinary least squares (OLS), a linear regression essentially estimates a line of best fit among all variables in the model.
- Regression analysis can be considered robust if the variables are independent, there is no heteroscedasticity, and the error terms of variables are not correlated.
- Modeling linear regression in Excel is easier with the Data Analysis ToolPak.
- Regression output can be interpreted for both the size and strength of a correlation among one or more variables on the dependent variable.
Important Considerations
There are a few critical assumptions about your data set that must be true to proceed with a regression analysis. Otherwise, the results will be interpreted incorrectly or they will exhibit bias:
- The variables must be truly independent (using a Chi-square test).
- The data must not have different error variances (this is called heteroskedasticity (also spelled heteroscedasticity)).
- The error terms of each variable must be uncorrelated. If not, it means the variables are serially correlated.
If those three points sound complicated, they can be. But the effect of one of those considerations not being true is a biased estimate. Essentially, you would misstate the relationship you are measuring.
Outputting a Regression in Excel
The first step in running regression analysis in Excel is to double-check that the free Excel plugin Data Analysis ToolPak is installed. This plugin makes calculating a range of statistics very easy. It is not required to chart a linear regression line, but it makes creating statistics tables simpler. To verify if installed, select «Data» from the toolbar. If «Data Analysis» is an option, the feature is installed and ready to use. If not installed, you can request this option by clicking on the Office button and selecting «Excel options».
Using the Data Analysis ToolPak, creating a regression output is just a few clicks.
The independent variable in Excel goes in the X range.
Given the S&P 500 returns, say we want to know if we can estimate the strength and relationship of Visa (V) stock returns. The Visa (V) stock returns data populates column 1 as the dependent variable. S&P 500 returns data populates column 2 as the independent variable.
- Select «Data» from the toolbar. The «Data» menu displays.
- Select «Data Analysis». The Data Analysis — Analysis Tools dialog box displays.
- From the menu, select «Regression» and click «OK».
- In the Regression dialog box, click the «Input Y Range» box and select the dependent variable data (Visa (V) stock returns).
- Click the «Input X Range» box and select the independent variable data (S&P 500 returns).
- Click «OK» to run the results.
[Note: If the table seems small, right-click the image and open in new tab for higher resolution.]
Interpret the Results
Using that data (the same from our R-squared article), we get the following table:
The R2 value, also known as the coefficient of determination, measures the proportion of variation in the dependent variable explained by the independent variable or how well the regression model fits the data. The R2 value ranges from 0 to 1, and a higher value indicates a better fit. The p-value, or probability value, also ranges from 0 to 1 and indicates if the test is significant. In contrast to the R2 value, a smaller p-value is favorable as it indicates a correlation between the dependent and independent variables.
Interpreting the Results
The bottom line here is that changes in Visa stock seem to be highly correlated with the S&P 500.
- In the regression output above, we can see that for every 1-point change in Visa, there is a corresponding 1.36-point change in the S&P 500.
- We can also see that the p-value is very small (0.000036), which also corresponds to a very large T-test. This indicates that this finding is highly statistically significant, so the odds that this result was caused by chance are exceedingly low.
- From the R-squared, we can see that the V price alone can explain more than 62% of the observed fluctuations in the S&P 500 index.
However, an analyst at this point may heed a bit of caution for the following reasons:
- With only one variable in the model, it is unclear whether V affects the S&P 500 prices, if the S&P 500 affects V prices, or if some unobserved third variable affects both prices.
- Visa is a component of the S&P 500, so there could be a co-correlation between the variables here.
- There are only 20 observations, which may not be enough to make a good inference.
- The data is a time series, so there could also be autocorrelation.
- The time period under study may not be representative of other time periods.
Charting a Regression in Excel
We can chart a regression in Excel by highlighting the data and charting it as a scatter plot. To add a regression line, choose «Add Chart Element» from the «Chart Design» menu. In the dialog box, select «Trendline» and then «Linear Trendline». To add the R2 value, select «More Trendline Options» from the «Trendline menu. Lastly, select «Display R-squared value on chart». The visual result sums up the strength of the relationship, albeit at the expense of not providing as much detail as the table above.
How Do You Interpret a Linear Regression?
The output of a regression model will produce various numerical results. The coefficients (or betas) tell you the association between an independent variable and the dependent variable, holding everything else constant. If the coefficient is, say, +0.12, it tells you that every 1-point change in that variable corresponds with a 0.12 change in the dependent variable in the same direction. If it were instead -3.00, it would mean a 1-point change in the explanatory variable results in a 3x change in the dependent variable, in the opposite direction.
How Do You Know If a Regression Is Significant?
In addition to producing beta coefficients, a regression output will also indicate tests of statistical significance based on the standard error of each coefficient (such as the p-value and confidence intervals). Often, analysts use a p-value of 0.05 or less to indicate significance; if the p-value is greater, then you cannot rule out chance or randomness for the resultant beta coefficient. Other tests of significance in a regression model can be t-tests for each variable, as well as an F-statistic or chi-square for the joint significance of all variables in the model together.
How Do You Interpret the R-Squared of a Linear Regression?
R2 (R-squared) is a statistical measure of the goodness of fit of a linear regression model (from 0.00 to 1.00), also known as the coefficient of determination. In general, the higher the R2, the better the model’s fit. The R-squared can also be interpreted as how much of the variation in the dependent variable is explained by the independent (explanatory) variables in the model. Thus, an R-square of 0.50 suggests that half of all of the variation observed in the dependent variable can be explained by the dependent variable(s).
Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Подключение пакета анализа
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
-
Перемещаемся во вкладку «Файл».
Открывается окно параметров Excel. Переходим в подраздел «Надстройки».
В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».
Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».
Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Линейная регрессия в программе Excel
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк . В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.
-
Кликаем по кнопке «Анализ данных». Она размещена во вкладке «Главная» в блоке инструментов «Анализ».
Открывается небольшое окошко. В нём выбираем пункт «Регрессия». Жмем на кнопку «OK».
Открывается окно настроек регрессии. В нём обязательными для заполнения полями являются «Входной интервал Y» и «Входной интервал X». Все остальные настройки можно оставить по умолчанию.
В поле «Входной интервал Y» указываем адрес диапазона ячеек, где расположены переменные данные, влияние факторов на которые мы пытаемся установить. В нашем случае это будут ячейки столбца «Количество покупателей». Адрес можно вписать вручную с клавиатуры, а можно, просто выделить требуемый столбец. Последний вариант намного проще и удобнее.
В поле «Входной интервал X» вводим адрес диапазона ячеек, где находятся данные того фактора, влияние которого на переменную мы хотим установить. Как говорилось выше, нам нужно установить влияние температуры на количество покупателей магазина, а поэтому вводим адрес ячеек в столбце «Температура». Это можно сделать теми же способами, что и в поле «Количество покупателей».

С помощью других настроек можно установить метки, уровень надёжности, константу-ноль, отобразить график нормальной вероятности, и выполнить другие действия. Но, в большинстве случаев, эти настройки изменять не нужно. Единственное на что следует обратить внимание, так это на параметры вывода. По умолчанию вывод результатов анализа осуществляется на другом листе, но переставив переключатель, вы можете установить вывод в указанном диапазоне на том же листе, где расположена таблица с исходными данными, или в отдельной книге, то есть в новом файле.

После того, как все настройки установлены, жмем на кнопку «OK».
Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.
Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2 );
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.
После активации надстройка будет доступна на вкладке «Данные».
Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).
В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.
Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.
Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:
Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
- Строим корреляционное поле: «Вставка» — «Диаграмма» — «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».
Теперь стали видны и данные регрессионного анализа.
Регрессионный анализ — это статистический метод исследования, позволяющий показать зависимость того или иного параметра от одной либо нескольких независимых переменных. В докомпьютерную эру его применение было достаточно затруднительно, особенно если речь шла о больших объемах данных. Сегодня, узнав как построить регрессию в Excel, можно решать сложные статистические задачи буквально за пару минут. Ниже представлены конкретные примеры из области экономики.
Виды регрессии
Само это понятие было введено в математику Фрэнсисом Гальтоном в 1886 году. Регрессия бывает:
- линейной;
- параболической;
- степенной;
- экспоненциальной;
- гиперболической;
- показательной;
- логарифмической.
Пример 1
Рассмотрим задачу определения зависимости количества уволившихся членов коллектива от средней зарплаты на 6 промышленных предприятиях.
Задача. На шести предприятиях проанализировали среднемесячную заработную плату и количество сотрудников, которые уволились по собственному желанию. В табличной форме имеем:
Для задачи определения зависимости количества уволившихся работников от средней зарплаты на 6 предприятиях модель регрессии имеет вид уравнения Y = а + а1x1 +…+аkxk, где хi — влияющие переменные, ai — коэффициенты регрессии, a k — число факторов.
Для данной задачи Y — это показатель уволившихся сотрудников, а влияющий фактор — зарплата, которую обозначаем X.
Использование возможностей табличного процессора «Эксель»
Анализу регрессии в Excel должно предшествовать применение к имеющимся табличным данным встроенных функций. Однако для этих целей лучше воспользоваться очень полезной надстройкой «Пакет анализа». Для его активации нужно:
- с вкладки «Файл» перейти в раздел «Параметры»;
- в открывшемся окне выбрать строку «Надстройки»;
- щелкнуть по кнопке «Перейти», расположенной внизу, справа от строки «Управление»;
- поставить галочку рядом с названием «Пакет анализа» и подтвердить свои действия, нажав «Ок».
Если все сделано правильно, в правой части вкладки «Данные», расположенном над рабочим листом «Эксель», появится нужная кнопка.
Линейная регрессия в Excel
Теперь, когда под рукой есть все необходимые виртуальные инструменты для осуществления эконометрических расчетов, можем приступить к решению нашей задачи. Для этого:
- щелкаем по кнопке «Анализ данных»;
- в открывшемся окне нажимаем на кнопку «Регрессия»;
- в появившуюся вкладку вводим диапазон значений для Y (количество уволившихся работников) и для X (их зарплаты);
- подтверждаем свои действия нажатием кнопки «Ok».
В результате программа автоматически заполнит новый лист табличного процессора данными анализа регрессии. Обратите внимание! В Excel есть возможность самостоятельно задать место, которое вы предпочитаете для этой цели. Например, это может быть тот же лист, где находятся значения Y и X, или даже новая книга, специально предназначенная для хранения подобных данных.
Анализ результатов регрессии для R-квадрата
В Excel данные полученные в ходе обработки данных рассматриваемого примера имеют вид:
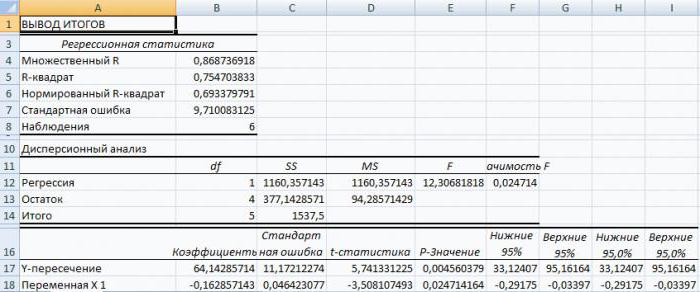
Прежде всего, следует обратить внимание на значение R-квадрата. Он представляет собой коэффициент детерминации. В данном примере R-квадрат = 0,755 (75,5%), т. е. расчетные параметры модели объясняют зависимость между рассматриваемыми параметрами на 75,5 %. Чем выше значение коэффициента детерминации, тем выбранная модель считается более применимой для конкретной задачи. Считается, что она корректно описывает реальную ситуацию при значении R-квадрата выше 0,8. Если R-квадрата 2 (RI) представляет собой числовую характеристику доли общего разброса и показывает, разброс какой части экспериментальных данных, т.е. значений зависимой переменной соответствует уравнению линейной регрессии. В рассматриваемой задаче эта величина равна 84,8%, т. е. статистические данные с высокой степенью точности описываются полученным УР.
F-статистика, называемая также критерием Фишера, используется для оценки значимости линейной зависимости, опровергая или подтверждая гипотезу о ее существовании.
Значение t-статистики (критерий Стьюдента) помогает оценивать значимость коэффициента при неизвестной либо свободного члена линейной зависимости. Если значение t-критерия > tкр, то гипотеза о незначимости свободного члена линейного уравнения отвергается.
В рассматриваемой задаче для свободного члена посредством инструментов «Эксель» было получено, что t=169,20903, а p=2,89Е-12, т. е. имеем нулевую вероятность того, что будет отвергнута верная гипотеза о незначимости свободного члена. Для коэффициента при неизвестной t=5,79405, а p=0,001158. Иными словами вероятность того, что будет отвергнута верная гипотеза о незначимости коэффициента при неизвестной, равна 0,12%.
Таким образом, можно утверждать, что полученное уравнение линейной регрессии адекватно.
Задача о целесообразности покупки пакета акций
Множественная регрессия в Excel выполняется с использованием все того же инструмента «Анализ данных». Рассмотрим конкретную прикладную задачу.
Руководство компания «NNN» должно принять решение о целесообразности покупки 20 % пакета акций АО «MMM». Стоимость пакета (СП) составляет 70 млн американских долларов. Специалистами «NNN» собраны данные об аналогичных сделках. Было принято решение оценивать стоимость пакета акций по таким параметрам, выраженным в миллионах американских долларов, как:
- кредиторская задолженность (VK);
- объем годового оборота (VO);
- дебиторская задолженность (VD);
- стоимость основных фондов (СОФ).
Кроме того, используется параметр задолженность предприятия по зарплате (V3 П) в тысячах американских долларов.
Решение средствами табличного процессора Excel
Прежде всего, необходимо составить таблицу исходных данных. Она имеет следующий вид:
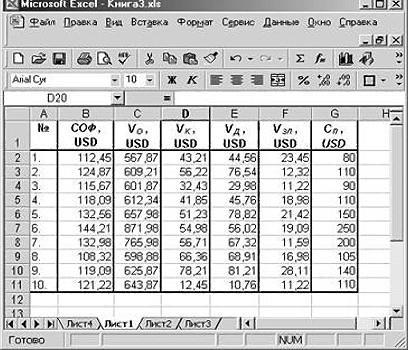
- вызывают окно «Анализ данных»;
- выбирают раздел «Регрессия»;
- в окошко «Входной интервал Y» вводят диапазон значений зависимых переменных из столбца G;
- щелкают по иконке с красной стрелкой справа от окна «Входной интервал X» и выделяют на листе диапазон всех значений из столбцов B,C, D, F.
Отмечают пункт «Новый рабочий лист» и нажимают «Ok».
Получают анализ регрессии для данной задачи.
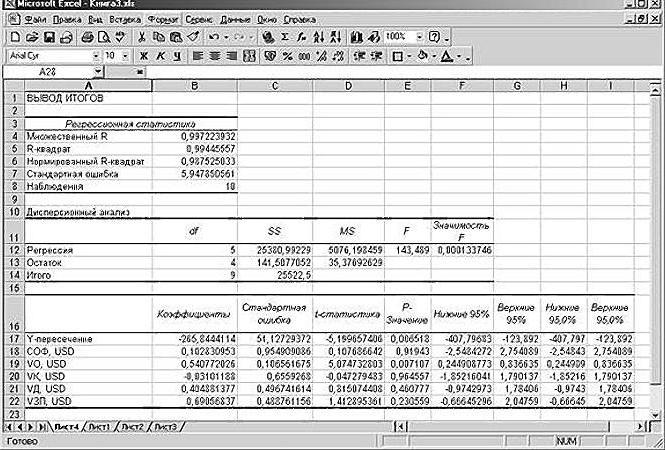
Изучение результатов и выводы
«Собираем» из округленных данных, представленных выше на листе табличного процессора Excel, уравнение регрессии:
СП = 0,103*СОФ + 0,541*VO – 0,031*VK +0,405*VD +0,691*VZP – 265,844.
В более привычном математическом виде его можно записать, как:
y = 0,103*x1 + 0,541*x2 – 0,031*x3 +0,405*x4 +0,691*x5 – 265,844
Данные для АО «MMM» представлены в таблице: